Предлагаемый способ относится к системам автоматизированного определения языка или языковой группы текста, использующим электронно-вычислительные средства (далее по тексту ЭВМ) и может быть использован в процессе автоматизированного анализа и/или перевода текстов, например, в случае отбора (сортировки) текстов на разных языках по тематике, языку, языковым группам или машинного перевода текста на нужный язык.
Известен способ автоматического определения языка распознаваемого текста при многоязычном распознавании, в котором по отдельным распознанным символам текста формируются гипотезы о языковой принадлежности группы символов, которые проверяются с помощью лингвистических моделей с предварительно определенными признаками различных языков, что приводит к получению вероятностного определения языка [1]. Этот способ разработан для систем распознавания изображений (знаков) и не предлагает оригинального решения для определения языка текста, так как определение языковой принадлежности распознаваемого текста осуществляется по известным лингвистическим моделям и словарям.
Эффективность этого и других известных способов недостаточно высока вследствие необходимости перебора отдельных словосочетаний и/или слов по словарям, создания лингвистических моделей, сравнения символов национальных письменных систем или групп символов по набранной статистике встречаемости их комбинаций, что требует затраты нецелесообразного количества ресурсов. Эффективность определения языка текста снижается также из-за того, что во многих языках отдельные словосочетания, слова и комбинации символов могут полностью совпадать, что приводит к ошибкам определения языка или к вероятностным результатам.
Известен способ идентификации языка текста по наборам определенных байтовых последовательностей (комбинаций символов) в соответствии с заранее набранной статистикой встречаемости таких последовательностей в текстах на каждом определяемом языке [2]. Этот способ является функциональным аналогом предлагаемого здесь способа, так как цель, последовательность операций и результаты его применения наиболее близки к предлагаемому способу. Недостатком этого способа является необходимость набора статистических данных по встречаемости определенных байтовых последовательностей в большом количестве текстов на идентифицируемых языках. Другим недостатком этого способа является вероятностный результат, который не позволяет однозначно определить язык или языковую группу проанализированного текста.
Кроме того, в тексте могут встречаться фрагменты на других языках, отличных от языка самого текста (например, в текстах русских писателей 18-19 веков часто встречаются выражения на французском языке), или части, записанные другой письменной системой. Например, в одном тексте часто совместно используются кириллица и латиница, к примеру, при иноязычных включениях, описании терминов, либо используется латиница вместо обычной кириллицы при транслитерации и транскрипции или допустимых вариантах написания.
Основным недостатком этого и большинства известных способов определения языка текста является необходимость подробного анализа текста, например, при построении лингвистических моделей (графов), или перебора и сравнения больших объемов данных (например, словарей определяемых языков), что требует нецелесообразной затраты ресурсов. Другим их недостатком является получение вероятностного результата при определении языка.
Указанные недостатки приводят к нерациональной затрате ресурсов и частым ошибкам при определении языка. Например, при определении языка моноязычного текста известными способами, данный текст может быть отнесен к нескольким языкам разных групп с примерно одинаковой вероятностью. В результате чего невозможно понять, к какой категории отнести данный текст при классификации, для какой группы языков требуется специалист (или какая требуется программа) для дальнейшей обработки и/или перевода данного текста.
Технический результат предлагаемого способа - автоматизированный режим определения языка текста, при этом реализуются:
1) возможность работы с многоязычными текстами и точного определения всех языков, используемых в анализируемом тексте, при наличии в нем форм глаголов из набора идентифицирующих элементов;
2) возможность точного определения языковой семьи, ветви или группы языков, к которой относится язык анализируемого текста (например, славянская, германская, романская, кельтская и т.д.);
3) возможность идентифицировать язык по формам и/или их семантически значимым частям, например, основам или корням небольшой группы глаголов, например вспомогательных, модальных, наиболее употребительных и т.д. (в каждой группе по несколько глаголов), или комбинации таких групп.
