Изобретение относится к системам телекоммуникаций и вычислительной техники и может найти применение в устройствах приема информации из канала передачи или воспроизведения информации с высоким уровнем ошибок.
Известно устройство обнаружения и исправления ошибок в кодах Рида-Соломона (PC-кодах), предназначенное для защиты внешней памяти ЭВМ от ошибок в считываемых данных [1], содержащее: вычислитель остатков и синдромов; блоки буферной памяти; блок преобразования синдромов; вычислитель ошибок; коммутатор и блок сумматоров по модулю два.
Известное устройство реализует алгоритм пошагового декодирования и позволяет исправить два пакета ошибок в блоке перемеженных слов PC-кода с минимальной задержкой декодирования.
Недостаток устройства - относительно высокая вероятность ошибочного декодирования, объясняемая тем, что невозможно гарантированное обнаружение дополнительных ошибок к двум исправляемым ошибкам в кодовом слове PC-кода.
Известен вычислитель ошибок декодера PC-кода [2], содержащий: вычислитель синдромов; 6 сумматоров элементов поля; 2 перемножителя; квадратор; преобразователь кода; 2 блока логических элементов И; логические элементы И, ИЛИ, ИЛИ-НЕ.
Использование вычислителя в пошаговом декодере PC-кода с дополнительным символом проверки на четность позволяет после обработки кодового слова распознать ситуацию наличия в кодовом слове 3 неисправимых ошибочных символов. В такой ситуации декодер может отменить неверную коррекцию и объявить принятое слово неисправимым. Это позволяет несколько уменьшить вероятность ошибочного декодирования.
К недостаткам такого пошагового декодера можно отнести:
- недостаточно низкую вероятность ошибочного декодирования, обусловленную невозможностью гарантированного обнаружения более чем одной дополнительной ошибки к двум гарантированно исправлямым ошибкам;
- отмена ложной коррекции только после завершения обработки всего слова приводит к потере важного достоинства пошаговых декодеров - минимальной задержке декодирования, равной одному слову.
Наиболее близким по технической сущности к заявляемому изобретению является выбранное в качестве прототипа устройство вылавливания кратных ошибок (Multiple error trapping) [3], предназначенное для исправления ошибок в данных, закодированных PC-кодом. Устройство-прототип содержит: схему деления на порождающий многочлен G(x), буферную память данных, матрицу умножителей на постоянные коэффициенты, комбинаторную логику.
Устройство-прототип осуществляет декодирование PC-кодов модифицированным методом вылавливания ошибок. Модификация заключается в следующем. Для принятого из канала кодового слова выбираются позиции контрольных символов таким образом, чтобы ошибочные символы заданной кратности все разместились в позициях контрольных символов на каком-то шаге в процессе циклического сдвига кодового слова. Для принятого слова вычисляются виртуальные контрольные символы (выполняется специальная процедура кодирования). Эти виртуальные символы вычитаются из контрольных символов, принятых из канала. Если на каком-то шаге количество получившихся ненулевых символов меньше или равно (d-1)/2, это значит, что все ошибочные символы разместились на позициях контрольных символов. При этом отличные от нуля символы дадут значения ошибок.
В [3] рассмотрен случай вылавливания двух ошибок для PC-кода с (n,k)=(31,25).
К недостаткам прототипа можно отнести:
- недостаточно низкую вероятность ошибочного декодирования, поскольку в прототипе не рассматриваются возможности обнаружения дополнительных ошибок к двум гарантированно исправляемым ошибкам;
- необходимость использования большего числа контрольных символов, чем требуется для исправления ошибок известными алгебраическими методами исправления ошибок (декодер Питерсона-Горенстейна-Цирлера) [4].
Технической задачей изобретения является обеспечение заранее заданной низкой величины вероятности ошибочного декодирования PC-кода при исправлении двух ошибочных символов пошаговым декодером.
Поставленная техническая задача решается тем, что в устройство декодирования кодов Рида-Соломона, содержащее буферную память данных, схему деления на порождающий многочлен PC-кода, r селекторов нулевого элемента поля (r - количество контрольных символов в слове PC-кода), схему анализа веса остатка q(x), первый и второй сумматоры элементов поля, причем первый вход буферной памяти данных и первый вход схемы деления на порождающий многочлен PC-кода подключены к шине входных данных, выходы r селекторов нулевого элемента поля соединены с r входами схемы анализа веса остатка q(x), согласно изобретению введены первый - (r+1)-ый умножители на постоянные коэффициенты, первый и второй блоки нахождения обратного элемента поля, первая - (r-3)-ая комбинационно-логические схемы вычисления Q′l, комбинационно-логическая схема вычисления q′0, первая - (r-1)-ая схемы сравнения кодов, первый и второй блоки элементов И, селектор нулевого кода, счетчик символов, элемент ИСКЛЮЧАЮЩЕЕ ИЛИ, элемент И, элемент ИЛИ, элемент НЕ-ИЛИ-НЕ, выходы q1, ..., qr-1 схемы деления на порождающий многочлен PC-кода соединены со входами первого - (r-1)-го умножителя на постоянные коэффициенты соответственно, выходы первого - (r-3)-го умножителя на постоянные коэффициенты соединены со входами первого - (r-3)-го селекторов нулевого элемента поля и первыми входами первой - (r-3)-ой схемы сравнения кодов соответственно, выход (r-1)-го умножителя на постоянные коэффициенты соединен со входом первого блока нахождения обратного элемента поля, входом r-го умножителя на постоянный коэффициент, первым входом (r-1)-ой схемы сравнения кодов и входом (r-2)-го селектора нулевого элемента поля, выход (r-2)-го умножителя на постоянные коэффициенты соединен со входом второго блока нахождения обратного элемента поля, входом (r+1)-го умножителя на постоянный коэффициент, вторым входом (r-1)-ой схемы сравнения кодов и входом (r-1)-го селектора нулевого элемента поля, выход первого блока нахождения обратного элемента поля соединен с первыми входами комбинационно-логических схем вычисления Q′l и q′0, выход второго блока нахождения обратного элемента поля соединен со вторыми входами комбинационно-логических схем вычисления Q′l и q′0, выход q0 схемы деления на порождающий многочлен PC-кода соединен со входом r-го селектора нулевого элемента поля и входом первого блока элементов И, выходы первого - (r-1)-го селекторов нулевого элемента поля соединены со входами элемента НЕ-ИЛИ-НЕ, выход r-го умножителя на постоянный коэффициент соединен с первым входом (r-2)-ой схемы сравнения кодов, выход (r+1)-го умножителя на постоянный коэффициент соединен со вторым входом (r-2)-ой схемы сравнения кодов, выходы первой - (r-3)-ой комбинационно-логических схем вычисления Q′l соединены со вторыми входами первой - (r-3)-ой схем сравнения кодов соответственно, выход комбинационно-логической схемы вычисления q′0 соединен со входом второго блока элементов И, выходы первой - (r-1)-ой схем сравнения кодов соединены с первым - (r-1)-им входами элемента И, выход НЕ-ИЛИ-НЕ соединен с r-ым входом элемента И, выход первого блока элементов И соединен с первым входом первого сумматора элементов поля, выход второго блока элементов И соединен со вторым входом первого сумматора элементов поля, выход элемента И соединен с первым входом элемента ИЛИ и управляющим входом второго блока элементов И, второй выход схемы анализа веса остатка q(x) соединен со вторым входом элемента ИЛИ, выход элемента ИЛИ соединен с управляющим входом первого блока элементов И, выход первого сумматора элементов поля соединен с первым входом второго сумматора элементов поля и с шестым входом схемы деления на порождающий многочлен PC-кода, выход буферной памяти данных соединен со вторым входом второго сумматора элементов поля, первый выход счетчика символов соединен с третьим входом схемы деления на порождающий многочлен PC-кода и третьим входом буферной памяти данных, второй выход счетчиков символов соединен со входом селектора нулевого кода и четвертым входом буферной памяти данных, третий выход счетчиков символов соединен с первым входом элемента ИСКЛЮЧАЮЩЕЕ ИЛИ, выход селектора нулевого кода соединен с четвертым входом схемы деления на порождающий многочлен PC-кода, выход элемента ИСКЛЮЧАЮЩЕЕ ИЛИ соединен с пятым входом буферной памяти данных и с пятым входом схемы деления на порождающий многочлен PC-кода, на второй вход схемы деления на порождающий многочлен PC-кода, второй вход буферной памяти данных, вход счетчиков символов и второй вход элемента ИСКЛЮЧАЮЩЕЕ ИЛИ подается управляющий сигнал "Выдача/Прием", первый выход схемы анализа веса остатка q(x) формирует выходной сигнал устройства "Ошибок нет", выход второго сумматора элементов поля подключен к шине выходных данных.
