ОБЛАСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение относится к векторным системам на основе аденоассоциированного вируса (AAV) и векторам AAV для экспрессии белка ABCA4 человека в клетке-мишени. Векторные системы AAV и векторы AAV по изобретению можно использовать в профилактике или лечении заболеваний, ассоциированных с деградацией клеток сетчатки, таких как болезнь Штаргардта.
ПРЕДПОСЫЛКИ ИЗОБРЕТЕНИЯ
Болезнь Штаргардта является наследственным заболеванием сетчатки, которое может приводить к слепоте по причине деструкции светочувствительных фоторецепторных клеток в глазу. Заболевание, как правило, дебютирует в детском возрасте, приводя к слепоте у молодых людей.
Наиболее распространенной формой болезни Штаргардта является рецессивное нарушение, связанное с мутациями в гене, кодирующем белок АТФ-связывающей кассеты, подсемейство A, члена 4 (ABCA4). ABCA4 является крупным трансмембранным белком, играющим роль в кругообороте светочувствительных пигментов в клетках сетчатки. При болезни Штаргардта мутации в гене ABCA4 приводят к отсутствию функционального белка ABCA4 в клетках сетчатки. Это, в свою очередь, приводит к образованию и накоплению бисретиноидных побочных продуктов, что приводит к образованию токсических гранул липофусцина в клетках пигментного эпителия сетчатки (RPE). Это вызывает деградацию и конечную деструкцию клеток RPE, что приводит к утрате фоторецепторных клеток, вызывающей прогрессирующую потерю зрения и, в конечном итоге, слепоту.
Генная терапия является перспективным направлением лечения болезни Штаргардта. Целью является коррекция недостаточности, лежащей в основе заболевания, с использованием вектора для встраивания функционального гена ABCA4 в пораженные фоторецепторные клетки и, таким образом, восстановления функции ABCA4.
Векторы, полученные из аденоассоциированного вируса (AAV), в настоящее время находятся на стадии исследования с целью генной терапии сетчатки. AAV является небольшим вирусом, имеющим очень низкую иммуногенность и не ассоциированным с каким-либо известным заболеванием человека. Отсутствие ассоциированного с ним воспалительного ответа означает, что AAV не вызывает повреждение сетчатки при инъекции в глаз.
Однако размер капсида AAV накладывает ограничение на количество ДНК, которую можно в него упаковывать. Размер генома AAV составляет приблизительно 4,7 тысяч пар нуклеотидов (т.п.н.), и полагают, что соответствующий верхний предел размера для упаковки ДНК в AAV составляет приблизительно 5 т.п.н. (Wu et al., Molecular Therapy, vol. 18, No. 1, Jan 2010). Размер кодирующей последовательности гена ABCA4 составляет приблизительно 6,8 т.п.н. (с дополнительными генетическими элементами, необходимыми для экспрессии гена), что делает ее слишком большой для включения в стандартный вектор AAV.
Исследуют ряд подходов для преодоления этого верхнего предела размера и экспрессии крупных генов, таких как ABCA4, с векторов AAV. Эти подходы включают подходы с использованием вектора "большого размера" и подходы с использованием "двойного" вектора.
Векторы "большого размера"
Предпринят ряд попыток включения в векторы AAV генов значительно большего размера, чем нативный геном в 4,7 т.п.н., с некоторым успехом при трансдукции клеток-мишеней. В качестве примера, Allocca et al. (J. Clin. Invest. vol.118, No. 5, мая 2008) получали векторы AAV большого размера, в которые упаковывали гены ABCA4 мыши и MYO7A человека, и демонстрировали экспрессию белка после трансдукции клеток сетчатки мыши. Однако, хотя Allocca et al. предположили, что конкретные капсиды AAV могут включать до 8,9 т.п.н., последующие исследования показали, что подход с использованием вектора "большого размера" фактически не позволяет преодолевать верхний предел размера при упаковке, но скорее приводит к укорачиванию трансгена случайным образом, что приводит к получению гетерогенной популяции векторов AAV, каждый из которых содержит фрагмент трансгена (Dong et al., Molecular Therapy, vol. 18, No. 1, Jan 2010). Полагают, что часть векторов большого размера в указанной популяции упаковывает достаточно крупные фрагменты трансгена большого размера таким образом, что существуют области перекрывания между фрагментами, что позволяет им повторно собираться в полноразмерный ген после трансдукции клетки-мишени. Однако этот способ является непредсказуемым и неэффективным, демонстрирует отсутствие контроля упаковки и последующую неудачу рекомбинации, что представляет собой существенное препятствие для последовательного, определимого успеха.
"Двойные" векторы
Альтернативным подходом является получение двойных векторных систем, в которых трансген с пределом более приблизительно 5 т.п.н. разделяют приблизительно пополам на два отдельных вектора определенной последовательности: "вышележащий" вектор, содержащий 5'-часть трансгена, и "нижележащий" вектор, содержащий 3'-часть трансгена. Трансдукция клетки-мишени с использованием вышележащих и нижележащих векторов позволяет полноразмерному трансгену повторно собираться из двух фрагментов с использованием различных внутриклеточных механизмов.
В так называемом походе "транс-сплайсирующегося" двойного вектора сигнал донора сплайсинга помещают на 3'-конец вышележащего фрагмента трансгена и сигнал акцептора сплайсинга помещают на 5'-конец нижележащего фрагмента трансгена. После трансдукции клетки-мишени с использованием двойных векторов последовательности инвертированных концевых повторов (ITR), присутствующие в геноме AAV, опосредуют конкатемеризацию фрагментов трансгена по принципу "голова-хвост", и транс-сплайсинг транскриптов приводит к продукции полноразмерной последовательности мРНК, что делает возможной экспрессию полноразмерного белка.
В альтернативной двойной векторной системе используют подход с "перекрыванием". В перекрывающейся двойной векторной системе часть кодирующей последовательности на 3'-конце вышележащей части кодирующей последовательности перекрывается с гомологичной последовательностью на 5'-конце нижележащей части кодирующей последовательности. После трансдукции клетки-мишени с использованием вышележащих и нижележащих векторов гомологичная рекомбинация между вышележащими и нижележащими частями кодирующей последовательности делает возможным восстановление полноразмерного трансгена, с которого может транскрибироваться соответствующая мРНК и может экспрессироваться полноразмерный белок.
В WO 2014/170480 описывают получение двойной векторной системы AAV, кодирующей белок ABCA4 человека.
Таким образом, в этой области существует потребность в альтернативных и/или улучшенных векторных системах AAV, кодирующих белок ABCA4 и пригодных для использования в генной терапии.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Настоящее изобретение направлено на решение указанных выше проблем, существующих в этой области, посредством получения векторных систем на основе аденоассоциированного вируса (AAV), как описано в формуле изобретения.
Преимущественно, векторная система AAV по изобретению ассоциирована с неожиданно высокими уровнями экспрессии полноразмерного белка ABCA4 в трансдуцированных клетках с ограниченной продукцией нежелательных укороченных фрагментов ABCA4.
В одном из аспектов изобретение относится к векторной системе AAV для экспрессии белка ABCA4 человека в клетке-мишени, векторной системе AAV, содержащей первый вектор AAV, содержащий первую последовательность нуклеиновой кислоты, и второй вектор AAV, содержащий вторую последовательность нуклеиновой кислоты; где первая последовательность нуклеиновой кислоты содержит 5'-концевую часть кодирующей последовательности (CDS) ABCA4, и вторая последовательность нуклеиновой кислоты содержит 3'-концевую часть CDS ABCA4, и 5'-концевая часть и 3'-концевая часть вместе включают целую CDS ABCA4; где первая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, соответствующую нуклеотидам 105-3597 SEQ ID NO: 1; где вторая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, соответствующих нуклеотидам 3806-6926 SEQ ID NO: 1; где каждая из первой последовательности нуклеиновой кислоты и второй последовательности нуклеиновой кислоты содержит область перекрывания последовательностей друг с другом; и где область перекрывания последовательностей содержит по меньшей мере приблизительно 20 смежных нуклеотидов из последовательности нуклеиновой кислоты, соответствующей нуклеотидам 3598-3805 SEQ ID NO: 1.
Область перекрывания последовательностей может составлять от 20 до 550 нуклеотидов в длину; предпочтительно - от 50 до 250 нуклеотидов в длину; более предпочтительно - от 175 до 225 нуклеотидов в длину; и наиболее предпочтительно - от 195 до 215 нуклеотидов в длину.
Область перекрывания последовательностей также может содержать по меньшей мере приблизительно 50 смежных нуклеотидов из последовательности нуклеиновой кислоты, соответствующей нуклеотидам 3598-3805 SEQ ID NO: 1; предпочтительно - по меньшей мере приблизительно 75 смежных нуклеотидов; более предпочтительно - по меньшей мере приблизительно 100 смежных нуклеотидов; даже более предпочтительно - по меньшей мере приблизительно 150 смежных нуклеотидов; и наиболее предпочтительно - по меньшей мере приблизительно 200 смежных нуклеотидов.
В одном из вариантов осуществления первая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, состоящую из нуклеотидов 105-3597 SEQ ID NO: 1. В одном из вариантов осуществления вторая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, состоящую из нуклеотидов 3806-6926 SEQ ID NO: 1.
В одном из вариантов осуществления первая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, состоящую из нуклеотидов 105-3597 SEQ ID NO: 2. В одном из вариантов осуществления вторая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, состоящую из нуклеотидов 3806-6926 SEQ ID NO: 2.
В одном из вариантов осуществления область перекрывания последовательностей содержит по меньшей мере приблизительно 20 смежных нуклеотидов из последовательности нуклеиновой кислоты, состоящей из нуклеотидов 3598-3805 SEQ ID NO: 1. В одном из вариантов осуществления область перекрывания последовательностей содержит по меньшей мере приблизительно 20 смежных нуклеотидов из последовательности нуклеиновой кислоты, состоящей из нуклеотиды 3598-3805 SEQ ID NO: 2.
В одном из вариантов осуществления область перекрывания последовательностей содержит по меньшей мере приблизительно 50 смежных нуклеотидов из последовательности нуклеиновой кислоты, состоящей из нуклеотиды 3598-3805 SEQ ID NO: 1; предпочтительно - по меньшей мере приблизительно 75 смежных нуклеотидов; более предпочтительно - по меньшей мере приблизительно 100 смежных нуклеотидов; даже более предпочтительно - по меньшей мере приблизительно 150 смежных нуклеотидов; и наиболее предпочтительно - по меньшей мере приблизительно 200 смежных нуклеотидов. В одном из вариантов осуществления область перекрывания последовательностей содержит по меньшей мере приблизительно 50 смежных нуклеотидов из последовательности нуклеиновой кислоты, состоящей из нуклеотиды 3598-3805 SEQ ID NO: 2; предпочтительно - по меньшей мере приблизительно 75 смежных нуклеотидов; более предпочтительно - по меньшей мере приблизительно 100 смежных нуклеотидов; даже более предпочтительно - по меньшей мере приблизительно 150 смежных нуклеотидов; и наиболее предпочтительно - по меньшей мере приблизительно 200 смежных нуклеотидов.
В одном из вариантов осуществления первая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, соответствующую нуклеотидам 105-3805 SEQ ID NO: 1; и вторая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, соответствующую нуклеотидам 3598-6926 SEQ ID NO: 1.
В одном из вариантов осуществления первая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, состоящую из нуклеотидов 105-3805 SEQ ID NO: 1; и вторая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, состоящую из нуклеотидов 3598-6926 SEQ ID NO: 1.
В одном из вариантов осуществления первая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, состоящую из нуклеотидов 105-3805 SEQ ID NO: 2; и вторая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, состоящую из нуклеотидов 3598-6926 SEQ ID NO: 2.
Первый вектор AAV может содержать промотор GRK1, функционально связанный с 5'-концевой частью кодирующей последовательности ABCA4 (CDS).
Первая последовательность нуклеиновой кислоты может содержать нетранслируемую область (UTR), локализованную выше 5'-концевой части кодирующей последовательности ABCA4 (CDS).
Вторая последовательность нуклеиновой кислоты может содержать посттранскрипционный чувствительный элемент (PRE); предпочтительно - посттранскрипционный чувствительный элемент вируса гепатита сурков (WPRE).
Вторая последовательность нуклеиновой кислоты может содержать последовательность полиаденилирования бычьего гормона роста (bGH).
В другом аспекте изобретение относится к способу экспрессии белка ABCA4 человека в клетке-мишени, включающему стадии: трансдукции клетки-мишени с использованием первого вектора AAV и второго вектора AAV, как определено выше, таким образом, что функциональный белок ABCA4 экспрессируется в клетке-мишени.
В дополнительном аспекте изобретение относится к вектору AAV, содержащему последовательность нуклеиновой кислоты, содержащую 5'-концевую часть CDS ABCA4, где 5'-концевая часть CDS ABCA4 состоит из последовательности смежных нуклеотидов, соответствующей нуклеотидам 105-3805 SEQ ID NO: 1. В одном из вариантов осуществления этот вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 9. В одном из вариантов осуществления 5'-концевая часть CDS ABCA4 состоит из нуклеотидов 105-3805 SEQ ID NO: 1. В одном из вариантов осуществления 5'-концевая часть CDS ABCA4 состоит из нуклеотидов 105-3805 SEQ ID NO: 2.
В дополнительном аспекте изобретение относится к вектору AAV, содержащему последовательность нуклеиновой кислоты, содержащую 3'-концевую часть CDS ABCA4, где 3'-концевая часть CDS ABCA4 состоит из последовательности смежных нуклеотидов, соответствующей нуклеотидам 3598-6926 SEQ ID NO: 1. В одном из вариантов осуществления этот вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 10. В одном из вариантов осуществления 3'-концевая часть CDS ABCA4 состоит из нуклеотидов 3598-6926 SEQ ID NO: 1. В одном из вариантов осуществления 3'-концевая часть CDS ABCA4 состоит из нуклеотидов 3598-6926 SEQ ID NO: 2.
В другом аспекте изобретение относится к нуклеиновой кислоте, содержащей первую последовательность нуклеиновой кислоты, как определено выше.
В другом аспекте изобретение относится к нуклеиновой кислоте, содержащей вторую последовательность нуклеиновой кислоты, как определено выше.
Изобретение также относится к нуклеиновой кислоте, содержащей последовательность нуклеиновой кислоты SEQ ID NO: 9, и нуклеиновой кислоте, содержащей последовательность нуклеиновой кислоты SEQ ID NO: 10.
В дополнительном аспекте изобретение относится к набору, содержащему векторную систему AAV, как описано выше, или вышележащий вектор AAV и нижележащий вектор AAV, как описано выше.
Изобретение также относится к набору, содержащему нуклеиновую кислоту, содержащую первую последовательность нуклеиновой кислоты, и нуклеиновую кислоту, содержащую вторую последовательность нуклеиновой кислоты, как описано выше, или нуклеиновую кислоту, содержащую последовательность нуклеиновой кислоты SEQ ID NO: 9, и нуклеиновую кислоту, содержащую последовательность нуклеиновой кислоты SEQ ID NO: 10, как описано выше.
В еще одном дополнительном аспекте изобретение относится к фармацевтической композиции, содержащей векторную систему AAV, как описано выше, и фармацевтически приемлемый эксципиент.
В дополнительном аспекте изобретение относится к векторной системе AAV, как описано выше, набору, как описано выше, или фармацевтической композиции, как описано выше, для применения в профилактике или лечении заболевания, отличающегося деградацией клеток сетчатки; предпочтительно, для применения в профилактике или лечении болезни Штаргардта.
В другом аспекте изобретение относится к способу профилактики или лечения заболевания, отличающегося деградацией клеток сетчатки, такого как болезнь Штаргардта, включающему введение нуждающемуся в этом индивидууму эффективного количества векторной системы AAV, как описано выше, набору, как описано выше, или фармацевтической композиции, как описано выше.
В другом аспекте изобретение относится к векторной системе AAV для экспрессии белка ABCA4 человека в клетке-мишени, содержащей первый вектор AAV, содержащий первую последовательность нуклеиновой кислоты, и второй вектор AAV, содержащий вторую последовательность нуклеиновой кислоты; где первая последовательность нуклеиновой кислоты содержит 5'-концевую часть кодирующей последовательности ABCA4 (CDS), и вторая последовательность нуклеиновой кислоты содержит 3'-концевую часть CDS ABCA4, и 5'-концевая часть и 3'-концевая часть вместе включают целую CDS ABCA4; где первая последовательность нуклеиновой кислоты содержит последовательность, имеющую по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8, 99,9 или 100%) идентичности последовательности по отношению к нуклеотидам 105-3597 SEQ ID NO: 1; где вторая последовательность нуклеиновой кислоты содержит последовательность, имеющую по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8, 99,9 или 100%) идентичности последовательности по отношению к нуклеотидам 3806-6926 SEQ ID NO: 1; где каждая из первой последовательности нуклеиновой кислоты и второй последовательности нуклеиновой кислоты содержит область перекрывания последовательностей друг с другом; и где область перекрывания последовательностей содержит по меньшей мере приблизительно 20 смежных нуклеотидов из последовательности нуклеиновой кислоты, имеющей по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8, 99,9 или 100%) идентичности последовательности по отношению к нуклеотидам 3598-3805 SEQ ID NO: 1.
В другом аспекте изобретение относится к векторной системе AAV для экспрессии белка ABCA4 человека в клетке-мишени, содержащей первый вектор AAV, содержащий первую последовательность нуклеиновой кислоты, и второй вектор AAV, содержащий вторую последовательность нуклеиновой кислоты, где первая последовательность нуклеиновой кислоты содержит 5'-концевую часть кодирующей последовательности ABCA4 (CDS), и вторая последовательность нуклеиновой кислоты содержит 3'-концевую часть CDS ABCA4, и 5'-концевая часть и 3'-концевая часть вместе включают целую CDS ABCA4; где 5'-концевая часть CDS ABCA4 состоит из последовательности, имеющей по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8, 99,9 или 100%) идентичности последовательности по отношению к нуклеотидам 105-3805 SEQ ID NO: 1, и где 3'-концевая часть CDS ABCA4 состоит из последовательности, имеющей по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8, 99,9 или 100%) идентичности последовательности по отношению к нуклеотидам 3598-6926 SEQ ID NO: 1.
В другом аспекте изобретение относится к вектору AAV, содержащему последовательность нуклеиновой кислоты, содержащую 5'-концевую часть CDS ABCA4, где 5'-концевая часть CDS ABCA4 состоит из последовательности, имеющей по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8, 99,9 или 100%) идентичности последовательности по отношению к нуклеотидам 105-3805 SEQ ID NO: 1.
В другом аспекте изобретение относится к вектору AAV, содержащему последовательность нуклеиновой кислоты, содержащую 3'-концевую часть CDS ABCA4, где 3'-концевая часть CDS ABCA4 состоит из последовательности, имеющей по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8, 99,9 или 100%) идентичности последовательности по отношению к нуклеотидам 3598-6926 SEQ ID NO: 1.
В другом аспекте изобретение относится к векторной системе AAV для экспрессии белка ABCA4 человека в клетке-мишени, содержащей первый вектор AAV, содержащий первую последовательность нуклеиновой кислоты, и второй вектор AAV, содержащий вторую последовательность нуклеиновой кислоты; где первая последовательность нуклеиновой кислоты содержит 5'-концевую часть кодирующей последовательности ABCA4 (CDS), и вторая последовательность нуклеиновой кислоты содержит 3'-концевую часть CDS ABCA4, и 5'-концевая часть и 3'-концевая часть вместе включают целую CDS ABCA4; где первая последовательность нуклеиновой кислоты содержит последовательность, имеющую по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8, 99,9 или 100%) идентичности последовательности по отношению к нуклеотидам 105-3597 SEQ ID NO: 2; где вторая последовательность нуклеиновой кислоты содержит последовательность, имеющую по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8, 99,9 или 100%) идентичности последовательности по отношению к нуклеотидам 3806-6926 SEQ ID NO: 2; где каждая из первой последовательности нуклеиновой кислоты и второй последовательности нуклеиновой кислоты содержит область перекрывания последовательностей друг с другом; и где область перекрывания последовательностей содержит по меньшей мере приблизительно 20 смежных нуклеотидов из последовательности нуклеиновой кислоты, имеющей по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8, 99,9 или 100%) идентичности последовательности по отношению к нуклеотидам 3598-3805 SEQ ID NO: 2.
В другом аспекте изобретение относится к векторной системе AAV для экспрессии белка ABCA4 человека в клетке-мишени, содержащей первый вектор AAV, содержащий первую последовательность нуклеиновой кислоты, и второй вектор AAV, содержащий вторую последовательность нуклеиновой кислоты, где первая последовательность нуклеиновой кислоты содержит 5'-концевую часть кодирующей последовательности ABCA4 (CDS), и вторая последовательность нуклеиновой кислоты содержит 3'-концевую часть CDS ABCA4, и 5'-концевая часть и 3'-концевая часть вместе включают целую CDS ABCA4; где 5'-концевая часть CDS ABCA4 состоит из последовательности, имеющей по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8, 99,9 или 100%) идентичности последовательности по отношению к нуклеотидам 105-3805 SEQ ID NO: 2, и где 3'-концевая часть CDS ABCA4 состоит из последовательности, имеющей по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8, 99,9 или 100%) идентичности последовательности по отношению к нуклеотидам 3598-6926 SEQ ID NO: 2.
В другом аспекте изобретение относится к вектору AAV, содержащему последовательность нуклеиновой кислоты, содержащую 5'-концевую часть CDS ABCA4, где 5'-концевая часть CDS ABCA4 состоит из последовательности, имеющей по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8, 99,9 или 100%) идентичности последовательности по отношению к нуклеотидам 105-3805 SEQ ID NO: 2.
В другом аспекте изобретение относится к вектору AAV, содержащему последовательность нуклеиновой кислоты, содержащую 3'-концевую часть CDS ABCA4, где 3'-концевая часть CDS ABCA4 состоит из последовательности, имеющей по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8, 99,9 или 100%) идентичности последовательности по отношению к нуклеотидам 3598-6926 SEQ ID NO: 2.
Изобретение также относится к нуклеиновой кислоте, содержащей последовательность нуклеиновой кислоты, имеющую по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8 или 99,9%) идентичности последовательности по отношению к SEQ ID NO: 9, и нуклеиновой кислоте, содержащей последовательность нуклеиновой кислоты, имеющую по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8 или 99,9%) идентичности последовательности по отношению к SEQ ID NO: 10.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фигура 1. Структуры вышележащего и нижележащего трансгенов, комбинируемых с образованием полного трансгена ABCA4.
Фигура 2. Определение белка ABCA4 в сетчатках Abca4-/- через 6 недель после инъекции с использованием варианта двойного вектора C (5'C) и без (C) дополнительной последовательности UTR. Единицы соответствуют кратному повышению относительно образцов KO без инъекции. Планки погрешностей соответствуют SEM. Односторонний ANOVA, ретроспективный анализ с использованием критерия Тьюки, p=**0,009.
Фигура 3. Представление CDS ABCA4, содержащейся в вышележащем и нижележащем трансгенах, составляющих перекрывающиеся варианты A, B, C, D, E, F и X. (a) Определение белка ABCA4 после трансдукции с использованием различных вариантов векторов с зонами перекрывания in vitro и (b) in vivo. Единицы соответствуют кратному повышению относительно необработанных образцов (-=необработанные клетки HEK293T; KO=сетчатки Abca4-/- без инъекции). Планки погрешностей соответствуют SEM. Односторонний ANOVA и ретроспективный анализ с использованием критерия Тьюки показали, что in vitro с помощью вариантов B и C двойного вектора получали значимо больше белка ABCA4, чем во всех других образцах, но не наблюдали значимых различий между B и C. In vivo с помощью варианта C двойного вектора получали значимо больше белка ABCA4, чем в случае всех других вариантов (за исключением B).
Фигура 4. (a) Укороченные варианты белка ABCA4, определимые в клетках HEK293T, обработанных нерекомбинировавшими нижележащими векторами; (b) укороченный и полноразмерный белок ABCA4, определяемый в образцах сетчатки Abca4-/-, в которую инъецировали двойной вектор 5'B или 5'C; (c) в таблице представлена процентная доля полноразмерного ABCA4, присутствующего в общей популяции белков ABCA4, определяемого посредством вестерн-блоттинга сетчатки, подвергнутой инъекции; (d) различия в кратном изменении экспрессии ABCA4 между сетчаткой, подвергнутой инъекции варианта перекрывания C двойного вектора, и сетчаткой, подвергнутой инъекции варианта перекрывания B двойного вектора, на уровне транскрипта и белка. Планки погрешностей соответствуют SEM.
Фигура 5. a) Перекрывающаяся последовательность C с кодонами AUG не в рамке считывания перед кодоном AUG в рамке считывания; b) прогнозируемые вторичные структуры перекрывающихся зон C и B.
Фигура 6. Окрашивание на ABCA4 (зеленый) во внешних сегментах фоторецепторных клеток в сетчатке Abca4-/-, собранной через 6 недель после инъекции. Метки окрашивания HCN1 (красный) во внутренних сегментах. Пример окрашивания на локализацию нативного Abca4 в сетчатке WT также включен вместе с доказательством отсутствия окрашивания в сетчатке Abca4-/- без инъекции.
Фигура 7. Окрашивание на Abca4/ABCA4 (зеленый) и Hcn1 (красный) в глазах дикого типа (WT) и Abca4-/-.
Фигура 8. Окрашивание на Abca4/ABCA4 (зеленый) и родопсин (красный) во внешних сегментах фоторецепторных клеток в глазах дикого типа (WT) и Abca4-/-.
Фигура 9. Апикальное окрашивание RPE на Abca4/ABCA4 (зеленый) и родопсин (красный) в глазах дикого типа (WT) и Abca4-/-.
Фигура 10. Диаграмма примера перекрывающихся векторов.
Фигура 11. На левой стороне диаграммы представлен нормальный ретиноидный цикл. Образование бисретиноидов и A2E, повышенное у мышей с недостаточностью Abca4 и людей, представлено справа. Молекулы, показанные в рамках на правой стороне диаграммы, оценивали у мышей Abca4-/- (пример 6.)
Фигура 12. Уровни бисретиноидов и изоформ A2E в парных глазах 13 мышей Abca4-/-, которым проводили инъекцию имитации или средства. Наблюдали значительное снижение уровней бисретиноидов и A2E между глазами, в которые вводили имитацию и средство (p=0,017, F=5,849). Кроме того, для всех измерений бисретиноидов и A2E наименьшие уровни наблюдали в глазах, в которые вводили двойной вектор (пример 6.)
СПИСОК ПОСЛЕДОВАТЕЛЬНОСТЕЙ
SEQ ID NO: 1: последовательность нуклеиновой кислоты ABCA4 человека. SEQ ID NO: 1 идентична референсной последовательности NCBI NM_000350.2.
SEQ ID NO: 2: вариант последовательности нуклеиновой кислоты ABCA4 человека. SEQ ID NO: 2 идентична SEQ ID NO: 1 за исключением следующих мутаций: нуклеотид 1640 G>T, нуклеотид 5279 G>A, нуклеотид 6173 T>C.
SEQ ID NO: 3: Пример последовательности вышележащего вектора, содержащего ITR, промотор, CDS, ITR.
SEQ ID NO: 4: Пример последовательности нижележащего вектора, содержащего ITR, CDS, посттранскрипционный чувствительный элемент, последовательность полиаденилирования, ITR.
SEQ ID NO: 5: Последовательность промотора GRK1.
SEQ ID NO: 6: Последовательность UTR.
SEQ ID NO: 7: Посттранскрипционный чувствительный элемент вируса гепатита сурков.
SEQ ID NO: 8: Последовательность полиаденилирования бычьего гормона роста.
SEQ ID NO: 9: Пример частичной последовательности вышележащего вектора, содержащего промотор, CDS.
SEQ ID NO: 10: Пример частичной последовательности нижележащего вектора, содержащего CDS, посттранскрипционный чувствительный элемент, последовательность полиаденилирования.
ПОДРОБНОЕ ОПИСАНИЕ
Вирусные векторы получают из вирусов дикого типа, модифицированных с использованием технологий рекомбинантных нуклеиновых кислот для встраивания ненативной последовательности нуклеиновой кислоты (или трансгена) в вирусный геном. Способность вирусов направленно воздействовать и инфицировать конкретные клетки используют для доставки трансгена в клетку-мишень, что приводит к экспрессии гена и продукции кодируемого продукта гена.
Настоящее изобретение относится к векторам, полученным из аденоассоциированного вируса (AAV).
В первом аспекте изобретение относится к векторной системе на основе аденоассоциированного вируса (AAV) для экспрессии белка ABCA4 человека в клетке-мишени, векторной системе AAV, содержащей первый вектор AAV, содержащий первую последовательность нуклеиновой кислоты, и второй вектор AAV, содержащий вторую последовательность нуклеиновой кислоты; где первая последовательность нуклеиновой кислоты содержит 5'-концевую часть кодирующей последовательности ABCA4 (CDS), и вторая последовательность нуклеиновой кислоты содержит 3'-концевую часть CDS ABCA4, и 5'-концевая часть и 3'-концевая часть вместе включают целую CDS ABCA4; где первая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, соответствующую нуклеотидам 105-3597 SEQ ID NO: 1; где вторая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, соответствующую нуклеотидам 3806-6926 SEQ ID NO: 1; где каждая из первой последовательности нуклеиновой кислоты и второй последовательности нуклеиновой кислоты содержит область перекрывания последовательностей друг с другом; и где область перекрывания последовательностей содержит по меньшей мере приблизительно 20 смежных нуклеотидов из последовательности нуклеиновой кислоты, соответствующей нуклеотидам 3598-3805 SEQ ID NO: 1.
Векторы AAV, в целом, хорошо известны в этой области, и специалисту в этой области будут знакомы общие способы, подходящие для их получения, из общих знаний в этой области. Специалисту в этой области будут известны способы, подходящие для встраивания интересующей последовательности нуклеиновой кислоты в геном вектора AAV.
Термин "векторная система AAV" используют для обозначения того, что первый и второй векторы AAV должны действовать совместно взаимодополняющим образом.
Первый и второй векторы AAV векторной системы AAV по изобретению вместе кодируют целый трансген ABCA4. Таким образом, для экспрессии кодируемого трансгена ABCA4 в клетке-мишени необходима трансдукция клетки-мишени с использованием первого (вышележащего) и второго (нижележащего) векторов.
Векторы AAV векторной системы AAV по изобретению, как правило, находятся в форме частиц AAV (также обозначаемых как вирионы). Частица AAV содержит белковую оболочку (капсид), окружающую кор нуклеиновой кислоты, являющейся геномом AAV. Настоящее изобретение также включает последовательности нуклеиновой кислоты, кодирующие геномы вектора AAV векторной системы AAV, представленной в настоящем описании.
SEQ ID NO: 1 является последовательностью нуклеиновой кислоты ABCA4 человека, соответствующей референсной последовательности NCBI NM_000350.2. SEQ ID NO: 1 идентична референсной последовательности NCBI NM_000350.2. Кодирующая последовательность ABCA4 охватывает нуклеотиды 105-6926 SEQ ID NO: 1.
Первый вектор AAV содержит первую последовательность нуклеиновой кислоты, содержащую 5'-концевую часть CDS ABCA4. 5'-концевая часть CDS ABCA4 является частью CDS ABCA4, включающей ее 5'-конец. Т.к. она является лишь частью CDS, 5'-концевая часть CDS ABCA4 не является полноразмерной (т.е. не является целой) CDS ABCA4. Таким образом, первая последовательность нуклеиновой кислоты (и, таким образом, первый вектор AAV) не содержит полноразмерную CDS ABCA4.
Второй вектор AAV содержит вторую последовательность нуклеиновой кислоты, содержащую 3'-концевую часть CDS ABCA4. 3'-концевая часть CDS ABCA4 является частью CDS ABCA4, включающей ее 3'-конец. Т.к. она является лишь частью CDS, 3'-концевая часть CDS ABCA4 не является полноразмерной (т.е. не является целой) CDS ABCA4. Таким образом, вторая последовательность нуклеиновой кислоты (и, таким образом, второй вектор AAV) не содержит полноразмерную CDS ABCA4.
5'-концевая часть и 3'-концевая часть вместе включают целую CDS ABCA4 (с областью перекрывания последовательностей, как описано ниже). Таким образом, полноразмерная CDS ABCA4 содержится в векторной системе AAV по изобретению разделенной между первым и вторым векторами AAV, и она может повторно собираться в клетке-мишени после трансдукции клетки-мишени с использованием первого и второго векторов AAV.
Первая последовательность нуклеиновой кислоты, как описано выше, содержит последовательность смежных нуклеотидов, соответствующую нуклеотидам 105-3597 SEQ ID NO: 1. CDS ABCA4 начинается с нуклеотида 105 SEQ ID NO: 1.
Вторая последовательность нуклеиновой кислоты, как описано выше, содержит последовательность смежных нуклеотидов, соответствующую нуклеотидам 3806-6926 SEQ ID NO: 1.
Для включения целой CDS ABCA4 каждая из первой и второй последовательности нуклеиновой кислоты дополнительно содержит, по меньшей мере, часть CDS ABCA4, соответствующую нуклеотидам 3598-3805 SEQ ID NO: 1, таким образом, что когда первую и вторую последовательности нуклеиновой кислоты выравнивают, включенной оказывается вся CDS ABCA4, соответствующая нуклеотидам 3598-3805 SEQ ID NO: 1. Таким образом, при выравнивании первая и вторая последовательности нуклеиновой кислоты вместе включают целую CDS ABCA4.
Кроме того, первая и вторая последовательности нуклеиновой кислоты содержат область перекрывания последовательностей, что делает возможной восстановление целой CDS ABCA4 как части полноразмерного трансгена внутри клетки-мишени, трансдуцированной с использованием первого и второго векторов AAV по изобретению.
Если первую и вторую последовательности нуклеиновой кислоты выравнивают друг с другом, область на 3'-конце первой последовательности нуклеиновой кислоты перекрывается с соответствующей областью на 5'-конце второй последовательности нуклеиновой кислоты. Таким образом, и первая, и вторая последовательности нуклеиновой кислоты содержат часть CDS ABCA4, образующую область перекрывания последовательностей.
Авторы настоящего изобретения обнаружили, что особенно предпочтительные результаты получают, когда область перекрывания между первой и второй последовательностями нуклеиновой кислоты содержит по меньшей мере приблизительно 20 смежных нуклеотидов из части CDS ABCA4, соответствующей нуклеотидам 3598-3805 SEQ ID NO: 1.
Область перекрывания может распространяться выше и/или ниже указанных 20 смежных нуклеотидов. Таким образом, область перекрывания может составлять более 20 нуклеотидов в длину.
Область перекрывания может содержать нуклеотиды выше положения, соответствующего нуклеотиду 3598 SEQ ID NO: 1. Альтернативно или дополнительно, область перекрывания может содержать нуклеотиды ниже положения, соответствующего нуклеотиду 3805 SEQ ID NO: 1.
Альтернативно, область перекрывания последовательностей нуклеиновой кислоты может содержаться в части CDS ABCA4, соответствующей нуклеотидам 3598-3805 SEQ ID NO: 1.
Таким образом, в одном из вариантов осуществления область перекрывания последовательностей нуклеиновой кислоты составляет от 20 до 550 нуклеотидов в длину; предпочтительно - от 50 до 250 нуклеотиды в длину; предпочтительно - от 175 до 225 нуклеотидов в длину; предпочтительно - от 195 до 215 нуклеотидов в длину.
В одном из вариантов осуществления область перекрывания последовательностей нуклеиновой кислоты содержит по меньшей мере приблизительно 50 смежных нуклеотидов из последовательности нуклеиновой кислоты, соответствующей нуклеотидам 3598-3805 SEQ ID NO: 1; предпочтительно - по меньшей мере приблизительно 75 смежных нуклеотидов; предпочтительно - по меньшей мере приблизительно 100 смежных нуклеотидов; предпочтительно - по меньшей мере приблизительно 150 смежных нуклеотидов; предпочтительно - по меньшей мере приблизительно 200 смежных нуклеотидов; предпочтительно - все 208 смежных нуклеотидов.
