Изобретение относится к системам обработки информации, а именно к способам построения систем распознавания речи.
Известен способ распознавания, построенный с использованием методов фонемного анализа (патент США №5315689, МПК G 10 L 5/06, 1995), в котором применяется двухуровневая обработка речевого сигнала. Блок первого уровня осуществляет распознавание слова (команды) как звукового (слухового) образа в целом. Альтернативный блок второго уровня производит фонемное распознавание звукового сигнала.
Недостатком этого способа является снижение степени вероятности правильного распознавания слов (фраз) при увеличении объема словаря распознаваемых слов.
В качестве ближайшего аналога автором принят способ обработки речевого сигнала с использованием блока первого уровня, построенного на основании метода динамического программирования, и блока второго уровня, построенного с использованием методов фонемного анализа (патент RU №2103753, МПК G 10 L 5/04, приоритет 03.02.97 г.). Блок первого уровня отбирает наиболее вероятных кандидатов слов для анализируемого сигнала и выбора на втором уровне наиболее вероятной альтернативы из отобранных кандидатов, отличающийся тем, что результаты распознавания речевого сигнала на первом и втором уровнях анализируют блоком принятия решения и в случае несоответствия указанного результата требованиям блока принятия решения формируют сигнал переспроса блока первого уровня.
Основным недостатком способа по патенту RU №2103753 является снижение степени вероятности правильного распознавания слов (фраз) при увеличении объема словаря распознаваемых слов.
Перед заявителем изобретения поставлена задача повышения вероятности правильного фонемного распознавания звуков речи, осуществляемого без предварительной подстройки под голос диктора.
Указанная задача решается за счет того что применяется способ дикторонезависимого фонемного распознавания звуков речи, образующих слова, содержащий многоуровневую обработку сигнала. Отличительная особенность способа состоит в том, что ведут многоуровневую обработку речевого сигнала, при которой определяют фонемное соответствие обрабатываемого сигнала с использованием интеграции значений таких его информативных признаков, как амплитуда и частота первых трех формант.
Технический результат заявленного изобретения состоит в повышении вероятности правильного распознавания звуков речи, входящих в состав слов. Указанная задача решается за счет того что применяется способ дикторонезависимого распознавания звуков речи, образующих слова, содержащий многоуровневую обработку сигнала, с определением на первом уровне периодичности таких акустических составляющих звукового сигнала, которые позволяют соотносить звуковой сегмент (предварительная сегментация) по способу его образования к одному из трех видов: голосовому, шумовому, шумно-голосовому. На втором уровне осуществляется основная сегментация звуков речи. На третьем - посегментное определение значений таких иформативных признаков звуков речи, как амплитуда и частота первых трех формант (пики в спектре звука). На четвертом уровне производится фонемное распознавание каждого звукового сегмента на основании интеграции значений информативных признаков обрабатываемого сигнала и сопоставления с имеющимся банком данных, отдельно для каждого вида и типа (сигнал с одной, двумя и тремя формантами) звука. На пятом уровне в зависимости от изменения фонемной принадлежности сегмента устанавливаются временные границы звуков речи. На шестом уровне принимается итоговое фонемное решение относительно распознаваемого звука речи и представление его в виде буквенного или транскрипционного обозначения.
Указанные выше отличительные признаки каждый в отдельности и все совместно направлены на решение поставленной задачи и являются существенными. Использование предлагаемого сочетания существенных отличительных признаков в известном уровне техники не обнаружено, следовательно, предлагаемое техническое решение соответствует критерию патентоспособности “новизна”.
Единая совокупность новых существенных признаков с общими, известными обеспечивает решение поставленной задачи, является не очевидной для специалистов в данной области техники и свидетельствует о соответствии заявленного технического решения критерию патентоспособности “изобретательский уровень”.
Пример осуществления изобретения
Настоящее изобретение конкретно иллюстрируется следующим примером осуществления изобретения, который иллюстрирует, но не ограничивает объем использования изобретения.
Основой способа является классификация и интеграция информативных признаков звуков речи, таких как частотные и амплитудные значения первых трех условных формант звука, частотные значения их основного тона, акустические характеристики, соответствующие источнику звука (шум-голос), и общие длительности их звучания. В структурном виде рассматриваемый способ распознавания можно представить следующим образом.
1. Определение участия голосового источника в образовании звука речи.
2. Определение участия шумового источника в образовании звука речи.
Далее в зависимости от условий образования звука речи (голосовой, шумный, шумно-голосовой) и количества достаточно четко выраженных формант (пиков в спектре звука речи) до трех включительно выбирается один из девяти возможных вариантов распознавания:
1. Голосовой одноформантный.
2. Шумный одноформантный.
3. Шумно-голосовой одноформантный.
4. Голосовой двухформантный.
5. Шумный двухформантный.
6. Шумно-голосовой двухформантный.
7. Голосовой трехформантный.
8. Шумный трехформантный.
9. Шумно-голосовой трехформантный.
