Изобретение было сделано при правительственной поддержке, контракт № В600738, заключенный Министерством энергетики. Правами на это изобретение обладает правительство.
Область техники, к которой относится изобретение
Это описание относится к вычислительным системам, в частности (но, не ограничиваясь) к накристальным межсоединениям.
Краткое описание чертежей
На фиг. 1А приведена структурная схема совокупности или группировки ядер процессора или SoC в соответствии с вариантом осуществления изобретения.
На фиг. 1В структурная схема нескольких процессорных площадок в соответствии с вариантом осуществления.
На фиг. 2 приведена структурная схема SoC или другого процессора в соответствии с вариантом осуществления изобретения.
На фиг. 3 приведена структурная схема сетевого коммутатора в соответствии с вариантом осуществления изобретения.
На фиг. 4 приведена блок-схема последовательности операций маршрутизации пакетов через сетевой коммутатор в соответствии с вариантом осуществления изобретения.
На фиг. 5 приведена структурная схема системы в соответствии с вариантом осуществления изобретения.
На фиг. 6 приведена структурная схема примера системы, в которой могут применяться варианты осуществления.
На фиг. 7 приведена структурная схема другого примера системы, в которой могут применяться варианты осуществления.
На фиг. 8 приведена структурная схема однокристальной системы в соответствии с вариантом осуществления.
На фиг. 9 приведена структурная схема системы в соответствии с вариантом осуществления изобретения.
Подробное описание изобретения
По мере развития компьютерной технологии все большую вычислительную мощность можно реализовать на одном полупроводниковом кристалле. В настоящее время доступны процессоры, имеющие 4, 8 или больше ядер. Ожидается, что будущие процессоры смогут объединять сотни или даже тысячи малых вычислительных ядер на одном кремниевом кристалле. Тем не менее существующие в настоящее время структуры межсоединений не могут эффективно масштабироваться на такое большое число узлов, особенно с минимальным энергопотреблением и запаздыванием, обеспечивая при этом приемлемую полосу пропускания. Обычные сетевые топологии, включая топологии двумерной сети, кольцевой шины или кольцевой сети, не могут эффективно увеличиваться для таких ожидаемых процессоров, что приводит к избыточным задержкам и чрезмерному энергопотреблению, в основном, из-за большого числа промежуточных транзитных участков и буферизации в сети.
В различных вариантах осуществления предложена топология накристального межсоединения, чтобы использовать имеющиеся в изобилии ресурсы межсоединений, выполненных посредством существующей технологии производства полупроводниковых приборов, и уникальные свойства запаздывания/энергетические свойства/полосу частот/ретрансляционный интервал иерархического построения стека металлических слоев. Таким образом, структура межсоединения в соответствии с вариантом осуществления может достичь масштабируемости сети до 1000 узлов с низкой задержкой/энергопотреблением и приемлемой полосой пропускания для эффективности приложения.
Варианты осуществления задействуют наличие узлов усовершенствованной технологии для субмикронной технологии производства полупроводниковых приборов. В качестве примера металлический стек, приспособленный для полупроводникового кристалла, обеспечивает богатое множество металлических ресурсов (например, 9 или более слоев). В варианте осуществления для структуры накристального межсоединения может использоваться 4 или более таких металлических слоев. Каждый металлический слой обладает различными характеристиками, включая, но, не ограничиваясь, различную ширину/интервал/свойства материала. В качестве примеров различные слои могут обладать различными энергетическими характеристиками (например, энергия/миллиметр(мм)), характеристиками запаздывания (например, задержка/мм), характеристиками полосы пропускания (число соединений/мм) и характеристиками оптимального ретрансляционного интервала. Отметим, что в некоторых вариантах осуществления размер ядер или других вычислительных схем, которые необходимо соединить между собой, может быть меньше, чем оптимальный ретрансляционный интервал для металлических слоев более высокого уровня, и можно избавиться от необходимости ретрансляторов как таковых, а соединения в металлических слоях более высокого уровня (которые могут быть больше и/или толще, чем в металлических слоях более низкого уровня) могут обеспечить меньшее запаздывание и пересекать/проходить через несколько ядер за один такт.
Структура межсоединения в соответствии с вариантом осуществления может использовать иерархию соединений, в которой слои более низкого/среднего уровня включают в себя проводники, имеющие достаточную полосу пропускания, чтобы соединять кластеры соседних ядер (или группы ядер) посредством межсоединения "точка - точка". В свою очередь, металлические слои более высокого уровня включают в себя проводники, которые проходят через несколько групп ядер и соединяют их за один такт посредством межсоединения "точка - группа точек". Варианты осуществления обеспечивают топологию иерархической сети, имеющую горизонтальную иерархию логических переключателей и иерархии проводников, которые иерархически соединяют физически/логически смежные и отдаленные узлы. Из-за малого размера ядер (узлов) может быть нереально выстроить переключатели горизонтально поядерно, а вместо этого горизонтальная топология может быть выполнена на группах ядер.
Топология, как описано в этом документе, охватывает горизонтально выстроенные коммутаторы высокой степени связности, которые соединены между собой посредством иерархических межсоединений "точка - точка" и "точка - группа точек". Приведение коммутатора с повышенной связностью к горизонтальной структуре для иерархических проводников коммутатора увеличивает степень связности коммутатора, минимизируя число транзитных участков и общее запаздывание/энергопотребление сети. Энергопотребление отдельного коммутатора существенно не увеличивается (в первом приближении), пока полоса пропускания остается постоянной. Топологию сети можно оптимизировать для заданной технологии (ресурсов), числа ядер и прикладных требований путем поиска компромисса между степенью связности коммутатора, полосой пропускания и протяженностью и числом ответвлений иерархических проводников. Например, выбор ширины/интервала металлических слоев определяет компромисс между полосой пропускания/запаздыванием. Широкие металлические проводники с большим интервалом дают низкое запаздывание за счет меньшей полосы пропускания (число проводников на мм). Аналогично, если размер ядра уменьшить, то за один такт можно соединить больше ядер.
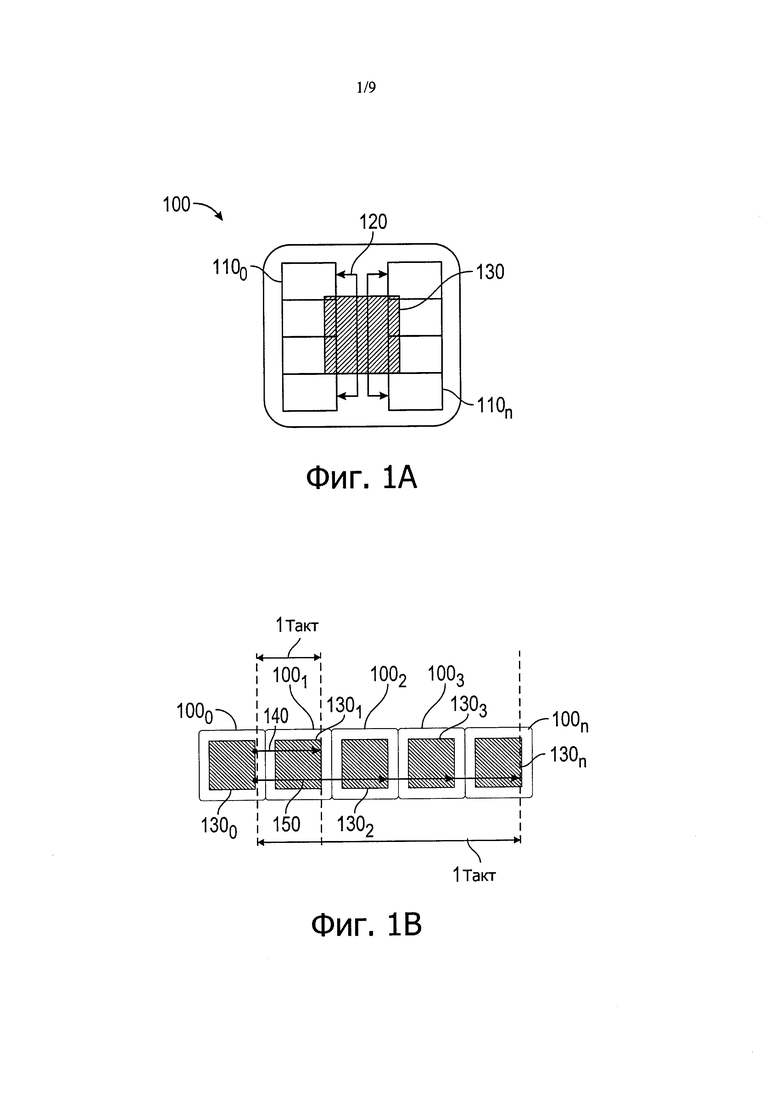
Более конкретно, в вариантах осуществления применяется коммутатор горизонтальной структуры на каждой площадке. Группы из N ядер (площадка) совместно используют сетевой коммутатор. Ядра на площадке соединены с использованием сети перекрестных соединений. Теперь обратимся к фиг. 1А, здесь приведена структурная схема совокупности или группировки ядер процессора или SoC в соответствии с вариантом осуществления изобретения. На фиг. 1А совокупность 100 можно называть доменом или площадкой. В некоторых вариантах осуществления площадки могут представлять собой области с независимым напряжением и частотой. Как видно, имеется несколько ядер 1100-110n. Хотя варианты осуществления отличаются, в показанном примере имеется 8 ядер; тем не менее понятно, что на данной площадке в различных вариантах осуществления может иметься больше или меньше ядер.
