Изобретение относится к автоматике и вычислительной технике и может быть использовано в системах управления технологическим, бытовым и другим оборудованием, в автоматических справочных системах, системах автоматического перевода, системах понимания речи и т.д.
Известен способ распознавания слов в слитной речи, реализованный в системе автоматического понимания речи фирмы LDC [1].
Суть способа состоит в том, что с произнесением речевого высказывания периодически берут выборки акустического сигнала этого высказывания, оцифрованного с заданной частотой квантования, через фиксированные интервалы времени и по совокупности этих выборок вычисляют функционал, определяющий текущее акустическое состояние, при этом полученную последовательность текущих акустических состояний используют для восстановления последовательности слов (рабочей гипотезы), произнесенных в исходном речевом высказывании.
Особенностью известного способа является то, что последовательность текущих акустических состояний преобразуют в А-матрицу, которая используется при дальнейшем анализе вместо исходного речевого сигнала. А-матрица содержит различные параметры речевого сигнала, включая его фонетическую транскрипцию. На основе А-матрицы получают рабочую гипотезу, т.е. последовательность слов, которая предположительно произнесена в исходном речевом высказывании. Обработку А-матрицы производят слева направо - блок предварительного выделения слов обрабатывает слова из списка наиболее вероятных слов и формирует информацию о степени совпадения данного слова и начального участка речевого сигнала, далее блок управления анализирует полученную информацию и при помощи имеющейся синтаксической и семантической информации определяет список слов, которые могут следовать за данным словом, и передает их в блок предварительного выделения слов, далее процедура повторяется, пока не достигнут конец речевого высказывания.
Недостатком этого способа является низкая точность распознавания, обусловленная тем, что: 1) стратегия поиска рабочей гипотезы не является оптимальной в смысле максимума степени ее совпадения с исходным речевым сигналом, поскольку решение об оптимальности гипотезы принимается при каждом сравнении слова с речевым сигналом и возможна потеря оптимальной гипотезы; 2) поиск рабочей гипотезы является двухэтапным процессом - на первом этапе вычисляется А-матрица, на втором этапе находится гипотеза, таким образом, поиск рабочей гипотезы основывается на фонетической транскрипции, которая может содержать ошибки.
Известен способ распознавания слов в слитной речи, реализованный в системе автоматического понимания речи HWIM фирмы BBN [2].
Суть способа состоит в том, что с произнесением речевого высказывания периодически берут выборки акустического сигнала этого высказывания, оцифрованного с заданной частотой квантования, через фиксированные интервалы времени и по совокупности этих выборок вычисляют функционал, определяющий текущее акустическое состояние, при этом полученную последовательность текущих акустических состояний используют для восстановления последовательности слов (рабочей гипотезы), произнесенных в исходном речевом высказывании.
Особенность этого способа состоит в том, что последовательность текущих акустических состояний преобразуют в ряд фонетических транскрипций, которые записывают в виде сегментной сетки. Полученную сегментную сетку используют при поиске рабочей гипотезы. Конструкции, в наибольшей степени соответствующие словам, независимо от их расположения, направляются в блок проверки слов, где производится оценка степени совпадения. Результаты проверки объединяются с результатами лексического подбора, и, если показатель этого объединенного результата достаточно высок, слова направляются в блок синтаксического предсказания. Слова, сформированные в блоке синтаксического предсказания в соответствии с правилами используемой грамматики, добавляются справа и слева к основному слову и направляются в блок проверки слов. Далее процесс повторяется, пока не будет распознан весь речевой сигнал. Подбор слов осуществляется при помощи лексических декодирующих сетей, которые представляют всевозможные фонетические представления слова во всех возможных фонетических контекстах.
Недостатком этого способа является низкая точность распознавания, обусловленная следующими факторами: 1) стратегия поиска рабочей гипотезы не является оптимальной в смысле максимума степени ее совпадения с исходным речевым сигналом, поскольку решение об оптимальности гипотезы принимается при каждом сравнении слова с речевым сигналом и возможна потеря оптимальной гипотезы; 2) поиск рабочей гипотезы является двухэтапным процессом - на первом этапе вычисляется сегментная сетка, на втором этапе находится рабочая гипотеза, таким образом, поиск рабочей гипотезы основывается на сегментной сетке, которая может содержать ошибки, однако в отличие от первого аналога этот способ является более устойчивым к ошибкам фонетического транскрибирования.
Наиболее близким к предлагаемому является способ распознавания слов в слитной речи [3], принятый за прототип, состоящий в том, что с произнесением речевого высказывания периодически берут выборки акустического сигнала этого высказывания, оцифрованного с заданной частотой квантования, через фиксированные интервалы времени и по совокупности этих выборок вычисляют функционал, определяющий текущее акустическое состояние, при этом полученную последовательность текущих акустических состояний используют для восстановления последовательности слов (рабочей гипотезы), произнесенных в исходном речевом высказывании.
