Область техники:
[0001] Изобретение относится к области вычислительной техники для агрегирования, индексации и вывода данных пользователю.
Уровень техники:
[0002] В настоящее время существует множество систем индексации данных. Одним из примеров таких систем является система сбора и консолидации разнородных удаленных бизнес-данных с использованием динамической обработки данных, описанная в US 9740757 B1. Известная система предназначена для управления сбором данных из разнородных источников данных. Данные извлекаются независимо от источника данных с использованием, по крайней мере, двух типов управляющих сообщений, чтобы скрыть детали реализации для гетерогенных источников данных. Система получает от разнородных источников данных запрос на первый тип управляющего сообщения, который определяет данные, которые должны быть извлечены из разнородных источников данных. В ответ на получение запроса система отправляет первый тип управляющих сообщений в разнородные источники данных. Далее система получает от разнородных источников данных второй тип управляющего сообщения, который включает данные, извлеченные из разнородных источников данных, которые были определены в первом типе управляющего сообщения. Система также сохраняет в хранилище данных полученные данные, идентифицированные в первом типе управляющего сообщения и извлеченные из разнородных источников данных.
[0003] Однако, известному решению присущи недостатки. Недостаток известного решения заключается в том, что точность агрегирования и индексации данных для их последующего предоставления пользователю является низкой. Данный недостаток обусловлен тем, что в известной системе не предусмотрена работа с внешними данными различных типов и форматов, а также адаптация типов данных в зависимости от формата хранения в хранилище индексации данных. Отсутствие данной адаптации приводит к неверной индексации и неверному предоставлению данных пользователю и, как следствие, к низкой точности индексации данных для их последующего предоставления пользователю.
Раскрытие изобретения:
[0004] Задачей изобретения является устранение указанных выше недостатков.
[0005] Техническим результатом при этом является повышение точности агрегирования и индексации данных для их последующего предоставления пользователю.
[0006] Дополнительным техническим результатом является обеспечение адаптации работы множества внешних вычислительных устройств, сервера агрегирования данных, хранилища индексации данных и вычислительного устройства пользователя к взаимодействию с различным типом данных для их дальнейшей индексации и выводу пользователю.
[0007] Для достижения технического результата предложена система агрегирования и индексации данных для их вывода пользователю, содержащая: множество внешних вычислительных устройств, каждое из которых содержит хранилище данных и выполнено с возможностью передачи серверу агрегирования данных; сервер агрегирования, выполненный с возможностью приема и агрегирования данных; при этом сервер агрегирования содержит процессор и память, хранящую машиночитаемые инструкции, побуждающие процессор выполнять: определение типа данных, сохраненных в упомянутых хранилищах внешних вычислительных устройств; установку соединения с упомянутыми хранилищами с последующим чтением данных из упомянутых хранилищ в память сервера агрегирования, при этом чтение данных выполняется способом, зависящим от типа данных; сохранение считанных данных в памяти сервера агрегирования в виде временного файла; создание базы данных агрегирования в виде кластера хранения считанных данных в памяти сервера агрегирования; и сохранение считанных данных в созданной базе данных агрегирования из упомянутого временного файла с последующим удалением временного файла и закрытием соединения с хранилищем внешнего вычислительного устройства; хранилище индексации данных, выполненное с возможностью индексации и хранения проиндексированных данных, где хранилище индексации данных выполнено на основе платформы Solr для полнотекстового поиска с открытым исходным кодом (далее - хранилище Solr); при этом хранилище индексации данных выполнено с возможностью: а) создания конфигурационного файла ядра в файловой системе хранилища Solr и размещение в этом файле параметров подключения к ранее созданной базе данных агрегирования; б) обращения в программный интерфейс (API) хранилища Solr по протоколу http с командой на запуск индексации ядра; в) выполнения хранилищем Solr запроса к упомянутой базе данных агрегирования для получения сохраненных в ней данных; г) выполнения индексации полученных данных в хранилище Solr и формирование ядра на основе выполненной индексации; и д) размещения сформированного ядра в части хранилища Solr, доступной для чтения данных вычислительным устройством пользователя; вычислительное устройство пользователя, выполненное с возможностью получения от сервера агрегирования проиндексированных данных, при этом предоставление проиндексированных данных выполняется в соответствии с этапами, на которых выполняют: i) получение сервером агрегирования настроек чтения данных или идентификатора сохраненных настроек, с последующим чтением этих настроек из базы данных агрегирования; ii) преобразование упомянутых настроек в формат, принимаемый API хранилища Solr; iii) отправку запроса через протокол http к хранилищу Solr в соответствующее текущим настройкам ядро с приложенными в формате JSON преобразованными настройками; iv) получение сервером агрегирования из хранилища Solr проиндексированных данных; v) передачу вычислительному устройству пользователя проиндексированных данных для их последующего вывода пользователю.
