Область техники, к которой относится изобретение
Настоящее решение относится к способу и системе сравнения аудиотреков с использованием хромапринтов с быстрой процедурой выбора кандидата.
Уровень техники
У распознавания аудиофайлов есть две задачи: распознавание частей аудиозаписей и сравнение полных аудиотреков.
Технология распознавания используется для идентификации аудиозаписей с помощью использования относительно короткого, но потенциально искаженного и зашумленного фрагмента аудиотрека. Типичным примером является Shazam - коммерческий сервис распознавания музыки на базе смартфонов. Shazam использует встроенный микрофон смартфона, чтобы получить короткий фрагмент проигрываемой музыки. Он создает на основе этого фрагмента аудиосигнатуру и сравнивает ее с базой данных. После того, как произведено распознавание, нет необходимости любой дальнейшей обработки, например, дополнительного сравнения с подобранным в базе данных файлов. Поэтому когда пользователь слушает музыкальный микс из разных мелодий и пытается определить мелодию, Shazam определит название той мелодии, которая проигрывается в данный момент.
Задачей сравнения является поиск дубликатов. Дубликатом музыкального микса из композиций будет являться такой же микс из тех же самых композиций. Однако, аудиотреки могут рассматриваться как дубликаты, если различие между ними состоит в небольшом различии по длительности, в небольшом сдвиге по времени или в различии по качеству.
Поскольку целью сравнения является поиск дубликатов, необходимо сравнение более крупных частей аудиосигнатур. Сравнение более крупных частей аудиосигнатур является ресурсозатратным (затрачивается производительная мощность и т.д.)
Раскрытие изобретения
Задачей настоящего решения является устранение по меньшей мере некоторых недостатков, присущих известному уровню техники.
Первым объектом осуществления решения является способ сравнения первого входящего аудиотрека с индексированным аудиотреком. Способ выполняется на сервере. Способ включает в себя: (1) выбор индексированного аудиотрека из множества индексированных аудиотреков в качестве аудиотрека-кандидата; выбор осуществляется с помощью выполнения следующих этапов: (а) определение первой короткой аудиосигнатуры (аудиоотпечатка), причем первая короткая аудиосигнатура является аудиосигнатурой первой части первого входящего аудиотрека и содержит первое хромаслово, причем первая часть первого аудиотрека имеет предварительно определенную длительность от начала первого входящего аудиотрека; (b) определение аудиотрека-кандидата из набора индексированных аудиотреков, при этом у аудиотрека-кандидата имеется вторая короткая аудиосигнатура, которая содержит второе хромаслово, причем начальная часть второго хромаслова является идентичной начальной части первого хромаслова, а вторая короткая аудиосигнатура является аудиосигнатурой первой части аудиотрека-кандидата, причем первая часть аудиотрека-кандидата имеет первую предварительно определенную длительность от начала аудиотрека-кандидата; (2) проверку на совпадение аудиотрека-кандидата с первым аудиотреком с помощью выполнения следующих этапов: (а) определение первой длинной аудиосигнатуры, которая является аудиосигнатурой второй части первого входящего аудиотрека; (b) извлечение второй длинной аудиосигнатуры, причем вторая длинная аудиосигнатура является аудиосигнатурой второй части аудиотрека-кандидата; и вторая часть первого аудиотрека и вторая часть аудиотрека-кандидата имеют вторую предварительно определенную длительность от начала, соответственно, первого аудиотрека и аудиотрека-кандидата; и первые части соответствующего первого аудиотрека и аудиотрека-кандидата полностью входят во вторые части соответствующего первого аудиотрека и аудиотрека-кандидата; а также осуществление побитного сравнения первой длинной аудиосигнатуры со второй длинной аудиосигнатурой.
В некоторых вариантах осуществления начальные части хромаслова содержат комбинацию из: (i) любого из первого байта и первой многобайтовой последовательности, причем первая многобайтовая последовательность является последовательностью байтов в начале начальной части соответствующего хромаслова, а также первая многобайтовая последовательность имеет предварительно определенное число байтов; и (ii) любого из последующих байтов и второй многобайтовой последовательности, причем вторая многобайтовая последовательность является последовательностью байтов, следующей либо за первой многобайтовой последовательностью, либо за первым байтом каждого соответствующего хромаслова, причем во второй многобайтовой последовательности имеется предварительно определенное число байтов.
В некоторых вариантах осуществления первая предварительно определенная длительность составляет меньший из интервалов: предварительно определенной длительности в промежутке от 9 до 27 секунд или длительности соответствующего аудиотрека.
В некоторых вариантах осуществления первая предварительно определенная длительность составляет меньший из интервалов: 21 секунды или длительности соответствующего аудиотрека.
В некоторых вариантах осуществления вторая предварительно определенная длительность составляет меньший из интервалов: предварительно определенной длительности в промежутке от 96 до 141 секунд, или длительности соответствующего аудиотрека.
В некоторых вариантах осуществления вторая предварительно определенная длительность составляет меньший из интервалов: 120 секунд или длительности соответствующего аудиотрека.
В некоторых вариантах осуществления и первое хромаслово, и второе хромаслово характеризуют часть соответствующего аудиотрека, а длительность части аудиотрека находится между 1/2 и 8 секундами.
В некоторых вариантах осуществления способ также содержит формирование указанного первого хромаслова и указанного второго хромаслова.
В некоторых вариантах осуществления и первое хромаслово, и второе хромаслово содержат указание на идентификатор (ID) трека, связанный с соответствующим аудиотреком.
В некоторых вариантах осуществления каждое хромаслово содержит указание на информацию о длительности трека, связанную с соответствующим аудиотреком.
В некоторых вариантах осуществления идентификатор трека описывается третьей многобайтовой последовательностью, следующей либо за (i) последующим байтом, либо за (и) второй многобайтовой последовательностью.
В некоторых вариантах осуществления длительность трека характеризуется одним байтом, который следует либо за (i) последующим байтом, либо за (ii) второй многобайтовой последовательностью.
В некоторых вариантах осуществления определение аудиотрека-кандидата содержит сравнение соответствующей длительности первого входящего аудиотрека и аудиотрека-кандидата.
В некоторых вариантах осуществления способ также содержит определение того, что аудиотрек-кандидат не является совпадающим с первым входящим треком кандидатом из-за того, что длительность трека отличается на значение, превышающее предварительно установленное значение.
В некоторых вариантах осуществления аудиотрек-кандидат содержит множество аудиотреков-кандидатов, а способ содержит выбор подгруппы множества аудиотреков-кандидатов на основе предварительно определенного порогового числа кандидатов.
В некоторых вариантах осуществления побитное сравнение первой длинной аудиосигнатуры со второй длинной аудиосигнатурой содержит смещение первой длинной аудиосигнатуры по отношению ко второй длинной аудиосигнатуре.
В некоторых вариантах осуществления смещение содержит амплитуду смещения, которая находится в промежутке плюс или минус 20 секунд.
В некоторых вариантах осуществления определение, что начальная часть второго хромаслова идентична начальной части первого хромаслова, выполняется с помощью определения, что вся последовательность байтов в начальной части второго хромаслова совпадает со всей последовательностью байтов в начальной части первого хромаслова.
В некоторых вариантах осуществления по меньшей мере одна из короткой аудиосигнатуры и длинной аудиосигнатуры содержит указание на идентификатор (ID) трека, связанный с соответствующим аудиотреком.
В некоторых вариантах осуществления до определения первой короткой аудиосигнатуры способ также содержит получение сервером по меньшей мере части первого входящего аудиотрека.
В некоторых вариантах осуществления получение второй короткой аудиосигнатуры содержит извлечение с использованием индекса.
В некоторых вариантах осуществления индекс является инвертированным индексом аудиотрека.
В некоторых вариантах осуществления инвертированный индекс аудиотрека является либо: (i) прюнинг-индексом (от англ. pruning - обрезка), сформированным для множества коротких аудиосигнатур, либо (и) индексом проверки (валидации), сформированным для множества длинных аудиосигнатур.
Другим объектом осуществления является сервер, включающий в себя постоянный носитель компьютерной информации (машиночитаемый носитель). Постоянный носитель информации содержит инвертированный индекс аудиотрека. Инвертированный индекс аудиотрека содержит: множество наборов списков словопозиций (постинг-листов), причем каждый список словопозиций в множестве наборов списков словопозиций является списком словопозиций хромаслов, а каждое хромаслово является компонентом аудиосигнатуры; каждое хромасловослово поделено на множество байтов и содержит начальную часть хромаслова, которая является подмножеством байтов, имеющим первый байт и последующий байт, причем последующий байт расположен непосредственно за первым байтом; в рамках данного набора списков словопозиций из множества списков словопозиций: каждый список словопозиций содержит хромаслова, у которых один и тот же первый байт в начальной части хромаслова, и первый из множества списков словопозиций отличается от второго из множества списков словопозиций тем, что связанные хромаслова имеют иной последующий байт, который является уникальным для данного набора списков словопозиций.
В некоторых вариантах осуществления каждый из данных наборов списков словопозиций связан с ключом индекса, который является уникальным в рамках множества наборов списков словопозиций.
В некоторых вариантах осуществления ключ индекса необходим для быстрого определения положения данного набора списка словопозиций в рамках индекса.
В некоторых вариантах осуществления каждый список словопозиций из данных наборов списков словопозиций связан с ключом сортировки, который является уникальным для данного набора списков словопозиций.
В некоторых вариантах осуществления ключ сортировки используется для быстрого определения местоположения списка словопозиций в рамках данного набора списков словопозиций.
В некоторых вариантах осуществления первый байт является первой многобайтовой последовательностью, которая является последовательностью байтов в начале начальной части каждого соответствующего хромаслова, а число байтов в каждой первой многобайтовой последовательности является одним и тем же.
В некоторых вариантах осуществления ключ индекса содержит в себе первую многобайтовую последовательность.
В некоторых вариантах осуществления последующий байт является второй многобайтовой последовательностью, которая является последовательностью байтов, следующих либо за первым байтом, либо за первой многобайтовой последовательностью каждого соответствующего хромаслова.
В некоторых вариантах осуществления число байтов в каждой из вторых многобайтовых последовательностей является одним и тем же.
В некоторых вариантах осуществления первая многобайтовая последовательность является последовательностью из трех байтов.
В некоторых вариантах осуществления начальная часть каждого хромаслова содержит в себе предварительно определенное число байтов.
В некоторых вариантах осуществления начальная часть каждого хромаслова содержит в себе 4 байта.
В некоторых вариантах осуществления каждый из данных наборов списков словопозиций является связанным с ключом индекса, который является уникальным в рамках множества наборов списков словопозиций, и каждый список словопозоций в данном наборе списков словопозиций является связанным с ключом сортировки, который является уникальным в рамках данного набора списков словопозиций.
В некоторых вариантах осуществления аудиосигнатура является либо (i) короткой аудиосигнатурой, являющаяся аудиосигнатурой первой части аудиотрека, причем первая часть аудиотрека обладает первой предварительно определенной длительностью от начала аудиотрека, либо (и) длинной аудиосигнатурой, которая является аудиосигнатурой второй части аудиотрека, причем вторая часть аудиотрека обладает второй предварительно определенной длительностью от начала аудиотрека.
В некоторых вариантах осуществления по меньшей мере одна из короткой и длинной аудиосигнатуры содержит идентификатор (ID) трека.
В некоторых вариантах осуществления либо короткая, либо длинная аудиосигнатура сохраняются в инвертированном индексе аудиотрека, осуществленном либо как: (i) прюнинг-индекс, сформированный для множества коротких аудиосигнатур, либо как (и) индекс проверки, сформированный для множества длинных аудиосигнатур.
Другим объектом является способ создания и поддержки инвертированного индекса аудиотрека, способ содержит: (i) получение аудиотрека для индексации; (ii) определение первого хромаслова, разделенного на множество байтов, причем первое хромаслово содержит начальную часть хромаслова, которая является подмножеством байтов с первым байтом и последующим байтом, причем последующий байт расположен сразу после первого байта; (iii) определение на основе первого байта конкретного набора списков словопозиций в рамках множества наборов списков словопозиций, причем этот конкретный набор содержит списки словопозиций, которые содержат ссылки на хромаслова с одинаковым первым байтом; (iv) сохранение указания на первое хромаслово в данном списке словопозиций в ответ на то, что второй байт первого хромаслова совпадает с любым вторым байтом любых хромаслов, хранящихся в данном списке словопозиций в рамках конкретного набора списков словопозиций; (v) создание нового списка словопозиций в рамках конкретного набора списков словопозиций, хранящего указание на первое хромаслово в ответ на то, что второй байт первого хромаслова не совпадает с любым вторым байтом любых хромаслов, хранящихся в списках словопозиций.
В некоторых вариантах осуществления первый байт является первой многобайтовой последовательностью, которая является последовательностью байтов в начале начальной части нового хромаслова, причем число байтов является предварительно определенным.
В некоторых вариантах осуществления последующий байт является второй многобайтовой последовательностью, которая является последовательностью байтов, следующих либо за первой многобайтовой последовательностью, либо за первым байтом нового хромаслова, причем число байтов в каждой второй многобайтовой последовательности является предварительно определенным.
