Область техники
Изобретение относится к системам обработки информации, в частности к системе обработки и способу ее функционирования.
Предпосылки изобретения
Суперскалярная система обработки включает блоки многократного выполнения для одновременного выполнения многократных команд. В некоторых системах обработки команды выполнимы вне очереди относительно их запрограммированной последовательности в потоке команд. Несмотря на это, выбранные одна или более команды могут подвергаться преобразованию в последовательную форму выполнения, когда преобразованная в последовательную форму выполнения команда выполняется только в порядке ее запрограммированной последовательности. В соответствии с типовыми ранее известными способами такая последовательно выполняемая команда оказывает отрицательное влияние на выполнение других команд, расположенных далее в запрограммированной последовательности.
Таким образом, возникает необходимость в системе обработки и в способе ее функционирования, при которых последовательно выполняемая команда оказывает меньшее отрицательное влияние на выполнение команд, расположенных далее в запрограммированной последовательности.
Сущность изобретения
В системе обработки и способе ее функционирования особая команда направляется в исполнительную схему для выполнения. После диспетчеризации особой команды на исполнительную схему передается преобразованная в последовательную форму выполнения команда до завершения выполнения особой команды.
Техническим преимуществом настоящего изобретения является то, что преобразованная в последовательную форму выполнения команда оказывает меньшее отрицательное влияние на выполнение последующих команд в запрограммированной последовательности.
Краткое описание чертежей
Пример исполнения настоящего изобретения и его преимущества поясняются в нижеследующем описании и со ссылками на иллюстрирующие его чертежи, на которых представлено следующее:
Фиг. 1 - блок-схема процессора для обработки информации в соответствии с предпочтительным вариантом осуществления;
Фиг. 2 - блок-схема исполнительного блока с фиксированной запятой, используемого в процессоре по фиг. 1;
Фиг. 3 - блок-схема блока упорядочивания последовательности, используемого в процессоре по фиг. 1;
Фиг. 4 - концептуальная иллюстрация буфера переупорядочения блока упорядочивания последовательности по фиг. 3;
Фиг. 5a-b - иллюстрации различных стадий команд, обрабатываемых процессором по фиг. 1;
Фиг. 6 - концептуальная иллюстрация буфера переупорядочения, используемого в процессоре по фиг. 1.
Фиг. 7 - иллюстрация различных стадий четырех команд по фиг. 6;
Фиг. 8a-d - концептуальная иллюстрация буферов переименования, используемого в процессоре по фиг. 1;
Фиг. 9 - иллюстрация различных стадий четырех команд в ситуации без использования существенных признаков предпочтительного варианта осуществления;
Фиг. 10a-d - концептуальные иллюстрации буферов переименования процессора по фиг. 9;
Фиг. 11 - блок-схема альтернативного варианта осуществления буферов переименования процессора по фиг. 1;
Фиг. 12a-c - концептуальные иллюстрации буфера переупорядочения процессора по фиг. 1;
Фиг. 13 - иллюстрация различных стадий пяти команд, показанных на фиг. 12a-c;
Фиг. 14a-g - концептуальные иллюстрации буферов переименования процессора по фиг. 1;
Фиг. 15 - иллюстрация различных стадий пяти команд, показанных на фиг. 12a-c, в ситуации без использования существенных признаков предпочтительного варианта осуществления;
Фиг. 16a-h - концептуальные иллюстрации буферов переименования процессора по фиг. 1 для различных циклов обработки команды, проиллюстрированных на фиг. 15.
Детальное описание
Пример осуществления настоящего изобретения и его преимущества поясняются с помощью фиг. 1-16h, где одинаковые номера используются для обозначения одинаковых и соответствующих элементов прилагаемых чертежей.
На фиг. 1 представлена блок-схема процессора 10 системы для обработки информации в соответствии с предпочтительным вариантом осуществления. В предпочтительном варианте процессор 10 выполнен в виде единой интегральной схемы суперскалярного микропроцессора. Соответственно, как описывается далее, процессор 10 содержит различные блоки, регистры, буферы, память и другие элементы, каждый из которых формируется в составе интегральной схемы. Кроме этого, в предпочтительном варианте осуществления процессор 10 работает в соответствии со способом обработки с использованием сокращенного набора команд (RISC). Как показано на фиг. 1, системная шина 11 связана с блоком интерфейса 12 шины процессора 10. Блок интерфейса 12 шины управляет передачей информации между процессором 10 и системной шиной 11.
Блок интерфейса 12 шины связан с быстродействующей памятью (кэшем) команд 14 и с кэшем данных 16 процессора 10. Кэш команд 14 выдает команды на блок упорядочивания 18 последовательности. В ответ на такие команды от кэша команд 14 блок упорядочивания 18 избирательно выдает команды на другие схемы исполнения команд процессора 10.
Кроме блока упорядочивания 18 в предпочтительном варианте осуществления исполнительная схема процессора 10 содержит блоки многократного выполнения, а именно блок ветвления 20, блок фиксированной запятой A (FXUA) 22, блок фиксированной запятой B (FXUB) 24, комплексный блок с фиксированной запятой (CFXU) 26, блок загрузки/хранения (LSU) 28 и блок плавающей запятой (FPU) 30. FXUA 22, FХUB 24, CFXU 26 и LSU 28 вводят информацию их исходного операнда из регистров архитектуры общего назначения (GPR) 32 и из буферов переименования 34 с фиксированной запятой. Более того, FXUA 22 и FXUB 24 вводят "разряд переноса" из регистра бита переноса (CA) 42. FXUA 22, FXUB 24, CFXU 26 и LSU 28 выдают результаты (информацию операнда назначения) их операций для хранения на выбранных входах буфером 34 переименования с фиксированной запятой. Кроме этого, CFXU 26 вводит и выводит информацию исходного операнда и операнда назначения в регистры 40 специального назначения (SPR) и из них.
FPU 30 вводит информацию своего исходного операнда из архитектурных регистров с плавающей запятой (FPR) 36 и из буферов переименования с плавающей запятой 38. FPU 30 выдает результаты (информацию операнда назначения) своей операции для хранения на выбранных входах буферов переименования с плавающей запятой 38.
В ответ на команду загрузки LSU 28 вводит информацию из кэша данных 16 и копирует эту информацию в один из выбранных буферов переименования 34 и 38. Если такая информация не хранится в кэше данных 16, то кэш данных 16 вводит (посредством BIU 12 и системной шины 11) такую информацию из системной памяти 39, связанной с системной шиной 11. Более того, кэш данных 16 имеет возможность выдавать (посредством BIU 12 и системной шины 11) информацию из кэша данных 16 в системную память 39, связанную с системной шиной 11. В ответ на команду Store LSU 28 вводит информацию из одного из выбранных GPR 32 и FPR 36 и копирует эту информацию в кэш данных 16.
Блок упорядочивания 18 последовательности вводит и выводит информацию от GPR 32 и FPR 36 и соответственно выводит ее из этих блоков. Блок ветвления 20 вводит из блока упорядочивания 18 команды и сигналы, указывающие текущее состояние процессора 10. В ответ на такие команды и сигналы блок ветвления 20 выдает (на блок упорядочивания 18 последовательности) сигналы, указывающие соответствующие адреса памяти, в которых хранится последовательность команд для выполнения процессором 10. В ответ на такие сигналы от блока ветвления 20 блок упорядочивания 18 последовательности вводит указанную последовательность команд из кэша команд 14. Если одна или более последовательностей команд не сохранились в кэше команд 14, то кэш команд 14 вводит (посредством BIU 12 и системной шины 11) такие команды из системной памяти 39, связанной с системной шиной 11.
В ответ на команды, введенные из кэша команд 14, блок упорядочивания 18 последовательности избирательно пересылает команды на один из выбранных блоков 20, 22, 24, 26, 28 и 30. Каждый исполнительный блок выполняет одну или более команду из конкретного класса команд. Например, FXUA 22 и FXUB 24 выполняют первый класс математических операций с фиксированной запятой для операндов, таких как сложение, вычитание, операцию AND, операцию OR, операцию XOR. CFXU 26 выполняет второй класс операций с фиксированной запятой для исходных операндов, таких как умножение и деление с фиксированной запятой. FPU 30 выполняет действия с плавающей запятой с исходными операндами, такие как умножение и деление с плавающей запятой.
После запоминания информации в одном из буферов переименования 34 такая информация связывается с ячейкой памяти (например, с одним из регистров GPR 32 или CA 42) в соответствии с командной, для которой назначается выбранный буфер переименования. Информация, хранимая в одном из буферов переименования 34, копируется в связанный с ней один из GPR 32 (или в регистр CA 42) в ответ на сигналы от блока упорядочивания последовательности 18. Как описывается ниже, в соответствии с фиг. 6-10 блок упорядочивания 18 последовательности направляет такую скопированную информацию, хранимую в одном из выбранных буферов переименования 34, в ответ на "завершение" команды, которая сформировала эту информацию. Такое копирование называется "обратной записью".
После запоминания информации в одном из выбранных буферов переименования 38 такая информация связывается с одним из FPR 36. Информация, сохраненная в одном из выбранных буферов переименования 38, копируется в связанный с ней один из FPR 36 в ответ на сигналы от блока упорядочивания 18, который управляет таким копированием информации, запоминаемой в одном из выбранных буферов 38 в ответ на "завершение" команды, которая сформировала эту информацию.
Высокая производительность процессора 10 достигается путем обработки множества команд одновременно в различных исполнительных блоках 20, 22, 24, 26, 28 и 30. Соответственно каждая команда обрабатывается как последовательность стадий, каждая из которых выполняется параллельно с выполнением стадий других команд. Такой способ называется "конвейерной обработкой". В соответствии с важным аспектом предпочтительного выполнения команда обычно обрабатывается как шесть стадий, а именно выборка, декодирование, передача, выполнение, завершение и обратная запись.
На стадии выборки блок упорядочивания 18 избирательно вводит (из кэша команд 14) одну или более команд из одного или более адреса памяти, по которому хранится последовательность команд, рассматриваемых далее в связи с блоком ветвления 20 и блоком упорядочивания 18.
На стадии декодирования блок упорядочивания 18 декодирует до четырех выбранных команд.
На стадии диспетчеризации блок упорядочивания 18 избирательно направляет до четырех декодированных команд на один из выбранных (в ответ на декодирование на стадии декодирования) исполнительных блоков 20, 22, 24, 26, 28 и 30 после резервирования элементов буфера переименования для каждого результата выполнения переданной команды (информация операнда назначения). На этапе диспетчеризации информация операнда передается на выбранные исполнительные блоки для направляемых команд. Процессор 10 направляет команды в порядке, соответствующем запрограммированной последовательности.
На стадии выполнения исполнительные блоки выполняют переданные им команды и выдают результаты (информацию операнда назначения) их работы для сохранения в выбранных элементах буферов переименования 34 и 38 в соответствии с описываемым далее. Таким образом, процессор 10 имеет возможность выполнять команды вне очереди по отношению к их запрограммированной последовательности.
На стадии завершения блок упорядочивания 18 указывает, что команда "завершена" в соответствии с описанным далее со ссылками на фиг. 3-4. Процессор 10 "завершает" выполнение команд в соответствии с их запрограммированной последовательностью.
На стадии обратной записи блок упорядочивания 18 управляет копированием информации из буферов переименования 34 и 38 в GPR 32 и FPR 36 соответственно. Блок упорядочивания 18 управляет таким копированием информации, запоминаемой в выбранном буфере переименования в соответствии с описанным далее со ссылками на фиг. 6-10. Аналогично, в состоянии обратной записи конкретной команды процессор 10 обновляет свои состояния конфигурации в ответ на конкретную команду. Процессор 10 обрабатывает соответствующие стадии "обратной записи" команд в соответствии с их запрограммированной последовательностью. В соответствии с тем, что описывается далее со ссылками на фиг. 6-10, предпочтительно, чтобы процессор 10 в определенных ситуациях совмещал стадии завершения команд и стадии обратной записи.
В предпочтительном исполнении необходим один машинный цикл для завершения каждой стадии выполнения команды. Тем не менее, для выполнения некоторых команд (например, комплексные команды с фиксированной запятой, выполняемые CFXU 26) необходимо более одного машинного цикла. Соответственно может возникнуть различное запаздывание между выполнением различных команда и стадиями завершения в зависимости от различного времени, необходимого для завершения предыдущих команд.
На фиг. 2 представлена блок-схема FXUA (исполнительного блока с фиксированной запятой) 22 процессора 10. FXUA 22 содержит устройства резервирования, обозначенные как 50a и 50b. Аналогично, каждый блок ветвления 20, FXUB 24, CFXU 26, LSU 28 и FPU 30 имеет соответствующие устройства резервирования. Для ясности, далее описывается работа только FXUA 22 и его устройства резервирования в качестве примера работы других блоков и их соответствующих устройств резервирования.
Каждое устройство резервирования 50a-b имеет возможность сохранять информацию для соответствующих команд, переданных от блока упорядочивания 18 последовательности для выполнения в FXUA 22. Каждое устройство резервирования содержит соответствующее поле регистра назначения, поле операнда A, поле операнда B и поле кода операции. Более того, в соответствии с важным аспектом предпочтительного выполнения каждое устройство резервирования далее содержит соответствующее поле разрешения выполнения (EOK).
В своем поле регистра назначения устройство резервирования указывает по меньшей мере один регистр назначения (как определено блоком упорядочивания 18) для соответствующей команды устройства резервирования. Аналогично, в своих соответствующих полях операнда A и операнда B устройство резервирования запоминает информацию об исходном операнде (от GPR 32, от буферов переименования 34, FXUB 24, CFXU 26 или LSU 28) для соответствующей команды устройства резервирования. Устройство резервирования в своем поле операции хранит код операции (в соответствии с тем, что определено блоком упорядочивания 18), указывающий операцию, которая должна быть выполнена FXUA 22 над информацией исходного операнда в ответ на соответствующую команду устройства резервирования.
В ответ на сигналы от логики управления 56 исполнительная логика 54 вводит информацию исходного операнда из полей операндов A и B устройства резервирования и выполняет операцию (указанную запомненным кодом операции устройства резервирования) над ними. Информация, полученная в результате выполнения такой операции, выдается от исполнительной логики 54 на буферы переименования 34, FXUB 24, CFXU 26 и LSU 28. Такая информация сохраняется в одном из выбранных буферов переименования 34. В ответ на указание регистра назначения выходной информацией мультиплексора 58 запомненная информация назначается (в выбранном буфере переименования) одному из GPR 32.
В соответствии с важным аспектом предпочтительного исполнения устройство резервирования далее запоминает информацию EOK (в соответствии с тем, что определяется блоком упорядочивания 18) в его поле EOK. Предпочтительно, чтобы такая информация EOK соответствовала определенным ситуациям, когда процессор 10 задерживает выполнение последовательно выполняемой команды. Последовательное выполнение является способом задержки выполнения команды в процессорах многократного конвейера с внеочередным выполнением, примером которых является процессор 10. В первой ситуации, когда процессор 10 задерживает выполнение последовательно выполняемой команды, эта команда не должна быть выполнена теоретически. Во второй ситуации, когда процессор 10 задерживает выполнение последовательно выполняемой команды, выполнение команды задерживается до момента, когда информация всех ее исходных операндов станет доступной и правильной.
Что касается первой ситуации (когда команда теоретически не должна выполняться), процессор 10 обычно выполняет команды умозрительно так, чтобы команды выполнялись вне очереди относительно их запрограммированной последовательности в потоке команд. Соответственно, не обязательно, чтобы результаты выполнения команд (информация операнда назначения) были доступны в соответствии с запрограммированной последовательностью этих команд. Однако процессор 10 записывает результаты выполнения команд обратно в регистры конфигурации (например, GPR 32 и FPR 36) в порядке, соответствующем запрограммированной последовательности команд. Для этой цели процессор 10 имеет буферы переименования 34 и 38 для промежуточного хранения результатов выполнения команд до подходящего момента (т.е. до окончания выполнения всех предыдущих команд без условий исключения) для записи временно хранимых результатов обратно в архитектурные регистры.
