Предполагаемое изобретение относится к области информационной безопасности, а более конкретно - к способу обнаружения фишинговых веб-страниц путем анализа доменных имен.
Уровень техники
В настоящее время распространенным видом интернет-мошенничества является фишинг.Фишинг - это вид интернет-мошенничества, целью которого является получение доступа к конфиденциальным данным пользователей сети Интернет. Для реализации фишинговых атак злоумышленники могут подделывать веб-страницы различных ресурсов (интернет-банков, онлайн-магазинов, корпоративных сервисов компаний), на которых вводятся конфиденциальные данные пользователей (авторизационные данные, платежные данные). Для этого злоумышленники могут создавать поддельные веб-сайты, содержащие веб-страницы с формами ввода конфиденциальных данных, делая их визуально похожими на легитимные, а затем размещать вебсайты на веб-адресах, доменные имена которых незначительно отличаются от легитимных доменных имен.
Известны техники создания фишинговых доменных имен, нацеленные на создание доменных имен, визуально похожих на легитимные, но фактически отличающихся от них. Целенаправленное применение таких техник с целью мошенничества называют тайпсквоттингом (от англ. «typosquatting»: «typo» - опечатка, «cybersquatting» - самовольный захват доменного имени). К техникам тайпсквот-тинга относят пропуск, повторение, добавление, перестановку символов, замену символов на омоглифы (графически одинаковые или похожие, но фактически отличающиеся символы), замену символов на соседние по раскладке на клавиатуре и др. (Jeffrey Spaulding, DaeHun Nyang, and Aziz Mohaisen. 2017. Understanding the effectiveness of typosquatting techniques. In Proceedings of the fifth ACM/IEEE Workshop on Hot Topics in Web Systems and Technologies (HotWeb'17). Association for Computing Machinery, New York, NY, USA, Article 9, 1-8, DOI: https://doi.org/10.1145/3132465.3132467; патент США №8285830 от 09.10.2012 г.; патент США №7756987 от 13.07.2010 г.). Использование доменных имен, созданных с применением техник тайпсквоттинга, позволяет рассчитывать на то, что для пользователя поддельное доменное имя на первый взгляд будет неотличимо от оригинального. Используя методы социальной инженерии, злоумышленники добиваются того, что пользователи переходят по фишинговым адресам и вводят там конфиденциальные данные. После этого злоумышленники захватывают данные пользователей через поддельную форму ввода и получают возможность их неправомерного использования.
Существующие способы обнаружения фишинговых веб-сайтов могут условно быть разделены на два типа. К первому типу относятся такие способы, которые для своей работы требуют загрузки содержимого анализируемой веб-страницы. Согласно некоторым из них, для обнаружения фишинговых веб-страниц анализируют исходный код веб-страницы на предмет соответствия специфическим шаблонам, характерным для мошеннических веб-страниц. Общий признак таких подходов одновременно является их недостатком: загрузка содержимого потенциально вредоносной веб-страницы должна производиться в безопасном изолированном окружении, чтобы исключить возможный вред. Такой подход накладывает ограничения на программно-аппаратную реализацию средств обнаружения и на их быстродействие.
Ко второму типу способов обнаружения фишинговых веб-сайтов относятся такие, которые для своей работы не требуют загрузки содержимого анализируемой веб-страницы. Согласно некоторым из них, для обнаружения фишинговых веб-страниц производится анализ веб-адреса и доменного имени на предмет соответствия специфическим шаблонам, характерным для мошеннических веб-адресов. Такой подход позволяет обеспечить высокую скорость обработки доменных имен и не требует специального изолированного окружения. Для обнаружения фишинговых доменных имен, созданных с применением техник тайпсквоттинга, предпочтительно применение способов, основанных на анализе доменных имен и не требующих загрузки содержимого анализируемой веб-страницы.
Известен способ защиты пользователя от сообщений со ссылками на вредоносные веб-сайты (патент Великобритании №2550657 от 29.11.2017 г.), согласно которому обнаружение вредоносных веб-сайтов производится путем анализа гиперссылок, содержащихся в текстах электронных сообщений пользователей. Способ предполагает предварительное составление списка легитимных доменных имен, часто встречающихся в текстах электронных сообщений пользователей. Анализ гиперссылки, содержащейся в электронном сообщении, начинается с выяснения факта отношения доменного имени в гиперссылке к одному из легитимных доменных имен. В случае, если гиперссылка относится к одному из легитимных доменных имен, она признается невредоносной, и происходит анализ следующей гиперссылки в электронном сообщении. В случае, если доменное имя в гиперссылке не относится ни к одному из легитимных доменных имен, происходит анализ данного доменного имени на предмет текстовой и визуальной схожести с легитимными доменными именами, а также анализ регистрационных данных доменного имени. Анализ доменного имени на предмет текстовой и визуальной схожести с легитимными доменными именами производится с целью обнаружения доменного имени, подозрительно похожего на одно из легитимных доменных имен, но не идентичного ни одному из них.
Отличительным признаком известного способа является анализ доменного имени в гиперссылке на предмет визуальной схожести с легитимными доменными именами. Для этого, согласно известному способу, цифровое изображение начертания анализируемого доменного имени в электронном сообщении с учетом типографических особенностей (размера и цвета текста, шрифта и др.) сравнивается с цифровыми изображениями начертаний легитимных доменных имен. При анализе доменного имени на предмет текстовой схожести с легитимными доменными именами, согласно известному способу, предлагается использование различных эвристических правил, в которых учитываются возможные замены символов в легитимном доменном имени на омоглифы этих символов. Анализ регистрационных данных доменного имени, таких как дата и страна регистрации и т.п., производится путем обращения к сторонним сервисам, предоставляющим такую информацию.
Описанный способ имеет следующие недостатки:
 не описаны конкретные алгоритмы анализа доменного имени на предмет текстовой и визуальной схожести с легитимными доменными именами, приводятся лишь общие рассуждения и примеры эвристических правил;
не описаны конкретные алгоритмы анализа доменного имени на предмет текстовой и визуальной схожести с легитимными доменными именами, приводятся лишь общие рассуждения и примеры эвристических правил;
информация о возможном применении злоумышленником известных техник для создания фишинговых доменных имен (техник тайпсквоттинга) используется не в полной мере: приведенные примеры правил для анализа доменного имени на предмет текстовой схожести с легитимными доменными именами учитывают только замену символов в доменном имени на омоглифы и не учитывают другие техники создания фишинговых доменных имен, такие как пропуск, добавление, повторение, перестановку символов, и т.п.
Известен также способ блокирования целевых атак с использованием захвата домена (патент США №10419477 от 17.09.2019 г.), согласно которому обнаружение вредоносных доменных имен производится путем сравнения на предмет текстовой схожести неидентифицированного доменного имени со списком легитимных доменных имен. Анализ доменного имени на предмет текстовой схожести с легитимными доменными именами производится с целью обнаружения доменного имени, подозрительно похожего на одно из легитимных доменных имен, но не идентичного ни одному из них. Для этого предварительно получают список легитимных доменных имен. Согласно известному способу, в качестве такого списка то могут быть выбраны наиболее популярные доменные имена в сети Интернет. Также, согласно известному способу, список может дополняться новыми доменными именами или включать специфические доменные имена пользователя (например, если предприятие, имеющее собственные доменные имена, использует известный способ для их защиты).
После получения списка легитимных доменных имен производится сравнение неидентифицированного доменного имени с легитимными доменными именами путем вычисления расстояния от неидентифицированного доменного имени до каждого из легитимных доменных имен. Затем на основе результатов сравнения производится определение того, является ли неидентифицированное доменное имя попыткой захвата одного из легитимных доменных имен. Результатом обработки неидентифицированного доменного имени является уведомление пользователя об обнаруженной попытке захвата доменного имени и/или блокирование неидентифицированного доменного имени.
Согласно известному способу, расстояние от неидентифицированного доменного имени до каждого из легитимных доменных имен определяется как взвешенная комбинация множества расстояний между доменными именами, где множество расстояний может включать в себя расстояние Левенштейна, коэффициент Серенсена -Дайса и индекс Жаккара, а весовые коэффициенты во взвешенной комбинации настраиваются динамически на основании истории обнаружений. Также на основании истории обнаружений динамически настраивается пороговое значение расстояния между неидентифицированным доменным именем и списком легитимных доменных имен, относительно которого принимается решение о попытке захвата домена. При этом конкретный алгоритм для динамической настройки указанных параметров не приводится.
Этот способ принимается в качестве прототипа.
