ССЫЛКА НА ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ, ПОДАННЫЙ В ЭЛЕКТРОННОМ ВИДЕ
[1] Содержание перечня последовательностей, предоставленного в электронном виде в виде текстового файла в формате ASCII (название: 4159_493PC01_ST25; размер: 434561 байт и дата создания: 9 августа 2018 г.), включено в данный документ посредством ссылки во всей своей полноте.
ПРЕДПОСЫЛКИ К СОЗДАНИЮ ИЗОБРЕТЕНИЯ
[2] Генная терапия предоставляет характеризующиеся длительным действием средства лечения ряда различных заболеваний. В прежнее время генная терапия, как правило, основывалась на применении вирусов. Имеется множество вирусных средств, которые могут быть выбраны для данной цели, каждое из которых характеризуется отличающимися свойствами, которые будут делать их более или менее подходящими для генной терапии. Zhou et al., Adv Drug Deliv Rev. 106(Pt A):3-26, 2016. Однако нежелательные свойства некоторых вирусных векторов, в том числе их иммуногенные профили или их склонность вызывать рак, привели к появлению опасений в отношении клинической безопасности и до недавнего времени ограничивали их текущее применение в клинической практике определенными областями применения, например связанными с вакцинами и онколитическими стратегиями. Cotter et al., Front Biosci. 10:1098-105 (2005).
[3] Аденоассоциированный вирус (AAV) является одним из наиболее широко исследуемых генотерапевтических векторов. AAV представляет собой белковую оболочку, окружающую и защищающую геном на основе небольшой однонитевой ДНК, составляющей примерно 4,8 тысяч пар нуклеотидов (т. п. н.). Naso et al., BioDrugs, 31(4): 317-334, 2017. AAV принадлежит к семейству парвовирусов и для осуществления своей репликации полагается на коинфекцию другими вирусами, главным образом аденовирусами. Id. Его однонитевой геном содержит три гена: Rep (репликация), Cap (капсид) и aap (сборка). Id. Данные кодирующие последовательности фланкированы инвертированными концевыми повторами (ITR), которые необходимы для репликации и упаковки генома. Id. Оба цис-действующих ITR AAV характеризуются длиной, составляющей примерно 145 нуклеотидов, с наличием прерывающихся палиндромных последовательностей, которые могут сворачиваться в Т-образные шпилечные структуры, которые функционируют в качестве праймеров в ходе инициации репликации ДНК.
[4] Однако применение стандартного AAV в качестве вектора доставки генов привело к некоторым недостаткам. Один из основных недостатков связан с ограниченной пакующей способностью вируса AAV, составляющей приблизительно 4,5 т. п. н. гетерологичной ДНК. (Dong et al., Hum Gene Ther. 7(17): 2101-12, 1996). Кроме того, введение векторов на основе AAV может индуцировать иммунный ответ у людей. Хотя было показано, что AAV характеризуется меньшей степенью иммуногенности, чем некоторые другие вирусы (т. е. аденовирус), капсидные белки могут активировать различные компоненты иммунной системы человека. См. Naso et al., 2017. AAV является распространенным вирусом в человеческой популяции, и большинство людей подвергалось воздействию AAV, соответственно у большинства людей уже развился иммунный ответ в отношении конкретных вариантов, воздействию которых они подвергались ранее. Данный предсуществующий адаптивный ответ может включать NAb и T-клетки, которые могут снижать клиническую эффективность последующих повторных инфекций, вызванных AAV, и/или уничтожение клеток, которые были подвергнуты трансдукции, что делает пациентов с предсуществующим иммунитетом в отношении AAV неподходящими для лечения с применением генной терапии на основе AVV. Независимо от того, вводят его местно или системно, вирус будет рассматриваться как чужеродный белок, в связи с чем адаптивная иммунная система будет производить попытки к его устранению. Кроме того, нейтрализующее антитело к AAV, индуцированное введением AAV, препятствует проведению многократных процедур лечения с помощью AAV в случае, когда терапевтический уровень эффективности не был достигнут при первой процедуре лечения с помощью AAV. Кроме того, имеются данные, свидетельствующие о том, что T-образные шпилечные петли ITR AAV подвержены подавлению белками/белковыми комплексами клетки-хозяина, которые связывают T-образные шпилечные структуры ITR AAV. См., например, Zhou et al., Scientific Reports 7:5432 (July 14, 2017).
[5] Таким образом, в данной области техники существует потребность в эффективной и устойчивой экспрессии целевых последовательностей, например, терапевтических белков и/или miRNA, в условиях in vitro и in vivo, избегая при этом некоторых из нежелательных последствий и ограничений, присущих существующей технологии векторов на основе AAV.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[6] В одном аспекте настоящее изобретение направлено на молекулу нуклеиновой кислоты, содержащую первый инвертированный концевой повтор (ITR), второй ITR и генную кассету, кодирующую терапевтический белок; где первый ITR и/или второй ITR представляют собой ITR вируса, отличного от аденоассоциированного вируса (вируса, отличного от AAV), при этом генная кассета расположена между первым ITR и вторым ITR, и где терапевтический белок предусматривает фактор свертывания крови. В некоторых вариантах осуществления вирус, отличный от AAV, выбран из группы, состоящей из представителей семейства вирусов Parvoviridae и любой их комбинации. В некоторых вариантах осуществления первый ITR представляет собой ITR вируса, отличного от AAV, и второй ITR представляет собой ITR аденоассоциированного вируса (AAV), или где первый ITR представляет собой ITR AAV, и второй ITR представляет собой ITR вируса, отличного от AAV. В других вариантах осуществления первый ITR и второй ITR представляют собой ITR вируса, отличного от AAV. В некоторых вариантах осуществления первый ITR и второй ITR являются идентичными. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат палиндромную последовательность, которая является непрерывной. В других вариантах осуществления первый ITR и/или второй ITR содержат палиндромную последовательность, которая является прерывистой.
[7] В некоторых вариантах осуществления вирус, отличный от AAV, в молекуле нуклеиновой кислоты является представителем семейства вирусов Parvoviridae. В некоторых вариантах осуществления представитель семейства вирусов Parvoviridae выбран из группы, состоящей из Bocavirus, Dependovirus, Erythrovirus, Amdovirus, Parvovirus, Densovirus, Iteravirus, Contravirus, Aveparvovirus, Copiparvovirus, Protoparvovirus, Tetraparvovirus, Ambidensovirus, Brevidensovirus, Hepandensovirus, Penstyldensovirus и любой их комбинации. В некоторых вариантах осуществления представителем семейства вирусов Parvoviridae является эритровирус, представляющий собой парвовирус B19 (вирус человека). В некоторых вариантах осуществления представитель семейства вирусов Parvoviridae представляет собой штамм парвовируса мускусных уток (MDPV). В некоторых вариантах осуществления штамм MDPV представляет собой аттенуированный штамм FZ91-30. В некоторых вариантах осуществления штамм MDPV представляет собой патогенный штамм YY. Еще в некоторых вариантах осуществления представителем рода Dependoparvovirus является представитель Dependovirus, представляющий собой штамм парвовируса гусей (GPV). В некоторых вариантах осуществления штамм GPV представляет собой аттенуированный штамм 82-0321V. В некоторых вариантах осуществления штамм GPV представляет собой патогенный штамм B. В некоторых вариантах осуществления представитель семейства вирусов Parvoviridae выбран из группы, состоящей из парвовируса свиней (U44978), мелкого вируса мышей (U34256), собачьего парвовируса (M19296), вируса энтерита норок (D00765) и любой их комбинации.
[8] В некоторых вариантах осуществления молекула нуклеиновой кислоты дополнительно содержит промотор. В некоторых вариантах осуществления промотор представляет собой тканеспецифический промотор. В некоторых вариантах осуществления промотор управляет экспрессией терапевтического белка в гепатоцитах, эндотелиальных клетках, мышечных клетках, синусоидальных клетках или любой их комбинации. В некоторых вариантах осуществления промотор расположен в направлении 5' относительно последовательности нуклеиновой кислоты, кодирующей фактор свертывания крови. В некоторых вариантах осуществления промотор выбран из группы, состоящей из промотора тиретина мыши (mTTR), эндогенного промотора фактора VIII человека (F8), промотора альфа-1-антитрипсина человека (hAAT), минимального промотора альбумина человека, промотора альбумина мыши, промотора тристетрапролина (TTP), промотора CASI, промотора CAG, промотора цитомегаловируса (CMV), промотора α1-антитрипсина (AAT), мышечной креатинкиназы (MCK), тяжелой цепи миозина альфа (αMHC), миоглобина (MB), десмина (DES), SPc5-12, 2R5Sc5-12, dMCK, tMCK, фосфоглицераткиназы (PGK) и любой их комбинации. В некоторых вариантах осуществления промотор предусматривает промотор TTP.
[9] В некоторых вариантах осуществления молекула нуклеиновой кислоты дополнительно содержит интронную последовательность. В некоторых вариантах осуществления интронная последовательность расположен в направлении 5' относительно последовательности нуклеиновой кислоты, кодирующей фактор свертывания крови. В некоторых вариантах осуществления интронная последовательность расположена в направлении 3' относительно промотора. В некоторых вариантах осуществления при этом интронная последовательность предусматривает синтетическую интронную последовательность. В некоторых вариантах осуществления интронная последовательность содержит SEQ ID NO: 115.
[10] В некоторых вариантах осуществления молекула нуклеиновой кислоты содержит посттранскрипционный регуляторный элемент. В некоторых вариантах осуществления посттранскрипционный регуляторный элемент расположен в направлении 3' относительно последовательности нуклеиновой кислоты, кодирующей фактор свертывания крови. В некоторых вариантах осуществления посттранскрипционный регуляторный элемент предусматривает мутантный посттранскрипционный регуляторный элемент вируса гепатита сурков (WPRE), сайт связывания microRNA, последовательность, направляющую ДНК к ядру, или любую их комбинации. В некоторых вариантах осуществления сайт связывания microRNA предусматривает сайт связывания с miR142-3p.
[11] В некоторых вариантах осуществления молекула нуклеиновой кислоты содержит последовательность poly(А)-хвоста 3'-UTR. В некоторых вариантах осуществления последовательность poly(А)-хвоста 3'-UTR выбрана из группы, состоящей из poly(A) bGH, poly(A) актина, poly(A) гемоглобина и любой их комбинации. В некоторых вариантах осуществления последовательность poly(А)-хвоста 3'-UTR предусматривает poly(A) bGH.
[12] В некоторых вариантах осуществления молекула нуклеиновой кислоты содержит энхансерную последовательность. В некоторых вариантах осуществления энхансерная последовательность расположена между первым ITR и вторым ITR.
[13] В некоторых вариантах осуществления молекула нуклеиновой кислоты содержит в следующем порядке: первый ITR, генную кассету и второй ITR; где генная кассета содержит последовательность тканеспецифического промотора, интронную последовательность, последовательность нуклеиновой кислоты, кодирующей терапевтический белок, например фактор свертывания крови, или miRNA, посттранскрипционный регуляторный элемент и последовательность poly(А)-хвоста 3'-UTR.
[14] В некоторых вариантах осуществления молекула нуклеиновой кислоты содержит в следующем порядке: последовательность тканеспецифического промотора, интронную последовательность, последовательность нуклеиновой кислоты, кодирующей полипептид FVIII, посттранскрипционный регуляторный элемент и последовательность poly(А)-хвоста 3'-UTR.
[15] В одном варианте осуществления молекула нуклеиновой кислоты содержит
(a) первый ITR, представляющий собой ITR вируса, отличного от AAV, являющегося представителем семейства Parvoviridae;
(b) последовательность тканеспецифического промотора, например промотора TTP;
(c) интрон, например синтетический интрон;
(d) нуклеотидную последовательность, кодирующую терапевтический белок, например фактор свертывания крови, или miRNA;
(e) посттранскрипционный регуляторный элемент, например WPRE;
(f) последовательность poly(А)-хвоста 3'-UTR, например bGHpA; и
(g) второй ITR, представляющий собой ITR вируса, отличного от AAV, являющегося представителем семейства Parvoviridae.
[16] В некоторых вариантах осуществления молекула нуклеиновой кислоты предусматривает однонитевую нуклеиновую кислоту. В некоторых вариантах осуществления генная кассета предусматривает двухнитевую нуклеиновую кислоту.
[17] В некоторых вариантах осуществления молекула нуклеиновой кислоты содержит ген, кодирующий терапевтический белок, например фактор свертывания крови, где фактор свертывания крови экспрессируется гепатоцитами, эндотелиальными клетками, мышечными клетками, синусоидальными клетками или любой их комбинацией. В некоторых вариантах осуществления фактор свертывания крови включает фактор I (FI), фактор II (FII), фактор V (FV), фактор VII (FVII), фактор VIII (FVIII), фактор IX (FIX), фактор X (FX), фактор XI (FXI), фактор XII (FXII), фактор XIII (FVIII), фактор фон Виллебранда (VWF), прекалликреин, высокомолекулярный кининоген, фибронектин, антитромбин III, кофактор гепарина II, белок C, белок S, белок Z, ингибитор белок Z-подобной протеазы (ZPI), плазминоген, альфа-2-антиплазмин, тканевой активатор плазминогена (tPA), урокиназу, ингибитор активатора плазминогена 1 (PAI-1), ингибитор активатора плазминогена 2 (PAI2) или любую их комбинацию. В некоторых вариантах осуществления фактор свертывания крови представляет собой FVIII. В некоторых вариантах осуществления FVIII предусматривает полноразмерный зрелый FVIII. В некоторых вариантах осуществления FVIII содержит аминокислотную последовательность, которая на по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична аминокислотной последовательности под SEQ ID NO: 106. В некоторых вариантах осуществления FVIII содержит домен A1, домен A2, домен A3, домен C1, домен C2 и частичный домен B или вообще не содержит его. В некоторых вариантах осуществления FVIII содержит аминокислотную последовательность, которая на по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична аминокислотной последовательности под SEQ ID NO:109.
[18] В некоторых вариантах осуществления фактор свертывания крови содержит гетерологичный компонент. В некоторых вариантах осуществления гетерологичный компонент выбран из группы, состоящей из альбумина или его фрагмента, Fc-области иммуноглобулина, C-концевого пептида (CTP) β-субъединицы хорионического гонадотропина человека, последовательности PAS, последовательности HAP, трансферрина или его фрагмента, альбумин-связывающего компонента, их производного и любой их комбинации. В некоторых вариантах осуществления гетерологичный компонент связан с N-концом или C-концом FVIII или вставлен между двумя аминокислотами в FVIII. В некоторых вариантах осуществления гетерологичный компонент вставлен между двумя аминокислотами в одном или нескольких сайтах вставки, выбранных из сайтов вставки, перечисленных в таблице 5. В некоторых вариантах осуществления FVIII дополнительно содержит домен A1, домен A2, домен C1, домен C2, необязательный домен B и гетерологичный компонент, где гетерологичный компонент вставлен непосредственно ниже аминокислоты 745, соответствуя зрелому FVIII (SEQ ID NO: 106).
[19] В некоторых вариантах осуществления FVIII дополнительно содержит партнера по связыванию FcRn. В некоторых вариантах осуществления партнер по связыванию FcRn предусматривает Fc-область константного домена иммуноглобулина. В некоторых вариантах осуществления последовательность нуклеиновой кислоты, кодирующая FVIII, является кодон-оптимизированной. В некоторых вариантах осуществления последовательность нуклеиновой кислоты, кодирующая FVIII, является кодон-оптимизированной для экспрессии у человека.
[20] В некоторых вариантах осуществления последовательность нуклеиновой кислоты, кодирующая FVIII, предусматривает нуклеотидную последовательность, которая на по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или приблизительно 100% идентична нуклеотидной последовательности под SEQ ID NO: 107. В некоторых вариантах осуществления последовательность нуклеиновой кислоты, кодирующая FVIII, предусматривает нуклеотидную последовательность, которая на по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или приблизительно 100% идентична нуклеотидной последовательности под SEQ ID NO: 71.
[21] В некоторых вариантах осуществления молекула нуклеиновой кислоты составлена со средством доставки. В некоторых вариантах осуществления средство доставки предусматривает одну или несколько липидных наночастиц. В некоторых вариантах осуществления средство доставки выбрано из группы, состоящей из липосом, нелипидных полимерных молекул, эндосом и любой их комбинации.
[22] В некоторых вариантах осуществления молекула нуклеиновой кислоты составлена для внутривенной, трансдермальной, внутрикожной, подкожной, пульмональной или пероральной доставки или любой их комбинации. В некоторых вариантах осуществления молекула нуклеиновой кислоты составлена для внутривенной доставки.
[23] В некоторых вариантах осуществления в данном документе представлен вектор, содержащий молекулу нуклеиновой кислоты, как описано в тексте настоящего раскрытия. В некоторых вариантах осуществления в данном документе представлен полипептид, кодируемый молекулой нуклеиновой кислоты, как описано в тексте настоящего раскрытия. В некоторых вариантах осуществления в данном документе представлена клетка-хозяин, содержащая молекулу нуклеиновой кислоты, как описано в тексте настоящего раскрытия.
[24] В некоторых вариантах осуществления в данном документе представлена фармацевтическая композиция, содержащая (a) нуклеиновую кислоту, как описано в данном документе, вектор, содержащий молекулу нуклеиновой кислоты, как описано в тексте настоящего раскрытия, полипептид, кодируемый молекулой нуклеиновой кислоты, как описано в тексте настоящего раскрытия, или клетку-хозяина, содержащую молекулу нуклеиновой кислоты, как описано в тексте настоящего раскрытия; (b) LNP и (c) фармацевтически приемлемое вспомогательное вещество. В некоторых вариантах осуществления в данном документе представлен набор, содержащий молекулу нуклеиновой кислоты, как описано в тексте настоящего раскрытия, и инструкции по введению молекулы нуклеиновой кислоты нуждающемуся в этом субъекту. В некоторых вариантах осуществления в данном документе представлена бакуловирусная система получения молекулы нуклеиновой кислоты, описанной в данном документе. В некоторых вариантах осуществления в данном документе представлена бакуловирусная система, где молекулу нуклеиновой кислоты, раскрытую в данном документе, получают в клетках насекомого.
[25] В некоторых вариантах осуществления в данном документе представлена система доставки на основе наночастиц для экспрессионных конструкций, где экспрессионная конструкция содержит молекулу нуклеиновой кислоты, описанную в данном документе.
[26] Также в данном документе раскрыт способ получения полипептида со свертывающей активностью, включающий культивирование клетки-хозяина, раскрытой в данном документе, в подходящих условиях и извлечение полипептида со свертывающей активностью. В некоторых вариантах осуществления в данном документе раскрыт способ обеспечения экспрессии фактора свертывания крови у нуждающегося в этом субъекта, включающий введение субъекту молекулы нуклеиновой кислоты, раскрытой в данном документе, вектора, раскрытого в данном документе, полипептида, раскрытого в данном документе, или фармацевтической композиции, раскрытой в данном документе. В некоторых вариантах осуществления в данном документе раскрыт способ лечения субъекта, имеющего дефицит фактора свертывания крови, включающий введение субъекту молекулы нуклеиновой кислоты, раскрытой в данном документе, вектора, раскрытого в данном документе, полипептида, раскрытого в данном документе, или фармацевтической композиции, раскрытой в данном документе. В некоторых вариантах осуществления молекула нуклеиновой кислоты вводится внутривенно, трансдермально, внутрикожно, подкожно, перорально, пульмонально или любой их комбинацией. В некоторых вариантах осуществления молекула нуклеиновой кислоты вводится внутривенно. В некоторых вариантах осуществления способ дополнительно включает введение субъекту второго средства. В некоторых вариантах осуществления субъектом является млекопитающее. В некоторых вариантах осуществления субъект представляет собой человека.
[27] В некоторых вариантах осуществления введение молекулы нуклеиновой кислоты субъекту приводит к увеличению активности FVIII относительно активности FVIII у субъекта до введения, где активность FVIII увеличивается в по меньшей мере приблизительно 2 раза, по меньшей мере приблизительно 3 раза, по меньшей мере приблизительно 4 раза, по меньшей мере приблизительно 5 раз, по меньшей мере приблизительно 6 раз, по меньшей мере приблизительно 7 раз, по меньшей мере приблизительно 8 раз, по меньшей мере приблизительно 9 раз, по меньшей мере приблизительно 10 раз, по меньшей мере приблизительно 11 раз, по меньшей мере приблизительно 12 раз, по меньшей мере приблизительно 13 раз, по меньшей мере приблизительно 14 раз, по меньшей мере приблизительно 15 раз, по меньшей мере приблизительно 20 раз, по меньшей мере приблизительно 25 раз, по меньшей мере приблизительно 30 раз, по меньшей мере приблизительно 35 раз, по меньшей мере приблизительно 40 раз, по меньшей мере приблизительно 50 раз, по меньшей мере приблизительно 60 раз, по меньшей мере приблизительно 70 раз, по меньшей мере приблизительно 80 раз, по меньшей мере приблизительно 90 раз или по меньшей мере приблизительно 100 раз.
[28] В некоторых вариантах осуществления у субъекта имеется нарушение свертываемости крови. В некоторых вариантах осуществления нарушение свертываемости крови представляет собой гемофилию. В некоторых вариантах осуществления нарушение свертываемости крови представляет собой гемофилию A.
КРАТКОЕ ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
[29] На фиг. 1A показано схематическое представление однонитевой кассеты экспрессии фактора свертывания крови (например, FVIII). Показаны местоположения 5'-ITR от вируса, отличного от AAV (со шпилечной петлей на конце ssDNA-структуры), 3'-ITR от вируса, отличного от AAV (со шпилечной петлей), последовательности промотора (например, TTPp) и последовательности трансгена, например последовательности FVIIIco6XTEN с XTEN144, вставленным в пределах домена B. В иллюстративной кассете экспрессии также показаны дополнительные возможные элементы, например последовательность интрона, последовательность WPREmut и последовательность bGHpA.
[30] На фиг. 1B-1D показаны схематические представления плазмид, применяемых для получения однонитевых кассет экспрессии фактора свертывания крови, таких как кассета, показанная на фиг. 1A, где ITR кассеты получены от AAV2 (фиг. 1B), B19 (фиг. 1C) или GPV (фиг. 1D). Плазмидная конструкция, содержащая кассету экспрессии ssFVIII, как показано в данном документе, подвергалась расщеплению посредством PvuII (в сайтах PvuII) (фиг. 1B) или LguI (в сайтах LguI) (фиг. 1C и 1D) с высвобождением вирусного генома. Двухнитевую ДНК нагревали до 95oC с получением ssDNA, а затем инкубировали при 4°C для обеспечения образования структуры, образуемой ITR.
[31] На фиг. 2A показано филогенетическое древо, иллюстрирующее взаимосвязь между различными представителями семейства парвовирусов. B19, AAV-2 и GPV обозначены посредством очерченных рамок.
[32] На фиг. 2B показано схематическое изображение различных кассет, включая шпилечные структуры.
[33] На фиг. 3A и 3B показаны выравнивания для ITR B19, GPV и AAV2 (фиг. 3A) и B19 и GPV (фиг. 3B). Области, выделенные серым, показывают гомологию.
[34] На фиг. 4A-4C показана активность FVIII в плазме крови после введения однонитевой "оголенной" ДНК FVIII-AAV (ssAAV-FVIII; фиг. 2A), ssDNA-B19 FVIII (фиг. 2B) или ssDNA-GPV FVIII (фиг. 2C) посредством гидродинамической инъекции (HDI) у мышей Hem A. Измеряли активность FVIII (как процентную долю относительно контроля) в образцах плазмы крови через 24 часа, 3 дня, 2 недели, 3 недели, 1 месяц, 2 месяца, 3 месяца и 4 месяца у мышей, обработанных посредством одной HDI ssDNA в количестве 50 мкг/мышь (фиг. 2C), 20 мкг/мышь (фиг. 2A и 2B), 10 мкг/мышь (фиг. 2A и 2C) или 5 мкг/мышь (фиг. 2A). HDI 5 мкг/мышь плазмидной ДНК осуществляли в качестве контроля (фиг. 2A-2C).
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[35] В настоящем изобретении описываются плазмидоподобные молекулы нуклеиновой кислоты, содержащие первый инвертированный концевой повтор (ITR), второй ITR и генную кассету, например, кодирующую терапевтический белок или miRNA, где первый ITR и/или второй ITR представляют собой ITR вируса, отличного от аденоассоциированного вируса (например, первый ITR и/или второй ITR получены от вируса, отличного от AAV). В некоторых вариантах осуществления генная кассета кодирует терапевтический белок. В некоторых вариантах осуществления терапевтический белок предусматривает белок, выбранный из фактора свертывания крови, фактора роста, гормона, цитокина, антитела, их фрагмента или их комбинации. В некоторых вариантах осуществления генная кассета кодирует X-сцепленный дистрофин, MTM1 (миотубуларин), тирозингидроксилазу, AADC, циклогидролазу, SMN1, FXN (фратаксин), GUCY2D, RS1, CFH, HTRA, ARMS, CFB/CC2, CNGA/CNGB, Prf65, ARSA, PSAP, IDUA (MPS I), IDS (MPS II), PAH, GAA (кислую альфа-глюкозидазу) или любую их комбинацию.
[36] В некоторых вариантах осуществления терапевтический белок предусматривает фактор свертывания крови. В одном конкретном варианте осуществления терапевтический белок предусматривает белок FVIII или FIX.
[37] В некоторых вариантах осуществления генная кассета кодирует miRNA. В некоторых вариантах осуществления miRNA понижает экспрессию целевого гена, выбранного из SOD1, HTT, RHO или любой их комбинации.
[38] В определенных вариантах осуществления вирус, отличный от AAV, выбран из группы, состоящей из представителей семейства вирусов Parvoviridae и любой их комбинации. Настоящее изобретение дополнительно направлено на способы обеспечения экспрессии терапевтического белка, например фактора свертывания крови, например FVIII, у нуждающегося в этом субъекта, включающие введение субъекту молекулы нуклеиновой кислоты, содержащей первый инвертированный концевой повтор (ITR), второй ITR и генную кассету, например, кодирующую терапевтический белок или miRNA, где первый ITR и/или второй ITR представляют собой ITR вируса, отличного от аденоассоциированного вируса (вируса, отличного от AAV). В некоторых вариантах осуществления в настоящем изобретении описывается выделенная молекула нуклеиновой кислоты, содержащая нуклеотидную последовательность, которая характеризуется гомологией последовательностей с нуклеотидной последовательностью, выбранной из SEQ ID NO: 113 и 120.
[39] Иллюстративные конструкции согласно настоящему изобретению проиллюстрированы в прилагаемых фигурах и перечне последовательностей. В целях обеспечения четкого понимания описания и формулы изобретения следующие определения представлены ниже.
I. Определения
[40] Следует отметить, что форма единственного числа объекта относится к одному или нескольким таким объектам; например, под "нуклеотидной последовательностью" понимают одну или несколько нуклеотидных последовательностей. Аналогичным образом, под "терапевтическим белком" и "miRNA" понимают один или несколько терапевтических белков и одну или несколько miRNA соответственно. В связи с этим формы единственного числа, термины "один или несколько" и "по меньшей мере один" могут использоваться в данном документе взаимозаменяемо.
[41] Термин "приблизительно" используется в данном документе в значении примерно, порядка, около или ориентировочно. Если термин "приблизительно" используется в сочетании с числовым диапазоном, то он модифицирует данный диапазон, расширяя границы выше и ниже изложенных числовых значений. В целом, термин "приблизительно" применяют в данном документе для модификации числового значения выше и ниже заявленного значения с отклонением на 10 процентов, вверх или вниз (выше или ниже).
[42] Также используемый в данном документе "и/или" относится к и охватывает любые и все возможные комбинации одного или нескольких соответствующих перечисленных объектов, а также отсутствие комбинаций в случае интерпретации как альтернативы ("или").
[43] "Нуклеиновые кислоты", "молекулы нуклеиновой кислоты", "нуклеотиды", "нуклеотидная(-ые) последовательность(-и)" и "полинуклеотид" применяются взаимозаменяемо и относятся к полимерной форме сложных фосфатных эфиров рибонуклеозидов (аденозина, гуанозина, уридина или цитидина; "молекулам РНК") или дезоксирибонуклеозидов (дезоксиаденозина, дезоксигуанозина, дезокситимидина или дезоксицитидина; "молекулам ДНК") или любым сложным фосфатным эфирам их аналогов, как например фосфоротиоаты и сложные тиоэфиры, находящимся либо в однонитевой форме, либо в виде двухнитевой спирали. Последовательности однонитевой нуклеиновой кислоты относятся к однонитевой ДНК (ssDNA) или однонитевой РНК (ssRNA). Возможны двухнитевые спирали ДНК-ДНК, ДНК-РНК и РНК-РНК. Термин молекула нуклеиновой кислоты, и в частности молекула ДНК или РНК, относится только к первичной и вторичной структуре молекулы и не ограничивает ее какими-либо конкретными третичными формами. Таким образом, данный термин включает двухнитевую ДНК, обнаруживаемую, среди прочего, в линейных или кольцевых молекулах ДНК (например, фрагментах рестрикции), плазмидах, сверхспиральной ДНК и хромосомах. В рамках обсуждения структуры конкретной двухнитевой молекулы ДНК последовательности могут описываться в данном документе в соответствии с обычными правилами, предусматривающими приведение только последовательности в направлении 5'-3' вдоль нетранскрибируемый нити ДНК (т. е. нити, имеющей последовательность, гомологичную mRNA). "Рекомбинантная молекула ДНК" представляет собой молекулу ДНК, которая была подвергнута молекулярно-биологической манипуляции. ДНК включает без ограничения cDNA, геномную ДНК, плазмидную ДНК, синтетическую ДНК и полусинтетическую ДНК. "Композиция на основе нуклеиновой кислоты" согласно настоящему изобретению содержит одну или несколько нуклеиновых кислот, описанных в данном документе.
[44] Используемый в данном документе "инвертированный концевой повтор" (или "ITR") относится к подподпоследовательности нуклеиновой кислоты, расположенной на либо 5'-, либо 3'-конце последовательности однонитевой нуклеиновой кислоты, которая содержит набор нуклеотидов (исходную последовательность), ниже которой следует обратный комплемент, т. е. палиндромная последовательность. Промежуточная последовательность нуклеотидов между исходной последовательностью и обратным комплементом может характеризоваться любой длиной, в том числе нулевой. В одном варианте осуществления ITR, пригодный в настоящем изобретении, содержит одну или несколько "палиндромных последовательностей". ITR может выполнять любое количество функций. В некоторых вариантах осуществления ITR, описанный в данном документе, образует шпилечную структуру. В некоторых вариантах осуществления ITR образует T-образную шпилечная структура. В некоторых вариантах осуществления ITR образует отличную от T-образной шпилечную структуру, например U-образную шпилечную структуру. В некоторых вариантах осуществления ITR способствует долговременному сохранению молекулы нуклеиновой кислоты в ядре клетки. В некоторых вариантах осуществления ITR способствует постоянному сохранению молекулы нуклеиновой кислоты в ядре клетки (например, в течение всей продолжительности жизни клетки). В некоторых вариантах осуществления ITR способствует стабильности молекулы нуклеиновой кислоты в ядре клетки. В некоторых вариантах осуществления ITR способствует удерживанию молекулы нуклеиновой кислоты в ядре клетки. В некоторых вариантах осуществления ITR способствует непрерывности нахождения молекулы нуклеиновой кислоты в ядре клетки. В некоторых вариантах осуществления ITR подавляет или предупреждает разрушение молекулы нуклеиновой кислоты в ядре клетки.
[45] В одном варианте осуществления исходная последовательность и/или обратный комплемент содержат приблизительно 2-600 нуклеотидов, приблизительно 2-550 нуклеотидов, приблизительно 2-500 нуклеотидов, приблизительно 2-450 нуклеотидов, приблизительно 2-400 нуклеотидов, приблизительно 2-350 нуклеотидов, приблизительно 2-300 нуклеотидов или приблизительно 2-250 нуклеотидов. В некоторых вариантах осуществления исходная последовательность и/или обратный комплемент содержат приблизительно 5-600 нуклеотидов, приблизительно 10-600 нуклеотидов, приблизительно 15-600 нуклеотидов, приблизительно 20-600 нуклеотидов, приблизительно 25-600 нуклеотидов, приблизительно 30-600 нуклеотидов, приблизительно 35-600 нуклеотидов, приблизительно 40-600 нуклеотидов, приблизительно 45-600 нуклеотидов, приблизительно 50-600 нуклеотидов, приблизительно 60-600 нуклеотидов, приблизительно 70-600 нуклеотидов, приблизительно 80-600 нуклеотидов, приблизительно 90-600 нуклеотидов, приблизительно 100-600 нуклеотидов, приблизительно 150-600 нуклеотидов, приблизительно 200-600 нуклеотидов, приблизительно 300-600 нуклеотидов, приблизительно 350-600 нуклеотидов, приблизительно 400-600 нуклеотидов, приблизительно 450-600 нуклеотидов, приблизительно 500-600 нуклеотидов или приблизительно 550-600 нуклеотидов. В некоторых вариантах осуществления исходная последовательность и/или обратный комплемент содержат приблизительно 5-550 нуклеотидов, приблизительно 5-500 нуклеотидов, приблизительно 5-450 нуклеотидов, приблизительно 5-400 нуклеотидов, приблизительно 5-350 нуклеотидов, приблизительно 5-300 нуклеотидов или приблизительно 5-250 нуклеотидов. В некоторых вариантах осуществления исходная последовательность и/или обратный комплемент содержат приблизительно 10-550 нуклеотидов, приблизительно 15-500 нуклеотидов, приблизительно 20-450 нуклеотидов, приблизительно 25-400 нуклеотидов, приблизительно 30-350 нуклеотидов, приблизительно 35-300 нуклеотидов или приблизительно 40-250 нуклеотидов. В некоторых вариантах осуществления исходная последовательность и/или обратный комплемент содержат приблизительно 225 нуклеотидов, приблизительно 250 нуклеотидов, приблизительно 275 нуклеотидов, приблизительно 300 нуклеотидов, приблизительно 325 нуклеотидов, приблизительно 350 нуклеотидов, приблизительно 375 нуклеотидов, приблизительно 400 нуклеотидов, приблизительно 425 нуклеотидов, приблизительно 450 нуклеотидов, приблизительно 475 нуклеотидов, приблизительно 500 нуклеотидов, приблизительно 525 нуклеотидов, приблизительно 550 нуклеотидов, приблизительно 575 нуклеотидов или приблизительно 600 нуклеотидов. В конкретных вариантах осуществления исходная последовательность и/или обратный комплемент содержат приблизительно 400 нуклеотидов.
[46] В других вариантах осуществления исходная последовательность и/или обратный комплемент содержат приблизительно 2-200 нуклеотидов, приблизительно 5-200 нуклеотидов, приблизительно 10-200 нуклеотидов, приблизительно 20-200 нуклеотидов, приблизительно 30-200 нуклеотидов, приблизительно 40-200 нуклеотидов, приблизительно 50-200 нуклеотидов, приблизительно 60-200 нуклеотидов, приблизительно 70-200 нуклеотидов, приблизительно 80-200 нуклеотидов, приблизительно 90-200 нуклеотидов, приблизительно 100-200 нуклеотидов, приблизительно 125-200 нуклеотидов, приблизительно 150-200 нуклеотидов или приблизительно 175-200 нуклеотидов. В других вариантах осуществления исходная последовательность и/или обратный комплемент содержат приблизительно 2-150 нуклеотидов, приблизительно 5-150 нуклеотидов, приблизительно 10-150 нуклеотидов, приблизительно 20-150 нуклеотидов, приблизительно 30-150 нуклеотидов, приблизительно 40-150 нуклеотидов, приблизительно 50-150 нуклеотидов, приблизительно 75-150 нуклеотидов, приблизительно 100-150 нуклеотидов или приблизительно 125-150 нуклеотидов. В других вариантах осуществления исходная последовательность и/или обратный комплемент содержат приблизительно 2-100 нуклеотидов, приблизительно 5-100 нуклеотидов, приблизительно 10-100 нуклеотидов, приблизительно 20-100 нуклеотидов, приблизительно 30-100 нуклеотидов, приблизительно 40-100 нуклеотидов, приблизительно 50-100 нуклеотидов или приблизительно 75-100 нуклеотидов. В других вариантах осуществления исходная последовательность и/или обратный комплемент содержат приблизительно 2-50 нуклеотидов, приблизительно 10-50 нуклеотидов, приблизительно 20-50 нуклеотидов, приблизительно 30-50 нуклеотидов, приблизительно 40-50 нуклеотидов, приблизительно 3-30 нуклеотидов, приблизительно 4-20 нуклеотидов или приблизительно 5-10 нуклеотидов. В другом варианте осуществления исходная последовательность и/или обратный комплемент состоят из двух нуклеотидов, трех нуклеотидов, четырех нуклеотидов, пяти нуклеотидов, шести нуклеотидов, семи нуклеотидов, восьми нуклеотидов, девяти нуклеотидов, десяти нуклеотидов, 11 нуклеотидов, 12 нуклеотидов, 13 нуклеотидов, 14 нуклеотидов, 15 нуклеотидов, 16 нуклеотидов, 17 нуклеотидов, 18 нуклеотидов, 19 нуклеотидов или 20 нуклеотидов. В других вариантах осуществления промежуточный нуклеотид между исходной последовательностью и обратным комплементом предусматривает (например, состоит из) 0 нуклеотидов, 1 нуклеотид, два нуклеотида, три нуклеотида, четыре нуклеотида, пять нуклеотидов, шесть нуклеотидов, семь нуклеотидов, восемь нуклеотидов, девять нуклеотидов, 10 нуклеотидов, 11 нуклеотидов, 12 нуклеотидов, 13 нуклеотидов, 14 нуклеотидов, 15 нуклеотидов, 16 нуклеотидов, 17 нуклеотидов, 18 нуклеотидов, 19 нуклеотидов или 20 нуклеотидов.
[47] Следовательно, "ITR", используемый в данном документе, может заворачиваться на себя и образовывать двухнитевой сегмент. Например, последовательность GATCXXXXGATC содержит исходную последовательность GATC и ее комплемент (3'CTAG5') при сворачивании с образованием двойной спирали. В некоторых вариантах осуществления ITR содержит непрерывную палиндромную последовательность (например, GATCGATC) между исходной последовательностью и обратным комплементом. В некоторых вариантах осуществления ITR содержит прерывистую палиндромную последовательность (например, GATCXXXXGATC) между исходной последовательностью и обратным комплементом. В некоторых вариантах осуществления комплементарные участки непрерывной или прерывистой палиндромной последовательности взаимодействуют друг с другом с образованием структуры "шпилечной петли". Применяемая в данном документе структура "шпилечной петли" образуется, когда по меньшей мере две комплементарные последовательности в однонитевой нуклеотидной молекуле подвергаются спариванию оснований с образованием двухнитевого участка. В некоторых вариантах осуществления только часть ITR образует шпилечную петлю. В других вариантах осуществления весь ITR образует шпилечную петлю.
[48] В настоящем изобретении по меньшей мере один ITR представляет собой ITR вируса, отличного от аденоассоциированного вируса (вируса, отличного от AAV). В некоторых вариантах осуществления ITR представляет собой ITR вируса, отличного от AAV, являющегося представителем семейства вирусов Parvoviridae. В некоторых вариантах осуществления ITR представляет собой ITR вируса, отличного от AAV, являющегося представителем рода Dependovirus или рода Erythrovirus. В конкретных вариантах осуществления ITR представляет собой ITR парвовируса гусей (GPV), парвовируса мускусных уток (MDPV) или эритровируса, представляющего собой парвовирус B19 (также известного как парвовирус B19, эритропарвовирус приматов 1, вирус B19 и эритровирус). В некоторых вариантах осуществления один ITR из двух ITR представляет собой ITR AAV. В других вариантах осуществления один ITR из двух ITR в конструкции представляет собой ITR AAV серотипа, выбранного из серотипа 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11 и любой их комбинации. В одном конкретном варианте осуществления ITR получен из AAV серотипа 2, например ITR AAV серотипа 2.
[49] В определенных аспектах настоящего изобретения молекула нуклеиновой кислоты содержит два ITR, представляющие собой 5'-ITR и 3'-ITR, где 5'-ITR располагается на 5'-конце молекулы нуклеиновой кислоты, и 3'-ITR располагается на 3'-конце молекулы нуклеиновой кислоты. 5'-ITR и 3'-ITR могут быть получены из одного и того же вируса или различных вирусов. В некоторых вариантах осуществления 5'-ITR получен из AAV и 3'-ITR не является полученным из вируса AAV (например, вируса, отличного от AAV). В некоторых вариантах осуществления 3'-ITR получен из AAV и 5'-ITR не является полученным из вируса AAV (например, вируса, отличного от AAV). В других вариантах осуществления 5'-ITR не является полученным из вируса AAV (например, вируса, отличного от AAV) и 3'-ITR получен из того же или другого вируса, отличного от вируса AAV.
[50] Термин "парвовирус", используемый в данном документе, охватывает семейство Parvoviridae, в том числе без ограничения автономно реплицирующиеся парвовирусы и депендовирусы. Автономные парвовирусы включают, например, представителей родов Bocavirus, Dependovirus, Erythrovirus, Amdovirus, Parvovirus, Densovirus, Iteravirus, Contravirus, Aveparvovirus, Copiparvovirus, Protoparvovirus, Tetraparvovirus, Ambidensovirus, Brevidensovirus, Hepandensovirus, и Penstyldensovirus.
[51] Иллюстративные автономные парвовирусы включают без ограничения парвовирус свиней, мелкий вирус мышей, собачий парвовирус, вирус энтерита норок, парвовирус крупного рогатого скота, куриный парвовирус, вирус панлейкопении у кошек, кошачий парвовирус, парвовирус гусей, парвовирус H1, парвовирус мускусных уток, парвовирус змей и вирус B19. Другие автономные парвовирусы известны специалистам в данной области техники. См., например, FIELDS et al. VIROLOGY, volume 2, chapter 69 (4th ed., Lippincott-Raven Publishers).
[52] Термин "вирус, отличный от AAV", используемый в данном документе, охватывает нуклеиновые кислоты, белки и вирусы семейства Parvoviridae, за исключением любых аденоассоциированных вирусов (AAV) семейства Parvoviridae. "Вирус, отличный от AAV", включает без ограничения автономно реплицирующихся представителей родов Bocavirus, Dependovirus, Erythrovirus, Amdovirus, Parvovirus, Densovirus, Iteravirus, Contravirus, Aveparvovirus, Copiparvovirus, Protoparvovirus, Tetraparvovirus, Ambidensovirus, Brevidensovirus, Hepandensovirus и Penstyldensovirus.
[53] Используемый в данном документе термин "аденоассоциированный вирус" (AAV) включает без ограничения AAV типа 1, AAV типа 2, AAV типа 3 (в том числе типов 3A и 3B), AAV типа 4, AAV типа 5, AAV типа 6, AAV типа 7, AAV типа 8, AAV типа 9, AAV типа 10, AAV типа 11, AAV типа 12, AAV типа 13, AAV змей, AAV птиц, AAV крупного рогатого скота, AAV собак, AAV лошадей, AAV овец, AAV коз, AAV креветок, серотипы и клады AAV, раскрытые в Gao et al. (J. Virol. 78:6381 (2004)) и Moris et al. (Virol. 33:375 (2004)), и любой другой AAV, известный в настоящее время или открытый впоследствии. См., например, FIELDS et al. VIROLOGY, volume 2, chapter 69 (4th ed., Lippincott-Raven Publishers).
[54] Термин "полученный из", используемый в данном документе, относится к компоненту, который выделен из или изготовлен с применением указанных молекулы или организма, или информации (например, аминокислотной последовательности или последовательности нуклеиновой кислоты), полученной из указанных молекулы или организма. Например, последовательность нуклеиновой кислоты (например, ITR), которая получена из второй последовательности нуклеиновой кислоты (например, ITR), может предусматривать нуклеотидную последовательность, которая является идентичной или по сути аналогичной нуклеотидной последовательности второй последовательности нуклеиновой кислоты. В случае нуклеотидов или полипептидов производные молекулы могут быть получены путем, например, естественного мутагенеза, искусственного направленного мутагенеза или искусственного случайного мутагенеза. Мутагенез, применяемый для получения нуклеотидов или полипептидов, может являться преднамеренно направленным, или преднамеренно случайным, или их комбинацией. Мутагенез нуклеотида или полипептида с созданием отличающегося нуклеотида или полипептида, полученного из первого, может быть случайным событием (например, обусловленным неточностью работы полимеразы), и идентификация полученного нуклеотида или полипептида может быть осуществлена путем подходящих способов скрининга, например, как рассматривается в данном документе. Мутагенез полипептида, как правило, предусматривает манипуляции с полинуклеотидом, который кодирует полипептид. В некоторых вариантах осуществления нуклеотидная или аминокислотная последовательность, которая получена из второй нуклеотидной или аминокислотной последовательности, характеризуется по меньшей мере 50%, по меньшей мере 51%, по меньшей мере 52%, по меньшей мере 53%, по меньшей мере 54%, по меньшей мере 55%, по меньшей мере 56%, по меньшей мере 57%, по меньшей мере 58%, по меньшей мере 59%, по меньшей мере 60%, по меньшей мере 61%, по меньшей мере 62%, по меньшей мере 63%, по меньшей мере 64%, по меньшей мере 65%, по меньшей мере 66%, по меньшей мере 67%, по меньшей мере 68%, по меньшей мере 69%, по меньшей мере 70%, по меньшей мере 71%, по меньшей мере 72%, по меньшей мере 73%, по меньшей мере 74%, по меньшей мере 75%, по меньшей мере 76%, по меньшей мере 77%, по меньшей мере 78%, по меньшей мере 79%, по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100% идентичностью последовательности со второй нуклеотидной или аминокислотной последовательностью соответственно, где первая нуклеотидная или аминокислотная последовательность сохраняет биологическую активность второй нуклеотидной или аминокислотной последовательности. В других вариантах осуществления ITR, полученный из ITR вируса, отличного от AAV (или AAV), характеризуется по меньшей мере 90% идентичностью с ITR вируса, отличного от AAV (или ITR AAV соответственно), где ITR вируса, отличного от AAV (или AAV), сохраняет функциональное свойство ITR вируса, отличного от AAV (или ITR AAV соответственно). В некоторых вариантах осуществления ITR, полученный из ITR вируса, отличного от AAV (или AAV), характеризуется по меньшей мере 80% идентичностью с ITR вируса, отличного от AAV (или ITR AAV соответственно), где ITR вируса, отличного от AAV (или AAV), сохраняет функциональное свойство ITR вируса, отличного от AAV (или ITR AAV соответственно). В некоторых вариантах осуществления ITR, полученный из ITR вируса, отличного от AAV (или AAV), характеризуется по меньшей мере 70% идентичностью с ITR вируса, отличного от AAV (или ITR AAV соответственно), где ITR вируса, отличного от AAV (или AAV), сохраняет функциональное свойство ITR вируса, отличного от AAV (или ITR AAV соответственно). В некоторых вариантах осуществления ITR, полученный из ITR вируса, отличного от AAV (или AAV), характеризуется по меньшей мере 60% идентичностью с ITR вируса, отличного от AAV (или ITR AAV соответственно), где ITR вируса, отличного от AAV (или AAV), сохраняет функциональное свойство ITR вируса, отличного от AAV (или ITR AAV соответственно). В некоторых вариантах осуществления ITR, полученный из ITR вируса, отличного от AAV (или AAV), характеризуется по меньшей мере 50% идентичностью с ITR вируса, отличного от AAV (или ITR AAV соответственно), где ITR вируса, отличного от AAV (или AAV), сохраняет функциональное свойство ITR вируса, отличного от AAV (или ITR AAV соответственно).
[55] В некоторых вариантах осуществления ITR, полученный из ITR вируса, отличного от AAV (или AAV), содержит или состоит из фрагмента ITR вируса, отличного от AAV (или AAV). В некоторых вариантах осуществления ITR, полученный из ITR вируса, отличного от AAV (или AAV), содержит или состоит из фрагмента ITR вируса, отличного от AAV (или AAV), где фрагмент содержит по меньшей мере приблизительно 5 нуклеотидов, по меньшей мере приблизительно 10 нуклеотидов, по меньшей мере приблизительно 15 нуклеотидов, по меньшей мере приблизительно 20 нуклеотидов, по меньшей мере приблизительно 25 нуклеотидов, по меньшей мере приблизительно 30 нуклеотидов, по меньшей мере приблизительно 35 нуклеотидов, по меньшей мере приблизительно 40 нуклеотидов, по меньшей мере приблизительно 45 нуклеотидов, по меньшей мере приблизительно 50 нуклеотидов, по меньшей мере приблизительно 55 нуклеотидов, по меньшей мере приблизительно 60 нуклеотидов, по меньшей мере приблизительно 65 нуклеотидов, по меньшей мере приблизительно 70 нуклеотидов, по меньшей мере приблизительно 75 нуклеотидов, по меньшей мере приблизительно 80 нуклеотидов, по меньшей мере приблизительно 85 нуклеотидов, по меньшей мере приблизительно 90 нуклеотидов, по меньшей мере приблизительно 95 нуклеотидов, по меньшей мере приблизительно 100 нуклеотидов, по меньшей мере приблизительно 125 нуклеотидов, по меньшей мере приблизительно 150 нуклеотидов, по меньшей мере приблизительно 175 нуклеотидов, по меньшей мере приблизительно 200 нуклеотидов, по меньшей мере приблизительно 225 нуклеотидов, по меньшей мере приблизительно 250 нуклеотидов, по меньшей мере приблизительно 275 нуклеотидов, по меньшей мере приблизительно 300 нуклеотидов, по меньшей мере приблизительно 325 нуклеотидов, по меньшей мере приблизительно 350 нуклеотидов, по меньшей мере приблизительно 375 нуклеотидов, по меньшей мере приблизительно 400 нуклеотидов, по меньшей мере приблизительно 425 нуклеотидов, по меньшей мере приблизительно 450 нуклеотидов, по меньшей мере приблизительно 475 нуклеотидов, по меньшей мере приблизительно 500 нуклеотидов, по меньшей мере приблизительно 525 нуклеотидов, по меньшей мере приблизительно 550 нуклеотидов, по меньшей мере приблизительно 575 нуклеотидов или по меньшей мере приблизительно 600 нуклеотидов; где ITR, полученный из ITR вируса, отличного от AAV (или AAV), сохраняет функциональное свойство ITR вируса, отличного от AAV (или ITR AAV соответственно). В некоторых вариантах осуществления ITR, полученный из ITR вируса, отличного от AAV (или AAV), содержит или состоит из фрагмента ITR вируса, отличного от AAV (или AAV), где фрагмент содержит по меньшей мере приблизительно 129 нуклеотидов, и где ITR, полученный из ITR вируса, отличного от AAV (или AAV) сохраняет функциональное свойство ITR вируса, отличного от AAV (или ITR AAV соответственно). В некоторых вариантах осуществления ITR, полученный из ITR вируса, отличного от AAV (или AAV), содержит или состоит из фрагмента ITR вируса, отличного от AAV (или AAV), где фрагмент содержит по меньшей мере приблизительно 102 нуклеотидов, и где ITR, полученный из ITR вируса, отличного от AAV (или AAV) сохраняет функциональное свойство ITR вируса, отличного от AAV (или ITR AAV соответственно).
[56] В некоторых вариантах осуществления ITR, полученный из ITR вируса, отличного от AAV (или AAV), содержит или состоит из фрагмента ITR вируса, отличного от AAV (или AAV), где фрагмент составляет по меньшей мере приблизительно 5%, по меньшей мере приблизительно 10%, по меньшей мере приблизительно 15%, по меньшей мере приблизительно 20%, по меньшей мере приблизительно 25%, по меньшей мере приблизительно 30%, по меньшей мере приблизительно 35%, по меньшей мере приблизительно 40%, по меньшей мере приблизительно 45%, по меньшей мере приблизительно 50%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% от длины ITR вируса, отличного от AAV (или AAV).
[57] В некоторых вариантах осуществления нуклеотидная или аминокислотная последовательность, которая получена из второй нуклеотидной или аминокислотной последовательности, характеризуется по меньшей мере 50%, по меньшей мере 51%, по меньшей мере 52%, по меньшей мере 53%, по меньшей мере 54%, по меньшей мере 55%, по меньшей мере 56%, по меньшей мере 57%, по меньшей мере 58%, по меньшей мере 59%, по меньшей мере 60%, по меньшей мере 61%, по меньшей мере 62%, по меньшей мере 63%, по меньшей мере 64%, по меньшей мере 65%, по меньшей мере 66%, по меньшей мере 67%, по меньшей мере 68%, по меньшей мере 69%, по меньшей мере 70%, по меньшей мере 71%, по меньшей мере 72%, по меньшей мере 73%, по меньшей мере 74%, по меньшей мере 75%, по меньшей мере 76%, по меньшей мере 77%, по меньшей мере 78%, по меньшей мере 79%, по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100% идентичностью последовательности с гомологичной частью второй нуклеотидной или аминокислотной последовательности соответственно, когда они выравнены надлежащим образом, где первая нуклеотидная или аминокислотная последовательность сохраняет биологическую активность второй нуклеотидной или аминокислотной последовательности. В других вариантах осуществления ITR, полученный из ITR вируса, отличного от AAV (или AAV), характеризуется по меньшей мере 90% идентичностью с гомологичной частью ITR вируса, отличного от AAV (или ITR AAV соответственно), когда они выравнены надлежащим образом, где первая нуклеотидная или аминокислотная последовательность сохраняет биологическую активность второй нуклеотидной или аминокислотной последовательности. В некоторых вариантах осуществления ITR, полученный из ITR вируса, отличного от AAV (или AAV), характеризуется по меньшей мере 80% идентичностью с гомологичной частью ITR вируса, отличного от AAV (или ITR AAV соответственно), когда они выравнены надлежащим образом, где первая нуклеотидная или аминокислотная последовательность сохраняет биологическую активность второй нуклеотидной или аминокислотной последовательности. В некоторых вариантах осуществления ITR, полученный из ITR вируса, отличного от AAV (или AAV), характеризуется по меньшей мере 70% идентичностью с гомологичной частью ITR вируса, отличного от AAV (или ITR AAV соответственно), когда они выравнены надлежащим образом, где первая нуклеотидная или аминокислотная последовательность сохраняет биологическую активность второй нуклеотидной или аминокислотной последовательности. В некоторых вариантах осуществления ITR, полученный из ITR вируса, отличного от AAV (или AAV), характеризуется по меньшей мере 60% идентичностью с гомологичной частью ITR вируса, отличного от AAV (или ITR AAV соответственно), когда они выравнены надлежащим образом, где первая нуклеотидная или аминокислотная последовательность сохраняет биологическую активность второй нуклеотидной или аминокислотной последовательности. В некоторых вариантах осуществления ITR, полученный из ITR вируса, отличного от AAV (или AAV), характеризуется по меньшей мере 50% идентичностью с гомологичной частью ITR вируса, отличного от AAV (или ITR AAV соответственно), когда они выравнены надлежащим образом, где первая нуклеотидная или аминокислотная последовательность сохраняет биологическую активность второй нуклеотидной или аминокислотной последовательности.
[58] "Не имеющие капсида" или "безкапсидные" вектор или молекула нуклеиновой кислоты относятся к векторной конструкции, не предусматривающей наличия капсида. В некоторых вариантах осуществления безкапсидный вектор или молекула нуклеиновой кислоты не содержат последовательностей, кодирующих, например, белок Rep AAV.
