Область техники, к которой относится изобретение
Настоящее изобретение относится к области транспортных средств и, в частности, к средствам управления различными системами транспортных средств с помощью голосовых команд.
Уровень техники
[0001] Транспортные средства с распознаванием голоса предоставляют возможность пассажиру управлять некоторыми функциями транспортного средства с помощью голосовых команд. Голосовые команды предоставляют возможность пассажиру управлять информационно-развлекательной системой, развлекательной системой, системой управления климатом и т.д., произнося некоторые команды, понятные транспортному средству. Транспортное средство будет обрабатывать и выполнять голосовые команды, выводя различные управляющие сигналы в соответствии с принимаемыми голосовыми командами.
В документе US2014136187 раскрыт персональный цифровой помощник для транспортного средства, который позволяет пользователю управлять различными средствами транспортного средства посредством голосовых команд (через интерактивный диалог с цифровым помощником). Известный цифровой помощник включает в себя модули для интерпретации ввода, представляющего собой речь пользователя, осуществления поиска необходимой информации в базе данных транспортного средства и/или других источниках данных и реагирования на ввод пользователя интерактивным способом. Диалог между пользователем и цифровым помощником может быть инициирован пользователем или автоматически цифровым помощником на основе событий, которые могут происходить применительно к транспортному средству.
В документе US2015112684 раскрыта система распознавания говорящего на основе контента, включающая в себя, среди прочего, средства для анализа фонем в образце речи, внесения фонем в модель говорящего и использования модели говорящего для его распознавания.
Раскрытие изобретения
Согласно первому аспекту настоящего изобретения, предложен голосовой процессор транспортного средства, содержащий устройство обработки и носитель для хранения данных, при этом устройство обработки запрограммировано с возможностью:
принимать идентификационную информацию от носимого устройства;
идентифицировать говорящего из идентификационной информации;
идентифицировать диалект, ассоциированный с говорящим, из идентификационной информации;
выбирать предварительно определенную акустическую модель; и
корректировать предварительно определенную акустическую модель на основе, по меньшей мере, частично, идентифицированного диалекта.
В одном варианте осуществления голосового процессора устройство обработки запрограммировано с возможностью формировать откалиброванную акустическую модель на основе, по меньшей мере, частично, предварительно определенной акустической модели, скорректированной в соответствии с диалектом, идентифицированным из идентификационной информации.
В одном варианте осуществления голосового процессора устройство обработки запрограммировано с возможностью применять откалиброванную акустическую модель к акустическому сигналу.
В одном варианте осуществления голосового процессора устройство обработки запрограммировано с возможностью выводить команду транспортному средству на основе, по меньшей мере, частично, акустического сигнала и откалиброванной акустической модели.
В одном варианте осуществления голосового процессора корректировка предварительно определенной акустической модели включает в себя выбор характеристики речи из множества характеристик речи.
В одном варианте осуществления голосового процессора корректировка предварительно определенной акустической модели включает в себя корректировку весового коэффициента, ассоциированного с выбранной характеристикой речи.
В одном варианте осуществления голосового процессора корректировка предварительно определенной акустической модели включает в себя корректировку весового коэффициента, ассоциированного, по меньшей мере, с одной из множества характеристик речи.
В одном варианте осуществления голосового процессора каждая из множества характеристик речи ассоциирована с фонемой.
В одном варианте осуществления голосовой процессор дополнительно содержит устройство связи, запрограммированное с возможностью соединения с носимым устройством.
В одном варианте осуществления голосовой процессор дополнительно содержит микрофон, выполненный с возможностью принимать аналоговый акустический сигнал.
Согласно второму аспекту настоящего изобретения, предложен способ, содержащий этапы, на которых:
принимают идентификационную информацию от носимого устройства;
идентифицируют говорящего из идентификационной информации;
идентифицируют диалект, ассоциированный с говорящим, из идентификационной информации;
выбирают предварительно определенную акустическую модель; и
корректируют предварительно определенную акустическую модель на основе, по меньшей мере, частично, идентифицированного диалекта.
В одном варианте осуществления вышеупомянутый способ дополнительно содержит этап, на котором формируют откалиброванную акустическую модель на основе, по меньшей мере, частично, предварительно определенной акустической модели, скорректированной в соответствии с диалектом, идентифицированным из идентификационной информации.
В одном варианте осуществления вышеупомянутый способ дополнительно содержит этап, на котором применяют откалиброванную акустическую модель к акустическому сигналу.
В одном варианте осуществления в вышеупомянутом способе выводят команду транспортному средству, на основе, по меньшей мере, частично, акустического сигнала и откалиброванной акустической модели.
В одном варианте осуществления вышеупомянутого способа корректировка предварительно определенной акустической модели включает в себя этап, на котором выбирают характеристику речи из множества характеристик речи.
В одном варианте осуществления вышеупомянутого способа корректировка предварительно определенной акустической модели включает в себя корректировку весового коэффициента, ассоциированного, по меньшей мере, с одной из множества характеристик речи.
В одном варианте осуществления вышеупомянутого способа каждая из множества характеристик речи ассоциируется с фонемой.
Согласно третьему аспекту настоящего изобретения, предложена система транспортного средства, содержащая:
устройство связи, запрограммированное с возможностью соединения с носимым устройством;
микрофон, выполненный с возможностью принимать акустический сигнал; и
голосовой процессор, запрограммированный с возможностью принимать идентификационную информацию от носимого устройства, идентифицировать говорящего из идентификационной информации, идентифицировать диалект, ассоциированный с говорящим, из идентификационной информации, выбирать предварительно определенную акустическую модель, корректировать предварительно определенную акустическую модель на основе, по меньшей мере, частично, идентифицированного диалекта, чтобы формировать откалиброванную акустическую модель, и применять откалиброванную акустическую модель к акустическому сигналу.
