Область техники, к которой относится изобретение
Настоящее изобретение относится к кодированию/декодированию цифровых сигналов, таких как аудиосигналы, видеосигналы, и в целом мультимедийные сигналы, с целью их записи или их передачи. В частности, изобретением предлагается решение проблем, возникающих при кодировании и декодировании перестановочных кодов.
Обычно изобретение применяется также к дуальной схеме кодирования источника: канального кодирования или «модуляции».
Кодирование/декодирование со сжатием цифровых сигналов в рамках настоящего изобретения может быть использовано для квантования коэффициентов трансформанты частотных кодеров речевых сигналов и/или аудиосигналов.
Уровень техники
Векторное квантование
Очень распространенным решением при сжатии цифровых сигналов является векторное квантование. Векторное квантование представляет входной вектор в виде вектора одинакового размера, выбранного из конечного множества. Квантор на М уровней (или «векторов-кодов») является примером не биективного применения множества входных векторов, как правило, реального евклидового n-размерного пространства Rn или подмножества Rn в конечном подмножестве Y Rn с М отдельных элементов: Y={y0, y1, …, ym-1}.
Y называют алфавитом воспроизведения или «словарем» или «справочником», а его элементы векторов-кодов - «кодовыми словами» (или «выходными точками» или «репрезентантами»).
Пропускная способность по размеру r квантора (или его «разрешение») определяют.отношением:
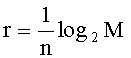
При векторном квантовании блок из n выборочных значений обрабатывают как вектор размера n.Согласно теории кодирования источника, когда размер становится очень большим, эффективность векторного квантования приближается к границе пропускная способность - искажение источника. Словари векторных кванторов могут быть разработаны на основании статистических методов, таких как обобщенный алгоритм Ллойда (или "GLA" от "Generalized Lloyd Algorithm"), основанный на необходимых условиях оптимальности векторного квантора. Полученные таким образом статистические векторные кванторы не имеют никакой структуры, что делает их просмотр сложным и дорогим с точки зрения вычислительных или записывающих ресурсов, поскольку сложность как при кодировании, так и при записи прямо пропорциональна: n2nr.
Показанный на фиг.1А векторный квантор используют для трех основных операций: двух при кодировании и одной при декодировании. Входной вектор кодируют (этап COD), выбирая сначала вектор-код из словаря. Речь идет о наиболее «похожем» на него векторе-коде (операция ОР1 на фиг.1А). Затем, определяют индекс этого вектора-кода (этап IND) для передачи или введения в память (операция ОР2 на фиг.1А). На декодере (этап DEC) вектор-код определяется по его индексу (операция ОР3 на фиг.1А).
При модуляции тоже используют три операции ОР1, ОР2 и ОР3, показанные на фиг.1А, но в другом порядке. Согласно фиг.1В, которая иллюстрирует эту дуальность модуляция/квантование, предусматривают переход от индекса к вектору-коду (этап COD' на фиг.1В, соответствующий операции ОР3 на фиг.1А). Затем после передачи на зашумленном канале выявляют вектор-код, наиболее близкий к полученному вектору (этап DEC на фиг.1В, соответствующий операции ОР1 на фиг.1А). Наконец, на третьем этапе (этап IND' на фиг.1В, соответствующий операции ОР2 на фиг.1А) производят декодирование индекса вектора-кода.
Экспоненциальное возрастание сложности в зависимости от размера векторов и от пропускной спосоюности ограничивает применение не структурированных векторных кванторов при небольших размерах и/или низкой пропускной способности для их использования в реальном времени. В случае не структурированного векторного квантора поиск наиболее близкого вектора-кода (операция ОР1) требует исчерпывающего поиска среди всех элементов словаря для выбора элемента словаря, который минимизирует измерение расстояния между ним и входным вектором. Две последние операции (индексация ОР2 и обратная операция ОР3) обычно осуществляют путем простого считывания таблиц, но они все равно занимают много места в объеме памяти. Чтобы устранить проблемы размера и расстояния, были изучены многие варианты базового векторного квантования. Они призваны решить проблему отсутствия структурности словаря и помогают снизить сложность, но в ущерб качеству. И все-таки компромисс эффективность/сложность был улучшен, что позволяет расширить диапазон разрешений и/или размеров, в котором можно эффективно применять векторное квантование с точки зрения стоимости. Было предложено много схем структурированных векторных кванторов и, в частности, векторный квантор, использующий описанный ниже «перестановочный код».
Перестановочные коды
В векторном кванторе с «перестановочным кодом» векторы-коды получают путем перестановок компонент первого вектора-кода (в смысле лексикографического порядка), называемого «лидером» (или «вектором-директором»). Эти компоненты принимают свои значения в алфавите А={a0, a1, aq-1} размером q (алфавита А q-площадь, где ai≠aj при i≠j). Компоненты ai являются вещественными (или целыми) числами. Весовой коэффициент wi (где i является индексом от 0 до q-1) является числом повторений буквы a1 алфавита. Весовые коэффициенты wi являются положительными целыми числами, такими, при которых 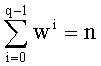

Понятно, что можно выбрать другой порядок компонент, например a0<a1<…<aq-1.
Вектор-лидер называют «лидером со знаком», и перестановочный код называют «типа I». Путем перестановок компонент y0 получают другие векторы-коды. Общее число М перестановок равно:
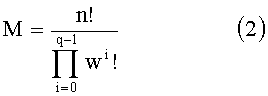
Существует другой тип перестановочного кода (тип II). Вектор-лидер имеет ту же форму, что и в предыдущем случае, но его компоненты должны быть положительными (a0>a1>…>aq-1≥0). Путем перестановок компонент y0 получают также другие векторы-коды, присваивая им все возможные комбинации знаков. Общее число М перестановок равно:
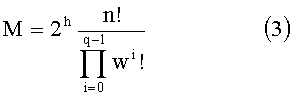
где h=n, если aq-1>0, и h=n-wq-1 в остальных случаях.
В этом случае вектор-лидер называют абсолютным лидером.
Векторный квантор с «перестановочным кодом» был распространен на состав (или объединение) перестановочных кодов, и недавно эта структура с объединением перестановочных кодов была общепринята для векторного квантования с переменными размером и разрешением (в документе WO-04/00219 на имя заявителя). Перестановочные коды используют не только при статистическом векторном квантовании. Они находят свое применение также при алгебраическом векторном квантовании, для которого используют сильно структурированные словари, получаемые из правильных сетей точек или из кодов корректировки погрешностей. Эти перестановочные коды применяют также при модуляции.
Использование структуры с перестановочным кодом позволяет разрабатывать оптимальные и быстрые алгоритмы поиска наиболее близкого вектора-кода (операция ОР1 на фиг.1А). Вместе с тем индексация (или нумерация) векторов-кодов (операция ОР2 на фиг.1А) и обратная операция декодирования (операция ОР3 на фиг.1А) требуют большего числа вычислений, чем в случае не структурированных векторных квантований.
Существует несколько способов нумерации перестановок. Одним из таких способов является алгоритм Шальквийка: "An algorithm for source coding" Schalkwijk J.P.M., в ГЕЕЕ Trans, on information Theory, том IT-18, №3, стр.396-399, май 1972.
Используя комбинаторный анализ, эти способы позволяют индексировать вектор-код перестановочного кода (операция ОР2), а также осуществлять обратную операцию декодирования индекса (операция ОР3). Среди алгоритмов индексации перестановок следует еще раз упомянуть алгоритм Шальквийка, широко используемый в стандартах:
- [3GPP TS 26.273] (ANSI-C code for the Fixed-point Extended AMR-Wideband (AMR-WB+) cjdec; V6.1.0 (2005-06) (Release 6)), и
- [3GPP TS 26.304] (Extended Adaptive Multi-Rate - Windeband (AMR-WB+) codec; Floating-point ANSI-C code; V6.3.0 (2005-06) (Release 6), июнь 2005).
Вычисление ранга перестановки при кодировании (операция ОР2 на фиг.1)
Ставится задача упорядочения и индексации всех возможных перестановок компонент вектора y=(y0, y1, …, yn-1). Порядок является лексикографическим, и в данном случае индекс называют «рангом». Вычисление ранга вектора у приводит к вычислению вектора D=(d0, d1, …, dn-1), связанного с у и такого, что dk соответствует значению индекса d, если и только если Уk=ad.
Например, вектор у размером n=8 имеет следующие компоненты:
Y=(4, 2, 4, 0, 0, 4, 4, 2)
Алфавит из q=3 букв (компоненты разных значений) вытекает из А={4, 2, 0} при a0=4, a1=2 и a2=0.
При этом с вектором y связывают вектор D=(0, 1, 0, 2, 2, 0, 0, 1), компоненты которого являются просто индексами q букв алфавита А.
Ранги y и D являются идентичными, но определение вектора D позволяет ограничиться вычислением ранга последовательности D со значениями в множестве {0, 1, q-1} (содержащем то же число элементов, что и алфавит {a0, a1, …, aq-1}).
Весовые коэффициенты векторов y и D являются идентичными, поскольку вхождения их соответствующих компонент являются идентичными. Определяют также промежуточный весовой коэффициент 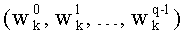 как весовой коэффициент вектора с компонентами (yk, yk+1, …, yn-1), который, таким образом, соответствует усеченному вектору y, оставляя позиции от k до n-1. Таким образом:
как весовой коэффициент вектора с компонентами (yk, yk+1, …, yn-1), который, таким образом, соответствует усеченному вектору y, оставляя позиции от k до n-1. Таким образом:
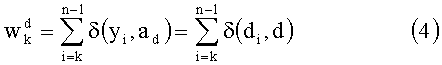
где δ(x,y) является оператором Кронекера (δ(x,y)=1, если x=y и 0, если нет).
Получаем: 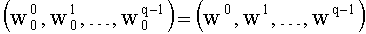
При комбинаторном анализе ранг t вектора y можно вычислить при помощи следующей формулы:
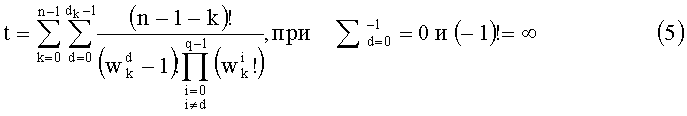
Эту формулу можно упростить до:
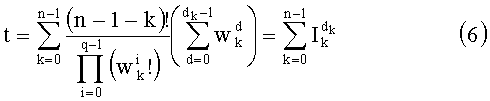
Именно эту последнюю формулу используют чаще всего, и ее мы будет применят в данном случае. В дальнейшем 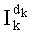 будет называться «частичным рангом порядка k», при:
будет называться «частичным рангом порядка k», при:
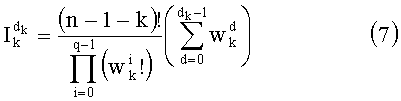
Декодирование ранга (операция ОР3): Определение перестановки по ее индексу Декодирование ранга t состоит в нахождении вектора D=(d0, d1, …, dn-1), связанного с y. Метод последовательного поиска значений dk описан ниже. Сначала определяют компоненту d0, затем компоненту d1, … до компоненты dn-1.
* Определение d0:
Чтобы найти d0, используют формулу, содержащую неравенства:
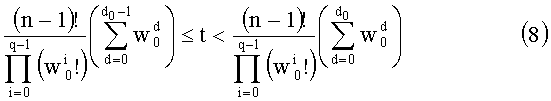
Члены (n-1)!, t, 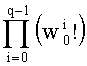 и значения
и значения 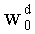 при d=0, …, q-1 известны.
при d=0, …, q-1 известны.
Чтобы найти значение d0, исходят из того, что d0=0, осуществляют последовательную инкрементацию d0 на 1 до тех пор, пока формула (8) не будет проверена. Если записать формулу (8) с частичными рангами, то значение d0 будет таким, что:
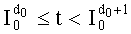 при
при 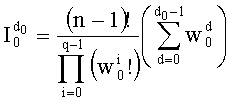
*Определение d1:
Чтобы найти d1, используют отношение:
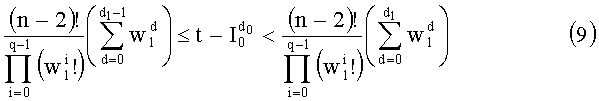
Значения 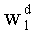 при d=0,…,q-1 вытекают из
при d=0,…,q-1 вытекают из 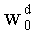 следующим образом:
следующим образом:
- 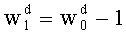
- и 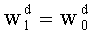 , если d≠d0 (в этом случае
, если d≠d0 (в этом случае 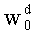 повторяют, пока d отличается от d0).
повторяют, пока d отличается от d0).
Приходим к той же проблеме, что и при определении компоненты d0. Чтобы найти значение d1, исходят из того, что d1=0, и осуществляют последовательную инкрементацию d1 на 1, пока не будет проверено неравенство (9)
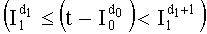
*Определение других dk:
Вычисление следующих dk подобно предыдущим рассмотренным случаям. Чтобы найти значение dk, исходят из того, что dk=0, и осуществляют последовательную инкрементацию dk на 1, пока не будет проверено неравенство 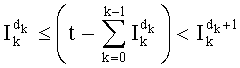 .
.
После декодирования вектора D=(d0, …, dn-1) из него выводят вектор y путем простого транспонирования алфавита.
Индексация перестановочного кода и обратная операция являются сложными операциями. Применяемые алгоритмы используют комбинаторный анализ. Индексация комбинаций и обратная операция требуют деления произведений факториалов.
Сложность деления
Несмотря на достижения в области интегральных схем и процессоров обработки сигнала, деление остается сложной операцией. Обычно деление целого числа, представленного на 16 бит, на целое число, представленное на 16 бит, требует в 18 раз больше затрат, чем умножение. Весовой коэффициент деления 32-битового целого числа на 16-битовое целое число составляет 32, тогда как весовой коэффициент их умножения составляет 5.
Кадрирование переменных
Стоимость деления не является единственной проблемой. Кадрирование переменных является еще одной проблемой, что видно из нижеследующей таблицы 1.
На 16-битовых целых словах можно отобразить только факториалы целых чисел, меньших или равных 8. Для чисел, больших 12, представление факториалов на 32-битоых целых словах не представляется возможным.
Кроме того, сложность операций возрастает также с числом используемых бит для представления переменных. Так, деление 32-битового целого числа на 16-битовое целое число почти в два раза сложнее (весовой коэффициент 32), чем деление 16-битового целого числа (весовой коэффициент 18).
Были предложены решения для снижения сложности операции ОР1. Проблема сложности операций ОР2 и ОР3 изучена мало. Вместе с тем, в кодер/декодер TDAC, запатентованном заявителем, или в кодер 3GPP-AMR-WB+ были внесены упрощения алгоритмов кодирования и декодирования при помощи формулы Шальквийка.
Упрощения перечисления перестановок и обратной операции (операции ОР2 и ОР3)
Вычисление ранга t перестановки и обратную операцию ускорили за счет указанных ниже упрощений вычисления n членов 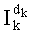 , определение которых можно напомнить:
, определение которых можно напомнить:
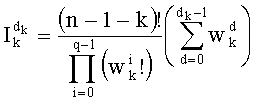 , (0≤k≤n-1)
, (0≤k≤n-1)
Два первых упрощения служат для снижения сложности как кодирования, так и декодирования. Третье используют при кодировании, а два последних - при декодировании.
Метод кодирования показан на фиг.2 и 3. В частности, на фиг.3 показано вычисление ранга при помощи формулы Шальквийка в рамках известных решений, тогда как на фиг.2 показаны предварительные этапы (обозначенные "ЕР-n", для n-го предварительного этапа на фиг.2).
Как показано на фиг.2, обработка начинается с этапа ЕР-1, на котором получают компоненты вектора у=(y0, …, yn-1). Следующий общий этап ЕР-2 предусматривает вычисление элементов алфавита для вектора А=(a0, …, aq-1), а также определение максимального индекса q. Для этого после этапа инициализации ЕР-21, на котором устанавливают q=1, а0=у0, образуют петлю на индексе k, заключенном между 1 и n-1 (завершающий тест ЕР-26 или, если нет, инкрементация ЕР-27), с целью поиска элементов aq следующим образом:
- если компонента yk текущего индекса k уже не находится среди элементов {а0, …, aq-1} (тест ЕР-22), необходимо присвоить новый элемент aq, такой как aq=yk (этап ЕР-23) множеству {а0, …, aq-i}, и произвести инкрементацию q на 1 (этап ЕР-25).
Следующий общий предварительный этап ЕР-3 является вычислением вектора D=(d0, …, dn-1) следующим образом:
- при k, возрастающем от 0 до n-1 (этап ЕР-31 инициализации к на 0, завершающий тест ЕР-37 на k и инкрементация ЕР-38 если нет), находят значение d во множестве индексов (0,…, q-1), при котором yk=ad (тест ЕР-23 в петле на d и инкрементация ЕР-26 с d=d+1 если нет).
Далее со ссылками на фиг.3 следует описание этапов вычисления ранга t, которые следуют за предварительной обработкой, показанной на фиг.2. Этапы, показанные на фиг.3, обозначены "СА-n" для обозначения n-ого этапа кодирования в рамках известных решений.
Этап СА-1 является инициализацией ранга t на 0, переменной Р на 1 (знаменатель, участвующий в вычислении ранга на этапе СА-13) и q весовых коэффициентов w0, …, wq-1 на 0.
В данном случае производят декременацию значения к от n-1 до 0 (этап СА-2 инициализации к на n-1, завершающий тест СА-14 и декрементация СА-15, если нет). Преимущество такого выбора будет указано ниже. После этого используют компоненты dk вектора D, полученного на предварительном этапе ЕР-3, и для текущего k фиксируют d=dk (этап СА-3). Обновляют соответствующий весовой коэффициент wd (Wd+1 на этапе СА-4) для определения члена Р (Р=Px Wd на этапе СА-5). Производят инициализацию на 0 (этап СА-6) суммы S, участвующей в числителе при вычислении соответствующего ранга на этапе СА-13, и после этого производят петлю на индексе i весовых коэффициентов wi (завершающий тест СА-9 и, если нет, инкрементация СА-10 до d-1) для обновления суммы S (S=S+Wi на этапе СА-8). Перед вычислением ранга t на этапе СА-13 проверяют, чтобы сумма S не равнялась нулю (тест СА-11). Преимущество этого выполнения описано ниже.
Вычисление ранга t (этап СА-13) требует использования члена-факториала (n-k-1)! следующим образом:
t=t+(S/P)(n-k-1)!
Вместо вычисления члена (n-k-1)! при каждом обновлении ранга t эти значения предварительно вводят в память и для получения текущего значения (n-k-1)! просто обращаются к памяти (этап СА-12).