[59] Как используется в данном документе, "кодирующая область" или "кодирующая последовательность" представляют собой часть полинуклеотида, состоящую из кодонов, транслируемых в аминокислоты. Хотя "стоп-кодон" (TAG, TGA или TAA), как правило, не транслируется в аминокислоту, он может считаться частью кодирующей области, однако любые фланкирующие последовательности, например промоторы, сайты связывания рибосом, терминаторы транскрипции, интроны и т. п., не составляют часть кодирующей области. Границы кодирующей области обычно определяются старт-кодоном на 5'-конце, кодирующим амино-конец получаемого полипептида, и стоп-кодоном трансляции на 3'-конце, кодирующим карбоксильный конец получаемого полипептида. Две или более кодирующие области могут присутствовать в одной полинуклеотидной конструкции, например, в одном векторе, или в отдельных полинуклеотидных конструкциях, например, в отдельных (различных) векторах. Отсюда следует, что один вектор может содержать только одну кодирующую область или содержать две или более кодирующих областей.
[60] Определенные белки, секретируемые клетками млекопитающих, связаны с секреторным сигнальным пептидом, отщепляющимся от зрелого белка после начала экспорта растущей белковой цепи через гранулярный эндоплазматический ретикулум. Специалистам в данной области техники известно, что сигнальные полипептиды обычно слиты с N-концом полипептида, и отщепляются от полного или "полноразмерного" полипептида с образованием секретируемой или "зрелой" формы полипептида. В определенных вариантах осуществления применяют нативный сигнальный пептид или функциональное производное такой последовательности, которое сохраняет способность к управлению секрецией полипептида, функционально связанного с ним. В качестве альтернативы, можно применять гетерологичный сигнальный пептид млекопитающего, например, тканевой активатор плазминогена (ТРА) человека или сигнальный пептид ß-глюкуронидазы мыши или его функциональное производное.
[61] Термин "ниже" относится к нуклеотидной последовательности, которая расположена в направлении 3' относительно эталонной нуклеотидной последовательности. В определенных вариантах осуществления расположенные ниже нуклеотидные последовательности относятся к последовательностям, которые следуют за точкой начала транскрипции. Например, кодон инициации трансляции гена расположен ниже относительно сайта начала транскрипции.
[62] Термин "выше" относится к нуклеотидной последовательности, которая расположена в направлении 5' относительно эталонной нуклеотидной последовательности. В определенных вариантах осуществления расположенные выше нуклеотидные последовательности относятся к последовательностям, которые расположены со стороны 5'-конца относительно кодирующей области или точки начала транскрипции. Например, большинство промоторов расположены выше сайта начала транскрипции.
[63] Как используется в данном документе, термин "регуляторная область гена" или "регуляторная область" относится к нуклеотидным последовательностям, расположенным выше (5'-некодирующие последовательности), в пределах или ниже (3'-некодирующие последовательности) кодирующей области, и которые влияют на транскрипцию, процессинг РНК, стабильность или трансляцию связанной кодирующей области. Регуляторные области могут включать промоторы, лидерные последовательности трансляции, интроны, последовательности, узнающие сайты полиаденилирования, сайты процессинга РНК, сайты связывания эффекторов и структуры "стебель-петля". Если кодирующая область предназначена для экспрессии в эукариотической клетке, сигнал полиаденилирования и последовательность терминации транскрипции обычно будут размещены в направлении 3' относительно кодирующей последовательности.
[64] Полинуклеотид, который кодирует продукт, например miRNA или продукт гена (например, полипептид, такой как терапевтический белок), может содержать промотор и/или другие элементы, осуществляющие контроль экспрессии (например, транскрипции или трансляции), функционально связанные с одной или несколькими кодирующими областями. В функциональной связи кодирующая область для продукта гена, например полипептида, связана с одной или несколькими регуляторными областями таким образом, что экспрессия продукта гена находится под влиянием или контролем регуляторной(-ых) области(-ей). Например, кодирующая область и промотор считаются "функционально связанными", если индуцирование функции промотора приводит к транскрипции mRNA, кодирующей продукт гена, кодируемого кодирующей областью, и если природа связи между промотором и кодирующей областью не препятствует способности промотора управлять экспрессией продукта гена или не препятствует способности ДНК-матрицы транскрибироваться. Другие элементы, осуществляющие контроль экспрессии, помимо промотора, например энхансеры, операторы, репрессоры и сигналы терминации транскрипции, также могут быть функционально связаны с кодирующей областью для управления экспрессией продукта гена.
[65] "Последовательности, осуществляющие контроль транскрипции", относятся к регуляторным последовательностям ДНК, таким как промоторы, энхансеры, терминаторы и т. п., которые обеспечивают осуществление экспрессии кодирующей последовательности в клетке-хозяине. Специалистам в данной области техники известны разнообразные области, осуществляющие контроль транскрипции. Они включают без ограничения области, осуществляющие контроль транскрипции, функционирующие в клетках позвоночных, такие как без ограничения промоторные и энхансерные сегменты цитомегаловирусов (промотор гена немедленного раннего ответа вместе с интроном A), вируса обезьян 40 (промотор гена раннего ответа) и ретровирусов (таких как вирус саркомы Рауса). Другие области, осуществляющие контроль транскрипции, включают области, полученные из генов позвоночных, таких как гены актина, белка теплового шока, бычьего гормона роста и ß-глобина кролика, а также другие последовательности, способные осуществлять контроль экспрессии генов в эукариотических клетках. Дополнительные подходящие области, осуществляющие контроль транскрипции, включают тканеспецифические промоторы и энхансеры, а также индуцируемые лимфокинами промоторы (например, промоторы, индуцируемые интерферонами или интерлейкинами).
[66] Аналогично, разнообразные элементы, осуществляющие контроль трансляции, известны средним специалистам в данной области техники. Они включают без ограничения сайты связывания рибосомы, кодоны инициации и терминации трансляции и элементы, полученные из пикорнавирусов (в частности, сайт внутренней посадки рибосомы или IRES, также называемый CITE-последовательностью).
[67] Термин "экспрессия", используемый в данном документе, относится к процессу, посредством которого из полинуклеотида вырабатывается продукт гена, например, РНК или полипептид. Она включает без ограничения транскрипцию полинуклеотида с образованием матричной РНК (mRNA), транспортной РНК (tRNA), малой шпилечной РНК (shRNA), малой интерферирующей РНК (siRNA) или любого другого продукта, представляющего собой РНК, и трансляцию mRNA с образованием полипептида. Экспрессия приводит к образованию "продукта гена". Как используется в данном документе, продукт гена может представлять собой либо нуклеиновую кислоту, например, информационную РНК, получаемую путем транскрипции гена, либо полипептид, который транслируется с транскрипта. Продукты гена, описанные в данном документе, дополнительно включают нуклеиновые кислоты с посттранскрипционными модификациями, например, полиаденилированием или сплайсингом, или полипептиды с посттрансляционными модификациями, например, метилированием, гликозилированием, добавлением липидов, ассоциацией с другими белковыми субъединицами, протеолитическим расщеплением. Термин "выход", используемый в данном документе, относится к количеству полипептида, полученному посредством экспрессии гена.
[68] "Вектор" относится к любому носителю для клонирования нуклеиновой кислоты и/или ее переноса в клетку-хозяина. Вектор может представлять собой репликон, к которому может быть присоединен другой сегмент нуклеиновой кислоты так, чтобы обеспечить репликацию присоединенного сегмента. "Репликон" относится к любому генетическому элементу (например, плазмиде, фагу, космиде, хромосоме, вирусу), который функционирует как автономная единица репликации in vivo, т. e. способен реплицироваться под своим собственным контролем. Термин "вектор" включает носители для введения нуклеиновой кислоты в клетку in vitro, ex vivo или in vivo. В данной области техники известно и используется большое количество векторов, в том числе, например, плазмиды, модифицированные вирусы эукариот или модифицированные бактериофаги. Вставка полинуклеотида в подходящий вектор может быть осуществлена посредством лигирования соответствующих полинуклеотидных фрагментов в выбранный вектор, который имеет комплементарные "липкие" концы.
[69] Векторы могут быть сконструированы так, чтобы кодировать селектируемые маркеры или репортерные гены, которые обеспечивают отбор или идентификацию клеток, в которые встроился вектор. Экспрессия селектируемых маркеров или репортерных генов обеспечивает идентификацию и/или отбор клеток-хозяев, которые содержат и экспрессируют другие кодирующие области, содержащиеся в векторе. Примеры генов селектируемых маркеров, известных и применяемых в данной области техники, включают гены, обеспечивающие устойчивость к ампициллину, стрептомицину, гентамицину, канамицину, гигромицину, гербициду биалафосу, сульфонамиду и т. п.; и гены, которые применяют в качестве фенотипических маркеров, т. е. гены, регулирующие синтез антоцианов, ген изопентанилтрансферазы и т. п. Примеры репортерных генов, известных и применяемых в данной области техники, включают люциферазу (Luc), зеленый флуоресцентный белок (GFP), хлорамфениколацетилтрансферазу (CAT), β-галактозидазу (LacZ), β-глюкуронидазу (Gus) и т. п. Селектируемые маркеры также можно рассматривать как репортерные гены.
[70] Термин "клетка-хозяин", используемый в данном документе, относится, например, к микроорганизмам, клеткам дрожжей, клеткам насекомых и клеткам млекопитающих, которые можно применять или применяются в качестве реципиентов ssDNA или векторов. Термин включает потомство исходной клетки, которая была трансдуцирована. Таким образом, применяемая в данном документе "клетка-хозяин", как правило, относится к клетке, которая была трансдуцирована последовательностью экзогенной ДНК. Следует понимать, что потомство одной родительской клетки не обязательно является полностью идентичным исходному родителю в отношении морфологии или в отношении комплемента геномной или общей ДНК вследствие естественной, случайной или преднамеренной мутации. В некоторых вариантах осуществления клетка-хозяин может представлять собой клетку-хозяина in vitro.
[71] Термин "селектируемый маркер" относится к идентифицирующему фактору, обычно гену антибиотика или устойчивости к химическому воздействию, в отношении которого можно осуществлять селекцию на основе эффекта маркерного гена, например устойчивость к антибиотику, устойчивость к гербициду, колориметрические маркеры, ферменты, флуоресцентные маркеры и т. п., где эффект применяют для отслеживания наследуемости представляющей интерес нуклеиновой кислоты и/или идентификации клетки или организма, которые унаследовали представляющую интерес нуклеиновую кислоту. Примеры генов селектируемых маркеров, известных и применяемых в данной области техники, включают гены, обеспечивающие устойчивость к ампициллину, стрептомицину, гентамицину, канамицину, гигромицину, гербициду биалафосу, сульфонамиду и т. п.; и гены, которые применяют в качестве фенотипических маркеров, т. е. гены, регулирующие синтез антоцианов, ген изопентанилтрансферазы и т. п.
[72] Термин "репортерный ген" относится к нуклеиновой кислоте, кодирующей идентифицирующий фактор, идентификацию которого можно осуществлять на основе эффекта репортерного гена, где эффект применяют для отслеживания наследуемости представляющей интерес нуклеиновой кислоты, идентификации клетки или организма, которые унаследовали представляющую интерес нуклеиновую кислоту, и/или для измерения индуцирования экспрессии гена или транскрипции. Примеры репортерных генов, известных и применяемых в данной области техники, включают люциферазу (Luc), зеленый флуоресцентный белок (GFP), хлорамфениколацетилтрансферазу (CAT), β-галактозидазу (LacZ), β-глюкуронидазу (Gus) и т. п. Гены селективных маркеров также можно рассматривать как репортерные гены.
[73] "Промотор" и "промоторная последовательность" применяют взаимозаменяемо и относятся к последовательности ДНК, способной к осуществлению контроля экспрессии кодирующей последовательности или функциональной РНК. В целом, кодирующая последовательность расположена в направлении 3' относительно промоторной последовательности. Промоторы могут быть получены целиком из нативного гена или состоять из различных элементов, полученных из различных промоторов, встречающихся в природе, или даже содержать сегменты синтетической ДНК. Специалистам в данной области техники будет понятно, что различные промоторы могут управлять экспрессией гена в различных тканях или типах клеток, или на различных стадиях развития, или в ответ на различные условия окружающей среды или физиологические условия. Промоторы, которые обуславливают экспрессию гена в большинстве типов клеток в большинстве случаев, обычно называют "конститутивными промоторами". Промоторы, которые обуславливают экспрессию гена в конкретном типе клеток, обычно называют "клеточноспецифическими промоторами" или "тканеспецифическими промоторами". Промоторы, которые обуславливают экспрессию гена на конкретной стадии развития или дифференцировки клеток, обычно называют "промоторами, специфическими для стадии развития" или "промоторами, специфическими в отношении дифференцировки клеток". Промоторы, которые являются индуцируемыми и обуславливают экспрессию гена после подвергания воздействию или обработки клетки средством, биологической молекулой, химическим веществом, лигандом, светом или т. п., которые индуцируют промотор, обычно называют "индуцибельными промоторами" или "регулируемыми промоторами". Кроме того, следует понимать, что поскольку в большинстве случаев точные границы регуляторных последовательностей полностью определены не были, фрагменты ДНК различной длины могут характеризоваться идентичной промоторной активностью.
[74] Промоторная последовательность, как правило, ограничена со стороны своего 3'-конца сайтом инициации транскрипции и продолжается выше (в 5'-направлении) с включением минимального числа оснований или элементов, необходимых для инициации транскрипции на поддающихся обнаружению находящихся выше фонового уровнях. В пределах промоторной последовательности можно будет обнаружить сайт инициации транскрипции (в подходящем случае определенный, например, посредством картирования с помощью нуклеазы S1), а также домены связывания белка (консенсусные последовательности), ответственные за связывание РНК-полимеразы.
[75] В некоторых вариантах осуществления молекула нуклеиновой кислоты содержит тканеспецифический промотор. В определенных вариантах осуществления тканеспецифический промотор управляет экспрессией терапевтического белка, например фактора свертывания крови, в печени, например в гепатоцитах и/или эндотелиальных клетках. В конкретных вариантах осуществления промотор выбран из группы, состоящей из промотора тиретина мыши (mTTR), эндогенного промотора фактора VIII человека (F8), промотора альфа-1-антитрипсина человека (hAAT), минимального промотора альбумина человека, промотора альбумина мыши, промотора тристетрапролина (TTP), промотора CASI, промотора CAG, промотора цитомегаловируса (CMV), промотора фосфоглицераткиназы (PGK) и любой их комбинации. В некоторых вариантах осуществления промотор выбран из специфического для печени промотора (например, α1-антитрипсина (AAT)), специфического для мышц промотора (например, мышечной креатинкиназы (MCK), тяжелой цепи миозина альфа (αMHC), миоглобина (MB) и десмина (DES)), синтетического промотора (например, SPc5-12, 2R5Sc5-12, dMCK и tMCK) и любой их комбинации. В одном конкретном варианте осуществления промотор предусматривает промотор TTP.
[76] Термины "рестрикционная эндонуклеаза" и "рестрикционный фермент" применяются взаимозаменяемо и относятся к ферменту, который связывается и вносит разрывы в пределах конкретной нуклеотидной последовательности в пределах двухнитевой ДНК.
[77] Термин "плазмида" относится к внехромосомному элементу, зачастую несущему ген, который не является частью центрального метаболизма клетки, и обычно имеющему форму кольцевых двухнитевых молекул ДНК. Такие элементы могут представлять собой автономно реплицирующиеся последовательности, интегрирующиеся в геном последовательности, фаговые или нуклеотидные последовательности, линейные, кольцевые или сверхспиральные, из одно- или двухнитевой ДНК или РНК, полученные из любого источника, к которым присоединен или добавлен путем рекомбинации ряд нуклеотидных последовательностей с образованием уникальной конструкции, которая способна вводить промоторный фрагмент и последовательность ДНК, кодирующую выбранный продукт гена, вместе с соответствующей 3'-нетранслируемой последовательностью в клетку.
[78] Векторы на основе вирусов эукариот, которые можно применять, включают без ограничения векторы на основе аденовируса, векторы на основе ретровируса, векторы на основе аденоассоциированного вируса, на основе поксвируса, например, векторы на основе вируса осповакцины, векторы на основе бакуловируса или векторы на основе герпесвируса. Отличные от вирусных векторы включают плазмиды, липосомы, электрически заряженные липиды (цитофектины), комплексы ДНК-белок и биополимеры.
[79] "Клонирующий вектор" относится к "репликону", который представляет собой единицу длины нуклеиновой кислоты, которая реплицируется последовательно и которая содержит точку начала репликации, такую как плазмида, фаг или космида, к которой может быть присоединен другой сегмент нуклеиновой кислоты так, чтобы обеспечить репликацию присоединенного сегмента. Определенные клонирующие векторы способны реплицироваться в одном типе клеток, например бактериях, а экспрессироваться в другом, например эукариотических клетках. Клонирующие векторы обычно содержат одну или несколько последовательностей, которые можно применять для отбора клеток, содержащих вектор, и/или один или несколько сайтов множественного клонирования для вставки последовательностей нуклеиновых кислот, представляющих интерес.
[80] Термин "вектор экспрессии" относится к носителю, сконструированному с возможностью обеспечения экспрессии вставленной последовательности нуклеиновой кислоты после вставки в клетку-хозяина. Вставленная последовательность нуклеиновой кислоты находится в функциональной связи с регуляторными областями, как описано выше.
[81] Векторы вводят в клетки-хозяева с помощью способов, хорошо известных из уровня техники, например, посредством трансфекции, электропорации, микроинъекции, трансдукции, слияния клеток, DEAE-декстрана, осаждения фосфатом кальция, липофекции (слияния лизосом), применения генной пушки или транспортера ДНК-вектора. Термины "культура", "культивировать" и "культивирование", как используется в данном документе, означают инкубацию клеток в условиях in vitro, которые обеспечивают рост или деление клеток или поддержание клеток в живом состоянии. Используемый в данном документе термин "культивируемые клетки" означает клетки, которые размножаются in vitro.
[82] Подразумевается, что используемый в данном документе термин "полипептид" охватывает "полипептид" в единственном числе, а также "полипептиды" во множественном числе и относится к молекуле, состоящей из мономеров (аминокислот), линейно связанных амидными связями (также известными как пептидные связи). Термин "полипептид" относится к любой цепи или цепям из двух или более аминокислот и не относится к конкретной длине продукта. Таким образом, пептиды, дипептиды, трипептиды, олигопептиды, "белок", "аминокислотная цепь" или любой другой термин, используемый для обозначения цепи или цепей из двух или более аминокислот, включены в определение "полипептида", и термин "полипептид" можно использовать вместо любого из этих терминов или взаимозаменяемо с любым из них. Также подразумевается, что термин "полипептид" относится к продуктам постэкспрессионных модификаций полипептида, включая без ограничения гликозилирование, ацетилирование, фосфорилирование, амидирование, получение производных с помощью известных защитных/блокирующих групп, протеолитическое расщепление или модификацию с помощью аминокислот, не встречающихся в природе. Полипептид может происходить из природного биологического источника или быть получен с помощью рекомбинантной технологии, но не обязательно транслирован с определенной последовательности нуклеиновой кислоты. Он может быть получен любым способом, в том числе путем химического синтеза.
[83] Термин "аминокислота" включает аланин (Ala или A); аргинин (Arg или R); аспарагин (Asn или N); аспарагиновую кислоту (Asp или D); цистеин (Cys или C); глутамин (Gln или Q); глутаминовую кислоту (Glu или E); глицин (Gly или G); гистидин (His или H); изолейцин (Ile или I): лейцин (Leu или L); лизин (Lys или K); метионин (Met или M); фенилаланин (Phe или F); пролин (Pro или P); серин (Ser или S); треонин (Thr или T); триптофан (Trp или W); тирозин (Tyr или Y) и валин (Val или V). Нетрадиционные аминокислоты также находятся в пределах объема настоящего изобретения и включают норлейцин, орнитин, норвалин, гомосерин и другие аналоги аминокислотных остатков, такие как описанные в Ellman et al. Meth. Enzym. 202:301-336 (1991). Для получения таких не встречающихся в природе аминокислотных остатков можно использовать процедуры согласно вышеуказанному Noren et al. Science 244:182 (1989) и Ellman et al.. Вкратце, такие процедуры предусматривают химическую активацию супрессорной tRNA c не встречающимся в природе аминокислотным остатком с последующими транскрипцией и трансляцией РНК in vitro. Введения нетрадиционной аминокислоты можно также достигать с применением химических способов образования пептидной связи, известных из уровня техники. Используемый в данном документе термин "полярная аминокислота" включает аминокислоты, которые характеризуются нулевым суммарным зарядом, однако характеризуются отличными от нуля частичными зарядами в различных частях своих боковых цепей (например, M, F, W, S, Y, N, Q, C). Такие аминокислоты могут участвовать в гидрофобных взаимодействиях и электростатических взаимодействиях. Используемый в данном документе термин "заряженная аминокислота" включает аминокислоты, которые характеризуются отличным от нуля суммарным зарядом на своих боковых цепях (например, R, K, H, E, D). Такие аминокислоты могут участвовать в гидрофобных взаимодействиях и электростатических взаимодействиях.
[84] Также в настоящее изобретение включены фрагменты или варианты полипептидов и любая их комбинация. Термины "фрагмент" или "вариант" в отношении полипептидных связывающих доменов или связывающих молекул по настоящему изобретению, включают любые полипептиды, которые сохраняют по меньшей мере некоторые из свойств эталонного полипептида (например, аффинность связывания FcRn для FcRn-связывающего домена или варианта Fc, коагуляционную активность для варианта FVIII или FVIII-связывающую активность для фрагмента VWF). Фрагменты полипептидов включают фрагменты, полученные посредством протеолиза, а также фрагменты, полученные посредством делеции, в дополнение к конкретным фрагментам антитела, обсуждаемым в данном документе в другом месте, но не включают встречающийся в природе полноразмерный полипептид (или зрелый полипептид). Варианты полипептидных связывающих доменов или связывающих молекул по настоящему изобретению, включают фрагменты, описанные выше, а также полипептиды с аминокислотными последовательностями, измененными в результате аминокислотных замен, делеций или вставок. Варианты могут быть встречающимися в природе или не встречающимися в природе. Не встречающиеся в природе варианты можно получить с помощью известных из уровня техники методик мутагенеза. Вариантные полипептиды могут содержать консервативные или неконсервативные аминокислотные замены, делеции или добавления.
[85] "Консервативная аминокислотная замена" представляет собой замену, при которой аминокислотный остаток замещается аминокислотным остатком со сходной боковой цепью. Семейства аминокислотных остатков, имеющих сходные боковые цепи, определены в уровне техники, включая основные боковые цепи (например, лизин, аргинин, гистидин), кислые боковые цепи (например, аспарагиновая кислота, глутаминовая кислота), незаряженные полярные боковые цепи (например, глицин, аспарагин, глутамин, серин, треонин, тирозин, цистеин), неполярные боковые цепи (например, аланин, валин, лейцин, изолейцин, пролин, фенилаланин, метионин, триптофан), бета-разветвленные боковые цепи (например, треонин, валин, изолейцин) и ароматические боковые цепи (например, тирозин, фенилаланин, триптофан, гистидин). Таким образом, если аминокислота в полипептиде замещается другой аминокислотой из того же семейства боковых цепей, то замена считается консервативной. В другом варианте осуществления нить из аминокислот можно подвергнуть консервативному замещению сходной в структурном отношении нитью, которая отличается порядком расположения и/или составом представителей семейства боковых цепей.
[86] Термин "процентная идентичность", известный из уровня техники, означает взаимосвязь между двумя или более полипептидными последовательностями или двумя или более полинуклеотидными последовательностями, определенную путем сравнения последовательностей. В уровне техники "идентичность" также означает степень сходства последовательности между полипептидными или полинуклеотидными последовательностями, в соответствующих случаях, определенную по степени соответствия между нитями таких последовательностей. "Идентичность" может быть легко рассчитана с помощью известных способов, в том числе без ограничения тех, которые описаны в Computational Molecular Biology (Lesk, A. M., ed.) Oxford University Press, New York (1988); Biocomputing: Informatics and Genome Projects (Smith, D. W., ed.) Academic Press, New York (1993); Computer Analysis of Sequence Data, Part I (Griffin, A. M., and Griffin, H. G., eds.) Humana Press, New Jersey (1994); Sequence Analysis in Molecular Biology (von Heinje, G., ed.) Academic Press (1987) и Sequence Analysis Primer (Gribskov, M. and Devereux, J., eds.) Stockton Press, New York (1991). Предпочтительные способы определения идентичности разработаны с обеспечением самой высокой степени соответствия между исследуемыми последовательностями. Способы определения идентичности запрограммированы в находящихся в открытом доступе компьютерных программах. Выравнивание последовательностей и расчеты процентной идентичности можно осуществлять с применением программного обеспечения для анализа последовательностей, такого как программа Megalign из программного пакета для биоинформационных вычислений LASERGENE (DNASTAR Inc., Мадисон, Висконсин), пакет программ GCG (Wisconsin Package версии 9.0, Genetics Computer Group (GCG), Мадисон, Висконсин), BLASTP, BLASTN, BLASTX (Altschul et al., J. Mol. Biol. 215:403 (1990)) и DNASTAR (DNASTAR, Inc. 1228 С. Парк Стрит, Мадисон, Висконсин, 53715, США). В контексте настоящей заявки будет понятно, что в случаях применения программного обеспечения для анализа последовательностей результаты анализа будут основываться на "значениях по умолчанию" рассматриваемой программы, если не указано иное. Используемые в данном документе "значения по умолчанию" будут означать любой набор значений или параметров, которые изначально загружаются с программным обеспечением при первом запуске. Для целей определения процентной идентичности между последовательностью терапевтического белка, например фактора свертывания крови, согласно настоящему изобретению и эталонной последовательностью только нуклеотиды в эталонной последовательности, соответствующие нуклеотидам в последовательности терапевтического белка, например фактора свертывания крови, согласно настоящему изобретению, используют для расчета процентной идентичности. Например, при сравнении нуклеотидной последовательности полноразмерного FVIII, содержащего домен B, с оптимизированной нуклеотидной последовательностью FVIII с удаленным доменом B (BDD) согласно настоящему изобретению часть выравнивания, включающая домен A1, A2, A3, C1 и C2, будет использоваться для расчета процентной идентичности. Нуклеотиды в части последовательности полноразмерного FVIII, кодирующей домен B (что приведет к большому "гэпу" в выравнивании), не будут учитываться в качестве несовпадений. Кроме того, при определении процентной идентичности между оптимизированной последовательностью FVIII с BDD согласно настоящему изобретению или ее указанной частью (например, нуклеотидами 58-2277 и 2320-4374 из SEQ ID NO:3) и эталонной последовательностью процентная идентичность будет рассчитана при выравнивании с делением числа совпадающих нуклеотидов на общее число нуклеотидов в полной последовательности оптимизированной последовательности FVIII с BDD или ее указанной части, как указано в данном документе.
[87] Как используется в данном документе, нуклеотиды, соответствующие нуклеотидам в конкретной последовательности согласно настоящему изобретению, идентифицированы путем выравнивания последовательности согласно настоящему изобретению с обеспечением максимальной идентичности с эталонной последовательностью. Номер, используемый для идентификации эквивалентной аминокислоты в эталонной последовательности соответствует номеру, используемому для идентификации соответствующей аминокислоты в последовательности согласно настоящему изобретению.
[88] "Слитый" или "химерный" белок содержит первую аминокислотную последовательность, соединенную со второй аминокислотной последовательностью, с которой она естественным образом не соединена в природе. Аминокислотные последовательности, которые в обычных условиях существуют в отдельных белках, могут быть объединены в слитом полипептиде, или аминокислотные последовательности, которые в обычных условиях существуют в одном и том же белке, могут быть размещены в новом порядке в слитом полипептиде, например, при слиянии домена фактора VIII по настоящему изобретению с Fc-доменом Ig. Слитый белок создают, например, путем химического синтеза или путем создания полинуклеотида, в котором области пептида кодируются в необходимом взаиморасположении, и обеспечения его трансляции. Химерный белок может дополнительно содержать вторую аминокислотную последовательность, связанную с первой аминокислотной последовательностью с помощью ковалентной непептидной связи или нековалентной связи.
[89] Используемый в данном документе термин "сайт вставки" относится к положению в полипептиде или его фрагменте, варианте или производном, которое находится непосредственно выше положения, в которое может быть вставлен гетерологичный компонент. "Сайт вставки" указан в виде числа, причем число является номером аминокислоты в эталонной последовательности. Например, "сайт вставки" в FVIII относится к номеру аминокислоты в последовательности в зрелом нативном FVIII (SEQ ID NO: 15), которому соответствует сайт вставки, который располагается непосредственно за положением вставки в направлении N-конца. Например, фраза "a3 содержит гетерологичный компонент в сайте вставки, который соответствует аминокислоте 1656 из SEQ ID NO: 15" указывает на то, что гетерологичный компонент расположен между двумя аминокислотами, соответствующими аминокислоте 1656 и аминокислоте 1657 из SEQ ID NO: 15.
[90] Используемая в данном документе фраза "непосредственно ниже аминокислоты" относится к положению прямо после концевой карбоксильной группы аминокислоты. Аналогично, фраза "непосредственно выше аминокислоты" относится к положению прямо после концевой аминогруппы аминокислоты.
[91] Термины "вставленный", "вставлен", "вставлен в" или грамматически родственные термины, используемые в данном документе, относятся к положению гетерологичного компонента в полипептиде, например, фактора свертывания крови, относительно аналогичного положения в родительском полипептиде. Например, в определенном варианте осуществления "вставлен" и т. п. относятся к положению гетерологичного компонента в полипептиде рекомбинантного FVIII относительно аналогичного положения в нативном зрелом FVIII человека. Используемые в данном документе термины относятся к характеристикам полипептида и не указывают, не подразумевают или не предполагают каких-либо способов или процесса, с помощью которых был получен полипептид.
[92] Используемый в данном документе термин "период полужизни" относится к биологическому периоду полужизни конкретного полипептида in vivo. Период полужизни можно выразить в виде времени, необходимого для выведения из кровотока и/или других тканей животного половины количества, введенного субъекту. Если кривую клиренса данного полипептида строят в виде функции времени, кривая обычно является двухфазной с быстрой α-фазой и более длинной β-фазой. Обычно α-фаза отображает уравновешивание содержания введенного полипептида Fc между внутри- и внесосудистым пространством и частично определяется размером полипептида. Обычно β-фаза отображает катаболизм полипептида во внутрисосудистом пространстве. В некоторых вариантах осуществления терапевтический белок, например фактор свертывания крови, например FVIII, и химерные белки, содержащие его, являются монофазными и, таким образом, характеризуются отсутствием альфа-фазы и наличием только отдельной бета-фазы. Следовательно, в определенных вариантах осуществления термин период полужизни, используемый в данном документе, относится к периоду полужизни полипептида в β-фазе.
[93] Термин "соединенный", используемый в данном документе, относится к первой аминокислотной последовательности или нуклеотидной последовательности, ковалентно или нековалентно присоединенной соответственно ко второй аминокислотной последовательности или нуклеотидной последовательности. Первая аминокислотная или нуклеотидная последовательность может быть непосредственно присоединена ко второй аминокислотной или нуклеотидной последовательности или объединена с ней, или, в качестве альтернативы, промежуточная последовательность может ковалентно соединять первую последовательность со второй последовательностью. Термин "соединенный" означает не только слияние первой аминокислотной последовательности со второй аминокислотной последовательностью на С-конце или N-конце, но также включает вставку всей первой аминокислотной последовательности (или второй аминокислотной последовательности) между любыми двумя аминокислотами во второй аминокислотной последовательности (или соответственно в первой аминокислотной последовательности). В одном варианте осуществления первая аминокислотная последовательность может быть соединена со второй аминокислотной последовательностью с помощью пептидной связи или линкера. Первая нуклеотидная последовательность может быть соединена со второй нуклеотидной последовательностью с помощью фосфодиэфирной связи или линкера. Линкер может представлять собой пептид или полипептид (в случае полипептидных цепей), или нуклеотид или цепь нуклеотидов (в случае цепей нуклеотидов), или любой химический компонент (как в случае полипептидных, так и полинуклеотидных цепей). Термин "соединенный" также обозначается дефисом (-).
[94] Гемостаз, используемый в данном документе, означает остановку или замедление кровотечения или кровоизлияния; или остановку или замедление кровотока через кровеносный сосуд или часть тела.
[95] Гемостатическое нарушение, как используется в данном документе, означает генетически наследуемое или приобретенное состояние, характеризующееся склонностью к кровоизлиянию, происходящему спонтанно либо в результате травмы, из-за нарушенной способности или неспособности образовывать фибриновый сгусток. Примеры таких нарушений включают формы гемофилии. Тремя основными формами являются гемофилия A (дефицит фактора VIII), гемофилия B (дефицит фактора IX или "болезнь Кристмаса") и гемофилия C (дефицит фактора XI, легкая склонность к кровотечению). Другие гемостатические нарушения включают, например, болезнь фон Виллебранда, дефицит фактора XI (дефицит PTA), дефицит фактора XII, дефициты или аномалии структуры фибриногена, протромбина, фактора V, фактора VII, фактора X или фактора XIII, синдром Бернара-Сулье, который представляет собой дефект или дефицит GPIb. GPIb, рецептор vWF, может быть дефектным и приводить к невозможности образования первичного сгустка (первичного гемостаза) и повышенной склонности к кровотечению, а также к тромбастении Гланцманна-Негели (тромбастении Гланцманна). При печеночной недостаточности (острой и хронической формах) имеет место недостаточная выработка печенью факторов коагуляции; это может увеличивать риск кровотечения.
[96] Выделенные молекулы нуклеиновой кислоты, выделенные полипептиды или векторы, содержащие выделенную молекулу нуклеиновой кислоты, согласно настоящему изобретению можно применять профилактически. Используемый в данном документе термин "профилактическое лечение" относится к введению молекулы до эпизода кровотечения. В одном варианте осуществления субъект, нуждающийся в общем гемостатическом средстве, подвергается или вскоре подвергнется хирургическому вмешательству. Полинуклеотид, полипептид или вектор согласно настоящему изобретению можно вводить до или после хирургического вмешательства в качестве профилактического средства. Полинуклеотид, полипептид или вектор согласно настоящему изобретению можно вводить во время или после хирургического вмешательства для контроля эпизода острого кровотечения. Хирургическое вмешательство может включать без ограничения трансплантацию печени, резекцию печени, стоматологические процедуры или трансплантацию стволовых клеток.
[97] Выделенные молекулы нуклеиновой кислоты, выделенные полипептиды или векторы согласно настоящему изобретению также применяют для лечения по необходимости. Термин "лечение по необходимости" относится к введению выделенной молекулы нуклеиновой кислоты, выделенного полипептида или вектора в ответ на симптомы эпизода кровотечения или перед действием, которое может вызвать кровотечение. В одном аспекте лечение по необходимости может быть назначено субъекту, когда начинается кровотечение, например после травмы, или когда ожидается кровотечение, например перед хирургическим вмешательством. В другом аспекте лечение по необходимости может быть назначено перед действиями, которые увеличивают риск кровотечения, такими как контактные виды спорта.
[98] Используемый в данном документе термин "острое кровотечение" относится к эпизоду кровотечения независимо от первопричины. Например, у субъекта может быть травма, уремия, наследственное нарушение гемостаза (например, дефицит фактора VII), тромбоцитарное нарушение или устойчивость вследствие развития антител к факторам свертывания крови.
[99] "Лечить", "лечение" или "осуществление лечения", как используется в данном документе, относится, например, к уменьшению тяжести заболевания или состояния; уменьшению продолжительности течения заболевания; облегчению одного или нескольких симптомов, ассоциированных с заболеванием или состоянием; обеспечению благоприятных эффектов у субъекта с заболеванием или состоянием, при этом не обязательно с излечением заболевания или состояния, или профилактике одного или нескольких симптомов, связанных с заболеванием или состоянием. В одном варианте осуществления термин "осуществление лечения" или "лечение" означает поддержание у субъекта, например, остаточного уровня содержания FVIII на уровне по меньшей мере приблизительно 1 МЕ/дл, 2 МЕ/дл, 3 МЕ/дл, 4 МЕ/дл, 5 МЕ/дл, 6 МЕ/дл, 7 МЕ/дл, 8 МЕ/дл, 9 МЕ/дл, 10 МЕ/дл, 11 МЕ/дл, 12 МЕ/дл, 13 МЕ/дл, 14 МЕ/дл, 15 МЕ/дл, 16 МЕ/дл, 17 МЕ/дл, 18 МЕ/дл, 19 МЕ/дл, 20 МЕ/дл, 25 МЕ/дл, 30 МЕ/дл, 35 МЕ/дл, 40 МЕ/дл, 45 МЕ/дл, 50 МЕ/дл, 55 МЕ/дл, 60 МЕ/дл, 65 МЕ/дл, 70 МЕ/дл, 75 МЕ/дл, 80 МЕ/дл, 85 МЕ/дл, 90 МЕ/дл, 95 МЕ/дл, 100 МЕ/дл, 105 МЕ/дл, 110 МЕ/дл, 115 МЕ/дл, 120 МЕ/дл, 125 МЕ/дл, 130 МЕ/дл, 135 МЕ/дл, 140 МЕ/дл, 145 МЕ/дл или 150 МЕ/дл путем введения выделенной молекулы нуклеиновой кислоты, выделенного полипептида или вектора согласно настоящему изобретению. В другом варианте осуществления осуществление лечения или лечение означает поддержание остаточного уровня содержания FVIII на уровне от приблизительно 1 до приблизительно 150 МЕ/дл, от приблизительно 1 до приблизительно 125 МЕ/дл, от приблизительно 1 до приблизительно 100 МЕ/дл, от приблизительно 1 до приблизительно 90 МЕ/дл, от приблизительно 1 до приблизительно 85 МЕ/дл, от приблизительно 1 до приблизительно 80 МЕ/дл, от приблизительно 1 до приблизительно 75 МЕ/дл, от приблизительно 1 до приблизительно 70 МЕ/дл, от приблизительно 1 до приблизительно 65 МЕ/дл, от приблизительно 1 до приблизительно 60 МЕ/дл, от приблизительно 1 до приблизительно 55 МЕ/дл, от приблизительно 1 до приблизительно 50 МЕ/дл, от приблизительно 1 до приблизительно 45 МЕ/дл, от приблизительно 1 до приблизительно 40 МЕ/дл, от приблизительно 1 до приблизительно 35 МЕ/дл, от приблизительно 1 до приблизительно 30 МЕ/дл, от приблизительно 1 до приблизительно 25 МЕ/дл, от приблизительно 25 до приблизительно 125 МЕ/дл, от приблизительно 50 до приблизительно 100 МЕ/дл, от приблизительно 50 до приблизительно 75 МЕ/дл, от приблизительно 75 до приблизительно 100 МЕ/дл, от приблизительно 1 до приблизительно 20 МЕ/дл, от приблизительно 2 до приблизительно 20 МЕ/дл, от приблизительно 3 до приблизительно 20 МЕ/дл, от приблизительно 4 до приблизительно 20 МЕ/дл, от приблизительно 5 до приблизительно 20 МЕ/дл, от приблизительно 6 до приблизительно 20 МЕ/дл, от приблизительно 7 до приблизительно 20 МЕ/дл, от приблизительно 8 до приблизительно 20 МЕ/дл, от приблизительно 9 до приблизительно 20 МЕ/дл или от приблизительно 10 до приблизительно 20 МЕ/дл. Лечение или осуществление лечения заболевания или состояния может также включать поддержание активности FVIII у субъекта на уровне, сравнимом по меньшей мере приблизительно с 1%, 2%, 3%, 4%, 5%, 6%, 7%, 8%, 9%, 10%, 11%, 12%, 13%, 14%, 15%, 16%, 17%, 18%, 19%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, 55%, 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 100%, 105%, 110%, 115%, 120%, 125%, 130%, 135%, 140%, 145%, или 150% активности FVIII у субъекта, не страдающего гемофилией. Минимальный остаточный уровень, необходимый для лечения, может быть измерен с помощью одного или нескольких известных способов и может быть скорректирован (увеличен или уменьшен) для каждого человека.
[100] "Введение", как используется в данном документе, означает предоставление фармацевтически приемлемой молекулы нуклеиновой кислоты, полипептида, экспрессируемого посредством нее, или вектора, содержащего молекулу нуклеиновой кислоты, согласно настоящему изобретению субъекту фармацевтически приемлемым путем. Пути введения могут быть внутривенными, например внутривенной инъекцией и внутривенной инфузией. Дополнительные пути введения включают, например, подкожное, внутримышечное, пероральное, назальное и легочное введение. Молекулы нуклеиновой кислоты, полипептиды и векторы можно вводить в составе фармацевтической композиции, содержащей по меньшей мере одно вспомогательное вещество.
[101] Термин "фармацевтически приемлемый", используемый в данном документе, относится к молекулярным объектам и композициям, которые являются физиологически переносимыми и, как правило, не вызывают токсичности или аллергической или подобной нежелательной реакции, такой как расстройство желудка, головокружение и т. п., при введении человеку. Необязательно, используемый в данном документе термин" фармацевтически приемлемый" означает одобрение регулирующим органом федерального правительства или правительства штатов или приведение в Фармакопее США или другой общепризнанной фармакопее для применения у животных, и более конкретно у людей.
[102] Используемая в данном документе фраза "нуждающийся в этом субъект" включает субъектов, таких как субъекты-млекопитающие, которые получат пользу от введения молекулы нуклеиновой кислоты, полипептида или вектора согласно настоящему изобретению, например в отношении улучшения гемостаза. В одном варианте осуществления субъекты включают без ограничения индивидуумов с гемофилией. В другом варианте осуществления субъекты включают без ограничения индивидуумов, у которых выработался ингибитор терапевтического белка, например фактора свертывания крови, например FVIII, и которые, таким образом, нуждаются в терапии шунтирующего действия. Субъектом может являться взрослый или несовершеннолетний (например, в возрасте до 12 лет).
[103] Используемый в данном документе термин "терапевтический белок" относится к любому полипептиду, известному из уровня техники, который можно вводить субъекту. В некоторых вариантах осуществления терапевтический белок предусматривает белок, выбранный из фактора свертывания крови, фактора роста, антитела, их функционального фрагмента или их комбинации. Используемый в данном документе термин "фактор свертывания крови" относится к молекулам или их аналогам, встречающимся в природе или полученным рекомбинантным путем, которые предупреждают или снижают продолжительность эпизода кровотечения у субъекта. Другими словами, он подразумевает молекулы, характеризующиеся положительной свертывающей активностью, т. е. отвечающими за превращение фибриногена в сеть из нерастворимого фибрина, обуславливающую коагулирование или свертывание крови. "Фактор свертывания крови", используемый в данном документе, включает активированный фактор свертывания крови, его зимоген или активируемый фактор свертывания крови. "Активируемый фактор свертывания крови" представляет собой фактор свертывания крови в неактивной форме (например, в форме его зимогена), который способен к переходу в активную форму. Термин "фактор свертывания крови" включает без ограничения фактор I (FI), фактор II (FII), фактор V (FV), FVII, FVIII, FIX, фактор X (FX), фактор XI (FXI), фактор XII (FXII), фактор XIII (FXIII), фактор фон Виллебранда (VWF), прекалликреин, высокомолекулярный кининоген, фибронектин, антитромбин III, кофактор гепарина II, белок C, белок S, белок Z, ингибитор белок Z-подобной протеазы (ZPI), плазминоген, альфа-2-антиплазмин, тканевой активатор плазминогена (tPA), урокиназу, ингибитор активатора плазминогена 1 (PAI-1), ингибитор активатора плазминогена 2 (PAI2), их зимогены, их активированные формы или любую их комбинацию.
[104] Свертывающая активность, применяемая в данном документе, означает способность принимать участие в каскаде биохимических реакций, который приводит к образованию фибринового сгустка и/или уменьшает тяжесть, продолжительность или частоту кровоизлияния или эпизода кровотечения.
[105] "Фактор роста", используемый в данном документе, включает любой фактор роста, известный из уровня техники, в том числе цитокины и гормоны. В некоторых вариантах осуществления фактор роста выбран из адреномедуллина (AM), ангиопоэтина (Ang), аутокринного фактора миграции, костного морфогенетического белка (BMP) (например, BMP2, BMP4, BMP5, BMP7), представителя семейства цилиарных нейротрофических факторов (например, цилиарного нейротрофического фактора (CNTF), фактора, ингибирующего лейкоз (LIF), интерлейкина-6 (IL-6)), колониестимулирующего фактора (например, макрофагального колониестимулирующего фактора (m-CSF), гранулоцитарного колониестимулирующего фактора (G-CSF), гранулоцитарно-макрофагального колониестимулирующего фактора (GM-CSF)), эпидермального фактора роста (EGF), эфрина (например, эфрина A1, эфрина A2, эфрина A3, эфрина A4, эфрина A5, эфрина B1, эфрина B2, эфрина B3), эритропоэтина (EPO), фактора роста фибробластов (FGF) (например, FGF1, FGF2, FGF3, FGF4, FGF5, FGF6, FGF7, FGF8, FGF9, FGF10, FGF11, FGF12, FGF13, FGF14, FGF15, FGF16, FGF17, FGF18, FGF19, FGF20, FGF21, FGF22, FGF23), фетального бычьего соматотропина (FBS), представителя семейства GDNF (например, нейротрофического фактора линии глиальных клеток (GDNF), нейротурина, персефина и артемина), фактора роста и дифференцировки-9 (GDF9), фактора роста гепатоцитов (HGF), фактора роста, происходящего из гепатомы (HDGF), инсулина, инсулиноподобных факторов роста (например, инсулиноподобного фактора роста-1 (IGF-1) или IGF-2, интерлейкина (IL) (например, IL-1, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7), фактора роста кератиноцитов (KGF), фактора, стимулирующего миграцию (MSF), белка, стимулирующего макрофаги (MSP или белка, подобного фактору роста гепатоцитов (HGFLP)), миостатина (GDF-8), нейрегулина (например, нейрегулина 1 (NRG1), NRG2, NRG3, NRG4), нейротрофина (например, нейротрофического фактора головного мозга (BDNF), фактор роста нервов (NGF), нейротрофина-3 (NT-3), NT-4, плацентарного фактора роста (PGF), тромбоцитарного фактора роста (PDGF), реналазы (RNLS), фактора роста Т-клеток (TCGF), тромбопоэтина (TPO), трансформирующего фактора роста (например, трансформирующего фактора роста-альфа (TGF-α), TGF-β, фактора некроза опухоли-альфа (TNF-α) и фактора роста эндотелия сосудов (VEGF).
[106] В некоторых вариантах осуществления терапевтический белок кодируется геном, выбранным из X-сцепленного дистрофина, MTM1 (миотубуларина), тирозингидроксилазы, AADC, циклогидролазы, SMN1, FXN (фратаксина), GUCY2D, RS1, CFH, HTRA, ARMS, CFB/CC2, CNGA/CNGB, Prf65, ARSA, PSAP, IDUA (MPS I), IDS (MPS II), PAH, GAA (кислой альфа-глюкозидазы) или любой их комбинации.
[107] Используемые в данном документе термины "гетерологичный" или "экзогенный" относятся к таким молекулам, которые, в данном контексте, обычно не встречаются, например, в клетке или в полипептиде. Например, экзогенная или гетерологичная молекула может быть введена в клетку и присутствуют только после проведения манипуляции с клеткой, например, путем трансфекции или других способов генной инженерии, или гетерологичная аминокислотная последовательность может быть представлена в белке, в котором она обычно не встречается.
[108] Используемый в данном документе термин "гетерологичная нуклеотидная последовательность" относится к нуклеотидной последовательности, которая не встречается в природе с данной полинуклеотидной последовательностью. В одном варианте осуществления гетерологичная нуклеотидная последовательность кодирует полипептид, способный обеспечивать увеличение периода полужизни терапевтического белка, например фактора свертывания крови, например FVIII. В другом варианте осуществления гетерологичная нуклеотидная последовательность кодирует полипептид, который увеличивает гидродинамический радиус терапевтического белка, например фактора свертывания крови, например FVIII. В других вариантах осуществления гетерологичная нуклеотидная последовательность кодирует полипептид, который улучшает одно или несколько фармакокинетических свойств терапевтического белка без значительного влияния на его биологическую активность или функцию (например, прокоагулянтную активность). В некоторых вариантах осуществления терапевтический белок связан с кодируемым гетерологичной нуклеотидной последовательностью полипептидом или присоединен к нему с помощью линкера. Неограничивающие примеры полипептидных компонентов, кодируемых гетерологичными нуклеотидными последовательностями, включают константную область иммуноглобулина или ее часть, альбумин или его фрагмент, альбумин-связывающий компонент, трансферрин, полипептиды PAS согласно заявке на патент США № 20100292130, последовательность HAP, трансферрин или его фрагмент, C-концевой пептид (CTP) β-субъединицы хорионического гонадотропина человека, альбумин-связывающую малую молекулу, последовательность XTEN, компоненты, связывающие FcRn (например, полные Fc-области или их части, которые связываются с FcRn), одноцепочечные Fc-области (ScFc-области, например, описанные в US 2008/0260738, WO 2008/012543 или WO 2008/1439545), полиглициновые линкеры, полисериновые линкеры, пептиды и короткие полипептиды из 6-40 аминокислот на основе двух типов аминокислот, выбранных из глицина (G), аланина (A), серина (S), треонина (T), глутамата (E) и пролина (P), характеризующиеся различной степенью образования вторичной структуры, составляющей от менее 50% до более 50%, среди прочего, или две или более их комбинаций. В некоторых вариантах осуществления полипептид, кодируемый гетерологичной нуклеотидной последовательностью, связан с компонентом, не являющимся полипептидом. Неограничивающие примеры компонентов, не являющихся полипептидом, включают полиэтиленгликоль (PEG), альбумин-связывающие малые молекулы, полисиаловую кислоту, гидроксиэтилкрахмал (HES), их производное или любые их комбинации.
[109] Используемый в данном документе термин "Fc-область" определяется как часть полипептида, которая соответствует Fc-области нативного Ig, т. e. образована путем димерной ассоциации соответствующих Fc-доменов двух его тяжелых цепей. Нативная Fc-область образует гомодимер с другой Fc-областью. В отличие от этого, термины "генетически слитая Fc-область" или "одноцепочечная Fc-область" (scFc-область), используемые в данном документе, относятся к синтетической димерной Fc-области, состоящей из Fc-доменов, генетически соединенных в одну полипептидную цепь (т. е. кодируемых одной непрерывной генетической последовательностью).
[110] В одном варианте осуществления "Fc-область" относится к части одной тяжелой цепи Ig, начинающейся в шарнирной области непосредственно выше сайта расщепления папаином (т. е. остатком 216 в IgG, если принять первый остаток константной области тяжелой цепи за 114) и заканчивающейся на С-конце антитела. Соответственно, полный Fc-домен содержит по меньшей мере шарнирный домен, CH2-домен и CH3-домен.
[111] Fc-область константной области Ig в зависимости от изотипа Ig может включать в себя домены CH2, CH3 и CH4, а также шарнирную область. Химерные белки, содержащие Fc-область Ig, наделяют химерный белок несколькими необходимыми свойствами, включая увеличенную стабильность, увеличенный период полужизни в сыворотке крови (см. Capon et al., 1989, Nature 337:525), а также связывание с Fc-рецепторами, такими как неонатальный Fc-рецептор (FcRn) (патенты США №№ 6086875, 6485726, 6030613; WO 03/077834; US2003-0235536A1, которые включены в данный документ посредством ссылки во всей своей полноте).
[112] "Эталонная нуклеотидная последовательность", при использовании в данном документе для сравнения с нуклеотидной последовательностью согласно настоящему изобретению, представляет собой полинуклеотидную последовательность, по сути идентичную нуклеотидной последовательности согласно настоящему изобретению, за исключением того, что последовательность не является оптимизированной. Например, эталонная нуклеотидная последовательность для молекулы нуклеиновой кислоты, состоящей из кодон-оптимизированной FVIII с BDD под SEQ ID NO: 1 и гетерологичной нуклеотидной последовательности, которая кодирует одноцепочечную Fc-область, связанной с SEQ ID NO: 1 со стороны своего 3'-конца, представляет собой молекулу нуклеиновой кислоты, состоящую из исходной (или "родительской") FVIII с BDD под SEQ ID NO: 16 и идентичной гетерологичной нуклеотидной последовательности, которая кодирует одноцепочечную Fc-область, связанную с SEQ ID NO: 16 со стороны своего 3'-конца.
[113] Используемый в данном документе в отношении нуклеотидных последовательностей термин "оптимизированный" относится к полинуклеотидной последовательности, которая кодирует полипептид, где полинуклеотидная последовательность была подвергнута мутации для улучшения какого-либо свойства данной полинуклеотидной последовательности. В некоторых вариантах осуществления оптимизацию выполняют для повышения уровней транскрипции, повышения уровней трансляции, повышения устойчивых уровней mRNA, повышения или снижения связывания регуляторных белков, таких как общие факторы транскрипции, повышения или снижения сплайсинга или повышения выхода полипептида, получаемого из полинуклеотидной последовательности. Примеры изменений, которые можно вносить в полинуклеотидную последовательность для ее оптимизации, включают оптимизацию в отношении кодонов, оптимизацию содержания G/C, удаление последовательностей повторов, удаление богатых AT элементов, удаление криптических сайтов сплайсинга, удаление элементов, действующих в цис-положении, которые подавляют транскрипцию или трансляцию, добавление или удаление последовательностей poly-T или poly-A, добавление последовательностей около сайта инициации транскрипции, которые усиливают транскрипцию, как например консенсусные последовательности Козак, удаление последовательностей, которые могут образовывать структуры "стебель-петля", удаление дестабилизирующих последовательностей и две или более их комбинаций.
II. Молекулы нуклеиновой кислоты
[114] Настоящее изобретение направлено на плазмидоподобную не предусматривающую наличия капсида молекулу нуклеиновой кислоты, которая кодирует терапевтический белок или ген, который может модулировать экспрессию целевого белка. Капсид, представляющий собой белковую оболочку вируса, заключает в себе генетический материал вируса. Известно, что капсиды способствуют выполнению функций вириона путем защиты вирусного генома, доставки генома к хозяину и взаимодействия с хозяином. Тем не менее, вирусные капсиды могут являться фактором, ограничивающим пакующую способность векторов и/или индуцирующим иммунные ответы, особенно при применении в генной терапии.
[115] Векторы на основе AAV стали одним из наиболее распространенных типов генотерапевтических векторов. Однако наличие капсида ограничивает применимость вектора на основе AAV в генной терапии. В частности, капсид сам по себе может ограничивать размер трансгена, который включают в вектор, до менее 4,5 т. п. н. Различные терапевтические белки, которые могут быть применимыми в генной терапии, легко могут превышать данный размер даже до добавления регуляторных элементов.
[116] Кроме того, белки, из которых состоит капсид, могут выступать в качестве антигенов, которые могут становиться мишенью для иммунной системы субъекта. AAV широко распространен среди населения в целом, при этом большинство людей подвергались воздействию AAV в течение своей жизни. В результате этого у большинства потенциальных реципиентов генной терапии, по всей вероятности, уже развился иммунный ответ в отношении AAV, и, таким образом, для них с большей долей вероятности терапия окажется неэффективной.
[117] Определенные аспекты настоящего изобретения направлены на преодоление таких недостатков векторов на основе AAV. В частности, определенные аспекты настоящего изобретения направлены на молекулу нуклеиновой кислоты, содержащую первый ITR, второй ITR и генную кассету, например, кодирующую терапевтический белок и/или miRNA. В некоторых вариантах осуществления молекула нуклеиновой кислоты не содержит ген, кодирующий капсидный белок, белок репликации и/или белок сборки. В некоторых вариантах осуществления генная кассета кодирует терапевтический белок. В некоторых вариантах осуществления терапевтический белок предусматривает фактор свертывания крови. В некоторых вариантах осуществления генная кассета кодирует miRNA. В некоторых вариантах осуществления генная кассета расположена между первым ITR и вторым ITR. В некоторых вариантах осуществления молекула нуклеиновой кислоты дополнительно содержит одну или несколько некодирующих областей. В некоторых вариантах осуществления одна или несколько некодирующих областей включают промоторную последовательность, интрон, посттранскрипционный регуляторный элемент, последовательность poly(А) 3'-UTR или любую их комбинацию.