Ядра 110 соединены друг с другом через межсоединение 120 первой топологии. В качестве примера межсоединение 120 может представлять собой сеть перекрестных соединений, чтобы ядра могли сообщаться друг с другом. Площадка 100 также включает в себя сетевой коммутатор 130. В варианте осуществления коммутатор 130 представляет собой коммутатор высокой степени связности. Коммутатор 130 обеспечивает взаимное соединение и связь между ядрами в совокупности 100 и другими участками процессора или SoC (и, в свою очередь, с элементами за пределами микросхемы). Кроме того, как будет описано в этом документе, сетевой коммутатор 130 может осуществлять связь с другими доменами или площадками через межсоединения различных типов, где по меньшей мере часть этих межсоединений выполнена на различных металлических слоях построенного стека. Путем использования характеристик различных металлических слоев этого построенного стека, которые сами обладают различными свойствами, среди других рабочих характеристик меняют рабочие характеристики самих межсоединений, такие как запаздывание, полоса пропускания. Такие характеристики могут являться функцией выбора ширины/интервала металлических проводов. Более низкие слои могут быть расположены с меньшими интервалами и могут быть уже, что дает большую полосу частот (на мм) и большее запаздывание из-за повышенного сопротивления. Более высокие слои имеют большую ширину и расположены с большими интервалами, и в результате получается меньшая полоса пропускания (на мм), но меньшее запаздывание из-за снижения сопротивления.
В примере осуществления первое множество выходных портов сетевого коммутатора 130 сообщается со смежными доменами или площадками через межсоединения "точка - точка" (не показано для простоты иллюстрации на фиг. 1А). В свою очередь, второе множество выходных портов сетевого коммутатора 130 сообщается с несмежными доменами или площадками через межсоединения "точка - группа точек" (не показано для простоты иллюстрации на фиг. 1А). Понятно, что хотя пример на фиг. 1А показан на высоком уровне, возможно множество изменений и альтернатив.
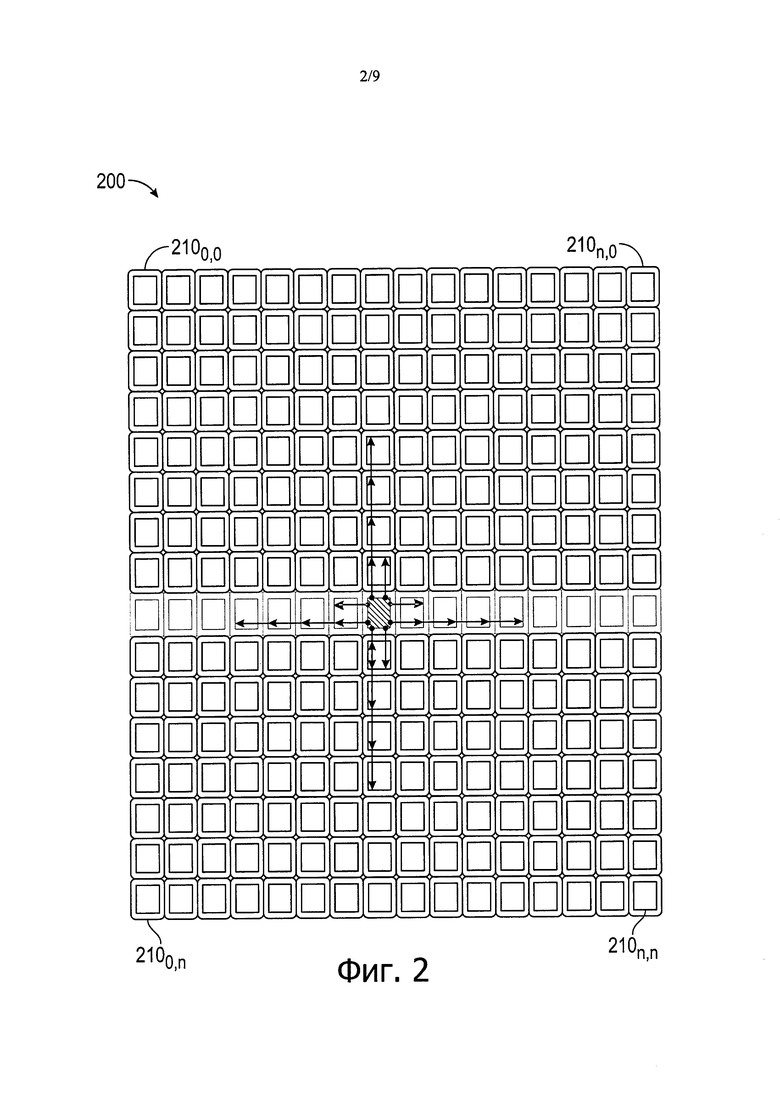
Со ссылкой на фиг. 1В показана структурная схема нескольких процессорных площадок в соответствии с вариантом осуществления. Как видно, имеется пять площадок ядер 1100-110n. Хотя пример показан на высоком общем уровне, понятно, что каждая площадка может включать в себя однородные ресурсы, которые могут включать в себя несколько ядер (например, 8), сеть перекрестных соединений и коммутатор. При использовании уникальных характеристик различных металлических слоев, на которых выполнены по меньшей мере части межсоединений, которые связывают друг с другом различные площадки, могут возникать различные запаздывания. Таким образом, как видно на фиг. 1В, за один такт (например) первый выходной порт сетевого коммутатора 1300 выдает выходной блок (например, пакет) на соответствующий входной порт сетевого коммутатора 1301 смежной площадки 1001 через межсоединение 140, которое в варианте осуществления реализовано в виде межсоединения "точка - точка", выполненное по меньшей мере частично на первом металлическом слое (например, на металлическом слое среднего уровня построенного стека). Между тем второй выходной порт сетевого коммутатора 1300 выдает выходной блок на соответствующий входной порт нескольких сетевых коммутаторов, а именно, сетевых коммутаторов 1302, 1303 и 130n. Отметим, что эта передача от этого выходного порта сетевого коммутатора 1300 может осуществляться через межсоединение 150 "точка - группа точек", выполненное по меньшей мере частично на втором металлическом слое (например, на более высоком металлическом слое построенного стека, по меньшей мере более высокого, чем металлический слой среднего уровня).
Хотя описание было приведено на примере, показанном на фиг. 1В, понятно, что варианты осуществления не ограничены многоточечными межсоединениями, которые связывают только три несмежных площадки. В других вариантах осуществления такие межсоединения могут связывать дополнительные несмежные межсоединения (и, как вариант, также могут связывать смежные площадки). Более того, хотя описание было приведено для запаздывания связи на один такт, понятно, что объем изобретения в этом отношении не ограничен, и в других примерах запаздывание связи до данного пункта назначения, с которым связано межсоединение, может быть меньше или больше, чем один такт.
В одном примере структура накристального межсоединения может быть реализована для SoC эксафлопсного класса или процессора, имеющего следующие компоненты: 2048 ядер, организованных в виде 256 площадок по 8 ядер на площадке в сети узлов 16×16 и с одним коммутатором на площадку. В этом примере топологии каждый сетевой коммутатор может включать в себя несколько выходных портов, причем четыре порта предназначены для связи с ближайшими соседями в четырех направлениях, и четыре порта - для связи с межсоединениями "точка - группа точек", охватывающими четыре площадки в каждом направлении. Другое предположение этой конструкции включает в себя упорядоченную по измерениям XY маршрутизацию с двумя виртуальными каналами (по одному для запроса и ответа), размером пакета 64 байта (Б) и минимальную входящую полосу пропускания 64 гигабайт в секунду (ГБ/с) на площадку при случайном равномерном трафике.
