Изобретение относится к области обработки информации, а именно к способам и методам поиска информации, а также создания структур данных, предназначенных для этой цели.
Характеристики систем поиска ключевых слов в потоке данных зависят как от используемого алгоритма поиска, так и от количества ключевых слов. Существенными характеристиками являются скорость поиска и объем оперативной памяти, используемой при проведении поиска. Скорость работы большинства алгоритмов поиска существенно падает при увеличении количества ключевых слов. С другой стороны, алгоритмы, скорость работы которых не зависит от количества ключевых слов, требуют наличия больших объемов памяти. Подбор соответствующего алгоритма поиска при заданных условиях является нетривиальной задачей.
Алгоритм цифрового поиска на основе префиксного дерева является наилучшим по критерию наибольшей скорости поиска [Fredkin, Е. 1960. Trie memory. Communications of the ACM 3, 490-499]. Его достоинствами являются независимость от количества ключевых слов и простота реализации. Недостатком данного метода является большой объем памяти для хранения структуры данных вследствие ее сильной разреженности (количество занятых ненулевых элементов в структуре низко по отношению к их общему количеству). Разреженность структуры данных может быть устранена либо модификацией, либо уплотнением структуры данных.
Известны способы модификации структуры данных, заключающиеся в изменении структуры узла [патент США №7720854 В2 от 18.05.2010, МПК G06F 7/00 (2006.01), G06F 17/30 (2006.01); патент США №6675171 В2 от 06.01.2004, МПК G06F 17/30; патент США №6671694 В1 от 30.12.2003, МПК G06F 17/30]. Данные способы обладают двумя недостатками. Во-первых, усложнение структуры узла приводит к усложнению алгоритма поиска. Во-вторых, уход от прямой адресации элементов внутри узла приводит к увеличению времени итерации по ключу. Это приводит к уменьшению скорости работы алгоритма поиска.
Процесс уплотнения структуры данных путем слияния узлов с использованием незанятых элементов получил малое распространение из-за требований к статичности пространства ключевых слов (после процесса уплотнения процесс вставки нового ключевого слова приводит к большим временным затратам). Для определенного круга задач данное требование является допустимым.
В общем случае, решение задачи уплотнения сводится к поиску такой перестановки из всех возможных, при которой достигается наилучшее (максимальное) отношение количества занятых элементов к их общему количеству. Существует доказательство NP-полноты данного процесса [Dill, J. М. Optimal trie compaction is NP-complete. TR-CSD-167, Pennsylvania State Univ., March 1987].
Наиболее близким, взятым в качестве прототипа, является метод, система, программа и структура данных компактного массива для хранения символьных строк [патент США №6470347 В1 от 22.10.2002, МПК G06F 17/00]. Метод описывает структуру данных для хранения строк в виде префиксного дерева. Уплотнение структуры данных достигается в два этапа. На первом этапе удаляются повторяющиеся узлы, т.е. узлы с ненулевыми элементами в одних и тех же позициях. На втором этапе производится слияние узлов друг с другом. Условие слияния: ненулевые элементы узла-источника могут быть вставлены на место пустых элементов узла-приемника. Допускается смещение элементов одного узла относительно элементов другого.
Данный метод обладает двумя недостатками. Во-первых, удаление повторяющихся узлов недопустимо, т.к. это приводит к потере свойства ассоциативности, когда в конце итерации поиска можно однозначно сопоставить найденный ключ с определенными данными. Во-вторых, слияние узлов по принципу первого найденного варианта приводит к отклонению результирующей плотности сжатия от максимально возможного значения.
Указанные недостатки в целом приводят к невозможности использования прототипа при выполнении процедур поиска с количеством ключевых слов, превышающим 106.
Задачей заявленного изобретения является создание способа уплотнения структуры данных префиксного дерева, позволяющего добиться уменьшения объема оперативной памяти, требуемого для хранения данной структуры данных. Усложнения алгоритма поиска, а также уменьшения скорости поиска информации при этом не происходит.
