Область техники, к которой относится изобретение
Настоящее изобретение в общем относится к компьютерным системам, в частности к системам и способам проверки адреса возврата процедуры.
Уровень техники
Вредоносное программное обеспечение может использовать разнообразные способы искажения адреса возврата для осуществления атаки посредством возвратно-ориентированного программирования (return-oriented programming (ROP)). Программирование ROP представляет собой способ захвата или перехвата потока выполнения текущего процесса посредством использования команды возврата, которая, во многих процессорных архитектурах, вызывает с вершины стека адрес следующей подлежащей выполнению команды, обычно представляющей собой команду, следующую за соответствующей командой вызова в вызывающей подпрограмме. Таким образом, посредством модификации адреса возврата в стеке атакующая сторона (далее - взломщик) может перенаправить поток выполнения текущего процесса в произвольную область памяти. Захватив поток выполнения, взломщик может, например, инициализировать аргументы и осуществить вызов библиотечной функции. Этот способ известен под названием «возврат в библиотеку» (“return-into-library”). В другом примере взломщик может находить в пределах сегмента кода последовательности из нескольких команд для выполнения. Этот подход известен под названием «способ заимствования кусков кода» (“borrowed code chunks technique”).
Взломщик может использовать разнообразные способы для первоначального повреждения стека, которое также именуется «подменой стека» или «поворотом стека» (“stack pivoting”). Например, способ переполнения буфера (buffer overflow) предусматривает передачу большего объема входных данных, чем ожидает принять подпрограмма, в предположении, что входной буфер расположен в стеке.
Краткое описание чертежей
Настоящее изобретение проиллюстрировано примерами, не служащими для ограничения, и может быть более полно понято с использованием последующего подробного описания, которое следует рассматривать вместе с чертежами, где:
фиг. 1 представляет диаграмму компонентов высокого уровня, составляющих пример компьютерной системы, согласно одному или более аспектам настоящего изобретения;
фиг. 2 представляет блок-схему процессора согласно одному или более аспектам настоящего изобретения;
фиг. 3a-3b схематично иллюстрируют элементы микроархитектуры процессора согласно одному или более аспектам настоящего изобретения;
фиг. 4 схематично иллюстрирует некоторые аспекты примера процессора и других компонентов примера компьютерной системы 100, показанной на фиг. 1, согласно одному или более аспектам настоящего изобретения;
фиг. 5 упрощенно иллюстрирует один пример схемы распределения памяти в стеке компьютерной системы согласно одному или более аспектам настоящего изобретения;
фиг. 6 упрощенно иллюстрирует один пример схемы распределения памяти в буфере адреса возврата согласно одному или более аспектам настоящего изобретения;
фиг. 7 представляет логическую схему способа обнаружения несанкционированной подмены стека согласно одному или более аспектам настоящего изобретения;
фиг. 8 представляет блок-схему примера компьютерной системы согласно одному или более аспектам настоящего изобретения;
фиг. 9 представляет блок-схему примера системы на кристалле (system on a chip (SoC)), согласно одному или более аспектам настоящего изобретения;
фиг. 10 представляет блок-схему примера компьютерной системы согласно одному или более аспектам настоящего изобретения; и
фиг. 11 представляет блок-схему примера системы на кристалле (SoC), согласно одному или более аспектам настоящего изобретения.
Осуществление изобретения
Здесь предложены компьютерные системы и способы проверки адреса возврата процедуры. Несанкционированная модификация или подмена стека может быть использована потенциальным взломщиком в попытке осуществить атаку способом возвратно-ориентированного программирования (ROP). Такая атака может содержать несанкционированную модификацию адреса возврата процедуры, записанного в стеке, с целью перенаправить поток выполнения текущего процесса в произвольную область памяти. Взломщик может использовать разнообразные способы для несанкционированной модификации стека. Например, способ переполнения буфера использует передачу в буфер большего объема данных, чем подпрограмма ожидает принять, в предположении, что входной буфер расположен в рассматриваемом стеке.
Для предотвращения несанкционированной модификации стека компьютерная система может поддерживать буфер адреса возврата, предназначенный для резервного хранения, вместе со стеком компьютерной системы, адресов возврата процедур. В ответ на прием команды вызова процессор компьютерной системы может поместить адрес возврата и в стек, и в буфер адреса возврата. В ответ на прием команды возврата процессор может вызвать и сравнить адреса возврата из стека и из буфера адреса возврата. Если два адреса совпадут, процессор может продолжить выполнение команды возврата; в противном случае процессор может генерировать исключение, предотвращая тем самым захват потока выполнения текущего процесса потенциальным взломщиком. Разнообразные аспекты перечисленных выше способов и систем рассмотрены ниже подробно на примерах, а не посредством ограничений.
В последующем описании приведены многочисленные конкретные подробности, такие как примеры конкретных типов процессоров и конфигураций системы, конкретные структуры аппаратуры, конкретные подробности архитектуры и микроархитектуры, конкретные конфигурации регистров, конкретные типы команд, конкретные компоненты систем, конкретные размеры/высоты, конкретные ступени и операции процессорного конвейера с целью предоставления полного понимания настоящего изобретения. Специалисту в рассматриваемой области должно быть очевидно, однако, что все эти конкретные подробности не обязательно должны быть использованы в конкретной практической реализации описываемых здесь способов. В других случаях хорошо известные компоненты или способы, такие как конкретные и альтернативные архитектуры процессоров, конкретные логические схемы/коды для описываемых алгоритмов, конкретные коды встроенного программного обеспечения, конкретные соединительные операции, конкретные логические конфигурации, конкретные способы изготовления и материалы, конкретные реализации компиляторов, конкретные выражения алгоритмов в виде кода, конкретные способы/логические схемы выключения питания/стробирования и другие конкретные детали работы компьютерных систем здесь не были рассмотрены подробно, чтобы избежать ненужного «затемнения» предмета настоящего изобретения.
Хотя последующие варианты описаны здесь со ссылками на процессор, другие варианты могут быть применены к другим типам интегральных схем и логических устройств. Способы и принципы, аналогичные рассматриваемым здесь вариантам, могут быть применены к другим типам схем или полупроводниковых приборов, которые могут выиграть от более высокой пропускной способности систем конвейерного типа и повышенной производительности. Принципы рассматриваемых здесь вариантов применимы к любому процессору или машине, осуществляющим манипуляции с данными. Однако настоящее изобретение не ограничивается процессорами или машинами, осуществляющими операции с размерностью 512 разрядов, 256 разрядов, 128 разрядов, 64 разряда, 32 разряда или 16 разрядов над данными, и может быть применено к любому процессору и машине, в которых осуществляется манипуляция с данными или управление данными. Кроме того, последующее описание предлагает примеры, а прилагаемые чертежи показывают различные примеры с целью иллюстрации. Однако эти примеры не следует толковать в ограничительном смысле, поскольку они предназначены только служить примерами описываемых здесь вариантов, а не создать исчерпывающий перечень всех возможных реализаций описываемых здесь вариантов.
Хотя приведенные ниже примеры описывают обработку и распределение команд в контексте исполнительных модулей и логических схем, другие варианты систем и способов, описываемых здесь, могут быть реализованы с применением данных и команд, записанных на машиночитаемом материальном носителе, так что при выполнении этих команд машина осуществляет функции, соответствующие по меньшей мере одному из описываемых здесь вариантов. В одном из вариантов функции, ассоциированные с рассматриваемыми здесь вариантами, воплощены в исполняемых машиной командах. Выполняя указанные команды, процессор общего или специального назначения, запрограммированный этими командами, может осуществлять рассматриваемые здесь способы. Рассматриваемые здесь варианты могут быть реализованы в виде компьютерного программного продукта или программного обеспечения, которое может быть выполнено в виде машиночитаемого или читаемого компьютером носителя с записанными на нем командами, каковые могут быть использованы для программирования компьютера (или других электронных устройств) с целью осуществления одной или нескольких операций согласно рассматриваемым здесь вариантам. В качестве альтернативы, операции описываемых здесь вариантов могут быть выполнены специализированными компонентами аппаратуры, содержащими логические устройства с фиксированными функциями для осуществления этих операций, или посредством какого-либо сочетания программируемых компьютерных компонентов и компонентов аппаратуры с фиксированными функциями.
Команды, используемые для программирования логических устройств с целью осуществления описываемых здесь способов, могут быть сохранены в памяти системы, такой как динамическое запоминающее устройство с произвольной выборкой (динамическое ЗУПВ (DRAM)), кэш-память, флэш-память или другое запоминающее устройство. Более того, команды можно распределять через сеть связи или посредством какого-либо другого компьютерного носителя. Таким образом, машиночитаемый носитель может содержать какой-либо механизм для сохранения или передачи информации в форме, читаемой машиной (например, компьютером), не ограничиваясь прилагаемым перечнем, дискеты, оптические диски, постоянное запоминающее устройство на компакт-дисках (Compact Disc, Read-Only Memory (CD-ROM)), и магнитооптические диски, постоянные запоминающие устройства (ПЗУ (Read-Only Memory (ROM))), запоминающие устройства с произвольной выборкой (ЗУПВ (Random Access Memory (RAM))), стираемые программируемые постоянные запоминающие устройства (СППЗУ (Erasable Programmable Read-Only Memory (EPROM))), электрически стираемые и программируемые постоянные запоминающие устройства (ЭСППЗУ (Electrically Erasable Programmable Read-Only Memory (EEPROM))), магнитные или оптические карточки, флэш-память или какой-либо материальный машиночитаемый носитель, используемый при передаче информации через Интернет посредством распространяющихся сигналов в электрической, оптической, акустической или иной форме (например, волны несущих, инфракрасные сигналы, цифровые сигналы и т.п.). Соответственно, машиночитаемый носитель представляет собой материальный машиночитаемый носитель какого-либо типа, подходящий для хранения или передачи электронных команд или информации в форме, читаемой машиной (например, компьютером).
Термин «процессор» здесь будет обозначать устройство, способное выполнять команды, кодирующие арифметические и логические операции, а также операции ввода/вывода. В одном из иллюстративных примеров процессор может быть построен в соответствии с архитектурной моделью фон Неймана и может содержать арифметико-логическое устройство ((arithmetic logic unit (ALU)), модуль управления и несколько регистров. В следующем аспекте процессор может содержать одно или несколько процессорных ядер и, следовательно, представлять собой либо одноядерный процессор, обычно способный обрабатывать один конвейер команд, либо многоядерный процессор, который может обрабатывать одновременно множество конвейеров команд. В другом аспекте процессор может быть реализован в виде одной интегральной схемы, двух или более интегральных схем либо может быть компонентом многокристального модуля (например, модуля, в котором кристаллы индивидуальных микропроцессоров могут быть смонтированы в одном корпусе интегральной схемы и, следовательно, совместно использовать одно гнездо (сокет)).
На фиг. 1 представлена диаграмма компонентов высокого уровня, составляющих пример компьютерной системы, согласно одному или более аспектам настоящего изобретения. Компьютерная система 100 может содержать процессор 102 для использования исполнительных модулей, имеющих в составе логические устройства, для осуществления алгоритмов обработки данных в соответствии с рассматриваемыми здесь вариантами. Система 100 является представителем систем обработки данных на основе микропроцессоров типов PENTIUM III™, PENTIUM 4™, Xeon™ и/или Itanium, выпускаемых корпорацией «Интел» в г. Санта-Клара, Калифорния (Intel Corporation of Santa Clara, California), хотя могут быть также использованы и другие системы (включая персональные компьютеры на основе других микропроцессоров, инженерные рабочие станции, приставки и другие подобные устройства). В другом варианте система 100, служащая примером, исполняет версию операционной системы WINDOWS™, разработанной корпорацией «Майкрософт» из г. Редмонд, шт. Вашингтон (Microsoft Corporation of Redmond, Washington), хотя могут быть использованы и другие операционные системы (например, UNIX и Linux), встроенное программное обеспечение и/или графические интерфейсы пользователя. Таким образом, рассматриваемые здесь варианты не ограничиваются каким-либо конкретным сочетанием аппаратуры и программного обеспечения.
Варианты изобретения не ограничиваются компьютерными системами. Альтернативные варианты описываемых здесь систем и способов могут быть использованы в других устройствах, таких как ручные устройства и встроенные приложения. Среди некоторых примеров таких устройств можно указать сотовые телефоны, устройства Интернет-протокола, цифровые видео камеры, персональные цифровые помощники (PDA) и ручные персональные компьютеры. Встроенные приложения могут представлять собой микроконтроллер, цифровой процессор сигнала (digital signal processor (DSP)), систему на кристалле, сетевые компьютеры (network computers (NetPC)), приставки, сетевые концентраторы, коммутаторы глобальных сетей связи (wide area network (WAN)) или какие-либо другие системы, которые могут выполнять одну или несколько команд в соответствии по меньшей мере с одним из вариантов.
В этом иллюстрируемом варианте процессор 102 содержит один или более исполнительных модулей 108 для осуществления алгоритма, иными словами для выполнения по меньшей мере одной команды. Один из вариантов может быть рассмотрен в контексте однопроцессорного настольного компьютера или серверной системы, но альтернативные варианты могут входить в многопроцессорную систему. Система 100 является примером системной архитектуры «концентратора» (‘hub’). Компьютерная система 100 содержит процессор 102 для обработки сигналов данных. Этот процессор 102, в качестве одного иллюстративного примера может представлять собой микропроцессор компьютера с полным набором команд (complex instruction set computer (CISC)), микропроцессор компьютера с сокращенным набором команд (reduced instruction set computing (RISC)), микропроцессор с очень длинным командным словом (very long instruction word (VLIW)), процессор, реализующий сочетание наборов команд, или какое-либо другое процессорное устройство, такое как цифровой процессор сигнала, например. Процессор 102 соединен с шиной 110 процессора, осуществляющей передачу сигналов данных между этим процессором 102 и другими компонентами системы 100. Элементы системы 100 (например, графический ускоритель 112, концентратор 116 контроллера памяти, запоминающее устройство 120, концентратор 130 контроллера ввода/вывода, радио приемопередатчик 126, флэш-BIOS 128, контроллер 134 сети, аудио контроллер 136, последовательный порт 138 расширения, контроллер 140 ввода/вывода и т.д.) осуществляют свои обычные функции, хорошо известные всем, кто достаточно знаком с рассматриваемой областью.
В одном из вариантов процессор 102 содержит внутренний кэш 104 Уровня 1 (Level 1 (L1)). В зависимости от архитектуры процессор 102 может иметь один внутренний кэш или несколько уровней внутренних кэшей. Другие варианты содержат сочетание внутренних и внешних кэшей в зависимости от конкретной реализации потребностей. Регистровый файл 106 служит для хранения различных типов данных в разнообразных регистрах, включая целочисленные регистры, регистры с плавающей запятой, векторные регистры, банки регистров, теневые регистры, регистры контрольных точек, регистры состояния и регистр указателя команд.
Исполнительный модуль 108, содержащий логические устройства для осуществления целочисленных операций и операций с плавающей запятой, также располагается в процессоре 102. Этот процессор 102 в одном из вариантов содержит ПЗУ (ROM) микрокода (μcode) для сохранения микрокода, при выполнении которого происходит осуществление алгоритмов для некоторых макрокоманд или обработка сложных сценариев. Здесь микрокод является потенциально обновляемым для обработки логических ошибок/исправлений в процессоре 102. В одном из вариантов исполнительный модуль 108 содержит логические устройства для обработки набора 109 команд для упакованных данных. Включив набор 109 команд для обработки упакованных данных в набор команд процессора 102 общего назначения вместе с ассоциированной схемой для выполнения этих команд, можно операции, применяемые многими приложениями мультимедиа, выполнить с использованием упакованных данных в процессоре 102 общего назначения. Таким образом, происходит ускорение и более эффективное выполнение многих приложений мультимедиа с использованием полной ширины шины данных процессора для осуществления операций с упакованными данными. Это потенциально устраняет необходимость передавать блоки данных меньшего размера по шине данных процессора с целью выполнения одной или более операций, по одному элементу данных за один раз. Альтернативные варианты исполнительного модуля 108 могут быть также использованы в микроконтроллерах, встроенных процессорах, графических устройствах, процессорах DSP и логических схемах других типов.