Особенностью этого способа является то, что рабочая гипотеза находится непосредственно из последовательности текущих акустических состояний при помощи сети лексического декодирования, вершинами которой являются эталонные акустические состояния, а переходы между ними задают следующие возможные эталонные акустические состояния. Сеть лексического декодирования задает закономерности следования эталонных акустических состояний в соответствии с грамматическими и фонетическими правилами языка.
Процесс декодирования начинается с выбора начальных вершин сети лексического декодирования и нахождения вершины, которой соответствует эталонное акустическое состояние, наиболее близкое текущему акустическому состоянию. Номер наиболее близкой вершины фиксируется в блоке хранения рабочего пути, который представляет собой последовательность номеров вершин. Очередное текущее акустическое состояние сравнивается с состояниями, связанными со следующими возможными вершинами сети. Наиболее близкая вершина фиксируется в блоке хранения рабочего пути. Процесс повторяется до завершения поступления текущих акустических состояний, соответствующих речевому сигналу. После завершения процесса найденный рабочий путь преобразуется в рабочую гипотезу.
Недостатком прототипа является низкая точность распознавания, связанная со следующими факторами: 1) стратегия поиска рабочей гипотезы не является оптимальной в смысле максимума степени ее совпадения с исходным речевым сигналом, поскольку решение об оптимальности гипотезы принимается в каждый момент времени; 2) при построении сети лексического декодирования не используется модель языка [5, стр.539]; 3) при расчете степени совпадения не учитывается информация о средней длительности акустических состояний [4, стр.259].
Технический результат, получаемый от внедрения изобретения, заключается в повышении точности распознавания слов в слитной речи.
Данный технический результат достигают за счет того, что в известном способе распознавания слов в слитной речи, заключающемся в том, что с произнесением речевого высказывания периодически берут выборки акустического сигнала этого высказывания, оцифрованного с заданной частотой квантования, через фиксированные интервалы времени и по совокупности этих выборок вычисляют функционал, определяющий текущее акустическое состояние, при этом полученную последовательность текущих акустических состояний используют для восстановления последовательности слов (рабочей гипотезы), произнесенных в исходном речевом высказывании путем применения сети лексического декодирования, задающей закономерности следования эталонных акустических состояний в языке, при этом с целью повышения точности распознавания проводится поиск рабочей гипотезы, являющейся оптимальной в смысле максимума степени ее совпадения с исходным речевым сигналом, путем использования алгоритма перемещаемого маркера, а рабочую гипотезу восстанавливают из маркера, находящегося в данный момент времени в конечной вершине сети лексического декодирования.
Особенностью данного способа является то, что поиск рабочей гипотезы является оптимальным в смысле максимума степени ее совпадения с исходным речевым сигналом, поскольку в основе алгоритма перемещаемого маркера, который используется для поиска рабочей гипотезы, лежит метод динамического программирования [6, стр.74].
Также при построении сети лексического декодирования могут быть использованы модель языка [5, р.539] и/или вероятности перехода между состояниями, посредством которых учитывают средние длительности фонем.
Изобретение поясняется чертежами, где на фиг.1-7 которого представлены этапы построения сети лексического декодирования; на фиг.8, 9 - алгоритм перемещаемого маркера; на фиг.10-12 - устройство, реализующее способ.
Сеть лексического декодирования создается путем выполнения следующих операций: представление речи конечным набором слов, построение возможных фонетических представлений слов, построение модели языка, создание базы данных контекстно-зависимых фонем (Трифонов), создание графа слов на основе модели языка, создание для каждого слова из множества Y фонетической сети слова, задающей возможные фонетические реализации слова, расширение графа слов при помощи фонетических сетей и замены фонем на трифоны.
Суть этих операций состоит в следующем.
1) Представляют речь конечным набором слов:
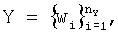
где wi - i-е слово, i=1, ..., nY.
2) Представляют слова как последовательности фонем:
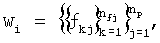
где nр - количество возможных фонетических представлений слова wi, nfj - количество фонем в j-м фонетическом представлении слова wi, fkj - k-я фонема в j-м фонетическом представлении слова wi.
3) Создают модель языка, для этого вычисляют вероятности:
p(wi/Wn),
где Wn - последовательность слов, предшествующих слову wi, длиной n.
4) Создают базу данных моделей контекстно-зависимых фонем (Трифонов), представляющих собой сеть (фиг.6), вершинами которой являются эталонные акустические состояния, а переходы между ними задают возможные переходы между эталонными акустическими состояниями в языке. С переходами связаны вероятности перехода между состояниями, которые неявным образом задают длительности акустических состояний.