Данная задача решается тем, что способ уплотнения структуры данных префиксного дерева, заключающийся в слиянии узлов дерева друг с другом по принципу первого найденного варианта, при котором ненулевые элементы узла-источника вставляют на место пустых элементов узла-приемника, согласно изобретению дополнен тем, что слияние узлов происходит только после ранжирования и нахождения наиболее подходящих пар слияния.
Для этого на каждой итерации происходит вычисление числовых характеристик случайных величин для всех узлов, участвующих в уплотнении. Далее, для каждого узла, согласно выбранному критерию, выбирается наилучший предполагаемый узел для слияния. Если слияние не удалось, выбирается следующий узел и т.д. либо до удачного слияния, либо до конца списка. Итерации продолжаются до тех пор, пока есть потенциальная возможность слияния хотя бы одной пары узлов.
Следствием использования предлагаемого способа является увеличение времени, необходимого для уплотнения структуры данных. Учитывая, что добавление новых ключевых слов после уплотнения не предполагается, данным увеличением можно пренебречь.
Проведенный анализ уровня современной вычислительной техники позволил установить, что аналоги, характеризующиеся совокупностью признаков, тождественных всем признакам заявленного технического решения, отсутствуют, что указывает на соответствие заявленного способа условию патентоспособности «новизна».
Результаты поиска известных решений в данной и смежных областях техники с целью выявления признаков, совпадающих с отличительными от прототипа признаками заявленного объекта, показали, что они не следуют явным образом из уровня техники. Из уровня техники также не выявлена известность отличительных существенных признаков, обусловливающих тот же технический результат, который достигнут в заявляемом способе. Следовательно, заявленное изобретение соответствует условию патентоспособности «изобретательский уровень».
Заявленный способ поясняется чертежами, на которых показано:
фиг.1 - общая схема устройства, реализующего способ уплотнения структуры данных префиксного дерева;
фиг.2 - структура полей элементов таблицы состояний и переходов структуры данных;
фиг.3 - структура полей элементов оптимизированной таблицы состояний и переходов структуры данных;
фиг.4 - структура полей элементов вспомогательной оптимизированной таблицы переходов;
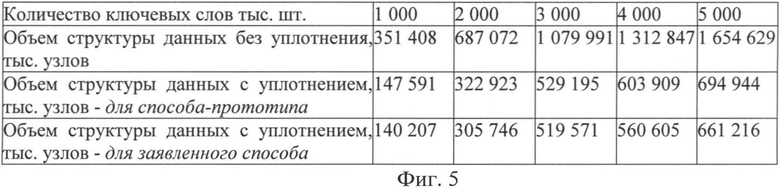
фиг.5 - сравнение экспериментальных результатов уплотнения префиксного дерева для способа-прототипа и предлагаемого способа.
Устройство, реализующее заявленный способ, общая схема которого представлена на фиг.1, работает следующим образом.
Из набора ключевых слов (входные данные блока 1) с помощью блока генератора разреженного префиксного дерева (блок 2) формируется разреженная структура данных. Далее, структура данных подается на вход решающего блока 2, который определяет дальнейшее действие: либо завершить процесс, либо начать очередную итерацию уплотнения. Положительное решение о начале новой итерации уплотнения принимается в двух случаях. Во-первых, после первичной генерации структуры данных блоком 1. Во-вторых, после завершения очередной итерации уплотнения с положительным исходом. Положительный исход итерации определяется тем, что нашлось как минимум два узла, для которых удалось выполнить процедуру слияния. Начало новой итерации уплотнения происходит после передачи управления решающего блока 2 в блок вычисления числовых характеристик случайных величин (блок 3). Далее, в блоке вычисления коэффициентов и формирования списка пар слияния (блок 4) производится ранжирование коэффициентов слияния и определение списка пар узлов, для которых должна быть произведена операция слияния в порядке приоритетности. Согласно данному списку в соответствующем блоке производится слияние узлов (блок 5). После завершения итерации управление снова подается на вход решающего блока 2. После принятия решения о завершении цикла итераций уплотнения структура данных передается на вход блока завершающей итерации уплотнения (блок 6). Далее, окончательно уплотненная структура подается на вход блока оптимизации структуры данных (блок 7). Оптимизированная структура данных является результатом работы блока 7.
