Изобретение в общем относится к синтезированию речи на основе текста (TTS-синтез). В частности, настоящее изобретение можно использовать для преобразования буквы в звук при синтезированном произношении сегмента текста.
Уровень техники
Преобразование текста в речь, часто называемое синтезированием речи на основе связного текста, позволяет электронным устройствам принимать вводимую текстовую строку и создавать преобразованное представление этой строки в виде синтезированной речи. Однако при работе устройства, которое может потребоваться для синтеза речи из недетерминированного числа принятых текстовых строк, могут возникнуть трудности при создании высококачественной и реалистичной синтезированной речи. Одна из трудностей основана на преобразовании буквы в звук, при котором одинаковые буквы или группы букв могут иметь различное звучание и характеризоваться различающимся ударением/акцентированием на гласных, в зависимости от других соседних букв и положения в синтезируемом сегменте текста.
В данном описании, включая пункты Формулы изобретения, предполагается, что термины "содержит", "содержащий" или аналогичные означают не исключающие включения, поэтому способ или устройство, которое содержит перечень элементов, не включает только эти элементы, а может также включать и другие элементы, которые не перечислены.
Раскрытие изобретения
Согласно одному из аспектов настоящего изобретения предлагается способ синтезирования речи на основе текста, и этот способ содержит следующие этапы:
- принимают текстовую строку и выбирают из нее, по меньшей мере, одно слово;
- разделяют упомянутое слово на подслова, образующие последовательность подслов, в которой, по меньшей мере, одно из подслов содержит, по меньшей мере, две буквы;
- определяют фонемы для упомянутых подслов;
- соединяют упомянутые фонемы в последовательность фонем; и
- выполняют синтезирование речи на основе упомянутой последовательности фонем.
Соответственно упомянутую последовательность подслов определяют путем анализа возможных подслов, которые могут составлять слово.
В предпочтительном случае каждое из возможных подслов имеет соответствующий заранее определенный вес.
Соответственно, для создания последовательности подслов выбирают подслова, образующие выбранное слово, с максимальными объединенными весами. Последовательность подслов надлежащим образом определяют из анализа ориентированного ациклического графа.
Соответственно, при определении фонем используют таблицу идентификаторов фонем, содержащую фонемы, соответствующие, по меньшей мере, одному упомянутому подслову.
В предпочтительном случае таблица идентификаторов также содержит указатель относительного положения, который указывает относительное положение подслова в упомянутом слове.
Кроме того, может существовать вес фонемы, связанный с указателем относительного положения.
Краткое описание чертежей
Чтобы облегчить понимание настоящего изобретения и его реализацию на практике, рассмотрим его предпочтительный вариант, описанный со ссылкой на сопровождающие чертежи, из которых:
- Фиг.1 представляет собой структурную схему электронного устройства, соответствующего настоящему изобретению;
- Фиг.2 представляет собой блок-схему способа синтезирования речи на основе текста;
- на Фиг.3 изображен ориентированный ациклический граф (DAG);
- Фиг.4 представляет собой часть таблицы отображения, которая ставит в соответствие фонемам символы;
- Фиг.5 представляет собой часть таблицы идентификаторов фонем; и
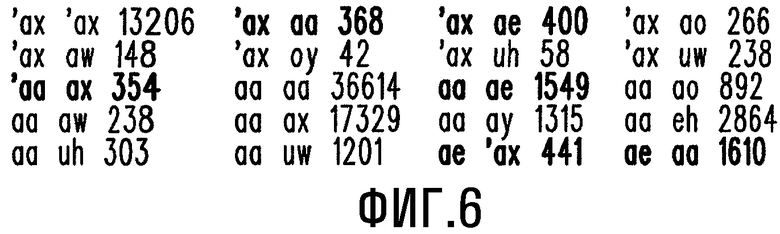
- Фиг.6 представляет собой часть таблицы пар гласных.
Осуществление изобретения
На Фиг.1 изображено электронное устройство 100, представляющее собой радиотелефон и содержащее процессор 102, соединенный посредством шины 103 с интерфейсом 104 пользователя, который в типичном случае представляет собой сенсорный экран, либо в качестве альтернативы - экран монитора и клавиатуру. Кроме того, электронное устройство 100 содержит фонд 106 произношения, синтезатор 110 речи, энергонезависимую память 120, постоянное запоминающее устройство (ПЗУ) 118 и блок 116 радиосвязи, которые соединены с процессором 102 посредством шины 103. Сигнал, создаваемый синтезатором 110 речи, поступает из него для озвучивания в громкоговоритель 112. Фонд 106 произношения включает представления слов, или фонемы, и соответствующие дискретизированные, оцифрованные и обработанные сигналы произношения. Другими словами, и как будет описано ниже, для синтезирования речи на основе текста используется энергонезависимая память 120 (блок памяти), при этом текст может приниматься блоком 116 радиосвязи, либо иным образом. Кроме того, упомянутый фонд произношения содержит дискретизированные и оцифрованные сигналы произношения в виде фонем и акцента/подчеркивания просодических особенностей.