В некоторых вариантах процессор 102 может дополнительно содержать нижний регистр 421 защиты памяти стека, верхний регистр 423 защиты памяти стека и логическую схему 150 проверки адреса возврата. В одном иллюстративном примере процессор 102 может иметь пару регистров защиты памяти стека для каждого из двух или более режимов работы, например режима 32-разрядного пользователя, режим 64-разрядного пользователя режим супервизора. Функционирование этого логического устройства 150 проверки адреса возврата подробно описано ниже.
Система 100 содержит запоминающее устройство 120. Это запоминающее устройство 120 может представлять собой динамическое запоминающее устройство с произвольной выборкой (DRAM), статическое запоминающее устройство с произвольной выборкой (SRAM), устройство флэш-памяти или другое запоминающее устройство. Запоминающее устройство 120 сохраняет команды 121 и/или данные 123, представленные сигналами данных, для выполнения процессором 102. В некоторых вариантах совокупность команд 121 может содержать команды, используемые логическим устройством 150 проверки адреса возврата для обнаружения попыток нарушить границы защиты стека, как более подробно описано ниже.
Кристалл 116 логической интегральной схемы системы соединен с шиной 110 процессора и запоминающим устройством 120. Этот кристалл 116 логической интегральной схемы системы в иллюстрируемом варианте представляет собой концентратор контроллера памяти (memory controller hub (МСН)). Процессор 102 может осуществлять связь с концентратором МСН 116 через шину 110 процессора. Концентратор МСН 116 создает тракт 118 обращения к памяти с очень широкой полосой пропускания к запоминающему устройству 120 для сохранения команд и данных и для сохранения графических команд, данных и текстур. Концентратор МСН 116 предназначен для передачи сигналов данных между процессором 102, запоминающим устройством 120 и другими компонентами системы 100 и для выполнения функций моста для передачи сигналов данных между шиной 110 процессора, запоминающим устройством 120 и модулем 122 ввода/вывода системы. В некоторых вариантах кристалл 116 логической интегральной схемы системы может создавать графический порт для соединения с графическим контроллером 112. Концентратор МСН 116 соединен с запоминающим устройством 120 через интерфейс 118 памяти. Графическая карта 112 соединена с концентратором МСН 116 через соединение 114 ускоренного графического порта (Accelerated Graphics Port (AGP)).
Система 100 использует собственную шину 122 интерфейса концентратора для соединения концентратора МСН 116 с концентратором 130 контроллера ввода/вывода (I/O controller hub (ICH)). Концентратор ICH 130 предоставляет прямые соединения для некоторых устройств ввода/вывода через локальную шину ввода/вывода. Эта локальная шина ввода/вывода представляет собой высокоскоростную шину ввода/вывода для соединения периферийных устройств с запоминающим устройством 120, чипсетом и процессором 102. К некоторым примерам относятся аудио контроллер, концентратор 128 с встроенным программным обеспечением (флэш-BIOS) 128, радио приемопередатчик 126, запоминающее устройство 124 данных, контроллер ввода/вывода известных устройств, содержащий интерфейсы ввода пользователя и клавиатуры, последовательный порт расширения, такой как (Universal Serial Bus (USB)), и контроллер 134 сети. Запоминающее устройство 124 данных может содержать накопитель на жестком диске, дисковод для дискет, устройство CD-ROM, устройство флэш-памяти или другое запоминающее устройство большой емкости. Запоминающее устройство 124 данных может сохранять исполняемые команды для выполнения процессором 102. В некоторых вариантах совокупность команд 121 может содержать команды, используемые логическим устройством 150 проверки адреса возврата для обнаружения попыток нарушить границы защиты стека, как более подробно описано ниже.
Для другого варианта системы команда согласно одному из вариантов может быть использована в системе на кристалле. Один из вариантов системы на кристалле содержит процессор и запоминающее устройство. Запоминающее устройство для одной такой системы представляет собой флэш-память. Эта флэш-память может располагаться на том же кристалле, где выполнены процессор и другие компоненты системы. Кроме того, в составе этой системы на кристалле могут находиться и другие логические блоки, такие как контроллер памяти или графический контроллер.
На фиг. 2 представлена блок-схема микроархитектуры процессора 200, содержащего логические схемы и устройства для выполнения команд согласно одному или более аспектам настоящего изобретения. В некоторых вариантах команда согласно одному из вариантов может быть реализована для оперирования с элементами данных, имеющими размер один байт, слово, двойное слово, счетверенное слово и т.д., равно как с различными типами данных, такими как целочисленные данные с обычной и с удвоенной точностью и данные с плавающей запятой, также с обычной и с удвоенной точностью. В одном из вариантов работающий по порядку команд входной блок 201 является частью процессора 200, которая осуществляет выборку команд для исполнения и подготовку этих команд к использованию в процессорном конвейере в дальнейшем. Этот входной блок 201 может содержать несколько модулей. В одном из вариантов блок 226 упреждающей выборки команд выбирает команды из запоминающего устройства и передает их в декодер 228 команд, который, в свою очередь, декодирует или интерпретирует эти команды. Например, в одном из вариантов этот декодер осуществляет декодирование полученной им команды и преобразует ее в одну или несколько операций, именуемых «микрокомандами» или «микрооперациями» (также обозначаемыми как μop), так что машина может выполнить эти микрооперации. В других вариантах декодер анализирует команду и разбивает ее на код операции (opcode) и соответствующие данные и поля управления, используемые микроархитектурой для выполнения операций в соответствии с одним из вариантов. В одном из вариантов трассовый кэш 230 принимает декодированные микрооперации и собирает из них упорядоченные программные последовательности или трассы в очереди 234 микроопераций для исполнения. Когда трассовый кэш 230 сталкивается с комплексной командой, ROM 232 микрокодов выдает микрооперации, необходимые для выполнения соответствующей операции.
Некоторые команды преобразуются в одну микрооперацию, тогда как другие нуждаются во множестве микроопераций для выполнения полной операции. В одном из вариантов, если для выполнения команды нужно больше четырех микроопераций, декодер 228 обращается в ROM 232 микрокодов, чтобы выполнить команду. В некоторых вариантах команда может быть декодирована и преобразована в небольшое число микроопераций для обработки в декодере 228 команд. В другом варианте, если для выполнения операции требуется целый ряд микроопераций, эта команда может быть сохранена в ROM 232 микрокодов. Трассовый кэш 230 обращается в точку входа программируемой логической матрицы (programmable logic array (PLA)) для определения правильного указателя микрокоманды с целью считывания из ROM 232 микрокодов последовательностей микрокодов для завершения выполнения одной или нескольких команд согласно одному из вариантов. После того как ROM 232 микрокодов завершит построение последовательности микроопераций для выполнения какой-либо команды, входной блок 201 машины возобновляет выборку микроопераций из трассового кэша 230.
Механизм 203 внеочередного выполнения команд представляет собой блок, в котором производится подготовка команд к выполнению. Логическая схема для выполнения команд не по порядку содержит ряд буферов для «сглаживания» и переупорядочения потока команд с целью оптимизации работы системы, когда эти команды проходят по конвейеру, и происходит их планирование для исполнения. Логическая схема распределителя назначает буферы и ресурсы машины, которые нужны каждой микрооперации для выполнения. Логическая схема совмещения регистров отображает логические регистры на входы в регистровый файл. Распределитель назначает также вход для каждой микрооперации в одну из двух очередей микроопераций, одну очередь для операций, требующих обращения к памяти, и одну очередь для операций, не требующих обращения к памяти, перед планировщиками команд: планировщиком памяти, быстрым планировщиком 202, планировщиком 204 для медленных/обычных операций с плавающей запятой и простым планировщиком 206 операций с плавающей запятой. Планировщики 202, 204, 206 микроопераций определяют, когда микрооперация готова к выполнению, на основе готовности зависимых регистровых источников входных операндов для этой микрооперации и доступности исполнительных ресурсов, которые нужны для выполнения соответствующих микроопераций. Быстрый планировщик 202 в одном из вариантов может планировать в каждой половине главного тактового периода, тогда как другие планировщики могут осуществлять планирование один раз в каждом главном тактовом периоде процессора. Эти планировщики принимают «арбитражное» решение относительно диспетчирования портов при планировании микроопераций для исполнения.
Между планировщиками 202, 204, 206 и исполнительными модулями 212, 214, 216, 218, 220, 222, 224 в исполнительном блоке 211 располагаются физические регистровые файлы 208, 210. Система имеет раздельные регистровые файлы 208, 210 для целочисленных операций и операций с плавающей запятой соответственно. Каждый регистровый файл 208, 210 в одном из вариантов содержит также схему обхода, направляющую только что полученные результаты, которые еще не были записаны в регистровый файл, к новым зависимым микрооперациям. Регистровый файл 208 для целочисленных операций и регистровый файл 210 для операций с плавающей запятой могут также передавать данные один другому. В одном из вариантов регистровый файл 208 для целочисленных операций разделен на два отдельных регистровых файла, один регистровый файл для 32 младших разрядов (битов) данных и второй регистровый файл для 32 старших разрядов (битов) данных. В одном из вариантов регистровый файл 210 для операций с плавающей запятой имеет входы шириной 128 бит, поскольку команды с плавающей запятой обычно имеют операнды шириной от 64 до 128 бит.
Исполнительный блок 211 содержит исполнительные модули 212, 214, 216, 218, 220, 222, 224, где реально происходит выполнение команд. Эта секция содержит регистровые файлы 208, 210, сохраняющие величины целочисленных операндов и операндов с плавающей запятой, которые нужны для выполнения микрокоманд. Процессор 200 в одном из вариантов содержит ряд исполнительных модулей: модуль генератора адреса (address generation unit (AGU)) 212, генератор AGU 214, быстрое ALU 216, быстрое ALU 218, медленное ALU 220, ALU 222 с плавающей запятой, модуль 224 перемещения плавающей запятой. В одном из вариантов исполнительные модули 222, 224 с плавающей запятой выполняют операции с плавающей запятой, операции мультимедийного расширения ММХ, операции в формате одна команда-множество данных (SIMD), операции с потоковыми SIMD-расширениями (SSE) или другие операции. ALU 222 с плавающей запятой в одном из вариантов содержит делитель с плавающей запятой 64-разрядного числа на 64-разрядное число для выполнения микроопераций деления, вычисления корня квадратного и определения остатка. Для описываемых здесь систем и способов обработку команд, содержащих величины с плавающей запятой, может осуществлять аппаратура для операций с плавающей запятой. В одном из вариантов операции ALU передают в исполнительные модули 216, 218 высокоскоростных ALU. Эти быстрые ALU 216, 218 в одном из вариантов могут выполнять быстрые операции с эффективной задержкой в половину тактового периода. В одном из вариантов более сложные целочисленные операции передают в медленное ALU 220, поскольку это медленное ALU 220 содержит аппаратуру для выполнения целочисленных операций, связанных с большой задержкой, таких как умножение, сдвиг, определение флага и ветвление. Операции загрузки/сохранения в памяти выполняются генераторами AGU 212, 214 адресов. В одном из вариантов целочисленные ALU 216, 218, 220 описаны в контексте выполнения целочисленных операций над 64-разрядными операндами данных. В альтернативных вариантах эти ALU 216, 218, 220 могут быть реализованы для поддержки различной разрядности данных, и в том числе 16 бит, 32, 128, 256 бит и т.д. Аналогично модули 222, 224 для операций с плавающей запятой могут быть реализованы для поддержки работы с операндами с различной разрядностью. В одном из вариантов модули 222, 224 для операций с плавающей запятой могут оперировать с упакованными операндами данных шириной 128 бит в сочетании с командами SIMD и мультимедийными командами.
В одном из вариантов планировщики 202, 204, 206 микроопераций распределяют (диспетчируют) зависимые операции прежде, чем будет закончено выполнение первичной («родительской») нагрузки. Поскольку планирование и выполнение микроопераций в процессоре 200 осуществляется на основе гипотез, этот процессор 200 содержит также логические схемы и устройства для обработки промахов в памяти. В случае промаха поиска нагрузки данных в кэше данных возможно наличие в конвейере зависимых операций в стадии выполнения, которые предоставили планировщику временно неправильные данные. Механизм повторного выполнения отслеживает и повторно выполняет команды, использовавшие неправильные данные. Зависимые операции должны быть выполнены повторно, а независимым операциям дают возможность завершиться. Планировщики и механизм повторного выполнения в одном из вариантов процессора рассчитаны также для «вылавливания» последовательностей команд для выполнения операций сравнения текстовых строк.
Термин «регистры» может относиться к расположенным в составе процессора областям памяти, используемым как часть команд для идентификации операндов. Другими словами, регистры могут быть используемыми извне процессора (с точки зрения программиста). Однако понятие регистров в каком-либо варианте не следует ограничивать каким-либо конкретным типом схем. Напротив, регистры в любом варианте способны сохранять и предоставлять данные и осуществлять описываемые здесь функции. Описываемые здесь регистры могут быть реализованы посредством схем внутри процессора с использованием различных способов, таких как выделенные физические регистры, динамически назначаемые физические регистры с использованием наложения регистров, сочетания выделенных и динамически назначаемых физических регистров и т.п. В одном из вариантов целочисленные регистры сохраняют 32-разрядные целочисленные данные. Регистровый файл в одном из вариантов содержит также восемь мультимедийных SIMD-регистров для упакованных данных. Для последующего обсуждения под регистрами понимают регистры данных, рассчитанные на хранение упакованных данных, такие как 64-разрядные ММХ-регистры (также называемые в некоторых случаях ‘mm’-регистрами) в микропроцессорах, поддерживающих технологию ММХ™, от корпорации «Интел» (Intel Corporation). Эти ММХ-регистры, доступные и в форме целочисленных регистров, и в форме регистров для чисел с плавающей запятой, могут работать с упакованными элементами данных, сопровождающими команды SIMD и SSE. Аналогично для хранения таких упакованных операндов данных могут быть использованы 128-разрядные ХММ-регистры, относящиеся к технологии SSE2, SSE3, SSE4 или выше (обобщенно именуемой “SSEx”). В одном из вариантов для хранения упакованных данных и целочисленных данных регистрам нет необходимости различать эти два типа данных. В одном из вариантов целочисленные данные и данные с плавающей запятой могут находиться в одном и том же регистровом файле или в разных регистровых файлах. Более того, в одном из вариантов данные с плавающей запятой и целочисленные данные могут находиться в разных регистрах или в одном и том же регистре.
На фиг. 3a-3b схематично показаны элементы микроархитектуры процессора согласно одному или более аспектам настоящего изобретения. Как показано на фиг. 3a, конвейер 400 процессора содержит ступень 402 выборки, ступень 404 декодирования длины, ступень 406 декодирования, ступень 408 распределения, ступень 410 переименования, ступень 412 планирования (также известная как ступень диспетчирования или выпуска), ступень 414 чтения регистров/чтения памяти, ступень 416 выполнения, ступень 418 обратной записи/записи в память, ступень 422 обработки исключений и ступень 424 завершения.
На фиг. 3b стрелками показаны связи между двумя или более модулями, а направление стрелок указывает направление потока данных между этими модулями. На фиг. 3b показано процессорное ядро 490, содержащее входной блок 430, соединенный с модулем 450 механизма выполнения, причем и входной блок, и модуль механизма исполнения связаны с модулем 470 памяти.
Ядро 490 может представлять собой ядро процессора с сокращенным набором команд (RISC), ядро процессора с полным набором команд (CISC), ядро процессора с очень длинным командным словом (VLIW) либо ядро гибридного или альтернативного типа. В качестве еще одной опции ядро 490 может представлять ядро специального назначения, такое как сетевое ядро или ядро связи, механизм сжатия данных, графическое ядро или другое подобное ядро.
