ОБЛАСТЬ ТЕХНИКИ
[0001] Изобретение относится к средствам распознавания документов. Более конкретно, предлагаемая группа изобретений относится к средствам, позволяющим определить, содержит ли текст документа на изображении китайские, японские или корейские символы.
УРОВЕНЬ ТЕХНИКИ
[0002] В процессе распознавания документа важным шагом является анализ его изображения для извлечения различной информации о распознаваемом документе. При анализе изображения документа можно определить части документа, содержащие текст, рисунки и таблицы, а также язык документа, ориентацию документа, логическую структуру документа и т.д.
[0003] Информация о том, содержится ли в распознаваемом документе текст на восточноазиатских языках (в первую очередь подразумеваются символы китайского, японского и корейского языков) (в дальнейшем именуемые «символы CJK»,), является крайне важной информацией о распознаваемом документе. Для документов, содержащих символы CJK, в ходе анализа изображения документа, а также во время распознавания символов используются специализированные методы.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0004] Изобретение относится к системам, машиночитаемым носителям и методам определения того, содержит ли текст китайские, японские или корейские символы. Полученное изображение документа бинаризуется. В бинаризованном изображении документа производится поиск связных компонент. На основании связных компонент определяется множество фрагментов. Для каждого фрагмента из множества фрагментов формулируется гипотеза о принадлежности к определенному языку (гипотеза о языке фрагмента). Гипотеза о принадлежности к определенному языку получает оценку вероятности. Из множества фрагментов выбирается подмножество, имеющее наивысшие оценки вероятности. Гипотеза о принадлежности к определенному языку проверяется для каждого фрагмента из выбранного подмножества фрагментов. Решение о наличии китайских, японских или корейских символов принимается, как минимум, на основе проверки гипотез о языке фрагментов выбранного подмножества.
[0005] Техническим результатом, на достижение которого направлено заявленное изобретение, является повышение достоверности определения наличия в тексте китайских, японских или корейских символов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
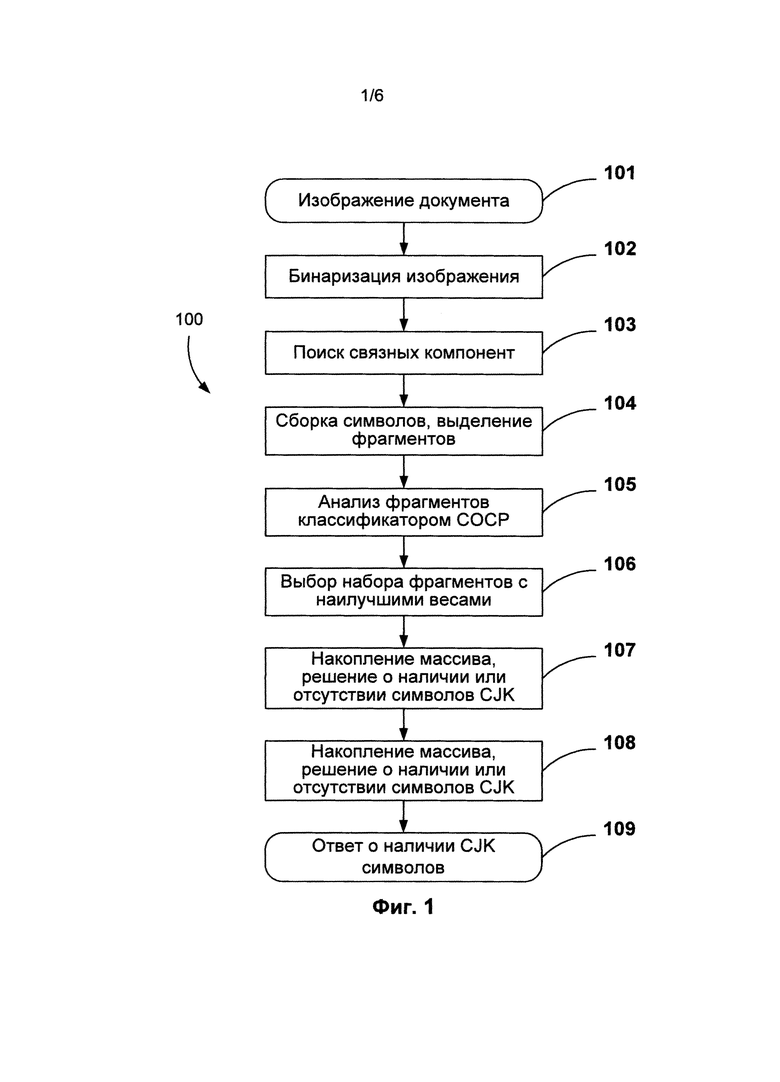
[0006] На Фиг. 1 приведена блок-схема последовательности операций для определения наличия символов CJK на изображении документа, используемая в соответствии с одним из вариантов осуществления изобретения.
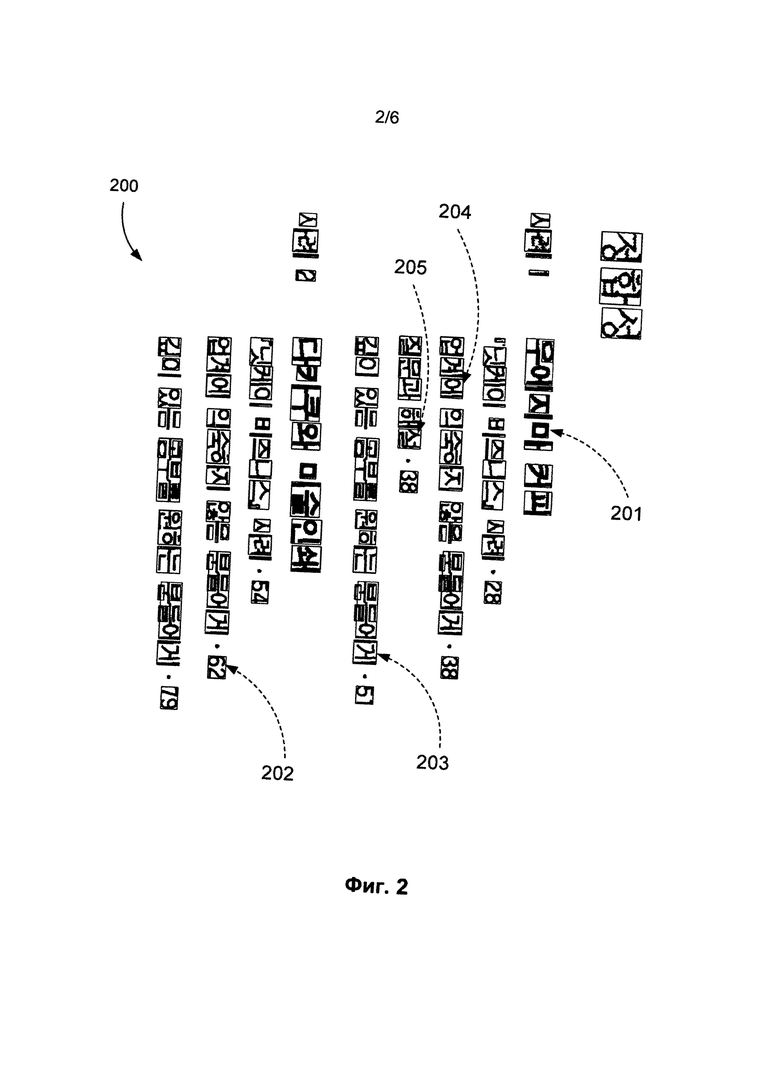
[0007] На Фиг. 2 приведен пример результата сборки символов на изображении документа, содержащего корейский текст, смешанный с цифрами, в соответствии с одним из вариантов осуществления изобретения.
