Изобретение относится к приборостроению и может быть использовано при автоматическом распознавании речевых сигналов,
Подавляющее большинство известных в настоящее время способов автоматического распознавания речевых сигналов базируется на определенных математических формализмах, как например, матстатисти- ка, теория вероятности, теория нечетких множеств, скрытые марковские модели, быстрое преобразование Фурье, функции Уол- ша, способы линейного и нелинейного предсказания и другие.
Недостатком таких способов является сложность процесса распознавания речевых сигналов. Устройства распознавания речевых сигналов, реализующие такие способы, используют достаточно дорогое специализированное оборудовайие. Для выделения отличительных параметров требуется либо высокоскоростной цифровой компьютер, либо большое количество аналоговых каналов связи, ели они работают в реальном времени. Сопоставление образов также является трудоемким процессом с вычислительной точки зрения и сопряжено со значительными временными затратами.
Наиболее близким к предлагаемому изобретению является способ распознавания речевых сигналов, заключающийся в сегментации речевого сигнала, формировэXI
х|
3
со
О
нии эталонов и определении степени подобия речевого сигнала с эталонами, по результатам которого производят распознавание речевых сигналов. В качестве сегмента в этом способе используют Г- С-Г слоги (гласная-согласная-гласная), В качестве отличительного параметра входного речевого сигнала выделяют коэффициент автокорреляции речевого сигнала на основании спектрального анализа методом мак- симального правдоподобия. При осуществлении согласования выделенных из входного речевого сигнала сегментов со стандартными кодами-эталонами осуществляют и: нейное согласование без фикси- рования конечных точек, в результате чего обеспечивается возможность распознавания сегментов с высокой точностью, а также повышается степень распознавания отдельных слов.
Способ вычисления коэффициентов автокорреляции речевого сигнала на основании спектрального анализа является сложным и громоздким, так как требует анализа большого количества спектральных со- ставляющих. Его реализация сопряжена со значительными временными затратами, затратами специальных аппаратных средств и памяти, что, в свою очередь, приводит к удорожанию устройства..
Целью изобретения является упрощение процесса распознавания речевых сигналов и повышение его быстродействия.
Поставленная цель достигается тем, что в способе распознавания речевых сигналов, заключающемся в сегментации речевого сигнала, формировании эталонов и определении степени подобия речевого сигнала с эталонами, по результатам которого производят распознавание речевых сигналов, со- гласно изобретению, формируют непрерывную последовательность отсчетов входного речевого сигнала в заданные моменты изменения направлений приращения его амплитуд, полученное сжатое параметрическое отображение сигнала сегментируют по инвариантным к диктбру при- знакам, эталоны речевых сигналов формируют по фиксированкому числу классифицирующих параметров, не зависящих от темпа произнесения и изменения частоты основного тона голоса, на каждом сегменте, на этапе распознавания формируют с учетом классифицирующих параметров модели входных речевых сигналов, находят эталон по максимальной степени его подобия с моделью, а степень подобия речевого сигнала с эталонами определяют при нормированном сравнении модели только с полученным эталоном.
Формирование сжатого параметрического отображения входного речевого сигнала при сохранении достаточного минимума продуктивных элементов для анализа и классификации обеспечивает по сравнению с прототипом сокращение объема памяти и уменьшение времени на анализ. Для последующего анализа в отличие от применяемых в прототипе универсальных математических методов обработки сигнала в заявляемом способе используется система правил, основанных на точных знаниях определенных общих свойств речевых сигналов, заключающихся в сегментации речевого сигнала по инвариантным к диктору признакам, формировании на каждом сегменте эталонов речевых сигналов по фиксированному числу классифицирующих параметров, не зависящих от темпа произнесения и изменения частоты основного тона голоса, формировании на этапе распознавания параметров модели входных речевых сигналов с учетом классифицирующих параметров, нахождении эталона по максимальной степени его подобия с моделью и определении степени подобия речевого сигнала с эталонами при нормированном сравнении модели только с полученным эталоном. Причем эти правила реализуются преимущественно элементарными логическими операциями проверки типа равно-не равно, больше- меньше, в результате чего также упрощается процесс обработки речевого сигнала и уменьшаются затраты на его выполнение.