[0008] В Solr термин «ядро» используется для обозначения одного индекса и связанного с ним журнала транзакций и файлов конфигурации (включая, среди прочих, файлы Schema и solrconfig.xml). По факту в изобретении используется множество ядер, что позволяет индексировать данные с различными структурами на одном сервере и сохранять больший контроль над тем, как данные представлены разным аудиториям.
[0009] Дополнительно данные могут иметь, по меньшей мере, один из следующих типов: MySQL данные, PostgreSQL данные, Clickhouse данные, Google Sheets данные, CSV данные.
[0010] Очевидно, что как предыдущее общее описание, так и последующее подробное описание даны лишь для примера и пояснения и не являются ограничениями данного изобретения.
Краткое описание чертежей:
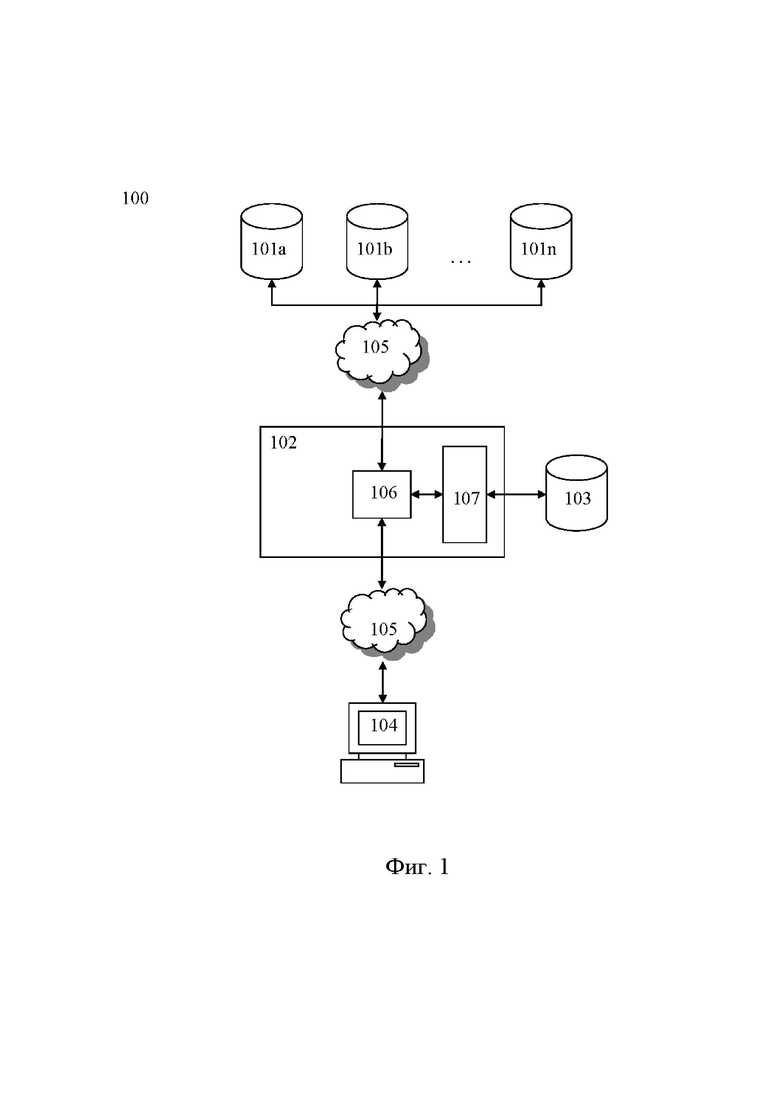
[0011] Фиг. 1 - схематичное изображение системы агрегирования и индексации данных для их вывода пользователю.