Тем не менее, в качестве примера в предпочтительном выполнении некоторые команды действуют на SPR 40 (фиг. 1), причем результаты выполнения команды записываются непосредственно в SPR 40 без временного хранения в буферах переименования. Примером такой команды является команда Move To, в соответствии с которой CFXU 26 перемещает информацию в один из SPR 40 от одного из GPR 32. Как показано на фиг. 1, CFXU 26 связан с SPR 40. Команда Move To немедленно обновляет один из SPR 40 после выполнения. В качестве другого примера результат выполнения команды Store непосредственно записывается в ячейку памяти в кэш данных 16 без временного хранения в буферах переименования.
Процессор 10 теоретически не выполняет таких команд (т.е. когда результаты выполнения команд записываются непосредственно в регистр архитектуры или ячейку памяти без промежуточного хранения в буферах переименования), так что процессор 10 имеет возможность достичь точных прерываний и точных исключений. Более того, так как результаты выполнения команд непосредственно записываются в регистр архитектуры или ячейку памяти без предварительного хранения в буферах переименования, то такие команды обрабатываются без стадии обратной записи. Соответственно, для гарантии завершения в порядке очереди и обратной записи процессор 10 задерживает выполнение такой команды до завершения выполнения всех предыдущих команд.
В соответствии с другой ситуацией (когда выполнение команды задерживается до момента, когда информация всех ее исходных операторов станет доступной и правильной), указанной на фиг. 3, устройство резервирования временно сохраняет информацию соответствующей команды, для которой информация исходного операнда не доступна на момент передачи этой команды от блока упорядочивания 18. После того, как информация исходного операнда станет доступной от исполнительного блока, устройство резервирования вводит и сохраняет такую информацию исходного операнда. В подходящий момент устройство резервирования передает информацию этого исходного операнда исполнительной логике 54.
В предпочтительном исполнении большинство команд в качестве исходных операндов определяют один или более GPR 32 и FPR 36. Соответственно, в предпочтительном исполнении устройства резервирования включают цепь для продвижения информации от исполнительных блоков.
Несмотря на это, в предпочтительном исполнении устройства резервирования не содержат схем для продвижения информации от исходных операндов других типов, таких как регистр CA 42 или SPR 40. Это происходит по той причине, что размер и цена таких схем не соответствуют частоте команд, которые определяют такие непродвинутые исходные операнды. Вместо этого процессор 10 предпочтительного исполнения задерживает выполнение последовательно выполняемой команды, определяющей по меньшей мере один непродвинутый исходный операнд, до завершения выполнения всех предыдущих команд. В ответ на завершение выполнения всех предыдущих команд эти ненаправленные исходные операнды считываются из одного из определенных архитектурных регистров (например, SPR 40). Примерами таких команд являются (1) расширенная арифметическая операция, которая считывает регистр CA 42, и (2) команда Move From, которая перемещает информацию от одного из SPR 40 в один из GPR 32.
Наконец, процессор 10 задерживает выполнение команды последовательного выполнения, по меньшей мере, до завершения всех предыдущих команд в двух ситуациях. В первой ситуации команда не должна выполняться теоретически. Во второй ситуации команда определяет по меньшей мере один исходный операнд, для которого процессор 10 не включает схемы для продвижения. Предпочтительно, чтобы такие ситуации обрабатывались блоком упорядочивания 18, определяющим информацию EOK, которая должна храниться в устройстве резервирования.
Если команда должна выполняться последовательно, то блок упорядочивания 18 очищает бит EOK (информации EOK, которая хранится в поле EOK устройства резервирования) и устанавливает его в состояние логического "0" во время передачи команды на FXUA 22. После установки бита EOK в состояние логического "0" блок упорядочивания 18 последовательности предотвращает выполнение команды FXUA 22, даже если эта команда готова к выполнению. Соответственно FXUA 22 выполняет такие последовательно выполняемые команды только в ответ на выдачу блоком упорядочивания 18 сигнала по линии 60 в соответствии с тем, что описано далее.
В отличие от вышесказанного, если команда не должна выполняться последовательно, то блок упорядочивания 18 последовательности устанавливает бит EOK в состояние логической "1" во время передачи команды на FXUA 22. Посредством установки бита EOK в состояние логической "1" блок упорядочивания 18 позволяет FXUA 22 выполнять команду, как только информация исходного операнда команды будет правильной и доступной.
На фиг. 3 представлена блок-схема блока упорядочивания 18 последовательности. Как указывалось ранее, на стадии выборки блок упорядочивания 18 выполняет избирательный ввод команд количеством до четырех из кэша команды 14 и сохраняет такие команды в буфере команд 70. На стадии декодирования логика декодирования 72 вводит и декодирует до четырех выбранных команд из буфера команд 70. На стадии диспетчеризации логика диспетчеризации 74 избирательно передает до четырех декодированных команд на выбранный (в ответ на выполнение декодирования на стадии декодирования) один из исполнительных блоков 20, 22, 24, 26, 28 и 30.
На фиг. 4 представлена концептуальная иллюстрация буфера переупорядочения 76 блока упорядочивания 18 последовательности предпочтительного исполнения. Как показано на фиг. 4, буфер переупорядочения 76 имеет шестнадцать входов, соответственно обозначаемых номерами буферов 0-15. Каждый вход имеет пять основных полей, а именно поле "типа команды", поле "количества назначений GPR", поле "количества назначений FPR", поле "завершение" и поле "исключение". Кроме того, поле "типа команды" имеет подполе "исполнительного блока" и подполе "EOK".
Согласно фиг. 3 после того, как логика диспетчеризации 74 передаст команду на исполнительный блок, блок упорядочивания 18 назначает переданную команду соответствующему входу в буфере переупорядочения 76 переданным командам по принципу "первым пришел - первым обслужен" и циклическим образом так, что блок упорядочивания 18 назначает вход 0, за которым следуют последовательно входы 1-15, а затем вновь вход 0. После назначения соответствующему входу переданной команды в буфере переупорядочения 76 логика диспетчеризации 74 выдает информацию, соответствующую переданной команде для хранения в различных полях и подполях назначенного входа буфера переупорядочения 76.
Например, для входа 0 (фиг. 4) буфер переупорядочения 76 указывает, что команда была передана на FXUA 22. Более того, вход 0 указывает, что переданная команда выполняется последовательно так, что EOK = 0 и процессор 10 должен задержать выполнение переданной команды по меньшей мере до тех пор, пока не завершится выполнение всех предыдущих команд. Кроме этого, для входа 1 буфер переупорядочения 76 указывает, что последующая команда должна выполняться последовательно так, что EOK = 0.
В соответствии с другими важными аспектами предпочтительного исполнения вход 0 далее указывает, что переданная команда имеет один GPR регистр назначения (такой, как "количество назначений GPR" = 1), имеет регистры нулевого назначения FPR (такие, как "количество назначений FPR" = 0), еще не завершена (так, что "завершение" = 0) и еще не вызывала исключение (так, что "исключение" = 0).
Исполнительный блок выполняет переданную команду, блок выполнения преобразует вход, назначенный команде в буфере переупорядочения 76. Более конкретно, в ответ на завершение выполнения переданной команды исполнительный блок изменяет поле "завершение" входа (так, чтобы "завершение" = 1). Если исполнительный блок встретит исключение во время выполнения переданной команды, то исполнительный блок изменяет поле "исключение" входа (так, чтобы "исключение" = 1).
Согласно фиг. 3 входы буфера переупорядочения 76 считываются логикой завершения 80 и логикой исключения 82 блока упорядочивания 18 последовательности. Более того, в соответствии с одним из важных аспектов предпочтительного исполнения входы буфера переупорядочения 76 считываются логикой последовательного исполнения 84 блока упорядочивания 18. В ответ на поля "исключения" буфера переупорядочения 76 логика исключения 82 обрабатывает исключительные ситуации, которые встретились во время выполнения переданных команд.
В ответ на поля "завершение" и поля "исключения" буфера переупорядочения 76 логика завершения 80 выдает сигналы логике диспетчеризации 74, логике последовательного выполнения 84, а также буферу переупорядочения 76. Посредством этих сигналов логика завершения 80 указывает "завершение" команд в соответствии с их запрограммированной последовательностью. Логика завершения 80 указывает "завершение" команды, если она удовлетворяет следующим условиям:
Условие 1 - исполнительный блок (которому была передана команда) заканчивает выполнение команды (так что "завершение" = 1 для назначенных команде входов в буфере переупорядочения 76);
Условие 2 - не возникло никаких исключительных ситуаций в связи с каким-либо состоянием обработки команды (так что "исключение" = 0 для входов, назначенных команде в буфере переупорядочения 76); а также
Условие 3 - любая ранее переданная команда удовлетворяет условиям 1 и 2.
В ответ на информацию буфера переупорядочения 76 логика диспетчеризации 74 определяет подходящее количество дополнительных команд для передачи.
В соответствии с важным аспектом предпочтительного выполнения, в ответ на сигналы от логики завершения 80, логика последовательного выполнения 84 избирательно выдает сигналы на FXUA 22 по линии 60. Если связанный с переданной на FXUA 22 командой бит EOK (в поле "типа команды" входа, назначенного команде в буфере переупорядочения 76) установлен в состояние логического "0", то логика последовательного выполнения 84 выдает сигнал по линии 60 в ответ на "завершение" всех команд, предшествующих переданной команде. FXUA 22 выполняет такую переданную команду только в ответ на передачу логикой последовательного выполнения 84 сигнала по линии 60. После передачи логикой последовательного выполнения 84 сигнала по линии 60 такой переданной командой (для которой назначенные бит EOK установлен в состояние логического "0") будет самая старая команда, ожидающая выполнения в устройстве резервирования 50a-b FXUA 22, так как команды "завершаются" в соответствии с их запрограммированной последовательностью.
Аналогично, логика последовательного выполнения 84 избирательно выдает сигналы на исполнительные блоки 20, 24, 26, 28 и 30 по линиям 86, 88, 90, 92 и 94, соответствующим образом связанных с ней.
На фиг. 5a-b проиллюстрированы различные стадии команд. Согласно фиг. 5a выполнение (цикл 6) последовательно выполняемой команды INST n+1 (например, команды Move To или команды Move From) задерживается до завершения выполнения всех предыдущих команда (например, до цикла 5 предыдущей команды INST n). Тем не менее, предпочтительно, что процессор 10 не задерживает диспетчеризацию (цикл 3) или выполнение (цикл 4) команды INST n+2, которой предшествует команда последовательного выполнения INST n+1. Таким образом, процессор 10 обеспечивает непрерывную диспетчеризацию команд (таких, как INST n+2), которым предшествует последовательно выполняемая команда (такая, как INST n+1). Кроме этого, исполнительный блок процессора 10 имеет возможность подавать команды вне очереди от устройства резервирования исполнительных блоков на свою исполнительную логику (например, исполнительную логику 54 по фиг. 2), даже если самая старая команда, ожидающая выполнения в устройстве резервирования исполнительного блока, выполняется последовательно.
Процессор 10 в предпочтительном варианте выполнения достигает более высокой производительности, чем в альтернативных случаях. Как показано на фиг. 5b, в соответствии с одним из таких альтернативных способов передача (цикл 8) команды INST i+2 задерживается в ответ на декодирование (цикл 2) команды INST i+1, которая выполняется последовательно. В соответствии с таким альтернативным способом команда передачи команды INST i+2 выполняется только после "завершения" всех ранее переданных команд (например, после цикла 7 выполнения предыдущей последовательно выполняемой команды INST i+1). Узким местом такого альтернативного способа является то, что выполнение задерживается для любой команды (такой, как INST i+2), которой предшествует последовательно выполняемая команда (такая, как INST i+1).
Как указывалось ранее, процессор 10 обеспечивает непрерывную диспетчеризацию команд, которым предшествует последовательно выполняемая команда. Команда Move From является последовательно выполняемой командой и поэтому обеспечивает преимущества от использования способа преобразования в последовательную форму выполнения в варианте предпочтительного осуществления. Кроме того, в соответствии с другим важным аспектом предпочтительного варианта осуществления процессор 10 содержит схемы для вывода результатов (информации операнда назначения) команды Move From для хранения в выбранном буфере переименования перед обратной записью информации операнда назначения в один из GPR 32.
Процессор 10 поддерживает такое переименование независимо от того, является ли регистр назначения команды Move From одним из GPR 32. Таким образом, процессор 10 использует схемы продвижения своих устройств резервирования совместно со схемой поиска буферов переименования для корректного согласования информации операнда назначения (команды Move From) с исходным регистром команды, переданной после команды Move From. Соответственно, другие команды, которым предшествует команда Move From, могут передаваться в любое время после передачи команды Move From. Без использования такой схемы для команды Move From другие команды, которым предшествует команда Move From, не будут передаваться до "завершения" команды Move From, так как для выполнения других команд (в качестве информации их исходного операнда) может потребоваться информация операнда назначения команды Move From.
В соответствии с другим важным аспектом предпочтительного варианта осуществления процессор 10 упорядочивает диспетчеризацию команд, реагируя на выборку команд и связанные с декодированием исключения (IFDRE) оптимальным образом. Процессор 10 определяет выборку команды или исключение, связанное с декодированием, на этапе выборки или декодирования, если условие исключения может быть определено полностью на основании анализа команды и состояния процессора 10. Примерами таких выборок команд или исключений, связанных с декодированием, являются неисправность страницы доступа к команде, нарушение защиты памяти доступа к команде, нарушение привилегированной команды, а также несанкционированные команды.
В основном, в ответ на такое выявление выборки команды или исключения, связанного с декодированием, блок упорядочивания 18 передает команду, обусловленную IFDRE, на устройство резервирования исполнительного блока, но одновременно устанавливает бит EOK в состояние логического "0", как указано ранее со ссылкой на фиг. 2-4. Кроме того, блок упорядочивания 18 запоминает указатель условия IFDRE посредством установки "исключение" = 1 (одновременно "завершение" = 0) для входа, назначенного для команды, вызывающей IFDRE в буфере переупорядочения 76. Такой указатель определяет команду как команду, обусловившую IFDRE.
Как указывалось ранее со ссылкой на фиг. 2-4, путем установки бита EOK в логическое состояние "0" блок упорядочивания 18 предотвращает выполнение исполнительным блоком переданной команды, даже если эта команда готова к выполнению. Соответственно, исполнительный блок выполняет такую команду только в ответ на сигнал от блока упорядочивания 18, переданный по одной из соответствующим образом подключенной линии 60, 86, 88, 90, 92 и 94, как указывалось ранее со ссылкой на фиг. 2-4.
В ответ на завершение всех команд, предшествующих команде, обусловившей IFDRE, блок упорядочивания 18 обрабатывает выборку или исключение, связанное с декодированием, вместо того, чтобы передавать сигнал на исполнительный блок посредством одной из соответствующих линий 60, 86, 88, 90, 92 и 94. Таким образом, команда, обусловившая IFDRE, никогда не будет выполнена исполнительным блоком. Блок упорядочивания 18 определяет команду как обусловившую IFDRE в ответ на "исключение" = 1 и "завершение" = 0 для входа, связанного с командой, обусловившей IFDRE, в буфере переупорядочения 76.
Таким образом, процессор 10 упорядочивает и ускоряет передачу команды посредством логики диспетчеризации 74 (фиг. 3), что ускоряет работу критической схемы в суперскалярном процессоре. Соответственно, процессор 10 предпочтительного варианта осуществления достигает более высокой производительности по сравнению с альтернативными вариантами. В соответствии с одним из таких альтернативных способов процессор никогда не передает команду, обусловившую IFDRE. Такой альтернативный способ приводит к сложной и медленной передаче, так как для каждой команды процессору необходимо определить выборку каждой команды и условие исключения, связанное с декодированием, перед определением, куда необходимо передавать команду. Например, в соответствии с таким альтернативным способом процессор определяет, куда необходимо передать n-ую команду в ответ на определение, имела ли n-ая команда или какая-либо более предшествующая (n-1)-ая команда выборку или связанное с декодированием условие исключения.