Краткое описание чертежей
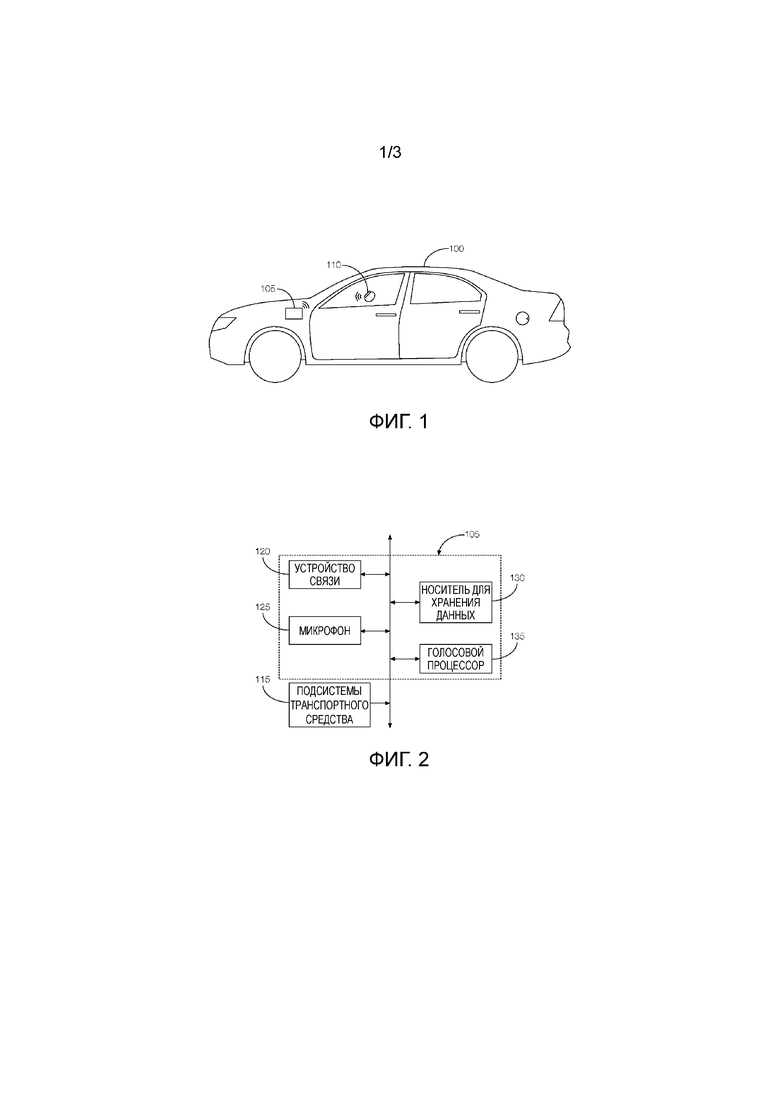
[0002] Фиг. 1 иллюстрирует примерное транспортное средство, имеющее систему обработки голоса на связи с носимым устройством.
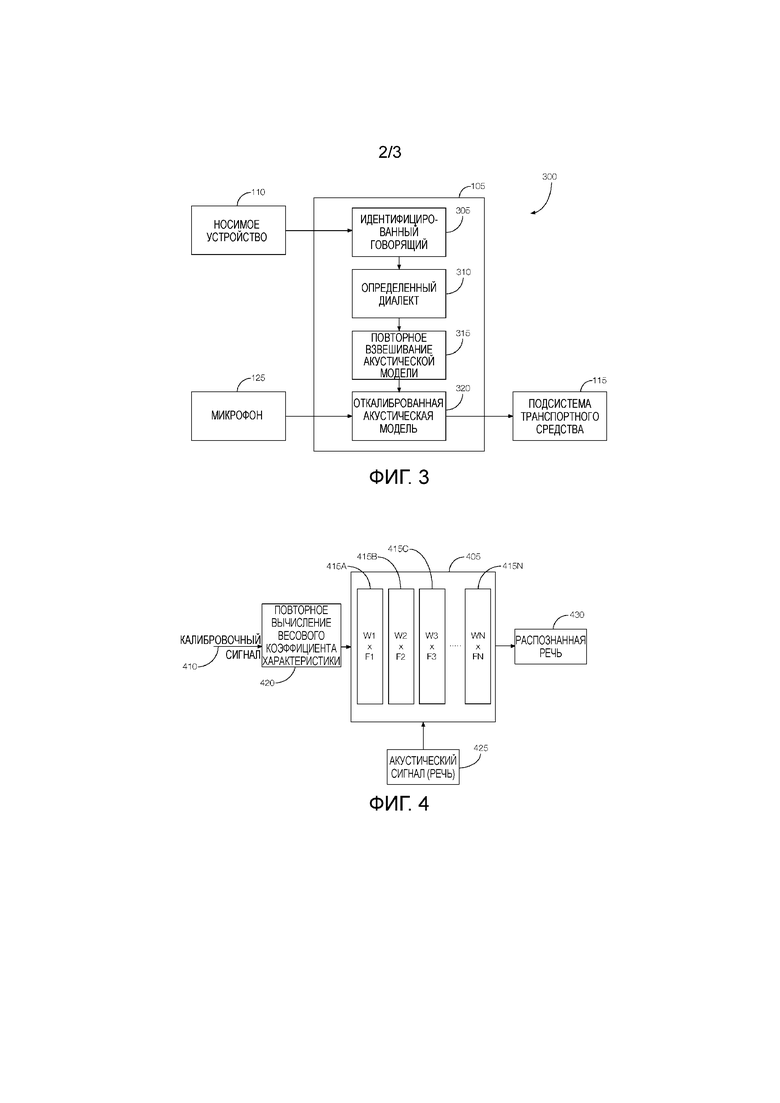
[0003] Фиг. 2 - это блок-схема, показывающая примерные компоненты системы обработки голоса.