Таким образом, некоторые из преимуществ обработки, показанной на фиг.3, будут использованы при применении настоящего изобретения. Эти преимущества будут уточнены ниже.
*Ведение в память факториалов
Чтобы избежать вычисления членов (n-k-1)! и 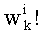
*Тест на накопление промежуточных весовых коэффициентов для избежания деления
Нет необходимости вычислять 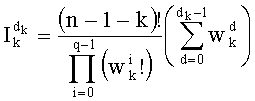 , если член
, если член 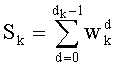
*Инверсия петли на позициях кодирования
Весовые коэффициенты 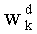 (где d=0, 1,…, q-1) выводят из весовых коэффициентов
(где d=0, 1,…, q-1) выводят из весовых коэффициентов 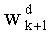 путем инкрементации
путем инкрементации 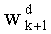 на 1 и повторения других значений
на 1 и повторения других значений 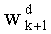 для d≠dk. В этом случае можно реализовать петлю (этапы СА-2, СА-14, СА-15 на фиг.3), начиная от последней позиции (k=n-1) вектора до первой (k=0). Эта «инверсированная» петля после инициализации на 1 позволяет вычислить член Pk:
для d≠dk. В этом случае можно реализовать петлю (этапы СА-2, СА-14, СА-15 на фиг.3), начиная от последней позиции (k=n-1) вектора до первой (k=0). Эта «инверсированная» петля после инициализации на 1 позволяет вычислить член Pk:
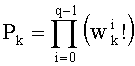 ,
,
только с одной инкрементацией и одним умножением путем итерации, то есть
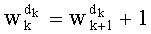
и 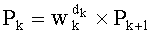
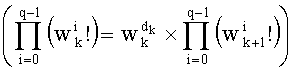
Кроме того, можно обработать две последние позиции отдельно (k=n-1 и k=n-2).
Действительно,
- для последней позиции (k=n-1), 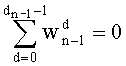 , следовательно
, следовательно 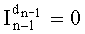
- для предпоследней позиции (k=n-2),
если dn-2>dn-1, 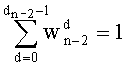 и
и 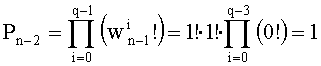 , следовательно
, следовательно 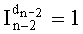 ,
,
если нет (dn-2≤dn-1), 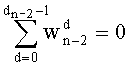 , следовательно
, следовательно 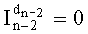 , при Pn-2=2, если dn-2=dn-1, и, если нет, то Pn-2=1.
, при Pn-2=2, если dn-2=dn-1, и, если нет, то Pn-2=1.
Можно также предусмотреть другие детали преимущественного выполнения, описанные ниже.
*Исключение деления при декодировании
Чтобы избежать деления при декодировании во время поиска d0, неравенство (8) можно преобразовать следующим образом:
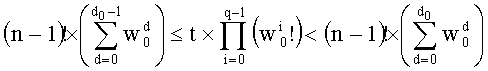
Точно так же, исключают деление во время поиска d1 путем преобразования неравенства (9) следующим образом:
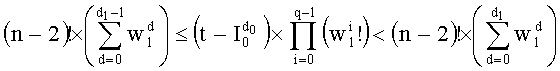
или даже:
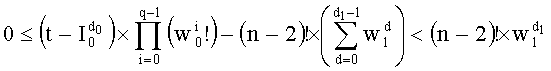
Следует отметить, что, если таким образом можно исключить деление во время поиска dk (0<k<n-1), то все равно необходимо осуществить (n-1) операций деления для вычисления 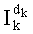 (0<k<n-3).
(0<k<n-3).
*Тест на весовые коэффициенты при декодировании
Таким образом, в последних позициях для некоторых значений d, 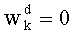 (для
(для 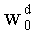 компонент значения d, занимающих позиции, предшествующие позиции k) нет необходимости вычислять члены неравенств (8) и (9) для этих значений d.
компонент значения d, занимающих позиции, предшествующие позиции k) нет необходимости вычислять члены неравенств (8) и (9) для этих значений d.
Другие проблемы известных решений: кадрирование переменных
Проблема кадрирования переменных была затронута в кодере TDAC заявителя.
Первое решение состоит в установлении четкого различия между обработкой размеров, превышающих 12, и обработкой более малых размеров. Для малых размеров (n<12) вычисления производят на 32-битовых целых числах без знака. Для более значительных размеров используют переменные двойной точности с плавающей запятой, пренебрегая возрастанием сложности вычисления (операции двойной плавающей точности стоят дороже, чем их эквиваленты по полной точности) и увеличением требуемой емкости памяти.
Кроме того, если максимальная точность ограничена 32-битовыми целыми числами без знака (выполняется процессорами обработки чисел с фиксированной запятой), то факториалы целых чисел более 12 не могут быть заранее введены в память напрямую, и векторы размером более 12 должны кодироваться отдельно. Для решения этой проблемы используют представление с псевдоплавающей запятой по мантиссе и показателю факториалов n! в виде 2j×r. Это разложение подробно показано в нижеследующей таблице 2. Введение в память n! (при n меньшем или равном 16) сводится к записи в память r с точностью не более 30 бит, а также показателя степени j, который соответствует простому смещению бит.
Таким образом, в большинстве случаев методы из предшествующего уровня техники не решают проблему кадрирования переменных с ограниченной точностью, в частности, с фиксированной запятой. Применение в кодере TDAC хотя и позволяет регулировать проблему кадрирования, но не позволяет избежать дорогостоящих операций деления двух целых чисел. Кроме того, при более значительных размерах промежуточные вычисления (например, числитель и знаменатель частичных рангов 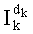 ) могут приближаться к состоянию насыщения. В этом случае представленные выше упрощения не могут быть использованы в обработке декодирования, и необходимо возвращаться к формулам неравенств (8) и (9), то есть возобновлять многочисленные операции деления.
) могут приближаться к состоянию насыщения. В этом случае представленные выше упрощения не могут быть использованы в обработке декодирования, и необходимо возвращаться к формулам неравенств (8) и (9), то есть возобновлять многочисленные операции деления.
Методы перечисления, такие как метод Шальквийка, характеризуются такими же проблемами. Как только в них применяют комбинаторный метод, они требуют вычисления произведений факториалов, а также операций их деления.
Сущность изобретения
Задачей настоящего изобретения является улучшение этой ситуации.
В этой связи его объектом прежде всего является способ кодирования/декодирования цифровых сигналов, использующий перестановочные коды с вычислением комбинаторных выражений, в котором комбинаторные выражения представлены разложениями на степени простых множителей и определяются путем считывания из памяти заранее записанных представлений разложений выбранных целых чисел.
При этом настоящее изобретение дает эффективное решение проблем, связанных как с индексацией перестановочного кода, так и с обратной операцией. Оно одновременно решает обе проблемы кадрирования переменных и деления.
Действительно, в предпочтительном варианте выполнения заранее записанные представления содержат характеристические значения показателей степени, записанные в соответствии с характеристическими значениями последовательных простых чисел для каждого из указанных целых чисел.
Таким образом, уже решается проблема из предшествующего уровня техники, связанная с кадрированием переменных.
Эта проблема кадрирования возрастает еще больше, когда речь идет об операциях с факториалами.
В предпочтительном варианте выполнения, чтобы производить операции с комбинаторными выражениями, когда они содержат значения факториалов целых чисел, заранее записанные представления содержат, по меньшей мере, представления разложений значений факториалов.
Таким образом, этот вариант выполнения позволяет снять проблему кадрирования переменных и за счет этого раздвинуть общепринятые установленные пределы, что касается размера n рассматриваемых перестановочных кодов.
Согласно другому предпочтительному отличительному признаку, по меньшей мере, одно из указанных комбинаторных выражений содержит частное от деления целого числителя на целый знаменатель, и это частное представлено в виде разложения на степени простых множителей, при этом каждая степень является разностью показателей, соответственно связанных с числителем и с знаменателем и относящихся к одному и тому же простому числу.
Таким образом, решается проблема известных решений, связанная с операциями деления, которые заменяются простыми операциями вычитания.
В первом варианте выполнения предусмотрено обращение к напоминающему устройству для поиска заранее записанного разложения одного из вышеуказанных выбранных целых чисел. Для этого заранее записанное представление выбранного целого числа хранится в адресном ЗУ, при этом обращение к указанному ЗУ дает последовательность показателей степени, присваиваемых соответствующих простым числам, для разложения выбранного целого числа.
Предпочтительно заранее записанное представление выбранного целого числа сохраняется в виде последовательности адресов, каждый из которых для простого числа дает показатель степени, присваиваемый этому простому числу, для реконструкции выбранного целого числа.
В дальнейшем этот признак первого варианта будет называться термином «разуплотненное представление разложений».
Согласно второму варианту выполнения, заранее записанные преставления сохраняются в памяти в виде слов, содержащих последовательность групп бит, при этом каждая группа имеет:
- весовой коэффициент, являющийся функцией простого числа, и
- значение, являющееся функцией показателя степени, связываемого с этим простым числом.
Предпочтительно определение простых показателей степени осуществляют в этом случае путем последовательных наложений, по меньшей мере, частичной маски на битовое слово с последовательными смещениями в зависимости от весового коэффициента бит и со считыванием остающихся бит.
В дальнейшем этот признак согласно второму варианту будет называться «уплотненное представление разложений».
Само развертывание способа для вычисления комбинаторного выражения в целом может содержать следующие этапы:
- идентификация, среди указанных выбранных целых чисел, членов, появляющихся в произведении и/или в частном, образующих указанное комбинаторное выражение,
- считывание в памяти показателей степени, участвующих в разложениях указанных членов на простые множители,
- сложение и/или соответственно вычитание считанных показателей степени для определения показателей, участвующих в разложении указанного комбинаторного выражения на степени простых множителей, и последующее вычисление указанного комбинаторного выражения на основании его разложения на степени простых множителей.
Что касается вычисления произведения, которое следует осуществлять рекуррентно и в котором при каждой рекурренции участвует новый член, то предпочтительно временно вводить в память разложение вычисления произведения, осуществленного при предыдущей рекурренции. Таким образом, если способ содержит рекуррентный этап вычисления произведения, на котором при каждой рекурренции появляется член, умножаемый на произведение, определенное во время предыдущей рекурренции:
- указанное произведение, определенное при предыдущей рекурренции, предпочтительно сохраняют в памяти в виде разложения на степени простых множителей,
- указанный член, умножаемый на произведение, предпочтительно является одним из выбранных целых чисел, разложение которых заранее введено в память, и
- для определения указанного произведения на текущей рекурренции достаточно прибавлять, по одному на простое число, показатели степени, полученные из соответствующих разложений указанного произведения, определенного на предыдущей рекурренции, и указанного члена, умножаемого на произведение.
Точно так же, если способ содержит рекуррентный этап вычисления деления, в котором на каждой рекурренции появляется член, делящий частное, определенное на предыдущей рекурренции:
- указанное частное, определенное на предыдущей рекурренции, предпочтительно сохраняют в памяти в виде разложения на степени простых множителей,
- указанный член, делящий частное, предпочтительно является одним из выбранных целых чисел, разложение которых заранее введено в память, и
- для определения указанного деления на текущей рекурренции вычитают, по одному на простое число, показатели степени, полученные из разложения указанного частного, определенного на предыдущей рекурренции.
Это временное сохранение в памяти промежуточных разложений рекуррентно вычисляемых произведений и/или частных является особенно предпочтительным для определения рекуррентных частичных рангов, накопление которых характеризует ранг перестановки.
Таким образом, в предпочтительном варианте выполнения изобретения перестановочные коды сопровождаются вычислением количества, характерного для ранга перестановки, содержащего накопление частичных рангов, при этом каждый частичный ранг соответствует в этом случае одному из указанных комбинаторных выражений.
Вычисление ранга перестановки можно применять при кодировании цифровых сигналов с векторным квантованием для индексации перестановок компонент вектора-директора (операция ОР2 на фиг.1А), причем эти перестановки были осуществлены на предварительном этапе (операция ОР1) для определения вектора-кода, наиболее близкого к входному вектору.
Точно так же, при декодировании цифровых сигналов с векторным квантованием определение ранга перестановки осуществляют в случае, когда на основании данного значения ранга перестановки:
- вычисляют, по меньшей мере, количество, характеризующее ранг перестановки (операция ОР3 на фиг.1А), приближающееся к указанному данному значению, в зависимости, по меньшей мере, от одной предполагаемой компоненты создаваемого вектора-кода,
- выбор предполагаемой компоненты подтверждают, если это количество проверяет условие близости с данным значением ранга.
В примере выполнения это условие близости проверяют, если данное значение ранга может быть охвачено накоплениями частичных рангов до частичного ранга, связанного с предполагаемой компонентой, с одной стороны, и до частичного ранга, связанного с компонентой, соответствующей инкрементации предполагаемой компоненты, с другой стороны.
Таким образом, это условие близости может соответствовать общей формуле описанных ранее неравенств (8) в случае перечисления Шальквийка;
Таким образом, настоящее изобретение предпочтительно можно применять для кодирования/декодирования источника с векторным квантованием согласно фиг.1А.
Вместе с тем, кодирование/декодирование может быть кодированием/ декодированием канала с модуляцией согласно фиг.1В, которое содержит:
- перед передачей: определение вектора-кода на основании ранга перестановки (одинаковая операция ОР3 на фиг.1А и 1В), и
- при приеме: вычисление ранга перестановки на основании вектора-кода, соответствующего принятому вектору (одинаковая операция ОР2 на фиг.1А и 1В).
Вычисление частичного ранга использует члены (в произведении или в частном), которые, как будет показано ниже, остаются меньшими или равными максимальному размеру n перестановочных кодов. Таким образом, в предпочтительном варианте выбранные целые числа, разложения которых заранее введены в память, содержат, по меньшей мере:
- целые числа от 1 до максимального размера n,
- значение факториала целого числа 0,
- и, предпочтительно, значения факториалов целых чисел от 1 до максимального размера n.
В факультативном частном варианте выбранные целые числа могут также содержать значение 0.
Таким образом, если перестановочный код использует перечисление Шальквийка, частичный ранг 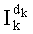 , связанный с усечением (yk, …, yn-1), вектора-кода (y0, …, yn-1), записывают как:
, связанный с усечением (yk, …, yn-1), вектора-кода (y0, …, yn-1), записывают как:
, где:
- запись 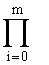 обозначает произведение для целого индекса i, возрастающего от 0 до m,
обозначает произведение для целого индекса i, возрастающего от 0 до m,
- запись 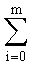 обозначает сумму для целого индекса i, возрастающего от 0 до m,
обозначает сумму для целого индекса i, возрастающего от 0 до m,
- запись l! является значением факториала целого числа l при l!=1×2×3×…(l-1)×l для l>0 и 0!=1,
- целое число n является размером перестановочного кода, соответствующим общему числу компонент, которое содержит вектор-код,
- целое число k, составляющее от 0 до n-1, является индексом k-ой компоненты yk вектора-кода, определяемой на основании значения ранга при декодировании источника (соответственно при кодировании канала), или когда требуется индексировать перестановки при кодировании источника (соответственно при декодировании канала),
- целое число q является числом отдельных компонент, которое содержит вектор-код, и
- член 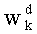 (называемый «промежуточным весовым коэффициентом») представляет собой число компонент с индексами от k до n-1, которые имеют значение, равное значению такой же компоненты с индексом d.
(называемый «промежуточным весовым коэффициентом») представляет собой число компонент с индексами от k до n-1, которые имеют значение, равное значению такой же компоненты с индексом d.
В этом случае выбранными целыми числами, разложения которых заранее записаны в память и которые необходимо будет идентифицировать в выражении частичного ранга 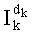 , в произведении и/или частном, предпочтительно являются:
, в произведении и/или частном, предпочтительно являются:
- члены-факториалы (n-1-k)! для всех целых чисел k от 0 до n-1 (то есть значения факториалов для всех целых чисел от 0 до (n-1)),
- значение каждого члена 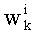 и/или значение его факториала, участвующее в произведении , при этом каждый член
и/или значение его факториала, участвующее в произведении , при этом каждый член 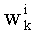 составляет от 0 до n, и
составляет от 0 до n, и
- члены 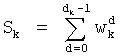 , каждый из которых составляет от 1 до n-1, для всех целых чисел к от 0 до n-1.
, каждый из которых составляет от 1 до n-1, для всех целых чисел к от 0 до n-1.
В том же частном случае перечисления Шальквийка временное сохранение промежуточных разложений предпочтительно применяют следующим образом: сумма показателей в разложении члена 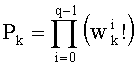 временно сохраняется в памяти для предыдущего индекса k, чтобы с ней сложить или из нее вычесть показатели разложения члена
временно сохраняется в памяти для предыдущего индекса k, чтобы с ней сложить или из нее вычесть показатели разложения члена 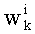 для текущего индекса k.
для текущего индекса k.
Краткое описание чертежей
Другие отличительные признаки и преимущества изобретения будут более очевидны из нижеследующего подробного описания со ссылками на прилагаемые чертежи, на которых, за исключением уже описанных фигур 1А, 1В и 3:
Фиг.4 - принципы кодирования/декодирования ранга перестановки с применением изобретения.
Фиг.5 - обработка для кодирования ранга перестановки с применением изобретения согласно первому варианту выполнения, в котором предусматривают разуплотненное представление показателей разложения на степени простых чисел членов, участвующих в вычислении.
Фиг.6 - обработка для кодирования ранга перестановки с применением изобретения согласно первому варианту выполнения, в котором предусматривают уплотненное представление показателей разложения.
Фиг.7 - обработка для декодирования ранга перестановки с применением изобретения согласно первому варианту выполнения, в котором предусматривают разуплотненное представление показателей разложения.
Фиг.8 - обработка для декодирования ранга перестановки с применением изобретения согласно второму варианту выполнения, в котором предусматривают уплотненное представление показателей разложения.
Фиг.9 - схема устройства кодирования/декодирования, в которой применяется настоящее изобретение.
Подробное описание чертежей
Следует напомнить (в частности, в связи с фиг.4-8), что:
- термин «кодирование» предполагает вычисление ранга t перестановки (операция ОР2 на фиг.1А и 1В), и
- термин «декодирование» предполагает определение перестановки на основании этого ранга t (операция ОР3 на фиг.1А и 1В).
Эти названия операций принимаются в связи с кодированием/декодированием источника с векторным квантованием. Следует напомнить, что эти операции можно также применять при декодировании/декодировании канала с модуляцией.
Для иллюстрации принципа изобретения прежде всего следует описать факторизацию простых чисел.