[118] В одном варианте осуществления генная кассета предусматривает однонитевую нуклеиновую кислоту. В другом варианте осуществления генная кассета предусматривает двухнитевую нуклеиновую кислоту.
[119] В одном варианте осуществления молекула нуклеиновой кислоты содержит
(a) первый ITR, который представляет собой ITR вируса, отличного от AAV, являющегося представителем семейства Parvoviridae;
(b) последовательность тканеспецифического промотора, например промотора TTP;
(c) интрон, например синтетический интрон;
(d) нуклеотид, кодирующий miRNA или терапевтический белок, например фактор свертывания крови;
(e) посттранскрипционный регуляторный элемент, например WPRE;
(f) последовательность poly(А)-хвоста 3'-UTR, например bGHpA;
(g) второй ITR, который представляет собой ITR вируса, отличного от AAV, являющегося представителем семейства Parvoviridae.
[120] В одном варианте осуществления молекула нуклеиновой кислоты содержит
(a) первый ITR, который представляет собой ITR вируса, отличного от AAV, являющегося представителем семейства Parvoviridae;
(b) последовательность тканеспецифического промотора, например промотора TTP;
(c) интрон, например синтетический интрон;
(d) нуклеотид, кодирующий miRNA, где miRNA понижает экспрессию целевого гена, выбранного из SOD1, HTT, RHO и любой их комбинации;
(e) посттранскрипционный регуляторный элемент, например WPRE;
(f) последовательность poly(А)-хвоста 3'-UTR, например bGHpA;
(g) второй ITR, который представляет собой ITR вируса, отличного от AAV, являющегося представителем семейства Parvoviridae.
[121] В одном варианте осуществления молекула нуклеиновой кислоты содержит
(a) первый ITR, который представляет собой ITR вируса, отличного от AAV, являющегося представителем семейства Parvoviridae;
(b) последовательность тканеспецифического промотора, например промотора TTP;
(c) интрон, например синтетический интрон;
(d) нуклеотид, кодирующий X-сцепленный дистрофин, MTM1 (миотубуларин), тирозингидроксилазу, AADC, циклогидролазу, SMN1, FXN (фратаксин), GUCY2D, RS1, CFH, HTRA, ARMS, CFB/CC2, CNGA/CNGB, Prf65, ARSA, PSAP, IDUA (MPS I), IDS (MPS II), PAH, GAA (кислую альфа-глюкозидазу) или любую их комбинацию;
(e) посттранскрипционный регуляторный элемент, например WPRE;
(f) последовательность poly(А)-хвоста 3'-UTR, например bGHpA;
(g) второй ITR, который представляет собой ITR вируса, отличного от AAV, являющегося представителем семейства Parvoviridae.
[122] В одном варианте осуществления молекула нуклеиновой кислоты содержит
(a) первый ITR, который представляет собой ITR AAV, например генома AAV серотипа 2;
(b) последовательность тканеспецифического промотора, например промотора TTP;
(c) интрон, например синтетический интрон;
(d) нуклеотид, кодирующий FVIII; где нуклеотид характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидной последовательностью, выбранной из SEQ ID NO: 1-14 или SEQ ID NO: 71, при этом FVIII, кодируемый нуклеотидом, сохраняет активность FVIII;
(e) посттранскрипционный регуляторный элемент, например WPRE;
(f) последовательность poly(А)-хвоста 3'-UTR, например bGHpA; и
(g) второй ITR, который представляет собой ITR AAV, например генома AAV серотипа 2.
[123] В одном варианте осуществления молекула нуклеиновой кислоты содержит
(a) первый ITR, который представляет собой ITR AAV, например генома AAV серотипа 2;
(b) последовательность тканеспецифического промотора, например промотора TTP;
(c) интрон, например синтетический интрон;
(d) нуклеотид, кодирующий miRNA, где miRNA понижает экспрессию целевого гена, например SOD1, HTT, RHO и любой их комбинации;
(f) последовательность poly(А)-хвоста 3'-UTR, например bGHpA; и
(g) второй ITR, который представляет собой ITR AAV, например генома AAV серотипа 2.
[124] В одном варианте осуществления молекула нуклеиновой кислоты содержит
(a) первый ITR, который представляет собой ITR AAV, например генома AAV серотипа 2;
(b) последовательность тканеспецифического промотора, например промотора TTP;
(c) интрон, например синтетический интрон;
(d) нуклеотид, кодирующий X-сцепленный дистрофин, MTM1 (миотубуларин), тирозингидроксилазу, AADC, циклогидролазу, SMN1, FXN (фратаксин), GUCY2D, RS1, CFH, HTRA, ARMS, CFB/CC2, CNGA/CNGB, Prf65, ARSA, PSAP, IDUA (MPS I), IDS (MPS II), PAH, GAA (кислую альфа-глюкозидазу) или любую их комбинацию;
(f) последовательность poly(А)-хвоста 3'-UTR, например bGHpA; и
(g) второй ITR, который представляет собой ITR AAV, например генома AAV серотипа 2.
[125] В другом варианте осуществления молекула нуклеиновой кислоты содержит
(a) первый ITR;
(b) последовательность тканеспецифического промотора, например промотора TTP;
(c) интрон, например синтетический интрон;
(d) нуклеотид, кодирующий miRNA или терапевтический белок, например фактор свертывания крови;
(e) посттранскрипционный регуляторный элемент, например WPRE;
(f) последовательность poly(А)-хвоста 3'-UTR, например bGHpA; и
(g) второй ITR,
где один из первого ITR или второго ITR представляет собой ITR вируса, отличного от AAV, являющегося представителем семейства Parvoviridae, и другой ITR представляет собой ITR AAV, например генома AAV серотипа 2.
[126] В другом варианте осуществления молекула нуклеиновой кислоты содержит
(a) первый ITR;
(b) последовательность тканеспецифического промотора, промотора TTP;
(c) интрон, например синтетический интрон;
(d) нуклеотид, кодирующий miRNA или терапевтический белок, например фактор свертывания крови;
(e) посттранскрипционный регуляторный элемент, например WPRE;
(f) последовательность poly(А)-хвоста 3'-UTR, например bGHpA; и
(g) второй ITR,
где первый ITR является синтетическим ITR, второй ITR является синтетическим ITR, или как первый ITR, так и второй ITR являются синтетическими ITR.
A. Инвертированные концевые повторы
[127] Определенные аспекты настоящего изобретения направлены на молекулу нуклеиновой кислоты, содержащую первый ITR, например 5'-ITR, и второй ITR, например 3'-ITR. Как правило, ITR вовлечены в репликацию и спасение ДНК парвовируса (например, AAV) или вырезание из прокариотических плазмид (Samulski et al., 1983, 1987; Senapathy et al., 1984; Gottlieb and Muzyczka, 1988). Кроме того, ITR, очевидно, представляют собой минимальные последовательности, требующиеся для провирусной интеграции AAV и для упаковки ДНК AAV в вирионы (McLaughlin et al., 1988; Samulski et al., 1989). Такие элементы являются ключевыми для эффективного размножения генома парвовируса. Предполагается, что минимальные определяющие элементы, совершенно необходимые для функции ITR, представляют собой Rep-связывающий сайт (например, RBS; GCGCGCTCGCTCGCTC (SEQ ID NO: 104) для AAV2) и сайт концевого разрешения (например, TRS; AGTTGG (SEQ ID NO: 105) для AAV2) с вариабельной палиндромной последовательностью, обеспечивающей возможность образования шпилечной структуры. Палиндромные нуклеотидные области, как правило, осуществляют свою функцию вместе в цис-положении в качестве точки начала репликации ДНК и в качестве сигнальных последовательностей упаковки для вируса. Комплементарные последовательности в ITR подвергаются укладке в шпилечную структуру в ходе репликации ДНК. В некоторых вариантах осуществления ITR подвергаются укладке в шпилечную T-образную структуру. В других вариантах осуществления ITR подвергаются укладке в шпилечные структуры, отличные от T-образной, например, в U-образную шпилечную структуру. Данные свидетельствуют о том, что T-образные шпилечные структуры в ITR AAV могут подавлять экспрессию трансгена, фланкированного ITR. См., например, Zhou et al., Scientific Reports 7:5432 (July 14, 2017). За счет использования ITR, которые не образует T-образные шпилечные структуры, этой формы подавления можно избежать. Следовательно, в определенных аспектах полинуклеотид, содержащий ITR не из AAV, характеризуется улучшенной экспрессией трансгена по сравнению с полинуклеотидом, содержащим ITR AAV, который образует T-образную шпильку.
[128] В некоторых вариантах осуществления ITR содержит встречающийся в природе ITR, например, ITR содержит весь ITR парвовируса или его часть. В некоторых вариантах осуществления ITR содержит синтетическую последовательность. В одном варианте осуществления первый ITR или второй ITR содержат синтетическую последовательность. В другом варианте осуществления каждый из первого ITR и второго ITR содержит синтетическую последовательность. В некоторых вариантах осуществления первый ITR или второй ITR содержат встречающуюся в природе последовательность. В другом варианте осуществления каждый из первого ITR и второго ITR содержит встречающуюся в природе последовательность.
[129] В некоторых вариантах осуществления ITR содержит часть встречающегося в природе ITR, например усеченного ITR, или состоит из него. В некоторых вариантах осуществления ITR содержит фрагмент встречающегося в природе ITR или состоит из него, где фрагмент содержит по меньшей мере приблизительно 5 нуклеотидов, по меньшей мере приблизительно 10 нуклеотидов, по меньшей мере приблизительно 15 нуклеотидов, по меньшей мере приблизительно 20 нуклеотидов, по меньшей мере приблизительно 25 нуклеотидов, по меньшей мере приблизительно 30 нуклеотидов, по меньшей мере приблизительно 35 нуклеотидов, по меньшей мере приблизительно 40 нуклеотидов, по меньшей мере приблизительно 45 нуклеотидов, по меньшей мере приблизительно 50 нуклеотидов, по меньшей мере приблизительно 55 нуклеотидов, по меньшей мере приблизительно 60 нуклеотидов, по меньшей мере приблизительно 65 нуклеотидов, по меньшей мере приблизительно 70 нуклеотидов, по меньшей мере приблизительно 75 нуклеотидов, по меньшей мере приблизительно 80 нуклеотидов, по меньшей мере приблизительно 85 нуклеотидов, по меньшей мере приблизительно 90 нуклеотидов, по меньшей мере приблизительно 95 нуклеотидов, по меньшей мере приблизительно 100 нуклеотидов, по меньшей мере приблизительно 125 нуклеотидов, по меньшей мере приблизительно 150 нуклеотидов, по меньшей мере приблизительно 175 нуклеотидов, по меньшей мере приблизительно 200 нуклеотидов, по меньшей мере приблизительно 225 нуклеотидов, по меньшей мере приблизительно 250 нуклеотидов, по меньшей мере приблизительно 275 нуклеотидов, по меньшей мере приблизительно 300 нуклеотидов, по меньшей мере приблизительно 325 нуклеотидов, по меньшей мере приблизительно 350 нуклеотидов, по меньшей мере приблизительно 375 нуклеотидов, по меньшей мере приблизительно 400 нуклеотидов, по меньшей мере приблизительно 425 нуклеотидов, по меньшей мере приблизительно 450 нуклеотидов, по меньшей мере приблизительно 475 нуклеотидов, по меньшей мере приблизительно 500 нуклеотидов, по меньшей мере приблизительно 525 нуклеотидов, по меньшей мере приблизительно 550 нуклеотидов, по меньшей мере приблизительно 575 нуклеотидов или по меньшей мере приблизительно 600 нуклеотидов; где ITR сохраняет функциональное свойство встречающегося в природе ITR. В определенных вариантах осуществления ITR содержит фрагмент встречающегося в природе ITR или состоит из него, где фрагмент содержит по меньшей мере приблизительно 129 нуклеотидов; где ITR сохраняет функциональное свойство встречающегося в природе ITR. В определенных вариантах осуществления ITR содержит фрагмент встречающегося в природе ITR или состоит из него, где фрагмент содержит по меньшей мере приблизительно 102 нуклеотида; где ITR сохраняет функциональное свойство встречающегося в природе ITR.
[130] В некоторых вариантах осуществления ITR содержит часть встречающегося в природе ITR вируса или состоит из нее, где фрагмент составляет по меньшей мере приблизительно 5%, по меньшей мере приблизительно 10%, по меньшей мере приблизительно 15%, по меньшей мере приблизительно 20%, по меньшей мере приблизительно 25%, по меньшей мере приблизительно 30%, по меньшей мере приблизительно 35%, по меньшей мере приблизительно 40%, по меньшей мере приблизительно 45%, по меньшей мере приблизительно 50%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% от длины встречающегося в природе ITR; где фрагмент сохраняет функциональное свойство встречающегося в природе ITR.
[131] В определенных вариантах осуществления ITR содержит или состоит из последовательности, которая характеризуется по меньшей мере 50%, по меньшей мере 51%, по меньшей мере 52%, по меньшей мере 53%, по меньшей мере 54%, по меньшей мере 55%, по меньшей мере 56%, по меньшей мере 57%, по меньшей мере 58%, по меньшей мере 59%, по меньшей мере 60%, по меньшей мере 61%, по меньшей мере 62%, по меньшей мере 63%, по меньшей мере 64%, по меньшей мере 65%, по меньшей мере 66%, по меньшей мере 67%, по меньшей мере 68%, по меньшей мере 69%, по меньшей мере 70%, по меньшей мере 71%, по меньшей мере 72%, по меньшей мере 73%, по меньшей мере 74%, по меньшей мере 75%, по меньшей мере 76%, по меньшей мере 77%, по меньшей мере 78%, по меньшей мере 79%, по меньшей мере 80%, по меньшей мере 81%, по меньшей мере 82%, по меньшей мере 83%, по меньшей мере 84%, по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98%, по меньшей мере 99% или 100% идентичностью последовательности с гомологичной частью встречающегося в природе ITR при их соответствующем выравнивании; где ITR сохраняет функциональное свойство встречающегося в природе ITR. В других вариантах осуществления ITR содержит или состоит из последовательности, которая характеризуется по меньшей мере 90% идентичностью последовательности с гомологичной частью встречающегося в природе ITR при их соответствующем выравнивании; где ITR сохраняет функциональное свойство встречающегося в природе ITR. В некоторых вариантах осуществления ITR содержит или состоит из последовательности, которая характеризуется по меньшей мере 80% идентичностью последовательности с гомологичной частью встречающегося в природе ITR при их соответствующем выравнивании; где ITR сохраняет функциональное свойство встречающегося в природе ITR. В некоторых вариантах осуществления ITR содержит или состоит из последовательности, которая характеризуется по меньшей мере 70% идентичностью последовательности с гомологичной частью встречающегося в природе ITR при их соответствующем выравнивании; где ITR сохраняет функциональное свойство встречающегося в природе ITR. В некоторых вариантах осуществления ITR содержит или состоит из последовательности, которая характеризуется по меньшей мере 60% идентичностью последовательности с гомологичной частью встречающегося в природе ITR при их соответствующем выравнивании; где ITR сохраняет функциональное свойство встречающегося в природе ITR. В некоторых вариантах осуществления ITR содержит или состоит из последовательности, которая характеризуется по меньшей мере 50% идентичностью последовательности с гомологичной частью встречающегося в природе ITR при их соответствующем выравнивании; где ITR сохраняет функциональное свойство встречающегося в природе ITR.
[132] В некоторых вариантах осуществления ITR содержит ITR из генома AAV. В некоторых вариантах осуществления ITR представляет собой ITR из генома AAV, выбранного из AAV1, AAV2, AAV3, AAV4, AAV5, AAV6, AAV7, AAV8, AAV9, AAV10, AAV11 и любой их комбинации. В конкретном варианте осуществления ITR представляет собой ITR из генома AAV2. В другом варианте осуществления ITR представляет собой синтетическую последовательность, генетически сконструированную с включением на ее 5′- и 3′-концах ITR, полученных из одного или нескольких геномов AAV.
[133] В некоторых вариантах осуществления ITR не является полученным из генома AAV. В некоторых вариантах осуществления ITR представляет собой ITR вируса, отличного от AAV. В некоторых вариантах осуществления ITR представляет собой ITR из генома вируса, отличного от AAV, из семейства вирусов Parvoviridae, выбранного из группы, состоящей без ограничения из Bocavirus, Dependovirus, Erythrovirus, Amdovirus, Parvovirus, Densovirus, Iteravirus, Contravirus, Aveparvovirus, Copiparvovirus, Protoparvovirus, Tetraparvovirus, Ambidensovirus, Brevidensovirus, Hepandensovirus, Penstyldensovirus и любой их комбинации. В определенных вариантах осуществления ITR получен из эритровируса, представляющего собой парвовирус B19 (вирус человека). В другом варианте осуществления ITR получен из штамма парвовируса мускусных уток (MDPV). В определенных вариантах осуществления штамм MDPV является аттенуированным, например, представляет собой штамм FZ91-30 MDPV. В других вариантах осуществления штамм MDPV является патогенным, например, представляет собой штамм YY MDPV. В некоторых вариантах осуществления ITR получен из парвовируса свиней, например, парвовируса U44978 свиней. В некоторых вариантах осуществления ITR получен из мелкого вируса мышей, например, мелкого вируса мышей U34256. В некоторых вариантах осуществления ITR получен из собачьего парвовируса, например, собачьего парвовируса M19296. В некоторых вариантах осуществления ITR получен из вируса энтерита норок, например, вируса энтерита норок D00765. В некоторых вариантах осуществления ITR получен из вируса рода Dependoparvovirus. В одном варианте осуществления Dependoparvovirus представляет собой штамм парвовируса гусей (GPV) рода Dependovirus. В конкретном варианте осуществления штамм GPV является аттенуированным, например, представляет собой штамм 82-0321V GPV. В другом конкретном варианте осуществления штамм GPV является патогенным, например, представляет собой штамм B GPV.
[134] Первый ITR и второй ITR молекулы нуклеиновой кислоты могут быть получены из одного и того же генома, например, из генома одного и того же вируса, или из различных геномов, например, из геномов двух или более различных геномов вирусов. В определенных вариантах осуществления первый ITR и второй ITR получены из одного и того же генома AAV. В конкретном варианте осуществления два ITR, присутствующих в молекуле нуклеиновой кислоты по настоящему изобретению, являются одинаковыми, и могут, в частности, представлять собой ITR AAV2. В других вариантах осуществления первый ITR получен из генома AAV, а второй ITR не является полученным из генома AAV (например, генома вируса, отличного от AAV). В других вариантах осуществления первый ITR не является полученным из генома AAV (например, генома вируса, отличного от AAV), а второй ITR получен из генома AAV. В еще одних вариантах осуществления как первый ITR, так и второй ITR не являются полученными из генома AAV (например, генома вируса, отличного от AAV). В одном конкретном варианте осуществления первый ITR и второй ITR являются идентичными.
[135] В некоторых вариантах осуществления первый ITR получен из генома AAV, а второй ITR получен из генома, выбранного из группы, состоящей из Bocavirus, Dependovirus, Erythrovirus, Amdovirus, Parvovirus, Densovirus, Iteravirus, Contravirus, Aveparvovirus, Copiparvovirus, Protoparvovirus, Tetraparvovirus, Ambidensovirus, Brevidensovirus, Hepandensovirus, Penstyldensovirus и любой их комбинации. В других вариантах осуществления второй ITR получен из генома AAV, а первый ITR получен из генома, выбранного из группы, состоящей из Bocavirus, Dependovirus, Erythrovirus, Amdovirus, Parvovirus, Densovirus, Iteravirus, Contravirus, Aveparvovirus, Copiparvovirus, Protoparvovirus, Tetraparvovirus, Ambidensovirus, Brevidensovirus, Hepandensovirus, Penstyldensovirus и любой их комбинации. В других вариантах осуществления первый ITR и второй ITR получены из генома, выбранного из группы, состоящей из Bocavirus, Dependovirus, Erythrovirus, Amdovirus, Parvovirus, Densovirus, Iteravirus, Contravirus, Aveparvovirus, Copiparvovirus, Protoparvovirus, Tetraparvovirus, Ambidensovirus, Brevidensovirus, Hepandensovirus, Penstyldensovirus, и любой их комбинации, где первый ITR и второй ITR получены из одного и того же генома. В других вариантах осуществления первый ITR и второй ITR получены из генома, выбранного из группы, состоящей из Bocavirus, Dependovirus, Erythrovirus, Amdovirus, Parvovirus, Densovirus, Iteravirus, Contravirus, Aveparvovirus, Copiparvovirus, Protoparvovirus, Tetraparvovirus, Ambidensovirus, Brevidensovirus, Hepandensovirus, Penstyldensovirus и любой их комбинации, где первый ITR и второй ITR получены из различных геномов.
[136] В некоторых вариантах осуществления первый ITR получен из генома AAV, а второй ITR получен из эритровируса, представляющего собой парвовирус B19 (вирус человека). В других вариантах осуществления второй ITR получен из генома AAV, а первый ITR получен из эритровируса, представляющего собой парвовирус B19 (вирус человека).
[137] В определенных вариантах осуществления первый ITR и/или второй ITR содержат весь или часть ITR, полученного из B19, или состоят из них. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, которая на по меньшей мере приблизительно 50%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична нуклеотидной последовательности, выбранной из SEQ ID NO: 167, 168, 169, 170 и 171, где первый ITR и/или второй ITR сохраняют функциональное свойство ITR B19, из которого они были получены. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, которая на по меньшей мере приблизительно 50%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична нуклеотидной последовательности, выбранной из SEQ ID NO: 167, 168, 169, 170 и 171, где первый ITR и/или второй ITR являются способными к образованию шпилечной структуры. В определенных вариантах осуществления шпилечная структура не содержит T-образную шпильку.
[138] В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, выбранной из SEQ ID NO: 167, 168, 169, 170 и 171. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, изложенной под SEQ ID NO: 167. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, изложенной под SEQ ID NO: 168. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, изложенной под SEQ ID NO: 169. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, изложенной под SEQ ID NO: 170. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, изложенной под SEQ ID NO: 171.
Таблица 1. Образцы последовательностей ITR парвовируса
(п.о.)
[139] В определенных вариантах осуществления первый ITR и/или второй ITR содержат нуклеотидную последовательность, где нуклеотидная последовательность содержит минимальную нуклеотидную последовательность, изложенную под SEQ ID NO: 169, и где нуклеотидная последовательность на по меньшей мере приблизительно 50%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична нуклеотидной последовательности, изложенной под SEQ ID NO: 167, сохраняют функциональное свойство ITR B19, из которого они были получены. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат нуклеотидную последовательность, где нуклеотидная последовательность содержит минимальную нуклеотидную последовательность, изложенную под SEQ ID NO: 169, и где нуклеотидная последовательность на по меньшей мере приблизительно 50%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична нуклеотидной последовательности, изложенной под SEQ ID NO: 167, где первый ITR и/или второй ITR являются способными к образованию шпилечной структуры. В определенных вариантах осуществления шпилечная структура не содержит T-образную шпильку.
[140] В некоторых вариантах осуществления первый ITR получен из генома AAV, а второй ITR получен из GPV. В других вариантах осуществления второй ITR получен из генома AAV, а первый ITR получен из GPV.
[141] В определенных вариантах осуществления первый ITR и/или второй ITR содержат весь или часть ITR, полученного из GPV, или состоят из них. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, которая на по меньшей мере приблизительно 50%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична нуклеотидной последовательности, выбранной из SEQ ID NO: 172, 173, 174, 175 и 176, где первый ITR и/или второй ITR сохраняют функциональное свойство ITR GPV, из которого они были получены. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат весь или часть ITR, полученного из GPV, или состоят из них. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, которая на по меньшей мере приблизительно 50%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична нуклеотидной последовательности, выбранной из SEQ ID NO: 172, 173, 174, 175 и 176, где первый ITR и/или второй ITR являются способными к образованию шпилечной структуры. В определенных вариантах осуществления шпилечная структура не содержит T-образную шпильку. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, выбранной из SEQ ID NO: 172, 173, 174, 175 и 176. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, изложенной под SEQ ID NO: 172. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, изложенной под SEQ ID NO: 173. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, изложенной под SEQ ID NO: 174. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, изложенной под SEQ ID NO: 175. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, изложенной под SEQ ID NO: 176.
[142] В определенных вариантах осуществления первый ITR и/или второй ITR содержат нуклеотидную последовательность, где нуклеотидная последовательность содержит минимальную нуклеотидную последовательность, изложенную под SEQ ID NO: 174, и где нуклеотидная последовательность на по меньшей мере приблизительно 50%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична нуклеотидной последовательности, изложенной под SEQ ID NO: 172, где первый ITR и/или второй ITR сохраняют функциональное свойство ITR GPV, из которого они были получены. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат нуклеотидную последовательность, где нуклеотидная последовательность содержит минимальную нуклеотидную последовательность, изложенную под SEQ ID NO: 174, и где нуклеотидная последовательность на по меньшей мере приблизительно 50%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична нуклеотидной последовательности, изложенной под SEQ ID NO: 172, где первый ITR и/или второй ITR являются способными к образованию шпилечной структуры. В определенных вариантах осуществления шпилечная структура не содержит T-образную шпильку.
[143] В определенных вариантах осуществления первый ITR и/или второй ITR содержат нуклеотидную последовательность, где нуклеотидная последовательность содержит минимальную нуклеотидную последовательность, изложенную под SEQ ID NO: 176, и где нуклеотидная последовательность на по меньшей мере приблизительно 50%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична нуклеотидной последовательности, изложенной под SEQ ID NO: 172, где первый ITR и/или второй ITR сохраняют функциональное свойство ITR GPV, из которого они были получены. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат нуклеотидную последовательность, где нуклеотидная последовательность содержит минимальную нуклеотидную последовательность, изложенную под SEQ ID NO: 176, и где нуклеотидная последовательность на по меньшей мере приблизительно 50%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична нуклеотидной последовательности, изложенной под SEQ ID NO: 172, где первый ITR и/или второй ITR являются способными к образованию шпилечной структуры. В определенных вариантах осуществления шпилечная структура не содержит T-образную шпильку.
[144] В определенных вариантах осуществления один из первого ITR и/или второго ITR содержит весь или часть ITR, полученного из AAV2, или состоит из них. В некоторых вариантах осуществления первый ITR или второй ITR содержат или состоят из нуклеотидной последовательности, которая на по меньшей мере приблизительно 50%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична нуклеотидной последовательности, изложенной под SEQ ID NO: 177 или 178, где первый ITR и/или второй ITR сохраняют функциональное свойство ITR AAV2, из которого они были получены. В некоторых вариантах осуществления первый ITR или второй ITR содержат или состоят из нуклеотидной последовательности, которая на по меньшей мере приблизительно 50%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична нуклеотидной последовательности, изложенной под SEQ ID NO: 177 или 178, где первый ITR и/или второй ITR являются способными к образованию шпилечной структуры. В определенных вариантах осуществления шпилечная структура не содержит T-образную шпильку. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, изложенной под SEQ ID NO: 177 или 178. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, изложенной под SEQ ID NO: 177. В некоторых вариантах осуществления первый ITR и/или второй ITR содержат или состоят из нуклеотидной последовательности, изложенной под SEQ ID NO: 178.
[145] В некоторых вариантах осуществления первый ITR получен из генома AAV, а второй ITR получен из штамма парвовируса мускусных уток (MDPV). В других вариантах осуществления второй ITR получен из генома AAV, а первый ITR получен из штамма парвовируса мускусных уток (MDPV). В определенных вариантах осуществления штамм MDPV является аттенуированным, например, представляет собой штамм FZ91-30 MDPV. В других вариантах осуществления штамм MDPV является патогенным, например, представляет собой штамм YY MDPV.
[146] В некоторых вариантах осуществления первый ITR получен из генома AAV, а второй ITR получен из Dependoparvovirus. В некоторых вариантах осуществления второй ITR получен из генома AAV, а первый ITR получен из Dependoparvovirus. В других вариантах осуществления первый ITR получен из генома AAV, а второй ITR получен из штамма парвовируса гусей (GPV), относящегося к роду Dependovirus. В других вариантах осуществления второй ITR получен из генома AAV, а первый ITR получен из штамма GPV, относящегося к роду Dependovirus. В определенных вариантах осуществления штамм GPV является аттенуированным, например, представляет собой штамм 82-0321V GPV. В других вариантах осуществления штамм GPV является патогенным, например, представляет собой штамм В GPV.
[147] В определенных вариантах осуществления первый ITR получен из генома AAV, а второй ITR получен из генома, выбранного из группы, состоящей из парвовируса свиней, например, штамма U44978 парвовируса свиней; мелкого вируса мышей, например, штамма U34256 мелкого вируса мышей; парвовируса собак, например, штамма M19296 парвовируса собак; вируса энтерита норок, например, штамма D00765 вируса энтерита норок; и любой их комбинации. В других вариантах осуществления второй ITR получен из генома AAV, а первый ITR получен из генома, выбранного из группы, состоящей из парвовируса свиней, например, штамма U44978 парвовируса свиней; мелкого вируса мышей, например, штамма U34256 мелкого вируса мышей; парвовируса собак, например, штамма M19296 парвовируса собак; вируса энтерита норок, например, штамма D00765 вируса энтерита норок; и любой их комбинации.
[148] В другом конкретном варианте осуществления ITR представляет собой синтетическую последовательность, генетически сконструированную с включением на ее 5′- и 3′-концах ITR, не полученных из генома AAV. В другом конкретном варианте осуществления ITR представляет собой синтетическую последовательность, генетически сконструированную с включением на ее 5′- и 3′-концах ITR, полученных из одного или нескольких геномов вирусов, отличных от AAV. Два ITR, присутствующих в молекуле нуклеиновой кислоты по настоящему изобретению, могут быть из одного и того же или различных геномов вирусов, отличных от AAV. В частности, ITR могут быть получены из одного и того же генома вируса, отличного от AAV. В конкретном варианте осуществления два ITR, присутствующих в молекуле нуклеиновой кислоты по настоящему изобретению, являются одинаковыми, и могут, в частности, представлять собой ITR AAV2.
[149] В некоторых вариантах осуществления последовательность ITR содержит одну или несколько палиндромных последовательностей. Палиндромная последовательность ITR, раскрытого в данном документе, включает без ограничения нативные палиндромные последовательности (т. е. последовательности, выявленные в природе), синтетические последовательности (т. е. последовательности, не выявленные в природе), такие как псевдопалиндромные последовательности, и их комбинации или модифицированные формы. "Псевдопалиндромная последовательность" представляет собой палиндромную последовательность ДНК, включающую несовершенную палиндромную последовательность, которая обладает менее 80%, в том числе менее 70%, 60%, 50%, 40%, 30%, 20%, 10% или 5% идентичностью или не обладает идентичностью последовательности нуклеиновой кислоты c последовательностями в нативной AAV или отличной от AAV палиндромной последовательности, которая образует вторичную структуру. Нативные палиндромные последовательности могут быть получены или выделены из любого генома, раскрытого в данном документе. Синтетическая палиндромная последовательность может быть основана на любом геноме, раскрытом в данном документе.
[150] Палиндромная последовательность может быть непрерывный или прерывистой. В некоторых вариантах осуществления палиндромная последовательность является прерывистой, при этом палиндромная последовательность содержит вставку в виде второй последовательность. В некоторых вариантах осуществления вторая последовательность содержит промотор, энхансер, сайт интеграции для интегразы (например, сайты для Cre- или Flp-рекомбиназы), открытую рамку считывания для генного продукта или их комбинацию.
[151] В некоторых вариантах осуществления ITR образует структуры типа "шпилька-петля". В одном варианте осуществления первый ITR образует шпилечную структуру. В другом варианте осуществления второй ITR образует шпилечную структуру. Еще в одном варианте осуществления как первый ITR, так и второй ITR образуют шпилечные структуры. В некоторых вариантах осуществления первый ITR и/или второй ITR не образуют T-образную шпилечную структуру. В определенных вариантах осуществления первый ITR и/или второй ITR образуют шпилечную структуру, отличную от T-образной. В некоторых вариантах осуществления шпилечная структура, отличная от T-образной, предусматривает U-образную шпилечную структуру.
[152] В некоторых вариантах осуществления ITR в молекуле нуклеиновой кислоты, описанной в данном документе, может представлять собой транскрипционно активируемый ITR. Транскрипционно активируемый ITR может содержат весь ITR дикого типа или его часть, которые были транскрипционно активированы за счет включения по меньшей мере одного транскрипционно активного элемента. Различные типы транскрипционно активных элементов являются подходящими для применения в данном контексте. В некоторых вариантах осуществления транскрипционно активный элемент представляет собой конститутивный транскрипционно активный элемент. Конститутивные транскрипционно активные элементы обеспечивает уровень транскрипции гена на постоянной основе, и они являются предпочтительными, если требуется, чтобы трансген экспрессировался на постоянной основе. В других вариантах осуществления транскрипционно активный элемент является индуцируемым траскрипционно активным элементом. Индуцируемые транскрипционно активные элементы в целом проявляют низкую активность в отсутствие индуктора (или индуцирующего условия), но положительно регулируются в присутствии индуктора (или при переключении в индуцирующее условие). Индуцируемые транскрипционно активные элементы могут быть предпочтительными, если экспрессия требуется лишь в течение определенных периодов времени или в определенных местоположениях, или если требуется повысить уровень экспрессии с применением индуцирующего средства. Транскрипционно активные элементы также могут быть тканеспецифическими; то есть они проявляют активность только в некоторых типах тканей или клеток.
[153] Транскрипционно активные элементы могут быть встроены в ITR посредством различных способов. В некоторых вариантах осуществления транскрипционно активный элемент встроен на 5′-конце относительно любой части ITR или 3′-конце относительно любой части ITR. В других вариантах осуществления транскрипционно активный элемент транскрипционно активированного ITR расположен между двумя последовательностями ITR. Если транскрипционно активный элемент содержит два или более элементов, которые должны быть расположены раздельно друг от друга, тогда эти элементы могут чередоваться с частями ITR. В некоторых вариантах осуществления шпилечная структура ITR удалена и заменена инвертированными повторами транскрипционного элемента. Данный последняя структура будет образовывать шпильку, имитирующую удаленную часть в структуре. Множественные тандемные транскрипционно активные элементы также могут присутствовать в транскрипционно активированном ITR, при этом они могут быть расположены смежно или раздельно друг от друга. Кроме того, сайты связывания белка (например, Rep-связывающие сайты) можно вводить в транскрипционно активные элементы транскрипционно активированных ITR. Транскрипционно активный элемент может содержат любую последовательность, обеспечивающую возможность контролируемой транскрипции ДНК за счет РНК-полимеразы с образованием РНК, и может содержать, например, транскрипционно активный элемент, который определен ниже.
[154] Транскрипционно активированные ITR обеспечивают как транскрипционную активацию, так и функции ITR в молекуле нуклеиновой кислоты в нуклеотидной последовательности относительно ограниченной длины, которая эффективно увеличивает длину трансгена до максимума, который может переноситься, и экспрессироваться из молекулы нуклеиновой кислоты. Встраивание транскрипционно активного элемента в ITR может быть выполнено посредством множества способов. Сравнение последовательности ITR и требование последовательности в отношении транскрипционно активного элемента может обеспечить возможность тщательного анализа способов кодирования данного элемента в пределах ITR. Например, транскрипционная активность может быть добавлена в ITR посредством введения специфических изменений в последовательность ITR, что обеспечивает репликацию функциональных элементов транскрипционно активного элемента. В данной области техники существует ряд методик эффективного добавления, удаления и/или изменения конкретных нуклеотидных последовательностей в конкретных сайтах (см., например, Deng and Nickoloff (1992) Anal. Biochem. 200:81-88). Другой способ создания транскрипционно активируемых ITR включает введение сайта для рестриктазы в требуемом местоположении в ITR. Кроме того, множественные транскрипционно активные элементы могут быть включены в транскрипционно активируемый ITR с применением способов, известных из уровня техники.
[155] В качестве примера транскрипционно активируемые ITR могут быть получены путем включения одного или нескольких транскрипционно активных элементов, таких как TATA-бокс, GC-бокс, CCAAT-бокс, сайт Sp1, область Inr, сайт CRE (регуляторный элемент cAMP), сайт ATF-1/CRE, APBβ-бокс, APBα-бокс, CArG-бокс, CCAC-бокс, или любого другого элемента, вовлеченного в транскрипцию и известного из уровня техники.
B. Терапевтические белки
[156] Определенные аспекты настоящего изобретения направлены на молекулу нуклеиновой кислоты, содержащую первый ITR, второй ITR и генную кассету, кодирующую терапевтический белок. В некоторых вариантах осуществления генная кассета кодирует один терапевтический белок. В некоторых вариантах осуществления генная кассета кодирует более одного терапевтического белка. В некоторых вариантах осуществления генная кассета кодирует две или более копий одного и того же терапевтического белка. В некоторых вариантах осуществления генная кассета кодирует два или более вариантов одного и того же терапевтического белка. В некоторых вариантах осуществления генная кассета кодирует два или более различных терапевтических белка.
[157] Определенные варианты осуществления настоящего изобретения направлены на молекулу нуклеиновой кислоты, содержащую первый ITR, второй ITR и генную кассету, кодирующую терапевтический белок, где терапевтический белок представляет собой фактор свертывания крови. В некоторых вариантах осуществления фактор свертывания крови выбран из группы, состоящей из FI, FII, FIII, FIV, FV, FVI, FVII, FVIII, FIX, FX, FXI, FXII, FXIII), VWF, прекалликреина, высокомолекулярного кининогена, фибронектина, антитромбина III, кофактора II гепарина, белка C, белка S, белка Z, ингибитора протеазы, связанного с Z-белком (ZPI), плазминогена, альфа-2-антиплазмина, тканевого активатора плазминогена (tPA), урокиназы, ингибитора-1 активатора плазминогена (PAI-1), ингибитора-2 активатора плазминогена (PAI2), их любого зимогена, их любой активной формы и любой их комбинации. В одном варианте осуществления фактор свертывания крови представляет собой FVIII или его вариант или фрагмент. В другом варианте осуществления фактор свертывания крови представляет собой FIX или его вариант или фрагмент. В другом варианте осуществления фактор свертывания крови представляет собой FVII или его вариант или фрагмент. В другом варианте осуществления фактор свертывания крови представляет собой VWF или его вариант или фрагмент.
1. Факторы свертывания крови
[158] В некоторых вариантах осуществления молекула нуклеиновой кислоты содержит первый ITR, второй ITR и генную кассету, кодирующую терапевтический белок, где терапевтический белок представляет собой полипептид фактора VIII. Используемый в данном документе термин "фактор VIII", сокращенно называемый по всей настоящей заявке как "FVIII", означает функциональный полипептид FVIII с его нормальной функцией в коагуляции, если не указано иное. Таким образом, термин "FVIII" включает варианты полипептидов, которые являются функционально активными. "Белок FVIII" используется взаимозаменяемо с полипептидом (или белком) FVIII или FVIII. Примеры функций FVIII включают без ограничения способность активировать коагуляцию, способность действовать в качестве кофактора для фактора IX или способность образовывать теназный комплекс с фактором IX в присутствии Ca2+ и фосфолипидов, который затем обеспечивает превращение фактора X в активированную форму Xa. Белок FVIII может представлять собой белок FVIII человека, свиньи, собаки, крысы или мыши. Кроме того, путем сравнения FVIII людей и FVIII других видов идентифицировали консервативные остатки, которые, вероятно, необходимы для функционирования (Cameron et al., Thromb. Haemost. 79:317-22 (1998); US 6251632). Известны полноразмерные полипептидные и полинуклеотидные последовательности, а также многие функциональные фрагменты, мутантные и модифицированные варианты. Различные аминокислотные и нуклеотидные последовательности FVIII раскрыты, например, в публикациях заявок на патент США №№ 2015/0158929 A1, 2014/0308280 A1 и 2014/0370035 A1 и в международной публикации № WO 2015/106052 A1. Полипептиды FVIII включают, например, полноразмерный FVIII, полноразмерный FVIII без Met на N-конце, зрелый FVIII (без сигнальной последовательности), зрелый FVIII с дополнительным Met на N-конце и/или FVIII с полной или частичной делецией домена B. Варианты FVIII содержат делеции домена B, будь то частичные или полные делеции.
a. FVIII и полинуклеотидные последовательности, кодирующие белок FVIII
[159] В некоторых вариантах осуществления молекула нуклеиновой кислоты содержит первый ITR, второй ITR и генную кассету, кодирующую терапевтический белок, где терапевтический белок представляет собой полипептид фактора VIII. Используемый в данном документе термин "фактор VIII", сокращенно называемый по всей настоящей заявке как "FVIII", означает функциональный полипептид FVIII с его нормальной функцией в коагуляции, если не указано иное. Таким образом, термин "FVIII" включает варианты полипептидов, которые являются функционально активными. "Белок FVIII" используется взаимозаменяемо с полипептидом (или белком) FVIII или FVIII. Примеры функций FVIII включают без ограничения способность активировать коагуляцию, способность действовать в качестве кофактора для фактора IX или способность образовывать теназный комплекс с фактором IX в присутствии Ca2+ и фосфолипидов, который затем обеспечивает превращение фактора X в активированную форму Xa. Белок FVIII может представлять собой белок FVIII человека, свиньи, собаки, крысы или мыши. Кроме того, путем сравнения FVIII людей и FVIII других видов идентифицировали консервативные остатки, которые, вероятно, необходимы для функционирования (Cameron et al., Thromb. Haemost. 79:317-22 (1998); US 6251632). Известны полноразмерные полипептидные и полинуклеотидные последовательности, а также многие функциональные фрагменты, мутантные и модифицированные варианты. Различные аминокислотные и нуклеотидные последовательности FVIII раскрыты, например, в публикациях заявок на патент США №№ 2015/0158929 A1, 2014/0308280 A1 и 2014/0370035 A1 и в международной публикации № WO 2015/106052 A1. Полипептиды FVIII включают, например, полноразмерный FVIII, полноразмерный FVIII без Met на N-конце, зрелый FVIII (без сигнальной последовательности), зрелый FVIII с дополнительным Met на N-конце и/или FVIII с полной или частичной делецией домена B. Варианты FVIII содержат делеции домена B, будь то частичные или полные делеции.
[160] Часть FVIII в химерном белке, используемом в данном документе, обладает активностью FVIII. Активность FVIII можно измерять с помощью любого способа, известного из уровня техники. Доступен ряд тестов для оценки функции системы коагуляции: определение активированного частичного тромбопластинового времени (aPTT), хромогенный анализ, анализ ROTEM, определение протромбинового времени (PT) (также используется для определения INR), определение концентрации фибриногена (чаще всего с помощью метода Клаусса), подсчет количества тромбоцитов, определение тромбоцитарной функции (чаще всего с помощью PFA-100), TCT, определение времени свертывания крови, тест смешивания (устраняется ли аномалия при смешивании плазмы крови пациента с нормальной плазмой крови), анализы факторов коагуляции, определение антител к фосфолипидам, D-димера, генетические тесты (например, определение фактора V Лейдена, мутации протромбина G20210A), определение времени свертывания с разбавленным ядом гадюки Рассела (dRVVT), различные тесты тромбоцитарной функции, тромбоэластография (TEG или Sonoclot), тромбоэластометрия (TEM®, например ROTEM®) или определение времени лизиса эуглобулина (ELT).
[161] Тест aPTT является показателем функционирования, измеряющим эффективность как "внутреннего" (также называемого контактным путем активации), так и общего путей коагуляции. Этот тест обычно используют для измерения свертывающей активности коммерчески доступных рекомбинантных факторов свертывания крови, например, FVIII. Он используется в сочетании с протромбиновым временем (PT), с помощью которого измеряют внешний путь.
[162] Анализ ROTEM предоставляет информацию о всей кинетике гемостаза: времени свертывания крови, образовании сгустка, стабильности и лизисе сгустка. Различные параметры тромбоэластометрии зависят от активности системы плазменной коагуляции, функции тромбоцитов, фибринолиза или многих факторов, которые влияют на эти взаимодействия. Этот анализ может дать полное представление о вторичном гемостазе.
[163] Механизм хромогенного анализа основан на принципах каскада коагуляции крови, где активированный FVIII ускоряет превращение фактора X в фактор Xa в присутствии активированного фактора IX, фосфолипидов и ионов кальция. Активность фактора Ха оценивают путем гидролиза субстрата п-нитроанилида (pNA), специфического для фактора Ха. Начальная скорость высвобождения п-нитроанилина, измеренная при 405 нМ, прямо пропорциональна активности фактора Xa и, следовательно, активности FVIII в образце.
[164] Хромогенный анализ рекомендован подкомитетом по FVIII и фактору IX научного и стандартизационного комитета (SSC) Международного общества по тромбозу и гемостазу (ISTH). С 1994 года хромогенный анализ также являлся эталонным способом определения эффективности концентрата FVIII в Европейской фармакопее. Таким образом, в одном варианте осуществления химерный полипептид, содержащий FVIII, обладает активностью FVIII, сопоставимой с таковой у химерного полипептида, содержащего зрелый FVIII или BDD FVIII (например, ADVATE®, REFACTO® или ELOCTATE®).
[165] В другом варианте осуществления химерный белок, содержащий FVIII, согласно настоящему изобретению характеризуется скоростью образования фактора Xa, сопоставимой с таковой у химерного белка, содержащего зрелый FVIII или BDD FVIII (например, ADVATE®, REFACTO® или ELOCTATE®).
[166] Чтобы активировать фактор X в фактор Xa, активированный фактор IX (фактор IXa) гидролизует одну связь между аргинином и изолейцином в факторе X с образованием фактора Xa в присутствии Ca2+, мембранных фосфолипидов и кофактора FVIII. Следовательно, взаимодействие FVIII с фактором IX является критически важным в пути коагуляции. В определенных вариантах осуществления химерный полипептид, содержащий FVIII, может взаимодействовать с фактором IXa со скоростью, сопоставимой с таковой у химерного полипептида, содержащего зрелую последовательность FVIII или BDD FVIII (например, ADVATE®, REFACTO® или ELOCTATE®).
[167] Кроме того, FVIII связывается с фактором фон Виллебранда, находясь в неактивной форме, в кровотоке. FVIII быстро разрушается, когда он не связан с VWF, и отщепляется от VWF под действием тромбина. В некоторых вариантах осуществления химерный полипептид, содержащий FVIII, связывается с фактором фон Виллебранда на уровне, сопоставимом с таковым у химерного полипептида, содержащего последовательность зрелого FVIII или BDD FVIII (например, ADVATE®, REFACTO® или ELOCTATE®).
[168] FVIII можно инактивировать с помощью активированного белка С в присутствии кальция и фосфолипидов. Активированный белок C расщепляет тяжелую цепь FVIII после аргинина 336 в домене A1, что разрушает сайт взаимодействия с субстратом фактора X, и расщепляет после аргинина 562 в домене A2, что усиливает диссоциацию домена A2, а также разрушает сайт взаимодействия с фактором IXa. Это расщепление также обеспечивает разделение пополам домена A2 (43 кДа) и образование доменов A2-N (18 кДа) и A2-C (25 кДа). Таким образом, активированный белок C может катализировать множественные сайты расщепления в тяжелой цепи. В одном варианте осуществления химерный полипептид, содержащий FVIII, инактивируется активированным белком С на уровне, сопоставимом с таковым у химерного полипептида, содержащего зрелую последовательность FVIII или BDD FVIII (например, ADVATE®, REFACTO® или ELOCTATE®).
[169] В других вариантах осуществления химерный полипептид, содержащий FVIII, обладает активностью FVIII in vivo, сопоставимой с таковой у химерного полипептида, содержащего зрелую последовательность FVIII или BDD FVIII (например, ADVATE®, REFACTO® или ELOCTATE®). В конкретном варианте осуществления химерный полипептид, содержащий FVIII, способен обеспечивать защиту у мыши с HemA на уровне, сопоставимом с таковым у химерного полипептида, содержащего зрелую последовательность FVIII или BDD FVIII (например, ADVATE®, REFACTO® или ELOCTATE®), на модели рассечения хвостовой вены у мышей HemA.
[170] "Домен B" в FVIII, используемый в данном документе, является тем же доменом B, известным из уровня техники, который определяют по идентичности внутренней аминокислотной последовательности и сайтам протеолитического расщепления тромбином, например, остаткам Ser741-Arg1648 зрелого FVIII человека. Другие домены FVIII человека определяют по следующим аминокислотным остаткам относительно зрелого FVIII человека: A1, остатки Ala1-Arg372; A2, остатки Ser373-Arg740; A3, остатки Ser1690-Ile2032; C1, остатки Arg2033-Asn2172; C2, остатки Ser2173-Tyr2332 зрелого FVIII. Номера остатков последовательности, используемые в данном документе, без ссылки на какие-либо номера SEQ ID соответствуют последовательности FVIII без последовательности сигнального пептида (19 аминокислот), если не указано иное. Последовательность A3-C1-C2, также известная как тяжелая цепь FVIII, включает остатки Ser1690-Tyr2332. Оставшаяся последовательность, остатки Glu1649-Arg1689, обычно относится к активационному пептиду легкой цепи FVIII. Из уровня техники также известны местоположения границ всех доменов, в том числе доменов B, для FVIII свиньи, мыши и собаки. В одном варианте осуществления домен B FVIII удален посредством делеции ("FVIII с делецией домена В" или "BDD FVIII"). Примером BDD FVIII является REFACTO® (рекомбинантный BDD FVIII). В одном конкретном варианте осуществления вариант FVIII с делецией домена B содержит делецию аминокислотных остатков 746-1648 зрелого FVIII.
[171] "FVIII с делецией домена B" может характеризоваться полной или частичной делециями, раскрытыми в патентах США №№ 6316226, 6346513, 7041635, 5789203, 6060447, 5595886, 6228620, 5972885, 6048720, 5543502, 5610278, 5171844, 5112950, 4868112 и 6458563 и в международной публикации № WO 2015106052 A1 (PCT/US2015/010738). В некоторых вариантах осуществления последовательность FVIII с делецией домена B, используемая в способах согласно настоящему изобретению, содержит любую из делеций, раскрытых от столбца 4, строки 4 до столбца 5, строки 28 и в примерах 1-5 патента США № 6316226 (также в US 6346513). В другом варианте осуществления фактор VIII с делецией домена В представляет собой фактор VIII с делецией домена В S743/Q1638 (SQ BDD FVIII) (например, фактор VIII, имеющий делецию от аминокислоты 744 до аминокислоты 1637, например, фактор VIII, содержащий аминокислоты 1-743 и аминокислоты 1638-2332 зрелого FVIII). В некоторых вариантах осуществления FVIII с делецией домена B, используемый в способах согласно настоящему изобретению, имеет делецию, раскрытую в столбце 2, строках 26-51 и в примерах 5-8 патента США № 5789203 (также в US 6060447, US 5595886 и US 6228620). В некоторых вариантах осуществления фактор VIII с делецией домена В имеет делецию, описанную от столбца 1, строки 25 до столбца 2, строки 40 в патенте США № 5972885; в столбце 6, строках 1-22 и в примере 1 патента США № 6048720; в столбце 2, строках 17-46 патента США № 5543502; от столбца 4, строки 22 до столбца 5, строки 36 патента США № 5171844; в столбце 2, строках 55-68, на фигуре 2 и в примере 1 патента США № 5112950; от столбца 2, строки 2 до столбца 19, строки 21 и в таблице 2 патента США № 4868112; от столбца 2, строки 1 до столбца 3, строки 19, от столбца 3, строки 40 до столбца 4, строки 67, от столбца 7, строки 43 до столбца 8, строки 26 и от столбца 11, строки 5 до столбца 13, строки 39 патента США № 7041635 или в столбце 4, строках 25-53 патента США № 6458563. В некоторых вариантах осуществления FVIII с делецией домена B имеет делецию большей части домена В, но все еще содержит аминоконцевые последовательности домена В, которые необходимы для протеолитического процессинга in vivo первичного продукта трансляции в две полипептидные цепи, как это раскрыто в WO 91/09122. В некоторых вариантах осуществления FVIII с делецией домена B конструируют с делецией аминокислот 747-1638, т. е. практически с полной делецией домена В. Hoeben R.C., et al. J. Biol. Chem. 265 (13): 7318-7323 (1990). Фактор VIII с делецией домена В также может содержать делецию аминокислот 771-1666 или аминокислот 868-1562 FVIII. Meulien P., et al. Protein Eng. 2(4): 301-6 (1988). Дополнительные делеции домена В, которые являются частью настоящего изобретения, включают делецию аминокислот 982-1562 или 760-1639 (Toole et al., Proc. Natl. Acad. Sci. U.S.A. (1986) 83, 5939-5942)), 797-1562 (Eaton, et al. Biochemistry (1986) 25:8343-8347)), 741-1646 (Kaufman (опубликованная заявка согласно PCT № WO 87/04187)), 747-1560 (Sarver, et al., DNA (1987) 6:553-564)), 741-1648 (Pasek (заявка согласно PCT № 88/00831)), или 816-1598, или 741-1648 (Lagner (Behring Inst. Mitt. (1988) No 82:16-25, EP 295597)). В одном конкретном варианте осуществления FVIII с делецией домена B содержит делецию аминокислотных остатков 746-1648 зрелого FVIII. В другом варианте осуществления FVIII с делецией домена B содержит делецию аминокислотных остатков 745-1648 зрелого FVIII. В некоторых вариантах осуществления BDD FVIII включает одноцепочечный FVIII, который содержит делецию аминокислот 765-1652, соответствующих зрелому полноразмерному FVIII (также известный как одноцепочечный rVIII и AFSTYLA®). См. патент США № 7041635.
[172] В других вариантах осуществления BDD FVIII включает полипептид FVIII, содержащий фрагменты домена В, в которых сохранены один или несколько сайтов N-связанного гликозилирования, например, остатки 757, 784, 828, 900, 963 или необязательно 943, которые соответствуют аминокислотной последовательности полноразмерной последовательности FVIII. Примеры фрагментов домена В включают 226 аминокислот или 163 аминокислоты из домена В, как это раскрыто в Miao, H.Z., et al., Blood 103(a): 3412-3419 (2004), Kasuda, A, et al., J. Thromb. Haemost. 6. 1352-1359 (2008) и Pipe, S.W., et al., J. Thromb. Haemost. 9. 2235-2242 (2011) (т. e. первые 226 аминокислот или 163 аминокислоты из домена В сохранены). В еще одних других вариантах осуществления BDD FVIII дополнительно содержит точечную мутацию в остатке 309 (из Phe в Ser) для улучшения экспрессии белка BDD FVIII. См. Miao, H.Z., et al., Blood 103(a): 3412-3419 (2004). В еще одних других вариантах осуществления BDD FVIII включает полипептид FVIII, содержащий часть домена В, но не содержащий один или несколько сайтов расщепления фурином (например, Arg1313 и Arg 1648). См. Pipe, S.W., et al., J. Thromb. Haemost. 9. 2235-2242 (2011). В некоторых вариантах осуществления BDD FVIII включает одноцепочечный FVIII, который содержит делецию аминокислот 765-1652, соответствующих зрелому полноразмерному FVIII (также известный как одноцепочечный rVIII и AFSTYLA®). См. патент США № 7041635. Каждая из вышеизложенных делеций может быть осуществлена в любой последовательности FVIII.