Осуществление изобретения:
[0012] Схематическое изображение заявленной системы 100 агрегирования и индексации данных для их вывода пользователю показано на фиг. 1. Система 100 содержит множество внешних вычислительных устройств 101a, 101b … 101n, где n целое число ≥ 2, сервер 102 агрегирования, хранилище 103 индексации данных и вычислительное устройство пользователя 104. Соединение вычислительных устройств 101a, 101b … 101n, сервера 102 агрегирования и вычислительного устройства пользователя 104 выполнено посредством сети 105 приема и передачи данных. Необходимо отметить, что в рамках настоящего решения хранилище 103 индексации данных может быть выполнено в составе сервера 102 агрегирования или в виде отдельного сервера и соединено с сервером агрегирования также посредством сети 105. Сервер 102 агрегирования также содержит процессор 106 и память 107.
[0013] В контексте настоящего решения сеть 105 приема и передачи данных может являться, по меньшей мере, одной из следующих сетей: TCP/IP сетью, Интернет, Wi-Fi, GPRS, 3G, 4G, 5G, WiMax, сетью на основе технологий LTE или LTE-A, спутниковой сетью передачи данных и т.д.
[0014] В контексте настоящего решения процессор 106 может быть микропроцессором, микроконтроллером, контроллером и любым другим устройством, выполняющим обработку, прием и передачу данных. Также в состав сервера 102 входит сетевая карта (не показана на фиг.), выполненная с возможностью обеспечения приема и передачи данных между сервером 102 и внешними устройствами, например такими, как множество внешних вычислительных устройств 101a, 101b … 101n и вычислительное устройство пользователя 104.
[0015] В контексте настоящего решения память 107 выполнена с возможностью хранения ПО и данных. Следует принимать во внимание, что память 107, входящая в состав сервера 102 в данном документе, может быть энергозависимыми запоминающими устройствами или энергонезависимыми запоминающими устройствами, либо может включать в себя и энергозависимое, и энергонезависимое запоминающее устройство. В качестве иллюстрации, но не ограничения, память может включать в себя постоянное запоминающее устройство (ROM), программируемое ROM (PROM), электрически программируемое ROM (EPROM), флэш-память (SSD). Энергозависимое запоминающее устройство может включать в себя синхронное RAM (SRAM), динамическое RAM (DRAM), синхронное DRAM (SDRAM), SDRAM с двойной скоростью передачи данных (DDR SDRAM), улучшенное SDRAM (ESDRAM), Synchlink DRAM (SLDRAM) и direct Rambus RAM (DRRAM).
[0016] Каждое из внешних вычислительных устройств 101a, 101b … 101n содержит хранилище данных и выполнено с возможностью передачи серверу агрегирования данных. Данными в контексте настоящего решения могут являться, по меньшей мере, одними из следующих типов: MySQL данными, PostgreSQL данными, Clickhouse данными, Google Sheets данными, CSV данными.
[0017] Сервер 102 агрегирования выполнен с возможностью приема и агрегирования данных. Сервер 102 выполняет определение типа данных, сохраненных в упомянутых хранилищах внешних вычислительных устройств, установку соединения с упомянутыми хранилищами с последующим чтением данных из упомянутых хранилищ в память сервера агрегирования, при этом чтение данных выполняется способом, зависящим от типа данных, сохранение считанных данных в памяти 107 сервера 102 агрегирования в виде временного файла, создание базы данных агрегирования в виде кластера хранения считанных данных в памяти сервера агрегирования, и сохранение считанных данных в созданной базе данных агрегирования из упомянутого временного файла с последующим удалением временного файла и закрытием соединения с хранилищем внешнего вычислительного устройства.