Вместе с этим имеется независимость от системы письма или представления информации в анализируемом тексте, значительное повышение точности идентификации языка при небольших объемах текста (от одного до нескольких предложений). Использование ЭВМ при определении языка или языковой группы текста предлагаемым способом не предусматривает сложных алгоритмов и мощных вычислительных средств.
Технический результат достигается тем, что в способе автоматизированного определения языка или языковой группы текста, заключающемся в том, что:
- создают набор идентифицирующих элементов каждого определяемого языка и сохраняют его на носителе информации;
- производят сопоставление каждого идентифицирующего элемента данного набора с соответствующими элементами анализируемого текста,
при выявлении совпадений элементов из набора идентифицирующих элементов с элементами анализируемого текста язык определяют по принадлежности совпавших элементов к определенному языку из данного набора, согласно изобретению создают набор идентифицирующих элементов из групп наиболее употребительных глаголов каждого определяемого языка или языковой группы, а в качестве идентифицирующих элементов используют грамматические формы и семантически значимые части глаголов (корни и основы) каждого определяемого языка и сохраняют его на носителе информации.
Описание изобретения
Предлагаемый способ может быть реализован с помощью программно-аппаратных средств электронно-вычислительных машин и использован при автоматизированном определении языка или языковой группы в системах обработки информации, например, в бюро переводов (с одного языка на другой), отделах по обработке корреспонденции, почтовых отделениях или программах по работе с электронной почтой, библиотеках, программных комплексах по сбору и обработке информации, системах автоматизированного перевода (с одного языка на другой), текстовых процессорах, классификаторах текстовых документов и т.д., а также при определении языка транслитерированных, транскрибированных и записанных специальной (например, шрифтом Брайля) или необычной письменной системой. Например тексты на языках бывшей Югославии могут быть записаны как кириллицей, так и латиницей, а тексты на языках Средней Азии могут также записываться арабской письменностью. Транслитерацию и транскрипцию часто используют люди при общении в компьютерных сетях, например, в Интернете, в силу того, что у корреспондента не всегда есть клавиатура (или соответствующая таблица символов) для переписки на нужном языке.
Для применения предлагаемого способа достаточно иметь (или составить) набор определенных форм нескольких глаголов каждого идентифицируемого языка или языковой группы и не требуется использование словарей, грамматических справочников, лингвистических моделей (или графов), баз данных, статистики встречаемости определенных последовательностей символов и т.д. для каждого идентифицируемого языка.
Суть предлагаемого способа определения языка или языковой группы текста состоит в использовании определенного небольшого набора форм глаголов (или их семантически значимых частей) идентифицируемых языков (по несколько глаголов для каждого языка), который является своеобразной матрицей для определения языка или языковой группы. Данный набор может быть представлен в удобном для хранения, воспроизведения и оперирования виде, например, списком с определенной структурой, таблицей или многомерным массивом, где будут представлены одна или несколько групп глаголов (например, вспомогательные, наиболее употребительные и/или модальные глаголы) каждого идентифицируемого языка, указана связь этих групп с конкретным языком или языковой группой (и/или подгруппой), а также языковой ветвью, семьей и макросемьей по мере необходимости. Такая иерархия набора идентифицирующих элементов позволяет определять языковые ветви, группы или подгруппы без определения самого языка анализируемого текста. Например, для русского языка может быть использована следующая упрощенная языковая иерархия:
русский → восточнославянская группа → балто-славянская ветвь.
При этом данная иерархия может быть разветвленная и многоуровневая (где, например, глаголы близкородственных языков находятся на одном уровне отдельной ветви иерархии), а для каждой языковой группы и каждого языка могут даваться уточнения или более подробная языковая классификация, например, деление на подгруппы, варианты и/или диалекты. К примеру, английский язык относится к западногерманской языковой группе и для него существуют британский, американский и австралийский варианты со множеством диалектов внутри каждого из них.
В качестве идентифицирующих элементов набора могут быть выбраны какие-то конкретные грамматические формы глаголов (например, только формы настоящего времени или только наиболее употребительные) и/или их семантически значимые части (например, корни или основы).
