ОБЛАСТЬ ТЕХНИКИ
Изобретение относится к области распознавания данных, в частности к способу распознавания химической информации из изображений документов и система для его осуществления.
Представленное решение может быть использовано, по меньшей мере, в фармацевтических компаниях для сбора данных по разнообразной химической информации, например, химическим соединениям, представленным в различных форматах, химическим реакциям и дополнительной химической информации, в других областях техники, в которых необходимо осуществлять сбор данных по такой химической информации. Также настоящее решение может использоваться провайдерами химической информации для составления баз данных.
УРОВЕНЬ ТЕХНИКИ
В заявке на изобретение CN111860507A, дата публикации 30.10.2020, описан способ извлечения молекулярной структурной формулы составного изображения, основанный на состязательном обучении, относящемся к области глубокого обучения, распознавания изображений и извлечения составной молекулярной формулы. Способ извлечения молекулярной структурной формулы составного изображения, основанный на состязательном обучении, включает следующие этапы: построение набора пар данных, состоящих из составных изображений, и молекулярных структур в виде нотации SMILES; создание состязательных сетей: генератора SMILES и распознавателя структур в нотации SMILES, и состязательное обучение предложенной нейросетевой модели.
В международной заявке на изобретение WO2019148852A1, дата публикации 08.08.2019, раскрыт способ распознавания химической информации из изображений рисунков, нарисованных от руки, путем идентификации структур, идентификации рукописного шрифта, идентификации атомов, соответствующих структурам, идентификации связей с помощью методов глубокого обучения.
В патентном документе EP2567338B1, дата публикации 08.04.2020, раскрыто устройство для электронной идентификации и составления химических структур, обнаруженных в хранилище, в котором хранятся электронные файлы. Модуль распознавания оптической структуры идентифицирует множество возможных химических структур в электронных файлах хранилища, при этом, по крайней мере, один из электронных файлов содержит невстроенные изображения химических структур, идентифицируемых оптической структурой. Модуль распознавания выводит (для каждой идентифицированной потенциальной химической структуры) объект химической структуры со связанным набором свойств, включая количество атомов углерода (например, число гетероатомов, число связей, число связей выбранного порядка связи, число колец и вес формулы). Модуль распознавания оптической структуры также применяет (для каждого производного объекта химической структуры) один или несколько фильтров, включая фильтр для исключения объектов, идентифицированных как имеющие менее выбранного количества атомов углерода, при этом выбранное количество атомов углерода конфигурируется и устанавливается пользователем на основе ожидаемого содержимого электронных файлов, и сохраняет объекты, не удаленные одним или несколькими фильтрами, в доступной для поиска электронной базе данных идентифицированных объектов.
В заявке на изобретение CN112818645A, дата публикации 18.05.2021, описан способ и устройство извлечения химической информации, в которых осуществляют получение документа, содержащего химическую информацию, вычленение изображения и текста из документа, содержащего химическую информацию, извлечение химической структуры и соответствующей ей метки, установление связи между химической структурой и меткой, извлечение химического объекта и отношения между химическими объектами из текста.
В статье [1] авторы представили новую модель DECIMER (Deep lEarning for Chemical ImagE Recognition). Раскрыта сеть на основе нейронной архитектуры Трансформера, которая может распознавать молекулярные структуры в виде нотации SMILES с точностью более 96% для изображений химических структур без стереохимической информации и с точностью более 89% для изображений со стереохимической информацией.
В статье [2] авторы обращаются к проблеме трансляции изображения в текст специально для молекулярных структур, где результатом будет предсказанное химическое обозначение в формате InChI для данной молекулярной структуры. Текущие подходы в основном основаны на правилах или методологии на основе CNN + RNN. Тем не менее, по заявлению авторов работы [2] они показывают худшие результаты на зашумленных изображениях и изображениях с небольшим количеством различимых деталей. Чтобы преодолеть данные ограничения, авторы предложили сквозную модель трансформера. По сравнению с основанными на внимании методами, предлагаемая модель демонстрирует лучшую производительность.
В статье [3] авторы представляют быструю и точную модель, сочетающую глубокую сверточную нейронную сеть, обучающуюся на основе изображений молекул, и предварительно обученный декодер, который переводит скрытое представление в представление молекул SMILES. Метод, названный авторами Img2Mol, способен правильно распознавать до 88% молекулярных изображений и конвертировать в представление SMILES.
В химических журналах, научных статьях, патентах, технических отчетах, диссертациях и прочих химических документах ключевая информация представлена в виде изображения не только молекулярных структур в стандартизированном формате, но и структур, записанных в нестандартизированном формате, с указанием «псевдохимических групп» R1, R2 и т. п. В общем виде такие структуры называются структурами Маркуша. Также в состав химических формул часто входят обозначения химических групп в виде сокращений – например «Ph-», «MeO-». Кроме этого, ключевая химическая информация также представлена в виде химических реакций. Однако, в решениях из уровня техники отсутствует возможность оптического распознавания из исходных оптических сканов различных химических документов химической информации в виде структур, записанных в нестандартизированном или сокращенном формате, а также в виде химических реакций.
Оптическое распознавание подобного рода информации – сложнейшая задача. Техническая проблема, на решение которой направлено заявляемое изобретение, заключается в распознавании из химических документов химической информации, содержащей как химические структуры, записанные в стандартизированном, так и нестандартизированном или сокращенном формате, а также химические реакции.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Техническим результатом заявляемого изобретения является обеспечение автоматического распознавания из изображений документов химической информации, содержащей как химические структуры, записанные в стандартизированном, так и нестандартизированном или сокращенном формате, а также химические реакции, сокращение времени и повышение точности распознавания химической информации из изображений документов. Дополнительным техническим результатом является увеличение производительности вычислительной системы при решении поставленной задачи, т.е. настоящее решение позволяет производить обработку документов с получением результата распознавания за меньшее количество времени, тем самым снижая нагрузку на центральный процессор вычислительного устройства.
