Изобретение относится к области предотвращения утечек информации.
Уровень техники
В связи с возросшим в последнее время числом киберпреступлений и увеличившимся количеством краж информации все более востребованными становятся системы предотвращения утечек информации (англ. DLP - Data Leak Prevention). Одной из основных задач систем DLP является предотвращение утечек электронных копий персональных и конфиденциальных документов, таких как: паспорт, свидетельство о рождении, водительское удостоверение, конфиденциальный договор и др.
Для обнаружения персональных и конфиденциальных документов широкое применение нашли технологии машинного обучения, в частности технологии распознавания образов, а также технологии оптического распознавания символов (англ. optical character recognition, OCR). Для этого на вход классификатору подается набор похожих документов интересующих категорий, на основании данного набора документов формируются признаки, по которым затем выполняется отнесение новых документов к одной из категорий.
Однако существующие технологии зачастую показывают хорошее качество классификации только для фиксированного набора категорий документов. При добавлении новой категории документов необходимо заново выполнить обучение классификатора на большом массиве похожих документов. К тому же, если новый документ не может быть отнесен ни к одной из категорий, он все равно может содержать конфиденциальные данные. Кроме того, при построении большинства классификаторов существенную роль играет настройка классификатора аналитиком, однако зачастую это не позволяет достичь высокого качества классификации.
Таким образом, возникает техническая проблема, заключающаяся в сложности построения классификатора, обеспечивающего высокое качество классификации.
Из уровня техники известна технология классификации изображений документов на основании их содержимого, описанная в заявке US 20160092730. С использованием технологий OCR из цифровой копии документа извлекается различная текстовая информация и графическая информация. Затем на основании содержимого документа формируется набор признаков, использующийся далее для классификации документов. В то же время упомянутое изобретение не решает заявленную техническую проблему, т.к. в ряде случаев не обеспечивает высокое качество классификации, в частности, не позволяет классифицировать документы, содержащие конфиденциальные данные и не относящиеся ни к одной из известных категорий и, кроме того, для определения признаков в упомянутом изобретении необходимо распознать содержащийся в документе текст.
Раскрытие сущности изобретения
Первый технический результат заключается в повышении качества определения категории документа классификатором.
Второй технический результат заключается в реализации назначения.
Согласно варианту реализации, используется реализуемый компьютером способ обучения классификатора, предназначенного для определения категории документа, в котором: получают документы, которые принадлежат, в частности, к одной категории; для каждого полученного документа определяют содержащиеся в нем объекты, в частности, являющиеся графическими элементами; для каждого полученного документа формируют набор признаков, состоящий из определенных объектов, при этом упомянутые признаки включают, в частности, следующие: наличие объекта; местоположение объекта; количество объектов; расположение одного объекта по отношению к другому объекту; размеры объекта; угол наклона объекта; выполняют построение классификатора на основании значений сформированных признаков для полученных документов.
Согласно одному из частных вариантов реализации получают дополнительные документы, принадлежащие к каждой сформированной категории классификатора, и рассчитывают ошибку классификации упомянутых дополнительных документов с использованием упомянутого классификатора, при этом если ошибка классификации превышает заданное значение, повторяют построение классификатора с учетом дополнительных документов.
Согласно другому частному варианту реализации дополнительно получают документы, принадлежащие к каждой сформированной категории классификатора и по меньшей мере к одной другой категории, и рассчитывают ошибку классификации дополнительных документов с использованием упомянутого классификатора, при этом, если ошибка классификации превышает заданное значение, повторяют шаги а)-г), с тем отличием, что на шаге а) получают документы, одна часть указанных документов принадлежит к одной из сформированных категорий, а другая часть указанных документов принадлежит по меньшей мере к одной другой категории.
Согласно еще одному частному варианту реализации ошибку классификации рассчитывают с использованием, в частности, одного из алгоритмов: минимизация эмпирического риска; скользящий контроль.
Согласно одному из частных вариантов реализации построение классификатора на основании сформированных признаков включает: выбор модели классификации; обучение классификатора согласно выбранной модели классификации, где в качестве признакового описания документа выступают сформированные признаки, а в качестве классов - в частности, одна категория документа.
Согласно другому частному варианту реализации выбирают одну из следующих моделей классификации: Байесовский классификатор; нейронная сеть; Вейвлет Хаара; Локальные бинарные шаблоны; Гистограмма направленных градиентов.
Согласно еще одному частному варианту реализации содержатся, в частности, следующие категории документов: паспорт; водительское удостоверение; свидетельство о рождении.
Согласно одному из частных вариантов реализации объектами дополнительно являются графические элементы - распознанные изображения по меньшей мере одного из следующих: лица человека; герба страны; флага страны; печати; логотипа; всего документа.
Согласно другому частному варианту реализации упомянутые объектами являются композицией следующих объектов: отрезок; точка; сплайн; эллипс.
Согласно еще одному частному вариантов реализации категорией документа дополнительно является совокупность из двух и более категорий, а также подкатегория известной категории.
Согласно одному из частных вариантов реализации добавляют новую категорию, включающую, в частности, две и более существующих категорий, при этом при построении классификатора из числа сформированных признаков выбирают признаки, свойственные для новой категории.
Согласно другому частному варианту реализации объекты дополнительно являются текстовыми элементами.
Согласно еще одному частному варианту реализации признаки дополнительно включают следующие: гистограмма цветов объекта; метаданные объекта; множество объектов, объединенных по определенному признаку; количество одинаковых объектов; соответствие гистограммы цветов объекта заданному шаблону; соответствие заданной комбинации объектов шаблону взаимного расположения; преобразование Фурье гистограммы цветов объекта; наличие искажений на изображении объекта; тип искажений на изображении объекта.
Краткое описание чертежей
Дополнительные цели, признаки и преимущества настоящего изобретения будут очевидными из прочтения последующего описания осуществления изобретения со ссылкой на прилагаемые чертежи, на которых:
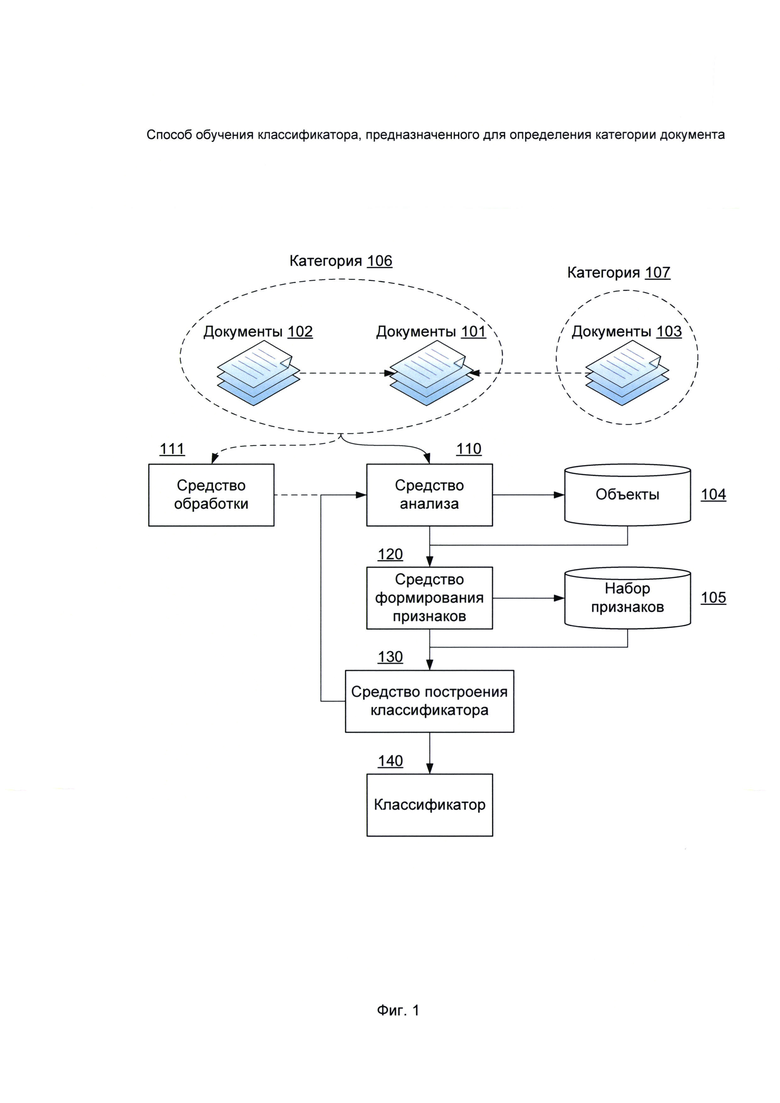
На Фиг. 1 представлена система обучения классификатора, предназначенного для определения категории документа.