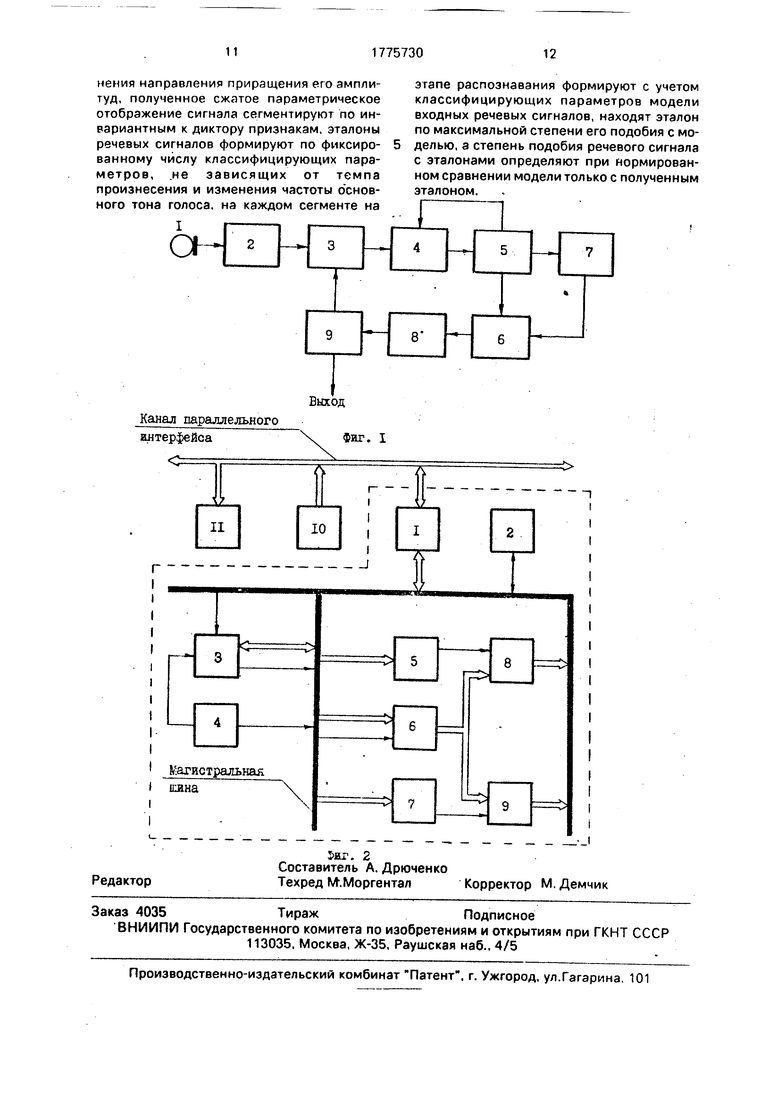
На фиг,1 представлена блок-схема одного из возможных вариантов устройства для осуществления предложенного способа автоматического распознавания речевых сигналов; на фиг.2 - блок-схема анализатора речевых сигналов.
Предлагаемый способ заключается в следующем.