Указанный технический результат достигается за счёт того, что компьютерно-реализуемый способ распознавания химической информации из изображений документов, в котором вычислительное устройство, содержащее процессор и память, хранит в памяти инструкции, исполняемые процессором, и исполняют инструкции, включающие этапы, на которых:
- на вход детектора подают изображение страницы документа; детектор с помощью первой нейронной сети идентифицирует на странице один или более фрагментов, содержащих химическую информацию; для каждого идентифицированного фрагмента получают координаты фрагмента на странице; и классифицируют фрагменты по меньшей мере по следующим категориям: химическая структура, стрелка реакции;
- на вход блока распознавания структур подают один или более идентифицированных фрагментов химических структур, причем каждый фрагмент представляет собой изображение; блок распознавания структур для каждого фрагмента распознает химическую структуру с помощью второй нейронной сети;
- на вход блока распознавания стрелок подают один или более идентифицированных фрагментов стрелок реакций; блок распознавания стрелок с помощью третьей нейронной сети определяет тип стрелки, и с помощью четвертой нейронной сети получают координаты на странице для каждой стрелки, и атрибуты реакции;
- на вход блока распознавания реакций передают координаты на странице каждого фрагмента распознанных химических структур, соответствующие распознанные химические структуры, координаты на странице каждой стрелки реакции, тип стрелки, атрибуты реакции; и на основании полученных данных блок распознавания реакций определяет, как стрелки связывают распознанные химические структуры;
- в результате на основании распознанных данных для изображения страницы документа получают одну или более распознанных химических структур, координаты на странице для каждой распознанной химической структуры, распознанные отношения между веществами, участвующими в химической реакции, представленными в виде химических структур, координаты на странице для каждого распознанного отношения.
В способе химическая структура может являться, по меньшей мере, химическим соединением, структурой Маркуша, химической структурой с заместителями.
В способе дополнительно могут идентифицировать фрагменты, содержащие дополнительную информацию, способствующую распознаванию реакций.
В способе дополнительная информация может включать, по меньшей мере, следующее: заголовок, легенда.
В способе детектор дополнительно для каждого идентифицированного фрагмента может определять уверенность - число от 0 до 1, которое оценивает достоверность идентифицированного фрагмента, где 0 - абсолютно не уверен, 1 - полностью уверен.
В способе идентифицированные фрагменты могут фильтроваться по предустановленному порогу уверенности.
В способе может быть установлен порог уверенности для каждой категории фрагментов.
В способе первая нейронная сеть может являться нейронной сетью Faster R-CNN или другой сверточной сетью равной или большей мощности.
В способе вторая нейронная сеть может являться нейронной сетью на базе архитектуры трансформера, и блок распознавания структур содержит сверточный блок и декодер трансформера.
В способе в качестве сверточного блока может использоваться ResNet-50 без последних двух слоев или другая сверточная сеть, работающая с изображениями.
В способе распознанная химическая структура может представлять собой текстовую последовательность, однозначно описывающую химическую структуру.
В способе могут описывать химическую структуру в виде текстовой последовательности с помощью модификации SMILES, способной описать структуры Маркуша и химические структуры с заместителями.
В способе может быть реализован механизм конвертации модификации SMILES, способной описать структуры Маркуша и химические структуры с заместителями, в SMILES и обратно.
В способе третья и четвертая нейронные сети могут являться сверточными нейронными сетями на базе ResNet.
В способе стрелки могут быть классифицированы по следующим типам: прямая стрелка, стрелка, которая не является прямой стрелкой.
В способе веществами, участвующими в химической реакции, могут являться исходные вещества химической реакции, продукты химической реакции.
Система распознавания химической информации из изображений документов содержит:
- детектор;
- блок распознавания структур;
- блок распознавания стрелок;
- блок распознавания реакций;
и в которой вычислительное устройство, содержащее процессор и память, хранящую инструкции, исполняемые процессором, осуществляет вышеописанный способ.
ОПИСАНИЕ ЧЕРТЕЖЕЙ
Реализация изобретения будет описана в дальнейшем в соответствии с прилагаемыми чертежами, которые представлены для пояснения сути изобретения и никоим образом не ограничивают область изобретения.
Заявляемое изобретение проиллюстрировано фигурами 1-4, на которых изображены:
Фиг. 1 иллюстрирует блок-схему системы распознавания химической информации из изображений документов.
Фиг. 2 иллюстрирует блок-схему модифицированного трансформера.
Фиг. 3а, 3б, 3в, 3г иллюстрируют пример работы системы распознавания химической информации из изображений документов.
Фиг. 4 иллюстрирует общую схему вычислительного устройства для реализации настоящего изобретения.
ДЕТАЛЬНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
В приведенном ниже подробном описании реализации изобретения приведены многочисленные детали реализации, призванные обеспечить отчетливое понимание настоящего изобретения. Однако, квалифицированному в предметной области специалисту будет очевидно, каким образом можно использовать настоящее изобретение, как с данными деталями реализации, так и без них. В других случаях хорошо известные методы, процедуры и компоненты не были описаны подробно, чтобы не затруднять излишне понимание особенностей настоящего изобретения.
Кроме того, из приведенного изложения будет ясно, что изобретение не ограничивается приведенной реализацией. Многочисленные возможные модификации, изменения, вариации и замены, сохраняющие суть и форму настоящего изобретения, будут очевидными для квалифицированных в предметной области специалистов.
Настоящее изобретение представляет собой автоматизированный механизм распознавания химической информации из реальных химических документов.