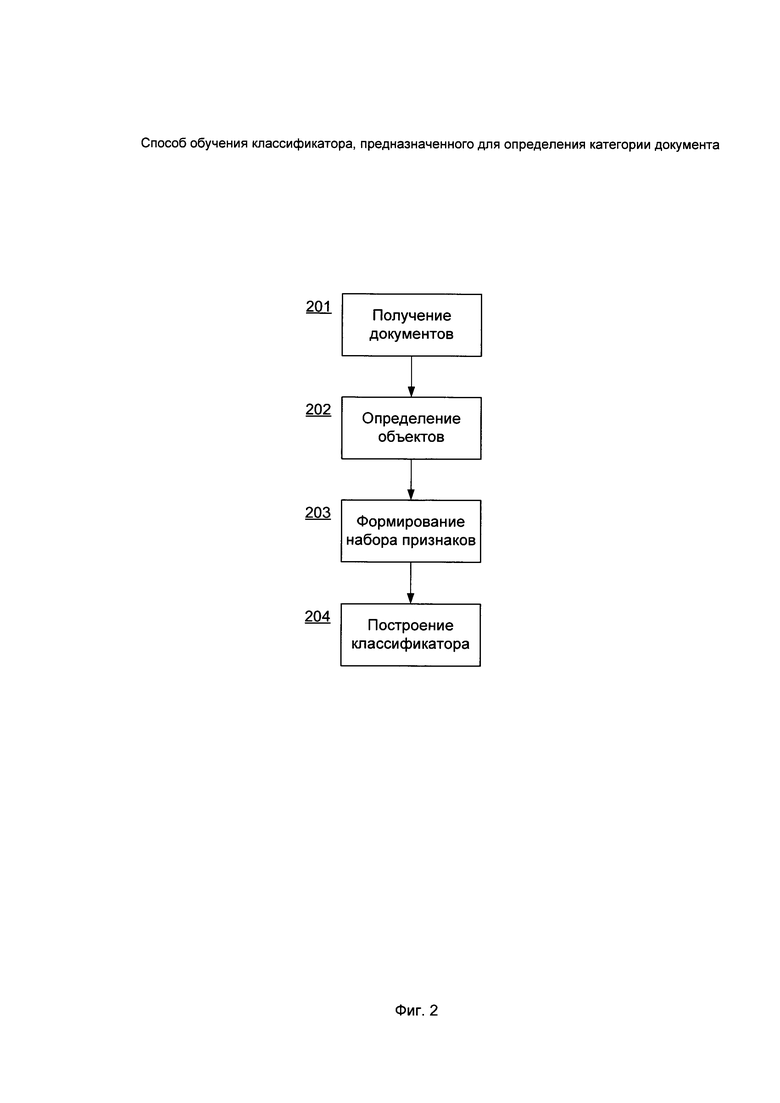
На Фиг. 2 представлен способ обучения классификатора.
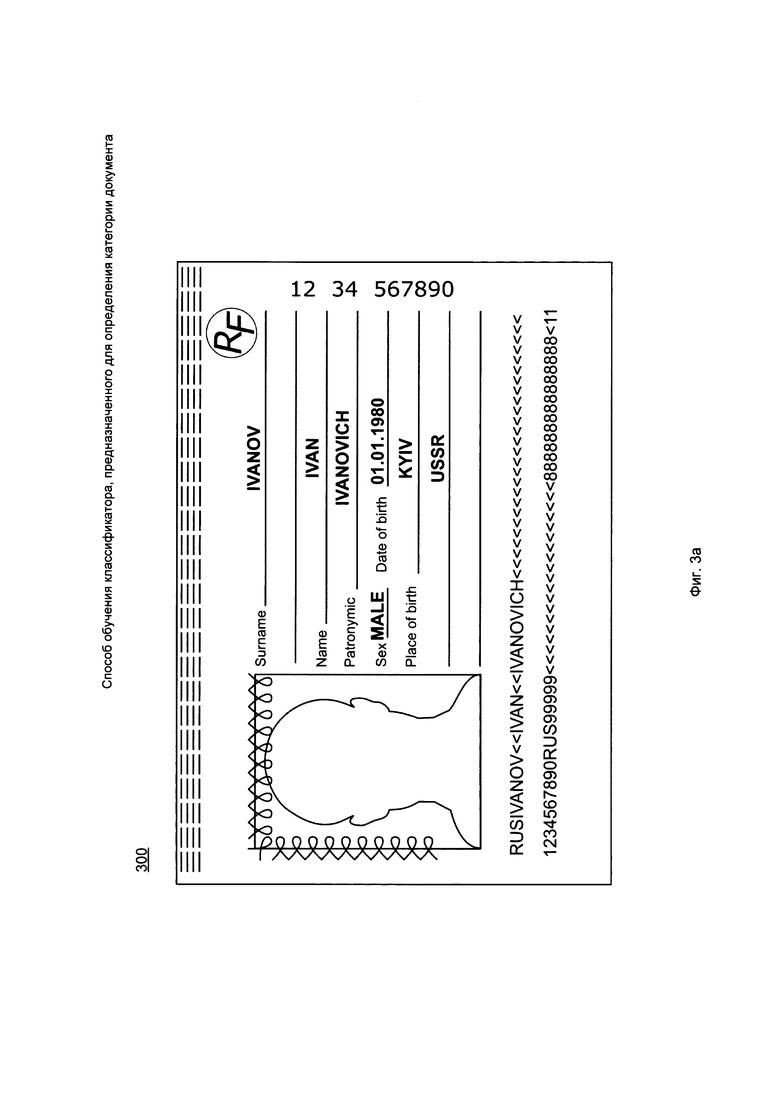
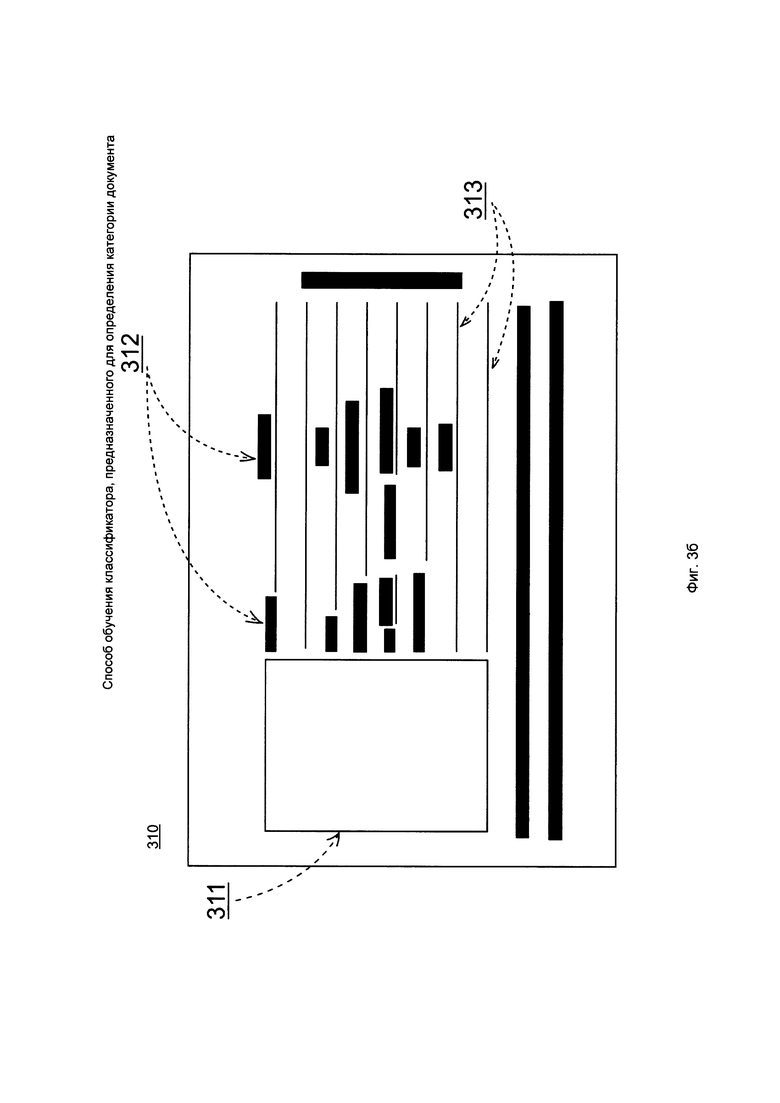
На Фиг. 3а-3в изображен пример документа и различные примеры определения содержащихся на документе объектов.
На Фиг. 4а-4б изображен еще один пример документа и различные примеры определения содержащихся на документе объектов.
Фиг. 5 представляет пример компьютерной системы общего назначения.
Осуществление изобретения
Объекты и признаки настоящего изобретения, способы для достижения этих объектов и признаков станут очевидными посредством отсылки к примерным вариантам осуществления. Однако настоящее изобретение не ограничивается примерными вариантами осуществления, раскрытыми ниже, оно может воплощаться в различных видах. Сущность, приведенная в описании, является ничем иным, как конкретными деталями, обеспеченными для помощи специалисту в области техники в исчерпывающем понимании изобретения, и настоящее изобретение определяется в объеме приложенной формулы.
На Фиг. 1 представлена система обучения классификатора, предназначенного для определения категории документа. Под электронным документом (далее - документ) понимается любой компьютерный файл, содержащий графическую и/или текстовую информацию. Такой файл может иметь графический формат данных (JPEG, PNG, TIFF и др.) или формат электронных документов (PDF, DOC, DOCX и др.). Настоящее изобретение служит для построения классификатора, предназначенного для определения категории документа. В частном варианте реализации рассматриваются документы, которые потенциально могут содержать персональные данные, конфиденциальные данные или любые другие данные, представляющие ценность. Некоторым документам может быть заранее задана категория, характеризующая их принадлежность к настоящим бумажным документам (паспорт, водительское удостоверение, свидетельство о рождении и пр.). Категория документа может быть задана, например, аналитиком, пользователем или компьютерной системой.
Средство анализа 110 служит для получения документов 101, которые принадлежат к одной категории 106. Документы 101 служат обучающей выборкой для построения классификатора 140 (средство, реализующее модель классификации для определения категории произвольного документа). Для реализации изобретения средству анализа 110 достаточно получить один документ 101. Однако, качество классификации будет выше, если обучающая выборка будет содержать достаточно большое количество документов 101. Для каждого полученного документа 101 средство анализа 110 определяет содержащиеся в нем объекты 104, являющиеся, в частности, графическими и/или текстовыми