Входной речевой сигнал преобразуют в последовательность чисел (отсчетов), являющихся параметрическим отображением соответствующих фрагментов речевого сигнала на фиксированных отрезках времени длительностью 10-12 миллисекунд. При этом сигнал сжимают до нескольких сот бит в секунду. Преобразованный входной речевой сигнал расчленяют на отдельные участки, называемые сегментами, по инвериантным к диктору признакам, например в местах разрывов. Полученное число таких сегментов запоминают как классифицирующий параметр. На каждом сегменте определяют 6 локальных классифицирующих параметров, не зависящих от темпа произнесения и изменения частоты основного тона голоса: начальное среднее, начальный пик-максимум, конечное среднее, конечный пик-максимум, глобальный пик- максимум и глобальный средний максимум. Начальное среднее определяют путем ус- реднения первых L отсчетов сегмента. Начальное среднее всегда попадает в область первого звука сегмента, который несет на себе отпечатки коартикуляционных процессов. Начальный пик-максимум опреде- ляют как максимальное собственное значение, выявленное на первых L отсчетах сегмента. Как и начальное среднее, начальный пик-максимум всегда характеризует первый звук сегмента, испытывающий на себе влияние последующего звука в силу дейстг.ия закона коартикуляции. Конечное среднее определяют в конце сегмента аналогично определению начального среднего. Конечный пик-максимум определяют в кон- це сегмента аналогично определению начального пик-максимума. Глобальный пик-максимум определяют как максималь- ноа собственное значение отсчета, выявленное на сегменте в целом. Глобальный пик-максимум, независимо от того, какое место он занимает на сегменте, всегда является признаком одного и того же функционального фрагмента, испытывающего воздействие коартикуляции, обусловлен- ной только данным фонетическим наполнением. Глобальный средний максимум получают путем усреднения каждых L смежных отсчетов на всем сегменте. Глобальный средний максимум представляет собой фун- кционально детерминированную область, отражающую фонетическое окружение на конкретном сегменте. Вышеуказанные классифицирующие параметры, полученные для каждого сегмента, а также число сегментов в речевом сигнале на этапе обучения заносят в память как эталоны речевых сигналов. На этапе распознавания по правилам, перечисленным выше, формируют модели входных речевых сигналов, которые сравнивают с хранящимися в памяти эталонами. Первоначально сравнивают только те эталоны, число сегментов в которых равно числу сегментов в модели. Сравнение осу- ществляют путем вычитания меньшего соб- ственного значения одноименного классифицирующего параметра из большего. Полученные при каждом таком вычитании разности суммируют и запоминают. Запоминают также порядковые номера эта- лонов, для которых были получены соответствующие суммы разностей, и их адреса в памяти. После сравнения модели речевого сигнала с последним эталоном находят эталон, для которого была получена минимальная сумма разностей. Далее осуществляют процедуру нормированного сравнения модели с этим единственным эталоном. Сравнение производят также путем вычитания меньшего собственного значения одноименного классифицирующего параметра из большего и накопления суммы разностей, предварительно проверяя, является ли большее больше некоторого эмпирически получен ного числа К. Если получают отрицательный результат, то оба сравниваемых числа удваивают, после чего вновь осуществляют проверку, является ли большее больше К. Вычитание меньшего из большего и накопление суммы разностей выполняют после выполнения вышеуказанного условия. После завершения сравнения всех одноименных классифицирующих параметров эталона и модели полученную сумму разностей делят на число сегментов, подвергавшихся анализу, и частное сравнивают с некоторым эмпирически полученным числом Р. Если частное меньше числа Р, то предъявленный для распознавания речевой сигнал принадлежит к тому же классу, что и выбранный эталон. Задача распознавания считается решенной.
Изобретение иллюстрируется следующими примерами.
Устройство для реализации предлагаемого способа (фиг.1) содержит микрофон 1, подключенный ко входу блока 2 перекодирования речевого сигнала, выход которого соединен с первым входом блока 3 определения границы начала и конца речевого сигнала. Выход блока 3 связан с первым входом блока 4 сегментации, выход которого подключен ко входу блока 5 формирования классифицирующих параметров. Первый выход блока 5 формирования классифицирующих параметров подключен ко второму входу блока 4 сегментации, второй выход - к первому входу блока 6 сравнения классифицирующих параметров, а третий выход - ко входу блока 7 эталонов, выход которого соединен со вторым входом блока 6 сравнения классифицирующих -параметров. Выход блока 6 сравнения классифицирующих параметров через блок 8 нормирования связан со входом классификатора 9, выход которого подключен ко второму входу блока 3 определения границ начала и конца речевого сигнала. Выход классификатора 9 является выходом устройства.
Способ осуществляется следующим образом.
