Область техники, к которой относится изобретение
Изобретение относится к области получения обработанного изображения с выбираемым пользователем показателем качества. Описание известного уровня техники
Генеративно-состязательные сети (GAN) - класс генеративных платформ, которые основаны на конкуренции между двумя нейронными сетями, а именно генератором и дискриминатором [23-25]. В то время как последний выполняет задачу классификации (решает, является ли сгенерированное изображение реальным или нет), первый синтезирует изображение из целевого распределения.
Условные GAN являются разновидностью оригинальной платформы [52]. Их архитектура позволяет вводить дополнительную информацию, которая используется для ограничения целевого пространства в соответствии с ней. Следовательно, можно осуществлять подгонку сети к требуемым условиям, используя, например, маску [35], метку [55] или текст [60].
В последние годы наблюдается рост популярности нейронных аватаров головы как практического метода для создания моделей головы.
Они позволяют воссоздавать лицо с заданным выражением и позой. Такие модели можно разделить на две группы - модели со скрытой геометрией [5, 15, 17, 81, 82] и модели с 3d априором, например сеткой головы [16, 20, 28, 43, 43, 48, 85]. Кроме того, ряд работ ориентирован на все тело человека, включая голову и лицо, которые можно разделить по требованиям к входным данным.
В некоторых из них берется всего несколько изображений [1], а в других требуется видео [7, 22, 31, 33, 40, 41, 58, 80, 86].
Генеративные DNN являются мощным инструментом для синтеза изображений, но они ограничены своей вычислительной нагрузкой. С другой стороны, при наличии обученной модели и задачи, например, генерации лиц в рамках некоторого диапазона характеристик, показатель качества выходного изображения будет неравномерно распределен между изображениями с различными характеристиками. Отсюда следует, что на некоторых экземплярах можно ограничить сложность модели с сохранением высокого показателя качества.
В последние время большое внимание стало уделяться синтезу изображений с помощью генеративно-состязательных сетей (GAN) [64, 72], его области применения простираются от преобразования одного изображения в другое изображение [35] до визуализации текста в изображение [21], генерации нейронных аватаров головы, [17] и многое другое. Однако при создании фотореалистичных изображений этот подход страдает от большой вычислительной нагрузки. В основу настоящего изобретения положено наблюдение, что глубокие нейронные сети (DNN) выводят изображения с различным, но постоянным показателем качества, когда они обусловлены определенными параметрами. Так как их
выразительность неодинакова в наборе возможно генерируемых изображений, следовательно, для некоторых примеров может быть достаточно более простой DNN для генерации вывода с требуемым показателем качества.
С другой стороны, отличные результаты показало применение подходов, нацеленных на снижение большой вычислительной нагрузки DNN, которые существенно уменьшают избыточность вычислений [2,13]. В то время как такие стратегии, как обрезка [46, 53, 65] или дистилляция знаний [4, 9, 26], создают DNN с меньшим количеством параметров, конфигурация раннего выхода (Early Exit, ЕЕ) [42, 7 9] позволяет динамически изменять вычислительную нагрузку и поэтому является идеальным кандидатом для стратегии генерации изображений, нацеленной на вывод изображений с постоянным показателем качества, исключая при этом чрезмерные вычисления, обусловленные неравномерной сложностью рендеринга.
Несмотря на это, реализация стратегий ЕЕ остается за рамками исследований на генеративных моделях. Возможно, это связано с тем, что ЕЕ обрабатывает логиты промежуточных уровней, тем самым ограничивая их область применения задачами, где эти уровни имеют значение (например, в классификации), и исключая конвейеры, в которых значимые выходы выдаются только на последнем уровне (например, в генеративных сверточных сетях).
Ранние выходы представляют собой стратегию экономии вычислительных ресурсов, используемую в основном в задачах классификации [45,62]. Они характеризуются добавлением выходов в DNN, по которым можно получить аппроксимацию конечного результата при меньших вычислительных затратах. В процессе времени ранние выходы были открыты заново как самостоятельный подход, несмотря на то, что изначально они были реализованы в таких архитектурах, как Inception [68], в качестве меры противодействия переобучению. Иногда этот подход также называли каскадным обучением [47,51,74], адаптивной нейронной сетью [3] или просто ветвлением [61]. Предлагаемые реализации различаются тремя вариантами дизайна: архитектуре выходов, т.е. какой тип слоев использовать для обработки логитов основной сети; куда присоединять выходы, чтобы равномерно распределить между ними вычисления; и как выбрать путь вычислений. Последняя задача часто решается путем внедрения механизма доверия и выбора единственного выхода [42, 69, 87] или путем повторного использования прогнозов для дальнейших вычислений [77,7 9]. В меньшей степени также предлагались политики обучаемого выхода [8, 12, 61].
В качестве метода эффективного использования одного выхода во время логического вывода предлагается изменение пути вычислений для каждого ввода [4 9, 54]. Основанием для возникновения предложенного подхода стал метод, впервые примененный в области поиска нейронной архитектуры: использование так называемого предиктора для ускорения оценки производительности данной архитектуры [6, 76], а также при обработке естественного языка [18, 78], который применялся для логического вывода посредством ранних выходов для периферийного AI с ограниченными ресурсами. [14].
Ранние методы синтеза изображений были основаны на поиске примеров в больших базах данных изображений [30, 34, 39, 44]. В этом их отличие от современных технологий DNN, которые основаны на большом количестве параметров для вывода фотореалистичных изображений. С другой стороны, была предложена полупараметрическая генерация для использования сильных сторон обоих подходов [59, 66, 70]. В частности, использование фрагментов, напоминающие старые методы, позволяет достигать большой точности [27, 50, 71].
Хранение большой базы данных изображений создает проблему, когда дело доходит до запроса к ней для извлечения необходимого образца. При поиске направляющих изображений необходимо использовать алгоритм, который быстро найдет похожее изображение или фрагмент. С этой целью используются кэши [2 9, 56] и, в частности, поиск ближайших соседей [27, 36, 83], где предобученные модели используются в качестве экстракторов визуальных признаков, а веса кодировщиков изображений фиксированы.
Предлагаемое изобретение основано на наблюдении, что DNN выдают изображения с различным, но постоянным показателем качества, когда они обусловлены по определенным параметрам.
Поскольку их выразительность неравномерна в пределах набора возможно генерируемых изображений, следовательно, для некоторых примеров может быть достаточно более простой DNN для генерации вывода с требуемым показателем качества.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Предложена система для получения обработанного изображения, имеющего выбираемый пользователем показатель качества, содержащая:
- электронное устройство, память, хранящую входные изображения и набор генеративных искусственных нейронных сетей (GAN), причем электронное устройство выполнено с возможностью выполнения операций искусственной нейронной сети;
- каждая GAN выполнена с возможностью выбора пользователем из набора хранящихся в памяти GAN для получения изображения с предопределенным показателем качества, и каждая GAN предварительно обучена и состоит из:
N вычислительных модулей, образующих основную сеть, и
множества ветвей более раннего выхода, каждая из которых присоединена после каждого вычислительного модуля, за исключением последнего вычислительного модуля основной сети, причем каждая ветвь более раннего выхода содержит столько вычислительных модулей, сколько их остается в основной сети после точки присоединения ветви более раннего выхода до выхода основной сети, при этом каждый вычислительный модуль каждой ветви более раннего выхода выполняет ту же самую функцию, что и соответствующий оставшийся вычислительный модуль в основной сети, и вычислительный ресурс каждой ветви более раннего выхода меньше вычислительного ресурса соответствующих оставшихся вычислительных модулей основной сети до выхода основной сети,
причем чем ближе конкретная ветвь более раннего выхода расположена к выходу основной сети, тем выше вычислительный ресурс для получения выходного изображения, генерируемого конкретной ветвью более раннего выхода, и
причем показатели качества выходного изображения, сгенерированного ветвями более раннего выхода, отличаются друг от друга;
- набор предикторов, каждый из которых представляет собой искусственную нейронную сеть, при этом каждый предиктор создается и предварительно обучается для конкретной GAN, хранящейся в памяти, предиктор сконфигурирован прогнозировать показатель качества обрабатываемого изображения для вывода из каждой ветви более раннего выхода конкретной GAN на основе входного изображения, которое пользователь намерен подать на вход конкретной GAN;
причем GAN сконфигурирована выводить обработанные выходные изображения из той ветви более раннего выхода, которая генерирует обработанное выходное изображение, имеющее показатель качества, наиболее соответствующий показателю качества, выбранному пользователем.
При этом, чем ближе конкретная ветвь более раннего выхода расположена к выходу основной сети, тем выше показатель качества обработанного изображения, генерируемого данной конкретной ветвью более раннего выхода.
Каждая ветвь раннего выхода предварительно обучена на состязательной функции потерь с копиями исходного дискриминатора основной сети.
Система может дополнительно содержать базу данных, хранящую направляющие данные, при этом основная сеть дополнительно сконфигурирована осуществлять выборку из базы данных направляющих данных для исходных изображений, введенных в основную сеть, причем направляющие данные соединяются с данными из вычислительного модуля перед точкой присоединения ветви более раннего выхода, и полученные после соединения данные подаются в ветвь более раннего выхода для дальнейшей обработки. Иными словами, система может дополнительно содержать базу данных, хранящую направляющие данные, при этом GAN дополнительно сконфигурирована извлекать из базы данных направляющие данные и соединять их с исходными данными изображения, введенными в GAN, причем направляющие данные соединяются с данными из вычислительного модуля перед ветвью более раннего выхода, и соединенные данные передаются в ветвь более раннего выхода для дальнейшей обработки. Направляющие данные могут быть направляющими признаками. Направляющие данные могут быть изображениями, фрагментами изображений, признаками или фрагментами признаков (промежуточными тензорами). Размер фрагмента может варьироваться и быть таким же большим, как исходное изображение или признак.
Предложен способ для получения обработанного изображения, имеющего выбираемый пользователем показателем качества, использующий предложенную систему, заключающийся в том, что:
выбирают посредством пользователя из памяти входные изображения, предварительно обученную GAN и предварительно обученный предиктор, соответствующий данной GAN;
выбирают посредством пользователя показатель качества для обработанных выходных изображений;
подают по меньшей мере одно из входных изображений в соответствующий предварительно обученный предиктор;
прогнозируют на основании по меньшей мере одного из поданных входных изображений посредством соответствующего предварительно обученного предиктора показатель качества для обработанных выходных изображений, которые будут сгенерированы каждой ветвью более раннего выхода;
выбирают одну ветвь более раннего выхода, генерирующую обработанное выходное изображение, имеющее показатель качества, наиболее соответствующий показателю качества, выбранному пользователем;
преобразуют входные изображения во входные данные, которые могут быть обработаны GAN;
подают входные данных в GAN с выбранной ветвью более раннего выхода для обработки;
обрабатывают входные данные посредством GAN с выбранной ветвью более раннего выхода;
получают на выходе выбранной ветви более раннего выхода обработанные выходные изображения.
Альтернативно, согласно предложенному способу:
выбирают пользователем из памяти по меньшей мере одно исходное изображение, предобученную GAN и соответствующий предобученный предиктор,
подают исходное изображение в предиктор;
прогнозируют посредством предиктора показатель качества для каждого изображения, сгенерированного основной сетью и каждой ветвью более раннего выхода GAN;
выбирают посредством пользователя показатель качества на основе прогноза;
преобразуют входные изображения во входные данные, подлежащие обработке GAN;
подают входные данные в GAN с ветвью более раннего выхода для обработки;
обрабатывают входные данные посредством GAN и
отображают на дисплее электронного устройства готовое обработанное изображение, выведенное из выхода основной сети или одной из ветвей более раннего выхода, которая обеспечивает выбранный показатель качества.
Согласно способу, дополнительно сохраняют в памяти готовые обработанные выходные изображения, выведенные из выхода основной сети или одной ветви более раннего выхода, которая обеспечивает выбранный показатель качества изображения.
Готовые обработанные выходные изображения могут
отображаться на дисплее электронного устройства или передаваться на другие средства обработки для дальнейшего использования.
Чем ближе конкретная ветвь более раннего вывода расположена к выходу основной сети, тем выше показатель качества обработанного изображения, сгенерированного конкретной ветвью более раннего выхода. Показатель качества выражается в единицах FID.
Также предложен способ получения обработанного изображения с выбранным пользователем показателем качества, использующий предложенную систему, заключающийся в том, что:
выбирают посредством пользователя из памяти входные данные, предобученную GAN и предобученный предиктор, соответствующий данной GAN,
выбирают посредством пользователя показатель качества для обработанных выходных изображений;
подают по меньшей мере одно из входных изображений в соответствующий предварительно обученный предиктор;
прогнозируют на основании поданного по меньшей мере одного из входных изображений посредством соответствующего
предварительно обученного предиктора показатель качества для обработанных выходных изображений, которые будут сгенерированы каждой ветвью более раннего выхода;
выбирают одну ветвь более раннего выхода, генерирующую обработанное выходное изображение, имеющее показатель качества, наиболее соответствующий выбранному пользователем показателю качества;
преобразуют входные изображения во входные данные, подлежащие обработке GAN;
подают входные данные в GAN с ветвью более раннего выхода для обработки;
обрабатывают входные данные посредством GAN с выбранной ветвью более раннего выхода,
при этом во время обработки:
- выбирают из базы данных направляющие данные, соответствующие направляющим данным для по меньшей мере одного из входных изображений,
- соединяют направляющие данные с выводом данных из вычислительного модуля перед выбранной ветвью более раннего выхода,
- подают соединенные данные в выбранную ветвь более раннего выхода или в основную сеть для дальнейшей обработки;
получают на выходе из выбранной ветви более раннего выхода обработанные выходные изображения. Согласно способу,
дополнительно сохраняют в памяти готовые обработанные выходные изображения, выведенные из выхода основной сети или одной ветви более раннего выхода, которая обеспечивает выбранный показатель качества изображения.
Готовые обработанные выходные изображения можно отображать на дисплее электронного устройства или передавать на другие устройства для дальнейшего использования.
Чем ближе конкретная ветвь более раннего выхода расположена к выходу основной сети, тем выше показатель качества обработанного изображения, сгенерированного данной конкретной ветвью более раннего выхода. Показатель качества может выражаться в единицах FID.
Направляющие данные могут быть изображениями, фрагментами изображения, признаками или фрагментами признаков.
Альтернативно, согласно предложенному способу:
выбирают посредством пользователя из памяти по меньшей мере одно исходное изображение, предобученную GAN и соответствующий предобученный предиктор,
подают по меньшей мере одно исходное изображение в предиктор;
прогнозируют посредством предиктора показатель качества для каждого изображения, сгенерированного основной сетью и каждой ветвью более раннего выхода GAN;
выбирают посредством пользователя показатель качества на основе прогноза;
преобразуют входные изображения во входные данные, которые могут быть обработаны GAN;
подают входные данные в GAN;
обрабатывают входные данные посредством GAN, причем во время обработки:
- выбирают из базы данных направляющие данные, соответствующие направляющему изображению,
- соединяют направляющие данные с данными из вычислительного модуля перед ветвью более раннего выхода,
- подают соединенные данные в ветвь более раннего выхода для дальнейшей обработки;
сохраняют в памяти готовое обработанное изображение, выведенное из выхода основной сети или одной ветви более раннего выхода, которая обеспечивает выбранный показатель качества.
Готовое изображение можно, например, отобразить на дисплее электронного устройства. Пользователь может сохранить эти изображения заранее на основе исходных изображений, выбранных из памяти.
Предложен машиночитаемый носитель, хранящий инструкции для выполнения любого из предложенных способов электронным устройством.
По меньшей мере, один из множества вычислительных модулей может быть реализован моделью искусственного интеллекта (AI). Функция, связанная с AI, может выполняться посредством энергонезависимой памяти, энергозависимой памяти и процессора.
Процессор может включать в себя один или несколько процессоров. В настоящее время один или несколько процессоров могут быть процессорами общего назначения, такими как центральный процессор (CPU), прикладной процессор (АР), графический процессор (GPU), визуальный процессор (VPU), и/или специальный процессор для AI, такой как нейронный процессор (NPU) и т.п.
Эти один или несколько процессоров управляют обработкой входных данных в соответствии с предопределенным рабочим правилом или моделью искусственного интеллекта (AI), хранящейся в энергонезависимой памяти и энергозависимой памяти. Предопределенное рабочее правило или модель искусственного интеллекта предоставляется путем изучения или обучения.
В данном контексте предоставление посредством обучения означает, что, применяя алгоритм обучения к множеству обучающих данных, создается предопределенное рабочее правило или модель AI с требуемой характеристикой. Обучение может выполняться в самом устройстве, в котором выполняется AI согласно варианту осуществления, и/или может быть реализовано на отдельном сервере/системе.
Модель AI может состоять из множества уровней нейронной сети. Каждый уровень имеет множество значений весов и выполняет операцию уровня посредством вычисления предыдущего уровня и оперирования множеством весов. Примеры нейронных сетей включают, без ограничения перечисленным, сверточную нейронную сеть (CNN), глубокую нейронную сеть (DNN), рекуррентную нейронную сеть (RNN), ограниченную машину Больцмана (RBM), глубокую сеть доверия (DBN), двунаправленную рекуррентную глубокую нейронную сеть (BRDNN), генеративно-состязательные сети (GAN) и глубокие Q-сети.
Кроме того, предлагаемый способ, выполняемый электронным устройством, может быть реализован с использованием модели искусственного интеллекта.
Модель искусственного интеллекта можно получить путем обучения. В данном контексте "полученный путем обучения" означает, что предопределенное рабочее правило или модель искусственного интеллекта, обеспечивающая выполнение требуемой функции (или цели), получают путем обучения базовой модели искусственного интеллекта на множестве частей обучающих данных с помощью обучающего алгоритма. Модель искусственного интеллекта может включать в себя множество слоев нейронной сети. Каждый из множества слоев нейронной сети включает в себя множество значений параметров сети и выполняет вычисления нейронной сети путем вычисления между результатом вычисления предыдущего слоя и множеством значений параметров.
Визуальное понимание - это метод распознавания и обработки вещей аналогично человеческому зрению, и оно включает, например, распознавание объекта, отслеживание объекта, поиск изображений, распознавание людей, распознавание сцен, 3D реконструкцию/локализацию или улучшение изображения.
Прогнозирование рассуждений в искусственном интеллекте это метод логических рассуждений и получения прогнозов путем определения информации, который включает в себя, например, формирование рассуждений на основе знаний, прогнозирование оптимизации, планирование на основе предпочтений или рекомендации.
Краткое описание чертежей
Представленные выше и/или другие аспекты станут более очевидными из описания примерных вариантов осуществления со ссылкой на прилагаемые чертежи, на которых:
Фиг. 1 иллюстрирует пример предлагаемой системы для получения обработанного изображения, имеющего выбираемый пользователем показатель качества.
Фиг. 2 иллюстрирует взаимосвязь между показателем качества (выраженным в единицах FID) и вычислениями для всех ветвей при различных коэффициентах масштабирования реализации OASIS с использованием базы направляющих данных.
Фиг. 3 иллюстрирует примеры выходов ветвей для конвейера OASIS.
Фиг. 4 иллюстрирует распределение вычислений между ветвями основной сети OASIS для множества заданных порогов LPIPS.
Фиг. 5 иллюстрирует примеры выходов ветвей для конвейера MegaPortraits.
Фиг. 6 иллюстрирует зависимость между показателем качества (выраженным в единицах LPIPS) и вычислениями для всех ветвей.
Фиг. 7 иллюстрирует распределение вычислений между ветвями основной сети MegaPortraits для множества заданных порогов LPIPS.
Фиг. 8 иллюстрирует конвейер OASIS, распределение изображений, направленных в разные ветви в зависимости от их угла поворота головы (в конвейере OASIS).
Фиг. 9 иллюстрирует сравнение между распределением показателей качества отдельных ветвей OASIS и распределением показателей качества, полученным с помощью предиктора (Р).
Фиг. 10 иллюстрирует сравнение между показателем качества и вычислениями конвейера OASIS.
Фиг. 11 иллюстрирует сравнение эффективности различных коэффициентов масштабирования (в конвейере OASIS).
Фиг. 12 иллюстрирует сравнение эффективности различных коэффициентов масштабирования (в конвейере OASIS).
Фиг. 13 иллюстрирует сравнение эффективности различных коэффициентов масштабирования (в конвейере MegaPortraits).
Фиг. 14 иллюстрирует сравнение влияния базы данных на распределение показателя качества для различных коэффициентов масштабирования (в конвейере OASIS).
Фиг.15 иллюстрирует распределение изображений, направляемых в различные ветви в зависимости от их угла поворота головы (в конвейере MegaPortraits).
Подробное описание
Предлагаемое изобретение ускоряет работу генеративных нейронных сетей, позволяет нейронным сетям работать быстрее или снизить энергопотребление, обеспечивая при этом требуемую частоту выхода. Тем самым можно снизить потребление мощности электроэнергии, а также нагрев устройств, используемых для работы нейронной сети, таких как дискретные графические карты для ПК, серверов или ноутбуков, или SoC смартфона.
Настоящее изобретение может найти применение в любых нейронных сетях, предназначенных для генерации изображений на основе скрытого вектора, архитектура которых состоит из множества блоков. Показанные на фиг.1 блоки 11, 12, 13, 14 -это модули архитектуры нейронной сети. Каждый блок выполняет функцию небольшой нейронной сети, преобразуя вводы в соответствии с умножением на веса, добавляя смещения и применяя нелинейную функцию активации и другие операции. Конкретно, настоящее изобретение можно применять в любых многослойных нейронных сетях, включая любую GAN.
Изобретение позволяет ускорить работу нейронных сетей или снизить энергопотребление, обеспечивая при этом требуемую частоту вывода в реальном времени. Также изобретение позволяет снизить нагрузку, энергопотребление и нагрев устройств, которые используются для реализации данной нейронной сети, и изобретение используется в таких устройствах, как дискретная видеокарта для ПК, сервера или ноутбука, а также SoC для смартфона, и в любом электронном устройстве, имеющем центральный процессор. Кроме того, предлагается машиночитаемый носитель, на котором хранится компьютерный код для выполнения предложенного способа компьютером или подходящим электронным устройством. При этом электронное устройство может содержать дисплей, память для хранения изображений и набор искусственных нейронных сетей (ANN), и электронное устройство также выполнено с возможностью выполнения операций искусственной нейронной сети.
Предлагаемый способ позволяет уменьшить объем вычислений путем добавления так называемых ветвей раннего выхода к исходной архитектуре (основной сети) и динамического переключения пути вычислений в зависимости от сложности рендеринга вывода.
Основной сетью является любая генеративная модель, использующая декодер, а именно, нейронная сеть, которая принимает скрытый вектор и выдает результат, обычно после обработки сигнала несколькими слоями. Сложность определяется показателем качества исходного изображения (набора входных данных). Чем хуже показатель качества исходного изображения, тем выше сложность. Показатель качества измеряется обычными метриками изображения (FID, LPIPS). Создается несколько путей с разным количеством параметров и обучается нейронная сеть, называемая предиктор, для прогнозирования, какой показатель качества изображений будет получен из каждого пути. Если пользователь устанавливает более низкий показатель качества при генерации изображений, предиктор предлагает наиболее простой способ для удовлетворения этого требования.
Следует отметить, что нейронная сеть работает с тензорами данных, поэтому изображения, подлежащие вводу в нейронную сеть и обработке в ней, следует преобразовать в тензоры данных. Операция преобразования изображений в тензоры общеизвестна и не рассматривается в настоящем описании.
Таким образом, в дальнейшем описании термин "входное изображение" подразумевает использование термина "тензоры данных", полученные в результате преобразования входных изображений для дальнейшей обработки нейронной сетью.
Предлагаемый способ позволяет выводить изображения с заданным пользователем более низким предопределенным показателем качества выходных изображений и может применяться везде, где имеется модель, генерирующая изображения с использованием декодера. В качестве примеров рассматривается применение данного способа для генерации на основе семантической карты (известной из уровня техники) и перекрестного воспроизведения выражений лица. Генерация изображения на основе семантической карты - это задача создания изображения со списком всех пикселей, принадлежащих определенному классу, в качестве ввода. Например, для фотографии улицы семантическая карта содержит список всех пикселей, которые должны содержать дорогу, деревья, здания и т.д. Перекрестное воспроизведение выражений лица - это задача, в которую вводятся два портрета, один определяет личность, а второй - выражение и положение головы, которые требуется придать первой личности. Настоящее изобретение позволяет сократить наполовину вычисления нейронной сети (по сравнению с исходной основной сетью) для показателя качества LPIPS (Learned Perceptual Image Patch Similarity) ≤ 0,1 изображения, сгенерированного нейронной сетью.
В предлагаемом способе используется стратегия "раннего выхода" для синтеза изображения, которая динамически направляет поток вычислений к требуемым ветвям раннего выхода в зависимости от сложности изображений, что снижает избыточность вычислений, сохраняя при этом требуемый показатель качества, предопределенного пользователем.
Выходные ветви раннего выхода присоединены к исходной базовой независимой искусственной нейронной сети (называемой основной сетью) которая состоит из входа, вычислительных модулей и выхода), как показано фиг.1. Вычислительные модули раннего выхода обозначены как  соответствующими номерами в порядке возрастания показателя качества (обозначены как 1, 2, 3 в кружках, при этом 4 в кружке обозначает выход из основной сети). Эти вычислительные модули построены по облегченной версии (т.е. с меньшим количеством параметров) вычислительных модулей, составляющих архитектуру основной сети, их сложность может настраиваться в соответствии с требуемым показателем качества, предопределенным пользователем. Чем меньше параметров в сети, тем меньше будет производиться вычислений, от этого будет страдать показатель качества вывода, и поэтому выходы создаются с учетом баланса между потерей показателя качества и ускорением вычислений.
соответствующими номерами в порядке возрастания показателя качества (обозначены как 1, 2, 3 в кружках, при этом 4 в кружке обозначает выход из основной сети). Эти вычислительные модули построены по облегченной версии (т.е. с меньшим количеством параметров) вычислительных модулей, составляющих архитектуру основной сети, их сложность может настраиваться в соответствии с требуемым показателем качества, предопределенным пользователем. Чем меньше параметров в сети, тем меньше будет производиться вычислений, от этого будет страдать показатель качества вывода, и поэтому выходы создаются с учетом баланса между потерей показателя качества и ускорением вычислений.
На фиг.1 показан пример предлагаемой системы для получения обработанного изображения, имеющего показатель качества, выбираемый пользователем (предопределенный показатель качества). Предлагаемая система содержит искусственные нейронные сети (ИНС), также включающие в себя GAN. Память электронного устройства содержит множество GAN для разных задач. Каждая хранящаяся в памяти GAN содержит N вычислительных модулей, образующих основную сеть, и множество ветвей более раннего выхода, каждая из которых присоединена после каждого вычислительного модуля основной сети, за исключением последнего вычислительного модуля основной сети. Каждая ветвь более раннего выхода содержит столько вычислительных модулей, сколько их остается в основной сети после точки присоединения ветви более раннего выхода до выхода основной сети. Каждый вычислительный модуль каждой ветви более раннего выхода выполняет ту же функцию, что и соответствующий оставшийся вычислительный модуль в основной сети. Вычислительный ресурс (количество вычислений) каждой ветви более раннего выхода меньше вычислительного ресурса соответствующих оставшихся вычислительных модулей основной сети до выхода основной сети.
Например (см. фиг.1), генератор основной сети состоит из вычислительных модулей с l1 по l4. Каждая ветвь более раннего выхода присоединена после каждого вычислительного модуля основной сети (выходы 1, 2, 3 в кружках на фиг.1). На фиг.1 показаны три ветви раннего выхода, что добавляет ранние выходы 1, 2, 3. Каждая ветвь более раннего выхода содержит столько вычислительных модулей , сколько их остается в основной сети после точки подключения ветви более раннего выхода до выхода основной сети. Каждый вычислительный модуль каждой ветви более раннего выхода выполняет ту же функцию, что и соответствующий оставшийся вычислительный модуль в основной сети. Чем ближе конкретная ветвь более раннего выхода к выходу основной сети, тем выше вычислительный ресурс для получения обработанного изображения и показатель качества обработанного изображения, генерируемого конкретной ветвью более раннего выхода.
Как показано на фиг.1, каждая ветвь имеет различную глубину (глубина - это количество вычислительных модулей) и состоит из облегченных вычислительных модулей , то есть вычислительных модулей, которые содержат меньше параметров, чем вычислительные модули основной сети, хотя их структуры аналогичны.
Например (данный пример не ограничивает область применения изобретения), входными данными для основной сети являются 2 изображения, выбранные пользователем из памяти электронного устройства. Одно изображение, личность которого необходимо сохранить, и второе изображение, выражение лица которого необходимо сохранить. На выходе необходимо получить первую личность со вторым выражением лица. Память содержит предварительно подготовленную основную сеть с подключенными предобученными ветвями раннего выхода, на выходе которых показатель качества результирующего изображения ниже показателя качества изображения, полученного во время работы основной сети, а вычислительный ресурс каждой ветви значительно меньше вычислительного ресурса исходной основной сети. Пользователь извлекает из памяти электронного устройства GAN, то есть основную сеть с присоединенными ветвями раннего выхода, причем эта основная сеть пригодна для обработки изображений, выбранных пользователем из памяти. При этом выбранная основная сеть может выполнять обработку с получением готового изображения с максимальным показателем качества, и для получения изображения с максимальным показателем качества используются вычислительные модули основной сети, имеющие высокий вычислительный ресурс.
Память электронного устройства также содержит набор предикторов, каждый из которых представляет собой искусственную нейронную сеть. Каждый предиктор генерируется и предварительно обучается для конкретной GAN, хранящейся в памяти. Предиктор сконфигурирован прогнозировать показатель качества обработанного изображения для каждого выхода каждой ветви более раннего выхода конкретной GAN на основе исходного изображения, которое пользователь намерен подать на вход конкретной GAN. Предикторы сгруппированы с соответствующей основной сетью с присоединенной ветвью более раннего выхода в памяти.
Например, выбирают посредством пользователя из памяти электронного устройства два изображения. Одно изображение является источником, это изображение человека, внешность которого пользователь хочет сохранить (человек слева (например, изображения (а) или (b)) на фиг.1), другое изображение является драйвером, это любая другая фотография лица, выражение которого хочет передать пользователь (например, это изображение человека справа (изображения (а) или (b)) на фиг.1)). То есть в примере, показанном на фиг.1, изображения человека слева (изображения (а) или (b)) принимаются в качестве личности, которая отображается с выражением лица человека справа (изображения (а) или (b)).
На фиг.1 показан в качестве примера путь вычислений для двух отдельных вводов:
первый ввод (изображения а): источник - человек слева (изображение а), драйвер - человек справа (изображение а);
второй ввод (изображения b): источник - человек слева (изображение b), драйвер - человек справа (изображение b).
Каждое изображение (а) и (b) обрабатывается отдельно, на фиг.1 они показаны вместе только для иллюстрации.
Пользователь выбирает изображение (а) из памяти. Уже подготовленная и предобученная GAN (основная сеть с присоединенными ветвями раннего выхода) и соответствующий предобученный предиктор уже хранятся в памяти для решения такой задачи обработки изображения. Поэтому пользователь выбирает подходящую GAN вместе с предиктором из памяти после выбора изображений.
Пользователь выбирает требуемый показатель качества обрабатываемого выходного изображения. Изображение человека справа из изображений (а) подается в предиктор. Предиктор прогнозирует показатель качества изображения, сгенерированного основной сетью и каждой ветвью более раннего выхода выбранной GAN. При обработке изображений (а) с помощью GAN будет использоваться ветвь более раннего выхода, которая генерирует обработанное выходное изображение, имеющее показатель качества, наиболее соответствующий (или соответствующий) показателю качества, выбранному пользователем.
Если пользователю изначально требуется получить изображение с максимальным показателем качества, будет использоваться основная сеть без ветвей раннего выхода.
Например, на фиг.1 для максимального показателя качества, запрошенного пользователем для изображений (а), будет использоваться вся основная сеть без использования каких-либо ветвей более раннего выхода (выход 4). Для показателя качества, запрошенного пользователем для изображений (b), будет использоваться основная сеть с ветвью раннего выхода 2, так как согласно прогнозам предиктора показатель качества выходного изображения ветви более раннего выхода с выходом 2 в этом случае наиболее соответствует выбранному пользователем показателю качества.
Примеры изображений на выходе после l1 или l3, не показаны.
Для приведенных примеров (а) и (b) задачей нейронной сети является замена изображения головы второго человека (драйвера) на втором изображении или видео на голову первого человека (источника). Если подается видео, сеть заменяет голову драйвера на голову источника не только для одного изображения, но и на протяжении всего видео.
Готовое обработанное изображение, выводимое с выхода основной сети или одной из ветвей более раннего выхода, обеспечивающих заданный показатель качества, отображается, например, на дисплее электронного устройства. Чем сложнее изображение, тем больше требуется вычислений для получения требуемого предопределенного показателя качества.
Предиктор - это DNN, предварительно обученная на выходах предложенных ветвей и способная указывать выход, необходимый для вывода изображения с предопределенным показателем качества. Предиктор обучается с учителем, устанавливающим функцию потерь, как минимальную среднеквадратическую ошибку между ее прогнозом и фактическим показателем качества. Предиктор обучается на примерах и может прогнозировать показатель качества на выходе всех присоединенных к основной сети ранних выходов для данных входных изображений. При этом выход 4 назначается более сложному изображению (а) для сохранения требуемого показателя качества. А для нижнего входного изображения (b) (сплошная линия) требуется только выход 2, чтобы поддерживать требуемый предопределенный пользователем показатель качества.
В процессе работы изображение драйвера пропускается через предиктор и получаются порядковые номера ранних выходов, которые, согласно прогнозу предиктора, могут обеспечить требуемый предопределенный показатель качества выходного изображения, заданный предварительно. Блоки (например, 11,12,13,14 на фиг.1) основной нейронной сети (основной сети), к которым применяется предлагаемый способ, не требуют модификации. Ветви раннего выхода обеспечивают более ранний выход окончательного изображения из сети, чем обычный выход из основной сети без ветвей раннего выхода.
Показатель качества изображения вычисляется с использованием обычных мер (LPIPS, FID), а предиктор представляет собой вспомогательную сеть, обученную на примерах и предопределенном показателе качества сгенерированного
изображения.
Таким образом, после предоставления пользователем данных входного изображения предиктор вычисляет, какой показатель качества генерации будет иметь каждый выход. Это позволяет выбрать наиболее быстрый (с точки зрения вычислений) выход из тех, которые удовлетворяют данному условию показателя качества.
Предиктор является абсолютно независимой нейронной сетью. Его вывод представляет собой список показателей качества изображения, сгенерированных всеми ранними выходами для данного ввода. Предиктор используется в предлагаемом способе для выбора вывода с показателем качества, наиболее соответствующим выбранному пользователем показателю качества. Предиктор определяет показатель качества вывода в виде метрики LPIPS (известной в данной области техники).
Количество вычислительных модулей (т.е. глубина) ранних выходов варьируется в зависимости от количества модулей основной сети, оставшихся после присоединения к ней данного раннего выхода. Таким образом, обеспечивается достаточная обработка промежуточных логитов основной сети, причем вычисления происходят быстрее, так как вычислительные модули раннего выхода имеют меньше параметров, чем вычислительные модули основной сети. Следует отметить, что количество вычислительных модулей раннего выхода равно количеству вычислительных модулей, оставшихся в основной сети, т.е. невостребованных вычислительных модулей основной сети. Например, если от точки присоединения раннего выхода до конца основного пути осталось 4 вычислительных модуля, то ранний выход будет иметь 4 вычислительных модуля.
При этом поддерживается следующее условие: вычислительный ресурс выхода ветви раннего выхода в сумме с вычислительным ресурсом предыдущих выходов в блок-схеме основной сети всегда меньше вычислительного ресурса раннего выхода с более высоким порядковым номером. Это условие необходимо для того, чтобы иметь множество выходов с возрастающим количеством вычислений и, соответственно, с лучшим показателем качества.
Предлагаемая система может дополнительно содержать базу, хранящую направляющие данные (примеры), из которой извлекаются направляющие примеры, имеющие, например, изображение человека, совпадающее с изображением человека на входном изображении-источнике (человек слева на изображениях а или b на фиг.1), и подаются в каждую ветвь. При этом поза человека на направляющем изображении наиболее близка к позе человека на входном изображении-драйвере, но имеет внешний вид источника (человек слева на изображениях а или b на фиг.1). Для одной задачи извлекается один пример, т.е. один пример за проход. База примеров формируется заранее для каждой задачи, например, пользователем.
Для обоих примеров (а) и (b) на фиг.1 направляющее изображение человека слева (изображения а или b) извлекается из базы данных, чтобы улучшить показатель качества генерации. Для улучшения показателя качества генерации направляющие данные соединяются с данными из вычислительного модуля перед ветвью более раннего выхода, и соединенные данные передаются в ветвь более раннего выхода для дальнейшей обработки.
Например, если пользователь хочет получить свое изображение с позой другого человека, изображенного на другом изображении, то он сначала составляет базу направляющих примеров собственных фотографий в разных позах (фотографий в разных ракурсах), затем подает любое изображение пользователя (изображение-источник) и изображение с другим человеком (изображение-драйвер) на вход нейросети с ранними выходами. В процессе работы нейросети с ранними выходами из сформированной пользователем базы данных направляющих примеров выбирается направляющий пример из изображений пользователя, в котором пользователь изображен в позе, наиболее близкой к позе изображения-драйвера. Если пользователь желает получить видео со своими изображениями (изображениями-источниками), но с позами другого человека (изображениями-драйверами), то нейросеть с ранними выходами обрабатывает отдельно каждое изображение из последовательности видео, извлекая из базы данных направляющих примеров для каждого кадра изображение пользователя (изображение-источник) с позой, наиболее близкой к позе человека на соответствующем кадре (изображение-драйвер) последовательности видео, подаваемой в данный момент на вход нейронной сети с ранними выходами.
Наличие базы направляющих примеров обеспечивает прирост показателя качества для ветвей более раннего выхода за счет небольшого объема памяти и вычислений и тем самым гармонизирует выходной показатель качества на выходах. Это очень удобно для установок, в которых требуется рендеринг в реальном времени и можно легко обеспечить направляющие примеры, например, при создании нейронного аватара. Имеется ввиду задача создания аватара, т.е. виртуального образа человека. Например, пользователь желает во время цифровой конференции в режиме реального времени наложить на свое лицо другую личность, сохранив при этом все свои воспроизводимые выражения лица. При этом пользователь может заранее сделать снимок своего лица с разных ракурсов и загрузить его в базу данных. Это окажет существенную помощь при генерации, но не является абсолютно необходимым шагом.
Предлагаемый способ можно применять как к необученным, так и к уже обученным моделям, но требует дополнительного обучения для новых вводимых компонентов.
Основная сеть всегда фиксированная, а предиктор указывает только тот вывод, на котором будет получен требуемый пользователем показатель качества. Следует отметить, что при работе GAN (основной сети и ветвей более раннего выхода) используется только та ветвь раннего выхода, которая дает выходное изображение требуемого качества (наиболее
соответствующее показателю качества, выбранному пользователем) на выходе. Для этого в коде реализуется любой подходящий известный механизм переключения, и все остальные ветви раннего выхода, не требующиеся для выполнения выбранного раннего выхода, не используются.
Предлагаемый способ можно применять к любым задачам генерации, необходимо только наличие генератора, т.е. нейронной сети, создающей изображения из скрытого вектора. Основной результат предлагаемого способа можно резюмировать следующим образом: этот способ легко применить в уже существующих и обученных генеративных моделях, содержащих генератор (основную сеть), то есть нейронную сеть, создающую изображения из скрытого вектора.
Предлагаемый способ позволяет выводить изображения с установленным пользователем более низким порогом показателя качества путем маршрутизации более легких изображений по более коротким вычислительным путям, и основной выигрыш с точки зрения экономии вычислений на потерю показателя качества составляет, соответственно, 1,2×103 и 1,3×103 GFLOPs/LPIPS для этих двух применений.
Иными словами, предлагаемое изобретение позволяет сократить количество вычислений за счет потери показателя качества. Чем больше вычислений приводится к "единице показателя качества" (мера LPIPS), тем лучше.
Сети GAN состоят из двух конкурирующих DNN: генератора G и дискриминатора D. Генератор G предназначен для синтеза произвольных изображений, когда задан случайный вектор признаков низкой размерности: G : z → g, where z - ввод, a g - сгенерированное изображение. Дискриминатор D учится отличать распределение сгенерированных изображений 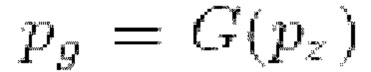 от одного из исходных примеров
от одного из исходных примеров  . Их цели можно обобщенно представить в виде минимаксной игры (минимаксная игра известна из уровня техники и означает решающее правило для минимизации возможных потерь из тех, которые лицо, принимающее решение, не может предотвратить в худшем сценарии):
. Их цели можно обобщенно представить в виде минимаксной игры (минимаксная игра известна из уровня техники и означает решающее правило для минимизации возможных потерь из тех, которые лицо, принимающее решение, не может предотвратить в худшем сценарии):
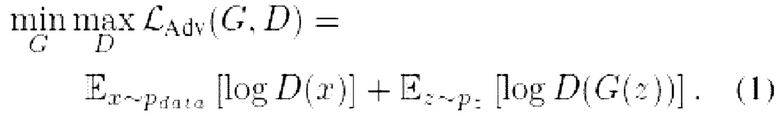
где  - функция потерь, которую веса генератора G должны минимизировать, а веса дискриминатора D максимизировать;
- функция потерь, которую веса генератора G должны минимизировать, а веса дискриминатора D максимизировать;
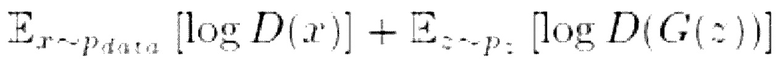 - ожидаемое значение
- ожидаемое значение  выражения, когда выбирается случайная величина х с распределением вероятностей р; D(x) и G(z) - выводы дискриминатора D и генератора G.
выражения, когда выбирается случайная величина х с распределением вероятностей р; D(x) и G(z) - выводы дискриминатора D и генератора G.
При обеспечении условия с (например, в виде меток) как генератору, так и дискриминатору, первый сможет научиться синтезировать изображения из подпространства pg:  , где G(x) - вывод генератора; pz и pg - вероятностные распределения входного шума и выходных изображений, и с - согласующий параметр.
, где G(x) - вывод генератора; pz и pg - вероятностные распределения входного шума и выходных изображений, и с - согласующий параметр.
Любой генератор GAN состоит из ряда сверточных модулей, обозначенных li. Вывод каждого модуля, а именно  , является кандидатом для раннего выхода, но он не является визуализированным изображением. По этой причине его необходимо обработать серией дополнительных сверток, прежде чем из него можно будет извлечь изображение. Эти
, является кандидатом для раннего выхода, но он не является визуализированным изображением. По этой причине его необходимо обработать серией дополнительных сверток, прежде чем из него можно будет извлечь изображение. Эти  новые сверточные вычислительные модули составляют то, что называется ветвью, это и есть ранние выходы.
новые сверточные вычислительные модули составляют то, что называется ветвью, это и есть ранние выходы.
Для основной сети, построенной из N вычислительных модулей, после вычислительного модуля к добавляется ветвь длиной N - k. Вычислительные модули ветвей менее сложны, чем модули основных сетей, их ширина, т.е. количество каналов, уменьшена. Следовательно, с выхода каждой ветви  извлекается изображение, визуализированное с меньшим количеством вычислений, чем изображение, извлекаемое на выходе основной сети. Каждая ветвь раннего выхода обучается предварительно на состезательной функции потерь с копиями исходного дискриминатора основной сети.
извлекается изображение, визуализированное с меньшим количеством вычислений, чем изображение, извлекаемое на выходе основной сети. Каждая ветвь раннего выхода обучается предварительно на состезательной функции потерь с копиями исходного дискриминатора основной сети.
На этапе логического вывода, имея набор обученных ветвей, каждое изображение можно синтезировать через другой выход. При заданном показателе качества необходимо иметь возможность выбрать только ту ветвь, которая достигнет его, выполнив наименьшие возможные вычисления. Есть единственный порог показателя качества (то есть предопределенный показатель качества, указанный пользователем) для всех ветвей, необходимо выбрать ветвь, которая будет выводить изображения с равным или более высоким показателем качества (т.е. показателем качества, наиболее соответствующим выбранному пользователем показателю качества), выполняя при этом минимально возможный объем вычислений. С этой целью используется предиктор Р, состоящий из сверточных и полносвязных слоев. Предлагаемый предиктор обучается с учителем, используя входные условия с в качестве обучающих примеров и векторы оценок LPIPS S для изображений, сгенерированных ветвями, в качестве меток. Следует отметить, что обучение созданию семантической карты и обучение созданию перекрестного воспроизведения выражений лица ничем не отличаются.
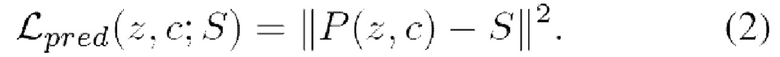
где с - согласующие параметры, S - оценка LPIPS для изображения, созданного с вышеупомянутыми параметрами, и P(z, с) - вывод предиктора.
Таким образом, подавая ввод в обученный предиктор, можно получить оценку показателя качества вывода каждой ветви и, следовательно, использовать эту информацию для направления вычислительного потока к выходу, который выполняет наименьшее количество вычислений, сохраняя при этом порог показателя качества.
Для дальнейшего улучшения показателя качества синтеза необходимо перейти от чисто параметрического метода к полупараметрическому, в котором процесс генерации направляется фрагментами данных, то есть данными, извлеченными из базы данных. Данные, обрабатываемые вычислительными модулями основной сети, расположенными перед вычислительными модулями ветви раннего выхода, являются недообработанными тензорами. Для дальнейшего улучшения показателя качества синтеза
недообработанные тензоры соединяются с фрагментами данных перед подачей в ветвь раннего выхода.
Таким образом обеспечивается более заметное увеличение показателя качества на более ранних выходах, которые являются самыми быстрыми, но больше всего страдают от снижения показателя качества из-за меньшего количества параметров в них. Добавив умеренное количество памяти и вычислений, достигаются лучшие результаты, что гармонизирует показатель качества вывода различных ветвей.
Например, в качестве направляющих данных в базе данных хранится набор тензорных пар, которые называются парами ключ-значение. В этом случае направляющие данные генерируются основной сетью при формировании базы данных. Когда происходит процесс генерации изображения, направляющие данные уже есть в базе данных и извлекаются из нее во время работы GAN при создании изображения. Ключи получаются путем применения к исходным данным всех обученных слоев основной сети до первой ветви раннего выхода и разрезания полученных тензоров, называемых направляющими признаками, на неперекрывающиеся фрагменты. Иными словами, ключи получают следующим образом: данные исходных изображений подаются в основную сеть, результат перед первой ветвью раннего выхода разбивается на фрагменты, и эти фрагменты являются ключами. Значения получают путем применения обученных слоев основной сети к исходным изображениям и разрезания полученных признаков на фрагменты данных с разделением их на N фрагментов. Было замечено, что лучший результат достигается при применении обученных слоев основной сети до ее середины к исходным изображения. На основе входных данных в базе данных производится поиск наиболее похожих изображений из хранящихся там изображений. Полное изображение ищется в фрагментах данных. Для этого вводы обрабатываются несколькими слоями исходной основной сети, чтобы уменьшить размерность входных изображений и ускорить поиск похожих изображений. При обнаружении похожих фрагментов найденный фрагмент отправляется в ветвь раннего выхода.
Во время логического вывода основная сеть обрабатывает каждый ввод до уровня, предшествующего первой ветви. Берутся полученные признаки, разрезаются на фрагменты данных, и для каждого фрагмента данных в базе данных ищется ближайший ключ. После извлечения значений, соответствующих всем фрагментам данных, они склеиваются, и полученные признаки соединяются с вводом каждой ветви. Имея все ключи вспомогательных данных (на фиг.1 изображение человека слева (изображения а или Ь) для наиболее похожего изображения, соответствующие обработанные данные подаются на вход раннего выхода. Это делается для улучшения показателя качества генерации, что особенно помогает ранним выходам, расположенным ближе к началу основной сети.
Для количественной оценки успешности предлагаемого способа введем простую меру сэкономленных вычислений. В качестве единиц измерения используем соответственно GFLOP (операции с плавающей запятой) и LPIPS [84]. Например, при перекрестном воспроизведении выражений лица достигается средний прирост показателя качества 1,3×103 GFLOP/LPIPS, а это означает, что снижение порога показателя качества на +0,01 LPIPS приведет к снижению на 13 GFLOP.
Предлагаемый способ можно применить в множестве DNN для различных задач синтеза. Чтобы продемонстрировать его универсальность, применим его, например, к двум различным задачам синтеза изображений:
1) синтез фотографий на открытом воздухе, стартующий с карты семантических меток, на основе архитектуры OASIS в качестве основной сети [63];
2) перекрестное воспроизведение выражений лица, синтез нейронных аватаров головы, стартующее с изображения, которое является целевым выражением и положением аватара, на основе архитектуры MegaPortraits в качестве основной сети [17].
В первом примере конвейер реализован на основе модели OASIS в качестве основной сети [63]. Генератор OASIS состоит из б модулей SPADE ResNet [57], которые составляют вычислительные модули li, i ∈ основной сети [1, 6]]. Добавлены 4 ветви, по одной после каждого модуля основной сети с l1 по l4. Вычислительные модули  ветвей также является модулями SPADE ResNet, и их
ветвей также является модулями SPADE ResNet, и их  длина варьируется для сохранения, где len - число вычислительных модулей более раннего выхода, k - число выходов. То есть, если число выходов к равно 2, то число вычислительных модулей ветви более раннего выхода равно 4.
длина варьируется для сохранения, где len - число вычислительных модулей более раннего выхода, k - число выходов. То есть, если число выходов к равно 2, то число вычислительных модулей ветви более раннего выхода равно 4.
Вычислительные модули ветвей раннего выхода представляют собой облегченный вариант вычислительных модулей основной сети, так как их ширина, т.е. количество каналов, уменьшена путем задания коэффициента масштабирования (SF) s=1/2, 1/3, 1/4 для уменьшения вычислений.
Таким образом, создается всего 5 вычислительных маршрутов для каждого коэффициента масштабирования для основной сети модели OASIS, их GFLOPs (операции с плавающей запятой) перечислены в таблице 1. GFLOPs определяет количество операций, выполняемых за один прогон. Чем больше параметров, тем больше операций, так как эти параметры перемножаются, и так далее. Различные SF по-разному сокращают количество параметров. ВВ - это основная сеть, приведенная в таблице для сравнения, на нее не влияет показатель качества. SF - это коэффициент сжатия; если исходный вычислительный модуль имеет N каналов, то сжатие в номах будет N*SF. 64 - произвольное число. Каналы являются частью архитектуры сверточных сетей.

Таблица 1 иллюстрирует сравнение GFLOPs всех 5 вычислительных маршрутов через ветви 1-4 и основную сеть OASIS (ВВ), крайний правый столбец). Разные строки соответствуют разным коэффициентам масштабирования (SF). Как видно из таблицы, SF не одинаково влияет на все вычислительные модули, так как задается минимальное количество каналов, равное 64, после чего дальнейшее масштабирование не задается. Следует отметить, что число 64 установлено произвольно и меняется в следующих тестах. Канал - это стандартный термин, RGB-изображения имеют 3 канала, сверточные сети создают другие каналы в зависимости от их архитектуры, в общем, это параметр сети, который требуется уменьшить.
Для реализации предложенного способа обучаются все ветви и предиктор. Каждая ветвь обучается путем задания состязательной функции потерь, как в уравнении (1), полученных путем конкуренции с копиями дискриминатора OASIS. Наряду с этим задаются потери VGG [37] и LPIPS [84] при использовании изображения, синтезированного основной сетью, в качестве эталона.

где 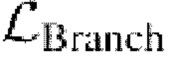 - общая потеря, состоящая из исходной потери
- общая потеря, состоящая из исходной потери 
 , а также потерь VGG и LPIPS
, а также потерь VGG и LPIPS  . α и β - это гиперпараметры, выбираемые для выравнивания вклада потерь; общая скорость обучения установлена на 4×10-4, а коэффициенты установлены на α=10 и β=5, чтобы уравнять вклад потерь. Дискриминаторы сохраняют свои первоначальные потери. Генератор и дискриминаторы обучены с помощью оптимизации Адама [89] с β1=0, β2=0, 999. Эти вычисления выполнялись с использованием распределенных данных из библиотеки PyTorch [10] параллельно на двух графических процессорах NVIDIA Р40 с пакетом=2 и длились примерно 6 дней. Полученные результаты представлены в таблицах 2 и 3.
. α и β - это гиперпараметры, выбираемые для выравнивания вклада потерь; общая скорость обучения установлена на 4×10-4, а коэффициенты установлены на α=10 и β=5, чтобы уравнять вклад потерь. Дискриминаторы сохраняют свои первоначальные потери. Генератор и дискриминаторы обучены с помощью оптимизации Адама [89] с β1=0, β2=0, 999. Эти вычисления выполнялись с использованием распределенных данных из библиотеки PyTorch [10] параллельно на двух графических процессорах NVIDIA Р40 с пакетом=2 и длились примерно 6 дней. Полученные результаты представлены в таблицах 2 и 3.

В таблице 2 представлены количественные результаты для конвейера OASIS. Минимальное количество каналов равно 64. При таком минимальном количестве каналов задается нижний порог показателя качества. Для трех разных коэффициентов масштабирования SF (первый столбец) конвейер тестировался с направляющей базой данных и без нее, что отмечено в столбце Bank (база данных) галочкой (с направляющей базой данных) или крестиком (без направляющей базы данных). Четыре столбца, по одному для каждой ветви, содержат оценки FID (начальное расстояние Фреше, мера показателя качества) и mIOU (среднее пересечение по соединению, мера показателя качества); внизу эти два значения представлены для основной сети. Из таблицы 2 можно сделать вывод, что добавление базы данных обеспечивает более высокое улучшение показателя качества первых выходов, чем последних. Она также наглядно показывает, как коэффициент сжатия влияет на показатель качества. Подойдет любое сжатие, его выбор зависит от того, какой показатель качества требуется. Чем меньше параметр FID, тем выше показатель качества. Чем выше mIOU, тем выше показатель качества.
Из таблицы 2 можно сделать вывод, что добавление базы данных обеспечивает более высокое улучшение показателя качества первых выходов, чем последних. Она также наглядно показывает, как степень сжатия влияет на показатель качества. Из таблицы 2 видно, что наибольший коэффициент масштабирования, при котором число параметров остается достаточно большим, дает лучшие результаты с базой данных (FID=52,8; mIOU=67,5), чем без базы данных (FID=64,2; mIOU=59,8). Кроме того, чем меньше параметров (S=1/4) в одной и той же ветви раннего выходаэ (ветвь 1), тем хуже показатель качества выходного изображения. Однако при наличии базы данных (FID=54, 9; mIOU=65,5) показатель качества выходного изображения лучше, чем без базы данных (FID=69,6; mIOU=5 7,5). Кроме того, чем ближе ветвь раннего выхода s к выходу из основной сети, тем лучше показатель качества изображения, но также показатель качества выходного изображения с базой данных лучше, чем без базы данных. Очевидно, что показатель качества выходного изображения для основной сети без модулей раннего выхода является лучшим.

В таблице 3 приведены количественные результаты для конвейера OASIS при различных коэффициентах масштабирования. Минимальное количество каналов равно 32. Для 4 различных коэффициентов масштабирования SF конвейер тестировался с направляющей базой данных и без нее, что отмечено в столбце "Bank" галочкой или крестиком. Четыре столбца, по одному для каждой ветви, содержат оценки FID (начальное расстояние Фреше) и mIOU (среднее пересечение по соединению); внизу эти два значения приведены для основной сети. Можно сделать вывод, что добавление банка обеспечивает более высокое улучшение показателя качества первых выходов, чем последних. Она также наглядно показывает, как коэффициент сжатия влияет на показатель качества. Подойдет любое сжатие, его выбор зависит от того, какой показатель качества требуется.
Из таблицы 3, также как из таблицы 2 видно, что добавление базы данных улучшает показатель качества выходного изображения, а увеличение коэффициентов масштабирования SF ухудшает показатель качества выходного изображения, кроме того, чем выше номер выхода ветви раннего выхода, тем выше показатель качества выходного изображения.
Предиктор OASIS был обучен выводить показатель качества изображений для каждой ветви. Была задана минимальная квадратичная потеря ошибки между его прогнозами и фактическими качествами, как было описано выше:

где с - согласующие параметры; S - оценка LPIPS для изображения, созданного с вышеупомянутыми параметрами; и Р(с) вывод предиктора.
Скорость обучения была установлена на 0,01, потери оптимизировались с помощью стохастического градиентного спуска с косинусным законом снижения [90]. Скорость обучения является общепринятым в данной области параметром, который необходим для обучения; если пользователь желает воспроизводить эксперименты с высокой точностью, ему необходимо знать этот коэффициент. Однако это не является частью изобретения.
Выбор обучающего набора данных для предиктора был нетривиальным, поскольку ввод конвейера состоит из семантической карты, соединенной с трехмерным тензором шума. Из-за высокой размерности шумового пространства равномерная выборка из него не гарантирует какой-либо сходимости для процесса обучения. Вместо этого случайным образом извлекаются 100 трехмерных тензоров шума и соединяются с 500 семантическими картами, что дает 50000 примеров. Затем этот метод тестируется с использованием 100, 300 и 500 тензоров шума. После обучения измеряется ошибка предиктора с использованием 500 семантических карт, соединенных с теми же шумами, которые использовались для обучения, и с новыми шумами. Результаты представлены в таблицах 4 и 5, соответственно.

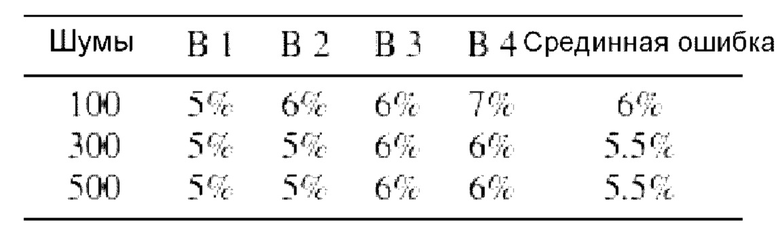
В таблице 4 показана ошибка проверки достоверности для предиктора OASIS. Проверочный набор данных был создан путем соединения шумов (случайный сигнал), используемых для обучения с 500 семантическими картами. В первом столбце показано количество шумов, использованных для обучения предиктора, а в столбцах В1-В4 показана ошибка, полученная отдельными ветвями с 1 по 4 при проверке достоверности. В последнем столбце показано среднее значение всех ошибок. В таблице показано, как уменьшается ошибка при увеличении шума, используемого для обучения.

В таблице S4 показывает ошибку тестирования для предиктора OASIS. Тестовый набор данных был создан путем соединения случайных шумов с 500 семантическими картами. В первом столбце показано количество шумов, использованных для обучения предиктора, а в столбцах В1-В4 - ошибка, полученная отдельными ветвями с 1 по 4 при тестировании. В последнем столбце показано среднее значение всех ошибок. В таблице показано, как уменьшается ошибка при увеличении шума, используемого для обучения.
Чтобы реализовать базу данных для направления генерации изображений, ее заполняют 500 случайно извлеченными изображениями из обучающего набора данных.
Для каждого из случайно извлеченных изображений создается 100 различных вводов с использованием фиксированного набора 3D-шумов (шумов, имеющих структуру не двумерной матрицы, а трехмерного тензора). Эти вводы подаются в первый 2D-сверточный слой и последующий модуль ResNet основной сети. Затем полученные признаки делятся на 8×16=128 неперекрывающихся фрагментов данных в соответствии с их разрешением, которые дают ключи для поиска наиболее похожего изображения. Значения извлекаются путем обработки вводов до третьего модуля ResNet основной сети (вычислительный модуль архитектуры OASIS) и разрезания полученных признаков на одинаковые фрагменты данных. База данных заполняется один раз в начале этапа обучения. Для уменьшения избыточности в ключах к ним применяется выборка FPS [19] (поскольку многие изображения могут быть чрезвычайно похожими и нет смысла хранить все, для этого используется алгоритм выборки FPS, который выбирает всего одно изображение из каждого кластера подобия) на фазе прямого вывода, после обработки ввода первым 2D-сверточным слоем и следующим слоем ResNet его делят на 128 идентичных фрагментов данных (128 - это произвольное число, сохраняющее пропорции. Это делается для того, чтобы выбрать более одного изображения, в некоторой степени похожего на исходное, но выделить более похожие элементы - улицу, угол дома и т.п.Затем в базе данных производится поиск ключа, наиболее похожего на каждый фрагмент данных, с помощью библиотеки FAISS [38]. Все 128 извлеченных значений затем соответствующим образом склеиваются (извлекаемые значения представляет собой
прямоугольные участки плоскости, и эта плоскость всегда разрезается на 128 фрагментов данных, они склеиваются путем записи в общую матрицу нужного размера).
Этот составной признак используется для управления процессом синтеза путем соединения его с вводом каждой ветви после надлежащего изменения размера, выполняемого путем свертки. На фиг.2 показано полученное распределение показателя качества среди всех ветвей, оцененное по начальному расстоянию Фреше (FID) [32]. Фиг. 2 показывает соотношение между показателем качества (выраженным в единицах FID) и вычислениями для всех ветвей при различных коэффициентах масштабирования реализации OASIS с использованием направляющей базы данных. Три кривые на графике соединяют значения FID, полученные выходами 1-4 (ветви 1-4) для разных коэффициентов масштабирования. Квадратики обозначают коэффициент масштабирования 1/2, точки - коэффициент масштабирования 1/3, а треугольники - коэффициент
масштабирования 1/2. Более высокий масштаб экономит вычисления, снижая показатель качества. Звездочка показывает исходный показатель качества и вычисления для конвейера OASIS. Как уже отмечалось выше, чем больше FID, тем ниже показатель качества выходного изображения, а также ниже вычислительные затраты. И наконец, конвейер, охватывающий все генерирующие ветви и основную сеть, вместе с базой направляющих данных, используется для создания набора данных для обучения предиктора. Ввод OASIS состоит из семантической карты и высокоразмерного пространства случайных шумов (набора многомерных векторов, состоящих из случайных чисел). Это обучение ограничено 100 фиксированными векторами шума в сочетании с обучающим набором Cityscape. На фиг.3 показаны примеры выводов ветвей конвейера OASIS. Верхнее левое изображение представляет семантическую карту, используемую в качестве ввода в конвейер, верхнее среднее изображение - вывод исходной модели OASIS (основной сети), верхнее правое изображение - вывод, полученный первой ветвью с соответствующим показателем качества 0,13 LPIPS, нижнее левое изображение вывод второй ветви с соответствующим показателем качества 0,11 LPIPS; нижнее среднее изображение - вывод третьей ветви с соответствующим показателем качества 0,10 LPIPS; нижнее правое изображение - вывод четвертой ветви (ранний выход) с соответствующим показателем качества 0,10 LPIPS. На фиг.3 показано готовое изображение, полученное на каждой ветви. Можно заметить, как ухудшается показатель качества при уменьшении порядка вывода, т.е. первый вывод имеет наихудший показатель качества.
На фиг.4 представлен общий результат для всего конвейера при SF=1/4. Фиг. 4 иллюстрирует распределение вычислений между ветвями основной сети OASIS для диапазона заданных порогов LPIPS (нижний предел показателя качества, измеренный в метриках LPIPS, является общепринятым в уровне техники). Ветвь 1 - "а"; ветвь 2 - "b"; ветвь 3 - "с"; ветвь 4 - "d"; основная сеть - "е". Для каждого порога показателя качества предиктор направляет вычисления к одному из пяти возможных выходов в зависимости от сложности ввода, который он изучил. При снижении требований к показателю качества использование первых ветвей становится более выраженным. Все распределения получены путем выборки одних и тех же 500 тестовых изображений с использованием коэффициента масштабирования 1/4. Общие показатели GFLOP для каждого распределения показаны сплошной линией, а их абсолютные значения показаны справа. Последнее значение показывает распределение ветвей, выбранных предиктором, при различных порогах показателя качества. Можно заметить, как разные пороги показателя качества влияют на выбор выхода: при задании очень высокого показателя качества сужается спектр возможных выходов, при более низких (тем не менее высоких) требованиях используются все дополнительные ветви. Что наиболее важно, подсчет GFLOP показывает резкое уменьшение вычислений при использовании более ранних ветвей. Аппроксимируя кривую GFLOP к постоянному склону, можно оценить средний выигрыш 1,2x103 GFLOP/LPIPS. Ratio - это доля вычислений относительно количества вычислений в основной сети. То есть, например, 1 соответствует количеству вычислений, совпадающему с количеством вычислений в основной сети, а 0,5 - это половина вычислений основной сети.
Реализация нейронного аватара головы основана на методе генерации MegaPortraits [17] для изображений размером 512 × 512 пикселей. Этот конвейер состоит из нескольких этапов, обеспечивающих передачу характерных черт от лица-источника лицу-драйверу, т.е. тому, ориентацию и выражение которого необходимо получить. В качестве вычислительных модулей основной сети используется li, i ∈ [1, 9], его окончательный набор вычислительных модулей охватывает 9 остаточных блоков, что в сумме составляет 213 GFLOP. Присоединены 3 ветви, по одной после блоков номер 2, 4 и 6 основной сети. Их вычислительные модули  являются такими же остаточными блоками, а их соответствующая глубина, т.е. количество вычислительных модулей, зеркально отражает оставшийся путь: 8, 6 и 4, сохраняя тем самым k+len=9
являются такими же остаточными блоками, а их соответствующая глубина, т.е. количество вычислительных модулей, зеркально отражает оставшийся путь: 8, 6 и 4, сохраняя тем самым k+len=9  {2, 4, 6}. Для облегчения ветвей к ширине вычислительных модулей, т.е. количеству каналов, применяются три различных коэффициента масштабирования. Их общие GFLOP перечислены в таблице б.
{2, 4, 6}. Для облегчения ветвей к ширине вычислительных модулей, т.е. количеству каналов, применяются три различных коэффициента масштабирования. Их общие GFLOP перечислены в таблице б.
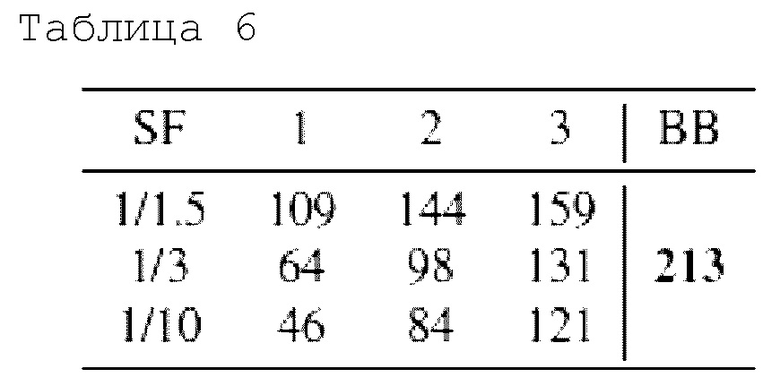
Таблица 6 иллюстрирует сравнение GFLOP всех 4 вычислительных маршрутов через ветви и основную сеть MegaPortraits (ВВ, крайний правый столбец). Разные строки соответствуют разным коэффициентам масштабирования (SF). В таблице 6 показаны вычисления всех выводов. Можно заметить, что чем раньше выход, тем меньше вычислений.
Ветви обучаются путем задания состязательной функции потерь, как в уравнении (1), полученных в результате конкуренции с копиями дискриминатора Mega-Portraits. Вместе с этим задаются потери VGG [37], MS-SSIM [75] и  между синтетическими изображениями ветвей и основной сети. Кроме того, используются промежуточные логиты основной сети, чтобы задать потерю соответствия признаков (FM) [73] и сохранить исходную потерю взгляда (GL) [17].
между синтетическими изображениями ветвей и основной сети. Кроме того, используются промежуточные логиты основной сети, чтобы задать потерю соответствия признаков (FM) [73] и сохранить исходную потерю взгляда (GL) [17].
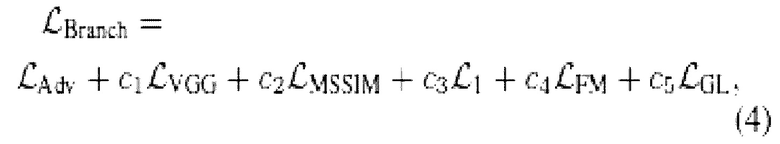
где  - стандартная состязательная функция потерь для сетей GAN;
- стандартная состязательная функция потерь для сетей GAN;  - потеря VGG [37];
- потеря VGG [37];  - потеря MS-SSIM [75];
- потеря MS-SSIM [75];  - потеря L1,
- потеря L1,  - потеря соответствия признаков [73]; and
- потеря соответствия признаков [73]; and  - потеря взгляда [17]. Коэффициенты C1 выбраны для гармонизации эффектов потерь.
- потеря взгляда [17]. Коэффициенты C1 выбраны для гармонизации эффектов потерь.
База данных заполняется изображениями лица-источника с множеством различных ориентаций и выражений. На каждой итерации в базе данных ищется лицо, наиболее похожее на лицо-драйвер, т.е. такое, ориентацию и выражение которого необходимо получить. Для выполнения этого поиска драйвер подается в первый вычислительный модуль MegaPortraits, который экстраполирует углы, описывающие направление лица, и многомерный вектор, кодирующий выражение лица. Авторы ограничились 3 углами для кодирования направлений лица, а пространство выражений было 512-мерным. В результате получается вектор, характеризующий драйвера, наиболее близкий из изображений в базе данных. Затем полученное изображение соединяется со вводом каждого вычислительного модуля  ветвей после соответствующего изменения размера.
ветвей после соответствующего изменения размера.
На фиг.5 показаны примеры выводов ветвей для конвейера MegaPortraits. Верхний ряд использует в качестве источника и драйвера соответственно первое и второе изображение. Внешний вид источника наложен на выражение драйвера. Третье изображение -это вывод исходного конвейера MegaPortraits, четвертое изображение извлечено из базы данных. Далее следуют выводы ветви 1 с LPIPS 0,1, ветви 2 с LPIPS 0,08 и ветви 3 с LPIPS 0,05. Нижний ряд зеркально отражает верхний, только изменены изображения источника (изображение человека слева на фиг.1(b)) и драйвера (изображение человека справа на фиг.1(b)).
На фиг.6 показано полученное распределение показателя качества по ветвям. Фиг. 6 иллюстрирует соотношение между показателем качества (выраженным в единицах LPIPS) и вычислениями для всех ветвей при различных коэффициентах масштабирования реализации MegaPortraits с использованием направляющей базы данных. На фиг.6 три кривые на графике соединяют значения FID, полученные выходами 1-3 (ветви 1-3) для разных коэффициентов масштабирования. Точки обозначают коэффициент масштабирования 1/3, квадратики - 1/6, и квадратики 1/15. Можно заметить, что более высокий коэффициент масштабирования экономит вычисления, снижая показатель качества. Звездочка показывает исходный показатель качества и вычисления для конвейера OASIS.
В завершение, обучается предиктор. После этого можно задать любой порог показателя качества, и предиктор сможет выбрать путь, который удовлетворит его с наименьшими вычислениями. На фиг.7 представлены общие результаты для всего конвейера. Ветвь 1 - "а"; ветвь 2 - "b"; ветвь 3 - "с"; основная сеть - "d". Фиг. 7 иллюстрирует распределение вычислений между ветвями основной сети MegaPortraits для множества заданных порогов LPIPS. Для каждого порога показателя качества предиктор направляет вычисления к одному из четырех возможных выходов в зависимости от сложности ввода, который он изучил. Это показано четырьмя разными столбцами для каждого значения LPIPS. Столбцы "а", "b", "с" и "d" соответствуют соотношению выводов, маршрутизируемых через выходы 1,2,3, соответственно, и основную сеть. Все распределения были получены путем выборки одних и тех же 7 02 тестовых изображений с использованием SF=1/15. Общие GFLOP для каждого распределения показаны сплошной линией, а их абсолютные значения показаны справа. Можно видеть, как можно поддерживать более низкие пороги показателя качества при значительном снижении GFLOP благодаря использованию более легких ветвей. Аппроксимируя кривую GFLOP к постоянному склону, можно оценить средний выигрыш 1,3 × 103 GFLOP/LPIPS.
Хотя генерация изображений возможна и без базы направляющих данных изображений, она необходима для обеспечения показателя качества более ранних ветвей. Фактически, можно утверждать, что ее реализация гармонизирует показатель качества выводов на выходах, влияя на самые ранние ветви, о чем свидетельствует фиг.8. Количества изображений на оси у указывают количества изображений с показателем качества LPIPS на оси х. На фиг.8 показано сравнение распределений показателей качества для конвейера OASIS с SF=1/4 с использованием направляющей базы данных и без нее. LPIPS были получены путем сравнения с изображениями основных сетей. Распределения показателей качества каждой ветви пронумерованы по по-разному: 1, 1', 2, 2', 3, 3', 4, 4'. Распределения без использования базы данных показаны пунктирной кривой (1', 2', 3', 4'), а распределения, полученные с использованием базы данных, показаны сплошной кривой (1, 2, 3, 4). Чем ближе к левому краю кривой, тем лучше показатель качества выходного изображения. Видно, что распределения показателей качества для первых ветвей больше смещены в сторону лучшего качества после внедрения базы данных. Например, пунктирная линия 1' резко смещается влево, становясь сплошной кривой 1 при использовании базы данных, в то время как пунктирная кривая 4' смещается меньше, становясь сплошной линией 4. Были построены кривые для выборки 500 изображений с применением оценки плотности ядра с полосой пропускания 0,3.
Кроме того, эту базу данных можно использовать для компенсации недостатка обучающей выборки. Сложность рендеринга частично связана с отсутствием обучения DNN, что вполне может быть присуще конкретной задаче, например, генерации нейронных аватаров голов.
Как обсуждалось выше, в основу предлагаемой реализации динамической маршрутизации положено создание подходящего раннего выхода, а также использование предиктора. Последнее необходимо для принудительного применения устанавливаемых пользователем порогов показателя качества, поскольку при использовании одиночных выходов создаются изображения только с фиксированным распределением показателя качества.
Кроме того, хотя все ветви имеют определенный средний показатель качества, зафиксированный их FID (см. в качестве примера фиг.2), нельзя полагаться только на одну ветвь для получения изображений с подходящим показателем качества. Разброс показателей качества каждого выхода довольно велик, и он становится шире у самых ранних выходов, как видно на фиг.8. Предиктор предотвращает это путем выбора более тяжелой ветви (имеющей больше параметров), когда более легкая ветвь не может обеспечить показатель качества.
На фиг.9 показано сравнение распределений показателей качества изображений, полученных из отдельных ветвей, и распределений, полученных с использованием предиктора, настроенного на выдачу порога, равного среднему показателю качества ветвей (сплошная кривая с предиктором, пунктирная - без предиктора). Количества изображений по оси Y указывают количества изображений с показателем качества LPIPS по оси X. Хорошо видно, как предиктор обеспечивает данный порог показателя качества, направляя сложные изображения к следующим ветвям и тем самым сдвигая распределение. Фиг. 9 иллюстрирует сравнение между распределениями показателей качества отдельных ветвей OASIS и распределениями показателей качества, полученными с
использованием предиктора (Р). Предиктор был настроен на принудительное применение порогов, равных среднему показателю качества ветвей. LPIPS получены путем сравнения изображений ветвей для SF=1/4 с изображениями основной сети. Выборка каждого распределения осуществлялась путем ввода 500 семантических карт со случайными шумами. Кривые являются результатом оценки плотности ядра с полосой пропускания 0,3. Все четыре графика содержат два распределения: пунктирная кривая 1' представляет распределение более высокого показателя качества для предлагаемого способа, когда задаются выходные изображения с порогом более низкого показателя качества, равным средним распределениям ветвей 1-4. Сплошная кривая 1 на каждом графике представляет распределение ветви. Видно, как реализация предиктора, который направляет вычисления для обеспечения порога более низкого показателя качества, сдвигает распределения в сторону более высокого показателя качества, тем самым подтверждая свою эффективность.
Не все изображения одинаково сложно создавать. Эта неравномерность заложена в основу предлагаемого способа. Такое неравномерное распределение сложности обусловлено множеством причин. Некоторые повороты головы или выражения лица могут быть менее выражены на этапе обучения, и поэтому для вывода изображений с высоким показателем качества требуется более тяжелая модель. Для решения этой проблемы применяется анализ путем сравнения изображений с разными поворотами головы и выражениями лица, а также их показателя качества. В частности, с помощью предложенного конвейера были сгенерированы 7 02 аватара головы и проверено, в какой ветви они были маршрутизированы предиктором.
На фиг.10 показано сравнение количества изображений, направляемых в разные ветви, в зависимости от поворота головы. Как видно на фиг.10, чем больше угол между двумя изображениями, тем выше сложность. На оси X показано расстояние в градусах, означающее угол между головой из базы данных и головой драйвера.
Использовались ветви для SF=1/15. Были получены распределения для выборки из 7 02 изображений в сумме. Кривые являются результатом оценки плотности ядра с полосой пропускания 0,5. Порог показателя качества был установлен на 0,09 LPIPS. Видно, что ветвь 1 используется для вывода большинства изображений, на которых голова драйвера лишь незначительно повернута относительно исходного изображения (до 6 градусов), а ветви 2 и 3 отвечают за углы большего размера, что подтверждает корреляцию между углом и сложностью в установке MegaPortraits. По оси Z представлены значения количества изображений, нормализованных к 1, т.е. 1=100 изображений.
Хотя предлагаемый метод позволяет сэкономить большое количество вычислений, он имеет некоторые ограничения. Весь конвейер применим только к архитектурам, содержащим декодер, его нельзя применить без изменения к преобразователям и другим алгоритмам синтеза, не имеющим декодер. Не существует единого рецепта заполнения базы данных. Авторы приняли решение заполнять ее случайным образом, но фактически это может быть не лучшим выбором. Поскольку необходимо создать обучающий набор данных для предиктора, необходимы дополнительные обучающие вводы, поэтому размер эффективных баз данных будет больше. Все ветви нуждаются в дополнительном обучении, а память, используемая для хранения всего конвейера, больше, чем та, которая использовалась для исходной DNN.
Экономия вычислений имеет большое значение для эксплуатации сложных алгоритмов, которые дают наилучшие выводы, но они могут быть реализованы, в основном, на "мощном" оборудовании.
Было показано, как можно создавать ранние выходы в декодерах, в которых внутренние логиты должны быть тщательно обработаны, прежде чем они смогут выдать изображение. Создан полупараметрический алгоритм для управления синтезом, способствующий более ранним выходам. Затем показано, как динамически выбирать маршрут вычислений с помощью нейронной сети, обученной на примерах вводов и показателей качества выходов. Предлагаемое изобретение делает шаг в этом направлении, а именно снижает избыточность вычислений. Кроме того, необходимо подчеркнуть, насколько важны экономия вычислений и, следовательно, энергии в наши дни [67].
Исходная генеративная сеть DNN OASIS [63] состоит из начального 2D-сверточного слоя, за которым следуют 6 модулей SPADEResBlock [57] и заключительные Conv2D, LeakyRelu и TanH. Общее количество ее параметров составляет 74М. К сети присоединены 4 ветви после ResBlock 1, 2, 3 и 4, соответственно. Каждая ветвь состоит из такого же количества модулей ResBlock, как и остальная часть основной сети. Для создания более легких вычислительных путей уменьшено количество каналов вычислительных модулей ветвей. Для обеспечения согласованности необходимо равномерно уменьшать масштаб всех каналов, умножая их на коэффициент масштабирования (SF). Поскольку такое масштабирование с произвольными коэффициентами может привести к слишком малому количеству каналов для их использования, его эффект ограничивается заданием минимального количества каналов, при котором масштабирование не применяется. Иными словами, если минимальное количество равно 64 и применяется коэффициент 1/3, начиная с 128, то новое количество каналов будет 64 вместо 43.


В таблице 7 представлены размеры модулей для всех ветвей в следующем виде: (входные каналы, выходные каналы, высота изображения, ширина изображения). Таблица разделена на три подтаблицы в соответствии с примененным коэффициентом масштабирования. В первом столбце показан тип модуля, т.е. преобразование, примененное к входным данным; столбцы 2-5 показывают размеры вычислительных модулей ветвей 1-4. Внизу каждой подтаблицы показано общее количество параметров с добавлением вспомогательной базы данных и без него.
Из таблицы 7 видно, что чем выше SF, то есть чем больше количество вычислительных параметров для каждой ветви раннего выхода, тем больше входных и выходных каналов имеет эта ветвь раннего выхода, при этом высота и ширина выходного изображения не изменяется. Чем выше номер ветви раннего выхода, тем меньше входных каналов и выходных каналов, при этом высота и ширина выходного изображения увеличиваются.
Во всех ветвях после каждого SPADE-ResBlock, кроме последнего, также применяется двумерная повышающая дискретизация ближайшего соседа, что удваивает высоту и ширину. При использовании базы данных входные каналы для первого ResBlock в каждой ветви умножаются на 1,5.
На фиг.11 представлено сравнение эффективности различных коэффициентов масштабирования. Минимальное количество каналов 64. Сверху вниз: SF=1/2, 1/3, 1/4. Ветвь 1 - "а"; ветвь 2 - "b"; ветвь 3 - "с"; ветвь 4 - "d"; основная сеть - "е". По оси X указаны пороговые значения показателя качества, выраженные в LPIPS, а по оси Y - вычисления, необходимые для вывода изображений, выраженные в GFLOP. Столбцы на графике показывают, насколько каждая ветвь используется для вывода изображений с заданным порогом показателя качества. Сумма всех столбцов для каждого порогового значения равна 1. Кривая сверху представляет общее число GFLOP, необходимое для принудительного применения порога показателя качества. Эта кривая используется для оценки эффективности предложенной модели с точки зрения ее наклона, то есть экономии вычислительных ресурсов за счет потери показателя качества. Более высокое сжатие (SF=1/4) приводит к большему выигрышу с точки зрения экономии вычислительных ресурсов, поскольку его наклон выше (почти достигает 127 Гб в самой правой точке, в то время как другие коэффициенты масштабирования насыщаются раньше).
Используемая база данных была создана из 500 семантических карт, выбранных произвольно из обучающего набора данных, каждая из которых была соединена со 100 различными тензорами 3D шума для получения множества различных вводов, которые были обработаны и разделены на 128 неперекрывающихся фрагментов данных, что дало в общей сложности 500×100×128=6,4 млн пар ключ-значение. Поскольку избыточность в пространстве ключей весьма вероятна, из этого множества пар извлекается только до 5К для каждого используемого семантического класса.
Выборка FPS [19] составила всего 122 100 пар. Каждый ключ представляет собой 102 4-мерный вектор, а каждое значение состоит из тензора float32 размерностей (512, 4, 4). Таким образом, общий размер сохраненных параметров составляет 1,1 ГБ.
Во время поиска направляющие признаки берутся после первых блоков Conv2D и ResNet основной сети. Затем для каждого из N ∈ [1, 35] семантических классов, присутствующих во вводе, эти признаки разрезаются на 128 фрагментов данных и их 1024-мерное пространство сканируется для нахождения ближайшего ключа из базы данных с соответствующим семантическим классом. Этот поиск выполняется достаточно быстро благодаря библиотеке FAISS [38] и, таким образом, не утяжеляет вычисления.
После извлечения всех 12 8 фрагментов данных создается направляющий признак путем склеивания этих фрагментов. Этот признак соединяется с вводом каждой ветви, и поэтому количество каналов в них необходимо увеличить. При использовании базы данных входные каналы для первых ResBlocks в каждой ветви, указанные в таблице 8, умножаются на 1,5.
Последним ключевым компонентом предлагаемого конвейера является предиктор. Его архитектура представлена в таблице 8.

Таблица 8 описывает архитектуру предикторов MegaPortraits и OASIS. Размеры представлены в следующем виде: (входные каналы, выходные каналы). В обеих подтаблицах левый столбец показывает, из каких слоев состоит нейронная сеть, а правый столбец размеры ее вводов и выводов. В нижних строках показано общее количество параметров, составляющих эти сети, и количество операций, необходимых для их однократного выполнения.
Исходная генеративная сеть DNN MegaPortraits [17] для изображений с разрешением 512×512 пикселей состоит из множества вычислительных модулей, прогнозирующих объемное представление, и другого набора, называемого G2D, который визуализирует выходное изображение из обработанного объема. Его общее количество параметров составляет 32М. Предлагаемые ветви добавляются после модулей 2, 4, 6 ResBlock2D. Их соответствующая длина равна 7, 5, 3. Как и прежде, более легкие вычислительные пути создаются путем равномерного уменьшения масштаба всех каналов. Новые количества каналов получают умножением исходных каналов на коэффициент масштабирования. Как и прежде, эффект этого масштабирования ограничивается путем задания минимального количества каналов, равного 24, параметра, выбранного без строгого обоснования. Это не обязательная часть способа, ее можно заменить другой, как показывает дальнейший анализ, при которой дальнейшее масштабирование не требуется. Задается множество различных коэффициентов масштабирования, которые представлены в таблице 9.

Таблица 9 описывает конвейер MegaPortraits. Размеры вычислительных модулей для всех ветвей представлены в следующем виде: (входные каналы, выходные каналы). Таблица разделена на четыре подтаблицы в соответствии с примененным коэффициентом масштабирования. В первом столбце показан тип вычислительного модуля, т.е. преобразование, примененное к входным данным; в столбцах 2,3 и 4 показаны размеры ветвей 1-3 вычислительных модулей. В нижней части каждой подтаблицы указано общее количество параметров, включая добавление вспомогательной базы данных. Res-Block2D состоит из слоев BatchNorm2D, h-swish, Conv2D, BatchNorm2D, h-swish, Conv2D, Conv2D с пропущенными соединениями. Во всех ветвях перед каждым ResBlock2D применяется двумерная билинейная повышающая дискретизация. При использовании этой базы данных все количества входных каналов следует увеличить на 3.
Для этой задачи использовалась база данных, содержащая 960 пар ключ-значение. Значения состояли из RGB-изображений субъекта-источника, равномерно покрывающих пространство
поворотов головы и выражений. Ключи были получены с помощью начальных вычислительных модулей MegaPortraits, так называемых энкодеров, которые выдают углы Эйлера, на которые поворачивается голова, а также множество параметров, кодирующих выражение лица. Каждый ключ кодировал 3 угла и 512-мерный вектор для выражений лица.
Таким образом, общий размер хранимых параметров составил 109. Поиск ближайшего ключа в базе данных выполнялся на этапе логического вывода с помощью библиотеки FAISS [38]. Каждое извлеченное изображение затем присоединялось ко вводу всех модулей ResBlock2D в каждой ветви, поэтому при использовании базы данных необходимо добавить 3 канала ко всем входным каналам в таблице S9. Архитектура предиктора MegaPortraits в общем представлена в таблице 10.

В таблице 10 показана архитектура предиктора MegaPortraits и предикторов OASIS. Размеры указаны в следующем виде: (входные каналы, выходные каналы). В обеих подтаблицах левый столбец показывает, из каких слоев состоит нейронная сеть, а правый столбец - размеры ее вводов и выводов. В нижних строках указано общее количество параметров, составляющих эти сети, и количество операций, необходимых для их однократного выполнения.
Детали обучения
Для конвейера MegaPortraits обучаются ветви, использующие кусочно-линейные состязательные функции потерь, каждая ветвь конкурирует с копией многомасштабного дискриминатора фрагментов данных [11]. Кроме того, задаются потеря согласования признаков [73], перцептивные потери VGG19 [37] и потери L1 и MS-SSIM [75]. Также используется специализированная потеря взгляда, рассчитанная с помощью сети VGG16, которая объединяет системы обнаружения взгляда (RT-GENE, [89]) и обнаружения моргания (RT-BENE, [2]) в одну модель. Более подробную информацию об этих потерях можно найти в MegaPortraits [17]. Все потери вычисляются по отношению к изображениям основной сети и с использованием только областей переднего плана. В целом общая потеря составляет

где  - стандартная состязательная функция потерь для сетей GAN;
- стандартная состязательная функция потерь для сетей GAN;  - потеря VGG [37];
- потеря VGG [37];  - потеря MS-SSIM
- потеря MS-SSIM  [75];
[75];  - потеря L1, - потеря согласования признаков [73]; и
- потеря L1, - потеря согласования признаков [73]; и  - потеря взгляда [17]; со следующими весами: c1=18, с2=0,84, с3=0,16, с4=40, с5=5. Ветви и дискриминаторы обучались с помощью оптимизаторов AdamW [91] с β1=0,05, β2=0,999, ∈=10-8, с уменьшением веса = 10-2 и начальной скоростью обучения = 2 × 10-4. Во время обучения использовались косинусные планировщики скорости обучения с минимальной скоростью обучения 10~6. Вычисления проводились параллельно с помощью распределенных данных PyTorch. Модель обучалась со смешанной точностью на двух графических процессорах NVIDIA Р40 с эффективным размером пакета 6 в течение примерно 3 дней. Полученные качества можно найти в таблице 11.
- потеря взгляда [17]; со следующими весами: c1=18, с2=0,84, с3=0,16, с4=40, с5=5. Ветви и дискриминаторы обучались с помощью оптимизаторов AdamW [91] с β1=0,05, β2=0,999, ∈=10-8, с уменьшением веса = 10-2 и начальной скоростью обучения = 2 × 10-4. Во время обучения использовались косинусные планировщики скорости обучения с минимальной скоростью обучения 10~6. Вычисления проводились параллельно с помощью распределенных данных PyTorch. Модель обучалась со смешанной точностью на двух графических процессорах NVIDIA Р40 с эффективным размером пакета 6 в течение примерно 3 дней. Полученные качества можно найти в таблице 11.

В таблице 11 представлены количественные результаты конвейера MegaPortraits для перекрестного воспроизведения. Для четырех различных коэффициентов масштабирования SF (первый столбец) конвейер тестировался с базой направляющих данных и без нее, что отмечено в столбце Bank галочкой или крестиком. Три столбца, по одному для каждой ветви, содержат оценки FID (начальное расстояние Фреше) и mIOU (среднее пересечение по соединению); внизу показаны эти два значения для основной сети. Таким образом, разные сжатия влияют на показатель качества - чем сильнее сжатие, тем ниже показатель качества. Также добавление банка улучшает показатель качества, особенно в первом выводе.
Для каждого ввода предиктор оценивает LPIPS для всех ветвей. Для его обучения вводится потеря МАЕ между спрогнозированным состоянием и состоянием подобия истинности, как было описано выше:

где с - согласующие параметры; S - оценка LPIPS для изображения, созданного с упомянутыми параметрами; и Р(с) выход предиктора.
Используется оптимизатор AdamW с β1=0,05, β2=0/ 999 и начальной скоростью обучения 2×10-4 вместе с косинусным планировщиком скорости обучения.
Были реализованы все архитектуры, перечисленные в таблице 7 и таблице 9. Общие результаты для конвейера OASIS можно сравнить на фиг.11 и фиг.12, а на фиг.13 они показаны для конвейера Mega-Portraits. Фиг. 12 иллюстрирует конвейер OASIS. Минимальное количество каналов - 32. Ветвь 1 - "а"; ветвь 2 - "b"; ветвь 3 -"с"; ветвь 4 - "d"; основная сеть - "е". Представлено сравнение эффективности различных коэффициентов масштабирования. Сверху вниз, слева направо: SF=1/2, 1/3, 1/4, 1/6. Фиг. 13 иллюстрирует конвейер MegaPortraits, сравнение эффективности различных коэффициентов масштабирования. Слева направо: SF=1/3, 1/6, 1/8, 1/15. Можно заметить, как разные коэффициенты масштабирования дают различные распределения ветвей. Для всех этих графиков по оси X показаны пороговые значения, выраженные в LPIPS, а по оси Y - вычисления, необходимые для вывода изображений, выраженные в GFLOP. Столбцы на графике показывают, насколько каждая ветвь используется для вывода изображений с заданным порогом показателя качества. Сумма всех столбцов для каждого порога равна 1. Кривая сверху представляет собой общее количество GFLOP, необходимое для обеспечения соблюдения указанного порога показателя качества. Эта кривая используется для оценки эффективности предложенной модели с точки зрения ее наклона, то есть экономии вычислительных ресурсов за счет потери показателя качества. Чем выше сжатие, тем выше выигрыш с точки зрения экономии вычислительных ресурсов.
На фиг.14 показано влияние базы данных на ветви всех коэффициентов масштабирования. Фиг. 14 иллюстрирует конвейер OASIS, сравнение влияния базы данных на распределение показателей качества для различных коэффициентов
масштабирования. Распределение показателей качества каждой ветви пронумеровано по-разному: 1, 1', 2, 2', 3, 3', 4, 4'. Распределения без использования базы данных показаны пунктирной кривой (1', 2', 3', 4'), а распределения, полученные с использованием базы данных, показаны сплошной кривой (1, 2, 3, 4). Минимальное количество каналов 64. Слева направо: SF=1/2, 1/3, 1/4. По оси X показан показатель качества в единицах LPIPS, а по оси Y - количество изображений, выведенных с указанным показателем качества. Разные ветви выводят распределения показателя качества, окрашенные в разные цвета. Распределения показателей качества, полученные без внедрения базы данных, показаны пунктирной кривой, а показатели качества с использованием базы данных - сплошной кривой. Можно отчетливо увидеть, что реализация базы данных больше всего повлияла на первые ветви, поскольку распределение показателей качества для этих первых ветвей больше всего сдвинуто в сторону лучших значений. Следовательно, база данных является действенным инструментом для гармонизации показателя качества вывода.
Для конвейера MegaPortraits показатель качества
синтезированных изображений коррелирует с углом поворота головы. Это также находит отражение в предлагаемом методе. Действительно, головы, повернутые под углами большего размера, с большей вероятностью будут направлены в более позднюю ветвь, как видно на фиг.15. Фиг. 15 иллюстрирует конвейер MegaPortraits, распределение изображений, направленных в разные ветви, в зависимости от угла поворота головы. Первый ряд SF=1/8, второй ряд SF=1/15. По оси X показан угол между эталонной головой и головой на выводимом изображении, а по оси Y - количество изображений, выводимых с указанным углом. Можно отчетливо видеть, что для малых углов большая часть изображений выводится первой ветвью, а более широкие углы обрабатываются второй и третьей ветвями для получения вывода. Можно сделать вывод, что одним из источников сложности рендеринга является поворот головы, а значит не все положения требуют столько вычислений, сколько малые углы, что подтверждает необходимость реализации предложенных ветвей и предикторов.
Описанные выше иллюстративные варианты осуществления являются примерами и не должны рассматриваться как ограничивающие. Кроме того, описание этих вариантов осуществления предназначено для иллюстрации, а не для ограничения объема формулы изобретения, и многие альтернативы, модификации и варианты будут очевидны для специалистов в данной области техники.
Литература:
[1] Thiemo Alldieck, Mihai Zanfir, and Cristian Sminchisescu. Photorealistic monocular 3d reconstruction of humans wearing clothing. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1506-1515. 2022.
[2] Ali Alqahtani, Xianghua Xie, and Mark W. Jones. Literature review of deep network compression. Informatics, 8(4). 2021.
[3] Tolga Bolukbasi, Joseph Wang, Ofer Dekel, and Venkatesh Saligrama. Adaptive neural networks for efficient inference. In International Conference on Machine Learning, pages 527-536. PMLR. 2017.
[4] Cristian Bucilu"a, Rich Caruana, and Alexandru Niculescu-Mizil. Model compression. In Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, KDD '06, page 535-541, New York, NY, USA. Association for Calculating Machinery. 2006.
[5] Egor Burkov, Igor Pasechnik, Artur Grigorev, and Victor Lempitsky. Neural head reenactment with latent pose descriptors. In IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2020.
[6] Han Cai, Chuang Gan, Tianzhe Wang, Zhekai Zhang, and Song Han. Once for all: Train one network and specialize it for efficient deployment. In International Conference on Learning Representations. 2020.
[7] Jianchuan Chen, Ying Zhang, Di Kang, Xuefei Zhe, Linchao Bao, Xu Jia, and Huchuan Lu. Animatable neural radiance fields from monocular rgb videos. arXiv preprint arXiv:2106.13629. 2021.
[8] Xinshi Chen, Hanjun Dai, Yu Li, Xin Gao, and Le Song. Learning to stop while learning to predict. In Proceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 1520-1530. PMLR. 2020.
[9] Jang Hyun Cho and Bharath Hariharan. On the efficacy of knowledge distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 2019.
[10] Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Kopf, Edward Yang, Zachary DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai, and Soumith Chintala. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32, pages 8024-8035. Curran Associates, Inc. 2019.
[11] Jun-Yan Zhu, Taesung Park, Phillip Isola, and Alexei A. Efros. Unpaired image-to-image translation using cycleconsistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2017
[12] Xin Dai, Xiangnan Kong, and Tian Guo. Epnet: Learning to exit with flexible multi-branch network. In Proceedings of the 29th ACM International Conference on Information and Knowledge Management, CIKM '20, page 235-244, New York, NY, USA. Association for Calculating Machinery. 2020.
[13] Lei Deng, Guoqi Li, Song Han, Luping Shi, and Yuan Xie. Model compression and hardware acceleration for neural networks: A comprehensive survey. Proceedings of the IEEE, 108(4):485-532. 2020.
[14] Rongkang Dong, Yuyi Mao, and Jun Zhang. Resourceconstrained edge ai with early exit prediction. Journal of Communications and Information Networks, 7(2):122-134. 2022.
[15] Michail Christos Doukas, Evangelos Ververas, Viktoriia Sharmanska, and Stefanos Zafeiriou. Free-headgan: Neural talking head synthesis with explicit gaze control. arXiv preprint arXiv:2208.02210. 2022.
[16] Michail Christos Doukas, Stefanos Zafeiriou, and Viktoriia Sharmanska. Headgan: One-shot neural head synthesis and editing. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 14398-14407. 2021.
[17] Nikita Drobyshev, Jenya Chelishev, Taras Khakhulin, Aleksei Ivakhnenko, Victor Lempitsky, and Egor Zakharov. Megaportraits: One-shot megapixel neural head avatars. In Proceedings of the 30th ACM International Conference on Multimedia. Association for Calculating Machinery. 2022.
[18] Maha Elbayad, Jiatao Gu, Edouard Grave, and Michael Auli. Depth-adaptive transformer. In ICLR 2020-Eighth International Conference on Learning Representations, pages 1-14. 2020.
[19] Y. Eldar, M. Lindenbaum, M. Porat, and Y.Y. Zeevi. The
farthest point strategy for progressive image sampling. IEEE Transactions on Image Processing, б(9):1305-1315. 1997.
[20] Yao Feng, Haiwen Feng, Michael J. Black, and Timo Bolkart. Learning an animatable detailed 3d face model from in-the-wild images. ACM Trans. Graph., 40(4). 2021.
[21] Stanislav Frolov, Tobias Hinz, Federico Raue, J"orn Hees, and Andreas Dengel. Adversarial text-to-image synthesis: A review. Neural Networks, 144:187-209. 2021.
[22] Anna Fr"uhst"uck, Krishna Kumar Singh, Eli Shechtman, Niloy J. Mitra, Peter Wonka, and Jingwan Lu. Insetgan for full-body image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 7723-7732. 2022.
[23] Liang Gonog and Yimin Zhou. A review: Generative adversarial networks. In 2019 14th IEEE Conference on Industrial Electronics and Applications (ICIEA), pages 505-510. 2019.
[24] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, DavidWarde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in Neural Information Processing Systems, volume 27. Curran Associates, Inc. 2014.
[25] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, DavidWarde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial networks. Commun. ACM, 63(11):139-144. 2020.
[26] Jianping Gou, Baosheng Yu, Stephen J Maybank, and Dacheng Tao. Knowledge distillation: A survey. International Journal of Computer Vision, 129(6):1789-1819. 2021.
[27] Niv Granot, Ben Feinstein, Assaf Shocher, Shai Bagon, and Michal Irani. Drop the gan: In defense of patches nearest neighbors as single image generative models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 13460-13469. 2022.
[28] Philip-William Grassal, Malte Prinzler, Titus Leistner, Carsten Rother, Matthias Niesner, and Justus Thies. Neural head avatars from monocular rgb videos. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 18653-18664. 2022.
[29] Edouard Grave, Armand Joulin, and Nicolas Usunier. Improving neural language models with a continuous cache. In International Conference on Learning Representations. 2017.
[30] James Hays and Alexei A Efros. Scene completion using millions of photographs. ACM Transactions on Graphics (SIGGRAPH 2007), 26(3). 2007.
[31] Tong He, Yuanlu Xu, Shunsuke Saito, Stefano Soatto, and Tony Tung. Arch++: Animation-ready clothed human reconstruction revisited. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 11046-11056. 2021.
[32] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In I. Guyon, U. Von Luxburq, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems, volume 30. Curran Associates, Inc. 2017.
[33] Tao Hu, Tao Yu, Zeronq Zhenq, He Zhang, Yebin Liu, and Matthias Zwicker. Hvtr: Hybrid volumetric-textural rendering for human avatars. arXiv preprint arXiv:2112.10203. 2021.
[34] Phillip Isola and Ce Liu. Scene collaqinq: Analysis and synthesis of natural images with semantic layers. In Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2013.
[35] Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, and Alexei A. Efros. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017.
[36] Menglin Jia, Bor-Chun Chen, Zuxuan Wu, Claire Cardie, Serge Belongie, and Ser-Nam Lim. Rethinking nearest neighbors for visual classification. arXiv preprint arXiv:2112.08459. 2021.
[37] Justin Johnson, Alexandre Alahi, and Li Fei-Fei. Perceptual losses for real-time style transfer and super-resolution. In Computer Vision - ECCV 2016, pages 694-711, Cham. Springer International Publishing. 2016.
[38] Jeff Johnson, Matthijs Douze, and Herv'e J'egou. Billionscale similarity search with GPUs. IEEE Transactions on Biq Data, 7(3):535-547. 2019.
[39] Mica K. Johnson, Kevin Dale, Shai Avidan, Hanspeter Pfister, William T. Freeman, and Wojciech Matusik. Cg2real: Improving the realism of computer generated images using a large collection of photographs. IEEE Transactions on Visualization and Computer Graphics, 17(9):1273-1285. 2009.
[40] Moritz Kappel, Vladislav Golyanik, Mohamed Elgharib, Jann-Ole Henningson, Hans-Peter Seidel, Susana Castillo, Christian Theobalt, and Marcus Magnor. Hiqh-fidelity neural human motion transfer from monocular video. In Proceedinqs of the IEEE/CVF Conference on Computer Vision and Pattern Recoqnition (CVPR), paqes 1541-1550. 2021.
[41] Moritz Kappel, Vladislav Golyanik, Mohamed Elgharib, Jann-Ole Henningson, Hans-Peter Seidel, Susana Castillo, Christian Theobalt, and Marcus Magnor. High-fidelity neural human motion transfer from monocular video. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 1541-1550. 2021.
[42] Yigitcan Kaya, Sanghyun Hong, and Tudor Dumitras. Shallow-deep networks: Understanding and mitigating network overthinking. In Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 3301-3310. PMLR. 2019.
[43] Taras Khakhulin, Vanessa Sklyarova, Victor Lempitsky, and Egor Zakharov. Realistic one-shot mesh-based head avatars. In European Conference of Computer vision (ECCV). 2022.
[44] Jean-Franc ' ois Lalonde, Derek Hoiem, Alexei A. Efros, Carsten Rother, John Winn, and Antonio Criminisi. Photo clip art. ACM Transactions on Graphics (SIGGRAPH 2007), 26(3):3. 2007.
[45] Stefanos Laskaridis, Alexandros Kouris, and Nicholas D. Lane. Adaptive inference through early-exit networks: Design, challenges and directions. In Proceedings of the 5th InternationalWorkshop on Embedded and Mobile Deep Learning, EMDL' 21, page 1-6, New York, NY, USA. Association for Calculating Machinery. 2021.
[46] Yann LeCun, John Denker, and Sara Solla. Optimal brain damage. In Advances in Neural Information Processing Systems, volume 2. Morgan-Kaufmann. 1989.
[47] Sam Leroux, Steven Bohez, Elias De Coninck, Tim Verbelen, Bert Vankeirsbi1ck, Pieter Simoens, and Bart Dhoedt. The cascading neural network: building the internet of smart things. Knowledge and Information Systems, 52(3):791-814. 2017.
[48] Tianye Li, Timo Bolkart, Michael. J. Black, Hao Li, and Javier Romero. Learning a model of facial shape and expression from 4D scans. ACM Transactions on Graphics, (Proc. SIGGRAPH Asia), 36(6): 194:1-194:17. 2017.
[49] Xiangjie Li, Chenfei Lou, Zhengping Zhu, Yuchi Chen, Yingtao Shen, Yehan Ma, and An Zou. Predictive exit: Prediction of fine-grained early exits for computation-and energy-efficient inference. arXiv preprint arXiv:2206.04685. 2022.
[50] Yikang LI, Tao Ma, Yeqi Bai, Nan Duan, Sining Wei, and Xiaogang Wang. Pastegan: A semi-parametric method to generate image from scene graph. In Advances in Neural Information Processing Systems, volume 32. Curran Associates, Inc. 2019.
[51] Enrique S. Marquez, Jonathon S. Hare, and Mahesan Niranjan. Deep cascade learninq. IEEE Transactions on Neural Networks and Learninq Systems, 29(11):5475-5485. 2018.
[52] Mehdi Mirza and Simon Osindero. Conditional qenerative adversarial nets. arXiv preprint arXiv:1411.1784. 2014.
[53] Pavlo Molchanov, Arun Mallya, Stephen Tyree, Iuri Frosio, and Jan Kautz. Importance estimation for neural network pruninq. In 2019 IEEE/CVF Conference on Computer Vision and Pattern Recoqnition (CVPR), paqes 11256-11264. 2019.
[54] Augustus Odena, Dieterich Lawson, and Christopher Olah. Changing model behavior at test-time using reinforcement learning. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Workshop Track Proceedings. OpenReview.net. 2017.
[55] Augustus Odena, Christopher Olah, and Jonathon Shlens. Conditional image synthesis with auxiliary classifier GANs. In Proceedings of the 34th International Conference on Machine Learning, volume 70 of Proceedings of Machine Learning Research, pages 2642-2651. PMLR. 2017.
[56] Emin Orhan. A simple cache model for image recognition. In Advances in Neural Information Processing Systems, volume 31. Curran Associates, Inc. 2018.
[57] Taesung Park, Ming-Yu Liu, Ting-Chun Wang, and Jun-Yan Zhu. Semantic image synthesis with spatially-adaptive normalization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recoqnition (CVPR). 2019.
[58] Sida Penq, Zhen Xu, Juntinq Donq, Qianqian Wanq, Shanqzhan Zhanq, Qinq Shuai, Hu j un Bao, and Xiaowei Zhou. Animatable implicit neural representations for creatinq realistic avatars from videos. arXiv preprint arXiv:2203.08133. 2022.
[59] Xiaojuan Qi, Qifenq Chen, Jiaya Jia, and Vladlen Koltun. Semi-parametric imaqe synthesis. In Proceedinqs of the IEEE Conference on Computer Vision and Pattern Recoqnition (CVPR). 2 018.
[60] Scott Reed, Zeynep Akata, Xinchen Yan, Lajanuqen Loqeswaran, Bernt Schiele, and Honqlak Lee. Generative adversarial text to image synthesis. In Proceedings of The 33 International Conference on Machine Learning, volume 48 of Proceedings of Machine Learning Research, pages 1060-1069, New York, New York, USA. PMLR. 2016.
[61] Simone Scardapane, Danilo Cominini el lo, Michele Scarpiniti, Enzo Baccarelli, and Aurelio Uncini. Differentiable branching in deep networks for fast inference. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 4167-4171. 2020.
[62] Simone Scardapane, Michele Scarpiniti, Enzo Baccarelli, and Aurelio Uncini. Why should we add early exits to neural networks? Cognitive Computation, 12(5):954-966. 2020.
[63] Edgar Schonfeld, Vadim Sushko, Dan Zhang, Juergen Gall, Bernt Schiele, and Anna Khoreva. You only need adversarial supervision for semantic image synthesis. In International Conference on Learning Representations. 2021.
[64] Pourya Shamsolmoali, Masoumeh Zareapoor, Eric Granger, Huiyu Zhou, RuiliWang, M. Emre Celebi, and Jie Yang. Image synthesis with adversarial networks: A comprehensive survey and case studies. Information Fusion, 72:126-146. 2021.
[65] Maying Shen, Pavlo Molchanov, Hongxu Yin, and Jose M. Alvarez. When to prune? a policy towards early structural pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12247-12256. 2022.
[66] Yupeng Shi, Xiao Liu, Yuxiang Wei, Zhongqin Wu, and Wangmeng Zuo. Retrieval-based spatially adaptive normalization for semantic image synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11224-11233. 2022.
[67] Emma Strubell, Ananya Ganesh, and Andrew McCallum. Energy and policy considerations for deep learning in NLP. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 3645-3650, Florence, Italy. Association for Computational Linguistics. 2019.
[68] Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2015.
[69] Surat Teerapittayanon, Bradley McDanel, and H.T. Kung. Branchynet: Fast inference via early exiting from deep neural networks. In 2016 23rd International Conference on Pattern Recognition (ICPR), pages 2464-2469. 2016.
[70] Yi-Hsuan Tsai, Xiaohui Shen, Zhe Lin, Kalyan Sunkavalli, Xin Lu, and Ming-Hsuan Yang. Deep image harmonization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017.
[71] Hung-Yu Tseng, Hsin-Ying Lee, Lu Jiang, Ming-Hsuan Yang, and Weilong Yang. Retrievegan: Image synthesis via differentiable patch retrieval. In Computer Vision - ECCV 2020, pages 242-257. Springer International Publishing. 2020.
[72] Lei Wang, Wei Chen, Wenjia Yang, Fangming Bi, and Fei Richard Yu. A state-of-the-art review on image synthesis with generative adversarial networks. IEEE Access, 8:63514-63537. 2020.
[73] Ting-Chun Wang, Ming-Yu Liu, Jun-Yan Zhu, Andrew Tao, Jan Kautz, and Bryan Catanzaro. High-resolution image synthesis and semantic manipulation with conditional gans. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2018.
[74] Xin Wang, Yujia Luo, Daniel Crankshaw, Alexey Tumanov, Fisher Yu, and Joseph E Gonzalez. Idk cascades: Fast deep learning by learning not to overthink. arXiv preprint arXiv:1706.00885. 2017.
[75] Z. Wang, E.P. Simoncelli, and A.C. Bovik. Multiscale structural similarity for image quality index assessment. In The Thrity-
Seventh Asilomar Conference on Signals, Systems & Computers, volume 2, pages 1398-1402. 2003.
[76] Wei Wen, Hanxiao Liu, Yiran Chen, Hai Li, Gabriel Bender,
and Pieter-Jan Kindermans. Neural predictor for neural architecture search. In Computer Vision - ECCV 2020, pages 660-676. Springer International Publishing. 2020.
[77] Maciej Wol czyk, Bartosz W'ojcik, Klaudia Bal azy, Igor T Podolak, Jacek Tabor, Marek ' Smieja, and Tomasz Trzcinski. Zero time waste: Recycling predictions in early exit neural networks. In Advances in Neural Information Processing Systems, volume 34, pages 2516-2528. Curran Associates, Inc. 2021.
[78] Ji Xin, Raphael Tang, Yaoliang Yu, and Jimmy Lin. Berxit: Early exiting for bert with better fine-tuning and extension to regression. In Proceedings of the 16th conference of the European chapter of the association for computational linguistics: Main Volume, pages 91-104. 2021.
[79] Qunliang Xing, Mai Xu, Tianyi Li, and Zhenyu Guan. Early exit or not: Resource-efficient blind quality index enhancement for compressed imaqes. In Computer Vision - ECCV 2020, paqes 275-292. Sprinqer International Publishinq. 2020.
[80] Jae Shin Yoon, Duyqu Ceylan, Tuanfenq Y. Wanq, Jinqwan Lu, Jimei Yanq, Zhixin Shu, and Hyun Soo Park. Learninq motion-dependent appearance for hiqh-fidelity renderinq of dynamic humans from a single camera. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3407-3417. 2022.
[81] Egor Zakharov, Aleksei Ivakhnenko, Aliaksandra Shysheya, and Victor Lempitsky. Fast bi-layer neural synthesis of oneshot realistic head avatars. In Andrea Vedaldi, Horst Bischof, Thomas Brox, and Jan-Michael Frahm, editors, Computer Vision - ECCV 2020, pages 524-540. Springer International Publishing. 2020.
[82] Egor Zakharov, Aliaksandra Shysheya, Egor Burkov, and Victor Lempitsky. Few-shot adversarial learning of realistic neural talking head models. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 2019.
[83] Renrui Zhang, Rongyao Fang, Peng Gao, Wei Zhang, Kunchang Li, Jifeng Dai, Yu Qiao, and Hongsheng Li. Tip-adapter: Training-free clip-adapter for better visionlanguage modeling. arXiv preprint arXiv:2111.03930. 2021.
[84] Richard Zhanq, Phillip Isola, Alexei A. Efros, Eli Shechtman, and Oliver Wanq. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedinqs of the IEEE Conference on Computer Vision and Pattern Recoqnition (CVPR). 2018.
[85] Yufenq Zhenq, Victoria Fern'andez Abrevaya, Marcel C. B"uhler, Xu Chen, Michael J. Black, and Otmar Hilliges. I m avatar: Implicit morphable head avatars from videos. In Proceedinqs of the IEEE/CVF Conference on Computer Vision and Pattern Recoqnition (CVPR), paqes 13545-13555. 2022.
[86] Zeronq Zhenq, Han Huanq, Tao Yu, Honqwen Zhanq, Yandong Guo, and Yebin Liu. Structured local radiance fields for human avatar modeling. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 15893-15903. 2022.
[87] Wangchunshu Zhou, Canwen Xu, Tao Ge, Julian McAuley, Ke Xu, and Furu Wei. Bert loses patience: Fast and robust inference with early exit. In Advances in Neural Information Processing Systems, volume 33, pages 18330-18341. Curran Associates, Inc. 2020.
[88] Kevin Cortacero, Tobias Fischer, and Yiannis Demiris. Rtbene: A dataset and baselines for real-time blink estimation in natural environments. In Proceedings of the IEEE International Conference on Computer Vision Workshops.
[88] Tobias Fischer, Hyung Jin Chang, and Yiannis Demiris. RTGENE: Real-Time Eye Gaze Estimation in Natural Environments. In European Conference on Computer Vision, pages 339-357.
[89] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980.2014.
[90] Ilya Loshchilov and Frank Hutter. SGDR: stochastic gradient descent with warm restarts. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net.
[91] Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. In International Conference on Learning Representations. 2019.
| название | год | авторы | номер документа |
|---|---|---|---|
| ТЕКСТУРИРОВАННЫЕ НЕЙРОННЫЕ АВАТАРЫ | 2019 |
|
RU2713695C1 |
| СПОСОБ ИНТЕРАКТИВНОЙ СЕГМЕНТАЦИИ ОБЪЕКТА НА ИЗОБРАЖЕНИИ И ЭЛЕКТРОННОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО ДЛЯ ЕГО РЕАЛИЗАЦИИ | 2020 |
|
RU2742701C1 |
| Быстрый двухслойный нейросетевой синтез реалистичных изображений нейронного аватара по одному снимку | 2020 |
|
RU2764144C1 |
| Способ синтеза двумерного изображения сцены, просматриваемой с требуемой точки обзора, и электронное вычислительное устройство для его реализации | 2020 |
|
RU2749749C1 |
| Способ 3D-реконструкции человеческой головы для получения рендера изображения человека | 2022 |
|
RU2786362C1 |
| МОДЕЛИРОВАНИЕ ЧЕЛОВЕЧЕСКОЙ ОДЕЖДЫ НА ОСНОВЕ МНОЖЕСТВА ТОЧЕК | 2021 |
|
RU2776825C1 |
| СИСТЕМА ДЛЯ ГЕНЕРАЦИИ ВИДЕО С РЕКОНСТРУИРОВАННОЙ ФОТОРЕАЛИСТИЧНОЙ 3D-МОДЕЛЬЮ ЧЕЛОВЕКА, СПОСОБЫ НАСТРОЙКИ И РАБОТЫ ДАННОЙ СИСТЕМЫ | 2024 |
|
RU2834188C1 |
| Способ обеспечения компьютерного зрения | 2022 |
|
RU2791587C1 |
| РАСПОЗНАВАНИЕ СОБЫТИЙ НА ФОТОГРАФИЯХ С АВТОМАТИЧЕСКИМ ВЫДЕЛЕНИЕМ АЛЬБОМОВ | 2020 |
|
RU2742602C1 |
| Совместная неконтролируемая сегментация объектов и подрисовка | 2019 |
|
RU2710659C1 |