элементами. В частном варианте реализации объектами 104 могут быть, например, следующие: изображение лица человека, рамки фотографии лица, герба или флага страны, печати, логотипа или всего документа 101, если формат документа 101 является графическим. В другом частном варианте реализации объекты 104 могут также являться композицией таких объектов, как отрезок, точка, сплайн, эллипс или других примитивов.
Так, например, для документов категории «паспорт» характерно наличие таких объектов 104, как фотографии, изображения герба, текстовых полей, например, «фамилия», «имя», «отчество», «дата рождения», «место рождения», «дата выдачи», «подразделение выдачи» и др. Стоит отметить, что в одном варианте реализации текстовые объекты могут быть распознаны с использованием технологий OCR средством обработки 111.
В другом примере реализации текстовые поля не распознаются как текст, но распознаются как область, в которой находится текст. В этом случае текстовые поля могут быть определены как отдельные прямоугольные графические объекты - это незначительно снизит качество классификации, но в то же время существенно повысит скорость работы классификатора, так как средство обработки 111 не будет выполнять трудоемкую задачу распознавания текста.
В еще одном частном примере реализации может быть использован гибридный подход - в части текстовых полей текст распознается (например, поля «фамилия», «имя» и пр.), а в части текстовых полей текст не распознается, и эти текстовые поля определяются как прямоугольные объекты. При этом напротив поля «фамилия», вероятно, будет прямоугольный объект, обозначающий конкретную фамилию. В этом случае в качестве дополнительного признака может быть выбрана ширина этого прямоугольного объекта. Большинство российских фамилий, например, обычно содержит от 3 до 8 букв. Поэтому в качестве признака для упомянутого прямоугольного объекта может быть выбран флаг, указывающий на выполнение или невыполнения условия, что ширина объекта находится в диапазоне, соответствующему 3-8 буквам.
В частном варианте реализации, в системе содержится средство обработки 111, необходимое для предварительной обработки документов 101. Например, в одном графическом файле может содержаться несколько документов 101. В этом случае средство обработки 111 выделит все документы, содержащиеся в графическом файле, и передаст их средству анализа 110 для определения содержащихся в выделенных документах объектов. В другом примере изображение документа 101 может содержать искажения или дефекты изображения, такие как дисторсию, поворот, искажение перспективы, блики и другие дефекты, свойственные, например, при фотографировании или сканировании документа.