В некоторых вариантах осуществления способ перед определением первого хромаслова, связанного с новым аудиотреком для индексирования, содержит определение аудиосигнатуры нового аудиотрека для индексирования, причем хромаслово является частью аудиосигнатуры.
В некоторых вариантах осуществления аудиосигнатура является либо (i) короткой аудиосигнатурой первой части нового аудиотрека, причем первая часть нового аудиотрека обладает первой предварительно определенной длительностью от начала нового аудиотрека, либо (ii) длинной аудиосигнатурой второй части нового аудиотрека, причем вторая часть нового аудиотрека обладает второй предварительно определенной длительностью от начала нового аудиотрека.
В некоторых вариантах осуществления первая предварительно определенная длительность составляет меньший интервал из: предварительно определенной длительности в промежутке от 9 до 27 секунд или длительности нового аудиотрека.
В некоторых вариантах осуществления первая предварительно определенная длительность составляет меньший из интервалов: 21 секунда или длительность нового аудиотрека.
В некоторых вариантах осуществления вторая предварительно определенная длительность составляет меньший из интервалов: предварительно определенной длительности в промежутке от 96 до 141 секунд или длительности нового аудиотрека.
В некоторых вариантах осуществления вторая предварительно определенная длительность составляет меньший из интервалов: 120 секунд или длительность соответствующего аудиотрека.
В некоторых вариантах осуществления хромаслово характеризует часть аудиотрека, а длительность части аудиотрека находится между 1/2 и 8 секундами.
В некоторых вариантах осуществления длительность части аудиотрека составляет 3 секунды.
В некоторых вариантах осуществления каждое хромаслово содержит указание на идентификатор (ID) трека, связанный с соответствующим аудиотреком.
В некоторых вариантах осуществления каждое хромаслово содержит указание на информацию о длительности трека, связанную с соответствующим аудиотреком.
В некоторых вариантах осуществления идентификатор (ID) трека описывается одним байтом, который следует либо за (i) следующим байтом, либо за (ii) второй многобайтовой последовательностью.
В некоторых вариантах осуществления длительность трека описывается одним байтом, который следует либо за (i) следующим байтом, либо за (ii) второй многобайтовой последовательностью.
В некоторых вариантах осуществления короткая аудиосигнатура сохраняется в инвертированном индексе аудиотрека, причем этот индекс исполняется как прюнинг-индекс, сформированный для коротких аудиосигнатур.
В контексте настоящего описания "аудиосигнатура" является сжатой цифровой информацией (сигналом), детерминированно созданной из аудиосигнала, которая может быть использована для идентификации образца аудио или быстрого определения положения элементов в базе данных аудио.
В контексте настоящего описания "хромаслово" является компонентом аудиосигнатуры, причем каждое хромаслово является последовательностью байтов, описывающих часть аудио. Как неограничивающий пример, хромаслово может являться компонентом аудиосигнатуры, созданным с использованием технологии "хромапринт".
В контексте настоящего описания "аудиотрек" является аудиофайлом; видеофайлом, который содержит аудиотрек; любой другой записью аудиосигнала, подходящего для машинного анализа; а также незаписанным аудиосигналом, например, аудиосигналом, исходящим из преобразователя, например, микрофона.
В контексте настоящего описания «сервер» подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от клиентских устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным. В контексте описания использование выражения «сервер» не означает, что каждая задача (например, полученные команды или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение «по меньшей мере один сервер».
В контексте настоящего описания «клиентское устройство» подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Таким образом, примерами клиентских устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что устройство, ведущее себя как клиентское устройство в настоящем контексте, может вести себя как сервер по отношению к другим клиентским устройствам. Использование выражения «клиентское устройство» не исключает возможности использования множества клиентских устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов вышеописанного способа.
В контексте настоящего описания «база данных» подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступны для использования. База данных может находиться на том же оборудовании, выполняющем процесс, который сохраняет или использует информацию, хранящуюся в базе данных, или же она может находиться на отдельном оборудовании, например, выделенном сервере или множестве серверов.
В контексте настоящего описания «информация» включает в себя любую информацию любого типа, которую можно хранить в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (изображения, видео, звукозаписи, презентации и т.д.), данные (данные о местоположении, цифровые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, таблицы и т.д.
В контексте настоящего описания «компонент» подразумевает под собой программное обеспечение (соответствующее конкретному аппаратному контексту), которое является необходимым и достаточным для выполнения конкретной(ых) указанной(ых) функции(й).
В контексте настоящего описания «используемый компьютером носитель компьютерной информации» подразумевает под собой носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д.
В контексте настоящего описания слова «первый», «второй», «третий» и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной связи между этими существительными. Так, например, следует иметь в виду, что использование терминов "первый сервер" и "третий сервер" не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание "первого" элемента и "второго" элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, "первый" сервер и "второй" сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
Каждый вариант осуществления преследует по меньшей мере одну из вышеупомянутых целей. Следует иметь в виду, что некоторые объекты решения, полученные в результате попыток достичь вышеупомянутой цели, могут удовлетворять другим целям, отдельно не указанным здесь.
Дополнительные и/или альтернативные характеристики, аспекты и преимущества вариантов осуществления станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
Краткое описание чертежей
Для лучшего понимания решения, а также других его аспектов и характерных черт, сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
На Фиг. 1 представлена принципиальная схема, изображающая аудиосигнатуру 1001, которая является вариантом осуществления аудиосигнатуры в соответствии с вариантами осуществления решения.
На Фиг. 2 представлена принципиальная схема, изображающая аудиосигнатуру 1002, которая является вариантом осуществления аудиосигнатуры в соответствии с вариантами осуществления решения.
На Фиг. 3 представлена принципиальная схема, изображающая множество наборов 200 списков словопозиций, причем множество наборов 200 списков словопозиций сформировано в соответствии с комбинацией 202 байтов, в соответствии с вариантами осуществления.
На Фиг. 4 представлена принципиальная схема, изображающая фрагмент 300 прюнинг-индекса 724 для конкретного набора 2004 из списков словопозиций 304, причем фрагмент 300 прюнинг-индекса 724 реализован в соответствии с вариантами осуществления, не ограничивающими объем решения.
На Фиг. 5 представлена принципиальная схема списка 304 словопозиций, реализованного в соответствии с вариантами осуществления.
На Фиг. 6 представлена блок-схема способа 500 выбора индексированного аудиотрека как аудиотрека-кандидата из множества индексированных аудиотреков, причем способ 500 выполнен в соответствии с вариантами осуществления решения.
На Фиг. 7 представлена блок-схема способа 600 сверки аудиотрека-кандидата с первым аудиотреком, причем способ 600 выполнен в соответствии с вариантами осуществления настоящего решения.
На Фиг. 8 представлена принципиальная схема системы 700, реализованной в соответствии с вариантами осуществления решения.
Осуществление изобретения
Одним объектом настоящего решения является способ сравнения входящего аудиотрека с аудиотреками, которые уже проиндексированы и/или сохранены в базе данных, доступной серверу. В широком смысле способ содержит этапы (i) быстрого выбора аудиотрека-кандидата и (ii) проверку кандидатов.
Другим объектом настоящего решения является постоянный носитель компьютерной информации (машиночитаемый носитель информации), на котором хранится инвертированный индекс аудиотрека. В некоторых вариантах осуществления инвертированный индекс аудиотрека может быть выполнен как два различных индекса: (i) прюнинг-индекс 7241, сформированный для множества коротких аудиосигнатур, либо как (ii) индекс 7242 проверки, сформированный для множества длинных аудиосигнатур.
Еще одним объектом настоящего решения является способ поддержки инвертированного индекса аудиотрека, который может быть выполнен как два отдельных индекса: (i) прюнинг-индекс 7241, сформированный для множества коротких аудиосигнатур, либо как (ii) индекс 7242 проверки, сформированный для множества длинных аудиосигнатур.
На Фиг. 8 представлена принципиальная схема системы 700, реализованной в соответствии с вариантами осуществления настоящего решения.
Принципиальная схема системы 700, может быть реализована как вариант осуществления решения, не ограничивающий объем решения. Важно иметь в виду, что нижеследующее описание системы 700 представляет собой описание показательных вариантов осуществления. Таким образом, все последующее описание представлено только как описание показательного примера. Это описание не предназначено для определения объема или установления границ решения. Некоторые полезные примеры модификаций системы 700 также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ решения. Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что система 700 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления, и в подобных случаях он представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления будут обладать гораздо большей сложностью.
Система 700 включает в себя электронное устройство 702. Электронное устройство 702 обычно связано с пользователем 740 и, таким образом, иногда может упоминаться как «клиентское устройство». Следует отметить, что тот факт, что электронное устройство 702 связано с пользователем, не подразумевает какого-либо конкретного режима работы, равно как и необходимости входа в систему, регистрации, или чего-либо подобного.
Варианты электронного устройства 702 конкретно не ограничены, но в качестве примера электронного устройства 702 могут использоваться персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) или беспроводные устройства передачи данных (смартфоны, планшеты и т.п.). Электронное устройство 702 включает в себя аппаратное и/или прикладное программное, и/или системное программное обеспечение (или их комбинацию), как известно в данной области техники, чтобы исполнять приложение 704, которое может являться веб-браузером или любым другим приложением, предоставляющим возможность загрузки аудиотреков на сервер 720 или на носитель, доступный серверу 720.
В соответствии вариантами осуществления приложение 704 может поддерживать передачу данных серверу 720 или носителю, доступному серверу 720. Действительно, приложение 740 может также поддерживать загрузку данных с сервера 720 или любого другого источника.
Приложение 704 может быть любым известным веб-браузером или любым другим приложением, которое позволяет загружать контент. В качестве неограничивающего примера, приложение 704 может быть осуществлено как браузерное приложение Yandexтм. Важно иметь в виду, что любое другое коммерчески доступное или собственное приложение может быть использовано для реализации вариантов осуществления.
Электронное устройство 702 соединено с сетью 710 передачи данных через линию передачи данных (отдельно не пронумерована). В некоторых вариантах осуществления, сеть 710 передачи данных может представлять собой Интернет. В других вариантах осуществления сеть 710 передачи данных может быть реализована иначе - в виде глобальной сети передачи данных, локальной сети передачи данных, частной сети передачи данных и т.п.
Реализация линии передачи данных не ограничена и будет зависеть от того, какое электронное устройство 702 используется. В качестве примера, но не ограничения, в данных вариантах осуществления в случаях, когда электронное устройство 702 представляет собой беспроводное устройство связи (например, смартфон), линия передачи данных представляет собой беспроводную сеть передачи данных (например, среди прочего, линия передачи данных 3G, линия передачи данных 4G, беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.). В тех случаях, когда электронное устройство 702 представляет собой портативный компьютер, линия передачи данных может быть как беспроводной (беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п) так и проводной (соединение на основе сети Ethernet).
Важно иметь в виду, что варианты осуществления электронного устройства 702, линия передачи данных и сеть 710 передачи данных даны исключительно для наглядности. Таким образом, специалисты в данной области техники смогут понять подробности других конкретных вариантов осуществления электронного устройства 702, линии передачи данных и сети 710 передачи данных. То есть представленные здесь примеры не ограничивают объем решения.
Сервер 720 может представлять собой обычный компьютерный сервер. В примере варианта осуществления сервер 720 может представлять собой сервер Dellтм PowerEdgeтм, на котором используется операционная система Microsoftтм Windows Serverтм. Излишне говорить, что сервер 720 может представлять собой любое другое подходящее аппаратное и/или прикладное программное, и/или системное программное обеспечение или их комбинацию. В общем случае задачей сервера 720 является предоставление пользователю 740 возможности загружать аудиотреки; выполнять сравнение полученных аудиотреков и сохраненных аудиотреков.
Сервер 720 содержит используемый компьютером носитель 722 информации, также упоминаемый как носитель 722 или машиночитаемый носитель информации. Носитель 722 может содержать любой тип медиа, включая (но не ограничиваясь) ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), твердотельные накопители, накопители на магнитной ленте и т.д. В общем случае задачей носителя 722 является хранение машиночитаемых команд (кодов), а также других данных, например, прюнинг-индекса 7241 и индекса 7242 проверки и т.д. В альтернативных вариантах осуществления прюнинг-индекс 7241 и индекс 7242 проверки могут быть выполнены как единственный инвертированный индекс 7241 аудиотрека (не изображен). В альтернативных вариантах осуществления прюнинг-индекс 7241 и индекс 7242 проверки могут быть выполнены как три и более индекса.
Прюнинг-индекс 7241 содержит множество наборов 200 списков словопозиций, причем множество наборов 200 списков словопозиций сформировано в соответствии с комбинацией 202 байтов, в соответствии с вариантами осуществления решения.
Прюнинг-индекс 7241 содержит множество наборов 200 списков 304 словопозиций, созданных для коротких аудиосигнатур, как будет описано подробнее ниже.
Индекс 7241 проверки содержит файл ключей и файл сигнатур. Файл сигнатур содержит последовательность длинных сигнатур. В этом осуществлении сигнатуры расположены в файле сигнатур одна за другой, без разделителей. В этом осуществлении каждая длинная сигнатура в файле сигнатур начинается с двух первых байтов, описывающих длину соответствующей сигнатуры. Файл ключей содержит идентификаторы (ID) трека (не показаны на Фиг. 8), связанные с соответствующим аудиотреком, и имеющие ссылки на начала длинных сигнатур в файле сигнатур, как будет описано подробнее ниже.