Входной блок 430 содержит модуль 432 прогнозирования ветвления, соединенный с модулем 434 кэша команд, который связан с буфером 436 динамической трансляции (translation lookaside buffer (TLB)) команд. Этот буфер соединен с модулем 438 выборки команд, который соединен с модулем 440 декодера. Модуль декодера или декодер может декодировать команды и генерировать на выходе одну или несколько микроопераций, входных точек микрокода, микрокоманд, других команд или других сигналов управления, декодированных из исходных команд, или отражающих исходные команды другим способом, или полученных из исходных команд. Декодер может быть реализован с использованием разнообразных механизмов. К примерам таких разнообразных механизмов относятся, не ограничиваясь этим, преобразовательные таблицы, аппаратные схемы, программируемые логические матрицы (PLA), ROM микрокода и т.п. Модуль 434 кэша команд дополнительно соединен с модулем 476 кэша уровня 2 (L2) в составе модуля 470 памяти. Модуль 440 декодера соединен с модулем 452 распределения/переименования в составе модуля 450 механизма выполнения.
Модуль 450 механизма выполнения содержит модуль 452 переименования/распределения, соединенный с модулем 454 изъятия и группой из одного или более модулей 456 планировщиков. Эти модули 456 планировщиков представляют какое-то число различных планировщиков, включая станции резервирования, центральное окно команд и т.п. Модули 456 планировщиков соединены с модулями 458 физических регистровых файлов. Каждый из модулей 458 физических регистровых файлов представляет собой один или более физических регистровых файлов, каждый из которых сохраняет данные одного или более различных типов, таких как скалярные целочисленные данные, скалярные данные с плавающей запятой, упакованные целочисленные данные, упакованные данные с плавающей запятой, векторные целочисленные данные, векторные данные с плавающей запятой и т.п., данные состояния (например, указатель команды, иными словами, адрес следующей команды, которую нужно выполнить) и т.д. На модули 458 физических регистровых файлов наложен модуль 454 изъятия для иллюстрации различных способов, какими может осуществляться наложение регистров и внеочередное (не по порядку) выполнение (например, с использованием буферов переупорядочения и регистровых файлов изъятия; с использованием файлов будущего, файлов истории и регистровых файлов изъятия; с использованием карт регистров и пула регистров; и т.п.). В общем случае архитектурные регистры видны извне процессора или с точки зрения программиста. Эти регистры не ограничиваются каким-либо конкретным типом схем. Здесь могут быть использованы регистры разных типов до тех пор, пока они способны сохранять и предоставлять данные, как описано здесь. Среди примеров подходящих регистров можно указать, не ограничиваясь, выделенные физические регистры, динамически назначаемые физические регистры с использованием наложения регистров, сочетания выделенных и динамически назначаемых физических регистров и т.п. Модуль 454 изъятия и модули 458 физических регистровых файлов соединены с исполнительными кластерами 460. Исполнительный кластер 460 содержит один или более исполнительных модулей 462 и группу из одного или более модулей 464 доступа к памяти. Исполнительные модули 462 могут осуществлять разнообразные операции (например, сдвиги, суммирование, вычитание, умножение) и над различными типами данных (например, над скалярными данными с плавающей запятой, упакованными целочисленными данными, упакованными данными с плавающей запятой, векторными целочисленными данным, векторными данными с плавающей запятой). Тогда как некоторые варианты могут содержать ряд исполнительных модулей, выделенных для конкретных функций или групп функций, другие варианты могут содержать только один исполнительный модуль или несколько исполнительных модулей, где все модули выполняют все функции. Модули 456 планировщиков, модули 458 физических регистровых файлов и исполнительные кластеры 460 показаны для варианта с несколькими такими модулями, поскольку некоторые варианты создают раздельные конвейеры для некоторых типов данных/операций (например, конвейер для скалярных целочисленных данных, конвейер для скалярных данных с плавающей запятой/упакованных скалярных целочисленных данных/упакованных данных с плавающей запятой/векторных целочисленных данных/векторных данных с плавающей запятой и/или конвейер доступа к памяти, так что каждый из этих конвейеров имеет собственный модуль планировщика, модуль физических регистровых файлов и/или исполнительный кластер - и в случае отдельного конвейера для доступа к памяти реализуются некоторые варианты, в которых исполнительный кластер этого конвейера имеет модули 464 для доступа к памяти). Следует также понимать, что в случае использования раздельных конвейеров один или несколько из этих конвейеров могут служить для внеочередного выпуска/выполнения, а остальные - для работы по порядку.
Группа модулей 464 доступа к памяти соединена с модулем памяти 470, содержащим модуль 472 буфера данных TLB, соединенный с модулем 474 кэша данных, связанным с модулем 476 кэша уровня 2 (L2). В примере одного из вариантов модули 464 доступа к памяти могут содержать модуль загрузки, модуль сохранения адреса и модуль сохранения данных, каждый из которых соединен с модулем 472 буфера данных TLB в составе модуля 470 памяти. Модуль 476 кэша L2 соединен с одним или несколькими другими уровнями кэша и в конечном итоге с главной памятью.
В качестве примера, архитектура с наложением регистров и ядром для внеочередного выпуска/выполнения может реализовать конвейер 400 следующим образом: модуль 438 выборки команд реализует ступени 402 и 404 выборки и декодирования длины; модуль 440 декодера реализует ступень 406 декодирования; модуль 452 переименования/распределения реализует ступень 408 распределения и ступень 410 переименования; модули 456 планировщиков реализуют ступень 412 планирования; модули 458 регистровых файлов и модуль 470 памяти реализуют ступень 414 чтения регистров/чтения памяти; исполнительный кластер 460 реализует ступень выполнения 416; модуль 470 памяти и модули 458 физических регистровых файлов реализуют ступень 418 обратной записи/записи в память; различные модули могут участвовать в реализации ступени 422 обработки исключений; а модуль 454 изъятия и модули 458 физических регистровых файлов реализуют ступень 424 завершения.
Ядро 490 может поддерживать один или более наборов команд (например, набор команд x86 (с некоторыми расширениями, которые были добавлены в более новых версиях); набор команд MIPS, разработанный компанией MIPS Technologies из Солнечной долины, Калифорния (MIPS Technologies, Sunnyvale, СА); набор команд ARM (с дополнительными расширениями, такими как NEON), разработанный компанией ARM Holdings of Sunnyvale, CA).
В некоторых вариантах ядро может поддерживать многопоточность (выполнение двух или более параллельных наборов операций или потоков) и может делать это различными способами, включая многопоточность с разделением времени, одновременную многопоточность (где одно физическое ядро создает свое логическое ядро для каждого из потоков, которые должно выполнять это физическое ядро в многопоточном режиме), или их сочетание (например, выборка и декодирование в режиме разделения времени и затем одновременная многопоточность в соответствии с технологией Intel® Hyperthreading).
Тогда как иллюстрируемый вариант процессора также содержит раздельные модули 434/474 кэшей данных и совместно используемый модуль 476 кэша L2, альтернативные варианты могут иметь один внутренний кэш и для команд, и для данных, такой как, например, внутренний кэш Уровня 1 (L1), или многоуровневый внутренний кэш. В некоторых вариантах система может содержать сочетание внутреннего кэша и внешнего кэша, находящегося вне ядра и/или процессора. В качестве альтернативы весь кэш может быть внешним относительно ядра и/или процессора.
Фиг. 4 иллюстрирует блок-схему примера процессора 102 компьютерной системы 100 согласно одному или более аспектам настоящего изобретения. Как показано на фиг. 4, процессорное ядро 490 может содержать модуль 202 выборки, осуществляющий выборку команд для выполнения ядром 490. Команды могут быть выбраны из одного или более запоминающих устройств, таких как запоминающее устройство 115. Процессорное ядро может дополнительно содержать модуль 440 декодера для осуществления декодирования выбранной команды с целью преобразования ее в одну или более микроопераций (μops). Процессорное ядро 490 может дополнительно содержать модуль 446 планировщика для сохранения декодированной команды, принятой от модуля 440 декодера, до тех пор, пока команда не станет готова к выдаче, например до тех пор, пока не станут доступны величины операндов для декодированной команды. Модуль 446 планировщика может планировать и/или выдавать декодированные команды исполнительному модулю 450.
Исполнительный модуль 450 может содержать одно или более арифметико-логических устройств (ALU), один или более исполнительных модулей для операций с целыми числами, один или более исполнительных модулей для операций с плавающей запятой и/или других исполнительных модулей. В некоторых вариантах исполнительный модуль 450 может выполнять команды не по порядку (out-of-order (ООО)). Процессорное ядро 490 может дополнительно содержать модуль 454 изъятия для исключения выполненных команд после завершения их выполнения.
В некоторых вариантах процессор может дополнительно содержать логическое устройство 150 проверки адреса возврата, предназначенное для проверки адреса возврата процедуры с целью предотвращения несанкционированной подмены стека. Это логическое устройство 150 проверки адреса возврата может содержать указатель 421 буфера адреса возврата, конфигурированный для ссылки на элемент в буфере 423 адреса возврата. Даже хотя на фиг. 4 буфер 423 адреса возврата, указатель 421 буфера адреса возврата и логическое устройство 150 показаны внутри ядра 490, по меньшей мере некоторые из перечисленных выше элементов могут находиться где-нибудь еще в компьютерной системе 100. Например, буфер 423 адреса возврата может частично располагаться в запоминающем устройстве, внешнем по отношению к процессору 102. Более того, буфер 423 адреса возврата, указатель 421 буфера адреса возврата, логическое устройство 150 и/или некоторые компоненты этих блоков могут совместно использоваться несколькими процессорными ядрами.
Многочисленные языки программирования поддерживают сообщение о процедуре, являющееся блоком кода, имеющим точку входа и по меньшей мере одну команду возврата. Процедура может быть инициирована командой вызова, выполненной в другой процедуре. Команда возврата может заставить процессор переключить поток выполнения назад, в вызвавшую процедуру (например, к команде, следующей за соответствующей командой вызова в вызвавшей процедуре). В некоторых архитектурах процессоров адрес возврата и/или параметры, передаваемые какой-либо процедуре, могут храниться в стеке, под которым понимают структуру данных в системной памяти компьютера. Стек может быть представлен линейным массивом, поддерживающим парадигму доступа «получен последним - выдан первым» (“last in - first out” (LIFO)), как схематично иллюстрирует фиг. 5.
В иллюстративном примере, показанном на фиг. 5, стек растет в направлении меньших адресов памяти. Элементы данных могут быть помещены в стек с использованием команды PUSH и вызваны из стека с использованием команды POP. Чтобы поместить элемент данных в стек, процессор может модифицировать (например, уменьшить) величину указателя стека и затем скопировать элемент данных в область памяти, на которую показывает указатель стека. Следовательно, указатель стека всегда показывает на самый верхний элемент стека. Для вызова элемента данных из стека процессор 102 может считывать элемент данных, на который показывает указатель стека, и затем модифицировать (например, увеличить) величину указателя стека, чтобы он показал на элемент, который был помещен в стек непосредственно перед вызываемым элементом. В некоторых архитектурах процессоров указатель стека может быть сохранен в выделенном регистре процессора, обозначенном как SP или ESP.
Процессор 102 может использовать несколько сегментных регистров для поддержки механизма сегментации памяти. В некоторых вариантах процессор 102 может дополнительно поддерживать классификацию сегментов памяти по типам, чтобы ограничить операции доступа к памяти, которые могут осуществляться на сегментах конкретного типа. Классификация сегментов по типам может поддерживаться путем ассоциирования типов памяти с регистрами сегментов. В одном из примеров процессор 102 может иметь по меньшей мере один регистр сегмента кода (который может быть также обозначен CS), два или более регистров сегментов данных (которые могут быть также обозначены как DS, ES, FS и GS) и по меньшей мере один регистр сегмента стека (который может быть также обозначен как SS).
При выполнении команды вызова процесса 102 может, перед выполнением перехода к первой команде вызванной процедуры, поместить адрес, хранящийся в регистре указателя команд (EIP), в текущий стек. Этот адрес, именуемый также указателем команды возврата, указывает на команду, с которой выполнение вызвавшей процедуры должно возобновиться после возврата из вызванной процедуры. При выполнении команды возврата в рамках вызванной процедуры процессор 102 может вызвать указатель команды возврата из стека назад в регистр EIP и, таким образом, возобновить выполнение вызвавшей процедуры.
Следует отметить, что в некоторых вариантах процессор 102 не требует, чтобы указатель команды возврата указал назад на вызвавшую процедуру. Перед выполнением этой команды возврата программное обеспечение может осуществить манипуляцию с указателем команды возврата, хранящимся в стеке (например, путем выполнения команды PUSH), для указания на произвольный адрес.
Для того чтобы потенциальный взломщик, не смог использовать этот момент для перенаправления потока выполнения в произвольную область памяти, процессор 102 может, в ответ на прием команды вызова, сохранить указатель команды возврата не только в стеке, но также и в буфере 423 адреса возврата. В ответ на прием команды возврата в вызванной процедуре процессор 102 может вызвать и сравнить указатели команды возврата из стека и из буфера адреса возврата. Если эти два адреса совпадут, процессор может продолжить выполнение команды возврата; в противном случае процессор может сформировать исключение.
В некоторых вариантах буфер 423 адреса возврата может содержать первый буфер 423-1, хранящийся во внутренней памяти 602 процессора 102, и второй буфер 423-2, хранящийся во внешней памяти 604, которая может поддерживать связь с процессором 102 по системной шине 608, как схематично на фиг. 6. Второй буфер 423-2, резидентный во внешней памяти 604, может быть использован в качестве буфера «переполнения», если размер первичного буфера 423-1 станет недостаточным для сохранения адресов возврата.
Для осуществления функций «переполнения» в одном иллюстративном примере указатель 421 буфера адреса возврата может быть инициализирован для указания на основание внутреннего буфера 423-1 адреса возврата и может быть модифицирован (например, уменьшен), когда в буфер 423 адреса возврата помещают новый адрес возврата. Когда будет достигнута граница внутреннего буфера 423-1, следующая операция модификации может направить указатель 421 буфера адреса возврата, чтобы указывать на основания внешнего буфера 423-2 адреса возврата. Аналогичная функция может быть реализована для переключения указателя 421 буфера адреса возврата из внешнего буфера 423-2 во внутренний буфер 423-1 в ответ на удаление адреса возврата из буфера 423.
В некоторых вариантах по меньшей мере часть внешнего буфера 423-2 адреса возврата может быть кэширована в одном или более кэшах 104 процессора 102, таких как кэш L2 и/или кэш L1. В одном из иллюстративных примеров множество входных позиций в кэш данных самого низкого уровня в процессоре 102 могут быть зарезервированы для кэширования множества входных позиций внешнего буфера 423-2 адреса возврата.
В другом аспекте область памяти, где находится внешний буфер 423-2 памяти, может быть конфигурирована таким образом, чтобы позволить доступ только привилегированному коду путем использования механизма защиты памяти процессора, предоставляющего множество уровней привилегий доступа. В одном из примеров уровни привилегий доступа, также именуемые кольцами защиты, могут быть пронумерованы от 0 до 3, причем больший номер может означать меньший объем привилегий. Кольцо защиты под номером 0 может быть зарезервировано для наиболее привилегированных кода, данных стеков, таких как ядро операционной системы. Внешние кольца защиты могут быть использованы для прикладных программ. В некоторых вариантах операционные системы могут использовать подгруппу из множества колец защиты, например кольцо 0 для ядра операционной системы и кольцо 3 для приложений. Процессор может использовать уровни привилегий, чтобы не допустить доступа процесса, работающего на меньшем уровне привилегий, к сегменту с более высоким уровнем привилегий. Текущий уровень привилегий (current privilege level (CPL)) представляет собой уровень привилегий, исполняемого в текущий момент процесса. Уровень CPL может быть сохранен в битах 0 и 1 регистров CS и SS сегментов. Уровень CPL может быть равен уровню привилегий сегмента кода, из которого выбирают команды в текущий момент. Процессор может изменять уровень CPL, когда программное управление переходит к сегменту кода, имеющему другой уровень привилегий. Процессор может проверять уровень привилегий путем сравнения уровня CPL с уровнем привилегий сегмента или шлюза доступа, к которому осуществляется доступ (дескрипторный уровень привилегий (descriptor privilege level, DPL)) и/или запрашиваемый уровень привилегий (requested privilege level (RPL)), т.е. уровнем, назначенным селектору сегмента, к которому производится обращение. Когда процессор обнаружит нарушение уровня привилегий, он может сформировать исключение общей защиты.