В предпочтительном варианте осуществления область перекрывания последовательностей нуклеиновой кислоты начинается с нуклеотида, соответствующего нуклеотиду 3598 SEQ ID NO: 1. Термин "начинается" означает, что область перекрывания последовательностей нуклеиновой кислоты расположена в 5'-3' направлении, начиная с нуклеотида, соответствующего нуклеотиду 3598 SEQ ID NO: 1. Таким образом, в предпочтительном варианте осуществления самый близкий к 5'-концу нуклеотид области перекрывания последовательностей нуклеиновой кислоты соответствует нуклеотиду 3598 SEQ ID NO: 1.
В дополнительном предпочтительном варианте осуществления область перекрывания последовательностей нуклеиновой кислоты между первой последовательностью нуклеиновой кислоты и второй последовательностью нуклеиновой кислоты в векторе соответствует нуклеотидам 3598-3805 SEQ ID NO: 1.
Дополнительным преимуществом настоящего изобретения является то, что конструирование двойных векторов AAV, содержащих область перекрывания последовательностей нуклеиновой кислоты, как описано выше, успешно может снижать уровень трансляции нежелательных укороченных пептидов ABCA4.
Проблема трансляции укороченных пептидов ABCA4 может возникнуть при использовании двойных векторных систем AAV, если трансляция инициируется с транскриптов мРНК, полученных только с нижележащего вектора. В связи с этим, ITR AAV, такие как 5' ITR AAV2, могут иметь промоторную активность; это, а также наличие в нижележащем векторе WPRE bGH последовательностей полиаденилирования (как описано ниже) может приводить к образованию стабильных транскриптов мРНК из нерекомбинировавших нижележащих векторов. CDS ABCA4 дикого типа несет множество кодонов AUG в рамке считывания в своей нижележащей части, которые нельзя заменить другими кодонами без изменения аминокислотной последовательности. Это создает возможность трансляции стабильных транскриптов, что приводит к наличию укороченных пептидов ABCA4.
В предпочтительных вариантах осуществления изобретения, где область перекрывания последовательностей нуклеиновой кислоты начинается с нуклеотида, соответствующего нуклеотиду 3598 SEQ ID NO: 1, начальная последовательность зоны перекрывания включает кодон AUG (инициаторный) не в рамке считывания в хорошем контексте (касающемся потенциальной консенсусной последовательности Козак) перед кодоном AUG в рамке считывания в более слабом контексте для инициации аппарата трансляции для инициации трансляции только нерекомбинировавших нижележащих транскриптов с участка не в рамке считывания. В особенно предпочтительных вариантах осуществления изобретения есть всего четыре кодона AUG не в рамке считывания в различных контекстах перед AUG в рамке считывания. Все из них будут транслироваться до стоп-кодона в пределах 10 аминокислот, таким образом, предотвращая трансляцию нежелательных укороченных пептидов ABCA4.
Предпочтительно, первая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, соответствующую нуклеотидам 105-3805 SEQ ID NO: 1, и вторая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, соответствующую нуклеотидам 3598-6926 SEQ ID NO: 1, включая, таким образом, особенно предпочтительную область перекрывания последовательностей нуклеиновой кислоты, как описано выше.
Таким образом, в предпочтительном варианте осуществления 5'-концевая часть CDS ABCA4 состоит из последовательности смежных нуклеотидов, соответствующей нуклеотидам 105-3805 SEQ ID NO: 1, и 3'-концевая часть CDS ABCA4 состоит из последовательности смежных нуклеотидов, соответствующей нуклеотидам 3598-6926 SEQ ID NO: 1.
В дополнительном предпочтительном варианте осуществления 5'-концевая часть CDS ABCA4 состоит из нуклеотидов 105-3805 SEQ ID NO: 1, и 3'-концевая часть CDS ABCA4 состоит из нуклеотидов 3598-6926 SEQ ID NO: 1.
Таким образом, в предпочтительном варианте осуществления изобретение относится к векторной системе AAV для экспрессии белка ABCA4 человека в клетке-мишени, содержащей первый вектор AAV, содержащий первую последовательность нуклеиновой кислоты, и второй вектор AAV, содержащий вторую последовательность нуклеиновой кислоты, где первая последовательность нуклеиновой кислоты содержит 5'-концевую часть кодирующей последовательности ABCA4 (CDS), и вторая последовательность нуклеиновой кислоты содержит 3'-концевую часть CDS ABCA4, и 5'-концевая часть и 3'-концевая часть вместе включают целую CDS ABCA4; где 5'-концевая часть CDS ABCA4 состоит из последовательности смежных нуклеотидов, соответствующей нуклеотидам 105-3805 SEQ ID NO: 1, и где 3'-концевая часть CDS ABCA4 состоит из последовательности смежных нуклеотидов, соответствующей нуклеотидам 3598-6926 SEQ ID NO: 1.
В дополнительном предпочтительном варианте осуществления изобретение относится к векторной системе AAV для экспрессии белка ABCA4 человека в клетке-мишени, векторной системе AAV, содержащей первый вектор AAV, содержащий первую последовательность нуклеиновой кислоты, и второй вектор AAV, содержащий вторую последовательность нуклеиновой кислоты, где первая последовательность нуклеиновой кислоты содержит 5'-концевую часть кодирующей последовательности ABCA4 (CDS), и вторая последовательность нуклеиновой кислоты содержит 3'-концевую часть CDS ABCA4, и 5'-концевая часть и 3'-концевая часть вместе включают целую CDS ABCA4; где 5'-концевая часть CDS ABCA4 состоит из нуклеотидов 105-3805 SEQ ID NO: 1, и где 3'-концевая часть CDS ABCA4 состоит из нуклеотидов 3598-6926 SEQ ID NO: 1.
В соответствии с термином "состоит из", в вариантах осуществления, где 5'-концевая часть CDS ABCA4 и 3'-концевая часть CDS ABCA4 состоят из конкретных последовательностей смежных нуклеотидов, как описано выше, каждая из первой последовательности нуклеиновой кислоты и второй последовательности нуклеиновой кислоты не содержит какую-либо дополнительную CDS ABCA4.
Как правило, каждый из первого вектора AAV и второго вектора AAV содержит 5'- и 3'-инвертированные концевые повторы (ITR).
Как правило, геном AAV природного серотипа, изолята или клады AAV содержит по меньшей мере одну последовательность инвертированного концевого повтора (ITR). Последовательность ITR действует в цис-положении, предоставляя функциональный участок начала репликации и делая возможной интеграцию и эксцизию вектора из генома клетки. Считают, что ITR AAV способствуют образованию конкатемеров в ядре инфицированной AAV клетки, например, после преобразования одноцепочечного вектора ДНК в двухцепочечную ДНК под действием ДНК-полимераз клетки-хозяина. Образование таких эписомных конкатемеров может защищать конструкцию вектора в течение жизни клетки-хозяина, таким образом, делая возможной длительную экспрессию трансгена in vivo.
Таким образом, в одном из вариантов осуществления ITR являются ITR AAV (т.е. последовательностями ITR, полученными из последовательностей ITR, обнаруживаемых в геноме AAV).
Первый и второй векторы AAV векторной системы AAV по изобретению вместе содержат все компоненты, необходимые для повторной сборки полностью функционального трансгена ABCA4 в клетке-мишени после трансдукции с использованием обоих векторов. Специалисту в этой области будут известны дополнительные генетические элементы, общеупотребительные для обеспечения экспрессии трансгена в клетке, трансдуцированной с использованием вирусного вектора. Их можно обозначать как последовательности контроля экспрессии. Таким образом, векторы AAV вирусной векторной системы AAV по изобретению, как правило, содержат последовательности контроля экспрессии (например, содержат последовательность промотора), функционально связанные с нуклеотидными последовательностями, кодирующими трансген ABCA4.
5'-последовательности контроля экспрессии локализуются в первом ("вышележащем") векторе AAV вирусной векторной системы, в то время как 3'-последовательности контроля экспрессии локализуются во втором ("нижележащем") векторе AAV вирусной векторной системы.
Таким образом, первый вектор AAV, как правило, содержит промотор, функционально связанный с 5'-концевой частью CDS ABCA4. В связи с природой промотора необходимо, чтобы он локализовался в 5'-направлении относительно CDS ABCA4, таким образом, он локализуется в первом векторе AAV.
Можно использовать любой подходящий промотор, выбор которого может осуществлять специалист в этой области. Последовательность промотора может являться конститутивно активной (т.е. функциональной в любых условиях клетки-хозяина) или, альтернативно, она может являться активной только в конкретных условиях клетки-хозяина, таким образом, делая возможной направленную экспрессию трансгена в конкретном типе клеток (например, тканеспецифический промотор). Промотор может проявлять индуцируемую экспрессию в ответ на присутствие другого фактора, например, фактора, присутствующего в клетке-хозяине. В любом случае, если вектор вводят для терапии, предпочтительно, промотор должен быть функциональным в условиях клетки-мишени.
В некоторых вариантах осуществления предпочтительно, чтобы промотор проявлял специфическую экспрессию в клетках сетчатки, чтобы позволить трансгену экспрессироваться только в популяциях клеток сетчатки. Таким образом, экспрессия с промотора может являться специфической в отношении клеток сетчатки, например ограниченной только клетками нейросенсорной части сетчатки и пигментного эпителия сетчатки.
Примером промотора, пригодного для использования в настоящем изобретении, является промотор бета-актина курицы (CBA), необязательно, в комбинации с энхансерным элементом цитомегаловируса (CMV). Другим примером промотора для использования в изобретении является гибридный промотор CBA/CAG, например, промотор, используемый в экспрессирующей кассете rAVE (GeneDetect.com).
Примеры промоторов на основе последовательностей человека, которые будут индуцировать специфическую в отношении сетчатки экспрессию генов, включают родопсинкиназу в случае палочек и колбочек, PR2.1 в случае только колбочек, и RPE65 в случае пигментного эпителия сетчатки.
Авторы настоящего изобретения обнаружили, что особенно предпочтительных уровней экспрессии генов можно достигать с использованием промотора GRK1. Таким образом, в предпочтительном варианте осуществления промотор является промотором родопсинкиназы человека (GRK1).
Последовательность промотора GRK1 по изобретению может составлять 199 нуклеотидов в длину и содержать нуклеотиды -112-+87 гена GRK1. В предпочтительном варианте осуществления промотор содержит последовательность нуклеиновой кислоты SEQ ID NO: 5 или ее вариант, имеющий по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4 или 99,5, 99,6, 99,7, 99,8 или 99,9%) идентичности последовательности.
Первый вектор AAV может содержать нетранслируемую область (UTR), локализованную между промотором и вышележащей последовательностью нуклеиновой кислоты ABCA4 (т.е. 5'-UTR).
Можно использовать любую подходящую последовательность UTR, выбор которой может осуществлять специалист в этой области.
UTR может содержать один или несколько из следующих элементов: фрагмент интрона 1 β-актина (CBA) Gallus gallus, фрагмент интрона 2 β-глобина (RBG) Oryctolagus cuniculus и фрагмент экзона 3 β-глобина Oryctolagus cuniculus.
UTR может содержать консенсусную последовательность Козак. Можно использовать любую подходящую консенсусная последовательность Козак, выбор которой может осуществлять специалист в этой области.
В предпочтительном варианте осуществления UTR содержит последовательность нуклеиновой кислоты, определенную в SEQ ID NO: 6, или ее вариант, имеющий по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8 или 99,9%) идентичности последовательности.
UTR SEQ ID NO: 6 составляет 186 нуклеотиды в длину и включает фрагмент интрона 1 β-актина (CBA) Gallus gallus (с прогнозируемым донорным участком для сплайсинга), фрагмент интрона 2 β-глобина (RBG) Oryctolagus cuniculus (включая спрогнозированную точку ветвления и акцепторный участок для сплайсинга) и фрагмент экзона 3 β-глобина Oryctolagus cuniculus непосредственно перед консенсусной последовательностью Козак.
Авторы настоящего изобретения неожиданно обнаружили, что наличие UTR, как описано выше, в частности, последовательности UTR, определенной в SEQ ID NO: 6, или ее варианта, имеющего по меньшей мере 90% идентичности последовательности, успешно повышает выход трансляции трансгена ABCA4.
Второй ("нижележащий") вектор AAV векторной системы AAV по изобретению может содержать посттранскрипционный чувствительный элемент (также известный как посттранскрипционный регуляторный элемент) или PRE. Можно использовать любой подходящий PRE, выбор которого может осуществлять специалист в этой области. Присутствие подходящего PRE может повышать экспрессию трансгена ABCA4.
В предпочтительном варианте осуществления PRE является PRE вируса гепатита сурков (WPRE). В особенно предпочтительном варианте осуществления WPRE имеет последовательность, определенную в SEQ ID NO: 7, или ее вариант, имеющий по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8 или 99,9%) идентичности последовательности.
Второй вектор AAV может содержать последовательность полиаденилирования, локализованную в 3'-направлении относительно нижележащей последовательности нуклеиновой кислоты ABCA4. Можно использовать любую подходящую последовательность полиаденилирования, выбор которой может осуществлять специалист в этой области.
В предпочтительном варианте осуществления последовательность полиаденилирования является последовательностью полиаденилирования бычьего гормона роста (bGH). В особенно предпочтительном варианте осуществления последовательность полиаденилирования bGH имеет последовательность, определенную в SEQ ID NO: 8, или ее вариант, имеющий по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8 или 99,9%) идентичности последовательности.
В предпочтительном варианте осуществления векторной системы AAV по изобретению первый вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 9, и второй вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 10.
В другом предпочтительном варианте осуществления векторной системы AAV по изобретению первый вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 3, и второй вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 4.
Векторная система AAV по изобретению подходит для экспрессии белка ABCA4 человека в клетке-мишени.
Таким образом, в одном из аспектов изобретение относится к способу экспрессии белка ABCA4 человека в клетке-мишени, включающему стадии: трансдукции клетки-мишени с использованием первого вектора AAV и второго вектора AAV, как описано выше, таким образом, что функциональный белок ABCA4 экспрессируется в клетке-мишени.
Для экспрессии белка ABCA4 человека необходимо трансдуцировать клетку-мишень с использованием первого вектора AAV и второго вектора AAV; однако, порядок не важен. Таким образом, клетку-мишень можно трансдуцировать с использованием первого вектора AAV и второго вектора AAV в любом порядке (первого вектора AAV, а затем второго вектора AAV, или второго вектора AAV, а затем первого вектора AAV) или одновременно.
Способы трансдукции клеток-мишеней с использованием векторов AAV известны в этой области и знакомы специалисту в этой области.
Клетка-мишень, предпочтительно, является клеткой глаза, предпочтительно, клеткой сетчатки (например, нейрональной фоторецепторной клеткой, палочковой клеткой, колбочковой клеткой или клеткой пигментного эпителия сетчатки).
Настоящее изобретение также относится к первому вектору AAV, как определено выше. Настоящее изобретение также относится ко второму вектору AAV, как определено выше.
В другом аспекте изобретение относится к вектору AAV, содержащему последовательность нуклеиновой кислоты, содержащую 5'-концевую часть CDS ABCA4, где 5'-концевая часть CDS ABCA4 состоит из последовательности смежных нуклеотидов, соответствующей нуклеотидам 105-3805 SEQ ID NO: 1. Таким образом, этот вектор AAV не содержит какую-либо дополнительную CDS ABCA4 помимо указанной последовательности смежных нуклеотидов.
Первый вектор AAV может содержать 5'- и 3'-ITR, предпочтительно, ITR AAV; промотор, предпочтительно, промотор GRK1; и/или UTR; указанные элементы расположены относительно векторной системы AAV по изобретению, как описано выше.
В одном из вариантов осуществления первый вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 9.
В одном из вариантов осуществления первый вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 9 или ее вариант, имеющий по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8 или 99,9%) идентичности последовательности.
В одном из вариантов осуществления первый вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 9 при условии, что нуклеотид в положении, соответствующем нуклеотиду 1640 SEQ ID NO: 1, представляет собой G, или ее вариант, имеющий по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8 или 99,9%) идентичности последовательности.
В одном из вариантов осуществления первый вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 3.
В одном из вариантов осуществления первый вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 3 или ее вариант, имеющий по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8 или 99,9%) идентичности последовательности.
В одном из вариантов осуществления первый вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 3 при условии, что нуклеотид в положении, соответствующем нуклеотиду 1640 SEQ ID NO: 1, представляет собой G, или ее вариант, имеющий по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8 или 99,9%) идентичности последовательности.
В другом аспекте изобретение относится к вектору AAV, содержащему последовательность нуклеиновой кислоты, содержащую 3'-концевую часть CDS ABCA4, где 3'-концевая часть CDS ABCA4 состоит из последовательности смежных нуклеотидов, соответствующей нуклеотидам 3598-6926 SEQ ID NO: 1. Таким образом, этот вектор AAV не содержит какую-либо дополнительную CDS ABCA4 помимо указанной последовательности смежных нуклеотидов.
Второй вектор может содержать 5'- и 3'-ITR, предпочтительно, ITR AAV; PRE, предпочтительно, WPRE; и/или последовательность полиаденилирования, предпочтительно, последовательность полиаденилирования bGH; указанные элементы расположены, как описано выше, в отношении векторной системы AAV по изобретению.
В одном из вариантов осуществления второй вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 10.
В одном из вариантов осуществления второй вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 10 или ее вариант, имеющий по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8 или 99,9%) идентичности последовательности.
В одном из вариантов осуществления второй вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 10 при условии, что нуклеотид в положении, соответствующем нуклеотиду 5279 SEQ ID NO: 1, представляет собой G, и нуклеотид в положении, соответствующем нуклеотиду 6173 SEQ ID NO: 1, представляет собой T, или ее вариант, имеющий по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8 или 99,9%) идентичности последовательности.
В одном из вариантов осуществления второй вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 4.
В одном из вариантов осуществления второй вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 4 или ее вариант, имеющий по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8 или 99,9%) идентичности последовательности.
В одном из вариантов осуществления второй вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 4 при условии, что нуклеотид в положении, соответствующем нуклеотиду 5279 SEQ ID NO: 1, представляет собой G, и нуклеотид в положении, соответствующем нуклеотиду 6173 SEQ ID NO: 1, представляет собой T, или ее вариант, имеющий по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8 или 99,9%) идентичности последовательности.
Изобретение также относится к нуклеиновым кислотам, содержащим последовательности нуклеиновой кислоты, описанные выше.
Изобретение также относится к геному вектора AAV, получаемому из вектора AAV, как описано выше.
Изобретение также относится к набору, содержащему первый вектор AAV и второй вектор AAV, как описано выше. Векторы AAV можно предоставлять в наборах в форме частиц AAV.
Изобретение также относится к набору, содержащему нуклеиновую кислоту, содержащую первую последовательность нуклеиновой кислоты, и нуклеиновую кислоту, содержащую вторую последовательность нуклеиновой кислоты, как описано выше.
Изобретение также относится к фармацевтической композиции, содержащей векторную систему AAV, как описано выше, и фармацевтически приемлемый эксципиент.
Векторную систему AAV по изобретению, набор по изобретению, и фармацевтическую композицию по изобретению можно использовать в генной терапии. Например, векторную систему AAV по изобретению, набор по изобретению и фармацевтическую композицию по изобретению можно использовать в профилактике или лечении заболевания.
Для применения по настоящему изобретению для профилактики или лечения заболевания необходимо введение первого вектора AAV и второго вектора AAV в клетку-мишень для обеспечения экспрессии белка ABCA4.
Предпочтительно, заболевание, подлежащее профилактике или лечению, отличается деградацией клеток сетчатки. Примером такого заболевания является болезнь Штаргардта. Таким образом, первый и второй векторы AAV по изобретению можно вводить в глаз пациента, предпочтительно, в ткань сетчатки глаза, таким образом, что функциональный ABCA4 белок экспрессируется для компенсации мутаций, присутствующих при заболевании.
Векторы AAV по изобретению можно составлять в виде фармацевтических композиций или лекарственных средств.
Пример векторной системы AAV по изобретению содержит первый вектор AAV и второй вектор AAV; где первый вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 9; и второй вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 10.
Дополнительный пример векторной системы AAV по изобретению содержит первый вектор AAV и второй вектор AAV; где первый вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 9 или ее вариант, имеющий по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8 или 99,9%) идентичности последовательности; и второй вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 10 или ее вариант, имеющий по меньшей мере 90% (например, по меньшей мере 90, 95, 96, 97, 98, 99, 99,1, 99,2, 99,3, 99,4, 99,5, 99,6, 99,7, 99,8 или 99,9%) идентичности последовательности.
Настоящее изобретение также можно осуществлять, если в качестве референсной последовательности используют SEQ ID NO: 2 вместо SEQ ID NO: 1.
В связи с этим, SEQ ID NO: 2 является идентичной SEQ ID NO: 1 за исключением следующих мутаций: нуклеотид 1640 G>T, нуклеотид 5279 G>A, нуклеотид 6173 T>C. Эти мутации не изменяют кодируемую аминокислотную последовательность, и, таким образом, белок ABCA4, кодируемый SEQ ID NO: 2, идентичен белку ABCA4, кодируемому SEQ ID NO: 1.
Таким образом, в альтернативных вариантах осуществления изобретения указанные выше ссылки на SEQ ID NO: 1 можно заменять ссылками на SEQ ID NO: 2.
Соответствие последовательностей
В рамках изобретения термин "соответствующий" при использовании в отношении нуклеотидов в указанной последовательности нуклеиновой кислоты определяет положения нуклеотидов со ссылкой на конкретную SEQ ID NO. Однако когда делают такую ссылку, следует понимать, что изобретение не ограничено конкретной последовательностью, приведенной в конкретной упомянутой SEQ ID NO, а включает вариант последовательности. Нуклеотиды, соответствующие положениям нуклеотидов в SEQ ID NO: 1, легко можно определять посредством выравнивания последовательностей, например, с использованием программ для выравнивания последовательностей, хорошо известных в этой области. В связи с этим, специалисту в этой области будет понятно, что вырожденная природа генетического кода означает, что в последовательности нуклеиновой кислоты, кодирующей указанный полипептид, могут присутствовать изменения, не изменяющие аминокислотную последовательность кодируемого полипептида. Таким образом, предусматривают идентификацию положений нуклеотидов в других кодирующих последовательностях ABCA4 (т.е. нуклеотидов в положениях, которые специалист в этой области будет считать соответствующими положениям, идентифицированным, например, в SEQ ID NO: 1).
В качестве примера, SEQ ID NO: 2 идентична SEQ ID NO: 1 за исключением трех конкретных мутаций, как описано выше (эти три мутации не изменяют аминокислотную последовательность кодируемого полипептида ABCA4). В этом случае, специалист в этой области будет, таким образом, считать, что указанное положение нуклеотида в SEQ ID NO: 2 соответствует эквивалентному пронумерованному положению нуклеотида в SEQ ID NO: 1.
Векторы AAV
Вирусные векторы по изобретению являются векторами на основе аденоассоциированного вируса (AAV). Вектор AAV по изобретению может находиться в форме зрелой частицы или вириона AAV или, т.е. нуклеиновой кислоты, окруженной белковым капсидом AAV.
Вектор AAV может содержать геном AAV или его производное.
Геном AAV представляет собой полинуклеотидную последовательность, кодирующую функции, необходимые для продукции частицы AAV. Эти функции включают функции, выполняемые в цикле репликации и упаковки AAV в клетке-хозяине, включая инкапсидирование генома AAV в частицу AAV. Природные AAV являются дефектными по репликации, и для них необходимы хелперные функции в транс-положении для осуществления цикла репликации и упаковки. Таким образом, геном AAV вектора по изобретению, как правило, является дефектным по репликации.
Геном AAV может находиться в одноцепочечной форме, как положительной, так и отрицательной, или альтернативно в двухцепочечной форме. Использование двухцепочечной формы позволяет обходить стадию репликации ДНК в клетке-мишени и, таким образом, может повышать экспрессию трансгена.
Геном AAV вектора по изобретению, как правило, находится в одноцепочечной форме.
Геном AAV можно получать из любого природного серотипа, изолята или клады AAV. Таким образом, геном AAV может являться полным геномом природного AAV. Как известно специалисту, AAV, встречающиеся в природе, можно классифицировать в соответствии с различными биологическими системами.
Как правило, AAV обозначают в соответствии с их серотипом. Серотип соответствует варианту подвида AAV, который, вследствие своего профиля экспрессии поверхностных антигенов капсида, имеет различную реактивность, которую можно использовать для различения его и другого варианта подвида. Как правило, вирус, имеющий конкретный серотип AAV, по существу, не реагирует перекрестно с нейтрализующими антителами, специфичными для любого другого серотипа AAV.
Серотипы AAV включают AAV1, AAV2, AAV3, AAV4, AAV5, AAV6, AAV7, AAV8, AAV9, AAV10 и AAV11, а также рекомбинантные серотипы, такие как Rec2 и Rec3, недавно идентифицированные в головном мозге приматов. Любой из этих серотипов AAV можно использовать в изобретении. Таким образом, в одном из вариантов осуществления изобретения вектор AAV по изобретению можно получать из AAV1, AAV2, AAV3, AAV4, AAV5, AAV6, AAV7, AAV8, AAV9, AAV10, AAV11, Rec2 или Rec3 AAV.
Обзоры серотипов AAV можно найти в Choi et al. (2005) Curr. Gene Ther. 5: 299-310 и Wu et al. (2006) Molecular Therapy 14: 316-27. Последовательности геномов AAV или элементов геномов AAV, включая последовательности ITR, гены rep или cap, можно получать из следующих последовательностей с регистрационными номерами из полногеномных последовательностей AAV: аденоассоциированный вирус 1 NC_002077, AF063497; аденоассоциированный вирус 2 NC_001401; аденоассоциированный вирус 3 NC_001729; аденоассоциированный вирус 3B NC_001863; аденоассоциированный вирус 4 NC_001829; аденоассоциированный вирус 5 Y18065, AF085716; аденоассоциированный вирус 6 NC_001862; AAV птиц ATCC VR-865 AY186198, AY629583, NC_004828; AAV птиц, штамм DA-1 NC_006263, AY629583; бычий AAV NC_005889, AY388617.
AAV также можно обозначать в терминах клад или клонов. Это относится к филогенетической взаимосвязи природных AAV и, как правило, к филогенетической группе AAV, которые можно отслеживать до общего предка, и они включают всех его потомков. Кроме того, AAV можно обозначать в терминах конкретного изолята, т.е. генетического изолята конкретного AAV, обнаруживаемого в природе. С помощью термина "генетический изолят" описывают популяцию AAV, подвергнутых ограниченному генетическому смешиванию с другими природными AAV, таким образом, определяя популяцию, узнаваемо отличающуюся на генетическом уровне.
Специалист в этой области может выбирать подходящий серотип, кладу, клон или изолят AAV для использования в изобретении на основе общих знаний. Например, показано, что с помощью капсида AAV5 эффективно трансдуцировали колбочковые фоторецепторы приматов, о чем свидетельствует успешная коррекция наследственного дефекта цветного зрения (Mancuso et al. (2009) Nature 461: 784-7).
Серотип AAV определяет тканеспецифичность инфекции (или тропизм) вируса AAV. Таким образом, предпочтительными серотипами AAV для использования в AAV, вводимых пациентам по изобретению, являются серотипы, имеющие природный тропизм к клеткам-мишеням в глазу или высокую эффективность их инфицирования. В одном из вариантов осуществления серотипами AAV для использования в изобретении являются серотипы, инфицирующие клетки нейросенсорной части сетчатки, пигментный эпителий сетчатки и/или хориоидеи.
Как правило, геном AAV природного серотипа, изолята или клады AAV содержит по меньшей мере одну последовательность инвертированного концевого повтора (ITR). Последовательность ITR действует в цис-положении, предоставляя функциональный участок начала репликации и делая возможной интеграцию и эксцизию вектора из генома клетки. Геном AAV, как правило, также содержит упаковывающие гены, такие как гены rep и/или cap, кодирующие упаковывающие функции частицы AAV. Ген rep кодирует один или несколько белков Rep78, Rep68, Rep52 и Rep40 или их вариантов. Ген cap кодирует один или несколько белков капсида, таких как VP1, VP2 и VP3 или их варианты. Эти белки составляют капсид частицы AAV. Варианты капсида описаны ниже.
Промотор будет функционально связан с каждым из упаковывающих генов. Конкретные примеры таких промоторов включают промоторы p5, p19 и p40 (Laughlin et al. (1979) Proc. Natl. Acad. Sci. USA 76: 5567-5571). Например, промоторы p5 и p19, как правило, используют для экспрессии гена rep, в то время как промотор p40, как правило, используют для экспрессии гена cap.
Таким образом, геном AAV, используемый в векторе по изобретению, может представлять собой полный геном природного AAV. Например, вектор, содержащий полный геном AAV, можно использовать для получения вектора AAV in vitro. Однако, хотя такой вектор, в принципе, можно вводить пациентам, это редко будет осуществлено на практике. Предпочтительно, геном AAV будут дериватизировать в целях введения пациентам. Такая дериватизация является стандартом в этой области, и настоящее изобретение относится к применению любого известного производного генома AAV и производным, которые можно получать способами, известными в этой области. Дериватизация генома AAV и капсида AAV описана в Coura and Nardi (2007) Virology Journal 4: 99, и Choi et al. и Wu et al., упомянутых выше.
Производные генома AAV включают любые укороченные или модифицированные формы генома AAV, делающие возможной экспрессию трансгена с вектора по изобретению in vivo. Как правило, можно значительно укорачивать геном AAV для включения минимальной вирусной последовательности, сохраняющей указанную выше функцию. В целях безопасности предпочтительно снижать риск рекомбинации вектора с вирусом дикого типа, а также избегать запуска клеточного иммунного ответа на присутствие вирусных белков в клетке-мишени.
Как правило, производное генома AAV будет включать по меньшей мере одну последовательность инвертированного концевого повтора (ITR), предпочтительно, несколько ITR, например, два или более ITR. Один или несколько ITR можно получать из геномов AAV, имеющих разные серотипы, или он может являться химерным или мутантным ITR. Предпочтительным мутантом ITR является ITR, имеющий делецию trs (участка концевого разрешения). Эта делеция делает возможной непрерывную репликацию генома с образованием одноцепочечного генома, содержащего кодирующую и комплементарную последовательности, т.е. самокомплементарный геном AAV. Это позволяет обходить репликацию ДНК в клетке-мишени и, таким образом, повышать экспрессию трансгена.
Включение одного или нескольких ITR является предпочтительным для облегчения образования конкатемеров вектора по изобретению в ядре клетки-хозяина, например, после преобразования одноцепочечного вектора ДНК в двухцепочечную ДНК под действием ДНК-полимераз клетки-хозяина. Образование таких эписомных конкатемеров защищает конструкцию вектора в течение жизни клетки-хозяина, таким образом, делая возможной длительную экспрессию трансгена in vivo.
В предпочтительных вариантах осуществления элементы ITR будут единственными последовательностями, сохраненными в производном из нативного генома AAV. Таким образом, производное, предпочтительно, не будет включать гены rep и/или cap нативного генома и любые другие последовательности нативного генома. Это является предпочтительным по причинам, описанным выше, а также для снижения вероятности интеграции вектора в геном клетки-хозяина. Кроме того, снижение размера генома AAV делает возможной повышенную гибкость при встраивании других элементов последовательности (таких как регуляторные элементы) в вектор в дополнение к трансгену.
Таким образом, в производном по изобретению могут быть удалены следующие части: одна последовательность инвертированного концевого повтора (ITR), гены репликации (rep) и капсида (cap). Однако в некоторых вариантах осуществления производные могут дополнительно включать один или несколько генов rep и/или cap или другие вирусные последовательности генома AAV. Природный AAV с высокой частотой интегрируется в конкретный участок на хромосоме 19 человека и демонстрирует незначительную частоту случайно интеграции, таким образом, в терапевтических условиях сохранение способности к интеграции вектора может быть допустимым.
Если производное содержит белки капсида, т.е. VP1, VP2 и/или VP3, производное может являться химерным, перетасованным или капсид-модифицированным производным одного или нескольких природных AAV. В частности, настоящее изобретение относится к получению последовательностей белков капсида различных серотипов, клад, клонов или изолятов AAV в одном векторе (т.е. псевдотипированном векторе).
Химерные, перетасованные или капсид-модифицированные производные, как правило, будут выбирать так, чтобы обеспечивать одну или несколько желаемых функций вирусного вектора. Таким образом, эти производные могут демонстрировать повышенную эффективность доставки генов, сниженную иммуногенность (гуморальную или клеточную), измененный диапазон тропизма и/или улучшенный таргетинг конкретного типа клеток по сравнению с вектором AAV, содержащим природный геном AAV, такой как геном AAV2. Повышенная эффективность доставки генов может реализоваться посредством улучшенного связывания рецептора или корецептора на поверхности клетки, улучшенной интернализации, улучшенного транспорта внутри клетки и в ядро, улучшенного "раздевания" вирусной частицы и улучшенного преобразования одноцепочечного генома в двухцепочечную форму. Повышенная эффективность также может относиться к измененному диапазону тропизма или таргетингу конкретной популяции клеток, таким образом, что доза вектора не рассредотачивается при введении в ткани, для которых она не предназначена.
Химерные белки капсида включают белки, полученные посредством рекомбинации между двумя или более кодирующими последовательностями капсида природных серотипов AAV. Это можно осуществлять например с помощью подхода спасения маркера, при котором неинфекционные последовательности капсида одного серотипа котрансфицируют с последовательностями капсида другого серотипа, и направленную селекцию используют для селекции последовательностей капсида, обладающих желаемыми свойствами. Последовательности капсида других серотипов можно изменять посредством гомологичной рекомбинации в клетке для получения новых химерных белков капсида.
Химерные белки капсида также включают белки, полученные посредством конструирования последовательностей белков капсида для переноса конкретных доменов белков капсида, поверхностных петель или конкретных аминокислотных остатков между двумя или более белками капсида, например, между двумя или более белками капсида разных серотипов.
Перетасованные или химерные белки капсида также можно получать посредством перестановки ДНК или подверженной ошибкам ПЦР. Гибридные гены капсида AAV можно получать посредством случайной фрагментации последовательностей родственных генов AAV, например, генов, кодирующих белки капсида множества различных серотипов, а затем повторной сборки фрагментов в самопраймирующейся полимеразной реакции, которая также может вызывать кроссинговеры в областях гомологии последовательностей. Библиотеку гибридных генов AAV, полученных, таким образом, посредством перетасовки генов капсида нескольких серотипов, можно подвергать скринингу для идентификации вирусных клонов, имеющих желаемые функции. Аналогично, подверженную ошибкам ПЦР можно использовать для случайного мутагенеза генов капсида AAV для получения разнообразной библиотеки вариантов, которые затем можно подвергать селекции на желаемое свойство.
Последовательности генов капсида также можно генетически модифицировать для встраивания конкретных делеций, замен или инсерций относительно нативной последовательности дикого типа. В частности, гены капсида можно модифицировать посредством инсерции последовательности неродственного белка или пептида в открытой рамке считывания кодирующей последовательности капсида или на N- и/или C-конце кодирующей последовательности капсида.
Неродственный белок или пептид, предпочтительно, может являться белком или пептидом, действующим в качестве лиганда для конкретного типа клеток, таким образом, придавая свойство улучшенного связывания с клеткой-мишенью или улучшая специфичность таргетинга вектора в отношении конкретной популяции клеток. Неродственный белок также может являться белком, способствующим очистке вирусной частицы как части способа получения, т.е. эпитопной или аффинной меткой. Участок инсерции, как правило, будут выбирать таким образом, чтобы не мешать другим функциям вирусной частицы, например, интернализации, транспорту вирусной частицы. Специалист в этой области может идентифицировать подходящие участки для инсерции, используя общие знания. Конкретные участки описывают в Choi et al., упомянутой выше.
Изобретение дополнительно включает предоставление последовательностей генома AAV в ином порядке и конфигурации, чем в нативном геноме AAV. Изобретение также относится к замене одной или нескольких последовательностей или генов AAV последовательностями из другого вируса или химерными генами, состоящими из последовательностей из нескольких вирусов. Такие химерные гены могут состоять из последовательностей из двух или более родственных вирусных белков других видов вирусов.
Векторы AAV по изобретению включают транскапсидированные формы, где геном AAV или производное, содержащие ITR одного серотипа, упаковывают в капсид другого серотипа. Векторы AAV по изобретению также включают мозаичные формы, где смесь немодифицированных белков капсида двух или более разных серотипов составляет вирусный капсид. Вектор AAV также может включать химически модифицированные формы, несущие лиганды, адсорбированные на поверхности капсида. Например, такие лиганды могут включать антитела для таргетинга конкретного рецептора поверхности клетки.