[173] Известно множество функциональных вариантов FVIII, обсуждаемых выше и ниже. Кроме того, у пациентов с гемофилией были идентифицированы сотни нефункциональных мутаций в FVIII, и было определено, что эффект данных мутаций в отношении функции FVIII обусловлен в большей степени их местом положения в 3-мерной структуре FVIII, а не природой замены (Cutler et al., Hum. Mutat. 19:274-8 (2002), включенная в данный документ посредством ссылки во всей своей полноте). Кроме того, путем сравнения FVIII от людей и FVIII от других видов идентифицировали консервативные остатки, которые, вероятно, необходимы для функционирования (Cameron et al., Thromb. Haemost. 79:317-22 (1998); US 6251632, включенные в данный документ посредством ссылки во всей своей полноте).
[174] В некоторых вариантах осуществления FVIII полипептид содержит вариант FVIII или его фрагмент, где вариант FVIII или его фрагмент обладает активностью FVIII. В некоторых вариантах осуществления генная кассета кодирует полноразмерный полипептид FVIII. В других вариантах осуществления генная кассета кодирует полипептид FVIII с удаленным доменом B (BDD), где весь домен B FVIII или его часть удалены. В одном конкретном варианте осуществления генная кассета кодирует полипептид, содержащий аминокислотную последовательность, характеризующуюся по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с SEQ ID NO: 106, 107, 109, 110, 111 или 112. В некоторых вариантах осуществления генная кассета кодирует полипептид, характеризующийся аминокислотной последовательностью под SEQ ID NO: 17, или его фрагмент. В некоторых вариантах осуществления генная кассета кодирует полипептид, характеризующийся аминокислотной последовательностью под SEQ ID NO: 106, или его фрагмент. В некоторых вариантах осуществления генная кассета содержит нуклеотидную последовательность, которая характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с SEQ ID NO: 107. В некоторых вариантах осуществления генная кассета кодирует полипептид, характеризующийся аминокислотной последовательностью под SEQ ID NO: 109, или его фрагмент. В некоторых вариантах осуществления генная кассета содержит нуклеотидную последовательность, которая характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с SEQ ID NO: 16. В некоторых вариантах осуществления генная кассета содержит нуклеотидную последовательность, которая характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с SEQ ID NO: 109.
[175] В некоторых вариантах осуществления генная кассета по настоящему изобретению кодирует полипептид FVIII, содержащий сигнальный пептид или его фрагмент. В других вариантах осуществления генная кассета кодирует полипептид FVIII, в котором отсутствует сигнальный пептид. В некоторых вариантах осуществления сигнальный пептид содержит аминокислоты 1-19 из SEQ ID NO: 17.
[176] В некоторых вариантах осуществления генная кассета содержит нуклеотидную последовательность, кодирующую полипептид FVIII, где нуклеотидная последовательность является кодон-оптимизированной. В определенных вариантах осуществления генная кассета содержит нуклеотидную последовательность, которая раскрыта в международной заявке PCT/US2017/015879, которая включена посредством ссылки во всей своей полноте. В некоторых вариантах осуществления генная кассета содержит нуклеотидную последовательность, кодирующую полипептид FVIII, где нуклеотидная последовательность является кодон-оптимизированной. В определенных вариантах осуществления генная кассета содержит нуклеотидную последовательность, которая характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидной последовательностью, выбранной из SEQ ID NO: 1-14. В некоторых вариантах осуществления генная кассета содержит нуклеотидную последовательность, которая характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с SEQ ID NO: 71. В некоторых вариантах осуществления генная кассета содержит нуклеотидную последовательность, которая характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с SEQ ID NO: 19.
i. Кодон-оптимизированные нуклеотидные последовательности, кодирующие полипептиды FVIII
[177] В некоторых вариантах осуществления молекула нуклеиновой кислоты по настоящему изобретению содержит первый ITR, второй ITR и генную кассету, кодирующую терапевтический белок, где первый ITR и второй ITR получены из генома AAV, и где генная кассета содержит кодон-оптимизированную нуклеотидную последовательность, кодирующую полипептид FVIII. В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность кодирует полноразмерный полипептид FVIII. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность кодирует полипептид FVIII с удаленным доменом B (BDD), где весь домен B FVIII или его часть удалены. В одном конкретном варианте осуществления кодон-оптимизированная нуклеотидная последовательность кодирует полипептид, содержащий аминокислотную последовательность, характеризующуюся по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с SEQ ID NO: 17, или его фрагмент. В одном варианте осуществления кодон-оптимизированная нуклеотидная последовательность кодирует полипептид, характеризующийся аминокислотной последовательностью под SEQ ID NO: 17, или его фрагмент.
[178] В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность по настоящему изобретению кодирует полипептид FVIII, содержащий сигнальный пептид, или его фрагмент. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность кодирует полипептид FVIII, в котором отсутствует сигнальный пептид. В некоторых вариантах осуществления сигнальный пептид содержит аминокислоты 1-19 из SEQ ID NO: 17.
[179] В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, которая содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где первая последовательность нуклеиновой кислоты характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с (i) нуклеотидами 58-1791 из SEQ ID NO: 3 или (ii) нуклеотидами 58-1791 из SEQ ID NO: 4; и где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII. В одном конкретном варианте осуществления первая последовательность нуклеиновой кислоты характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-1791 из SEQ ID NO: 3. В другом варианте осуществления первая последовательность нуклеиновой кислоты характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-1791 из SEQ ID NO: 4. В других вариантах осуществления первая нуклеотидная последовательность содержит нуклеотиды 58-1791 из SEQ ID NO: 3 или нуклеотиды 58-1791 из SEQ ID NO: 4.
[180] В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, которая содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где первая последовательность нуклеиновой кислоты характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с (i) нуклеотидами 1-1791 из SEQ ID NO: 3 или (ii) нуклеотидами 1-1791 из SEQ ID NO: 4; и где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII. В одном варианте осуществления первая нуклеотидная последовательность содержит нуклеотиды 1-1791 из SEQ ID NO: 3 или нуклеотиды 1-1791 из SEQ ID NO: 4. В другом варианте осуществления вторая нуклеотидная последовательность характеризуется по меньшей мере 60%, по меньшей мере 70%, по меньшей мере 80%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 1792-4374 из SEQ ID NO: 3 или 1792-4374 из SEQ ID NO: 4. В одном конкретном варианте осуществления вторая нуклеотидная последовательность содержит нуклеотиды 1792-4374 из SEQ ID NO: 3 или 1792-4374 из SEQ ID NO: 4. В еще одном варианте осуществления вторая нуклеотидная последовательность характеризуется по меньшей мере 60%, по меньшей мере 70%, по меньшей мере 80%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 3 или 1792-2277 и 2320-4374 из SEQ ID NO: 4 (т. е. нуклеотидами 1792-4374 из SEQ ID NO: 3 или 1792-4374 из SEQ ID NO: 4 без нуклеотидов, кодирующих домен B или фрагмент домена B). В одном конкретном варианте осуществления вторая нуклеотидная последовательность содержит нуклеотиды 1792-2277 и 2320-4374 из SEQ ID NO: 3 или 1792-2277 и 2320-4374 из SEQ ID NO: 4 (т. е. нуклеотиды 1792-4374 из SEQ ID NO: 3 или 1792-4374 из SEQ ID NO: 4 без нуклеотидов, кодирующих домен B или фрагмент домена B).
[181] В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, которая содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где вторая последовательность нуклеиновой кислоты характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с (i) нуклеотидами 1792-4374 из SEQ ID NO: 5 или (ii) нуклеотидами 1792-4374 из SEQ ID NO: 6; и где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII. В определенных вариантах осуществления вторая последовательность нуклеиновой кислоты характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 1792-4374 из SEQ ID NO: 5. В других вариантах осуществления вторая последовательность нуклеиновой кислоты характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 1792-4374 из SEQ ID NO: 6. В одном конкретном варианте осуществления вторая последовательность нуклеиновой кислоты содержит нуклеотиды 1792-4374 из SEQ ID NO: 5 или 1792-4374 из SEQ ID NO: 6. В некоторых вариантах осуществления первая последовательность нуклеиновой кислоты, связанная со второй последовательностью нуклеиновой кислоты, приведенной выше, характеризуется по меньшей мере 60%, по меньшей мере 70%, по меньшей мере 80%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-1791 из SEQ ID NO: 5 или нуклеотидами 58-1791 из SEQ ID NO: 6. В других вариантах осуществления первая последовательность нуклеиновой кислоты, связанная со второй последовательностью нуклеиновой кислоты, приведенной выше, характеризуется по меньшей мере 60%, по меньшей мере 70%, по меньшей мере 80%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 1-1791 из SEQ ID NO: 5 или нуклеотидами 1-1791 из SEQ ID NO: 6.
[182] В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, которая содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где вторая последовательность нуклеиновой кислоты характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с (i) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 5 (т. е. нуклеотидами 1792-4374 из SEQ ID NO: 5 без нуклеотидов, кодирующих домен B или фрагмент домена B) или (ii) 1792-2277 и 2320-4374 из SEQ ID NO: 6 (т. е. нуклеотидами 1792-4374 из SEQ ID NO: 6 без нуклеотидов, кодирующих домен B или фрагмент домена B); и где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII. В определенных вариантах осуществления вторая последовательность нуклеиновой кислоты характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 5 (т. е. нуклеотидами 1792-4374 из SEQ ID NO: 5 без нуклеотидов, кодирующих домен B или фрагмент домена B). В других вариантах осуществления вторая последовательность нуклеиновой кислоты характеризуется по меньшей мере 85%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 6 (т. е. нуклеотидами 1792-4374 из SEQ ID NO: 6 без нуклеотидов, кодирующих домен B или фрагмент домена B). В одном конкретном варианте осуществления вторая последовательность нуклеиновой кислоты содержит нуклеотиды 1792-2277 и 2320-4374 из SEQ ID NO: 5 или 1792-2277 и 2320-4374 из SEQ ID NO: 6 (т. е. нуклеотиды 1792-4374 из SEQ ID NO: 5 или 1792-4374 из SEQ ID NO: 6 без нуклеотидов, кодирующих домен B или фрагмент домена B). В некоторых вариантах осуществления первая последовательность нуклеиновой кислоты, связанная со второй последовательностью нуклеиновой кислоты, приведенной выше, характеризуется по меньшей мере 60%, по меньшей мере 70%, по меньшей мере 80%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-1791 из SEQ ID NO: 5 или нуклеотидами 58-1791 из SEQ ID NO: 6. В других вариантах осуществления первая последовательность нуклеиновой кислоты, связанная со второй последовательностью нуклеиновой кислоты, приведенной выше, характеризуется по меньшей мере 60%, по меньшей мере 70%, по меньшей мере 80%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 1-1791 из SEQ ID NO: 5 или нуклеотидами 1-1791 из SEQ ID NO: 6.
[183] В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, которая содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где первая последовательность нуклеиновой кислоты характеризуется по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с (i) нуклеотидами 58-1791 из SEQ ID NO: 1, (ii) нуклеотидами 58-1791 из SEQ ID NO: 2, (iii) нуклеотидами 58-1791 из SEQ ID NO: 70 или (iv) нуклеотидами 58-1791 из SEQ ID NO: 71; и где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII. В других вариантах осуществления первая нуклеотидная последовательность содержит нуклеотиды 58-1791 из SEQ ID NO: 1, нуклеотиды 58-1791 из SEQ ID NO: 2, (iii) нуклеотиды 58-1791 из SEQ ID NO: 70 или (iv) нуклеотиды 58-1791 из SEQ ID NO: 71.
[184] В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, которая содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где первая последовательность нуклеиновой кислоты характеризуется по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с (i) нуклеотидами 1-1791 из SEQ ID NO: 1, (ii) нуклеотидами 1-1791 из SEQ ID NO: 2, (iii) нуклеотидами 1-1791 из SEQ ID NO: 70 или (iv) нуклеотидами 1-1791 из SEQ ID NO: 71; и где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII. В одном варианте осуществления первая нуклеотидная последовательность содержит нуклеотиды 1-1791 из SEQ ID NO: 1, нуклеотиды 1-1791 из SEQ ID NO: 2, (iii) нуклеотиды 1-1791 из SEQ ID NO: 70 или (iv) нуклеотиды 1-1791 из SEQ ID NO: 71. В другом варианте осуществления вторая нуклеотидная последовательность, связанная с первой нуклеотидной последовательностью, характеризуется по меньшей мере 60%, по меньшей мере 70%, по меньшей мере 80%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 1792-4374 из SEQ ID NO: 1, 1792-4374 из SEQ ID NO: 2, (iii) нуклеотидами 1792-4374 из SEQ ID NO: 70 или (iv) нуклеотидами 1792-4374 из SEQ ID NO: 71. В одном конкретном варианте осуществления вторая нуклеотидная последовательность, связанная с первой нуклеотидной последовательностью, содержит (i) нуклеотиды 1792-4374 из SEQ ID NO: 1, (ii) нуклеотиды 1792-4374 из SEQ ID NO: 2, (iii) нуклеотиды 1792-4374 из SEQ ID NO: 70 или (iv) нуклеотиды 1792-4374 из SEQ ID NO: 71. В других вариантах осуществления вторая нуклеотидная последовательность, связанная с первой нуклеотидной последовательностью, характеризуется по меньшей мере 60%, по меньшей мере 70%, по меньшей мере 80%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с (i) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 1, (ii) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 2, (iii) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 70 или (iv) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 71. В одном варианте осуществления вторая нуклеотидная последовательность содержит (i) нуклеотиды 1792-2277 и 2320-4374 из SEQ ID NO: 1, (ii) нуклеотиды 1792-2277 и 2320-4374 из SEQ ID NO: 2, (iii) нуклеотиды 1792-2277 и 2320-4374 из SEQ ID NO: 70 или (iv) нуклеотиды 1792-2277 и 2320-4374 из SEQ ID NO: 71.
[185] В другом варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, которая содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где вторая последовательность нуклеиновой кислоты характеризуется по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с (i) нуклеотидами 1792-4374 из SEQ ID NO: 1, (ii) нуклеотидами 1792-4374 из SEQ ID NO: 2, (iii) нуклеотидами 1792-4374 из SEQ ID NO: 70 или (iv) нуклеотидами 1792-4374 из SEQ ID NO: 71; и где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII. В одном конкретном варианте осуществления вторая последовательность нуклеиновой кислоты содержит (i) нуклеотиды 1792-4374 из SEQ ID NO: 1, (ii) нуклеотиды 1792-4374 из SEQ ID NO: 2, (iii) нуклеотиды 1792-4374 из SEQ ID NO: 70 или (iv) нуклеотиды 1792-4374 из SEQ ID NO: 71. В некоторых вариантах осуществления кодон-оптимизированная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, которая содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где вторая последовательность нуклеиновой кислоты характеризуется по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с (i) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 1, (ii) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 2, (iii) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 70 или (iv) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 71 (т. е. нуклеотидами 1792-4374 из SEQ ID NO: 1, нуклеотидами 1792-4374 из SEQ ID NO: 2, нуклеотидами 1792-4374 из SEQ ID NO: 70 или нуклеотидами 1792-4374 из SEQ ID NO: 71 без нуклеотидов, кодирующих домен B или фрагмент домена B); и где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII. В одном варианте осуществления вторая последовательность нуклеиновой кислоты содержит (i) нуклеотиды 1792-2277 и 2320-4374 из SEQ ID NO: 1, (ii) нуклеотиды 1792-2277 и 2320-4374 из SEQ ID NO: 2, (iii) нуклеотиды 1792-2277 и 2320-4374 из SEQ ID NO: 70 или (iv) нуклеотиды 1792-2277 и 2320-4374 из SEQ ID NO: 71 (т. е. нуклеотиды 1792-4374 из SEQ ID NO: 1, нуклеотиды 1792-4374 из SEQ ID NO: 2, нуклеотиды 1792-4374 из SEQ ID NO: 70 или нуклеотиды 1792-4374 из SEQ ID NO: 71 без нуклеотидов, кодирующих домен B или фрагмент домена B).
[186] В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, кодирующую полипептид с активностью FVIII, где нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-4374 из SEQ ID NO: 1. В других вариантах осуществления нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-2277 и 2320-4374 из SEQ ID NO: 1 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 1 без нуклеотидов, кодирующих домен B или фрагмент домена B). В других вариантах осуществления последовательность нуклеиновой кислоты характеризуется по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с SEQ ID NO: 1. В других вариантах осуществления нуклеотидная последовательность содержит нуклеотиды 58-2277 и 2320-4374 из SEQ ID NO: 1 (т. е. нуклеотиды 58-4374 из SEQ ID NO: 1 без нуклеотидов, кодирующих домен B или фрагмент домена B) или нуклеотиды 58-4374 из SEQ ID NO: 1. В еще одних других вариантах осуществления нуклеотидная последовательность содержит нуклеотиды 1-2277 и 2320-4374 из SEQ ID NO: 1 (т. е. нуклеотиды 1-4374 из SEQ ID NO: 1 без нуклеотидов, кодирующих домен B или фрагмент домена B) или нуклеотиды 1-4374 из SEQ ID NO: 1.
[187] В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, кодирующую полипептид с активностью FVIII, где нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-4374 из SEQ ID NO: 2. В других вариантах осуществления нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-2277 и 2320-4374 из SEQ ID NO: 2. В других вариантах осуществления последовательность нуклеиновой кислоты характеризуется по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с SEQ ID NO: 2. В других вариантах осуществления нуклеотидная последовательность содержит нуклеотиды 58-2277 и 2320-4374 из SEQ ID NO: 2 (т. е. нуклеотиды 58-4374 из SEQ ID NO: 2 без нуклеотидов, кодирующих домен B или фрагмент домена B) или нуклеотиды 58-4374 из SEQ ID NO: 2. В еще одних других вариантах осуществления нуклеотидная последовательность содержит нуклеотиды 1-2277 и 2320-4374 из SEQ ID NO: 2 (т. е. нуклеотиды 1-4374 из SEQ ID NO: 2 без нуклеотидов, кодирующих домен B или фрагмент домена B) или нуклеотиды 1-4374 из SEQ ID NO: 2.
[188] В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, кодирующую полипептид с активностью FVIII, где нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-4374 из SEQ ID NO: 70. В других вариантах осуществления нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-2277 и 2320-4374 из SEQ ID NO: 70 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 70 без нуклеотидов, кодирующих домен B или фрагмент домена B). В других вариантах осуществления последовательность нуклеиновой кислоты характеризуется по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с SEQ ID NO: 70. В других вариантах осуществления нуклеотидная последовательность содержит нуклеотиды 58-2277 и 2320-4374 из SEQ ID NO: 70 (т. е. нуклеотиды 58-4374 из SEQ ID NO: 70 без нуклеотидов, кодирующих домен B или фрагмент домена B) или нуклеотиды 58-4374 из SEQ ID NO: 70. В еще одних других вариантах осуществления нуклеотидная последовательность содержит нуклеотиды 1-2277 и 2320-4374 из SEQ ID NO: 70 (т. е. нуклеотиды 1-4374 из SEQ ID NO: 70 без нуклеотидов, кодирующих домен B или фрагмент домена B) или нуклеотиды 1-4374 из SEQ ID NO: 70.
[189] В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, кодирующую полипептид с активностью FVIII, где нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-4374 из SEQ ID NO: 71. В других вариантах осуществления нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-2277 и 2320-4374 из SEQ ID NO: 71 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 71 без нуклеотидов, кодирующих домен B или фрагмент домена B). В других вариантах осуществления последовательность нуклеиновой кислоты характеризуется по меньшей мере 85%, по меньшей мере 86%, по меньшей мере 87%, по меньшей мере 88%, по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с SEQ ID NO: 71. В других вариантах осуществления нуклеотидная последовательность содержит нуклеотиды 58-2277 и 2320-4374 из SEQ ID NO: 71 (т. е. нуклеотиды 58-4374 из SEQ ID NO: 71 без нуклеотидов, кодирующих домен B или фрагмент домена B) или нуклеотиды 58-4374 из SEQ ID NO: 71. В еще одних других вариантах осуществления нуклеотидная последовательность содержит нуклеотиды 1-2277 и 2320-4374 из SEQ ID NO: 71 (т. е. нуклеотиды 1-4374 из SEQ ID NO: 71 без нуклеотидов, кодирующих домен B или фрагмент домена B) или нуклеотиды 1-4374 из SEQ ID NO: 71.
[190] В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, кодирующую полипептид с активностью FVIII, где нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-4374 из SEQ ID NO: 3. В других вариантах осуществления нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-2277 и 2320-4374 из SEQ ID NO: 3 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 3 без нуклеотидов, кодирующих домен B или фрагмент домена B). В определенных вариантах осуществления последовательность нуклеиновой кислоты характеризуется по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с SEQ ID NO: 3. В некоторых вариантах осуществления нуклеотидная последовательность содержит нуклеотиды 58-2277 и 2320-4374 из SEQ ID NO: 3 (т. е. нуклеотиды 58-4374 из SEQ ID NO: 3 без нуклеотидов, кодирующих домен B или фрагмент домена B) или нуклеотиды 58-4374 из SEQ ID NO: 3. В еще одних других вариантах осуществления нуклеотидная последовательность содержит нуклеотиды 58-2277 и 2320-4374 из SEQ ID NO: 3 (т. е. нуклеотиды 1-4374 из SEQ ID NO: 3 без нуклеотидов, кодирующих домен B или фрагмент домена B) или нуклеотиды 1-4374 из SEQ ID NO: 3.
[191] В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, кодирующую полипептид с активностью FVIII, где нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-4374 из SEQ ID NO: 4. В других вариантах осуществления нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-2277 и 2320-4374 из SEQ ID NO: 4 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 4 без нуклеотидов, кодирующих домен B или фрагмент домена B). В других вариантах осуществления последовательность нуклеиновой кислоты характеризуется по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с SEQ ID NO: 4. В других вариантах осуществления нуклеотидная последовательность содержит нуклеотиды 58-2277 и 2320-4374 из SEQ ID NO: 4 (т. е. нуклеотиды 58-4374 из SEQ ID NO: 4 без нуклеотидов, кодирующих домен B или фрагмент домена B) или нуклеотиды 58-4374 из SEQ ID NO: 4. В еще одних других вариантах осуществления нуклеотидная последовательность содержит нуклеотиды 1-2277 и 2320-4374 из SEQ ID NO: 4 (т. е. нуклеотиды 1-4374 из SEQ ID NO: 4 без нуклеотидов, кодирующих домен B или фрагмент домена B) или нуклеотиды 1-4374 из SEQ ID NO: 4.
[192] В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, кодирующую полипептид с активностью FVIII, где нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-4374 из SEQ ID NO: 5. В других вариантах осуществления нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-2277 и 2320-4374 из SEQ ID NO: 5 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 5 без нуклеотидов, кодирующих домен B или фрагмент домена B). В определенных вариантах осуществления последовательность нуклеиновой кислоты характеризуется по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с SEQ ID NO: 5. В некоторых вариантах осуществления нуклеотидная последовательность содержит нуклеотиды 58-2277 и 2320-4374 из SEQ ID NO: 5 (т. е. нуклеотиды 58-4374 из SEQ ID NO: 5 без нуклеотидов, кодирующих домен B или фрагмент домена B) или нуклеотиды 58-4374 из SEQ ID NO: 5. В еще одних других вариантах осуществления нуклеотидная последовательность содержит нуклеотиды 1-2277 и 2320-4374 из SEQ ID NO: 5 (т. е. нуклеотиды 1-4374 из SEQ ID NO: 5 без нуклеотидов, кодирующих домен B или фрагмент домена B) или нуклеотиды 1-4374 из SEQ ID NO: 5.
[193] В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, кодирующую полипептид с активностью FVIII, где нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-4374 из SEQ ID NO: 6. В других вариантах осуществления нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с нуклеотидами 58-2277 и 2320-4374 из SEQ ID NO: 6 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 6 без нуклеотидов, кодирующих домен B или фрагмент домена B). В определенных вариантах осуществления последовательность нуклеиновой кислоты характеризуется по меньшей мере 89%, по меньшей мере 90%, по меньшей мере 91%, по меньшей мере 92%, по меньшей мере 93%, по меньшей мере 94%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98% или по меньшей мере 99% идентичностью последовательности с SEQ ID NO: 6. В некоторых вариантах осуществления нуклеотидная последовательность содержит нуклеотиды 58-2277 и 2320-4374 из SEQ ID NO: 6 (т. е. нуклеотиды 58-4374 из SEQ ID NO: 6 без нуклеотидов, кодирующих домен B или фрагмент домена B) или нуклеотиды 58-4374 из SEQ ID NO: 6. В еще одних других вариантах осуществления нуклеотидная последовательность содержит нуклеотиды 1-2277 и 2320-4374 из SEQ ID NO: 6 (т. е. нуклеотиды 1-4374 из SEQ ID NO: 6 без нуклеотидов, кодирующих домен B или фрагмент домена B) или нуклеотиды 1-4374 из SEQ ID NO: 6.
[194] В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность по настоящему изобретению кодирует полипептид FVIII, содержащий последовательность нуклеиновой кислоты, кодирующую сигнальный пептид. В определенных вариантах осуществления сигнальный пептид представляет собой сигнальный пептид FVIII. В некоторых вариантах осуществления последовательность нуклеиновой кислоты, кодирующая сигнальный пептид, является кодон-оптимизированной. В одном конкретном варианте осуществления последовательность нуклеиновой кислоты, кодирующая сигнальный пептид, характеризуется по меньшей мере 60%, по меньшей мере 70%, по меньшей мере 80%, по меньшей мере 90%, по меньшей мере 95%, по меньшей мере 96%, по меньшей мере 97%, по меньшей мере 98, по меньшей мере 99% или по меньшей мере 100% идентичностью последовательности с (i) нуклеотидами 1-57 из SEQ ID NO: 1; (ii) нуклеотидами 1-57 из SEQ ID NO: 2; (iii) нуклеотидами 1-57 из SEQ ID NO: 3; (iv) нуклеотидами 1-57 из SEQ ID NO: 4; (v) нуклеотидами 1-57 из SEQ ID NO: 5; (vi) нуклеотидами 1-57 из SEQ ID NO: 6; (vii) нуклеотидами 1-57 из SEQ ID NO: 70; (viii) нуклеотидами 1-57 из SEQ ID NO: 71 или (ix) нуклеотидами 1-57 из SEQ ID NO: 68.
[195] SEQ ID NO: 1-6, 70 и 71 являются оптимизированными вариантами SEQ ID NO: 16, исходной, или "родительской", или "дикотипной" нуклеотидной последовательности FVIII. SEQ ID NO: 16 кодирует FVIII человека с удаленным доменом B. Хотя SEQ ID NO: 1-6, 70 и 71 получены из конкретной формы FVIII с удаленным доменом B (SEQ ID NO: 16), следует понимать, что настоящее изобретение также включает оптимизированные варианты нуклеиновых кислот, кодирующих другие варианты FVIII. Например, другие варианты FVIII могут включать полноразмерные FVIII, FVIII с другими делециями домена B (описанные в данном документе) или другие фрагменты FVIII, сохраняющие активность FVIII.
[196] В одном варианте осуществления генная кассета содержит конструкцию на основе FVIII, которая включает полинуклеотидную последовательность (6526 нуклеотидов), приведенную в таблицах 2A - 2C. В одном варианте осуществления генная кассета содержит конструкцию на основе FVIII, которая включает полинуклеотидную последовательность (6526 нуклеотидов), приведенную в таблице 2В.
[197] В определенных вариантах осуществления выделенная молекула нуклеиновой кислоты содержит нуклеотидную последовательность, характеризующуюся по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или приблизительно 100% идентичностью последовательности с нуклеотидной последовательностью под SEQ ID NO: 179 или 182, где выделенная молекула нуклеиновой кислоты сохраняет способность к экспрессии функционального белка FVIII.
Таблица 2A. Пример конструкции на основе FVIII (нуклеотиды 1-6526; SEQ ID NO: 110)
GGTCGCCCGGCCTCAGTGAGCGAGCGAGCGCGCAGAGAGGGAGTGGCCAACTCCATCACTAGGGGTTCCT -- 130
CTTAAGGTAGCCCCGGGACGCGTCAATTGAGATCTGGATCCGGTACCGAATTCGCGGCCGCCTCGACGACTAGCGTTTAATTAA -- 272
GCAAGGTTCATATTTGTGTAGGTTACTTATTCTCCTTTTGTTGACTAAGTCAATAATCAGAATCAGCAGGTTTGGAGTCAGCTTGGCAGGGATCAGCAGCCTGGGTTGGAAGGAGGGGGTATAAAAGCCCCTTCACCAGGAGAAGCCGTCACACAGATCCACAAGCTCCTG -- 501
TGCCTTGAATTACTGACACTGACATCCACTTTTTCTTTTTCTCCACAG --609
CCACTCGCCGGTACTACCTTGGAGCCGTGGAGCTTTCATGGGACTACATGCAGAGCGACCTGGGCGAACTCCCCGTGGATGCCAGATTCCCCCCCCGCGTGCCAAAGTCCTTCCCCTTTAACACCTCCGTGGTGTACAAGAAAACCCTCTTTGTCGAGTTCACTGACCACCTGTTCAACATCGCCAAGCCGCGCCCACCTTGGATGGGCCTCCTGGGACCGACCATTCAAGCTGAAGTGTACGACACCGTGGTGATCACCCTGAAGAACATGGCGTCCCACCCCGTGTCCCTGCATGCGGTCGGAGTGTCCTACTGGAAGGCCTCCGAAGGAGCTGAGTACGACGACCAGACTAGCCAGCGGGAAAAGGAGGACGATAAAGTGTTCCCGGGCGGCTCGCATACTTACGTGTGGCAAGTCCTGAAGGAAAACGGACCTATGGCATCCGATCCTCTGTGCCTGACTTACTCCTACCTTTCCCATGTGGACCTCGTGAAGGACCTGAACAGCGGGCTGATTGGTGCACTTCTCGTGTGCCGCGAAGGTTCGCTCGCTAAGGAAAAGACCCAGACCCTCCATAAGTTCATCCTTTTGTTCGCTGTGTTCGATGAAGGAAAGTCATGGCATTCCGAAACTAAGAACTCGCTGATGCAGGACCGGGATGCCGCCTCAGCCCGCGCCTGGCCTAAAATGCATACAGTCAACGGATACGTGAATCGGTCACTGCCCGGGCTCATCGGTTGTCACAGAAAGTCCGTGTACTGGCACGTCATCGGCATGGGCACTACGCCTGAAGTGCACTCCATCTTCCTGGAAGGGCACACCTTCCTCGTGCGCAACCACCGCCAGGCCTCTCTGGAAATCTCCCCGATTACCTTTCTGACCGCCCAGACTCTGCTCATGGACCTGGGGCAGTTCCTTCTCTTCTGCCACATCTCCAGCCATCAGCACGACGGAATGGAGGCCTACGTGAAGGTGGACTCATGCCCGGAAGAACCTCAGTTGCGGATGAAGAACAACGAGGAGGCCGAGGACTATGACGACGATTTGACTGACTCCGAGATGGACGTCGTGCGGTTCGATGACGACAACAGCCCCAGCTTCATCCAGATTCGCAGCGTGGCCAAGAAGCACCCCAAAACCTGGGTGCACTACATCGCGGCCGAGGAAGAAGATTGGGACTACGCCCCGTTGGTGCTGGCACCCGATGACCGGTCGTACAAGTCCCAGTATCTGAACAATGGTCCGCAGCGGATTGGCAGAAAGTACAAGAAAGTGCGGTTCATGGCGTACACTGACGAAACGTTTAAGACCCGGGAGGCCATTCAACATGAGAGCGGCATTCTGGGACCACTGCTGTACGGAGAGGTCGGCGATACCCTGCTCATCATCTTCAAAAACCAGGCCTCCCGGCCTTACAACATCTACCCTCACGGAATCACCGACGTGCGGCCACTCTACTCGCGGCGCCTGCCGAAGGGCGTCAAGCACCTGAAAGACTTCCCTATCCTGCCGGGCGAAATCTTCAAGTATAAGTGGACCGTCACCGTGGAGGACGGGCCCACCAAGAGCGATCCTAGGTGTCTGACTCGGTACTACTCCAGCTTCGTGAACATGGAACGGGACCTGGCATCGGGACTCATTGGACCGCTGCTGATCTGCTACAAAGAGTCGGTGGATCAACGCGGCAACCAGATCATGTCCGACAAGCGCAACGTGATCCTGTTCTCCGTGTTTGATGAAAACAGATCCTGGTACCTCACTGAAAACATCCAGAGGTTCCTCCCAAACCCCGCAGGAGTGCAACTGGAGGACCCTGAGTTTCAGGCCTCGAATATCATGCACTCGATTAACGGTTACGTGTTCGACTCGCTGCAACTGAGCGTGTGCCTCCATGAAGTCGCTTACTGGTACATTCTGTCCATCGGCGCCCAGACTGACTTCCTGAGCGTGTTCTTTTCCGGTTACACCTTTAAGCACAAGATGGTGTACGAAGATACCCTGACCCTGTTCCCTTTCTCCGGCGAAACGGTGTTCATGTCGATGGAGAACCCGGGTCTGTGGATTCTGGGATGCCACAACAGCGACTTTCGGAACCGCGGAATGACTGCCCTGCTGAAGGTGTCCTCATGCGACAAGAACACCGGAGACTACTACGAGGACTCCTACGAGGATATCTCAGCCTACCTCCTGTCCAAGAACAACGCGATCGAGCCGCGCAGCTTCAGCCAGAACGGCGCGCCAACATCAGAGAGCGCCACCCCTGAAAGTGGTCCCGGGAGCGAGCCAGCCACATCTGGGTCGGAAACGCCAGGCACAAGTGAGTCTGCAACTCCCGAGTCCGGACCTGGCTCCGAGCCTGCCACTAGCGGCTCCGAGACTCCGGGAACTTCCGAGAGCGCTACACCAGAAAGCGGACCCGGAACCAGTACCGAACCTAGCGAGGGCTCTGCTCCGGGCAGCCCAGCCGGCTCTCCTACATCCACGGAGGAGGGCACTTCCGAATCCGCCACCCCGGAGTCAGGGCCAGGATCTGAACCCGCTACCTCAGGCAGTGAGACGCCAGGAACGAGCGAGTCCGCTACACCGGAGAGTGGGCCAGGGAGCCCTGCTGGATCTCCTACGTCCACTGAGGAAGGGTCACCAGCGGGCTCGCCCACCAGCACTGAAGAAGGTGCCTCGAGCCCGCCTGTGCTGAAGAGGCACCAGCGAGAAATTACCCGGACCACCCTCCAATCGGATCAGGAGGAAATCGACTACGACGACACCATCTCGGTGGAAATGAAGAAGGAAGATTTCGATATCTACGACGAGGACGAAAATCAGTCCCCTCGCTCATTCCAAAAGAAAACTAGACACTACTTTATCGCCGCGGTGGAAAGACTGTGGGACTATGGAATGTCATCCAGCCCTCACGTCCTTCGGAACCGGGCCCAGAGCGGATCGGTGCCTCAGTTCAAGAAAGTGGTGTTCCAGGAGTTCACCGACGGCAGCTTCACCCAGCCGCTGTACCGGGGAGAACTGAACGAACACCTGGGCCTGCTCGGTCCCTACATCCGCGCGGAAGTGGAGGATAACATCATGGTGACCTTCCGTAACCAAGCATCCAGACCTTACTCCTTCTATTCCTCCCTGATCTCATACGAGGAGGACCAGCGCCAAGGCGCCGAGCCCCGCAAGAACTTCGTCAAGCCCAACGAGACTAAGACCTACTTCTGGAAGGTCCAACACCATATGGCCCCGACCAAGGATGAGTTTGACTGCAAGGCCTGGGCCTACTTCTCCGACGTGGACCTTGAGAAGGATGTCCATTCCGGCCTGATCGGGCCGCTGCTCGTGTGTCACACCAACACCCTGAACCCAGCGCATGGACGCCAGGTCACCGTCCAGGAGTTTGCTCTGTTCTTCACCATTTTTGACGAAACTAAGTCCTGGTACTTCACCGAGAATATGGAGCGAAACTGTAGAGCGCCCTGCAATATCCAGATGGAAGATCCGACTTTCAAGGAGAACTATAGATTCCACGCCATCAACGGGTACATCATGGATACTCTGCCGGGGCTGGTCATGGCCCAGGATCAGAGGATTCGGTGGTACTTGCTGTCAATGGGATCGAACGAAAACATTCACTCCATTCACTTCTCCGGTCACGTGTTCACTGTGCGCAAGAAGGAGGAGTACAAGATGGCGCTGTACAATCTGTACCCCGGGGTGTTCGAAACTGTGGAGATGCTGCCGTCCAAGGCCGGCATCTGGAGAGTGGAGTGCCTGATCGGAGAGCACCTCCACGCGGGGATGTCCACCCTCTTCCTGGTGTACTCGAATAAGTGCCAGACCCCGCTGGGCATGGCCTCGGGCCACATCAGAGACTTCCAGATCACAGCAAGCGGACAATACGGCCAATGGGCGCCGAAGCTGGCCCGCTTGCACTACTCCGGATCGATCAACGCATGGTCCACCAAGGAACCGTTCTCGTGGATTAAGGTGGACCTCCTGGCCCCTATGATTATCCACGGAATTAAGACCCAGGGCGCCAGGCAGAAGTTCTCCTCCCTGTACATCTCGCAATTCATCATCATGTACAGCCTGGACGGGAAGAAGTGGCAGACTTACAGGGGAAACTCCACCGGCACCCTGATGGTCTTTTTCGGCAACGTGGATTCCTCCGGCATTAAGCACAACATCTTCAACCCACCGATCATAGCCAGATATATTAGGCTCCACCCCACTCACTACTCAATCCGCTCAACTCTTCGGATGGAACTCATGGGGTGCGACCTGAACTCCTGCTCCATGCCGTTGGGGATGGAATCAAAGGCTATTAGCGACGCCCAGATCACCGCGAGCTCCTACTTCACTAACATGTTCGCCACCTGGAGCCCCTCCAAGGCCAGGCTGCACTTGCAGGGACGGTCAAATGCCTGGCGGCCGCAAGTGAACAATCCGAAGGAATGGCTTCAAGTGGATTTCCAAAAGACCATGAAAGTGACCGGAGTCACCACCCAGGGAGTGAAGTCCCTTCTGACCTCGATGTATGTGAAGGAGTTCCTGATTAGCAGCAGCCAGGACGGGCACCAGTGGACCCTGTTCTTCCAAAACGGAAAGGTCAAGGTGTTCCAGGGGAACCAGGACTCGTTCACACCCGTGGTGAACTCCCTGGACCCCCCACTGCTGACGCGGTACTTGAGGATTCATCCTCAGTCCTGGGTCCATCAGATTGCATTGCGAATGGAAGTCCTGGGCTGCGAGGCCCAGGACCTGTACTGA -- 5444
TGTTGCTCCTTTTACGCTATGTGGATACGCTGCTTTAATGCCTTTGTATCATGCTATTGCTTCCCGTATGGCTTTCATTTTCTCCTCCTTGTATAAATCCTGGTTGCTGTCTCTTTATGAGGAGTTGTGGCCCGTTGTCAGGCAACGTGGCGTGGTGTGCACTGTGTTTGCTGACGCAACCCCCACTGGTTGGGGCATTGCCACCACCTGTCAGCTCCTTTCCGGGACTTTCGCTTTCCCCCTCCCTATTGCCACGGCGGAACTCATCGCCGCCTGCCTTGCCCGCTGCTGGACAGGGGCTCGGCTGTTGGGCACTGACAATTCCGTGGTGTTGTCGGGGAAATCATCGTCCTTTCCTTGGCTGCTCGCCTGTGTTGCCACCTGGATTCTGCGCGGGACGTCCTTCTGCTACGTCCCTTCGGCCCTCAATCCAGCGGACCTTCCTTCCCGCGGCCTGCTGCCGGCTCTGCGGCCTCTTCCGCGTCTTCGCCTTCGCCCTCAGACGAGTCGGATCTCCCTTTGGGCCGCCTCCCCGCTG -- 6058
TGACCCTGGAAGGTGCCACTCCCACTGTCCTTTCCTAATAAAATGAGGAAATTGCATCGCATTGTCTGAGTAGGTGTCATTCTATTCTGGGGGGTGGGGTGGGGCAGGACAGCAAGGGGGAGGATTGGGAAGACAATAGCAGGCATGCTGGGGA --6277
ATCCTCTCTTAAGGTAGCATCGAGATTTAAATTAGGGATAACAGGGTAATGGCGCGGGCCGC -- 6396
AGGCCGGGCGACCAAAGGTCGCCCGACGCCCGGGCTTTGCCCGGGCGGCCTCAGTGAGCGAGCGAGCGCGCAG -- 6526
Таблица 2B. Пример конструкции B19-FVIII (нуклеотиды 1-6762; SEQ ID NO: 179)
Таблица 2C. Пример конструкции GPV-FVIII (нуклеотиды 1-6830; SEQ ID NO: 182)
A. Индекс адаптации кодонов
[198] В одном варианте осуществления генная кассета содержит кодон-оптимизированную нуклеотидную последовательность, кодирующую полипептид FVIII, где индекс адаптации кодонов человека для кодон-оптимизированной нуклеотидной последовательности повышен по сравнению с SEQ ID NO: 16. Например, кодон-оптимизированная нуклеотидная последовательность может характеризоваться индексом адаптации кодонов человека, составляющим по меньшей мере приблизительно 0,75 (75%), по меньшей мере приблизительно 0,76 (76%), по меньшей мере приблизительно 0,77 (77%), по меньшей мере приблизительно 0,78 (78%), по меньшей мере приблизительно 0,79 (79%), по меньшей мере приблизительно 0,80 (80%), по меньшей мере приблизительно 0,81 (81%), по меньшей мере приблизительно 0,82 (82%), по меньшей мере приблизительно 0,83 (83%), по меньшей мере приблизительно 0,84 (84%), по меньшей мере приблизительно 0,85 (85%), по меньшей мере приблизительно 0,86 (86%), по меньшей мере приблизительно 0,87 (87%), по меньшей мере приблизительно 0,88 (88%), по меньшей мере приблизительно 0,89 (89%), по меньшей мере приблизительно 0,90 (90%), по меньшей мере приблизительно 0,91 (91%), по меньшей мере приблизительно 0,92 (92%), по меньшей мере приблизительно 0,93 (93%), по меньшей мере приблизительно 0,94 (94%), по меньшей мере приблизительно 0,95 (95%), по меньшей мере приблизительно 0,96 (96%), по меньшей мере приблизительно 0,97 (97%), по меньшей мере приблизительно 0,98 (98%) или по меньшей мере приблизительно 0,99 (99%). В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность характеризуется индексом адаптации кодонов человека, который составляет по меньшей мере приблизительно 0,88 (88%). В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность характеризуется индексом адаптации кодонов человека, который составляет по меньшей мере приблизительно 0,91 (91%). В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность характеризуется индексом адаптации кодонов человека, который составляет по меньшей мере приблизительно 0,91 (97%).
[199] В одном конкретном варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, которая содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где первая последовательность нуклеиновой кислоты характеризуется по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-1791 из SEQ ID NO: 3; (ii) нуклеотидами 1-1791 из SEQ ID NO: 3; (iii) нуклеотидами 58-1791 из SEQ ID NO: 4 или (iv) нуклеотидами 1-1791 из SEQ ID NO: 4; где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII; и где индекс адаптации кодонов человека для нуклеотидной последовательности повышен по сравнению с SEQ ID NO: 16. В некоторых вариантах осуществления нуклеотидная последовательность характеризуется индексом адаптации кодонов человека, составляющим по меньшей мере приблизительно 0,75 (75%), по меньшей мере приблизительно 0,76 (76%), по меньшей мере приблизительно 0,77 (77%), по меньшей мере приблизительно 0,78 (78%), по меньшей мере приблизительно 0,79 (79%), по меньшей мере приблизительно 0,80 (80%), по меньшей мере приблизительно 0,81 (81%), по меньшей мере приблизительно 0,82 (82%), по меньшей мере приблизительно 0,83 (83%), по меньшей мере приблизительно 0,84 (84%), по меньшей мере приблизительно 0,85 (85%), по меньшей мере приблизительно 0,86 (86%), по меньшей мере приблизительно 0,87 (87%), по меньшей мере приблизительно 0,88 (88%), по меньшей мере приблизительно 0,89 (89%), по меньшей мере приблизительно 0,90 (90%) или по меньшей мере приблизительно 0,91 (91%). В одном конкретном варианте осуществления нуклеотидная последовательность характеризуется индексом адаптации кодонов человека, который составляет по меньшей мере приблизительно 0,88 (88%). В другом варианте осуществления нуклеотидная последовательность характеризуется индексом адаптации кодонов человека, который составляет по меньшей мере приблизительно 0,91 (91%).
[200] В другом варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, которая содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где вторая последовательность нуклеиновой кислоты характеризуется по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 5 или (ii) 1792-2277 и 2320-4374 из SEQ ID NO: 6; где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII; и где индекс адаптации кодонов человека для нуклеотидной последовательности повышен по сравнению с SEQ ID NO: 16. В некоторых вариантах осуществления нуклеотидная последовательность характеризуется индексом адаптации кодонов человека, составляющим по меньшей мере приблизительно 0,75 (75%), по меньшей мере приблизительно 0,76 (76%), по меньшей мере приблизительно 0,77 (77%), по меньшей мере приблизительно 0,78 (78%), по меньшей мере приблизительно 0,79 (79%), по меньшей мере приблизительно 0,80 (80%), по меньшей мере приблизительно 0,81 (81%), по меньшей мере приблизительно 0,82 (82%), по меньшей мере приблизительно 0,83 (83%), по меньшей мере приблизительно 0,84 (84%), по меньшей мере приблизительно 0,85 (85%), по меньшей мере приблизительно 0,86 (86%), по меньшей мере приблизительно 0,87 (87%) или по меньшей мере приблизительно 0,88 (88%). В одном конкретном варианте осуществления нуклеотидная последовательность характеризуется индексом адаптации кодонов человека, который составляет по меньшей мере приблизительно 0,83 (83%). В другом варианте осуществления нуклеотидная последовательность характеризуется индексом адаптации кодонов человека, который составляет по меньшей мере приблизительно 0,88 (88%).
[201] В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит нуклеотидную последовательность, кодирующую полипептид с активностью FVIII, где нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с нуклеотидами 58-2277 и 2320-4374 из аминокислотной последовательности, выбранной из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 и 71 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 или 71 без нуклеотидов, кодирующих домен B или фрагмент домена B); и где индекс адаптации кодонов человека для нуклеотидной последовательности повышен по сравнению с SEQ ID NO: 16. В некоторых вариантах осуществления нуклеотидная последовательность характеризуется индексом адаптации кодонов человека, составляющим по меньшей мере приблизительно 0,75 (75%), по меньшей мере приблизительно 0,76 (76%), по меньшей мере приблизительно 0,77 (77%), по меньшей мере приблизительно 0,78 (78%), по меньшей мере приблизительно 0,79 (79%), по меньшей мере приблизительно 0,80 (80%), по меньшей мере приблизительно 0,81 (81%), по меньшей мере приблизительно 0,82 (82%), по меньшей мере приблизительно 0,83 (83%), по меньшей мере приблизительно 0,84 (84%), по меньшей мере приблизительно 0,85 (85%), по меньшей мере приблизительно 0,86 (86%), по меньшей мере приблизительно 0,87 (87%) или по меньшей мере приблизительно 0,88 (88%). В одном конкретном варианте осуществления нуклеотидная последовательность характеризуется индексом адаптации кодонов человека, который составляет по меньшей мере приблизительно 0,75 (75%). В другом варианте осуществления нуклеотидная последовательность характеризуется индексом адаптации кодонов человека, который составляет по меньшей мере приблизительно 0,83 (83%). В другом варианте осуществления нуклеотидная последовательность характеризуется индексом адаптации кодонов человека, который составляет по меньшей мере приблизительно 0,88 (88%). В другом варианте осуществления нуклеотидная последовательность характеризуется индексом адаптации кодонов человека, который составляет по меньшей мере приблизительно 0,91 (91%). В другом варианте осуществления нуклеотидная последовательность характеризуется индексом адаптации кодонов человека, который составляет по меньшей мере приблизительно 0,97 (97%).
[202] В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII по настоящему изобретению, характеризуется повышенной частотой используемости оптимальных кодонов (FOP) по сравнению с SEQ ID NO: 16. В определенных вариантах осуществления FOP для кодон-оптимизированной нуклеотидной последовательности, кодирующей полипептид FVIII, составляет по меньшей мере приблизительно 40, по меньшей мере приблизительно 45, по меньшей мере приблизительно 50, по меньшей мере приблизительно 55, по меньшей мере приблизительно 60, по меньшей мере приблизительно 64, по меньшей мере приблизительно 65, по меньшей мере приблизительно 70, по меньшей мере приблизительно 75, по меньшей мере приблизительно 79, по меньшей мере приблизительно 80, по меньшей мере приблизительно 85 или по меньшей мере приблизительно 90.
[203] В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII по настоящему изобретению, характеризуется повышенной относительной частотой используемости синонимичных кодонов (RCSU) по сравнению с SEQ ID NO: 16. В некоторых вариантах осуществления RCSU для выделенной молекулы нуклеиновой кислоты составляет более 1,5. В других вариантах осуществления RCSU для выделенной молекулы нуклеиновой кислоты составляет более 2,0. В определенных вариантах осуществления RCSU для выделенной молекулы нуклеиновой кислоты составляет по меньшей мере приблизительно 1,5, по меньшей мере приблизительно 1,6, по меньшей мере приблизительно 1,7, по меньшей мере приблизительно 1,8, по меньшей мере приблизительно 1,9, по меньшей мере приблизительно 2,0, по меньшей мере приблизительно 2,1, по меньшей мере приблизительно 2,2, по меньшей мере приблизительно 2,3, по меньшей мере приблизительно 2,4, по меньшей мере приблизительно 2,5, по меньшей мере приблизительно 2,6 или по меньшей мере приблизительно 2,7.
[204] В еще одних других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII по настоящему изобретению, характеризуется повышенным эффективным количеством кодонов по сравнению с SEQ ID NO: 16. В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, характеризуется эффективным количеством кодонов, составляющим менее приблизительно 50, менее приблизительно 45, менее приблизительно 40, менее приблизительно 35, менее приблизительно 30 или менее приблизительно 25. В одном конкретном варианте осуществления выделенная молекула нуклеиновой кислоты характеризуется эффективным количеством кодонов, составляющим приблизительно 40, приблизительно 35, приблизительно 30, приблизительно 25 или приблизительно 20.
B. Оптимизация содержания G/C
[205] В некоторых вариантах осуществления генная кассета содержит кодон-оптимизированную нуклеотидную последовательность, кодирующий полипептид FVIII, где кодон-оптимизированная нуклеотидная последовательность содержит более высокую процентную долю G/C нуклеотидов по сравнению с процентной долей G/C нуклеотидов в SEQ ID NO: 16. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, характеризуется содержанием G/C, составляющим по меньшей мере приблизительно 45%, по меньшей мере приблизительно 46%, по меньшей мере приблизительно 47%, по меньшей мере приблизительно 48%, по меньшей мере приблизительно 49%, по меньшей мере приблизительно 50%, по меньшей мере приблизительно 51%, по меньшей мере приблизительно 52%, по меньшей мере приблизительно 53%, по меньшей мере приблизительно 54%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 56%, по меньшей мере приблизительно 57%, по меньшей мере приблизительно 58%, по меньшей мере приблизительно 59% или по меньшей мере приблизительно 60%.
[206] В одном конкретном варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где первая последовательность нуклеиновой кислоты характеризуется по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-1791 из SEQ ID NO: 3; (ii) нуклеотидами 1-1791 из SEQ ID NO: 3; (iii) нуклеотидами 58-1791 из SEQ ID NO: 4 или (iv) нуклеотидами 1-1791 из SEQ ID NO: 4; где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII; и где нуклеотидная последовательность содержит более высокую процентную долю G/C нуклеотидов по сравнению с процентной долей G/C нуклеотидов в SEQ ID NO: 16. В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, характеризуется содержанием G/C, составляющим по меньшей мере приблизительно 45%, по меньшей мере приблизительно 46%, по меньшей мере приблизительно 47%, по меньшей мере приблизительно 48%, по меньшей мере приблизительно 49%, по меньшей мере приблизительно 50%, по меньшей мере приблизительно 51%, по меньшей мере приблизительно 52%, по меньшей мере приблизительно 53%, по меньшей мере приблизительно 54%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 56%, по меньшей мере приблизительно 57% или по меньшей мере приблизительно 58%. В одном конкретном варианте осуществления нуклеотидная последовательность, которая кодирует полипептид с активностью FVIII, характеризуется содержанием G/C, составляющим по меньшей мере приблизительно 58%.
[207] В другом варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где вторая последовательность нуклеиновой кислоты характеризуется по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 1792-4374 из SEQ ID NO: 5; (ii) нуклеотидами 1792-4374 из SEQ ID NO: 6, (iii) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 5 (т. е. нуклеотидами 1792-4374 из SEQ ID NO: 5 без нуклеотидов, кодирующих домен B или фрагмент домена B) или (iv) 1792-2277 и 2320-4374 из SEQ ID NO: 6 (т. е. нуклеотидами 1792-4374 из SEQ ID NO: 6 без нуклеотидов, кодирующих домен В или фрагмент домена В); где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII; и где кодон-оптимизированная нуклеотидная последовательность содержит более высокую процентную долю G/C нуклеотидов по сравнению с процентной долей G/C нуклеотидов в SEQ ID NO: 16. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, характеризуется содержанием G/C, составляющим по меньшей мере приблизительно 45%, по меньшей мере приблизительно 46%, по меньшей мере приблизительно 47%, по меньшей мере приблизительно 48%, по меньшей мере приблизительно 49%, по меньшей мере приблизительно 50%, по меньшей мере приблизительно 51%, по меньшей мере приблизительно 52%, по меньшей мере приблизительно 53%, по меньшей мере приблизительно 54%, по меньшей мере приблизительно 55%, по меньшей мере приблизительно 56% или по меньшей мере приблизительно 57%. В одном конкретном варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, характеризуется содержанием G/C, составляющим по меньшей мере приблизительно 52%. В другом варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, характеризуется содержанием G/C, составляющим по меньшей мере приблизительно 55%. В другом варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, характеризуется содержанием G/C, составляющим по меньшей мере приблизительно 57%.
[208] В других вариантах осуществления генная кассета содержит кодон-оптимизированную нуклеотидную последовательность, кодирующую полипептид FVIII, где кодон-оптимизированная нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-4374 или (ii) нуклеотидами 58-2277 и 2320-4374 из аминокислотной последовательности, выбранной из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 и 71 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 или 71 без нуклеотидов, кодирующих домен B или фрагмент домена B); и где нуклеотидная последовательность содержит более высокую процентную долю G/C нуклеотидов по сравнению с процентной долей G/C нуклеотидов в SEQ ID NO: 16. В другом варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, характеризуется содержанием G/C, составляющим по меньшей мере приблизительно 45%. В одном конкретном варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, характеризуется содержанием G/C, составляющим по меньшей мере приблизительно 52%. В другом варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, характеризуется содержанием G/C, составляющим по меньшей мере приблизительно 55%. В другом варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, характеризуется содержанием G/C, составляющим по меньшей мере приблизительно 57%. В другом варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, характеризуется содержанием G/C, составляющим по меньшей мере приблизительно 58%. В еще одном варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, характеризуется содержанием G/C, составляющим по меньшей мере приблизительно 60%.
