ОБЛАСТЬ ТЕХНИКИ
Настоящее изобретение относится к определенным новым способам отбора эпитопов белков-мишеней, применяемых для получения антитела (например, функционального антитела), но не ограничиваясь указанным. Настоящее изобретение, таким образом, согласно некоторым аспектам относится к способу получения антитела. Такие способы, как правило, включают идентификацию антигенного эпитопа и получение (индукцию синтеза) антитела против указанного антигенного эпитопа. Настоящее изобретение также относится к антигенным эпитопам и к антителам, которые связываются с такими антигенными эпитопами.
УРОВЕНЬ ТЕХНИКИ
Терапевтические средства на основе антител становятся все более распространенными, во многом благодаря клиническомй эффективности, которая наблюдается в случае некоторых вариантов терапии на основе моноклональных антител (МАТ), включающей антитела Хумира, Авастин, Герцептин, и благодаря потенциалу, например, новых вариантов лечения для снижения уровня холестерола на основе МАТ, нацеленных на PCSK9, таких как алирокумаб и эволокумаб. Однако все антитела, которые на сегодняшний день присутствуют на рынке, и все антитела, находящиеся на поздних стадиях клинической разработки, как правило, нацелены на внеклеточные мишени, и данные антитела обычно обнаруживают и разрабатывают с применением платформ скрининга, основное внимание в которых уделяется силе аффинности или связывания. Однако разработка действующих внутри клеток антител и антител, направленных на «сложные мишени», т.е. мишени, в случае которых традиционная методика обнаружения антител оказалась неудачной, представляет собой крайне серьезную проблему, для решения которой требуется применение новых достижений технического прогресса с целью обнаружения и разработки эффективных антител. В случае действующих внутри клеток антител также необходимы новые инструменты для интернализации антител в клетки в правильных органах-мишенях.
Более того, в существующих платформах для обнаружения и разработки антител, как правило, отсутствуют функциональные, фармакологические соотношения и соотношения механизма действия, которые позволяют прогнозировать работу конкретного антитела в данной биологической системе, например, при патологическом состоянии.
На сегодняшний день стратегии разработки и обнаружения эффективных терапевтических средств на основе антител не ограничены полноразмерными моноклональными антителами. Благодаря достижениям в белковой инженерии в течение двух последних десятилетий было получено широкое множество сконструированных фрагментов антител, включая Fab-фрагменты, ScFv-фрагменты, диатела, тетратела, функционализированные конъюгатами белков фрагменты антител, а также биспецифичные фрагменты, связывающиеся с двумя антигенами. Данные новые конструкции обеспечивают значительно больший набор инструментов для возможностей разработки антител и биологических средств на основе антител с высокой специфичностью и аффинностью, глубоким проникновением в ткани, высокой стабильностью и низкой токсичностью. Однако все еще сохраняется одно из главных препятствий в случае терапевтических средств на основе антител, которое заключается в том, что указанные терапевтические средства ограничены внеклеточными мишенями. Антитела являются слишком большими и крайне полярными, чтобы проходить через клеточную мембрану. Дополнительно, антитела, как правило, являются нестабильными в восстановительной среде цитозоля. Для изучения внутриклеточных мишеней было разработано несколько методик, включая транспортирование антител через клеточную мембрану с помощью различных транспортирующих векторов, например, реактивов для трансфекции и доменов белковой трансдукции (protein transduction domains, PTD), а также экспрессия антитела непосредственно внутри клетки-мишени, что приводит к образованию так называемых интрател. Также применяли методики электропорации, хотя в случае антител и не так широко, как в случае малых молекул и генетического материала. Интратела можно сконструировать для нацеливания на различные компартменты клетки посредством слияния генетической последовательности интратела с сигналами внутриклеточного транспорта. Потребность в эффективных векторах доставки, тем не менее, является критически важным этапом терапии интрателами, поскольку генетический материал, кодирующий интратело, еще должен быть доставлен в клетку-мишень.
Получение моноклональных антител с применением гибридомных технологий впервые было разработано в 1975 году. Вкратце, млекопитающим инъецируют антиген, представляющий интерес, который запускает у указанных млекопитающих иммунный ответ. Затем из селезенки животного отбирают спленоциты, которые сливают с иммортализованными клетками миеломы. Клетки разбавляют до степени разведения в одну клетку и разделяют на многолуночных планшетах. Поскольку начало каждой отдельной колонии дает одна клетка, наработанные антитела в одной лунке будут являться моноклональными. Следующий этап заключается в скрининге всех различных лунок для выбора наилучшего кандидата для связывания с антигеном.
Огромное преимущество фрагментов антител меньшего размера по сравнению с полноразмерными антителами заключается в том, что такие фрагменты можно получить в различных системах экспрессии, например, в Escherichia coli, дрожжах и клетках млекопитающих, и данные фрагменты больше не ограничены получением с помощью гибридомной технологии. Данное преимущество делает возможной крупномасштабную наработку при меньших затратах и обеспечивает множество возможностей для модуляции свойств антитела генетическим способом. Фрагменты антитела могут быть экспонированы на поверхности нитевидного бактериофага, так называемый фаговый дисплей, что можно использовать для создания больших библиотек антител, скрининг которых проводят в отношении целевого антигена. В ходе процедуры скрининга оценивают антитела- кандидаты, которые связываются с антигеном. Такой скрининг часто повторяют в ходе нескольких циклов по причине неспецифичного связывания на первых циклах. Условия в ходе циклов скрининга можно менять для обнаружения кандидатов, наиболее подходящих для определенных условий, например, посредством применения агрессивных условий можно выбрать более стабильные антитела. Другой способ выбора антител с очень высокой аффинностью заключается в осуществлении скрининга с очень низкой концентрацией антигена, в результате чего при таких условиях останутся исключительно антитела, способные к связыванию. Некоторые компании разработали свои собственные технологии скрининга и часто имеют обширные библиотеки антител, см., например, Regeneron (regeneron.com) или Alligator bioscience (alligatorscience.se).
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Согласно одному аспекту в настоящем изобретении предложен способ создания антитела против белка, причем указанный способ включает:
(i) идентификацию антигенного эпитопа в указанном белке посредством воздействия на белок ограниченного или частичного протеолиза путем осуществления контакта белка с по меньшей мере одной протеазой с образованием по меньшей мере одной расщепленной, деконструированной (разобранной) или усеченной версии указанного белка и по меньшей мере одного экспонированного на поверхности пептида, который отщепляется от указанного белка под действием указанной протеазы, и создание антигенного эпитопа на основе указанного экспонированного на поверхности пептида; и
(ii) получение антитела против указанного антигенного эпитопа.
Согласно другому аспекту в настоящем изобретении предложен способ создания антитела против белка, причем указанный способ включает:
(i) воздействие на белок ограниченного или частичного протеолиза путем осуществления контакта указанного белка с по меньшей мере одной протеазой с образованием по меньшей мере одной расщепленной, деконструированной или усеченной версии указанного белка и по меньшей мере одного экспонированного на поверхности пептида, который отщепляется от указанного белка под действием указанной протеазы; и
(ii) идентификацию антигенного эпитопа посредством идентификации экспонированного на поверхности эпитопа среди по меньшей мере одного экспонированного на поверхности пептида, присутствующего в области белка, которая приводит к утрате или существенному изменению биологической функции указанного белка, когда пептид отщепляют или удаляют от указанного белка в течение ограниченного или частичного протеолиза; или выбор по меньшей мере одной области-мишени в указанном белке на основании биоинформационных данных и/или известных данных о биологической функции указанного белка и идентификацию антигенного эпитопа посредством идентификации экспонированного на поверхности эпитопа среди по меньшей мере одного экспонированного на поверхности пептида, присутствующего в указанной по меньшей мере одной области- мишени; и
(iii) получение антитела против указанного антигенного эпитопа.
Согласно другому аспекту в настоящем изобретении предложен способ идентификации антигенного эпитопа, причем указанный способ включает:
(i) воздействие на белок ограниченного или частичного протеолиза путем осуществления контакта указанного белка с по меньшей мере одной протеазой с образованием по меньшей мере одной расщепленной, деконструированной или усеченной версии белка и по меньшей мере одного экспонированного на поверхности пептида, который отщепляется от указанного белка под действием указанной протеазы; и
(ii) идентификацию антигенного эпитопа посредством идентификации экспонированного на поверхности эпитопа среди по меньшей мере одного экспонированного на поверхности пептида, присутствующего в области указанного белка, которая приводит к утрате или существенному изменению биологической функции указанного белка, когда пептид отщепляют или удаляют от указанного белка в течение ограниченного или частичного протеолиза; или выбор по меньшей мере одной области-мишени в указанном белке на основании биоинформационных данных и/или известных данных о биологической функции указанного белка и идентификацию антигенного эпитопа посредством идентификации экспонированного на поверхности эпитопа среди по меньшей мере одного экспонированного на поверхности пептида, присутствующего в указанной по меньшей мере одной области- мишени.
Настоящее изобретение относится к способам обнаружения и идентификации аминокислотных последовательностей в белках, причем указанные аминокислотные последовательности являются значительно экспонированными и соответствующими с функциональной точки зрения, по меньшей мере, данные последовательности являются значительно экспонированными. Таким образом, данные аминокислотные последовательности, которые авторы настоящего изобретения называют «горячими точками», можно применять в качестве антигенных эпитопов, направляющих нацеливание, обнаружение и разработку антител. Более того, данные аминокислотные последовательности можно классифицировать в зависимости от их появления после протеолитического расщепления и в зависимости от функциональной значимости на основании уже известных биоинформационных данных или данных функционального/фармакологического исследования. Таким образом, из перечня нескольких аминокислотных последовательностей, полученных в результате протеолитического расщепления, можно выбрать наиболее подходящие аминокислотные последовательности (на основании функциональных и структурных данных) для обнаружения и разработки антигенного эпитопа. Протеолитическое расщепление проводят при лимитирующих условиях, т.е. активность протеазы или нескольких протеаз является очень низкой, в результате чего лишь один или несколько экспонированных на поверхности пептидов отщепляются от белка-мишени в данный момент времени. Таким образом, протеазы используют в качестве зондов для определения возможности применения антитела, связывающегося с белком-мишенью, в качестве лекарственного препарата.
Согласно варианту реализации настоящего изобретения антитела являются фармакологически активными. Согласно другому варианту реализации настоящего изобретения антитела являются фармакологически активными и разработанными для терапевтического применения. Более конкретно, такие способы включают применение инструментов протеомики для выявления эпитопов горячих точек белков-мишеней.
Согласно аспекту настоящего изобретения белок расщепляют, деконструируют (обеспечивают его разборку) и/или усекают под действием протеазы, и все значительно экспонированные аминокислотные последовательности используют для создания антигенного эпитопа, и антитела, разработанные на основе указанных антигенных эпитопов, изучают в отношении биологической активности, эффективности, фармакологического профилирования и других тестов, которые являются общепринятыми при обнаружении антител, используемых в фармацевтической промышленности.
Согласно аспекту настоящего изобретения белок расщепляют, деконструируют и/или усекают под действием протеазы и параллельно исследуют в функциональном анализе расщепленного, деконструированного и/или усеченного белка для определения функционально важных областей белка. Соответствующий белок иногда называют в настоящей заявке белком-мишенью.
Согласно варианту реализации настоящего изобретения расщепление, деконструирование и/или усечение белка-мишени проводят параллельно с функциональным анализом для определения функционально важных областей белка- мишени для направления селекции эпитопов с целью создания антитела.
Согласно варианту реализации настоящего изобретения расщепление, деконструирование и/или усечение и функциональный анализ расщепленного, деконструированного и/или усеченного белка и нативного белка-мишени объединяют с другими биоинформационными данными и другими известными фактами о функции белка для определения функционально важных областей белка-мишени для направления селекции эпитопов с целью создания антитела.
Согласно варианту реализации настоящего изобретения для расщепления, деконструирования и/или усечения белка-мишени можно использовать одну протеазу.
Согласно другому варианту реализации настоящего изобретения для расщепления, деконструирования и/или усечения белка-мишени можно использовать несколько протеаз, последовательно по одной в данный момент времени или параллельно. Примерами таких протеаз являются, не ограничиваясь указанным, протеиназа Arg-C, эндопептидаза Asp-N, клострипаин, глутамилэндопептидаза, Lys-C, Lys-N, трипсин, химотрипсин, протеиназа K и термолизин. Область, которую легко расщепляют несколько протеаз, должна располагаться в экспонированной области белка, и область, которая расщепляется исключительно одной протеазой, вероятно, располагается в более скрытой области. В качестве альтернативы, протеаза обладает уникальной специфичностью расщепления или/и физико-химическими свойствами или/и структурными свойствами, в результате чего может идентифицировать экспонированные на поверхности пептиды на белке-мишени, что не свойственно другим протеазам. Таким образом, применение нескольких протеаз является предпочтительным, и каждая отличная протеаза может привести к получению комплементарной или уникальной информации о пригодности экспонированных на поверхности пептидов в качестве антигенных эпитопов.
Варианты реализации настоящего изобретения делают возможной новую методологию/технологию для быстрой и точной разработки фармакологически активных антител, которые можно использовать для фармакологических исследований, например, которые можно использовать в качестве инструмента для обнаружения биологических соединений, например, в анализах на клетках или in vitro. Более важно то, что указанные антитела можно использовать для лечения медицинского состояния у людей и животных.
Варианты реализации настоящего изобретения можно применять в отношении всех белков, растворимых или мембраносвязанных, внеклеточных или внутриклеточных. Более того, варианты реализации настоящего изобретения можно использовать для получения нового фундаментального понимания функции белка.
В настоящем изобретении также предложено антитело, созданное способом согласно настоящему изобретению.
В настоящем изобретении также предложен антигенный эпитоп, идентифицированный способом согласно настоящему изобретению.
В настоящем изобретении также предложено антитело против антигенного эпитопа согласно настоящему изобретению.
Другие свойства и преимущества настоящего изобретения будут очевидны из следующего подробного описания.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Варианты реализации настоящего изобретения вместе с дополнительными целями и преимуществами указанного изобретения станут более понятными посредством ссылки на следующее описание, которое следует рассматривать вместе с прилагаемыми чертежами, на которых:
Фигура 1
Пептиды, обнаруженные в TRPV1 (transient receptor potential vanilloid 1, ваниллоидном ионном канале типа 1 с транзиторным рецепторным потенциалом) после ограниченного протеолиза под действием 5 мкг/мл трипсина при комнатной температуре, n=6. A: Расположение обнаруженных пептидов показано на 3D-модели TRPV1. Пептиды были обнаружены через 0,5 мин. (пурпурный цвет), 5 мин. (оранжевый цвет) и 15 мин. (синий цвет) B: Расположение обнаруженных пептидов показано на схематическом изображении TRPV1. Пептиды были обнаружены через 0,5 мин. (пурпурный цвет), 5 мин. (оранжевый цвет) и 15 мин. (синий цвет). C: Столбчатый график обнаруженных пептидов, полученных в результате расщепления TRPV1 после ограниченного протеолиза под действием 5 мкг/мл трипсина, с указанием, в какие временные точки данные пептиды были подтверждены.
Фигура 2
Пептиды, полученные в результате расщепления TRPV1 через 5 мин. воздействия 5 мкг/мл, 20 мкг/мл или 40 мкг/мл трипсина (Тр.), и изменение ответа тока после удаления трипсина. A-C: Расположение расщепленных пептидов TRPV1, демонстрирующее пептиды, расщепленные в проточной ячейке (голубой цвет), и пептиды, расщепленные в проточной ячейке с последующим полным расщеплением в течение ночи (желтый цвет). D:
Иллюстративные кривые результатов анализа TRPV1 методом «наружная сторона внутри» при активации 1 мкМ капсайцином (Кап.) с последующим воздействием в течение 5 мин. буфером или трипсином и дополнительной активацией капсайцином. Сверху вниз: 5 мин. воздействия буфером, 5 мкг/мл, 20 мкг/мл и 40 мкг/мл трипсина, соответственно. Кривые фильтровали цифровым способом при 100 Гц исключительно для лучшей визуализации фигуры.
Фигура 3
Результаты анализа функции TRPV1 методом электрофизиологического пэтч-клампа (фиксации потенциала), демонстрирующие интеграл времени кривой тока для второй активации капсайцином, рассчитанный в виде процента интеграла для первой активации капсайцином после обработки буфером, n=11, или антителом, n=6. Данные представлены в виде среднего значения ± С.О.С. (стандартная ошибка среднего).
Фигура 4
Расположение антигенной детерминанты (красный цвет) для OTV1, пептида aa96-117, визуализированного на модели поверхности hTRPV1 (TRPV1 человека). A: Боковая проекция TRPV1, на которой каждый мономер окрашен в синий или пурпурный цвет. B: TRPV1, вид сверху, на котором каждый мономер окрашен в синий или пурпурный цвет.
Фигура 5
Расположение антигенной детерминанты (красный цвет) для OTV2, пептида aa785-799, визуализированного на модели поверхности hTRPV1. A: Боковая проекция TRPV1, на которой два мономера были опущены с целью лучшей визуализации. B: TRPV1, вид снизу, на котором каждый мономер окрашен в синий или пурпурный цвет.
Фигура 6
Локализация OTV1 (слева) и OTV2 (справа) в фиксированных клетках с экспрессией (A) и без экспрессии (B) TRPV1. OTV1 и OTV2 визуализировали с применением вторичного антитела козы против иммуноглобулинов кролика Alexa 488. Значения интенсивности вдоль линейного сегмента (черный цвет), пересекающего ячейку, приведены под каждым изображением. В случае OTV1 и OTV2 использовали различные настройки лазера, поэтому не следует проводить сравнения между антителами.
Фигура 7
Результаты анализа функции TRPV1 методом электрофизиологического пэтч-клампа после обработки антителом. A: Интеграл времени кривой тока для второй активации капсайцином, рассчитанный в виде процента интеграла для первой активации капсайцином после обработки буфером (n=11) или OTV1 (n=6). B: Интеграл времени кривой тока для второй активации капсайцином в присутствии кальмодулина (CaM) и OTV2, рассчитанный в виде процента интеграла для первой активации капсайцином, после обработки исключительно кальмодулином (n=11) или кальмодулином и OTV2. Обработка OTV2 разделена на измерения в течение 15 минут после кратковременной обработки ультразвуком (n=4) и измерения в течение 30 минут после кратковременной обработки ультразвуком (n=7). Данные представлены в виде среднего значения ± С.О.С.
Фигура 8
A: Опосредованное TRPV1 поглощение YO-PRO после электропорации OTV1 в ФБР (фосфатном буферном растворе), не содержащем кальция. Верхний чертеж: Интенсивность флуоресценции в случае OTV1 (n=11) и контроля (n=11). Нижний чертеж: Соответствующая степень интенсивности флуоресценции в случае OTV1 и контроля. B: Опосредованное TRPV1 поглощение YO-PRO после электропорации OTV2 в присутствии 50 мкМ Ca2+. Верхний чертеж: Интенсивность флуоресценции в случае OTV2 (n=9) и контроля (n=7). Нижний чертеж: Соответствующая степень интенсивности флуоресценции в случае OTV2 (зеленый цвет) и контроля (красный цвет). Данные представлены в виде среднего значения ± С.О.С.
Фигура 9
Валидация интернализации антител посредством электропорации с применением флуоресценции. Клетки подвергали электропорации, фиксировали, пермебеализовали и инкубировали с вторичным антителом козы против иммуноглобулинов кролика Alexa 488. Интенсивности флуоресценции измеряли методом конфокальной микроскопии. Интенсивности сравнивали между клетками, подвергавшимися и не подвергавшимися электропорации, после воздействия OTV1 или OTV2, а также клетками, на которые воздействовали исключительно вторичным антителом. В случае OTV1 и OTV2 использовали различные настройки лазера, поэтому не следует проводить сравнения значений интенсивности. Данные представлены в виде среднего значения ± С.О.С.
Фигура 10
Пептиды, обнаруженные в TRPV1 после ограниченного протеолиза трипсином.
Расположение обнаруженных пептидов показано на 3D-модели TRPV1. Детали эксперимента приведены в примере 3. Пептиды, отщепленные первыми, показаны черным цветом. Пептиды, отщепленные позже, показаны серым цветом.
Фигура 11
Пептиды, обнаруженные в TRPV1 после ограниченного протеолиза Asp-N. Расположение обнаруженных пептидов показано на 3D-модели TRPV1. Детали эксперимента приведены в примере 3. Пептиды, отщепленные первыми, показаны черным цветом. Пептиды, отщепленные позже, показаны серым цветом.
Фигура 12
Пептиды, обнаруженные в TRPV1 после ограниченного протеолиза химотрипсином. Расположение обнаруженных пептидов показано на 3D-модели TRPV1. Детали эксперимента приведены в примере 3. Пептиды, отщепленные первыми, показаны черным цветом. Пептиды, отщепленные позже, показаны серым цветом.
Фигура 13
Пептиды, обнаруженные в TRPV1 после ограниченного протеолиза пепсином. Расположение обнаруженных пептидов показано на 3D-модели TRPV1. Детали эксперимента приведены в примере 3. Пептиды, отщепленные первыми, показаны черным цветом. Пептиды, отщепленные позже, показаны серым цветом.
Фигура 14
Пептиды, обнаруженные в TRPV1 после ограниченного протеолиза протеиназой K.
Расположение обнаруженных пептидов показано на 3D-модели TRPV1. Детали эксперимента приведены в примере 3. Пептиды, отщепленные первыми, показаны черным цветом. Пептиды, отщепленные позже, показаны серым цветом.
Фигура 15
На данной фигуре представлен процесс (d), подходящий для исследования пропущенных сайтов разрезания: нарабатывали антитела против последовательностей длиной 7 – 8 аминокислот, содержащих пропущенные сайты разрезания, с применением подхода сдвига рамки (с применением вложенного множества эпитопов) с целью охвата подходящей области (например, от -20 до +20 аминокислот, окружающих сайт разрезания). Проводили скрининг антител для обнаружения антител, которые связывались наилучшим образом.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Вышеизложенные и другие аспекты настоящего изобретения теперь будут описаны более подробно в отношении описания и методологий, представленных в настоящей заявке. Следует понимать, что настоящее изобретение может быть реализовано в различных формах, и данное изобретение не следует истолковывать как ограниченное вариантами реализации, изложенными в настоящей заявке. Напротив, данные варианты реализации предложены для того, чтобы данное описание изобретения являлось обстоятельным и полным и полностью отражало объем настоящего изобретения для специалистов в данной области техники.
Если не определено обратное, все технические и научные термины, используемые в настоящей заявке, имеют то же значение, которое обычно понимается средним специалистом в области техники, к которой относится настоящее изобретение. В настоящем описании формы единственного числа также включают множественное число, если контекст однозначно не диктует обратное. Несмотря на то, что при реализации на практике или тестировании настоящего изобретения можно использовать способы и материалы, подобные или эквивалентные таковым, описанным в настоящей заявке, подходящие способы и материалы описаны ниже. Все публикации, заявки на патенты, патенты и другие источники, упомянутые в настоящей заявке, включены в настоящую заявку посредством ссылки. Источники, ссылки на которые содержатся в настоящей заявке, не признаются предшествующим уровнем техники в отношении заявленного изобретения. В случае конфликта настоящее описание, включая определения, будет являться определяющим. Кроме того, материалы, способы и примеры являются исключительно иллюстративными и не подразумеваются как ограничивающие.
Терминология, используемая в описании настоящего изобретения в настоящей заявке, предназначена исключительно для описания конкретных вариантов реализации и не предназначена для ограничения настоящего изобретения. В описании вариантов реализации настоящего изобретения формы единственного числа предназначены для включения также форм множественного числа, если контекст однозначно не указывает обратное. Также в настоящей заявке термин «и/или» означает и охватывает любые и все возможные комбинации одного или нескольких связанных перечисленных элементов.
Более того, термин «приблизительно» в настоящей заявке при использовании в отношении измеряемого значения, такого как количество соединения, доза, время, температура и т.п., предназначен для включения вариаций на 20%, 10%, 5%, 1%, 0,5% или даже 0,1% от указанного количества. Когда применяется диапазон (например, диапазон от x до y), это означает, что измеряемое значение представляет собой диапазон от приблизительно x до приблизительно y или любой диапазон в пределах указанного диапазона, такой как от приблизительно x1 до приблизительно y1 и т.д. Следует также понимать, что термины «содержит», «включает» и/или «содержащий», «включающий» в настоящем описании обозначают наличие указанных свойств, целых чисел, этапов, операций, элементов и/или компонентов, но не исключают наличия или добавления одного или нескольких других свойств, целых чисел, этапов, операций, элементов, компонентов и/или их групп. Если не определено обратное, все термины, включая технические и научные термины, используемые в настоящем описании, имеют то же значение, которое обычно понимается средним специалистом в области техники, к которой относится настоящее изобретение.
Согласно одному аспекту в настоящем изобретении предложен способ создания антитела против белка, причем указанный способ включает:
(i) идентификацию антигенного эпитопа в указанном белке посредством воздействия на белок ограниченного или частичного протеолиза путем осуществления контакта белка с по меньшей мере одной протеазой с образованием по меньшей мере одной расщепленной, деконструированной или усеченной версии белка и по меньшей мере одного экспонированного на поверхности пептида, который отщепляется от белка под действием указанной протеазы, и создание антигенного эпитопа на основе указанного экспонированного на поверхности пептида; и
(ii) получение антитела против антигенного эпитопа.
Согласно другому аспекту в настоящем изобретении предложен способ создания антитела против белка, причем указанный способ включает:
(i) воздействие на белок ограниченного или частичного протеолиза путем осуществления контакта белка с по меньшей мере одной протеазой с образованием по меньшей мере одной расщепленной, деконструированной или усеченной версии белка и по меньшей мере одного экспонированного на поверхности пептида, который отщепляется от белка под действием указанной протеазы; и
(ii) идентификацию антигенного эпитопа посредством идентификации экспонированного на поверхности эпитопа среди по меньшей мере одного экспонированного на поверхности пептида, присутствующего в области белка, которая приводит к утрате или существенному изменению биологической функции белка, когда пептид отщепляют или удаляют от белка в течение ограниченного или частичного протеолиза; или
выбор по меньшей мере одной области-мишени в белке на основании биоинформационных данных и/или известных данных о биологической функции белка и идентификацию антигенного эпитопа посредством идентификации экспонированного на поверхности эпитопа среди по меньшей мере одного экспонированного на поверхности пептида, присутствующего в указанной по меньшей мере одной области-мишени; и
(iii) получение антитела против антигенного эпитопа.
В качестве альтернативы, в настоящем изобретении предложен способ создания антитела против белка, причем указанный способ включает:
(i) воздействие на белок ограниченного или частичного протеолиза путем осуществления контакта белка с по меньшей мере одной протеазой с образованием по меньшей мере одной расщепленной, деконструированной или усеченной версии белка и по меньшей мере одного экспонированного на поверхности пептида, который отщепляется от белка под действием указанной протеазы; и
(ii) идентификацию антигенного эпитопа посредством идентификации экспонированного на поверхности пептида, который отщепляется, содержащего аминокислотную последовательность, которая обладает или которая согласно прогнозу обладает функциональной важностью в отношении указанного белка, и создание антигенного эпитопа на основе указанного экспонированного на поверхности пептида; и
(iii) получение антитела против указанного антигенного эпитопа.
Согласно другому аспекту в настоящем изобретении предложен способ создания антитела против белка, причем указанный способ включает:
(i) идентификацию экспонированного на поверхности пептида в указанном белке посредством воздействия на белок ограниченного или частичного протеолиза путем осуществления контакта белка с по меньшей мере одной протеазой с образованием по меньшей мере одной расщепленной, деконструированной или усеченной версии белка и по меньшей мере одного пептида, который отщепляется от белка под действием указанной протеазы; и
(ii) конструирование линейного или конформационного антигенного эпитопа на основе по меньшей мере одного экспонированного на поверхности пептида; и
(iii) получение антитела против антигенного эпитопа.
Согласно другому аспекту в настоящем изобретении предложен способ создания антитела против белка, причем указанный способ включает:
(i) идентификацию экспонированного на поверхности пептида в указанном белке посредством воздействия на белок ограниченного или частичного протеолиза путем осуществления контакта белка с по меньшей мере одной протеазой с образованием по меньшей мере одной расщепленной, деконструированной или усеченной версии белка и по меньшей мере одного экспонированного на поверхности пептида, который отщепляется от белка под действием указанной протеазы; и
(ii) идентификацию экспонированного на поверхности пептида, который при отщеплении или удалении от белка в течение ограниченного или частичного протеолиза приводит к утрате или существенному изменению биологической функции указанного белка; или
выбор по меньшей мере одного из идентифицированных экспонированных на поверхности пептидов согласно (i) на основании соотнесения указанных экспонированных на поверхности пептидов с биоинформационными и/или известными данными о биологической функции белка; и
(iii) конструирование линейного или конформационного антигенного эпитопа на основе по меньшей мере одного экспонированного на поверхности пептида; и
(iv) получение антитела против антигенного эпитопа.
Согласно другому аспекту в настоящем изобретении предложен способ создания антитела против белка, причем указанный способ включает:
(i) идентификацию антигенного эпитопа в указанном белке посредством воздействия на белок ограниченного или частичного протеолиза путем осуществления контакта белка с по меньшей мере одной протеазой с образованием по меньшей мере одной расщепленной, деконструированной или усеченной версии белка и по меньшей мере одного экспонированного на поверхности пептида, который отщепляется от белка под действием указанной протеазы; и
(ii) получение антитела против антигенного эпитопа.
Согласно другому аспекту способ создания антитела согласно настоящему изобретению может представлять собой, в качестве альтернативы, способ получения антитела, которое специфично связывается с белком. Иллюстративные и предпочтительные варианты реализации способов создания антитела, описанные в настоящей заявке, с соответствующими изменениями также применяют в отношении способов получения антитела, которое специфично связывается с белком.
Согласно другому аспекту в настоящем изобретении предложен способ идентификации антигенного эпитопа, причем указанный способ включает:
(i) воздействие на белок ограниченного или частичного протеолиза путем осуществления контакта белка с по меньшей мере одной протеазой с образованием по меньшей мере одной расщепленной, деконструированной или усеченной версии белка и по меньшей мере одного экспонированного на поверхности пептида, который отщепляется от белка под действием указанной протеазы; и
(ii) идентификацию антигенного эпитопа посредством идентификации экспонированного на поверхности эпитопа среди по меньшей мере одного экспонированного на поверхности пептида, присутствующего в области белка, которая приводит к утрате или существенному изменению биологической функции белка, когда пептид отщепляют или удаляют от белка в течение ограниченного или частичного протеолиза; или
выбор по меньшей мере одной области-мишени в белке на основании биоинформационных данных и/или известных данных о биологической функции белка и идентификацию антигенного эпитопа посредством идентификации экспонированного на поверхности эпитопа среди по меньшей мере одного экспонированного на поверхности пептида, присутствующего в указанной по меньшей мере одной области-мишени.
Необязательно данный способ также включает этап получения антитела против указанного антигенного эпитопа.
В качестве альтернативы, в настоящем изобретении предложен способ идентификации антигенного эпитопа, причем указанный способ включает:
(i) воздействие на белок ограниченного или частичного протеолиза путем осуществления контакта белка с по меньшей мере одной протеазой с образованием по меньшей мере одной расщепленной, деконструированной или усеченной версии белка и по меньшей мере одного экспонированного на поверхности пептида, который отщепляется от белка под действием указанной протеазы; и
(ii) идентификацию антигенного эпитопа посредством идентификации экспонированного на поверхности пептида, который отщепляется, содержащего аминокислотную последовательность, которая обладает или которая согласно прогнозу обладает функциональной важностью в отношении указанного белка, и создание антигенного эпитопа на основе указанного экспонированного на поверхности пептида.
Необязательно данный способ также включает этап получения антитела против указанного антигенного эпитопа.
Подробная информация относительно экспонированных на поверхности функционально активных эпитопов в белке может способствовать разработке эффективных антител и может уменьшить потребность в сложных процедурах скрининга посредством уменьшения количества антител-кандидатов. Возможным способом изучения топологии поверхности белка является ограничение активности протеазы для расщепления исключительно наиболее гибких и экспонированных на поверхности частей белка посредством осуществления ограниченного и контролируемого протеолиза. Идея заключается в замедлении кинетики активности протеазы настолько, чтобы пептиды отщеплялись по одному в течение определенного периода времени или не более чем по несколько в течение определенного периода времени. Затем отщепленные пептиды можно классифицировать на основании порядка их появления после воздействия протеазы. Пептиды, которые отщепляются от белка первыми, являются значительно экспонированными белком и являются легкодоступными для протеазы. Авторы настоящего изобретения отнесли данные пептиды к наивысшему классу и выдвинули гипотезу, что пептиды, легко отщепляемые протеазой, также легко распознаются антителом. Пептиды, которые отщепляются позже, авторы настоящего изобретения отнесли к низшему классу, и всем пептидам между указанными пептидами присваивали показатели от высокого до низкого в зависимости от их появления во времени после воздействия протеазы. Таким образом, способ основан на аминокислотной последовательности, и, поскольку авторам настоящего изобретения известна последовательность, конкретно известно, где именно антитело будет связываться с указанным белком-мишенью. На втором этапе, поскольку авторам настоящего изобретения известны конкретные аминокислотные последовательности, которые являются мишенями в белке, можно исследовать функциональную значимость указанной аминокислотной последовательности на основании опубликованных данных или других известных биоинформационных данных либо данных фармакологических исследований усеченных белков. Если аминокислотная последовательность совпадает или является близкой либо перекрывается с известной аминокислотной последовательностью, имеющей функциональную важность, например, сайтом связывания, сайтом модулирования, сайтом, важным со структурной точки зрения, областью канала и т.д., тогда указанному пептиду присваивают высокий показатель, и данный пептид считают хорошим кандидатом на роль антигенного эпитопа и для последующей разработки антитела. Такого результата можно достичь, в частности, посредством контроля активности протеазы с использованием, например, низких температур, низких концентраций и/или короткого времени расщепления. Когда ограниченный протеолиз проводили в отношении белков с известной структурой, главным образом, были распознаны три структурные детерминанты, которые оказывают влияние на то, где возникает протеолитическая активность. Данные детерминанты включают гибкость, экспонирование на поверхности и количество локальных взаимодействий. Для того чтобы цепь пептида поступила в активный сайт протеазы, требуется гибкость и способность белка к локальному развертыванию. Экспонирование на поверхности, более вероятно, обеспечивает сайт расщепления для протеолиза, поскольку области на поверхности имеют тенденцию более легко разворачиваться, а также создают меньшее количество стерических препятствий. Количество локальных взаимодействий применительно к водородным связям и дисульфидным мостикам также является важным. Меньшее количество локальных взаимодействий способствует протеолизу. Все три данные структурные детерминанты обычно соотносятся в белке. Вследствие этого в ходе ограниченного протеолиза, главным образом, отщепляются экспонированные на поверхности области при условии, что цепь белка может локально разворачиваться. Данный факт был использован в качестве способа определения экспонированных на поверхности областей в белках, подробная структура которых неизвестна.
Технология иммобилизации белка на основе липидов (lipid-based protein immobilization, LPI) делает возможной осуществление гибкой химии на мембранных белках. Посредством получения протеолипосом из клеток и их иммобилизации в проточной ячейке создают неподвижную фазу мембранных белков, которую можно подвергнуть взаимодействию с несколькими сериями растворов и различными типами химических модуляций, например, с помощью ферментов. Был разработан протокол поэтапного триптического расщепления для протеомной характеризации, в котором пептиды, полученные в результате ступенчатого ферментативного расщепления протеолипосом, анализируют методом жидкостной хроматографии с тандемной масс-спектрометрией (ЖХ-МС/МС) [1-3].
Согласно некоторым вариантам реализации способов согласно настоящему изобретению белок представляет собой белок (например, мембранный белок), который присутствует (например, в липидном двойном слое) в протеолипосоме (например, в протеолипосоме, полученной из клеток, например, из клеток человека). Соответственно, согласно некоторым вариантам реализации настоящего изобретения ограниченный протеолиз проводят в отношении протеолипосом. Протеолипосомы представляют собой липидные везикулы, содержащие белки. Протеолипосомы могут быть восстановлены из очищенных мембранных белков и липидов или могут быть получены напрямую из мембраны клетки (например, посредством пузырения) либо посредством лизиса клетки. Предпочтительно, протеолипосомы получают (готовят) из клеточных мембран лизированных клеток. Протеолипосомы можно получить из любого типа клеток, представляющих интерес.
Подходящий тип клеток представляет собой клетки яичников китайского хомячка (chinese hamster ovary, CHO).
Способы получения протеолипосом известны в данной области техники, и можно использовать любой из таких способов (например, способ, описанный в публикации Jansson et al. Anal. Chem., 2012, 84:5582-5588). Иллюстративный и предпочтительный способ получения протеолипосом описан в примерах в настоящей заявке. Как правило, предпочтительными являются протеолипосомы диаметром от приблизительно 50 нм до приблизительно 150 нм.
Использование протеолипосом, полученных (приготовленных) из клеточных мембран лизированных клеток, является предпочтительным, поскольку протеолипосомы, полученные таким образом (например, с применением способа, указанного в примерах), могут представлять внутриклеточные части (или домены) мембранных белков на внешней стороне протеолипосомы, что делает доступными для протеолитического расщепления (и, следовательно, для идентификации антигенного эпитопа) некоторые части белка, которые в противном случае будут недоступны для протеазы.
Согласно одному аспекту авторы настоящего изобретения разработали технологию адресных антител посредством применения микрожидкостной платформы LPI [1, 4] для создания потенциальных эпитопов-кандидатов. Данная методология скорее основана на механизме, чем на скрининге. Вкратце, технология LPI делает возможной осуществление гибкой химии, такой как ограниченный протеолиз, на мембранных белках. Посредством получения протеолипосом из клеток и их иммобилизации в проточной ячейке создают неподвижную фазу мембранных белков. Был разработан протокол поэтапного расщепления для протеомной характеризации, в котором пептиды, полученные в результате ступенчатого ферментативного расщепления протеолипосом, анализируют методом ЖХ–МС/МС. Такие пептиды, созданные в процессе кинетически контролируемого расщепления в проточной ячейке LPI, позволяют выявить в белке-мишени экспонированные и доступные области, области, которые потенциально могут быть доступными для связывания с антителом. Затем данные потенциальные эпитопы соотносят с известными функциональными данными с целью обнаружения эпитопов, которые позволяют получить антитела с одинаково превосходными характеристиками связывания и биологической эффективностью. Наконец, выбранные эпитопы/пептиды можно использовать для иммунизации животного-хозяина с целью получения антител. Следует упомянуть, что в данной области техники известны другие способы и методики для осуществления ограниченного протеолитического расщепления, которые также можно использовать, например, в случае растворимых белков.
Согласно некоторым вариантам реализации настоящего изобретения белок (например, мембранный белок) иммобилизуют (например, на твердой подложке) перед ограниченным или частичным протеолизом для получения неподвижной фазы белка. Таким образом, согласно некоторым вариантам реализации настоящего изобретения белок является связанным с поверхностью.
Согласно некоторым вариантам реализации настоящего изобретения белок (например, мембранный белок) присутствует в (или присутствует на) протеолипосоме (например, протеолипосоме, полученной из клеток), и указанную протеолипосому иммобилизуют (например, на твердой подложке) перед ограниченным или частичным протеолизом для получения неподвижной фазы белка.
Согласно некоторым вариантам реализации способов согласно настоящему изобретению белок представляет собой мембранный белок, который присутствует в протеолипосоме, полученной из клеток, причем указанную протеолипосому иммобилизуют в проточной ячейке для получения неподвижнной фазы мембранных белков. Подходящие проточные ячейки известны в данной области техники, например, проточная ячейка, описанная в публикации Jansson et al. (Anal. Chem., 2012, 84:5582-5588).
Согласно некоторым вариантам реализации настоящего изобретения белок (например, мембранный белок) присутствует в (или присутствует на) протеолипосоме (например, протеолипосоме, полученной из клеток), и указанные протеолипосомы находятся в суспензии (например, суспендированы в растворе).
Согласно некоторым вариантам реализации настоящего изобретения указанный белок находится в (или присутствует на) липидной везикуле, содержащей белок, которая является связанной с поверхностью или находится в суспензии (например, суспендирована в растворе).
Согласно некоторым вариантам реализации настоящего изобретения указанный белок может представлять собой часть любой соответствующей структуры либо может быть представлен на любой соответствующей структуре, в результате чего сохраняется функциональная или природная конформация белка, например, белок может представлять собой часть липидного бислоя или мембраны либо может быть представлен на каркасе или частице.
Согласно некоторым вариантам реализации настоящего изобретения указанный белок находится в (или представлен на) частице, такой как наночастица или любая другая коллоидная частица, которая является связанной с поверхностью или находится в суспензии (например, суспендирована в растворе).
Согласно некоторым вариантам реализации настоящего изобретения указанный белок находится в (или представлен на) каркасе или другой химической структуре, такой как каркасные соединения, которая является связанной с поверхностью или находится в суспензии (например, суспендирована в растворе).
Согласно некоторым вариантам реализации настоящего изобретения указанный белок находится в (или представлен на) интактной клетке (биологической клетке, например, клетке человека), которая является связанной с поверхностью или находится в суспензии (например, суспендирована в растворе).
«В» в контексте белков в протеолипосомах, везикулах, содержащих белок, или интактных клетках включает белки, которые простираются до внешней поверхности протеолипосомы, липидной везикулы, содержащей белок, или клетки (и которые, таким образом, экспонированы на указанной внешней поверхности).
Согласно некоторым вариантам реализации настоящего изобретения указанный белок находится в растворе. Раствор может представлять собой раствор очищенного белка или может содержать смесь белков.
Согласно некоторым вариантам реализации настоящего изобретения клетки (например, клетки CHO) сверхэкспрессируют белок, например, посредством индуцибельной (например, индуцибельной тетрациклином) системы экспрессии. Согласно некоторым вариантам реализации настоящего изобретения используют протеолипосомы, полученные из таких клеток.
Авторы настоящего изобретения изучали пептиды, полученные в результате ограниченного протеолиза ваниллоидного ионного канала типа 1 с транзиторным рецепторным потенциалом (transient receptor potential vanilloid 1, TRPV1), с целью обнаружения потенциальных эпитопов для разработки биологически активных антител, которые обладают способностью модулировать функции данного ионного канала. TRPV1 подвергали ограниченному протеолизу двумя различными протеазами, и отщепленные пептиды соотносили с функциональными данными. Авторы настоящего изобретения, используя данную информацию, разработали два поликлональных антитела, OTV1 и OTV2, действующие на внутриклеточной стороне ионного канала TRPV1 человека (hTRPV1, human TRPV1). Оба антитела являются фармакологически активными, и области–мишени эпитопа указанных антител были выбраны на основании простоты отщепления (или экспонирования на поверхности (пептиды высокого класса после ограниченного протеолиза)), а также функциональной важности. OTV1 демонстрирует мощное ингибирующее действие в отношении белка при стимуляции агонистом капсайцином. OTV2 препятствует кальмодулин/Ca2+-зависимой десенсибилизации TRPV1, представляющей собой процесс, который запускается притоком кальция через TRPV1. Эффективность OTV1 и OTV2 исследовали методом пэтч-кламп «наружная сторона внутри», в ходе которого внутриклеточную сторону TRPV1 можно экспонировать в раствор антитела, а также посредством анализа поглощения опосредованной TRPV1 флуоресценции после того, как антитела электропорировали внутрь живых клеток.
Способы, в которых используют проточную ячейку LPI в сочетании с микрожидкостной проточной ячейкой открытого объема для быстрой смены раствора, подходящие для экспериментов с применением метода пэтч-кламп, были описаны ранее. Преимущество данного подхода заключается в том, что мембраны клеток можно вывернуть наизнанку и можно непосредственно исследовать внутриклеточные домены ионного канала. С помощью данного подхода можно получить согласованные структурные и функциональные данные, используя ограниченный и контролируемый протеолиз. TRPV1 представляет собой катионный канал, который экспрессируется в ноцицептивных первичных сенсорных нейронах. Подробная кристаллическая структура полноразмерного белка отсутствует, но для TRPV1 крысы был успешно кристаллизован домен анкириновых повторов (ankyrin repeat domain, ARD) N-конца. Пептиды, отщепленные в течение коротких периодов времени при осуществлении ограниченного протеолиза TRPV1, сравнивали с известными функционально активными областями. Треть обнаруженных пептидов содержала остатки, которые, как было предположено, являются функционально важными. Скрининг топологии поверхности TRPV1, как описано в исследованиях в данной области техники, осуществляли посредством иммобилизации протеолипосом, содержащих TRPV1, в проточной ячейке и посредством последующего воздействия на протеолипосомы ограниченного протеолиза трипсином [1, 4]. Активность трипсина контролировали посредством применения различных времен расщепления при комнатной температуре.
Использовали поэтапный протокол с нарастающими временами инкубации, и отщепленные пептиды обнаруживали методом ЖХ–МС/МС. Увеличивающееся количество пептидов было обнаружено в зависимости от времени, что позволило выявить области белка, которые были доступны и легко расщеплялись, а также более устойчивые области. Данные результаты проиллюстрированы на фигуре 1. Несколько областей, которые были обнаружены методом ЖХ–МС/МС в качестве отщепленных пептидов после ограниченного протеолиза TRPV1 в проточной ячейке LPI, согласовывались с известными сайтами взаимодействия с кальмодулином, АТФ и PIP2.
Авторы настоящего изобретения также исследовали функциональность TRPV1 после удаления различных структурных сегментов посредством расщепления трипсином [4].
Активность ионного канала TRPV1 исследовали с помощью анализа методом пэтч-кламп «наружная сторона внутри» и расщеплений в проточной ячейке, после чего следовал протеомный анализ, в котором оценивали структурные эффекты химического усечения. Авторы настоящего изобретения использовали конфигурацию анализа пэтч-кламп «наружная сторона внутри», которая позволяет подвергать воздействию трипсина внутриклеточную часть TRPV1, и определяли уменьшение ответа тока при увеличении концентрации трипсина (фигура 2).
Авторы настоящего изобретения продемонстрировали, что ионный канал TRPV1 можно подвергнуть ограниченному и контролируемому протеолизу трипсином в двух различных микрожидкостных проточных ячейках в идентичных условиях эксперимента. В одном случае анализ методом пэтч-кламп проводили с целью фармакологических исследований, которые позволили получить информацию о динамике функции канала в микрожидкостном устройстве открытого объема. Данный дизайн позволяет с помощью пипетки для пэтч- кламп и фрагмента клетки получить доступ к перфузионным каналам. В другом случае использовали эквивалентную проточную ячейку закрытого объема для отщепления пептидов от ионного канала, не вызывая разведения образца. Отщепленные пептиды идентифицировали методом ЖХ–МС/МС. Затем сравнивали данные, полученные в двух экспериментах, и оценивали отношение структура–функция. Используя данный методологический подход, авторы настоящего изобретения идентифицировали в высокой степени гибкие области TRPV1, а также ключевые области, которые влияют на функциональные свойства канала в ходе активации последнего агонистом капсайцином.
Данный тип методологии можно также использовать для других белков (т.е. белков, отличных от TRPV1).
Аминокислотная последовательность hTRPV1 представлена ниже (SEQ ID NO:1).
