Фиг 1
Изобретение относится к вычислительной технике и может быть использовано в системах помехоустойчивого кодирования.
Цель изобретения - упрощение устройства.
На фиг. 1 приведена блок-схема устройства; на фиг. 2 - соединение входов и выходов первого коммутатора; на фиг. 3 и 4 - последовательность обработки символа кодового слова в режиме соответственно декодирования и кодирования.
Устройство содержит блок 1 оперативной памяти, блок 2 умножения на постоянные коэффициенты, блок 3 суммирования по модулю два, первый - третий буферные регистры 4-6, первый 7 и второй 8 формирователи адреса, первый 9 и второй 10 коммутаторы и источник 11 нулевого кода.
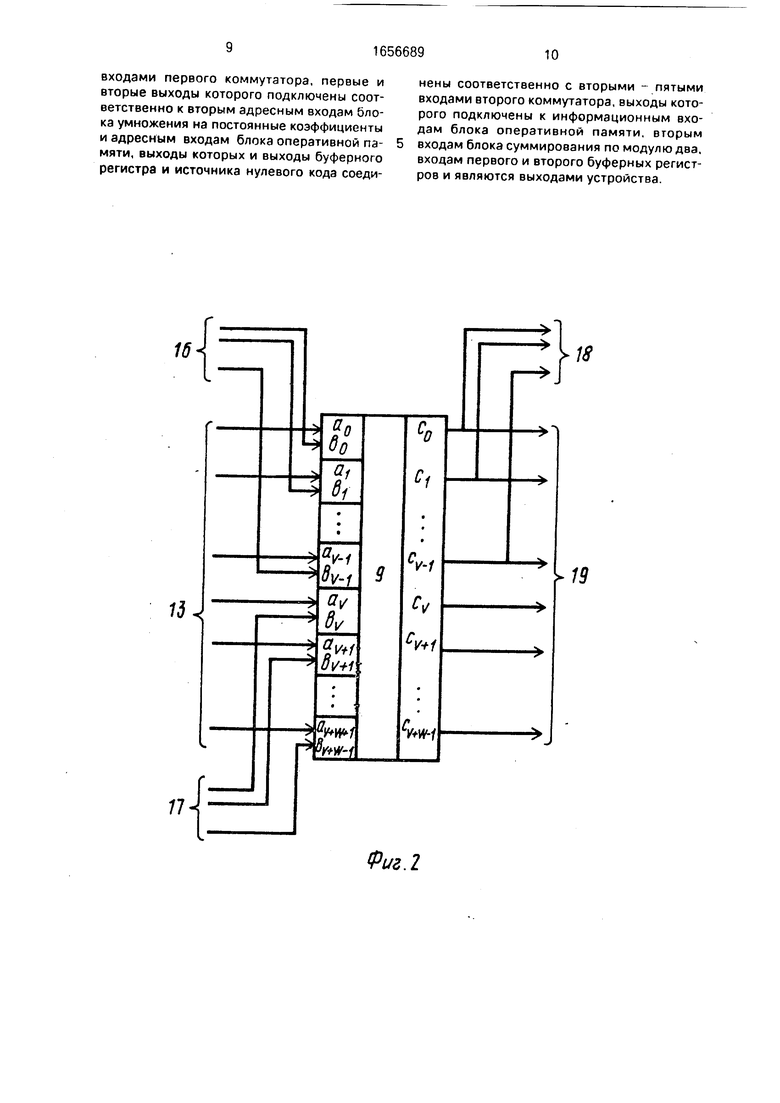
На фиг. 1 обозначены информационные входы 12, адресные входы 13, вход 14 управления режимом, выходы 15, а также вторые 16 и третьи 17 входы первого коммутатора 9 и его первые 18 и вторые 19 выходы, Конкретное подключение входов и выходов первого коммутатора 9 показано на фиг. 2.
Блок 2 умножения на постоянные коэффициенты реализуется на программируемом ПЗУ.
Формирователи 7 и 8 адреса выполнены на счетчиках импульсов.