[209] "Содержание G/C" (или содержание гуанина-цитозина) или "процентная доля G/C нуклеотидов" относится к процентной доле азотистых оснований в молекуле ДНК, которые представляют собой либо гуанин, либо цитозин. Содержание G/C можно рассчитать с использованием следующей формулы:
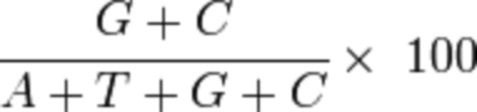 (III).
(III).
[210] Гены человека в значительной степени являются неоднородными по содержанию в них G/C, при этом некоторые гены характеризуются содержанием G/C, составляющим всего лишь 20%, а другие гены характеризуются содержанием G/C, составляющим вплоть до 95%. В целом гены, богатые G/C, имеют более высокий уровень экспрессии. В действительности было продемонстрировано, что повышение содержания G/C в гене может привести к повышенной экспрессии данного гена, главным образом из-за повышения транскрипции и более высоких уровней mRNA в состоянии равновесия. См. Kudla et al., PLoS Biol., 4(6): e180 (2006).
C. Последовательности, подобные области прикрепления к матриксу
[211] В некоторых вариантах осуществления генная кассета содержит кодон-оптимизированную нуклеотидную последовательность, кодирующую полипептид FVIII, где кодон-оптимизированная нуклеотидная последовательность содержит меньше последовательностей MARS/ARS по сравнению с SEQ ID NO: 16. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 6, не более 5, не более 4, не более 3 или не более 2 последовательностей MARS/ARS. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 1 последовательности MARS/ARS. В еще одних вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, не содержит последовательности MARS/ARS.
[212] В одном конкретном варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где первая последовательность нуклеиновой кислоты характеризуется по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-1791 из SEQ ID NO: 3; (ii) нуклеотидами 1-1791 из SEQ ID NO: 3; (iii) нуклеотидами 58-1791 из SEQ ID NO: 4 или (iv) нуклеотидами 1-1791 из SEQ ID NO: 4; где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII; и где кодон-оптимизированная нуклеотидная последовательность содержит меньше последовательностей MARS/ARS по сравнению с SEQ ID NO: 16. В других вариантах осуществления нуклеотидная последовательность, кодирующая полипептид с активностью FVIII, содержит не более 6, не более 5, не более 4, не более 3 или не более 2 последовательностей MARS/ARS. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 1 последовательности MARS/ARS. В еще одних вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, не содержит последовательности MARS/ARS.
[213] В другом варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где вторая последовательность нуклеиновой кислоты характеризуется по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 1792-4374 из SEQ ID NO: 5; (ii) нуклеотидами 1792-4374 из SEQ ID NO: 6, (iii) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 5 (т. е. нуклеотидами 1792-4374 из SEQ ID NO: 5 без нуклеотидов, кодирующих домен B или фрагмент домена B) или (iv) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 6 (т. е. нуклеотидами 1792-4374 из SEQ ID NO: 6 без нуклеотидов, кодирующих домен В или фрагмент домена В); где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII; и где кодон-оптимизированная нуклеотидная последовательность содержит меньше последовательностей MARS/ARS по сравнению с SEQ ID NO: 16. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 6, не более 5, не более 4, не более 3 или не более 2 последовательностей MARS/ARS. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 1 последовательности MARS/ARS. В еще одних вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, не содержит последовательности MARS/ARS.
[214] В других вариантах осуществления генная кассета содержит кодон-оптимизированную нуклеотидную последовательность, кодирующую полипептид FVIII, где кодон-оптимизированная нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-4374 из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 или 71 или (ii) нуклеотидами 58-2277 и 2320-4374 из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 или 71 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 или 71 без нуклеотидов, кодирующих домен B или фрагмент домена B); и где кодон-оптимизированная нуклеотидная последовательность содержит меньше последовательностей MARS/ARS по сравнению с SEQ ID NO: 16. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 6, не более 5, не более 4, не более 3 или не более 2 последовательностей MARS/ARS. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 1 последовательности MARS/ARS. В еще одних вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, не содержит последовательности MARS/ARS.
[215] Были идентифицированы богатые AT элементы в нуклеотидной последовательности FVIII человека, которая обладает сходством последовательности с автономно реплицирующимися последовательностями (ARS) и областями прикрепления к матриксу (MAR) Saccharomyces cerevisiae. (Fallux et al., Mol. Cell. Biol. 16:4264-4272 (1996). Один из данных элементов продемонстрировал связывание с ядерными факторами in vitro и подавление экспрессии репортерного гена хлорамфеникол-ацетилтрансферазы (CAT). Id. Было сделано предположение, что такие последовательности могут способствовать подавлению транскрипции гена FVIII человека. Таким образом, в одном варианте осуществления все последовательности MAR/ARS удалены в кодон-оптимизированной нуклеотидной последовательности, кодирующей полипептид FVIII по настоящему изобретению. Существует четыре последовательности MAR/ARS ATATTT (SEQ ID NO: 21) и три последовательности MAR/ARS AAATAT (SEQ ID NO: 22) в родительской последовательности FVIII (SEQ ID NO: 16). Все данные сайта подвергали мутации с разрушением последовательностей MAR/ARS в оптимизированных последовательностях FVIII (SEQ ID NO: 1-6). Местоположение каждого из данных элементов и последовательность соответствующих нуклеотидов в оптимизированных последовательностях показаны в таблице 3 ниже.
Таблица 3. Краткое описание изменений в репрессирующих элементах
NO: 16)
NO: 2
NO: 3
NO: 4
NO: 5
NO: 6
NO: 70
NO: 71
D. Дестабилизирующие последовательности
[216] В некоторых вариантах осуществления генная кассета содержит кодон-оптимизированную нуклеотидную последовательность, кодирующую полипептид FVIII, где кодон-оптимизированная нуклеотидная последовательность содержит меньше дестабилизирующих элементов по сравнению с SEQ ID NO: 16. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 9, не более 8, не более 7, не более 6 или не более 5 дестабилизирующих элементов. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 4, не более 3, не более 2 или не более 1 дестабилизирующего элемента. В еще одних вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, не содержит дестабилизирующего элемента.
[217] В одном конкретном варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где первая последовательность нуклеиновой кислоты характеризуется по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-1791 из SEQ ID NO: 3; (ii) нуклеотидами 1-1791 из SEQ ID NO: 3; (iii) нуклеотидами 58-1791 из SEQ ID NO: 4 или (iv) нуклеотидами 1-1791 из SEQ ID NO: 4; где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII; и где кодон-оптимизированная нуклеотидная последовательность содержит меньше дестабилизирующих элементов по сравнению с SEQ ID NO: 16. В других вариантах осуществления нуклеотидная последовательность, кодирующая полипептид с активностью FVIII, содержит не более 9, не более 8, не более 7, не более 6 или не более 5 дестабилизирующих элементов. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 4, не более 3, не более 2 или не более 1 дестабилизирующего элемента. В еще одних вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, не содержит дестабилизирующего элемента.
[218] В другом варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где вторая последовательность нуклеиновой кислоты характеризуется по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 1792-4374 из SEQ ID NO: 5; (ii) нуклеотидами 1792-4374 из SEQ ID NO: 6; (iii) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 5 (т. е. нуклеотидами 1792-4374 из SEQ ID NO: 5 без нуклеотидов, кодирующих домен B или фрагмент домена B) или (iv) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 6 (т. е. нуклеотидами 1792-4374 из SEQ ID NO: 6 без нуклеотидов, кодирующих домен В или фрагмент домена В); где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII; и где кодон-оптимизированная нуклеотидная последовательность содержит меньше дестабилизирующих элементов по сравнению с SEQ ID NO: 16. В других вариантах осуществления нуклеотидная последовательность, кодирующая полипептид с активностью FVIII, содержит не более 9, не более 8, не более 7, не более 6 или не более 5 дестабилизирующих элементов. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 4, не более 3, не более 2 или не более 1 дестабилизирующего элемента. В еще одних вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, не содержит дестабилизирующего элемента.
[219] В других вариантах осуществления генная кассета содержит кодон-оптимизированную нуклеотидную последовательность, кодирующую полипептид FVIII, где кодон-оптимизированная нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-4374 из аминокислотной последовательности, выбранной из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 и 71, или (ii) нуклеотидами 58-2277 и 2320-4374 из аминокислотной последовательности, выбранной из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 и 71 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 или 71 без нуклеотидов, кодирующих домен B или фрагмент домена B); и где кодон-оптимизированная нуклеотидная последовательность содержит меньше дестабилизирующих элементов по сравнению с SEQ ID NO: 16. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 9, не более 8, не более 7, не более 6 или не более 5 дестабилизирующих элементов. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 4, не более 3, не более 2 или не более 1 дестабилизирующего элемента. В еще одних вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, не содержит дестабилизирующего элемента.
[220] Существует десять дестабилизирующих элементов в родительской последовательности FVIII (SEQ ID NO: 16): шесть последовательностей ATTTA (SEQ ID NO: 23) и четыре последовательности TAAAT (SEQ ID NO: 24). В одном варианте осуществления последовательности данных сайтов подвергали мутации с целью разрушения дестабилизирующих элементов в оптимизированных FVIII SEQ ID NO: 1-6, 70 и 71. Местоположение каждого из данных элементов и последовательность соответствующих нуклеотидов в оптимизированных последовательностях показаны в таблице 3.
Е. Потенциальные сайты связывания промотора
[221] В некоторых вариантах осуществления генная кассета содержит кодон-оптимизированную нуклеотидную последовательность, кодирующую полипептид FVIII, где нуклеотидная последовательность содержит меньше потенциальных сайтов связывания промотора по сравнению с SEQ ID NO: 16. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 9, не более 8, не более 7, не более 6 или не более 5 потенциальных сайтов связывания промотора. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 4, не более 3, не более 2 или не более 1 потенциального сайта связывания промотора. В еще одних вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, не содержит потенциального сайта связывания промотора.
[222] В одном конкретном варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где первая последовательность нуклеиновой кислоты характеризуется по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-1791 из SEQ ID NO: 3; (ii) нуклеотидами 1-1791 из SEQ ID NO: 3; (iii) нуклеотидами 58-1791 из SEQ ID NO: 4 или (iv) нуклеотидами 1-1791 из SEQ ID NO: 4; где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII; и где кодон-оптимизированная нуклеотидная последовательность содержит меньше потенциальных сайтов связывания промотора по сравнению с SEQ ID NO: 16. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 9, не более 8, не более 7, не более 6 или не более 5 потенциальных сайтов связывания промотора. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 4, не более 3, не более 2 или не более 1 потенциального сайта связывания промотора. В еще одних вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, не содержит потенциального сайта связывания промотора.
[223] В другом варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где вторая последовательность нуклеиновой кислоты характеризуется по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 1792-4374 из SEQ ID NO: 5; (ii) нуклеотидами 1792-4374 из SEQ ID NO: 6; (iii) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 5 (т. е. нуклеотидами 1792-4374 из SEQ ID NO: 5 без нуклеотидов, кодирующих домен B или фрагмент домена B) или (iv) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 6 (т. е. нуклеотидами 1792-4374 из SEQ ID NO: 6 без нуклеотидов, кодирующих домен В или фрагмент домена В); где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII; и где кодон-оптимизированная нуклеотидная последовательность содержит меньше потенциальных сайтов связывания промотора по сравнению с SEQ ID NO: 16. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 9, не более 8, не более 7, не более 6 или не более 5 потенциальных сайтов связывания промотора. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 4, не более 3, не более 2 или не более 1 потенциального сайта связывания промотора. В еще одних вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, не содержит потенциального сайта связывания промотора.
[224] В других вариантах осуществления генная кассета содержит кодон-оптимизированную нуклеотидную последовательность, кодирующую полипептид FVIII, где нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-4374 из аминокислотной последовательности, выбранной из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 и 71, или (ii) нуклеотидами 58-2277 и 2320-4374 из аминокислотной последовательности, выбранной из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 и 71 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 или 71 без нуклеотидов, кодирующих домен B или фрагмент домена B); и где кодон-оптимизированная нуклеотидная последовательность содержит меньше потенциальных сайтов связывания промотора по сравнению с SEQ ID NO: 16. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 9, не более 8, не более 7, не более 6 или не более 5 потенциальных сайтов связывания промотора. В других вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит не более 4, не более 3, не более 2 или не более 1 потенциального сайта связывания промотора. В еще одних вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, не содержит потенциального сайта связывания промотора.
[225] TATA-боксы представляют собой регуляторные последовательности, часто выявляемые в промоторных участках у эукариот. Они служат в качестве сайта связывания TATA-связывающего белка (TBP), основного транскрипционного фактора. TATA-боксы обычно содержат последовательность TATAA (SEQ ID NO: 28) или ее родственный вариант. Однако в пределах кодирующей последовательности TATA-боксы могут подавлять трансляцию полноразмерного белка. Существует десять потенциальных последовательностей связывания промотора в последовательности BDD FVIII дикого типа (SEQ ID NO: 16): пять последовательностей TATAA (SEQ ID NO: 28) и пять последовательностей TTATA (SEQ ID NO: 29). В некоторых вариантах осуществления по меньшей мере 1, по меньшей мере 2, по меньшей мере 3 или по меньшей мере 4 сайта связывания промотора удалены в генах FVIII по настоящему изобретению. В некоторых вариантах осуществления по меньшей мере 5 сайтов связывания промотора удалены в генах FVIII по настоящему изобретению. В других вариантах осуществления по меньшей мере 6, по меньшей мере 7 или по меньшей мере 8 сайтов связывания промотора удалены в генах FVIII по настоящему изобретению. В одном варианте осуществления по меньшей мере 9 сайтов связывания промотора удалены в генах FVIII по настоящему изобретению. В одном конкретном варианте осуществления все сайты связывания промотора удалены в генах FVIII по настоящему изобретению. Местоположение каждого данного сайта связывания промотора и последовательность соответствующих нуклеотидов в оптимизированных последовательностях показаны в таблице 3.
F. Другие отрицательные регуляторные элементы, действующие в цис-положении
[226] В дополнение к последовательностям MAR/ARS дестабилизирующим элементам и потенциальным сайтам связывания промотора, описанным выше, несколько дополнительный потенциально ингибиторных последовательностей можно идентифицировать в последовательности BDD FVIII дикого типа (SEQ ID NO: 16). Две последовательности богатых AU элементов (ARE) можно идентифицировать (ATTTTATT (SEQ ID NO: 30) и ATTTTTAA (SEQ ID NO: 31) наряду с сайтом poly-A (AAAAAAA; SEQ ID NO: 26), сайтом poly-T (TTTTTT; SEQ ID NO: 25) и сайтом сплайсинга (GGTGAT; SEQ ID NO: 27) в неоптимизированной последовательности BDD FVIII. Один или несколько таких элементов можно удалить из оптимизированных последовательностей FVIII. Местоположение каждого из данных сайтов и последовательность соответствующих нуклеотидов в оптимизированных последовательностях показаны в таблице 3.
[227] В определенных вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где первая последовательность нуклеиновой кислоты характеризуется по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-1791 из SEQ ID NO: 3; (ii) нуклеотидами 1-1791 из SEQ ID NO: 3; (iii) нуклеотидами 58-1791 из SEQ ID NO: 4 или (iv) нуклеотидами 1-1791 из SEQ ID NO: 4; где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII; и где кодон-оптимизированная нуклеотидная последовательность не содержит одного или нескольких отрицательных регуляторных элементов, действующих в цис-положении, например, сайт сплайсинга, последовательность poly-T, последовательность poly-A, последовательность ARE или любые их комбинации.
[228] В другом варианте осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где вторая последовательность нуклеиновой кислоты характеризуется по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 1792-4374 из SEQ ID NO: 5; (ii) нуклеотидами 1792-4374 из SEQ ID NO: 6; (iii) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 5 (т. е. нуклеотидами 1792-4374 из SEQ ID NO: 5 без нуклеотидов, кодирующих домен B или фрагмент домена B) или (iv) нуклеотидами 1792-2277 и 2320-4374 из SEQ ID NO: 6 (т. е. нуклеотидами 1792-4374 из SEQ ID NO: 6 без нуклеотидов, кодирующих домен В и фрагмент домена В; где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII; и где кодон-оптимизированная нуклеотидная последовательность не содержит одного или нескольких отрицательных регуляторных элементов, действующих в цис-положении, например, сайт сплайсинга, последовательность poly-Т, последовательность poly-A, последовательность ARE или любые их комбинации.
[229] В других вариантах осуществления генная кассета содержит кодон-оптимизированную нуклеотидную последовательность, кодирующую полипептид FVIII, где нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-4374 из аминокислотной последовательности, выбранной из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 и 71, или (ii) нуклеотидами 58-2277 и 2320-4374 из аминокислотной последовательности, выбранной из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 и 71 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 или 71 без нуклеотидов, кодирующих домен B или фрагмент домена B); и где кодон-оптимизированная нуклеотидная последовательность не содержит одного или нескольких отрицательных регуляторных элементов, действующих в цис-положении, например, сайт сплайсинга, последовательность poly-Т, последовательность poly-A, последовательность ARE или любые их комбинации.
[230] В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где первая последовательность нуклеиновой кислоты характеризуется по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-1791 из SEQ ID NO: 3; (ii) нуклеотидами 1-1791 из SEQ ID NO: 3; (iii) нуклеотидами 58-1791 из SEQ ID NO: 4 или (iv) нуклеотидами 1-1791 из SEQ ID NO: 4; где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII; и где кодон-оптимизированная нуклеотидная последовательность не содержит сайта сплайсинга GGTGAT (SEQ ID NO: 27). В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где первая последовательность нуклеиновой кислоты характеризуется по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-1791 из SEQ ID NO: 3; (ii) нуклеотидами 1-1791 из SEQ ID NO: 3; (iii) нуклеотидами 58-1791 из SEQ ID NO: 4 или (iv) нуклеотидами 1-1791 из SEQ ID NO: 4; где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII; и где кодон-оптимизированная нуклеотидная последовательность не содержит последовательности poly-T (SEQ ID NO: 25). В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где первая последовательность нуклеиновой кислоты характеризуется по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-1791 из SEQ ID NO: 3; (ii) нуклеотидами 1-1791 из SEQ ID NO: 3; (iii) нуклеотидами 58-1791 из SEQ ID NO: 4 или (iv) нуклеотидами 1-1791 из SEQ ID NO: 4; где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII; и где кодон-оптимизированная нуклеотидная последовательность не содержит последовательности poly-A (SEQ ID NO: 26). В некоторых вариантах осуществления кодон-оптимизированная нуклеотидная последовательность, кодирующая полипептид FVIII, содержит первую последовательность нуклеиновой кислоты, кодирующую N-концевую часть полипептида FVIII, и вторую последовательность нуклеиновой кислоты, кодирующую C-концевую часть полипептида FVIII; где первая последовательность нуклеиновой кислоты характеризуется по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 86%, по меньшей мере приблизительно 87%, по меньшей мере приблизительно 88%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-1791 из SEQ ID NO: 3; (ii) нуклеотидами 1-1791 из SEQ ID NO: 3; (iii) нуклеотидами 58-1791 из SEQ ID NO: 4 или (iv) нуклеотидами 1-1791 из SEQ ID NO: 4; где N-концевая часть и C-концевая часть вместе обладают активностью полипептида FVIII; и где кодон-оптимизированная нуклеотидная последовательность не содержит элемента ARE (SEQ ID NO: 30 или SEQ ID NO: 31).
[231] В некоторых вариантах осуществления генная кассета содержит кодон-оптимизированную нуклеотидную последовательность, кодирующую полипептид FVIII, где кодон-оптимизированная нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-4374 из аминокислотной последовательности, выбранной из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 и 71, или (ii) нуклеотидами 58-2277 и 2320-4374 из аминокислотной последовательности, выбранной из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 и 71 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 или 71 без нуклеотидов, кодирующих домен B или фрагмент домена B); и где кодон-оптимизированная нуклеотидная последовательность не содержит сайта сплайсинга GGTGAT (SEQ ID NO: 27). В некоторых вариантах осуществления генная кассета содержит кодон-оптимизированную нуклеотидную последовательность, кодирующую полипептид FVIII, где кодон-оптимизированная нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-4374 из аминокислотной последовательности, выбранной из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 и 71, или (ii) нуклеотидами 58-2277 и 2320-4374 из аминокислотной последовательности, выбранной из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 и 71 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 или 71 без нуклеотидов, кодирующих домен B или фрагмент домена B); и где кодон-оптимизированная нуклеотидная последовательность не содержит последовательности poly-T (SEQ ID NO: 25). В некоторых вариантах осуществления генная кассета содержит кодон-оптимизированную нуклеотидную последовательность, кодирующую полипептид FVIII, где кодон-оптимизированная нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-4374 из аминокислотной последовательности, выбранной из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 и 71, или (ii) нуклеотидами 58-2277 и 2320-4374 из аминокислотной последовательности, выбранной из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 и 71 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 или 71 без нуклеотидов, кодирующих домен B или фрагмент домена B); и где кодон-оптимизированная нуклеотидная последовательность не содержит последовательности poly-A (SEQ ID NO: 26). В некоторых вариантах осуществления генная кассета содержит кодон-оптимизированную нуклеотидную последовательность, кодирующую полипептид FVIII, где кодон-оптимизированная нуклеотидная последовательность содержит последовательность нуклеиновой кислоты, характеризующуюся по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 89%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 91%, по меньшей мере приблизительно 92%, по меньшей мере приблизительно 93%, по меньшей мере приблизительно 94%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98% или по меньшей мере приблизительно 99% идентичностью последовательности с (i) нуклеотидами 58-4374 из аминокислотной последовательности, выбранной из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 и 71, или (ii) нуклеотидами 58-2277 и 2320-4374 из аминокислотной последовательности, выбранной из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 и 71 (т. е. нуклеотидами 58-4374 из SEQ ID NO: 1, 2, 3, 4, 5, 6, 70 или 71 без нуклеотидов, кодирующих домен B или фрагмент домена B); и где кодон-оптимизированная нуклеотидная последовательность не содержит элемента ARE (SEQ ID NO: 30 или SEQ ID NO: 31).
[232] В других вариантах осуществления оптимизированная последовательность FVIII по настоящему изобретению не содержит одного или нескольких из противовирусных мотивов, структур типа "cтебель-петля" и последовательностей повтора.
[233] В еще одних других вариантах осуществления нуклеотиды, окружающие сайт инициации транскрипции, заменены на консенсусную последовательность Козак (GCCGCCACCATGC (SEQ ID NO: 32), где подчеркнутые нуклеотиды представляют собой старт-кодон). В других вариантах осуществления сайты рестрикции можно добавить или удалить с целью улучшения процесса клонирования.
b. FIX и полинуклеотидные последовательности, кодирующие белок FIX
[234] В некоторых вариантах осуществления молекула нуклеиновой кислоты содержит первый ITR, второй ITR и генную кассету, кодирующую терапевтический белок, где терапевтический белок содержит полипептид FIX. В некоторых вариантах осуществления полипептид FIX содержит FIX или его вариант или фрагмент, где FIX или его вариант или фрагмент характеризуется активностью FIX.
[235] FIX человека представляет собой сериновую протеазу, которая является важным компонентом внутреннего пути каскада коагуляции крови. "Фактор IX" или "FIX", как используется в данном документе, относится к белку, представляющему собой фактор коагуляции, и его разновидностям и вариантам с отличающейся последовательностью и включает без ограничения одноцепочечную последовательность полипептида-предшественника FIX человека из 461 аминокислоты ("препро"-форму), одноцепочечную последовательность зрелого FIX человека из 415 аминокислот (SEQ ID NO: 125) и вариант FIX с R338L (Padua) (SEQ ID NO: 126). FIX включает любую форму молекулы FIX с типичными характеристиками фактора коагуляции крови FIX. Подразумевается, что "фактор IX" и "FIX", как используется в данном документе, охватывают полипептиды, которые содержат домены Gla (область, содержащую остатки γ-карбоксиглутаминовой кислоты), EGF1 и EGF2 (области, содержащие последовательности, гомологичные эпидермальному фактору роста человека), активационный пептид ("AP", образованный остатками R136-R180 зрелого FIX) и C-концевой протеазный домен ("Pro") или эти домены под синонимичными названиями, известными из уровня техники, или могут представлять собой усеченный фрагмент или вариант с отличающейся последовательностью, сохраняющий по меньшей мере часть биологической активности нативного белка. FIX или варианты с отличающейся последовательностью были клонированы, как описано в патентах США №№ 4770999 и 7700734, и кДНК, кодирующая FIX человека, была выделена, охарактеризована и клонирована в векторы экспрессии (см., например, Choo et al., Nature 299:178-180 (1982); Fair et al., Blood 64:194-204 (1984); и Kurachi et al., Proc. Natl. Acad. Sci., U.S.A. 79:6461-6464 (1982)). Один конкретный вариант FIX, вариант FIX с R338L (Padua) (SEQ ID NO: 2), охарактеризованный Simioni et al., 2009, содержит мутацию, обуславливающую приобретение функции, что коррелирует с увеличением активности варианта Padua почти в 8 раз по сравнению с нативным FIX (таблица 4). Варианты FIX также могут включать любой полипептид FIX, имеющий одну или несколько консервативных аминокислотных замен, которые не влияют на активность полипептида FIX в качестве FIX. В некоторых вариантах осуществления вариант FIX содержит rFIX-альбумин, слитый с помощью расщепляемого линкера, например, IDELVION®. См. US 7939632, полностью включенный в данный документ посредством ссылки.
Таблица 4. Иллюстративные примеры последовательностей FIX
61:SCKDDINSYE CWCPFGFEGK NCELDVTCNI KNGRCEQFCK NSADNKVVCS CTEGYRLAEN 121:QKSCEPAVPF PCGRVSVSQT SKLTRAETVF PDVDYVNSTE AETILDNITQ STQSFNDFTR
181:VVGGEDAKPG QFPWQVVLNG KVDAFCGGSI VNEKWIVTAA HCVETGVKIT VVAGEHNIEE
241:TEHTEQKRNV IRIIPHHNYN AAINKYNHDI ALLELDEPLV LNSYVTPICI ADKEYTNIFL
301:KFGSGYVSGW GRVFHKGRSA LVLQYLRVPL VDRATCLRST KFTIYNNMFC AGFHEGGRDS
361:CQGDSGGPHV TEVEGTSFLT GIISWGEECA MKGKYGIYTK VSRYVNWIKE KTKLT
61:SCKDDINSYE CWCPFGFEGK NCELDVTCNI KNGRCEQFCK NSADNKVVCS CTEGYRLAEN 121:QKSCEPAVPF PCGRVSVSQT SKLTRAETVF PDVDYVNSTE AETILDNITQ STQSFNDFTR
181:VVGGEDAKPG QFPWQVVLNG KVDAFCGGSI VNEKWIVTAA HCVETGVKIT VVAGEHNIEE
241:TEHTEQKRNV IRIIPHHNYN AAINKYNHDI ALLELDEPLV LNSYVTPICI ADKEYTNIFL
301:KFGSGYVSGW GRVFHKGRSA LVLQYLRVPL VDRATCLLST KFTIYNNMFC AGFHEGGRDS
361:CQGDSGGPHV TEVEGTSFLT GIISWGEECA MKGKYGIYTK VSRYVNWIKE KTKLT
CESNPCLNGG SCKDDINSYE CWCPFGFEGK NCELDVTCNI KNGRCEQFCK 100
NSADNKVVCS CTEGYRLAEN QKSCEPAVPF PCGRVSVSQT SKLTRAETVF 150
PDVDYVNSTE AETILDNITQ STQSFNDFTR VVGGEDAKPG QFPWQVVLNG 200
KVDAFCGGSI VNEKWIVTAA HCVETGVKIT VVAGEHNIEE TEHTEQKRNV 250
IRIIPHHNYN AAINKYNHDI ALLELDEPLV LNSYVTPICI ADKEYTNIFL 300
KFGSGYVSGW GRVFHKGRSA LVLQYLRVPL VDRATCLRST KFTIYNNMFC 350
AGFHEGGRDS CQGDSGGPHV TEVEGTSFLT GIISWGEECA MKGKYGIYTK 400
VSRYVNWIKE KTKLTPVSQT SKLTRAETVF PDVDAHKSEV AHRFKDLGEE 450
NFKALVLIAF AQYLQQCPFE DHVKLVNEVT EFAKTCVADE SAENCDKSLH 500
TLFGDKLCTV ATLRETYGEM ADCCAKQEPE RNECFLQHKD DNPNLPRLVR 550
PEVDVMCTAF HDNEETFLKK YLYEIARRHP YFYAPELLFF AKRYKAAFTE 600
CCQAADKAAC LLPKLDELRD EGKASSAKQR LKCASLQKFG ERAFKAWAVA 650
RLSQRFPKAE FAEVSKLVTD LTKVHTECCH GDLLECADDR ADLAKYICEN 700
QDSISSKLKE CCEKPLLEKS HCIAEVENDE MPADLPSLAA DFVESKDVCK 750
NYAEAKDVFL GMFLYEYARR HPDYSVVLLL RLAKTYETTL EKCCAAADPH 800
ECYAKVFDEF KPLVEEPQNL IKQNCELFEQ LGEYKFQNAL LVRYTKKVPQ 850
VSTPTLVEVS RNLGKVGSKC CKHPEAKRMP CAEDYLSVVL NQLCVLHEKT 900
PVSDRVTKCC TESLVNRRPC FSALEVDETY VPKEFNAETF TFHADICTLS 950
EKERQIKKQT ALVELVKHKP KATKEQLKAV MDDFAAFVEK CCKADDKETC 1000
FAEEGKKLVA ASQAALGL 1018
* Серая штриховка=сигнальный пептид; подчеркивание=последовательность XTEN; жирный шрифт=Fc.
** SEQ ID NO: 67 из патента США № 9856468, включенного в данный документ посредством ссылки во всей своей полноте.
[236] Полипептид FIX имеет размер 55 кДа, синтезируется в виде полипептидной цепи, представляющей собой препроформу (SEQ ID NO: 125), которая состоит из трех следующих областей: сигнального пептида из 28 аминокислот (аминокислоты с 1 по 28 из SEQ ID NO: 127), пропептида из 18 аминокислот (аминокислоты с 29 по 46), который необходим для гамма-карбоксилирования остатков глутаминовой кислоты, и зрелого фактора IX из 415 аминокислот (SEQ ID NO: 125 или 126). Пропептид представляет собой последовательность из 18 аминокислотных остатков, расположенную с N-концевой стороны от гамма-карбоксиглутаматного домена. Пропептид связывается с витамин K-зависимой гамма-карбоксилазой и затем отщепляется от полипептида-предшественника FIX под действием эндогенной протеазы, наиболее вероятно PACE (фермента, расщепляющего белок в месте спаренных основных аминокислот), также известной как фурин или PCSK3. Без гамма-карбоксилирования домен Gla не способен связывать кальций, принимая правильную конформацию, необходимую для заякоривания белка на отрицательно заряженных фосфолипидных поверхностях, что тем самым делает фактор IX нефункциональным. Даже в случае, когда домен Gla является карбоксилированным, его надлежащее функционирование также зависит от отщепления пропептида, поскольку остающийся пропептид препятствует конформационным изменениям домена Gla, необходимым для оптимального связывания с кальцием и фосфолипидами. У людей образующийся в результате зрелый фактор IX секретируется клетками печени в кровоток в виде неактивного зимогена, одноцепочечного белка из 415 аминокислотных остатков, который содержит примерно 17% по весу углеводов (Schmidt, A. E., et al. (2003) Trends Cardiovasc Med, 13: 39).
[237] Зрелый FIX состоит из нескольких доменов, которыми в конфигурации от N- к C-концу являются: домен Gla, домен EGF1, домен EGF2, домен активационного пептида (AP) и протеазный (или каталитический) домен. Короткий линкер соединяет домен EGF2 с доменом AP. FIX содержит два активационных пептида, образованных соответственно из R145-A146 и R180-V181. После активации одноцепочечный FIX становится 2-цепочечной молекулой, в которой две цепи связаны дисульфидной связью. Факторы свертывания крови можно сконструировать путем замещения их активационных пептидов, что в результате приводит к изменению специфичности активации. У млекопитающих зрелый FIX должен быть активирован активированным фактором XI с получением фактора IXa. Протеазный домен при активации FIX до FIXa обеспечивает каталитическую активность FIX. Активированный фактор VIII (FVIIIa) представляет собой специфический кофактор, необходимый для полного проявления активности FIXa.
[238] В определенных вариантах осуществления полипептид FIX представляет собой плазматический FIX в виде его аллельной формы по Thr148 и обладает структурными и функциональными характеристиками, сходными с характеристиками эндогенного FIX.
[239] Многие функциональные варианты FIX известны из уровня техники. В международной публикации № WO 02/040544 A3 на странице 4 в строках 9-30 и на странице 15 в строках 6-31 раскрыты мутантные формы, демонстрирующие увеличенную устойчивость к ингибированию гепарином. В международной публикации № WO 03/020764 A2 в таблицах 2 и 3 (на страницах 14-24) и на странице 12 в строках 1-27 раскрыты мутантные формы FIX с пониженной T-клеточной иммуногенностью. В международной публикации № WO 2007/149406 A2 от страницы 4, строки 1 до страницы 19, строки 11 раскрыты функциональные мутантные молекулы FIX, демонстрирующие увеличенную стабильность белков, увеличенный период полужизни in vivo и in vitro и увеличенную устойчивость к протеазам. В WO 2007/149406 A2 от страницы 19, строки 12 до страницы 20, строки 9 также раскрыты химерные и другие вариантные молекулы FIX. В международной публикации № WO 08/118507 A2 от страницы 5, строки 14 до страницы 6, строки 5 раскрыты мутантные формы FIX, демонстрирующие увеличенную свертывающую активность. В международной публикации № WO 09/051717 A2 от страницы 9, строки 11 до страницы 20, строки 2 раскрыты мутантные формы FIX, имеющие увеличенное количество сайтов N-связанного и/или O-связанного гликозилирования, что приводит к увеличению периода полужизни и/или степени обнаружения. В международной публикации № WO 09/137254 A2 от страницы 2, абзаца [006] до страницы 5, абзаца [011] и от страницы 16, абзаца [044] до страницы 24, абзаца [057] также раскрыты мутантные формы фактора IX с увеличенным количеством сайтов гликозилирования. В международной публикации № WO 09/130198 A2 от страницы 4, строки 26 до страницы 12, строки 6 раскрыты функциональные мутантные молекулы FIX, которые имеют увеличенное количество сайтов гликозилирования, что приводит к увеличению периода полужизни. В международной публикации № WO 09/140015 A2 от страницы 11, абзаца [0043] до страницы 13, абзаца [0053] раскрыты функциональные мутантные формы FIX, имеющие увеличенное количество остатков Cys, которые можно использовать для конъюгирования с полимером (например, PEG). Полипептиды FIX, описанные в международной заявке № PCT/US2011/043569, поданной 11 июля 2011 г. и опубликованной как WO 2012/006624 12 января 2012 г., также включены в данный документ посредством ссылки во всей своей полноте. В некоторых вариантах осуществления полипептид FIX содержит полипептид FIX, слитый с альбумином, например, FIX-альбумин. В определенных вариантах осуществления полипептид FIX представляет собой IDELVION® или rIX-FP.
[240] В дополнение, у субъектов с гемофилией были идентифицированы сотни нефункциональных мутаций в FIX, многие из которых раскрыты в таблице 6 на страницах 11-14 международной публикации № WO 09/137254 A2. Такие нефункциональные мутации не включены в настоящее изобретение, но обеспечивают дополнительные указания в отношении того, какие мутации с большей или меньшей долей вероятности приводят к образованию функционального полипептида FIX.
[241] В одном варианте осуществления полипептид FIX (или часть слитого полипептида, представляющая собой фактор IX) содержит аминокислотную последовательность, на по меньшей мере 70%, на по меньшей мере 80%, на по меньшей мере 85%, на по меньшей мере 90%, на по меньшей мере 95%, на по меньшей мере 96%, на по меньшей мере 97%, на по меньшей мере 98%, на по меньшей мере 99% или на 100% идентичную последовательности, изложенной под SEQ ID NO: 1 или 2 (аминокислоты с 1 по 415 из SEQ ID NO: 125 или 126), или, в качестве альтернативы, последовательность пропептида или последовательность пропептида и сигнальную последовательность (полноразмерный FIX). В другом варианте осуществления полипептид FIX содержит аминокислотную последовательность, на по меньшей мере 70%, на по меньшей мере 80%, на по меньшей мере 85%, на по меньшей мере 90%, на по меньшей мере 95%, на по меньшей мере 96%, на по меньшей мере 97%, на по меньшей мере 98%, на по меньшей мере 99% или на 100% идентичную последовательности, изложенной под SEQ ID NO: 2.
[242] Коагулянтная активность FIX выражается в международных единицах (МЕ). Одна МЕ активности FIX примерно соответствует количеству FIX в одном миллилитре нормальной плазмы крови человека. Доступны несколько анализов для измерения активности FIX, в том числе одностадийный анализ свертывания крови (активированного частичного тромбопластинового времени; aPTT), анализ времени образования тромбина (TGA) и ротационная тромбоэластометрия (ROTEM®). Настоящее изобретение охватывает последовательности, характеризующиеся гомологией с последовательностями FIX, фрагменты последовательностей, которые являются природными, как, например, полученными от людей, приматов, отличных от человека, млекопитающих (в том числе домашних животных), и неприродные варианты последовательностей, которые сохраняют по меньшей мере часть биологической активности или биологической функции FIX и/или которые являются применимыми для предупреждения, лечения заболевания, дефицита, нарушения или состояния, связанного с фактором коагуляции (например, эпизодов кровотечения, связанных с травмой, хирургической операцией, при дефиците фактора коагуляции), опосредованного влияния на него или уменьшения интенсивности его проявлений. Последовательности, характеризующиеся гомологией с FIX человека, можно найти с помощью стандартных методик поиска гомологии, таких как BLAST от NCBI.
[243] В определенных вариантах осуществления последовательность FIX является кодон-оптимизированной. Примеры кодон-оптимизированных последовательностей FIX включают без ограничения SEQ ID NO: 1 и 54-58 из международной публикации № WO 2016/004113 А1, которая включена в данный документ посредством ссылки во всей своей полноте.
c. FVII и полинуклеотидные последовательности, кодирующие белок FVII
[244] В некоторых вариантах осуществления молекула нуклеиновой кислоты содержит первый ITR, второй ITR и генную кассету, кодирующую терапевтический белок, где терапевтический белок содержит полипептид, представляющий собой фактор VII. В некоторых вариантах осуществления полипептид FVII содержит FVII или его вариант или фрагмент, где его вариант или фрагмент характеризуется активностью FVII.
[245] "Фактор VII" ("FVII" или "F7"; также упоминается как фактор 7, фактор свертывания крови VII, сывороточный фактор VII, сывороточный ускоритель превращения протромбина, SPCA, проконвертин и эптаког альфа) представляет собой сериновую протеазу, которая является частью каскада коагуляции крови. В одном варианте осуществления фактор свертывания крови, кодируемый нуклеиновой кислотой, описанной в данном документе, представляет собой FVII. Рекомбинантный активированный фактор VII ("FVII") стал широко использоваться для лечения массивного кровотечения, такого как возникающее у пациентов с гемофилией A или B, дефицитом фактора свертывания крови XI, FVII, нарушением функции тромбоцитов, тромбоцитопенией или болезнью фон Виллебранда.
[246] Рекомбинантный активированный FVII (rFVIIa; NovoSeven®) используется для лечения эпизодов кровотечения у (i) пациентов с гемофилией с нейтрализующими антителами к FVIII или FIX (ингибиторами), (ii) пациентов с дефицитом FVII или (iii) пациентов с гемофилией A или B с ингибиторами, проходящими хирургические процедуры. Однако, NovoSeven® демонстрирует низкую эффективность. Часто требуются повторные дозы FVIIa в высокой концентрации для контроля кровотечения из-за его низкого сродства к активированным тромбоцитам, короткого периода полужизни и низкой ферментативной активности в отсутствие тканевого фактора. Соответственно, существует неудовлетворенная медицинская потребность в лучших вариантах лечения и предупреждения для пациентов с гемофилией с ингибиторами FVIII и FIX и/или с дефицитом FVII.
[247] В одном варианте осуществления генная кассета кодирует зрелую форму FVII или его вариант. FVII содержит домен Gla, два домена EGF (EGF-1 и EGF-2) и домен сериновой протеазы (или домен пептидазы S1), который является высококонсервативным среди всех представителей сериновых протеаз семейства пептидаз S1, таких как, например, химотрипсин. FVII встречается в виде одноцепочечного зимогена (т. е. активируемого FVII) и полностью активированной двухцепочечной формы.
C. Факторы роста
[248] В некоторых вариантах осуществления молекула нуклеиновой кислоты содержит первый ITR, второй ITR и генную кассету, кодирующую терапевтический белок, где терапевтический белок содержит фактор роста. Фактор роста может быть выбран из любого фактора роста, известного из уровня техники. В некоторых вариантах осуществления фактор роста представляет собой гормон. В других вариантах осуществления фактор роста представляет собой цитокин. В некоторых вариантах осуществления фактор роста представляет собой хемокин.
[249] В некоторых вариантах осуществления фактор роста представляет собой адреномедуллин (AM). В некоторых вариантах осуществления фактор роста представляет собой ангиопоэтин (Ang). В некоторых вариантах осуществления фактор роста представляет собой аутокринный фактор миграции. В некоторых вариантах осуществления фактор роста представляет собой костный морфогенетический белок (BMP). В некоторых вариантах осуществления BMP выбран из BMP2, BMP4, BMP5 и BMP7. В некоторых вариантах осуществления фактор роста является представителем семейства цилиарных нейротрофических факторов. В некоторых вариантах осуществления представитель семейства цилиарных нейротрофических факторов выбран из цилиарного нейротрофического фактора (CNTF), фактора, ингибирующего лейкоз (LIF), интерлейкина-6 (IL-6). В некоторых вариантах осуществления фактор роста представляет собой колониестимулирующий фактор. В некоторых вариантах осуществления колониестимулирующий фактор выбран из макрофагального колониестимулирующего фактора (m-CSF), гранулоцитарного колониестимулирующего фактора (G-CSF) и гранулоцитарно-макрофагального колониестимулирующего фактора (GM-CSF). В некоторых вариантах осуществления фактор роста представляет собой эпидермальный фактор роста (EGF). В некоторых вариантах осуществления фактор роста представляет собой эфрин. В некоторых вариантах осуществления эфрин выбран из эфрина А1, эфрина А2, эфрина А3, эфрина А4, эфрина А5, эфрина В1, эфрина В2 и эфрина В3. В некоторых вариантах осуществления фактор роста представляет собой эритропоэтин (EPO). В некоторых вариантах осуществления фактор роста представляет собой фактор роста фибробластов (FGF). В некоторых вариантах осуществления FGF выбран из FGF1, FGF2, FGF3, FGF4, FGF5, FGF6, FGF7, FGF8, FGF9, FGF10, FGF11, FGF12, FGF13, FGF14, FGF15, FGF16, FGF17, FGF18, FGF19, FGF20, FGF21, FGF22 и FGF23. В некоторых вариантах осуществления фактор роста представляет собой фетальный бычий соматотропин (FBS). В некоторых вариантах осуществления фактор роста является представителем семейства GDNF. В некоторых вариантах осуществления представитель семейства GDNF выбран из нейротрофического фактора линии глиальных клеток (GDNF), нейротурина, персефина и артемина. В некоторых вариантах осуществления фактор роста представляет собой фактор роста и дифференцировки-9 (GDF9). В некоторых вариантах осуществления фактор роста представляет собой фактор роста гепатоцитов (HGF). В некоторых вариантах осуществления фактор роста представляет собой фактор роста, происходящий из гепатомы (HDGF). В некоторых вариантах осуществления фактор роста представляет собой инсулин. В некоторых вариантах осуществления фактор роста представляет собой инсулиноподобный фактор роста. В некоторых вариантах осуществления инсулиноподобный фактор роста представляет собой инсулиноподобный фактор роста-1 (IGF-1) или IGF-2. В некоторых вариантах осуществления фактор роста представляет собой интерлейкин (IL). В некоторых вариантах осуществления IL выбран из IL-1, IL-2, IL-3, IL-4, IL-5, IL-6 и IL-7. В некоторых вариантах осуществления фактор роста представляет собой фактор роста кератиноцитов (KGF). В некоторых вариантах осуществления фактор роста представляет собой фактор, стимулирующий миграцию (MSF). В некоторых вариантах осуществления фактор роста представляет собой белок, стимулирующий макрофаги (MSP или белок, подобный фактору роста гепатоцитов (HGFLP)). В некоторых вариантах осуществления фактор роста представляет собой миостатин (GDF-8). В некоторых вариантах осуществления фактор роста представляет собой нейрегулин. В некоторых вариантах осуществления нейрегулин выбран из нейрегулина 1 (NRG1), NRG2, NRG3 и NRG4. В некоторых вариантах осуществления фактор роста представляет собой нейротрофин. В некоторых вариантах осуществления фактор роста представляет собой нейротрофический фактор головного мозга (BDNF). В некоторых вариантах осуществления фактор роста представляет собой фактор роста нервов (NGF). В некоторых вариантах осуществления NGF представляет собой нейротрофин-3 (NT-3) или NT-4. В некоторых вариантах осуществления фактор роста представляет собой плацентарный фактор роста (PGF). В некоторых вариантах осуществления фактор роста представляет собой фактор роста тромбоцитов (PDGF). В некоторых вариантах осуществления фактор роста представляет собой реналазу (RNLS). В некоторых вариантах осуществления фактор роста представляет собой фактор роста Т-клеток (TCGF). В некоторых вариантах осуществления фактор роста представляет собой тромбопоэтин (TPO). В некоторых вариантах осуществления фактор роста представляет собой трансформирующий фактор роста. В некоторых вариантах осуществления трансформирующий фактор роста представляет собой трансформирующий фактор роста-альфа (TGF-α) или TGF-β. В некоторых вариантах осуществления фактор роста представляет собой фактор некроза опухоли-альфа (TNF-α). В некоторых вариантах осуществления фактор роста представляет собой фактор роста эндотелия сосудов (VEGF).
D. MicroRNA (miRNA)
[250] MicroRNA (miRNA) представляют собой небольшие некодирующие молекулы РНК (приблизительно 18-22 нуклеотидов), которые отрицательно регулируют экспрессию генов, ингибируя трансляцию или индуцируя деградацию информационной РНК (mRNA). С момента их открытия стало известно, что miRNA участвуют в различных клеточных процессах, в том числе в апоптозе, дифференцировке и пролиферации клеток, и они, как было показано, играют ключевую роль в канцерогенезе. Способность miRNA регулировать экспрессию генов делает экспрессию miRNA in vivo ценным инструментом в генной терапии.
[251] Определенные аспекты настоящего изобретения относятся к плазмидоподобным молекулам нуклеиновой кислоты, содержащим первый ITR, второй ITR и генную кассету, кодирующую miRNA, где первый ITR и/или второй ITR представляют собой ITR, полученные из вируса, отличного от аденоассоциированного вируса (например, первый ITR и/или второй ITR получены из вируса, отличного от AAV). miRNA может представлять собой любую miRNA, известную из уровня техники. В некоторых вариантах осуществления miRNA понижает экспрессию гена-мишени. В определенных вариантах осуществления ген-мишень выбран из SOD1, HTT, RHO или любой их комбинации.
[252] В некоторых вариантах осуществления генная кассета кодирует одну miRNA. В некоторых вариантах осуществления генная кассета кодирует более одной miRNA. В некоторых вариантах осуществления генная кассета кодирует две или более различные miRNA. В некоторых вариантах осуществления генная кассета кодирует две или более копии одной и той же miRNA. В некоторых вариантах осуществления генная кассета кодирует два или более варианта одного и того же терапевтического белка. В определенных вариантах осуществления генная кассета кодирует одну или несколько miRNA и один или несколько терапевтических белков.
[253] В некоторых вариантах осуществления miRNA представляет собой miRNA, встречающуюся в природе. В некоторых вариантах осуществления miRNA представляет собой сконструированную miRNA. В некоторых вариантах осуществления miRNA представляет собой искусственную miRNA. В определенных вариантах осуществления miRNA включает сконструированную miRNA для miHTT, раскрытую в Evers et al., Molecular Therapy 26(9):1-15 (электронная публикация до выхода в печать в июне 2018 г.). В определенных вариантах осуществления miRNA включает в себя искусственную miRNA miR-SOD1, раскрытую в Dirren et al., Annals of Clinical and Translational Neurology 2(2):167-84 (февраль 2015 г.). В определенных вариантах осуществления miRNA включает в себя miR-708, которая нацеливается на RHO (см. Behrman et al., JCB 192(6):919-27 (2011).
[254] В некоторых вариантах осуществления miRNA повышает экспрессию гена путем понижения экспрессии ингибитора гена. В некоторых вариантах осуществления ингибитор представляет собой природный ингибитор, например, ингибитор дикого типа. В некоторых вариантах осуществления ингибитор образуется на мутантном, гетерологичном и/или неправильно экспрессирующемся гене.
E. Гетерологичные компоненты
[255] В некоторых вариантах осуществления молекула нуклеиновой кислоты содержит первый ITR, второй ITR и генную кассету, кодирующую терапевтический белок, где терапевтический белок содержит по меньшей мере один гетерологичный компонент. В некоторых вариантах осуществления гетерологичный компонент слит с N-концом или C-концом терапевтического белка. В других вариантах осуществления гетерологичный компонент вставлен между двумя аминокислотами в терапевтическом белке.
[256] В некоторых вариантах осуществления терапевтический белок содержит полипептид FVIII и гетерологичный компонент, который вставлен между двумя аминокислотами в полипептиде FVIII. В некоторых вариантах осуществления гетерологичный компонент вставлен в полипептид FVIII в одном или нескольких сайтах вставки, выбранных из таблицы 5. В некоторых вариантах осуществления гетерологичная аминокислотная последовательность может быть вставлена в полипептид, представляющий собой фактор свертывания крови, кодируемый молекулой нуклеиновой кислоты по настоящему изобретению, в любом сайте, раскрытом в международной публикации № WO 2013/123457 A1, WO 2015/106052 A1 или публикации заявки на патент США № 2015/0158929 А1, которые включены в данный документ посредством ссылки во всей своей полноте. В одном конкретном варианте осуществления терапевтический белок содержит FVIII и гетерологичный компонент, где гетерологичный компонент вставлен в FVIII непосредственно ниже аминокислоты 745 относительно зрелого FVIII. В одном конкретном варианте осуществления терапевтический белок содержит FVIII и XTEN, где XTEN вставлен в FVIII непосредственно ниже аминокислоты 745 относительно зрелого FVIII. В одном конкретном варианте осуществления FVIII содержит делецию аминокислот 746-1646, соответствующих зрелому FVIII человека (SEQ ID NO:15), и гетерологичный компонент вставлен непосредственно ниже аминокислоты 745, соответствующей зрелому FVIII человека (SEQ ID NO:15).
Таблица 5. Сайты вставки гетерологичного компонента в FVIII
вставки
вставки
[257] В некоторых вариантах осуществления терапевтический белок содержит полипептид FIX и гетерологичный компонент, который вставлен между двумя аминокислотами в полипептиде FIX. В некоторых вариантах осуществления гетерологичный компонент вставлен в полипептид FIX в одном или нескольких сайтах вставки, выбранных из таблицы 5. В некоторых вариантах осуществления гетерологичная аминокислотная последовательность может быть вставлена в полипептид, представляющий собой фактор свертывания крови, кодируемый молекулой нуклеиновой кислоты по настоящему изобретению, в любом сайте, раскрытом в международной заявке № PCT/US2017/015879, которая включена в данный документ посредством ссылки во всей своей полноте. В одном конкретном варианте осуществления терапевтический белок содержит полипептид FIX и гетерологичный компонент, где гетерологичный компонент вставлен в полипептид FIX непосредственно ниже аминокислоты 166 относительно зрелого FIX. В одном конкретном варианте осуществления терапевтический белок содержит полипептид FIX и XTEN, где XTEN вставлен в FIX непосредственно ниже аминокислоты 166 относительно зрелого FVIII.
Таблица 6. Сайты вставки гетерологичного компонента в FIX
вставки
вставки
[258] В других вариантах осуществления терапевтические белки по настоящему изобретению дополнительно содержат две, три, четыре, пять, шесть, семь или восемь гетерологичных нуклеотидных последовательностей. В некоторых вариантах осуществления все гетерологичные компоненты являются идентичными. В некоторых вариантах осуществления по меньшей мере один гетерологичный компонент отличается от других гетерологичных компонентов. В некоторых вариантах осуществления настоящее изобретение может включать два, три, четыре, пять, шесть или более семи гетерологичных компонентов в тандеме.
[259] В некоторых вариантах осуществления гетерологичный компонент увеличивает период полужизни (является "средством, удлиняющим период полужизни") терапевтического белка.
[260] В некоторых вариантах осуществления гетерологичный компонент представляет собой пептид или полипептид с неструктурными или структурными характеристиками, которые связаны с продлением периода полужизни in vivo при встраивании в белок по настоящему изобретению. Неограничивающие примеры включают альбумин, фрагменты альбумина, Fc-фрагменты иммуноглобулинов, C-концевой пептид (CTP) β-субъединицы хорионического гонадотропина человека, последовательность HAP, последовательность XTEN, трансферрин или его фрагмент, полипептид PAS, полиглициновые линкеры, полисериновые линкеры, альбумин-связывающие компоненты или любые фрагменты, производные, варианты или комбинации этих полипептидов. В одном конкретном варианте осуществления гетерологичная аминокислотная последовательность представляет собой константную область иммуноглобулина или ее часть, трансферрин, альбумин или последовательность PAS. В некоторых аспектах гетерологичный компонент включает в себя фактор фон Виллебранда или его фрагмент. В других связанных аспектах гетерологичный компонент может включать в себя сайт присоединения (например, аминокислоту цистеин) компонента, не являющегося полипептидом, такого как полиэтиленгликоль (PEG), гидроксиэтилкрахмал (HES), полисиаловая кислота или любые производные, варианты или комбинации этих элементов. В некоторых аспектах гетерологичный компонент включает в себя аминокислоту цистеин, которая функционирует как сайт присоединения компонента, не являющегося полипептидом, такого как полиэтиленгликоль (PEG), гидроксиэтилкрахмал (HES), полисиаловая кислота или любые производные, варианты или комбинации этих элементов.
[261] В одном конкретном варианте осуществления первый гетерологичный компонент представляет собой молекулу, удлиняющую период полужизни, которая известна из уровня техники, и второй гетерологичный компонент представляет собой молекулу, удлиняющую период полужизни, которая известна из уровня техники. В определенных вариантах осуществления первый гетерологичный компонент (например, первый Fc-компонент) и второй гетерологичный компонент (например, второй Fc-компонент) связаны друг с другом с образованием димера. В одном варианте осуществления второй гетерологичный компонент представляет собой второй Fc-компонент, где второй Fc-компонент соединен или связан с первым гетерологичным компонентом, например, с первым Fc-компонентом. Например, второй гетерологичный компонент (например, второй Fc-компонент) может быть связан с первым гетерологичным компонентом (например, первым Fc-компонентом) с помощью линкера или связан с первым гетерологичным компонентом ковалентной или нековалентной связью.