В отличие от этого в предпочтительном выполнении логика диспетчеризации 74 (фиг. 3) работает независимо от выборки или условий исключения, связанных с декодированием. Даже после принятия решения о промежуточной передаче команды на исполнительный блок для исполнения блок упорядочивания 18 определяет, существует ли условие IFDRE для данной команды. Если блок упорядочивания 18 определит, что условие IFDRE существует для данной команды, то блок упорядочивания 18 выдаст указатель условия IFDRE для запрещения выполнения команды исполнительным блоком. Кроме того, предусматривается выдача на один или несколько выбранных исполнительных блоков исполнительной схемы процессора дополнительного указания начать выполнение переданной последовательно выполняемой команды упомянутыми исполнительными блоками в ответ на завершение выполнения упомянутой команды из конкретного класса команд. Более конкретно, в ответ на определение блоком упорядочивания 18 существования условия IFDRE для данной команды блок упорядочивания 18 выдает такой указатель во время действительной передачи посредством (1) установки "исключение" = 1 (при этом "завершение" = 0) для входа, назначенного команде, вызывающей IFDRE в буфере переупорядочения 76, и (2) установкой бита EOK в устройстве резервирования команды, обусловившей IFDRE, в логическое состояние "0".
Это обеспечивает преимущества, так как после принятия решения диспетчеризации команды на практике обычно не осуществляется реверсирование такого решения, чтобы в определенных ситуациях не осуществлять передачу команды. Кроме того, в цикле диспетчеризации выполняются дополнительные операции после принятия решения относительно передачи данной команды. Соответственно, процессору 10 нет необходимости определять какое-либо условие исключения до принятия решения о необходимости передачи данной команды. Для блока упорчдочивания 18 особенно выгодно передавать множество команд в одиночном цикле процессора 10.
Фиг. 6 является концептуальной иллюстрацией буфера переупорядочения 76, где показаны четыре команды во время завершения выполнения ("завершение" = 1) в течение того же цикла процессора 10. Фиг. 7 является иллюстрацией различных стадий четырех команд по фиг. 6. Фиг. 8a-d являются концептуальными иллюстрациями буферов переименования 34 процессора 10.
Согласно фиг. 6-8 в соответствии с важным аспектом предпочтительного осуществления обратная запись не зависит от завершения выполнения команды так, что состояние "обратная запись" команды, обрабатываемой процессором 10, отделимо от состояния "завершения" команды. Предпочтительно, посредством отделения "обратной записи" от "завершения" подобным образом процессор 10 достигает эффективной работы, используя меньшее количество портов обратной записи между буферами переименования и регистрами конфигурации. Например, как показано на фиг. 1, процессор 10 предпочтительного варианта осуществления содержит два порта обратной записи между буферами переименования 34 и GPR 32, а также два порта обратной записи между буферами переименования 38 и FPR 36. Одновременно с использованием меньшего количества портов уменьшаются и физические размеры буферов переименования 34 и 38 и регистров конфигурации 32 и 36. Кроме того, логика завершения 80 (фиг. 3) становится более простой, так что процессор 10 быстрее определяет, может ли быть "завершена" конкретная команда во время текущего цикла.
В предпочтительном варианте осуществления процессор 10 имеет возможность "завершать" до четырех команд за цикл. Кроме того, в предпочтительном варианте осуществления каждая команда может иметь до двух операндов назначения. Соответственно, если процессор 10 не поддерживает отделение обратной записи от завершения, то процессору 10 необходимо будет использовать восемь портов обратной записи (например, между буферами переименования 34 и GPR 32) для завершения выполнения четырех команд в течение конкретного цикла, если каждая из четырех команд имеет два операнда назначения. Это объясняется тем, что для "завершения" команды потребуется, чтобы порт обратной записи был доступен для каждого операнда назначения команды, который должен быть скопирован из буфера переименования в назначенный регистр конфигурации.
При использовании меньшего количества портов обратной записи становится более сложной проверка доступности порта обратной записи, так как в течение того же цикла рассматривается большее количество команд для обратной записи. Это происходит из-за того, что доступность порта обратной записи для конкретной команды в течение конкретного цикла зависит от количества портов обратной записи, используемых для предыдущих команд в течение того же цикла или на предыдущих циклах.
Соответственно, путем отделения обратной записи от завершения логика завершения 80 (фиг. 3) процессора 10 становится более упорядоченной. Это объясняется тем, что "завершение" команды зависит от следующих условий:
Условие 1 - исполнительный блок (которому передается команда) завершает выполнение этой команды;
Условие 2 - не возникло ни одного исключения в связи с какой-либо стадией обработки данной команды;
Условие 3 - какая-либо из переданных команд удовлетворяет условию 1 и условию 2.
Посредством отделения завершения от обратной записи процессор 10 копирует информацию операнда назначения завершенной команды из буфера переименования для хранения в регистре конфигурации в течение конкретного цикла, если порт обратной записи доступен в течение этого цикла. Если порт обратной записи не доступен во время этого цикла, то процессор 10 копирует информацию операнда назначения завершенной команды из буфера переименования в регистр конфигурации во время следующего цикла, когда порт обратной записи доступен.
В соответствии с фиг. 6 буфер переупорядочения 76 запоминает информацию для четырех команд, завершающих выполнение во время одного и того же цикла процессора 10. На фиг. 7 показаны различные стадии четырех команд INST x, INST x+1, INST x+2, а также INST x+3, которые соответствующим образом назначаются номерам 7, 8, 9 и 10 буфера переупорядочения по фиг. 6. Соответственно, команда INST x имеет один операнд назначения ("количество назначений GPR" = 1). Кроме этого, команда INST x+1 имеет один операнд назначения ("количество назначений GRP" = 1). В отличие от этого команда INST x+2 имеет два операнда назначения ("количество назначений GPR" = 2). Аналогично, команда INST x+3 имеет два операнда назначения ("количество назначений GPR" = 2). Как показано на фиг. 7, каждая из команда INST x, INST x+2 и INST x+3 завершает свое выполнение к концу цикла 4.
Фиг. 8a-d являются концептуальными иллюстрациями буферов переименования 34 процессора 10. Для простоты, далее рассматривается только работа буферов переименования с фиксированной запятой 34 в качестве примера работы буферов переименования с плавающей запятой 38. Как показано на фиг. 8a-d, буферы переименования 34 содержат двенадцать буферов переименования, соответственно обозначенных номерами буферов 0-11. Блок упорядочивания 18 назначает номера 0-11 передаваемым командам по принципу "первым пришел - первым обслужен" и циклическим образом так, что блок упорядочивания 18 назначает номер буфера переименования 0, за которыми следуют номера 1-11 буферов переименования, а затем вновь номер 0 буфера переименования.
В соответствии с фиг. 8a-d буфер переименования 2 назначается для хранения информации операнда назначения для команды INST x. Буфер переименования 3 назначается для хранения информации операнда назначения для команды INST x+1. Так как команда INST x+2 имеет два операнда назначения, то оба буфера переименования 4 и 5 назначаются для хранения информации операнда назначения для команды INST x+2. Аналогично, оба буфера переименования 6 и 7 назначаются для хранения информации операнда назначения для команды INST x+3.
На фиг. 8a показано состояние указателя назначения 80, указателя обратной записи 82, а также указателя завершения 84 в начале циклов 4 и 5 по фиг. 7.
Процессор 10 поддерживает такие указатели для управления чтением и записью в буферы переименования 34. Процессор 10 поддерживает указатель назначения 80 для указания, назначен ли буфер переименования конкретной команде. Как показано на фиг. 8a, указатель назначения 80 указывает на буфер переименования 8, указывая тем самым, что буфер переименования 8 является следующим буфером переименования, доступным для назначения команде.
В соответствии с важным аспектом предпочтительного варианта выполнения процессор 10 далее поддерживает указатель обратной записи 82 для указания, доступен ли буфер переименования (ранее назначены конкретной команде) для переназначения другой команде. Как показано на фиг. 8a, указатель обратной записи 82 указывает на буфер переименования 2, тем самым указывая, что буфер переименования 2 является следующим буфером переименования, из которого процессор 10 будет копировать информацию операнда назначения (которая находилась в поле "информация" буфера переименования фиг. 8a) в одно из GPR 32 (в соответствии с тем, что указано в поле "номер регистра" буфера переименования фиг. 8a).
Соответственно, процессор 10 продвигает указатель обратной записи 82 (после буфера переименования, ранее назначенного конкретной команде) в ответ на копирование процессором 10 результата (информации операнда назначения) выполнения конкретной команды из буфера переименования для хранения в регистре конфигурации. Таким образом, процессор 10 принимает назначенный буфер переименования для хранения результата (информации операнда назначения) конкретной команды до тех пор, пока процессор 10 не скопирует результат в регистр конфигурации.
Кроме того, процессор 10 поддерживает указатель завершения 84 для указания (буферу переименования, ранее назначенному конкретной команде), удовлетворяет ли конкретная команда следующим условиям:
Условие 1 - исполнительный блок (которому была передана команда) завершил выполнение команды;
Условие 2 - отсутствуют какие-либо исключительные ситуации в связи с какой-либо стадией обработки данной команды;
Условие 3 - какая-либо из переданных команд удовлетворяет условию 1 и условию 2.
Как показано на фиг. 8a, указатель завершения 84 указывает на буфер переименования 2, тем самым указывая, что буфер переименования 2 является следующим буфером переименования, который имеет возможность удовлетворить условиям 1, 2 и 3. В соответствии с важным аспектом предпочтительного варианта осуществления процессор 10 поддерживает указатель завершения 84 независимо от того, был ли скопирован результат выполнения команды из буфера переименования для хранения в регистре конфигурации.
Соответственно, "входы переименования" могут быть определены как буфер переименования, на который указывает указатель завершения 84, и как его последующие буферы переименования, которые предшествуют буферу переименования, указанному указателем назначения 80. "Входы обратной записи" могут быть определены как буфер переименования, на который указывает указатель обратной записи 82, и как его последующие буферы переименования, которые предшествуют буферу переименования, на который указывает указатель завершения 84. Входы обратной записи хранят результаты выполнения команд, которые "завершились", но чьи результаты не были скопированы из буферов переименования в регистры конфигурации, например, из-за недоступности портов записи в регистры конфигурации.
Концептуально входы обратной записи расположены между входами переименования и регистрами конфигурации. Преимуществом является то, что результат может обойти входы обратной записи и непосредственно записаться в регистры конфигурации, если порт обратной записи доступен на стадии завершения. Более того, подобно входам переименования процессор 10 обрабатывает входы обратной записи для выдачи информации на исполнительный блок в ситуациях, когда исполнительный блок выполняет команду, определяющую регистры конфигурации, связанные с такой информацией.
Например, на фиг. 8b показано состояние указателя назначения 80, указателя обратной записи 82, а также указателя завершения 84 на начальном цикле 6 по фиг. 7. Как показано на фиг. 8b, указатель назначения 80 не изменился, так как процессор 10 не передал дополнительных команд. В отличие от этого указатель завершения 84 был продвинут от регистра переименования номер 2 к регистру переименования номер 8, тем самым указывая на завершение в течение цикла 5 четырех команд INST x, INST x+1, INST x+2 и INST x+3, которые в совокупности имеют шесть операндов назначения.
Кроме того, на фиг. 8b указатель обратной записи 82 был продвинут от регистра переименования номер 2 к регистру переименования номер 4, тем самым указывая на обратную запись в течение цикла 5 информации операндов назначения для команд INST x и INST x+1. На фиг. 7 этот факт проиллюстрирован путем указания завершения и обратной записи (COMP/WBACK), которые выполняются одновременно в течение цикла 5 для команд INST x и INST x+1. Таким образом, результаты (в регистре переименования номер 2 и регистре переименования номер 3) команд INST x и INST x+1 обходят входы обратной записи и непосредственно записываются в GPR 32, так как два порта обратной записи были доступны вначале цикла 5. На фиг. 8b указатель обратной записи 82 не продвигается за регистр переименования номер 4, так как оба порта обратной записи используются в течение цикла 5 для обратной записи результатов выполнения команд INST x и INST x+1.
На фиг. 8c показано состояние указателя назначения 80, указателя обратной записи 82 и указателя завершения 84 в начале цикла 7 по фиг. 7. Как показано на фиг. 7 и 8c, оба порта обратной записи используются в течение цикла 6 для обратной записи обоих результатов команды INST x+2. Соответственно указатель обратной записи 82 продвигается от регистра переименования номер 4 к регистру переименования номер 6. Указатель назначения 80 не изменяется, так как процессор 10 не передал дополнительных команд. Кроме этого, указатель завершения 84 тоже не изменяется, так как процессор 10 не завершил дополнительных команд.
На фиг. 8d показано состояние указателя назначения 80, указателя обратной записи 82 и указателя завершения 84 вначале цикла 8 по фиг. 7. Как показано на фиг. 7 и 8c, оба порта обратной записи используются в течение цикла 7 для обратной записи обоих результатов выполнения команды INST x+3. Соответственно, указатель обратной записи 82 продвигается от регистра переименования номер 6 к регистру переименования номер 8. Указатель назначения 80 не изменяется, так как процессор 10 не передал дополнительных команд. Кроме этого, указатель завершения 84 тоже не изменяется, так как процессор 10 не завершил выполнение дополнительных команд.
На фиг. 9 проиллюстрированы различные состояния четырех команд в ситуации без использования существенных признаков предпочтительного варианта осуществления, в котором процессор 10 отделяет завершение от обратной записи. Для иллюстрации такой ситуации на фиг. 9 показаны различные стадии четырех команд INST y, INST y+1, INST y+2 и INST y+3, которые соответствующим образом назначены номерам 7, 8, 9 и 10 буферов переупорядочения по фиг. 6.
Фиг. 10a-d являются концептуальными иллюстрациями буферов переименования процессора в соответствии с фиг. 9. Более конкретно, на фиг. 10a показано состояние указателя назначения 90 и указателя завершения 94 вначале циклов 4 и 5 по фиг. 9. На фиг. 10b показано состояние указателя назначения 90 и указателя завершения 94 вначале цикла 6 по фиг. 9. На фиг. 10c показано состояние указателя назначения 90 и указателя завершения 94 вначале цикла 7 по фиг. 9. На фиг. 10d показано состояние указателя назначения и указателя завершения 94 вначале цикла 8 по фиг. 9.
Как показано на фиг. 10a-d, без использования существенных признаков предпочтительного варианта осуществления, где процессор 10 отделяет завершение от обратной записи, конкретная команда (имеющая назначенный буфер переименования) должна завершится только после того, как результат выполнения конкретной команды будет на самом деле скопирован из назначенного буфера переименования для хранения в регистре конфигурации. В отличие от этого в соответствии с важным аспектом предпочтительного варианта осуществления, в соответствии с которым процессор 10 отделяет завершение от обратной записи, процессор 10 далее поддерживает указатель обратной записи 82 для указания, является ли буфер переименования (ранее назначенный конкретной команде) доступным для повторного назначения другой команде. Более того, процессор 10 "завершает" конкретную команду независимо от того, был ли результат выполнения конкретной команды на самом деле скопирован из назначенного буфера переименования для хранения в регистре конфигурации. Соответственно, процессор 10 имеет возможность "завершить" до четырех команд в течение конкретного цикла, даже если каждая из четырех команд имеет два операнда назначения, а также даже тогда, когда в GPR 32 копируются не все операнды назначения в течение конкретного цикла.
Фиг. 11 является блок-схемой альтернативного исполнения буферов переименования 34, в которых хранятся "входы переименования" в буфере 110, отделенном от "входов переименования". "Входы переименования" хранятся в буфере 112. Информация от "входа переименования" буфера 112 передается для хранения на "вход обратной записи" буфера 110 в течение конкретного цикла в ответ на завершение, в течение конкретного цикла, конкретной команды, для которой был назначен "вход переименования". Информация из "входа обратной записи" буфера 110 выдается для хранения в одном из GPR 32 в течение конкретного цикла в ответ на доступность, в течение конкретного цикла, одного из двух портов обратной записи для GPR 32.