Как очевидно специалисту данной области техники, блок 116 радиосвязи в типичном случае представляет собой объединенные приемник и передатчик, которые имеют общую антенну. Блок 116 радиосвязи содержит трансивер (приемопередатчик), соединенный с антенной через усилитель высокой частоты. Кроме того, трансивер соединен с объединенным модулятором/демодулятором, который соединяет блок 116 радиосвязи с процессором 102. Кроме того, в этом варианте реализации настоящего изобретения в энергонезависимой памяти 120 (блоке памяти) хранится телефонная книга, реализованная в виде создаваемой пользователем базы данных, а в ПЗУ 118 хранится рабочая программа для процессора 102 электронного устройства.
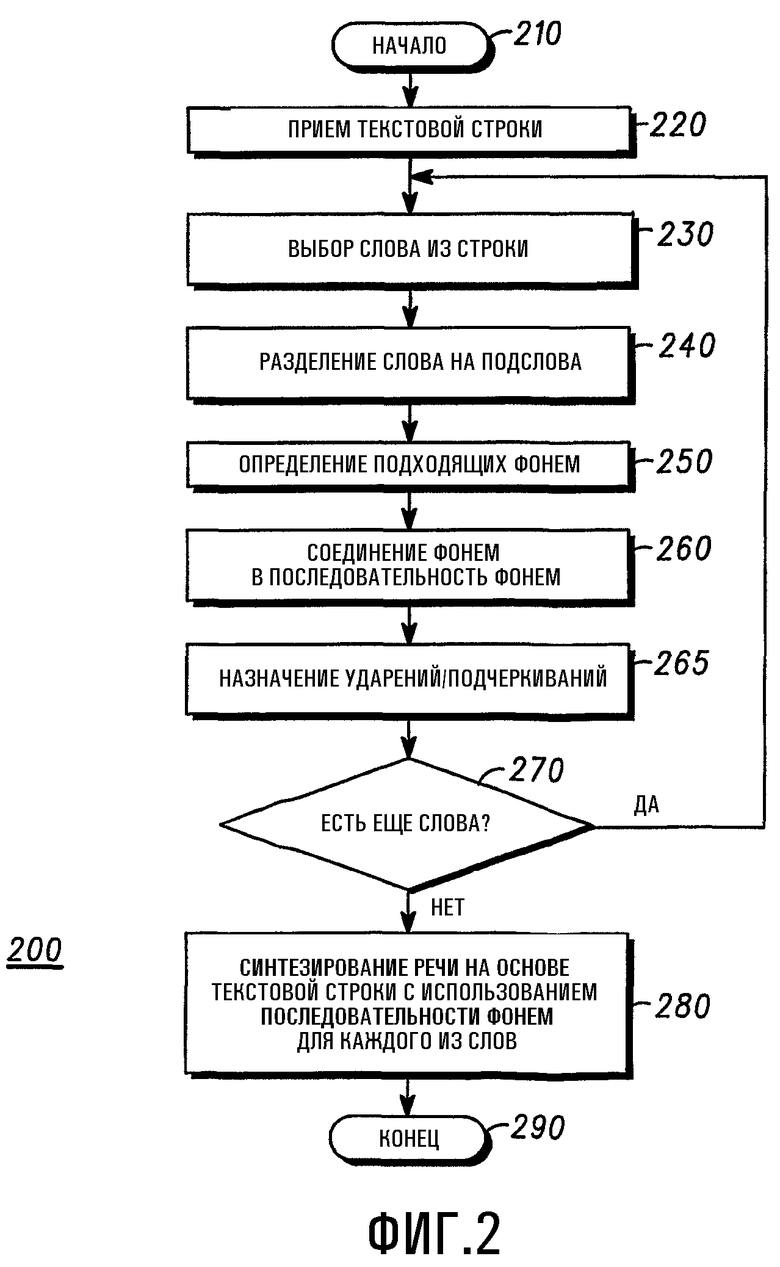
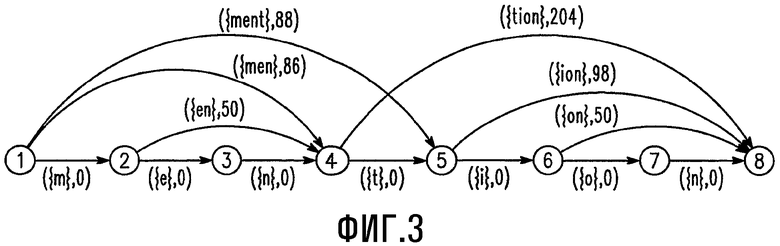
На Фиг.2 изображена блок-схема способа 200 синтезирования речи на основе текста. Выполнение способа начинается на начальном этапе 210, после которого выполняется этап 220 приема текстовой строки TS из энергонезависимой памяти 120. Текстовая строка TS может быть получена из текстового сообщения, принятого блоком 116 радиосвязи или любым другим средством. Этап 230 обеспечивает выбор, по меньшей мере, одного слова из упомянутой текстовой строки TS, а этап 240 обеспечивает разделение этого слова на подслова, образующие последовательность подслов, в которой, по меньшей мере, одно из подслов содержит, по меньшей мере, две буквы. Затем на этапе 250 выполняется определение фонем для упомянутых подслов. После чего на этапе 260 выполняется соединение фонем в последовательность фонем. Упомянутая последовательность подслов определяется путем анализа всех возможных подслов, которые могут составлять выбранное слово. Например, как схематично показано на ориентированном ациклическом графе, приведенном на Фиг.3, если выбранном словом было "mention", то этот граф построен с использованием всех возможных подслов, которые могут составлять выбранное слово "mention". Вместе с каждым подсловом приводится заранее определенный вес WT, например, как показано на данном чертеже, подслова "ment", "men" и "tion" соответственно имеют веса 88, 86 и 204. Таким образом, на этапе 260 соединения выполняется просмотр ориентированного ациклического графа и выбор подслов, имеющих максимальные объединенные (суммированные) веса WT, которые образуют выбранное слово. В случае слово "mention" будут выбраны подслова "men" и "tion".