[262] В некоторых вариантах осуществления гетерологичный компонент представляет собой полипептид, содержащий по меньшей мере приблизительно 10, по меньшей мере приблизительно 100, по меньшей мере приблизительно 200, по меньшей мере приблизительно 300, по меньшей мере приблизительно 400, по меньшей мере приблизительно 500, по меньшей мере приблизительно 600, по меньшей мере приблизительно 700, по меньшей мере приблизительно 800, по меньшей мере приблизительно 900, по меньшей мере приблизительно 1000, по меньшей мере приблизительно 1100, по меньшей мере приблизительно 1200, по меньшей мере приблизительно 1300, по меньшей мере приблизительно 1400, по меньшей мере приблизительно 1500, по меньшей мере приблизительно 1600, по меньшей мере приблизительно 1700, по меньшей мере приблизительно 1800, по меньшей мере приблизительно 1900, по меньшей мере приблизительно 2000, по меньшей мере приблизительно 2500, по меньшей мере приблизительно 3000 или по меньшей мере приблизительно 4000 аминокислот, состоящий по сути из них или состоящий из них. В других вариантах осуществления гетерологичный компонент представляет собой полипептид, содержащий от приблизительно 100 до приблизительно 200 аминокислот, от приблизительно 200 до приблизительно 300 аминокислот, от приблизительно 300 до приблизительно 400 аминокислот, от приблизительно 400 до приблизительно 500 аминокислот, от приблизительно 500 до приблизительно 600 аминокислот, от приблизительно 600 до приблизительно 700 аминокислот, от приблизительно 700 до приблизительно 800 аминокислот, от приблизительно 800 до приблизительно 900 аминокислот или от приблизительно 900 до приблизительно 1000 аминокислот, состоящий по сути из них или состоящий из них.
[263] В определенных вариантах осуществления гетерологичный компонент улучшает одно или несколько фармакокинетических свойств терапевтического белка без значительного влияния на его биологическую активность или функцию.
[264] В определенных вариантах осуществления гетерологичный компонент увеличивает период полужизни in vivo и/или in vitro терапевтического белка по настоящему изобретению. В других вариантах осуществления гетерологичный компонент способствует визуализации или локализации терапевтического белка по настоящему изобретению или его фрагмента (например, фрагмента, содержащего гетерологичный компонент после протеолитического расщепления белка FVIII). Визуализация и/или локализация терапевтического белка по настоящему изобретению или его фрагмента может выполняться в условиях in vivo, in vitro, ex vivo или в их комбинациях.
[265] В других вариантах осуществления гетерологичный компонент увеличивает стабильность терапевтического белка по настоящему изобретению или его фрагмента (например, фрагмента, содержащего гетерологичный компонент после протеолитического расщепления терапевтического белка, например, фактора свертывания крови). Используемый в данном документе термин "стабильность" относится к принятому в данном области техники показателю, отображающему поддержание одного или нескольких физических свойств терапевтического белка в ответ на условия окружающей среды (например, повышенную или пониженную температуру). В определенных аспектах физическое свойство может представлять собой поддержание ковалентной структуры терапевтического белка (например, отсутствие протеолитического расщепления, нежелательного окисления или дезамидирования). В других аспектах физическое свойство также может представлять собой присутствие терапевтического белка в правильно свернутом состоянии (например, отсутствие растворимых или нерастворимых агрегатов или осадков). В одном аспекте стабильность терапевтического белка измеряют путем анализа биофизического свойства терапевтического белка, например, термостабильности, профиля разворачивания под действием pH, стабильного удаления сайтов гликозилирования, растворимости, биохимической функции (например, способности связываться с белком, рецептором или лигандом) и т. д. и/или их комбинации. В другом аспекте биохимическая функция демонстрируется по аффинности связывания при взаимодействии. В одном аспекте показателем стабильности белка является термостабильность, т. е. устойчивость к тепловой нагрузке. Стабильность можно измерять с применением способов, известных из уровня техники, таких как HPLC (высокоэффективная жидкостная хроматография), SEC (эксклюзионная хроматография), DLS (динамическое рассеяние света) и т. д. Способы измерения термостабильности включают без ограничения дифференциальную сканирующую калориметрию (DSC), дифференциальную сканирующую флуориметрию (DSF), круговой дихроизм (CD) и анализ стабильности при тепловой нагрузке.
[266] В определенных аспектах терапевтический белок, кодируемый молекулой нуклеиновой кислоты по настоящему изобретению, содержит по меньшей мере одно средство, удлиняющее период полужизни, т. е. гетерологичный компонент, который увеличивает период полужизни in vivo терапевтического белка по сравнению с периодом полужизни in vivo соответствующего терапевтического белка, в котором отсутствует такой гетерологичный компонент. Период полужизни терапевтического белка in vivo может быть определен с помощью любых способов, известных специалистам в данной области, например, посредством анализов активности (например, хромогенного анализа или одностадийного анализа свертывания крови с определением aPTT, где терапевтический белок содержит полипептид FVIII), ELISA, ROTEM® и т. д.
[267] В некоторых вариантах осуществления присутствие одного или нескольких средств, удлиняющих период полужизни, приводит к увеличению периода полужизни терапевтического белка по сравнению с периодом полужизни соответствующего белка, в котором отсутствуют такие одно или несколько средств, удлиняющих период полужизни. Период полужизни терапевтического белка, содержащего средство, удлиняющее период полужизни, является в по меньшей мере приблизительно 1,5 раза, по меньшей мере приблизительно 2 раза, по меньшей мере приблизительно 2,5 раза, по меньшей мере приблизительно 3 раза, по меньшей мере приблизительно 4 раза, по меньшей мере приблизительно 5 раз, по меньшей мере приблизительно 6 раз, по меньшей мере приблизительно 7 раз, по меньшей мере приблизительно 8 раз, по меньшей мере приблизительно 9 раз, по меньшей мере приблизительно 10 раз, по меньшей мере приблизительно 11 раз или по меньшей мере приблизительно 12 раз более длительным, чем период полужизни in vivo соответствующего терапевтического белка, в котором отсутствует такое средство, удлиняющее период полужизни.
[268] В одном варианте осуществления период полужизни терапевтического белка, содержащего средство, удлиняющее период полужизни, является в от приблизительно 1,5 раза до приблизительно 20 раз, от приблизительно 1,5 раза до приблизительно 15 раз или от приблизительно 1,5 раза до приблизительно 10 раз более длительным, чем период полужизни in vivo соответствующего белка, в котором отсутствует такое средство, удлиняющее период полужизни. В другом варианте осуществления период полужизни терапевтического белка, содержащего средство, удлиняющее период полужизни, является удлиненным в от приблизительно 2 раз до приблизительно 10 раз, от приблизительно 2 раз до приблизительно 9 раз, от приблизительно 2 раз до приблизительно 8 раз, от приблизительно 2 раз до приблизительно 7 раз, от приблизительно 2 раз до приблизительно 6 раз, от приблизительно 2 раз до приблизительно 5 раз, от приблизительно 2 раз до приблизительно 4 раз, от приблизительно 2 раз до приблизительно 3 раз, от приблизительно 2,5 раза до приблизительно 10 раз, от приблизительно 2,5 раза до приблизительно 9 раз, от приблизительно 2,5 раза до приблизительно 8 раз, от приблизительно 2,5 раза до приблизительно 7 раз, от приблизительно 2,5 раза до приблизительно 6 раз, от приблизительно 2,5 раза до приблизительно 5 раз, от приблизительно 2,5 раза до приблизительно 4 раз, от приблизительно 2,5 раза до приблизительно 3 раз, от приблизительно 3 раз до приблизительно 10 раз, от приблизительно 3 раз до приблизительно 9 раз, от приблизительно 3 раз до приблизительно 8 раз, от приблизительно 3 раз до приблизительно 7 раз, от приблизительно 3 раз до приблизительно 6 раз, от приблизительно 3 раз до приблизительно 5 раз, от приблизительно 3 раз до приблизительно 4 раз, от приблизительно 4 раз до приблизительно 6 раз, от приблизительно 5 раз до приблизительно 7 раз или от приблизительно 6 раз до приблизительно 8 раз по сравнению с периодом полужизни in vivo соответствующего белка, в котором отсутствует такое средство, удлиняющее период полужизни.
[269] В других вариантах осуществления период полужизни терапевтического белка, содержащего средство, удлиняющее период полужизни, составляет по меньшей мере приблизительно 17 часов, по меньшей мере приблизительно 18 часов, по меньшей мере приблизительно 19 часов, по меньшей мере приблизительно 20 часов, по меньшей мере приблизительно 21 час, по меньшей мере приблизительно 22 часа, по меньшей мере приблизительно 23 часа, по меньшей мере приблизительно 24 часа, по меньшей мере приблизительно 25 часов, по меньшей мере приблизительно 26 часов, по меньшей мере приблизительно 27 часов, по меньшей мере приблизительно 28 часов, по меньшей мере приблизительно 29 часов, по меньшей мере приблизительно 30 часов, по меньшей мере приблизительно 31 час, по меньшей мере приблизительно 32 часа, по меньшей мере приблизительно 33 часа, по меньшей мере приблизительно 34 часа, по меньшей мере приблизительно 35 часов, по меньшей мере приблизительно 36 часов, по меньшей мере приблизительно 48 часов, по меньшей мере приблизительно 60 часов, по меньшей мере приблизительно 72 часа, по меньшей мере приблизительно 84 часа, по меньшей мере приблизительно 96 часов или по меньшей мере приблизительно 108 часов.
[270] В еще нескольких других вариантах осуществления период полужизни терапевтического белка, содержащего средство, удлиняющее период полужизни, составляет от приблизительно 15 часов до приблизительно двух недель, от приблизительно 16 часов до приблизительно одной недели, от приблизительно 17 часов до приблизительно одной недели, от приблизительно 18 часов до приблизительно одной недели, от приблизительно 19 часов до приблизительно одной недели, от приблизительно 20 часов до приблизительно одной недели, от приблизительно 21 часа до приблизительно одной недели, от приблизительно 22 часов до приблизительно одной недели, от приблизительно 23 часов до приблизительно одной недели, от приблизительно 24 часов до приблизительно одной недели, от приблизительно 36 часов до приблизительно одной недели, от приблизительно 48 часов до приблизительно одной недели, от приблизительно 60 часов до приблизительно одной недели, от приблизительно 24 часов до приблизительно шести дней, от приблизительно 24 часов до приблизительно пяти дней, от приблизительно 24 часов до приблизительно четырех дней, от приблизительно 24 часов до приблизительно трех дней или от приблизительно 24 часов до приблизительно двух дней.
[271] В некоторых вариантах осуществления средний период полужизни терапевтического белка, содержащего средство, удлиняющее период полужизни, у субъекта составляет приблизительно 15 часов, приблизительно 16 часов, приблизительно 17 часов, приблизительно 18 часов, приблизительно 19 часов, приблизительно 20 часов, приблизительно 21 час, приблизительно 22 часа, приблизительно 23 часа, приблизительно 24 часа (1 день), приблизительно 25 часов, приблизительно 26 часов, приблизительно 27 часов, приблизительно 28 часов, приблизительно 29 часов, приблизительно 30 часов, приблизительно 31 час, приблизительно 32 часа, приблизительно 33 часа, приблизительно 34 часа, приблизительно 35 часов, приблизительно 36 часов, приблизительно 40 часов, приблизительно 44 часа, приблизительно 48 часов (2 дня), приблизительно 54 часа, приблизительно 60 часов, приблизительно 72 часа (3 дня), приблизительно 84 часа, приблизительно 96 часов (4 дня), приблизительно 108 часов, приблизительно 120 часов (5 дней), приблизительно шесть дней, приблизительно семь дней (одна неделя), приблизительно восемь дней, приблизительно девять дней, приблизительно 10 дней, приблизительно 11 дней, приблизительно 12 дней, приблизительно 13 дней или приблизительно 14 дней.
[272] Одно или несколько средств, удлиняющих период полужизни, могут быть слиты с С-концом или N-концом терапевтического белка или вставлены в терапевтический белок.
1. Константная область иммуноглобулина или ее часть
[273] В другом аспекте гетерологичный компонент содержит одну или несколько константных областей иммуноглобулина или их частей (например, Fc-область). В одном варианте осуществления выделенная молекула нуклеиновой кислоты по настоящему изобретению дополнительно содержит гетерологичную последовательность нуклеиновой кислоты, которая кодирует константную область иммуноглобулина или ее часть. В некоторых вариантах осуществления константная область иммуноглобулина или ее часть представляет собой Fc-область.
[274] Константная область иммуноглобулина состоит из доменов, обозначенных как СН- (константные, тяжелая цепь) домены (СН1, СН2 и т. д.). В зависимости от изотипа (т. е. IgG, IgM, IgA, IgD или IgE) константная область может состоять из трех или четырех доменов СН. Константные области некоторых изотипов (например, IgG) также содержат шарнирную область. См. Janeway et al. 2001, Immunobiology, Garland Publishing, N.Y., N.Y.
[275] Константная область иммуноглобулина или ее часть по настоящему изобретению могут быть получены из ряда различных источников. В одном варианте осуществления константная область иммуноглобулина или ее часть получены из иммуноглобулина человека. Однако, следует понимать, что константная область иммуноглобулина или ее часть могут быть получены из иммуноглобулина другого вида млекопитающего, в том числе, например, вида грызуна (например, мыши, крысы, кролика, морской свинки) или примата, отличного от человека (например, шимпанзе, макака). Кроме того, константная область иммуноглобулина или ее часть могут быть получены из любого класса иммуноглобулинов, в том числе IgM, IgG, IgD, IgA и IgE, и любого изотипа иммуноглобулинов, в том числе IgG1, IgG2, IgG3 и IgG4. В одном варианте осуществления применяют изотип IgG1 человека.
[276] Разнообразные последовательности генов константных областей иммуноглобулинов (например, последовательности генов константных областей человека) доступны в форме общедоступных депонирований. Можно выбрать последовательность домена константной области, обладающую конкретной эффекторной функцией (или не обладающую конкретной эффекторной функцией) или имеющую конкретную модификацию для снижения иммуногенности. Было опубликовано большое количество последовательностей антител и генов, кодирующих антитела, и подходящие последовательности константных областей Ig (например, последовательности шарнирных областей, СН2 и/или СН3 или их части) могут быть получены из этих последовательностей с применением методик, принятых в данной области техники. Генетический материал, полученный с применением любого из вышеуказанных способов, можно затем подвергать изменению или синтезу с получением полипептидов по настоящему изобретению. Дополнительно следует понимать, что объем настоящего изобретения охватывает аллели, варианты и мутации последовательностей ДНК константных областей.
[277] Последовательности константной области иммуноглобулина или ее части могут быть клонированы, например, с применением полимеразной цепной реакции и праймеров, выбранных для амплификации домена, представляющего интерес. Для клонирования константной области иммуноглобулина или ее части из антитела можно выделить мРНК из клеток гибридомы, селезенки или лимфатических клеток, подвергнуть ее обратной транскрипции с образованием ДНК и амплифицировать гены антитела с помощью ПЦР. Способы ПЦР-амплификации подробно описаны в патентах США №№ 4683195; 4683202; 4800159; 4965188 и, например, в "PCR Protocols: A Guide to Methods and Applications" Innis et al. eds., Academic Press, San Diego, CA (1990); Ho et al. 1989. Gene 77:51; Horton et al. 1993. Methods Enzymol. 217:270). ПЦР можно инициировать с помощью консенсусных праймеров для константной области или с помощью более специфичных праймеров на основе опубликованных последовательностей ДНК и аминокислот, соответствующих тяжелым и легким цепям. ПЦР также можно применять для выделения ДНК-клонов, кодирующих легкие и тяжелые цепи антител. В этом случае можно осуществлять скрининг библиотек с помощью консенсусных праймеров или более крупных гомологичных зондов, таких как зонды для константных областей мыши. Из уровня техники известны многочисленные наборы праймеров, подходящие для амплификации генов антител (например, 5’-праймеры на основе N-концевой последовательности очищенных антител (Benhar and Pastan. 1994. Protein Engineering 7:1509); праймеры для быстрой амплификации концов кДНК (Ruberti, F. et al. 1994. J. Immunol. Methods 173:33); праймеры для лидерных последовательностей антител (Larrick et al. 1989 Biochem. Biophys. Res. Commun. 160:1250). Клонирование последовательностей антител дополнительно описано в выданном Newman et al. патенте США № 5658570, заявка на который была подана 25 января 1995 г., который включен в данный документ посредством ссылки.
[278] Используемая в данном документе константная область иммуноглобулина может включать все домены и шарнирную область или их части. В одном варианте константная область иммуноглобулина или ее часть содержат домен СН2, домен СН3 и шарнирную область, т. е. Fc-область или партнера по связыванию FcRn.
[279] Используемый в данном документе термин "Fc-область" определяется как часть полипептида, которая соответствует Fc-области нативного Ig, т. e. образована путем димерной ассоциации соответствующих Fc-доменов двух его тяжелых цепей. Нативная Fc-область образует гомодимер с другой Fc-областью. В отличие от этого, термины "генетически слитая Fc-область" или "одноцепочечная Fc-область" (scFc-область), используемые в данном документе, относятся к синтетической димерной Fc-области, состоящей из Fc-доменов, генетически соединенных в одну полипептидную цепь (т. е. кодируемых одной непрерывной генетической последовательностью). См. международную публикацию № WO 2012/006635, включенную в данный документ посредством ссылки во всей своей полноте.
[280] В одном варианте осуществления "Fc-область" относится к части одной тяжелой цепи Ig, начинающейся в шарнирной области непосредственно выше сайта расщепления папаином (т. е. остатком 216 в IgG, если принять первый остаток константной области тяжелой цепи за 114) и заканчивающейся на С-конце антитела. Соответственно, полная Fc-область содержит по меньшей мере шарнирный домен, CH2-домен и CH3-домен.
[281] Константная область иммуноглобулина или ее часть может быть партнером по связыванию FcRn. FcRn активен в зрелых эпителиальных тканях и экспрессируется в просвете кишечника, легочных дыхательных путях, поверхностях носа, поверхностях влагалища, поверхностях толстой и прямой кишки (патент США № 6485726). Партнер по связыванию FcRn представляет собой часть иммуноглобулина, которая связывается с FcRn.
[282] Рецептор FcRn был выделен у некоторых видов млекопитающих, в том числе у людей. Известны последовательности FcRn человека, FcRn обезьяны, FcRn крысы и FcRn мыши (Story et al. 1994, J. Exp. Med. 180:2377). Рецептор FcRn связывает IgG (но не иммуноглобулины из других классов, таких как IgA, IgM, IgD и IgE) при относительно низком значении pH, осуществляет активный транспорт IgG через клетки по направлению от просвета к серозной оболочке, а затем высвобождает IgG при относительно более высоком значении pH, обнаруживаемом в интерстициальных жидкостях. Он экспрессируется в зрелой эпителиальной ткани (патенты США №№ 6485726, 6030613, 6086875; WO 03/077834; US2003-0235536A1), в том числе в эпителии легких и кишечника (Israel et al. 1997, Immunology 92:69), эпителии почечных проксимальных канальцев (Kobayashi et al. 2002, Am. J. Physiol. Renal Physiol. 282: F358), а также эпителии полости носа, на поверхностях влагалища и поверхностях билиарного дерева.
[283] Партнеры по связыванию FcRn, применимые в настоящем изобретении, охватывают молекулы, которые могут специфично связываться с рецептором FcRn, в том числе целый IgG, Fc-фрагмент IgG и другие фрагменты, которые включают в себя полную связывающую область для рецептора FcRn. Область Fc-части IgG, которая связывается с рецептором FcRn, была описана с использованием рентгеноструктурной кристаллографии (Burmeister et al. 1994, Nature 372:379). Основная область контакта Fc с FcRn находится вблизи стыка доменов CH2 и CH3. Все области контакта Fc-FcRn находятся в пределах одной тяжелой цепи Ig. Партнеры по связыванию FcRn включают целый IgG, Fc-фрагмент IgG и другие фрагменты IgG, которые включают в себя полную связывающую область для FcRn. Основные сайты контакта включают аминокислотные остатки 248, 250-257, 272, 285, 288, 290-291, 308-311 и 314 из домена CH2 и аминокислотные остатки 385-387, 428 и 433-436 из домена CH3. Все из ссылок на нумерацию аминокислот иммуноглобулинов или фрагментов или областей иммуноглобулинов приводятся согласно Kabat et al. 1991, Sequences of Proteins of Immunological Interest, U.S. Department of Public Health, Bethesda, Md.
[284] Fc-области или партнеры по связыванию FcRn, связанные с FcRn, могут эффективно переноситься через эпителиальные барьеры с помощью FcRn с обеспечением таким образом неинвазивного способа системного введения желаемой терапевтической молекулы. Кроме того, слитые белки, содержащие Fc-область или партнера по связыванию FcRn, подвергаются эндоцитозу клетками, экспрессирующими FcRn. Но вместо маркировки для деградации эти слитые белки снова возвращаются в кровоток, что, таким образом, увеличивает период полужизни этих белков in vivo. В определенных вариантах осуществления части константных областей иммуноглобулина представляют собой Fc-область или партнера по связыванию FcRn, который обычно связывается посредством дисульфидных связей и других неспецифических взаимодействий с другой Fc-областью или другим партнером по связыванию FcRn с образованием димеров и мультимеров более высокого порядка.
[285] Два рецептора FcRn могут связывать одну молекулу Fc. Кристаллографические данные позволяют предположить, что каждая молекула FcRn связывает один полипептид гомодимера Fc. В одном варианте осуществления связывание партнера по связыванию FcRn, например, Fc-фрагмента IgG, с биологически активной молекулой обеспечивает способ доставки биологически активной молекулы пероральным, трансбуккальным, сублингвальным, ректальным, вагинальным путем, в виде аэрозоля, вводимого назально или посредством легочного пути, или посредством глазного пути. В другом варианте осуществления белок, представляющий собой фактор свертывания крови, можно вводить инвазивным способом, например, подкожным, внутривенным путем.
[286] Область партнера по связыванию FcRn представляет собой молекулу или ее часть, которая может специфично связываться с рецептором FcRn с последующим активным транспортом Fc-области с помощью рецептора FcRn. "Специфично связывающийся" относится к двум молекулам, образующим комплекс, который является относительно стабильным при физиологических условиях. Специфичное связывание характеризуется высокой аффинностью и емкостью от низкой до умеренной, в отличие от неспецифичного связывания, которое обычно характеризуется низкой аффинностью и емкостью от умеренной до высокой. Как правило, связывание считается специфичным, если константа аффинности KA превышает 106 M-1 или превышает 108 M-1. При необходимости неспецифичное связывание можно снизить без существенного влияния на специфичное связывание путем изменения условий связывания. Соответствующие условия связывания, такие как концентрация молекул, ионная сила раствора, температура, допустимое время связывания, концентрация блокирующего средства (например, сывороточного альбумина, казеина молока) и т. д., могут быть оптимизированы специалистом в данной области с применением обычных методик.
[287] В определенных вариантах осуществления терапевтический белок, кодируемый молекулой нуклеиновой кислоты согласно настоящему изобретению, содержит одну или несколько усеченных Fc-областей, которые, тем не менее, являются достаточными для придания Fc-области свойств связывания с Fc-рецептором (FcR). Например, часть Fc-области, которая связывается с FcRn (т. e. FcRn-связывающая часть), содержит приблизительно аминокислоты 282-438 из IgG1 согласно нумерации EU (при этом основными сайтами контакта являются аминокислоты 248, 250-257, 272, 285, 288, 290-291, 308-311 и 314 из CH2-домена и аминокислотные остатки 385-387, 428 и 433-436 из CH3-домена). Таким образом, Fc-область согласно настоящему изобретению может содержать FcRn-связывающую часть или состоять из нее. FcRn-связывающие части могут быть получены из тяжелых цепей любого изотипа, в том числе IgG1, IgG2, IgG3 и IgG4. В одном варианте осуществления применяют FcRn-связывающую часть из антитела изотипа IgG1 человека. В другом варианте осуществления применяют FcRn-связывающую часть из антитела изотипа IgG4 человека.
[288] Fc-область может быть получена из ряда различных источников. В одном варианте осуществления Fc-область полипептида получена из иммуноглобулина человека. Однако, следует понимать, что Fc-компонент может быть получен из иммуноглобулина другого вида млекопитающего, в том числе, например, вида грызуна (например, мыши, крысы, кролика, морской свинки) или примата, отличного от человека (например, шимпанзе, макака). Более того, полипептидные Fc-домены или их части могут быть получены из любого класса иммуноглобулинов, в том числе IgM, IgG, IgD, IgA и IgE, и любого изотипа иммуноглобулинов, в том числе IgG1, IgG2, IgG3 и IgG4. В другом варианте осуществления применяют изотип IgG1 человека.
[289] В определенных вариантах осуществления вариант Fc обеспечивает изменение по меньшей мере одной эффекторной функции, придаваемой Fc-компонентом, содержащим указанный Fc-домен дикого типа (например, улучшение или снижение способности Fc-области к связыванию с Fc-рецепторами (например, FcγRI, FcγRII или FcγRIII) или белками системы комплемента (например, C1q) или к запуску антителозависимой цитотоксичности (ADCC), фагоцитоза или комплементзависимой цитотоксичности (CDCC)). В других вариантах осуществления в варианте Fc представлен сконструированный цистеиновый остаток.
[290] В качестве Fc-области по настоящему изобретению можно использовать известные из уровня техники варианты Fc, которые, как известно, придают изменение (например, усиление или снижение) эффекторной функции и/или связывания FcR или FcRn. В частности, Fc-область по настоящему изобретению может содержать, например, изменение (например, замену) в одном или нескольких аминокислотных положениях, раскрытых в международных публикациях согласно PCT WO88/07089A1, WO96/14339A1, WO98/05787A1, WO98/23289A1, WO99/51642A1, WO99/58572A1, WO00/09560A2, WO00/32767A1, WO00/42072A2, WO02/44215A2, WO02/060919A2, WO03/074569A2, WO04/016750A2, WO04/029207A2, WO04/035752A2, WO04/063351A2, WO04/074455A2, WO04/099249A2, WO05/040217A2, WO04/044859, WO05/070963A1, WO05/077981A2, WO05/092925A2, WO05/123780A2, WO06/019447A1, WO06/047350A2 и WO06/085967A2; публикациях заявок на патент США №№ US2007/0231329, US2007/0231329, US2007/0237765, US2007/0237766, US2007/0237767, US2007/0243188, US20070248603, US20070286859, US20080057056 или патентах США №№ 5648260; 5739277; 5834250; 5869046; 6096871; 6121022; 6194551; 6242195; 6277375; 6528624; 6538124; 6737056; 6821505; 6998253; 7083784; 7404956 и 7317091, каждый из которых включен в данный документ посредством ссылки. В одном варианте осуществления конкретное изменение (например, конкретная замена одной или нескольких аминокислот, раскрытых в уровне техники) может быть осуществлено в одном или нескольких раскрытых аминокислотных положениях. В другом варианте осуществления может быть осуществлено другое изменение в одном или нескольких раскрытых аминокислотных положениях (например, другая замена в одном или нескольких аминокислотных положениях, раскрытых в уровне техники).
[291] Fc-область IgG или его партнер по связыванию FcRn могут быть модифицированы в соответствии с хорошо известными процедурами, такими как сайт-направленный мутагенез и т. п., с получением модифицированных IgG или Fc-фрагментов или их частей, которые будут связываться с FcRn. Такие модификации включают модификации в отдалении от сайтов контакта с FcRn, а также модификации в пределах сайтов контакта, которые обеспечивают сохранение или даже усиление связывания с FcRn. Например, следующие отдельные аминокислотные остатки в Fc IgG1 человека (Fcγ1) могут быть заменены без значительной потери аффинности связывания Fc в отношении FcRn: P238A, S239A, K246A, K248A, D249A, M252A, T256A, E258A, T260A, D265A, S267A, H268A, E269A, D270A, E272A, L274A, N276A, Y278A, D280A, V282A, E283A, H285A, N286A, T289A, K290A, R292A, E293A, E294A, Q295A, Y296F, N297A, S298A, Y300F, R301A, V303A, V305A, T307A, L309A, Q311A, D312A, N315A, K317A, E318A, K320A, K322A, S324A, K326A, A327Q, P329A, A330Q, P331A, E333A, K334A, T335A, S337A, K338A, K340A, Q342A, R344A, E345A, Q347A, R355A, E356A, M358A, T359A, K360A, N361A, Q362A, Y373A, S375A, D376A, A378Q, E380A, E382A, S383A, N384A, Q386A, E388A, N389A, N390A, Y391F, K392A, L398A, S400A, D401A, D413A, K414A, R416A, Q418A, Q419A, N421A, V422A, S424A, E430A, N434A, T437A, Q438A, K439A, S440A, S444A, и K447A, где, например, P238A представляет пролин дикого типа, замененный аланином в положении под номером 238. В качестве примера, конкретный вариант осуществления включает мутацию N297A, обеспечивающую удаление высококонсервативного сайта N-гликозилирования. Аминокислоты дикого типа в положениях, указанных выше, могут быть заменены, в дополнение к аланину, другими аминокислотами. Мутации могут быть введены в Fc по отдельности, что приводит к образованию более ста Fc-областей, отличных от нативного Fc. Кроме того, комбинации из двух, трех или более из этих отдельных мутаций могут быть введены вместе, что приводит к образованию еще нескольких сотен Fc-областей.
[292] Определенные из вышеуказанных мутаций могут придавать новое функциональное свойство Fc-области или партнеру по связыванию FcRn. Например, один вариант осуществления включает N297A, обеспечивающую удаление высококонсервативного сайта N-гликозилирования. Эффект этой мутации заключается в снижении иммуногенности, за счет чего увеличивается период полужизни Fc-области в кровотоке, и обеспечении отсутствия у Fc-области способности к связыванию с FcγRI, FcγRIIA, FcγRIIB и FcγRIIIA без нарушения аффинности в отношении FcRn (Routledge et al. 1995, Transplantation 60:847; Friend et al. 1999, Transplantation 68:1632; Shields et al. 1995, J. Biol. Chem. 276:6591). В качестве дополнительного примера нового функционального свойства, возникающего в результате вышеописанных мутаций, аффинность в отношении FcRn в некоторых случаях может увеличиваться, превышая таковую у дикого типа. Эту увеличенную аффинность могут отражать увеличенная скорость ассоциации, сниженная скорость диссоциации или как увеличенная скорость ассоциации, так и сниженная скорость диссоциации. Примеры мутаций, которые, как полагают, придают увеличенную аффинность в отношении FcRn, включают без ограничения T256A, T307A, E380A и N434A (Shields et al. 2001, J. Biol. Chem. 276:6591).
[293] Кроме того, по меньшей мере три Fc-гамма-рецептора человека, по-видимому, распознают сайт связывания в IgG в нижней шарнирной области, обычно аминокислоты 234-237. Следовательно, другой пример нового функционального свойства и потенциальной сниженной иммуногенности может возникать в результате мутаций в этой области, как, например, путем замещения аминокислот 233-236 "ELLG" IgG1 человека (SEQ ID NO: 45) соответствующей последовательностью "PVA" из IgG2 (с одной аминокислотной делецией). Было показано, что FcγRI, FcγRII, и FcγRIII, которые опосредуют различные эффекторные функции, не будут связываться с IgG1 при введении таких мутаций. Ward and Ghetie 1995, Therapeutic Immunology 2:77, и Armour et al. 1999, Eur. J. Immunol. 29:2613.
[294] В другом варианте осуществления константная область иммуноглобулина или ее часть содержит аминокислотную последовательность в шарнирной области или ее части, которая образует одну или несколько дисульфидных связей со второй константной областью иммуноглобулина или ее частью. Вторая константная область иммуноглобулина или ее часть может быть связана со вторым полипептидом с объединением терапевтического белка и второго полипептида. В некоторых вариантах осуществления второй полипептид представляет собой энхансерный компонент. Используемый в данном документе термин "энхансерный компонент" относится к молекуле, ее фрагменту или компоненту полипептида, которые способны усиливать активность терапевтического белка. Энхансерный компонент может представлять собой кофактор, как, например, в случае, когда терапевтический белок представляет собой фактор свертывания крови, растворимый тканевой фактор (sTF) или прокоагулянтный пептид. Таким образом, после активации фактора свертывания крови энхансерный компонент доступен для усиления активности фактора свертывания крови.
[295] В определенных вариантах осуществления терапевтический белок, кодируемый молекулой нуклеиновой кислоты по настоящему изобретению, содержит аминокислотную замену в константной области иммуноглобулина или ее части (например, варианты Fc), обеспечивающую изменение антигеннезависимых эффекторных функций константной области Ig, в частности периода полужизни белка в кровотоке.
2. scFc-области
[296] В другом аспекте гетерологичный компонент содержит scFc-область (одноцепочечный Fc). В одном варианте осуществления выделенная молекула нуклеиновой кислоты по настоящему изобретению дополнительно содержит гетерологичную последовательность нуклеиновой кислоты, которая кодирует scFc-область. scFc-область содержит по меньшей мере две константные области иммуноглобулина или их части (например, Fc-компоненты или домены (например, 2, 3, 4, 5, 6 или более Fc-компонентов или доменов)) в одной и той же линейной полипептидной цепи, которая способна к сворачиванию (например, внутримолекулярному или межмолекулярному сворачиванию) с образованием одной функциональной scFc-области, связанной воедино пептидным линкером для Fc. Например, в одном варианте осуществления полипептид по настоящему изобретению способен связываться посредством его scFc-области с по меньшей мере одним Fc-рецептором (например, FcRn, рецептором FcγR (например, FcγRIII) или белком системы комплемента (например, C1q)) для улучшения периода полужизни, или запуска иммунной эффекторной функции (например, антителозависимой цитотоксичности (ADCC), фагоцитоза или комплементзависимой цитотоксичности (CDCC)), и/или для улучшения технологичности.
3. CTP
[297] В другом аспекте гетерологичный компонент содержит один C-концевой пептид (CTP) β-субъединицы хорионического гонадотропина человека или его фрагмент, вариант или производное. Известно, что один или несколько CTP-пептидов, вставленных в рекомбинантный белок, увеличивают период полужизни in vivo этого белка. См., например, патент США № 5712122, включенный в данный документ посредством ссылки во всей своей полноте.
[298] Иллюстративные CTP-пептиды включают DPRFQDSSSSKAPPPSLPSPSRLPGPSDTPIL (SEQ ID NO: 33) или SSSSKAPPPSLPSPSRLPGPSDTPILPQ (SEQ ID NO: 34). См., например, публикацию заявки на патент США № US 2009/0087411 A1, включенную посредством ссылки.
4. Последовательность XTEN
[299] В некоторых вариантах осуществления гетерологичный компонент содержит одну или несколько последовательностей XTEN, их фрагментов, вариантов или производных. Как используется в данном документе, "последовательность XTEN" относится к полипептидам увеличенной длины с не встречающимися в природе по сути неповторяющимися последовательностями, которые состоят в основном из небольших гидрофильных аминокислот, при этом последовательность характеризуется низкой степенью образования или отсутствием вторичной или третичной структуры при физиологических условиях. Являясь гетерологичным компонентом, XTEN могут служить в качестве компонента, удлиняющего период полужизни. Кроме того, XTEN может обеспечивать желаемые свойства, в том числе без ограничения улучшенные фармакокинетические параметры и характеристики растворимости.
[300] Встраивание гетерологичного компонента, содержащего последовательность XTEN, в белок по настоящему изобретению может придавать белку одно или несколько из следующих преимущественных свойств: конформационную гибкость, повышенную растворимость в воде, высокую степень устойчивости к протеазам, низкую иммуногенность, низкую степень связывания с рецепторами млекопитающих или увеличенные значения гидродинамического радиуса (или радиуса Стокса).
[301] В некоторых аспектах последовательность XTEN может обеспечивать увеличение фармакокинетических свойств, как, например, увеличение длительности периода полужизни in vivo или увеличение площади под кривой (AUC), так что белок по настоящему изобретению сохраняется in vivo и обладает прокоагулянтной активностью в течение увеличенного периода времени по сравнению с таким же белком, но без гетерологичного компонента XTEN.
[302] В некоторых вариантах осуществления последовательность XTEN, применимая в настоящем изобретении, представляет собой пептид или полипептид, содержащий более чем приблизительно 20, 30, 40, 50, 60, 70, 80, 90, 100, 150, 200, 250, 300, 350, 400, 450, 500, 550, 600, 650, 700, 750, 800, 850, 900, 950, 1000, 1200, 1400, 1600, 1800, или 2000 аминокислотных остатков. В определенных вариантах осуществления XTEN представляет собой пептид или полипептид, содержащий более чем от приблизительно 20 до приблизительно 3000 аминокислотных остатков, более чем от 30 до приблизительно 2500 остатков, более чем от 40 до приблизительно 2000 остатков, более чем от 50 до приблизительно 1500 остатков, более чем от 60 до приблизительно 1000 остатков, более чем от 70 до приблизительно 900 остатков, более чем от 80 до приблизительно 800 остатков, более чем от 90 до приблизительно 700 остатков, более чем от 100 до приблизительно 600 остатков, более чем от 110 до приблизительно 500 остатков или более чем от 120 до приблизительно 400 остатков. В одном конкретном варианте осуществления XTEN содержит аминокислотную последовательность длиной более 42 аминокислот и менее 144 аминокислот.
[303] Последовательность XTEN по настоящему изобретению может содержать один или несколько мотивов последовательности из 5-14 (например, от 9 до 14) аминокислотных остатков или аминокислотную последовательность, на по меньшей мере 80%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99% идентичную мотиву последовательности, где мотив содержит 4-6 типов аминокислот (например, 5 аминокислот), выбранных из группы, состоящей из глицина (G), аланина (A), серина (S), треонина (T), глутамата (E) и пролина (P), состоит по сути из них или состоит из них. См. US 2010-0239554 A1.
[304] В некоторых вариантах осуществления XTEN содержит неперекрывающиеся мотивы последовательностей, в которых приблизительно 80%, или по меньшей мере приблизительно 85%, или по меньшей мере приблизительно 90%, или приблизительно 91%, или приблизительно 92%, или приблизительно 93%, или приблизительно 94%, или приблизительно 95%, или приблизительно 96%, или приблизительно 97%, или приблизительно 98%, или приблизительно 99%, или приблизительно 100% последовательности состоит из нескольких звеньев неперекрывающихся последовательностей, выбранных из одного семейства мотивов, выбранного из таблицы 7, что в результате дает последовательность, характерную для определенного семейства. Используемый в данном документе термин "семейство" означает, что XTEN содержит мотивы, выбранные только из одной категории мотивов из таблицы 7, т. е. XTEN на основе AD, AE, AF, AG, AM, AQ, BC или BD, и что любые другие аминокислоты в XTEN, не относящиеся к мотиву из семейства, выбраны для достижения необходимого свойства, как, например, для обеспечения встраивания сайта рестрикции рядом с кодирующими нуклеотидами, встраивания последовательности для расщепления или для достижения лучшего связывания с терапевтическим белком. В некоторых вариантах осуществления семейств XTEN последовательность XTEN содержит несколько звеньев неперекрывающихся мотивов последовательностей из семейства мотивов AD, или семейства мотивов AE, или семейства мотивов AF, или семейства мотивов AG, или семейства мотивов AM, или семейства мотивов AQ, или семейства BC, или семейства BD, в результате чего XTEN демонстрирует диапазон гомологии, описанный выше. В других вариантах осуществления XTEN содержит несколько звеньев последовательностей мотивов из двух или более семейств мотивов из таблицы 7. Эти последовательности могут быть выбраны для достижения необходимых физических/химических характеристик, в том числе таких свойств, как суммарный заряд, гидрофильность, отсутствие вторичной структуры или отсутствие повторяемости, которые определяются аминокислотным составом мотивов, которые более полно описаны ниже. В вариантах осуществления, описанных выше в данном абзаце данного документа, мотивы, встраиваемые в XTEN, могут быть отобраны и собраны с применением способов, описанных в данном документе, для получения XTEN из от приблизительно 36 до приблизительно 3000 аминокислотных остатков.
Таблица 7. Мотивы последовательностей XTEN из 12 аминокислот и семейства мотивов
* Обозначает отдельные последовательности мотивов, которые при совместном применении в различных перестановках дают в результате "последовательность, характерную для определенного семейства".
[305] Примеры последовательностей XTEN, которые можно применять в качестве гетерологичных компонентов в терапевтических белках по настоящему изобретению, раскрыты, например, в публикациях заявок на патент США №№ 2010/0239554 A1, 2010/0323956 A1, 2011/0046060 A1, 2011/0046061 A1, 2011/0077199 A1 или 2011/0172146 A1 или публикациях международных заявок на патент №№ WO 2010091122 A1, WO 2010144502 A2, WO 2010144508 A1, WO 2011028228 A1, WO 2011028229 A1 или WO 2011028344 A2, каждая из которых включена в данный документ посредством ссылки во всей своей полноте.
[306] XTEN может иметь различную длину в случае вставки в терапевтический белок или связывания с ним. В одном варианте осуществления длину последовательности(последовательностей) XTEN выбирают с учетом свойства или функции, которые должны быть достигнуты в слитом белке. В зависимости от предполагаемого свойства или функции XTEN может представлять собой короткую последовательность или последовательность средней длины или более длинную последовательность, которые могут служить в качестве носителей. В определенных вариантах осуществления XTEN включает короткие сегменты из от приблизительно 6 до приблизительно 99 аминокислотных остатков, сегменты средней длины из от приблизительно 100 до приблизительно 399 аминокислотных остатков и более длинные сегменты из от приблизительно 400 до приблизительно 1000 и не более чем приблизительно 3000 аминокислотных остатков. Таким образом, XTEN, вставленный в терапевтический белок или связанный с ним, может иметь длину, составляющую приблизительно 6, приблизительно 12, приблизительно 36, приблизительно 40, приблизительно 42, приблизительно 72, приблизительно 96, приблизительно 144, приблизительно 288, приблизительно 400, приблизительно 500, приблизительно 576, приблизительно 600, приблизительно 700, приблизительно 800, приблизительно 864, приблизительно 900, приблизительно 1000, приблизительно 1500, приблизительно 2000, приблизительно 2500 или не более чем приблизительно 3000 аминокислотных остатков. В других вариантах осуществления длина последовательностей XTEN составляет от приблизительно 6 до приблизительно 50, от приблизительно 50 до приблизительно 100, от приблизительно 100 до 150, от приблизительно 150 до 250, от приблизительно 250 до 400, от приблизительно 400 до приблизительно 500, от приблизительно 500 до приблизительно 900, от приблизительно 900 до 1500, от приблизительно 1500 до 2000 или от приблизительно 2000 до приблизительно 3000 аминокислотных остатков. Точная длина XTEN, вставленного в терапевтический белок или связанного с ним, может варьироваться, при этом не оказывая отрицательного влияния на активность терапевтического белка. В одном варианте осуществления один или несколько из XTEN, применяемых в данном документе, имеют длину 42 аминокислоты, 72 аминокислоты, 144 аминокислоты, 288 аминокислот, 576 аминокислот или 864 аминокислоты и могут быть выбраны из одной или нескольких последовательностей, характерных для определенного семейства XTEN, т. е. AD, AE, AF, AG, AM, AQ, BC или BD.
[307] В некоторых вариантах осуществления терапевтический белок содержит полипептид FVIII и XTEN, где XTEN содержит 288 аминокислот. В одном варианте осуществления терапевтический белок содержит полипептид FVIII и XTEN, где XTEN содержит 288 аминокислот, и XTEN вставлен в домен B полипептида FVIII. В одном конкретном варианте осуществления терапевтический белок содержит полипептид FVIII и XTEN, содержащий SEQ ID NO:109, и XTEN вставлен в домен B полипептида FVIII. В одном конкретном варианте осуществления терапевтический белок содержит полипептид FVIII и XTEN, содержащий SEQ ID NO:109, и XTEN вставлен в полипептид FVIII непосредственно ниже аминокислоты 745 зрелого FVIII.
[308] В некоторых вариантах осуществления терапевтический белок содержит полипептид FIX и XTEN, где XTEN содержит 72 аминокислоты. В одном варианте осуществления терапевтический белок содержит полипептид FIX и XTEN, где XTEN содержит 72 аминокислоты, и XTEN вставлен в полипептид FIX непосредственно ниже аминокислоты 166 зрелого FIX.
[309] В некоторых вариантах осуществления последовательность XTEN, применяемая в настоящем изобретении, является на по меньшей мере 60%, 70%, 80%, 85%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, или 100% идентичной последовательности, выбранной из группы, состоящей из AE42, AG42, AE48, AM48, AE72, AG72, AE108, AG108, AE144, AF144, AG144, AE180, AG180, AE216, AG216, AE252, AG252, AE288, AG288, AE324, AG324, AE360, AG360, AE396, AG396, AE432, AG432, AE468, AG468, AE504, AG504, AF504, AE540, AG540, AF540, AD576, AE576, AF576, AG576, AE612, AG612, AE624, AE648, AG648, AG684, AE720, AG720, AE756, AG756, AE792, AG792, AE828, AG828, AD836, AE864, AF864, AG864, AM875, AE912, AM923, AM1318, BC864, BD864, AE948, AE1044, AE1140, AE1236, AE1332, AE1428, AE1524, AE1620, AE1716, AE1812, AE1908, AE2004A, AG948, AG1044, AG1140, AG1236, AG1332, AG1428, AG1524, AG1620, AG1716, AG1812, AG1908, AG2004, и любой их комбинации. См. US 2010-0239554 A1. В одном конкретном варианте осуществления XTEN содержит AE42, AE72, AE144, AE288, AE576, AE864, AG 42, AG72, AG144, AG288, AG576, AG864, или любую их комбинацию.
[310] Иллюстративные последовательности XTEN, которые можно применять в качестве гетерологичных компонентов в терапевтическом белке по настоящему изобретению, включают XTEN AE42-4 (SEQ ID NO: 46, кодируемую SEQ ID NO: 47), XTEN AE144-2A (SEQ ID NO: 48, кодируемую SEQ ID NO: 49), XTEN AE144-3B (SEQ ID NO: 50, кодируемую SEQ ID NO: 51), XTEN AE144-4A (SEQ ID NO: 52, кодируемую SEQ ID NO: 53), XTEN AE144-5A (SEQ ID NO: 54, кодируемую SEQ ID NO: 55), XTEN AE144-6B (SEQ ID NO: 56, кодируемую SEQ ID NO: 57), XTEN AG144-1 (SEQ ID NO: 58, кодируемую SEQ ID NO: 59), XTEN AG144-A (SEQ ID NO: 60, кодируемую SEQ ID NO: 61), XTEN AG144-B (SEQ ID NO: 62, кодируемую SEQ ID NO: 63), XTEN AG144-C (SEQ ID NO: 64, кодируемую SEQ ID NO: 65), а также XTEN AG144-F (SEQ ID NO: 66, кодируемую SEQ ID NO: 67). В одном конкретном варианте осуществления XTEN кодируется SEQ ID NO:18.
[311] В другом варианте осуществления последовательность XTEN выбрана из группы, состоящей из AE36 (SEQ ID NO: 130), AE42 (SEQ ID NO: 131), AE72 (SEQ ID NO: 132), AE78 (SEQ ID NO: 133), AE144 (SEQ ID NO: 134), AE144_2A (SEQ ID NO: 48), AE144_3B (SEQ ID NO: 50), AE144_4A (SEQ ID NO: 52), AE144_5A (SEQ ID NO: 54), AE144_6B (SEQ ID NO: 135), AG144 (SEQ ID NO: 136), AG144_A (SEQ ID NO: 137), AG144_B (SEQ ID NO: 62), AG144_C (SEQ ID NO: 64), AG144_F (SEQ ID NO: 66), AE288 (SEQ ID NO: 138), AE288_2 (SEQ ID NO: 139), AG288 (SEQ ID NO: 140), AE576 (SEQ ID NO: 141), AG576 (SEQ ID NO: 142), AE864 (SEQ ID NO: 143), AG864 (SEQ ID NO: 144), XTEN_AE72_2A_1 (SEQ ID NO:145), XTEN_AE72_2A_2 (SEQ ID NO: 146), XTEN_AE72_3B_1 (SEQ ID NO: 147), XTEN_AE72_3B_2 (SEQ ID NO: 148), XTEN_AE72_4A_2 (SEQ ID NO: 149), XTEN_AE72_5A_2 (SEQ ID NO: 150), XTEN_AE72_6B_1 (SEQ ID NO: 151), XTEN_AE72_6B_2 (SEQ ID NO: 152), XTEN_AE72_1A_1 (SEQ ID NO: 153), XTEN_AE72_1A_2 (SEQ ID NO: 154), XTEN_AE144_1A (SEQ ID NO: 155), AE150 (SEQ ID NO: 156), AG150 (SEQ ID NO: 157), AE294 (SEQ ID NO: 158), AG294 (SEQ ID NO: 159), и любых их комбинаций. В конкретном варианте осуществления последовательность XTEN выбрана из группы, состоящей из AE72, AE144 и AE288. Аминокислотные последовательности для определенных последовательностей XTEN по настоящему изобретению показаны в таблице 8.
Таблица 8. Последовательности XTEN
(SEQ ID NO: 130)
(SEQ ID NO: 131)
(SEQ ID NO: 132)
(SEQ ID NO: 133)
(SEQ ID NO: 134)
(SEQ ID NO: 135)
(SEQ ID NO:136)
(SEQ ID NO: 137)
(SEQ ID NO: 138)
(SEQ ID NO: 139)
(SEQ ID NO: 140)
(SEQ ID NO: 141)
(SEQ ID NO: 142)
(SEQ ID NO: 143)
(SEQ ID NO: 144)
(SEQ ID NO: 145)
(SEQ ID NO: 146)
(SEQ ID NO:147)
(SEQ ID NO: 148)
(SEQ ID NO: 149)
(SEQ ID NO: 150)
(SEQ ID NO: 152)
(SEQ ID NO: 153)
(SEQ ID NO: 154)
(SEQ ID NO: 155)
(SEQ ID NO: 156)
(SEQ ID NO: 157)
(SEQ ID NO: 158)
(SEQ ID NO: 159)
[312] В некоторых вариантах осуществления менее 100% аминокислот XTEN выбраны из глицина (G), аланина (A), серина (S), треонина (T), глутамата (E) и пролина (P) или менее чем 100% последовательности состоит из мотивов последовательностей из таблицы 7 или последовательностей XTEN, представленных в данном документе. В таких вариантах осуществления остальные аминокислотные остатки XTEN выбраны из любых других 14 природных L-аминокислот, но могут быть предпочтительно выбраны из гидрофильных аминокислот, так чтобы последовательность XTEN содержала по меньшей мере приблизительно 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или по меньшей мере приблизительно 99% гидрофильных аминокислот. Содержание гидрофобных аминокислот в XTEN, используемом в конструкциях, получаемых путем конъюгации, может представлять собой содержание гидрофобных аминокислот, составляющее менее 5%, или менее 2%, или менее 1%. Гидрофобные остатки, которые являются менее предпочтительными при конструировании XTEN, включают триптофан, фенилаланин, тирозин, лейцин, изолейцин, валин и метионин. Кроме того, последовательности XTEN могут содержать менее 5%, или менее 4%, или менее 3%, или менее 2%, или менее 1%, или ни одной из следующих аминокислот: метионина (например, во избежание окисления) или аспарагина и глутамина (во избежание дезамидирования).
[313] Одна или несколько последовательностей XTEN могут быть вставлены на С-конце или на N-конце терапевтического белка или вставлены между двумя аминокислотами в аминокислотной последовательности терапевтического белка. Например, если терапевтический белок содержит полипептид FVIII, XTEN может быть вставлен между двумя аминокислотами в одном или нескольких сайтах вставки, выбранных из таблицы 5. Если терапевтический белок содержит полипептид FIX, XTEN может быть вставлен между двумя аминокислотами в одном или нескольких сайтах вставки, выбранных из таблицы 5.
[314] Дополнительные примеры последовательностей XTEN, которые можно применять согласно настоящему изобретению, раскрыты в публикациях заявок на патент США №№ 2010/0239554 A1, 2010/0323956 A1, 2011/0046060 A1, 2011/0046061 A1, 2011/0077199 A1 или 2011/0172146 A1 или международных заявках на патент №№ WO 2010091122 A1, WO 2010144502 A2, WO 2010144508 A1, WO 2011028228 A1, WO 2011028229 A1, WO 2011028344 A2, WO 2014/011819 A2 или WO 2015/023891.
5. Альбумин или его фрагмент, производное или его вариант
[315] В некоторых вариантах осуществления гетерологичный компонент включает в себя альбумин или его функциональный фрагмент. Сывороточный альбумин человека (HSA или HA), белок из 609 аминокислот в своей полноразмерной форме, отвечает за значительную долю осмотического давления сыворотки крови, а также выполняет функцию носителя эндогенных и экзогенных лигандов. Термин "альбумин", используемый в данном документе, включает полноразмерный альбумин или его функциональный фрагмент, вариант, производное или аналог. Примеры альбумина или его фрагментов или вариантов раскрыты в публикациях заявок на патент США №№ 2008/0194481A1, 2008/0004206 A1, 2008/0161243 A1, 2008/0261877 A1 или 2008/0153751 A1 или в публикациях заявок согласно PCT №№ 2008/033413 A2, 2009/058322 A1 или 2007/021494 A2, которые включены в данный документ посредством ссылки во всей своей полноте.
[316] В одном варианте осуществления терапевтический белок по настоящему изобретению содержит альбумин, его фрагмент или вариант, который дополнительно связан со вторым гетерологичным компонентом, выбранным из группы, состоящей из константной области иммуноглобулина или ее части (например, Fc-области), последовательности PAS, HES, PEG и любой их комбинации.
6. Альбумин-связывающий компонент
[317] В определенных вариантах осуществления гетерологичный компонент представляет собой альбумин-связывающий компонент, который включает в себя альбумин-связывающий пептид, бактериальный альбумин-связывающий домен, фрагмент альбумин-связывающего антитела или любые их комбинации.
[318] Например, альбумин-связывающий белок может представлять собой бактериальный альбумин-связывающий белок, антитело или фрагмент антитела, в том числе доменные антитела (см. патент США № 6696245). Альбумин-связывающий белок, например, может представлять собой бактериальный альбумин-связывающий домен, такой как домен стрептококкового белка G (Konig, T. and Skerra, A. (1998) J. Immunol. Methods 218, 73-83). Другими примерами альбумин-связывающих пептидов, которые можно применять в качестве партнера по конъюгации, являются, например, пептиды, имеющие консенсусную последовательность Cys-Xaa1-Xaa2-Xaa3-Xaa4-Cys, где Xaa1 представляет собой Asp, Asn, Ser, Thr или Trp; Xaa2 представляет собой Asn, Gln, His, Ile, Leu или Lys; Xaa3 представляет собой Ala, Asp, Phe, Trp или Tyr; и Xaa4 представляет собой Asp, Gly, Leu, Phe, Ser или Thr, как описано в заявке на патент США 2003/0069395 или у Dennis et al. (Dennis et al. (2002) J. Biol. Chem. 277, 35035-35043).
[319] Домен 3 из стрептококкового белка G, раскрытого в Kraulis et al., FEBS Lett. 378:190-194 (1996) и Linhult et al., Protein Sci. 11:206-213 (2002), является примером бактериального альбумин-связывающего домена. Примеры альбумин-связывающих пептидов включают ряд пептидов, содержащих сердцевинную последовательность DICLPRWGCLW (SEQ ID NO: 35). См., например, Dennis et al., J. Biol. Chem. 2002, 277: 35035-35043 (2002). Примеры фрагментов альбумин-связывающих антител раскрыты в Muller and Kontermann, Curr. Opin. Mol. Ther. 9:319-326 (2007); Roovers et al., Cancer Immunol. Immunother. 56:303-317 (2007), и Holt et al., Prot. Eng. Design Sci., 21:283-288 (2008), которые включены в данный документ посредством ссылки во всей своей полноте. Примером такого альбумин-связывающего компонента является 2-(3-малеимидопропанамидо)-6-(4-(4-йодфенил)бутанамидо)гексаноат (метка "Albu"), раскрытый в Trussel et al., Bioconjugate Chem. 20:2286-2292 (2009).