Разложение положительного простого числа K, не равного нулю, на степени простых чисел, записывается как:
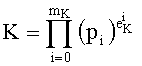
при этом pi является i-ым простым числом (p0=1, p1=2, p2=3, p3=5, p4=7, p5=11, p6=13, p7=7, и т.д.)
Показатель степени pi, в разложении целого числа K обозначают 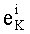 , а индекс наибольшего простого множителя, участвующего в разложении К показателя, не равного нулю, обозначают mk.
, а индекс наибольшего простого множителя, участвующего в разложении К показателя, не равного нулю, обозначают mk.
Например, число К=120 (то есть 5!) записывают:
120=1.23.31.51 и в данном случае m=3, так как наибольший множитель «5» имеет индекс 3 (p3=5) Таким образом, получают: 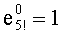 ,
, 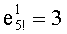 ,
, 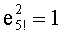 и
и 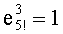 .
.
На практике, поскольку число «1» является нейтральным элементом умножения, из разложения можно исключить р0, то есть:
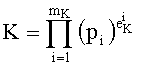
Разумеется, К=0 не разлагается на степени простых множителей.
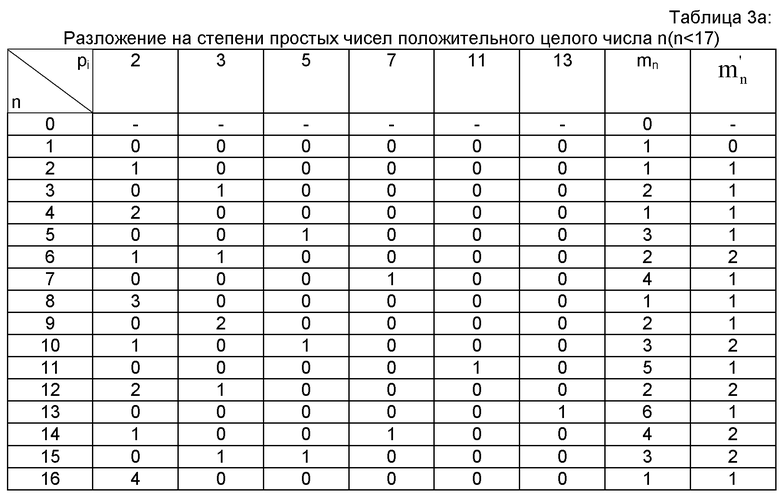
Разложение положительных целых чисел, меньших или равных 16, на произведения степеней простых чисел представлено в таблице 3а, а разложение их факториалов - в таблице 3а. В этом разложении участвуют 6 простых чисел (2, 3, 5, 7, 11 и 13). Столбцы индексированы простым числом pi, а строки - n, элемент таблицы 3а. (соответственно 3b) на пересечении столбца pi и строки n является показателем степени 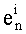 (соответственно
(соответственно 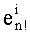 ) простого числа pi в разложении на произведение степеней простых чисел числа n (соответственно n!).
) простого числа pi в разложении на произведение степеней простых чисел числа n (соответственно n!).
Для любого положительного целого числа n>1 число mn! простых множителей n! является таким, что: pmn!≤n≤pmn!+1 Число mn! (соответственно число mn) указано в последнем (соответственно в предпоследнем) столбце таблицы 3b (соответственно 3a). Отмечается следующее неравенство: mn<mn!.
Как видно из таблицы 3а, многие показатели разложения числа n равны нулю. В последнем столбце таблицы 3а отмечается число 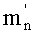 не равных нулю показателей в разложении n. Отсутствие разложения (и, следовательно, показателей) для n=0 указано в строке n=0 таблицы 3а знаком ″-″.
не равных нулю показателей в разложении n. Отсутствие разложения (и, следовательно, показателей) для n=0 указано в строке n=0 таблицы 3а знаком ″-″.
Ниже описано применение такого разложения для вычисления частичного ранга перестановочного кода в случае формулы Шальквийка на первом этапе, затем в общем случае.
Напомним, что частичный ранг, обозначаемый 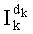 , дается вышеуказанным отношением (7):
, дается вышеуказанным отношением (7):
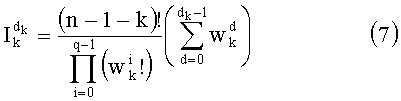
таким образом, что три члена можно разложить на простые числа. Речь идет о членах: (n-1-k)!, и 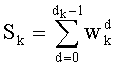
На основании показателей разложений (n-1-k)!, Pk и Sk путем простых сложений и вычитаний вычисляют показатели разложения 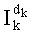 .
.
Действительно показатель 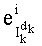 простого множителя pi в разложении
простого множителя pi в разложении 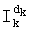 вычисляют на основании трех показателей pi в разложениях трех членов (n-1-k)!, Pk и Sk. Показатель
вычисляют на основании трех показателей pi в разложениях трех членов (n-1-k)!, Pk и Sk. Показатель 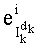 равен сумме показателей pi двух первых членов (числитель
равен сумме показателей pi двух первых членов (числитель 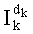 ), из которой вычитают показатель pi последнего члена (знаменатель
), из которой вычитают показатель pi последнего члена (знаменатель 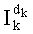 ). Это замечание можно записать в виде формулы:
). Это замечание можно записать в виде формулы:
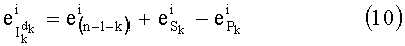
На фиг.4 показаны общие этапы (обозначенные “G-n” для n-го общего этапа), которые могут применяться в обработке в рамках настоящего изобретения как для кодирования, так и для декодирования.
Так, как показано на фиг.4, прежде всего следует отметить, что на основании текущего индекса k (этап G-1) и через промежуточные этапы, которые подробно будут описаны ниже, предусмотрена ссылка к заранее введенным в память таблицам (обозначенным Dl и Dl! на этапе G-2, представленном на фиг.4 в качестве примера) для вычисления общего показателя 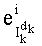 по вышеуказанному отношению (10) (этап G-3), и этот показатель характерен для разложения промежуточного ранга
по вышеуказанному отношению (10) (этап G-3), и этот показатель характерен для разложения промежуточного ранга 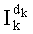 на степени простых множителей. Отсюда выводят значение промежуточного ранга
на степени простых множителей. Отсюда выводят значение промежуточного ранга 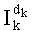 (этап G-4), в случае необходимости реализуя петлю на индексе i, соответствующем простым множителям. Вычисление этого промежуточного ранга может сопровождаться обновлением общего ранга t перестановки (этап G-5):
(этап G-4), в случае необходимости реализуя петлю на индексе i, соответствующем простым множителям. Вычисление этого промежуточного ранга может сопровождаться обновлением общего ранга t перестановки (этап G-5):
- при помощи отношения типа 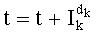 для кодирования ранга с декрементацией индекса k (этап G-6),
для кодирования ранга с декрементацией индекса k (этап G-6),
- или при помощи отношения типа 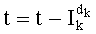 для декодирования ранга с инкрементаценией индекса k (этап G-6), что будет показано ниже.
для декодирования ранга с инкрементаценией индекса k (этап G-6), что будет показано ниже.
В конечном счете, получают ранг t перестановки при кодировании на этапе G-7 или при декодировании (показано пунктиром на фиг.4), выводят неравенства вышеуказанной формулы (8) компонент dk вектора D на этапе G-8 и далее - компонент вектора Y при помощи вышеуказанного отношения yk=ad.
В общем случае и независимо от перечисления Шальквийка, если частичный ранг t'(t'>0) перестановки выглядит в виде числителя Nt, членов vj(1≤j≤Nt') и знаменателя Dt , членов ρj(1≤j≤Dt') таким образом, что:
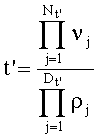
тогда показатели 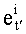 разложения частичного ранга t' определяют на основании промежуточных разложений, которыми являются разложения Nt, vj, и Dt ρj, что записывается как:
разложения частичного ранга t' определяют на основании промежуточных разложений, которыми являются разложения Nt, vj, и Dt ρj, что записывается как:
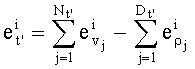
В дальнейшем будет использовано также разложение на множители простых чисел для формулирования по произведениям частных целых чисел частичного ранга t'.
Опять-таки в общем случае, если 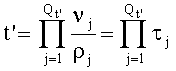 , то
, то 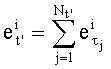 .
.
Возвращаясь к частному случаю перечисления Шальквийка, чтобы произвести вычисление частичного ранга 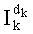 на основании его разложения, сразу после завершения этого разложения можно поступить следующим образом.
на основании его разложения, сразу после завершения этого разложения можно поступить следующим образом.
Держа в уме отношение 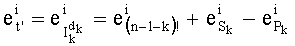
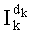 вычисляют, просто перемножая соответствующие степени:
вычисляют, просто перемножая соответствующие степени:
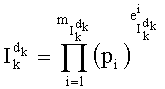
Здесь следует указать, что члены (n-1-k)! и Рк являются исключительно положительными целыми числами, но член Sk может быть равным нулю и, следовательно, не подлежать разложению. В этом случае частичный ранг 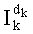 равен нулю. В этом случае следует предусмотреть тест на значение члена Sk (Sk=0?), чтобы вычисление частичного ранга
равен нулю. В этом случае следует предусмотреть тест на значение члена Sk (Sk=0?), чтобы вычисление частичного ранга 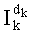 производить, только если Sk≠0, как было указано выше (этап СА-11 на фиг.3).
производить, только если Sk≠0, как было указано выше (этап СА-11 на фиг.3).
В целом, если , то 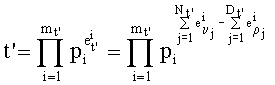
и, если 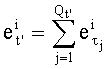 , то (t'>0)
, то (t'>0)
При этом следует учитывать, что факторизация на простые множители членов, образующих частичный ранг, позволяет исключить деления, заменяя их умножениями степеней простых множителей, в частности с простыми сложениями и вычитаниями показателей степени, связанных с этими простыми числами.
Таким образом, в соответствии с настоящим изобретением предусматривают следующие этапы, на основании ограниченного числа разложений целых чисел на простые множители, сохраненных в памяти (в дальнейшем называемых «базовыми разложениями»):
- определение разложений на простые множители членов (таких как (n-1-k)!, 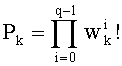 и
и 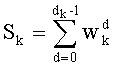 , появляющихся в ранге перестановки (в дальнейшем называемых «промежуточными разложениями») в рамках этапа G-2 на фиг.4,
, появляющихся в ранге перестановки (в дальнейшем называемых «промежуточными разложениями») в рамках этапа G-2 на фиг.4,
- на основании этих промежуточных разложений - определение разложения на простые множители частичного ранга 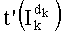 перестановки, в частности, путем вычисления показателей, участвующих в разложении этого частичного ранга (например, при помощи отношения типа
перестановки, в частности, путем вычисления показателей, участвующих в разложении этого частичного ранга (например, при помощи отношения типа 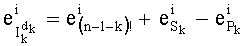 , в рамках этапа G-3 на фиг.4, и
, в рамках этапа G-3 на фиг.4, и
- вычисление частичного ранга 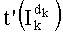 на основании его разложения (например, используя отношение типа
на основании его разложения (например, используя отношение типа 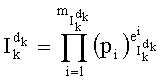 ), в рамках этапа G-4 на фиг.4.
), в рамках этапа G-4 на фиг.4.
Разумеется, сохраняемые в памяти базовые разложения предпочтительно должны быть предметом преимущественного выбора. В предпочтительном, но не ограничительном варианте сохраняемые в памяти базовые разложения следует выбирать в зависимости от максимального размера рассматриваемых перестановочных кодов (этот максимальный размер обозначается n). Таким образом, предпочтительно базовыми разложениями являются:
- разложения факториалов целого числа l (обозначаемые l!), при этом целое число l является таким, что 0≤l≤n,
- и разложения самого целого числа l, но на этот раз 1≤l≤n,
при этом следует напомнить, что n является максимальным размером рассматриваемых перестановочных кодов.
После этого можно идентифицировать базовое разложение по числу m, дающему:
- число m рассматриваемых простых множителей,
- сами эти простые множители m,
- и их соответствующие показатели степени.
Примеры такого подхода будут описаны ниже со ссылками на таблицы 4a-4d в рамках так называемого «разуплотненного» представления разложений. Следует указать, что так называемое «уплотненное» представление, подробно описанное ниже, состоит в сохранении в памяти простого слова, биты которого дают все показатели степени, участвующие в разложении.
В этом случае можно определить различные наборы базовых разложений, а также процедуры представления и введения в память этих базовых разложений.
Кроме того, выбор членов, для которых определяют промежуточные разложения, а также само определение этих промежуточных разложений являются объектом предпочтительных вариантов выполнения, которые будут описаны ниже. Разложение частичного ранга и вычисление частичного ранга на основании его разложения являются также объектом предпочтительных вариантов выполнения, описанных ниже.
Далее следует описание выбора сохраняемых в памяти базовых разложений.
В целом и независимо от метода перечисления перестановочного кода размером n, при вычислении ранга перестановки используют целые числа l(0≤l≤n) и прежде всего их факториалы l!(0≤l≤n). В предпочтительном варианте выполнения базовыми разложениями являются разложения факториалов l!(0≤l≤n) и l(1≤l≤n), где n является максимальным размером рассматриваемых перестановочных кодов, как было указано выше. Следовательно, в этом предпочтительном варианте выполнения предусматривают (2n+1) базовых разложений.
Вместе с тем, возможны и другие варианты выполнения.
Например, можно предусмотреть только (n+1) базовых разложений, а именно разложения l(1≤l≤n) и 0!. Таким образом, если для вычисления частичного ранга требуется разложение l!(l>0), его вычисляют на этапе определения промежуточных разложений на основании l базовых разложений j(1≤j≤l) при помощи 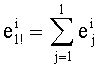 .
.
И, наоборот, можно предусмотреть только (n+1) разложений l! (0≤l≤n). Если для вычисления частичного ранга необходимо разложение l (l>0), его вычисляют на этапе определения промежуточных разложений на основании двух базовых разложений l! и (l-1)! и при помощи отношения:
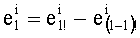
Таким образом, понятно, что выбор набора базовых разложений предпочтительно вытекает из компромисса между минимизацией памяти, необходимой для хранения представлений этих базовых разложений, и минимизацией сложности этапа определения промежуточных разложений.
Ниже следует описание представления разложений в соответствии с настоящим изобретением.
Как было указано выше, разложение (будь-то разложение частичного ранга, промежуточное или базовое) определяется числом m, дающим число рассматриваемых простых множителей, эти m простых множителей и их соответствующие показатели степени. Ниже предложено несколько решений для представления разложений и сохранения данных для базовых разложений.
Разуплотненное представление показателей степени
Представление факториалов l!(0≤1≤n)
Число ml! простых множителей, участвующих в разложении значения l!, возрастает пропорционально числу l. Первое решение для представления разложения l!(0≤l≤n) состоит в сохранении, для каждого значения l(0≤l≤n), числа ml! и ml! показателей степеней pi(1≤i≤ml!).
Следует учитывать, что ml! показателей l! не равны нулю.
В более предпочтительном варианте набор базовых разложений разделяет одинаковое число ml! простых множителей, и в память вводят ml! показателей для каждого базового разложения, при этом показатели базового разложения l! с индексом, превышающим ml!, равны нулю. Это решение позволяет использовать таблицу показателей, предусматривая регулярное обращение к этой таблице. Вместе с тем, такой вариант выполнения требует наличия большого объема памяти. Эта таблица содержит ml!×(n+1) значений, и показатель 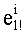 хранится по адресу (ml!, l+(i-1)) этой таблицы, где обозначение (х, у) относится к клетке этой таблицы в строке х и в столбце у. Разумеется, можно рассматривать и другие условные ситуации. Так, вместо рассмотрения двухмерной таблицы с m столбцов и N строк, которая содержит, таким образом, m×N клеток (или элементов), можно рассматривать таблицу с размером из m×N элементов, при этом элемент, находившийся по адресу (х, у) в двухмерной таблице, оказывается по адресу m×х+у одномерной таблицы. Показатель
хранится по адресу (ml!, l+(i-1)) этой таблицы, где обозначение (х, у) относится к клетке этой таблицы в строке х и в столбце у. Разумеется, можно рассматривать и другие условные ситуации. Так, вместо рассмотрения двухмерной таблицы с m столбцов и N строк, которая содержит, таким образом, m×N клеток (или элементов), можно рассматривать таблицу с размером из m×N элементов, при этом элемент, находившийся по адресу (х, у) в двухмерной таблице, оказывается по адресу m×х+у одномерной таблицы. Показатель 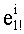 , хранившийся по адресу (l, (i-l) двухмерной таблицы, теперь хранится во адресу (ml!×l+(i-1) одномерной таблицы. Например, показатели разложений факториалов чисел от 0 до 8 могут храниться в двухмерной таблице из 32 элементов, состоящей из 4 столбцов (столбцы pi=2, 3, 5, 7) таблицы 3b и из 9 строк (строки n=0,…, 8). Эти же показатели могут храниться в одномерной таблице Dl! из 36 элементов, представленной ниже (приложение А-11). Элемент по адресу (х, у) первой таблицы равен элементу по адресу Dl!: 4×x+y.
, хранившийся по адресу (l, (i-l) двухмерной таблицы, теперь хранится во адресу (ml!×l+(i-1) одномерной таблицы. Например, показатели разложений факториалов чисел от 0 до 8 могут храниться в двухмерной таблице из 32 элементов, состоящей из 4 столбцов (столбцы pi=2, 3, 5, 7) таблицы 3b и из 9 строк (строки n=0,…, 8). Эти же показатели могут храниться в одномерной таблице Dl! из 36 элементов, представленной ниже (приложение А-11). Элемент по адресу (х, у) первой таблицы равен элементу по адресу Dl!: 4×x+y.
Можно дополнительно предусмотреть сохранение (n+1) значений ml!, чтобы сократить вычисления промежуточных разложений с использованием базового разложения l!.
Представление целых чисел l(0≤1≤n)
Для представления базового разложения l(1≤l≤n) можно предусмотреть несколько решений. Первое решение состоит в сохранении, для каждого значения l, числа ml и ml показателей степени pi (1≤i≤ml) этого значения l. В варианте, можно сохранять столько же показателей, что и для l! (ml! или mn!) показателей. Базовые разложения l и l! разделяют в этом случае одинаковое число m.
В другом варианте можно использовать тот факт, что число 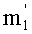 не равных нулю показателей разложения l является небольшим. Например, из таблицы 2а выяснилось, что это число
не равных нулю показателей разложения l является небольшим. Например, из таблицы 2а выяснилось, что это число 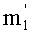 было не больше 2 (при l≤6). Таким образом, можно сохранить только это число и соответствующие значения pi или индексы i. Вместе с тем, необходимо предусмотреть также сохранение индексов i этих простых множителей не равной нулю степени, так как они больше не распознаются имплицитно по адресу соответствующего показателя в таблице.