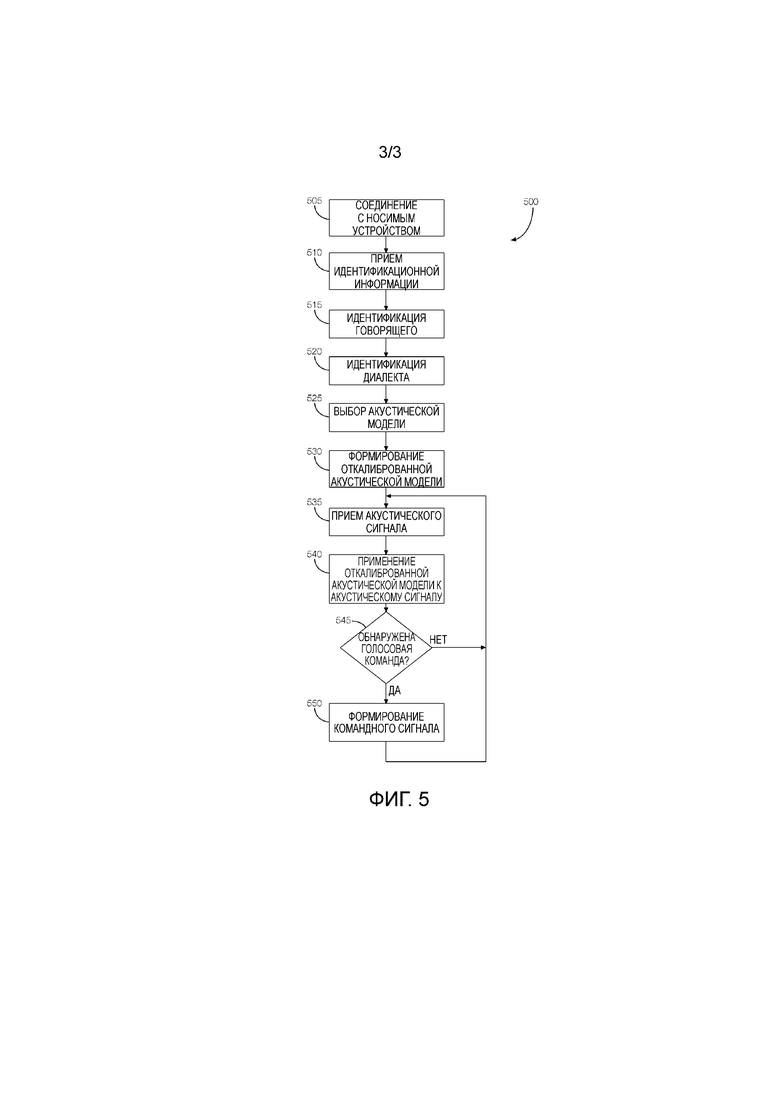
[0004] Фиг. 3 - это блок-схема, иллюстрирующая примерный поток данных.
[0005] Фиг. 4 - это блок-схема, иллюстрирующая примерную регулировку акустической модели, которая может быть включена в систему обработки голоса.
[0006] Фиг. 5 - это блок-схема последовательности операций примерного процесса, который может быть выполнен системой обработки голоса, чтобы учитывать образцы голоса конкретного пользователя.
Осуществление изобретения
[0007] Улучшение того, как пассажиры взаимодействуют с транспортными средствами посредством речи, будут улучшать восприятие нахождения в транспортном средстве. Естественная речевая модель, которая предоставляет возможность пассажирам почувствовать себя, словно они общаются со своим транспортным средством вместо простого предоставления ему команды, является одним способом улучшать взаимодействие пассажир-транспортное средство. Прежде чем естественные речевые модели могут стать повсеместно распространенными в транспортных средствах, транспортное средство должно быть приспособлено, чтобы распознавать речь более согласованно и более точно.
[0008] Один способ, чтобы увеличивать согласованность и точность систем распознавания голоса в транспортном средстве, включает в себя модификацию способа, которым система распознавания голоса обрабатывает речь. Традиционные акустические модели являются статическими и обучаются при множестве условий, которые будут считаться типичными для случаев использования автоматического распознавания речи (ASR). Т.е., традиционные акустические модели обучаются согласно характерным для человека ожидаемым образцам голоса. Будет непомерно дорого, если не невозможно, содержать акустическую модель для каждого возможного диалекта и акцента. Кроме того, фоновый шум затрудняет для традиционных акустических моделей точную обработку речи.
[0009] Носимые устройства могут предоставлять возможность транспортному средству лучше идентифицировать и понимать образцы голоса конкретного пассажира. Примерный голосовой процессор транспортного средства, который может приспосабливать акустическую модель для конкретного человека на основе данных от носимого устройства человека, включает в себя устройство обработки и носитель для хранения данных. Устройство обработки программируется, чтобы принимать идентификационную информацию от носимого устройства, идентифицировать говорящего из идентификационной информации, идентифицировать диалект, ассоциированный с говорящим, из идентификационной информации, выбирать предварительно определенную акустическую модель и корректировать предварительно определенную акустическую модель на основе, по меньшей мере, частично, идентифицированного диалекта.
[0010] Соответственно, голосовой процессор может динамически повторно взвешивать акустическую модель как функцию идентификационной информации посредством носимого устройства. Поскольку традиционные акустические модели строятся как линейное сочетание векторов признаков, полученных из обучающих наборов при множестве соответствующих сочетаний, и, поскольку множество статических моделей делают плохую работу по обработке речи с акцентом, голосовой процессор может калибровать акустическую модель для конкретного говорящего, идентифицированного посредством носимого устройства. Калибровка акустической модели может включать в себя, например, выбор и взвешивание применимых векторов признаков.
[0011] Таким образом, голосовой процессор, может максимально использовать данные, собранные посредством носимого устройства. Данные могут включать в себя базовую классификационную информацию, такую как раса, этническая принадлежность, основной язык и т.д., предложенную пользователем при настройке носимого устройства. Альтернативно или в дополнение, данные могут включать в себя классификации, выполняемые посредством алгоритмов машинного обучения, чтобы точно идентифицировать, как отклоняются распределения фонем пользователя. С помощью этой информации голосовой процессор может повторно взвешивать акустическую модель до оптимального линейного сочетания векторов признаков для говорящего, значительно улучшая распознавание речи. Дополнительно, распознавание голоса (идентификация говорящего по голосу) может быть использовано с адаптивными парадигмами обучения, встроенными, например, в информационно-развлекательную систему, чтобы дополнительно улучшать распознавание, поскольку информационно-развлекательная система может строить профиль, который постоянно увеличивает весовые коэффициенты векторов признаков.
[0012] Показанные элементы могут принимать множество различных форм и включать в себя множество и/или альтернативные компоненты и средства. Проиллюстрированные примерные компоненты не имеют намерение быть ограниченными. Фактически, могут использоваться дополнительные или альтернативные компоненты и/или реализации. Дополнительно, показанные элементы не обязательно нарисованы в масштабе, если в явной форме не указано иное.