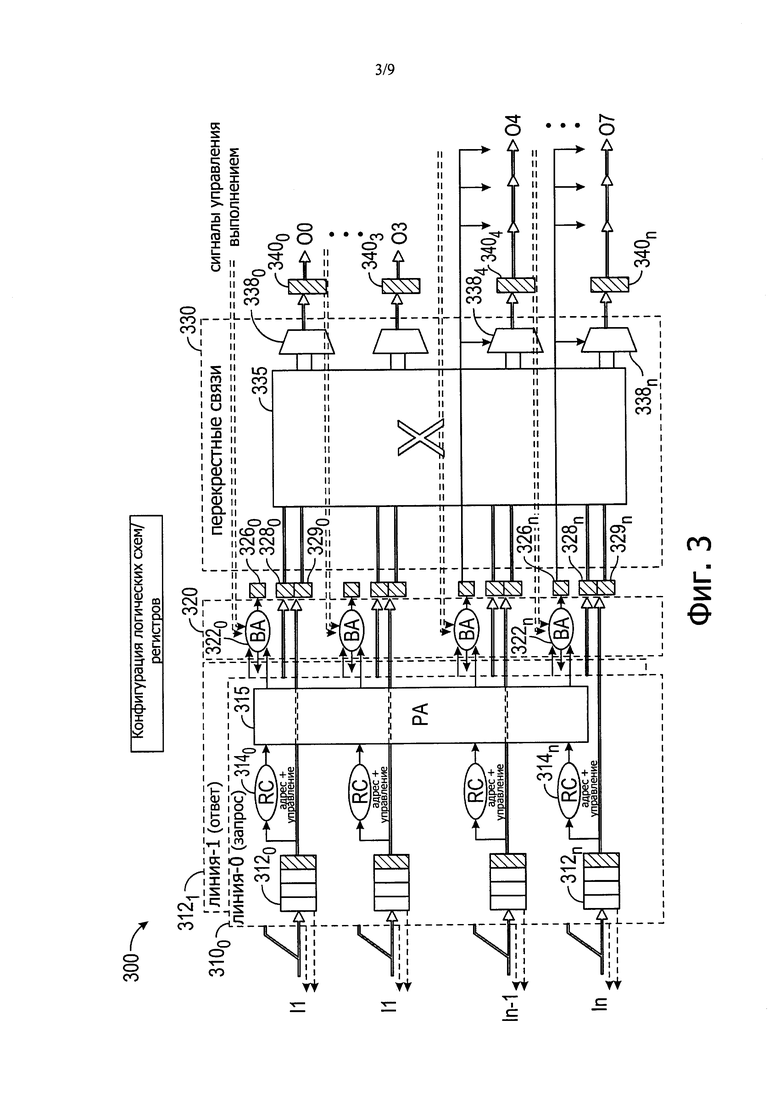
Со ссылкой на фиг. 2 приведена структурная схема SoC или другого процессора в соответствии с вариантом осуществления изобретения. В примере на фиг. 2 процессор 200 представляет собой процессор эксафлопсного класса, включающий в себя очень большое число ядер. В качестве примера может быть 1024 или 2048 ядер. В общем, ядра могут быть выстроены по площадкам. На высоком уровне показано, что имеется матрица 16×16 площадок 2100,0-210n,n. Каждая площадка может включать в себя заданное число ядер. В различных примерах могут быть предусмотрены однородные ядра или смесь различных ядер. Чтобы обеспечить межсоединение, структура накристального межсоединения может быть реализована посредством нескольких сетевых коммутаторов, например сетевых коммутаторов с высокой степенью связности, имеющихся на каждой площадке, в целом, выполненных так, как описано выше касательно фиг. 1А и 1В.
В связи с этим каждый сетевой коммутатор 130 осуществляет связь через межсоединение первого типа (а именно межсоединение "точка - точка") со смежными по направлению X и по направлению Y площадками (понятно, что площадки на периметре кристалла могут не быть связанными с четырьмя смежными площадками). Кроме того, каждый сетевой коммутатор 130 также осуществляет связь через межсоединение второго типа (а именно межсоединение "точка - группа точек") с несмежными площадками.
Отметим, что топология в соответствии с вариантом осуществления может достичь меньшего запаздывания в условиях низкой загрузки, и для такой же полосы пропускания достигает до трех раз большей входящей скорости до насыщения сети при случайном равномерном трафике по сравнению с сетью с двумерной сетчатой структурой. Для сильно локализованной модели трафика между ближайшими соседями топология работает не хуже сети с двумерной сетчатой структурой.
Понятно, что топология на фиг. 2 является общим примером топологии, а точные спецификации могут быть основаны на выборе технологии, параметрах схемы, числе/размере ядер и т.д. Таким образом, варианты осуществления обеспечивают гибкую реализацию структуры накристального межсоединения. Отметим, что протяженность и число транзитных участков каждого межсоединения "точка - группа точек" могут быть заданы спецификацией основной технологии (например, числом металлических слоев, числом проводов/мм, оптимальным ретрансляционным интервалом и т.д.), параметрами схемы (например, помимо прочего, напряжением, периодом тактовых импульсов) и числом ядер. Эти аспекты могут быть сбалансированы относительно желаемого диаметра сети (энергопотребления/запаздывания) и полосы пропускания. Для заданной входящей/исходящей полосы пропускания сетевого коммутатора большее число проводников/мм для металлических слоев среднего уровня можно использовать для обеспечения большей полосы пропускания для локальной связи.
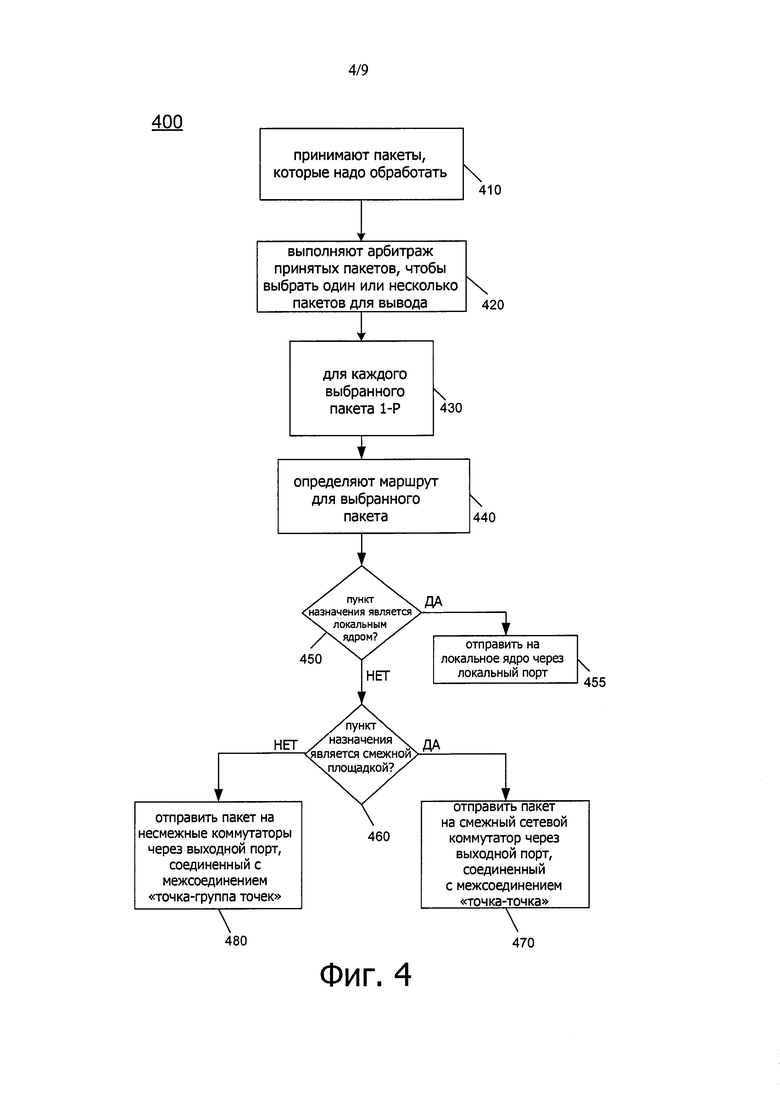
Теперь со ссылкой на фиг. 3 приведена структурная схема сетевого коммутатора в соответствии с вариантом осуществления изобретения. Как показано на фиг. 3, сетевой коммутатор 300 может быть реализован на различных доменах или площадках процессоров или SoC. Используя этот коммутатор, можно выполнить различную маршрутизацию, арбитраж и связанные с этим операции. Как видно, сетевой коммутатор 300 принимает вход через несколько входных портов I0-In, которые выполнены с возможностью принимать входные сигналы от других площадок (например, через межсоединения "точка - точка" или межсоединения "точка - группа точек"). Другие входные порты могут быть соединены с различными локальными ядрами площадки, в которой расположен сетевой коммутатор 300. В связи с этим число входных портов больше, чем число выходных портов (в показанном варианте осуществления выполнены выходные порты О0-О7).
Относительно поступающей информации, которая может быть в виде информации запроса или информации ответа, поступающую информацию подают на соответствующую линию или виртуальный канал 3100, который соответствует виртуальному каналу запроса, и виртуальный канал 3101, который соответствует виртуальному каналу ответа. Как видно, каждый канал включает в себя множество независимых буферов 3120-312n. Входящую информацию, которая может быть принята в виде заданных входных блоков, например, с размером пакетов для заданного процессора, подают на логическую схему 3140-314n вычисления маршрутизации, чтобы определить соответствующий пункт назначения для передачи, например, исходя из адреса и управляющей информации, включенной в данный пакет. На основе этой информации определения маршрута может быть выполнен арбитраж портов в устройстве 315 разрешения конфликтов портов, чтобы определить соответствующий выходной порт, к которому надо доставить данный пакет.
Тем не менее перед выводом сначала происходит арбитраж шины в устройстве 320 разрешения конфликтов шины. Как видно, на этой стадии арбитража полагается, что информация управления выполнением определяет, имеет ли данный пункт назначения достаточные ресурсы, чтобы принять соответствующий пакет. Таким образом, как видно, информация управления выполнением может быть предоставлена в виде обратной связи в устройство 320 разрешения конфликтов шины (и более конкретно на независимые логические схемы 3220-322n арбитража шины).
Пакеты после арбитража из соответствующих логических схем 322 разрешения конфликтов шины поступают на соответствующие конвейерные каскады 3260, 3280, 3290-326n, 328n, 329n. Как видно, пакеты передают на перекрестный маршрутизатор 330, включающий в себя логическую схему 335 перекрестных соединений. Таким образом, пакеты могут быть переданы на выбранный пункт назначения (включая локальные ядра, соединенные с сетью 330 перекрестных соединений, не показанные на фиг. 3 для простоты иллюстрации). Как показано, для того, чтобы выдать пакет из заданного выходного порта сетевого коммутатора 300, передачу осуществляют через соответствующий селектор или мультиплексор 3380-3387. Выходные пакеты, как таковые, передают либо на смежные площадки через конвейерные каскады 3400-3403, соединенные с выходными портами О0-О3 (каждый из которых, в свою очередь, соединен с межсоединением типа "точка - точка"), где пакеты могут быть переданы с запаздыванием на один такт на смежные сетевые коммутаторы смежных площадок. Наоборот, пакеты, которые необходимо передать на одну из нескольких несмежных площадок через соответствующие сетевые коммутаторы, отправляют из мультиплексоров 3384-3387 и через соответствующие конвейерные каскады 3404-3407 на соответствующие выходные порты O4-O7 (каждый из которых, в свою очередь, соединен с межсоединением типа "точка - группа точек").
Таким образом, как показано, сетевой коммутатор 300 представляет собой коммутатор высокой степени связности для накристальной структуры. Хотя на этой конкретной иллюстрации показано, что имеются отдельные линии или виртуальные каналы для запросов и ответов, понятно, что изобретение в этом отношении не ограничено, и что в других реализациях могут быть выполнены дополнительные или другие виртуальные каналы.
Теперь со ссылкой на фиг. 4 показана блок-схема последовательности операций маршрутизации пакетов через сетевой коммутатор в соответствии с вариантом осуществления изобретения. Как показано на фиг. 4, способ 400 может быть выполнен с применением различных логических схем в сетевом коммутаторе. Как видно, способ 400 начинается с приема множества пакетов, которые необходимо обработать (блок 410). Такие пакеты могут быть приняты в сетевом коммутаторе от локальных относительно него ядер, а также от межсоединений "точка - точка" и "точка - группа точек", связанных с различными входными портами сетевого коммутатора. Затем в блоке 420 может быть выполнен арбитраж, чтобы определить подходящие пакеты для выхода. Арбитраж может быть основан на алгоритме кругового обслуживания с учетом равнодоступности, так что пакеты из определенных источников не задерживаются и не предотвращают передачу пакетов из других источников. Также арбитраж, включая арбитраж порта и арбитраж шины, может учитывать информацию управления выполнением, так что не выбирают пакеты, где пункт назначения не обладает достаточными ресурсами для обработки входящих пакетов.
Также со ссылкой на фиг. 4, далее, в блоке 430 логической схемой сетевого коммутатора для каждого данного пакета, который надо подать на выход (например, 1-Р, где выходных портов меньше, чем входных портов), может быть выполнена обработка. Как видно, может быть определена (блок 440) маршрутизация для выбранного пакета. Затем на основе маршрутизации можно определить, является ли пункт назначения локальным ядром (ромб 450). Если является, то управление для данного пакета переходит на блок 455, где он может быть передан на локальное ядро через локальный порт (который может быть частью сети перекрестных соединений, чтобы, таким образом, передать пакет на внутреннее ядро площадки).
Наоборот, если пункт назначения не является локальным ядром, управление переходит на ромб 460, чтобы определить, находится ли пункт назначения на смежной площадке. Если так, то управление переходит на блок 470, где пакет может быть отправлен на смежный сетевой коммутатор через выходной порт, который соединен с межсоединением "точка - точка". В противном случае, если пункт назначения не является смежной площадкой, то управление переходит на блок 480, где пакет может быть отправлен на множество несмежных сетевых коммутаторов через выходной порт, соединенный с межсоединением "точка - группа точек". Отметим, что при отправлении пакета на межсоединение "точка - группа точек" также могут быть переданы управляющие сигналы на боковой полосе, чтобы гарантировать, что пакет подан на коммутатор, который должен действовать только в качестве транзитного, перенаправляя пакет на конечный пункт назначения (что может быть основано на таблицах маршрутизации в данных сетевых коммутаторах). Таким образом, пакет не попадет на другие коммутаторы (не являющиеся пунктом назначения/не являющиеся транзитными), соединенные с межсоединением. Таким образом, при использовании информации межсоединения в боковой полосе для пакета не должно выполняться вычисление маршрута на коммутаторах, не являющихся пунктом назначения. Хотя на высоком уровне на фиг. 4 показан вариант осуществления, понятно, что объем изобретения не ограничен в этом отношении.
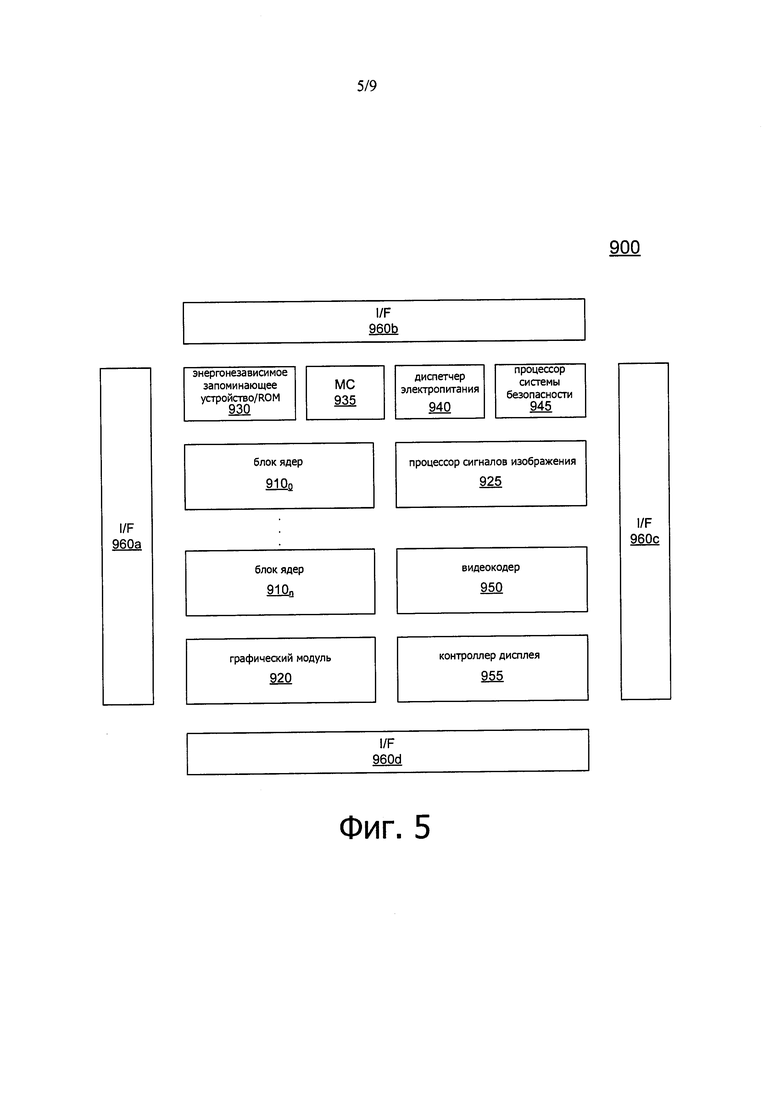
Понятно, что процессоры или SoC эксафлопсного класса (или другие интегральные схемы), включающие в себя накристальные межсоединения, как описано выше, могут использоваться во многих различных системах, начиная от небольших портативных устройств, заканчивая высокопроизводительными вычислительными системами и сетями. Теперь со ссылкой на фиг. 5 приведена структурная схема системы в соответствии с вариантом осуществления изобретения. В варианте осуществления на фиг. 5 система 900 может представлять собой SoC, включающую в себя несколько доменов, каждый из которых может работать на независимом рабочем напряжении и рабочей частоте. Отметим, что каждый из доменов может быть однородной площадкой, включающей в себя сетевой коммутатор, соединенной, как описано выше. В качестве характерного иллюстративного примера система 900 может быть SoC на основе архитектуры Intel® Core™, такой как i3, i5, i7, или другим процессором от корпорации Intel. Тем не менее вместо них в других вариантах осуществления, таких как процессор Apple А7, процессор Qualcomm Snapdragon или ОМАР процессор от Texas Instruments, могут присутствовать другие SoC или процессоры малой мощности, например, от корпорации Advanced Micro Devices, Inc. (AMD), г. Саннивейл (США, штат Калифорния), на основе ARM-архитектуры от ARM Holdings, Ltd, или их лицензиаты, или на основе MIPS-архитектуры от MIPS Technologies, Inc., г. Саннивейл (США, штат Калифорния), или их лицензиаты или последователи. Такая SoC может использоваться в системе малой мощности, такой как смартфон, планшетный компьютер, фаблет, Ultrabook™, устройство IoT, носимое или другое портативное вычислительное устройство.
На приведенной на фиг. 5 высокоуровневой схеме SoC 900 включает в себя несколько блоков 9100-910n ядер. Каждый блок ядер может включать в себя одно или несколько ядер, одну или несколько кэш-памятей и другие схемы. Каждый блок 910 ядер может поддерживать один или несколько наборов инструкций (например, набор инструкций х86 (с некоторыми расширениями, которые были добавлены в новых версиях); набор инструкций MIPS; набор инструкций ARM (с опциональными дополнительными расширениями, такими как NEON)) или другие наборы инструкций или их сочетания. Отметим, что некоторые из блоков ядер могут представлять собой разнотипные ресурсы (например, различных конструкций). Кроме того, каждое такое ядро может быть соединено с кэш-памятью (не показана), которая в варианте осуществления может представлять собой общую кэш-память второго уровня (L2). Энергонезависимое запоминающее устройство 930 может использоваться для хранения различных программ и других данных. Например, это запоминающее устройство может использоваться для хранения по меньшей мере частей микрокода, загрузочной информации, такой как BIOS, другого системного программного обеспечения и так далее.
Каждый блок 910 ядер также может включать в себя интерфейс, такой как сетевой интерфейс для возможности соединения с дополнительной схемой SoC. В варианте осуществления каждый блок 910 ядер соединен с когерентной структурой, образованной из накристального межсоединения, которая может действовать в качестве первичного кэша, связанного с накристальным межсоединением, которое, в свою очередь, соединяется с контроллером 935 памяти. В свою очередь, контроллер 935 памяти управляет связью с памятью, такой как DRAM (не показана для простоты иллюстрации на фиг. 5).
В дополнение к блокам ядер, в процессоре имеются дополнительные механизмы обработки, включая по меньшей мере один графический модуль 920, который может включать в себя один или несколько графических процессоров (GPU) для выполнения обработки графических данных, а также, возможно, для выполнения операций общего назначения на графическом процессоре (так называемых операций GPGPU (графического процессора общего назначения)). Кроме того, может иметься по меньшей мере один процессор 925 сигнала изображения. Процессор 925 сигнала может быть выполнен с возможностью обрабатывать поступающие данные изображения, принимаемые от одного или нескольких захватывающих устройств, либо находящихся в SoC, либо за пределами микросхемы.
Также могут присутствовать другие ускорители. На иллюстрации на фиг. 5, видеокодер 950 может выполнять операции кодирования, включая кодирование и декодирование видеоинформации, например, обеспечивая поддержку аппаратного ускорения для видеоконтента высокой четкости. Также может быть выполнен контроллер 955 дисплея для ускорения операций отображения, включая обеспечение поддержки для внутренних и внешних дисплеев системы. Кроме того, может иметься процессор 945 системы безопасности для выполнения операций по обеспечению безопасности. Каждый из блоков может обладать собственным энергопотреблением, управляемым посредством диспетчера 940 электропитания, который может включать в себя управляющую схему для реализации различных технологий управления питанием.
В некоторых вариантах осуществления SoC 900 также может включать в себя некогерентную структуру, связанную с когерентной структурой, с которой могут быть соединены различные периферийные устройства. Один или несколько интерфейсов 960а-960d позволяют осуществлять связь с одним или несколькими устройствами за пределами микросхемы. Такая коммуникация может выполняться в соответствии с различными протоколами связи, такими как PCIe™, GPIO, USB, I2C, UART, MIPI, SDIO, DDR, SPI, HDMI, помимо других типов протоколов связи. Хотя на высоком уровне на фиг. 5 показан вариант осуществления, понятно, что объем изобретения не ограничен в этом отношении.
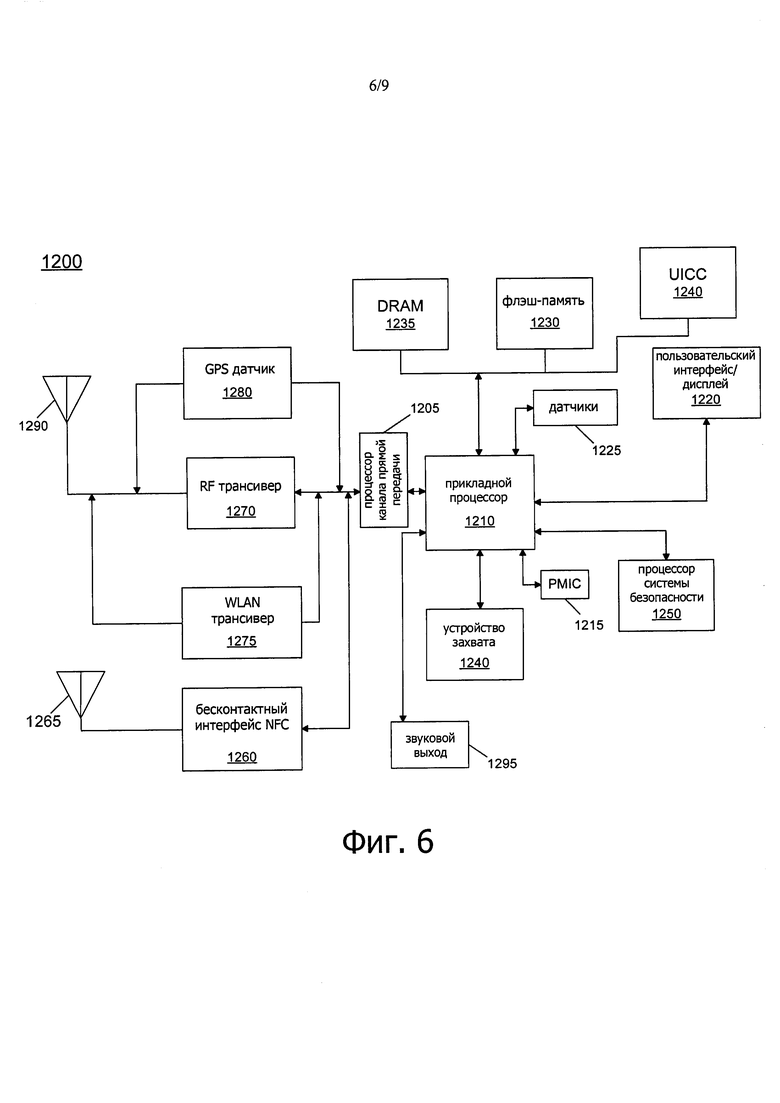
Теперь со ссылкой на фиг. 6 приведена структурная схема примера системы, в которой могут применяться варианты осуществления. Как видно, система 1200 может представлять собой смартфон или другое беспроводное устройство связи. Процессор 1205 канала прямой передачи выполнен с возможностью осуществлять различную обработку сигналов в отношении сигналов связи, которые необходимо передать от или принять посредством системы. В свою очередь, процессор 1205 канала прямой передачи соединен с прикладным процессором 1210, который может представлять собой основную SoC системы для выполнения ОС и другого системного программного обеспечения в дополнение к пользовательским приложениям, таким как широко известные мультимедийные и социальные приложения. Прикладной процессор 1210 также может быть выполнен с возможностью выполнять различные другие вычислительные операции для устройства и может включать в себя архитектуру накристального межсоединения, как описано в этом документе.
В свою очередь, прикладной процессор 1210 может соединяться с пользовательским интерфейсом/дисплеем 1220, например с сенсорным экраном. Кроме того, прикладной процессор 1210 может соединяться с системой памяти, включая энергонезависимую память, а именно флэш-память 1230, и системную память, а именно динамическую оперативную память (DRAM) 1235. Как также видно, прикладной процессор 1210 также связан с устройством 1240 захвата, таким как одно или несколько устройств захвата видео, которые могут записывать видео и/или неподвижные изображения.
Также, обращаясь к фиг. 6, универсальная карта 1240 с интегральной схемой (UICC), содержащая модуль идентификации абонента и, возможно, защищенное запоминающее устройство и криптопроцессор, также связана с прикладным процессором 1210. Система 1200 также может включать в себя процессор 1250 системы безопасности, который может быть связан с прикладным процессором 1210. Несколько датчиков 1225 могут быть соединены с прикладным процессором 1210 для ввода различных сигналов от датчиков, таких как акселерометр, и другой информации об окружающей среде. Устройство 1295 вывода звука может обеспечивать интерфейс для вывода звука, например, в виде речевых сообщений, воспроизводимых или потоковых звуковых данных и так далее.
Как также показано, имеется бесконтактный интерфейс 1260 беспроводной связи ближнего радиуса действия (NFC), который осуществляет связь в ближней зоне NFC через NFC-антенну 1265. Хотя на фиг. 6 показана отдельная антенна, понятно, что в некоторых реализациях может быть выполнена одна антенна или другой набор антенн для обеспечения различной беспроводной функциональности.
Интегральная схема 1215 управления питанием (PMIC) соединена с прикладным процессором 1210 для осуществления управления питанием на уровне платформы. Для этого PMIC 1215 может выдавать запросы управления питанием, чтобы прикладной процессор 1210 при необходимости переходил в определенные состояния с низким энергопотреблением. Более того, исходя из ограничений платформы, PMIC 1215 также может управлять уровнем энергопотребления других компонентов системы 1200.
Чтобы можно было принимать и отправлять сообщения, между процессором 1205 канала прямой передачи и антенной 1290 могут быть выполнены различные схемы. В частности, может иметься радиочастотный (RF) трансивер 1270 и трансивер 1275 беспроводной локальной сети (WLAN). В общем, RF трансивер 1270 может использоваться для приема и передачи беспроводных данных и вызовов в соответствии с заданным протоколом беспроводной связи, таким как протокол беспроводной связи 3G или 4G, например в соответствии со стандартом множественного доступа с кодовым разделением каналов (CDMA), стандартом глобальной системы мобильной связи (GSM), стандартом "Долгосрочное развитие" (LTE), или другой протокол. В дополнение может иметься GPS датчик 1280. Также могут быть обеспечены другие виды беспроводной связи, как, например, прием или передача радиосигналов, например AM/FM и других сигналов. Кроме того, также может быть реализован WLAN трансивер 1275, локальная беспроводная связь, например, в соответствии со стандартом Bluetooth™ или стандартом IEEE 802.11, таким как IEEE 802.11a/b/g/n.
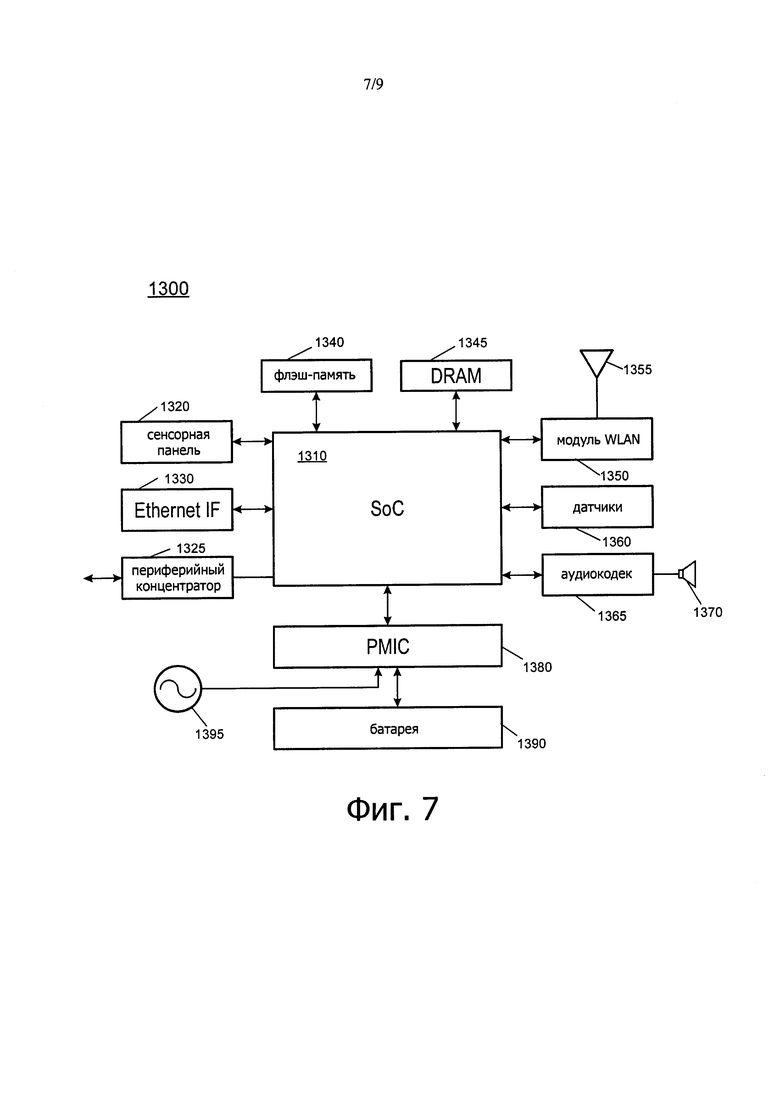
Теперь со ссылкой на фиг. 7 приведена структурная схема другого примера системы, в которой могут применяться варианты осуществления. На иллюстрации на фиг. 7 система 1300 может представлять собой мобильную маломощную систему, такую как планшетный компьютер, 2:1 планшет, фаблет, или другую трансформируемую или отдельную планшетную систему. Как показано, имеется SoC 1310, и она может быть выполнена с возможностью работать в качестве прикладного процессора устройства. SoC 1310 может включать в себя архитектуру накристального межсоединения, как описано в этом документе.
С SoC 1310 могут быть связаны различные устройства. На показанной иллюстрации подсистема памяти включает в себя флэш-память 1340 и DRAM 1345, соединенные с SoC 1310. Кроме того, с SoC 1310 соединена сенсорная панель, чтобы обеспечить возможность отображения и ввода данных пользователем посредством касания, включая предусмотренную виртуальную клавиатуру на дисплее сенсорной панели 1320. Чтобы обеспечить возможность соединения с проводной сетью, SoC 1310 связана с интерфейсом 1330 Ehternet. Периферийный концентратор 1325 соединен с SoC 1310 для сопряжения с различными периферийными устройствами, такими, которые могут быть соединены с системой 1300 через любой из различных портов или другие соединители.
В дополнение к внутренней схеме и функциональности управления электропитанием в рамках SoC 1310 с SoC 1301 соединена микросхема управления питанием PMIC 1380, чтобы обеспечить зависящее от платформы управление питанием, например, в зависимости от того, осуществляется ли питание системы от батареи 1390 или осуществляется питание переменным током через сетевой адаптер 1395. В дополнение к этому управлению питанием в зависимости от источника питания PMIC 1380 может также выполнять действия по управлению питанием платформы на основе окружающих условий и условий использования. Также PMIC 1380 может передавать управляющую информацию и информацию о состоянии на SoC 1310, чтобы вызвать в SoC 1310 различные действия по управлению питанием.
Также со ссылкой на фиг. 7, для обеспечения возможностей беспроводной связи, с SoC 1310 соединен модуль 1350 WLAN, который, в свою очередь, соединен с антенной 1355. В различных реализациях модуль 1350 WLAN может обеспечивать осуществление связи в соответствии с одним или несколькими протоколами беспроводной связи, включая протокол IEEE 802.11, протокол Bluetooth™ или любой другой протокол беспроводной связи.
Как также показано, с SoC 1310 может быть соединено несколько датчиков 1360. Эти датчики могут включать в себя акселерометр, различные датчики окружающей среды и другие датчики, включая датчики пользовательских жестов. Наконец, с SoC 1310 соединен аудиокодек 1365 для обеспечения интерфейса с устройством 1370 вывода звука. Конечно, понятно, что хотя на фиг. 7 показана конкретная реализация, возможно множество вариантов и альтернатив.
Теперь со ссылкой на фиг. 8 показан вариант конструкции SoC в соответствии с вариантом осуществления. В качестве специфического иллюстративного примера SoC 2000 входит в состав в пользовательского оборудования (UE). В одном варианте осуществления UE относится к любому устройству, предназначенному для использования конечным пользователем, такому как носимое устройство, портативный телефон, смартфон, планшет, ультратонкий ноутбук, ноутбук, IoT устройство или любое другое аналогичное устройство. Зачастую UE соединяется с базовой станцией или узлом, который потенциально соответствует, по сути, мобильной станции (MS) в GSM сети.
Здесь, SoC 2000 включает в себя 2 ядра - 2006 и 2007. Аналогично тому, что обсуждалось выше, ядра 2006 и 2007 могут соответствовать архитектуре набора команд, такой как процессор на основе архитектуры Intel® Core™, процессор от Advanced Micro Devices, Inc. (AMD), процессор на основе MIPS, процессор на основе ARM архитектуры или их клиенты, а также их лицензиаты или последователи. Ядра 2006 и 2007 соединены с контроллером 2008 кэш-памяти, который связан с блоком 2009 интерфейса шины и L2 кэшем 2010, чтобы осуществлять связь с другими частями системы 2000. Межсоединение 2010 включает в себя накристальное межсоединение, которое может представлять собой межсоединение гетерогенной иерархической архитектуры, описанной в этом документе.
Межсоединение 2010 обеспечивает каналы связи к другим компонентам, таким как загрузочное постоянное запоминающее устройство 2035, предназначенное для хранения загрузочного кода для выполнения ядрами 2006 и 2007, чтобы инициализировать и осуществить загрузку SoC 2000, SDRAM контроллер 2040 для сопряжения с внешней памятью (например, DRAM 2060), флэш-контроллер 2045 для сопряжения с энергонезависимой памятью (например, флэш 2065), периферийный контроллер 2050 (например, последовательный периферийный интерфейс) для сопряжения с периферией, видеокодеки 2020 и видеоинтерфейс 2025 для отображения и приема ввода (например, сенсорного ввода) через MIPI или HDMI/DP интерфейс, GPU 2015 для выполнения вычислений, связанных с графикой, и т.д.
Кроме того, в системе показаны периферийные устройства для осуществления связи, такие как модуль 2070 Bluetooth, 3G модем 2075, GPS 2080 и WiFi 2085. Также в систему входит контроллер 2055 электропитания.
Теперь со ссылкой на фиг. 9 приведена структурная схема системы в соответствии с вариантом осуществления изобретения. Как показано на фиг. 9, многопроцессорная система 1500, такая как высокопроизводительная система, которая, в свою очередь, соединяется с другими системами НРС-сети, включает в себя первый процессор 1570 и второй процессор 1580, соединенные посредством межсоединения 1550 "точка - точка". Как показано на фиг. 9, каждый из процессоров 1570 и 1580 может представлять собой многоядерный процессор, включающий в себя типичные первое и второе процессорные ядра (т.е. процессорные ядра 1574а и 1574b и процессорные ядра 1584а и 1584b), например, двух площадок из 100 или более площадок, которые могут быть взаимосвязаны посредством архитектуры накристального межсоединения, как описано в этом документе.