Чтобы обеспечить сравнение, создаются короткие и длинные аудиосигнатуры всех сохраненных треков. Длина всех коротких аудиосигнатур и всех длинных аудиосигнатур из начала каждого соответствующего аудиофайла может быть предварительно определена и может быть постоянной для всех соответствующих коротких и длинных сигнатур.
Например, все короткие аудиосигнатуры могут быть созданы не более чем для 20 первых секунд каждого сохраненного аудиотрека, и все длинные сигнатуры могут быть созданы не более чем для 120 первых секунд каждого сохраненного аудиотрека. Однако, если длина конкретного аудиотрека меньше, чем предварительно определенное значение для соответствующей короткой или длинной аудиосигнатуры, соответствующая короткая или длинная аудиосигнатура создается для аудиотрека полностью.
Поэтому, в рамках еще одного варианта осуществления, длина соответствующей короткой или длинной сигнатуры может быть короче, чем соответствующее предварительно определенное значение. Кроме того, если длина аудиотрека меньше, чем предварительно определенное значение для короткой аудиосигнатуры, то длина короткой аудиосигнатуры и длинной аудиосигнатуры может быть идентичной.
Каждая аудиосигнатура содержит хромаслова, которые характеризуют небольшие равные части связанного аудиотрека. Хромаслова могут характеризовать перекрывающиеся части аудиотрека. Каждое хромаслово может быть представлено как последовательность байтов. Структура и характеристики аудиосигнатур и хромаслов будут описаны подробнее ниже, в основном, при описании Фиг. 1.
Когда сервер 720 получает входящий аудиотрек, создается короткая аудиосигнатура не более чем для 20 первых секунд входящего аудиотрека.
Процедура сравнения содержит два этапа: этап быстрого выбора кандидата и этап проверки кандидата.
Как уже упоминалось ранее, сервер 720 может поддерживать два индекса: прюнинг-индекс 7241, содержащий короткие аудиосигнатуры, и индекс 7241 проверки, содержащий длинные аудиосигнатуры. Последовательности байтов в хромасловах могут быть использованы как ключи, чтобы найти совпадающие аудиотреки. То, как индексы сформированы и поддерживаются, будет описано ниже, в основном, при описании Фиг. 3-5.
В течение первого этапа процедуры сравнения, быстрого выбора кандидата, сервер 720 находит аудиотрек-кандидат, используя первую короткую аудиосигнатуру (короткую аудиосигнатуру входящего аудиотрека) в прюнинг-индексе 7241. Аудиотрек-кандидат может также являться аудиотреком, который содержит по меньшей мере одно хромаслово, полностью совпадающее с хромасловом, идентифицированным во входящем аудиотреке.
В течение второго этапа процедуры сравнения, этапа проверки, сервер 720 создает первую длинную аудиосигнатуру. Первая длинная аудиосигнатура может описать часть аудиотрека длительностью до 120 первых секунд входящего аудиотрека.
После этого сервер 720 осуществляет проверку аудиотрека-кандидата с помощью побитного сравнения длинной аудиосигнатуры входящего аудиотрека с длинной аудиосигнатурой, сохраненной в базе данных и доступной серверу 720, с использованием индекса 7241 проверки. На этом этапе сервер 720 может учесть разное качество сравниваемых аудиотреков, а также сдвиг по времени между сравниваемыми аудиотреками.
На этом этапе сервер 720 исключает из списка кандидатов те проиндексированные аудиотреки, чья длина отличается от длины входящего аудиотрека на предварительно определенное время, например, на 10 секунд, 30 секунд, минуту и так далее. Совпадение аудиотреков устанавливается при совпадении их аудиосигнатур на предварительно определенном уровне. Например, в некоторых вариантах осуществления совпадение битов в длинных аудиосигнатурах входящего аудиотрека и аудиотрека-кандидата не обязательно должно быть стопроцентным. В таких случаях байты длинной аудиосигнатуры треков совпадают на 90%, 80%, 70% и так далее.
Следует отметить, что конкретные варианты осуществления аудиосигнатур никак не ограничены и, в таком случае, могут быть использованы различные подходы известного уровня техники к созданию аудиосигнатур. Пример такого подхода, который может быть использован для создания аудиосигнатуры, предложен в патенте США US7013301 «Аудиосигнатурная система и способ».
Другой подход к созданию аудиосигнатуры описан в статье "Как функционирует хромапринт?" за авторством Lukas Lalinsky, опубликованной на веб-странице https://oxyqene.sk/2011/01/how-does-chromaprint-work/. "Хромапринт" является клиентской библиотекой, которая осуществляет пользовательский алгоритм для извлечения аудиосигнатур из источника аудио. Гиперссылки на исходный код опубликованы на https://acoustid.org/chromaprint. Исходный код доступен для авторизации по лицензии LGPL2.1+ (стандартная общественная лицензия ограниченного применения).
Технология "Хромапринт" позволяет представить аудиотрек как спектрограмму, которая показывает, как на конкретных частотах меняется с течением времени интенсивность. Для создания спектрограммы аудиотрек делится на множество перекрывающихся интервалов, которые обрабатываются с помощью функции преобразования Фурье.
В случае хромапринта входящий аудиотрек может быть преобразован с частотой 11025 Гц и размером интервалов 4096 (0,371 с) с перекрытием 2/3. Хромапринт далее обрабатывает информацию, преобразуя частоты в ноты, и в итоге получается 12 ячеек, каждая из которых содержит соответствующую ноту. В результате создается представление аудио, которое устойчиво к изменениям.
Соответственно, на каждую из них применяется предварительно определенный набор из 16 фильтров, причем эти фильтры улавливают различия в интенсивности в нотах по времени. В результате создается "хромаслово". "Хромаслово" является компонентом аудиосигнатуры, причем каждое хромаслово является последовательностью байтов, описывающих часть аудио.
Как будет понятно специалистам в данной области, могут быть использованы другие способы создания аудиосигнатур. Кроме того, могут быть использованы описанные способы с модификациями.
Однако, следует понимать, что в некоторых вариантах осуществления, после того, как конкретный способ создания аудиосигнатур был выбран, он применяется для создания и коротких, и длинных аудиосигнатур. В других вариантах осуществления могут быть применены различные подходы для создания коротких и длинных аудиосигнатур.
На Фиг. 1 представлена аудиосигнатура 1001. Например, аудиосигнатура является аудиосигнатурой входящего аудиотрека (входящий аудиотрек является аудиотреком, полученным сервером 720 от пользователя 740 электронного устройства 702 (как изображено на Фиг. 8).
На этот момент времени еще не известно, является ли этот аудиотрек проиндексированным и/или сохраненным в базе данных (не изображена), которая доступна для сервера 720. Сервер 720 создает аудиосигнатуру входящего аудиотрека. Сервер 720 затем сравнивает таким образом созданную аудиосигнатуру с множеством вторых аудиосигнатур, причем вторые аудиосигнатуры уже были проиндексирваны и сохранены в базах данных и/или в индексах (например, в индексе 7241 проверки), доступных серверу 720. Если аудиосигнатура совпадает с одной из множества вторых аудиосигнатур, то определяется потенциально совпадающий трек.
Более конкретно, вторая аудиосигнатура 1001 является аудиосигнатурой аудиотрека, который уже был проиндексирован и/или сохранен в базе данных, причем эта база данных доступна серверу 720. Для одного и того же аудиотрека может быть более одной второй аудиосигнатуры 1001, поскольку может быть создана вторая аудиосигнатура для аудиофайла с первой предварительно определенной длительностью (вторая короткая аудиосигнатура) и со второй предварительно определенной длительностью (вторая длинная аудиосигнатура). Например, вторая короткая аудиосигнатура 1001 и вторая длинная аудиосигнатура 1001 могут быть созданы для одного и того же аудиотрека, но при этом у них будет разная длительность от начала аудиотрека (например, первые 21 секунда с начала аудиотрека и первые 120 секунд с начала аудиотрека). Вторая аудиосигнатура сохраняется в базе данных (не изображена), которая доступна для сервера 720. Вторая аудиосигнатура 100 является представлением одной из множества вторых аудиосигнатур, сохраненных в базе данных.
В некоторых вариантах осуществления, каждая из вторых аудиосигнатур содержит указание на идентификатор 402 трека, связанный с соответствующим аудиотреком, которому принадлежит эта каждая из вторых аудиосигнатур, и возможно определение, что для входящего аудиотрека есть совпадающий сохраненный аудиотрек. Эту информацию можно использовать разными способами. Например, информация о совпадающем сохраненном аудиотреке может быть использована для предоставления лучшего варианта этого музыкального трека пользователю. Альтернативно или дополнительно эта информация может быть использована для определения обладателя авторских прав и/или получения авторизации для использования аудиотрека и/или осуществления лицензионной выплаты (роялти) владельцу авторских прав. Альтернативно или дополнительно эта информация может быть использована для нахождения и удаления дубликатов.
Со ссылкой на Фиг. 1 следует отметить, что аудиосигнатура 1001 связана с первым входящим аудиотреком, и что длина первого входящего аудиотрека в этом примере составляет 5 минут 41 секунду.
Как изображено на Фиг. 1, аудиосигнатура 1001 содержит хромаслова 1021, созданные в течение процесса создания аудиосигнатур из первого входящего аудиотрека. Аудиосигнатура может содержать (помимо хромаслов) другие компоненты, например, указание на длительность первого входящего аудиотрека и тому подобное.
Размер каждого хромаслова 1021 в рамках аудиосигнатуры 1001 является одним и тем же: каждое хромаслово 1021 состоит из четырех байтов 104. Поскольку один байт равен восьми битам и имеет 28 или 256 возможных значений, от 0 до 255, байты в примере, изображенном на Фиг. 1 представлены как значения в ряду от 5000 до 5255.
Байты 104 каждого хромаслова 1021 любой аудиосигнатуры могут быть сгруппированы не менее чем в две группы. Первые две группы образуют начальную часть 106 хромаслова, как показано на Фиг. 1. Число байтов в каждой из первых двух групп может быть предварительно определено. В качестве примера, число байтов в первых двух группах может составлять по меньшей мере единицу.
Как будет понятно специалистам в данной области техники, в различных вариантах осуществления число байтов в каждой из первых двух групп может быть предварительно определено разными способами. Например, в начальной части 106 хромаслова (размер начальной части хромаслова составляет четыре байта), возможны следующие комбинации:
1 байт и 3 байта;
2 байта и 2 байта;
3 байта и 1 байт;
Поэтому, в широком смысле, в любом четырехбайтовом хромаслове возможны следующие комбинации групп:
первый байт (не изображен) и вторая многобайтовая последовательность (не изображена);
первая многобайтовая последовательность (которая является двухбайтовой последовательностью) и вторая многобайтовая последовательность, которая также является двухбайтовой последовательностью; и
первая многобайтовая последовательность 108, которая является трехбайтовой последовательностью, и последующий байт 110.
Такой конкретный пример изображен на Фиг. 1: байты 104 в каждом хромаслове 1021 аудиосигнатуры 1001 сгруппированы в две группы: (i) первую многобайтовую последовательность 108, которая является последовательностью байтов 104, которая, в свою очередь, расположена в начальной части соответствующего хромаслова, и (ii) последующий байт 110. В некоторых вариантах осуществления последующих байтов может быть несколько: 110, 112, 114. Другими словами, байты в каждом хромаслове 102 делятся на две группы, причем размер первой группы составляет три байта, а размер второй группы - один байт (как изображено на фиг. 1).
В общем случае начальная часть 106 хромаслова является частью хромаслова, которая содержит комбинацию первой многобайтовой последовательности (или первого байта, в зависимости от обстоятельств) и второй многобайтовой последовательности (или последующего байта, в зависимости от обстоятельств).
В альтернативных вариантах осуществления байты в хромасловах могут быть сгруппированы более чем в две группы, например, как на фиг. 2.
Однако начальная часть 106 хромаслова может не обязательно совпадать с самим хромасловом.
Сервер 720 может создавать аудиосигнатуру 1002 для входящего трека целиком, а также для части входящего аудиотрека. В рамках вариантов осуществления сервер 720 может создавать более чем одну аудиосигнатуру для входящего аудиотрека. Например, в некоторых вариантах осуществления, сервер 720 создает первую короткую аудиосигнатуру и первую длинную аудиосигнатуру.
Короткая аудиосигнатура является аудиосигнатурой первой части аудиотрека и длится первое предварительно определенное время от начала аудиотрека. В некоторых вариантах осуществления первая предварительно определенная длительность является меньшим из двух интервалов: предварительно определенной длительности в промежутке от 9 до 27 секунд или длительности аудиотрека.
В приведенном примере варианта осуществления первая предварительно определенная длительность от начала аудиотрека составляет меньший из двух интервалов: 21 секунда или длительность аудиотрека. Учитывая, что длительность входящего аудиотрека составляет 5 минут 41 секунду, что больше, чем 21 секунда, сервер 720 создает первую короткую аудиосигнатуру для первой 21 секунды входящего аудиотрека.