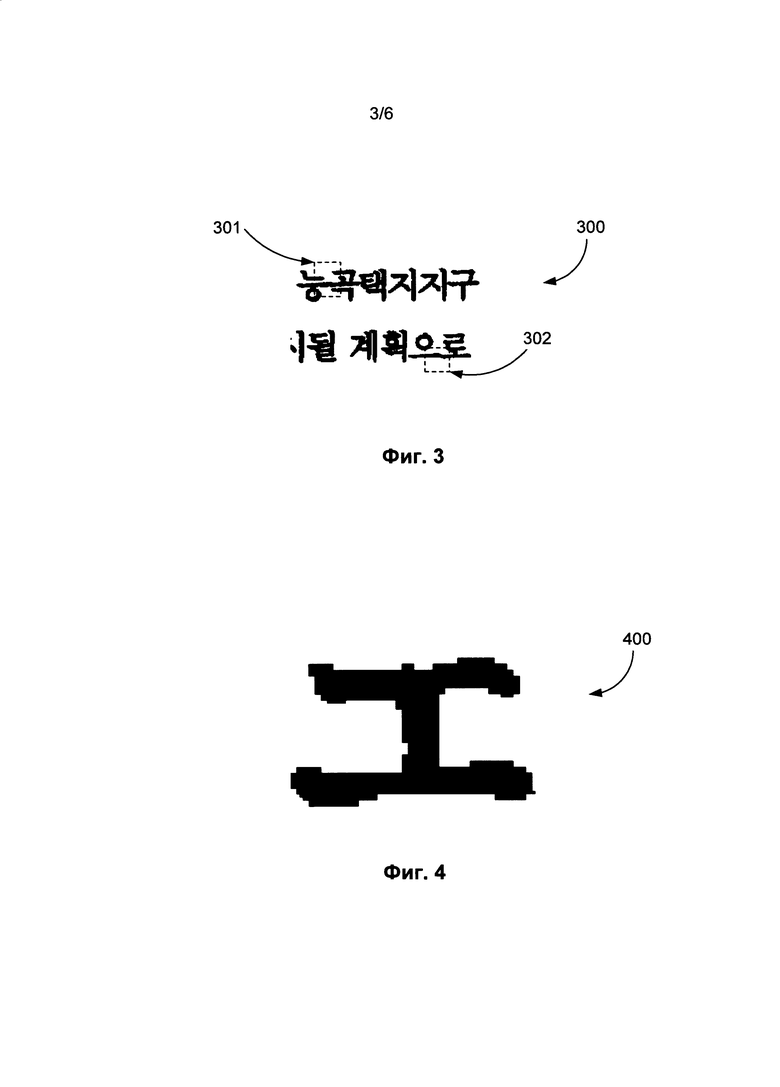
[0008] На Фиг. 3 приведен пример части изображения документа, содержащего корейской текст, в соответствии с одним из вариантов осуществления изобретения.
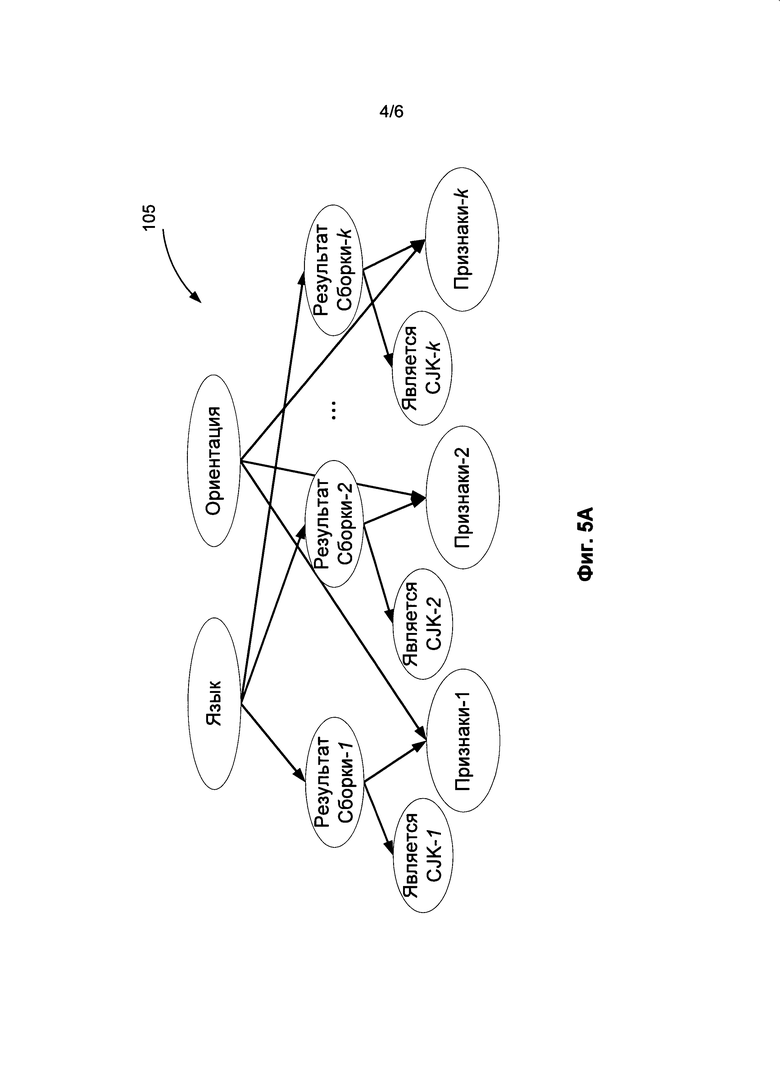
[0009] На Фиг. 4 приведен пример символа CJK, который невозможно отличить от символа европейского языка, в соответствии с одним из вариантов осуществления изобретения.
[0010] На Фиг. 5А приведена схема работы грубого классификатора наличия восточноазиатских символов в соответствии с одним из вариантов осуществления изобретения.