[0013] Как иллюстрировано на фиг. 1, рассматриваемое транспортное средство 100 включает в себя систему 105 обработки голоса на связи с носимым устройством 110. Хотя иллюстрировано как седан, рассматриваемое транспортное средство 100 может включать в себя любое пассажирское или коммерческое транспортное средство, такое как легковой автомобиль, грузовик, внедорожник, кроссовер, фургон, минивэн, такси, автобус и т.д. В некоторых возможных подходах транспортное средство 100 является автономным транспортным средством, сконфигурированным, чтобы работать в автономном (например, без водителя) режиме, частично автономном режиме и/или неавтономном режиме.
[0014] Носимое устройство 110 может включать в себя любое число схем или компонентов, которые предоставляют возможность носимому устройству 110 беспроводным образом связываться с системой 105 обработки голоса. Носимое устройство 110 может быть сконфигурировано, чтобы связываться с помощью любого числа технологий беспроводной связи, таких как, например, Bluetooth®, Bluetooth Low Energy®, Wi-Fi, Wi-Fi Direct и т.д. Носимое устройство 110 может быть запрограммировано с возможностью соединения с системой 105 обработки голоса, что может предоставлять возможность носимому устройству 110 и системе 105 обработки голоса обмениваться данными. Например, носимое устройство 110 может быть запрограммировано, чтобы передавать идентификационную информацию, ассоциированную с человеком, носящим носимое устройство 110, системе 105 обработки голоса. Идентификационная информация может включать в себя, например, личность говорящего. Личность говорящего может быть основана, например, на информации, предоставленной говорящим, когда носимое транспортное средство 110 настраивается. Настройка носимого устройства 110 может включать в себя формирование профиля и ассоциирование профиля с носимым устройством 110. Идентификация может включать в себя, например, уникальный идентификатор, ассоциированный с говорящим, и уникальный идентификатор может быть передан рассматриваемому транспортному средству 100 вместе с идентификационной информацией.
[0015] Идентификационная информация может дополнительно включать в себя информацию о диалекте. Например, носимое устройство 110 может привлекаться в непрерывной функции "обучения", когда носимое устройство 110 постоянно пытается понять речь пользователя, например, сопоставляя произнесенные фонемы с ожидаемыми фонемами. Различия между произнесенными фонемами и ожидаемыми фонемами могут быть охарактеризованы как диалект говорящего. Информация о диалекте, следовательно, может идентифицировать диалект говорящего или другое представление произнесенных фонем относительно ожидаемых фонем.
[0016] Система 105 обработки голоса может быть запрограммирована с возможностью соединения с и принимать идентификационную информацию от носимого устройства 110. Система 105 обработки голоса может обрабатывать идентификационную информацию, чтобы идентифицировать говорящего. С идентифицированным говорящим система 105 обработки голоса может выбирать акустическую модель. Акустическая модель, которая может называться "предварительно определенной акустической моделью", может быть стандартной моделью, включенной в систему 105 обработки голоса.
[0017] Система 105 обработки голоса может дополнительно идентифицировать диалект говорящего. Диалект может быть определен из идентичности говорящего или другой информации о говорящем, включающей в себя информацию о диалекте, передаваемую от носимого устройства 110. Например, диалекты могут быть ассоциированы с различными географическими областями, которые могут включать в себя настоящую географическую область говорящего или предыдущую географическую область говорящего (географическую область, где говорящий вырос или провел большую часть времени). В качестве примера, один диалект может быть выбран для говорящего, который провел большую часть своей жизни рядом с Бостоном, и другой диалект может быть выбран для говорящего, который провел большую часть своей жизни в южных Соединенных Штатах. Вместо или в дополнение к географии система 105 обработки голоса может определять диалект говорящего на основе "обучения", выполняемого посредством носимого устройства 110.
[0018] Система 105 обработки голоса может корректировать предварительно определенную акустическую модель, чтобы создавать откалиброванную акустическую модель, на основе идентифицированного диалекта. Корректировка предварительно определенной акустической модели может включать в себя, например, выбор характеристики речи среди множества характеристик речи. Каждая характеристика речи может быть ассоциирована с конкретной фонемой. Корректировка предварительно определенной акустической модели может дополнительно включать в себя корректировку весового коэффициента, применяемого к выбранной характеристике речи. Применяемый весовой коэффициент может указывать, насколько большое влияние конкретная фонема должна принимать в интерпретации речи говорящего. Таким образом, увеличение весового коэффициента может делать характеристику более влиятельной, в то время как уменьшение весового коэффициента может делать характеристику менее влиятельной.
[0019] Система 105 обработки голоса может принимать акустический сигнал (т.е., речь, произносимую человеком, носящим носимое устройство 110) и применять откалиброванную акустическую модель к акустическому сигналу. Система 105 обработки голоса может обрабатывать акустический сигнал согласно откалиброванной акустической модели и формировать соответствующие команды, согласующиеся с голосовыми командами, представленными акустическим сигналом, для одной или более подсистем 115 транспортного средства (см. фиг. 2).
[0020] Фиг. 2 - это блок-схема, показывающая примерные компоненты системы 105 обработки голоса. Как показано, система 105 обработки голоса включает в себя устройство 120 связи, микрофон 125, носитель 130 для хранения данных и голосовой процессор 135.
[0021] Устройство 120 связи может включать в себя любое число схем или компонентов, которые обеспечивают связь между носимым устройством 110 и голосовым процессором 135. Устройство 120 связи может быть запрограммировано, чтобы связываться с носимым устройством 110 через любое число технологий беспроводной связи, таких как, например, Bluetooth®, Bluetooth Low Energy®, Wi-Fi, Wi-Fi Direct и т.д. Устройство 120 связи может быть запрограммировано с возможностью соединения с носимым устройством 110 и беспроводным образом принимать идентификационную информацию, включающую в себя информацию о диалекте, от носимого устройства 110. Устройство 120 связи может быть запрограммировано, чтобы передавать идентификационную информацию, например, голосовому процессору 135.
[0022] Микрофон 125 может включать в себя любое число схем или компонентов, которые могут принимать акустический сигнал, такой как речь, и преобразовывать акустический сигнал в электрический сигнал, который может называться "аналоговым акустическим сигналом". Например, микрофон 125 может включать в себя первичный измерительный преобразователь, который формирует аналоговый акустический сигнал в соответствии с речью. Микрофон 125 может быть расположен, например, в пассажирском салоне рассматриваемого транспортного средства 100. В некоторых возможных реализациях микрофон 125 может быть сконфигурирован или запрограммирован, чтобы выводить аналоговый акустический сигнал, например, преобразователю сигнала, так что аналоговый акустический сигнал может быть преобразован в цифровой акустический сигнал.
