Область техники, к которой относится изобретение
Настоящее изобретение в целом относится к устранению ошибок синхронизации предварительного декодирования в процессорном конвейере, который обрабатывает команды, имеющие различные длины, и более конкретно к преимущественным методикам для заполняющего программного кода из условия, что механизм предварительного декодирования корректно определяет команды переменной длины как команды во время предварительного декодирования строки команд, включающей внедренные данные.
Уровень техники
Сегодняшние процессоры типично поддерживают наборы команд, которые имеют команды переменной длины. Например, набор команд ARM® состоит из команд, которые имеют длину 32 бит, и команды, которые имеют длину 16 бит. Конвейерные процессоры, которые поддерживают команды переменной длины, могут содержать конвейерный уровень предварительного декодирования для частичного декодирования команды, чтобы упростить уровень последовательного декодирования и, таким образом, упорядочить конвейер. Типичный конвейерный уровень предварительного декодирования проверяет по кодовой строке с помощью базового компонента кодовой строки по программному коду, предварительно кодирует кодовую строку и записывает предварительно декодированную информацию в кэш-память совместно с кодовой строкой. В зависимости от компилятора, используемого для создания программы или объектного кода, программный код может содержать внедренные данные совместно с командами.
Внедренные данные могут случайно оказаться похожими с командой или частью команды. В подобном случае механизм предварительного декодирования будет типично неверно понимать внедренные данные. Таким образом, где механизм предварительного декодирования некорректно предварительно декодирует 16 бит данных как первую часть 32-битовой команды, следующая 16-битовая команда может затем, в свою очередь, быть интерпретирована как вторая половина 32-битовой команды так, что неправильно предварительно декодированная информация будет храниться в кэш-памяти, и процесс предварительного декодирования может выйти из синхронизации для предварительного декодирования следующей команды. Типично этого не случится до следующего уровня декодирования, который определила ошибка синхронизации. Подобные результаты синхронизации ошибок в процессоре задерживают и не используют затраты мощности, когда пытаются восстановить от ошибки предварительного декодирования.
Традиционные подходы к вышеизложенной проблеме включают в себя предоставление механизма восстановления для повторной синхронизации механизма предварительного декодирования.
Сущность изобретения
Среди его нескольких аспектов первый вариант осуществления изобретения определяет, что существует необходимость в методике, которая мешает механизму предварительного декодирования из-за вынужденной повторной синхронизации, когда внедренные данные случайно кодируются как команда в потоке команд, причем поток команд содержит команды из набора команд переменной длины и внедренные данные. С этой целью этот вариант осуществления включает в себя определение гранулы, которая равна команде наименьшей длины в наборе команд, и определение числа гранул, которые составляют самую длинную команду в наборе команд как MAX. Вариант осуществления дополнительно включает в себя определение конца сегмента внедренных данных, когда программу компилируют или ассемблируют в строку команд, и вставку заполнения длиной MAX-1 в строку команд в конце внедренных данных. При последовательном предварительном декодировании заполненного потока команд устройство предварительного декодирования преимущественно поддерживает синхронизацию с командами в заполненном потоке команд, даже если внедренные данные случайно совпадут с существующей командой или частью команды в наборе команд переменной длины.
Более полное понимание настоящего изобретения, а также дополнительные признаки и преимущества изобретения будут очевидны из последующего подробного описания и сопроводительных чертежей.
Краткое описание чертежей
Фиг.1 показывает примерную беспроводную систему связи, в которой вариант осуществления изобретения может преимущественно использоваться.
Фиг.2 является блок-схемой комплекса процессоров, в котором вариант осуществления изобретения может преимущественно использоваться.
Фиг.3 показывает иллюстративный программный сегмент, который содержит заполнение для набора команд переменной длины, который имеет размеры команд 16 и 32 бита согласно первому варианту осуществления изобретения, в котором используется заполнение фиксированной длины.
Фиг.4 показывает иллюстративный программный сегмент, содержащий три холостых байта для набора команд переменной длины, который имеет размеры команд 8, 16, 24 и 32 бита согласно первому варианту осуществления изобретения.
Фиг.5 показывает иллюстративный программный сегмент, который содержит два холостых байта для набора команд переменной длины, который имеет размеры команд 8, 16, 24 и 32 бита согласно второму варианту осуществления изобретения, в котором используется заполнение переменной длины.
Фиг.6 показывает иллюстративный программный сегмент, который содержит один холостой байт для набора команд переменной длины, который имеет размеры команд 8, 16, 24 и 32 бита согласно второму варианту осуществления изобретения.
Фиг.7 является блок-схемой машиноисполняемого программного обеспечения согласно идеям изобретения.
Фиг.8 является блок-схемой процессорного конвейера, который действует согласно варианту осуществления изобретения.
Фиг.9 иллюстрирует телескопический подход к кодированию для постоянного размера заполнения согласно варианту осуществления изобретения.
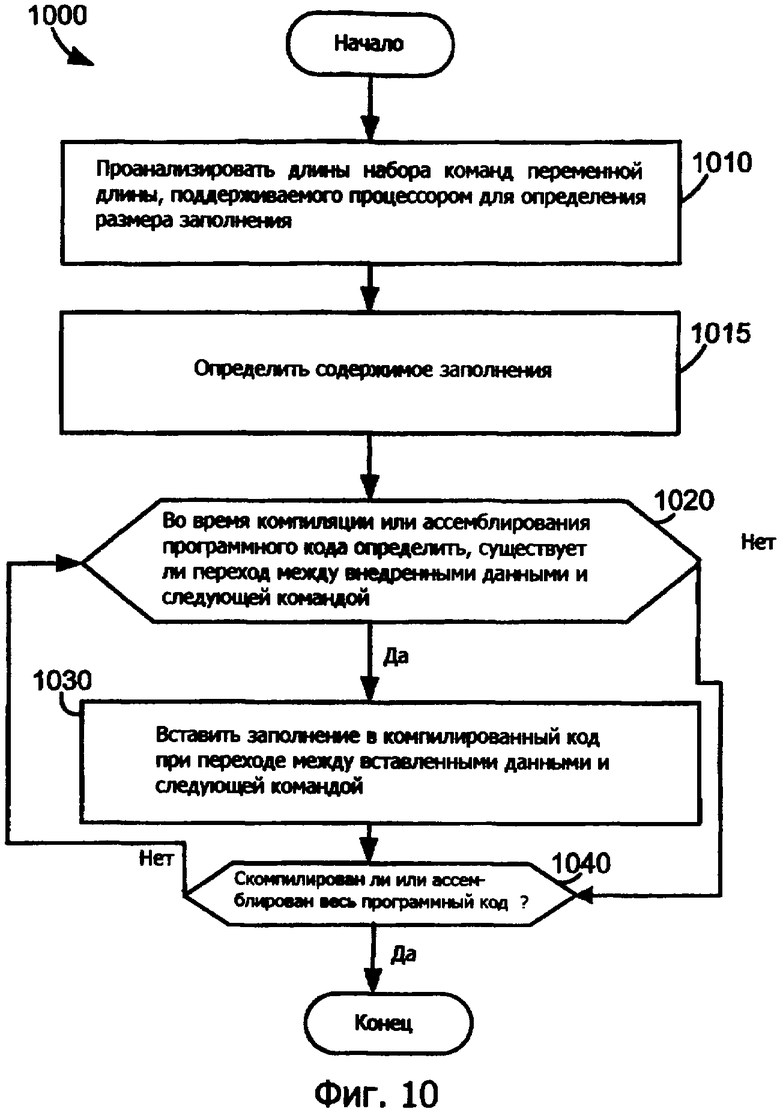
Фиг.10 является блок-схемой последовательности операций способа, которая иллюстрирует способ для вставки заполнения постоянного размера в программный код согласно первому варианту осуществления изобретения.