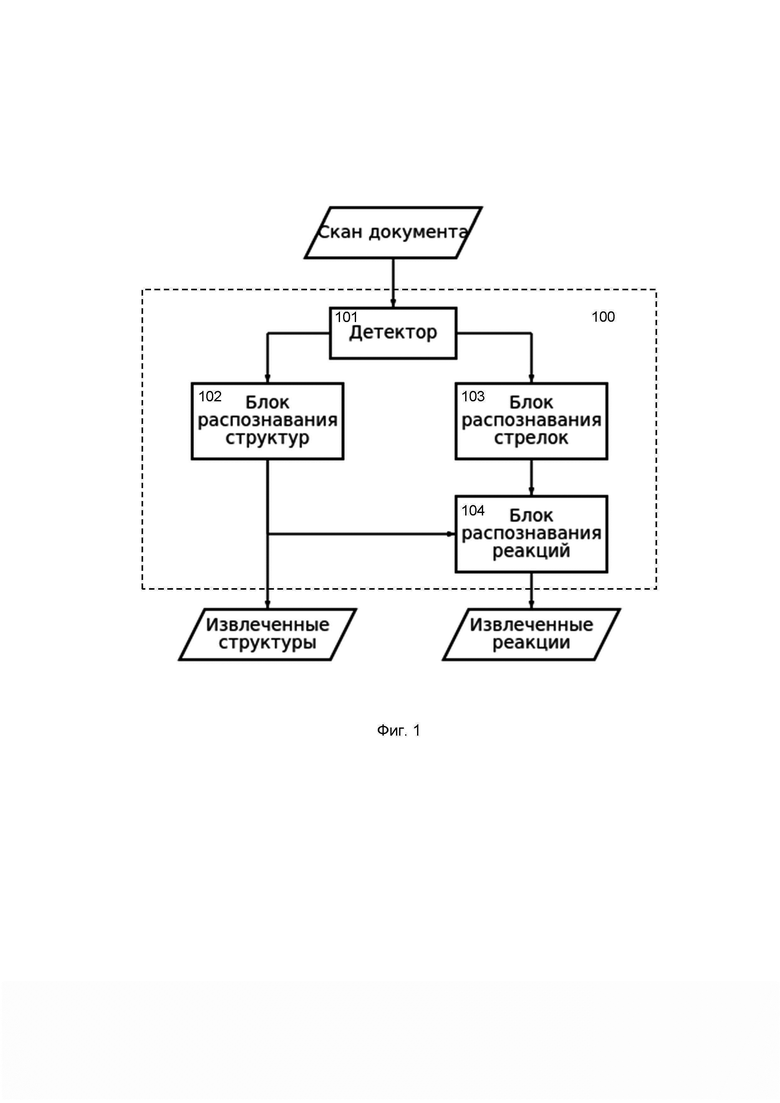
На Фиг. 1 представлена архитектура системы распознавания химической информации из изображений документов. Система (100) содержит следующие основные блоки:
- Детектор (101), который выполняет локализацию отдельных элементов химической информации на скане химического документа с помощью нейронной сети на базе архитектуры «Faster R-CNN» или любой другой более мощной сверточной сети.
- Блок распознавания структур (102), который с помощью нейронной сети на базе модифицированной архитектуры трансформер (Transformer) решает задачу трансляции изображения в текст (image captioning). Архитектура Transformer модифицирована таким образом, чтобы на вход сети подавать не последовательность, а изображение. В модифицированной архитектуре Transformer отсутствует блок энкодера.
- Блок распознавания стрелок (103), который классифицирует стрелки, изображающие направление протекания реакции, с помощью нейронной сети. Нейронная сеть распознает координаты начала и конца стрелок, а также атрибуты реакций.
- Блок распознавания реакций (104), который определяет, как стрелки связывают распознанные химические структуры.
На вход системы подается скан страницы документа, который передается в детектор (101). Детектор (101) с помощью нейронной сети находит на странице прямоугольные области, содержащие химическую информацию — молекулы и стрелки реакций, а также дополнительную информацию, помогающую в распознавании реакций, например, заголовки и легенды схем.
Детектор (101) в своей основе имеет сеть Faster R-CNN, но в равной степени может быть реализован на базе любой нейросетевой архитектуры, решающей задачу детекции (YOLO, SDD, EfficientDet и т. д.).
Для каждого найденного фрагмента возвращаются:
1. Координаты на исходной странице;
2. Категория (молекула, стрелка, заголовок, легенда);
3. Уверенность - число от 0 (абсолютно не уверен) до 1 (полностью уверен).
Полученные объекты фильтруются по предустановленному порогу уверенности (например, 0.8), т. е. фрагмент со значением уверенности меньше 0.8 будет отброшен как недостоверный. Порог может быть установлен свой для каждой категории фрагментов.
Для обучения детектора (101) использовались данные, размеченные вручную с помощью специально написанного для этой цели интерфейса разметки. Всего было размечено 2500 страниц из статей. Дальнейшее наполнение набора обучающих данных возможно в полуавтоматическом режиме, когда прогноз детектора корректируется вручную.