[0023] Носитель 130 для хранения данных может включать в себя любое число схем или компонентов, которые могут хранить электронные данные. В одном возможном подходе носитель 130 для хранения данных может включать в себя компьютерно-исполняемые инструкции. Носитель 130 для хранения данных может также или альтернативно хранить акустические модели. Акустические модели могут включать в себя, например, любое число предварительно определенных акустических моделей, которые, как обсуждалось выше, могут быть стандартными моделями, включенными в систему 105 обработки голоса. Дополнительно, носитель 130 для хранения данных может быть запрограммирован или сконфигурирован, чтобы хранить одну или более откалиброванных акустических моделей.
[0024] Голосовой процессор 135 может включать в себя любое число схем или компонентов, сконфигурированных или запрограммированных, чтобы обрабатывать речь. В одном возможном подходе голосовой процессор 135 может быть запрограммирован, чтобы принимать идентификационную информацию от устройства 120 связи и идентифицировать говорящего (т.е., человека, носящего носимое устройство 110) из идентификационной информации. Голосовой процессор 135 может быть дополнительно сконфигурирован, чтобы идентифицировать диалект, ассоциированный с говорящим. Диалект может быть определен из идентификационной информации, которая, как обсуждалось выше, может включать в себя информацию о диалекте. Голосовой процессор 135 может быть запрограммирован, чтобы выбирать одну из предварительно определенных акустических моделей, сохраненных на носителе 130 для хранения данных. Выбор предварительно определенной акустической модели может быть основан, например, на идентификационной информации. Дополнительно, голосовой процессор 135 может быть запрограммирован, чтобы корректировать выбранную предварительно определенную акустическую модель на основе, например, информации о диалекте, либо принятой от носимого устройства 110, либо логически выведенной из идентификационной информации (например, логически выведенной из географической области, ассоциированной с человеком, носящим носимое устройство 110). Как обсуждалось выше, скорректированная предварительно определенная акустическая модель может называться откалиброванной акустической моделью, и голосовой процессор 135 может быть запрограммирован, чтобы хранить откалиброванную акустическую модель на носителе 130 для хранения данных. С сформированной откалиброванной акустической моделью голосовой процессор 135 может принимать аналоговые или цифровые акустические сигналы в реальном времени и применять откалиброванную акустическую модель к любым принятым акустическим сигналам, чтобы лучше понимать произношение говорящего человека. Если речь включает в себя голосовые команды, голосовой процессор 135 может формировать и выводить командные сигналы одной или более подсистемам 115 транспортного средства, которые выполняют голосовую команду.
[0025] Фиг. 3 - это блок-схема 300, иллюстрирующая примерный поток данных. Носимое устройство 110 отправляет идентификационную информацию системе 105 обработки голоса. В блоке 305 система 105 обработки голоса идентифицирует говорящего, и в блоке 310 система 105 обработки голоса определяет диалект говорящего. В блоке 315 система 105 обработки голоса корректирует акустическую модель согласно диалекту, чтобы формировать откалиброванную акустическую модель, которая показана в блоке 320. Речь принимается в системе 105 обработки голоса, через микрофон 125, и преобразуется в акустический сигнал. Акустический сигнал обрабатывается посредством откалиброванной акустической модели, которая помогает системе 105 обработки голоса лучше обрабатывать и интерпретировать речь. Если речь включает в себя голосовую команду, система 105 обработки голоса может выводить команду одной или более подсистемам 115 транспортного средства.
[0026] Фиг. 4 - это блок-схема 400, иллюстрирующая примерную корректировку акустической модели, которая может быть включена в систему 105 обработки голоса. Откалиброванная (т.е., скорректированная) акустическая модель показана в блоке 405. Голосовой процессор 135 может применять калибровочный сигнал 410 к предварительно определенной акустической модели. Калибровочный сигнал может идентифицировать конкретные изменения, которые должны быть выполнены по отношению к весовому коэффициенту, примененному к одной или более характеристикам, показанным в блоках 415A-415N. Блок 420 указывает программирование голосового процессора 135, чтобы повторно взвешивать каждую из характеристик 415A-415N согласно калибровочному сигналу. Как обсуждалось выше, повторное взвешивание характеристик 415A-415N может включать в себя выбор одной или более характеристик 415A-415N голоса, где каждая характеристика голоса ассоциируется с конкретной фонемой, и корректировку весового коэффициента, примененного к любой из выбранных характеристик голоса. Применяемый весовой коэффициент может указывать, насколько большое влияние конкретная фонема должна принимать в интерпретации речи говорящего. Таким образом, увеличение весового коэффициента может делать характеристику более влиятельной, в то время как уменьшение весового коэффициента может делать характеристику менее влиятельной. Акустический сигнал, представленный блоком 425, может проходить через откалиброванную акустическую модель, и выходные данные откалиброванной акустической модели 405, показанные в блоке 430, могут включать в себя распознанную речь.
[0027] Фиг. 5 - это блок-схема последовательности операций примерного процесса 500, который может быть выполнен системой 105 обработки голоса, чтобы учитывать образцы речи конкретного пользователя. Процесс 500 может выполняться, в то время как рассматриваемое транспортное средство 100 движется. Например, процесс 500 может начинаться, когда рассматриваемое транспортное средство 100 впервые включается, и продолжает выполняться, пока рассматриваемое транспортное средство 100 не будет выключено, пока все пассажиры не выйдут из рассматриваемого транспортного средства 100, пока ни одно носимое устройство 110 не будет соединено с рассматриваемым транспортным средством 100, или пока рассматриваемое транспортное средство 100 иным образом больше не будет иметь возможности принимать и обрабатывать голосовые команды.
[0028] На этапе 505 система 105 обработки голоса может соединяться с носимым устройством 110. Система 105 обработки голоса может соединяться с носимым устройством 110, ассоциированным, например, с водителем или другим пассажиром транспортного средства. Соединение может быть обеспечено, например, посредством устройства 120 связи.
[0029] На этапе 510 система 105 обработки голоса может принимать идентификационную информацию от носимого устройства 110. Идентификационная информация может, в одном возможном подходе, включать в себя информацию о диалекте. Идентификационная информация может быть принята через устройство 120 связи и передана, например, голосовому процессору 135.
[0030] На этапе 515 система 105 обработки голоса может идентифицировать говорящего. Т.е., система 105 обработки голоса может обрабатывать идентификационную информацию, чтобы определять, кто носит носимое устройство 110. В некоторых случаях голосовой процессор 135 может идентифицировать говорящего и выбирать профиль, ассоциированный с говорящим, с носителя 130 для хранения данных.
[0031] На этапе 520 система 105 обработки голоса может идентифицировать диалект, ассоциированный с человеком, идентифицированным на этапе 515. Голосовой процессор 135 может, в одной возможной реализации, определять диалект, например, из идентификационной информации.
[0032] На этапе 525 система 105 обработки голоса может выбирать одну из предварительно определенных акустических моделей. Множество предварительно определенных акустических моделей может быть сохранено на носителе 130 для хранения данных, и голосовой процессор 135 может выбирать одну из предварительно определенных акустических моделей среди сохраненных моделей.
[0033] На этапе 530 система 105 обработки голоса может корректировать предварительно определенную акустическую модель, выбранную на этапе 525. Например, голосовой процессор 135 может, с помощью диалекта, идентифицированного на этапе 520, или возможно другой информации, принятой от носимого устройства 110, корректировать предварительно определенную акустическую модель, чтобы формировать откалиброванную акустическую модель. Один способ, чтобы корректировать предварительно определенную акустическую модель, включает в себя выбор одной или более характеристик речи, среди множества характеристик речи, и корректировку весового коэффициента, который применяется к одной или более характеристикам речи. Как обсуждалось выше, каждая характеристика речи ассоциируется с фонемой, таким образом, корректировка весового коэффициента для характеристики речи указывает величину влияния, которая должна быть предоставлена каждой фонеме. Увеличение весового коэффициента может означать более влиятельную фонему, в то время как уменьшение весового коэффициента может указывать менее влиятельную фонему.
[0034] На этапе 535 система 105 обработки голоса может принимать акустический сигнал. Акустический сигнал может быть принят через микрофон 125 и может представлять речь, произносимую в пассажирском салоне рассматриваемого транспортного средства 100.
[0035] На этапе 540 система 105 обработки голоса может применять откалиброванную модель к акустическому сигналу. Например, голосовой процессор 135 может принимать акустический сигнал от микрофона и применять откалиброванную акустическую модель, сформированную на этапе 530, к акустическому сигналу.
[0036] На этапе 545 решения система 105 обработки голоса может определять, включает ли в себя акустический сигнал какие-либо голосовые команды. Голосовой процессор 135, например, может выполнять такое определение, сравнивая фрагменты речи, представленные посредством акустического сигнала, с взвешенными характеристиками, и определяя, представляют ли фрагменты речи фонемы, ассоциированные с голосовыми командами. Если акустический сигнал включает в себя голосовые команды, процесс 500 может переходить к этапу 550. Иначе процесс 500 может возвращаться к этапу 535.
[0037] На этапе 550 система 105 обработки голоса может формировать и выводить соответствующий командный сигнал. Голосовой процессор 135 может формировать командный сигнал, ассоциированный с голосовой командой, обнаруженной на этапе 545. Дополнительно, голосовой процессор 135 может выводить командный сигнал соответствующей подсистеме транспортного средства, так что голосовая команда может быть выполнена. Процесс 500 может продолжаться на этапе 535.
[0038] Соответственно, раскрытая система 105 обработки голоса может динамически повторно взвешивать предварительно определенную акустическую модель как функцию идентификационной информации, предоставленную посредством носимого устройства 110. Поскольку традиционные акустические модели строятся как линейное сочетание векторов признаков, полученных из обучающих наборов при множестве соответствующих сочетаний, и, поскольку множество статических моделей делают плохую работу по обработке речи с акцентом, система 105 обработки голоса может калибровать акустическую модель для конкретного говорящего, идентифицированного посредством носимого устройства 110. Калибровка акустической модели может включать в себя, например, выбор и взвешивание применимых векторов признаков.
[0039] В целом, описанные вычислительные системы и/или устройства могут применять любую из множества компьютерных операционных систем, включающих в себя, но не считающихся ограниченными, версии и/или разновидности операционной системы Ford Sync®, операционной системы Microsoft Windows®, операционной системы Unix (например, операционной системы Solaris®, распространяемой корпорацией Oracle из Редвуд Шорс, Калифорния), операционной системы AIX UNIX, распространяемой компанией International Business Machines из Армонка, Нью-Йорк, операционной системы Linux, операционных систем Mac OS X и iOS, распространяемых компанией Apple Inc. из Купертино, Калифорния, BlackBerry OS, распространяемой компанией Blackberry Ltd из Ватерлоо, Канада, и операционной системы Android, разрабатываемой компанией Google Inc. открытым альянсом мобильных телефонов. Примеры вычислительных устройств включают в себя, без ограничения, бортовой компьютер транспортного средства, компьютерную рабочую станцию, сервер, настольный компьютер, ноутбук, портативный или карманный компьютер или некоторую другую вычислительную систему и/или устройство.
[0040] Вычислительные устройства, в общем, включают в себя компьютерно-читаемые инструкции, причем инструкции могут выполняться посредством одного или более вычислительных устройств, таких как вычислительные устройства, упомянутые выше. Компьютерно-исполняемые инструкции могут быть компилированы или интерпретированы из компьютерных программ, созданных с использованием множества языков и/или технологий программирования, включающих в себя, без ограничения и отдельно или в комбинации, Java™, C, C++, Visual Basic, Java Script, Perl, HTML и т.д. В общем, процессор (например, микропроцессор) принимает инструкции, например, из памяти, компьютерно-читаемого носителя и т.д. и выполняет эти инструкции, за счет этого выполняя один или более процессов, включающих в себя один или более процессов, описанных в данном документе. Такие инструкции и другие данные могут быть сохранены и передаваться с помощью множества компьютерно-читаемых носителей.
[0041] Компьютерно-читаемый носитель (также называемый процессорно-читаемым носителем) включает в себя любой нетранзиторный (например, материальный) носитель, который участвует в предоставлении данных (например, инструкций), которые могут быть считаны компьютером (например, процессором компьютера). Такой носитель может принимать многие формы, включающие в себя, но не только, энергонезависимые носители и энергозависимые носители. Энергонезависимые носители могут включать в себя, например, оптические или магнитные диски и другое постоянное запоминающее устройство. Энергозависимые носители могут включать в себя, например, динамическое оперативное запоминающее устройство (DRAM), которое типично составляет основную память. Такие инструкции могут быть переданы посредством одной или более сред передачи данных, включающих в себя коаксиальные кабели, медный провод и оптические волокна, включающие в себя провода, которые содержат системную шину, соединенную с процессором компьютера. Обычные формы компьютерно-читаемых носителей включают в себя, например, гибкий диск, дискету, жесткий диск, магнитную ленту, любой другой магнитный носитель, CD-ROM, DVD, любой другой оптический носитель, перфорационные карты, бумажную ленту, любой другой физический носитель с рисунками отверстий, RAM, PROM, EPROM, FLASH-EEPROM, любую другую микросхему памяти или картридж, или любой другой носитель, с которого компьютер может выполнять считывание.
[0042] Базы данных, репозитории данных или другие хранилища данных, описанные в данном документе, могут включать в себя различные виды механизмов для сохранения, осуществления доступа и извлечения различных видов данных, включающих в себя иерархическую базу данных, набор файлов в файловой системе, базу данных приложений в собственном формате, систему управления реляционными базами данных (RDBMS) и т.д. Каждое такое хранилище данных, в общем, включается в вычислительное устройство с использованием компьютерной операционной системы, к примеру, одной из компьютерных операционных систем, упомянутых выше, и является доступным через сеть любым одним или более из множества способов. Файловая система может быть доступна из операционной системы компьютера и может включать в себя файлы, сохраненные в различных форматах. RDBMS, как правило, применяет язык структурированных запросов (SQL) в дополнение к языку для создания, хранения, редактирования и выполнения сохраненных процедур, такой как язык PL/SQL, упомянутый выше.
[0043] В некоторых примерах элементы системы могут быть реализованы как компьютерно-читаемые инструкции (например, программное обеспечение) на одном или более вычислительных устройствах (например, серверах, персональных компьютерах и т.д.), сохраненные на считываемых компьютером носителях, ассоциированных с ним (например, дисках, запоминающих устройствах и т.д.). Компьютерный программный продукт может содержать такие инструкции, сохраненные на считываемых компьютером носителях, для выполнения функций, описанных в данном документе.
[0044] Что касается процессов, систем, способов, эвристических правил и т.д., описанных в данном документе, должно быть понятно, что, хотя этапы таких процессов и т.д. были описаны как происходящие согласно некой упорядоченной последовательности, такие процессы могут быть применены на практике с помощью описанных этапов, выполняемых в порядке, отличном от порядка, описанного в данном документе. Дополнительно должно быть понятно, что некоторые этапы могут выполняться одновременно, что другие этапы могут быть добавлены, или что некоторые этапы, описанные в данном документе, могут быть опущены. Другими словами, описания процессов в данном документе предоставлены с целью иллюстрации некоторых вариантов осуществления и не должны никоим образом истолковываться как ограничивающие формулу изобретения.
[0045] Соответственно, должно быть понятно, что вышеприведенное описание предназначено быть иллюстративным, а не ограничивающим. Множество вариантов осуществления и вариантов применения, отличных от предоставленных примеров, должны становиться очевидными после прочтения вышеприведенного описания. Объем должен определяться не со ссылкой на вышеприведенное описание, а вместо этого должен определяться со ссылкой на прилагаемую формулу изобретения, наряду с полным объемом эквивалентов, на которые уполномочена такая формула изобретения. Ожидается и предполагается, что будущие разработки произойдут в технологиях, обсужденных в данном документе, и что раскрытые системы и способы будут включены в такие будущие варианты осуществления. В общем, следует понимать, что заявка допускает модификацию и варьирование.
[0046] Все термины, используемые в формуле изобретения, предполагают получение их обычных значений, которые понятны специалистам, осведомленных в технологиях, описанных в данном документе, пока явное указание на противоположное не будет выполнено в данном документе. В частности, использование элементов или этапов в единственном числе не исключает их множества, пока в формула изобретение в явном виде не указано иное.
[0047] Реферат предоставлен для того, чтобы обеспечивать возможность читателю быстро выявлять характер технического раскрытия сущности. Он представляется с пониманием того, что он не должен использоваться для того, чтобы интерпретировать или ограничивать объем или смысл формулы изобретения. Помимо этого, в вышеприведенном подробном описании можно видеть, что различные признаки группируются в различных вариантах осуществления с целью упрощения раскрытия сущности. Этот способ открытия не должен быть интерпретирован как отражающий замысел того, что заявленные варианты осуществления требуют больше признаков, чем точно перечислено в каждом пункте формулы. Скорее, как отражает последующая формула, изобретенный предмет изучения лежит в менее чем всех признаках одного раскрытого варианта осуществления. Таким образом, последующая формула объединена с разделом «Осуществление изобретения», причем каждый пункт формулы зависит от себя самого, как отдельно заявленный объект изобретения.