Входной речевой сигнал с микрофона 1 поступает на блок 2 перекодирования речевого сигнала постоянно, независимо от того, содержится в нем полезная информация или нет. Блок 2 перекодирования речевого сигнала осуществляет непрерывный подсчет моментов изменения направления при- ращения амплитуд сигнала в его положительной области на фиксированных отрезках длительностью 10-12 миллисекунд. В результате через каждые 10-12 миллисекунд на выходе блока 2 перекодирования речевого сигнала появляется семиразрядный код целевого положительного числа, называемый отсчетом, Непрерывная последовательность отсчетов, полученная на всем протяжении исходного речевого сигнала, является его полным и сжатым параметрическим отображением. При этом для кодирования исходного речевого сигнала длительностью в 1 секунду понадобится в данном случае не более 700 бит. С выхода блока 2 перекодирования речевого сигнала сигнал поступает на первый вход блока 3 определения границы начала и конца речевого сигнала, который осуществляет текущую проверку каждого отсчета. Если собственное значение проверяемых отсчетов меньше J и на текущий момент начало речевого сигнала в потоке данных не выявлено, то он блокирует их передачу на последующие блоки. В том случае, когда хотя бы М следующих подряд отсчетов превысят знач&ние J, блок 3 определения границы начала и конца речевого сигнала обеспечивает передачу всех отсчетов в блок 4 сегментации и их запись в буферную память до того момента, пока не будут выявлены N следующих подряд отсчетов с собственным значением J, В этом случае блок 3 определения границы начала и конца речевого сигнала прекращает проверку отсчетов, продолжающих поступать с выхода блока 2 перекодирования речевого сигнала, и вырабатывает сигнал, разрешающий дальнейшую обработку содержимого буферной памяти в блоке 4 сегментации. Блок 4 сегментации осуществляет расчленение последовательности отсчетов на сегменты в местах разрывов. Под разрывами прдразу- меваются те участки последовательности параметричесхого отображения, на которых собственные значения смежных отсчетов меньше J. Адреса границ сегментов передаются в блок 5 формирования классифицирующих параметров, в котором на каждом сегменте определяются 6 классифицирующих параметров: начальное среднее сегмента на L отсчетах, начальный пик-максимум на L отсчетах, конечное среднее сегмента на L отсчетах, конечный пик- максимум на L отсчетах, глобальный пик-максимум на сегменте, глобальный
средний максимум сегмента на L отсчетах. Для каждого классифицирующего параметра резервируется 1 байт памяти. Максимальное число анализируемых сегментов
равно 5. Если в речевом сигнале более 5 сегментов, анализируются только первые пять. Фактическое число сегментов, выявленных на &сей последовательности параметрического отображения входного
0 речевого сигнала, запоминается в отдельном ведущем байте и в дальнейшем используется как классифицирующий параметр и как указатель направления перебора эталонов в процессе их сравнения с моделью
5 входного речевого сигнала при его распознавании. На этапе обучения данные, полученные в блоке 5 формирования классифицирующих параметров, запоминаются в блоке 7 эталонов как исходные эта0 лоны. В режиме распознавания схема работает аналогичным образом с той разницей, что после завершения формирования классифицирующих параметров, т.е. получения модели речевого сообщения, управ5 ление пеоедается блоку б сравнения классифицирующих параметров. Блок 6 сравнения классифицирующих параметров осуществляет сравнение эталонов, хранящихся в блоке 7 эталонов, с полученной мо0 делью речевого сигнала, причем сравниваются только те эталоны, сегментный состав которых адекватен модели. В процессе сравнения вычисляется сумма разностей одноименных классифицирую5 щих параметров модели и эталона. Порядковый номер эталона, для которого была получена минимальная сумма разностей, запоминается в специальной ячейке памяти. Кроме того, в другой ячейке памяти запо0 минается адрес начала эталона в блоке 7 эталонов, После завершения сравнения модели входного речевого сигнала с эталонами из памяти блока 7 эталонов извлекается эталон, давший минимальную сумму разно5 стей, и управление передается блоку 8 нор- мирования. Блок 8 нормирования осуществляет ступенчатое нормированное сравнение по правилам параметров эталона и модели и вычисляет нормированную сум0 му разностей. В классификаторе 9 осуществляется сравнение нормированной суммы разностей с эмпирически полученной константой доверительного интервала Р. Влчэм случае, когда вычисленная нормированная
5 сумма разностей больше Р, устройство выдает сообщение Повторите, в противном случае оно выдает порядковый номер распознанного речевого сигнала согласно используемому рабочему словарю Дальнейшее преобразование результата
распознавания в адекватную реакцию конкретной системы обеспечивается пользователем по его усмотрению с учетом специфики решаемой задачи. После выдачи результата распознавания классификатор 9 снимает блокировку в блоке 3 определения границы начала и конца речевого сигнала и процесс обработки сигнала, поступающего с микрофона, повторяется аналогичным образом.