5) Конструируют сеть лексического декодирования с учетом п.1, п.2, п.3, п.4.
Этапы построения сети лексического декодирования представлены на примере сети, использующей двуграммную модель языка.
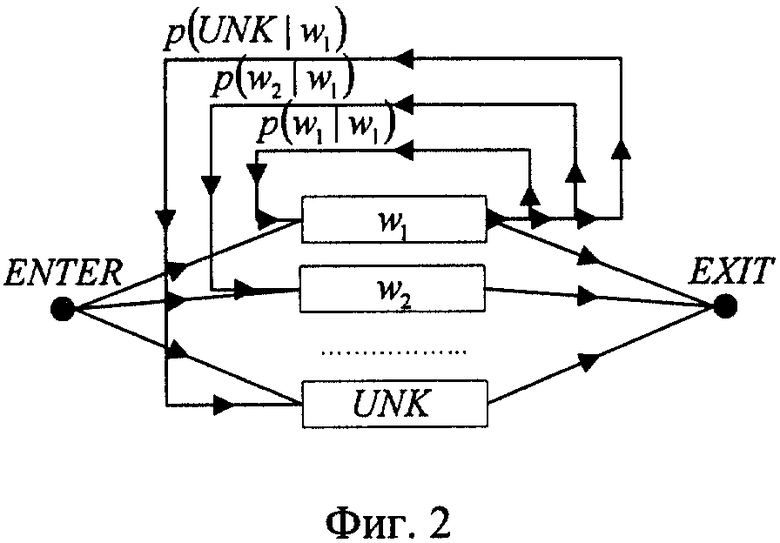
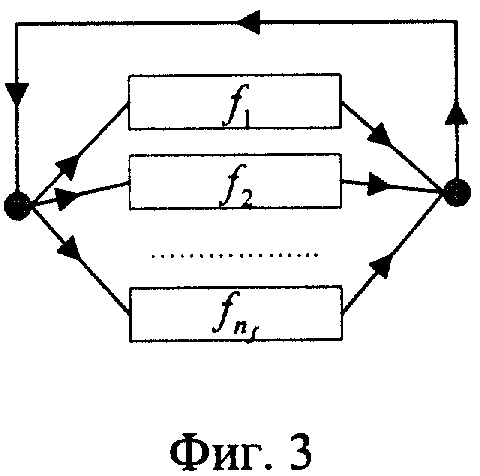
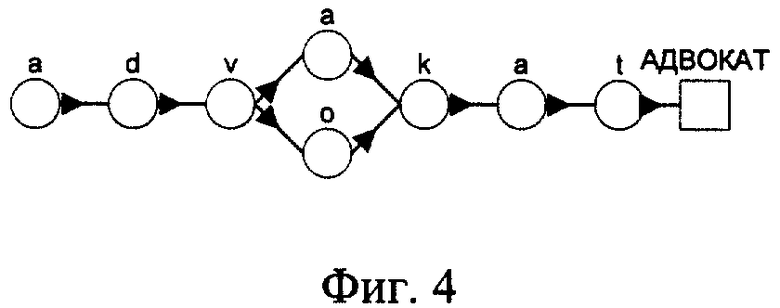
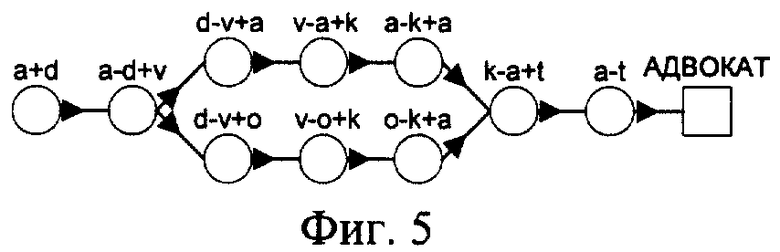
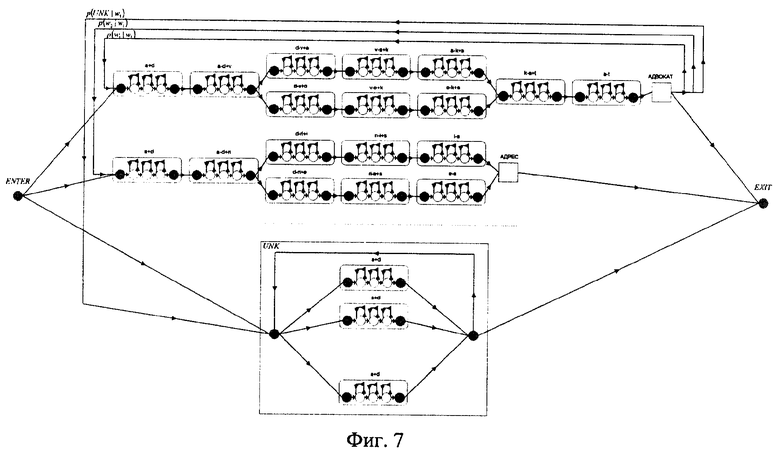
Этапы построения сети лексического декодирования поясняются чертежами: на фиг.1 изображены орфографическое и фонетическое представление слов; на фиг.2 - граф слов, основанный на двуграммной модели языка, который используется для задания возможных в языке последовательностей слов; фиг.3 - подграф UNK, используемый для моделирования слов, не входящих во множество Y; фиг.4 - фонетическая сеть слова "АДВОКАТ"; фиг.5 - трифонная сеть слова "АДВОКАТ"; фиг.6 - сеть слова адвокат, вершинами которой являются акустические состояния; фиг.7 - лексическая сеть декодирования.