Тактовые и управляющие входы блоков на фиг. 1 не показаны, последовательности управляющих сигналов в разных режимах приведены на фиг, 3 и 4.
При описании устройства использованы следующие обозначения: п- длина кодового слова; к - длина информационной части кодового слова; I - количество контрольных символов в кодовом слове; А- глубина перемежения кодовых слов в секторе данных; г - размер символа кодового слова (в битах); v - наименьшее целое, большее или равное Iog2l; W - наименьшее целое, большее или равное Iog2 Я.
Источник 11 нулевого кода имеет размерность выходов г.
Рассмотрим процедуры вычисления синдрома и кодирования для кода Рида-Соломона (PC) определенного в поле Галуа GF(2r). В этом поле операции сложения и вычитания элементов поля совпадают. Порождающий многочлен PC кода с I контрольными символами имеет следующий вид:
д(х) (х-оь)(х-оь + 1)...
...(),
где а- примитивный элемент GF( 2 г); b - константа.
Пусть с(х) - кодовый многочлен степени п (его коэффициенты - символы кодового слова), е(х)- многочлен ошибок (его коэффициенты - значения ошибок) и U(x)c(x}+ е(х)многочлен декодируемого слова (его коэффициенты - символы считанные из ВЗУ). Компоненты синдрома определяются подстановкой корней порождающего многочлена д(х) в многочлен декодируемого
слова
(ol+b) C(ai+b)+
+ e() e(ai+b), i 6J-:1, и зависят только от многочлена ошибок. Значение U(x) чаще всего вычисляют по
схеме Горнера:
U(xH-(Un-i х+ Un-2)x+...Ui)x+U0. Тогда 1-ю компоненту синдрома дает последний член последовательности Si , Si, с з с t с t+i с п Ь| ,...-oi . о) ,...,о| ,
Вычисление членов последовательности осуществляется по рекуррентной формуле
S + 1 Sfai+b fUn-i-1. ,
При глубине перемежения символов кодовых слов в секторе, равной А, сектор дан- ных можно представить в виде последовательности символов Vn-io, Vn1,1Vn-i, A-i: Vn-2.o, Vn-2,i,, Vn-2A-i,...; Voo
Vo.iV0. A-1.
Тогда вычисление синдромов кодовых слоев в секторе данных можно реализовать .по формуле
Sfj+1 Sl1iflrl+b+Un-t-ij. (1)
где i меняется от 0 до 1-1: J - от 0 до А-1; t от 0 до n-1; Sftj 0 для всех I и J.
Кодирование систематического кода Рида-Соломона заключается в размещении информационных символов в старших разрядах кодового слова и вычислении контрольных символов.
Пусть а(х) информационный многочлен степени k-1. тогда кодовое слово можно представить в виде
с(х)х -a(x) + q(x),
где q(x) - остаток от деления многочлена х х х а(х) на многочлен д(х) (коэффициенты q(x) - контрольные символы).
Остаток можно получить в результате завершения после k шагов рекуррентной процедуры, имеющей следующий вид: q x) ql(x) х+ д(х) (qVi + ак-1-t),
или с учетом перемежения
чЬ+ 1 ql - и + QI (ак -1 - t.j + q| -i.j) (2)
где I меняется от 0 до 1-1; j - от 0 доЯ-1; t - отОдок-1и qfj 0, q -i,j 0. .
Устройство работает следующим образом.
При вычислении синдромов по формуле (1) текущие компоненты синдрома Sij хранятся в блоке 1 оперативной памяти по адресу, определяемому первым формирователем 7 - счетчиком компонент синдрома и контрольных символов и вторым формирователем 8 - счетчиком кодовых слов. Первый формирователь 7 предназначен для реализации перебора значений индекса I из формулы (1), второй формирователь 8 предназначен для реализации перебора значений индекса. Счетчики формирователей 7 и 8 - двоичные с коэффициентами пересчета соответственно I и А.