Длинная аудиосигнатура является аудиосигнатурой второй части аудиотрека и длится второе предварительно определенное время от начала аудиотрека. В некоторых вариантах осуществления вторая предварительно определенная длительность является меньшим из двух интервалов: предварительно определенной длительности в промежутке от 99 до 141 секунд или длительности аудиотрека. В приведенном примере варианта осуществления вторая предварительно определенная длительность от начала аудиотрека составляет меньший из двух интервалов: 120 секунд или длительности аудиотрека. Учитывая, что длительность входящего аудиотрека составляет 5 минут 41 секунду, что больше, чем 120 секунда, сервер 720 создает первую длинную аудиосигнатуру для первых 120 секунд входящего аудиотрека.
Аудиосигнатура 1002, изображенная на Фиг. 2 может быть любой из следующих аудиосигнатур: первой короткой аудиосигнатуры, первой длинной аудиосигнатуры, второй короткой аудиосигнатуры и второй длинной аудиосигнатуры. Структура этих аудиосигнатур входящего аудиотрека может быть одной и той же, кроме того, что первая длинная аудиосигнатура содержит больше хромаслов. И первая длинная, и первая короткая аудиосигнатуры одного и того же аудиотрека создаются с использованием той же самой технологии, с учетом, соответственно, длинной и короткой части одного и того же аудиоитрека с его начала, причем первая короткая аудиосигнатура идентична началу первой длинной аудиосигнатуры.
Как будет понятно специалистам в данной области техники, в различных вариантах осуществления число байтов в каждой из первых двух групп может быть предварительно определено разными способами. Например, в начальной части 106 хромаслова (причем размер начальной части хромаслова составляет четыре байта), возможны следующие комбинации:
1 байт и 3 байта;
2 байта и 2 байта;
3 байта и 1 байт;
Поэтому, в широком смысле, в любом четырехбайтовом хромаслове возможны следующие комбинации групп:
первый байт (не изображен) и вторая многобайтовая последовательность (не изображена);
первая многобайтовая последовательность (которая является двухбайтовой последовательностью) и вторая многобайтовая последовательность, которая также является двухбайтовой последовательностью; и
первая многобайтовая последовательность 108, которая является трехбайтовой последовательностью, и последующий байт 110.
На Фиг. 3 изображена принципиальная схема множества наборов 200 списков слоповозиций. Каждый набор списков словопозиций изображен как большой четырехугольник и отдельно пронумерован: 2001, 2002, 2003, …2004, 2005… и т.д.
Список словопозиций является структурой данных индекса, хранящей преобразованный контент, например, аудиотрек, в его местоположении в файле базы данных, или в документе, или в наборе документов. Задачей списка словопозиций является предоставление возможности быстрого поиска аудиотрека за счет усиления процесса обработки, когда аудиотрек добавляется в базу данных.
Список 304 словопозиций изображен на Фиг. 4. Список 304 словопозиций является одним из списков словопозиций, сгруппированных в набор 200 списков словопозиций. Список 304 словопозиций для каждого хромаслова 1021 может содержать идентификатор 402 трека, связанный с аудиотреком, характеризующий соответствующее хромаслово 1021. Идентификатор 402 трека может быть многобайтовой последовательностью. В этом варианте идентификатор 402 трека является последовательностью четырех байтов. Список 304 словопозиций для каждого хромаслова 1021 может содержать указание 404 на длительность трека, связанное с аудиотреком, из которого создано соответствующее хромаслово 1021. Кроме того, список 304 словопозиций для каждого хромаслова 1021 может содержать указание 406 положения хромаслова 1021 в аудиотреке, который описывает соответствующее слово 1021.
Существует только один конкретный список 304 словопозиций для всех хромаслов 1021, которые имеют одну и ту же начальную часть 106. Например, при существовании нескольких хромаслов 1021, и при том, что начальная часть каждого из трех хромаслов 102 выглядит как 5214-5255-5008-5047, будет только один список словопозиций для всех этих трех хромаслов 1021 с начальной частью 106, которая выглядит как 5214-5255-5008-5047.
В данном наборе 200 списков 304 словопозиций множества списков 304 словопозиций, каждый список 304 словопозиций содержит хромаслово 1021 с такой же первой многобайтовой последовательностью 108 хромаслов 1021. Следует учитывать, что первая многобайтовая последовательность 108 хромаслова 1021 меньше, чем начальная часть 106 хромаслова 1021. В дополнение к первой многобайтовой последовательности 108 начальная часть 106 хромаслова 1021 также содержит последующий байт 110. Другими словами, каждый набор 200 списков 304 словоформ содержит только те списки 304 словоформ, которые ссылаются на хромаслова 1021 с той же самой многобайтовой последовательностью 108, например, 5214-5255-5008 (или тот же самый первый байт, в зависимости от обстоятельств в некоторых вариантах осуществления). Это означает, что каждый набор 200 списков 304 словопозиций содержит списки 304 словопозиций, которые могут быть созданы для разных хромаслов с одинаковой первой многобайтовой последовательностью 108, но различными последующими байтами 110; например, один набор 200 списков 304 словопозиций может быть создан для следующих хромаслов: 5214-5255-5008-5008, 5214-5255-5008-5012, 5214-5255-5008-5047, 5214-5255-5008-5077, 5214-5255-5008-5201.
Фиг. 3 иллюстрирует наборы 200 списков 304 словопозиций, которые созданы для хромаслов 1021. Поскольку каждое хромаслово 1021 имеет первую многобайтовую последовательность 108, которая является последовательностью трех байтов, то каждый список словопозиций сгруппирован в набор 200 списков 304 словопозиций, причем набор 200 начинается с последовательности в три байта.
Поскольку в этом примере каждое хромаслово имеет первую многобайтовую последовательность из трех байтов, каждый набор 200 списков 304 словопозиций также определен любой возможной комбинацией трех байтов, начиная с первого набора 2001, который определяется комбинацией байтов 2021 (5000-5000-5000), и заканчивая последним набором 2005, который определяется комбинацией байтов 2025 (5255-5255-5255).
Все эти комбинации байтов от 2021 до 2025 могут быть использованы как соответствующие ключи индекса из множества ключей индекса 202, как будет описано позже. Поскольку, как уже было отмечено ранее, один байт равен восьми битам и имеет 28 или 256 возможных значений, от 0 до 255, байты в примере, изображенном на Фиг. 2 представлены как значения в ряду от 5000 до 5255. Поэтому возможны 16777216 комбинаций трех байтов (2563). Все эти комбинации байтов будут использованы как ключи 202 индекса, как будет описано ниже. Поскольку наборы 200 списков словопозиций определяются числом байтов, равным числу байтов в первой многобайтовой последовательности 108, будет 16777216 наборов 200 списков 304 словопозиций.
Число наборов 200 списков 304 словопозиций может быть меньше или больше, чем 16777216, в зависимости от длины первой многобайтовой последовательности. Например, первая многобайтовая последовательность 108 состоит из единственного байта (из "первого байта"), тогда будет существовать 256 наборов 200 списков 304 словопозиций.
Возможна ситуация, когда для хромаслов нет списков словопозиций, начиная с определенного первого байта или с определенной первой многобайтовой последовательности. Пусть во всей базе данных аудиотреков нет аудиосигнатур, которые содержали бы хромаслова, начинающиеся с первой многобайтовой последовательности 5010-5127-5206. В этом случае набор 200, связанный с многобайтовой последовательностью 5010-5127-5206 будет пуст и не будет содержать ни одного списка словопозиций. Возможно добавление списка словопозиций в существующий набор 200, причем набор 200 определяется многобайтовой последовательностью 5010-5127-5206, если будет получена аудиосигнатура нового аудиотрека и по меньшей мере одно новое хромаслово 1021 будет начинаться с многобайтовой последовательности 5010-5127-5206.
В рамках данного набора списков словопозиций, один из списков 304 отличается от другого списка 304 словопозиций тем, что у связанных хромаслов 1021 различные последующие байты (или различные вторые многобайтовые последовательности, в зависимости от обстоятельств в некоторых вариантах осуществления). Различные последующие байты (или вторые многобайтовые последовательности (в зависимости от обстоятельств в некоторых вариантах осуществления)) уникальны для данного набора списков словопозиций.
Возьмем в качестве примера набор 2004, изображенный на Фиг. З. Набор 2004 содержит все списки 304 словопозиций для индексированных хромаслов 1022, которые имеют ту же самую многобайтовую последовательность 5214-5255-5008. Все хромаслова 1022 имеют одну и ту же первую многобайтовую последовательность 5214-5255-5008, отличаясь друг от друга последующим байтом 110 (или второй многобайтовой последовательностью, в зависимости от обстоятельств в некоторых вариантах осуществления).
Поскольку конкретный список словопозиций имеет отсылки для всех элементов конкретного хромаслова, такой список словопозиций является уникальным в данном наборе списков словопозиций. Поэтому в одном и том же наборе 200 списков 304 словопозиций последующий байт 110 (или вторая многобайтовая последовательность, в зависимости от обстоятельств в некоторых вариантах осуществления) отличает один список 304 словопозиций от другого.
Например, набор 2004 списков словопозиций, начинающихся с последовательности байтов 5214-5255-5008, будет содержать множество списков словопозиций, начинающихся с комбинации байтов 5214-5255-5008, где каждый список словопозиций будет иметь другой следующий байт 302, соответствующий последующему байту 110. Упомянутая комбинация 2024 байтов 5214-5255-5008 может быть использована как ключ индекса 2024 (см. Фиг. 4). Следующий байт 302 является идентичным последующему байту 110 соответствующего хромаслова 1022 и используется как ключ 302 сортировки для инвертированного индекса аудиотрека. В некоторых вариантах осуществления следующий байт 302 является многобайтовой последовательностью, которая идентична второй многобайтовой последовательности, и также используется как ключ 302 сортировки.
Одним из объектов настоящего решения является постоянный носитель 722 компьютерной информации, схематическое представление которого изображено на Фиг. 8. Постоянный носитель 722 компьютерной информации содержит инвертированный индекс аудиотрека.
Инвертированный индекс аудиотрека может храниться в двух различных индексах, прюнинг-индексе 7241 и индексе 7242 проверки. Для создания и поддержки прюнинг-индекса 7241 и индекса 7242 проверки может быть использована та же самая технология. И прюнинг-индекс 7241, и индекс 7242 проверки будут также совместно упоминаться как инвертированный индекс аудиотрека (не изображен).
Когда делается отсылка на инвертированный индекс аудиотрека, она применима и к прюнинг-индексу 7241, и к индексу 7242 проверки. Как будет понятно специалисту в данной области техники, представление прюнинг-индекса 7241 и индекса 7241 проверки упрощено; оба индекса могут содержать другие компоненты, которые не изображены на Фиг. 8, например, ключи 202 индекса и ключи 302 сортировки.
Фиг. 4 представляет часть 300 прюнинг-индекса 7241, из конкретного набора 2004 списков словопозиций. Весь инвертированный индекс 7241 аудиотрека (не изображен) содержит множество таких частей 300, представляющих все возможные наборы 200 списков словопозиций.
Инвертированный индекс аудиотрека содержит множество 200 наборов списков 304 словопозиций, причем в каждом таком списке содержатся хромаслова 1022, каждое из которых является компонентом аудиосигнатуры 1012.
В некоторых вариантах осуществления каждый из наборов 200 списков 304 словопозиций связан с ключом 202 индекса. Как изображено на Фиг. 3, все наборы 200 списков 304 словопозиций являются уникальными: набор 2001, набор 2002, набор 2003, 2004, 2005 и так далее, причем каждое множество наборов 200 определяется уникальной комбинацией 2021, 2022, 2023, 2024, 2025 и т.д. байтов. Поскольку один конкретный ключ 202 индекса из множества ключей индекса связан с одним конкретным набором из множества наборов 200, каждый ключ 202 индекса уникален, так что конкретный ключ 202 индекса соответствует конкретному набору 200 списков словопозиций. Например, конкретный набор 2004 списков словопозиций, будучи уникальным, соответствует комбинации 2024 байтов 5214-5255-5008, которая используется как ключ 2024 индекса, который тоже является уникальным.
В некоторых вариантах осуществления ключ 202 индекса необходим для быстрого определения положения данного набора 200 списков 304 словопозиций в рамках инвертированного индекса 724 аудиотрека. Использование ключа 202 индекса позволяет определить специализированный набор 200 списков словопозиций, который содержит конкретный список словопозиций для конкретного хромаслова. Поэтому сужение поиска позволяет быстро определить положение данного набора 200 списков 304 словопозиций в рамках индекса.
В некоторых вариантах осуществления каждый список 304 словопозиций из данного набора 200 списков словопозиций связан с ключом 302 сортировки, который является уникальным для данного набора списков словопозиций.
В некоторых вариантах осуществления ключ 302 сортировки необходим для быстрого определения положения списка слопозиций в рамках данного набора списков словопозиций, поскольку использование ключа 302 сортировки позволяет отличить один список 304 словопозиций от всех других списков 304 словопозиций в рамках данного набора 200 списков словопозиций.
В некоторых вариантах осуществления ключ 202 индекса содержит в себе первую многобайтовую последовательность 108. Поэтому ключ 202 индекса будет идентичным первой многобайтовой последовательности 108, которая также определяет наборы 200 списков 304 словопозиций.
Другим объектом является способ создания и поддержки прюнинг-индекса 7241.