Таким образом, в одном из иллюстративных примеров, область памяти, где располагается внешний буфер 423-2 памяти, может быть конфигурирована так, чтобы позволить доступ только привилегированному коду, такому как ядро операционной системы, имеющее текущий уровень привилегий (CPL), равен 0. В качестве альтернативы область памяти, где располагается внешний буфер 423-2 памяти, может быть конфигурирована таким образом, чтобы разрешить доступ только для чтения, вследствие чего эта область может быть модифицирована только логическим устройством 150 проверки адреса возврата.
Как отмечено выше, в ответ на прием команды вызова процессор 102 может, перед переходом к первой команде вызванной процедуры, поместить адрес, записанный в регистре указателя команд (EIP), в текущий стек и в буфер 423 адреса возврата. При выполнении команды возврата в вызванной процедуре процессор 102 может вызвать и сравнить указатели команды возврата из стека и из буфера адреса возврата. Если эти два адреса совпадут, процессор может продолжить выполнение команды возврата; в противном случае процессор может сформировать исключение.
Еще в одном аспекте в зависимости от архитектуры процессора и/или операционной системы стек вызова может быть законно модифицирован способом, отличным от команды вызова. Например, функции setjump/longjump стандартной библиотеки языка С дают возможность заново установить состояние программы, включая указатель команды, даже через несколько уровней вызовов процедур. В другом примере команда возврата может быть использована для передачи управления в динамически вычисленную точку входа, например, путем помещения динамически вычисленного адреса в стек. Для того чтобы позволить правильно обработать эти и другие ситуации, когда стек вызовов законно модифицирован способом, отличным от команды вызова, процессор 102 может предоставить альтернативный (т.е. отличный от выполнения команды вызова) механизм для модификации содержания буфера адреса возврата и/или указателя буфера адреса возврата.
Таким образом, в некоторых вариантах процессор 102 может иметь набор команд, содержащий команду модификации указателя буфера адреса возврата и/или команду модификации буфера адреса возврата. В ответ на прием команды модификации указателя буфера адреса возврата процессор 102 может модифицировать (например, увеличить или уменьшить) указатель буфера адреса возврата без модификации содержания этого буфера адреса возврата. В ответ на прием команды модификации указателя буфера адреса возврата процессор 102 может модифицировать содержание буфера адреса возврата (например, сохранить в буфере новый адрес возврата или удалить какой-нибудь адрес возврата из буфера) и может далее соответственно модифицировать (например, увеличить или уменьшить указатель буфера адреса возврата. В некоторых вариантах команда модификации указателя буфера адреса возврата и/или команда модификации буфера адреса возврата могут быть привилегированными командами, например, выполняемыми только процессом или потоком кольца 0, предотвращая тем самым несанкционированную модификацию буфера адреса возврата, которую мог бы попытаться осуществить процесс или поток пользователя.
На фиг. 7 представлена логическая схема примера способа проверки адреса возврата процедуры согласно одному или нескольким аспектам настоящего изобретения. Способ 700 может быть осуществлен компьютерной системой, которая может содержать аппаратуру (например, схемы, специализированные логические устройства и/или программируемые логические устройства), программное обеспечение (например, команды, выполняемые компьютерной системой для имитации аппаратуры) или сочетания аппаратуры и программного обеспечения. Способ 700 и/или каждая из его функций, программ, подпрограмм или операций, могут быть выполнены одним или несколькими физическими процессорами в составе компьютерной системы, осуществляющей этот способ. Две или более функции, программ, подпрограмм или операций способа 700 могут быть выполнены параллельно или в порядке, который может отличаться от порядка, описанного выше. В одном из примеров, как показано на фиг. 7, способ 700 может быть осуществлен компьютерной системой 100, показанной на фиг. 1.
Как показано на фиг. 7, в блоке 710 процессор компьютерной системы 100 может модифицировать указатель стека. В одном из примеров процессор может модифицировать указатель стека, поместив в стек адрес возврата в ответ на прием команды вызова, как описано более подробно выше. В качестве альтернативы процессор может непосредственно модифицировать стек, например путем записи в стек динамически вычисленного адреса возврата, как описано более подробно выше.
В блоке 720 процессор может модифицировать указатель буфера адреса возврата. В одном из примеров процессор может модифицировать указатель буфера адреса возврата, поместив адрес возврата в буфер адреса возврата в ответ на прием команды вызова, как более подробно описано выше. В качестве альтернативы процессор может непосредственно модифицировать буфер адреса возврата, чтобы отразить непосредственную модификацию стека, например, когда в стек был помещен динамически вычисленный адрес возврата, как это более подробно описано выше.
В блоке 730 процессор может, в качестве опции, выполнить одну или несколько команд, например, процедуру, вызванную посредством команды вызова, которая привела к осуществлению модификаций стека и указателя буфера адреса возврата, что обозначено блоками 710-720.
В блоке 740 процессор может принять команду возврата (RET).
В ответ на установление, в блоке 750, что адрес возврата, на который показывает указатель стека, равен адресу возврата, на который показывает указатель буфера адреса возврата, процессор может выполнить команду RET, схематично обозначенную блоком 760, путем сохранения указателя команды возврата из стека в регистре EIP с целью возобновить выполнение вызвавшей процедуры.
В ответ на установление, в блоке 750, что адрес возврата, на который показывает указатель стека, не совпадает с адресом возврата, на который показывает указатель буфера адреса возврата, процессор может генерировать исключение «Ошибка стека» (Stack Fault).
Способы и системы, описываемые выше, могут быть реализованы, посредством компьютерной системы, которая может обладать разнообразными архитектурами, конструкциями и конфигурациями для портативных компьютеров, настольных компьютеров, ручных персональных компьютеров, персональных цифровых помощников, инженерных рабочих станций, серверов, сетевых устройств, сетевых концентраторов, коммутаторов, встроенных процессоров, цифровых процессоров сигнала (DSP), графических устройств, видеоигровых устройств, приставок, микроконтроллеров, сотовых телефонов, портативных медиа плееров, ручных устройств и разнообразных других электронных устройств, так что такие системы подходят также для осуществления описываемых здесь способов. В общем случае самые разнообразные системы или электронные устройства, способные содержать процессор и/или другие исполнительные логические устройства, описываемые здесь, в целом подходят для реализации рассматриваемых здесь систем и способов.
На фиг. 8 представлена блок-схема примера компьютерной системы согласно одному или нескольким аспектам настоящего изобретения. Как показано на фиг. 8, мультипроцессорная система 800 представляет собой систему с двухпунктовым соединением и содержит первый процессор 870 и второй процессор 880, связанные один с другим посредством двухпунктового соединения 850. Каждый из процессоров 870 и 880 может представлять собой некую версию процессора 102, способного осуществлять проверку адреса возврата, как более подробно описано выше. Хотя показаны только два процессора 870, 880, следует понимать, что объем настоящего изобретения этим не ограничивается. В других вариантах в примере компьютерной системы могут присутствовать один или несколько дополнительных процессоров.
Показано, что процессоры 870 и 880 содержат встроенные модули 872 и 882 соответственно контроллеров памяти. Процессор 870 содержит также, в качестве составной части своих модулей контроллеров шин, двухпунктовые (point-to-point (Р-Р)) интерфейсы 876 и 878; аналогично, второй процессор 880 содержит Р-Р интерфейсы 886 и 888. Процессоры 870, 880 могут обмениваться информацией через Р-Р интерфейс 750 с использованием интерфейсных Р-Р схем 878, 888. Как показано на фиг. 7, модули 872 и 882 встроенных контроллеров памяти (IMC) связывают процессоры с соответствующими запоминающими устройствами, а именно с запоминающим устройством 832 и запоминающим устройством 834, которые могут быть частями главного запоминающего устройства, локально присоединенными к соответствующим процессорам.
Каждый из процессоров 870, 880 может обмениваться информацией с чипсетом 890 через индивидуальные Р-Р интерфейсы 852, 854 с использованием двухпунктовых интерфейсных схем 876, 894, 886, 898. Чипсет 890 может также обмениваться информацией с высокопроизводительной графической схемой 838 через высокопроизводительный графический интерфейс 839.
Совместно используемый кэш (не показан) может входить в состав какого-либо из процессоров либо располагаться вне обоих процессоров, будучи при этом связан с этими процессорами посредством Р-Р соединения, так что локальная кэшируемая информация какого-либо из процессоров или обоих процессоров может быть сохранена в этом совместно используемом кэше, если соответствующий процессор переведен в режим пониженного энергопотребления.
Чипсет 890 может быть соединен с первой шиной 816 через интерфейс 896. В одном из вариантов первая шина 816 может представлять собой шину соединения периферийных устройств (Peripheral Component Interconnect (PCI)) или быть такой шиной, как шина стандарта PCI Express, или какой-либо другой соединительной шиной ввода-вывода третьего поколения, хотя объем настоящего изобретения этим не ограничивается.
Как показано на фиг. 8, с первой шиной 816 могут быть соединены разнообразные устройства 814 ввода/вывода вместе с мостом 818, который соединяет первую шину 816 со второй шиной 820. В одном из вариантов эта вторая шина 820 может представлять собой шину с небольшим числом контактов (low pin count (LPC)). В одном из вариантов со второй шиной 820 могут быть соединены разнообразные устройства, например клавиатура и/или мышь 822, устройства 827 связи и модуль 828 запоминающего устройства, такого как дисковод или другое запоминающее устройство большой емкости, в котором могут храниться команды/код и данные 830. Кроме того, со второй шиной 820 может быть соединено аудио устройство 824 ввода/вывода.
На фиг. 9 представлена блок-схема примера системы на кристалле (SoC) согласно одному или более аспектам настоящего изобретения. Процессор 910 может быть способен осуществлять проверку адреса возврата, как это более подробно описано выше. Как схематично показано на фиг. 9, соединительные модули 902 могут быть связаны с: процессором 910 приложений, содержащим группу из одного или нескольких ядер 902А-N и совместно используемый кэш 906; модуль 910 системного агента; модули 916 контроллеров шин; модули 914 встроенных контроллеров памяти; группу из одного или более медиа процессоров 920, которые могут содержать встроенное графическое логическое устройство 908, процессор 924 изображений для предоставления функций фото и/или видеокамеры, аудио процессор 926 для аппаратного аудио ускорения и видео процессор 928 для ускорения кодирования/декодирования видео; модуль 930 статического запоминающего устройства произвольного доступа (static random access memory (SRAM)); модуль 932 прямого доступа к памяти (DMA); и модуль 940 отображения для соединения с одним или более внешними устройствами отображения.
На фиг. 10 представлена блок-схема примера компьютерной системы согласно одному или более аспектам настоящего изобретения. Процессор 1610 может представлять собой некую версию процессора 102, способную осуществлять проверку адреса возврата, как это более подробно описано выше.
Система 1610, схематично иллюстрируемая на фиг. 10, может содержать какое-либо сочетание компонентов, реализованных в виде интегральных схем, частей интегральных схем, дискретных электронных устройств или других модулей, логических устройств, аппаратуры, загружаемого или встроенного программного обеспечения и/или сочетаний этих компонентов, подходящих для создания компьютерной системы, или компонентов, каким-либо другим способом встроенных в шасси компьютерной системы. Блок-схема на фиг. 10 предназначена для демонстрации вида высокого уровня многих компонентов компьютерной системы. Однако следует понимать, что в других вариантах некоторые из показанных на чертеже компонентов могут быть исключены, могут присутствовать дополнительные компоненты, а также возможна другая компоновка компонентов, отличная от показанной на чертеже.
Процессор 1610 может представлять собой микропроцессор, многоядерный процессор, многопоточный процессор, ультра низковольтный процессор, встроенный процессор или другой известный процессорный элемент. В иллюстрируемом варианте процессор 1610 служит главным процессорным модулем и центральным концентратором для связи с разнообразными компонентами системы 1600. В качестве одного из примеров процессор 1610 может представлять собой процессор на основе архитектуры Intel® Architecture Core™, такой как i3, i5, i7 или другой подобный процессор, выпускаемый корпорацией Intel Corporation, Santa Clara, CA.
Процессор 1610 может осуществлять связь с системным запоминающим устройством 1615. В различных вариантах индивидуальные запоминающие устройства могут быть выполнены в корпусах различных типов, таких как однокристальный корпус (single die package (SDP)), двухкристальный корпус (dual die package (DDP)) или четырехкристальный корпус (quad die package (IP)). В некоторых вариантах эти устройства могут быть припаяны непосредственно к материнской плате для получения низкопрофильной конструкции, тогда как в других вариантах устройства могут быть конфигурированы в виде одного или нескольких модулей памяти, которые, в свою очередь, связаны с материнской платой специальным разъемом. Возможны и другие варианты реализации памяти, такие как другие типы модулей памяти, например модули памяти с двухрядным расположением выводов (dual inline memory modules (DIMMs)) в различных вариантах, включая, но не ограничиваясь, microDIMMs, MiniDIMMs. В одном из иллюстративных примеров запоминающее устройство может иметь емкость от 2 Гбайт до 16 Гбайт и может быть конфигурировано в корпусе типа DDR3LM или в виде низкопрофильного запоминающего устройства LPDDR2 или LPDDR3, припаянного к материнской плате посредством матрицы шариковых выводов memory (ball grid array (BGA)).
Для обеспечения постоянного хранения информации, такой как данные, приложения, одна или более операционных систем и т.д., с процессором 1610 может быть также соединено запоминающее устройство 1620 большой емкости. В некоторых вариантах для получения более тонкой и легкой конструкции системы, а также повышения быстродействия системы запоминающее устройство 1620 большой емкости может быть выполнено на основе твердотельного SSD-накопителя. В других вариантах запоминающее устройство большой емкости может быть построено на основе накопителя на жестком магнитном диске (hard disk drive (HDD)) с добавлением твердотельного SSD-накопителя меньшей емкости для использования в качестве SSD-кэша, чтобы обеспечить энергонезависимое сохранение состояния контекста и другой подобной информации на время выключения питания с целью предоставления возможности более быстрого включения системы при возобновлении ее работы.
Как показано на фиг. 10, с процессором 1610 может быть соединено устройство 1622 флэш-памяти, например, через последовательный периферийный интерфейс (serial peripheral interface (SPI)). Это устройство 1622 флэш-памяти может осуществлять энергонезависимое хранение системного программного обеспечения, включая программное обеспечение базовой системы ввода/вывода (basic input/output software (BIOS)), равно как и другое встроенное программное обеспечение системы.
В разнообразных вариантах запоминающее устройство большой емкости в системе может быть реализовано на основе только твердотельного SSD-накопителя или на основе дисковода, оптического или другого накопителя в сочетании с SSD-кэшем. В некоторых вариантах запоминающее устройство большой емкости может быть реализовано на основе SSD-накопителя или накопителя на жестком диске (HDD) в сочетании с модулем восстановительного (restore (RST)) кэша. Указанный SSD-кэш может быть конфигурирован в виде одноуровневого кэша (single level cache (SLC)) или многоуровневого кэша (multi-level cache (MLC)) для обеспечения соответствующего уровня быстродействия.
В систему 1600 могут входить разнообразные устройства ввода/вывода, включая, например, устройство 1624 отображения, которое может быть построено на основе жидкокристаллической (LCD) или светодиодной (LED) панели высокой четкости, встроенной в крышку шасси. Эта панель отображения может также иметь сенсорный экран 1625, наложенный снаружи на панель отображения, так что, взаимодействуя с этим сенсорным экраном, пользователь может вводить в систему данные и команды для выполнения нужных ему операций, например, относительно представления информации на устройстве отображения, доступа к информации и т.п. В некоторых вариантах устройство 1624 отображения может быть связано с процессором 1610 посредством дисплейного соединения, которое может быть выполнено в виде высокопроизводительного графического соединения. Сенсорный экран 1625 может быть связан с процессором 1610 посредством другого соединения, которое в одном из вариантов может быть соединением типа I2C (межсхемный интерфейс интегральных схем). Помимо сенсорного экрана 1625 пользователь может осуществлять сенсорный ввод также посредством сенсорной панели 1630, которая может быть встроена в шасси и может быть также соединена с процессором посредством того же соединения типа I2C, как и сенсорный экран 1625.