Умножение Si.j на О: осуществляется с помощью блока 2, содержащего 21 таблиц умножения на постоянные коэффициенты. Каждая из таблиц содержит 2Г г-разрядных строк. Для умножения элемента поля, хранящегося в первом регистре 4, на постоянный коэффициент необходимо с помощью управляющего входа 14 блока 2 выбрать группу из I таблиц, используемых при декодировании, и с помощью вторых адресных входов блока 2 выбрать таблицу
умножения на коэффициент d ь . Для реализации сложения в формуле (1) используется блок 3 суммирования по модулю два, реализующий поразрядное суммирование по модулю два элементов поля.
Реализация вычисления синдромов по формуле (1) позволяет устройству обрабатывать сектор данных в процессе считывания его с носителя (в процессе ввода с входов 12). Вычисление всех синдромов завершается после считывания последнего символа последнего кодового слова в секторе,
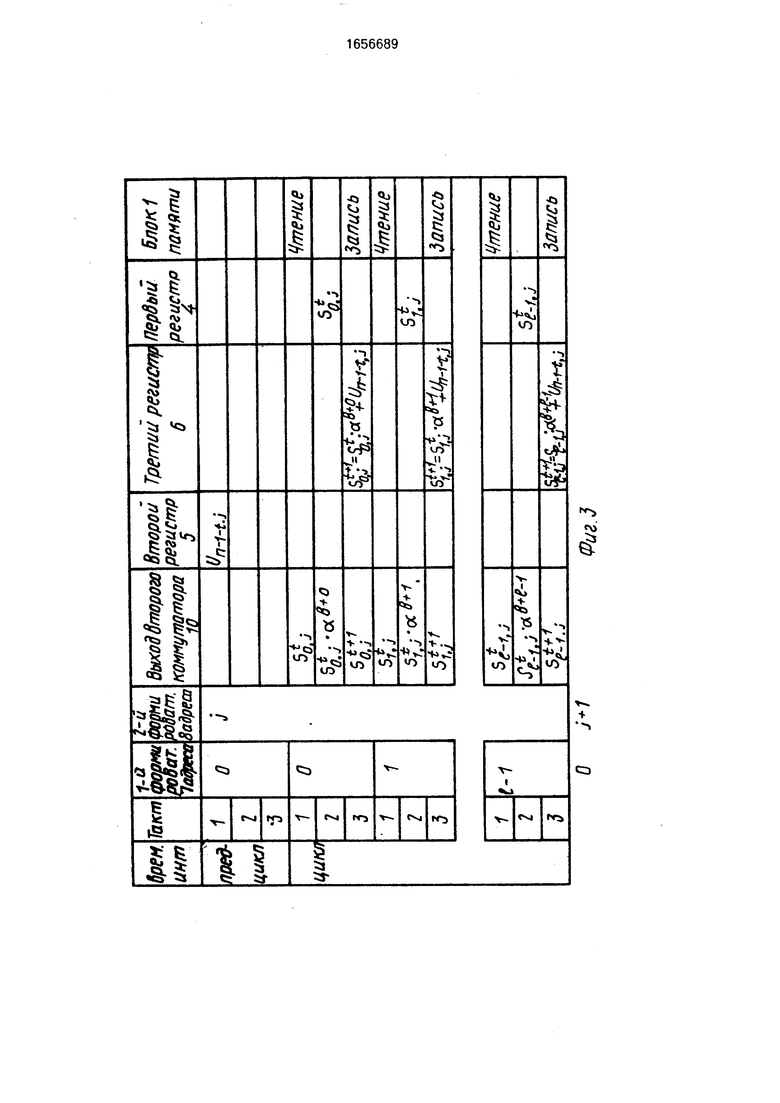
На фиг. 3 изображен процесс обработки очередного поступившего в устройство символа j-ro кодового слова. Обработка симво- ла осуществляется за 3(1+1) тактов. Интервал времени, состоящий из первых трех тактов, называют предциклом, интервал времени, состоящий из последующих 31 тактов, называют циклом. В предцикле через второй коммутатор 10 во второй регистр 5 помещается символ кодового слова U n-1-t.j. поданный на информационные входы 12 устройства. Содержимое первого формирователя 7 адреса не меняется и равно нулю (). Цикл состоит из I групп, каждая из трех тактов. Содержимое первого формирователя 7 увеличивается на 1 по модулю
5
I в момент завершения третьего такта в группе ().