Далее следует операция интеграции значений информативных признаков звуков речи и обращение к файлам-идентификаторам, в которых хранятся значения интегральных амплитудно-частотных характеристик формант, чем в итоге и определяется фонемная принадлежность того или иного звука речи. На завершающем этапе распознавания на основании значений относительной временной длительности дифференцируются краткие звуки речи, такие, как й, к, п, б и др.
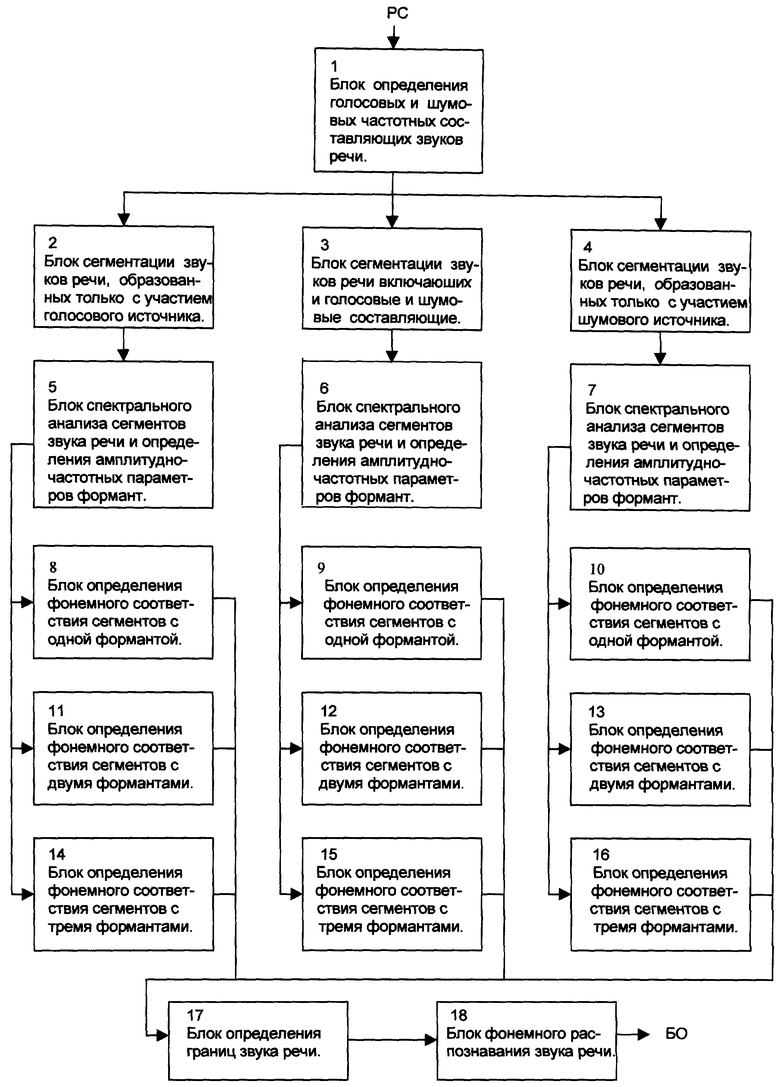
На чертеже изображена схема осуществления предлагаемого способа фонемного распознавания звуков речи.
На первом уровне 1 производится определение периодичности таких акустических составляющих речевого (звукового) сигнала (PC), которые позволяют соотносить звуковой сегмент по способу его образования к одному из трех видов звуков речи: голосовому, шумному, шумно-голосовому, при этом временная длительность обрабатываемого сигнала определяется его предварительной сегментацией. На втором уровне 2-4 осуществляется основная сегментация звуков речи по трем различным режимам, в зависимости от определенного на первом уровне вида обрабатываемого звукового сигнала. На третьем уровне 5-7 проводится спектральный анализ и посегментное определение значений таких иформативных признаков звуков речи, как амплитуда и частота первых трех формант (пики в спектре звука). На четвертом уровне 8-16 производится фонемное распознавание каждого звукового сегмента на основании интеграции значений информативных признаков обрабатываемого сигнала и сопоставления с имеющимся банком данных отдельно для каждого вида и типа (сигнал с одной, двумя и тремя формантами) звука. На пятом уровне 17, в зависимости от изменения фонемной принадлежности сегмента, устанавливаются временные границы звуков речи. На шестом 18 уровне принимается итоговое фонемное решение относительно распознаваемого звука речи и представление его в виде буквенного или транскрипционного обозначения (БО).