Взаимодействие введенных функциональных блоков обеспечивает гарантированное исправление до двух ошибочных символов в кодовом слове и блокировку ложной коррекции при наличии в слове от трех до te+2 (te=r-4) ошибочных символов. Гарантированное обнаружение te дополнительных ошибок к двум исправляемым ошибкам приводит к достижению заданной низкой величины вероятности ошибочного декодирования. Введение (r-1)-го и (r-2)-го умножителей на постоянные коэффициенты, первого и второго блоков нахождения обратного элемента поля, комбинационно-логической схемы вычисления q′0, второго блоков элементов И позволяет вычислить значение ошибки в младшем контрольном символе кодового слова при наличии одного ошибочного символа в информационной части кодового слова. Введение r-го и (r+1)-го умножителей на постоянные коэффициенты, комбинационно-логических схем вычисления Q′l, схем сравнения кодов, элементов И и ИЛИ обеспечивает блокировку коррекции ошибок в случае нахождения от 2 до te+2 ошибок во всех символах кодового слова, кроме младшего контрольного.
Сущность изобретения состоит в том, что для исправления двух ошибочных символов в слове PC-кода используется модифицированный метод вылавливания ошибок. Этот метод так же, как классический метод вылавливания ошибок [4], предполагает исправление ошибки в контрольном символе слова PC-кода для всех циклических сдвигов принятого слова. Однако в отличие от классического модифицированный метод допускает исправление ошибки в контрольном символе и при наличии одной ошибки среди информационных символов. Влияние этой ошибки на фиксированный контрольный символ (в изобретении в этом качестве используется последний контрольный символ) устраняется вычислением поправки q0′ как функции от любых двух коэффициентов (кроме коэффициента, соответствующего исправляемому символу) многочлена остатка q(x) (в изобретении это коэффициенты qr-1 и qr-2). Оставшиеся коэффициенты многочлена остатков используются для блокировки коррекции ошибок в случае, если среди всех символов кодового слова, кроме исправляемого, находится от 2 до te+2 ошибочных. Всякий раз при исправлении ошибки многочлен q(x) соответствующим образом корректируется для устранения вклада в него составляющей, обусловленной исправленной ошибкой. Если после завершения всех сдвигов кодового слова многочлен q(x) отличается от нуля, это означает то, что в кодовом слове произошло более 2 ошибок.
На фиг.1 приведена функциональная схема предлагаемого устройства декодирования PC-кода; на фиг.2 - функциональная схема схемы деления на порождающий многочлен PC-кода; на фиг.3 - функциональная схема схемы анализа веса остатка q(x). На фиг.4 изображены функциональные схемы комбинационно-логических схем вычисления Q′l (a) и q0′ (б), а также таблица формирования значения ошибки Y (в). На фиг.5 показана работа декодера по шагам при исправлении одного ошибочного символа в кодовом слове; на фиг.6 - при исправлении двух ошибочных символов; на фиг.7 - при наличии трех ошибочных символов в кодовом слове.
В описании устройства и на чертежах используются следующие обозначения:
m - разрядность элемента расширенного поля Галуа GF(2m);
n - количество символов в кодовом слове PC-кода;
k - количество информационных символов в слове;
r - количество контрольных символов в слове;
d - минимальное кодовое расстояние PC-кода, d=r+1;
t - число гарантированно исправляемых ошибок;
te - число гарантированно обнаруживаемых дополнительных ошибок, te=d-1-2·t;
λ - глубина перемежения символов кодовых слов;
r(х)=rn-1xn-1+rn-2xn-2+...+r1x+r0 - многочлен принятого из канала кодового слова;
NC - номер обрабатываемого символа кодового слова;
NБ - номер блока, к которому относится обрабатываемый символ;
NKC - номер кодового слова, к которому относится обрабатываемый символ;
α - примитивный элемент поля Галуа GF(2m);
b - целочисленная константа, определяющая первый корень порождающего многочлена PC-кода в виде αb+1;
G(x)=xr+Gr-1xr-1+Gr-2xr-2+...+G1x+G0 - порождающий многочлен PC-кода,
g(x)=gr-1xr-1+gr-2xr-2+...+g1x+g0 - вспомогательный многочлен, g(x)=G(x)/(x-ab+1);
q(x)=qr-1xr-1+qr-2xr-2+...+q1x+q0 - многочлен остатка от деления многочлена кодового слова на порождающий многочлен G(x) PC-кода, q(x)=ResG(x)[r(x)];
Q(x)=Qr-1xr-1+Qr-2xr-2+...+Q1x+Q0 - нормированный многочлен остатка, Qi=qi/(gi·αi);
Q′(x)=Q′r-1xr-1+Q′r-2xr-2+...+Q′1x+Q′0 - нормированный виртуальный многочлен остатка, Qi′=qi′/(gi·ai);
q0′ - младший символ виртуального многочлена остатка;
wt(x) - вес многочлена х (количество отличных от нуля символов многочлена);
Y - вычисленное значение ошибки;
y1-y6 - вспомогательные логические переменные.
Устройство декодирования PC-кода (фиг.1) содержит буферную память данных (1) емкостью в 2·λ·n m-разрядных ячеек, схему деления на порождающий многочлен PC-кода (2), первый - (r-1)-ый умножители на постоянные коэффициенты (3.1-3.r-1), r-ый и (r+1)-ый умножители на постоянные коэффициенты (6, 7), первый и второй блоки нахождения обратного элемента поля (4, 5), первую - (r-3)-ую комбинационно-логические схемы вычисления Q′l (8.1-8.r-3), комбинационно-логическую схему вычисления q′0 (9), первый - (r-3)-ый селекторы нулевого элемента поля (10.1-10.r-3), (r-2)-ый - r-ый селекторы нулевого элемента поля (11-13), схему анализа веса остатка q(x) (14), первую - (r-3)-ую схемы сравнения кодов (17.1-17.r-3), (r-2) и (r-1)-ую схемы сравнения кодов (15, 16), первый и второй блоки элементов И (19, 20), селектор нулевого кода (21), счетчик символов (22), элемент ИСКЛЮЧАЮЩЕЕ ИЛИ (23), элемент И (24), элемент ИЛИ (25), элемент НЕ-ИЛИ-НЕ (18), первый и второй сумматоры элементов поля (26, 27).