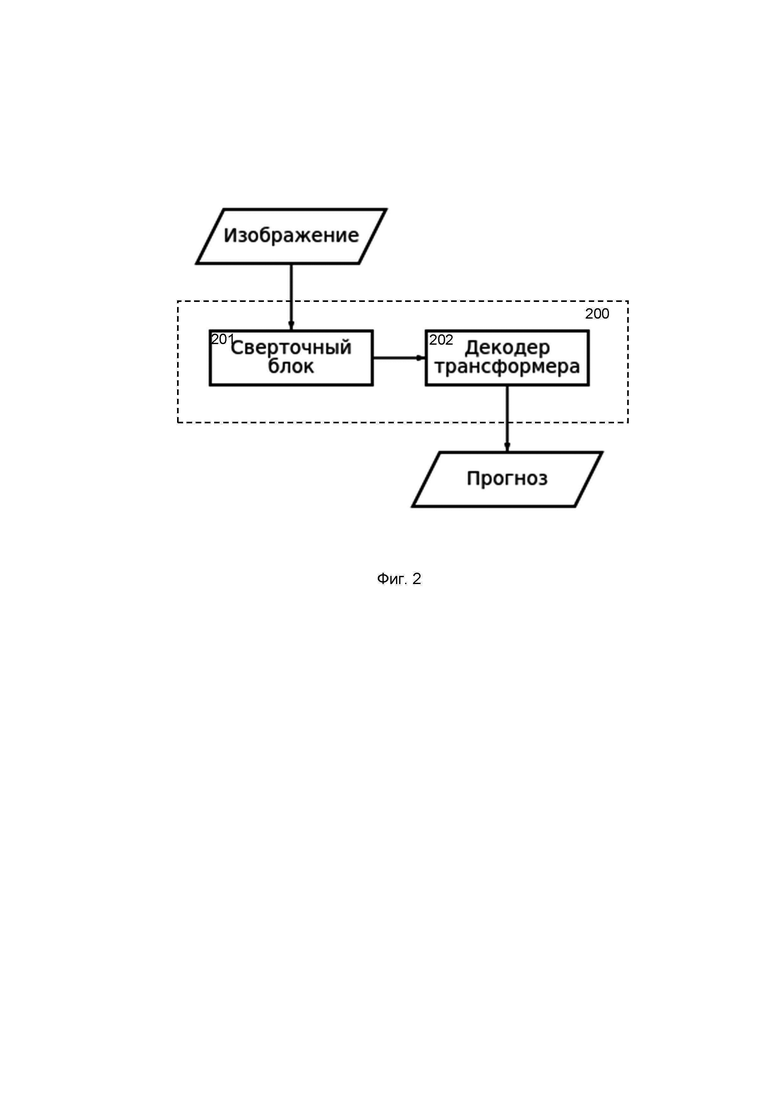
Блок распознавания структур (102) преобразует изображения химических структур в химических документах в структуры в виде текстовой последовательности с помощью нейронной сети. Изображения химических структур, которые подают в блок распознавания структур (102), описывают, например, пространственные структуры молекул, исходные вещества, участвующие в химических реакциях, продукты химических реакций и т.д. Кроме того, блок распознавания структур (102) распознает химические структуры, которые изображаются как в стандартизированном, так и нестандартизированном или сокращенном формате. Нейронная сеть реализована на базе архитектуры Transformer. Обычный трансформер решает задачу sequence2sequence, т. е. трансляцию из одной последовательности в другую, например, машинный перевод. В настоящем изобретении на вход подается не 1D-последовательность, а изображение (2D-последовательность), поэтому используется модифицированный вариант трансформера (Фиг. 2). Модифицированный трансформер (200) содержит сверточный блок (201) и декодер трансформера (202). Блок энкодера, который используется в обычном трансформере, полностью заменен на сверточный блок (201). В качестве сверточного блока (201) используется ResNet-50 без последних двух слоев. Таким образом, при подаче изображения размером 384x384 на выходе из сверточного блока (201) получается матрица размерности 512x48x48, что эквивалентно энкодеру трансформера с глубиной 512 и длиной входной последовательности 48. В то же время, сверточный блок (201) может быть не только ResNet, но любой другой сверточной сетью, работающей с изображением, из множества вариантов, например, EfficientNet, DenseNet и т.д.
Трансформер (200) преобразует изображение в текстовую последовательность, однозначно описывающую пространственную структуру молекулы. Языком описания молекулы может быть любое представление: SMILES и его вариации (DeepSMILES, SELFIES), а также InChI или IUPAC имя. Варианты на основе SMILES являются предпочтительными, т. к. являются наиболее краткими и отражают непосредственно структуру.
Для текстового представления структур Маркуша, а также структур с заместителями, разработан язык FG-SMILES (Functional Group SMILES). FG-SMILES является расширением обычного языка текстового описания химических структур SMILES. FG-SMILES позволяет записывать как структуры с функциональными группами в сокращенном виде, так и структуры Маркуша. Язык CXSMILES - известный аналог для записи групп-заместителей и структур Маркуша, в сравнении с FG-SMILES, является слишком многословным, и также не позволяет записывать R-группы в неопределенной позиции. Кроме этого, для FG-SMILES реализован механизм конвертации в SMILES и обратно.
Данная нотация позволяет записывать функциональные группы как заместители атомов, например:
[Et]N([Et])CCCNc1nc([X])nc([R3])c1[R2]
В классическом SMILES в квадратных скобках записываются неорганические атомы, ионы, изотопы, а также стерео-атомы. В данной модификации аналогичным образом записываются сокращенные имена функциональных групп, а также R-группы. Представлен также способ привязки R-группы к циклу, а не к конкретной позиции в цикле (если требуется показать, что R-группа находится в неопределенной позиции в цикле).
Существует также расширение CXSMILES, которое решает аналогичную задачу (за исключением неопределенной позиции), но соответствующее представление не интуитивно и многократно длиннее, что негативно сказывается на возможности использовать CXSMILES в машинном обучении. CXSMILES строка, соответствующая приведенному выше примеру:
*c1nc(*)c(*)c(NCCCN(*)*)n1 |atomProp:0.dummyLabel.X:4.dummyLabel.R3:6.dummyLabel.R2:13.dummyLabel.Et:14.dummyLabel.Et|
Реализованный механизм конвертации SMILES ↔ FG-SMILES позволяет находить в SMILES известные функциональные группы и заменять их. В список функциональных групп вошли более 100 групп. Это не все возможные группы, однако этот список покрывает подавляющее большинство реальных примеров из статей, а также может быть дополнен.
Данные для обучения модели распознавания структур генерируются искусственно с помощью генератора данных на основе метода создания искусственного датасета, имитирующего данные из реальных научных статей. Это обусловлено тем, что авторы реальных химических статей допускают значительные вольности при изображении структур. Помимо отличий в шрифтах, толщинах линий и отступах, часто встречаются элементы художественного оформления. Чтобы модель была устойчива к таким особенностям реальных данных, генератор применяет случайные нелинейные геометрические искажения к изображениям, а также добавляет случайный химически-осмысленный мусор - фрагменты других молекул, стрелки и надписи в свободное пространство изображения.