Предлагаемый способ, реализованный в виде макетной программы распознавания неассимилированных звуков современной русской речи, позволяет проводить их распознавание без предварительной подстройки под голос диктора с надежностью, практически равняющейся 100%.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ дикторонезависимого распознавания фонемы в речевом сигнале | 2021 |
|
RU2763124C1 |
| СИСТЕМА И СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ | 2011 |
|
RU2466468C1 |
| СПОСОБ ГИБРИДНОЙ ГЕНЕРАТИВНО-ДИСКРИМИНАТИВНОЙ СЕГМЕНТАЦИИ ДИКТОРОВ В АУДИО-ПОТОКЕ | 2013 |
|
RU2530314C1 |
| СИСТЕМА И СПОСОБ ПЕРЕВОДА РЕЧЕВОГО СИГНАЛА В ТРАНСКРИПЦИОННОЕ ПРЕДСТАВЛЕНИЕ С МЕТАДАННЫМИ | 2014 |
|
RU2589851C2 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ НА ОСНОВЕ ДВУХУРОВНЕВОГО МОРФОФОНЕМНОГО ПРЕФИКСНОГО ГРАФА | 2015 |
|
RU2597498C1 |
| Способ и устройство классификации сегментов зашумленной речи с использованием полиспектрального анализа | 2014 |
|
RU2606566C2 |
| СПОСОБ РАСПОЗНАВАНИЯ ИЗОЛИРОВАННЫХ СЛОВ РЕЧИ С АДАПТАЦИЕЙ К ДИКТОРУ | 1994 |
|
RU2047912C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ГОВОРЯЩЕГО ПО ФОНОГРАММАМ ПРОИЗВОЛЬНОЙ УСТНОЙ РЕЧИ НА ОСНОВЕ ФОРМАНТНОГО ВЫРАВНИВАНИЯ | 2009 |
|
RU2419890C1 |
| СПОСОБ ДИКТОРОНЕЗАВИСИМОГО РАСПОЗНАВАНИЯ КЛЮЧЕВЫХ СЛОВ В СЛИТНОЙ РЕЧИ | 2005 |
|
RU2294024C2 |
| СПОСОБ РАСПОЗНАВАНИЯ СЛОВ РЕЧИ | 2005 |
|
RU2296376C2 |
Изобретение относится к распознаванию речи. Его использование позволяет получить технический результат в виде повышения вероятности правильного распознавания звуков речи. Способ включает в себя сегментацию речевого сигнала по времени, определение периодичности каждого звукового сегмента для соотнесения звукового сегмента к конкретному виду звуков речи, определение амплитуды и частоты каждой из первых трёх формант в спектре звукового сегмента в качестве информативных признаков, интеграция этих признаков для каждого звукового сегмента, фонемное распознавание каждого звукового сегмента путём сопоставления его интегральных значений, принятие решения о распознаваемом звуке речи и представление его в виде буквенного обозначения. Технический результат достигается благодаря тому что соотнесение звукового сегмента осуществляют к голосовому, шумному или шумно-голосовому виду звуков речи, выполняют основную сегментацию речевого сигнала по трём основным режимам, при фонемном распознавании сопоставляют интегральные значения информативных признаков каждого звукового сегмента в зависимости от числа формант в звуковом сегменте, устанавливают временные границы звуков речи в зависимости от изменения фонемной принадлежности звукового сегмента, после чего и принимают решение относительно распознаваемого звука речи. 1 ил.
Способ дикторонезависимого распознавания звуков речи, включающий в себя предварительную сегментацию речевого сигнала для определения временной длительности звуковых сегментов, определение периодичности каждого сегмента акустических составляющих речевого сигнала для соотнесения звукового сегмента по способу его образования к конкретному виду звуков речи, определение амплитуды и частоты каждой из первых трёх формант в спектре звукового сегмента в качестве информативных признаков звуков речи, интеграция упомянутых информативных признаков для каждого звукового сегмента, фонемное распознавание каждого звукового сегмента путём сопоставления интегральных значений его информативных признаков с имеющимся банком данных отдельно для каждого вида звуков речи, принятие решения относительно распознаваемого звука речи и представление его в виде буквенного или транскрипционного обозначения, отличающийся тем, что упомянутое соотнесение звукового сегмента осуществляют к голосовому, шумному или шумно-голосовому виду звуков речи, далее выполняют основную сегментацию речевого сигнала по трём основным режимам в зависимости от ранее найденного вида звукового сегмента, при упомянутом фонемном распознавании сопоставляют интегральные значения информативных признаков каждого звукового сегмента как для каждого упомянутого вида звуков речи, так и для каждого типа в зависимости от числа формант в звуковом сегменте, затем устанавливают временные границы звуков речи в зависимости от изменения фонемной принадлежности звукового сегмента, после чего и принимают упомянутое решение относительно распознаваемого звука речи.
| СПОСОБ ДИКТОРОНЕЗАВИСИМОГО РАСПОЗНАВАНИЯ ИЗОЛИРОВАННЫХ РЕЧЕВЫХ КОМАНД | 1997 |
|
RU2103753C1 |
| RU 2000113854 A1, 27.10.2000 | |||
| RU 2000113855 A1, 27.10.2000 | |||
| US 5893058 A, 06.04.1999 | |||
| US 5315689 A, 24.05.1994 | |||
| US 5913188 A, 15.06.1999 | |||
| US 5873062 A, 16.02.1999 | |||
| US 5864809 A, 26.01.1999 | |||
| КАЛИНЦЕВ Ю.К | |||
| Разборчивость речи в цифровых вокодерах | |||
| – М.: Радио и связь, 1991, с | |||
| Коридорная многокамерная вагонеточная углевыжигательная печь | 1921 |
|
SU36A1 |