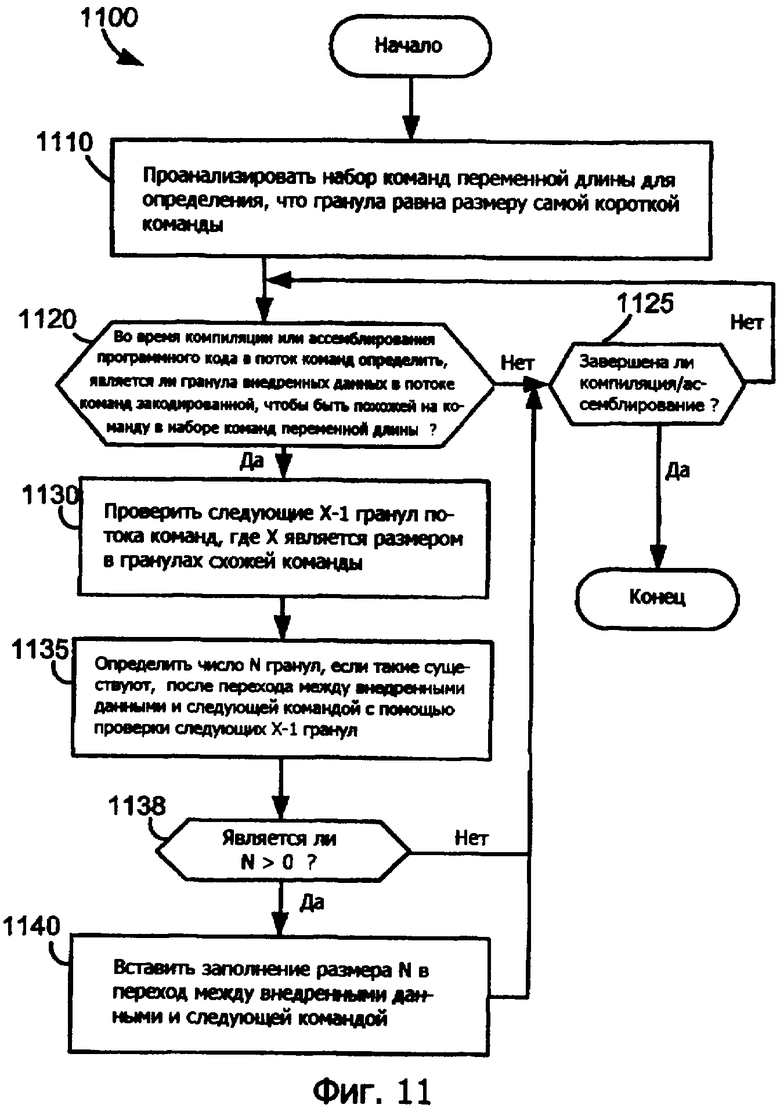
Фиг.11 является блок-схемой последовательности операций способа, которая иллюстрирует способ для вставки заполнения переменного размера в программный код согласно второму варианту осуществления изобретения.
Подробное описание
Теперь настоящее изобретение будет описано более полно со ссылкой на сопроводительные чертежи, в которых показаны несколько вариантов осуществления изобретения. Это изобретение может, однако, быть реализовано в различных формах и не должно толковаться как ограничивающее варианты осуществления, изложенные в данном документе. Скорее эти варианты осуществления предусматриваются так, что это раскрытие изобретения будет детальным и полным и будет полностью передавать объем изобретения специалистам в данной области техники.
Будет принято во внимание, что настоящее изобретение может быть реализовано как способы, системы или компьютерные программные продукты. Соответственно настоящее изобретение может принять форму варианта осуществления аппаратного обеспечения, варианта осуществления программного обеспечения или вариант осуществления, объединяющий программные и аппаратные аспекты. Более того, настоящее изобретение может принимать форму компьютерного программного продукта на машиноиспользуемом носителе информации, который имеет машиноиспользуемый программный код, реализованный в носителе информации. Любой подходящий машиночитаемый носитель информации может использоваться, включая приводы на жестком диске, компакт-диски, оптические устройства хранения данных, флэш-ПЗУ (постоянные запоминающие устройства) или магнитные запоминающие устройства.
Компьютерный программный код, который может быть компилирован, ассемблирован, предварительно декодирован после компилирования или ассемблирования или тому подобного согласно идеям изобретения, может быть сначала записан в языке программирования, например С, С++, в собственной системе команд Ассемблера, JAVA®, Smalltalk, JavaScript®, Visual Basic®, TSQL, Perl или в других различных языках программирования. Программный код или машиночитаемый носитель информации ссылается на код машинного языка, например, объектный код, формат которого понятен процессору. Программные варианты осуществления изобретения не зависят от их реализации с помощью конкретного языка программирования.
Фиг.1 показывает примерную беспроводную систему 100 связи, в которой вариант осуществления изобретения может быть преимущественно использован. Для целей иллюстрации фиг.1 показывает три удаленных блока 120, 130 и 150 и две базовых станции 140. Признается, что типичная беспроводная система связи может иметь много удаленных блоков и базовых станций. Удаленные блоки 120, 130 и 150 включают в себя компоненты аппаратного обеспечения, выполняющие программный код 125А, 125В и 125С, соответственно. Программный код 125А, 125В и 125С изменяется согласно идеям изобретения, как обсуждается дополнительно ниже. Фиг.1 показывает сигнал 180 опережающей линии связи от базовых станций 140 и удаленных блоков 12, 13 и 15 и сигнал 190 обратной линии связи от удаленных блоков 12, 13 и 15 к базовым станциям 140.
На фиг.1 удаленный блок 120 показан как мобильный телефон, удаленный блок 130 показан как портативный компьютер и удаленный блок 150 показан как удаленный блок фиксированного расположения в системе местной радиосвязи. Например, удаленные блоки могут быть сотовыми телефонами, карманными устройствами системы персональной связи (PCS), портативными устройствами данных, например персональными цифровыми помощниками или устройствами данных фиксированного расположения, например оборудование с показаниями прибора. Хотя фиг.1 иллюстрирует удаленные блоки согласно идеям изобретения, изобретение не ограничено этими примерными иллюстративными блоками. Изобретение может быть соответственно использовано в любой среде конвейерной обработки, где используется уровень предварительного декодирования или механизм для предварительного декодирования строки команд, которая включает в себя команды переменной длины и внедренные данные.
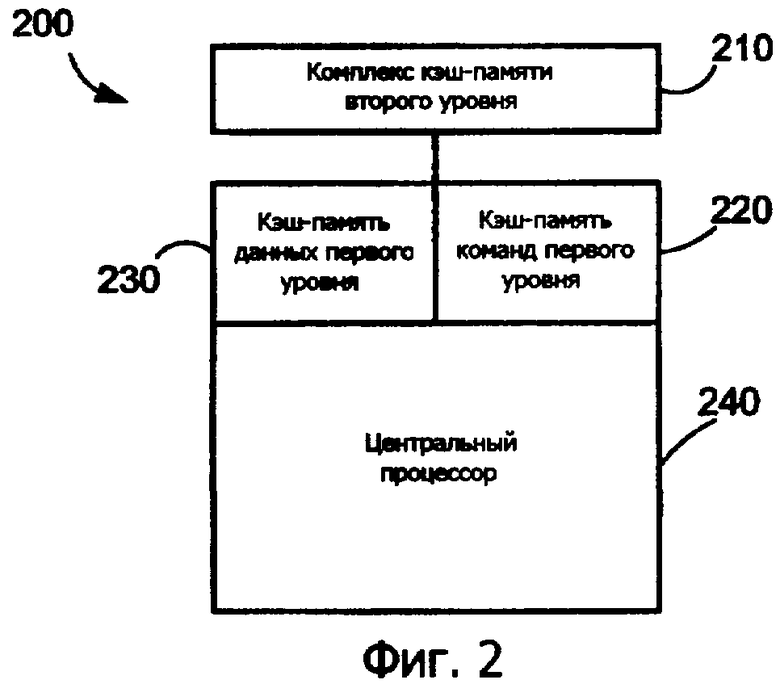
Фиг.2 показывает комплекс 200 процессоров, в котором вариант осуществления изобретения может быть преимущественно использован. Комплекс 200 процессоров может быть соответствующим образом использован для выполнения и хранения программного кода 125A-C, измененного согласно идеям изобретения. Комплекс 200 процессоров включает в себя центральный процессор 240 (CPU), кэш-память 230 данных первого уровня, кэш-память 220 команд первого уровня и кэш-память 210 команд и данных второго уровня. CPU 240 соединяется с кэш-памятью 230 данных первого уровня, кэш-памятью 220 команд первого уровня и кэш-памятью 210 команд второго уровня. CPU 240 во время этапа предварительного декодирования предварительно декодирует программный код и записывает предварительно декодированную информацию с программным кодом либо в кэш-память 220 команд первого уровня, либо в кэш-память 210 команд второго уровня, если кэш-память команд первого уровня заполнена. CPU 240 извлекает команды и данные из кэш-памяти иерархическим образом. Например, когда CPU 240 необходимо вызвать команду, CPU 240 будет осуществлять доступ к кэш-памяти 220 команд первого уровня, чтобы определить соответствие. Если нет соответствия в кэш-памяти 220 команд первого уровня, CPU 240 будет осуществлять доступ к кэш-памяти 210 команд и данных второго уровня. Аналогично, когда CPU 240 необходимо вызвать данные, CPU 240 будет осуществлять доступ к кэш-памяти 230 данных первого уровня для определения соответствия. Если нет соответствия в кэш-памяти 230 данных первого уровня, CPU 240 будет осуществлять доступ к кэш-памяти 210 команд и данных второго уровня. Варианты осуществления изобретения не ограничиваются проиллюстрированным комплексом 200 процессоров и дополнительно применимы к любому комплексу процессоров, использующему механизм предварительного декодирования, например любые процессоры компьютера с сокращенным набором команд (RISC), с помощью примера. Признается, что изобретение не ограничивается средой RISC.