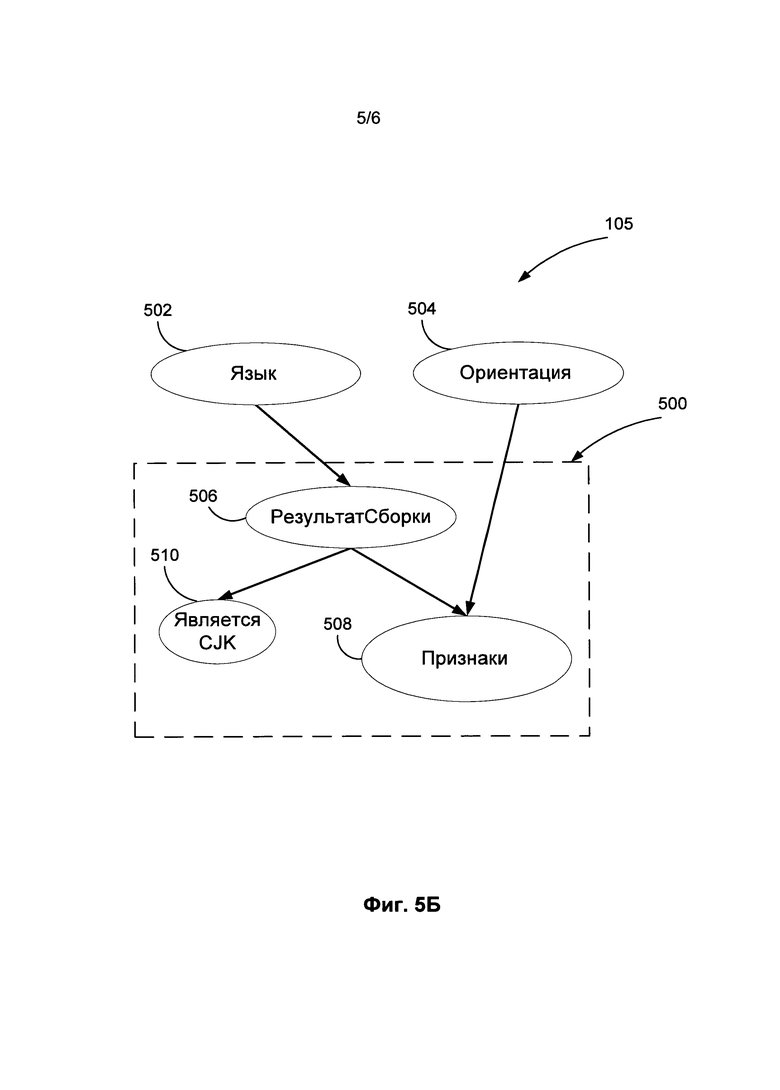
[0011] На Фиг. 5Б приведена схема группы переменных, которые можно сериализовать в распределенную сеть в соответствии с одним из вариантов осуществления изобретения.
[0012] На Фиг. 6 показан пример вычислительного средства, которое может использоваться в соответствии с одним из вариантов осуществления изобретения.
ПОДРОБНОЕ ОПИСАНИЕ
[0013] В данном разделе описаны системы и методы определения того, содержатся ли символы CJK на изображении документа, причем изображение документа может иметь любую неизвестную ориентацию. Определить наличие CJK символов можно, основываясь на подмножестве символов, обнаруженных на изображении документа. Например, присутствие символов CJK в документе можно установить, даже если на изображении документа имеется всего одна строка с символами CJK. Исходя из установленного присутствия или отсутствия символов CJK в документе, может приниматься решение об исключении языков CJK из языков, используемых для распознавания символов документа, чтобы избежать запуска ресурсоемких методов распознавания языков CJK.
[0014] В одном из вариантов осуществления изобретения не важно, каким образом было получено изображение документа. Например, изображение документа может быть получено путем сканирования или фотографирования документа, создано искусственно, получено от третьих лиц и т.д.
[0015] На Фиг. 1 приведена блок-схема последовательности операций (100), позволяющей определить наличие CJK символов на изображении документа. Чтобы найти текстовые элементы, изображение документа (101) бинаризуется (102). Например, изображение документа может быть бинаризовано с использованием метода, описанного в патентной заявке №13/328,239 (U.S. 20120087587) под названием «БИНАРИЗАЦИЯ ИЗОБРАЖЕНИЯ», поданной в США 16 декабря 2011 года, которая целиком включена в настоящую заявку посредством ссылки. На бинаризованном изображении документа может быть выполнен поиск связных компонент (103). Связной компонентой называется точка или набор точек на бинаризованном изображении документа, которые имеют одинаковое значение и расположены рядом друг с другом. Например, связную компоненту можно найти, выбрав точку на бинаризованном изображении документа и найдя все окружающие точки, имеющие такое же значение. Эта операция повторяется для каждой из найденных прилегающих точек до тех пор, пока число новых обнаруженных точек не окажется равным нулю. Результатом такого поиска является одна связная компонента. На бинаризованном изображении документа, который включает в себя текст, связная компонента может содержать символ, часть символа или нескольких символов.
[0016] Процесс сборки символа (104) может осуществляться для связных компонент с целью объединения нескольких связных компонент, которые являются частями одного символа. Процесс сборки символа может быть эвристическим. Например, процесс сборки символа может основываться на различных геометрических данных, таких как расстояние между связными компонентами, их относительные размеры, взаимное расположение компонент, средняя высота связных компонент, предположительная высота строки, пропорции полученных символов и т.п.
[0017] Результатом процесса сборки символа являются отдельные фрагменты, которые представляют собой описывающие прямоугольники, предположительно содержащие по одному символу. Фрагмент - это часть текста, которая представляет собой один символ, два или более склеенных символа, часть одного символа, один символ и часть второго символа и т.д. Если фрагмент состоит из одной связной компоненты (например, символ европейского языка без диакритических знаков, простой символ CJK, цифра, знак пунктуации и т.д.), то описывающий фрагмент прямоугольник содержит только одну связную компоненту. На Фиг. 2 приведен пример изображения документа (200) с корейским текстом, смешанным с цифровыми символами, после выполнения процесса сборки символов. Изображение документа (200) повернуто по часовой стрелке на 90 градусов. Фрагменты 201, 202, 203, 204 и 205 являются примерами фрагментов, полученных в процессе сборки символов (104). Каждый прямоугольник предположительно содержит один символ, однако процесс сборки символов может в результате ошибки привести к тому, что символ не будет собран полностью. Например, фрагмент (201) является фрагментом, содержащим часть символа. Также ошибка при сборке символов может привести к пересборке символа, например, когда обнаруженный фрагмент будет содержать склеенные символы. Например, фрагмент (202) содержит два склеенных символа. В другом примере фрагмент (203) содержит один символ и ошибочно приклеенную часть второго символа.
[0018] При работе результаты сборки символов анализируются (105) с помощью грубого классификатора, который называется «грубым классификатором наличия восточноазиатских символов» (далее он обозначается «СОСР»). Классификатор СОСР может получать входную информацию, например фрагменты, которые были найдены на изображении документа. Анализируя фрагменты, классификатор СОСР может определять ориентацию документа и наличие символов CJK. Ориентация документа и/или присутствие символов CJK также может использоваться в качестве входной информации классификатора СОСР. Например, ориентацию документа, основанную на анализе классификатора СОСР, можно использовать в качестве входных данных при анализе фрагментов. Кроме того, классификатор СОСР может оценить вероятность того, что фрагмент содержит символ CJK. Так, если на изображении документа имеются символы CJK, то фрагментам с настоящими правильно собранными символами CJK, классификатор, как правило, присваивает наивысшую оценку вероятности. При этом фрагменты, которые содержат неполные или склеенные символы, получают другие оценки вероятности - как правило, более низкие. Классификатор СОСР также может повторно проанализировать один или несколько фрагментов в случае изменения значений ориентации и/или присутствия символов CJK. В ходе работы может быть выбран набор фрагментов с наивысшими оценками классификатора СОСР (106).
[0019] В одном из вариантов осуществления изобретения классификатор СОСР использует байесовскую сеть. Байесовская сеть может моделировать различные гипотезы о содержании конкретного фрагмента. Например, для каждого фрагмента байесовская сеть может предположить на основе моделирования, содержит ли некоторый фрагмент корейский символ, английский символ, часть символа, несколько символов и т.д. Обобщенная информация о различных фрагментах может использоваться для определения того, что содержит конкретный фрагмент.