Система может иметь разнообразные датчики, которые могут быть соединены с процессором 1610 различными способами. Некоторые инерциальные датчики и датчики состояния окружающей среды могут быть связаны с процессором 1610 через концентратор 1640 датчиков, например, посредством соединения типа I2C. Среди этих датчиков могут быть акселерометр 1641, датчик 1642 внешней освещенности (ambient light sensor (ALS)), компас 1643 и гироскоп 1644. Среди других датчиков состояния окружающей среды могут быть один или несколько датчиков 1646 температуры, которые в некоторых вариантах могут быть связаны с процессором 1610 через системную управляющую шину (system management bus (SMBus)). В некоторых вариантах могут иметь место один или более инфракрасных или других термочувствительных элементов либо какой-либо другой элемент для обнаружения присутствия пользователя.
Разнообразные периферийные устройства могут быть связаны с процессором 1610 через соединение с небольшим числом контактов (LPC). В некоторых вариантах различные компоненты могут быть связаны через встроенный контроллер 1635. Среди таких компонентов могут быть клавиатура 1636 (например, соединенная через интерфейс PS2), вентилятор 1637 и датчик 1639 температуры. В некоторых вариантах сенсорная панель 1630 может быть также соединена с контроллером ЕС 1635 через интерфейс PS2. Кроме того, с процессором 1610 может быть также связан через указанное соединение LPC процессор системы безопасности, такой как доверенный платформенный модуль (trusted platform module (ТРМ)) 1638 в соответствии с техническими условиями Группы по доверенным вычислениям (Trusted Computing Group (TCG)) ТРМ Specification Version 1.2, от 2 октября 2003 г.
В некоторых портах для периферийных устройств могут присутствовать разъем мультимедийного интерфейса высокой четкости (high definition media interface (HDMI)) (который может иметь различные форм-факторы, такие как полноразмерный, мини или микро); один или несколько USB-портов, таких как полноразмерные внешние порты согласно техническим условиям Universal Serial Bus Revision 3.0 Specification (ноябрь 2008), так что по меньшей мере один из этих портов получает энергию для зарядки USB-устройств (таких как смартфоны), когда система находится в соединенном ждущем состоянии (Connected Standby) и подключена к розетке сети переменного тока. Кроме того, могут присутствовать один или более портов типа ThunderboltTM. Среди других портов могут быть доступное извне устройство для считывания карточек, такое как считыватель для полноразмерных карточек SD-XC и/или считыватель SIM-карт для глобальной сети радиосвязи (WWAN) (например, 8-штырьковый считыватель карточек). Для аудио сигналов может быть предусмотрено гнездо диаметром 3,5 мм с возможностями ввода/вывода стереозвука и присоединения микрофона (например, комбинированные функции) с поддержкой обнаружения типа присоединяемого к гнезду устройства (например, поддержка только головных телефонов с использованием микрофона, встроенного в крышку, либо поддержка головных телефонов с микрофоном по кабелю). В некоторых вариантах это гнездо может иметь переключаемые функции для поддержки либо только вывода сигнала к стерео головным телефонам, либо только ввода от стерео микрофона. Кроме того, может быть предусмотрено гнездо питания для соединения с внешним блоком питания от переменного тока.
Система 1600 может осуществлять связь с внешними устройствами различными способами, включая беспроводную связь. В варианте, показанном на фиг. 10, показаны различные модули беспроводной связи, каждый из которых конфигурирован для связи в соответствии со своим конкретным протоколом радиосвязи. Один из таких способов радиосвязи представляет собой связь на коротких расстояниях с использованием поля ближней зоны, осуществляемую посредством модуля 1645 связи в ближней зоне (near field communication (NFC)), который может в одном из вариантов поддерживать связь с процессором 1610 через шину SMBus.
Другие модули беспроводной связи могут содержать модули других систем связи на коротких расстояниях, включая модуль 1650 для работы в локальной сети радиосвязи (WLAN) и модуль 1652 связи согласно стандарту Bluetooth. Используя модуль 1652 для сети WLAN, можно реализовать связь Wi-Fi™ согласно стандарту 802.11 Института инженеров по электротехнике и электронике (IEEE), тогда как через модуль Bluetooth 1652 можно осуществлять связь малой дальности согласно протоколу Bluetooth. Эти модули могут осуществлять связь с процессором 1610 через, например, USB-линию связи или через линию связи в стандарте универсальных асинхронных приемопередатчиков (universal asynchronous receiver transmitter (UART)). Эти модули могут быть в качестве альтернативы связаны с процессором 1610 согласно протоколу Peripheral Component Interconnect Express™ (PCIe™), например, в соответствии с техническими условиями PCI ExpressTM Specification Base Specification version 3.0 (опубликовано 17 января 2007), или согласно другому подобному протоколу, такому как стандарт последовательно ввода/вывода данных (serial data input/output (SDIO)). standard. Безусловно, реальное физическое соединение между этими периферийными устройствами, которые могут быть конфигурированы на одной или нескольких расширительных платах, может быть реализовано посредством разъемов типа NGFF, монтируемых на материнской плате.
Кроме того, радиосвязь в глобальной сети, например связь согласно протоколу сотовой связи или протоколу другой глобальной сети радиосвязи, может осуществляться через модуль WWAN 1656, который, в свою очередь, может быть связан с модулем идентификации абонента (subscriber identity module (SIM)) 1657. Кроме того, для обеспечения возможности приема и использования информации о местонахождении может быть предусмотрен модуль GPS 1655.
Для создания аудио входов и выходов аудио процессор может быть реализован посредством цифрового процессора сигнала (DSP) 1660, который может быть связан с процессором 1610 аудио каналом высокой четкости (high definition audio (HDA)). Аналогично, процессор DSP 1660 может осуществлять связь с интегральным кодером/декодером (CODEC) и усилителем 1662, который, в свою очередь, может быть связан с внешними громкоговорителями 1663, каковые могут быть размещены внутри шасси. Аналогично усилитель и CODEC 1662 может быть соединен для получения входных аудио сигналов от микрофона 1665.
На фиг. 11 представлена блок-схема примера системы на кристалле (SoC) согласно одному или более аспектам настоящего изобретения. В качестве конкретного примера система SOC 1700 может входить в состав абонентского оборудования (user equipment (UE)) или терминала. В одном из вариантов терминал UE обозначает какое-либо устройство, которое может использовать конечный пользователь для связи, такое как ручной телефон, смартфон, планшет, ультратонкий ноутбук, ноутбук с широкополосным адаптером или какое-либо другое подобное устройство связи. Часто терминал UE устанавливает связь с базовой станцией или узлом, что потенциально по природе соответствует работе мобильной станции (mobile station (MS)) в сети стандарта GSM.
Как схематично показано на фиг. 11, система SOC 1700 может содержать два ядра. Ядра 1706 и 1707 могут быть связаны со схемой 1708 управления кэшем, которая ассоциирована с модулем 1709 интерфейса шины и кэшем L2 1710, для связи с другими частями системы 1710. Соединение 1710 может представлять собой какое-либо соединение на кристалле, такое как IOSF, АМВА или другое соединение.
Интерфейс 1710 может создать каналы связи с другими компонентами, такими как модуль идентификации абонента (Subscriber Identity Module (SIM)) 1730 для сопряжения с SIM-картой, ПЗУ ROM 1735 загрузчика для сохранения кода загрузки для выполнения ядрами 1706 и 1707 с целью инициализации и загрузки системы SOC 1700, контроллер 1740 запоминающих устройств с произвольной выборкой (SDRAM) для сопряжения с внешними запоминающими устройствами (например, динамическим ЗУПВ DRAM 1760), контроллер 1745 флэш-памяти для сопряжения с энергонезависимой памятью, например флэш-памятью 1765), контроллер 1750 периферийных устройств (например, последовательный периферийный интерфейс) для сопряжения с периферийными устройствами, видео кодеками 1720 и видео интерфейсом 1725 для сопряжения с дисплеем и приема вводимых данных и команд (например, сенсорный ввод), графический процессор GPU 1715 для осуществления вычислений, связанных с графикой, и т.п. Кроме того, система может содержать периферийные устройства для связи, такие как модуль Bluetooth 1770, 3G-модем 1775, модуль GPS 1780 и модуль WiFi 1785.
Для реализации систем и способов, рассматриваемых здесь, могут также подходить и другие конструкции и конфигурации компьютерных систем. Приведенные далее примеры иллюстрируют различные варианты согласно одному или нескольким аспектам настоящего изобретения.
Пример 1 представляет процессорную систему, содержащую: указатель стека, конфигурированный, чтобы показывать на первый адрес возврата, сохраненный в стеке; указатель буфера адреса возврата, конфигурированный, чтобы показывать на второй адрес возврата, сохраненный в буфере адреса возврата; и логическое устройство проверки адреса возврата, конфигурированное для сравнения первого адреса возврата со вторым адресом возврата в ответ на прием команды возврата.
В Примере 2 логическое устройство проверки адреса возврата в процессорной системе согласно Примеру 1 может быть дополнительно конфигурировано для выполнения команды возврата в ответ на определение, что первый адрес возврата равен второму адресу возврата.
В Примере 3 логическое устройство проверки адреса возврата в процессорной системе согласно Примеру 1 может быть дополнительно конфигурировано для генерации исключения из-за ошибки стека в ответ на определение, что первый адрес возврата отличается от второго адреса возврата.
В Примере 4 логическое устройство проверки адреса возврата в процессорной системе согласно Примеру 1 может быть дополнительно конфигурировано для сохранения адреса возврата в стеке и в буфере адреса возврата в ответ на прием команды вызова.
В Примере 5 логическое устройство проверки адреса возврата в процессорной системе согласно Примеру 1 может быть дополнительно конфигурировано для выполнения, в ответ на прием команды модификации буфера адреса возврата, по меньшей мере одного из действий: сохранения адреса возврата в буфере адреса возврата или удаления адреса возврата из буфера адреса возврата.
В Примере 6 логическое устройство проверки адреса возврата в процессорной системе согласно Примеру 1 может быть дополнительно конфигурировано для выполнения, в ответ на прием команды модификации буфера адреса возврата, по меньшей мере одного из действий: увеличения указателя буфера адреса возврата или уменьшения указателя буфера адреса возврата.
В Примере 7 команда модификации буфера адреса возврата согласно Примерам 5-6 может представлять собой привилегированную команду.
В Примере 8 стек процессорной системы согласно какому-либо из Примеров 1-7 может быть резидентным в запоминающем устройстве, связанном с процессорной системой.
В Примере 9 буфер адреса возврата в составе процессорной системы согласно какому-либо из Примеров 1-7 может быть по меньшей мере частично резидентным в запоминающем устройстве в составе процессорной системы.
В Примере 10 буфер адреса возврата в составе процессорной системы согласно какому-либо из Примеров 1-7 может содержать первую часть, резидентную в запоминающем устройстве в составе процессорной системы, и вторую часть, резидентную во внешней памяти.
В Примере 11 внешнее запоминающее устройство процессорной системы согласно Примеру 10 может быть реализовано посредством постоянного запоминающего устройства.
В Примере 12 вторая часть буфера адреса возврата процессорной системы согласно какому-либо из Примеров 10-11 может быть конфигурирована для работы в качестве буфера переполнения относительно первой части.
Пример 13 представляет способ проверки адреса возврата процедуры, содержащий этапы, на которых: осуществляют модификацию, посредством процессорной системы, указателя стека; модификацию указателя буфера адреса возврата; принимают команды возврата; сравнивают первый адрес возврата, на который указывает указатель стека, со вторым адресом возврата, на который указывает указатель буфера адреса возврата; и выполняют команды возврата в ответ на определение, что первый адрес возврата равен второму адресу возврата.
В Примере 14 способ согласно Примеру 13 может дополнительно содержать этап, на котором: генерируют исключения из-за ошибки стека в ответ на определение, что первый адрес возврата отличается от второго адреса возврата.
В Примере 15 способ согласно Примеру 13 может дополнительно содержать этап, на котором: сохраняют адрес возврата в стеке и в буфере адреса возврата в ответ на прием команды вызова.
В Примере 16 способ согласно Примеру 13 может дополнительно содержать этап, на котором: принимают команды модификации буфера адреса возврата; и выполняют по меньшей мере одного из действий: сохранение адреса возврата в буфере адреса возврата или удаление адреса возврата из буфера адреса возврата.
В Примере 17 способ согласно Примеру 13 может дополнительно содержать этап, на котором: принимают команды модификации буфера адреса возврата; и выполняют по меньшей мере одного из действий: увеличение указателя буфера адреса возврата или уменьшение указателя буфера адреса возврата.
В Примере 18 способ согласно Примеру 13 может дополнительно содержать этап, на котором: инициализируют указатель буфера адреса возврата, так что он указывает позицию во внутреннем буфере адреса возврата; модифицируют указатель буфера адреса возврата; определяют, что достигнута граница внутреннего буфера адреса возврата; и направляют указатель буфера адреса возврата в позицию во внешнем буфере адреса возврата.
Пример 19 представляет устройство, содержащее запоминающее устройство и процессорную систему, связанную с указанным запоминающим устройством, так что процессорная система конфигурирована для осуществления способа согласно какому-либо из Примеров 13-18.
Пример 20 представляет компьютерный энергонезависимый носитель информации, имеющий исполняемые команды, при выполнении которых процессорная система осуществляет операции, содержащие: модификацию указателя стека; модификацию указателя буфера адреса возврата; прием команды возврата; сравнения первого адреса возврата, на который показывает указатель стека, со вторым адресом возврата, на который показывает указатель буфера адреса возврата; и выполнение команды возврата в ответ на определение, что первый адрес возврата равен второму адресу возврата.
В Примере 21 компьютерный энергонезависимый носитель информации согласно Примеру 20 может дополнительно содержать исполняемые команды, при выполнении которых компьютерная система генерирует исключение из-за ошибки стека в ответ на определение, что первый адрес возврата отличается от второго адреса возврата.
В Примере 22 компьютерный энергонезависимый носитель информации согласно Примеру 20 может дополнительно содержать исполняемые команды, при выполнении которых компьютерная система сохраняет адрес возврата в стеке и в буфере адреса возврата в ответ на прием команды вызова.
В Примере 23 компьютерный энергонезависимый носитель информации согласно Примеру 20 может дополнительно содержать исполняемые команды, при выполнении которых компьютерная система принимает команду модификации буфера адреса возврата, и выполняет по меньшей мере одно из действий: сохраняет адрес возврата в буфере адреса возврата или удаляет адрес возврата из буфера адреса возврата.
В Примере 24 компьютерный энергонезависимый носитель информации согласно Примеру 20 может дополнительно содержать исполняемые команды, при выполнении которых компьютерная система принимает команду модификации буфера адреса возврата, и выполняет по меньшей мере одно из действий: увеличивает указатель буфера адреса возврата или уменьшает указатель буфера адреса возврата.
В Примере 25 компьютерный энергонезависимый носитель информации согласно Примеру 20 может дополнительно содержать исполняемые команды, при выполнении которых компьютерная система инициализирует указатель буфера адреса возврата, так что он показывает позицию во внутреннем буфере адреса возврата; модифицирует указатель буфера адреса возврата; определяет, что достигнута граница внутреннего буфера адреса возврата; направляет указатель буфера адреса возврата в позицию во внешнем буфере адреса возврата.
Некоторые фрагменты этого подробного описания составлены в терминах алгоритмов и символических представлений битов данных в памяти компьютера. Эти алгоритмические описания и представления являются средством, используемым специалистами в области обработки данных, для наиболее эффективной передачи существа их работы другим специалистам в этой области. Под алгоритмом здесь и в общем случае понимают самосогласованную последовательность операций, ведущую к желаемому результату. Эти операции требуют физических манипуляций с физическими величинами. Обычно, хотя и необязательно, эти величины принимают форму электрических или магнитных сигналов, которые можно хранить, передавать, комбинировать, сравнивать и осуществлять с ними другие манипуляции. Иногда удобно, главным образом по причинам широкого использования, называть эти сигнала битами, величинами, элементами, символами, знаками, членами, числами или другими подобными терминами.