Таким образом, например, векторы AAV по изобретению включают векторы с геномом AAV2 и белками капсида AAV2 (AAV2/2), векторы с геномом AAV2 и белками капсида AAV5 (AAV2/5) и векторы с геномом AAV2 и белками капсида AAV8 (AAV2/8).
Вектор AAV по изобретению может содержать мутантный белок капсида AAV. В одном из вариантов осуществления вектор AAV по изобретению содержит мутантный белок капсида AAV8. Предпочтительно, мутантный белок капсида AAV8 является белком капсида AAV8 Y733F.
Способы введения
Вирусные векторы по изобретению можно вводить в глаз индивидуума посредством субретинальной, прямой ретинальной или интравитреальной инъекции.
Специалисту в этой области будут известны субретинальные, прямые ретинальные или интравитреальные инъекции, и он будет способен их осуществлять.
Субретинальная инъекция
Субретинальные инъекции являются инъекциями в субретинальное пространство, т.е. под нейросенсорную часть сетчатки. При субретинальной инъекции инъецируемый материал направляют в слои фоторецепторных клеток и клеток пигментного эпителия сетчатки (RPE) и создают пространство между ними.
Если инъекцию осуществляют посредством небольшой ретинотомии, может происходить отслоение сетчатки. Отслоившийся индуцированный слой сетчатки, образованный инъецируемым материалом, обозначают как "пузырь".
Отверстие, образующееся при субретинальной инъекции, должно быть достаточно небольшим, чтобы после введения инъецируемый раствор не затекал обратно в полость стекловидного тела в большом количестве. Такой обратный ток может стать проблемой при инъекции лекарственного средства, т.к. эффекты лекарственного средства будут направлены вне целевой зоны. Предпочтительно, при инъекции создают самовосстанавливающееся отверстие в нейросенсорной части сетчатки, т.е. после удаления инъекционной иглы отверстие, проделанное иглой, затягивается таким образом, что очень мало инъецируемого материала вытекает через отверстие или он, по существу, не вытекает.
Для облегчения этого действия коммерчески доступный специальные иглы для субретинальных инъекций (например, игла для субретинальных инъекций DORC 41G Teflon, Dutch Ophthalmic Research Center International BV, Zuidland, The Netherlands). Они являются иглами, созданными для осуществления субретинальных инъекций.
Если при инъекции не происходит повреждение сетчатки, и при условии, что используют достаточно небольшую иглу, по существу, весь инъецируемый материал остается между отслоившейся нейросенсорной частью сетчатки и RPE в месте локализованного отслоения сетчатки (т.е. не вытекает в полость стекловидного тела). Фактически, типичное существование пузыря в течение короткого периода времени свидетельствует о том, что, как правило, происходит небольшое истечение инъецируемого материала в стекловидное тело. Пузырь может рассасываться в течение более длительного периода времени с абсорбцией инъецируемого материала.
Перед операцией можно осуществлять визуализацию глаза, в частности, сетчатки, например, с использованием оптической когерентной томографии.
Двухстадийная субретинальная инъекция
Векторы AAV по изобретению можно вводить с повышенной точностью и безопасностью с использованием двухстадийного способа, при котором локализованного отслоения сетчатки достигают посредством субретинальной инъекции первого раствора. Первый раствор не содержит вектор. Затем вторую субретинальную инъекцию используют для доставки лекарственного средства, содержащего вектор, в субретинальную жидкость пузыря, полученного посредством первой субретинальной инъекции. Т.к. инъекцию, с помощью которой доставляют лекарственное средство, не используют для отслаивания сетчатки, на этой второй стадии можно инъецировать конкретный объем раствора.
Вектор AAV по изобретению можно доставлять посредством:
(a) введения раствора индивидууму посредством субретинальной инъекции в количестве, эффективном для, по меньшей мере, частичного отслаивания сетчатки для получения субретинального пузыря, где раствор не содержит вектор; и
(b) введения композиции лекарственного средства посредством субретинальной инъекции в пузырь, полученный на стадии (a), где лекарственное средство содержит вектор.
Объем раствора, инъецируемого на стадии (a) для, по меньшей мере, частичного отслаивания сетчатки, может составлять, например, приблизительно 10-1000 мкл, например, приблизительно 50-1000, 100-1000, 250-1000, 500-1000, 10-500, 50-500, 100-500, 250-500 мкл. Объем может составлять, например, 10 приблизительно 50, 100, 200, 300, 400, 500, 600, 700, 800, 900 или 1000 мкл.
Объем композиции лекарственного средства, инъецируемый на стадии (b), может составлять, например, приблизительно 10-500 мкл, например, приблизительно 50-500, 100-500, 200-500, 300-500, 400-500, 50-250, 100-250, 200-250 или 50-150 мкл. Объем может составлять, например, 10 приблизительно 50, 100, 150, 200, 250, 300, 350, 400, 450 или 500 мкл. Предпочтительно, объем композиции лекарственного средства, инъецируемый на стадии (b), составляет 100 мкл. Более крупные объемы могут повышать риск растяжения сетчатки, в то время как меньшие объемы может быть трудно увидеть.
Раствор, несодержащий лекарственное средство (т.е. "первый раствор" на стадии (a)) можно составлять аналогично раствору, несодержащему лекарственное средство, как описано ниже. Предпочтительный раствор, несодержащий лекарственное средство, является сбалансированным физиологическим раствором (BSS) или схожим буферным раствором, совпадающим по pH и осмоляльности с субретинальным пространством.
Визуализация сетчатки при хирургическом вмешательстве
В конкретных условиях, например, при дегенерации сетчатки терминальной стадии, определение сетчатки затруднено, т.к. она является тонкой, прозрачной и ее трудно увидеть на фоне разрушенного и сильно пигментированного эпителия, на котором она находится. Использование синего витального красителя (например, Brilliant Peel®, Geuder; MembraneBlue-Dual®, Dorc) может облегчать идентификацию отверстия в сетчатке, сделанного для отслаивания сетчатки (т.е. на стадии (a) в двухстадийном способе субретинальной инъекции по изобретению) таким образом, что лекарственное средство можно вводить через то же отверстие без риска его вытекания обратно в полость стекловидного тела.
Использование синего витального красителя также позволяет идентифицировать любые области сетчатки, в которых есть утолщенная внутренняя пограничная мембрана или эпиретинальная мембрана, т.к. инъекция через любую из этих структур будет препятствовать хорошему доступу в субретинальное пространство. Кроме того, сокращение любой из этих структур в промежуточный послеоперационный период может приводить к растяжению отверстия в сетчатке, что может приводить к вытеканию лекарственного средства обратно в полость стекловидного тела.
Фармацевтические композиции и инъецируемые растворы
Векторы AAV и векторную систему AAV по изобретению можно составлять в фармацевтических композициях. Эти композиции могут содержать, в дополнение к лекарственному средству, фармацевтически приемлемый носитель, дилюент, эксципиент, буфер, стабилизатор или другие материалы, хорошо известные в этой области. Такие материалы должны быть нетоксичными и не должны нарушать эффективность активного ингредиента. Конкретную природу носителя или другого материала может определять специалист в этой области в соответствии с путем введения, например, субретинальной, прямой ретинальной или интравитреальной инъекции.
Фармацевтическая композиция, как правило, находится в жидкой форме. Жидкие фармацевтические композиции, как правило, включают жидкий носитель, такой как вода, нефтепродукт, животные или растительные масла, минеральное масло или синтетическое масло. Можно включать физиологический раствор, хлорид магния, декстрозу или раствор другого сахарида, или гликоли, такие как этиленгликоль, пропиленгликоль или полиэтиленгликоль. В некоторых случаях можно использовать поверхностно-активное вещество, такое как 0,001% плюрониловая кислота (PF68).
В случае инъекции в очаг повреждения, активный ингредиент может находиться в форме водного раствора, не являющегося пирогенным, и имеет подходящий pH, изотоничность и стабильность. Специалист в этой области может получать подходящие растворы с использованием, например, изотонических наполнителей, таких как хлорид натрия для инъекций, раствор Рингера для инъекций или лактат Рингера для инъекций. При необходимости, можно включать консерванты, стабилизаторы, буферы, антиоксиданты и/или другие добавки.
В случае отсроченного высвобождения, лекарственное средство можно включать в фармацевтическую композицию, составленную для замедленного высвобождения, такую как микрокапсулы, полученные из биосовместимых полимеров, или липосомные системы носителей, известными в этой области способами.
Способ лечения
Следует понимать, что все ссылки на лечение в настоящем описании включают излечивающее, паллиативное и профилактическое лечение; кроме того, в контексте изобретения ссылки на профилактику, как правило, связаны с профилактическим лечением. Лечение также может включать прекращение прогрессирования тяжести заболевания.
Лечение млекопитающих, особенно людей, является предпочтительным. Однако в объем изобретения входит лечение и человека, и животных.
Варианты, производные, аналоги, гомологи и фрагменты
В дополнение к конкретным белкам и нуклеотидам, упомянутым в настоящем описании, изобретение также относится к применению их вариантов, производных, аналогов, гомологов и фрагментов.
В контексте изобретения вариант любой указанной последовательности является последовательностью, в которой конкретную последовательность остатков (остатков аминокислот или нуклеиновых кислот) модифицируют таким образом, что рассматриваемый полипептид или полинуклеотид, по существу, сохраняет свою функцию. Вариант последовательности можно получать посредством добавления, делеции, замены, модификации и/или изменения по меньшей мере одного остатка, присутствующего в природном белке.
В рамках изобретения термин "производное" в отношении белков или полипептидов по изобретению включает любую замену, изменение, модификацию, делецию и/или добавление одного (или нескольких) аминокислотных остатков в последовательности при условии, что полученный белок или полипептид, по существу, сохраняет по меньшей мере одну из своих эндогенных функций.
В рамках изобретения термин "аналог" в отношении полипептидов или полинуклеотидов включает любой миметик, т.е. химическое соединение, обладающее по меньшей мере одной из эндогенных функций полипептидов или полинуклеотидов, которые оно имитирует.
Как правило, можно осуществлять замены аминокислот, например, от 1, 2 или 3 до 10 или 20 замен при условии, что модифицированная последовательность, по существу, сохраняет необходимую активность или способность. Замены аминокислот могут включать использование неприродных аналогов.
Белки, используемые в изобретении, также могут иметь делеции, инсерции или замены аминокислотных остатков, приводящие к "молчащим" изменениям и функционально эквивалентному белку. Преднамеренные замены аминокислот можно осуществлять с учетом сходства полярности, заряда, растворимости, гидрофобности, гидрофильности и/или амфипатической природы остатков при условии, что эндогенная функция сохраняется. Например, отрицательно заряженные аминокислоты включают аспарагиновую кислоту и глутаминовую кислоту; положительно заряженные аминокислоты включают лизин и аргинин; и аминокислоты с незаряженными полярными концевыми группами, имеющие схожие значения гидрофильности, включают аспарагин, глутамин, серин, треонин и тирозин.
Можно осуществлять консервативные замены, например, в соответствии с таблицей, представленной ниже. Аминокислоты в одном блоке во второй колонке и, предпочтительно, в одной строке в третьей колонке можно заменять друг другом:
В рамках изобретения термин "гомолог" означает вещество, имеющее конкретную гомологию с аминокислотной последовательностью дикого типа и нуклеотидной последовательностью дикого типа. Термин "гомология" можно приравнять к термину "идентичность".
Гомологичная последовательность может включать аминокислотную последовательность, которая может являться по меньшей мере на 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85% или 90% идентичной, предпочтительно - по меньшей мере на 95% или 97% или 99% идентичной рассматриваемой последовательности. Как правило, гомологи будут содержать те же активные центры и т.д., что и рассматриваемая аминокислотная последовательность. Хотя гомологию также можно рассматривать в терминах сходства (т.е. аминокислотные остатки, имеющие схожие химические свойства/функции), в контексте изобретения предпочтительно выражать гомологию в терминах идентичности последовательности.
Гомологичная последовательность может включать нуклеотидную последовательность, которая может являться по меньшей мере на 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85% или 90% идентичной, предпочтительно - по меньшей мере на 95% или 97% или 99% идентичной рассматриваемой последовательности. Хотя гомологию также можно рассматривать в терминах сходства, в контексте изобретения предпочтительно выражать гомологию в терминах идентичности последовательности.
Предпочтительно, ссылка на последовательность, имеющую процент идентичности по отношению к любой из SEQ ID NO, приведенной в настоящем описании, относится к последовательности, имеющей указанный процент идентичности по всей длине SEQ ID NO, на которую ссылаются.
Сравнения гомологии можно осуществлять визуально или, чаще, с помощью доступных программ для сравнения последовательностей. С помощью этих коммерчески доступных компьютерных программ можно вычислять процент гомологии или идентичности между двумя или более последовательностями.
Процент гомологии можно вычислять для смежных последовательностей, т.е. одну последовательность выравнивают относительно другой последовательности и каждую аминокислоту в одной последовательности напрямую сравнивают с соответствующей аминокислотой в другой последовательности, один остаток за один раз. Это называют выравниванием "без пропусков". Как правило, такое выравнивание без пропусков осуществляют только в отношении относительно небольшого количества остатков.
Хотя этот способ является очень простым и последовательным, с помощью него нельзя учитывать, например, в ином случае идентичную пару последовательностей, одна инсерция или делеция в нуклеотидной последовательности может приводить к тому, что последующие кодоны будут выбиваться из выравнивания, таким образом, потенциально приводя к значительному снижению процента гомологии при осуществлении глобального выравнивания. Таким образом, большинство способов сравнения последовательностей созданы для осуществления оптимального выравнивания, при котором учитывают возможные инсерции и делеции без ненадлежащего штрафа в отношении общих баллов гомологии. Этого достигают посредством включения "пропусков" при выравнивании последовательностей, чтобы попытаться максимизировать локальную гомологию.
Однако, с помощью этих более сложных способов "штраф за пропуск" приписывают каждому пропуску, возникающему при выравнивании, таким образом, что для того же количества идентичных аминокислот при выравнивании последовательностей с наименьшими возможными пропусками, отражающими более высокое родство между двумя сравниваемыми последовательностями, будут достигать более высоких баллов, чем при большом количестве пропусков. Как правило, используют "аффинные штрафы за пропуски", приводящие к вычитанию большого количества баллов за существование пропуска и меньшего количества за каждый последующий остаток в пропуске. Это является наиболее общеупотребительной системой балльной оценки пропусков. Высокие штрафы за пропуски, разумеется, будут приводить к оптимизированному выравниванию с меньшим количеством пропусков. В большинстве программ для выравнивания допускают модификацию штрафов за пропуски. Однако при использовании такого программного обеспечения для сравнения последовательностей предпочтительно использовать значения по умолчанию. Например, при использовании пакета программ GCG Wisconsin Bestfit штраф за пропуск по умолчанию для аминокислотных последовательностей составляет -12 для пропуска и -4 для каждого удлинения.
Таким образом, для вычисления максимального процента гомологии сначала необходимо осуществление оптимального выравнивания с учетом штрафов за пропуски. Подходящей компьютерной программой для осуществления такого выравнивания является пакет программ GCG Wisconsin Bestfit (University of Wisconsin, U.S.A.; Devereux et al. (1984) Nucleic Acids Res. 12: 387). Неограничивающие примеры другого программного обеспечения, с помощью которого можно осуществлять сравнение последовательностей, включают пакет BLAST (см. Ausubel et al. (1999) там же - Ch. 18), FASTA (Atschul et al. (1990) J. Mol. Biol. 403-410) и пакет инструментов для сравнения GENEWORKS. BLAST и FASTA доступны для поиска офлайн и онлайн (см. Ausubel et al. (1999) там же, стр. с 7-58 по 7-60). Однако в некоторых случаях предпочтительно использовать программу GCG Bestfit. Для сравнения белковых и нуклеотидных последовательностей также доступен другой инструмент под названием BLAST 2 Sequences (см. FEMS Microbiol. Lett. (1999) 174: 247-50; FEMS Microbiol. Lett. (1999) 177: 187-8).
Хотя конечный процент гомологии можно измерять в терминах идентичности, само выравнивание, как правило, не основано на сравнении пар по принципу "все или ничего". Вместо этого, как правило, используют масштабированную матрицу для балльной оценки сходства, с помощью которой приписывают баллы каждому попарному сравнению с учетом химического сходства или эволюционного расстояния. Примером такой общеупотребительной матрицы является матрица BLOSUM62 - матрица по умолчанию в пакете программ BLAST. В программах GCG Wisconsin, как правило, используют общедоступные значения по умолчанию или специальную таблицу сравнения символов, если ее поставляют (см. руководство пользователя). В некоторых случаях, предпочтительно использовать общедоступные значения по умолчанию для пакета GCG или, в случае другого программного обеспечения, матрицу по умолчанию, такую как BLOSUM62.
После достижения оптимального выравнивания с помощью программного обеспечения можно вычислять процент гомологии, предпочтительно, процент идентичности последовательности. Как правило, это осуществляют с помощью программного обеспечения как часть сравнения последовательностей и получают числовой результат.
"Фрагменты" также являются вариантами, и термин, как правило, относится к выбранной области полипептида или полинуклеотида, представляющего интерес функционально или, например, в анализе. Таким образом, термин "фрагмент" относится к аминокислотной последовательности или последовательности нуклеиновой кислоты, являющейся частью полноразмерного полипептида или полинуклеотида.
Такие варианты можно получать стандартными способами рекомбинантной ДНК, такими как сайт-специфический мутагенез. Если необходимо сделать инсерции, можно получать синтетическую ДНК, кодирующую инсерцию вместе с 5'- и 3'-фланкирующими областями, соответствующими природной последовательности с любой стороны от участка инсерции. Фланкирующие области будут содержать подходящие участки рестрикции, соответствующие участкам в природной последовательности таким образом, что последовательность можно расщеплять с использованием подходящих ферментов и можно лигировать синтетическую ДНК в участок расщепления. Затем ДНК экспрессируют по изобретению для получения кодируемого белка. Эти способы представляют собой исключительно иллюстрации многочисленных стандартных способов, известных в этой области для манипуляции с последовательностями ДНК, и также можно использовать другие известные способы.
Оптимизация кодонов
Настоящее изобретение относится к кодон-оптимизированным вариантам последовательностей нуклеиновой кислоты, представленных в настоящем описании.
При оптимизации кодонов используют преимущество избыточности генетического кода, чтобы изменять нуклеотидную последовательность с сохранением той же аминокислотной последовательности кодируемого белка.
Как правило, оптимизацию кодонов осуществляют для облегчения повышения или снижения экспрессии кодируемого белка. Это осуществляют посредством адаптации использования кодонов в нуклеотидной последовательности к конкретному типу клеток, таким образом, используя преимущество клеточного индекса случайности использования синонимичных кодонов, соответствующего случайности относительного избытка конкретных тРНК в типе клеток. Изменяя кодоны в нуклеотидной последовательности таким образом, что их адаптируют для соответствия относительному избытку соответствующих тРНК, можно повышать экспрессию. И наоборот, можно снижать экспрессию, выбирая кодоны, для которых, как известно, соответствующие тРНК редки в конкретном типе клеток.
Способы оптимизации кодонов в последовательностях нуклеиновой кислоты известны в этой области и будут знакомы специалисту в этой области.
ПОСЛЕДОВАТЕЛЬНОСТИ
SEQ ID NO: 1