[0020] Затем выбранный набор фрагментов может проверяться путем распознавания выбранных фрагментов (107). Например, чтобы определить, содержит ли документ символы CJK, могут быть рассмотрены фрагменты, получившие наивысшие оценки вероятности. Например, 10, 20, 30, 50 и т.д. фрагментов с наивысшими оценками СОСР могут быть распознаны, чтобы сделать вывод о наличии или отсутствии символов CJK в документе.
[0021] Способность отличать склеенные корейские символы (пересобранные) от настоящих корейских символов является довольно сложной задачей для классификации. На первый взгляд может показаться, что корейские символы мало отличимы от китайских или японских символов, однако имеются некоторые отличительные особенности, которые можно использовать, чтобы отделить корейский текст от китайского или японского. Например, корейский текст на изображении документа может содержать так называемые «склеенные символы». На Фиг. 3 приведен пример части изображения документа (300), который включает в себя корейский текст, содержащий два примера склеенных символов (301) и (302). Склеенные символы - это два или более символов, которые соприкасаются друг с другом. Символы сливаются при печати документа из-за малого расстояния между ними. Кроме того, при получении изображения документа такие соединения могут создаваться, даже если ранее они отсутствовали. Поэтому склеенные корейские символы образуют единую связную компоненту, и их невозможно разделить. Склеенные символы снижают качество выделения фрагментов, они представляют собой еще одну причину того, почему в описанном вокруг одного фрагмента прямоугольнике может содержаться более одного символов.
[0022] Классификаторы обычно анализируют каждый фрагмент независимо от других, относя фрагмент к тому или иному классу только на основании некоторого набора признаков, которым был обучен данный классификатор. Основной проблемой независимых классификаторов, используемых в задаче обнаружения символов CJK, является низкая способность независимого классификатора отличать склеенные (пересобранные) корейские символы от настоящих корейских символов, поскольку при определенных ориентациях страницы склеенные и настоящие корейские символы могут иметь сходные признаки. В результате при грубой фильтрации неправильно склеенные символы могут оказаться среди лучших гипотез CJK фрагментов, найденных на странице. Однако на этапе подтверждающего распознавания эти фрагменты не будут распознаны, а это приведет к тому, что наличие CJK символов в документе будет ошибочно опровергнуто.
[0023] Одна из причин ошибочных результатов работы независимых классификаторов заключается в том, что зная только признаки одного фрагмента, невозможно понять, является ли фрагмент корейским символом (нормальным или повернутым), либо этот фрагмент склеен из символов, а страница повернута на 90 градусов. Чтобы такой классификатор давал приемлемый результат, ему необходим ряд сложных признаков, которые не только сложно подобрать но и потребуются значительные ресурсы для их вычисления.
[0024] Классификатор СОСР, используемый в описанных выше вариантах осуществления изобретения, не анализирует каждый фрагмент независимо. Вместо этого классификатор СОСР использует информацию, накопленную в ходе анализа других фрагментов на изображении документа. Например, ориентация документа может быть определена в процессе классификации, и в то же время ее можно использовать для классификации фрагментов. Накопленную информацию можно использовать, чтобы сделать выводы о текущем фрагменте, а также для пересмотра предыдущих выводов, если имеются основания считать их ошибочными. Например, если классификатор СОСР первоначально предполагает, что документ имеет нормальное или перевернутое положение, но при анализе большего числа фрагментов классификатор СОСР позже определит, что документ повернут по часовой стрелке или против часовой стрелки, то некоторые или все ранее классифицированные или оцененные фрагменты могут быть проанализированы повторно. Это позволяет проанализировать каждый фрагмент на основании определенных характеристик изображения документа.
[0025] В одном из вариантов осуществления изобретения классификатор СОСР реализован с помощью байесовской сети, которая позволяет делать выводы о текущем фрагменте и повторно рассматривать ранее сделанные выводы. Информация о растровых и геометрических свойствах текущего фрагмента может использоваться в качестве признаков, а также может автоматически вычисляться в процессе выделения связных компонент. Эти признаки могут использоваться как для анализа изображения документа, так и в процессе распознавания, таким образом их вычисление не требует дополнительного времени и ресурсов. Множество признаков могут быть вычислены. Например, вычисляются следующие признаки:
1. Натуральный логарифм удлинения, при этом удлинение может вычисляться как отношение ширины к высоте;
2. Количество горизонтальных штрихов, разделенное на высоту фрагмента (число горизонтальных штрихов/высота);
3. Количество вертикальных штрихов, разделенное на ширину фрагмента (число вертикальных штрихов/ширина);
4. Длина самого длинного черного горизонтального штриха, разделенная на высоту фрагмента (максимальная длина горизонтального штриха/высота); и
5. Длина самого длинного белого горизонтального штриха, разделенная на ширину фрагмента (максимальная длина белого горизонтального штриха/ширина);
[0026] Таким образом, классификатор СОСР использует информацию, которую он уже имеет для определения признаков цифрового изображения. Эти признаки также могут использоваться для классификации фрагментов. Поскольку СОСР анализирует все фрагменты на изображении документа, СОСР может найти не только китайские и японские символы, но также и корейские символы, имеющие произвольную ориентацию. В одном варианте осуществления изобретения классификатор СОСР включает, например, одно или более из следующих экспертных знаний о характеристиках, которые может иметь любое изображение документа:
[0027] 1. Объекты на странице могут находиться в одной из двух ориентаций: «нормальная/перевернутая» и «повернутая по часовой/против часовой стрелки» (NormalOrUpsidedown и ClockwiseOrCounterclockwise). Два типа ориентации достаточны для проведения анализа, поскольку признаки инвариантны относительно поворота на 180 градусов;
[0028] 2. Наиболее вероятно, что все символы на странице находятся в одной ориентации. Например, крайне маловероятно наличие символов CJK в нескольких различных ориентациях на одной странице, и
[0029] 3. На странице корейского текста или среди корейского текста более вероятно обнаружить склеенные символы, чем на странице китайского или японского текста или среди китайского или японского текста.
[0030] Поскольку классификатор СОСР анализирует все фрагменты на странице, он может сделать вывод, что страница повернута набок и содержит корейские символы. Описание этого варианта осуществления изобретения приведено ниже. Поскольку классификатор СОСР может сделать вывод об ориентации страницы, он способен, например, отличить склеенные символы от настоящих корейских символов.
[0031] Переменные и параметры в классификаторе СОСР можно настраивать в зависимости от решаемых задач и условий. В одном варианте осуществления изобретения классификатор СОСР может использовать следующие переменные (случайные величины) и их возможные значения:
[0032] Язык - это язык страницы. Возможные значения: ChineseOrJapanese (китайский или японский), Korean (корейский), Other (другие языки).
[0033] Ориентация - это ориентация страницы. Возможные значения: NormalOrUpsidedown (нормальная или перевернутая), ClockwiseOrCounterclockwise (повернутая по часовой или против часовой стрелки).
[0034] Результат Сборки-i - это результат сборки i-го фрагмента. Возможные значения: CJCharacter (китайский или японский символ), KoreanCharacter (корейский символ), LetterOrNumber (европейская буква или цифра), OverbuildOrUnderbuild (пересборка символа или не полностью собранный символ), Other (другие варианты).