Генератор данных производит случайную модификацию базовой молекулы, производит изображение модифицированной молекулы, а также соответствующий FG-SMILES.
Генератор принимает на вход SMILES-строку. Затем он ищет в соответствующей молекуле функциональные группы, и случайно выбранную их часть заменяет на короткое представление, формируя таким образом FG-SMILES. Часть метильных заместителей меняются на случайную R-группу. Затем молекула отрисовывается средствами библиотеки RDKit в соответствии с тем, какие замены функциональных групп были произведены. Полученные пары «изображение-FG-SMILES» используются для обучения модели.
Обученная модель возвращает прогноз в виде строки FG-SMILES, а также уверенность в прогнозе - число от 0 до 1. Выявлена четкая закономерность между возвращаемым значением уверенности и корректностью ответа. Без учета значений уверенности базовая модель имеет на тестовых данных точность около 90%. Под точностью понимается доля полных соответствий между реальным значением и прогнозом, вплоть до различения индексов и количества штрихов около R-групп. Если отбрасывать примеры со значением уверенности меньше 0.98, то отбрасывается 10%, но на оставшихся примерах точность становится 97%. По порогу 0.99 отрезается 15%, точности на оставшихся — 98.6%, по порогу 0.995 отрезается 22%, точность на оставшихся 99.8%.
Фактически это позволяет говорить о достижении абсолютной точности, если не ставится задача распознать все. В задаче массового распознавания структур и реакций для автоматического наполнения баз данных не имеет принципиального значения, если часть структур будет отброшена, однако имеет принципиальное значение не допустить попадания ложных данных в базы данных. Таким образом, отрезание по порогу позволяет добиться практически абсолютной точности.
Фрагменты исходной страницы, распознанные детектором (101) как «стрелки реакций», передаются в блок распознавания стрелок (103). Первая сеть в блоке распознавания стрелок определяет, является ли фрагмент прямой стрелкой, означающей протекание реакции. По архитектуре сеть является простейшей сверточной сетью на базе ResNet. Сеть училась на 10 000 фрагментах, полученных из детектора (101), и размеченных вручную. Сеть возвращает «Да», если фрагмент — одна прямая стрелка, означающая необратимую реакцию, и «Нет» в остальных случаях. Таким образом, исключаются варианты, когда стрелка представляет обратимую реакцию, равновесное состояние, механизм реакции, либо фрагмент ошибочно возвращен детектором (101).
Координаты начала и конца стрелки распознаются другой сверточной сетью на базе ResNet с четырьмя выходами, означающими положение X и Y координат начала и конца стрелки соответственно, в долях длины/ширины фрагмента. Для обучения сети были размечены вручную 7000 реальных фрагментов, полученных с помощью детектора (101), для которых первая сеть вернула «Да».
Задачи, которые стоят перед обеими сетями, не являются сложными по меркам современных технологий в отличие от детектора (101) или блока распознавания структур (102), обе сети обучились с точностью, близкой к 100%.
Блок распознавания стрелок реакций (103) определяет координаты начала и конца стрелок на исходной странице. Вместе с координатами прямоугольников распознанных структур, эта информация передается в блок распознавания реакций (104), который представляет собой логический алгоритм, который определяет для каждой стрелки, есть ли для нее распознанная структура рядом с началом и концом стрелки. Если найден правдоподобный вариант, то структура у начала стрелки считается реагентом, а структура за концом стрелки — продуктом реакции. Блок распознавания реакций (104) формирует результат в виде готовых реакций. На выходе блока (104) формируется список распознанных структур с координатами и значениями уверенности, а также список реакций.
Таким образом, после обработки скана страницы на выходе системы (100) получают распознанные химические структуры, координаты на странице для каждой распознанной химической структуры, распознанные отношения между реактантами, агентами и продуктами химической реакции, представленными в виде химических структур, координаты на странице для каждого распознанного отношения.
Пример распознавания химической информации из изображений документов, который представлен для пояснения сути изобретения и никоим образом не ограничивает область изобретения.
На вход детектора (101) подают изображение страницы документа (Фиг. 3а), содержащей химическую информацию. Детектор (101) с помощью первой нейронной сети идентифицирует на странице фрагменты, содержащие химическую информацию. На Фиг. 3б идентифицированные детектором (101) фрагменты выделены прямоугольниками. Для каждого идентифицированного фрагмента получают координаты фрагмента на странице; и классифицируют фрагменты по следующим категориям: химическая структура – прямоугольники со структурой молекул, стрелка реакции - прямоугольник со стрелкой, дополнительная информация – под прямоугольниками молекул два маленьких прямоугольника «AZD9496», «A1», и один длинный прямоугольник, содержащий дополнительную информацию о химической реакции, а также прямоугольник заголовка «Scheme 1» (Фиг. 3б). Прямоугольники молекул имеют класс image, прямоугольник со стрелкой – класс condition, два маленьких прямоугольника и один длинный – класс description, прямоугольник заголовка – класс legend.
На вход блока распознавания структур (102) подают один или более идентифицированных фрагментов химических структур, причем каждый фрагмент представляет собой изображение (Фиг. 3в, 301, 302); блок распознавания структур (102) для каждого фрагмента распознает химическую структуру с помощью второй нейронной сети.
Для фрагмента (301) блок распознает FG-SMILES:
FC=1C=C(C=C(C1[C@H]1N([C@@H](CC2C1NC1=CC=CC=C21)C)CC(C)(C)F)F)/C=C/C(=O)O
Для фрагмента (302) блок распознает FG-SMILES:
C[C@@H]1CC2c3ccccc3N(C)C2[C@@H](c2c(F)cc(/C=C/C(=O)O)cc2F)N1CC(C)(C)F
На вход блока распознавания стрелок (103) подают идентифицированный фрагмент стрелки реакций (Фиг. 3г). Блок распознавания стрелок (103) с помощью третьей нейронной сети определяет тип стрелки – прямая стрелка, и с помощью четвертой нейронной сети получает координаты начала и конца стрелки на странице, и атрибуты реакции.
