Настоящее изобретение относится к полинуклеотидам, кодирующим новые слитые полипептиды, состоящие по сути из сигнального пептида для транслокации через мембрану и полипептида, обеспечивающего α-1,6-глюкозидазную активность, а также к бактериям, содержащим указанные полинуклеотиды. Настоящее изобретение, кроме того, относится к способам получения химических продуктов тонкого синтеза с использованием сред, содержащих изомальтозу и/или панозу в качестве источника углерода.
Штаммы рода Corynebacterium, в частности, вида Corynebacterium glutamicum, являются известными продуцентами L-аминокислот, таких как протеиногенные аминокислоты, например, L-лизин, L-треонин, L-валин или L-изолейцин, и других химических продуктов тонкого синтеза, таких как витамины, нуклеозиды и нуклеотиды. Ввиду большого экономического значения этих химических веществ постоянно проводится работа по улучшению их способов получения. Улучшения могут касаться генетической конституции микроорганизма, применяемой технологии ферментации или обработки продукта до желаемой формы. Применяемыми способами улучшения генетической конституции являются способы мутагенеза, селекции и выбора мутантов. Способы технологии рекомбинантной ДНК также применялись на протяжении многих лет для улучшения штаммов этой группы бактерий. Обобщенные справочные сведения, касающиеся Corynebacterium, в частности, Corynebacterium glutamicum, можно найти у L. Eggeling и M. Bott (Handbook of Corynebacterium glutamicum, CRC Press, 2005), A. Burkovski (Corynebacteria Genomics and Molecular Biology, Caister Academic Press, 2008) или H. Yukawa и M. Inui (Corynebacterium glutamicum Biology and Biotechnology, Springer Verlag, 2013).
Одним из основных источников углерода, используемых для размножения этой группы бактерий и для образования желаемого химического вещества, является глюкоза. Глюкозу, используемую в бродильном производстве, как правило, получают из крахмала путем ферментативного гидролиза. Крахмал представляет собой смесь двух различных полисахаридов, каждый из которых состоит из цепей связанных повторяющихся звеньев глюкозы. Данная смесь состоит главным образом из двух отдельных полисахаридов - амилозы и амилопектина. Амилоза является практически линейным полисахаридом с глюкозными звеньями, соединенными практически исключительно α-1,4-гликозидными связями. Глюкозные звенья в амилопектине, кроме того, соединены α-1,6-гликозидными связями. Содержание амилозы в крахмале таких видов растений, как маис, пшеница или рис, составляет приблизительно 20-30%, а содержание амилопектина - приблизительно 80-70%. Подробную информацию о крахмале можно найти у J. Bemiller и R. Whistler (Starch: Chemistry and Technology, 3. ed., Elsevier, 2009).
Ферментативный гидролиз крахмала до глюкозы включает два основных этапа. На первом этапе, также называемом ожижением, крахмал обрабатывают α-амилазой (4-α-D-глюканглюканогидролазой; EC 3.2.1.1). Продуктами данной реакции являются олигомеры глюкозы с α-1,4-связями, также называемые мальтодекстрином, содержащие такие молекулы, как мальтотриоза (O-α-D-Glcp-(1→4)-O-α-D-Glcp-(1→4)-D-Glcp) и мальтогексаоза (соответствующий гексамер D-глюкозы c α-(1→4)-связями), а также олигомеры глюкозы, содержащие α-1,6-связь, также называемые предельным декстрином. На втором этапе, также называемом осахариванием, эту смесь обрабатывают глюкоамилазой, также называемой в данной области техники амилоглюкозидазой (4-α-D-глюканглюкогидролазой; EC 3.2.1.3). Этот фермент быстро гидролизует α-1,4-связь. Также он гидролизует α-1,6-связь, но с меньшей скоростью. В уровне техники также описывается использование пуллуланазы (пуллулан-6-α-глюканогидролазы) для гидролиза α-1,6-связи, содержащейся в предельных декстринах. Продуктом этого второго этапа является раствор глюкозы, содержащий, помимо прочего, остаточную мальтозу (4-O-(α-D-глюкопиранозил)-D-глюкопиранозу), изомальтозу (6-O-(α-D-глюкопиранозил)-D-глюкопиранозу) и панозу (O-α-D-Glcp-(1→6)-O-α-D-Glcp-(1→4)-D-Glcp) в качестве побочных продуктов. Эти побочные продукты являются результатом обратных ферментативных реакций вследствие высокой концентрации глюкозы, накапливающейся в ходе этапа осахаривания. Обратная реакция, катализируемая глюкоамилазой, дает мальтозу и изомальтозу. Поскольку коммерческие ферментативные препараты могут содержать трансглюкозидазу (1,4-α-глюкан-6-α-глюкозилтрансферазу; EC 2.4.1.24), присутствие этого фермента также способствует образованию изомальтозы и панозы. Существуют многочисленные видоизменения этой основной процедуры благодаря доступным ферментам, их смесям и условиям реакции.
Обобщенные сведения, касающиеся ферментативного гидролиза крахмала до глюкозы и образуемых побочных продуктов, можно найти у P.H. Blanchard (Technology of Corn Wet Milling and Associated Processes, Elsevier, 1992), M.W. Kearsley и S.Z. Dziedzic (Handbook of Starch Hydrolysis Products and their Derivatives, Chapmann & Hall, 1995), B.H. Lee (Fundamentals of Food Biotechnology, VCH Publishers, 1996) или H. Uhlig (Industrial Enzymes and their Application, John Wiley & Sons 1998). Данные, касающиеся состава гидролизатов крахмала, производимых таким образом, можно найти у A. Converti (Starch/Stärke 46 (7), 260-265, 1994), M. Chaplin и C. Bucke (Enzyme Technology, Cambridge University Press, 1990), Amarakone, P. B и соавт. (Journal of the Japanese Society of Starch Science, 31(1), 1-7, 1984), WO9927124 A1 и WO2005100583 A2. Содержание глюкозы в таких гидролизатах крахмала составляет приблизительно 85-97% (в пересчете на содержание сухого вещества).
Для промышленного ферментативного получения серийно производимых химических продуктов тонкого синтеза, таких как L-аминокислоты, например, L-лизин, неэкономично сначала очищать глюкозу от гидролизата крахмала, а затем использовать ее в процессе ферментации. Вместо этого используют сам гидролизат крахмала в качестве недорогого содержащего глюкозу сырья.
Corynebacterium glutamicum не может использовать изомальтозу или панозу в качестве источника углерода. Соответственно, эти соединения накапливаются в ферментативном бульоне в процессе получения при использовании указанного гидролизата крахмала в качестве сырья. Присутствие этих сахаров, в свою очередь, является неблагоприятным, поскольку они представляют собой дополнительную нагрузку на сточные воды заводов. Кроме того, они могут приводить к потерям продукта в ходе этапов обработки для производства конечного продукта. Например, известно, что восстанавливающий конец молекулы сахара может реагировать с аминогруппой L-аминокислот, например, L-лизина, с образованием продуктов реакции Майяра (M.W. Kearsley and S.Z. Dziedzic: Handbook of Starch Hydrolysis Products and their Derivatives, Chapmann & Hall, 1995).
Чтобы избежать этих недостатков, были разработаны способы превращения изомальтозы и/или панозы в глюкозу в ходе процесса ферментации. В WO2005100583 A2, WO2014093312 A1 и WO2015061289 A1 описывается добавление трансглюкозидазы в ферментативный бульон, содержащий гидролизат крахмала или сахарный сироп в качестве источника углерода. Этот подход имеет недостаток, заключающийся в том, что фермент следует получать отдельно, что таким образом увеличивает производственные затраты.
Другого подхода придерживаются в EP2241632 A1. В ней предлагается придавать микроорганизму изомальтазную активность. В качестве микроорганизмов представлены Enterobacteriaceae, в том числе E. coli и коринеформные бактерии, в том числе конкретные примеры этой группы бактерий. В EP2241632 A1, кроме того, сообщается, что можно использовать внутриклеточную или внеклеточную изомальтазу. В случае если предоставляется внутриклеточная изомальтаза, а клетка не обладает активностью поглощения изомальтозы, предпочтительно придавать как внутриклеточную изомальтазную активность, так и активность поглощения изомальтозы клеткой. В качестве примеров гена изомальтазы показаны гены maIL и glvA Bacillus subtilis и их гомологи. В качестве генов транспортеров изомальтозы показаны ген glvC Bacillus subtilis и другие гены, выполняющие аналогичную функцию, различного происхождения. В ходе экспертизы был представлен экспериментальный пример, в котором гены glvA и glvC Bacillus subtilis экспрессировались в штамме C. glutamicum, выделяющем L-лизин. Сконструированный штамм продемонстрировал благоприятное потребление изомальтозы и образование L-лизина по сравнению с эталоном. Однако в EP2241632 A1 не говорится о том, позволит ли данная система клетке C. glutamicum потреблять панозу.
В EP2241632 A1, кроме того, в целом предполагается, что ген внеклеточной изомальтазы можно получить путем лигирования кодирующей области гена изомальтазы с последовательностью, кодирующей сигнальный пептид для секреции белка в поверхностный слой клетки или за пределы клетки. В качестве сигнального пептида предлагается белок A Staphylococcus aureus. Посредством слияния указанного сигнального пептида белка A с изомальтазой MaIL Bacillus subtilis приводится технический пример для E. coli. В документе не говорится о том, разрушает ли также эта секретируемая изомальтаза панозу. Кроме того, в документе не говорится о подходящих сигнальных пептидах для Corynebacterium glutamicum или о том, как выбрать соответствующий сигнальный пептид, подходящий для изомальтазы.
В EP2241632 A1 также представлены два перечня предполагаемых генов изомальтазы из различных микроорганизмов. В таблице 1 EP2241632 A1 представлены потенциальные изомальтазы в качестве гомологов MaIL, обладающих, помимо прочего, функцией многофункциональной G-амилазы, продуцирующей олигосахариды, олиго-1,6-глюкозидазы, каталитической области альфа-амилазы или трегалозо-6-фосфатгидролазы. В таблице 2 представлены потенциальные гены изомальтазы в качестве гомологов, обладающих функцией мальтозо-6'-фосфатглюкозидазы или 6-фосфо-альфа-глюкозидазы.
Аналогичным образом, S. Jiang и L. Ma раскрыли нуклеотидную последовательность гена олиго-1,6-глюкозидазы штамма HB002 Bacillus subtilis (доступного в Национальном центре биотехнологической информации (NCBI) под номером доступа в GenBank AY008307.1). В записи не говорится об активности кодируемого белка в отношении изомальтозы и панозы.
В уровне техники сообщается о различных внутриклеточных α-1,6-глюкозидазах (EC 3.2.1.10), обладающих способностью разрушать α-1,6-связь в изомальтозе и/или панозе.
Нуклеотидная последовательность гена IMA1 штамма S288c Saccharomyces cerevisiae, кодирующего олиго-1,6-глюкозидазу, доступна в NCBI под номером доступа в GenBank NC_001139 с идентификатором локуса YGR287C. В этой записи кодируемый белок раскрывается как изомальтаза. В записи не говорится о ее активности в отношении панозы.
Ген dexB Streptococcus mutans кодирует внутриклеточную глюкан-1,6-альфа-глюкозидазу (Whiting et al, Journal of General Microbiology 139, 2019-2026, 1993), обладающую способностью гидролизовать α-1,6-связь в изомальтозе и панозе.
WO2004018645 A2 относится к секвенированию генома Bifidobacterium breve ATCC 15700 и, в частности, к идентификации генов, кодирующих ферменты, обладающие способностью гидролизовать α-1,6-связь в изомальтозе и панозе.
У Pokusaeva и соавт. (Applied and Environmental Microbiology 75, 1135-1143, 2009) описываются два гена agl1 и agl2 Bifidobacterium breve UCC2003, кодирующие ферменты Agl1 и Agl2, оба из которых обладают активностью α-1,6-глюкозидаз. Данные ферменты способны гидролизовать α-1,6-связь в панозе и изомальтозе. У Pokusaeva и соавт. отсутствует четкое объяснение внутри- или внеклеточной локализации этих двух ферментов. Однако в обзорной статье Pokusaeva и соавт. (Genes and Nutrition 6, 285-306, 2011) два фермента Agl1 и Agl2 классифицируются как «цитоплазматические ферменты» (см. страницы 299-300).
У C. glutamicum существует два пути секреции белков. Один называется Sec-путем и опосредует транслокацию белков-предшественников в развернутом состоянии через мембрану. Другой называется Tat-путем и опосредует перенос белков-предшественников в их свернутом состоянии. Сигнальный пептид белка-предшественника отщепляется от белка-предшественника пептидазой в ходе процесса секреции, и зрелый белок высвобождается в культуральную среду. Обобщенные сведения, касающиеся секреции белков у Corynebacterium glutamicum, были представлены A. A. Vertes входящими в состав публикации H. Yukawa и M. Inui Corynebacterium glutamicum Biology and Biotechnology, Springer Verlag, 2013), а также Liu и соавт. (Critical Reviews in Biotechnology 1-11, 2016).
Имеется ряд сообщений об успешной секреции у C. glutamicum различных белков от различных видов или различного происхождения. Однако большинство из этих белков секретируется их естественными хозяевами, что указывает на тот факт, что эти белки обладают присущей им способностью секретироваться.
Liebl и соавт. (Journal of Bacteriology 174, 1854-1861, 1992) сообщали об успешной экспрессии и секреции стафилококковой нуклеазы, внеклеточном ферменте Staphylococcus aureus, у C. glutamicum с помощью сигнального пептида первоначального хозяина.
Billman-Jacobe и соавт. (Applied and Environmental Microbiology 61, 1610-1613, 1995) сообщали об экспрессии и секреции основной протеазы Dichelobacter nodosus и субтилизина Bacillus subtilis у C. glutamicum. Поскольку секреция субтилизина управляется его собственным сигнальным пептидом, естественный сигнальный пептид основной протеазы не способствует секреции. После замещения естественной сигнальной последовательности сигнальной последовательностью субтилизина основная протеаза секретировалась у C. glutamicum.
Salim и соавт. (Applied and Environmental Microbiology 63, 4392-4400, 1997) сообщали об экспрессии и секреции белка антигена 85 Mycobacterium tuberculosis у C. glutamicum. Этот белок в естественных условиях встречается в культуральных фильтратах M. tuberculosis.
EP1375664 A1 относится к продуцированию и секреции гетерологичных белков, таких как протрансглутаминаза Streptoverticillium mobaraense или человеческий эпидермальный фактор роста (hEGF), у Corynebacterium glutamicum путем слияния указанных белков с последовательностями сигнальных пептидов белков клеточной поверхности C. glutamicum или C. ammoniagenes. Протрансглутаминаза Streptoverticillium mobaraense является ферментом, который секретируется его естественным хозяином (Pasternack et al; European Journal of Biochemistry 257, 570-576, 1998). Человеческий эпидермальный фактор роста представляет собой секретируемый пептид, изначально обнаруженный Cohen, S. и Carpenter, G. (Proceedings of National Academy of Sciences USA 72(4), 1317-1321, 1975) в моче человека.
EP1748077 A1 относится к продуцированию и секреции гетерологичных белков у коринеформных бактерий c использованием области, представляющей собой зависимый от Tat-системы сигнальный пептид. В частности, изомальтодекстраназа Arthrobacter globiformis (6-α-D-глюканизомальтогидролаза) секретировалась у C. glutamicum при использовании сигнальной последовательности изомальтодекстраназы или сигнальной последовательности белка поверхностного слоя клеток SlpA C. ammoniagenes. Протеинглутаминаза Chryseobacterium proteolyticum секретировалась у C. glutamicum при использовании сигнальной последовательности изомальтодекстраназы A. globiformis, сигнальной последовательности SlpA C. ammoniagenes или сигнальной последовательности TorA Escherichia coli. Изомальтодекстраназа Arthrobacter globiformis является ферментом, который секретируется его естественным хозяином (Iwai et al; Journal of Bacteriology 176, 7730-7734, 1994). Протеинглутаминаза Chryseobacterium proteolyticum также является ферментом, который секретируется в культуральную среду его естественным хозяином (Kikuchi et al; Applied Microbiology and Biotechnology 78, 67-74, 2008).
Watanabe и соавт. (Microbiology 155, 741-750, 2009) идентифицировали N-конец продукта гена CgR0949 и другие продукты генов C. glutamicum R как сигнальные пептиды, направляющие белки по секреторному Tat-пути. Сигнальные последовательности CgR0949 содержат последовательность из 30 аминокислотных остатков. После добавления этой сигнальной аминокислотной последовательности к α-амилазе Geobacillus stearothermophilus, из которой был удален естественный сигнальный пептид, фермент секретировался хозяином C. glutamicum в культуральную среду. α-Амилаза Geobacillus stearothermophilus является ферментом, который секретируется его естественным хозяином (Fincan and Enez, Starch 66, 182-189, 2014).
Breitinger, K. J. (диссертация на соискание ученой степени доктора философии, Ульмский университет, 2013) раскрыл экспрессию слитого полипептида, состоящего из предполагаемой сигнальной последовательности белка, кодируемого геном cg0955 C. glutamicum ATCC 13032, и пуллуланазы PulA Klebsiella pneumoniae UNF5023, в штамме C. glutamicum,, продуцирующем L-лизин. Пуллуланазную активность выявили в клеточном лизате и в мембранной фракции указанных клеток C. glutamicum, но не в надосадочной жидкости культуры указанного штамма. Пуллуланаза PulA Klebsiella pneumoniae UNF5023 является ферментом, который секретируется его естественным хозяином (Kornacker and Pugsley, Molecular Microbiology 4, 73-85, 1990). Breitinger, K. J., кроме того, установил, что 5'-конец гена Cg0955 C. glutamicum ATCC 13032 демонстрирует 95% степень гомологии по отношению к сигнальной последовательности гена cgR0949 C. glutamicum R. Сигнальная последовательность белка, кодируемого геном cgR0949, была классифицирована как сигнальная последовательность Tat-типа Watanabe и соавт. (Microbiology 155, 741-750, 2009).
Hyeon и соавт. (Enzyme and Microbial Technology 48, 371-377, 2011) сконструировали вектор pMT1s, предназначенный для секреции продуктов генов в культуральную среду с помощью нуклеотидной последовательности cg0955, кодирующей Tat-сигнальный пептид. Таким образом, они смогли достичь секреции поддерживающего белка CbpA Cellulomonas cellulovorans и эндоглюканазы CelE Clostridium thermocellum у C. glutamicum для получения миницеллюлосом. Эти белки секретируются и представляются на поверхности клетки у их естественных хозяев.
Kim и соавт. (Enzyme and Microbial Technology 66, 67-73, 2014) аналогичным образом обеспечивали экспрессию и секрецию эндоглюканазы CelE и β-глюкозидазы BglA C. thermocellum у C. glutamicum для представления их на поверхности клетки. У их естественного хозяина эти ферменты являются составляющими целлюлосом, расположенных на поверхности клетки своего хозяина.
Matano и соавт. (BMC Microbiology 16, 177, 2016) исследовали экспрессию и секрецию N-ацетилглюкозаминидазы из различных микроорганизмов. Ген под названием nagA2 идентифицировали в хромосоме C. glutamicum. После его экспрессии ферментативную активность выявляли в цитоплазматической фракции и надосадочной жидкости культуры. После замещения предполагаемого сигнального пептида NagA2 другими сигнальными последовательностями Tat-типа, в том числе SP0955 (другое название сигнального пептида, кодируемого cg0955), эффективность секреции улучшалась. Matano и соавт., кроме того, достигли секреции экзохитиназы ChiB Serratia marcescens путем слияния последовательности, кодирующей Tat-сигнальный пептид для секреции, из гена cg0955 C. glutamicum с chiB. Следует отметить, что экзохитиназа ChiB Serratia marcescens является ферментом, который экспортируется в периплазму своим естественным хозяином (Brurberg et al, Microbiology 142, 1581-1589 (1996)). Matano и соавт. дополнительно исследовали секрецию N-ацетилглюкозаминидазы Bacillus subtilis, кодируемой nagZ, у C. glutamicum. Этот фермент неэффективно секретируется своим естественным хозяином. Экспрессию N-ацетилглюкозаминидазы NagZ также обеспечивали при использовании различных сигнальных пептидов C. glutamicum для повышения количества ферментов в надосадочной жидкости. Однако слияние с этими сигнальными пептидами, в том числе с сигнальным пептидом из Cg0955, не оказывало эффект на количество фермента, секретируемого в надосадочную жидкость культуры. В частности, следует отметить, что слияние с сигнальным пептидом из Cg0955 существенно повышало величину внутриклеточной ферментативной активности.
Yim и соавт. (Applied Microbiology and Biotechnology 98, 273-284, 2014) сообщали о секреции рекомбинантного одноцепочечного вариабельного фрагмента антитела к сибиреязвенному токсину у C. glutamicum. Использование сигнального пептида TorA, направляющего по Tat-пути, приводило к весьма незначительной секреции, тогда как использование сигнального пептида PorB, направляющего по Sec-пути, приводило к измеримой секреции. Авторы также установили, что использование кодон-оптимизированной последовательности гена было одной из составляющих высокого уровня продуцирования белка.
WO2008049782 A1 относится к повышению экспрессии генов у C. glutamicum путем корректирования частоты использования кодонов в генах в соответствии с таковой для наиболее широко распространенных белков в клетке-хозяине.
Зеленый флуоресцентный белок (GFP) привлекает большой интерес в молекулярной биологии в качестве модельного белка, удобного для наблюдения благодаря своей флуоресценции. Он встречается у медуз, таких как Aequorea victoria, где он локализован в специальных фотоцитах (J. M. Kendall and M. N. Badminton, Tibtech, 216-224, 1998). Meissner и соавт. (Applied Microbiology and Biotechnology 76, 633-642, 2007) исследовали секрецию белка с помощью зеленого флуоресцентного белка у трех разных грамположительных бактерий Staphylococcus carnosus, Bacillus subtilis и Corynebacterium glutamicum. У всех трех микроорганизмов слияние Tat-сигнального пептида с GFP приводило к его транслокации через цитоплазматическую мембрану. Однако у S. carnosus GFP полностью задерживался в клеточной стенке и не высвобождался в надосадочную жидкость. У Bacillus subtilis GFP секретировался в надосадочную жидкость в неактивной форме. У C. glutamicum использовали различные Tat-сигнальные пептиды: сигнальный пептид TorA из E. coli, сигнальную последовательность PhoD из C. glutamicum и сигнальную последовательность PhoD из Bacillus subtilis. Хотя GFP секретировался во всех трех случаях, количество секретируемого белка существенно различалось. Сигнальная последовательность PhoD из B. subtilis на удивление давала наилучший результат.
Teramoto и соавт. (Applied Microbiology and Biotechnology 91, 677-687, 2011) использовали сигнальный пептид CgR0949 для достижения высокого выхода секреции GFP у C. glutamicum.
Следует отметить, что Hemmerich и соавт. (Microbial Cell Factory 15(1), 208, 2016) после поиска подходящего сигнального пептида для секреции кутиназы Fusarium solani pisi у Corynebacterium glutamicum заключили, что наилучший сигнальный пептид для конкретного целевого белка каждый раз должен оцениваться заново.
Изомальтоза и/или паноза содержатся в гидролизате крахмала в сравнительно небольших количествах. Соответственно, для исследовательской программы, направленной на получение штамма C. glutamicum, продуцирующего химический продукт тонкого синтеза, например, L-лизин, с высоким выходом и с использованием сравнительно низких количеств этих сахаров в качестве дополнительного источника углерода, нежелательно продуцировать и секретировать фермент, гидролизирующий α-1,6-гликозидную связь в этих сахарах, с высоким выходом. Оба соединения, химический продукт тонкого синтеза и фермент, будут конкурировать за один и тот же (одни и те же) источник(источники) углерода, и, таким образом, это будет отрицательно влиять на выход соединения, представляющего коммерческий интерес, которое представляет собой химический продукт тонкого синтеза. В этом случае продуцируемый и секретируемый фермент станет метаболической нагрузкой для продуцента химического продукта тонкого синтеза.
До сих пор направление внутриклеточного фермента микроорганизма, обладающего способностью к гидролизу α-1,6-гликозидной связи изомальтозы и/или панозы, на внеклеточный матрикс, т. e. надосадочную жидкость культуры, не было продемонстрировано для Corynebacterium glutamicum.
Однако желательно обеспечить ферментативный процесс для получения химического продукта тонкого синтеза из недорогого сырьевого материала для ферментации, содержащего панозу и/или изомальтозу, такого как гидролизат крахмала, с помощью Corynebacterium, в частности, Corynebacterium glutamicum, обладающей способностью к гидролизу α-1,6-гликозидной связи панозы и/или изомальтозы, что таким образом делает доступным получение больших количеств этих олигомеров глюкозы и образование из них химических продуктов тонкого синтеза.
Целью настоящего изобретения является обеспечение полинуклеотида, кодирующего полипептид, который обладает α-1,6-глюкозидазной активностью, и при этом данный полипептид может секретироваться Corynebacterium, предпочтительно Corynebacterium glutamicum.
Дополнительная цель настоящего изобретения заключается в обеспечении Corynebacterium, предпочтительно Corynebacterium glutamicum, содержащей указанный полинуклеотид.
Кроме того, целью настоящего изобретения является обеспечение способа получения химического продукта тонкого синтеза, такого как L-аминокислоты, витамины, нуклеозиды и нуклеотиды, из источника углерода, содержащего олигосахариды, состоящие по меньшей мере из двух соединенных α-1-6-гликозидной связью глюкозных мономеров, таких как паноза (O-α-D-Glcp-(1→6)-O-α-D-Glcp-(1→4)-D-Glcp) или изомальтоза (O-α-D-Glcp-(1→6)-O-α-D-Glcp), с помощью указанной Corynebacterium.
Для достижения указанной в общих чертах выше цели в настоящем изобретении обеспечиваются полинуклеотиды, кодирующие новые слитые полипептиды, по сути содержащие Tat-сигнальный пептид CgR0949 или Cg0955 и полипептиды Agl2 или Agl1 Bifidobacterium breve UCC2003, а также их варианты, обеспечивающие α-1,6-глюкозидазную активность.
В настоящем изобретении, кроме того, обеспечиваются бактерии рода Corynebacterium и Escherichia, несущие указанные полинуклеотиды, и способы получения химических продуктов тонкого синтеза из олигосахаридов, состоящих по меньшей мере из двух соединенных α-1-6-гликозидной связью глюкозных мономеров, таких как паноза и/или изомальтоза, с помощью указанных бактерий.
Цели, лежащие в основе настоящего изобретения, достигаются с помощью выделенного полинуклеотида, предпочтительно дезоксирибополинуклеотида, кодирующего слитый полипептид, содержащий аминокислотные последовательности a), b) и c), при этом
a) представляет собой N-концевой Tat-сигнальный пептид, состоящий из аминокислотной последовательности, выбранной из
a1) положений 1-33 SEQ ID NO: 10 или положений 1-33 SEQ ID NO: 12 и
a2) положений 1-33 SEQ ID NO: 10 с Ala в положении 13 или положений 1-33 SEQ ID NO: 12 с Ala в положении 13;
b) представляет собой C-концевой полипептид, обладающий α-1,6-глюкозидазной активностью, состоящий из аминокислотной последовательности, выбранной из
b1) по меньшей мере на (≥) 95% идентичной, предпочтительно на ≥ 99% идентичной последовательности из положений 37-639 SEQ ID NO: 10, и
b2) по меньшей мере на (≥) 95% идентичной, предпочтительно на ≥ 99% идентичной последовательности из положений 37-643 SEQ ID NO: 12, и
c) представляет собой от 0 до максимум 10 аминокислотных остатков, предпочтительно от 1 до 3 аминокислотных остатков, особенно предпочтительно 3 аминокислотных остатка, между a) и b).
В случае если аминокислотная последовательность c) состоит из 3 аминокислотных остатков, предпочтительно, чтобы эти 3 аминокислоты имели последовательность Met Thr Ser.
Можно показать, что предусматриваемый полинуклеотид, в котором кодирующая последовательность для специфического Tat-сигнального пептида согласно a1) или a2) объединена со специфической α-1,6-глюкозидазой согласно b1) или b2), обеспечивает разрушение панозы и изомальтозы при экспрессии у бактерии из рода Corynebacterium или Escherichia, продуцирующей химический продукт тонкого синтеза. Экспрессия полинуклеотида в соответствии с настоящим изобретением не возлагает метаболическую нагрузку на продуцирование указанного химического продукта тонкого синтеза. Экспрессия полинуклеотида в соответствии с настоящим изобретением, кроме того, улучшает выход химического продукта тонкого синтеза, продуцируемого бактерией, продуцирующей химический продукт тонкого синтеза, делая доступными панозу и изомальтозу в качестве источника углерода.
Предусматриваемый полинуклеотид в соответствии с настоящим изобретением, таким образом, решает следующие задачи:
- обеспечения α-1,6-глюкозидазы со специфичностью, которая позволяет осуществлять деполимеризацию изомальтозы и панозы в условиях ферментации;
- экспрессии α-1,6-глюкозидазы у бактерии, продуцирующей химический продукт тонкого синтеза, без возникновения метаболической нагрузки на продуцирование химического продукта тонкого синтеза;
- достижения секреции α-1,6-глюкозидазы в окружающую среду бактерии, продуцирующей химический продукт тонкого синтеза, путем объединения кодирующей последовательности для α-1,6-глюкозидазы с подходящим сигнальным пептидом, совместимым со специфической α-1,6-глюкозидазой;
- обеспечения дополнительного метаболизируемого источника углерода для продуцирования химического продукта тонкого синтеза и повышения суммарного выхода химического продукта тонкого синтеза, продуцируемого бактерией, посредством достижения того, что экспрессия секретируемой α-1,6-глюкозидазы не конкурирует с продуцированием химического продукта тонкого синтеза за источник углерода.
В случае если аминокислотная последовательность a) непосредственно прилегает или, соответственно, присоединена к аминокислотной последовательности b), число аминокислотных остатков c) равняется 0 (нулю).
В случае если число аминокислотных остатков c) равняется 3 (трем), предпочтительно, чтобы последовательность указанных аминокислотных остатков представляла собой Met Thr Ser или Ile Leu Val.
Предпочтительно, чтобы N-концевой Tat-сигнальный пептид a) состоял из аминокислотной последовательности a1), которая представляет собой аминокислотную последовательность из положений 1-33 SEQ ID NO: 10 или положений 1-33 SEQ ID NO: 12.
Кроме того, предпочтительно, чтобы аминокислотная последовательность C-концевого полипептида b1) была выбрана из положений 37-639 SEQ ID NO: 10 и из положений 37-639 SEQ ID NO: 10 с дополнительным Met перед положением 37, как показано под SEQ ID NO: 6, и особенно предпочтительной является аминокислотная последовательность из положений 37-639 SEQ ID NO: 10.
Термин «дополнительный Met перед положением 37, как показано под SEQ ID NO: 6» означает, что аминокислота Met встроена в аминокислотную последовательность SEQ ID NO: 10 между положениями 36 и 37.
Кроме того, предпочтительно, чтобы C-концевой полипептид b2) был выбран из положений 39-643 SEQ ID NO: 12, положений 38-643 SEQ ID NO: 12 и положений 37-643 SEQ ID NO: 12, и особенно предпочтительной является аминокислотная последовательность из положений 37-643 SEQ ID NO: 12.
Подробности, касающиеся биохимических свойств и химической структуры полинуклеотидов и полипептидов, присутствующих в живых организмах, например, бактериях, таких как Corynebacterium или Escherichia, можно найти, например, помимо прочего, в учебнике "Biochemie" Berg и соавт. (Spektrum Akademischer Verlag Heidelberg, Berlin, Germany, 2003; ISBN 3-8274-1303-6).
Полинуклеотиды, состоящие из дезоксирибонуклеотидных мономеров, содержащих нуклеотидные основания или, соответственно, основания аденин (a), гуанин (g), цитозин (c) и тимин (t), называются дезоксирибополинуклеотидами или дезоксирибонуклеиновой кислотой (ДНК). Полинуклеотиды, состоящие из рибонуклеотидных мономеров, содержащих нуклеотидные основания или основания аденин (a), гуанин (g), цитозин (c) и урацил (u), называются рибополинуклеотидами или рибонуклеиновой кислотой (РНК). Мономеры в указанных полинуклеотидах ковалентно соединены друг с другом 3',5'-фосфодиэфирной связью. Принято, что однонитевые полинуклеотиды записывают в 5'-3'-направлении. Соответственно, полинуклеотид имеет 5'-конец и 3'-конец. Для целей настоящего изобретения предпочтительны дезоксирибополинуклеотиды. У бактерий, например, Corynebacterium или Escherichia, ДНК, как правило, присутствует в двухнитевой форме. Соответственно, длина молекулы ДНК, как правило, приводится в парах оснований (п.о.).
Полипептиды состоят из L-аминокислотных мономеров, соединенных пептидными связями. Для сокращения L-аминокислот используют однобуквенный код и трехбуквенный код IUPAC. Благодаря природе биосинтеза полипептидов полипептиды имеют амино-конец и карбоксильный конец, также называемые N-концом и C-концом. Полипептиды также называют белками.
Слитые полипептиды, также называемые в данной области техники слитыми белками или химерными белками, представляют собой полипептиды, создаваемые посредством соединения двух или более генов, которые изначально кодировали отдельные полипептиды. В результате трансляции такого слитого гена получают полипептид с функциональными свойствами каждого из исходных полипептидов.
В ходе работы над настоящим изобретением часть, содержащую 5'-конец нуклеотидной последовательности различных генов, кодирующих N-концевую часть полипептидов, обладающих способностью к транслокации через цитоплазматическую мембрану бактерии, сливали с нуклеотидными последовательностями генов или их частей, кодирующими полипептиды, обладающие α-1,6-глюкозидазной ферментативной активностью, при этом указанные полипептиды, таким образом, составляют C-концевую часть или, соответственно, C-концевой полипептид в слитом полипептиде.
У бактерий, таких как Corynebacterium и Escherichia, имеются два основных пути секреции белков или, соответственно, полипептидов через цитоплазматическую мембрану. Один называют общим секреторным путем или Sec-путем, а другой называют путем диаргининовой транслокации или Tat-путем. Общий обзор этих двух путей транслокации был представлен Natale и соавт. (Biochimica et Biophysica Acta 1778, 1735 -1756, 2008), а обзор конкретно для Corynebacterium glutamicum был дан Liu и соавт. (Critical Reviews in Biotechnology 2016) и Freudl (Journal of Biotechnology http://dx.doi.org/10.1016/j.jbiotec.2017.02.023).
Функциональный анализ пути диаргининовой транслокации у Corynebacterium glutamicum был представлен Kikuchi и соавт. (Applied and Environmental Microbiology 72, 7183 - 7192, 2006).
Нуклеотидная последовательность кодирующей области (cds) cgR0949 штамма R Corynebacterium glutamicum показана под SEQ ID NO: 3, а аминокислотная последовательность кодируемого полипептида CgR0949 показана под SEQ ID NO: 4 в перечне последовательностей. Нуклеотидную последовательность кодирующей области cgR0949 также можно найти в NCBI по идентификатору локуса CGR_RS04950 геномной последовательности, доступной под № NC_009342. Аминокислотную последовательность CgR0949, также обозначаемую в данной области техники как CgR_0949, можно найти под номером доступа в GenBank BAF53923.1.
Watanabe и соавт. (Microbiology 155, 741 - 750, 2009) идентифицировали аминокислотную последовательность из положений 1-30 SEQ ID NO: 4 как сигнальную последовательность или, соответственно, сигнальный пептид, направляющие по Tat-пути, и последовательность Leu Gly Ala, показанную в положениях 31-33 SEQ ID NO: 4, как предполагаемый сайт расщепления.
Нуклеотидная последовательность кодирующей области (cds) cg0955 штамма ATCC13032 Corynebacterium glutamicum показана под SEQ ID NO: 1, а аминокислотная последовательность кодируемого полипептида Cg0955 показана под SEQ ID NO: 2 в протоколе последовательностей. Нуклеотидную последовательность кодирующей области cg0955 также можно найти в NCBI по идентификатору локуса NCgl0801 геномной последовательности, доступной под № NC_003450. Аминокислотную последовательность Cg0955 можно найти под номером доступа NP_600064.1.
В настоящем изобретении термин «сигнальный пептид CgR0949», или «Tat-сигнальный пептид CgR0949», или «сигнальный пептид Cg0955», или «Tat-сигнальный пептид Cg0955» включает аминокислотную последовательность сигнальной последовательности и предполагаемый сайт расщепления Leu Gly Ala, как определено у Watanabe и соавт. (см. фигуру 3 на стр. 745 у Watanabe и соавт.).
Аминокислотная последовательность из положений 1-33 SEQ ID NO: 2 идентична аминокислотной последовательности из положений 1-33 SEQ ID NO: 4 за исключением положения 13. Аминокислота в положении 13 SEQ ID NO: 2 представляет собой Thr, а аминокислота в положении 13 SEQ ID NO: 4 представляет собой Ala.
Аминокислотная последовательность из положений 1-33 SEQ ID NO: 2 полностью идентична аминокислотной последовательности из положений 1-33 SEQ ID NO: 10 и полностью идентична аминокислотной последовательности SEQ ID NO: 12.
Термин «α-1,6-глюкозидаза» означает фермент, который обладает активностью гидролиза α-1,6-связи в некоторых олигосахаридах, получаемых из крахмала или гликогена. Для целей настоящего изобретения фермент обладает по меньшей мере способностью гидролизовать α-1,6-связь, содержащуюся в изомальтозе и/или панозе. Согласно Номенклатурному комитету Международного союза биохимии и молекулярной биологии (NC-IUBMB) принятым названием фермента является «олиго-1,6-глюкозидаза», а систематическим названием - «олигосахарид-α-1,6-глюкогидролаза». EC-номером фермента является EC 3.2.1.10. Инструкции по измерению активности указанного фермента можно найти у Pokusaeva и соавт. (Applied and Environmental Microbiology 75, 1135-1143, 2009). Активность фермента также можно оценивать с помощью хромогенного субстрата, такого как пара-нитрофенил-α-глюкозид, как описано, например, у Deng и соавт. (FEBS Open Bio 4, 200 - 212, 2014).
В одном наборе предпочтительных вариантов осуществления настоящего изобретения C-концевая часть полипептида или, соответственно, C-концевой полипептид слитого полипептида представляют собой α-1,6-глюкозидазу Agl2 штамма UCC2003 Bifidobacterium breve (см. Pokusaeva и соавт.) и ее варианты. Эту группу C-концевых полипептидов также называют далее C-концевыми полипептидами Agl2-типа. Аминокислотная последовательность кодируемого полипептида α-1,6-глюкозидазы Agl2 штамма UCC2003 Bifidobacterium breve находится в открытом доступе в базе данных GenBank NCBI (Национальный центр биотехнологической информации, Национальная библиотека медицины США, Роквилл-Пайк 8600, Бетесда, Мэриленд, 20894, США) под номером доступа FJ386390. Она также показана под SEQ ID NO: 6 в протоколе последовательностей. Аминокислотная последовательность из положений 2-604 SEQ ID NO: 6 идентична аминокислотной последовательности из положений 37-639 SEQ ID NO: 10. Аминокислотная последовательность из положений 37-639 SEQ ID NO: 10 представляет собой C-концевой полипептид кодируемого слитого полипептида, показанного под SEQ ID NO: 10.
В соответствии с настоящим изобретением можно использовать варианты указанного C-концевого полипептида, которые имеют аминокислотную последовательность, на ≥ 95% идентичную, предпочтительно на ≥ 99%, особенно предпочтительно на 100% идентичную аминокислотной последовательности из положений 37-639 SEQ ID NO: 10. Пример C-концевого полипептида, имеющего аминокислотную последовательность, на ≥ 99% идентичную таковой из положений 37-639 SEQ ID NO: 10, показан под SEQ ID NO: 6.
Было обнаружено, что при присоединении Tat-сигнального пептида Cg0955 к указанным α-1,6-глюкозидазам Agl2 цели настоящего изобретения достигались эффективным образом.
Эти C-концевые полипептиды Agl2-типа предпочтительно присоединены к Tat-сигнальному пептиду Cg0955, показанному в положениях 1-33 аминокислотной последовательности SEQ ID NO: 2. Аминокислотная последовательность из положений 1-33 SEQ ID NO: 2 идентична аминокислотной последовательности из положений 1-33 SEQ ID NO: 10. Они могут быть соединены непосредственно или с помощью последовательности максимум из 10 аминокислот, предпочтительно 1-3, особенно предпочтительно 3 аминокислот. Предпочтительно, чтобы эти 3 аминокислоты имели последовательность Met Thr Ser.
Соответственно, в настоящем изобретении обеспечивается выделенный полинуклеотид, кодирующий слитый полипептид, содержащий аминокислотную последовательность SEQ ID NO: 10, предпочтительно состоящий из нее и обладающий α-1,6-глюкозидазной активностью. Кодируемый слитый полипептид, показанный под SEQ ID NO: 10, был обозначен как Tat-'Agl2.
Аминокислотная последовательность C-концевого полипептида в слитом полипептиде, показанном под SEQ ID NO: 10, которая представляет собой аминокислотную последовательность из положений 37-639 SEQ ID NO: 10, может кодироваться нуклеотидной последовательностью из положений 4-1812 SEQ ID NO: 5, которая представляет собой нуклеотидную последовательность кодирующей области гена agl2, содержащегося в Bifidobacterium breve UCC2003, без стартового кодона atg. Нуклеотидную последовательность из положений 4-1812 SEQ ID NO: 5 также называют 'agl2.
Из уровня техники известно, что генетический код является вырожденным, что означает, что определенная аминокислота может кодироваться несколькими различными триплетами. Термин «частота использования кодонов» относится к наблюдению того, что некий организм, как правило, не будет использовать каждый возможный кодон для определенной аминокислоты с одной и той же частотой. Вместо этого организм обычно будет демонстрировать определенные предпочтения для конкретных кодонов, что означает, что эти кодоны обнаруживаются чаще в кодирующей последовательности транскрибируемых генов организма. Если некоторый ген, чужеродный для своего будущего хозяина, т. e. из другого вида, должен быть экспрессирован в будущем организме-хозяине, то тогда кодирующая последовательность указанного гена должна быть скорректирована в соответствии с частотой использования кодонов указанного будущего организма-хозяина. В настоящем изобретении указанным геном, чужеродным для своего будущего хозяина, являются agl2 Bifidobacterium breve UCC2003 или его варианты, а указанным будущим хозяином является Corynebacterium, предпочтительно Corynebacterium glutamicum. Идеи, касающиеся оптимизации частоты использования кодонов, можно найти у Fath и соавт. (PLos ONE, 6(3), e17596, 2011) и в WO2008049782.
Согласно дополнительному варианту осуществления настоящего изобретения указанная аминокислотная последовательность из положений 37-639 SEQ ID NO: 10 кодируется выделенным полинуклеотидом, имеющим нуклеотидную последовательность, оптимизированную по частоте использования кодонов для Corynebacterium glutamicum, при этом указанная нуклеотидная последовательность является на ≥ 99,0%, особенно предпочтительно на ≥ 99,5%, более особенно предпочтительно на 100% идентичной нуклеотидной последовательности из положений 109-1917 SEQ ID NO: 9.
Нуклеотидную последовательность из положений 109-1917 SEQ ID NO: 9, являющуюся оптимизированной по частоте использования кодонов (cuo) для Corynebacterium glutamicum, в настоящем изобретении также называют «'agl2_cuo».
В соответствии с настоящим изобретением выделенный полинуклеотид, кодирующий слитый полипептид, содержащий аминокислотную последовательность из положений 1-33 SEQ ID NO: 10, непосредственно после которой расположена последовательность из трех аминокислот, предпочтительно аминокислотная последовательность из положений 34-36 SEQ ID NO: 10, непосредственно после которой расположена аминокислотная последовательность из положений 37-639 SEQ ID NO: 10, может кодироваться нуклеотидной последовательностью, содержащей нуклеотиды 1-1917 SEQ ID NO: 9, предпочтительно содержащей SEQ ID NO: 9. Более конкретно, указанная нуклеотидная последовательность может состоять из нуклеотидов 1-1917 SEQ ID NO: 9 или SEQ ID NO: 9.
В другом наборе вариантов осуществления настоящего изобретения C-концевая часть полипептида или, соответственно, C-концевой полипептид слитого полипептида представляют собой α-1,6-глюкозидазу Agl1 штамма UCC2003 Bifidobacterium breve (см. Pokusaeva и соавт.) и ее варианты. Эту группу C-концевых полипептидов также называют далее C-концевыми полипептидами Agl1-типа. Аминокислотная последовательность кодируемого полипептида α-1,6-глюкозидазы Agl1 штамма UCC2003 Bifidobacterium breve находится в открытом доступе в базе данных GenBank NCBI (Национальный центр биотехнологической информации, Национальная библиотека медицины США, Роквилл-Пайк 8600, Бетесда, Мэриленд, 20894, США) под номером доступа FJ386389. Она также показана под SEQ ID NO: 8 в протоколе последовательностей. Аминокислотная последовательность из положений 1-607 SEQ ID NO: 8 идентична аминокислотной последовательности из положений 37-643 SEQ ID NO: 12. Аминокислотная последовательность из положений 37-643 SEQ ID NO: 12 представляет собой C-концевой полипептид кодируемого слитого полипептида, показанного под SEQ ID NO: 12. В соответствии с настоящим изобретением можно использовать варианты указанного C-концевого полипептида, которые имеют аминокислотную последовательность, на ≥ 95% идентичную, предпочтительно на ≥ 99%, особенно предпочтительно на 100% идентичную аминокислотной последовательности из положений 37-643 SEQ ID NO: 12. Примерами C-концевых полипептидов, имеющих аминокислотную последовательность, на ≥ 99% идентичную таковой из положений 37-643 SEQ ID NO: 12, являются C-концевые полипептиды, имеющие аминокислотную последовательность из 38-643 SEQ ID NO: 12 или из 39-643 SEQ ID NO: 12.
Эти C-концевые полипептиды Agl1-типа предпочтительно присоединены к Tat-сигнальному пептиду Cg0955, показанному аминокислотной последовательностью SEQ ID NO: 2 из положений 1-33. Аминокислотная последовательность из положений 1-33 SEQ ID NO: 2 идентична аминокислотной последовательности из положений 1-33 SEQ ID NO: 12. Они могут быть соединены непосредственно или с помощью последовательности максимум из 10 аминокислот, предпочтительно 1-3, особенно предпочтительно 3 аминокислот. Предпочтительно, чтобы эти 3 аминокислоты имели последовательность Ile Leu Val.
Соответственно, в настоящем изобретении обеспечивается выделенный полинуклеотид, кодирующий слитый полипептид, содержащий аминокислотную последовательность SEQ ID NO: 12, предпочтительно состоящий из нее и обладающий α-1,6-глюкозидазной активностью. Кодируемый слитый полипептид, показанный под SEQ ID NO: 12, был обозначен как Tat-Agl1.
Аминокислотная последовательность C-концевого полипептида в слитом полипептиде, показанном под SEQ ID NO: 12, которая представляет собой аминокислотную последовательность из положений 37-643 SEQ ID NO: 12, может кодироваться нуклеотидной последовательностью из положений 1-1821 SEQ ID NO: 7, которая представляет собой нуклеотидную последовательность кодирующей области гена agl1, содержащегося в Bifidobacterium breve UCC2003.
Из уровня техники известно, что генетический код является вырожденным, что означает, что определенная аминокислота может кодироваться несколькими различными триплетами. Термин «частота использования кодонов» относится к наблюдению того, что некий организм, как правило, не будет использовать каждый возможный кодон для определенной аминокислоты с одной и той же частотой. Вместо этого организм обычно будет демонстрировать определенные предпочтения для конкретных кодонов, что означает, что эти кодоны обнаруживаются чаще в кодирующей последовательности транскрибируемых генов организма. Если некоторый ген, чужеродный для своего будущего хозяина, т. e. из другого вида, должен быть экспрессирован в будущем организме-хозяине, то тогда кодирующая последовательность указанного гена должна быть скорректирована в соответствии с частотой использования кодонов указанного будущего организма-хозяина. В настоящем изобретении указанным геном, чужеродным для своего будущего хозяина, являются agl1 Bifidobacterium breve UCC2003 или его варианты, а указанным будущим хозяином является Corynebacterium, предпочтительно Corynebacterium glutamicum. В соответствии с настоящим изобретением предпочтительно, чтобы указанная аминокислотная последовательность из положений 37-639 SEQ ID NO: 12 кодировалась выделенным полинуклеотидом, имеющим нуклеотидную последовательность, оптимизированную по частоте использования кодонов для Corynebacterium glutamicum, при этом указанная нуклеотидная последовательность является на ≥ 99,0%, особенно предпочтительно на ≥ 99,5%, более особенно предпочтительно на 100% идентичной нуклеотидной последовательности из положений 109-1929 SEQ ID NO: 11.
Нуклеотидную последовательность из положений 109-1929 SEQ ID NO: 11, являющуюся оптимизированной по частоте использования кодонов (cuo) для Corynebacterium glutamicum, в настоящем изобретении также называют «agl1_cuo».
В соответствии с настоящим изобретением, кроме того, предпочтительно, чтобы выделенный полинуклеотид, кодирующий слитый полипептид, содержащий аминокислотную последовательность из положений 1-33 SEQ ID NO: 12, непосредственно после которой расположена последовательность из трех аминокислот, предпочтительно аминокислотная последовательность из положений 34-36 SEQ ID NO: 12, непосредственно после которой расположена аминокислотная последовательность из положений 37-643 SEQ ID NO: 12, кодировался нуклеотидной последовательностью, содержащей нуклеотиды 1-1929 SEQ ID NO: 11, предпочтительно содержащей SEQ ID NO: 11. Более конкретно, предпочтительно, чтобы указанная нуклеотидная последовательность состояла из нуклеотидов 1-1929 SEQ ID NO: 11 или SEQ ID NO: 11.
Ввиду двухнитевой структуры ДНК нить, комплементарная нити, показанной в протоколе последовательностей, например, под SEQ ID NO: 9 или SEQ ID NO: 11, также является объектом настоящего изобретения. Для достижения экспрессии полинуклеотидов в соответствии с настоящим изобретением указанные полинуклеотиды функционально связаны с промотором.
Соответственно, в настоящем изобретении обеспечивается выделенный полинуклеотид, кодирующий слитый полипептид в соответствии с настоящим изобретением, функционально связанный с промотором.
Промотор означает полинуклеотид, предпочтительно дезоксирибополинуклеотид, который функционально связан с полинуклеотидом, подлежащим транскрипции, и определяет точку и частоту инициации транскрипции полинуклеотида, обеспечивая таким образом экспрессию полинуклеотида. Термин «функционально связанный» в данном контексте означает расположение промотора последовательно с полинуклеотидом, подлежащим экспрессии, что в результате приводит к транскрипции указанного полинуклеотида. При таких порядках расположения расстояние между 3'-концом промотора и 5'-концом кодирующей последовательности, как правило, составляет ≤ 300 пар оснований, предпочтительно ≤ 200 пар оснований, особенно предпочтительно ≤ 100 пар оснований, более особенно предпочтительно ≤ 60 пар оснований. В контексте настоящего изобретения указанный полинуклеотид, подлежащий экспрессии, кодирует слитый полипептид в соответствии с настоящим изобретением, как, например, показано под SEQ ID NO: 10 или SEQ ID NO: 12.
Термин «транскрипция» означает процесс, посредством которого продуцируется молекула комплементарной РНК, начиная с ДНК-матрицы. В этом процессе участвуют специфические белки, например, РНК-полимераза. Затем синтезированная РНК (информационная РНК) служит в качестве матрицы в процессе трансляции, в результате которого получают полипептид или, соответственно, белок. Транскрипция, как правило, заканчивается на нуклеотидной последовательности, называемой терминатором транскрипции. Примером терминатора транскрипции является терминатор транскрипции гена gap Corynebacterium glutamicum, идентифицированный Eikmanns, B. J. (Journal of Bacteriology 174(19), 6067 - 6068, 1992) и показанный под SEQ ID NO: 13 перечня последовательностей.
Дополнительные подробности, касающиеся экспрессии генов, биосинтеза ДНК, биосинтеза РНК, можно найти в учебниках по биохимии и молекулярной генетике, известных из уровня техники.
Промоторы для Corynebacterium, предпочтительно Corynebacterium glutamicum, хорошо известны из уровня техники. См., например, M. Patek (Regulation of gene expression, в: L. Eggeling and M. Bott (Handbook of Corynebacterium glutamicum, CRC Press, 2005)) или Patek и соавт. (Microbial Biotechnology 6, 103 - 117, 2013).
Подходящие промоторы включают в себя промоторы, описанные в WO2002040679, предпочтительно промоторы, показанные в ней под SEQ ID NO: 4-22, tac-промоторы, описанные De Boer и соавт. (Proceedings of the National Academy of Sciences USA 80, 21 - 25, 1983; см. также Morinaga и соавт. (Journal of Biotechnology 5, 305 - 312, 1987)), предпочтительно промоторы PtacI или PtacII, особенно предпочтительно PtacI, определенный нуклеотидной последовательностью из положений 1-75 SEQ ID NO: 14 в перечне последовательностей, промотор Pef-tu фактора элонгации трансляции белка TU, описанный в WO2005059093, предпочтительно промотор, показанный в ней под SEQ ID NO: 1, промотор Pgro, описанный в WO2005059143, предпочтительно промотор, показанный в ней под SEQ ID NO: 1, промотор Psod, описанный в WO2005059144, предпочтительно промотор, показанный в ней под SEQ ID NO: 1, варианты промотора гена gap, описанные в WO2013000827, предпочтительно промоторы Pgap3, показанные в ней под SEQ ID NO: 3, и Pg3N3, показанный в ней под SEQ ID NO: 34, а также варианты промотора гена dapB, описанные в US8637295, предпочтительно промотор PdapBN1, показанный в нем под SEQ ID NO: 13.