AGGACACAGCGTCCGGAGCCAGAGGCGCTCTTAACGGCGTTTATGTCCTTTGCTGTCTGAGGGGCCTCAGCTCTGACCAATCTGGTCTTCGTGTGGTCATTAGCATGGGCTTCGTGAGACAGATACAGCTTTTGCTCTGGAAGAACTGGACCCTGCGGAAAAGGCAAAAGATTCGCTTTGTGGTGGAACTCGTGTGGCCTTTATCTTTATTTCTGGTCTTGATCTGGTTAAGGAATGCCAACCCGCTCTACAGCCATCATGAATGCCATTTCCCCAACAAGGCGATGCCCTCAGCAGGAATGCTGCCGTGGCTCCAGGGGATCTTCTGCAATGTGAACAATCCCTGTTTTCAAAGCCCCACCCCAGGAGAATCTCCTGGAATTGTGTCAAACTATAACAACTCCATCTTGGCAAGGGTATATCGAGATTTTCAAGAACTCCTCATGAATGCACCAGAGAGCCAGCACCTTGGCCGTATTTGGACAGAGCTACACATCTTGTCCCAATTCATGGACACCCTCCGGACTCACCCGGAGAGAATTGCAGGAAGAGGAATACGAATAAGGGATATCTTGAAAGATGAAGAAACACTGACACTATTTCTCATTAAAAACATCGGCCTGTCTGACTCAGTGGTCTACCTTCTGATCAACTCTCAAGTCCGTCCAGAGCAGTTCGCTCATGGAGTCCCGGACCTGGCGCTGAAGGACATCGCCTGCAGCGAGGCCCTCCTGGAGCGCTTCATCATCTTCAGCCAGAGACGCGGGGCAAAGACGGTGCGCTATGCCCTGTGCTCCCTCTCCCAGGGCACCCTACAGTGGATAGAAGACACTCTGTATGCCAACGTGGACTTCTTCAAGCTCTTCCGTGTGCTTCCCACACTCCTAGACAGCCGTTCTCAAGGTATCAATCTGAGATCTTGGGGAGGAATATTATCTGATATGTCACCAAGAATTCAAGAGTTTATCCATCGGCCGAGTATGCAGGACTTGCTGTGGGTGACCAGGCCCCTCATGCAGAATGGTGGTCCAGAGACCTTTACAAAGCTGATGGGCATCCTGTCTGACCTCCTGTGTGGCTACCCCGAGGGAGGTGGCTCTCGGGTGCTCTCCTTCAACTGGTATGAAGACAATAACTATAAGGCCTTTCTGGGGATTGACTCCACAAGGAAGGATCCTATCTATTCTTATGACAGAAGAACAACATCCTTTTGTAATGCATTGATCCAGAGCCTGGAGTCAAATCCTTTAACCAAAATCGCTTGGAGGGCGGCAAAGCCTTTGCTGATGGGAAAAATCCTGTACACTCCTGATTCACCTGCAGCACGAAGGATACTGAAGAATGCCAACTCAACTTTTGAAGAACTGGAACACGTTAGGAAGTTGGTCAAAGCCTGGGAAGAAGTAGGGCCCCAGATCTGGTACTTCTTTGACAACAGCACACAGATGAACATGATCAGAGATACCCTGGGGAACCCAACAGTAAAAGACTTTTTGAATAGGCAGCTTGGTGAAGAAGGTATTACTGCTGAAGCCATCCTAAACTTCCTCTACAAGGGCCCTCGGGAAAGCCAGGCTGACGACATGGCCAACTTCGACTGGAGGGACATATTTAACATCACTGATCGCACCCTCCGCCTGGTCAATCAATACCTGGAGTGCTTGGTCCTGGATAAGTTTGAAAGCTACAATGATGAAACTCAGCTCACCCAACGTGCCCTCTCTCTACTGGAGGAAAACATGTTCTGGGCCGGAGTGGTATTCCCTGACATGTATCCCTGGACCAGCTCTCTACCACCCCACGTGAAGTATAAGATCCGAATGGACATAGACGTGGTGGAGAAAACCAATAAGATTAAAGACAGGTATTGGGATTCTGGTCCCAGAGCTGATCCCGTGGAAGATTTCCGGTACATCTGGGGCGGGTTTGCCTATCTGCAGGACATGGTTGAACAGGGGATCACAAGGAGCCAGGTGCAGGCGGAGGCTCCAGTTGGAATCTACCTCCAGCAGATGCCCTACCCCTGCTTCGTGGACGATTCTTTCATGATCATCCTGAACCGCTGTTTCCCTATCTTCATGGTGCTGGCATGGATCTACTCTGTCTCCATGACTGTGAAGAGCATCGTCTTGGAGAAGGAGTTGCGACTGAAGGAGACCTTGAAAAATCAGGGTGTCTCCAATGCAGTGATTTGGTGTACCTGGTTCCTGGACAGCTTCTCCATCATGTCGATGAGCATCTTCCTCCTGACGATATTCATCATGCATGGAAGAATCCTACATTACAGCGACCCATTCATCCTCTTCCTGTTCTTGTTGGCTTTCTCCACTGCCACCATCATGCTGTGCTTTCTGCTCAGCACCTTCTTCTCCAAGGCCAGTCTGGCAGCAGCCTGTAGTGGTGTCATCTATTTCACCCTCTACCTGCCACACATCCTGTGCTTCGCCTGGCAGGACCGCATGACCGCTGAGCTGAAGAAGGCTGTGAGCTTACTGTCTCCGGTGGCATTTGGATTTGGCACTGAGTACCTGGTTCGCTTTGAAGAGCAAGGCCTGGGGCTGCAGTGGAGCAACATCGGGAACAGTCCCACGGAAGGGGACGAATTCAGCTTCCTGCTGTCCATGCAGATGATGCTCCTTGATGCTGCTGTCTATGGCTTACTCGCTTGGTACCTTGATCAGGTGTTTCCAGGAGACTATGGAACCCCACTTCCTTGGTACTTTCTTCTACAAGAGTCGTATTGGCTTGGCGGTGAAGGGTGTTCAACCAGAGAAGAAAGAGCCCTGGAAAAGACCGAGCCCCTAACAGAGGAAACGGAGGATCCAGAGCACCCAGAAGGAATACACGACTCCTTCTTTGAACGTGAGCATCCAGGGTGGGTTCCTGGGGTATGCGTGAAGAATCTGGTAAAGATTTTTGAGCCCTGTGGCCGGCCAGCTGTGGACCGTCTGAACATCACCTTCTACGAGAACCAGATCACCGCATTCCTGGGCCACAATGGAGCTGGGAAAACCACCACCTTGTCCATCCTGACGGGTCTGTTGCCACCAACCTCTGGGACTGTGCTCGTTGGGGGAAGGGACATTGAAACCAGCCTGGATGCAGTCCGGCAGAGCCTTGGCATGTGTCCACAGCACAACATCCTGTTCCACCACCTCACGGTGGCTGAGCACATGCTGTTCTATGCCCAGCTGAAAGGAAAGTCCCAGGAGGAGGCCCAGCTGGAGATGGAAGCCATGTTGGAGGACACAGGCCTCCACCACAAGCGGAATGAAGAGGCTCAGGACCTATCAGGTGGCATGCAGAGAAAGCTGTCGGTTGCCATTGCCTTTGTGGGAGATGCCAAGGTGGTGATTCTGGACGAACCCACCTCTGGGGTGGACCCTTACTCGAGACGCTCAATCTGGGATCTGCTCCTGAAGTATCGCTCAGGCAGAACCATCATCATGTCCACTCACCACATGGACGAGGCCGACCTCCTTGGGGACCGCATTGCCATCATTGCCCAGGGAAGGCTCTACTGCTCAGGCACCCCACTCTTCCTGAAGAACTGCTTTGGCACAGGCTTGTACTTAACCTTGGTGCGCAAGATGAAAAACATCCAGAGCCAAAGGAAAGGCAGTGAGGGGACCTGCAGCTGCTCGTCTAAGGGTTTCTCCACCACGTGTCCAGCCCACGTCGATGACCTAACTCCAGAACAAGTCCTGGATGGGGATGTAAATGAGCTGATGGATGTAGTTCTCCACCATGTTCCAGAGGCAAAGCTGGTGGAGTGCATTGGTCAAGAACTTATCTTCCTTCTTCCAAATAAGAACTTCAAGCACAGAGCATATGCCAGCCTTTTCAGAGAGCTGGAGGAGACGCTGGCTGACCTTGGTCTCAGCAGTTTTGGAATTTCTGACACTCCCCTGGAAGAGATTTTTCTGAAGGTCACGGAGGATTCTGATTCAGGACCTCTGTTTGCGGGTGGCGCTCAGCAGAAAAGAGAAAACGTCAACCCCCGACACCCCTGCTTGGGTCCCAGAGAGAAGGCTGGACAGACACCCCAGGACTCCAATGTCTGCTCCCCAGGGGCGCCGGCTGCTCACCCAGAGGGCCAGCCTCCCCCAGAGCCAGAGTGCCCAGGCCCGCAGCTCAACACGGGGACACAGCTGGTCCTCCAGCATGTGCAGGCGCTGCTGGTCAAGAGATTCCAACACACCATCCGCAGCCACAAGGACTTCCTGGCGCAGATCGTGCTCCCGGCTACCTTTGTGTTTTTGGCTCTGATGCTTTCTATTGTTATCCCTCCTTTTGGCGAATACCCCGCTTTGACCCTTCACCCCTGGATATATGGGCAGCAGTACACCTTCTTCAGCATGGATGAACCAGGCAGTGAGCAGTTCACGGTACTTGCAGACGTCCTCCTGAATAAGCCAGGCTTTGGCAACCGCTGCCTGAAGGAAGGGTGGCTTCCGGAGTACCCCTGTGGCAACTCAACACCCTGGAAGACTCCTTCTGTGTCCCCAAACATCACCCAGCTGTTCCAGAAGCAGAAATGGACACAGGTCAACCCTTCACCATCCTGCAGGTGCAGCACCAGGGAGAAGCTCACCATGCTGCCAGAGTGCCCCGAGGGTGCCGGGGGCCTCCCGCCCCCCCAGAGAACACAGCGCAGCACGGAAATTCTACAAGACCTGACGGACAGGAACATCTCCGACTTCTTGGTAAAAACGTATCCTGCTCTTATAAGAAGCAGCTTAAAGAGCAAATTCTGGGTCAATGAACAGAGGTATGGAGGAATTTCCATTGGAGGAAAGCTCCCAGTCGTCCCCATCACGGGGGAAGCACTTGTTGGGTTTTTAAGCGACCTTGGCCGGATCATGAATGTGAGCGGGGGCCCTATCACTAGAGAGGCCTCTAAAGAAATACCTGATTTCCTTAAACATCTAGAAACTGAAGACAACATTAAGGTGTGGTTTAATAACAAAGGCTGGCATGCCCTGGTCAGCTTTCTCAATGTGGCCCACAACGCCATCTTACGGGCCAGCCTGCCTAAGGACAGGAGCCCCGAGGAGTATGGAATCACCGTCATTAGCCAACCCCTGAACCTGACCAAGGAGCAGCTCTCAGAGATTACAGTGCTGACCACTTCAGTGGATGCTGTGGTTGCCATCTGCGTGATTTTCTCCATGTCCTTCGTCCCAGCCAGCTTTGTCCTTTATTTGATCCAGGAGCGGGTGAACAAATCCAAGCACCTCCAGTTTATCAGTGGAGTGAGCCCCACCACCTACTGGGTGACCAACTTCCTCTGGGACATCATGAATTATTCCGTGAGTGCTGGGCTGGTGGTGGGCATCTTCATCGGGTTTCAGAAGAAAGCCTACACTTCTCCAGAAAACCTTCCTGCCCTTGTGGCACTGCTCCTGCTGTATGGATGGGCGGTCATTCCCATGATGTACCCAGCATCCTTCCTGTTTGATGTCCCCAGCACAGCCTATGTGGCTTTATCTTGTGCTAATCTGTTCATCGGCATCAACAGCAGTGCTATTACCTTCATCTTGGAATTATTTGAGAATAACCGGACGCTGCTCAGGTTCAACGCCGTGCTGAGGAAGCTGCTCATTGTCTTCCCCCACTTCTGCCTGGGCCGGGGCCTCATTGACCTTGCACTGAGCCAGGCTGTGACAGATGTCTATGCCCGGTTTGGTGAGGAGCACTCTGCAAATCCGTTCCACTGGGACCTGATTGGGAAGAACCTGTTTGCCATGGTGGTGGAAGGGGTGGTGTACTTCCTCCTGACCCTGCTGGTCCAGCGCCACTTCTTCCTCTCCCAATGGATTGCCGAGCCCACTAAGGAGCCCATTGTTGATGAAGATGATGATGTGGCTGAAGAAAGACAAAGAATTATTACTGGTGGAAATAAAACTGACATCTTAAGGCTACATGAACTAACCAAGATTTATCCAGGCACCTCCAGCCCAGCAGTGGACAGGCTGTGTGTCGGAGTTCGCCCTGGAGAGTGCTTTGGCCTCCTGGGAGTGAATGGTGCCGGCAAAACAACCACATTCAAGATGCTCACTGGGGACACCACAGTGACCTCAGGGGATGCCACCGTAGCAGGCAAGAGTATTTTAACCAATATTTCTGAAGTCCATCAAAATATGGGCTACTGTCCTCAGTTTGATGCAATTGATGAGCTGCTCACAGGACGAGAACATCTTTACCTTTATGCCCGGCTTCGAGGTGTACCAGCAGAAGAAATCGAAAAGGTTGCAAACTGGAGTATTAAGAGCCTGGGCCTGACTGTCTACGCCGACTGCCTGGCTGGCACGTACAGTGGGGGCAACAAGCGGAAACTCTCCACAGCCATCGCACTCATTGGCTGCCCACCGCTGGTGCTGCTGGATGAGCCCACCACAGGGATGGACCCCCAGGCACGCCGCATGCTGTGGAACGTCATCGTGAGCATCATCAGAGAAGGGAGGGCTGTGGTCCTCACATCCCACAGCATGGAAGAATGTGAGGCACTGTGTACCCGGCTGGCCATCATGGTAAAGGGCGCCTTTCGATGTATGGGCACCATTCAGCATCTCAAGTCCAAATTTGGAGATGGCTATATCGTCACAATGAAGATCAAATCCCCGAAGGACGACCTGCTTCCTGACCTGAACCCTGTGGAGCAGTTCTTCCAGGGGAACTTCCCAGGCAGTGTGCAGAGGGAGAGGCACTACAACATGCTCCAGTTCCAGGTCTCCTCCTCCTCCCTGGCGAGGATCTTCCAGCTCCTCCTCTCCCACAAGGACAGCCTGCTCATCGAGGAGTACTCAGTCACACAGACCACACTGGACCAGGTGTTTGTAAATTTTGCTAAACAGCAGACTGAAAGTCATGACCTCCCTCTGCACCCTCGAGCTGCTGGAGCCAGTCGACAAGCCCAGGACTGATCTTTCACACCGCTCGTTCCTGCAGCCAGAAAGGAACTCTGGGCAGCTGGAGGCGCAGGAGCCTGTGCCCATATGGTCATCCAAATGGACTGGCCAGCGTAAATGACCCCACTGCAGCAGAAAACAAACACACGAGGAGCATGCAGCGAATTCAGAAAGAGGTCTTTCAGAAGGAAACCGAAACTGACTTGCTCACCTGGAACACCTGATGGTGAAACCAAACAAATACAAAATCCTTCTCCAGACCCCAGAACTAGAAACCCCGGGCCATCCCACTAGCAGCTTTGGCCTCCATATTGCTCTCATTTCAAGCAGATCTGCTTTTCTGCATGTTTGTCTGTGTGTCTGCGTTGTGTGTGATTTTCATGGAAAAATAAAATGCAAATGCACTCATCACAAA
SEQ ID NO: 2
AGGACACAGCGTCCGGAGCCAGAGGCGCTCTTAACGGCGTTTATGTCCTTTGCTGTCTGAGGGGCCTCAGCTCTGACCAATCTGGTCTTCGTGTGGTCATTAGCATGGGCTTCGTGAGACAGATACAGCTTTTGCTCTGGAAGAACTGGACCCTGCGGAAAAGGCAAAAGATTCGCTTTGTGGTGGAACTCGTGTGGCCTTTATCTTTATTTCTGGTCTTGATCTGGTTAAGGAATGCCAACCCGCTCTACAGCCATCATGAATGCCATTTCCCCAACAAGGCGATGCCCTCAGCAGGAATGCTGCCGTGGCTCCAGGGGATCTTCTGCAATGTGAACAATCCCTGTTTTCAAAGCCCCACCCCAGGAGAATCTCCTGGAATTGTGTCAAACTATAACAACTCCATCTTGGCAAGGGTATATCGAGATTTTCAAGAACTCCTCATGAATGCACCAGAGAGCCAGCACCTTGGCCGTATTTGGACAGAGCTACACATCTTGTCCCAATTCATGGACACCCTCCGGACTCACCCGGAGAGAATTGCAGGAAGAGGAATACGAATAAGGGATATCTTGAAAGATGAAGAAACACTGACACTATTTCTCATTAAAAACATCGGCCTGTCTGACTCAGTGGTCTACCTTCTGATCAACTCTCAAGTCCGTCCAGAGCAGTTCGCTCATGGAGTCCCGGACCTGGCGCTGAAGGACATCGCCTGCAGCGAGGCCCTCCTGGAGCGCTTCATCATCTTCAGCCAGAGACGCGGGGCAAAGACGGTGCGCTATGCCCTGTGCTCCCTCTCCCAGGGCACCCTACAGTGGATAGAAGACACTCTGTATGCCAACGTGGACTTCTTCAAGCTCTTCCGTGTGCTTCCCACACTCCTAGACAGCCGTTCTCAAGGTATCAATCTGAGATCTTGGGGAGGAATATTATCTGATATGTCACCAAGAATTCAAGAGTTTATCCATCGGCCGAGTATGCAGGACTTGCTGTGGGTGACCAGGCCCCTCATGCAGAATGGTGGTCCAGAGACCTTTACAAAGCTGATGGGCATCCTGTCTGACCTCCTGTGTGGCTACCCCGAGGGAGGTGGCTCTCGGGTGCTCTCCTTCAACTGGTATGAAGACAATAACTATAAGGCCTTTCTGGGGATTGACTCCACAAGGAAGGATCCTATCTATTCTTATGACAGAAGAACAACATCCTTTTGTAATGCATTGATCCAGAGCCTGGAGTCAAATCCTTTAACCAAAATCGCTTGGAGGGCGGCAAAGCCTTTGCTGATGGGAAAAATCCTGTACACTCCTGATTCACCTGCAGCACGAAGGATACTGAAGAATGCCAACTCAACTTTTGAAGAACTGGAACACGTTAGGAAGTTGGTCAAAGCCTGGGAAGAAGTAGGGCCCCAGATCTGGTACTTCTTTGACAACAGCACACAGATGAACATGATCAGAGATACCCTGGGGAACCCAACAGTAAAAGACTTTTTGAATAGGCAGCTTGGTGAAGAAGGTATTACTGCTGAAGCCATCCTAAACTTCCTCTACAAGGGCCCTCGGGAAAGCCAGGCTGACGACATGGCCAACTTCGACTGGAGGGACATATTTAACATCACTGATCGCACCCTCCGCCTTGTCAATCAATACCTGGAGTGCTTGGTCCTGGATAAGTTTGAAAGCTACAATGATGAAACTCAGCTCACCCAACGTGCCCTCTCTCTACTGGAGGAAAACATGTTCTGGGCCGGAGTGGTATTCCCTGACATGTATCCCTGGACCAGCTCTCTACCACCCCACGTGAAGTATAAGATCCGAATGGACATAGACGTGGTGGAGAAAACCAATAAGATTAAAGACAGGTATTGGGATTCTGGTCCCAGAGCTGATCCCGTGGAAGATTTCCGGTACATCTGGGGCGGGTTTGCCTATCTGCAGGACATGGTTGAACAGGGGATCACAAGGAGCCAGGTGCAGGCGGAGGCTCCAGTTGGAATCTACCTCCAGCAGATGCCCTACCCCTGCTTCGTGGACGATTCTTTCATGATCATCCTGAACCGCTGTTTCCCTATCTTCATGGTGCTGGCATGGATCTACTCTGTCTCCATGACTGTGAAGAGCATCGTCTTGGAGAAGGAGTTGCGACTGAAGGAGACCTTGAAAAATCAGGGTGTCTCCAATGCAGTGATTTGGTGTACCTGGTTCCTGGACAGCTTCTCCATCATGTCGATGAGCATCTTCCTCCTGACGATATTCATCATGCATGGAAGAATCCTACATTACAGCGACCCATTCATCCTCTTCCTGTTCTTGTTGGCTTTCTCCACTGCCACCATCATGCTGTGCTTTCTGCTCAGCACCTTCTTCTCCAAGGCCAGTCTGGCAGCAGCCTGTAGTGGTGTCATCTATTTCACCCTCTACCTGCCACACATCCTGTGCTTCGCCTGGCAGGACCGCATGACCGCTGAGCTGAAGAAGGCTGTGAGCTTACTGTCTCCGGTGGCATTTGGATTTGGCACTGAGTACCTGGTTCGCTTTGAAGAGCAAGGCCTGGGGCTGCAGTGGAGCAACATCGGGAACAGTCCCACGGAAGGGGACGAATTCAGCTTCCTGCTGTCCATGCAGATGATGCTCCTTGATGCTGCTGTCTATGGCTTACTCGCTTGGTACCTTGATCAGGTGTTTCCAGGAGACTATGGAACCCCACTTCCTTGGTACTTTCTTCTACAAGAGTCGTATTGGCTTGGCGGTGAAGGGTGTTCAACCAGAGAAGAAAGAGCCCTGGAAAAGACCGAGCCCCTAACAGAGGAAACGGAGGATCCAGAGCACCCAGAAGGAATACACGACTCCTTCTTTGAACGTGAGCATCCAGGGTGGGTTCCTGGGGTATGCGTGAAGAATCTGGTAAAGATTTTTGAGCCCTGTGGCCGGCCAGCTGTGGACCGTCTGAACATCACCTTCTACGAGAACCAGATCACCGCATTCCTGGGCCACAATGGAGCTGGGAAAACCACCACCTTGTCCATCCTGACGGGTCTGTTGCCACCAACCTCTGGGACTGTGCTCGTTGGGGGAAGGGACATTGAAACCAGCCTGGATGCAGTCCGGCAGAGCCTTGGCATGTGTCCACAGCACAACATCCTGTTCCACCACCTCACGGTGGCTGAGCACATGCTGTTCTATGCCCAGCTGAAAGGAAAGTCCCAGGAGGAGGCCCAGCTGGAGATGGAAGCCATGTTGGAGGACACAGGCCTCCACCACAAGCGGAATGAAGAGGCTCAGGACCTATCAGGTGGCATGCAGAGAAAGCTGTCGGTTGCCATTGCCTTTGTGGGAGATGCCAAGGTGGTGATTCTGGACGAACCCACCTCTGGGGTGGACCCTTACTCGAGACGCTCAATCTGGGATCTGCTCCTGAAGTATCGCTCAGGCAGAACCATCATCATGTCCACTCACCACATGGACGAGGCCGACCTCCTTGGGGACCGCATTGCCATCATTGCCCAGGGAAGGCTCTACTGCTCAGGCACCCCACTCTTCCTGAAGAACTGCTTTGGCACAGGCTTGTACTTAACCTTGGTGCGCAAGATGAAAAACATCCAGAGCCAAAGGAAAGGCAGTGAGGGGACCTGCAGCTGCTCGTCTAAGGGTTTCTCCACCACGTGTCCAGCCCACGTCGATGACCTAACTCCAGAACAAGTCCTGGATGGGGATGTAAATGAGCTGATGGATGTAGTTCTCCACCATGTTCCAGAGGCAAAGCTGGTGGAGTGCATTGGTCAAGAACTTATCTTCCTTCTTCCAAATAAGAACTTCAAGCACAGAGCATATGCCAGCCTTTTCAGAGAGCTGGAGGAGACGCTGGCTGACCTTGGTCTCAGCAGTTTTGGAATTTCTGACACTCCCCTGGAAGAGATTTTTCTGAAGGTCACGGAGGATTCTGATTCAGGACCTCTGTTTGCGGGTGGCGCTCAGCAGAAAAGAGAAAACGTCAACCCCCGACACCCCTGCTTGGGTCCCAGAGAGAAGGCTGGACAGACACCCCAGGACTCCAATGTCTGCTCCCCAGGGGCGCCGGCTGCTCACCCAGAGGGCCAGCCTCCCCCAGAGCCAGAGTGCCCAGGCCCGCAGCTCAACACGGGGACACAGCTGGTCCTCCAGCATGTGCAGGCGCTGCTGGTCAAGAGATTCCAACACACCATCCGCAGCCACAAGGACTTCCTGGCGCAGATCGTGCTCCCGGCTACCTTTGTGTTTTTGGCTCTGATGCTTTCTATTGTTATCCCTCCTTTTGGCGAATACCCCGCTTTGACCCTTCACCCCTGGATATATGGGCAGCAGTACACCTTCTTCAGCATGGATGAACCAGGCAGTGAGCAGTTCACGGTACTTGCAGACGTCCTCCTGAATAAGCCAGGCTTTGGCAACCGCTGCCTGAAGGAAGGGTGGCTTCCGGAGTACCCCTGTGGCAACTCAACACCCTGGAAGACTCCTTCTGTGTCCCCAAACATCACCCAGCTGTTCCAGAAGCAGAAATGGACACAGGTCAACCCTTCACCATCCTGCAGGTGCAGCACCAGGGAGAAGCTCACCATGCTGCCAGAGTGCCCCGAGGGTGCCGGGGGCCTCCCGCCCCCCCAGAGAACACAGCGCAGCACGGAAATTCTACAAGACCTGACGGACAGGAACATCTCCGACTTCTTGGTAAAAACGTATCCTGCTCTTATAAGAAGCAGCTTAAAGAGCAAATTCTGGGTCAATGAACAGAGGTATGGAGGAATTTCCATTGGAGGAAAGCTCCCAGTCGTCCCCATCACGGGGGAAGCACTTGTTGGGTTTTTAAGCGACCTTGGCCGGATCATGAATGTGAGCGGGGGCCCTATCACTAGAGAGGCCTCTAAAGAAATACCTGATTTCCTTAAACATCTAGAAACTGAAGACAACATTAAGGTGTGGTTTAATAACAAAGGCTGGCATGCCCTGGTCAGCTTTCTCAATGTGGCCCACAACGCCATCTTACGGGCCAGCCTGCCTAAGGACAGGAGCCCCGAGGAGTATGGAATCACCGTCATTAGCCAACCCCTGAACCTGACCAAGGAGCAGCTCTCAGAGATTACAGTGCTGACCACTTCAGTGGATGCTGTGGTTGCCATCTGCGTGATTTTCTCCATGTCCTTCGTCCCAGCCAGCTTTGTCCTTTATTTGATCCAGGAGCGGGTGAACAAATCCAAGCACCTCCAGTTTATCAGTGGAGTGAGCCCCACCACCTACTGGGTAACCAACTTCCTCTGGGACATCATGAATTATTCCGTGAGTGCTGGGCTGGTGGTGGGCATCTTCATCGGGTTTCAGAAGAAAGCCTACACTTCTCCAGAAAACCTTCCTGCCCTTGTGGCACTGCTCCTGCTGTATGGATGGGCGGTCATTCCCATGATGTACCCAGCATCCTTCCTGTTTGATGTCCCCAGCACAGCCTATGTGGCTTTATCTTGTGCTAATCTGTTCATCGGCATCAACAGCAGTGCTATTACCTTCATCTTGGAATTATTTGAGAATAACCGGACGCTGCTCAGGTTCAACGCCGTGCTGAGGAAGCTGCTCATTGTCTTCCCCCACTTCTGCCTGGGCCGGGGCCTCATTGACCTTGCACTGAGCCAGGCTGTGACAGATGTCTATGCCCGGTTTGGTGAGGAGCACTCTGCAAATCCGTTCCACTGGGACCTGATTGGGAAGAACCTGTTTGCCATGGTGGTGGAAGGGGTGGTGTACTTCCTCCTGACCCTGCTGGTCCAGCGCCACTTCTTCCTCTCCCAATGGATTGCCGAGCCCACTAAGGAGCCCATTGTTGATGAAGATGATGATGTGGCTGAAGAAAGACAAAGAATTATTACTGGTGGAAATAAAACTGACATCTTAAGGCTACATGAACTAACCAAGATTTATCCAGGCACCTCCAGCCCAGCAGTGGACAGGCTGTGTGTCGGAGTTCGCCCTGGAGAGTGCTTTGGCCTCCTGGGAGTGAATGGTGCCGGCAAAACAACCACATTCAAGATGCTCACTGGGGACACCACAGTGACCTCAGGGGATGCCACCGTAGCAGGCAAGAGTATTTTAACCAATATTTCTGAAGTCCATCAAAATATGGGCTACTGTCCTCAGTTTGATGCAATCGATGAGCTGCTCACAGGACGAGAACATCTTTACCTTTATGCCCGGCTTCGAGGTGTACCAGCAGAAGAAATCGAAAAGGTTGCAAACTGGAGTATTAAGAGCCTGGGCCTGACTGTCTACGCCGACTGCCTGGCTGGCACGTACAGTGGGGGCAACAAGCGGAAACTCTCCACAGCCATCGCACTCATTGGCTGCCCACCGCTGGTGCTGCTGGATGAGCCCACCACAGGGATGGACCCCCAGGCACGCCGCATGCTGTGGAACGTCATCGTGAGCATCATCAGAGAAGGGAGGGCTGTGGTCCTCACATCCCACAGCATGGAAGAATGTGAGGCACTGTGTACCCGGCTGGCCATCATGGTAAAGGGCGCCTTTCGATGTATGGGCACCATTCAGCATCTCAAGTCCAAATTTGGAGATGGCTATATCGTCACAATGAAGATCAAATCCCCGAAGGACGACCTGCTTCCTGACCTGAACCCTGTGGAGCAGTTCTTCCAGGGGAACTTCCCAGGCAGTGTGCAGAGGGAGAGGCACTACAACATGCTCCAGTTCCAGGTCTCCTCCTCCTCCCTGGCGAGGATCTTCCAGCTCCTCCTCTCCCACAAGGACAGCCTGCTCATCGAGGAGTACTCAGTCACACAGACCACACTGGACCAGGTGTTTGTAAATTTTGCTAAACAGCAGACTGAAAGTCATGACCTCCCTCTGCACCCTCGAGCTGCTGGAGCCAGTCGACAAGCCCAGGACTGATCTTTCACACCGCTCGTTCCTGCAGCCAGAAAGGAACTCTGGGCAGCTGGAGGCGCAGGAGCCTGTGCCCATATGGTCATCCAAATGGACTGGCCAGCGTAAATGACCCCACTGCAGCAGAAAACAAACACACGAGGAGCATGCAGCGAATTCAGAAAGAGGTCTTTCAGAAGGAAACCGAAACTGACTTGCTCACCTGGAACACCTGATGGTGAAACCAAACAAATACAAAATCCTTCTCCAGACCCCAGAACTAGAAACCCCGGGCCATCCCACTAGCAGCTTTGGCCTCCATATTGCTCTCATTTCAAGCAGATCTGCTTTTCTGCATGTTTGTCTGTGTGTCTGCGTTGTGTGTGATTTTCATGGAAAAATAAAATGCAAATGCACTCATCACAAA
SEQ ID NO: 3
TTGGCCACTCCCTCTCTGCGCGCTCGCTCGCTCACTGAGGCCGGGCGACCAAAGGTCGCCCGACGCCCGGGCTTTGCCCGGGCGGCCTCAGTGAGCGAGCGAGCGCGCAGAGAGGGAGTGGCCAACTCCATCACTAGGGGTTCCTGCGGCAATTCAGTCGATAACTATAACGGTCCTAAGGTAGCGATTTAAATGGTACCGGGCCCCAGAAGCCTGGTGGTTGTTTGTCCTTCTCAGGGGAAAAGTGAGGCGGCCCCTTGGAGGAAGGGGCCGGGCAGAATGATCTAATCGGATTCCAAGCAGCTCAGGGGATTGTCTTTTTCTAGCACCTTCTTGCCACTCCTAAGCGTCCTCCGTGACCCCGGCTGGGATTTAGCCTGGTGCTGTGTCAGCCCCGGGTGCCGCAGGGGGACGGCTGCCTTCGGGGGGGACGGGGCAGGGCGGGGTTCGGCTTCTGGCGTGTGACCGGCGGCTCTAGAGCCTCTGCTAACCATGTTCATGCCTTCTTCTTTTTCCTACAGCTCCTGGGCAACGTGCTGGTTATTGTGCTGTCTCATCATTTTGGCAAAGAATTACCACCATGGGCTTCGTGAGACAGATACAGCTTTTGCTCTGGAAGAACTGGACCCTGCGGAAAAGGCAAAAGATTCGCTTTGTGGTGGAACTCGTGTGGCCTTTATCTTTATTTCTGGTCTTGATCTGGTTAAGGAATGCCAACCCGCTCTACAGCCATCATGAATGCCATTTCCCCAACAAGGCGATGCCCTCAGCAGGAATGCTGCCGTGGCTCCAGGGGATCTTCTGCAATGTGAACAATCCCTGTTTTCAAAGCCCCACCCCAGGAGAATCTCCTGGAATTGTGTCAAACTATAACAACTCCATCTTGGCAAGGGTATATCGAGATTTTCAAGAACTCCTCATGAATGCACCAGAGAGCCAGCACCTTGGCCGTATTTGGACAGAGCTACACATCTTGTCCCAATTCATGGACACCCTCCGGACTCACCCGGAGAGAATTGCAGGAAGAGGAATACGAATAAGGGATATCTTGAAAGATGAAGAAACACTGACACTATTTCTCATTAAAAACATCGGCCTGTCTGACTCAGTGGTCTACCTTCTGATCAACTCTCAAGTCCGTCCAGAGCAGTTCGCTCATGGAGTCCCGGACCTGGCGCTGAAGGACATCGCCTGCAGCGAGGCCCTCCTGGAGCGCTTCATCATCTTCAGCCAGAGACGCGGGGCAAAGACGGTGCGCTATGCCCTGTGCTCCCTCTCCCAGGGCACCCTACAGTGGATAGAAGACACTCTGTATGCCAACGTGGACTTCTTCAAGCTCTTCCGTGTGCTTCCCACACTCCTAGACAGCCGTTCTCAAGGTATCAATCTGAGATCTTGGGGAGGAATATTATCTGATATGTCACCAAGAATTCAAGAGTTTATCCATCGGCCGAGTATGCAGGACTTGCTGTGGGTGACCAGGCCCCTCATGCAGAATGGTGGTCCAGAGACCTTTACAAAGCTGATGGGCATCCTGTCTGACCTCCTGTGTGGCTACCCCGAGGGAGGTGGCTCTCGGGTGCTCTCCTTCAACTGGTATGAAGACAATAACTATAAGGCCTTTCTGGGGATTGACTCCACAAGGAAGGATCCTATCTATTCTTATGACAGAAGAACAACATCCTTTTGTAATGCATTGATCCAGAGCCTGGAGTCAAATCCTTTAACCAAAATCGCTTGGAGGGCGGCAAAGCCTTTGCTGATGGGAAAAATCCTGTACACTCCTGATTCACCTGCAGCACGAAGGATACTGAAGAATGCCAACTCAACTTTTGAAGAACTGGAACACGTTAGGAAGTTGGTCAAAGCCTGGGAAGAAGTAGGGCCCCAGATCTGGTACTTCTTTGACAACAGCACACAGATGAACATGATCAGAGATACCCTGGGGAACCCAACAGTAAAAGACTTTTTGAATAGGCAGCTTGGTGAAGAAGGTATTACTGCTGAAGCCATCCTAAACTTCCTCTACAAGGGCCCTCGGGAAAGCCAGGCTGACGACATGGCCAACTTCGACTGGAGGGACATATTTAACATCACTGATCGCACCCTCCGCCTTGTCAATCAATACCTGGAGTGCTTGGTCCTGGATAAGTTTGAAAGCTACAATGATGAAACTCAGCTCACCCAACGTGCCCTCTCTCTACTGGAGGAAAACATGTTCTGGGCCGGAGTGGTATTCCCTGACATGTATCCCTGGACCAGCTCTCTACCACCCCACGTGAAGTATAAGATCCGAATGGACATAGACGTGGTGGAGAAAACCAATAAGATTAAAGACAGGTATTGGGATTCTGGTCCCAGAGCTGATCCCGTGGAAGATTTCCGGTACATCTGGGGCGGGTTTGCCTATCTGCAGGACATGGTTGAACAGGGGATCACAAGGAGCCAGGTGCAGGCGGAGGCTCCAGTTGGAATCTACCTCCAGCAGATGCCCTACCCCTGCTTCGTGGACGATTCTTTCATGATCATCCTGAACCGCTGTTTCCCTATCTTCATGGTGCTGGCATGGATCTACTCTGTCTCCATGACTGTGAAGAGCATCGTCTTGGAGAAGGAGTTGCGACTGAAGGAGACCTTGAAAAATCAGGGTGTCTCCAATGCAGTGATTTGGTGTACCTGGTTCCTGGACAGCTTCTCCATCATGTCGATGAGCATCTTCCTCCTGACGATATTCATCATGCATGGAAGAATCCTACATTACAGCGACCCATTCATCCTCTTCCTGTTCTTGTTGGCTTTCTCCACTGCCACCATCATGCTGTGCTTTCTGCTCAGCACCTTCTTCTCCAAGGCCAGTCTGGCAGCAGCCTGTAGTGGTGTCATCTATTTCACCCTCTACCTGCCACACATCCTGTGCTTCGCCTGGCAGGACCGCATGACCGCTGAGCTGAAGAAGGCTGTGAGCTTACTGTCTCCGGTGGCATTTGGATTTGGCACTGAGTACCTGGTTCGCTTTGAAGAGCAAGGCCTGGGGCTGCAGTGGAGCAACATCGGGAACAGTCCCACGGAAGGGGACGAATTCAGCTTCCTGCTGTCCATGCAGATGATGCTCCTTGATGCTGCTGTCTATGGCTTACTCGCTTGGTACCTTGATCAGGTGTTTCCAGGAGACTATGGAACCCCACTTCCTTGGTACTTTCTTCTACAAGAGTCGTATTGGCTTGGCGGTGAAGGGTGTTCAACCAGAGAAGAAAGAGCCCTGGAAAAGACCGAGCCCCTAACAGAGGAAACGGAGGATCCAGAGCACCCAGAAGGAATACACGACTCCTTCTTTGAACGTGAGCATCCAGGGTGGGTTCCTGGGGTATGCGTGAAGAATCTGGTAAAGATTTTTGAGCCCTGTGGCCGGCCAGCTGTGGACCGTCTGAACATCACCTTCTACGAGAACCAGATCACCGCATTCCTGGGCCACAATGGAGCTGGGAAAACCACCACCTTGTCCATCCTGACGGGTCTGTTGCCACCAACCTCTGGGACTGTGCTCGTTGGGGGAAGGGACATTGAAACCAGCCTGGATGCAGTCCGGCAGAGCCTTGGCATGTGTCCACAGCACAACATCCTGTTCCACCACCTCACGGTGGCTGAGCACATGCTGTTCTATGCCCAGCTGAAAGGAAAGTCCCAGGAGGAGGCCCAGCTGGAGATGGAAGCCATGTTGGAGGACACAGGCCTCCACCACAAGCGGAATGAAGAGGCTCAGGACCTATCAGGTGGCATGCAGAGAAAGCTGTCGGTTGCCATTGCCTTTGTGGGAGATGCCAAGGTGGTGATTCTGGACGAACCCACCTCTGGGGTGGACCCTTACTCGAGACGCTCAATCTGGGATCTGCTCCTGAAGTATCGCTCAGGCAGAACCATCATCATGTCCACTCACCACATGGACGAGGCCGACCTCCTTGGGGACCGCATTGCCATCATTGCCCAGGGAAGGCTCTACTGCTCAGGCACCCCACTCTTCCTGAAGAACTGCTTTGGCACAGGCTTGTACTTAACCTTGGTGCGCAAGATGAAAAACATCCAGAGCCAAAGGAAAGGCAGTGAGGGGACCTGCAGCTGCTCGTCTAAGGGTTTCTCCACCACGTGTCCAGCCCACGTCGATGACCTAACTCCAGAACAAGTCCTGGATGGGGATGTAAATGAGCTGATGGATGTAGTTCTCCACCATGTTCCAGAGGCAAAGCTGGTGGAGTGCATTGGTCAAGAACTTATCTTCCTTCTTCCATTTAAATTAGGGATAACAGGGTAATGGCGCGGGCCGCAGGAACCCCTAGTGATGGAGTTGGCCACTCCCTCTCTGCGCGCTCGCTCGCTCACTGAGGCCGCCCGGGCAAAGCCCGGGCGTCGGGCGACCTTTGGTCGCCCGGCCTCAGTGAGCGAGCGAGCGCGCAGAGAGGGAGTGGCCAA
SEQ ID NO: 4
TTGGCCACTCCCTCTCTGCGCGCTCGCTCGCTCACTGAGGCCGGGCGACCAAAGGTCGCCCGACGCCCGGGCTTTGCCCGGGCGGCCTCAGTGAGCGAGCGAGCGCGCAGAGAGGGAGTGGCCAACTCCATCACTAGGGGTTCCTGCGGCAATTCAGTCGATAACTATAACGGTCCTAAGGTAGCGATTTAAATAACATCCAGAGCCAAAGGAAAGGCAGTGAGGGGACCTGCAGCTGCTCGTCTAAGGGTTTCTCCACCACGTGTCCAGCCCACGTCGATGACCTAACTCCAGAACAAGTCCTGGATGGGGATGTAAATGAGCTGATGGATGTAGTTCTCCACCATGTTCCAGAGGCAAAGCTGGTGGAGTGCATTGGTCAAGAACTTATCTTCCTTCTTCCAAATAAGAACTTCAAGCACAGAGCATATGCCAGCCTTTTCAGAGAGCTGGAGGAGACGCTGGCTGACCTTGGTCTCAGCAGTTTTGGAATTTCTGACACTCCCCTGGAAGAGATTTTTCTGAAGGTCACGGAGGATTCTGATTCAGGACCTCTGTTTGCGGGTGGCGCTCAGCAGAAAAGAGAAAACGTCAACCCCCGACACCCCTGCTTGGGTCCCAGAGAGAAGGCTGGACAGACACCCCAGGACTCCAATGTCTGCTCCCCAGGGGCGCCGGCTGCTCACCCAGAGGGCCAGCCTCCCCCAGAGCCAGAGTGCCCAGGCCCGCAGCTCAACACGGGGACACAGCTGGTCCTCCAGCATGTGCAGGCGCTGCTGGTCAAGAGATTCCAACACACCATCCGCAGCCACAAGGACTTCCTGGCGCAGATCGTGCTCCCGGCTACCTTTGTGTTTTTGGCTCTGATGCTTTCTATTGTTATCCCTCCTTTTGGCGAATACCCCGCTTTGACCCTTCACCCCTGGATATATGGGCAGCAGTACACCTTCTTCAGCATGGATGAACCAGGCAGTGAGCAGTTCACGGTACTTGCAGACGTCCTCCTGAATAAGCCAGGCTTTGGCAACCGCTGCCTGAAGGAAGGGTGGCTTCCGGAGTACCCCTGTGGCAACTCAACACCCTGGAAGACTCCTTCTGTGTCCCCAAACATCACCCAGCTGTTCCAGAAGCAGAAATGGACACAGGTCAACCCTTCACCATCCTGCAGGTGCAGCACCAGGGAGAAGCTCACCATGCTGCCAGAGTGCCCCGAGGGTGCCGGGGGCCTCCCGCCCCCCCAGAGAACACAGCGCAGCACGGAAATTCTACAAGACCTGACGGACAGGAACATCTCCGACTTCTTGGTAAAAACGTATCCTGCTCTTATAAGAAGCAGCTTAAAGAGCAAATTCTGGGTCAATGAACAGAGGTATGGAGGAATTTCCATTGGAGGAAAGCTCCCAGTCGTCCCCATCACGGGGGAAGCACTTGTTGGGTTTTTAAGCGACCTTGGCCGGATCATGAATGTGAGCGGGGGCCCTATCACTAGAGAGGCCTCTAAAGAAATACCTGATTTCCTTAAACATCTAGAAACTGAAGACAACATTAAGGTGTGGTTTAATAACAAAGGCTGGCATGCCCTGGTCAGCTTTCTCAATGTGGCCCACAACGCCATCTTACGGGCCAGCCTGCCTAAGGACAGGAGCCCCGAGGAGTATGGAATCACCGTCATTAGCCAACCCCTGAACCTGACCAAGGAGCAGCTCTCAGAGATTACAGTGCTGACCACTTCAGTGGATGCTGTGGTTGCCATCTGCGTGATTTTCTCCATGTCCTTCGTCCCAGCCAGCTTTGTCCTTTATTTGATCCAGGAGCGGGTGAACAAATCCAAGCACCTCCAGTTTATCAGTGGAGTGAGCCCCACCACCTACTGGGTAACCAACTTCCTCTGGGACATCATGAATTATTCCGTGAGTGCTGGGCTGGTGGTGGGCATCTTCATCGGGTTTCAGAAGAAAGCCTACACTTCTCCAGAAAACCTTCCTGCCCTTGTGGCACTGCTCCTGCTGTATGGATGGGCGGTCATTCCCATGATGTACCCAGCATCCTTCCTGTTTGATGTCCCCAGCACAGCCTATGTGGCTTTATCTTGTGCTAATCTGTTCATCGGCATCAACAGCAGTGCTATTACCTTCATCTTGGAATTATTTGAGAATAACCGGACGCTGCTCAGGTTCAACGCCGTGCTGAGGAAGCTGCTCATTGTCTTCCCCCACTTCTGCCTGGGCCGGGGCCTCATTGACCTTGCACTGAGCCAGGCTGTGACAGATGTCTATGCCCGGTTTGGTGAGGAGCACTCTGCAAATCCGTTCCACTGGGACCTGATTGGGAAGAACCTGTTTGCCATGGTGGTGGAAGGGGTGGTGTACTTCCTCCTGACCCTGCTGGTCCAGCGCCACTTCTTCCTCTCCCAATGGATTGCCGAGCCCACTAAGGAGCCCATTGTTGATGAAGATGATGATGTGGCTGAAGAAAGACAAAGAATTATTACTGGTGGAAATAAAACTGACATCTTAAGGCTACATGAACTAACCAAGATTTATCCAGGCACCTCCAGCCCAGCAGTGGACAGGCTGTGTGTCGGAGTTCGCCCTGGAGAGTGCTTTGGCCTCCTGGGAGTGAATGGTGCCGGCAAAACAACCACATTCAAGATGCTCACTGGGGACACCACAGTGACCTCAGGGGATGCCACCGTAGCAGGCAAGAGTATTTTAACCAATATTTCTGAAGTCCATCAAAATATGGGCTACTGTCCTCAGTTTGATGCAATCGATGAGCTGCTCACAGGACGAGAACATCTTTACCTTTATGCCCGGCTTCGAGGTGTACCAGCAGAAGAAATCGAAAAGGTTGCAAACTGGAGTATTAAGAGCCTGGGCCTGACTGTCTACGCCGACTGCCTGGCTGGCACGTACAGTGGGGGCAACAAGCGGAAACTCTCCACAGCCATCGCACTCATTGGCTGCCCACCGCTGGTGCTGCTGGATGAGCCCACCACAGGGATGGACCCCCAGGCACGCCGCATGCTGTGGAACGTCATCGTGAGCATCATCAGAGAAGGGAGGGCTGTGGTCCTCACATCCCACAGCATGGAAGAATGTGAGGCACTGTGTACCCGGCTGGCCATCATGGTAAAGGGCGCCTTTCGATGTATGGGCACCATTCAGCATCTCAAGTCCAAATTTGGAGATGGCTATATCGTCACAATGAAGATCAAATCCCCGAAGGACGACCTGCTTCCTGACCTGAACCCTGTGGAGCAGTTCTTCCAGGGGAACTTCCCAGGCAGTGTGCAGAGGGAGAGGCACTACAACATGCTCCAGTTCCAGGTCTCCTCCTCCTCCCTGGCGAGGATCTTCCAGCTCCTCCTCTCCCACAAGGACAGCCTGCTCATCGAGGAGTACTCAGTCACACAGACCACACTGGACCAGGTGTTTGTAAATTTTGCTAAACAGCAGACTGAAAGTCATGACCTCCCTCTGCACCCTCGAGCTGCTGGAGCCAGTCGACAAGCCCAGGACTGAAAGCTTATCGATAATCAACCTCTGGATTACAAAATTTGTGAAAGATTGACTGGTATTCTTAACTATGTTGCTCCTTTTACGCTATGTGGATACGCTGCTTTAATGCCTTTGTATCATGCTATTGCTTCCCGTATGGCTTTCATTTTCTCCTCCTTGTATAAATCCTGGTTGCTGTCTCTTTATGAGGAGTTGTGGCCCGTTGTCAGGCAACGTGGCGTGGTGTGCACTGTGTTTGCTGACGCAACCCCCACTGGTTGGGGCATTGCCACCACCTGTCAGCTCCTTTCCGGGACTTTCGCTTTCCCCCTCCCTATTGCCACGGCGGAACTCATCGCCGCCTGCCTTGCCCGCTGCTGGACAGGGGCTCGGCTGTTGGGCACTGACAATTCCGTGGTGTTGTCGGGGAAATCATCGTCCTTTCCTTGGCTGCTCGCCTGTGTTGCCACCTGGATTCTGCGCGGGACGTCCTTCTGCTACGTCCCTTCGGCCCTCAATCCAGCGGACCTTCCTTCCCGCGGCCTGCTGCCGGCTCTGCGGCCTCTTCCGCGTCTTCGCCTTCGCCCTCAGACGAGTCGGATCTCCCTTTGGGCCGCCTCCCCGCATGCCGCTGATCAGCCTCGACTGTGCCTTCTAGTTGCCAGCCATCTGTTGTTTGCCCCTCCCCCGTGCCTTCCTTGACCCTGGAAGGTGCCACTCCCACTGTCCTTTCCTAATAAAATGAGGAAATTGCATCGCATTGTCTGAGTAGGTGTCATTCTATTCTGGGGGGTGGGGTGGGGCAGGACAGCAAGGGGGAGGATTGGGAAGACAATAGCAGGCATGCTGGGGATGCGGTGGGCTCTATGGCTTCTGAGGCGGAAAGAACCAGCTGGGGATTTAAATTAGGGATAACAGGGTAATGGCGCGGGCCGCAGGAACCCCTAGTGATGGAGTTGGCCACTCCCTCTCTGCGCGCTCGCTCGCTCACTGAGGCCGCCCGGGCAAAGCCCGGGCGTCGGGCGACCTTTGGTCGCCCGGCCTCAGTGAGCGAGCGAGCGCGCAGAGAGGGAGTGGCCAA
SEQ ID NO: 5
GGGCCCCAGAAGCCTGGTGGTTGTTTGTCCTTCTCAGGGGAAAAGTGAGGCGGCCCCTTGGAGGAAGGGGCCGGGCAGAATGATCTAATCGGATTCCAAGCAGCTCAGGGGATTGTCTTTTTCTAGCACCTTCTTGCCACTCCTAAGCGTCCTCCGTGACCCCGGCTGGGATTTAGCCTGGTGCTGTGTCAGCCCCGGG
SEQ ID NO: 6
GTGCCGCAGGGGGACGGCTGCCTTCGGGGGGGACGGGGCAGGGCGGGGTTCGGCTTCTGGCGTGTGACCGGCGGCTCTAGAGCCTCTGCTAACCATGTTCATGCCTTCTTCTTTTTCCTACAGCTCCTGGGCAACGTGCTGGTTATTGTGCTGTCTCATCATTTTGGCAAAGAATTACCACCATGG
SEQ ID NO: 7
ATCGATAATCAACCTCTGGATTACAAAATTTGTGAAAGATTGACTGGTATTCTTAACTATGTTGCTCCTTTTACGCTATGTGGATACGCTGCTTTAATGCCTTTGTATCATGCTATTGCTTCCCGTATGGCTTTCATTTTCTCCTCCTTGTATAAATCCTGGTTGCTGTCTCTTTATGAGGAGTTGTGGCCCGTTGTCAGGCAACGTGGCGTGGTGTGCACTGTGTTTGCTGACGCAACCCCCACTGGTTGGGGCATTGCCACCACCTGTCAGCTCCTTTCCGGGACTTTCGCTTTCCCCCTCCCTATTGCCACGGCGGAACTCATCGCCGCCTGCCTTGCCCGCTGCTGGACAGGGGCTCGGCTGTTGGGCACTGACAATTCCGTGGTGTTGTCGGGGAAATCATCGTCCTTTCCTTGGCTGCTCGCCTGTGTTGCCACCTGGATTCTGCGCGGGACGTCCTTCTGCTACGTCCCTTCGGCCCTCAATCCAGCGGACCTTCCTTCCCGCGGCCTGCTGCCGGCTCTGCGGCCTCTTCCGCGTCTTCGCCTTCGCCCTCAGACGAGTCGGATCTCCCTTTGGGCCGCCTCCCC
SEQ ID NO: 8
CGCTGATCAGCCTCGACTGTGCCTTCTAGTTGCCAGCCATCTGTTGTTTGCCCCTCCCCCGTGCCTTCCTTGACCCTGGAAGGTGCCACTCCCACTGTCCTTTCCTAATAAAATGAGGAAATTGCATCGCATTGTCTGAGTAGGTGTCATTCTATTCTGGGGGGTGGGGTGGGGCAGGACAGCAAGGGGGAGGATTGGGAAGACAATAGCAGGCATGCTGGGGATGCGGTGGGCTCTATGGCTTCTGAGGCGGAAAGAACCAGCTGGGG
SEQ ID NO: 9