[0035] Является CJK-i - это вспомогательная детерминированная логическая переменная. Она имеет значение true, если Результат Сборки-i==CJCharacter или Результат Сборки-i==KoreanCharacter, а в остальных случаях она имеет значение false.
[0036] Признаки-i - это признаки i-го фрагмента; один из возможных наборов признаков был приведен выше.
[0037] На Фиг. 5А показана схема работы классификатора СОСР. В одном из вариантов осуществления изобретения количество групп переменных (например, Результат Сборки-i, Является CJK-i, Признаки-i) зависит от числа фрагментов, найденных на странице. На Фиг. 5Б та же схема показана с использованием «плиточной модели», в которой показана группа переменных для одного фрагмента (500). При классификации конкретного изображения документа группу переменных (500) можно сериализовать в подробную (развернутую) сеть в зависимости от количества выявленных фрагментов.
[0038] На Фиг. 5Б с каждым узлом переменной (502, 504, 506, 508, 510) может быть связано распределение условной вероятности состояния узла, при условии его родителей P(X|Patents(X)). Численные значения распределения вероятностей могут быть, например, подобраны во время предварительного обучения. Переменная Признаки (508) не является дискретной, поэтому распределение условной вероятности для переменной Признаки (508) представляет собой набор плотностей, по одной для каждой комбинации переменной Результат Сборки (506) и переменной Ориентация (504). Например, плотность смешанного нормального распределения можно использовать для набора плотностей.
[0039] В некоторых вариантах осуществления изобретения классификатор СОСР может руководствоваться введенными значениями переменных. Таким образом, пользователь может повлиять на работу классификатора СОСР путем ввода значения некоторых переменных, включая, без ограничений, такие: указание допустимых значений переменной Ориентация (504), допустимых значений переменной Язык (502) и т.д. Введенные пользователем значения добавляются в модель как новые наблюдения, изменяя апостериорное распределение значений переменных Ориентация и Язык.
[0040] Доступная информация для фрагмента (например, признаки, запрещенные языки, запрещенные ориентации и т.д.) может быть задана как «наблюдения», она обозначается е. Фрагменты изображения документа можно отсортировать в соответствии с апостериорной вероятностью Р(Является CJK=true|е).
[0041] В одном варианте осуществления изобретения классификатор СОСР может быть настроен для специальных условий (задач) путем добавления в модель или удаления из модели различных наблюдений. Например, любое изображение документа может иметь одну из двух ориентаций с равной вероятностью. Другими словами, априорная вероятность переменной Ориентация равна P(NormalOrUpsidedown)=0,5, P(ClockwiseOrCounterclockwise)=0,5. Если системе предоставлено наблюдение, что некоторое изображение документа имеет нормальную ориентацию, то апостериорное значение переменной Ориентация может быть смещено к одному значению (сконцентрировано в нем). Другими словами, апостериорная вероятность может быть следующей: P(NormalOrUpsidedown)=1, P(ClockwiseOrCounterclockwise)=0. Такое распределение вероятностей может изменить апостериорные распределения вероятностей других переменных и повысить надежность результатов классификации.
[0042] В некоторых случаях не все символы CJK можно отличить от европейских букв, особенно если ориентация символа неизвестна. На Фиг. 4 показан пример символа CJK, который невозможно отличить от европейской буквы. Например, символ (400) невозможно отличить от символа Н в ориентации ClockwiseOrCounterclockwise. В одном из вариантов осуществления изобретения, если имеется европейский символ (например, буква, сочетание букв, символ и т.д.), который в некоторой ориентации визуально похож на какой-либо символ CJK, то мы будем говорить, что этот символ CJK имеет европейского соседа в соответствующей ориентации. Наличие таких символов затрудняет принятие решения о том, имеется ли восточноазиатская письменность в данном документе. Если классификатор СОСР находит европейских соседей в некотором европейском тексте, то эти фрагменты могут быть распознаны на этапе подтверждающего распознавания наилучших гипотез CJK на этой странице. Для того чтобы избежать таких ошибок, информация о символах CJK, имеющих европейских соседей, может храниться в системе с указанием соответствующей ориентации. Например, информация о соседе может храниться в таблице, базе данных или в какой-либо другой форме.
[0043] В одном из вариантов осуществления изобретения определение наличия символов CJK может быть основано на операции подтверждающего распознавания (107) для выбранного набора фрагментов (106). Например, предположим, что классификатор СОСР определил несколько (например, 20) наилучших гипотез символов CJK (106). Операция подтверждающего распознавания (107) может выполняться для выбранных фрагментов, где для каждой гипотезы распознавание выполняется в четырех возможных ориентациях. Ориентация может быть определена как О, где О∈{NoRotation, Clockwise, Counterclockwise, Upsidedown}. Для каждой возможной ориентации О хранится массив голосов, куда могут быть записаны идентификатор распознанного символа (например, в кодировке Unicode), и уверенность распознавания данного символа (108). Если в одной из ориентации фрагмент может быть распознан с достаточно высокой уверенностью, например, превышающей некоторый порог уверенности Т, то этот результат можно рассматривать как «голос», и его параметры добавляются к массиву голосов для соответствующей ориентации.
[0044] Вычисляется суммарная уверенность для каждой ориентации в наборе ориентации и выбирается ориентация О*, которая подходит наилучшим образом. Например, можно производить суммарный подсчет голосов для каждой ориентации. В другом варианте осуществления изобретения суммарная уверенность может быть подсчитана как средняя уверенность распознания всех голосов. Ориентация О* может быть, например, ориентацией с максимальной суммарной уверенностью. Решение о наличии символов CJK в документе может быть принято на основе нескольких условий, включая, без ограничений,:
1. Суммарная уверенность наилучшей ориентации О* превышает заданный порог t;
2. Суммарная уверенность для ориентации О* значительно выше, чем суммарная уверенность следующей по суммарной уверенности ориентации. Например, суммарная уверенность может быть выше, чем уверенность следующей лучшей ориентации в 1,5-2 раза; и
3. Символы из массива голосов для ориентации О* содержат голос в каждой из четырех ориентаций, который не имеет европейского соседа в этой ориентации. Другими словами, для каждой ориентации найдется голос в массиве О*, который не имеет европейского соседа в рассматриваемой ориентации.
[0045] Классификатор СОСР можно изменить, используя заранее заданные значения. Например, можно заранее определить степень различия, а также число гипотез, проверяемых на этапе (106). Предварительно заданные значения могут быть, в том числе но без ограничений, предоставлены пользователем, взяты из базы данных или из удаленного местоположения.
[0046] Если накопленный набор фрагментов отвечает описанным условиям, то может быть принято решение о присутствии символов CJK в документе, и операция подтверждающего распознавания (107) может быть остановлена. Однако если накопленный набор фрагментов не соответствует указанным условиям и распознаны все гипотезы, представленные СОСР, то может быть принято решение, что символы CJK в документе отсутствуют (108). На этапе (109) может быть предоставлен ответ о наличии символов CJK. Например, этот ответ может быть основан на решении о том, что символы CJK присутствуют или отсутствуют в этом документе.