На первый вход буферной памяти (1) и первый вход схемы деления на порождающий многочлен PC-кода (2) поступают входные данные (ВхД); на второй вход схемы деления на порождающий многочлен PC-кода (2), второй вход буферной памяти данных (1), вход счетчиков символов (22) и второй вход элемента ИСКЛЮЧАЮЩЕЕ ИЛИ (23) подается управляющий сигнал "Выдача/Прием" (В/П), выходы q1, ..., qr-1 схемы деления на порождающий многочлен PC-кода (2) соединены со входами первого - (r-1)-го умножителя на постоянные коэффициенты (3.1-3.r-1) соответственно, выходы первого - (r-3)-го умножителя на постоянные коэффициенты (3.1-3.r-3) соединены со входами первого - (r-3)-го селекторов нулевого элемента поля (10.1-10.r-3) и первыми входами первой - (r-3)-ой схемы сравнения кодов (17.1-17.r-3) соответственно, выход (r-1)-го умножителя на постоянные коэффициенты (3.r-1) соединен со входом первого блока нахождения обратного элемента поля (4), входом r-го умножителя на постоянный коэффициент (6), первым входом (r-1)-ой схемы сравнения кодов (16) и входом (r-2)-го селектора нулевого элемента поля (11), выход (r-2)-го умножителя на постоянные коэффициенты (3.r-2) соединен со входом второго блока нахождения обратного элемента поля (5), входом (r+1)-го умножителя на постоянный коэффициент (7), вторым входом (r-1)-ой схемы сравнения кодов (16) и входом (r-1)-го селектора нулевого элемента поля (12), выход первого блока нахождения обратного элемента поля (4) соединен с первыми входами комбинационно-логических схем вычисления Q′l и q0′ (8.1-8.r-3, 9), выход второго блока нахождения обратного элемента поля (5) соединен со вторыми входами комбинационно-логических схем вычисления Q′l и q0′ (8.1-8.r-3, 9), выход q0 схемы деления на порождающий многочлен PC-кода (2) соединен со входом r-го селектора нулевого элемента поля (13) и входом первого блока элементов И (19), выходы первого - (r-1)-го селекторов нулевого элемента поля (10.1-10.r-3, 11, 12) соединены со входами элемента НЕ-ИЛИ-НЕ (18), и с r-1 входами схемы анализа веса остатка q(x) (14), выход r-го селектора нулевого элемента поля (13) соединен с r-ым входом схемы анализа веса остатка q(x) (14), выход r-го умножителя на постоянный коэффициент (6) соединен с первым входом (r-2)-ой схемы сравнения кодов (15), выход (r+1)-го умножителя на постоянный коэффициент (7) соединен со вторым входом (r-2)-ой схемы сравнения кодов (15), выходы первой - (r-3)-ой комбинационно-логических схем вычисления Q′l (8.1-8.r-3) соединены со вторыми входами первой - (r-3)-ой схем сравнения кодов (17.1-17.r-3) соответственно, выход комбинационно-логической схемы вычисления q′0 (9) соединен со входом второго блока элементов И (20), выходы первой - (r-1)-ой схем сравнения кодов (17.1-17.r-3, 15, 16) соединены с первым - (r-1)-им входами элемента И (24), выход НЕ-ИЛИ-НЕ (18) соединен с r-ым входом элемента И (24), выход первого блока элементов И (19) соединен с первым входом первого сумматора элементов поля (26), выход второго блока элементов И (20) соединен со вторым входом первого сумматора элементов поля (26), выход элемента И (24) соединен с первым входом элемента ИЛИ (25) и управляющим входом второго блока элементов И (20), второй выход схемы анализа веса остатка q(x) (14) соединен со вторым входом элемента ИЛИ (25), выход элемента ИЛИ (25) соединен с управляющим входом первого блока элементов И (19), выход первого сумматора элементов поля (26) соединен с первым входом второго сумматора элементов поля (27) и с шестым входом схемы деления на порождающий многочлен PC-кода (2), выход буферной памяти данных (1) соединен со вторым входом второго сумматора элементов поля (27), с первого выхода счетчика символов (22) на третий вход схемы деления на порождающий многочлен PC-кода (2) и третий вход буферной памяти данных (1) подается (log2NKC)-разрядный номер кодового слова NKC, со второго выхода счетчика символов (22) на вход селектора нулевого кода (21) и четвертый вход буферной памяти данных (1) подается (log2NC)-разрядный номер символа кодового слова NC, с третьего выхода счетчика символов (22) подается на первый вход элемента ИСКЛЮЧАЮЩЕЕ ИЛИ (23) одноразрядный номер кодового блока NБ, выход селектора нулевого кода (21) соединен с четвертым входом схемы деления на порождающий многочлен PC-кода (2), выход элемента ИСКЛЮЧАЮЩЕЕ ИЛИ (23) соединен с пятым входом буферной памяти данных (1) и с пятым входом схемы деления на порождающий многочлен PC-кода (2), первый выход схемы анализа веса остатка q(x) (14) формирует выходной сигнал устройства "Ошибок нет", выход второго сумматора элементов поля (27) подключен к шине выходных данных (ВыхД).
Все линии связи, соединяющие блоки на фиг.1, 2, 4, по которым передаются данные в виде элементов поля, являются m-разрядными.
Первый вход буферной памяти (1) является входом данных, второй ее вход управляет режимом "Чтение/Запись" (если на него подается логическая единица, осуществляется чтение, в противном случае - запись). Третий-пятый входы памяти (1) являются адресными входами. Выходы селекторов нулевого элемента поля (10.1-10.r-3, 11-12) - инверсные, при подаче нулевого элемента на вход селектора его выход принимает значение логического нуля. Выходы (r-2)-ой и (r-1)-ой схемы сравнения кодов (15, 16) также являются инверсными, они принимают нулевое значение при равенстве кодов, поступающих на их входы.
Счетчик символов (22) состоит из трех секций с коэффициентами пересчета λ, n и 2 соответственно. На выходе первой секции формируется номер кодового слова NKC. На выходе второй секции - номер символа кодового слова NC. На выходе третьей секции - одноразрядный номер кодового блока NБ.
Умножители на постоянные коэффициенты (3.1-3.r-1) реализуют умножение на (g1·α1)-1, (g2·α2)-1, ..., (gr-1·αr-1)-1 соответственно. Умножители на постоянные коэффициенты (6, 7) реализуют умножение на αr-1 и αr-2 соответственно.
Сумматоры элементов поля, умножители на постоянные коэффициенты и блоки нахождения обратного элемента поля, могут быть реализованы известным образом, в частности сумматоры могут быть реализованы на m двухвходовых элементах ИСКЛЮЧАЮЩЕЕ ИЛИ (сумматорах по модулю 2), умножители на постоянные коэффициенты могут быть реализованы на многовходовых элементах ИСКЛЮЧАЮЩЕЕ ИЛИ, блоки нахождения обратного элемента могут быть реализованы табличным способом.
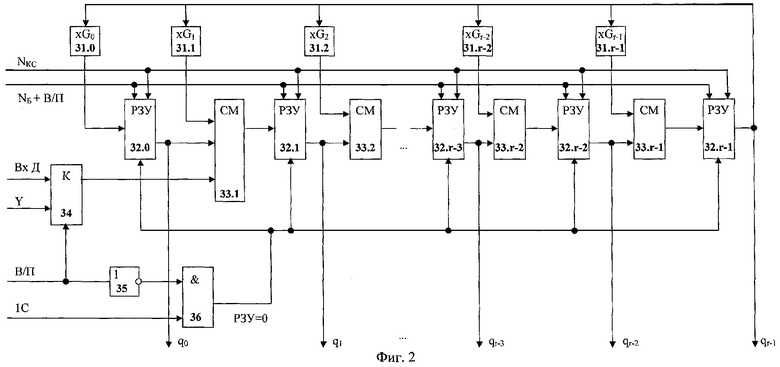
Схема деления на порождающий многочлен PC-кода (2) (фиг.2) содержит r регистровых запоминающих устройств (РЗУ) (32.0-32.r-1), r-1 сумматоров элементов поля (33.1-33.r-1), r умножителей на постоянные коэффициенты (31.0-31.r-1), каждый из которых представляет соответствующий коэффициент порождающего многочлена G(x), двухвходовый коммутатор (34), элемент НЕ (35), элемент И (36). Каждое РЗУ представляет из себя набор регистров, один регистр которого, выбранный в соответствии с состоянием адресных входов РЗУ, доступен для чтения и записи. При подаче логической единицы на управляющий вход РЗУ его выход принудительно принимает значение нуля.