было не больше 2 (при l≤6). Таким образом, можно сохранить только это число и соответствующие значения pi или индексы i. Вместе с тем, необходимо предусмотреть также сохранение индексов i этих простых множителей не равной нулю степени, так как они больше не распознаются имплицитно по адресу соответствующего показателя в таблице.
*Представление других разложений, отличных от базового
Представление промежуточного разложения зависит от представления базовых разложений, на основании которых его определяют. Точно так же, представление разложения частичного ранга зависит от представления промежуточных разложений, на основании которых его определяют.
*Сохранение базовых разложений
В качестве примера можно привести четыре возможных решения для сохранения и проиллюстрировать их при помощи нижеследующих таблиц 4a-4d для перестановочного кода с размером 8 (n=8), где рассматриваются четыре (m8!=4) простых числа (2, 3, 5 и 7). Эти примеры можно применить для кодера 3GPP AMR-WB+ (стандарты [3GPPTS26.273] и [3GPPTS26.304]. Этот кодер использует алгебраическое векторное квантование, словарем которого является объединение перестановочных кодов сети Gosset RE8 размером 8.
Первые три решения (таблицы 4а-4с) представляют и сохраняют базовые разложения l! одинаково. Действительно, предусматривают сохранение ml! и ml! показателей степени pi(1≤i≤ml!)l!. Они различаются в том, что касается представления и сохранения базовых разложений l. Таблица 4а показывает первое решение, предполагающее сохранение ml и ml показателей степени pi(1≤i≤ml!)l. Таблица 4b показывает второе решение, предполагающее сохранение ml! показателей степени pi (1≤i≤ml!)l.
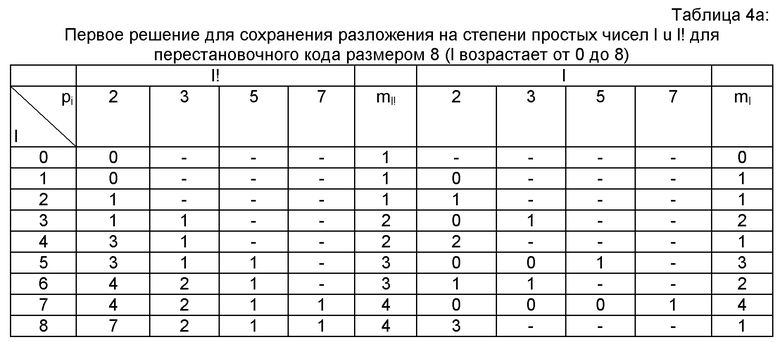
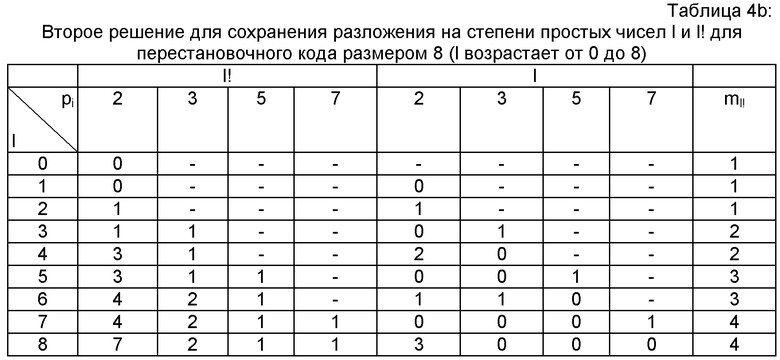
Нижеследующая таблица 4с показывает третье решение, предполагающее сохранение числа , не равных нулю степеней pi для l, с соответствующими индексами i, а также их показателей. В представленной таблице для большей ясности указаны простые множители pi.
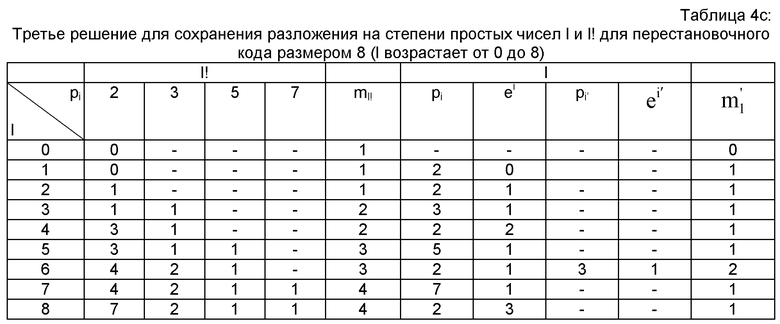
В четвертом решении (показанном на нижеследующей таблице 4d) представлен набор базовых разложений для числа mn!, и для каждого базового разложения (l или l!) сохраняют mn!, показателей. Таблица 4d является извлечением из четырех столбцов (pi=2, 3, 5 и 7) и 9 строк (n=от 0 до 8) приведенных выше таблиц 3а и 3b.
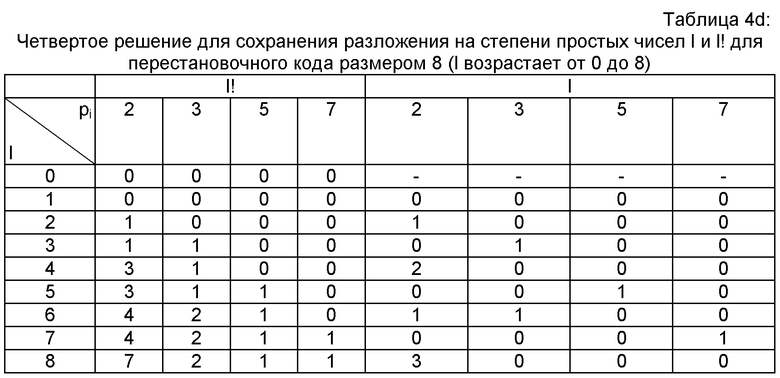
В кодере TDAC, который использует статистическое векторное квантование с переменными размером и разрешением, с максимальным размером 15, рассматриваются шесть (m15!=6) простых чисел: 2, 3, 5, 7, 11 и 13. 6 столбцов (pi=2, 3, 5, 7, 11 и 13) и 16 строк (n= от 0 до 15) таблиц 3a и 3b могут проиллюстрировать сохранение набора базовых разложений для четвертого решения.
Уплотненное представление показателей
Далее следует описание предпочтительного решения, которое позволяет минимизировать сохранение и которое состоит в уплотненном представлении показателей базового разложения на ограниченном числе слов. В этом варианте представления базовых разложений промежуточные разложения и разложения частичных рангов тоже представлены в уплотненном виде. Предпочтительно это решение позволяет также свести к минимуму сложность определения этих разложений, что будет показано ниже.
*Уплотненное представление разложений
Для каждого простого множителя pi, требуется определить верхний предел βi максимального значения его показателя степени в числителе частичных рангов. Этот предел дает максимальное число возможных значений показателя pi, то есть βi+1. Обозначив 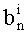 целое число бит для двоичного представления значения (βi+1), получаем:
целое число бит для двоичного представления значения (βi+1), получаем:
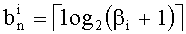 и
и 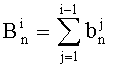 (при
(при 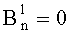 )
)
где x обозначает целое число, непосредственно старшее или равное x(x-1<x≤x).
Показатели разложения на простые множители члена К, участвующего в частичном ранге t', могут быть представлены в уплотненном виде словом eK из Bn бит 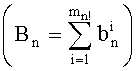
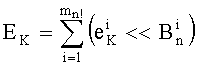
Обозначение «<<В» представляет собой смещение влево на В бит.
Необходимо отметить, что если число n является большим, то Bn может быть больше числа бит В0, используемых для представления целых чисел (16, 32 или 40 бит). В этом случае показатели разложения на простые множители целого числа К, участвующего в t', представлены в виде М целых слов eK(m), 0≤m≤М (разумеется, при М>1).
Предпочтительно М слов могут быть сформированы следующим образом:
- ek(0) содержит i0 первых показателей (показатели от p1 до pi0):
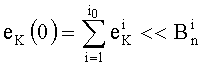 , где
, где 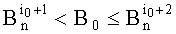
- eK(1) содержит показатели от pi0+1 до pil:
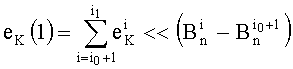
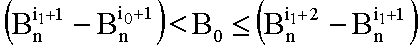
- Это последнее отношение можно распространить на любое m вплоть до составления последнего слова, которое содержит показатель степени pmn!.
Разумеется, можно предусмотреть и другие варианты. Например, в варианте можно сохранять показатель p1 отдельно и применять писанную выше обработку, начиная от показателя р2.
*Определение верхнего предела
Пределы βi можно определять разными способами. Используя данные о перестановочном коде (размер q алфавита, весовой коэффициент wi 0≤i≤q) можно четко определить максимальное значение каждого показателя степени числителя частичного ранга. Если используются несколько перестановочных кодов (возможно, разного размера), предпочтительно для каждого показателя выбирают наибольшее из максимальных значений.
Настоящие изобретением предлагается предпочтительная общая обработка для определения верхнего предела в рамках перечисления Шальквийка. Обработка изначально не использует никакой другой информации о перестановочных кодах, кроме максимального размера. Она просто использует отношение:
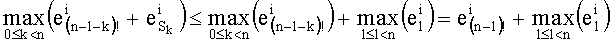
чтобы выбрать в этом случае 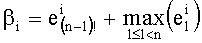
Эта очень общая обработка является особенно предпочтительной, когда используют широкое разнообразие перестановочных кодов.
В таблице 5а представлены верхние пределы максимальных значений показателей в числителях 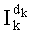
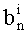
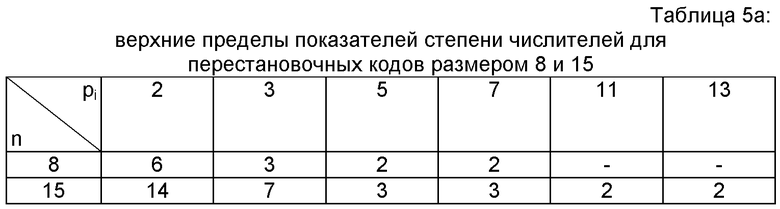
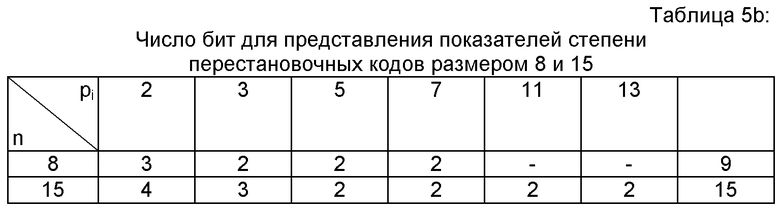
Таблица 6а (соответственно 6b) дает уплотненное представление показателей l и l! для размера n, равного 8 (соответственно 15).
В качестве исключительно иллюстративного примера попробуем определить разложение целого числа l=12 при помощи таблицы 6b.
Предпочтительно в таблице 6b, поскольку максимальный размер кодов является n=15, показатель степени «2» представлен на 4 битах, показатель «3» - на 3 битах и другие простые множители 5, 7, 11, 13 - на 2 битах. В таблице в столбце l=12 читаем его уплотненный показатель e12=18.
Исходя из нижеприведенной таблицы, двоичным представлением 18(=16+2) на В15=15 бит является: 000000000010010, то есть 000000000010010, если перегруппировать соответствующие биты одного и того же простого числа.
4 бит меньшей значимости (весовой коэффициент i=от 4 до 6) являются показателем степени простого множителя 2, то есть 0010=2, что означает, что 2 является показателем степени для простого числа 2.
Следующие 3 бит (весовой коэффициент i=от 4 до 6) являются показателем степени простого множителя 3, то есть 001=3, что означает, что 1 является показателем степени для простого числа 3.
Следующие 2 бит (весовой коэффициент i=от 7 до 8) являются показателем степени простого множителя 5, то есть 00=0.
Следующие 2 бит (весовой коэффициент i=от 9 до 10) являются показателем степени простого множителя 7, то есть 00=0.
Следующие 2 бит (весовой коэффициент i=от 7 до 12) являются показателем степени простого множителя 11, то есть 00=0.
Следующие 2 бит (весовой коэффициент i=от 13 до 14) являются показателем степени простого множителя 13, то есть 00=0.
Процедура извлечения состоит в маскировании битов большой значимости для извлечения показателя степени простого множителя, содержащегося в битах меньшей значимости, затем в смещении уплотненного показателя на число извлеченных бит, чтобы перейти к показателю степени следующего простого множителя.
Так, при размере 15 извлечение производится для 6 показателей, начиная с показателя 2.
Двоичное представление показателя степени числа 2 соответствует 4 бит малой значимости 18, то есть 0010, что соответствует 2. Для их извлечения маскируют биты большей значимости 18 при помощи 15 (обозначается 18&15), что соответствует:
24-1=1111.
Получают e12=18&(2<<4-1)=2, и это значит, что 2 является показателем степени для простого числа 2.
Затем производят смещение 18 на 4 бит вправо и получают: 00000000001=1
Двоичное представление показателя 3 соответствует 3 бит меньшей значимости 1, то есть 001(=1). Для их извлечения маскируют биты большой значимости 1 при помощи 7 (обозначается 1&7 и соответствует 23-1=111).
Получают 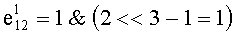
Затем производят смещение 1 на 2 бит вправо и получают: 00000000=0 для всех других бит большой значимости.
Таким образом, степенями для 1=12 являются:
- 2 для простого числа 2, и
- 1 для простого числа 3,
то есть l=12=22 ×31
*Верхний предел для знаменателя
В данном случае предполагается, что для каждого простого множителя его показатель степени в знаменателе частичного ранга f меньше или равен его показателю степени в числителе t'. Таким является случай, когда t' является строго положительным, так как 
На практике, используя формулу Шальквийка, если q>1, значение 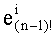
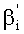
Следовательно, достаточно проверить неравенство 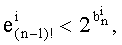
В других случаях можно четко определять 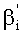
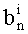
В случае, если q=1, понятно, что в перестановочном коде участвует только одно слово кода известного ранга (t=0), и нет необходимости производить вычисления ранга и соответствующие обратные операции. Вместе с тем, если этот частный случай обрабатывать отдельно не желательно, можно предусмотреть вычисление значения 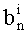
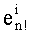
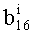
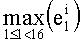
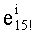
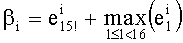
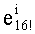
Далее следует краткое описание объемов памяти, необходимых для сохранения базовых разложений.
Независимо от выбранного решения для представления базовых разложений, сохранение базового разложения происходит в таблицах, и поэтому требуется обращение к этим таблицам во время операций кодирования и декодирования ранга. Хотя разложение 0 не возможно (и, кстати, не применяется), предпочтительно все же ввести в память «искусственные» показатели степени для разложения 0 (например нули или единицы) с целью упрощения вычисления адреса. В нижеследующей таблице 8 представлен объем памяти, необходимый для сохранения данных, связанных с базовыми разложениями, для пяти представленных решений по этим двум случаям (сохранение или не сохранение искусственного разложения 0).
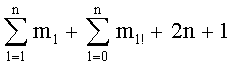
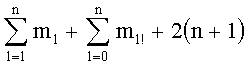
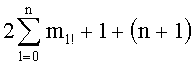
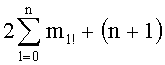
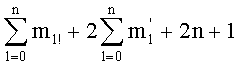
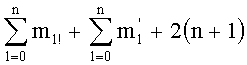
В пятом решении учитывалось сохранение (+mn!) чисел на 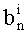
В таблице 9 представлен объем памяти, необходимый для сохранения данных, связанных с показателями разложения по этим пяти решениям для nmax=8 и 15 (с искусственным сохранением 0).
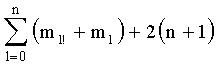
Далее следует описание сохранения степеней простых множителей.
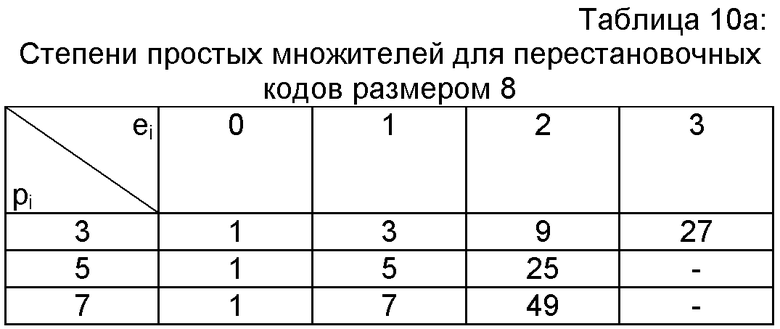
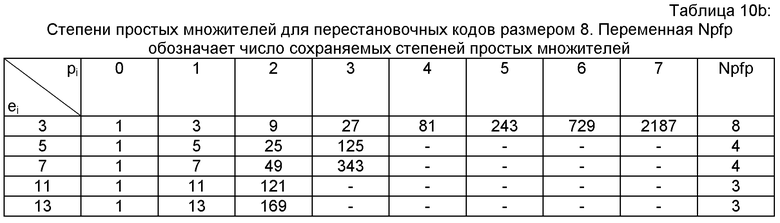
Не считая базовых разложений, в настоящем изобретении используются степени простых множителей для вычисления частичного ранга на основании его разложения. Используя таблицу этих простых множителей, можно вычислять их степени в режиме реального времени («он-лайн»). Предпочтительно степени простых чисел, отличных от 2, вычисляют заранее и вводят в память и в реальном времени вычисляют только степени 2. В нижеследующей таблице 10а представлены степени 3, 5 и 7, необходимые для перестановочного кода размером 8 (аналогично используемые в кодере AMR-WB+). В таблице 10b представлены перестановочные коды с максимальным размером 15 (используемые в кодере TDAC).
В данном случае тоже можно сохранять только необходимое число степеней для каждого простого множителя. В варианте, если предпочтительно иметь только одну регулярно посещаемую таблицу степеней, можно для каждого простого множителя предусмотреть столько же значений, сколько и необходимых степеней р2 (р2=3). Для не используемых степеней можно, разумеется, применять сохранение искусственных значений, таких как 1 или 0.
Далее следует описание вычисления ранга перестановки для осуществления кодирования с применением настоящего изобретения.
Существует несколько вариантов в зависимости от выбранного набора базовых разложений и от их представления. Для упрощения изложение представленных ниже возможных вариантов ограничивается случаем предпочтительного варианта выполнения для набора базовых разложений с разложениями факториалов l! и l.