Также со ссылкой на фиг. 9 первый процессор 1570 дополнительно включает в себя контроллер-концентратор 1572 памяти (МСН) и интерфейсы 1576 и 1578 "точка - точка" (Р-Р). Аналогично второй процессор 1580 включает в себя МСН 1582 и Р-Р интерфейсы 1586 и 1588. Как показано на фиг. 9, МСН 1572 и 1582 соединяют процессоры с соответствующими памятями, а именно с памятью 1532 и памятью 1534, которые могут представлять собой часть системной памяти (например, DRAM), локально присоединенной к соответствующим процессорам. Первый процессор 1570 и второй процессор 1580 могут быть соединены с чипсетом 1590 через Р-Р межсоединения 1562 и 1564 соответственно. Как показано на фиг. 9, чипсет 1590 включает в себя Р-Р интерфейсы 1594 и 1598.
Более того, чипсет 1590 включает в себя интерфейс 1592 для соединения чипсета 1590 с высокопроизводительным графическим процессором 1538 посредством Р-Р межсоединения 1539. В свою очередь, чипсет 1590 может быть связан с первой шиной 1516 через интерфейс 1596. Как показано на фиг. 9, к первой шине 1516 могут быть присоединены различные устройства 1514 ввода/вывода (I/O), а также межшинный мост 1518, которой связывает первую шину 1516 со второй шиной 1520. Ко второй шине 1520 могут быть присоединены различные устройства, включая, например, клавиатуру/мышь 1522, устройства 1526 связи и блок 1528 хранения данных, такой как накопитель на дисках или другое запоминающее устройство, которое может включать в себя код 1530, в одном варианте осуществления. Кроме того, ко второй шине 1520 может быть присоединено устройство 1524 ввода/вывода (I/O) звука.
Следующие примеры относятся к дополнительным вариантам осуществления.
В одном примере устройство содержит: несколько площадок, выполненных на полупроводниковом кристалле, по меньшей мере две из нескольких площадок имеют несколько ядер; и несколько сетевых коммутаторов, выполненных на полупроводниковом кристалле, которые должны быть связаны с несколькими площадками, где первый сетевой коммутатор из нескольких сетевых коммутаторов содержит несколько выходных портов, причем выходные порты первого множества из нескольких выходных портов предназначены для соединения с соответствующим сетевым коммутатором площадки через межсоединение типа "точка - точка", а выходные порты второго множества выходных портов предназначены для соединения с соответствующими сетевыми коммутаторами нескольких площадок через межсоединение "точка - группа точек".
В примере межсоединение "точка - точка" по меньшей мере частично выполнено на первом металлическом слое.
В примере межсоединение "точка - группа точек" выполнено по меньшей мере частично на втором металлическом слое, причем второй металлический слой является металлическим слоем, расположенным выше, чем первый металлический слой.
В примере ширина проводника межсоединения "точка - точка", выполненного на первом металлическом слое, больше, чем ширина проводника межсоединения "точка - группа точек", выполненного на более высоком металлическом слое.
В примере межсоединение "точка - группа точек" выполнено для того, чтобы передавать выходную информацию из сетевого коммутатора на соответствующие сетевые коммутаторы нескольких площадок за такт, причем несколько площадок физически не являются соседними к площадке сетевого коммутатора.
В примере межсоединение "точка - точка" выполнено для того, чтобы передавать выходную информацию из сетевого коммутатора на соответствующий сетевой коммутатор площадки за такт, причем площадка физически является соседней к площадке сетевого коммутатора.
В примере устройство дополнительно содержит структуру накристального межсоединения, содержащую несколько сетевых коммутаторов, межсоединений "точка - точка" и межсоединений "точка - группа точек".
В примере структура накристального межсоединения содержит иерархическую сеть, включающую в себя несколько сетей перекрестных соединений, каждая из которых предназначена для соединения между собой нескольких ядер площадки, несколько межсоединений "точка - точка" для соединения между собой смежных площадок и несколько межсоединений "точка - группа точек" для соединения между собой несмежных площадок.
В другом примере устройство содержит: сетевой коммутатор, выполненный на полупроводниковом кристалле, причем сетевой коммутатор содержит: несколько входных портов для приема информации от других сетевых коммутаторов; первое множество выходных портов для соединения с множеством смежных сетевых коммутаторов через первый металлический слой; и второе множество выходных портов для соединения с множеством несмежных сетевых коммутаторов через второй металлический слой.
В примере количество входных портов больше, чем сумма числа портов из первого множества выходных портов и числа портов из второго множества выходных портов.
В примере сетевой коммутатор также содержит: по меньшей мере один первый буфер, связанный с первым виртуальным каналом; по меньшей мере один второй буфер, связанный со вторым виртуальным каналом; сеть перекрестных соединений для соединения нескольких ядер с сетевым коммутатором, причем несколько ядер находятся на одной площадке; и устройство разрешения конфликтов для выполнения арбитража между выходными запросами по меньшей мере от некоторых из множества ядер.
В примере по меньшей мере один из первого множества выходных портов предназначен для соединения со смежным сетевым коммутатором через межсоединение "точка - точка", выполненное по меньшей мере частично на первом металлическом слое.
В примере по меньшей мере один из второго множества выходных портов предназначен для соединения с несколькими несмежными сетевыми коммутаторами через межсоединение "точка - группа точек", выполненное по меньшей мере частично на втором металлическом слое, причем второй металлический слой является слоем, расположенным выше, чем первый металлический слой, где первый и второй металлический слои являются слоями построенного стека, выполненного на полупроводниковом кристалле.
В примере по меньшей мере один из первого множества выходных портов предназначен для передачи выходного блока на смежный сетевой коммутатор в первом такте и по меньшей мере один из второго множества выходных портов предназначен для передачи выходного блока на несколько несмежных сетевых коммутаторов в первом такте.
В примере устройство содержит SoC эксафлопсного класса, включающую в себя несколько ядер.
В примере SoC эксафлопсного класса содержит несколько площадок, каждая из которых содержит часть множества ядер и сетевой коммутатор.
В другом примере имеется машиночитаемый носитель, на котором хранятся инструкции, которые при выполнении их машиной заставляют машину выполнять способ, содержащий следующее: принимают несколько пакетов в сетевом коммутаторе накристального межсоединения; определяют маршрут для первого пакета из нескольких пакетов; отправляют первый пакет на смежный сетевой коммутатор через первый выходной порт, соединенный с межсоединением "точка - точка", если первый пакет предназначен для логической схемы назначения в домене, связанном со смежным сетевым коммутатором; и отправляют первый пакет на несколько несмежных сетевых коммутаторов через второй выходной порт, соединенный с межсоединением "точка - группа точек", если первый пакет предназначен для логической схемы назначения в домене, связанном с одним из нескольких несмежных сетевых коммутаторов.
В примере способ также содержит следующее: отправляют первый пакет на локальное ядро домена, включающего в себя сетевой коммутатор, если первый пакет предназначен для локального ядра.
В примере способ также содержит следующее: отправляют первый пакет на смежный сетевой коммутатор через межсоединение "точка - точка", выполненное по меньшей мере частично на первом металлическом слое.
В примере способ также содержит следующее: отправляют первый пакет на несколько несмежных сетевых коммутаторов через межсоединение "точка - группа точек", выполненное по меньшей мере частично на втором металлическом слое, причем второй металлический слой является слоем, расположенным выше, чем первый металлический слой.
Варианты осуществления можно использовать во многих различных типах систем. Например, в одном варианте осуществления устройство связи может быть устроено так, чтобы выполнять различные способы и технологии, описанные в этом документе. Конечно, объем изобретения не ограничен устройством связи, и вместо него другие варианты осуществления могут быть направлены на другие типы устройств для обработки инструкций, или один или несколько машиночитаемых носителей информации, включающих в себя инструкции, которые при их исполнении на вычислительном устройстве, заставляют устройство выполнять один или несколько способов и технологий, описанных в этом документе.
Варианты осуществления могут быть реализованы в коде и могут быть сохранены на постоянном носителе, на котором хранятся инструкции, которые можно использовать для программирования системы для выполнения инструкций. Носитель информации может включать в себя, но, не ограничиваясь, диск любого типа, включая флоппи-диски, оптические диски, твердотельные накопители (SSD), компакт-диски только для чтения (CD-ROM), перезаписываемые компакт-диски (CD-RW) и магнитно-оптические диски, полупроводниковые устройства, такие как постоянная память (ROM), память произвольного доступа (RAM), такая как динамическая память произвольного доступа (DRAM), статическая память произвольного доступа (SRAM), стираемую программируемую постоянную память (EPROM), флэш-память, программируемое запоминающее устройство с электронным стиранием (EEPROM), магнитные или оптические карты или любой другой тип носителя, пригодного для хранения электронных инструкций.
Хотя изобретение было описано в отношении ограниченного числа вариантов осуществления, специалистам в области техники будут понятны их многочисленные модификации и варианты. Предполагается, что прилагаемая формула изобретения охватывает все такие модификации и варианты как попадающие под объем и сущность изобретения.