Предпочтительными промоторами являются tac-промоторы, промотор PdapBN1, промотор Pgap3 и промотор Pg3N3.
Особенно предпочтительными являются промотор PtacI, показанный под SEQ ID NO: 14 в положениях 1-75, и промотор PdapBN1, показанный под SEQ ID NO: 15 перечня последовательностей настоящего изобретения. Указанные промоторы соединяют с полинуклеотидом, кодирующим слитый полипептид в соответствии с настоящим изобретением, путем конструирования единицы экспрессии, которая представляет собой выделенный полинуклеотид, содержащий промотор, предпочтительно промотор, подробно описанный выше, особенно предпочтительно промотор PdapBN1, и функционально связанную с указанным промотором нуклеотидную последовательность, кодирующую слитый полипептид в соответствии с настоящим изобретением.
Предпочтительно, чтобы указанная единица экспрессии, которая представляет собой выделенный полинуклеотид, содержала промотор PdapBN1, показанный под SEQ ID NO: 16 в положениях 32-91 в протоколе последовательностей, и с указанным промотором была функционально связана, предпочтительно непосредственно с помощью нуклеотидной последовательности из положений 92-121 SEQ ID NO: 16, нуклеотидная последовательность, кодирующая слитый полипептид SEQ ID NO: 17, предпочтительно нуклеотидная последовательность из положений 122-2038 SEQ ID NO: 16.
Особенно предпочтительно, чтобы указанная единица экспрессии, который представляет собой выделенный полинуклеотид, содержала нуклеотидную последовательность из положений 32-2038 SEQ ID NO: 16, более особенно предпочтительно нуклеотидную последовательность из положений 32-2041 SEQ ID NO: 16.
В дополнительном варианте осуществления единица экспрессии, который представляет собой выделенный полинуклеотид, содержит нуклеотидную последовательность из 32-2088 SEQ ID NO: 16, предпочтительно SEQ ID NO: 16. Нуклеотидная последовательность из положений 2053-2088 SEQ ID NO: 16 идентична нуклеотидной последовательности из положений 3-38 SEQ ID NO: 13, при этом SEQ ID NO: 13 является терминатором транскрипции гена gap, как описано у B. J. Eickmanns (Journal of Bacteriology 174(19), 6076-6086, 1992). Для осуществления настоящего изобретения использовали терминатор транскрипции под названием Tgap*, имеющий нуклеотидную последовательность из положений 3-38 SEQ ID NO: 13.
Указанную единицу экспрессии можно встроить в подходящий плазмидный вектор. Подобным образом указанную единицу экспрессии можно создать путем встраивания выделенного полинуклеотида, кодирующего слитый полипептид в соответствии с настоящим изобретением, ниже промотора, предоставляемого вектором экспрессии, доступным в данной области техники, как указано в общих чертах ниже.
Подходящие плазмидные векторы для Corynebacterium glutamicum хорошо известны из уровня техники. Обобщенная информация о подходящих плазмидных векторов, в том числе нативных плазмид, клонирующих векторов, векторов экспрессии и плазмидных векторов, обеспечивающих хромосомную интеграцию, приведена в M. Patek and J. Nesvera: Promoters and Plasmid Vectors of Corynebacterium glutamicum (H. Yukawa and M. Inui: Corynebacterium glutamicum Biology and Biotechnology, Springer Verlag, 2013), а также в L. Eggeling and O. Reyes: Experiments (L. Eggeling and M. Bott: Handbook of Corynebacterium glutamicum, CRC Press 2005).
Примером подходящего плазмидного вектора, предпочтительно вектора экспрессии, является pVWEx1, описанный у Peters-Wendisch и соавт. (Journal of Molecular Microbiology and Biotechnology 3, 295 - 300, 2001). Нуклеотидная последовательность pVWEx1 доступна в базе данных GenBank под номером доступа MF034723. Плазмидный вектор pVWEx1 обладает способностью к автономной репликации у Corynebacterium glutamicum и Escherichia coli. Поэтому его также называют челночным вектором. Он предоставляет промотор PtacI и подходящие сайты клонирования, например, сайт рестрикции для PstI и BamHI, на 3'-конце или, соответственно, ниже указанного промотора PtacI. Дополнительные элементы и подробности, касающиеся этого вектора экспрессии, можно найти у Peters-Wendisch и соавт. После встраивания нуклеотидной последовательности, кодирующей слитый полипептид в соответствии с настоящим изобретением, например, полинуклеотида, показанного под SEQ ID NO: 21, в указанные сайты клонирования она функционально связывается с указанным промотором PtacI, и, соответственно, ее экспрессия контролируется указанным промотором PtacI. Таким образом, полученный в результате плазмидный вектор содержит единицу экспрессии, описанную выше.
Другим примером подходящих плазмидных векторов, предпочтительно плазмидных векторов, обеспечивающих хромосомную интеграцию, являются pK*mob и pK*mobsacB, особенно предпочтительно pK18mobsacB, описанный у Schäfer и соавт. (Gene 145, 69 - 73, 1994). Нуклеотидная последовательность pk18mobsacB доступна в NCBI под номером доступа FJ437239. Эти плазмидные векторы способны к автономной репликации у Escherichia coli, но не у Corynebacterium. Однако благодаря своей мобилизуемой природе их можно переносить из Escherichia coli в Corynebacterium glutamicum путем конъюгации. Благодаря присутствию системы отбора на основе гена sacB, придающей своему хозяину чувствительность к сахарозе, плазмидный вектор pK18mobsacB обеспечивает средство отбора двойных рекомбинантов после гомологичной рекомбинации. Таким образом, это позволяет выделять штаммы, несущие ген, представляющий интерес, интегрированный в целевой сайт их хромосом. Аналогичные плазмидные векторы описаны, например, в WO2002070685 и WO2003014362. В контексте настоящего изобретения термин «ген, представляющий интерес» означает выделенные полинуклеотиды в соответствии с настоящим изобретением.
Целевым сайтом в данном контексте является нуклеотидная последовательность, которая является необязательной для роста штамма Corynebacterium и образования им химического продукта тонкого синтеза. Перечень подходящих целевых сайтов, представляющих собой кодирующие последовательности, необязательные для образования L-лизина, например, ген aecD, кодирующий C-S-лиазу (Rossol and Pühler, Journal of Bacteriology 174(9), 2968 - 2977, 1992), у Corynebacterium glutamicum показан в таблице 3 WO2003040373. Целевые сайты, кроме того, включают в себя нуклеотидные последовательности, кодирующие фаги или компоненты фагов, например, показанные в таблице 13 WO2004069996. Целевые сайты, кроме того, включают в себя межгенные области. Межгенная область представляет собой нуклеотидную последовательность, расположенную между двумя кодирующими последовательностями и являющуюся нефункциональной. Перечень подходящих межгенных областей показан, например, в таблице 12 WO2004069996.
В ходе работы над настоящим изобретением идентифицировали новый подходящий целевой сайт.
Предпочтительным целевым сайтом является межгенная область между кодирующими последовательностями, идентифицированными по идентификатору локуса NCgl2176 и идентификатору локуса NCgl2177 хромосомы Corynebacterium glutamicum ATCC13032, предпочтительно SEQ ID NO: 18 в положениях 1036-1593, и соответствующий (гомологичный) целевой сайт в различных штаммах вида. Нуклеотидная последовательность хромосомы Corynebacterium glutamicum ATCC13032 доступна в NCBI под номером доступа NC_003450.
Из уровня техники известно, что гомологичные нуклеотидные последовательности или, соответственно, аллели в хромосоме вида Corynebacterium glutamicum варьируются у разных штаммов дикого типа и мутантов, полученных из них.
Соответствующая (гомологичная) последовательность по отношению к SEQ ID NO: 18 в штамме ATCC13869 показана под SEQ ID NO: 19. Соответствующая межгенная область расположена между кодирующими последовательностями, идентифицированными по идентификатору локуса BBD29_10725 и идентификатору локуса BBD29_1730, и предпочтительно представляет собой SEQ ID NO: 19 в положениях 1036-1593. SEQ ID NO: 19 в положениях 1036-1593 на > 98% идентична SEQ ID NO: 18 в положениях 1036-1593. Нуклеотидная последовательность хромосомы Corynebacterium glutamicum ATCC13869 доступна в NCBI под номером доступа NZ_CP016335.1.
Соответствующая (гомологичная) последовательность по отношению к SEQ ID NO: 18 в штамме ATCC14067 показана под SEQ ID NO: 20. Межгенная область предпочтительно расположена в положениях 1036-1593 SEQ ID NO: 20. SEQ ID NO: 20 в положениях 1036-1593 на > 97 % идентична SEQ ID NO: 18 в положениях 1036-1593.
Соответственно, предпочтительный целевой сайт на > 95%, предпочтительно на > 97%, особенно предпочтительно на > 98%, особенно сильно предпочтительно на > 99% идентичной, наиболее особенно предпочтительно на 100% идентичен SEQ ID NO: 18 в положениях 1036-1593.
Для осуществления интеграции выделенных полинуклеотидов в соответствии с настоящим изобретением, предпочтительно функционально связанных с промотором, в целевой сайт с помощью гомологичной рекомбинации их 5'-конец и их 3'-конец связывают с полинуклеотидами, содержащими нуклеотидные последовательности выше и ниже целевого сайта. В данной области техники эти последовательности также называются фланкирующими последовательностями, в частности, 5'-фланкирующей последовательностью и 3'-фланкирующей последовательностью. Фланкирующие последовательности, как правило, имеет длину от ≥ 200 до ≤ 2000 пар оснований.
Плазмидный вектор для осуществления интеграции желаемого полинуклеотида в хромосому желаемой Corynebacterium содержит полинуклеотид, содержащий в 5'-3'-направлении: 5'-фланкирующую последовательность, желаемый полинуклеотид и 3'-фланкирующую последовательность.
Соответственно, плазмидный вектор для осуществления интеграции полинуклеотида в соответствии с настоящим изобретением в хромосому подходящей Corynebacterium содержит полинуклеотид, содержащий в 5'-3'-направлении: 5'-фланкирующую последовательность, полинуклеотид в соответствии с настоящим изобретением и 3'-фланкирующую последовательность.
После двух событий гомологичной рекомбинации, включающих в себя событие рекомбинации в 5'-фланкирующей последовательности, предоставляемой плазмидным вектором, с гомологичной последовательностью хромосомы Corynebacterium и событие рекомбинации в 3'-фланкирующей последовательности, предоставляемой плазмидным вектором, с гомологичной последовательностью хромосомы Corynebacterium, полинуклеотид в соответствии с настоящим изобретением интегрируется в хромосому Corynebacterium.
Событие гомологичной рекомбинации также может называться кроссинговером.
В предпочтительном варианте осуществления указанные фланкирующие последовательности выбраны из нуклеотидных последовательностей, содержащихся в SEQ ID NO: 18, которая содержит межгенную область между локусом с идентификатором NCgl2176 и локусом с идентификатором NCgl2177, или из нуклеотидных последовательностей, на > 95%, предпочтительно на > 97%, особенно предпочтительно на > 98%, особенно сильно предпочтительно на > 99% идентичных SEQ ID NO: 18.
Подобным образом указанные фланкирующие последовательности могут быть выбраны из нуклеотидных последовательностей, содержащихся в SEQ ID NO: 19 или SEQ ID NO: 20, обе из которых характеризуются > 99% идентичностью по отношению к SEQ ID NO: 18. Соответственно, в настоящем изобретении обеспечиваются плазмидные векторы, содержащие выделенные полинуклеотиды в соответствии с настоящим изобретением.
Идеи и информацию, касающиеся синтеза, анализа полинуклеотидов и обращения с ними, можно найти, помимо прочего, в книге P. Fu и S. Panke (Systems Biology and Synthetic Biology, Wiley, 2009), книге S. Narang (Synthesis and Applications of DNA and RNA Academic Press, 1987), руководстве J. Sambrook и соавт. (Molecular Cloning, A Laboratory Manual, Cold Spring Harbor Laboratory Press, 1989), учебнике C. R. Newton и A. Graham (PCR, Spektrum Akademischer Verlag, 1994) и руководстве D. Rickwood и B. D. Hames (Gel electrophoresis of nucleic acids, a practical approach, IRL Press, 1982).
Анализ последовательностей полинуклеотидов и полипептидов, например, выравнивания последовательностей, можно выполнять с помощью общедоступного программного обеспечения, такого как CLC Genomics Workbench (Qiagen, Хильден, Германия) или программа MUSCLE, предоставляемая Европейским институтом биоинформатики (EMBL-EBI, Хинкстон, Великобритания).
Выделенные полинуклеотиды в соответствии с настоящим изобретением переносят в штаммы Corynebacterium, предпочтительно Corynebacterium glutamicum, или Escherichia, предпочтительно Escherichia coli, посредством трансформации с помощью физико-химических способов или посредством конъюгации с помощью плазмидных векторов, содержащих указанные полинуклеотиды. Для физико-химической трансформации Corynebacterium можно применять способы электропорации по Dunican и Shivnan (Bio/Technology 7, 1067 - 1070, 1989) или Ruan и соавт. (Biotechnology letters, 2015, DOI 10.1007/s10529-015-1934-x) или способ трансформации сферопластов и протопластов по Thierbach и соавт. (Applied Microbiology and Biotechnology 29, 356 -362, 1988). Для конъюгационного переноса или, соответственно, конъюгации из Escherichia coli в Corynebacterium можно применять способ по Schäfer и соавт. (Journal of Bacteriology 172, 1663 - 1666, 1990). Для отбора штаммов Corynebacterium, несущих полинуклеотид в соответствии с настоящим изобретением в целевом сайте хромосомы после двух событий гомологичной рекомбинации, можно применять способ по Schäfer и соавт. Технические подробности в отношении различных целевых сайтов можно найти, например, в WO2003040373 и WO2004069996. Дополнительные подробности также можно найти в статье «Experiments» L. Eggeling и O. Reyes, входящей в состав публикации L. Eggeling и M. Bott (Handbook of Corynebacterium glutamicum, CRC Press, 2005).
Для целей настоящего изобретения термины «трансформация» и «конъюгация» могут быть обобщены термином «трансформация».
Перенос полинуклеотидов в соответствии с настоящим изобретением можно подтвердить посредством саузерн-гибридизации с использованием зонда, комплементарного полинуклеотиду в соответствии с настоящим изобретением или его части, посредством полимеразной цепной амплификации (PCR) полинуклеотида в соответствии с настоящим изобретением или его части, предпочтительно с последующим анализом нуклеотидной последовательности продукта амплификации, или посредством измерения α-1,6-глюкозидазной активности.
В ходе работы над настоящим изобретением было обнаружено, что после трансформации бактерий из рода Corynebacterium, предпочтительно бактерий вида Corynebacterium glutamicum, выделенным полинуклеотидом, кодирующим полипептид в соответствии с настоящим изобретением, предпочтительно связанный с промотором, полученные трансформанты обладали способностью секретировать полипептид, обладающий α-1,6-глюкозидазной активностью, в среду.
Кроме того, было обнаружено, что кодируемый полипептид Tat-'Agl2, показанный под SEQ ID NO: 10, после секреции в среду указанной Corynebacterium glutamicum имел аминокислотную последовательность из положений 31-639 SEQ ID NO: 10 или аминокислотную последовательность из положений 38-639 SEQ ID NO: 10.
Указанные полипептид или, соответственно, полипептиды, секретируемые в среду указанной Corynebacterium, гидролизуют изомальтозу с получением глюкозы и гидролизуют панозу с получением глюкозы и мальтозы. Таким образом, указанная Corynebacterium обладает способностью использовать панозу и/или изомальтозу в качестве источника углерода.
Соответственно, в настоящем изобретении обеспечивается бактерия, выбранная из рода Corynebacterium, предпочтительно Corynebacterium glutamicum, или Escherichia, предпочтительно Escherichia coli, содержащая выделенный полинуклеотид, кодирующий полипептид в соответствии с настоящим изобретением, предпочтительно связанный с промотором, при этом указанная бактерия обладает способностью секретировать полипептид, обладающий α-1,6-глюкозидазной активностью, кодируемый указанным выделенным полинуклеотидом.
Соответственно, в настоящем изобретении, кроме того, обеспечивается Corynebacterium, предпочтительно Corynebacterium glutamicum, обладающая способностью секретировать полипептид, обладающий α-1,6-глюкозидазной активностью и имеющий аминокислотную последовательность из положений 31-639 SEQ ID NO: 10 или аминокислотную последовательность из положений 38-639 SEQ ID NO: 10.
Выделенные полинуклеотиды в соответствии с настоящим изобретением могут содержаться в плазмидном векторе, автономно реплицирующемся у Corynebacterium, или могут содержаться в хромосоме Corynebacterium. В случае когда выделенный полинуклеотид в соответствии с настоящим изобретением содержится в хромосоме, он реплицируется как часть хромосомы. Предпочтительно, чтобы указанный выделенный полинуклеотид содержался в хромосоме бактерии. Особенно предпочтительно, чтобы указанный выделенный полинуклеотид содержался в последовательности хромосомы (целевом сайте), на > 95% идентичной SEQ ID NO: 18 в положениях 1036-1593, как указано в общих чертах выше.
Число копий (копий на клетку Corynebacterium) единицы экспрессии, содержащей выделенный полинуклеотид в соответствии с настоящим изобретением, связанный с промотором, как правило, не превышает 40. Предпочтительно, чтобы указанное число копий составляло ≤ 10, особенно предпочтительно ≤ 5, особенно сильно предпочтительно ≤ 2, наиболее особенно предпочтительно 1.
Описание рода Corynebacterium и видов, составляющих этот род, можно найти в статье «Corynebacterium» K. A. Bernard и G. Funke в Bergey's Manual of Systematics of Archaea and Bacteria (Bergey's Manual Trust, 2012).
В роде Corynebacterium предпочтительным видом является Corynebacterium glutamicum. Подходящими штаммами являются, например, штаммы ATCC13032, ATCC14067 и ATCC13869, штаммы, также называемые в данной области техники штаммами дикого типа, и полученные из них штаммы, выделяющие химические продукты тонкого синтеза. Штамм ATCC13032 (также доступный как DSM20300) является штаммом, представляющим собой типовой таксон вида Corynebacterium glutamicum. Штамм ATCC14067 (также доступный как DSM20411) также известен под устаревшим названием Brevibacterium flavum. Штамм ATCC13869 (также доступный как DSM1412) также известен под устаревшим названием Brevibacterium lactofermentum. Таксономическое исследование этой группы бактерий на основании гибридизации ДНК-ДНК было выполнено Liebl и соавт. (International Journal of Systematic Bacteriology 41(2), 255-260, 1991). Сравнительный анализ различных штаммов вида Corynebacterium glutamicum на основании анализа геномных последовательностей был предоставлен Yang и Yang (BMC Genomics 18(1):940).
На протяжении последних десятилетий в данной области техники было получено большое количество штаммов из рода Corynebacterium, выделяющих химический продукт тонкого синтеза, начиная с таких штаммов, как ATCC13032, ATCC14067, ATCC13869 и т. п. Их получали в результате осуществления программ разработки штаммов с помощью, помимо прочего, таких способов, как классический мутагенез, селекция на устойчивость к антиметаболитам, а также амплификация и модификация промоторов генов пути биосинтеза рассматриваемого химического продукта тонкого синтеза с помощью способов генной инженерии. Обобщенные сведения можно найти у L. Eggeling и M. Bott (Handbook of Corynebacterium glutamicum, CRC Press, 2005) или H. Yukawa и M. Inui (Corynebacterium glutamicum Biology and Biotechnology, Springer Verlag, 2013).
Штаммы Corynebacterium, предпочтительно Corynebacterium glutamicum, подходящие для измерений в соответствии с настоящим изобретением, имеют функциональный Tat-путь (диаргининовой транслокации) секреции белка. Белки Tat-пути Corynebacterium glutamicum кодируются генами tatA, tatB, tatC и tatE и описаны у Kikuchi и соавт. (Applied and Environmental Microbiology 72(11), 7183 - 7192, 2006).
Термин «химический продукт тонкого синтеза» включает L-аминокислоты, витамины, нуклеозиды и нуклеотиды, при этом L-аминокислоты являются предпочтительными.
Термин «витамин» включает рибофлавин.
Термин «L-аминокислота» включает протеиногенные L-аминокислоты, а также L-орнитин и L-гомосерин. Протеиногенные L-аминокислоты следует понимать как означающие L-аминокислоты, присутствующие в природных белках, то есть в белках микроорганизмов, растений, животных и людей. Протеиногенные L-аминокислоты включают в себя L-аспарагиновую кислоту, L-аспарагин, L-треонин, L-серин, L-глутаминовую кислоту, L-глутамин, L-глицин, L-аланин, L-цистеин, L-валин, L-метионин, L-изолейцин, L-лейцин, L-тирозин, L-фенилаланин, L-гистидин, L-лизин, L-триптофан, L-аргинин, L-пролин и в некоторых случаях L-селеноцистеин и L-пирролизин.
Химический продукт тонкого синтеза предпочтительно выбран из группы, состоящей из протеиногенной L-аминокислоты, L-орнитина и L-гомосерина. Особенное предпочтение отдается протеиногенным L-аминокислотам, выбранным из L-лизина, L-треонина, L-валина и L-изолейцина, при этом L-лизин является особенно сильно предпочтительным.
Термин «L-аминокислоты» при упоминании в настоящем документе в контексте образования продукта также включает их соли, например, моногидрохлорид L-лизина или сульфат L-лизина в случае L-аминокислоты L-лизина.
Штаммы вида Corynebacterium glutamicum, выделяющие L-лизин, широко известны из уровня техники и могут использоваться для целей настоящего изобретения. Например, Blombach и соавт. (Applied and Environmental Microbiology 75(2), 419-427, 2009) описывают штамм DM1933, депонированный под номером доступа DSM25442; в WO2008033001 описывается штамм KFCC10881-C14, депонированный под номером доступа KCCM10770P, а EP0841395 относится к штамму AJ11082, депонированному под номером доступа NRRL B-1147. Кроме того, можно использовать штамм DM2031 Corynebacterium glutamicum, выделяющий L-лизин, депонированный в соответствии с Будапештским договором как DSM32514. Штамм DM2031 является усовершенствованным производным DM1933, обладающим повышенной способностью к выделению L-лизина.
Обобщенные сведения, касающиеся выведения штаммов Corynebacterium glutamicum, выделяющих L-лизин, можно найти, помимо прочего, у L. Eggeling и M. Bott (Handbook of Corynebacterium glutamicum, CRC Press, 2005), V. F. Wendisch (Amino Acid Biosynthesis - Pathways, Regulation and Metabolic Engineering, Springer Verlag, 2007), H. Yukawa и M. Inui (Corynebacterium glutamicum Biology and Biotechnology, Springer Verlag, 2013), а также у Eggeling и Bott (Applied Microbiology and Biotechnology 99 (9), 3387-3394, 2015).
Штаммы вида Corynebacterium glutamicum, выделяющие L-треонин, известны из уровня техники и могут использоваться для целей настоящего изобретения. Например, в EP0385940 описывается штамм DM368-2, депонированный под номером DSM5399.
Штаммы вида Corynebacterium glutamicum, выделяющие L-валин, известны из уровня техники и могут использоваться для целей настоящего изобретения. Например, в US5188948 описывается штамм AJ12341, депонированный под номером FERM BP-1763, а в EP2811028 описывается штамм ATCC14067_PprpD2-ilvBN.
Штаммы вида Corynebacterium glutamicum, выделяющие L-изолейцин, известны из уровня техники и могут использоваться для целей настоящего изобретения. Например, в US4656135 описывается штамм AJ12152, депонированный под номером FERM BP-760.
Штаммы вида Corynebacterium glutamicum, выделяющие рибофлавин, описываются в EP2787082.
Термин «DSM» означает депозитарий Немецкой коллекции микроорганизмов и клеточных культур, расположенный в Брауншвейге, Германия. Термин «KCCM» означает депозитарий Корейского центра культур микроорганизмов, расположенный в Сеуле, Корея. Термин «NRRL» означает депозитарий Коллекции культур Службы сельскохозяйственных исследований, расположенный в Пеории, Иллинойс, США. Термин «ATCC» означает депозитарий Американской коллекции типовых культур, расположенный в Манассасе, Виргиния, США. Термин «FERM» означает депозитарий Национального института технологии и оценки (NITE), расположенный в Токио, Япония.
Для получения бактерии из рода Corynebacterium, выделяющей химический продукт тонкого синтеза, предпочтительно Corynebacterium glutamicum, обладающей способностью секретировать полипептид, обладающий α-1,6-глюкозидазной активностью, кодируемый выделенным полинуклеотидом в соответствии с настоящим изобретением, бактерию из рода Corynebacterium, выделяющую химический продукт тонкого синтеза, трансформируют выделенным полинуклеотидом в соответствии с настоящим изобретением, предпочтительно выделенным полинуклеотидом, связанным с промотором (единицей экспрессии).
Таким образом получают бактерию из рода Corynebacterium, выделяющую химический продукт тонкого синтеза, предпочтительно Corynebacterium glutamicum, обладающую способностью использовать панозу и/или изомальтозу в качестве источника углерода для роста и выделения химического продукта тонкого синтеза.
Подобным образом возможно получать бактерию, выделяющую химический продукт тонкого синтеза в соответствии с настоящим изобретением, сначала трансформируя штамм дикого типа из рода Corynebacterium, предпочтительно Corynebacterium glutamicum, такой как, например, ATCC13032, ATCC13869 или ATCC14067, полинуклеотидом в соответствии с настоящим изобретением, а затем используя полученного трансформанта в качестве исходной точки для программы разработки штамма, направленной на получение желаемого химического продукта тонкого синтеза.
Соответственно, в настоящем изобретении обеспечивается Corynebacterium, выделяющая химический продукт тонкого синтеза, предпочтительно Corynebacterium glutamicum, содержащая выделенный полинуклеотид в соответствии с настоящим изобретением, обладающая, таким образом, способностью использовать панозу и/или изомальтозу для роста, а также для выделения и продуцирования химического продукта тонкого синтеза. В настоящем изобретении, кроме того, обеспечивается ферментативный процесс продуцирования химического продукта тонкого синтеза с помощью Corynebacterium в соответствии с настоящим изобретением.
Ферментативный процесс может являться непрерывным процессом или прерывным процессом, таким как периодический процесс или периодический процесс с подпиткой. Обобщенная информация, касающаяся общей природы процессов ферментации, доступна в учебнике H. Chmiel (Bioprozesstechnik, Spektrum Akademischer Verlag, 2011), в учебнике C. Ratledge и B. Kristiansen (Basic Biotechnology, Cambridge University Press, 2006) или в учебнике V.C. Hass и R. Pörtner (Praxis der Bioprozesstechnik Spektrum Akademischer Verlag, 2011).
В рамках ферментативного процесса Corynebacterium в соответствии с настоящим изобретением культивируют в подходящей среде.
Подходящая среда, используемая для продуцирования химического продукта тонкого синтеза с помощью ферментативного процесса, содержит источник углерода, источник азота, источник фосфора, неорганические ионы и при необходимости другие органические соединения. Компоненты, используемые в ферментативном процессе, также называют в данной области техники исходными материалами.
В рамках ферментативного процесса в соответствии с настоящим изобретением Corynebacterium, предпочтительно Corynebacterium glutamicum, содержащую выделенный полинуклеотид в соответствии с настоящим изобретением и обладающую способностью выделять химический продукт тонкого синтеза, культивируют в среде, подходящей для продуцирования и накопления указанного химического продукта тонкого синтеза, с использованием источника углерода, содержащего по меньшей мере один олигомер α-D-глюкозы, состоящий по меньшей мере из двух соединенных α-1-6-гликозидной связью глюкозных мономеров, такой как изомальтоза и паноза, предпочтительно содержащего глюкозу и по меньшей мере один олигомер глюкозы, выбранный из изомальтозы и панозы.
В дополнительных вариантах осуществления настоящего изобретения указанный источник углерода содержит глюкозу и изомальтозу, или содержит глюкозу и панозу, или содержит глюкозу, изомальтозу и панозу.
В соответствии с экономическими потребностями источник углерода может дополнительно содержать, помимо глюкозы, изомальтозы и панозы, другие соединения, которые используются Corynebacterium, предпочтительно Corynebacterium glutamicum, для роста, а также выделения и продуцирования химического продукта тонкого синтеза. Эти соединения включают в себя сахара, такие как мальтоза, сахароза или фруктоза, или органические кислоты, такие как молочная кислота. Содержание изомальтозы в указанном источнике углерода составляет ≥ 0,1%, предпочтительно ≥ 0,2% по сухому веществу. Содержание изомальтозы в указанном источнике углерода не превышает (≤) 50% по сухому веществу, не превышает (≤) 40% по сухому веществу, не превышает (≤) 30% по сухому веществу, не превышает (≤) 20% по сухому веществу или не превышает (≤) 10% по сухому веществу при подаче смесей соединений, служащих источником углерода.
Содержание панозы в указанном источнике углерода составляет ≥ 0,1%, предпочтительно ≥ 0,2% по сухому веществу. Содержание панозы в указанном источнике углерода не превышает (≤) 50% по сухому веществу, не превышает (≤) 40% по сухому веществу, не превышает (≤) 30% по сухому веществу, не превышает (≤) 20% по сухому веществу или не превышает (≤) 10% по сухому веществу при подаче смесей соединений, служащих источником углерода.
Содержание глюкозы в указанном источнике углерода составляет ≥ 30%, предпочтительно ≥ 40% по сухому веществу, особенно предпочтительно ≥ 50% по сухому веществу. Содержание глюкозы в указанном источнике углерода не превышает (≤) 99,9% по сухому веществу, не превышает (≤) 99,8% по сухому веществу, не превышает (≤) 99,6% по сухому веществу или не превышает (≤) 99% по сухому веществу при подаче смесей соединений, служащих источниками углерода.
Рядовому специалисту в данной области будет ясно, что сумма всех компонентов в сухом веществе, служащих в качестве источника углерода, не превышает 100%.
Примером источника углерода, содержащего глюкозу и олигомер глюкозы, выбранный из изомальтозы и панозы, являются гидролизаты крахмала.
Гидролизаты крахмала получают путем гидролиза крахмала, как правило, произведенного из зерен кукурузы, пшеницы, ячменя или риса, или из клубней картофеля, или из корней маниока. Благодаря режиму гидролиза крахмала получают различные продукты, как правило, с основным компонентом, например, глюкозой или мальтозой, и различными побочными компонентами, например, мальтозой, изомальтозой, панозой или мальтотриозой.
Для целей настоящего изобретения гидролизат крахмала определяют как продукт, полученный путем гидролиза, предпочтительно ферментативного гидролиза, из крахмала, произведенного из зерен кукурузы, пшеницы, ячменя или риса, или из клубней картофеля, или из корней маниока, предпочтительно из зерен кукурузы, пшеницы или риса, и имеющий следующий состав сухого вещества (вес/вес): глюкоза ≥ 80%, предпочтительно ≥ 90%, не выше (≤) 99% или не выше (≤) 98%; изомальтоза ≥ 0,1%, предпочтительно ≥ 0,2%, не выше (≤) 4%; паноза ≥ 0,1%, предпочтительно ≥ 0,2%, не выше (≤) 3%. Гидролизат крахмала, используемый для целей настоящего изобретения, как правило, дополнительно содержит мальтозу при ≥ 0,1% или ≥ 0,2%, не выше (≤) 5% по сухому веществу. Кроме того, гидролизат крахмала, используемый для целей настоящего изобретения, может содержать дополнительные олигомеры глюкозы, а также неорганические ионы и белки. Рядовому специалисту в данной области будет ясно, что сумма всех компонентов в сухом веществе не превышает 100%. Сухое вещество коммерческих жидких гидролизатов крахмала обычно находится в диапазоне 55-75% (вес/вес). Идеи, касающиеся анализа гидролизатов крахмала, можно найти у M.W. Kearsley и S.Z. Dziedzic (Handbook of Starch Hydrolysis Products and their Derivatives, Chapmann & Hall, 1995).
В качестве источника азота можно использовать органические азотсодержащие соединения, такие как пептоны, мясной экстракт, соевые гидролизаты или мочевина, или неорганические соединения, таких как сульфат аммония, хлорид аммония, фосфат аммония, карбонат аммония, нитрат аммония, газообразный аммиак или водный аммиак.
В качестве источника фосфора можно использовать фосфорную кислоту, дигидрофосфат калия или гидрофосфат дикалия или соответствующие натрийсодержащие соли.
Неорганические ионы, такие как ионы калия, натрия, магния, кальция, железа и дополнительные следовые элементы и т. п., предоставляются в виде солей серной кислоты, фосфорной кислоты или хлористоводородной кислоты.
Другие органические соединения означают незаменимые факторы роста, такие как витамины, например, тиамин или биотин, или L-аминокислоты, например, L-гомосерин.
Компоненты среды можно добавлять в культуру в виде единой партии или можно подавать надлежащим образом в ходе культивирования.
В ходе ферментативного процесса pH в культуре можно контролировать посредством использования надлежащим образом основных соединений, таких как гидроксид натрия, гидроксид калия, аммиак или водный аммиак, или кислых соединений, таких как фосфорная кислота или серная кислота. pH, как правило, доводят до значения 6,0-8,5, предпочтительно 6,5-8,0. Для контроля пенообразования возможно использовать противовспенивающие средства, такие как, например, сложные эфиры жирных кислот и полигликолей. Для поддержания стабильности плазмид возможно добавлять в среду подходящие селективные вещества, такие как, например, антибиотики. Ферментативный процесс предпочтительно осуществляют в аэробных условиях. Для поддержания таких условий в культуру вводят кислород или кислородсодержащие газовые смеси, такие как, например, воздух. Ферментативный процесс осуществляют при необходимости при повышенном давлении, например, при повышенном давлении 0,03-0,2 MПa. Температура культуры обычно составляет от 25°C до 40°C, предпочтительно от 30°C до 37°C. В прерывном процессе культивирование продолжают до тех пор, пока не образуется количество желаемого химического продукта тонкого синтеза, достаточное для извлечения. Тогда культивирование завершают. Данной цели обычно достигают в пределах периода от 10 часов до 160 часов. В непрерывных процессах возможны более длительные периоды культивирования.
Примеры подходящих сред и условий культивирования можно найти, помимо прочего, у L. Eggeling и M. Bott (Handbook of Corynebacterium glutamicum, CRC Press, 2005) и в патентных документах US5770409, US5990350, US 5275940, US5763230 и US6025169.
Благодаря способности Corynebacterium в соответствии с настоящим изобретением выделять и продуцировать химический продукт тонкого синтеза в среду в ходе ферментативного процесса концентрация химического продукта тонкого синтеза повышается, и он накапливается в среде.
Таким образом, в результате ферментативного процесса образуется ферментативный бульон, который содержит желаемый химический продукт тонкого синтеза, предпочтительно L-аминокислоту. Затем продукт, содержащий химический продукт тонкого синтеза, извлекают в жидкой или твердой форме.
«Ферментативный бульон» означает среду, в которой культивировали Corynebacterium в соответствии с настоящим изобретением в течение определенного времени и при определенных условиях.
По завершении ферментативного процесса полученный в результате ферментативный бульон соответственно содержит:
a) биомассу (клеточную массу) Corynebacterium в соответствии с настоящим изобретением, при этом указанная биомасса была получена за счет размножения клеток указанной Corynebacterium,
b) желаемый химический продукт тонкого синтеза, накопленный в ходе ферментативного процесса,
c) побочные органические продукты, накопленные в ходе ферментативного процесса, и
d) компоненты используемой среды, которые не были потреблены в ходе ферментативного процесса.
Побочные органические продукты включают в себя соединения, которые могут быть образованы Corynebacterium в соответствии с настоящим изобретением в ходе ферментативного процесса в дополнение к продуцированию желаемого химического продукта тонкого синтеза.
Ферментативный бульон удаляют из сосуда для культивирования или ферментационного чана, при необходимости собирают и используют для получения продукта, содержащего химический продукт тонкого синтеза, предпочтительно продукта, содержащего L-аминокислоту, в жидкой или твердой форме. Выражение «извлечение продукта, содержащего химический продукт тонкого синтеза» также используют для данного контекста. В самом простом случае сам содержащий химический продукт тонкого синтеза ферментативный бульон, который был удален из ферментационного чана, представляет собой извлеченный продукт.
Ферментативный бульон затем можно подвергнуть одному или нескольким воздействиям, выбранным из группы, состоящей из:
a) от частичного (от > 0% до < 80%) до полного (100%) или практически полного (≥ 80%, ≥ 90%, ≥ 95%, ≥ 96%, ≥ 97%, ≥ 98%, ≥ 99%) удаления воды,
b) от частичного (от > 0% до < 80%) до полного (100%) или практически полного (≥ 80%, ≥ 90%, ≥ 95%, ≥ 96%, ≥ 97%, ≥ 98%, ≥ 99%) удаления биомассы, при этом последнюю необязательно инактивируют перед удалением,
c) от частичного (от > 0% до < 80%) до полного (100%) или практически полного (≥ 80%, ≥ 90%, ≥ 95%, ≥ 96%, ≥ 97%, ≥ 98%, ≥ 99%, ≥ 99,3%, ≥ 99,7%) удаления побочных органических продуктов, образовавшихся в ходе ферментативного процесса, и
d) от частичного (> 0%) до полного (100%) или практически полного (≥ 80%, ≥ 90%, ≥ 95%, ≥ 96%, ≥ 97%, ≥ 98%, ≥ 99%, ≥ 99,3%, ≥ 99,7%) удаления остаточных компонентов используемой среды или, соответственно, остаточных исходных материалов, которые не были потреблены в ходе ферментативного процесса.
Для воздействий a), b), c) и d) из уровня техники доступно множество технических инструкций.
Удаление воды (воздействие a) можно осуществлять, помимо прочего, путем выпаривания с помощью, например, испарителя с падающей пленкой, путем обратного осмоса или нанофильтрации. Концентраты, полученные таким образом, можно дополнительно обработать путем распылительной сушки или распылительной грануляции. Подобным образом возможно непосредственно высушивать ферментативный бульон с применением распылительной сушки или распылительной грануляции.
Удаление биомассы (воздействие b) можно осуществлять, помимо прочего, путем центрифугирования, фильтрации или декантации или их комбинации.
Удаление побочных органических продуктов (воздействие c) или удаление остаточных компонентов среды (воздействие d) можно осуществлять, помимо прочего, с помощью хроматографии, например, ионообменной хроматографии, обработки активированным углем или кристаллизации. В случае присутствия побочных органических продуктов или остаточных компонентов среды в ферментативном бульоне в виде твердых веществ их можно удалить посредством воздействия b).
Общие инструкции по способам разделения, очистки и грануляции можно найти, помимо прочего, в книге R. Ghosh «Principles of Bioseparation Engineering» (World Scientific Publishing, 2006), книге F. J. Dechow «Separation and Purification Techniques in Biotechnology» (Noyes Publications, 1989), статье «Bioseparation» Shaeiwitz и соавт. (Ullmann's Encyclopedia of Industrial Chemistry, Wiley-VCH, 2012) и книге P. Serno и соавт. «Granulieren» (Editio Cantor Verlag, 2007).
Схему последовательной переработки для получения L-лизиновых продуктов можно найти в статье «L-lysine Production» R. Kelle и соавт. (L. Eggeling and M. Bott (Handbook of Corynebacterium glutamicum, CRC Press, 2005)). В US5279744 сообщается о производстве очищенного L-лизинового продукта с помощью ионообменной хроматографии. В US4956471 сообщается о производстве очищенного L-валинового продукта с помощью ионообменной хроматографии. В US5431933 сообщается о производстве сухих L-аминокислотных продуктов, например, L-лизинового продукта или L-валинового продукта, содержащего большую часть составляющих ферментативного бульона.
Таким образом осуществляют концентрирование или очистку желаемого химического продукта тонкого синтеза и получают продукт, имеющий желаемое содержание указанного химического продукта тонкого синтеза.
Анализ L-аминокислот для определения концентрации в один или более моментов времени в ходе ферментации можно проводить путем разделения L-аминокислот с помощью ионообменной хроматографии, предпочтительно катионообменной хроматографии, с последующей постколоночной дериватизацией с использованием нингидрина, как описано у Spackman и соавт. (Analytical Chemistry 30: 1190-1206 (1958)). Также для постколоночной дериватизации возможно использовать ортофталевый альдегид вместо нингидрина. Обзорную статью по ионообменной хроматографии можно найти у Pickering (LC.GC (Magazine of Chromatographic Science) 7(6), 484-487 (1989)). Подобным образом возможно осуществлять предколоночную дериватизацию, например, с использованием ортофталевого альдегида или фенилизотиоцианата, и фракционировать полученные производные аминокислот с помощью обращенно-фазовой хроматографии (RP), предпочтительно в форме высокоэффективной жидкостной хроматографии (HPLC). Этот тип способа описан, например, у Lindroth и соавт. (Analytical Chemistry 51:1167-1174 (1979)). Выявление осуществляют фотометрическим способом (поглощение, флуоресценция). Обзор в отношении анализа аминокислот можно найти, помимо прочего, в учебнике «Bioanalytik» Lottspeich и Zorbas (Spektrum Akademischer Verlag, Heidelberg, Germany 1998).
ЭКСПЕРИМЕНТАЛЬНАЯ ЧАСТЬ
A) МАТЕРИАЛЫ И СПОСОБЫ
В данном разделе кратко описываются используемые молекулярно-биологические наборы, праймеры и химические вещества, а также некоторые подробности применяемых способов.
1. Химические вещества
a. IPTG (изопропил-β-D-1-тиогалактопиранозид) приобретали у Carl-Roth (Карлсруэ, Германия, № по каталогу 2316.4).
b. Раствор канамицина из Streptomyces kanamyceticus приобретали у Sigma Aldrich (Сент-Луис, США, № по каталогу K0254).
c. Натриевую соль налидиксовой кислоты приобретали у Sigma Aldrich (Сент-Луис, США, № по каталогу N4382).
d. Пептон из соевой муки приобретали у Merck KGaA (Дармштадт, Германия, № по каталогу 1.017212.0500).
e. Гемикальциевую соль пропионовой кислоты (C3H5O2 x ½ Ca) приобретали у Sigma Chemical CO. (Сент-Луис, США, № по каталогу P-2005).
f. Жидкий кукурузный экстракт (CSL) SOLULYS® 048K с содержанием сухих веществ от 48% до 52% по весу приобретали у ROQUETTE AMERICA INC (Киокак, Айова, США).
g. Гидролизат крахмала Clearsweet®, 95% неочищенный жидкий декстрозный кукурузный сироп, приобретали у Cargill, Incorporated (Миннеаполис, Миннесота, США). Он имел общее содержание твердых веществ 70,5-71,5% по весу.
h. Если не указано иное, все другие химические вещества приобретали чистыми для анализа у Merck (Дармштадт, Германия), Sigma Aldrich (Сент-Луис, США) или Carl-Roth (Карлсруэ, Германия).
2. Культивирование
Если не указано иное, все процедуры культивирования/инкубирования выполняли согласно описанному ниже.
a. Бульон LB (MILLER) от Merck (Дармштадт, Германия, № по каталогу 110285) использовали для культивирования штаммов E. coli в жидкой среде. Жидкие культуры (10 мл жидкой среды на 100-миллилитровую колбу Эрленмейера с 3 перегородками) инкубировали в стандартном шейкере-инкубаторе Infors HT Multitron от Infors AG (Боттминген, Швейцария) при 37°C и 200 оборотах в минуту.
b. Агар LB (MILLER) от Merck (Дармштадт, Германия № по каталогу 110283) использовали для культивирования штаммов E. coli на чашке с агаром. Чашки с агаром инкубировали при 37°C в мини-инкубаторе INCU-Line® от VWR (Раднор, США).
c. Бульон с сердечно-мозговым экстрактом (BHI) от Merck (Дармштадт, Германия; № по каталогу 110493) использовали для культивирования штаммов C. glutamicum в жидкой среде. Жидкие культуры (10 мл жидкой среды на 100-миллилитровую колбу Эрленмейера с 3 перегородками) инкубировали в стандартном шейкере-инкубаторе Infors HT Multitron от Infors AG (Боттминген, Швейцария) при 33°C и 200 оборотах в минуту.
d. Агар с сердечно-мозговым экстрактом (BHI-агар) от Merck (Дармштадт, Германия; № по каталогу 113825) использовали для культивирования штаммов C. glutamicum на чашках с агаром. Чашки с агаром инкубировали при 33°C в инкубаторе от Heraeus Instruments с контроллером температуры Kelvitron® (Ханау, Германия).
3. Определение оптической плотности
a. Оптическую плотность бактериальных суспензий в культурах во встряхиваемых колбах определяли при 600 нм (OD600) с помощью BioPhotometer от Eppendorf AG (Гамбург, Германия).
b. Оптическую плотность бактериальных суспензий, получаемых в микроферментационной системе BioLector® (48-луночном FlowerPlate®), определяли при 660 нм (OD660) с помощью устройства для считывания планшетов GENios™ от Tecan Group AG (Меннедорф, Швейцария).
4. Центрифугирование
a. Настольная центрифуга для реакционных пробирок объемом до 2 мл
Вызывали осаждение бактериальных суспензий с максимальным объемом 2 мл при использовании 1-миллилитровых или 2-миллилитровых реакционных пробирок (например, пробирок Eppendorf® 3810X) с помощью центрифуги Eppendorf 5417 R в течение 5 минут при 13000 оборотов в минуту.
b. Настольная центрифуга для пробирок объемом до 50 мл
Вызывали осаждение бактериальных суспензий с максимальным объемом 50 мл при использовании 15-миллилитровых или 50-миллилитровых центрифужных пробирок (например, 50-миллилитровых конических центрифужных пробирок FalconTM) с помощью центрифуги Eppendorf 5810 R в течение 10 минут при 4,000 оборотов в минуту.
5. Выделение ДНК
a. Плазмидную ДНК выделяли из клеток E. coli с помощью набора QIAprep для центрифугирования культур малого объема от Qiagen (Хильден, Германия, № по каталогу 27106) согласно инструкциям производителя.
b. Выделение плазмид из C. glutamicum осуществляли с помощью того же набора, который описан в разделе a., но клетки предварительно инкубировали в 600 мкл буфера P1, дополненного 12,5 мг лизоцима и 10 ед. мутанолизина (из Streptomyces globisporus ATCC 21553, Sigma Aldrich, Сент-Луис, США, № по каталогу M4782) в течение 2 часов при 37°C.
c. Общую ДНК из C. glutamicum выделяли с помощью способа по Eikmanns и соавт. (Microbiology 140, 1817-1828, 1994).
6. Синтез генов
Молекулы ДНК синтезировали в компании GeneArt (Thermo Fisher Scientific GENEART GmbH, Регенсбург, Германия) с помощью их собственного процесса GeneAssemble. Способ включает синтез олигонуклеотидов de novo и самосборку перекрывающихся комплементарных олигонуклеотидов с последующей ПЦР-амплификацией. Способ кратко изложен Graf и соавт. в статье «Rationales of Gene Design and De Novo Gene Construction» в Systems Biology and Synthetic Biology под ред. P. Fu и S. Panke (John Wiley, 411-438, 2009).
7. Полимеразная цепная реакция (ПЦР)
a. Базовый набор Taq для ПЦР (набор Taq) от Qiagen (Хильден, Германия, № по каталогу 201203) использовали для амплификации желаемого сегмента ДНК для подтверждения ее присутствия или для проверки последовательности с помощью способа Сэнгера. Набор использовали согласно инструкциям производителя (см. таблицу 1).
Таблица 1. Условия термоциклирования для ПЦР с использованием базового набора Taq для ПЦР (набора Taq) от Qiagen
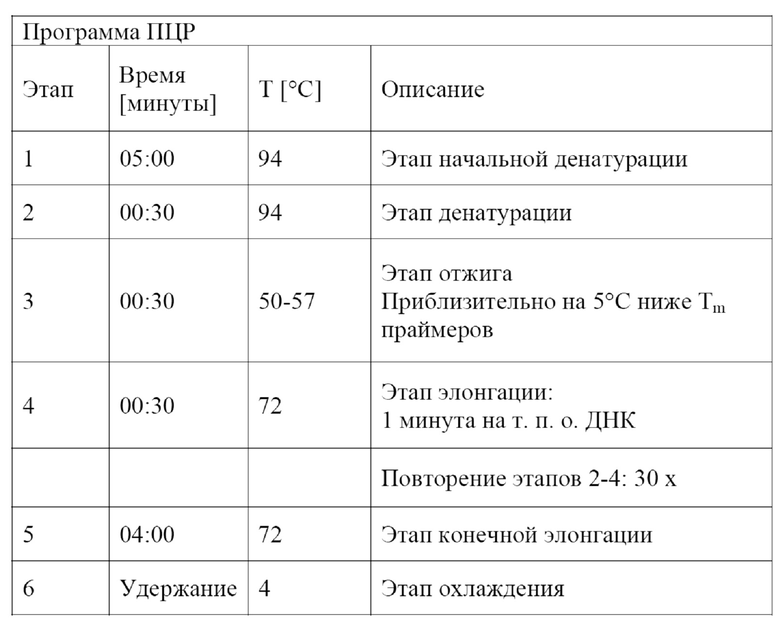
b. Мастер-микс SapphireAmp® для быстрой ПЦР (смесь Sapphire) от Takara Bio Inc (Takara Bio Europe S.A.S., Сен-Жермен-ан-Ле, Франция; № по каталогу RR350A/B) использовали в качестве альтернативы для подтверждения присутствия желаемого сегмента ДНК в клетках, взятых из колоний E. coli или C. glutamicum, согласно инструкциям производителя (см. таблицу 2).
Таблица 2. Условия термоциклирования для ПЦР с использованием мастер-микса SapphireAmp® для быстрой ПЦР (смеси Sapphire) от Takara Bio Inc.
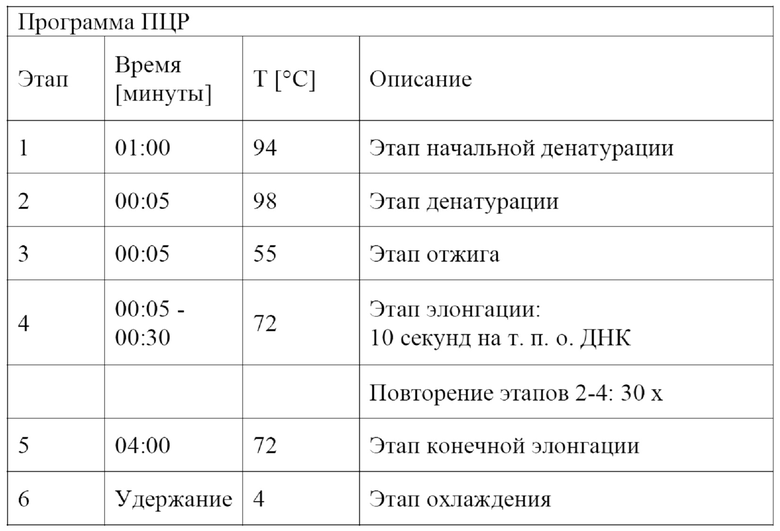
c. Праймер
Используемые олигонуклеотиды синтезировали в Eurofins Genomics GmbH (Эберсберг, Германия) с помощью фосфорамидитного способа, описанного у McBride и Caruthers (Tetrahedron Lett. 24, 245-248, 1983).
d. Матрица
В качестве ПЦР-матрицы использовали либо надлежащим образом разбавленный раствор выделенной плазмидной ДНК, либо общую ДНК, содержащуюся в колонии (ПЦР колоний). Для указанной ПЦР колоний матрицу получали путем отбора клеточного материала с помощью зубочистки из колонии на чашке с агаром и помещения клеточного материала непосредственно в реакционную пробирку для ПЦР. Клеточный материал нагревали в течение 10 секунд при 800 Вт в микроволновой печи типа Mikrowave & Grill от SEVERIN Elektrogeräte GmbH (Зундерн, Германия), а затем к матрице в реакционной пробирке для ПЦР добавляли мастер-микс для ПЦР от Takara Bio Inc.
e. Циклер для ПЦР
ПЦР осуществляли в циклерах для ПЦР типа Mastercycler или Mastercycler Nexus Gradient от Eppendorf AG (Гамбург, Германия).
8. Расщепление ДНК рестрикционными ферментами
Рестрикционные эндонуклеазы FastDigest (FD) и соответствующий буфер от ThermoFisher Scientific (Уолтем, США) использовали для рестрикционного расщепления плазмидной ДНК. Реакции осуществляли согласно инструкциям из руководства от производителя.
9. Лигирование фрагментов ДНК
Для лигирования рестриктированной векторной ДНК с желаемыми фрагментами ДНК использовали ДНК-лигазу T4 Ready-To-Go от Amersham Biosciences Corp (приобретенную у GE Healthcare, Чалфонт-Сент-Джайлс, Великобритания, № по каталогу 27036101) согласно инструкциям производителя.