[0047] Приведем пример, чтобы наглядно показать, как классификатор СОСР корректирует выводы о содержимом фрагмента по сравнению с независимым классификатором, который работает на основе таких же признаков. На Фиг. 2 фрагменты (202) и (203) являются склейками более чем одного символа, однако независимый классификатор дал им достаточно высокую оценку (т.е. высока вероятность того, что этот фрагмент содержит символ CJK). Фрагмент (202) который склеен из цифр 6 и 2 и повернут набок, получил оценку вероятности того, что это CJK символ, равную 0,877, а фрагмент 203, который является склейкой корейского символа и вертикальной линии от соседнего символа, получил оценку 0,860. Если эти фрагменты окажутся среди лучших представителей гипотез CJK на странице и будут переданы на подтверждающее распознавание, то они не будут распознаны ни в одной ориентации. В противоположность этому, описанный выше классификатор СОСР смог правильно определить, что данная страница была повернута, поскольку были проанализированы все фрагменты в совокупности. Оценки вероятности, полученные от СОСР для фрагментов (202) и (203), составляют 0,005 и 0,044, соответственно.
[0048] В другом примере фрагменты (204) и (205) являются правильно выделенными одиночными корейскими символами, но независимый классификатор дал им низкие оценки вероятности 0,120 и 0,435, соответственно, потому что классификатор не смог понять, что данная страница была повернута набок. Напротив, классификатор СОСР присвоил этим фрагментам высокие оценки вероятности: 0,847 и 0,959, соответственно, потому что классификатор СОСР определил ориентацию документа и использовал эту ориентацию при анализе фрагментов. Таким образом, фрагменты (204) и (205) вошли в список лучших представителей гипотез CJK, и наличие корейских символов в документе было обнаружено правильно.
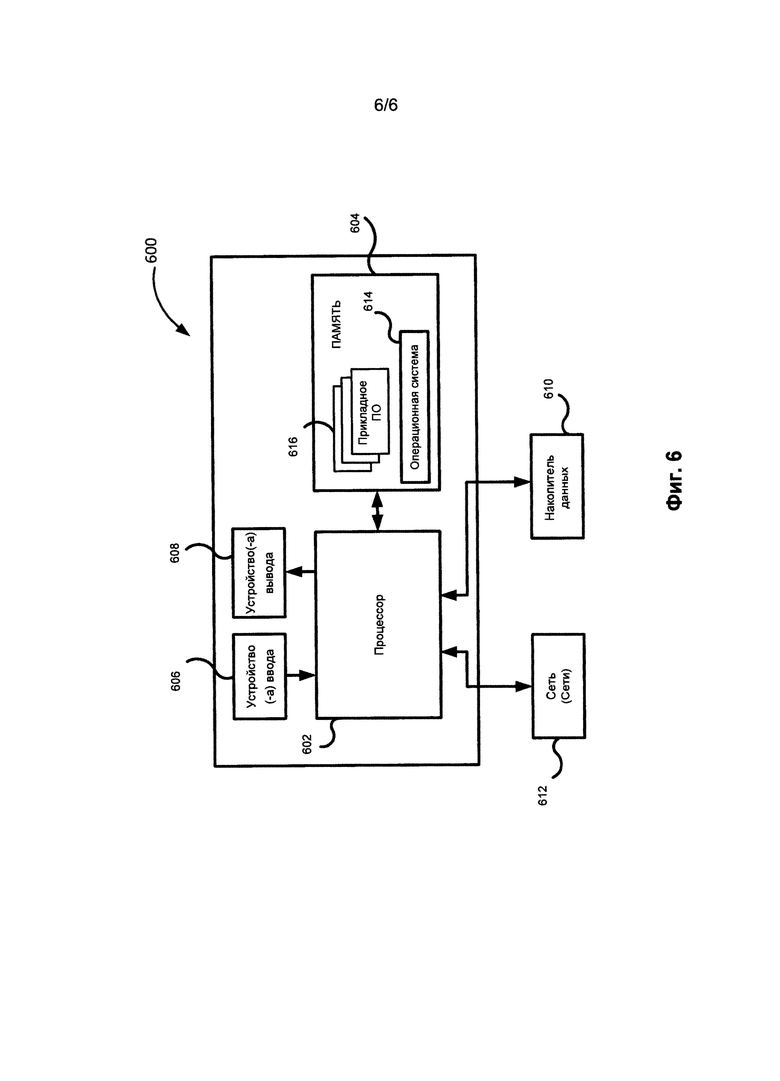
[0049] На Фиг. 6 показан возможный пример вычислительного средства (600), которое может быть использовано для осуществления описанных вариантов осуществления изобретения. Это вычислительное средство (600) содержит по меньшей мере один процессор (602), соединенный с памятью (604). Процессор (602) может содержать один или несколько процессоров, он может содержать одно, два или больше ядер процессора. Память (604) может представлять собой оперативную память (оперативное запоминающее устройство - ОЗУ), она может также содержать память любого другого типа или вида, в частности, энергонезависимые запоминающие устройства (например, флэш-накопители) или постоянные запоминающие устройства, такие как жесткие диски и так далее. Кроме того, можно рассматривать устройство, в котором память (604) содержит носители информации, физически расположенные где-либо еще в составе вычислительного средства (600), например, кэш-память в процессоре (602), или память, используемая в качестве виртуальной памяти, которая находится на внешнем или внутреннем запоминающем устройстве (610).
[0050] Кроме того, вычислительное средство (600) обычно имеет некоторое количество портов ввода и вывода для передачи и получение информации. Для взаимодействия с пользователем вычислительное средство (600) может содержать одно или несколько устройств ввода (например, клавиатуру, мышь, сканер, и др.) и устройство вывода (608) (например, жидкокристаллический дисплей). Вычислительное средство (600) также может иметь одно или несколько постоянных запоминающих устройств (610), таких как привод оптических дисков (CD-, DVD- или другой), жесткий диск или ленточный накопитель. Кроме того, вычислительное средство (600) может иметь интерфейс с одной или несколькими сетями (612), которые обеспечивают соединение с другими сетями и компьютерными устройствами. В частности, это может быть локальная сеть (LAN), беспроводная сеть Wi-Fi, при этом возможно подключение к сети Интернет (World Wide Web), либо оно может отсутствовать. Подразумевается, что вычислительное средство (600) включает соответствующие аналоговые и/или цифровые интерфейсы между процессором (602) и каждым из компонентов (604, 606, 608, 610 и 612).
[0051] Вычислительное средство (600) работает под управлением операционной системой (614) и выполняет различные приложения, компоненты, программы, объекты, модули и т.д., совместно обозначенные числом 616.
[0052] В целом, процедуры, выполняемые для осуществления вариантов изобретения, могут быть реализованы как часть операционной системы или конкретного приложения, компонента, программы, объекта, модуля или последовательности команд, упомянутых как «компьютерные программы». Как правило, компьютерные программы содержат один или более наборов команд, установленных в разное время в различных элементах памяти и в различных запоминающих устройствах компьютера, которые после считывания и выполнения одним или несколькими процессорами в компьютере приводят к тому, что компьютер выполняет операции, необходимые для выполнения элементов описанных вариантов осуществления. Кроме того, различные варианты осуществления изобретения были описаны в контексте полностью работоспособных компьютеров и компьютерных систем, и специалистам в данной области техники будет понятно, что различные варианты осуществления изобретения могут распространяться в виде программного продукта в различных формах, и что это не зависит от конкретного типа машиночитаемых носителей, используемых для фактического распространения. Примеры машиночитаемых носителей включают в себя, без ограничений, носители с возможностью записи, такие как энергозависимые и энергонезависимые запоминающие устройства, гибкие диски и другие съемные диски, жесткие диски, оптические диски (например, компакт-диски, доступные только для чтения (CD-ROM), универсальные цифровые диски (DVD), флэш-накопители и т.д.). Другой тип распространения может быть реализован путем загрузки из сети Интернет.