Изобретение относится к области транспортных средств. Технический результат – повышение согласованности и точности систем распознавания голоса в транспортном средстве. Голосовой процессор транспортного средства включает в себя устройство обработки и носитель для хранения данных. Устройство обработки запрограммировано с возможностью принимать идентификационную информацию от носимого устройства, идентифицировать говорящего из идентификационной информации, идентифицировать диалект, ассоциированный с говорящим, из идентификационной информации, выбирать предварительно определенную акустическую модель и корректировать предварительно определенную акустическую модель на основе по меньшей мере идентифицированного диалекта. 3 н. и 12 з.п. ф-лы, 5 ил.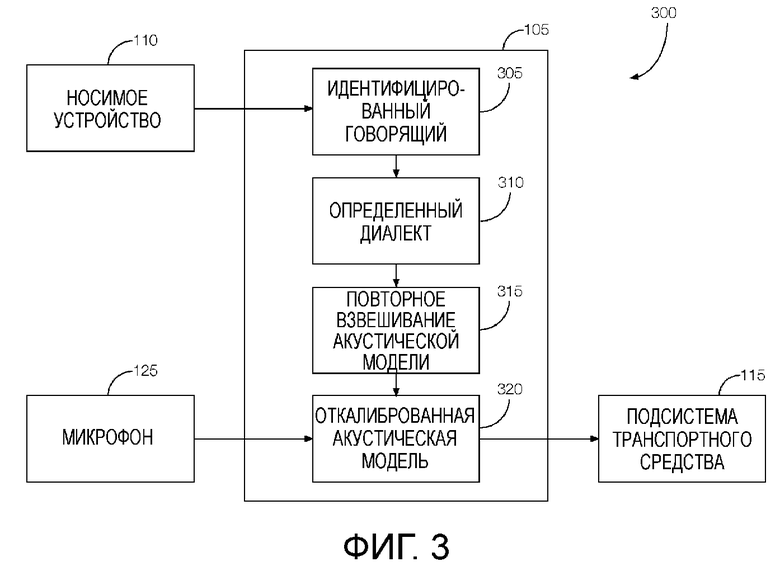
1. Голосовой процессор транспортного средства, содержащий устройство обработки и носитель для хранения данных, при этом устройство обработки запрограммировано с возможностью:
принимать идентификационную информацию от носимого устройства;
идентифицировать говорящего из идентификационной информации;
идентифицировать диалект, ассоциированный с говорящим, из идентификационной информации;
выбирать предварительно определенную акустическую модель; и
корректировать предварительно определенную акустическую модель на основе по меньшей мере частично идентифицированного диалекта;
при этом корректировка предварительно определенной акустической модели включает в себя выбор характеристики речи из множества характеристик речи, и корректировку весового коэффициента, ассоциированного с выбранной характеристикой речи.
2. Голосовой процессор транспортного средства по п. 1, в котором устройство обработки запрограммировано с возможностью формировать откалиброванную акустическую модель на основе по меньшей мере частично предварительно определенной акустической модели, скорректированной в соответствии с диалектом, идентифицированным из идентификационной информации.
3. Голосовой процессор транспортного средства по п. 1, в котором устройство обработки запрограммировано с возможностью применять откалиброванную акустическую модель к акустическому сигналу.
4. Голосовой процессор транспортного средства по п. 3, в котором устройство обработки запрограммировано с возможностью выводить команду транспортному средству на основе по меньшей мере частично акустического сигнала и откалиброванной акустической модели.
5. Голосовой процессор транспортного средства по п. 1, в котором корректировка предварительно определенной акустической модели включает в себя корректировку весового коэффициента, ассоциированного по меньшей мере с одной из множества характеристик речи.
6. Голосовой процессор транспортного средства по п. 5, в котором каждая из множества характеристик речи ассоциирована с фонемой.
7. Голосовой процессор транспортного средства по п. 1, дополнительно содержащий устройство связи, запрограммированное с возможностью соединения с носимым устройством.
8. Голосовой процессор транспортного средства по п. 1, дополнительно содержащий микрофон, выполненный с возможностью принимать аналоговый акустический сигнал.
9. Способ выбора акустической модели на основе принятой идентификационной информации, содержащий этапы, на которых:
принимают идентификационную информацию от носимого устройства;
идентифицируют говорящего из идентификационной информации;
идентифицируют диалект, ассоциированный с говорящим, из идентификационной информации;
выбирают предварительно определенную акустическую модель; и
корректируют предварительно определенную акустическую модель на основе по меньшей мере частично идентифицированного диалекта;
при этом корректировка предварительно определенной акустической модели включает в себя этап, на котором выбирают характеристику речи из множества характеристик речи; и корректировку весового коэффициента, ассоциированного с выбранной характеристикой речи.
10. Способ по п. 9, дополнительно содержащий этап, на котором формируют откалиброванную акустическую модель на основе по меньшей мере частично предварительно определенной акустической модели, скорректированной в соответствии с диалектом, идентифицированным из идентификационной информации.
11. Способ по п. 9, дополнительно содержащий этап, на котором применяют откалиброванную акустическую модель к акустическому сигналу.
12. Способ по п. 11, в котором выводят команду транспортному средству на основе по меньшей мере частично акустического сигнала и откалиброванной акустической модели.
13. Способ по п. 9, в котором корректировка предварительно определенной акустической модели включает в себя корректировку весового коэффициента, ассоциированного по меньшей мере с одной из множества характеристик речи.
14. Способ по п. 13, в котором каждая из множества характеристик речи ассоциируется с фонемой.
15. Система транспортного средства, содержащая:
устройство связи, запрограммированное с возможностью соединения с носимым устройством;
микрофон, выполненный с возможностью принимать акустический сигнал; и
голосовой процессор, запрограммированный с возможностью принимать идентификационную информацию от носимого устройства, идентифицировать говорящего из идентификационной информации, идентифицировать диалект, ассоциированный с говорящим, из идентификационной информации, выбирать предварительно определенную акустическую модель, корректировать предварительно определенную акустическую модель на основе по меньшей мере частично идентифицированного диалекта, чтобы формировать откалиброванную акустическую модель, и применять откалиброванную акустическую модель к акустическому сигналу;
при этом корректировка предварительно определенной акустической модели включает в себя выбор характеристики речи из множества характеристик речи, и корректировку весового коэффициента, ассоциированного с выбранной характеристикой речи.
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| US 2015112684 A1, 23.04.2015 | |||
| СИСТЕМА И СПОСОБ ОСЛАБЛЕНИЯ ЗВУКА В ТРАНСПОРТНОМ СРЕДСТВЕ ДЛЯ ПРОСЛУШИВАНИЯ УКАЗАНИЙ ОТ МОБИЛЬНЫХ ПРИЛОЖЕНИЙ | 2014 |
|
RU2627127C2 |
| УСТРОЙСТВО И СПОСОБ УПРАВЛЕНИЯ РАБОТОЙ В КОНФИДЕНЦИАЛЬНОМ РЕЖИМЕ В ТРАНСПОРТНОМ СРЕДСТВЕ | 2010 |
|
RU2536336C2 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| СПОСОБ ПОЛУЧЕНИЯ ГИДРИРОВАННОГО НИТРИЛЬНОГО КАУЧУКА, ОБЛАДАЮЩЕГО НИЗКОЙ МОЛЕКУЛЯРНОЙ МАССОЙ | 2010 |
|
RU2548681C9 |
| Токарный резец | 1924 |
|
SU2016A1 |