На первом этапе определяют словарь Y речевого общения. Множество Y содержит слово-класс UNK, который отвечает за слова, не попавшие в это множество. Далее определяют лексическое и фонетическое представление каждого слова (фиг.1), строят модель языка для данного словаря Y и базу данных Трифонов языка. На втором этапе создается шаблон сети декодирования (фиг.2) в соответствии с имеющейся моделью языка. Шаблон сети декодирования содержит начальный узел, в котором система находится перед началом процесса распознавания, и конечный узел, в котором система находится после завершения процесса распознавания. Узел, соответствующий слову UNK, является подграфом (фиг.3) и предназначен для моделирования слов, не входящих в словарь. Структура подграфа UNK выбрана таким образом, чтобы он мог моделировать любую последовательность фонем. На третьем этапе для каждого слова строится граф, который моделирует все ожидаемые фонетические представления слов (фиг.4). Вершинами графа являются фонемы, а дугами - указатели на следующие возможные фонемы. Конечное состояние графа слова обозначено прямоугольником. Оно предназначено для того, чтобы обозначать конец слова. Далее вместо фонем подставляют контекстно-зависимые фонемы (трифоны) (фиг.5) и далее акустические состояния, из которых они состоят (фиг.6), которые берут из базы данных Трифонов. На четвертом этапе построенные графы слов подставляют в шаблон сети декодирования, в результате чего получают сеть лексического декодирования (фиг.7).
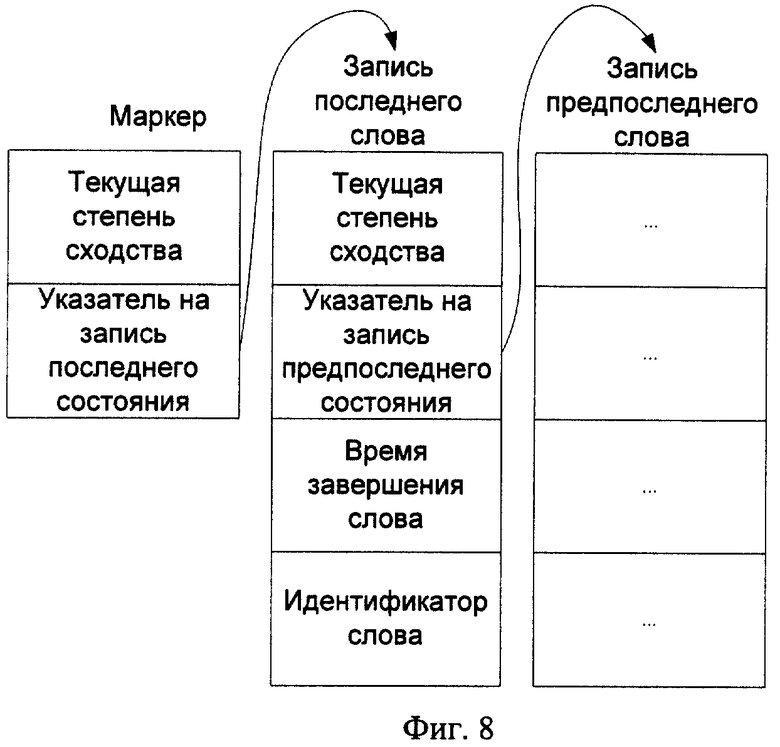
Работа алгоритма перемещаемого маркера поясняется фиг.8, 9; фиг.8 представляет структуру данных, называемую маркером, фиг.9 представляет алгоритм перемещаемого маркера.