Входные данные "ВхД" подаются на первый вход коммутатора (34), являющийся первым входом схемы деления на порождающий многочлен PC-кода (2). Вычисленное значение ошибки Y подается на второй вход коммутатора (34), являющийся шестым входом схемы деления на порождающий многочлен PC-кода (2). Управляющий сигнал "Выдача/Прием" (В/П) через второй вход схемы деления на порождающий многочлен PC-кода (2) подается на управляющий вход коммутатора (34) и на вход элемента НЕ (35). Управляющий сигнал "Первый символ слова" (1С) через четвертый вход схемы деления на порождающий многочлен PC-кода (2) подается на второй вход элемента И (36). Управляющий сигнал "NБ+В/П" через пятый вход схемы деления на порождающий многочлен PC-кода (2) подается на первые адресные входы всех РЗУ (32.0-32.r-1). Номер кодового слова NKC через шину третьего входа схемы деления на порождающий многочлен PC-кода (2) подается на вторые адресные входы всех РЗУ (32.0-32.r-1).
Выход коммутатора (34) соединен с третьим входом сумматора (33.1). Выход элемента НЕ (35) соединен с первым входом элемента И (36). Выход элемента И (36) соединен с управляющими входами всех РЗУ (32.0-32.r-1). Выход умножителя (31.0) соединен со входом данных первого РЗУ (32.0). Выходы остальных умножителей (31.1-31.r-1) подключены соответственно к первым входам сумматоров (33.1-33.r-1). Выходы первого - (r-1)-го РЗУ (32.0-32.r-2) подключены соответственно ко вторым входам сумматоров (33.1-33.r-1). Выход r-го РЗУ (32.r-1) соединен со входами всех г умножителей на постоянные коэффициенты (31.0-31.r-1). Выходы сумматоров (33.1-33.r-1) соединены соответственно со входами данных второго - r-го РЗУ (32.1-32.r-1).
Выходы первого - r-го РЗУ (32.0-32.r-1) являются выходами q0-qr-1 схемы деления на порождающий многочлен PC-кода (2).
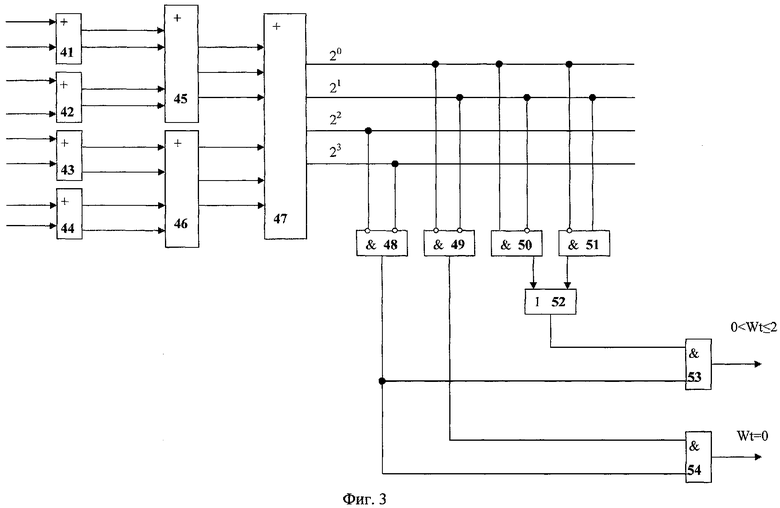
Комбинационно-логическая схема анализа веса остатка q(x) (14) приведена на фиг.3 для случая r=8. Она легко модифицируется для другого значения r. Схема содержит четыре двухвходовых одноразрядных сумматора (41-44), два двухвходовых двухразрядных сумматора (45, 46), один двухвходовый трехразрядный сумматор (47), логические элементы (48-54).
Входы одноразрядных сумматоров (41-44) являются входами схемы анализа веса (14). Их выходы соединены со входами двузразрядных сумматоров (45, 46). Выходы последних подключены ко входам трехразрядного сумматора (47). Выходы сумматора (47) обрабатываются схемой дешифрации, реализованной на логических элементах (48-54). Выход элемента И (54) является первым выходом схемы анализа веса остатка q(x) (14), на нем формируется сигнал логическая 1, если вес многочлена q(x) равен нулю. Выход элемента И (53) является вторым выходом схемы анализа веса остатка q(x) (14), на нем формируется сигнал логическая 1, если вес многочлена q(x) больше нуля, но меньше или равен 2.
Сумматоры (41-47), включенные по пирамидальной схеме, предназначены для формирования двоичного представления значения количества единиц на входах схемы анализа веса. Разрядность двоичного представления (число выходов сумматора 47) равняется наименьшему целому, большему или равному log2(r+1). При увеличении значения г в два раза в схему добавится еще один слой сумматоров. Схема дешифрации (48-54) выделяет три двоичных кода на выходе сумматора (47), соответствующих весам 0 (элементы НЕ-И 48, 49 и элемент И 54), 1 и 2 (элементы 48, 50-53).
Каждая комбинационно-логическая схема вычисления 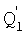 (8.1-8.r-3) содержит: (фиг.4а) три умножителя на постоянные коэффициенты элементов конечного поля (55, 56, 59); сумматор элементов конечного поля (57); схему нахождения обратного элемента поля (58). Умножитель (55) реализует умножение на (αl+αj), умножитель (56) реализует умножение на (αl+αi) и умножитель (59) реализует умножение на (αi+αj).
(8.1-8.r-3) содержит: (фиг.4а) три умножителя на постоянные коэффициенты элементов конечного поля (55, 56, 59); сумматор элементов конечного поля (57); схему нахождения обратного элемента поля (58). Умножитель (55) реализует умножение на (αl+αj), умножитель (56) реализует умножение на (αl+αi) и умножитель (59) реализует умножение на (αi+αj).
Вход умножителя (55) является первым входом комбинационно-логической схемы вычисления Ql′. Вход умножителя (56) является вторым входом комбинационно-логической схемы вычисления Ql′. Выход умножителя (59) является выходом комбинационно-логической схемы вычисления Ql′.
Комбинационно-логическая схема вычисления q0′ (9) содержит: (фиг.4б) три умножителя на постоянные коэффициенты элементов конечного поля (60, 61, 64); сумматор элементов конечного поля (62); схему нахождения обратного элемента поля (63). Умножитель (60) реализует умножение на (α0+αj), умножитель (61) реализует умножение на (α0+αi) и умножитель (64) реализует умножение на g0α0 (αi+αj).
Вход умножителя (60) является первым входом комбинационно-логической схемы вычисления q0′ (9). Вход умножителя (61) является вторым входом комбинационно-логической схемы вычисления q0′ (9). Выход умножителя (64) является выходом комбинационно-логической схемы вычисления q0′ (9).
Пошаговые декодеры используют свойство цикличности кодов, которое заключается в том, что циклический сдвиг кодового слова также является кодовым словом. Эти декодеры последовательно вычисляют значения ошибок для каждого из n символов принятого из канала закодированного слова, обрабатывая определенный тем или иным образом синдром. Декодеры вычисляют значение ошибки Y как функцию f от синдрома для фиксированного символа циклически сдвигаемого кодового слова. При этом на каждом шаге синдром модифицируется в соответствии с циклическим сдвигом кодового слова [4,5].
В данном изобретении в качестве синдрома используется многочлен q(x) остатка от деления многочлена принятого слова r(x) на порождающий многочлен PC-кода G(x), ошибки исправляются в самом младшем контрольном разряде кодового слова.
Характеристики пошагового декодера во многом определяются свойствами функции Y=f(q(x)) [5]. Для исключения ложной коррекции функция гарантированно должна равняться нулю, если число ошибок в слове больше t и меньше или равно t+te. Такого рода функцию можно получить для пошаговых декодеров с неполным вылавливанием ошибок (t=2), используя следующую теорему и следствия из нее.
Теорема.