Однако, известный способ имеет невысокую вероятность обнаружения фишинговых доменных имен, поскольку:
 не используется информация о возможном применении злоумышленником известных техник для создания фишинговых доменных имен (техник тайпсквоттинга);
не используется информация о возможном применении злоумышленником известных техник для создания фишинговых доменных имен (техник тайпсквоттинга);
 настройка параметров способа (весовых коэффициентов и порогового значения для решающего правила) происходит на основании истории обнаружений, то есть в процессе работы системы, что снижает вероятность обнаружения на начальном этапе работы, когда история обнаружений еще не накоплена;
настройка параметров способа (весовых коэффициентов и порогового значения для решающего правила) происходит на основании истории обнаружений, то есть в процессе работы системы, что снижает вероятность обнаружения на начальном этапе работы, когда история обнаружений еще не накоплена;
 не приводятся алгоритмы настройки параметров способа (весовых коэффициентов во взвешенной комбинации множества расстояний и порогового значения расстояния).
не приводятся алгоритмы настройки параметров способа (весовых коэффициентов во взвешенной комбинации множества расстояний и порогового значения расстояния).
Раскрытие изобретения
Техническим результатом является повышение вероятности обнаружения фишинговых доменных имен.
Для этого предлагается способ обнаружения фишинговых доменных имен, реализуемый в вычислительной системе, которая включает:
 по крайней мере, одно вычислительное средство, имеющее установленную операционную систему и прикладные программы и выполненное с возможностью:
по крайней мере, одно вычислительное средство, имеющее установленную операционную систему и прикладные программы и выполненное с возможностью:
 хранить и обрабатывать числовые массивы данных;
хранить и обрабатывать числовые массивы данных;
 хранить и обрабатывать данные строкового типа; заключающийся в том, что:
хранить и обрабатывать данные строкового типа; заключающийся в том, что:
 составляют множество легитимных доменных имен, для которых обеспечивается защита;
составляют множество легитимных доменных имен, для которых обеспечивается защита;
 создают множество псевдофишинговых доменных имен, состоящее из измененных легитимных доменных имен, для чего в каждое легитимное доменное имя вносят изменения, включая:
создают множество псевдофишинговых доменных имен, состоящее из измененных легитимных доменных имен, для чего в каждое легитимное доменное имя вносят изменения, включая:
 добавление символов латинского алфавита в конец домена второго уровня;
добавление символов латинского алфавита в конец домена второго уровня;
 вставку символов латинского алфавита в различные места между символами в домене второго уровня;
вставку символов латинского алфавита в различные места между символами в домене второго уровня;
 вставку символа «дефис» (-) в различные места между символами в домене второго уровня;
вставку символа «дефис» (-) в различные места между символами в домене второго уровня;
 вставку символа «точка» (.) в различные места между символами в домене второго уровня;
вставку символа «точка» (.) в различные места между символами в домене второго уровня;
 замену символов в домене второго уровня на омоглифы этих символов;
замену символов в домене второго уровня на омоглифы этих символов;
 замену символов гласных букв в домене второго уровня на символы других гласных букв;
замену символов гласных букв в домене второго уровня на символы других гласных букв;
 замену символов в домене второго уровня на соседние по раскладке на клавиатуре символы;
замену символов в домене второго уровня на соседние по раскладке на клавиатуре символы;
 пропуск символов в домене второго уровня;
пропуск символов в домене второго уровня;
 повторение символов в домене второго уровня;
повторение символов в домене второго уровня;
 перестановку соседних символов в домене второго уровня;
перестановку соседних символов в домене второго уровня;
 для каждого доменного имени из множества псевдофишинговых доменных имен определяют расчетное расстояние до множества легитимных доменных имен, при этом в качестве расчетного расстояния принимают минимальное из нормированных расстояний Дамерау - Левенштейна между данным доменным именем и каждым доменным именем из множества легитимных доменных имен, и формируют из расчетных расстояний одномерный числовой массив;
для каждого доменного имени из множества псевдофишинговых доменных имен определяют расчетное расстояние до множества легитимных доменных имен, при этом в качестве расчетного расстояния принимают минимальное из нормированных расстояний Дамерау - Левенштейна между данным доменным именем и каждым доменным именем из множества легитимных доменных имен, и формируют из расчетных расстояний одномерный числовой массив;
 на основании числового массива расчетных расстояний определяют пороговое расчетное расстояние;
на основании числового массива расчетных расстояний определяют пороговое расчетное расстояние;
 обнаруживают фишинговые доменные имена, для чего с доменным именем, поступившим на обработку, выполняют следующие действия:
обнаруживают фишинговые доменные имена, для чего с доменным именем, поступившим на обработку, выполняют следующие действия:
 определяют расчетное расстояние до множества легитимных доменных имен, при этом в качестве расчетного расстояния принимают минимальное из нормированных расстояний Дамерау - Левенштейна между данным доменным именем и каждым доменным именем из множества легитимных доменных имен;
определяют расчетное расстояние до множества легитимных доменных имен, при этом в качестве расчетного расстояния принимают минимальное из нормированных расстояний Дамерау - Левенштейна между данным доменным именем и каждым доменным именем из множества легитимных доменных имен;
 если расчетное расстояние равно нулю, то данное доменное имя считают легитимным, и на этом его обработку завершают;
если расчетное расстояние равно нулю, то данное доменное имя считают легитимным, и на этом его обработку завершают;
 если расчетное расстояние не равно нулю, то:
если расчетное расстояние не равно нулю, то:
 сравнивают расчетное расстояние с пороговым расчетным расстоянием;
сравнивают расчетное расстояние с пороговым расчетным расстоянием;
 если расчетное расстояние больше порогового расчетного расстояния, то данное доменное имя не считают фишинговым, и на этом его обработку завершают;
если расчетное расстояние больше порогового расчетного расстояния, то данное доменное имя не считают фишинговым, и на этом его обработку завершают;
 если расчетное расстояние меньше порогового расчетного расстояния или равно ему, то данное доменное имя считают фишинговым и выполняют следующие действия:
если расчетное расстояние меньше порогового расчетного расстояния или равно ему, то данное доменное имя считают фишинговым и выполняют следующие действия:
 определяют для данного доменного имени легитимное доменное имя, до которого нормированное расстояние Дамерау - Левенштейна минимально;
определяют для данного доменного имени легитимное доменное имя, до которого нормированное расстояние Дамерау - Левенштейна минимально;
 при необходимости, формируют отчет об обнаруженном фи-шинговом доменном имени с указанием определенного легитимного доменного имени, расчетного расстояния до него и порогового расчетного расстояния;
при необходимости, формируют отчет об обнаруженном фи-шинговом доменном имени с указанием определенного легитимного доменного имени, расчетного расстояния до него и порогового расчетного расстояния;
 завершают обработку данного доменного имени.
завершают обработку данного доменного имени.
Дополнительно в способе для определения порогового расчетного расстояния выбирают допустимый уровень ошибки второго рода β, где 0<β<1, и в качестве порогового расчетного расстояния принимают выборочную квантиль порядка (1-β) распределения расчетных расстояний в числовом массиве расчетных расстояний.
Кроме того, в способе в качестве порогового расчетного расстояния принимают значение dth, вычисляемое согласно выражению
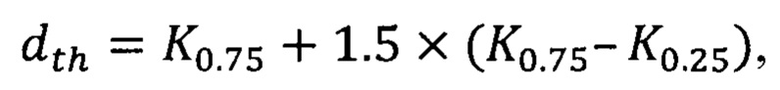
где K0,75 и K0,25 - соответственно выборочные 0,75- и 0,25-квантили распределения расчетных расстояний в числовом массиве расчетных расстояний.
В предлагаемом способе исходным объектом является множество легитимных доменных имен, для которых обеспечивается защита. Данное множество, в общем случае, может быть составлено по усмотрению пользователя. Так как целью фишинговых атак является получение несанкционированного доступа к конфиденциальным (например, авторизационным или платежным) данным пользователей, то целесообразно включение в данное множество доменных имен тех ресурсов, на которых пользователи вводят такие данные. Например, в него могут быть включены доменные имена онлайн-банков, платежных систем, сервисов электронной почты, социальных сетей, медицинских учреждений, сервисов государственных услуг и т.п. Также защита может обеспечиваться для доменных имен корпоративных ресурсов предприятий.
В том случае, если предприятие использует способ для защиты сотрудников от фишинговых атак, то в множество легитимных доменных имен могут быть дополнительно включены доменные имена корпоративных ресурсов предприятия. Например, это могут быть доменные имена ресурсов корпоративной электронной почты, корпоративного веб-портала и т.п.