[320] Жирные кислоты, в частности длинноцепочечные жирные кислоты (LCFA) и альбумин-связывающие соединения, подобные длинноцепочечным жирным кислотам, могут применяться для удлинения периода полужизни in vivo белков, представляющих собой факторы свертывания крови, по настоящему изобретению. Примером LCFA-подобного альбумин-связывающего соединения является 16-(1-(3-(9-(((2,5-диоксопирролидин-1-илокси)карбонилокси)метил)-7-сульфо-9H-флуорен-2-иламино)-3-оксопропил)-2,5-диоксопирролидин-3-илтио)гексадекановая кислота (см., например, WO 2010/140148).
7. Последовательность PAS
[321] В других вариантах осуществления гетерологичный компонент представляет собой последовательность PAS. Последовательность PAS, как используется в данном документе, означают аминокислотную последовательность, содержащую в основном аланиновые и сериновые остатки или содержащую в основном аланиновые, сериновые и пролиновые остатки, при этом аминокислотная последовательность образует случайную спиральную конформацию при физиологических условиях. Соответственно, последовательность PAS представляет собой структурный блок, полимер из аминокислот или последовательность-кассету, которые содержат аланин, серин и пролин, состоят по сути из них или состоят из них, которые можно применять в качестве части гетерологичного компонента в химерном белке. Тем не менее, специалист в данной области знает, что полимер из аминокислот также может образовывать случайную спиральную конформацию при добавлении в последовательность PAS остатков, отличных от аланина, серина и пролина, в качестве дополнительного составляющего. Используемый в данном документе термин "дополнительное составляющее" означает, что аминокислоты, отличные от аланина, серина и пролина, могут быть добавлены в последовательность PAS в определенной мере, например, в количестве не более чем приблизительно 12%, т. е. приблизительно 12 из 100 аминокислот последовательности PAS, не более чем приблизительно 10%, т. е. приблизительно 10 из 100 аминокислот последовательности PAS, не более чем приблизительно 9%, т. е. приблизительно 9 из 100 аминокислот, не более чем приблизительно 8%, т. е. приблизительно 8 из 100 аминокислот, приблизительно 6%, т. е. приблизительно 6 из 100 аминокислот, приблизительно 5%, т. е. приблизительно 5 из 100 аминокислот, приблизительно 4%, т. е. приблизительно 4 из 100 аминокислот, приблизительно 3%, т. е. приблизительно 3 из 100 аминокислот, приблизительно 2%, т. е. приблизительно 2 из 100 аминокислот, приблизительно 1%, т. е. приблизительно 1 из 100 аминокислот. Аминокислоты, отличные от аланина, серина и пролина, могут быть выбраны из группы, состоящей из Arg, Asn, Asp, Cys, Gln, Glu, Gly, His, Ile, Leu, Lys, Met, Phe, Thr, Trp, Tyr и Val.
[322] При физиологических условиях отрезок последовательности PAS образует случайную спиральную конформацию и тем самым может опосредовать увеличение стабильности in vivo и/или in vitro у белка, представляющего собой фактор свертывания крови. Поскольку домен со случайной спиральной конформацией не принимает стабильную структуру или функцию сам по себе, биологическая активность, опосредованная белком, представляющим собой фактор свертывания крови, по существу сохраняется. В других вариантах осуществления последовательности PAS, которые образуют домен со случайной спиральной конформацией, являются биологически инертными, особенно в отношении протеолиза в плазме крови, иммуногенности, изоэлектрической точки/электростатического поведения, связывания с рецепторами клеточной поверхности или интернализации, но по-прежнему являются биоразлагаемыми, что обеспечивает явные преимущества по сравнению с синтетическими полимерами, такими как PEG.
[323] Неограничивающие примеры последовательностей PAS, образующих случайную спиральную конформацию, включают аминокислотную последовательность, выбранную из группы, состоящей из ASPAAPAPASPAAPAPSAPA (SEQ ID NO: 36), AAPASPAPAAPSAPAPAAPS (SEQ ID NO: 37), APSSPSPSAPSSPSPASPSS (SEQ ID NO: 38), APSSPSPSAPSSPSPASPS (SEQ ID NO: 39), SSPSAPSPSSPASPSPSSPA (SEQ ID NO: 40), AASPAAPSAPPAAASPAAPSAPPA (SEQ ID NO: 41), ASAAAPAAASAAASAPSAAA (SEQ ID NO: 42) и любых их комбинаций. Дополнительные примеры последовательностей PAS известны, например, из публикации заявки на патент США № 2010/0292130 A1 и публикации заявки согласно PCT № WO 2008/155134 A1.
8. Последовательность HAP
[324] В определенных вариантах осуществления гетерологичный компонент представляет собой богатый глицином гомополимер из аминокислот (HAP). Последовательность HAP может содержать последовательность из повторяющихся остатков глицина, которая имеет длину по меньшей мере 50 аминокислот, по меньшей мере 100 аминокислот, 120 аминокислот, 140 аминокислот, 160 аминокислот, 180 аминокислот, 200 аминокислот, 250 аминокислот, 300 аминокислот, 350 аминокислот, 400 аминокислот, 450 аминокислот или 500 аминокислот. В одном варианте осуществления последовательность HAP способна обеспечивать удлинение периода полужизни компонента, слитого или связанного с последовательностью HAP. Неограничивающие примеры последовательности HAP включают без ограничения (Gly)n, (Gly4Ser)n или S(Gly4Ser)n, где n равняется 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, или 20. В одном варианте осуществления n равняется 20, 21, 22, 23, 24, 25, 26, 26, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, или 40. В другом варианте осуществления n равняется 50, 60, 70, 80, 90, 100, 110, 120, 130, 140, 150, 160, 170, 180, 190, или 200.
9. Трансферрин или его фрагмент
[325] В определенных вариантах осуществления гетерологичный компонент представляет собой трансферрин или его фрагмент. Можно применять любой трансферрин для получения белков, представляющих собой факторы свертывания крови, по настоящему изобретению. В качестве примера, TF человека дикого типа (TF) представляет собой белок из 679 аминокислот размером примерно 75 кДа (без учета гликозилирования) с двумя основными доменами N (приблизительно 330 аминокислот) и C (приблизительно 340 аминокислот), которые, по-видимому, образуются в результате дупликации гена. См. номера доступа в GenBank NM001063, XM002793, M12530, XM039845, XM 039847 и S95936 (www.ncbi.nlm.nih.gov/), все из которых включены в данный документ посредством ссылки во всей своей полноте. Трансферрин содержит два домена: N-домен и C-домен. N-домен содержит два субдомена N1-домен и N2-домен, а C-домен содержит два субдомена C1-домен и C2-домен.
[326] В одном варианте осуществления гетерологичный компонент трансферрин включает в себя сплайс-вариант трансферрина. В одном примере сплайс-вариант трансферрина может представлять собой сплайс-вариант трансферрина человека, например, с номером доступа в Genbank AAA61140. В другом варианте осуществления часть химерного белка, представляющая собой трансферрин, включает в себя один или несколько доменов последовательности трансферрина, например, N-домен, C-домен, N1-домен, N2-домен, C1-домен, C2-домен или любые их комбинации.
10. Рецепторы, опосредующие выведение
[327] В определенных вариантах осуществления гетерологичный компонент представляет собой рецептор, опосредующий выведение, его фрагмент, вариант или производное. LRP1 представляет собой интегральный мембранный белок размером 600 кДа, который участвует в рецептор-опосредованном выведении различных белков, таких как фактор X. См., например, Narita et al., Blood 91:555-560 (1998).
11. Фактор фон Виллебранда или его фрагменты
[328] В определенных вариантах осуществления гетерологичный компонент представляет собой фактор фон Виллебранда (VWF) или один или несколько его фрагментов.
[329] VWF (также известный как F8VWF) представляет собой крупный мультимерный гликопротеин, присутствующий в плазме крови и продуцируемый конститутивно в эндотелии (в тельцах Вайбеля-Паладе), мегакариоцитах (α-гранулах тромбоцитов) и субэндотелиальной соединительной ткани. Основным мономером VWF является белок из 2813 аминокислот. Каждый мономер содержит ряд специфических доменов с конкретной функцией - домены D' и D3 (которые связываются с фактором VIII), домен A1 (который связывается с тромбоцитарным рецептором GPIb, гепарином и/или, возможно, коллагеном), домен A3 (который связывается с коллагеном), домен C1 (в котором домен RGD связывается с тромбоцитарным интегрином αIIbβ3, когда он активирован) и домен "цистеиновый узел" на C-конце белка (который является общим для VWF и тромбоцитарного фактора роста (PDGF), трансформирующего фактора роста β (TGFβ) и β-субъединицы хорионического гонадотропина человека (βHCG)).
[330] Последовательность мономерного VWF человека из 2813 аминокислот приведена в Genbank под номером доступа NP000543.2. Нуклеотидная последовательность, кодирующая VWF человека, приведена в Genbank под номером доступа NM000552.3. SEQ ID NO: 129 представляет собой аминокислотную последовательность, кодируемую SEQ ID NO: 128. Домен D’ включает аминокислоты с 764 по 866 SEQ ID NO: 129. Домен D3 включает аминокислоты с 867 по 1240 SEQ ID NO: 44.
[331] В плазме крови 95-98% FVIII циркулирует в виде плотного нековалентного комплекса с полноразмерным VWF. Образование этого комплекса важно для поддержания надлежащих уровней FVIIII в плазме крови in vivo. Lenting et al., Blood. 92(11): 3983-96 (1998); Lenting et al., J. Thromb. Haemost. 5(7): 1353-60 (2007). При активации FVIII вследствие протеолиза в положениях 372 и 740 в тяжелой цепи и в положении 1689 в легкой цепи VWF, связанный с FVIII, удаляется от активированного FVIII.
[332] В определенных вариантах осуществления гетерологичный компонент представляет собой полноразмерный фактор фон Виллебранда. В других вариантах осуществления гетерологичный фрагмент представляет собой фрагмент фактора фон Виллебранда. Используемый в данном документе термин "фрагмент VWF" или "фрагменты VWF" означает любые фрагменты VWF, которые взаимодействуют с FVIII и сохраняют по меньшей мере одно или несколько свойств, которые обычно обеспечиваются у FVIII благодаря полноразмерному VWF, например, предотвращение преждевременной активации до FVIIIa, предотвращение преждевременного протеолиза, предотвращение ассоциации с фосфолипидными мембранами, которая может привести к преждевременному выведению, предотвращение связывания с рецепторами, опосредующими выведение FVIII, которые могут связываться с "голым" FVIII, но не с FVIII, связанным с VWF, и/или стабилизацию взаимодействий тяжелой цепи и легкой цепи FVIII. В конкретном варианте осуществления гетерологичный компонент представляет собой фрагмент (VWF), содержащий домен D’ и домен D3 VWF. Фрагмент VWF, содержащий домен D’ и домен D3, может дополнительно содержать домен VWF, выбранный из группы, состоящей из домена A1, домена A2, домена A3, домена D1, домена D2, домена D4, домена B1, домена B2, домена B3, домена C1, домена C2, домена CK, одного или нескольких их фрагментов и любых их комбинаций. Дополнительные примеры полипептида, характеризующегося активностью FVIII, слитого с фрагментом VWF, раскрыты в предварительной заявке на патент США № 61/667901, поданной 3 июля 2012 г., и публикации заявки на патент США № 2015/0023959 А1, обе из которых включены в данный документ посредством ссылки во всей своей полноте.
12. Линкерные компоненты
[333] В определенных вариантах осуществления гетерологичный компонент представляет собой пептидный линкер.
[334] Используемые в данном документе термины "пептидные линкеры" или "линкерные компоненты" относятся к пептидной или полипептидной последовательности (например, синтетической пептидной или полипептидной последовательности), которая соединяет два домена в виде линейной аминокислотной последовательности полипептидной цепи.
[335] В некоторых вариантах осуществления пептидные линкеры могут быть вставлены между терапевтическим белком по настоящему изобретению и гетерологичным компонентом, описанным выше, таким как альбумин. Пептидные линкеры могут обеспечивать гибкость для молекулы химерного полипептида. Обычно линкеры не расщепляются, однако такое расщепление может быть желательным. В одном варианте осуществления эти линкеры не удаляются во время обработки.
[336] Тип линкера, который может присутствовать в химерном белке по настоящему изобретению, представляет собой линкер, расщепляемый протеазами, который содержит сайт расщепления (т. е. субстрат с сайтом расщепления протеазами, например, фактор XIa, Xa или сайт расщепления тромбином) и который может содержать дополнительные линкеры с N-концевой, с С-концевой либо с обеих сторон от сайта расщепления. Эти расщепляемые линкеры при встраивании в конструкцию по настоящему изобретению дают в результате химерную молекулу, имеющую гетерологичный сайт расщепления.
[337] В одном варианте осуществления терапевтический белок, кодируемый молекулой нуклеиновой кислоты по настоящему изобретению, содержит два или более Fc-домена или компонента, связанных с помощью cscFc-линкера с образованием Fc-области, содержащейся в одной полипептидной цепи. cscFc-линкер фланкирован по меньшей мере одним сайтом внутриклеточного процессинга, т. е. сайтом, расщепляемым внутриклеточным ферментом. Расщепление полипептида в по меньшей мере одном сайте внутриклеточного процессинга приводит к образованию полипептида, который содержит по меньшей мере две полипептидные цепи.
[338] В конструкции по настоящему изобретению необязательно могут применяться другие пептидные линкеры, например, для соединения белка, представляющего собой фактор свертывания крови, с Fc-областью. Некоторые иллюстративные линкеры, которые можно применять в связи с настоящим изобретением, включают, например, полипептиды, содержащие аминокислоты GlySer, более подробно описанные ниже.
[339] В одном варианте осуществления пептидный линкер является синтетическим, т. е. не встречающимся в природе. В одном варианте осуществления пептидный линкер включает в себя пептиды (или полипептиды) (которые могут быть встречающимися или не встречающимися в природе), которые содержат аминокислотную последовательность, которая обеспечивает связывание или генетическое слияние первой линейной последовательности аминокислот и второй линейной последовательности аминокислот, с которой она в естественных условиях не связана или генетически не слита в природе. Например, в одном варианте осуществления пептидный линкер может содержать не встречающиеся в природе полипептиды, которые являются модифицированными формами встречающихся в природе полипептидов (например, содержащие мутацию, такую как добавление, замена или делеция). В другом варианте осуществления пептидный линкер может содержать не встречающиеся в природе аминокислоты. В другом варианте осуществления пептидный линкер может содержать встречающиеся в природе аминокислоты, представленные в виде линейной последовательности, которая не встречается в природе. В еще одном варианте осуществления пептидный линкер может содержать встречающуюся в природе полипептидную последовательность.
[340] Например, в определенных вариантах осуществления пептидный линкер можно применять для слияния идентичных Fc-компонентов с образованием таким образом гомодимерной scFc-области. В других вариантах осуществления пептидный линкер можно применять для слияния различных Fc-компонентов (например, Fc-компонента дикого типа и варианта Fc-фрагмента) с образованием таким образом гетеродимерной scFc-области.
[341] В другом варианте осуществления пептидный линкер содержит линкер Gly-Ser или состоит из него. В одном варианте осуществления scFc или cscFc-линкер содержит по меньшей мере часть шарнирной области иммуноглобулина и линкер Gly-Ser. Используемый в данном документе термин "линкер Gly-Ser" относится к пептиду, который состоит из глициновых и сериновых остатков. В определенных вариантах осуществления указанный линкер Gly-Ser может быть вставлен между двумя другими последовательностями пептидного линкера. В других вариантах осуществления линкер Gly-Ser присоединен на одном или обоих концах другой последовательности пептидного линкера. В еще нескольких других вариантах осуществления два или более линкера Gly-Ser последовательно встроены в пептидный линкер. В одном варианте осуществления пептидный линкер по настоящему изобретению содержит по меньшей мере часть верхней шарнирной области (например, полученной из молекулы IgG1, IgG2, IgG3 или IgG4), по меньшей мере часть средней шарнирной области (например, полученной из молекулы IgG1, IgG2, IgG3 или IgG4) и последовательный ряд аминокислотных остатков Gly/Ser.
[342] Пептидные линкеры по настоящему изобретению имеют длину, составляющую по меньшей мере одну аминокислоту, и могут иметь различную длину. В одном варианте осуществления пептидный линкер по настоящему изобретению имеет длину, составляющую от приблизительно 1 до приблизительно 50 аминокислот. Как используется в данном контексте, термин "приблизительно" обозначает +/- два аминокислотных остатка. Поскольку длина линкера должна представлять собой положительное целое число, длина от приблизительно 1 до приблизительно 50 аминокислот в длину означает длину от 1-3 до 48-52 аминокислот в длину. В другом варианте осуществления пептидный линкер по настоящему изобретению имеет длину, составляющую от приблизительно 10 до приблизительно 20 аминокислот. В другом варианте осуществления пептидный линкер по настоящему изобретению имеет длину, составляющую от приблизительно 15 до приблизительно 50 аминокислот. В другом варианте осуществления пептидный линкер по настоящему изобретению имеет длину, составляющую от приблизительно 20 до приблизительно 45 аминокислот. В другом варианте осуществления пептидный линкер по настоящему изобретению имеет длину, составляющую от приблизительно 15 до приблизительно 35 или от приблизительно 20 до приблизительно 30 аминокислот. В другом варианте осуществления пептидный линкер по настоящему изобретению имеет длину, составляющую приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 40, 50, 60, 70, 80, 90, 100, 500, 1000, или 2000 аминокислот. В одном варианте осуществления пептидный линкер по настоящему изобретению имеет длину, составляющую 20 или 30 аминокислот.
[343] В некоторых вариантах осуществления пептидный линкер может содержать по меньшей мере две, по меньшей мере три, по меньшей мере четыре, по меньшей мере пять, по меньшей мере 10, по меньшей мере 20, по меньшей мере 30, по меньшей мере 40, по меньшей мере 50, по меньшей мере 60, по меньшей мере 70, по меньшей мере 80, по меньшей мере 90 или по меньшей мере 100 аминокислот. В других вариантах осуществления пептидный линкер может содержать по меньшей мере 200, по меньшей мере 300, по меньшей мере 400, по меньшей мере 500, по меньшей мере 600, по меньшей мере 700, по меньшей мере 800, по меньшей мере 900 или по меньшей мере 1000 аминокислот. В некоторых вариантах осуществления пептидный линкер может содержать по меньшей мере приблизительно 10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 150, 200, 300, 400, 500, 600, 700, 800, 900, 1000, 1100, 1200, 1300, 1400, 1500, 1600, 1700, 1800, 1900, или 2000 аминокислот. Пептидный линкер может содержать 1-5 аминокислот, 1-10 аминокислот, 1-20 аминокислот, 10-50 аминокислот, 50-100 аминокислот, 100-200 аминокислот, 200-300 аминокислот, 300-400 аминокислот, 400-500 аминокислот, 500-600 аминокислот, 600-700 аминокислот, 700-800 аминокислот, 800-900 аминокислот или 900-1000 аминокислот.
[344] Пептидные линкеры можно вводить в полипептидные последовательности с помощью методик, известных из уровня техники. Модификации можно подтверждать с помощью анализа последовательности ДНК. Для трансформации клеток-хозяев для стабильного продуцирования получаемых полипептидов можно применять плазмидную ДНК.
13. Мономерно-димерные гибриды
[345] В некоторых вариантах осуществления терапевтический белок по настоящему изобретению содержит мономерно-димерную гибридную молекулу, содержащую фактор свертывания крови.
[346] Используемый в данном документе термин "мономерно-димерный гибрид" относится к химерному белку, содержащему первую полипептидную цепь и вторую полипептидную цепь, которые связаны друг с другом дисульфидной связью, где первая цепь содержит фактор свертывания крови, например, FVIII, и первую Fc-область, а вторая цепь содержит вторую Fc-область без фактора свертывания крови, состоит по сути из нее или состоит из нее. Таким образом, мономерно-димерная гибридная конструкция представляет собой гибрид, содержащий мономерный компонент, имеющий только один фактор свертывания крови, и димерный компонент, имеющий две Fc-области.
14. Последовательности, контролирующие экспрессию
[347] В некоторых вариантах осуществления молекула нуклеиновой кислоты по настоящему изобретению дополнительно содержит по меньшей мере одну последовательность, контролирующую экспрессию. Последовательность, контролирующая экспрессию, как используется в данном документе, представляет собой любую регуляторную нуклеотидную последовательность, такую как промоторная последовательность или комбинация промотор-энхансер, которая способствует эффективной транскрипции и трансляции кодирующей нуклеиновой кислоты, с которой она функционально связана. Например, молекула нуклеиновой кислоты по настоящему изобретению может быть функционально связана с по меньшей мере одной последовательностью, контролирующей транскрипцию. Последовательность, контролирующая экспрессию гена, может, например, представлять собой промотор млекопитающего или вируса, такой как конститутивный или индуцируемый промотор.
[348] Конститутивные промоторы млекопитающих включают без ограничения промоторы следующих генов: гипоксантин-фосфорибозилтрансферазы (HPRT), аденозиндезаминазы, пируваткиназы, промотор гена бета-актина и другие конститутивные промоторы. Иллюстративные вирусные промоторы, которые функционируют конститутивно в эукариотических клетках, включают, например, промоторы из цитомегаловируса (CMV), вируса обезьян (например, SV40), вируса папилломы, аденовируса, вируса иммунодефицита человека (HIV), вируса саркомы Рауса, цитомегаловируса, длинные концевые повторы (LTR) вируса лейкоза Молони и других ретровирусов, а также промотор гена тимидинкиназы вируса простого герпеса. Средним специалистам в данной области известны другие конститутивные промоторы. Промоторы, применимые в качестве последовательностей, контролирующих экспрессию генов, согласно настоящему изобретению, также включают индуцируемые промоторы. Индуцируемые промоторы обеспечивают экспрессию в присутствии индуцирующего средства. Например, промотор гена металлотионеина индуцируется, способствуя транскрипции и трансляции, в присутствии определенных ионов металлов. Средним специалистам в данной области известны другие индуцируемые промоторы.
[349] В одном варианте осуществления настоящее изобретение предусматривает экспрессию трансгена под контролем тканеспецифического промотора и/или энхансера. В другом варианте осуществления промотор или другая последовательность, контролирующая экспрессию, избирательно усиливает экспрессию трансгена в клетках печени. В определенных вариантах осуществления промотор или другая последовательность, контролирующая экспрессию, избирательно усиливает экспрессию трансгена в гепатоцитах, синусоидальных клетках и/или эндотелиальных клетках. В одном конкретном варианте осуществления промотор или другая последовательность, контролирующая экспрессию, избирательно усиливает экспрессию трансгена в эндотелиальных клетках. В определенных вариантах осуществления промотор или другая последовательность, контролирующая экспрессию, избирательно усиливает экспрессию трансгена в мышечных клетках, клетках центральной нервной системы, глаза, печени, сердца или любой их комбинации. Примеры специфичных для печени промоторов включают без ограничения промотор гена тиретина мыши (mTTR), эндогенный промотор гена фактора VIII человека (F8), промотор гена альфа-1-антитрипсина человека (hAAT), минимальный промотор гена альбумина человека и промотор гена альбумина мыши. В одном конкретном варианте осуществления промотор включает в себя промотор mTTR. Промотор mTTR описан в R. H. Costa et al., 1986, Mol. Cell. Biol. 6:4697. Промотор F8 описан в Figueiredo and Brownlee, 1995, J. Biol. Chem. 270:11828-11838. В некоторых вариантах осуществления промотор выбран из специфичного для печени промотора (например, гена α1-антитрипсина (AAT)), специфичного для мышц промотора (например, гена мышечной креатинкиназы (MCK), тяжелой цепи миозина альфа (αMHC), миоглобина (MB) и десмина (DES)), синтетического промотора (например, SPc5-12, 2R5Sc5-12, dMCK и tMCK) и любой их комбинации.
[350] В одном варианте осуществления промотор выбран из группы, состоящей из промотора гена тиретина мыши (mTTR), эндогенного промотора гена фактора VIII человека (F8), промотора гена альфа-1-антитрипсина человека (hAAT), минимального промотора гена альбумина человека, промотора гена альбумина мыши, TTPp, промотора CASI, промотора CAG, промотора цитомегаловируса (CMV), промотора гена α1-антитрипсина (AAT), мышечной креатинкиназы (MCK), тяжелой цепи миозина альфа (αMHC), миоглобина (MB), десмина (DES), SPc5-12, 2R5Sc5-12, dMCK и tMCK, фосфоглицераткиназы (PGK) и любой их комбинации.
[351] Уровни экспрессии можно дополнительно повысить для достижения терапевтической эффективности с применением одного или нескольких энхансеров. Один или несколько энхансеров могут предоставляться отдельно или вместе с одним или несколькими промоторными элементами. Как правило, последовательность, контролирующая экспрессию, содержит множество энхансерных элементов и тканеспецифический промотор. В одном варианте осуществления энхансер содержит одну или несколько копий энхансера гена α-1-микроглобулина/бикунина (Rouet et al., 1992, J. Biol. Chem. 267:20765-20773; Rouet et al., 1995, Nucleic Acids Res. 23:395-404; Rouet et al., 1998, Biochem. J. 334:577-584; Ill et al., 1997, Blood Coagulation Fibrinolysis 8:S23-S30). В другом варианте осуществления энхансер получен из сайтов связывания специфичных для печени факторов транскрипции, таких как EBP, DBP, HNF1, HNF3, HNF4, HNF6, при этом Enh1 содержит HNF1 (смысловая) - HNF3 (смысловая) - HNF4 (антисмысловая) - HNF1 (антисмысловая) - HNF6 (смысловая) - EBP (антисмысловая) - HNF4 (антисмысловая).
[352] В конкретном примере промотор, применимый для настоящего изобретения, содержит SEQ ID NO: 69 (т. е. промотор ET), который также известен под номером доступа в GenBank AY661265. См. также Vigna et al., Molecular Therapy 11(5):763 (2005). Примеры других подходящих векторов и регуляторных элементов генов описаны в WO 02/092134, EP 1395293 или патентах США №№ 6808905, 7745179 или 7179903, которые включены в данный документ посредством ссылки во всей своей полноте.
[353] В одном варианте осуществления молекула нуклеиновой кислоты по настоящему изобретению дополнительно содержит интронную последовательность. В некоторых вариантах осуществления интронная последовательность расположена в направлении 5' относительно последовательности нуклеиновой кислоты, кодирующей полипептид FVIII. В некоторых вариантах осуществления интронная последовательность представляет собой встречающуюся в природе интронную последовательность. В некоторых вариантах осуществления интронная последовательность представляет собой синтетическую последовательность. В некоторых вариантах осуществления интронная последовательность получена из встречающейся в природе интронной последовательности. В определенных вариантах осуществления интронная последовательность содержит малый Т-интрон SV40. В одном варианте осуществления интронная последовательность содержит SEQ ID NO: 115.
[354] В некоторых вариантах осуществления молекула нуклеиновой кислоты дополнительно содержит посттранскрипционный регуляторный элемент. В определенных вариантах осуществления посттранскрипционный регуляторный элемент включает в себя мутантный посттранскрипционный регуляторный элемент вируса гепатита сурков (WPRE). В одном конкретном варианте осуществления посттранскрипционный регуляторный элемент содержит SEQ ID NO: 120.
[355] В некоторых вариантах осуществления молекула нуклеиновой кислоты содержит сайт связывания microRNA (miRNA). В одном варианте осуществления сайт связывания miRNA представляет собой сайт связывания miRNA для miR-142-3p. В других вариантах осуществления сайт связывания miRNA выбран из сайта связывания miRNA, раскрытого в Rennie et al., RNA Biol. 13(6):554-560 (2016), а также в STarMirDB, доступной по адресу http://sfold.wadsworth.org/starmirDB.php, которые включены в данный документ посредством ссылки во всей своей полноте.
[356] В некоторых вариантах осуществления молекула нуклеиновой кислоты содержит одну или несколько последовательностей, направляющих ДНК к ядру (DTS). DTS способствует транслокации молекул ДНК, содержащих такие последовательности, в ядро. В определенных вариантах осуществления DTS содержит энхансерную последовательность SV40. В определенных вариантах осуществления DTS содержит энхансерную последовательность c-Myc. В некоторых вариантах осуществления DTS расположены между первым ITR и вторым ITR. В некоторых вариантах осуществления DTS расположена в направлении 3' относительно первого ITR и в направлении 5' относительно терапевтического белка. В других вариантах осуществления DTS расположена в направлении 3' относительно терапевтического белка и в направлении 5' относительно второго ITR.
[357] В некоторых вариантах осуществления молекула нуклеиновой кислоты дополнительно содержит последовательность poly(A)-хвоста 3'-UTR. В одном варианте осуществления последовательность poly(A)-хвоста 3'-UTR включает в себя poly(A) bGH. В одном варианте осуществления последовательность poly(A)-хвоста 3'-UTR содержит сайт poly(A) гена актина. В одном варианте осуществления последовательность poly(A)-хвоста 3'-UTR содержит сайт poly(A) гена гемоглобина.
[358] В одном конкретном варианте осуществления последовательность poly(A)-хвоста 3'-UTR содержит SEQ ID NO: 122.
III. Тканеспецифическая экспрессия
[359] В определенных вариантах осуществления будет полезно включить в вектор одну или несколько последовательностей-мишеней для miRNA, которые, например, функционально связаны с трансгеном, кодирующим фактор свертывания крови. Таким образом, в настоящем изобретении также предусмотрена по меньшей мере одна последовательность-мишень для miRNA, функционально связанная с нуклеотидной последовательностью, кодирующей фактор свертывания крови, или иным образом вставленная в вектор. Более чем одна копия последовательности-мишени для miRNA, включенная в вектор, может повысить эффективность системы. Также включены различные последовательности-мишени для miRNA. Например, в векторах, которые экспрессируют более одного трансгена, трансген может находиться под контролем более чем одной последовательности-мишени для miRNA, которые могут быть одинаковыми или разными. Последовательности-мишени для miRNA могут быть расположены в тандеме, но также включены другие схемы расположения. Трансгенная кассета экспрессии, содержащая последовательности-мишени для miRNA, также может быть вставлена в вектор в антисмысловой ориентации. Антисмысловая ориентация может быть применима при получении вирусных частиц во избежание экспрессии продуктов генов, которые в противном случае могут быть токсичными для клеток-продуцентов. В других вариантах осуществления вектор содержит 1, 2, 3, 4, 5, 6, 7 или 8 копий одной и той же или разных последовательностей-мишеней для miRNA. Однако, в определенных других вариантах осуществления вектор не будет содержать какую-либо последовательность-мишень для miRNA. Выбор того, следует ли включать последовательность-мишень для miRNA (и в каком количестве), будет обусловлен известными параметрами, такими как предполагаемая ткань-мишень, требуемый уровень экспрессии и т. д.
[360] В одном варианте осуществления последовательность-мишень представляет собой мишень для miR-223, которая, как сообщалось, наиболее эффективно блокирует экспрессию в миелоидных коммитированных клетках-предшественниках и по меньшей мере частично в более примитивных HSPC. Мишень для miR-223 может блокировать экспрессию в дифференцированных миелоидных клетках, в том числе гранулоцитах, моноцитах, макрофагах, миелоидных дендритных клетках. Мишень для miR-223 также может быть подходящей для путей применения в генной терапии, что основывается на устойчивой экспрессии трансгена в лимфоидной или эритроидной линии дифференцировки. Мишень для miR-223 также может очень эффективно блокировать экспрессию в HSC человека.
[361] В другом варианте осуществления последовательность-мишень представляет собой мишень для miR142 (tccataaagt aggaaacact aca (SEQ ID NO: 43)). В одном варианте осуществления вектор содержит 4 копии последовательностей-мишеней для miR-142. В определенных вариантах осуществления последовательность, комплементарная microRNA, специфичной для гемопоэтических клеток, такой как miR-142 (142T), встроена в 3'-нетранслируемую область вектора, например, лентивирусных векторов (LV), что делает транскрипт, кодируемый трансгеном, чувствительным к понижению экспрессии, опосредованному miRNA. Посредством данного способа можно предотвратить экспрессию трансгена в антигенпрезентирующих клетках (АРС) гемопоэтической линии дифференцировки с поддержанием при этом ее в клетках, отличных от гемопоэтических (Brown et al., Nat Med 2006). С помощью такой стратегии можно производить строгий посттранскрипционный контроль экспрессии трансгена и, таким образом, обеспечивать стабильную доставку и долговременную экспрессию трансгенов. В некоторых вариантах осуществления посредством регуляции с помощью miR-142 предотвращается иммуноопосредованное выведение трансдуцированных клеток и/или индуцируется образование антигенспецифических регуляторных T-клеток (Treg) и опосредуется устойчивая иммунологическая толерантность к антигену, кодируемому трансгеном.
[362] В некоторых вариантах осуществления последовательность-мишень представляет собой мишень для miR181. В Chen C-Z and Lodish H, Seminars in Immunology (2005) 17(2):155-165 раскрыты miR-181, miRNA, специфично экспрессирующиеся в В-клетках костного мозга мышей (Chen and Lodish, 2005). Также раскрыто, что некоторые miRNA человека связаны с формами лейкоза.
[363] Последовательность-мишень может быть полностью или частично комплементарной по отношению к miRNA. Термин "полностью комплементарная" означает, что последовательность-мишень имеет последовательность нуклеиновой кислоты, которая на 100% комплементарна последовательности miRNA, которая ее распознает. Термин "частично комплементарная" означает, что последовательность-мишень является только частично комплементарной последовательности miRNA, которая ее распознает, и при этом частично комплементарная последовательность по-прежнему распознается miRNA. Другими словами, частично комплементарная последовательность в контексте настоящего изобретения является эффективной в распознавании соответствующей miRNA и в осуществлении предотвращения или снижения экспрессии трансгена в клетках, экспрессирующих эту miRNA. Примеры последовательностей-мишеней для miRNA описаны в WO2007/000668, WO2004/094642, WO2010/055413 или WO2010/125471, которые включены в данный документ посредством ссылки во всей своей полноте.
[364] В некоторых вариантах осуществления экспрессия трансгена нацелена на печень. В определенных вариантах осуществления экспрессия трансгена нацелена на гепатоциты. В другом варианте осуществления экспрессия трансгена нацелена на эндотелиальные клетки. В одном конкретном варианте осуществления экспрессия трансгена нацелена на любую ткань, которая в естественных условиях экспрессирует эндогенный FVIII.
[365] В некоторых вариантах осуществления экспрессия трансгена нацелена на центральную нервную систему. В определенных вариантах осуществления экспрессия трансгена нацелена на нейроны. В некоторых вариантах осуществления экспрессия трансгена нацелена на афферентные нейроны. В некоторых вариантах осуществления экспрессия трансгена нацелена на эфферентные нейроны. В некоторых вариантах осуществления экспрессия трансгена нацелена на вставочные нейроны. В некоторых вариантах осуществления экспрессия трансгена нацелена на глиальные клетки. В некоторых вариантах осуществления экспрессия трансгена нацелена на астроциты. В некоторых вариантах осуществления экспрессия трансгена нацелена на олигодендроциты. В некоторых вариантах осуществления экспрессия трансгена нацелена на микроглию. В некоторых вариантах осуществления экспрессия трансгена нацелена на эпендимальные клетки. В некоторых вариантах осуществления экспрессия трансгена нацелена на шванновские клетки. В некоторых вариантах осуществления экспрессия трансгена нацелена на сателлитные клетки.
[366] В некоторых вариантах осуществления экспрессия трансгена нацелена на мышечную ткань. В некоторых вариантах осуществления экспрессия трансгена нацелена на гладкую мускулатуру. В некоторых вариантах осуществления экспрессия трансгена нацелена на сердечную мускулатуру. В некоторых вариантах осуществления экспрессия трансгена нацелена на скелетную мускулатуру.
[367] В некоторых вариантах осуществления экспрессия трансгена нацелена на глаз. В некоторых вариантах осуществления экспрессия трансгена нацелена на фоторецепторные клетки. В некоторых вариантах осуществления экспрессия трансгена нацелена на ганглиозные клетки сетчатки.
IV. Клетки-хозяева
[368] В настоящем изобретении также предусмотрена клетка-хозяин, содержащая молекулу нуклеиновой кислоты или вектор по настоящему изобретению. Используемый в данном документе термин "трансформация" должен использоваться в широком смысле для обозначения введения ДНК в реципиентную клетку-хозяина, что приводит к изменениям генотипа и, следовательно, имеет результатом изменение в реципиентной клетке.
[369] "Клетки-хозяева" относятся к клеткам, которые были трансформированы посредством векторов, сконструированных с использованием методик рекомбинантной ДНК и кодирующих по меньшей мере один гетерологичный ген. Клетки-хозяева по настоящему изобретению предпочтительно происходят от млекопитающих; наиболее предпочтительно происходят от человека или от мыши. Специалистам в данной области вменяется в заслугу способность преимущественно определять конкретные линии клеток-хозяев, которые лучше всего подходят для их цели. Иллюстративные линии клеток-хозяев включают без ограничения CHO, DG44 и DUXB11 (линии клеток яичников китайского хомячка, DHFR-отрицательные), HELA (клетки карциномы шейки матки человека), CVI (линия клеток почки обезьяны), COS (производное CVI с T-антигеном SV40), R1610 (фибробласты китайского хомячка), BALBC/3T3 (фибробласты мыши), HAK (линия клеток почки хомячка), SP2/0 (клетки миеломы мыши), P3×63-Ag3.653 (клетки миеломы мыши), BFA-1c1BPT (эндотелиальные клетки крупного рогатого скота), RAJI (лимфоциты человека), PER.C6®, NS0, CAP, BHK21 и HEK 293 (клетки почки человека). В одном конкретном варианте осуществления клетка-хозяин выбрана из группы, состоящей из клетки CHO, клетки HEK293, клетки BHK21, клетки PER.C6®, клетки NS0, клетки CAP и любой их комбинации. В некоторых вариантах осуществления клетки-хозяева по настоящему изобретению происходят от насекомых. В одном конкретном варианте осуществления клетки-хозяева представляют собой клетки SF9. Линии клеток-хозяев обычно доступны из коммерческих служб, Американской коллекции тканевых культур или из опубликованной литературы.
[370] Введение молекул нуклеиновой кислоты или векторов по настоящему изобретению в клетку-хозяина можно осуществлять посредством различных методик, хорошо известных специалистам в данной области. Они включают без ограничения трансфекцию (в том числе электрофорез и электропорацию), слияние протопластов, осаждение фосфатом кальция, слияние клеток с ДНК в оболочке, микроинъекцию и инфицирование интактным вирусом. См., Ridgway, A. A. G. "Mammalian Expression Vectors" Chapter 24.2, pp. 470-472 Vectors, Rodriguez and Denhardt, Eds. (Butterworths, Boston, Mass. 1988). Более предпочтительно, введение плазмиды в хозяина осуществляют посредством электропорации. Трансформированные клетки выращивают в условиях, подходящих для продуцирования легких цепей и тяжелых цепей, и анализируют в отношении синтеза белков тяжелой и/или легкой цепи. Иллюстративные методики анализа включают иммуноферментный анализ (ELISA), радиоиммунологический анализ (RIA) или анализ по методу сортировки клеток с активированной флуоресценцией (FACS), иммуногистохимический анализ и т. п.
[371] Клетки-хозяева, содержащие выделенные молекулы нуклеиновой кислоты или векторы по настоящему изобретению, выращивают в подходящей среде для роста. Используемый в данном документе термин "подходящая среда для роста" означает среду, содержащую питательные вещества, необходимые для роста клеток. Питательные вещества, необходимые для роста клеток, могут включать источник углерода, источник азота, незаменимые аминокислоты, витамины, минералы и факторы роста. Среда необязательно может содержать один или несколько факторов для отбора. Среда необязательно может содержать сыворотку крови новорожденных телят или фетальную телячью сыворотку крови (FCS). В одном варианте осуществления среда по существу не содержит IgG. В среде для роста, как правило, происходит отбор клеток, содержащих ДНК-конструкцию, например, путем отбора по чувствительности к лекарственному средству или дефициту незаменимого питательного вещества, что дополняется наличием селектируемого маркера, присутствующего в ДНК-конструкции или трансфицируемого совместно с ДНК-конструкцией. Культивируемые клетки млекопитающих обычно выращивают в коммерчески доступных средах, содержащих сыворотку крови, или бессывороточных средах (например, MEM, DMEM, DMEM/F12). В одном варианте осуществления среда представляет собой CD OptiCHO (Invitrogen, Карлсбад, Калифорния). В другом варианте осуществления среда представляет собой CD17 (Invitrogen, Карлсбад, Калифорния). Выбор среды, подходящей для конкретной применяемой линии клеток, находится в пределах уровня знаний средних специалистов в данной области.
V. Получение полипептидов
[372] В настоящем изобретении также предусмотрен полипептид, кодируемый молекулой нуклеиновой кислоты по настоящему изобретению. В других вариантах осуществления полипептид по настоящему изобретению кодируется вектором, содержащим нуклеиновые молекулы по настоящему изобретению. В еще нескольких других вариантах осуществления полипептид по настоящему изобретению продуцируется клеткой-хозяином, содержащей нуклеиновые молекулы по настоящему изобретению.
[373] В других вариантах осуществления в настоящем изобретении также предусмотрен способ получения полипептида с активностью фактора свертывания крови, например, FVIII, включающий культивирование клетки-хозяина по настоящему изобретению в условиях, при которых продуцируется полипептид с активностью фактора свертывания крови, например, FVIII, и извлечение полипептида с активностью фактора свертывания крови, например, FVIII. В некоторых вариантах осуществления экспрессия полипептида с активностью фактора свертывания крови, например, FVIII, увеличена относительно клетки-хозяина, культивируемой в тех же условиях, но содержащей эталонную нуклеотидную последовательность (например, SEQ ID NO: 16, родительскую последовательность гена FVIII).
[374] В других вариантах осуществления в настоящем изобретении предусмотрен способ увеличения экспрессии полипептида с активностью фактора свертывания крови, например, FVIII, включающий культивирование клетки-хозяина по настоящему изобретению в условиях, при которых полипептид с активностью фактора свертывания крови, например, FVIII, экспрессируется молекулой нуклеиновой кислоты, где экспрессия полипептида с активностью фактора свертывания крови, например, FVIII, увеличена относительно клетки-хозяина, культивируемой в тех же условиях, содержащей эталонную молекулу нуклеиновой кислоты (например, SEQ ID NO: 16, родительскую последовательность гена FVIII).
[375] В других вариантах осуществления в настоящем изобретении предусмотрен способ улучшения выхода полипептида с активностью фактора свертывания крови, например, FVIII, включающий культивирование клетки-хозяина в условиях, при которых полипептид с активностью фактора свертывания крови, например, FVIII, продуцируется молекулой нуклеиновой кислоты, раскрытой в данном документе, где выход полипептида с активностью фактора свертывания крови, например, FVIII, увеличен относительно клетки-хозяина, культивируемой в тех же условиях, содержащей эталонную последовательность нуклеиновой кислоты (например, SEQ ID NO: 16, родительскую последовательность гена FVIII).
[376] Терапевтический белок, например, фактор свертывания крови, по настоящему изобретению может синтезироваться у трансгенного животного, такого как грызун, коза, овца, свинья или корова. Термин "трансгенные животные" относится к животным, отличным от человека, в геном которых встроен чужеродный ген. Поскольку этот ген присутствует в тканях зародышевой линии, он передается от родителей к потомству. Экзогенные гены вводят в одноклеточные эмбрионы (Brinster et al. 1985, Proc. Natl. Acad.Sci. USA 82:4438). Из уровня техники известны способы получения трансгенных животных, в том числе трансгенных объектов, которые продуцируют молекулы иммуноглобулинов (Wagner et al. 1981, Proc. Natl. Acad. Sci. USA 78: 6376; McKnight et al. 1983, Cell 34: 335; Brinster et al. 1983, Nature 306: 332; Ritchie et al. 1984, Nature 312: 517; Baldassarre et al. 2003, Theriogenology 59: 831; Robl et al. 2003, Theriogenology 59: 107; Malassagne et al. 2003, Xenotransplantation 10 (3): 267).
VII. Фармацевтическая композиция
[377] Композиции, содержащие молекулу нуклеиновой кислоты, полипептид, кодируемый молекулой нуклеиновой кислоты, вектор или клетку-хозяина по настоящему изобретению, могут содержать подходящий фармацевтически приемлемый носитель. Например, они могут содержать вспомогательные вещества и/или вспомогательные средства, которые способствуют переработке активных соединений в препараты, предназначенные для доставки в место действия.
[378] В одном варианте осуществления настоящее изобретение относится к фармацевтической композиции, содержащей (а) молекулу нуклеиновой кислоты, вектор, полипептид или клетку-хозяина, раскрытые в данном документе; и (b) фармацевтически приемлемое вспомогательное вещество.
[379] В некоторых вариантах осуществления фармацевтическая композиция дополнительно содержит средство доставки. В определенных вариантах осуществления средство доставки содержит липидную наночастицу (LNP). В других вариантах осуществления фармацевтическая композиция дополнительно содержит липосомы, другие полимерные молекулы и экзосомы.
[380] Фармацевтическая композиция может быть составлена для парентерального введения (т. е. внутривенного, подкожного или внутримышечного) путем болюсной инъекции. Составы для инъекций могут быть представлены в стандартной лекарственной форме, например, в ампулах или в многодозовых контейнерах с добавленным консервантом. Композиции могут иметь такие формы, как суспензии, растворы или эмульсии в масляных или водных средах-носителях, и содержать средства для составления, такие как суспендирующие, стабилизирующие и/или диспергирующие средства. В качестве альтернативы, активный ингредиент может быть представлен в форме порошка для разведения подходящей средой-носителем, например, апирогенной водой.
[381] Подходящие составы для парентерального введения также включают водные растворы активных соединений в водорастворимой форме, например, водорастворимые соли. Кроме того, можно вводить суспензии активных соединений в виде подходящих масляных инъекционных суспензий. Подходящие липофильные растворители или среды-носители включают жирные масла, например, кунжутное масло, или синтетические сложные эфиры жирных кислот, например, этилолеат или триглицериды. Водные инъекционные суспензии могут содержать вещества, которые увеличивают вязкость суспензии, в том числе, например, натрий-карбоксиметилцеллюлозу, сорбит и декстран. Суспензия также необязательно может содержать стабилизаторы. Также можно применять липосомы для инкапсулирования молекул по настоящему изобретению для доставки в клетки или интерстициальные пространства. Иллюстративными фармацевтически приемлемыми носителями являются физиологически совместимые растворители, дисперсионные среды, покрытия, антибактериальные и противогрибковые средства, изотонические средства и средства, замедляющие всасывание, вода, солевой раствор, фосфатно-солевой буферный раствор, декстроза, глицерин, этанол и т. п. В некоторых вариантах осуществления композиция содержит изотонические средства, например, сахара, многоатомные спирты, такие как маннит, сорбит, или хлорид натрия. В других вариантах осуществления композиции содержат фармацевтически приемлемые вещества, такие как смачивающие средства или незначительные количества вспомогательных веществ, таких как смачивающие или эмульгирующие средства, консерванты или буферы, которые увеличивают срок годности или эффективность активных ингредиентов.
[382] Композиции по настоящему изобретению могут быть представлены в различных формах, в том числе, например, в форме жидкости (например, инъекционных и инфузионных растворов), дисперсий, суспензий, полутвердых и твердых лекарственных форм. Предпочтительная форма зависит от способа введения и терапевтического применения.
[383] Композиция может быть составлена в виде раствора, микроэмульсии, дисперсии, липосомы или другой упорядоченной структуры, подходящей для высокой концентрации лекарственного средства. Стерильные инъекционные растворы можно получить путем помещения активного ингредиента в необходимом количестве в соответствующий растворитель с одним ингредиентом или комбинацией ингредиентов, перечисленных выше, если необходимо, с последующей стерилизующей фильтрацией. Как правило, дисперсии получают путем помещения активного ингредиента в стерильную среду-носитель, которая содержит основную дисперсионную среду и необходимые другие ингредиенты из перечисленных выше. В случае со стерильными порошками для получения стерильных инъекционных растворов предпочтительные способы получения представляют собой вакуумную сушку и сублимационную сушку, которые приводят к получению порошка активного ингредиента и любого дополнительного требуемого ингредиента из их раствора, предварительно подвергнутого стерилизующей фильтрации. Надлежащую текучесть раствора можно поддерживать, например, путем применения покрытия, такого как лецитин, путем поддержания необходимого размера частиц в случае с дисперсией и путем применения поверхностно-активных веществ. Пролонгированное всасывание инъекционных композиций может обеспечиваться включением в композицию средств, которые замедляют всасывание, например, моностеаратных солей и желатина.
[384] Активный ингредиент может быть составлен в составе или устройстве с контролируемым высвобождением. Примеры таких составов и устройств включают имплантаты, трансдермальные пластыри и микроинкапсулированные системы доставки. Можно применять биоразлагаемые, биосовместимые полимеры, такие как этиленвинилацетат, полиангидриды, полигликолевую кислоту, коллаген, сложные полиортоэфиры и полимолочную кислоту. Способы получения таких составов и устройств известны из уровня техники. См., например, Sustained and Controlled Release Drug Delivery Systems, J. R. Robinson, ed., Marcel Dekker, Inc., New York, 1978.
[385] Инъекционные депо-составы можно получать путем образования микроинкапсулированных матриц с лекарственным средством в биоразлагаемых полимерах, таких как сополимер лактида и гликолида. В зависимости от соотношения лекарственного средства и полимера и природы используемого полимера можно контролировать скорость высвобождения лекарственного средства. Другими иллюстративными биоразлагаемыми полимерами являются сложные полиортоэфиры и полиангидриды. Инъецируемые депо-составы также можно получать путем захвата лекарственного средства в липосомы или микроэмульсии.
[386] В композиции могут быть включены дополнительные активные соединения. В одном варианте осуществления молекула нуклеиновой кислоты по настоящему изобретению составлена с фактором свертывания крови или его вариантом, фрагментом, аналогом или производным. Например, фактор свертывания крови включает без ограничения фактор V, фактор VII, фактор VIII, фактор IX, фактор X, фактор XI, фактор XII, фактор XIII, протромбин, фибриноген, фактор фон Виллебранда или рекомбинантный растворимый тканевой фактор (rsTF) или активированные формы любого из предшествующих. Фактор свертывания крови в гемостатическом средстве также может включать в себя антифибринолитические лекарственные средства, например, эпсилон-аминокапроновую кислоту, транексамовую кислоту.
[387] Схемы дозирования могут быть скорректированы для обеспечения оптимального желаемого ответа. Например, можно вводить однократную болюсную дозу, можно вводить несколько разделенных доз на протяжении некоторого периода времени, или дозу можно пропорционально уменьшить или увеличить, как указывают потребности терапевтической ситуации. Преимущественным является составление композиций для парентерального применения в виде лекарственной формы с однократной дозировкой для удобства введения и однородности дозирования. См., например, Remington's Pharmaceutical Sciences (Mack Pub. Co., Easton, Pa. 1980).
[388] В дополнение к активному соединению жидкая лекарственная форма может содержать инертные ингредиенты, такие как вода, этиловый спирт, этилкарбонат, этилацетат, бензиловый спирт, бензилбензоат, пропиленгликоль, 1,3-бутиленгликоль, диметилформамид, масла, глицерин, тетрагидрофурфуриловый спирт, полиэтиленгликоли и сложные эфиры жирных кислот и сорбитана.
[389] Неограничивающие примеры подходящих фармацевтических носителей также описаны в Remington's Pharmaceutical Sciences, E.W. Martin. Некоторые примеры вспомогательных веществ включают крахмал, глюкозу, лактозу, сахарозу, желатин, солод, рис, муку, мел, силикагель, стеарат натрия, моностеарат глицерина, тальк, хлорид натрия, сухое обезжиренное молоко, глицерин, пропиленгликоль, воду, этанол и т. п. Композиция также может содержать рН-буферные реагенты, а также смачивающие или эмульгирующие средства.
[390] Для перорального введения фармацевтическая композиция может иметь форму таблеток или капсул, полученных с помощью традиционных способов. Композиция также может быть получена в виде жидкости, например, сиропа или суспензии. Жидкость может содержать суспендирующие средства (например, сорбитовый сироп, производные целлюлозы или гидрогенизированные пищевые жиры), эмульгирующие средства (лецитин или аравийскую камедь), неводные среды-носители (например, миндальное масло, масляные сложные эфиры, этиловый спирт или фракционированные растительные масла) и консерванты (например, метил- или пропил-п-гидроксибензоаты или сорбиновую кислоту). Препараты могут также содержать ароматизаторы, красители и подсластители. В качестве альтернативы, композиция может быть представлена в виде сухого продукта для разведения с помощью воды или другой подходящей среды-носителя.
[391] Для трансбуккального введения композиция может иметь форму таблеток или пастилок в соответствии с традиционными протоколами.
[392] Для введения путем ингаляции соединения для применения по настоящему изобретению в целях удобства доставляются в форме распыляемого аэрозоля со вспомогательными веществами или без них или в форме аэрозольного спрея из упаковки под давлением или распылителя, необязательно с пропеллентом, например, дихлордифторметаном, трихлорфторметаном, дихлортетрафторметаном, диоксидом углерода или другим подходящим газом. В случае с аэрозолем под давлением единица дозирования может определяться благодаря обеспечению наличия клапана для доставки отмеренного количества. Капсулы и картриджи из, например, желатина для применения в ингаляторе или инсуффляторе могут быть составлены так, чтобы они содержали порошковую смесь соединения и подходящей порошковой основы, такой как лактоза или крахмал.
[393] Фармацевтическая композиция также может быть составлена для ректального введения в виде суппозитория или удерживающей клизмы, например, содержащей традиционные суппозиторные основы, такие как масло какао или другие глицериды.
[394] В некоторых вариантах осуществления композицию вводят посредством пути, выбранного из группы, состоящей из местного введения, внутриглазного введения, парентерального введения, интратекального введения, субдурального введения и перорального введения. Парентеральное введение может представлять собой внутривенное или подкожное введение.
VIII. Способы лечения
[395] В некоторых вариантах осуществления молекула нуклеиновой кислоты содержит первый ITR, второй ITR и генную кассету, где генная кассета содержит фактор свертывания крови, и где молекула нуклеиновой кислоты применяется для лечения заболевания или состояния, затрагивающего свертываемость крови, у нуждающегося в этом субъекта. Заболевание или состояние, затрагивающее свертываемость крови, выбрано из группы, состоящей из коагуляционного нарушения свертываемости крови, гемартроза, мышечного кровотечения, внутриротового кровотечения, кровоизлияния, кровоизлияния в мышцы, внутриротового кровоизлияния, травмы, черепно-мозговой травмы, желудочно-кишечного кровотечения, внутричерепного кровоизлияния, внутрибрюшного кровоизлияния, внутригрудного кровоизлияния, перелома кости, кровотечения в центральной нервной системе, кровотечения в заглоточном пространстве, кровотечения в забрюшинном пространстве, кровотечения во влагалище подвздошно-поясничной мышцы или любой их комбинации. В еще нескольких других вариантах осуществления у субъекта запланировано проведение хирургического вмешательства. В еще нескольких других вариантах осуществления лечение проводится в режиме профилактики или по требованию.