Выбор конкретных форм глаголов зависит от языка, цели и уровня идентификации. Например, для определения только языковой группы и для определения конкретного варианта или диалекта будут использоваться различные наборы глагольных форм. Количество идентифицирующих глаголов для каждого определяемого языка может варьироваться в различных пределах, но для определения языковой группы или подгруппы, а часто и отдельного языка, достаточно взять часто используемые формы (например, настоящего и простого прошедшего времен) наиболее употребительных глаголов, таких как вспомогательные глаголы («быть», «иметь» и т.п.) и глагола «делать». С помощью комбинаций различных групп и форм глаголов идентифицируемых языков и при условии исключения из составляемых наборов совпадающих форм в разных языках и/или языковых группах можно добиться высокой точности идентификации языка или языковой группы текста.
Составление наборов глагольных форм с указанием на соответствие конкретному языку или языковой группе (а также с другими нужными индикаторами) является необходимым и единственным достаточным условием для использования предлагаемого способа (изобретения). Такие наборы могут быть составлены как вручную, так и с помощью ЭВМ в автоматизированном режиме.
Реализация предлагаемого способа сводится к сравнению (сопоставлению) идентифицирующих элементов упомянутого выше набора с соответствующими элементами анализируемого текста. При обнаружении совпадений слов текста (и/или их частей) с соответствующими элементами какой-либо группы из набора идентифицирующих глаголов анализируемый текст ассоциируется с языком, соответствующим данной группе элементов в наборе, и сравнение завершается. При анализе многоязычного текста сопоставление проводится с формами каждой группы идентифицирующих глаголов вне зависимости от того, были ли обнаружены совпадения. А по завершении сравнения всех элементов набора с соответствующими элементами данного текста выдается список всех языков или языковых групп (зависит от цели идентификации), с формами глаголов которых были обнаружены совпадения. Затем результат проведенного анализа текста фиксируется в удобном для восприятия, хранения, воспроизведения (считывания) виде. Впоследствии, на основании полученных результатов, могут быть сделаны уточнения. Например, по количеству и встречаемости совпавших форм глаголов каждого определенного языка может быть вычислен основной или преобладающий язык проанализированного текста.
В целом предлагаемый способ имеет более широкую сферу возможных применений, обеспечивает получение новых технических результатов, обладает рядом преимуществ перед известными способами, решающими аналогичные задачи, и является одним из наиболее рациональных способов определения (идентификации) языковой принадлежности текста на текущий момент времени. Применение предлагаемого способа на практике позволит существенно повысить качество и/или скорость определения языковой принадлежности текста, а технические результаты такого применения позволят существенно сократить затраты и сэкономить ресурсы при определении языка или языковой группы текста.
При реализации предлагаемого способа на ЭВМ значительно сократится занимаемое программой (и ее компонентами) место в памяти ЭВМ и на устройстве хранения информации, а также потребление вычислительных ресурсов. Это позволяет отводить на идентификацию языка гораздо меньше времени, а также освободить часть ресурсов для решения других задач или создавать менее мощные машины или менее требовательные к ресурсам программы. Особенно это важно в области web-приложений, мобильных компьютеров и т.д.
Технический результат применения предлагаемого способа определения языка или языковой группы текста позволяет получить значительный экономический эффект. При сортировке корреспонденции, публикаций и книг на разных языках предложенный способ определения языка или языковой группы может применяться с участием сотрудника, не являющегося специалистом в области филологии и языкознания. При выборе программы перевода (например, для перевода письма или публикации) языковая группа определяется с высокой точностью.