Другим возможным источником легитимных доменных имен могут являться сервисы, предоставляющие списки наиболее популярных веб-сайтов в сети Интернет. К таким сервисам, например, относятся «А1еха Top Sites» (сведения по адресу https://www.alexa.com/topsites) и «Similarweb» (сведения по адресу https://www.similarweb.com/ru/top-websites/). Тем не менее, использование подобных сервисов в качестве источника легитимных доменных имен не исключает возможности добавления доменных имен по своему усмотрению, как это описано выше.
Отличительной особенностью предлагаемого способа является этап создания множества псевдофишинговых доменных имен. Под псевдофишинговым доменным именем понимается доменное имя, фактически отличающееся от некоторого легитимного, но визуально похожее на него вследствие применения техник тайпсквоттинга. При этом приставка «псевдо-» указывает на то, что созданные таким образом доменные имена не являются в полной мере фишинговыми, так как они не регистрируются и не используются с целью фишинга в сети Интернет. Поскольку техники создания фишинговых доменных имен (техники тайпсквоттинга) известны и описаны (см., например, Jeffrey Spaulding, DaeHun Nyang, and Aziz Mohaisen. 2017. Understanding the effectiveness of typosquatting techniques. In Proceedings of the fifth ACM/IEEE Workshop on Hot Topics in Web Systems and Technologies (HotWeb'17). Association for Computing Machinery, New York, NY, USA, Article 9, 1-8. DOI:https://doi.org/10.1145/3132465.3132467; патент США №8285830 от 09.10.2012 г.; патент США №7756987 от 13.07.2010 г.), то представляется возможным прогнозирование наиболее вероятных действий злоумышленника в отношении легитимных доменных имен.
Рассмотрим применение таких техник на примере одного легитимного доменного имени. Пусть таковым является «infotecs.ru». Примеры применения различных техник тайпсквоттинга для создания псевдофишинговых доменных имен приведены в табл. 1.
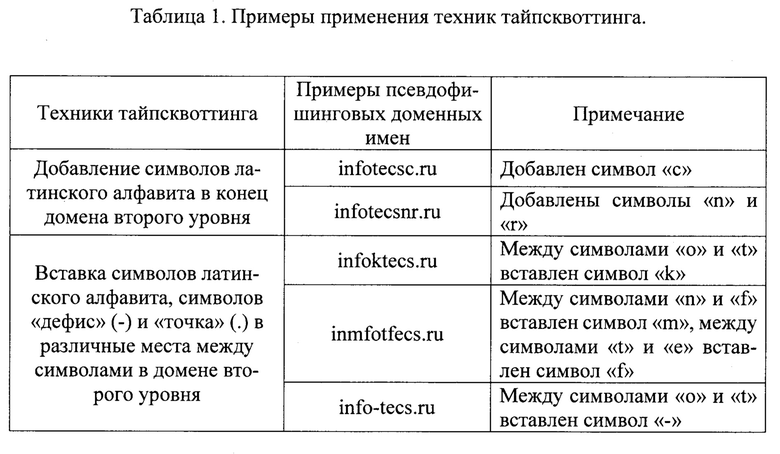
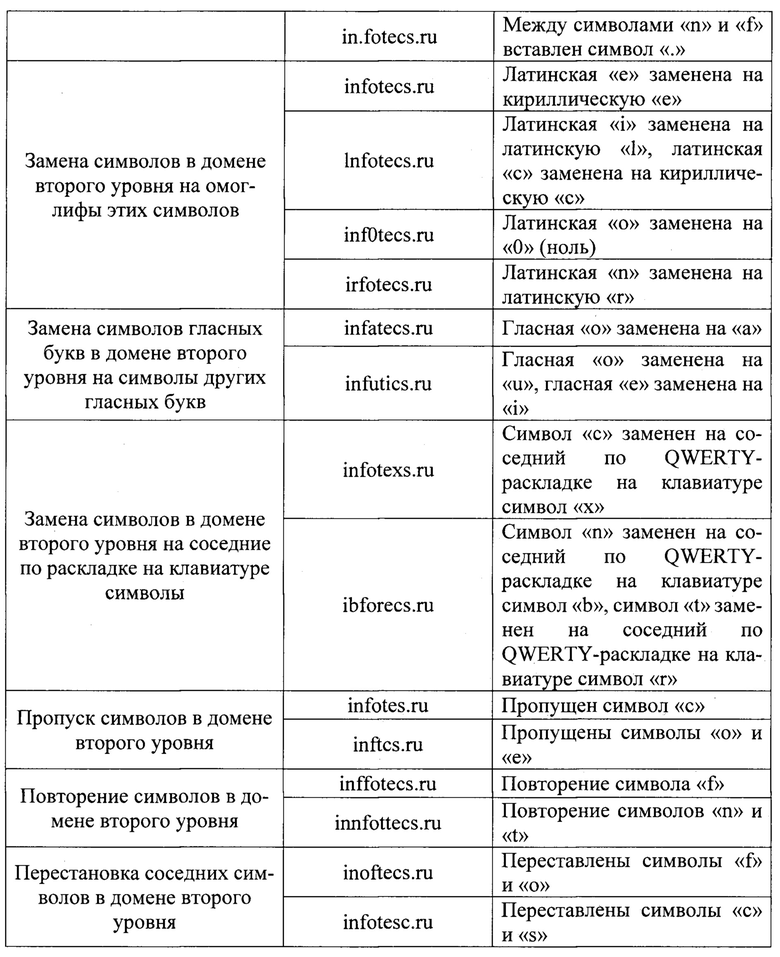
Приведенные примеры не являются исчерпывающими, так как возможны и другие многочисленные варианты добавления, вставки, замены, пропуска, повторения и перестановки символов в легитимном доменном имени. Таким образом, применение техник тайпсквоттинга к каждому легитимному доменному имени позволяет создать большое количество псевдофишинговых доменных имен, и, тем самым, спрогнозировать различные варианты действий злоумышленника. При этом, чем большее количество известных техник будет применено, тем более широким будет такое прогнозирование.
Созданное в результате данного этапа множество псевдофишинговых доменных имен, фактически, будет являться репрезентативной выборкой из генеральной совокупности фишинговых доменных имен, относящихся к заданным легитимным доменным именам. Репрезентативность выборки обеспечивается актуальностью применяемых техник тайпсквоттинга. Данная выборка позволит настроить параметры способа до начала действий по фактическому обнаружению фишинговых доменных имен. Такая предварительная настройка, в свою очередь, позволит с высокой вероятностью обнаруживать фишинговые доменные имена, не дожидаясь накопления какой-либо истории обнаружений.
Обнаружение фишинговых доменных имен в способе основывается на сравнении обрабатываемого доменного имени с множеством легитимных доменных имен. Целью этого сравнения является обнаружение доменного имени, подозрительно похожего на одно из легитимных доменных имен, но не идентичного ни одному из них. Для определения операции сравнения доменных имен между собой требуется ввести некую меру схожести между ними. Отметим, что доменные имена можно рассматривать как объекты строкового типа, то есть как последовательности символов. Известны различные меры схожести, которые могут быть введены для сравнения последовательностей символов. Например, к ним относятся такие меры, как сходство Джаро - Винклера, расстояние Левенштейна, расстояние Дамерау - Левенштейна, расстояние Хэмминга, коэффициент Серенсена и другие (Категория: Меры схожести строк [Электронный ресурс]. URL: https://ru.wikipe-dia.org/wiki/Категория:Меры_схожести_строк).
Применительно к сравнению псевдофишинговых доменных имен, созданных с применением техник тайпсквоттинга, с легитимными доменными именами, наиболее подходящим по существу является расстояние Дамерау - Левенштейна.
Расстояние Дамерау - Левенштейна - это мера разницы двух строк символов, определяемая как минимальное количество операций вставки, удаления, замены и перестановки двух соседних символов, необходимых для перевода одной строки в другую. Оно является модификацией расстояния Левенштейна, которое определяется схожим образом, но допускает только операции вставки, удаления и замены символов. Расстояние Дамерау - Левенштейна выбирается как мера схожести при решении данной задачи за счет комплементарности определяющих его операций (вставка, удаление, замена, перестановка) и операций, применяемых в техниках тайпсквоттинга (пропуск, добавление, вставка, повторение, замена, перестановка).
Расстояние Дамерау - Левенштейна dDL{S1, S2) между двумя строками S1 и S2, длины 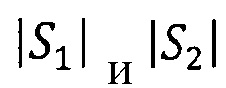 соответственно, обладает следующими свойствами:
соответственно, обладает следующими свойствами:
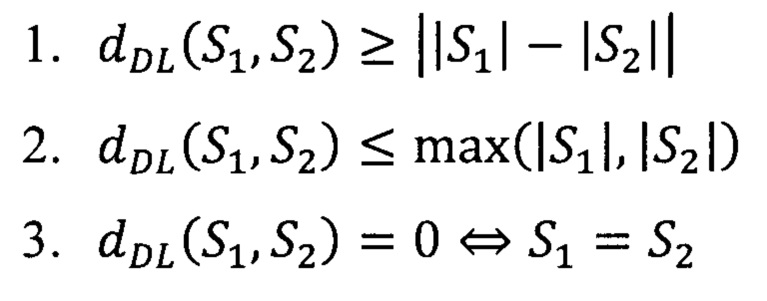
Свойство 2 говорит о том, что расстояние Дамерау - Левенштейна ограничено сверху максимальной длиной строки из S1 и S2. Говоря о текстовом анализе доменных имен, стоит отметить, чем более длинное доменное имя анализируется, тем потенциально больше в нем может быть изменений и опечаток по сравнению с легитимным доменным именем. Принимая это во внимание, а также с учетом того, что длина доменных имен в сети Интернет варьируется от единиц до десятков символов, для корректного сравнения требуется отнормировать расстояние Дамерау - Левенштейна, чтобы привести его к единому числовому диапазону для доменных имен различной длины.
Для этого в способе предлагается использование нормированного расстояния Дамерау - Левенштейна dNDL(S1,S2), вычисляемого по формуле
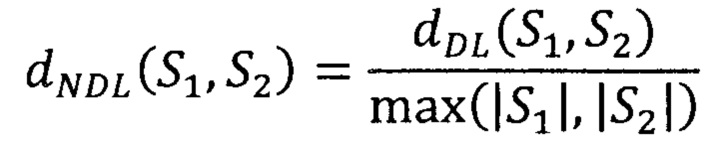
При данном способе нормировки, нормированное расстояние Дамерау - Левенштейна будет ограничено отрезком 0<dNDL(S1,S2)<1. При этом равенство расстояния нулю dNDL(S1,S2)=0 будет означать полное соответствие Sx и S2, а равенство расстояния единице dNDL(S1,S2)=1 - их максимальное различие.
Нормированное расстояние Дамерау - Левенштейна применяется для определения расчетного расстояния от некоторого доменного имени до множества легитимных доменных имен. Расчетное расстояние dcalc(S) для доменного имени S1 принимают равным минимальному из нормированных расстояний Дамерау - Левенштейна между данным доменным именем и каждым доменным именем из множества легитимных доменных имен:
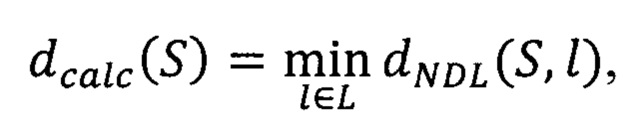
где 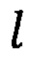 - легитимное доменное имя,
- легитимное доменное имя,
L - множество легитимных доменных имен. Данное определение расчетного расстояния вводится исходя из предположения, что для фишингового доменного имени S найдется такое схожее легитимное доменное имя l из множества L, что нормированное расстояние Дамерау - Левенштейна между ними окажется достаточно мало, чтобы обнаружить доменное имя S как фишинговое. При этом в обратном случае, если доменное имя S не является фи-шинговым, то нормированное расстояние Дамерау - Левенштейна от него до всех легитимных доменных имен будет достаточно велико, чтобы не обнаружить его как фишинговое. В таком случае верно следующее: чем меньше величина расчетного расстояния для некоторого доменного имени, тем более достоверна гипотеза о том, что данное доменное имя является фишинговым, а также верно и обратное.
Данное определение расчетного расстояния позволяет рассчитывать на то, что расчетные расстояния для фишинговых доменных имен будут оказываться закономерно меньше, чем расчетные расстояния для доменных имен, не являющихся фи-шинговыми. Тогда распределения расчетных расстояний для данных двух классов доменных имен будут закономерно отличаться, и отнесение некоторого доменного имени к одному из данных классов может быть выполнено относительно некоторого порогового расчетного расстояния. При этом отнесении неизбежно возникнут вероятности ошибки первого и второго рода.
Ошибкой первого рода, или ложноположительным заключением, назовем ситуацию, когда доменное имя, не являющееся фишинговым, ложно обнаруживается как фишинговое.
Ошибкой второго рода, или ложноотрицательным заключением, назовем ситуацию, когда истинно фишинговое доменное имя не обнаруживается как таковое, то есть происходит его пропуск.
Пороговое расчетное расстояние dth может быть определено исходя из множества псевдофишинговых доменных имен. Так как данное множество является репрезентативной выборкой фишинговых доменных имен, относящихся к заданным легитимным доменным именам, то массив расчетных расстояний для псевдофишинговых доменных имен можно рассматривать как репрезентативную числовую выборку, описывающую свойство расстояния между фишинговыми доменными именами и легитимными доменными именами. В таком случае, в качестве порогового расчетного расстояния может быть принята выборочная квантиль распределения расчетных расстояний для псевдофишинговых доменных имен, порядок которой определяется допустимым уровнем ошибки второго рода.
Квантиль - это числовая характеристика случайной величины и соответствующего распределения вероятностей. Квантилью порядка р, 0<р<1, называют число Kp такое, что
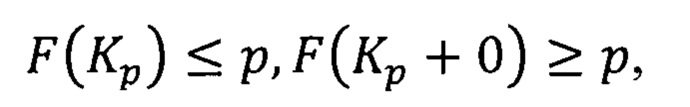
где F(x) - функция распределения случайной величины X (Вероятность и математическая статистика: Энциклопедия / Гл. ред. Ю.В. Прохоров. - М.: Большая Российская энциклопедия, 1999, 910 с, стр. 225). Выборочная квантиль порядка 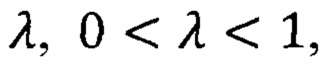 - это элемент вариационного ряда, построенного по выборке
- это элемент вариационного ряда, построенного по выборке 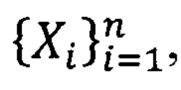 с номером
с номером 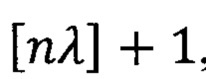 , где
, где 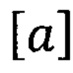 - целая часть
- целая часть 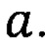
При этом вариационным рядом называется вектор 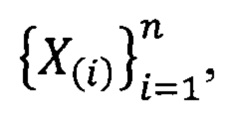 состоящий из упорядоченных по возрастанию
состоящий из упорядоченных по возрастанию 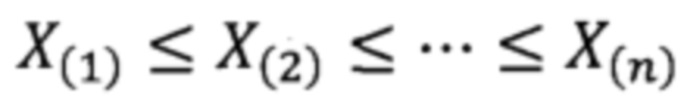 элементов выборки
элементов выборки 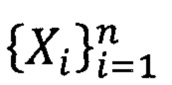 (Вероятность и математическая статистика: Энциклопедия / Гл. ред. Ю.В. Прохоров. - М.: Большая Российская энциклопедия, 1999, 910 с, стр. 75; 120).
(Вероятность и математическая статистика: Энциклопедия / Гл. ред. Ю.В. Прохоров. - М.: Большая Российская энциклопедия, 1999, 910 с, стр. 75; 120).
Согласно одному из вариантов предлагаемого способа, для определения порогового расчетного расстояния выбирают допустимый уровень ошибки второго рода β, где 0<β<1, и в качестве порогового расчетного расстояния dth принимают выборочную квантиль порядка (1-β) распределения расчетных расстояний в числовом массиве расчетных расстояний.
Согласно еще одному из вариантов предлагаемого способа, в качестве порогового расчетного расстояния принимают значение dth, вычисляемое согласно выражению
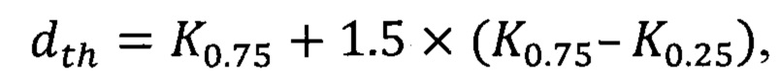
где K0,75 и K0,25 - соответственно выборочные 0,75- и 0,25-квантили распределения расчетных расстояний в числовом массиве расчетных расстояний.
В таком случае расчетные расстояния для доменных имен, не являющихся фи-шинговыми, могут быть обнаружены как выбросы относительно выборочного распределения расчетных расстояний для псевдофишинговых доменных имен.
Известен способ обнаружения выбросов в одномерных данных, при котором в качестве нижней и верхней границы выбросов принимают значения, вычисляемые согласно выражениям:
 нижняя граница: Q1-k×(Q3-Q1);
нижняя граница: Q1-k×(Q3-Q1);
 верхняя граница: Q3+k×(Q3-Q1), где
верхняя граница: Q3+k×(Q3-Q1), где
Q1=K0.25 - первая квартиль или 0,25-квантиль,
Q3=K0,75 - третья квартиль или 0,75-квантиль,
k - константа, рекомендованное значение которой равно 1,5 (ГОСТ Р ИСО 16269-4-2017; Tukey, J.W. Exploratory data analysis. Reading, Massachusetts: Addison-Wesley, 1977).
Исходя из того, что расчетные расстояния для доменных имен, не являющихся фишинговыми, должны превышать пороговое расчетное расстояние, то для обнаружения их как выбросов принимается односторонний критерий, а в качестве порогового расчетного расстояния dth принимают значение, вычисляемое согласно выражению для верхней границы выбросов при k=1,5.
Отдельно в предлагаемом способе обрабатывается ситуация, когда при обнаружении расчетное расстояние доменного имени до множества легитимных доменных имен оказывается равным нулю. Согласно определению расчетного расстояния, это значит, что данное доменное имя в точности совпало с одним из легитимных доменных имен, а значит оно само является легитимным.
В предлагаемом способе также предусмотрена возможность формирования отчета по факту обнаружения фишингового доменного имени. Для этого предварительно определяют то легитимное доменное имя Sleg, до которого нормированное расстояние Дамерау - Левенштейна минимально:
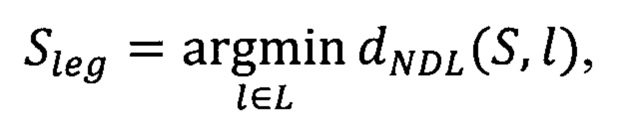
где S - обнаруженное фишинговое доменное имя,
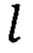 - легитимное доменное имя,
- легитимное доменное имя,
L - множество легитимных доменных имен.
Таким образом, нормированное расстояние Дамерау - Левенштейна позволяет определить то легитимное доменное имя, с которым данное фишинговое имеет наибольшую схожесть.
В отчет по факту обнаружения может включаться обнаруженное фишинговое доменное имя, определенное легитимное доменное имя, расчетное расстояние до него, а также пороговое расчетное расстояние. На основе сформированного отчета может быть принято решение о ложном срабатывании средства обнаружения, и в таком случае о пропуске обнаруженного доменного имени, либо об истинном срабатывании средства обнаружения, и в таком случае о блокировке обнаруженного фи-шингового доменного имени.
Далее приводится экспериментальное обоснование применимости изложенного подхода для обнаружения фишинговых доменных имен. В эксперименте в качестве множества легитимных доменных имен были выбраны 100 наиболее популярных доменных имен в России, полученных от сервиса «А1еха Top Sites in Russia» (сведения по адресу https://www.alexa.com/topsites/countries/RU). С помощью применения техник тайпсквоттинга было создано множество псевдофишинговых доменных имен, состоящее из 251829 доменных имен. В целях эксперимента было также получено множество внешних доменных имен, не относящихся к легитимным и не являющихся псевдофишинговыми, также состоящее из 251829 элементов. Источником внешних доменных имен стал общедоступный набор данных «А1еха Тор 1 Million Sites» (сведения по адресу https://www.kaggle.com/cheedcheed/toplm), содержащий один миллион наиболее популярных доменных имен во всем мире, из которого случайным образом было отобрано указанное количество доменных имен.
Далее для каждого из псевдофишинговых и внешних доменных имен было вычислено расчетное расстояние до множества легитимных доменных имен. Таким образом была получена выборка, состоящая из 503658 значений расчетных расстояний, разделенная на два класса: «псевдофишинговые» и «внешние».
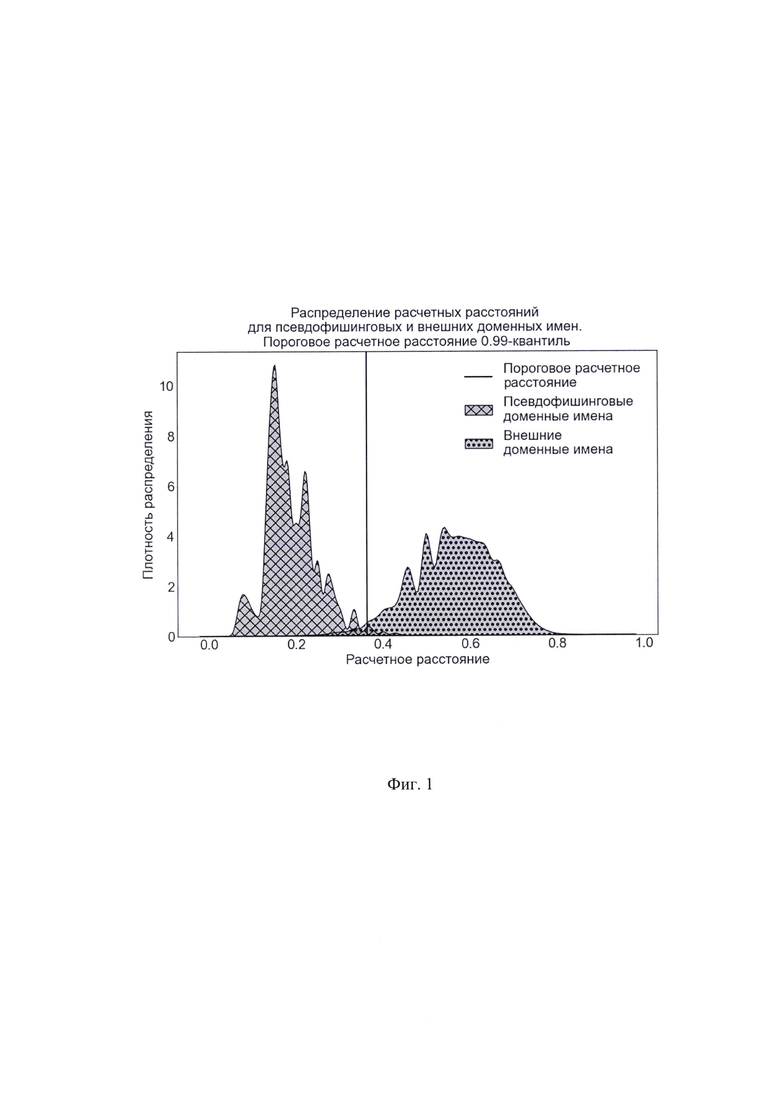
Далее на основании расчетных расстояний для псевдофишинговых доменных имен было вычислено пороговое расчетное расстояние dth. Для этого, согласно одному из вариантов предлагаемого способа, допустимый уровень ошибки второго рода β был принят равным 0,01, и в качестве порогового расчетного расстояния была принята выборочная квантиль порядка 0,99 распределения расчетных расстояний для псевдофишинговых доменных имен, которая оказалась равной 0,364.