MKKWSSTDLGAAADPLQKDTCPDPLDGDPNSRPPPAKPQLSTAKSRTRLFGKGDSEEAFPVD CPHEEGELDSCPTITVSPVITIQRPGDGPTGARLLSQDSVAASTEKTLRLYDRRSIFEAVAQNNC QDLESLLLFLQKSKKHLTDNEFKDPETGKTCLLKAMLNLHDGQNTTIPLLLEIARQTDSLKELVN ASYTDSYYKGQTALHIAIERRNMALVTLLVENGADVQAAAHGDFFKKTKGRPGFYFGELPLSLA ACTNQLGIVKFLLQNSWQTADISARDSVGNTVLHALVEVADNTADNTKFVTSMYNEILMLGAKL HPTLKLEELTNKKGMTPLALAAGTGKIGVLAYILQREIQEPECRHLSRKFTEWAYGPVHSSLYDL SCIDTCEKNSVLEVIAYSSSETPNRHDMLLVEPLNRLLQDKWDRFVKRIFYFNFLVYCLYMIIFTM AAYYRPVDGLPPFKMEKTGDYFRVTGEILSVLGGVYFFFRGIQYFLQRRPSMKTLFVDSYС.О. СLFFLQSLFMLATVVLYFSHLKEYVASMVFSLALGWTNMLYYTRGFQQMGIYAVMIEKMILRDL CRFMFVYIVFLFGFSTAVVTLIEDGKNDSLPSESTSHRWRGPACRPPDSSYNSLYSTCLELFKF TIGMGDLEFTENYDFKAVFIILLLAYVILTYILLLNMLIALMGETVNKIAQESKNIWKLQRAITILDTE KSFLKCMRKAFRSGKLLQVGYTPDGKDDYRWCFRVDEVNWTTWNTNVGIINEDPGNCEGVK RTLSFSLRSSRVSGRHWKNFALVPLLREASARDRQSAQPEEVYLRQFSGSLKPEDAEVFKSPA ASGEK
Вследствие этого настоящее изобретение делает возможным проведение функциональных исследований специфичных эпитопов или оценку предполагаемых сайтов связывания новых антител для мембранного белка-мишени, находящегося в нативном липидном окружении.
Согласно настоящему изобретению антигенный эпитоп, как правило, основан на экспонированном на поверхности пептиде, который был отщеплен от белка в процессе ограниченного или частичного протеолиза. В качестве альтернативы, экспонированный на поверхности пептид, как правило, используют для получения антигенного эпитопа.
В этой связи антигенный эпитоп может содержать аминокислотную последовательность экспонированного на поверхности пептида или последовательность, по существу гомологичную указанной последовательности. Антигенный эпитоп может состоять из аминокислотной последовательности экспонированного на поверхности пептида или последовательности, по существу гомологичной указанной последовательности. Антигенный эпитоп может перекрываться с аминокислотной последовательностью экспонированного на поверхности пептида или последовательностью, по существу гомологичной указанной последовательности.
Аминокислотные последовательности, которые являются «по существу гомологичными» экспонированным на поверхности пептидам, включают последовательности, имеющие, или последовательности, содержащие последовательность, которая содержит 1, 2 или 3 замены аминокислот (предпочтительно, 1 или 2, более предпочтительно, 1) по сравнению с аминокислотной последовательностью данного экспонированного на поверхности пептида.
Аминокислотные последовательности, которые являются «по существу гомологичными» экспонированным на поверхности пептидам, включают последовательности, которые содержат по меньшей мере 5 или по меньшей мере 6 последовательных аминокислот экспонированных на поверхности пептидов либо которые состоят из указанных аминокислот (или которые содержат по меньшей мере 7, по меньшей мере 8, по меньшей мере 9, по меньшей мере 10, по меньшей мере 11, по меньшей мере 12, по меньшей мере 15, по меньшей мере 20 или по меньшей мере 25 последовательных аминокислот экспонированного на поверхности пептида либо которые состоят из указанных аминокислот). Шесть аминокислот составляют типичную длину последовательности пептида/белка, которая распознается или связывается антителом.
Аминокислотные последовательности, которые являются «по существу гомологичными» экспонированным на поверхности пептидам, включают последовательности, имеющие, или последовательности, содержащие последовательность, которая характеризуется идентичностью последовательности по меньшей мере 25%, по меньшей мере 30%, по меньшей мере 35%, по меньшей мере 40%, по меньшей мере 45%, по меньшей мере 50%, по меньшей мере 55%, по меньшей мере 60%, по меньшей мере 65%, по меньшей мере 70%, по меньшей мере 75%, по меньшей мере 80%, по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95% или по меньшей мере 98% данной последовательности экспонированного на поверхности пептида. Предпочтительными являются идентичности последовательностей, составляющие по меньшей мере 70%, по меньшей мере 75%, по меньшей мере 80%, по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95% или по меньшей мере 98%.
Антигенный эпитоп может содержать удлиненную версию экспонированного на поверхности пептида или удлиненную версию аминокислотной последовательности, по существу гомологичной экспонированному на поверхности пептиду (или может состоять из указанных последовательностей). Например, одна или более дополнительных аминокислот (например, по меньшей мере 2, по меньшей мере 3, по меньшей мере 4, по меньшей мере 5, по меньшей мере 6, по меньшей мере 7, по меньшей мере 8 или по меньшей мере 9, по меньшей мере 10, по меньшей мере 15 или по меньшей мере 20 аминокислот) могут присутствовать на одном конце или на обоих концах последовательности экспонированного на поверхности пептида (или последовательности, по существу гомологичной указанной последовательности). Согласно некоторым вариантам реализации до 2, до 3, до 4, до 5, до 6, до 7, до 8, до 9, до 10, до 15 или до 20 аминокислот могут присутствовать на одном конце или на обоих концах последовательности экспонированного на поверхности пептида (или последовательности, по существу гомологичной указанной последовательности).
Антигенный эпитоп может содержать усеченную версию экспонированного на поверхности пептида или усеченную версию аминокислотной последовательности, по существу гомологичной экспонированному на поверхности пептиду (или может состоять из указанных последовательностей). Например, одна или более аминокислот (например, по меньшей мере 2, по меньшей мере 3, по меньшей мере 4, по меньшей мере 5, по меньшей мере 6, по меньшей мере 7, по меньшей мере 8 или 9, по меньшей мере 10) могут отсутствовать с одного или обоих концов последовательности экспонированного на поверхности пептида (или последовательности, по существу гомологичной указанной последовательности). Согласно некоторым вариантам реализации настоящего изобретения до 2, до 3, до 4, до 5, до 6, до 7, до 8, до 9 или до 10, до 15 или до 20 аминокислот могут отсутствовать с одного или обоих концов последовательности экспонированного на поверхности пептида (или последовательности, по существу гомологичной указанной последовательности).
Антигенный эпитоп может представлять собой циклический пептид, например, по существу гомологичный одному или нескольким экспонированным на поверхности пептидам, причем экспонированные на поверхности пептиды расположены близко друг к другу в пространстве.
Антигенные эпитопы могут составлять по меньшей мере 5 или по меньшей мере 6, или по меньшей мере 7 аминокислот в длину, например, от 6 до 10, от 6 до 12, от 6 до 15, от 6 до 20, от 6 до 25, от 6 до 30, от 6 до 40, от 6 до 50, от 6 до 60 или от 6 до 75 аминокислот в длину. Антигенные эпитопы могут составлять, например, до 7, до 8, до 9, до 10, до 15, до 20, до 25, до 30, до 35 или до 40 аминокислот в длину. Антигенные эпитопы могут составлять, например, от 5 до 30, от 6 до 30, от 7 до 30, от 5 до 25, от 6 до 25 или от 7 до 25 аминокислот в длину. Антигенные эпитопы могут составлять, например, от 5 до 7, или от 5 до 8, или от 5 до 9 (например, от 7 до 9 аминокислот) в длину. Во избежание разночтений отметим, что более длинные белки или полипептиды, например, таковые длиной более 100 аминокислот, не считают эпитопами согласно настоящему изобретению.
Гомологию (например, идентичность последовательности) можно оценить любым подходящим способом. Однако пригодными для определения степени гомологии (например, идентичности) между последовательностями являются компьютерные программы, которые позволяют проводить множественные выравнивания последовательностей, например Clustal W (Thompson, Higgins, Gibson, Nucleic Acids Res., 22:4673-4680, 1994). При необходимости, алгоритм Clustal W можно использовать вместе с матрицей замен BLOSUM 62 (Henikoff and Henikoff, Proc. Natl. Acad. Sci. USA, 89:10915–10919, 1992), а также штрафом за открытие пропуска 10 и штрафом за удлинение пропуска 0,1, для получения соответствия наивысшего порядка между двумя последовательностями, причем, чтобы по меньшей мере 50% общей длины одной из последовательностей было вовлечено в выравнивание. Другие способы, которые можно использовать для выравнивания последовательностей, представляют собой способ выравнивания Нидлмана и Вунша (Needleman and Wunsch, J. Mol. Biol., 48:443, 1970), пересмотренный Смитом и Вотерманом (Smith and Waterman, Adv. Appl. Math., 2:482, 1981), для получения соответствия наивысшего порядка между двумя последовательностями и для определения количества идентичных аминокислот между двумя последовательностями. Другие способы расчета процента идентичности между двумя аминокислотными последовательностями, как правило, известны в данной области техники и включают, например, таковые, описанные в публикации Carillo and Lipton (Carillo and Lipton, SIAM J. Applied Math., 48:1073, 1988), и таковые, описанные в руководстве Computational Molecular Biology, Lesk, e.d. Oxford University Press, New York, 1988, Biocomputing: Informatics and Genomics Projects.
Как правило, для таких расчетов будут использовать компьютерные программы. Пригодными для данной цели также являются программы, которые сравнивают и выравнивают пары последовательностей, такие как ALIGN (Myers and Miller, CABIOS, 4:11-17, 1988), FASTA (Pearson and Lipman, Proc. Natl. Acad. Sci. USA, 85:2444-2448, 1988; Pearson, Methods in Enzymology, 183:63-98, 1990) и gapped BLAST (Altschul et al., Nucleic Acids Res., 25:3389-3402, 1997), BLASTP, BLASTN или GCG (Devereux, Haeberli, Smithies, Nucleic Acids Res., 12:387, 1984). Более того, сервер Dali Европейского института биоинформатики предлагает выравнивания на основании структуры последовательностей белка (Holm, Trends in Biochemical Sciences, 20:478-480, 1995; Holm, J. Mol. Biol., 233:123-38, 1993; Holm, Nucleic Acid Res., 26:316-9, 1998).
Антигенные эпитопы согласно настоящему изобретению могут являться линейными эпитопами или конформационными эпитопами.
Согласно некоторым вариантам реализации настоящего изобретения антигенные эпитопы согласно настоящему изобретению могут являться циклизированными эпитопами.
Общепринятая методика, используемая для получения линейных антигенных эпитопов, применяемых для иммунизации, представляет собой ТФПС (твердофазный пептидный синтез) на основе Fmoc. В ТФПС небольшие пористые бусины обрабатывают функциональными линкерами, на которых могут быть построены цепи пептидов с использованием повторяющихся циклов промывки – сочетания – промывки. Затем синтезированный пептид освобождают от бусин с использованием химического отщепления. Для синтеза циклических пептидов в общепринятых способах используют циклизацию посредством образования дисульфидного мостика (причем мостик образуется между двумя цистеинами) или посредством образования мостика по типу «голова-хвост», причем мостик состоит из типичных пептидных связей. Циклические пептиды могут быть образованы на твердой подложке. Антитела против конформационных эпитопов обычно синтезируют с использованием целого белка или больших частей белка.
Ограниченный или частичный протеолиз включает протеолитическое расщепление белка, которое проходит не до конца. Таким образом, посредством ограниченного или частичного протеолиза данный белок может быть расщеплен только частично (или частично деконструирован или частично усечен). Ограниченный или частичный протеолиз можно рассматривать как неполный протеолиз. Если данный белок содержит определенное количество потенциальных точек расщепления данной протеазой (т.е. сайтов, распознаваемых данной протеазой для расщепления), при ограниченном или частичном протеолизе протеаза может расщеплять исключительно часть данных сайтов расщепления.
Ограниченный или частичный протеолиз также включает протеолиз, проводимый при лимитирующих условиях, посредством чего кинетика активности протеазы замедляется до такой степени, что пептиды отщепляются от белка по одному в данный момент времени или не более чем по несколько в данный момент времени. Согласно некоторым вариантам реализации настоящего изобретения кинетическая активность указанной по меньшей мере одной протеазы замедляется настолько, что указанные экспонированные на поверхности пептиды отщепляются по одному в данный момент времени или не более чем по несколько в данный момент времени, например, не более чем 8 (1, 2, 3, 4, 5, 6, 7 или 8) в данный момент времени (например, не более чем 8 пептидов или не более чем 8 уникальных пептидов в образце, например, как описано в другом месте в настоящей заявке), или не более чем 7 (1, 2, 3, 4, 5, 6 или 7) в данный момент времени (например, не более чем 7 пептидов или не более чем 7 уникальных пептидов в образце, например, как описано в другом месте в настоящей заявке), или не более чем 5 (1, 2, 3, 4 или 5) в данный момент времени (например, не более чем 5 пептидов или не более чем 5 уникальных пептидов в образце, например, как описано в другом месте в настоящей заявке). Согласно некоторым таким вариантам реализации настоящего изобретения реакция протеолиза может проходить до завершения, в результате чего в белке исчерпываются пептиды, которые могут отщепляться данной протеазой.
Как описано в другом месте в настоящей заявке, как правило, ограниченный или частичный протеолиз приводит к тому, что протеазой расщепляются исключительно наиболее гибкие и/или экспонированные на поверхности части белка.
Согласно некоторым вариантам реализации настоящего изобретения указанную по меньшей мере одну протеазу используют в условиях, которые приводят к получению не более чем 8 экспонированных на поверхности пептидов (например, 1, 2, 3, 4, 5, 6, 7 или 8 экспонированных на поверхности пептидов), отщепленных от белка под действием указанной протеазы (например, не более чем 8 пептидов или не более чем 8 уникальных пептидов в образце, например, как описано в другом месте в настоящей заявке).
Согласно предпочтительному варианту реализации настоящего изобретения указанную по меньшей мере одну протеазу используют в условиях, которые приводят к получению не более чем 7 экспонированных на поверхности пептидов (например, 1, 2, 3, 4, 5, 6 или 7 экспонированных на поверхности пептидов) или не более чем 5 экспонированных на поверхности пептидов (например, 1, 2, 3, 4 или 5 экспонированных на поверхности пептидов), отщепленных от белка под действием указанной протеазы (например, не более чем 7 или не более чем 5 пептидов, или не более чем 7 или не более чем 5 уникальных пептидов в образце, например, как описано в другом месте в настоящей заявке).
Ограниченного или частичного протеолиза согласно настоящему изобретению можно, как правило, достичь посредством уменьшения активности протеазы, например, посредством замедления кинетики активности протеазы до такой степени, что пептиды отщепляются от белка по одному в данный момент времени или не более чем по несколько в данный момент времени. Согласно некоторым вариантам реализации настоящего изобретения кинетическая активность указанной по меньшей мере одной протеазы замедляется настолько, что указанные экспонированные на поверхности пептиды отщепляются по одному в данный момент времени или не более чем по несколько в данный момент времени, например, не более чем 8 (1, 2, 3, 4, 5, 6, 7 или 8) в данный момент времени или не более чем 7 в данный момент времени (1, 2, 3, 4, 5, 6 или 7), или не более чем 5 (1, 2, 3, 4 или 5) в данный момент времени, например, как описано выше.
Для ограниченного или частичного протеолиза можно использовать любые подходящие условия для получения исключительно наиболее гибких и/или экспонированных на поверхности частей белка, отщепляемых протеазой, например, для получения не более чем 8 экспонированных на поверхности пептидов или не более чем 7 экспонированных на поверхности пептидов, или не более чем 5 экспонированных на поверхности пептидов, отщепляемых протеазой. Условия, которые приводят к ограниченному или частичному протеолизу, можно установить посредством варьирования температуры реакции расщепления и/или концентрации протеазы, и/или продолжительности реакции расщепления, и/или буферных условий. Количество пептидов, отщепляемых от пептида в конкретных условиях, может определить специалист в данной области техники (например, методом масс-спектрометрии или химии белка либо биохимии). Подходящие способы установления соответствующих условий ограниченного или частичного протеолиза также описаны в другом месте в настоящей заявке. Соответствующие условия для ограниченного или частичного протеолиза можно установить для различных белков или для различных протеаз либо для конкретной комбинации используемых белка и протеазы. В особенности предпочтительные условия для ограниченного или частичного протеолиза описаны в примерах в настоящей заявке. Условия, используемые для ограниченного или частичного протеолиза, как правило, не изменяют (или значительно не изменяют) нативную конфигурацию (нативную форму) белка. Кофакторы белка могут присутствовать, но не обязательно присутствуют в течение ограниченного или частичного протеолиза.
Соответствующие условия для ограниченного или частичного протеолиза могут отличаться в зависимости от протеазы и/или белка, но представляют собой, как правило, условия, которые не являются оптимальными для протеазы, о которой идет речь, например, в результате чего кинетика активности протеазы значительно замедляется или уменьшается.
Как правило, используют условия, которые предоставляют (или обеспечивают) низкую протеолитическую активность протеазы (например, меньшую или значительно меньшую, чем оптимальная протеолитическая активность). Такие условия включают, но не ограничены указанными, использование низкой концентрации протеазы и/или рабочей температуры, которая не является оптимальной для протеазы, о которой идет речь, и/или нестандартного или неоптимального буфера для протеазы, о которой идет речь, и/или короткого времени контакта (инкубации) протеазы с белком.
Согласно некоторым вариантам реализации настоящего изобретения ограниченный или частичный протеолиз (например, при использовании трипсина или, например, при использовании протеазы с оптимальной рабочей температурой, составляющей, например, 37°C или выше) проводят при комнатной температуре (например, приблизительно 20°C или 17 – 23°C, или 20 – 25 °C).
Согласно некоторым вариантам реализации настоящего изобретения ограниченный или частичный протеолиз проводят при температуре, которая по меньшей мере на 2°C, по меньшей мере на 5 °C, по меньшей мере на 10 °C или по меньшей мере на 20 °C выше или ниже либо значительно выше или ниже (предпочтительно, ниже) оптимальной рабочей температуры используемой протеазы. Согласно некоторым вариантам реализации ограниченный или частичный протеолиз проводят при температуре, которая по меньшей мере на 2°C – 5°C, 2°C – 10°C, 2°C – 20°C, 2°C – 30°C, 5°C – 10°C, 5°C – 20°C, 5°C – 30°C, 10°C – 20°C, 10°C – 30°C, 20°C – 30°C выше или ниже (предпочтительно, ниже) оптимальной рабочей температуры используемой протеазы.
Согласно некоторым вариантам реализации настоящего изобретения для ограниченного или частичного протеолиза используют концентрации до 5 мкг/мл протеазы (например, трипсина). Согласно некоторым вариантам реализации для ограниченного или частичного протеолиза используют концентрации до 0,5 мкг/мл, до 1 мкг/мл, до 2 мкг/мл, до 5 мкг/мл, до 10 мкг/мл или до 20 мкг/мл протеазы. Предпочтительно, для ограниченного или частичного протеолиза используют концентрацию 5 мкг/мл протеазы или менее (например, до 1 мкг/мл, до 2 мкг/мл, до 3 мкг/мл, до 4 мкг/мл или до 5 мкг/мл). Согласно некоторым вариантам реализации настоящего изобретения реакции ограниченного протеолиза позволяют протекать в течение не более чем или менее чем 5 минут, 10 минут, 15 минут, 30 минут, одного часа или пяти часов, причем более короткие времена инкубации, как правило, являются предпочтительными. Например, согласно некоторым вариантам реализации настоящего изобретения реакции ограниченного протеолиза позволяют протекать в течение не более чем или менее чем 5 минут, 10 минут, 15 минут, 30 минут. Согласно некоторым предпочтительным вариантам реализации настоящего изобретения реакция ограниченного или частичного протеолиза представляет собой реакцию, которой позволяют протекать в течение 5 минут или менее (например, 4 минут или менее, 3 минут или менее, 2 минут или менее или 1 минуты или менее). Как правило, если используют высокую (или более высокую) концентрацию протеазы, тогда используют короткое (или более короткое) время инкубации. Исключительно в качестве примера, если используют концентрацию 20 мкг/мл протеазы (или выше), тогда можно использовать время инкубации 5 минут или менее. Согласно некоторым таким вариантам реализации настоящего изобретения ограниченный протеолиз проводят при комнатной температуре. Таким образом, согласно некоторым вариантам реализации настоящего изобретения ограниченный протеолиз проводят с концентрацией не более чем 5 мкг/мл протеазы (например, приблизительно 5 мкг/мл протеазы) в течение не более чем приблизительно 5 минут (например, приблизительно 5 минут) при комнатной температуре.
Согласно некоторым вариантам реализации настоящего изобретения ограниченный протеолиз или частичный протеолиз представляет собой протеолиз (реакцию протеолиза), который приводит к расщеплению 15% или менее, или 10% или менее, или 5% или менее (например, 1%, 2%, 3%, 4% или 5%) сайтов (связей) в белке, которые являются потенциально расщепляемыми (перевариваемыми) используемой протеазой, или обеспечивает указанное расщепление. В качестве альтернативы, согласно некоторым вариантам реализации настоящего изобретения ограниченный протеолиз обеспечивает 15% или менее, или 10% или менее, или 5% или менее (например, 1%, 2%, 3%, 4% или 5%) протеолиза. Специалист может с легкостью идентифицировать сайты в данном белке, которые являются потенциально расщепляемыми используемой протеазой, на основании информации о последовательности белка и субстратной специфичности используемой протеазы (например, с применением компьютера, например, программного обеспечения Peptidecutter (Expasy, SIB, Swiss Institute of Bioinformatics, Швейцарский институт биоинформатики). Как правило, расщепление во всех потенциальных сайтах в линейной аминокислотной последовательности будет представлять собой значение «100%» (хотя значение «100%» можно, в качестве альтернативы, задать и в виде суммарного числа потенциальных сайтов в белке, которые в случае расщепления высвободят (или позволят получить) пептиды, длину которых можно с легкостью обнаружить применяемым инструментом, например, применяемым инструментом МС). В качестве альтернативы, значение «100%» можно задать в виде числа потенциальных расщепляемых сайтов в белке, которые, как известно (или согласно прогнозу, например, с применением инструмента моделирования белков), находятся в области белка, доступной для протеазы (например, во внеклеточной части или домене белка, или, например, не в части или области либо домене белка, которые находятся в пределах мембраны клетки, или не в богатой цистеином части белка, или не в посттрансляционно модифицированной части белка, или не в бета-листе). Специалист также может с легкостью определить число (и расположение) сайтов, которые фактически расщепляются протеазой (например, с применением масс-спектрометрии), и, таким образом, может с легкостью определить процент потенциально расщепляемых сайтов, которые фактически были расщеплены.
Согласно некоторым вариантам реализации настоящего изобретения ограниченный или частичный протеолиз можно рассматривать как протеолитический этап, который осуществляют при одном или нескольких условиях, описанных в настоящей заявке применительно к ограниченному или частичному протеолизу.
Согласно некоторым вариантам реализации настоящего изобретения реакции протеолитического расщепления можно остановить с использованием муравьиной кислоты или водного аммиака. Например, активность трипсина, Asp-N, протеиназы K и химотрипсина можно остановить с использованием муравьиной кислоты, а активность пепсина можно остановить с использованием водного аммиака.
Согласно некоторым вариантам реализации настоящего изобретения отщепленные экспонированные на поверхности пептиды классифицируют на основании порядка их появления после осуществления контакта с указанной по меньшей мере одной протеазой, причем экспонированным на поверхности пептидам, которые отщепляются первыми (или раньше) и обнаруживаются в первых (или ранних) точках отбора образца, присваивают высокий класс, и экспонированным на поверхности пептидам, которые отщепляются позже и обнаруживаются в последующих точках отбора образца, присваивают низкий класс. Пептиды высокого класса, которые быстро отделяются от белка-мишени, а также характеризуются функциональной значимостью, можно, как правило, использовать для разработки эпитопа, иммунизации и последующего создания антитела.
Согласно некоторым вариантам реализации настоящего изобретения экспонированным на поверхности пептидам, которые отщепляются в условиях низкой (менее жесткой) протеолитической активности, как описано в настоящей заявке (например, при (более) низкой концентрации протеазы, при (более) низкой температуре инкубации и/или при (более) коротком времени инкубации, как правило, легко расщепляемым пептидам), присваивают высокий класс, и экспонированным на поверхности пептидам, которые отщепляются в условиях высокой (более жесткой) протеолитической активности, как описано в настоящей заявке (например, при (более) высокой концентрации протеазы, при (более) высокой температуре инкубации и/или при (более) длительной температуре инкубации, как правило, менее легко расщепляемым пептидам), присваивают низкий класс.
Согласно некоторым вариантам реализации настоящего изобретения несколько образцов расщепленного протеолитическим способом материала (или элюата реакции протеолитического расщепления) можно отобрать в течение реакции ограниченного или частичного протеолиза (например, последовательно), и/или несколько образцов (например, несколько реакций ограниченного или частичного протеолиза) можно обрабатывать (или анализировать) по отдельности (например, обрабатывать или анализировать параллельно).
Согласно некоторым вариантам реализации настоящего изобретения несколько образцов расщепленного протеолитическим способом материала (или элюата реакции протеолитического расщепления) отбирают (или получают) через определенные интервалы времени (например, с интервалами в 1 минуту, 2,5 минуты или 5 минут) в течение ограниченного или частичного протеолиза белка. Согласно некоторым таким вариантам реализации настоящего изобретения протеаза и/или (как правило, «и») концентрация протеазы (и/или другие условия, которые могут оказывать влияние на протеолиз, как описано в другом месте в настоящей заявке) могут являться постоянными для каждого (или в каждом) из образцов, а варьировать будет время (или продолжительность) контакта (или инкубации) с протеазой. Согласно некоторым таким вариантам реализации настоящего изобретения образцы можно получить последовательно (последовательное расщепление).
Согласно некоторым вариантам реализации настоящего изобретения несколько образцов (например, несколько реакций ограниченного или частичного расщепления) обрабатывают (или анализируют) по отдельности, причем каждый образец характеризуется различными протеолитическими условиями или протеолитическими активностями для ограниченного или частичного протеолиза белка, например, как обсуждается в другом месте в настоящей заявке, например, для различных образцов можно использовать различные протеазы и/или различные концентрации протеазы, и/или различные температуры, и/или различные времена инкубации. Согласно некоторым таким вариантам реализации настоящего изобретения время (или продолжительность) контакта (или инкубации) с протеазой, как правило (и предпочтительно) являются постоянными для каждого (или в каждом) из образцов. Согласно некоторым таким вариантам реализации настоящего изобретения образцы можно обрабатывать (или анализировать) параллельно.
Согласно некоторым вариантам реализации способов согласно настоящему изобретению количество экспонированных на поверхности пептидов, отщепленных от белка под действием указанной протеазы, контролируют посредством времени при постоянной концентрации протеазы, и несколько образцов отбирают в течение времени, либо количество экспонированных на поверхности пептидов, отщепленных от белка под действием указанной протеазы, контролируют посредством концентрации протеазы при постоянном времени, и некоторые образцы можно отбирать (или анализировать) при нескольких различных концентрациях протеазы, либо количество экспонированных на поверхности пептидов, отщепленных от белка под действием указанной протеазы, контролируют посредством как времени, так и концентрации указанной протеазы.
Каждый образец (или предпочтительные образцы) может, предпочтительно, содержать один или более пептидов (например, не более 8 пептидов или не более 8 уникальных пептидов), которые были отщеплены от белка. Таким образом, в каждом образце можно обнаружить один или несколько более (например, не более 8 пептидов или не более 8 уникальных пептидов), которые были отщеплены от белка. Уникальный пептид представляет собой пептид, который не присутствует в предшествующем образце или не присутствует в образце с более слабыми (или менее жесткими) протеолитическими условиями (например, отличный или отличающийся от пептидов, присутствующих в предшествующем образце или в образце с более слабыми протеолитическими условиями). Соответственно, образец, который содержит не более 8 уникальных пептидов, может содержать более 8 различных пептидов, но один или более из данных пептидов могли быть обнаруженными в предшествующем образце или в образце с более слабыми протеолитическими условиями (и, таким образом, один или более из данных пептидов могут являться неуникальными пептидами).
В идеальном случае и предпочтительно, каждый образец будет содержать исключительно один отщепленный пептид. Например, один отщепленный пептид может быть обнаружен в первом образце (или точке отбора образца), и один отщепленный пептид может быть обнаружен в одном или нескольких последующих образцах (или точках отбора образца). В других примерах несколько отщепленных пептидов (например, не более 8 пептидов или не более 8 уникальных пептидов) могут быть обнаружены в первом и/или последующих образцах (точках отбора образца). Условия, которые приводят к получению одного или нескольких отщепленных пептидов на образец (например, не более 8 пептидов или не более 8 уникальных пептидов на образец), можно установить посредством применения коротких интервалов отбора образца, различных концентраций протеазы, различных составов буфера, различных температур, различных концентраций соли или ингибиторов протеазы (или комбинации указанных факторов). Отщепленные пептиды можно классифицировать в зависимости от образца (точки отбора образца), в котором появляются данные пептиды. Например, в условиях, которые приводят к обнаружению исключительно одного пептида на точку отбора образца, пептиду в первом отобранном образце присваивают наивысший класс, пептиду во втором отобранном образце присваивают класс 2 и т.д. При использовании условий, посредством которых в каждой точке отбора образца обнаруживают исключительно один отщепленный пептид, возможно классифицировать отдельные пептиды. При использовании условий, посредством которых в каждой точке отбора образца обнаруживают несколько отщепленных пептидов, возможно классифицировать группы пептидов.
Согласно некоторым вариантам реализации настоящего изобретения экспонированные на поверхности пептиды (отщепленные пептиды) высокого класса являются предпочтительными. Согласно некоторым вариантам реализации настоящего изобретения экспонированный на поверхности пептид (например, пептид высокого класса) согласно настоящему изобретению представляет собой отщепленный пептид, который обнаруживают (или который присутствует) в первом отобранном образце. Согласно некоторым вариантам реализации настоящего изобретения экспонированный на поверхности пептид согласно настоящему изобретению (например, пептид высокого класса) представляет собой отщепленный пептид, который представляет собой один из пептидов первых 8 классов (например, уникальных пептидов первых 8 классов), или присутствует в образце, содержащем один из пептидов первых 8 классов (например, первых 7 классов или первых 5 классов) пептидов (например, первых 8, первых 7 или первых 5 классов уникальных пептидов), на основании порядка появления пептидов в образце (образцах), отобранных в течение ограниченного или частичного протеолиза белка. Такие пептиды могут быть обнаружены (или могут присутствовать) в первом отобранном образце или могут присутствовать в одном или нескольких последовательно отобранных образцах.
Пептиды, которые отщепляются от белка первыми (или раньше) (например, таковые из первого отобранного образца (из первой точки отбора образца), как описано выше, или таковые, которые классифицируют в первые 8 пептидов (например, уникальные пептиды первых 8 классов) на основании порядка появления в течение ограниченного или частичного протеолиза, как описано выше), являются, как правило, значительно экспонированными (например, экспонированными на поверхности), и, таким образом, легкодоступными для протеазы. Таким первым (или ранее) отщепляемым пептидам присваивают высокий класс (например, пептиду, который появляется первым, присваивают класс 1, второму присваивают класс 2 и т.д.). Пептиды, которые отщепляются от белка позже (например, в более поздней точке отбора образца, чем ранние пептиды), не являются, как правило, значительно экспонированными, и, таким образом, не являются легкодоступными для протеазы. Таким позже отщепляемым пептидам присваивают более низкий класс. В настоящем изобретении пептиды высокого класса являются, как правило, предпочтительными.
Согласно некоторым вариантам реализации настоящего изобретения отщепленные пептиды (экспонированные на поверхности пептиды), содержащие аминокислотные последовательности, наиболее экспонированные на поверхности белка, являются предпочтительными для разработки антигенного эпитопа.
Согласно некоторым вариантам реализации настоящего изобретения пептиды (отщепленные пептиды) можно классифицировать на основании функциональной важности или прогнозируемой функциональной важности данных пептидов в отношении белка. Как правило, таким пептидам, содержащим аминокислотные последовательности, которые являются или которые согласно прогнозу являются функционально важными в отношении белка, присваивают более высокий класс, чем таковым, которые не являются или которые согласно прогнозу не являются функционально важными. Согласно некоторым вариантам реализации настоящего изобретения пептиды высокого класса являются предпочтительными.
Согласно некоторым вариантам реализации настоящего изобретения пептиды, содержащие аминокислотные последовательности, которые являются или которые согласно прогнозу являются функционально важными в отношении белка (например, характеризуются высоким классом функциональной важности) и которые дополнительно характеризуются высоким классом на основании экспонирования на поверхности (например, пептид из первого отобранного образца (из первой точки отбора образца), как описано выше, или таковые, которые классифицируют в первые 8 пептидов (например, уникальные пептиды первых 8 классов) на основании порядка появления в течение ограниченного или частичного протеолиза, как описано выше), являются предпочтительными для разработки антигенного эпитопа (или, другими словами, являются предпочтительными пептидами, на основе которых можно получить антигенный эпитоп).
Согласно некоторым вариантам реализации настоящего изобретения пептиды, содержащие аминокислотные последовательности, которые являются или которые согласно прогнозу являются функционально важными в отношении белка (например, характеризуются высоким классом функциональной важности), но которые дополнительно не характеризуются высоким классом на основании экспонирования на поверхности (например, не являются пептидами из первого отобранного образца (из первой точки отбора образца), как описано выше, или таковые, которые классифицируют в первые 8 пептидов (например, уникальные пептиды первых 8 классов) на основании порядка появления в течение ограниченного или частичного протеолиза, как описано выше), можно использовать для разработки антигенного эпитопа.
Согласно некоторым вариантам реализации настоящего изобретения пептиды, содержащие аминокислотные последовательности, которые не являются или которые согласно прогнозу не являются функционально важными в отношении белка (например, характеризуются низким классом функциональной важности), но которые характеризуются высоким классом на основании экспонирования на поверхности (например, пептид из первого отобранного образца (из первой точки отбора образца), как описано выше, или таковые, которые классифицируют в первые 8 пептидов (например, уникальные пептиды первых 8 классов) на основании порядка появления в течение ограниченного или частичного протеолиза, как описано выше), можно использовать для разработки антигенного эпитопа.
Согласно некоторым вариантам реализации настоящего изобретения антигенный эпитоп основан на экспонированном на поверхности пептиде, который отщепляется первым (или раньше) от указанного белка (например, на пептиде из первого отобранного образца (из первой точки отбора образца), как описано выше, или на пептиде, который классифицируют в первые 8 пептидов (например, уникальные пептиды первых 8 классов), на основании порядка появления в течение ограниченного или частичного протеолиза, как описано выше), вне зависимости от функциональной важности или прогнозируемой функциональной важности аминокислотной последовательности отщепленного пептида.
Согласно некоторым вариантам реализации настоящего изобретения антигенный эпитоп основан на экспонированном на поверхности пептиде, который классифицируют в первые 8 пептидов (например, уникальные пептиды первых 8 классов) на основании порядка появления в течение ограниченного или частичного протеолиза, среди таковых пептидов, дополнительно содержащих аминокислотную последовательность, которая является или которая согласно прогнозу является функционально важной в отношении белка. Данные пептиды не обязательно должны быть (но могут являться) теми же, что и набор пептидов первых 8 классов на основании порядка появления самого по себе (как описано выше).
Согласно некоторым вариантам реализации настоящего изобретения в белке идентифицируют или выявляют область, представляющую интерес, которая является или которая согласно прогнозу является функционально важной в отношении белка, и антигенный эпитоп основан на экспонированном на поверхности пептиде, который классифицируют в первые 8 пептидов (например, уникальные пептиды первых 8 классов) на основании порядка появления в течение ограниченного или частичного протеолиза, среди таковых пептидов, дополнительно содержащих аминокислотную последовательность, которая отщепляется от указанной области, представляющей интерес. Данные пептиды не обязательно должны быть (но могут являться) теми же, что и набор пептидов первых 8 классов на основании порядка появления самого по себе (как описано выше).
Согласно некоторым вариантам реализации настоящего изобретения антигенные эпитопы для получения антитела основаны на аминокислотной последовательности пептида (экспонированного на поверхности пептида), который был отщеплен первым (или раньше) (например, пептида из первого отобранного образца (из первой точки отбора образца), как описано выше, или пептида, который классифицируют в первые 8 пептидов (например, уникальные пептиды первых 8 классов) на основании порядка появления в течение ограниченного или частичного протеолиза, как описано выше) от указанного белка под действием протеазы в течение ограниченного протеолиза, и, таким образом, который характеризуется высоким классом.
Таким образом, согласно некоторым вариантам реализации настоящего изобретения способы согласно настоящему изобретению включают выбор экспонированного на поверхности пептида, который характеризуется высоким классом (например, пептида из первого отобранного образца (из первой точки отбора образца), как описано выше, или пептида, который классифицируют в первые 8 пептидов (например, уникальные пептиды первых 8 классов) на основании порядка появления в течение ограниченного или частичного протеолиза, как описано выше), для разработки антигенного эпитопа и получения антитела против указанного антигенного эпитопа, который основан на указанном экспонированном на поверхности пептиде (или разработан из указанного пептида).
Согласно некоторым вариантам реализации настоящего изобретения способы согласно настоящему изобретению включают выбор экспонированного на поверхности пептида, который характеризуется высоким классом (например, пептида из первого отобранного образца (из первой точки отбора образца), как описано выше, или пептида, который классифицируют в первые 8 пептидов (например, уникальные пептиды первых 8 классов на основании порядка появления в течение ограниченного или частичного протеолиза, как описано выше), конструирование антигенного эпитопа на основе указанного экспонированного на поверхности пептида и получение антитела против указанного антигенного эпитопа.
Согласно некоторым вариантам реализации настоящего изобретения способы согласно настоящему изобретению включают выбор экспонированного на поверхности пептида, который характеризуется высоким классом (например, пептида из первого отобранного образца (из первой точки отбора образца), как описано выше, или пептида, который классифицируют в первые 8 пептидов (например, уникальные пептиды первых 8 классов) на основании порядка появления в течение ограниченного или частичного протеолиза, как описано выше), и соотнесение указанного пептида с определенным биологическим свойством (или биологической функцией) белка, конструирование антигенного эпитопа на основе указанного экспонированного на поверхности пептида и получение антитела против указанного антигенного эпитопа. Пептиды, содержащие аминокислотную последовательность, которая соотносится с определенным биологическим свойством (или биологической функцией) белка, являются, как правило, предпочтительными.
Для идентификации отщепленных пептидов (экспонированных на поверхности пептидов) можно применять любые средства. Согласно некоторым вариантам реализации настоящего изобретения отщепленные пептиды идентифицируют с использованием масс- спектрометрии. Согласно некоторым вариантам реализации настоящего изобретения используют жидкостную хроматографию в сочетании с масс-спектрометрией. Предпочтительно, отщепленные пептиды (экспонированные на поверхности пептиды) идентифицируют методом ЖХ-МС/МС (жидкостной хроматографии – тандемной масс- спектрометрии). Иллюстративные и предпочтительные методологии масс-спектрометрии описаны в примерах. Поиск в тандемных масс-спектрах можно проводить с помощью программного обеспечения MASCOT (Matrix Science, Лондон, Великобритания) по сравнению с соответствующей базой данных, например, как описано в примерах.
Расщепленный, деконструированный или усеченный белок, как указано в настоящей заявке, представляет собой белок, который был расщеплен в одном или нескольких сайтах по всей его длине протеазой. Такое протеолитическое расщепление приводит к тому, что один или более пептидов (экспонированных на поверхности пептидов) отщепляются (т.е. высвобождаются) от белка. Таким образом, экспонированный на поверхности пептид представляет собой пептид, который был отщеплен от белка под действием протеазы.
Термин «экспонированный на поверхности» отражает тот факт, что, как правило, в контексте полноразмерного белка (т.е. нерасщепленного белка) часть белка, которая соответствует последовательности отщепленного (высвободившегося) пептида, является значительно экспонированной и доступной для протеазы.
В настоящем изобретении предложены новые способы обнаружения терапевтических антител и новые фармакологически активные антитела, направленные на белок TRPV1 человека.
Настоящее изобретение относится к способам обнаружения эпитопов на белках, которые являются значительно экспонированными и которые, таким образом, можно использовать в качестве ориентиров для нацеливания антитела.
Некоторые способы согласно настоящему изобретению включают этап идентификации антигенного эпитопа посредством идентификации экспонированного на поверхности пептида, который отщепляется, содержащего аминокислотную последовательность, которая характеризуется или которая согласно прогнозу характеризуется функциональной важностью (например, биологической важностью) в отношении указанного белка, и создание антигенного эпитопа на основе такого экспонированного на поверхности пептида. Согласно некоторым вариантам реализации настоящего изобретения получают антитела против такого антигенного эпитопа.
Обнаружение того, содержит или не содержит экспонированный на поверхности пептид, который отщепляется от указанного белка, аминокислотную последовательность, которая является или которая согласно прогнозу является функционально важной в отношении указанного белка, можно провести посредством любых подходящих средств, и специалист в данной области техники способен с легкостью осуществить такое обнаружение.
Например, согласно некоторым вариантам реализации настоящего изобретения белок, который расщепляют, деконструируют или усекают в течение ограниченного или частичного протеолиза, исследуют в функциональном анализе для оценки того, была ли изменена функция или функциональные активности данного белка (например, биологическая функция). Данную оценку можно провести посредством сравнения уровня функциональной активности расщепленного, деконструированного или усеченного белка с уровнем функциональной активности белка, который не подвергали ограниченному или частичному протеолизу (уровень функциональной активности белка, который не подвергали ограниченному или частичному протеолизу, можно считать контрольным уровнем). Если биологическая функция белка изменяется после (или в течение) ограниченного или частичного протеолиза, это свидетельствует, что отщепленный пептид (пептиды) (экспонированный на поверхности пептид (пептиды)), были отщеплены (высвободились) из области белка, которая обладает функциональной значимостью в отношении белка (например, из области, обладающей биологической важностью). Соответственно, отщепленные экспонированные на поверхности пептиды можно соотнести с функциональными данными для оценки функциональной важности экспонированных на поверхности пептидов в отношении белка. Отщепленный пептид (пептиды) можно идентифицировать (например, последовательность (последовательности) отщепленного пептида (пептидов) можно идентифицировать), например, в параллельном эксперименте, как описано в другом месте в настоящей заявке (например, методом ЖХ-МС/МС). Если отщепление пептида (экспонированного на поверхности пептида) от белка приводит к изменению функциональной активности белка, это свидетельствует, что экспонированный на поверхности пептид может быть в особенности пригодным для создания антигенного эпитопа согласно настоящему изобретению. В качестве альтернативы, антигенный эпитоп на основе такого экспонированного на поверхности пептида может быть в особенности пригодным и предпочтительным для создания антитела.
Согласно одному варианту реализации настоящего изобретения белок представляет собой TRPV1, и анализ для определения функциональной важности отщепленных пептидов в отношении TRPV1 представляет собой анализ методом пэтч-кламп «наружная сторона внутри», как описано в другом месте в настоящей заявке.
«Измененная» или «изменение» функции или функциональной активности может представлять собой любое измеряемое изменение, предпочтительно, значимое изменение, более предпочтительно, статистически значимое изменение. «Измененная» функция или «изменение функции» может представлять собой увеличение или уменьшение функции. Иллюстративные изменения функции представляют собой изменения ≥ 2%, ≥ 3%, ≥ 5%, ≥ 10%, ≥ 25%, ≥ 50%, ≥75%, ≥100%, ≥200%, ≥300%, ≥400%, ≥500%, ≥600%, ≥700%, ≥800%, ≥900%, ≥1000%, ≥2000%, ≥5000% или ≥10000%. Изменения, как правило, оценивают по сравнению с соответствующим контрольным уровнем функции или функциональной активности, например, по сравнению с функцией или функциональной активностью эквивалентного белка, который не подвергали ограниченному или частичному протеолизу.
Согласно некоторым вариантам реализации настоящего изобретения антигенный эпитоп основан на аминокислотной последовательности экспонированного на поверхности пептида, которая при отщеплении от белка приводит к изменению функции или функциональной активности белка.
Согласно некоторым вариантам реализации настоящего изобретения то, характеризуется или не характеризуется экспонированная на поверхности пептида последовательность функциональной важностью (например, биологической важностью), прогнозируют или определяют посредством биоинформационных средств и/или посредством применения другой уже известной информации (например, из научной литературы) относительно функционально важных областей белка. Соответственно, отщепленные экспонированные на поверхности пептиды можно соотнести с известными данными относительно функционально важных областей белка для прогнозирования или определения функциональной важности отщепленного пептида в отношении белка. Если известно, что аминокислотная последовательность экспонированного на поверхности пептида характеризуется (или согласно прогнозу характеризуется) функциональной важностью, это свидетельствует, что экспонированный на поверхности пептид может быть в особенности пригодным для создания антигенного эпитопа согласно настоящему изобретению. В качестве альтернативы, антигенный эпитоп на основе такого экспонированного на поверхности пептида может быть в особенности пригодным и предпочтительным для создания антитела.
Таким образом, согласно некоторым вариантам реализации настоящего изобретения антигенный эпитоп основан на аминокислотной последовательности экспонированного на поверхности пептида, которая, как известно, является (или согласно прогнозу является) функционально важной, например, на основании биоинформационного анализа и/или на основании другой уже известной информации (например, из научной литературы) относительно функционально важных областей белка.
Согласно некоторым вариантам реализации настоящего изобретения антигенный эпитоп представляет собой антигенный эпитоп TRPV1, основанный на аминокислотной последовательности экспонированного на поверхности пептида, которая соотносится с последовательностью TRPV1, связывающей кальмодулин, или с сайтом связывания капсайцина TRPV1 (или соответствует указанным последовательностям).
Согласно некоторым вариантам реализации настоящего изобретения функциональный анализ для определения функциональной важности экспонированного на поверхности пептида проводят дополнительно к прогнозированию или определению функциональной важности экспонированного на поверхности пептида с помощью биоинформационных средств и/или посредством применения другой уже известной информации (например, из научной литературы) относительно функционально важных областей белка.
«Биоинформационные средства», «биоинформационный анализ», «биоинформационные данные» и «биоинформационная информация» включают, но не ограничены указанными, проведение поиска в базах данных (например, проведение поиска в базе данных BLAST), структурное моделирование или структурную биологию, а также данные/информацию, которые получают посредством указанных способов. Функция (например, биологическая функция) может включать любую соответствующую с биологической или физиологической точки зрения функцию белка, о котором идет речь. Функция (например, биологическая функция) включает, но не ограничена указанными, способность белка связываться с мишенью (такой как лиганд или рецептор) или с другим партнером связывания, например, кофактором, активность по передаче сигналов, ферментативную активность белка и активность ионного канала, активность транспортера, высвобождение, например, механизмы высвобождения и поглощения инсулина, и т.д. Таким образом, соответствующие с функциональной точки зрения или функционально важные области белка включают, но не ограничены указанными, области, которые обеспечивают способность белка к связыванию с мишенью (такой как лиганд или рецептор) или с другим партнером связывания, например, кофактором, области, которые обеспечивают активность передачи сигналов, области, которые обладают ферментативной активностью белка, области, которые обеспечивают активность ионного канала, области, обеспечивающие активность транспортера, и области, обеспечивающие высвобождение и поглощение молекул (например, инсулина).