Способ содержит получение сервером 720 аудиотрека для индексации. Это получение может быть осуществлено, например, от правообладателя. Затем аудиотрек может быть загружен в базу данных (не изображена), сохранен на сервере 720 или доступен для сервера 720.
Способ содержит определение первого хромаслова 1021, связанного с новым аудиотреком для индексации, причем хромаслово 1021 разделено на множество байтов 104, а также первое хромаслово 1021 содержит начальную часть 106 хромаслова, которая является подмножеством байтов с первым байтом и последующим байтом 110, причем последующий байт 110 расположен сразу после первого байта. Следовательно, в этом варианте осуществления начальная часть 106 хромаслова 1021 содержит два байта.
Кроме того, способ содержит определение на основе первого байта конкретного набора 200 списков 304 словопозиций в рамках множества наборов 200 списков 304 словопозиций, причем этот конкретный набор содержит списки словопозиций, которые содержат ссылки на хромаслова с одинаковым первым байтом в начальной части 106. Число наборов 200 может быть равно 256, поскольку наборы списков словопозиций могут быть созданы в соответствии с любым возможным первым байтом. Поскольку, как было указано выше, один байт равен восьми битам, возможны 28 или 256 значений.
Кроме того, способ содержит: сохранение указания на первое хромаслово в данном списке 304 словопозиций в ответ на то, что последующий байт 110 первого хромаслова 1021 совпадает с любым последующим байтом 110 любых хромаслов 1021, хранящихся в данном списке 304 словопозиций в рамках конкретного набора 200 списков 304 словопозиций. Альтернативно способ содержит: создание нового списка 304 словопозиций в рамках конкретного набора 200 списков 304 словопозиций, хранящего указание на новое хромаслово 1021 в ответ на то, что последующий байт 110 первого хромаслова 1021 не совпадает с любым последующим байтом 110 любых хромаслов 1021, хранящихся в данном списке 304 словопозиций.
В некоторых вариантах осуществления способ также перед определением первого хромаслова 1021, связанного с новым аудиотреком для индексирования, содержит определение аудиосигнатуры 1001 нового аудиотрека для индексирования.
Другими словами, сервер 720 может создавать аудиосигнатуру 1001 для входящего аудиотрека; затем он определяет по меньшей мере одно хромаслово 1021 для индексации, причем это слово содержится в аудиосигнатуре 1001. Хромаслово 1021 содержит начальную часть 106 хромаслова 1021, причем эта начальная часть 106 содержит первый байт и последующий байт 110. Используя первый байт как ключ 202 индекса, сервер 720 определяет соответствующий набор 200 списков 304 словопозиций как определенный одинаковым байтом, первым байтом соответствующего хромаслова. Затем, используя последующий байт 110 как ключ 302 сортировки, сервер 720 ищет такой список 302 словопозиций, чтобы в нем все хромаслова имели одинаковую комбинацию первого байта и последующего байта 110 в своей начальной части 106. Конкретный список 304 словопозиций должен быть определен с помощью тех же двух байтов, содержащихся в начальной части 106 хромаслова 1021 для индексации.
Ранее уже указывалось, что набор 200 списков 304 словопозиций может быть пустым, при условии, что нет индексированных хромаслов 1021 с конкретным первым байтом (или первой многобайтовой последовательностью, как бывает в некоторых вариантах осуществления). В этом случае поиск с использованием ключа 302 сортировки покажет отсутствие релевантного списка словопозиций. В таком случае будет создан новый список словопозиций для этого конкретного хромаслова.
В некоторых вариантах осуществления первый байт является первой многобайтовой последовательностью 108, которая является последовательностью байтов в начале начальной части 106 каждого нового хромаслова 1021, а число байтов 104 в каждой первой многобайтовой последовательности 108 является одним и тем же.
В некоторых вариантах осуществления последующий байт 110 является второй многобайтовой последовательностью, которая является последовательностью байтов, следующих либо за первой многобайтовой последовательностью 108, либо за первым байтом каждого нового хромаслова 1021, причем число байтов 104 в каждой второй многобайтовой последовательности является тем же самым.
В некоторых вариантах осуществления аудиосигнатура 1001 является либо короткой, либо длинной аудиосигнатурой.
В некоторых вариантах осуществления короткая аудиосигнатура хранится в прюнинг-индексе 7241, который сформирован для множества коротких аудиосигнатур. Прюнинг-индекс 7241 используется для быстрого выбора аудиоитреков-кандидатов.
В некоторых вариантах осуществления длинная аудиосигнатура хранится в индексе 7242 проверки, который сформирован для множества длинных аудиосигнатур. Индекс 7242 проверки используется для проверки аудиотреков на совпадение с входящим аудиотреком.
Индекс 7241 проверки содержит файл ключей и файл сигнатур. Файл сигнатур содержит последовательность длинных сигнатур. В этом осуществлении сигнатуры расположены в файле сигнатур одна за другой, без разделителей. В этом осуществлении каждая длинная сигнатура в файле сигнатур начинается с двух первых байтов, описывающих длину соответствующей сигнатуры. Файл ключей содержит идентификаторы (ID) трека (не показаны на Фиг. 8), связанные с соответствующим аудиотреком, и имеющие ссылки на начала длинных сигнатур в файле сигнатур.
Другим объектом решения является способ сравнения первого входящего аудиотрека с индексированным аудиотреком. Способ выполняется на сервере 720.
В общем случае способ содержит два главных этапа: (1) выбор индексированного аудиотрека из множества индексированных аудиотреков в качестве аудиотрека-кандидата; и (2) проверка аудиотрека-кандидата на совпадение с первым аудиотреком:
На Фиг. 6 представлена блок-схема способа 500 выбора индексированного аудиотрека как аудиотрека-кандидата из множества индексированных аудиотреков, причем способ 500 выполнен в соответствии с вариантами осуществления решения.
Способ 500 начинается на этапе 502.
На этапе 502 сервер 720 определяет первую короткую аудиосигнатуру, которая является аудиосигнатурой первой части первого входящего аудиотрека и содержит первое хромаслово 1021, причем первая часть первого аудиотрека имеет предварительно определенную длительность от начала первого входящего аудиотрека.
На этапе 504 сервер 720 определяет хромаслова 1021 первой короткой аудиосигнатуры. Определение хромаслов 1021 является частью процесса создания аудиосигнатур, как это было описано ранее.
На этапе 506 сервер 720 осуществляет поиск индексированных хромаслов 1021 с такой же начальной частью 106, что и у слова 1021 первой короткой аудиосигнатуры.
В качестве неограничивающего примера, поиск может быть выполнен с использованием прюнинг-индекса 7241. Прюнинг-индекс 7241 используется для быстрого выбора аудиотреков-кандидатов. В некоторых вариантах осуществления короткая аудиосигнатура хранится в прюнинг-индексе 7241, который сформирован для множества коротких аудиосигнатур.
Поиск может быть осуществлен следующим образом: сначала сервер 720 извлекает первую многобайтовую последовательность 108 соответствующего хромаслова первой короткой аудиосигнатуры и находит индекс 202 ключа, соответствующий первой многобайтовой последовательности 108. Если хромаслово 1021 первой короткой аудиосигнатуры выглядит как 5214-5255-5008-5047, соответствующим индексом 202 ключа является индекс 2024 ключа 5214-5255-5008, изображенный на Фиг. 4.
Как изображено на Фиг. 3, набор 2004 списков словопозиций соответствует ключу 2024 индекса. Сервер 720 извлекает этот набор 2004 списков словопозиций. Затем сервер 720 извлекает последующий байт 110 соответствующего хромаслова 1021 первой короткой аудиосигнатуры и находит ключ 302 сортировки, соответствующий последующему байту 110 хромаслова 1021 первой короткой аудиосигнатуры.
Например, если хромаслово 1021 первой короткой аудиосигнатуры выглядит как 5214-5255-5008-5047, соответствующий ключ 302 сортировки будет являться ключом 302 сортировки (5047), изображенным на Фиг. 4. Используя этот ключ 302 сортировки, сервер 720 извлекает список 304 словопозиций для хромаслова 5214-5255-5008-5047.
Затем на этапе 508 с уже извлеченным списком 304 словопозиций сервер 720 может находить и выбирать аудиотреки, в которых появляется хромаслово 5214-5255-5008-5047. В качестве неограничивающего примера, аудиотрек-кандидат может быть найден с помощью использования идентификатора 402 трека, содержащегося в списке словопозиций соответствующего проиндексированного хромаслова 1021. Поскольку одно и то же хромаслово 1021 может быть найдено в нескольких различных индексированных аудиотреках, несколько соответствующих индексированных аудиотреков с несколькими соответствующими идентификаторами 402 трека могут быть выбраны как аудиотреки-кандидаты. Таким образом, для одного хромаслова 1021 первой короткой аудиосигнатуры могут быть выбраны несколько аудиотреков-кандидатов.
На этапе 510 сервер 720 повторяет этапы с 504 по 508 для каждого хромаслова 1021 первой короткой аудиосигнатуры. Когда определен дополнительный аудиотрек-кандидат в ответ на поиск, осуществленный с учетом каждого следующего хромаслова 1021 первой короткой аудиосигнатуры, эти дополнительные аудиотреки должны быть добавлены ко множеству аудиотреков-кандидатов. Таким образом, множество аудиотреков-кандидатов может содержать все аудиотреки, причем каждый аудиотрек имеет по меньшей мере одно хромаслово 1021, которое соответствует любому из множества хромаслов 1021 первой короткой аудиосигнатуры. Существует возможность того, что некоторые аудиотреки-кандидиаты содержат более высокое или более низкое число хромаслов, соответствующих хромаслову 1021 первой короткой аудиосигнатуры.
Затем способ 500 завершается.
На Фиг. 7 представлена блок-схема способа 600 сверки аудиотрека-кандидата с первым аудиотреком, причем способ 600 выполнен в соответствии с вариантами осуществления решения.
Способ 600 начинается на этапе 602, на котором сервер 720 определяет первую длинную аудиосигнатуру, которая является аудиосигнатурой второй части первого входящего аудиотрека. Сервер 720 определяет вторую длинную аудиосигнатуру, используя идентификатор 402 аудиотрека, который был определен на этапе 508.
Как было указано ранее, если одно и то же хромаслово 1021 было найдено в нескольких разных проиндексированных аудиотреках, может быть обнаружено несколько вторых длинных аудиосигнатур.
Затем способ переходит к этапу 604.
На этапе 604 сервер 720 определяет вторую длинную аудиосигнатуру, которая является аудиосигнатурой второй части аудиотрека-кандидата.
Как это было показано в описании способа 500 сервер 720 определяет первую короткую аудиосигнатуру, состоящую из хромаслов и, используя прюнинг-индекс 7241, находит идентификатор аудиотрека, который содержит хромаслово, представленное в первой короткой аудиосигнатуре. Затем способ 500 предоставляет возможность определить аудиотрек-кандидат и его идентификатор 402 трека. Как поймут специалисты в данной области техники, может быть найдено более одного аудиотрека-кандидата и, соответственно, более одного идентификатора 402 трека.
Длинная аудиосигнатура аудиотрека-кандидата сохраняется в индексе 7242 проверки с другими длинными аудиосигнатурами других треков.
Индекс 7242 проверки может быть сформирован для множества длинных аудиосигнатур. Индекс проверки используется для проверки аудиотреков на совпадение с входящим аудиотреком. Длинные аудиосигнатуры могут храниться в индексе 7242 проверки как единственная запись, одна длинная аудиосигнатура за другой длинной аудиосигнатурой. В начале каждой длинной аудиосигнатуры может быть расположена многобайтовая последовательность, указывающая на длину следующей длинной аудиосигнатуры. В этом варианте осуществления многобайтовая последовательность, указывающая на длину последующей длинной аудиосигнатуры, является последовательностью двух байтов.
Сервер 720 извлекает вторую длинную аудиосигнатуру, используя идентификатор 402 аудиотрека.
Извлечение может быть произведено из файла сигнатур. Извлечение может быть произведено следующим образом.
Индекс 7242 проверки содержит файл ключей и файл сигнатур.
Файл сигнатур может содержать последовательность вторых длинных сигнатур. В этом варианте осуществления вторые длинные сигнатуры расположены в файле сигнатур одна за другой, без разделителей. В этом осуществлении решения каждая вторая длинная сигнатура в файле сигнатур начинается с двух первых байтов, описывающих длину соответствующей сигнатуры.
Файл ключей может содержать идентификаторы трека (не изображены на Фиг. 7), связанные с соответствующим аудиотреком в файле сигнатур и иметь ссылки на начала длинных аудиосигнатур в файле сигнатур, причем эти начала являются, в данном варианте осуществления, двумя первыми байтами, описывающими длительность соответствующей сигнатуры.
Как было описано выше, когда выполняются этапы способа 500, сервер 720 определяет аудиотрек-кандидат с использованием прюнинг-индекса 7241 и находит идентификатор этого трека. Чтобы извлечь вторую длинную аудиосигнатуру из файла сигнатур, сервер 720 может использовать идентификатор 402 трека, который был определен на этапе 508. Сервер 720 может найти тот же самый идентификатор 402 трека в файле ключей и затем найти начало второй длинной сигнатуры в файле сигнатур.