GGTACCGGGCCCCAGAAGCCTGGTGGTTGTTTGTCCTTCTCAGGGGAAAAGTGAGGCGGCCCCTTGGAGGAAGGGGCCGGGCAGAATGATCTAATCGGATTCCAAGCAGCTCAGGGGATTGTCTTTTTCTAGCACCTTCTTGCCACTCCTAAGCGTCCTCCGTGACCCCGGCTGGGATTTAGCCTGGTGCTGTGTCAGCCCCGGGTGCCGCAGGGGGACGGCTGCCTTCGGGGGGGACGGGGCAGGGCGGGGTTCGGCTTCTGGCGTGTGACCGGCGGCTCTAGAGCCTCTGCTAACCATGTTCATGCCTTCTTCTTTTTCCTACAGCTCCTGGGCAACGTGCTGGTTATTGTGCTGTCTCATCATTTTGGCAAAGAATTACCACCATGGGCTTCGTGAGACAGATACAGCTTTTGCTCTGGAAGAACTGGACCCTGCGGAAAAGGCAAAAGATTCGCTTTGTGGTGGAACTCGTGTGGCCTTTATCTTTATTTCTGGTCTTGATCTGGTTAAGGAATGCCAACCCGCTCTACAGCCATCATGAATGCCATTTCCCCAACAAGGCGATGCCCTCAGCAGGAATGCTGCCGTGGCTCCAGGGGATCTTCTGCAATGTGAACAATCCCTGTTTTCAAAGCCCCACCCCAGGAGAATCTCCTGGAATTGTGTCAAACTATAACAACTCCATCTTGGCAAGGGTATATCGAGATTTTCAAGAACTCCTCATGAATGCACCAGAGAGCCAGCACCTTGGCCGTATTTGGACAGAGCTACACATCTTGTCCCAATTCATGGACACCCTCCGGACTCACCCGGAGAGAATTGCAGGAAGAGGAATACGAATAAGGGATATCTTGAAAGATGAAGAAACACTGACACTATTTCTCATTAAAAACATCGGCCTGTCTGACTCAGTGGTCTACCTTCTGATCAACTCTCAAGTCCGTCCAGAGCAGTTCGCTCATGGAGTCCCGGACCTGGCGCTGAAGGACATCGCCTGCAGCGAGGCCCTCCTGGAGCGCTTCATCATCTTCAGCCAGAGACGCGGGGCAAAGACGGTGCGCTATGCCCTGTGCTCCCTCTCCCAGGGCACCCTACAGTGGATAGAAGACACTCTGTATGCCAACGTGGACTTCTTCAAGCTCTTCCGTGTGCTTCCCACACTCCTAGACAGCCGTTCTCAAGGTATCAATCTGAGATCTTGGGGAGGAATATTATCTGATATGTCACCAAGAATTCAAGAGTTTATCCATCGGCCGAGTATGCAGGACTTGCTGTGGGTGACCAGGCCCCTCATGCAGAATGGTGGTCCAGAGACCTTTACAAAGCTGATGGGCATCCTGTCTGACCTCCTGTGTGGCTACCCCGAGGGAGGTGGCTCTCGGGTGCTCTCCTTCAACTGGTATGAAGACAATAACTATAAGGCCTTTCTGGGGATTGACTCCACAAGGAAGGATCCTATCTATTCTTATGACAGAAGAACAACATCCTTTTGTAATGCATTGATCCAGAGCCTGGAGTCAAATCCTTTAACCAAAATCGCTTGGAGGGCGGCAAAGCCTTTGCTGATGGGAAAAATCCTGTACACTCCTGATTCACCTGCAGCACGAAGGATACTGAAGAATGCCAACTCAACTTTTGAAGAACTGGAACACGTTAGGAAGTTGGTCAAAGCCTGGGAAGAAGTAGGGCCCCAGATCTGGTACTTCTTTGACAACAGCACACAGATGAACATGATCAGAGATACCCTGGGGAACCCAACAGTAAAAGACTTTTTGAATAGGCAGCTTGGTGAAGAAGGTATTACTGCTGAAGCCATCCTAAACTTCCTCTACAAGGGCCCTCGGGAAAGCCAGGCTGACGACATGGCCAACTTCGACTGGAGGGACATATTTAACATCACTGATCGCACCCTCCGCCTTGTCAATCAATACCTGGAGTGCTTGGTCCTGGATAAGTTTGAAAGCTACAATGATGAAACTCAGCTCACCCAACGTGCCCTCTCTCTACTGGAGGAAAACATGTTCTGGGCCGGAGTGGTATTCCCTGACATGTATCCCTGGACCAGCTCTCTACCACCCCACGTGAAGTATAAGATCCGAATGGACATAGACGTGGTGGAGAAAACCAATAAGATTAAAGACAGGTATTGGGATTCTGGTCCCAGAGCTGATCCCGTGGAAGATTTCCGGTACATCTGGGGCGGGTTTGCCTATCTGCAGGACATGGTTGAACAGGGGATCACAAGGAGCCAGGTGCAGGCGGAGGCTCCAGTTGGAATCTACCTCCAGCAGATGCCCTACCCCTGCTTCGTGGACGATTCTTTCATGATCATCCTGAACCGCTGTTTCCCTATCTTCATGGTGCTGGCATGGATCTACTCTGTCTCCATGACTGTGAAGAGCATCGTCTTGGAGAAGGAGTTGCGACTGAAGGAGACCTTGAAAAATCAGGGTGTCTCCAATGCAGTGATTTGGTGTACCTGGTTCCTGGACAGCTTCTCCATCATGTCGATGAGCATCTTCCTCCTGACGATATTCATCATGCATGGAAGAATCCTACATTACAGCGACCCATTCATCCTCTTCCTGTTCTTGTTGGCTTTCTCCACTGCCACCATCATGCTGTGCTTTCTGCTCAGCACCTTCTTCTCCAAGGCCAGTCTGGCAGCAGCCTGTAGTGGTGTCATCTATTTCACCCTCTACCTGCCACACATCCTGTGCTTCGCCTGGCAGGACCGCATGACCGCTGAGCTGAAGAAGGCTGTGAGCTTACTGTCTCCGGTGGCATTTGGATTTGGCACTGAGTACCTGGTTCGCTTTGAAGAGCAAGGCCTGGGGCTGCAGTGGAGCAACATCGGGAACAGTCCCACGGAAGGGGACGAATTCAGCTTCCTGCTGTCCATGCAGATGATGCTCCTTGATGCTGCTGTCTATGGCTTACTCGCTTGGTACCTTGATCAGGTGTTTCCAGGAGACTATGGAACCCCACTTCCTTGGTACTTTCTTCTACAAGAGTCGTATTGGCTTGGCGGTGAAGGGTGTTCAACCAGAGAAGAAAGAGCCCTGGAAAAGACCGAGCCCCTAACAGAGGAAACGGAGGATCCAGAGCACCCAGAAGGAATACACGACTCCTTCTTTGAACGTGAGCATCCAGGGTGGGTTCCTGGGGTATGCGTGAAGAATCTGGTAAAGATTTTTGAGCCCTGTGGCCGGCCAGCTGTGGACCGTCTGAACATCACCTTCTACGAGAACCAGATCACCGCATTCCTGGGCCACAATGGAGCTGGGAAAACCACCACCTTGTCCATCCTGACGGGTCTGTTGCCACCAACCTCTGGGACTGTGCTCGTTGGGGGAAGGGACATTGAAACCAGCCTGGATGCAGTCCGGCAGAGCCTTGGCATGTGTCCACAGCACAACATCCTGTTCCACCACCTCACGGTGGCTGAGCACATGCTGTTCTATGCCCAGCTGAAAGGAAAGTCCCAGGAGGAGGCCCAGCTGGAGATGGAAGCCATGTTGGAGGACACAGGCCTCCACCACAAGCGGAATGAAGAGGCTCAGGACCTATCAGGTGGCATGCAGAGAAAGCTGTCGGTTGCCATTGCCTTTGTGGGAGATGCCAAGGTGGTGATTCTGGACGAACCCACCTCTGGGGTGGACCCTTACTCGAGACGCTCAATCTGGGATCTGCTCCTGAAGTATCGCTCAGGCAGAACCATCATCATGTCCACTCACCACATGGACGAGGCCGACCTCCTTGGGGACCGCATTGCCATCATTGCCCAGGGAAGGCTCTACTGCTCAGGCACCCCACTCTTCCTGAAGAACTGCTTTGGCACAGGCTTGTACTTAACCTTGGTGCGCAAGATGAAAAACATCCAGAGCCAAAGGAAAGGCAGTGAGGGGACCTGCAGCTGCTCGTCTAAGGGTTTCTCCACCACGTGTCCAGCCCACGTCGATGACCTAACTCCAGAACAAGTCCTGGATGGGGATGTAAATGAGCTGATGGATGTAGTTCTCCACCATGTTCCAGAGGCAAAGCTGGTGGAGTGCATTGGTCAAGAACTTATCTTCCTTCTTCC
SEQ ID NO: 10
ACATCCAGAGCCAAAGGAAAGGCAGTGAGGGGACCTGCAGCTGCTCGTCTAAGGGTTTCTCCACCACGTGTCCAGCCCACGTCGATGACCTAACTCCAGAACAAGTCCTGGATGGGGATGTAAATGAGCTGATGGATGTAGTTCTCCACCATGTTCCAGAGGCAAAGCTGGTGGAGTGCATTGGTCAAGAACTTATCTTCCTTCTTCCAAATAAGAACTTCAAGCACAGAGCATATGCCAGCCTTTTCAGAGAGCTGGAGGAGACGCTGGCTGACCTTGGTCTCAGCAGTTTTGGAATTTCTGACACTCCCCTGGAAGAGATTTTTCTGAAGGTCACGGAGGATTCTGATTCAGGACCTCTGTTTGCGGGTGGCGCTCAGCAGAAAAGAGAAAACGTCAACCCCCGACACCCCTGCTTGGGTCCCAGAGAGAAGGCTGGACAGACACCCCAGGACTCCAATGTCTGCTCCCCAGGGGCGCCGGCTGCTCACCCAGAGGGCCAGCCTCCCCCAGAGCCAGAGTGCCCAGGCCCGCAGCTCAACACGGGGACACAGCTGGTCCTCCAGCATGTGCAGGCGCTGCTGGTCAAGAGATTCCAACACACCATCCGCAGCCACAAGGACTTCCTGGCGCAGATCGTGCTCCCGGCTACCTTTGTGTTTTTGGCTCTGATGCTTTCTATTGTTATCCCTCCTTTTGGCGAATACCCCGCTTTGACCCTTCACCCCTGGATATATGGGCAGCAGTACACCTTCTTCAGCATGGATGAACCAGGCAGTGAGCAGTTCACGGTACTTGCAGACGTCCTCCTGAATAAGCCAGGCTTTGGCAACCGCTGCCTGAAGGAAGGGTGGCTTCCGGAGTACCCCTGTGGCAACTCAACACCCTGGAAGACTCCTTCTGTGTCCCCAAACATCACCCAGCTGTTCCAGAAGCAGAAATGGACACAGGTCAACCCTTCACCATCCTGCAGGTGCAGCACCAGGGAGAAGCTCACCATGCTGCCAGAGTGCCCCGAGGGTGCCGGGGGCCTCCCGCCCCCCCAGAGAACACAGCGCAGCACGGAAATTCTACAAGACCTGACGGACAGGAACATCTCCGACTTCTTGGTAAAAACGTATCCTGCTCTTATAAGAAGCAGCTTAAAGAGCAAATTCTGGGTCAATGAACAGAGGTATGGAGGAATTTCCATTGGAGGAAAGCTCCCAGTCGTCCCCATCACGGGGGAAGCACTTGTTGGGTTTTTAAGCGACCTTGGCCGGATCATGAATGTGAGCGGGGGCCCTATCACTAGAGAGGCCTCTAAAGAAATACCTGATTTCCTTAAACATCTAGAAACTGAAGACAACATTAAGGTGTGGTTTAATAACAAAGGCTGGCATGCCCTGGTCAGCTTTCTCAATGTGGCCCACAACGCCATCTTACGGGCCAGCCTGCCTAAGGACAGGAGCCCCGAGGAGTATGGAATCACCGTCATTAGCCAACCCCTGAACCTGACCAAGGAGCAGCTCTCAGAGATTACAGTGCTGACCACTTCAGTGGATGCTGTGGTTGCCATCTGCGTGATTTTCTCCATGTCCTTCGTCCCAGCCAGCTTTGTCCTTTATTTGATCCAGGAGCGGGTGAACAAATCCAAGCACCTCCAGTTTATCAGTGGAGTGAGCCCCACCACCTACTGGGTAACCAACTTCCTCTGGGACATCATGAATTATTCCGTGAGTGCTGGGCTGGTGGTGGGCATCTTCATCGGGTTTCAGAAGAAAGCCTACACTTCTCCAGAAAACCTTCCTGCCCTTGTGGCACTGCTCCTGCTGTATGGATGGGCGGTCATTCCCATGATGTACCCAGCATCCTTCCTGTTTGATGTCCCCAGCACAGCCTATGTGGCTTTATCTTGTGCTAATCTGTTCATCGGCATCAACAGCAGTGCTATTACCTTCATCTTGGAATTATTTGAGAATAACCGGACGCTGCTCAGGTTCAACGCCGTGCTGAGGAAGCTGCTCATTGTCTTCCCCCACTTCTGCCTGGGCCGGGGCCTCATTGACCTTGCACTGAGCCAGGCTGTGACAGATGTCTATGCCCGGTTTGGTGAGGAGCACTCTGCAAATCCGTTCCACTGGGACCTGATTGGGAAGAACCTGTTTGCCATGGTGGTGGAAGGGGTGGTGTACTTCCTCCTGACCCTGCTGGTCCAGCGCCACTTCTTCCTCTCCCAATGGATTGCCGAGCCCACTAAGGAGCCCATTGTTGATGAAGATGATGATGTGGCTGAAGAAAGACAAAGAATTATTACTGGTGGAAATAAAACTGACATCTTAAGGCTACATGAACTAACCAAGATTTATCCAGGCACCTCCAGCCCAGCAGTGGACAGGCTGTGTGTCGGAGTTCGCCCTGGAGAGTGCTTTGGCCTCCTGGGAGTGAATGGTGCCGGCAAAACAACCACATTCAAGATGCTCACTGGGGACACCACAGTGACCTCAGGGGATGCCACCGTAGCAGGCAAGAGTATTTTAACCAATATTTCTGAAGTCCATCAAAATATGGGCTACTGTCCTCAGTTTGATGCAATCGATGAGCTGCTCACAGGACGAGAACATCTTTACCTTTATGCCCGGCTTCGAGGTGTACCAGCAGAAGAAATCGAAAAGGTTGCAAACTGGAGTATTAAGAGCCTGGGCCTGACTGTCTACGCCGACTGCCTGGCTGGCACGTACAGTGGGGGCAACAAGCGGAAACTCTCCACAGCCATCGCACTCATTGGCTGCCCACCGCTGGTGCTGCTGGATGAGCCCACCACAGGGATGGACCCCCAGGCACGCCGCATGCTGTGGAACGTCATCGTGAGCATCATCAGAGAAGGGAGGGCTGTGGTCCTCACATCCCACAGCATGGAAGAATGTGAGGCACTGTGTACCCGGCTGGCCATCATGGTAAAGGGCGCCTTTCGATGTATGGGCACCATTCAGCATCTCAAGTCCAAATTTGGAGATGGCTATATCGTCACAATGAAGATCAAATCCCCGAAGGACGACCTGCTTCCTGACCTGAACCCTGTGGAGCAGTTCTTCCAGGGGAACTTCCCAGGCAGTGTGCAGAGGGAGAGGCACTACAACATGCTCCAGTTCCAGGTCTCCTCCTCCTCCCTGGCGAGGATCTTCCAGCTCCTCCTCTCCCACAAGGACAGCCTGCTCATCGAGGAGTACTCAGTCACACAGACCACACTGGACCAGGTGTTTGTAAATTTTGCTAAACAGCAGACTGAAAGTCATGACCTCCCTCTGCACCCTCGAGCTGCTGGAGCCAGTCGACAAGCCCAGGACTGAAAGCTTATCGATAATCAACCTCTGGATTACAAAATTTGTGAAAGATTGACTGGTATTCTTAACTATGTTGCTCCTTTTACGCTATGTGGATACGCTGCTTTAATGCCTTTGTATCATGCTATTGCTTCCCGTATGGCTTTCATTTTCTCCTCCTTGTATAAATCCTGGTTGCTGTCTCTTTATGAGGAGTTGTGGCCCGTTGTCAGGCAACGTGGCGTGGTGTGCACTGTGTTTGCTGACGCAACCCCCACTGGTTGGGGCATTGCCACCACCTGTCAGCTCCTTTCCGGGACTTTCGCTTTCCCCCTCCCTATTGCCACGGCGGAACTCATCGCCGCCTGCCTTGCCCGCTGCTGGACAGGGGCTCGGCTGTTGGGCACTGACAATTCCGTGGTGTTGTCGGGGAAATCATCGTCCTTTCCTTGGCTGCTCGCCTGTGTTGCCACCTGGATTCTGCGCGGGACGTCCTTCTGCTACGTCCCTTCGGCCCTCAATCCAGCGGACCTTCCTTCCCGCGGCCTGCTGCCGGCTCTGCGGCCTCTTCCGCGTCTTCGCCTTCGCCCTCAGACGAGTCGGATCTCCCTTTGGGCCGCCTCCCCGCATGCCGCTGATCAGCCTCGACTGTGCCTTCTAGTTGCCAGCCATCTGTTGTTTGCCCCTCCCCCGTGCCTTCCTTGACCCTGGAAGGTGCCACTCCCACTGTCCTTTCCTAATAAAATGAGGAAATTGCATCGCATTGTCTGAGTAGGTGTCATTCTATTCTGGGGGGTGGGGTGGGGCAGGACAGCAAGGGGGAGGATTGGGAAGACAATAGCAGGCATGCTGGGGATGCGGTGGGCTCTATGGCTTCTGAGGCGGAAAGAACCAGCTGGGG
ПРИМЕРЫ
Пример 1. Получение вышележащего и нижележащего векторов AAV
Для получения указанного вектора AAV необходимы три плазмиды: pTransgene, pRepCap и pHelper. pTransgene содержит вышележащий или нижележащий трансген ABCA4, как подробно описано ниже (с подтверждением целостности ITR). pRepCap содержит гены rep и cap из генома AAV. Гены rep получают из генома AAV2, в то время как гены cap будут варьироваться в зависимости от требований к серотипу. pHelper содержит необходимые аденовирусные гены, необходимые для успешного получения AAV. Плазмиды комплексируют с полиэтиленимином (PEI) для получения тройной смеси для трансфекции, используемой для клеток HEK293T. Через три дня после трансфекции клетки собирают и лизируют. Лизат обрабатывают бензоназой и очищают перед нанесением на градиент йодиксанола, состоящий из фаз 15%, 25%, 40% и 60%. Образцы в градиенте центрифугируют при 59000 об./мин в течение 1 часа 30 минут, а затем отбирают фракцию 40%. Затем эту фазу AAV очищают и концентрируют с использованием фильтров Amicon Ultra 100K. После этой стадии получают 100-200 мкл очищенного AAV в PBS.
Пример 2. Структура примеров векторов AAV
Вышележащий вектор
Этот вектор содержит промотор, нетранслируемую область (UTR) и вышележащий сегмент CDS ABCA4 с ITR AAV2 на каждом конце трансгена (фигура 1). ABCA4 экспрессируют в фоторецепторных клетках сетчатки и, таким образом, включают промоторный элемент родопсинкиназы человека (GRK1). Конкретная последовательность промотора GRK1, содержащегося в вышележащем векторе, является такой, как описано Khani et al. (Investigative Ophthalmology и Visual Science, 48(9), 3954-3961, 2007), содержащей нуклеотиды -112-+87 гена GRK1 и используемой в доклинических исследованиях для генной терапии, направленной на фоторецепторные клетки.
После 199 нуклеотидов промотора GRK1 следует нетранслируемая область (UTR) из 186 нуклеотидов. Эту нуклеотидную последовательность выбирали из более крупной UTR (443 нуклеотидов), содержащейся в векторе REP1 для клинического исследования (MacLaren et al., 2014). В частности, выбранная последовательность включает фрагмент интрона 1 β-актина (CBA) Gallus gallus (с прогнозируемым донорным участком для сплайсинга), фрагмент интрона 2 β-глобина (RBG) Oryctolagus cuniculus (включая спрогнозированную точку ветвления и акцепторный участок для сплайсинга) и фрагмент экзона 3 β-глобина Oryctolagus cuniculus непосредственно перед консенсусной последовательностью Козак, что приводит к получению CDS ABCA4. Этот фрагмент UTR добавляют к исходному промоторному элементу GRK1 для повышения выхода трансляции (Rafiq et al., 1997; Chatterjee et al., 2009). Сам по себе промотор GRK1 демонстрирует очень хорошую экспрессию генов в фоторецепторных клетках, что позволяет предполагать отсутствие основных признаков ингибирования экспрессии.
Сравнение сетчаток Abca4-/-, в которые инъецировали двойной вектор, показало, что значительно больше белка ABCA4 образовывалось в глазах, в случае которых вышележащий вектор содержал элемент GRK1.5'UTR, по сравнению с промоторным элементом GRK1 в отдельности (фигура 2).
После консенсусной последовательности Козак в вышележащем векторе следует CDS ABCA4 с нуклеотидами 1-3701 (105-3805 в референсном файле NCBI NM_000350). Конечные 208 нуклеотидов CDS ABCA4 образуют первые 208 нуклеотидов CDS, содержащихся в нижележащем векторе, и служат в качестве зоны перекрывания. Фрагмент кодирующей последовательности, содержащийся в вышележащем векторе, совпадает с референсной последовательностью NM_000350, за исключением замены основания в нуклеотиде 1536 (NM_000350, 1640) G>T. Оно является третьим основанием кодона, и его замена не приводит к изменению аминокислотной последовательности. CDS ABCA4 является укороченной в области экзона 25 с 3'-ITR ниже ее.
Нижележащий вектор
Этот вектор содержит нижележащий сегмент CDS ABCA4, посттранскрипционный чувствительный элемент вируса гепатита сурков (WPRE) и сигнал полиаденилирования бычьего гормона роста (поли-A bGH) с ITR AAV2 на каждом конце трансгена (фигура 1). CDS ABCA4 начинается ниже 5'-ITR в положении 3494 (NM_000350, 3598) и продолжается до стоп-кодона в положении 6822 (NM_000350, 6926). Первые 208 нуклеотидов CDS ABCA4 являются такими же, как и конечные 208 нуклеотидов CDS ABCA4, содержащихся в вышележащем векторе, и они служат в качестве зоны перекрывания между трансгенами. Фрагмент кодирующей последовательности, содержащийся в нижележащем векторе, совпадает с референсной последовательностью NM_000350, за исключением замены основания в нуклеотиде 5175 (NM_000350, 5279) G>A и 6069 (NM_000350, 6173) T>C. Эти замены расположены в третьем основании кодона и не приводят к изменению аминокислотной последовательности.
Участок рестрикции HindIII отделяет стоп-кодон CDS ABCA4 от WPRE. Этот элемент составляет 593 нуклеотидов в длину и соответствует WPRE с инактивированным антигеном X, содержащемуся в векторе REP1 для клинического исследования. Участок рестрикции SphI отделяет WPRE от поли-A-сигнала bGH, составляющего 269 нуклеотидов в длину и соответствующего поли-A-сигналу bGH, присутствующему в векторе REP1 для клинического исследования. 3'-ITR расположен ниже поли-A-сигнала.
Известно, что 5'-ITR AAV2 имеет промоторную активность, и с использованием WPRE и поли-A-сигнала bGH в нижележащем трансгене будут получать стабильные транскрипты из нерекомбинировавших нижележащих векторов. CDS ABCA4 дикого типа, содержащаяся в нижележащем трансгене, содержит множество кодонов AUG в рамке считывания, которые нельзя заменить другими кодонами без изменения аминокислотной последовательности. Это делает возможной трансляцию со стабильных транскриптов, что приводит к наличию укороченных пептидов ABCA4, определяемых посредством вестерн-блоттинга (фигура 4a). Начальную последовательность выбранной зоны перекрывания тщательно выбирают так, чтобы она включала кодон AUG не в рамке считывания в хорошем контексте (что касается потенциальной консенсусной последовательности Козак) перед кодоном AUG в рамке считывания в более слабом контексте (фигура 5a) для активации аппарата трансляции для инициации с использованием участка не в рамке считывания. Есть всего четыре кодона AUG не в рамке считывания в различных контекстах перед AUG в рамке считывания. Все из них будут приводить к трансляции до стоп-кодона в пределах 10 аминокислот. Наличие этих кодонов AUG не в рамке считывания может предотвращать трансляцию укороченных белков ABCA4 с нерекомбинировавших нижележащих трансгенов.
Пример 3. Оценка зон перекрывания
Оптимальную зону перекрывания определяли после оценок in vitro и in vivo шести вариантов перекрывания (фигуры 3a и 3b, соответственно). Их обозначают как A, B, C, D, E и F, и они представляют собой следующие зоны перекрывания (X соответствует отсутствию перекрывания): A. 1173 нуклеотидов (3259-4430); B. 506 нуклеотидов (3300-3805); C. 208 нуклеотидов (3598-3805); D. 99 нуклеотидов (3707-3805); E. 49 нуклеотидов (3757-3805) и F. 24 нуклеотида (3782-3805). Все нижележащие трансгены для зон перекрывания B-X спарены с одним и тем же вышележащим трансгеном. Варианты перекрывания B и C имели лучшие свойства, чем все другие варианты, или были схожи между собой, но по различным причинам выбирали версию C двойного вектора. Во-первых, по причине ограниченной продукции укороченного ABCA4 с нерекомбинировавших нижележащих трансгенов (фигура 4a). Нерекомбинировавшие нижележащие трансгены с вариантов C, D, E, F и X приводили к значительно сниженным уровням укороченного белка ABCA4, чем версии A или B. В контексте двойного вектора перекрывание C приводит к наименьшей доле укороченного ABCA4 по сравнению с полноразмерным ABCA4 (фигуры 4b и 4c). Это позволяет предполагать, что вариант перекрывания трансгена C не только ограничивает нежелательную экспрессию с нерекомбинировавших трансгенов, но также рекомбинирует с большей эффективностью, чем вариант перекрывания B. Дополнительное доказательство этого получали при сравнении различий кратного изменения транскрипта и кратного изменения белка между сетчатками ABCA4-/-, в которые инъецировали варианты перекрывания C и B. С помощью праймеров к вышележащей части CDS ABCA4 (таким образом, определяя транскрипты нерекомбинировавших вышележащих трансгенов в дополнение к полноразмерным транскриптам ABCA4 из рекомбинировавших трансгенов) определяли очень высокие уровни транскриптов, присутствующих в сетчатках, в которые инъецировали двойные векторы с вариантами перекрывания B и C. Однако вариант перекрывания C приводил к достижению менее чем половины уровней транскрипта варианта перекрывания B, но в тоже время и к получению в 1,5 раза большего количества белка ABCA4 (фигура 4d). Учитывая, что обоим вариантам перекрывания соответствует один и тот же вышележащий вектор, и они отличаются только последовательностью нижележащего трансгена, предполагают, что зона перекрывания, выбранная для варианта перекрывания C, рекомбинирует с большей эффективностью, чем вариант перекрывания B.
Выбранная зона перекрывания имеет содержание GC-пар 52% и прогнозируемый уровень свободной энергии -19,60 ккал/моль, что приблизительно в три раза меньше значений для зоны перекрывания B в -55,60 ккал/моль (содержание GC-пар 53%), фигура 5b. Это снижение свободной энергии позволяет предполагать, что вторичную структуру, образованную нерекомбинировавшим вариантом перекрывания C, будет разрешить легче, чем в случае варианта перекрывания B, что, как прогнозируют авторы настоящего изобретения, сделает ее более доступной для взаимодействия с зоной перекрывания на противоположном трансгене.
Пример 4. Протоколы экспериментов
Фигура 2.
Мышам Abca4 -/- делали субретинальную инъекцию 2 мкл смеси двойных векторов (1:1), вводя 1E+9 копий генома каждого вектора на глаз. Энуклеацию глаза осуществляли через 6 недель после инъекции, иссекая нейросенсорную часть сетчатки из глазного яблока и лизируя ее в буфере RIPA. Ткань гомогенизировали и после центрифугирования выделяли супернатант. Супернатанты смешивали с денатурирующим буфером для внесения и анализировали с помощью 7,5% геля TGX в денатурирующих условиях. Белки переносили на мембрану PVDF и определяли ABCA4 с использованием поликлонального антитела кролика против ABCA4 (Abcam) и Gapdh с использованием моноклонального антитела мыши против GAPDH (Origene). Полосы визуализировали и анализировали с использованием системы визуализации LICOR. Уровни ABCA4 нормализовали по Gapdh для каждого образца, а затем представляли относительно глаз Abca4 -/- без инъекций.
Фигура 3a.
Клетки HEK293T использовали для засевания 6-луночных планшетов для культивирования в количестве 2E5 клеток на лунку. Через 24 часа отбирали одну лунку с клетками и осуществляли подсчет. Полученное количество использовали для определения соответствующего количества вектора для внесения в каждую лунку для достижения множественности заражения (MOI) 10000 на вектор. Удаляли среды для культивирования и добавляли AAV в 1 мл среды, несодержащей эмбриональную телячью сыворотку (FBS). Клетки инкубировали в течение одного часа при 37°C перед добавлением 1 мл среды, содержащей 20% FBS. Через 48 часа после трансдукции удаляли среду и добавляли свежую среду, содержащую 10% FBS. Клетки инкубировали в течение еще 48 часов, после чего снова меняли среду. Через 24 часа клетки собирали и трижды промывали холодным PBS с использованием щадящего цикла центрифугирования. После последней промывки удаляли PBS и замораживали клеточный осадок. Клеточный осадок размораживали на льду, а затем лизировали в буфере RIPA. Лизаты обрабатывали так же, как и в случае анализа вестерн-блоттинга образцов сетчатки, описанного выше.
Фигура 3b.
Как для фигуры 2.
Фигура 4a.
Клетки HEK293T использовали для засевания 6-луночных планшетов для культивирования в количестве 1E6 клеток на лунку. Через 24 часа смесь для трансфекции, содержащую 1 мкг плазмиды, комплексированной с реагентом для трансфекции LT1 (GeneFlow), наносили на клетки. Тестируемые плазмиды несли нижележащие трансгены, использованные при получении векторов AAV. Через 48 часов после трансфекции клетки промывали, собирали и оценивали посредством вестерн-блоттинга, как описано выше.
Фигура 4b.
Как для фигуры 2.
Фигура 4d.
Уровни белка ABCA4 получали посредством анализа вестерн-блоттинга, как описано для фигуры 2, и сравнивали кратное изменение в случае обработки двойными векторами с вариантами перекрывания C и B. Для сравнения уровней транскрипта получали образцы ткани в RNAlater (Ambion) и выделяли мРНК с использованием Dynabeads-oligodT mRNA DIRECT (Life Technologies). Синтез кДНК осуществляли с использованием 500 нг мРНК с использованием праймера oligodT и SuperScript III (Life Technologies). Образцы очищали с использованием центрифужных колонок для очистки продуктов ПЦР (QIAGEN) и элюировали в 50 мкл обработанной DEPC воды. Анализировали кДНК посредством qPCR вышележащей части CDS ABCA4. Уровни ABCA4 нормализовали по уровням актина и выражали относительно образцов Abca4 -/- без инъекции. Затем сравнивали кратное изменение уровней транскрипта ABCA4 в случае обработки двойными векторами с вариантами перекрывания C и B.
Пример 5. AAV-опосредованная доставка ABCA4 в фоторецепторы мышей Abca4-/- с использованием стратегии перекрывающихся двойных векторов
Данные, представленные в этом примере, свидетельствуют о том, что экспрессия белка ABCA4 специфически локализовалась во внешних фоторецепторных сегментах в модели мыши Abca4-/- после субретинальной инъекции системы перекрывающихся двойных векторов по изобретению.
Дизайн и получение трансгена:
Перекрывающиеся трансгены ABCA4 упаковывали в капсиды AAV8 Y733F. Вышележащий трансген содержал промотор родопсинкиназы человека (GRK1) и вышележащую часть кодирующей последовательности ABCA4 (CDS) между инвертированными концевыми повторами (ITR) AAV2. Нижележащий трансген содержал нижележащую часть CDS ABCA4, посттранскрипционный регуляторный элемент вируса гепатита сурков (WPRE) и поли-A-сигнал (pA). Вышележащий и нижележащий трансгены содержали область перекрывания CDS ABCA4.
Инъекции:
Мышам Abac4-/- в возрасте 4-5 недель делали субретинальную инъекцию 2 мкл, содержащих смесь 1:1 вышележащего и нижележащего векторов (1×1013 копий генома/мл). Через 6 недель после инъекции глаза собирали для иммуногистохимического анализа (IHC).
Иммуногистохимическое окрашивание:
Целые глазные яблоки с удаленными хрусталиками фиксировали в 4% параформальдегиде (PFA) в течение 20 минут, а затем инкубировали в 30% сахарозе в течение ночи при 4°C. Глаза замораживали в среде для заливки перед получением срезов. Срезы тканей сушили в течение ночи при комнатной температуре, а затем трижды промывали фосфатно-солевым буфером (PBS) в течение 5 минут. Образцы пермеабилизовали с использованием 0,2% Triton-X-100 в течение 20 минут, а затем трижды промывали PBS перед инкубацией с 10% сывороткой осла (DS), 1% бычьим сывороточным альбумином (BSA), 0,1% Triton-X-100 в течение одного часа. Антитела разводили 1/200 в 1% DS, 0,1% BSA, наносили на срезы и оставляли на два часа при комнатной температуре. Определение Abca4/ABCA4 осуществляли с использованием антитела козла против ABCA4 (AntibodiesOnline), активируемый гиперполяризацией управляемый циклическими нуклеотидами канал 1 (Hcn1) определяли с использованием антитела мыши против Hcn1 (Abcam) и родопсин определяли с использованием антитела мыши против 1D4 (Abcam). Срезы трижды промывали 0,05% Tween-20, а затем наносили вторичные антитела (разведенные 1/400) на один час в темноте. Срезы дважды промывали 0,05% Tween-20, затем инкубировали с красителем Хехст (1/1,000) в течение 15 минут. Срезы промывали PBS, затем оставляли сушиться. Среду для заливки против выгорания Diamond наносили на каждый срез и оставляли срезы на ночь перед визуализацией.
Результаты:
Экспрессия ABCA4 локализовалась во внешних сегментах фоторецепторных клеток.
На фигуре 7 показано окрашивание на Abca4/ABCA4 (зеленый) и Hcn1 (красный) в глазах дикого типа (WT) и Abca4-/-. Глаза WT SVEV 129, глаза Abca4-/- с инъекцией и без нее окрашивали на маркер внутренних сегментов фоторецепторов Hcn1 и Abca4/ABCA4. При анализе глаз WT и глаз Abca4-/-, обработанных двойным вектором, выявляли специфическую локализацию Abca4/ABCA4 во внешних сегментах фоторецепторных клеток.
Колокализация ABCA4 и родопсина.
На фигуре 8 показано окрашивание Abca4/ABCA4 (зеленый) и родопсин (красный) во внешних сегментах фоторецепторных клеток в глазах дикого типа (WT) и Abca4-/-. При анализе глаз WT и глаз Abca4-/-, обработанных двойными векторами, выявляли колокализацию родопсина и Abca4/ABCA4 во внешних сегментах фоторецепторных клеток.