Согласно одному варианту реализации способ согласно настоящему изобретению также включает этап создания in silico набора предполагаемых пептидов (например, всех предполагаемых пептидов), которые могут быть отщеплены от белка одной или несколькими протеазами (например, посредством применения компьютерной программы, способной идентифицировать точки расщепления в белке на основании известной последовательности (последовательностей) распознавания указанной одной или нескольких протеаз), и необязательно фильтрацию указанного набора созданных in silico предполагаемых пептидов для удаления пептидов, которые были описаны ранее (например, в базах данных последовательностей, например, посредством поиска в базе данных BLAST или в другой литературе), в результате чего получают отфильтрованный перечень предполагаемых пептидов, сравнение указанного отфильтрованного перечня предполагаемых пептидов с перечнем пептидов, идентифицированных в результате ограниченного или частичного протеолиза белка, идентификацию пептидов, которые присутствуют как в указанном отфильтрованном перечне, так и в указанном перечне пептидов, идентифицированных в результате ограниченного или частичного протеолиза белка, идентификацию (или конструирование) антигенного эпитопа на основе пептида, присутствующего в обоих перечнях, и необязательно получение антитела против указанного антигенного эпитопа.
Согласно другому аспекту в настоящем изобретении предложен способ идентификации антигенного эпитопа, причем указанный способ включает:
(i) воздействие на первый белок ограниченного или частичного протеолиза путем осуществления контакта первого белка с по меньшей мере одной протеазой с образованием по меньшей мере одной расщепленной, деконструированной или усеченной версии первого белка и по меньшей мере одного экспонированного на поверхности пептида, который отщепляется от первого белка под действием указанной протеазы;
(ii) идентификацию аминокислотной последовательности области (или доли либо части) второго белка, которая является идентичной или по существу гомологичной аминокислотной последовательности экспонированного на поверхности пептида, который отщепляется от первого белка; и
(iii) создание антигенного эпитопа на основании аминокислотной последовательности указанной области (или доли либо части) указанного второго белка, которая является идентичной или по существу гомологичной аминокислотной последовательности экспонированного на поверхности пептида, который отщепляется от первого белка; и необязательно
(iv) получение антитела против антигенного эпитопа.
Иллюстративные типы по существу гомологичной последовательности обсуждаются в другом месте в настоящей заявке. Такой способ может облегчить создание антигенного эпитопа для белка (второго белка) на основании ограниченного или частичного протеолиза, который проводят на отличном белке (первом белке). Данный подход может быть в особенности пригодным, когда первый и второй белки относятся к одному и тому же семейству белков или являются иным способом связанными, например, данные от ограниченного или частичного протеолиза, проведенного в отношении TRPV1, можно использовать для идентификации антигенного эпитопа TRPV2. Определение (или идентификацию) по существу гомологичных белков на втором белке можно проводить с использованием любых подходящих средств (например, компьютерных программ), которые известны специалисту. Исключительно в качестве примера, подходящей компьютерной программой является программа EMBOSS Needle, предоставленная EMBL- EBI. EMBOSS Needle считывает две входные последовательности и записывает оптимальное всеобщее выравнивание последовательности с помощью вычисления с использованием алгоритма выравнивания Нидлмана и Вунша для обнаружения оптимального выравнивания (включая пропуски) двух последовательностей по всей длине.
Согласно некоторым вариантам реализации настоящего изобретения антигенный эпитоп не основан на экспонированном на поверхности пептиде, содержащем аминокислотную последовательность, которая является консервативной в отношении другого белка (белков) (например, консервативную в ходе эволюции последовательность или последовательность, идентичную или по существу гомологичную аминокислотной последовательности экспонированного на поверхности пептида). Данный факт может минимизировать перекрестную реактивность (или неспецифичное связывание) антител, синтез которых был индуцирован против таких антигенных эпитопов. Другими словами, согласно некоторым вариантам реализации настоящего изобретения можно использовать антигенные эпитопы на основе уникальных аминокислотных последовательностей (или последовательностей, не обнаруженных в других белках).
Настоящее изобретение относится к способам обнаружения эпитопов на белках, которые являются соответствующими с функциональной точки зрения и которые, таким образом, можно применять в качестве ориентиров для нацеливания антитела. Более конкретно, такие способы включают применение инструментов протеомики для выявления эпитопов горячих точек белков-мишеней. Данные эпитопы, которые потенциально можно использовать в качестве антигенов при получении антител, обозначены в настоящей заявке как антигенные эпитопы.
Согласно аспекту настоящего изобретения белок расщепляют, деконструируют и/или усекают под действием протеазы и параллельно проводят один или несколько функциональных анализов расщепленного, деконструированного и/или усеченного белка для определения функционально важной области (областей) белка.
Согласно варианту реализации настоящего изобретения расщепление, деконструирование и/или усечение белка можно проводить параллельно с функциональным анализом (анализами) для определения функционально важных областей белка для направления селекции эпитопов с целью создания антитела.
Согласно варианту реализации настоящего изобретения для расщепления, деконструирования и/или усечения белка можно использовать одну протеазу. Согласно другому варианту реализации настоящего изобретения для расщепления, деконструирования и/или усечения белка-мишени можно использовать несколько протеаз, последовательно по одной или параллельно. Примерами таких протеаз являются, не ограничиваясь указанным, протеиназа Arg-C, эндопептидаза Asp-N, клострипаин, глутамилэндопептидаза, Lys-C, Lys-N, трипсин, химотрипсин, протеиназа K и термолизин. Область, которую легко расщепляют несколько протеаз, должна располагаться в экспонированной области белка, и область, которая расщепляется исключительно одной протеазой, вероятно, располагается в более скрытой области. В качестве альтернативы, протеаза обладает уникальной специфичностью расщепления или/и физико-химическими свойствами или/и структурными свойствами, в результате чего может идентифицировать экспонированные на поверхности пептиды на белке-мишени, что не свойственно другим протеазам. Таким образом, применение нескольких протеаз является предпочтительным, и каждая отличная протеаза может привести к получению комплементарной или уникальной информации о пригодности экспонированных на поверхности пептидов в качестве антигенных эпитопов.
Последовательное применение нескольких протеаз означает, что различные протеазы инкубируют с белком одну за другой, т.е. инкубируют одну протеазу, после чего в более позднюю временную точку инкубируют другую, и необязательно в более позднюю временную точку (или точки) – одну или несколько других различных протеаз.
Последовательное применение одной протеазы означает, что одну и ту же протеазу (например, ту же концентрацию протеазы) инкубируют с белком несколько раз, например, в нескольких различных (последовательных) временных точках, или что из реакции протеолитического расщепления в течение времени отбирают несколько образцов, и появление новых или уникальных пептидов, полученных в реакции, обнаруживают и отслеживают в течение времени.
Параллельное применение означает, что проводят несколько отдельных реакций расщепления одной протеазой, каждую реакцию с различной протеазой или с одной и той же протеазой, но в различных протеолитических условиях, например, как описано в другом месте в настоящей заявке, например, при различных концентрациях протеазы и/или температурах, и/или временных точках.
С целью идентификации перекрывающихся, комплементарных или уникальных экспонированных на поверхности пептидов можно использовать несколько протеаз. В данном контексте «перекрывающийся» означает, что экспонированный на поверхности пептид, идентифицированный посредством ограниченного или частичного протеолиза одной протеазой, содержит аминокислотную последовательность, которая перекрывается (частично или полностью) с аминокислотной последовательностью экспонированного на поверхности пептида, идентифицированного посредством ограниченного или частичного протеолиза одной или несколькими другими (т.е. отличными) протеазами. В данном контексте «комплементарный» означает, что экспонированный на поверхности пептид, идентифицированный посредством ограниченного или частичного протеолиза одной протеазой, содержит аминокислотную последовательность, которая в контексте последовательности всего белка (т.е. последовательности всего белка до ограниченного или частичного протеолиза) лежит следом за аминокислотной последовательностью экспонированного на поверхности пептида, идентифицированного посредством ограниченного или частичного протеолиза одной или несколькими другими (т.е. отличными) протеазами, или поблизости от указанной последовательности (или даже частично перекрывается с указанной последовательностью). «Уникальный» экспонированный на поверхности пептид представляет собой экспонированный на поверхности пептид, который был идентифицирован исключительно после ограниченного или частичного протеолиза одной или несколькими (меньшей частью) исследованных протеаз.
Не опираясь на какую-либо теорию, считают, что область белка, которая отщепляется более чем одной протеазой, вероятно, находится в значительно экспонированной (например, экспонированной на поверхности) области белка, и, таким образом, экспонированные на поверхности пептиды из области белка, которая отщепляется более чем одной протеазой, могут представлять собой в особенности пригодные экспонированные на поверхности пептиды, на основе которых можно получить антигенные эпитопы.
Использование нескольких протеаз включает, но не ограничено указанным, использование 2, 3, 4, 5 протеаз.
Согласно некоторым вариантам реализации способов согласно настоящему изобретению протеаза выбрана из группы, состоящей из трипсина, протеиназы Arg-C, эндопептидазы Asp-N, клострипаина, глутамилэндопептидазы, Lys-C, Lys-N, химотрипсина, протеиназы K, термолизина, пепсина, каспазы 1, каспазы 2, каспазы 3, каспазы 4, каспазы 5, каспазы 6, каспазы 7, каспазы 8, каспазы 9, каспазы 10, энтерокиназы, фактора Xa, гранзима B, нейтрофильной эластазы, пролинэндопептидазы, стафилококковой пептидазы I и тромбина.
Согласно некоторым предпочтительным вариантам реализации настоящего изобретения протеаза выбрана из группы, состоящей из трипсина, Asp-N эндопептидазы, химотрипсина, пепсина и протеиназы K. Согласно предпочтительным вариантам реализации настоящего изобретения протеаза представляет собой трипсин.
Согласно еще одному аспекту настоящего изобретения коктейль нескольких протеаз используют вместе в одном или нескольких воздействиях, разделенных во времени, при постоянных или варьирующих концентрациях одной или нескольких протеаз. Таким образом, согласно некоторым вариантам реализации настоящего изобретения используют единый коктейль (смесь) нескольких протеаз.
Если используют несколько протеаз, упорядоченный по классам перечень может быть получен для каждой отдельной протеазы.
Данный способ позволяет получить новое фундаментальное понимание функции белка и новую методологию/технологию для быстрой и точной разработки фармакологически активных антител, которые можно использовать для лечения медицинского состояния у людей и/или животных. Способ может быть распространен на белки, растворимые или мембраносвязанные, внеклеточные или внутриклеточные.
Перечень эпитопов, полученный с помощью предлагаемого способа, предпочтительно, сортируют в зависимости от специально подобранных биоинформационных данных и функционального анализа (анализов). В способе, предпочтительно, используют входящие данные из обоих экспериментов, а также биоинформационную информацию. Согласно варианту реализации настоящего изобретения основное внимание будет уделено мембранным и мембраносвязанным белкам. Примерами таких белков являются, не ограничиваясь указанными, ноцицептор TRPV1 человека, другие ионные каналы суперсемейства TRP, а также некоторые рецепторы возбуждающей аминокислоты, включая NMDA-рецептор, и G-белки. Данные белки (например, ионные каналы) обладают тем преимуществом, что данные белки можно непосредственно подробно исследовать с использованием, например, метода пэтч-кламп. Другие классы белков, представляющих интерес, относятся к онкогенным белкам, включая онкогенные малые ГТФазы KRAS, NRAS и HRAS. KRAS представляет собой ключевой белок при некоторых метастатических злокачественных новообразованиях, включая карциному поджелудочной железы, карциному толстой кишки и карциному легких. ГТФазную активность можно исследовать, например, посредством радиоизотопного мечения ГТФ с последующим измерением свободного 32P после гидролиза ГТФ до ГДФ или с применением анализов преобразования с последующим анализом методом вестернблоттинга. Другие представляющие интерес классы белка представляют собой иммуномодулирующие белки, вовлеченные в иммуномодуляцию при противораковой терапии, такие как PD1, PDL1, CD40 в качестве лишь нескольких примеров.
«Белок» согласно настоящему изобретению может представлять собой любой белок.
Согласно некоторым вариантам реализации настоящего изобретения белок представляет собой мембраносвязанный белок, растворимый (например, циркулирующий) белок, внеклеточный белок или внутриклеточный белок.
Согласно некоторым вариантам реализации настоящего изобретения белок представляет собой мембранный или мембраносвязанный белок.
Согласно некоторым вариантам реализации настоящего изобретения белок представляет собой ионный канал, например, ионный канал суперсемейства TRP (например, TRPV1 или TRPV2). Согласно предпочтительным вариантам реализации настоящего изобретения белок представляет собой TRPV1.
Согласно некоторым вариантам реализации настоящего изобретения белок представляет собой рецептор возбуждающей аминокислоты. Согласно некоторым таким вариантам реализации настоящего изобретения белок представляет собой NMDA-рецептор или G- белок.
Согласно некоторым вариантам реализации настоящего изобретения белок представляет собой онкогенный белок. Согласно некоторым таким вариантам реализации настоящего изобретения белок представляет собой онкогенную малую ГТФазу, которая выбрана из группы, состоящей из KRAS, NRAS и HRAS.
Согласно некоторым вариантам реализации настоящего изобретения белок представляет собой иммуномодулирующий белок. Согласно некоторым таким вариантам реализации настоящего изобретения белок выбран из группы, состоящей из PD1, PDL1, CD40, OX40, VISTA, LAG-3, TIM-3, GITR и CD20.
Согласно некоторым вариантам реализации настоящего изобретения белок представляет собой белок, включенный в любую из таблиц 9, 10, 11 или 12 настоящей заявки. Таким образом, согласно некоторым вариантам реализации настоящего изобретения белок представляет собой белок, выбранный из группы, состоящей из маннозил-олигосахарид 1,2-альфа-маннозидазы IA, дегидрогеназы альдегидов жирных кислот, антигена CD81, рецептора обоняния 1B1, CLIC-подобного белка 1 канала ионов хлорида, вероятно, сопряженного с G-белком рецептора 83, белка 3 семейства PRA1, глицерол-3-фосфат ацилтрансферазы 4, члена F семейства анкиринового домена POTE, НАДН-цитохром b5 редуктазы 3, кининогена-1, ро-зависимого ГТФ-связывающего белка RhoC, натриевого/водородного обменника 6, амилоид-подобного белка 2, мембраносвязанного компонента 1 прогестеронового рецептора, фосфолипазы D4, матриксной металлопротеиназы-14, атластина-3, белка YIF1A, везикуло-ассоциированного мембранного белка 1, CLIC-подобного белка 1 канала ионов хлорида, члена 1 подсемейства B гольджина, члена 7B семейства дегидрогеназы/редуктазы SDR, анионообменного транспортера, трансмембранного белка 192, белка 1, содержащего трансмембранный и убиквитин-подобный домен, белка 1, связывающего полипиримидиновый тракт, гомолога 2 РНК-связывающего белка мусаши, ассоциированного с доменом смерти белка 6, предполагаемого убиквитин-конъюгирующего E2 N-подобного фермента, убиквитин-конъюгирующего фермента E2 N, альфа-центрактина, субъединицы бета комплекса AP-2, мРНК-декепирующего фермента 1A, калуменина и РНК-связывающего белка 14, или из группы, включающей указанные белки.
Согласно некоторым вариантам реализации настоящего изобретения белок не является рецептором активатора плазминогена урокиназного типа (urokinase plasminogen activator receptor, u-PAR), трансглутаминазу 3 (transglutaminase, TGase3), белок Neisseria meningitidis или каннабиноидный рецептор (например, CB1).
Согласно некоторым вариантам реализации настоящего изобретения белок представляет собой эукариотический белок. Например, согласно некоторым вариантам реализации настоящего изобретения белок представляет собой белок млекопитающего, предпочтительно, белок человека.
Согласно некоторым вариантам реализации настоящего изобретения белок представляет собой любой белок протеома человека. Другими словами, белки человека являются предпочтительными.
Применение протокола ограниченного расщепления одной или несколькими протеазами в отношении данных мишеней приведет к обнаружению новых антител, направленных на эпитопы горячих точек. Различные протеазы будут образовывать различные отщепленные пептиды. Согласно варианту реализации настоящего изобретения мембранные белки деконструируют, и эффекты данного усечения по частям исследуют в отношении влияния на функцию белка. Редкие точки, наблюдаемые исключительно при применении определенных протеаз, также будут идентифицированы. Затем идентифицированные данные будут анализировать в зависимости от специально подобранных биоинформационных данных, а также данных функциональных анализов усеченных белков для выявления функционально важных областей белка, о котором идет речь.
Аспект вариантов реализации настоящего изобретения относится к способу идентификации антигенного эпитопа в белке. Способ включает воздействие на белок ограниченного или частичного протеолиза путем осуществления контакта белка с по меньшей мере одной протеазой с образованием по меньшей мере одной расщепленной, деконструированной или усеченной версии белка и по меньшей мере одного экспонированного на поверхности пептида. Согласно другому варианту реализации настоящего изобретения способ также включает исследование по меньшей мере одной расщепленной, деконструированной или усеченной версии белка в функциональном анализе, в котором изучают, проверяют или подтверждают по меньшей мере одну биологическую функцию белка. Способ также включает идентификацию антигенного эпитопа в белке как экспонированного на поверхности пептида среди по меньшей мере одного экспонированного на поверхности пептида и присутствующего в области белка, вовлеченной в выполнение биологической функции белка, что определено на основании функционального анализа.
Согласно варианту реализации настоящего изобретения воздействие на белок ограниченного или частичного протеолиза включает осуществление контакта белка с по меньшей мере одной протеазой i) при выбранной температуре или диапазоне температуры, ii) при выбранной концентрации или диапазоне концентрации по меньшей мере одной протеазы (относительно концентрации белка) и/или ii) в течение выбранной продолжительности времени. Данный подход, в свою очередь, позволяет по меньшей мере одной протеазе отщеплять экспонированные на поверхности области белка, но не негибкие и/или внутренние области белка.
Воздействие на белок ограниченного или частичного протеолиза путем осуществления контакта белка с по меньшей мере одной протеазой предусматривает, что белок подвергают мягкому протеолизу. Как следствие, в особенности экспонированная на поверхности и гибкая пептидная часть (части) белка будет отщеплена от аминокислотной последовательности под действием по меньшей мере одной протеазы. Температура, концентрация и/или продолжительность, применяемые для протеолиза, как правило, зависят от конкретной протеазы (протеаз) и используемого белка. Таким образом, согласно варианту реализации настоящего изобретения сначала исследуют набор потенциальных условий протеолиза с целью выбрать или идентифицировать подходящую температуру, концентрацию протеазы и/или продолжительность, используемые для расщепления, и буферных условий для деконструирования или усечения белка и получения по меньшей мере одного экспонированного на поверхности пептида. Например, протеолиз можно провести при нескольких, т.е. по меньшей мере двух различных температурах реакции, при нескольких различных концентрациях протеазы (относительно концентрации белка) и/или при нескольких различных длительностях реакции, включая различные буферные условия, как показано на фигуре 1, с целью идентифицировать наиболее соответствующие условия протеолиза для текущей комбинации белка и протеазы (протеаз).
Подходящие условия для протеазы представляют собой, например, температуру, концентрацию и/или продолжительность, которые приводят к расщеплению, деконструированию или усечению белка на один или не более чем N экспонированных на поверхности пептидов. Типичное значение параметра N составляет 7, предпочтительно, 6 или 5, более предпочтительно, 4 или 3 или, еще более предпочтительно, 2 или 1.
Согласно варианту реализации настоящего изобретения в функциональном анализе изучают, проверяют или подтверждают по меньшей мере одну биологическую функцию белка. Неограничивающие примеры такой биологической функции включают способность белка связываться с мишенью, такой как лиганд или рецептор; ферментативную активность белка; активность ионного канала; и т.д.
Согласно варианту реализации настоящего изобретения воздействие на белок ограниченного или частичного протеолиза включает воздействие на белок ограниченного или частичного протеолиза путем осуществления контакта белка с несколькими протеазами с образованием нескольких отщепленных, деконструированных или усеченных версий белка и нескольких экспонированных на поверхности пептидов. Согласно конкретному варианту реализации настоящего изобретения осуществляют контакт белка с несколькими протеазами последовательно, т.е. одной за другой. Согласно другому конкретному варианту реализации настоящего изобретения осуществляют контакт белка с несколькими протеазами параллельно.
Согласно варианту реализации настоящего изобретения идентификация антигенного эпитопа включает идентификацию экспонированного на поверхности эпитопа среди по меньшей мере одного экспонированного на поверхности пептида, присутствующего в области, которая приводит к утрате или существенному изменению биологической функции белка, когда область отщепляют или удаляют от белка в течение ограниченного или частичного протеолиза.
Согласно варианту реализации настоящего изобретения способ также включает выбор по меньшей мере одной области-мишени в белке на основании биоинформационных данных и/или известных данных о биологической функции белка. В данном случае идентификация антигенного эпитопа включает идентификацию экспонированного на поверхности пептида среди по меньшей мере одного экспонированного на поверхности пептида, присутствующего в области белка среди по меньшей мере одной области-мишени.
Согласно данному варианту реализации настоящего изобретения биоинформационные и/или другие известные данные о биологической функции используют для направления селекции антигенных эпитопов. Это означает, что в качестве кандидатов при идентификации или выборе антигенного эпитопа используют исключительно экспонированные на поверхности пептиды, которые присутствуют в выбранной области- мишени (или областях-мишенях). Соответственно, количество кандидатов можно уменьшить посредством удаления или пропуска экспонированных на поверхности пептидов, которые присутствуют в областях, в которых, как известно, отсутствует любая биологическая функция, и/или которые, как известно, не вовлечены в осуществление биологической функции белка.
Другой аспект вариантов реализации настоящего изобретения относится к антигенному эпитопу, идентифицированному согласно вышеописанному способу идентификации антигенного эпитопа в белке.
Согласно одному варианту реализации в настоящем изобретении предложен антигенный эпитоп TRPV1, содержащий аминокислотную последовательность (или состоящий из аминокислотной последовательности), которая выбрана из группы, состоящей из:
LLSQDSVAASTEK (SEQ ID NO:2); LLSQDSVAASTEKTLR (SEQ ID NO:3); и QFSGSLKPEDAEVFKSPAASGEK (SEQ ID NO:4),
или последовательность, по существу гомологичную указанной последовательности.
Согласно другому варианту реализации в настоящем изобретении предложен антигенный эпитоп TRPV1, содержащий аминокислотную последовательность (или состоящий из аминокислотной последовательности), которая выбрана из группы, состоящей из:
LLSQDSVAASTEKTLRLYDRRS (SEQ ID NO:5); и GRHWKNFALVPLLRE (SEQ ID NO:6).
Согласно одному варианту реализации в настоящем изобретении предложен антигенный эпитоп TRPV1, содержащий аминокислотную последовательность (или состоящий из аминокислотной последовательности) LVENGADVQAAAHGDF (SEQ ID NO:7) или последовательность, по существу гомологичную указанной последовательности.
Согласно другому варианту реализации в настоящем изобретении предложен антигенный эпитоп TRPV1, содержащий аминокислотную последовательность (или состоящий из аминокислотной последовательности), которая выбрана из группы, состоящей из:
DGPTGARLLSQ (SEQ ID NO:8); и
DAEVFKSPAASGEK (SEQ ID NO:9),
или последовательность, по существу гомологичную указанной последовательности.
Согласно другому варианту реализации в настоящем изобретении предложен антигенный эпитоп TRPV1, содержащий аминокислотную последовательность (или состоящий из аминокислотной последовательности), которая выбрана из группы, состоящей из: SQDSVAASTEKTL (SEQ ID NO:10); и
SGSLKPEDAEVF (SEQ ID NO:11),
или последовательность, по существу гомологичную указанной последовательности.
Согласно одному варианту реализации в настоящем изобретении предложен антигенный эпитоп TRPV1, содержащий аминокислоту (или состоящий из аминокислоты), которая выбрана из группы, состоящей из:
VSPVITIQRPGD (SEQ ID NO:12); VSPVITIQRPGDGPTGA (SEQ ID NO:13); LNLHDGQNTTIPLLL (SEQ ID NO:14); YTDSYYKGQ (SEQ ID NO:15) SLPSESTSH (SEQ ID NO:16) EDPGNCEGVKR (SEQ ID NO:17) DRQSAQPEEVYLR (SEQ ID NO:18); и QSAQPEEVYLR(SEQ ID NO:19),
или последовательность, по существу гомологичную указанной последовательности.
Согласно некоторым вариантам реализации в настоящем изобретении предложен антигенный эпитоп TRPV1, содержащий аминокислотную последовательность, представленную под вторым заголовком (заголовком, отмеченным двумя звездочками (**)) в каждой из таблиц 2, 3, 4, 5 и 6 в примере 3 в настоящей заявке, или последовательность, по существу гомологичную указанной последовательности. Такие пептиды, отщепляемые с использованием более высокой протеолитической активности (или более жестких или строгих протеолитических условий), являются, как правило, менее предпочтительными, чем пептиды, отщепляемые с использованием меньшей протеолитической активности (или менее жестких или слабых протеолитических условий) (например, более короткого времени и/или меньшей концентрации, например, представленные под первыми заголовком (заголовком, помеченным одной звездочкой (*) в каждой из таблиц 2, 3, 4, 5 и
6); однако особенный интерес представляет, если данные пептиды характеризуются или согласно прогнозу характеризуются функциональной важностью в отношении белка.
Пептиды, представленные под вторыми заголовками в таблицах 2, 3, 4, 5 и 6 (**), можно считать пептидами, которые отщепляются позже, и пептиды, представленные под первыми заголовками в таблицах 2, 3, 4, 5 и 6 (*), можно считать пептидами, которые отщепляются первыми.
В контексте вышеописанных антигенных эпитопов TRPV1 указанная по существу гомологичная последовательность может представлять собой последовательность, содержащую 1, 2, 3, 4, 5 или 6 (предпочтительно, 1, 2 или 3) замен или делеций аминокислот по сравнению с данной аминокислотной последовательностью, или представляет собой последовательность, которая характеризуется идентичностью последовательности по меньшей мере 70% данной аминокислотной последовательности, или представляет собой последовательность, содержащую по меньшей мере 6 последовательных аминокислот данной аминокислотной последовательности. Другие примеры «по существу гомологичных» последовательностей описаны в другом месте в настоящей заявке в отношении аминокислотных последовательностей, которые являются «по существу гомологичными» экспонированным на поверхности пептидам, и данные примеры «по существу гомологичных» последовательностей также применимы к специфичным последовательностям пептидов, упомянутым выше. Специфичные последовательности пептидов, упомянутые выше, представляют собой последовательности экспонированного на поверхности пептида.
Согласно некоторым вариантам реализации в настоящем изобретении предложен антигенный эпитоп, который содержит удлиненную, усеченную или циклическую версию последовательности пептида, упомянутой выше (или состоит из указанной последовательности), или последовательность, по существу гомологичную указанной последовательности. Удлиненная, усеченная и циклическая версии пептидов обсуждаются в другом месте в настоящей заявке в контексте удлиненных, усеченных и циклических экспонированных на поверхности пептидов, и данное обсуждение также применимо к последовательностям пептидов, упомянутым выше. Конкретные последовательности пептида, упомянутые выше, представляют собой экспонированные на поверхности последовательности пептида.
Согласно одному варианту реализации в настоящем изобретении предложен антигенный эпитоп TRPV2, содержащий аминокислоту (или состоящий из аминокислоты), которая выбрана из группы, состоящей из:
FAPQIRVNLNYRKGTG (SEQ ID NO:20); ASQPDPNRFDRDR (SEQ ID NO:21) LNLKDGVNACILPLL (SEQ ID NO:22) CTDDYYRGH (SEQ ID NO:23) LVENGANVHARACGRF (SEQ ID NO:24) EDPSGAGVPR (SEQ ID NO:25); и GASEENYVPVQLLQS (SEQ ID NO:26), или последовательность, по существу гомологичную указанной последовательности.
Иллюстративные по существу гомологичные последовательности обсуждаются в другом месте в настоящей заявке.
Следующий аспект вариантов реализации настоящего изобретения относится к конъюгату, конфигурированному для использования с целью получения антител. Конъюгат содержит по меньшей мере один антигенный эпитоп, как определено выше, присоединенный к пептиду-носителю или смешанный с пептидом-носителем.
Таким образом, согласно одному аспекту в настоящем изобретении предложен конъюгат, содержащий антигенный эпитоп согласно настоящему изобретению или идентифицированный согласно настоящему изобретению (либо полученный согласно настоящему изобретению). Конъюгаты могут содержать антигенный эпитоп и любую отличную структуру (т.е. любую структуру, отличную от антигенного эпитопа), например, метку или пептид-носитель. Конъюгаты, как правило, содержат антигенный эпитоп и пептид-носитель, причем указанный антигенный эпитоп присоединен к пептиду-носителю или смешан с пептидом-носителем.
Согласно варианту реализации настоящего изобретения пептид-носитель выбран из группы, состоящей из гемоцианина фисуреллы (keyhole limpet hemocyanin, KLH) и овальбумина. Присоединение может, например, представлять собой ковалентное присоединение или дисульфидный мостик. Согласно одному варианту реализации настоящего изобретения гемоцианин фисуреллы является предпочтительным пептидом-носителем. Согласно некоторым вариантам реализации настоящего изобретения может быть обеспечен антигенный эпитоп с остатком цистеина на N- или C- конце (предпочтительно, на N-конце). Такой остаток цистеина может облегчить присоединение антигенного эпитопа к пептиду-носителю (например, KLH).
Другой аспект вариантов реализации настоящего изобретения относится к применению антигенного эпитопа и/или конъюгата согласно вышеуказанному аспекту для получения антитела, которое специфично связывается с белком.
Еще один аспект вариантов реализации настоящего изобретения относится к способу получения антитела, которое специфично связывается с белком. Способ включает получение антитела против антигенного эпитопа и/или конъюгата согласно вышеуказанному аспекту и выделение антитела. Выделение антитела может включать выделение антитела из клетки (например, клетки-хозяина), в которой антитело было получено или наработано, и/или из среды роста/супернатанта.
Согласно конкретному варианту реализации настоящего изобретения способ включает воздействие на белок ограниченного или частичного протеолиза путем осуществления контакта белка с по меньшей мере одной протеазой с образованием по меньшей мере одной расщепленной, деконструированной или усеченной версии белка и по меньшей мере одного экспонированного на поверхности пептида. Способ также включает исследование по меньшей мере одной расщепленной, деконструированной или усеченной версии белка в функциональном анализе, в котором изучают, проверяют или подтверждают по меньшей мере одну биологическую функцию белка. Способ также включает идентификацию антигенного эпитопа в белке как экспонированного на поверхности пептида среди по меньшей мере одного экспонированного на поверхности пептида и присутствующего в области белка, вовлеченной в осуществление биологической функции белка, что определено на основании функционального анализа. Способ также включает получение антитела против антигенного эпитопа и выделение антитела.
Получение антитела против антигенного эпитопа можно осуществить согласно методикам, известным в данной области техники, включая, например, методику гибридомы, технологию фагового дисплея и т.д., как было описано в настоящей заявке ранее.
Следующий аспект вариантов реализации настоящего изобретения относится к антителу против антигенного эпитопа и/или конъюгата согласно вышеуказанному аспекту. Антитело специфично связывается с белком.
Таким образом, согласно одному аспекту в настоящем изобретении предложено антитело, созданное (или полученное) посредством способа согласно настоящему изобретению.
Согласно другому аспекту в настоящем изобретении предложено антитело против антигенного эпитопа согласно настоящему изобретению. В качестве альтернативы, в настоящем изобретении предложено антитело, которое связывается с антигенным эпитопом согласно настоящему изобретению. В качестве альтернативы, в настоящем изобретении предложено антитело, которое специфично связывается с антигенным эпитопом согласно настоящему изобретению.
В качестве примера, в настоящем изобретении предложено антитело против антигенного эпитопа, содержащего аминокислотную последовательность, которая выбрана из группы, состоящей из LLSQDSVAASTEKTLRLYDRRS (SEQ ID NO:5) и GRHWKNFALVPLLRE (SEQ ID NO:6), или состоящего из указанной последовательности. Согласно одному варианту реализации настоящего изобретения антитело против антигенного эпитопа, содержащего аминокислотную последовательность LLSQDSVAASTEKTLRLYDRRS (SEQ ID NO:5), или состоящего из указанной последовательности, представляет собой антагонистическое (ингибиторное) антитело против TRPV1, предпочтительно, обладающее одним или несколькими из функциональных свойств, описанных в разделе примеров в отношении антитела OTV1. Данный эпитоп соответствует аминокислотной последовательности, которая расположена в N-концевом внутриклеточном домене TRPV1. Согласно одному варианту реализации настоящего изобретения антитело против антигенного эпитопа, содержащего аминокислотную последовательность GRHWKNFALVPLLRE (SEQ ID NO:6), или состоящего из указанной последовательности, представляет собой агонистическое антитело против TRPV1, предпочтительно, обладающее одним или несколькими из функциональных свойств, описанных в разделе примеров в отношении антитела OTV2. Данный эпитоп соответствует аминокислотной последовательности, которая расположена в C-концевом внутриклеточном домене TRPV1.
Согласно некоторым вариантам реализации настоящего изобретения антитело может быть направлено против внутриклеточного эпитопа (или домена) TRPV1. Согласно некоторым таким вариантам реализации настоящего изобретения антитело может представлять собой антагонистическое (ингибиторное) антитело против внутриклеточного эпитопа (или домена) TRPV1. Согласно другим таким вариантам реализации настоящего изобретения антитело может представлять собой агонистическое антитело против внутриклеточного эпитопа (или домена) TRPV1.
Согласно варианту реализации настоящего изобретения связывание антитела с белком приводит к отсутствию или существенному изменению биологической функции белка.
Таким образом, антитело может представлять собой функциональное антитело, например, агонистическое антитело или антагонистическое антитело (например, антагонистическое или агонистическое антитело против TRPV1 или TRPV2). Антагонистическое антитело способно к связыванию с белком и ингибированию или уменьшению функции белка.
Агонистическое антитело способно к связыванию с белком и усилению или увеличению функции белка. В случае TRPV1 или TRPV2 (или любого другого ионного канала) функция, о которой идет речь, может представлять собой активность транспорта ионов. Например, можно оценить способность антитела блокировать (уменьшать) или усиливать (увеличивать) связывание с капсайцином или кальмодулином. Антитела с такими свойствами составляют предпочтительные варианты реализации настоящего изобретения.
Связанный аспект вариантов реализации настоящего изобретения определяет антитело согласно вышеуказанному аспекту для применения в качестве лекарственного препарата.
Антитело против антигенного эпитопа и/или конъюгата можно получить посредством иммунизации животного одним или несколькими антигенными эпитопами и/или одним или несколькими конъюгатами согласно вариантам реализации настоящего изобретения. Иммунизированное животное можно выбрать из группы, состоящей из людей, мышей, крыс, кроликов, овец, нечеловекообразных приматов, коз, лошадей и сельскохозяйственных птиц.
Антитело согласно вариантам реализации настоящего изобретения можно также получить посредством способов иммунизации in vitro с использованием одного или нескольких антигенных эпитопов и/или одного или нескольких конъюгатов согласно вариантам реализации настоящего изобретения.
Антитело согласно настоящему изобретению может представлять собой поликлональное антитело или моноклональное антитело.
Антитело может представлять собой лиганд, один или более фрагментов антитела, такие как Fab-фрагмент (fragment antigen binding, антигенсвязывающий фрагмент), F(ab)'2-фрагмент (фрагмент, содержащий два Fab), ScFv-фрагмент (single-chain variable fragment, одноцепочечный вариабельный фрагмент), диатело, тетратело или интактное антитело.
Антитело согласно настоящему изобретению, как правило, способно к связыванию (например, специфичному связыванию) с полноразмерной версией белка, против которого направлено данное антитело, например, с полноразмерной версией белка в нативной форме (например, в клетке или на клетке).
Согласно некоторым вариантам реализации настоящего изобретения антитело представляет собой антитело против одного из белков (или типов белков), описанных в другом месте в настоящей заявке.
Антитела и антигенные эпитопы можно выделить или очистить. Термин «выделенный» или «очищенный» в данном контексте означает такие молекулы, которые выделены, очищены из своего природного окружения или по существу свободны от своего природного окружения, например, выделены или очищены из организма (если данные молекулы действительно существуют в природе), или означает такие молекулы, которые были получены в результате технологического процесса, т.е. включает рекомбинантные и полученные синтетическим путем молекулы. Таким образом, термин «выделенный» или «очищенный», как правило, означает антитело или антигенный эпитоп, по существу свободный от клеточного материала или других белков того источника, из которого были получены антитело или антигенный эпитоп. Согласно некоторым вариантам реализации настоящего изобретения такие выделенные или очищенные молекулы являются по существу свободными от культуральной среды при получении с помощью рекомбинантных методик или от химических исходных веществ или других химических веществ, когда данные молекулы являются синтезированными химическим способом.
Можно оценить функциональный эффект антител, полученных в настоящем изобретении, в отношении белка-мишени, и специалист с легкостью определит подходящие для применения анализы, например, исходя из природы белка-мишени. Например, если антитело представляет собой антитело против TRPV1 (или любого другого ионного канала), функциональный эффект антитела можно оценить, например, с использованием электрофизиологии и/или анализа поглощения YO-PRO, описанного в примере 2 в настоящей заявке.
Способы согласно настоящему изобретению можно использовать для создания антитела, которое затем можно выделить, получить или произвести для различных последующих применений. Таким образом, согласно следующему аспекту в настоящем изобретении предложен способ получения или производства и/или выделения антитела.
После того как одно или более антител были созданы, получены, выбраны, идентифицированы, выделены и/или очищены с применением способов согласно настоящему изобретению, данные антитела или компонент, фрагмент, вариант или производное указанных антител можно произвести и при необходимости приготовить в состав с по меньшей мере одним фармацевтически приемлемым носителем или вспомогательным веществом. Такие произведенные молекулы или компоненты, фрагменты, варианты или производные указанных молекул также охватываются настоящим изобретением. В качестве альтернативы, данные молекулы могут принимать форму нуклеиновых кислот, кодирующих указанные антитела, причем указанные нуклеиновые кислоты могут, в свою очередь, быть встроенными в соответствующий вектор экспрессии и/или могут содержаться в подходящих клетках-хозяевах. Таким образом, молекулы нуклеиновой кислоты, кодирующие указанные антитела, или векторы экспрессии, содержащие указанные молекулы нуклеиновой кислоты, образуют следующие аспекты настоящего изобретения.
После того как конкретное антитело или компонент, фрагмент, вариант или производное указанного антитела было создано или получено согласно настоящему изобретению, вектор экспрессии, кодирующий антитело, можно с легкостью применять (или приспособить для применения) с целью получения достаточных количеств молекулы посредством экспрессии в соответствующих клетках-хозяевах или системах и посредством выделения антител из клетки-хозяина или системы либо из среды роста или супернатанта указанной среды, в зависимости от обстоятельств. В случае поликлональных антител антитела можно выделить или очистить из сыворотки иммунизированного животного.
Таким образом, согласно следующему аспекту настоящего изобретения предложен способ получения или производства антитела, включающий этапы создания или получения антитела согласно способам согласно настоящему изобретению, как описано выше, производства или получения указанного антитела или компонента, фрагмента, варианта или производного указанного антитела, и необязательно приготовления в состав указанного произведенного антитела с по меньшей мере одним фармацевтически приемлемым носителем или вспомогательным веществом.
Указанные варианты или производные антитела включают пептоидные эквиваленты, молекулы с непептидным синтетическим остовом и полипептиды, родственные или полученные из исходного идентифицированного полипептида, в которых аминокислотная последовательность была модифицирована на одну или более замен, добавлений и/или делеций аминокислот, которые могут, в качестве альтернативы или дополнительно, содержать замены или добавления аминокислот, которые были модифицированы химическим способом, например, посредством дегликозилирования или гликозилирования. Для удобства такие производные или варианты могут характеризоваться идентичностью последовательности по меньшей мере 60, 70, 80, 90, 95 или 99% исходному полипептиду, из которого были получены данные производные.
Поскольку настоящее изобретение относится к получению антител, указанные варианты или производные также включают преобразование одного формата молекулы антитела в другой формат (например, преобразование из Fab в scFv или наоборот либо преобразование между любыми форматами молекул антитела, описанными в другом месте в настоящей заявке, например, преобразование в любой другой тип фрагмента антитела, как описано в настоящей заявке), или преобразование молекулы антитела в молекулу антитела конкретного класса (например, преобразование молекулы антитела в IgG или подкласс указанного класса, например, IgG1 или IgG3, которые являются в особенности подходящими для терапевтических антител) либо гуманизацию или образование химерной версии любого антитела.
Указанные варианты или производные также включают объединение антител с другими функциональными компонентами, которые могут, например, являться пригодными в последующих применениях указанных антител. Например, антитела можно объединить с компонентами, которые нацеливают данные антитела к конкретному участку тела, или с обнаруживаемыми группами, пригодными, например, при визуализации или других диагностических применениях, или с грузом, таким как радиоактивный изотоп, токсин или химиотерапевтическое средство в форме иммуноконъюгата.
Очевидно, что основное требование к таким компонентам, фрагментам, вариантам или производным, которые являются партнерами связывания молекул или структур-мишеней, заключается в том, что данные компоненты сохраняют свою исходную функциональную активность в отношении способности к связыванию или обладают улучшенными функциональными активностями.
Молекулы антитела, созданные или полученные либо произведенные с применением способов согласно настоящему изобретению, можно использовать в любых способах, в которых необходимы антитела, специфичные к структуре-мишени (например, антитела, специфичные к конкретному антигену). Таким образом, антитела можно использовать в качестве молекулярных инструментов, и согласно следующему аспекту настоящего изобретения предложен реактив, который содержит такие антитела, как определено в настоящей заявке. Кроме того, такие молекулы можно использовать для терапевтических или профилактических применений in vivo, диагностики или применений для визуализации in vivo или in vitro либо для анализов in vitro.
Некоторые конкретные варианты реализации настоящего изобретения изложены ниже:
1. Способ создания антитела против белка, причем указанный способ включает:
i) идентификацию антигенного эпитопа в указанном белке посредством воздействия на белок ограниченного или частичного протеолиза путем осуществления контакта белка с по меньшей мере одной протеазой с образованием по меньшей мере одной расщепленной, деконструированной или усеченной версии указанного белка и по меньшей мере одного экспонированного на поверхности пептида, который отщепляется от указанного белка под действием указанной протеазы, и создание антигенного эпитопа на основе указанного экспонированного на поверхности пептида; и
(ii) получение антитела против указанного антигенного эпитопа.
2. Способ создания антитела против белка, причем указанный способ включает:
(i) воздействие на белок ограниченного или частичного протеолиза путем осуществления контакта указанного белка с по меньшей мере одной протеазой с образованием по меньшей мере одной расщепленной, деконструированной или усеченной версии указанного белка и по меньшей мере одного экспонированного на поверхности пептида, который отщепляется от указанного белка под действием указанной протеазы; и
(ii) идентификацию антигенного эпитопа посредством идентификации экспонированного на поверхности эпитопа среди по меньшей мере одного экспонированного на поверхности пептида, присутствующего в области белка, которая приводит к утрате или существенному изменению биологической функции указанного белка, когда пептид отщепляют или удаляют от указанного белка в течение ограниченного или частичного протеолиза; или выбор по меньшей мере одной области-мишени в указанном белке на основании биоинформационных данных и/или известных данных о биологической функции указанного белка и идентификацию антигенного эпитопа посредством идентификации экспонированного на поверхности эпитопа среди по меньшей мере одного экспонированного на поверхности пептида, присутствующего в указанной по меньшей мере одной области-мишени; и
(iii) получение антитела против указанного антигенного эпитопа.
3. Способ согласно варианту реализации 1 или варианту реализации 2, отличающийся тем, что указанную по меньшей мере одну протеазу используют в условиях, которые приводят к получению не более чем 8, или не более чем 7, или не более чем 5 экспонированных на поверхности пептидов, или не более чем 7, или не более чем 5 уникальных экспонированных на поверхности пептидов, отщепленных от белка под действием указанной протеазы в образце материала, расщепляемого протеолитическим способом, и при этом несколько образцов необязательно отбирают или анализируют последовательно или параллельно, необязательно через различные периоды времени и/или при различных концентрациях указанной протеазы.
4. Способ согласно любому из вариантов реализации 1 – 3, отличающийся тем, что указанную по меньшей мере одну протеазу используют в условиях, которые приводят к получению не более чем 8 или не более чем 7, или не более чем 5 экспонированных на поверхности пептидов, отщепленных от указанного белка под действием указанной протеазы.
5. Способ согласно любому из вариантов реализации 1 – 4, отличающийся тем, что кинетическая активность указанной по меньшей мере одной протеазы замедляется настолько, что указанные экспонированные на поверхности пептиды отщепляются по одному в данный момент времени или не более чем по несколько в данный момент времени, например, не более чем 8 или не более чем 7, или не более чем 5 в данный момент времени в образце, и при этом несколько образцов необязательно отбирают или анализируют последовательно или параллельно.
6. Способ согласно любому из вариантов реализации 1 – 5, отличающийся тем, что указанные отщепленные экспонированные на поверхности пептиды классифицируют на основании порядка их образования после осуществления контакта с указанной по меньшей мере одной протеазой, причем экспонированным на поверхности пептидам, которые отщепляются первыми или при меньших концентрациях указанной протеазы, присваивают высокий класс, и экспонированным на поверхности пептидам, которые отщепляются позже или при более высоких концентрациях указанной протеазы, присваивают низкий класс, и экспонированные на поверхности пептиды, которые отщепляются в промежутке между отщеплением указанных пептидов, необязательно можно классифицировать в порядке их возникновения.
7. Способ согласно варианту реализации 6, отличающийся тем, что указанный способ включает выбор экспонированного на поверхности пептида, который характеризуется высоким классом, для разработки антигенного эпитопа и получение антитела против указанного антигенного эпитопа.
8. Способ согласно варианту реализации 6, отличающийся тем, что указанный способ включает выбор экспонированного на поверхности пептида, который характеризуется высоким классом, конструирование антигенного эпитопа на основе указанного экспонированного на поверхности пептида и получение антитела против указанного антигенного эпитопа.
9. Способ согласно варианту реализации 6, отличающийся тем, что указанный способ включает выбор экспонированного на поверхности пептида, который характеризуется высоким классом, соотнесение указанного экспонированного на поверхности пептида с определенным биологическим свойством указанного белка, конструирование антигенного эпитопа на основе указанного экспонированного на поверхности пептида и получение5 антитела против указанного антигенного эпитопа.
10. Способ согласно любому из вариантов реализации 1-9, отличающийся тем, что
для расщепления, деконструирования и/или усечения указанного белка используют одну протеазу.
11. Способ согласно любому из вариантов реализации 1 – 9, отличающийся тем, что для расщепления, деконструирования и/или усечения указанного белка используют несколько протеаз.
12. Способ согласно варианту реализации 11, отличающийся тем, что указанные несколько протеаз используют последовательно по одной, используют параллельно или используют в едином коктейле из нескольких протеаз.
13. Способ согласно варианту реализации 11 или варианту реализации 12, отличающийся тем, что указанные несколько протеаз используют для идентификации перекрывающихся, комплементарных или уникальных экспонированных на поверхности пептидов.