Фиг.3 показывает иллюстративный программный сегмент 300, содержащий заполнение согласно первому варианту осуществления изобретения, в которое вставляется заполнение постоянной длины. Программный сегмент 300 может быть соответствующим образом сохранен в строке кэш-памяти или строках кэш-памяти второго уровня, например кэш-памяти 210 второго уровня или в программном запоминающем устройстве. Следует заметить, что хотя для целей иллюстрации программный сегмент предполагается извлекать из строки кэш-памяти или строк, идеи изобретения применимы к обработке программного сегмента безотносительно запоминающего устройства, из которого извлекается программный сегмент. Так как строка кэш-памяти типично имеет фиксированную длину, термины строки команд или потока команд типично относятся к одному или более программным сегментам, которые могут охватывать или не охватывать строку кэш-памяти. Более того, программный сегмент 300 может также иллюстрировать часть строки кэш-памяти.
Иллюстративный программный сегмент 300 включает в себя команду 310, внедренные данные 320 и заполнение 330. Команды 310 происходят из набора команд переменной длины. Несколько примерных команд проиллюстрированы на фиг.3 из набора команд переменной длины. Команды в наборе команд переменной длины в этом примере равны 16 или 32 битам. Для иллюстративных целей признак 305 байта иллюстрирует расположение байт в строке кэш-памяти, где начинается команда, и указывает размер команды. Например, команда загрузки 0A начинается в положении 00 байта и заканчивается в положении 03 байта. Таким образом, загрузка 0A является командой из 32 бит. Аналогично команды сложения являются командами из 16 бит, а команда ветвления равна 32 битам. В программном сегменте 300 байты 322 и 324 внедренных данных следуют за командой ветвления. Холостые байты 332 и 334 заполнения 330 были вставлены согласно идее изобретения после байта 324 данных. Команда 326 сложения следует за холостым байтом 334.
Внедренные данные 320 не являются непосредственными данными и в целом относятся к близлежащей команде в программном сегменте, например команде 312 загрузки. Расположенность внедренных данных, в целом, является предметом удобства для стандартного компилятора. Многие стандартные компиляторы, например компилятор ARM®, типично формируют внедренные данные 320 в пределах программного сегмента. Одной причиной, что стандартный компилятор может внедрять данные, не связанные с прилегающими командами, является то, что необходимо предоставить близлежащим командам более легкий доступ к пространству данных. Например, команды загрузки могли бы допускать использовать меньше бит смещения, когда адресуют данные. Ссылаясь на фиг.3, команда 312 загрузки 0A загружает байты 322 и 324 данных, которые начинаются в смещении 0А.
Для того чтобы проиллюстрировать преимущественную отличительную черту изобретения с помощью примера, сначала опишем ситуацию, в которой внедренные данные 230 случайно подобны первым двум байтам команды загрузки в 32 бита, и заполнение 330 не добавлено. В этом обстоятельстве во время операции предварительного декодирования конвейерного процессора устройство предварительного декодирования обрабатывает строку кэш-памяти проверкой с помощью команд строки кэш-памяти проверкой в 16 бит в момент времени.
Устройство предварительного декодирования частично декодирует каждую команду и последовательно записывает полную строку кэш-памяти с предварительно декодированной информацией обратно в кэш-память, например кэш-память 220 команды первого уровня и, если кэш-память первого уровня является полной, в кэш-память 210 второго уровня. Предварительно декодированная информация, в целом, может включать в себя информацию, например, где начинается команда в строке кэш-памяти для операции последовательного декодирования, является ли командой загрузки или хранения, является ли команда арифметической, является ли команда первой или второй половиной большей команды, является ли команда сложной и тому подобное. Из-за присутствия внедренных данных 320, которые мы подразумевали схожими с первой частью команды загрузки, внедренные данные будут некорректно интерпретированы как часть команды загрузки устройством предварительного декодирования. В этом примере последовательная команда 336 сложения будет некорректно предварительно декодирована как вторая половина команды загрузки.
Обращаясь к операции устройства предварительного декодирования с заполнением 330, добавленного, как показано на фиг.3, устройство предварительного декодирования будет выполнять шаг по строке 300 кэш-памяти в грануле с помощью базового компонента гранулы. Гранула является единицей измерения, равной размеру команды самой короткой длины в наборе команд переменной длины. Для этого примера набор команд содержит 16-битовые и 32-битовые команды. Таким образом, одна гранула равняется 16 битам. В целом размер внедренных данных является кратным грануле для набора команд. Относительно программного сегмента 300 устройство предварительного декодирования сначала проверяет первую гранулу, первые 16 бит команды 312 загрузки 0А, за которой следует вторая гранула, вторые 16 бит команды 312 загрузки 0А. Во-вторых, устройство предварительного декодирования проверяет следующую гранулу, 16 битов 16-битовой команды сложения. В-третьих, устройство предварительного декодирования проверяет следующую гранулу, первые 16 битов команды ветвления 0Е. Так как внедренные данные 320 оказываются первыми 16 битами команды загрузки, устройство предварительного декодирования предварительно декодирует внедренные данные 320, за которыми следует заполнение 330, как если бы они вместе составляли 32-битовую команду загрузки. Таким образом, из-за вставленного заполнения согласно идеям изобретения устройство предварительного декодирования преимущественно поддерживает синхронизацию со следующей командой в строке кэш-памяти так, что когда оно проверяет следующую гранулу, команда сложения, начинающаяся в положении 0Е байта, оно правильно определяет команду сложения. Как обсуждено выше, без вставленного заполнения, устройство предварительного декодирования будет предварительно декодировать команду 336 сложения, как если бы это были остающиеся 16 битов команды загрузки, что приводит в устройстве предварительного декодирования к некорректному предварительному декодированию команды 336 сложения и, возможно, также последующих команд.
Если строка кэш-памяти предварительно декодирована, строка кэш-памяти и предварительно декодированная информация записывается в кэш-память и готова для последовательной операции декодирования и выполнения. Следует отметить, что устройство предварительного декодирования может сформировать неверную предварительно декодированную информацию из-за предварительного декодирования внедренных данных и заполнения 330 как остающихся 16 битов команды загрузки. Подобная неверная предварительно декодированная информация не имеет значения, так как, когда программа действительно выполняется, по свойству последовательности выполнения программы, указатель команд не будет направлен для выполнения внедренных данных или внедренного заполнения. Например, после выполнения команды ветвления 0Е указатель команд будет указывать на адрес 0Е и вызывать дальнейшее выполнение команды 336 сложения, пренебрегая внедренными данными 320 и заполнением 330 и любой ассоциативно связанной неправильной предварительно декодированной информацией.
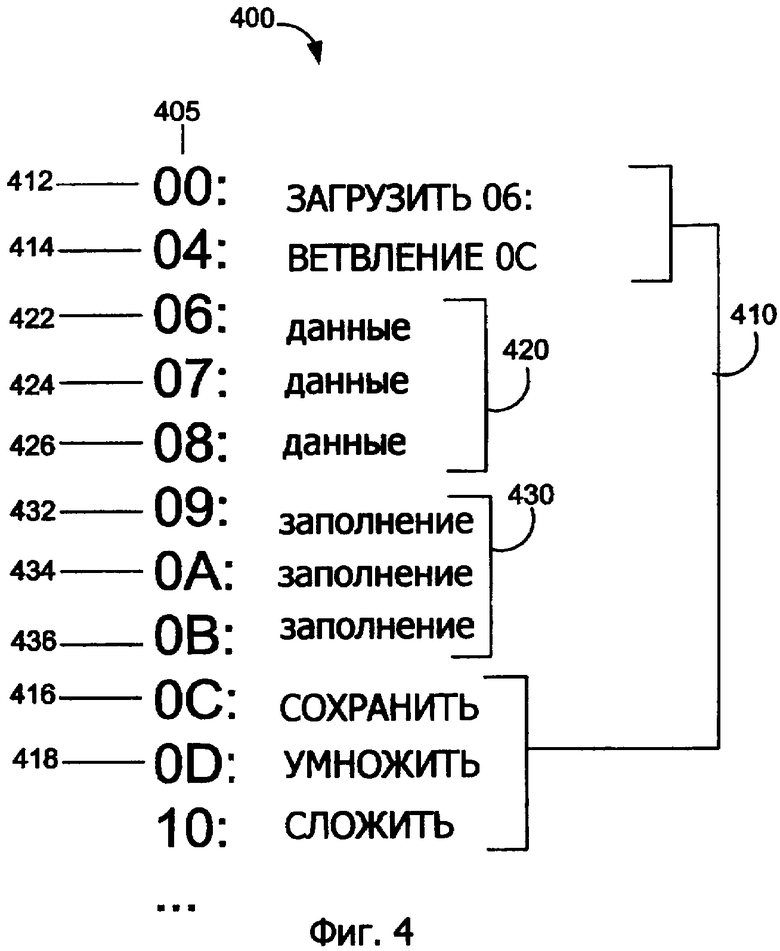
Фиг.4 показывает иллюстративный программный сегмент 400, который содержит три холостых байта для набора команд переменной длины, который имеет размеры команда 8, 16, 24 и 32 бита согласно первому варианту осуществления изобретения. Программный сегмент 400 может быть подходящим образом сохранен как часть строки кэш-памяти, строка кэш-памяти или множественные строки кэш-памяти кэш-памяти второго уровня, например, кэш-памяти 210 второго уровня. Альтернативно программный сегмент 400 может храниться в некоторой другой форме программного запоминающего устройства. Программный сегмент включает в себя команды 400, внедренные данные 420 и заполнение 430. В этом примере команды 410 исходят от набора команд переменной длины, который имеет длины в 8, 16, 24 или 32 бита. Размер гранулы для набора команд переменной длины равен 8 битам или одному байту. Для целей пояснения признак 405 байта иллюстрирует расположение байта в строке кэш-памяти. В программном сегменте 400 внедренные данные 420 следуют за командой 414 ветвления. Байты 432, 434 и 436 заполнения 430 были вставлены согласно идее изобретения после байта 426 данных в положениях 09, 0А и 0В байта, соответственно. Команда 416 сохранения (команда STOR), 8-битовая команда, следует за холостым байтом 436 и начинается в положении ОС байта. Команда 418 умножения (MULT), 24-битовая команда, начинается в следующем положении 0D байта.