Для реализации алгоритма перемещаемого маркера (фиг.9) каждая вершина сети лексического декодирования содержит указатель на структуру данных, называемую маркером (фиг.8), которая хранит информацию о частичном пути, заканчивающемся в данной вершине сети лексического декодирования. Структуру маркера можно представить в виде 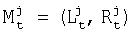 , где
, где 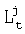 - степень совпадения частичного пути, прошедшего через вершину j в момент времени t,
- степень совпадения частичного пути, прошедшего через вершину j в момент времени t, 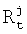 - запись о состоянии, соответствующем вершине j в момент времени t.
- запись о состоянии, соответствующем вершине j в момент времени t.
При инициализации алгоритма в начальный узел сети помещают маркер с нулевой степенью совпадения. Далее начинается работа алгоритма. При поступлении очередного текущего акустического состояния копии маркеров из каждой вершины сети лексического декодирования перемещаются во все вершины, которые возможны после данной, при этом степень совпадения маркера пересчитывается в соответствии с формулой
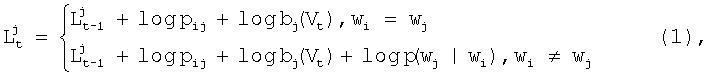
где 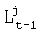 - предыдущее значение степени совпадения, рij - вероятность перехода между эталонными состояниями, связанными с вершинами сети лексического декодирования i и j, bj(Vt) - степень совпадения между текущим акустическим состоянием Vt и эталонным состоянием, связанным с вершиной сети лексического декодирования j, wi - слово, которому принадлежит состояние i, wj. - слово, которому принадлежит состояние, связанное с вершиной сети лексического декодирования j. Далее исходные маркеры удаляются. В каждой вершине сети лексического декодирования удаляются все маркеры, кроме маркера, имеющего максимальную степень совпадения, эта процедура называется нормализацией множества маркеров. После того, как обработаны все текущие акустические состояния, соответствующие речевому сигналу, работа алгоритма завершается. Из маркера, находящегося в конечной вершине сети лексического декодирования, извлекается рабочий путь, из которого находится рабочая гипотеза.
- предыдущее значение степени совпадения, рij - вероятность перехода между эталонными состояниями, связанными с вершинами сети лексического декодирования i и j, bj(Vt) - степень совпадения между текущим акустическим состоянием Vt и эталонным состоянием, связанным с вершиной сети лексического декодирования j, wi - слово, которому принадлежит состояние i, wj. - слово, которому принадлежит состояние, связанное с вершиной сети лексического декодирования j. Далее исходные маркеры удаляются. В каждой вершине сети лексического декодирования удаляются все маркеры, кроме маркера, имеющего максимальную степень совпадения, эта процедура называется нормализацией множества маркеров. После того, как обработаны все текущие акустические состояния, соответствующие речевому сигналу, работа алгоритма завершается. Из маркера, находящегося в конечной вершине сети лексического декодирования, извлекается рабочий путь, из которого находится рабочая гипотеза.
Устройство для реализации способа распознавания слов в слитной речи может быть выполнено в виде программы для ЭВМ. В этом случае устройство представляет собой структуры данных в оперативной памяти ЭВМ.
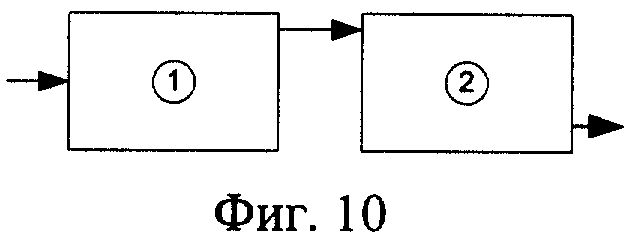
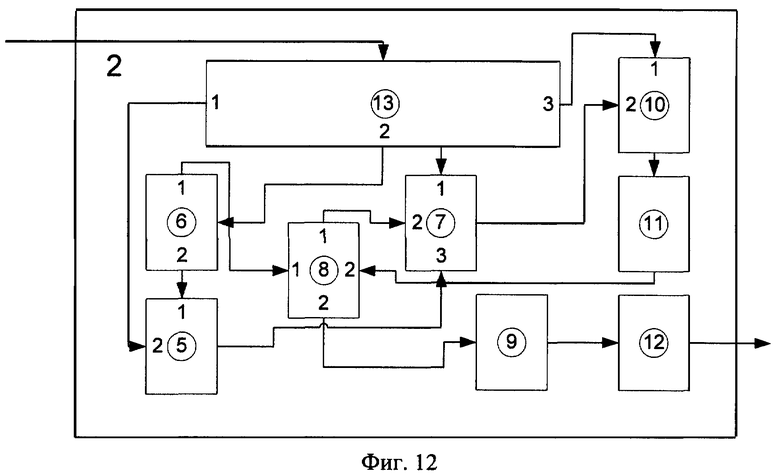
Устройство для реализации способа распознавания слов в слитной речи представлено на фиг.10, 11 и 12. На фиг.10 изображена структурная схема системы; на фиг.11 - структурная схема блока акустического анализатора; на фиг.12 - структурная схема лексического анализатора.