14. Способ согласно любому из вариантов реализации 1 – 13, отличающийся тем, что указанная протеаза выбрана из группы, состоящей из: трипсина, протеиназы Arg-C, эндопептидазы Asp-N, клострипаина, глутамилэндопептидазы, Lys-C, Lys-N, химотрипсина, протеиназы K, термолизина, пепсина, каспазы 1, каспазы 2, каспазы 3, каспазы 4, каспазы 5, каспазы 6, каспазы 7, каспазы 8, каспазы 9, каспазы 10, энтерокиназы, фактора Xa, гранзима B, нейтрофильной эластазы, пролинэндопептидазы, стафилококковой пептидазы I и тромбина.
15. Способ согласно любому из вариантов реализации 1 – 14, отличающийся тем, что указанная протеаза представляет собой трипсин.
16. Способ согласно любому из вариантов реализации 1 – 15, отличающийся тем, что указанный белок представляет собой мембранный белок, который присутствует в протеолипосоме, полученной из клеток.
17. Способ согласно любому из вариантов реализации 1 – 16, отличающийся тем, что указанную протеолипосому иммобилизуют в проточной ячейке для получения неподвижной фазы мембранных белков.
18. Способ согласно любому из вариантов реализации 1 – 15, отличающийся тем, что указанный белок находится в белок-содержащей липидной везикуле, которая является связанной с поверхностью или суспендированной в растворе.
19. Способ согласно любому из вариантов реализации 1 – 15, отличающийся тем, что указанный белок находится в интактной клетке, которая является связанной с поверхностью или суспендированной в растворе.
20. Способ согласно любому из вариантов реализации 1 – 15, отличающийся тем, что указанный белок находится в растворе.
21. Способ согласно любому из вариантов реализации 1-20, отличающийся тем, что указанный белок представляет собой любой белок протеома человека.
22. Способ согласно любому из вариантов реализации 1 – 21, отличающийся тем, что указанный белок представляет собой мембраносвязанный белок, растворимый белок, внеклеточный белок или внутриклеточный белок.
23. Способ согласно любому из вариантов реализации 1 – 22, отличающийся тем, что указанный белок представляет собой мембранный или мембраносвязанный белок.
24. Способ согласно любому из вариантов реализации 1 – 23, отличающийся тем, что указанный белок представляет собой ионный канал суперсемейства TRP.
25. Способ согласно варианту реализации 24, отличающийся тем, что указанный белок представляет собой TRPV1 или TRPV2.
26. Способ согласно любому из вариантов реализации 1 – 23, отличающийся тем, что указанный белок представляет собой рецептор возбуждающей аминокислоты.
27. Способ согласно варианту реализации 26, отличающийся тем, что указанный белок представляет собой NMDA-рецептор или G-белок.
28. Способ согласно любому из вариантов реализации 1 – 23, отличающийся тем, что указанный белок представляет собой онкогенный белок.
29. Способ согласно варианту реализации 28, отличающийся тем, что указанный белок представляет собой онкогенную малую ГТФазу, которая выбрана из группы, состоящей из KRAS, NRAS и HRAS.
30. Способ согласно любому из вариантов реализации 1 – 23, отличающийся тем, что указанный белок представляет собой иммуномодулирующий белок.
31. Способ согласно варианту реализации 30, отличающийся тем, что указанный белок выбран из группы, состоящей из PD1, PDL1, CD40, OX40, VISTA, LAG-3, TIM-3, GITR и CD20.
32. Способ согласно любому из вариантов реализации 1 – 31, отличающийся тем, что указанные отщепленные пептиды идентифицируют путем масс-спектрометрии.
33. Способ согласно варианту реализации 24, отличающийся тем, что указанные отщепленные пептиды идентифицируют путем ЖХ-МС/МС.
34. Способ согласно любому из вариантов реализации 2 – 33, отличающийся тем, что указанная биологическая функция выбрана из группы, состоящей из способности указанного белка связываться с мишенью, такой как лиганд или рецептор, ферментативной активности указанного белка, активности ионного канала, активности транспортера и высвобождения, такого как механизм высвобождения и поглощения инсулина.
35. Способ согласно любому из вариантов реализации 1 – 34, отличающийся тем, что получение антитела против указанного антигенного эпитопа осуществляют посредством гибридомной технологии, технологии фагового дисплея или посредством иммунизации животного указанным антигенным эпитопом.
36. Способ согласно любому из вариантов реализации 1 – 35, отличающийся тем, что указанное антитело представляет собой моноклональное или поликлональное антитело.
37. Антитело, полученное способом согласно любому из вариантов реализации 1 – 36.
38. Антигенный эпитоп TRPV1, содержащий аминокислотную последовательность, которая выбрана из группы, состоящей из:
LLSQDSVAASTEK (SEQ ID NO:2); LLSQDSVAASTEKTLR (SEQ ID NO:3); и QFSGSLKPEDAEVFKSPAASGEK (SEQ ID NO:4)
или последовательность, по существу гомологичную указанной последовательности, причем указанная по существу гомологичная последовательность представляет собой последовательность, содержащую 1, 2 или 3 замены или делеции аминокислот по сравнению с данной аминокислотной последовательностью, или представляет собой последовательность, которая по меньшей мере на 70% идентична данной аминокислотной последовательности, или представляет собой последовательность, содержащую по меньшей мере 6 последовательных аминокислот данной аминокислотной последовательности.
39. Антигенный эпитоп TRPV1, содержащий аминокислотную последовательность, которая выбрана из группы, состоящей из:
LLSQDSVAASTEKTLRLYDRRS (SEQ ID NO:5); и
GRHWKNFALVPLLRE (SEQ ID NO:6).
40. Антигенный эпитоп TRPV1, содержащий аминокислотную последовательность LVENGADVQAAAHGDF (SEQ ID NO:7) или последовательность, по существу гомологичную указанной последовательности,
причем указанная по существу гомологичная последовательность представляет собой последовательность, содержащую 1, 2 или 3 замены или делеции аминокислот по сравнению с данной аминокислотной последовательностью, или представляет собой последовательность, которая по меньшей мере на 70% идентична данной аминокислотной последовательности, или представляет собой последовательность, содержащую по меньшей мере 6 последовательных аминокислот данной аминокислотной последовательности.
41. Антигенный эпитоп TRPV1, содержащий аминокислотную последовательность, которая выбрана из группы, состоящей из:
DGPTGARLLSQ (SEQ ID NO:8); и
DAEVFKSPAASGEK (SEQ ID NO:9).
или последовательность, по существу гомологичную указанной последовательности, причем указанная по существу гомологичная последовательность представляет собой последовательность, содержащую 1, 2 или 3 замены или делеции аминокислот по сравнению с данной аминокислотной последовательностью, или представляет собой последовательность, которая по меньшей мере на 70% идентична данной аминокислотной последовательности, или представляет собой последовательность, содержащую по меньшей мере 6 последовательных аминокислот данной аминокислотной последовательности.
42. Антигенный эпитоп TRPV1, содержащий аминокислоту, которая выбрана из группы, состоящей из:
SQDSVAASTEKTL (SEQ ID NO:10); и
SGSLKPEDAEVF (SEQ ID NO:11).
или последовательность, по существу гомологичную указанной последовательности, причем указанная по существу гомологичная последовательность представляет собой последовательность, содержащую 1, 2 или 3 замены или делеции аминокислот по сравнению с данной аминокислотной последовательностью, или представляет собой последовательность, которая по меньшей мере на 70% идентична данной аминокислотной последовательности, или представляет собой последовательность, содержащую по меньшей мере 6 последовательных аминокислот данной аминокислотной последовательности.
43. Антигенный эпитоп TRPV1, содержащий аминокислоту, которая выбрана из группы, состоящей из:
VSPVITIQRPGD (SEQ ID NO:12); VSPVITIQRPGDGPTGA (SEQ ID NO:13); LNLHDGQNTTIPLLL (SEQ ID NO:14); YTDSYYKGQ (SEQ ID NO:15); SLPSESTSH (SEQ ID NO:16); EDPGNCEGVKR (SEQ ID NO:17); DRQSAQPEEVYLR (SEQ ID NO:18); и QSAQPEEVYLR (SEQ ID NO:19);
или последовательность, по существу гомологичную указанной последовательности,
причем указанная по существу гомологичная последовательность представляет собой последовательность, содержащую 1, 2 или 3 замены или делеции аминокислот по сравнению с данной аминокислотной последовательностью, или представляет собой последовательность, которая по меньшей мере на 70% идентична данной аминокислотной последовательности, или представляет собой последовательность, содержащую по меньшей мере 6 последовательных аминокислот данной аминокислотной последовательности.
44. Антигенный эпитоп TRPV2, содержащий аминокислоту, которая выбрана из группы, состоящей из:
FAPQIRVNLNYRKGTG (SEQ ID NO:20); ASQPDPNRFDRDR (SEQ ID NO:21); LNLKDGVNACILPLL (SEQ ID NO:22); CTDDYYRGH (SEQ ID NO:23); LVENGANVHARACGRF (SEQ ID NO:24); EDPSGAGVPR (SEQ ID NO:25); и GASEENYVPVQLLQS (SEQ ID NO:26).
или последовательность, по существу гомологичную указанной последовательности, причем указанная по существу гомологичная последовательность представляет собой последовательность, содержащую 1, 2 или 3 замены или делеции аминокислот по сравнению с данной аминокислотной последовательностью, или представляет собой последовательность, которая по меньшей мере на 70% идентична данной аминокислотной последовательности, или представляет собой последовательность, содержащую по меньшей мере 6 последовательных аминокислот данной аминокислотной последовательности.
45. Антитело против антигенного эпитопа согласно любому из вариантов реализации 38 – 44.
Как отмечается выше, авторы настоящего изобретения разработали методологию для идентификации экспонированных на поверхности антигенных эпитопов, которая позволяет получать фармакологически активные антитела с применением кинетически контролируемого протеолиза (т.е. ограниченного или частичного протеолиза). В идеальном случае протеолитический этап (этап ограниченного или частичного протеолиза) осуществляют настолько медленно, что под действием протеазы в данный момент времени от антигена отрывается один или более пептидов. Пептиды, которые появляются первыми, и, в особенности, их соответствующие сайты разрезания, являются экспонированными на поверхности и легкодоступными для антитела, и вследствие этого, как правило, являются предпочтительными по сравнению с пептидами, которые появляются позже. Затем данные пептиды можно перекрестно соотнести для определения функциональной значимости на основании последовательности с использованием специально подобранных биоинформационных данных, а также функциональных анализов, которые проводят с усеченными белками.
Однако в настоящем изобретении также предложены способы, которые характеризуются улучшениями по сравнению со способами, описанными выше, которые делают возможной дальнейшую оптимизацию дизайна эпитопа и/или идентификацию следующих (дополнительных) эпитопов. Такой улучшенный способ описан ниже и также обозначен как способ С.
Улучшенный способ представляет собой мультипротеазный способ, который включает последовательное использование нескольких протеаз в отношении одного и того же белка с целью максимизации числа идентифицированных эпитопов. В данном улучшенном способе используют два различных этапа протеолиза; этап ограниченного или частичного протеолиза, например, как описано выше, после которого происходит следующий этап протеолиза (например, этап неограниченного протеолиза) с использованием протеазы или протеаз, отличных от тех, которые использовали на этапе ограниченного или частичного протеолиза (протеаз с отличной специфичностью). Такие способы, предпочтительно, можно использовать для идентификации доступных для протеазы сайтов разрезания, в которых пептиды, однако, не высвобождаются, и которые вследствие этого необязательно идентифицируют или обнаруживают посредством способов на основе одного этапа ограниченного протеолиза, описанных выше. Таким образом, способ обеспечивает средства для идентификации эпитопов на нативных белках в доступных для протеазы сайтах разрезания или поблизости от них, в которых пептиды, однако, не высвобождаются.
В целом, данные улучшенные способы должны улучшить разработку антитела и позволить получить новые терапевтически и фармакологически активные антитела для борьбы с заболеванием. Фармакологически активные антитела, действующие как внутри-, так и внеклеточно, можно получить с применением способов, описанных в настоящей заявке.
В способах согласно настоящему изобретению, в отличие от множества известных методик обнаружения новых антител, антитело можно сконструировать с самого начала для связывания с конкретным сайтом и необязательно для выполнения конкретной функции вместо получения вслепую, когда изначальным приоритетом, как правило, является аффинность, а не функциональность, а затем подмножество антител, демонстрирующих хорошие характеристики связывания, исследуют для определения биологических эффектов.
Применение способов ограниченного протеолиза, описанных выше, в качестве инструмента для проверки доступных областей для связывания антитела основывается на высвобождении пептидов из белка, т.е. основывается на ситуации, что протеазы разрезают в двух доступных сайтах, окружающих последовательность правильного размера, для обнаружения, например, методом масс-спектрометрии. Информация, полученная в таком эксперименте, может обеспечить проверку доступности двух сайтов разрезания, которые были расщеплены и вызвали высвобождение пептида. Однако некоторые области в белке, представляющие интерес, могут не удовлетворять данным критериям. Протеаза может разрезать только один сайт, создавая разрыв, но не высвобождая пептид. Для высвобождения пептида необходимо два разреза. Если пептид не высвободился, отсутствует доказательство (например, основанное на МС доказательство) события связывания или протеолитической активности. Один разрез остается необнаруженным. Другие причины необнаружения могут включать гликозилирование на пептиде или то, что пептид остается связанным с белком ионными или ковалентными связями. Один из путей обхода данной проблемы заключается в создании антител против последовательностей, в которых расположен такой сайт разрезания. Однако сначала необходимо найти способ обнаружения или идентификации данных доступных сайтов разрезания, из которых не высвободились пептиды. В настоящем изобретении предложен такой способ.
Авторы настоящего изобретения разработали дополнительные и улучшенные способы, поскольку при применении предшествующих способов несколько потенциальных связывающих антитело сайтов (эпитопов) могут быть пропущены, так как некоторые пептиды не высвобождаются. Такое может произойти, например, если протеаза расщепляет только один из двух сайтов расщепления, окружающих определенную аминокислотную последовательность, или если протеаза разрезает в одном сайте, и пептид не высвобождается по какой-либо другой причине. В улучшенном способе, описанном ниже (способе C), можно обнаружить уникальные и новые связывающие антитело сайты (эпитопы) и, кроме того, можно получить новые структурные данные для нативных, а также частично расщепленных белков. Данная методика, таким образом, может обеспечить комплексные инструменты для исследования структуры и функции белка.
Способ C
Согласно одному аспекту в настоящем изобретении предложен способ идентификации эпитопа, с которым может связываться антитело, на белке, причем указанный способ включает:
(i) осуществление ограниченного или частичного протеолиза указанного белка с использованием одной первой протеазы или комбинации первых протеаз;
(ii) осуществление неограниченного протеолиза или осуществление ограниченного или частичного протеолиза указанного белка с использованием одной второй протеазы или комбинации вторых протеаз, причем указанная вторая протеаза или протеазы все отличаются от протеазы или протеаз, используемых на этапе (i);
(iii) анализ пептидов, которые высвободились из указанного белка на этапе (ii), для идентификации пептидов, в которых один конец был разрезан указанной первой протеазой, а другой конец был разрезан указанной второй протеазой;
(iv) исследование одного или нескольких эпитопов в области белка, содержащей или фланкирующей сайт разрезания указанной первой протеазы, как определено на этапе (iii), с помощью одного или нескольких антител, направленных на указанные эпитопы, посредством этого идентифицируя один или более эпитопов на белке, с которыми может связываться антитело.
Согласно одному аспекту в настоящем изобретении предложен способ идентификации эпитопа, с которым может связываться антитело, на белке, причем указанный способ включает:
(i) осуществление ограниченного или частичного протеолиза указанного белка с использованием одной первой протеазы или комбинации первых протеаз;
(ii) осуществление неограниченного протеолиза указанного белка с использованием одной второй протеазы или комбинации вторых протеаз, причем указанная вторая протеаза или протеазы все отличаются от протеазы или протеаз, используемых на этапе (i);
(iii) анализ пептидов, которые высвободились из указанного белка на этапе (i) и этапе (ii), для идентификации пептидов, в которых один конец был разрезан указанной первой протеазой, а другой конец был разрезан указанной второй протеазой;
(iv) исследование одного или нескольких эпитопов в области белка, содержащей или фланкирующей сайт разрезания указанной первой протеазы, как определено на этапе (iii), с помощью одного или нескольких антител, направленных на указанные эпитопы, посредством этого идентифицируя один или более эпитопов на белке, с которыми может связываться антитело.
Согласно другому аспекту в настоящем изобретении предложен способ идентификации эпитопа, с которым может связываться антитело, на белке, причем указанный способ включает:
(i) осуществление ограниченного или частичного протеолиза указанного белка с использованием одной первой протеазы или комбинации первых протеаз;
(ii) осуществление неограниченного протеолиза или осуществление ограниченного или частичного протеолиза указанного белка с использованием одной второй протеазы или комбинации вторых протеаз, причем указанная вторая протеаза или протеазы все отличаются от протеазы или протеаз, используемых на этапе (i);
(iii) анализ пептидов, которые высвободились из указанного белка на этапе (i) и этапе (ii), для идентификации пептидов, в которых один конец был разрезан указанной первой протеазой, а другой конец был разрезан указанной второй протеазой;
(iv) исследование одного или нескольких эпитопов в области белка, содержащей или фланкирующей сайт разрезания указанной первой протеазы, как определено на этапе (iii), с помощью одного или нескольких антител, направленных на указанные эпитопы, посредством этого идентифицируя один или более эпитопов на белке, с которыми может связываться антитело.
Этап (i)
Этап ограниченного или частичного протеолиза (этап (i) способа C) можно осуществлять посредством любого подходящего способа или этапа ограниченного или частичного протеолиза, описанного в другом месте в настоящей заявке. Такой этап также можно обозначить как ограниченное или частичное расщепление протеазой или этап, на котором выбранный белок подвергают воздействию ограниченного или частичного протеолиза.
Иными словами, этап ограниченного или частичного протеолиза представляет собой этап протеолиза (или протеолитического расщепления), который не приводит к завершению, или не протекает до завершения, или не осуществляется до завершения. Таким образом, на данном этапе данный белок может быть лишь частично расщеплен (или подвергнут частичному протеолизу). Данный этап удобно проводить посредством осуществления контакта выбранного белка (нативного белка) с одной или несколькими соответствующими протеазами в условиях, которые приводят к ограниченному или частичному протеолизу (описанным в другом месте в настоящей заявке). При таких условиях осуществление контакта белка с протеазой или протеазами приводит к образованию по меньшей мере одного расщепленного, деконструированного или усеченного белка и по меньшей мере одного экспонированного на поверхности пептида, который отщепляется от указанного белка под действием указанной протеазы или протеаз.
Для данного этапа можно использовать одну протеазу. В качестве альтернативы, можно использовать несколько протеаз вместе в комбинации (например, можно использовать коктейль протеаз, которые одновременно добавляют к образцу белка или приводят в контакт с образцом белка). Согласно некоторым вариантам реализации настоящего изобретения использование одной протеазы является предпочтительным. Одну или более протеаз, используемых на данном этапе, также называют в настоящей заявке «первая протеаза или протеазы» или «протеаза или протеазы А». Такое обозначение предназначено для того, чтобы отличать данные протеазы от протеаз, используемых на этапе (ii) способа (которые также называют в настоящей заявке «вторая протеаза или протеазы» или «протеаза или протеазы B»). Протеаза или протеазы, используемые на этапе (ii) способа, будут отличаться от протеаз, используемых на этапе (i); это означает, что протеазы будут характеризоваться отличной специфичностью (отличной субстратной специфичностью).
Можно использовать любую соответствующую протеазу, и подходящие протеазы, которые можно использовать на данном этапе ограниченного или частичного протеолиза, описаны в другом месте в настоящей заявке. Как правило, предпочтительные протеазы являются таковыми, которые характеризуются устойчивой или высокой специфичностью (например, не характеризуются тенденцией расщеплять аминокислоты за пределами их специфичности), и/или которые хорошо отвалидированы и охарактеризованы, например, применительно к специфичности (иными словами, аминокислотная последовательность, перевариваемая или расщепляемая протеазой, является известной и постоянной).
Одна из предпочтительных групп протеаз для использования на этапе ограниченного или частичного протеолиза (i) (т.е. примеры первой протеазы или протеаз, протеазы или протеаз А, или протеаз для первого этапа расщепления), включает одну или несколько протеаз, выбранных из трипсина, Arg-C, Lys-C и Lys-N (иногда обозначаются в настоящей заявке как протеазы группы 1).
Другая предпочтительная группа протеаз для использования на этапе ограниченного или частичного протеолиза (i) (т.е. примеры первой протеазы или протеаз, протеазы или протеаз А, или протеаз для первого этапа расщепления), включает одну или несколько протеаз, выбранных из пепсина, химотрипсина и Glu-C (иногда обозначаются в настоящей заявке как протеазы группы 2).
Согласно некоторым вариантам реализации настоящего изобретения протеазу Asp-N можно также использовать в комбинации с любой из данных групп (иногда обозначаются в настоящей заявке как протеазы группы 3).
Согласно некоторым вариантам реализации настоящего изобретения на этапе ограниченного или частичного протеолиза (i) используют протеазу, выбранную из группы, состоящей из трипсина, химотрипсина и протеиназы K (или включающей указанные протеазы).
Как упомянуто выше, согласно данному аспекту (способу С) можно использовать любое из условий ограниченного или частичного протеолиза, описанных в настоящей заявке. Согласно некоторым вариантам реализации настоящего изобретения на этапе (i) используют концентрацию протеазы до 2 мкг/мл, например, приблизительно 0,5 мкг/мл, 1 мкг/мл или приблизительно 2 мкг/мл. Согласно некоторым таким вариантам реализации настоящего изобретения ограниченный или частичный протеолиз проводят при комнатной температуре.
Согласно некоторым вариантам реализации настоящего изобретения на этапе (i) используют концентрацию протеазы до 5 мкг/мл, например, приблизительно 1 мкг/мл, приблизительно 2 мкг/мл, приблизительно 3 мкг/мл, приблизительно 4 мкг/мл или приблизительно 5 мкг/мл. Согласно некоторым таким вариантам реализации настоящего изобретения ограниченный или частичный протеолиз проводят при комнатной температуре.
Согласно некоторым вариантам реализации настоящего изобретения ограниченный или частичный протеолиз на этапе (i) осуществляют в течение до 5 минут (например, 1, 2, 3, 4 или 5 минут). Согласно некоторым таким вариантам реализации настоящего изобретения ограниченный или частичный протеолиз проводят при комнатной температуре.
Согласно некоторым вариантам реализации настоящего изобретения ограниченный или частичный протеолиз на этапе (i) осуществляют с помощью 2 мкг/мл химотрипсина в течение 5 минут при комнатной температуре.
Согласно некоторым вариантам реализации настоящего изобретения ограниченный или частичный протеолиз на этапе (i) осуществляют с помощью 5 мкг/мл трипсина в течение 5 минут при комнатной температуре.
Согласно некоторым вариантам реализации настоящего изобретения ограниченный или частичный протеолиз на этапе (i) осуществляют с помощью 2 мкг/мл протеиназы K в течение 5 минут при комнатной температуре.
Этап (ii)
Согласно некоторым предпочтительным вариантам реализации настоящего изобретения этап (ii) описанного выше способа (способа C) представляет собой этап неограниченного протеолиза, и его осуществляют в отношении белка, который подвергали ограниченному или частичному протеолизу на этапе (i), т.е. этапы (i) и (ii) проводят последовательно в отношении одного и того же образца белка, и белок, анализ которого проводят, подвергают последовательному протеолизу.
После осуществления этапа ограниченного протеолиза (i) белок будет, вероятно, содержать несколько дополнительных сайтов для протеазы или протеаз, используемых на этапе (i), которые были переварены (расщеплены) в течение этапа ограниченного протеолиза, в которых пептиды, однако, остались присоединенными (т.е. не высвободились), например, поскольку отсутствует другой сайт для протеазы или протеаз, достаточно близкий к данному сайту (сайту разрезания), или поскольку пептид удерживается на белке какими-либо другими способами, например, в результате молекулярных взаимодействий или сил, например, ионных связей. Такие сайты разрезания представляют собой сайты, которые представляют собой экспонированные (доступные) сайты протеазы в нативном белке (например, представляют собой экспонированные на поверхности сайты), и вследствие этого представляют потенциальный интерес как образующие часть подходящего эпитопа, на который могут быть нацелены антитела, но которые могут быть пропущены при применении других способов, включающих ограниченный протеолиз, описанных в другом месте в настоящей заявке, поскольку пептид с данным сайтом разрезания на одном конце не будет отщепляться от белка под действием протеазы, и вследствие этого сайт разрезания (и соответствующий ему эпитоп) не будет идентифицирован (например, с применением МС). Однако для высвобождения данных пептидов можно использовать второй протеолитический этап (этап второго расщепления), этап (ii) способа C, который вследствие этого позволяет проводить идентификацию сайта разрезания и исследование эпитопов в данном сайте разрезания или вокруг него в нативном белке с применением, например, последующих этапов способа C, описанных в настоящей заявке.
Этап второго расщепления (этап (ii)) можно проводить как этап неограниченного протеолиза с целью извлечения максимального перекрывания последовательности в белке.
Согласно некоторым вариантам реализации настоящего изобретения этап (ii) способа (способа C) представляет собой этап протеолиза, который представляет собой этап неограниченного протеолиза (или нечастичного, или неограниченного протеолиза). Данный этап прямо противоположен ограниченному или частичному протеолизу, который осуществляют на этапе (i). Например, этап (i), как правило, осуществляют в условиях мягкого протеолиза с целью максимального сохранения структуры нативного белка, тогда как на этапе (ii) способа нет необходимости сохранять нативную структуру белка (и, в действительности, часто целостность белка в значительной степени нарушается либо структура не сохраняется), целью этапа (ii) является переваривание (расщепление) как можно большего числа сайтов протеазы (и, вследствие этого, высвобождение как можно большего числа пептидов), например, высвобождение максимального числа пептидов. Однако высвобожденные пептиды необходимо проанализировать на этапе (iii) способа, например, методом масс-спектрометрии (МС). Таким образом, этап (ii), как правило, осуществляют с целью переваривания (расщепления) как можно большего числа сайтов протеазы и высвобождения как можно большего числа обнаруживаемых пептидов (например, обнаруживаемых методом МС). Иными словами, целью является расщепление максимального числа сайтов расщепления, что приведет к наибольшему числу пептидов, которые все еще являются оптимизированными для обнаружения, например, обнаружения методом МС (расщепление, оптимизированное для обнаружения методом МС).
Таким образом, согласно некоторым вариантам реализации настоящего изобретения этап неограниченного (неограничивающего) протеолиза, который осуществляют на этапе (ii) способа C, представляет собой, предпочтительно, таковой, при котором этап протеолиза осуществляют до завершения, или этап, на котором данный белок полностью расщепляется (что иногда обозначают как полный протеолиз). Однако, если такое полное расщепление приведет к появлению значительного числа пептидов, которые являются необнаруживаемыми, например, методом МС, например, поскольку они являются слишком короткими, тогда, предпочтительно, расщепление остановят до достижения данной точки, например, когда максимальное число или значительное число пептидов все еще можно обнаружить, иными словами, когда произойдет почти полное расщепление.
Специалист в данной области техники с легкостью может определить, была ли реакция протеолиза доведена до завершения или почти до завершения (например, до стадии, на которой высвободилось как можно большее число обнаруживаемых пептидов), или нет, и являлось ли определяемым соответствующее число пептидов, или нет. Это будет зависеть, например, от способности обнаружения используемого инструмента, например, диапазона массы масс-спектрометра. Обычные длины пептидов для масс-спектрометра будут составлять по меньшей мере 4, 5, 6, 7 или 8 аминокислот. Таким образом, расщепление (протеолиз), предпочтительно, остановят в точке, когда большинство (или максимальное число) расщепленных пептидов являются обнаруживаемыми, например, методом масс-спектрометрии.
Подходящие условия для этапа неограниченного протеолиза (ii) по сравнению с условиями, используемыми для ограниченного или частичного протеолиза этапа (i), будут с легкостью очевидны специалисту. Например, в то время как этапы ограниченного или частичного протеолиза осуществляют в субоптимальных/недостаточных условиях для соответствующей протеазы или протеаз, этап неограниченного протеолиза можно осуществлять в оптимальных (или более близких к оптимальным, или нормальных, или рекомендуемых, например, рекомендуемых производителем, или стандартных) условиях для соответствующей протеазы или протеаз.
Примеры соответствующих условий для этапа (ii) могут представлять собой один или более (или все) из параметров, выбранных из буфера, pH и температуры. Другим соответствующим условием может быть концентрация (например, высокая, или насыщенная, или максимальная, или оптимальная концентрация) протеазы. Таким образом, этап неограниченного протеолиза можно осуществить посредством использования одного или нескольких (или всех) параметров из оптимальных буферов для данной протеазы, оптимального pH и/или оптимальных температур расщепления. Применительно к соответствующим концентрациям протеазы или протеаз для использования на этапе неограниченного протеолиза (ii) соответствующие концентрации будут, как правило, соответствовать концентрациям, которые приводят к максимальной, или оптимальной, или полной (целой), или почти полной (в соответствующем случае) активности протеазы, например, к максимальному, или оптимальному, или полному (или почти полному, в соответствующем случае) расщеплению пептида (в отличие от концентраций, приводящих к субоптимальной активности, которые можно использовать для ограниченного или частичного протеолиза).
Несмотря на то, что этап неограниченного протеолиза (этап (ii)) можно осуществлять с использованием оптимальных условий для данной протеазы, на этапе неограниченного протеолиза не всегда обязательно использовать оптимальные условия для протеазы. На этапе неограниченного протеолиза можно использовать субоптимальные условия для данной протеазы при условии, что все еще происходит соответствующее количество расщепления белка (например, как описано в другом месте в настоящей заявке). Исключительно в качестве примера, если на этапе (ii) протеазу используют при субоптимальной температуре (например, трипсин или химотрипсин используют при <37°C, например, при комнатной температуре), протеолиз можно все еще считать неограниченным, если, например, используют высокую (или более высокую) концентрацию протеазы и/или используют длительное (или более длительное) время инкубации. Как правило, высокая (или более высокая) концентрация протеазы в данном контексте будет представлять собой концентрацию, которая является более высокой (например, в значительной степени более высокой), чем концентрация протеазы, используемая на этапе (i). Как правило, длительное (или более длительное) время инкубации в данном контексте будет представлять собой время инкубации, которое является более длительным (например, в значительной степени более длительным), чем время инкубации, которое используют на этапе (i). Исключительно в качестве примера, если реакцию ограниченного протеолиза (этап (i)) проводят с использованием 5 мкг/мл протеазы или менее (например, 0,5, 1, 2, 3, 4 или 5 мкг/мл) в течение 5 минут или менее при комнатной температуре (например, 20-25°C), тогда этап (ii), который проводят при комнатной температуре с более высокой концентрацией протеазы (например, 20 мкг/мл протеазы) и/или при более длительном времени инкубации (например, 1 час), можно считать этапом неограниченного протеолиза.
Таким образом, некоторые иллюстративные условия для неограниченного протеолиза с помощью конкретной протеазы или протеаз можно получить посредством сравнения с соответствующими условиями для ограниченного или частичного протеолиза с помощью данной протеазы, например, описанными в другом месте в настоящей заявке. Например, оптимальная рабочая температура для трипсина составляет 37°C, и, таким образом, согласно вариантам реализации, в которых для этапа неограниченного протеолиза используют трипсин, данная температура является предпочтительной. Однако согласно некоторым вариантам реализации настоящего изобретения температура, используемая для протеолиза на этапах (i) и (ii), может быть одинаковой (например, комнатная температура). Согласно вариантам реализации, в которых этап (ii) представляет собой этап неограниченного протеолиза, и как для этапа (i), так и для этапа (ii) используют одинаковую температуру инкубации, условия для этапа (ii) протеолиза, как правило, корректируют относительно условий, используемых для этапа (i), с целью обеспечения более жесткого (или более полного, или почти полного) протеолиза на этапе (ii) относительно этапа (i), например, посредством использования на этапе (ii) концентрации протеазы, которая является более высокой, чем концентрация протеазы, используемая на этапе (i), и/или посредством использования более длительного времени инкубации на этапе (ii), чем время инкубации на этапе (i) (и/или посредством корректирования любого другого условия на этапе (ii) с целью обеспечения более жесткого (или более полного, или почти полного) протеолиза на этапе (ii)).
Согласно вариантам реализации, в которых, например, для ограниченного или частичного протеолиза будут использовать конкретную концентрацию протеазы, тогда, например, для неограниченного протеолиза можно использовать более высокие, предпочтительно, в значительной степени более высокие концентрации, например, концентрации, которые являются по меньшей мере в 2 раза, в 3 раза, в 4 раза, в 5 раз или в 10 раз (или более) более высокими.
Согласно некоторым вариантам реализации настоящего изобретения, когда на этапе ограниченного протеолиза (этап (i)) используют данную концентрацию первой протеазы (или комбинации первых протеаз), тогда для неограниченного протеолиза (этап (ii)) используют более высокую, предпочтительно, в значительной степени более высокую концентрацию второй протеазы (или комбинации вторых протеаз), например, концентрации, которые являются по меньшей мере в 2 раза, в 3 раза, в 4 раза, в 5 раз или в 10 раз (или более) более высокими. В качестве примера, согласно некоторым вариантам реализации настоящего изобретения, если концентрация первой протеазы (или комбинации первых протеаз), используемой для ограниченного или частичного протеолиза, составляет 5 мкг/мл или менее, концентрация второй протеазы (или комбинации вторых протеаз), используемой для неограниченного протеолиза (этап (ii)), может составлять 20 мкг/мл или более.
Согласно вариантам реализации, в которых, например, для ограниченного или частичного протеолиза будут использовать конкретное время инкубации с протеазой, тогда, если для неограниченного протеолиза предпочтительно использовать данную протеазу, например, можно использовать более длительные, предпочтительно, в значительной степени более длительные времена инкубации, например, времена инкубации, которые являются по меньшей мере в 2 раза, в 3 раза, в 4 раза, в 5 раз, в 10 раз, в 20 раз (или более) более длительными. Например, когда время инкубации конкретной протеазы для ограниченного или частичного протеолиза будет составлять порядка минут, тогда, если для неограниченного протеолиза предпочтительно использовать данную протеазу, можно использовать время инкубации, составляющее по меньшей мере час (например, по меньшей мере 1, 2, 3, 4 или 5 часов, или использовать инкубацию в течение ночи). В качестве альтернативы, реакции можно позволить протекать до завершения, например, до тех пор, пока активность протеазы будет исчерпана, или до тех пор, пока последующее расщепление будет невозможным, или почти до завершения (в соответствующем случае).
Согласно некоторым вариантам реализации настоящего изобретения, когда на этапе ограниченного протеолиза (этапе (i)) используют данное время инкубации с первой протеазой (или комбинацией первых протеаз), тогда для неограниченного протеолиза (этапа (ii)) используют более длительное, предпочтительно, в значительной степени более длительное время инкубации со второй протеазой (или комбинацией вторых протеаз), например, времена инкубации, которые являются по меньшей мере в 2 раза, в 3 раза, в 4 раза, в 5 раз или в 10 раз (или более) более длительными. В качестве примера, согласно некоторым вариантам реализации настоящего изобретения, если время инкубации с первой протеазой (или комбинацией первых протеаз), используемой для ограниченного или частичного протеолиза, составляет 5 минут или менее, тогда для этапа неограниченного протеолиза со второй протеазой (или комбинацией вторых протеаз) (этапа (ii)) можно использовать время инкубации по меньшей мере час (например, по меньшей мере 1, 2, 3, 4 или 5 часов, или использовать инкубацию в течение ночи).
Поскольку является предпочтительным, чтобы расщепление (протеолиз) на этапе (ii) протекал до завершения или почти до завершения (или до тех пор, когда будет расщеплено/переварено максимально возможное число сайтов протеазы в белке, например, с целью получения максимального или значительного числа обнаруживаемых пептидов, например, пептидов, обнаруживаемых методом МС), тогда, как обсуждается выше, время инкубации представляет собой иллюстративное условие для обеспечения или осуществления неограниченного протеолиза, например, посредством осуществления расщепления в течение длительного времени, например до тех пор, пока активность протеазы будет исчерпана, или до тех пор, пока последующее расщепление будет невозможным, или до тех пор, пока любое последующее расщепление приведет к увеличению, например, измеряемому или значительному увеличению, числа или доли необнаруживаемых пептидов (например, поскольку они являются слишком короткими для обнаружения, например, методом МС).
В наиболее широком смысле этап неограниченного протеолиза (ii) можно рассматривать как этап, на котором осуществляют больше, предпочтительно, в значительной степени больше протеолиза, чем на этапе (i), и соответствующие протеазы (и условия) можно соответствующим образом выбрать, при условии, что на этапе (i) и этапе (ii) используют отличную протеазу или протеазы, то есть, протеазу или протеазы с отличными специфичностями. В качестве альтернативы, этап неограниченного протеолиза (ii) можно рассматривать как этап, на котором протеолиз (или условия протеолиза) является более жестким (или более сильным, или более строгим), чем протеолиз (или условия протеолиза), используемый на этапе (i). Также, в качестве альтернативы, этап неограниченного протеолиза (ii) можно рассматривать как протеолиз, который является более жестким (или более сильным, или более строгим) по сравнению с протеолизом на этапе (i).
Таким образом, если данный белок содержит определенное число потенциальных точек/сайтов расщепления данной протеазы (т.е. сайтов, распознаваемых данной протеазой для расщепления), тогда при выбранных условиях ограниченного или частичного протеолиза протеаза может расщепить только подмножество из данных сайтов расщепления, тогда как если данную протеазу вместо этого выбрали для использования в условиях неограниченного протеолиза, тогда будут выбраны такие условия, чтобы протеаза могла расщеплять во всех (или в значительной степени во всех) из данных сайтов расщепления, или в увеличенном числе, предпочтительно, в увеличенном в значительной степени числе из данных сайтов расщепления, чем были бы расщеплены в условиях для ограниченного или частичного протеолиза.
Таким образом, если данный белок содержит определенное число потенциальных точек/сайтов расщепления данной протеазы A (т.е. сайтов, распознаваемых данной протеазой для расщепления), тогда при выбранных условиях ограниченного или частичного протеолиза протеаза может расщепить только подмножество из данных сайтов расщепления, тогда как при выбранных условиях неограниченного протеолиза на этапе (ii) с отличной протеазой, протеазой B, протеаза может расщепить во всех (или в значительной степени во всех) из ее сайтов расщепления, или в увеличенном числе, предпочтительно, в значительной степени в увеличенном числе сайтов расщепления, чем были бы расщеплены в условиях для ограниченного или частичного протеолиза.
С целью прогнозирования числа потенциальных точек/сайтов расщепления данной протеазы можно использовать этап расщепления протеазой in silico либо любой другой подходящий способ или методику прогнозирования расщепления белка протеазой. Например, аминокислотную последовательность белка можно осмотреть визуально, и спрогнозированные сайты разрезания (т.е. сайты, которые согласно прогнозу будут разрезаны протеазой) можно идентифицировать на основании информации о специфичности данной протеазы и правил. В качестве альтернативы и для удобства, прогнозирование с помощью компьютерных способов на основе специфичности данной протеазы и правил является предпочтительным. Во всех данных способах можно принимать во внимание специфичность протеазы и правила, например, трипсин будет разрезать только по аргинину или лизину в C-концевом положении. Правила и исключения при расщеплении для большинства протеаз известны, см., например, компьютерную программу Peptidecutter (Expasy, SIB, Швейцарский институт биоинформатики).
Согласно некоторым вариантам реализации настоящего изобретения неограниченный протеолиз (этап (ii)) представляет собой протеолиз (реакцию протеолиза), который приводит к расщеплению по меньшей мере 60%, или по меньшей мере 65%, или по меньшей мере 70%, или по меньшей мере 75%, или по меньшей мере 80%, или по меньшей мере 85%, или по меньшей мере 90%, или по меньшей мере 95%, или по меньшей мере 98%, или по меньшей мере 99%, или даже 100% сайтов (связей) в белке, которые являются потенциально расщепляемыми (перевариваемыми) используемой протеазой (или обеспечивает такое расщепление). В качестве альтернативы, согласно некоторым вариантам реализации настоящего изобретения неограниченный протеолиз обеспечивает по меньшей мере 60%, или по меньшей мере 65%, или по меньшей мере 70%, или по меньшей мере 75%, или по меньшей мере 80%, или по меньшей мере 85%, или по меньшей мере 90%, или по меньшей мере 95%, или по меньшей мере 98%, или по меньшей мере 99%, или даже 100% протеолиза. Специалист может с легкостью идентифицировать сайты в данном белке, которые являются потенциально расщепляемыми используемой протеазой, на основании информации о последовательности белка и субстратной специфичности используемой протеазы (например, с применением компьютера, например, программного обеспечения Peptidecutter (Expasy, SIB Швейцарский институт биоинформатики). Как правило, расщепление во всех потенциальных сайтах в линейной аминокислотной последовательности будет представлять собой значение «100%» (хотя значение «100%» можно, в качестве альтернативы, задать и в виде суммарного числа потенциальных сайтов в белке, которые в случае расщепления высвободят (или позволят получить) пептиды, длину которых можно с легкостью обнаружить применяемым инструментом, например, применяемым инструментом МС). В качестве альтернативы, значение «100%» можно задать в виде числа потенциальных расщепляемых сайтов в белке, которые, как известно (или согласно прогнозу, например, с применением инструмента моделирования белков), находятся в области белка, доступной для протеазы (например, во внеклеточной части или домене белка, или, например, не в части или области либо домене белка, которые находятся в пределах мембраны клетки, или не в богатой цистеином части белка, или не в посттрансляционно модифицированной части белка, или не в бета-листе). Специалист также может с легкостью определить число (и расположение) сайтов, которые фактически расщепляются протеазой (например, с применением масс-спектрометрии), и, таким образом, может с легкостью определить процент потенциально расщепляемых сайтов, которые фактически были расщеплены,.
Согласно некоторым вариантам реализации настоящего изобретения неограниченный протеолиз (этап (ii)) представляет собой протеолиз (реакцию протеолиза), обеспечивающий уровень (или количество) расщепления белка (например, которое оценивают на основании высвобождения или отщепления пептидов от белка, например, которое определяют методом МС), который не увеличивается (или не увеличивается в значительной степени), например, если используют более длительное время инкубации (или реакции), и/или если используют более высокую концентрацию протеазы, и/или если используют температуру, более близкую к оптимальной температуре для протеазы, и/или если используют одно или более других условий, более близких к оптимальным условиям для протеазы (например, одно или более других условий, описанных в другом месте в настоящей заявке).
Несмотря на то, что ограниченный или частичный протеолиз включает протеолиз, который осуществляют при ограничивающих условиях (при ограничивающей кинетике), посредством чего кинетика активности протеазы замедляется до такой степени, что пептиды отщепляются от белка по одному в данный момент времени или не более чем по несколько в данный момент времени, этап неограниченного протеолиза включает условия, когда кинетика активности протеазы не замедляется или снижается (или не замедляется или снижается в значительной степени либо измеряемо), или является оптимизированной, нормальной или максимизированной. Таким образом, согласно некоторым вариантам реализации настоящего изобретения кинетическая активности указанной протеазы на таких этапах неограниченного протеолиза является такой, что несколько (предпочтительно, 8 или более) или как можно больше пептидов отщепятся одновременно.
Как упомянуто выше, в наиболее широком смысле неограниченный протеолиз можно рассматривать как этап, на котором осуществляют больше (например, применительно к числу сайтов расщепления), предпочтительно, в значительной степени больше протеолиза, чем если бы ту же протеазу вместо этого использовали при ограниченном протеолизе. Таким образом, согласно вариантам реализации, в которых условия ограниченного протеолиза заданы так, чтобы кинетическая активность указанной протеазы замедлялась настолько, чтобы указанные экспонированные на поверхности пептиды отщеплялись по одному в данный момент времени или не более чем по несколько в данный момент времени, например, не более 8 (1, 2, 3, 4, 5, 6, 7 или 8) в данный момент времени (например, не более 8 пептидов или не более 8 уникальных пептидов в образце, например, как описано в другом месте в настоящей заявке), тогда, если бы ту же протеазу вместо этого использовали на этапе (ii), условия для неограниченного протеолиза могут быть заданы так, чтобы больше и, предпочтительно, в значительной степени больше пептидов отщеплялось в данный момент времени, чем в условиях ограниченного протеолиза (например, более чем 2, 3, 4, 5, 6, 7 или 8 в данный момент времени, в соответствующих случаях).
Согласно предпочтительным вариантам реализации настоящего изобретения реакция неограниченного протеолиза может протекать до завершения так, чтобы белок был истощен пептидами, которые могут быть отщеплены данной протеазой, или до тех пор, пока последующее расщепление будет невозможным, или до тех пор, пока любое последующее расщепление приведет к увеличению, например, измеряемому или значительному увеличению, числа или доли необнаруживаемых пептидов (например, поскольку они являются слишком короткими для обнаружения, например, методом МС).
Для данного этапа неограниченного протеолиза (ii) можно использовать одну протеазу. В качестве альтернативы, можно использовать несколько протеаз. Такие несколько протеаз можно использовать вместе в комбинации (например, можно использовать коктейль протеаз, которые одновременно добавляют к образцу белка или приводят в контакт с образцом белка) или такие несколько протеаз можно использовать последовательно, например, одну за другой (согласно некоторым вариантам реализации настоящего изобретения последовательное использование является предпочтительным). Одна или несколько протеаз, используемых на данном этапе или этапах, обозначены в настоящей заявке как «вторая протеаза или протеазы» или «протеаза или протеазы B». Такое обозначение предназначено для того, чтобы отличать данные протеазы от протеаз, используемых на этапе (i) способа (которые обозначены в настоящей заявке «первая протеаза или протеазы» или «протеаза или протеазы А»). Протеаза или протеазы, используемые на этапе (ii) способа, будут отличаться от протеаз, используемых на этапе (i); это означает, что протеазы будут характеризоваться отличной специфичностью (отличной субстратной специфичностью.
Можно использовать любую соответствующую протеазу, и подходящие протеазы, которые можно использовать на таком этапе неограниченного протеолиза, хорошо известны специалисту в данной области техники. Как правило, предпочтительные протеазы являются таковыми, которые характеризуются устойчивой или высокой специфичностью (например, не характеризуются тенденцией расщеплять аминокислоты за пределами их специфичности), и/или которые хорошо отвалидированы и охарактеризованы, например, применительно к специфичности (иными словами, аминокислотная последовательность, перевариваемая или расщепляемая протеазой, является известной и постоянной). Для неограниченного протеолиза можно использовать любые из протеаз, обсуждаемых в другом месте настоящей заявки.
Одна из предпочтительных групп протеаз для использования на этапе неограниченного протеолиза (ii) (т.е. примеры второй протеазы или протеаз, протеазы или протеаз B, или протеаз для второго этапа расщепления) включает одну или несколько протеаз из трипсина, Arg-C, Lys-C и Lys-N (протеазы группы 1).
Другая предпочтительная группа протеаз для использования на этапе неограниченного протеолиза (ii) (т.е. примеры второй протеазы или протеаз, протеазы или протеаз B, или протеаз для второго этапа расщепления) включает одну или несколько протеаз из пепсина, химотрипсина и Glu-C (протеазы группы 2).
Согласно некоторым вариантам реализации настоящего изобретения протеазу Asp-N можно также использовать в комбинации с любой из данных групп (протеазы группы 3).
Таким образом, например, для осуществления способов согласно настоящему изобретению для ограниченного протеолиза на первом этапе (этапе (i)) можно использовать одну или несколько протеаз в комбинации из группы 1 с последующим использованием одной или нескольких протеаз в комбинации (или последовательно) из группы 2 в течение неограниченного протеолиза на втором этапе (этапе (ii)).