Буфер 112 передает информацию на буфер 110 посредством одного из восьми портов, показанных на фиг. 11, так, что буфер 112 имеет возможность передавать информацию на буфер 110 от "входов переименования" количеством до восьми в течение какого-либо конкретного цикла процессора 10. Соответственно, процессор 10 имеет возможность "завершить" до четырех команд в течение конкретного цикла, даже если каждая из четырех команд имеет два операнда назначения и даже если в GPR 32 копируются не все операнды назначения в течение конкретного цикла. Преимуществом является то, что результат (информация операнда назначения) может обойти "входы обратной записи" буфера 110 и записаться непосредственно в GPR 32, если порт обратной записи доступен на стадии завершения. Процессор 10 выполняет такой обход посредством соответствующей работы мультиплексоров 113a и 113b, которые связаны с буферами 110 и 112, а также с GPR 32, как показано на фиг. 11.
Преимущество альтернативного выполнения буферов переименования 34 по фиг. 11 заключается в том, что вход переименования в буфере 112 может быть повторно назначен другой команде после завершения (пока еще до обратной записи) команды, ранее назначенной входам переименования (для которой вход переименования был назначен ранее), так как информация входа переименования передается соответствующим образом для хранения на входе обратной записи буфера 110 в ответ на завершение ранее назначенной команды. В соответствии с другим аспектом фиг. 11 мультиплексор 114 соответствующим образом передает выбранную информацию на исполнительные блоки от буфера 110 или от буфера 112 в ситуациях, когда исполнительный блок выполняет команду, определяющую регистр конфигурации, связанный с такой информацией. Хотя процессор 10 предпочтительного исполнения имеет два порта обратной записи между буферами переименования и регистрами конфигурации, но подходящее количество портов обратной записи для конкретного исполнения является функцией вероятности того, что входы переименования и входы обратной записи переполняется, что вызовет задержку передачи команд.
Как было указано ранее со ссылкой на фиг. 2-5, процессор 10 задерживает выполнение последовательно выполняемой команды по меньше мере до тех пор, пока не завершатся все предыдущие команды в двух ситуациях. В первой ситуации команда не должна выполняться теоретически. Во второй ситуации команда определяет по меньшей мере один исходный операнд, для которого процессор 10 не использует схему продвижения.
В соответствии с первой ситуацией некоторые команды действуют на специализированные регистры конфигурации (SPR) 40 (фиг. 1), когда результаты выполнения команд непосредственно записываются в SPR 40 без промежуточного хранения в буферах переименования. Примером таких команд является команда Move To, которая продвигает информацию в один из SPR 40 от одного из GPR 32. Как показано на фиг. 1, такие команды Move To выполняются посредством CFXU 26. Команда Move To немедленно обновляет один из SPR 40 во время выполнения. Аналогично, команда Store немедленно обновляет ячейку памяти в кэше данных 16 (фиг. 1) во время выполнения. Процессор 10 теоретически не выполняет таких команд (т. е. когда результаты выполнения команд записываются непосредственно в регистры архитектуры или ячейки памяти без промежуточного хранения в буферах переименования), так что процессор 10 имеет возможность достичь точных прерываний и точных исключений. Соответственно, для гарантии завершения и обратной записи в порядке очереди процессор 10 задерживает выполнение команды Move To и команды Store до завершения выполнения всех предыдущих команд.
Если для команды, переданной на исполнительный блок, соответствующий бит EOK (в поле "типа команды" входа, назначенного команде в буфере переупорядочения 76) устанавливается в состояние логического "0", то логика последовательного выполнения 84 выдает сигнал (по одной из соответствующих линий 60, 86, 88, 90, 92 и 94, связанных с исполнительным блоком) в ответ на "завершение" всех команд, предшествующих переданной команде. Исполнительный блок выполняет такие переданные команды только в ответ на сигнал от логики последовательного выполнения 84.
Фиг. 12a-c представляют собой концептуальную иллюстрацию буфера изменения порядка 76. Фиг. 13 является иллюстрацией различных стадий пяти команд фиг. 12a-c. Фиг. 14a-f являются концептуальной иллюстрацией буферов переименования 34 процессора 10.
На фиг. 12a показано состояние буфера переупорядочения 76 вначале цикла 4 фиг. 13. Соответственно на фиг. 12a буфер переупорядочения 76 хранит информацию для четырех команд, переданных в течение цикла 3 по фиг. 13. На фиг. 13 показаны различные стадии четырех команд INST a, INST a+1, INST a+2 и INST a+3, которые соответствующим образом назначаются номерам 3, 4, 5 и 6 буфера переупорядочения по фиг. 12a.
Как показано на фиг. 12a, команда INST a передается на FXUA 22 и имеет два операнда назначения ("количество назначений GPR" = 2). В отличие от этого команда INST a+1 передается на FXUB 24, но имеет один операнд назначения ("количество назначений GPR" = 1). Команда INST a+2 является командой Store, передаваемой на LSU 28, и имеет нулевые операнды назначения ("количество назначений GPR" = 0); более того, буфер переупорядочения номер 5 (назначенный команде INST a+2) имеет EOK = 0 в ответ на выполнение команды INST a+2, которая является последовательно выполняемой. Команда INST a+3 передается на CFXU 26 и имеет один операнд назначения ("количество назначений GPR" = 1).
В соответствии с важным аспектом предпочтительного варианта выполнения блок упорядочивания 18 определяет, возможно ли выполнение на основании выполнения команды. Блок упорядочивания 18 осуществляет это определение заранее, до выполнения команды. Если исключение невозможно для этой команды, то блок упорядочивания 18 в основном устанавливает (в ответ на передачу команды) "завершение" = 1 для входа, связанного с буфером переупорядочения команды, независимо от того, завершил ли на самом деле процессор 10 выполнение команды, выполнение которой невозможно.
Более того, в такой ситуации процессор 10 "завершает" выполнение команды в ответ на завершение процессором 10 всех предыдущих команд, независимо от того, завершил ли на самом деле процессор 10 выполнение команды, для которой невозможно исключение. Соответственно, процессор 10 "завершает" выполнение команды в ответ на определение, что исключение не следует из выполнения команды и из выполнения каждой предыдущей команды, предшествующей команде в запрограммированной последовательности независимо от того, завершил ли процессор 10 выполнение команд, выполнение которых невозможно. Таким образом, возможно предшествование состояния завершения выполнения команды состоянию выполнения команды; так процессор 10 поддерживает "раннее завершение" команды.
Поддерживая "раннее завершение", процессор 10 в основном имеет возможность быстрее выполнять следующие, последовательно выполняемые команды (такие, как команды Move To или команды Store), причем результаты выполнения команд записываются непосредственно в регистры конфигурации или в ячейку памяти без промежуточного хранения в буферах переименования. Все это верно независимо от возможности процессора 10 достигать точных прерываний и точных исключений. Это происходит из-за того, что все предыдущие команды либо (1) уже закончили свое выполнение без исключений, либо (2) закончат выполнение без исключений. Посредством такого способа процессор 10 продолжает обеспечивать завершение и обратную запись в порядке очереди.
Например, на фиг. 12a команды INST a+1 и INST a+3 не имеют возможность вызвать исключение так, что "завершение" = 1 в буфере переупорядочения под номером 4 и 6.
На фиг. 14a показано состояние указателя назначения (AL) 80, указателя обратной записи (WB) 82, а также указателя завершения (CO) 84 буферов переименования 34 вначале цикла 4 по фиг. 13. Таким образом, фиг. 14a соответствует фиг. 12a. Как показано на фиг. 14a, WB 82 и CO 84 указывают на буфер переименования 2, а AL 80 указывает на буфер переименования 6. Буферы переименования 2 и 3 назначаются команде INST a. Буфер переименования 4 назначается команде INST a+1, а буфер переименования 5 назначается команде INST a+3. Следует учесть, что команде INST a+2 не назначается буфер переименования, так как команда INST a+2 имеет нулевой операнд назначения. В буферах переименования 2-5 "правильная информация" = 0 указывает, что в поле "информация" этих буферов переименования не содержится правильных данных. Вначале цикла 4 (фиг. 13) "правильная информация" = 0, так как команды INST a, INST a+2, а также INST a+3 еще не закончили выполнение.
В буфере переименования 4 "исполнить правильно" = 1 указывает, что INST a+1 изменяет регистр CA 42. Необходимо учитывать, что, как указывалось ранее, команда INST a+1 не имеет возможности вызвать исключение, так что "завершение" = 1 в буфере переупорядочения 4 (фиг. 12a). Соответственно, процессор 10 поддерживает "раннее завершение" команд, которые изменяют регистр CA 42.
Как показано на фиг. 14a-g, информация бита CA временно хранится в буферах переименования 34. Несмотря на это, процессор 10 предпочтительного исполнения не использует схему для продвижения информации такого бита CA к исполнительным блокам от буферов переименования 34. Если информация исходного операнда конкретной команды содержатся в регистре CA 42, то информация исходного операнда конкретной команды зависит от результатов выполнения предыдущей команды (если такая имеется), которая изменяет регистр CA 42.
На фиг. 12b показано состояние буфера переупорядочения вначале цикла 5 по фиг. 13. Соответственно, на фиг. 12b буфер переупорядочения 76 хранит информацию для команды INST a+4, передаваемой в течение цикла 4 по фиг. 13. На фиг. 13 показаны различные стадии команды INST a+4, которая назначается буферу переупорядочения номер 7. Как показано на фиг. 12b, команда INST a+4 передается на FXUA 22 и имеет один операнд назначения ("количество назначений GPR" = 1); более того, буфер переупорядочения номер 7 (назначенный команде INST a+4) имеет EOK = 0 в ответ на команду INST a+4, которая выполняется последовательно.
Более того, так как команда INST a завершает свое выполнение в течение цикла 4, то "завершение" = 1 в буфере переупорядочения номер 3 на фиг. 12b. В соответствии с фиг. 13 команда INST a+2 является командой Store. В течение цикла 4 LSU 28 завершило первый этап выполнения EXEC A команды Store INST a+2. В течение выполнения EXEC A LSU 28 преобразует команду Store и проверяет команду Store на защиту памяти. Соответственно "завершено" = 1 для буфера переупорядочения номер 5 фиг. 12b.
На фиг. 14b показано состояние указателя назначения (AL) 80, указателя обратной записи (WB) 82, а также указателя завершения (CO) 84 буферов переименования 34 вначале цикла 5 по фиг. 13. Таким образом, фиг. 14b соответствует фиг. 12b. Как показано на фиг. 14b, WB 82 и CO 84 продолжают указывать на буфер переименования 2, а AL 80 продвигается от буфера переименования 6 и указывает на буфер переименования 7. Соответственно, буфер переименования 6 назначается команде INST a+4.
В буфере переименования 6 "правильная информация" = 0, что указывает, что поле "информация" этого буфера переименования не хранит правильных данных. Вначале цикла 5 (фиг. 13) "правильная информация" = 0 для буфера переименования 6, так как выполнение команды INST a+4 еще не завершено. В отличие от этого для фиг. 14b "правильная информация" = 1 для буферов переименования 2 и 3 в ответ на завершение выполнения команд INST a и INST a+1 в течение цикла 4, как показано на фиг. 13, что указывает, что в полях "информация" буферов переименования 2 и 3 хранятся правильные данные (представленные на фиг. 14b как "данные" в полях "информация").
В буфере переименования 6 "исполнить правильно" = 1, что указывает, что INST a+4 изменяет регистр CA 42. Более того, информация исходного операнда команды INST a+4 содержится в регистре CA 42 так, что INST a+4 является последовательно выполняемой командой, причем информация исходного операнда зависит от результата выполнения предшествующей команды INST a+1, которая изменяет регистр CA 42. Хотя команда INST a+3 не изменяет регистр CA 42, но информация исходного операнда команды INST a+3 тоже зависит от результатов выполнения предыдущей команды INST a+1, как указывается на фиг. 13 стрелкой 100.
На фиг. 12c показано состояние буфера переупорядочения 76 вначале цикла 6 по фиг. 13. На фиг. 14c показано состояние указателя назначения (AL) 80, указателя обратной записи (WB) 82, а также указателя завершения (CO) 84 буферов переименования 34 вначале цикла 6 по фиг. 13. Таким образом, фиг. 14c соответствует фиг. 12c.
Как показано на фиг. 12c, информация буферов переупорядочения под номерами 3, 4, 5 и 6 была стерта в ответ на выполнение команд INST a, INST a+1, INST a+2 и INST a+3, "завершенных" в течение цикла 5, как показано на фиг. 13. Необходимо учитывать, что команда INST a+1 "ранее выполнена" в течение цикла 6 до выполнения команды INST a+1 в течение цикла 5, что показано на фиг. 13 посредством ECOMP/EXEC; команда INST a+1 является членом класса команд, для выполнения которых необходимо более одного цикла процессора 10.
В соответствии с фиг. 14c процессор 10 продвигает CO 84 после буфера переименования (например, после буфера переименования 5 до начала цикла 6), который ранее был назначен конкретной команде (например, команде INST a+3) в ответ на завершение процессором 10 всех предыдущих команд (например, INST a, INST a+1, а также INST a+2), независимо от того, действительно ли процессор 10 завершил выполнение конкретной команды (например, INST a+3, выполнение которой продолжается в течение циклов 6-8).
Кроме этого, в течение цикла 5 логика последовательного выполнения 84 (фиг. 3) передает сигнал по линии 92, связанной с LSU 28, в ответ на завершение выполнения команда INST a и INST a+1; это следует их того факта, что для команды INST a+2 (которая была передана на LSU 28 во время цикла 3) соответствующий назначенный бит EOK в буфере переупорядочения 5 установлен в логическое состояние "0".
На цикле 5 "завершается" команда Store a+2 в ответ на завершение (цикл 4) выполнения стадии EXEC A без исключений и в ответ на завершение (цикл 5) предыдущих команд INST a и INST a+1. На второй стадии выполнения EXEC B LSU 28 действительно записывает информацию в ячейку памяти кэша данных 16. LSU 28 выполняет этап EXEC B команды Store INST a+2 только в ответ на переданный логикой последовательного выполнения 84 сигнал по линии 92.
Как показано на фиг. 14c, AL 80 продолжает указывать на буфер переименования 7 и CO 84 продвигается от буфера переименования 2 и указывает на буфер переименования 6 в ответ на "завершение" предыдущих команд INST a, INST a+1 и INST a+3 в течение цикла 5. Более того, как показано на фиг. 13, оба результата выполнения команды INST a копируются из буферов переименования 2 и 3 в GPR 32 (фиг. 1) в течение цикла 5. Соответственно, как показано на фиг. 14c, WB 82 сдвигается от буфера переименования 2 и указывает на буфер переименования 4; более того, информация в буферах переименования 2 и 3 стирается в ответ на копирование двух результатов выполнения команды INST a из буферов переименования 2 и 3 в GPR 32 (фиг. 1) в течение цикла 5.
На фиг. 14c "правильная информация" = 1 в буфере переименования 4 в ответ на завершение выполнения команды INST a+1 в течение цикла 5, как показано на фиг. 13. Это указывает, что поле "информация" буфера переименования 4 хранит правильные данные (представленные на фиг. 14c как "данные" в поле "информация") и что поле "выполнить" или буфер переименования 4 хранит правильные данные (представленные на фиг. 14c как CA в поле "выполнить"). Так как команда INST a+4 является последовательно выполняемой командой, информация исходного операнда которой зависит от результатов выполнения команды INST a+1, которая изменяет регистр CA 42, и так как поле "выполнить" буферов переименования 34 не продвинуто, то процессор 10 задерживает выполнение команды INST a+4 до копирования результата "выполнения" команды INST a+1 из буфера переименования 4 в GPR 32 (фиг. 1) на стадии обратной записи (WBACK) команды INST a+1 на цикле 6.
В отличие от этого информация исходного операнда команды INST a+3 тоже зависит от данных, которые являются результатом выполнения команды INST a+1, но поле "информация" буферов переименования 34 продвигается. Соответственно, в ответ на "правильная информация" = 1 в буфере переименования 4 (что указывает на завершение выполнения команды INST a+1 на цикле 5) процессор 10 начинает выполнение команды INST a+3 в течение цикла 6 до завершения стадии обратной записи команды INST a+1.