На этапе 250 определение фонем используются две таблицы, хранящиеся в энергонезависимой памяти 120, одна из таблиц, часть которой изображена на Фиг.4, представляет собой таблицу отображения MT, которая ставит в соответствие фонемам определенные символы. Как показано на данном чертеже, фонема ае обозначается символом @, в то время как фонема th обозначается символом D. Другая таблица представляет собой таблицу PIT идентификаторов фонем, часть которой изображена на Фиг.5. Таблица PIT идентификаторов фонем содержит следующие поля: поле подслова, поле веса фонем, поле (поля) относительного положения или указатели относительного положения, и поле (поля) идентификаторов фонем. Например, первой строкой на Фиг.5 является аа 120 А_С, где аа представляет собой подслово, 120 является весом фонем, буква А представляет собой относительное положение и "С" представляет собой идентификатор фонем, соответствующий подслову аа. Относительное положение может обозначаться следующим образом: А - относится ко всем положениям, I - относится к подсловам в начале слова, М - относится к подсловам в середине слова и F - относится к подсловам в конце слова. Таким образом, этап 250 определения фонем можно выполнить, используя таблицу PIT идентификаторов фонем, и с учетом положения подслов в слове.
Веса фонем и веса на ориентированном ациклическом графе (заранее определенные веса WT) представляют собой одинаковые веса, полученные на основе Фиг.5. Эти веса были определены таким образом, что, если мы выбираем в качестве веса время возникновения, то одна подстрока имеет более высокий вес, чем сама строка. Как следствие, если мы выбираем в результате форму разделения с максимальным весом, то короткая морфемоподобная строка всегда является предпочтительной. Например, слово seeing будет разделено как s|ee|in|g вместо s|ee|ing. Но в итоге взаимосвязь между длинной строкой и последовательностью фонем является более надежной. Чтобы обеспечить высокий приоритет длинной морфемоподобной строки, мы учитываем следующие аспекты:
- Аффикс. Если одна короткая строка является префиксом или суффиксом длинной строки, мы добавляем ее время возникновения к этой длинной строке, но при этом другие подстроки не учитываются.