Примеры реализации предлагаемого способа
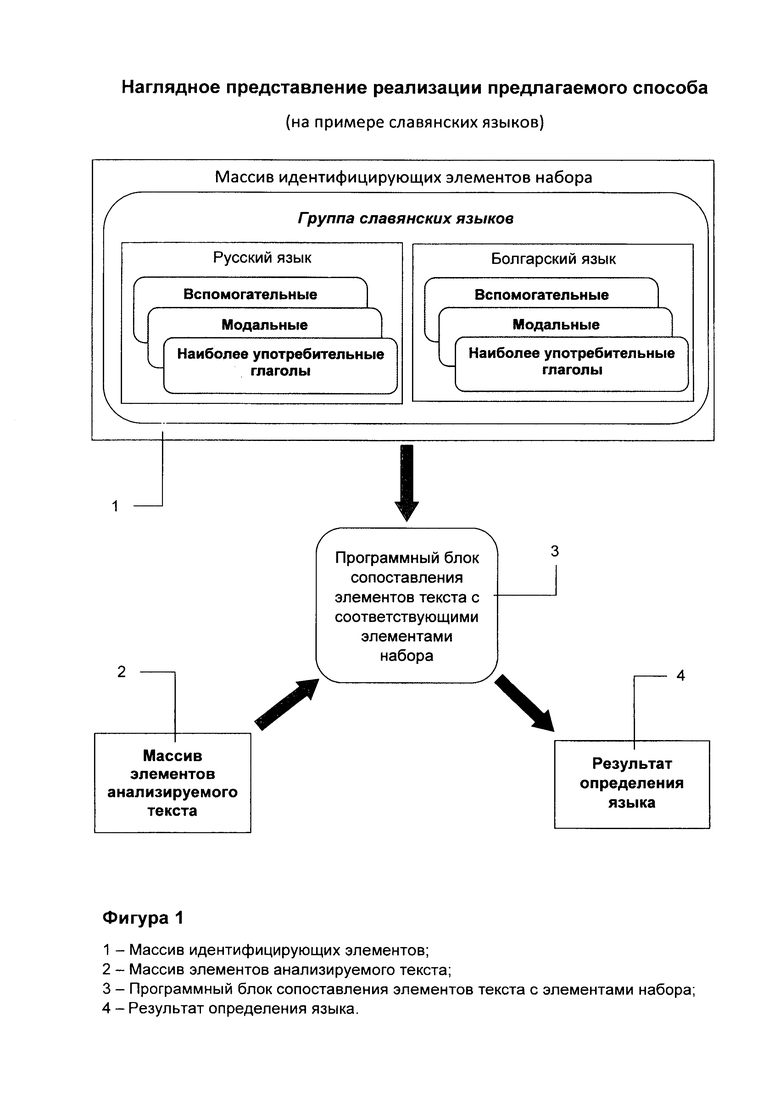
На фиг. 1 представлена функциональная схема реализации предлагаемого способа со следующими блоками:
1 - Массив идентифицирующих элементов;
2 - Массив элементов анализируемого текста;
3 - Программный блок сопоставления элементов текста с элементами набора;
4 - Результат определения языка.
В качестве примера практического применения и наглядной демонстрации предлагаемого способа описывается упрощенная последовательность операций, используемых при анализе следующего текста (фрагмент типового договора):
«Споры или разногласия, которые могут возникнуть по настоящему договору или в связи с ним и не могут быть решены путем переговоров, подлежат рассмотрению в Арбитражном суде по месту нахождения Ответчика».
Производят следующие операции:
- создание массива данных на основе имеющегося набора идентифицирующих элементов;
- создание массива слов анализируемого текста;
- перебор элементов созданных массивов;
- сопоставление (в процессе перебора) слов анализируемого текста с элементами массива данных, в котором хранится набор идентифицирующих форм глаголов и их соответствия определенным языкам.
Этот набор формируется на основе простого текстового файла со следующей структурой (приводится в сокращенном и упрощенном виде):

В данном примере для определения языка используются грамматические формы нескольких наиболее употребительных глаголов каждого идентифицируемого языка различных языковых групп Европы (без указания на эти группы). С помощью данного набора идентифицирующих элементов можно определить язык текста в случае, если формы глаголов в анализируемом тексте не имеют совпадений со словами других языков. В противном случае язык не будет определен. Для определения принадлежности языка текста к одной из языковых групп структура предлагаемого файла (набора) может быть изменена следующим образом (приводится в сокращенном и упрощенном виде):

Для краткости и наглядности здесь приведены только 4 языка славянской группы, без деления на подгруппы (восточнославянскую, южнославянскую и западнославянскую), которое может быть добавлено при необходимости, а названия языков указаны в скобках для уточнения принадлежности форм глаголов.