На вход блока распознавания реакций (104) передают координаты на странице каждого фрагмента распознанных химических структур, соответствующие распознанные химические структуры, координаты на странице каждой стрелки реакции, тип стрелки, атрибуты реакции; и на основании полученных данных блок распознавания реакций (104) определяет, как стрелки связывают распознанные химические структуры.
В результате на основании распознанных данных для изображения страницы документа получают одну или более распознанных химических структур, координаты на странице для каждой распознанной химической структуры, распознанные отношения между веществами, участвующими в химической реакции, представленными в виде химических структур, координаты на странице для каждого распознанного отношения.
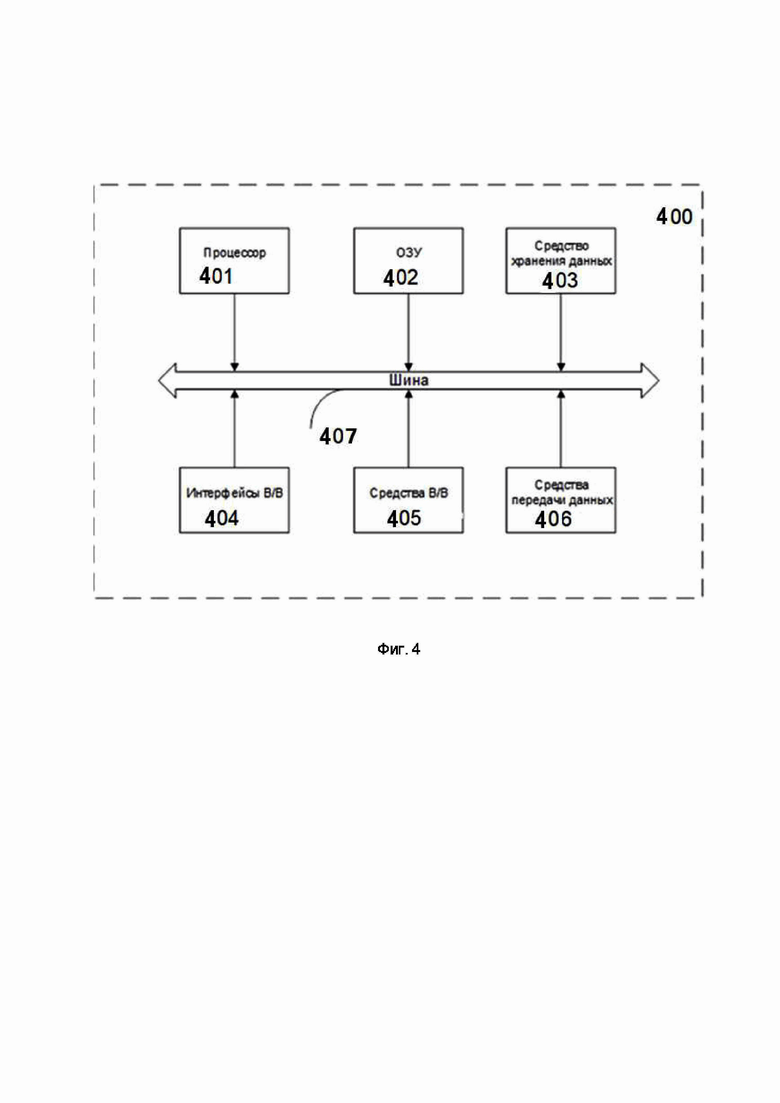
На Фиг. 4 представлена общая схема вычислительного устройства (400), обеспечивающего обработку данных, необходимую для реализации заявленного решения.
В общем случае устройство (400) содержит такие компоненты, как: один или более процессоров (401), по меньшей мере одну память (402), средство хранения данных (403), интерфейсы ввода/вывода (404), средство В/В (405), средства сетевого взаимодействия (406).
Процессор (401) устройства выполняет основные вычислительные операции, необходимые для функционирования устройства (400) или функциональности одного или более его компонентов. Процессор (401) исполняет необходимые машиночитаемые команды, содержащиеся в оперативной памяти (402).
Память (402), как правило, выполнена в виде ОЗУ и содержит необходимую программную логику, обеспечивающую требуемый функционал.
Средство хранения данных (403) может выполняться в виде HDD, SSD дисков, рейд массива, сетевого хранилища, флэш-памяти, оптических накопителей информации (CD, DVD, MD, Blue-Ray дисков) и т.п. Средство (403) позволяет выполнять долгосрочное хранение различного вида информации.
Интерфейсы (404) представляют собой стандартные средства для подключения и работы с серверной частью, например, USB, RS232, RJ45, LPT, COM, HDMI, PS/2, Lightning, FireWire и т.п.
Выбор интерфейсов (404) зависит от конкретного исполнения устройства (400), которое может представлять собой персональный компьютер, мейнфрейм, серверный кластер, тонкий клиент, смартфон, ноутбук и т.п.
В качестве средств В/В данных (405) в любом воплощении системы должна использоваться клавиатура. Аппаратное исполнение клавиатуры может быть любым известным: это может быть, как встроенная клавиатура, используемая на ноутбуке или нетбуке, так и обособленное устройство, подключенное к настольному компьютеру, серверу или иному компьютерному устройству. Подключение при этом может быть, как проводным, при котором соединительный кабель клавиатуры подключен к порту PS/2 или USB, расположенному на системном блоке настольного компьютера, так и беспроводным, при котором клавиатура осуществляет обмен данными по каналу беспроводной связи, например, радиоканалу, с базовой станцией, которая, в свою очередь, непосредственно подключена к системному блоку, например, к одному из USB-портов. Помимо клавиатуры, в составе средств В/В данных также может использоваться: джойстик, дисплей (сенсорный дисплей), проектор, тачпад, манипулятор мышь, трекбол, световое перо, динамики, микрофон и т.п.