Каждый элемент узла разреженного префиксного дерева имеет формат, представленный на фиг.2. В элементе присутствуют 5 полей. Поле State (состояние) определяет тип элемента. При нулевом значении поля State (0) элемент считается пустым и может быть использован для размещения ненулевого элемента другого узла при слиянии. В этом случае значения остальных полей игнорируются и могут иметь произвольное значение. Значение поля State, равное единице (1), определяет, что произошло совпадение символа и необходимо произвести переход к следующему узлу, номер которого указан в поле Index. На данном этапе (в разреженном префиксном дереве) значения остальных полей игнорируются и могут иметь произвольное значение. Значение поля State, равное двум (2), определяет, что найдено ключевое слово и ассоциированное с ним уникальное числовое значение указано в поле Index. В качестве уникального значения обычно используется порядковый номер ключевого слова в первоначальном списке ключевых слов, из которых формируется разреженный массив. В этом случае значения остальных полей игнорируются и могут иметь произвольное значение. Другие значения поля State недопустимы.
Вычисление коэффициентов слияния, ранжирования коэффициентов и определения списка приоритетности пар узлов производится только для узлов с количеством ненулевых элементов более одного. Уплотнение узлов с единичным количеством ненулевых элементов производится в блоке завершающей итерации уплотнения (блок 6).
Вычисление числовых характеристик случайных величин происходит следующим образом.
Префиксное дерево представляется в виде набора независимых дискретных случайных величин (каждая случайная величина определяется отдельным узлом в структуре данных):
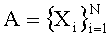
Значения, принимаемые случайными величинами, определяются размером алфавита M (диапазон значений 0..M-1).
Закон распределения каждой случайной величины представляется соответствующим рядом распределения, который определяется совокупностью занятых элементов в соответствующем узле:
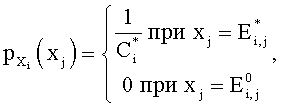
где
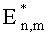
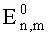
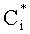
Математическое ожидание для i-го узла:
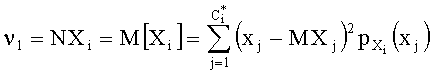
Дисперсия для i-го узла:
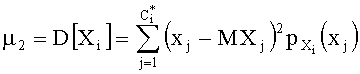
Числовые характеристики вычисляются для всех возможных смещений узла. Диапазон смещений определяется по крайним ненулевым (непустым) элементам узла. Диапазон определяется следующим образом. Допустим, в узле первый ненулевой элемент содержится в позиции Shigh, а последний - в позиции Slow. При этом максимальное значение позиции элемента в узле равно Smax. Это означает, что можно производить смещение элементов данного узла вверх Shigh раз и при этом ненулевые узлы не выйдут за границы диапазона 0..Smax. Также можно производить смещение элементов данного узла вниз Smax-Slow раз и при этом ненулевые узлы не выйдут за границы диапазона 0..Smax. Таким образом, диапазон смещений элементов данного узла задается следующими значениями: -Shigh..Smax-Slow. Отрицательное значение определяет смещение вверх. Диапазон всегда имеет, по крайней мере, одно значение: 0.
Коэффициент слияния для i-го и j-го узлов с k-м и l-м смещением соответственно определяется следующим образом:
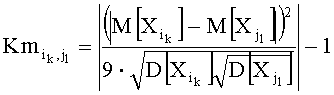
Ранжирование коэффициентов слияния производится методом сортировки по возрастанию. Чем ближе значение коэффициента к нулю, тем более приоритетной и вероятной является возможность слияния заданных узлов в заданных смещениях.
Уплотнение двух узлов происходит следующим образом. Узел-источник является перемещаемым узлом, а узел-приемник - узлом, чьи пустые элементы используются для размещения перемещаемого узла. Определяется номер виртуального узла в узле-приемнике VIndex: находится первое неиспользуемое значение поля VIndexnew из всех ненулевых элементов узла-приемника, начиная с 1. Для каждого ненулевого элемента узла-источника происходит копирование значений его полей Index, VTo, Shift в поля нулевого элемента узла-приемника по заданному смещению. При этом в поле VIndex всех формируемых элементов записывается определенное выше значение VIndexnew. Далее, происходит удаление узла-источника и корректировка ссылок на него из других элементов. Для всех элементов-переходов всех узлов, имеющих значение поля Index, равное значению индекса узла-источника, производится замена его на значение индекса узла-приемника. После этого происходит освобождение блока оперативной памяти, используемого для хранения узла-источника.