На фиг. 14d показано состояние указателя назначения (AL) 80, указателя обратной записи (WB) 82 и указателя завершения (CO) 84 буферов переименования 34 вначале цикла 7 по фиг. 13. Как показано на фиг. 14d, AL 80 продолжает указывать на буфер переименования 7, а CO 84 продолжает указывать на буфер переименования 6. Как показано на фиг. 13, результат выполнения команды INST a+1 был скопирован из буфера переименования 4 в GPR 32 (фиг. 1) в течение цикла 6. Соответственно, как показано на фиг. 14d, WB 82 был продвинут от буфера переименования 4 и указывает на буфер переименования 5; более того, информация в буфере переименования 4 была стерта в ответ на копирование результата выполнения команды INST a+1 из буфера переименования 4 в GPR 32 (фиг. 1) в течение цикла 6.
В предпочтительном исполнении для последовательно выполняемой команды (например, INST a+4), информация исходного операнда которой зависит от непродвинутого операнда (например, информация бита CA, предназначенная для регистра CA 42), процессор 10 выполняет последовательно выполняемую команду (например, INST a+4) в ответ на следующие указания буферов переименования 34:
(1) все предыдущие команды "завершены" и
(2) если состояние обратной записи какой-либо предшествующей "завершенной" команды еще не завершилось, то любая такая предыдущая команда не должна изменять непродвинутый операнд.
Соответственно, на фиг. 14d CO 84 указвает на буфер переименования 6, тем самым указывая команде INST a+4, что выполнение всех предыдущих команд "завершено". Более того, на фиг. 14d WB 82 указывает на буфер переименования 5, тем самым указывая, что хотя состояние обратной записи предыдущей "завершенной" команды INST a+3 еще не завершено, но команда INST a+3 не изменяет какую-либо непродвинутую информацию, предназначенную для регистра CA 42 (так как "исполнить правильно" = 0 в буфере переименования 5). Таким образом, процессор 10 выполняет команду INST a+4 в течение цикла 7.
В альтернативном исполнении для последовательно выполняемой команды (например, INST a+4), информация исходного операнда которой зависит от непродвинутого операнда (например, информация бита CA, предназначенная для регистра CA 42), процессор 10 выполняет эту последовательно выполняемую команду (например, INST a+4) в ответ на следующие указания буфером переименования:
(1) "завершены" все предыдущие команды и
(2) завершены состояния обратной записи всех предшествующих "завершенных" команд, так что WB 82 и CO 84 указывают на один и тот же буфер переименования.
На фиг. 14e показано состояние указателя назначения (AL) 80, указателя обратной записи (WB) 82, а также указателя завершения (CO) 84 буферов переименования 34 вначале цикла 8 по фиг. 13. Как показано на фиг. 14e, AL 80 продолжает указывать на буфер переименования 7, а WB 82 продолжает указывать на буфер переименования 5. Команда INST a+4 выполнена и "завершена" в течение цикла 7 до завершения выполнения команды INST a+4 в течение цикла 7, как указывается на фиг. 13, посредством EXEC/COMP. Соответственно, как показано на фиг. 14e, CO 84 был продвинут от буфера переименования 6 и указывает на буфер переименования 7.
Преимуществом является то, что процессор 10 продвигает CO 84 после буфера переименования (например, после буфера 6 до начала цикла 8), ранее назначенного конкретной команде (например, INST a+4) в ответ на завершение процессором 10 всех предыдущих команд (например, INST a, INST a+1 и INST a+3), независимо от того, действительно ли закончил процессор 10 выполнение всех предыдущих команд (например, INST a+3, выполнение которой продолжается в течение цикла 8).
На фиг. 14e "правильная информация" = 1 в буфере переименования 6 в ответ на завершение выполнения команды INST a+4 в течение цикла 7, как показано на фиг. 13. Это указывает, что в поле "информация" буфера переименования 6 хранятся правильные данные (представленные на фиг. 14e как "данные" в поле "информация") и что в поле "выполнить" буфера переименования 6 хранятся правильные данные (представленные на фиг. 14e как CA в поле "выполнить").
На фиг. 14f показано состояние указателя назначения (AL) 80, указателя обратной записи (WB) 82 и указателя завершения (CO) 84 буферов переименования 34 вначале цикла 9 по фиг. 13. Как показано на фиг. 14f, AL 80 и CO 84 продолжают указывать на буфер переименования 7, а WB 82 продолжает указывать на буфер переименования 5. На фиг. 14f "правильная информация" = 1 в буфере переименования 5 в ответ на завершение выполнения команды INST a+3 в течение цикла 8. Это указывает, что в поле "информация" буфера переименования 5 хранятся правильные данные (представленные на фиг. 14e как "данные" в поле "информация").
На фиг. 14g показано состояние указателя назначения (AL) 80, указателя обратной записи (WB) 82 и указателя завершения (CO) 84 буферов переименования 34 вначале цикла 10 по фиг. 13. Как показано на фиг. 14, AL 80 и CO 84 продолжают указывать на буфер переименования 7. Как показано на фиг. 13, результаты выполнения команд INST a+3 и INST a+4 копируются из буферов переименования 5 и 6 соответственно в GPR 32 (фиг. 1) в течение цикла 9. Соответственно, как показано на фиг. 14d, WB 82 продвигается от буфера переименовани 5 и указывает на буфер переименования 7; более того, информация буферов переименования 5 и 6 была стерта в ответ на копирование результатов выполнения команд INST a+3 и INST a+4 из буферов переименования 5 и 6 в GPR 32 (фиг. 1) в течение цикла 9.
Фиг. 15 является иллюстрацией различных стадий пяти команда фиг. 12a-c в альтернативном исполнении без признака "раннего завершения", свойственного предпочтительному варианту выполнения. Фиг. 16a-h являются концептуальной иллюстрацией буферов переименования 34 процессора 10 на различных циклах обработки команды, проиллюстрированных на фиг. 15. Как показано на фиг. 15, без признака "раннего завершения", согласно предпочтительному варианту выполнения, выполнение команды INST a+4 задерживается до цикла 10, а завершение/обратная запись результатов выполнения команды INST a+4 задерживается до цикла 11. Это следует из того факта, что команда INST a+4 является последовательно выполняемой командой, выполнение которой задерживается до завершения выполнения всех предыдущих команд. Без признака "раннего завершения", согласно предпочтительному варианту выполнения, команда INST a+3 не завершается до цикла 9, тем самым задерживая выполнение команды INST a+4 до цикла 10.
В отличие от этого на фиг. 13 команда INST a+3 "завершается ранее" в течение цикла 5, а команда INST a+4 выполняется в течение цикла 7. Команда INST a+4 является последовательно выполняемой командой, информация исходного операнда которой зависит от результата выполнения предыдущей команды INST a+1, которая изменяет информацию непродвинутого бита CA, предназначенную для регистра CA 42. Тем не менее, на фиг. 13 выполнение команды INST a+4 осуществляется в течение цикла 7, а завершение/обратная запись результатов выполнения команд INST a+4 осуществляется в течение цикла 9. Соответственно, на фиг. 13 с использованием признака "раннего завершения", согласно предпочтительному варианту выполнения, этапы выполнения, завершения и обратной записи команды INST a+4 осуществляются раньше, чем на фиг. 15 без использования признака "раннего завершения".
Процессор 10 задерживает выполнение команды, определяющей непродвинутые исходные операнды (например, SPR 40 и регистр CA 42) по меньшей мере до завершения всех предыдущих команд. Это связано с тем, что, когда команда определяет непродвинутые исходные операнды, выполнение такой команды осуществляется в соответствии с информацией такого исходного операнда, которая доступна и верна в архитектурных регистрах. Примерами таких команд могут быть (1) расширенная арифметическая операция, которая считывает регистр CA 42, и (2) команда Move From, которая сдвигает информацию от одного из SPR 40 к одному из GPR 32.
Даже если "завершено" выполнение всех предыдущих команд, имеется возможность для "раннего завершения" предыдущей команды так, чтобы состояние ее завершения предшествовало состоянию ее выполнения. Как указывалось ранее со ссылкой на фиг. 1-5, процессор 10 содержит схему для продвижения информации к блокам выполнения от GPR 32, FPR 36, буферов переименования 34 и 38 и регистров управления. Если информация исходного операнда конкретной команды зависит от результатов выполнения предыдущих "ранее завершенных" команд и если информация исходного операнда обслуживается такой схемой продвижения процессора 10, то процессор 10 задерживает выполнение конкретной команды до завершения процессором 10 стадии выполнения "ранее завершенной" команды (когда результаты выполнения "ранее завершенной" команды будут доступными и правильными в буфере переименования).
В отличие от этого, если информация исходного операнда не обслуживается такой схемой продвижения процессора 10, то процессор 10 задерживает выполнение конкретной команды до завершения процессором 10 этапа обратной записи "ранее завершенной" команды (к моменту, когда результаты выполнения "ранее завершенной команды" будут доступными и правильными в регистре конфигурации). Если "ранее завершенная" команда не завершила выполнение, то результат выполнения команды (информация операнда назначения) не доступна. В такой ситуации процессор 10 соответствующим образом задерживает этап обратной записи "ранее завершенной" команды до завершения выполнения команды.
Если команда подвергается раннему завершению, то блок упорядочивания 18 выдает сигнал указания во время передачи команды на назначенный исполнительный блок команды. В ответ на такой сигнал указания назначенный исполнительный блок команды не предпринимает попыток изменить назначенный команде вход в буфере переупорядочения 76. Это происходит из-за того, что по завершении команды, назначенной входу буфера переупорядочения, вход буфера переупорядочения подвергается повторному назначению другой команде так, что информация входа буфера переупорядочения более не верна.
Соответственно, если команда подвергается раннему завершению, то назначенный команде вход буфера переупорядочения может быть верным до завершения выполнения команды исполнительным блоком этой команды. В предпочтительном выполнении в течение одного цикла процессора 10 блок упорядочивания 18 последовательности проверят четыре наиболее старых входа буфера переупорядочения, которые имеют правильную информацию, так что эти четыре команды являются кандидатами на одновременное завершение в течение одного цикла.
В предпочтительном выполнении команда Move From вводит информацию от SPR, а SPR изменяется только командой Move To. Преимуществом является то, что процессор 10 выполняет команду Move From в ответ на завершение выполнения всех предыдущих команд, даже если одна или более предыдущих команд "ранее завершены". Это возможно из-за того, что процессор 10 не "завершил ранее" команду (например, команду Move To или команду Store), которая не должна выполняться теоретически. Если предыдущие команды "завершены", то процессор 10 действительно завершил выполнение всех предыдущих команд Move To. Соответственно, процессор 10 выполняет команду Move From в ответ на завершение предыдущих команд, так как в такой ситуации процессор 10 на самом деле завершил выполнение всех предыдущих команд Move To.
В соответствии с другим важным аспектом предпочтительного выполнения процессор 10 поддерживает режим исключительной ситуации с неточной невосстанавливаемой плавающей запятой. Во время работы в таком режиме процессор 10 оповещает о состоянии исключительной операции с плавающей запятой, не точном или не информативном, что касается команды с плавающей запятой, обусловившей исключительную ситуацию. При обработке процессором 10 исключительной ситуации допускается, чтобы процессор 10 находился в состоянии, в котором он завершил различное количество команд до выполнения команды с плавающей запятой, обусловившей исключительную ситуацию. Во время работы в этом режиме процессор 10 достигает высокой производительности при выполнении последовательностей команд, которые нечувствительны к останову выполнения программы точно на команде с плавающей запятой, вызвавшей исключительную ситуацию.
При работе в режиме исключительной ситуации с точной плавающей запятой процессор 10 не выполняет "раннее завершение" команды с плавающей запятой до завершения выполнения команды плавающей запятой, даже если все предыдущие команды были завершены.
В отличие от этого при работе в режиме исключительной ситуации с неточной невосстанавливаемой плавающей запятой процессор 10 выполняет "раннее завершение" команды с плавающей запятой до завершения выполнения команды с плавающей запятой в ответ на завершение всех предыдущих команд. В режиме исключительной ситуации с неточной невосстанавливаемой плавающей запятой "ранее завершенные" команды плавающей запятой отличаются от "ранее завершенных" команд другого типа, так как процессор 10 "ранее завершает" команду с плавающей запятой, даже если последующее выполнение команды с плавающей запятой может фактически привести к условию исключительной ситуации с плавающей запятой. Каждый вход буфера переупорядочения указывает, является ли назначенная ему команда командой с плавающей запятой.
В ответ на завершение стадий выполнения и завершения команды с плавающей запятой результаты их выполнения временно сохраняются в буферах переименования с плавающей запятой 38. Эти результаты временно хранятся в буферах переименования 38 до копирования результатов выполнения всех ранее выполненных команд с плавающей запятой в FPR 36. Так, процессор 10 обрабатывает соответствующие стадии "обратной записи" команд с плавающей запятой в порядке их запрограммированной последовательности.
Буферы переименования 38 временно хранят результаты выполнения команд с плавающей запятой для дальнейшего копирования в FPR 36. Более того, буферы переименования 38 сохраняют, кроме этого, информацию о состоянии для изменения
соответствующим образом архитектурного состояния с плавающей запятой и регистров управления (FPSCR) (не показаны). В ответ на обнаружение исключительной ситуации с плавающей запятой (что указывается установкой бита FEX FPSCR) во время копирования результатов из буферов переименования 38 в FPR 36 и в FPSCR, процессор 10 оповещает об исключительной ситуации.
При работе в режиме исключительной ситуации с неточной невосстанавливаемой плавающей запятой процессор 10 оповещает об этой ситуации с плавающей запятой, которая не является точной или информативной и для которой команда с плавающей запятой вызвала исключительную ситуацию. Преимуществом является то, что в такой ситуации процессор 10 в предпочтительном варианте осуществления докладывает об исключении следующим образом.
Во-первых, процессор 10 останавливает выполнение команды в течение цикла, на котором процессор 10 определил исключительную ситуацию с плавающей запятой. Команда, на которой процессор 10 прекратил завершение, не имеет значение, так как состояние процессора 10 точно воспроизводит результаты всех выполненных команд, предшествующих команде, на которой процессор 10 остановил выполнение.
Во-вторых, процессор 10 заканчивает выполнение всех предыдущих "ранее завершенных" команд. Кроме того, процессор 10 копирует результаты выполнения таких команд в регистры конфигурации, так что все входы обратной записи в буферах переименования 34 и 38 становятся пустыми.
В-третьих, процессор 10 оповещает об исключительной ситуации с плавающей запятой. В режиме исключительной ситуации с неточной невосстанавливаемой плавающей запятой "ранее завершенные" команды с плавающей запятой отличаются от других типов "ранее завершенных" команд, так как процессор 10 "ранее завершает" команду с плавающей запятой, даже когда последующее выполнение команды с плавающей запятой фактически может вызвать условие исключительной ситуации с плавающей запятой. Соответственно, никакие другие исключительные ситуации не генерируются другими командами, которые "ранее завершились" или фактически завершились.
В ответ на определение исключительной ситуации, возникшей из-за выполнения команды с неплавающей запятой, процессор 10 задерживает оповещение об исключительной ситуации с неплавающей запятой до окончания выполнения процессором 10 всех предыдущих "ранее завершенных" команд с плавающей запятой без какой-либо исключительной ситуации с плавающей запятой. В такой ситуации процессор 10 согласно предпочтительному выполнению оповещает об исключительной ситуации следующим образом.
Во-первых, процессор 10 останавливает завершение команды в течение цикла, на котором процессор 10 определил исключительную ситуацию с неплавающей запятой. Процессор 10 останавливает завершение команды на команде, обусловившей исключительную ситуацию с неплавающей запятой, так что команда не завершается.
Во-вторых, процессор 10 заканчивает выполнение всех предыдущих "ранее завершенных" команд. Тем самым, определяется, может ли процессор 10 закончить выполнение всех предыдущих "ранее завершенных" команд с плавающей запятой без возникновения исключительной ситуации с плавающей запятой. Кроме того, процессор 10 копирует результаты выполнения таких команд в регистры конфигурации, так что все входы обратной записи в буферах переименования 34 и 38 становятся пустыми. Таким образом, имеет место непротиворечивое состояние процессора 10, когда он оповещает об исключительной ситуации. Кроме этого, выполняется ожидание освобождения всех других буферов обратной записи для обеспечения непротиворечивого состояния процессора, когда распознается исключительная ситуация.