Так как наименьшая команда в этом примере равна одному байту, гранула равна одному байту. Устройство предварительного декодирования будет проверять одну гранулу в момент обработки программного сегмента 400. Для всех программных сегментов 400, 500 и 600 фиг.4-6, соответственно, устройство предварительного декодирования действует по первым восьми байтам соответствующего программного сегмента тем же самым образом. Для того, чтобы упростить рассмотрение, опишем действие этих восьми байт со ссылкой на фиг.4. Устройство предварительного декодирования будет проверять первую гранулу команды 412 загрузки 06, будет определять, что первая гранула является командой загрузки, и последовательно проверять следующие три гранулы, положения 01-03 байта из строки кэш-памяти для предварительного декодирования команды 412 загрузки 06. Устройство предварительного декодирования затем будет проверять первую гранулу команды 414 ветвления 0С, определять, что первая гранула является командой ветвления 0С, и последовательно проверять следующую гранулу, положение 05 байта из строки кэш-памяти для предварительного декодирования команды 414 ветвления 0С. Байты 422 и 424 данных по-разному кодируются из любой команды в наборе команд переменной длины. Таким образом, устройство предварительного декодирования будет проверять гранулу в положении 06 байта, определять, что она содержит данные и продолжать. Оно продолжает проверять следующую гранулу в положении 07 байта, байт 424 данных и корректно определяет, что байт 424 данных также содержит данные.
Для примера, проиллюстрированного на фиг.4, байт 426 данных случайно совпадет с первыми 8 битами 32-битовой команды, например, команда загрузки. Последовательно, после того, как устройство предварительного декодирования предварительно декодирует байт 426 данных как первую часть 32-битовой команды загрузки, устройство предварительного декодирования будет рассматривать следующие три гранулы, холостые байты 432, 434 и 436, как если бы эти три байта являлись остатком этой случайной команды загрузки. Из-за заполнения 430 следующая команда 416 STOR будет корректно предварительно декодирована, таким образом, поддерживая синхронизацию между устройством предварительного декодирования и командами в строке кэш-памяти. Без вставляемого заполнения 430 устройство предварительного декодирования неправильно поймет байты, соответствующие команды 416 STOR и команды 418 MULTI, как байты, соответствующие последним 3 байтам случайной команды загрузки, что приводит в устройстве предварительного декодирования к предварительному декодированию команды 416 STOR, как второго байта случайной команды загрузки, и первых двух байтов команды 418 MULTI, как последних двух байтов случайной команде загрузки, таким образом заставляя устройство предварительного декодирования выйти из синхронизации с командами в строке кэш-памяти.
Как дополнительный пример, если байт 426 данных фиг.4 был закодирован, случайно совпадая с первыми 8 битами 24-битовой команды, подобно команде MULTI, устройство предварительного декодирования проверит следующие две гранулы, холостые байты 432 и 434, как если бы эти два байта принадлежали бы к случайной команде MULTI. Устройство предварительного декодирования проверяет затем следующую гранулу, холостой байт 436. Если холостой байт 436 был закодирован как 8-битовая команда или закодирован как данные, определяемые из набора команд, адресуемых дополнительно ниже, устройство предварительного декодирования проверяет затем следующую гранулу, найденную в положении 0С байта команды 416 STOR. Этот пример иллюстрирует, что безотносительно того, как байт 426 данных неверно понимается, заполнение 430 предотвращает целостность определения команды, следующей за внедренными данными.
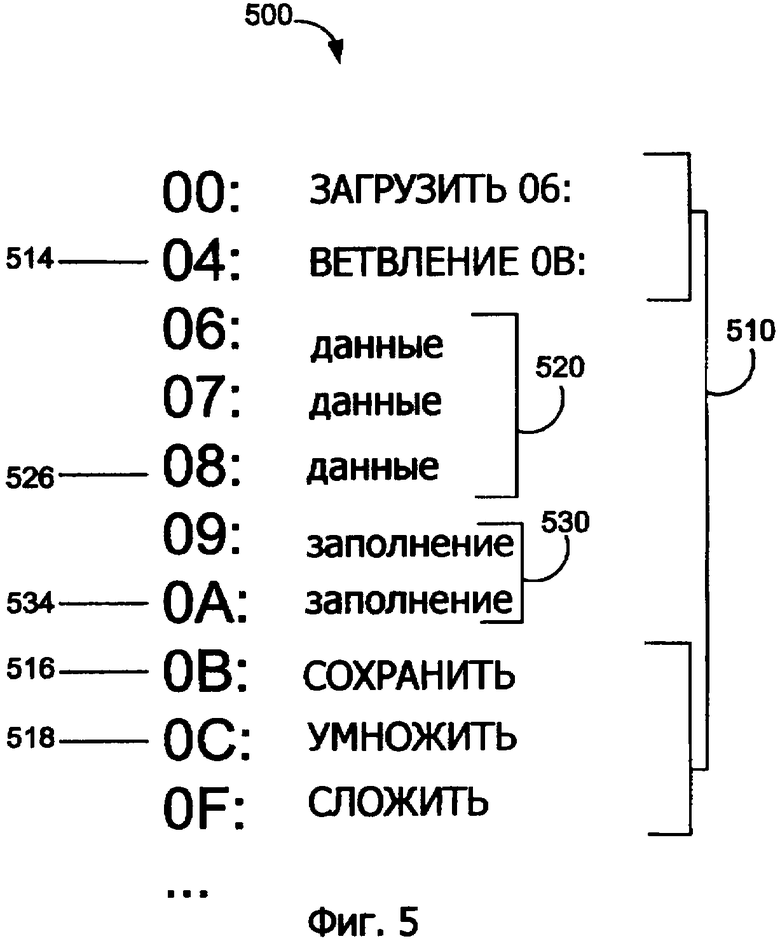
Фиг.5 показывает иллюстративный программный сегмент 500, содержащий два холостых байта для набора команд переменной длины, который имеет размеры команд 8, 16, 24 и 32 бита согласно второму варианту осуществления изобретения, в котором используется изменяющийся размер заполнения. Фиг.5 иллюстрирует, как другой размер заполнения может быть вставлен в программный код, зависящий от того, как внедренные данные, которые совпадают с командой, неправильно понимаются устройством предварительного декодирования. Использование заполнения переменной длины преимущественно уменьшает размер программного кода. Программный сегмент 500 включает в себя команды 510, данные 520 и заполнение 530. Программный сегмент 500 является тем же самым, как и программный сегмент 400, исключая, что программный сегмент 500 имеет на один холостой байт меньше в заполнении 530, и, таким образом, команды, следующие за холостым байтом 534, сдвигаются на одно положение байта вверх в строке кэш-памяти. Из-за сдвига конечный адрес команды 514 ветвления 0В уменьшен на один байт.
Пример, проиллюстрированный на фиг.5, включает в себя байт 526 данных, который случайно совпадает с первыми 8 битами 24-битовой команды в наборе команд переменной длины. Таким образом, когда устройство предварительного декодирования начинает предварительно декодировать байт 526 данных, устройство предварительного кодирования проверяет следующие две гранулы, холостые байты 532 и 534, как если бы эти два байта являлись остатком случайной 24-битовой команды. Устройство предварительного декодирования затем проверяет следующую гранулу, команду 516 STOR для предварительного декодирования, поддерживающего синхронизацию между устройством предварительного кодирования и командами в строке кэш-памяти. В примере, проиллюстрированном на фиг.5, заполнение двух байтов скорее является достаточным, чем заполнение трех байтов, используемого в фиг.4.
Без вставляемого заполнения 530 устройство предварительного декодирования неправильно понимает гранулы, соответствующие команде 516 STOR и команде 518 MULTI как байты, соответствующие последним двум байтам случайной 24-битовой команде, приводящей к выходу устройства предварительного декодирования из синхронизации с помощью строки кэш-памяти. Таким образом, целостность определения команды, следующей за внедренными данными, подвергается риску.