На фигуре 9 показано апикальное окрашивание RPE на Abca4/ABCA4 (зеленый) и родопсин (красный) в глазах дикого типа (WT) и Abca4-/-. При анализе глаз WT и глаз Abca4-/-, обработанных двойными векторами, выявляли колокализацию родопсина и Abca4/ ABCA4 в апикальных областях клеток RPE, как предполагают, происходящую от отшелушивающихся дисков внешних сегментов. В глазах Abca4-/-, не обработанных двойными векторами, наблюдали только окрашивание на родопсин в апикальной области клеток RPE. На изображении A в рамке представлен профиль экспрессии в трансдуцированных клетках RPE, свидетельствующий о диффузном профиле окрашивания в отличие от окрашивания Abca4/ABCA4/rho. На изображении B подтверждено отсутствие экспрессии RPE при использовании промотора GRK1.
Выводы:
Оптимизированную систему перекрывающихся двойных векторов можно использовать для достижения экспрессии ABCA4 в фоторецепторных клетках, в которых он транспортируется в желаемые структуры внешних сегментов на уровне, определимом посредством IHC.
Пример 6. Оценка бисретиноидов/A2E у мышей Abca4-/-, которым вводили двойные векторы
В модели Abca4-/- мыши наблюдают повышение уровней бисретиноидов и A2E с возрастом по сравнению с мышами дикого типа. Однако в отличие от людей повышение бисретиноидов не достигает уровня, необходимого, чтобы вызвать какую-либо значительную дегенерацию сетчатки. Это позволяет предполагать, что в глазу мышей с недостаточностью Abca4 могут существовать другие компенсаторные механизмы. В сетчатке дикого типа Abca4 облегчает движение ретиналя из мембран дисков внешних сегментов фоторецепторных клеток для рециклинга. В случае отсутствия функционального Abca4, как в модели мыши Abca4-/-, ретиналь сохраняется в мембранах дисков внешних сегментов, где он подвергается биохимическим изменениям в различные формы бисретиноидов (фигура 11). Фоторецепторные клетки постоянно генерируют новые диски внешних сегментов, и при этом происходит движение более старых, более дистальных дисков в сторону клеток RPE, которые затем подвергают их деградации посредством фагоцитоза. У мыши с недостаточностью Abca4 фагоцитируемые диски содержат повышенные уровни бисретиноидов. Далее в клетках RPE они преобразуются в изоформы A2E, накопление которых приводит к образованию липофусцина. Таким образом, хотя накопления бисретиноидов у мыши с недостаточностью Abca4 недостаточно, чтобы вызвать дегенерацию сетчатки, несмотря на это можно количественно анализировать образующиеся повышенные уровни выше базового уровня и, таким образом, получать биомаркер функции Abca4.
Бисретиноидные соединения и A2E можно точно измерять посредством высокоэффективной жидкостной хроматографии (ВЭЖХ). Таким образом, мерой терапевтической эффективности у мышей, подвергнутых генной терапии ABCA4, будет достижение снижения уровней бисретиноидов и A2E по сравнению с необработанными глазами. Однако есть два фактора, которые необходимо учитывать. В первом случае, для клинического применения необходимо использовать кодирующую последовательность ABCA4 человека и промотор фоторецепторов человека, и маловероятно, что это будет так же эффективно у мышей. Кроме того, измерения посредством ВЭЖХ осуществляют на целом глазу, а не только области, подвергнутой воздействию вектора при субретинальной инъекции. Таким образом, маловероятно, что при общем снижении бисретиноидов у мышей с недостаточностью Abca4 будут достигнуты уровни дикого типа. Вторым фактором является субретинальная инъекция, что может приводить к повреждению дисков внешних сегментов. Т.к. эти структуры богаты бисретиноидами, эффекты генной терапии ABCA4 необходимо сравнивать со схожей ложной инъекцией. Теоретически, для этого необходимо использовать противоположный глаз той же мыши для контроля размера глаза и воздействия света в течение жизни, что также может влиять на накопление бисретиноидов.
По этой причине авторы настоящего изобретения сравнивали уровни бисретиноидов/A2E в когорте мышей Abca4-/-, которым делали ложную инъекцию в один глаз и схожую лечебную инъекцию в противоположный глаз. В каждый глаз с ложной инъекцией вводили вышележащий вектор с той же общей дозой AAV, которую вводили в парный глаз, в который вводили двойные векторы. Таким образом, в оба глаза каждой мыши делали субретинальную инъекцию 2 мкл, получая пузырь, содержащий 2×1010 геномных частиц вектора AAV.
Всего 13 нокаутным по Abca4 мышам в возрасте 4-5 недель делали инъекцию и собирали глаза через 3 месяца после инъекции. Проводили адаптацию мышей в темноте в течение 16 часов перед получением ткани, которое проводили в темноте при тусклом красном освещении. Затем целые глаза анонимизировали и в замороженном виде доставляли в Jules Stein Eye Institute для анализа бисретиноидов/A2E с использованием описанного анализа ВЭЖХ. Каждый целый глаз отбирали и обрабатывали без диссекции. После оценки посредством ВЭЖХ всех 26 глаз раскрывали их обозначения и сравнивали уровни бисретиноидов/A2E в каждом обработанном глазу с парным глазом, в который делали ложную инъекцию. С помощью двухстороннего ANOVA определяли, что лечение имело достоверный эффект в отношении уровней бисретиноидов/A2E с наблюдаемым снижением в глазах, в которые вводили двойные векторы, по сравнением с парными глазами, в которые делали ложную инъекцию (p=0,0171), фигура 12.
Все публикации, упомянутые в представленном выше описании, включены в настоящее описание в качестве ссылок. Специалистам в этой области будут очевидны различные модификации и изменения описанных продуктов, систем, применения и способов по изобретению без отклонения от объема и сущности изобретения. Хотя изобретение описано в контексте конкретных предпочтительных вариантов осуществления, следует понимать, что изобретение не должно быть ограничено такими конкретными вариантами осуществления. Фактически, различные модификации описанных способов осуществления изобретения, очевидные специалистам в биохимии, биотехнологии или родственных областях, предназначены для включения в объем формулы изобретения.
--->
СПИСОК ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> Oxford University Innovation Limited
<120> ВЕКТОРНАЯ СИСТЕМА НА ОСНОВЕ АДЕНОАССОЦИИРОВАННОГО ВИРУСА
<130> P107080PCT
<150> GB 1610448.1
<151> 2016-06-15
<150> GB 1707261.2
<151> 2017-05-05
<160> 11
<170> PatentIn version 3.5
<210> 1
<211> 7326
<212> ДНК
<213> Homo sapiens
<400> 1
aggacacagc gtccggagcc agaggcgctc ttaacggcgt ttatgtcctt tgctgtctga 60
ggggcctcag ctctgaccaa tctggtcttc gtgtggtcat tagcatgggc ttcgtgagac 120
agatacagct tttgctctgg aagaactgga ccctgcggaa aaggcaaaag attcgctttg 180
tggtggaact cgtgtggcct ttatctttat ttctggtctt gatctggtta aggaatgcca 240
acccgctcta cagccatcat gaatgccatt tccccaacaa ggcgatgccc tcagcaggaa 300
tgctgccgtg gctccagggg atcttctgca atgtgaacaa tccctgtttt caaagcccca 360
ccccaggaga atctcctgga attgtgtcaa actataacaa ctccatcttg gcaagggtat 420
atcgagattt tcaagaactc ctcatgaatg caccagagag ccagcacctt ggccgtattt 480
ggacagagct acacatcttg tcccaattca tggacaccct ccggactcac ccggagagaa 540
ttgcaggaag aggaatacga ataagggata tcttgaaaga tgaagaaaca ctgacactat 600
ttctcattaa aaacatcggc ctgtctgact cagtggtcta ccttctgatc aactctcaag 660
tccgtccaga gcagttcgct catggagtcc cggacctggc gctgaaggac atcgcctgca 720
gcgaggccct cctggagcgc ttcatcatct tcagccagag acgcggggca aagacggtgc 780
gctatgccct gtgctccctc tcccagggca ccctacagtg gatagaagac actctgtatg 840
ccaacgtgga cttcttcaag ctcttccgtg tgcttcccac actcctagac agccgttctc 900
aaggtatcaa tctgagatct tggggaggaa tattatctga tatgtcacca agaattcaag 960
agtttatcca tcggccgagt atgcaggact tgctgtgggt gaccaggccc ctcatgcaga 1020
atggtggtcc agagaccttt acaaagctga tgggcatcct gtctgacctc ctgtgtggct 1080
accccgaggg aggtggctct cgggtgctct ccttcaactg gtatgaagac aataactata 1140
aggcctttct ggggattgac tccacaagga aggatcctat ctattcttat gacagaagaa 1200
caacatcctt ttgtaatgca ttgatccaga gcctggagtc aaatccttta accaaaatcg 1260
cttggagggc ggcaaagcct ttgctgatgg gaaaaatcct gtacactcct gattcacctg 1320
cagcacgaag gatactgaag aatgccaact caacttttga agaactggaa cacgttagga 1380
agttggtcaa agcctgggaa gaagtagggc cccagatctg gtacttcttt gacaacagca 1440
cacagatgaa catgatcaga gataccctgg ggaacccaac agtaaaagac tttttgaata 1500
ggcagcttgg tgaagaaggt attactgctg aagccatcct aaacttcctc tacaagggcc 1560
ctcgggaaag ccaggctgac gacatggcca acttcgactg gagggacata tttaacatca 1620
ctgatcgcac cctccgcctg gtcaatcaat acctggagtg cttggtcctg gataagtttg 1680
aaagctacaa tgatgaaact cagctcaccc aacgtgccct ctctctactg gaggaaaaca 1740
tgttctgggc cggagtggta ttccctgaca tgtatccctg gaccagctct ctaccacccc 1800
acgtgaagta taagatccga atggacatag acgtggtgga gaaaaccaat aagattaaag 1860
acaggtattg ggattctggt cccagagctg atcccgtgga agatttccgg tacatctggg 1920
gcgggtttgc ctatctgcag gacatggttg aacaggggat cacaaggagc caggtgcagg 1980
cggaggctcc agttggaatc tacctccagc agatgcccta cccctgcttc gtggacgatt 2040
ctttcatgat catcctgaac cgctgtttcc ctatcttcat ggtgctggca tggatctact 2100
ctgtctccat gactgtgaag agcatcgtct tggagaagga gttgcgactg aaggagacct 2160
tgaaaaatca gggtgtctcc aatgcagtga tttggtgtac ctggttcctg gacagcttct 2220
ccatcatgtc gatgagcatc ttcctcctga cgatattcat catgcatgga agaatcctac 2280
attacagcga cccattcatc ctcttcctgt tcttgttggc tttctccact gccaccatca 2340
tgctgtgctt tctgctcagc accttcttct ccaaggccag tctggcagca gcctgtagtg 2400
gtgtcatcta tttcaccctc tacctgccac acatcctgtg cttcgcctgg caggaccgca 2460
tgaccgctga gctgaagaag gctgtgagct tactgtctcc ggtggcattt ggatttggca 2520
ctgagtacct ggttcgcttt gaagagcaag gcctggggct gcagtggagc aacatcggga 2580
acagtcccac ggaaggggac gaattcagct tcctgctgtc catgcagatg atgctccttg 2640
atgctgctgt ctatggctta ctcgcttggt accttgatca ggtgtttcca ggagactatg 2700
gaaccccact tccttggtac tttcttctac aagagtcgta ttggcttggc ggtgaagggt 2760
gttcaaccag agaagaaaga gccctggaaa agaccgagcc cctaacagag gaaacggagg 2820
atccagagca cccagaagga atacacgact ccttctttga acgtgagcat ccagggtggg 2880
ttcctggggt atgcgtgaag aatctggtaa agatttttga gccctgtggc cggccagctg 2940
tggaccgtct gaacatcacc ttctacgaga accagatcac cgcattcctg ggccacaatg 3000
gagctgggaa aaccaccacc ttgtccatcc tgacgggtct gttgccacca acctctggga 3060
ctgtgctcgt tgggggaagg gacattgaaa ccagcctgga tgcagtccgg cagagccttg 3120
gcatgtgtcc acagcacaac atcctgttcc accacctcac ggtggctgag cacatgctgt 3180
tctatgccca gctgaaagga aagtcccagg aggaggccca gctggagatg gaagccatgt 3240
tggaggacac aggcctccac cacaagcgga atgaagaggc tcaggaccta tcaggtggca 3300
tgcagagaaa gctgtcggtt gccattgcct ttgtgggaga tgccaaggtg gtgattctgg 3360
acgaacccac ctctggggtg gacccttact cgagacgctc aatctgggat ctgctcctga 3420
agtatcgctc aggcagaacc atcatcatgt ccactcacca catggacgag gccgacctcc 3480
ttggggaccg cattgccatc attgcccagg gaaggctcta ctgctcaggc accccactct 3540
tcctgaagaa ctgctttggc acaggcttgt acttaacctt ggtgcgcaag atgaaaaaca 3600
tccagagcca aaggaaaggc agtgagggga cctgcagctg ctcgtctaag ggtttctcca 3660
ccacgtgtcc agcccacgtc gatgacctaa ctccagaaca agtcctggat ggggatgtaa 3720
atgagctgat ggatgtagtt ctccaccatg ttccagaggc aaagctggtg gagtgcattg 3780
gtcaagaact tatcttcctt cttccaaata agaacttcaa gcacagagca tatgccagcc 3840
ttttcagaga gctggaggag acgctggctg accttggtct cagcagtttt ggaatttctg 3900
acactcccct ggaagagatt tttctgaagg tcacggagga ttctgattca ggacctctgt 3960
ttgcgggtgg cgctcagcag aaaagagaaa acgtcaaccc ccgacacccc tgcttgggtc 4020
ccagagagaa ggctggacag acaccccagg actccaatgt ctgctcccca ggggcgccgg 4080
ctgctcaccc agagggccag cctcccccag agccagagtg cccaggcccg cagctcaaca 4140
cggggacaca gctggtcctc cagcatgtgc aggcgctgct ggtcaagaga ttccaacaca 4200
ccatccgcag ccacaaggac ttcctggcgc agatcgtgct cccggctacc tttgtgtttt 4260
tggctctgat gctttctatt gttatccctc cttttggcga ataccccgct ttgacccttc 4320
acccctggat atatgggcag cagtacacct tcttcagcat ggatgaacca ggcagtgagc 4380
agttcacggt acttgcagac gtcctcctga ataagccagg ctttggcaac cgctgcctga 4440
aggaagggtg gcttccggag tacccctgtg gcaactcaac accctggaag actccttctg 4500
tgtccccaaa catcacccag ctgttccaga agcagaaatg gacacaggtc aacccttcac 4560
catcctgcag gtgcagcacc agggagaagc tcaccatgct gccagagtgc cccgagggtg 4620
ccgggggcct cccgcccccc cagagaacac agcgcagcac ggaaattcta caagacctga 4680
cggacaggaa catctccgac ttcttggtaa aaacgtatcc tgctcttata agaagcagct 4740
taaagagcaa attctgggtc aatgaacaga ggtatggagg aatttccatt ggaggaaagc 4800
tcccagtcgt ccccatcacg ggggaagcac ttgttgggtt tttaagcgac cttggccgga 4860
tcatgaatgt gagcgggggc cctatcacta gagaggcctc taaagaaata cctgatttcc 4920
ttaaacatct agaaactgaa gacaacatta aggtgtggtt taataacaaa ggctggcatg 4980
ccctggtcag ctttctcaat gtggcccaca acgccatctt acgggccagc ctgcctaagg 5040
acaggagccc cgaggagtat ggaatcaccg tcattagcca acccctgaac ctgaccaagg 5100
agcagctctc agagattaca gtgctgacca cttcagtgga tgctgtggtt gccatctgcg 5160
tgattttctc catgtccttc gtcccagcca gctttgtcct ttatttgatc caggagcggg 5220
tgaacaaatc caagcacctc cagtttatca gtggagtgag ccccaccacc tactgggtga 5280
ccaacttcct ctgggacatc atgaattatt ccgtgagtgc tgggctggtg gtgggcatct 5340
tcatcgggtt tcagaagaaa gcctacactt ctccagaaaa ccttcctgcc cttgtggcac 5400
tgctcctgct gtatggatgg gcggtcattc ccatgatgta cccagcatcc ttcctgtttg 5460
atgtccccag cacagcctat gtggctttat cttgtgctaa tctgttcatc ggcatcaaca 5520
gcagtgctat taccttcatc ttggaattat ttgagaataa ccggacgctg ctcaggttca 5580
acgccgtgct gaggaagctg ctcattgtct tcccccactt ctgcctgggc cggggcctca 5640
ttgaccttgc actgagccag gctgtgacag atgtctatgc ccggtttggt gaggagcact 5700
ctgcaaatcc gttccactgg gacctgattg ggaagaacct gtttgccatg gtggtggaag 5760
gggtggtgta cttcctcctg accctgctgg tccagcgcca cttcttcctc tcccaatgga 5820
ttgccgagcc cactaaggag cccattgttg atgaagatga tgatgtggct gaagaaagac 5880
aaagaattat tactggtgga aataaaactg acatcttaag gctacatgaa ctaaccaaga 5940
tttatccagg cacctccagc ccagcagtgg acaggctgtg tgtcggagtt cgccctggag 6000
agtgctttgg cctcctggga gtgaatggtg ccggcaaaac aaccacattc aagatgctca 6060
ctggggacac cacagtgacc tcaggggatg ccaccgtagc aggcaagagt attttaacca 6120
atatttctga agtccatcaa aatatgggct actgtcctca gtttgatgca attgatgagc 6180
tgctcacagg acgagaacat ctttaccttt atgcccggct tcgaggtgta ccagcagaag 6240
aaatcgaaaa ggttgcaaac tggagtatta agagcctggg cctgactgtc tacgccgact 6300
gcctggctgg cacgtacagt gggggcaaca agcggaaact ctccacagcc atcgcactca 6360
ttggctgccc accgctggtg ctgctggatg agcccaccac agggatggac ccccaggcac 6420
gccgcatgct gtggaacgtc atcgtgagca tcatcagaga agggagggct gtggtcctca 6480
catcccacag catggaagaa tgtgaggcac tgtgtacccg gctggccatc atggtaaagg 6540
gcgcctttcg atgtatgggc accattcagc atctcaagtc caaatttgga gatggctata 6600
tcgtcacaat gaagatcaaa tccccgaagg acgacctgct tcctgacctg aaccctgtgg 6660
agcagttctt ccaggggaac ttcccaggca gtgtgcagag ggagaggcac tacaacatgc 6720
tccagttcca ggtctcctcc tcctccctgg cgaggatctt ccagctcctc ctctcccaca 6780
aggacagcct gctcatcgag gagtactcag tcacacagac cacactggac caggtgtttg 6840
taaattttgc taaacagcag actgaaagtc atgacctccc tctgcaccct cgagctgctg 6900
gagccagtcg acaagcccag gactgatctt tcacaccgct cgttcctgca gccagaaagg 6960
aactctgggc agctggaggc gcaggagcct gtgcccatat ggtcatccaa atggactggc 7020
cagcgtaaat gaccccactg cagcagaaaa caaacacacg aggagcatgc agcgaattca 7080
gaaagaggtc tttcagaagg aaaccgaaac tgacttgctc acctggaaca cctgatggtg 7140
aaaccaaaca aatacaaaat ccttctccag accccagaac tagaaacccc gggccatccc 7200
actagcagct ttggcctcca tattgctctc atttcaagca gatctgcttt tctgcatgtt 7260
tgtctgtgtg tctgcgttgt gtgtgatttt catggaaaaa taaaatgcaa atgcactcat 7320
cacaaa 7326
<210> 2
<211> 7326
<212> ДНК
<213> Homo sapiens
<400> 2
aggacacagc gtccggagcc agaggcgctc ttaacggcgt ttatgtcctt tgctgtctga 60
ggggcctcag ctctgaccaa tctggtcttc gtgtggtcat tagcatgggc ttcgtgagac 120
agatacagct tttgctctgg aagaactgga ccctgcggaa aaggcaaaag attcgctttg 180
tggtggaact cgtgtggcct ttatctttat ttctggtctt gatctggtta aggaatgcca 240
acccgctcta cagccatcat gaatgccatt tccccaacaa ggcgatgccc tcagcaggaa 300
tgctgccgtg gctccagggg atcttctgca atgtgaacaa tccctgtttt caaagcccca 360
ccccaggaga atctcctgga attgtgtcaa actataacaa ctccatcttg gcaagggtat 420
atcgagattt tcaagaactc ctcatgaatg caccagagag ccagcacctt ggccgtattt 480
ggacagagct acacatcttg tcccaattca tggacaccct ccggactcac ccggagagaa 540
ttgcaggaag aggaatacga ataagggata tcttgaaaga tgaagaaaca ctgacactat 600
ttctcattaa aaacatcggc ctgtctgact cagtggtcta ccttctgatc aactctcaag 660
tccgtccaga gcagttcgct catggagtcc cggacctggc gctgaaggac atcgcctgca 720
gcgaggccct cctggagcgc ttcatcatct tcagccagag acgcggggca aagacggtgc 780
gctatgccct gtgctccctc tcccagggca ccctacagtg gatagaagac actctgtatg 840
ccaacgtgga cttcttcaag ctcttccgtg tgcttcccac actcctagac agccgttctc 900
aaggtatcaa tctgagatct tggggaggaa tattatctga tatgtcacca agaattcaag 960
agtttatcca tcggccgagt atgcaggact tgctgtgggt gaccaggccc ctcatgcaga 1020
atggtggtcc agagaccttt acaaagctga tgggcatcct gtctgacctc ctgtgtggct 1080
accccgaggg aggtggctct cgggtgctct ccttcaactg gtatgaagac aataactata 1140
aggcctttct ggggattgac tccacaagga aggatcctat ctattcttat gacagaagaa 1200
caacatcctt ttgtaatgca ttgatccaga gcctggagtc aaatccttta accaaaatcg 1260
cttggagggc ggcaaagcct ttgctgatgg gaaaaatcct gtacactcct gattcacctg 1320
cagcacgaag gatactgaag aatgccaact caacttttga agaactggaa cacgttagga 1380
agttggtcaa agcctgggaa gaagtagggc cccagatctg gtacttcttt gacaacagca 1440
cacagatgaa catgatcaga gataccctgg ggaacccaac agtaaaagac tttttgaata 1500
ggcagcttgg tgaagaaggt attactgctg aagccatcct aaacttcctc tacaagggcc 1560
ctcgggaaag ccaggctgac gacatggcca acttcgactg gagggacata tttaacatca 1620
ctgatcgcac cctccgcctt gtcaatcaat acctggagtg cttggtcctg gataagtttg 1680
aaagctacaa tgatgaaact cagctcaccc aacgtgccct ctctctactg gaggaaaaca 1740
tgttctgggc cggagtggta ttccctgaca tgtatccctg gaccagctct ctaccacccc 1800
acgtgaagta taagatccga atggacatag acgtggtgga gaaaaccaat aagattaaag 1860
acaggtattg ggattctggt cccagagctg atcccgtgga agatttccgg tacatctggg 1920
gcgggtttgc ctatctgcag gacatggttg aacaggggat cacaaggagc caggtgcagg 1980
cggaggctcc agttggaatc tacctccagc agatgcccta cccctgcttc gtggacgatt 2040
ctttcatgat catcctgaac cgctgtttcc ctatcttcat ggtgctggca tggatctact 2100
ctgtctccat gactgtgaag agcatcgtct tggagaagga gttgcgactg aaggagacct 2160
tgaaaaatca gggtgtctcc aatgcagtga tttggtgtac ctggttcctg gacagcttct 2220
ccatcatgtc gatgagcatc ttcctcctga cgatattcat catgcatgga agaatcctac 2280
attacagcga cccattcatc ctcttcctgt tcttgttggc tttctccact gccaccatca 2340
tgctgtgctt tctgctcagc accttcttct ccaaggccag tctggcagca gcctgtagtg 2400
gtgtcatcta tttcaccctc tacctgccac acatcctgtg cttcgcctgg caggaccgca 2460
tgaccgctga gctgaagaag gctgtgagct tactgtctcc ggtggcattt ggatttggca 2520
ctgagtacct ggttcgcttt gaagagcaag gcctggggct gcagtggagc aacatcggga 2580
acagtcccac ggaaggggac gaattcagct tcctgctgtc catgcagatg atgctccttg 2640
atgctgctgt ctatggctta ctcgcttggt accttgatca ggtgtttcca ggagactatg 2700
gaaccccact tccttggtac tttcttctac aagagtcgta ttggcttggc ggtgaagggt 2760
gttcaaccag agaagaaaga gccctggaaa agaccgagcc cctaacagag gaaacggagg 2820
atccagagca cccagaagga atacacgact ccttctttga acgtgagcat ccagggtggg 2880
ttcctggggt atgcgtgaag aatctggtaa agatttttga gccctgtggc cggccagctg 2940
tggaccgtct gaacatcacc ttctacgaga accagatcac cgcattcctg ggccacaatg 3000
gagctgggaa aaccaccacc ttgtccatcc tgacgggtct gttgccacca acctctggga 3060
ctgtgctcgt tgggggaagg gacattgaaa ccagcctgga tgcagtccgg cagagccttg 3120
gcatgtgtcc acagcacaac atcctgttcc accacctcac ggtggctgag cacatgctgt 3180
tctatgccca gctgaaagga aagtcccagg aggaggccca gctggagatg gaagccatgt 3240
tggaggacac aggcctccac cacaagcgga atgaagaggc tcaggaccta tcaggtggca 3300
tgcagagaaa gctgtcggtt gccattgcct ttgtgggaga tgccaaggtg gtgattctgg 3360