В случае очередного удачного слияния двух узлов из списка ранжированных коэффициентов удаляются все элементы, ссылающиеся хотя бы на один из узлов пары слияния. Это происходит потому, что после слияния меняется структура узла-приемника и все определенные для него характеристики теряют свою актуальность. Коэффициенты для узла-источника также теряют свою актуальность, так как узел уже не существует.
Завершающая итерация уплотнения заключается в слиянии всех узлов-источников, содержащих только один ненулевой элемент, с любым узлом-приемником, содержащим более одного ненулевого элемента. Если не осталось узлов-приемников, содержащих более одного ненулевого элемента, то производится слияние с любым возможным узлом-приемником с минимальным индексом расположения.
Уплотненное дерево в общем случае состоит из преобладающего количества элементов двух типов - перехода (State = 1) и удачного завершения поиска (State = 2). Количество пустых элементов (State = 0) относительно мало. В этом случае налицо нерациональное использование памяти устройства, т.к. поля VTo и Shift используются только для элементов перехода. Процесс оптимизации позволяет устранить данную нерациональность. Для этого формируется оптимизированная таблица состояний и переходов и новая вспомогательная оптимизированная таблица переходов. Формат элемента оптимизированной таблицы состояний и переходов представлен на фиг.3. Формат элемента вспомогательной оптимизированной таблицы переходов представлен на фиг.4. Смысл оптимизации состоит в следующем. Для всех элементов типа переход (State = 1) с одновременным одинаковым значением трех полей Index, VTo и Shift формируется новый элемент во вспомогательной оптимизированной таблице переходов с теми же самыми значениями полей Index, VTo и Shift. Тогда сами переходные элементы оптимизированной таблицы состояний и переходов в поле Index будут содержать номер соответствующего элемента во вспомогательной оптимизированной таблице переходов.
Алгоритм поиска информации с помощью уплотненной структуры данных может быть описан следующим образом.
Состояние поиска формируется набором переменных: Index - индекс физического узла, используемого в текущей итерации поиска; VIndex - индекс виртуального узла (внутри физического), используемого в текущей итерации поиска; Shift - текущее смещение кодов символов. Начальное состояние поиска определяется нулевыми значениями всех переменных из набора. Из входного потока, в котором производится поиск, получается очередной байт информации с кодом символа С. Если значение (С + Shift) выходит за границы значений индексов узла Index, текущая итерация поиска завершается неудачей, начальное состояние обнуляется, происходит переход к следующему символу из входного потока. Иначе, если значение (С + Shift) не выходит за границы значений индексов узла Index, производится анализ полей элемента узла Index в позиции (С + Shift). Если значение поля VIndex элемента не равно значению поля VIndex состояния поиска, текущая итерация поиска завершается неудачей, начальное состояние обнуляется, происходит переход к следующему символу из входного потока. Иначе, производится анализ значения поля State элемента узла Index в позиции (С + Shift). В случае нулевого значения поля State (State = 0) текущая итерация поиска завершается неудачей, начальное состояние обнуляется, происходит переход к следующему символу из входного потока. В случае когда поле State имеет значение 2 (State = 2), текущая итерация поиска завершается удачей, числовое значение, ассоциируемое с найденным ключевым словом, содержится в поле Index элемента, далее, если необходимо, начальное состояние обнуляется, происходит переход к следующему символу из входного потока. В случае когда поле State имеет значение 1 (State = 1), значения полей Index, VIndex, Shift, обновляются значениями соответствующих полей Index, VTo, Shift, взятых из вспомогательной таблицы переходов, по индексу, взятому из значения поля Index элемента в позиции (С + Shift), далее происходит переход к следующему символу из входного потока. Для защиты от внешних ошибок, когда поле State имеет иное значение, отличное от 0..2, текущая итерация поиска завершается неудачей, начальное состояние обнуляется, происходит переход к следующему символу из входного потока.