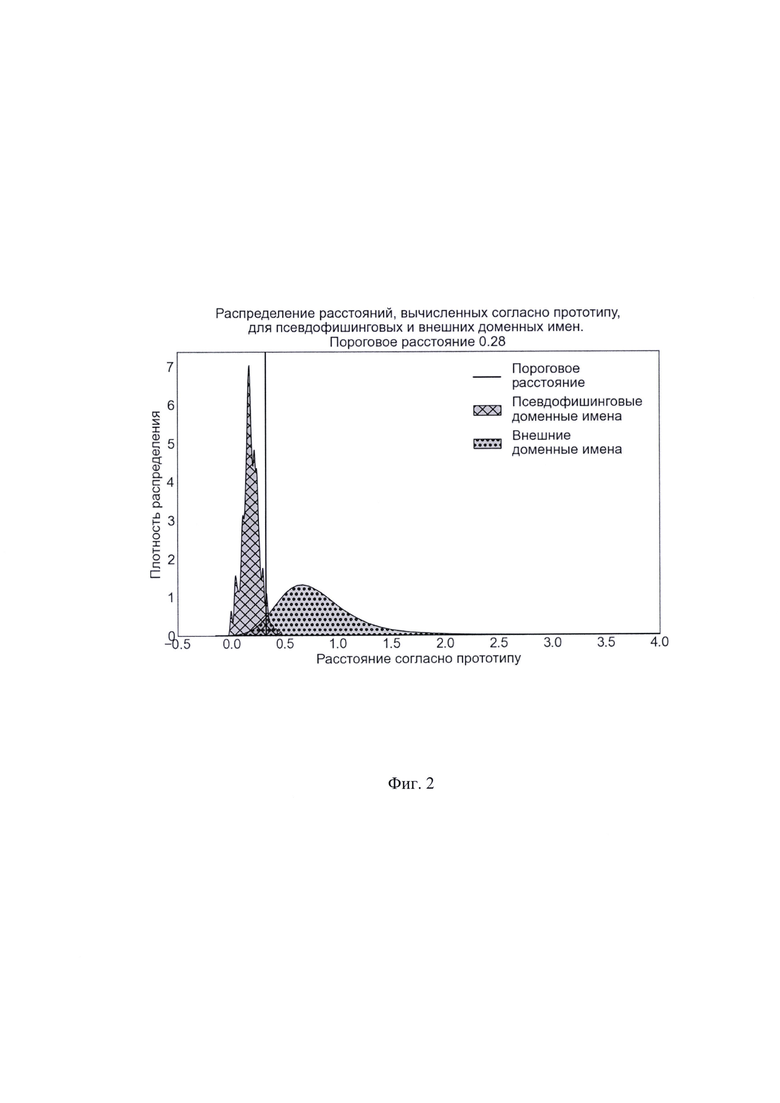
На фиг. 1 приведены графики распределения расчетных расстояний для псевдофишинговых и внешних доменных имен, а также отображено пороговое расчетное расстояние. Видно, что расчетные расстояния для двух классов доменных имен имеют различные распределения.
Для оценки качества обнаружения были определены количества истинных и ложных срабатываний.
Истинное срабатывание - результат обнаружения, при котором псевдофи-шинговое доменное имя было обнаружено как фишинговое (истинно-положительное срабатывание, True Positive, TP), или внешнее доменное имя было обнаружено как не фишинговое (истинно-отрицательное срабатывание, True Negative, TN).
Ложное срабатывание - результат обнаружения, при котором псевдофишин-говое доменное имя было обнаружено как не фишинговое (ложноотрицательное срабатывание, False Negative, FN), или внешнее доменное имя было обнаружено как фишинговое (ложноположительное срабатывание, False Positive, FP).
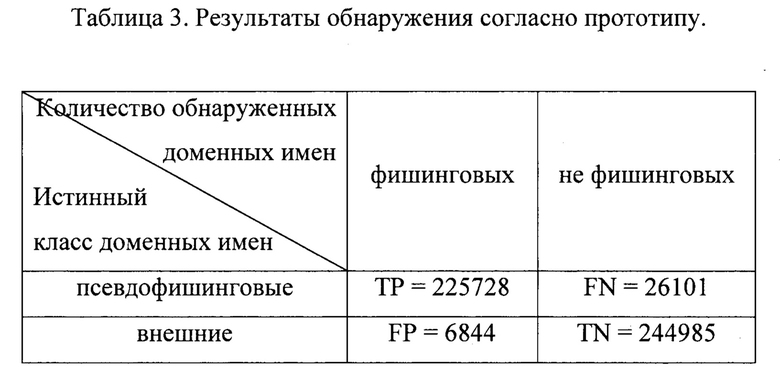
Результаты обнаружения согласно предлагаемому способу приведены в табл. 2.

На основе результатов эксперимента, вероятность обнаружения фишинговых доменных имен Pd может быть оценена как отношение количества истинных срабатываний к общему числу доменных имен. Такую оценку называют точностью или аккуратностью (accuracy) средства обнаружения. В данном случае эта величина оказалась приблизительно равной
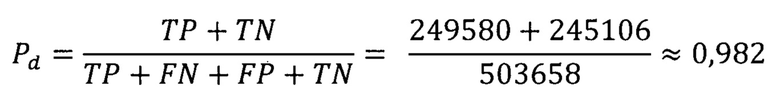
Такая вероятность обнаружения достаточна для практического применения средства обнаружения в данной прикладной области.
Эксперимент также включал в себя сравнение предлагаемого способа с прототипом. Согласно способу-прототипу, расстояние d(S) между доменным именем S и множеством легитимных доменных имен определяется как взвешенная комбинация множества расстояний, где множество расстояний включает в себя коэффициент Серенсена - Дайса dSD, индекс Жаккара dj и расстояние Левенштейна dL:
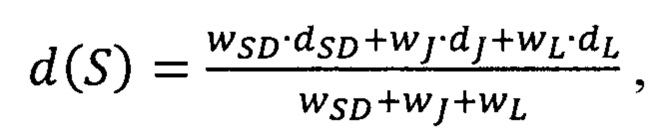
где wSD, wj, wL - соответствующие весовые коэффициенты. В описании прототипа приводятся следующие возможные значения весовых коэффициентов во взвешенной сумме:
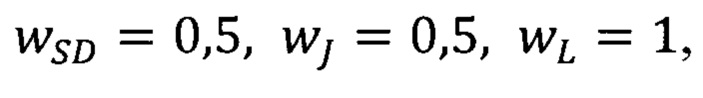
а пороговое расстояние может принимать значение
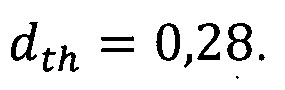
На фиг. 2 приведены графики распределения расстояний, вычисленных для псевдофишинговых и внешних доменных имен согласно прототипу, а также отображено пороговое расстояние согласно прототипу. В табл. 3 приведены результаты обнаружения согласно прототипу.
Результаты применения способа-прототипа дают следующую экспериментально определенную вероятность обнаружения Pd:
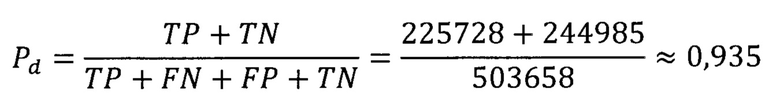
По результатам эксперимента вероятность обнаружения по способу-прототипу оказалась ниже, чем по предлагаемому способу. К тому же, экспериментально определенная вероятность обнаружения согласно способу-прототипу может являться недостаточной для практического применения средства обнаружения в данной прикладной области.
Заявленный технический результат достигается благодаря следующему:
 создание множества псевдофишинговых доменных имен с применением известных техник создания фишинговых доменных имен (техник тайпсквоттинга) позволяет спрогнозировать наиболее вероятные действия злоумышленника в отношении легитимных доменных имен и настроить параметры системы до начала работы по обнаружению реальных фишинговых доменных имен;
создание множества псевдофишинговых доменных имен с применением известных техник создания фишинговых доменных имен (техник тайпсквоттинга) позволяет спрогнозировать наиболее вероятные действия злоумышленника в отношении легитимных доменных имен и настроить параметры системы до начала работы по обнаружению реальных фишинговых доменных имен;
 использование для принятия решения статистического анализа позволяет автоматизировать процесс вычисления параметров алгоритма (в частности, порогового расчетного значения) и избежать применения в качестве решающего правила эвристик, являющихся ограниченными. В результате, вероятность обнаружения фишинговых доменных имен повышается.
использование для принятия решения статистического анализа позволяет автоматизировать процесс вычисления параметров алгоритма (в частности, порогового расчетного значения) и избежать применения в качестве решающего правила эвристик, являющихся ограниченными. В результате, вероятность обнаружения фишинговых доменных имен повышается.
Краткое описание чертежей На фиг. 1 показано распределение расчетных расстояний для псевдофишинговых и внешних доменных имен. Пороговое расчетное расстояние - выборочная 0,99-квантиль выборки расчетных расстояний для псевдофишинговых доменных имен.
На фиг. 2 показано распределение расстояний, вычисленных согласно прототипу, для псевдофишинговых и внешних доменных имен. Пороговое расстояние 0,28.
Осуществление изобретения
Предлагаемый способ может быть реализован в следующей программно-аппаратной среде.
В качестве вычислительной системы выбирается персональный компьютер со следующими аппаратными характеристиками:
 процессор Intel Core i7-7770 3.60 GHz;
процессор Intel Core i7-7770 3.60 GHz;
 оперативная память 32 GB;
оперативная память 32 GB;
 жесткий диск SSD 240 GB, и установленным программным обеспечением:
жесткий диск SSD 240 GB, и установленным программным обеспечением:
 операционная система Microsoft Windows 10;
операционная система Microsoft Windows 10;
 Python 3.6.8;
Python 3.6.8;
 модули Python: numpy 1.19.5, jellyfish 0.8.2, dnstwist 20201228. Далее рассмотрим вариант реализации способа. Пусть в качестве множества легитимных доменных имен принимают 100 наиболее популярных доменных имен в России, полученных от сервиса «А1еха Top Sites in Russia» (сведения по адресу https://www.alexa.com/topsites/countries/RU). Фрагмент данного множества приведен в табл. 4.
модули Python: numpy 1.19.5, jellyfish 0.8.2, dnstwist 20201228. Далее рассмотрим вариант реализации способа. Пусть в качестве множества легитимных доменных имен принимают 100 наиболее популярных доменных имен в России, полученных от сервиса «А1еха Top Sites in Russia» (сведения по адресу https://www.alexa.com/topsites/countries/RU). Фрагмент данного множества приведен в табл. 4.

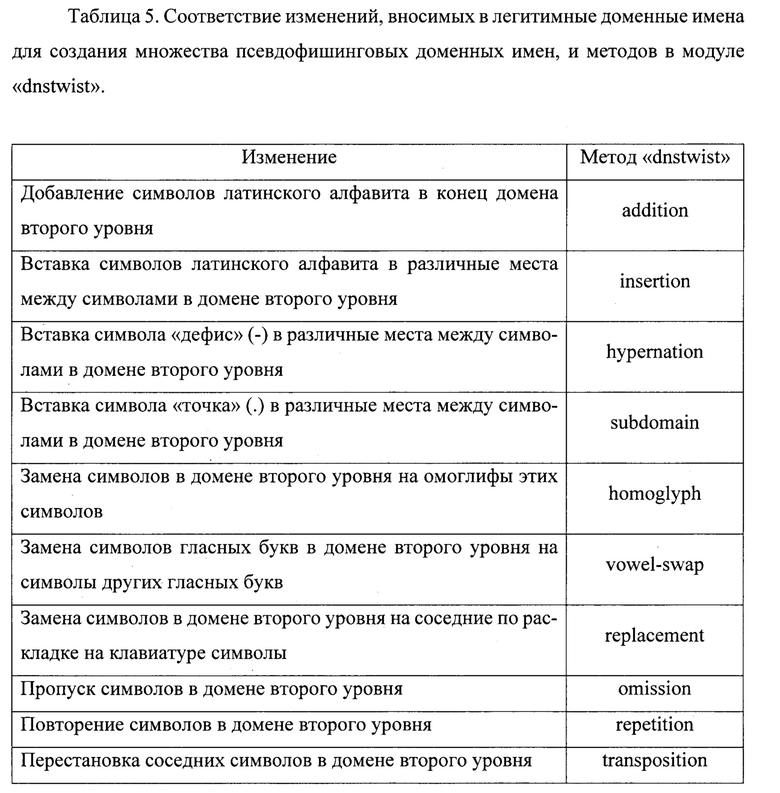
Далее на основе множества легитимных доменных имен создают множество псевдофишинговых доменных имен. Для этого используют модуль «dnstwist» языка программирования Python (сведения по адресу https://github.com/elceef/dnstwist). Данный модуль позволяет для заданного доменного имени сгенерировать множество схожих доменных имен, путем внесения различных изменений. Методы внесения изменений в легитимные доменные имена, описанные в способе, соответствуют методам в модуле «dnstwist», согласно табл. 5.
В результате применения данных методов к каждому из легитимных доменных имен получают множество псевдофишинговых доменных имен, состоящее из 251829 доменных имен. Фрагмент данного множества приведен в табл. 6.

Далее для каждого доменного имени из множества псевдофишинговых доменных имен определяют расчетное расстояние до множества легитимных доменных имен, при этом в качестве расчетного расстояния принимают минимальное из нормированных расстояний Дамерау - Левенштейна между данным доменным именем и каждым доменным именем из множества легитимных доменных имен. Вычисление расстояния Дамерау - Левенштейна между псевдофишинговым доменным именем и легитимным доменным именем производят с помощью функции damerau le-venshtein_distance из модуля «jellyfish» языка программирования Python (сведения по адресу https://pypi.org/project/jellyfish/). Из вычисленных расчетных расстояний для псевдофишинговых доменных имен составляют одномерный числовой массив, состоящий из 251829 элементов.
Далее определяют пороговое расчетное расстояние. Для этого выбирают допустимый уровень ошибки второго рода β=0,01, и в качестве порогового расчетного расстояния принимают выборочную квантиль порядка (1-β)=0,99 распределения расчетных расстояний в числовом массиве расчетных расстояний. Для вычисления выборочной квантили указанного порядка из числового массива расчетных расстояний составляют вариационный ряд, и в качестве выборочной квантили выбирают элемент вариационного ряда с номером [251829×0.99]+1=249311. В данном случае выборочная квантиль порядка 0.99 оказывается равной 0,364.
Далее обнаруживают фишинговые доменные имена. Пусть для обработки поступает доменное имя 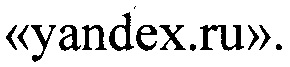 Вычисляют расчетное расстояние от него до множества легитимных доменных имен. Для данного доменного имени расчетное расстояние равно нулю. Это значит, что поступившее на обработку доменное имя является легитимным и на этом его обработку завершают.
Вычисляют расчетное расстояние от него до множества легитимных доменных имен. Для данного доменного имени расчетное расстояние равно нулю. Это значит, что поступившее на обработку доменное имя является легитимным и на этом его обработку завершают.
Пусть для обработки поступает доменное имя “example.com” Вычисляют расчетное расстояние от него до множества легитимных доменных имен. Для данного доменного имени расчетное расстояние равно 0,455. Расчетное расстояние не равно нулю, поэтому сравнивают расчетное расстояние с пороговым расчетным расстоянием 0,364. Расчетное расстояние больше порогового расчетного расстояния, следовательно, поступившее на обработку доменное имя не считают фишинговым и на этом его обработку завершают.
Пусть для обработки поступает доменное имя 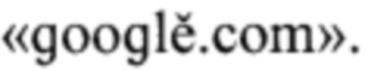 Вычисляют расчетное расстояние от него до множества легитимных доменных имен. Для данного доменного имени расчетное расстояние равно 0,3. Расчетное расстояние не равно нулю, поэтому сравнивают расчетное расстояние с пороговым расчетным расстоянием 0,364. Расчетное расстояние меньше порогового расчетного расстояния, следовательно, поступившее на обработку доменное имя считают фишинговым. Далее для него определяют легитимное доменное имя, до которого нормированное расстояние Дамерау - Левенштейна минимально. Таким доменным именем является “google.com”.
Вычисляют расчетное расстояние от него до множества легитимных доменных имен. Для данного доменного имени расчетное расстояние равно 0,3. Расчетное расстояние не равно нулю, поэтому сравнивают расчетное расстояние с пороговым расчетным расстоянием 0,364. Расчетное расстояние меньше порогового расчетного расстояния, следовательно, поступившее на обработку доменное имя считают фишинговым. Далее для него определяют легитимное доменное имя, до которого нормированное расстояние Дамерау - Левенштейна минимально. Таким доменным именем является “google.com”.
Далее может быть сформирован отчет об обнаруженном фишинговом доменном имени с указанием определенного легитимного доменного имени, расчетного расстояния до него и порогового расчетного расстояния. На этом обработку завершают. Возможная форма отчета приведена на в табл. 7.

В другом варианте осуществления изобретения в качестве порогового расчетного расстояния принимают значение dth, вычисляемое согласно выражению
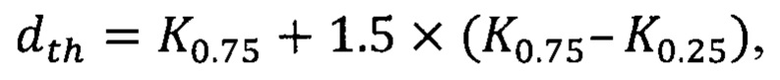
где K0,75 и K0,25 - соответственно выборочные 0,75- и 0,25-квантили распределения расчетных расстояний в числовом массиве расчетных расстояний.
Следует отметить, что приведенные сведения являются примерами, которые не ограничивают объем предложенного технического решения. Специалисту в данной области понятно, что могут существовать и другие варианты осуществления предложенного технического решения.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ определения фишингового электронного сообщения | 2020 |
|
RU2790330C2 |
| Система и способ обнаружения фишинговых веб-страниц | 2024 |
|
RU2836604C1 |
| СИСТЕМА И СПОСОБ ОБНАРУЖЕНИЯ ФИШИНГОВЫХ ВЕБ-СТРАНИЦ | 2016 |
|
RU2637477C1 |
| ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО И СПОСОБ ДЛЯ ОБНАРУЖЕНИЯ ВРЕДОНОСНЫХ ДОМЕННЫХ ИМЕН В СЕТЕВОМ ТРАФИКЕ | 2018 |
|
RU2668710C1 |
| СИСТЕМА И СПОСОБ СБОРА ИНФОРМАЦИИ ДЛЯ ОБНАРУЖЕНИЯ ФИШИНГА | 2016 |
|
RU2671991C2 |
| Способ классификации объектов для предотвращения распространения вредоносной активности | 2023 |
|
RU2808385C1 |
| Система и способ активного обнаружения вредоносных сетевых ресурсов | 2021 |
|
RU2769075C1 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КЛАСТЕРИЗАЦИИ ФИШИНГОВЫХ ВЕБ-РЕСУРСОВ НА ОСНОВЕ ИЗОБРАЖЕНИЯ ВИЗУАЛЬНОГО КОНТЕНТА | 2021 |
|
RU2778460C1 |
| СИСТЕМА И СПОСОБ ВЕРИФИКАЦИИ СЕРТИФИКАТА ОТКРЫТОГО КЛЮЧА С ЦЕЛЬЮ ПРОТИВОДЕЙСТВИЯ АТАКАМ ТИПА "ЧЕЛОВЕК ПОСЕРЕДИНЕ" | 2012 |
|
RU2514138C1 |
| Система и способ внешнего контроля поверхности кибератаки | 2021 |
|
RU2778635C1 |
Изобретение относится к области информационной безопасности. Техническим результатом является повышение вероятности обнаружения фишинговых доменных имен. Технический результат достигается за счет того, что способ обнаружения содержит этапы, на которых: составляют множество легитимных доменных имен; создают множество псевдофишинговых доменных имен путем внесения изменений в легитимные имена; для каждого псевдофишингового доменного имени определяют расчетное расстояние до множества легитимных имен и формируют из расчетных расстояний одномерный числовой массив; на основании чего определяют пороговое расчетное расстояние; анализируют поступившее доменное имя: определяют расчетное расстояние до множества легитимных имен; если расчетное расстояние равно нулю, то данное имя считают легитимным; если расчетное расстояние не равно нулю, то: сравнивают расчетное расстояние с пороговым расчетным расстоянием; если расчетное расстояние больше порогового, то данное доменное имя не считают фишинговым; если расчетное расстояние меньше порогового или равно ему, то данное имя считают фишинговым и выполняют следующие действия: определяют для данного доменного имени легитимное доменное имя, до которого нормированное расстояние минимально; формируют отчет об обнаруженном фишинговом доменном имени; завершают обработку данного доменного имени. 2 з.п. ф-лы, 7 табл., 2 ил.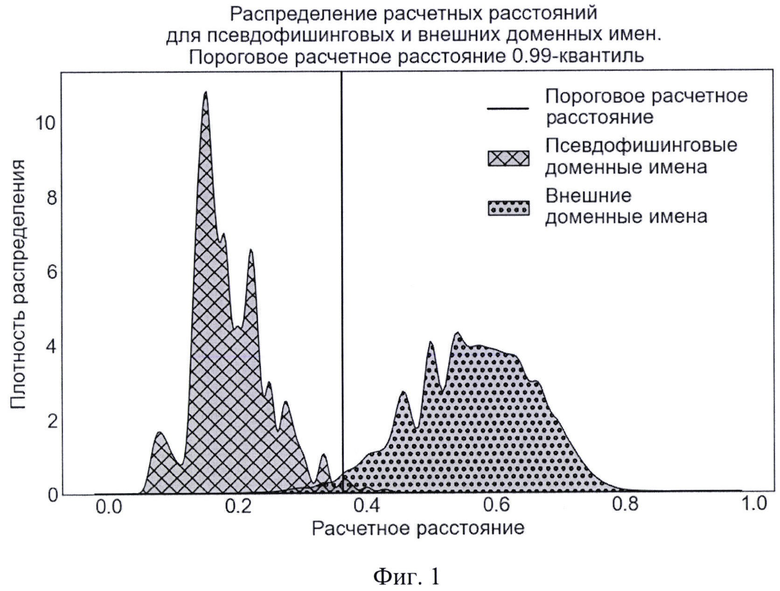
1. Способ обнаружения фишинговых доменных имен, реализуемый в вычислительной системе, которая включает:
по крайней мере одно вычислительное средство, имеющее установленную операционную систему и прикладные программы и выполненное с возможностью:
хранить и обрабатывать числовые массивы данных; хранить и обрабатывать данные строкового типа; заключающийся в том, что
составляют множество легитимных доменных имен, для которых обеспечивается защита;
создают множество псевдофишинговых доменных имен, состоящее из измененных легитимных доменных имен, для чего в каждое легитимное доменное имя вносят изменения, включая:
добавление символов латинского алфавита в конец домена второго уровня;
вставку символов латинского алфавита в различные места между символами в домене второго уровня;
вставку символа «дефис» (-) в различные места между символами в домене второго уровня;
вставку символа «точка» (.) в различные места между символами в домене второго уровня;
замену символов в домене второго уровня на омоглифы этих символов;
замену символов гласных букв в домене второго уровня на символы других гласных букв;
замену символов в домене второго уровня на соседние по раскладке на клавиатуре символы;
пропуск символов в домене второго уровня;
повторение символов в домене второго уровня;
перестановку соседних символов в домене второго уровня;
для каждого доменного имени из множества псевдофишинговых доменных имен определяют расчетное расстояние до множества легитимных доменных имен, при этом в качестве расчетного расстояния принимают минимальное из нормированных расстояний Дамерау - Левенштейна между данным доменным именем и каждым доменным именем из множества легитимных доменных имен, и формируют из расчетных расстояний одномерный числовой массив;
на основании числового массива расчетных расстояний определяют пороговое расчетное расстояние;
обнаруживают фишинговые доменные имена, для чего с доменным именем, поступившим на обработку, выполняют следующие действия:
определяют расчетное расстояние до множества легитимных доменных имен, при этом в качестве расчетного расстояния принимают минимальное из нормированных расстояний Дамерау - Левенштейна между данным доменным именем и каждым доменным именем из множества легитимных доменных имен;
если расчетное расстояние равно нулю, то данное доменное имя считают легитимным, и на этом его обработку завершают; если расчетное расстояние не равно нулю, то:
сравнивают расчетное расстояние с пороговым расчетным расстоянием;
если расчетное расстояние больше порогового расчетного расстояния, то данное доменное имя не считают фишинговым, и на этом его обработку завершают;
если расчетное расстояние меньше порогового расчетного расстояния или равно ему, то данное доменное имя считают фишинговым и выполняют следующие действия:
определяют для данного доменного имени легитимное доменное имя, до которого нормированное расстояние Дамерау - Левенштейна минимально;
при необходимости, формируют отчет об обнаруженном фишинговом доменном имени с указанием определенного легитимного доменного имени, расчетного расстояния до него и порогового расчетного расстояния; завершают обработку данного доменного имени.
2. Способ по п. 1, в котором для определения порогового расчетного расстояния выбирают допустимый уровень ошибки второго рода β, где 0<β<1, и в качестве порогового расчетного расстояния принимают выборочную квантиль порядка (1-β) распределения расчетных расстояний в числовом массиве расчетных расстояний.
3. Способ по п. 1, в котором в качестве порогового расчетного расстояния принимают значение dth, вычисляемое согласно выражению
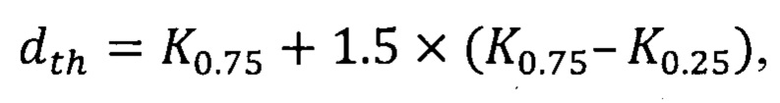
где K0,75 и K0,25 - соответственно выборочные 0,75- и 0,25-квантили распределения расчетных расстояний в числовом массиве расчетных расстояний.
| СИСТЕМА И СПОСОБ СБОРА ИНФОРМАЦИИ ДЛЯ ОБНАРУЖЕНИЯ ФИШИНГА | 2016 |
|
RU2671991C2 |
| СИСТЕМА И СПОСОБ ОБНАРУЖЕНИЯ ФИШИНГОВЫХ ВЕБ-СТРАНИЦ | 2016 |
|
RU2637477C1 |
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| US 9218482 B2, 22.12.2015 | |||
| СИСТЕМЫ И СПОСОБЫ ДИНАМИЧЕСКОГО АГРЕГИРОВАНИЯ ПОКАЗАТЕЛЕЙ ДЛЯ ОБНАРУЖЕНИЯ СЕТЕВОГО МОШЕННИЧЕСТВА | 2012 |
|
RU2607229C2 |