В-третьих, если процессор 10 не обнаружил исключительную ситуацию с плавающей запятой, то он оповещает об исключительной ситуации с точной неплавающей запятой. В отличие от этого, если процессор 10 обнаружил исключительную ситуацию с плавающей запятой, то он оповещает об исключительной ситуации с неточной невосстанавливаемой плавающей запятой.
Хотя выше был детально описан пример осуществления настоящего изобретения и его преимущества, следует иметь в виду, что они были описаны в качестве примера, без какого-либо ограничения. В данном примере осуществления могут выполняться изменения, замены и доработки в соответствии с сутью, духом и содержанием настоящего изобретения. Сущность и объем настоящего изобретения не должны ограничиваться примером его осуществления, а должны определяться только в соответствии со следующей формулой изобретения и ее эквивалентами.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ ФУНКЦИОНИРОВАНИЯ СИСТЕМЫ ОБРАБОТКИ | 1994 |
|
RU2142157C1 |
| ЦИФРОВОЙ КОМПЬЮТЕР С ВОЗМОЖНОСТЬЮ ПАРАЛЛЕЛЬНОГО ВЫПОЛНЕНИЯ ДВУХ И БОЛЕЕ КОМАНД | 1991 |
|
RU2109333C1 |
| СПОСОБ ОБЕСПЕЧЕНИЯ СВЯЗИ В КОММУНИКАЦИОННОЙ СРЕДЕ, КОМПЬЮТЕРНАЯ СИСТЕМА И ЭНЕРГОНЕЗАВИСИМЫЙ МАШИНОЧИТАЕМЫЙ НОСИТЕЛЬ ДАННЫХ | 2012 |
|
RU2574815C2 |
| СХЕМНОЕ УСТРОЙСТВО ДЛЯ ПАРАЛЛЕЛЬНОЙ ОБРАБОТКИ ДВУХ ИЛИ БОЛЕЕ КОМАНД В ЦИФРОВОМ КОМПЬЮТЕРЕ | 1991 |
|
RU2111531C1 |
| КОМАНДА ВЕКТОРНОГО ТИПА НА ПОЛЕ ГАЛУА ПЕРЕМНОЖЕНИЯ, СУММИРОВАНИЯ И НАКОПЛЕНИЯ | 2014 |
|
RU2613726C2 |
| КОМАНДА НА НЕТРАНЗАКЦИОННОЕ СОХРАНЕНИЕ | 2012 |
|
RU2568324C2 |
| БЛОК ДИАГНОСТИКИ ТРАНЗАКЦИЙ | 2012 |
|
RU2571397C2 |
| СИСТЕМА СВЯЗИ | 1991 |
|
RU2111532C1 |
| СРАВНЕНИЕ И ЗАМЕНА ПОЗИЦИИ ТАБЛИЦЫ ДИНАМИЧЕСКОЙ ТРАНСЛЯЦИИ АДРЕСА | 2012 |
|
RU2550558C2 |
| ТРАНСФОРМАЦИЯ ПРЕРЫВИСТЫХ СПЕЦИФИКАТОРОВ КОМАНД В НЕПРЕРЫВНЫЕ СПЕЦИФИКАТОРЫ КОМАНД | 2012 |
|
RU2568241C2 |
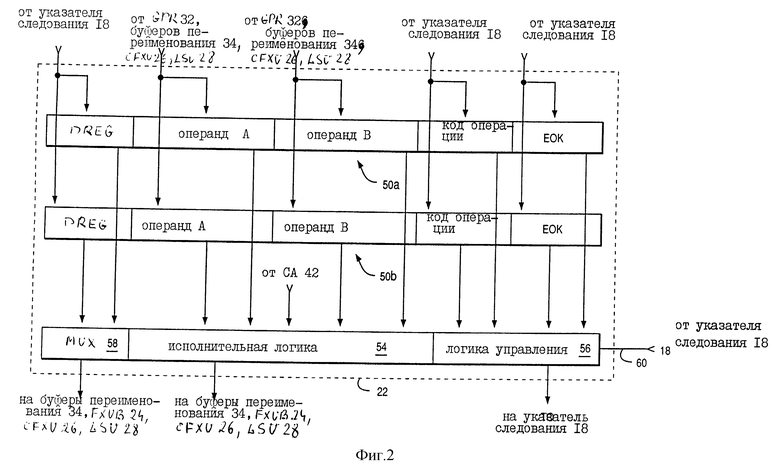
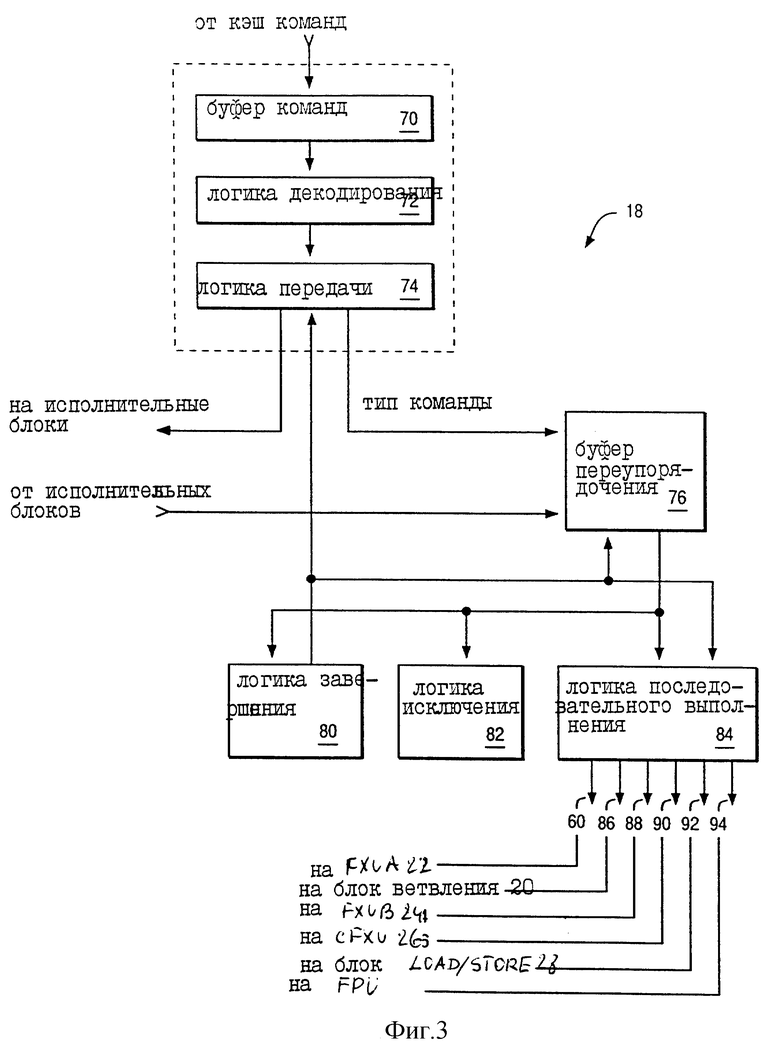
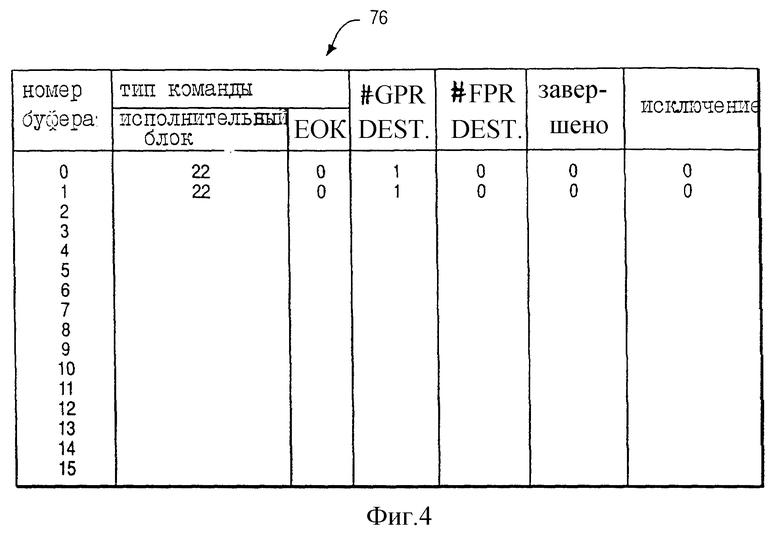
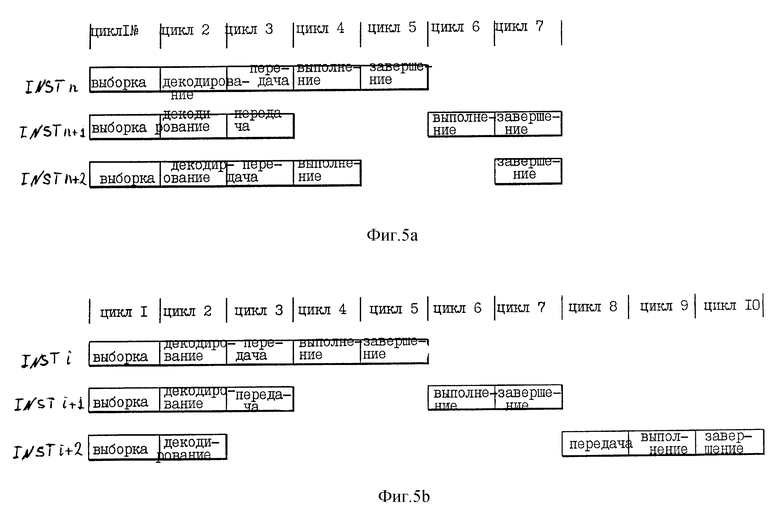
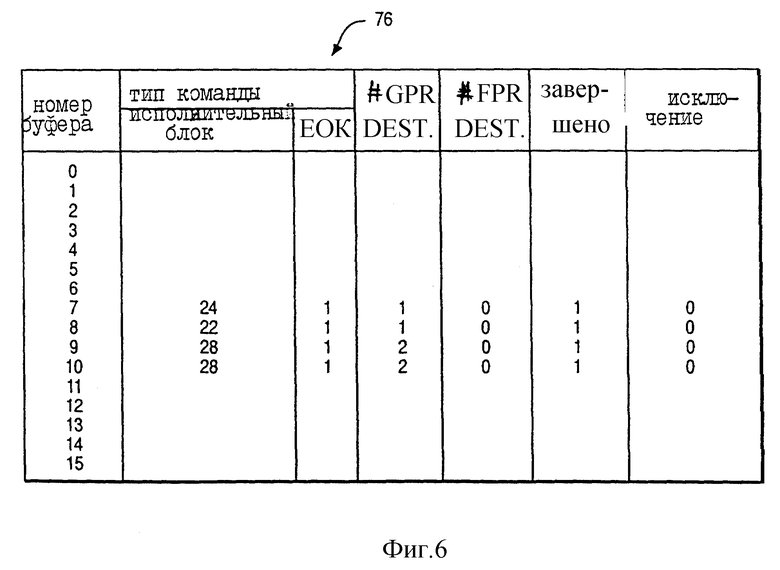
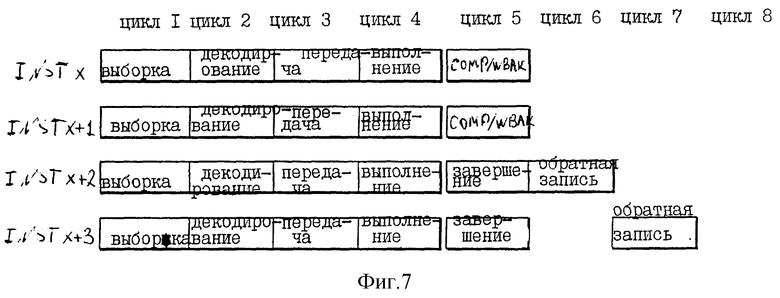
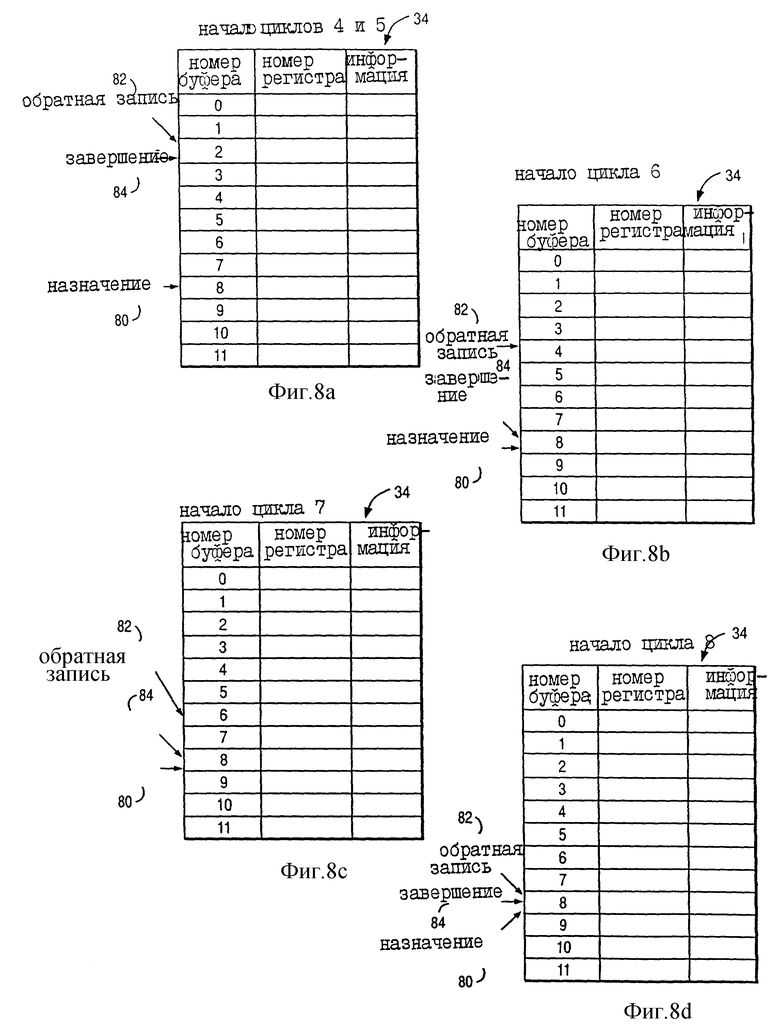
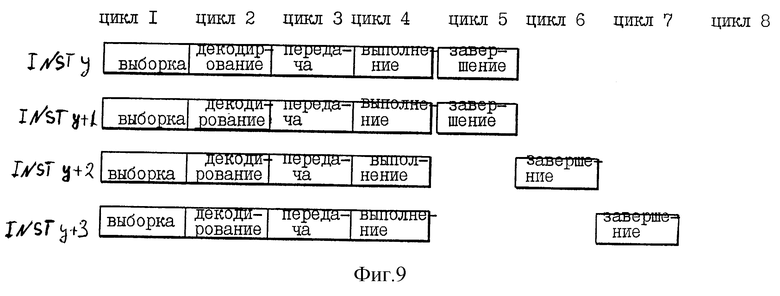
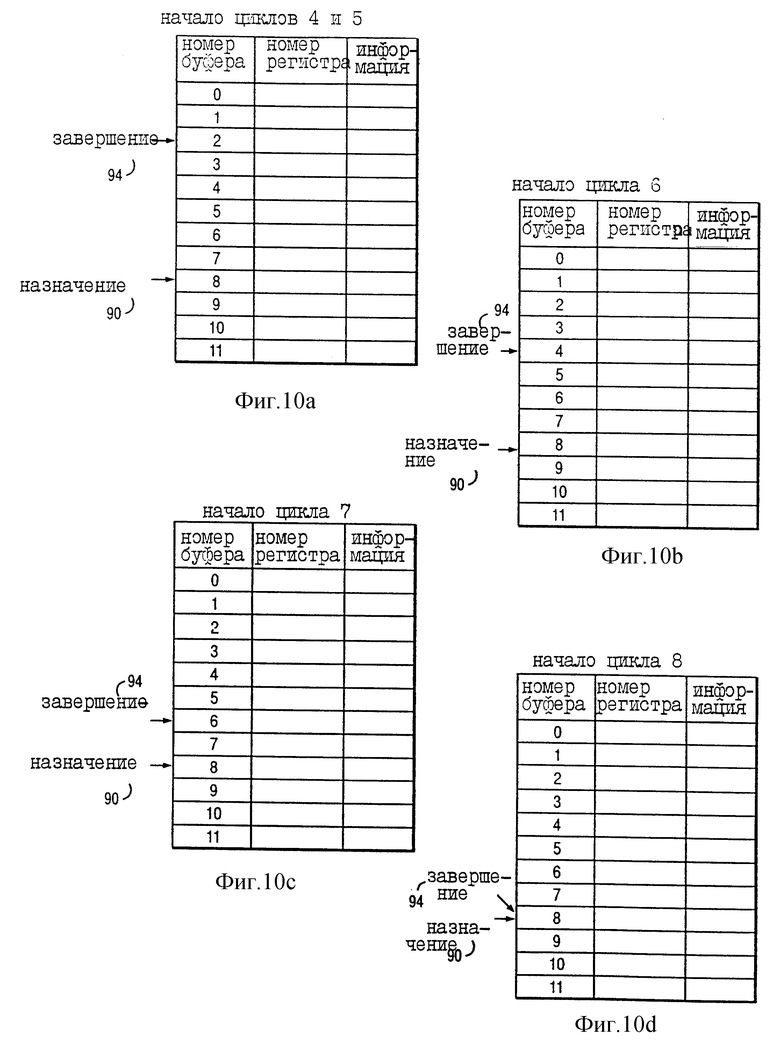
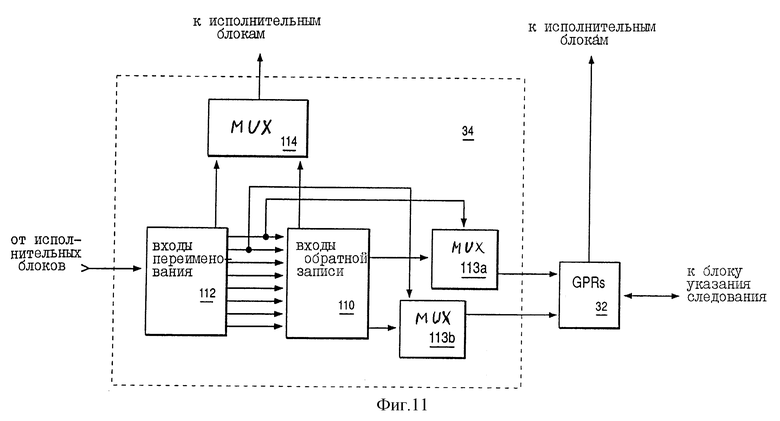