В качестве альтернативы, для ограниченного протеолиза на первом этапе (этапе (i)) можно использовать одну или несколько протеаз в комбинации из группы 2 с последующим использованием одной или нескольких протеаз в комбинации (или последовательно) из группы 1 в течение неограниченного протеолиза на втором этапе (этапе (ii)).
Протеазу группы 3 можно необязательно сочетать с группой 1 или группой 2.
Согласно некоторым вариантам реализации настоящего изобретения неограниченный протеолиз можно рассматривать как протеолитический этап, который осуществляют при одном или нескольких условиях, описанных в настоящей заявке применительно к неограниченному протеолизу.
Как упомянуто выше, в соответствии с данным аспектом (способом C) можно использовать любое из условий неограниченного протеолиза, описанных в настоящей заявке. Согласно некоторым вариантам реализации настоящего изобретения на этапе (ii) используют концентрацию протеазы (например, трипсина или химотрипсина) приблизительно 20 мкг/мл. Согласно некоторым таким вариантам реализации настоящего изобретения ограниченный или частичный протеолиз проводят при комнатной температуре.
Согласно некоторым вариантам реализации настоящего изобретения этап (ii) неограниченного протеолиза осуществляют в течение приблизительно 1 часа. Согласно некоторым таким вариантам реализации настоящего изобретения ограниченный или частичный протеолиз проводят при комнатной температуре.
Согласно некоторым вариантам реализации настоящего изобретения этап (ii) неограниченного протеолиза осуществляют с помощью 20 мкг/мл химотрипсина в течение 1 часа минут при комнатной температуре.
Согласно некоторым вариантам реализации настоящего изобретения этап (ii) неограниченного протеолиза осуществляют с помощью 20 мкг/мл трипсина в течение 1 часа при комнатной температуре.
Исключительно в качестве иллюстрации, конкретный пример соответствующих протеаз и условий может представлять собой:
Этап (i): Ограниченный протеолиз химотрипсином - 5 мкг/мл, 5 мин., буфер: например,
100 мМ NH4HCO3, pH 8,0, 21°C
Этап (ii): Неограниченный протеолиз трипсином – 20 мкг/мл, 2 ч, буфер: например, 100 мМ NH4HCO3, pH 8,0, 37°C.
В качестве другой иллюстрации, конкретный пример соответствующих протеаз и условий может представлять собой:
Этап (i): Ограниченный протеолиз химотрипсином - 2 мкг/мл, 5 мин., комнатная температура, буфер: например, 100 мМ Tris-HCl и 10 мМ CaCl2, pH 8,0.
Этап (ii): Неограниченный протеолиз трипсином – 20 мкг/мл, 1 ч, комнатная температура, буфер: например, 100 мМ бикарбонат аммония, pH 8.
В качестве другой иллюстрации, конкретный пример соответствующих протеаз и условий может представлять собой:
Этап (i): Ограниченный протеолиз трипсином - 5 мкг/мл, 5 мин., комнатная температура, буфер: например, 100 мМ бикарбонат аммония, pH 8.
Этап (ii): Ограниченный протеолиз химотрипсином – 20 мкг/мл, 5 мин., комнатная температура, буфер: например, 100 мМ Tris-HCl и 10 мМ CaCl2, pH 8,0.
В качестве другой иллюстрации, конкретный пример соответствующих протеаз и условий может представлять собой:
Этап (i): Ограниченный протеолиз протеиназой K - 2 мкг/мл, 5 мин., комнатная температура, буфер: например, 100 мМ Tris-HCl и 10 мМ CaCl2, pH 8,0.
Этап (ii): Неограниченный протеолиз трипсином – 20 мкг/мл, 1 ч комнатная температура, буфер: например, 100 мМ бикарбонат аммония, pH 8.
Можно видеть, что одна и та же протеаза или протеазы могут являться подходящими для использования на этапе ограниченного протеолиза (i) или на этапе неограниченного протеолиза (ii). Ключевой особенностью при осуществлении некоторых вариантов реализации данного способа (способа C) является то, что условия, при которых белок подвергается воздействию протеазы или протеаз, выбирают соответствующим образом в зависимости от используемой протеазы или протеаз для обеспечения ограниченного либо неограниченного протеолиза. Также для данных способов важно, чтобы для двух этапов использовали различные протеазы (протеазы с различными специфичностями). Под протеазой с отличной специфичностью подразумевают, что протеаза переваривает или расщепляет в отличной аминокислотной последовательности.
Использование нескольких протеаз, как описано в настоящей заявке, включает, без ограничения, использование 2, 3, 4, 5 различных протеаз.
Согласно некоторым вариантам реализации способа используют только две различные протеазы; одну протеазу на этапе (i) и отличную протеазу на этапе (ii). Согласно некоторым вариантам реализации способа осуществляют только два этапа протеолиза (один этап протеолиза (i) и один этап протеолиза (ii)).
Согласно некоторым вариантам реализации данного способа (способа C), в котором на этапе (ii) осуществляют неограниченный протеолиз, указанный способ также включает после этапа (i), но перед этапом (ii), дополнительный этап (например, один или несколько этапов) осуществления ограниченного или частичного протеолиза указанного белка с использованием указанной одной второй протеазы или комбинации вторых протеаз, которые используют (предназначены для использования) на этапе (ii). Такой способ может включать этап анализа пептидов, которые высвобождаются из указанного белка на дополнительном этапе ограниченного протеолиза, который осуществляют перед этапом (ii), и необязательно также анализ пептидов, которые высвободились из указанного белка на этапе (i) и/или этапе (ii), для идентификации пептидов, в которых один конец был разрезан указанной первой протеазой, а другой конец был разрезан указанной второй протеазой. Также можно провести исследование одного или нескольких эпитопов в области белка, содержащей или фланкирующей указанный идентифицированный сайт разрезания для указанной первой протеазы, с помощью одного или нескольких антител, направленных на указанные эпитопы, посредством этого идентифицируя один или несколько эпитопов на белке, с которыми может связываться антитело. Не опираясь на какую-либо теорию, считают, что включение такого дополнительного этапа ограниченного или частичного протеолиза с использованием второй протеазы или комбинации вторых протеаз, которые используют (предназначены для использования) на этапе (ii), может являться благоприятным, поскольку на таком дополнительном этапе ограниченного протеолиза, как правило, высвободится меньшее число пептидов относительно числа пептидов, высвободившихся на этапе неограниченного протеолиза (ii), и, таким образом, после дополнительного этапа ограниченного протеолиза пептиды, в которых один конец был разрезан указанной первой протеазой, а другой конец был разрезан указанной второй протеазой, будет легче обнаружить (например, методом МС), чем после этапа (ii), поскольку в связи со сниженным числом высвободившихся пептидов, в которых оба конца были разрезаны второй протеазой, будет наблюдаться меньше «шума».
Специалист в данной области техники обладает надлежащим оборудованием для выбора соответствующих протеаз с целью использования на различных этапах способа. Как правило, предпочтительные протеазы являются таковыми, которые характеризуются устойчивой или высокой специфичностью (например, не характеризуются тенденцией расщеплять аминокислоты за пределами их специфичности), и/или которые хорошо отвалидированы и охарактеризованы, например, применительно к специфичности (иными словами, аминокислотная последовательность, перевариваемая или расщепляемая протеазой, является известной и постоянной). Как описано в другом месте в настоящей заявке, одним из основных критериев является то, что протеаза или протеазы, используемые на этапе (i), характеризуются различными специфичностями, например, применительно к перевариваемой/расщепляемой аминокислотной последовательности, по сравнению с протеазой или протеазами, используемыми на этапе (ii).
По данной причине (например, устойчивая и высокая, и надежная специфичность) протеазы групп 1, 2 и 3, как описано выше, являются предпочтительными и отнесены к одной группе, поскольку они расщепляют после подмножества одной или нескольких аминокислот. Группу протеаз можно, таким образом, объединить (выбрать) на основании свойства расщепления в одной или относительно небольшой группе (подмножестве) аминокислот (например, 1, 2, 3, 4 или 5 аминокислот, например, до 2, 3, 4 или 5 аминокислот). Таким образом, все протеазы группы 1 расщепляют после аргинина и/или лизина. Протеазы в группе 2 расщепляют после тирозина, триптофана, фенилаланина и/или лейцина. Это означает, что две группы характеризуются полностью различной специфичностью, и, например, все пептиды с разрезом после аргинина можно отнести к расщепляемым группой 1 (и, таким образом, к расщепляемым на любом этапе способа, на котором используют одну или несколько протеаз группы 1). Группы можно дополнительно разделить, например, группу 1 можно разделить на группы протеаз, которые расщепляют после аргинина (т.е. одной аминокислоты), и отличную группу, которая расщепляет после лизина. Таким образом, при желании специалист в данной области техники, разумеется, может обеспечить или выбрать альтернативные или соответствующие единичные протеазы или группы протеаз.
С целью увеличения вероятности того, что в белке расщеплено максимальное число сайтов протеазы (или с целью дополнительного увеличения перекрывания последовательности посредством способа), можно необязательно осуществить дополнительный этап денатурации. Такой этап денатурации можно провести перед (до), во время (в течение) или после этапа неограниченного протеолиза. Соответствующие условия, предназначенные для использования с целью способствования или вызова денатурации белка, хорошо известны специалисту в данной области техники, например, использование соответствующих средств денатурации, буферов, pH и/или температур. Условия денатурации варьируют в зависимости от белка, но обычно используемые средства представляют собой мочевину и хлорид гуанидиния, буферы с высокими или низкими концентрациями соли и/или высоким или низким pH, а также температуры выше 40°C.
Несмотря на то, что способы, в которых первый этап протеолиза (этап (i)) представляет собой этап ограниченного или частичного протеолиза, и второй этап протеолиза (этап (ii)) представляет собой этап неограниченного протеолиза, являются предпочтительными, согласно некоторым вариантам реализации настоящего изобретения для получения пептидов и идентификации эпитопов могут быть подходящими способы, включающие два этапа ограниченного протеолиза, т.е. этап (i) и (ii) описанных выше способов (способа C), которые представляют собой этапы ограниченного или частичного протеолиза, например, описанного в другом месте в настоящей заявке.
Согласно одному аспекту в настоящем изобретении предложен способ идентификации эпитопа, с которым может связываться антитело, на белке, причем указанный способ включает:
(i) осуществление ограниченного или частичного протеолиза указанного белка с использованием одной первой протеазы или комбинации первых протеаз;
(ii) осуществление протеолиза указанного белка с использованием одной второй протеазы или комбинации вторых протеаз, причем указанная вторая протеаза или протеазы все отличаются от протеазы или протеаз, используемых на этапе (i);
(iii) анализ пептидов, которые высвободились из указанного белка на этапе (i) и этапе (ii), для идентификации пептидов, в которых один конец был разрезан указанной первой протеазой, а другой конец был разрезан указанной второй протеазой;
(iv) исследование одного или нескольких эпитопов в области белка, содержащей или фланкирующей сайт разрезания указанной первой протеазы, как определено на этапе (iii), с помощью одного или нескольких антител, направленных на указанные эпитопы, посредством этого идентифицируя один или несколько эпитопов на белке, с которыми может связываться антитело.
В отношении данного аспекта настоящего изобретения можно применять предпочтительные свойства других способов, описанных в настоящей заявке, с соответствующими изменениями.
Согласно другому аспекту в настоящем изобретении предложен способ идентификации эпитопа, с которым может связываться антитело, на белке, причем указанный способ включает:
(i) осуществление протеолиза указанного белка с использованием одной первой протеазы или комбинации первых протеаз;
(ii) осуществление протеолиза указанного белка с использованием одной второй протеазы или комбинации вторых протеаз, причем указанная вторая протеаза или протеазы все отличаются от протеазы или протеаз, используемых на этапе (i);
причем протеолиз, осуществляемый на этапе (ii), является более жестким (или более полным, или более строгим), чем протеолиз, осуществляемый на этапе (i);
(iii) анализ пептидов, которые высвободились из указанного белка на этапе (i) и этапе (ii), для идентификации пептидов, в которых один конец был разрезан указанной первой протеазой, а другой конец был разрезан указанной второй протеазой;
(iv) исследование одного или нескольких эпитопов в области белка, содержащей или фланкирующей сайт разрезания указанной первой протеазы, как определено на этапе (iii), с помощью одного или нескольких антител, направленных на указанные эпитопы, посредством этого идентифицируя один или несколько эпитопов на белке, с которыми может связываться антитело.
Специалист может с легкостью определить условия протеолиза для этапа (ii), которые являются более жесткими, чем условия протеолиза, используемые на этапе (i), например, на основании обсуждения, приведенного в другом месте в настоящей заявке. В отношении данного аспекта настоящего изобретения можно применять предпочтительные свойства других способов, описанных в настоящей заявке, с соответствующими изменениями.
Согласно некоторым вариантам реализации настоящего изобретения переваренные, высвобожденные или расщепленные пептиды, например, пептиды, отщепленные или высвободившиеся из белка на этапе (i) и этапе (ii), замораживают (или хранят иным соответствующим способом) до осуществления этапа (iii).
Этап (iii)
На этапе (iii) способа переваренные, высвободившиеся или расщепленные пептиды, например, пептиды, отщепленные или высвободившиеся из белка на этапе (ii) (и необязательно пептиды, отщепленные или высвободившиеся из белка на этапе (i)), анализируют, например, собирают и анализируют. Такой анализ можно проводить посредством любой соответствующей методики, но удобно и предпочтительно проводить с применением метода масс-спектрометрии, например, описанного в другом месте в настоящей заявке и в примерах.
Данный этап используют для идентификации пептидов, в которых один конец (например, N-конец или C-конец) был разрезан указанной первой протеазой, т.е. протеазой, используемой на этапе ограниченного протеолиза (протеазой A), а другой конец (например, C-конец или N-конец, в соответствующих случаях) был разрезан указанной второй протеазой, т.е. протеазой, используемой на этапе неограниченного протеолиза (протеазой B). Затем данный подход позволяет проводить идентификацию сайтов в нативном белке, соответствующих концу, который был разрезан указанной первой протеазой, т.е. протеазой, используемой на этапе ограниченного протеолиза. Данные сайты в нативном белке представляют собой доступные для протеазы сайты, которые, вероятно, соответствуют сайтам, которые разрезаются протеазой (сайтам разрезания) на этапе ограниченного протеолиза, из которых пептиды, однако, не высвободились. Данные сайты также идентифицируют области нативного белка, которые могут содержать один или несколько подходящих эпитопов, с которыми могут связываться или на которые могут нацеливаться антитела (или другие специфичные связывающие средства). Таким образом, сайты, идентифицированные в части (iii) описанного выше способа, можно обозначить как сайты разрезания.
Таким образом, на данном этапе, как правило, нежелательно идентифицировать пептиды, которые были разрезаны на обоих концах одной протеазой, например, разрезаны на обоих концах одной из протеаз, используемых на этапе ограниченного протеолиза, или разрезаны на обоих концах одной из протеаз, используемых на этапе неограниченного протеолиза. Однако согласно некоторым вариантам реализации настоящего изобретения данный подход может быть подходящим для идентификации пептидов, полученных на этапе (ii), но не полученных на этапе (i), которые были разрезаны на обоих концах одной из протеаз, используемых на этапе ограниченного протеолиза. Такие пептиды могут соответствовать доступным для протеазы сайтам в нативном белке, которые, вероятно, соответствуют сайтам, которые разрезаются протеазой (сайтам разрезания) на двух концах на этапе ограниченного протеолиза (т.е. разрезаются на обоих концах первой протеазой, протеазой A, т.е. пептиды A---A), из которых пептиды, однако, не высвободились, поскольку они удерживаются на белке какими-либо другими способами, например, в результате молекулярных взаимодействий или сил, например, ионных связей. Данные пептиды (пептиды A---A) могут высвобождаться на этапе (ii) и могут также идентифицировать области нативного белка, которые могут содержать один или несколько подходящих эпитопов, с которыми могут связываться или на которые могут нацеливаться антитела (или другие специфичные связывающие средства). Согласно некоторым вариантам реализации настоящего изобретения способ также включает на этапе (iii) (или, в качестве альтернативы, включает на этапе (iii)) идентификацию пептидов, высвободившихся на этапе (ii), но не высвободившихся на этапе (i), которые были разрезаны на обоих концах одной из первых протеаз, используемых на этапе ограниченного протеолиза (этапе (i)).
После этапа (i) и этапа (ii) можно провести отдельный анализ или этап идентификации, и такой подход, как правило, является предпочтительным. Однако после этапа (ii) можно провести один этап анализа в отношении пептидов, которые высвободились из белка на этапах (i) и (ii). На практике этап ограниченного протеолиза (этап (i)) должен быть остановлен до (этапа (ii)) (например, когда начинается этап (ii) неограниченного протеолиза). Таким образом, перед добавлением протеаз для этапа (ii) (например, этапа неограниченного протеолиза), можно удалить протеазы, используемые для проведения ограниченного протеолиза (например, посредством промывки). Пример подходящего буфера для промывки описан в разделе примеров в настоящей заявке. Использование проточной ячейки с целью проведения этапов протеолиза согласно способам обеспечивает удобные средства для достижения данной цели.
Анализ или идентификацию пептидов (последовательностей пептидов), высвободившихся из указанного белка в результате расщепления протеазой на этапе (ii) (и необязательно пептидов, высвободившихся из белка в результате расщепления протеазой на этапе (i)) описанного выше способа (способа C), с целью идентификации, например, пептидов, в которых один конец был разрезан указанной первой протеазой (протеазой A), а другой конец был разрезан указанной второй протеазой (протеазой B), в данном случае пептидов A---B или B---A, можно осуществить любым соответствующим способом или методикой, например, методом масс-спектрометрии (например, ЖХ-МС/МС). Идентифицировав пептиды (последовательности пептидов), высвободившиеся (или расщепленные) из указанного белка, легко идентифицировать сайты на нативном белке, в которых одна или несколько протеаз разрезали указанный белок (сайты разрезания), поскольку данные о последовательности пептида или пептидов, которые высвободились от белка в результате протеолиза (например, идентифицированные методом масс-спектрометрии), являются источником информации о сайтах разрезания, например, на основании картирования последовательностей назад к последовательности нативного белка. В этой связи остатки на концах высвободившегося пептида или пептидов (отщепленных пептидов) являются источником информации о сайте разрезания в белке (например, в нативном или полноразмерном белке).
Согласно предпочтительному варианту реализации настоящего изобретения расщепленные пептиды собирают и анализируют с применением метода масс- спектрометрии, например, описанного в другом месте в настоящей заявке. Идентификацию спектра пептидов можно осуществить с помощью поисковой программы, такой как, без ограничения, MASCOT. В поисковой программе можно задать условия для идентификации пептидов на основании правил расщепления для всех используемых протеаз и/или без конкретных протеаз. В качестве уточняющего примера, правила расщепления, применяемые в MASCOT, могут определить поиск для пептидов с разрезом трипсином или разрезом пепсином, если такую комбинацию применяли экспериментально. Объединяя данные о последовательности из всех идентифицированных пептидов на этапе (i) и этапе (ii), можно отличить сайты разрезания, которые были расщеплены с использованием ограниченного протеолиза на нативном белке, однако пептиды не высвободились или пептид все еще оставался присоединенным (данные пептиды будут соответствовать пептидам с концами, соответствующими первой и второй протеазам, используемым в способе, например, пептидам A---B или B---A, или иногда пептидам A---A, как обсуждается выше), из сайтов разрезания, которые были расщеплены с использованием ограниченного протеолиза на нативном белке, но в которых пептид высвободился/отщепился от нативного белка под действием протеазы на этапе (i) способа (данные пептиды будут, как правило, соответствовать пептидам с обоими концами, соответствующими первой протеазе, используемой на этапе ограниченного протеолиза в способе, пептидам A---A, и будут обнаруживаемыми после этапа (i) способа).
Согласно некоторым вариантам реализации способов согласно настоящему изобретению на этапе (iii) анализируют исключительно пептиды, которые высвобождаются из указанного белка на этапе (ii) (или после данного этапа) (например, пептиды, которые высвобождаются на этапе (i) (или после данного этапа), не анализируют). Однако согласно некоторым вариантам реализации настоящего изобретения этап (iii) включает анализ пептидов, которые высвобождаются из белка на этапе (i) и этапе (ii).
В некоторых способах согласно настоящему изобретению анализируют исключительно пептиды, которые высвободились из белка на дополнительном этапе ограниченного протеолиза, который осуществляют с использованием указанной одной второй протеазы или комбинации вторых протеаз после этапа (i), но перед этапом (ii) (например, как описано в другом месте в настоящей заявке). В некоторых способах согласно настоящему изобретению анализируют пептиды, которые высвободились из белка на дополнительном этапе ограниченного протеолиза, который осуществляют с использованием указанной одной второй протеазы или комбинации вторых протеаз после этапа (i), но перед этапом (ii) (например, как описано в другом месте в настоящей заявке), и анализируют пептиды, которые высвободились из белка на этапе (i) и/или этапе (ii).
Этап (iv)
Этап (iv) способа включает этап исследования одного или нескольких эпитопов в области белка, содержащей или фланкирующей сайт разрезания указанной первой протеазы, как определено на этапе (iii), с помощью одного или нескольких антител, направленных на указанные эпитопы, посредством этого идентифицируя один или несколько эпитопов на белке, с которыми может связываться антитело. В качестве альтернативы, этап (iv) способа включает исследование одного или нескольких эпитопов в области белка, содержащей или фланкирующей сайт разрезания указанной первой протеазы, как определено на этапе (iii), с помощью одного или нескольких антител, и идентификацию того, связывается ли указанное одно или несколько антител с указанным одним или несколькими эпитопами или нет, посредством этого идентифицируя эпитоп, с которым может связываться антитело, на белке.
«Сайт разрезания» в соответствии с этапом (iv) описанного выше способа (способа C) описан выше применительно к этапу (iii). Согласно некоторым вариантам реализации настоящего изобретения «сайт разрезания» можно также рассматривать как сайт (или положение) в аминокислотной последовательности белка (например, в нативном белке, или полноразмерном белке, или белке дикого типа, или белке in situ, или неденатурированном белке), соответствующий сайту, разрезанному протеазой (сайту разрезания) на (этапе (i)), из которого, однако, на этапе (i) не высвободился пептид. В качестве альтернативы, согласно некоторым вариантам реализации настоящего изобретения «сайт разрезания» на этапе (iv) описанного выше способа (способа C) можно рассматривать как сайт (или положение) в аминокислотной последовательности белка (например, в нативном белке, или полноразмерном белке, или белке дикого типа), соответствующий концу пептида, идентифицированного на этапе (iii), который был разрезан первой протеазой.
Исследование одного или нескольких (например, совокупности) эпитопов, как описано в настоящей заявке, означает, что один или несколько эпитопов (или потенциальных эпитопов) на белке (например, нативном или полноразмерном белке) анализируют (или оценивают, или изучают) в отношении их способности быть связанными антителами, которые были получены против выделенных эпитопов (или связываются с выделенными эпитопами), соответствующих эпитопу (или потенциальному эпитопу) на белке. Согласно предпочтительному варианту реализации исследуют совокупность (или матрицу) эпитопов.
Согласно некоторым вариантам реализации настоящего изобретения способ может также включать (до этапа (iv)) этап образования (или синтеза) одного или нескольких (например, совокупности, например, 2 или более, 3 или более, 5 или более, 10 или более, 20 или более, 50 или более, например, до 3, до 4, до 5, до 10, до 20 или до 50) выделенных эпитопов, последовательности которых соответствуют одному или нескольким эпитопам (или последовательностям) на указанном белке, которые расположены в области белка, содержащей или фланкирующей сайт разрезания указанной первой протеазы, как определено на этапе (iii), и образование (получение) антител (например, поликлональных антител), которые направлены на указанные выделенные эпитопы (связываются с указанными выделенными эпитопами). Согласно предпочтительному варианту реализации настоящего изобретения получают совокупность (или матрицу) эпитопов и получают совокупность (или матрицу) антител. Такие антитела затем можно использовать на этапе (iv) описанного выше способа для исследования одного или нескольких эпитопов на указанном белке (например, в нативном или полноразмерном белке). Можно использовать любой соответствующий способ или методику образования выделенных эпитопов или образования антител (например, как описано в другом месте в настоящей заявке), и специалисту известны такие способы и методики.
Согласно некоторым вариантам реализации настоящего изобретения эпитопы характеризуются различными длинами и/или последовательностями. Таким образом, среди совокупности (или группы) эпитопов могут присутствовать эпитопы, которые отличаются друг от друга длинами и/или последовательностями. Согласно другим вариантам реализации настоящего изобретения эпитопы характеризуются одинаковыми (или подобными) длинами и обычно различными последовательностями. Таким образом, согласно некоторым вариантам реализации настоящего изобретения среди совокупности (или группы) эпитопов эпитопы характеризуются одинаковой (или подобной) длиной.
Эпитопы могут характеризоваться любой соответствующей длиной. Согласно некоторым вариантам реализации настоящего изобретения выделенные эпитопы составляют 7 – 8 аминокислот в длину или характеризуются длиной, как описано в другом месте в настоящей заявке.
Согласно предпочтительным вариантам реализации настоящего изобретения эпитопы содержат сайт разрезания (или перекрываются с сайтом разрезания, или окружают сайт разрезания). Согласно другим вариантам реализации настоящего изобретения эпитопы фланкируют сайт разрезания.
Как правило, эпитопы (или по меньшей мере часть любого данного эпитопа) будут находиться в пределах 50 аминокислот от сайта разрезания (сайта разрезания, который представляет собой сайт разрезания указанной первой протеазы, протеазы A, идентифицированный на этапе (iii), который, вероятно, является доступным для протеазы сайтом разрезания, в котором пептиды, однако, не высвобождаются), т.е. от +50 до -50 аминокислот относительно сайта разрезания. Предпочтительно, эпитопы (или по меньшей мере часть любого данного эпитопа) будут находиться в пределах 20 аминокислот от сайта разрезания (сайта разрезания, который представляет собой сайт разрезания указанной первой протеазы, как определено на этапе (iii)), т.е. от +20 до -20 аминокислот относительно сайта разрезания, или в пределах 10 аминокислот от сайта разрезания, т.е. от +10 до -10 аминокислот относительно сайта разрезания, или в пределах 5 аминокислот от сайта разрезания, т.е. от +5 до -5 аминокислот относительно сайта разрезания.
Согласно некоторым вариантам реализации настоящего изобретения «в области белка, содержащей или фланкирующей сайт разрезания», может означать «в пределах 50 аминокислот от сайта разрезания», т.е. от +50 до -50 аминокислот относительно сайта разрезания, предпочтительно, «в пределах 20 аминокислот от сайта разрезания», т.е. от +20 до -20 аминокислот относительно сайта разрезания, или «в пределах 10 аминокислот от сайта разрезания», т.е. от +10 до -10 аминокислот относительно сайта разрезания, или «в пределах 5 аминокислот от сайта разрезания», т.е. от +5 до -5 аминокислот относительно сайта разрезания.
Согласно некоторым вариантам реализации настоящего изобретения совокупность эпитопов (более одного эпитопа) представляет собой множество (или группу) эпитопов, причем последовательность каждого эпитопа во множестве смещена по сравнению с другим эпитопом во множестве на одну или несколько (например 1, 2 или 3), предпочтительно, одну, аминокислоту. Иными словами, согласно некоторым вариантам реализации настоящего изобретения во множестве (совокупности) эпитопов последовательность каждого эпитопа сдвинута на одну или несколько (например 1, 2 или 3), предпочтительно, одну, аминокислоту относительно последовательности другого эпитопа во множестве. Таким образом, совокупность эпитопов может представлять собой вложенное множество эпитопов, например, как проиллюстрировано на фигуре 15. Как правило, такое вложенное множество эпитопов будет охватывать до приблизительно 50 аминокислот последовательности белка в любом направлении (или в обоих направлениях) относительно (или в окружении) сайта разрезания (сайта разрезания указанной первой протеазы, как определено на этапе (iii), который, вероятно, является доступным для протеазы сайтом разрезания, в котором пептиды, однако, не высвобождаются).
Предпочтительно, такое вложенное множество эпитопов будет охватывать до приблизительно 20 аминокислот последовательности белка в любом направлении (или в обоих направлениях) относительно (или в окружении) сайта разрезания (сайта разрезания указанной первой протеазы, как определено на этапе (iii)). Согласно некоторым вариантам реализации настоящего изобретения такое вложенное множество эпитопов будет охватывать до приблизительно 6 аминокислот последовательности белка в любом направлении (или в обоих направлениях, предпочтительно, в обоих направлениях) относительно (или в окружении) сайта разрезания (сайта разрезания указанной первой протеазы, как определено на этапе (iii)).
Когда используют вложенное множество эпитопов, согласно предпочтительным вариантам реализации настоящего изобретения значительное число эпитопов будет содержать сайт разрезания, предпочтительно, по существу все из эпитопов во вложенном множестве будут содержать сайт разрезания, более предпочтительно, все эпитопы во вложенном множестве будут содержать сайт разрезания.
Как описано выше, исследование эпитопов на белке, которые содержат сайт разрезания или перекрываются с сайтом разрезания, или которые расположены в области, фланкирующей сайт разрезания, можно провести с помощью антител, направленных против указанных эпитопов (т.е. антитела выступают в качестве зондов). В действительности, исследование с помощью антител (например, Fab-фрагментов или других фрагментов антитела) является предпочтительным. Однако, в качестве альтернативы, другие связывающие молекулы можно использовать в качестве зондов (например, можно использовать другие аффинные зонды или связывающие средства). Антитела представляют собой один из примеров аффинного зонда, который можно использовать.
Согласно одному аспекту в настоящем изобретении предложен эпитоп (или антигенный эпитоп), например, выделенный эпитоп, идентифицированный способом идентификации эпитопа, с которым может связываться антитело, на белке, как описано выше (способа C). Иллюстративные и предпочтительные свойства эпитопов описаны в другом месте в настоящей заявке. Согласно одному аспекту в настоящем изобретении предложено антитело, которое связывается (специфично связывается) с таким эпитопом на белке.
Иллюстративные и предпочтительные свойства антител описаны в другом месте в настоящей заявке. Согласно некоторым вариантам реализации настоящего изобретения антитела, которые связываются в непосредственной близости от сайта разрезания, как описано в настоящей заявке, например, в пределах 5, 10, 20 или 50 аминокислот от сайта разрезания, являются предпочтительными. Специалисту в данной области техники известны способы или методики образования эпитопов (например, выделенных эпитопов) и антител против данных эпитопов, и можно использовать любой соответствующий способ (например, как описано в другом месте в настоящей заявке). Предпочтительные типы антител также описаны в другом месте в настоящей заявке. Способы согласно настоящему изобретению (например, способ C), таким образом, включают способы, включающие дополнительный этап, на котором получают или создают антитело против одного или нескольких идентифицированных эпитопов. Таким образом, также предложены способы создания антитела (антител) против белка. Такие способы создания (или получения, или производства) антитела могут также включать этап очистки антитела или белкового продукта и/или приготовления антитела или продукта в состав в композиции, содержащей по меньшей мере один дополнительный компонент, такой как фармацевтически приемлемый носитель или вспомогательное вещество.
Согласно одному аспекту в настоящем изобретении предложен конъюгат, который можно использовать для создания (или получения) антител. Конъюгат может содержать по меньшей мере один эпитоп, как определено в настоящей заявке, присоединенный к пептиду-носителю или смешанный с пептидом-носителем. Другие свойства конъюгатов описаны в другом месте в настоящей заявке.
Согласно одному аспекту в настоящем изобретении предложена композиция (например, фармацевтическая композиция), содержащая антитело или эпитоп согласно настоящему изобретению. Такие композиции, как правило, содержат один или несколько разбавителей, вспомогательных веществ и/или буферов.
Согласно одному аспекту в настоящем изобретении предложен антигенный эпитоп, содержащий аминокислотную последовательность (или состоящий из аминокислотной последовательности), выбранную из группы, состоящей из любой из SEQ ID NO: 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 30 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183 и 184 (или из группы, содержащей указанные последовательности), или последовательность, по существу гомологичную указанной последовательности. SEQ ID NO 82 – 184 представлены в таблицах 9 – 14 настоящей заявки. Последовательности, «по существу гомологичные указанной последовательности», описаны в другом месте в настоящей заявке.
Согласно некоторым вариантам реализации в настоящем изобретении предложен антигенный эпитоп, содержащий аминокислотную последовательность (или состоящий из аминокислотной последовательности), выбранную из группы, состоящей из любой из SEQ ID NO: 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183 и 184 (или из группы, содержащей указанные последовательности), или последовательность, по существу гомологичную указанной последовательности, причем указанная по существу гомологичная последовательность представляет собой последовательность, содержащую 1, 2 или 3 замены или делеции аминокислот по сравнению с данной аминокислотной последовательностью, или представляет собой последовательность, которая характеризуется идентичностью последовательности по меньшей мере 70% данной аминокислотной последовательности, или представляет собой последовательность, которая характеризуется по меньшей мере 6 последовательными аминокислотами данной аминокислотной последовательности.
Согласно одному аспекту в настоящем изобретении предложен антигенный эпитоп, содержащий аминокислотную последовательность (или состоящий из аминокислотной последовательности), выбранную из группы, состоящей из любой из SEQ ID NO: 82, 88, 90, 94, 95, 96, 98, 99, 102, 104, 107, 110, 114, 115, 121, 122, 126, 130, 132, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 163, 165, 167, 168, 169, 171, 173, 174, 175, 176, 178, 180, 181 и 182 (или из группы, содержащей указанные последовательности), или последовательность, по существу гомологичную указанной последовательности. Последовательности, «по существу гомологичные указанной последовательности», описаны в другом месте в настоящей заявке.
Согласно некоторым вариантам реализации в настоящем изобретении предложен антигенный эпитоп, содержащий аминокислотную последовательность (или состоящий из аминокислотной последовательности), выбранную из группы, состоящей из любой из SEQ ID NO: 82, 88, 90, 94, 95, 96, 98, 99, 102, 104, 107, 110, 114, 115, 121, 122, 126, 130, 132, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 163, 165, 167, 168, 169, 171, 173, 174, 175, 176, 178, 180, 181 и 182 (или из группы, содержащей указанные последовательности), или последовательность, по существу гомологичную указанной последовательности, причем указанная по существу гомологичная последовательность представляет собой последовательность, содержащую 1, 2 или 3 замены или делеции аминокислот по сравнению с данной аминокислотной последовательности, или представляет собой последовательность, которая характеризуется идентичностью последовательности по меньшей мере 70% данной аминокислотной последовательности, или представляет собой последовательность, которая характеризуется по меньшей мере 6 последовательными аминокислотами данной аминокислотной последовательности.
Согласно некоторым вариантам реализации в настоящем изобретении предложен антигенный эпитоп, содержащий аминокислотную последовательность (или состоящий из аминокислотной последовательности), выбранную из группы, состоящей из любой из SEQ ID NO: 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105 и 106 (или из группы, содержащей указанные последовательности), или последовательность, по существу гомологичную указанной последовательности.
Согласно некоторым вариантам реализации в настоящем изобретении предложен антигенный эпитоп, содержащий аминокислотную последовательность (или состоящий из аминокислотной последовательности), выбранную из группы, состоящей из любой из SEQ ID NO: 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136 (или из группы, содержащей указанные последовательности), или последовательность, по существу гомологичную указанной последовательности.
Согласно некоторым вариантам реализации в настоящем изобретении предложен антигенный эпитоп, содержащий аминокислотную последовательность (или состоящий из аминокислотной последовательности), выбранную из группы, состоящей из любой из SEQ ID NO: 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154 и 155 (или из группы, содержащей указанные последовательности), или последовательность, по существу гомологичную указанной последовательности.
Согласно некоторым вариантам реализации в настоящем изобретении предложен антигенный эпитоп, содержащий аминокислотную последовательность (или состоящий из аминокислотной последовательности), выбранную из группы, состоящей из любой из SEQ ID NO: 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183 и 184 (или из группы, содержащей указанные последовательности), или последовательность, по существу гомологичную указанной последовательности.
Согласно одному аспекту в настоящем изобретении предложено антитело, которое связывается (специфично связывается) с эпитопом на белке, причем указанный эпитоп содержит аминокислотную последовательность (или состоит из аминокислотной последовательности), выбранную из группы, состоящей из любой из SEQ ID NO: 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100, 101, 102, 103, 104, 105, 106, 107, 108, 109, 110, 111, 112, 113, 114, 115, 116, 117, 118, 119, 120, 121, 122, 123, 124, 125, 126, 127, 128, 129, 130, 131, 132, 133, 134, 135, 136, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 148, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 160, 161, 162, 163, 164, 165, 166, 167, 168, 169, 170, 171, 172, 173, 174, 175, 176, 177, 178, 179, 180, 181, 182, 183 и 184 (или из группы, содержащей указанные последовательности), или последовательность, по существу гомологичную указанной последовательности. Предпочтительные по существу гомологичные последовательности описаны в другом месте в настоящей заявке. Белки, в которых обнаружены такие последовательности (и, таким образом, с которыми могут связываться определенные антитела согласно настоящему изобретению), представлены в таблицах 9 – 12 настоящей заявки.
Согласно одному аспекту в настоящем изобретении предложено антитело, которое связывается (специфично связывается) с эпитопом на белке, причем указанный эпитоп содержит аминокислотную последовательность (или состоит из аминокислотной последовательности), выбранную из группы, состоящей из любой из SEQ ID NO: 82, 88, 90, 94, 95, 96, 98, 99, 102, 104, 107, 110, 114, 115, 121, 122, 126, 130, 132, 137, 138, 139, 140, 141, 142, 143, 144, 145, 146, 147, 149, 150, 151, 152, 153, 154, 155, 156, 157, 158, 159, 163, 165, 167, 168, 169, 171, 173, 174, 175, 176, 178, 180, 181 и 182 (или из группы, содержащей указанные последовательности), или последовательность, по существу гомологичную указанной последовательности. Предпочтительные по существу гомологичные последовательности описаны в другом месте в настоящей заявке. Белки, в которых обнаружены такие последовательности (и, таким образом, с которыми могут связываться определенные антитела согласно настоящему изобретению), представлены в таблицах 9– 12 настоящей заявки.
Согласно одному аспекту в настоящем изобретении предложено антитело, которое связывается с эпитопом на белке, содержащим или фланкирующим (предпочтительно, содержащим) сайт разрезания, который представляет собой сайт разрезания указанной первой протеазы, как определено на этапе (iii) (который, вероятно, является доступным для протеазы сайтом разрезания, в котором пептиды, однако, не высвобождаются).
Антитела (например, одно или несколько, или панель или матрицу антител, или большое число антител), нацеленные на эпитопы (предпочтительно, совокупность эпитопов) на белке можно исследовать в отношении их способности связываться с белком, например, для оценки их аффинности связывания или другого функционального эффекта (например, как описано в другом месте в настоящей заявке) в отношении белка. Таким образом, можно провести скрининг антител для идентификации антител, которые связываются наилучшим образом. Таким образом, можно идентифицировать в особенности подходящие эпитопы (например, для нацеливания на них антител), например, эпитопы, которые являются в особенности подходящими для нацеливания на них высокоаффинных антител, или нацеливание на которые приводит к значительному или измеряемому функциональному эффекту в отношении белка-мишени (например, антагонистическому или агонистическому эффекту). Соответственно, можно идентифицировать оптимальные эпитопы (например, для нацеливания на них антител, например, для вариантов терапевтического применения).
Таким образом, в качестве альтернативы, в настоящем изобретении предложен способ оптимизации дизайна эпитопа или выбора оптимального эпитопа (например, для антител, которые получают против данного эпитопа или которые нацелены на данный эпитоп). Способ может позволить определять оптимальную длину и положение эпитопа относительно сайта разрезания.
Антитела, которые связываются с эпитопами, идентифицированными способом С (или эпитопами, идентифицированными способом С), можно использовать в терапии.
Более конкретное описание для иллюстрации варианта реализации настоящего изобретения и преимуществ представлено ниже.
На этапе (i) с использованием протеазы A отщепленные пептиды (идентифицированные пептиды) будут представлять собой пептиды с сайтами расщепления протеазы A на обоих концах (пептиды, в которых оба конца были разрезаны протеазой A, пептиды A---A). Однако нельзя будет получить (идентифицировать) пептиды, в которых один конец был разрезан протеазой A, в которых пептид, однако, не высвободился (не был расщеплен) по какой- либо причине, например, поскольку отсутствовал другой сайт протеазы или протеаз, достаточно близкий к данному сайту (сайту разрезания), или поскольку пептид удерживался на белке какими-либо другими способами, например, в результате молекулярных взаимодействий или сил, например, ионных связей.
На этапе (ii) с использованием протеазы B отщепленные пептиды (идентифицированные пептиды) будут представлять собой пептиды с сайтами расщепления протеазы B на обоих концах (пептиды, в которых оба конца были разрезаны протеазой B, пептиды B---B), но также пептиды с сайтами расщепления протеазы B на одном конце и протеазы A на другом (пептиды, в которых один конец был разрезан первой протеазой, а второй конец был разрезан второй протеазой, пептиды B---A, пептиды A---B, или иногда также идентифицируют дополнительные пептиды A---A, описанные в другом месте в настоящей заявке). Изучение пептидов B-A (или A-B) (или иногда дополнительных пептидов A-A) позволяет идентифицировать (на этапе (iii)) сайты разрезания протеазы A, которые в противном случае не будут обнаружены на этапе (i), поскольку пептиды физически не были отщеплены (не высвободились) от белка.
Данные сайты разрезания протеазы A, идентифицированные на этапе (iii), представляют интерес, поскольку они обычно являются экспонированными на поверхности в нативном пептиде, так как они получены на этапе ограниченного протеолиза, как описано в другом месте в настоящей заявке, и они могут быть разработаны для нацеливания на экспонированные на поверхности пептиды и аминокислотные остатки (например, они представляют собой предпочтительный экспонированный на поверхности пептид, описанный в другом месте в настоящей заявке, предпочтительно, экспонированный на поверхности пептид высокого класса, например, таковой, который отщепляется первым или при наиболее низкой концентрации протеазы, или при наиболее неоптимальных или мягких протеолитических условиях, и будет отщеплен, за исключением случаев, когда другие факторы не позволяют проводить расщепление, например, когда другой сайт протеазы A не расположен достаточно близко). По этой причине сайты, которые расположены на поверхности нативного белка или являются по иной причине доступными, могут, таким образом, также представлять собой подходящую часть белка, на которой может основываться или на которую может быть нацелен дизайн эпитопа.
Важно отметить, что, поскольку согласно некоторым вариантам реализации настоящего изобретения этап протеазы B (этап (ii)) осуществляют при неограничивающих условиях, например, до завершения (или почти до завершения), это означает, что вследствие этого высвободятся все (или в значительной степени все, или большое число) пептидов B-A, A- B или дополнительных пептидов типа A-A, что обеспечит идентификацию всех (или в значительной степени всех, или большого числа) сайтов протеазы A, которые были разрезаны, но не высвободились, на этапе ограниченного протеолиза (i). Вследствие этого можно идентифицировать увеличенное число потенциально подходящих сайтов, например, экспонированных на поверхности сайтов, и, как следствие, – потенциально подходящих эпитопов по сравнению с ситуацией, когда был осуществлен только этап ограниченного протеолиза или когда этап (ii) осуществляли в условиях ограниченного протеолиза.
Вместе с тем способ, включающий два этапа ограниченного протеолиза, т.е. этап (i) и (ii) описанных выше способов (способа C), которые представляют собой этапы ограниченного или частичного протеолиза, например, как описано в другом месте в настоящей заявке, может быть подходящим для получения пептидов и идентификации эпитопов.
Предпочтительные свойства других способов, описанных в настоящей заявке, можно применять с соответствующими изменениями в отношении данного аспекта настоящего изобретения (способа C). Например, подходящие белки, на которых можно идентифицировать эпитопы с применением способа C, описаны в другом месте в настоящей заявке. Кроме того, подходящая и предпочтительная методология, например, использование масс-спектрометрии для анализа расщепленных пептидов и использование проточных ячеек, например, микрожидкостных ячеек или микрожидкостных платформ, и или протеолипосом для осуществления этапов протеолиза, описана в другом месте в настоящей заявке. Кроме того, этапы способа (способа C), как правило, проводят in vitro.
Способ C можно предпочтительно применять для идентификации доступных для протеазы/разрезаемых протеазой, но не высвобождающихся эпитопов на поверхности белков. В способе применяют расщепление протеазой in vitro с использованием нескольких (2 или более) протеаз последовательно на этапе ограниченного протеолиза (с использованием одной или нескольких протеаз) с последующим этапом неограниченного протеолиза или следующим этапом ограниченного протеолиза (с использованием одной или нескольких протеаз). В способе для расщепления можно использовать микрожидкостную платформу, описанную в другом месте в настоящей заявке. Для идентификации пептидов, высвобождаемых протеазами из белка-мишени, можно использовать масс-спектрометрию (МС), предпочтительно, ЖХ-МС/МС. Определенные экспериментальным путем сайты разрезания выясняют на основании пептидных карт, например, получаемых методом МС. Сайты разрезания, представляющие интерес, т.е. сайты разрезания протеазы, используемой на этапе ограниченного протеолиза, в которых пептиды, однако, не высвобождаются, можно исследовать с применением антител против последовательностей, охватывающих сайты разрезания (например, от -20 до +20 аминокислот, окружающих сайты разрезания).
Целью данного способа является идентификация сайтов связывания антитела (эпитопов) и/или установление структуры белка с применением новых процедур, в которых антитела используют для идентификации доступных для протеазы/разрезаемых протеазой, но не высвобождающихся эпитопов. Способ основан на расщеплении протеазой in vitro с последовательным использованием нескольких (2 или более) протеаз на этапе ограниченного протеолиза (с использованием одной или нескольких протеаз) с последующим этапом неограниченного протеолиза или следующим этапом ограниченного протеолиза (с использованием одной или нескольких протеаз). Можно использовать микрожидкостное расщепление несколькими протеазами с обнаружением методом МС- МС. Процедуры делают возможным обнаружение уникальных и новых сайтов связывания антитела (эпитопов) и могут позволить получить новые структурные данные для нативных, а также частично расщепленных белков.
Этапы протеолиза, как правило, проводят in vitro. Таким образом, проводят эксперименты по протеолизу in vitro. В случае мембраносвязанных белков протеолипосомы, содержащие нативный белок, можно расщепить в микрожидкостной проточной ячейке (LPI, Nanoxis Consulting AB). Технология проточной ячейки обеспечивает возможность проведения гибкой химии, такой как ограниченный и неограниченный протеолиз, на мембранных белках, содержащихся в неподвижной фазе (Jansson ET, Trkulja CL, Olofsson J, et al.
Microfluidic flow cell for sequential digestion of immobilized proteoliposomes. Anal Chem. 2012;84(13):5582-5588), которые можно подвергнуть воздействию нескольких раундов растворов и различным типам химических модуляций, например, с помощью ферментов. Таким образом, этапы ограниченного и неограниченного протеолиза можно осуществлять последовательно. Этап ограниченного протеолиза должен быть остановлен до начала неограниченного протеолиза или следующего этапа ограниченного протеолиза. Таким образом, протеазы, используемые для осуществления ограниченного протеолиза, можно удалить (например, посредством промывки) перед добавлением протеаз для этапа неограниченного протеолиза или следующего этапа ограниченного протеолиза. Клеточные мембраны можно вывернуть наизнанку, и как внутриклеточные, так и внеклеточные домены пронизывающих мембрану белков можно подробно исследовать напрямую. Растворимые белки можно подвергнуть ограниченному и неограниченному протеолизу с применением стандартных методик в растворе.