acgaacccac ctctggggtg gacccttact cgagacgctc aatctgggat ctgctcctga 3420
agtatcgctc aggcagaacc atcatcatgt ccactcacca catggacgag gccgacctcc 3480
ttggggaccg cattgccatc attgcccagg gaaggctcta ctgctcaggc accccactct 3540
tcctgaagaa ctgctttggc acaggcttgt acttaacctt ggtgcgcaag atgaaaaaca 3600
tccagagcca aaggaaaggc agtgagggga cctgcagctg ctcgtctaag ggtttctcca 3660
ccacgtgtcc agcccacgtc gatgacctaa ctccagaaca agtcctggat ggggatgtaa 3720
atgagctgat ggatgtagtt ctccaccatg ttccagaggc aaagctggtg gagtgcattg 3780
gtcaagaact tatcttcctt cttccaaata agaacttcaa gcacagagca tatgccagcc 3840
ttttcagaga gctggaggag acgctggctg accttggtct cagcagtttt ggaatttctg 3900
acactcccct ggaagagatt tttctgaagg tcacggagga ttctgattca ggacctctgt 3960
ttgcgggtgg cgctcagcag aaaagagaaa acgtcaaccc ccgacacccc tgcttgggtc 4020
ccagagagaa ggctggacag acaccccagg actccaatgt ctgctcccca ggggcgccgg 4080
ctgctcaccc agagggccag cctcccccag agccagagtg cccaggcccg cagctcaaca 4140
cggggacaca gctggtcctc cagcatgtgc aggcgctgct ggtcaagaga ttccaacaca 4200
ccatccgcag ccacaaggac ttcctggcgc agatcgtgct cccggctacc tttgtgtttt 4260
tggctctgat gctttctatt gttatccctc cttttggcga ataccccgct ttgacccttc 4320
acccctggat atatgggcag cagtacacct tcttcagcat ggatgaacca ggcagtgagc 4380
agttcacggt acttgcagac gtcctcctga ataagccagg ctttggcaac cgctgcctga 4440
aggaagggtg gcttccggag tacccctgtg gcaactcaac accctggaag actccttctg 4500
tgtccccaaa catcacccag ctgttccaga agcagaaatg gacacaggtc aacccttcac 4560
catcctgcag gtgcagcacc agggagaagc tcaccatgct gccagagtgc cccgagggtg 4620
ccgggggcct cccgcccccc cagagaacac agcgcagcac ggaaattcta caagacctga 4680
cggacaggaa catctccgac ttcttggtaa aaacgtatcc tgctcttata agaagcagct 4740
taaagagcaa attctgggtc aatgaacaga ggtatggagg aatttccatt ggaggaaagc 4800
tcccagtcgt ccccatcacg ggggaagcac ttgttgggtt tttaagcgac cttggccgga 4860
tcatgaatgt gagcgggggc cctatcacta gagaggcctc taaagaaata cctgatttcc 4920
ttaaacatct agaaactgaa gacaacatta aggtgtggtt taataacaaa ggctggcatg 4980
ccctggtcag ctttctcaat gtggcccaca acgccatctt acgggccagc ctgcctaagg 5040
acaggagccc cgaggagtat ggaatcaccg tcattagcca acccctgaac ctgaccaagg 5100
agcagctctc agagattaca gtgctgacca cttcagtgga tgctgtggtt gccatctgcg 5160
tgattttctc catgtccttc gtcccagcca gctttgtcct ttatttgatc caggagcggg 5220
tgaacaaatc caagcacctc cagtttatca gtggagtgag ccccaccacc tactgggtaa 5280
ccaacttcct ctgggacatc atgaattatt ccgtgagtgc tgggctggtg gtgggcatct 5340
tcatcgggtt tcagaagaaa gcctacactt ctccagaaaa ccttcctgcc cttgtggcac 5400
tgctcctgct gtatggatgg gcggtcattc ccatgatgta cccagcatcc ttcctgtttg 5460
atgtccccag cacagcctat gtggctttat cttgtgctaa tctgttcatc ggcatcaaca 5520
gcagtgctat taccttcatc ttggaattat ttgagaataa ccggacgctg ctcaggttca 5580
acgccgtgct gaggaagctg ctcattgtct tcccccactt ctgcctgggc cggggcctca 5640
ttgaccttgc actgagccag gctgtgacag atgtctatgc ccggtttggt gaggagcact 5700
ctgcaaatcc gttccactgg gacctgattg ggaagaacct gtttgccatg gtggtggaag 5760
gggtggtgta cttcctcctg accctgctgg tccagcgcca cttcttcctc tcccaatgga 5820
ttgccgagcc cactaaggag cccattgttg atgaagatga tgatgtggct gaagaaagac 5880
aaagaattat tactggtgga aataaaactg acatcttaag gctacatgaa ctaaccaaga 5940
tttatccagg cacctccagc ccagcagtgg acaggctgtg tgtcggagtt cgccctggag 6000
agtgctttgg cctcctggga gtgaatggtg ccggcaaaac aaccacattc aagatgctca 6060
ctggggacac cacagtgacc tcaggggatg ccaccgtagc aggcaagagt attttaacca 6120
atatttctga agtccatcaa aatatgggct actgtcctca gtttgatgca atcgatgagc 6180
tgctcacagg acgagaacat ctttaccttt atgcccggct tcgaggtgta ccagcagaag 6240
aaatcgaaaa ggttgcaaac tggagtatta agagcctggg cctgactgtc tacgccgact 6300
gcctggctgg cacgtacagt gggggcaaca agcggaaact ctccacagcc atcgcactca 6360
ttggctgccc accgctggtg ctgctggatg agcccaccac agggatggac ccccaggcac 6420
gccgcatgct gtggaacgtc atcgtgagca tcatcagaga agggagggct gtggtcctca 6480
catcccacag catggaagaa tgtgaggcac tgtgtacccg gctggccatc atggtaaagg 6540
gcgcctttcg atgtatgggc accattcagc atctcaagtc caaatttgga gatggctata 6600
tcgtcacaat gaagatcaaa tccccgaagg acgacctgct tcctgacctg aaccctgtgg 6660
agcagttctt ccaggggaac ttcccaggca gtgtgcagag ggagaggcac tacaacatgc 6720
tccagttcca ggtctcctcc tcctccctgg cgaggatctt ccagctcctc ctctcccaca 6780
aggacagcct gctcatcgag gagtactcag tcacacagac cacactggac caggtgtttg 6840
taaattttgc taaacagcag actgaaagtc atgacctccc tctgcaccct cgagctgctg 6900
gagccagtcg acaagcccag gactgatctt tcacaccgct cgttcctgca gccagaaagg 6960
aactctgggc agctggaggc gcaggagcct gtgcccatat ggtcatccaa atggactggc 7020
cagcgtaaat gaccccactg cagcagaaaa caaacacacg aggagcatgc agcgaattca 7080
gaaagaggtc tttcagaagg aaaccgaaac tgacttgctc acctggaaca cctgatggtg 7140
aaaccaaaca aatacaaaat ccttctccag accccagaac tagaaacccc gggccatccc 7200
actagcagct ttggcctcca tattgctctc atttcaagca gatctgcttt tctgcatgtt 7260
tgtctgtgtg tctgcgttgt gtgtgatttt catggaaaaa taaaatgcaa atgcactcat 7320
cacaaa 7326
<210> 3
<211> 4464
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Пример последовательности вышележащего вектора, содержащего ITR,
промотор CDS, ITR
<400> 3
ttggccactc cctctctgcg cgctcgctcg ctcactgagg ccgggcgacc aaaggtcgcc 60
cgacgcccgg gctttgcccg ggcggcctca gtgagcgagc gagcgcgcag agagggagtg 120
gccaactcca tcactagggg ttcctgcggc aattcagtcg ataactataa cggtcctaag 180
gtagcgattt aaatggtacc gggccccaga agcctggtgg ttgtttgtcc ttctcagggg 240
aaaagtgagg cggccccttg gaggaagggg ccgggcagaa tgatctaatc ggattccaag 300
cagctcaggg gattgtcttt ttctagcacc ttcttgccac tcctaagcgt cctccgtgac 360
cccggctggg atttagcctg gtgctgtgtc agccccgggt gccgcagggg gacggctgcc 420
ttcggggggg acggggcagg gcggggttcg gcttctggcg tgtgaccggc ggctctagag 480
cctctgctaa ccatgttcat gccttcttct ttttcctaca gctcctgggc aacgtgctgg 540
ttattgtgct gtctcatcat tttggcaaag aattaccacc atgggcttcg tgagacagat 600
acagcttttg ctctggaaga actggaccct gcggaaaagg caaaagattc gctttgtggt 660
ggaactcgtg tggcctttat ctttatttct ggtcttgatc tggttaagga atgccaaccc 720
gctctacagc catcatgaat gccatttccc caacaaggcg atgccctcag caggaatgct 780
gccgtggctc caggggatct tctgcaatgt gaacaatccc tgttttcaaa gccccacccc 840
aggagaatct cctggaattg tgtcaaacta taacaactcc atcttggcaa gggtatatcg 900
agattttcaa gaactcctca tgaatgcacc agagagccag caccttggcc gtatttggac 960
agagctacac atcttgtccc aattcatgga caccctccgg actcacccgg agagaattgc 1020
aggaagagga atacgaataa gggatatctt gaaagatgaa gaaacactga cactatttct 1080
cattaaaaac atcggcctgt ctgactcagt ggtctacctt ctgatcaact ctcaagtccg 1140
tccagagcag ttcgctcatg gagtcccgga cctggcgctg aaggacatcg cctgcagcga 1200
ggccctcctg gagcgcttca tcatcttcag ccagagacgc ggggcaaaga cggtgcgcta 1260
tgccctgtgc tccctctccc agggcaccct acagtggata gaagacactc tgtatgccaa 1320
cgtggacttc ttcaagctct tccgtgtgct tcccacactc ctagacagcc gttctcaagg 1380
tatcaatctg agatcttggg gaggaatatt atctgatatg tcaccaagaa ttcaagagtt 1440
tatccatcgg ccgagtatgc aggacttgct gtgggtgacc aggcccctca tgcagaatgg 1500
tggtccagag acctttacaa agctgatggg catcctgtct gacctcctgt gtggctaccc 1560
cgagggaggt ggctctcggg tgctctcctt caactggtat gaagacaata actataaggc 1620
ctttctgggg attgactcca caaggaagga tcctatctat tcttatgaca gaagaacaac 1680
atccttttgt aatgcattga tccagagcct ggagtcaaat cctttaacca aaatcgcttg 1740
gagggcggca aagcctttgc tgatgggaaa aatcctgtac actcctgatt cacctgcagc 1800
acgaaggata ctgaagaatg ccaactcaac ttttgaagaa ctggaacacg ttaggaagtt 1860
ggtcaaagcc tgggaagaag tagggcccca gatctggtac ttctttgaca acagcacaca 1920
gatgaacatg atcagagata ccctggggaa cccaacagta aaagactttt tgaataggca 1980
gcttggtgaa gaaggtatta ctgctgaagc catcctaaac ttcctctaca agggccctcg 2040
ggaaagccag gctgacgaca tggccaactt cgactggagg gacatattta acatcactga 2100
tcgcaccctc cgccttgtca atcaatacct ggagtgcttg gtcctggata agtttgaaag 2160
ctacaatgat gaaactcagc tcacccaacg tgccctctct ctactggagg aaaacatgtt 2220
ctgggccgga gtggtattcc ctgacatgta tccctggacc agctctctac caccccacgt 2280
gaagtataag atccgaatgg acatagacgt ggtggagaaa accaataaga ttaaagacag 2340
gtattgggat tctggtccca gagctgatcc cgtggaagat ttccggtaca tctggggcgg 2400
gtttgcctat ctgcaggaca tggttgaaca ggggatcaca aggagccagg tgcaggcgga 2460
ggctccagtt ggaatctacc tccagcagat gccctacccc tgcttcgtgg acgattcttt 2520
catgatcatc ctgaaccgct gtttccctat cttcatggtg ctggcatgga tctactctgt 2580
ctccatgact gtgaagagca tcgtcttgga gaaggagttg cgactgaagg agaccttgaa 2640
aaatcagggt gtctccaatg cagtgatttg gtgtacctgg ttcctggaca gcttctccat 2700
catgtcgatg agcatcttcc tcctgacgat attcatcatg catggaagaa tcctacatta 2760
cagcgaccca ttcatcctct tcctgttctt gttggctttc tccactgcca ccatcatgct 2820
gtgctttctg ctcagcacct tcttctccaa ggccagtctg gcagcagcct gtagtggtgt 2880
catctatttc accctctacc tgccacacat cctgtgcttc gcctggcagg accgcatgac 2940
cgctgagctg aagaaggctg tgagcttact gtctccggtg gcatttggat ttggcactga 3000
gtacctggtt cgctttgaag agcaaggcct ggggctgcag tggagcaaca tcgggaacag 3060
tcccacggaa ggggacgaat tcagcttcct gctgtccatg cagatgatgc tccttgatgc 3120
tgctgtctat ggcttactcg cttggtacct tgatcaggtg tttccaggag actatggaac 3180
cccacttcct tggtactttc ttctacaaga gtcgtattgg cttggcggtg aagggtgttc 3240
aaccagagaa gaaagagccc tggaaaagac cgagccccta acagaggaaa cggaggatcc 3300
agagcaccca gaaggaatac acgactcctt ctttgaacgt gagcatccag ggtgggttcc 3360
tggggtatgc gtgaagaatc tggtaaagat ttttgagccc tgtggccggc cagctgtgga 3420
ccgtctgaac atcaccttct acgagaacca gatcaccgca ttcctgggcc acaatggagc 3480
tgggaaaacc accaccttgt ccatcctgac gggtctgttg ccaccaacct ctgggactgt 3540
gctcgttggg ggaagggaca ttgaaaccag cctggatgca gtccggcaga gccttggcat 3600
gtgtccacag cacaacatcc tgttccacca cctcacggtg gctgagcaca tgctgttcta 3660
tgcccagctg aaaggaaagt cccaggagga ggcccagctg gagatggaag ccatgttgga 3720
ggacacaggc ctccaccaca agcggaatga agaggctcag gacctatcag gtggcatgca 3780
gagaaagctg tcggttgcca ttgcctttgt gggagatgcc aaggtggtga ttctggacga 3840
acccacctct ggggtggacc cttactcgag acgctcaatc tgggatctgc tcctgaagta 3900
tcgctcaggc agaaccatca tcatgtccac tcaccacatg gacgaggccg acctccttgg 3960
ggaccgcatt gccatcattg cccagggaag gctctactgc tcaggcaccc cactcttcct 4020
gaagaactgc tttggcacag gcttgtactt aaccttggtg cgcaagatga aaaacatcca 4080
gagccaaagg aaaggcagtg aggggacctg cagctgctcg tctaagggtt tctccaccac 4140
gtgtccagcc cacgtcgatg acctaactcc agaacaagtc ctggatgggg atgtaaatga 4200
gctgatggat gtagttctcc accatgttcc agaggcaaag ctggtggagt gcattggtca 4260
agaacttatc ttccttcttc catttaaatt agggataaca gggtaatggc gcgggccgca 4320
ggaaccccta gtgatggagt tggccactcc ctctctgcgc gctcgctcgc tcactgaggc 4380
cgcccgggca aagcccgggc gtcgggcgac ctttggtcgc ccggcctcag tgagcgagcg 4440
agcgcgcaga gagggagtgg ccaa 4464
<210> 4
<211> 4581
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Пример последовательности нижележащего вектора, содержащего ITR,
CDS,посттранскрипционный чувствительный элемент, последовательность
полиаденилирования, ITR
<400> 4
ttggccactc cctctctgcg cgctcgctcg ctcactgagg ccgggcgacc aaaggtcgcc 60
cgacgcccgg gctttgcccg ggcggcctca gtgagcgagc gagcgcgcag agagggagtg 120
gccaactcca tcactagggg ttcctgcggc aattcagtcg ataactataa cggtcctaag 180
gtagcgattt aaataacatc cagagccaaa ggaaaggcag tgaggggacc tgcagctgct 240
cgtctaaggg tttctccacc acgtgtccag cccacgtcga tgacctaact ccagaacaag 300
tcctggatgg ggatgtaaat gagctgatgg atgtagttct ccaccatgtt ccagaggcaa 360
agctggtgga gtgcattggt caagaactta tcttccttct tccaaataag aacttcaagc 420
acagagcata tgccagcctt ttcagagagc tggaggagac gctggctgac cttggtctca 480
gcagttttgg aatttctgac actcccctgg aagagatttt tctgaaggtc acggaggatt 540
ctgattcagg acctctgttt gcgggtggcg ctcagcagaa aagagaaaac gtcaaccccc 600
gacacccctg cttgggtccc agagagaagg ctggacagac accccaggac tccaatgtct 660
gctccccagg ggcgccggct gctcacccag agggccagcc tcccccagag ccagagtgcc 720
caggcccgca gctcaacacg gggacacagc tggtcctcca gcatgtgcag gcgctgctgg 780
tcaagagatt ccaacacacc atccgcagcc acaaggactt cctggcgcag atcgtgctcc 840
cggctacctt tgtgtttttg gctctgatgc tttctattgt tatccctcct tttggcgaat 900
accccgcttt gacccttcac ccctggatat atgggcagca gtacaccttc ttcagcatgg 960
atgaaccagg cagtgagcag ttcacggtac ttgcagacgt cctcctgaat aagccaggct 1020
ttggcaaccg ctgcctgaag gaagggtggc ttccggagta cccctgtggc aactcaacac 1080
cctggaagac tccttctgtg tccccaaaca tcacccagct gttccagaag cagaaatgga 1140
cacaggtcaa cccttcacca tcctgcaggt gcagcaccag ggagaagctc accatgctgc 1200
cagagtgccc cgagggtgcc gggggcctcc cgccccccca gagaacacag cgcagcacgg 1260
aaattctaca agacctgacg gacaggaaca tctccgactt cttggtaaaa acgtatcctg 1320
ctcttataag aagcagctta aagagcaaat tctgggtcaa tgaacagagg tatggaggaa 1380
tttccattgg aggaaagctc ccagtcgtcc ccatcacggg ggaagcactt gttgggtttt 1440
taagcgacct tggccggatc atgaatgtga gcgggggccc tatcactaga gaggcctcta 1500
aagaaatacc tgatttcctt aaacatctag aaactgaaga caacattaag gtgtggttta 1560
ataacaaagg ctggcatgcc ctggtcagct ttctcaatgt ggcccacaac gccatcttac 1620
gggccagcct gcctaaggac aggagccccg aggagtatgg aatcaccgtc attagccaac 1680
ccctgaacct gaccaaggag cagctctcag agattacagt gctgaccact tcagtggatg 1740
ctgtggttgc catctgcgtg attttctcca tgtccttcgt cccagccagc tttgtccttt 1800
atttgatcca ggagcgggtg aacaaatcca agcacctcca gtttatcagt ggagtgagcc 1860
ccaccaccta ctgggtaacc aacttcctct gggacatcat gaattattcc gtgagtgctg 1920
ggctggtggt gggcatcttc atcgggtttc agaagaaagc ctacacttct ccagaaaacc 1980
ttcctgccct tgtggcactg ctcctgctgt atggatgggc ggtcattccc atgatgtacc 2040
cagcatcctt cctgtttgat gtccccagca cagcctatgt ggctttatct tgtgctaatc 2100
tgttcatcgg catcaacagc agtgctatta ccttcatctt ggaattattt gagaataacc 2160
ggacgctgct caggttcaac gccgtgctga ggaagctgct cattgtcttc ccccacttct 2220
gcctgggccg gggcctcatt gaccttgcac tgagccaggc tgtgacagat gtctatgccc 2280
ggtttggtga ggagcactct gcaaatccgt tccactggga cctgattggg aagaacctgt 2340
ttgccatggt ggtggaaggg gtggtgtact tcctcctgac cctgctggtc cagcgccact 2400
tcttcctctc ccaatggatt gccgagccca ctaaggagcc cattgttgat gaagatgatg 2460
atgtggctga agaaagacaa agaattatta ctggtggaaa taaaactgac atcttaaggc 2520
tacatgaact aaccaagatt tatccaggca cctccagccc agcagtggac aggctgtgtg 2580
tcggagttcg ccctggagag tgctttggcc tcctgggagt gaatggtgcc ggcaaaacaa 2640
ccacattcaa gatgctcact ggggacacca cagtgacctc aggggatgcc accgtagcag 2700
gcaagagtat tttaaccaat atttctgaag tccatcaaaa tatgggctac tgtcctcagt 2760
ttgatgcaat cgatgagctg ctcacaggac gagaacatct ttacctttat gcccggcttc 2820
gaggtgtacc agcagaagaa atcgaaaagg ttgcaaactg gagtattaag agcctgggcc 2880
tgactgtcta cgccgactgc ctggctggca cgtacagtgg gggcaacaag cggaaactct 2940
ccacagccat cgcactcatt ggctgcccac cgctggtgct gctggatgag cccaccacag 3000
ggatggaccc ccaggcacgc cgcatgctgt ggaacgtcat cgtgagcatc atcagagaag 3060
ggagggctgt ggtcctcaca tcccacagca tggaagaatg tgaggcactg tgtacccggc 3120
tggccatcat ggtaaagggc gcctttcgat gtatgggcac cattcagcat ctcaagtcca 3180
aatttggaga tggctatatc gtcacaatga agatcaaatc cccgaaggac gacctgcttc 3240
ctgacctgaa ccctgtggag cagttcttcc aggggaactt cccaggcagt gtgcagaggg 3300
agaggcacta caacatgctc cagttccagg tctcctcctc ctccctggcg aggatcttcc 3360
agctcctcct ctcccacaag gacagcctgc tcatcgagga gtactcagtc acacagacca 3420
cactggacca ggtgtttgta aattttgcta aacagcagac tgaaagtcat gacctccctc 3480
tgcaccctcg agctgctgga gccagtcgac aagcccagga ctgaaagctt atcgataatc 3540
aacctctgga ttacaaaatt tgtgaaagat tgactggtat tcttaactat gttgctcctt 3600
ttacgctatg tggatacgct gctttaatgc ctttgtatca tgctattgct tcccgtatgg 3660
ctttcatttt ctcctccttg tataaatcct ggttgctgtc tctttatgag gagttgtggc 3720
ccgttgtcag gcaacgtggc gtggtgtgca ctgtgtttgc tgacgcaacc cccactggtt 3780
ggggcattgc caccacctgt cagctccttt ccgggacttt cgctttcccc ctccctattg 3840
ccacggcgga actcatcgcc gcctgccttg cccgctgctg gacaggggct cggctgttgg 3900
gcactgacaa ttccgtggtg ttgtcgggga aatcatcgtc ctttccttgg ctgctcgcct 3960
gtgttgccac ctggattctg cgcgggacgt ccttctgcta cgtcccttcg gccctcaatc 4020
cagcggacct tccttcccgc ggcctgctgc cggctctgcg gcctcttccg cgtcttcgcc 4080
ttcgccctca gacgagtcgg atctcccttt gggccgcctc cccgcatgcc gctgatcagc 4140
ctcgactgtg ccttctagtt gccagccatc tgttgtttgc ccctcccccg tgccttcctt 4200
gaccctggaa ggtgccactc ccactgtcct ttcctaataa aatgaggaaa ttgcatcgca 4260
ttgtctgagt aggtgtcatt ctattctggg gggtggggtg gggcaggaca gcaaggggga 4320
ggattgggaa gacaatagca ggcatgctgg ggatgcggtg ggctctatgg cttctgaggc 4380
ggaaagaacc agctggggat ttaaattagg gataacaggg taatggcgcg ggccgcagga 4440
acccctagtg atggagttgg ccactccctc tctgcgcgct cgctcgctca ctgaggccgc 4500
ccgggcaaag cccgggcgtc gggcgacctt tggtcgcccg gcctcagtga gcgagcgagc 4560
gcgcagagag ggagtggcca a 4581
<210> 5
<211> 199
<212> ДНК
<213> Homo sapiens
<400> 5
gggccccaga agcctggtgg ttgtttgtcc ttctcagggg aaaagtgagg cggccccttg 60
gaggaagggg ccgggcagaa tgatctaatc ggattccaag cagctcaggg gattgtcttt 120
ttctagcacc ttcttgccac tcctaagcgt cctccgtgac cccggctggg atttagcctg 180
gtgctgtgtc agccccggg 199
<210> 6
<211> 186
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность нетранслируемой области (UTR)
<400> 6
gtgccgcagg gggacggctg ccttcggggg ggacggggca gggcggggtt cggcttctgg 60
cgtgtgaccg gcggctctag agcctctgct aaccatgttc atgccttctt ctttttccta 120
cagctcctgg gcaacgtgct ggttattgtg ctgtctcatc attttggcaa agaattacca 180
ccatgg 186
<210> 7
<211> 593
<212> ДНК
<213> Вирус гепатита сурков
<400> 7
atcgataatc aacctctgga ttacaaaatt tgtgaaagat tgactggtat tcttaactat 60
gttgctcctt ttacgctatg tggatacgct gctttaatgc ctttgtatca tgctattgct 120
tcccgtatgg ctttcatttt ctcctccttg tataaatcct ggttgctgtc tctttatgag 180
gagttgtggc ccgttgtcag gcaacgtggc gtggtgtgca ctgtgtttgc tgacgcaacc 240
cccactggtt ggggcattgc caccacctgt cagctccttt ccgggacttt cgctttcccc 300
ctccctattg ccacggcgga actcatcgcc gcctgccttg cccgctgctg gacaggggct 360
cggctgttgg gcactgacaa ttccgtggtg ttgtcgggga aatcatcgtc ctttccttgg 420
ctgctcgcct gtgttgccac ctggattctg cgcgggacgt ccttctgcta cgtcccttcg 480
gccctcaatc cagcggacct tccttcccgc ggcctgctgc cggctctgcg gcctcttccg 540
cgtcttcgcc ttcgccctca gacgagtcgg atctcccttt gggccgcctc ccc 593
<210> 8
<211> 269
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность полиаденилирования бычьего гормона роста
<400> 8
cgctgatcag cctcgactgt gccttctagt tgccagccat ctgttgtttg cccctccccc 60
gtgccttcct tgaccctgga aggtgccact cccactgtcc tttcctaata aaatgaggaa 120
attgcatcgc attgtctgag taggtgtcat tctattctgg ggggtggggt ggggcaggac 180
agcaaggggg aggattggga agacaatagc aggcatgctg gggatgcggt gggctctatg 240
gcttctgagg cggaaagaac cagctgggg 269
<210> 9
<211> 4087
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Пример частичной последовательности вышележащего вектора, содержащего
промотор, CDS
<400> 9
ggtaccgggc cccagaagcc tggtggttgt ttgtccttct caggggaaaa gtgaggcggc 60
cccttggagg aaggggccgg gcagaatgat ctaatcggat tccaagcagc tcaggggatt 120
gtctttttct agcaccttct tgccactcct aagcgtcctc cgtgaccccg gctgggattt 180
agcctggtgc tgtgtcagcc ccgggtgccg cagggggacg gctgccttcg ggggggacgg 240
ggcagggcgg ggttcggctt ctggcgtgtg accggcggct ctagagcctc tgctaaccat 300
gttcatgcct tcttcttttt cctacagctc ctgggcaacg tgctggttat tgtgctgtct 360
catcattttg gcaaagaatt accaccatgg gcttcgtgag acagatacag cttttgctct 420
ggaagaactg gaccctgcgg aaaaggcaaa agattcgctt tgtggtggaa ctcgtgtggc 480
ctttatcttt atttctggtc ttgatctggt taaggaatgc caacccgctc tacagccatc 540
atgaatgcca tttccccaac aaggcgatgc cctcagcagg aatgctgccg tggctccagg 600
ggatcttctg caatgtgaac aatccctgtt ttcaaagccc caccccagga gaatctcctg 660
gaattgtgtc aaactataac aactccatct tggcaagggt atatcgagat tttcaagaac 720
tcctcatgaa tgcaccagag agccagcacc ttggccgtat ttggacagag ctacacatct 780
tgtcccaatt catggacacc ctccggactc acccggagag aattgcagga agaggaatac 840
gaataaggga tatcttgaaa gatgaagaaa cactgacact atttctcatt aaaaacatcg 900
gcctgtctga ctcagtggtc taccttctga tcaactctca agtccgtcca gagcagttcg 960
ctcatggagt cccggacctg gcgctgaagg acatcgcctg cagcgaggcc ctcctggagc 1020