Сначала будет представлено решение разуплотненного представления показателей степени с mn! показателей на одно базовое разложение, что является наиболее общим случаем. Далее будут описаны варианты разуплотненного представления показателей. Наконец, будет описано решение уплотненного представления показателей базовых разложений, а также некоторые из его вариантов. Из этого описания будет ясно видно, что изобретение можно идеально применять для обработки кодирования ранга перестановки.
В качестве примера обработки перечисления опять вернемся к алгоритму Шальквийка.
Разуплотненное представление показателей разложения
Пусть n будет максимальный размер используемых перестановочных кодов, и mn! - число простых множителей, участвующих в разложении величины n!.
Далее следует описание первого варианта выполнения кодирования с использованием разуплотненного представления показателей разложения
Кодирование согласно первому варианту выполнения
В данном случае показатели базовых разложений l и l! предпочтительно сохраняются в памяти согласно «четвертому» решению приведенной выше таблицы 4d с искусственным сохранением для l=0 в двух одномерных таблицах, обозначенных соответственно Dl и Dl!, содержащих mn!×(n+1) элементов. Как было указано выше, можно рассматривать также двухмерные таблицы, содержащие mn! столбцов и (n+1) строк. Поскольку показатели l сохраняются регулярно (каждый на mn! значений), операции считывания показателей базового разложения требуют вычисления адреса в таблице Dl (соответственно Dl!). Для считывания показателей разложения l! (соответственно l) необходимо обратиться по адресу (l×mn!) таблицы Dl! (соответственно Dl) и найти, таким образом, адрес показателя 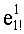
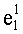
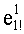
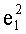
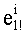
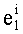
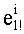
Необходимо отметить, что, если искусственное сохранение для l=0 не предусмотрено, вычислением адреса в таблице D; n базовых разложений l (l>0) является: (l-1)×mn!.
Инициализация
- Производят инициализацию на ноль mn! показателей промежуточного разложения Pk (сохраненных в таблице Р с mn! элементами, которую предпочтительно обновляют по каждой позиции, что будет показано ниже в связи с этапом С-3). Таким образом, командами являются:
- P[i]=0,1≤i≤mn!
- Инициализируют также на ноль ранг t и q весовых коэффициентов 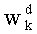
- t=0
- w[i]=0, 0≤i≤q
- k=n-1
Итерации на индексе k
Чтобы проследить итерацию по n позиций (с петлей на переменной k), обратимся к фиг.5. Буквой «С» в обозначениях этапов С-n фиг.5 обозначено слово «кодирование».
На этапе С-1 считывают переменную dk. На этапе С-2 обновляют элемент dk таблицы w: w[dk]=w[dk]+1.
На этапе С-3 производят обновление показателей разложения Pk (таблица P) и, в частности, производят:
- считывание mn! показателей 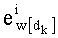
- обновление: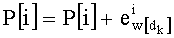
Таким образом, для осуществления этапа С-31 первый показатель базового разложения w[dk] в таблице Dl, обозначенный 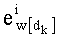
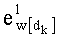
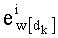
Параллельно на этапе С-4 вычисляют Sk при помощи обычного отношения 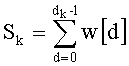
Этап С-5 является тестом на значение Sk. Если Sk равно нулю (стрелка О), что предполагает, что частичный ранг 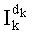
Параллельно на этапе С-7 считывают mn! показателей 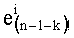
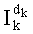
На этапе С-8 результаты различных считываний в таблицах можно сгруппировать, чтобы сначала вычислить mn! показателей разложения частичного ранга 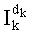
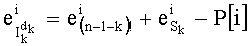
Наконец, на этапе С-9 вычисляют сам частичный ранг 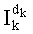
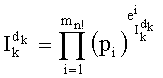
Следует напомнить, что член w[dk] является весовым коэффициентом, обязательно меньшим или равным максимальному размеру n рассматриваемого перестановочного кода. Точно так же, сумма Sk таких весовых коэффициентов остается меньше максимального размера n, и это же относится, разумеется, к (n-1-k). Разложения w[dk], Sk и (n-1-k)! находятся в таблицах разложений целых чисел или факториалов целых чисел, достигающих максимального размера n, таких как таблица 4d. На основании разложения w[dk], записанного в таблицу, и разложения Pk-1, определенного на предыдущей петле (k-1) и сохраненного в памяти, определяют разложение Pk.
Исключительно в качестве примера, иллюстрирующего этапы вычисления частичного ранга, показанные на фиг.5, рассмотрим перестановочный код размером n=8 и q=4. В этом примере показатели записаны в двухмерной таблице с четырьмя столбцами и девятью строками, то есть содержащей 36 элементов. Таким образом, его можно извлечь из приведенной выше таблицы 4d, где мы имеем pi=2, 3, 5, 7 в столбцах и l=0,…, 8 в строках.
В этом примере предполагают, что в предыдущей позиции k=3 таблица весовых коэффициентов w дает {1, 1, 0, 3} и, следовательно, P3=1! 1 0! 3!=6. Таким образом, таблица Р показателей разложения Р3 (=2l×31×50×70) дает {1, 1, 0, 0}.
В позиции k=2 для этапа С-1 предположим, что в результате считывания d2=2.
В этом примере на этапе С-2 обновляют элемент w[2] путем инкрементации на 1 (w[2]=0+1=1).
На этапе С-31 считывают четыре показателя разложения 1(=w[2]), то есть 0, 0, 0, 0 (см. в таблице 4d: 6-й - 9-й столбцы и 3-ю строку l=1).
Затем (этап С-32) обновляют таблицу Р и получают Р={1, 1, 0, 0}.
На этапе С-4 вычисляют Sk: Sk=w[0]+w[l]=1+1=2. Таким образом, Sk не равна нулю (тест С-5).
- Считывают (этап С-6) четыре показателя разложения Sk (обращаясь по-прежнему к таблице 4d: 6-й - 9-й столбцы, но 4-ю строку l=2): для p1=2 (6-й столбец) показателем является 1, а для pi=3, 5, 7 (7-й - 9-й столбцы) показатель равен нулю.
- Считывают (этап С-7) четыре показателя разложения 5! (что соответствует (n-1-k)!), обращаясь по-прежнему к таблице 4d, но на этот раз 2-й - 5-й столбцы и 7-я строка l=5. Для p1=2 (2-й столбец) показателем является 3. Для р2=3 (3-1 столбец) показателем является 1, и для р3=5 (4-й столбец) показатель тоже равен 1. Зато для р4=7 (5-й столбец) показатель равен нулю.
- На этапе С-8 вычисляют четыре показателя разложения частичного ранга 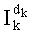
- для р1=2, 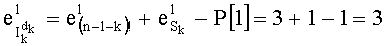
- для р2=3, 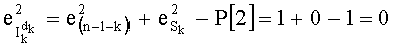
- для р3=5, 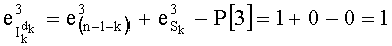
- для р4=7, 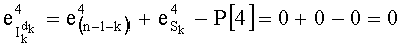
На этапе С-9 частичный ранг 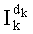
Как показано на фиг.5, сам общий ранг t перестановки определяют путем обновления (с добавлением частичного ранга
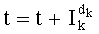
После этого этап С-11 предполагает декрементацию переменной k (k=k-1), а этап С-12 является тестом на значение k для продолжения или не продолжения обработки. Так, если k≥0 (стрелка О на выходе теста С-12), повторяют этапы обработки, начиная с первого этапа С-1, со значением k, уменьшенным на одну единицу. В противном случае (стрелка N на выходе теста С-12) обработку заканчивают на завершающем этапе С-13 ("END").
Таким образом, понятно, что вышеуказанный этап С-9 предназначен для вычисления частичного ранга на основании его разложения, определенного на этапе С-8, которое, в свою очередь, определяют на основании трех промежуточных разложений:
- (n-1-k)!
- Sk и
- Pk.
Определение двух из них (n-1-k)! и Sk осуществляют на этапах С-6 и С-1, и оно состоит в простом считывании в двух соответствующих таблицах базовых разложений Dl и Dl!. Определение третьего разложения (Pk) можно тоже осуществить просто на основании q базовых разложений w[d]!, считанных в таблице Dl!, при помощи отношения типа 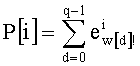
Прямые варианты
Этап С-3 имеет более предпочтительный вариант определения этого промежуточного разложения. Действительно, промежуточное разложение Pk можно определить на основании базового разложения, считанного в таблице и другого промежуточного разложения (разложения Pk+1), вычисленного для другого частичного ранга 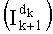
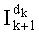
Ранее, вычисление было произведено при помощи петли от последней позиции (k=n-1) до первой позиции (k=0). Однако изобретение можно применить, разумеется, для петли от первой до последней позиции. Достаточно поменять фазу инициализации и адаптировать этапы С-2 и С-3 и их порядок. Для этого таблицу весовых коэффициентов w можно инициализировать с q весовых коэффициентов 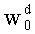
Затем, после этапа С-10 и перед этапом С-2 наступает этап С-3. Промежуточное разложение Р обновляют путем вычитания из P[i] показателя 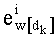
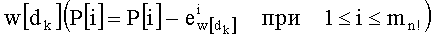
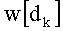
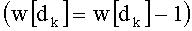
Наконец, коротко можно сказать, что для перестановочных кодов с переменным размером n вместо осуществления 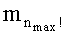
Общие версии первого варианта выполнения
В целом вариант, показанный на фиг.5 для кодирования в соответствии с настоящим изобретением, допускает много версий.
Так, в первой версии каждое базовое разложение (l или l!) тоже содержит число тц. Считывание числа mn! (0≤l≤n) имеет преимущества. Действительно, этапы С-3 и С-6 - С-10 не осуществляют mn! раз для каждого, а только:
- 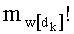
- 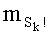
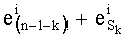
- 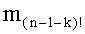
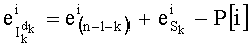
Если, кроме того, сохранили также значения ml, то остается только осуществить:
- 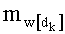
- 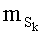
В другой версии кодирования, если используют также сохранение показателей базового разложения l по третьему решению (вышеуказанная таблица 4 с), этап С-3 можно осуществлять для 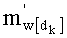
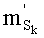
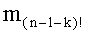
- 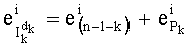
- и 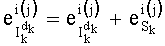
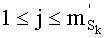
В третьей версии, вместо разложения частичного ранга на три члена (два в числителе и один в знаменателе), его разлагают два члена, один из которых является частным. Таким образом, частичный ранг 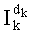
- сумма Sk
- и частное 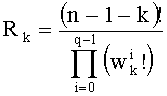
Это частное можно обновить при помощи следующего отношения:
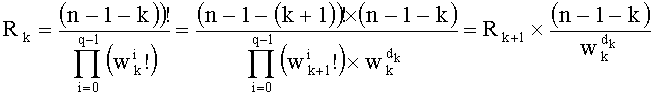
Таким образом, вместо определения разложения Rk на основании q+1 базовых разложений (разложений (n-1-k)! и разложений q w[d]!, считанных в таблице Dl!) определяют промежуточное разложение Rk на основании промежуточного разложения Rk+1 и базовых разложений (n-1-k) и q w[d] (эти два базовых разложения считывают в таблице Dl!), что записывается как: 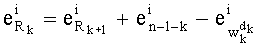
По сравнению с предыдущими версиями вместо определения и сохранения в памяти промежуточного разложения знаменателя 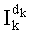
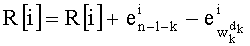
Согласно факультативу сохранения, это обновление можно произвести путем mn! сложений и вычитаний или 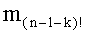
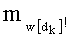
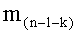
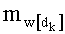
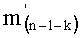
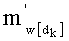
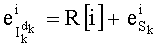
Согласно факультативу сохранения, в этом случае насчитывают mn! сложений или 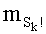
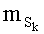
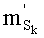
Следует отметить, что это соотношение Rk не обязательно является целым числом, то есть показатели R[i] могут быть отрицательными. В этой версии разложение факториалов при кодировании (то есть таблица Dl!) уже не нужно, поскольку можно использовать только один простой набор (n+1) базовых разложений целых чисел l (l<n), вводя в память только таблицу
Уплотненное представление показателей разложения
Далее следует описание второго варианта кодирования, основанного на уплотненном представлении показателей разложения.
Показатели базового разложения представлены в уплотненном виде, а не в разуплотненном виде, как было описано выше в связи с первым вариантом выполнения. Для упрощения будет представлен только случай, когда уплотненное представление показателей содержится только в одном слове. Эти слова введены в память, как было указано выше, с сохранением искусственного слова при l=0 в двух таблицах, обозначенных соответственно 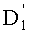
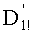
Необходимо заметить, что в отсутствие сохранения искусственного слова для l=0 слово, соответствующее базовому разложению l (при l>0), находится в таблице
Кодирование согласно второму варианту выполнения
Инициализация
- Инициализируют на ноль слово ер, содержащее уплотненное представление mn! показателей промежуточного разложения Pk: ep=0.
Слово ep будет обновляться на каждой позиции (ниже следующий этап СС-3).
- Как и в предыдущем случае, на нулевое значение инициализируют также ранг t и q весовых коэффициентов 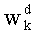
- t=0
- w[i]=0, 0≤i≤q
- k=n-1
Итерация на n позициях (петля на k)
Обратимся теперь к фиг.6, чтобы проследить основные этапы кодирования в этом втором варианте выполнения, Буквы «СС» в обозначениях этапов СС-n на фиг.6 обозначают слово «кодирование» с «уплотненным представлением».
На этапе СС-1 считывают переменную dk. Этап СС-2 состоит в обновлении переменной w: 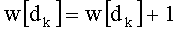
Этап СС-3 является обновлением слова ep, и, в частности:
- на этапе СС-31 - считывание слова ew(dk), содержащего уплотненное представление показателей разложения 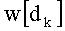
- на этапе СС-32 - собственно обновление слова 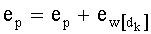
Параллельно на этапе СС-4 вычисляют сумму Sk:
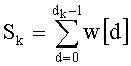
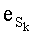
Параллельно (и предпочтительно в зависимости от результата СС-5) считывают слово 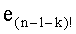
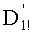
На этапе СС-8 результаты, полученные на различных этапах СС-3, СС-6, СС-7, группируют для вычисления слова 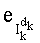
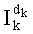
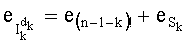
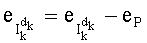
Этап СС-9 предусматривает извлечение mn! показателей 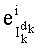
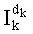
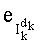
i'1) 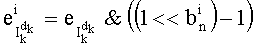
i'2) 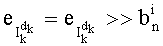
Следует напомнить, что обозначения “<<b” и “>>b” обозначают соответственно смещение влево и смещение вправо на b бит. Кроме того, обозначение “&” обозначает побитовый логический оператор «И». Команда i'1) предусматривает извлечение 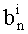
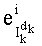
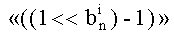
Иначе говоря, сначала (для индекса петли 1, равного 1) применяют маску из 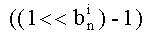
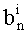
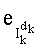
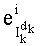
Затем:
- смещают биты 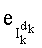
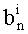
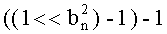
- затем извлекают показатель 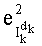
- после этого применяют смещение на 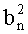
и так далее до i=mn!
На следующем этапе СС-10 вычисляют частичный ранг 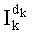
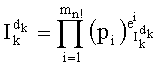
После этого частичный ранг 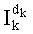
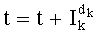
На следующем этапе СС-12 производят декрементацию индекса k(k=k-1) и, прежде чем возобновить этапы СС-4, СС-1, СС-7 и следующие с этим декрементированным значением, при помощи теста СС-13 проверяют, не достигло ли значение k-1(k<0), и в этом случае обработка завершена (этап СС-14).
Таким образом, независимо от представления разложений, настоящее изобретение позволяет эффективно вычислять частичные ранги. Этап СС-10 предусматривает вычисление частичного ранга на основании его разложения, завершенного на предыдущих этапах СС-8 и СС-9. Используют три промежуточных разложения (членов (n-1-k)!, Sk и Pk). Определение двух из них ((n-1-k)! и Sk), произведенное на этапах СС-6 и СС-7, состоит в простом считывании их уплотненного представления в таблицах 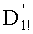
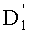
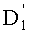
Как было указано выше в связи с первым вариантом выполнения, сохранение в памяти значений тд (0≤l≤n) позволяет уменьшить сложность этапов СС-9 и СС-10. Петлю извлечения показателей разложения частичного ранга 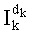
Далее следует описание декодирования ранга перестановки с применением настоящего изобретения. Здесь тоже существует несколько версий в зависимости от решения представления базовых разложений (разуплотненное или уплотненное). Ниже следует описание первого варианта декодирования, аналогичного описанному выше первому варианту выполнения для кодирования с использованием разуплотненного представления разложений и их сохранения согласно четвертому решению, связанному с приведенной выше таблицей 4d. Как будет показано, изобретение идеально применяется для декодирования ранга перестановки, для чего в качестве примера будет взят алгоритм Шальквийка.
Декодирование согласно первому варианту выполнения
Декодирование с использованием разуплотненного представления показателей разложения предпочтительно начинается с инициализации данных следующим образом.
Инициализация
- Инициализируют таблицу значений w с q весовых коэффициентов 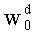
- 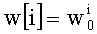
- Вычисляют mn! показателей разложения члена (Р0 (сохраненных в таблице Р, содержащей mn! элементов и тоже обновляемой по каждой позиции в конце петли на каждой позиции на этапе D-18, описанного ниже). Соответствующими командами могут быть:
- P[i]=0 для 1≤i≤mn!
- Петля от d=0 до q-1
- считывание mn! показателей 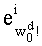
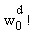
- затем 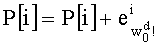
- Наконец, инициализируют k=0.
Далее обратимся к фиг.7, чтобы проследить основные этапы декодирования согласно первому варианту выполнения. Буква «D» в обозначениях этапов D-n на фиг.7 обозначает слово «декодирование».