Можно использовать несколько протеаз с различными специфичностями в последовательных реакциях с целью охвата как можно большего числа последовательностей. Ограничивающие условия уже установлены, например, для ограничения протеолиза поверхностью белка можно использовать концентрации протеазы в диапазоне 2 – 5 мкг/мл и 5 минут расщепления. Высвободившиеся пептиды можно идентифицировать методом масс-спектрометрии (например, ЖХ-МС/МС), предпочтительно, с применением масс-спектрометра с высоким разрешением (например, Q Exactive, Thermo Fisher) и идентификации пептидов/белков в базе данных Mascot. Затем, получив пептидные карты, можно определить, какие сайты разрезания являлись физически доступными для протеаз. Затем можно провести этап неограниченного протеолиза, описанный в другом месте в настоящей заявке.
С целью точного определения сайтов, которые являются доступными для протеазы/разрезаемыми протеазой, однако не высвобождаются, после этапа неограниченного протеолиза можно проанализировать высвобожденные пептиды методом масс-спектрометрии для идентификации пептидов, в которых один конец был разрезан одной из протеаз, используемых на этапе ограниченного протеолиза, и другой конец был разрезан протеазой, используемой на этапе неограниченного протеолиза (это можно с легкостью осуществить посредством осмотра аминокислотной последовательности белка и концов высвобожденных пептидов и на основании правил специфичности используемых протеаз).
Последовательности пептидов, предпочтительно, составляющие 7 – 8 аминокислот в длину, содержащие данные сайты, можно синтезировать и применять для получения поликлональных антител (ПАТ). Причина выбора длины заключается в том, что последовательность-мишень необходимо минимизировать для минимизации поликлональности ПАТ, но данная последовательность не должна быть настолько короткой, чтобы стать слабо иммуногенной.
Сдвиги рамки на одну аминокислоту можно использовать для выбора линейных последовательностей данной длины в пределах установленного расстояния на каждой стороне сайта разрезания (например, 6 аминокислот). После этого данные последовательности можно использовать для создания матрицы нацеленных на последовательность ПАТ, скрининг которых можно затем провести в отношении связывания с нативным интактным белком с применением, например, метода ELISA.
В отношении данного аспекта настоящего изобретения (способа C) можно применять предпочтительные свойства других способов, описанных в настоящей заявке, с соответствующими изменениями.
Согласно одному аспекту в настоящем изобретении предложен способ идентификации экспонированного на поверхности сайта (или доступного на поверхности сайта, например, доступного для протеазы или антитела) на белке, причем указанный способ включает:
(i) осуществление ограниченного или частичного протеолиза указанного белка с использованием одной первой протеазы или комбинации первых протеаз;
(ii) осуществление неограниченного протеолиза или осуществление ограниченного или частичного протеолиза указанного белка с использованием одной второй протеазы или комбинации вторых протеаз, причем указанная вторая протеаза или протеазы все отличаются от протеазы или протеаз, используемых на этапе (i);
(iii) анализ пептидов, которые высвободились из указанного белка на этапе (ii), для идентификации пептидов, в которых один конец был разрезан указанной первой протеазой, а другой конец был разрезан указанной второй протеазой;
причем конец (например, остаток на конце) пептида, идентифицированного на этапе (iii), который был разрезан указанной первой протеазой, соответствует экспонированному на поверхности сайту в белке (нативном белке, или белке дикого типа, или полноразмерном белке), и посредством этого идентифицируют экспонированный на поверхности сайт на белке. В отношении данного аспекта настоящего изобретения можно применять предпочтительные свойства других способов, описанных в настоящей заявке, с соответствующими изменениями.
Другие свойства и преимущества настоящего изобретения станут очевидными на основании примеров, представленных ниже. Приведенные примеры иллюстрируют различные компоненты и методологии, пригодные при реализации настоящего изобретения на практике. Примеры не ограничивают заявленное изобретение. На основании представленного описания изобретения специалист может обнаружить и применять другие компоненты и методологию, пригодные для реализации настоящего изобретения на практике.
ПРИМЕРЫ
ПРИМЕР 1
В данном примере описан эффективный подход, с помощью которого авторы настоящего изобретения обнаружили и разработали поликлональное антитело OTV1, действующее на внутриклеточной стороне ионного канала TRPV1 человека, на основе предложенного изобретения, включая способы. Антитело является фармакологически активным и демонстрирует мощное ингибирующее действие в отношении белка при стимуляции агонистом капсайцином. Насколько известно авторам настоящего изобретения, впервые было обнаружено ингибиторное антитело, нацеленное на внутриклеточные домены TRPV1. Это подтверждает, что данная идея характеризуется высокой вероятностью использования, и что даже лучшие и оптимизированные антитела можно идентифицировать, если будет доступна исходная матрица эпитопов, полученных из гораздо более богатого набора данных от множества протеаз. Антитело было выбрано из множества совпадений при поиске после ограниченного протеолиза и биоинформационного анализа. Сначала было выбрано антитело, после чего было продемонстрировано убедительное доказательство его эффективности. Данный подход представляет собой значительное достижение и дополняет имеющиеся на сегодняшний день попытки идентификации антитела, ведь в данном подходе отсутствует необходимость в этапе скрининга, поскольку подход непосредственно приводит к идентификации уникальных эпитопов, которые могут стать мишенями фармакологически активного антитела.
Область-мишень эпитопа выбирали на основании ограниченного расщепления белка- мишени с использованием оптимизированных протоколов на микрожидкостной платформе LPI и дополнительно оптимизировали. Поликлональное антитело было создано посредством модификации пептидного эпитопа-мишени остатком цистеина и присоединения к последнему гемоцианина фисуреллы (KLH). Получение специфичного антитела проводили посредством иммунизации специфичных свободных от патогенной флоры (СПФ) кроликов после инъекции KLH с присоединенным специфичным пептидом.
Антитела очищали и подвергали анализу методом ELISA (enzyme-linked immunosorbent assay, твердофазного иммуноферментного анализа) согласно стандартным протоколам. Титр антитела против линейного эпитопа определяли методом ELISA, что привело к определению концентрации 0,25 мкг/мл. Эффективность антитела против нативного TRPV1 исследовали методом пэтч-кламп «наружная сторона внутри», в котором внутриклеточную сторону TRPV1 можно экспонировать в раствор антитела. Анализ методом «наружная сторона внутри» проводили с использованием микрожидкостного устройства для анализа методом пэтч-кламп (Dynaflow, Cellectricon AB, Гетеборг, Швеция).
Амплитуды тока измеряли посредством воздействия на фрагменты, содержащие несколько ионных каналов, капсайцином с антителом и без антитела. На контроли воздействовали 1 мкМ капсайцина в течение 30 с с последующим воздействием буфером в течение 70 с, а затем снова воздействовали 1 мкМ капсайцина в течение 30 с. На обработанные антителом фрагменты воздействовали 1 мкМ капсайцина в течение 30 с с последующим воздействием 0,14 мг/мл антитела в течение 70 с, а затем воздействовали 1 мкМ капсайцина вместе с 0,14 мг/мл антитела в течение 30 с. Для всех измерений активность антитела сравнивали с активностью после воздействия исключительно буфера с целью исключить любые эффекты десенсибилизации или потенцирования.
Рассчитывали проинтегрированные площади ток – время, и соотношение между проинтегрированными площадями для второго и первого тока рассчитывали и сравнивали между обработками. В случае клеток, обработанных антителом, наблюдалось уменьшение ответа тока на 50% по сравнению клетками, с обработанными исключительно буфером (фигура 3). Статистическую значимость рассчитывали с помощью t-критерия Стьюдента (p>0,05).
ПРИМЕР 2
Рынок терапевтических МАТ быстро растет и, согласно прогнозу, в 2020 году его объем составит приблизительно 125 миллиардов долларов США. Новые МАТ непрерывно получают регуляторное одобрение, и на сегодняшний день интенсивно обсуждаются МАТ на иммунной основе, такие как ингибиторы PD1, поскольку данные МАТ значительно улучшают исходы при определенных типах сложных метастатических вариантов рака. Однако обнаружение новых антител для терапевтических целей основано, главным образом, на скрининге и проводится вслепую. Основное внимание уделяют аффинности, а затем подмножество антител, демонстрирующих хорошие характеристики связывания, исследуют для определения биологических эффектов. Детали относительно взаимодействия связывания, антигенных детерминант и механизмов действия остаются неизвестными.
Авторы настоящего изобретения представляют способ, который позволяет выбирать эпитопы антигена на основании ограниченного протеолитического кинетического воздействия с использованием подхода на основе микрожидкостных технологий и масс- спектрометрии. Протеолитический этап проводят настолько медленно, что после воздействия протеазы в данный момент времени от антигена отрывается один или несколько пептидов. Пептиды, которые появляются первыми, являются легкодоступными для ПАТ (поликлональных антител) или МАТ, и вследствие этого являются предпочтительными по сравнению с пептидами, которые появляются позже и находятся в более труднодоступных областях белка. Затем данные пептиды классифицируют и перекрестно соотносят для определения функциональной значимости на основании последовательности с использованием специально подобранных биоинформационных данных. Пептиды высокого класса, быстро поступающие от белка-мишени, также обладающие функциональной значимостью, используют для разработки эпитопа, иммунизации и последующего создания антитела. Усеченные белки также можно использовать для фармакологического исследования. Данный способ основан на информации, полученной на основании последовательности, и представляет собой фармакологический, основанный на механизме действия подход для обнаружения антитела, который можно использовать как для внутриклеточных, так и для циркулирующих и внеклеточных мишеней. Авторы настоящего изобретения использовали данный способ для разработки двух антител: активирующего, нацеленного на кальмодулин-связывающую последовательность, и ингибиторного, нацеленного на сайт связывания капсайцина на N- конце внутриклеточной области ионного канала TRPV1 человека.
Двумя важными параметрами при разработке терапевтических антител являются аффинность связывания и биологическая эффективность. Антитела представляют собой большие белки молекулярной массой приблизительно 150 кДа и связываются в первую очередь с антигенными сайтами, расположенными на поверхности белка. Локализация аминокислот в непосредственной близости от поверхности структур нативного белка может направлять идентификацию и прогнозирование данных сайтов. Авторы настоящего изобретения использовали ограниченный протеолиз для анализа экспонирования на поверхности и гибкости белка. В данном способе активность протеазы ограничена контролем температуры, концентрации и/или времени расщепления. В таких условиях будут расщепляться исключительно гибкие области, которые могут локально разворачиваться и обеспечивать размещение протеазы, экспонированные на поверхности области и области с несколькими локальными взаимодействиями, такими как водородные связи и дисульфидные мостики. Авторы настоящего изобретения последовательно использовали несколько протеаз с целью увеличить до максимума поиск структурной информации. Области, которые легко расщепляются несколькими протеазами, должны располагаться в наиболее экспонированных, наиболее доступных областях белка и должны характеризоваться высокой пригодностью для последующей разработки антитела. Области, которые расщепляются исключительно одной протеазой, вероятно, расположены в скрытой области белка, и являются менее доступными. В таких случаях физико-химические свойства протеазы, способность достигать и расщеплять данные области может потенциально направлять разработку антитела. Авторы настоящего изобретения классифицировали отщепленные пептиды на основании простоты их отщепления в зависимости от того, какие параметры использовали для ограничения протеолиза. Данные параметры могут представлять собой временную точку, в которую были отщеплены пептиды, использованную концентрацию или температуру. Затем пептиды, полученные в результате расщепления каждой протеазой, соотносили друг с другом с целью обнаружения пептидов, происходящих из наиболее доступных областей белка.
В процессе общепринятой разработки антител биологическую эффективность, как правило, исследуют и подтверждают после положительного связывания между антителом и антигеном. Авторы настоящего изобретения считают, что ранний механистически управляемый подход будет полезным при разработке антитела благодаря фокусированию иммунизации на доступных сайтах в биологически активном сайте или в непосредственной близости от указанного сайта вместо создания антител, нацеленных на все возможные антигенные сайты. Данный подход минимизирует процедуры скрининга, а также риск необходимости оптимизации антител, которые обладают высокой аффинностью связывания с областями, отдаленными от биологически активного сайта. Целью авторов настоящего изобретения был поиск доступных эпитопов, которые также обладают функциональной важностью в отношении белка-мишени. Данного результата достигли посредством соотнесения классифицированных пептидов после ограниченного протеолиза с биоинформационными данными.
Авторы настоящего изобретения продемонстрировали свой механистически управляемый подход с использованием в качестве модельного белка ионного канала TRPV1 человека. TRPV1 представляет собой ионный канал, чувствительный к вредным стимулам, таким как низкий уровень pH, высокая температура (T>42°C), капсайцин и некоторые воспалительные медиаторы. Ионный канал TRPV1, главным образом, расположен в ноцицептивных нейронах периферической нервной системы и организован в тетрамерную конформацию. Каждый из четырех мономеров данного канала состоит из шести трансмембранных областей, N- и C-концы которых обращены к внутриклеточной стороне плазматической мембраны. Область поры состоит из 5ой и 6ой трансмембранных областей.
Внутриклеточная часть TRPV1 содержит множество регуляторных областей, важных для тепловой активации, сенсибилизации и десенсибилизации.
Создание эпитопа
Протеолипосомы, содержащие TRPV1, получали из клеток CHO и подвергали ограниченному протеолизу в проточной ячейке LPI с использованием трипсина и Asp-N по отдельности. Активность протеаз ограничивали до такой степени, что отщеплялось исключительно несколько пептидов, с применением комнатной температуры и низких концентраций. Затем отщепленные пептиды обнаруживали методом жидкостной хроматографии с тандемной масс-спектрометрией (ЖХ-МС/МС). Три пептида были обнаружены после протеолиза трипсином, и один пептид – после протеолиза Asp-N. Пептиды сравнивали с известными функциональными данными, и несколько пептидов соотносились с функционально важными областями, перечисленными в таблице 1. Для последующей разработки антитела были выбраны два пептида, aa96-117 и aa785-799, названные OTV1 и OTV2, соответственно. Визуализация эпитопов в структуре TRPV1 представлена на фигурах 4 и 5. Последовательность пептида OTV1 содержит arg115 (arg114 в случае rTRPV1), который, как было показано, является важным для активации капсайцином или протонами. Обе протеазы расщепляли области в непосредственной близости от данной аминокислоты, что подтверждало вероятность того, что в третичной структуре белка данная область является экспонированной. Последовательность пептида OTV2 содержит сайт связывания кальмодулина aa786- aa798 (aa785-aa797 в случае rTRPV1) и расщепляется исключительно трипсином. Сайты расщепления Asp-N, который отщепляет Asp и Cys с N-концевой стороны, в данной части TRPV1 отсутствовали.
Синтетические пептиды aa96-117 и aa785-799 связывали с гемоцианином фисуреллы (KLH), а затем использовали для получения поликлональных антител посредством иммунизации кроликов после инъекции пептидов, связанных с KLH. Полученные антитела демонстрируют тенденцию к агрегации в процессе замораживания и со временем в растворе. Вследствие этого свежеоттаянные антитела перед применением подвергали кратковременной обработке ультразвуком, и все эксперименты проводили в течение 30 минут после кратковременной обработки ультразвуком.
Таблица 1 – Пептиды, расщепляемые Asp-N и трипсином, и биологическая значимость данных пептидов
Y
Иммуноцитохимия
Исследование методом иммуноцитохимии проводили с целью визуализации распределения антитела в клетках CHO, экспрессирующих TRPV1 (фигура 6).
Неиндуцированные клетки выступали в качестве контроля неспецифичного связывания. Клетки фиксировали и окрашивали OTV1 или OTV2 с последующим окрашиванием вторичным антителом козы против иммуноглобулинов кролика Alexa 488. Четкое окрашивание плазматической мембраны, которое было видимым исключительно в индуцированных клетках, наблюдали как в случае OTV1, так и в случае OTV2.
Неспецифичное связывание вторичного антитела являлось незначительным (данные не показаны).
Электрофизиология
Функциональный эффект OTV1 на индуцированную капсайцином активность TRPV1, а также эффект OTV2 на кальмодулин/Ca2+-зависимую десенсибилизацию оценивали с использованием анализа методом пэтч-кламп «наружная сторона внутри». Фрагменты мембраны, содержащие несколько ионных каналов, вырезали из клеток CHO, делая возможным воздействие антитела на внутриклеточные области TRPV1. В случае OTV1 TRPV1 активировали капсайцином, затем обрабатывали OTV1, после чего следовала активация капсайцином в присутствии OTV1. Контроли активировали капсайцином, обрабатывали буфером и снова активировали капсайцином. Наблюдали уменьшение опосредованных капсайцином токов на 50% при сравнении обработки OTV1 с обработкой исключительно буфером (фигура 7). Исследовали способность OTV2 препятствовать кальмодулин/Ca2+-зависимой десенсибилизации. TRPV1 активировали капсайцином, затем обрабатывали кальмодулином, Ca2+ и OTV2, после чего следовала активация капсайцином в присутствии кальмодулина, Ca2+ и OTV2. Контроли активировали капсайцином, обрабатывали кальмодулином и Ca2+ и активировали капсайцином в присутствии кальмодулина и Ca2+. Кальмодулин десентизировал TRPV1 в присутствии кальция. Обработка OTV2 уменьшала данный эффект на 45% (фигура 7).
Анализ опосредованного TRPV1 поглощения YO-PRO
Эффективности антител в цельных клетках исследовали с использованием электропорации в качестве способа доставки с последующим измерением опосредованного TRPV1 поглощения YO-PRO методом лазерной сканирующей конфокальной микроскопии. Клетки подвергали электропорации с использованием системы трансфекции Neon (Life Technologies) в присутствии OTV1, OTV2 или буфера. На клетки, которые подвергали электропорации с использованием OTV1 или буфера, воздействовали капсайцином и YO-PRO в ФБР (фосфатном буферном растворе), содержащем хелатор кальция. Затем контролировали внутриклеточное увеличение флуоресценции в связи с опосредованным TRPV1 поглощением YO-PRO. Наблюдали уменьшение степени поглощения на 60% в случае клеток, обработанных OTV1, в течение первых 12 с активации, и наибольшая скорость поглощения в случае клеток, обработанных OTV1, наблюдалась через 20 с по сравнению с 8 с в случае контроля (фигура 8). Клетки, которые подвергали электропорации с использованием OTV2 или буфера, подвергали воздействию капсайцина и YO-PRO в ФБР, содержащем кальций, опираясь на десенсибилизацию посредством эндогенного кальмодулина, который запускался наносимым кальцием. В случае клеток, обработанных OTV2, наблюдали увеличение скорости поглощения на 80% через 15 с активации. Интернализацию антител в результате электропорации валидировали с использованием метода иммуноцитохимии (фигура 9).
Авторы настоящего изобретения разработали микрожидкостный способ создания антитела, который позволяет определять местонахождение экспонированных и доступных антигенных сайтов в функционально важных областях белка-мишени и/или в непосредственной близости от указанных областей. Доступные области исследуют с использованием частичного с кинетической точки зрения протеолиза в проточной ячейке LPI. Белок-мишень поддерживают в нативном состоянии, при этом сложность его окружения можно тщательно контролировать, например, посредством присутствия кофакторов. Данный подход позволяет получить лучшее понимание доступности антигенных сайтов по сравнению с анализами связывания с использованием очищенных белков. Способ хорошо подходит для трансмембранных мишеней, которые в противном случае сложно очистить и использовать в анализах связывания без добавления детергентов. При использовании данного подхода мишенями могут выступать как внутриклеточные, так и внеклеточные домены.
Информация о расположении антигенного сайта, а также его биологической функции имеет огромное значение для прогнозирования и оценки неспецифичного связывания и перекрестной реактивности с другими белками. Эпитопы, расположенные в очень консервативных областях, можно исключить из анализа потенциальных эпитопов- кандидатов с целью минимизации перекрестной реактивности.
Антитела, разработанные в настоящей заявке, являются поликлональными, несмотря на то, что не были получены в результате иммунизации целым белком. Предложенный способ совместим с общепринятыми протоколами получения моноклональных антител с использованием гибридом и последующими процедурами скрининга. Использование поликлональных антител в качестве первого этапа экспериментальной валидации биологической эффективности для нескольких многообещающих эпитопов-кандидатов с последующим получением моноклональных антител с использованием наилучшего эпитопа/эпитопов и процедуры скрининга для выявления высокой аффинности связывания объединяет лучшее от двух подходов.
Подтверждение интернализации антитела
Интернализацию антител посредством электропорации валидировали через 24 часа после электропорации методом иммуноцитохимии. Клетки подвергали электропорации в присутствии 0,14 мг/мл OTV1 или 0,27 мг/мл OTV2 в ФБР. Затем электропорированные клетки культивировали в течение 24 часов в чашках со стеклянным дном (Willco wells). Готовили два различных контроля. Один контроль не подвергали электропорации, но на всех остальных этапах обрабатывали эквивалентным способом и подвергали воздействию тех же растворов антитела; второй контроль не подвергали воздействию OTV1 и OTV2. Последний использовали, чтобы количественно подсчитать неспецифичное связывание вторичного антитела. Через 24 часа культивирования клетки тщательно промывали ФБР для удаления каких-либо остатков антител, которые в противном случае могли поступить в клетки в течение фиксации. Затем клетки фиксировали и пермебеализовали с использованием набора для фиксации и пермебеализации Image-iT® (Invitrogen). Фиксированные и пермебеализованные клетки инкубировали с вторичным антителом козы против иммуноглобулинов кролика Alexa 488 (Invitrogen) в течение 30 мин. при комнатной температуре. Клетки визуализировали после этапа финальной промывки, и сравнивали интенсивности флуоресценции в случае клеток, которые подвергали электропорации, клеток, которые не подвергали электропорации, и клеток, которые подвергали воздействию исключительно вторичных антител (фигура 9). Наблюдали очевидное различие в значениях интенсивности между клетками, которые подвергали электропорации, и клетками, которые не подвергали электропорации. Статистический анализ проводили с применением t-критерия Стьюдента, и p < 0,05 считали статистически значимым. В клетках, которые подвергали электропорации, были обнаружены низкие уровни первичных антител, которые, вероятно, представляют собой остаточные антитела, поступившие в течение фиксации и пермебеализации.
Авторы настоящего изобретения в настоящей заявке предложили способ создания высокоаффинных биологически активных антител с применением комбинации микрожидкостных технологий и ограниченного протеолиза. Способ валидировали с использованием ионного канала TRPV1 человека, и были разработаны два антитела. Оба антитела вызывали прогнозируемое изменение ответа TRPV1 на основании функциональной важности соответствующей области эпитопа указанных антител.
Материалы и методы
Химические реактивы
Среду для культивирования клеток (DMEM/среду Хэма F12 с глутамином), эмбриональную телячью сыворотку и аккутазу заказывали в компании PAA. Зеоцин, Na4BAPTA, K4BAPTA и вторичное антитело козы против иммуноглобулинов кролика Alexa 488 заказывали в компании Invitrogen. Модифицированный трипсин степени чистоты для секвенирования и Asp-N степени чистоты для секвенирования заказывали в компании Promega. Все другие химические реактивы заказывали в компании Sigma. Использовали следующие буферы: A:
300 мМ NaCl, 10 мМ Tris, pH 8,0, B: 20 мМ NH4HCO3, pH 8,0. C: 140 мМ NaCl, 5 мМ KCl, 1 мМ MgCl2 10 мМ HEPES, 10 мМ D-глюкоза, 10 мМ Na4BAPTA pH 7,4, D: 140 мМ NaCl, 2,7 мМ KCl, 10 мМ Na2HPO4, 10 мМ K4BAPTA pH 7,2, E: 140 мМ NaCl, 2,7 мМ KCl, 10 мМ Na2HPO4, pH 7,2. F: 140 мМ NaCl, 2,7 мМ KCl, 10 мМ Na2HPO4, pH 7,4. G: 120 мМ KCl, 2 мМ MgCl2, 10 мМ HEPES, 10 мМ K4BAPTA pH 8,0
Культура клеток
Адгерентные клетки яичников китайского хомячка (CHO) с регулируемой тетрациклином системой экспрессии (T-REx) культивировали в среде (DMEM/F12 с глутамином) с добавлением 10% эмбриональной телячьей сыворотки, зеоцина (350 мкг/мл) и бластицидина (5 мкг/мл) в культуральных колбах или культуральных чашках (Nunc) со стеклянными пластинами и без таковых. За 18 – 24 часа до применения клетки инкубировали в среде (DMEM/F12 с глутамином) с добавлением 10% эмбриональной телячьей сыворотки и доксициклина (1 мкг/мл) с целью индукции экспрессии TRPV1 человека. Линию клеток исследовали общепринятым способом для инфицирования микоплазмой.
Получение протеолипосом
Протеолипосомы получали, как описано ранее в публикации [1], в буфере A. Каждый препарат протеолипосом происходил из нескольких различных культуральных колб.
Протоколы расщепления
Однократные расщепления в проточной ячейке проводили, как описано в публикации [1]. 5 мкг/мл трипсина и 5 мкг/мл Asp-N растворяли в буферах G и B, соответственно. Расщепления в проточной ячейке каждой протеазой проводили при комнатной температуре в течение 5 мин. Последующие расщепления в элюатах ингибировали добавлением муравьиной кислоты до конечной концентрации 12%.
Жидкостная хроматография с тандемной масс-спектрометрией
Образцы пептида после расщепления протеолипосом CHO анализировали с помощью системы Proteomics Core Facility в Гетеборгском университете, Гетеборг, Швеция, как описано ранее [1]. Поиски во всех тандемных масс-спектрах проводили с помощью программного обеспечения MASCOT (Matrix Science, Лондон, Великобритания) по сравнению с базой знаний UniProtKB, выпуск 2013_04 (человек, [Homo sapiens]) в случае расщепления трипсином и выпуск 2015_06 (человек, [Homo sapiens]) в случае расщепления Asp-N. Программное обеспечение Thermo Proteome Discoverer v. 1.3 (Thermo Scientific) использовали для валидации идентификации пептида и белка на основе МС/МС. Уровень ложноположительных результатов, составляющий 0,01 на уровне пептида, использовали и определяли посредством поиска в обратной базе данных.
Разработка антитела
Синтезировали и очищали синтетические пептиды aa96-117 и aa785-799 на основании аминокислотной последовательности hTRPV1, включая дополнительный остаток цистеина на N-концевой стороне. Затем пептиды присоединяли посредством остатка цистеина к гемоцианину фисуреллы (KLH), после чего использовали для получения поликлональных антител посредством иммунизации специфичных свободных от патогенной флоры (СПФ) кроликов после инъекции пептидов, связанных с KLH. Антитела очищали и подвергали анализу методом ELISA. Получение как синтетических пептидов, так и поликлональных антител проводили с помощью компании Innovagen AB (Лунд, Швеция).
Антитела использовали свежеоттаянными и в течение 30 мин. после кратковременной обработки ультразвуком. Антитела обрабатывали ультразвуком при амплитуде 14% три раза, с интервалами с перерывом в 1 мин. с использованием ультразвукового гомогенизатора Vibra Cell VCX 600 от компании Sonics & Materials Inc. (Ньютаун, Коннектикут, США). Суммарное время обработки ультразвуком составило 40 с, причем время поступления импульса составляло 0,5 с, и время покоя составляло 0,5 с с целью уменьшения нагревания пробы.
Электрофизиология
Анализ методом «наружная сторона внутри» проводили с использованием микрожидкостного устройства для анализа методом пэтч-кламп (Dynaflow, Cellectricon AB, Гетеборг, Швеция) и амплификатора для пэтч-кламп HEKA EPC10 (Heka Elektronik, Германия). Омывающий раствор и раствор для пипетирования содержали буфер C.
Фрагменты фиксировали при +60 мВ, и сигналы тока регистрировали при частоте замеров 20 кГц и фильтрации низких частот при 5 кГц.
В случае OTV1 амплитуды тока измеряли посредством воздействия на фрагменты, содержащие несколько ионных каналов, капсайцином с антителом и без антитела. На контроли воздействовали 1 мкМ капсайцина в буфере D в течение 30 с с последующим воздействием буфером D в течение 70 с, а затем снова воздействовали 1 мкМ капсайцина в буфере D в течение 30 с. На фрагменты, обработанные OTV1, воздействовали 1 мкМ капсайцина в буфере D в течение 30 с с последующим воздействием 0,14 мг/мл антитела в буфере D в течение 70 с, а затем воздействовали 1 мкМ капсайцина вместе с 0,14 мг/мл антитела в буфере D в течение 30 с. В случае OTV2 амплитуды тока измеряли посредством воздействия на фрагменты капсайцина с антителом и без антитела и кальмодулина/Ca2+.
На контроли воздействовали 1 мкМ капсайцина в буфере E в течение 30 с с последующим воздействием 0,5 мкМ кальмодулина и 50 мкМ Ca2+ в буфере E в течение 70 с, а затем снова воздействовали 1 мкМ капсайцина в буфере E в течение 30 с. На фрагменты, обработанные антителом, воздействовали 1 мкМ капсайцина в буфере E в течение 30 с с последующим воздействием 0,14 мг/мл антитела, 0,5 мкМ кальмодулина и 50 мкМ Ca2+ в буфере E в течение 70 с, а затем воздействовали 1 мкМ капсайцина вместе с 0,14 мг/мл антитела, 0,5 мкМ кальмодулина и 50 мкМ Ca2+ в буфере E в течение 30 с. Измерения, которые после обработки в значительной степени смещались в сопротивление уплотнения, исключали из последующего анализа.
Анализ данных электрофизиологии
Для всех измерений активность после обработки антителом сравнивали с активностью после воздействия исключительно буфера с целью исключить любые эффекты десенсибилизации или потенцирования, обусловленные повторным активированием. В случае данных, содержащих кривые тока, проинтегрированные площади ток – время рассчитывали с использованием программного обеспечения Fitmaster (HEKA Elektronik, Германия) и Matlab (Mathworks, Массачусетс, США) для каждой активации капсайцином между нанесением и удалением OTV1 и между полной активацией (через 10 с) и удалением в случае OTV2. Соотношение между проинтегрированными площадями для второго и первого тока рассчитывали и сравнивали между обработками. В случае OTV2 данные наблюдений группировали на две категории (<15 мин. после кратковременной обработки ультразвуком и < 30 мин. после кратковременной обработки ультразвуком) в связи с зависимым от времени уменьшением эффекта.
Статистический анализ проводили с помощью однофакторного дисперсионного анализа в сочетании с апостериорным критерием Даннетта и t-критерием Стьюдента, где применимо. p < 0,05 считали статистически значимым. Данные представлены в виде среднего значения ±С.О.С.
Электропорация
Доставку антитела в цитозоль проводили с использованием системы трансфекции Neon (Life Technologies). Адгерентные клетки CHO отсоединяли с использованием аккутазы и промывали буфером F. 105 клеток осаждали центрифугированием и ресуспендировали в буфере F, 0,14 мг/мл OTV1 в буфере F или 0,27 мг/мл OTV2 в буфере F. 10 мкл суспензии клеток/антитела пипетировали с использованием микродозатора Neon и подвергали электропорации в системе станции для пипетирования. Использовали протокол, оптимизированный для доставки антител [5], в котором клетки подвергали воздействию 1550 В в течение 10 мс и в течение 3 импульсов. Клетки, которые подвергали электропорации, переносили на чашки со стеклянным дном (Willco wells).
Визуализация
Локализацию антитела посредством иммуноцитохимии и опосредованного TRPV1 поглощения YO-PRO измеряли с использованием измерения области, представляющий интерес (region of interest, ROI), на флуоресцентных микроснимках. Микроснимки получали с использованием системы Thorlabs CLS, оснащенной сканером Galvo:Resonant и высокочувствительными фотоэлектронными умножительными трубками на основе арсенида-фосфида галлия (gallium arsenide phosphide photomultiplier tubes, GaAsP PMT), и регистрировали в программном обеспечении ThorImageLS (Thorlabs Inc, Нью-Джерси, США). Устройство для сканирования устанавливали на микроскоп Leica DMIRB, оснащенный объективом с масляной иммерсией 63× NA 1,47 Leica HCX PL APO. Флуоресцентную детекцию проводили от одной клетки с возбуждением при 488 нм с использованием лазера Coherent Sapphire 488 LP (Coherent Inc., Калифорния, США), и эмиссию регистрировали при длине волны 500 – 550 нм. Данные ROI анализировали с использованием программного обеспечения Image J и Matlab (Mathworks, Массачусетс, США).
Иммуноцитохимия
Клетки культивировали на чашках со стеклянным дном (Willco wells), и за 18 – 24 часа до применения в некоторых чашках индуцировали экспрессию TRPV1. Чашки, содержащие как клетки, экспрессирующие TRPV1, так и неиндуцированные клетки, промывали буфером F, а затем фиксировали и пермебеализовали с использованием набора для фиксации и пермеабилизации Image-iT® (Invitrogen). Фиксированные и пермебеализованные клетки подвергали воздействию 25 мкг/мл антитела в буфере F в течение 30 мин. при температуре 37°C, затем промывали буфером F, после чего следовала инкубация с вторичным антителом козы против иммуноглобулинов кролика Alexa 488 в течение 30 мин. при комнатной температуре. Клетки визуализировали после этапа финальной промывки, и распределение антитела сравнивали в случае индуцированных и неиндуцированных клеток.
Опосредованное TRPV1 поглощение YO-PRO
Чашки со стеклянным дном, содержащие 10 мкл клеток, которые подвергали электропорации, устанавливали на микроскоп. Регистрацию начинали при скорости 0,5 Гц. В случае OTV1 на клетки после электропорации аккуратно пипетировали каплю объемом 20 мкл, содержащую капсайцин, YO-PRO и K4BAPTA в буфере F, с целью минимизации отсоединения, что приводило к получению конечной концентрации 1 мкМ капсайцина, 1 мкМ YO-PRO и 10 мМ K4BAPTA. В случае OTV2 на клетки после электропорации аналогичным способом пипетировали каплю объемом 20 мкл, содержащую капсайцин, YO- PRO и Ca2+ в буфере F, что приводило к получению конечной концентрации 1 мкМ капсайцина, 1 мкМ YO-PRO и 50 мкМ Ca2+.
Варианты реализации настоящего изобретения, описанные выше, следует понимать как несколько иллюстративных примеров настоящего изобретения. Специалисту в данной области техники очевидно, что в пределах объема настоящего изобретения в варианты реализации настоящего изобретения могут быть внесены различные модификации, комбинации и изменения. В частности, различные части растворов в различных вариантах реализации настоящего изобретения можно объединить в других конфигурациях, когда это технически возможно.
ПЕРЕЧЕНЬ ЛИТЕРАТУРНЫХ ИСТОЧНИКОВ:
1 Jansson, E. T.; et. al., Anal. Chem. 2012, 84: 5582-5588.
2 Международная заявка на патент № WO 2006/068619.
3 Европейская заявка на патент № EP 2174908.
4 Trkulja, C. L., et al., J. Am. Chem. Soc. 2014, 136: 14875–14882.
5 Freund, G. et al., MAbs, 2013, 5: 518–522.
ПРИМЕР 3
Идентификация пептида посредством ограниченного расщепления и масс- спектрометрии ионного канала TRPV1, экспрессированного в клетках CHO, с использованием нескольких протеаз
В данном примере описано параллельное применение нескольких протеаз для идентификации специфичных к протеазе наборов пептидов TRPV1. Протеазы, использованные в данном примере, представляли собой трипсин, Asp-N, пепсин, протеиназу K и химотрипсин. По сравнению друг с другом, специфичные к протеазе наборы пептидов могут являться перекрывающимися, комплементарными или уникальными.
Различные протеолитические активности обеспечивали посредством применения различных концентраций протеазы, а в нескольких примерах – посредством применения различных времен инкубации.
Материалы и методы
Культура клеток
Вкратце, клетки CHO культивировали согласно публикации Trkulja et al. (J. Am. Chem. Soc. 2014, 136, 14875−14882). Вкратце, адгерентные клетки яичников китайского хомячка (CHO) с регулируемой тетрациклином системой экспрессии (T-REx) культивировали в среде (DMEM/F12 с глутамином) с добавлением 10% ФБР, зеоцина (350 мкг/мл) и бластицидина (5 мкг/мл) в культуральных колбах T175 или T500 (Nunc) или на стеклянных чашках. Перед применением (за 18 – 24 ч) клетки инкубировали в среде (DMEM/F12 с глутамином) с добавлением 10% ФБР и доксициклина (1 мкг/мл) с целью индукции экспрессии TRPV1 человека. Линию клеток исследовали общепринятым способом для инфицирования микоплазмой. После сбора клетки замораживали и хранили при температуре -80 градусов. Затем клетки обрабатывали, как описано ниже.
Лизис и гомогенизция клеток
Суспензии клеток центрифугировали при 580g в течение 3 минут. Супернатант отбрасывали, и пробирки аккуратно наполняли 4 мл ледяного ФБР. Осадки клеток аккуратно ресуспендировали, а затем в пробирки наливали до 14 мл ледяного ФБР. Суспензии клеток снова центрифугировали при 580g в течение 3 минут, и процедуру повторяли дважды.
Осадки клеток (~800 мл по объему) ресуспендировали в приблизительно 6 мл лизирующего буфера (10 мМ NaHCO3, pH 7,4) и выдерживали на льду в течение 10 минут.
Клетки в лизирующем буфере переносили в гомогенизатор Даунса (7 мл), один для каждой суспензии клеток. Затем клетки подвергали гомогенизации с помощью жесткого пестика с использованием 20 движений. После гомогенизации лизированные клетки подвергали этапу центрифугирования при 580g в течение 3 минут. Супернатант собирали, осадок клеток отбрасывали. Супернатанты подвергали второму этапу центрифугирования при 580g в течение 3 минут, и осадок клеток (небольшой) отбрасывали.
Супернатанты объединяли и переносили в пробирку для центрифугирования Beckman (50 мл), добавляли лизирующий буфер до 20 мл. Супернатанты центрифугировали в течение 10 минут при 7300g для удаления митохондрий и дебриса клеток. Супернатант разделяли на две пробирки Falcon (по 10 мл каждая) и замораживали в морозильной камере при температуре -80 для последующей обработки.
Ультрацентрифугирование
Супернатанты оттаивали на льду и переносили в две чистые пробирки для ультрацентрифугирования Beckman (Beckman Coulter, артикул 344057). Пробирки заполняли ледяным буфером (10 мМ Tris, 300 мМ NaCl, pH 8) и тщательно уравновешивали перед центрифугированием при 100000g (32900 об./мин.) в течение 45 минут с использованием ротора SW55 Ti (Beckman Coulter). Супернатанты отбрасывали, осадки ресуспендировали в ледяном буфере (10 мМ Tris, 300 мМ NaCl, pH 8), а затем пробирки заливали тем же ледяным буфером. После тщательного уравновешивания и центрифугирования при 100000g (32900 об./мин.) в течение 45 минут супернатант отбрасывали, осадки ресуспендировали в ледяном буфере (10 мМ Tris, 300 мМ NaCl, pH 8), приблизительно по 800 мкл на осадок. Собирали препарат мембран с суммарным объемом приблизительно 1,6 мл и замораживали при температуре -80 градусов.
Кратковременная обработка ультразвуком
Замороженный препарат мембран оттаивали на льду и объединяли перед обработкой ультразвуком в ледяной конической виале с использованием ультразвукового аппарата (Vibracell). Препарат мембран сначала разводили до объема 4 мл ледяным буфером (10 мМ Tris, 300 мМ NaCl, pH 8) и подвергали 30 секундам обработки ультразвуком с использованием амплитуды 15% и цикла импульса/покоя 0,5 секунд. После этого коническую виалу и препарат мембран охлаждали на льду в течение нескольких минут, а затем препарат мембран подвергали воздействию другого цикла с использованием амплитуды 15% и импульса/покоя 0,5 секунд в течение 30 секунд, процедуру повторяли снова. Полученный в результате препарат мембран (протеолипосомы) замораживали в виде аликвот объемом 310 мкл при температуре -80 градусов.
Протеазы
Все протеазы заказывали в компании Promega. Все растворы готовили с использованием воды степени чистоты для ЖХ-МС от компании Fisher Scientific.
Кат. № V1621
Asp-N степени чистоты для секвенирования, 2 мкг.
Кат. № V1959
Пепсин, 250 мг.
Кат. № V3021
Протеиназа K, 100 мг.
Кат. № V1062
Химотрипсин степени чистоты для секвенирования, 25 мкг.
Кат. № V5111
Модифицированный трипсин степени чистоты для секвенирования, 20 мкг.
Трипсин
Трипсин растворяли в 100 мМ бикарбонате аммония, Ambic, pH 8.
Asp-N
Asp-N растворяли в 100 мМ бикарбонате аммония, Ambic, pH 8.
Пепсин
Пепсин растворяли в 100 мМ бикарбонате аммония, Ambic, pH 8.
Протеиназа K
Протеиназу K растворяли в 100 мМ бикарбонате аммония, Ambic, pH 8.
Химотрипсин
Химотрипсин растворяли в 100 мМ Tris-HCl, 10 мМ CaCl2, pH 8.
Использование LPI
Эксперименты проводили с использованием для расщепления датчиков LPI HexaLane.
Одну дорожку на каждом датчике использовали для одного расщепления. Вкратце, аликвоты протеолипосом оттаивали при комнатной температуре, вручную инжектировали на дорожки с применением пипетки объемом 100 мкл и иммобилизовали в течение 1 часа.
Промывку дорожек также проводили вручную с использованием пипетки объемом 100 мкл.
Каждую из ячеек промывали по 200 мкл буфера для промывки (такого же, что и буфер для расщепления, за исключением протокола расщепления пепсином, в котором в качестве буфера для промывки использовали 100 мМ Ambic, pH 8. Данный подход применяли во избежание низкого значения pH в проточной ячейке в течение длительного времени). Затем дорожки промывали по 4 x 100 мкл буфера для промывки с использованием пипетки объемом 100 мкл.
После этого в дорожку инжектировали протеазу и проводили инкубацию согласно инструкциям, приведенным ниже. После расщепления пептиды элюировали с дорожки с использованием 200 мкл буфера для расщепления (2 x 100 мкл). Активность протеазы останавливали посредством добавления 4 мкл муравьиной кислоты в результате окисления полученного раствора пептида до значения pH приблизительно 2. Данный этап проводили для всех образцов, за исключением пепсина, в который вместо этого добавляли 16 мкл раствора аммиака (25%), чтобы сделать раствор основным (pH 9).
Использовали следующие условия расщепления, по одному в каждой дорожке: Трипсин:
0,5 мкг/мл в течение 2,5 мин.
0,5 мкг/мл в течение 5 мин.
2 мкг/мл в течение 5 мин.
5 мкг/мл в течение 5 мин.
10 мкг/мл в течение 5 мин.
20 мкг/мл в течение 5 мин.
Asp-N
20 мкг/мл в течение 5 мин.
2 мкг/мл в течение 24 часов
Химотрипсин
5 мкг/мл в течение 5 мин.
10 мкг/мл в течение 5 мин.
20 мкг/мл в течение 5 мин.
Протеиназа K
5 мкг/мл в течение 5 мин.
10 мкг/мл в течение 5 мин.
20 мкг/мл в течение 5 мин.
Пепсин
2 мкг/мл в течение 5 мин.
5 мкг/мл в течение 5 мин.
10 мкг/мл в течение 5 мин.
20 мкг/мл в течение 5 мин.
Образцы метили и замораживали при температуре -80 °C.
Анализ методом МС
Триптические пептиды обессоливали на спин-колонках PepClean C18 (Thermo Fisher Scientific, Inc., Уолтем, Массачусетс, США) согласно руководствам производителя, высушивали и восстанавливали с помощью 15 микролитров 0,1% муравьиной кислоты (Sigma Aldrich, Сент-Луис, Миссури) в 3% ацетонитриле градиентной чистоты (Merck KGaA, Дармштадт, Германия). Инжекцию двух микролитров образца вносили с помощью автоматического дозатора Easy-nLC (Thermo Fisher Scientific, Inc., Уолтем, Массачусетс, США) и анализировали на гибридном масс-спектрометре Q Exactive, снабженном интерфейсом (Thermo Fisher Scientific). Пептиды удерживали на предколонке (внутр. диаметр 45 x 0,075 мм) и разделяли на колонке с обращенной фазой, 200 x 0,075 мм, самостоятельно упакованной частицами Reprosil-Pur C18-AQ размером 3 мкм (Dr. Maisch, Аммербух, Германия). Градиент nanoLC (жидкостная хроматография) анализировали при 200 нг/мин., начиная с 7% ацетонитрила (ACN) в 0,2% муравьиной кислоте, увеличивая до 27% ACN в течение 25 мин., затем увеличивая до 40% в течение 5 мин. и, наконец, до 80% ACN в течение 5 мин., и поддерживали при 80% ACN в течение 10 мин.
Ионы получали и распыляли в масс-спектрометр под напряжением 1,8 кВ и при температуре капилляра 320 градусов по Цельсию в информационно-зависимом режиме определения положительных ионов. Спектры полного сканирования (MS1) получали в орбитальной ионной ловушке Orbitrap в диапазоне m/z (масса/заряд) 400-1600, диапазоне заряда 2 – 6 при разрешении 70000 до целевого значения AGC (Automatic Gain Control, автоматический выбор числа уловленных ионов) 1e6 при максимуме 250 мс. Спектры МС/МС получали с использованием диссоциации, индуцируемой высокоэнергетическим соударением (higher energy collision dissociation, HCD), при 30% от m/z 110 для десяти наиболее распространенных родительских ионов при разрешении 35000 с использованием окна выделения предшественников 2 Да до целевого значения AGC 1e5 в течение времени инжекции 110 мс. Динамическое исключение в течение 30 с после выбора МС/МС было включено для обнаружения как можно большего количества возможных предшественников.
Краткое изложение результатов
На фигуре 10 представлено расположение пептидов, обнаруженных после ограниченного протеолиза трипсином, на 3D-модели TRPV1. Последовательности обнаруженных пептидов после ограниченного протеолиза трипсином показаны ниже в таблице 2. Пептиды, расщепленные 0,5 мкг/мл трипсина в течение 2,5 мин., показаны первыми. Пептиды, расщепленные 0,5 мкг/мл трипсина в течение 5 мин., 2 мкг/мл трипсина в течение 5 мин., 5 мкг/мл трипсина в течение 5 мин., 10 мкг/мл трипсина в течение 5 мин. и 20 мкг/мл трипсина в течение 5 мин., соответственно, были объединены с целью лучшей визуализации и показаны вторыми.
Таблица 2
На фигуре 11 представлено расположение пептидов, обнаруженных после ограниченного протеолиза Asp-N, на 3D-модели TRPV1. Последовательности обнаруженных пептидов после ограниченного протеолиза Asp-N показаны ниже в таблице 3. Пептиды, расщепленные 20 мкг/мл Asp-N в течение 5 мин., показаны первыми. Пептиды, расщепленные 2 мкг/мл Asp-N в течение 24 часов, показаны вторыми.
Таблица 3
На фигуре 12 представлено расположение пептидов, обнаруженных после ограниченного протеолиза химотрипсином, на 3D-модели TRPV1. Последовательности обнаруженных пептидов после ограниченного протеолиза химотрипсином показаны ниже в таблице 4. Пептиды, расщепленные 5 мкг/мл химотрипсина в течение 5 мин., показаны первыми. Пептиды, расщепленные 10 мкг/мл химотрипсина в течение 5 мин. и 20 мкг/мл химотрипсина в течение 5 мин., соответственно, были объединены с целью лучшей визуализации и показаны вторыми.