В одном примере реализации, средство обработки 111 может выполнить исправление искажений с использованием известных из уровня техники способов прежде, чем документы 101 будут переданы для последующего анализа средством анализа 110. В этом примере средство обработки 111 может также выполнить исправление искажений на новом документе 102 прежде, чем построенный классификатор 140 определит категорию этого нового документа 102, для которого не задана категория (подробнее о классификаторе 140 будет описано далее). В другом примере реализации средство обработки 111 не будет выполнять исправление искажений документа 101. В этом примере средство обработки 111 также не будет выполнять исправление искажений на новом документе 102 перед тем, как определить его категорию построенным классификатором 140.
В еще одном частном варианте реализации средство анализа 110 изначально получает обработанные документы 101.
Для каждого документа 101 средство формирования признаков 120 формирует набор признаков 105, состоящий из определенных объектов 104. Признаки являются характеристиками документа 101. Признаки могут быть бинарными, номинальными, порядковыми или количественными. Признаки могут включать, в частности, следующие:
- наличие объекта;
- местоположение объекта (например, координаты);
- количество объектов;
- расположение одного объекта по отношению к другому объекту (например, расстояние между объектами, угол между центрами объектов и пр.);
- размеры объекта (например, площадь);
- угол наклона объекта.
Числовые признаки из указанных могут принимать как абсолютные значения, так и относительные - по отношению к соответствующим параметрам всего документа.
В частном примере реализации в качестве признака может выступать результат работы алгоритма классификации.
В еще одном частном примере реализации в качестве признака могут выступать наличие искажения изображения объекта, а также его тип (дисторсия, поворот, искажение перспективы, наличие блика и др.).
Кроме того, при наличии искажения изображения объекта другие признаки могут быть ослаблены. Т.к., например, блик изображения всего документа может закрыть один или несколько объектов, и, следовательно, присутствие одного или нескольких таких объектов может быть необязательным.
В итоге средство построения классификатора 130 выполняет построение классификатора 140 на основании значений сформированных признаков 105 для документов 101 и, в частности, одной категории 106, к которой принадлежат упомянутые документы 101.
Построенный классификатор 140 далее используется для выполнения классификации (то есть присвоения категории) документов, которым ранее не была присвоена категория.
В частном варианте реализации средство анализа 110 получает дополнительные документы 102-103, часть из которых принадлежит к категории 106 (документы 102), а другая часть принадлежит к другой категории 107 (документы 103), и рассчитывает ошибку классификации дополнительных документов с использованием классификатора 140. В качестве ошибки классификации может выступать, например, вероятность неправильной классификации документов (например, документы из категории 107 были классифицированы как принадлежащие к категории 106, а документы из категории 106 были классифицированы, как не принадлежащие к категории 106). При этом, если ошибка классификации превышает заданное значение (например, более 5%), построение классификатора повторяется (т.е. повторяется работа средства анализа 110, средства формирования признаков 120 и средства построения классификатора 130) с тем отличием, что средство анализа получает документы 101, 102 и 103, одна часть которых принадлежат к категории 106 (документы 101 и 102), а другая часть принадлежит категории 107 (документы 103). В противном случае средство построение классификатора 130 завершает построение классификатора 140. В еще одном частном варианте реализации, кроме категорий 106-107, могут быть дополнительные категории. В другом частном варианте реализации ошибка классификации рассчитывается с использованием, в частности, одного из алгоритмов: минимизации эмпирического риска, скользящего контроля.
В еще одном частном примере реализации получают дополнительные документы, принадлежащие к каждой сформированной категории классификатора, и рассчитывают ошибку классификации упомянутых дополнительных документов с использованием упомянутого классификатора, при этом, если ошибка классификации превышает заданное значение, повторяют построение классификатора с учетом дополнительных документов, иначе - завершают построение классификатора.
Средство построения классификатора 130 выполняет построение классификатора 140 путем выбора модели (алгоритма) классификации и последующего обучения классификатора 140, где в качестве признакового описания документа выступают сформированные признаки, а в качестве классов - в частности, одна категория документа.
В частном варианте реализации выбирают одну из следующих моделей (алгоритмов) классификации:
- Байесовский классификатор;
- нейронная сеть;
- Вейвлет Хаара;
- локальные бинарные шаблоны;
- логистическая регрессия;
- гистограмма направленных градиентов.
Обучение классификатора 140 осуществляется с использованием известных из уровня техники методов.
В качестве примера, положим, что документы принадлежат к одной категории у (у=1, если документ принадлежит к указанной категории и у=0 в противном случае). Такой категорией может быть, например, паспорт или удостоверение личности, или любая другая категория.
Допустим, средством построения классификатора 130 была выбрана модель логистической регрессии. В этом случае, построение классификатора 140 заключается в построении модели вероятности P(у=1|x)=f(z), z=ΘTx, где х и Θ - векторы значений сформированных признаков х и параметров регрессии, f(z) - логистическая функция, f(z)=1/(1+e-z).
Для подбора параметров Θ, средство построения классификатора 130 использует метод максимального правдоподобия, заключающийся в нахождении таких параметров Θ, которые максимизируют функцию правдоподобия на обучающей выборке (т.е. на сформированном наборе признаков и значений, которые принимают эти признаки для документов 101, про которые известно, что они принадлежат к указанной категории).
В итоге, с использованием классификатора 140 для произвольного нового документа, которому не задана категория, может быть определено, что он относится или не относится к указанной категории. Для этого, в новом документе будут определены содержащиеся в нем объекты, а затем определены значения сформированных признаков и рассчитана вероятность Р(у=1|х). И, если рассчитанное значение вероятности выше 0.5, то будет определено, что новый документ относится к указанной категории. Иначе, новый документ не будет определен к данной категории.
В частном варианте реализации выбор той или иной модели классификации может быть задан аналитиком. В еще одном частном варианте реализации, способ обучения классификатора (см. Фиг. 2) может быть применен для одинакового набора документов для различных моделей, и, в итоге, будет выбран классификатор 140, обеспечивающий наименьшую ошибку классификации на наборе дополнительных документов (тестовая выборка), для которых известна категория.
В еще одном частном варианте реализации категорией документа дополнительно является совокупность из двух и более категорий, а также подкатегория известной категории. Например, у категории «паспорт» могут быть следующие подкатегории: «внутренний паспорт», «заграничный паспорт», «дипломатический паспорт», паспорта различных стран мира. Данные подкатегории, очевидно, сами по себе являются категориями в указанном варианте реализации.
В итоге будет решена заявленная техническая проблема и достигнут заявленный технический результат, заключающийся в повышении качества определения категории документа классификатором. Таким способом, например, документ «вид на жительство» может быть определен к большой категории «удостоверение личности», т.к. содержит все упомянутые выше признаки, хотя он не является ни «паспортом» ни «водительскими правами» и не может быть определен ни к одной из этих двух категорий.
В частном варианте реализации признаки дополнительно включают следующие:
- гистограмма цветов объекта;
- метаданные объекта (например, EXIF файла изображения документа);
- множество объектов, объединенных по определенному признаку;
- количество одинаковых объектов;
- соответствие гистограммы цветов объекта заданному шаблону;
- соответствие заданной комбинации объектов шаблону взаимного расположения;
- преобразование Фурье гистограммы цветов объекта;
- наличие искажений на изображении объекта (как геометрических, так и оптических);
- тип искажений на изображении объекта (например, дисторсия, поворот, искажение перспективы, наличие блика и др.).