10. Определение размера фрагментов ДНК
В зависимости от числа и размера фрагментов ДНК, подлежащих исследованию, использовали автоматизированный капиллярный электрофорез или электрофорез в агарозном геле.
a. Капиллярный электрофорез
Размер фрагментов ДНК определяли посредством автоматизированного капиллярного электрофореза с использованием QIAxcel от Qiagen (Хильден, Германия).
b. Электрофорез в агарозном геле
Для разделения фрагментов ДНК после рестрикционного расщепления или ПЦР использовали агарозные гели с 0,8% агарозы (Biozym LE Agarose, Хессиш-Ольдендорф, Германия) в 1x TAE (буфере трис-ацетат-EDTA; исходный раствор: 50 x буфер TAE (AppliChem, Дармштадт, Германия)). Разделение осуществляли с помощью оборудования для электрофореза Mini-Sub Cell GT от BioRad (Bio-Rad Laboratories GmbH, Мюнхен, Германия) при 100 В в течение 45 минут. Маркер длины ДНК O'GeneRuler размером 1 т. п.о. (Thermo Scientific, Шверте, Германия) использовали в качестве эталона для определения размера фрагментов. Спустя 20 минут инкубирования геля в ванне для окрашивания, содержащей краситель для нуклеиновых кислот GelRedTM от Biotrend (Кельн, Германия, разбавление согласно инструкциям изготовителя: 1:10000), фрагменты ДНК визуализировали посредством УФ-облучения с использованием устройства для визуализации Gel iX20 от Intas (Геттинген, Германия).
11. Очистка ПЦР-амплификатов и рестрикционных фрагментов
ПЦР-амплификаты и рестрикционные фрагменты очищали с помощью набора для очистки продуктов ПЦР QIAquick от Qiagen (Хильден, Германия, № по каталогу 28106) согласно инструкциям производителя.
После электрофореза в геле и вырезания желаемого фрагмента ДНК использовали набор для экстракции из геля Qiagen MinElute (Хильден, Германия, № по каталогу 28604) согласно инструкциям производителя.
12. Определение концентрации ДНК
Концентрацию ДНК измеряли с использованием спектрофотометра NanoDrop ND-1000 от PEQLAB Biotechnologie GmbH, торговой марки VWR с 2015 года (Эрланген, Германия).
13. Сборка по Гибсону
Векторы экспрессии и интегрирующие векторы получали с помощью способа по Gibson и соавт. (Science 319, 1215-20, 2008). Использовали набор Gibson Assembly от New England BioLabs Inc. (Ипсвич, США, № по каталогу E2611) для этой цели. Реакционную смесь, содержащую рестриктированный вектор и по меньшей мере одну ДНК-вставку, инкубировали при 50°C в течение 60 минут. Для эксперимента по трансформации использовали 0,5 мкл смеси для сборки.
14. Химическая трансформация E. coli
a. Химически компетентные клетки E. coli Stellar™ приобретали у Clontech Laboratories Inc. (Маунтин-Вью, США, № по каталогу 636763) и трансформировали согласно протоколу производителя (PT5055-2).
Эти клетки использовали в качестве хозяев для трансформации реакционными смесями после сборки по Гибсону. Трансформационные партии культивировали на протяжении ночи в течение приблизительно 18 часов при 37°C, и трансформантов, содержащих плазмиды, отбирали на агаре LB, дополненном 50 мг/л канамицина.
b. Штамм S17-1 E. coli K-12 использовали в качестве донора для конъюгационного переноса плазмид на основе pK18mobsacB из E. coli в C. glutamicum. Штамм S17-1 описан у Simon, R. и соавт. (Bio/Technology 1, 784-794, 1983). Он доступен из Американской коллекции типовых культур под номером доступа ATCC47055.
Химически компетентные клетки E. coli S17-1 получали следующим образом. В предварительную культуру в виде 10 мл среды LB (10 мл жидкой среды на 100-миллилитровую колбу Эрленмейера с 3 перегородками) инокулировали 100 мкл бактериальной суспензии штамма S17-1, и культуру инкубировали на протяжении ночи в течение приблизительно 18 часов при 37°C и 250 оборотах в минуту. В основную культуру (70 мл LB, содержащейся в 250-миллилитровой колбе Эрленмейера с 3 перегородками) инокулировали 300 мкл предварительной культуры, и ее инкубировали до OD600 0,5-0,8 при 37°C. Культуру центрифугировали в течение 6 минут при 4°C и 4000 оборотов в минуту, и надосадочную жидкость сливали. Клеточный осадок ресуспендировали в 20 мл стерильного охлажденного льдом раствора 50 мM CaCl2 и инкубировали на льду в течение 30 минут. После следующего этапа центрифугирования осадок ресуспендировали в 5 мл охлажденного льдом раствора 50 мM CaCl2, и суспензию инкубировали на льду в течение 30 минут. Клеточную суспензию затем доводили до конечной концентрации 20% глицерина (объем/объем) 85% стерильным охлажденным льдом глицерином. Суспензию разделяли на аликвоты по 50 мкл и хранили при -80°C.
Для трансформации клеток S17-1 использовали протокол согласно Tang и соавт. (Nucleic Acids Res. 22(14), 2857-2858, 1994) с тепловым шоком в течение 45 секунд.
15. Трансформация C. glutamicum путем электропорации
Плазмидные векторы на основе pVWEx1 переносили в клетки C. glutamicum с помощью модифицированного способа электропорации по Van der Rest и соавт. (Appl Microbiol Biotechnol 52, 541-545, 1999).
Для получения компетентных клеток C. glutamicum штаммы размножали в среде BHIS (37 г/л BHI, 91 г/л сорбита (Sigma Aldrich, Сент-Луис, США)) посредством предварительного культивирования и последующего основного культивирования. Предварительная культура состояла из 10 мл среды BHIS, содержащейся в 100-миллилитровой колбе Эрленмейера с 3 перегородками. В нее инокулировали 100 мкл исходной культуры в глицерине, и ее инкубировали на протяжении ночи в течение приблизительно 18 часов при 33°C и 200 оборотах в минуту. Основная культура состояла из 250 мл среды BHIS, содержащейся в 1-литровой колбе Эрленмейера с 4 перегородками. В нее инокулировали 5 мл предварительной культуры, и ее инкубировали в течение 4 часов при 33°C и 150 оборотах в минуту до OD600 примерно 1,8.
Следующие технологические этапы осуществляли на льду с использованием стерильных охлажденных льдом буферов или, соответственно, растворов. Основную культуру центрифугировали в течение 20 минут при 4°C и 4000 оборотов в минуту. Надосадочную жидкость сливали, клеточный осадок ресуспендировали в 2 мл буфера TG (1 мM трис(гидроксиметил)-аминометана, 10% глицерина, доведенного до pH 7,5 с помощью HCl), и к клеточной суспензии добавляли еще 20 мл буфера TG. Этот этап промывания повторяли дважды. После указанных этапов промывания следовали два дополнительных этапа промывания, на которых буфер TG заменяли 10% (объем/объем) раствором глицерина. После конечного этапа центрифугирования к клеточному осадку добавляли 2 мл 10% (объем/объем) глицерина. Затем полученную клеточную суспензию разделяли на аликвоты в виде порций по 100 мкл и хранили при -80°C.
Электропорацию штаммов C. glutamicum осуществляли согласно описанному у Van der Rest и соавт. В отступление от этой процедуры, температура культивирования составляла 33°C, а средой для культивирования на чашках с агаром был BHI-агар. Трансформантов отбирали на чашках с BHI-агаром, дополненным 25 мг/л канамицина.
16. Конъюгация C. glutamicum
Плазмидную систему pK18mobsacB, описанную у Schäfer и соавт. (Gene 145, 69 - 73, 1994), использовали для интеграции желаемых фрагментов ДНК в хромосому C. glutamicum. Модифицированный способ конъюгации по Schäfer и соавт. (Journal of Bacteriology 172, 1663 - 1666, 1990) использовали для переноса соответствующей плазмиды в желаемый реципиентный штамм C. glutamicum.
Культивирование штаммов C. glutamicum осуществляли в виде жидких культур в среде BHI при 33°C. Воздействие тепловым шоком осуществляли при 48,5°C в течение 9 минут. Трансконъюганты, образующиеся в результате первого события рекомбинации, отбирали путем высевания конъюгационной партии на агар EM8 (таблица 3), который был дополнен 25 мг/л канамицина и 50 мг/л налидиксовой кислоты. Чашки с агаром EM8 инкубировали в течение 72 часов при 33°C.
Таблица 3. Состав агара EM8
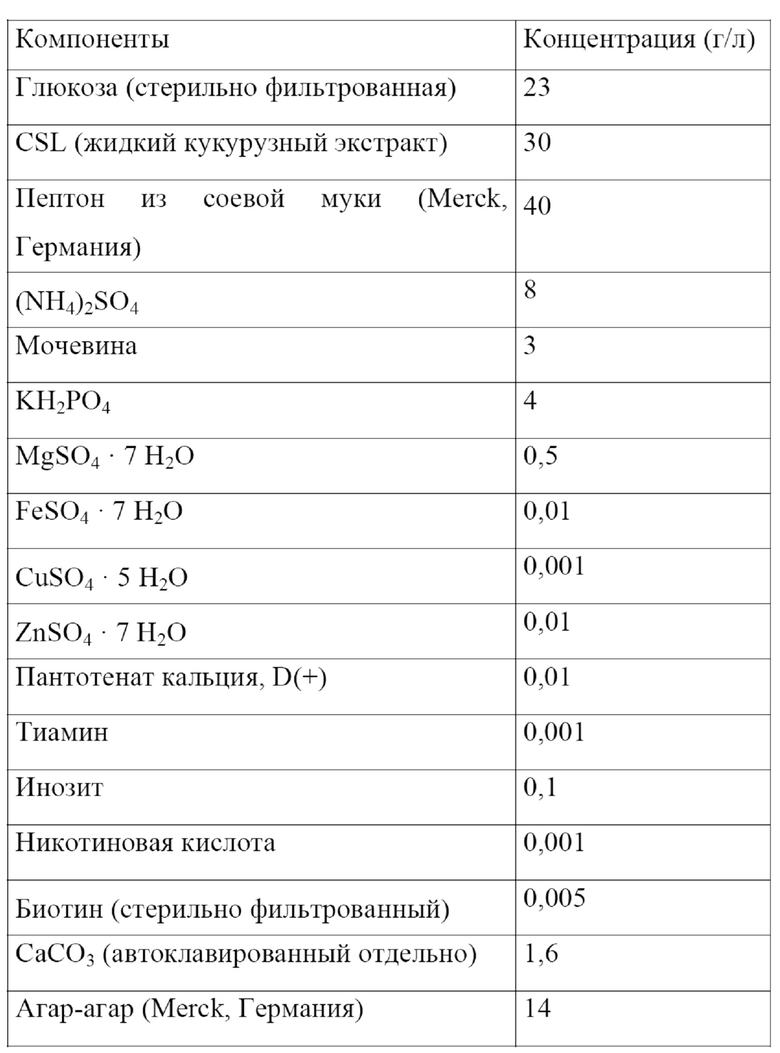
Для переноса трансконъюгантов на BHI-агар, который был дополнен 25 мг/л канамицина и 50 мг/л налидиксовой кислоты, использовали стерильные зубочистки. Чашки с агаром инкубировали в течение 20 часов при 33°C. Затем культуры соответствующих трансконъюгантов, полученные таким образом, размножали в течение еще 24 часов при 33°C в 10 мл среды BHI, содержащейся в 100-миллилитровых колбах Эрленмейера с 3 перегородками. Для выделения клонов, в которых имеет место второе событие рекомбинации, из жидкой культуры отбирали аликвоту, соответствующим образом разбавляли и высевали (как правило, 100-200 мкл) на BHI-агар, который был дополнен 10% сахарозой. Чашки с агаром инкубировали в течение 48 часов при 33°C. Затем колонии, растущие на чашках с агаром, содержащим сахарозу, изучали в отношении фенотипа чувствительности к канамицину. Чтобы сделать это, использовали зубочистку для удаления клеточного материала из колонии и переноса его на BHI-агар, содержащий 25 мг/л канамицина, и на BHI-агар, содержащий 10% сахарозу. Чашки с агаром инкубировали в течение 60 часов при 33°C. Клоны трансконъюгантов, которые оказывались чувствительными к канамицину и устойчивыми к сахарозе, изучали в отношении интеграции желаемого фрагмента ДНК в хромосому посредством ПЦР.
17. Определение нуклеотидных последовательностей
Нуклеотидные последовательности молекул ДНК определяли в Eurofins Genomics GmbH (Эберсберг, Германия) с помощью циклического секвенирования с использованием дидезоксинуклеотидного способа обрыва цепи по Sanger и соавт. (Proceedings of the National Academy of Sciences USA 74, 5463 - 5467, 1977) на анализаторе ДНК 3730xl от Applied Biosystems® (Карлсбад, Калифорния, США). Для визуализации и оценивания последовательностей использовали программное обеспечение Clone Manager Professional 9 от Scientific & Educational Software (Денвер, США).
18. Исходные культуры штаммов E. coli и C. glutamicum в глицерине
Для длительного хранения получали исходные культуры штаммов E. coli и C. glutamicum в глицерине. Выбранные клоны E. coli культивировали в 10 мл среды LB, дополненной 2 г/л глюкозы. Выбранные клоны C. glutamicum культивировали в двукратно концентрированной среде BHI, дополненной 2 г/л глюкозы. Культуры содержащих плазмиды штаммов E. coli дополняли 50 мг/л канамицина. Культуры содержащих плазмиды штаммов C. glutamicum дополняли 25 мг/л канамицина. Среда содержалась в 100-миллилитровых колбах Эрленмейера с 3 перегородками. В нее инокулировали петлю с клетками, взятыми из колонии, и культуру инкубировали в течение приблизительно 18 часов при 37°C и 200 оборотах в минуту в случае с E. coli и 33°C и 200 оборотах в минуту в случае с C. glutamicum. После указанного периода инкубирования в культуру добавляли 1,2 мл 85% (объем/объем) стерильного глицерина. Полученную клеточную суспензию, содержащую глицерин, затем разделяли на аликвоты в виде порций по 2 мл и хранили при -80°C.
19. Система для культивирования BioLector®
Для исследования функциональных характеристик сконструированных штаммов C. glutamicum использовали микроферментационную систему BioLector® (m2p-labs GmbH, Басвайлер, Германия).
Для этой цели использовали 48-луночный FlowerPlate® (m2p-labs GmbH, Басвайлер, Германия, № по каталогу MTP-48-BO), заполненный 1 мл среды на лунку. Лунки FlowerPlate® были оснащены оптодом для анализа содержания растворенного кислорода в жидкости. BioLector® дополнительно оснащен оптическим устройством для измерения интенсивности света, рассеиваемого клеточными частицами в микробной культуре, содержащейся в лунке FlowerPlate®. Этот так называемый сигнал обратного рассеяния (Samorski et al., Biotechnol Bioeng. 92(1):61-8, 2005) коррелирует с концентрацией клеточных частиц. Это позволяет неинвазивным путем отслеживать в режиме онлайн рост микробной культуры.
Предварительные культуры штаммов получали в 10 мл двукратно концентрированной среды BHI. В случае с содержащими плазмиды (pVWEx1 и ее производные) штаммами среда была дополнена 25 мг/л канамицина. Среда содержалась в 100-миллилитровой колбе Эрленмейера с 3 перегородками. В нее инокулировали 100 мкл исходной культуры в глицерине, и культуру инкубировали в течение 24 часов при 33°C и 200 оборотах в минуту.
После указанного периода инкубирования определяли значения оптической плотности OD600 предварительных культур.
Основные культуры получали путем инокулирования в лунки 48-луночного FlowerPlate®, содержащие 1 мл среды, аликвоты предварительной культуры с получением оптической плотности OD600 0,1.
В качестве среды для модификаций основной культуры использовали среду CGXII, описанную у Keilhauer и соавт. (J. Bacteriol. 1993 Sep; 175(17): 5595-5603). Для удобства состав среды CGXII показан в таблице 4.
Таблица 4. Состав среды CGXII по Keilhauer
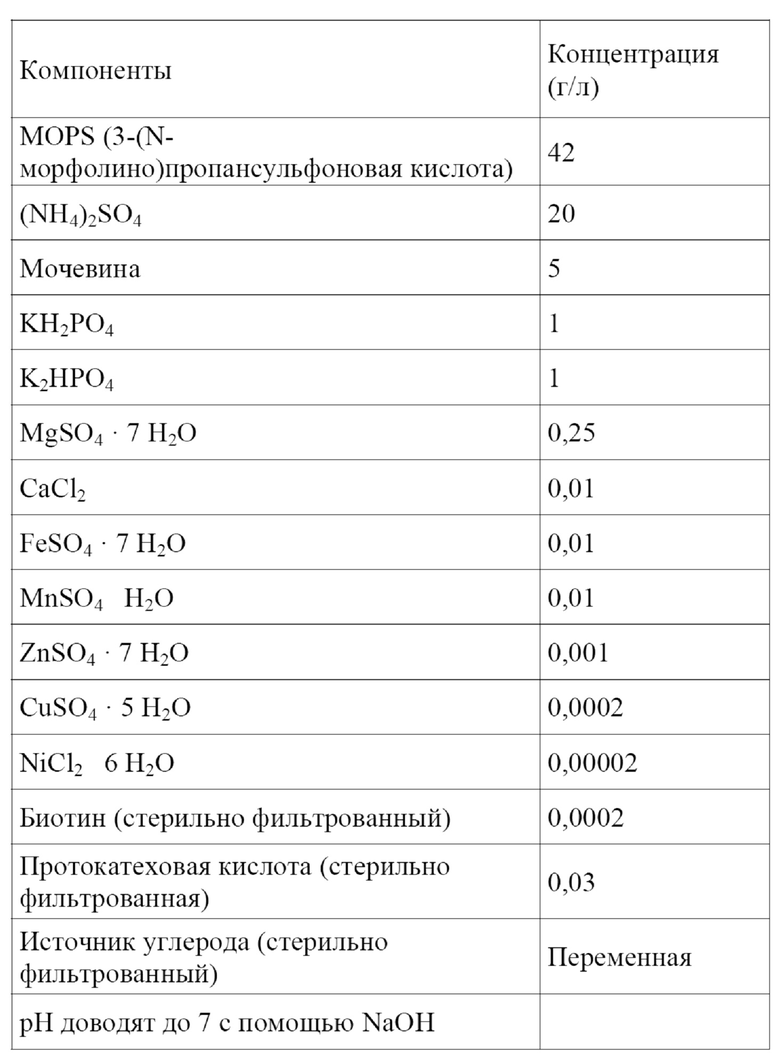
Среда, называемая CGXII_CSL, дополнительно содержит жидкий кукурузный экстракт в концентрации 7,5 г/л. Среда, называемая CGXII_YE, дополнительно содержит дрожжевой экстракт в концентрации 7,5 г/л.
В случае с содержащими плазмиды (pVWEx1 и ее производные) штаммами среда дополнительно была дополнена 25 мг/л канамицина и 0,3 мM IPTG для индуцирования экспрессии под контролем промотора PtacI.
Эти основные культуры инкубировали в течение периода до 48 часов при 33°C и 800 оборотах в минуту в системе BioLector® до полного потребления глюкозы.
Концентрацию глюкозы в суспензии анализировали глюкометром OneTouch Vita® от LifeScan (Johnson & Johnson Medical GmbH, Нойс, Германия).
После культивирования суспензионные культуры переносили в микропланшет с глубокими лунками. Часть суспензионной культуры соответствующим образом разбавляли для измерения OD600. Другую часть культуры центрифугировали, и в надосадочной жидкости анализировали концентрацию L-аминокислот, например, L-лизина или L-валина, и остаточного источника углерода, такого как паноза.
20. Культивирование в 2-литровых колбах
Продуцирование L-лизина при использовании гидролизата крахмала в качестве источника углерода выполняли в 2-литровых колбах следующим образом.
Предварительные культуры штаммов C. glutamicum получали в 10 мл двукратно концентрированной среды BHI. Среда содержалась в 100-миллилитровых колбах Эрленмейера с 3 перегородками. В нее инокулировали 100 мкл исходной культуры в глицерине. Затем культуру инкубировали в течение 24 часов при 33°C и 200 оборотах в минуту. После указанного периода инкубирования определяли значения оптической плотности OD600 предварительных культур.
Основные культуры получали путем инокулирования в 200 мл среды, содержащей гидролизат крахмала (стерилизованный отдельно в стерилизаторе непрерывного действия) в качестве источника углерода, содержащейся в 2-литровых колбах Эрленмейера, имеющих 4 перегородки, аликвоты предварительной культуры с получением оптической плотности OD600 0,5. Культуры инкубировали в течение 57 часов при 33°C и 150 оборотах в минуту.
21. Анализатор аминокислот
Концентрацию L-лизина и других L-аминокислот, например, L-валина, в образцах надосадочной жидкости культуры определяли с помощью ионообменной хроматографии с использованием анализатора аминокислот SYKAM S433 от SYKAM Vertriebs GmbH (Фюрштенфельдбрук, Германия). В качестве твердой фазы использовали колонку со сферическими гранулами полистирольного катионообменника (PEEK LCA N04/Na, с размерами 150 × 4,6 мм) от SYKAM. В зависимости от L-аминокислоты разделение происходило в изократическом режиме с использованием смеси буферов A и B для элюирования или путем градиентного элюирования с использованием указанных буферов. В качестве буфера A использовали водный раствор, содержащий в 20 л 263 г цитрата тринатрия, 120 г лимонной кислоты, 1100 мл метанола, 100 мл 37% HCl и 2 мл октановой кислоты (конечное значение pH 3,5). В качестве буфера B использовали водный раствор, содержащий в 20 л 263 г цитрата тринатрия, 100 г борной кислоты и 2 мл октановой кислоты (конечное значение pH 10,2). Свободные аминокислоты окрашивали нингидрином посредством постколоночной дериватизации и выявляли фотометрическим способом при 570 нм.
22. Определение глюкозы с использованием непрерывно-проточной системы (CFS)
Для определения концентрации глюкозы в надосадочной жидкости использовали многоканальный непрерывно-проточный анализатор SANplus от SKALAR analytic GmbH (Эркеленц, Германия). Глюкозу выявляли с помощью сопряженного ферментного анализа (гексокиназного/глюкозо-6-фосфатдегидрогеназного) по образованию NADH.
23. Анализ панозы и изомальтозы
Для определения концентрации панозы и изомальтозы в надосадочной жидкости культуры использовали компактную систему для HPLC (жидкостной хроматографии высокого давления) от Thermo Fisher Scientific Inc. (Уолтем, Массачусетс, США). Разделение выполняли с помощью распределительной хроматографии на амино-модифицированном силикагеле с ионообменными свойствами (колонка с аминосорбентом YMC Polyamine II S-5 мкм, 250*4,6 мм; Thermo Fisher Scientific Inc., Уолтем, Массачусетс, США) с использованием элюента, состоящего из 30% воды и 70% ацетонитрила (объем/объем). Выявление происходило с помощью детектора RI (показателя преломления) (Thermo Fisher Scientific Inc., Уолтем, Массачусетс, США).
24. Получение надосадочной жидкости культуры для анализа секретируемого слитого белка на основе α-1,6-глюкозидазы
Предварительную культуру штамма C. glutamicum получали в 10 мл двукратно концентрированной среды BHI, дополненной 25 мг/л канамицина. Среда содержалась в 100-миллилитровой колбе Эрленмейера с 3 перегородками. В нее инокулировали 100 мкл исходной культуры в глицерине. Затем культуру инкубировали в течение 24 часов при 33°C и 200 оборотах в минуту.
После указанного периода инкубирования определяли оптическую плотность OD600 предварительной культуры.
Основные культуры состояли из 2x 50 мл среды CGXII_CSL (см. таблицу 5), дополненной 25 мг/л канамицина и 0,3 мM IPTG, содержащейся в 500-миллилитровых колбах Эрленмейера с 4 перегородками. В нее инокулировали аликвоту предварительной культуры с получением оптической плотности OD600 0,8, и ее инкубировали в течение 24 часов при 33°C и 150 оборотах в минуту.
После указанного периода инкубирования значения оптической плотности OD600 основных культур составляли 41. Культуры центрифугировали в течение 10 минут при 4000 оборотов в минуту. Полученную надосадочную жидкость фильтровали с помощью высокопоточного шприцевого фильтра Minisart® (0,22 мкм) от Sartorius (Геттинген, Германия, № по каталогу 16532). Фильтрат концентрировали с помощью центрифужного фильтрующего блока Amicon Ultra-15 (30K) от Merck Millipore Ltd. (Корк, Ирландия, № по каталогу UFC903024) для повышения содержания белка. Для этого надосадочную жидкость (максимум 12 мл) пипеткой переносили в фильтровальное устройство и помещали в предусмотренную центрифужную пробирку. В центрифужном фильтрующем блоке проводили центрифугирование в течение 45 минут при 10°C и 4000 оборотов в минуту. После центрифугирования надосадочную жидкость в фильтрующем блоке переносили пипеткой в отдельную пробирку.
Содержание белка в концентрате определяли согласно Бредфорду (Anal. Biochem. 72, 248-254, 1976) с использованием окрашивающего реагента для анализа белков Bio-Rad от BioRad (Bio-Rad Laboratories GmbH, Мюнхен, Германия, № по каталогу 5000006) согласно инструкциям производителя. В качестве стандарта использовали бычий сывороточный альбумин. Концентрация белка в концентрате составляла 0,8 мг/мл.
25. Выявление сайта расщепления слитого белка
Надосадочную жидкость культуры клеток, экспрессирующих слитый полипептид, исследовали с помощью LC-MS (жидкостной хроматографии в сочетании с масс-спектрометрией) с использованием электрораспылительной ионизации (ESI). В качестве инструмента использовали систему для UPLC Accela 1250, соединенную с Orbitrap Elite от Thermo Fisher (Scientific Inc., Уолтем, США) с колонкой Poroshell SB300-C18, 75 x 2,1 мм от Agilent (Санта-Клара, США). В качестве элюента A использовали водный раствор 0,1% TFA (трифторуксусной кислоты), а в качестве элюента B - 0,1% TFA, растворенную в ацетонитриле/1-пропаноле (60/40). Для разделения градиент, показанный в таблице 5, использовали при скорости потока 0,3 мл/минута при 70°C. Перед измерением образец разбавляли 1:20 в водном 50 мM трис-буфере (pH 7,5). Объем вводимого образца составлял 15 мкл.
Таблица 5. Градиент элюирования
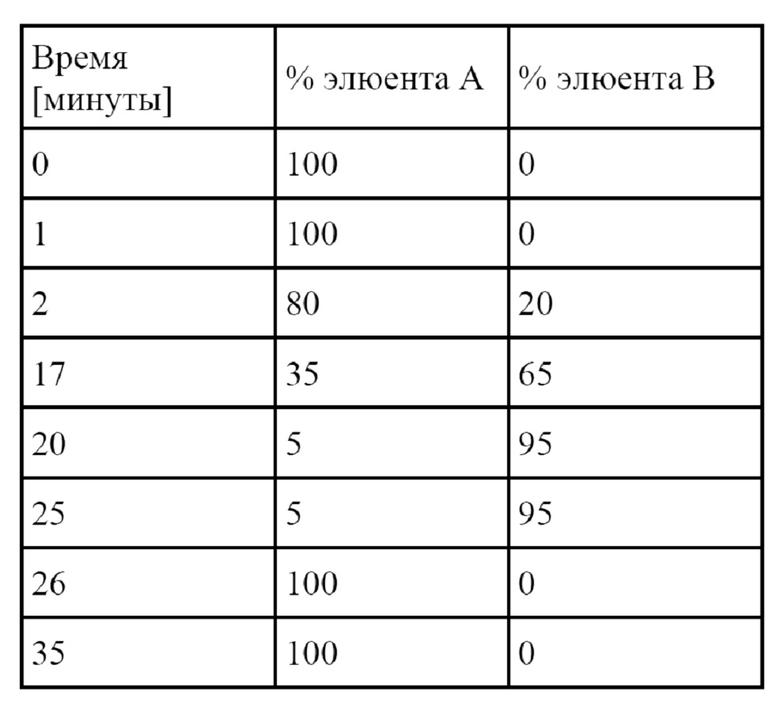
С помощью способа ESI белки ионизируются как многократно протонированные молекулярные ионы [M+nH]n+. Это позволяет выявлять даже высокомолекулярные соединения в ограниченном окне диапазона масс. Молекулярный вес незаряженного белка также можно пересчитать с помощью программного обеспечения для деконволюции по зарядовому состоянию Promass 2.8 для Xcalibur от Novatia, LLC (Нью-Джерси, США). Белковые фракции элюируются в области времени удержания от 8 до 12 минут.
26. Измерение α-1,6-глюкозидазной ферментативной активности
α-1,6-Глюкозидазную активность в образцах надосадочной жидкости культуры определяли с использованием пара-нитрофенил-α-глюкозида в качестве хромогенного субстрата, как описано у Deng и соавт. (FEBS Open Bio 4, 200 - 212, 2014).
Образцы надосадочной жидкости, используемые для анализа, получали путем центрифугирования культур и последующей фильтрации образцов надосадочной жидкости с использованием высокопоточного шприцевого фильтра Minisart® (0,22 мкм) от Sartorius (Геттинген, Германия, № по каталогу 16532).
Анализ выполняли при 34°C в реакционной смеси, имеющей конечный объем 1500 мкл. 750 мкл 100 мM калий-фосфатного буфера (pH 7), 150 мкл 10 мг/мл BSA (бычьего сывороточного альбумина) и 150 мкл 40 мM пара-нитрофенил-α-глюкозида переносили пипеткой в реакционную пробирку, и реакцию начинали путем добавления 450 мкл надосадочной жидкости культуры. Через 2, 4, 6 и 8 минут 200 мкл образцов удаляли из реакционной смеси и переносили пипеткой в 800 мкл 1 M раствора карбоната натрия. Концентрацию п-нитрофенола определяли при 405 нм с использованием спектрофотометра U-3200 от Hitachi Scientific Instruments (Nissel Sangyo GmbH, Дюссельдорф, Германия). Коэффициент молярной экстинкции для п-нитрофенола определяли как ε = 17,6 см2/ммоль при 405 нм в 0,8 M растворе карбоната натрия с pH 11 и при 34°C. Одну единицу (ед.) определяют как количество фермента, которое катализирует превращение 1 мкмоль субстрата в минуту.
B) РЕЗУЛЬТАТЫ ЭКСПЕРИМЕНТОВ
Пример 1
Идентификация подходящей α-1,6-глюкозидазы
Пример 1.1
Схема эксперимента
Гены различного происхождения, кодирующие глюкозидазы, которые, как сообщалось, гидролизуют α-1,6-связи в олигомерах глюкозы, тестировали в отношении их способности придавать C. glutamicum признак разложения панозы. Библиографические подробности генов кратко изложены в таблице 6.
Таблица 6. Происхождение тестируемых α-1,6-глюкозидазных функций и используемого Tat-сигнального пептида
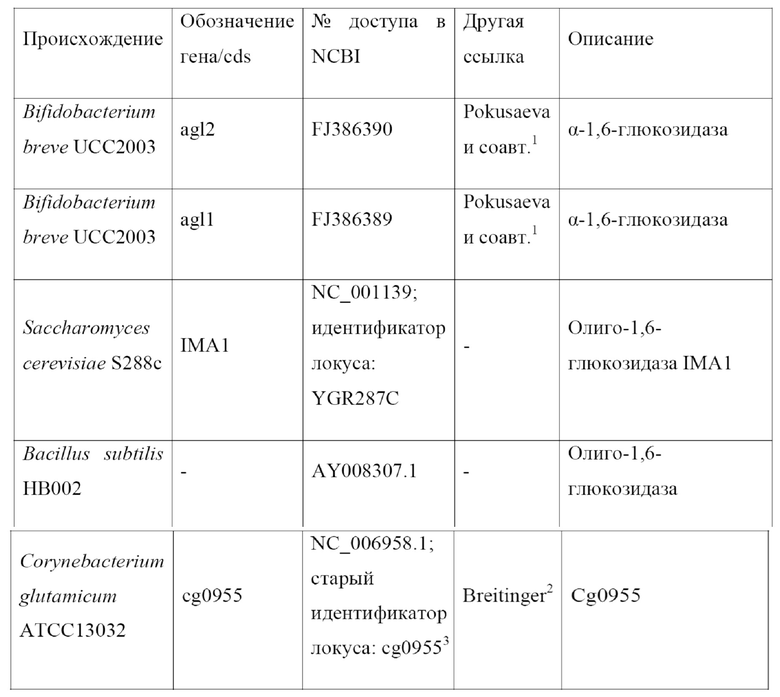
1 (Applied and Environmental Microbiology 75, 1135-1143, 2009)
2 (Диссертация, Ульмский университет, 2013)
3 (идентификатор локуса: CGTRNA_RS04205); под номером доступа NC_003450.3; та же cds доступна под идентификатором локуса NCgl0801)
В сущности кодирующие последовательности перечисленных в таблице 6 генов, кодирующих полипептиды, обеспечивающие ферментативную функцию, приспосабливали под частоту использования кодонов Corynebacterium glutamicum (cuo = оптимизированная частота использования кодонов) и сливали с нуклеотидной последовательностью, кодирующей Tat-сигнальный пептид Cg0955, описанный у Breitinger (диссертация, Ульмский университет, 2013). Аминокислотная последовательность Tat-сигнального пептида Cg0955 и кодирующая ее нуклеотидная последовательность показаны под SEQ ID NO: 2 и SEQ ID NO: 1 в перечне последовательностей. Полинуклеотиды, кодирующие полученные в результате слитые полипептиды, клонировали в вектор экспрессии pVWEx1, описанный Peters-Wendisch и соавт. (Journal of Molecular Microbiology and Biotechnology 3, 295 - 300, 2001). Нуклеотидная последовательность pVWEx1 доступна в базе данных GenBank под номером доступа MF034723. Карта плазмиды pVWEx1 показана на фигуре 1.
Штамм Corynebacterium glutamicum, продуцирующий L-лизин, трансформировали сконструированными векторами экспрессии, и полученных в результате трансформантов тестировали в отношении их способности разлагать панозу.
Пример 1.2
Разработка и синтез слитых генов
Полинуклеотиды, кодирующие слитые полипептиды, разрабатывали и синтезировали с сайтом рестрикции для эндонуклеазы PstI (CTGCAG) на 5'-конце и с терминатором транскрипции Tgap* (см. SEQ ID NO: 13) и сайтом рестрикции для эндонуклеазы BamHI (GGATCC) на 3'-конце нуклеотидной последовательности. Сайты рестрикции для PstI и BamHI обеспечивают возможность клонирования в челночный вектор pVWEx1 для E. coli и C. glutamicum.
Слитый ген tat-'agl2_cuo
Нуклеотидная последовательность полинуклеотида, синтезированного и содержащего кодирующую последовательность слитого гена tat-'agl2_cuo, показана под SEQ ID NO: 21. Аминокислотная последовательность слитого полипептида Tat-'Agl2 показана под SEQ ID NO: 22. Аминокислотная последовательность слитого полипептида в положениях 1-33 идентична аминокислотной последовательности Cg0955, показанной под SEQ ID NO: 2 в положениях 1-33. Эту часть аминокислотной последовательности слитого полипептида также называют N-концевым Tat-сигнальным пептидом.
Аминокислотная последовательность слитого полипептида в положениях 37-639 SEQ ID NO: 22 идентична аминокислотной последовательности полипептида Agl2, показанной под SEQ ID NO: 6 в положениях 2-604. Отсутствие начальной аминокислоты метионина (Met) в Agl2 в слитом полипептиде указано как “'” в обозначении слитого полипептида.
Содержание G + C в нуклеотидной последовательности, кодирующей C-концевой полипептид слитого полипептида ('agl2_cuo), показанной под SEQ ID NO: 21 в положениях 122-1930, составляет 58,2%. Содержание G + C в нуклеотидной последовательности, кодирующей полипептид Agl2 Bifidobacterium breve UCC2003 и не имеющей стартового кодона atg ('agl2), показанной под SEQ ID NO: 5 в положениях 4-1812, составляет 65,6%.
Полинуклеотид tat-'agl2_cuo, показанный под SEQ ID NO: 21, клонировали в челночный вектор pVWEx1. Для этой цели полинуклеотид, показанный под SEQ ID NO: 21, разрезали рестрикционными эндонуклеазами PstI и BamHI и лигировали в вектор, обработанный рестрикционными эндонуклеазами PstI и BamHI. Полученную плазмиду назвали pVWEx1_tat-'agl2_cuo. Карта плазмиды pVWEx1_tat-'agl2_cuo показана на фигуре 2.
Слитый ген tat-agl1_cuo
Нуклеотидная последовательность полинуклеотида, синтезированного и содержащего кодирующую последовательность слитого гена tat-agl1_cuo, показана под SEQ ID NO: 23. Аминокислотная последовательность слитого полипептида Tat-Agl1 показана под SEQ ID NO: 24. Аминокислотная последовательность слитого полипептида в положениях 1-33 идентична аминокислотной последовательности Cg0955, показанной под SEQ ID NO: 2 в положениях 1-33. Эту часть аминокислотной последовательности слитого полипептида также называют N-концевым Tat-сигнальным пептидом.
Аминокислотная последовательность слитого полипептида в положениях 37-643 SEQ ID NO: 24 идентична аминокислотной последовательности полипептида Agl1, показанной под SEQ ID NO: 8.
Содержание G + C в нуклеотидной последовательности, кодирующей C-концевой полипептид слитого полипептида (agl1_cuo), показанной под SEQ ID NO: 23 в положениях 122-1942, составляет 58,1%. Содержание G + C в нуклеотидной последовательности, кодирующей полипептид Agl1 Bifidobacterium breve UCC2003 (agl1), показанной под SEQ ID NO: 7 в положениях 1-1821, составляет 58,6%.
Полинуклеотид tat-agl1_cuo, показанный под SEQ ID NO: 23, клонировали в челночный вектор pVWEx1. Для этой цели полинуклеотид, показанный под SEQ ID NO: 23, разрезали рестрикционными эндонуклеазами PstI и BamHI и лигировали в вектор, обработанный рестрикционными эндонуклеазами PstI и BamHI. Полученную плазмиду назвали pVWEx1_tat-agl1_cuo.
Слитый ген tat-'IMA1_cuo
Нуклеотидная последовательность полинуклеотида, синтезированного и содержащего кодирующую последовательность слитого гена tat-'IMA1_cuo, показана под SEQ ID NO: 25. Аминокислотная последовательность слитого полипептида Tat-'IMA1 показана под SEQ ID NO: 26. Аминокислотная последовательность слитого полипептида в положениях 1-33 идентична аминокислотной последовательности Cg0955, показанной под SEQ ID NO: 2 в положениях 1-33. Эту часть аминокислотной последовательности слитого полипептида также называют N-концевым Tat-сигнальным пептидом.
Аминокислотная последовательность слитого полипептида в положениях 37-624 SEQ ID NO: 26 идентична аминокислотной последовательности полипептида IMA1, показанного под номером доступа NP_11803, в положениях 2-589. Отсутствие начальной аминокислоты метионина (Met) в IMA1 в слитом полипептиде указано как “'” в обозначении слитого полипептида.
Содержание G + C в нуклеотидной последовательности, кодирующей C-концевой полипептид слитого полипептида ('IMA1_cuo), показанной под SEQ ID NO: 25 в положениях 122-1885, составляет 53,2%. Содержание G + C в нуклеотидной последовательности, кодирующей полипептид IMA1 Saccharomyces cerevisiae S288c и не имеющей стартового кодона atg ('IMA1), составляет 42,4%.
Полинуклеотид tat-'IMA1_cuo, показанный под SEQ ID NO: 25, клонировали в челночный вектор pVWEx1. Для этой цели полинуклеотид, показанный под SEQ ID NO: 25, разрезали рестрикционными эндонуклеазами PstI и BamHI и лигировали в вектор, обработанный рестрикционными эндонуклеазами PstI и BamHI. Полученную плазмиду назвали pVWEx1_tat-'IMA1_cuo.
Слитый ген tat-'AY008307_cuo
Нуклеотидная последовательность полинуклеотида, синтезированного и содержащего кодирующую последовательность слитого гена tat-'AY008307_cuo, показана под SEQ ID NO: 27. Аминокислотная последовательность слитого полипептида Tat-'AY008307 показана под SEQ ID NO: 28. Аминокислотная последовательность слитого полипептида в положениях 1-33 идентична аминокислотной последовательности Cg0955, показанной под SEQ ID NO: 2 в положениях 1-33. Эту часть аминокислотной последовательности слитого полипептида также называют N-концевым Tat-сигнальным пептидом.
Аминокислотная последовательность слитого полипептида в положениях 37-596 SEQ ID NO: 28 идентична аминокислотной последовательности полипептида олиго-1,6-глюкозидазы, показанного под номером доступа AAG23399, в положениях 2-561. Отсутствие исходной аминокислоты метионина (Met) в слитом полипептиде указано как “'” в обозначении слитого полипептида.
Содержание G + C в нуклеотидной последовательности, кодирующей C-концевой полипептид слитого полипептида ('AY008307_cuo), показанной под SEQ ID NO: 27 в положениях 122-1801, составляет 53,1%. Содержание G + C в нуклеотидной последовательности, кодирующей полипептид AY008307 Bacillus subtilis HB002 и не имеющей стартового кодона atg ('AY008307), составляет 44,0%.
Полинуклеотид tat-'AY008307_cuo, показанный под SEQ ID NO: 27, клонировали в челночный вектор pVWEx1. Для этой цели полинуклеотид, показанный под SEQ ID NO: 27, разрезали рестрикционными эндонуклеазами PstI и BamHI и лигировали в вектор, обработанный рестрикционными эндонуклеазами PstI и BamHI. Полученную плазмиду назвали pVWEx1_tat-'AY008307_cuo.
Ген agl2_cuo
Нуклеотидная последовательность полинуклеотида, содержащего кодирующую последовательность гена agl2_cuo, показана под SEQ ID NO: 29, а кодируемая аминокислотная последовательность полипептида Agl2 показана под SEQ ID NO: 30. Аминокислотная последовательность полипептида в положениях 1-604 идентична аминокислотной последовательности Agl2, показанной под SEQ ID NO: 6 в положениях 1-604. Аминокислотная последовательность полипептида, показанная под SEQ ID NO: 30 в положениях 2-604, идентична аминокислотной последовательности слитого белка Tat-Agl2, показанной под SEQ ID NO: 10 в положениях 37-639.
Для демонстрации эффекта Tat-сигнального пептида в отношении секреции фермента или, соответственно, разложения панозы разрабатывали и конструировали контрольную плазмиду, содержащую полную кодирующую последовательность гена agl2_cuo, но не имеющую нуклеотидной последовательности, кодирующей сигнальный пептид. Эту контрольную плазмиду назвали pVWEx1_agl2_cuo.
Для этой цели разрабатывали и синтезировали полинуклеотид Wo_tat, показанный под SEQ ID NO: 31.
Wo_tat содержит от 5'-конца к 3'-концу сайт распознавания для эндонуклеазы MauBI, промотор PtacI, сайты распознавания для эндонуклеаз PstI и SexAI и 5'-конец кодирующей последовательности agl2_cuo, содержащий сайт распознавания для эндонуклеазы FspAI (см. SEQ ID NO: 21). Указанный 5'-конец кодирующей последовательности agl2_cuo состоит из нуклеотидной последовательности из положений 14-77 SEQ ID NO: 29, кодирующей первую 21 N-концевую аминокислоту полипептида Agl2, в том числе начальную аминокислоту метионин.
Плазмиду pVWEx1_agl2_cuo конструировали следующим образом. Плазмиду pVWEx1_tat-'agl2_cuo (см. фигуру 2) расщепляли рестрикционными эндонуклеазами MauBI и FspI. Таким образом получали два фрагмента ДНК: один фрагмент ДНК длиной 473 п.о., содержащий промотор PtacI и 5'-конец слитого гена tat-'agl2_cuo, фактически кодирующий Tat-сигнальный пептид (отмеченный как tat на фигуре 2), и второй фрагмент ДНК длиной 10116 п.о., содержащий последовательность pVWEx1 и 3'-конец слитого гена tat-'agl2_cuo, фактически кодирующий α-1,6-глюкозидазу Agl2 (отмеченную как 'agl2_cuo на фигуре 2). Эти два фрагмента ДНК разделяли посредством электрофореза в агарозном геле. Фрагмент ДНК размером 473 п.о. отбрасывали, а фрагмент ДНК размером 10116 п.о. выделяли из агарозного геля и очищали. Полинуклеотид Wo_tat также обрабатывали рестрикционными эндонуклеазами MauBI и FspAI и очищали. Эти два фрагмента ДНК, полученные таким образом, лигировали, и лигированную смесь использовали для трансформации химически компетентных клеток E. coli Stellar™. Нуклеотидную последовательность agl2_cuo (также показанную под SEQ ID NO: 29) в выделенной плазмиде трансформанта подтверждали с помощью способа секвенирования по Сэнгеру.
Таким образом, получали плазмиду pVWEx1_agl2_cuo. Ее карта показана на фигуре 3.
Пример 1.3
Конструирование штамма
В качестве хозяина для оценивания способности сконструированных слитых генов придавать виду C. glutamicum способность к разложению панозы был выбран штамм DM1933.
Штамм DM1933 является продуцентом L-лизина, описанным Blombach и соавт. (Applied and Environmental Microbiology 75(2), 419-427, 2009). Он депонирован согласно Будапештскому договору под номером доступа DSM25442.
Штамм DM1933 трансформировали выделенной плазмидной ДНК pVWEx1, pVWEx1_tat-'agl2_cuo, pVWEx1_tat-agl1_cuo, pVWEx1_tat-'IMA1_cuo, pVWEx1_tat-'AY008307_cuo и pVWEx1_agl2_cuo путем электропорации. Отбор трансформантов, размножение трансформантов и получение исходных культур в глицерине выполняли согласно описанному в разделе «Материалы и способы» и в присутствии канамицина.
Конкретные нуклеотидные последовательности трансформантов амплифицировали с помощью ПЦР колоний для проверки плазмидного статуса трансформантов. Используемые праймеры и размер ПЦР-амплификатов кратко изложены в таблице 7.
Таблица 7. Перечень используемых праймеров и размер амплификатов при ПЦР-анализе трансформантов
Для ПЦР использовали набор Taq (см. таблицу 1) с температурой на этапе отжига (этапе 3), установленной на 53°C, и продолжительностью этапа элонгации (этапа 4), установленной на 13 секунд. Определение размера амплификатов выполняли посредством капиллярного электрофореза.
Нуклеотидные последовательности используемых праймеров также показаны в перечне последовательностей под SEQ ID NO: 33 - SEQ ID NO: 37.
Трансформантов, полученных и проанализированных таким образом, использовали для дальнейшего исследования.
Пример 1.4
Разложение панозы
Трансформантов из примера 1.3 анализировали в отношении их способности разлагать панозу путем периодического культивирования с использованием системы BioLector®.
В качестве среды использовали CGXII_CSL, содержащую 15 г/л глюкозы и 4,8 г/л панозы в качестве источника углерода. Среда, кроме того, была дополнена канамицином и IPTG. Культуры инкубировали в течение приблизительно 20 часов до полного потребления глюкозы, что подтверждалось в анализе уровня глюкозы с использованием глюкометра, и определяли значения оптической плотности культур и концентрацию остаточной панозы.
Результат эксперимента представлен в таблице 8 и демонстрирует, что α-1,6-глюкозидазы Agl1 и Agl2, слитые с Tat-сигнальным пептидом Cg0955, т. e. Tat-Agl1 и Tat-'Agl2, были способны придавать C. glutamicum признак разложения панозы, при этом Tat-'Agl2 превосходил Tat-Agl1.
Таблица 8. Разложение панозы различными трансформантами DM1933, экспрессирующими различные α-1,6-глюкозидазы, слитые с сигнальным пептидом Cg0955
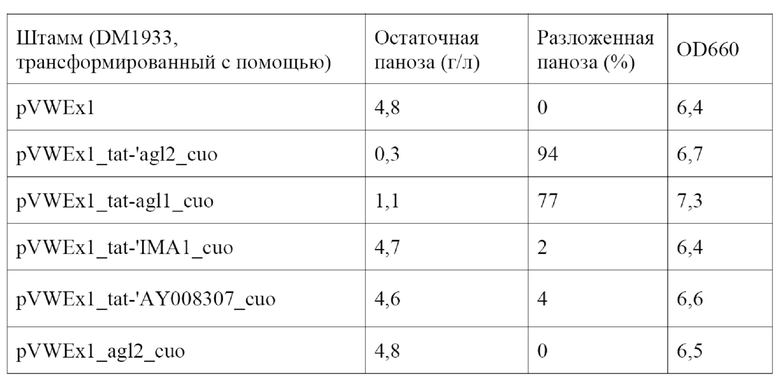
Пример 2
Идентификация подходящего сигнального пептида
Пример 2.1
Схема эксперимента
Tat-сигнальные пептиды для секреции различных секретируемых белков C. glutamicum тестировали в отношении их способности направлять секрецию α-1,6-глюкозидазы Agl2 в надосадочную жидкость культуры C. glutamicum.
Watanabe и соавт. (Microbiology 155, 741-750, 2009) оценивали эффективность различных Tat-сигнальных пептидов C. glutamicum R в отношении направления α-амилазы Geobacillus stearothermophilus, лишенной своего естественного сигнального пептида, в надосадочную жидкость культуры C. glutamicum R с помощью анализа диффузии на чашках с агаром. См. фигуру 3 на странице 745 у Watanabe и соавт.
В аналогичном подходе сигнальные пептиды полипептидов CgR0079, CgR0120, CgR0124, CgR0900, CgR0949, CgR1023, CgR1448, CgR2137, CgR2627 и CgR2926 оценивали в отношении их способности направлять α-1,6-глюкозидазу Agl2 B. breve UCC2003 в надосадочную жидкость культуры C. glutamicum путем измерения разложения панозы в надосадочной жидкости культуры. Соответственно, нуклеотидные последовательности, кодирующие сигнальные пептиды указанных полипептидов, сливали с геном agl2, оптимизированным по частоте использования кодонов для C. glutamicum ('agl2_cuo).
Нуклеотидные последовательности, кодирующие полипептиды, и аминокислотные последовательности полипептидов доступны в NCBI под номером доступа в GenBank NC_009342 (полный геном C. glutamicum R). В частности, их также можно идентифицировать по старым идентификаторам локусов cgR_0079, cgR_0120, cgR_0124, cgR_0900, cgR_0949, cgR_1023, cgR_1448, cgR_2137, cgR_2627 и cgR_2926. Кодирующая последовательность cgR0949 или, соответственно, cgR_0949 также показана под SEQ ID NO: 3 в перечне последовательностей.
Пример 2.2
Разработка и синтез слитых генов
В качестве исходной точки для конструирования различных слитых генов использовали плазмиду pVWEx1_tat-'agl2_cuo. Нуклеотидную последовательность, кодирующую Tat-сигнальный пептид Cg0955 (текущий идентификатор локуса NCgl0801), содержащуюся в плазмиде, заменяли нуклеотидной последовательностью, кодирующей сигнальный пептид CgR0079, CgR0120, CgR0124, CgR0900, CgR0949, CgR1023, CgR1448, CgR2137, CgR2627 или CgR2926.
Для этой цели плазмиду pVWEx1_tat-'agl2_cuo (см. фигуру 2) расщепляли рестрикционными эндонуклеазами SexAI и SpeI. Таким образом получали два фрагмента ДНК: один фрагмент ДНК длиной 109 п.о., кодирующий сигнальный пептид, и второй фрагмент ДНК длиной 10332 п.о., состоящий по сути из последовательностей ДНК pVWEx1 и 'agl2_cuo. Эти два фрагмента ДНК разделяли посредством электрофореза в агарозном геле. Фрагмент ДНК размером 109 п.о. отбрасывали, а фрагмент ДНК размером 10332 п.о. выделяли из агарозного геля и очищали.
Полинуклеотиды или, соответственно, молекулы ДНК, кодирующие различные сигнальные пептиды, содержащие предполагаемый сайт расщепления, описанные Watanabe и соавт., показаны под SEQ ID NO: 38-57.
За исключением полинуклеотида, кодирующего сигнальный пептид CgR0124, их конструировали и синтезировали с обеспечением возможности клонирования путем сборки по Гибсону. Для этой цели полинуклеотиды содержат на своих 5'-конце и 3'-конце последовательности длиной 25-45 п.о. и 24-54 п.о., которые перекрываются с соответствующими концами фрагмента ДНК размером 10332 п.о.
Для трансформации химически компетентных клеток E. coli Stellar™ использовали индивидуальные смеси Gibson Assembly из полинуклеотида, кодирующего сигнальный пептид CgR0079, CgR0120, CgR0900, CgR0949, CgR1023, CgR1448, CgR2137, CgR2627 и CgR2926, и указанного фрагмента ДНК pVWEx1_tat-'agl2_cuo размером 10332 п.о.
Разрабатывали и синтезировали полинуклеотид, кодирующий сигнальный пептид CgR0124 (см. SEQ ID NO: 42), для обеспечения возможности клонирования с использованием ДНК-лигазы. Для этой цели полинуклеотид содержит на своем 5'-конце сайт распознавания для SexAI, а на своем 3'-конце сайт распознавания для SpeI. Лигированную смесь, содержащую полинуклеотид, обработанный двумя рестрикционными эндонуклеазами, и указанный выделенный фрагмент ДНК pVWEx1_tat-'agl2_cuo размером 10332 п.о., использовали для трансформации химически компетентных клеток E. coli Stellar™.