[0053] В приведенном выше описании многие конкретные детали изложены для пояснения. Однако специалистам в данной области техники очевидно, что эти конкретные детали являются лишь примерами. В других случаях структуры и устройства показаны только в виде блок-схемы для упрощения изложения.
[0054] Ссылка в данном описании на «один вариант осуществления» или «осуществление» означает, что конкретный признак, структура или характеристика, описанные в связи с данным осуществлением изобретения, включены по меньшей мере в один вариант осуществления изобретения. Появление формулировки «в одном варианте осуществления» в различных местах описания не обязательно относится к тому же самому варианту осуществлению изобретения, а отдельные или альтернативные варианты осуществления изобретения не являются взаимоисключающими с другими вариантами осуществления. Кроме того, приведено описание различных особенностей, которые могут использоваться в одних вариантах осуществления изобретения, но не использоваться в других вариантах осуществления изобретения. Аналогично приведено описание различных требований, которые могут относиться к одним вариантам осуществления изобретения, но не относиться к другим вариантам его осуществления.
[0055] Некоторые конкретные варианты осуществления изобретения описаны и проиллюстрированы на прилагаемых чертежах. Однако следует понимать, что такие варианты осуществления изобретения являются лишь иллюстративными и не ограничивают раскрытые варианты осуществления изобретения, и что эти варианты осуществления изобретения не ограничиваются конкретными показанными и описанными конструкциями и компоновками, поскольку специалисты в данной области техники после изучения описания могут создавать другие модификации. В области подобных технологий, где развитие происходит быстро, и дальнейшие достижения не так легко предвидеть, раскрытые варианты осуществления изобретения можно легко подвергать изменениям в устройстве и деталях благодаря развитию технологии, не отступая при этом от принципов настоящего раскрытия.
[0056] Это описание показывает основной изобретательский замысел, который не может быть ограничен упоминавшимися выше аппаратными средствами. Следует отметить, что аппаратные средства в первую очередь предназначены для решения узкой задачи. С течением времени и по мере развития технологии такая задача становится более сложной. Возникают новые инструменты, способные удовлетворить новые требования. В этом смысле следует рассматривать данные аппаратные устройства с точки зрения класса решаемых ими технических задач, а не просто в качестве технического осуществления изобретения на некоторой элементной базе.
Изобретение относится к средствам распознавания документов. Техническим результатом является повышение достоверности определения наличия в тексте китайских, японских или корейских символов. В способе определения того, содержит ли текст китайские, японские или корейские символы получают изображение документа. Полученное изображение документа бинаризуется. На бинаризованном изображении документа производится поиск связных компонент. На основе полученных связных компонент выявляется множество фрагментов и определяется ориентация документа. Для каждого фрагмента из множества фрагментов формулируется гипотеза о принадлежности языку. Для гипотезы о принадлежности языку вычисляется оценка вероятности. Из множества фрагментов выбирается подмножество, имеющее наивысшие оценки вероятности. Гипотеза о принадлежности языку проверяется для каждого фрагмента из подмножества фрагментов. Решение о наличии китайских, японских и корейских символов принимается на основе, как минимум, проверки гипотезы о языке фрагментов выбранного подмножества. 3 н. и 17 з.п. ф-лы, 7 ил.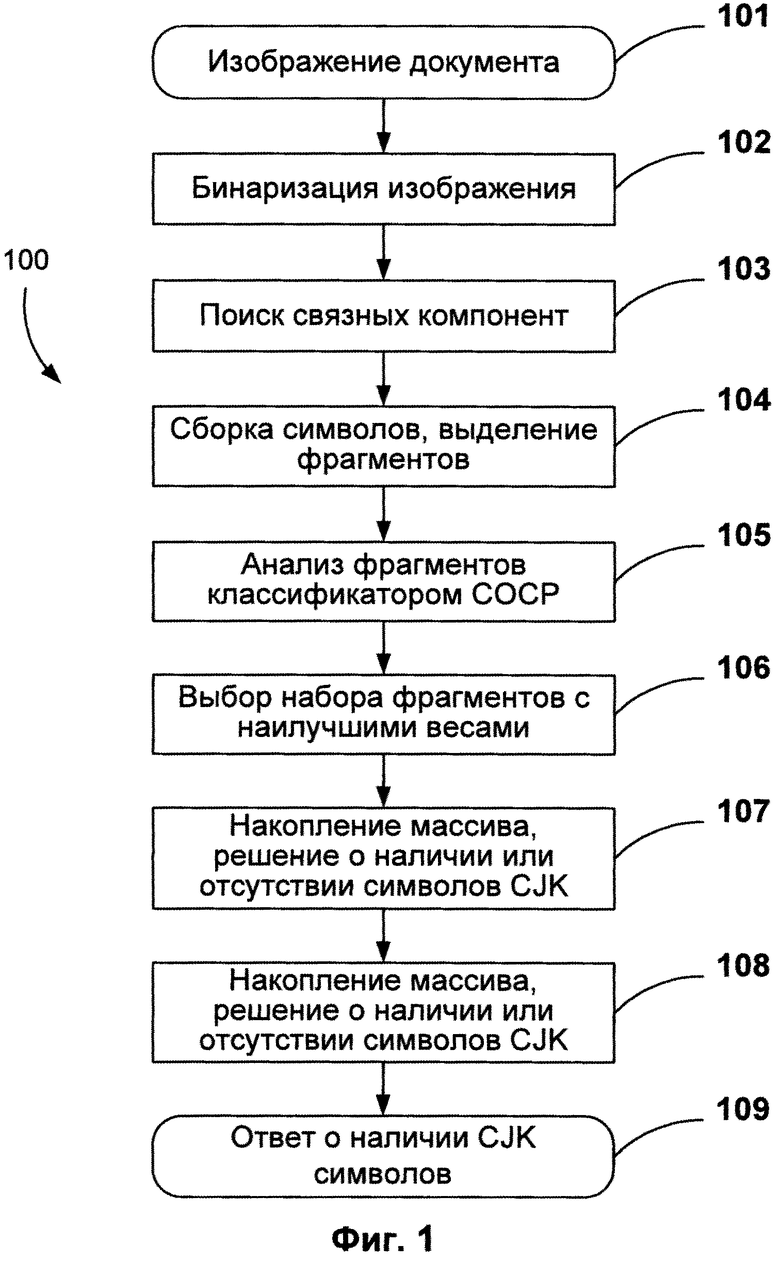
1. Способ определения того, что текст содержит символы китайского, японского или корейского языка, включающий в себя:
получение изображения документа;
бинаризацию изображения документа;
поиск связных компонент на бинаризованном изображении документа;
выявление множества фрагментов на основе связных компонент и определение ориентации документа;
формулировку для каждого фрагмента из множества фрагментов гипотезы о принадлежности языку с оценкой вероятности этой гипотезы;
выбор из множества фрагментов подмножества фрагментов, имеющих наивысшие оценки вероятности;
проверку, с использованием процессора, гипотезы о принадлежности языку для каждого фрагмента в подмножестве фрагментов; и
определение с помощью процессора наличия китайских, японских и корейских (CJK) символов на основании, по меньшей мере, проверки гипотезы о принадлежности языку для подмножества фрагментов с учетом указанной определенной ориентации документа.