В результате анализа приведенного выше текста находят все имеющиеся в предложенном наборе формы, в данном случае глаголов «быть» и «мочь» (если он был включен в этот набор). Таким образом, при сравнении (сопоставлении) элементов текста (слов) и элементов предложенного набора будут выявлены следующие совпадения (выделены полужирным шрифтом):
«Споры или разногласия, которые могут возникнуть по настоящему договору или в связи с ним и не могут быть решены путем переговоров, подлежат рассмотрению в Арбитражном суде по месту нахождения Ответчика.»
Затем на основании первого приведенного выше варианта набора идентифицирующих элементов находится ассоциация с определенным языком, которому соответствуют совпавшие формы глаголов. И поскольку совпадения обнаружились с формами только одной группы глаголов, будет выдано название только одного языка - русского, что исключает возможность ошибки, получения вероятностного результата при определении языка текста либо неопределенности при его идентификации. При использовании второго предложенного варианта набора идентифицирующих элементов определяется языковая группа, к которой относится язык проанализированного текста. Наличие названий самих языков для определения языковой группы необязательны.
В приведенных примерах набора идентифицирующих элементов сознательно исключены совпадающие формы глаголов в близкородственных языках (например, южнославянских: сербского и болгарского), чтобы избежать ошибок определения языка, а также не используются семантически значимые части глаголов (например, корни или основы) для упрощения понимания сути предлагаемого способа. Однако, как явствует из приведенных наборов идентифицирующих элементов, наличие совпадений форм глаголов в языках одной группы (например, славянской) не повлияет на результат, если целью анализа текста является только определение языковой группы. В таком случае указания на конкретный язык могут быть исключены из набора идентифицирующих элементов, а совпадающие формы глаголов в близкородственных языках в него добавлены, чтобы улучшить результат определения языковой группы.
Также из приведенных примеров наборов идентифицирующих элементов следует, что предлагаемый способ определения языка или языковой группы не зависит от используемой в анализируемом тексте системы письма или фиксации информации, так как в самом наборе могут быть использованы различные системы письма и фиксации информации (например, слоговые знаки, идеограммы или комбинации точек шрифта Брайля).
Приведенный пример иллюстрирует практическое применение предлагаемого способа, а также суть использования и структуры описанного выше набора идентифицирующих элементов. От качества составления данного набора зависят эффективность и область применения предлагаемого способа, количество идентифицируемых языков и точность определения языка или языковой группы текста.
Таким образом, осуществляется возможность регулирования функциональности, точности определения и скорости работы с помощью расширения и уточнения или сокращения и упрощения предварительно составляемых наборов форм глаголов идентифицируемых языков или языковых групп. Способ не требует использования словарей определяемых языков и баз данных, а также предварительного обучения (например, изучения грамматики, создания дерева (или модели) грамматических зависимостей, сбора статистики по использованию комбинаций символов и т.д.) или предварительного анализа множества текстов на определяемых языках. Текст может быть представлен в различной воспринимаемой ЭВМ форме (например, в виде изображений символов, идеограмм, комбинаций точек шрифта Брайля и т.д. с применением одной из известных систем письменности, а также передан в виде блока (набора) сигналов, например, звуковых волн, азбуки Морзе и т.п.), что делает предлагаемый способ более универсальным. Количество идентифицирующих элементов и операций сравнения при использовании предлагаемого набора в сотни раз меньше, чем при использовании словарей, лингвистических моделей или последовательностей символов (байтовых последовательностей) известными способами.
Список использованных источников
1. Патент РФ №2251737. «Способ автоматического определения языка распознаваемого текста при многоязычном распознавании», G06K 9/68 (опубл. 10.05.2005).
2. Патент РФ №2500024. «Способ автоматизированного определения языка и(или) кодировки текстового документа», G06F 17/00 (опубл. 27.11.2013).