На Фиг. 2 представлен способ обучения классификатора. Средство анализа 110 на шаге 201 получает документы 101, которые принадлежат к одной категории 106 и, затем, на шаге 202 для каждого полученного документа определяет содержащиеся в нем объекты. На шаге 203 для каждого документа средство формирования признаков 120 формирует набор признаков, состоящий из определенных объектов. В итоге, на шаге 204 средство построения классификатора 130 выполняет построение классификатора 140 на основании сформированных признаков для документов. При этом, ввиду того, что категория может содержать документы разных подкатегорий (например, паспорт и водительское удостоверение), решается заявленная техническая проблема и достигается технический результат, заключающийся в повышении качества определения категории документа классификатором.
В частном варианте реализации на шаге 204 средство анализа 110 получает дополнительные документы 102, принадлежащие к категории 106 и рассчитывает ошибку классификации дополнительных документов с использованием классификатора 140. При этом, если ошибка классификации превышает заданное значение, шаги 201-204 будут повторены с тем отличием, что на шаге 201 будут получены документы, которые принадлежат к одной из двух (или более) категорий - например категория 106 и новая категория 107, отличная от категории 106. В противном случае - построение классификатора завершают. Стоит отметить, что заявленный способ будет работать аналогичным образом, если категорий больше двух. В этом случае, шаги способа 201-204 будут повторены соответствующее число раз.
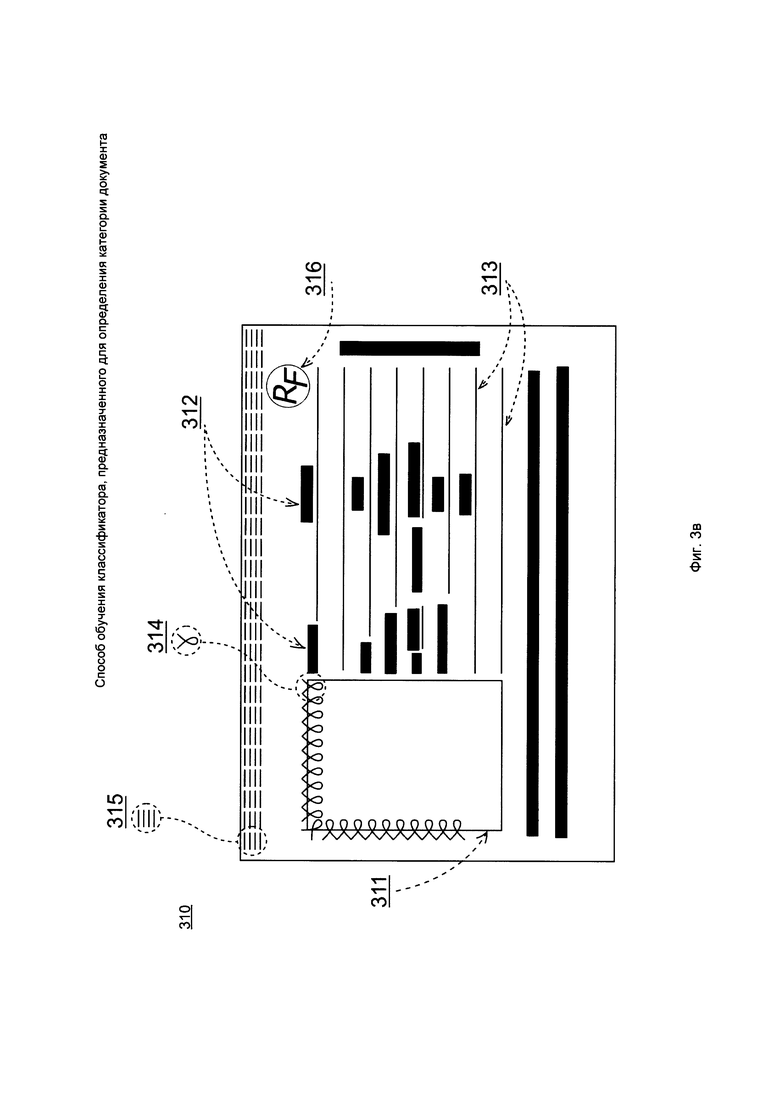
На Фиг. 3а-3в изображен пример документа и различные примеры определения содержащихся на документе объектов. На Фиг. 3а представлен внутренний паспорт Российской Федерации 300. Средство анализа 110 может определить содержащиеся в документе 300 объекты, например, представленные на Фиг. 3б и 3в.
В первом примере, на Фиг. 3б, объектами могут быть, например, фотография 311, текстовые поля 312 и отрезок 313. При этом содержащиеся символы в текстовых полях 312 или в части текстовых полей 312 могут быть распознаны с использованием OCR или не распознаны в зависимости от варианта реализации. В одном варианте реализации, текстовые поля 312 будут определены как прямоугольные области, в которых содержится текст документа 310 (документ 300 с выделенными объектами). В рассматриваемом примере всего было выделено 16 текстовых полей 312, а также 9 отрезков 313.
В качестве признаков могут быть сформированы, например, следующие:
- наличие объектов: фотографии 311, текстовых полей 312, отрезков 313;
- местоположения объектов: координаты объектов 311-313 относительно границ документа 310;
- количество объектов 311-313 (в данном примере, одна фотография 311, шестнадцать текстовых полей 312 и девять отрезков 313);
- взаимное расположение объектов, например, расстояние между отрезками 313, расстояние и угол между отрезками 313 и фотографией 311, расстояние и угол между фотографией 311 и текстовыми полями 312 и т.д.;
- размеры объекта, например, отношение площади фотографии 311 к площади всего документа 310, отношение площади всех текстовых полей 312 к площади документа 310 и пр.;
- угол наклона объекта, например, угол наклона отрезков 313 по отношению к рамкам документа 310.
Еще один возможный пример того, как средство анализа 110 может определить объекты, содержащиеся на документе 310, приведен на Фиг. 3в. Так, дополнительно к фотографии 311, текстовым полям 312 и отрезкам 313 будут определены такие объекты, как: узоры 314 и узоры 315, надпись РФ 316. Дополнительными признаками, в данном примере могут быть, например, следующие:
- количество узоров 314 (всего 21), количество узоров 315 (всего 25);
- угол наклона узоров 314 по отношению к рамкам документа 320 (10 объектов под углом 0 градусов, 1 под углом 45 градусов, 10 под углом 90 градусов);
- местоположение надписи РФ 316 (правый верхний угол);
- взаимное расположение узоров 314 (в виде буквы Г на равном расстоянии друг от друга) и узоров 315 (в виде горизонтальной линии на равном расстоянии друг от друга).
В еще одном частном примере реализации, символы в части или всех текстовых полях 312 могут быть распознаны с использованием OCR. В этом примере могут быть дополнительно сформирован признак наличия текстовых полей: фамилии, имени, отчества, пола, даты рождения, места рождения. Также может быть сформирован признак наличия числа, удовлетворяющего требования к номеру паспорта и другие признаки.
Стоит отметить, что два нижних текстовых поля являются машиночитаемым текстом (например, в соответствии со стандартом ИКАО 9303) и могут быть быстро распознаны с использованием существующих алгоритмов. В этом случае, наличие машиночитаемого текста может быть дополнительным признаком.
Зачастую, документы, удостоверяющие личность, например, паспорт 300, имеют характерный сетчатый фон определенного цвета. В этом примере, в качестве дополнительного признака может быть выбран преобладающий цвет на гистограмме цветов всего документа 300.