В каждой группе цикла устройство выполняет одни и те же операции над различными компонентами синдрома (таблицы умножения на постоянные коэффициенты при этом используются разные). В первом такте каждой группы текущая компонента синдрома Sij1 считывается мз блока 1 опера0 тивной памяти через второй коммутатор 10 в первый регистр 4. Во втором такте значение Sij1. умноженное на сР , через второй коммутатор 10 подается на вторые входы блока 3 суммирования и по окончаниютактасумма
Sfj о5 + Un - 1 - t,j запоминается в третьем регистре 6. В третьем такте новое значение компоненты синдрома Si.jt+ че0 рез второй коммутатор 10 записывается в блок 1 оперативной памяти. Таким образом, каждая компонента сидрома обрабатывается три такта. В конце цикла содержимое второго формирователя 8 адреса увеличива5 ется на единицу по модулю А и устройство готово обработать символ следующего кодового слова Un-i-t,j+ 1 (или Un-2-t.o, если Я-1).
Перед началом вычисления синдромов
0 первый 7 и второй 8 формирователи адреса должны быть установлены в О. Обработка первых А символов Un-i,o,Un-i.i... .Vn - 1 X - 1 отличается от обработки всех других символов тем, что в первом такте
5 каждой группы цикла в первый регистр 4 через второй коммутатор 10 заносится не содержимое определенной ячейки блока 1 оперативной памяти, а нулевой элемент поля из источника 11 нулевого кода. Таким
0 образом реализуются начальные условия формулы (1) Si,..
При выгрузке синдромов из устройства содержимое блока 1 оперативной памяти через второй коммутатор 10 подается на
5 выходы 15 устройства. После выгрузки одной компоненты синдрома содержимое первого формирователя 7 увеличивается на 1 по модулю I. После завершения выгрузки синдрома целиком содержимое второго
0 формирователя 8 увеличивается на единицу.
В режиме кодирования реализация вычисления контрольных символов по формуле (2) позволяет устройству обрабатывать
5 информационную последовательность в процессе записи ее на носитель. Вычисление всех контрольных символов завершается после поступления в устройство последнего символа информационной последовательности, после чего контрольные
символы всех кодовых слов сразу же записываются на носитель.
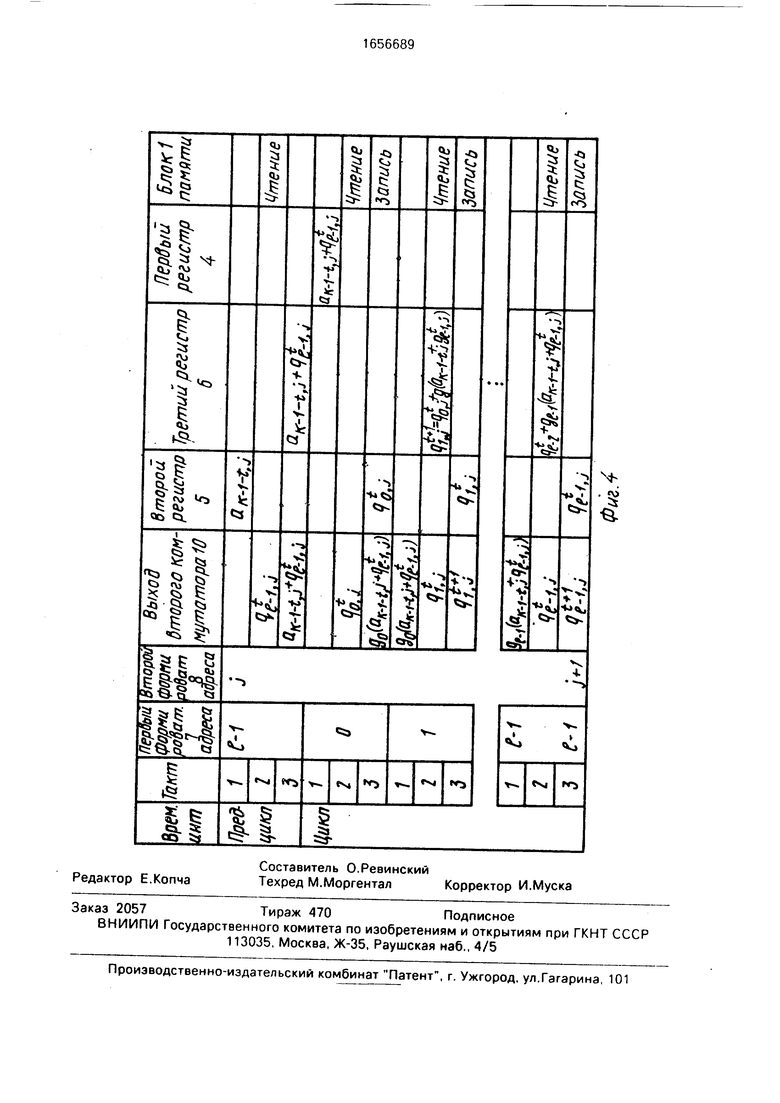