Следует все время помнить, однако, что все эти и подобные термины относятся к соответствующим физическим величинам и являются просто удобными ярлыками, применимыми к этим величинам. Как очевидно из приведенного выше обсуждения, если специально не указано иное, должно быть понятно, что в пределах всего описания настоящего изобретения такие термины как «шифрование», «дешифровка», «сохранение», «предоставление», «вывод», получение», «прием», «аутентификация», «удаление», «выполнение», «запрашивание», «связь» или другие подобные термины обозначают действия и процессы в компьютерной системе или аналогичном электронном вычислительном устройстве, осуществляющем манипуляции с данными и преобразование этих данных, представленных в виде физических (например, электронных) величин в регистрах и запоминающих устройствах компьютерной системы, в другие данные, аналогичным образом представленные в виде физических величин в запоминающих устройствах или регистрах компьютерной системы, или в других подобных устройствах для хранения информации, передачи данных или представления их на дисплее.
Слова «пример» и «примерный» используются здесь в значении «служащий примером, отдельным случаем или иллюстрацией». Любые аспекты или конструкции, описываемые здесь как «пример» или «примерные», не обязательно толковать как предпочтительные или предоставляющие преимущество перед другими аспектами или конструкциями. Напротив, использование слов «пример» и «примерный» предназначено здесь для представления концепций в каком-либо конкретном виде. В настоящей заявке термин «или» используется как включающее «или», а не как исключающее «или». Иными словами, если иначе не указано или не ясно из контекста, «X включает (содержит) A или B» должно означать какую-либо из естественных включающих перестановок. Иными словами, если X включает A; X включает B; или X включает и A, и B, тогда «X включает A или B» выполняется в любом из перечисленных ранее случаев. Кроме того, неопределенные артикли “а” и “an”, как они используются в настоящей заявке и прилагаемой Формуле изобретения, следует в общем случае толковать «как один или несколько», если иное не указано или не следует ясно из контекста, что они направлены на единственное число. Более того, использование терминов «какой-либо вариант», «один из вариантов», «какая-либо реализация» или «одна из реализаций» не должно обозначать один и тот же вариант или реализацию, если это явно не указано. Кроме того, термины «первый», «второй», «третий», «четвертый» и т.д., как они используются здесь, означают здесь только ярлыки для различения разных элементов и необязательно имеют обычное значение согласно цифровому наименованию.
Описываемые здесь варианты могут также относиться к аппаратуре для выполнения приведенных здесь операций. Эта аппаратура может быть специально сконструирована для осуществления требуемых целей, либо она может содержать компьютер общего назначения, избирательно активизируемый или реконфигурируемый посредством компьютерной программы, хранящейся в памяти компьютера. Такая компьютерная программа может храниться на энергонезависимом компьютерном носителе информации, таком как, не ограничиваясь, диск любого типа, включая дискеты, оптические диски, CD-ROM и магнитооптические диски, постоянные запоминающие устройства (read-only memories (ROM)), запоминающие устройства с произвольной выборкой ((random access memories (RAM)), стираемые программируемые ROM (EPROM), электрически стираемые и программируемые ROM (EEPROM), магнитные или оптические карточки, флэш-память или носитель любого типа, способный сохранять электронные команды. Термин «компьютерный носитель информации» следует рассматривать как обозначение одного носителя или нескольких носителей (например, централизованную или распределенную базу данных и/или ассоциированные кэши и серверы), сохраняющих один или несколько наборов команд. Кроме того, термин «компьютерный носитель информации» следует считать охватывающим любой носитель, способный хранить, кодировать или переносить набор команд для выполнения машиной, так что при выполнении этих наборов команд машина осуществляет один или несколько способов согласно настоящему изобретению. Этот термин «компьютерный носитель информации» следует, соответственно, считать охватывающим, не ограничиваясь, твердотельные запоминающие устройства, оптические носители, магнитные носители и другие носители, способные хранить набор команд для выполнения машиной, так что при выполнении этого набора команд машина осуществляет один или несколько способов согласно настоящему изобретению.