Устройство распознавания слов в слитной речи, использующее сеть лексического декодирования представлено на фиг.10. Оно состоит из акустического анализатора, представленного блоком 1, и лексического анализатора, представленного блоком 2.
Блок 1 предназначен для определения текущего акустического состояния Vt.
Блок 2 предназначен для поиска рабочей гипотезы. Вход блока 1 соединен с микрофоном. Выход блока 1 соединен со входом блока 2. С выхода блока 2 получают искомый результат.
Блок 1, структурная схема которого представлена на фиг.11, содержит: блок 3 - частотный анализатор спектра, блок 4 - вычислитель текущего акустического состояния Vt.
Блок 2, структурная схема которого представлена на фиг.12, содержит: блок 5 -хранилище множества состояний; блок 6 - хранилище сети лексического декодирования; блок 7 - вычислитель степени совпадения bj(Vt) между текущим акустическим состоянием Vt и эталонным акустическим состоянием, связанным с текущей вершиной сети лексического декодирования j; блок 8 - хранилище маркеров; блок 9 - формирователь результата распознавания; блок 10 - хранилище пересчитанных маркеров; блок 11 - блок нормализации множества маркеров; блок 12 - блок вывода результатов распознавания; блок 13 - блок управления.
Блок 3 предназначен для вычисления спектра текущего участка речевого высказывания и преобразования его в цифровой вид.
Блок 4 предназначен для вычисления текущего акустического состояния Vt, соответствующего текущему речевому участку речи.
Блок 5 представляет собой устройство, в котором хранится база данных акустических состояний.
Блок 6 представляет собой устройство, в котором хранится сеть лексического декодирования.
Блок 7 предназначен для вычисления оценки степени совпадения bj(Vt) между текущим акустическим состоянием Vt и эталонным акустическим состоянием, соответствующим данной вершине сети лексического декодирования j.
Блок 8 представляет собой устройство, в котором хранится база данных маркеров.
Блок 9 предназначен для формирования результатов распознавания с использованием информации, хранящейся в маркере из конечной вершины в конечный момент времени.
Блок 10 представляет собой устройство, в котором хранится база данных пересчитанных маркеров.
Блок 11 предназначен для нормализации множества маркеров.
Блок 12 предназначен для вывода результатов распознавания.
Блок 13 предназначен для управления системой распознавания.
Работа системы распознавания слов в слитной речи осуществляется следующим образом (см. фиг.10, 11 и 12). Входное высказывание с микрофона поступает на вход блока 3 акустического анализатора 1.
Блок 3 с помощью полосовых фильтров выделяет частотный спектр и преобразует его в цифровую форму в соответствии с прототипом. Эти оцифрованные сигналы подаются на вход блока 4.
Блок 4 вычисляет текущее акустическое состояние Vt и одновременно определяет содержит ли текущий участок сигнала речь в соответствии с прототипом. После этого текущее акустическое состояние передается на вход блока 13 лексического анализатора.
Блок 13 в отличие от прототипа управляет работой лексического анализатора. Получив от акустического анализатора текущее акустическое состояние, блок управления дает команду блоку 7 создать маркер 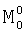 , связанный с начальной вершиной сети лексического декодирования 0.
, связанный с начальной вершиной сети лексического декодирования 0.
Блок 7 в отличие от прототипа создает маркер , связанный с начальной вершиной сети лексического декодирования 0, и через блоки 10 и 11 передает его в блок 8. Далее блок 13 дает команду блоку 6 начать обход вершин сети лексического декодирования.
Блок 6 переходит к рассмотрению очередной вершины i сети лексического декодирования и передает на вход блока 8 индекс маркера  , связанного с данной вершиной. Также на вход блока 5 передается последовательность номеров состояний, связанных с вершинами, в которые система может перейти из текущей вершины.
, связанного с данной вершиной. Также на вход блока 5 передается последовательность номеров состояний, связанных с вершинами, в которые система может перейти из текущей вершины.
Блок 8 на вход блока 7 передает текущий маркер .
Блок 5, получив команду с блока управления, передает на вход блока 7 очередное состояние, связанное с вершиной j сети лексического декодирования.
Блок 7 создает копию маркера , полученного из блока 8, для состояния, связанного с вершиной j, полученного из блока 5, пересчитывая степень совпадения по формуле (1). Вновь созданный маркер 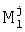 передается в блок 10, который является хранилищем созданных маркеров.