Итерация на n позициях (петля на индексе k)
Первый этап D-1 состоит в считывании mn! показателей 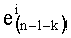
На следующем этапе D-2 устанавливают значения dk=0 и 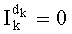
После этого производят поиск первого значения dk из алфавита, при котором 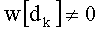
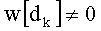
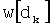
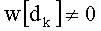
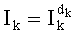
Следующий этап D-8 является вычислением обновления суммы Sk=Sk+w[dk]. За ним следует считывание из таблицы Dl (этап D-9) mn! показателей 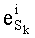
Этап D-10 предусматривает вычисление mn! показателей разложения частичного ранга на основании отношения 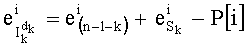
Этап D-11 предусматривает вычисление ранга из: 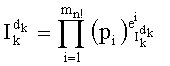
Три следующих этапа предусматривают тест на значение общего ранга t, сравнивая его со значением частичного ранга. Для этого на этапе D-12 инкрементируют значение dk(dk=dk+1), и тест D-13 является: 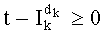
Если неравенство установлено (стрелка О), этапы D-7-D-13 повторяют с новым инкрементированным значением dk. Если нет (стрелка N), обработка продолжается этапом D-14 декрементации значения dk(dk=dk+1), чтобы вернуться к значению dk до этапа D-12. При этом значении dk частичный ранг 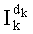
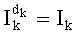
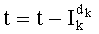
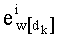
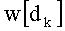
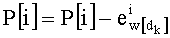
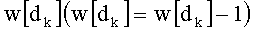
До замыкания петли на первом этапе D-1 проверяют, все ли n компонент были обработаны. Для этого предусматривают тест D-21 на значение k, сравнивая его с n (k<n). Если индекс k не достиг значения n (стрелка О теста D-21), обработку возобновляют с этапа D-1 для следующего значения k. В противном случае (стрелка N на выходе теста D-21), обработку завершают на конечном этапе D-22.
Следует учитывать, что этап D-11 предусматривает вычисление частичного ранга с использованием разложения, определенного на этапе D-10 на основании трех промежуточных разложений последовательных членов (n-1-k)! и Sk и Pk. Определение двух из них ((n-1-k)и Sk) произведенное на этапах D-1 и D-9, состоит в простом считывании в соответствующих таблицах Dl! и Dl. Определение третьего промежуточного разложения (Pk), произведенное на этапе D-18, тоже осуществляют считыванием из таблицы Dl (этап D-17) с последующим обновлением показателей считанного базового разложения (этап D-18). Описанная выше инициализация этого промежуточного разложения требует q считываний из таблицы Dl с последующим обновлением показателями этого промежуточного разложения путем добавления показателей считанных q базовых разложений.
Как и при описанном выше кодировании, обработка, показанная на фиг.7, допускает версии, которые, в случае необходимости, позволяют снизить сложность некоторых этапов.
Одна версия состоит в использовании показателей соотношения Rk (что было описано выше) и является наиболее предпочтительной. Действительно в описанной выше со ссылками на фиг.7 обработке декодирования для данной позиции к вычисляют показатели 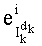
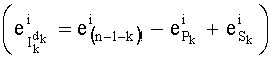
Вместе с тем, версия, использующая показатели отношения Rk, требует всего одного сложения 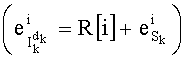
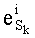
Декодирование согласно второму варианту выполнения.
Далее со ссылками на фиг.8 следует описание примера выполнения декодирования с использованием уплотненного представления разложений.
Предварительно предусматривают инициализацию данных следующим образом.
Инициализация
- Обратимся сначала к таблице w с q элементами для определения членов 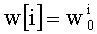
- Вычисляют слово ер, содержащее уплотненное представление mn! показателей разложения Pk. Для этого:
- устанавливают ер=0
- и предусматривают петлю от d=0 до q-1:
- со считыванием слова 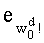
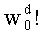
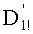
- и с обновлением 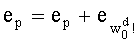
- После этого устанавливают k=0.
Итерация на n позициях (петля на k)
Буквы «DC» в обозначениях этапов DC-n на фиг.8 обозначают слово «декодирование» с «уплотненным представлением».
На этапе DC-1 считывают слово е(n-1-k)! содержащее уплотненное представление mn! показателей члена (n-1-k)! в таблице 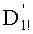
Этапы DC-2 - DC-8 аналогичны этапам D-2 - D-8, описанным выше со ссылками на фиг.7.
Что же касается этапа DC-9, то считывают слово 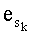
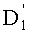
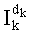
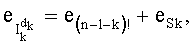
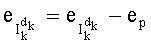
В целом общий этап DC-11 состоит в извлечении показателей частичного ранга 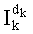
- петлю на i (1≤i≤mn!) (инициализация i=l на этапе DC-111 и после описанного ниже извлечения показателя 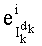
- извлечение показателя 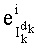
представленного в битах малой значимости уплотненного показателя 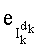
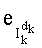
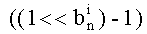
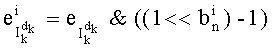
при этом указанное маскирование сопровождается смещением вправо на 
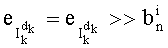
Этот общий этап DC-11 аналогичен общему этапу СС-9 фиг.6 для кодирования.
Этапы DC-12 - DC-17 аналогичны этапам D-11 - D-16, описанным выше со ссылками на фиг.7 в связи с декодированием в разуплотненном представлении.
Но зато обновление показателей Pk (таблица Р) на общем этапе DC-18 происходит на этапе DC-181 путем считывания слова 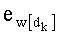
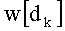
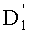
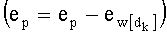
После этого, этапы DC-19 - DC-22 аналогичны этапам D-19 - D-22 фиг.7 для декодирования с использованием разуплотненного разложения.
Далее будут показаны различные преимущества, обеспечиваемые вышеуказанными версиями.
Версии первого варианта выполнения с разуплотненным представлением, в котором используют таблицы ml!, (и/или ml или 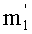
В этом случае выигрыш в сложности является значительным, особенно для последних позиций (то есть когда m(n-k),
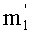
Интересным компромиссом является регулярное сохранение в памяти базовых разложений (с mn! показателей) для облегчения обращения к таблицам Dl и Dl! и сохранение значений ml в таблице Dm с (n+1) элементами. В этом случае следует сохранять также значения ml для эффективного уменьшения числа сложений/вычитаний. Однако эта мера сопровождается обязательным считыванием значений 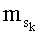
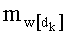
Кроме того, по сравнению с разуплотненным представлением уплотненное представление имеет следующие преимущества:
- этап обновления таблицы Р в данном случае содержит только одно сложение (соответственно вычитание) при кодировании (соответственно при декодировании),
- вычисление показателя 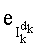
- вычисления адреса для считывания слов ek являются прямыми и для каждого значения К требуют только одного обращения и считывания в памяти.
Вместе с тем, уплотненное представление требует извлечения показателей частичного ранга 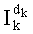
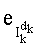
Далее следует описание преимуществ таких версий для вычисления частичного ранга на основании его разложения на простые множители.
Сложность этапа вычисления произведения степеней простых множителей в рамках этапов С-9 и СС-10 (соответственно D-11 и DC-12) при кодировании (соответственно при декодировании) существенно возрастает с числом множителей, даже если она остается гораздо ниже сложности деления в соответствии с известными решениями. Однако на практике многие показатели разложения частичного ранга равны нулю и, следовательно, соответствующие степени равны 1. Часто все показатели равны нулю, или только первые показатели не равны нулю. Поэтому необходимо иметь возможность выявлять и сохранять только степени показателей, не равных нулю. В подробном представлении это выявление можно осуществить только при помощи mn! тестов или m(n-1-k)! тестов (или через простой множитель).
Предпочтительно уплотненное представление позволяет проверить при помощи всего одного теста, все ли показатели равны нулю 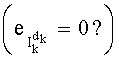
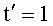
Кроме того, выявление бита большой значимости et , позволяет получить индекс наибольшего простого множителя не равного нулю показателя в ранге 
Вместе с тем следует отметить, что выявление не равных нулю показателей как в развернутом представлении, так и в уплотненном представлении повышает сложность. Если все показатели не равны нулю, сложность умножения степеней простых множителей остается такой же, и к ней добавляется сложность процедуры выявления не равных нулю показателей.
Таким образом, в другой версии выявление показателей, равных нулю, можно осуществлять, только если возможное число простых множителей становится большим (k намного меньше n), и сложность умножения их степеней выше сложности процедуры выявления. Для этого можно предусмотреть различные петли по позициям, даже если это происходит в ущерб возрастанию линии команд.
Можно также комбинировать разуплотненное и уплотненное представления. Для последних позиций (значение ml! является незначительным) вычисление промежуточных разложений не требует много операций. В этом случае отдается предпочтение использованию разуплотненного представления, которое не требует извлечения показателей частичного ранга. Зато для первых позиций, наоборот, лучше использовать уплотненное представление.
Далее следует описание нескольких примеров выполнения в существующих кодерах/декодерах.
Кодер 3GPP AMR-WB+
Кодер 3GPP AMR-WB+ (стандарт [3GPPTS26.304]) использует алгебраическое векторное квантование, словарем которого является объединение перестановочных кодов сети Gosset RE8 с размером 8.
Технология ТСХ соответствует кодированию с предсказанием при помощи трансформанты. В частности, речь идет о методе кодирования при помощи трансформанты FFT, применяемом после фильтрования перцептивного взвешивания. В стандарте [3GPPTS26.304] полученный спектр FFT делят на субполосы (или субвекторы) размером n=8, и эти субвекторы кодируют раздельно. При квантовании субвекторов используют правильную сеть точек RE8. Словари квантования по размеру 8 содержат объединение перестановочных кодов типа I, полученных из точечной сети RE8.
В кодере ТСХ согласно стандарту [3GPPTS26.304] каждый перестановочный код соответствует данному вектору-лидеру со знаком по размеру n=8. Индекс квантования точки сети RE8 вычисляют при помощи формулы типа:
индекс = смещение кардинальности + ранг перестановки
Ранг вычисляют при помощи формулы Шальквийка, тогда как смещение кардинальности занесено в таблицу. Вместе с тем, эти лидеры со знаком представлены через свои абсолютные лидеры, чтобы оптимизировать сохранение и поиск в перестановочных кодах. Список соответствующих лидеров по абсолютной величине можно найти в:
"Low-complexity multi-rate lattice vector quantization with application to wideband TCX speech coding at 32 kbit/s", Ragot S., Bessette В., Lefebvre R., Proc. ICASSP, том 1, май 2004, стр.501-4.
Для иллюстрации различных вариантов изобретения ниже представлены три примера выполнения. Два первых примера выполнения относятся к вычислению ранга перестановки (кодирование), при этом в одном используют разуплотненное представление разложения, а в другом - уплотненное представление.
В этих примерах выполнения и соответствующих приложениях таблицы R и Р индексированы от R[0] до R[mn!-1] и от Р[0] до P[mn!-1] (а не от 1 до mn!, как было указано в качестве примера выше), причем без какого-либо особенного влияния на обработку для вычисления ранга.
Первый пример выполнения (кодирование)
В этом варианте выполнения используют разуплотненное представление базовых разложений.
Их показатели записывают в две таблицы с 36 элементами (=(8+1)×4). Речь идет о таблицах, приведенных в приложении А-11 и обозначенных Dl [36] (содержащих показатели разложений целых чисел l (0≤l≤8), то есть с сохранением искусственного разложения для 0) и Dl! [36] (содержащих показатели разложений их факториалов).
В память вводят также три таблицы степеней 3, 5 и 7:
Pow3[4]={1, 3, 9, 27}; Pow5[3]={1, 5, 25}; Pow7[3]={1, 7, 49};
В этом варианте выполнения разложение частичного ранга определяют на основании двух промежуточных разложений, при этом одно из них является базовым разложением целого числа Sk, а другое - промежуточным разложением частного:
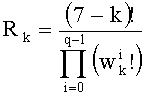
Как было указано выше, вместо определения промежуточного разложения Rk на основании базовых разложений, соответствующих (q+1) базовых разложений (7-k)! и 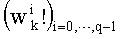
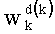
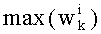
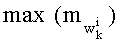
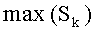
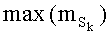
Изобретение использует знание m(7-k)! и максимальных значений 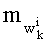
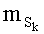
Соответствующая обработка представлена в приложении А-12. Отмечается, что петля на Позициях является разуплотненной. Отмечается также, что показатель простого множителя pi частного сохранен в элементе R[i-1] таблицы из 4 элементов.
Второй пример выполнения (кодирование)
В варианте с кодером 3GPP AMR-WB+ базовые разложения представлены в уплотненном виде. Слова, содержащие их показатели, записывают в таблицы с 9 элементами (=(8+1)). Как видно из приложения А-21, таблица 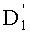
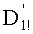
Сохраняют также степени 3, 5 и 7 в таблице Pow[12] с 12 элементами (с искусственным сохранением 0 для не используемых степеней).
Разложение частичного ранга определяют на основании трех промежуточных разложений, два из которых являются базовыми разложениями целого числа Sk и факториала (7-k)!, а третье - промежуточным разложением знаменателя частичного ранга:
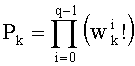
Как было указано выше, вместо определения промежуточного разложения Pk на основании q базовых разложений 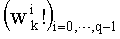
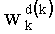
Здесь тоже используют знание m(7-k)!, чтобы извлекать только m(7-k)! показателей уплотненного слова, представляющего разложение частичного ранга.
Соответствующая обработка представлена в приложении А-22. В данном случае петля по позициям тоже является разуплотненной.
Третий пример выполнения (декодирование)
Третий пример выполнения относится к декодированию ранга перестановки при кодировании в 3GPP AMR-WB+.
Предпочтительно используют разуплотненное представление базовых разложений, как и в первом примере выполнения, и разложение частичного ранга на три члена, как во втором примере выполнения. Однако петля по позициям не является разуплотненной.
Как было указано выше, вместо определения промежуточного разложения Pk на основании базовых разложений его определяют на основании промежуточного разложения Pk-1 и базового разложения 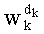
Соответствующая обработка представлена в приложении А-3. Отмечается, что показатель простого множителя pi частного (соответственно произведения) записан в элементе R[i-1] (соответственно P[i-1]) таблицы R (соответственно Р) с четырьмя элементами.
Таким образом, в вышеуказанном первом примере используют разложение частичного ранга на два члена (из которых один является частным), а в двух других примерах используют разложение на три члена (два из которых для числителя и один для знаменателя). Вариант для декодирования использует только m8!(=4) членов, тогда как два варианта для кодирования используют раздельную обработку позиций для использования ml! или ml членов, которые не считываются, а являются «схемно-заданными» в алгоритме, с разуплотнением на 8 позициях точки сети Gosset.
Пример выполнения для кодера TDAC
Последний пример выполнения касается частотного перцептивного кодера TDAC, запатентованного заявителем и используемого для кодирования цифровых дискретизированных аудиосигналов на 16 кГц (распшренньш диапазон), принцип которого представлен ниже.
Кодер TDAC использует статическое векторное квантование с переменными размером и разрешением и с максимальным размером 15.
В случае перестановочных кодов правильной сетки точек RE8 с размером 8 изобретение в основном позволяет снизить сложность. Что же касается кодера TDAC, который использует перестановочные коды с размером более 12, изобретение оказалось очень эффективным, так как оно не только позволяет снизить сложность, но также обеспечивает реализацию кодера на процессорах с фиксированной запятой, максимальная точность которых ограничена 32-битовыми целыми числами без знака. Без изобретения это было бы очень трудно осуществить.
Принцип этого кодера заключается в следующем.
Аудиосигнал, ограниченный по полосе 7 кГц и дискретизированный по 16 кГц, делят на блоки по 320 образцов (20 мс). Применяют модифицированную дискретную трансформанту по косинусу (или "MDCT") для блоков входного сигнала по 640 образцов с перекрыванием 50% (что соответствует обновлению анализа MDCT каждые 20 мс). Спектр ограничивают по 7225 Гц, устанавливая на ноль 31 последних коэффициентов (в этом случае только 289 первых коэффициентов отличаются от 0). Кривую маскировки определяют из этого спектра, и все маскируемые коэффициенты устанавливают на ноль. Спектр делят на 32 полосы неравной ширины. Возможные маскированные полосы определяют в зависимости от трансформированных коэффициентов сигналов. Для каждой полосы спектра вычисляют энергию коэффициентов MDCT (чтобы произвести оценку масштабных множителей). 32 масштабных множителя образуют огибающую спектра сигнала, которую затем квантуют, кодируют и передают в блок. Динамическое распределение базовых бит на кривой маскирования на полосу вычисляют на основании деквантованной версии огибающей спектра таким образом, чтобы достичь совместимости между двоичным распределением кодера и декодера. После этого нормализованные в каждой полосе коэффициенты MDCT квантуют при помощи векторных кванторов, использующих словари, распределенные по размеру, при этом словари состоят из объединения перестановочных кодов типа II. Наконец, информация по тональности и звонкости, а также огибающая спектра и кодированные коэффициенты уплотняют и передают в виде блока.
Пример выполнения для вычисления ранга перестановки (кодирование) использует в данном случае уплотненное представление разложений. Используют самый разный размер перестановочных кодов, при этом петля по позициям не является разуплотненной. Этот вариант выполнения иллюстрирует процедуру выявления не равных нулю показателей разложения частичного ранга.
В данном случае базовые разложения представлены в уплотненном виде. Вводят в память слова, содержащие их показатели, в две таблицы с шестнадцатью элементами (=(15+1)). В приложении В-1 таблица
Сохраняют также степени 3 в таблице с восемью элементами (обозначенной Pow3) и степени 5, 7, 11 и 13 в таблице (обозначенной Pow) с двадцатью элементами (с искусственным сохранением 0 для не используемых степеней).
Соответствующая обработка представлена в приложении В-2.
Разумеется, настоящее изобретение не ограничивается вариантами выполнения, представленными выше в качестве примеров; оно распространяется и на другие варианты.
По мнению заявителя, настоящее изобретение состоит в первом использовании разложений на степени простых множителей в перестановочных кодах. Однако это использование является особенно предпочтительным, если предусмотрены вычисления комбинаторных выражений, как в векторном квантовании с перестановочными кодами. Таким образом, в целом, настоящим изобретением предусмотрено это использование разложений на степени простых множителей для любого комбинаторного выражения, даже отличного от ранга перестановки, при кодировании/декодировании при помощи перестановочного кода или перестановочных кодов.
Настоящее изобретение находит свое предпочтительное применение в кодировании/декодировании речевых сигналов, например, в телефонных терминалах, в частности, в системе сотовой связи. Вместе с тем, оно применяется для кодирования/декодирования сигналов любого другого типа, в частности, сигналов изображения или видеосигналов, а также при кодированной модуляции.