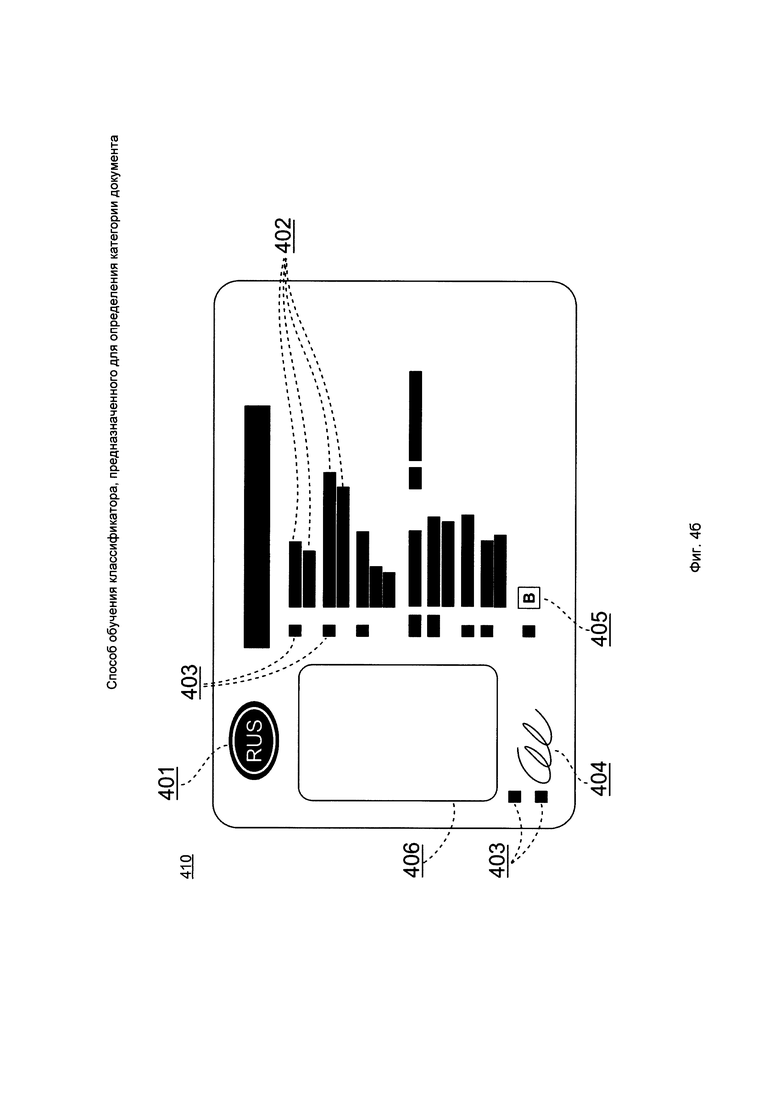
На Фиг. 4а и 4б изображен еще один пример документа и различные примеры определения содержащихся на документе объектов. На Фиг. 4а представлены водительское удостоверение Российской Федерации 400. Средство анализа 110 может определить содержащиеся в документе 400 объекты, например, представленные на Фиг. 4б.
В примере на Фиг. 4б объектами могут быть, например, фотография 406, текстовые поля 402, текстовые поля 403, название (код) страны 401, подпись 404 и категория 405. При этом содержащиеся символы в текстовых полях 402-403 или в части текстовых полей 402-403 могут быть распознаны с использованием OCR или не распознаны в зависимости от варианта реализации. В одном варианте реализации, текстовые поля 402-403 будут определены как прямоугольные области, в которых содержится текст документа 410 (документ 400 с выделенными объектами). В рассматриваемом примере всего было выделено 11 текстовых полей 403 и 14 текстовых полей 402.
В качестве признаков могут быть сформированы, например, следующие:
- наличие объектов: фотографии 406, текстовых полей 402-403, названия страны 401, подписи 404, категории 405;
- местоположения объектов: фотографии 406, текстовых полей 402-403, названия страны 401, подписи 404, категории 405;
- количество объектов 401-406 (в данном примере, одна фотография 406, 11 текстовых полей 403, 14 текстовых полей 402, одна подпись 404, одна категория 405, одно название страны 401);
- взаимное расположение объектов, например, расстояние и угол между фотографией 406 и текстовыми полями 402 и т.д.;
- размеры объекта, например, отношение площади фотографии 406 к площади всего документа 410, отношение площади всех текстовых полей 402-403 к площади документа 410 и пр.;
- угол наклона объекта, например, угол наклона текстовых полей 402 по отношению к рамкам документа 410.
В частном примере реализации, категории «паспорт» и «водительские права» могут быть объединены в одну большую категорию «удостоверение личности». Упомянутые две категории содержат множество одинаковых объектов 104 (например, фотография, название страны, текстовые поля: фамилия, имя, отчество, дата рождения) и для них может быть сформирован набор одинаковых признаков и, таким образом, с использованием заявленного изобретения может быть построен классификатор 140, позволяющий определить категорию новых документов, для которых не задана категория.
Такими признаками в данном примере могут быть, например, наличие таких объектов, как, фотография (311 для паспорта и 406 для водительского удостоверения), название страны (316 для паспорта и 401 для водительского удостоверения), наличие текстовых полей, таких как, фамилия, имя, отчество, дата рождения (часть полей 313 для паспорта и часть полей 402 для водительского удостоверения).
Таким образом, с использованием упомянутых выше признаков, будет построен классификатор, определяющий категорию «удостоверение личность» как для паспорта 300, так и для водительского удостоверения 400. Кроме того, построенный классификатор также определит к категории «удостоверение личности» другие аналогичные документы, имеющие такие же значения сформированного набора признаков. Такими документами, будут, в частности, вид на жительство, заграничный паспорт, паспорт других стран и другие документы, у которых присутствует фотография, название страны, наличие текстовых полей (фамилия, имя, отчество, дата рождения).
В итоге будет решена заявленная техническая проблема и достигнут заявленный технический результат, заключающийся в повышении качества определения категории документа классификатором.