Алгоритмы и представляемые на дисплее изображения, приведенные здесь, не «привязаны» по своему существу к какому-либо конкретному компьютеру или другой аппаратуре. Разнообразные системы общего назначения могут быть использованы для выполнения этих программ в соответствии с изложенными здесь принципами, или может оказаться более удобным построить более специализированную аппаратуру для выполнения требуемых операций способов. Необходимая структура различных систем для такой цели должна быть понятна из приведенного ниже описания. Кроме того, представленные варианты не описываются с привязкой к какому-либо конкретному языку программирования. Должно быть понятно, что для воплощения принципов рассмотренных здесь вариантов могут быть использованы самые разнообразные языки программирования.
В приведенном выше описании указаны многочисленные конкретные подробности, такие как примеры конкретных систем, компонентов, способов и т.п., с целью обеспечить хорошее понимание нескольких вариантов. Специалисту в рассматриваемой области должно быть понятно, однако, что по меньшей мере некоторые варианты могут быть практически осуществлены и без этих конкретных подробностей. В других случаях хорошо известные компоненты или способы не описываются подробно или представлены в формате упрощенной блок-схемы, чтобы избежать ненужного загромождения описания и затемнения смысла предлагаемых вариантов. Таким образом, приведенные выше конкретные подробности являются просто примерами. Конкретные варианты могут иметь отклонения от этих примеров подробностей и все равно оставаться в пределах объема предлагаемых вариантов.
Следует понимать, что приведенное выше описание имеет целью только иллюстрации, а не ограничения. Многочисленные другие варианты станут ясны специалистам в рассматриваемой области после прочтения и уяснения приведенного выше описания. Объем предлагаемых вариантов следует поэтому определять на основе прилагаемой Формулы изобретения вместе с полным комплексом эквивалентов, к которым относится эта Формула.
| название | год | авторы | номер документа |
|---|---|---|---|
| ИСПОЛЬЗОВАНИЕ АУТЕНТИФИЦИРОВАННЫХ МАНИФЕСТОВ ДЛЯ ОБЕСПЕЧЕНИЯ ВНЕШНЕЙ СЕРТИФИКАЦИИ МНОГОПРОЦЕССОРНЫХ ПЛАТФОРМ | 2014 |
|
RU2599340C2 |
| РЕЖИМ СЛЕЖЕНИЯ В УСТРОЙСТВЕ ОБРАБОТКИ В СИСТЕМАХ ТРАССИРОВКИ КОМАНД | 2013 |
|
RU2635044C2 |
| СИСТЕМЫ И СПОСОБЫ ПРЕДОТВРАЩЕНИЯ НЕСАНКЦИОНИРОВАННОГО ПЕРЕМЕЩЕНИЯ СТЕКА | 2014 |
|
RU2629442C2 |
| МОДУЛЬ СОПРОЦЕССОРА КЭША | 2011 |
|
RU2586589C2 |
| УСТРОЙСТВО И СПОСОБ РЕВЕРСИРОВАНИЯ И ПЕРЕСТАНОВКИ БИТОВ В РЕГИСТРЕ МАСКИ | 2014 |
|
RU2636669C2 |
| ИНСТРУКЦИЯ И ЛОГИКА ДЛЯ ИДЕНТИФИКАЦИИ ИНСТРУКЦИЙ ДЛЯ УДАЛЕНИЯ В МНОГОПОТОЧНОМ ПРОЦЕССОРЕ С ИЗМЕНЕНИЕМ ПОСЛЕДОВАТЕЛЬНОСТИ | 2013 |
|
RU2644528C2 |
| КОМАНДА И ЛОГИКА ДЛЯ ОБЕСПЕЧЕНИЯ ФУНКЦИОНАЛЬНЫХ ВОЗМОЖНОСТЕЙ ЦИКЛА ЗАЩИЩЕННОГО ХЕШИРОВАНИЯ С ШИФРОМ | 2014 |
|
RU2637463C2 |
| ИНСТРУКЦИЯ И ЛОГИКА ДЛЯ ДОСТУПА К ПАМЯТИ В КЛАСТЕРНОЙ МАШИНЕ ШИРОКОГО ИСПОЛНЕНИЯ | 2013 |
|
RU2662394C2 |
| КОМАНДА И ЛОГИЧЕСКАЯ СХЕМА ДЛЯ СОРТИРОВКИ И ВЫГРУЗКИ КОМАНД СОХРАНЕНИЯ | 2014 |
|
RU2663362C1 |
| СПОСОБ, УСТРОЙСТВО И СИСТЕМА ДЛЯ ПРЕДВАРИТЕЛЬНОЙ РАСПРЕДЕЛЕННОЙ ОБРАБОТКИ СЕНСОРНЫХ ДАННЫХ И УПРАВЛЕНИЯ ОБЛАСТЯМИ ИЗОБРАЖЕНИЯ | 2013 |
|
RU2595760C2 |
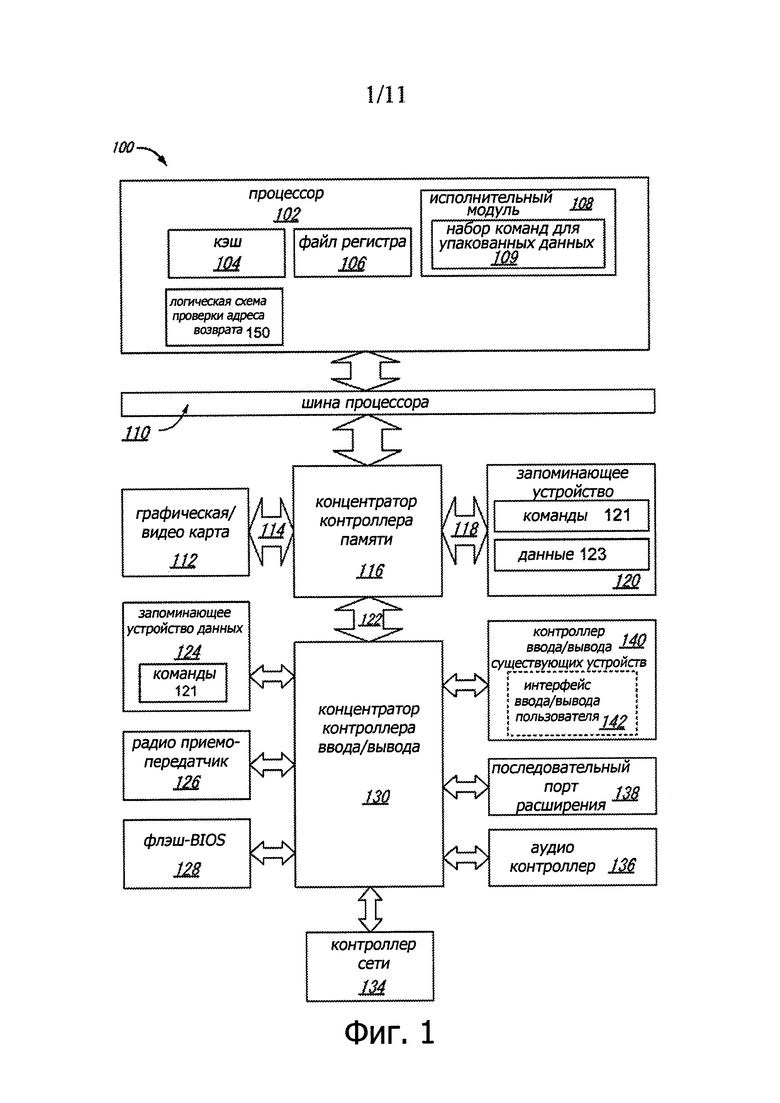
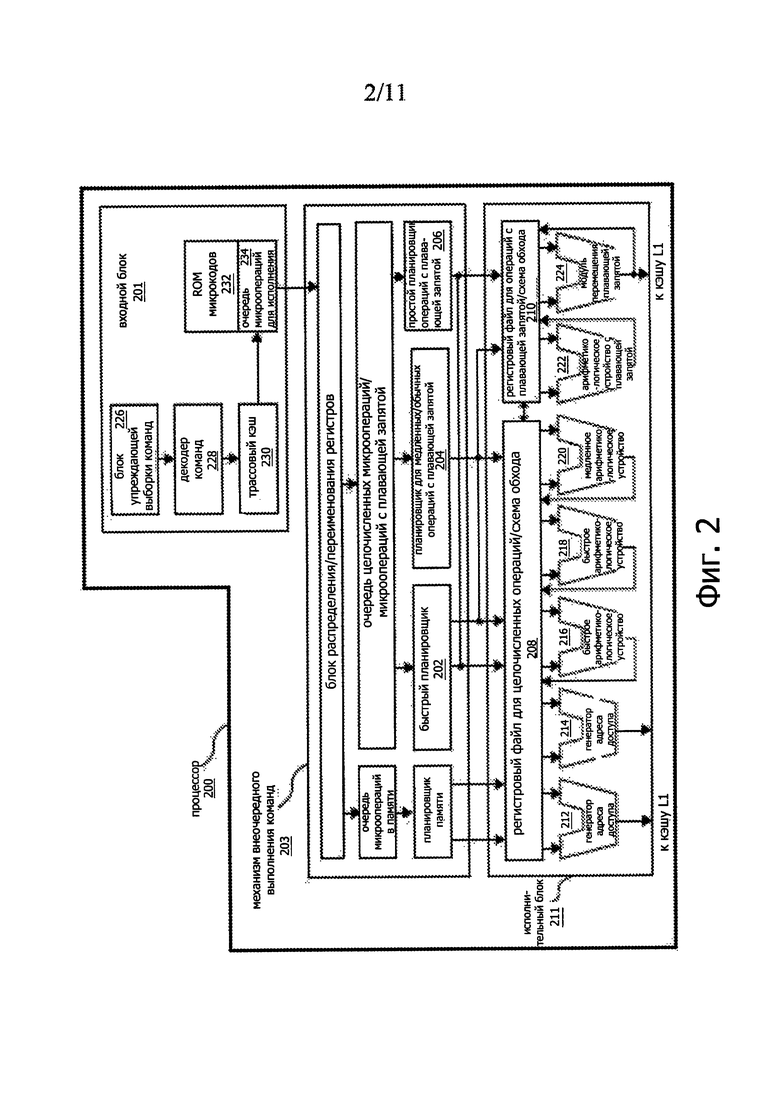
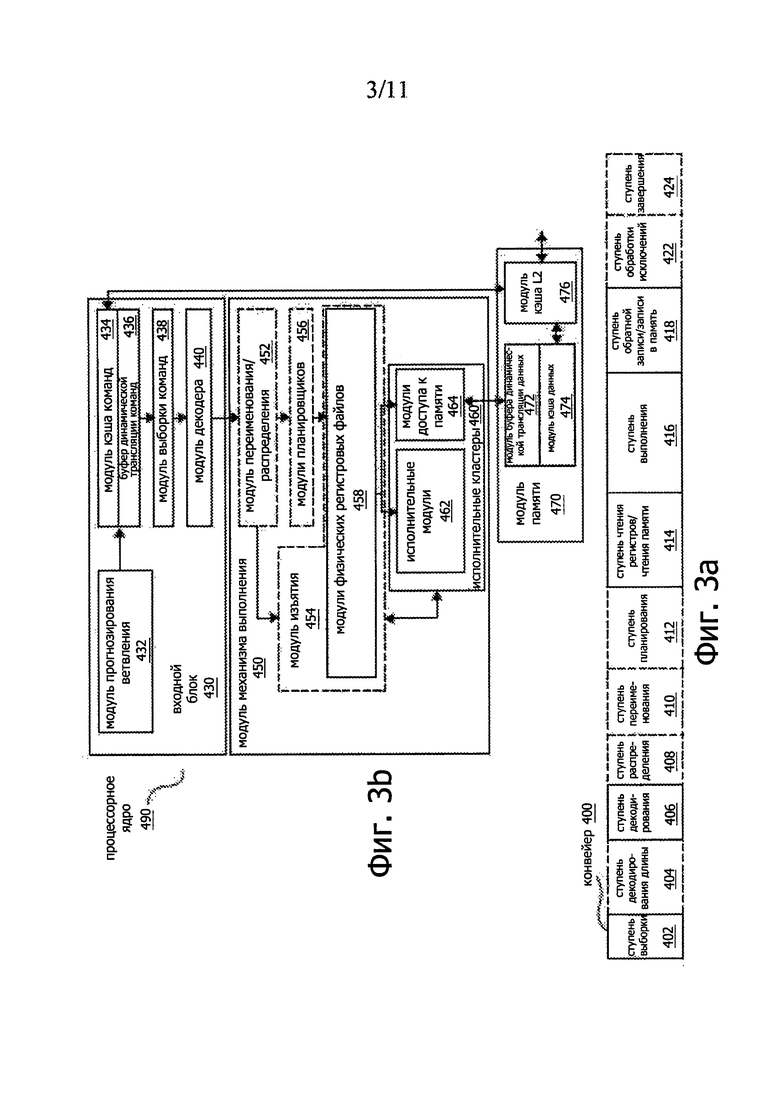
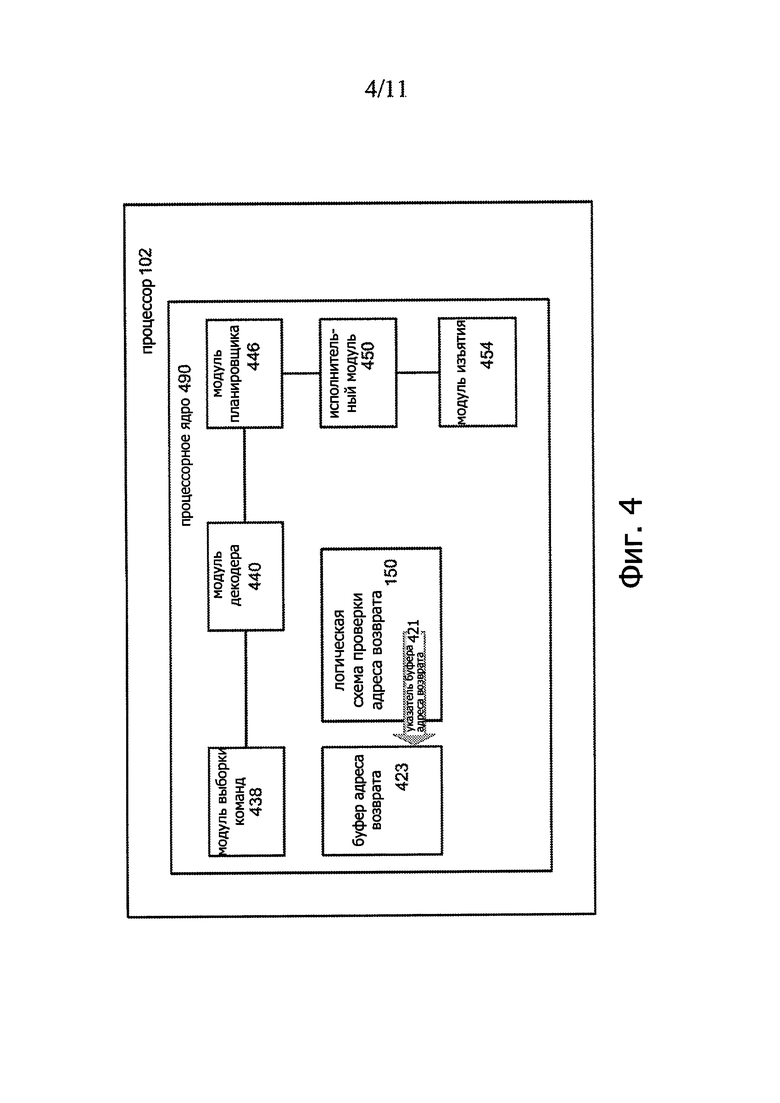
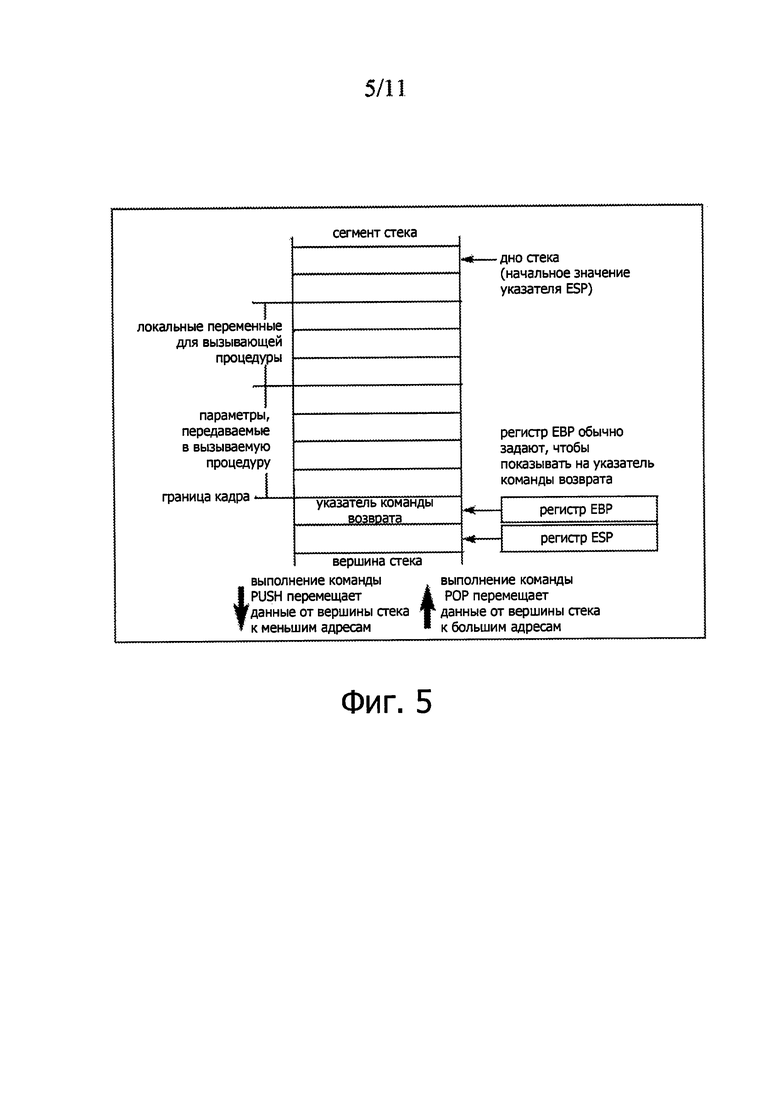
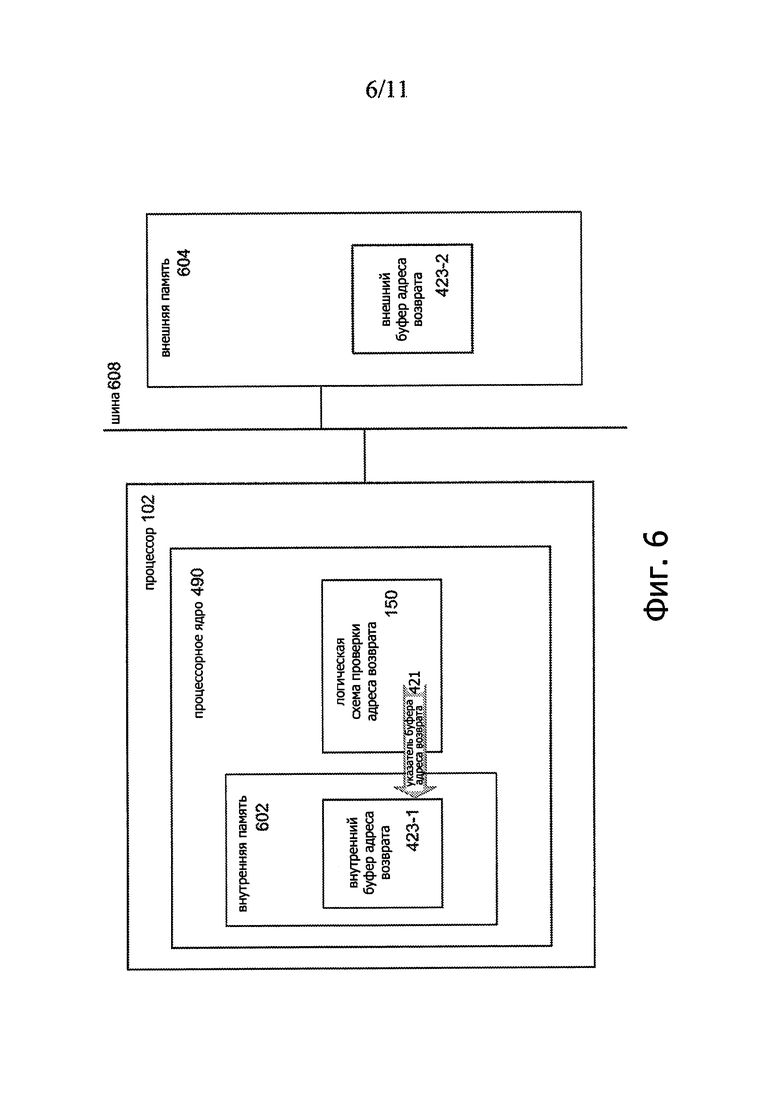
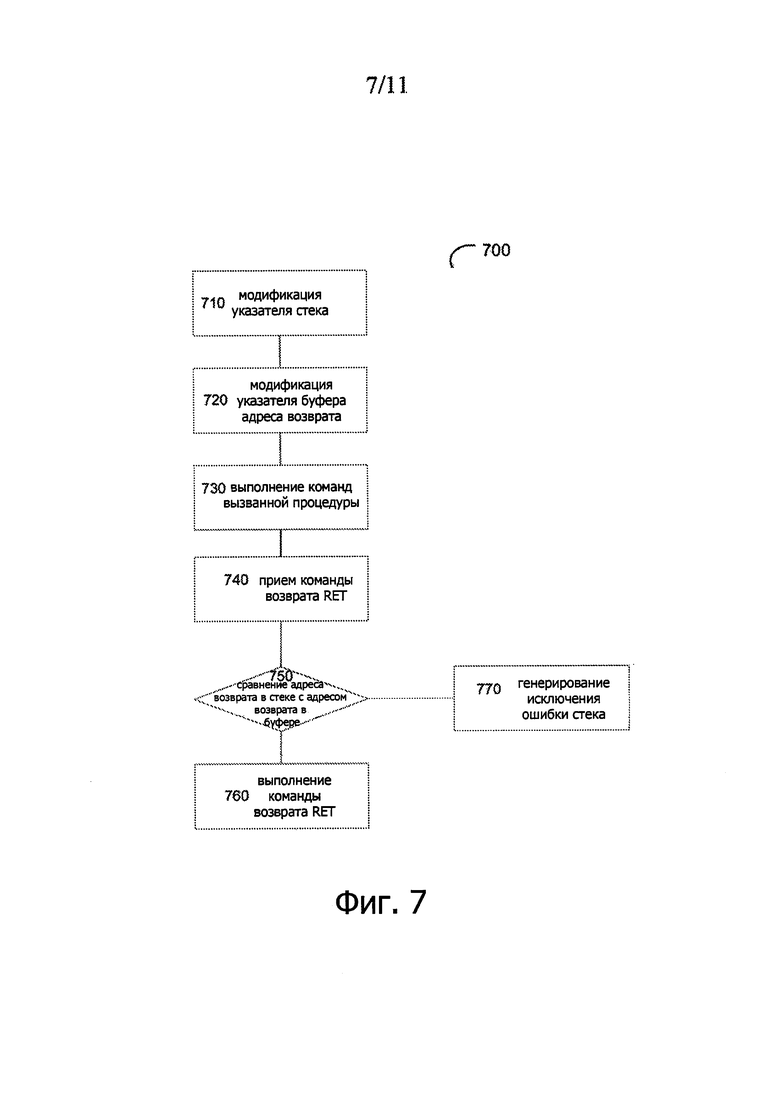
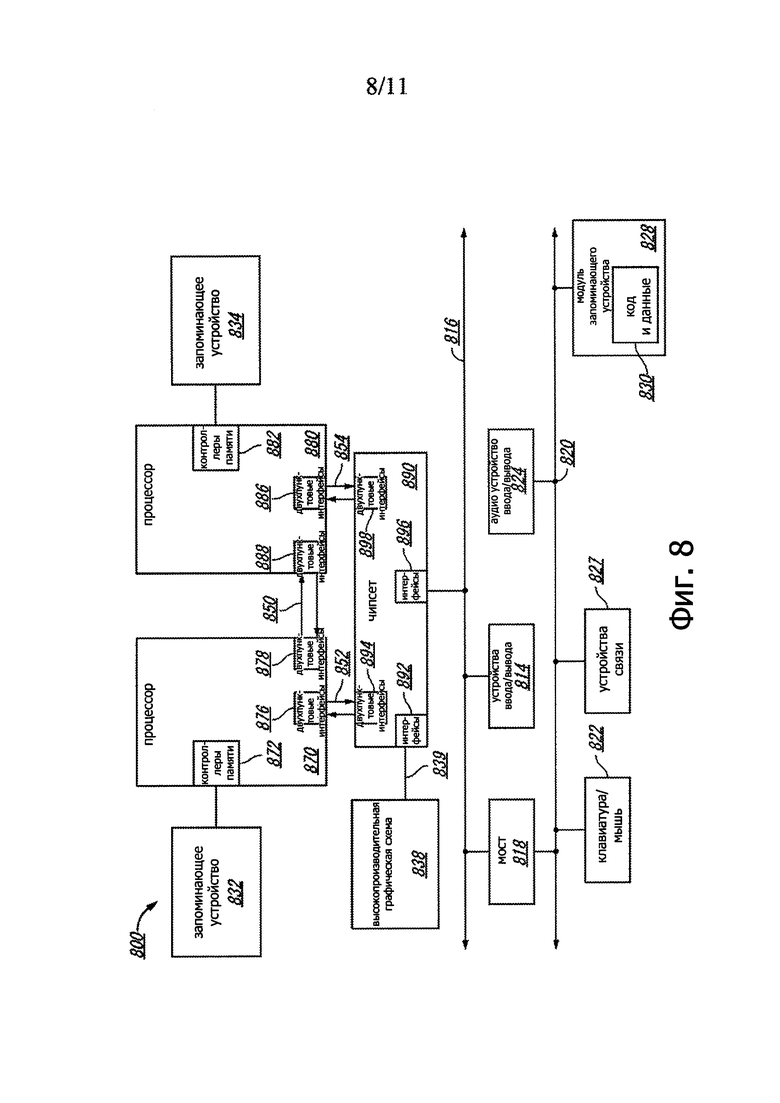
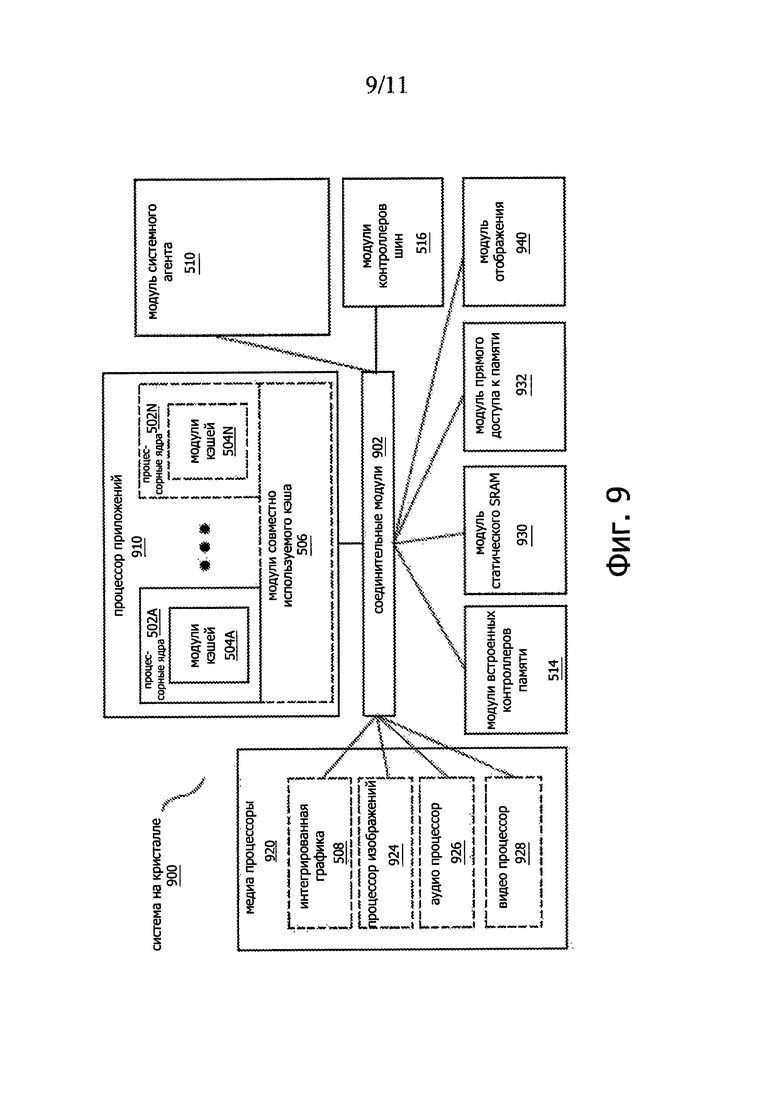
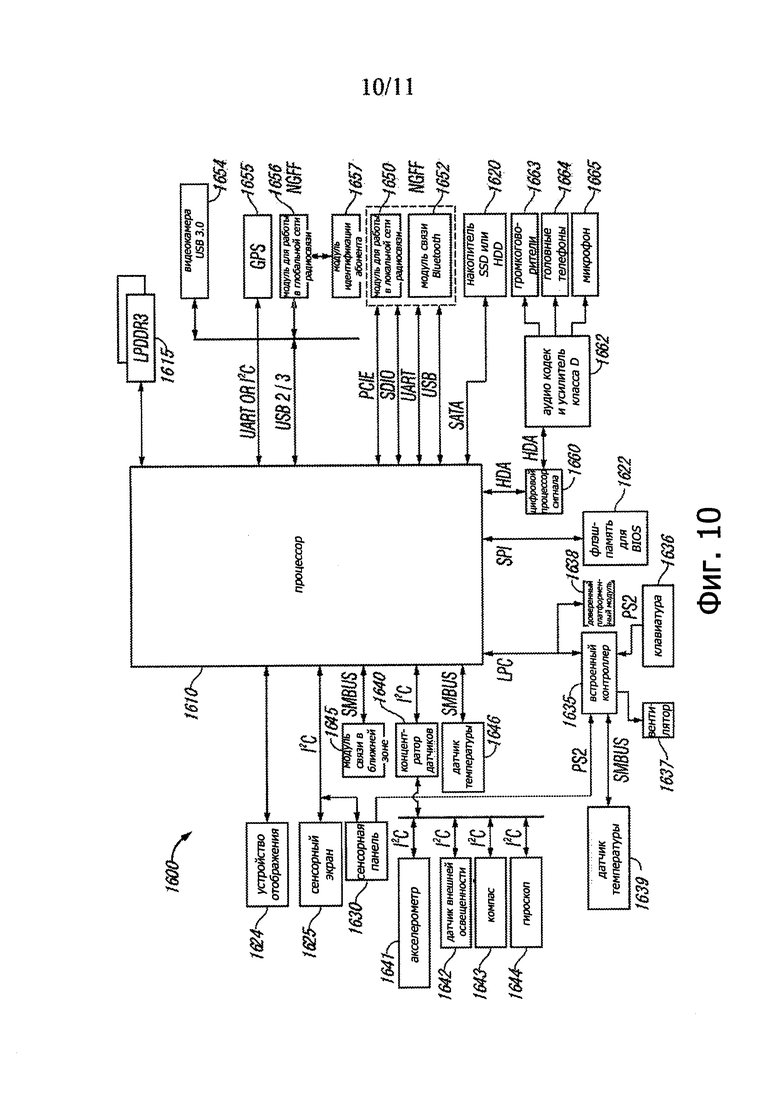
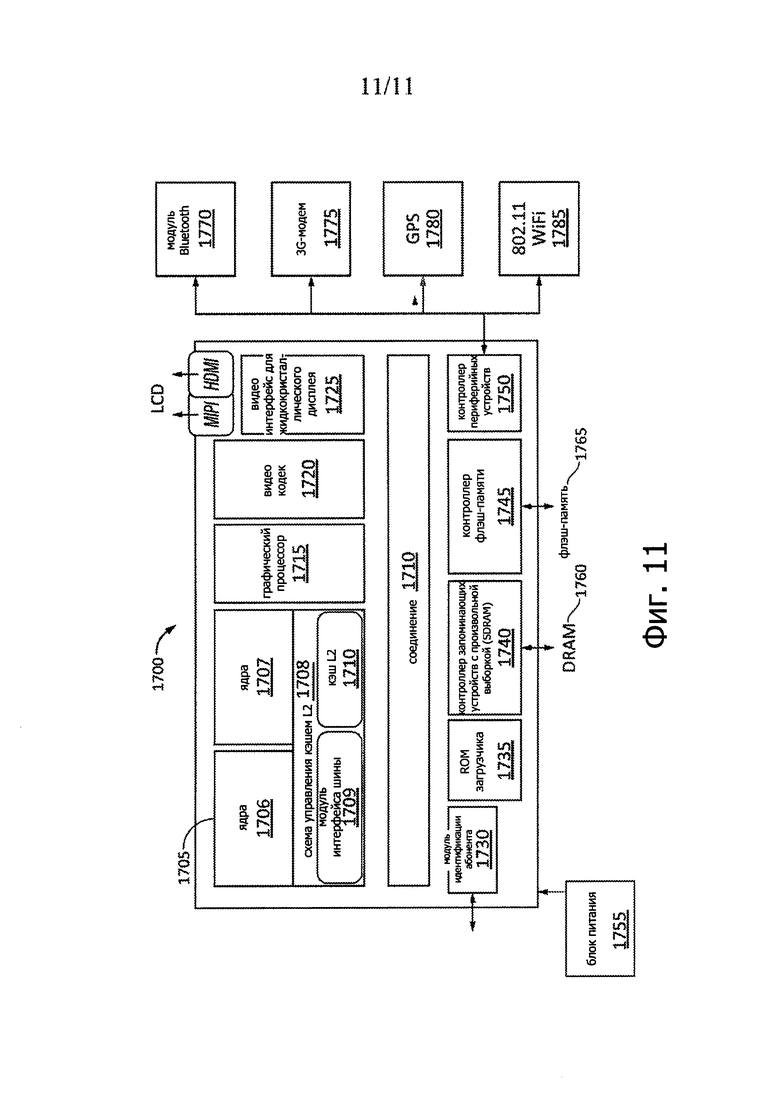
Группа изобретений относится к компьютерной технике и может быть использована для проверки адреса возврата процедуры. Техническим результатом является предотвращение несанкционированной модификации стека. Устройство содержит указатель стека для указания на первый адрес возврата, хранящийся в стеке; указатель буфера адреса возврата для указания на второй адрес возврата, хранящийся в буфере адреса возврата; и логическое устройство проверки адреса возврата для сравнения первого адреса возврата со вторым адресом возврата в ответ на прием команды возврата и исполнения, в ответ на прием команды модификации буфера адреса возврата, по меньшей мере одного действия из: сохранения адреса возврата в буфере адреса возврата или удаления адреса возврата из буфера адреса возврата, причем команда модификации буфера адреса возврата является привилегированной командой. 3 н. и 14 з.п. ф-лы, 12 ил.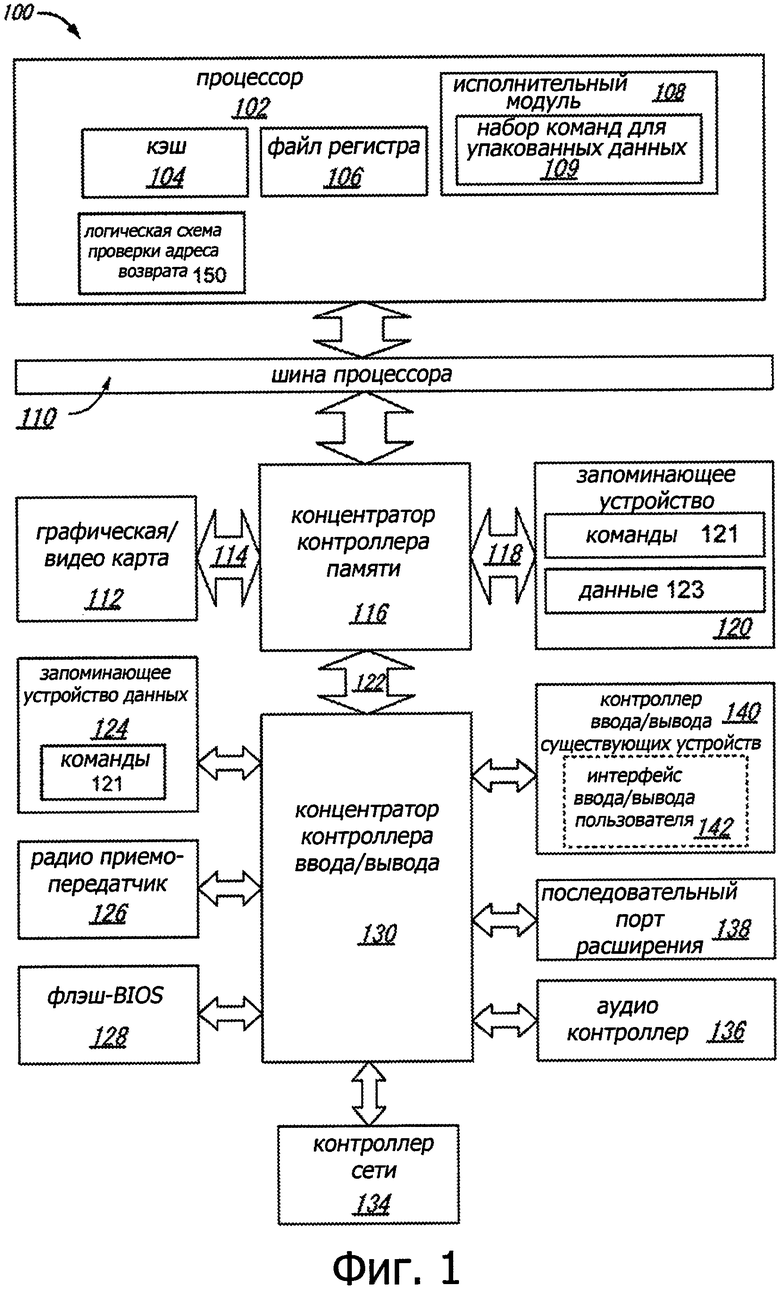
1. Процессорная система проверки адреса возврата процедуры, содержащая:
указатель стека для указания на первый адрес возврата, хранящийся в стеке;
указатель буфера адреса возврата для указания на второй адрес возврата, хранящийся в буфере адреса возврата; и
логическое устройство проверки адреса возврата для сравнения первого адреса возврата со вторым адресом возврата в ответ на прием команды возврата и
исполнения, в ответ на прием команды модификации буфера адреса возврата, по меньшей мере одного действия из: сохранения адреса возврата в буфере адреса возврата или удаления адреса возврата из буфера адреса возврата, причем команда модификации буфера адреса возврата является привилегированной командой.