- Неоднозначность. В некоторых случаях одна морфемоподобная строка может соответствовать нескольким последовательностям фонем, например, en может произноситься как ehn и axn. Чтобы снизить неопределенность, мы используем такие положения строки, как начало слова, середина слова и окончание слова. Даже при этом условии морфемоподобная строка может соответствовать более чем одной последовательности фонем. Чтобы устранить эту проблему, мы выбираем последовательность фонем с максимальным временем возникновения и вычисляем отношение r следующим образом:
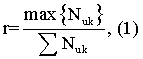
где u - индекс строки, а k - индекс положения.
Если r <α (α - пороговое значение, α=0,7), мы исключаем эту морфемоподобную строку. Например, окончание слова en может произноситься как ehn и axn, если общее время равно 1000 и если время, соответствующее axn, равно 800 (разумеется, это максимальное время), r =0,8. Следовательно, мы добавим окончание слова en в список.
- Минимальное время возникновения. Мы также задаем минимальное время возникновения min (min =9) в качестве порогового значения. Каждая строка, чье время возникновения меньше этого значения, отбрасывается.
При соблюдении этих ограничений мы присваиваем каждой строке вес Ws следующим образом: Ws= 10 ln Ns, где Ns - установленное время возникновения.
Затем в способе 200 выполняется этап 265 назначения ударения или подчеркивания фонемам, которые представляют гласные. На этом этапе происходит определение гласных из фонем, надлежащим образом определенных на предыдущем этапе 250. По существу, на этапе 265 происходит просмотр таблицы пар гласных с относительной силой/слабостью, которая хранится в энергонезависимой памяти 120. Часть этой таблицы пар гласных изображена на Фиг.6. Для примера рассмотрим три гласных, которые в слове могут быть идентифицированы как фонемы, эти гласные обозначены символами 'ax, aa и ае (полученными из таблицы отображения MT). Из анализа таблицы пар гласных видно, что если 'ax возникает ранее aa, то вес ударения равен 368, и наоборот - вес ударения равен 354, когда aa возникает ранее 'ax. Поэтому анализ таблицы пар гласных для 'ax, aa и ае дает следующие результаты: гласная, обозначенная символом ае, имеет первичное (наибольшее) ударение; гласная, обозначенная символом 'ax, имеет вторичное ударение; и гласная, обозначенная символом аа, не имеет ударения. По существу веса ударений определяются с использованием обучающего словаря. Каждая запись в этом словаре имеет формат слова и соответствующее ему произношение, включая ударение, границы слогов и соответствие букв фонемам. На основе этого словаря ударение определялось путем статистического анализа. В этом случае ударение отражает соотношение "сильная/слабая" между гласными. Таким образом, для генерации необходимых данных был проведен статистический анализ для всех записей в словаре. Если говорить более подробно, в пределах одного слова, если гласная vi является ударной, а гласная vj является безударной, мы присваиваем одно очко паре (vi,vj) и ноль очков паре (vj,vi). Если обе гласные являются безударными, то количество очков также составляет ноль.
После чего выполняется этап 270 проверки, чтобы определить, имеются ли еще слова в текстовой строке TS, которые необходимо обработать. Если да, то при выполнении способа 200 происходит возврат на этап 230, в противном случае на этапе 280 выполняется синтезирование речи на основе последовательности фонем. Синтезирование речи осуществляется синтезатором 110 речи на основе последовательности фонем для каждого из слов. После чего способ 200 завершается на окончательном этапе 290.
При выполнении синтезирования речи на этапе 280 также используется ударение на гласные (первичное, вторичное или без ударения, в зависимости от ситуации), чтобы обеспечить улучшенное качество синтезированной речи за счет подходящего акцентирования/подчеркивания.
Преимуществом настоящего изобретения является то, что оно улучшает или, по меньшей мере, смягчает звучание и акцентирование/подчеркивание гласных в зависимости от других соседних букв и положения в синтезируемом сегменте текста.