Затем анализировали плазмидную ДНК произвольно выбранных трансформантов, полученных из различных смесей Gibson Assembly и лигированной смеси. Для этой цели трансформантов анализировали с помощью ПЦР колоний с использованием смеси Sapphire (см. таблицу 2) с праймером pVW_4 и праймером «Wtat», перечисленными в таблице 9, с последующим определением размеров амплификатов посредством капиллярного электрофореза. Праймеры также показаны под SEQ ID NO: 58 - SEQ ID NO: 68 в перечне последовательностей.
Таблица 9. Перечень используемых праймеров и размер амплификатов при ПЦР-анализе трансформантов
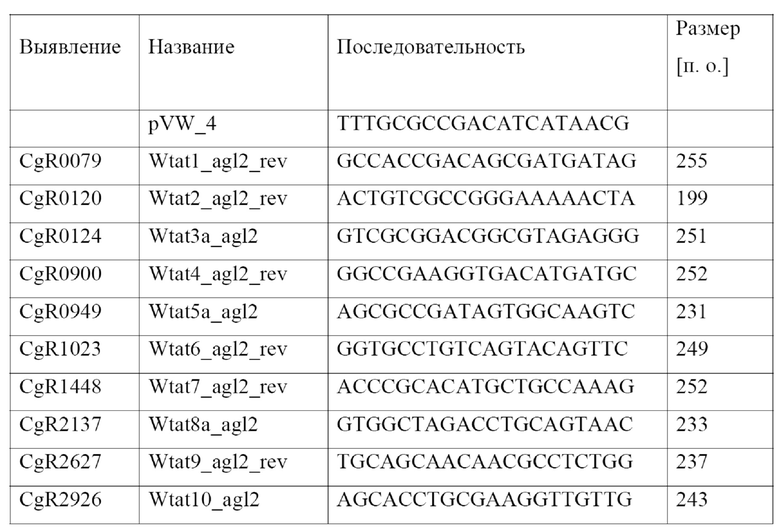
Таким образом, идентифицировали трансформантов, содержащих плазмиды, имеющие желаемую последовательность, кодирующую конкретный сигнальный пептид, связанный с полипептидом Agl2.
Несмотря на несколько попыток, не было получено трансформантов, несущих плазмиду, имеющую последовательность, кодирующую сигнальный пептид CgR0124.
Затем определяли нуклеотидные последовательности слитых генов, содержащихся в соответствующих плазмидах. Для этой цели плазмидную ДНК выделяли из трансформантов, и нуклеотидные последовательности отдельных слитых генов анализировали путем секвенирования по Сэнгеру.
Таким образом, идентифицировали плазмиды на основе pVWEx1, имеющие нуклеотидную последовательность, кодирующую сигнальный пептид CgR0079, CgR0120, CgR0900, CgR0949, CgR1023, CgR1448, CgR2137, CgR2627 и CgR2926, слитую с нуклеотидной последовательностью 'agl2_cuo.
Пример 2.3
Конструирование штамма
Штамм DM1933 C. glutamicum трансформировали описанными выше плазмидами путем электропорации. Трансформантов анализировали с помощью ПЦР колоний с использованием смеси Sapphire (см. таблицу 2) с праймерами из таблицы 9 и последующего анализа длины посредством капиллярного электрофореза.
Исходные культуры трансформантов в глицерине получали в присутствии канамицина и использовали в качестве исходного материала для дальнейших исследований.
Пример 2.4
Разложение панозы
Трансформантов, несущих различные слитые гены из примера 2.3, анализировали в отношении их способности разлагать панозу путем периодического культивирования с использованием системы для культивирования BioLector®.
В качестве среды использовали CGXII_CSL, содержащую 15 г/л глюкозы и 4,8 г/л панозы в качестве источника углерода. Среда, кроме того, была дополнена канамицином и IPTG.
Культуры инкубировали в течение приблизительно 20 часов до полного потребления глюкозы, что подтверждалось в анализе уровня глюкозы с использованием глюкометра. Затем определяли значения оптической плотности культур и концентрации остаточной панозы.
Результат эксперимента показан в таблице 10. Для удобства в таблицу были включены результаты Watanabe и соавт., касающиеся секреции α-амилазы.
Таблица 10. Разрушение панозы различными трансформантами DM1933, экспрессирующими различные сигнальные пептиды, слитые с α-1,6-глюкозидазой Agl2
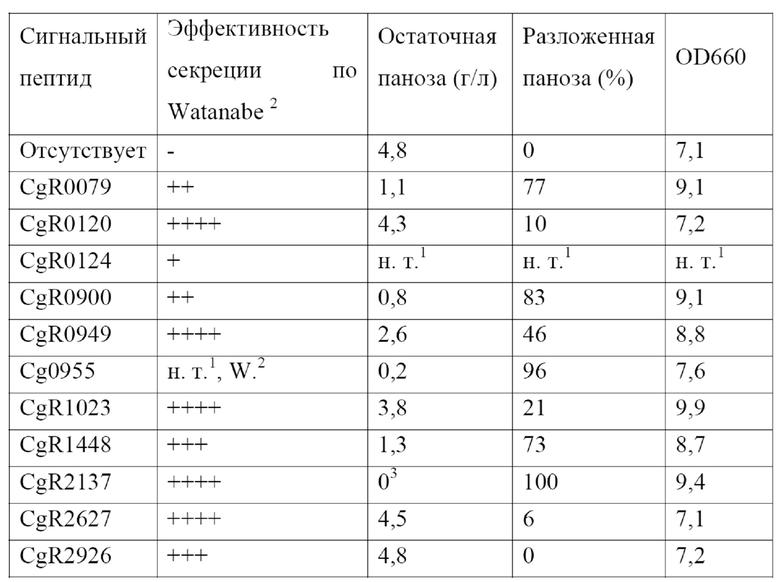
1 не тестировали
2 Watanabe и соавт.
3 не выявляемая
Наилучшего разложения панозы достигали с помощью штаммов, несущих слитые гены, кодирующие сигнальный пептид CgR2137 или Cg0955.
В дальнейшем штамм, экспрессирующий слитый полипептид, имеющий сигнальный пептид Cg0955, называется DM1933/pVWEx1_tat-'agl2_cuo (см. пример 1.3), а штамм, экспрессирующий слитый полипептид, имеющий сигнальный пептид CgR2137, называется DM1933/pVWEx1_cgR2137-'agl2_cuo.
Пример 2.5
Продуцирование L-лизина различными трансформантами штамма DM1933
Штаммы DM1933/pVWEx1, DM1933/pVWEx1_tat-'agl2_cuo и DM1933/pVWEx1_cgR2137-'agl2_cuo анализировали в отношении их способности продуцировать L-лизин из смеси глюкозы и панозы путем периодического культивирования с использованием системы BioLector®.
В качестве среды использовали CGXII_CSL, содержащую 15 г/л глюкозы и 4,8 г/л панозы в качестве источника углерода. Среда, кроме того, была дополнена канамицином и IPTG. Культуры инкубировали в течение приблизительно 20 часов до полного потребления глюкозы, что подтверждалось в анализе уровня глюкозы с использованием глюкометра, и определяли концентрации L-лизина, панозы и оптическую плотность OD660. Результат эксперимента представлен в таблице 11.
Таблица 11. Образование L-лизина при использовании смеси глюкозы и панозы в качестве источника углерода
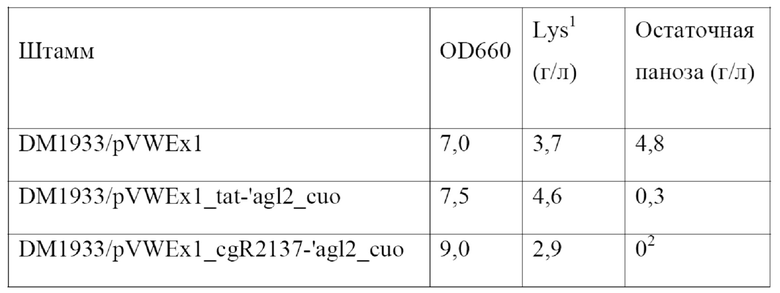
1 L-лизин в виде L-лизин x HCl
2 не выявляемая
Эксперимент показал, что образование L-лизина было сильно сниженным у штамма DM1933/pVWEx1_cgR2137-'agl2_cuo. Соответственно, работу со слитым геном cgR2137-'agl2_cuo больше не проводили.
Эксперимент, кроме того, показал, что штамм DM1933/pVWEx1_tat-'agl2_cuo способен продуцировать L-лизин из панозы.
Пример 3
Эффект экспрессии слитого гена tat-'agl2_cuo в отношении роста и выхода L-лизина
Разрабатывали эксперименты для оценивания того, может ли экспрессия слитого гена tat-'agl2_cuo, содержащегося в pVWEx1_tat-'agl2_cuo, отрицательно влиять на скорость роста своего хозяина и на продуцирование L-лизина.
Пример 3.1
Эффект в отношении роста при использовании глюкозы в качестве источника углерода
Штаммы DM1933/pVWEx1 и DM1933/pVWEx1_tat-'agl2_cuo культивировали с использованием системы BioLector®, и образование биомассы регистрировали путем измерения рассеянного света (сигнала обратного рассеяния).
В качестве среды использовали CGXII_CSL, содержащую 20 г/л глюкозы в качестве источника углерода. Среда, кроме того, была дополнена канамицином и IPTG. В конце культивирования измеряли α-1,6-глюкозидазную ферментативную активность в надосадочной жидкости культуры.
Результат представлен на фигуре 4 и в таблице 12. Показано, что экспрессия слитого гена tat-agl2_cuo, содержащегося в единице экспрессии, содержащей промотор PtacI, которая содержится в штамме DM1933/pVWEx1_tat-'agl2_cuo, не оказывает неблагоприятного влияния на скорость роста своего штамма-хозяина.
Таблица 12. α-1,6-Глюкозидазная ферментативная активность в надосадочной жидкости культуры штаммов DM1933/pVWEx1 и DM1933/pVWEx1_tat-'agl2_cuo после роста на глюкозе

Пример 3.2
Эффект в отношении продуцирования L-лизина при использовании глюкозы в качестве источника углерода
Штаммы DM1933/pVWEx1 и DM1933/pVWEx1_tat-'agl2_cuo культивировали с использованием системы BioLector®, и в конце культивирования измеряли концентрацию образовавшегося L-лизина.
В качестве среды использовали CGXII_CSL, содержащую 20 г/л глюкозы в качестве источника углерода. Среда, кроме того, была дополнена канамицином и IPTG. Культуры инкубировали в течение приблизительно 20 часов до полного потребления глюкозы, что подтверждалось в анализе уровня глюкозы с использованием глюкометра, и измеряли концентрацию образовавшегося L-лизина и оптическую плотность OD660.
Результат представлен в таблице 13. Показано, что экспрессия слитого гена tat-'agl2_cuo, содержащегося в единице экспрессии, содержащей промотор PtacI, которая содержится в штамме DM1933/pVWEx1_tat-'agl2_cuo, не оказывает неблагоприятного влияния на выход продуцируемого L-лизина.
Таблица 13. Продуцирование L-лизина штаммами DM1933/pVWEx1 и DM1933/pVWEx1_tat-'agl2_cuo при использовании глюкозы в качестве источника углерода
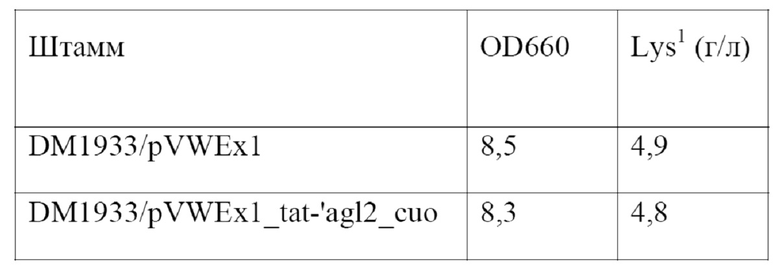
1 L-лизин в виде L-лизин x HCl
Пример 4
Продуцирование L-лизина при использовании трансформантов штамма DM2031
Продуцент L-лизина C. glutamicum DM2031 является потомком штамма DM1933, характеризующегося повышенной способностью продуцировать L-лизин. Он содержит дополнительную копию оперона lysC(T311I)asd, экспрессируемого под контролем промотора Pg3N3 (WO2013000827) и встроенного в межгенную область между NCgl0038 и NCgl0039. Кроме того, он содержит копию аллеля pyc(P458S), расположенного тандемно в сайте pyc(P458S), как описано в WO2003014330. Штамм был депонирован согласно Будапештскому договору в DSMZ под номером указания DSM32514.
Штамм DM2031 трансформировали плазмидами pVWEx1_tat-'agl2_cuo и pVWEx1. Штаммы DM2031/pVWEx1 и DM2031/pVWEx1_tat-'agl2_cuo, полученные таким образом, культивировали с использованием системы BioLector®, и в конце культивирования измеряли концентрацию образовавшегося L-лизина.
В качестве среды использовали CGXII_CSL, содержащую 8 г/л глюкозы либо 8 г/л глюкозы и 5,7 г/л панозы в качестве источника углерода. Среды, кроме того, были дополнены канамицином и IPTG. Культуры инкубировали в течение приблизительно 20 часов до полного потребления глюкозы, что подтверждалось в анализе уровня глюкозы с использованием глюкометра, и измеряли концентрацию образовавшегося L-лизина.
Таблица 14. Продуцирование L-лизина трансформантами штамма DM2031 при использовании глюкозы и смеси глюкозы и панозы в качестве источника углерода
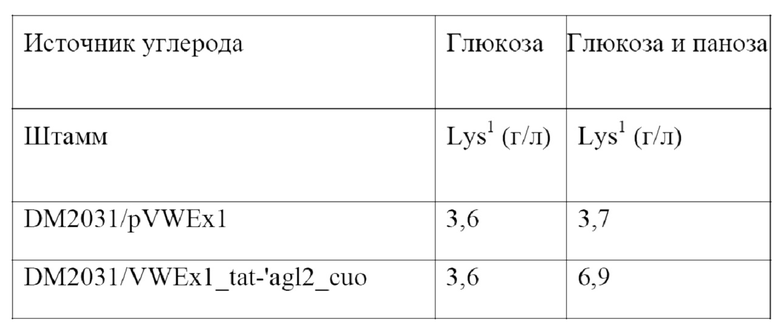
1 L-лизин в виде L-лизин x HCl
Результат представлен в таблице 14. Показано, что штамм DM2031/pVWEx1_tat-'agl2_cuo способен продуцировать L-лизин из панозы.
Пример 5
Хромосомная интеграция и экспрессия слитого гена tat-'agl2_cuo
Единицу экспрессии (см. SEQ ID NO: 16), содержащую промотор PdapBN1 (см. SEQ ID NO: 15), слитый ген tat-'agl2_cuo (см. SEQ ID NO: 9) и терминатор транскрипции Tgap* (см. SEQ ID NO: 13), разрабатывали, синтезировали и интегрировали в целевой сайт, который представляет собой межгенную область между локусами с идентификаторами NCgl2176 и NCgl2177 (см. SEQ ID NO: 18) в хромосоме продуцента L-лизина DM1933.
Для переноса единицы экспрессии в хромосому использовали плазмиду pK18mobsacB вместе со штаммом S17-1 E. coli, как описано у Schäfer и соавт. (Gene 145, 69 - 73, 1994). Нуклеотидная последовательность pK18mobsacB доступна в базе данных GenBank под номером доступа FJ437239.
Пример 5.1
Конструирование плазмиды pK18mobsacB_INT::PBN1-tat-'agl2_cuo
На первом этапе разрабатывали и синтезировали полинуклеотид или, соответственно, молекулу ДНК для предоставления фланкирующих последовательностей, необходимых для интеграции единицы экспрессии в целевой сайт в хромосоме хозяина C. glutamicum путем гомологичной рекомбинации. Полинуклеотид назвали INT.
Нуклеотидная последовательность полинуклеотида (молекулы ДНК) INT показана под SEQ ID NO: 69. Она содержит от своего 5'-конца до своего 3'-конца сайт распознавания для рестрикционной эндонуклеазы EcoRI, часть (3'-конец) гена, идентифицируемую по идентификатору локуса NCgl2176, межгенную область (IR) между локусами с идентификаторами NCgl2176 и NCgl2177, имеющую сайты распознавания для рестрикционных эндонуклеаз EcoRV (GATATC), AvrII (CCTAGG) и SmaI (CCCGGG), искусственно созданные путем обмена нуклеотидов, нуклеотидную последовательность гена, идентифицируемую по идентификатору локуса NCgl2177 (в комплементарной нити молекулы ДНК), последовательность, расположенную выше NCgl2177, и сайт распознавания для рестрикционной эндонуклеазы HindIII (AAGCTT).
Два сайта рестрикции для EcoRI и HindIII на 5'- и 3'-конце молекулы ДНК использовали для клонирования полинуклеотида в вектор pK18mobsacB, разрезанный рестрикционными эндонуклеазами EcoRI и HindIII.
В результате получали вектор pK18mobsacB, содержащий полинуклеотид INT. Эту плазмиду назвали pK18mobsacB_INT.
На втором этапе разрабатывали и синтезировали полинуклеотид, содержащий единицу экспрессии под названием PBN1-tat-'agl2_cuo. Он содержит промотор PdapBN1, слитый ген tat-'agl2_cuo и терминатор транскрипции Tgap*. Его нуклеотидная последовательность показана под SEQ ID NO: 70. Она содержит нуклеотидную последовательность SEQ ID NO: 16 и дополнительно содержит 20 нуклеотидов (GCGTCTAGAACTGATGAACA) на 5'-конце и 9 нуклеотидов (GGATCCGCG) на 3'-конце. Карта единицы экспрессии PBN1-tat-'agl2_cuo показана на фигуре 5.
На третьем этапе полинуклеотид PBN1-tat-'agl2_cuo обрабатывали рестрикционной эндонуклеазой XbaI и клонировали в вектор pK18mobsacB_INT, линеаризованный путем обработки рестрикционной эндонуклеазой AvrII. Химически компетентные клетки E. coli Stellar™ использовали в качестве хозяев для трансформации.
Плазмидную ДНК выделяли из трансформантов и обрабатывали рестрикционной эндонуклеазой HincII. Фрагменты ДНК разделяли посредством электрофореза в агарозном геле (0,8% вес/объем агарозы).
Плазмиды, содержащие единицу экспрессии PBN1-tat-'agl2_cuo в желаемой ориентации в межгенной области (IR) полинуклеотида INT, при этом желаемая ориентация представляет собой 5'-'NCgl2176-PBN1-tat-'agl2_cuo-NCgl2177-3', идентифицировали по картине расположения фрагментов ДНК, имеющих длину 3197 п.о., 2928 п.о., 2314 п.о. и 822 п.о. Одну из плазмид, идентифицированных таким образом, назвали pK18mobsacB_INT::PBN1-tat-'agl2_cuo. Целостность единицы INT::PBN1-tat-'agl2_cuo в плазмиде подтверждали путем определения ее нуклеотидной последовательности с помощью способа Сэнгера. Карта указанной единицы INT::PBN1-tat-'agl2_cuo показана на фигуре 6. В сущности она состоит из признаков 'NCgl2176, IR', единицы экспрессии PBN1-tat-'agl2_cuo, 'IR и NCgl2177. Сегмент с признаками 'NCgl2176 и IR' представляет собой 5'-фланкирующую последовательность, а сегмент с признаками 'IR и NCgl2177 представляет собой 3'-фланкирующую последовательность, необходимые для интеграции единицы экспрессии PBN1-tat-'agl2_cuo в хромосому. Карта плазмиды pK18mobsacB_INT::PBN1-tat-'agl2_cuo показана на фигуре 7.
Пример 5.2
Конструирование штамма DM1933_INT::PBN1-tat-'agl2_cuo
Плазмиду pK18mobsacB_INT::PBN1-tat-'agl2_cuo использовали для интеграции единицы экспрессии PBN1-tat-'agl2_cuo в хромосому продуцента L-лизина DM1933.
Для этой цели штамм S17-1 E. coli трансформировали плазмидной ДНК, полученной в примере 5.1. Модифицированный способ конъюгации по Schäfer и соавт. (Journal of Bacteriology 172, 1663 - 1666, 1990), описанный в разделе «Материалы и способы», использовали для конъюгационного переноса в штамм DM1933 и отбора клонов трансконъюгантов на основании их фенотипа устойчивости к сахарозе и чувствительности к канамицину.
Клоны трансконъюгантов анализировали с помощью ПЦР колоний с использованием набора Taq с праймерами IR_1 и IR_2, перечисленными в таблице 15, с последующим определением размеров амплификатов посредством капиллярного электрофореза. Праймеры также показаны под SEQ ID NO: 71 и SEQ ID NO: 72 в перечне последовательностей. Для ПЦР использовали набор Taq (см. таблицу 1) с температурой на этапе отжига (этапе 3), установленной на 55°C, и продолжительностью этапа элонгации (этапа 4), установленной на 40 секунд.
Таблица 15. Перечень используемых праймеров и размер амплификата при ПЦР-анализе клонов трансконъюгантов

Нуклеотидные последовательности продуктов ПЦР клонов трансконъюгантов, имеющих надлежащий размер, дополнительно анализировали путем секвенирования по Сэнгеру.
Одного из клонов трансконъюгантов, охарактеризованных таким образом, назвали DM1933_INT::PBN1-tat-'agl2_cuo. Исходную культуру клона трансконъюганта в глицерине получали и использовали в качестве исходного материала для дальнейших исследований.
Пример 5.3
Продуцирование L-лизина штаммом DM1933_INT::PBN1-tat-'agl2_cuo при использовании глюкозы и смеси глюкозы и панозы в качестве источника углерода
Штаммы DM1933_INT::PBN1-tat-'agl2_cuo и DM1933 в качестве контроля анализировали в отношении их способности продуцировать L-лизин из глюкозы или из смеси глюкозы и панозы путем периодического культивирования с использованием системы BioLector®.
В качестве среды использовали CGXII_CSL, содержащую 20 г/л глюкозы, либо 15 г/л глюкозы, либо смесь 15 г/л глюкозы и 4,8 г/л панозы. Культуры инкубировали в течение приблизительно 20 часов до полного потребления глюкозы, что подтверждалось в анализе уровня глюкозы с использованием глюкометра. Затем измеряли значения оптической плотности OD660 и концентрации L-лизина и панозы.
Результат эксперимента представлен в таблице 16. Показано, что присутствие единицы экспрессии PBN1-tat-'agl2_cuo в штамме DM1933_INT::PBN1-tat-'agl2_cuo не оказывает отрицательного эффекта на выход L-лизина на глюкозе. Кроме того, показано, что штамм DM1933_INT::PBN1-tat-'agl2_cuo способен продуцировать L-лизин из панозы.
Таблица 16. Продуцирование L-лизина штаммом DM1933_INT::PBN1-tat'-agl2_cuo
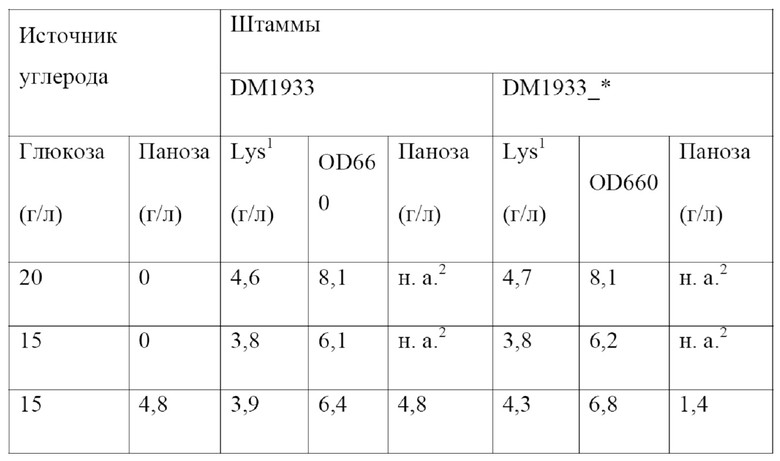
*INT::PBN1-tat-'agl2_cuo
1 L-лизин в виде L-лизин x HCl
2 не анализировали
Пример 6
Продуцирование L-лизина штаммом DM1933_INT::PBN1-tat-'agl2_cuo при использовании гидролизата крахмала в качестве источника углерода
Штаммы DM1933 и DM1933_INT::PBN1-tat-'agl2_cuo культивировали в среде CGXII_CSL с использованием гидролизата крахмала в качестве источника углерода (77,3 мл гидролизата крахмала Clear Sweet®/л). Среда, полученная таким образом, содержала 60 г/л глюкозы, 0,4 г/л панозы и 1,2 г/л изомальтозы.
Культивирование выполняли в 2-литровых колбах Эрленмейера, как описано в разделе «Материалы и способы». Образцы отбирали из культур в различные моменты времени, и измеряли значения оптической плотности OD660 и концентрации L-лизина, изомальтозы, панозы и глюкозы. Результат эксперимента кратко изложен в таблице 17. Показано, что штамм DM1933_INT::PBN1-tat-'agl2_cuo способен потреблять изомальтозу и панозу, содержащиеся в гидролизате крахмала.
Таблица 17. Продуцирование L-лизина при использовании гидролизата крахмала в качестве источника углерода
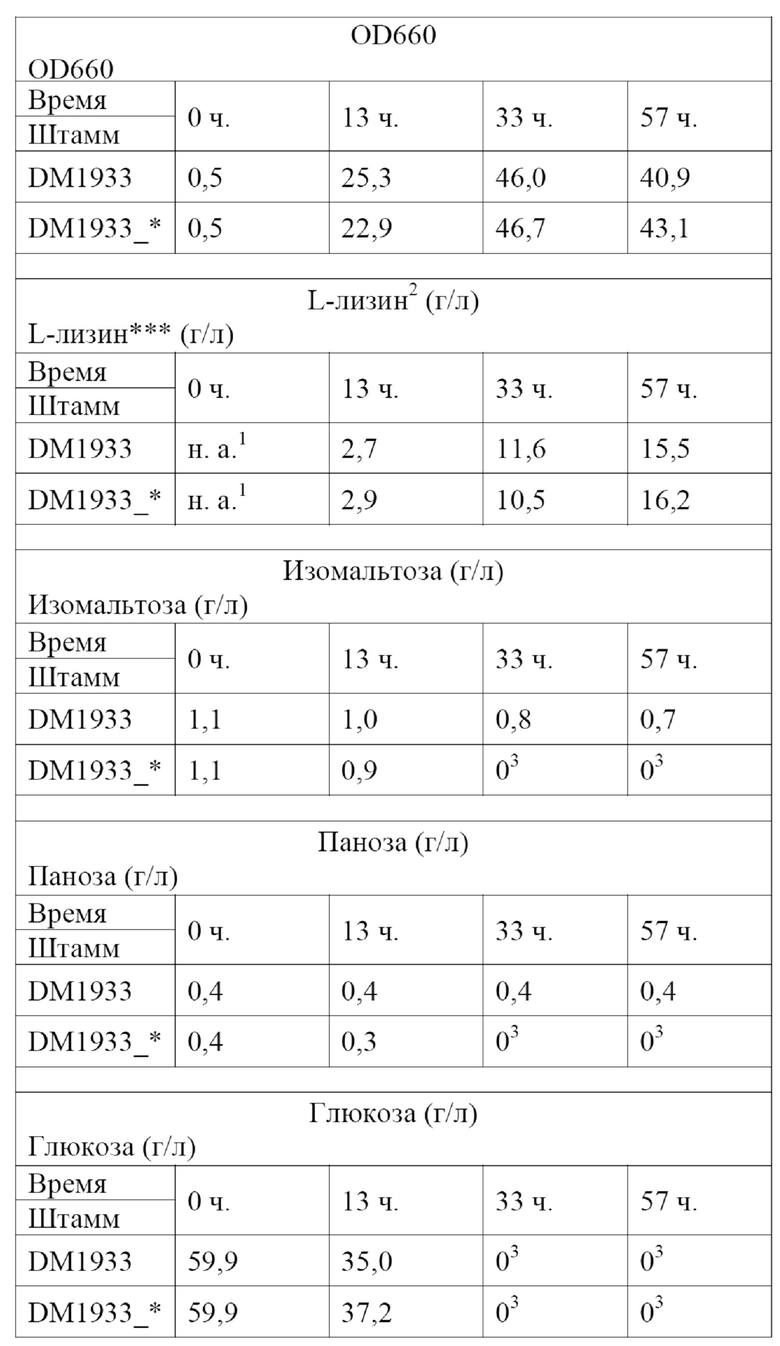
* INT::PBN1-tat-'agl2_cuo 2 в виде L-лизин x HCl
1 не анализировали 3 не выявляемая
Пример 7
Определение аминокислотной последовательности секретируемого слитого белка на основе α-1,6-глюкозидазы
Штамм DM1933_INT::PBN1-tat-'agl2_cuo культивировали, и надосадочную жидкость культуры собирали, фильтровали и концентрировали, как подробно описано в разделе «Материалы и способы». Затем концентрированную надосадочную жидкость анализировали с помощью жидкостной хроматографии в сочетании с масс-спектрометрией (LC-MS).
В надосадочной жидкости культуры было обнаружено два вида полипептидов. Один, имеющий общую формулу C3031 H4582 N844 O958 S18, соответствует аминокислотной последовательности SEQ ID NO: 10 в положениях 31-639. Другой, имеющий общую формулу C3004 H4535 N837 O948 S17, соответствует аминокислотной последовательности SEQ ID NO: 10 в положениях 38-639. Оба полипептида были обнаружены в отношении приблизительно 1:1.
Пример 8
Продуцирование L-валина
Исследовали продуцирование L-валина из панозы с использованием слитого гена tat-'agl2_cuo.
Пример 8.1
Конструирование продуцента L-валина, содержащего слитый ген tat-'agl2_cuo
Штамм ATCC14067_PprpD2-ilvBN является продуцентом L-валина, принадлежащим к виду C. glutamicum. Конструирование штамма, начиная со штамма ATCC14067, описано в EP2811028 A1.
Штамм ATCC14067_PprpD2-ilvBN трансформировали выделенной плазмидной ДНК pVWEx1 и pVWEx1_tat-'agl2_cuo путем электропорации. Отбор трансформантов, размножение трансформантов и получение исходных культур в глицерине выполняли согласно описанному в разделе «Материалы и способы» и в присутствии канамицина.
Конкретные нуклеотидные последовательности трансформантов амплифицировали с помощью ПЦР колоний для проверки плазмидного статуса трансформантов. Используемые праймеры и размер ПЦР-амплификатов кратко изложены в таблице 18.
Таблица 18. Перечень используемых праймеров и размер амплификатов при ПЦР-анализе трансформантов

Для ПЦР использовали смесь Sapphire (см. таблицу 2) с температурой на этапе отжига (этапе 3), установленной на 53°C, и продолжительностью этапа элонгации (этапа 4), установленной на 10 секунд. Определение размера амплификатов выполняли посредством капиллярного электрофореза.
Нуклеотидные последовательности используемых праймеров также показаны в перечне последовательностей под SEQ ID NO: 33 - SEQ ID NO: 36.
Трансформантов ATCC14067_PprpD2-ilvBN/pVWEx1 и ATCC14067_PprpD2-ilvBN/pVWEx1_tat-'agl2_cuo, полученных и проанализированных таким образом, использовали для дальнейшего исследования.
Пример 8.2
Продуцирование L-валина штаммом ATCC14067_PprpD2-ilvBN/pVWEx1_tat-'agl2_cuo при использовании глюкозы и смеси глюкозы и панозы в качестве источника углерода
Штаммы ATCC14067_PprpD2-ilvBN/pVWEx1_tat-'agl2_cuo и ATCC14067_PprpD2-ilvBN/pVWEx1 в качестве контроля анализировали в отношении их способности продуцировать L-валин из глюкозы или из смеси глюкозы и панозы путем периодического культивирования с использованием системы BioLector®.
В качестве среды использовали CGXII_YE, содержащую 15 г/л глюкозы либо смесь 15 г/л глюкозы и 4,8 г/л панозы. Среды, кроме того, были дополнены канамицином, IPTG и гемикальциевой солью пропионовой кислоты (0,75 г/л). Культуры инкубировали в течение приблизительно 25 часов до полного потребления глюкозы, что подтверждалось в анализе уровня глюкозы с использованием глюкометра. Затем измеряли значения оптической плотности OD660 и концентрации L-валина и панозы.
Результат эксперимента представлен в таблице 19. Показано, что присутствие слитого гена tat-'agl2, содержащегося в единице экспрессии, содержащей промотор PtacI, которая содержится в штамме ATCC14067_PprpD2-ilvBN/pVWEx1_tat-'agl2_cuo, позволяет штамму продуцировать L-валин из панозы.
Таблица 19. Продуцирование L-валина штаммом ATCC14067_PprpD2-ilvBN/pVWEx1_tat-'agl2_cuo
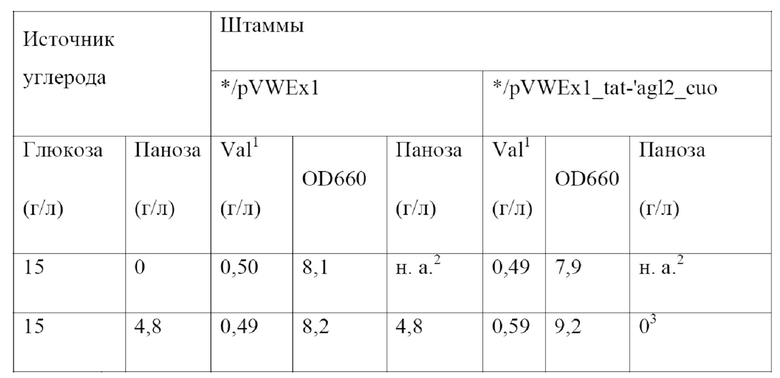
* ATCC14067_PprpD2-ilvBN
1 L-валин
2 не анализировали
3 не выявляемая
ПЕРЕЧЕНЬ СОКРАЩЕНИЙ
'agl2_cuo оптимизированная по частоте использования кодонов кодирующая последовательность гена agl2 Bifidobacterium breve UCC2003, не имеющая стартового кодона ATG
'IR 3'-концевая последовательность межгенной области (IR) между генами, идентифицируемыми по идентификаторам локусов Ncgl2177 и Ncgl2176
'Ncgl2176 3'-концевая последовательность кодирующей последовательности, идентифицируемая по идентификатору локуса Ncgl2176
(AvrII/XbaI) гибридная последовательность, полученная после лигирования «липких» концов, созданных с помощью рестрикционных эндонуклеаз AvrII и XbaI
agl2_cuo оптимизированная по частоте использования кодонов кодирующая последовательность гена agl2 Bifidobacterium breve UCC2003
BamHI последовательность, распознаваемая рестрикционной эндонуклеазой BamHI
EcoRI последовательность, распознаваемая рестрикционной эндонуклеазой EcoRI
FspAI последовательность, распознаваемая рестрикционной эндонуклеазой FspAI
ч. часы
HincII последовательность, распознаваемая рестрикционной эндонуклеазой HincII
HindIII последовательность, распознаваемая рестрикционной эндонуклеазой HindIII
IR' 5'-концевая последовательность межгенной области (IR) между генами, идентифицируемыми по идентификаторам локусов Ncgl2177 и Ncgl2176
lacI ген, кодирующий репрессор LacI
lacZ-альфа 5'-концевая последовательность гена lacZ, кодирующего α-пептид β-галактозидазы
MauBI последовательность, распознаваемая рестрикционной эндонуклеазой MauBI
MCS сайт множественного клонирования
Ncgl2177 кодирующая последовательность, идентифицируемая по идентификатору локуса Ncgl2177
neo ген, кодирующий аминогликозид-3'-фосфотрансферазу
nptII ген, кодирующий неомицинфосфотрансферазу
ori p15A точка начала репликации плазмиды p15A E. coli
ori pCG1 точка начала репликации плазмиды pCG1 C. glutamicum
ori pMB1 точка начала репликации плазмиды pMBI E. coli
PBN1 последовательность промотора PdapBN1
PtacI последовательность промотора PtacI
PstI последовательность, распознаваемая рестрикционной эндонуклеазой PstI
RP4-mob последовательность области mob плазмиды RP4
sacB ген, кодирующий левансахаразу
SexAI последовательность, распознаваемая рестрикционной эндонуклеазой SexAI
SpeI последовательность, распознаваемая рестрикционной эндонуклеазой SpeI
tat 5'-конец кодирующей последовательности cg0955 C. glutamicum ATCC13032, кодирующей Tat-сигнальный пептид (диаргининовый транслокатор)
tat-'agl2_cuo последовательность слитого гена, кодирующая слитый полипептид Tat-'Agl2
Tgap* последовательность терминатора Tgap*
XbaI последовательность, распознаваемая рестрикционной эндонуклеазой XbaI
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> Эвоник Дегусса ГмбХ
<120> Способ получения химических продуктов тонкого синтеза
с помощью Corynebacterium, секретирующей модифицированные
альфа-1,6-глюкозидазы
<130> 201700156
<160> 72
<170> PatentIn, версия 3.5
<210> 1
<211> 843
<212> ДНК
<213> Corynebacterium glutamicum ATCC13032
<220>
<221> CDS
<222> (1)..(840)
<223> cg0955
<220>
<221> прочая_сигнальная_последовательность
<222> (1)..(99)
<223> 5'-концевая последовательность cg0955, кодирующая
Tat-сигнальный пептид Cg0955
<220>
<221> прочий_признак
<222> (1)..(101)
<223> 5'-концевая последовательность cg0955
<220>
<221> прочий_признак
<222> (102)..(102)
<223> нуклеотидное основание цитозин
<220>
<221> прочий_признак
<222> (841)..(843)
<223> стоп-кодон
<400> 1
atg caa ata aac cgc cga ggc ttc tta aaa gcc acc aca gga ctt gcc 48
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr Thr Gly Leu Ala
1 5 10 15
act atc ggc gct gcc agc atg ttt atg cca aag gcc aac gcc ctt gga 96
Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala Asn Ala Leu Gly
20 25 30
gca atc aag ggc acc gtc atc gac tac gca gca ggc gtc ccc agc gca 144
Ala Ile Lys Gly Thr Val Ile Asp Tyr Ala Ala Gly Val Pro Ser Ala
35 40 45
gca tcc att aaa aat gca ggg cac ctt gga gct gtc cgt tac gtg tca 192
Ala Ser Ile Lys Asn Ala Gly His Leu Gly Ala Val Arg Tyr Val Ser
50 55 60
cag cga cgc ccc ggc act gaa tcc tgg atg atc ggc aag cca gtc aca 240
Gln Arg Arg Pro Gly Thr Glu Ser Trp Met Ile Gly Lys Pro Val Thr
65 70 75 80
ctg gca gaa acc cga gct ttt gaa caa aac ggc ctc aaa acc gca tcc 288
Leu Ala Glu Thr Arg Ala Phe Glu Gln Asn Gly Leu Lys Thr Ala Ser
85 90 95
gtc tat caa tac gga aag gca gag acc gcc gat tgg aag aac ggc gcc 336
Val Tyr Gln Tyr Gly Lys Ala Glu Thr Ala Asp Trp Lys Asn Gly Ala
100 105 110
gca gga gcg gca acc cac gct cca cag gca att gcg ctt cac gtg gca 384
Ala Gly Ala Ala Thr His Ala Pro Gln Ala Ile Ala Leu His Val Ala
115 120 125
gct ggt ggc cct aaa aat cgc ccc atc tac gtg gcg atc gac gac aac 432
Ala Gly Gly Pro Lys Asn Arg Pro Ile Tyr Val Ala Ile Asp Asp Asn
130 135 140
cca agc tgg tct gaa tac acc aat cag att cgc ccc tac ctc cag gca 480
Pro Ser Trp Ser Glu Tyr Thr Asn Gln Ile Arg Pro Tyr Leu Gln Ala
145 150 155 160
ttc aat gtt gcg ctg tcc gct gcc ggc tac cag tta ggt gtc tac ggc 528
Phe Asn Val Ala Leu Ser Ala Ala Gly Tyr Gln Leu Gly Val Tyr Gly
165 170 175
aac tac aac gtc att aat tgg gct atc gcc gac ggc ctt gga gaa ttc 576
Asn Tyr Asn Val Ile Asn Trp Ala Ile Ala Asp Gly Leu Gly Glu Phe
180 185 190
ttc tgg atg cac aac tgg gga tca gaa gga aag atc cac cca cgc acc 624
Phe Trp Met His Asn Trp Gly Ser Glu Gly Lys Ile His Pro Arg Thr
195 200 205
acc atc cac cag atc cgc att gat aag gac acc ctc gac gga gtc ggc 672
Thr Ile His Gln Ile Arg Ile Asp Lys Asp Thr Leu Asp Gly Val Gly
210 215 220
atc gac atg aac aat gtc tat gca gac gac tgg ggt cag tgg acc cca 720
Ile Asp Met Asn Asn Val Tyr Ala Asp Asp Trp Gly Gln Trp Thr Pro
225 230 235 240
ggc aac gcg gtt gac gat gcc atc ccc acc att cct gga aac tcc aac 768
Gly Asn Ala Val Asp Asp Ala Ile Pro Thr Ile Pro Gly Asn Ser Asn
245 250 255
acg gga aca ggt act gga att gat gct gac acc atc aac caa gta atc 816
Thr Gly Thr Gly Thr Gly Ile Asp Ala Asp Thr Ile Asn Gln Val Ile
260 265 270
aag att ctt ggc acc cta tct agc taa 843
Lys Ile Leu Gly Thr Leu Ser Ser
275 280
<210> 2
<211> 280
<212> БЕЛОК
<213> Corynebacterium glutamicum ATCC13032
<400> 2
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr Thr Gly Leu Ala
1 5 10 15
Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala Asn Ala Leu Gly
20 25 30
Ala Ile Lys Gly Thr Val Ile Asp Tyr Ala Ala Gly Val Pro Ser Ala
35 40 45
Ala Ser Ile Lys Asn Ala Gly His Leu Gly Ala Val Arg Tyr Val Ser
50 55 60
Gln Arg Arg Pro Gly Thr Glu Ser Trp Met Ile Gly Lys Pro Val Thr
65 70 75 80
Leu Ala Glu Thr Arg Ala Phe Glu Gln Asn Gly Leu Lys Thr Ala Ser
85 90 95
Val Tyr Gln Tyr Gly Lys Ala Glu Thr Ala Asp Trp Lys Asn Gly Ala
100 105 110
Ala Gly Ala Ala Thr His Ala Pro Gln Ala Ile Ala Leu His Val Ala
115 120 125
Ala Gly Gly Pro Lys Asn Arg Pro Ile Tyr Val Ala Ile Asp Asp Asn
130 135 140
Pro Ser Trp Ser Glu Tyr Thr Asn Gln Ile Arg Pro Tyr Leu Gln Ala
145 150 155 160
Phe Asn Val Ala Leu Ser Ala Ala Gly Tyr Gln Leu Gly Val Tyr Gly
165 170 175
Asn Tyr Asn Val Ile Asn Trp Ala Ile Ala Asp Gly Leu Gly Glu Phe
180 185 190
Phe Trp Met His Asn Trp Gly Ser Glu Gly Lys Ile His Pro Arg Thr
195 200 205
Thr Ile His Gln Ile Arg Ile Asp Lys Asp Thr Leu Asp Gly Val Gly
210 215 220
Ile Asp Met Asn Asn Val Tyr Ala Asp Asp Trp Gly Gln Trp Thr Pro
225 230 235 240
Gly Asn Ala Val Asp Asp Ala Ile Pro Thr Ile Pro Gly Asn Ser Asn
245 250 255
Thr Gly Thr Gly Thr Gly Ile Asp Ala Asp Thr Ile Asn Gln Val Ile
260 265 270
Lys Ile Leu Gly Thr Leu Ser Ser
275 280
<210> 3
<211> 843
<212> ДНК
<213> Corynebacterium glutamicum R
<220>
<221> CDS
<222> (1)..(840)
<223> cgR0949
<220>
<221> прочая_сигнальная_последовательность
<222> (1)..(99)
<223> 5'-концевая последовательность cgR0949, кодирующая
Tat-сигнальный пептид CgR0949
<220>
<221> прочий_признак
<222> (1)..(101)
<223> 5'-концевая последовательность cgR0949
<220>
<221> прочий_признак
<222> (102)..(102)
<223> нуклеотидное основание цитозин
<220>
<221> прочий_признак
<222> (841)..(843)
<223> стоп-кодон
<400> 3
atg caa ata aac cgc cga ggc ttc tta aaa gcc acc gca gga ctt gcc 48
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr Ala Gly Leu Ala
1 5 10 15
act atc ggc gct gcc agc atg ttt atg cca aag gcc aac gcc ctt gga 96
Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala Asn Ala Leu Gly
20 25 30
gca atc aag ggc acc gtc atc gac tac gca gca ggc gtc ccc agc gca 144
Ala Ile Lys Gly Thr Val Ile Asp Tyr Ala Ala Gly Val Pro Ser Ala
35 40 45
gca tcc att aaa aat gca ggg cac ctt gga gct gtc cgt tac gtg tca 192
Ala Ser Ile Lys Asn Ala Gly His Leu Gly Ala Val Arg Tyr Val Ser
50 55 60
cag cga cgc ccc ggc act gaa tcc tgg atg atc ggc aag cca gtc aca 240
Gln Arg Arg Pro Gly Thr Glu Ser Trp Met Ile Gly Lys Pro Val Thr
65 70 75 80
ctg gca gaa acc cga tct ttt gaa caa aac ggc ctc aaa acc gca tcc 288
Leu Ala Glu Thr Arg Ser Phe Glu Gln Asn Gly Leu Lys Thr Ala Ser
85 90 95
gtt tat caa tac gga aag gca gag acc gcc gat tgg aag aac ggc gcc 336
Val Tyr Gln Tyr Gly Lys Ala Glu Thr Ala Asp Trp Lys Asn Gly Ala
100 105 110
gca gga gcg gca acc cac gct cca cag gca att gcg ctt cac gtg gca 384
Ala Gly Ala Ala Thr His Ala Pro Gln Ala Ile Ala Leu His Val Ala
115 120 125
gct ggt ggc cct aaa aat cgc ccc atc tac gtg gcg atc gac gac aac 432
Ala Gly Gly Pro Lys Asn Arg Pro Ile Tyr Val Ala Ile Asp Asp Asn
130 135 140
cca agc tgg tct gaa tac acc aat cag att cgc cct tac ctc cag gca 480
Pro Ser Trp Ser Glu Tyr Thr Asn Gln Ile Arg Pro Tyr Leu Gln Ala
145 150 155 160
ttc aat gtt gcg ctg tcc gct gcc ggc tac cag tta ggt gtg tac ggc 528
Phe Asn Val Ala Leu Ser Ala Ala Gly Tyr Gln Leu Gly Val Tyr Gly
165 170 175
aac tac aac gtc att gat tgg gct atc gcc gac ggc ctt gga gaa ttc 576
Asn Tyr Asn Val Ile Asp Trp Ala Ile Ala Asp Gly Leu Gly Glu Phe
180 185 190
ttc tgg atg cac aac tgg gga tca gaa gga aag atc cac cca cgc acc 624
Phe Trp Met His Asn Trp Gly Ser Glu Gly Lys Ile His Pro Arg Thr
195 200 205
acc atc cac cag atc cgc att gat aaa gac aac ctc gag ggt gtt ggc 672
Thr Ile His Gln Ile Arg Ile Asp Lys Asp Asn Leu Glu Gly Val Gly
210 215 220
att gac atg aac aat gtc tat gca gac gac tgg ggc cag tgg acc cca 720
Ile Asp Met Asn Asn Val Tyr Ala Asp Asp Trp Gly Gln Trp Thr Pro
225 230 235 240
gac aat gcg gtt gac gat gtc ttc ccc acc att ccc gga aac tcc aac 768
Asp Asn Ala Val Asp Asp Val Phe Pro Thr Ile Pro Gly Asn Ser Asn
245 250 255
acg gga aca ggt act gga att gat gct gac acc atc aac caa gta atc 816
Thr Gly Thr Gly Thr Gly Ile Asp Ala Asp Thr Ile Asn Gln Val Ile
260 265 270
aag att ctt ggc acc ctg tct agc taa 843
Lys Ile Leu Gly Thr Leu Ser Ser
275 280
<210> 4
<211> 280
<212> БЕЛОК
<213> Corynebacterium glutamicum R
<400> 4
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr Ala Gly Leu Ala
1 5 10 15
Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala Asn Ala Leu Gly
20 25 30
Ala Ile Lys Gly Thr Val Ile Asp Tyr Ala Ala Gly Val Pro Ser Ala
35 40 45
Ala Ser Ile Lys Asn Ala Gly His Leu Gly Ala Val Arg Tyr Val Ser
50 55 60
Gln Arg Arg Pro Gly Thr Glu Ser Trp Met Ile Gly Lys Pro Val Thr
65 70 75 80
Leu Ala Glu Thr Arg Ser Phe Glu Gln Asn Gly Leu Lys Thr Ala Ser
85 90 95
Val Tyr Gln Tyr Gly Lys Ala Glu Thr Ala Asp Trp Lys Asn Gly Ala
100 105 110
Ala Gly Ala Ala Thr His Ala Pro Gln Ala Ile Ala Leu His Val Ala
115 120 125
Ala Gly Gly Pro Lys Asn Arg Pro Ile Tyr Val Ala Ile Asp Asp Asn
130 135 140
Pro Ser Trp Ser Glu Tyr Thr Asn Gln Ile Arg Pro Tyr Leu Gln Ala
145 150 155 160
Phe Asn Val Ala Leu Ser Ala Ala Gly Tyr Gln Leu Gly Val Tyr Gly
165 170 175
Asn Tyr Asn Val Ile Asp Trp Ala Ile Ala Asp Gly Leu Gly Glu Phe
180 185 190
Phe Trp Met His Asn Trp Gly Ser Glu Gly Lys Ile His Pro Arg Thr
195 200 205
Thr Ile His Gln Ile Arg Ile Asp Lys Asp Asn Leu Glu Gly Val Gly
210 215 220
Ile Asp Met Asn Asn Val Tyr Ala Asp Asp Trp Gly Gln Trp Thr Pro
225 230 235 240
Asp Asn Ala Val Asp Asp Val Phe Pro Thr Ile Pro Gly Asn Ser Asn
245 250 255
Thr Gly Thr Gly Thr Gly Ile Asp Ala Asp Thr Ile Asn Gln Val Ile
260 265 270
Lys Ile Leu Gly Thr Leu Ser Ser
275 280
<210> 5
<211> 1815
<212> ДНК
<213> Bifidobacterium breve UCC2003
<220>
<221> CDS
<222> (1)..(1812)
<223> agl2
<220>
<221> прочий_признак
<222> (4)..(1812)
<223> 'agl2
<220>
<221> прочий_признак
<222> (1813)..(1815)
<223> стоп-кодон
<400> 5
atg acc tct ttc aac cgt gaa ccc ctg ccc gac gcc gtc cgc acg aat 48
Met Thr Ser Phe Asn Arg Glu Pro Leu Pro Asp Ala Val Arg Thr Asn
1 5 10 15
ggc gcc acg ccc aac ccg tgg tgg tcg aat gcg gtg gtg tac cag atc 96