Объектом настоящего изобретения является также компьютерная программа, предназначенная для введения в память устройства кодирования/декодирования цифровых сигналов с использованием перестановочных кодов. Эта программа содержит команды для осуществления этапов способа в соответствии с настоящим изобретением. Описанные выше фиг.4-8 могут соответствовать блок-схемам алгоритмов, которые может содержать такая программа.
Объектом настоящего изобретения является также устройство кодирования/декодирования цифровых сигналов, использующее перестановочные коды и содержащие, как показано на фиг.9:
- запоминающее устройство MEM для сохранения команд компьютерной программы вышеуказанного типа, а также заранее записанных представлений разложений выбранных целых чисел, и
- модуль вычисления PROC, имеющий доступ к этому запоминающему устройству MEM для осуществления способа в соответствии с настоящим изобретением.
Эти средства MEM, PROC могут быть предусмотрены:
- для получения ранга t перестановки на основании выбранного вектора-кода у (стрелки в виде сплошной линии на фиг.9):
- в модуле индексации кодера источника или
- в модуле индексации декодера канала,
- или для получения вектора-кода y, воспроизводимого на основании ранга перестановки (стрелки в виде пунктирной линии на фиг.9):
- в модуле декодирования декодера источника или
- в модуле кодирования кодера канала.
Разумеется, представления, заранее записанные в запоминающем устройстве MEM, могут быть в виде содержания адресов (разуплотненное представление) или в виде битовых слов (уплотненное представление).
А-12
Инициализация:
- t=0
- w[i]=0, 0≤i<q
- R[0]=0
Обработка позиций
- Позиция k=7:
- d7=d[7]; w[d7]=1
- Позиция k=6:
- d=d[6]; w[d]=w[d]+1
- If(d=d7)и тогда R[0]=1
в противном случае, если (d>d7) t=1
- Позиция k=5:
- d=d[5]; w[d]=w[d]+1
- R[0]=R[0]+Dl[4*2]-Dl[4*w[d]]
- R[1]=-Dl[4*w[d]+1]
- S=0; петля от j=0 до d-1: S=S+w[j]]
- Тест на S>0; если да:
- i2=R[0]+Dl[4*S]
- t=t+(1<<12)
- Позиции k=4 затем 3:
- d=d[k]; w[d]=w[d]+1
- R[0]=R[0]+Dl[4*(7-k)]-Dl[4*w[d]]
- R[1]=R[1]+Dl[4*(7-k)+1]-Dl[4*w[d]+1]
- S=0; петля от j=0 до d-1: S=S+w[j]
- Тест на S>0; если да:
- i2=R[0]+Dl[[4*S]
- i3=R[1]+Dl[4*S+1]
- t=t+pow3[i3]*(1<<i2)
- R[2]=-Dl[4*w[d]+2]
- Позиции k=2 затем 1:
- d=d[k]; w[d]=w[d]+1
- R[0]=R[0]+Dl[4*(7-k)]-Dl[4*w[d]]
- R[1]=R[1]+Dl[4*(7-k)+1]-Dl[4*w[d]+1]
- R[2]=R[2]+Dl[4*(7-k)+2]-Dl[4*w[d]+2]
- S=0; петля от j=0 до d-1: S=S+w[j]
- Тест на S>0; если да:
- i2=R[0]+Dl[4*S]
- i3=R[1]+Dl[4*S+1]
- i5=R[2]+Dl[4*S+2]
- t=t+pow5[i5]*pow3[i3]*(1<<i2)
- R[3]=-Dl[4*w[d]+3]
- Позиция k=0:
- d=d[0]; w[d]=w[d]+1
- R[0]=R[0]+Dl[4*7]-Dl[4*w[d]]
- R[1]=R[1]+Dl[4*7+1]-Dl[4*w[d]+1]
- R[2]=R[2]+Dl[4*7+2]-Dl[4*w[d]+2]
- R[3]=R[2]+Dl[4*7+3]-Dl[4*w[d]+3]
- S=0; петля от j=0 до d-1: S-S+w[j]
- Тест на S>0; если да:
- i2=R[0]+Dl[4*S]
- i3=R[1]+Dl[4*S+1]
- i5=R[2]+Dl[4*S+2]
- i7=R[3]+Dl[4*S+3]
- t=t+pow7[i7]*pow5[i5]*pow3[i3]*(1<<i2)
А-21
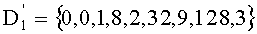
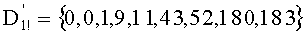
Pow[12]={
1, 3, 9, 27,
1, 5, 25, 0,
1, 7, 49, 0};
А-22
Инициализация:
- t=0
- w[i]=0, 0≤i<q
- еР=0
Обработка позиций
- Позиция k=7:
- d7=d[7]; w[d7]=1
- Позиция k=6:
- d=d[6]; w[d]=w[d]+1
- Если (d=d7), то еР=1
в противном случае, если (d>d7) t=1
- Позиция k=5:
- d=d[5]; w[d]=w[d]+1
- 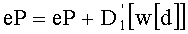
- S=0; петля от j=0 до d-1: S=S+w[j]
- Тест на S>0; если да:
- 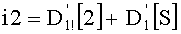
- i2=i2-eP
- t=t+(1<<i2)
- Позиции k=4 затем 3:
- d=d[k]; w[d]=w[d]+1
- 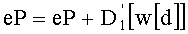
- S=0; петля от j=0 до d-1:S=S+w[j]
- Тест на S>0; если да:
- 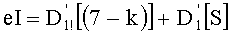
- eI=eI-eP
- i2=eI&(0×7)
- i3=eI>>3
- t=t+pow[i3]*(1<<i2)
- Позиции k=2 затем 1:
- d=d[kw[d]=w[d]+1
- 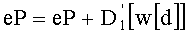
- S=0; петля от j=0 до d-1: S=S+w[j]
- Тест на S>0; если да:
- 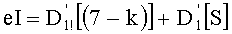
- eI=eI-eP
- i2=eI&(0×7)
- eI=eI>>3
- i3=eI&(0×3)
- eI=eI>>2
- i5=eI&(0×3)
- t=t+pow[4+i5]*pow[i3]*(1<<i2)
- Позиция k=0:
- d=d[0]; w[d]=w[d]+1
- 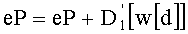
- S=0; петля от j=0 до d-1:S=S+w
- Тест на S>0; если да:
- 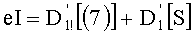
- eI=eI-eP
- i2=eI&(0×7)
- eI=eI>>3
- i3=eI&(0×3)
- eI=eI>>2
- i5=eI&(0×3)
- eI=eI>>2
- i7=eI&(0×3)
- t=t+pow[8+i7]*pow[4+i5]*pow[i3]*(1<<i2)
A-3
Инициализация:
- Петля от i=0 до 3, P[i]=Dl![4*w[0]+i]
- Петля от d=1 до q-1:
- Петля от i=0 до 3:P[i]=P[i]+Dl![4*w[d]+i]
Обработка позиций
- Петля от k=0 до 7:
- Петля от i=0 до 3:R[i]=Dl![4*(7-k)+i]-P[i]
- I=0
- d=0
- Повторить, пока w[d]=0, d=d+1
- R[0]=R[0]+Dl[4*(7-k)]-Dl[4*w[d]]
- R[1]=R[1]+Dl[4*(7-k)+1]-Dl[4*w[d]+1]
- R[2]=R[2]+Dl[4*(7-k)+2]-Dl[4*w[d]+2]
- S=0
- Повторить, пока (t-I>0)
- I'=I
- S=S+w[d]
- i2=R[0]+Dl[4*S]
- i3=R[1]+Dl[4*S+1]
- i5=R[2]+Dl[4*S+2]
- i7=R[3]+Dl[4*S+3]
- I=pow7[i7]*pow5[i5]*pow3[i3]*(1<<i2)
- d=d+1
- d=d-l
- I=I'
- t=t-I
- Петля от i=0 до 3, P[i]=P[i]-Dl[4*w[d]+i]
- w[d]=w[d]-1
- x[k]=a[d]
B-1
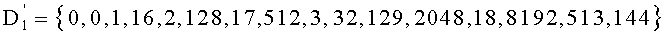
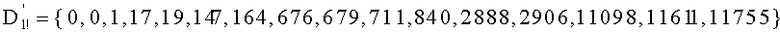
Pow3[8]={1, 3, 9, 27, 81, 243, 729, 2187}
Pow[4*5]={1, 5, 25, 125, 625, 1, 7, 49, 343, 0, 1,11, 121, 0, 0, 1, 13, 169, 0, 0}
В-2
Инициализация:
- t=0
- w[i]=0, 0≤i<q
- eP=0
Обработка позиций
- Позиция k=n-1
- dn1=d[n-1]; w[dn1]=1
- Позиция k=n-2
- d=d[n-2]; w[d]=w[d]+1
- Если (d-dn1), то еР=1
- Если (d>dn1) t=1
- Позиции от k=n-3 до 0:
- d=d[k]
- w[d]=w[d]+1
- 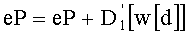
- S=0; петля от j=0 до d-1:S-S+w[j]
- Тест на S>0; если да:
- t'=1
- 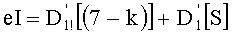
- eI=eI-еР
- Тест на (eI>0); если да
- i2=eI&(0×F)
- Pow[0]=1;
- mI=0
- i3=(eI>>4)&0×7
- if (i3>0)
- pow[0]=Pow3[i3]
- mI=mI+1
- eI=eI>>7
- ifeI>0
- mI'=(16-norm_s(eI))>>1
- петля от j=0 до mI'
- i=eI&0×3
- ifi>0
- ifi>0
- pow[mI]=Pow[i+5*j]
- mI=mI+1
- eI=eI>>2
- петля от i=0 до (mI-1):t'=t'×pow[i]
- t'=t'×i2
- t=t+t'
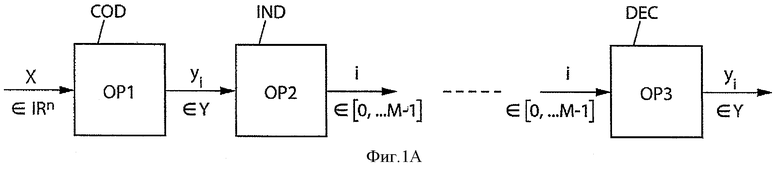
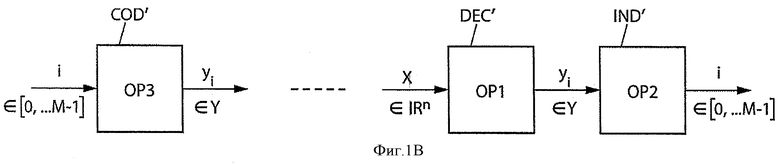
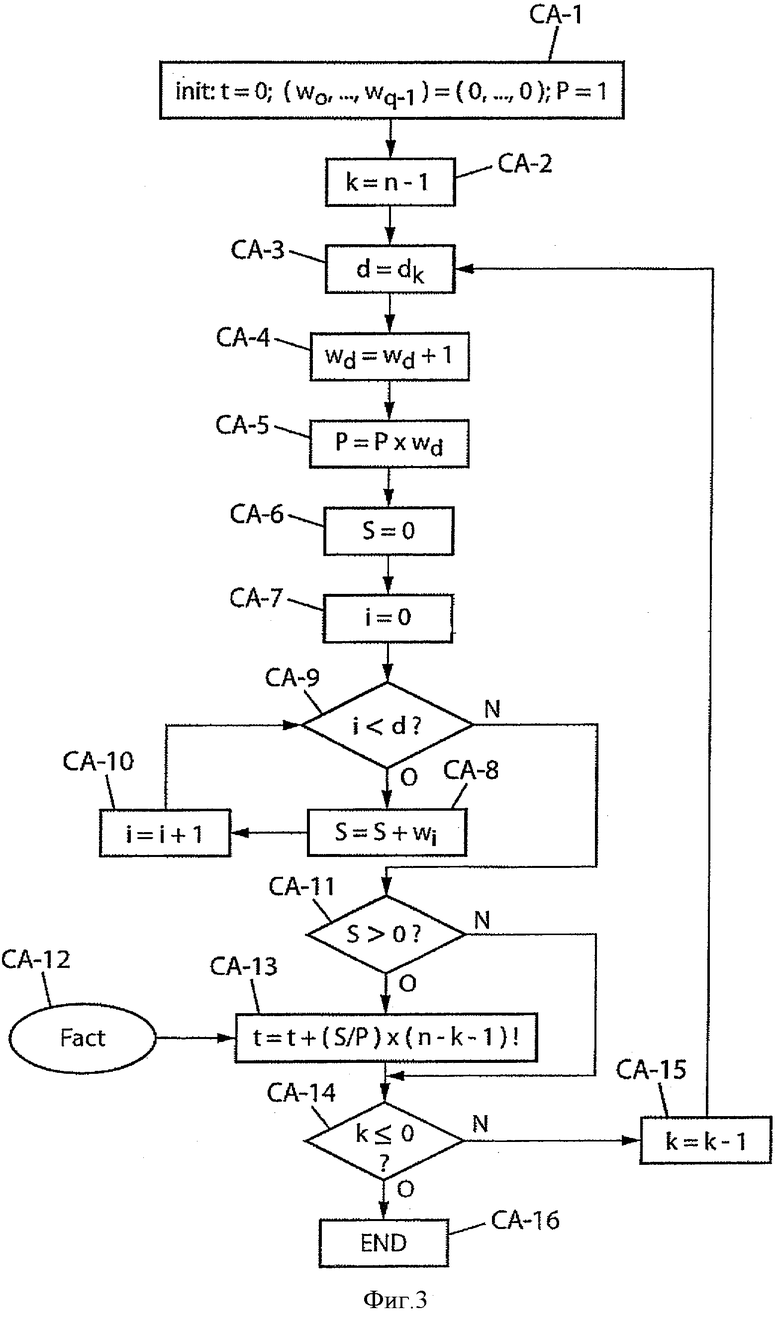
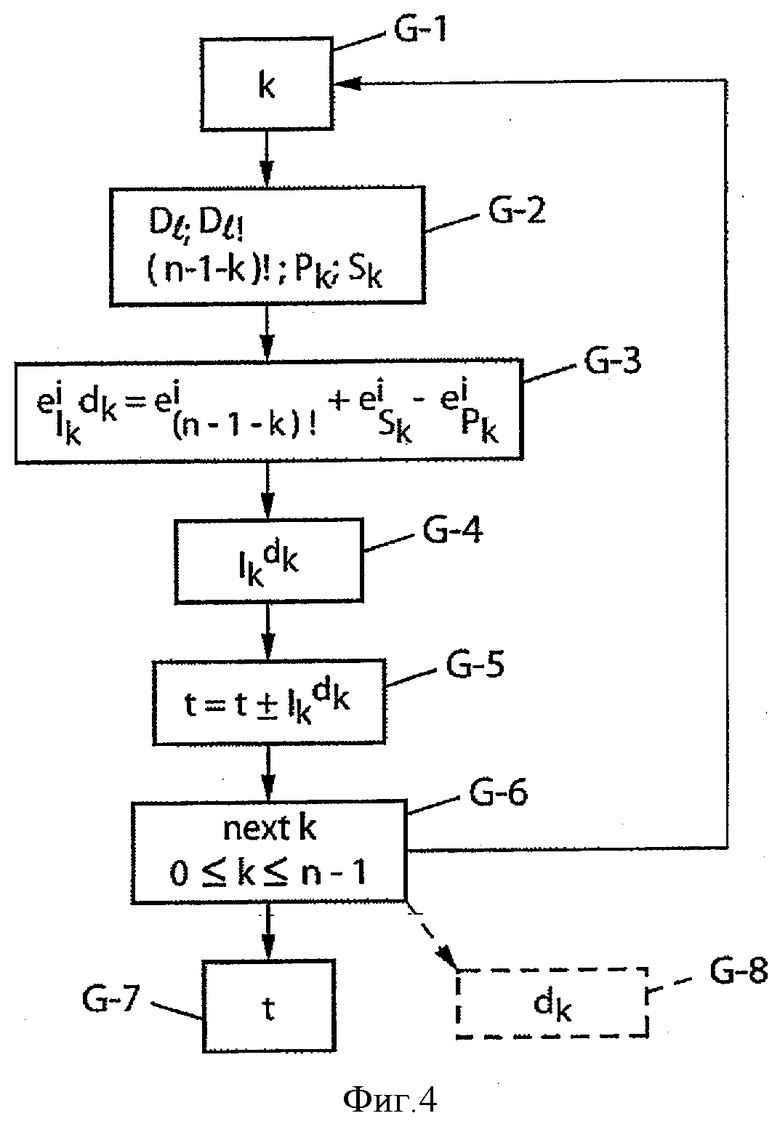
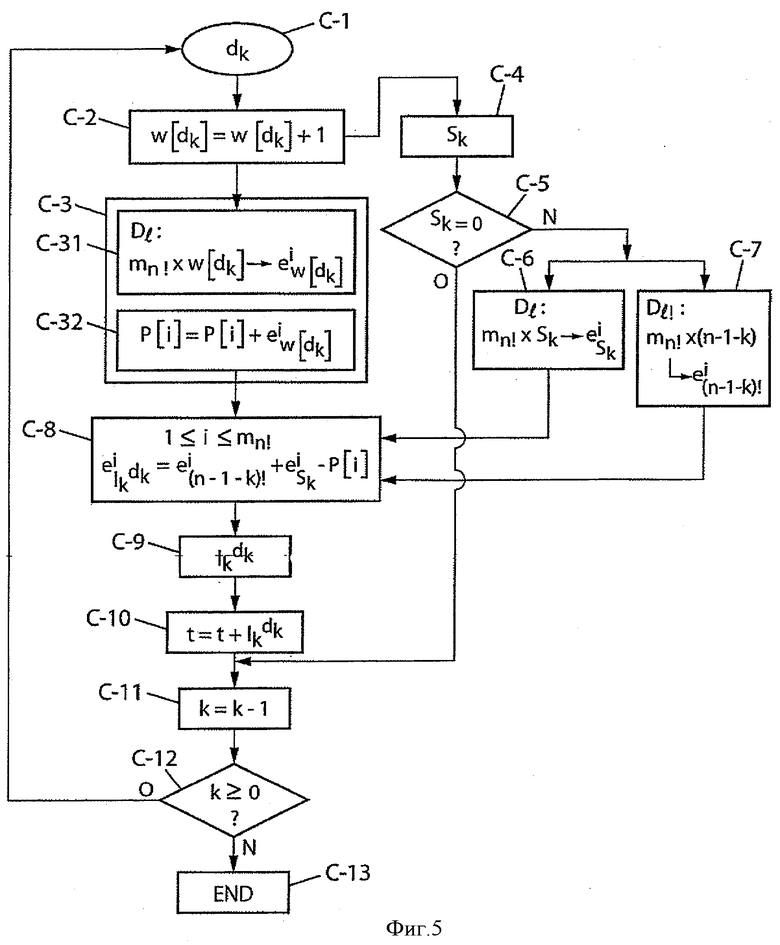
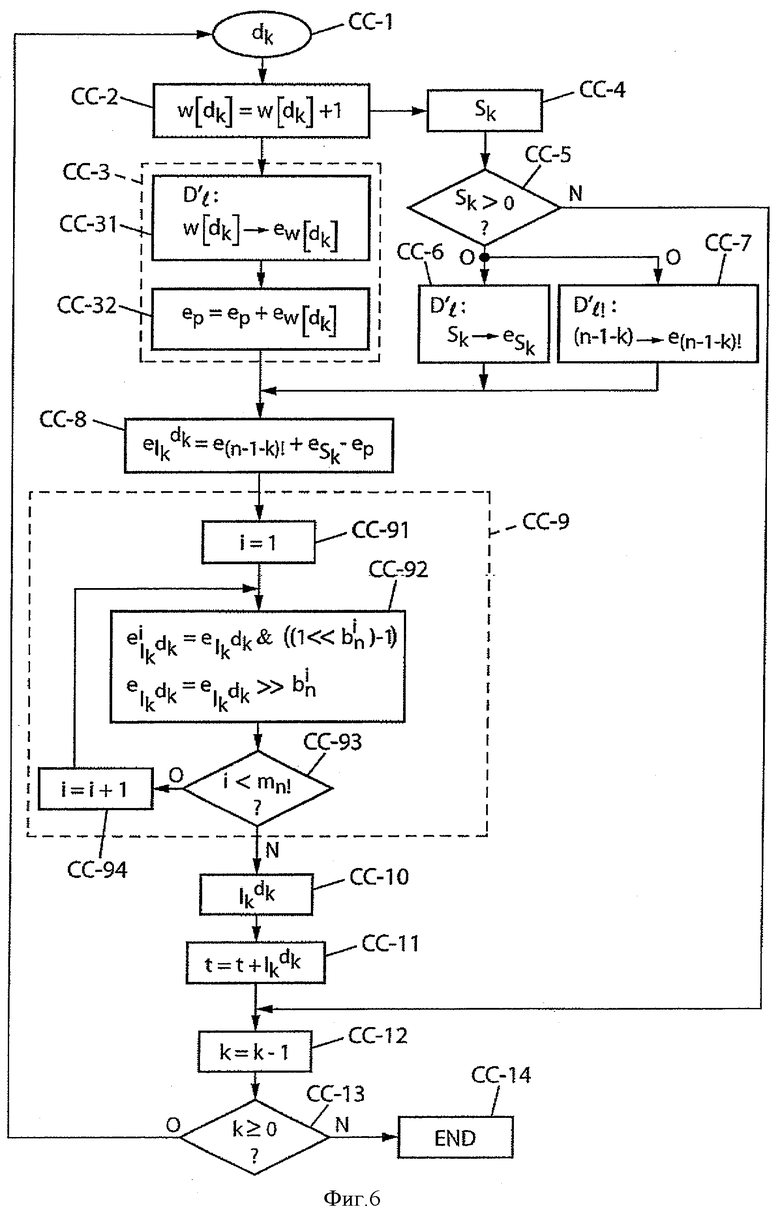
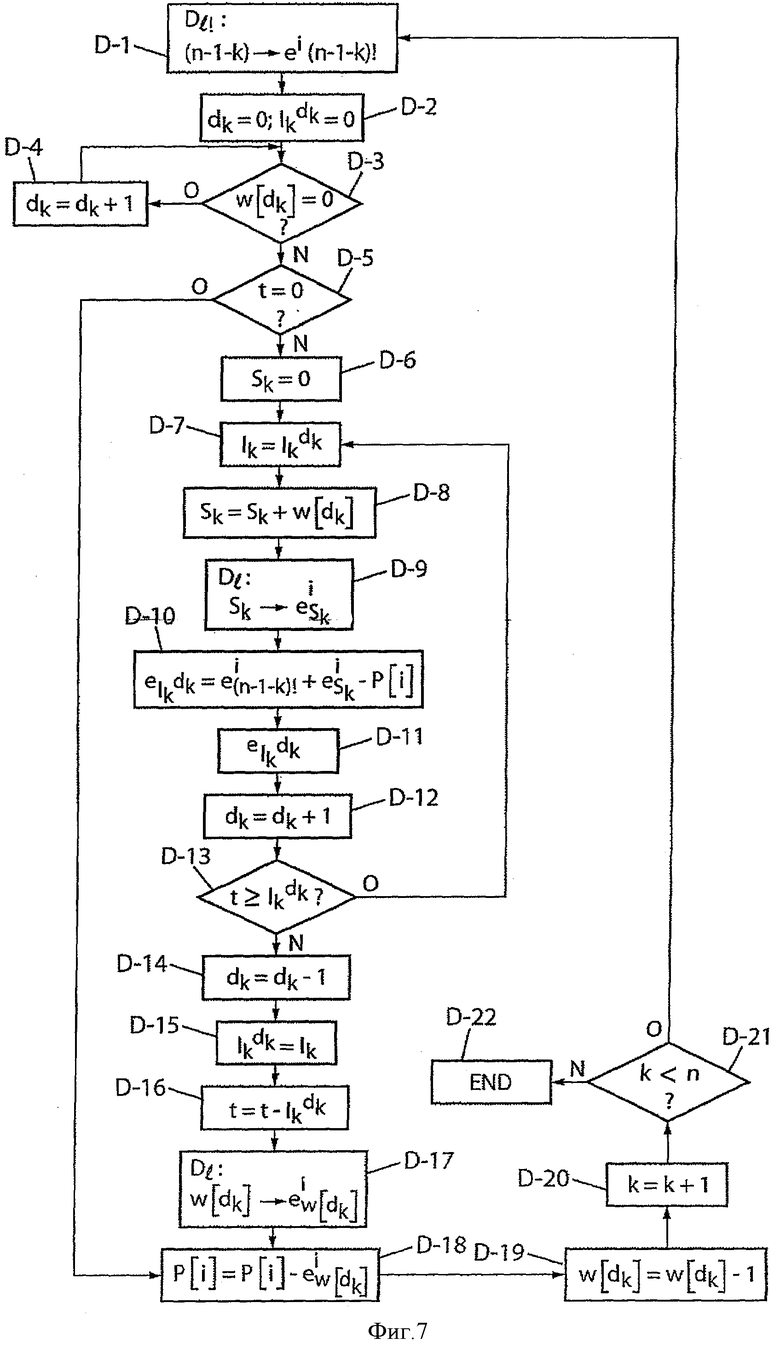
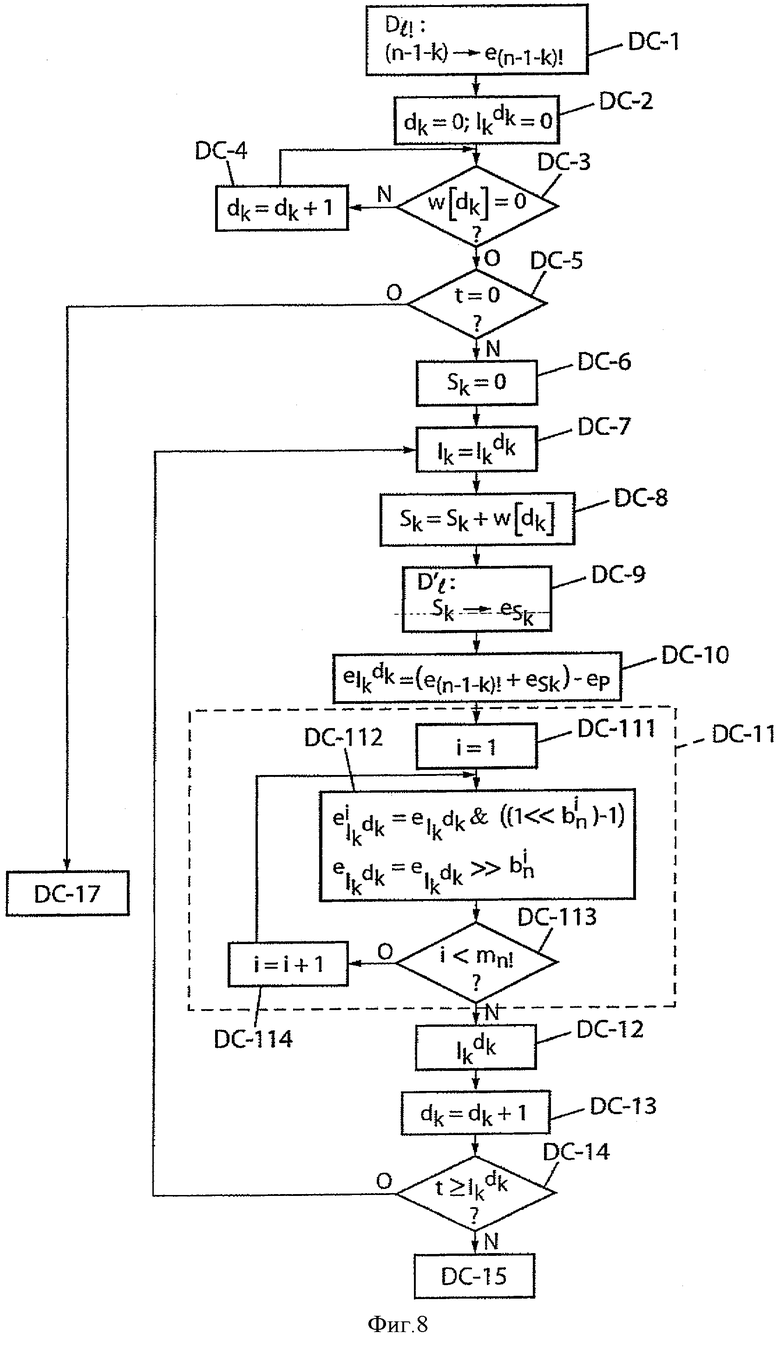