передается в блок 10, который является хранилищем созданных маркеров.
После того, как обход всех вершин сети лексического декодирования выполнен, блок управления подает на вход блока 10 сигнал о нормализации маркеров, накопленных в блоке 10. Для нормализации маркеры передаются в блок 11.
Блок 11 выполняет нормализацию множества маркеров, удаляя все маркеры, связанные с одной вершиной сети лексического декодирования, кроме маркера, имеющего максимальную величину степени совпадения 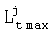 . Нормализованное множество маркеров передается на вход блока 8.
. Нормализованное множество маркеров передается на вход блока 8.
На этом обработка текущего акустического состояния V1 завершается. Система переходит к следующему текущему акустическому состоянию V2. Процедура распознавания завершается, когда текущий речевой участок не содержит речь. В этом случае блок управления подает сигнал на вход блока 6 о завершении процедуры распознавания. Блок 6 передает в блок 8 индекс маркера 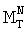 , связанного с конечной вершиной N сети лексического декодирования. Блок 8 передает в блок 9 данный маркер , по которому блок 9 формирует результат распознавания в виде последовательности распознанных слов. Эта последовательность передается в блок 12, который отображает результат распознавания в удобном для оператора виде.
, связанного с конечной вершиной N сети лексического декодирования. Блок 8 передает в блок 9 данный маркер , по которому блок 9 формирует результат распознавания в виде последовательности распознанных слов. Эта последовательность передается в блок 12, который отображает результат распознавания в удобном для оператора виде.
Таким образом, задача повышения точности распознавания достигается за счет того, что поиск рабочей гипотезы является оптимальным в смысле максимума степени ее совпадения с исходным речевым сигналом, поскольку в основе используемого алгоритма перемещаемого маркера лежит метод динамического программирования, а также при построении сети лексического декодирования используется модель языка и вероятности перехода между состояниями, посредством которых учитывают средние длительности фонем.
Источники информации
1. Klatt D.H. Review of the ARPA Speech Understanding Project, J. Acoust. Soc. America, 62, №4, pp.1366, 1977.
2. Woods W.A., Bates M., Brown G., et al. Speech Understanding Systems: Final Tech. Progress Report, Bolt, Beranek, Newman, Inc. Rep. №3438, Cambridge, 1976.
3. Патент РФ №2101782 С1,кл. 7 G10L 15/00.
4. Rabiner L.R.A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition, proceedings of the IEEE, vol. 77, №2, February 1989.
5. Huang X., Acero A., Hon H.-W. Spoken Language Processing: a guide to theory, algorithms, and system development. - Prentice-Hall, Inc., 2001.
6. Моттль В.В., Мучник И.Б. Скрытые Марковские модели в структурном анализе сигналов. - M.: ФИЗМАТЛИТ, 1999.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ РАСПОЗНАВАНИЯ СЛОВ В СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1996 |