Затем сервер 720 считывает два байта в начале соответствующей второй длинной аудиосигнатуры и оценивает длительность второй длинной аудиосигнатуры с помощью этих двух байтов второй длинной аудиосигнатуры в файле сигнатур, и извлекает вторую длинную аудиосигнатуру.
Затем способ переходит к этапу 606.
На этапе 606 сервер 720 выполняет побитное сравнение первой длинной аудиосигнатуры и второй длинной аудиосигнатуры. Аудиотрек-кандидат считается проверенным при совпадении по меньшей мере одной из множества вторых длинных аудиосигнатур с первой длинной аудиосигнатурой на стадии побитного сравнения.
В некоторых вариантах осуществления, чтобы аудиотрек-кандидат считался совпадающим в первым аудиотреком, абсолютное совпадение аудиосигнатуры, установленное при побитном сравнении, не является необходимым. Две аудиосигнатуры могут считаться совпадающими даже при том, что определенное число битов не совпадает.Например, может быть предварительно определено, что аудиосигнатуры совпадают, если в множестве битов один бит из тридцатидвухбитовой последовательности в каждой аудиосигнатуре не совпадает.
Дополнительно или альтернативно входящий аудиотрек и аудиотрек-кандидат могут иметь разную длительность. Это может случиться, когда у входящего аудиотрека нет начала или конца, или есть несколько секунд тишины в начале или в конце. Даже если идентичны не все биты аудиосигнатур обоих аудиотреков, эти аудиотреки могут считаться совпадающими.
В некоторых вариантах осуществления определение того факта, что аудиотрек-кандидат не является совпадающим с первым входящим аудиотреком, осуществляется в ответ на то, что длительность трека отличается на значение, превышающее предварительно установленное значение. Например, предварительно установленное значение составляет 30 секунд, в другом случае соответствующий кандидат будет считаться несовпадающим, если его длительность отличается более чем на 30 секунд по сравнению со входящим аудиотреком.
Поэтому в некоторых вариантах осуществления определение аудиотрека-кандидата содержит сравнение соответствующей длительности первого входящего аудиотрека и аудиотрека-кандидата. В качестве неограничивающего примера длительность аудиотрека-кандидата может быть извлечена из списка 304 словопозиций с использованием идентификатора 402 трека, связанного с аудиотреком, и указания 404 на информацию о длительности трека, связанной с аудиотреком. Указание 404 на информацию о длительности трека может быть единственным байтом или многобайтовой последовательностью. В этом варианте осуществления указание 402 на информацию о длительности трека является последовательностью двух байтов.
Затем способ 600 завершается.
В некоторых вариантах осуществления аудиотрек-кандидат содержит множество аудиотреков-кандидатов, а способ дополнительно содержит выбор подгруппы множества аудиотреков-кандидатов на основе предварительно определенного порогового числа кандидатов. Предварительно установленный порог числа кандидатов может являться предварительно определенным минимальным числом совпадающих хромаслов 1021 в первой короткой аудиосигнатуре и во второй короткой аудиосигнатуре, в которой предварительно определенное минимальное число совпадающих хромаслов зависит от числа предварительно определенных кандидатов и числа совпадающих хромаслов в предварительно определенных кандидатах. Например, если в большом множестве предварительно определенных кандидатов большое число предварительно выбранных кандидатов имеет два или более совпадающих хромаслов, предварительно определенное пороговое число кандидатов может быть установлено как 2, или 3, или 4 и так далее хромаслов. Таким образом, если предварительно определенное пороговое число кандидатов установлено как 3 хромаслова, поднабор множества аудиотреков-кандидатов будет включать вторые длинные аудиосигнатуры с минимум тремя хромасловами 1021, совпадающими с хромасловом 1021 из первой длинной аудиосигнатуры.
В некоторых вариантах осуществления побитное сравнение первой длинной аудиосигнатуры со второй длинной аудиосигнатурой содержит смещение первой длинной аудиосигнатуры по отношению ко второй длительной аудиосигнатуре. Смещение первой длинной аудиосигнатуры по отношению ко второй длинной аудиосигнатуре удобно, когда входящий аудиотрек укорочен в начале, или его начало содержит несколько секунд тишины, шума, помех и т.д. В некоторых вариантах осуществления смещение содержит амплитуду смещения. Например, амплитуда может находиться в промежутке плюс или минус 20 секунд или 15 секунд.
В некоторых вариантах осуществления определение того, что начальная часть второго хромаслова идентична начальной части первого хромаслова, выполняется с помощью определения того, что вся последовательность байтов в начальной части второго хромаслова совпадает со всей последовательностью байтов в начальной части первого хромаслова.
В некоторых вариантах осуществления по меньшей мере одна из короткой аудиосигнатуры и длинной аудиосигнатуры содержит указание на идентификатор 402 трека, связанный с соответствующим аудиотреком.
В некоторых вариантах осуществления до определения первой короткой аудиосигнатуры способ содержит получение сервером 720 по меньшей мере части первого входящего аудиотрека. Получение может быть осуществлено, например, когда пользователь компьютерного устройства загружает новый аудиотрек в социальную сеть или в другое место, которое доступно серверу 720.