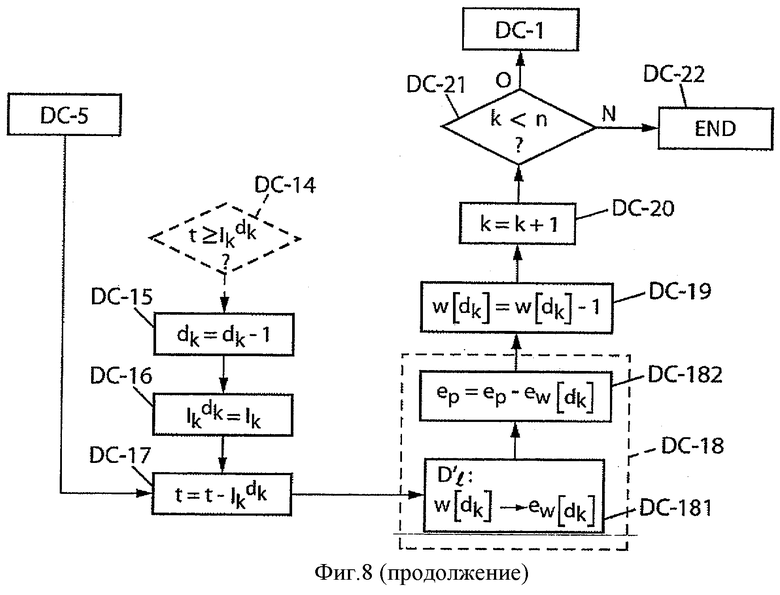
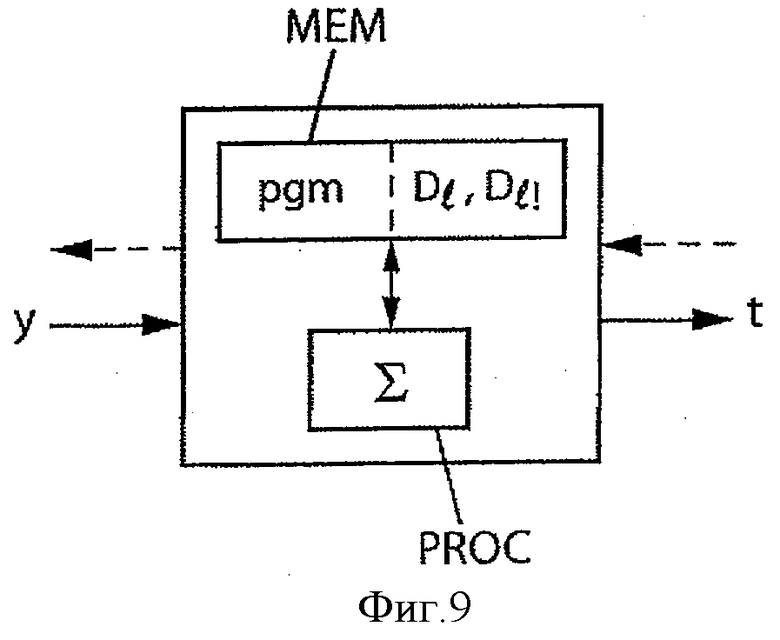
Объектом изобретения является кодирование/декодирование цифровых сигналов, использующее, в частности, перестановочные коды, сопровождающиеся вычислением комбинаторных выражений. Согласно изобретению, эти комбинаторные выражения представлены разложениями на степени простых множителей и определяются путем считывания в памяти заранее записанных представлений разложений выбранных целых чисел. Технический результат - обеспечение эффективного декодирования перестановочных кодов. 3 н. и 5 з.п. ф-лы, 9 ил., 18 табл., 7 прил.
1. Способ кодирования или декодирования цифровых сигналов, содержащий выбор подходящего вектора, представляющего цифровой сигнал, который необходимо закодировать/декодировать, при этом выбранный вектор ищут в словаре, причем задают порядок поиска и выполняют поиск путем использования перестановочных кодов с вычислением комбинаторных выражений, отличающийся тем, что комбинаторные выражения представлены разложениями на степени простых множителей и определяются путем считывания из памяти заранее записанных представлений разложений выбранных целых чисел, в котором
по меньшей мере, одно из указанных комбинаторных выражений содержит частное от деления целого числителя на целый знаменатель,
и способ содержит следующие этапы:
считывают из памяти предварительно записанные представления разложений упомянутого целого числителя и упомянутого целого знаменателя,
определяют это частное на основании разложения на степени простых множителей, при этом каждую степень получают в результате вычитания из показателей соответственно связанных с целым числителем, показателей связанных с целым знаменателем и относящихся к одному и тому же простому числу.
2. Способ по п.1, отличающийся тем, что для вычисления комбинаторного выражения содержит следующие этапы:
идентификацию, среди указанных выбранных целых чисел, целых чисел, появляющихся в произведении и/или в частном, образующих указанное комбинаторное выражение,
считывание из памяти показателей, участвующих в разложениях указанных целых чисел на простые множители,
сложение и/или соответственно вычитание считанных показателей для определения показателей, участвующих в разложении указанного комбинаторного выражения на степени простых множителей, и последующее вычисление указанного комбинаторного выражения на основании его разложения на степени простых множителей.
3. Способ по п.2, содержащий этап вычисления произведения, который повторяют для того, чтобы вычислить произведения, на котором на каждом повторе этапа участвует целое число, которое умножают на произведение, определенное во время предыдущего выполнения этапа вычисления произведения, отличающийся тем, что:
указанное произведение, определенное при предыдущем выполнении, сохраняют в памяти в виде разложения на степени простых множителей,
указанное целое число, умножаемое на произведение, является одним из выбранных целых чисел, разложение которых заранее введено в память, и
для определения указанного произведения на текущем выполнении прибавляют, по одному на простое число, показатели степени, полученные из соответствующих разложений указанного произведения, определенного на предыдущем выполнении, и указанного целого числа, умножаемого на произведение.
4. Способ по п.2, содержащий этап вычисления деления для вычисления деления, на котором на каждом повторе этапа участвует целое число, делящее частное, определенное на предыдущем выполнении этапа вычисления деления, отличающийся тем, что:
указанное частное, определенное при предыдущем выполнении, сохраняют в памяти в виде разложения на степени простых множителей,
указанное целое число, делящее частное, является одним из выбранных целых чисел, разложение которых заранее введено в память, и
для определения указанного деления на текущем выполнении вычитают, по одному на простое число, показатели степени, полученные из соответствующих разложений указанного делящего целого числа, из показателей степени, полученных из разложения указанного частного, определенного на предыдущем выполнении.
5. Способ по п.1, отличающийся тем, что перестановочный код использует перечисление Шальквийка, и тем, что частичный ранг 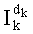
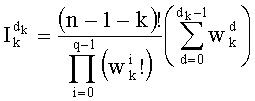
где запись 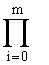
запись 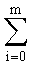
запись l! является значением факториала целого числа l при l!=1·2·3·…(l-1)·l для l>0 и 0!=1,
- целое число n является размером перестановочного кода, соответствующим общему числу компонент, которое содержит вектор-код,
целое число k, составляющее от 0 до n-1, является индексом k-й компоненты yk вектора-кода,
целое число q является числом отдельных компонент, которые содержит вектор-код, и
член 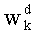
члены-факториалы (n-1-k)! для всех целых чисел k от 0 до n-1,
значение каждого члена 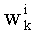
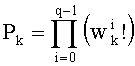
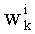
члены 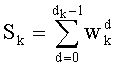
6. Способ по п.5, отличающийся тем, что сумму показателей в разложении члена 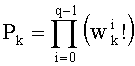
7. Машиночитаемый носитель информации, содержащий сохраненные на нем инструкции компьютерной программы устройства кодирования или декодирования цифровых сигналов, в котором указанные инструкции, когда считываются процессором, заставляют процессор осуществлять этапы способа по п.1.
8. Устройство кодирования или декодирования цифровых сигналов, содержащее средство, включающее:
запоминающее устройство для сохранения заранее записанных представлений разложений выбранных целых чисел, и
модуль вычисления, имеющий доступ к запоминающему устройству для осуществления способа по п.1.
| Способ обработки целлюлозных материалов, с целью тонкого измельчения или переведения в коллоидальный раствор | 1923 |
|
SU2005A1 |
| СПОСОБ ИТЕРАТИВНОГО ШИФРОВАНИЯ БЛОКОВ ЦИФРОВЫХ ДАННЫХ | 2001 |
|
RU2222868C2 |
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| СПОСОБ ИТЕРАТИВНОГО ШИФРОВАНИЯ БЛОКОВ ЦИФРОВЫХ ДАННЫХ | 2000 |
|
RU2199826C2 |
| US 5832443 A, 03.11.1998. | |||