В приведенном выше подробном описании в качестве примера рассмотрен только предпочтительный вариант реализации настоящего изобретения и в этом описании не предполагается ограничения объема, сферы применения или структуры настоящего изобретения. Скорее данное подробное описание приведенного в качестве примера предпочтительного варианта реализации настоящего изобретения позволяет специалистам в этой области техники реализовать предложенный вариант на практике. Необходимо понимать, что различные изменения, сделанные применительно к функциям и структуре составляющих элементов, не будут выходить за пределы сущности и объема настоящего изобретения, определенного приложенной формулой изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ ЧТЕНИЯ ПЛОСКОПЕЧАТНОГО ТЕКСТА | 1996 |
|
RU2113726C1 |
| СПОСОБ АВТОМАТИЗИРОВАННОЙ ОБРАБОТКИ ТЕКСТА И КОМПЬЮТЕРНОЕ УСТРОЙСТВО ДЛЯ РЕАЛИЗАЦИИ ЭТОГО СПОСОБА | 2011 |
|
RU2460154C1 |
| СПОСОБ СИНТЕЗА РЕЧИ | 2009 |
|
RU2421827C2 |
| СПОСОБ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКИ ТЕКСТА | 2007 |
|
RU2386178C2 |
| УНИВЕРСАЛЬНЫЕ ОРФОГРАФИЧЕСКИЕ МНЕМОСХЕМЫ | 2005 |
|
RU2441287C2 |
| ЗАКОДИРОВАННЫЕ КОДОВЫМИ КОМБИНАЦИЯМИ СЛОВАРИ | 2006 |
|
RU2421809C2 |
| АРХИТЕКТУРА РАСПОЗНАВАНИЯ ДЛЯ ГЕНЕРАЦИИ АЗИАТСКИХ ИЕРОГЛИФОВ | 2008 |
|
RU2477518C2 |
| УСТРОЙСТВО СИНТЕЗА РЕЧИ | 2014 |
|
RU2606312C2 |
| СПОСОБ КОМПЛЕКСНОЙ КОРРЕКЦИИ НАРУШЕНИЙ РЕЧИ У ДЕТЕЙ | 2016 |
|
RU2640392C1 |
| СПОСОБ АНАЛИЗА ТЕКСТА | 2008 |
|
RU2392666C1 |
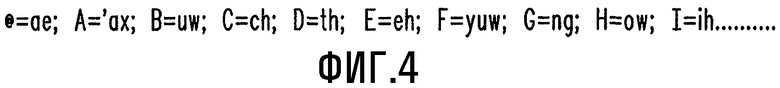

Изобретение относится к области синтезирования речи из текста. Техническим результатом заявленного изобретения является акцентирование гласных в зависимости от других соседних букв и положения в синтезируемом сегменте текста. Технический результат достигается тем, что разделяют слово, выбранное из принятой текстовой строки, на подслова, образующие последовательность подслов, в которой, по меньшей мере, одно из подслов содержит, по меньшей мере, две буквы, а каждое из возможных подслов имеет заранее определенный вес, причем для создания последовательности подслов выбирают подслова с максимальными объединенными весами; определяют фонемы для подслов при помощи таблицы идентификаторов фонем; соединяют фонемы в последовательность фонем и выполняют синтезирование речи на основе последовательности фонем. 3 з.п. ф-лы, 6 ил.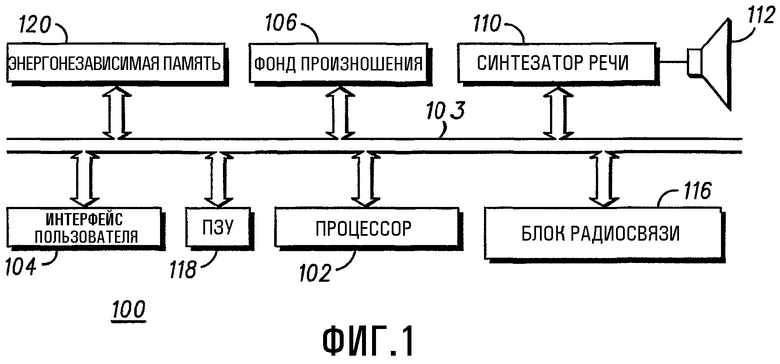
принимают текстовую строку и выбирают из нее, по меньшей мере, одно слово;
разделяют упомянутое слово на подслова, образующие последовательность подслов, в которой по меньшей мере одно из подслов содержит по меньшей мере две буквы, при этом последовательность подслов определяют путем анализа возможных подслов, которые могут составлять слово, а каждое из возможных подслов имеет соответствующий заранее определенный вес, причем для создания последовательности подслов выбирают подслова, образующие выбранное слово, с максимальными объединенными весами;
определяют фонемы для подслов при помощи таблицы идентификаторов фонем, содержащей фонемы, соответствующие по меньшей мере одному подслову;
соединяют фонемы в последовательность фонем; и
выполняют синтезирование речи на основе последовательности фонем.
| 0 |
|
SU401062A1 | |
| Способ отбойки посредством ВВ полезных ископаемых | 1959 |
|
SU126091A1 |
| JP 2003208191 А, 25.07.2003 | |||
| US 6064960 А, 16.05.2000 | |||
| US 5682501 А, 28.10.1997. | |||