Экспериментальная проверка характеристик способа уплотнения структуры данных префиксного дерева была выполнена на ЭВМ с использованием языка программирования С++ при следующих исходных данных:
1. Объем набора F ключевых слов: от 100 тыс. до 10 млн;
2. Размер алфавита М количеством состояний 1 байта информации (количество размещений с повторениями, при n=2, k=8):
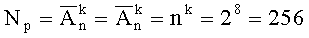
3. Размер алфавита М не может изменяться в процессе уплотнения. Сравнение результатов эксперимента, приведенное на фиг.5, показывает, что применение предлагаемого способа дает выигрыш по объему оперативной памяти, занимаемой сжатым префиксным деревом (количество узлов в дереве после сжатия) при равных условиях на 5-7% (в зависимости от количества ключевых слов и их символьного содержания) по сравнению со способом-прототипом.
Результаты эксперимента позволяют сделать вывод о том, что заявленный способ решает поставленную задачу.
Промышленная применимость изобретения обусловлена тем, что устройство, реализующее предложенный способ, может быть осуществлено с помощью современной элементной базы, с достижением указанного в изобретении назначения, за счет того, что порядок слияния определяют путем вычисления значений числовых характеристик случайных величин для всех узлов, участвующих в уплотнении, и ранжирования для каждого узла-приемника узлов-источников в последовательности убывания приоритетности.



Изобретение относится к области обработки информации, а именно к способам и методам поиска информации, а также создания структур данных, предназначенных для этой цели. Техническим результатом является повышение плотности сжатия, позволяющего добиться уменьшения объема оперативной памяти, требуемого для хранения данной структуры данных, без усложнения алгоритма поиска и уменьшения скорости поиска информации. В способе уплотнения структуры данных префиксного дерева производят слияние узлов после ранжирования и нахождения наиболее подходящих пар слияния. Для этого на каждой итерации происходит вычисление значений числовых характеристик случайных величин для всех узлов, участвующих в уплотнении. Для каждого узла, согласно выбранному критерию, выбирается наилучший предполагаемый узел для слияния. Итерации продолжаются до тех пор, пока есть потенциальная возможность слияния хотя бы одной пары узлов. 5 ил.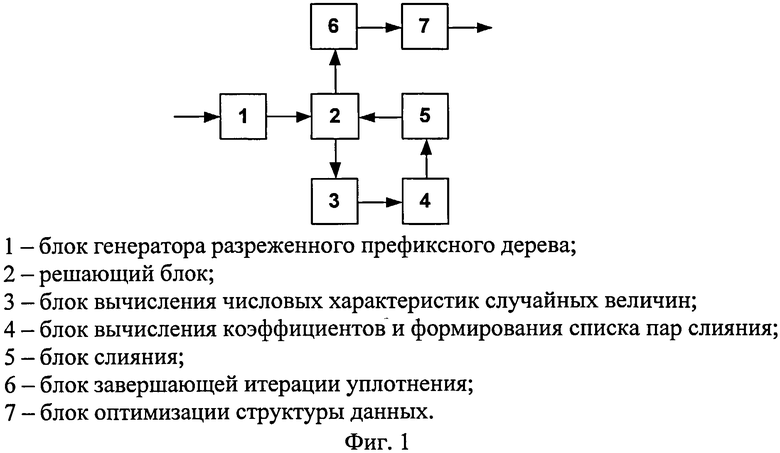
Способ уплотнения структуры данных префиксного дерева, заключающийся в слиянии узлов дерева друг с другом, при котором ненулевые элементы узла-источника вставляют на место пустых элементов узла-приемника, отличающийся тем, что порядок слияния определяют путем вычисления значений числовых характеристик случайных величин для всех узлов, участвующих в уплотнении, и ранжирования для каждого узла-приемника узлов-источников в последовательности убывания приоритетности.
| US 6470347 B1, 22.10.2002 | |||
| US 8055498 B2, 08.11.2011 | |||
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Устройство для подачи волокна от конденсера к прессу | 1956 |
|
SU105038A1 |