2. Способ по п. 1, дополнительно включающий в себя:
анализ признаков первого подмножества из множества фрагментов и
определение характеристики документа на основании анализа признаков первого подмножества из множества фрагментов, при этом формулировка гипотезы о принадлежности языку для каждого фрагмента частично основывается на характеристике документа.
3. Способ по п. 1, отличающийся тем, что при определении ориентации документа учитывается ориентация, по меньшей мере, одного фрагмента из указанного множества фрагментов.
4. Способ по п. 2, дополнительно включающий в себя:
определение второго, другого значения характеристики документа на основе анализа признаков второго, другого подмножества из множества фрагментов;
повторный анализ признаков первого подмножества из множества фрагментов с использованием второго, другого значения характеристик документа.
5. Способ по п. 1, дополнительно включающий в себя:
распознавание подмножества фрагментов в каждой из четырех ориентации;
вычисление уверенности распознавания каждого из выбранного подмножества фрагментов в каждой из четырех ориентаций;
определение для каждого из подмножества фрагментов «голоса» за ту или иную ориентацию исходя из вычисленного уровня уверенности и
определение ориентации изображения документа на основе подсчета голосов.
6. Способ по п. 1, отличающийся тем, что для формулировки гипотезы о принадлежности языку для каждого фрагмента из множества фрагментов используется байесовская сеть.
7. Способ по п. 1, отличающийся тем, что для формулировки гипотезы о принадлежности языку для фрагмента используется определение признаков фрагмента, причем эти признаки основаны на информации о растровых и геометрических свойствах фрагмента.
8. Способ по п. 7, отличающийся тем, что признаки фрагмента содержат, как минимум
натуральный логарифм отношения ширины фрагмента к его высоте; количество горизонтальных штрихов, разделенное на высоту; количество вертикальных штрихов, разделенное на ширину; длину самого длинного горизонтального штриха, разделенную на высоту; и длину самого длинного вертикального штриха.
9. Способ по п. 1, в котором фрагмент содержит одно из следующего: один символ, два или более склеенных символов, часть одного символа, один символ и часть второго символа.
10. Способ по п. 5, в котором каждый голос для первой ориентации дополнительно проверяется на наличие европейского символа в любой ориентации.
11. Система определения того, что текст содержит символы китайского, японского или корейского языка, включающая в себя:
один или более процессоров, сконфигурированных для:
получения изображения документа;
бинаризации изображения документа;
поиска связных компонент на бинаризованном изображении документа;
выявления множества фрагментов на основе связных компонент и определение ориентации документа;
определения гипотезы о принадлежности языку для каждого фрагмента из множества фрагментов, причем гипотеза о принадлежности языку имеет оценку вероятности;
выбора подмножества фрагментов из множества фрагментов, имеющих высокую оценку достоверности;
проверки гипотезы о принадлежности языку для каждого фрагмента в подмножестве фрагментов, и
определения наличия китайских, японских и корейских (CJK) символов на полученном изображении документа на основании, по меньшей мере, проверки гипотезы о принадлежности языку для подмножества фрагментов с учетом указанной определенной ориентации документа.
12. Система по п. 11, в которой один или более процессоров дополнительно сконфигурирован для:
анализа признаков первого подмножества из множества фрагментов, и
определения характеристики документа на основе анализируемых признаков первого подмножества из множества фрагментов, в котором формулировка гипотезы о принадлежности языку для каждого фрагмента частично основывается на характеристике документа.
13. Система по п. 11, дополнительно выполненная с возможностью при определении ориентации документа учета ориентация, по меньшей мере, одного фрагмента из указанного множества фрагментов.
14. Система по п. 12, в которой один или более процессоров дополнительно сконфигурированы для:
определения второго, другого значения характеристики документа на основе анализа признаков второго, другого подмножества из множества фрагментов;
повторного анализа признаков первого подмножества из множества фрагментов с использованием второго, другого значения характеристик документа.
15. Система по п. 11, отличающаяся тем, что один или несколько дополнительных процессоров сконфигурированы для:
распознавания подмножества фрагментов в каждой из четырех ориентаций;
вычисления уверенности распознавания каждого из выбранного подмножества фрагментов в каждой из четырех ориентаций;
определения для каждого из подмножества фрагментов «голоса» за ту или иную ориентацию исходя из вычисленного уровня уверенности и
определения ориентации изображения документа на основе подсчета голосов.
16. Энергонезависимый машиночитаемый носитель, в котором имеются команды, причем эти команды включают в себя:
команды для получения изображения документа;
команды для бинаризации изображения документа;
команды для поиска связной компоненты на бинаризованном изображении документа;
команды по выявлению множества фрагментов на основе связных компонент и определение ориентации документа;
команды для определения гипотезы о принадлежности языку для каждого фрагмента из множества фрагментов, в котором гипотеза о принадлежности языку имеет оценку вероятности;
команды для выбора подмножества фрагментов из множества фрагментов, имеющих наивысшие оценки достоверности;
команды по проверке гипотезы о принадлежности языку для каждого фрагмента в подмножестве фрагментов, а также
команды для определения присутствия китайских, японских и корейских (CJK) символов на полученном изображении документа на основании, по меньшей мере, проверки языковой гипотезы для подмножества фрагментов с учетом указанной определенной ориентации документа.
17. Энергонезависимый машиночитаемый носитель, по п. 16, команды на котором дополнительно включают в себя:
команды для анализа признаков первого подмножества из множества фрагментов, а также
команды для определения характеристики документа на основании анализируемых признаков первого подмножества из множества фрагментов, в котором формулировка гипотезы о принадлежности языку для каждого фрагмента частично основана на характеристике документа.
18. Энергонезависимый машиночитаемый носитель по п. 16, дополнительно содержащий команды, позволяющие при определении ориентации документа учитывать ориентацию, по меньшей мере, одного фрагмента из указанного множества фрагментов.
19. Энергонезависимый машиночитаемый носитель, по п. 17, команды на котором дополнительно включают в себя:
команды для определения второго, другого значения характеристики документа на основе анализа признаков второго, другого подмножества из множества фрагментов;
команды для повторного анализа признаков первого подмножества из множества фрагментов с использованием второго, другого значения характеристик документа.
20. Энергонезависимый машиночитаемый носитель, по п. 17, команды на котором дополнительно включают в себя:
команды для распознания подмножества фрагментов в каждой из четырех ориентаций;
команды для вычисления уверенности распознавания каждого из выбранного подмножества фрагментов в каждой из четырех ориентаций;
команды для определения для каждого из подмножества фрагментов «голоса» за ту или иную ориентацию исходя из вычисленного уровня уверенности и
команды для определения ориентации изображения документа на основе подсчета голосов.
| СПОСОБ АВТОМАТИЧЕСКОГО ОПРЕДЕЛЕНИЯ ЯЗЫКА РАСПОЗНАВАЕМОГО ТЕКСТА ПРИ МНОГОЯЗЫЧНОМ РАСПОЗНАВАНИИ | 2002 |
|
RU2251737C2 |
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| US 6047251 A, 04.04.2000 | |||
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |