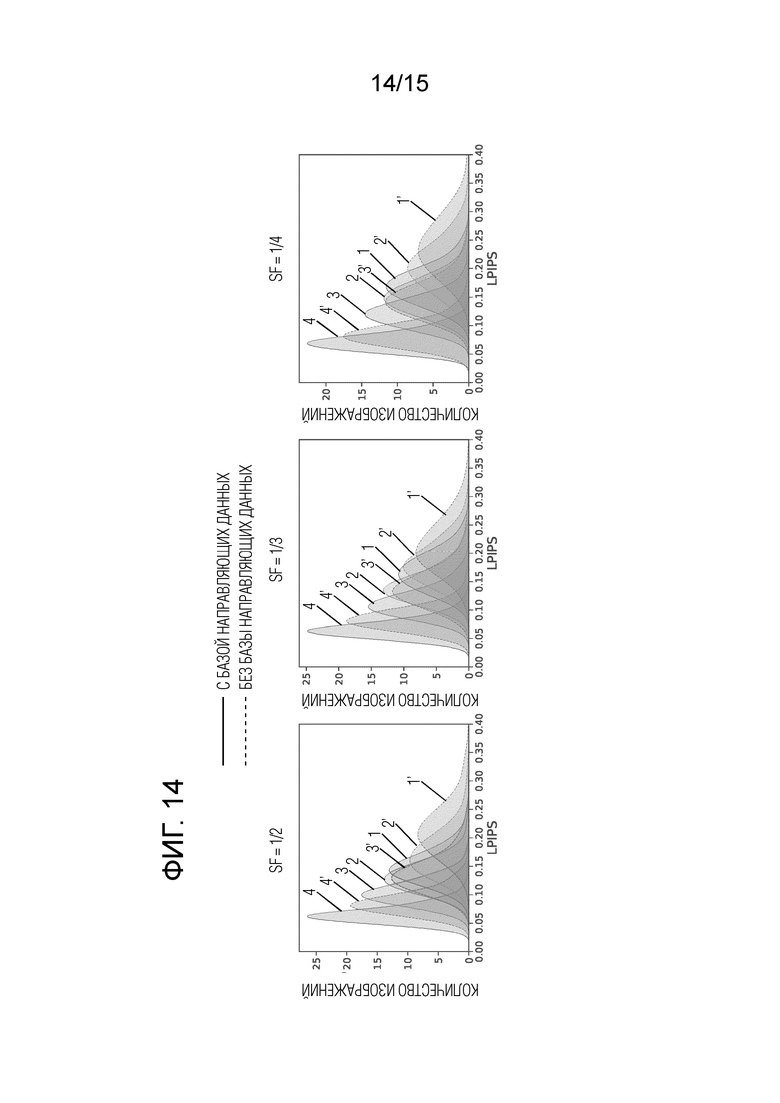

Изобретение относится к области вычислительной техники, а именно к обработке изображений. Технический результат заключается в уменьшении вычислительных нагрузок и уменьшении времени обработки. Предложены система и способ для получения обработанного изображения, имеющего выбираемый пользователем показатель качества, предназначенные для сокращения вычислений путем добавления ветвей раннего выхода к исходной основной сети, и динамического переключения пути вычислений в зависимости от того, насколько сложно будет визуализировать вывод. Система содержит электронное устройство, имеющее дисплей, память, хранящую исходные изображения и набор генеративно-состязательных сетей (GAN), и предиктор. Каждая GAN предварительно обучена и состоит из N вычислительных модулей, образующих основную сеть, и множества ветвей более раннего выхода, каждая из которых присоединена после каждого вычислительного модуля. Предиктор представляет собой искусственную нейронную сеть и сконфигурирован прогнозировать показатель качества обработанного изображения для каждого вывода из каждой ветви более раннего выхода на основе исходного изображения, которое пользователь намерен подать на вход выбранной GAN. 5 н. и 16 з.п. ф-лы, 15 ил.
1. Система для получения выходных изображений, имеющих выбираемый пользователем показатель качества, содержащая:
- электронное устройство, дисплей, память, хранящую входные изображения и набор генеративных искусственных нейронных сетей (GAN), причем электронное устройство выполнено с возможностью выполнения операций искусственной нейронной сети;
- каждая GAN выполнена с возможностью выбора пользователем из набора хранящихся в памяти GAN для получения изображения с предопределенным показателем качества, и каждая GAN предварительно обучена и состоит из:
N вычислительных модулей, образующих основную сеть, и множества ветвей более раннего выхода, каждая из которых присоединена после каждого вычислительного модуля, за исключением последнего вычислительного модуля основной сети, причем каждая ветвь более раннего выхода содержит столько вычислительных модулей, сколько их остается в основной сети после точки присоединения ветви более раннего выхода до выхода основной сети, при этом каждый вычислительный модуль каждой ветви более раннего выхода выполняет ту же самую функцию, что и соответствующий оставшийся вычислительный модуль в основной сети, и вычислительный ресурс каждой ветви более раннего выхода меньше вычислительного ресурса соответствующих оставшихся вычислительных модулей основной сети до выхода основной сети,
причем чем ближе конкретная ветвь более раннего выхода расположена к выходу основной сети, тем выше вычислительный ресурс для получения выходного изображения, генерируемого конкретной ветвью более раннего выхода,
причем чем ближе конкретная ветвь более раннего выхода расположена к выходу основной сети, тем выше показатель качества обработанного изображения, генерируемого данной конкретной ветвью более раннего выхода, и
причем показатели качества выходного изображения, сгенерированного ветвями более раннего выхода, отличаются друг от друга;
- набор предикторов, каждый из которых представляет собой искусственную нейронную сеть, при этом каждый предиктор создается и предварительно обучается для конкретной GAN, хранящейся в памяти, причем предиктор сконфигурирован прогнозировать показатель качества обрабатываемого изображения для вывода из каждой ветви более раннего выхода конкретной GAN на основе входного изображения, которое пользователь намерен подать на вход конкретной GAN;
причем GAN сконфигурирована выводить на дисплей электронного устройства обработанные выходные изображения из той ветви более раннего выхода, которая генерирует обработанное выходное изображение, имеющее показатель качества, наиболее соответствующий показателю качества, выбранному пользователем.
2. Система по п. 1, дополнительно содержащая базу данных, хранящую направляющие данные, при этом GAN дополнительно сконфигурирована осуществлять выборку из базы данных направляющих данных, соответствующих данному входному изображению, и соединять их с входными данными изображения, введенными в GAN, причем направляющие данные соединяются с данными из вычислительного модуля перед ветвью более раннего выхода, и полученные после соединения данные подаются в ветвь более раннего выхода для дальнейшей обработки.
3. Система по п. 2, в которой упомянутые направляющие данные являются фрагментами изображения.
4. Система по п. 2, в которой упомянутые направляющие данные являются признаками.
5. Система по п. 2, в которой упомянутые направляющие данные являются фрагментами признаков.
6. Система по любому из пп. 1-5, причем показатель качества выражается в единицах FID.
7. Способ для получения выходных изображений с выбранным пользователем показателем качества, использующий систему по п. 1, содержащий этапы, на которых:
выбирают, из памяти посредством пользователя, входные изображения, предварительно обученную GAN и предварительно обученный предиктор, соответствующий данной GAN;
выбирают, посредством пользователя, показатель качества для обработанных выходных изображений;
подают по меньшей мере одно из входных изображений, преобразованных во входные данные, подлежащие обработке предиктором, в соответствующий предварительно обученный предиктор;
прогнозируют на основании по меньшей мере одних из поданных входных данных посредством соответствующего предварительно обученного предиктора показатель качества для обработанных выходных изображений, которые будут сгенерированы каждой ветвью более раннего выхода;
выбирают одну ветвь более раннего выхода, генерирующую обработанное выходное изображение, имеющее показатель качества, наиболее соответствующий показателю качества, выбранному пользователем;
преобразуют входные изображения во входные данные для обработки GAN;
подают входные данные в GAN с выбранной ветвью более раннего выхода для обработки;
обрабатывают входные данные посредством GAN с выбранной ветвью более раннего выхода;
получают на выходе выбранной ветви более раннего выхода готовые обработанные выходные изображения.
8. Способ по п. 7, в котором дополнительно сохраняют в памяти готовые обработанные выходные изображение, выведенные из выхода основной сети или одной ветви более раннего выхода, которая обеспечивает выбранный показатель качества изображения.
9. Способ по любому из пп. 7, 8, в котором дополнительно отображают на дисплее электронного устройства готовое обработанное изображение, выведенное из выхода основной сети или одной из ветвей более раннего выхода, которая обеспечивает выбранный показатель качества.
10. Способ по любому из пп. 7-9, в котором показатель качества выражается в единицах FID.
11. Способ получения выходных изображений с выбранным пользователем показателем качества, использующий систему по п. 2, содержащий этапы, на которых:
выбирают, из памяти посредством пользователя, входные изображения, предобученную GAN и предобученный предиктор, соответствующий данной GAN,
выбирают, посредством пользователя, показатель качества для обработанных выходных изображений;
подают по меньшей мере одно из входных изображений, преобразованных во входные данные, подлежащие обработке предиктором, в соответствующий предварительно обученный предиктор;
прогнозируют на основании поданного по меньшей мере одного из входных изображений посредством соответствующего предварительно обученного предиктора показатель качества для обработанных выходных изображений, которые будут сгенерированы каждой ветвью более раннего выхода;
выбирают одну ветвь более раннего выхода, генерирующую обработанное выходное изображение, имеющее показатель качества, наиболее соответствующий выбранному пользователем показателю качества;
преобразуют входные изображения во входные данные, подлежащие обработке GAN;
подают входные данные в GAN с ветвью более раннего выхода для обработки;
обрабатывают входные данные посредством GAN с выбранной ветвью более раннего выхода,
при этом во время обработки:
- выбирают из базы данных направляющие данные, соответствующие направляющим данным для по меньшей мере одного из входных изображений,
- соединяют направляющие данные с выводом данных из вычислительного модуля перед выбранной ветвью более раннего выхода,
- подают соединенные данные в выбранную ветвь более раннего выхода или в основную сеть для дальнейшей обработки;
получают на выходе из выбранной ветви более раннего выхода обработанные выходные изображения.
12. Способ по п. 11, в котором дополнительно сохраняют в памяти готовые обработанные выходные изображения, выведенные из выхода основной сети или одной ветви более раннего выхода, которая обеспечивает выбранный показатель качества изображения.
13. Способ по любому из пп. 11, 12, в котором дополнительно отображают на дисплее электронного устройства готовое обработанное изображение, выведенное из выхода основной сети или одной из ветвей более раннего выхода, которая обеспечивает выбранный показатель качества.
14. Способ по любому из пп. 11-13, в котором упомянутые направляющие данные являются изображениями.
15. Способ по любому из пп. 11-13, в котором упомянутые направляющие данные являются фрагментами изображения.
16. Способ по любому из пп. 11-13, в котором упомянутые направляющие данные являются признаками.
17. Способ по любому из пп. 11-13, в котором упомянутые направляющие данные являются фрагментами признаков.
18. Способ по любому из пп. 11-17, в котором показатель качества выражается в единицах FID.
19. Способ по любому из пп. 11-17, в котором направляющие данные сохраняются пользователем в базе данных заранее на основе выбранных из памяти входных данных.
20. Машиночитаемый носитель, хранящий инструкции для выполнения способа по п. 7 посредством электронного устройства.
21. Машиночитаемый носитель, хранящий инструкции для выполнения способа по п. 11 посредством электронного устройства.
| Способ получения продуктов конденсации фенолов с формальдегидом | 1924 |
|
SU2022A1 |
| Способ восстановления спиралей из вольфрамовой проволоки для электрических ламп накаливания, наполненных газом | 1924 |
|
SU2020A1 |
| TERO KARRAS et al "ANALYZING AND IMPROVING THE IMAGE QUALITY OF STYLEGAN", опубл | |||
| Прибор для равномерного смешения зерна и одновременного отбирания нескольких одинаковых по объему проб | 1921 |
|
SU23A1 |
| ГЕНЕРАТОРЫ ИЗОБРАЖЕНИЙ С УСЛОВНО НЕЗАВИСИМЫМ СИНТЕЗОМ ПИКСЕЛЕЙ | 2021 |
|
RU2770132C1 |
| Повторный синтез изображения, использующий прямое деформирование изображения, дискриминаторы пропусков и основанное на координатах реконструирование | 2019 |
|
RU2726160C1 |

