Изобретение относится к нейрокибернетике и может быть использовано в искусственных нейронных сетях (НС) при решении различных задач обработки данных, таких как обработка изображений и распознавание образов, предсказание сигналов и т.д.
Как известно [1-5], традиционные технические и математические модели нейронов [1-5], используемые в НС различного назначения, имеют ограниченность в аппроксимации (приближении, моделировании или реализуемости) некоторых логических функций. При этом нереализуемые нейроном функции называют линейно-неразделимыми, т.е. для реализации которых недостаточно линейных разделяющих гиперплоскостей [1], и необходимо использовать нелинейные. Например, классическая модель нейрона [1-5] с двумя входами (n=2), перемножителями, сумматором и активационным блоком, в котором скалярное произведение вектора входа на вектор весовых коэффициентов (ВК) преобразуется функцией активации (ФА), способна реализовывать (довольно точно аппроксимировать) из полного набора 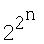 =16-ти для n=2, только 14 логических функций [1-5]. При этом класс линейно-неразделимых функций составляют две логические функции - неравнозначности (или "сложение по модулю 2n) и эквивалентности (равнозначности) [1-5]. В случае с тремя входами (n=3) ситуация более сложная: число реализуемых функций - 104 из полного набора =256 [1]. При дальнейшем росте числа переменных n отношение числа реализуемых функций к числу линейно-неразделимых резко падает [1]. Невозможность реализовывать (довольно точно аппроксимировать) линейно-неразделимые логические функции является существенным недостатком модели нейрона [1-5] и широко известна как проблема функциональной или аппроксимационной неполноты указанной модели нейрона [1-5]. Частным случаем данной проблемы, в случае двух переменных и реализации функции неравнозначности, является широко известная [1-5] проблема функции "Исключающее ИЛИ".
=16-ти для n=2, только 14 логических функций [1-5]. При этом класс линейно-неразделимых функций составляют две логические функции - неравнозначности (или "сложение по модулю 2n) и эквивалентности (равнозначности) [1-5]. В случае с тремя входами (n=3) ситуация более сложная: число реализуемых функций - 104 из полного набора =256 [1]. При дальнейшем росте числа переменных n отношение числа реализуемых функций к числу линейно-неразделимых резко падает [1]. Невозможность реализовывать (довольно точно аппроксимировать) линейно-неразделимые логические функции является существенным недостатком модели нейрона [1-5] и широко известна как проблема функциональной или аппроксимационной неполноты указанной модели нейрона [1-5]. Частным случаем данной проблемы, в случае двух переменных и реализации функции неравнозначности, является широко известная [1-5] проблема функции "Исключающее ИЛИ".
Необходимо отметить, что функциональная полнота рассматривается на примере булевых (переменные и значения функции - двоичные, 0 и 1) логических функций, но аппроксимации моделью нейрона этих функций представляют собой непрерывные функции, области определения (входы нейрона) и значения (выход нейрона) которых - непрерывный отрезок, как правило, от 0 до 1 [1-5]. Таким образом, булевы функции будут являться частным (двоичным) случаем соответствующих нейросетевых аппроксимаций [1-5].
Кроме того, другой серьезной проблемой моделей нейронов и НС является сходимость процесса обучения с учителем (градиентного) и обход локальных минимумов [1-5]. Обучение с учителем предполагает [1-5], что для каждого входного вектора существует целевой вектор, представляющий собой требуемый выход. Вместе они называются обучающей парой. Обычно сеть обучается на некотором числе таких обучающих пар. Предъявляется входной вектор, вычисляется выход сети и сравнивается с соответствующим целевым вектором, разность (градиент ошибки) с помощью обратной связи подается в сеть и ВК изменяются в направлении антиградиента, стремящимся минимизировать ошибку. Векторы обучающего множества предъявляются последовательно и многократно, вычисляются ошибки и ВК подстраиваются для каждого вектора до тех пор, пока ошибка по всему обучающему массиву не достигнет приемлемо низкого уровня [1-5]. При этом даже если модель нейрона обеспечивает теоретически реализуемость заданной логической функции (при определенных значениях ВК), нет гарантии, что в результате процедуры обучения (конечные значения ВК) модель обеспечит практическую представляемость заданной функции [1]. Нет гарантии и того, что ошибка будет уменьшаться с каждым шагом обучения [1]. Поверхность ошибки (зависимость ошибки от значений ВК) модели нейрона с n входами сильно изрезана и состоит из холмов и оврагов в n-мерном пространстве. Нейрон может попасть в локальный минимум (неглубокий овраг), когда на поверхности имеется гораздо более глубокий минимум. В точке локального минимума все направления ведут вверх, и модель неспособна из него выбраться [1].
Для обеспечения возможности реализации (аппроксимации) полного набора логических функций от n переменных x1, x2,…xn, известен способ моделирования НС, содержащей несколько n-входовых нейронов в первом слое, и один во втором [1-5]. При этом, при соответствующих настройках ВК, нейронов первого слоя и настройках ВК нейрона второго слоя, открывается дополнительная возможность аппроксимации НС линейно-неразделимых функций [1-5]. Недостатком данного способа является необходимость использования нескольких нейронов, объединенных в два слоя, большое число и сложность настройки ВК в ходе градиентного обучения, а сам механизм обучения может быть длительным и не гарантирует сходимости и обхода локальных минимумов (особенно при числе входов n≥3).
Известен другой способ [6] моделирования нейрона - построение нейрона высокого (второго) порядка для реализации логических функций. В этом случае нейрон, кроме входов x1, x2,…xn, имеет дополнительные входы, на которые подают попарные произведения x1x2,…,x1xn, x2x3,…,x3xn,, xn-1xn [6]. При этом сумма s на выходе сумматора формирует требуемую для аппроксимации линейно-неразделимых функций, сложную полиномиальную зависимость выхода от входов данной модели нейрона [6]. Недостатком данного способа является наличие множества дополнительных входов у модели (особенно при n≥3), достаточно большое число вычислительных операций в ходе обучения и рабочем режимах, длительность процедуры градиентного обучения, ее сходимость и обход локальных минимумов.
Необходимо отметить еще один способ моделирования нейрона, предложенный в [7] на основе введения двухпороговой равновесной ФА данного нейрона. Недостатками данного способа являются: 4 настраиваемых параметра ФА вместо 2 (ВК) при двух входах x1 и x2, отсутствие механизмов настройки 2 из 4 настраиваемых параметров ФА.
Известен также способ [8] моделирования нейрона, обеспечивающий реализацию (аппроксимацию) линейно-неразделимой функции неравнозначности (но не обеспечивающий функциональную полноту). Недостатками способа [8] являются: невозможность аппроксимации других, линейно-разделимых логических функций (в частности, функций «Штрих Шеффера», «Стрелка Пирса»), отсутствие возможности обучения (вследствие наличия «ступенек» ФА).
Наиболее близким по технической сущности к заявляемому способу является способ моделирования нейрона [1-5], обеспечивающий реализацию (аппроксимацию) ограниченного набора булевых функций (особенно для большого числа переменных n): 14 из 16 для n=2, 104 из 256 для n=3, 1882 из 65536 для n=4 и т.д. [1]. Способ заключается в том [1-5], что входные сигналы подают на входы x1, x2,…,xn, принимающие непрерывные значения от «0» до «1», перемножают в весовых блоках с соответствующими ВК w1, w2,…,wn, имеющими на первом шаге обучения небольшие случайные значения и изменяющиеся в процессе обучения в соответствии с градиентным правилом обучения, и суммируют в сумматоре вместе с ВК wn+1 (называемым также смещением), где wn+1 имеет небольшое начальное случайное значение и изменяющееся в соответствии с правилом обучения, s=x1w1+x2w2+…xnwn+wn+1, где s - сумма на выходе сумматора. ВК wn+1 необходим для смещения ФА по s при обучении аппроксимации необходимой логической функции. Перемножители и сумматор учитывают знаки величин. Затем сумму s, в целях возможности градиентного обучения, преобразуют в активационном блоке гладкой (как правило, сигмоидной) ФА f(s), получая функцию y(x1x2)=f(s) на выходе у модели нейрона. Таким образом, модель прототипа содержит n входов x1, x2,…xn, являющихся входами соответствующих весовых блоков (перемножителей), где x1, x2,…,xn перемножаются с ВК w1, w2,…,wn. Выходы перемножителей, а также вес wn+l являются входами сумматора, выход которого соединен со входом активационного блока. Выход активационного блока является выходом у модели нейрона, на котором получают функцию y(x1, x2,…,xn). В качестве сумматора, перемножителей и активационного блока могут использоваться различные известные технические устройства, например [9], реализующие заданные математические функции. В ходе процедуры обучения (заданной логической функции) на входы x1, x2,…,xn последовательно и многократно подают входные векторы X=[x1, x2…xn]T (где верхний индекс T здесь и далее означает операцию транспонирования), вычисляют каждый раз значения выхода нейрона y(x1, x2,…,xn) и сравнивают их с требуемым или целевым выходом (компонентами целевого вектора T=[t1, t2…tm]T) [1-5]. При этом каждый раз осуществляют корректировку значений ВК по градиентному правилу [1-5]. Данное градиентное правило обучения прототипа, содержащее производную f'(s) ФА, подробно обосновано в работах [1-5] и широко используется в настоящее время при обучении многих технических моделей НС.
Между тем способ [1-5] имеет два недостатка, первый из которых связан с невозможностью реализации (т.е. аппроксимации) полного набора из булевых логических функций от n переменных, особенно при большом числе переменных n, т.е. невозможностью обеспечения функциональной полноты. Второй касается механизма обучения, который может быть длительным по времени и не гарантирует сходимости модели нейрона и обхода локальных минимумов [1-5].
Предлагаемый способ направлен на достижение следующих технических эффектов:
1) обеспечение возможности реализации моделью нейрона любой заданной булевой логической функции из полного их набора от n переменных, т.е. обеспечение функциональной или аппроксимационной полноты модели нейрона;
2) отсутствие необходимости в довольно длительных механизмах обучения (с многократным использованием целевого вектора T), не гарантирующих, к тому же, сходимости и успешного преодоления локальных минимумов; замена этих механизмов обучения операцией однократного использования целевого вектора T;
3) расширение арсенала технических решений [1-6] по обеспечению функциональной полноты моделей нейронных структур.
Рассмотрим сущность предлагаемого способа. Совокупность действий, определяющая способ моделирования нейрона, представлена на фиг.1. Согласно предлагаемому способу, вектор входных сигналов x1, x2,…,xn (принимающих непрерывные значения от «0» до «1») подают на вход X=[x1, x2…xn]T, преобразуют в весовых блоках (блоки R1…R2n и W1…W2n на фиг.1) и суммируют в сумматоре (блок S на фиг.1). При этом выход s сумматора является входом активационного блока (блок F на фиг.1), в котором s преобразуют ФА f(s). Выход блока F является выходом y модели нейрона, на котором получают необходимую функцию y(x1, x2,…,xn). В отличие от прототипа входные сигналы x1, x2,…,xn преобразуют в весовых блоках по следующему правилу: в блоках R1…R2n на фиг.1 вычисляют квадраты евклидова расстояния rj(j=1…2n) от вектора X до каждого из n-мерных векторов P1, P2, …, 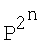 , представляющих собой координаты всех 2n вершин единичного n-мерного куба:
, представляющих собой координаты всех 2n вершин единичного n-мерного куба: 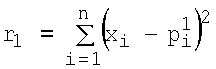 ,
, 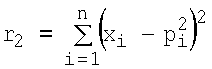 , …,
, …, 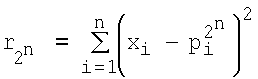 . Или в общем случае:
. Или в общем случае:
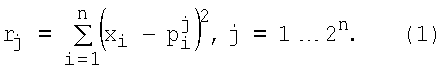
Под единичным n-мерным кубом будем понимать куб с n непараллельными ребрами (измерениями), длины которых равны единице [1, 4, 5]. Так при n=2 куб вырождается в плоский квадрат (2 измерения); при n=3 имеем обычный геометрический куб. Очевидно, что число вершин куба равно 2n.
Затем в блоках W1…W2n на фиг.1 каждое из 2n расстояний rj суммируют с коэффициентом α, где α=0.05, возводят в степень (-1) и перемножают соответственно с t1, t2,…,t2 n (компонентами целевого вектора T, которые представляет собой набор требуемых значений выхода нейрона в 2n вершинах единичного n-мерного куба для заданной реализуемой функции): w1=t1(r1+α)-1, w2=t2(r2+α)-1,…, 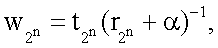 где t∈0,1. Или в общем случае:
где t∈0,1. Или в общем случае:
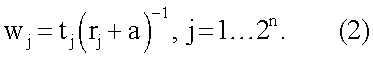
После совокупности действий (1) и (2) полученные коэффициенты wj (представляющие собой произведения «близости» 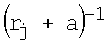 входной комбинации X к каждой из вершин n-мерного куба на элементы целевого вектора tj в вершинах n-мерного куба соответственно) суммируют в сумматоре S (фиг.1):
входной комбинации X к каждой из вершин n-мерного куба на элементы целевого вектора tj в вершинах n-мерного куба соответственно) суммируют в сумматоре S (фиг.1):

a s преобразуют в активационном блоке F (фиг.1) функцией
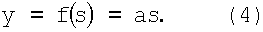
При этом в качестве весовых блоков (R1…R2n и W1…W2n), сумматора (S) и активационного блока (F) фиг.1 могут использоваться различные известные технические устройства, например [9], реализующие заданные математические функции (1), (2), (3) и (4) с учетом знака сигнала и непрерывности от «0» до «1» x1, x2,…,xn.
Проведенный сравнительный анализ заявленного способа и прототипа [1-5] показывает, что заявленный способ отличается тем, что изменена совокупность действий при преобразовании входных сигналов x1, x2,…,xn в выходной y(x1, x2,…,xn), поскольку перед суммированием и преобразованием ФА входные сигналы не перемножают с ВК w1, w2,…,wn, как в прототипе, а используют для определения в блоках R1…R2n квадратов евклидовых расстояний rj (1) от вектора X до каждого из n-мерных векторов P1, P2, …, 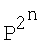 представляющих собой координаты всех 2n вершин единичного n-мерного куба, затем в блоках W1…W2n каждое из 2n расстояний rj суммируют с коэффициентом а (а=0.05), возводят в степень (-1) и перемножают соответственно t1, t2,…,
представляющих собой координаты всех 2n вершин единичного n-мерного куба, затем в блоках W1…W2n каждое из 2n расстояний rj суммируют с коэффициентом а (а=0.05), возводят в степень (-1) и перемножают соответственно t1, t2,…, 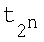 (по формуле (2)).
(по формуле (2)).
Рассмотрим предлагаемый способ моделирования нейрона. С целью простоты изложения рассмотрим случай, когда модель нейрона имеет два входа (число переменных n=2, полный набор булевых функций 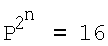 ).
).
Требуемые значения выхода y(x1,x2) (т.е. 16 четырехмерных целевых векторов Т) модели нейрона для аппроксимации любой из полного набора 16-ти булевых логических функций, в зависимости от двоичных комбинаций входа x1 и x2, приведены в таблице 1 (выделены два вектора, соответствующих линейно-неразделимым функциям - неравнозначности и эквивалентности).
Для реализации (аппроксимации) любой из 16-ти функций (получения наиболее близкого значения выхода y(x1,x2) к одному из векторов T), приведенных в таблице 1, моделирование нейрона предполагает наличие совокупности следующих действий. Входные сигналы x1 и x2 преобразуют в блоках R1, R2, R3, R4 (фиг.1) по следующему правилу: по формуле (1) вычисляют квадраты евклидова расстояния rj (j=1,2,3,4) от вектора 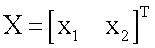 до каждого из векторов
до каждого из векторов 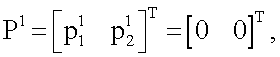
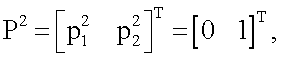
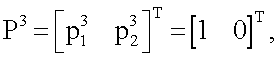
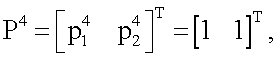 представляющих собой координаты всех 2n=4 вершин единичного двумерного куба (т.е. квадрата):
представляющих собой координаты всех 2n=4 вершин единичного двумерного куба (т.е. квадрата): 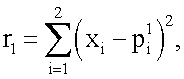
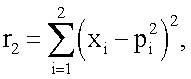
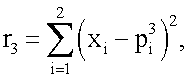
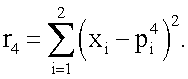 Затем в блоках W1, W2, W3, W4 (фиг.1) в соответствии с формулой (2) каждое из четырех расстояний rj суммируют с коэффициентом а, где а=0.05, возводят в степень (-1) и перемножают соответственно с t1, t2, t3 и t4 (компонентами целевого вектора T, которые представляет собой набор требуемых значений выхода нейрона в 4 вершинах единичного двумерного куба (квадрата) для заданной реализуемой функции): w1=t1(r1=a)-1, w2=t2(r2+а)-1, w3=t3(r3+а)-1, w4=t4(r4+a)-1, где t∈0,1. При этом зависимости коэффициентов wj (j=1,2,3,4) как функций от двух переменных x1, и x2 для случая, например, линейно-неразделимой функции неравнозначности
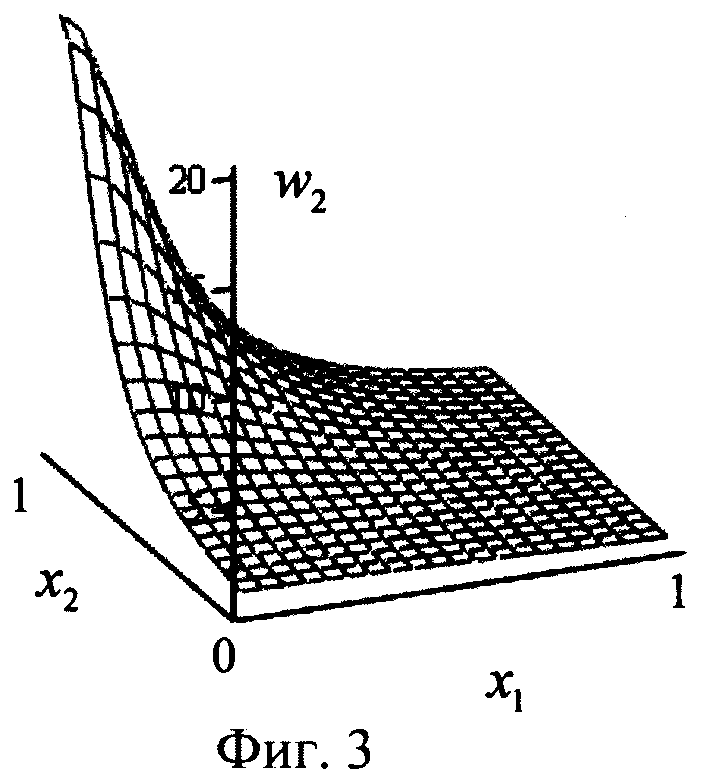
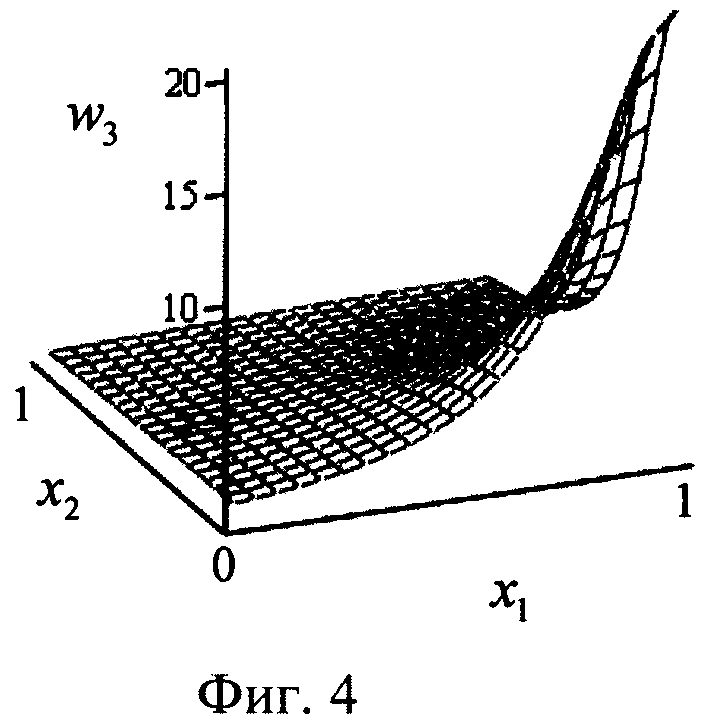
Затем в блоках W1, W2, W3, W4 (фиг.1) в соответствии с формулой (2) каждое из четырех расстояний rj суммируют с коэффициентом а, где а=0.05, возводят в степень (-1) и перемножают соответственно с t1, t2, t3 и t4 (компонентами целевого вектора T, которые представляет собой набор требуемых значений выхода нейрона в 4 вершинах единичного двумерного куба (квадрата) для заданной реализуемой функции): w1=t1(r1=a)-1, w2=t2(r2+а)-1, w3=t3(r3+а)-1, w4=t4(r4+a)-1, где t∈0,1. При этом зависимости коэффициентов wj (j=1,2,3,4) как функций от двух переменных x1, и x2 для случая, например, линейно-неразделимой функции неравнозначности 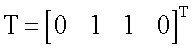 (выделена в таблице 1), будут иметь вид, представленный на фиг 2-4. Из фиг.2-4 видно, что в случаях, когда какой-либо компонент вектора Т равен нулю (t1 и t4), также нулевым является соответствующий коэффициент (w1 и w4 в данном случае, фиг.2). В тех случаях, когда компонент вектора T равен единице (t2 и t3), возникает плавный холм в соответствующей вершине двумерного куба (квадрата), поскольку осуществляется возведение в степень (-1) квадрата евклидова расстояния r2 (фиг.3) и r3 (фиг.4). При этом слагаемое а=0.05 необходимо для того, чтобы исключить ситуацию деления на ноль в формуле (2).
(выделена в таблице 1), будут иметь вид, представленный на фиг 2-4. Из фиг.2-4 видно, что в случаях, когда какой-либо компонент вектора Т равен нулю (t1 и t4), также нулевым является соответствующий коэффициент (w1 и w4 в данном случае, фиг.2). В тех случаях, когда компонент вектора T равен единице (t2 и t3), возникает плавный холм в соответствующей вершине двумерного куба (квадрата), поскольку осуществляется возведение в степень (-1) квадрата евклидова расстояния r2 (фиг.3) и r3 (фиг.4). При этом слагаемое а=0.05 необходимо для того, чтобы исключить ситуацию деления на ноль в формуле (2).
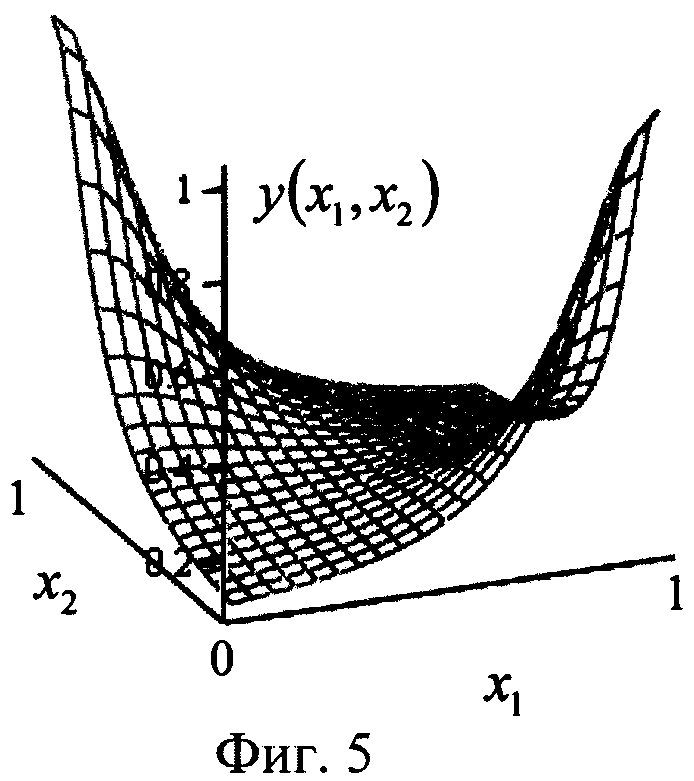
После этих действий коэффициенты wj (y=1,2,3,4) суммируют в сумматоре S (фиг.1) по формуле (3): 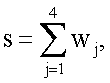 a s преобразуют в активационном блоке F (фиг.1) по формуле (4) функцией: y=f(s)=as. Функция активации f(s)=as выполняет роль нормировочного сомножителя, ограничивающего выходные значения модели нейрона. При этом зависимость выхода y(x1,x2) модели нейрона как функции двух переменных x1 и x2 для случая требуемой функции неравнозначности будет иметь вид, показанный на фиг.5. При этом на выходе нейрона получают следующие значения, в зависимости от предельных (двоичных 0 и 1) входных: y(0,0)≈0.095, y(0,1)≈1.024, y(1,0)≈1.024, y(1,1)≈0.095. Таким образом, зависимость выхода y(x1,x2) довольно точно аппроксимирует требуемую, линейно-неразделимую функцию неравнозначности
a s преобразуют в активационном блоке F (фиг.1) по формуле (4) функцией: y=f(s)=as. Функция активации f(s)=as выполняет роль нормировочного сомножителя, ограничивающего выходные значения модели нейрона. При этом зависимость выхода y(x1,x2) модели нейрона как функции двух переменных x1 и x2 для случая требуемой функции неравнозначности будет иметь вид, показанный на фиг.5. При этом на выходе нейрона получают следующие значения, в зависимости от предельных (двоичных 0 и 1) входных: y(0,0)≈0.095, y(0,1)≈1.024, y(1,0)≈1.024, y(1,1)≈0.095. Таким образом, зависимость выхода y(x1,x2) довольно точно аппроксимирует требуемую, линейно-неразделимую функцию неравнозначности 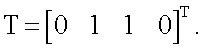
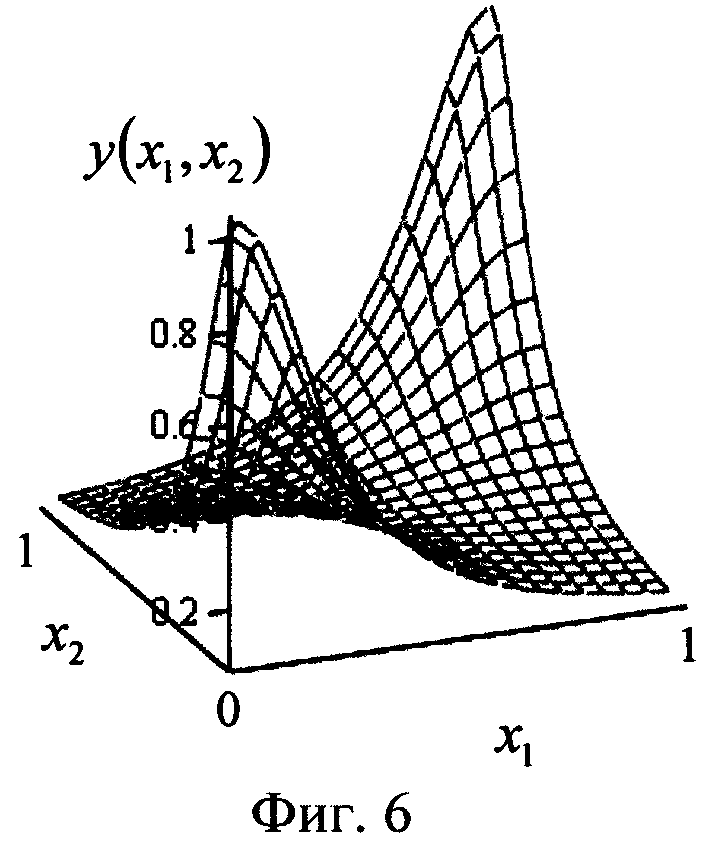
Подставляя в формулу (2) элементы любого другого (из оставшихся 15-ти) целевого вектора из таблицы 1, можно убедиться, что в соответствии с рассматриваемым способом все они довольно точно аппроксимируются (т.е. реализуются) моделью нейрона, представленной на фиг.1. Так, на фиг.6 представлена зависимость выхода y(x1,x2) модели нейрона для реализации второй из линейно-неразделимых функции - эквивалентности (равнозначности, также выделена в таблице 1), т.е. при целевом векторе 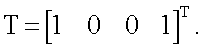 В этом случае (фиг.6) на выходе нейрона получают следующие значения, в зависимости от предельных (двоичных 0 и 1) входных: y(0,0)≈1.024, y(0,1)≈0.095, y(1,0)≈0.095, y(1,1)≈1.024.
В этом случае (фиг.6) на выходе нейрона получают следующие значения, в зависимости от предельных (двоичных 0 и 1) входных: y(0,0)≈1.024, y(0,1)≈0.095, y(1,0)≈0.095, y(1,1)≈1.024.
Рассматривая случай нескольких переменных (x1, x2,…,xn), также можно убедиться в том, что предлагаемый способ моделирования нейрона позволяет аппроксимировать любую булеву функцию от n переменных, поскольку компоненты целевого вектора T заданы в каждой вершине n-мерного куба.
Таким образом, предлагаемый способ моделирования нейрона позволяет обеспечить возможность реализации моделью нейрона фиг.1 любой заданной логической функции из полного их набора 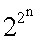 от n переменных, т.е. обеспечить функциональную полноту нейрона с n входами.
от n переменных, т.е. обеспечить функциональную полноту нейрона с n входами.
Кроме того, для реализации необходимой логической функции по предлагаемому способу нет необходимости осуществлять процедуру обучения модели нейрона, которая не всегда гарантирует сходимости и успешного преодоления локальных минимумов. В предлагаемом способе моделирования нейрона операция обучения заменена однократным использованием вектора требуемых значений T в блоках W1…W2n (фиг.1). При этом целевой вектор T используется один раз (а в известных градиентных процедурах обучения - многократно), а сам способ обеспечивает одновременно и функциональную полноту нейрона с « входами, и гарантирует состояние «обученности» модели нейрона одному из целевых векторов T.
На фиг.1 представлена функциональная схема устройства (модель нейрона), реализующего предлагаемый способ моделирования нейрона. Устройство фиг.1 содержит: вход, на который поступает n-мерный вектор 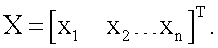 Данный вектор одновременно поступает на входы блоков R1…R2n (фиг.1), в которых вычисляют квадрат евклидова расстояния от вектора X до каждой из вершины n-мерного куба соответственно. Выходы блоков R1…R2n соединены со входами блоков W1…W2n соответственно (фиг.1). Сами блоки W1…W2n имеют вторые входы, на которые подают компоненты целевого вектора
Данный вектор одновременно поступает на входы блоков R1…R2n (фиг.1), в которых вычисляют квадрат евклидова расстояния от вектора X до каждой из вершины n-мерного куба соответственно. Выходы блоков R1…R2n соединены со входами блоков W1…W2n соответственно (фиг.1). Сами блоки W1…W2n имеют вторые входы, на которые подают компоненты целевого вектора 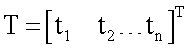 соответственно.
соответственно.
Выходы блоков W1…W2n являются входами сумматора S (фиг.1), выход которого соединен со входом активационного блока F, выход которого, в свою очередь, является выходом у модели нейрона (фиг.1), на котором получают функцию y[x1,x2,…,xn). В качестве весовых блоков (R1…R2n и W1…W2n), сумматора (S), и активационного блока (F) фиг.1, могут использоваться различные известные технические устройства, например [9], реализующие заданные математические функции (1), (2), (3) и (4) с учетом знака сигнала и непрерывности от «0» до «1» x1,x2,…,xn.
Работа модели нейрона, функционирующей по предлагаемому способу, выглядит следующим образом. На вход устройства подают входной вектор 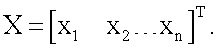 Этот вектор одновременно подают на каждый из блоков R1…R2n (фиг.1), в которых по формуле (1) вычисляют квадраты евклидова расстояния rj (j=1…2n) от вектора X до каждого из n-мерных векторов
Этот вектор одновременно подают на каждый из блоков R1…R2n (фиг.1), в которых по формуле (1) вычисляют квадраты евклидова расстояния rj (j=1…2n) от вектора X до каждого из n-мерных векторов 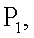
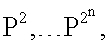 представляющих собой координаты всех 2n вершин единичного n-мерного куба. С выходов блоков R1…R2n (фиг.1) квадраты расстояний подают на соответствующие входы блоков W1…W2n, в которых каждое из 2n расстояний rj преобразуют в соответствии с формулой (2). На вторые входы блоков W1…W2n подают соответственно компоненты вектора требуемых значений
представляющих собой координаты всех 2n вершин единичного n-мерного куба. С выходов блоков R1…R2n (фиг.1) квадраты расстояний подают на соответствующие входы блоков W1…W2n, в которых каждое из 2n расстояний rj преобразуют в соответствии с формулой (2). На вторые входы блоков W1…W2n подают соответственно компоненты вектора требуемых значений 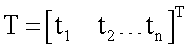 реализуемой логической функции. С выходов блоков W1…W2n (фиг.1) сигналы подают на вход сумматора S, где их суммируют по формуле (3). С выхода сумматора сигнал подают на вход активационного блока F, в котором его преобразуют ФА (4). С выхода блока F сигнал подают на выход устройства y, на котором получают требуемую функцию y(x1,x2,…,xn). В случае двух переменных (n=2) работа модели нейрона по предлагаемому способу выглядит следующим образом. Совокупность действий (1)-(4) определяет математическую модель нейрона в виде:
реализуемой логической функции. С выходов блоков W1…W2n (фиг.1) сигналы подают на вход сумматора S, где их суммируют по формуле (3). С выхода сумматора сигнал подают на вход активационного блока F, в котором его преобразуют ФА (4). С выхода блока F сигнал подают на выход устройства y, на котором получают требуемую функцию y(x1,x2,…,xn). В случае двух переменных (n=2) работа модели нейрона по предлагаемому способу выглядит следующим образом. Совокупность действий (1)-(4) определяет математическую модель нейрона в виде:
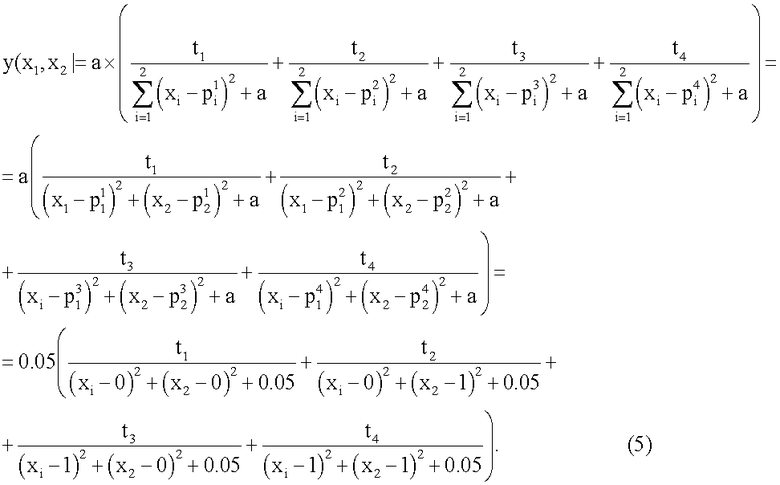
При этом для случая, например линейно-неразделимой функции неравнозначности (T=[0110]T, выделена в таблице 1), математическая модель нейрона (5) примет вид:
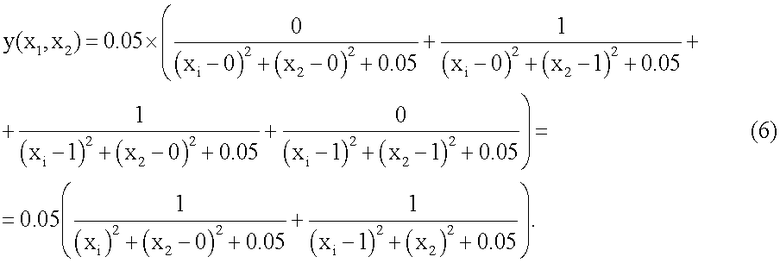
Подставляя в (6) двоичные (0 и 1) входные комбинации (двумерные векторы X), имеем следующие точные выходные значения: y(0,0)=0.095238, y(0,1)=1.0243902, y(1,0)=1.0243902, y(1,1)=0.095238, т.е. значения функции выхода y(x1,x2) модели нейрона, приведенной на фиг.5.
Подставляя в математическую модель нейрона (5) элементы любого другого (из оставшихся 15-ти) целевого вектора из таблицы, можно убедиться, что в соответствии с рассматриваемым способом все они довольно точно аппроксимируются (т.е. реализуются) данной моделью нейрона.
Составляя математическую модель нейрона для случая нескольких переменных (x1,x2,…,xn), также можно убедиться в том, что предлагаемый
способ моделирования нейрона позволяет аппроксимировать любую булеву функцию от n переменных, поскольку компоненты целевого вектора T заданы в каждой вершине n-мерного куба. При этом при росте числа n точность аппроксимации будет зависеть от выбора величины коэффициента а.
Таким образом, рассмотренная работа модели нейрона также показывает, что ей реализуется (аппроксимируется) любая булева функция от n переменных при однократном использовании вектора требуемых значений T без каких-либо механизмов обучения.
Таким образом, предлагаемый способ позволяет получить следующие технические эффекты:
1) обеспечение возможности реализации моделью нейрона любой заданной булевой логической функции из полного их набора 2 от и переменных, т.е. обеспечение функциональной или аппроксимационной полноты модели нейрона;
2) отсутствие необходимости в довольно длительных механизмах обучения (с многократным использованием целевого вектора T), не гарантирующих, к тому же, сходимости и успешного преодоления локальных минимумов; замена этих механизмов обучения операцией однократного использования целевого вектора T;
3) расширение арсенала технических решений [1-6] по обеспечению функциональной полноты моделей нейронных структур.
Указанные технические эффекты позволят расширить аппроксимационные (функциональные) возможности нейроподобных элементов, а также заменить длительную, и не всегда гарантирующую успех процедуру обучения операцией однократного использования вектора требуемых значений для заданной функции.
Источники информации
1. Wasserman P. Neurocomputing. Theory and practice, Nostram Reinhold, 1990. (Рус. перевод: Уоссермен Ф. Нейрокомпьютерная техника: теория и практика. / Пер. с англ. Ю.А.Зуев, В.А.Точенов. - М.: Мир, 1992. - 240 с.).
2. Круглов В.В., Борисов В.В. Искусственные нейронные сети. Теория и практика. - М: Горячая линия - Телеком, 2001. - 382 с.
3. Дьяконов В., Круглов В. Математические пакеты расширения MATLAB. Специальный справочник. - СПб.: Питер, 2001. - 480 с.
4. Danuta Rutkowska, Maciej Pilinski, Leszek Rutkowski. Sieci neuronowe, al-gorytmy genetyczne I systemy rozmyte. Wydawnictwo naukowe pwn. Warszawa LODZ, 1999. (Рус. перевод: Рутковская Д., Пилиньский М., Рутковский Л. Нейронные сети, генетические алгоритмы и нечеткие системы. / Пер. с польского И.Д.Рудинского. - М.: Горячая линия - Телеком, 2004. - 452 с.).
5. Stanislaw Osowski. Sieci neuronowe do przetwarzania informacji. // Oficyna mydawnicza politechniki Warszawskiej, Warszawa, 2000. (Рус. перевод: Осовский С.Нейронные сети для обработки информации. / Пер. с польского И.Д.Рудинского. - М: Финансы и статистика, 2004. - 344 с.
6. Терехов С.А. Нейросетевые информационные модели сложных инженерных систем. // Сб. Нейроинформатика / А.Н.Горбань, В.Л.Дунин-Барковский, А.Н.Кирдин и др. - Новосибирск: Наука, Сибирская издательская фирма РАН, 1998. С.103-141.
7. Терешков A.M. Однородная многослойная нейронная сеть прямого распространения с локальными связями с условно-рефлекторным механизмом обучения на основе двухпороговых равновесных нейроподобных элементов. // Изв. Томского политехи, ун-та. 2007. Т.310. №1. С.206-211.
8. Самойлин Е.А. Модель нейрона, реализующая логическую функцию неравнозначности. // Патент РФ №2269155, МПК G06G 7/06. Заявит. и патентообл. Самойлин Е.А. - №2003125926/09; заявл. 22.08.03; опубл. 27.01.06. Б.И. 2006. №3. - 7 с.
9. Галушкин А.И. Нейрокомпьютеры. Кн.3: Учеб. пособие для вузов / Общая ред. А.И. Галушкина. - М.: ИПРЖР, 2000. - 528 с.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ РЕАЛИЗАЦИИ НЕЙРОНОМ ЛОГИЧЕСКОЙ ФУНКЦИИ НЕРАВНОЗНАЧНОСТИ | 2006 |
|
RU2308758C1 |
| Способ управления реакцией нейропроцессора на входные сигналы | 2018 |
|
RU2724784C2 |
| МОДЕЛЬ НЕЙРОНА, РЕАЛИЗУЮЩАЯ ЛОГИЧЕСКУЮ ФУНКЦИЮ НЕРАВНОЗНАЧНОСТИ | 2003 |
|
RU2269155C2 |
| СПОСОБ ОБУЧЕНИЯ ИСКУССТВЕННОЙ НЕЙРОННОЙ СЕТИ | 2014 |
|
RU2566979C1 |
| СПОСОБ ПОМЕХОУСТОЙЧИВОГО ГРАДИЕНТНОГО ВЫДЕЛЕНИЯ КОНТУРОВ ОБЪЕКТОВ НА ЦИФРОВЫХ ИЗОБРАЖЕНИЯХ | 2008 |
|
RU2360289C1 |
| САМОПРОВЕРЯЕМЫЙ МОДУЛЯРНЫЙ ВЫЧИСЛИТЕЛЬ СИСТЕМ ЛОГИЧЕСКИХ ФУНКЦИЙ | 2009 |
|
RU2417405C2 |
| Модуль для логических преобразований булевых функций | 1989 |
|
SU1667050A1 |
| САМОПРОВЕРЯЕМЫЙ СПЕЦИАЛИЗИРОВАННЫЙ ВЫЧИСЛИТЕЛЬ СИСТЕМ БУЛЕВЫХ ФУНКЦИЙ | 2012 |
|
RU2485575C1 |
| СПОСОБ ПОМЕХОУСТОЙЧИВОГО ГРАДИЕНТНОГО ВЫДЕЛЕНИЯ КОНТУРОВ ОБЪЕКТОВ НА ЦИФРОВЫХ ИЗОБРАЖЕНИЯХ | 2015 |
|
RU2589301C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ЛОКАЛЬНОГО ПРАВИЛА СОСТЯЗАТЕЛЬНОГО ОБУЧЕНИЯ, КОТОРОЕ ПРИВОДИТ К РАЗРЕЖЕННОЙ СВЯЗНОСТИ | 2012 |
|
RU2586864C2 |
Изобретение относится к нейрокибернетике и может быть использовано в искусственных нейронных сетях при решении различных задач обработки данных, таких как обработка изображений и распознавание образов, предсказание сигналов. Техническим результатом является обеспечение возможности реализации (аппроксимации) моделью нейрона любой заданной булевой логической функции из полного их набора 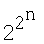 от n переменных (обеспечение функциональной полноты модели нейрона). Способ моделирования нейрона основан на том, что в весовых блоках вычисляют квадраты евклидова расстояния от вектора входа до каждой из 2n вершин единичного n-мерного куба, затем величины, обратные этим расстояниям, перемножают соответственно с компонентами целевого вектора, после чего суммируют в сумматоре и преобразуют в активационном блоке функцией активации. 6 ил., 1 табл.