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ УПОРЯДОЧЕНИЯ ДАННЫХ, ПРЕДСТАВЛЕННЫХ В ТЕКСТОВЫХ ИНФОРМАЦИОННЫХ БЛОКАХ ДАННЫХ | 2000 |
|
RU2210809C2 |
| Способ автоматизированного анализа текста и подбора релевантных рекомендаций по улучшению его читабельности | 2021 |
|
RU2769427C1 |
| СИСТЕМА И МЕТОД АВТОМАТИЧЕСКОГО СОЗДАНИЯ ШАБЛОНОВ | 2018 |
|
RU2697647C1 |
| КОМПЬЮТЕРНАЯ СИСТЕМА И СПОСОБ ПОДГОТОВКИ ТЕКСТА НА ИСХОДНОМ ЯЗЫКЕ И ПЕРЕВОДА НА ИНОСТРАННЫЕ ЯЗЫКИ | 1993 |
|
RU2136038C1 |
| ИСЧЕРПЫВАЮЩАЯ АВТОМАТИЧЕСКАЯ ОБРАБОТКА ТЕКСТОВОЙ ИНФОРМАЦИИ | 2014 |
|
RU2662699C2 |
| СПОСОБ СИНТЕЗА САМООБУЧАЮЩЕЙСЯ СИСТЕМЫ ИЗВЛЕЧЕНИЯ ЗНАНИЙ ИЗ ТЕКСТОВЫХ ДОКУМЕНТОВ ДЛЯ ПОИСКОВЫХ СИСТЕМ | 2002 |
|
RU2273879C2 |
| СПОСОБ ПРЕДВАРИТЕЛЬНОГО ПРЕОБРАЗОВАНИЯ СТРУКТУРИРОВАННОГО МАССИВА ДАННЫХ | 2014 |
|
RU2571405C1 |
| СПОСОБ ФОРМИРОВАНИЯ КАРТЫ СВЯЗЕЙ КОМПОНЕНТОВ ПРЕОБРАЗОВАННОГО СТРУКТУРИРОВАННОГО МАССИВА ДАННЫХ | 2014 |
|
RU2571407C1 |
| СПОСОБ ДВУХУРОВНЕВОГО ПОИСКА ИНФОРМАЦИИ В ПРЕДВАРИТЕЛЬНО ПРЕОБРАЗОВАННОМ СТРУКТУРИРОВАННОМ МАССИВЕ ДАННЫХ | 2014 |
|
RU2571406C1 |
| СПОСОБ ПОИСКА ИНФОРМАЦИИ В ПРЕДВАРИТЕЛЬНО ПРЕОБРАЗОВАННОМ СТРУКТУРИРОВАННОМ МАССИВЕ ДАННЫХ | 2014 |
|
RU2572367C1 |
Изобретение относится к автоматизированному определению языка или языковой группы (например, романская, германская, кельтская, славянская и т.д.), к которой относится язык анализируемого текста. Техническим результатом является обеспечение возможности работы с многоязычными текстами и точного определения всех языков, используемых в анализируемом тексте, при наличии в нем форм глаголов из набора идентифицирующих элементов. В способе автоматизированного определения языка или языковой группы текста создают набор идентифицирующих элементов из групп наиболее употребительных глаголов каждого определяемого языка или