gcttcatcat cttcagccag agacgcgggg caaagacggt gcgctatgcc ctgtgctccc 1080
tctcccaggg caccctacag tggatagaag acactctgta tgccaacgtg gacttcttca 1140
agctcttccg tgtgcttccc acactcctag acagccgttc tcaaggtatc aatctgagat 1200
cttggggagg aatattatct gatatgtcac caagaattca agagtttatc catcggccga 1260
gtatgcagga cttgctgtgg gtgaccaggc ccctcatgca gaatggtggt ccagagacct 1320
ttacaaagct gatgggcatc ctgtctgacc tcctgtgtgg ctaccccgag ggaggtggct 1380
ctcgggtgct ctccttcaac tggtatgaag acaataacta taaggccttt ctggggattg 1440
actccacaag gaaggatcct atctattctt atgacagaag aacaacatcc ttttgtaatg 1500
cattgatcca gagcctggag tcaaatcctt taaccaaaat cgcttggagg gcggcaaagc 1560
ctttgctgat gggaaaaatc ctgtacactc ctgattcacc tgcagcacga aggatactga 1620
agaatgccaa ctcaactttt gaagaactgg aacacgttag gaagttggtc aaagcctggg 1680
aagaagtagg gccccagatc tggtacttct ttgacaacag cacacagatg aacatgatca 1740
gagataccct ggggaaccca acagtaaaag actttttgaa taggcagctt ggtgaagaag 1800
gtattactgc tgaagccatc ctaaacttcc tctacaaggg ccctcgggaa agccaggctg 1860
acgacatggc caacttcgac tggagggaca tatttaacat cactgatcgc accctccgcc 1920
ttgtcaatca atacctggag tgcttggtcc tggataagtt tgaaagctac aatgatgaaa 1980
ctcagctcac ccaacgtgcc ctctctctac tggaggaaaa catgttctgg gccggagtgg 2040
tattccctga catgtatccc tggaccagct ctctaccacc ccacgtgaag tataagatcc 2100
gaatggacat agacgtggtg gagaaaacca ataagattaa agacaggtat tgggattctg 2160
gtcccagagc tgatcccgtg gaagatttcc ggtacatctg gggcgggttt gcctatctgc 2220
aggacatggt tgaacagggg atcacaagga gccaggtgca ggcggaggct ccagttggaa 2280
tctacctcca gcagatgccc tacccctgct tcgtggacga ttctttcatg atcatcctga 2340
accgctgttt ccctatcttc atggtgctgg catggatcta ctctgtctcc atgactgtga 2400
agagcatcgt cttggagaag gagttgcgac tgaaggagac cttgaaaaat cagggtgtct 2460
ccaatgcagt gatttggtgt acctggttcc tggacagctt ctccatcatg tcgatgagca 2520
tcttcctcct gacgatattc atcatgcatg gaagaatcct acattacagc gacccattca 2580
tcctcttcct gttcttgttg gctttctcca ctgccaccat catgctgtgc tttctgctca 2640
gcaccttctt ctccaaggcc agtctggcag cagcctgtag tggtgtcatc tatttcaccc 2700
tctacctgcc acacatcctg tgcttcgcct ggcaggaccg catgaccgct gagctgaaga 2760
aggctgtgag cttactgtct ccggtggcat ttggatttgg cactgagtac ctggttcgct 2820
ttgaagagca aggcctgggg ctgcagtgga gcaacatcgg gaacagtccc acggaagggg 2880
acgaattcag cttcctgctg tccatgcaga tgatgctcct tgatgctgct gtctatggct 2940
tactcgcttg gtaccttgat caggtgtttc caggagacta tggaacccca cttccttggt 3000
actttcttct acaagagtcg tattggcttg gcggtgaagg gtgttcaacc agagaagaaa 3060
gagccctgga aaagaccgag cccctaacag aggaaacgga ggatccagag cacccagaag 3120
gaatacacga ctccttcttt gaacgtgagc atccagggtg ggttcctggg gtatgcgtga 3180
agaatctggt aaagattttt gagccctgtg gccggccagc tgtggaccgt ctgaacatca 3240
ccttctacga gaaccagatc accgcattcc tgggccacaa tggagctggg aaaaccacca 3300
ccttgtccat cctgacgggt ctgttgccac caacctctgg gactgtgctc gttgggggaa 3360
gggacattga aaccagcctg gatgcagtcc ggcagagcct tggcatgtgt ccacagcaca 3420
acatcctgtt ccaccacctc acggtggctg agcacatgct gttctatgcc cagctgaaag 3480
gaaagtccca ggaggaggcc cagctggaga tggaagccat gttggaggac acaggcctcc 3540
accacaagcg gaatgaagag gctcaggacc tatcaggtgg catgcagaga aagctgtcgg 3600
ttgccattgc ctttgtggga gatgccaagg tggtgattct ggacgaaccc acctctgggg 3660
tggaccctta ctcgagacgc tcaatctggg atctgctcct gaagtatcgc tcaggcagaa 3720
ccatcatcat gtccactcac cacatggacg aggccgacct ccttggggac cgcattgcca 3780
tcattgccca gggaaggctc tactgctcag gcaccccact cttcctgaag aactgctttg 3840
gcacaggctt gtacttaacc ttggtgcgca agatgaaaaa catccagagc caaaggaaag 3900
gcagtgaggg gacctgcagc tgctcgtcta agggtttctc caccacgtgt ccagcccacg 3960
tcgatgacct aactccagaa caagtcctgg atggggatgt aaatgagctg atggatgtag 4020
ttctccacca tgttccagag gcaaagctgg tggagtgcat tggtcaagaa cttatcttcc 4080
ttcttcc 4087
<210> 10
<211> 4203
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Пример частичной последовательности нижележащего вектора,
содержащего CDS,посттранскрипционный чувствительный элемент,
последовательность полиаденилирования
<400> 10
acatccagag ccaaaggaaa ggcagtgagg ggacctgcag ctgctcgtct aagggtttct 60
ccaccacgtg tccagcccac gtcgatgacc taactccaga acaagtcctg gatggggatg 120
taaatgagct gatggatgta gttctccacc atgttccaga ggcaaagctg gtggagtgca 180
ttggtcaaga acttatcttc cttcttccaa ataagaactt caagcacaga gcatatgcca 240
gccttttcag agagctggag gagacgctgg ctgaccttgg tctcagcagt tttggaattt 300
ctgacactcc cctggaagag atttttctga aggtcacgga ggattctgat tcaggacctc 360
tgtttgcggg tggcgctcag cagaaaagag aaaacgtcaa cccccgacac ccctgcttgg 420
gtcccagaga gaaggctgga cagacacccc aggactccaa tgtctgctcc ccaggggcgc 480
cggctgctca cccagagggc cagcctcccc cagagccaga gtgcccaggc ccgcagctca 540
acacggggac acagctggtc ctccagcatg tgcaggcgct gctggtcaag agattccaac 600
acaccatccg cagccacaag gacttcctgg cgcagatcgt gctcccggct acctttgtgt 660
ttttggctct gatgctttct attgttatcc ctccttttgg cgaatacccc gctttgaccc 720
ttcacccctg gatatatggg cagcagtaca ccttcttcag catggatgaa ccaggcagtg 780
agcagttcac ggtacttgca gacgtcctcc tgaataagcc aggctttggc aaccgctgcc 840
tgaaggaagg gtggcttccg gagtacccct gtggcaactc aacaccctgg aagactcctt 900
ctgtgtcccc aaacatcacc cagctgttcc agaagcagaa atggacacag gtcaaccctt 960
caccatcctg caggtgcagc accagggaga agctcaccat gctgccagag tgccccgagg 1020
gtgccggggg cctcccgccc ccccagagaa cacagcgcag cacggaaatt ctacaagacc 1080
tgacggacag gaacatctcc gacttcttgg taaaaacgta tcctgctctt ataagaagca 1140
gcttaaagag caaattctgg gtcaatgaac agaggtatgg aggaatttcc attggaggaa 1200
agctcccagt cgtccccatc acgggggaag cacttgttgg gtttttaagc gaccttggcc 1260
ggatcatgaa tgtgagcggg ggccctatca ctagagaggc ctctaaagaa atacctgatt 1320
tccttaaaca tctagaaact gaagacaaca ttaaggtgtg gtttaataac aaaggctggc 1380
atgccctggt cagctttctc aatgtggccc acaacgccat cttacgggcc agcctgccta 1440
aggacaggag ccccgaggag tatggaatca ccgtcattag ccaacccctg aacctgacca 1500
aggagcagct ctcagagatt acagtgctga ccacttcagt ggatgctgtg gttgccatct 1560
gcgtgatttt ctccatgtcc ttcgtcccag ccagctttgt cctttatttg atccaggagc 1620
gggtgaacaa atccaagcac ctccagttta tcagtggagt gagccccacc acctactggg 1680
taaccaactt cctctgggac atcatgaatt attccgtgag tgctgggctg gtggtgggca 1740
tcttcatcgg gtttcagaag aaagcctaca cttctccaga aaaccttcct gcccttgtgg 1800
cactgctcct gctgtatgga tgggcggtca ttcccatgat gtacccagca tccttcctgt 1860
ttgatgtccc cagcacagcc tatgtggctt tatcttgtgc taatctgttc atcggcatca 1920
acagcagtgc tattaccttc atcttggaat tatttgagaa taaccggacg ctgctcaggt 1980
tcaacgccgt gctgaggaag ctgctcattg tcttccccca cttctgcctg ggccggggcc 2040
tcattgacct tgcactgagc caggctgtga cagatgtcta tgcccggttt ggtgaggagc 2100
actctgcaaa tccgttccac tgggacctga ttgggaagaa cctgtttgcc atggtggtgg 2160
aaggggtggt gtacttcctc ctgaccctgc tggtccagcg ccacttcttc ctctcccaat 2220
ggattgccga gcccactaag gagcccattg ttgatgaaga tgatgatgtg gctgaagaaa 2280
gacaaagaat tattactggt ggaaataaaa ctgacatctt aaggctacat gaactaacca 2340
agatttatcc aggcacctcc agcccagcag tggacaggct gtgtgtcgga gttcgccctg 2400
gagagtgctt tggcctcctg ggagtgaatg gtgccggcaa aacaaccaca ttcaagatgc 2460
tcactgggga caccacagtg acctcagggg atgccaccgt agcaggcaag agtattttaa 2520
ccaatatttc tgaagtccat caaaatatgg gctactgtcc tcagtttgat gcaatcgatg 2580
agctgctcac aggacgagaa catctttacc tttatgcccg gcttcgaggt gtaccagcag 2640
aagaaatcga aaaggttgca aactggagta ttaagagcct gggcctgact gtctacgccg 2700
actgcctggc tggcacgtac agtgggggca acaagcggaa actctccaca gccatcgcac 2760
tcattggctg cccaccgctg gtgctgctgg atgagcccac cacagggatg gacccccagg 2820
cacgccgcat gctgtggaac gtcatcgtga gcatcatcag agaagggagg gctgtggtcc 2880
tcacatccca cagcatggaa gaatgtgagg cactgtgtac ccggctggcc atcatggtaa 2940
agggcgcctt tcgatgtatg ggcaccattc agcatctcaa gtccaaattt ggagatggct 3000
atatcgtcac aatgaagatc aaatccccga aggacgacct gcttcctgac ctgaaccctg 3060
tggagcagtt cttccagggg aacttcccag gcagtgtgca gagggagagg cactacaaca 3120
tgctccagtt ccaggtctcc tcctcctccc tggcgaggat cttccagctc ctcctctccc 3180
acaaggacag cctgctcatc gaggagtact cagtcacaca gaccacactg gaccaggtgt 3240
ttgtaaattt tgctaaacag cagactgaaa gtcatgacct ccctctgcac cctcgagctg 3300
ctggagccag tcgacaagcc caggactgaa agcttatcga taatcaacct ctggattaca 3360
aaatttgtga aagattgact ggtattctta actatgttgc tccttttacg ctatgtggat 3420
acgctgcttt aatgcctttg tatcatgcta ttgcttcccg tatggctttc attttctcct 3480
ccttgtataa atcctggttg ctgtctcttt atgaggagtt gtggcccgtt gtcaggcaac 3540
gtggcgtggt gtgcactgtg tttgctgacg caacccccac tggttggggc attgccacca 3600
cctgtcagct cctttccggg actttcgctt tccccctccc tattgccacg gcggaactca 3660
tcgccgcctg ccttgcccgc tgctggacag gggctcggct gttgggcact gacaattccg 3720
tggtgttgtc ggggaaatca tcgtcctttc cttggctgct cgcctgtgtt gccacctgga 3780
ttctgcgcgg gacgtccttc tgctacgtcc cttcggccct caatccagcg gaccttcctt 3840
cccgcggcct gctgccggct ctgcggcctc ttccgcgtct tcgccttcgc cctcagacga 3900
gtcggatctc cctttgggcc gcctccccgc atgccgctga tcagcctcga ctgtgccttc 3960
tagttgccag ccatctgttg tttgcccctc ccccgtgcct tccttgaccc tggaaggtgc 4020
cactcccact gtcctttcct aataaaatga ggaaattgca tcgcattgtc tgagtaggtg 4080
tcattctatt ctggggggtg gggtggggca ggacagcaag ggggaggatt gggaagacaa 4140
tagcaggcat gctggggatg cggtgggctc tatggcttct gaggcggaaa gaaccagctg 4200
ggg 4203
<210> 11
<211> 208
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность перекрывания C с кодонами AUG не в рамке считывания
перед кодоном AUG в рамке считывания
<400> 11
acauccagag ccaaaggaaa ggcagugagg ggaccugcag cugcucgucu aaggguuucu 60
ccaccacgug uccagcccac gucgaugacc uaacuccaga acaaguccug gauggggaug 120
uaaaugagcu gauggaugua guucuccacc auguuccaga ggcaaagcug guggagugca 180
uuggucaaga acuuaucuuc cuucuucc 208
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| ГЕННОЕ РЕДАКТИРОВАНИЕ ГЛУБОКИХ ИНТРОННЫХ МУТАЦИЙ | 2016 |
|
RU2759335C2 |
| ГЕННАЯ ТЕРАПИЯ ОФТАЛЬМОЛОГИЧЕСКИХ НАРУШЕНИЙ | 2016 |
|
RU2762747C2 |
| ГЕНОТЕРАПЕВТИЧЕСКИЕ КОНСТРУКЦИИ ДЛЯ ЛЕЧЕНИЯ БОЛЕЗНИ ВИЛЬСОНА | 2020 |
|
RU2807158C2 |
| АДЕНОАССОЦИИРОВАННЫЕ ВИРУСНЫЕ ВЕКТОРЫ ДЛЯ ЛЕЧЕНИЯ МИОЦИЛИНОВОЙ (MYOC) ГЛАУКОМЫ | 2015 |
|
RU2746991C2 |
| МОДИФИЦИРОВАННЫЙ ФАКТОР IX, А ТАКЖЕ КОМПОЗИЦИИ, СПОСОБЫ И ВАРИАНТЫ ПРИМЕНЕНИЯ ПЕРЕНОСА ГЕНОВ В КЛЕТКИ, ОРГАНЫ И ТКАНИ | 2016 |
|
RU2811445C2 |
| ВЕКТОРНЫЕ КОМПОЗИЦИИ С МОДИФИЦИРОВАННЫМ АДЕНОАССОЦИИРОВАННЫМ ВИРУСОМ | 2013 |
|
RU2679843C2 |
| АДЕНОАССОЦИИРОВАННЫЙ ВИРУСНЫЙ ВЕКТОР, СОСТОЯЩИЙ ИЗ БЕЛКОВ КАПСИДА РНР.В, НУКЛЕИНОВОЙ КИСЛОТЫ, КОДИРУЮЩЕЙ БЕЛОК SMN, И ЕГО ПРИМЕНЕНИЕ | 2022 |
|
RU2833225C2 |
| АДЕНОАССОЦИИРОВАННЫЕ ВИРУСНЫЕ ВЕКТОРЫ ДЛЯ ЛЕЧЕНИЯ МИОЦИЛИНОВОЙ (MYOC) ГЛАУКОМЫ | 2015 |
|
RU2718047C2 |
| ВАРИАНТ СРЕДСТВА ДЛЯ RNAi | 2018 |
|
RU2789647C2 |
| СПОСОБЫ И КОМПОЗИЦИИ ДЛЯ ЛЕЧЕНИЯ НАРУШЕНИЙ И ЗАБОЛЕВАНИЙ, СВЯЗАННЫХ С RDH12 | 2017 |
|
RU2764920C2 |

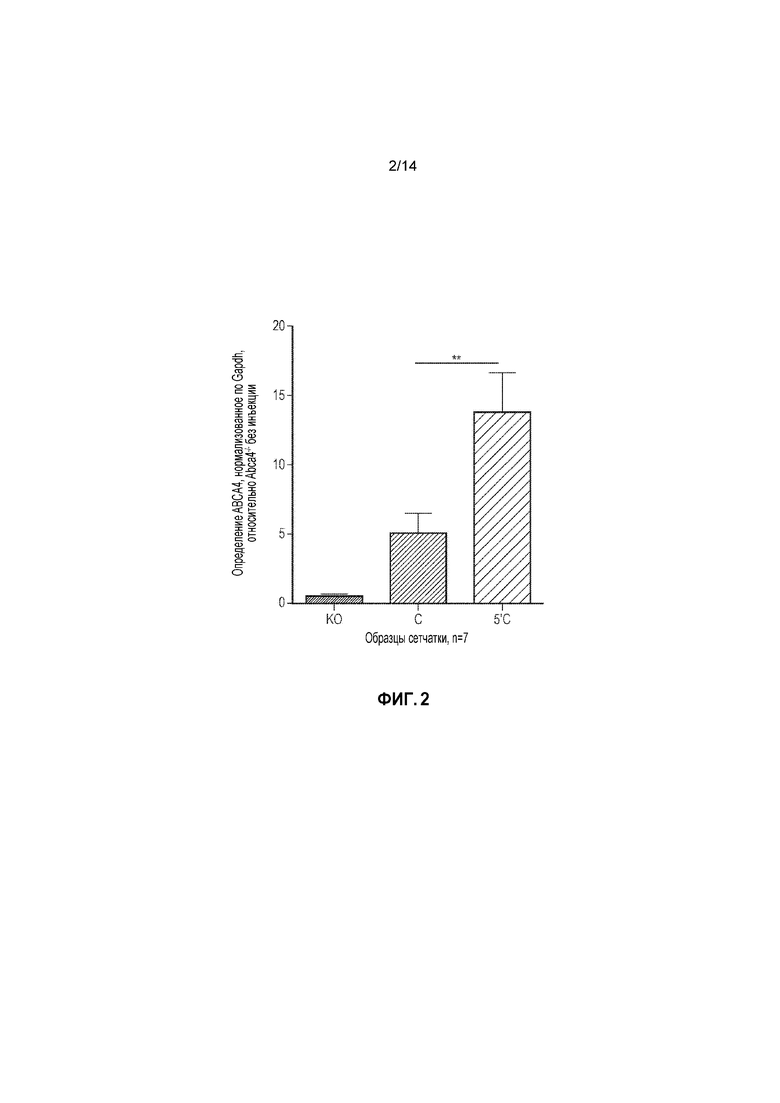
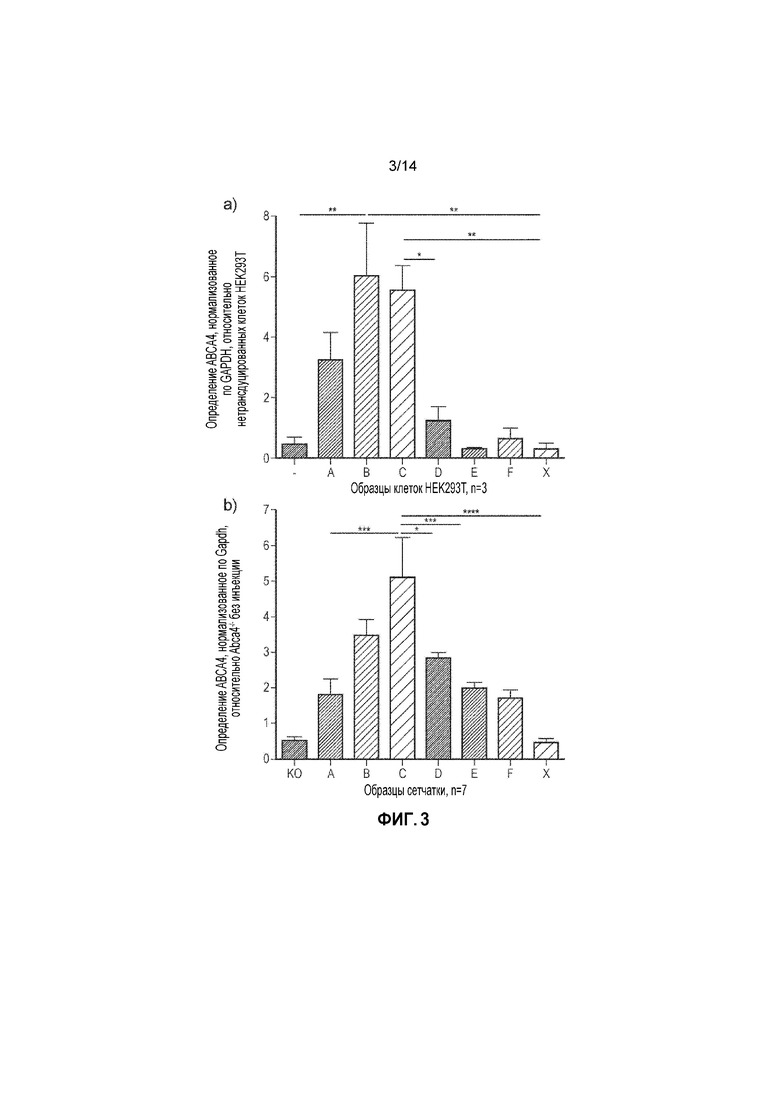
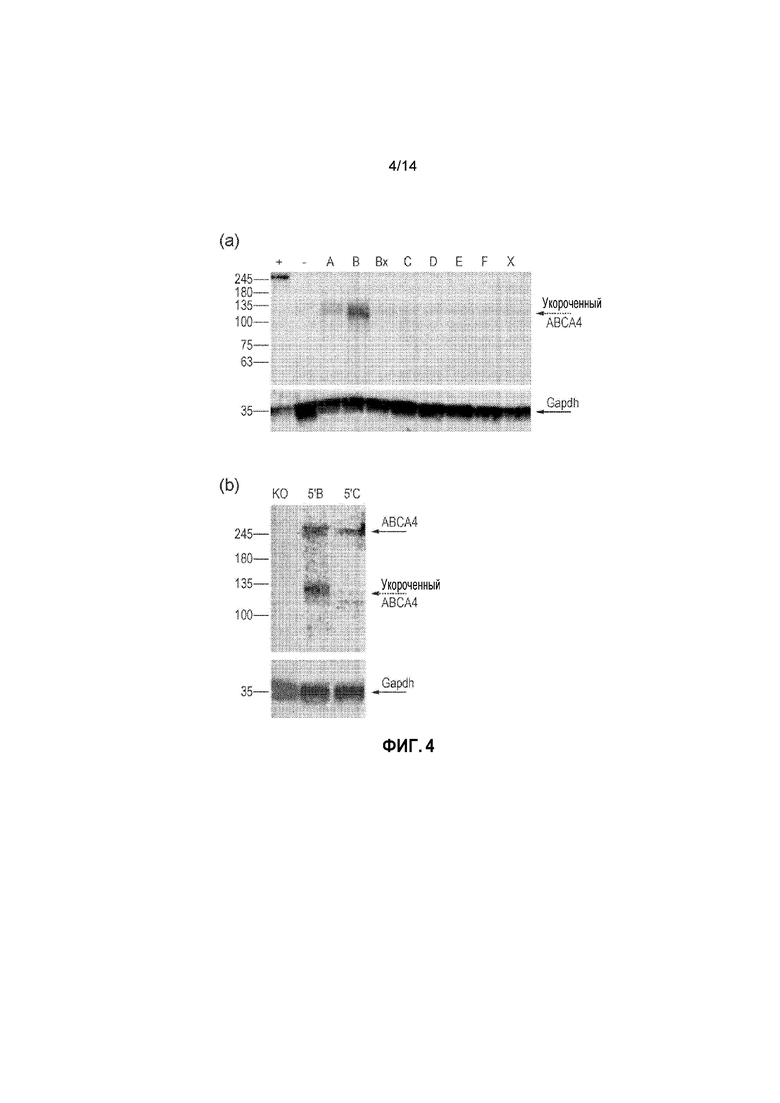
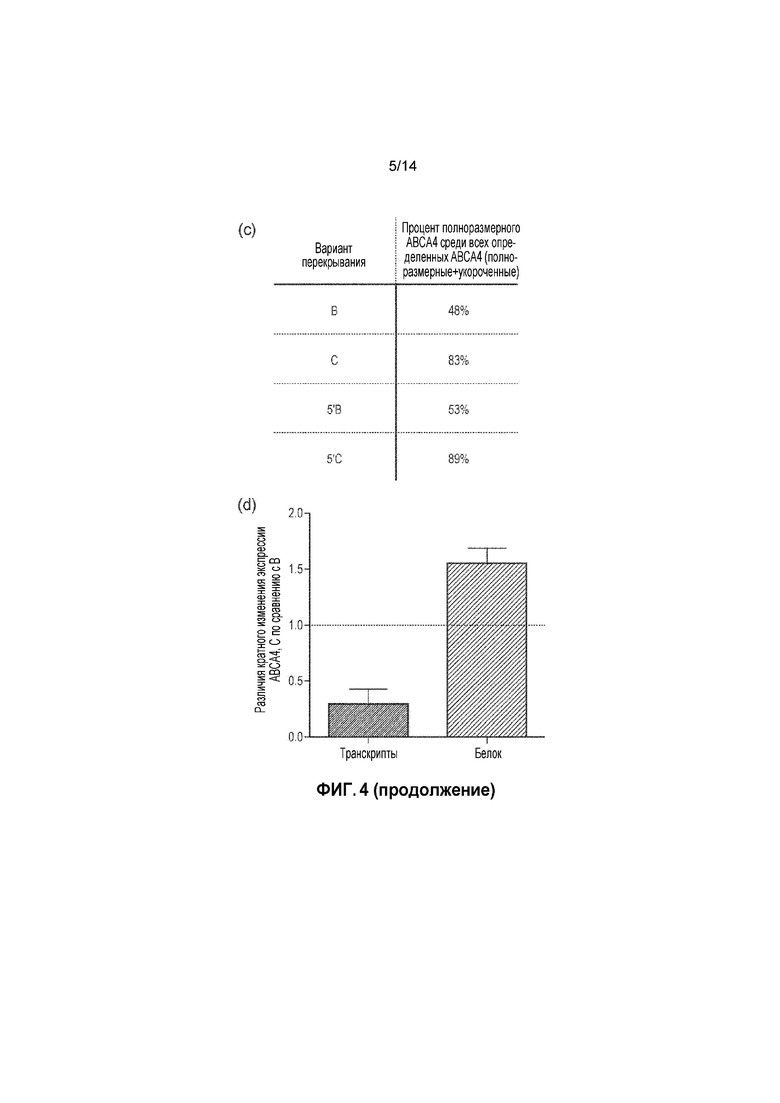
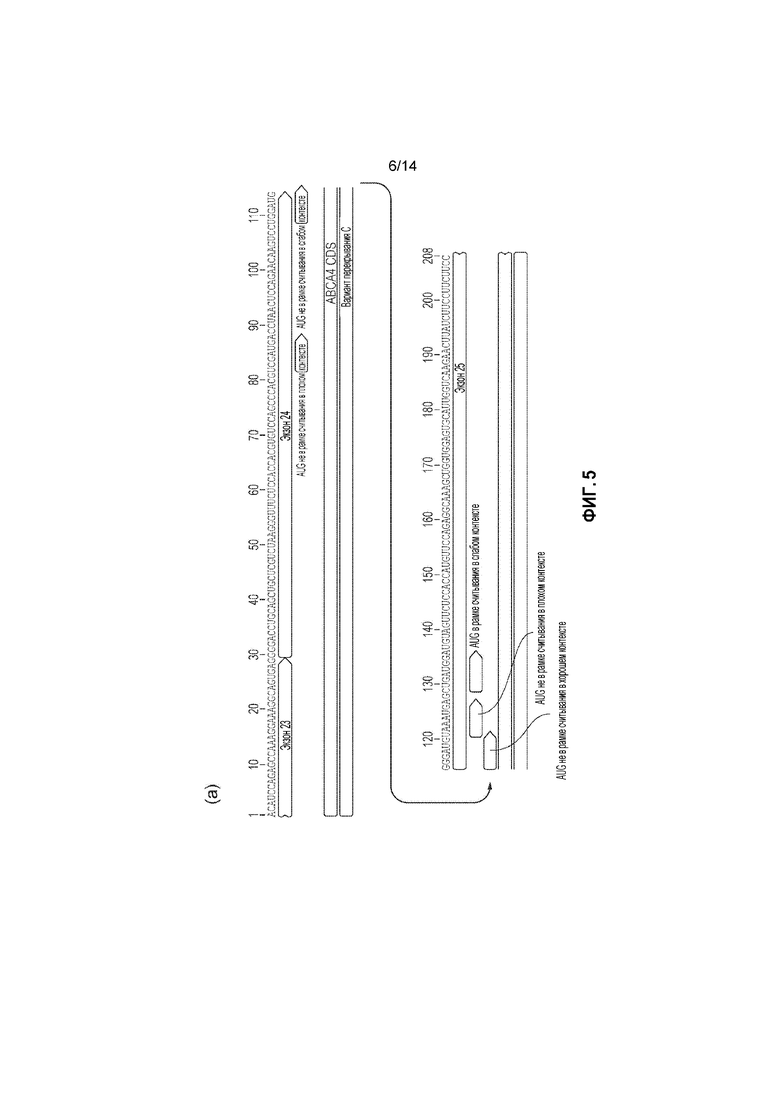
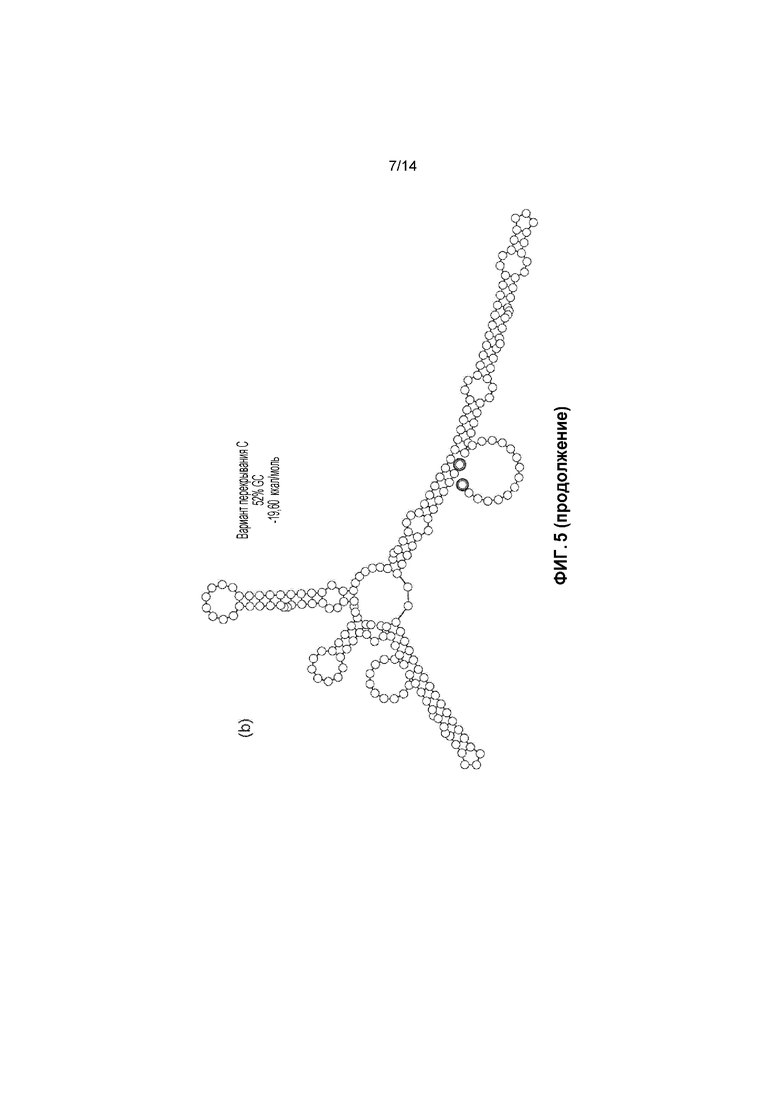
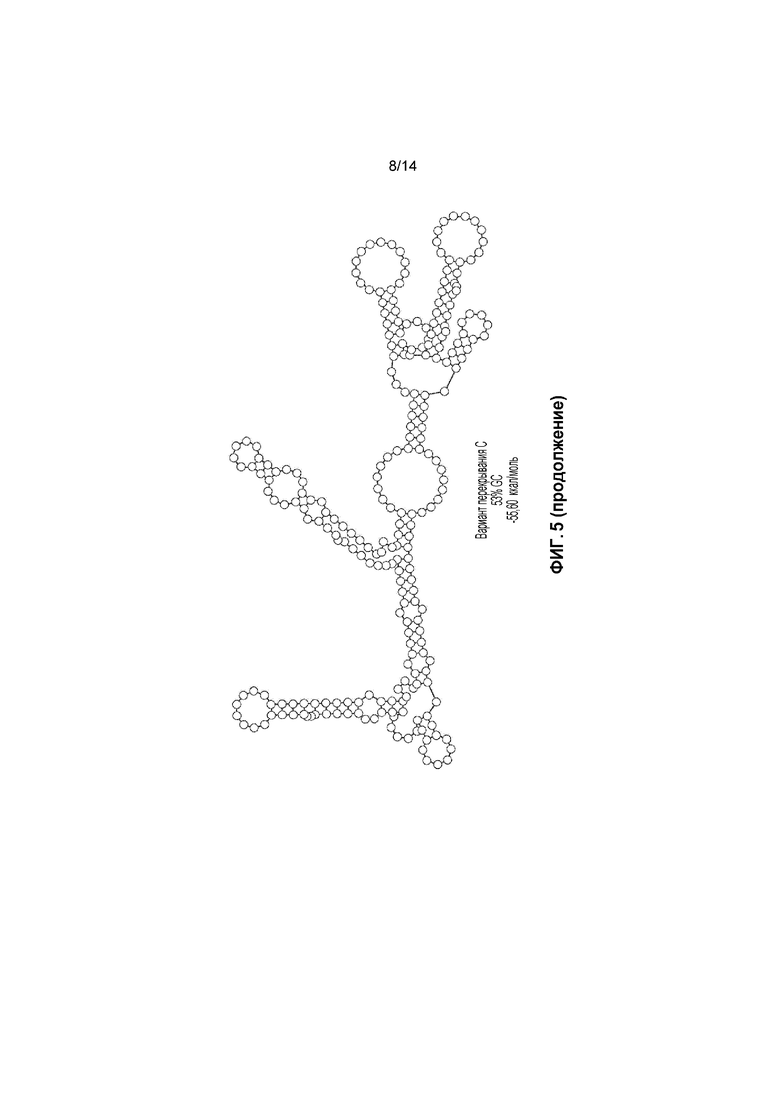
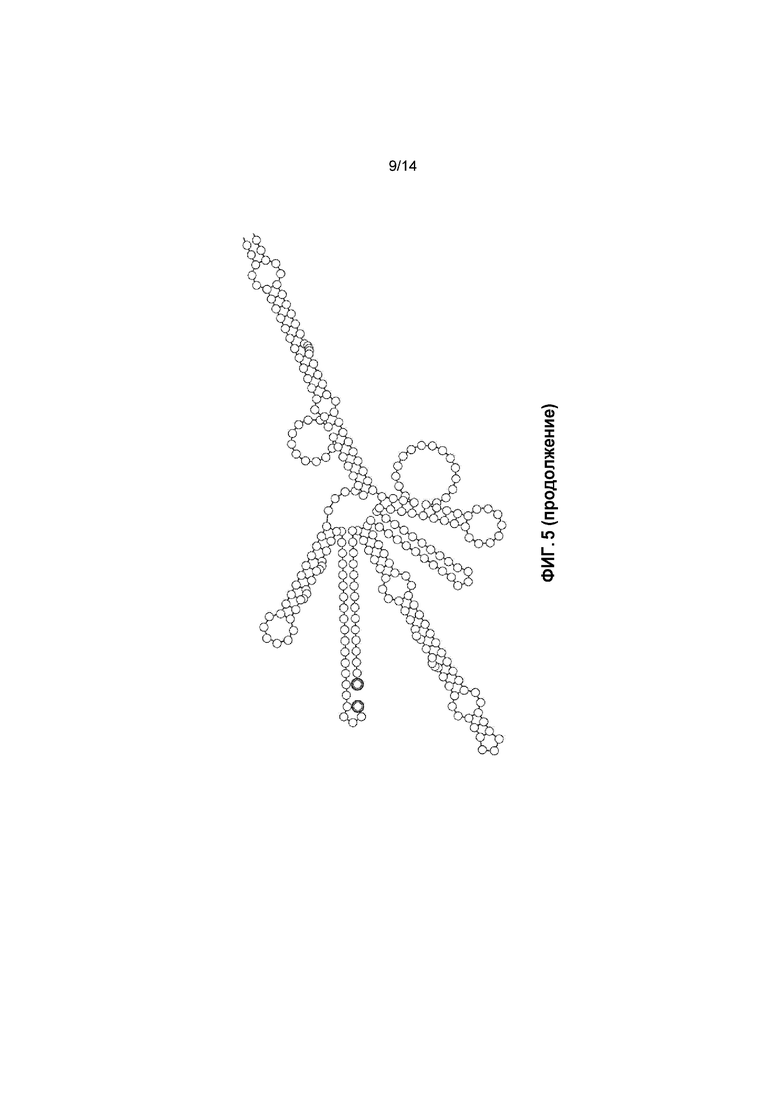

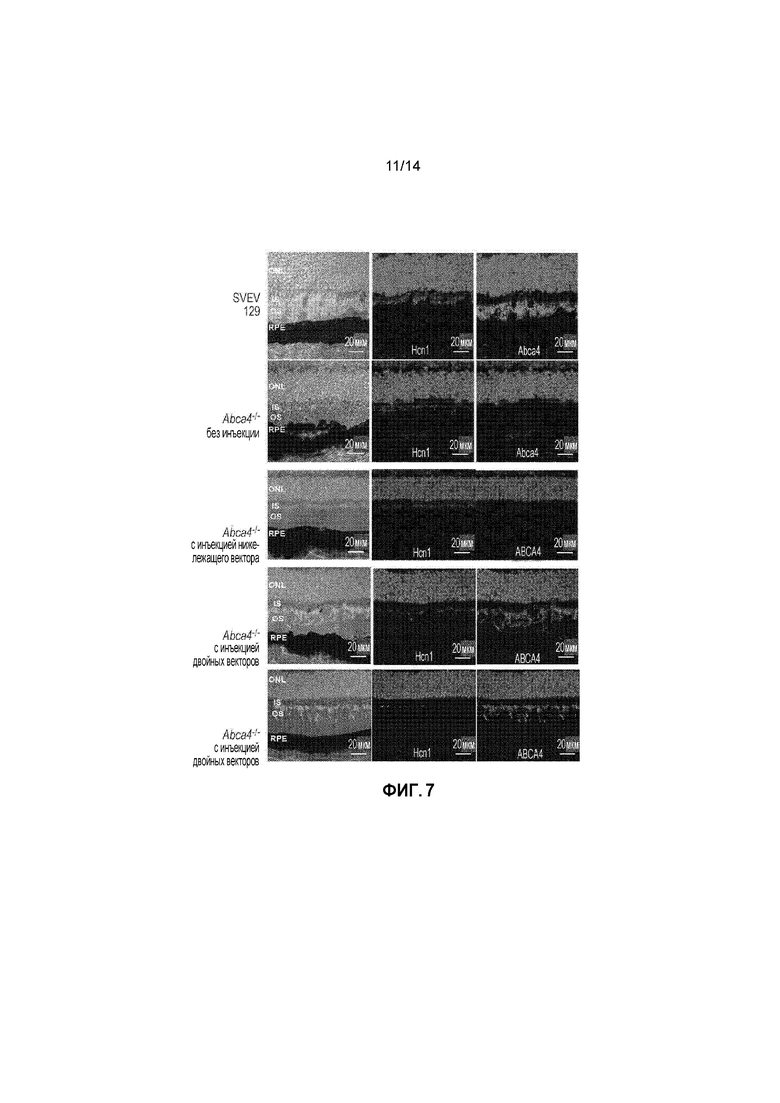

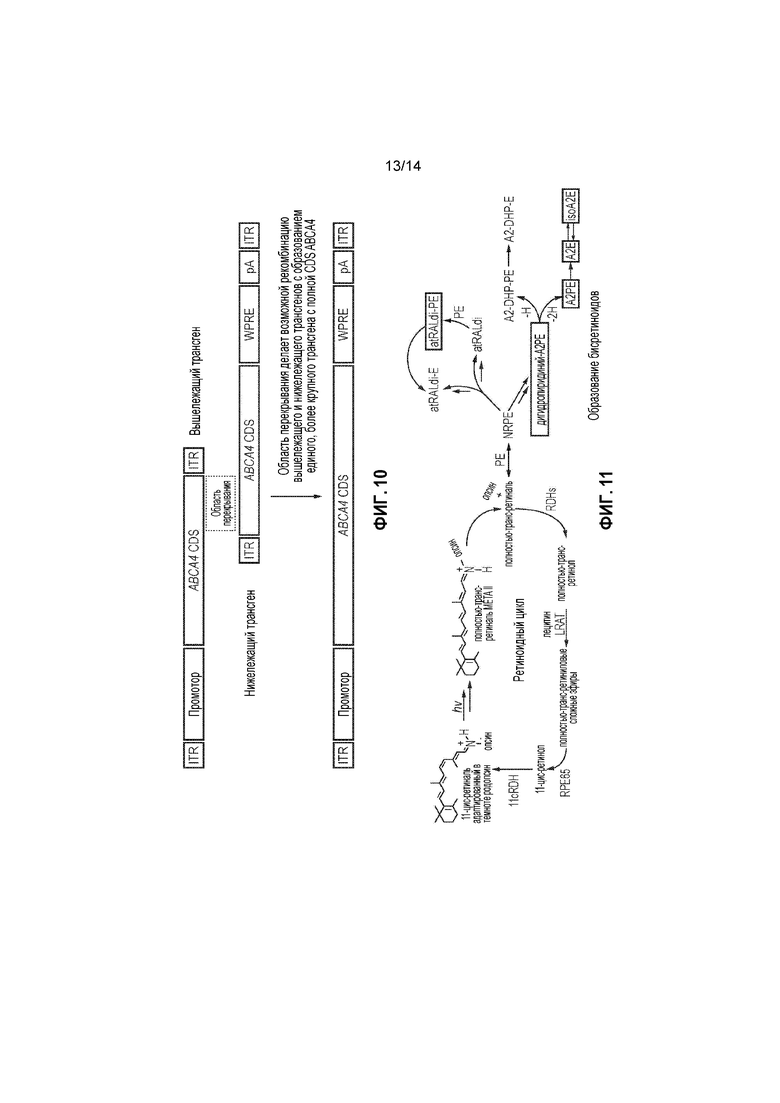
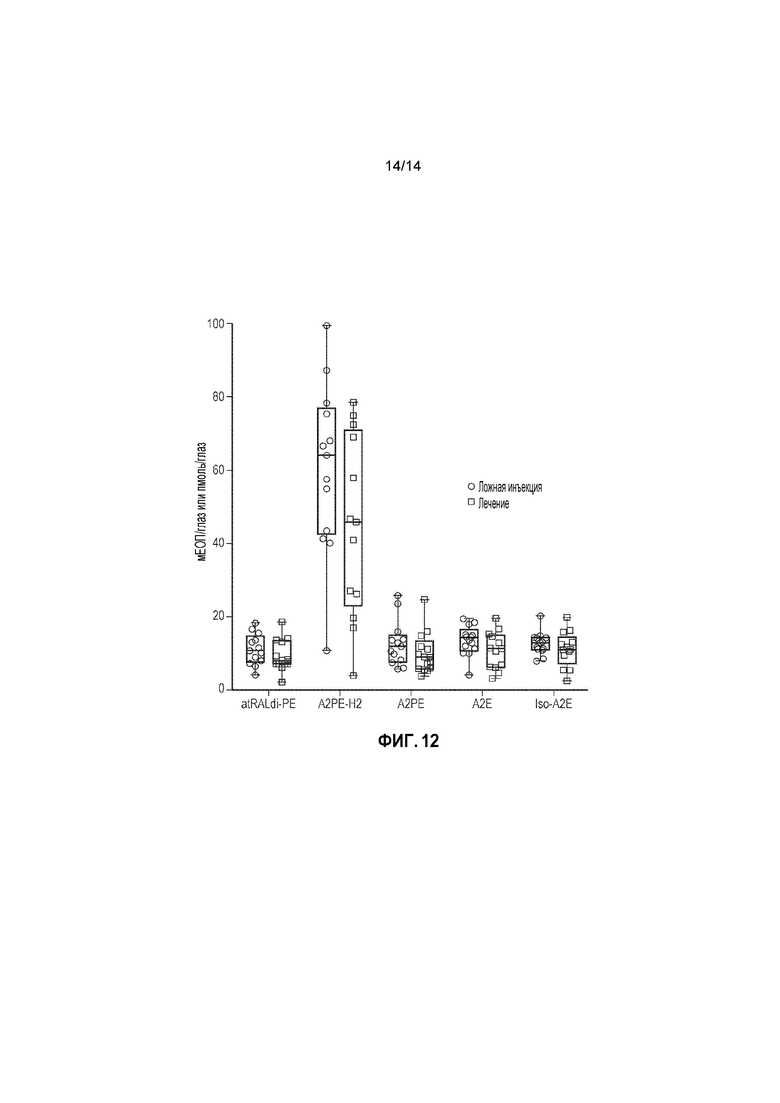
Изобретение относится к биотехнологии. Описана векторная система на основе аденоассоциированного вируса (AAV) для экспрессии белка АТФ-связывающей кассеты, подсемейство A, члена 4 (ABCA4) человека в клетке-мишени, содержащая первый вектор AAV, содержащий первую последовательность нуклеиновой кислоты, и второй вектор AAV, содержащий вторую последовательность нуклеиновой кислоты; где первая последовательность нуклеиновой кислоты содержит 5′-концевую часть кодирующей последовательности ABCA4 (CDS), и вторая последовательность нуклеиновой кислоты содержит 3′-концевую часть CDS ABCA4, и 5′-концевая часть и 3′-концевая часть вместе включают целую CDS ABCA4; где первая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, соответствующую нуклеотидам 105-3597 SEQ ID NO: 1 или SEQ ID NO: 2; где вторая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, соответствующую нуклеотидам 3806-6926 SEQ ID NO: 1 или SEQ ID NO: 2; где каждая из первой последовательности нуклеиновой кислоты и второй последовательности нуклеиновой кислоты содержит область перекрывания последовательностей друг с другом; и где область перекрывания последовательностей содержит по меньшей мере приблизительно 20 смежных нуклеотидов из последовательности нуклеиновой кислоты, соответствующей нуклеотидам 3598-3805 SEQ ID NO: 1 или SEQ ID NO: 2. Настоящее изобретение также относится к применению векторных систем AAV в профилактике или лечении заболевания, отличающегося деградацией клеток сетчатки, предпочтительно, болезни Штаргардта. Изобретение расширяет арсенал средств лечения заболеваний, отличающихся деградацией клеток сетчатки. 12 н. и 10 з.п. ф-лы, 12 ил., 6 пр.
1. Векторная система на основе аденоассоциированного вируса (AAV) для экспрессии белка АТФ-связывающей кассеты, подсемейство A, члена 4 (ABCA4) человека в клетке-мишени, содержащая первый вектор AAV, содержащий первую последовательность нуклеиновой кислоты, и второй вектор AAV, содержащий вторую последовательность нуклеиновой кислоты;
где первая последовательность нуклеиновой кислоты содержит 5′-концевую часть кодирующей последовательности ABCA4 (CDS), и вторая последовательность нуклеиновой кислоты содержит 3′-концевую часть CDS ABCA4, и 5′-концевая часть и 3′-концевая часть вместе включают целую CDS ABCA4;
где первая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, соответствующую нуклеотидам 105-3597 SEQ ID NO: 1 или SEQ ID NO: 2;
где вторая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, соответствующую нуклеотидам 3806-6926 SEQ ID NO: 1 или SEQ ID NO: 2;
где каждая из первой последовательности нуклеиновой кислоты и второй последовательности нуклеиновой кислоты содержит область перекрывания последовательностей друг с другом; и
где область перекрывания последовательностей содержит по меньшей мере приблизительно 20 смежных нуклеотидов из последовательности нуклеиновой кислоты, соответствующей нуклеотидам 3598-3805 SEQ ID NO: 1 или SEQ ID NO: 2.
2. Векторная система AAV по п.1, где область перекрывания последовательностей составляет от 20 до 550 нуклеотидов в длину; предпочтительно от 50 до 250 нуклеотидов в длину; предпочтительно от 175 до 225 нуклеотидов в длину; предпочтительно от 195 до 215 нуклеотидов в длину.
3. Векторная система AAV по п.1, где область перекрывания последовательностей содержит по меньшей мере приблизительно 50 смежных нуклеотидов из последовательности нуклеиновой кислоты, соответствующей нуклеотидам 3598-3805 SEQ ID NO: 1 или SEQ ID NO: 2; предпочтительно по меньшей мере приблизительно 75 смежных нуклеотидов; предпочтительно по меньшей мере приблизительно 100 смежных нуклеотидов; предпочтительно по меньшей мере приблизительно 150 смежных нуклеотидов; предпочтительно по меньшей мере приблизительно 200 смежных нуклеотидов; предпочтительно все 208 смежных нуклеотидов.
4. Векторная система AAV по любому из пп. 1-3,
где первая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, соответствующую нуклеотидам 105-3805 SEQ ID NO: 1 или SEQ ID NO: 2; и
где вторая последовательность нуклеиновой кислоты содержит последовательность смежных нуклеотидов, соответствующую нуклеотидам 3598-6926 SEQ ID NO: 1 или SEQ ID NO: 2.
5. Векторная система AAV по любому из пп. 1-4, где первая последовательность нуклеиновой кислоты содержит промотор GRK1, функционально связанный с 5′-концевой частью кодирующей последовательности ABCA4 (CDS).
6. Векторная система AAV по любому из пп. 1-5, где первая последовательность нуклеиновой кислоты содержит нетранслируемую область (UTR), находящуюся выше 5′-концевой части кодирующей последовательности ABCA4 (CDS).
7. Векторная система AAV по любому из пп. 1-6, где вторая последовательность нуклеиновой кислоты содержит посттранскрипционный чувствительный элемент (PRE); предпочтительно посттранскрипционный чувствительный элемент вируса гепатита сурков (WPRE).
8. Векторная система AAV по любому из пп. 1-7, где вторая последовательность нуклеиновой кислоты содержит последовательность полиаденилирования бычьего гормона роста (bGH).
9. Векторная система AAV по любому из пп. 1-8, где первый вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 9; и где второй вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 10.
10. Способ экспрессии белка ABCA4 человека в клетке-мишени, включающий стадии:
трансдукции клетки-мишени векторной системой AAV по любому из пп. 1-9, таким образом, что функциональный белок ABCA4 экспрессируется в клетке-мишени.
11. Вектор AAV для экспрессии белка ABCA4 человека в клетке-мишени, содержащий последовательность нуклеиновой кислоты, содержащую 5′-концевую часть CDS ABCA4, где 5′-концевая часть CDS ABCA4 состоит из последовательности смежных нуклеотидов, соответствующей нуклеотидам 105-3805 SEQ ID NO: 1 или SEQ ID NO: 2.
12. Вектор AAV по п.11, где вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 9.
13. Вектор AAV для экспрессии белка ABCA4 человека в клетке-мишени, содержащий последовательность нуклеиновой кислоты, содержащую 3′-концевую часть CDS ABCA4, где 3′-концевая часть CDS ABCA4 состоит из последовательности смежных нуклеотидов, соответствующей нуклеотидам 3598-6926 SEQ ID NO: 1 или SEQ ID NO: 2.
14. Вектор AAV по п.13, где вектор AAV содержит последовательность нуклеиновой кислоты SEQ ID NO: 10.
15. Нуклеиновая кислота для экспрессии белка ABCA4 человека в клетке-мишени, содержащая последовательность нуклеиновой кислоты SEQ ID NO: 9.
16. Нуклеиновая кислота для экспрессии белка ABCA4 человека в клетке-мишени, содержащая последовательность нуклеиновой кислоты SEQ ID NO: 10.
17. Набор для экспрессии белка ABCA4 человека в клетке-мишени, содержащий векторную систему AAV по любому из пп. 1-9 и инструкции по применению.
18. Набор для экспрессии белка ABCA4 человека в клетке-мишени, содержащий нуклеиновую кислоту по п.15 и нуклеиновую кислоту по п.16.
19. Фармацевтическая композиция для экспрессии белка ABCA4 человека в клетке-мишени, содержащая векторную систему AAV по любому из пп. 1-9 и фармацевтически приемлемый эксципиент, разбавитель, буфер или стабилизатор.
20. Применение векторной системы AAV по любому из пп. 1-9, набора по п.17 или 18 или фармацевтической композиции по п.19 для получения лекарственного средства для генной терапии заболевания, отличающегося деградацией клеток сетчатки; предпочтительно болезни Штаргардта.
21. Применение векторной системы AAV по любому из пп. 1-9, набора по п.17 или 18 или фармацевтической композиции по п.19 для получения лекарственного средства для профилактики или лечения заболевания, отличающегося деградацией клеток сетчатки; предпочтительно болезни Штаргардта.
22. Способ профилактики или лечения заболевания, отличающегося деградацией клеток сетчатки, предпочтительно, болезни Штаргардта, включающий введение пациенту эффективного количества векторной системы AAV по любому из пп. 1-9, набора по п.17 или 18 или фармацевтической композиции по п.19.
| WO 2014170480 A1, 23.10.2014 | |||
| IVANA TRAPANI et al., "Effective delivery of large genes to the retina by dual AAV vectors", EMBO MOLECULAR MEDICINE 2014,Vol | |||
| Приспособление для точного наложения листов бумаги при снятии оттисков | 1922 |
|
SU6A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| КОМПОЗИЦИЯ ДЛЯ ЛЕЧЕНИЯ ИНФЕКЦИИ ВИРУСОМ ГЕПАТИТА В | 2010 |
|
RU2555346C2 |