Таблица 4
20 мкг/мл химотрипсина в течение 5 мин. (**)
На фигуре 13 представлено расположение пептидов, обнаруженных после ограниченного протеолиза пепсином, на 3D-модели TRPV1. Последовательности обнаруженных пептидов после ограниченного протеолиза пепсином показаны ниже в таблице 5. Пептиды, расщепленные 2 мкг/мл пепсина в течение 5 мин., показаны первыми. Пептиды, расщепленные 5 мкг/мл пепсина в течение 5 мин., 10 мкг/мл пепсина в течение 5 мин. и 20 мкг/мл пепсина в течение 5 мин., соответственно, были объединены с целью лучшей визуализации и показаны вторыми.
Таблица 5
На фигуре 14 представлено расположение пептидов, обнаруженных после ограниченного протеолиза протеиназой K, на 3D-модели TRPV1. Последовательности обнаруженных пептидов после ограниченного протеолиза протеиназой K показаны ниже в таблице 6.
Пептиды, расщепленные 5 мкг/мл протеиназы K в течение 5 мин., показаны первыми. Пептиды, расщепленные 10 мкг/мл протеиназы K в течение 5 мин. и 20 мкг/мл протеиназы K в течение 5 мин., соответственно, были объединены с целью лучшей визуализации и показаны вторыми.
Таблица 6
мкг/мл протеиназы K в течение 5 мин. (**)
В таблицах 2, 3, 4, 5 и 6 термины «начало» и «конец» означают положения остатков
аминокислот в последовательности TRPV1.
В процессе оценки данных для Фильтров результатов (пептид) был установлен порог значимости Mascot, составляющий 0,01.
Трипсин позволял получить увеличенное количество пептидов и увеличенный доверительный интервал с увеличением концентрации протеазы.
Как пепсин, так и химотрипсин давали начало множеству пептидов и при низких, и при более высоких концентрациях.
ПРИМЕР 4
Данный пример относится к способу C.
Материалы и методы
Культура клеток, сбор клеток и получение протеолипосом
Эмбриональные клетки почек человека культивировали в пластиковых флаконах согласно стандартным способам культивирования при содержании CO2 5% и температуре 37°C в среде Хэма F12 (Invitrogen, кат. № 31765) с добавлением эмбриональной телячьей сыворотки (PAA, кат. № A15-649) и заменимых аминокислот (Invitrogen, кат. № 11140035).
Клетки исследовали общепринятым способом в отношении инфицирования микоплазмой. Клетки отсоединяли с применением аккутазы (PAA, кат. № L11-007), трижды промывали ФБР и осаждали центрифугированием. Осадки ресуспендировали в лизирующем буфере 1:1, который содержал маннитол (225 мМ), сахарозу (75 мМ), EGTA (0,1 мМ) и Tris-HCl (30 мМ), pH 7,4. После сбора клетки замораживали и хранили при температуре -80 градусов.
Осадки клеток оттаивали на льду и доводили объем с помощью лизирующего буфера. Суспензию клеток лизировали и гомогенизировали с использованием гомогенизатора Даунса с помощью жесткого пестика. Супернатанты очищали от митохондрий и дебриса клеток посредством двух повторяющихся процедур центрифугирования при 7000 g в течение 20 минут с использованием центрифуги Beckman Avanti J-301 с ротором JA-3050.
Внутриклеточные мембраны, включая плазматическую мембрану, осаждали из супернатанта центрифугированием в течение двух раундов ультрацентрифугирования при 100000 g с применением ультрацентрифуги Beckman Optima™ XE-90 с ротором SW 41 Ti. Ультрацентрифугирование проводили в течение 45 минут при температуре 4°C.
Супернатанты отбрасывали, и осадки ресуспендировали в ледяном ФБР и замораживали при температуре -20°C до последующего применения.
Препараты мембран оттаивали на льду и подвергали воздействию ультразвука в ледяной конической виале с применением ультразвукового аппарата (Vibracell) для получения протеолипосом. Полученный в результате препарат протеолипосом разводили в фосфатно-буферном солевом растворе (pH 7,4) и хранили при температуре -20°C до последующего применения.
Обработка образцов
Эксперименты проводили с применением проточных ячеек (Nanoxis Consulting AB, Гетенбург, Швеция). Вкратце, аликвоты образцов объемом 50 мкл оттаивали до комнатной температуры, вручную инжектировали в дорожки проточной ячейки и иммобилизовали в течение 1 часа. Каждую дорожку промывали 200 мкл буфера для промывки (100 мМ Ambic, pH 8) для удаления несвязавшегося материала, после чего вносили растворы протеазы или растворы для промывки согласно каждому конкретному протоколу. В случае ограниченных расщеплений расщепление образцов протеолипосом останавливали через 5 минут посредством элюирования раствора протеазы из проточной ячейки с применением 100 мкл 100 мМ бикарбоната аммония, pH 8. Немедленно добавляли трифторуксусную кислоту для снижения pH, а затем образец замораживали.
Протеазы получали в компании Promega (химотрипсин степени чистоты для секвенирования, 25 мкг, кат. № V1062; модифицированный трипсин степени чистоты для секвенирования, 20 мкг, кат. № V5111; протеиназа K, 100 мг, кат. № V3021). Рабочие растворы трипсина готовили в 100 мМ бикарбонате аммония, pH 8. Рабочие растворы протеиназы K и химотрипсина готовили в 100 мМ Tris-HCl + 10 мМ CaCl2, pH 8,0.
Для каждого протокола использовали 3 повтора каналов. Перед проведением анализа методом МС образцы пептидов объединяли.
Анализ методом МС
Анализировали пептиды, высвободившиеся в результате протеолиза на этапах 1 и 3 протоколов в таблице 7. Образцы, полученные после протеолиза на этапе 1, анализировали отдельно от образцов, полученных после протеолиза на этапе 3.
Пептиды обессоливали на спин-колонках PepClean C18 (Thermo Fisher Scientific, Inc., Уолтем, Массачусетс, США) согласно руководствам производителя, высушивали и восстанавливали с помощью 15 микролитров 0,1% муравьиной кислоты (Sigma Aldrich, Сент-Луис, Миссури) в 3% ацетонитриле градиентной чистоты (Merck KGaA, Дармштадт, Германия).
Инжекцию двух микролитров образца вносили с помощью автоматического дозатора Easy- nLC (Thermo Fisher Scientific, Inc., Уолтем, Массачусетс, США). Образцы анализировали на высокоточных приборах Orbitrap. Масс-спектрометры Orbitrap Fusion Tribrid, Q-Exactive или Orbitrap Elite (Thermo Fisher Scientific) связывали посредством интерфейса с системами для жидкостной хроматографии Easy nanoLC 1200. Пептиды разделяли с применением самостоятельно сконструированной аналитической колонки (внутренний диаметр 300 x 0,075 мм), упакованной частицами Reprosil-Pur C18-AQ размером 3 мкм (Dr. Maisch, Германия), с использованием градиента от 5 – 7% до 30 – 32% B через 35, 50 или 75 минут, после чего следовало и увеличение до 100% B в течение 5 мин. при потоке 300 нл/мин.
Растворитель A представлял собой 0,2% муравьиную кислоту в воде, растворитель B представлял собой 0,2% муравьиную кислоту в 80% ацетонитриле. Анализ методом МС/МС проводили в информационно-зависимом режиме, при котором для фрагментации отбирали наиболее интенсивные ионы-предшественники в зарядовых состояниях от 2 до
7. Динамическое исключение задавали как 30 с.
Каждый образец инжектировали 3 раза, и данные МС для 3 инжекций объединяли и обрабатывали как один образец.
Анализ данных проводили с применением программного обеспечения Proteome Discoverer, версия 1.4 (Thermo Fisher Scientific). В качестве поисковой системы использовали Mascot 2.3.2.0 (Matrix Science) с допуском по массе для предшественника 5 ч./млн. и допуском по массе для фрагмента 0,6 Да, и базу данных последовательностей получали из UniProt (раздел Swissprot, таксономическое деление = человек, версия 2017_03, приблизительно 20100 белковых последовательностей). Принимали пептиды с 1–3 пропущенными расщеплениями и варьирующими модификациями окисления метионина, алкилирования цистеина и ПНГазы F. Порог обнаруженного пептида в программном обеспечении задавали как 1% уровня ложноположительных результатов посредством проведения поиска в отношении обратной базы данных. Учитывали исключительно пептиды с высокой доверительностью идентификации. Критерии включения являлись следующими: включали пептиды с показателем, равным или превышающим 19, и доверительностью пептида 2 или 3 (где 3 является наилучшим случаем, а 1 – наихудшим). Данные критерии представляют собой значимость Mascot 0,01 или лучше – стандартный критерий, используемый для опубликованных протеомных данных. При данных настройках лишь 1% идентификаций пептидов, вероятно, будут ложными. Показатели пептидов присваивали посредством Mascot, и уровни достоверности присваивали посредством Proteome Discoverer.
Аннотации белков, включая ассоциации мембран, получали из универсального белкового ресурса (Universal Protein Resource, UniProt). UniProt представляет собой результат сотрудничества между Европейским институтом биоинформатики (European Bioinformatics Institute, EMBL-EBI), Швейцарским институт биоинформатики (SIB) и Информационным белковым ресурсом (Protein Information Resource, PIR).
Результаты
С применением мультипротеазных протоколов в примерах протеаза, которую использовали на первом этапе, расщепляла белки в различных положениях, которые определялись ее субстратной специфичностью. Иногда целые пептиды отрезались и были обнаружены методом масс-спектрометрии, и данные обнаруживаемые пептиды, как правило, составляют по меньшей мере 8 аминокислот и не более 30 – 40 аминокислот в длину в зависимости от природы метода анализа. В других случаях, в особенности, при использовании ограниченного расщепления, протеаза делает разрез, однако пептид не высвобождается. Другим путем рассмотрения данной ситуации является то, что протеаза создает разрывы. Например, химотрипсин будет создавать разрывы с C-концевой стороны от аминокислот F, W, L и Y. При ограниченном расщеплении разрывы на поверхности являются наиболее вероятными.
Разрезы, созданные на данном первом протеолитическом этапе, которые не были обнаружены на данном этапе, могут быть обнаружены на последующих этапах, когда на одном или нескольких последующих этапах применяют протеазу с субстратной специфичностью, отличной от таковой первой протеазы. Например, если на первом этапе применяют химотрипсин, а на втором этапе применяют трипсин, который разрезает с C- концевой стороны от аминокислот K и R, пептиды, обнаруженные на втором этапе, могут продемонстрировать, что химотрипсин не разрезал на одном конце (разрыв), а трипсин – на другом. На последующих этапах можно применять условия неограниченного расщепления, чтобы убедиться, что пептиды высвободились, но возможно применять несколько последовательных этапов ограниченного расщепления. Предпочтительно, протеаза на одном или нескольких последующих этапах обладает отличной специфичностью, чем таковая, применяемая на первом этапе, в результате чего станет очевидно, какие разрезы были образованы на первом этапе. Разрезы, или разрывы, созданные первой протеазой, являются доказательством экспонирования на поверхности, и вследствие этого их можно использовать для обнаружения эпитопа.
В следующих примерах представлены данные, полученные с применением протоколов таблицы 7, которые демонстрируют, как разрезы, полученные посредством ограниченного расщепления на первом этапе, обнаруживают посредством второго этапа расщепления. В таблице 8 приведена специфичность расщепления применяемых протеаз. В таблицах 9 –13 представлены белки и пептиды, идентифицированные с применением данных протоколов.
Таблица 7.
протокол 1
2 мкг/мл 5 мин.
мкг/мл 1 ч
остановка реакции, замораживание
протокол 2
мкг/мл 5 мин.
мкг/мл 5 мин.
остановка реакции, замораживание
протокол 3
2 мкг/мл 5 мин.
мкг/мл 1 ч
остановка реакции, замораживание
В мультипротеазных протоколах 1, 2 и 3 (см. таблицу 7) «этап 1» и «этап 3» осуществляли при комнатной температуре (20°C – 25°C).
В каждом из мультипротеазных протоколов 1, 2 и 3 «этап 1» представляет собой этап ограниченного или частичного протеолиза.
В каждом из мультипротеазных протоколов 1 и 3 «этап 3» представляет собой этап неограниченного протеолиза. В мультипротеазном протоколе 2 «этап 3» представляет собой этап ограниченного или частичного протеолиза.
Таблица 8.
В таблицах 9 – 12 в колонках «Учетн. №» и «Название белка» указаны учетный номер белка и название белка, соответственно, согласно номенклатуре в UniprotKB. В колонках
«Начало» и «Конец» приведены положения аминокислот в последовательности белка, N-концевые и C-концевые в пептиде. В колонке «Л_фланк.» указана левая (N-концевая) аминокислота, фланкирующая пептид в последовательности белка. В колонке «П_фланк.» указана последняя (C-концевая) аминокислота в последовательности пептида.
В таблице 9 представлено подмножество трансмембранных белков и их соответствующие пептиды, обнаруженные после этапа расщепления трипсином согласно мультипротеазному протоколу 1 (химотрипсин 2 мкг/мл 5 мин., затем трипсин 20 мкг/мл 1 ч). Образец содержал пептиды, разрезанные исключительно трипсином. Образец также содержал пептиды, которые были разрезаны на одном конце химотрипсином, а на другом – трипсином. В колонке под названием «МультиПротРазр», т.е. мультипротеазное разрезание (разрезание несколькими протеазами), данные пептиды отмечены звездочкой.
Примером является пептид SSPAGGVLGGGLGGGGGR из белка маннозил-олигосахарид 1,2-альфа-маннозидазы IA. Левая фланкирующая аминокислота представляет собой F, и последняя аминокислота в пептиде представляет собой R. Белок на первом этапе протеолиза был разрезан после F химотрипсином, а на втором этапе протеолиза – после R трипсином.
В зависимости от размера, изобилия и доступности сайтов разрезания каждого белка для каждого белка обнаруживают различное число пептидов. Перечисленные белки не были обнаружены на первом протеолитическом этапе (этапе 1).
В таблице 10 представлено подмножество нетрансмембранных белков для мультипротеазного протокола 1. Способ работает одинаково хорошо как для мембранных, так и для немембранных белков. Пептиды, которые разрезаются на одном конце химотрипсином, а на другом – трипсином, отмечены звездочкой в колонке под названием
«МультиПротРазр».
В таблице 11 представлено подмножество трансмембранных белков и их соответствующих пептидов, обнаруженных на этапе расщепления химотрипсином согласно мультипротеазному протоколу 2 (трипсин 5 мкг/мл 5 мин., затем химотрипсин 20 мкг/мл 5 мин.). Образец содержал пептиды, разрезанные исключительно химотрипсином. Образец также содержал пептиды, разрезанные на одном конце трипсином, а на другом – химотрипсином (отмечены звездочкой).
В таблице 12 представлено подмножество нетрансмембранных белков для мультипротеазного протокола 2. Образец также содержал пептиды, разрезанные на одном конце трипсином, а на другом – химотрипсином (отмечены звездочкой).
В двух приведенных выше примерах (протоколы 1 и 2) протеазы являлись одинаковыми, но порядок их использования был обратным; это демонстрирует, что способ работает вне зависимости от порядка протеаз.
Последовательности пептидов также идентифицировали с применением мультипротеазного протокола 3, включая последовательности пептидов, которые высвобождались в результате расщепления белка двумя различными протеазами, т.е. включая последовательности пептидов, в которых один конец был разрезан протеиназой K, а другой конец – трипсином.
В таблице 13 представлены аминокислоты, по которым в мультипротеазном протоколе 3 разрезает протеиназа K, и частота на аминокислоту на основании пептидов, разрезанных на одном конце трипсином, а на другом – протеиназой K. Приведенные сайты разрезания были получены из идентификаций пептидов с высокой достоверностью с показателями пептидов, равными или превышающими 19. Как видно, специфичность является достаточно широкой, и вследствие этого протеиназа K представляет собой тип протеазы, который можно предпочтительно использовать на одном из этапов ограниченного расщепления. Протеаза с широкой специфичностью является менее чувствительной к числу и положению доступных сайтов расщепления на поверхности белков.
Таблица 9. Мультипротеазный протокол 1 (химотрипсин 2 мкг/мл 5 мин., затем трипсин 20 мкг/мл 1 с). Трансмембранные белки.
азр
Таблица 10. Мультипротеазный протокол 1 (химотрипсин 2 мкг/мл 5 мин., затем трипсин 20 мкг/мл 1 ч. Нетрансмембранные белки.
.
.
Разр
POTE
RhoC
Таблица 11. Мультипротеазный протокол 2 (трипсин 5 мкг/мл 5 мин., затем химотрипсин 20 мкг/мл 5 мин.). Трансмембранные белки.
Таблица 12. Мультипротеазный протокол 2 (трипсин 5 мкг/мл 5 мин., затем химотрипсин 20 мкг/мл 5 мин.). Нетрансмембранные белки.
.
азр
N-подобный фермент
Таблица 13. Специфичность расщепления протеиназы K, мультипротеазный протокол 3.
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> Oblique Therapeutics AB
<120> Мультипротеазный способ
<130> 69.15.130484/01
<150> GB 1617002.9
<151> 2016-10-06
<160> 184
<170> PatentIn version 3.5
<210> 1
<211> 839
<212> PRT
<213> Homo sapiens
<400> 1
Met Lys Lys Trp Ser Ser Thr Asp Leu Gly Ala Ala Ala Asp Pro Leu
1 5 10 15
Gln Lys Asp Thr Cys Pro Asp Pro Leu Asp Gly Asp Pro Asn Ser Arg
20 25 30
Pro Pro Pro Ala Lys Pro Gln Leu Ser Thr Ala Lys Ser Arg Thr Arg
35 40 45
Leu Phe Gly Lys Gly Asp Ser Glu Glu Ala Phe Pro Val Asp Cys Pro
50 55 60
His Glu Glu Gly Glu Leu Asp Ser Cys Pro Thr Ile Thr Val Ser Pro
65 70 75 80
Val Ile Thr Ile Gln Arg Pro Gly Asp Gly Pro Thr Gly Ala Arg Leu
85 90 95
Leu Ser Gln Asp Ser Val Ala Ala Ser Thr Glu Lys Thr Leu Arg Leu
100 105 110
Tyr Asp Arg Arg Ser Ile Phe Glu Ala Val Ala Gln Asn Asn Cys Gln
115 120 125
Asp Leu Glu Ser Leu Leu Leu Phe Leu Gln Lys Ser Lys Lys His Leu
130 135 140
Thr Asp Asn Glu Phe Lys Asp Pro Glu Thr Gly Lys Thr Cys Leu Leu
145 150 155 160
Lys Ala Met Leu Asn Leu His Asp Gly Gln Asn Thr Thr Ile Pro Leu
165 170 175
Leu Leu Glu Ile Ala Arg Gln Thr Asp Ser Leu Lys Glu Leu Val Asn
180 185 190
Ala Ser Tyr Thr Asp Ser Tyr Tyr Lys Gly Gln Thr Ala Leu His Ile
195 200 205
Ala Ile Glu Arg Arg Asn Met Ala Leu Val Thr Leu Leu Val Glu Asn
210 215 220
Gly Ala Asp Val Gln Ala Ala Ala His Gly Asp Phe Phe Lys Lys Thr
225 230 235 240
Lys Gly Arg Pro Gly Phe Tyr Phe Gly Glu Leu Pro Leu Ser Leu Ala
245 250 255
Ala Cys Thr Asn Gln Leu Gly Ile Val Lys Phe Leu Leu Gln Asn Ser
260 265 270
Trp Gln Thr Ala Asp Ile Ser Ala Arg Asp Ser Val Gly Asn Thr Val
275 280 285
Leu His Ala Leu Val Glu Val Ala Asp Asn Thr Ala Asp Asn Thr Lys
290 295 300
Phe Val Thr Ser Met Tyr Asn Glu Ile Leu Met Leu Gly Ala Lys Leu
305 310 315 320
His Pro Thr Leu Lys Leu Glu Glu Leu Thr Asn Lys Lys Gly Met Thr
325 330 335
Pro Leu Ala Leu Ala Ala Gly Thr Gly Lys Ile Gly Val Leu Ala Tyr
340 345 350
Ile Leu Gln Arg Glu Ile Gln Glu Pro Glu Cys Arg His Leu Ser Arg
355 360 365
Lys Phe Thr Glu Trp Ala Tyr Gly Pro Val His Ser Ser Leu Tyr Asp
370 375 380
Leu Ser Cys Ile Asp Thr Cys Glu Lys Asn Ser Val Leu Glu Val Ile
385 390 395 400
Ala Tyr Ser Ser Ser Glu Thr Pro Asn Arg His Asp Met Leu Leu Val
405 410 415
Glu Pro Leu Asn Arg Leu Leu Gln Asp Lys Trp Asp Arg Phe Val Lys
420 425 430
Arg Ile Phe Tyr Phe Asn Phe Leu Val Tyr Cys Leu Tyr Met Ile Ile
435 440 445
Phe Thr Met Ala Ala Tyr Tyr Arg Pro Val Asp Gly Leu Pro Pro Phe
450 455 460
Lys Met Glu Lys Thr Gly Asp Tyr Phe Arg Val Thr Gly Glu Ile Leu
465 470 475 480
Ser Val Leu Gly Gly Val Tyr Phe Phe Phe Arg Gly Ile Gln Tyr Phe
485 490 495
Leu Gln Arg Arg Pro Ser Met Lys Thr Leu Phe Val Asp Ser Tyr Ser
500 505 510
Glu Met Leu Phe Phe Leu Gln Ser Leu Phe Met Leu Ala Thr Val Val
515 520 525
Leu Tyr Phe Ser His Leu Lys Glu Tyr Val Ala Ser Met Val Phe Ser
530 535 540
Leu Ala Leu Gly Trp Thr Asn Met Leu Tyr Tyr Thr Arg Gly Phe Gln
545 550 555 560
Gln Met Gly Ile Tyr Ala Val Met Ile Glu Lys Met Ile Leu Arg Asp
565 570 575
Leu Cys Arg Phe Met Phe Val Tyr Ile Val Phe Leu Phe Gly Phe Ser
580 585 590
Thr Ala Val Val Thr Leu Ile Glu Asp Gly Lys Asn Asp Ser Leu Pro
595 600 605
Ser Glu Ser Thr Ser His Arg Trp Arg Gly Pro Ala Cys Arg Pro Pro
610 615 620
Asp Ser Ser Tyr Asn Ser Leu Tyr Ser Thr Cys Leu Glu Leu Phe Lys
625 630 635 640
Phe Thr Ile Gly Met Gly Asp Leu Glu Phe Thr Glu Asn Tyr Asp Phe
645 650 655
Lys Ala Val Phe Ile Ile Leu Leu Leu Ala Tyr Val Ile Leu Thr Tyr
660 665 670
Ile Leu Leu Leu Asn Met Leu Ile Ala Leu Met Gly Glu Thr Val Asn
675 680 685
Lys Ile Ala Gln Glu Ser Lys Asn Ile Trp Lys Leu Gln Arg Ala Ile
690 695 700
Thr Ile Leu Asp Thr Glu Lys Ser Phe Leu Lys Cys Met Arg Lys Ala
705 710 715 720
Phe Arg Ser Gly Lys Leu Leu Gln Val Gly Tyr Thr Pro Asp Gly Lys
725 730 735
Asp Asp Tyr Arg Trp Cys Phe Arg Val Asp Glu Val Asn Trp Thr Thr
740 745 750
Trp Asn Thr Asn Val Gly Ile Ile Asn Glu Asp Pro Gly Asn Cys Glu
755 760 765
Gly Val Lys Arg Thr Leu Ser Phe Ser Leu Arg Ser Ser Arg Val Ser
770 775 780
Gly Arg His Trp Lys Asn Phe Ala Leu Val Pro Leu Leu Arg Glu Ala
785 790 795 800
Ser Ala Arg Asp Arg Gln Ser Ala Gln Pro Glu Glu Val Tyr Leu Arg
805 810 815
Gln Phe Ser Gly Ser Leu Lys Pro Glu Asp Ala Glu Val Phe Lys Ser
820 825 830
Pro Ala Ala Ser Gly Glu Lys
835
<210> 2
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 2
Leu Leu Ser Gln Asp Ser Val Ala Ala Ser Thr Glu Lys
1 5 10
<210> 3
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 3
Leu Leu Ser Gln Asp Ser Val Ala Ala Ser Thr Glu Lys Thr Leu Arg
1 5 10 15
<210> 4
<211> 23
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 4
Gln Phe Ser Gly Ser Leu Lys Pro Glu Asp Ala Glu Val Phe Lys Ser
1 5 10 15
Pro Ala Ala Ser Gly Glu Lys
20
<210> 5
<211> 22
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 5
Leu Leu Ser Gln Asp Ser Val Ala Ala Ser Thr Glu Lys Thr Leu Arg
1 5 10 15
Leu Tyr Asp Arg Arg Ser
20
<210> 6
<211> 15
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 6
Gly Arg His Trp Lys Asn Phe Ala Leu Val Pro Leu Leu Arg Glu
1 5 10 15
<210> 7
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 7
Leu Val Glu Asn Gly Ala Asp Val Gln Ala Ala Ala His Gly Asp Phe
1 5 10 15
<210> 8
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 8
Asp Gly Pro Thr Gly Ala Arg Leu Leu Ser Gln
1 5 10
<210> 9
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 9
Asp Ala Glu Val Phe Lys Ser Pro Ala Ala Ser Gly Glu Lys
1 5 10
<210> 10
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 10
Ser Gln Asp Ser Val Ala Ala Ser Thr Glu Lys Thr Leu
1 5 10
<210> 11
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 11
Ser Gly Ser Leu Lys Pro Glu Asp Ala Glu Val Phe
1 5 10
<210> 12
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 12
Val Ser Pro Val Ile Thr Ile Gln Arg Pro Gly Asp
1 5 10
<210> 13
<211> 17
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 13
Val Ser Pro Val Ile Thr Ile Gln Arg Pro Gly Asp Gly Pro Thr Gly
1 5 10 15
Ala
<210> 14
<211> 15
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 14
Leu Asn Leu His Asp Gly Gln Asn Thr Thr Ile Pro Leu Leu Leu
1 5 10 15
<210> 15
<211> 9
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 15
Tyr Thr Asp Ser Tyr Tyr Lys Gly Gln
1 5
<210> 16
<211> 9
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 16
Ser Leu Pro Ser Glu Ser Thr Ser His
1 5
<210> 17
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 17
Glu Asp Pro Gly Asn Cys Glu Gly Val Lys Arg
1 5 10
<210> 18
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 18
Asp Arg Gln Ser Ala Gln Pro Glu Glu Val Tyr Leu Arg
1 5 10
<210> 19
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 19
Gln Ser Ala Gln Pro Glu Glu Val Tyr Leu Arg
1 5 10
<210> 20
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 20
Phe Ala Pro Gln Ile Arg Val Asn Leu Asn Tyr Arg Lys Gly Thr Gly
1 5 10 15
<210> 21
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 21
Ala Ser Gln Pro Asp Pro Asn Arg Phe Asp Arg Asp Arg
1 5 10
<210> 22
<211> 15
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 22
Leu Asn Leu Lys Asp Gly Val Asn Ala Cys Ile Leu Pro Leu Leu
1 5 10 15
<210> 23
<211> 9
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 23
Cys Thr Asp Asp Tyr Tyr Arg Gly His
1 5
<210> 24
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 24
Leu Val Glu Asn Gly Ala Asn Val His Ala Arg Ala Cys Gly Arg Phe
1 5 10 15
<210> 25
<211> 10
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 25
Glu Asp Pro Ser Gly Ala Gly Val Pro Arg
1 5 10
<210> 26
<211> 15
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 26
Gly Ala Ser Glu Glu Asn Tyr Val Pro Val Gln Leu Leu Gln Ser
1 5 10 15
<210> 27
<211> 15
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 27
Trp Ser Ser Thr Asp Leu Gly Ala Ala Ala Asp Pro Leu Gln Lys
1 5 10 15
<210> 28
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 28
Leu Leu Ser Gln Asp Ser Val Ala Ala Ser Thr Glu Lys
1 5 10
<210> 29
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 29
Leu Leu Ser Gln Asp Ser Val Ala Ala Ser Thr Glu Lys Thr Leu Arg
1 5 10 15
<210> 30
<211> 21
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 30
Ala Met Leu Asn Leu His Asp Gly Gln Asn Thr Thr Ile Pro Leu Leu
1 5 10 15
Leu Glu Ile Ala Arg
20
<210> 31
<211> 19
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 31
Gln Thr Asp Ser Leu Lys Glu Leu Val Asn Ala Ser Tyr Thr Asp Ser
1 5 10 15
Tyr Tyr Lys
<210> 32
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 32
Gly Gln Thr Ala Leu His Ile Ala Ile Glu Arg
1 5 10
<210> 33
<211> 26
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 33
Asn Met Ala Leu Val Thr Leu Leu Val Glu Asn Gly Ala Asp Val Gln
1 5 10 15
Ala Ala Ala His Gly Asp Phe Phe Lys Lys
20 25
<210> 34
<211> 15
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 34
Phe Leu Leu Gln Asn Ser Trp Gln Thr Ala Asp Ile Ser Ala Arg
1 5 10 15
<210> 35
<211> 23
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 35
Asp Ser Val Gly Asn Thr Val Leu His Ala Leu Val Glu Val Ala Asp
1 5 10 15
Asn Thr Ala Asp Asn Thr Lys
20
<210> 36
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 36
Leu His Pro Thr Leu Lys Leu Glu Glu Leu Thr Asn Lys
1 5 10
<210> 37
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 37
Lys Gly Met Thr Pro Leu Ala Leu Ala Ala Gly Thr Gly Lys
1 5 10
<210> 38
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 38
Gly Met Thr Pro Leu Ala Leu Ala Ala Gly Thr Gly Lys
1 5 10
<210> 39
<211> 10
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 39
Ile Gly Val Leu Ala Tyr Ile Leu Gln Arg
1 5 10
<210> 40
<211> 9
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 40
Ala Ile Thr Ile Leu Asp Thr Glu Lys
1 5
<210> 41
<211> 7
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 41
Thr Leu Ser Phe Ser Leu Arg
1 5
<210> 42
<211> 9
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 42
Asn Phe Ala Leu Val Pro Leu Leu Arg
1 5
<210> 43
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 43
Glu Ala Ser Ala Arg Asp Arg Gln Ser Ala Gln Pro Glu Glu Val Tyr
1 5 10 15
Leu Arg
<210> 44
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 44
Asp Arg Gln Ser Ala Gln Pro Glu Glu Val Tyr Leu Arg
1 5 10
<210> 45
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 45
Gln Ser Ala Gln Pro Glu Glu Val Tyr Leu Arg
1 5 10
<210> 46
<211> 15
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 46