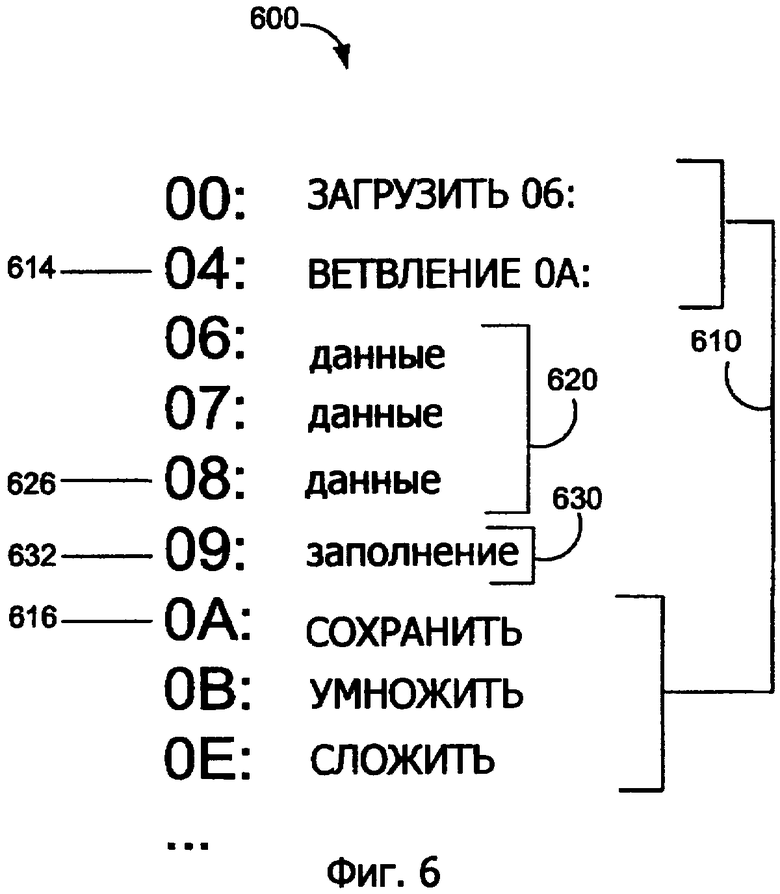
Фиг.6 показывает иллюстративный программный сегмент 600, содержащий один холостой байт для набора команд переменной длины, который имеет размеры команд 8, 16, 24 и 32 бита согласно второму варианту осуществления изобретения. Фиг.6 иллюстрирует, как только один холостой байт может быть вставлен в программный код в зависимости от того, как данные неправильно поняты устройством предварительного декодирования. Программный сегмент 600 включает в себя команду 610, данные 620 и заполнение 630. Программный сегмент 600 является тем же самым программным сегментов 500, исключая, что программный сегмент 600 на один холостой байт меньше в заполнении 630, и таким образом, команды, следующие за холостым байтом 632, сдвигаются на одно положение байта в строке кэш-памяти. Из-за сдвига конечный адрес команды 614 ветвления 0А уменьшен на один байт.
Пример, проиллюстрированный на фиг.6, включает в себя байт 626 данных, который случайно совпадает с первыми 8 битами 16-битовой команды в наборе команд переменной длины. Когда устройство предварительного декодирования начинает предварительно декодировать байт 626 данных, устройство предварительного декодирования проверяет следующую гранулу, холостой байт 632, как если бы холостой байт 632 принадлежал бы к 16-битовой команде, обозначаемой байтом 626 данных. Устройство предварительного декодирования затем проверяет следующую гранулу, команду 616 STOR для предварительного декодирования, поддерживая синхронизацию между устройством предварительного декодирования и командами в строке кэш-памяти. В примере, проиллюстрированном на фиг.6, так как байт 632 данных совпадает с первыми 8 битами 16-битовой команды, заполнение размером в один байт является достаточным.
Как показано в примерах, описанных в связи с фиг.5 и 6, размер заполнения, вставляемого после вставленных данных, может различаться. Так как программный компилятор или ассемблер, выполняющийся на компьютере, формирует программный код, имеющий команды и внедренные данные, как проиллюстрировано на фиг.3-6 с языка программирования более высокого уровня, компилятор или ассемблер могут определять, когда внедренные данные совпадают с командой из набора команд переменной длины и, соответственно, вставлять заполнение. Как обсуждается дополнительно ниже, может использоваться заполнение фиксированной длины или переменной длины.
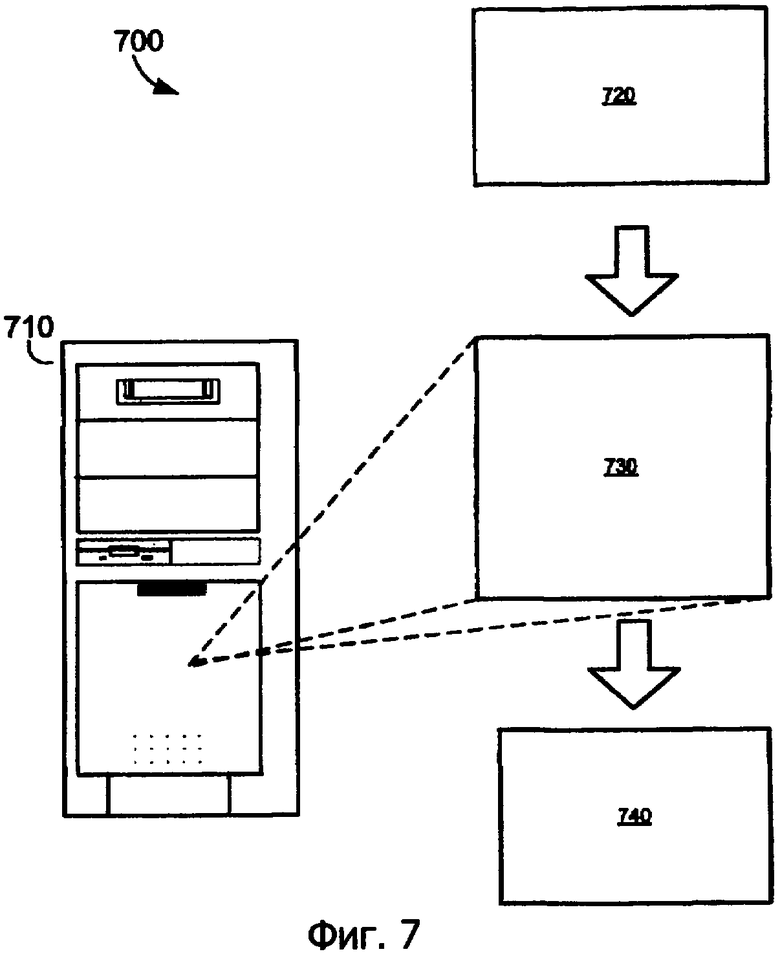
Фиг.7 является блок-схемой 700 компьютера 710, выполняющего программное обеспечение 730 согласно идеям изобретения. Хотя и не проиллюстрировано, компьютер 710 включает в себя внутренние компоненты, например процессор, запоминающее устройство, устройства ввода/вывода и шину для взаимодействия между этими внутренними компонентами. Программное обеспечение 730 может соответствующим образом быть компилятором или ассемблером, который изменяется согласно идеям изобретения. Программное обеспечение 730 постоянно хранится в запоминающем устройстве компьютера 710. Программное обеспечение 730 принимает программу 720 как ввод и формирует компилированный или ассемблированный программный код 740 с заполнением, вставленным согласно изобретению как вывод. Программа 720 может быть написана на C, С++, в собственной системе команд Ассемблера, JAVA®, Smalltalk, JavaScript®, Visual Basic®, TSQL, Perl или в других различных языках программирования. Программа 720 записывается для выполнения конкретной функции в целевом процессоре, например, содержащегося в сотовом телефоне, карманных устройствах системы персональной связи (PCS), компьютере и портативных устройствах данных, тогда как программный код 740 выполняется в целевом процессоре. Целевой процессор может являться или может не являться другим, чем компьютер 710, который выполняет программное обеспечение 730.
Программное обеспечение 730 включает в себя средство для проведения синтаксического анализа программы 720, чтобы определить структурное содержание программы 720 и если программа 720 синтаксически верная. Средство для проведения синтаксического анализа также преобразовывает программу 720 во внутреннюю форму. Программное обеспечение 730 дополнительно включает в себя средство для формирования кода. Средство для формирования кода транслирует внутреннюю форму в объектный код, который может выполняться целевым процессором. Объектный код состоит из одного или более программных сегментов, которые имеют внедренные данные и команды из набора команд переменной длины. Программное обеспечение 730 дополнительно включает в себя средство для вставки заполнения в конце сегмента внедренных данных.
Для того чтобы вычислить размер заполнения для вставки между вставленными данными и последующей команды, программное обеспечение 730 включает в себя дополнительное средство анализа для анализа содержимого сегмента внедренных данных. Сегмент внедренных данных является внедренными данными в потоке команд, окруженный командами. Программное обеспечение 730 дополнительно включает в себя дополнительное средство определения. Во время компиляции программы 720 средство определения определяет, были ли закодированы какие-либо гранулы в пределах сегмента внедренных данных, чтобы быть похожими на гранулу команды в наборе команд. Если так, то средство вставки вставляет множество холостых гранул после внедренных данных, принимая во внимание длину команды, с которой гранула внедренных данных имеет сходство, и расположение гранулы внедренных данных относительно последующей команды.