Пусть два произвольно выбранных ненулевых коэффициента qi и qj полинома остатка q(x) имеют свойства:

Смежный класс PC-кода с минимальным кодовым расстоянием d≥5 имеет лидер веса 1 с ненулевой компонентой, расположенной в информационной части слова, тогда и только тогда, когда другие d-3 коэффициента полинома остатка q(x) связаны с выбранными коэффициентами следующим образом:
 где g(x) - вспомогательный многочлен:
где g(x) - вспомогательный многочлен:

α - примитивный элемент конечного поля и b - целочисленная константа, G(x) - порождающий многочлен PC-кода.
Следствие 1.
Если в кодовом слове PC-кода с d≥5 произошла одна ошибка, и она расположена в информационной части слова, то все коэффициенты нормированного многочлена остатка Q(x) (Qk=qk/(gk·αk), k=0, ..., d-2) будут ненулевыми, для любых двух коэффициентов Q(x) будут выполняться следующие условия:


и любые d-3 коэффициента Q(x) однозначно определяются двумя не входящими в их число коэффициентами Qi и Qj этого многочлена следующим образом:
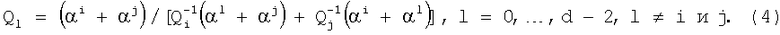
Следствие 2.
Если в первых n-1 символах кодового слова PC-кода с d≥5 произошло ν ошибок (1<ν<d-2), то следующая система уравнений не может выполняться:
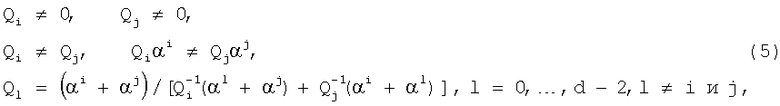
где i и j - любые ненулевые не равные друг другу целые числа, меньшие d-1.
Функция y=f(q(x)) для случая исправления ошибок в самом младшем символе кодового слова может быть получена на основе рассмотрения различных конфигураций ошибок в кодовом слове.
1. В кодовом слове нет ошибок. Тогда q(x)=0, wt(q(x))=0 и Y=0.
2. В кодовом слове произошла одна ошибка.
Если ошибка произошла среди контрольных символов кодового слова, то wt(q(x))=1, и единственный ненулевой символ многочлена остатка дает значение ошибки для соответствующего контрольного символа. Тогда мы можем записать Y=q0.
Если ошибка произошла среди информационных символов кодового слова, то в соответствии со Следствием 1 wt(q(x))=r, Qi и Qj не равны нулю, удовлетворяют условиям (3) и выполняются уравнения (4). При этом значение Y должно равняться нулю.
3. В кодовом слове произошли две ошибки.
Если обе ошибки находятся в контрольной части, то wt(q(x))=2 и Y=q0. Для любого другого расположения ошибок wt(q(x))=r или wt(q(x))=r-1.
Если одна ошибка расположена в информационной части и одна - в контрольной (но не в младшем контрольном разряде), то в соответствии со Следствием 2 соотношения (5) не могут выполняться и Y=0.
Если одна ошибка расположена в информационной части кодового слова и одна в младшем контрольном символе, то в соответствии со Следствием 1 соотношения (3, 4) и, следовательно, соотношения (1, 2), кроме l=0, будут выполняться. В этом случае младшую компоненту остатка q0 можно представить в виде q0=q0′+Y, где q0′ - компонента остатка от деления многочлена ошибки в информационной части. Тогда Y=q0-q0′, где
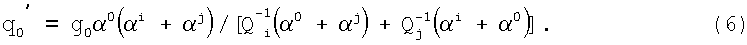
Если обе ошибки произошли в информационной части кодового слова, то в соответствии со Следствием 2 соотношения (5) не могут выполняться и Y=0.
4. В кодовом слове произошло от трех до te+2 ошибок (более двух, но менее d-2 ошибок).
В этом случае wt(q(x))>2. Среди первых n-1 символов кодового слова будет от двух до d-3 ошибочных. В соответствии со Следствием 2 соотношения (5) не могут выполняться и Y=0. В этом случае осуществляется блокирование ложной коррекции.
Теперь функция f(q(x)) может быть записана в следующем виде:

Отметим, что в случае наличия единственной ошибки в информационной части кодового слова wt(q(x))=r, выполняются соотношения (3-5) и Y=q0-q0′=0, поскольку в этом случае q0=q0′.
Для гарантированного обнаружения дополнительных te ошибок (к двум исправляемым) вводится обратная связь с выхода декодера в схему модификации многочлена остатка. При исправлении ошибки на каком-то шаге работы декодера из компоненты q0 остатка вычитается составляющая, вносимая этой ошибкой. Если по окончании работы декодера остаток будет ненулевой (при числе коррекций, меньшем или равном 2), это говорит о наличии неисправимых ошибок в кодовом слове.
Устройство декодирования PC-кодов обрабатывает входные данные, представляющие собой последовательность m-разрядных символов. Символы группируются в блоки перемеженных кодовых слов размером λ·n символов. Символы, относящиеся к одному кодовому слову PC-кода, поступают в устройство с периодом λ, обеспечивая тем самым эффективное исправление группирующихся ошибок.
В процессе обработки устройством кодового блока можно выделить две фазы.
В первой фазе обработки кодовый блок посимвольно загружается в буферную память 1 (фиг.1) и в схему вычисления многочленов остатков q(x) 2. После поступления в устройство последнего символа блока схема вычисления многочленов остатков 2 содержит λ многочленов остатков для всех кодовых слов входящих в блок.
Во второй фазе обработки кодовый блок выгружается из буферной памяти 1, и в процессе выгрузки в нем исправляются ошибки путем прибавления к выгружаемому символу вычисленного для него значения ошибки Y. В случае отсутствия ошибки в каком-либо символе исходного слова значение соответствующего символа Y будет равно нулю.
С целью поддержки потокового режима обработки входных кодовых блоков (без пауз) в устройстве совмещена обработка во времени двух кодовых блоков. Один кодовый блок (положим для определенности, что его однобитовый номер (NБ=0) находится в первой фазе обработки, другой блок с инверсным номером (NБ=1) находится во второй фазе обработки.
Для реализации такой совмещенной обработки используется временное мультиплексирование, управляемое с помощью входного сигнала "Выдача/Прием" (В/П). Когда этот сигнал имеет единичный уровень, обрабатывается кодовый блок во второй фазе, и на выходе "ВыхД" устройства появляется исправленный символ кодового блока. Когда этот сигнал имеет нулевой уровень, обрабатывается кодовый блок в первой фазе, и в буферную память записывается очередной символ нового кодового блока. Сигнал "В/П" один такт работы устройства имеет единичный уровень, следующий - нулевой.
Устройство декодирования PC-кодов представляет собой синхронный потоковый декодер, обрабатывающий входные данные в темпе их поступления. Выходные данные тактируются частотой входных данных и, следовательно, выдаются с такой же скоростью. Задержка данных в устройстве минимальна и равна времени поступления одного кодового блока. Размер буферной памяти 1 будет при этом минимален и равен 2·λ·n символам.
Рассмотрим подробнее обработку устройством кодового блока в первой фазе.
Символы входных данных, поступающие на шину "ВхД" (фиг.1), при нулевом уровне сигнала "В/П" поступают в схему деления на порождающий многочлен PC-кода 2 и одновременно записываются в буферную память 1 по адресу, определяемому счетчиком символов 22. Первые выходы счетчика содержат номер кодового слова NКС в блоке, к которому относится поступающий символ, вторые выходы содержат номер символа NC в слове, третьи - однобитовый номер кодового блока NБ. Содержимое всех выходов счетчика 22 подается на адресные входы блока памяти 1. Одновременно номер кодового слова подается на третий вход схемы деления 2. Селектор нулевого кода, на вход которого подается номер символа NC, во время поступления первых символов кодовых слов формирует сигнал "1С", необходимый для обнуления многочленов q(x) схемы деления 2.
Одновременно с записью символа кодового блока в память осуществляется его обработка схемой деления на порождающий многочлен PC-кода 2. Для этого символа схема 2 реализует один шаг деления многочлена поступающего кодового слова r(x) на G(x).