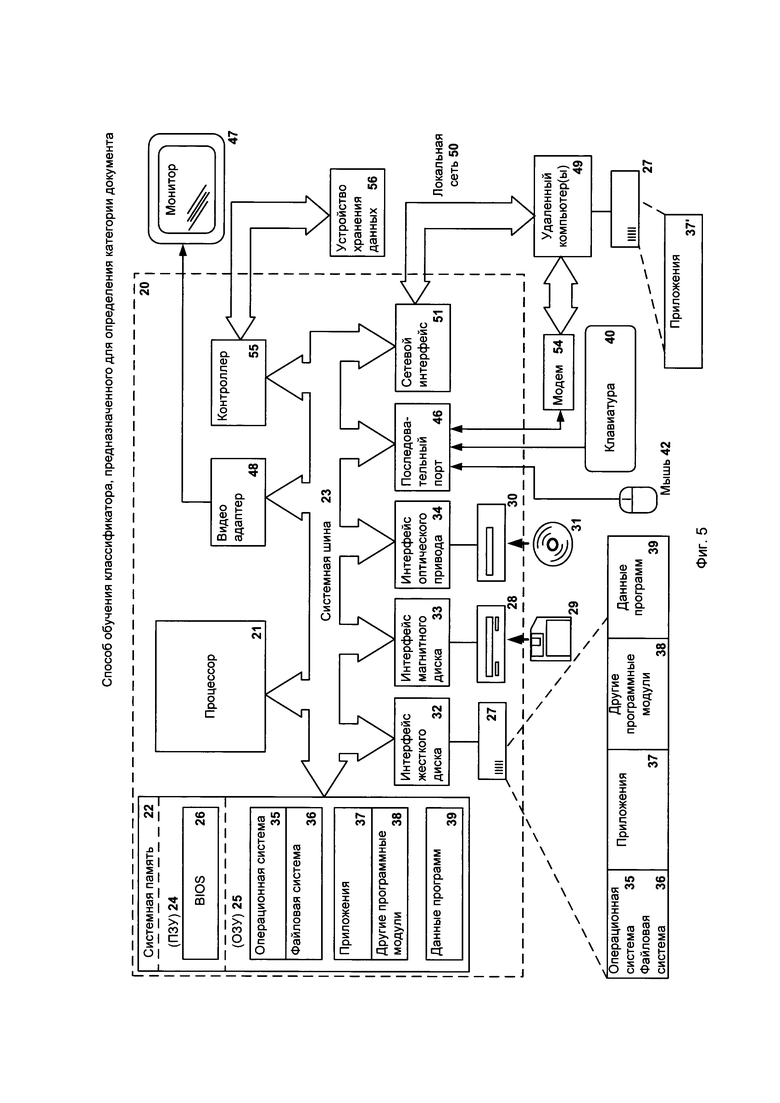
Фиг. 5 представляет пример компьютерной системы общего назначения, персональный компьютер или сервер 20, содержащий центральный процессор 21, системную память 22 и системную шину 23, которая содержит разные системные компоненты, в том числе память, связанную с центральным процессором 21. Системная шина 23 реализована, как любая известная из уровня техники шинная структура, содержащая в свою очередь память шины или контроллер памяти шины, периферийную шину и локальную шину, которая способна взаимодействовать с любой другой шинной архитектурой. Системная память содержит постоянное запоминающее устройство (ПЗУ) 24, память с произвольным доступом (ОЗУ) 25. Основная система ввода/вывода (BIOS) 26, содержит основные процедуры, которые обеспечивают передачу информации между элементами персонального компьютера 20, например, в момент загрузки операционной системы с использованием ПЗУ 24.
Персональный компьютер 20 в свою очередь содержит жесткий диск 27 для чтения и записи данных, привод магнитных дисков 28 для чтения и записи на сменные магнитные диски 29 и оптический привод 30 для чтения и записи на сменные оптические диски 31, такие как CD-ROM, DVD-ROM и иные оптические носители информации. Жесткий диск 27, привод магнитных дисков 28, оптический привод 30 соединены с системной шиной 23 через интерфейс жесткого диска 32, интерфейс магнитных дисков 33 и интерфейс оптического привода 34 соответственно. Приводы и соответствующие компьютерные носители информации представляют собой энергонезависимые средства хранения компьютерных инструкций, структур данных, программных модулей и прочих данных персонального компьютера 20.
Настоящее описание раскрывает реализацию системы, которая использует жесткий диск 27, сменный магнитный диск 29 и сменный оптический диск 31, но следует понимать, что возможно применение иных типов компьютерных носителей информации 56, которые способны хранить данные в доступной для чтения компьютером форме (твердотельные накопители, флеш-карты памяти, цифровые диски, память с произвольным доступом (ОЗУ) и т.п.), которые подключены к системной шине 23 через контроллер 55.
Компьютер 20 имеет файловую систему 36, где хранится записанная операционная система 35, а также дополнительные программные приложения 37, другие программные модули 38 и данные программ 39. Пользователь имеет возможность вводить команды и информацию в персональный компьютер 20 посредством устройств ввода (клавиатуры 40, манипулятора «мышь» 42). Могут использоваться другие устройства ввода (не отображены): микрофон, джойстик, игровая консоль, сканер и т.п. Подобные устройства ввода по своему обычаю подключают к компьютерной системе 20 через последовательный порт 46, который, в свою очередь, подсоединен к системной шине, но могут быть подключены иным способом, например, при помощи параллельного порта, игрового порта или универсальной последовательной шины (USB). Монитор 47 или иной тип устройства отображения также подсоединен к системной шине 23 через интерфейс, такой как видеоадаптер 48. В дополнение к монитору 47, персональный компьютер может быть оснащен другими периферийными устройствами вывода (не отображены), например, колонками, принтером и т.п.
Персональный компьютер 20 способен работать в сетевом окружении, при этом используется сетевое соединение с другим или несколькими удаленными компьютерами 49. Удаленный компьютер (или компьютеры) 49 являются такими же персональными компьютерами или серверами, которые имеют большинство или все упомянутые элементы, отмеченные ранее при описании существа персонального компьютера 20, представленного на Фиг. 5. В вычислительной сети могут присутствовать также и другие устройства, например, маршрутизаторы, сетевые станции, пиринговые устройства или иные сетевые узлы.
Сетевые соединения могут образовывать локальную вычислительную сеть (LAN) 50 и глобальную вычислительную сеть (WAN). Такие сети применяются в корпоративных компьютерных сетях, внутренних сетях компаний и, как правило, имеют доступ к сети Интернет. В LAN- или WAN-сетях персональный компьютер 20 подключен к локальной сети 50 через сетевой адаптер или сетевой интерфейс 51. При использовании сетей персональный компьютер 20 может использовать модем 54 или иные средства обеспечения связи с глобальной вычислительной сетью, такой как Интернет. Модем 54, который является внутренним или внешним устройством, подключен к системной шине 23 посредством последовательного порта 46. Следует уточнить, что сетевые соединения являются лишь примерными и не обязаны отображать точную конфигурацию сети, т.е. в действительности существуют иные способы установления соединения техническими средствами связи одного компьютера с другим.
В соответствии с описанием, компоненты, этапы исполнения, структура данных, описанные выше, могут быть выполнены, используя различные типы операционных систем, компьютерных платформ, программ.
В заключение следует отметить, что приведенные в описании сведения являются примерами, которые не ограничивают объем настоящего изобретения, определенного формулой.