Альтернативно программное обеспечение 730 может дополнительно включать в себя средство для вставки заполнения постоянного размера. Этот альтернативный подход преимущественно уменьшает сложность программного обеспечения 730 тем, что не нужно анализировать кодирование внедренных данных. В этом альтернативном варианте осуществления программное обеспечение 730 включает в себя средство для обнаружения перехода между концом сегмента внедренных данных и командой. Средство вставки затем вставляет заполнение, которое имеет постоянный номер холостых гранул, когда определяется переход от сегмента внедренных данных к команде. Каждая холостая гранула вставленного заполнения может быть соответствующим образом закодирована, чтобы содержать допустимую команду, которая имеет длину одной гранулы, уже определенной в наборе команд, или может просто содержать данные, которые необходимо кодировать и которые не имеют сходство с любой командой в наборе команд. Альтернативное кодирование заполнения обсуждается дополнительно в связи с рассмотрением фиг.9 ниже.
Для того чтобы определить число холостых гранул, формирующих заполнение постоянного размера, которое необходимо вставить в программный код 740, программное обеспечение 730 использует команды различной длины, которые формируют набор команд, поддерживаемый целевым процессором. Число холостых гранул, формирующих заполнение постоянного размера, может быть записано как:
PZ= (Max(instrlen) - Min(instrlen))/Min{instrlen)
(1),
что упрощается до
Pz = (Max(instrlen)/Min(instrlen)) -1 и для удобства
(2)
MAX = (Max(instrlen)/Min(instrlen)), таким образом упрощая
(3)
Pz = MAX-l  (4),
(4),
где Pz является размером заполнения в гранулах, Max(instrlen) является длиной самой длинной команды в битах, Min(instrlen) является длиной самой короткой команды в битах и MAX является длиной самой длинной команды в гранулах. Например, в наборе команд, имеющей 32- и 16-битовые команды, одна гранула равна 16 битам команды самой короткой длины. Число заполнений в гранулах равно (32[бита]/16[битов/гранула])-1, что равняется одной грануле или 16 битам. Таким образом, заполнение, содержащее 16-битовую команду, взятое из набора команд, может быть вставлено, где бы не существовал переход между данными и следующей командой.
С помощью другого примера в наборе команд, имеющем 32-, 16- и 8-битовые команды, одна гранула равняется 8 битам, самой короткой команды. Число заполнений в гранулах равно (32[бита]/8[битов/гранула])-1, что равняется трем гранулам или 24 битам. Таким образом, 24-битовое заполнение может затем быть вставлено, где бы ни существовал переход между данными и следующей командой. Другие возможные варианты того, что составляет 24-битовое заполнение, дополнительно описаны ниже в связи с рассмотрением фиг.9. Содержимое заполнения переменной длины описывается ниже в связи с фиг.11.
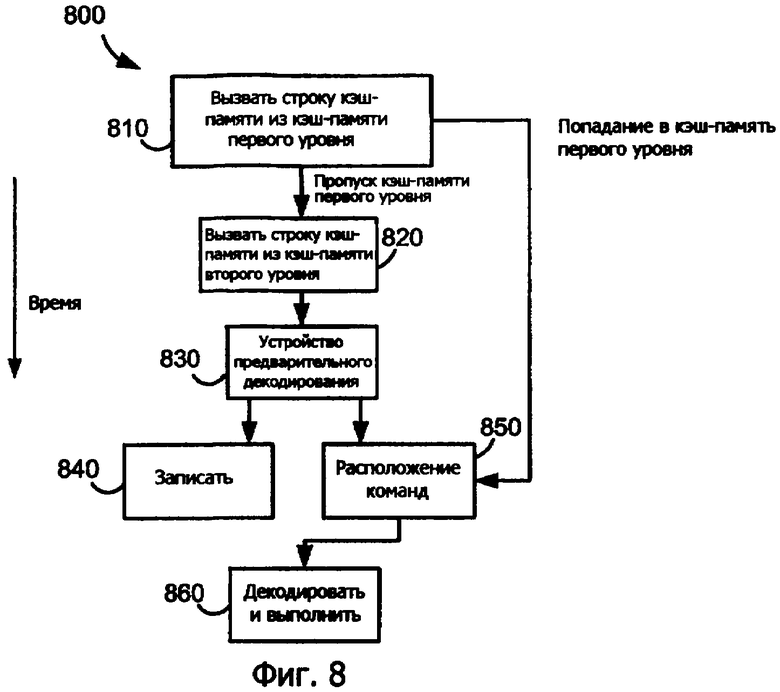
Фиг.8 является блок-схемой процессорного конвейера 800, который функционирует согласно варианту осуществления изобретения. Процессорный конвейер 800 включает в себя вызов из ячейки 810 кэш-памяти первого уровня, вызов из кэш-памяти 820 второго уровня, устройство 830 предварительного декодирования, ячейку 840 записи, ячейку 850 расположения команд и ячейку 860 декодирования и выполнения.
В вызове из ячейки 810 кэш-памяти первого уровня строка кэш-памяти вызывается из кэш-памяти первого уровня на основе адреса. Строка кэш-памяти может содержать один или более программных сегментов, которые могут быть аналогичны примерным программным сегментам, проиллюстрированным на фиг.3-6. Если существует пропуск в кэш-памяти, строка кэш-памяти вызывается из кэш-памяти второго уровня, как показано в ячейке 820 вызова, и направляется в устройство 830 предварительного декодирования. Устройство 830 предварительного декодирования определяет число гранул, которые составляют команду в строке кэш-памяти. Устройство 830 предварительного декодирования использует число гранул для выполнения соответствующего предварительного декодирования команды. Если предварительное декодирование команды завершается, итоговая предварительно декодированная информация сохраняется временно в буфере, и следующая команда в строке кэш-памяти предварительно декодируется. Если больше нет гранул для обработки в строке кэш-памяти, конвейер переходит к ячейке 840 записи. В ячейке 840 записи предварительно декодированная информация и строка кэш-памяти записываются в кэш-память первого уровня. Параллельно устройство 830 предварительного декодирования перемещает строку кэш-памяти и предварительно декодированную информацию в ячейку 850 расположения команд. В ячейке 850 расположения команд располагаются команды в строке кэш-памяти и готовы для ячейки 860 последующего декодирования и выполнения.
Следует заметить, что устройство 830 предварительного декодирования предварительно не декодирует внедренные данные, которые не совпадают с командой. Однако, если внедренные данные совпадают с командой, внедренные данные и потенциальное заполнение могут быть предварительно декодированы. Как описано выше, подобная ошибочная предварительно декодированная информация не имеет значения, так как, когда программа действительно выполняется благодаря процессу выполнения программы, указатель команд не направляется для выполнения внедренных данных или внедренного заполнения. Варианты осуществления изобретения не ограничены проиллюстрированным конвейером 800 и дополнительно применимы к любому конвейерному процессору, который включает в себя операцию предварительного декодирования, которая предварительно декодирует наборы команд переменной длины.
Для программных сегментов, как показано на фиг.3-6, устройство предварительного декодирования действует в программном сегменте в грануле на основе гранулы, пока гранула не определится как команда в наборе команд. Когда гранула определяется как команда в наборе команд, одна или более дополнительных гранул проверяются для предварительного декодирования целой команды. С помощью кодирования содержимого заполнения для сходства с командами в наборе команд устройство предварительного декодирования может отслеживать следующую команду более эффективно.
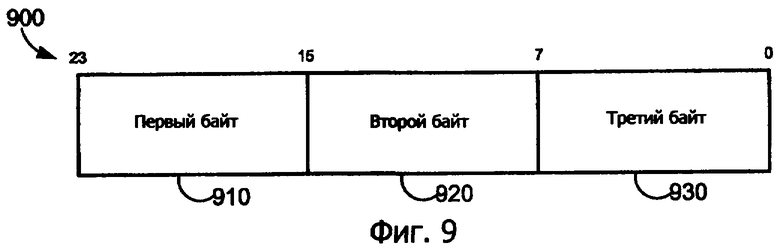
Фиг.9 иллюстрирует телескопический подход к кодированию для постоянного размера заполнения 900 для набора команд, который имеет 32-, 24-, 16- и 8-битовые команды согласно варианту осуществления изобретения. Согласно формуле (2) выше максимальный размер заполнения равен трем гранулам или байтам для этого конкретного набора команд переменной длины. Заполнение 900 вставляется, когда бы ни находился переход между внедренными данными и последующей командой в конце внедренных данных. Это заполнение 900 может состоять из данных, которые не определяются как гранула команды. Альтернативно заполнение 900 может состоять из изменяющихся комбинаций команд, взятых из набора команд. Например, заполнение может содержать три 8-битовых команды или телескопическое кодирование. Телескопическое кодирование может содержать первый байт 910, закодированный для определения как первый байт 24-битовой команды, второй байт 920, который закодирован для определения как первый байт 16-битовой команды, и третий байт 930, который закодирован для определения как 8-битовая команда. С помощью телескопического кодирования 24-битового заполнения 900 устройство 830 предварительного декодирования может синхронизироваться с последующей командой после того, как 24-битовое заполнение 900 безотносительно того, где в 24-битовом заполнении операция предварительного декодирования прекращается неправильным декодированием внедренных данных как команды.