Группа изобретений относится к вычислительным системам с большой вычислительной мощностью, реализованным на одном полупроводниковом кристалле. Техническим результатом является повышение масштабируемости сети с низкой задержкой и низким энергопотреблением. В одном варианте система содержит множество площадок, выполненных на полупроводниковом кристалле, по меньшей мере, две из множества площадок имеют множество ядер; и множество сетевых коммутаторов, выполненных на полупроводниковом кристалле, которые связаны с множеством площадок, где первый сетевой коммутатор из множества сетевых коммутаторов содержит множество выходных портов, причем выходные порты первого множества из множества выходных портов предназначены для соединения с соответствующим сетевым коммутатором площадки через межсоединение типа "точка - точка", а выходные порты второго множества выходных портов предназначены для соединения с соответствующими сетевыми коммутаторами множества площадок через межсоединение "точка - группа точек", в которой ширина проводника межсоединения "точка - точка" больше, чем ширина провода межсоединения "точка - группа точек". 3 н. и 15 з.п. ф-лы, 9 ил.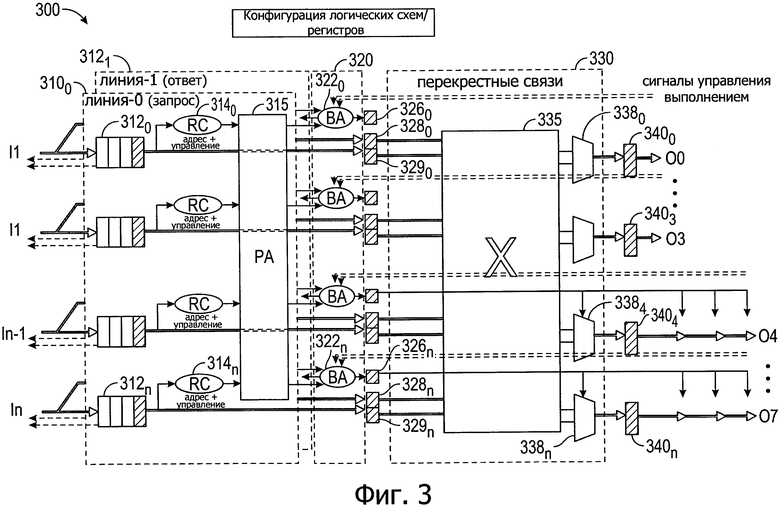
1. Система на кристалле, содержащая следующее:
множество площадок, выполненных на полупроводниковом кристалле, по меньшей мере две из множества площадок имеют множество ядер; и
множество сетевых коммутаторов, выполненных на полупроводниковом кристалле, которые связаны с множеством площадок, где первый сетевой коммутатор из множества сетевых коммутаторов содержит множество выходных портов, причем выходные порты первого множества из множества выходных портов предназначены для соединения с соответствующим сетевым коммутатором площадки через межсоединение типа "точка - точка", а выходные порты второго множества выходных портов предназначены для соединения с соответствующими сетевыми коммутаторами множества площадок через межсоединение "точка - группа точек", в которой ширина проводника межсоединения "точка - точка" больше, чем ширина провода межсоединения "точка - группа точек".
2. Система по п. 1, в которой межсоединение "точка - точка" по меньшей мере частично выполнено на первом металлическом слое.
3. Система по п. 2, в которой межсоединение "точка - группа точек" выполнено по меньшей мере частично на втором металлическом слое, причем второй металлический слой является металлическим слоем, расположенным выше, чем первый металлический слой.
4. Система по п. 1, в которой межсоединение "точка - группа точек" выполнено для того, чтобы передавать выходную информацию из сетевого коммутатора на соответствующие сетевые коммутаторы множества площадок за такт, причем множество площадок физически не являются соседними к площадке сетевого коммутатора.
5. Система по п. 4, в которой межсоединение "точка - точка" выполнено для того, чтобы передавать выходную информацию из сетевого коммутатора на соответствующий сетевой коммутатор площадки за такт, причем площадка физически является соседней относительно площадки сетевого коммутатора.
6. Система по п. 1, дополнительно содержащая структуру накристального межсоединения, содержащую множество сетевых коммутаторов, межсоединений "точка - точка" и межсоединений "точка - группа точек".
7. Система по п. 6, в которой структура накристального межсоединения содержит иерархическую сеть, включающую в себя множество сетей перекрестных соединений, каждая из которых предназначена для соединения между собой множества ядер площадки, множество межсоединений "точка - точка" для соединения между собой смежных площадок и множество межсоединений "точка - группа точек" для соединения между собой несмежных площадок.
8. Система на кристалле, содержащая следующее:
сетевой коммутатор, выполненный на полупроводниковом кристалле, причем сетевой коммутатор содержит:
множество входных портов для приема информации от других сетевых коммутаторов;
первое множество выходных портов для соединения с множеством смежных сетевых коммутаторов через первый металлический слой; и
второе множество выходных портов для соединения с множеством несмежных сетевых коммутаторов через второй металлический слой, в которой количество входных портов больше, чем сумма числа портов из первого множества выходных портов и числа портов из второго множества выходных портов.
9. Система по п. 8, в которой сетевой коммутатор дополнительно содержит:
по меньшей мере один первый буфер, связанный с первым виртуальным каналом;
по меньшей мере один второй буфер, связанный со вторым виртуальным каналом;
сеть перекрестных соединений для соединения множества ядер с сетевым коммутатором, причем множество ядер находятся на одной площадке; и
устройство разрешения конфликтов для выполнения арбитража между выходными запросами по меньшей мере от некоторых из множества ядер.
10. Система по п. 8, в которой по меньшей мере один из первого множества выходных портов предназначен для соединения со смежным сетевым коммутатором через межсоединение "точка - точка", выполненное по меньшей мере частично на первом металлическом слое.
11. Система по п. 10, в которой по меньшей мере один из второго множества выходных портов предназначен для соединения с множеством несмежных сетевых коммутаторов через межсоединение "точка - группа точек", выполненное по меньшей мере частично на втором металлическом слое, причем второй металлический слой является слоем, расположенным выше, чем первый металлический слой, причем первый и второй металлический слои являются слоями построенного стека, выполненного на полупроводниковом кристалле.
12. Система по п. 8, в которой по меньшей мере один из первого множества выходных портов предназначен для передачи выходного блока на смежный сетевой коммутатор в первом такте, и по меньшей мере один из второго множества выходных портов предназначен для передачи выходного блока на множество несмежных сетевых коммутаторов в первом такте.
13. Система по п. 8, причем система представляет собой однокристальную систему (SoC) эксафлопсного класса, включающую в себя множество ядер.
14. Система по п. 13, в которой SoC эксафлопсного класса содержит множество площадок, каждая из которых содержит часть множества ядер и сетевой коммутатор.
15. Машиночитаемый носитель, на котором хранятся инструкции, которые при выполнении их машиной заставляют машину выполнять способ маршрутизации пакетов, содержащий следующее:
принимают множество пакетов в сетевом коммутаторе накристального межсоединения, при этом сетевой коммутатор содержит множество входных портов для приема информации от других сетевых коммутаторов, первое множество выходных портов для соединения с множеством смежных сетевых коммутаторов через первый металлический слой и второе множество выходных портов для соединения с множеством несмежных сетевых коммутаторов через второй металлический слой, в которой количество нескольких входных портов больше, чем сумма числа портов из первого множества выходных портов и числа портов из второго множества выходных портов
определяют маршрут для первого пакета из множества пакетов;
отправляют первый пакет на смежный сетевой коммутатор через первый выходной порт, соединенный с межсоединением "точка - точка", если первый пакет предназначен для логической схемы назначения в домене, связанном со смежным сетевым коммутатором; и
отправляют первый пакет на множество несмежных сетевых коммутаторов через второй выходной порт, соединенный с межсоединением "точка - группа точек", если первый пакет предназначен для логической схемы назначения в домене, связанном с одним из множества несмежных сетевых коммутаторов.
16. Машиночитаемый носитель по п. 15, причем способ также содержит следующее: отправляют первый пакет на локальное ядро домена, включающего в себя сетевой коммутатор, если первый пакет предназначен для локального ядра.
17. Машиночитаемый носитель по п. 15, причем способ также содержит следующее: отправляют первый пакет на смежный сетевой коммутатор через межсоединение "точка - точка", выполненное по меньшей мере частично на первом металлическом слое.
18. Машиночитаемый носитель по п. 17, причем способ также содержит следующее: отправляют первый пакет на множество несмежных сетевых коммутаторов через межсоединение "точка - группа точек", выполненное по меньшей мере частично на втором металлическом слое, причем второй металлический слой является слоем, расположенным выше, чем первый металлический слой.
| Способ защиты переносных электрических установок от опасностей, связанных с заземлением одной из фаз | 1924 |
|
SU2014A1 |
| Бесколесный шариковый ход для железнодорожных вагонов | 1917 |
|
SU97A1 |
| US 6289021 B1, 11.09.2001 | |||
| US 2008219269 A1, 11.09.2008 | |||
| СПОСОБ СИНХРОННОЙ АССОЦИАТИВНОЙ МАРШРУТИЗАЦИИ/КОММУТАЦИИ | 2009 |
|
RU2447594C2 |