Средства сетевого взаимодействия (406) выбираются из устройств, обеспечивающих сетевой прием и передачу данных, например, Ethernet карту, WLAN/Wi-Fi модуль, Bluetooth модуль, BLE модуль, NFC модуль, IrDa, RFID модуль, GSM модем и т.п. С помощью средств (405) обеспечивается организация обмена данными по проводному или беспроводному каналу передачи данных, например, WAN, PAN, ЛВС (LAN), Интранет, Интернет, WLAN, WMAN или GSM, 3G, 4G, 5G.
Компоненты устройства (400) сопряжены посредством общей шины передачи данных (407).
В настоящих материалах заявки представлено предпочтительное раскрытие осуществления заявленного технического решения, которое не должно использоваться как ограничивающее иные, частные воплощения его реализации, которые не выходят за рамки испрашиваемого объема правовой охраны и являются очевидными для специалистов в соответствующей области техники.
Специалисту в данной области техники должно быть понятно, что различные вариации заявляемого способа и системы не изменяют сущность изобретения, а лишь определяют его конкретные воплощения и применения.
Источники
[1] Rajan et al., DECIMER 1.0: Deep Learning for Chemical Image Recognition using Transformers, 2021 https://chemrxiv.org/ndownloader/files/27775521
[2] Sundaramoorthy et al., End-to-End Attention-based Image Captioning», 30.04.2021 https://arxiv.org/pdf/2104.14721.pdf
[3] Clevert et al., Img2Mol-Accurate SMILES Recognition from Molecular Graphical Depictions, 2021 https://chemrxiv.org/ndownloader/files/27273986.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА РАСПОЗНАВАНИЯ ИЗОБРАЖЕНИЯ: BEORG SMART VISION | 2020 |
|
RU2777354C2 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ ПРИМЕНЕНИЯ СПЕЦИАЛИЗИРОВАННЫХ ФУНКЦИЙ УВЕРЕННОСТИ, РЕАЛИЗУЕМОЕ НА БАЗЕ НЕЙРОННЫХ СЕТЕЙ | 2018 |
|
RU2703270C1 |
| ОБУЧЕНИЕ НЕЙРОННОЙ СЕТИ ПОСРЕДСТВОМ СПЕЦИАЛИЗИРОВАННЫХ ФУНКЦИЙ ПОТЕРЬ | 2018 |
|
RU2707147C1 |
| РАСПОЗНАВАНИЕ РУКОПИСНОГО ТЕКСТА ПОСРЕДСТВОМ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2757713C1 |
| ИДЕНТИФИКАЦИЯ ПОЛЕЙ НА ИЗОБРАЖЕНИИ С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2018 |
|
RU2695489C1 |
| РАСПОЗНАВАНИЕ ТЕКСТА С ИСПОЛЬЗОВАНИЕМ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА | 2017 |
|
RU2691214C1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА НА ИЗОБРАЖЕНИЯХ ДОКУМЕНТОВ | 2021 |
|
RU2768544C1 |
| СПОСОБ ОБРАБОТКИ ИЗОБРАЖЕНИЙ С ИСПОЛЬЗОВАНИЕМ АДАПТИВНЫХ ТЕХНОЛОГИЙ НА ОСНОВЕ НЕЙРОСЕТЕЙ И КОМПЬЮТЕРНОГО ЗРЕНИЯ | 2020 |
|
RU2744769C1 |
| СПОСОБ И СИСТЕМА РАСПОЗНАВАНИЯ ЭМОЦИОНАЛЬНОГО СОСТОЯНИЯ СОТРУДНИКОВ | 2021 |
|
RU2768545C1 |
| Способ поиска машиночитаемой зоны документа на изображении с помощью ИНС, содержащей прямое и транспонированное преобразования Хафа | 2024 |
|
RU2833293C1 |




Изобретение относится к области вычислительной техники для распознавания данных. Техническим результатом является обеспечение автоматического распознавания из изображений документов химической информации, сокращение времени и повышение точности распознавания химической информации из изображений документов. Компьютерно-реализуемый способ включает следующие этапы: ввод изображения страницы документа в детектор; детектор идентифицирует фрагменты на странице; получение координат фрагмента на странице для каждого идентифицированного фрагмента; и классификация фрагментов; блок распознавания структуры распознает химическую структуру для каждого фрагмента; ввод идентифицированных фрагментов стрелок реакции в блок распознавания стрелок; получение координат на странице для каждой стрелки и атрибутов реакции; подачу на вход блока распознавания реакций координат на странице для каждого фрагмента распознанных химических структур; и на основании полученных данных блок распознавания реакций определяет, как стрелки относятся к распознаваемым химическим структурам; в результате на основе распознанных данных для изображения страницы документа получаются распознанные химические структуры. 2 н. и 15 з.п. ф-лы, 7 ил.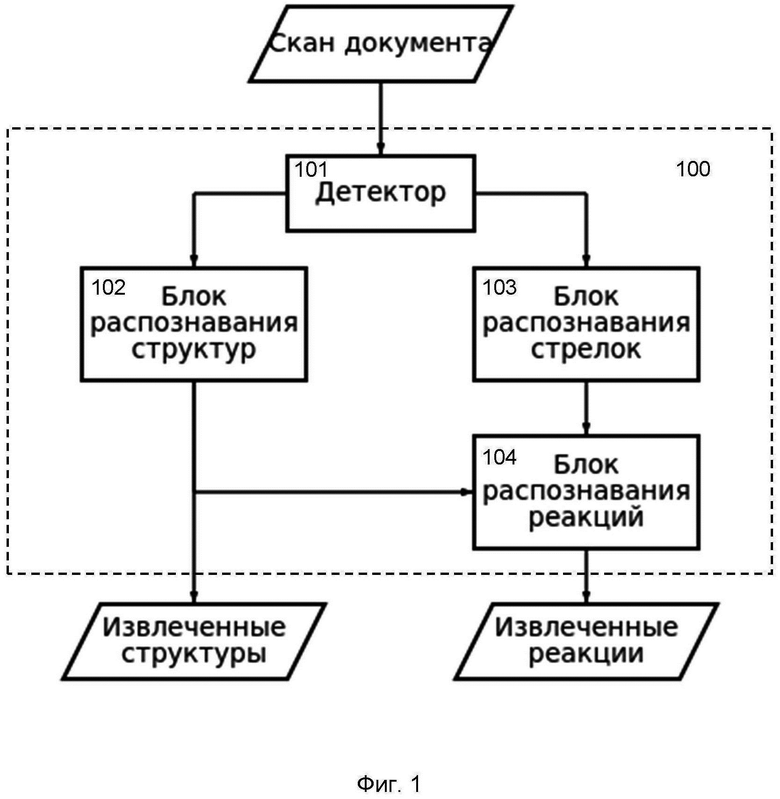
1. Компьютерно-реализуемый способ распознавания химической информации из изображений документов, в котором вычислительное устройство, содержащее процессор и память, хранит в памяти инструкции, исполняемые процессором, и исполняет инструкции, включающие этапы, на которых:
- на вход детектора подают изображение страницы документа; детектор с помощью первой нейронной сети идентифицирует на странице один или более фрагментов, содержащих химическую информацию; для каждого идентифицированного фрагмента получают координаты фрагмента на странице; и классифицируют фрагменты по меньшей мере по следующим категориям: химическая структура, стрелка реакции;