от n переменных (обеспечение функциональной полноты модели нейрона). Способ моделирования нейрона основан на том, что в весовых блоках вычисляют квадраты евклидова расстояния от вектора входа до каждой из 2n вершин единичного n-мерного куба, затем величины, обратные этим расстояниям, перемножают соответственно с компонентами целевого вектора, после чего суммируют в сумматоре и преобразуют в активационном блоке функцией активации. 6 ил., 1 табл.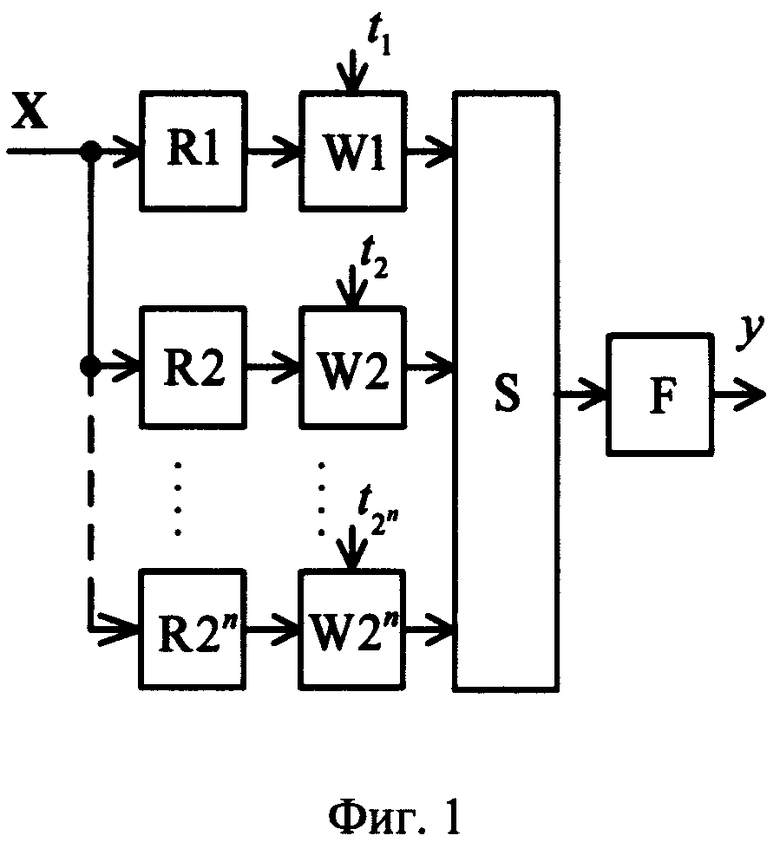
Способ моделирования нейрона со входами x1, x2,…xn, заключающийся в том, что входные сигналы x1, x2,…xn, составляющие вектор Х и принимающие непрерывные значения от «0» до «1», преобразуют в весовых блоках и суммируют в сумматоре, выход s которого является входом активационного блока, в котором s преобразуют функцией активации y=f(s), где у - выход модели нейрона, отличающийся тем, что, с целью обеспечения возможности реализации (получения на выходе у) любой заданной булевой логической функции из полного их набора 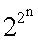 от n переменных, а также с целью замены длительных и не всегда сходящихся механизмов обучения операцией однократного использования целевого вектора Т для заданной реализуемой функции, входные сигналы преобразуют в весовых блоках по следующему правилу: вычисляют квадраты евклидова расстояния rj от вектора Х до каждого из n-мерных векторов
от n переменных, а также с целью замены длительных и не всегда сходящихся механизмов обучения операцией однократного использования целевого вектора Т для заданной реализуемой функции, входные сигналы преобразуют в весовых блоках по следующему правилу: вычисляют квадраты евклидова расстояния rj от вектора Х до каждого из n-мерных векторов 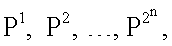 представляющих собой координаты всех 2n вершин единичного n-мерного куба:
представляющих собой координаты всех 2n вершин единичного n-мерного куба:  j=1…2n, затем каждое из 2n расстояний суммируют с коэффициентом а, где а=0,05, возводят в степень -1 и перемножают соответственно с
j=1…2n, затем каждое из 2n расстояний суммируют с коэффициентом а, где а=0,05, возводят в степень -1 и перемножают соответственно с 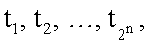 где целевой вектор Т представляет собой набор требуемых значений (tj∈0,1) в 2n вершинах единичного n-мерного куба для заданной реализуемой функции:
где целевой вектор Т представляет собой набор требуемых значений (tj∈0,1) в 2n вершинах единичного n-мерного куба для заданной реализуемой функции:
wj=tj(rj+a)-1 после чего коэффициенты wj суммируют в сумматоре: 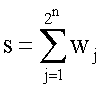 и преобразуют s в активационном блоке функцией: y=f(s)=as.
и преобразуют s в активационном блоке функцией: y=f(s)=as.
| МОДЕЛЬ НЕЙРОНА, РЕАЛИЗУЮЩАЯ ЛОГИЧЕСКУЮ ФУНКЦИЮ НЕРАВНОЗНАЧНОСТИ | 2003 |
|
RU2269155C2 |
| JP 3150661 А, 27.06.1991 | |||
| Коммутационное устройство | 1985 |
|
SU1312662A1 |
| КОМПОЗИЦИОННЫЙ МАТЕРИАЛ И СПОСОБ ЕГО ПОЛУЧЕНИЯ ДЛЯ РЕАЛИЗАЦИИ ТРЕБУЕМОГО КОЭФФИЦИЕНТА ТЕПЛОПЕРЕДАЧИ | 2002 |
|
RU2232786C2 |