языковой группы и сохраняют его на носителе информации. При этом в качестве идентифицирующих элементов используют грамматические формы и семантически значимые части глаголов (корни или основы) каждого определяемого языка. Производят сопоставление каждого идентифицирующего элемента набора с элементами анализируемого текста. При выявлении совпадений элементов язык определяют по принадлежности совпавших элементов к определенному языку из набора. 1 ил.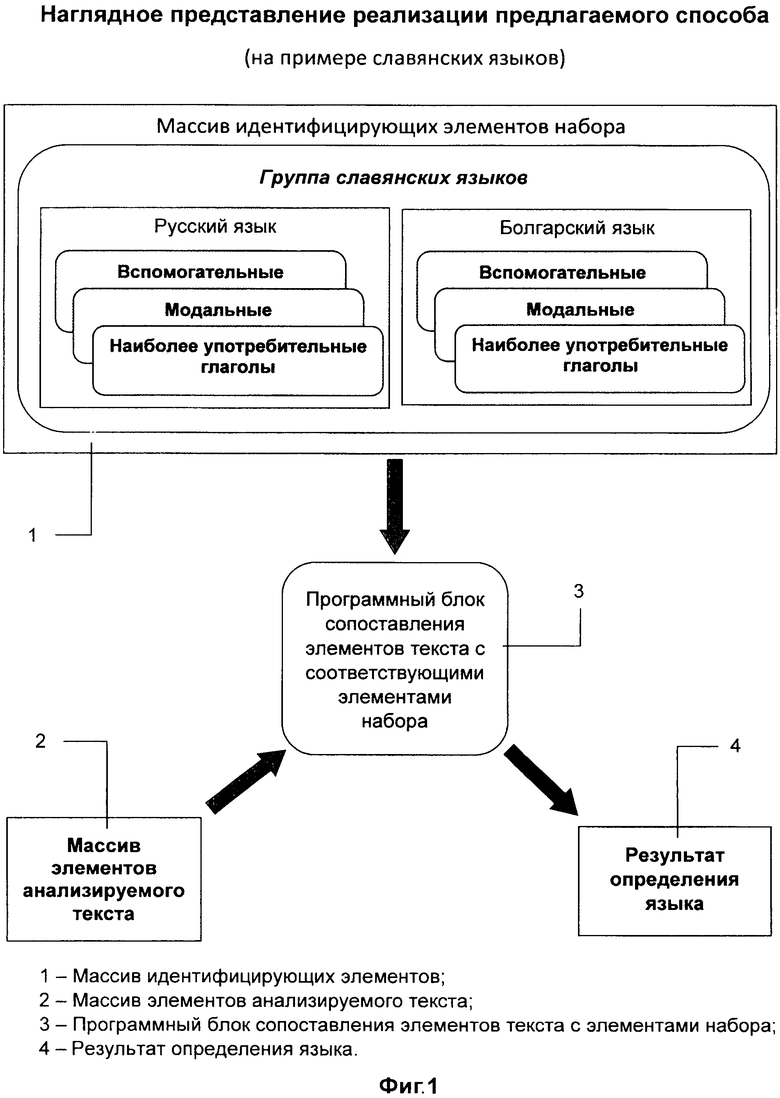
Способ автоматизированного определения языка или языковой группы текста, заключающийся в том, что:
- создают набор идентифицирующих элементов каждого определяемого языка и сохраняют его на носителе информации;
- производят сопоставление каждого идентифицирующего элемента данного набора с соответствующими элементами анализируемого текста;
- при выявлении совпадений элементов из набора идентифицирующих элементов с соответствующими элементами анализируемого текста язык определяют по принадлежности совпавших элементов к определенному языку в наборе, отличающийся тем, что создают набор идентифицирующих элементов из групп наиболее употребительных глаголов для каждого определяемого языка или языковой группы, а в качестве идентифицирующих элементов используют грамматические формы и семантически значимые части глаголов каждого определяемого языка или языковой группы и сохраняют набор на носителе информации.
| СПОСОБ АВТОМАТИЗИРОВАННОГО ОПРЕДЕЛЕНИЯ ЯЗЫКА И (ИЛИ) КОДИРОВКИ ТЕКСТОВОГО ДОКУМЕНТА | 2011 |
|
RU2500024C2 |
| СПОСОБ АВТОМАТИЧЕСКОГО ОПРЕДЕЛЕНИЯ ЯЗЫКА РАСПОЗНАВАЕМОГО ТЕКСТА ПРИ МНОГОЯЗЫЧНОМ РАСПОЗНАВАНИИ | 2002 |
|
RU2251737C2 |
| СПОСОБ УПОРЯДОЧЕНИЯ ДАННЫХ, ПРЕДСТАВЛЕННЫХ В ТЕКСТОВЫХ ИНФОРМАЦИОННЫХ БЛОКАХ ДАННЫХ | 2000 |
|
RU2210809C2 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |

