ОБЛАСТЬ ТЕХНИКИ
[0001] Настоящее изобретение в целом относится к идентификации и подсчету количества таксономических единиц, присутствующих в образце микробиома, и, более конкретно, к коррекции измеренных значений образца с использованием прогнозируемой частоты ошибок.
УРОВЕНЬ ТЕХНИКИ
[0002] Недавние исследования в области медицины были сфокусированы на анализе микробиома человека, экологического сообщества комменсальных, симбиотических и патогенных микроорганизмов, которые присутствуют в нашем организме, являясь потенциальной причиной заболеваний. Один из методов изучения включает геномное секвенирование бактерий, вирусов и/или грибов из различных сред, таких как рот, кишка и т.д. - область исследований, известная как метагеномика.
[0003] Существующие способы, применяемые для изучения метагеномных образцов, обладают недостатком, заключающимся в ошибочной классификации ридов, в результате чего могут быть не точно идентифицированы конкретные виды, присутствующие в образце, и/или некорректно оценена численность таких видов. Такие ошибочные классификации могут привести к неточному отображению образца микробиома, препятствуя точному анализу и диагностике состояния пациента.
[0004] Более точная идентификация видов, присутствующих в образце, и более точное определение их численности может обеспечить более точную идентификацию условий или причин заболевания пациента. Следовательно, существует необходимость в способах и системах для точной идентификации и определения количества видов и других таксономических единиц, присутствующие в образце микробиома.
РАСКРЫТИЕ СУЩНОСТИ ИЗОБРЕТЕНИЯ
[0005] Данное раскрытие сущности изобретения представлено для того, чтобы представить ряд концепций в упрощенной форме, которые дополнительно описаны ниже в разделе «Осуществление изобретения». Данное раскрытие не предназначено для определения или исключения ключевых или существенных признаков заявленного объекта изобретения, и не предназначено для использования в качестве средства определения объема заявленного объекта изобретения.
[0006] Варианты реализации настоящего изобретения в целом относятся к способам и устройствам для идентификации и подсчета количества таксономических единиц (например, видов), присутствующих в образце. Последовательности - риды классифицируют с использованием существующих методов, и результаты классификации и корректируют с учетом ожидаемого количества ошибочно классифицированных ридов, определенного посредством моделирования или экспериментоы по секвенированию с известными количествами микроорганизмов. При наличии статистических данных об ожидаемом количестве ошибочно классифицированных ридов, может быть использован линейный метод наименьших квадратов (неотрицательный или иной) или другой метод определения более точных значений количеств таксономических единиц, фактически присутствующих в образце, и исключения таксономических единиц, ошибочно определенных, как присутствующие в образце.
[0007] В одном аспекте варианты реализации настоящего изобретения относятся к реализованному с помощью компьютера способу оценки количества микроорганизмов в таксономической единице, присутствующей в образце. Способ включает обеспечение компьютерного процессора, выполненного с возможностью:
оценки показателя ошибочной классификации для микроорганизмов в таксономической единице,
приема измеренного значения количества ридов в образце, классифицированных по списку таксономических единиц; и
корректировки принятого измеренного значения с использованием оцененного показателя ошибочной классификации для оценки количества ридов, относящихся к каждой таксономической единице в образце; и
оценки количества микроорганизмов из таксономической единицы, присутствующей в образце, с использованием оцененного количества ридов, относящихся к каждой таксономической единице.
В одном варианте реализации компьютерный процессор также выполнен с возможностью оценки количества микроорганизмов в таксономической единице с использованием длины, гуанин-цитозинового (ГЦ) состава генома (геномов) микроорганизма (микроорганизмов) в таксономической единице или с использованием того и другого.
[0008] В одном варианте реализации компьютерный процессор, выполненный с возможностью оценки показателя ошибочной классификации, выполнен с возможностью:
моделирования ридов с использованием генома (геномов) микроорганизма (микроорганизмов) в таксономической единице с определяемыми эмпирическим путем длинами ридов и показателями ошибки секвенирования (или получения ридов последовательности из образца с известным составом микроорганизмов),
выполнения алгоритма классификации ридов на смоделированных ридах и
определения процентного содержания смоделированных ридов, классифицированных по списку представляющих интерес таксономических единиц.
В одном варианте реализации компьютерный процессор, выполненный с возможностью корректировки принятого измеренного значения, выполнен с возможностью корректировки принятого измеренного значения с использованием метода наименьших квадратов (неотрицательного или другого) до системы линейных уравнений, определенной оцененным показателем ошибочной классификации и количеством ридов из образца, классифицированным по списку таксономических единиц.
[0009] В одном варианте реализации образец содержит множество видов микроорганизмов, и показатель ошибочной классификации вычисляют для каждого из видов в образце, наличие которых предполагается в образце, и для близкородственных видов с подобными геномами. В одном варианте реализации показатель ошибочной классификации вычисляют для каждого из видов в базе данных, содержащей информацию для множества видов микроорганизмов. Измеренное значение может быть принято для каждого из видов в базе данных, и принятые измеренные значения могут быть скорректированы для каждого из видов в базе данных.
[0010] В одном варианте реализации способ также включает прием данных секвенирования из образца. В одном варианте реализации показатель ошибочной классификации оценивают для таксономических единиц различных представляющих интерес таксономических рангов, в том числе, без ограничения, ошибочной классификации видов, ошибочной классификации родов и ошибочной классификации подвидов.
[0011] В другом аспекте варианты реализации настоящего изобретения относятся к компьютерочитаемому носителю информации, содержащему исполняемые с помощью компьютера инструкции для оценки количества микроорганизмов в таксономической единице, присутствующей в образце. Носитель информации содержит исполняемые с помощью компьютера инструкции для оценки показателя ошибочной классификации для микроорганизмов в таксономической единице, исполняемые с помощью компьютера инструкции для приема измеренного значения количества ридов в образце, классифицируемых по списку таксономических единиц, и исполняемые с помощью компьютера инструкции для корректировки принятого измеренного значения с использованием оцененного показателя ошибочной классификации для оценки количества ридов, относящихся к каждой таксономической единице в образце; и исполняемые с помощью компьютера инструкции для оценки количества микроорганизмов из таксономической единицы, присутствующей в образце, с использованием оцененного количества ридов, относящихся к каждой таксономической единице. В одном варианте реализации носитель информации также содержит исполняемые с помощью компьютера инструкции для оценки количества микроорганизмов в таксономической единице с использованием длины, ГЦ-состава генома (геномов) микроорганизма (микроорганизмов) в таксономической единице или с использованием того и другого.
[0012] В одном варианте реализации исполняемые с помощью компьютера инструкции для оценки показателя ошибочной классификации содержат исполняемые с помощью компьютера инструкции для моделирования ридов с использованием генома (геномов) микроорганизма (микроорганизмов) в таксономической единице с определяемыми эмпирическим путем длинами рида и показателями ошибки секвенирования (или приема последовательностей-ридов из образца с известным составом микроорганизмов), исполняемые с помощью компьютера инструкции для выполнения алгоритма классификации рида на смоделированных ридах; и исполняемые с помощью компьютера инструкции для определения процентного содержания смоделированных ридов, классифицированных по списку рассматриваемых таксономических единиц. В одном варианте реализации исполняемые с помощью компьютера инструкции для корректировки принятого измеренного значения содержат исполняемые с помощью компьютера инструкции для корректировки принятого измеренного значения с применением метода наименьших квадратов (неотрицательного или другого) к системе линейных уравнений, определенной оцененным показателем ошибочной классификации и количеством ридов из образца, которые классифицированы по списку таксономических единиц.
[0013] В одном варианте реализации образец содержит множество видов микроорганизмов, и исполняемые с помощью компьютера инструкции вычисляют показатель ошибочной классификации для каждого из видов, наличие которых предполагается в образце, и для близкородственных видов с подобными геномами. В одном варианте реализации исполняемые с помощью компьютера инструкции обеспечивают возможность вычисления показателя ошибочной классификации для каждого из видов в базе данных, содержащей информацию для множества видов микроорганизмов. Принятое измеренное значение может быть принято для каждого из видов в базе данных, и исполняемые с помощью компьютера инструкции корректируют принятые измеренные значения для каждого из видов в базе данных.
[0014] В одном варианте реализации компьютерочитаемый носитель информации также содержит исполняемые с помощью компьютера инструкции для получения данных секвенирования для образца. В одном варианте реализации показатель ошибочной классификации оценивают для таксономических единиц различных представляющих интерес таксономических рангов, в том числе, без ограничения, ошибочной классификации видов, ошибочной классификации родов и ошибочной классификации подвидов.
[0015] Эти и другие признаки и преимущества, которые характеризуют настоящие неограниченные варианты реализации, станут очевидными после прочтения следующего подробного описания и ознакомления с соответствующими чертежами. Следует понимать, что как представленное выше общее описание, так и подробное описание, представленное далее, предназначены только для иллюстрации, и они не определяют четкие границы для неограничивающих заявленных вариантов реализации.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0016] Неограниченные и неисчерпывающие варианты реализации описаны со ссылкой на следующие фигуры, на которых:
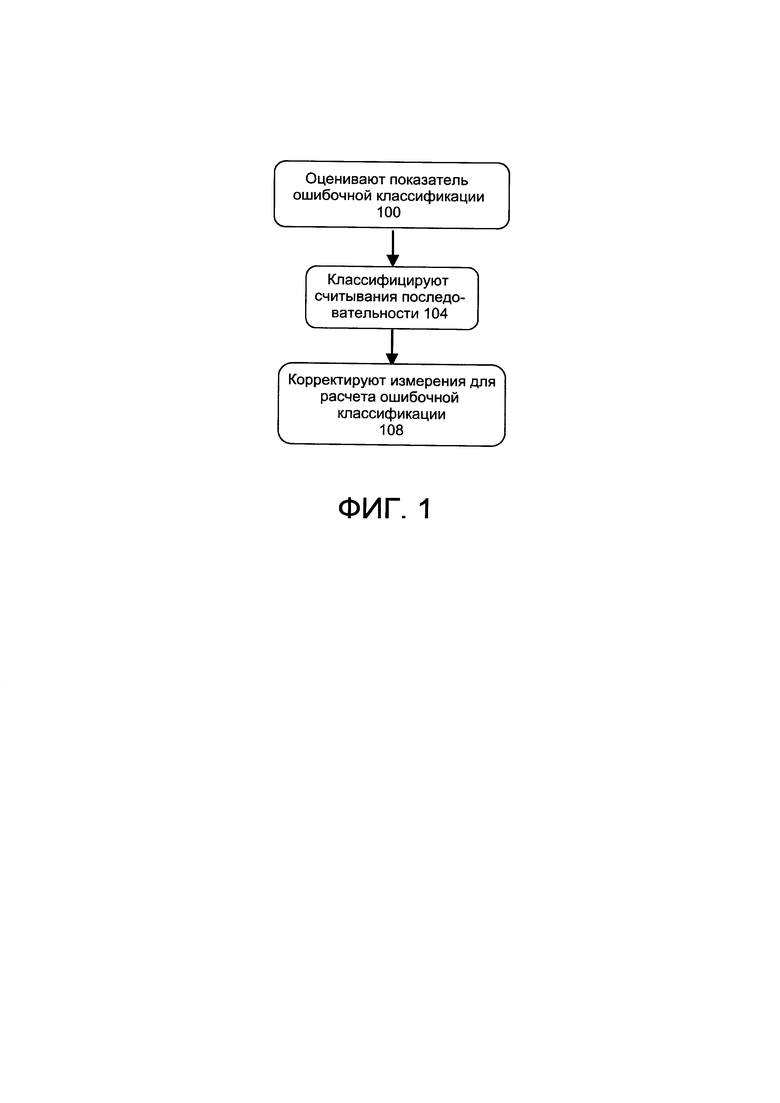
[0017] На фиг. 1 изображен пример одного варианта реализации способа идентификации микроорганизмов, присутствующих в образце, в соответствии с настоящим изобретением; и
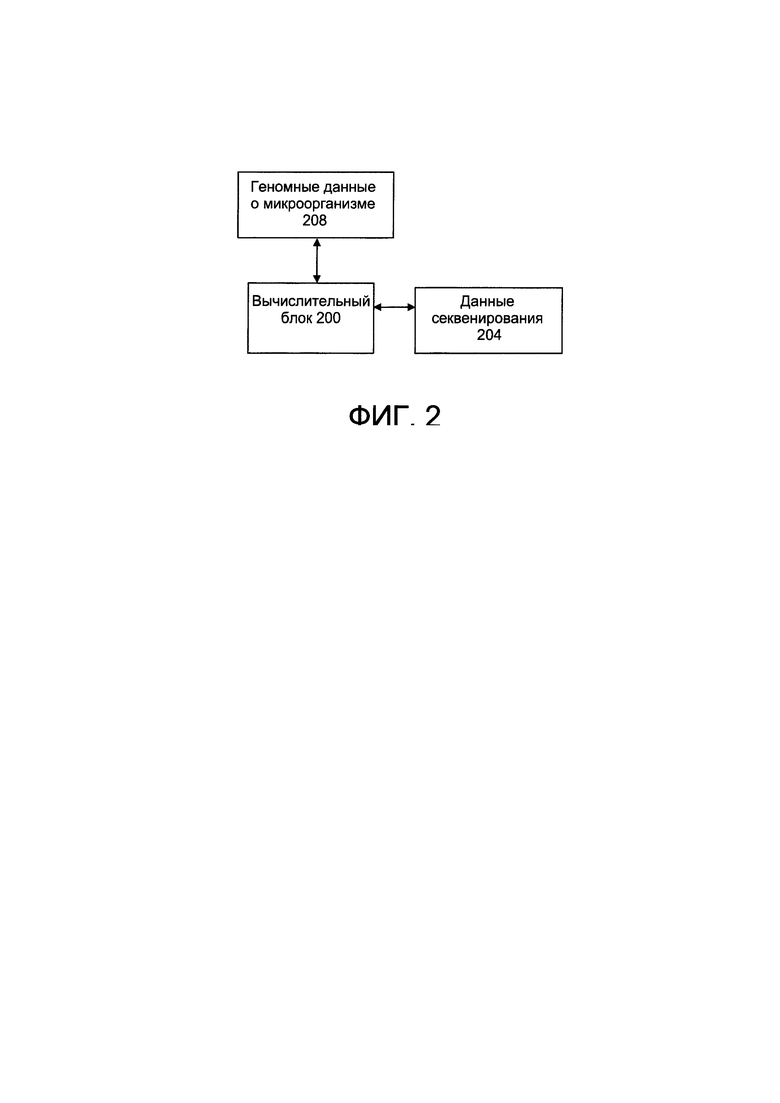
[0018] На фиг. 2 изображена блок-схема иллюстративной системы для метагеномного анализа образца, в соответствии с настоящим изобретением.
[0019] На чертежах подобные ссылочные обозначения в целом относятся к соответствующим частям на разных видах. Чертежи не обязательно выполнены в масштабе, поскольку ими проиллюстрированы замысел и принципы работы.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0020] Различные варианты реализации более подробно описаны ниже со ссылкой на сопроводительные чертежи, которые образуют их часть, и на которых показаны конкретные иллюстративные варианты реализации. Однако варианты реализации могут быть осуществлены во многих других формах, и их не следует считать ограничением для вариантов реализации, изложенных в настоящем документе; наоборот, данные варианты реализации представлены так, чтобы сделать данное раскрытие ясным и полным, и полностью передать объем вариантов реализации для специалистов в данной области техники. Варианты реализации могут быть реализованы на практике в виде способов, систем или устройств. Следовательно, варианты реализации могут принимать форму реализации в виде аппаратного обеспечения, полной реализации в виде программного обеспечения или реализации в виде сочетания аспектов программного и аппаратного обеспечения. Таким образом, представленный далее раздел «Осуществление изобретения» не следует рассматривать в ограничивающем смысле.
[0021] Ссылка в описании на «один вариант реализации» или «вариант реализации» означает, что конкретный признак, структура или характеристика, описанные в связи с вариантами реализации, включены по меньшей мере в один вариант реализации. Присутствие выражения «в одном варианте реализации» в разных местах в описании не обязательно представляет собой ссылку на один и тот же вариант реализации.
[0022] Некоторые части следующего далее описания представлены в виде символических представлений операций на некратковременных сигналах, хранящихся в памяти компьютера. Эти описания и представления являются средствами, используемыми специалисты в области обработки данных для наиболее эффективной передачи сущности своей работы другим специалистам в данной области техники. Такие операции обычно требуют физических манипуляций с физическими величинами. Как правило, хотя и необязательно, эти количественные величины принимают вид электрических, магнитных или оптических сигналов, выполненных с возможностью сохранения, передачи, комбинирования, сравнения или иной обработки. Иногда удобно, главным образом по причинам общего использования, называть эти сигналы битами, значениями, элементами, символами, свойствами, выражениями, числами или т.п. Кроме того, также иногда удобно называть некоторые конфигурации этапов, требующих физических манипуляций с физическими величинами такими, модулями или кодирующими устройствами, без потери обобщения.
[0023] Однако все эти и подобные термины следует связывать с соответствующими физическими количественными величинами, и они являются лишь удобными обозначениями, применяемыми к этим величинам. Если не указано иное, что очевидно из следующего далее описания, следует понимать, что используемые по всему описанию термины, такие как «обработка» или «вычисление», или «расчет», или «определение», или «отображение» или подобные, относятся к действию и процессам компьютерной системы или подобного электронного вычислительного устройства, которое выполняет манипуляции и преобразование данных, представленных в виде физических (в электронном виде) величин в памяти или регистрах компьютерной системы или других таких устройствах для хранения, передачи или отображения.
[0024] Некоторые аспекты настоящего изобретения включают этапы способа и инструкции, которые могут быть реализованы в программном обеспечении, прошивках или аппаратных средствах и при реализации могут быть загружены для хранения и работы с различных платформ, используемых разнообразными операционными системами.
[0025] Кроме того, настоящее изобретение относится к устройству для выполнения операций, описанных в настоящем документе. Данное устройство может быть специально разработано для представляющих интерес целей, или оно может содержать универсальный компьютер, выборочно активируемый или перенастроенный компьютерной программой, хранящейся в компьютере. Такая компьютерная программа может храниться на компьютерочитаемом носителе информации, таком как, без ограничения, любой вид диска, включая дискеты, оптические диски, компакт-диски, магнитооптические диски, постоянные запоминающие устройства (ПЗУ), оперативные запоминающие устройства (ОЗУ), стираемые программируемые постоянные запоминающие устройства (СППЗУ), электронные стираемые программируемые постоянные запоминающие устройства (ЭСППЗУ), магнитные или оптические карты, специализированные интегральные микросхемы (ASIC), или любой тип носителя, подходящего для хранения инструкций в электронном виде, при этом каждый из них соединен с шиной компьютерной системы или сервисной шиной. Кроме того, компьютеры, упоминаемые в описании, могут содержать один процессор или могут представлять собой архитектуры, использующие многопроцессорные конструкции, для увеличения вычислительных возможностей распределенным образом.
[0026] Процессы и средства отображения, представленные в настоящем документе, не связаны с каким-либо конкретным компьютером или другим устройством. Различные универсальные системы также могут быть использованы вместе с программами согласно идеям настоящего изобретения, или может быть удобным сконструировать более специализированное устройство для выполнения представляющих интерес этапов способа. Требуемая структура для этих разнообразных систем будет ясна из нижеследующего описания. Кроме того, настоящее изобретение не описано со ссылкой на какой-либо конкретный язык программирования. Следует понимать, что для реализации идей настоящего изобретения, описанного в настоящем документе, могут быть использованы разнообразные языки программирования, и любые ссылки ниже на конкретные языки представлены для раскрытия варианта возможности осуществления и наилучшего варианта реализации настоящего изобретения.
[0027] Кроме того, терминология, используемая в описании, преимущественно выбрана для обеспечения читаемости и инструктивных целей, и она выбрана не для ограничения объекта изобретения. Соответственно, раскрытие настоящего изобретения представлено в целях иллюстрации, а не ограничения, объема настоящего изобретения, изложенного в формуле изобретения.
Обзор
[0028] Варианты реализации настоящего изобретения относятся к улучшенной методологии подсчета численности конкретных таксономических единиц (например, видов) в метагеномном образце. Существующие инструменты, доступные для данной задачи, как правило, отображают риды в виде набора условных геномов или используют анализ последовательности для классификации ридов на конкретном таксономическом уровне (например, семейство, род, виды, подвиды, штамм, подштамм и т.д.). Однако такие инструменты часто некорректно отображают или ошибочно классифицируют некоторые риды как относящиеся к некорректной таксономической единице.
[0029] В отличие от этого, в настоящем изобретении предусмотрены способы и системы, которые оценивают численность таксономических единиц в образце путем подсчета типичного показателя ошибочной классификации используемого способа классификации рида (например, метод Кракена) посредством моделирования и применения технологий оптимизации (например, линейного метода наименьших квадратов) для расчета и корректировки в соответствии с оцененным показателем ошибочной классификации, определенным с помощью моделирования. Результатом этого процесса является более точная оценка присутствия и/или численности видов, подвидов и т.д., присутствующих в образце.
[0030] Ожидается, что классификация будет основана на данных секвенирования ДНК и РНК. Для ввода на основе ДНК можно классифицировать риды по геномам различных микроорганизмов для подсчета численности различных таксономических единиц. Для данных РНК можно классифицировать риды по некоторым генам (вместо целых геномов) и характеризовать уровень экспрессии генов в метагеномном образце с использованием количества ридов, классифицированных по каждому ген.
[0031] На фиг. 1 изображен иллюстративный способ идентификации микроорганизмов, присутствующих в образце, например, в образце микробиома, в соответствии с настоящим изобретением. Способ предполагает наличие образца по меньшей мере с одним микроорганизмом (например, бактерией, грибом, вирусом и т.д.), имеющим геном, который при заданной последовательности будет более или менее соответствовать геномной последовательности, хранящейся в базе данных. База данных может также хранить частичные или неполные геномные последовательности для некоторых микроорганизмов, для которых трудно получить полные геномы, но предложенные способы также могут быть применены, когда обе геномных последовательности, неполная и полная, находятся в базе данных. Кроме того, эта база данных может быть также намеренно заполнена только частичными геномными последовательностями с целью ограничения способа классификации по некоторым исследуемым областям генома (например, 16S) в случае применения способа направленного секвенирования. Кроме того, база данных может также хранить список последовательностей для исследуемых генов, которые могут быть использованы для классификации РНК-ридов с генов и подсчета их уровней экспрессии. Кроме того, предполагается, что база данных хранит таксономическое взаимоотношение между геномами (полными или частичными) микроорганизмов, хранящихся в базе данных. База данных может быть уже существующей базой данных, или она может быть создана конкретно для использования с вариантами реализации настоящего изобретения. Как указано выше, для точной оценки присутствия и/или численности микроорганизмов в образце способ оценивает показатель ошибочной классификации для способа классификации рида, подлежащего использованию с образцом, как правило, для каждого микроорганизма с геномом, содержащемся в базе данных (этап 100).
[0032] Образец секвенируют с использованием коммерчески доступных технологий секвенирования (например, Illumina HiSeq или MiSeq) для всего генома или направленного секвенирования (например, 16S). Направленное секвенирование 16S может быть более эффективным для секвенирования бактериальных образцов, а секвенирование полной геномной последовательности может быть более предпочтительным, когда считают, что образец содержит грибы или другие небактериальные микроорганизмы.
[0033] В одном варианте реализации алгоритм классификации применяют к результату процесса секвенирования с целью классификации каждого рида как выходящего из таксономической единицы, основанной на предоставленной базе данных генома (этап 104). Одним подходящим алгоритмом классификации для использования в вариантах реализации настоящего изобретения является метод Кракена, доступный на http://ccb.jhu.edu/software/kraken/ (доступ осуществлен 17 февраля 2015 г.).
[0034] Как только каждое считывание было классифицировано, могут быть вычислены статистические данные такие, как распространенность микроорганизмов из исследуемых таксономических единиц в образце. Однако известно, что такие статистические данные содержат некоторую составляющую ошибки ввиду ошибки и ошибочной классификации в основополагающих классификациях рида. Варианты реализации настоящего изобретения корректируют эти измеренные значения образцов для расчета этих ошибок классификации ридов (этап 108).
Корректировка на ошибочную классификацию последовательности
[0035] Поскольку показатель ошибочной классификации для способа классификации рида может быть разным для разных микроорганизмов, процесс моделирования для подсчета количества ошибочных классификаций может быть выполнен для каждого микроорганизма, присутствие которого ожидается в образце, или для каждого микроорганизма, присутствующего в базе данных геномных последовательностей. Оценка показателя ошибочной классификации может быть определена путем моделирования ридов с использованием известного генома для рассматриваемого микроорганизма (например, полученного в виде файла геномной последовательности формата .fasta, загруженного с сайта Национального центра биотехнологической информации - NCBI) и средств моделирования секвенирования, таких как MetaSim, доступных на http://ab.inf.uni-tuebinqen.de/software/metasim/ (доступ 17 февраля 2015 г.), которые предоставляют смоделированные риды (например, в виде файла формата .fastq) для алгоритма классификации для применения к фактическому образцу (например, Кракен), и вычисления показателя ошибочной классификации алгоритмом классификации для смоделированных ридов. В качестве альтернативы, показатель ошибочной классификации также может быть вычислен на основании эксперимента по секвенирования с известными количествами одного или более микроорганизмов.
[0036] Длина рида и показатели ошибки секвенирования в качестве входных данных для средств моделирования секвенирования, могут быть значениями, наблюдаемыми на практике для конкретной технологии секвенирования для использования с образцом (например, Illumina, 454 и т.д.) или определена другим эмпирическим способом. После этого выходные данные средств моделирования секвенирования могут быть предоставлены в алгоритм классификации рида.
[0037] В одном варианте реализации показатель ошибочной классификации для микроорганизма в таксономической единице i может быть выражен в виде части ридов, смоделированных для микроорганизма, которые классифицируются в качестве таксономической единицы j алгоритмом классификации рида, который будет обозначен как a(j, i), с микроорганизмом из таксономической единицы i, выбранной из вышеуказанной базы данных геномов микроорганизма. Как правило, предполагается присутствие одного генома для каждой исследуемой таксономической единицы, и что такой геном будет выступать в роли типичного представителя для всех микроорганизмов анализируемой таксономической единицы. В другом варианте реализации показатель ошибочной классификации для микроорганизма i может быть выражен в виде части ридов для смоделированного микроорганизма i, которые классифицируются в качестве нечто другого, отличающегося от микроорганизма i, алгоритмом классификации рида.
[0038] В другом варианте реализации оцененный показатель ошибочной классификации может быть вычислен только для таксономических единиц i, j, считающихся присутствующими в анализируемом образце и близкородственных с таксономическими единицами (с подобными геномами), по которым некоторые риды могут быть ошибочно классифицированы. Это определение может быть передано, например, через результаты секвенирования, полученные для образца, или через информацию в отношении источника образца и т.д. Например, эта информация может быть источником, из которого был взят образец, или другой клинической информацией, такой как основной диагноз пациента.
[0039] Для обозначения, значение а(0, i) будет представлять собой часть ридов из микроорганизма i, которые остались не классифицированными алгоритмом на представляющем интерес таксономическом уровне (например, при рассмотрении ридов, классифицированных на уровне видов, а(0, i) будет представлять собой число ридов, которые не были классифицированы на уровне видов). Когда имеется n исследуемых таксономических единиц, по которым планируется классифицировать наши микроорганизмы, отдельные значения a(j, i) будут собраны в матрицу А, для j в {0, 1, …, n} и i в {1, …, n}, с созданием матрицы, представляющей собой значение n+1 при n вводов по размеру.
[0040] Количество ридов из образца, которое точно соответствует конкретному микроорганизму i из базы данных геномов микроорганизма, может быть определено, как xi. Отдельные значения xi могут быть векторизованы в столбец х, который также представляет собой n вводов по размеру, т.е. количество рассматриваемых таксономических единиц.
[0041] Количество ридов из процесса секвенирования, которые были классифицированы алгоритмом классификации, как имеющие происхождение из микроорганизма i из базы данных геномов микроорганизма (как истинно-положительные, так и ложноположительные) могут быть определены, как bi. Отдельные значения bi могут быть векторизованы в столбец b, который представляет собой n+1 вводов по размеру, т.е. количество рассматриваемых таксономических единиц плюс одна (ввиду количества неклассифицированных ридов в исследуемом таксономическом ранге).
[0042] С такими определениями ожидается соблюдение матричного уравнения Ах=b. Однако, поскольку процесс является стохастическим, соблюдение Ах=b ожидается только с большим числом ридов, в соответствии с законом больших чисел. На практике, Ах=b не будет строго истинным ввиду произвольности, присущей процессу секвенирования (такой, как ошибка секвенирования) и ввиду ограниченного количества ридов секвенирования. Тем не менее, вектор b, представляющий собой количество ридов из образца, классифицированных по каждому организму из вышеуказанной базы данных, может быть вычислен так же, как и матрица А, представляющая собой смоделированные показатели ошибочной классификации каждого организма из базы данных. Неизвестным в уравнении является вектор х.
[0043] В одном варианте реализации х определяют следующим образом:
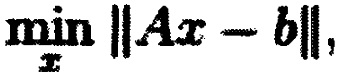
Проблема оптимизации может быть решена с использованием линейного метода наименьших квадратов, т.е.:
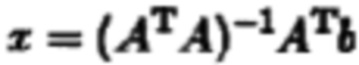
[0044] В других вариантах реализации могут быть использованы методы оптимизации, такие как наименьшие абсолютные значения, усеченный метод наименьших квадратов и т.д., и эти методы зачастую имеют варианты, для которых найденный вектор х должен быть или неотрицательным (например, неотрицательный линейный метод наименьших квадратов), целым числом или тем и другим. Предпочтительно, чтобы вектор х был неотрицательным и имел целые значения, поскольку он представляет собой количество ридов из каждой таксономической единицы, которое не может быть отрицательной. Еще в других вариантах реализации могут быть использованы методы, которые минимизируют количество ненулевых вводов в векторе х. Результат такого процесса может быть назван «самым простым» ответом ввиду того, что требуется наименьшее количество микроорганизмов из таксономических единиц для разъяснения наблюдаемых результатов секвенирования.
[0045] После вычисления вектора х с оценкой количества ридов из образца, соответствующих каждому микроорганизму, вектор х может быть нормирован для учета того факта, что некоторые микроорганизмы имеют более длинные геномы, чем другие микроорганизмы. Предполагается, что разница в длине генома будет смещать количество классифицированных ридов в пользу микроорганизмов, имеющих более длинные геномы, и может быть решена методом деления каждого ввода xi вектора х на длину генома микроорганизма i, с получением в результате нормированной оценки количества микроорганизмов i в образце.
[0046] Оцененное количество микроорганизмов, присутствующих в образце, может быть дополнительно уточнено с учетом гуанин-цитозинового (ГЦ) состава генома микроорганизма в дополнение или вместо его длины. В некоторых технологиях секвенирования затруднен захват геномных последовательностей, которые имеют несбалансированный ГЦ-состав, поэтому микроорганизмы с геномами, содержащими тяжелые или легкие ГЦ-участки, могут быть пересчитаны в образце микробиома. Процесс корректировки может учитывать этот систематический пересчет посредством, например, умножения каждого количества микроорганизмов на коэффициент пересчета, вычисленный на основе частоты тяжелых или легких ГЦ-участков в геноме микроорганизма, как отражено в базе данных.
[0047] Специалисту в данной области техники будет ясно, что порядок этапов в представленном выше описании не обязательно является установленным. Например, специалисту в данной области техники будет ясно, что оцененная ошибка для алгоритма классификации может быть вычислена после получения результатов секвенирования, позволяющих вычислить уменьшенную матрицу погрешности, которая ограничена таксономическими единицами, идентифицированными в образце.
[0048] Фиг. 2 представляет собой блок-схему иллюстративной системы для метагеномного анализа образца, в соответствии с настоящим изобретением. В данном варианте реализации вычислительный блок 200 сообщается с источником 208 геномных данных микроорганизмов и источником 204 данных секвенирования.
[0049] Вычислительный блок 200 в различных вариантах реализации может иметь самые разные формы. Иллюстративные вычислительные блоки, подходящие для использования с настоящим изобретением, включают стационарные компьютеры, портативные компьютеры, виртуальные компьютеры, серверные компьютеры, смартфоны, планшеты, фаблеты и т.д. Кроме того, источники 204, 208 данных могут иметь самые разные формы, в том числе, без ограничения, структурированные базы данных (например, базы данных SQL), неструктурированные базы данных (например, кластеры Hadoop, базы данных NoSQL), или другие источники данных, запускаемые на различных вычислительных устройствах (например, стационарных компьютерах, портативных компьютерах, виртуальных компьютерах, серверных компьютерах, смартфонах, планшетах, фаблетах и т.д.). Вычислительные блоки в различных вариантах реализации настоящего изобретения могут быть разнородными или однородными. В некоторых вариантах реализации источник 204 данных может быть частью оборудования для секвенирования, которое секвенирует геном по меньшей мере одного микроорганизма в образце. В некоторых вариантах реализации источником 208 данных может быть общедоступная или частная база геномных данных.
[0050] Компоненты систем могут быть соединены друг с другом с использованием широкого ряда сетевых технологий, которые могут быть разнородными или однородными в различных вариантах реализации. Подходящие сетевые технологии включают, без ограничения, соединения проводной сети (например, сеть Ethernet, гигабит Ethernet, сеть Token Ring и т.д.) и соединения беспроводной сети (например, Bluetooth, 802.11х, беспроводные технологии 3G/4G и т.д.).
[0051] При работе вычислительный блок 200 направляет источнику 204 данных секвенирования запрос на данные секвенирования для одного или более микроорганизмов в образце микробиома. Источник 204 данных секвенирования может содержать такую информацию, поскольку такой тест был выполнен на образце, или он мог получить такую информацию прямым или непрямым способом (например, через ввод или передачу данных) от части оборудования, на котором было выполнено такое тестирование.
[0052] При работе вычислительный блок 200 направляет источнику 208 геномных данных запрос на информацию о геномах для одного или более микроорганизмов, идентифицированных источником 204 данных секвенирования. Источник 208 геномных данных может содержать такую информацию, хранящуюся локально, или может взаимодействовать с другими вычислительными блоками для получения при необходимости релевантной геномной информации.
[0053] Как описано выше, после получения запрошенных данных секвенирования и геномных данных для одного или более микроорганизмов, вычислительный блок 200 приступает к оценке показателя ошибочной классификации для каждого микроорганизма. Вычислительный блок 200 выполняет это посредством моделирования ридов с использованием геномных данных для микроорганизма с определенными эмпирическим путем длиной рида и показателями ошибки секвенирования. В качестве альтернативы, также могут быть использованы риды из реального эксперимента по секвенированию с известными количествами одного или более микроорганизмов. Алгоритм классификации рида применим к смоделированным или экспериментально сгенерированным ридам и затем процентное содержание смоделированных ридов, классифицированных по каждой исследуемой таксономической единице, вычисляют для определения показателя ошибочной классификации.
[0054] Вычислительный блок 200 применяет алгоритм классификации рида к фактическим ридам, полученным из источника 204 данных секвенирования, посредством применения методов оптимизации, таких как линейный метод наименьших квадратов (неотрицательный или другой), к системе линейных уравнений, определенной количеством классифицированных ридов и оцененными показателями ошибочной классификации, как описано выше, предоставляет улучшенную оценку количества ридов, относящихся к микроорганизмам в каждой исследуемой таксономической единице. Как описано выше, исследуемые таксономические единицы могут быть ограничены единицами, присутствие которых предполагается в настоящем образце, или присутствующими в геномных данных 208.
[0055] Вычислительный блок 200 может сначала получить доступ к источнику 204, 208 данных или он может получить доступ к обоим источникам данных одновременно. В некоторых вариантах реализации вычислительный блок 200 является локальным для оператора, т.е. он расположен в локальной вычислительной сети, к которой имеет доступ оператор. В некоторых вариантах реализации вычислительный блок 200 доступен оператору через другое сетевое подключение (не показано), такое как глобальная вычислительная сеть или сеть Интернет, и графическое представление доставляют оператору по такому сетевому соединению. В некоторых вариантах реализации вычислительный блок 200 содержит функционал сервера безопасности и Интернета, стандартный для таких устройств с удаленным доступом.
[0056] Несмотря на то, что предшествующее описание сфокусировано на вариантах реализации настоящего изобретения, которые классифицируют микроорганизмы в образце на уровне видов, следует понимать, что некоторые алгоритмы классификации также могут классифицировать (или ошибочно классифицировать) рид последовательности, как относящихся к роду, подвидам или другому таксономическому рангу. Можно также выбрать классификацию ридов для любого произвольного набора таксономических единиц, которые могут быть основаны на характеристиках, таких как клинический фенотип, обусловленный микроорганизмом. Варианты реализации настоящего изобретения обеспечивают решение для этих видов алгоритмов классификации методом добавления дополнительных элементов а(l, i) к матрице А показателя ошибочной классификации с целью представления части ридов из микроорганизма i, которые классифицированы по каждой таксономической группе l в базе геномных данных, которая может относиться к разным таксономическим рангам, например, родам/подвидам, и дополнительные вводы bl для каждой таксономической группы l в каждой базе геномных данных. Следует отметить, что в дополнение к данным вводам также можно добавить вводы, которые представляют собой количество ридов, которые не могут быть классифицированы по разным таксономическим рангам, что может быть полезными знаниями, поскольку некоторые риды, например, могут быть классифицированы на уровне рода, но не пройдут классификацию на уровне подвида. Описанный выше метод наименьших квадратов или другой метод может быть использован в данных вариантах реализации также для нахождения подходящего вектора х, который лучше всех совпадает с наблюдаемым количеством классифицированных и неклассифицированных ридов.
[0057] Еще в одном варианте реализации ошибочная классификация и классификация микроорганизмов основана не только на таксономических единицах, но может быть основана на произвольной группе микроорганизмов. Эти группы могут быть основаны на критериях, таких как воздействие на здоровье человека. Даже в пределах одного вида подгруппа может образовывать штамм с уникальными характеристиками на молекулярном уровне, которые могут обуславливать различия в патогенных свойствах, способности использовать уникальный источник углерода или устойчивости к противомикробным агентам. Эти штаммы могут быть сгруппированы на основе их воздействия на здоровье человека - т.е. условно-патогенные микроорганизмы, в отличие от патогенных микроорганизмов. В дополнительных вариантах реализации можно классифицировать микроорганизмы на абсолютные патогены (например, микробактерия туберкулеза и гонококки) и условно-патогенные микроорганизмы (например, золотистый стафилококк, кишечная палочка).
[0058] Варианты реализации настоящего изобретения имеют несколько полезных вариантов коммерческого применения, включая идентификацию видов, присутствующих в метагеномном образце, подсчета присутствия видов в образце, анализ образца, и идентификацию инфекционных заболеваний.
[0059] Варианты реализации настоящего изобретения, например, описаны выше со ссылкой на блок-схемы и/или рабочие иллюстрации способов, систем и компьютерных программных продуктов, в соответствии с вариантами реализации настоящего изобретения. Функции/действия, указанные в блоках, могут выполняться в другом порядке, отличающемся от показанного на любой блок-схеме. Например, два блока, показанные последовательными, в действительности могут быть выполнены по существу одновременно, или иногда блоки могут быть выполнены в обратном порядке в зависимости от функционала/вовлеченных действий. Кроме того, не все блоки, отображенные в любой блок-схеме, должны быть выполнены и/или исполнены. Например, если представленная блок-схема содержит пять блоков, содержащих функции/действия, допускается выполнение и/или исполнение только трех блоков из пяти. В данном примере, любой из трех блоков из пяти может быть выполнен и/или исполнен.
[0060] Описание и иллюстрация одного или более вариантов реализации, представленных в настоящей заявке, не предназначены для ограничения или задания рамок объема настоящего исследования, заявленного в любом виде. Варианты реализации, примеры и особенности, представленные в настоящей заявке, следует считать достаточными для передачи сведений и обеспечения другим лицам возможности использования наилучшей версии заявленных вариантов реализации. Заявленные варианты реализации не следует рассматривать в качестве ограничения до какого-либо варианта реализации, примера или особенности, представленной в настоящей заявке. Независимо от отдельного или совместного описания, различные признаки (как структурные, так и методологические) предназначены для выборочного включения или опущения для получения варианта реализации с конкретной совокупностью признаков. Опираясь на описание и иллюстрацию настоящего изобретения, специалисту в данной области техники могут быть ясны вариации, модификации и альтернативные варианты реализации, входящие в объем более широких аспектов общего изобретательского замысла, реализованного в настоящей заявке, который не выходит за рамки более широкого объема заявленных вариантов реализации.
| название | год | авторы | номер документа |
|---|---|---|---|
| ФРЕЙМВОРК НА ОСНОВЕ ГЛУБОКОГО ОБУЧЕНИЯ ДЛЯ ИДЕНТИФИКАЦИИ ПАТТЕРНОВ ПОСЛЕДОВАТЕЛЬНОСТИ, КОТОРЫЕ ВЫЗЫВАЮТ ПОСЛЕДОВАТЕЛЬНОСТЬ-СПЕЦИФИЧНЫЕ ОШИБКИ (SSE) | 2019 |
|
RU2745733C1 |
| СПОСОБ И СИСТЕМА ФОРМИРОВАНИЯ ИНДИВИДУАЛЬНОГО РАЦИОНА ПРОДУКТОВ ПИТАНИЯ ПОСЛЕ ПЕРЕСАДКИ МИКРОБИОТЫ | 2018 |
|
RU2699283C1 |
| СИСТЕМА И СПОСОБ ИНТЕРПРЕТАЦИИ ДАННЫХ И ПРЕДОСТАВЛЕНИЯ РЕКОМЕНДАЦИЙ ПОЛЬЗОВАТЕЛЮ НА ОСНОВЕ ЕГО ГЕНЕТИЧЕСКИХ ДАННЫХ И ДАННЫХ О СОСТАВЕ МИКРОБИОТЫ КИШЕЧНИКА | 2017 |
|
RU2699284C2 |
| СПОСОБ И СИСТЕМА КОРРЕКЦИИ НЕЖЕЛАТЕЛЬНЫХ КОВАРИАЦИОННЫХ ЭФФЕКТОВ В МИКРОБИОМНЫХ ДАННЫХ | 2019 |
|
RU2742003C1 |
| КЛАССИФИКАЦИЯ САЙТОВ СПЛАЙСИНГА НА ОСНОВЕ ГЛУБОКОГО ОБУЧЕНИЯ | 2018 |
|
RU2780442C2 |
| СПОСОБЫ ОБУЧЕНИЯ ГЛУБОКИХ СВЕРТОЧНЫХ НЕЙРОННЫХ СЕТЕЙ НА ОСНОВЕ ГЛУБОКОГО ОБУЧЕНИЯ | 2018 |
|
RU2767337C2 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ИНДИВИДУАЛЬНЫХ РЕКОМЕНДАЦИЙ ПО ДИЕТЕ НА ОСНОВАНИИ АНАЛИЗА СОСТАВА МИКРОБИОТЫ | 2019 |
|
RU2724498C1 |
| ГЕНОМНАЯ ИНФРАСТРУКТУРА ДЛЯ ЛОКАЛЬНОЙ И ОБЛАЧНОЙ ОБРАБОТКИ И АНАЛИЗА ДНК И РНК | 2017 |
|
RU2804029C2 |
| ГЕНОМНАЯ ИНФРАСТРУКТУРА ДЛЯ ЛОКАЛЬНОЙ И ОБЛАЧНОЙ ОБРАБОТКИ И АНАЛИЗА ДНК И РНК | 2017 |
|
RU2761066C2 |
| СПОСОБ ОЦЕНКИ РИСКА ЗАБОЛЕВАНИЯ У ПОЛЬЗОВАТЕЛЯ НА ОСНОВАНИИ ГЕНЕТИЧЕСКИХ ДАННЫХ И ДАННЫХ О СОСТАВЕ МИКРОБИОТЫ КИШЕЧНИКА | 2018 |
|
RU2699517C2 |
Изобретение относится к биотехнологии. Представлен способ и устройство для идентификации и подсчета количества микроорганизмов, присутствующих в образце. Риды последовательности классифицируют с использованием существующих способов, но результаты классификации корректируют для расчета предполагаемого количества ридов, которые ожидаются, как ошибочно классифицированные, что определено посредством моделирования. При наличии статистических данных об ожидаемом количестве ридов с ошибочной классификацией может быть использован линейный метод наименьших квадратов (неотрицательный или другой) или другая соответствующая технология корректировки количества ридов, классифицированных по различным таксономическим единицам (например, видам) и для определения более точных значений количеств таксономических единиц, фактически присутствующих в образце, с устранением таксономических единиц, которые были ошибочно определены в качестве присутствующих в образце. Изобретение позволяет более точно идентифицировать виды, присутствующие в образце, и более точно определить их численность, обеспечивая более точную идентификацию условий или причин заболевания пациента. 2 н. и 15 з.п. ф-лы, 2 ил.
1. Способ оценки количества микроорганизмов в таксономической единице, присутствующей в образце, включающий:
обеспечение образца, содержащего множество микроорганизмов,
обеспечение компьютерного процессора, осуществляющего:
(a) оценку показателя ошибочной классификации для микроорганизмов, содержащихся в образце, в таксономической единице на основе cмоделированных считываний с использованием известного генома микроорганизма,
причем компьютерный процессор, выполненный с возможностью оценки показателя ошибочной классификации, выполнен с возможностью:
(a-1) моделирования считываний с использованием геномов микроорганизмов в таксономической единице с определенными эмпирическим путем длиной считывания и показателями ошибки секвенирования или получения считываний последовательности из образца с известным составом микроорганизмов;
(a-2) выполнения алгоритма классификации считывания на cмоделированных считываниях; и
(a-3) определения процентного содержания cмоделированных считываний, классифицированных по списку требуемых таксономических единиц;
(b) получение измерения количества считываний в образце, классифицированных по списку таксономических единиц;
(c) корректировку полученного измерения образца с использованием полученной оценки показателя ошибочной классификации для оценки количества считываний, относящихся к каждой таксономической единице в образце; и
(d) оценку количества микроорганизмов в образце из таксономической единицы, присутствующей в образце, с использованием оцененного количества считываний, относящихся к каждой таксономической единице образца.
2. Способ по п. 1, в котором компьютерный процессор также выполнен с возможностью корректировки оценки количества микроорганизмов посредством нормирования с использованием длины генома, умножения на коэффициент пересчета, основанного на гуанин-цитозиновом (ГЦ) составе геномов микроорганизмов в таксономической единице или с использованием обоих.
3. Способ по п. 1, в котором компьютерный процессор, выполненный с возможностью корректировки полученного измерения, выполнен с возможностью корректировки полученного измерения с применением линейного метода наименьших квадратов для решения системы линейных уравнений, определенных оцененным показателем ошибочной классификации и количеством считываний из образца, которые классифицированы по списку таксономических единиц.
4. Способ по п. 1, в котором образец содержит множество видов микроорганизмов, и показатель ошибочной классификации вычисляют для каждого из видов в образце.
5. Способ по п. 1, в котором показатель ошибочной классификации вычисляют для каждого из видов в базе данных, содержащей информацию для множества видов микроорганизмов.
6. Способ по п. 5, в котором измерение получают для каждого из видов в базе данных, и в котором полученное измерение корректируют для каждого из видов в базе данных.
7. Способ по п. 1, который также включает получение данных секвенирования из образца.
8. Способ по п. 1, в котором показатель ошибочной классификации оценивают для таксономических единиц, выбранных из одного или более требуемых таксономических разрядов.
9. Устройство для оценки количества микроорганизмов в таксономической единице, содержащее:
средство для обеспечения образца, содержащего множество микроорганизмов;
компьютерочитаемый носитель информации, содержащий компьютерную программу со средствами программного кода, сконфигурированный для выполнения компьютером этапов способа по п. 1 при выполнении указанной компьютерной программы на компьютере.
10. Устройство по п. 9, которое также содержит исполняемые с помощью компьютера инструкции для корректировки оценки количества микроорганизмов посредством нормирования с использованием длины генома, умножения на коэффициент пересчета, основанного на гуанин-цитозиновом (ГЦ) составе геномов микроорганизмов в таксономической единице или с использованием обоих.
11. Устройство по п. 9, в котором исполняемые с помощью компьютера инструкции для оценки показателя ошибочной классификации содержат:
(a-1) исполняемые с помощью компьютера инструкции для моделирования считываний с использованием геномов микроорганизмов в таксономической единице с определенными эмпирическим путем длинами считывания и показателями погрешности секвенирования или получения показателей последовательности из образца с известным составом микроорганизмов;
(a-2) исполняемые с помощью компьютера инструкции для выполнения алгоритма классификации считывания на смоделированных считываниях; и
(a-3) исполняемые с помощью компьютера инструкции для определения процентного содержания смоделированных считываний, классифицированных по списку требуемых таксономических единиц.
12. Устройство по п. 9, в котором исполняемые с помощью компьютера инструкции для корректировки полученного измерения содержат исполняемые с помощью компьютера инструкции для корректировки полученного измерения путем применения линейного метода наименьших квадратов для решения системы линейных уравнений, определенной оцененным показателем ошибочной классификации и количеством считываний из образца, которые классифицированы по списку таксономических единиц.
13. Устройство по п. 9, в котором образец включает множество видов микроорганизмов и исполняемые с помощью компьютера инструкции вычисляют показатель ошибочной классификации для каждого из видов в образце.
14. Устройство по п. 9, в котором исполняемые с помощью компьютера инструкции вычисляют показатель ошибочной классификации для каждого из видов в базе данных, содержащей данные для множества видов микроорганизмов.
15. Устройство по п. 14, в котором исполняемые с помощью компьютера инструкции получают измерение количества считываний для каждого из видов в базе данных, и в котором исполняемые с помощью компьютера инструкции корректируют полученное измерение для каждого из видов в базе данных.
16. Устройство по п. 9, которое также содержит исполняемые с помощью компьютера инструкции для получения данных секвенирования для образца.
17. Устройство по п. 9, в котором показатель ошибочной классификации оценен для таксономических единиц, выбранных из одного или более требуемых таксономических разрядов.
| ТЕРМИЧЕСКИ И ОПТИЧЕСКИ УПРАВЛЯЕМОЕ ФОКУСИРУЮЩЕЕ УСТРОЙСТВО | 2008 |
|
RU2390810C2 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОПРЕДЕЛЕНИЯ КОЛИЧЕСТВА КУЛЬТИВИРУЕМЫХ КЛЕТОК | 2009 |
|
RU2517618C2 |