В некоторых вариантах осуществления получение второй короткой аудиосигнатуры содержит извлечение с использованием индекса. В качестве неограничивающего примера, индекс может являться инвертированным индексом аудиотрека. Более конкретно, инвертированный индекс 7241 может быть индексом 7242 проверки.
Модификации и улучшения вышеописанных вариантов осуществления будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не несет никаких ограничений. Таким образом, объем настоящего решения ограничен только объемом прилагаемой формулы изобретения.
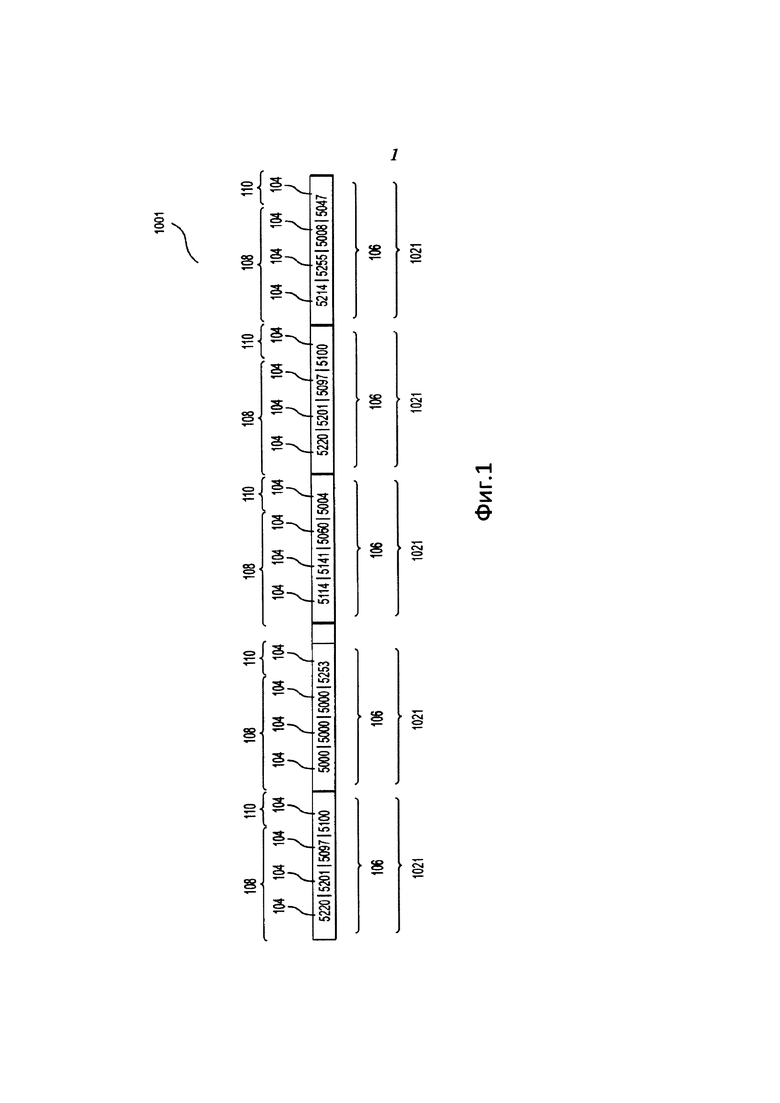
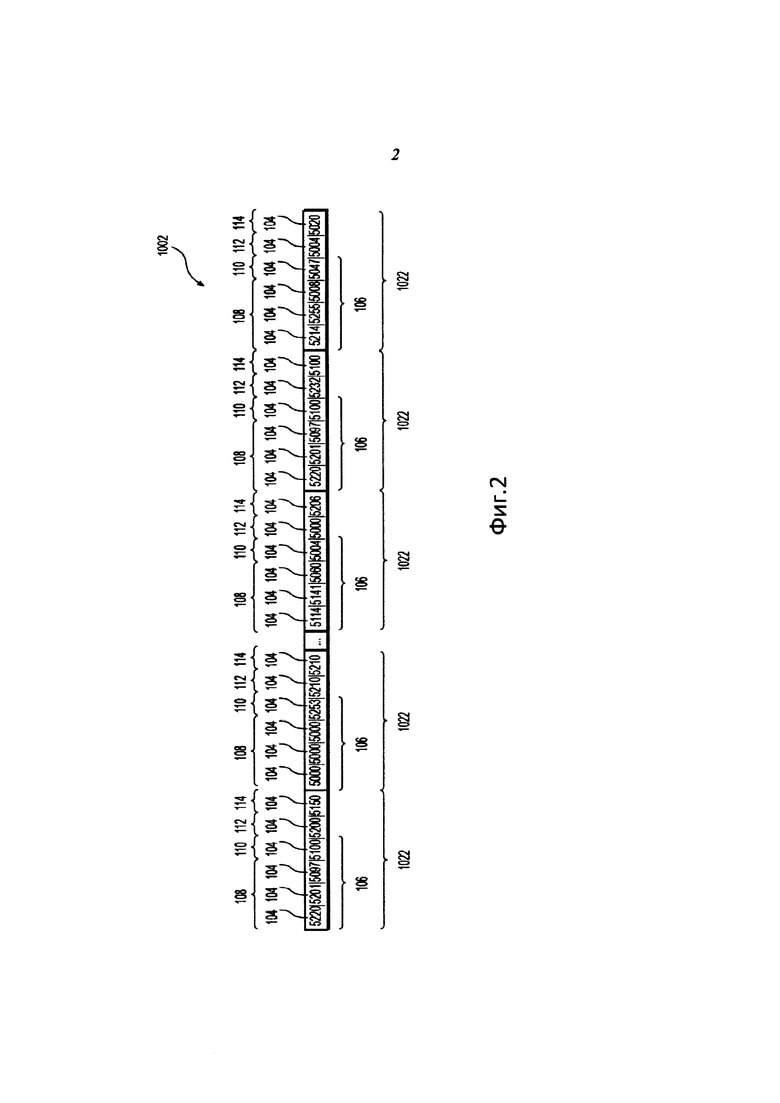
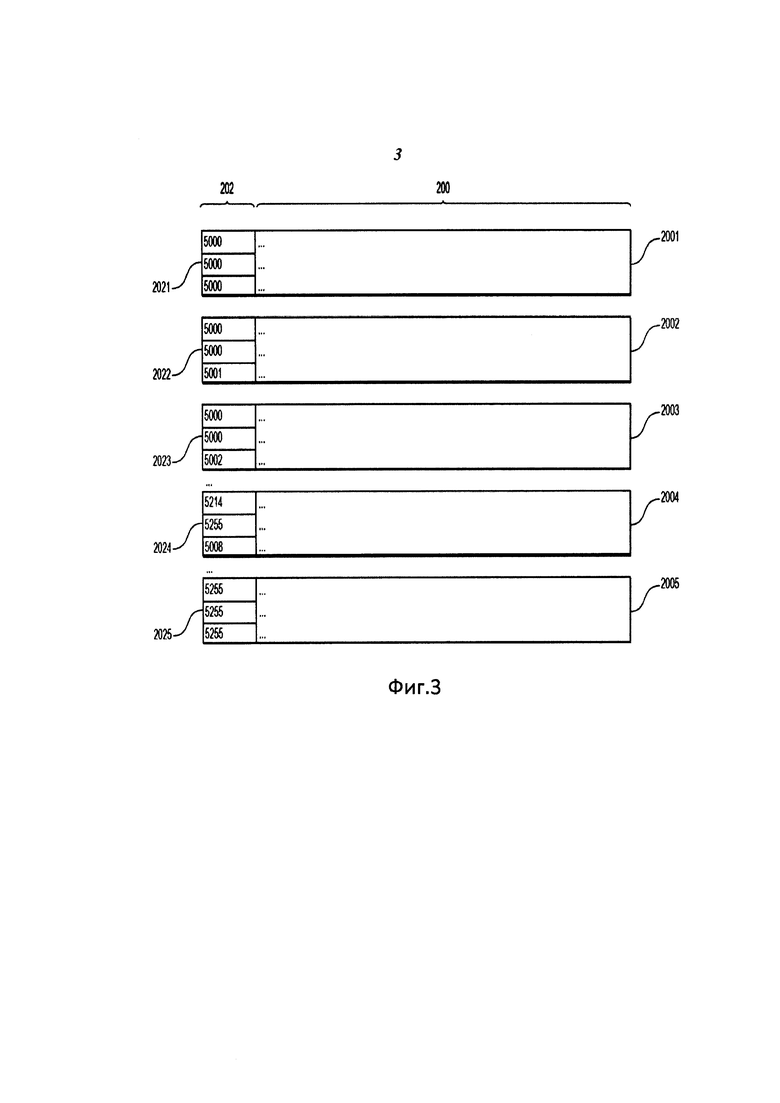
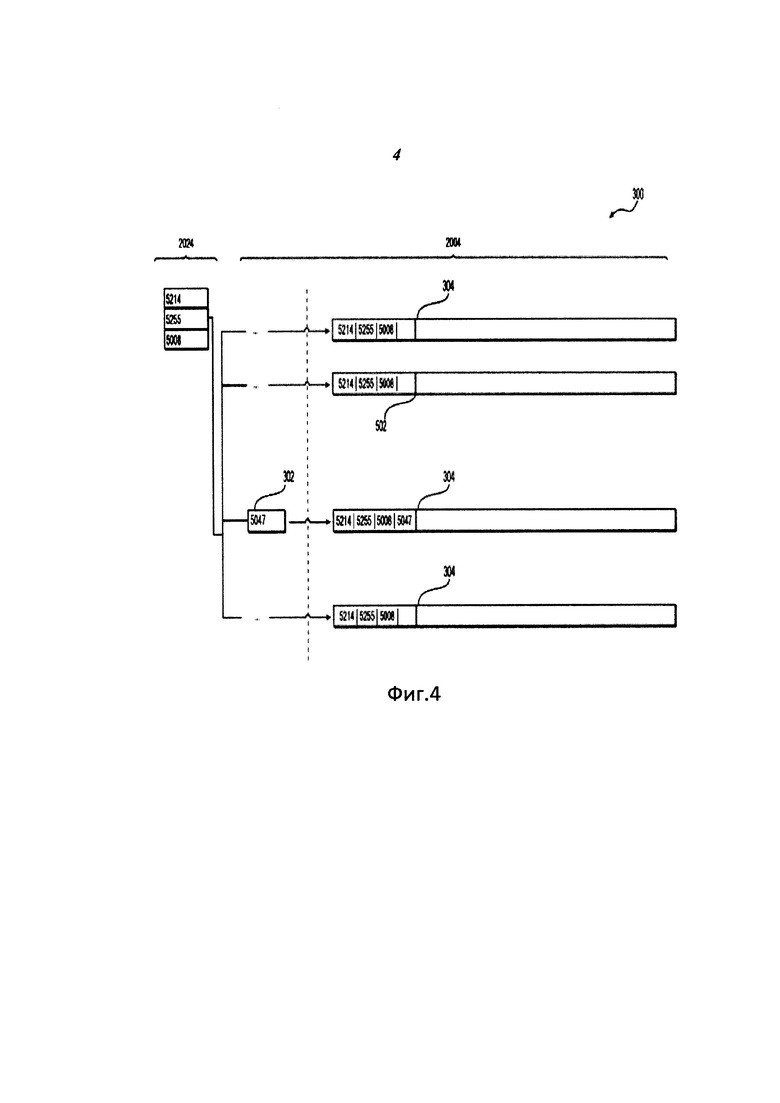
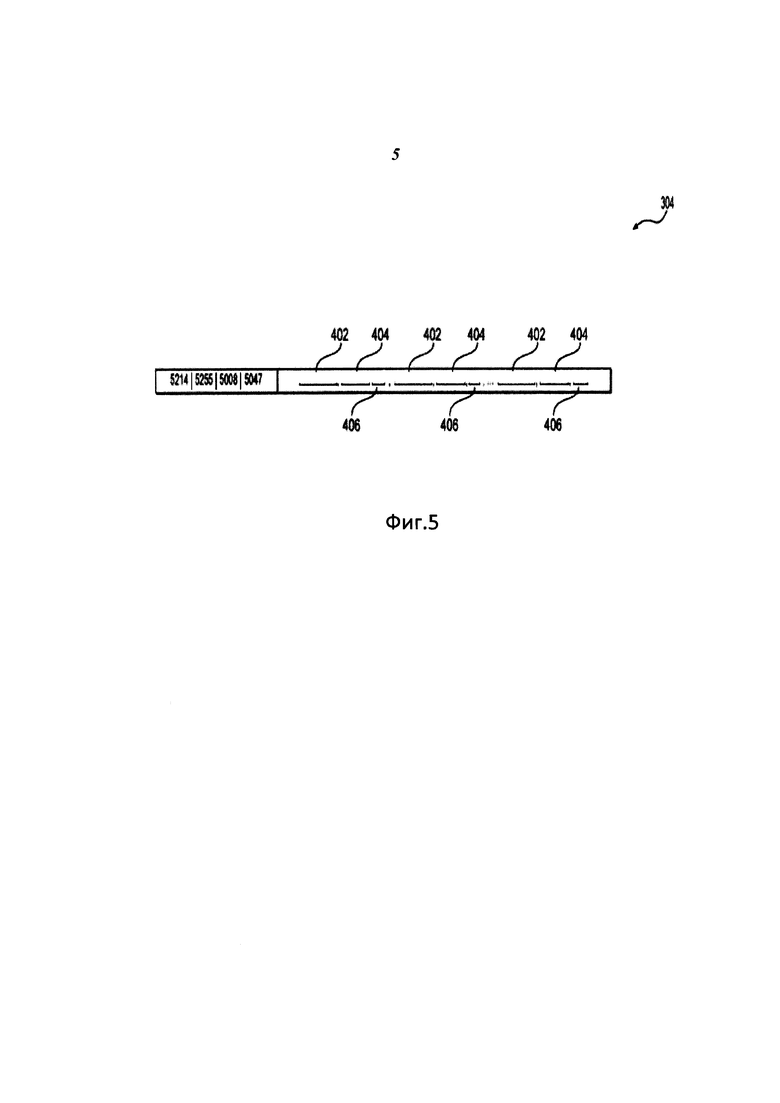
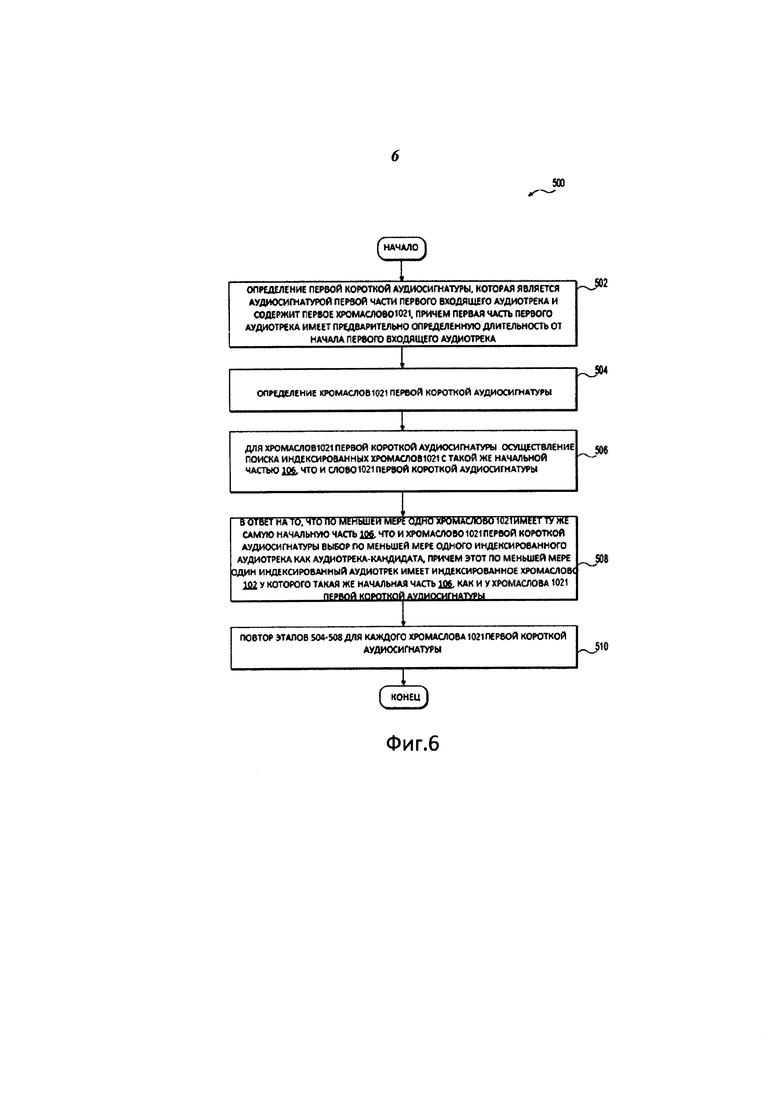
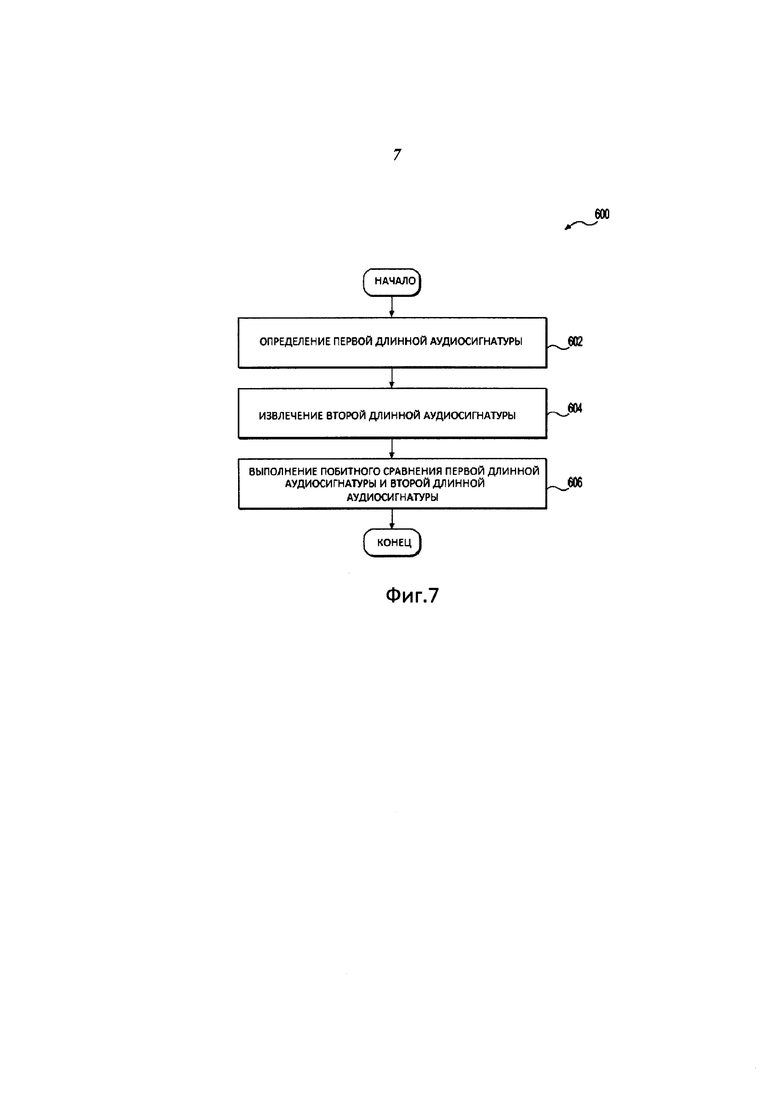
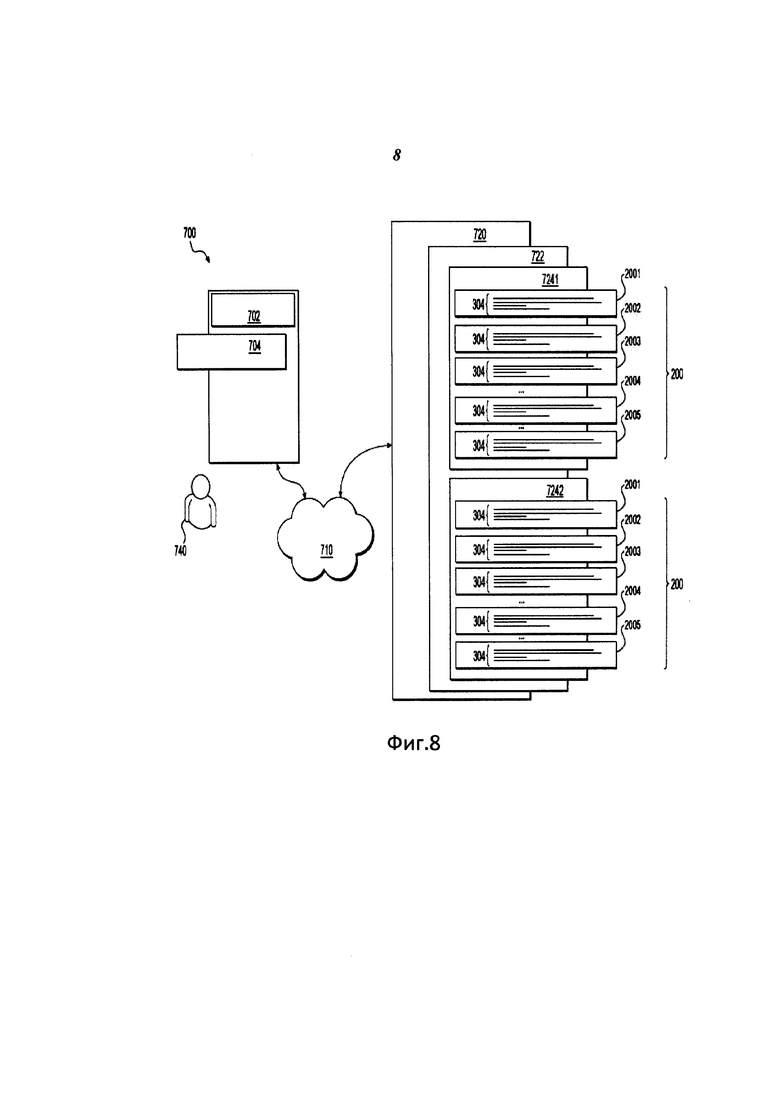
Изобретение относится к области распознавания аудиофайлов. Техническим результатом является эффективный поиск дубликатов музыкальных композиций. Способ формирования и использования инвертированного индекса аудиозаписи включает получение новой аудиозаписи для индексирования, определение первого хромаслова, связанного с новой аудиозаписью, для индексирования первого хромаслова, содержащего начальную часть хромаслова, которая является подмножеством байтов, имеющим первый байт и последующие байты, расположенные сразу после указанного первого байта, определение конкретного набора списков словопозиций на основе первого байта во множестве наборов списков словопозиций, при этом конкретный набор списков словопозиций содержит списки словопозиций, имеющие ссылки на хромаслова с одинаковыми первыми байтами в начальной части, при соответствии последующему байту первого хромаслова любого последующего байта любого хромаслова, хранящегося в данном списке записей в конкретном наборе списков записей, сохранение индикации нового первого хромаслова в данном списке записи, при несоответствии с последующим байтом первого хромаслова любого последующего байта любого хромаслова, сохраненного в списках записей, формирование нового списка записей в конкретном наборе списков записей с сохранением индикации нового хромаслова. 2 н. и 30 з.п. ф-лы, 8 ил.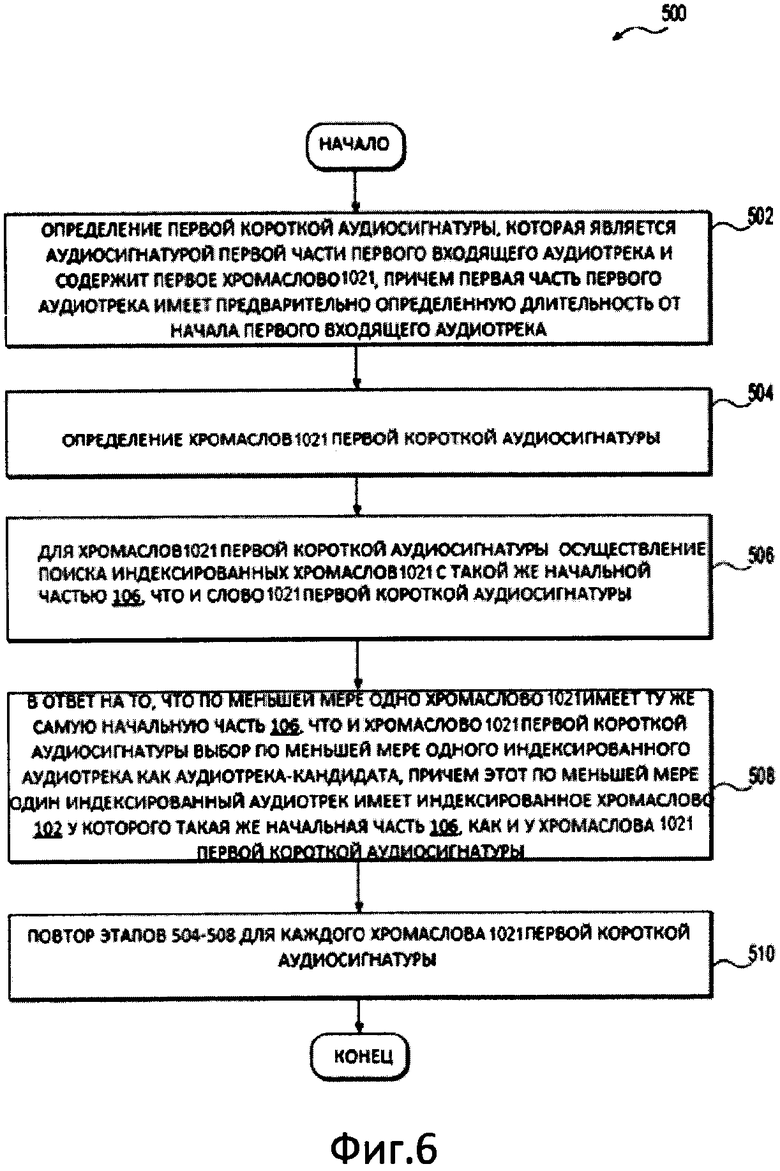
1. Машиночитаемый носитель информации, содержащий машиночитаемые коды с инвертированным индексом аудиозаписи, выполнение которых компьютером реализует способ формирования и использования инвертированного индекса аудиозаписи, включающий:
получение новой аудиозаписи для индексирования;
определение первого хромаслова, связанного с новой аудиозаписью, для индексирования первого хромаслова, содержащего начальную часть хромаслова, при этом начальная часть хромаслова является подмножеством байтов, имеющим первый байт и последующие байты, расположенные сразу после указанного первого байта;
определение конкретного набора списков словопозиций на основе первого байта во множестве наборов списков словопозиций, при этом конкретный набор списков словопозиций содержит списки словопозиций, имеющие ссылки на хромаслова с одинаковыми первыми байтами в начальной части;
при соответствии последующему байту первого хромаслова любого последующего байта любого хромаслова, хранящегося в данном списке записей в конкретном наборе списков записей, сохранение индикации нового первого хромаслова в данном списке записи;
при несоответствии с последующим байтом первого хромаслова любого последующего байта любого хромаслова, сохраненного в списках записей, формирование нового списка записей в конкретном наборе списков записей с сохранением индикации нового хромаслова.
2. Носитель по п. 1, в котором каждый из наборов списков записей связан с индексным ключом, уникальным в множестве наборов списков записей.
3. Носитель по п. 2, в котором упомянутый индексный ключ выполнен с возможностью быстрой локализации данного набора списков записей в индексе.
4. Носитель по п. 1, в котором каждый из списков записей в данном наборе списков записей ассоциирован с сортирующим ключом, уникальным для данного набора списков записей.
5. Носитель по п. 4, в котором сортирующий ключ выполнен с возможностью быстрой локализации списка записей в данном наборе списков записей.
6. Носитель по п. 1, в котором первый байт является первой последовательностью множества байтов, являющейся последовательностью байтов в начале начальной части каждого соответствующего хромаслова, число байтов в каждой первой последовательности множества байтов является одинаковым.
7. Носитель по п. 2, в котором индексный ключ содержит первую последовательность множества байтов.
8. Носитель по п. 1, в котором последующий байт является второй последовательностью множества байтов, являющейся последовательностью байтов, следующих за первым байтом, или первой последовательностью множества байтов соответствующего хромаслова.
9. Носитель по п. 8, в котором число байтов в каждой второй последовательности множества байтов одинаково.
10. Носитель по п. 6, в котором первая последовательность множества байтов является последовательностью трех байтов.
11. Носитель по п. 1, в котором начальная часть каждого хромаслова имеет предопределенное число байтов.
12. Носитель по п. 11, в котором начальная часть каждого хромаслова имеет четыре байта.