[0018] Хранилище 103 индексации данных выполнено с возможностью индексации и хранения проиндексированных данных. Хранилище 103 индексации данных выполнено на основе платформы Solr для полнотекстового поиска с открытым исходным кодом (далее - хранилище Solr). Также хранилище 103 индексации данных выполнено с возможностью: создания конфигурационного файла ядра в файловой системе хранилища Solr и размещение в этом файле параметров подключения к ранее созданной базе данных агрегирования, обращения в программный интерфейс (API) хранилища Solr по протоколу http с командой на запуск индексации ядра, выполнения хранилищем Solr запроса к упомянутой базе данных агрегирования для получения сохраненных в ней данных, выполнения индексации полученных данных в хранилище Solr и формирование ядра на основе выполненной индексации, и размещения сформированного ядра в части хранилища Solr, доступной для чтения данных вычислительным устройством пользователя.
[0019] Вычислительное устройство пользователя 104 выполнено с возможностью получения от сервера агрегирования проиндексированных данных, при этом предоставление проиндексированных данных выполняется в соответствии с этапами, на которых выполняют: получение сервером агрегирования настроек чтения данных или идентификатора сохраненных настроек, с последующим чтением этих настроек из базы данных агрегирования, преобразование упомянутых настроек в формат, принимаемый API хранилища Solr, отправку запроса через протокол http к хранилищу Solr в соответствующее текущим настройкам ядро с приложенными в формате JSON преобразованными настройками, получение сервером агрегирования из хранилища Solr проиндексированных данных, и передачу вычислительному устройству пользователя проиндексированных данных для их последующего вывода пользователю.
[0020] Хотя данное изобретение было показано и описано со ссылкой на определенные варианты его осуществления, специалистам в данной области техники будет понятно, что различные изменения и модификации могут быть сделаны в нем, не покидая фактический объем изобретения. Следовательно, описанные варианты осуществления имеют намерение охватывать все подобные преобразования, модификации и разновидности, которые попадают под сущность и объем прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА И СПОСОБ ОБРАБОТКИ ДАННЫХ ГРАФОВ | 2015 |
|
RU2708939C2 |
| Способ и система для управления устройствами и контроля устройств | 2017 |
|
RU2648564C1 |
| Система и способ перехвата файловых потоков | 2023 |
|
RU2816551C1 |
| СПОСОБ ПОСТРОЕНИЯ РАСПРЕДЕЛЕННОЙ ИНФОРМАЦИОННОЙ СИСТЕМЫ | 2018 |
|
RU2699683C1 |
| СПОСОБ И СИСТЕМА ПЕРЕМЕЩЕНИЯ ДАННЫХ В ОБЛАЧНОЙ СРЕДЕ | 2023 |
|
RU2822554C1 |
| СПОСОБ ИСКЛЮЧЕНИЯ ПРОЦЕССОВ ИЗ АНТИВИРУСНОЙ ПРОВЕРКИ НА ОСНОВАНИИ ДАННЫХ О ФАЙЛЕ | 2015 |
|
RU2595510C1 |
| СПОСОБ ИНТЕГРАЦИИ ПЕРИФЕРИЙНЫХ УСТРОЙСТВ ПРОГРАММНО-АППАРАТНЫХ КОМПЛЕКСОВ | 2019 |
|
RU2732729C1 |
| Способ извлечения информации и корпоративная система поиска информации | 2019 |
|
RU2729224C2 |
| Способ обработки данных в гибридном хранилище | 2023 |
|
RU2831216C1 |
| СИСТЕМА И СПОСОБ ПОИСКА ДАННЫХ В БАЗЕ ДАННЫХ ГРАФОВ | 2015 |
|
RU2707708C2 |