Схема деления 2 (фиг.2) реализована на основе широко распространенной техники деления многочленов с использованием регистров с обратной связью. Для удобства обработки перемеженных слов вместо регистров в ней используются регистровые запоминающие устройства (РЭУ) 32.0-32.r-1. Каждое РЗУ имеет емкость на 2·λ символов. Одна половина РЗУ хранит вычисляемые коэффициенты q(x) во время первой фазы обработки кодового блока, вторая - модифицируемые коэффициенты q(x) во время второй фазы обработки блока. Переключение этих половин осуществляется с помощью сигнала "NБП+В/П". Номер кодового слова NKC активизирует в РЗУ регистр, относящийся к конкретному многочлену остатков q(x).
Один шаг деления поступающего многочлена кодового слова r(x) на порождающий многочлен G(x) заключается в одновременном вычислении новых значений ячеек РЗУ, адресуемых данным NКС. Новое значение ячейки каждого i-го (i=3, ...r) РЗУ вычисляется как сумма по модулю 2 значения ячейки (i-1)-го РЗУ и значения ячейки r-го РЗУ 32.r-1, умноженного на коэффициент Gi-1 порождающего многочлена. Новое значение ячейки первого РЗУ 32.0 вычисляется путем умножения значения ячейки r-го РЗУ 32.r-1 на коэффициент G0 порождающего многочлена. Новое значение ячейки второго РЗУ 32.1 вычисляется как сумма по модулю 2 значения ячейки первого РЗУ 32.0, значения ячейки r-го РЗУ 32.r-1, умноженного на коэффициент G1 порождающего многочлена и входного символа кодового слова, поступающего на сумматор 33.1 через коммутатор 34.
Ввод входного символа на третий вход сумматора 33.1 необходим для того, чтобы после подачи на вход схемы деления 2 всех n символов кодового слова r(x) на ее выходах появился многочлен остатка q(x), соответствующий циклическому сдвигу r(x) в сторону старших символов. При этом старший символ исходного кодового слова можно рассматривать как самый младший контрольный символ сдвинутого кодового слова.
Обнуление значения многочленов q(x) при поступлении первых символов кодовых слов осуществляется с помощью сигнала "1С". Во время первой фазы обработки кодового блока этот сигнал проходит через элемент И 36 и поступает на входы РЗУ, приводя к принудительной установке их выходов в нулевое состояние.
После записи входного символа в память 1 и одновременной его обработки схемой деления 2 счетчик символов 22 (фиг.1) инкрементируется по фронту сигнала "В/П", и адрес буферной памяти, состоящий из NKC, NС и NБ, меняется. Таким образом осуществляется подготовка к приему следующего символа. Счетчик символов 22 состоит из трех последовательно включенных двоичных счетчиков с коэффициентами перечета, равными соответственно λ, n и 2.
После загрузки всего кодового блока в буферную память 1 схема деления 2 содержит значения многочленов остатков q(x) для всех кодовых слов. После этого наступает вторая фаза обработки кодового блока.
Рассмотрим подробно обработку устройством декодирования PC-кода кодового блока во второй фазе.
На первом шаге обработки первого кодового слова из памяти 1 выгружается его первый символ rn-1, на выходе схемы деления 2 появляется многочлен остатков q(x), вычисленный для левого циклического сдвига кодового слова. После чего осуществляется вычисление Y в соответствии с формулой (7). При вычислении Y символ rn-1 исходного слова интерпретируется как младший контрольный символ слова, полученного из исходного путем циклического сдвига. Вычисленное значение Y суммируется (в блоке 27) с rn-1 для исправления возможной ошибки. Одновременно схема деления 2 вычисляет значение q(x) для следующего циклического сдвига исходного кодового слова r(x). При этом составляющая, вносимая исправленной ошибкой, исключается из многочлена q(x) путем вычитания из соответствующего коэффициента q(x) значения Y.
В изобретении (фиг.1) без ограничения общности приведен вариант вычисления Y по формуле (7) с использованием в качестве базовых коэффициентов многочлена q(x) коэффициентов qr-1 и qr-2. В этом случае i=r-1, j=r-2.
Поясним с использованием вспомогательных логических переменных y1-y6 (фиг.1), как осуществляется вычисление Y. Переменная y1=1, если wt(q(x))=0, и y1=0 в противном случае. Переменная y2=1, если 0<wt(q(x))≤2, и y2=0 в противном случае. Эти переменные формируются схемой анализа веса остатка 14 на первом (y1) и втором (y2) выходах. Переменная y4=0, если хотя бы один из коэффициентов многочлена q(x) за исключением q0 равен нулю, и y4=1 в противном случае. Эта переменная формируется элементом НЕ-ИЛИ-НЕ 18. Переменная y5=0, если Qr-1=Qr-2, и y5=1 в противном случае, переменная формируется (r-1)-ой схемой сравнения кодов 16. Переменная y6=0, если Qr-1αr-1=Qr-2αr-2, и y6=1 в противном случае, переменная формируется (r-2)-ой схемой сравнения кодов 15. Переменная y3=1, если выполняются соотношения (5), и y3=0 в противном случае. Для вычисления y3 используются переменные y4-y6, подаваемые на входы элемента И 24, на другие входы этого элемента И подаются логические переменные, отражающие выполнение условий  .
.
Непосредственно для вычисления Y по формуле (7) используются первый и второй блоки элементов И 19, 20, подключенные ко входам первого сумматора элементов поля 26, управляемые логическими переменными y2 и y3. Значение Y на выходе сумматора 26 формируется в соответствии с таблицей, приведенной на фиг.4в. Строки таблицы соответствуют строкам формулы (7).
Схема деления 2 во второй фазе обработки работает так же, как в первой фазе, с двумя отличиями. На третий вход сумматора 33.1 (фиг.2) через коммутатор 34 вместо входного символа подается значение Y. При обработке первых символов кодовых слов цепь обнуления q(x) заблокирована путем подачи сигнала логического нуля с выхода инвертора 35 на первый вход элемента И 36.
Описанный процесс повторяется для всех первых символов оставшихся кодовых слов блока. При этом на первом выходе счетчика 22 последовательно появляются соответствующие номера кодового слова NKC. После обработки всех первых символов значение номера символа NC на втором выходе счетчика 22 инкрементируется, и осуществляется обработка вторых символов кодовых слов блока. При этом для схемы вычисления Y младшим контрольным символом будет уже являться символ rn-2 исходного слова.
Шаги повторяются до тех пор, пока не обработаются все символы кодового слова r(x) текущего блока данных. В случае наличия в кодовом слове от 3 до 2+te ошибок значения Y на всех шагах будет нулевое. Таким образом осуществляется блокировка ложной коррекции. Если по завершению обработки n символов многочлен остатка не стал равным нулю, то фиксируется наличие в кодовом слове неисправимых ошибок.