13. Носитель по п. 1, в котором каждый из наборов списков записей связан с индексным ключом, являющимся уникальным в множестве наборов списков записей, и каждый из списков записей в наборе списков записей связан с сортирующим ключом, уникальным для данного набора списка записей.
14. Носитель по п. 1, в котором аудиосигнатура является
короткой аудиосигнатурой, являющейся аудиосигнатурой первой части аудиозаписи с предопределенной длительностью от начала аудиозаписи, или
длинной аудиосигнатурой, являющейся аудиосигнатурой второй части аудиозаписи с предопределенной длительностью от начала аудиозаписи.
15. Носитель по п. 14, в котором по меньшей мере одна из коротких аудиосигнатур или длинных аудиосигнатур содержит идентификатор записи.
16. Носитель по п. 14, в котором одна из коротких аудиосигнатур или длинных аудиосигнатур хранится в инвертированном индексе аудиозаписи, выполненном как:
индекс обрезки, сформированный для множества коротких аудиосигнатур, или
индекс соответствия, сформированный для множества длинных аудиосигнатур.
17. Способ формирования и использования инвертированного индекса аудиозаписи, включающий:
получение новой аудиозаписи для индексирования;
определение первого хромаслова, связанного с новой аудиозаписью, для индексирования первого хромаслова, содержащего начальную часть хромаслова, при этом начальная часть хромаслова является подмножеством байтов, имеющим первый байт и последующие байты, расположенные сразу после указанного первого байта;
определение конкретного набора списков словопозиций на основе первого байта во множестве наборов списков словопозиций, при этом конкретный набор списков словопозиций содержит списки словопозиций, имеющие ссылки на хромаслова с одинаковыми первыми байтами в начальной части;
при соответствии последующему байту первого хромаслова любого последующего байта любого хромаслова, хранящегося в данном списке записей в конкретном наборе списков записей, сохранение индикации нового первого хромаслова в данном списке записи;
при несоответствии с последующим байтом первого хромаслова любого последующего байта любого хромаслова, сохраненного в списках записей, формирование нового списка записей в конкретном наборе списков записей с сохранением индикации нового хромаслова.
18. Способ по п. 17, в котором в качестве первого байта используют первую последовательность множества байтов, являющуюся последовательностью байтов в начале начальной части нового хромаслова, при этом число байтов является предопределенным.
19. Способ по п. 17, в котором последующий байт является второй последовательностью множества байтов, являющейся последовательностью байтов, следующих за любым из первых последовательностей множества байтов или первым байтом нового хромаслова, при этом число байтов в каждой второй последовательности множества является предопределенным.
20. Способ по п. 17, в котором перед определением первого хромаслова, связанного с новой индексируемой аудиозаписью, определяют аудиосигнатуры новой индексируемой аудиозаписи, а хромаслово является частью аудиосигнатуры.
21. Способ по п. 20, в котором аудиосигнатура является:
короткой аудиосигнатурой первой части новой аудиозаписи, являющейся первой предопределенной длительностью от начала новой аудиозаписи, или
длинной аудиосигнатурой второй части новой аудиозаписи, являющейся второй предопределенной длительностью от начала новой аудиозаписи.
22. Способ по п. 21, в котором первая предопределенная длительность является меньшей из предопределенной длительности в диапазоне от 9 до 27 с и длительности новой аудиозаписи.
23. Способ по п. 22, в котором первая предопределенная длительность является меньшей из интервала в 21 с и длительности новой аудиозаписи.
24. Способ по п. 21, в котором вторая предопределенная длительность является меньшей из предопределенной длительности в диапазоне от 96 до 141 с и длительности новой аудиозаписи.
25. Способ по п. 24, в котором вторая предопределенная длительность является меньшей из интервала в 120 с и длительности аудиозаписи.
26. Способ по п. 17, в котором упомянутое хромаслово характеризует отрезок аудиозаписи с длительностью в диапазоне от 1/2 с до 8 с.
27. Способ по п. 26, в котором упомянутая длительность отрезка аудиозаписи составляет 3 с.
28. Способ по п. 17, в котором каждое хромаслово содержит индикацию идентификатора записи, связанную с соответствующей аудиозаписью.
29. Способ по п. 17, в котором каждое хромаслово содержит индикацию информации о длительности записи, связанную с соответствующей аудиозаписью.
30. Способ по п. 28, в котором идентификатор записи характеризуется одним байтом, расположенным после любого из: последующих байтов, второй последовательности множества байтов.
31. Способ по п. 29, в котором индикация длительности записи характеризуется одним байтом, следующим непосредственно за любым из последующих байтов, второй последовательности множества байтов.
32. Способ по п. 21, в котором одна из короткой аудиосигнатуры или длинной аудиосигнатуры хранится в инвертированном индексе аудиозаписи, который выполнен как:
индекс обрезки, сформированный для множества коротких аудиосигнатур, и
индекс соответствия, сформированный для множества длинных аудиосигнатур.
| US 8497417 B2, 30.07.2013 | |||
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| УСТРОЙСТВО И СПОСОБ ФОРМИРОВАНИЯ СИГНАТУРЫ АКУСТИЧЕСКОГО СИГНАЛА, УСТРОЙСТВО ИДЕНТИФИКАЦИИ АКУСТИЧЕСКОГО СИГНАЛА | 2011 |
|
RU2459281C1 |
| СПОСОБ КОНТРОЛЯ ПРОВИСА ПРОВОДА ЛИНИИ ЭЛЕКТРОПЕРЕДАЧИ | 2012 |
|
RU2494511C1 |