Фиг.10 является блок-схемой последовательности операций способа, которая иллюстрирует способ 1000 для вставки заполнения постоянного размера в программный код, например, программный код 740 согласно первому варианту осуществления изобретения. Программное обеспечение 730, как описано выше, выполняющееся на компьютере 710, может реализовать этапы способа 1000. На этапе 1010 способ анализирует длины набора команд переменной длины, поддерживаемого конвейерным процессором для определения размера заполнения. На этапе 1010 уравнение (2), приведенное выше, используется для определения размера заполнения. На этапе 1015 определяется содержимое заполнения. Одним примером является составление заполнения известной команды из набора команд, длина которой равна размеру заполнения. Например, в наборе команд переменной длины, которая имеет и 16-битовые и 32-битовые команды, размер заполнения равен 16 битам. Таким образом, выбор 16-битовой команды из набора команд, который необходимо вставить как заполнение. В другом примере создание заполнения с помощью выбора самой короткой команды из набора команд и соединение его множество раз, пока оно не достигнет того же размера заполнения. Дополнительным примером является изобретение телескопического кодирования или выбор телескопической команды из набора команд, как описывается в фиг.9, если она существует. В другом примере заполнение может содержать данные, которые отличны от команд в наборе команд. Как описано выше в связи с фиг.3, предварительно декодированная информация, возникающая из предварительного декодирования внедренных данных, или заполнение не имеет значения, так как процесс выполнения программы обычно не приводит к выполнению внедренных данных или заполнения. Признается, что альтернативно ячейка выполнения может быть изменена для определения заполнения в маловероятной ситуации, где ячейка выполнения делает попытку выполнять внедренные данные или заполнение.
На этапе 1020 во время формирования программного кода либо программным компилятором, либо на этапе ассемблирования способ определяет, существует ли точка перехода между внедренными данными и следующей командой. Если не существует внедренных данных, способ переходит к этапу 1040. Если существуют внедренные данные, способ переходит к этапу 1030. На этапе 1030 заполнение вставляется в программный код в точке перехода между внедренными данными и следующей командой. На этапе 1040 способ определяет, завершено ли формирование программного кода. Если да, способ 1000 заканчивается, и программный код сформирован со вставленным в него заполнением. Если нет, способ 1000 приступает к этапу 1020, где он продолжает вставлять заполнение в переходах между внедренными данными и последующими командами. Когда способ завершается, сформированный программный код содержит заполнение так, чтобы допускать устройству предварительного декодирования корректно определять команды переменной длины как команды, если внедренные данные похожи на команду.
Фиг.11 является блок-схемой последовательности операций способа, которая иллюстрирует способ 1100 для вставки заполнения переменного размера в программный код согласно второму варианту осуществления изобретения. Программное обеспечение 730, как описано выше, выполняющееся на компьютере 710, может реализовать этапы способа 1100. На этапе 1110 способ анализирует набор команд переменной длины для определения, что гранула равна размеру самой короткой команды. Альтернативно способ может просто знать или ему могут сообщить размер гранулы. Этот этап может быть реализован как установка выбора компилятора в программном обеспечении 730, который передает данные программному обеспечению 730 о команде с самой короткой длиной в наборе команд. Альтернативно, так как программное обеспечение 730 формирует программный код, который включает в себя команды из набора команд, программное обеспечение 730 может уже знать длину самой короткой команды из условия, что этот этап всего лишь включает в себя чтение во время выполнения программного обеспечения 730 для определения размера одной гранулы. На этапе 1120 во время компиляции или ассемблирования программного кода в поток команд способ 1100 определяет, закодирована ли гранула внедренных данных, например, постоянная в потоке команд, чтобы быть похожей на команду из набора команд переменной длины. Если нет, способ 1100 приступает к этапу 1125. На этапе 1125 способ определяет, завершена ли компиляция или ассемблирование. Если да, способ 1100 заканчивается. Иначе способ 1100 продолжается переходом к этапу 1120.
Возвращаясь к этапу 1120, если гранула внедренных данных закодирована так, что она имеет сходство с командой, способ 1100 переходит к этапу 1130. На этапе 1130 способ 1100 проверяет следующие Х-1 гранулы потока команд, где Х является размером в гранулах схожей команды. На этапе 1135 способ 1100 определяет число N гранул, есть ли какие-либо после перехода между внедренными данными и следующей командой проверкой следующих Х-1 гранул, начиная после того, как гранула внедренных данных закодирована, чтобы быть похожей на команду.
Другими словами, этот этап определения рассматривает число гранул, которые последующее устройство предварительного декодирования проверяет для завершения предварительного декодирования команды, гранула внедренных данных которой похожа. Например, если гранула равна одному байту и гранула данных похожа на первый байт 32-битовой команды, способ 1100 проверяет первые три байта из потока команд для определения, существует ли переход от внедренных данных к следующей команде.
Способ 1100 переходит к этапу 1138, где он определяет, больше ли N, чем ноль. Если N не больше, чем ноль, гранула внедренных данных, которая похожа на команду, не будет иметь отношения к последующему устройству предварительного декодирования, так как объем замены, вызванной потенциальной ошибкой предварительного декодирования, находится все еще в пределах внедренных данных, которые имеют похожую команду. Таким образом, способ переходит к этапу 1125. Если N больше, чем ноль, способ переходит к этапу 1140. На этапе 1140 способ 1100 вставляет заполнение в переход между внедренными данными и следующей командой. Вставленное заполнение имеет размер N, равный числу гранул, которые прошли переход между внедренными данными и следующей командой, найденной на этапе 1130. Когда способ завершается, общий программный код будет содержать заполнение так, чтобы дать возможность устройству предварительного декодирования корректно определять команды переменной длины как команды, когда внедренные данные похожи на команду.
Так как фиг.5 показывает иллюстративный результат способа 1100, давайте сошлемся, например, на фиг.5 без заполнения. Повторный вызов этого байта 526 данных случайно похож на первые 8 бит 24-битовой команды, и что одна гранула равна 8 битам, способ 1100 проверяет следующую Х-1 или две гранулы после байта 526 данных. В проверке первой гранулы способ 1100 различает 8-битовую команду 516 STOR и определяет, что случился переход от внедренных данных к команде. В проверке второй гранулы способ 1100 определяет первый байт команды 518 MULTI. Так как первый байт команды 518 MULTI находится в двух гранулах от перехода, N равняется двум гранулам. Следовательно, две гранулы заполнения 530 затем вставляются в переход, как показано на фиг.6. Когда компиляция или ассемблирование завершаются, программный код может содержать вставляемое заполнение, которое имеет различную длину.
Тогда как изобретение раскрывается в контексте вариантов осуществления, признается, что широкий спектр вариантов осуществления может использоваться специалистами в данной области техники, которые согласуются с вышеприведенным обсуждением и формулой изобретения, которая следует ниже.