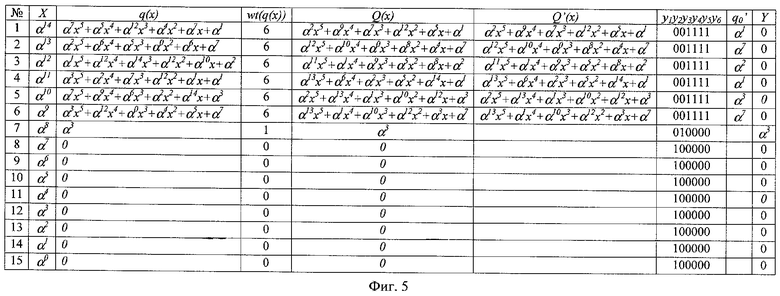
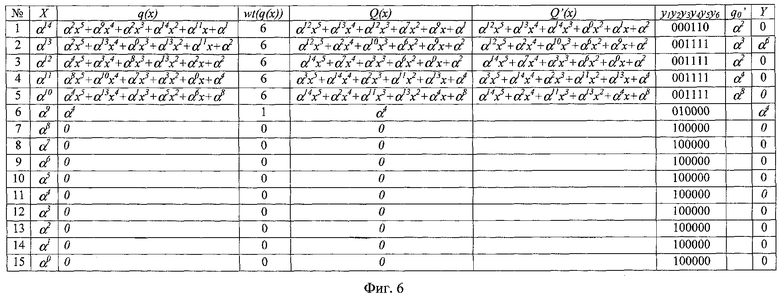
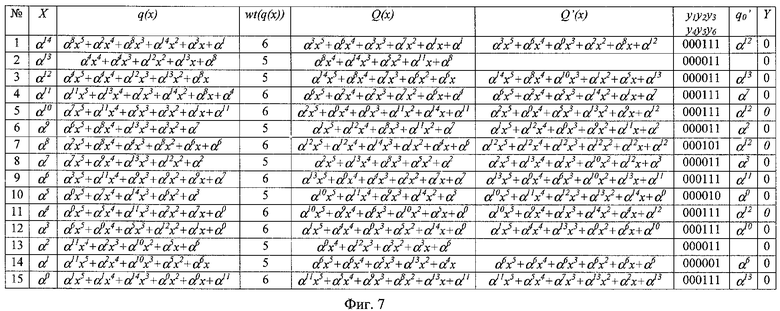
Примеры работы по шагам во второй фазе устройства декодирования PC-кода Галуа приведены на фиг.5-7. В самом левом столбце приведен номер шага, в следующем столбце - соответствующий ему локатор возможной ошибки. Для наглядности примеры даны для случая λ=1 (перемежение символов кодовых слов отсутствует).
В примерах используется PC-код (n, k)=(15, 9), определенный над полем Галуа GF(24) с порождающим поле многочленом х4+x+1. Для этого кода порождающий многочлен G(x)=х6+α9x5+α12х4+α1х3+α2х2+α4x+1 и вспомогательный многочлен g(x)=х5+α7х4+α2х3+α5х2+α1x+1. Исправление ошибок реализовано применительно к символу r0. В качестве базовых коэффициентов многочлена остатка q(x) используются q5 и q4.
В первом примере (фиг.5) показан процесс обработки кодового слова, содержащего один ошибочный символ (седьмой в слове) с локатором ошибки α8 и значением ошибки α3. На седьмом шаге вес q(x) становится равным 1, и Y определяется в соответствии с формулой (7) как Y=q0=α3. На этом шаге исправляется единственный ошибочный символ кодового слова.
Во втором примере (фиг.6) показан процесс обработки кодового слова, содержащего два ошибочных символа (второй и шестой) с локаторами ошибок α13 и α9 и значениями ошибок α6 и α4 соответственно. На втором шаге y3 становится равным 1 (выполняются условия (5)), и Y определяется в соответствии с формулой (7) как Y=q0-q0'=α2-α3=α6. На этом шаге исправляется первая ошибка. На шагах 3-5 также выполняются условия (5), но Y=0, т.к. для этих шагов q0=q0'. На шестом шаге вес q(x) становится равным 1 и Y=q0=α4. На этом шаге исправляется вторая ошибка.
В третьем примере (фиг.7) показан процесс обработки кодового слова, содержащего три ошибочных символа (первый, пятый и девятый) с локаторами ошибок α14, α10 и α6 и значениями ошибок α5, α7 и α9 соответственно. На всех шагах wt(q(x))>2 и y3=0 (не выполняются условия (5)), поэтому Y всегда равняется нулю. Ложные коррекции отсутствуют.
Предлагаемое устройство состоит из простых по своему функциональному назначению элементов и поэтому легко реализуется на серийно выпускаемых микросхемах и радиоэлементах. Для уменьшения габаритов устройства целесообразна его реализация на ПЛИС или специализированной БИС.
Предлагаемое устройство декодирования PC-кодов можно отнести к классу пошаговых декодеров с неполным "вылавливанием ошибок", введенном в [5]. Его использование в телекоммуникационной аппаратуре или внешних запоминающих устройствах ЭВМ позволяет с высокой скоростью исправлять наиболее часто встречающиеся ошибки. Предлагаемое устройство по сравнению с прототипом обладает преимуществом, заключающимся в предотвращении ложной коррекции при большем числе ошибок в кодовом слове без дополнительного буферирования данных.
Источники информации
1. А.с. 1381719 СССР, МКИ4 Н 03 М 13/00. Устройство обнаружения и исправления ошибок в кодах Рида-Соломона. / А.П.Типикин, В.В.Петров, Н.В.Горшков, В.В.Гвоздев, С.И.Егоров (СССР). №4061423/24-24; Заявл. 28.03.86; Опубл. 15.03.88, Бюл. №10, 10 с.
2. Патент РФ 2152130, МПК7 Н 03 М 13/51. Вычислитель ошибок помехоустойчивого декодера. / А.Г.Бабанин, Р.А.Казанский (РФ). №99112852/09; Заявл. 15.06.1999; Опубл. 27.06.2000, Бюл. №18, 12 с.
3. Патент РСТ WO 89/06071. МКИ4 Н 03 М 13/00. Multiple error trapping. / P.Tong (USA) - заявлено 09.12.88 PCT/US88/04406; приоритет от 17.12.87 US 134137; опубл. 29.06.89.
4. Блейхут Р. Теория и практика кодов, контролирующих ошибки: Пер. с англ. - М.: Мир, 1986. - 576 с.
5. Егоров С.И. Алгоритмы пошагового декодирования РСБКР-кодов // Методы и средства систем обработки информации. / Курск: Курский государственный технический университет, 1997, с.71-80.
| название | год | авторы | номер документа |
|---|---|---|---|
| Декодер циклического кода | 1988 |
|
SU1599996A1 |
| СПОСОБ И ДЕКОДИРУЮЩЕЕ УСТРОЙСТВО ИСПРАВЛЕНИЯ ДВУХ ОШИБОК В ПРИНИМАЕМОМ КОДЕ | 2006 |
|
RU2336559C2 |
| Устройство декодирования произведений кодов Рида-Соломона | 2017 |
|
RU2677372C1 |
| УСТРОЙСТВО ДЕКОДИРОВАНИЯ КОДОВ РИДА-СОЛОМОНА | 2010 |
|
RU2441318C1 |
| РЕКОНФИГУРИРУЕМЫЙ КОДЕР РИДА-СОЛОМОНА | 2015 |
|
RU2605672C1 |
| УСТРОЙСТВО КОДИРОВАНИЯ-ДЕКОДИРОВАНИЯ ИНФОРМАЦИИ | 1994 |
|
RU2115231C1 |
| ВЫЧИСЛИТЕЛЬ ОШИБОК ПОМЕХОУСТОЙЧИВОГО ДЕКОДЕРА | 1999 |
|
RU2152130C1 |
| Устройство для кодирования | 1986 |
|
SU1390801A1 |
| СПОСОБ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ ДАННЫХ ДЛЯ СИСТЕМЫ РАДИОВЕЩАТЕЛЬНОЙ ПЕРЕДАЧИ ЦИФРОВЫХ СООБЩЕНИЙ | 1994 |
|
RU2110148C1 |
| УСТРОЙСТВО ДЕКОДИРОВАНИЯ КОДОВ РИДА-СОЛОМОНА | 2013 |
|
RU2541869C1 |

Изобретение относится к системам телекоммуникаций и вычислительной техники и может найти применение в устройствах приема информации из канала передачи или воспроизведения информации с высоким уровнем ошибок. Технический результат - обеспечение заранее заданной низкой величины ошибочного декодирования кода Рида-Соломона (PC) при исправлении двух ошибочных символов пошаговым декодером. Для этого при исправлении двух ошибочных символов в слове PC-кода используется модифицированный метод вылавливания ошибок. Этот метод, также как классический метод вылавливания ошибок, предполагает исправление ошибки в контрольном символе слова PC-кода для всех циклических сдвигов принятого слова. Однако в отличие от классического модифицированный метод допускает исправление ошибки в контрольном символе и при наличии одной ошибки среди информационных символов. Влияние этой ошибки на фиксированный контрольный символ устраняется вычислением поправки как функции от любых двух коэффициентов (кроме коэффициента, соответствующего исправляемому символу) многочлена остатка q(x). Оставшиеся коэффициенты многочлена остатков используются для блокировки коррекции ошибок в случае, если среди всех символов кодового слова, кроме исправляемого, находится от 2 до te+2 ошибочных (где te - число гарантированно обнаруживаемых дополнительных ошибок). Всякий раз при исправлении ошибки многочлен q(x) соответствующим образом корректируется для устранения вклада в него составляющей, обусловленной исправленной ошибкой. Если после завершения всех сдвигов кодового слова многочлен q(x) отличается от нуля, это означает то, что в кодовом слове произошло более 2 ошибок. 7 ил.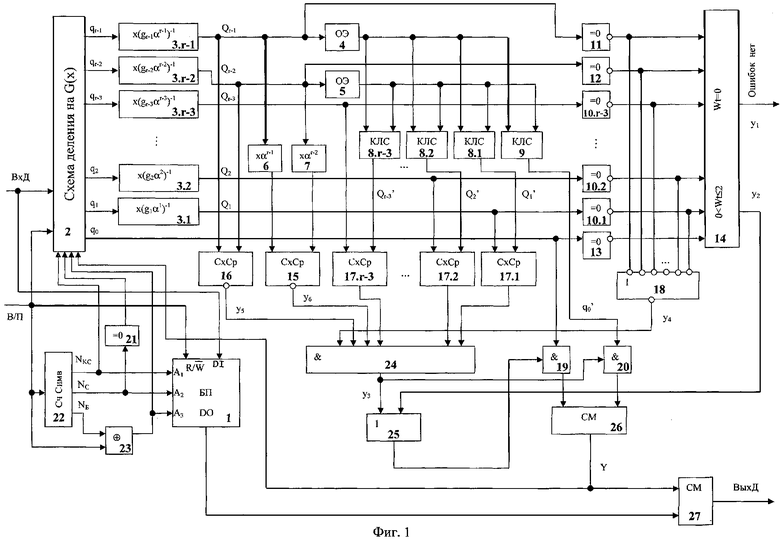