2. Процессорная система по п. 1, в которой логическое устройство проверки адреса возврата дополнительно выполнено с возможностью исполнения команды возврата в ответ на определение, что первый адрес возврата эквивалентен второму адресу возврата.
3. Процессорная система по п. 1, в которой логическое устройство проверки адреса возврата дополнительно выполнено с возможностью генерирования исключения из-за ошибки стека в ответ на определение, что первый адрес возврата отличается от второго адреса возврата.
4. Процессорная система по п. 1, в которой логическое устройство проверки адреса дополнительно выполнено с возможностью сохранения адреса возврата в стеке и в буфере адреса возврата в ответ на прием команды вызова.
5. Процессорная система по п. 1, в которой логическое устройство проверки адреса возврата в процессорной системе дополнительно выполнено с возможностью исполнения, в ответ на прием команды модификации буфера адреса возврата, по меньшей мере одного действия из: увеличения указателя буфера адреса возврата или уменьшения указателя буфера адреса возврата.
6. Процессорная система по п. 5, в которой команда модификации буфера адреса возврата является привилегированной командой.
7. Процессорная система по п. 1, в которой стек является резидентным в запоминающем устройстве, соединенном с возможностью связи с процессорной системой.
8. Процессорная система по любому из пп. 1-5, в которой буфер адреса возврата является по меньшей мере частично резидентным в запоминающем устройстве, встроенном в процессорную систему.
9. Процессорная система по п. 1, в которой буфер адреса возврата содержит первую часть, резидентную в запоминающем устройстве в составе процессорной системы, и вторую часть, резидентную во внешней памяти.
10. Процессорная система по п. 9, в которой внешнее запоминающее устройство реализовано посредством постоянного запоминающего устройства.
11. Процессорная система по п. 9, в которой вторая часть буфера адреса возврата выполнена с возможностью работы в качестве буфера переполнения относительно первой части.
12. Способ проверки адреса возврата процедуры, содержащий этапы, на которых:
инициируют указатель буфера адреса возврата, так что он указывает позицию во внутреннем буфере адреса возврата;
осуществляют модификацию, посредством процессорной системы, указателя стека;
осуществляют модификацию указателя буфера адреса возврата;
в ответ на определение, что достигнута граница внутреннего буфера адреса возврата, вызывают направление указателя буфера адреса возврата в позицию во внешнем буфере адреса возврата;
в ответ на прием команды возврата, сравнивают первый адрес возврата, на который указывает указатель стека, со вторым адресом возврата, на который указывает указатель буфера адреса возврата; и
выполняют команду возврата в ответ на определение, что первый адрес возврата эквивалентен второму адресу возврата.
13. Способ по п. 12, дополнительно содержащий этап, на котором генерируют исключение ошибки стека в ответ на определение, что первый адрес возврата отличается от второго адреса возврата.
14. Способ по п. 12, дополнительно содержащий этап, на котором сохраняют адрес возврата в стеке и в буфере адреса возврата в ответ на прием команды вызова.
15. Способ по п. 12, дополнительно содержащий этапы, на которых:
принимают команду модификации буфера адреса возврата; и
выполняют по меньшей мере одно действие из: сохранения адреса возврата в буфере адреса возврата или удаления адреса возврата из буфера адреса возврата.
16. Машиночитаемый энергонезависимый носитель информации, хранящий исполняемые команды, вызывающие при их исполнении процессорной системой, выполнение операций, содержащих этапы, на которых:
инициируют указатель буфера адреса возврата, так что он указывает позицию во внутреннем буфере адреса возврата;
осуществляют модификацию, посредством процессорной системы, указателя стека;
осуществляют модификацию указателя буфера адреса возврата;
в ответ на определение, что достигнута граница внутреннего буфера адреса возврата, вызывают направление указателя буфера адреса возврата в позицию во внешнем буфере адреса возврата;
в ответ на прием команды возврата, сравнивают первый адрес возврата, на который указывает указатель стека, со вторым адресом возврата, на который указывает указатель буфера адреса возврата; и
выполняют команду возврата в ответ на определение, что первый адрес возврата эквивалентен второму адресу возврата.
17. Машиночитаемый энергонезависимый носитель информации по п. 16, дополнительно содержащий исполняемые команды, вызывающие при их исполнении компьютерной системой, выполнение этапа, на котором генерируют исключение ошибки стека в ответ на определение, что первый адрес возврата отличается от второго адреса возврата.
| СПОСОБ КОНТРОЛЯ ВЫПОЛНЕНИЯ КОМПЬЮТЕРНЫХ ПРОГРАММ В СООТВЕТСТВИИ С ИХ НАЗНАЧЕНИЕМ | 1998 |
|
RU2220443C2 |
| US 2004049666 A1, 11.03.2004 | |||
| US 2004168078 A1, 26.08.2004 | |||
| US 2008301420 A1, 04.12.2008 | |||
| US 2013138931 A1, 30.05.2013. | |||