Анализатор речевых сигналов (фиг.2) представляет собой конкретную конструктивную реализацию блоков 2-9, представленных на фиг.1. Анализатор (на схеме выделен штриховыми линиями) выполнен на основе однокристального микропроцессора К1801ВМ1 и БИС серии К 588.
Анализатор речевых сигналов содержит блок 1 магистральных приемопередатчиков, выполненный на интегральных микросхе- мах (ИМС) К588ВА1; регистр 2 начального пуска, выполненный на элементах дискретной логики; однокристальный микропроцессор 3 на ИМС К1801ВМ1; узел 4 тактового генератора, выполненный на отдельных ло- гических элементах; схему 5 управления оперативным запоминающим устройством (ОЗУ), собранную на ИМС К588ВГ2; регистр 6 адреса на ИМС К588ИР1; схему 7 управления постоянным запоминающим устройст- вом, выполненную на ИМС К588ВГ2; блок 8 ОЗУ на ИМС К537РУЗ и блокЗПЗУ, выполненный на ИМС К573РФ4. Данные в анализатор поступают по каналу параллельного интерфейса с преобразователя 10 речевого сигнала. Результат распознавания выдается по каналу параллельного интерфейса на устройство 11 отображения (например, дисплей).
При включении питания регистр 2 на- чального пуска автоматически запускает однокристальный микропроцессор 3. Связь однокристального микропроцессора 3 со всеми блоками анализатора осуществляется через магистральную шину. Работой од- нокристального микропроцессора 3 управляет через магистральную шину блок 9 ПЗУ. В блоке 9 ПЗУ физически зашиты в виде дискретных сигналов все инструкции, которые должен выполнить однокристаль- ный микропроцессор 3 при обработке данных, поступающих с преобразователя 10 речевых сигналов через канал параллельного интерфейса и блок 1 магистральных приемопередатчиков на магистральную шину.
Речевой сигнал в виде последовательности отсчетов помещается в блок 8 ОЗУ. Здесь, в блоке 8 ОЗУ. осуществляется его полная обработка: на этапе обучения выполняется анализ, формируются и запоминаются эталоны речевых сигналов, на этапе распознавания выполняется анализ. Формируются модели входных речевых сигналов. которые затем сравниваются с эталонами и результат выдается через блок 1 магистральных приемопередатчиков и канал параллельного интерфейса на устройство 11 отображения. Адресным пространством ОЗУ и ПЗУ управляет регистр б адреса. Схема 5 управления ОЗУ обеспечивает режим записи и чтения данных в ОЗУ. Схема 7 управления ПЗУ обеспечивает считывание управляющих инструкций из блока 9 ПЗУ в однокристальный микропроцессор 3.
При реализации способа по изобретению в качестве речевых сигналов, предъявляемых для распознавания, могут использоваться как отдельные слова, так и короткие фразы любого индо-европёйского языка, произносимые слитно.
Таким образом, использование изобретения обеспечивает по сравнению с прототипом существенную простоту процесса распознавания речевых сигналов и повышение его быстродействия. Устройство, реализующее предлагаемый способ, не содержит громоздких и дорогостоящих блоков. Контрольные испытания устройства проводились в комплексе с микро-ЭВМ ДВК-3. Устройство имело статус речевого терминала, к которому могла обратится любая программа пользователя. Устройство ориентировано на произвольный предметный словарь средней трудности объемом до 200 фиксированных речевых сигналов, в качестве которых использовались кзк отдельные слова, так и короткие фразы длительностью до 3-4 секунд, произносимые слитно. Быстродействие устройства составило 0,1 с. Расход оперативной памяти: для средств программной поддержки - не более 2 кбайт, для эталонов - из расчета 32 байта на слово. Аппаратные средства выполнены на плате размерами 250x135x22 мм, на которой установлены 10 корпусов микросхем с малой степенью интеграции, Ориентировочная стоимость платы при условии мелкосерийного производства 300 руб.