На фиг. 4 изображен процесс обработки очередного символа информационной части j-ro кодового слова. В первом такте пред- цикла через второй коммутатор 10 во второй регистр 5 помещается символ информационной части кодового слова aic-1-t.j. подан- ный на информационные входы 12 устройства. Во втором такте предцикла из блока 1 оперативной памяти считывается текущий контрольный символ дм,) и через второй коммутатор 10 подается на вторые входы блока 3 суммирования по модулю два. В конце второго такта сумма ak-1-t.j + qi-i.j1 запоминается в третьем регистре 6. В третьем такте предцикла содержимое третьего регистра 6 через второй коммутатор 10 пересылается в первый регистр 4.
Первая группа тактов цикла отличается от последующих из-за необходимости учета условия q-i.). Во втором такте первой группы из блока 1 оперативной памяти считывается текущий контрольный символ qoj1, поступающий затем через второй коммутатор 10 на входы второго регистра 5, в котором он запоминается по окончанию такта для использования при вычислении qijt+ . В третьем такте с выходом блока 2 умноженияпроизведение
9о (aic - 1 - t.j + qf - i.j) (Ј. з а п и с ы - вается в блок 1 оперативной памяти.
Во второй - 1-й группах цикла устройство выполняет одни и те же операции над различными контрольными символами (таблицы умножения на постоянные коэффициенты при этом используют разные). В первом такте второй - 1-й групп произведение gi (ak - 1 - t.j + qf - i,j) через второй коммутатор 10 с выходов блока 2 умножения подается на вторые входы блока 3 суммирования по модулю два и в конце такта сумма
qf - i.j + di (ak - 1-tj + qf - i.j) запоминается в третьем регистре 6 Во втором такте из блока 1 оперативной памяти считывается текущий контрольный символ qi,/, который затем подается через второй коммутатор iO на входы второго регистра 5, где и запоминается по окончанию такта для использования при вычислении qi+i.jt+ В третьем такте с выходов третьего регистра 6 символ qi,jt+13:i tiCbiBaeTCfl в блок 1 оперативной памяти через второй коммутатсо 10
Содержимое первого формирователя 7 в конце третьего такта предцикла и в,,ех. групп цикла, кроме последней, увеличивается на 1 по модулю I. В конце цикля содержимое второго формирователя 8
увеличивается на 1 по модулю Я и устройство готово обработать следующий символ информационной последовательности. Начальная установка первого формирователя
7 в режиме кодирования равна 1-1, второго формирователя 8 равна нулю. Начальные условия формулы (2) qi,j° 0 реализованы таким же образом, как начальные условия формулы (1) Si,j° 0.
Обработка одного символа информационной последовательности занимает 3(1+1) тактов.