- на вход блока распознавания структур подают один или более идентифицированных фрагментов химических структур, причем каждый фрагмент представляет собой изображение; блок распознавания структур для каждого фрагмента распознает химическую структуру с помощью второй нейронной сети;
- на вход блока распознавания стрелок подают один или более идентифицированных фрагментов стрелок реакций; блок распознавания стрелок с помощью третьей нейронной сети определяет тип стрелки, и с помощью четвертой нейронной сети получают координаты на странице для каждой стрелки, и атрибуты реакции;
- на вход блока распознавания реакций передают координаты на странице каждого фрагмента распознанных химических структур, соответствующие распознанные химические структуры, координаты на странице каждой стрелки реакции, тип стрелки, атрибуты реакции; и на основании полученных данных блок распознавания реакций определяет, как стрелки связывают распознанные химические структуры;
- в результате на основании распознанных данных для изображения страницы документа получают одну или более распознанных химических структур, координаты на странице для каждой распознанной химической структуры, распознанные отношения между веществами, участвующими в химической реакции, представленными в виде химических структур, координаты на странице для каждого распознанного отношения.
2. Способ по п. 1, характеризующийся тем, что химическая структура является, по меньшей мере, химическим соединением, структурой Маркуша, химической структурой с заместителями.
3. Способ по п. 1, характеризующийся тем, что дополнительно идентифицируют фрагменты, содержащие дополнительную информацию, способствующую распознаванию реакций.
4. Способ по п. 3, характеризующийся тем, что дополнительная информация включает, по меньшей мере, следующее: заголовок, легенда.
5. Способ по п. 1, характеризующийся тем, что детектор дополнительно для каждого идентифицированного фрагмента определяет уверенность – число от 0 до 1, которое оценивает достоверность идентифицированного фрагмента, где 0 – абсолютно не уверен, 1 – полностью уверен.
6. Способ по п. 5, характеризующийся тем, что идентифицированные фрагменты фильтруют по предустановленному порогу уверенности.
7. Способ по п. 6, характеризующийся тем, что устанавливают порог уверенности для каждой категории фрагментов.
8. Способ по п. 1, характеризующийся тем, что первая нейронная сеть является нейронной сетью Faster R-CNN или другой сверточной сетью равной или большей мощности.
9. Способ по п. 1, характеризующийся тем, что вторая нейронная сеть является нейронной сетью на базе архитектуры трансформера, и блок распознавания структур содержит сверточный блок и декодер трансформера.
10. Способ по п. 9, характеризующийся тем, что в качестве сверточного блока используется ResNet-50 без последних двух слоев или другая сверточная сеть, работающая с изображениями.
11. Способ по п. 1, характеризующийся тем, что распознанная химическая структура представляет собой текстовую последовательность, однозначно описывающую химическую структуру.
12. Способ по п. 11, характеризующийся тем, что описывают химическую структуру в виде текстовой последовательности с помощью модификации SMILES, способной описать структуры Маркуша и химические структуры с заместителями.
13. Способ по п. 12, характеризующийся тем, что реализован механизм конвертации модификации SMILES, способной описать структуры Маркуша и химические структуры с заместителями, в SMILES и обратно.
14. Способ по п. 1, характеризующийся тем, что третья и четвертая нейронные сети являются сверточными нейронными сетями на базе ResNet.
15. Способ по п. 1, характеризующийся тем, что стрелки классифицируют по следующим типам: прямая стрелка, стрелка, которая не является прямой стрелкой.
16. Способ по п. 1, характеризующийся тем, что веществами, участвующими в химической реакции, являются исходные вещества химической реакции, продукты химической реакции.
17. Система распознавания химической информации из изображений документов, содержащая:
- детектор;
- блок распознавания структур;
- блок распознавания стрелок;
- блок распознавания реакций;
и в которой вычислительное устройство, содержащее процессор и память, хранящую инструкции, исполняемые процессором, осуществляет способ по пп. 1-16.
| CN 112818645 A, 18.05.2021 | |||
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| Многоступенчатая активно-реактивная турбина | 1924 |
|
SU2013A1 |
| CN 111860507 A, 30.10.2020 | |||
| СПОСОБ И УСТРОЙСТВО ДЛЯ УПРАВЛЕНИЯ ПРИЛОЖЕНИЕМ ПОСРЕДСТВОМ РАСПОЗНАВАНИЯ НАРИСОВАННОГО ОТ РУКИ ИЗОБРАЖЕНИЯ | 2013 |
|
RU2650029C2 |