Gly Ala Thr Pro Asn Pro Trp Trp Ser Asn Ala Val Val Tyr Gln Ile
20 25 30
tac ccg cgg tcg ttc cag gac acg aac ggc gac ggt ctc ggc gac ctg 144
Tyr Pro Arg Ser Phe Gln Asp Thr Asn Gly Asp Gly Leu Gly Asp Leu
35 40 45
aag ggc atc acc tcc cgc ctc gac tat ctc gcc gac ctc ggc gtg gat 192
Lys Gly Ile Thr Ser Arg Leu Asp Tyr Leu Ala Asp Leu Gly Val Asp
50 55 60
gtg ctc tgg ctc tcc ccg gtc tac agg tcc ccg caa gac gac aac ggc 240
Val Leu Trp Leu Ser Pro Val Tyr Arg Ser Pro Gln Asp Asp Asn Gly
65 70 75 80
tac gac atc tcc gac tac cgg gat atc gac ccg ctg ttc ggc acg ctc 288
Tyr Asp Ile Ser Asp Tyr Arg Asp Ile Asp Pro Leu Phe Gly Thr Leu
85 90 95
gac gac atg gac gag ctg ctc gcc gaa gcg cac aag cgc ggc ctc aag 336
Asp Asp Met Asp Glu Leu Leu Ala Glu Ala His Lys Arg Gly Leu Lys
100 105 110
atc gtg atg gac ctg gtg gtc aac cac acc tcc gac gag cac gcg tgg 384
Ile Val Met Asp Leu Val Val Asn His Thr Ser Asp Glu His Ala Trp
115 120 125
ttc gag gcg tcg aag gac aag gac gac ccg cac gcc gac tgg tac tgg 432
Phe Glu Ala Ser Lys Asp Lys Asp Asp Pro His Ala Asp Trp Tyr Trp
130 135 140
tgg cgt ccc gcc cgc ccc ggc cac gag ccg ggc acg ccc ggc gcc gag 480
Trp Arg Pro Ala Arg Pro Gly His Glu Pro Gly Thr Pro Gly Ala Glu
145 150 155 160
ccg aat cag tgg ggc tcc tac ttc ggc ggt tcc gca tgg gag tac agc 528
Pro Asn Gln Trp Gly Ser Tyr Phe Gly Gly Ser Ala Trp Glu Tyr Ser
165 170 175
ccg gag cgc ggc gag tac tac ctg cac cag ttc tcg aag aag cag cct 576
Pro Glu Arg Gly Glu Tyr Tyr Leu His Gln Phe Ser Lys Lys Gln Pro
180 185 190
gat ctc aac tgg gag aac ccg gcc gtg cgc cgc gcg gtg tac gac atg 624
Asp Leu Asn Trp Glu Asn Pro Ala Val Arg Arg Ala Val Tyr Asp Met
195 200 205
atg aac tgg tgg ctc gat cgc ggc atc gac ggc ttc cgt atg gat gtc 672
Met Asn Trp Trp Leu Asp Arg Gly Ile Asp Gly Phe Arg Met Asp Val
210 215 220
atc acc ctg atc tcc aag cgc acc gac ccc aac ggc agg ctc ccc ggc 720
Ile Thr Leu Ile Ser Lys Arg Thr Asp Pro Asn Gly Arg Leu Pro Gly
225 230 235 240
gag acc ggt tcc gag ctc cag gac ctg ccg gtg ggg gag gag ggc tac 768
Glu Thr Gly Ser Glu Leu Gln Asp Leu Pro Val Gly Glu Glu Gly Tyr
245 250 255
tcc agc ccg aac ccg ttc tgc gcc gac ggt ccg cgt cag gac gag ttc 816
Ser Ser Pro Asn Pro Phe Cys Ala Asp Gly Pro Arg Gln Asp Glu Phe
260 265 270
ctc gcc gag atg cgc cgc gag gtg ttc gac ggg cgt gac ggc ttc ctc 864
Leu Ala Glu Met Arg Arg Glu Val Phe Asp Gly Arg Asp Gly Phe Leu
275 280 285
acc gtc ggc gag gca ccc ggc atc acc gcc gaa cgc aac gag cac atc 912
Thr Val Gly Glu Ala Pro Gly Ile Thr Ala Glu Arg Asn Glu His Ile
290 295 300
acc gac ccc gcc aac ggc gaa ctc gac atg ctc ttc ctg ttc gaa cac 960
Thr Asp Pro Ala Asn Gly Glu Leu Asp Met Leu Phe Leu Phe Glu His
305 310 315 320
atg ggc gtc gac caa acc ccc gaa tcg aaa tgg gac gac aaa cca tgg 1008
Met Gly Val Asp Gln Thr Pro Glu Ser Lys Trp Asp Asp Lys Pro Trp
325 330 335
acg ccg gcc gac ctc gaa acc aag ctt gcc gaa caa cag gac gcc atc 1056
Thr Pro Ala Asp Leu Glu Thr Lys Leu Ala Glu Gln Gln Asp Ala Ile
340 345 350
gcc cga cgc ggc tgg gcc agc ctg ttc ctc gac aac cac gac cag ccg 1104
Ala Arg Arg Gly Trp Ala Ser Leu Phe Leu Asp Asn His Asp Gln Pro
355 360 365
cgt gtc gtc tcc cgt tgg ggc gac gac acc agc aag acc ggc cgc atc 1152
Arg Val Val Ser Arg Trp Gly Asp Asp Thr Ser Lys Thr Gly Arg Ile
370 375 380
cgc tcc gcc aag gcg ctc gcg ctg ctg ctg cac atg cac cgc ggc acc 1200
Arg Ser Ala Lys Ala Leu Ala Leu Leu Leu His Met His Arg Gly Thr
385 390 395 400
ccg tac gtc tac cag ggc gag gag ctc ggc atg acc aat gcg cac ttc 1248
Pro Tyr Val Tyr Gln Gly Glu Glu Leu Gly Met Thr Asn Ala His Phe
405 410 415
acc tcg ctc gac cag tac cgc gac ctc gaa tcc atc aac gcc tac cat 1296
Thr Ser Leu Asp Gln Tyr Arg Asp Leu Glu Ser Ile Asn Ala Tyr His
420 425 430
caa cgc gtc gag gaa acc ggg ata cgg aca tcg gag acc atg atg cga 1344
Gln Arg Val Glu Glu Thr Gly Ile Arg Thr Ser Glu Thr Met Met Arg
435 440 445
tcc ctc gcc cga tac ggc agg gac aac gcg cgc acc ccg atg caa tgg 1392
Ser Leu Ala Arg Tyr Gly Arg Asp Asn Ala Arg Thr Pro Met Gln Trp
450 455 460
gac gac tcc acc tac gcc ggc ttc acc atg ccc gac gcc ccg gtc gaa 1440
Asp Asp Ser Thr Tyr Ala Gly Phe Thr Met Pro Asp Ala Pro Val Glu
465 470 475 480
ccc tgg atc gcc gtc aac ccg aac cac acg gag atc aac gcc gcc gac 1488
Pro Trp Ile Ala Val Asn Pro Asn His Thr Glu Ile Asn Ala Ala Asp
485 490 495
gag acc gac gac ccc gac tcc gtg tac tcg ttc cac aaa cgg ctc atc 1536
Glu Thr Asp Asp Pro Asp Ser Val Tyr Ser Phe His Lys Arg Leu Ile
500 505 510
gcc ctg cgc cac acc gac ccc gtg gtc gcc gcc ggc gac tac cga cgc 1584
Ala Leu Arg His Thr Asp Pro Val Val Ala Ala Gly Asp Tyr Arg Arg
515 520 525
gtg gaa acc gga aac gac cgg atc atc gcc ttc acc aga acc ctc gac 1632
Val Glu Thr Gly Asn Asp Arg Ile Ile Ala Phe Thr Arg Thr Leu Asp
530 535 540
gag cga acc atc ctc acc gtc atc aac ctc tcg ccc aca cag gcc gca 1680
Glu Arg Thr Ile Leu Thr Val Ile Asn Leu Ser Pro Thr Gln Ala Ala
545 550 555 560
ccg gcc gga gaa ctg gaa acg atg ccc gac ggc acg atc ctc atc gcc 1728
Pro Ala Gly Glu Leu Glu Thr Met Pro Asp Gly Thr Ile Leu Ile Ala
565 570 575
aac acg gac gat ccc gta gga aac ctg aaa acc acg gga aca ctc gga 1776
Asn Thr Asp Asp Pro Val Gly Asn Leu Lys Thr Thr Gly Thr Leu Gly
580 585 590
cca tgg gag gcg ttc gcc atg gaa acc gat ccg gaa taa 1815
Pro Trp Glu Ala Phe Ala Met Glu Thr Asp Pro Glu
595 600
<210> 6
<211> 604
<212> БЕЛОК
<213> Bifidobacterium breve UCC2003
<400> 6
Met Thr Ser Phe Asn Arg Glu Pro Leu Pro Asp Ala Val Arg Thr Asn
1 5 10 15
Gly Ala Thr Pro Asn Pro Trp Trp Ser Asn Ala Val Val Tyr Gln Ile
20 25 30
Tyr Pro Arg Ser Phe Gln Asp Thr Asn Gly Asp Gly Leu Gly Asp Leu
35 40 45
Lys Gly Ile Thr Ser Arg Leu Asp Tyr Leu Ala Asp Leu Gly Val Asp
50 55 60
Val Leu Trp Leu Ser Pro Val Tyr Arg Ser Pro Gln Asp Asp Asn Gly
65 70 75 80
Tyr Asp Ile Ser Asp Tyr Arg Asp Ile Asp Pro Leu Phe Gly Thr Leu
85 90 95
Asp Asp Met Asp Glu Leu Leu Ala Glu Ala His Lys Arg Gly Leu Lys
100 105 110
Ile Val Met Asp Leu Val Val Asn His Thr Ser Asp Glu His Ala Trp
115 120 125
Phe Glu Ala Ser Lys Asp Lys Asp Asp Pro His Ala Asp Trp Tyr Trp
130 135 140
Trp Arg Pro Ala Arg Pro Gly His Glu Pro Gly Thr Pro Gly Ala Glu
145 150 155 160
Pro Asn Gln Trp Gly Ser Tyr Phe Gly Gly Ser Ala Trp Glu Tyr Ser
165 170 175
Pro Glu Arg Gly Glu Tyr Tyr Leu His Gln Phe Ser Lys Lys Gln Pro
180 185 190
Asp Leu Asn Trp Glu Asn Pro Ala Val Arg Arg Ala Val Tyr Asp Met
195 200 205
Met Asn Trp Trp Leu Asp Arg Gly Ile Asp Gly Phe Arg Met Asp Val
210 215 220
Ile Thr Leu Ile Ser Lys Arg Thr Asp Pro Asn Gly Arg Leu Pro Gly
225 230 235 240
Glu Thr Gly Ser Glu Leu Gln Asp Leu Pro Val Gly Glu Glu Gly Tyr
245 250 255
Ser Ser Pro Asn Pro Phe Cys Ala Asp Gly Pro Arg Gln Asp Glu Phe
260 265 270
Leu Ala Glu Met Arg Arg Glu Val Phe Asp Gly Arg Asp Gly Phe Leu
275 280 285
Thr Val Gly Glu Ala Pro Gly Ile Thr Ala Glu Arg Asn Glu His Ile
290 295 300
Thr Asp Pro Ala Asn Gly Glu Leu Asp Met Leu Phe Leu Phe Glu His
305 310 315 320
Met Gly Val Asp Gln Thr Pro Glu Ser Lys Trp Asp Asp Lys Pro Trp
325 330 335
Thr Pro Ala Asp Leu Glu Thr Lys Leu Ala Glu Gln Gln Asp Ala Ile
340 345 350
Ala Arg Arg Gly Trp Ala Ser Leu Phe Leu Asp Asn His Asp Gln Pro
355 360 365
Arg Val Val Ser Arg Trp Gly Asp Asp Thr Ser Lys Thr Gly Arg Ile
370 375 380
Arg Ser Ala Lys Ala Leu Ala Leu Leu Leu His Met His Arg Gly Thr
385 390 395 400
Pro Tyr Val Tyr Gln Gly Glu Glu Leu Gly Met Thr Asn Ala His Phe
405 410 415
Thr Ser Leu Asp Gln Tyr Arg Asp Leu Glu Ser Ile Asn Ala Tyr His
420 425 430
Gln Arg Val Glu Glu Thr Gly Ile Arg Thr Ser Glu Thr Met Met Arg
435 440 445
Ser Leu Ala Arg Tyr Gly Arg Asp Asn Ala Arg Thr Pro Met Gln Trp
450 455 460
Asp Asp Ser Thr Tyr Ala Gly Phe Thr Met Pro Asp Ala Pro Val Glu
465 470 475 480
Pro Trp Ile Ala Val Asn Pro Asn His Thr Glu Ile Asn Ala Ala Asp
485 490 495
Glu Thr Asp Asp Pro Asp Ser Val Tyr Ser Phe His Lys Arg Leu Ile
500 505 510
Ala Leu Arg His Thr Asp Pro Val Val Ala Ala Gly Asp Tyr Arg Arg
515 520 525
Val Glu Thr Gly Asn Asp Arg Ile Ile Ala Phe Thr Arg Thr Leu Asp
530 535 540
Glu Arg Thr Ile Leu Thr Val Ile Asn Leu Ser Pro Thr Gln Ala Ala
545 550 555 560
Pro Ala Gly Glu Leu Glu Thr Met Pro Asp Gly Thr Ile Leu Ile Ala
565 570 575
Asn Thr Asp Asp Pro Val Gly Asn Leu Lys Thr Thr Gly Thr Leu Gly
580 585 590
Pro Trp Glu Ala Phe Ala Met Glu Thr Asp Pro Glu
595 600
<210> 7
<211> 1824
<212> ДНК
<213> Bifidobacterium breve UCC2003
<220>
<221> CDS
<222> (1)..(1821)
<223> agl1
<220>
<221> прочий_признак
<222> (1822)..(1824)
<223> стоп-кодон
<400> 7
atg atg act act ttc aac cgc gca ata att ccc gac gcc atc cgc acc 48
Met Met Thr Thr Phe Asn Arg Ala Ile Ile Pro Asp Ala Ile Arg Thr
1 5 10 15
aac ggc gcc acc ccc aat ccg tgg tgg tcc aac gcg gtg gtc tat cag 96
Asn Gly Ala Thr Pro Asn Pro Trp Trp Ser Asn Ala Val Val Tyr Gln
20 25 30
att tac ccg cgt tct ttc caa gac acg aac ggc gat gga ttc ggc gat 144
Ile Tyr Pro Arg Ser Phe Gln Asp Thr Asn Gly Asp Gly Phe Gly Asp
35 40 45
ctt aag ggc atc acg tcg cgt ctt gat tac tta gct gat ctt ggc gtg 192
Leu Lys Gly Ile Thr Ser Arg Leu Asp Tyr Leu Ala Asp Leu Gly Val
50 55 60
gat gtg ctg tgg ctc tcc ccg gtc tat aag tcc ccg caa gac gac aac 240
Asp Val Leu Trp Leu Ser Pro Val Tyr Lys Ser Pro Gln Asp Asp Asn
65 70 75 80
ggc tat gac atc tct gac tat cag gac atc gac ccg ctg ttc ggc acg 288
Gly Tyr Asp Ile Ser Asp Tyr Gln Asp Ile Asp Pro Leu Phe Gly Thr
85 90 95
ctc gac gat atg gac gag ctg ctg gcc gaa gcg cat aag cgt ggg ctc 336
Leu Asp Asp Met Asp Glu Leu Leu Ala Glu Ala His Lys Arg Gly Leu
100 105 110
aaa gtc gtg atg gat ttg gtg gtc aat cac acc tcc gat gag cat gcc 384
Lys Val Val Met Asp Leu Val Val Asn His Thr Ser Asp Glu His Ala
115 120 125
tgg ttt gag gcg tcc aag aac aag gac gac gag cat gcc gat tgg tat 432
Trp Phe Glu Ala Ser Lys Asn Lys Asp Asp Glu His Ala Asp Trp Tyr
130 135 140
tgg tgg cgt ccg gct cgt ccc ggc acc acg ccc ggc gag ccc ggc tcc 480
Trp Trp Arg Pro Ala Arg Pro Gly Thr Thr Pro Gly Glu Pro Gly Ser
145 150 155 160
gag ccc aat cag tgg ggc tcc tac ttt ggc ggt tcc gca tgg gaa tat 528
Glu Pro Asn Gln Trp Gly Ser Tyr Phe Gly Gly Ser Ala Trp Glu Tyr
165 170 175
tgc ccc gag cgt ggt gag tac tat ctc cac cag ttc tcg aag aag cag 576
Cys Pro Glu Arg Gly Glu Tyr Tyr Leu His Gln Phe Ser Lys Lys Gln
180 185 190
ccc gat ctg aac tgg gag aac ccg gcc gtg cgc cga gcc gtg tac gac 624
Pro Asp Leu Asn Trp Glu Asn Pro Ala Val Arg Arg Ala Val Tyr Asp
195 200 205
atg atg aac tgg tgg ctt gac cga ggc atc gac ggc ttc cgc atg gat 672
Met Met Asn Trp Trp Leu Asp Arg Gly Ile Asp Gly Phe Arg Met Asp
210 215 220
gtc atc acc ctg atc tcc aag cgt acg gat gca aac ggc agg ctg ccc 720
Val Ile Thr Leu Ile Ser Lys Arg Thr Asp Ala Asn Gly Arg Leu Pro
225 230 235 240
ggc gag tac ggt tcc gag ctg gac gat ctg cct gtg ggc gag gaa ggc 768
Gly Glu Tyr Gly Ser Glu Leu Asp Asp Leu Pro Val Gly Glu Glu Gly
245 250 255
tat tcc aat ccc aac ccg ttc tgt gcc gat ggg ccg cgc caa gac gag 816
Tyr Ser Asn Pro Asn Pro Phe Cys Ala Asp Gly Pro Arg Gln Asp Glu
260 265 270
ttc ttg aag gaa atg cgt cgt gaa gtc ttt gcc gga cgc gag gga ttc 864
Phe Leu Lys Glu Met Arg Arg Glu Val Phe Ala Gly Arg Glu Gly Phe
275 280 285
ctc acc gtg ggc gag gct ccc ggc atc aca cct gtg cgc aac gaa cac 912
Leu Thr Val Gly Glu Ala Pro Gly Ile Thr Pro Val Arg Asn Glu His
290 295 300
atc acc aat ccg gcc aat ggg gag ctg gat atg ctg ttc ctg ttc gat 960
Ile Thr Asn Pro Ala Asn Gly Glu Leu Asp Met Leu Phe Leu Phe Asp
305 310 315 320
cat gtc gat ttt gat tgt gat ggc gtc aag tgg aag cct ctg ccg ctc 1008
His Val Asp Phe Asp Cys Asp Gly Val Lys Trp Lys Pro Leu Pro Leu
325 330 335
gat ttg ccg gga ttc aag cgg atc atg gcc gga tat cag act gct gtg 1056
Asp Leu Pro Gly Phe Lys Arg Ile Met Ala Gly Tyr Gln Thr Ala Val
340 345 350
gag aac gtg ggc tgg gca agc ttg ttc act ggt aac cac gat cag cca 1104
Glu Asn Val Gly Trp Ala Ser Leu Phe Thr Gly Asn His Asp Gln Pro
355 360 365
cgt gtg gtc tct cgt tgg ggc gat gac tcc tcg gag gaa tcc cgc gtg 1152
Arg Val Val Ser Arg Trp Gly Asp Asp Ser Ser Glu Glu Ser Arg Val
370 375 380
cgc tcg gcc aaa gcg ctt ggc ctg atg ttg cac atg cat cgc ggc act 1200
Arg Ser Ala Lys Ala Leu Gly Leu Met Leu His Met His Arg Gly Thr
385 390 395 400
ccg tac gta tat cag ggt gag gag ctg ggc atg acc aat gct cac ttc 1248
Pro Tyr Val Tyr Gln Gly Glu Glu Leu Gly Met Thr Asn Ala His Phe
405 410 415
acc agc ctc gat cag tac cgc gac ctt gaa tcc ctc aat gcc tat cgt 1296
Thr Ser Leu Asp Gln Tyr Arg Asp Leu Glu Ser Leu Asn Ala Tyr Arg
420 425 430
cag agg gtc gag gaa gcc aag gtg caa tcg ccg gaa tcg atg ttg gcg 1344
Gln Arg Val Glu Glu Ala Lys Val Gln Ser Pro Glu Ser Met Leu Ala
435 440 445
ggt atc gcc gcg cgc ggt cgc gac aat tcg cgt acc cca atg caa tgg 1392
Gly Ile Ala Ala Arg Gly Arg Asp Asn Ser Arg Thr Pro Met Gln Trp
450 455 460
gat ggt tct gcc tat gca ggt ttc acc gca ccg gat gca gcg acg gag 1440
Asp Gly Ser Ala Tyr Ala Gly Phe Thr Ala Pro Asp Ala Ala Thr Glu
465 470 475 480
ccg tgg att tcc gtc aac ccg aat cat gct gaa atc aat gcg gcc ggc 1488
Pro Trp Ile Ser Val Asn Pro Asn His Ala Glu Ile Asn Ala Ala Gly
485 490 495
gaa ttt gac gat cct gac tcg gtg tat gcc ttc tac aag aag ctc atc 1536
Glu Phe Asp Asp Pro Asp Ser Val Tyr Ala Phe Tyr Lys Lys Leu Ile
500 505 510
gcc ttg cgc cac aac agt tcg att gtg gcg gct ggc gag tgg cag ctg 1584
Ala Leu Arg His Asn Ser Ser Ile Val Ala Ala Gly Glu Trp Gln Leu
515 520 525
att gat gcg gat gac gcg cat gta tat gcg ttc acc cgc acg ctt ggc 1632
Ile Asp Ala Asp Asp Ala His Val Tyr Ala Phe Thr Arg Thr Leu Gly
530 535 540
aac gag cga ttg ctg gtt gtg gtt aac ctg tcc ggc cga acc gtc gac 1680
Asn Glu Arg Leu Leu Val Val Val Asn Leu Ser Gly Arg Thr Val Asp
545 550 555 560
ttg ccg cgt gaa tcc acc gag ctg att gcc ggc ggc gtc act gag cca 1728
Leu Pro Arg Glu Ser Thr Glu Leu Ile Ala Gly Gly Val Thr Glu Pro
565 570 575
gat atc att ctc tcc acg tac gac gcc cct cac act gtg gtc tcc ctc 1776
Asp Ile Ile Leu Ser Thr Tyr Asp Ala Pro His Thr Val Val Ser Leu
580 585 590
gcc aac cgt gag ctt gac ccg tgg gag gct gct gcc gtc cag ctg taa 1824
Ala Asn Arg Glu Leu Asp Pro Trp Glu Ala Ala Ala Val Gln Leu
595 600 605
<210> 8
<211> 607
<212> БЕЛОК
<213> Bifidobacterium breve UCC2003
<400> 8
Met Met Thr Thr Phe Asn Arg Ala Ile Ile Pro Asp Ala Ile Arg Thr
1 5 10 15
Asn Gly Ala Thr Pro Asn Pro Trp Trp Ser Asn Ala Val Val Tyr Gln
20 25 30
Ile Tyr Pro Arg Ser Phe Gln Asp Thr Asn Gly Asp Gly Phe Gly Asp
35 40 45
Leu Lys Gly Ile Thr Ser Arg Leu Asp Tyr Leu Ala Asp Leu Gly Val
50 55 60
Asp Val Leu Trp Leu Ser Pro Val Tyr Lys Ser Pro Gln Asp Asp Asn
65 70 75 80
Gly Tyr Asp Ile Ser Asp Tyr Gln Asp Ile Asp Pro Leu Phe Gly Thr
85 90 95
Leu Asp Asp Met Asp Glu Leu Leu Ala Glu Ala His Lys Arg Gly Leu
100 105 110
Lys Val Val Met Asp Leu Val Val Asn His Thr Ser Asp Glu His Ala
115 120 125
Trp Phe Glu Ala Ser Lys Asn Lys Asp Asp Glu His Ala Asp Trp Tyr
130 135 140
Trp Trp Arg Pro Ala Arg Pro Gly Thr Thr Pro Gly Glu Pro Gly Ser
145 150 155 160
Glu Pro Asn Gln Trp Gly Ser Tyr Phe Gly Gly Ser Ala Trp Glu Tyr
165 170 175
Cys Pro Glu Arg Gly Glu Tyr Tyr Leu His Gln Phe Ser Lys Lys Gln
180 185 190
Pro Asp Leu Asn Trp Glu Asn Pro Ala Val Arg Arg Ala Val Tyr Asp
195 200 205
Met Met Asn Trp Trp Leu Asp Arg Gly Ile Asp Gly Phe Arg Met Asp
210 215 220
Val Ile Thr Leu Ile Ser Lys Arg Thr Asp Ala Asn Gly Arg Leu Pro
225 230 235 240
Gly Glu Tyr Gly Ser Glu Leu Asp Asp Leu Pro Val Gly Glu Glu Gly
245 250 255
Tyr Ser Asn Pro Asn Pro Phe Cys Ala Asp Gly Pro Arg Gln Asp Glu
260 265 270
Phe Leu Lys Glu Met Arg Arg Glu Val Phe Ala Gly Arg Glu Gly Phe
275 280 285
Leu Thr Val Gly Glu Ala Pro Gly Ile Thr Pro Val Arg Asn Glu His
290 295 300
Ile Thr Asn Pro Ala Asn Gly Glu Leu Asp Met Leu Phe Leu Phe Asp
305 310 315 320
His Val Asp Phe Asp Cys Asp Gly Val Lys Trp Lys Pro Leu Pro Leu
325 330 335
Asp Leu Pro Gly Phe Lys Arg Ile Met Ala Gly Tyr Gln Thr Ala Val
340 345 350
Glu Asn Val Gly Trp Ala Ser Leu Phe Thr Gly Asn His Asp Gln Pro
355 360 365
Arg Val Val Ser Arg Trp Gly Asp Asp Ser Ser Glu Glu Ser Arg Val
370 375 380
Arg Ser Ala Lys Ala Leu Gly Leu Met Leu His Met His Arg Gly Thr
385 390 395 400
Pro Tyr Val Tyr Gln Gly Glu Glu Leu Gly Met Thr Asn Ala His Phe
405 410 415
Thr Ser Leu Asp Gln Tyr Arg Asp Leu Glu Ser Leu Asn Ala Tyr Arg
420 425 430
Gln Arg Val Glu Glu Ala Lys Val Gln Ser Pro Glu Ser Met Leu Ala
435 440 445
Gly Ile Ala Ala Arg Gly Arg Asp Asn Ser Arg Thr Pro Met Gln Trp
450 455 460
Asp Gly Ser Ala Tyr Ala Gly Phe Thr Ala Pro Asp Ala Ala Thr Glu
465 470 475 480
Pro Trp Ile Ser Val Asn Pro Asn His Ala Glu Ile Asn Ala Ala Gly
485 490 495
Glu Phe Asp Asp Pro Asp Ser Val Tyr Ala Phe Tyr Lys Lys Leu Ile
500 505 510
Ala Leu Arg His Asn Ser Ser Ile Val Ala Ala Gly Glu Trp Gln Leu
515 520 525
Ile Asp Ala Asp Asp Ala His Val Tyr Ala Phe Thr Arg Thr Leu Gly
530 535 540
Asn Glu Arg Leu Leu Val Val Val Asn Leu Ser Gly Arg Thr Val Asp
545 550 555 560
Leu Pro Arg Glu Ser Thr Glu Leu Ile Ala Gly Gly Val Thr Glu Pro
565 570 575
Asp Ile Ile Leu Ser Thr Tyr Asp Ala Pro His Thr Val Val Ser Leu
580 585 590
Ala Asn Arg Glu Leu Asp Pro Trp Glu Ala Ala Ala Val Gln Leu
595 600 605
<210> 9
<211> 1920
<212> ДНК
<213> искусственная последовательность
<220>
<223> слитый ген tat-'agl2_cuo
<220>
<221> CDS
<222> (1)..(1917)
<223> последовательность, кодирующая слитый полипептид Tat-'Agl2
<220>
<221> прочая_сигнальная_последовательность
<222> (1)..(99)
<223> 5'-концевая последовательность cg0955, кодирующая
Tat-сигнальный пептид Cg0955
<220>
<221> прочий_признак
<222> (1)..(101)
<223> 5'-концевая последовательность cg0955
<220>
<221> прочий_признак
<222> (102)..(102)
<223> нуклеотидное основание гуанин
<220>
<221> прочий_признак
<222> (103)..(108)
<223> сайт рестрикции для SpeI
<220>
<221> прочий_признак
<222> (109)..(1917)
<223> 'agl2_cuo
<220>
<221> прочий_признак
<222> (1918)..(1920)
<223> стоп-кодон
<400> 9
atg caa ata aac cgc cga ggc ttc tta aaa gcc acc aca gga ctt gcc 48
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr Thr Gly Leu Ala
1 5 10 15
act atc ggc gct gcc agc atg ttt atg cca aag gcc aac gcc ctt gga 96
Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala Asn Ala Leu Gly
20 25 30
gca atg act agt acc tcc ttc aac cgc gaa cca ctg cca gat gca gtg 144
Ala Met Thr Ser Thr Ser Phe Asn Arg Glu Pro Leu Pro Asp Ala Val
35 40 45
cgc acc aac ggt gca acc cca aac cca tgg tgg tcc aac gca gtg gtg 192
Arg Thr Asn Gly Ala Thr Pro Asn Pro Trp Trp Ser Asn Ala Val Val
50 55 60
tac cag atc tac cca cgc tcc ttc cag gat acc aac ggc gac ggc ctg 240
Tyr Gln Ile Tyr Pro Arg Ser Phe Gln Asp Thr Asn Gly Asp Gly Leu
65 70 75 80
ggc gat ctg aag ggc atc acc tcc cgc ttg gat tac ctg gca gat ctg 288
Gly Asp Leu Lys Gly Ile Thr Ser Arg Leu Asp Tyr Leu Ala Asp Leu
85 90 95
ggc gtg gat gtg ctg tgg ctg tcc cca gtg tac cgc tcc cca cag gat 336
Gly Val Asp Val Leu Trp Leu Ser Pro Val Tyr Arg Ser Pro Gln Asp
100 105 110
gat aac ggc tac gat atc tcc gat tac cgc gat atc gat cca ctg ttc 384
Asp Asn Gly Tyr Asp Ile Ser Asp Tyr Arg Asp Ile Asp Pro Leu Phe
115 120 125
ggc acc ctg gat gat atg gat gaa ctg ctg gca gag gca cac aag cgt 432
Gly Thr Leu Asp Asp Met Asp Glu Leu Leu Ala Glu Ala His Lys Arg
130 135 140
ggc ctg aag atc gtg atg gat ctg gtg gtg aac cac acc tcc gat gaa 480
Gly Leu Lys Ile Val Met Asp Leu Val Val Asn His Thr Ser Asp Glu
145 150 155 160
cac gca tgg ttc gaa gca tcc aag gat aag gat gat cca cac gca gat 528
His Ala Trp Phe Glu Ala Ser Lys Asp Lys Asp Asp Pro His Ala Asp
165 170 175
tgg tac tgg tgg cgt cca gca cgc cca ggc cac gaa cca ggc acc cca 576
Trp Tyr Trp Trp Arg Pro Ala Arg Pro Gly His Glu Pro Gly Thr Pro
180 185 190
ggc gca gaa cca aac cag tgg ggc tcc tac ttc ggt ggc tcc gca tgg 624
Gly Ala Glu Pro Asn Gln Trp Gly Ser Tyr Phe Gly Gly Ser Ala Trp
195 200 205
gaa tac tcc cca gaa cgc ggt gaa tac tac ctg cac cag ttc tcc aag 672
Glu Tyr Ser Pro Glu Arg Gly Glu Tyr Tyr Leu His Gln Phe Ser Lys
210 215 220
aag cag cca gat ctc aac tgg gaa aac cca gca gtg cgt cgc gca gtg 720
Lys Gln Pro Asp Leu Asn Trp Glu Asn Pro Ala Val Arg Arg Ala Val
225 230 235 240
tac gat atg atg aac tgg tgg ttg gat cgc ggt atc gat ggc ttc cgc 768
Tyr Asp Met Met Asn Trp Trp Leu Asp Arg Gly Ile Asp Gly Phe Arg
245 250 255
atg gat gtg atc acc ctg atc tcc aag cgc acc gat cca aac ggt cgc 816
Met Asp Val Ile Thr Leu Ile Ser Lys Arg Thr Asp Pro Asn Gly Arg
260 265 270
ctg cca ggt gaa acc ggc tcc gaa ctc cag gat ctg cca gtg ggc gaa 864
Leu Pro Gly Glu Thr Gly Ser Glu Leu Gln Asp Leu Pro Val Gly Glu
275 280 285
gaa ggc tac tcc tcc cca aac cct ttc tgc gca gat ggc cct cgc cag 912
Glu Gly Tyr Ser Ser Pro Asn Pro Phe Cys Ala Asp Gly Pro Arg Gln
290 295 300
gat gaa ttc ctg gca gaa atg cgt cgc gaa gtt ttc gat ggc cgt gat 960
Asp Glu Phe Leu Ala Glu Met Arg Arg Glu Val Phe Asp Gly Arg Asp
305 310 315 320
ggc ttc ctg acc gtg ggc gaa gca cca ggc atc acc gca gaa cgc aac 1008
Gly Phe Leu Thr Val Gly Glu Ala Pro Gly Ile Thr Ala Glu Arg Asn
325 330 335
gaa cac atc acc gat cca gca aac ggc gaa ctg gat atg ctg ttc ctg 1056
Glu His Ile Thr Asp Pro Ala Asn Gly Glu Leu Asp Met Leu Phe Leu
340 345 350
ttc gaa cac atg ggc gtg gat cag acc cca gaa tcc aag tgg gat gat 1104
Phe Glu His Met Gly Val Asp Gln Thr Pro Glu Ser Lys Trp Asp Asp
355 360 365
aag cca tgg acc cca gca gat ctg gaa acc aag ctg gca gaa cag cag 1152
Lys Pro Trp Thr Pro Ala Asp Leu Glu Thr Lys Leu Ala Glu Gln Gln
370 375 380
gat gca atc gca cgc cgt ggc tgg gcc tcc ctg ttc ctg gat aac cac 1200
Asp Ala Ile Ala Arg Arg Gly Trp Ala Ser Leu Phe Leu Asp Asn His
385 390 395 400
gat cag cca cgc gtg gtg tcc cgc tgg ggt gat gat acc tcc aag acc 1248
Asp Gln Pro Arg Val Val Ser Arg Trp Gly Asp Asp Thr Ser Lys Thr
405 410 415
ggt cgc atc cgc tcc gca aag gca ctg gca ctg ctg ctg cac atg cac 1296
Gly Arg Ile Arg Ser Ala Lys Ala Leu Ala Leu Leu Leu His Met His
420 425 430
cgt ggc acc cca tac gtg tac cag ggc gaa gaa ctg ggc atg acc aac 1344
Arg Gly Thr Pro Tyr Val Tyr Gln Gly Glu Glu Leu Gly Met Thr Asn
435 440 445
gca cac ttc acc tcc ctg gat cag tac cgc gat ctg gaa tcc atc aac 1392
Ala His Phe Thr Ser Leu Asp Gln Tyr Arg Asp Leu Glu Ser Ile Asn
450 455 460
gca tac cac caa cgc gtg gaa gaa acc ggc atc cgc acc tcc gaa acc 1440
Ala Tyr His Gln Arg Val Glu Glu Thr Gly Ile Arg Thr Ser Glu Thr
465 470 475 480
atg atg cgc tcc ctg gca cgc tac ggt cgc gat aac gca cgc acc cca 1488
Met Met Arg Ser Leu Ala Arg Tyr Gly Arg Asp Asn Ala Arg Thr Pro
485 490 495
atg cag tgg gat gat tcc acc tac gca ggc ttc acc atg cca gat gcc 1536
Met Gln Trp Asp Asp Ser Thr Tyr Ala Gly Phe Thr Met Pro Asp Ala
500 505 510
cca gtg gaa cca tgg atc gca gtg aac cca aac cac acc gaa atc aac 1584
Pro Val Glu Pro Trp Ile Ala Val Asn Pro Asn His Thr Glu Ile Asn
515 520 525
gca gca gat gaa acc gat gat cca gat tcc gtg tac tcc ttc cac aag 1632
Ala Ala Asp Glu Thr Asp Asp Pro Asp Ser Val Tyr Ser Phe His Lys
530 535 540
cgc ctg atc gca ctg cgc cac acc gat cca gtg gtg gca gca ggc gat 1680
Arg Leu Ile Ala Leu Arg His Thr Asp Pro Val Val Ala Ala Gly Asp
545 550 555 560
tac cgt cgc gtg gaa acc ggc aac gat cgc atc att gca ttc acc cgc 1728
Tyr Arg Arg Val Glu Thr Gly Asn Asp Arg Ile Ile Ala Phe Thr Arg
565 570 575
acc ctg gac gaa cgc acc atc ctg acc gtg atc aac ctg tcc cca acc 1776
Thr Leu Asp Glu Arg Thr Ile Leu Thr Val Ile Asn Leu Ser Pro Thr
580 585 590
cag gca gca cca gca ggc gaa ctg gaa acc atg cca gac ggc acc atc 1824
Gln Ala Ala Pro Ala Gly Glu Leu Glu Thr Met Pro Asp Gly Thr Ile
595 600 605
ttg atc gca aac acc gat gac cca gtg ggc aac ctc aag acc acc ggc 1872
Leu Ile Ala Asn Thr Asp Asp Pro Val Gly Asn Leu Lys Thr Thr Gly
610 615 620
acc ctg ggt cca tgg gaa gca ttc gca atg gaa acc gat cca gaa taa 1920
Thr Leu Gly Pro Trp Glu Ala Phe Ala Met Glu Thr Asp Pro Glu
625 630 635
<210> 10
<211> 639
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 10
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr Thr Gly Leu Ala
1 5 10 15
Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala Asn Ala Leu Gly
20 25 30
Ala Met Thr Ser Thr Ser Phe Asn Arg Glu Pro Leu Pro Asp Ala Val
35 40 45
Arg Thr Asn Gly Ala Thr Pro Asn Pro Trp Trp Ser Asn Ala Val Val
50 55 60
Tyr Gln Ile Tyr Pro Arg Ser Phe Gln Asp Thr Asn Gly Asp Gly Leu
65 70 75 80
Gly Asp Leu Lys Gly Ile Thr Ser Arg Leu Asp Tyr Leu Ala Asp Leu
85 90 95
Gly Val Asp Val Leu Trp Leu Ser Pro Val Tyr Arg Ser Pro Gln Asp
100 105 110
Asp Asn Gly Tyr Asp Ile Ser Asp Tyr Arg Asp Ile Asp Pro Leu Phe
115 120 125
Gly Thr Leu Asp Asp Met Asp Glu Leu Leu Ala Glu Ala His Lys Arg
130 135 140
Gly Leu Lys Ile Val Met Asp Leu Val Val Asn His Thr Ser Asp Glu
145 150 155 160
His Ala Trp Phe Glu Ala Ser Lys Asp Lys Asp Asp Pro His Ala Asp
165 170 175
Trp Tyr Trp Trp Arg Pro Ala Arg Pro Gly His Glu Pro Gly Thr Pro
180 185 190
Gly Ala Glu Pro Asn Gln Trp Gly Ser Tyr Phe Gly Gly Ser Ala Trp
195 200 205
Glu Tyr Ser Pro Glu Arg Gly Glu Tyr Tyr Leu His Gln Phe Ser Lys
210 215 220
Lys Gln Pro Asp Leu Asn Trp Glu Asn Pro Ala Val Arg Arg Ala Val
225 230 235 240
Tyr Asp Met Met Asn Trp Trp Leu Asp Arg Gly Ile Asp Gly Phe Arg
245 250 255
Met Asp Val Ile Thr Leu Ile Ser Lys Arg Thr Asp Pro Asn Gly Arg
260 265 270
Leu Pro Gly Glu Thr Gly Ser Glu Leu Gln Asp Leu Pro Val Gly Glu
275 280 285
Glu Gly Tyr Ser Ser Pro Asn Pro Phe Cys Ala Asp Gly Pro Arg Gln
290 295 300
Asp Glu Phe Leu Ala Glu Met Arg Arg Glu Val Phe Asp Gly Arg Asp
305 310 315 320
Gly Phe Leu Thr Val Gly Glu Ala Pro Gly Ile Thr Ala Glu Arg Asn
325 330 335
Glu His Ile Thr Asp Pro Ala Asn Gly Glu Leu Asp Met Leu Phe Leu
340 345 350
Phe Glu His Met Gly Val Asp Gln Thr Pro Glu Ser Lys Trp Asp Asp
355 360 365
Lys Pro Trp Thr Pro Ala Asp Leu Glu Thr Lys Leu Ala Glu Gln Gln
370 375 380
Asp Ala Ile Ala Arg Arg Gly Trp Ala Ser Leu Phe Leu Asp Asn His
385 390 395 400
Asp Gln Pro Arg Val Val Ser Arg Trp Gly Asp Asp Thr Ser Lys Thr
405 410 415
Gly Arg Ile Arg Ser Ala Lys Ala Leu Ala Leu Leu Leu His Met His
420 425 430
Arg Gly Thr Pro Tyr Val Tyr Gln Gly Glu Glu Leu Gly Met Thr Asn
435 440 445
Ala His Phe Thr Ser Leu Asp Gln Tyr Arg Asp Leu Glu Ser Ile Asn
450 455 460
Ala Tyr His Gln Arg Val Glu Glu Thr Gly Ile Arg Thr Ser Glu Thr
465 470 475 480
Met Met Arg Ser Leu Ala Arg Tyr Gly Arg Asp Asn Ala Arg Thr Pro
485 490 495
Met Gln Trp Asp Asp Ser Thr Tyr Ala Gly Phe Thr Met Pro Asp Ala
500 505 510
Pro Val Glu Pro Trp Ile Ala Val Asn Pro Asn His Thr Glu Ile Asn
515 520 525
Ala Ala Asp Glu Thr Asp Asp Pro Asp Ser Val Tyr Ser Phe His Lys
530 535 540
Arg Leu Ile Ala Leu Arg His Thr Asp Pro Val Val Ala Ala Gly Asp
545 550 555 560
Tyr Arg Arg Val Glu Thr Gly Asn Asp Arg Ile Ile Ala Phe Thr Arg
565 570 575
Thr Leu Asp Glu Arg Thr Ile Leu Thr Val Ile Asn Leu Ser Pro Thr
580 585 590
Gln Ala Ala Pro Ala Gly Glu Leu Glu Thr Met Pro Asp Gly Thr Ile
595 600 605
Leu Ile Ala Asn Thr Asp Asp Pro Val Gly Asn Leu Lys Thr Thr Gly
610 615 620
Thr Leu Gly Pro Trp Glu Ala Phe Ala Met Glu Thr Asp Pro Glu
625 630 635
<210> 11
<211> 1932
<212> ДНК
<213> искусственная последовательность
<220>
<223> слитый ген tat-agl1_cuo
<220>
<221> CDS
<222> (1)..(1929)
<223> последовательность, кодирующая слитый полипептид Tat-Agl1
<220>
<221> прочая_сигнальная_последовательность
<222> (1)..(99)
<223> 5'-концевая последовательность cg0955, кодирующая
Tat-сигнальный пептид Cg0955
<220>
<221> прочий_признак
<222> (1)..(101)
<223> 5'-концевая последовательность cg0955
<220>
<221> прочий_признак
<222> (102)..(102)
<223> нуклеотидное основание аденин
<220>
<221> прочий_признак
<222> (102)..(107)
<223> сайт рестрикции для SpeI
<220>
<221> прочий_признак
<222> (108)..(108)
<223> нуклеотидное основание аденин
<220>
<221> прочий_признак
<222> (109)..(1929)
<223> agl1_cuo
<220>
<221> прочий_признак
<222> (1930)..(1932)
<223> стоп-кодон
<400> 11
atg caa ata aac cgc cga ggc ttc tta aaa gcc acc aca gga ctt gcc 48
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr Thr Gly Leu Ala
1 5 10 15
act atc ggc gct gcc agc atg ttt atg cca aag gcc aac gcc ctt gga 96
Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala Asn Ala Leu Gly
20 25 30
gca ata cta gta atg atg acc acc ttc aac cgt gca atc atc cca gat 144
Ala Ile Leu Val Met Met Thr Thr Phe Asn Arg Ala Ile Ile Pro Asp
35 40 45
gca atc cgc acc aac ggt gca acc cca aac cca tgg tgg tcc aac gca 192
Ala Ile Arg Thr Asn Gly Ala Thr Pro Asn Pro Trp Trp Ser Asn Ala
50 55 60
gtg gtg tac cag atc tac cca cgc tcc ttc cag gat acc aac ggc gac 240
Val Val Tyr Gln Ile Tyr Pro Arg Ser Phe Gln Asp Thr Asn Gly Asp
65 70 75 80
ggc ttc ggc gat ctg aag ggc atc acc tcc cgc ttg gat tac ctg gca 288
Gly Phe Gly Asp Leu Lys Gly Ile Thr Ser Arg Leu Asp Tyr Leu Ala
85 90 95
gat ctg ggc gtg gat gtg ctg tgg ctg tcc cca gtg tac aag tcc cca 336
Asp Leu Gly Val Asp Val Leu Trp Leu Ser Pro Val Tyr Lys Ser Pro
100 105 110
cag gat gat aac ggc tac gat atc tcc gat tac cag gat atc gat cca 384
Gln Asp Asp Asn Gly Tyr Asp Ile Ser Asp Tyr Gln Asp Ile Asp Pro
115 120 125
ctg ttc ggc acc ctg gat gat atg gat gaa ctg ctg gca gag gca cac 432
Leu Phe Gly Thr Leu Asp Asp Met Asp Glu Leu Leu Ala Glu Ala His
130 135 140
aag cgt ggc ctg aag gtg gtg atg gat ctg gtg gtg aac cac acc tcc 480
Lys Arg Gly Leu Lys Val Val Met Asp Leu Val Val Asn His Thr Ser
145 150 155 160
gat gaa cac gca tgg ttc gaa gca tcc aag aac aag gat gat gaa cac 528
Asp Glu His Ala Trp Phe Glu Ala Ser Lys Asn Lys Asp Asp Glu His
165 170 175
gcc gat tgg tac tgg tgg cgt cca gca cgc cca ggc acc acc cca ggt 576
Ala Asp Trp Tyr Trp Trp Arg Pro Ala Arg Pro Gly Thr Thr Pro Gly
180 185 190
gaa cca ggc tcc gaa cca aac cag tgg ggc tcc tac ttc ggt ggc tcc 624
Glu Pro Gly Ser Glu Pro Asn Gln Trp Gly Ser Tyr Phe Gly Gly Ser
195 200 205
gca tgg gaa tac tgc cca gaa cgc ggt gaa tac tac ctg cac cag ttc 672
Ala Trp Glu Tyr Cys Pro Glu Arg Gly Glu Tyr Tyr Leu His Gln Phe
210 215 220
tcc aag aag cag cca gat ctc aac tgg gaa aac cca gca gtg cgt cgc 720
Ser Lys Lys Gln Pro Asp Leu Asn Trp Glu Asn Pro Ala Val Arg Arg
225 230 235 240
gca gtg tac gat atg atg aac tgg tgg ttg gat cgc ggt atc gat ggc 768
Ala Val Tyr Asp Met Met Asn Trp Trp Leu Asp Arg Gly Ile Asp Gly
245 250 255
ttc cgc atg gat gtg atc acc ctg atc tcc aag cgc acc gat gca aac 816
Phe Arg Met Asp Val Ile Thr Leu Ile Ser Lys Arg Thr Asp Ala Asn
260 265 270
ggt cgc ctg cca ggt gaa tac ggc tcc gaa ctg gat gat ctg cca gtg 864
Gly Arg Leu Pro Gly Glu Tyr Gly Ser Glu Leu Asp Asp Leu Pro Val
275 280 285
ggc gaa gaa ggc tac tcc aac cca aac ccg ttc tgc gca gat ggc cct 912
Gly Glu Glu Gly Tyr Ser Asn Pro Asn Pro Phe Cys Ala Asp Gly Pro
290 295 300
cgc cag gat gaa ttc ctg aaa gaa atg cgt cgc gaa gtg ttc gca ggt 960
Arg Gln Asp Glu Phe Leu Lys Glu Met Arg Arg Glu Val Phe Ala Gly
305 310 315 320
cgc gaa ggc ttc ctg acc gtg ggc gaa gca cca ggc atc acc cct gtg 1008
Arg Glu Gly Phe Leu Thr Val Gly Glu Ala Pro Gly Ile Thr Pro Val
325 330 335
cgc aac gaa cac atc acc aac cca gca aac ggc gaa ctg gat atg ctg 1056
Arg Asn Glu His Ile Thr Asn Pro Ala Asn Gly Glu Leu Asp Met Leu
340 345 350
ttc ctg ttc gat cac gtg gat ttc gat tgc gac ggc gtg aag tgg aag 1104
Phe Leu Phe Asp His Val Asp Phe Asp Cys Asp Gly Val Lys Trp Lys
355 360 365
cca ctg cca ctg gat ctg cca ggc ttc aag cgc atc atg gca ggc tac 1152
Pro Leu Pro Leu Asp Leu Pro Gly Phe Lys Arg Ile Met Ala Gly Tyr
370 375 380
cag acc gca gtg gaa aac gtg ggc tgg gca tcc ctg ttc acc ggc aac 1200
Gln Thr Ala Val Glu Asn Val Gly Trp Ala Ser Leu Phe Thr Gly Asn
385 390 395 400
cac gat cag cca cgc gtg gtg tcc cgc tgg ggt gat gat tcc tcc gaa 1248
His Asp Gln Pro Arg Val Val Ser Arg Trp Gly Asp Asp Ser Ser Glu
405 410 415
gaa tcc cgt gtg cgc tcc gca aag gca ctg ggc ctg atg ctg cac atg 1296
Glu Ser Arg Val Arg Ser Ala Lys Ala Leu Gly Leu Met Leu His Met
420 425 430
cac cgt ggc acc cca tac gtg tac cag ggc gaa gaa ctg ggc atg acc 1344
His Arg Gly Thr Pro Tyr Val Tyr Gln Gly Glu Glu Leu Gly Met Thr
435 440 445
aac gca cac ttc acc tcc ctg gat cag tac cgc gat ctg gaa tcc ctg 1392
Asn Ala His Phe Thr Ser Leu Asp Gln Tyr Arg Asp Leu Glu Ser Leu
450 455 460
aac gca tac cgc cag cgc gtg gaa gag gca aag gtg cag tcc cca gaa 1440
Asn Ala Tyr Arg Gln Arg Val Glu Glu Ala Lys Val Gln Ser Pro Glu
465 470 475 480
tcc atg ctg gca ggt atc gca gca cgc ggt cgc gat aac tcc cgc acc 1488
Ser Met Leu Ala Gly Ile Ala Ala Arg Gly Arg Asp Asn Ser Arg Thr
485 490 495
cca atg cag tgg gat ggc tcc gca tac gca ggc ttc acc gca cca gat 1536
Pro Met Gln Trp Asp Gly Ser Ala Tyr Ala Gly Phe Thr Ala Pro Asp
500 505 510
gca gca acc gaa cca tgg atc tcc gtg aac cca aac cac gca gaa atc 1584
Ala Ala Thr Glu Pro Trp Ile Ser Val Asn Pro Asn His Ala Glu Ile
515 520 525
aac gca gca ggc gaa ttc gat gat cca gat tcc gtg tac gca ttc tac 1632
Asn Ala Ala Gly Glu Phe Asp Asp Pro Asp Ser Val Tyr Ala Phe Tyr
530 535 540
aag aag ctg atc gca ctg cgc cac aac tcc tcc atc gtg gca gct ggc 1680
Lys Lys Leu Ile Ala Leu Arg His Asn Ser Ser Ile Val Ala Ala Gly
545 550 555 560
gaa tgg cag ctg atc gat gca gat gat gca cac gtg tac gcc ttc acc 1728
Glu Trp Gln Leu Ile Asp Ala Asp Asp Ala His Val Tyr Ala Phe Thr
565 570 575
cgc acc ctg ggc aac gaa cgc ctg ctc gtg gtg gtc aac ctg tcc ggt 1776
Arg Thr Leu Gly Asn Glu Arg Leu Leu Val Val Val Asn Leu Ser Gly
580 585 590
cgc acc gtg gat ctg cca cgc gaa tcc acc gaa ctg atc gca ggc ggt 1824
Arg Thr Val Asp Leu Pro Arg Glu Ser Thr Glu Leu Ile Ala Gly Gly
595 600 605
gtg acc gaa cca gat atc atc ctg tcc acc tac gat gca cca cac acc 1872
Val Thr Glu Pro Asp Ile Ile Leu Ser Thr Tyr Asp Ala Pro His Thr
610 615 620
gtg gtg tcc ctg gca aac cgc gaa ctc gat cca tgg gaa gca gca gca 1920
Val Val Ser Leu Ala Asn Arg Glu Leu Asp Pro Trp Glu Ala Ala Ala
625 630 635 640
gtg cag ctg taa 1932
Val Gln Leu
<210> 12
<211> 643
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 12