|
RU2101782C1 |
| СПОСОБ ЛЕКСИЧЕСКОЙ ИНТЕРПРЕТАЦИИ СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1997 |
|
RU2119196C1 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ НА ОСНОВЕ ДВУХУРОВНЕВОГО МОРФОФОНЕМНОГО ПРЕФИКСНОГО ГРАФА | 2015 |
|
RU2597498C1 |
| СИСТЕМА И СПОСОБ ПЕРЕВОДА РЕЧЕВОГО СИГНАЛА В ТРАНСКРИПЦИОННОЕ ПРЕДСТАВЛЕНИЕ С МЕТАДАННЫМИ | 2014 |
|
RU2589851C2 |
| СИСТЕМА И СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ | 2011 |
|
RU2466468C1 |
| СПОСОБ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКИ ТЕКСТА | 2007 |
|
RU2386178C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ДИНАМИЧЕСКОЙ РЕГУЛИРОВКИ ЛУЧА В ПОИСКЕ ПО ВИТЕРБИ | 2001 |
|
RU2276810C2 |
| Способ распознавания слитно произнесенных слов и устройство для его осуществления | 1983 |
|
SU1159059A1 |
| СПОСОБ ВЕРИФИКАЦИИ ПОЛЬЗОВАТЕЛЯ В СИСТЕМАХ САНКЦИОНИРОВАНИЯ ДОСТУПА | 2007 |
|
RU2351023C2 |
| СПОСОБ ИДЕНТИФИКАЦИИ ГОВОРЯЩЕГО ПО ФОНОГРАММАМ ПРОИЗВОЛЬНОЙ УСТНОЙ РЕЧИ НА ОСНОВЕ ФОРМАНТНОГО ВЫРАВНИВАНИЯ | 2009 |
|
RU2419890C1 |



Изобретение относится к автоматике и вычислительной технике. Его использование в системах управления технологическим, бытовым и другим оборудованием, в автоматических справочных системах, системах автоматического перевода, системах понимания речи и т.д. позволяет получить технический результат в виде повышения точности распознавания слов в слитной речи. Способ состоит в том, что с произнесением речевого высказывания периодически берут выборки акустического сигнала этого высказывания, оцифрованного с заданной частотой квантования, через фиксированные интервалы времени и по совокупности этих выборок вычисляют функционал, определяющий текущее акустическое состояние, при этом полученную последовательность текущих акустических состояний используют для восстановления последовательности слов (рабочей гипотезы), произнесенных в исходном речевом высказывании, для чего применяют сеть лексического декодирования, которая задает закономерности следования эталонных акустических состояний в языке. Технический результат достигается за счет того, что проводится поиск рабочей гипотезы, являющийся оптимальным в смысле максимума степени ее совпадения с исходным речевым сигналом, что обеспечивается использованием алгоритма перемещаемого маркера, при этом рабочую гипотезу восстанавливают из маркера, который в этот момент времени находится в конечной вершине сети лексического декодирования. 3 з.п. ф-лы, 12 ил.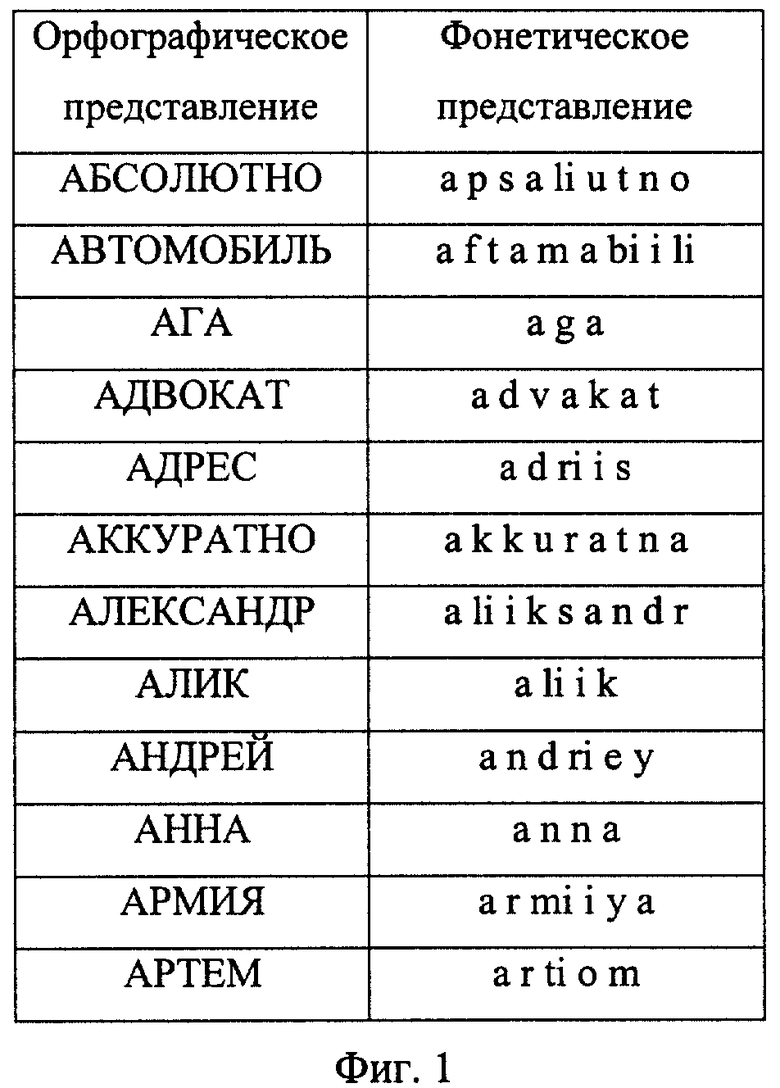
| СПОСОБ РАСПОЗНАВАНИЯ СЛОВ В СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1996 |
|
RU2101782C1 |
| US 6868381 B1, 15.03.2005 | |||
| US 6327561 B1, 04.12.2001 | |||
| US 5959710 А, 18.05.1999 | |||
| US 5425129 А, 13.06.1995 | |||
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| СИСТЕМА ОХЛАЖДЕНИЯ СИЛОВОЙ УСТАНОВКИ ДВУХДИЗЕЛЬНОГО ТЕПЛОВОЗА (ВАРИАНТЫ) | 2008 |
|
RU2375211C1 |
| Концевая приемно-отправочная станция однотрубной пневматической почты | 1982 |
|
SU1082719A1 |
| Способ приготовления мыла | 1923 |
|
SU2004A1 |