Gln Phe Ser Gly Ser Leu Lys Pro Glu Asp Ala Glu Val Phe Lys
1 5 10 15
<210> 47
<211> 23
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 47
Gln Phe Ser Gly Ser Leu Lys Pro Glu Asp Ala Glu Val Phe Lys Ser
1 5 10 15
Pro Ala Ala Ser Gly Glu Lys
20
<210> 48
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 48
Asp Gly Pro Thr Gly Ala Arg Leu Leu Ser Gln
1 5 10
<210> 49
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 49
Asp Ser Val Ala Ala Ser Thr Glu Lys Thr Leu Arg Leu Tyr
1 5 10
<210> 50
<211> 17
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 50
Asp Gly Gln Asn Thr Thr Ile Pro Leu Leu Leu Glu Ile Ala Arg Gln
1 5 10 15
Thr
<210> 51
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 51
Asp Ser Leu Lys Glu Leu Val Asn Ala Ser Tyr Thr
1 5 10
<210> 52
<211> 15
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 52
Asp Ser Val Gly Asn Thr Val Leu His Ala Leu Val Glu Val Ala
1 5 10 15
<210> 53
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 53
Asp Ala Glu Val Phe Lys Ser Pro Ala Ala Ser Gly Glu Lys
1 5 10
<210> 54
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 54
Leu Ser Gln Asp Ser Val Ala Ala Ser Thr Glu Lys Thr Leu
1 5 10
<210> 55
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 55
Ser Gln Asp Ser Val Ala Ala Ser Thr Glu Lys Thr Leu
1 5 10
<210> 56
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 56
Ser Gln Asp Ser Val Ala Ala Ser Thr Glu Lys Thr Leu Arg Leu Tyr
1 5 10 15
<210> 57
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 57
Asn Leu His Asp Gly Gln Asn Thr Thr Ile Pro Leu
1 5 10
<210> 58
<211> 17
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 58
Leu Val Glu Asn Gly Ala Asp Val Gln Ala Ala Ala His Gly Asp Phe
1 5 10 15
Phe
<210> 59
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 59
Gln Thr Ala Asp Ile Ser Ala Arg Asp Ser Val Gly Asn Thr Val Leu
1 5 10 15
<210> 60
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 60
His Ala Leu Val Glu Val Ala Asp Asn Thr Ala Asp Asn Thr Lys Phe
1 5 10 15
<210> 61
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 61
Ala Ala Gly Thr Gly Lys Ile Gly Val Leu Ala Tyr
1 5 10
<210> 62
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 62
Ser Gly Ser Leu Lys Pro Glu Asp Ala Glu Val Phe
1 5 10
<210> 63
<211> 10
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 63
Phe Gly Lys Gly Asp Ser Glu Glu Ala Phe
1 5 10
<210> 64
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 64
His Asp Gly Gln Asn Thr Thr Ile Pro Leu Leu
1 5 10
<210> 65
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 65
Leu Val Glu Asn Gly Ala Asp Val Gln Ala Ala Ala His Gly Asp Phe
1 5 10 15
<210> 66
<211> 15
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 66
Val Glu Asn Gly Ala Asp Val Gln Ala Ala Ala His Gly Asp Phe
1 5 10 15
<210> 67
<211> 15
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 67
Val Glu Asn Gly Ala Asp Val Gln Ala Ala Ala His Gly Asp Phe
1 5 10 15
<210> 68
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 68
His Ala Leu Val Glu Val Ala Asp Asn Thr Ala Asp Asn Thr Lys Phe
1 5 10 15
<210> 69
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 69
Val Glu Val Ala Asp Asn Thr Ala Asp Asn Thr Lys Phe
1 5 10
<210> 70
<211> 17
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 70
Glu Val Ile Ala Tyr Ser Ser Ser Glu Thr Pro Asn Arg His Asp Met
1 5 10 15
Leu
<210> 71
<211> 17
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 71
Val Ser Pro Val Ile Thr Ile Gln Arg Pro Gly Asp Gly Pro Thr Gly
1 5 10 15
Ala
<210> 72
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 72
Ile Gln Arg Pro Gly Asp Gly Pro Thr Gly Ala Arg
1 5 10
<210> 73
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 73
Arg Pro Gly Asp Gly Pro Thr Gly Ala Arg Leu Leu
1 5 10
<210> 74
<211> 15
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 74
Leu Asn Leu His Asp Gly Gln Asn Thr Thr Ile Pro Leu Leu Leu
1 5 10 15
<210> 75
<211> 8
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 75
Asp Thr Glu Lys Ser Phe Leu Lys
1 5
<210> 76
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 76
Glu Asp Pro Gly Asn Cys Glu Gly Val Lys Arg
1 5 10
<210> 77
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 77
Glu Asp Pro Gly Asn Cys Glu Gly Val Lys Arg Thr
1 5 10
<210> 78
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 78
Glu Asp Pro Gly Asn Cys Glu Gly Val Lys Arg Thr Leu
1 5 10
<210> 79
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 79
Ser Ala Arg Asp Arg Gln Ser Ala Gln Pro Glu Glu Val Tyr Leu Arg
1 5 10 15
<210> 80
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 80
Asp Arg Gln Ser Ala Gln Pro Glu Glu Val Tyr Leu Arg
1 5 10
<210> 81
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 81
Gln Ser Ala Gln Pro Glu Glu Val Tyr Leu Arg
1 5 10
<210> 82
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 82
Ser Ser Pro Ala Gly Gly Val Leu Gly Gly Gly Leu Gly Gly Gly Gly
1 5 10 15
Gly Arg
<210> 83
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 83
Phe Asp Gly Gly Val Glu Ala Ile Ala Thr Arg
1 5 10
<210> 84
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 84
Glu Lys Asp Ile Leu Thr Ala Ile Ala Ala Asp Leu Cys Lys
1 5 10
<210> 85
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 85
Phe Asp His Ile Phe Tyr Thr Gly Asn Thr Ala Val Gly Lys
1 5 10
<210> 86
<211> 9
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 86
Ile Leu Ser Leu Leu Glu Gly Gln Lys
1 5
<210> 87
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 87
Ile Ala Phe Gly Gly Glu Thr Asp Glu Ala Thr Arg
1 5 10
<210> 88
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 88
Ile Ala Phe Gly Gly Glu Thr Asp Glu Ala Thr Arg Tyr
1 5 10
<210> 89
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 89
Tyr Ile Ala Pro Thr Val Leu Thr Asp Val Asp Pro Lys
1 5 10
<210> 90
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 90
Ile Ala Pro Thr Val Leu Thr Asp Val Asp Pro Lys
1 5 10
<210> 91
<211> 17
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 91
Val Met Gln Glu Glu Ile Phe Gly Pro Ile Leu Pro Ile Val Pro Val
1 5 10 15
Lys
<210> 92
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 92
Asn Val Asp Glu Ala Ile Asn Phe Ile Asn Glu Arg
1 5 10
<210> 93
<211> 20
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 93
Gln Phe Tyr Asp Gln Ala Leu Gln Gln Ala Val Val Asp Asp Asp Ala
1 5 10 15
Asn Asn Ala Lys
20
<210> 94
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 94
Thr Phe His Glu Thr Leu Asp Cys Cys Gly Ser Ser Thr Leu
1 5 10
<210> 95
<211> 7
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 95
Ile Val Leu Ser Tyr Val Arg
1 5
<210> 96
<211> 24
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 96
Gly Ile Ser Gly Glu Lys Asp Val Ser Pro Asp Leu Ser Cys Ala Asp
1 5 10 15
Glu Ile Ser Glu Cys Tyr His Lys
20
<210> 97
<211> 8
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 97
Glu Thr Leu Leu Glu Ile Gln Lys
1 5
<210> 98
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 98
Gly Gln Met Gly Pro Thr Glu Gln Gly Pro Tyr
1 5 10
<210> 99
<211> 8
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 99
Leu Cys Leu Leu Pro Leu Val Arg
1 5
<210> 100
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 100
Ala Trp Asp Asp Phe Phe Pro Gly Ser Asp Arg
1 5 10
<210> 101
<211> 19
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 101
Thr Pro Met Gly Ile Val Leu Asp Ala Leu Glu Gln Gln Glu Glu Gly
1 5 10 15
Ile Asn Arg
<210> 102
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 102
Asp Ala Leu Glu Gln Gln Glu Glu Gly Ile Asn Arg
1 5 10
<210> 103
<211> 7
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 103
Leu Thr Asp Tyr Ile Ser Lys
1 5
<210> 104
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 104
Thr Val Leu Trp Gly Leu Gly Val Leu Ile Arg
1 5 10
<210> 105
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 105
Glu Ala Asp Glu Asp Ala Val Gln Phe Ala Asn Arg
1 5 10
<210> 106
<211> 15
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 106
Gln Gly Gly Leu Val Asp Leu Leu Trp Asp Gly Gly Leu Lys Arg
1 5 10 15
<210> 107
<211> 10
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 107
Val Ile Asp Asn Gly Ser Gly Met Cys Lys
1 5 10
<210> 108
<211> 10
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 108
Ala Gly Phe Ala Gly Asp Asp Ala Pro Arg
1 5 10
<210> 109
<211> 9
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 109
Ala Val Phe Pro Ser Ile Val Gly Arg
1 5
<210> 110
<211> 8
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 110
Pro Ser Ile Val Gly Arg Pro Arg
1 5
<210> 111
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 111
Ile Trp His His Thr Phe Tyr Asn Glu Leu Arg
1 5 10
<210> 112
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 112
Thr Thr Gly Ile Val Met Asp Ser Gly Asp Gly Val Thr His
1 5 10
<210> 113
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 113
Ser Tyr Glu Leu Pro Asp Gly Gln Val Ile Thr Ile Gly Asn Glu Arg
1 5 10 15
<210> 114
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 114
Glu Leu Pro Asp Gly Gln Val Ile Thr Ile Gly Asn Glu Arg
1 5 10
<210> 115
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 115
Ile Ser Lys Gln Glu Tyr Asp Glu Ser Gly Pro Ser Ile Val His Arg
1 5 10 15
<210> 116
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 116
Gln Glu Tyr Asp Glu Ser Gly Pro Ser Ile Val His
1 5 10
<210> 117
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 117
Gln Glu Tyr Asp Glu Ser Gly Pro Ser Ile Val His Arg
1 5 10
<210> 118
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 118
Ser Thr Pro Ala Ile Thr Leu Glu Ser Pro Asp Ile Lys
1 5 10
<210> 119
<211> 17
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 119
Ser Thr Pro Ala Ile Thr Leu Glu Ser Pro Asp Ile Lys Tyr Pro Leu
1 5 10 15
Arg
<210> 120
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 120
Leu Ile Asp Arg Glu Ile Ile Ser His Asp Thr Arg
1 5 10
<210> 121
<211> 10
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 121
Ile Asp Gly Asn Leu Val Val Arg Pro Tyr
1 5 10
<210> 122
<211> 17
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 122
Thr Pro Ile Ser Ser Asp Asp Asp Lys Gly Phe Val Asp Leu Val Ile
1 5 10 15
Lys
<210> 123
<211> 9
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 123
Val Tyr Phe Lys Asp Thr His Pro Lys
1 5
<210> 124
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 124
Gly Pro Ser Gly Leu Leu Val Tyr Gln Gly Lys
1 5 10
<210> 125
<211> 19
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 125
Ser Val Gly Met Ile Ala Gly Gly Thr Gly Ile Thr Pro Met Leu Gln
1 5 10 15
Val Ile Arg
<210> 126
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 126
Asp Ile Leu Leu Arg Pro Glu Leu Glu Glu Leu
1 5 10
<210> 127
<211> 9
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 127
Phe Lys Leu Trp Tyr Thr Leu Asp Arg
1 5
<210> 128
<211> 7
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 128
Leu Trp Tyr Thr Leu Asp Arg
1 5
<210> 129
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 129
Ala Pro Glu Ala Trp Asp Tyr Gly Gln Gly Phe Val Asn Glu Glu Met
1 5 10 15
Ile Arg
<210> 130
<211> 7
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 130
Phe Met Leu Asn Glu Val Lys
1 5
<210> 131
<211> 9
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 131
Thr Cys Leu Leu Ile Val Phe Ser Lys
1 5
<210> 132
<211> 10
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 132
Asp Thr Ala Gly Gln Glu Asp Tyr Asp Arg
1 5 10
<210> 133
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 133
His Phe Cys Pro Asn Val Pro Ile Ile Leu Val Gly Asn Lys
1 5 10
<210> 134
<211> 15
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 134
His Phe Cys Pro Asn Val Pro Ile Ile Leu Val Gly Asn Lys Lys
1 5 10 15
<210> 135
<211> 9
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 135
Val Pro Ile Ile Leu Val Gly Asn Lys
1 5
<210> 136
<211> 8
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 136
Glu Val Phe Glu Met Ala Thr Arg
1 5
<210> 137
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 137
Gly Asp Ser Thr Val Asn Thr Glu Pro Ala Thr Ser Ser Ala Pro Arg
1 5 10 15
<210> 138
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 138
Thr Ala Ser Ile Ser Glu Thr Pro Val Asp Val Arg
1 5 10
<210> 139
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 139
Ser Asp Glu Glu Glu Pro Lys Asp Glu Ser Ala Arg
1 5 10
<210> 140
<211> 8
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 140
Glu Pro Leu Glu Ala Glu Ala Arg
1 5
<210> 141
<211> 7
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 141
Glu Ser Ala Thr Pro Leu Arg
1 5
<210> 142
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 142
Gly Ala Asp Asp Ala Met Glu Ser Ser Lys Pro Gly Pro Val Gln Val
1 5 10 15
Val Leu
<210> 143
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 143
Ala Arg Ala Ala Pro Asp Pro Pro Pro Leu Phe Asp Asp Thr Ser Gly
1 5 10 15
Gly Tyr
<210> 144
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 144
Ala Ala Pro Asp Pro Pro Pro Leu Phe Asp Asp Thr Ser Gly Gly Tyr
1 5 10 15
<210> 145
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 145
Leu Ser Glu Leu Asp Asp Arg Ala Asp Ala Leu
1 5 10
<210> 146
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 146
Leu Ser Glu Leu Asp Asp Arg Ala Asp Ala Leu Gln Ala Gly Ala Ser
1 5 10 15
Gln Phe
<210> 147
<211> 17
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 147
Ala Gln Leu Lys Ser Glu Ala Ala Gly Ser Pro Asp Gln Gly Ser Thr
1 5 10 15
Tyr
<210> 148
<211> 22
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 148
Gln Ala Gln Leu Thr Gln Ala Gln Ala Glu Gln Pro Ala Gln Ser Ser
1 5 10 15
Thr Glu Met Glu Glu Phe
20
<210> 149
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 149
Ser Ser Ser Ala Glu Glu Ser Gly Gln Asp Val Leu Glu Asn Thr Phe
1 5 10 15
<210> 150
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 150
Asn Ile Asp Val Ala Pro Gly Ala Pro Gln Glu Lys
1 5 10
<210> 151
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 151
Gly Ala Asp Asp Ala Met Glu Ser Ser Lys Pro Gly Pro Val Gln Val
1 5 10 15
Val Leu
<210> 152
<211> 11
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 152
Ser Val Asn Ala Ile Thr Ala Asp Gly Ser Arg
1 5 10
<210> 153
<211> 7
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 153
Val Phe Leu Asn Ala Lys Lys
1 5
<210> 154
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 154
Ala Tyr Pro Ser Asn Ile Thr Ser Glu Thr Gly Phe Arg
1 5 10
<210> 155
<211> 17
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 155
Thr Ala Thr Pro Pro Ala Pro Asp Ser Pro Gln Glu Pro Leu Val Leu
1 5 10 15
Arg
<210> 156
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 156
Ile Met Ser Ser Asn Ser Ala Ser Ala Ala Asn Gly Asn Asp Ser Lys
1 5 10 15
<210> 157
<211> 17
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 157
Ile Met Ser Ser Asn Ser Ala Ser Ala Ala Asn Gly Asn Asp Ser Lys
1 5 10 15
Lys
<210> 158
<211> 8
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 158
Thr Ser Val Thr Pro Val Leu Arg
1 5
<210> 159
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 159
Ala Gln Ala Ala Leu Gln Ala Val Asn Ser Val Gln Ser Gly Asn Leu
1 5 10 15
<210> 160
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 160
Gln Ala Val Asn Ser Val Gln Ser Gly Asn Leu Ala Leu
1 5 10
<210> 161
<211> 7
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 161
Thr Ser Leu Asn Val Lys Tyr
1 5
<210> 162
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 162
Gly Leu Ser Val Pro Asn Val His Gly Ala Leu Ala Pro Leu
1 5 10
<210> 163
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 163
Ala Ile Pro Ser Ala Ala Ala Ala Ala Ala Ala Ala Gly Arg
1 5 10
<210> 164
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 164
Pro Ser Ala Ala Ala Ala Ala Ala Ala Ala Gly Arg
1 5 10
<210> 165
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 165
Glu Gly Gln Glu Asp Gln Gly Leu Thr Lys Asp Tyr
1 5 10
<210> 166
<211> 10
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 166
Gln Phe Pro Gly Phe Pro Ala Ala Ala Tyr
1 5 10
<210> 167
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 167
Gly Pro Val Ala Ala Ala Ala Val Ala Ala Ala Arg
1 5 10
<210> 168
<211> 16
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 168
Ser Leu Asp Pro Thr Asn Ala Glu Asn Thr Ala Ser Gln Ser Pro Arg
1 5 10 15
<210> 169
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 169
Lys Thr Asn Glu Ala Gln Ala Ile Glu Thr Ala Arg
1 5 10
<210> 170
<211> 17
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 170
Ser Ala Pro Asn Pro Asp Asp Pro Leu Ala Asn Asp Val Ala Glu Gln
1 5 10 15
Trp
<210> 171
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 171
Lys Thr Asn Glu Ala Gln Ala Ile Glu Thr Ala Arg
1 5 10
<210> 172
<211> 10
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 172
Val Tyr Ser Lys Asp Gln Leu Gln Thr Phe
1 5 10
<210> 173
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 173
Tyr Leu Pro Asp Gly Ser Thr Ile Glu Ile Gly Pro Ser Arg
1 5 10
<210> 174
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 174
Leu Pro Asp Gly Ser Thr Ile Glu Ile Gly Pro Ser Arg
1 5 10
<210> 175
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 175
Ser Leu Ala Thr Gln Asp Ser Asp Asn Pro Asp Leu Arg
1 5 10
<210> 176
<211> 19
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 176
Ser Asn Leu Gly Ser Thr Glu Thr Leu Glu Glu Met Pro Ser Gly Ser
1 5 10 15
Gln Asp Lys
<210> 177
<211> 13
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 177
Leu Asn Gln Pro Val Pro Glu Leu Ser His Ala Ser Leu
1 5 10
<210> 178
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 178
Asn Val Thr Asn Thr Ala Gly Thr Ser Leu Pro Ser Val Asp Leu Leu
1 5 10 15
Gln Lys
<210> 179
<211> 9
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 179
Leu Gly Ala Glu Glu Ala Lys Thr Phe
1 5
<210> 180
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 180
Ile Leu Pro Ser Asp Tyr Asp His Ala Glu Ala Glu Ala Arg
1 5 10
<210> 181
<211> 14
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 181
Val Gly Ser Gln Ala Thr Asp Phe Gly Glu Ala Leu Val Arg
1 5 10
<210> 182
<211> 12
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 182
Gly Asn Ser Thr Gly Gly Phe Asp Gly Gln Ala Arg
1 5 10
<210> 183
<211> 20
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 183
Arg Gly Gln Leu Ala Ser Pro Ser Ser Gln Ser Ala Ala Ala Ser Ser
1 5 10 15
Leu Gly Pro Tyr
20
<210> 184
<211> 18
<212> PRT
<213> Искусственная последовательность
<220>
<223> последовательность пептида
<400> 184
Arg Gly Gln Pro Gly Asn Ala Tyr Asp Gly Ala Gly Gln Pro Ser Ala
1 5 10 15
Ala Tyr
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| НОВЫЕ СПОСОБЫ СЕЛЕКЦИИ ЭПИТОПОВ | 2016 |
|
RU2764992C2 |
| ПОЛИПЕПТИД, СОДЕРЖАЩИЙ АНТИГЕНСВЯЗЫВАЮЩИЙ ДОМЕН И ТРАНСПОРТИРУЮЩИЙ СЕГМЕНТ | 2017 |
|
RU2827545C2 |
| ПОЛИПЕПТИД, ВКЛЮЧАЮЩИЙ АНТИГЕНСВЯЗЫВАЮЩИЙ ДОМЕН И ТРАНСПОРТИРУЮЩИЙ СЕГМЕНТ | 2018 |
|
RU2815452C2 |
| МУЛЬТСПЕЦИФИЧЕСКИЕ АНТИТЕЛА, МУЛЬТСПЕЦИФИЧЕСКИЕ АКТИВИРУЕМЫЕ АНТИТЕЛА И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2014 |
|
RU2815683C2 |
| МУЛЬТСПЕЦИФИЧЕСКИЕ АНТИТЕЛА, МУЛЬТСПЕЦИФИЧЕСКИЕ АКТИВИРУЕМЫЕ АНТИТЕЛА И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2014 |
|
RU2727836C2 |
| ИСКУССТВЕННЫЕ НЕИЗБИРАТЕЛЬНЫЕ ЭПИТОПЫ КЛЕТОК Т-ХЕЛПЕРОВ КАК ИММУННЫЕ СТИМУЛЯТОРЫ ДЛЯ СИНТЕТИЧЕСКИХ ПЕПТИДНЫХ ИММУНОГЕНОВ | 2019 |
|
RU2839585C2 |
| Эпитоп тиоредоксина-1 и моноклональное антитело, специфически связывающееся с ним | 2018 |
|
RU2797266C2 |
| ЭПИТОП ТИОРЕДОКСИНА-1, СПЕЦИФИЧНО СВЯЗЫВАЮЩИЙСЯ С МОНОКЛОНАЛЬНЫМ АНТИТЕЛОМ | 2018 |
|
RU2804126C2 |
| АНТИГЕННЫЕ ПОЛИПЕПТИДЫ НА ОСНОВЕ ПОСЛЕДОВАТЕЛЬНОСТИ РЕСПИРАТОРНО-СИНЦИТИАЛЬНОГО ВИРУСА | 2019 |
|
RU2807992C2 |
| Эпитоп тиоредоксина-1, специфично связывающийся с моноклональным антителом | 2018 |
|
RU2804772C2 |

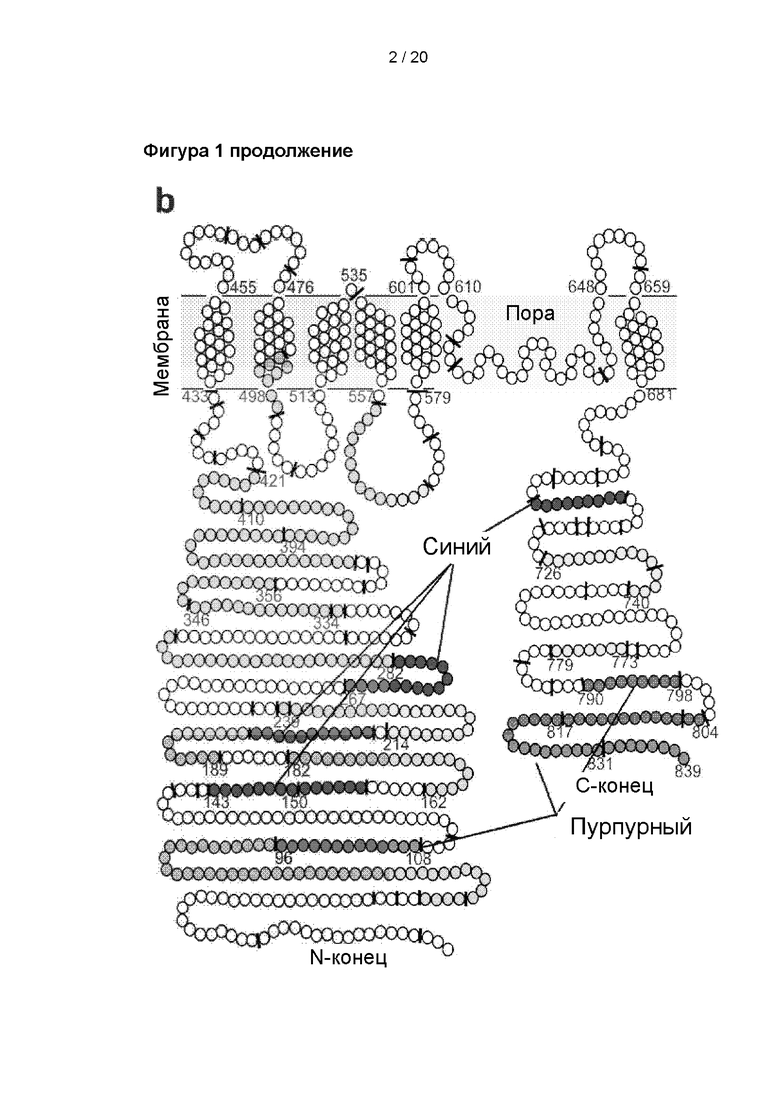
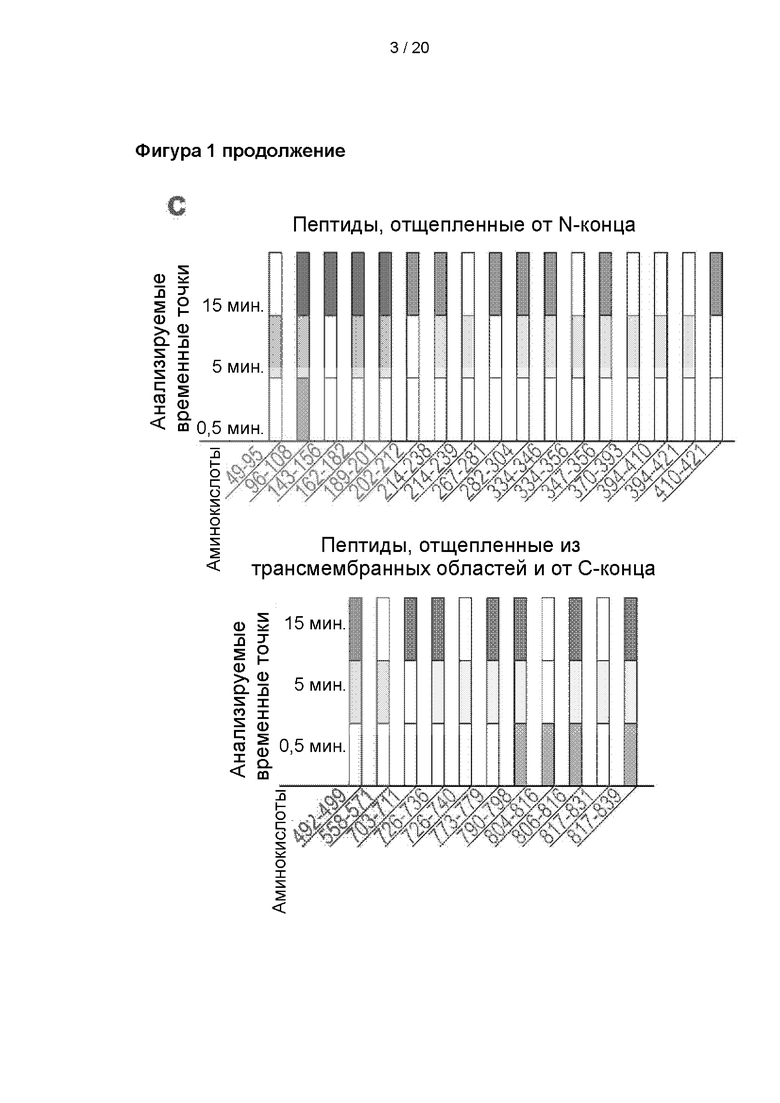


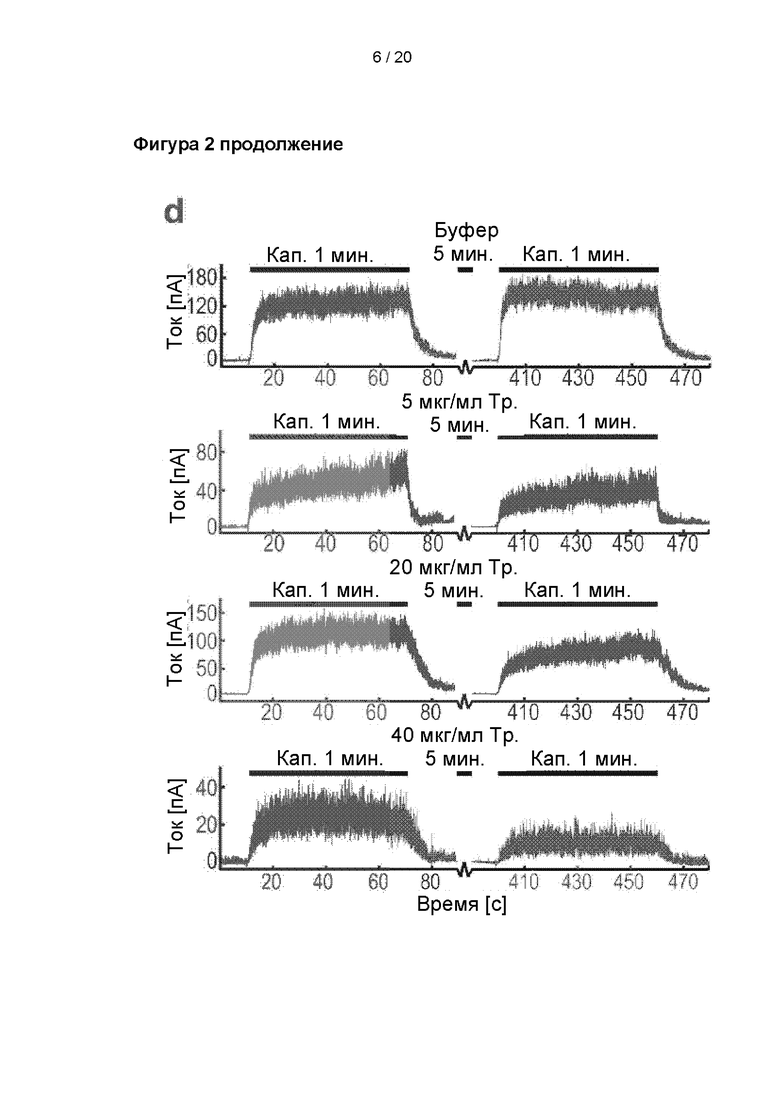
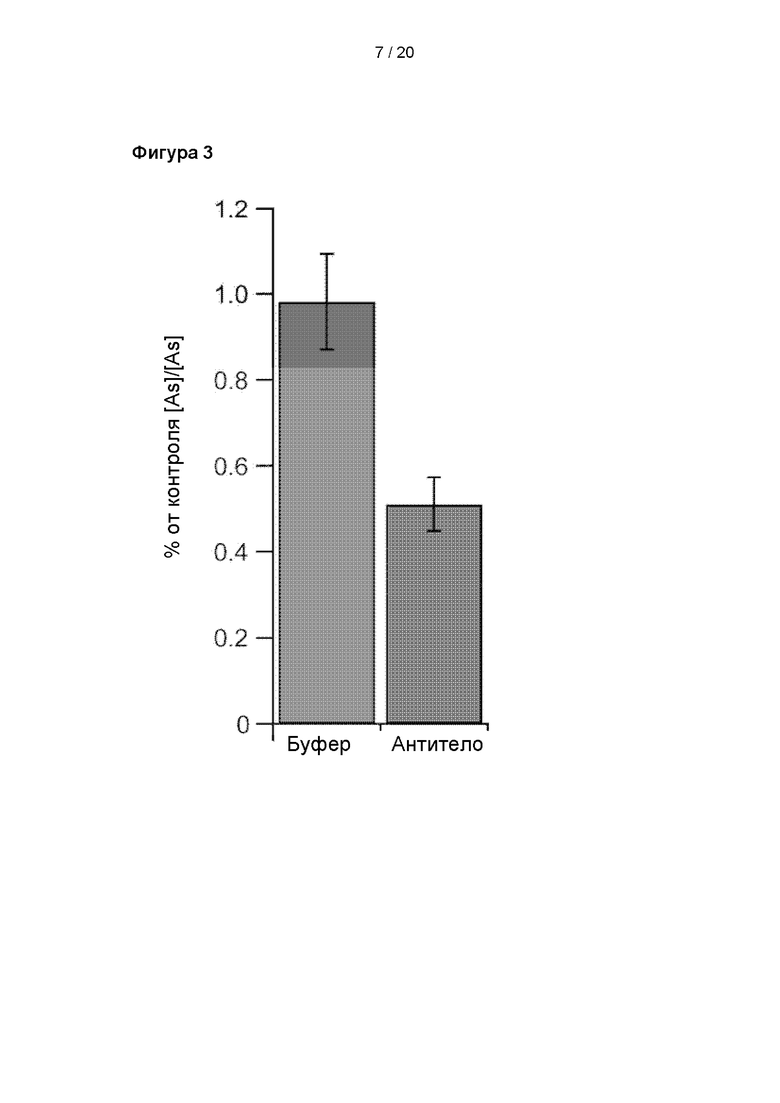
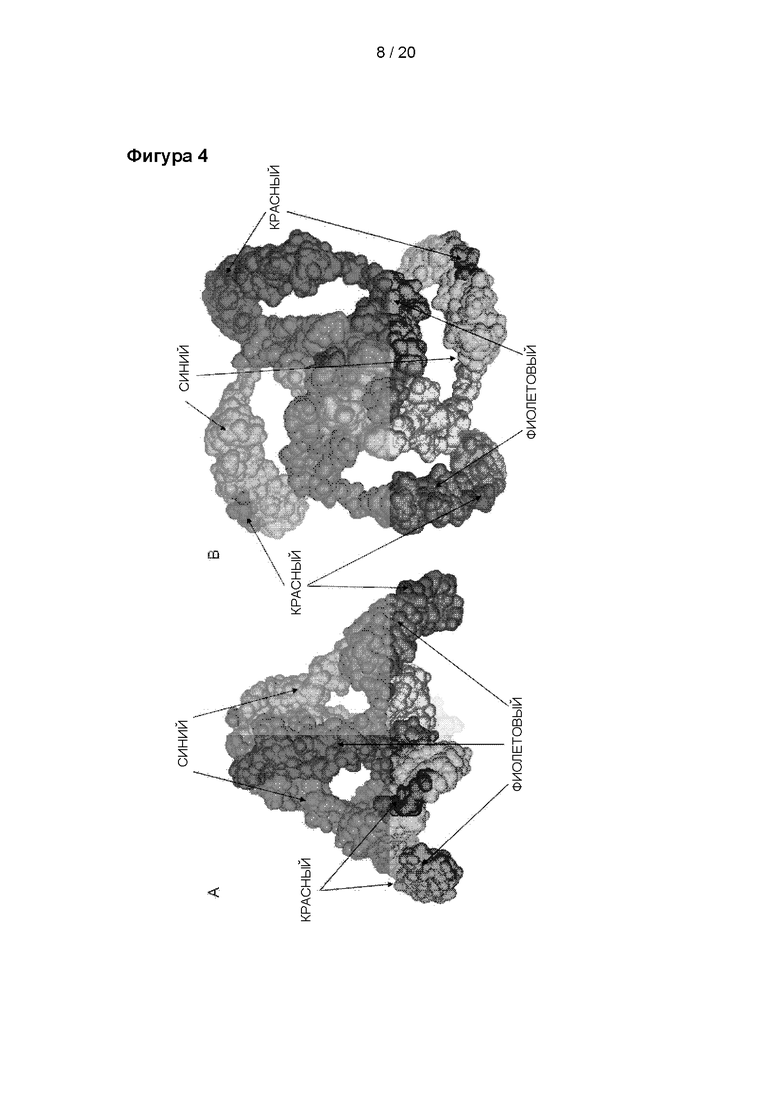
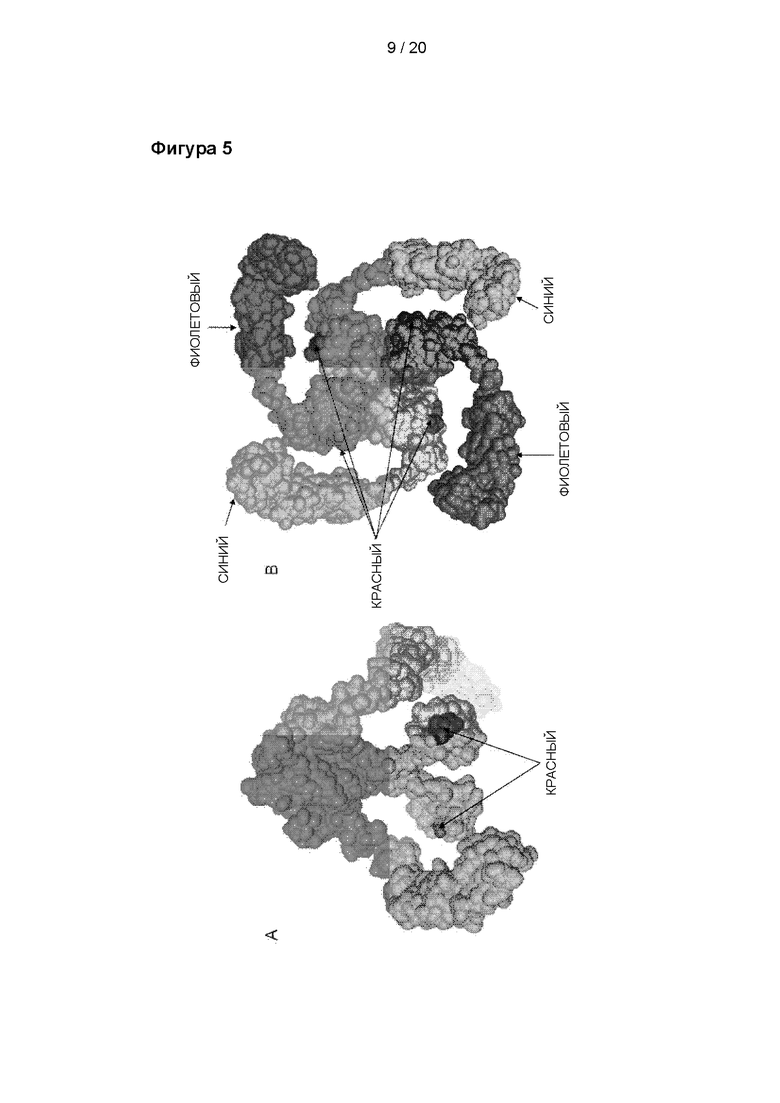
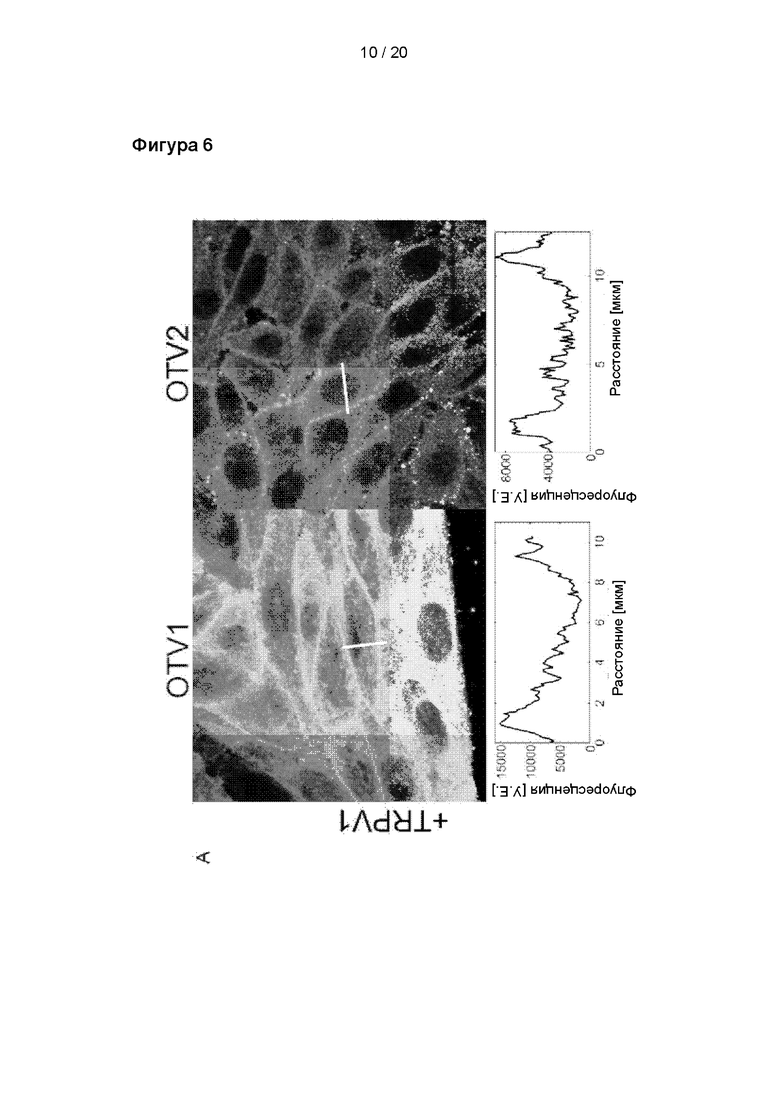
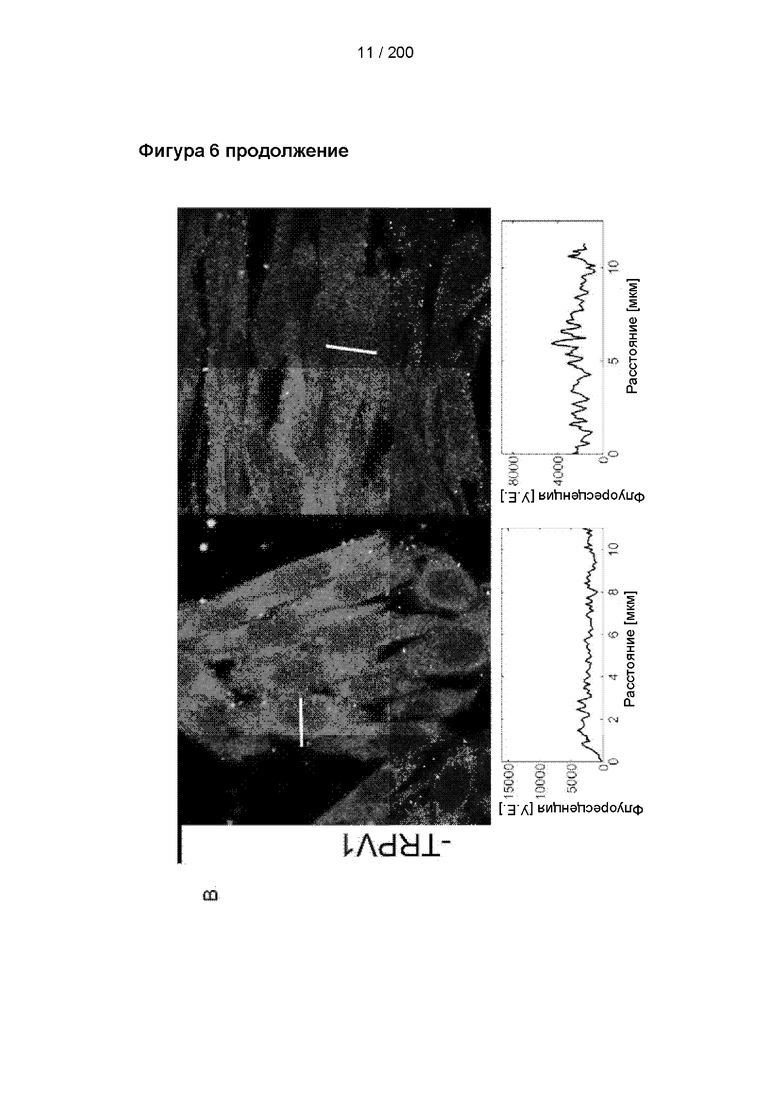
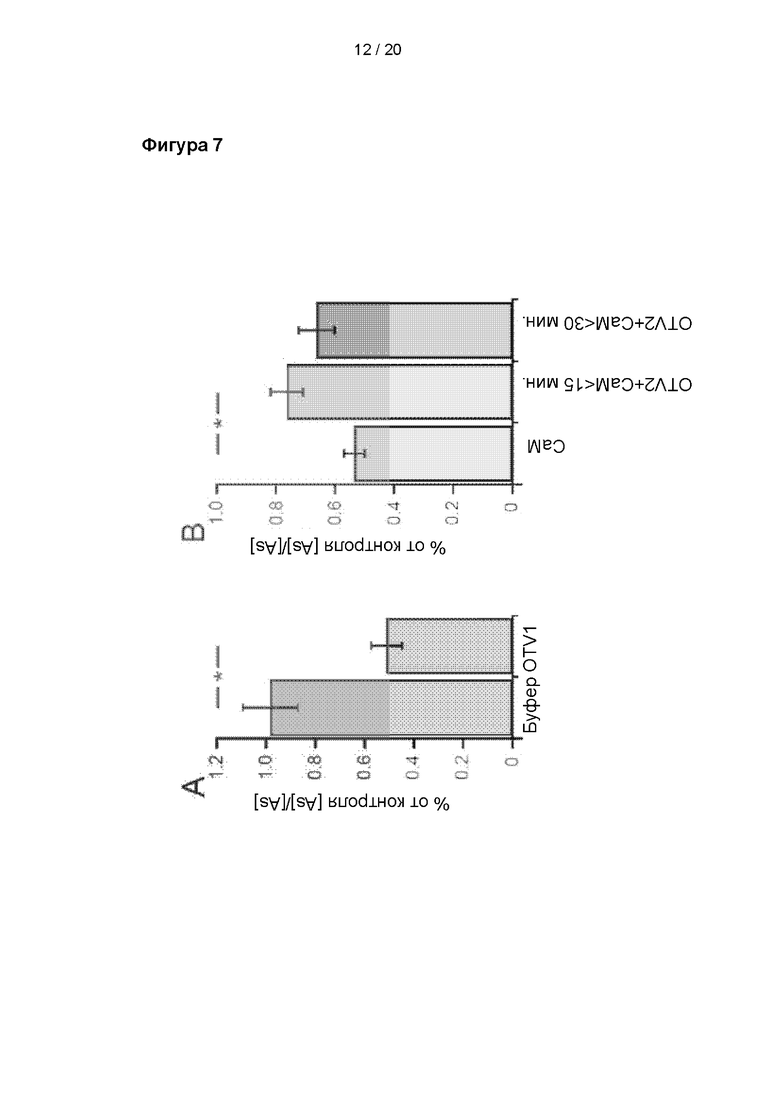
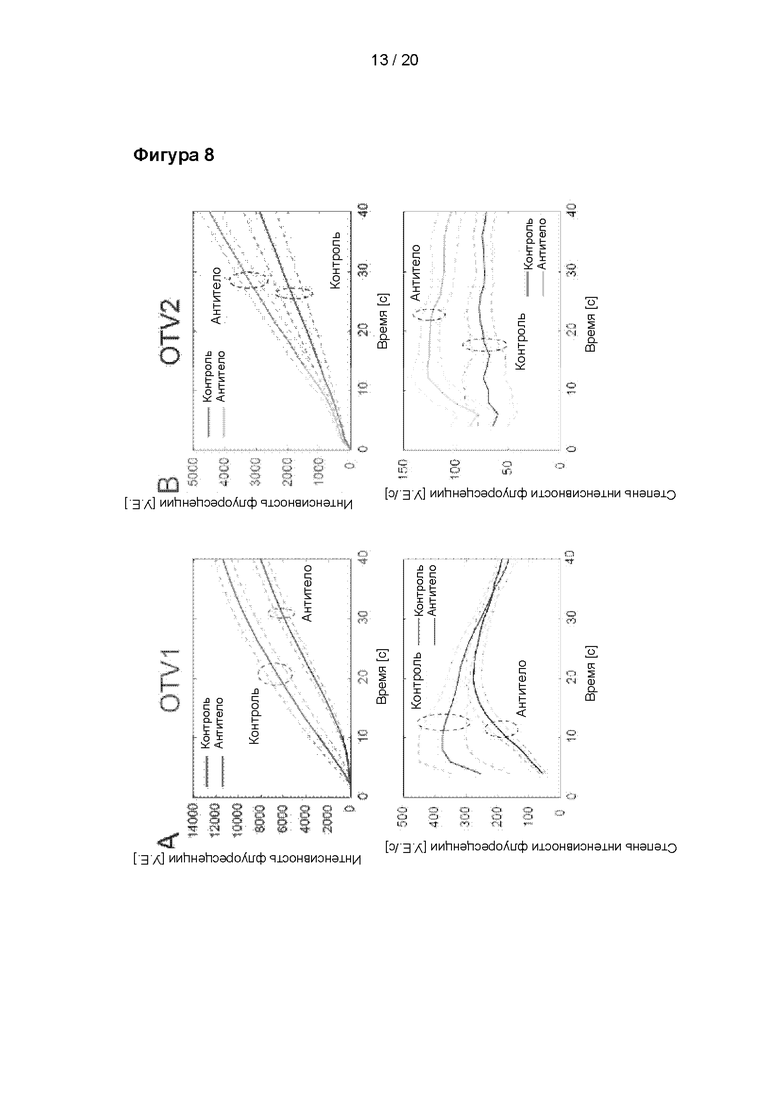
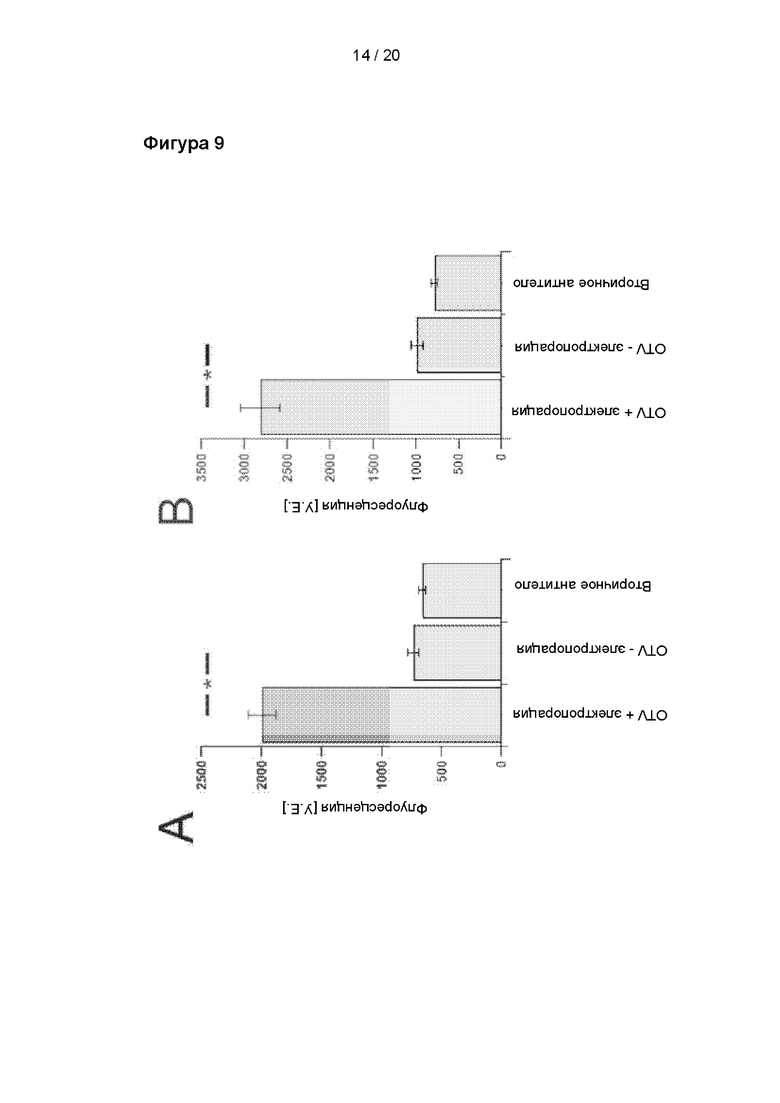



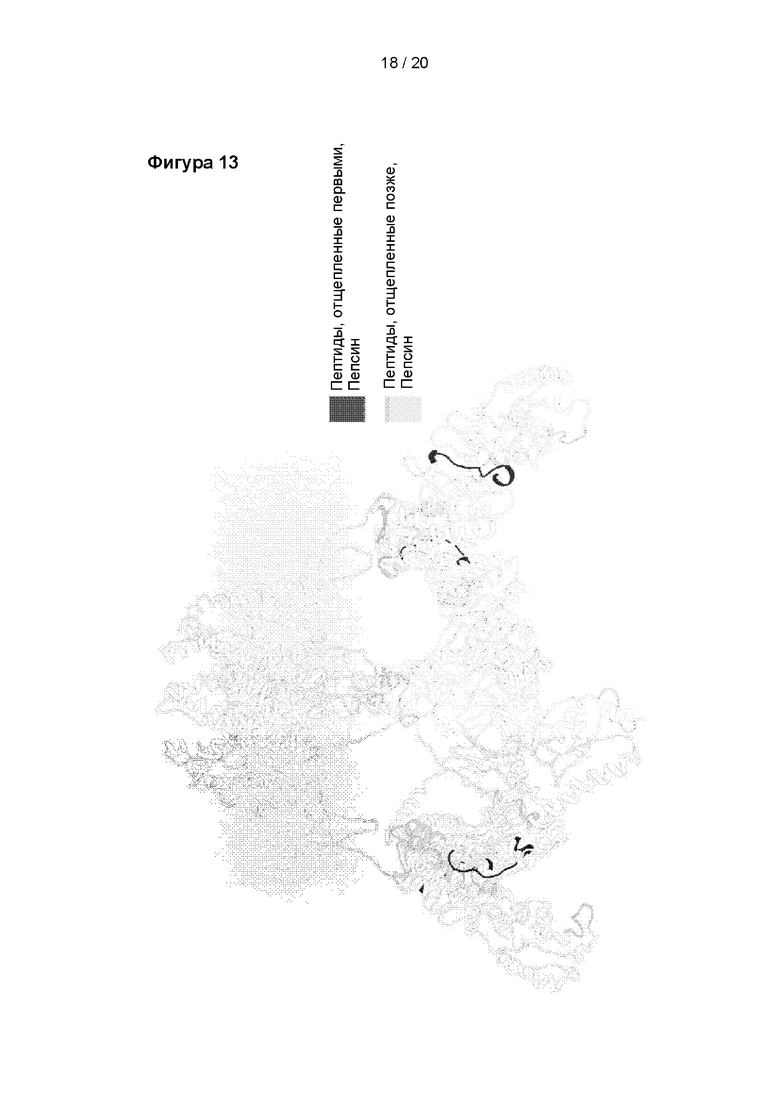

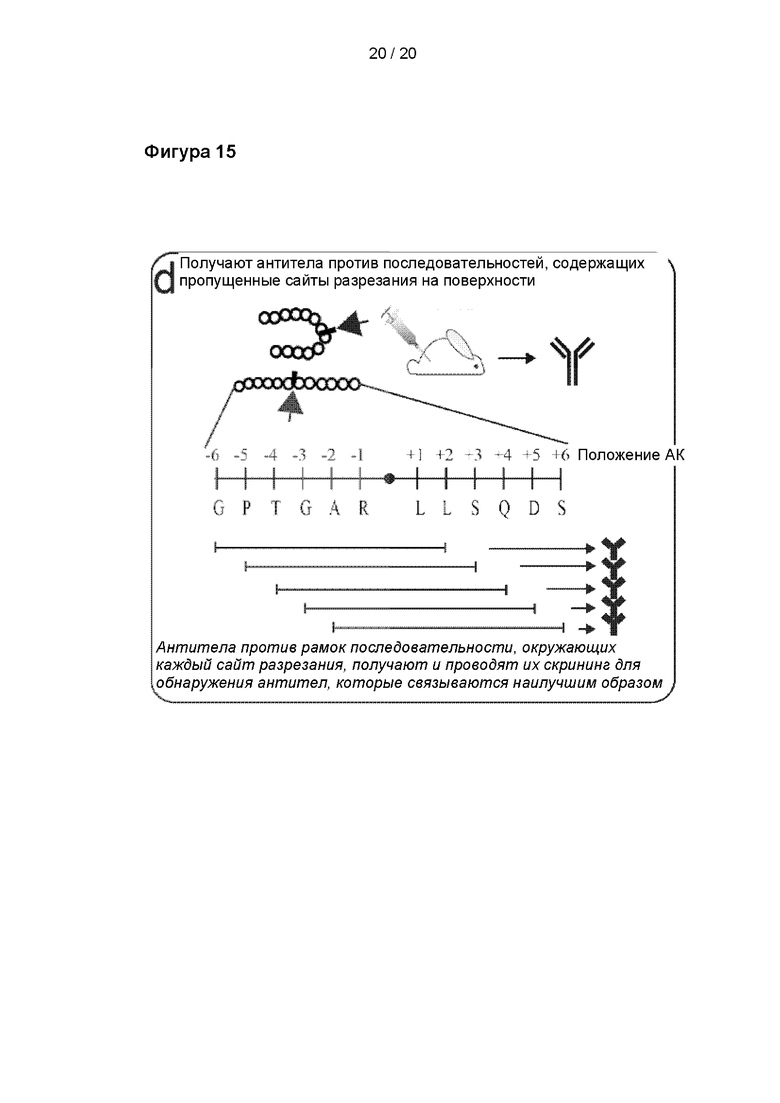
Настоящее изобретение относится к способу идентификации эпитопа на белке, с которым может связываться антитело. Способ включает этап ограниченного или частичного протеолиза белка с использованием одной первой протеазы или комбинации первых протеаз и следующий этап протеолиза с использованием одной второй протеазы или комбинации вторых протеаз, специфичность (специфичности) которых отличается от специфичности (специфичностей) первой протеазы или протеаз. Далее с применением масс-спектрометрии анализируют пептиды, которые высвободились, для идентификации пептидов, в которых один конец разрезан первой протеазой, а другой конец разрезан второй протеазой. Создают один или более выделенных эпитопов, которые находятся в области белка, содержащей или фланкирующей сайт разрезания первой протеазы. Получают антитела, направленные на выделенные эпитопы. С использованием указанных антител проводят исследования одного или более эпитопов на белке. Изобретение позволяет идентифицировать «пропущенные» участки разреза, т.е. участки, которые разрезаются первой протеазой, но при этом пептиды не высвобождаются, и которые представляют потенциальный интерес как образующие часть подходящего эпитопа. 16 з.п. ф-лы, 15 ил., 13 табл., 4 пр.
1. Способ идентификации эпитопа на белке, с которым может связываться антитело, причем указанный способ включает:
(i) осуществление ограниченного или частичного протеолиза указанного белка с использованием одной первой протеазы или комбинации первых протеаз;
(ii) осуществление неограниченного протеолиза или осуществление ограниченного или частичного протеолиза указанного белка с использованием одной второй протеазы или комбинации вторых протеаз, причем специфичность (специфичности) указанной второй протеазы или протеаз все отличаются от специфичности (специфичностей) протеазы или протеаз, используемых на этапе (i);
(iii) анализ пептидов, которые высвободились из указанного белка на этапе (ii), для идентификации пептидов, в которых один конец был разрезан указанной первой протеазой, а другой конец был разрезан указанной второй протеазой, причем указанные пептиды анализируют с применением масс-спектрометрии;
(iv) исследование одного или более эпитопов в области белка, содержащей или фланкирующей сайт разрезания указанной первой протеазы, как определено на этапе (iii), с помощью одного или более антител, направленных на указанные эпитопы, таким образом позволяя идентифицировать один или более эпитопов на белке, с которыми может связываться антитело;
при этом указанный способ дополнительно включает перед этапом (iv) этап создания одного или более выделенных эпитопов, последовательности которых соответствуют одному или более эпитопам на указанном белке, которые находятся в области белка, содержащей или фланкирующей сайт разрезания указанной первой протеазы, как определено на этапе (iii), и создания антител, которые направлены на указанные выделенные эпитопы, и использование указанных антител на этапе (iv) для исследования одного или более эпитопов на указанном белке.
2. Способ по п. 1, отличающийся тем, что на этапе (ii) осуществляют неограниченный протеолиз.
3. Способ по п. 1 или 2, отличающийся тем, что на этапе (i) используют одну первую протеазу.
4. Способ по любому из пп. 1–3, отличающийся тем, что на этапе (ii) используют одну вторую протеазу.
5. Способ по любому из пп. 1–4, отличающийся тем, что на этапе (ii) осуществляют неограниченный протеолиз и при этом указанный способ дополнительно включает после этапа (i), но перед этапом (ii), дополнительный этап осуществления ограниченного или частичного протеолиза указанного белка с использованием указанной одной второй протеазы или комбинации вторых протеаз, которые используют на этапе (ii).
6. Способ по любому из пп. 1–5, отличающийся тем, что указанная одна первая протеаза или указанная комбинация первых протеаз выбрана из группы, состоящей из трипсина, Arg-C, Lys-C и Lys-N.
7. Способ по любому из пп. 1–5, отличающийся тем, что указанная одна первая протеаза или указанная комбинация первых протеаз выбрана из группы, состоящей из пепсина, химотрипсина и Glu-C.
8. Способ по любому из пп. 1–6, отличающийся тем, что указанная одна вторая протеаза или указанная комбинация вторых протеаз выбрана из группы, состоящей из пепсина, химотрипсина и Glu-C.
9. Способ по любому из пп. 1–5 или 7, отличающийся тем, что указанная одна вторая протеаза или указанная комбинация вторых протеаз выбрана из группы, состоящей из трипсина, Arg-C, Lys-C и Lys-N.
10. Способ по любому из пп. 1–9, отличающийся тем, что указанный способ дополнительно включает этап денатурации, который проводят до, во время или после этапа (ii).
11. Способ по любому из пп. 1–10, отличающийся тем, что исследуют совокупность эпитопов.
12. Способ по любому из пп. 1–11, отличающийся тем, что указанный эпитоп находится в пределах 20 аминокислот от указанного сайта разрезания указанной первой протеазы.
13. Способ по любому из пп. 1–12, отличающийся тем, что исследуют совокупность эпитопов, и отличающийся тем, что указанная совокупность эпитопов представляет собой множество эпитопов, причем последовательность каждого эпитопа во множестве смещена по сравнению с другим эпитопом во множестве на 1, 2 или 3 аминокислоты.
14. Способ по любому из пп. 1–13, отличающийся тем, что указанный протеолиз на этапах (i) и (ii) осуществляют в отношении белка, который присутствует в протеолипосоме, полученной из клеток.
15. Способ по п. 14, отличающийся тем, что указанная протеолипосома иммобилизована в проточной ячейке для получения неподвижной фазы белка.
16. Способ по любому из пп. 1–15, отличающийся тем, что этап (iii) включает анализ пептидов, которые высвободились из указанного белка на этапе (i) и этапе (ii).
17. Способ по любому из пп. 1–16, отличающийся тем, что указанный способ также включает этап получения антитела против эпитопа, идентифицированного по любому из пп. 1–16.
| СПОСОБ ИЗГОТОВЛЕНИЯ КАТОДНОЙ СЕКЦИИ ЭЛЕКТРОЛИЗЕРА ДЛЯ ПОЛУЧЕНИЯ АЛЮМИНИЯ | 2000 |
|
RU2186879C2 |
| JANSSON E | |||
| T | |||
| et al | |||
| "Microfluidic Flow Cell for Sequential Digestion of Immobilized Proteoliposomes", ANALYTICAL CHEMISTRY, 2012, v.84, no.13, p | |||
| ПРИСПОСОБЛЕНИЕ ДЛЯ УСТАНОВКИ ФИЛЬМЫ В ГОВОРЯЩЕМ КИНЕМАТОГРАФЕ | 1925 |
|
SU5582A1 |
| US 2015309046 A1, 29.10.2015 | |||
| HAGER-BRAUN, C., & TOMER, K | |||
| B | |||
| "Determination of protein-derived epitopes by mass spectrometry" | |||
| Expert | |||