Устройство декодирования кодов Рида-Соломона, содержащее буферную память данных, схему деления на порождающий многочлен PC-кода, r селекторов нулевого элемента поля (r - количество контрольных символов в слове PC-кода), схему анализа веса остатка q(x), первый и второй сумматоры элементов поля, причем первый вход буферной памяти данных и первый вход схемы деления на порождающий многочлен PC-кода подключены к шине входных данных, выходы r селекторов нулевого элемента поля соединены с r входами схемы анализа веса остатка q(x), отличающееся тем, что в устройство введены первый - (r+1)-й умножители на постоянные коэффициенты, первый и второй блоки нахождения обратного элемента поля, первая - (r-3)-я комбинационно-логические схемы вычисления Q′1, комбинационно-логическая схема вычисления q′0, первая - (r-1)-я схемы сравнения кодов, первый и второй блоки элементов И, селектор нулевого кода, счетчик символов, элемент ИСКЛЮЧАЮЩЕЕ ИЛИ, элемент И, элемент ИЛИ, элемент НЕ-ИЛИ-НЕ, выходы q1, ..., qr-1 схемы деления на порождающий многочлен PC-кода соединены со входами первого - (r-1)-го умножителей на постоянные коэффициенты соответственно, выходы первого - (r-3)-го умножителей на постоянные коэффициенты соединены со входами первого - (r-3)-го селекторов нулевого элемента поля и первыми входами первой - (r-3)-й схем сравнения кодов соответственно, выход (r-1)-го умножителя на постоянные коэффициенты - с входом первого блока нахождения обратного элемента поля, входом r-го умножителя на постоянный коэффициент, первым входом (r-1)-й схемы сравнения кодов и входом (r-2)-го селектора нулевого элемента поля, выход (r-2)-го умножителя на постоянные коэффициенты соединен со входом второго блока нахождения обратного элемента поля, входом (r-1)-го умножителя на постоянный коэффициент, вторым входом (r-1)-й схемы сравнения кодов и входом (r-1)-го селектора нулевого элемента поля, выход первого блока нахождения обратного элемента поля соединен с первыми входами комбинационно-логических схем вычисления Q′1 и q′0, выход второго блока нахождения обратного элемента поля соединен со вторыми входами комбинационно-логических схем вычисления Q′1 и q′0, выход q0 схемы деления на порождающий многочлен PC-кода соединен со входом r-го селектора нулевого элемента поля и входом первого блока элементов И, выходы первого - (r-1)-го селекторов нулевого элемента поля соединены со входами элемента НЕ-ИЛИ-НЕ, выход r-го умножителя на постоянный коэффициент соединен с первым входом (r-2)-й схемы сравнения кодов, выход (r+1)-го умножителя на постоянный коэффициент соединен со вторым входом (r-2)-й схемы сравнения кодов, выходы первой - (r-3)-й комбинационно-логических схем вычисления Q′1 соединены со вторыми входами первой - (r-3)-й схем сравнения кодов соответственно, выход комбинационно-логической схемы вычисления q′0 соединен со входом второго блока элементов И, выходы первой - (r-1)-й схем сравнения кодов соединены с первым - (r-1)-м входами элемента И, выход НЕ-ИЛИ-НЕ соединен с r-м входом элемента И, выход первого блока элементов И соединен с первым входом первого сумматора элементов поля, выход второго блока элементов И соединен со вторым входом первого сумматора элементов поля, выход элемента И соединен с первым входом элемента ИЛИ и управляющим входом второго блока элементов И, второй выход схемы анализа веса остатка q(x) соединен со вторым входом элемента ИЛИ, выход элемента ИЛИ соединен с управляющим входом первого блока элементов И, выход первого сумматора элементов поля соединен с первым входом второго сумматора элементов поля и с шестым входом схемы деления на порождающий многочлен PC-кода, выход буферной памяти данных соединен со вторым входом второго сумматора элементов поля, первый выход счетчика символов соединен с третьим входом схемы деления на порождающий многочлен PC-кода и третьим входом буферной памяти данных, второй выход счетчиков символов соединен со входом селектора нулевого кода и четвертым входом буферной памяти данных, третий выход счетчиков символов соединен с первым входом элемента ИСКЛЮЧАЮЩЕЕ ИЛИ, выход селектора нулевого кода соединен с четвертым входом схемы деления на порождающий многочлен PC-кода, выход элемента ИСКЛЮЧАЮЩЕЕ ИЛИ соединен с пятым входом буферной памяти данных и с пятым входом схемы деления на порождающий многочлен PC-кода, второй вход схемы деления на порождающий многочлен PC-кода, второй вход буферной памяти данных, вход счетчиков символов и второй вход элемента ИСКЛЮЧАЮЩЕЕ ИЛИ подключены к шине управляющего сигнала "Выдача/Прием", первый выход схемы анализа веса остатка q(x) формирует выходной сигнал устройства "Ошибок нет", выход второго сумматора элементов поля подключен к шине выходных данных.
| Способ размножения копий рисунков, текста и т.п. | 1921 |
|
SU89A1 |
| Устройство для декодирования кода Рида-Соломона | 1985 |
|
SU1332539A1 |
| Декодер кодов Рида-Соломона | 1988 |
|
SU1690202A1 |
| УСТРОЙСТВО ДЕКОДИРОВАНИЯ КАСКАДНОГО КОДА РИДА-СОЛОМОНА | 1993 |
|
RU2036512C1 |
| УСТРОЙСТВО И СПОСОБ КАНАЛЬНОГО КОДИРОВАНИЯ/ДЕКОДИРОВАНИЯ | 1999 |
|
RU2204199C2 |
| US 5721745 А, 24.02.1998 | |||
| Покрытие гладильной подушки | 1978 |
|
SU735696A1 |