Формула изобретения
Способ автоматического распознавания речевых сигналов, заключающийся в сегментации речевого сигнала, формировании эталонов и определении степени подобия речевого сигнала с эталонами, по результатам которого производят распознавание речевых сигналов, отличающий- с я тем, что, с целью упрощения и повышения быстродействия, формируют непрерывную последовательность отсч-етов входного речевого сигнала в заданные моменты изменения направления приращения его амплитуд, полученное сжатое параметрическое отображение сигнала сегментируют по инвариантным к диктору признакам, эталоны речевых сигналов формируют по фиксированному числу классифицирующих параметров, не зависящих от темпа произнесения и изменения частоты о снов- ного тона голоса, на каждом сегменте на
аэтапе распознавания формируют с учетом классифицирующих параметров модели входных речевых сигналов, находят эталон по максимальной степени его подобия с моделью, а степень подобия речевого сигнала с эталонами определяют при нормированном сравнении модели только с полученным эталоном.




| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ РАСПОЗНАВАНИЯ ИЗОЛИРОВАННЫХ СЛОВ РЕЧИ С АДАПТАЦИЕЙ К ДИКТОРУ | 1994 |
|
RU2047912C1 |
| СПОСОБ КОНТАКТНО-РАЗНОСТНОЙ АКУСТИЧЕСКОЙ ИДЕНТИФИКАЦИИ ЛИЧНОСТИ | 2011 |
|
RU2451346C1 |
| МЕТОД РАСПОЗНАВАНИЯ ДИКТОРА И УСТРОЙСТВО ДЛЯ ЕГО ОСУЩЕСТВЛЕНИЯ | 2002 |
|
RU2230375C2 |
| СПОСОБ ГИБРИДНОЙ ГЕНЕРАТИВНО-ДИСКРИМИНАТИВНОЙ СЕГМЕНТАЦИИ ДИКТОРОВ В АУДИО-ПОТОКЕ | 2013 |
|
RU2530314C1 |
| СПОСОБ И УСТРОЙСТВО АВТОМАТИЧЕСКОЙ ВЕРИФИКАЦИИ ЛИЧНОСТИ ПО ГОЛОСУ | 2008 |
|
RU2399102C2 |
| СПОСОБ ВЕРИФИКАЦИИ ПОЛЬЗОВАТЕЛЯ В СИСТЕМАХ САНКЦИОНИРОВАНИЯ ДОСТУПА | 2007 |
|
RU2351023C2 |
| УСТРОЙСТВО ДЛЯ РАСПОЗНАВАНИЯ ИЗОЛИРОВАННЫХ СЛОВ | 1998 |
|
RU2136059C1 |
| СПОСОБ РАСПОЗНАВАНИЯ СЛОВ РЕЧИ | 2005 |
|
RU2296376C2 |
| СПОСОБ АУТЕНТИФИКАЦИИ ДИКТОРА ПО ПАРОЛЬНОЙ ФРАЗЕ | 2009 |
|
RU2422921C2 |
| Способ и устройство классификации сегментов зашумленной речи с использованием полиспектрального анализа | 2014 |
|
RU2606566C2 |
Изобретение относится к приборостроению. Цель изобретения - упрощение и по- вышение быстродействия, Способ заключается в сегментации речевого сигнала, формировании эталонов к определении степени подобия речевого сигнала с эталонами, по результатам которого производят распознавание речевых сигналов. Согласно изобретению формируют непрерывную последовательность отсчетов входного речевого сигнала в заданные моменты изменения направлений приращения его амплитуд. Полученное сжатое параметрическое отображение сигнала сегментируют по инвариантным к диктору признакам, эталоны речевых сигналов формируют по фиксированному числу классифицирующих параметров, не зависящих от темпа произнесения и изменения частоты основного тона голоса, на каждом сегменте, на этапе распознавания формируют с учетом классифицирующих параметров модели входных речевых сигналов, находят эталон по максимальной степени его подобия с моделью, а степень подобия речевого сигнала с эталонами определяют при нормированном срав- нении модели только с полученным эталоном. 2 ил. 10 С
Канал параллельного интерфейса
Фиг. I
| Патент США Nfe 4759068, кл | |||
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |
| Гребенчатая передача | 1916 |
|
SU1983A1 |
| Способ анализа и синтеза речи и устройство для его осуществления | 1986 |
|
SU1501138A1 |
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |
| Устройство для охлаждения водою паров жидкостей, кипящих выше воды, в применении к разделению смесей жидкостей при перегонке с дефлегматором | 1915 |
|
SU59A1 |
| кл | |||
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |
| Колосниковая решетка с чередующимися неподвижными и движущимися возвратно-поступательно колосниками | 1917 |
|
SU1984A1 |