Изобретение относится к системе агрегирования и индексации данных для их вывода пользователю. Технический результат заключается в повышении эффективности агрегирования и индексации данных. Система содержит множество внешних вычислительных устройств, каждое из которых содержит хранилище данных и выполнено с возможностью передачи серверу агрегирования данных; сервер агрегирования, выполненный с возможностью приема и агрегирования данных, содержащий процессор и память, хранящую машиночитаемые инструкции, побуждающие процессор выполнять: определение типа данных, сохраненных в упомянутых хранилищах внешних вычислительных устройств; установку соединения с упомянутыми хранилищами с чтением данных из упомянутых хранилищ в память сервера агрегирования, выполняемым в зависимости от типа данных; сохранение считанных данных в памяти сервера агрегирования в виде временного файла; создание базы данных агрегирования в виде кластера хранения считанных данных в памяти сервера агрегирования; и сохранение считанных данных в созданной базе данных агрегирования из упомянутого временного файла с последующим удалением временного файла и закрытием соединения с хранилищем внешнего вычислительного устройства; хранилище индексации данных, выполненное с возможностью индексации и хранения проиндексированных данных, где хранилище индексации данных выполнено на основе платформы Solr для полнотекстового поиска с открытым исходным кодом (далее – хранилище Solr); при этом хранилище Solr выполнено с возможностью формирования и использования множества ядер, где каждое ядро представляет собой индекс и связанный с ним журнал транзакций и файлов конфигурации, для индексирования данных с различными структурами на одном сервере, и обеспечивает: создание конфигурационного файла ядра в файловой системе хранилища Solr и размещение в этом файле параметров подключения к ранее созданной базе данных агрегирования; обращение в программный интерфейс (API) хранилища Solr по протоколу http с командой на запуск индексации ядра; выполнение хранилищем Solr запроса к упомянутой базе данных агрегирования для получения сохраненных в ней данных; выполнение индексации полученных данных в хранилище Solr и формирование ядра на основе выполненной индексации; и размещение сформированного ядра в части хранилища Solr, доступной для чтения данных вычислительным устройством пользователя; вычислительное устройство пользователя, выполненное с возможностью получения от сервера агрегирования проиндексированных данных, при этом предоставление проиндексированных данных выполняется в соответствии с этапами, на которых выполняют: получение сервером агрегирования настроек чтения данных или идентификатора сохраненных настроек с последующим чтением этих настроек из базы данных агрегирования; преобразование упомянутых настроек в формат, принимаемый API хранилища Solr; отправку запроса через протокол http к хранилищу Solr в соответствующее текущим настройкам ядро с приложенными в формате JSON преобразованными настройками; получение сервером агрегирования из хранилища Solr проиндексированных данных; и передачу вычислительному устройству пользователя проиндексированных данных для их последующего вывода пользователю. 1 з.п. ф-лы, 1 ил.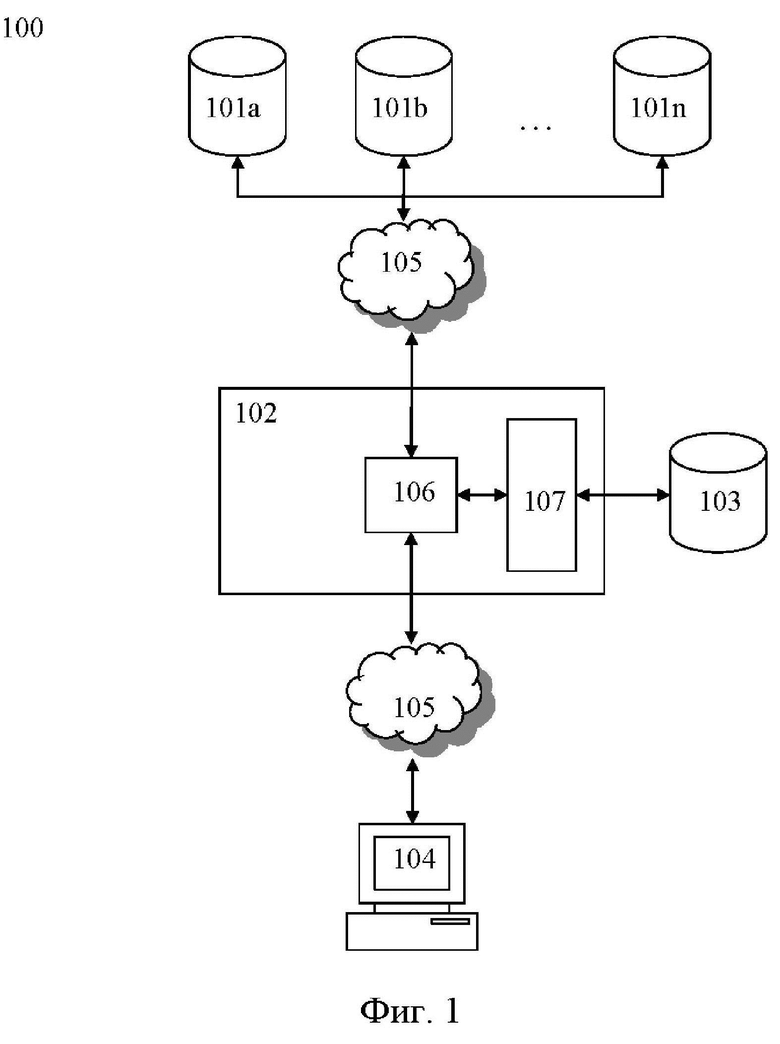
1. Система агрегирования и индексации данных для их вывода пользователю, содержащая:
- множество внешних вычислительных устройств, каждое из которых содержит хранилище данных и выполнено с возможностью передачи серверу агрегирования данных;
- сервер агрегирования, выполненный с возможностью приема и агрегирования данных; при этом сервер агрегирования содержит процессор и память, хранящую машиночитаемые инструкции, побуждающие процессор выполнять:
определение типа данных, сохраненных в упомянутых хранилищах внешних вычислительных устройств;
установку соединения с упомянутыми хранилищами с последующим чтением данных из упомянутых хранилищ в память сервера агрегирования, при этом чтение данных выполняется способом, зависящим от типа данных;
сохранение считанных данных в памяти сервера агрегирования в виде временного файла;
создание базы данных агрегирования в виде кластера хранения считанных данных в памяти сервера агрегирования; и
сохранение считанных данных в созданной базе данных агрегирования из упомянутого временного файла с последующим удалением временного файла и закрытием соединения с хранилищем внешнего вычислительного устройства;
- хранилище индексации данных, выполненное с возможностью индексации и хранения проиндексированных данных, где хранилище индексации данных выполнено на основе платформы Solr для полнотекстового поиска с открытым исходным кодом (далее – хранилище Solr); при этом хранилище Solr выполнено с возможностью формирования и использования множества ядер, где каждое ядро представляет собой индекс и связанный с ним журнал транзакций и файлов конфигурации, для индексирования данных с различными структурами на одном сервере, и обеспечивает:
а) создание конфигурационного файла ядра в файловой системе хранилища Solr и размещение в этом файле параметров подключения к ранее созданной базе данных агрегирования;
б) обращение в программный интерфейс (API) хранилища Solr по протоколу http с командой на запуск индексации ядра;
в) выполнение хранилищем Solr запроса к упомянутой базе данных агрегирования для получения сохраненных в ней данных;
г) выполнение индексации полученных данных в хранилище Solr и формирование ядра на основе выполненной индексации; и
д) размещение сформированного ядра в части хранилища Solr, доступной для чтения данных вычислительным устройством пользователя;
- вычислительное устройство пользователя, выполненное с возможностью получения от сервера агрегирования проиндексированных данных, при этом предоставление проиндексированных данных выполняется в соответствии с этапами, на которых выполняют:
i) получение сервером агрегирования настроек чтения данных или идентификатора сохраненных настроек с последующим чтением этих настроек из базы данных агрегирования;
ii) преобразование упомянутых настроек в формат, принимаемый API хранилища Solr;
iii) отправку запроса через протокол http к хранилищу Solr в соответствующее текущим настройкам ядро с приложенными в формате JSON преобразованными настройками;
iv) получение сервером агрегирования из хранилища Solr проиндексированных данных; и
v) передачу вычислительному устройству пользователя проиндексированных данных для их последующего вывода пользователю.
2. Система по п. 1, отличающаяся тем, что данные имеют по меньшей мере один из следующих типов: MySQL данные, PostgreSQL данные, Clickhouse данные, Google Sheets данные, CSV данные.