| название | год | авторы | номер документа |
|---|---|---|---|
| ПРЕДВАРИТЕЛЬНОЕ ДЕКОДИРОВАНИЕ ИНСТРУКЦИЙ ПЕРЕМЕННОЙ ДЛИНЫ | 2007 |
|
RU2412464C2 |
| КОМАНДЫ ЗАГРУЗКИ/ПЕРЕМЕЩЕНИЯ И КОПИРОВАНИЯ ДЛЯ ПРОЦЕССОРА | 2002 |
|
RU2292581C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КЭШИРОВАНИЯ КОМАНД ПЕРЕМЕННОЙ ДЛИНЫ | 2007 |
|
RU2435204C2 |
| ЦЕЛОЧИСЛЕННОЕ УМНОЖЕНИЕ ВЫСОКОГО ПОРЯДКА С ОКРУГЛЕНИЕМ И СДВИГОМ В АРХИТЕКТУРЕ С ОДНИМ ПОТОКОМ КОМАНД И МНОЖЕСТВОМ ПОТОКОВ ДАННЫХ | 2003 |
|
RU2263947C2 |
| ИНСТРУКЦИЯ И ЛОГИКА ДЛЯ ДОСТУПА К ПАМЯТИ В КЛАСТЕРНОЙ МАШИНЕ ШИРОКОГО ИСПОЛНЕНИЯ | 2013 |
|
RU2662394C2 |
| МОДУЛЬ СОПРОЦЕССОРА КЭША | 2011 |
|
RU2586589C2 |
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ МОДЕЛИРОВАНИЯ ПОВЕДЕНИЯ ПРЕДСКАЗАНИЯ ПЕРЕХОДОВ ЯВНОГО ВЫЗОВА ПОДПРОГРАММЫ | 2007 |
|
RU2417407C2 |
| КОМАНДА НА ШИФРОВАНИЕ СООБЩЕНИЯ С АУТЕНТИФИКАЦИЕЙ | 2017 |
|
RU2727152C1 |
| Связанное с выбранными архитектурными функциями администрирование обработки | 2015 |
|
RU2665243C2 |
| ОПРЕДЕЛЕНИЕ ФОРМАТОВ ТРАНСЛЯЦИИ ДЛЯ ФУНКЦИЙ АДАПТЕРА ВО ВРЕМЯ ВЫПОЛНЕНИЯ | 2010 |
|
RU2556418C2 |
Изобретение относится к способу обеспечения синхронного предварительного декодирования строки команд. Техническим результатом является обеспечение восстановления при повторной синхронизации за счет снижения ошибок синхронизации механизма предварительного декодирования строки команд. Способ включает в себя определение гранулы, которая равна команде наименьшей длины в наборе команд, и определение числа гранул, которые составляют команду с наибольшей длиной в наборе команд как МАХ. Дополнительно включает в себя определение конца сегмента внедренных данных, когда программа компилируется или ассемблируется в строку команд, и вставку заполнения длиной МАХ-1 в строку команд в конец внедренных данных. При предварительном декодировании заполненной строки команд устройство предварительного декодирования поддерживает синхронизацию с командами в заполненной строке команд, даже если внедренные данные случайно кодируются, являясь похожими с существующей командой в наборе команд переменной длины. Устройство реализует указанный способ. 5 н. и 15 з.п. ф-лы, 11 ил.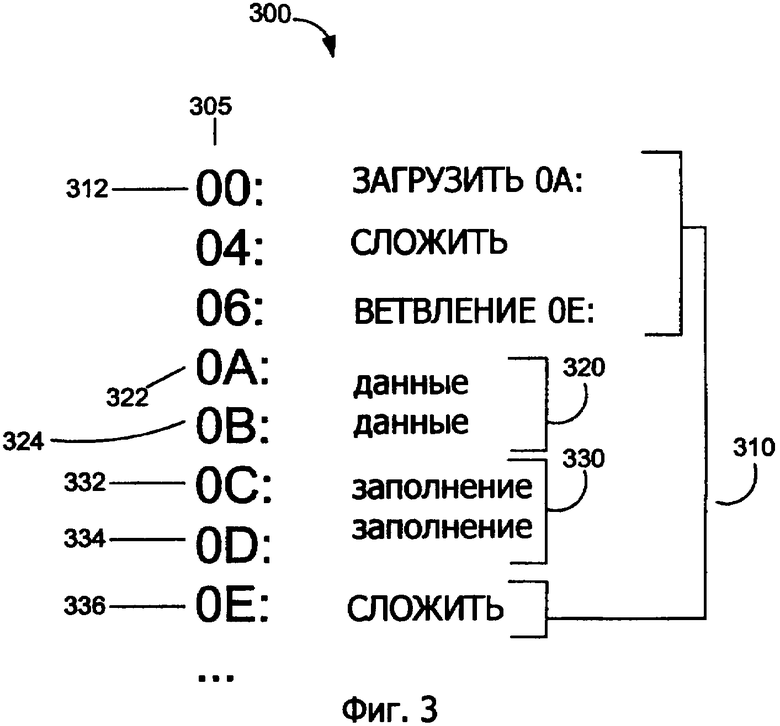
1. Способ обеспечения корректного предварительного декодирования команд в строке команд, содержащей команды из набора команд и сегмент внедренных данных, причем набор команд имеет команды переменной длины, длина наименьшей команды в наборе команд определяет гранулу, число гранул, которые составляют команду с наибольшей длиной в наборе команд, определяет число МАХ, при этом способ содержит этапы, на которых
определяют конец первого сегмента внедренных данных в строке команд, когда программу компилируют или ассемблируют в строку команд; и
вставляют заполнение длиной МАХ-1 гранул в конец первого сегмента внедренных данных для формирования заполненной строки команд, и
сохраняют заполненную строку команд.
2. Способ по п.1, в котором заполнение кодируют, чтобы быть отличным от любой команды в наборе команд.
3. Способ по п.1, в котором заполнение кодируют для включения множества команд из набора команд, связанных друг с другом.
4. Способ по п.1, в котором заполнение кодируют телескопически, чтобы синхронизировать предварительное декодирование внедренных данных в конце первого сегмента внедренных данных.
5. Способ по п.4, в котором самая длинная команда равна 32 битам, самая короткая команда равна 8 битам, другие команды равны 24 и 16 битам, заполнение равно трем байтам, и телескопически закодированное заполнение имеет первый байт, который оказывается первым байтом 24-битовой команды, второй байт, который оказывается первым байтом 16-битовой команды, и третий байт, который оказывается 8-битовой командой.
6. Способ по п.1, в котором этап определения конца сегмента внедренных данных дополнительно содержит этапы, на которых различают переход, когда последующая команда в строке команд следует за сегментом внедренных данных.
7. Способ по п.1, в котором самая короткая команда равна 8 битам.
8. Способ по п.1, который дополнительно содержит этапы, на которых определяют конец второго сегмента внедренных данных, и вставляют заполнение длиной МАХ-1 гранул в конец второго внедренного сегмента.
9. Способ по п.1, в котором самая короткая команда равна 16 битам.
10. Способ по п.9, в котором самая длинная команда равна 32 битам.
11. Способ обеспечения корректного предварительного декодирования команд в строке команд, содержащей команды из набора команд и внедренные данные, причем набор команд имеет команды переменной длины, команда наименьшей длины в наборе команд определяет гранулу, при этом способ содержит этапы, на которых
определяют, закодирована ли гранула внедренных данных в строке команд, чтобы быть похожей на команду в наборе команд;
проверяют, по меньшей мере, следующие Х-1 гранул строки команд для перехода между внедренными данными и следующей командой, где Х является размером в гранулах похожей команды;
определяют число Y гранул, не найденных на этапе, на котором проверяют X-1 гранул, в результате обнаружения перехода между внедренными данными и следующей командой в последовательности проверенных Х-1 гранул; и
вставляют заполнение размером Y после перехода, если Y больше, чем 0, для формирования заполненной строки команд; и
выводят заполненную строку команд.
12. Способ по п.11, в котором заполнение кодируют, чтобы быть отличным от любой команды в наборе команд.
13. Способ по п.11, в котором заполнение кодируют для включения множества команд из набора команд, связанных друг с другом.
14. Способ по п.11, в котором заполнение кодируют телескопически.
15. Способ по п.11, в котором самая короткая команда равна 8 битам.
16. Способ по п.11, в котором самая короткая команда равна 16 битам.
17. Машиночитаемый носитель информации, включающий в себя программные коды, хранимые на нем и исполняемые компьютером для обеспечения корректного предварительного декодирования команд в строке команд, причем программные коды содержат
первый программный код для чтения строки команд, содержащей, по меньшей мере, один сегмент внедренных данных;
второй программный код для идентификации данных в конце, по меньшей мере, одного сегмента внедренных данных как похожей команды переменной длины;
третий программный код для вставки на основании идентифицированных данных заполнения, примыкающего к, по меньшей мере, одному сегменту внедренных данных, для формирования заполненной строки команд; и
четвертый программный код для сохранения заполненной строки команд.
18. Машиночитаемый носитель информации по п.17, в котором длина наименьшей команды в наборе команд переменной длины определяет гранулу, и длина наибольшей команды является кратной одной или более гранулам, МАХ, при этом упомянутое заполнение является заполнением размером, равным МАХ-1 гранул.
19. Компьютерная система для обеспечения корректного предварительного декодирования строки команд, которая содержит команды из набора команд и внедренные данные, причем набор команд имеет команды переменной длины, команда наименьшей длины в наборе команд определяет гранулу, число гранул, которые составляют команду наибольшей длины в наборе команд, определяет число МАХ, при этом компьютерная система содержит
средство для обнаружения перехода, где последующая команда следует за внедренными данными в строке команд;
средство для вставки заполнения длиной МАХ-1 гранул после внедренных данных, формирующих заполненную строку команд; и
средство для сохранения заполненной строки команд.
20. Машиночитаемый носитель информации, включающий в себя программные коды, хранимые на нем и исполняемые компьютером для обеспечения корректного предварительного декодирования команд в строке команд, причем программные коды содержат
первый программный код для определения числа гранул, которые составляют команду наибольшей длины в наборе команд, МАХ;
второй программный код для обнаружения перехода в строке команд, где последующая команда следует за внедренными данными; и
третий программный код для вставки заполнения длиной МАХ-1 гранул после внедренных данных, формирующих заполненную строку команд; и
четвертый программный код для сохранения заполненной строки команд.
| ЦИФРОВОЙ КОМПЬЮТЕР С ВОЗМОЖНОСТЬЮ ПАРАЛЛЕЛЬНОГО ВЫПОЛНЕНИЯ ДВУХ И БОЛЕЕ КОМАНД | 1991 |
|
RU2109333C1 |
| US 6253309 B1, 26.06.2001 | |||
| US 5448746 A, 05.09.1995 | |||
| US 6023756 A, 08.02.2000 | |||
| US 6192465 B1, 20.02.2001. | |||