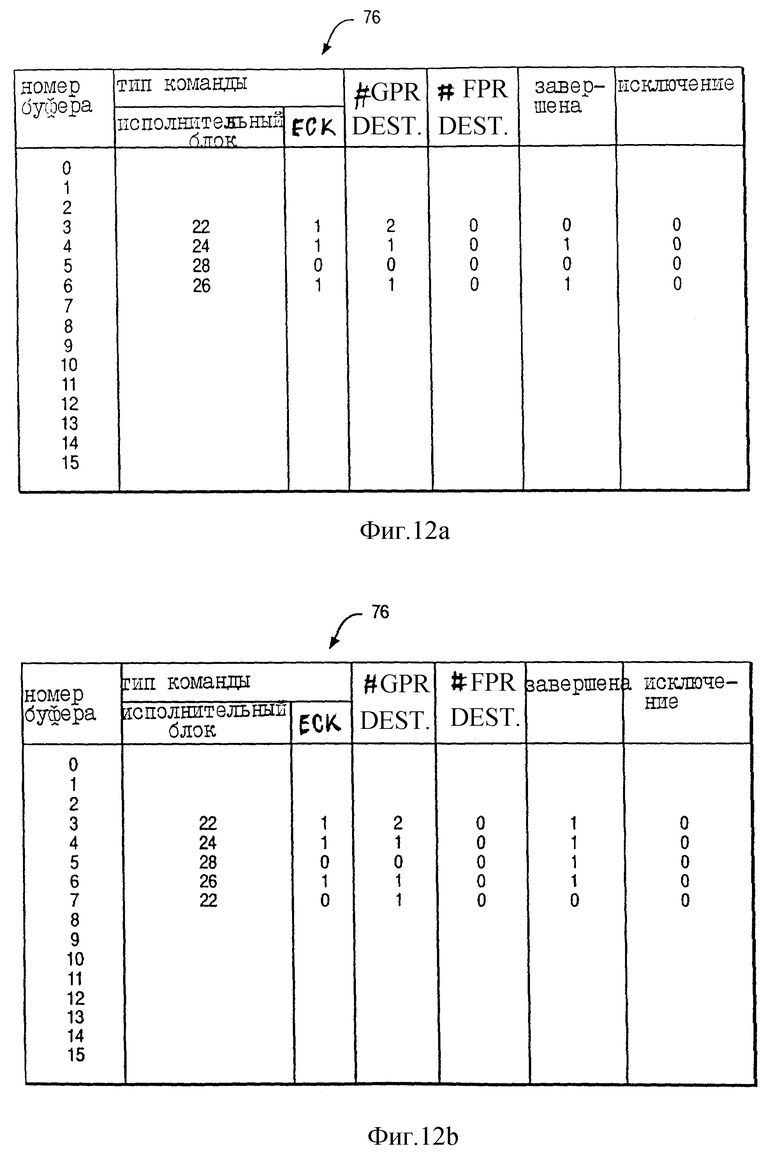
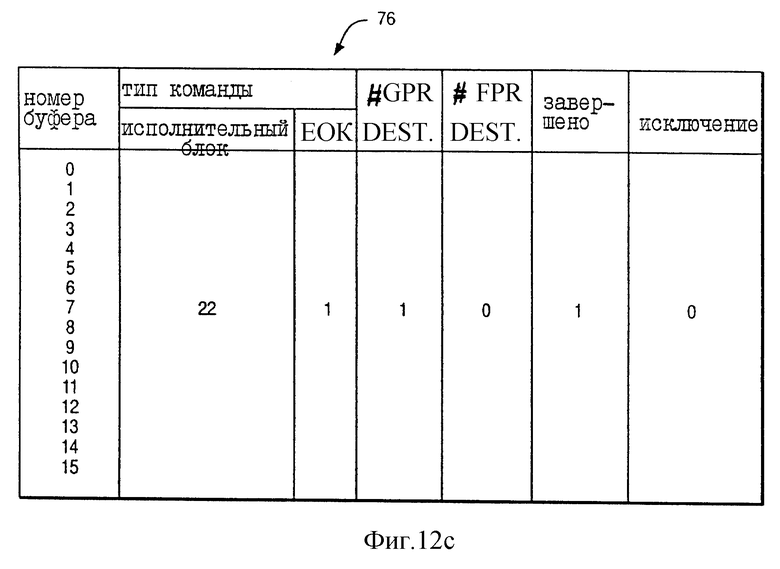
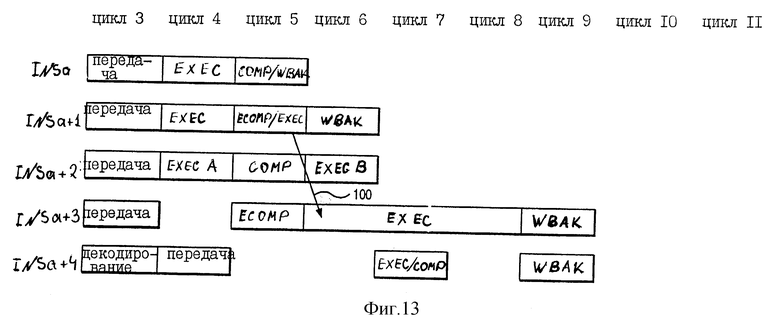
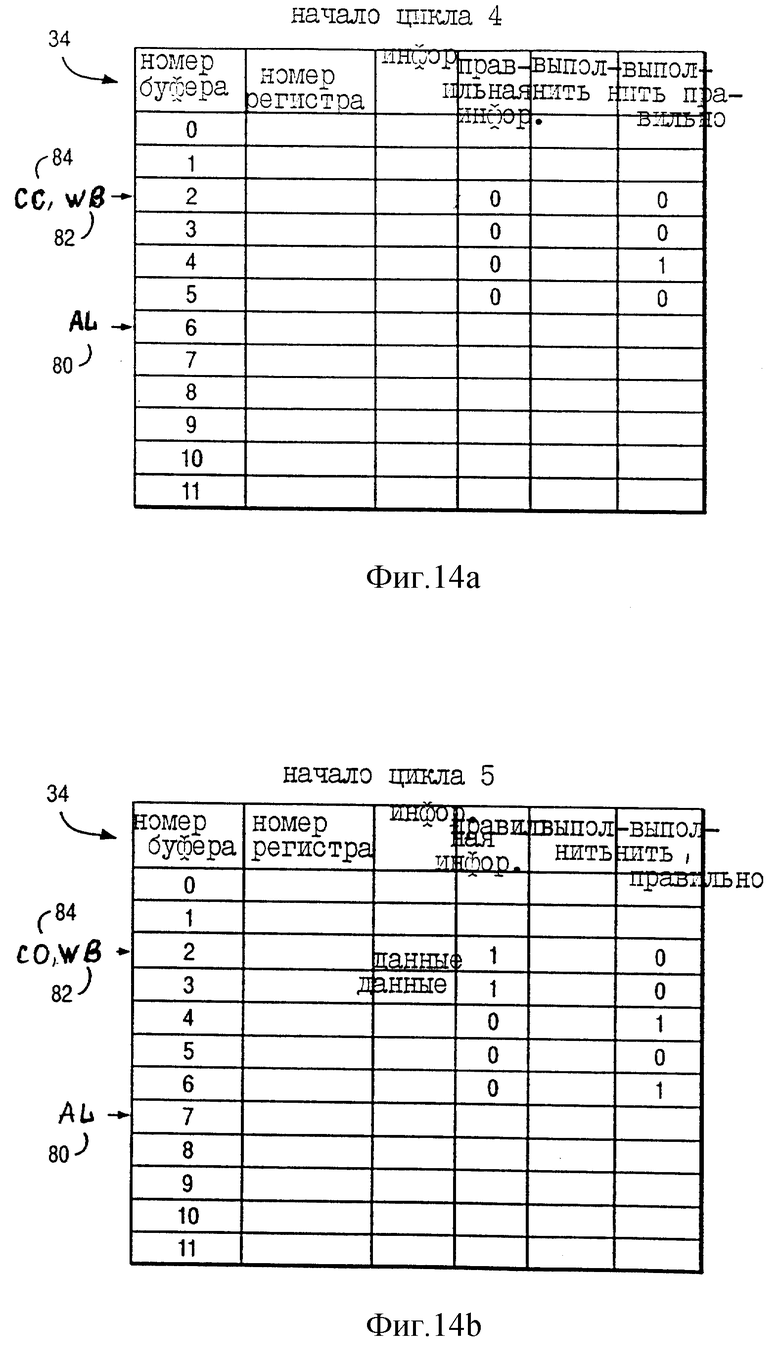
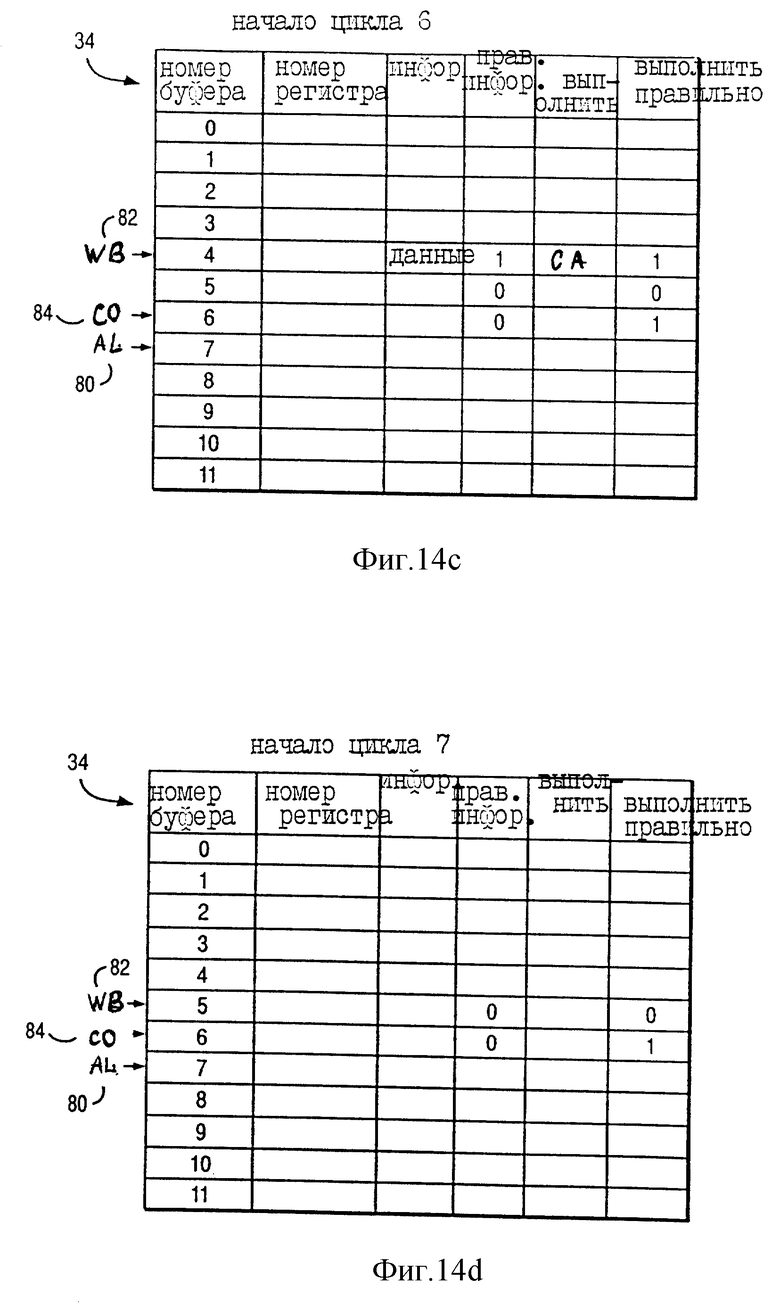
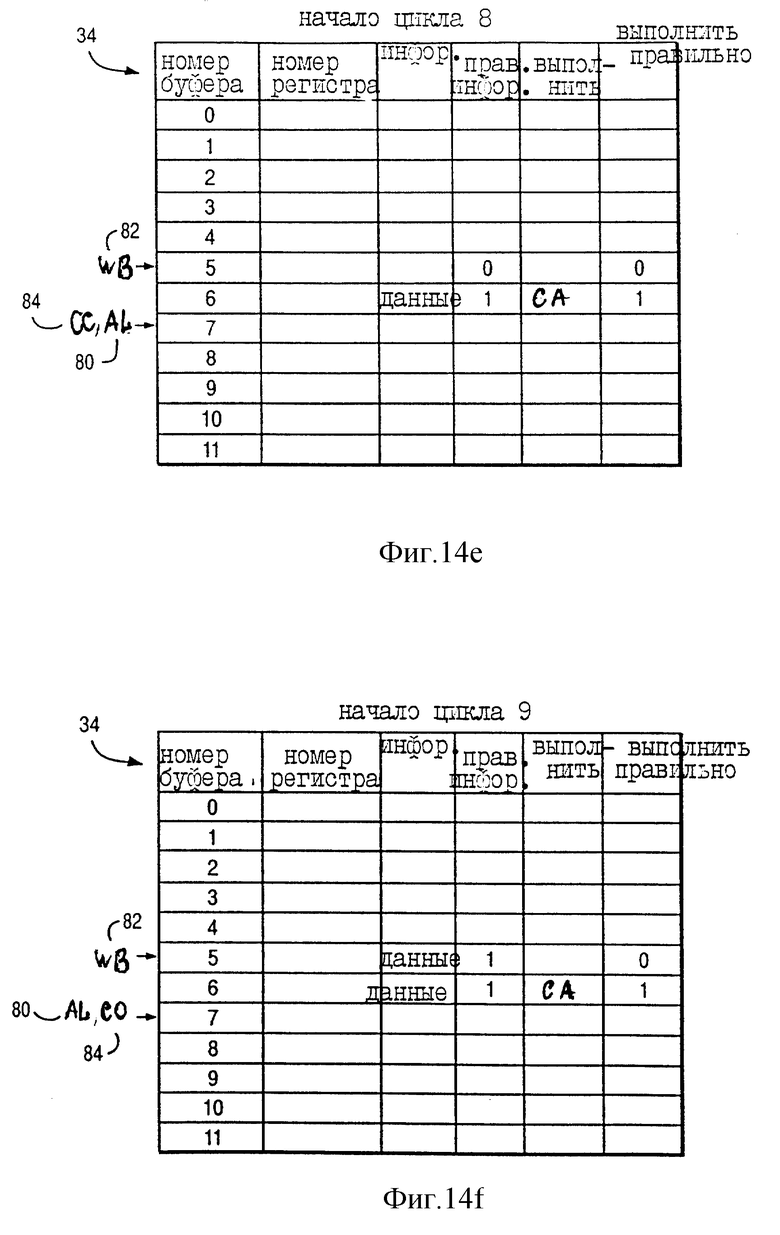


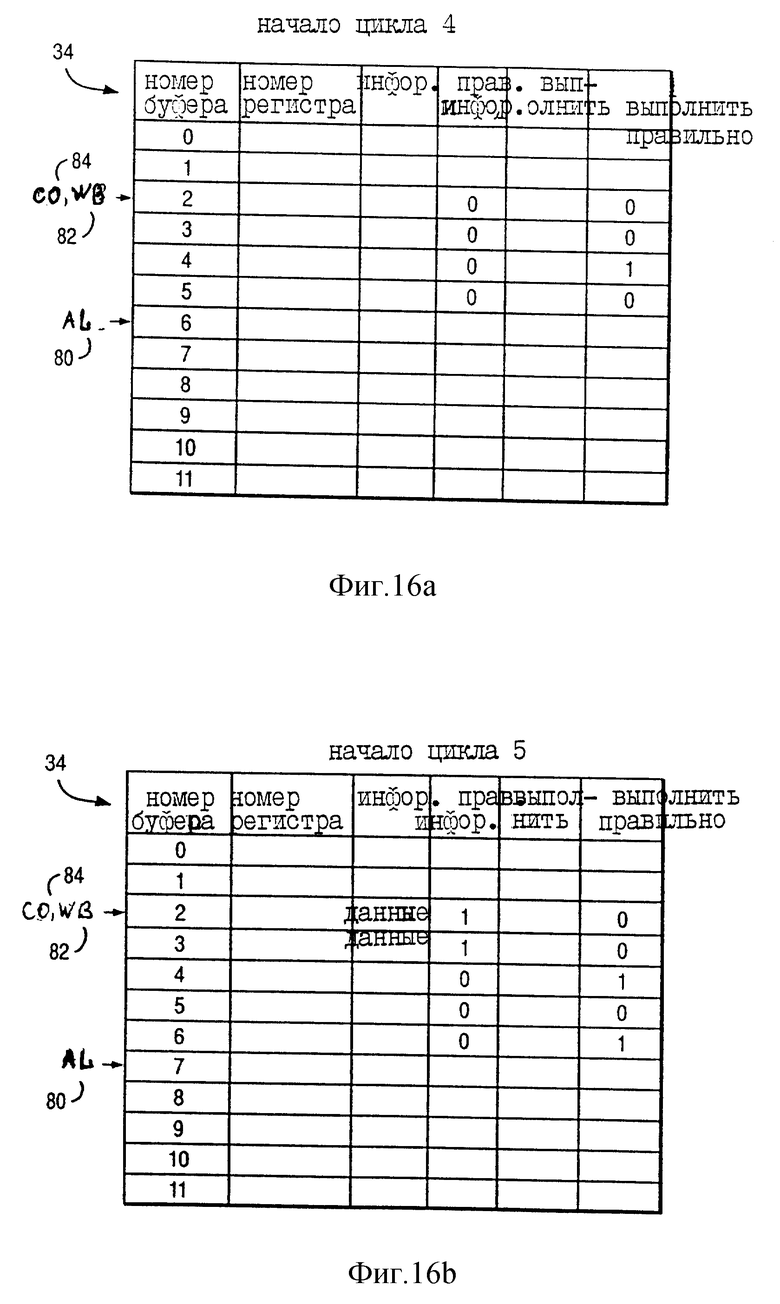
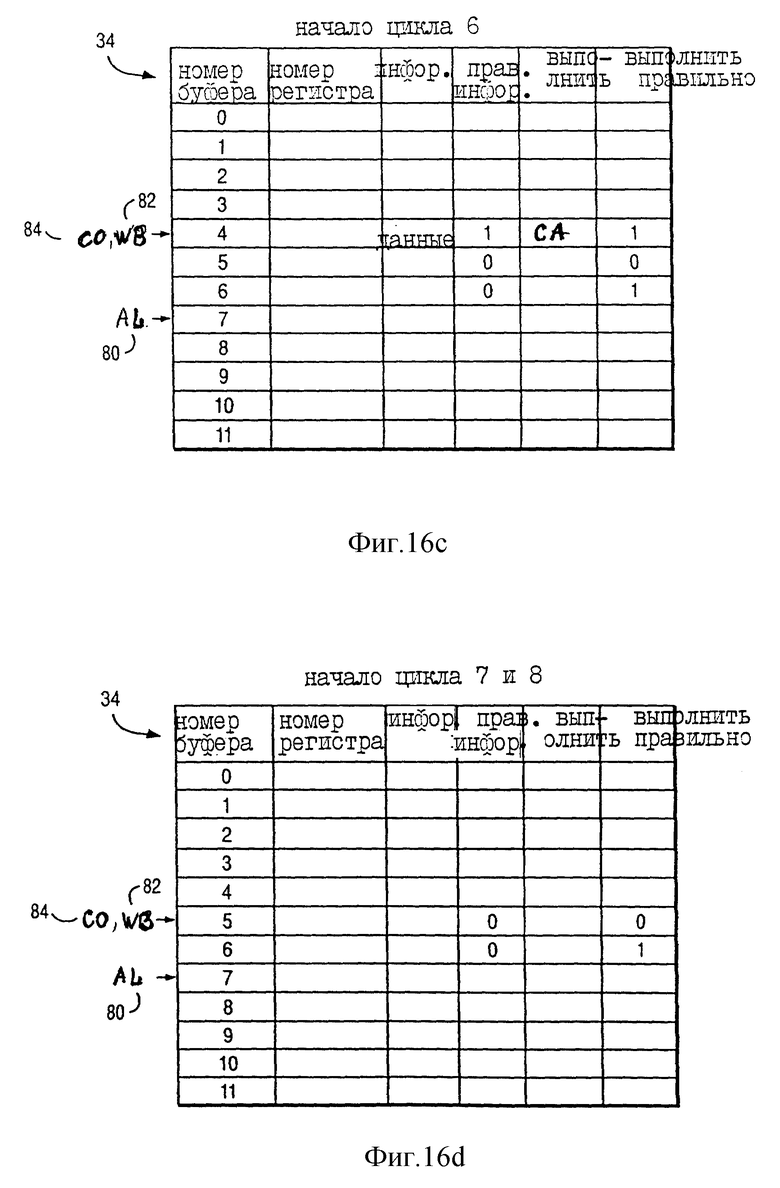
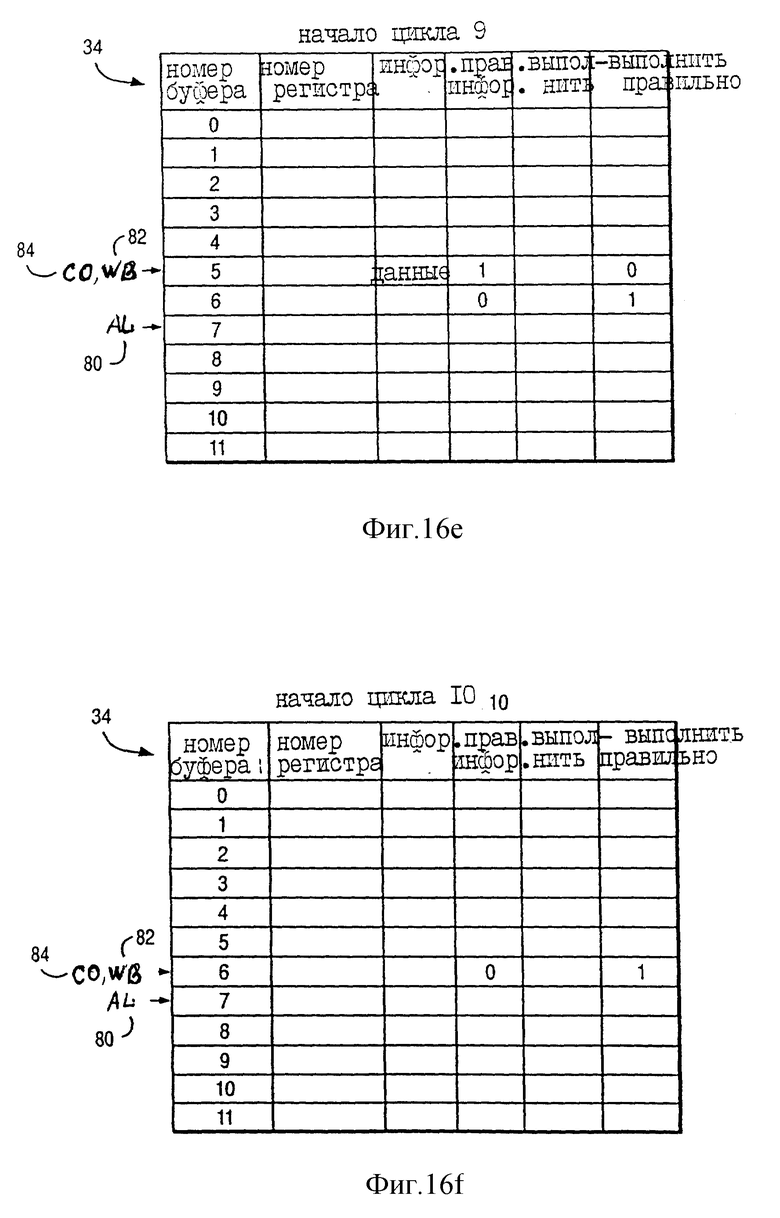
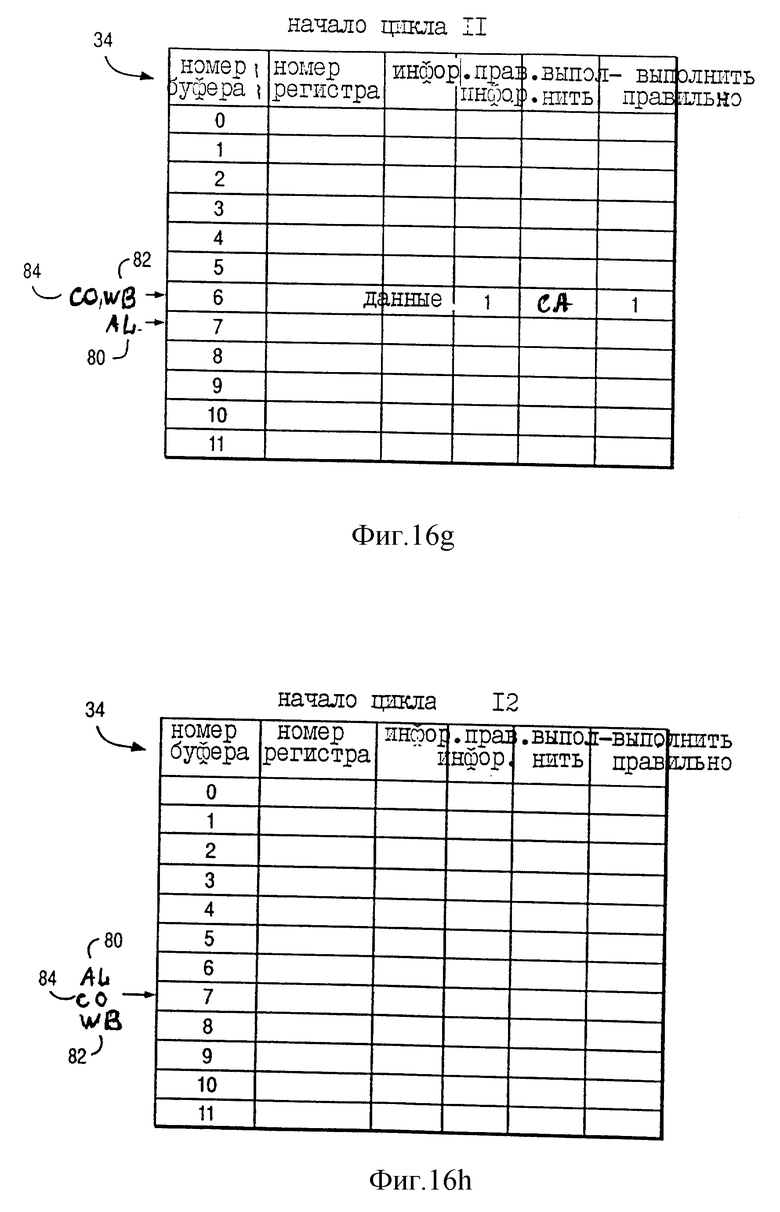
Изобретение относится к системам обработки информации. Техническим результатом является снижение отрицательного влияния на выполнение команд в запрограммированной последовательности. Система содержит исполнительную схему процессора, включающую в себя один или несколько исполнительных блоков и блок упорядочивания последовательности. Способ описывает работу данного устройства. 2 с. и 13 з.п. ф-лы, 16 ил.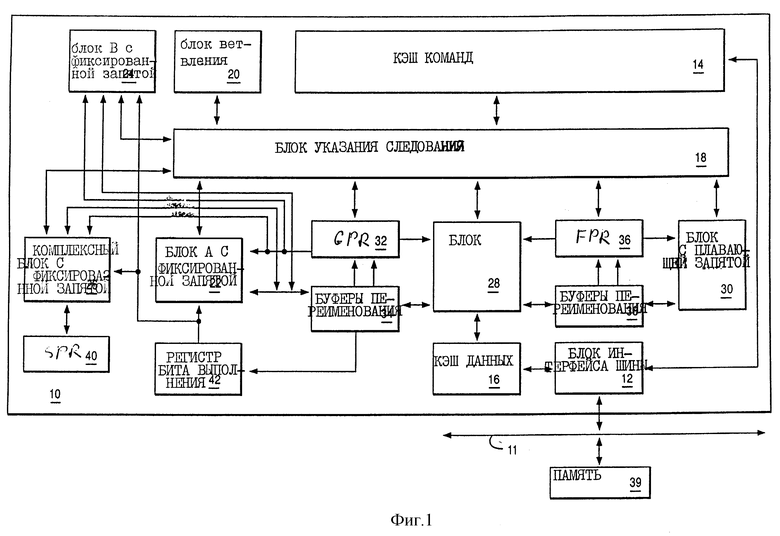
| Центробежный насос | 1974 |
|
SU529303A1 |
| УСТРОЙСТВО ДЛЯ ОБРАБОТКИ ИНФОРМАЦИИ | 1991 |
|
RU2029359C1 |
| Способ изготовления конусов для намотки ниток и пряжи | 1956 |
|
SU106670A1 |
| Устройство обработки информации | 1986 |
|
SU1451710A1 |