| название | год | авторы | номер документа |
|---|---|---|---|
| КЛАССИФИКАЦИЯ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ НА ОСНОВАНИИ КОНТЕНТА | 2014 |
|
RU2571545C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2021 |
|
RU2768544C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ ДОКУМЕНТОВ, СОДЕРЖАЩИХ ПЕРСОНАЛЬНЫЕ ДАННЫЕ | 2019 |
|
RU2793607C1 |
| Система и способ выявления изображения, содержащего идентификационный документ | 2018 |
|
RU2715515C2 |
| МЕТОД И СИСТЕМА ИЗВЛЕЧЕНИЯ ДАННЫХ ИЗ ИЗОБРАЖЕНИЙ СЛАБОСТРУКТУРИРОВАННЫХ ДОКУМЕНТОВ | 2015 |
|
RU2613846C2 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2804747C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2802549C1 |
| СПОСОБ ВЫЯВЛЕНИЯ ПЕРСОНАЛЬНЫХ ДАННЫХ ОТКРЫТЫХ ИСТОЧНИКОВ НЕСТРУКТУРИРОВАННОЙ ИНФОРМАЦИИ | 2013 |
|
RU2549515C2 |
| КЛАССИФИКАЦИЯ ДОКУМЕНТОВ ПО УРОВНЯМ КОНФИДЕНЦИАЛЬНОСТИ | 2019 |
|
RU2732850C1 |
| СПОСОБ И СИСТЕМА РАСПОЗНАВАНИЯ ЭМОЦИОНАЛЬНОГО СОСТОЯНИЯ СОТРУДНИКОВ | 2021 |
|
RU2768545C1 |
Изобретение относится к области предотвращения утечек информации, в частности к предотвращению утечек электронных копий персональных и конфиденциальных документов. Технический результат заключается в повышении качества определения категории документа классификатором. В способе обучения классификатора, предназначенного для определения категории документа, получают документы, которые принадлежат к категории. Для каждого полученного документа определяют содержащиеся в нем объекты, являющиеся графическими элементами. Для каждого полученного документа формируют набор признаков, состоящий из определенных объектов. При этом упомянутыми признаками являются признаки, характеризующие наличие объекта, местоположение объекта, количество объектов, расположение одного объекта по отношению к другому объекту, размеры объекта, угол наклона объекта. Выполняют построение классификатора на основании значений сформированных признаков для полученных документов. 12 з.п. ф-лы, 8 ил.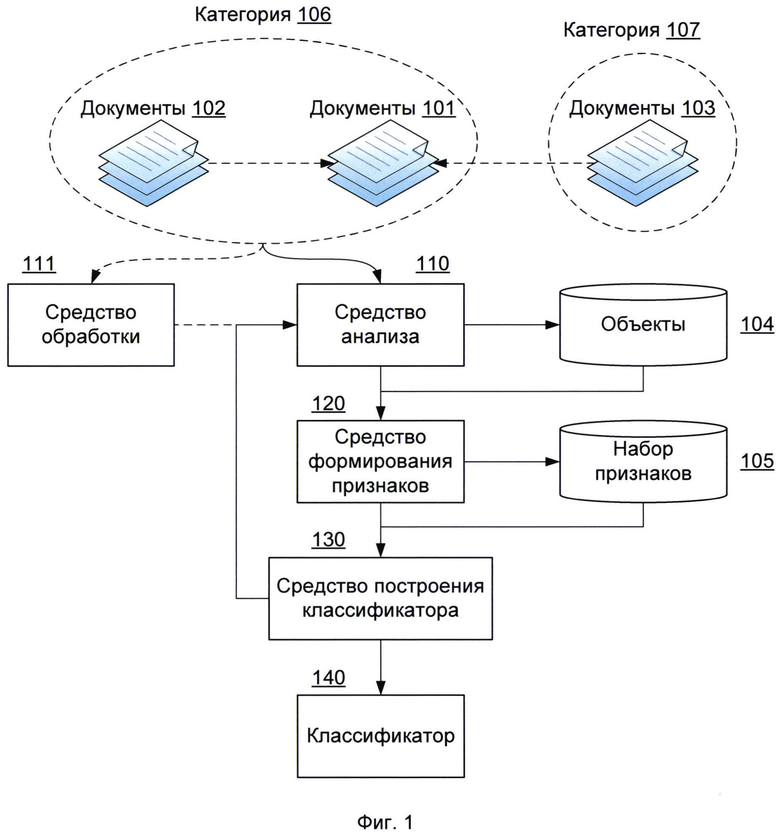
1. Реализуемый компьютером способ обучения классификатора, предназначенного для определения категории документа, в котором:
а) получают документы, которые принадлежат, в частности, к одной категории;
б) для каждого полученного документа определяют содержащиеся в нем объекты, в частности, являющиеся графическими элементами;
в) для каждого полученного документа формируют набор признаков, состоящий из определенных объектов, при этом упомянутые признаки включают, в частности, следующие:
- наличие объекта;
- местоположение объекта;
- количество объектов;
- расположение одного объекта по отношению к другому объекту;
- размеры объекта;
- угол наклона объекта;
г) выполняют построение классификатора на основании значений сформированных признаков для полученных документов.
2. Способ по п. 1, в котором после выполнения шага г) получают дополнительные документы, принадлежащие к каждой сформированной категории классификатора, и рассчитывают ошибку классификации упомянутых дополнительных документов с использованием упомянутого классификатора, при этом, если ошибка классификации превышает заданное значение, повторяют построение классификатора с учетом дополнительных документов.
3. Способ по п. 1, в котором дополнительно после выполнения шага г) получают документы, принадлежащие к каждой сформированной категории классификатора и по меньшей мере к одной другой категории, и рассчитывают ошибку классификации дополнительных документов с использованием упомянутого классификатора, при этом, если ошибка классификации превышает заданное значение, повторяют шаги а)-г) с тем отличием, что на шаге а) получают документы, одна часть указанных документов принадлежит к одной из сформированных категорий, а другая часть указанных документов принадлежит по меньшей мере к одной другой категории.
4. Способ по п. 2 или 3, в котором ошибку классификации рассчитывают с использованием, в частности, одного из алгоритмов: минимизация эмпирического риска, скользящий контроль.
5. Способ по п. 1, в котором построение классификатора на основании сформированных признаков включает:
а) выбор модели классификации;
б) обучение классификатора согласно выбранной модели классификации, где в качестве признакового описания документа выступают сформированные признаки, а в качестве классов - в частности, одна категория документа.
6. Способ по п. 1, в котором выбирают одну из следующих моделей классификации:
- Байесовский классификатор;
- нейронная сеть;
- Вейвлет Хаара;
- Локальные бинарные шаблоны;
- Гистограмма направленных градиентов.
7. Способ по п. 1, в котором содержатся, в частности, следующие категории документов:
- паспорт;
- водительское удостоверение;
- свидетельство о рождении.
8. Способ по п. 7, в котором объектами дополнительно являются графические элементы - распознанные изображения по меньшей мере одного из следующих:
- лицо человека;
- герб страны;
- флаг страны;
- печать;
- логотипа
- весь документ.
9. Способ по п. 8, в котором упомянутые объекты являются композицией следующих объектов:
- отрезок;
- точка;
- сплайн;
- эллипс.
10. Способ по п. 1, в котором категорией документа дополнительно является совокупность из двух и более категорий, а также подкатегория известной категории.
11. Способ по п. 10, в котором добавляют новую категорию, включающую, в частности, две и более существующих категорий, при этом при построении классификатора из числа сформированных признаков выбирают признаки, свойственные для новой категории.
12. Способ по п. 1, в котором объекты дополнительно являются текстовыми элементами.
13. Способ по п. 1, в котором признаки дополнительно включают следующие:
- гистограмма цветов объекта;
- метаданные объекта;
- множество объектов, объединенных по определенному признаку;
- количество одинаковых объектов;
- соответствие гистограммы цветов объекта заданному шаблону;
- соответствие заданной комбинации объектов шаблону взаимного расположения;
- преобразование Фурье гистограммы цветов объекта;
- наличие искажений на изображении объекта;
- тип искажений на изображении объекта.
| КЛАССИФИКАЦИЯ ИЗОБРАЖЕНИЙ ДОКУМЕНТОВ НА ОСНОВАНИИ КОНТЕНТА | 2014 |
|
RU2571545C1 |
| Колосоуборка | 1923 |
|
SU2009A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |