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr Thr Gly Leu Ala
1 5 10 15
Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala Asn Ala Leu Gly
20 25 30
Ala Ile Leu Val Met Met Thr Thr Phe Asn Arg Ala Ile Ile Pro Asp
35 40 45
Ala Ile Arg Thr Asn Gly Ala Thr Pro Asn Pro Trp Trp Ser Asn Ala
50 55 60
Val Val Tyr Gln Ile Tyr Pro Arg Ser Phe Gln Asp Thr Asn Gly Asp
65 70 75 80
Gly Phe Gly Asp Leu Lys Gly Ile Thr Ser Arg Leu Asp Tyr Leu Ala
85 90 95
Asp Leu Gly Val Asp Val Leu Trp Leu Ser Pro Val Tyr Lys Ser Pro
100 105 110
Gln Asp Asp Asn Gly Tyr Asp Ile Ser Asp Tyr Gln Asp Ile Asp Pro
115 120 125
Leu Phe Gly Thr Leu Asp Asp Met Asp Glu Leu Leu Ala Glu Ala His
130 135 140
Lys Arg Gly Leu Lys Val Val Met Asp Leu Val Val Asn His Thr Ser
145 150 155 160
Asp Glu His Ala Trp Phe Glu Ala Ser Lys Asn Lys Asp Asp Glu His
165 170 175
Ala Asp Trp Tyr Trp Trp Arg Pro Ala Arg Pro Gly Thr Thr Pro Gly
180 185 190
Glu Pro Gly Ser Glu Pro Asn Gln Trp Gly Ser Tyr Phe Gly Gly Ser
195 200 205
Ala Trp Glu Tyr Cys Pro Glu Arg Gly Glu Tyr Tyr Leu His Gln Phe
210 215 220
Ser Lys Lys Gln Pro Asp Leu Asn Trp Glu Asn Pro Ala Val Arg Arg
225 230 235 240
Ala Val Tyr Asp Met Met Asn Trp Trp Leu Asp Arg Gly Ile Asp Gly
245 250 255
Phe Arg Met Asp Val Ile Thr Leu Ile Ser Lys Arg Thr Asp Ala Asn
260 265 270
Gly Arg Leu Pro Gly Glu Tyr Gly Ser Glu Leu Asp Asp Leu Pro Val
275 280 285
Gly Glu Glu Gly Tyr Ser Asn Pro Asn Pro Phe Cys Ala Asp Gly Pro
290 295 300
Arg Gln Asp Glu Phe Leu Lys Glu Met Arg Arg Glu Val Phe Ala Gly
305 310 315 320
Arg Glu Gly Phe Leu Thr Val Gly Glu Ala Pro Gly Ile Thr Pro Val
325 330 335
Arg Asn Glu His Ile Thr Asn Pro Ala Asn Gly Glu Leu Asp Met Leu
340 345 350
Phe Leu Phe Asp His Val Asp Phe Asp Cys Asp Gly Val Lys Trp Lys
355 360 365
Pro Leu Pro Leu Asp Leu Pro Gly Phe Lys Arg Ile Met Ala Gly Tyr
370 375 380
Gln Thr Ala Val Glu Asn Val Gly Trp Ala Ser Leu Phe Thr Gly Asn
385 390 395 400
His Asp Gln Pro Arg Val Val Ser Arg Trp Gly Asp Asp Ser Ser Glu
405 410 415
Glu Ser Arg Val Arg Ser Ala Lys Ala Leu Gly Leu Met Leu His Met
420 425 430
His Arg Gly Thr Pro Tyr Val Tyr Gln Gly Glu Glu Leu Gly Met Thr
435 440 445
Asn Ala His Phe Thr Ser Leu Asp Gln Tyr Arg Asp Leu Glu Ser Leu
450 455 460
Asn Ala Tyr Arg Gln Arg Val Glu Glu Ala Lys Val Gln Ser Pro Glu
465 470 475 480
Ser Met Leu Ala Gly Ile Ala Ala Arg Gly Arg Asp Asn Ser Arg Thr
485 490 495
Pro Met Gln Trp Asp Gly Ser Ala Tyr Ala Gly Phe Thr Ala Pro Asp
500 505 510
Ala Ala Thr Glu Pro Trp Ile Ser Val Asn Pro Asn His Ala Glu Ile
515 520 525
Asn Ala Ala Gly Glu Phe Asp Asp Pro Asp Ser Val Tyr Ala Phe Tyr
530 535 540
Lys Lys Leu Ile Ala Leu Arg His Asn Ser Ser Ile Val Ala Ala Gly
545 550 555 560
Glu Trp Gln Leu Ile Asp Ala Asp Asp Ala His Val Tyr Ala Phe Thr
565 570 575
Arg Thr Leu Gly Asn Glu Arg Leu Leu Val Val Val Asn Leu Ser Gly
580 585 590
Arg Thr Val Asp Leu Pro Arg Glu Ser Thr Glu Leu Ile Ala Gly Gly
595 600 605
Val Thr Glu Pro Asp Ile Ile Leu Ser Thr Tyr Asp Ala Pro His Thr
610 615 620
Val Val Ser Leu Ala Asn Arg Glu Leu Asp Pro Trp Glu Ala Ala Ala
625 630 635 640
Val Gln Leu
<210> 13
<211> 38
<212> ДНК
<213> Corynebacterium glutamicum
<220>
<221> терминатор
<222> (1)..(38)
<223> терминатор транскрипции гена gap (B. J. Eikmanns 1992, фиг. 3)
<220>
<221> прочий_признак
<222> (3)..(38)
<223> последовательность терминатора Tgap*
<400> 13
aatagcccgg ggtgtgcctc ggcgcacccc gggctatt 38
<210> 14
<211> 85
<212> ДНК
<213> искусственная последовательность
<220>
<223> промотор
<220>
<221> промотор
<222> (1)..(85)
<223> последовательность, обозначенная как PtacI у De Boer и соавт. (1983)
<220>
<221> промотор
<222> (1)..(75)
<223> промотор PtacI
<400> 14
gagctgttga caattaatca tcggctcgta taatgtgtgg aattgtgagc ggataacaat 60
ttcacacagg aaacagaatt ctatg 85
<210> 15
<211> 60
<212> ДНК
<213> Corynebacterium glutamicum
<220>
<221> промотор
<222> (1)..(60)
<223> промотор PdapBN1
<400> 15
taggtatgga tatcagcacc ttctgaacgg gtacgggtat aatggtgggc gtttgaaaaa 60
<210> 16
<211> 2096
<212> ДНК
<213> искусственная последовательность
<220>
<223> слитый ген tat-'agl2_cuo, содержащий промотор и терминатор
<220>
<221> прочий_признак
<222> (1)..(121)
<223> вышерасположенная последовательность
<220>
<221> промотор
<222> (32)..(91)
<223> промотор PdapBN1
<220>
<221> CDS
<222> (122)..(2038)
<223> последовательность, кодирующая слитый полипептид Tat-'Agl2
<220>
<221> прочий_признак
<222> (2039)..(2041)
<223> стоп-кодон
<220>
<221> прочий_признак
<222> (2053)..(2088)
<223> последовательность терминатора Tgap*
<400> 16
atcgttaaca acacagacca aaacggtcag ttaggtatgg atatcagcac cttctgaacg 60
ggtacgggta taatggtggg cgtttgaaaa actcttcgcc ccacgaaaat gaaggagcat 120
a atg caa ata aac cgc cga ggc ttc tta aaa gcc acc aca gga ctt gcc 169
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr Thr Gly Leu Ala
1 5 10 15
act atc ggc gct gcc agc atg ttt atg cca aag gcc aac gcc ctt gga 217
Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala Asn Ala Leu Gly
20 25 30
gca atg act agt acc tcc ttc aac cgc gaa cca ctg cca gat gca gtg 265
Ala Met Thr Ser Thr Ser Phe Asn Arg Glu Pro Leu Pro Asp Ala Val
35 40 45
cgc acc aac ggt gca acc cca aac cca tgg tgg tcc aac gca gtg gtg 313
Arg Thr Asn Gly Ala Thr Pro Asn Pro Trp Trp Ser Asn Ala Val Val
50 55 60
tac cag atc tac cca cgc tcc ttc cag gat acc aac ggc gac ggc ctg 361
Tyr Gln Ile Tyr Pro Arg Ser Phe Gln Asp Thr Asn Gly Asp Gly Leu
65 70 75 80
ggc gat ctg aag ggc atc acc tcc cgc ttg gat tac ctg gca gat ctg 409
Gly Asp Leu Lys Gly Ile Thr Ser Arg Leu Asp Tyr Leu Ala Asp Leu
85 90 95
ggc gtg gat gtg ctg tgg ctg tcc cca gtg tac cgc tcc cca cag gat 457
Gly Val Asp Val Leu Trp Leu Ser Pro Val Tyr Arg Ser Pro Gln Asp
100 105 110
gat aac ggc tac gat atc tcc gat tac cgc gat atc gat cca ctg ttc 505
Asp Asn Gly Tyr Asp Ile Ser Asp Tyr Arg Asp Ile Asp Pro Leu Phe
115 120 125
ggc acc ctg gat gat atg gat gaa ctg ctg gca gag gca cac aag cgt 553
Gly Thr Leu Asp Asp Met Asp Glu Leu Leu Ala Glu Ala His Lys Arg
130 135 140
ggc ctg aag atc gtg atg gat ctg gtg gtg aac cac acc tcc gat gaa 601
Gly Leu Lys Ile Val Met Asp Leu Val Val Asn His Thr Ser Asp Glu
145 150 155 160
cac gca tgg ttc gaa gca tcc aag gat aag gat gat cca cac gca gat 649
His Ala Trp Phe Glu Ala Ser Lys Asp Lys Asp Asp Pro His Ala Asp
165 170 175
tgg tac tgg tgg cgt cca gca cgc cca ggc cac gaa cca ggc acc cca 697
Trp Tyr Trp Trp Arg Pro Ala Arg Pro Gly His Glu Pro Gly Thr Pro
180 185 190
ggc gca gaa cca aac cag tgg ggc tcc tac ttc ggt ggc tcc gca tgg 745
Gly Ala Glu Pro Asn Gln Trp Gly Ser Tyr Phe Gly Gly Ser Ala Trp
195 200 205
gaa tac tcc cca gaa cgc ggt gaa tac tac ctg cac cag ttc tcc aag 793
Glu Tyr Ser Pro Glu Arg Gly Glu Tyr Tyr Leu His Gln Phe Ser Lys
210 215 220
aag cag cca gat ctc aac tgg gaa aac cca gca gtg cgt cgc gca gtg 841
Lys Gln Pro Asp Leu Asn Trp Glu Asn Pro Ala Val Arg Arg Ala Val
225 230 235 240
tac gat atg atg aac tgg tgg ttg gat cgc ggt atc gat ggc ttc cgc 889
Tyr Asp Met Met Asn Trp Trp Leu Asp Arg Gly Ile Asp Gly Phe Arg
245 250 255
atg gat gtg atc acc ctg atc tcc aag cgc acc gat cca aac ggt cgc 937
Met Asp Val Ile Thr Leu Ile Ser Lys Arg Thr Asp Pro Asn Gly Arg
260 265 270
ctg cca ggt gaa acc ggc tcc gaa ctc cag gat ctg cca gtg ggc gaa 985
Leu Pro Gly Glu Thr Gly Ser Glu Leu Gln Asp Leu Pro Val Gly Glu
275 280 285
gaa ggc tac tcc tcc cca aac cct ttc tgc gca gat ggc cct cgc cag 1033
Glu Gly Tyr Ser Ser Pro Asn Pro Phe Cys Ala Asp Gly Pro Arg Gln
290 295 300
gat gaa ttc ctg gca gaa atg cgt cgc gaa gtt ttc gat ggc cgt gat 1081
Asp Glu Phe Leu Ala Glu Met Arg Arg Glu Val Phe Asp Gly Arg Asp
305 310 315 320
ggc ttc ctg acc gtg ggc gaa gca cca ggc atc acc gca gaa cgc aac 1129
Gly Phe Leu Thr Val Gly Glu Ala Pro Gly Ile Thr Ala Glu Arg Asn
325 330 335
gaa cac atc acc gat cca gca aac ggc gaa ctg gat atg ctg ttc ctg 1177
Glu His Ile Thr Asp Pro Ala Asn Gly Glu Leu Asp Met Leu Phe Leu
340 345 350
ttc gaa cac atg ggc gtg gat cag acc cca gaa tcc aag tgg gat gat 1225
Phe Glu His Met Gly Val Asp Gln Thr Pro Glu Ser Lys Trp Asp Asp
355 360 365
aag cca tgg acc cca gca gat ctg gaa acc aag ctg gca gaa cag cag 1273
Lys Pro Trp Thr Pro Ala Asp Leu Glu Thr Lys Leu Ala Glu Gln Gln
370 375 380
gat gca atc gca cgc cgt ggc tgg gcc tcc ctg ttc ctg gat aac cac 1321
Asp Ala Ile Ala Arg Arg Gly Trp Ala Ser Leu Phe Leu Asp Asn His
385 390 395 400
gat cag cca cgc gtg gtg tcc cgc tgg ggt gat gat acc tcc aag acc 1369
Asp Gln Pro Arg Val Val Ser Arg Trp Gly Asp Asp Thr Ser Lys Thr
405 410 415
ggt cgc atc cgc tcc gca aag gca ctg gca ctg ctg ctg cac atg cac 1417
Gly Arg Ile Arg Ser Ala Lys Ala Leu Ala Leu Leu Leu His Met His
420 425 430
cgt ggc acc cca tac gtg tac cag ggc gaa gaa ctg ggc atg acc aac 1465
Arg Gly Thr Pro Tyr Val Tyr Gln Gly Glu Glu Leu Gly Met Thr Asn
435 440 445
gca cac ttc acc tcc ctg gat cag tac cgc gat ctg gaa tcc atc aac 1513
Ala His Phe Thr Ser Leu Asp Gln Tyr Arg Asp Leu Glu Ser Ile Asn
450 455 460
gca tac cac caa cgc gtg gaa gaa acc ggc atc cgc acc tcc gaa acc 1561
Ala Tyr His Gln Arg Val Glu Glu Thr Gly Ile Arg Thr Ser Glu Thr
465 470 475 480
atg atg cgc tcc ctg gca cgc tac ggt cgc gat aac gca cgc acc cca 1609
Met Met Arg Ser Leu Ala Arg Tyr Gly Arg Asp Asn Ala Arg Thr Pro
485 490 495
atg cag tgg gat gat tcc acc tac gca ggc ttc acc atg cca gat gcc 1657
Met Gln Trp Asp Asp Ser Thr Tyr Ala Gly Phe Thr Met Pro Asp Ala
500 505 510
cca gtg gaa cca tgg atc gca gtg aac cca aac cac acc gaa atc aac 1705
Pro Val Glu Pro Trp Ile Ala Val Asn Pro Asn His Thr Glu Ile Asn
515 520 525
gca gca gat gaa acc gat gat cca gat tcc gtg tac tcc ttc cac aag 1753
Ala Ala Asp Glu Thr Asp Asp Pro Asp Ser Val Tyr Ser Phe His Lys
530 535 540
cgc ctg atc gca ctg cgc cac acc gat cca gtg gtg gca gca ggc gat 1801
Arg Leu Ile Ala Leu Arg His Thr Asp Pro Val Val Ala Ala Gly Asp
545 550 555 560
tac cgt cgc gtg gaa acc ggc aac gat cgc atc att gca ttc acc cgc 1849
Tyr Arg Arg Val Glu Thr Gly Asn Asp Arg Ile Ile Ala Phe Thr Arg
565 570 575
acc ctg gac gaa cgc acc atc ctg acc gtg atc aac ctg tcc cca acc 1897
Thr Leu Asp Glu Arg Thr Ile Leu Thr Val Ile Asn Leu Ser Pro Thr
580 585 590
cag gca gca cca gca ggc gaa ctg gaa acc atg cca gac ggc acc atc 1945
Gln Ala Ala Pro Ala Gly Glu Leu Glu Thr Met Pro Asp Gly Thr Ile
595 600 605
ttg atc gca aac acc gat gac cca gtg ggc aac ctc aag acc acc ggc 1993
Leu Ile Ala Asn Thr Asp Asp Pro Val Gly Asn Leu Lys Thr Thr Gly
610 615 620
acc ctg ggt cca tgg gaa gca ttc gca atg gaa acc gat cca gaa 2038
Thr Leu Gly Pro Trp Glu Ala Phe Ala Met Glu Thr Asp Pro Glu
625 630 635
taagcggccg ctgttagccc ggggtgtgcc tcggcgcacc ccgggctatt tttctaga 2096
<210> 17
<211> 639
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 17
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr Thr Gly Leu Ala
1 5 10 15
Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala Asn Ala Leu Gly
20 25 30
Ala Met Thr Ser Thr Ser Phe Asn Arg Glu Pro Leu Pro Asp Ala Val
35 40 45
Arg Thr Asn Gly Ala Thr Pro Asn Pro Trp Trp Ser Asn Ala Val Val
50 55 60
Tyr Gln Ile Tyr Pro Arg Ser Phe Gln Asp Thr Asn Gly Asp Gly Leu
65 70 75 80
Gly Asp Leu Lys Gly Ile Thr Ser Arg Leu Asp Tyr Leu Ala Asp Leu
85 90 95
Gly Val Asp Val Leu Trp Leu Ser Pro Val Tyr Arg Ser Pro Gln Asp
100 105 110
Asp Asn Gly Tyr Asp Ile Ser Asp Tyr Arg Asp Ile Asp Pro Leu Phe
115 120 125
Gly Thr Leu Asp Asp Met Asp Glu Leu Leu Ala Glu Ala His Lys Arg
130 135 140
Gly Leu Lys Ile Val Met Asp Leu Val Val Asn His Thr Ser Asp Glu
145 150 155 160
His Ala Trp Phe Glu Ala Ser Lys Asp Lys Asp Asp Pro His Ala Asp
165 170 175
Trp Tyr Trp Trp Arg Pro Ala Arg Pro Gly His Glu Pro Gly Thr Pro
180 185 190
Gly Ala Glu Pro Asn Gln Trp Gly Ser Tyr Phe Gly Gly Ser Ala Trp
195 200 205
Glu Tyr Ser Pro Glu Arg Gly Glu Tyr Tyr Leu His Gln Phe Ser Lys
210 215 220
Lys Gln Pro Asp Leu Asn Trp Glu Asn Pro Ala Val Arg Arg Ala Val
225 230 235 240
Tyr Asp Met Met Asn Trp Trp Leu Asp Arg Gly Ile Asp Gly Phe Arg
245 250 255
Met Asp Val Ile Thr Leu Ile Ser Lys Arg Thr Asp Pro Asn Gly Arg
260 265 270
Leu Pro Gly Glu Thr Gly Ser Glu Leu Gln Asp Leu Pro Val Gly Glu
275 280 285
Glu Gly Tyr Ser Ser Pro Asn Pro Phe Cys Ala Asp Gly Pro Arg Gln
290 295 300
Asp Glu Phe Leu Ala Glu Met Arg Arg Glu Val Phe Asp Gly Arg Asp
305 310 315 320
Gly Phe Leu Thr Val Gly Glu Ala Pro Gly Ile Thr Ala Glu Arg Asn
325 330 335
Glu His Ile Thr Asp Pro Ala Asn Gly Glu Leu Asp Met Leu Phe Leu
340 345 350
Phe Glu His Met Gly Val Asp Gln Thr Pro Glu Ser Lys Trp Asp Asp
355 360 365
Lys Pro Trp Thr Pro Ala Asp Leu Glu Thr Lys Leu Ala Glu Gln Gln
370 375 380
Asp Ala Ile Ala Arg Arg Gly Trp Ala Ser Leu Phe Leu Asp Asn His
385 390 395 400
Asp Gln Pro Arg Val Val Ser Arg Trp Gly Asp Asp Thr Ser Lys Thr
405 410 415
Gly Arg Ile Arg Ser Ala Lys Ala Leu Ala Leu Leu Leu His Met His
420 425 430
Arg Gly Thr Pro Tyr Val Tyr Gln Gly Glu Glu Leu Gly Met Thr Asn
435 440 445
Ala His Phe Thr Ser Leu Asp Gln Tyr Arg Asp Leu Glu Ser Ile Asn
450 455 460
Ala Tyr His Gln Arg Val Glu Glu Thr Gly Ile Arg Thr Ser Glu Thr
465 470 475 480
Met Met Arg Ser Leu Ala Arg Tyr Gly Arg Asp Asn Ala Arg Thr Pro
485 490 495
Met Gln Trp Asp Asp Ser Thr Tyr Ala Gly Phe Thr Met Pro Asp Ala
500 505 510
Pro Val Glu Pro Trp Ile Ala Val Asn Pro Asn His Thr Glu Ile Asn
515 520 525
Ala Ala Asp Glu Thr Asp Asp Pro Asp Ser Val Tyr Ser Phe His Lys
530 535 540
Arg Leu Ile Ala Leu Arg His Thr Asp Pro Val Val Ala Ala Gly Asp
545 550 555 560
Tyr Arg Arg Val Glu Thr Gly Asn Asp Arg Ile Ile Ala Phe Thr Arg
565 570 575
Thr Leu Asp Glu Arg Thr Ile Leu Thr Val Ile Asn Leu Ser Pro Thr
580 585 590
Gln Ala Ala Pro Ala Gly Glu Leu Glu Thr Met Pro Asp Gly Thr Ile
595 600 605
Leu Ile Ala Asn Thr Asp Asp Pro Val Gly Asn Leu Lys Thr Thr Gly
610 615 620
Thr Leu Gly Pro Trp Glu Ala Phe Ala Met Glu Thr Asp Pro Glu
625 630 635
<210> 18
<211> 2222
<212> ДНК
<213> Corynebacterium glutamicum ATCC13032
<220>
<221> прочий_признак
<222> (1)..(3)
<223> стартовый кодон atg NCgl2176
<220>
<221> прочий_признак
<222> (1033)..(1035)
<223> стоп-кодон tga NCgl2176
<220>
<221> прочий_признак
<222> (1594)..(1596)
<223> кодон cta; стоп-кодон tag NCgl2177 в комплементарной нити
<220>
<221> прочий_признак
<222> (2020)..(2022)
<223> кодон cat; стартовый кодон atg NCgl2177 в комплементарной нити
<220>
<221> прочий_признак
<222> (2023)..(2222)
<223> последовательность, расположенная выше NCgl2177
<400> 18
atggcatttg cagacattgt gcgcagcgtc gaaaaccgca ccaacgcagc gaccctcaac 60
tggtccatca aaaatggctg gaagcccgaa gtcaccggat tttccgggta cggctccggg 120
cgtcgagtgc gcgtccttgc gcgcgtgctc atgtccaacc ccgaaaattt gcttgtcgac 180
gccccctccc aatcaattac ccaacaagca cagcgcggtt ggcgccagtt cttcaccatc 240
caagtgccca acctgccagt aactgtcacc gttggtggga aaacagttac ctcatccacc 300
aacgacaacg gctacgttga cctcctggtg gaagaccaca accttgaccc cggctggcac 360
accatccaga tccaagccga aggttccacc cccgccgaag cccgcgtcct catcgtggaa 420
aacaccgccc gaatcggact catctccgac atcgacgaca ccatcatggt cacctggctt 480
ccccgagcac tcctcgccgc atggaactcg tgggttttgc acaccaacac ccgcaaacca 540
gtccccggaa tgaaccgctt ctacgaagaa ctcctcaaag accaccccga cgcacccgtg 600
ttctacctct ccaccggcgc atggaacacc tttgaaaccc tccaagagtt catcaacaaa 660
cacgcactcc ccgacggccc catgctgctc accgactggg gaccaacccc cacaggacta 720
ttccgctcag gtcaagagca caagaaagtc caactgcgca acctgtttat cgaatacccc 780
gacatgaaat ggatcctcgt cggcgacgat ggccaacacg atcccctcat ctacggcgaa 840
gcagtcgaag aacaccccaa ccgcatcgca ggcgttgcaa tccgtgagct ctcccccggc 900
gaacatgtgc tctcccacgg aacaactgcg tcactgtcca ccatcacgac caacgggggc 960
caaggagtcc cagtagttca cggccgcgat ggatatgagt tgctgcagcg ctacgagacg 1020
aagccgttcg cctgagtcct actgggtgtc tcatgaacca aaccgggtga ccagcgtcgc 1080
cttaattttg ggttcctcgg tcacctagtt tggtccttgg ttgcgttcgc gtatggcata 1140
aatgggcact gactattttt ggggcggggc cccgaggtaa aaggcgattt aagaggttga 1200
gatccccaaa taggcttttg gtatggagga cgcccgttga ggctcttaaa accgattctg 1260
agagacctcg gctttgtgac cagtgggaca gatgagattc ctgcgagctt gctgatcaag 1320
aactcaccac aattgtgtgg ccagaccgtc aaatcgaaca tatttttgca ctaactagac 1380
ccaaacttgc aaaaacccac cacaaacact gtctcgccag caatctgtgg tgaattttcg 1440
cataattgtt cgaccaagag tccgacggta atcaacacgt cacaaaccac cccacaaagt 1500
gcgccaaaaa cccgtggggc ctccctcttc ctctagagag gccccacggg ctggtctatt 1560
tacaccccgc cgagctaaag aatcactggc tttctagtca acgattcgca gctcaacttc 1620
aaaacggtat tcatcagcca gagattccag cactcctcga agtttgtcga gttcgcgtgg 1680
agttccggtg atcacctctc gacactcagt gaggccaagt tcgaatgggt cacggcgcca 1740
tgcagtgaac catcgtgcgg tgagcgggtc cctgttggag ccggacagct ccgaaggact 1800
cggaatacac acaaccattg cggattccac ggtctgacgc agttcctttg gcattccgct 1860
gatttctaga acagcggtat gcattgggag ggctacatcg tcgatggatt cttcgatggt 1920
agttttcagt tggggcaacc ccatgtcttc ccagaagtct gccgtgagca aatccgcctg 1980
atgacgggtc cgggttggca cggttaatgc attgttcgtc atgttcggtt tccttcggca 2040
acacttaact gccttcaatt cccgcacaca tatacaagta gatatgtgca gttactaaag 2100
gaagtaagac gaggttcgtc ttccccaacg gcctcgagct cgcttcaaaa tcccttgaat 2160
gactacacag gcgattgtgg ttgagtaagt ggaccccggc aaccctcaac ttaagcttta 2220
tc 2222
<210> 19
<211> 2222
<212> ДНК
<213> Corynebacterium glutamicum ATCC13869
<220>
<221> прочий_признак
<222> (1)..(2222)
<223> последовательность, гомологичная SEQ ID NO: 18
<220>
<221> прочий_признак
<222> (1)..(3)
<223> стартовый кодон atg BBD29_10725
<220>
<221> прочий_признак
<222> (1033)..(1035)
<223> стоп-кодон tga BBD29_10725
<220>
<221> прочий_признак
<222> (1594)..(1596)
<223> кодон cta; стоп-кодон tag BBD29_10730 в комплементарной нити
<220>
<221> прочий_признак
<222> (2020)..(2022)
<223> кодон cat; стартовый кодон atg BBD29_10730 в комплементарной нити
<220>
<221> прочий_признак
<222> (2023)..(2222)
<223> последовательность, расположенная выше BBD29_10730
<400> 19
atggcatttg cagacattgt gcgcagcgtc gaaaaccgca ccaacgcagc gacccttaac 60
tggtccatca aaaagggctg gaagcccgaa gtcaccggat tttccgggta cggctccggg 120
cgtcgagtgc gcgtccttgc gcgcgtgctc atgtccaacc ccgaaaattt gcttgtcgac 180
gccccctccc aatcaattac ccaacaagca cagcgcggtt ggcgccagtt cttcaccatc 240
caagtgccca acctgccagt aactgtcacc gttggtggga aaacagttac ctcatccacc 300
aacgacaacg gctacgttga cctcctggtg gaagaccaca accttgaccc cggctggcac 360
accatccaga tccaagccga aggttccacc cccgccgaag cccgcgtcct catcgtggaa 420
aacaccgccc gaatcggact catctccgac atcgacgaca ccatcatggt cacctggctt 480
ccccgagcac tcctcgccgc atggaactcg tgggttttgc acaccaacac ccgcaaacca 540
gtccccggaa tgaaccgctt ctacgaagaa ctcctcaaag accaccccga cgcacccgtg 600
ttctacctct ccaccggcgc atggaacacc tttgaaaccc tccaagagtt catcaacaaa 660
cacgcactcc ccgacggccc catgctgctc accgactggg gaccaacccc cacaggacta 720
ttccgctcag gtcaagagca caagaaagtc caactgcgca acctgtttat cgaatacccc 780
gacatgaaat ggatcctcgt cggcgacgat ggccaacacg atcccctcat ctacggcgaa 840
gcagtcgaag aacaccccaa ccgcatcgca ggcgttgcaa tccgtgagct ctcccccggc 900
gaacatgtgc tctcccacgg aacaactgcg tcactgtcca ccatcacgac caacggtggc 960
caaggagtcc cagtagttca cggccgcgat ggatatgagt tgctgcagcg ctacgagacg 1020
aagccgttcg cctgagtcct actgggtgtc tcatgaacca aaccgggtga ccagcgtcgc 1080
cttaattttg ggttcctcgg tcacctggtt tggtccttgg ttgcgttcgc gtatggcata 1140
aatgggcact gactattttt ggggcggggc cccgaggtaa aaggcgattt aagaggttga 1200
gatccccaaa taggcttttg gtatggagga cgcccgttga ggctcttaaa accgattctg 1260
agagacctcg gctttgtgac cagtgggaca gatgagattc ctgcgagctt gctgatcaag 1320
aactcaccac aatcgtgtgg ccagaccatc aaatcgaaca tatttttgca ctaactagac 1380
ccaaacttgc aaaaacccac cacaaaccct gtcccgccag caatctgtgg tgaattttcg 1440
cataattgtt cgactaagcg tccgacggta atcaacacgt cacaaaccac cccaaaaagt 1500
gcgccaaaaa cccgtggggc ctccctcttc ctctagagag gccccacggg ctggtctatt 1560
tacaccccgc cgagctaaag aatcactggc tttctagtca acgattcgca gctcaacttc 1620
aaaacggtat tcatcagcca gagattccag cactcctcga agtttgtcga gttcgcgtgg 1680
agttccggtg atcacctctc ggcactcagt gaggccaagt tcgaatgggt cacggcgcca 1740
tgcagtgaac catcgtgcgg tgagcgggtc ccggttggag ccggacagct ccgaaggact 1800
cggaatacac acaaccattg cggattccac ggtctgacgc agttcctttg gcattccgct 1860
gatttctaga acagcggtat gcattgggag ggctacatcg tcgatggatt cttcaatggt 1920
agttttcagt tggggcaacc ccatgtcttc ccagaagtct gccgtgagca aatccgcctg 1980
atgacgggtc cgggttggca cggttaatgc attgttcgtc atgttcggtt tccttcggca 2040
acacttaact gccttcaatt cccgcacaca tatacaagta gatatgtgca gttactaaag 2100
gaagtaagac gaggttcgtc ttccccaacg gcctcgagct cgcttcaaaa ttccttgaat 2160
gactacacag gcgattgtgg ttgagtaagt ggaccccggc aaccctcaac ttaagcttta 2220
tc 2222
<210> 20
<211> 2222
<212> ДНК
<213> Corynebacterium glutamicum ATCC14067
<220>
<221> прочий_признак
<222> (1)..(2222)
<223> последовательность, гомологичная SEQ ID NO: 18
<220>
<221> прочий_признак
<222> (1)..(3)
<223> стартовый кодон atg
<220>
<221> прочий_признак
<222> (1033)..(1035)
<223> стоп-кодон tag
<220>
<221> прочий_признак
<222> (1594)..(1596)
<223> кодон cta; стоп-кодон tag в комплементарной нити
<220>
<221> прочий_признак
<222> (2020)..(2022)
<223> кодон cat; стартовый кодон atg в комплементарной нити
<220>
<221> прочий_признак
<222> (2023)..(2222)
<223> последовательность, расположенная выше (в комплементарной нити)
cds, идентифицируемой в положениях 2022-1597
<400> 20
atggcatttg cagacattgt gcgcagcgtc gaaaaccgca ccaacgcagc gaccctcaac 60
tggtccatca aaaagggctg gaagcccgaa gtcaccggat tttccggtta cggctccggg 120
cgtcgagtgc gcgtccttgc gcgcgtgctc atgtccaacc ccgaaaattt gcttgtcgac 180
gccccctccc aatcaattac ccaacaagca cagcgcggtt ggcgccagtt cttcaccatc 240
caagtgccca acctgccagt aactgtcacc gttggtggga aaacagttac ctcatccacc 300
aacgacaacg gctacgttga cctcctggtg gaagaccaca accttgaccc cggctggcac 360
accatccaga tccaagccga aggttccacc cccgccgaag cccgcgtcct catcgtggaa 420
aacaccgccc gaatcggact catctccgac atcgacgaca ccatcatggt cacctggctt 480
ccccgagcac tcctcgccgc atggaactcg tgggttttgc acaccaacac ccgcaaacca 540
gtccccggaa tgaaccgctt ctacgaagaa ctcctcaaag accaccccga cgcacccgtg 600
ttctacctct ccaccggcgc atggaacacc tttgaaaccc tccaagagtt catcaacaaa 660
cacgcactcc ccgacggccc catgttgctc accgactggg gaccaacccc cacaggacta 720
ttccgctcag gtcaagagca caagaaagtc caactgcgca acctgtttat cgaatacccc 780
gacatgaaat ggatcctcgt cggcgacgat ggccaacacg atcccctcat ctacggcgaa 840
gcagtcgaag aacaccccaa ccgcatcgca ggtgttgcaa tccgtgagct ctcccccggc 900
gaacatgtgc tctcccacgg aacaactgcg tcactgtcca ccatcacgac caacggtggc 960
caaggagtcc cagtagttca cggccgcgat ggatatgagt tgctgcagcg ctacgagacg 1020
aagccgttcg cctgagtcct actgggtgtc tcatgaacca aaccgggtga ccagcgtcgc 1080
cttaactttg ggttcctcgg tcacctggtt tggtccttgg ttgcgttcgc gtatggcata 1140
aatgggcact gactattttt ggggcggggc cccgaggtaa aaggcgattt aagaggttga 1200
gatccccaaa taggcttttg gtatggagga cgcccgttga ggctcttaaa accgattctg 1260
agagacctcg gctttgtgac cagtgggaca gatgagattc ctgcgagctt gctgatcaag 1320
aactcaccac aatcgtgtgg ccagaccatc aaatcgaata gatttttgca ctaactagac 1380
ccaaacttgc aaaaacccac cacaaaccct gtcccgccag caatctgtgg tgaattttcg 1440
cataattatt cgaccaatcg tccgacggta atcaacacgt cacaaaccac cccaaaaagt 1500
gcgccaaaaa cccgtggggc ctccctcttc ctctagagag gccccacggg ctggtctatt 1560
tacgccccgc cgagctaaag aatcactggc tttctagtca acgattcgca gctcaacttc 1620
aaaacggtat tcatcagcca gagattccag cactcctcga agtttgtcga gttcgcgtgg 1680
agttccggtg atcacctctc gacactcagt gaggccaagt tcgaatgggt cacggcgcca 1740
tgcagtgaac catcgtgcgg tgagcgggtc cctgttggag ccggacagct ccgaaggact 1800
cggaatacac acaaccattg cggattccac ggtctgacgc agttcctttg gcattccgct 1860
gatttctaga acagcggtat gcattgggag ggctacatcg tcgatggatt cttcgatggt 1920
agttttcagt tggggcaacc ccatgtcttc ccagaagtct gccgtgagca aatccgcctg 1980
atgacgggtc cgggttggca cggttaatgc attgttcgtc atgttcggtt tccttcggca 2040
acacttaact gccttcaatt cccgcacaca tatacaagta gatatgtgca gttactaaag 2100
gaagtaagac gaggttcgtc ttccccaacg gcctcgagct cgcttcaaaa ttccttgaat 2160
gactacacag gcgattgtgg ttgagtaagt ggaccccggc aaccctcaac ttaagcttta 2220
tc 2222
<210> 21
<211> 1994
<212> ДНК
<213> искусственная последовательность
<220>
<223> слитый ген tat-'agl2_cuo
<220>
<221> прочий_признак
<222> (1)..(6)
<223> сайт рестрикции для PstI
<220>
<221> прочий_признак
<222> (7)..(13)
<223> сайт рестрикции для SexAI
<220>
<221> CDS
<222> (14)..(1930)
<223> последовательность, кодирующая слитый полипептид Tat-'Agl2
<220>
<221> прочая_сигнальная_последовательность
<222> (14)..(112)
<223> 5'-концевая последовательность cg0955, кодирующая
Tat-сигнальный пептид Cg0955
<220>
<221> прочий_признак
<222> (14)..(114)
<223> 5'-концевая последовательность cg0955
<220>
<221> прочий_признак
<222> (115)..(115)
<223> нуклеотидное основание гуанин
<220>
<221> прочий_признак
<222> (116)..(121)
<223> сайт рестрикции для SpeI
<220>
<221> прочий_признак
<222> (122)..(1930)
<223> 'agl2_cuo
<220>
<221> прочий_признак
<222> (155)..(162)
<223> сайт рестрикции для FspAI
<220>
<221> прочий_признак
<222> (1931)..(1933)
<223> стоп-кодон
<220>
<221> прочий_признак
<222> (1934)..(1941)
<223> сайт рестрикции для NotI
<220>
<221> прочий_признак
<222> (1945)..(1980)
<223> последовательность терминатора Tgap*
<220>
<221> прочий_признак
<222> (1983)..(1988)
<223> сайт рестрикции для XbaI
<220>
<221> прочий_признак
<222> (1989)..(1994)
<223> сайт рестрикции для BamHI
<400> 21
ctgcagacca ggt atg caa ata aac cgc cga ggc ttc tta aaa gcc acc 49
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr
1 5 10
aca gga ctt gcc act atc ggc gct gcc agc atg ttt atg cca aag gcc 97
Thr Gly Leu Ala Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala
15 20 25
aac gcc ctt gga gca atg act agt acc tcc ttc aac cgc gaa cca ctg 145
Asn Ala Leu Gly Ala Met Thr Ser Thr Ser Phe Asn Arg Glu Pro Leu
30 35 40
cca gat gca gtg cgc acc aac ggt gca acc cca aac cca tgg tgg tcc 193
Pro Asp Ala Val Arg Thr Asn Gly Ala Thr Pro Asn Pro Trp Trp Ser
45 50 55 60
aac gca gtg gtg tac cag atc tac cca cgc tcc ttc cag gat acc aac 241
Asn Ala Val Val Tyr Gln Ile Tyr Pro Arg Ser Phe Gln Asp Thr Asn
65 70 75
ggc gac ggc ctg ggc gat ctg aag ggc atc acc tcc cgc ttg gat tac 289
Gly Asp Gly Leu Gly Asp Leu Lys Gly Ile Thr Ser Arg Leu Asp Tyr
80 85 90
ctg gca gat ctg ggc gtg gat gtg ctg tgg ctg tcc cca gtg tac cgc 337
Leu Ala Asp Leu Gly Val Asp Val Leu Trp Leu Ser Pro Val Tyr Arg
95 100 105
tcc cca cag gat gat aac ggc tac gat atc tcc gat tac cgc gat atc 385
Ser Pro Gln Asp Asp Asn Gly Tyr Asp Ile Ser Asp Tyr Arg Asp Ile
110 115 120
gat cca ctg ttc ggc acc ctg gat gat atg gat gaa ctg ctg gca gag 433
Asp Pro Leu Phe Gly Thr Leu Asp Asp Met Asp Glu Leu Leu Ala Glu
125 130 135 140
gca cac aag cgt ggc ctg aag atc gtg atg gat ctg gtg gtg aac cac 481
Ala His Lys Arg Gly Leu Lys Ile Val Met Asp Leu Val Val Asn His
145 150 155
acc tcc gat gaa cac gca tgg ttc gaa gca tcc aag gat aag gat gat 529
Thr Ser Asp Glu His Ala Trp Phe Glu Ala Ser Lys Asp Lys Asp Asp
160 165 170
cca cac gca gat tgg tac tgg tgg cgt cca gca cgc cca ggc cac gaa 577
Pro His Ala Asp Trp Tyr Trp Trp Arg Pro Ala Arg Pro Gly His Glu
175 180 185
cca ggc acc cca ggc gca gaa cca aac cag tgg ggc tcc tac ttc ggt 625
Pro Gly Thr Pro Gly Ala Glu Pro Asn Gln Trp Gly Ser Tyr Phe Gly
190 195 200
ggc tcc gca tgg gaa tac tcc cca gaa cgc ggt gaa tac tac ctg cac 673
Gly Ser Ala Trp Glu Tyr Ser Pro Glu Arg Gly Glu Tyr Tyr Leu His
205 210 215 220
cag ttc tcc aag aag cag cca gat ctc aac tgg gaa aac cca gca gtg 721
Gln Phe Ser Lys Lys Gln Pro Asp Leu Asn Trp Glu Asn Pro Ala Val
225 230 235
cgt cgc gca gtg tac gat atg atg aac tgg tgg ttg gat cgc ggt atc 769
Arg Arg Ala Val Tyr Asp Met Met Asn Trp Trp Leu Asp Arg Gly Ile
240 245 250
gat ggc ttc cgc atg gat gtg atc acc ctg atc tcc aag cgc acc gat 817
Asp Gly Phe Arg Met Asp Val Ile Thr Leu Ile Ser Lys Arg Thr Asp
255 260 265
cca aac ggt cgc ctg cca ggt gaa acc ggc tcc gaa ctc cag gat ctg 865
Pro Asn Gly Arg Leu Pro Gly Glu Thr Gly Ser Glu Leu Gln Asp Leu
270 275 280
cca gtg ggc gaa gaa ggc tac tcc tcc cca aac cct ttc tgc gca gat 913
Pro Val Gly Glu Glu Gly Tyr Ser Ser Pro Asn Pro Phe Cys Ala Asp
285 290 295 300
ggc cct cgc cag gat gaa ttc ctg gca gaa atg cgt cgc gaa gtt ttc 961
Gly Pro Arg Gln Asp Glu Phe Leu Ala Glu Met Arg Arg Glu Val Phe
305 310 315
gat ggc cgt gat ggc ttc ctg acc gtg ggc gaa gca cca ggc atc acc 1009
Asp Gly Arg Asp Gly Phe Leu Thr Val Gly Glu Ala Pro Gly Ile Thr
320 325 330
gca gaa cgc aac gaa cac atc acc gat cca gca aac ggc gaa ctg gat 1057
Ala Glu Arg Asn Glu His Ile Thr Asp Pro Ala Asn Gly Glu Leu Asp
335 340 345
atg ctg ttc ctg ttc gaa cac atg ggc gtg gat cag acc cca gaa tcc 1105
Met Leu Phe Leu Phe Glu His Met Gly Val Asp Gln Thr Pro Glu Ser
350 355 360
aag tgg gat gat aag cca tgg acc cca gca gat ctg gaa acc aag ctg 1153
Lys Trp Asp Asp Lys Pro Trp Thr Pro Ala Asp Leu Glu Thr Lys Leu
365 370 375 380
gca gaa cag cag gat gca atc gca cgc cgt ggc tgg gcc tcc ctg ttc 1201
Ala Glu Gln Gln Asp Ala Ile Ala Arg Arg Gly Trp Ala Ser Leu Phe
385 390 395
ctg gat aac cac gat cag cca cgc gtg gtg tcc cgc tgg ggt gat gat 1249
Leu Asp Asn His Asp Gln Pro Arg Val Val Ser Arg Trp Gly Asp Asp
400 405 410
acc tcc aag acc ggt cgc atc cgc tcc gca aag gca ctg gca ctg ctg 1297
Thr Ser Lys Thr Gly Arg Ile Arg Ser Ala Lys Ala Leu Ala Leu Leu
415 420 425
ctg cac atg cac cgt ggc acc cca tac gtg tac cag ggc gaa gaa ctg 1345
Leu His Met His Arg Gly Thr Pro Tyr Val Tyr Gln Gly Glu Glu Leu
430 435 440
ggc atg acc aac gca cac ttc acc tcc ctg gat cag tac cgc gat ctg 1393
Gly Met Thr Asn Ala His Phe Thr Ser Leu Asp Gln Tyr Arg Asp Leu
445 450 455 460
gaa tcc atc aac gca tac cac caa cgc gtg gaa gaa acc ggc atc cgc 1441
Glu Ser Ile Asn Ala Tyr His Gln Arg Val Glu Glu Thr Gly Ile Arg
465 470 475
acc tcc gaa acc atg atg cgc tcc ctg gca cgc tac ggt cgc gat aac 1489
Thr Ser Glu Thr Met Met Arg Ser Leu Ala Arg Tyr Gly Arg Asp Asn
480 485 490
gca cgc acc cca atg cag tgg gat gat tcc acc tac gca ggc ttc acc 1537
Ala Arg Thr Pro Met Gln Trp Asp Asp Ser Thr Tyr Ala Gly Phe Thr
495 500 505
atg cca gat gcc cca gtg gaa cca tgg atc gca gtg aac cca aac cac 1585
Met Pro Asp Ala Pro Val Glu Pro Trp Ile Ala Val Asn Pro Asn His
510 515 520
acc gaa atc aac gca gca gat gaa acc gat gat cca gat tcc gtg tac 1633
Thr Glu Ile Asn Ala Ala Asp Glu Thr Asp Asp Pro Asp Ser Val Tyr
525 530 535 540
tcc ttc cac aag cgc ctg atc gca ctg cgc cac acc gat cca gtg gtg 1681
Ser Phe His Lys Arg Leu Ile Ala Leu Arg His Thr Asp Pro Val Val
545 550 555
gca gca ggc gat tac cgt cgc gtg gaa acc ggc aac gat cgc atc att 1729
Ala Ala Gly Asp Tyr Arg Arg Val Glu Thr Gly Asn Asp Arg Ile Ile
560 565 570
gca ttc acc cgc acc ctg gac gaa cgc acc atc ctg acc gtg atc aac 1777
Ala Phe Thr Arg Thr Leu Asp Glu Arg Thr Ile Leu Thr Val Ile Asn
575 580 585
ctg tcc cca acc cag gca gca cca gca ggc gaa ctg gaa acc atg cca 1825
Leu Ser Pro Thr Gln Ala Ala Pro Ala Gly Glu Leu Glu Thr Met Pro
590 595 600
gac ggc acc atc ttg atc gca aac acc gat gac cca gtg ggc aac ctc 1873
Asp Gly Thr Ile Leu Ile Ala Asn Thr Asp Asp Pro Val Gly Asn Leu
605 610 615 620
aag acc acc ggc acc ctg ggt cca tgg gaa gca ttc gca atg gaa acc 1921
Lys Thr Thr Gly Thr Leu Gly Pro Trp Glu Ala Phe Ala Met Glu Thr
625 630 635
gat cca gaa taagcggccg ctgttagccc ggggtgtgcc tcggcgcacc 1970
Asp Pro Glu
ccgggctatt tttctagagg atcc 1994
<210> 22
<211> 639
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 22
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr Thr Gly Leu Ala
1 5 10 15
Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala Asn Ala Leu Gly
20 25 30
Ala Met Thr Ser Thr Ser Phe Asn Arg Glu Pro Leu Pro Asp Ala Val
35 40 45
Arg Thr Asn Gly Ala Thr Pro Asn Pro Trp Trp Ser Asn Ala Val Val
50 55 60
Tyr Gln Ile Tyr Pro Arg Ser Phe Gln Asp Thr Asn Gly Asp Gly Leu
65 70 75 80
Gly Asp Leu Lys Gly Ile Thr Ser Arg Leu Asp Tyr Leu Ala Asp Leu
85 90 95
Gly Val Asp Val Leu Trp Leu Ser Pro Val Tyr Arg Ser Pro Gln Asp
100 105 110
Asp Asn Gly Tyr Asp Ile Ser Asp Tyr Arg Asp Ile Asp Pro Leu Phe
115 120 125
Gly Thr Leu Asp Asp Met Asp Glu Leu Leu Ala Glu Ala His Lys Arg
130 135 140
Gly Leu Lys Ile Val Met Asp Leu Val Val Asn His Thr Ser Asp Glu
145 150 155 160
His Ala Trp Phe Glu Ala Ser Lys Asp Lys Asp Asp Pro His Ala Asp
165 170 175
Trp Tyr Trp Trp Arg Pro Ala Arg Pro Gly His Glu Pro Gly Thr Pro
180 185 190
Gly Ala Glu Pro Asn Gln Trp Gly Ser Tyr Phe Gly Gly Ser Ala Trp
195 200 205
Glu Tyr Ser Pro Glu Arg Gly Glu Tyr Tyr Leu His Gln Phe Ser Lys
210 215 220
Lys Gln Pro Asp Leu Asn Trp Glu Asn Pro Ala Val Arg Arg Ala Val
225 230 235 240
Tyr Asp Met Met Asn Trp Trp Leu Asp Arg Gly Ile Asp Gly Phe Arg
245 250 255
Met Asp Val Ile Thr Leu Ile Ser Lys Arg Thr Asp Pro Asn Gly Arg
260 265 270
Leu Pro Gly Glu Thr Gly Ser Glu Leu Gln Asp Leu Pro Val Gly Glu
275 280 285
Glu Gly Tyr Ser Ser Pro Asn Pro Phe Cys Ala Asp Gly Pro Arg Gln
290 295 300
Asp Glu Phe Leu Ala Glu Met Arg Arg Glu Val Phe Asp Gly Arg Asp
305 310 315 320
Gly Phe Leu Thr Val Gly Glu Ala Pro Gly Ile Thr Ala Glu Arg Asn
325 330 335
Glu His Ile Thr Asp Pro Ala Asn Gly Glu Leu Asp Met Leu Phe Leu
340 345 350
Phe Glu His Met Gly Val Asp Gln Thr Pro Glu Ser Lys Trp Asp Asp
355 360 365
Lys Pro Trp Thr Pro Ala Asp Leu Glu Thr Lys Leu Ala Glu Gln Gln
370 375 380
Asp Ala Ile Ala Arg Arg Gly Trp Ala Ser Leu Phe Leu Asp Asn His
385 390 395 400
Asp Gln Pro Arg Val Val Ser Arg Trp Gly Asp Asp Thr Ser Lys Thr
405 410 415
Gly Arg Ile Arg Ser Ala Lys Ala Leu Ala Leu Leu Leu His Met His
420 425 430
Arg Gly Thr Pro Tyr Val Tyr Gln Gly Glu Glu Leu Gly Met Thr Asn
435 440 445
Ala His Phe Thr Ser Leu Asp Gln Tyr Arg Asp Leu Glu Ser Ile Asn
450 455 460
Ala Tyr His Gln Arg Val Glu Glu Thr Gly Ile Arg Thr Ser Glu Thr
465 470 475 480
Met Met Arg Ser Leu Ala Arg Tyr Gly Arg Asp Asn Ala Arg Thr Pro
485 490 495
Met Gln Trp Asp Asp Ser Thr Tyr Ala Gly Phe Thr Met Pro Asp Ala
500 505 510
Pro Val Glu Pro Trp Ile Ala Val Asn Pro Asn His Thr Glu Ile Asn
515 520 525
Ala Ala Asp Glu Thr Asp Asp Pro Asp Ser Val Tyr Ser Phe His Lys
530 535 540
Arg Leu Ile Ala Leu Arg His Thr Asp Pro Val Val Ala Ala Gly Asp
545 550 555 560
Tyr Arg Arg Val Glu Thr Gly Asn Asp Arg Ile Ile Ala Phe Thr Arg
565 570 575
Thr Leu Asp Glu Arg Thr Ile Leu Thr Val Ile Asn Leu Ser Pro Thr
580 585 590
Gln Ala Ala Pro Ala Gly Glu Leu Glu Thr Met Pro Asp Gly Thr Ile
595 600 605
Leu Ile Ala Asn Thr Asp Asp Pro Val Gly Asn Leu Lys Thr Thr Gly
610 615 620
Thr Leu Gly Pro Trp Glu Ala Phe Ala Met Glu Thr Asp Pro Glu
625 630 635
<210> 23
<211> 2006
<212> ДНК
<213> искусственная последовательность
<220>
<223> слитый ген tat-agl1_cuo
<220>
<221> прочий_признак
<222> (1)..(6)
<223> сайт рестрикции для PstI
<220>
<221> прочий_признак
<222> (7)..(13)
<223> сайт рестрикции для SexAI
<220>
<221> CDS
<222> (14)..(1942)
<223> последовательность, кодирующая слитый полипептид Tat-'Agl1
<220>
<221> прочая_сигнальная_последовательность
<222> (14)..(112)
<223> 5'-концевая последовательность cg0955, кодирующая
Tat-сигнальный пептид cg0955
<220>
<221> прочий_признак
<222> (14)..(114)
<223> 5'-концевая последовательность cg0955
<220>
<221> прочий_признак
<222> (115)..(115)
<223> нуклеотидное основание аденин
<220>
<221> прочий_признак
<222> (115)..(120)
<223> сайт рестрикции для SpeI
<220>
<221> прочий_признак
<222> (121)..(121)
<223> нуклеотидное основание аденин
<220>
<221> прочий_признак
<222> (122)..(1942)
<223> agl1_cuo
<220>
<221> прочий_признак
<222> (1943)..(1945)
<223> стоп-кодон
<220>
<221> прочий_признак
<222> (1946)..(1953)
<223> сайт рестрикции для NotI
<220>
<221> прочий_признак
<222> (1957)..(1992)
<223> последовательность терминатора Tgap*
<220>
<221> прочий_признак
<222> (1995)..(2000)
<223> сайт рестрикции для XbaI
<220>
<221> прочий_признак
<222> (2001)..(2006)
<223> сайт рестрикции для BamHI
<400> 23
ctgcagacca ggt atg caa ata aac cgc cga ggc ttc tta aaa gcc acc 49
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr
1 5 10
aca gga ctt gcc act atc ggc gct gcc agc atg ttt atg cca aag gcc 97
Thr Gly Leu Ala Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala
15 20 25
aac gcc ctt gga gca ata cta gta atg atg acc acc ttc aac cgt gca 145
Asn Ala Leu Gly Ala Ile Leu Val Met Met Thr Thr Phe Asn Arg Ala
30 35 40
atc atc cca gat gca atc cgc acc aac ggt gca acc cca aac cca tgg 193
Ile Ile Pro Asp Ala Ile Arg Thr Asn Gly Ala Thr Pro Asn Pro Trp
45 50 55 60
tgg tcc aac gca gtg gtg tac cag atc tac cca cgc tcc ttc cag gat 241
Trp Ser Asn Ala Val Val Tyr Gln Ile Tyr Pro Arg Ser Phe Gln Asp
65 70 75
acc aac ggc gac ggc ttc ggc gat ctg aag ggc atc acc tcc cgc ttg 289
Thr Asn Gly Asp Gly Phe Gly Asp Leu Lys Gly Ile Thr Ser Arg Leu
80 85 90
gat tac ctg gca gat ctg ggc gtg gat gtg ctg tgg ctg tcc cca gtg 337
Asp Tyr Leu Ala Asp Leu Gly Val Asp Val Leu Trp Leu Ser Pro Val
95 100 105
tac aag tcc cca cag gat gat aac ggc tac gat atc tcc gat tac cag 385
Tyr Lys Ser Pro Gln Asp Asp Asn Gly Tyr Asp Ile Ser Asp Tyr Gln
110 115 120
gat atc gat cca ctg ttc ggc acc ctg gat gat atg gat gaa ctg ctg 433
Asp Ile Asp Pro Leu Phe Gly Thr Leu Asp Asp Met Asp Glu Leu Leu
125 130 135 140
gca gag gca cac aag cgt ggc ctg aag gtg gtg atg gat ctg gtg gtg 481
Ala Glu Ala His Lys Arg Gly Leu Lys Val Val Met Asp Leu Val Val
145 150 155
aac cac acc tcc gat gaa cac gca tgg ttc gaa gca tcc aag aac aag 529
Asn His Thr Ser Asp Glu His Ala Trp Phe Glu Ala Ser Lys Asn Lys
160 165 170
gat gat gaa cac gcc gat tgg tac tgg tgg cgt cca gca cgc cca ggc 577
Asp Asp Glu His Ala Asp Trp Tyr Trp Trp Arg Pro Ala Arg Pro Gly
175 180 185
acc acc cca ggt gaa cca ggc tcc gaa cca aac cag tgg ggc tcc tac 625
Thr Thr Pro Gly Glu Pro Gly Ser Glu Pro Asn Gln Trp Gly Ser Tyr
190 195 200
ttc ggt ggc tcc gca tgg gaa tac tgc cca gaa cgc ggt gaa tac tac 673
Phe Gly Gly Ser Ala Trp Glu Tyr Cys Pro Glu Arg Gly Glu Tyr Tyr
205 210 215 220
ctg cac cag ttc tcc aag aag cag cca gat ctc aac tgg gaa aac cca 721
Leu His Gln Phe Ser Lys Lys Gln Pro Asp Leu Asn Trp Glu Asn Pro
225 230 235
gca gtg cgt cgc gca gtg tac gat atg atg aac tgg tgg ttg gat cgc 769
Ala Val Arg Arg Ala Val Tyr Asp Met Met Asn Trp Trp Leu Asp Arg
240 245 250
ggt atc gat ggc ttc cgc atg gat gtg atc acc ctg atc tcc aag cgc 817
Gly Ile Asp Gly Phe Arg Met Asp Val Ile Thr Leu Ile Ser Lys Arg
255 260 265
acc gat gca aac ggt cgc ctg cca ggt gaa tac ggc tcc gaa ctg gat 865
Thr Asp Ala Asn Gly Arg Leu Pro Gly Glu Tyr Gly Ser Glu Leu Asp
270 275 280
gat ctg cca gtg ggc gaa gaa ggc tac tcc aac cca aac ccg ttc tgc 913
Asp Leu Pro Val Gly Glu Glu Gly Tyr Ser Asn Pro Asn Pro Phe Cys
285 290 295 300
gca gat ggc cct cgc cag gat gaa ttc ctg aaa gaa atg cgt cgc gaa 961
Ala Asp Gly Pro Arg Gln Asp Glu Phe Leu Lys Glu Met Arg Arg Glu
305 310 315
gtg ttc gca ggt cgc gaa ggc ttc ctg acc gtg ggc gaa gca cca ggc 1009
Val Phe Ala Gly Arg Glu Gly Phe Leu Thr Val Gly Glu Ala Pro Gly
320 325 330
atc acc cct gtg cgc aac gaa cac atc acc aac cca gca aac ggc gaa 1057
Ile Thr Pro Val Arg Asn Glu His Ile Thr Asn Pro Ala Asn Gly Glu
335 340 345
ctg gat atg ctg ttc ctg ttc gat cac gtg gat ttc gat tgc gac ggc 1105
Leu Asp Met Leu Phe Leu Phe Asp His Val Asp Phe Asp Cys Asp Gly
350 355 360
gtg aag tgg aag cca ctg cca ctg gat ctg cca ggc ttc aag cgc atc 1153
Val Lys Trp Lys Pro Leu Pro Leu Asp Leu Pro Gly Phe Lys Arg Ile
365 370 375 380
atg gca ggc tac cag acc gca gtg gaa aac gtg ggc tgg gca tcc ctg 1201
Met Ala Gly Tyr Gln Thr Ala Val Glu Asn Val Gly Trp Ala Ser Leu
385 390 395
ttc acc ggc aac cac gat cag cca cgc gtg gtg tcc cgc tgg ggt gat 1249
Phe Thr Gly Asn His Asp Gln Pro Arg Val Val Ser Arg Trp Gly Asp
400 405 410
gat tcc tcc gaa gaa tcc cgt gtg cgc tcc gca aag gca ctg ggc ctg 1297
Asp Ser Ser Glu Glu Ser Arg Val Arg Ser Ala Lys Ala Leu Gly Leu
415 420 425
atg ctg cac atg cac cgt ggc acc cca tac gtg tac cag ggc gaa gaa 1345
Met Leu His Met His Arg Gly Thr Pro Tyr Val Tyr Gln Gly Glu Glu
430 435 440
ctg ggc atg acc aac gca cac ttc acc tcc ctg gat cag tac cgc gat 1393
Leu Gly Met Thr Asn Ala His Phe Thr Ser Leu Asp Gln Tyr Arg Asp
445 450 455 460
ctg gaa tcc ctg aac gca tac cgc cag cgc gtg gaa gag gca aag gtg 1441
Leu Glu Ser Leu Asn Ala Tyr Arg Gln Arg Val Glu Glu Ala Lys Val
465 470 475
cag tcc cca gaa tcc atg ctg gca ggt atc gca gca cgc ggt cgc gat 1489
Gln Ser Pro Glu Ser Met Leu Ala Gly Ile Ala Ala Arg Gly Arg Asp
480 485 490
aac tcc cgc acc cca atg cag tgg gat ggc tcc gca tac gca ggc ttc 1537
Asn Ser Arg Thr Pro Met Gln Trp Asp Gly Ser Ala Tyr Ala Gly Phe
495 500 505
acc gca cca gat gca gca acc gaa cca tgg atc tcc gtg aac cca aac 1585
Thr Ala Pro Asp Ala Ala Thr Glu Pro Trp Ile Ser Val Asn Pro Asn
510 515 520
cac gca gaa atc aac gca gca ggc gaa ttc gat gat cca gat tcc gtg 1633
His Ala Glu Ile Asn Ala Ala Gly Glu Phe Asp Asp Pro Asp Ser Val
525 530 535 540
tac gca ttc tac aag aag ctg atc gca ctg cgc cac aac tcc tcc atc 1681
Tyr Ala Phe Tyr Lys Lys Leu Ile Ala Leu Arg His Asn Ser Ser Ile
545 550 555
gtg gca gct ggc gaa tgg cag ctg atc gat gca gat gat gca cac gtg 1729
Val Ala Ala Gly Glu Trp Gln Leu Ile Asp Ala Asp Asp Ala His Val
560 565 570
tac gcc ttc acc cgc acc ctg ggc aac gaa cgc ctg ctc gtg gtg gtc 1777
Tyr Ala Phe Thr Arg Thr Leu Gly Asn Glu Arg Leu Leu Val Val Val
575 580 585
aac ctg tcc ggt cgc acc gtg gat ctg cca cgc gaa tcc acc gaa ctg 1825
Asn Leu Ser Gly Arg Thr Val Asp Leu Pro Arg Glu Ser Thr Glu Leu
590 595 600
atc gca ggc ggt gtg acc gaa cca gat atc atc ctg tcc acc tac gat 1873
Ile Ala Gly Gly Val Thr Glu Pro Asp Ile Ile Leu Ser Thr Tyr Asp
605 610 615 620
gca cca cac acc gtg gtg tcc ctg gca aac cgc gaa ctc gat cca tgg 1921
Ala Pro His Thr Val Val Ser Leu Ala Asn Arg Glu Leu Asp Pro Trp
625 630 635
gaa gca gca gca gtg cag ctg taagcggccg ctgttagccc ggggtgtgcc 1972
Glu Ala Ala Ala Val Gln Leu
640
tcggcgcacc ccgggctatt tttctagagg atcc 2006
<210> 24
<211> 643
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 24
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr Thr Gly Leu Ala
1 5 10 15
Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala Asn Ala Leu Gly
20 25 30
Ala Ile Leu Val Met Met Thr Thr Phe Asn Arg Ala Ile Ile Pro Asp
35 40 45
Ala Ile Arg Thr Asn Gly Ala Thr Pro Asn Pro Trp Trp Ser Asn Ala
50 55 60
Val Val Tyr Gln Ile Tyr Pro Arg Ser Phe Gln Asp Thr Asn Gly Asp
65 70 75 80
Gly Phe Gly Asp Leu Lys Gly Ile Thr Ser Arg Leu Asp Tyr Leu Ala
85 90 95
Asp Leu Gly Val Asp Val Leu Trp Leu Ser Pro Val Tyr Lys Ser Pro
100 105 110
Gln Asp Asp Asn Gly Tyr Asp Ile Ser Asp Tyr Gln Asp Ile Asp Pro
115 120 125
Leu Phe Gly Thr Leu Asp Asp Met Asp Glu Leu Leu Ala Glu Ala His
130 135 140
Lys Arg Gly Leu Lys Val Val Met Asp Leu Val Val Asn His Thr Ser
145 150 155 160
Asp Glu His Ala Trp Phe Glu Ala Ser Lys Asn Lys Asp Asp Glu His
165 170 175
Ala Asp Trp Tyr Trp Trp Arg Pro Ala Arg Pro Gly Thr Thr Pro Gly
180 185 190
Glu Pro Gly Ser Glu Pro Asn Gln Trp Gly Ser Tyr Phe Gly Gly Ser
195 200 205
Ala Trp Glu Tyr Cys Pro Glu Arg Gly Glu Tyr Tyr Leu His Gln Phe
210 215 220
Ser Lys Lys Gln Pro Asp Leu Asn Trp Glu Asn Pro Ala Val Arg Arg
225 230 235 240
Ala Val Tyr Asp Met Met Asn Trp Trp Leu Asp Arg Gly Ile Asp Gly
245 250 255
Phe Arg Met Asp Val Ile Thr Leu Ile Ser Lys Arg Thr Asp Ala Asn
260 265 270
Gly Arg Leu Pro Gly Glu Tyr Gly Ser Glu Leu Asp Asp Leu Pro Val
275 280 285
Gly Glu Glu Gly Tyr Ser Asn Pro Asn Pro Phe Cys Ala Asp Gly Pro
290 295 300
Arg Gln Asp Glu Phe Leu Lys Glu Met Arg Arg Glu Val Phe Ala Gly
305 310 315 320
Arg Glu Gly Phe Leu Thr Val Gly Glu Ala Pro Gly Ile Thr Pro Val
325 330 335
Arg Asn Glu His Ile Thr Asn Pro Ala Asn Gly Glu Leu Asp Met Leu
340 345 350
Phe Leu Phe Asp His Val Asp Phe Asp Cys Asp Gly Val Lys Trp Lys
355 360 365
Pro Leu Pro Leu Asp Leu Pro Gly Phe Lys Arg Ile Met Ala Gly Tyr
370 375 380
Gln Thr Ala Val Glu Asn Val Gly Trp Ala Ser Leu Phe Thr Gly Asn
385 390 395 400
His Asp Gln Pro Arg Val Val Ser Arg Trp Gly Asp Asp Ser Ser Glu
405 410 415
Glu Ser Arg Val Arg Ser Ala Lys Ala Leu Gly Leu Met Leu His Met
420 425 430
His Arg Gly Thr Pro Tyr Val Tyr Gln Gly Glu Glu Leu Gly Met Thr
435 440 445
Asn Ala His Phe Thr Ser Leu Asp Gln Tyr Arg Asp Leu Glu Ser Leu
450 455 460
Asn Ala Tyr Arg Gln Arg Val Glu Glu Ala Lys Val Gln Ser Pro Glu
465 470 475 480
Ser Met Leu Ala Gly Ile Ala Ala Arg Gly Arg Asp Asn Ser Arg Thr
485 490 495
Pro Met Gln Trp Asp Gly Ser Ala Tyr Ala Gly Phe Thr Ala Pro Asp
500 505 510
Ala Ala Thr Glu Pro Trp Ile Ser Val Asn Pro Asn His Ala Glu Ile
515 520 525
Asn Ala Ala Gly Glu Phe Asp Asp Pro Asp Ser Val Tyr Ala Phe Tyr
530 535 540
Lys Lys Leu Ile Ala Leu Arg His Asn Ser Ser Ile Val Ala Ala Gly
545 550 555 560
Glu Trp Gln Leu Ile Asp Ala Asp Asp Ala His Val Tyr Ala Phe Thr
565 570 575
Arg Thr Leu Gly Asn Glu Arg Leu Leu Val Val Val Asn Leu Ser Gly
580 585 590
Arg Thr Val Asp Leu Pro Arg Glu Ser Thr Glu Leu Ile Ala Gly Gly
595 600 605
Val Thr Glu Pro Asp Ile Ile Leu Ser Thr Tyr Asp Ala Pro His Thr
610 615 620
Val Val Ser Leu Ala Asn Arg Glu Leu Asp Pro Trp Glu Ala Ala Ala
625 630 635 640
Val Gln Leu
<210> 25
<211> 1949
<212> ДНК
<213> искусственная последовательность
<220>
<223> слитый ген tat-'IMA1_cuo
<220>
<221> прочий_признак
<222> (1)..(6)
<223> сайт рестрикции для PstI
<220>
<221> прочий_признак
<222> (7)..(13)
<223> сайт рестрикции для SexAI
<220>
<221> CDS
<222> (14)..(1885)
<223> последовательность, кодирующая слитый полипептид Tat-'IMA1
<220>
<221> прочая_сигнальная_последовательность
<222> (14)..(112)
<223> 5'-концевая последовательность cg0955, кодирующая
Tat-сигнальный пептид cg0955
<220>
<221> прочий_признак
<222> (14)..(114)
<223> 5'-концевая последовательность cg0955
<220>
<221> прочий_признак
<222> (115)..(115)
<223> нуклеотидное основание аденин
<220>
<221> прочий_признак
<222> (115)..(120)
<223> сайт рестрикции для SpeI
<220>
<221> прочий_признак
<222> (121)..(121)
<223> нуклеотидное основание аденин
<220>
<221> прочий_признак
<222> (122)..(1885)
<223> 'IMA1_cuo
<220>
<221> прочий_признак
<222> (1886)..(1888)
<223> стоп-кодон
<220>
<221> прочий_признак
<222> (1889)..(1896)
<223> сайт рестрикции для NotI
<220>
<221> прочий_признак
<222> (1900)..(1935)
<223> последовательность терминатора Tgap*
<220>
<221> прочий_признак
<222> (1938)..(1943)
<223> сайт рестрикции для XbaI
<220>
<221> прочий_признак
<222> (1944)..(1949)
<223> сайт рестрикции для BamHI
<400> 25
ctgcagacct ggt atg caa ata aac cgc cga ggc ttc tta aaa gcc acc 49
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr
1 5 10
aca gga ctt gcc act atc ggc gct gcc agc atg ttt atg cca aag gcc 97
Thr Gly Leu Ala Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala
15 20 25
aac gcc ctt gga gca ata cta gta acc atc tcc tcc gca cac cca gaa 145
Asn Ala Leu Gly Ala Ile Leu Val Thr Ile Ser Ser Ala His Pro Glu
30 35 40
acc gaa cca aag tgg tgg aaa gaa gca acc ttc tac cag atc tac cca 193
Thr Glu Pro Lys Trp Trp Lys Glu Ala Thr Phe Tyr Gln Ile Tyr Pro
45 50 55 60
gca tcc ttc aag gat tcc aac gat gat ggc tgg ggt gat atg aag ggt 241
Ala Ser Phe Lys Asp Ser Asn Asp Asp Gly Trp Gly Asp Met Lys Gly
65 70 75
atc gca tcc aag ctg gaa tac atc aaa gaa ctg ggt gca gat gca atc 289
Ile Ala Ser Lys Leu Glu Tyr Ile Lys Glu Leu Gly Ala Asp Ala Ile
80 85 90
tgg atc tcc cca ttc tac gat tcc cca cag gat gat atg ggc tac gat 337
Trp Ile Ser Pro Phe Tyr Asp Ser Pro Gln Asp Asp Met Gly Tyr Asp
95 100 105
atc gca aac tac gaa aag gtg tgg cca acc tac ggc acc aac gaa gat 385
Ile Ala Asn Tyr Glu Lys Val Trp Pro Thr Tyr Gly Thr Asn Glu Asp
110 115 120
tgc ttc gca ctg atc gaa aag acc cac aag ctg ggc atg aag ttc atc 433
Cys Phe Ala Leu Ile Glu Lys Thr His Lys Leu Gly Met Lys Phe Ile
125 130 135 140
acc gat ctg gtg atc aac cac tgc tcc tcc gaa cac gaa tgg ttc aaa 481
Thr Asp Leu Val Ile Asn His Cys Ser Ser Glu His Glu Trp Phe Lys
145 150 155
gaa tcc cgc tcc tcc aag acc aac cca aag cgc gat tgg ttc ttc tgg 529
Glu Ser Arg Ser Ser Lys Thr Asn Pro Lys Arg Asp Trp Phe Phe Trp
160 165 170
cgt cca cca aag ggc tac gat gca gaa ggc aag cca atc cca cca aac 577
Arg Pro Pro Lys Gly Tyr Asp Ala Glu Gly Lys Pro Ile Pro Pro Asn
175 180 185
aac tgg aag tcc tac ttc ggt ggc tcc gca tgg acc ttc gat gaa aag 625
Asn Trp Lys Ser Tyr Phe Gly Gly Ser Ala Trp Thr Phe Asp Glu Lys
190 195 200
acc caa gaa ttc tac ctg cgc ctg ttc tgc tcc acc cag cca gat ctc 673
Thr Gln Glu Phe Tyr Leu Arg Leu Phe Cys Ser Thr Gln Pro Asp Leu
205 210 215 220
aac tgg gaa aac gag gat tgc cgc aag gca atc tac gaa tcc gca gtg 721
Asn Trp Glu Asn Glu Asp Cys Arg Lys Ala Ile Tyr Glu Ser Ala Val
225 230 235
ggc tac tgg ctg gat cac ggc gtg gat ggc ttc cgc atc gat gtg ggc 769
Gly Tyr Trp Leu Asp His Gly Val Asp Gly Phe Arg Ile Asp Val Gly
240 245 250
tcc ctg tac tcc aag gtg gtg ggc ctg cca gat gca cca gtg gtg gat 817
Ser Leu Tyr Ser Lys Val Val Gly Leu Pro Asp Ala Pro Val Val Asp
255 260 265
aag aac tcc acc tgg cag tcc tcc gat cca tac acc ctg aac ggt cca 865
Lys Asn Ser Thr Trp Gln Ser Ser Asp Pro Tyr Thr Leu Asn Gly Pro
270 275 280
cgc atc cac gaa ttc cac caa gaa atg aac cag ttt atc cgc aac cgc 913
Arg Ile His Glu Phe His Gln Glu Met Asn Gln Phe Ile Arg Asn Arg
285 290 295 300
gtg aag gat ggt cgc gaa atc atg acc gtg ggc gaa atg cag cac gca 961
Val Lys Asp Gly Arg Glu Ile Met Thr Val Gly Glu Met Gln His Ala
305 310 315
tcc gat gaa acc aag cgc ctg tac acc tcc gca tcc cgt cac gaa ctg 1009
Ser Asp Glu Thr Lys Arg Leu Tyr Thr Ser Ala Ser Arg His Glu Leu
320 325 330
tcc gaa ctg ttc aac ttc tcc cac acc gat gtg ggc acc tcc cca ctg 1057
Ser Glu Leu Phe Asn Phe Ser His Thr Asp Val Gly Thr Ser Pro Leu
335 340 345
ttc cgc tac aac ctc gtg cca ttc gaa ctg aag gat tgg aag atc gca 1105
Phe Arg Tyr Asn Leu Val Pro Phe Glu Leu Lys Asp Trp Lys Ile Ala
350 355 360
ctg gca gaa ctc ttc cgc tac atc aac ggc acc gat tgc tgg tcc acc 1153
Leu Ala Glu Leu Phe Arg Tyr Ile Asn Gly Thr Asp Cys Trp Ser Thr
365 370 375 380
atc tac ctg gaa aac cac gat cag cca cgc tcc atc acc cgc ttc ggc 1201
Ile Tyr Leu Glu Asn His Asp Gln Pro Arg Ser Ile Thr Arg Phe Gly
385 390 395
gac gat tcc cca aag aac cgc gtg atc tcc ggc aag ctg ctg tcc gtg 1249
Asp Asp Ser Pro Lys Asn Arg Val Ile Ser Gly Lys Leu Leu Ser Val
400 405 410
ctg ctg tcc gca ctg acc ggc acc ctg tac gtg tac cag ggc caa gaa 1297
Leu Leu Ser Ala Leu Thr Gly Thr Leu Tyr Val Tyr Gln Gly Gln Glu
415 420 425
ctg ggc cag atc aac ttc aag aac tgg cca gtg gaa aag tac gaa gat 1345
Leu Gly Gln Ile Asn Phe Lys Asn Trp Pro Val Glu Lys Tyr Glu Asp
430 435 440
gtg gaa atc cgc aac aac tac aac gca atc aaa gaa gaa cac ggc gaa 1393
Val Glu Ile Arg Asn Asn Tyr Asn Ala Ile Lys Glu Glu His Gly Glu
445 450 455 460
aac tcc gaa gag atg aag aag ttt ctg gaa gca atc gca ctg atc tcc 1441
Asn Ser Glu Glu Met Lys Lys Phe Leu Glu Ala Ile Ala Leu Ile Ser
465 470 475
cgt gat cac gca cgc acc cca atg cag tgg tcc cgt gaa gaa cca aac 1489
Arg Asp His Ala Arg Thr Pro Met Gln Trp Ser Arg Glu Glu Pro Asn
480 485 490
gca ggc ttc tcc ggt cca tcc gca aag cca tgg ttc tac ctg aac gat 1537
Ala Gly Phe Ser Gly Pro Ser Ala Lys Pro Trp Phe Tyr Leu Asn Asp
495 500 505
tcc ttc cgc gaa ggc atc aac gtg gaa gat gaa atc aag gac cca aac 1585
Ser Phe Arg Glu Gly Ile Asn Val Glu Asp Glu Ile Lys Asp Pro Asn
510 515 520
tcc gtg ctg aac ttc tgg aaa gaa gcc ctg aag ttc cgc aag gca cac 1633
Ser Val Leu Asn Phe Trp Lys Glu Ala Leu Lys Phe Arg Lys Ala His
525 530 535 540
aag gat atc acc gtg tac ggc tac gat ttc gaa ttc atc gat ctg gat 1681
Lys Asp Ile Thr Val Tyr Gly Tyr Asp Phe Glu Phe Ile Asp Leu Asp
545 550 555
aac aaa aag ctg ttc tcc ttc acc aag aag tac aac aac aag acc ctg 1729
Asn Lys Lys Leu Phe Ser Phe Thr Lys Lys Tyr Asn Asn Lys Thr Leu
560 565 570
ttc gca gcc ctg aac ttc tcc tcc gat gca acc gat ttc aag atc cca 1777
Phe Ala Ala Leu Asn Phe Ser Ser Asp Ala Thr Asp Phe Lys Ile Pro
575 580 585
aac gat gat tcc tcc ttc aag ctg gaa ttc ggc aac tac cca aag aaa 1825
Asn Asp Asp Ser Ser Phe Lys Leu Glu Phe Gly Asn Tyr Pro Lys Lys
590 595 600
gaa gtg gac gca tcc tcc cgc acc ctg aag cca tgg gaa ggt cgc atc 1873
Glu Val Asp Ala Ser Ser Arg Thr Leu Lys Pro Trp Glu Gly Arg Ile
605 610 615 620
tac atc tcc gaa taagcggccg ctgttagccc ggggtgtgcc tcggcgcacc 1925
Tyr Ile Ser Glu
ccgggctatt tttctagagg atcc 1949
<210> 26
<211> 624
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 26
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr Thr Gly Leu Ala
1 5 10 15
Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala Asn Ala Leu Gly
20 25 30
Ala Ile Leu Val Thr Ile Ser Ser Ala His Pro Glu Thr Glu Pro Lys
35 40 45
Trp Trp Lys Glu Ala Thr Phe Tyr Gln Ile Tyr Pro Ala Ser Phe Lys
50 55 60
Asp Ser Asn Asp Asp Gly Trp Gly Asp Met Lys Gly Ile Ala Ser Lys
65 70 75 80
Leu Glu Tyr Ile Lys Glu Leu Gly Ala Asp Ala Ile Trp Ile Ser Pro
85 90 95
Phe Tyr Asp Ser Pro Gln Asp Asp Met Gly Tyr Asp Ile Ala Asn Tyr
100 105 110
Glu Lys Val Trp Pro Thr Tyr Gly Thr Asn Glu Asp Cys Phe Ala Leu
115 120 125
Ile Glu Lys Thr His Lys Leu Gly Met Lys Phe Ile Thr Asp Leu Val
130 135 140
Ile Asn His Cys Ser Ser Glu His Glu Trp Phe Lys Glu Ser Arg Ser
145 150 155 160
Ser Lys Thr Asn Pro Lys Arg Asp Trp Phe Phe Trp Arg Pro Pro Lys
165 170 175
Gly Tyr Asp Ala Glu Gly Lys Pro Ile Pro Pro Asn Asn Trp Lys Ser
180 185 190
Tyr Phe Gly Gly Ser Ala Trp Thr Phe Asp Glu Lys Thr Gln Glu Phe
195 200 205
Tyr Leu Arg Leu Phe Cys Ser Thr Gln Pro Asp Leu Asn Trp Glu Asn
210 215 220
Glu Asp Cys Arg Lys Ala Ile Tyr Glu Ser Ala Val Gly Tyr Trp Leu
225 230 235 240
Asp His Gly Val Asp Gly Phe Arg Ile Asp Val Gly Ser Leu Tyr Ser
245 250 255
Lys Val Val Gly Leu Pro Asp Ala Pro Val Val Asp Lys Asn Ser Thr
260 265 270
Trp Gln Ser Ser Asp Pro Tyr Thr Leu Asn Gly Pro Arg Ile His Glu
275 280 285
Phe His Gln Glu Met Asn Gln Phe Ile Arg Asn Arg Val Lys Asp Gly
290 295 300
Arg Glu Ile Met Thr Val Gly Glu Met Gln His Ala Ser Asp Glu Thr
305 310 315 320
Lys Arg Leu Tyr Thr Ser Ala Ser Arg His Glu Leu Ser Glu Leu Phe
325 330 335
Asn Phe Ser His Thr Asp Val Gly Thr Ser Pro Leu Phe Arg Tyr Asn
340 345 350
Leu Val Pro Phe Glu Leu Lys Asp Trp Lys Ile Ala Leu Ala Glu Leu
355 360 365
Phe Arg Tyr Ile Asn Gly Thr Asp Cys Trp Ser Thr Ile Tyr Leu Glu
370 375 380
Asn His Asp Gln Pro Arg Ser Ile Thr Arg Phe Gly Asp Asp Ser Pro
385 390 395 400
Lys Asn Arg Val Ile Ser Gly Lys Leu Leu Ser Val Leu Leu Ser Ala
405 410 415
Leu Thr Gly Thr Leu Tyr Val Tyr Gln Gly Gln Glu Leu Gly Gln Ile
420 425 430
Asn Phe Lys Asn Trp Pro Val Glu Lys Tyr Glu Asp Val Glu Ile Arg
435 440 445
Asn Asn Tyr Asn Ala Ile Lys Glu Glu His Gly Glu Asn Ser Glu Glu
450 455 460
Met Lys Lys Phe Leu Glu Ala Ile Ala Leu Ile Ser Arg Asp His Ala
465 470 475 480
Arg Thr Pro Met Gln Trp Ser Arg Glu Glu Pro Asn Ala Gly Phe Ser
485 490 495
Gly Pro Ser Ala Lys Pro Trp Phe Tyr Leu Asn Asp Ser Phe Arg Glu
500 505 510
Gly Ile Asn Val Glu Asp Glu Ile Lys Asp Pro Asn Ser Val Leu Asn
515 520 525
Phe Trp Lys Glu Ala Leu Lys Phe Arg Lys Ala His Lys Asp Ile Thr
530 535 540
Val Tyr Gly Tyr Asp Phe Glu Phe Ile Asp Leu Asp Asn Lys Lys Leu
545 550 555 560
Phe Ser Phe Thr Lys Lys Tyr Asn Asn Lys Thr Leu Phe Ala Ala Leu
565 570 575
Asn Phe Ser Ser Asp Ala Thr Asp Phe Lys Ile Pro Asn Asp Asp Ser
580 585 590
Ser Phe Lys Leu Glu Phe Gly Asn Tyr Pro Lys Lys Glu Val Asp Ala
595 600 605
Ser Ser Arg Thr Leu Lys Pro Trp Glu Gly Arg Ile Tyr Ile Ser Glu
610 615 620
<210> 27
<211> 1865
<212> ДНК
<213> искусственная последовательность
<220>
<223> слитый ген tat-'AY008307_cuo
<220>
<221> прочий_признак
<222> (1)..(6)
<223> сайт рестрикции для PstI
<220>
<221> прочий_признак
<222> (7)..(13)
<223> сайт рестрикции для SexAI
<220>
<221> CDS
<222> (14)..(1801)
<223> последовательность, кодирующая слитый полипептид Tat-'AY008307
<220>
<221> прочая_сигнальная_последовательность
<222> (14)..(112)
<223> 5'-концевая последовательность cg0955, кодирующая
Tat-сигнальный пептид
<220>
<221> прочий_признак
<222> (14)..(114)
<223> 5'-концевая последовательность cg0955
<220>
<221> прочий_признак
<222> (115)..(115)
<223> нуклеотидное основание аденин
<220>
<221> прочий_признак
<222> (115)..(120)
<223> сайт рестрикции для SpeI
<220>
<221> прочий_признак
<222> (121)..(121)
<223> нуклеотидное основание аденин
<220>
<221> прочий_признак
<222> (122)..(1801)
<223> 'AY008307_cuo
<220>
<221> прочий_признак
<222> (1802)..(1804)
<223> стоп-кодон
<220>
<221> прочий_признак
<222> (1805)..(1812)
<223> сайт рестрикции для NotI
<220>
<221> прочий_признак
<222> (1816)..(1851)
<223> последовательность терминатора Tgap*
<220>
<221> прочий_признак
<222> (1854)..(1859)
<223> сайт рестрикции для XbaI
<220>
<221> прочий_признак
<222> (1860)..(1865)
<223> сайт рестрикции для BamHI
<400> 27
ctgcagacct ggt atg caa ata aac cgc cga ggc ttc tta aaa gcc acc 49
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr
1 5 10
aca gga ctt gcc act atc ggc gct gcc agc atg ttt atg cca aag gcc 97
Thr Gly Leu Ala Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala
15 20 25
aac gcc ctt gga gca ata cta gta tcc gaa tgg tgg aaa gaa gca gtg 145
Asn Ala Leu Gly Ala Ile Leu Val Ser Glu Trp Trp Lys Glu Ala Val
30 35 40
gtc tac cag atc tac cca cgc tcc ttc tac gat gca aac ggc gac ggc 193
Val Tyr Gln Ile Tyr Pro Arg Ser Phe Tyr Asp Ala Asn Gly Asp Gly
45 50 55 60
ttc ggc gat ctc cag ggc gtg atc cag aag ctg gat tac atc aag aac 241
Phe Gly Asp Leu Gln Gly Val Ile Gln Lys Leu Asp Tyr Ile Lys Asn
65 70 75
ctg ggt gca gat gtg atc tgg ctg tcc cca gtg ttc gat tcc cca cag 289
Leu Gly Ala Asp Val Ile Trp Leu Ser Pro Val Phe Asp Ser Pro Gln
80 85 90
gat gat aac ggc tac gat atc tcc gat tac aag aac atg tac gaa aag 337
Asp Asp Asn Gly Tyr Asp Ile Ser Asp Tyr Lys Asn Met Tyr Glu Lys
95 100 105
ttc ggc acc aac gaa gat atg ttc cag ctg atc gat gaa gca cac aag 385
Phe Gly Thr Asn Glu Asp Met Phe Gln Leu Ile Asp Glu Ala His Lys
110 115 120
cgt ggc atg aag atc gtg atg cac ctc gtg gtg aac cac acc tcc gat 433
Arg Gly Met Lys Ile Val Met His Leu Val Val Asn His Thr Ser Asp
125 130 135 140
gaa cac gca tgg ttc gca gaa tcc cgc aag tcc aag gat aac cct tac 481
Glu His Ala Trp Phe Ala Glu Ser Arg Lys Ser Lys Asp Asn Pro Tyr
145 150 155
cgc gat tac tac ttc tgg aag gac cca aag tcc gat ggc tcc gaa cca 529
Arg Asp Tyr Tyr Phe Trp Lys Asp Pro Lys Ser Asp Gly Ser Glu Pro
160 165 170
aac aac tgg ggc tcc atc ttc tcc ggc tcc gca tgg acc tac gat gaa 577
Asn Asn Trp Gly Ser Ile Phe Ser Gly Ser Ala Trp Thr Tyr Asp Glu
175 180 185
ggc acc ggt cag tac tac ctg cac tac ttc tcc aag aag cag cca gat 625
Gly Thr Gly Gln Tyr Tyr Leu His Tyr Phe Ser Lys Lys Gln Pro Asp
190 195 200
ctc aac tgg gaa aac gaa gca gtg cgt cgc gaa gtg tac gat gtg atg 673
Leu Asn Trp Glu Asn Glu Ala Val Arg Arg Glu Val Tyr Asp Val Met
205 210 215 220
cgc ttc tgg atg gat cgc ggt gtg gat ggc tgg cgc atg gat gtg atc 721
Arg Phe Trp Met Asp Arg Gly Val Asp Gly Trp Arg Met Asp Val Ile
225 230 235
ggc tcc atc tcc aag tac acc gat ttc cca gat tac gaa acc gat cac 769
Gly Ser Ile Ser Lys Tyr Thr Asp Phe Pro Asp Tyr Glu Thr Asp His
240 245 250
tcc cgc tcc tac atc gtg ggt cgc tac cac tcc aac ggt cca cgc ctg 817
Ser Arg Ser Tyr Ile Val Gly Arg Tyr His Ser Asn Gly Pro Arg Leu
255 260 265
cac gat ttc atc caa gaa atg aac cgc gaa gtg ctg tcc cac tac gat 865
His Asp Phe Ile Gln Glu Met Asn Arg Glu Val Leu Ser His Tyr Asp
270 275 280
tgc atg acc gtg ggc gaa gca aac ggc tcc gat atc gaa gaa gca aag 913
Cys Met Thr Val Gly Glu Ala Asn Gly Ser Asp Ile Glu Glu Ala Lys
285 290 295 300
aag tac acc gac gca tcc cgt caa gaa ctg aac atg atc ttc acc ttc 961
Lys Tyr Thr Asp Ala Ser Arg Gln Glu Leu Asn Met Ile Phe Thr Phe
305 310 315
gaa cac atg gat atc gat acc gaa cag aac tcc cca aac ggc aag tgg 1009
Glu His Met Asp Ile Asp Thr Glu Gln Asn Ser Pro Asn Gly Lys Trp
320 325 330
cag atc aag cca ttc gat ctg atc gca ctg aag aaa acc atg acc cgc 1057
Gln Ile Lys Pro Phe Asp Leu Ile Ala Leu Lys Lys Thr Met Thr Arg
335 340 345
tgg cag acc ggc ttg atg aac gtg ggc tgg aac acc ctg tac ttc gaa 1105
Trp Gln Thr Gly Leu Met Asn Val Gly Trp Asn Thr Leu Tyr Phe Glu
350 355 360
aac cac gat cag cca cgc gtg atc tcc cgc tgg ggc aac gat ggc aag 1153
Asn His Asp Gln Pro Arg Val Ile Ser Arg Trp Gly Asn Asp Gly Lys
365 370 375 380
ctg cgc aaa gaa tgc gca aag gca ttc gca acc gat ctg gat ggc atg 1201
Leu Arg Lys Glu Cys Ala Lys Ala Phe Ala Thr Asp Leu Asp Gly Met
385 390 395
aag ggc acc cca ttc atc tac cag ggc gaa gaa atc ggc atg gtg aac 1249
Lys Gly Thr Pro Phe Ile Tyr Gln Gly Glu Glu Ile Gly Met Val Asn
400 405 410
cgc gat atg cca ctg gaa atg tac gat gat ctg gaa atc aag aac gca 1297
Arg Asp Met Pro Leu Glu Met Tyr Asp Asp Leu Glu Ile Lys Asn Ala
415 420 425
tac cgc gaa ctg gtg gtg gaa aac aag acc atg tcc gaa aaa gaa ttc 1345
Tyr Arg Glu Leu Val Val Glu Asn Lys Thr Met Ser Glu Lys Glu Phe
430 435 440
gtg aag gca gtg atg atc aag ggt cgc gat cac gca cgc acc cca atg 1393
Val Lys Ala Val Met Ile Lys Gly Arg Asp His Ala Arg Thr Pro Met
445 450 455 460
cag tgg gat gca ggc aag cac gca ggc ctg acc gca ggc gac cca tgg 1441
Gln Trp Asp Ala Gly Lys His Ala Gly Leu Thr Ala Gly Asp Pro Trp
465 470 475
att cca gtg aac tcc cgc tac cag gat atc aac gtg aaa gaa tcc ctg 1489
Ile Pro Val Asn Ser Arg Tyr Gln Asp Ile Asn Val Lys Glu Ser Leu
480 485 490
gaa gat cag gat tcc atc ttc ttc tac tac cag aag ctg atc cag ctg 1537
Glu Asp Gln Asp Ser Ile Phe Phe Tyr Tyr Gln Lys Leu Ile Gln Leu
495 500 505
cgc aag cag tac aaa atc atg atc tac ggc gat tac cag ctg ctg caa 1585
Arg Lys Gln Tyr Lys Ile Met Ile Tyr Gly Asp Tyr Gln Leu Leu Gln
510 515 520
gaa aac gat cct cag gtg ttc tcc tac ctg cgc gaa tac cgt ggc gaa 1633
Glu Asn Asp Pro Gln Val Phe Ser Tyr Leu Arg Glu Tyr Arg Gly Glu
525 530 535 540
aag ctg ctc gtg gtg gtc aac ctg tcc gaa gaa aag gca ctg ttc gaa 1681
Lys Leu Leu Val Val Val Asn Leu Ser Glu Glu Lys Ala Leu Phe Glu
545 550 555
gca cca cca gaa ctc atc cac gaa cgc tgg aag gtg ctg atc tcc aac 1729
Ala Pro Pro Glu Leu Ile His Glu Arg Trp Lys Val Leu Ile Ser Asn
560 565 570
tac cca caa gaa cgc gca gat ctg aag tcc atc tcc ctg aag cca tac 1777
Tyr Pro Gln Glu Arg Ala Asp Leu Lys Ser Ile Ser Leu Lys Pro Tyr
575 580 585
gaa gca gtg atg ggc atc tcc att taagcggccg ctgttagccc ggggtgtgcc 1831
Glu Ala Val Met Gly Ile Ser Ile
590 595
tcggcgcacc ccgggctatt tttctagagg atcc 1865
<210> 28
<211> 596
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 28
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr Thr Gly Leu Ala
1 5 10 15
Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala Asn Ala Leu Gly
20 25 30
Ala Ile Leu Val Ser Glu Trp Trp Lys Glu Ala Val Val Tyr Gln Ile
35 40 45
Tyr Pro Arg Ser Phe Tyr Asp Ala Asn Gly Asp Gly Phe Gly Asp Leu
50 55 60
Gln Gly Val Ile Gln Lys Leu Asp Tyr Ile Lys Asn Leu Gly Ala Asp
65 70 75 80
Val Ile Trp Leu Ser Pro Val Phe Asp Ser Pro Gln Asp Asp Asn Gly
85 90 95
Tyr Asp Ile Ser Asp Tyr Lys Asn Met Tyr Glu Lys Phe Gly Thr Asn
100 105 110
Glu Asp Met Phe Gln Leu Ile Asp Glu Ala His Lys Arg Gly Met Lys
115 120 125
Ile Val Met His Leu Val Val Asn His Thr Ser Asp Glu His Ala Trp
130 135 140
Phe Ala Glu Ser Arg Lys Ser Lys Asp Asn Pro Tyr Arg Asp Tyr Tyr
145 150 155 160
Phe Trp Lys Asp Pro Lys Ser Asp Gly Ser Glu Pro Asn Asn Trp Gly
165 170 175
Ser Ile Phe Ser Gly Ser Ala Trp Thr Tyr Asp Glu Gly Thr Gly Gln
180 185 190
Tyr Tyr Leu His Tyr Phe Ser Lys Lys Gln Pro Asp Leu Asn Trp Glu
195 200 205
Asn Glu Ala Val Arg Arg Glu Val Tyr Asp Val Met Arg Phe Trp Met
210 215 220
Asp Arg Gly Val Asp Gly Trp Arg Met Asp Val Ile Gly Ser Ile Ser
225 230 235 240
Lys Tyr Thr Asp Phe Pro Asp Tyr Glu Thr Asp His Ser Arg Ser Tyr
245 250 255
Ile Val Gly Arg Tyr His Ser Asn Gly Pro Arg Leu His Asp Phe Ile
260 265 270
Gln Glu Met Asn Arg Glu Val Leu Ser His Tyr Asp Cys Met Thr Val
275 280 285
Gly Glu Ala Asn Gly Ser Asp Ile Glu Glu Ala Lys Lys Tyr Thr Asp
290 295 300
Ala Ser Arg Gln Glu Leu Asn Met Ile Phe Thr Phe Glu His Met Asp
305 310 315 320
Ile Asp Thr Glu Gln Asn Ser Pro Asn Gly Lys Trp Gln Ile Lys Pro
325 330 335
Phe Asp Leu Ile Ala Leu Lys Lys Thr Met Thr Arg Trp Gln Thr Gly
340 345 350
Leu Met Asn Val Gly Trp Asn Thr Leu Tyr Phe Glu Asn His Asp Gln
355 360 365
Pro Arg Val Ile Ser Arg Trp Gly Asn Asp Gly Lys Leu Arg Lys Glu
370 375 380
Cys Ala Lys Ala Phe Ala Thr Asp Leu Asp Gly Met Lys Gly Thr Pro
385 390 395 400
Phe Ile Tyr Gln Gly Glu Glu Ile Gly Met Val Asn Arg Asp Met Pro
405 410 415
Leu Glu Met Tyr Asp Asp Leu Glu Ile Lys Asn Ala Tyr Arg Glu Leu
420 425 430
Val Val Glu Asn Lys Thr Met Ser Glu Lys Glu Phe Val Lys Ala Val
435 440 445
Met Ile Lys Gly Arg Asp His Ala Arg Thr Pro Met Gln Trp Asp Ala
450 455 460
Gly Lys His Ala Gly Leu Thr Ala Gly Asp Pro Trp Ile Pro Val Asn
465 470 475 480
Ser Arg Tyr Gln Asp Ile Asn Val Lys Glu Ser Leu Glu Asp Gln Asp
485 490 495
Ser Ile Phe Phe Tyr Tyr Gln Lys Leu Ile Gln Leu Arg Lys Gln Tyr
500 505 510
Lys Ile Met Ile Tyr Gly Asp Tyr Gln Leu Leu Gln Glu Asn Asp Pro
515 520 525
Gln Val Phe Ser Tyr Leu Arg Glu Tyr Arg Gly Glu Lys Leu Leu Val
530 535 540
Val Val Asn Leu Ser Glu Glu Lys Ala Leu Phe Glu Ala Pro Pro Glu
545 550 555 560
Leu Ile His Glu Arg Trp Lys Val Leu Ile Ser Asn Tyr Pro Gln Glu
565 570 575
Arg Ala Asp Leu Lys Ser Ile Ser Leu Lys Pro Tyr Glu Ala Val Met
580 585 590
Gly Ile Ser Ile
595
<210> 29
<211> 1889
<212> ДНК
<213> искусственная последовательность
<220>
<223> agl2 Bifidobacterium breve UCC2003, оптимизированная
по частоте использования кодонов для Corynebacterium glutamicum
<220>
<221> прочий_признак
<222> (1)..(6)
<223> сайт рестрикции для PstI
<220>
<221> прочий_признак
<222> (7)..(13)
<223> сайт рестрикции для SexAI
<220>
<221> CDS
<222> (14)..(1825)
<223> agl2_cuo (последовательность, кодирующая Agl2
Bifidobacterium breve UCC2003, оптимизированная
по частоте использования кодонов для Corynebacterium glutamicum)
<220>
<221> прочий_признак
<222> (50)..(57)
<223> сайт рестрикции для FspAI
<220>
<221> прочий_признак
<222> (1826)..(1828)
<223> стоп-кодон
<220>
<221> прочий_признак
<222> (1829)..(1836)
<223> сайт рестрикции для NotI
<220>
<221> прочий_признак
<222> (1840)..(1875)
<223> последовательность терминатора Tgap*
<220>
<221> прочий_признак
<222> (1884)..(1889)
<223> сайт рестрикции для BamHI
<400> 29
ctgcagacca ggt atg acc tcc ttc aac cgc gaa cca ctg cca gat gca 49
Met Thr Ser Phe Asn Arg Glu Pro Leu Pro Asp Ala
1 5 10
gtg cgc acc aac ggt gca acc cca aac cca tgg tgg tcc aac gca gtg 97
Val Arg Thr Asn Gly Ala Thr Pro Asn Pro Trp Trp Ser Asn Ala Val
15 20 25
gtg tac cag atc tac cca cgc tcc ttc cag gat acc aac ggc gac ggc 145
Val Tyr Gln Ile Tyr Pro Arg Ser Phe Gln Asp Thr Asn Gly Asp Gly
30 35 40
ctg ggc gat ctg aag ggc atc acc tcc cgc ttg gat tac ctg gca gat 193
Leu Gly Asp Leu Lys Gly Ile Thr Ser Arg Leu Asp Tyr Leu Ala Asp
45 50 55 60
ctg ggc gtg gat gtg ctg tgg ctg tcc cca gtg tac cgc tcc cca cag 241
Leu Gly Val Asp Val Leu Trp Leu Ser Pro Val Tyr Arg Ser Pro Gln
65 70 75
gat gat aac ggc tac gat atc tcc gat tac cgc gat atc gat cca ctg 289
Asp Asp Asn Gly Tyr Asp Ile Ser Asp Tyr Arg Asp Ile Asp Pro Leu
80 85 90
ttc ggc acc ctg gat gat atg gat gaa ctg ctg gca gag gca cac aag 337
Phe Gly Thr Leu Asp Asp Met Asp Glu Leu Leu Ala Glu Ala His Lys
95 100 105
cgt ggc ctg aag atc gtg atg gat ctg gtg gtg aac cac acc tcc gat 385
Arg Gly Leu Lys Ile Val Met Asp Leu Val Val Asn His Thr Ser Asp
110 115 120
gaa cac gca tgg ttc gaa gca tcc aag gat aag gat gat cca cac gca 433
Glu His Ala Trp Phe Glu Ala Ser Lys Asp Lys Asp Asp Pro His Ala
125 130 135 140
gat tgg tac tgg tgg cgt cca gca cgc cca ggc cac gaa cca ggc acc 481
Asp Trp Tyr Trp Trp Arg Pro Ala Arg Pro Gly His Glu Pro Gly Thr
145 150 155
cca ggc gca gaa cca aac cag tgg ggc tcc tac ttc ggt ggc tcc gca 529
Pro Gly Ala Glu Pro Asn Gln Trp Gly Ser Tyr Phe Gly Gly Ser Ala
160 165 170