При выгрузке контрольных символов из устройства кодирования и вычисления синдромов содержимое блока 1 оперативной памяти через второй коммутатор 10 подается на выходы 15 устройства. После оыгрузки очередного контрольного символа содержимое второго формирователя 8 увеличивается на 1 по модулю А. После выгрузки контрольных символов, расположенных на одной и той же позиции перемеженных кодовых слов, содержимое первого формирователя 7 уменьшается на 1. Перед
выгрузкой контрольных символов первый формирователь 7 должен хранить число 1-1, второй формирователь 8 - нуль.
Обьем оборудования в предлагаемом устройстве меньше, чем в известном на 1-1
блоков оперативной памяти, 21-1 блоков постоянной памяти, 1-1 блоков суммирования по модулю два, I регистров, один 1-входовый сумматор элементов поля Галуа.
Формула изобретения
Устройство кодирования и вычисления синдромов помехоустойчивых кодов для коррекции ошибок во внешней памяти ЭВМ, содержащее первый буферный регистр, выходы которого соединены с первыми адресными входами блока умножения на постоянные коэффициенты, второй буферный регистр, блок суммирования по модулю два, выходы которого подключены к входам
третьего буферного регистра, и блок опера- пивной памяти, отличающееся тем, что, с целью упрощения устройства, в него введены формирователи адреса, коммутаторы и источник нулевого кода, первые входы
первого и второго коммутаторов являются соответственно адресными информационными входами устройства, управляющий вход блока умножения на постоянные коэффициенты является входом управления режимом
устройства, выходы второго буферного регистра соединены с первыми входами блока суммирования по модулю два, выходы первого и второго формирователей адреса соединены соответственно с вторыми и третьими
входами первого коммутатора, первые и вторые выходы которого подключены соответственно к вторым адресным входам блока умножения на постоянные коэффициенты и адресным входам блока оперативной памяти, выходы которых и выходы буферного регистра и источника нулевого кода соединены соответственно с вторыми - пятыми входами второго коммутатора, выходы которого подключены к информационным входам блока оперативной памяти, вторым входам блока суммирования по модулю два, входам первого и второго буферных регистров и являются выходами устройства.


| название | год | авторы | номер документа |
|---|---|---|---|
| Устройство для вычисления синдромов кода Рида-Соломона | 1990 |
|
SU1751860A1 |
| Устройство обнаружения и исправления ошибок в кодах Рида-Соломона | 1986 |
|
SU1381719A1 |
| Устройство защиты от ошибок внешней памяти | 1981 |
|
SU1018119A1 |
| УСТРОЙСТВО КОДИРОВАНИЯ-ДЕКОДИРОВАНИЯ ИНФОРМАЦИИ | 1994 |
|
RU2115231C1 |
| Устройство для исправления ошибок | 1984 |
|
SU1216832A1 |
| Устройство для защиты от ошибок в памяти | 1982 |
|
SU1151969A1 |
| УСТРОЙСТВО ДЛЯ КОРРЕКЦИИ ОШИБОК | 1991 |
|
RU2037271C1 |
| Устройство для исправления стираний | 1989 |
|
SU1633498A1 |
| КОДЕК ПОМЕХОУСТОЙЧИВОГО ЦИКЛИЧЕСКОГО КОДА | 2003 |
|
RU2254676C2 |
| Канальный кодек | 1990 |
|
SU1798922A1 |
Изобретение относится к вычислительной технике. Его использование в системах помехоустойчивого кодирования позволяет упростить устройство, содержащее блок 1 оперативной памяти, блок 2 умножения на постоянные коэффициенты, блок 3 суммирования по модулю два, буферные регистры 4-6. Благодаря введению формирователей 7, 8 адреса, коммутаторов 9, 10 и источника 11 нулевого кода в устройстве организуются последовательные процедуры кодирования и вычисления синдромов. 4 ил.
Фиг.2
Ј
Ч
I
| Устройство обнаружения и исправления ошибок в кодах Рида-Соломона | 1986 |
|
SU1381719A1 |
| кл | |||
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| кл | |||
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