tgg gaa tac tcc cca gaa cgc ggt gaa tac tac ctg cac cag ttc tcc 577
Trp Glu Tyr Ser Pro Glu Arg Gly Glu Tyr Tyr Leu His Gln Phe Ser
175 180 185
aag aag cag cca gat ctc aac tgg gaa aac cca gca gtg cgt cgc gca 625
Lys Lys Gln Pro Asp Leu Asn Trp Glu Asn Pro Ala Val Arg Arg Ala
190 195 200
gtg tac gat atg atg aac tgg tgg ttg gat cgc ggt atc gat ggc ttc 673
Val Tyr Asp Met Met Asn Trp Trp Leu Asp Arg Gly Ile Asp Gly Phe
205 210 215 220
cgc atg gat gtg atc acc ctg atc tcc aag cgc acc gat cca aac ggt 721
Arg Met Asp Val Ile Thr Leu Ile Ser Lys Arg Thr Asp Pro Asn Gly
225 230 235
cgc ctg cca ggt gaa acc ggc tcc gaa ctc cag gat ctg cca gtg ggc 769
Arg Leu Pro Gly Glu Thr Gly Ser Glu Leu Gln Asp Leu Pro Val Gly
240 245 250
gaa gaa ggc tac tcc tcc cca aac cct ttc tgc gca gat ggc cct cgc 817
Glu Glu Gly Tyr Ser Ser Pro Asn Pro Phe Cys Ala Asp Gly Pro Arg
255 260 265
cag gat gaa ttc ctg gca gaa atg cgt cgc gaa gtt ttc gat ggc cgt 865
Gln Asp Glu Phe Leu Ala Glu Met Arg Arg Glu Val Phe Asp Gly Arg
270 275 280
gat ggc ttc ctg acc gtg ggc gaa gca cca ggc atc acc gca gaa cgc 913
Asp Gly Phe Leu Thr Val Gly Glu Ala Pro Gly Ile Thr Ala Glu Arg
285 290 295 300
aac gaa cac atc acc gat cca gca aac ggc gaa ctg gat atg ctg ttc 961
Asn Glu His Ile Thr Asp Pro Ala Asn Gly Glu Leu Asp Met Leu Phe
305 310 315
ctg ttc gaa cac atg ggc gtg gat cag acc cca gaa tcc aag tgg gat 1009
Leu Phe Glu His Met Gly Val Asp Gln Thr Pro Glu Ser Lys Trp Asp
320 325 330
gat aag cca tgg acc cca gca gat ctg gaa acc aag ctg gca gaa cag 1057
Asp Lys Pro Trp Thr Pro Ala Asp Leu Glu Thr Lys Leu Ala Glu Gln
335 340 345
cag gat gca atc gca cgc cgt ggc tgg gcc tcc ctg ttc ctg gat aac 1105
Gln Asp Ala Ile Ala Arg Arg Gly Trp Ala Ser Leu Phe Leu Asp Asn
350 355 360
cac gat cag cca cgc gtg gtg tcc cgc tgg ggt gat gat acc tcc aag 1153
His Asp Gln Pro Arg Val Val Ser Arg Trp Gly Asp Asp Thr Ser Lys
365 370 375 380
acc ggt cgc atc cgc tcc gca aag gca ctg gca ctg ctg ctg cac atg 1201
Thr Gly Arg Ile Arg Ser Ala Lys Ala Leu Ala Leu Leu Leu His Met
385 390 395
cac cgt ggc acc cca tac gtg tac cag ggc gaa gaa ctg ggc atg acc 1249
His Arg Gly Thr Pro Tyr Val Tyr Gln Gly Glu Glu Leu Gly Met Thr
400 405 410
aac gca cac ttc acc tcc ctg gat cag tac cgc gat ctg gaa tcc atc 1297
Asn Ala His Phe Thr Ser Leu Asp Gln Tyr Arg Asp Leu Glu Ser Ile
415 420 425
aac gca tac cac caa cgc gtg gaa gaa acc ggc atc cgc acc tcc gaa 1345
Asn Ala Tyr His Gln Arg Val Glu Glu Thr Gly Ile Arg Thr Ser Glu
430 435 440
acc atg atg cgc tcc ctg gca cgc tac ggt cgc gat aac gca cgc acc 1393
Thr Met Met Arg Ser Leu Ala Arg Tyr Gly Arg Asp Asn Ala Arg Thr
445 450 455 460
cca atg cag tgg gat gat tcc acc tac gca ggc ttc acc atg cca gat 1441
Pro Met Gln Trp Asp Asp Ser Thr Tyr Ala Gly Phe Thr Met Pro Asp
465 470 475
gcc cca gtg gaa cca tgg atc gca gtg aac cca aac cac acc gaa atc 1489
Ala Pro Val Glu Pro Trp Ile Ala Val Asn Pro Asn His Thr Glu Ile
480 485 490
aac gca gca gat gaa acc gat gat cca gat tcc gtg tac tcc ttc cac 1537
Asn Ala Ala Asp Glu Thr Asp Asp Pro Asp Ser Val Tyr Ser Phe His
495 500 505
aag cgc ctg atc gca ctg cgc cac acc gat cca gtg gtg gca gca ggc 1585
Lys Arg Leu Ile Ala Leu Arg His Thr Asp Pro Val Val Ala Ala Gly
510 515 520
gat tac cgt cgc gtg gaa acc ggc aac gat cgc atc att gca ttc acc 1633
Asp Tyr Arg Arg Val Glu Thr Gly Asn Asp Arg Ile Ile Ala Phe Thr
525 530 535 540
cgc acc ctg gac gaa cgc acc atc ctg acc gtg atc aac ctg tcc cca 1681
Arg Thr Leu Asp Glu Arg Thr Ile Leu Thr Val Ile Asn Leu Ser Pro
545 550 555
acc cag gca gca cca gca ggc gaa ctg gaa acc atg cca gac ggc acc 1729
Thr Gln Ala Ala Pro Ala Gly Glu Leu Glu Thr Met Pro Asp Gly Thr
560 565 570
atc ttg atc gca aac acc gat gac cca gtg ggc aac ctc aag acc acc 1777
Ile Leu Ile Ala Asn Thr Asp Asp Pro Val Gly Asn Leu Lys Thr Thr
575 580 585
ggc acc ctg ggt cca tgg gaa gca ttc gca atg gaa acc gat cca gaa 1825
Gly Thr Leu Gly Pro Trp Glu Ala Phe Ala Met Glu Thr Asp Pro Glu
590 595 600
taagcggccg ctgttagccc ggggtgtgcc tcggcgcacc ccgggctatt tttctagagg 1885
atcc 1889
<210> 30
<211> 604
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 30
Met Thr Ser Phe Asn Arg Glu Pro Leu Pro Asp Ala Val Arg Thr Asn
1 5 10 15
Gly Ala Thr Pro Asn Pro Trp Trp Ser Asn Ala Val Val Tyr Gln Ile
20 25 30
Tyr Pro Arg Ser Phe Gln Asp Thr Asn Gly Asp Gly Leu Gly Asp Leu
35 40 45
Lys Gly Ile Thr Ser Arg Leu Asp Tyr Leu Ala Asp Leu Gly Val Asp
50 55 60
Val Leu Trp Leu Ser Pro Val Tyr Arg Ser Pro Gln Asp Asp Asn Gly
65 70 75 80
Tyr Asp Ile Ser Asp Tyr Arg Asp Ile Asp Pro Leu Phe Gly Thr Leu
85 90 95
Asp Asp Met Asp Glu Leu Leu Ala Glu Ala His Lys Arg Gly Leu Lys
100 105 110
Ile Val Met Asp Leu Val Val Asn His Thr Ser Asp Glu His Ala Trp
115 120 125
Phe Glu Ala Ser Lys Asp Lys Asp Asp Pro His Ala Asp Trp Tyr Trp
130 135 140
Trp Arg Pro Ala Arg Pro Gly His Glu Pro Gly Thr Pro Gly Ala Glu
145 150 155 160
Pro Asn Gln Trp Gly Ser Tyr Phe Gly Gly Ser Ala Trp Glu Tyr Ser
165 170 175
Pro Glu Arg Gly Glu Tyr Tyr Leu His Gln Phe Ser Lys Lys Gln Pro
180 185 190
Asp Leu Asn Trp Glu Asn Pro Ala Val Arg Arg Ala Val Tyr Asp Met
195 200 205
Met Asn Trp Trp Leu Asp Arg Gly Ile Asp Gly Phe Arg Met Asp Val
210 215 220
Ile Thr Leu Ile Ser Lys Arg Thr Asp Pro Asn Gly Arg Leu Pro Gly
225 230 235 240
Glu Thr Gly Ser Glu Leu Gln Asp Leu Pro Val Gly Glu Glu Gly Tyr
245 250 255
Ser Ser Pro Asn Pro Phe Cys Ala Asp Gly Pro Arg Gln Asp Glu Phe
260 265 270
Leu Ala Glu Met Arg Arg Glu Val Phe Asp Gly Arg Asp Gly Phe Leu
275 280 285
Thr Val Gly Glu Ala Pro Gly Ile Thr Ala Glu Arg Asn Glu His Ile
290 295 300
Thr Asp Pro Ala Asn Gly Glu Leu Asp Met Leu Phe Leu Phe Glu His
305 310 315 320
Met Gly Val Asp Gln Thr Pro Glu Ser Lys Trp Asp Asp Lys Pro Trp
325 330 335
Thr Pro Ala Asp Leu Glu Thr Lys Leu Ala Glu Gln Gln Asp Ala Ile
340 345 350
Ala Arg Arg Gly Trp Ala Ser Leu Phe Leu Asp Asn His Asp Gln Pro
355 360 365
Arg Val Val Ser Arg Trp Gly Asp Asp Thr Ser Lys Thr Gly Arg Ile
370 375 380
Arg Ser Ala Lys Ala Leu Ala Leu Leu Leu His Met His Arg Gly Thr
385 390 395 400
Pro Tyr Val Tyr Gln Gly Glu Glu Leu Gly Met Thr Asn Ala His Phe
405 410 415
Thr Ser Leu Asp Gln Tyr Arg Asp Leu Glu Ser Ile Asn Ala Tyr His
420 425 430
Gln Arg Val Glu Glu Thr Gly Ile Arg Thr Ser Glu Thr Met Met Arg
435 440 445
Ser Leu Ala Arg Tyr Gly Arg Asp Asn Ala Arg Thr Pro Met Gln Trp
450 455 460
Asp Asp Ser Thr Tyr Ala Gly Phe Thr Met Pro Asp Ala Pro Val Glu
465 470 475 480
Pro Trp Ile Ala Val Asn Pro Asn His Thr Glu Ile Asn Ala Ala Asp
485 490 495
Glu Thr Asp Asp Pro Asp Ser Val Tyr Ser Phe His Lys Arg Leu Ile
500 505 510
Ala Leu Arg His Thr Asp Pro Val Val Ala Ala Gly Asp Tyr Arg Arg
515 520 525
Val Glu Thr Gly Asn Asp Arg Ile Ile Ala Phe Thr Arg Thr Leu Asp
530 535 540
Glu Arg Thr Ile Leu Thr Val Ile Asn Leu Ser Pro Thr Gln Ala Ala
545 550 555 560
Pro Ala Gly Glu Leu Glu Thr Met Pro Asp Gly Thr Ile Leu Ile Ala
565 570 575
Asn Thr Asp Asp Pro Val Gly Asn Leu Lys Thr Thr Gly Thr Leu Gly
580 585 590
Pro Trp Glu Ala Phe Ala Met Glu Thr Asp Pro Glu
595 600
<210> 31
<211> 414
<212> ДНК
<213> искусственная последовательность
<220>
<223> полинуклеотид Wo_tat
<220>
<221> прочий_признак
<222> (21)..(28)
<223> сайт рестрикции для MauBI
<220>
<221> прочий_признак
<222> (222)..(296)
<223> промотор PtacI
<220>
<221> прочий_признак
<222> (338)..(343)
<223> сайт рестрикции для PstI
<220>
<221> прочий_признак
<222> (344)..(350)
<223> сайт рестрикции для SexAI
<220>
<221> CDS
<222> (351)..(413)
<223> cds 5'-конца agl2_cuo
<220>
<221> прочий_признак
<222> (387)..(394)
<223> сайт рестрикции для FspAI
<400> 31
aatgcatgcc gcttcgcctt cgcgcgcgaa ttgcaagctg atccgggctt atcgactgca 60
cggtgcacca atgcttctgg cgtcaggcag ccatcggaag ctgtggtatg gctgtgcagg 120
tcgtaaatca ctgcataatt cgtgtcgctc aaggcgcact cccgttctgg ataatgtttt 180
ttgcgccgac atcataacgg ttctggcaaa tattctgaaa tgagctgttg acaattaatc 240
atcggctcgt ataatgtgtg gaattgtgag cggataacaa tttcacacag gaaacagaat 300
taaaagatat gaccatgatt acgccaagct tgcatgcctg cagaccaggt atg acc 356
Met Thr
1
tcc ttc aac cgc gaa cca ctg cca gat gca gtg cgc acc aac ggt gca 404
Ser Phe Asn Arg Glu Pro Leu Pro Asp Ala Val Arg Thr Asn Gly Ala
5 10 15
acc cca aac c 414
Thr Pro Asn
20
<210> 32
<211> 21
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 32
Met Thr Ser Phe Asn Arg Glu Pro Leu Pro Asp Ala Val Arg Thr Asn
1 5 10 15
Gly Ala Thr Pro Asn
20
<210> 33
<211> 23
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(23)
<223> праймер pVW_1
<400> 33
gtgagcggat aacaatttca cac 23
<210> 34
<211> 20
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(20)
<223> праймер pVW_2
<400> 34
tttgcgccga catcataacg 20
<210> 35
<211> 20
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(20)
<223> праймер pVW_3
<400> 35
tactgccgcc aggcaaattc 20
<210> 36
<211> 23
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(23)
<223> праймер gluc_rev
<400> 36
gtgagcggat aacaatttca cac 23
<210> 37
<211> 23
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(23)
<223> праймер gluc2_rev
<400> 37
tgctccaagg gcgttggcct ttg 23
<210> 38
<211> 202
<212> ДНК
<213> искусственная последовательность
<220>
<223> последовательность, кодирующая сигнальный пептид CgR_0079
<220>
<221> прочий_признак
<222> (1)..(25)
<223> 5'-концевое перекрывание для сборки по Гибсону
<220>
<221> CDS
<222> (26)..(202)
<220>
<221> прочий_признак
<222> (26)..(178)
<223> последовательность, кодирующая сигнальный пептид CgR0079
<220>
<221> прочий_признак
<222> (179)..(202)
<223> 3'-концевое перекрывание для сборки по Гибсону
<400> 38
aagcttgcat gcctgcagac caggt atg cct agc ttt aaa tct gct cga tgg 52
Met Pro Ser Phe Lys Ser Ala Arg Trp
1 5
agg atg aac aga cgc ctc ttc cta gga act tcc gca gct atc atc gct 100
Arg Met Asn Arg Arg Leu Phe Leu Gly Thr Ser Ala Ala Ile Ile Ala
10 15 20 25
gtc ggt ggc gtg ctc ggt gga gtg cag gtt gta cct tat att tcc tct 148
Val Gly Gly Val Leu Gly Gly Val Gln Val Val Pro Tyr Ile Ser Ser
30 35 40
ggt gaa atc caa acg tca gca tca tcg act atg act agt acc tcc ttc 196
Gly Glu Ile Gln Thr Ser Ala Ser Ser Thr Met Thr Ser Thr Ser Phe
45 50 55
aac cgc 202
Asn Arg
<210> 39
<211> 59
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 39
Met Pro Ser Phe Lys Ser Ala Arg Trp Arg Met Asn Arg Arg Leu Phe
1 5 10 15
Leu Gly Thr Ser Ala Ala Ile Ile Ala Val Gly Gly Val Leu Gly Gly
20 25 30
Val Gln Val Val Pro Tyr Ile Ser Ser Gly Glu Ile Gln Thr Ser Ala
35 40 45
Ser Ser Thr Met Thr Ser Thr Ser Phe Asn Arg
50 55
<210> 40
<211> 213
<212> ДНК
<213> искусственная последовательность
<220>
<223> последовательность, кодирующая сигнальный пептид CgR_0120
<220>
<221> прочий_признак
<222> (1)..(45)
<223> 5'-концевое перекрывание для сборки по Гибсону
<220>
<221> CDS
<222> (46)..(213)
<220>
<221> прочий_признак
<222> (46)..(159)
<223> последовательность, кодирующая сигнальный пептид CgR0120
<220>
<221> прочий_признак
<222> (160)..(213)
<223> 3'-концевое перекрывание для сборки по Гибсону
<400> 40
gatatgacca tgattacgcc aagcttgcat gcctgcagac caggt atg aca agt agt 57
Met Thr Ser Ser
1
ttt tcc cgg cga cag ttt ctg ctc ggc ggg ctc gta ctc gcc ggc acc 105
Phe Ser Arg Arg Gln Phe Leu Leu Gly Gly Leu Val Leu Ala Gly Thr
5 10 15 20
ggg gcc gtg gcc gcc tgc acc agc gac cct gga ccc gct gcc tcg gca 153
Gly Ala Val Ala Ala Cys Thr Ser Asp Pro Gly Pro Ala Ala Ser Ala
25 30 35
cca ggt atg act agt acc tcc ttc aac cgc gaa cca ctg cca gat gca 201
Pro Gly Met Thr Ser Thr Ser Phe Asn Arg Glu Pro Leu Pro Asp Ala
40 45 50
gtg cgc acc aac 213
Val Arg Thr Asn
55
<210> 41
<211> 56
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 41
Met Thr Ser Ser Phe Ser Arg Arg Gln Phe Leu Leu Gly Gly Leu Val
1 5 10 15
Leu Ala Gly Thr Gly Ala Val Ala Ala Cys Thr Ser Asp Pro Gly Pro
20 25 30
Ala Ala Ser Ala Pro Gly Met Thr Ser Thr Ser Phe Asn Arg Glu Pro
35 40 45
Leu Pro Asp Ala Val Arg Thr Asn
50 55
<210> 42
<211> 133
<212> ДНК
<213> искусственная последовательность
<220>
<223> последовательность, кодирующая сигнальный пептид CgR_0124
<220>
<221> прочий_признак
<222> (2)..(10)
<223> сайт рестрикции для SexAI
<220>
<221> CDS
<222> (9)..(131)
<220>
<221> прочий_признак
<222> (9)..(122)
<223> последовательность, кодирующая сигнальный пептид CgR_0124
<220>
<221> прочий_признак
<222> (126)..(131)
<223> сайт рестрикции для SpeI
<400> 42
gaccaggt atg acc acc ccg act tcc ccc ttg ctg ccg ctg gcc tcc gac 50
Met Thr Thr Pro Thr Ser Pro Leu Leu Pro Leu Ala Ser Asp
1 5 10
ggt tgt gga tgc tgc gcg ccc tct acg ccg tcc gcg acc gtc tcc gcc 98
Gly Cys Gly Cys Cys Ala Pro Ser Thr Pro Ser Ala Thr Val Ser Ala
15 20 25 30
ccg gcc gtg gcc gcg gca acc gac atg act agt ac 133
Pro Ala Val Ala Ala Ala Thr Asp Met Thr Ser
35 40
<210> 43
<211> 41
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 43
Met Thr Thr Pro Thr Ser Pro Leu Leu Pro Leu Ala Ser Asp Gly Cys
1 5 10 15
Gly Cys Cys Ala Pro Ser Thr Pro Ser Ala Thr Val Ser Ala Pro Ala
20 25 30
Val Ala Ala Ala Thr Asp Met Thr Ser
35 40
<210> 44
<211> 149
<212> ДНК
<213> искусственная последовательность
<220>
<223> последовательность, кодирующая сигнальный пептид CgR_0900
<220>
<221> прочий_признак
<222> (1)..(25)
<223> 5'-концевое перекрывание для сборки по Гибсону
<220>
<221> CDS
<222> (26)..(148)
<220>
<221> прочий_признак
<222> (26)..(121)
<223> последовательность, кодирующая сигнальный пептид CgR0900
<220>
<221> прочий_признак
<222> (122)..(149)
<223> 3'-концевое перекрывание для сборки по Гибсону
<400> 44
aagcttgcat gcctgcagac caggt atg cgc aga ccg gtc tca cgc cgc gcc 52
Met Arg Arg Pro Val Ser Arg Arg Ala
1 5
att ttt gca aca tct gtt ttg gtt gcg ggg gtg agc atc atg tca cct 100
Ile Phe Ala Thr Ser Val Leu Val Ala Gly Val Ser Ile Met Ser Pro
10 15 20 25
tcg gcc aac gca gct gag gct atg act agt acc tcc ttc aac cgc aac c 149
Ser Ala Asn Ala Ala Glu Ala Met Thr Ser Thr Ser Phe Asn Arg Asn
30 35 40
<210> 45
<211> 41
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 45
Met Arg Arg Pro Val Ser Arg Arg Ala Ile Phe Ala Thr Ser Val Leu
1 5 10 15
Val Ala Gly Val Ser Ile Met Ser Pro Ser Ala Asn Ala Ala Glu Ala
20 25 30
Met Thr Ser Thr Ser Phe Asn Arg Asn
35 40
<210> 46
<211> 149
<212> ДНК
<213> искусственная последовательность
<220>
<223> последовательность, кодирующая сигнальный пептид CgR_0949
<220>
<221> прочий_признак
<222> (1)..(25)
<223> 5'-концевое перекрывание для сборки по Гибсону
<220>
<221> CDS
<222> (26)..(148)
<220>
<221> прочий_признак
<222> (26)..(124)
<223> последовательность, кодирующая сигнальный пептид CgR0949
<220>
<221> прочий_признак
<222> (125)..(149)
<223> 3'-концевое перекрывание для сборки по Гибсону
<400> 46
aagcttgcat gcctgcagac caggt atg caa ata aac cgc cga ggc ttc tta 52
Met Gln Ile Asn Arg Arg Gly Phe Leu
1 5
aaa gcc acc gca gga ctt gcc act atc ggc gct gcc agc atg ttt atg 100
Lys Ala Thr Ala Gly Leu Ala Thr Ile Gly Ala Ala Ser Met Phe Met
10 15 20 25
cca aag gcc aac gcc ctt gga gca atg act agt acc tcc ttc aac cgc a 149
Pro Lys Ala Asn Ala Leu Gly Ala Met Thr Ser Thr Ser Phe Asn Arg
30 35 40
<210> 47
<211> 41
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 47
Met Gln Ile Asn Arg Arg Gly Phe Leu Lys Ala Thr Ala Gly Leu Ala
1 5 10 15
Thr Ile Gly Ala Ala Ser Met Phe Met Pro Lys Ala Asn Ala Leu Gly
20 25 30
Ala Met Thr Ser Thr Ser Phe Asn Arg
35 40
<210> 48
<211> 151
<212> ДНК
<213> искусственная последовательность
<220>
<223> последовательность, кодирующая сигнальный пептид CgR_1023
<220>
<221> прочий_признак
<222> (1)..(25)
<223> 5'-концевое перекрывание для сборки по Гибсону
<220>
<221> CDS
<222> (26)..(151)
<220>
<221> прочий_признак
<222> (26)..(127)
<223> последовательность, кодирующая сигнальный пептид CgR1023
<220>
<221> прочий_признак
<222> (128)..(151)
<223> 3'-концевое перекрывание для сборки по Гибсону
<400> 48
aagcttgcat gcctgcagac caggt gtg cgt aaa gga att tcc cgc gtc ctc 52
Val Arg Lys Gly Ile Ser Arg Val Leu
1 5
tcg gta gcg gtt gct agt tca atc gga ttc gga act gta ctg aca ggc 100
Ser Val Ala Val Ala Ser Ser Ile Gly Phe Gly Thr Val Leu Thr Gly
10 15 20 25
acc ggc atc gca gca gct caa gac tct atg act agt acc tcc ttc aac 148
Thr Gly Ile Ala Ala Ala Gln Asp Ser Met Thr Ser Thr Ser Phe Asn
30 35 40
cgc 151
Arg
<210> 49
<211> 42
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 49
Val Arg Lys Gly Ile Ser Arg Val Leu Ser Val Ala Val Ala Ser Ser
1 5 10 15
Ile Gly Phe Gly Thr Val Leu Thr Gly Thr Gly Ile Ala Ala Ala Gln
20 25 30
Asp Ser Met Thr Ser Thr Ser Phe Asn Arg
35 40
<210> 50
<211> 163
<212> ДНК
<213> искусственная последовательность
<220>
<223> последовательность, кодирующая сигнальный пептид CgR_1448
<220>
<221> прочий_признак
<222> (1)..(25)
<223> 5'-концевое перекрывание для сборки по Гибсону
<220>
<221> CDS
<222> (26)..(163)
<220>
<221> прочий_признак
<222> (26)..(139)
<223> последовательность, кодирующая сигнальный пептид CgR1448
<220>
<221> прочий_признак
<222> (140)..(163)
<223> 3'-концевое перекрывание для сборки по Гибсону
<400> 50
aagcttgcat gcctgcagac caggt atg gct cag att tct cgt cgt cac ttc 52
Met Ala Gln Ile Ser Arg Arg His Phe
1 5
ctg gct gca gca act gtt gca ggc gca ggc gca act ttg gca gca tgt 100
Leu Ala Ala Ala Thr Val Ala Gly Ala Gly Ala Thr Leu Ala Ala Cys
10 15 20 25
gcg ggt acc ggt gga agc act tct tcc tcc agc gat tct atg act agt 148
Ala Gly Thr Gly Gly Ser Thr Ser Ser Ser Ser Asp Ser Met Thr Ser
30 35 40
acc tcc ttc aac cgc 163
Thr Ser Phe Asn Arg
45
<210> 51
<211> 46
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 51
Met Ala Gln Ile Ser Arg Arg His Phe Leu Ala Ala Ala Thr Val Ala
1 5 10 15
Gly Ala Gly Ala Thr Leu Ala Ala Cys Ala Gly Thr Gly Gly Ser Thr
20 25 30
Ser Ser Ser Ser Asp Ser Met Thr Ser Thr Ser Phe Asn Arg
35 40 45
<210> 52
<211> 149
<212> ДНК
<213> искусственная последовательность
<220>
<223> последовательность, кодирующая сигнальный пептид CgR_2137
<220>
<221> прочий_признак
<222> (1)..(25)
<223> 5'-концевое перекрывание для сборки по Гибсону
<220>
<221> CDS
<222> (26)..(148)
<220>
<221> прочий_признак
<222> (26)..(121)
<223> последовательность, кодирующая сигнальный пептид CgR2137
<220>
<221> прочий_признак
<222> (122)..(149)
<223> 3'-концевое перекрывание для сборки по Гибсону
<400> 52
aagcttgcat gcctgcagac caggt atg cca cag tta agc aga cgc cag ttc 52
Met Pro Gln Leu Ser Arg Arg Gln Phe
1 5
ttg cag aca acc gcc gtt act gca ggt cta gcc act ttt ttg ggc aca 100
Leu Gln Thr Thr Ala Val Thr Ala Gly Leu Ala Thr Phe Leu Gly Thr
10 15 20 25
cct gca cgc gct gaa gaa cgc atg act agt acc tcc ttc aac cgc aac c 149
Pro Ala Arg Ala Glu Glu Arg Met Thr Ser Thr Ser Phe Asn Arg Asn
30 35 40
<210> 53
<211> 41
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 53
Met Pro Gln Leu Ser Arg Arg Gln Phe Leu Gln Thr Thr Ala Val Thr
1 5 10 15
Ala Gly Leu Ala Thr Phe Leu Gly Thr Pro Ala Arg Ala Glu Glu Arg
20 25 30
Met Thr Ser Thr Ser Phe Asn Arg Asn
35 40
<210> 54
<211> 178
<212> ДНК
<213> искусственная последовательность
<220>
<223> последовательность, кодирующая сигнальный пептид CgR_2627
<220>
<221> прочий_признак
<222> (1)..(25)
<223> 5'-концевое перекрывание для сборки по Гибсону
<220>
<221> CDS
<222> (26)..(178)
<220>
<221> прочий_признак
<222> (26)..(154)
<223> последовательность, кодирующая сигнальный пептид CgR2627
<220>
<221> прочий_признак
<222> (155)..(178)
<223> 3'-концевое перекрывание для сборки по Гибсону
<400> 54
aagcttgcat gcctgcagac caggt atg gtg aac acg ttg aac tct aaa acc 52
Met Val Asn Thr Leu Asn Ser Lys Thr
1 5
gtg aat gta ccc cgt ttt gcc aga ggc gtt gtt gct gca gcc aca gcg 100
Val Asn Val Pro Arg Phe Ala Arg Gly Val Val Ala Ala Ala Thr Ala
10 15 20 25
cta ttt ttt ggc gct ttg gta agc ctc gcg cct agt gcg ttg gcg cag 148
Leu Phe Phe Gly Ala Leu Val Ser Leu Ala Pro Ser Ala Leu Ala Gln
30 35 40
gaa cca atg act agt acc tcc ttc aac cgc 178
Glu Pro Met Thr Ser Thr Ser Phe Asn Arg
45 50
<210> 55
<211> 51
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 55
Met Val Asn Thr Leu Asn Ser Lys Thr Val Asn Val Pro Arg Phe Ala
1 5 10 15
Arg Gly Val Val Ala Ala Ala Thr Ala Leu Phe Phe Gly Ala Leu Val
20 25 30
Ser Leu Ala Pro Ser Ala Leu Ala Gln Glu Pro Met Thr Ser Thr Ser
35 40 45
Phe Asn Arg
50
<210> 56
<211> 172
<212> ДНК
<213> искусственная последовательность
<220>
<223> последовательность, кодирующая сигнальный пептид CgR_2926
<220>
<221> прочий_признак
<222> (1)..(25)
<223> 5'-концевое перекрывание для сборки по Гибсону
<220>
<221> CDS
<222> (26)..(172)
<220>
<221> прочий_признак
<222> (26)..(148)
<223> последовательность, кодирующая сигнальный пептид CgR2926
<220>
<221> прочий_признак
<222> (149)..(172)
<223> 3'-концевое перекрывание для сборки по Гибсону
<400> 56
aagcttgcat gcctgcagac caggt atg act caa cca gcc ccc atg tgt agc 52
Met Thr Gln Pro Ala Pro Met Cys Ser
1 5
cgc cgc atg ttt ctt ctt gga aca gca aca acc ttc gca ggt gct ttt 100
Arg Arg Met Phe Leu Leu Gly Thr Ala Thr Thr Phe Ala Gly Ala Phe
10 15 20 25
ctt gca gcc tgt ggt act gaa cca gat cag gag gta gcg gct act gaa 148
Leu Ala Ala Cys Gly Thr Glu Pro Asp Gln Glu Val Ala Ala Thr Glu
30 35 40
atg act agt acc tcc ttc aac cgc 172
Met Thr Ser Thr Ser Phe Asn Arg
45
<210> 57
<211> 49
<212> БЕЛОК
<213> искусственная последовательность
<220>
<223> синтетическая конструкция
<400> 57
Met Thr Gln Pro Ala Pro Met Cys Ser Arg Arg Met Phe Leu Leu Gly
1 5 10 15
Thr Ala Thr Thr Phe Ala Gly Ala Phe Leu Ala Ala Cys Gly Thr Glu
20 25 30
Pro Asp Gln Glu Val Ala Ala Thr Glu Met Thr Ser Thr Ser Phe Asn
35 40 45
Arg
<210> 58
<211> 20
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(20)
<223> праймер pVW_4
<400> 58
tttgcgccga catcataacg 20
<210> 59
<211> 20
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(20)
<223> праймер Wtat1_agl2_rev
<400> 59
gccaccgaca gcgatgatag 20
<210> 60
<211> 20
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(20)
<223> праймер Wtat2_agl2_rev
<400> 60
actgtcgccg ggaaaaacta 20
<210> 61
<211> 20
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(20)
<223> праймер Wtat3a_agl2
<400> 61
gtcgcggacg gcgtagaggg 20
<210> 62
<211> 20
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(20)
<223> праймер Wtat4_agl2_rev
<400> 62
ggccgaaggt gacatgatgc 20
<210> 63
<211> 20
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(20)
<223> праймер Wtat5a_agl2
<400> 63
agcgccgata gtggcaagtc 20
<210> 64
<211> 20
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(20)
<223> праймер Wtat6_agl2_rev
<400> 64
ggtgcctgtc agtacagttc 20
<210> 65
<211> 20
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(20)
<223> праймер Wtat7_agl2_rev
<400> 65
acccgcacat gctgccaaag 20
<210> 66
<211> 20
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(20)
<223> праймер Wtat8a_agl2
<400> 66
gtggctagac ctgcagtaac 20
<210> 67
<211> 20
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(20)
<223> праймер Wtat9_agl2_rev
<400> 67
tgcagcaaca acgcctctgg 20
<210> 68
<211> 20
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(20)
<223> праймер Wtat10_agl2
<400> 68
agcacctgcg aaggttgttg 20
<210> 69
<211> 1492
<212> ДНК
<213> искусственная последовательность
<220>
<223> полинуклеотид (молекула ДНК) INT
<220>
<221> прочий_признак
<222> (1)..(6)
<223> сайт рестрикции для EcoRI
<220>
<221> прочий_признак
<222> (7)..(401)
<223> 3'-конец нуклеотидной последовательности с идентификатором
локуса NCgl2176
<220>
<221> прочий_признак
<222> (398)..(401)
<223> стоп-кодон tga NCgl2176
<220>
<221> прочий_признак
<222> (402)..(959)
<223> межгенная область между NCgl2176 и NCgl2177, модифицированная
путем обменов нуклеотидов с образованием сайтов рестрикции
для EcoRV, AvRII
и SmaI
<220>
<221> прочий_признак
<222> (725)..(730)
<223> сайт рестрикции для EcoRV
<220>
<221> прочий_признак
<222> (736)..(741)
<223> сайт рестрикции для AvRII
<220>
<221> прочий_признак
<222> (746)..(751)
<223> сайт рестрикции для SmaII
<220>
<221> прочий_признак
<222> (960)..(962)
<223> кодон cta; стоп-кодон tag NCgl2177 в комплементарной нити
<220>
<221> прочий_признак
<222> (960)..(1388)
<223> нуклеотидная последовательность, комплементарная NCgl2177
<220>
<221> прочий_признак
<222> (1386)..(1388)
<223> кодон cat; стартовый кодон atg NCgl2177 в комплементарной нити
<220>
<221> прочий_признак
<222> (1389)..(1486)
<223> последовательность, расположенная выше NCgl2177
<220>
<221> прочий_признак
<222> (1487)..(1492)
<223> сайт рестрикции для HindIII
<400> 69
gaattctcca agagttcatc aacaaacacg cactccccga cggccccatg ctgctcaccg 60
actggggacc aacccccaca ggactattcc gctcaggtca agagcacaag aaagtccaac 120
tgcgcaacct gtttatcgaa taccccgaca tgaaatggat cctcgtcggc gacgatggcc 180
aacacgatcc cctcatctac ggcgaagcag tcgaagaaca ccccaaccgc atcgcaggcg 240
ttgcaatccg tgagctctcc cccggcgaac atgtgctctc ccacggaaca actgcgtcac 300
tgtccaccat cacgaccaac gggggccaag gagtcccagt agttcacggc cgcgatggat 360
atgagttgct gcagcgctac gagacgaagc cgttcgcctg agtcctactg ggtgtctcat 420
gaaccaaacc gggtgaccag cgtcgcctta attttgggtt cctcggtcac ctagtttggt 480
ccttggttgc gttcgcgtat ggcataaatg ggcactgact atttttgggg cggggccccg 540
aggtaaaagg cgatttaaga ggttgagatc cccaaatagg cttttggtat ggaggacgcc 600
cgttgaggct cttaaaaccg attctgagag acctcggctt tgtgaccagt gggacagatg 660
agattcctgc gagcttgctg atcaagaact caccacaatt gtgtggccag accgtcaaat 720
cgaagatatc tttgccctag gtagacccgg gcttgcaaaa acccaccaca aacactgtct 780
cgccagcaat ctgtggtgaa ttttcgcata attgttcgac caagagtccg acggtaatca 840
acacgtcaca aaccacccca caaagtgcgc caaaaacccg tggggcctcc ctcttcctct 900
agagaggccc cacgggctgg tctatttaca ccccgccgag ctaaagaatc actggctttc 960
tagtcaacga ttcgcagctc aacttcaaaa cggtattcat cagccagaga ttccagcact 1020
cctcgaagtt tgtcgagttc gcgtggagtt ccggtgatca cctctcgaca ctcagtgagg 1080
ccaagttcga atgggtcacg gcgccatgca gtgaaccatc gtgcggtgag cgggtccctg 1140
ttggagccgg acagctccga aggactcgga atacacacaa ccattgcgga ttccacggtc 1200
tgacgcagtt cctttggcat tccgctgatt tctagaacag cggtatgcat tgggagggct 1260
acatcgtcga tggattcttc gatggtagtt ttcagttggg gcaaccccat gtcttcccag 1320
aagtctgccg tgagcaaatc cgcctgatga cgggtccggg ttggcacggt taatgcattg 1380
ttcgtcatgt tcggtttcct tcggcaacac ttaactgcct tcaattcccg cacacatata 1440
caagtagata tgtgcagtta ctaaaggaag taagacgagg ttcgtcaagc tt 1492
<210> 70
<211> 2125
<212> ДНК
<213> искусственная последовательность
<220>
<223> слитый ген tat-'agl2_cuo, содержащий промотор и терминатор
<220>
<221> прочий_признак
<222> (1)..(20)
<223> 20 нуклеотидов
<220>
<221> прочий_признак
<222> (4)..(9)
<223> сайт рестрикции для XbaI
<220>
<221> промотор
<222> (52)..(111)
<223> промотор PdapBN1
<220>
<221> прочий_признак
<222> (142)..(2058)
<223> последовательность, кодирующая слитый полипептид Tat-'Agl2
<220>
<221> прочий_признак
<222> (2059)..(2061)
<223> стоп-кодон
<220>
<221> прочий_признак
<222> (2062)..(2069)
<223> сайт рестрикции для NotI
<220>
<221> прочий_признак
<222> (2073)..(2108)
<223> терминатор Tgap*
<220>
<221> прочий_признак
<222> (2111)..(2116)
<223> сайт рестрикции для XbaI
<220>
<221> прочий_признак
<222> (2117)..(2125)
<223> 9 нуклеотидов
<400> 70
gcgtctagaa ctgatgaaca atcgttaaca acacagacca aaacggtcag ttaggtatgg 60
atatcagcac cttctgaacg ggtacgggta taatggtggg cgtttgaaaa actcttcgcc 120
ccacgaaaat gaaggagcat aatgcaaata aaccgccgag gcttcttaaa agccaccaca 180
ggacttgcca ctatcggcgc tgccagcatg tttatgccaa aggccaacgc ccttggagca 240
atgactagta cctccttcaa ccgcgaacca ctgccagatg cagtgcgcac caacggtgca 300
accccaaacc catggtggtc caacgcagtg gtgtaccaga tctacccacg ctccttccag 360
gataccaacg gcgacggcct gggcgatctg aagggcatca cctcccgctt ggattacctg 420
gcagatctgg gcgtggatgt gctgtggctg tccccagtgt accgctcccc acaggatgat 480
aacggctacg atatctccga ttaccgcgat atcgatccac tgttcggcac cctggatgat 540
atggatgaac tgctggcaga ggcacacaag cgtggcctga agatcgtgat ggatctggtg 600
gtgaaccaca cctccgatga acacgcatgg ttcgaagcat ccaaggataa ggatgatcca 660
cacgcagatt ggtactggtg gcgtccagca cgcccaggcc acgaaccagg caccccaggc 720
gcagaaccaa accagtgggg ctcctacttc ggtggctccg catgggaata ctccccagaa 780
cgcggtgaat actacctgca ccagttctcc aagaagcagc cagatctcaa ctgggaaaac 840
ccagcagtgc gtcgcgcagt gtacgatatg atgaactggt ggttggatcg cggtatcgat 900
ggcttccgca tggatgtgat caccctgatc tccaagcgca ccgatccaaa cggtcgcctg 960
ccaggtgaaa ccggctccga actccaggat ctgccagtgg gcgaagaagg ctactcctcc 1020
ccaaaccctt tctgcgcaga tggccctcgc caggatgaat tcctggcaga aatgcgtcgc 1080
gaagttttcg atggccgtga tggcttcctg accgtgggcg aagcaccagg catcaccgca 1140
gaacgcaacg aacacatcac cgatccagca aacggcgaac tggatatgct gttcctgttc 1200
gaacacatgg gcgtggatca gaccccagaa tccaagtggg atgataagcc atggacccca 1260
gcagatctgg aaaccaagct ggcagaacag caggatgcaa tcgcacgccg tggctgggcc 1320
tccctgttcc tggataacca cgatcagcca cgcgtggtgt cccgctgggg tgatgatacc 1380
tccaagaccg gtcgcatccg ctccgcaaag gcactggcac tgctgctgca catgcaccgt 1440
ggcaccccat acgtgtacca gggcgaagaa ctgggcatga ccaacgcaca cttcacctcc 1500
ctggatcagt accgcgatct ggaatccatc aacgcatacc accaacgcgt ggaagaaacc 1560
ggcatccgca cctccgaaac catgatgcgc tccctggcac gctacggtcg cgataacgca 1620
cgcaccccaa tgcagtggga tgattccacc tacgcaggct tcaccatgcc agatgcccca 1680
gtggaaccat ggatcgcagt gaacccaaac cacaccgaaa tcaacgcagc agatgaaacc 1740
gatgatccag attccgtgta ctccttccac aagcgcctga tcgcactgcg ccacaccgat 1800
ccagtggtgg cagcaggcga ttaccgtcgc gtggaaaccg gcaacgatcg catcattgca 1860
ttcacccgca ccctggacga acgcaccatc ctgaccgtga tcaacctgtc cccaacccag 1920
gcagcaccag caggcgaact ggaaaccatg ccagacggca ccatcttgat cgcaaacacc 1980
gatgacccag tgggcaacct caagaccacc ggcaccctgg gtccatggga agcattcgca 2040
atggaaaccg atccagaata agcggccgct gttagcccgg ggtgtgcctc ggcgcacccc 2100
gggctatttt tctagaggat ccgcg 2125
<210> 71
<211> 20
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(20)
<223> праймер IR_1
<400> 71
gacctcggct ttgtgaccag 20
<210> 72
<211> 20
<212> ДНК
<213> искусственная последовательность
<220>
<223> праймер
<220>
<221> прочий_признак
<222> (1)..(20)
<223> праймер IR_2
<400> 72
ctcaccgcac gatggttcac 20
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| Вакцина против герпеса | 2019 |
|
RU2731073C1 |
| КОМПОЗИЦИИ И СПОСОБЫ ДЛЯ БИОЛОГИЧЕСКОГО ПОЛУЧЕНИЯ ЛАКТАТА ИЗ С1-СОЕДИНЕНИЙ С ПРИМЕНЕНИЕМ ТРАНСФОРМАНТОВ ЛАКТАТ ДЕГИДРОГЕНАЗЫ | 2014 |
|
RU2710714C2 |
| ИММУНОИНДУЦИРУЮЩЕЕ СРЕДСТВО | 2016 |
|
RU2744843C2 |
| ФАРМАЦЕВТИЧЕСКАЯ КОМПОЗИЦИЯ ДЛЯ ЛЕЧЕНИЯ И/ИЛИ ПРЕДОТВРАЩЕНИЯ ЗЛОКАЧЕСТВЕННОЙ ОПУХОЛИ | 2016 |
|
RU2714205C2 |
| СПОСОБ УПРАВЛЕНИЯ РИТМОМ СЕРДЦА И СОКРАЩЕНИЕМ ОТДЕЛЬНЫХ КАРДИОМИОЦИТОВ ПРИ ПОМОЩИ ТЕРМОГЕНЕТИКИ | 2022 |
|
RU2802995C1 |
| КОНСТРУКЦИИ НУКЛЕИНОВОЙ КИСЛОТЫ И ВЕКТОРЫ ДЛЯ ГЕНОТЕРАПИИ ДЛЯ ПРИМЕНЕНИЯ ДЛЯ ЛЕЧЕНИЯ БОЛЕЗНИ ВИЛЬСОНА И ДРУГИХ СОСТОЯНИЙ | 2015 |
|
RU2745567C2 |
| СПОСОБ ПОЛУЧЕНИЯ L-АМИНОКИСЛОТ С ПОМОЩЬЮ КОРИНЕБАКТЕРИЙ С ПРИМЕНЕНИЕМ СИСТЕМЫ РАСЩЕПЛЕНИЯ ГЛИЦИНА | 2015 |
|
RU2713298C2 |
| БИОСЕНСОРНАЯ СИСТЕМА ДЛЯ БЫСТРОГО ОБНАРУЖЕНИЯ ОПРЕДЕЛЯЕМЫХ КОМПОНЕНТОВ | 2016 |
|
RU2717658C2 |
| МАТЕРИАЛЫ И МЕТОДЫ, ИСПОЛЬЗУЕМЫЕ ДЛЯ ЛЕЧЕНИЯ РЕСПИРАТОРНЫХ ЗАБОЛЕВАНИЙ У СОБАК | 2020 |
|
RU2811752C2 |
| СПОСОБ ПРОДУЦИРОВАНИЯ ПОЧЕЧНЫХ КЛЕТОК-ПРЕДШЕСТВЕННИКОВ | 2016 |
|
RU2730861C2 |
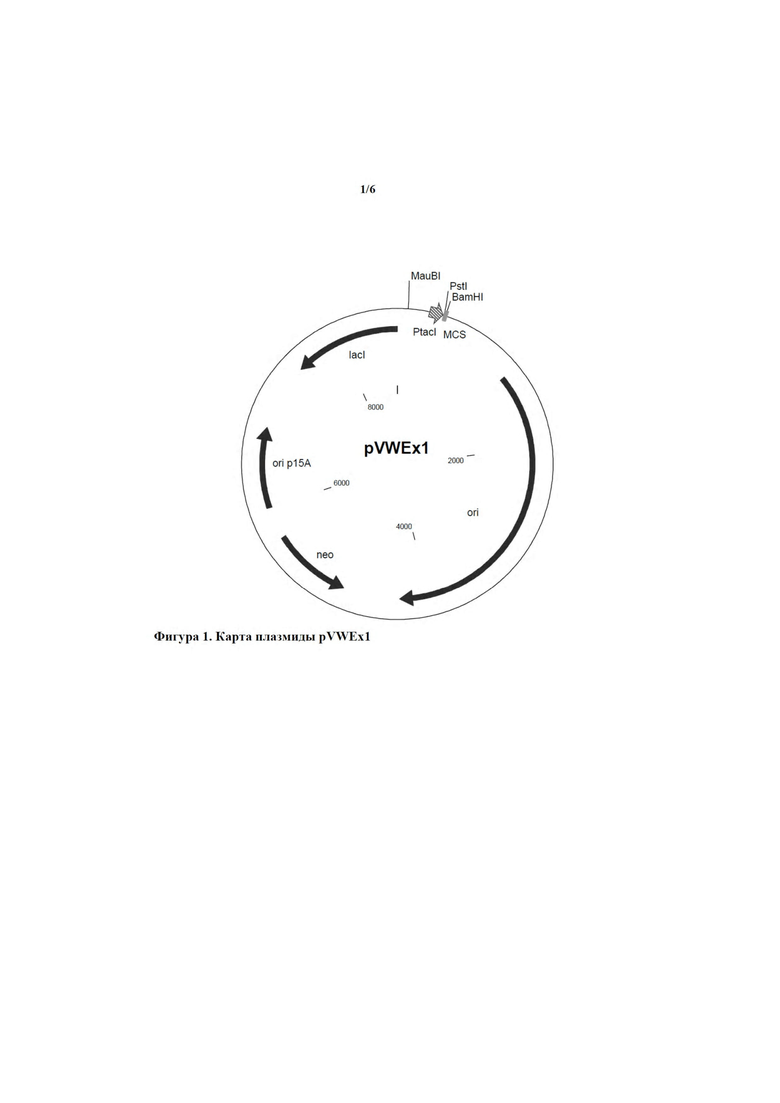
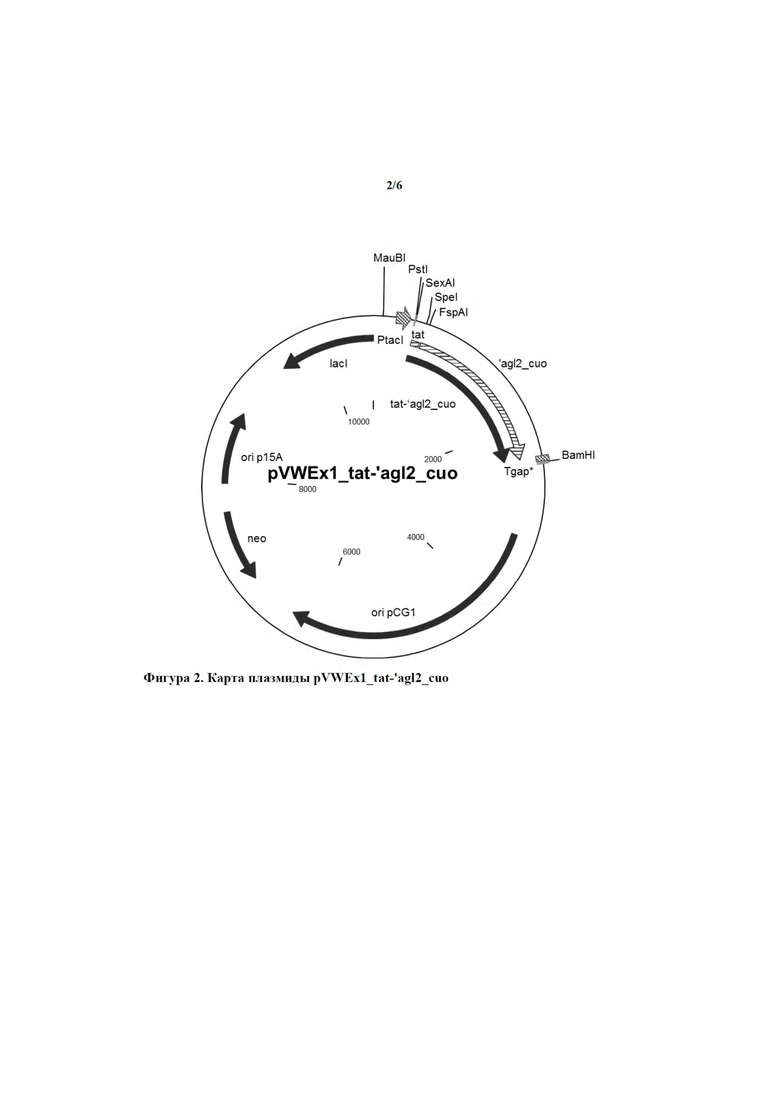
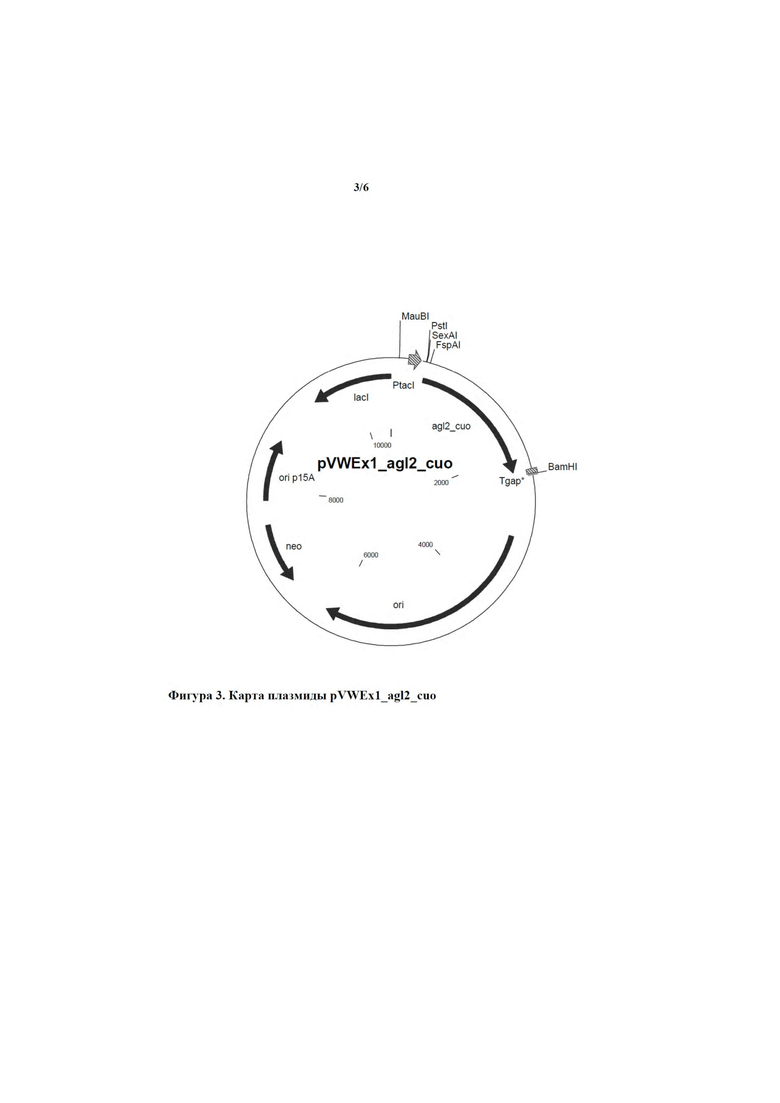


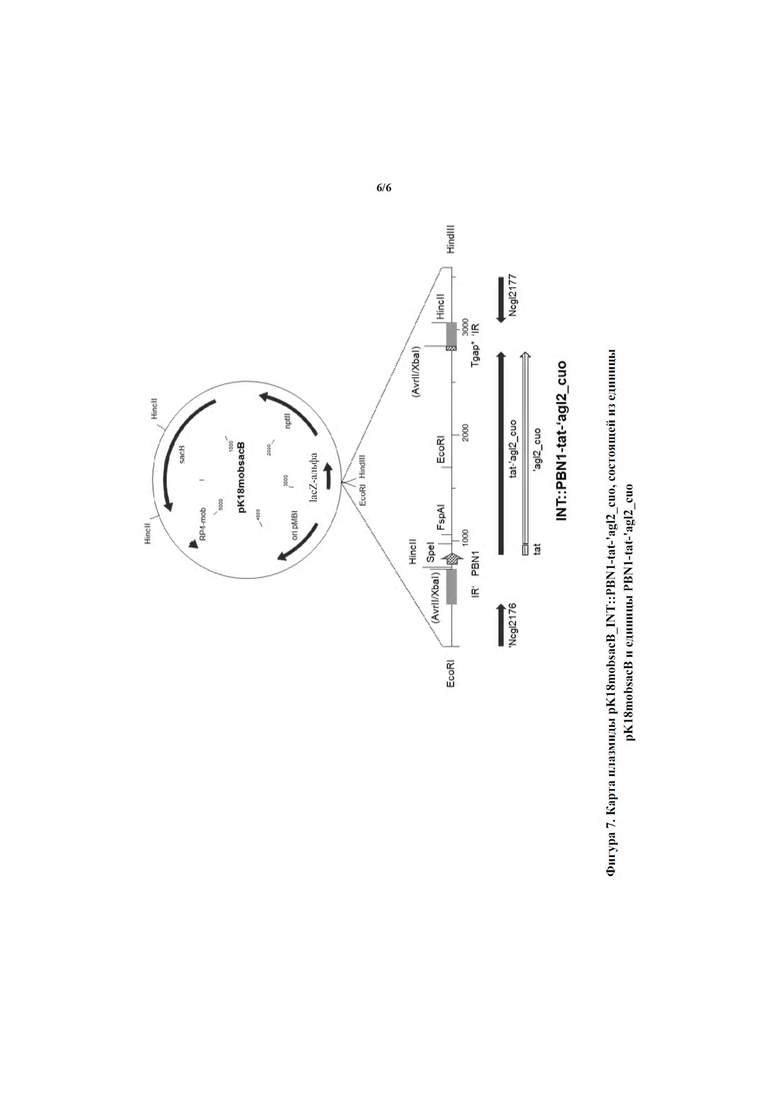
Изобретение относится к способу получения L-лизина. Предложен способ получения L-лизина, включающий культивирование бактерии рода Corynebacterium, продуцирующей L-лизин в подходящей среде. При этом для культивирования указанной бактерии используют источник углерода, содержащий олигомеры α-D-глюкозы, состоящие по меньшей мере из двух соединенных α-1-6-гликозидной связью глюкозных мономеров. Указанная бактерия содержит выделенный полинуклеотид, кодирующий слитый полипептид, содержащий аминокислотную последовательность, соответствующую SEQ ID NO: 22, при этом бактерия секретирует полипептид, обладающий α-1,6-глюкозидазной активностью, кодируемый указанным полинуклеотидом. Изобретение обеспечивает улучшение выхода L-лизина. 5 з.п. ф-лы, 7 ил., 19 табл., 8 пр.
1. Способ получения L-лизина, включающий культивирование бактерии рода Corynebacterium, продуцирующей L-лизин в подходящей среде, где для культивирования указанной бактерии используют источник углерода, содержащий олигомеры α-D-глюкозы, состоящие по меньшей мере из двух соединенных α-1-6-гликозидной связью глюкозных мономеров, отличающийся тем, что бактерия содержит выделенный полинуклеотид, кодирующий слитый полипептид, содержащий аминокислотную последовательность, соответствующую SEQ ID NO: 22;
при этом бактерия секретирует полипептид, обладающий α-1,6-глюкозидазной активностью, кодируемый указанным полинуклеотидом.
2. Способ по п. 1, где указанный полинуклеотид функционально связан с промотором.
3. Способ по п. 2, где указанный промотор представляет собой промотор PtacI, соответствующий нуклеотидной последовательности из положений 1-75 SEQ ID NO: 14, или промотор PdapBN1, соответствующий нуклеотидной последовательности SEQ ID NO: 15.
4. Способ по п. 3, где указанный промотор представляет собой промотор PdapBN1, соответствующий последовательности SEQ ID NO: 15.
5. Способ по любому из предыдущих пунктов, где полинуклеотид содержится в плазмидном векторе, автономно реплицирующемся в указанной бактерии или в хромосоме указанной бактерии.
6. Способ по любому из предыдущих пунктов, где указанная бактерия представляет собой Corynebacterium glutamicum.
| Способ приготовления мыла | 1923 |
|
SU2004A1 |
| MATANO C | |||
| et al | |||
| Corynebacterium glutamicum possesses β-N-acetylglucosaminidase | |||
| BMC Microbiol | |||
| Токарный резец | 1924 |
|
SU2016A1 |
| Печь-кухня, могущая работать, как самостоятельно, так и в комбинации с разного рода нагревательными приборами | 1921 |
|
SU10A1 |
| POKUSAEVA K | |||
| et al | |||
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Appl Environ Microbiol | |||
| Колосоуборка | 1923 |
|
SU2009A1 |