[396] В настоящем изобретении предусмотрен способ лечения нарушения свертываемости крови, включающий введение нуждающемуся в этом субъекту молекулы нуклеиновой кислоты, вектора или полипептида по настоящему изобретению. В некоторых вариантах осуществления нарушение свертываемости крови характеризуется дефицитом фактора свертывания крови, например, FVIII. В некоторых вариантах осуществления нарушение свертываемости крови представляет собой гемофилию. В некоторых вариантах осуществления нарушение свертываемости крови представляет собой гемофилию A. В некоторых вариантах осуществления способа лечения нарушения свертываемости крови активность фактора свертывания крови, например, FVIII, в плазме крови через 24 часа после введения увеличивается относительно субъекта, которому вводят эталонную молекулу нуклеиновой кислоты (например, SEQ ID NO: 16, родительскую последовательность гена FVIII), вектор, содержащий эталонную молекулу нуклеиновой кислоты, или полипептид, кодируемый эталонной молекулой нуклеиновой кислоты.
[397] Настоящее изобретение также относится к способу лечения, уменьшения интенсивности проявлений или предупреждения гемостатического нарушения у субъекта, включающему введение терапевтически эффективного количества выделенной молекулы нуклеиновой кислоты по настоящему изобретению или полипептида, характеризующегося активностью фактора свертывания крови, например, FVIII, кодируемого молекулой нуклеиновой кислоты по настоящему изобретению. Лечение, уменьшение интенсивности проявлений и предупреждение посредством выделенной молекулы нуклеиновой кислоты или кодируемого полипептида может представлять собой терапию шунтирующего действия. У субъекта, получающего терапию шунтирующего действия, может уже быть выработан ингибитор фактора свертывания крови, например, FVIII, или подлежит выработке ингибитор фактора свертывания крови.
[398] Молекулы нуклеиновой кислоты, векторы или полипептиды по настоящему изобретению обеспечивают лечение или предупреждение гемостатического нарушения посредством способствования образованию фибринового сгустка. Полипептид, характеризующийся активностью фактора свертывания крови, например, FVIII, кодируемого молекулой нуклеиновой кислоты по настоящему изобретению, может активировать элемент каскада коагуляции крови. Фактор свертывания крови может участвовать во внешнем пути, внутреннем пути или в них обоих.
[399] Молекулы нуклеиновой кислоты, векторы или полипептиды по настоящему изобретению можно применять для лечения гемостатических нарушений, которые, как известно, поддаются лечению с помощью фактора свертывания крови. Гемостатические нарушения, которые можно лечить посредством способов по настоящему изобретению, включают без ограничения гемофилию A, гемофилию B, болезнь фон Виллебранда, дефицит фактора XI (дефицит PTA), дефицит фактора XII, а также дефициты или аномалии структуры фибриногена, протромбина, фактора V, фактора VII, фактора X или фактора XIII, гемартроз, мышечное кровотечение, внутриротовое кровотечение, кровоизлияние, кровоизлияние в мышцы, внутриротовое кровоизлияние, травму, черепно-мозговую травму, желудочно-кишечное кровотечение, внутричерепное кровоизлияние, внутрибрюшное кровоизлияние, внутригрудное кровоизлияние, перелом кости, кровотечение в центральной нервной системе, кровотечение в заглоточном пространстве, кровотечение в забрюшинном пространстве и кровотечение во влагалище подвздошно-поясничной мышцы.
[400] В некоторых вариантах осуществления гемостатическое нарушение представляет собой наследственное нарушение. В одном варианте осуществления субъект имеет гемофилию А. В других вариантах осуществления гемостатическое нарушение является результатом дефицита фактора свертывания крови. В других вариантах осуществления гемостатическое нарушение является результатом дефицита FVIII. В других вариантах осуществления гемостатическое нарушение может быть результатом дефекта фактора свертывания крови FVIII.
[401] В другом варианте осуществления гемостатическое нарушение может представлять собой приобретенное нарушение. Приобретенное нарушение может быть обусловлено первопричинным вторичным заболеванием или состоянием. Несвязанное состояние может представлять собой, в качестве примера, без ограничения, рак, аутоиммунное заболевание или беременность. Приобретенное нарушение может быть обусловлено пожилым возрастом или приемом лекарственных препаратов для лечения первопричинного вторичного нарушения (например, химиотерапии рака).
[402] Настоящее изобретение также относится к способам лечения субъекта, у которого не имеется гемостатическое нарушение или вторичное заболевание или состояние, приводящее к приобретению гемостатического нарушения. Таким образом, настоящее изобретение относится к способу лечения субъекта, нуждающегося в гемостатическом средстве общего действия, включающему введение терапевтически эффективного количества выделенной молекулы нуклеиновой кислоты, вектора или полипептида по настоящему изобретению. Например, в одном варианте осуществления субъект, нуждающийся в гемостатическом средстве общего действия, подвергается или вскоре подвергнется хирургическому вмешательству. Выделенную молекулу нуклеиновой кислоты, вектор или полипептид по настоящему изобретению можно вводить до или после хирургического вмешательства в качестве профилактического средства. Выделенную молекулу нуклеиновой кислоты, вектор или полипептид по настоящему изобретению можно вводить во время или после хирургического вмешательства для контроля эпизода острого кровотечения. Хирургическое вмешательство может включать без ограничения трансплантацию печени, резекцию печени или трансплантацию стволовых клеток.
[403] В другом варианте осуществления выделенную молекулу нуклеиновой кислоты, вектор или полипептид по настоящему изобретению можно применять для лечения субъекта с эпизодом острого кровотечения, у которого не имеется гемостатическое нарушение. Эпизод острого кровотечения может быть результатом тяжелой травмы, например, хирургического вмешательства, автомобильной аварии, ранения, рваного огнестрельного ранения или другого травматического события, приводящего к неконтролируемому кровотечению.
[404] Выделенную молекулу нуклеиновой кислоты, вектор или белок можно применять для профилактического лечения субъекта с гемостатическим нарушением. Выделенную молекулу нуклеиновой кислоты, вектор или белок можно применения для лечения эпизода острого кровотечения у субъекта с гемостатическим нарушением.
[405] В другом варианте осуществления экспрессия белка, представляющего собой фактор свертывания крови, посредством введения выделенной молекулы нуклеиновой кислоты или вектора по настоящему изобретению не индуцирует иммунный ответ у субъекта. В некоторых вариантах осуществления иммунный ответ включает выработку антител к фактору свертывания крови. В одном варианте осуществления иммунный ответ включает выработку антител к FVIII. В некоторых вариантах осуществления иммунный ответ включает секрецию цитокинов. В некоторых вариантах осуществления иммунный ответ включает активацию B-клеток, T-клеток или как B-клеток, так и T-клеток. В некоторых вариантах осуществления иммунный ответ представляет собой ингибирующий иммунный ответ, где иммунный ответ у субъекта способствует снижению активности белка, представляющего собой фактор свертывания крови, относительно активности фактора свертывания крови у субъекта, у которого не развился иммунный ответ. В определенных вариантах осуществления экспрессия белка, представляющего собой фактор свертывания крови, посредством введения выделенной молекулы нуклеиновой кислоты или вектора по настоящему изобретению обеспечивает предупреждение ингибирующего иммунного ответа на белок, представляющий собой фактор свертывания крови, или белок, представляющий собой фактор свертывания крови, экспрессируемый из выделенной молекулы нуклеиновой кислоты или вектора.
[406] В некоторых вариантах осуществления композицию, содержащую выделенную молекулу нуклеиновой кислоты, вектор или белок, по настоящему изобретению вводят в комбинации с по меньшей мере одним другим средством, которое способствует гемостазу. Указанное другое средство способствует гемостазу в терапевтическом препарате с продемонстрированной свертывающей активностью. В качестве примера, без ограничения, гемостатическое средство может включать в себя FV, FVII, FIX, FX, FXI, FXII, FXIII, протромбин или фибриноген или активированные формы любого из предшествующих. Фактор свертывания крови или гемостатическое средство также могут включать в себя антифибринолитические лекарственные средства, например, эпсилон-аминокапроновую кислоту, транексамовую кислоту.
[407] В одном варианте осуществления настоящего изобретения композиция (например, выделенная молекула нуклеиновой кислоты, вектор или полипептид) представляет собой композицию, в которой фактор свертывания крови присутствует в форме, активируемой при введении субъекту. Такая активируемая молекула может активироваться in vivo в месте свертывания после введения субъекту.
[408] Выделенную молекулу нуклеиновой кислоты, вектор или полипептид можно вводить внутривенно, подкожно, внутримышечно или через любую поверхность слизистой оболочки, например, пероральным, сублингвальным, трансбуккальным, сублингвальным, назальным, ректальным, вагинальным или пульмональным путем. Белок, представляющий собой фактор свертывания крови, может быть имплантирован в твердую биополимерную подложку или связан с ней, что обеспечивает возможность медленного высвобождения химерного белка в желаемом месте.
[409] Для перорального введения фармацевтическая композиция может иметь форму таблеток или капсул, полученных с помощью традиционных способов. Композиция также может быть получена в виде жидкости, например, сиропа или суспензии. Жидкость может содержать суспендирующие средства (например, сорбитовый сироп, производные целлюлозы или гидрогенизированные пищевые жиры), эмульгирующие средства (лецитин или аравийскую камедь), неводные среды-носители (например, миндальное масло, масляные сложные эфиры, этиловый спирт или фракционированные растительные масла) и консерванты (например, метил- или пропил-п-гидроксибензоаты или сорбиновую кислоту). Препараты могут также содержать ароматизаторы, красители и подсластители. В качестве альтернативы, композиция может быть представлена в виде сухого продукта для разведения с помощью воды или другой подходящей среды-носителя.
[410] Для трансбуккального и сублингвального введения композиция может иметь форму таблеток, пастилок или быстрорастворимых пленок в соответствии с традиционными протоколами.
[411] Для введения путем ингаляции полипептид, характеризующийся активностью фактора свертывания крови, для применения по настоящему изобретению в целях удобства доставляется в форме аэрозольного спрея из упаковки под давлением или распылителя (например, в PBS) с подходящим пропеллентом, например, дихлордифторметаном, трихлорфторметаном, дихлортетрафторметаном, диоксидом углерода или другим подходящим газом. В случае с аэрозолем под давлением единица дозирования может определяться благодаря обеспечению наличия клапана для доставки отмеренного количества. Капсулы и картриджи из, например, желатина для применения в ингаляторе или инсуффляторе могут быть составлены так, чтобы они содержали порошковую смесь соединения и подходящей порошковой основы, такой как лактоза или крахмал.
[412] В одном варианте осуществления путь введения выделенной молекулы нуклеиновой кислоты, вектора или полипептида является парентеральным. Используемый в данном документе термин "парентеральный" включает внутривенное, внутриартериальное, внутрибрюшинное, внутримышечное, подкожное, ректальное или вагинальное введение. Внутривенная форма парентерального введения является предпочтительной. Хотя все эти формы введения явно рассматриваются как находящиеся в пределах объема настоящего изобретения, формой для введения будет раствор для инъекций, в частности, для внутривенной или внутриартериальной инъекции или капельного вливания. Обычно подходящая фармацевтическая композиция для инъекций может содержать буфер (например, ацетатный, фосфатный или цитратный буфер), поверхностно-активное вещество (например, полисорбат), необязательно стабилизирующее средство (например, альбумин человека) и т. д. Однако, в других способах, совместимых с изложенными в данном документе идеями, выделенная молекула нуклеиновой кислоты, вектор или полипептид могут доставляться непосредственно в место локализации нежелательной клеточной популяции, за счет чего увеличивается воздействие терапевтического средства на пораженную ткань.
[413] Препараты для парентерального введения включают стерильные водные или неводные растворы, суспензии и эмульсии. Примерами неводных растворителей являются пропиленгликоль, полиэтиленгликоль, растительные масла, такие как оливковое масло, и инъекционные органические сложные эфиры, такие как этилолеат. Водные носители включают воду, спиртовые/водные растворы, эмульсии или суспензии, в том числе солевой раствор и буферные среды. В рассматриваемом изобретении фармацевтически приемлемые носители включают без ограничения 0,01-0,1 M и предпочтительно 0,05 M фосфатный буфер или 0,8% солевой раствор. Другие распространенные среды-носители для парентерального введения включают растворы фосфата натрия, раствор Рингера с декстрозой, раствор декстрозы и хлорида натрия, лактатный раствор Рингера или нелетучие масла. Среды-носители для внутривенного введения включают растворы с добавками жидкости и питательных веществ, растворы с добавками электролитов, как, например, на основе раствора Рингера с декстрозой, и т. п. Могут также присутствовать консерванты и другие добавки, такие как, например, противомикробные средства, антиоксиданты, хелатообразующие средства и инертные газы и т. п.
[414] Более конкретно, фармацевтические композиции, подходящие для инъекционного применения, включают стерильные водные растворы (в случае растворимости в воде) или дисперсии и стерильные порошки для экстемпорального приготовления стерильных инъекционных растворов или дисперсий. В таких случаях композиция должна быть стерильной и должна быть текучей до такой степени, чтобы ее легко было вводить с помощью шприца. Она должна быть стабильной в условиях производства и хранения и предпочтительно будет защищена от загрязняющего действия микроорганизмов, таких как бактерии и грибы. Носитель может представлять собой растворитель или дисперсионную среду, содержащие, например, воду, этанол, многоатомный спирт (например, глицерин, пропиленгликоль и жидкий полиэтиленгликоль и т. п.) и их подходящие смеси. Надлежащую текучесть можно поддерживать, например, путем применения покрытия, такого как лецитин, путем поддержания необходимого размера частиц в случае с дисперсией и путем применения поверхностно-активных веществ.
[415] Фармацевтическая композиция также может быть составлена для ректального введения в виде суппозитория или удерживающей клизмы, например, содержащей традиционные суппозиторные основы, такие как масло какао или другие глицериды.
[416] Эффективные дозы композиций по настоящему изобретению для лечения состояний варьируются в зависимости от множества различных факторов, включающих способ введения, участок-мишень, физиологическое состояние пациента, того, является ли пациент человеком или животным, других вводимых лекарственных препаратов и того, является ли лечение профилактическим или терапевтическим. Обычно пациент является человеком, однако также можно лечить млекопитающих, отличных от человека, в том числе трансгенных млекопитающих. Для оптимизации безопасности и эффективности дозировки для лечения можно подбирать с помощью обычных способов, известных специалистам в данной области.
[417] Молекулу нуклеиновой кислоты, вектор или полипептиды по настоящему изобретению можно необязательно вводить в комбинации с другими средствами, которые являются эффективными при лечении нарушения или состояния, требующего лечения (например, профилактического или терапевтического).
[418] Как используется в данном документе, введение выделенных молекул нуклеиновой кислоты, векторов или полипептидов по настоящему изобретению в сочетании или в комбинации со вспомогательной терапией означает последовательное, одновременное, одинаковое по протяженности, сопутствующее, параллельное или совпадающее во времени введение или применение терапии и раскрытых полипептидов. Специалистам в данной области будет понятно, что введение или применение различных компонентов схемы комбинированной терапии может быть спланировано по времени для повышения общей эффективности лечения. Специалист в данной области (например, врач) сможет легко определить эффективные схемы комбинированной терапии без проведения излишних экспериментов на основании выбранной вспомогательной терапии и идей настоящего описания.
[419] Кроме того, следует понимать, что выделенную молекулу нуклеиновой кислоты, вектор или полипептид по настоящему изобретению можно применять в сочетании или в комбинации со средством или средствами (например, для обеспечения схемы комбинированной терапии). Иллюстративные средства, в комбинации с которыми можно применять полипептид или полинуклеотид по настоящему изобретению, включают средства, которые представляют современный стандарт оказания медицинской помощи при конкретном нарушении, подвергаемом лечению. Такие средства могут быть химическими или биологическими по природе. Термин "биологический препарат" или "биологическое средство" относится к любому фармацевтически активному средству, полученному из живых организмов и/или их продуктов, которое предназначено для применения в качестве терапевтического препарата.
[420] Количество средства, которое следует применять в комбинации с полинуклеотидами или полипептидами по настоящему изобретению, может варьироваться у различных субъектов или может вводиться в соответствии с тем, что известно из уровня техники. См., например, Bruce A Chabner et al., Antineoplastic Agents, в Goodman & Gilman's The Pharmacological Basis of Therapeutics 1233-1287 (Joel G. Hardman et al., eds., 9th ed. 1996). В другом варианте осуществления вводят количество такого средства, соответствующее стандарту оказания медицинской помощи.
[421] В одном варианте осуществления в данном документе также раскрыт набор, содержащий молекулу нуклеиновой кислоты, раскрытую в данном документе, и инструкции по введению молекулы нуклеиновой кислоты нуждающемуся в этом субъекту. В другом варианте осуществления в данном документе раскрыта бакуловирусная система для получения молекулы нуклеиновой кислоты, представленной в данном документе. Молекулу нуклеиновой кислоты получают в клетках насекомых. В другом варианте осуществления предусмотрена система доставки на основе наночастиц для экспрессионных конструкций. Экспрессионная конструкция содержит молекулу нуклеиновой кислоты, раскрытую в данном документе.
IX. Генная терапия
[422] В определенных аспектах настоящего изобретения предусмотрен способ обеспечения экспрессии генетической конструкции у субъекта, включающий введение выделенной молекулы нуклеиновой кислоты по настоящему изобретению нуждающемуся в этом субъекту. В некоторых аспектах в настоящем изобретении предусмотрен способ увеличения экспрессии полипептида у субъекта, включающий введение выделенной молекулы нуклеиновой кислоты по настоящему изобретению нуждающемуся в этом субъекту. В других аспектах в настоящем изобретении предусмотрен способ модулирования экспрессии полипептида у нуждающегося в этом субъекта, включающий введение выделенной молекулы нуклеиновой кислоты по настоящему изобретению, например, последовательности нуклеиновой кислоты, содержащей miRNA, субъекту. В некоторых аспектах в настоящем изобретении предусмотрен способ понижения экспрессии гена-мишени у нуждающегося в этом субъекта, включающий введение выделенной молекулы нуклеиновой кислоты по настоящему изобретению, например, последовательности нуклеиновой кислоты, содержащей miRNA, субъекту.
[423] Генную терапию соматических клеток исследовали как возможный метод лечения различных состояний, в том числе без ограничения гемофилии А. Генная терапия является особенно привлекательным методом лечения гемофилии, поскольку она обладает потенциалом излечения заболевания благодаря непрерывному эндогенному продуцированию фактора свертывания крови, например, FVIII, после однократного введения вектора. Гемофилия А является особенно пригодной для подхода на основе генной заместительной терапии, поскольку ее клинические проявления в полной мере объясняются отсутствием одного продукта гена (например, FVIII), который циркулирует в плазме крови в незначительных количествах (200 нг/мл).
[424] Белок, представляющий собой фактор свертывания крови, по настоящему изобретению может быть получен in vivo у млекопитающего, например, у пациента-человека, с применением подхода на основе генной терапии для лечения заболевания, затрагивающего свертываемость крови, или нарушения свертываемости крови, выбранного из группы, состоящей из коагуляционного нарушения свертываемости крови, гемартроза, мышечного кровотечения, внутриротового кровотечения, кровоизлияния, кровоизлияния в мышцы, внутриротового кровоизлияния, травмы, черепно-мозговой травмы, желудочно-кишечного кровотечения, внутричерепного кровоизлияния, внутрибрюшного кровоизлияния, внутригрудного кровоизлияния, перелома кости, кровотечения в центральной нервной системе, кровотечения в заглоточном пространстве, кровотечения в забрюшинном пространстве и кровотечения во влагалище подвздошно-поясничной мышцы, что было бы терапевтически благоприятным. В одном варианте осуществления заболевание, затрагивающее свертываемость крови, или нарушение свертываемости крови представляет собой гемофилию. В другом варианте осуществления заболевание, затрагивающее свертываемость крови, или нарушение свертываемости крови представляет собой гемофилию A.
[425] Другие состояния также подходят для лечения с применением молекул нуклеиновой кислоты, раскрытых в данном документе. В определенных вариантах осуществления способы, описанные в данном документе, применяют для лечения заболевания или состояния, которое поражает орган-мишень, выбранный из мышцы, центральной нервной системы (CNS), глаза, печени, сердца, почки, поджелудочной железы, легких, кожи, мочевого пузыря, мочевыводящих путей или любой их комбинации. В определенных вариантах осуществления способы, описанные в данном документе, применяют для лечения заболевания или состояния, выбранного из DMD (мышечной дистрофии Дюшенна), XLMTM (X-сцепленной миотубулярной миопатии), болезни Паркинсона, SMA (спинальной мышечной атрофии), атаксии Фридрейха, GUCY2D-LCA (врожденного амавроза Лебера), XLRS (X-сцепленного ретиношизиса), AMD (возрастной макулярной дегенерации), ACHM (ахроматопсии), RPF65-опосредованного IRD (таблица 9).
Таблица 9. Заболевания и нарушения, поддающиеся лечению посредством способов, раскрытых в данном документе.
(мышечная дистрофия Дюшенна)
X-сцепленный
(X-сцепленная миотубулярная миопатия)
гидроксилаза, AADC, циклогидролаза
(спинальная мышечная атрофия)
Врожденный амавроз Лебера
X-сцепленный ретиношизис
Возрастная макулярная дегенерация
HTRA
ARMS
CFB/CC2
Ахроматопсия
Метахроматическая лейкодистрофия
(Лизосомная болезнь накопления)
PSAP
Формы мукополисахаридоза
(Лизосомная болезнь накопления)
IDS (MPS II)
Фенилкетонурия
(Лизосомная болезнь накопления)
Болезнь накопления гликогена II типа
(кислая альфа-глюкозидаза)
Боковой амиотрофический склероз
Аутосомно-доминантный пигментный ретинит
(родопсин)
1. Мутация гена SOD1 обуславливала 20% случаев наследственного ALS. SOD1 дикого типа продемонстрировал антиапоптотические свойства в культурах нейронов, тогда как мутантный SOD1 согласно наблюдениям способствовал апоптозу в митохондриях спинного мозга, но не в митохондриях печени, хотя он в равной степени экспрессируется и там, и там. Понижение экспрессии мутантного SOD1 может обуславливать ингибирование дегенерации двигательных нейронов при ALS. 2. HD является одной из нескольких болезней экспансии тринуклеотидных повторов, которые вызваны превышением длины повторяющегося участка гена пределов нормального диапазона. HTT содержит последовательность из трех оснований ДНК цитозин-аденин-гуанин (CAG), которые повторяются многократно (т. е. ... CAGCAGCAG ...), что известно как тринуклеотидный повтор. CAG представляет собой 3-буквенный генетический код (кодон) для аминокислоты глутамина, поэтому последовательный ряд этих оснований приводит к продуцированию цепи из глутаминовых остатков, известной как полиглутаминовый тракт (или поли-Q-тракт), и повторяющейся части гена, поли-Q-области. Как правило, люди имеют менее 36 повторяющихся глутаминовых остатков в поли-Q-области, что приводит к продуцированию цитоплазматического белка хантингтина. Однако, последовательность из 36 или более глутаминовых остатков приводит к продуцированию белка, который имеет другие характеристики. Эта измененная форма, называемая мутантным хантингтином (mHTT), увеличивает скорость разрушения некоторых типов нейронов. Как правило, количество повторов CAG связано с тем, насколько сильно затронут этот процесс, и обуславливает приблизительно 60% изменчивости возраста начала проявления симптомов. Остальная доля изменчивости объясняется влиянием окружающей среды и других генов, которые модифицируют механизм развития HD. 36-39 повторов приводят к форме заболевания с пониженной пенетрантностью, с гораздо более поздним началом проявления и более медленным прогрессированием симптомов. В некоторых случаях начало проявления может быть настолько поздним, что симптомы так никогда и не отмечаются. При очень большом количестве повторов HD характеризуется полной пенетрантностью и может встречаться в возрасте до 20 лет, и в этом случае ее тогда называют ювенильной HD, акинетико-ригидной HD или вариантом Вестфаля HD. Это составляет приблизительно 7% случаев носительства HD. 3. Большинство мутаций гена RHO, отвечающих за пигментный ретинит, изменяют сворачивание или транспорт белка родопсина. Несколько мутаций вызывают конститутивную активацию родопсина вместо активации в ответ на воздействие света. Исследования позволяют предположить, что измененные варианты родопсина препятствуют осуществлению жизненно важных функций клеток, вызывая саморазрушение палочек (они подвергаются апоптозу). Поскольку палочки необходимы для зрения в условиях низкой освещенности, потеря этих клеток приводит к прогрессирующей ночной слепоте у людей с пигментным ретинитом.
[426] В некоторых вариантах осуществления способы, описанные в данном документе, применяют для лечения лизосомной болезни накопления. В некоторых вариантах осуществления лизосомная болезнь накопления выбрана из MLD (метахроматической лейкодистрофии), MPS (форм мукополисахаридоза), PKU (фенилкетонурии), болезни Помпе, представляющей собой болезнь накопления гликогена II типа, или любой их комбинации.
[427] В некоторых вариантах осуществления способы, описанные в данном документе, применяют в терапии с помощью microRNA (miRNA). В некоторых вариантах осуществления miRNA обеспечивает лечение состояния, вызванного сверхэкспрессией гена или белка. В некоторых вариантах осуществления miRNA обеспечивает лечение состояния, вызванного накоплением белка. В некоторых вариантах осуществления miRNA обеспечивает лечение состояния, вызванного неправильной экспрессией гена или белка. В некоторых вариантах осуществления miRNA обеспечивает лечение состояния, вызванного экспрессией мутантного гена. В некоторых вариантах осуществления miRNA обеспечивает лечение состояния, вызванного экспрессией гетерологичного гена. В определенных вариантах осуществления терапия с помощью miRNA обеспечивает лечение состояния, выбранного из ALS (бокового амиотрофического склероза), болезни Хантингтона, AdRP (аутосомно-доминантного пигментного ретинита) и любой их комбинации. В определенных вариантах осуществления способы по настоящему изобретению включают направленное лечение ALS путем введения молекулы нуклеиновой кислоты, раскрытой в данном документе, где молекула нуклеиновой кислоты содержит генную кассету, кодирующую miRNA, где miRNA целенаправленно воздействует на экспрессию SOD1. В определенных вариантах осуществления miRNA включает в себя искусственную miRNA miR-SOD1, раскрытую в Dirren et al., Annals of Clinical and Translational Neurology 2(2):167-84 (февраль 2015 г.). Мутация гена SOD1 обуславливает 20% случаев наследственного ALS. SOD1 дикого типа продемонстрировал антиапоптотические свойства в культурах нейронов, тогда как мутантный SOD1 согласно наблюдениям способствовал апоптозу в митохондриях спинного мозга, но не в митохондриях печени, хотя он в равной степени экспрессируется и там, и там. Понижение экспрессии мутантного SOD1 может обуславливать ингибирование дегенерации двигательных нейронов при ALS.
[428] В определенных вариантах осуществления способы по настоящему изобретению включают направленное лечение болезни Хантингтона путем введения молекулы нуклеиновой кислоты, раскрытой в данном документе, где молекула нуклеиновой кислоты содержит генную кассету, кодирующую miRNA, где miRNA целенаправленно воздействует на экспрессию HTT. В определенных вариантах осуществления miRNA включает сконструированную miRNA для miHTT, раскрытую в Evers et al., Molecular Therapy 26(9):1-15 (электронная публикация до выхода в печать в июне 2018 г.). Болезнь Хантингтона является одной из нескольких болезней экспансии тринуклеотидных повторов, которые вызваны превышением длины повторяющегося участка гена пределов нормального диапазона. HTT содержит последовательность из трех оснований ДНК цитозин-аденин-гуанин (CAG), которые повторяются многократно (т. е. ... CAGCAGCAG ...), что известно как тринуклеотидный повтор. CAG представляет собой 3-буквенный генетический код (кодон) для аминокислоты глутамина, поэтому последовательный ряд этих повторов приводит к продуцированию цепи из глутаминовых остатков, известной как полиглутаминовый тракт (или поли-Q-тракт), и повторяющейся части гена, поли-Q-области. Как правило, люди имеют менее 36 повторяющихся глутаминовых остатков в поли-Q-области, что приводит к продуцированию цитоплазматического белка хантингтина. Однако, последовательность из 36 или более глутаминовых остатков приводит к продуцированию белка, который имеет другие характеристики. Эта измененная форма, называемая мутантным хантингтином (mHTT), увеличивает скорость разрушения некоторых типов нейронов. Как правило, количество повторов CAG связано с тем, насколько сильно затронут этот процесс, и обуславливает приблизительно 60% изменчивости возраста начала проявления симптомов. Остальная доля изменчивости объясняется влиянием окружающей среды и других генов, которые модифицируют механизм развития болезни Хантингтона. 36-39 повторов приводят к форме заболевания с пониженной пенетрантностью, с гораздо более поздним началом проявления и более медленным прогрессированием симптомов. В некоторых случаях начало проявления может быть настолько поздним, что симптомы так никогда и не отмечаются. При очень большом количестве повторов болезнь Хантингтона характеризуется полной пенетрантностью и может встречаться в возрасте до 20 лет, и в этом случае ее тогда называют ювенильной болезнью Хантингтона, акинетико-ригидной болезнью Хантингтона или вариантом Вестфаля болезни Хантингтона. Это составляет приблизительно 7% случаев носительства болезни Хантингтона.
[429] В определенных вариантах осуществления способы по настоящему изобретению включают направленное лечение аутосомно-доминантного пигментного ретинита (AdRP) путем введения молекулы нуклеиновой кислоты, раскрытой в данном документе, где молекула нуклеиновой кислоты содержит генную кассету, кодирующую miRNA, где miRNA целенаправленно воздействует на экспрессию RHO (родопсина). В определенных вариантах осуществления miRNA включает в себя miR-708 (см. Behrman et al., JCB 192(6):919-27 (2011). Большинство мутаций гена RHO, отвечающих за пигментный ретинит, изменяют сворачивание или транспорт белка родопсина. Несколько мутаций вызывают конститутивную активацию родопсина вместо активации в ответ на воздействие света. Исследования позволяют предположить, что измененные варианты родопсина препятствуют осуществлению жизненно важных функций клеток, вызывая саморазрушение палочек (они подвергаются апоптозу). Поскольку палочки необходимы для зрения в условиях низкой освещенности, потеря этих клеток приводит к прогрессирующей ночной слепоте у людей с пигментным ретинитом.
[430] Все из различных аспектов, вариантов осуществления и возможностей выбора, описанных в данном документе, можно комбинировать во всех без исключения вариантах.
[431] Все публикации, патенты и заявки на патенты, упоминаемые в настоящем описании, включены в данный документ посредством ссылки в такой же степени, как если бы каждая отдельная публикация, патент или заявка на патент была конкретно и отдельно указана как включенная посредством ссылки.
[432] При наличии описания настоящего изобретения в общих чертах может быть достигнуто дополнительное понимание, если обратиться к представленным в данном документе примерам. Эти примеры служат лишь для иллюстративных целей и не предполагаются как ограничивающие.
ПРИМЕРЫ
Пример 1. Создание экспрессионных конструкций FVIII, несущих парвовирусные ITR из AAV и вирусов, отличных от AAV.
Пример 1a. Клонирование кодон-оптимизированного гена FVIII и областей инвертированных концевых повторов (ITR) из AAV в генные кассеты.
[433] Генную кассету FVIII создавали на основе генома AAV серотипа 2. Однако, в данном подходе можно применять и области ITR, происходящие из любого серотипа (в том числе синтетического) (фиг. 1A).
[434] Экспрессионная плазмида AAV2-FVIIIco6XTEN, кодирующая кодон-оптимизированную кодирующую последовательность FVIII под контролем специфичного для печени промотора (TTPp, фиг. 1A и 1B), фланкированную областями инвертированных концевых повторов (ITR) из AAV (AAV-FVIII), была разработана для экспрессии in vitro и in vivo, как показано на фиг. 1В. Генная кассета также содержит элементы WPRE и bGHpA для оптимальной экспрессии трансгена (фиг. 1A и 1B). Фланкированную ITR кодон-оптимизированную последовательность FVIII клонировали в плазмидный каркас, содержащий точку начала репликации ColE1 и кассету экспрессии для бета-лактамазы, которая придает устойчивость к ампициллину (фиг. 1B). Сайты распознавания для рестрикционной эндонуклеазы PvuII, фланкирующие кассету экспрессии, были сконструированы для обеспечения возможности точного вырезания конструкции AAV-FVIII при расщеплении с помощью PvuII (фиг. 1B).
Пример 1b. Клонирование кодон-оптимизированного гена FVIII и областей инвертированных концевых повторов (ITR) из парвовирусов, отличных от AAV, в генные кассеты.
[435] На основании филогенетических взаимоотношений между представителями семейства вирусов Parvoviridae, к которому принадлежит AAV (фиг. 2A), была выдвинута гипотеза, что другие, отличные от AAV, представители рода Dependovirus и представители рода Erythrovirus (и, возможно, все/многие другие представители данного семейства вирусов) используют аналогичные клеточные механизмы для поддержания жизненного цикла вируса и, что наиболее важно, для формирования устойчивой латентной инфекции. Следовательно, области ITR, происходящие из геномов этих вирусов, можно использовать для разработки AAV-подобных (но не на основе AAV) генных кассет экспрессии. Следующие парвовирусы тестировали в отношении пригодности их областей ITR для разработки генетических конструкций для путей применения в генной терапии: штамм B парвовируса гусей (GPV) из рода Dependovirus и эритровирус, представляющий собой парвовирус B19 (фиг. 2A).
[436] Нестабильность парвовирусных областей ITR во время размножения плазмидных векторов в бактериальных клетках является хорошо известным препятствием для создания генетических конструкций и манипуляций с ними. Хотя генетические конструкции, содержащие полноразмерные ITR AAV2 (145 п. о.), были успешно созданы несколькими группами, в том числе и авторами настоящего изобретения, эти конструкции являются крайне нестабильными, и большинство плазмид на основе ITR AAV2 содержат усеченный вариант области ITR размером 130 п. о. (проиллюстрированный в таблице 1). Аналогичным образом, плазмидные конструкции, несущие полноразмерные последовательности ITR как B19, так и GPV, которые были созданы, демонстрировали высокую степень нестабильности в бактериальном хозяине (данные не показаны), что значительно ограничивает применимость этих ITR для разработки генетических векторов для путей применения в генной терапии.
Ранее была разработана обратно-генетическая система для "спасения" рекомбинантного вируса B19, несущего усеченный вариант ITR (Manaresi et al., 2017, Virology, doi: 10.1016/j.virol.2017.05.006) (таблица 2B, ID ITR: B19d135). Таким образом, авторы настоящего изобретения использовали ITR B19d135 для создания генетически стабильной экспрессионной плазмиды FVIII B19-FVIIIco6XTEN (фиг. 1C). Чтобы дополнительно использовать этот подход для синтеза конструкции на основе ITR GPV, авторы настоящего изобретения сравнили полноразмерные последовательности дикого типа ITR B19, GPV и AAV2 (фиг. 3A). Исходя из гомологии первых 135 и 15 нуклеотидов последовательностей ITR B19 и AAV2 соответственно, которые не являются обязательными для функционирования ITR, авторы настоящего изобретения выдвинули гипотезу, что первые 162 нуклеотида ITR GPV можно удалить в целях синтеза стабильных генетических конструкций с полностью функциональными ITR (фиг. 3A, последовательности, заштрихованные серым цветом). Следовательно, аналогично конструкциям AAV2-FVIIIco6XTEN и B19-FVIIIco6XTEN, которые несут усеченные варианты соответствующих им ITR, авторы настоящего изобретения использовали GPVd162 (таблица 2C) для создания стабильной экспрессионной плазмидной конструкции FVIII GPV-FVIIIco6XTEN (фиг. 1D). Примечательно, что ITR как B19, так и GPV полной длины намного длиннее ITR AAV2 полной длины (таблица 1) и не образуют характерную Т-образную шпилечную структуру ITR AAV (фиг. 2B).
[437] Плазмиды B19-FVIIIco6XTEN (фиг. 1C; таблица 2B) и GPV-FVIIIco6XTEN (фиг. 1D; таблица 2C), содержащие кассеты экспрессии FVIII, фланкированные парвовирусными ITR из вирусов, отличных от AAV (B19d135-FVIII и GPVd162-FVIII), создавали согласно описанному в примере 1а. Сайты распознавания для рестрикционной эндонуклеазы LguI использовали для фланкирования обеих кассет экспрессии FVIII (фиг. 1C и 1D).
Пример 1c. Получение однонитевых фрагментов ДНК, содержащих кассеты экспрессии FVIII, фланкированные парвовирусными ITR из AAV и вирусов, отличных от AAV.
[438] Была выдвинута гипотеза, что образование шпилечных структур внутри областей ITR, фланкирующих кассету экспрессии FVIII, будет приводить к устойчивой трансдукции клеток-мишеней. Для исследований с целью подтверждения правильности концепции плазмиду AAV2-FVIIIco6XTEN на основе ITR AAV и плазмиды B19-FVIIIco6XTEN и GPV-FVIIIco6XTEN на основе ITR вируса, отличного от AAV, расщепляли соответственно с помощью PvuII и LguI. Однонитевой (ss) фрагмент AAV-FVIII, B19-FVIII или GPV-FVIII с образованными шпилечными структурами ITR создавали путем денатурации продуктов расщепления двухнитевого фрагмента ДНК (кассеты экспрессии FVIII и плазмидного каркаса) под действием PvuII или LguI при 95oC и последующего охлаждения при 4oC для обеспечения возможности сворачивания палиндромных последовательностей ITR (фиг. 1A). Полученные в результате ssAAV-FVIII, ssB19-FVIII или ssGPV-FVIII тестировали в мышиной модели HemA (гемофилии A) в отношении способности обеспечивать устойчивую трансдукцию гепатоцитов.
Пример 1d. Применение бакуловирусной системы экспрессии для создания экспрессионных конструкций FVIII
[439] Используется бакуловирусная система экспрессии, описанная в Li et al., PLoS ONE 8 (8): e69879 (2013), для получения конструкций AAV-FVIII, B19-FVIII и GPV-FVIII в форме молекул ДНК с замкнутыми концами (ceDNA) в клетках насекомых. Было продемонстрировано, что системная доставка кассет экспрессии на основе ceDNA обеспечивает устойчивую трансдукцию гепатоцитов и приводит к стабильной долговременной экспрессии трансгена в печени.
Пример 2. Системная инъекция генетических конструкций, содержащих кассеты экспрессии FVIII, фланкированные парвовирусными ITR из AAV и вирусов, отличных от AAV, приводит к долговременной экспрессии FVIII у мышей HemA.
Пример 2a. Оценивание in vivo экспрессии FVIII, опосредованной ssAAV-FVIII.
[440] Для подтверждения способности ssAAV-FVIII, несущей области ITR из AAV, опосредовать устойчивую экспрессию трансгена in vivo, обеспечивали системную доставку генной кассеты экспрессии посредством гидродинамической инъекции (HDI) мышам HemA в возрасте 5-12 недель (4 животных на группу) при 5 мкг, 10 мкг или 20 мкг генной кассеты экспрессии на основе ssDNA (ssAAV-FVIII) (фиг. 4A). HDI приводит к первичной доставке инъецированного материала в печень экспериментальных животных. Контрольные животные, которым инъецировали 5 мкг/мышь родительской экспрессионной плазмиды, демонстрировали высокие уровни активности FVIII в плазме крови вскоре после введения. Однако, уровень циркулирующего FVIII быстро снижался и становился невыявляемым через 15 дней после инъекции (p.i.). Образцы плазмы крови собирали у экспериментальных животных через 18 часов, 3 дня, 2 недели, 3 недели, 1 месяц, 2 месяца, 3 месяца и 4 месяца после однократной гидродинамической инъекции ssAAV-FVIII. Активность FVIII в плазме крови анализировали с помощью хромогенного анализа активности FVIII. У экспериментальных животных, которым инъецировали 5, 10 и 20 мкг/мышь ssAAV-FVIII, развивалась долговременная экспрессия трансгена со стабильными уровнями циркулирующего FVIII, составляющими приблизительно 8, 16 и 32% от нормального уровня FVIII соответственно (фиг. 4А). Следует подчеркнуть, что авторы настоящего изобретения наблюдали сильный дозозависимый эффект, что позволяет предположить высокую степень корреляции между инъецированной дозой и результатом лечения.
Пример 2b. Оценивание in vivo экспрессии FVIII, опосредованной ssB19-FVIII и ssGPV-FVIII.
[441] Для оценивания in vivo экспрессии FVIII из ssB19-FVIII и ssGPV-FVIII, которые несут парвовирусные области ITR из вирусов, отличных от AAV, B19d135 и GPVd162 соответственно, обеспечивали системную доставку генной кассеты экспрессии ssB19-FVIII при 10 или 20 мкг/мышь и ssGPV-FVIII при 10 или 50 мкг/мышь посредством HDI мышам в возрасте 5-12 недель с гемофилией А (HemA). Образцы крови собирали через 1, 3, 7, 14, 21 и 28 дней p.i., и активность FVIII в крови анализировали с помощью хромогенного анализа активности FVIII. Как наблюдалось ранее в экспериментах с конструкцией AAV-FVIII, контрольные животные, которым инъецировали 5 мкг/мышь родительской экспрессионной плазмиды FVIII, демонстрировали высокие уровни активности FVIII в плазме крови через 24 часа p.i., которые быстро снижались и становились невыявляемыми к моменту времени 14 дней p.i. Экспериментальные животные, которым инъецировали ssB19-FVIII, демонстрировали пиковую активность FVIII в плазме крови через 24 часа p.i., которая затем постепенно снижалась в течение периода 21 дня и стабилизировалась примерно через 28 дней p.i. (фиг. 4B). В то же время у мышей HemA, которым инъецировали ssGPV-FVIII, быстро развивались стабильные уровни активности FVIII в плазме крови примерно на 7 день, которые поддерживались в течение всего периода наблюдения 28 дней (фиг. 4C). Примечательно, что у животных, которым инъецировали 10 мкг/мышь ssAAV-FVIII (фиг. 4A) либо ssGPV-FVIII (фиг. 4C), развивались весьма сходные стабильные уровни активности FVIII в плазме крови, что позволяет предположить, что области ITR как AAV2, так и GPV содержат генетические факторы, необходимые для эффективного обеспечения устойчивой трансдукции клеток-мишеней.
Пример 3. Создание и оценивание in vivo экспрессионных конструкций FVIII, несущих производные парвовирусных ITR из вирусов, отличных от AAV, B19d135 и GPVd162.
Пример 3a. Определение минимальных существенных последовательностей ITR B19 и GPV.
[442] На основании сравнения последовательностей ITR депендовирусов AAV2 и GPV и эритровируса B19 (номера доступа в GenBank NC_001401.2, U25749.1 и KY940273.1 соответственно) авторы настоящего изобретения разработали минимальные последовательности ITR парвовирусов GPV и B19, которые будут необходимыми с дополнительными последовательностями (спейсерами, вставками, инверсиями, добавлениями и/или рекомбинациями с последовательностями дикого типа других парвовирусных ITR) или без них для устойчивой трансдукции эукариотических клеток генетическими конструкциями, несущими такие ITR (фиг. 3A и 3B). Таким образом, выравнивание последовательностей ITR AAV2, GPV и B19 выявило консервативные области B19v1 и GPVv1 среди всех трех видов вирусов, которые представлены в таблицах 2A-2C в виде непрерывных последовательностей без спейсерных областей вариабельной последовательности. Аналогично, варианты минимальных существенных последовательностей B19v3 и GPVv3 были разработаны на основании сравнения последовательностей ITR между B19 и GPR. Поскольку экспрессионные конструкции FVIII, несущие ITR GPVd162, показали лучшие результаты в экспериментах in vivo, чем генетические конструкции, несущие ITR B19d135, авторы настоящего изобретения предположили, что все генетические факторы, необходимые для устойчивой трансдукции, присутствуют в последовательности ITR GPV; однако, в последовательности ITR B19 отсутствуют некоторые из этих генетических факторов. Следовательно, последовательность B19v3 содержит области минимальной последовательности ITR B19, которые являются консервативными среди последовательностей ITR B19 и GPV, а последовательность GPVv3 содержит области минимальной последовательности ITR GPV, которые присутствуют в последовательности ITR GPV и отсутствуют в последовательности ITR B19 (таблицы 2B и 2C). Последовательности B19v2 и GPVv2 создавали путем исключения первых 135 и 162 нуклеотидов и соответствующих комплементарных 135 и 162 нуклеотидов в палиндромных областях ITR последовательностей ITR B19 и GPV соответственно (таблицы 2B и 2C).
Пример 3b. Ориентация палиндромных областей ITR B19 и GPV и их производных в функциональных генетических конструкциях.
[443] Часть парвовирусных ITR состоит из самокомплементарной палиндромной области. Ранее было продемонстрировано для рекомбинантных инфекционных парвовирусов В19, что "спасенные" вирусы, несущие палиндромные области в прямой и обратной ориентациях, демонстрируют сходные свойства роста (Manaresi et al., 2017, Virology, doi: 10.1016/j.virol.2017.05.006). Поэтому авторы настоящего изобретения предполагают, что генетические экспрессионные конструкции, несущие ITR B19 и GPV и их производные, остаются функциональными независимо от того, находятся ли палиндромные области таких ITR в прямой, обратной или любой возможной комбинации 5’ и 3’ ITR по отношению к генной кассете экспрессии.
Пример 3c. Системная инъекция генетических конструкций, несущих производные парвовирусных ITR из вирусов, отличных от AAV, B19d135 и GPVd162 у мышей HemA.
[444] Для оценивания экспрессии FVIII in vivo из конструкций ssDNA, которые несут производные парвовирусных ITR из вирусов, отличных от AAV, B19d135 и GPVd162, обеспечивают системную доставку 5, 10, 20 или 50 мкг/мышь каждой генной кассеты экспрессии на основе ssDNA посредством HDI мышам HemA в возрасте 5-12 недель. Образцы крови собирают через 1, 3, 7, 14, 21 и 28 дней p.i., а затем один раз в месяц в течение периода 4 месяцев. Активность FVIII в крови анализируют с помощью хромогенного анализа активности FVIII.
Пример 4. Получение и оценивание in vivo экспрессионных конструкций ceDNA, несущих производные парвовирусных ITR из вирусов, отличных от AAV, B19d135 и GPVd162, в клетках насекомых.
Пример 4a. Применение бакуловирусной системы экспрессии для создания экспрессионных конструкций ceDNA, несущих производные ITR B19d135 и GPVd162.
[445] Аналогично конструкциям AAV-FVIII, B19-FVIII и GPV-FVIII, описанным в примере 1d, авторы настоящего изобретения применяют бакуловирусную систему экспрессии для получения экспрессионных генетических конструкций FVIII, несущих производные парвовирусных ITR из вирусов, отличных от AAV, B19d135 и GPVd162 в форме ceDNA, в клетках насекомых.
Пример 4b. Системная инъекция экспрессионных конструкций ceDNA, несущих производные парвовирусных ITR из вирусов, отличных от AAV, B19d135 и GPVd162 у мышей HemA.
[446] Для оценивания экспрессии FVIII in vivo из конструкций ceDNA, которые несут производные парвовирусных ITR из вирусов, отличных от AAV, B19d135 и GPVd162, обеспечивают системную доставку 5, 10, 20 или 50 мкг/мышь каждой генной кассеты экспрессии на основе ceDNA посредством HDI мышам HemA в возрасте 5-12 недель. Образцы крови собирают через 1, 3, 7, 14, 21 и 28 дней p.i., а затем один раз в месяц в течение периода 4 месяцев. Активность FVIII в крови анализируют с помощью хромогенного анализа активности FVIII.
Пример 5. Получение составов на основе липидных наночастиц с экспрессионными конструкциями ssDNA и ceDNA FVIII
[447] После получения каждой ssDNA или ceDNA согласно описанному в примерах 1 и 4 каждую генетическую конструкцию составляют в липидных наночастицах (LNP) с применением соответствующих липидных композиций путем микрожидкостного перемешивания (LNP-ssDNA и LNP-ceDNA). Родительские плазмиды, кодирующие кассеты экспрессии FVIII, фланкированные парвовирусными ITR из AAV либо вирусов, отличных от AAV, составленные в LNP, применяют в качестве контролей эффективности трансдукции.
Пример 6. Оценивание in vitro и in vivo LNP-ssDNA и LNP-ceDNA
Пример 6a. Оценивание in vitro экспрессии FVIII, опосредованной ssDNA и ceDNA, в культивируемых гепатоцитах.
[448] Генетические экспрессионные конструкции ssDNA или ceDNA FVIII и соответствующие родительские контрольные плазмиды составляют в LNP согласно описанному в примере 5 для направленной доставки генов. Клетки Huh7 или HEK293T (контрольные, отличные от гепатоцитов) высевают в 24-луночные планшеты для культивирования тканей при 7×104 клеток/лунка и инкубируют в течение ночи. На следующий день составы на основе LNP-ssDNA или LNP-ceDNA добавляют к клеткам при 1000, 500, 250, 125 и 62,5 нг/лунка. Культуральную среду и клетки собирают через 24 и 48 часов после трансдукции. Активность FVIII в культуральной среде измеряют с помощью хромогенного анализа активности FVIII. Экспрессию FVIII в клетках также анализируют с помощью вестерн-блоттинга.
[449] Кроме того, в литературе было показано, что клеточные гистоны регулярно располагаются вдоль эписом rAAV, создавая хроматиноподобную структуру, сходную с нуклеосомным паттерном хромосомной ДНК в клетках. Следовательно, способность этих конструкций формировать хроматиноподобные нуклеосомные структуры, необходимые для устойчивой трансдукции клеток-мишеней, также оценивают с помощью Саузерн-блоттинга.
Пример 6b. Оценивание долговременной экспрессии FVIII, опосредованной ssDNA и ceDNA, составленными в LNP, у мышей HemA после внутривенного введения.
[450] Мышам HemA в возрасте 5-12 недель вводят LNP-ssDNA, LNP-ceDNA либо LNP-pDNA (контрольную плазмиду) при 5, 10, 20, 40, 100 мкг/мышь посредством IV инъекции, N=4/группа. Образцы крови собирают в выбранные моменты времени, начиная с 48 часов после инъекции в течение периода длительностью до 6 месяцев, и активность FVIII в крови анализируют с помощью хромогенного анализа активности FVIII. Профиль экспрессии FVIII у мышей, обработанных с помощью LNP-ssDNA или LNP-ceDNA, сравнивают с таковым у мышей, обработанных с помощью LNP-pDNA, для каждой генетической конструкции, описанной в примерах 1 и 4.
Пример 6c. Оценивание in vivo экспрессии FVIII, опосредованной ssDNA или ceDNA, после бустерной инъекции.
[451] Подгруппе мышей, обработанных с помощью LNP-ssDNA или LNP-ceDNA в примере 6b, дают дополнительную бустерную IV инъекцию соответствующих LNP в той же дозе через 2 месяца после первоначальной инъекции. Образцы крови собирают в выбранные моменты времени, начиная с 48 часов после бустерной инъекции в течение периода длительностью до 6 месяцев. Активность FVIII в крови анализируют с помощью хромогенного анализа активности FVIII. Профиль экспрессии FVIII у мышей, обработанных с помощью LNP-ssDNA или LNP-ceDNA, сравнивают с таковым у мышей, обработанных с помощью соответствующей LNP-pDNA.
Пример 7. Применимость генетических экспрессионных конструкций, несущих ITR, происходящие из B19 или GPV, для общего применения в генной терапии.
Пример 7a. Создание репортерных генетических конструкций, несущих ITR, происходящие из B19 или GPV.
[452] Для демонстрации применимости генетических систем экспрессии на основе ITR из вирусов, отличных от AAV, в качестве платформы для общего применения в путях применения в генной терапии создают репортерные конструкции, содержащие кассету экспрессии для зеленого флуоресцентного белка (GFP) или люциферазы (luc), фланкированную ITR из B19d135 или GPVd162, на основе конструкций, описанных в примере 1b. Таким образом, открытую рамку считывания (ORF) FVIII в B19-FVIIIco6XTEN (фиг. 1C) и GPV-FVIIIco6XTEN (фиг. 1D) заменяют на ORF GFP либо luc с помощью традиционных методик молекулярного клонирования.
[453] Кассеты экспрессии, фланкированные ITR из B19d135 или GPVd162, также создают для фенилаланингидроксилазы (PAH), которую применяют для оценивания экспрессии PAH в соответствующей мышиной модели.
Пример 7b. Получение репортерных генетических конструкций ssDNA, несущих ITR из B19 или GPV.
[454] Конструкции ssDNA репортер/PAH получают согласно описанному в примере 1c. Вкратце, плазмиды расщепляют с помощью LguI. Фрагменты ssDNA с образованными шпилечными структурами ITR создают путем денатурации продуктов расщепления двухнитевого фрагмента ДНК (репортерной кассеты экспрессии и плазмидного каркаса) под действием LguI при 95oC и последующего охлаждения при 4oC для обеспечения возможности сворачивания палиндромных последовательностей ITR (фиг. 1A). Полученные в результате конструкции ssDNA тестируют на мышах в отношении способности обеспечивать устойчивую трансдукцию в печени, мышечной ткани, фоторецепторах в глазу и центральной нервной системе (CNS).
Пример 7c. Оценивание in vivo экспрессии репортера, опосредованной ssDNA.
[455] Для подтверждения способности репортерных конструкций ssDNA, описанных в примере 7b, опосредовать устойчивую экспрессию трансгена in vivo мышам в возрасте 5-12 недель (4 животных на группу) инъецируют 5, 10 или 20 мкг/мышь репортерной ssDNA системно, местно для нацеливания на мышечную ткань и клетки CNS и/или субретинально для нацеливания на фоторецепторные клетки.
[456] Для оценивания экспрессии PAH из экспрессионных конструкций на основе ITR из В19 и GPV применяют соответствующую мышиную модель заболевания. Эти генетические конструкции доставляются системно посредством HDI для нацеливания на печень.
ВАРИАНТЫ ОСУЩЕСТВЛЕНИЯ
[457] E1. Молекула нуклеиновой кислоты, содержащая первый инвертированный концевой повтор (ITR), второй ITR и генную кассету, кодирующую терапевтический белок; где первый ITR и/или второй ITR представляют собой ITR вируса, отличного от аденоассоциированного вируса (вируса, отличного от AAV), где генная кассета расположена между первым ITR и вторым ITR, и где терапевтический белок содержит фактор свертывания крови.
[458] E2. Молекула нуклеиновой кислоты согласно E1, где вирус, отличный от AAV, выбран из группы, состоящей из представителя семейства вирусов Parvoviridae.
[459] E3. Молекула нуклеиновой кислоты согласно E1 или E2, где первый ITR представляет собой ITR вируса, отличного от AAV, а второй ITR представляет собой ITR аденоассоциированного вируса (AAV), или где первый ITR представляет собой ITR AAV, а второй ITR представляет собой ITR вируса, отличного от AAV.
[460] E4. Молекула нуклеиновой кислоты согласно E1 или E2, где первый ITR и второй ITR представляют собой ITR вируса, отличного от AAV.
[461] E5. Молекула нуклеиновой кислоты согласно любому из E1, E2 и E4, где первый ITR и второй ITR являются идентичными.
[462] E6. Молекула нуклеиновой кислоты согласно любому из E1-E5, где первый ITR и/или второй ITR содержат палиндромную последовательность, которая является непрерывной.
[463] E7. Молекула нуклеиновой кислоты согласно любому из E1-E5, где первый ITR и/или второй ITR содержат палиндромную последовательность, которая является прерывистой.
[464] E8. Молекула нуклеиновой кислоты согласно любому из E1-E7, где вирус, отличный от AAV, является представителем семейства вирусов Parvoviridae.
[465] E9. Молекула нуклеиновой кислоты согласно E8, где представитель семейства вирусов Parvoviridae выбран из группы, состоящей из Bocavirus, Dependovirus, Erythrovirus, Amdovirus, Parvovirus, Densovirus, Iteravirus, Contravirus, Aveparvovirus, Copiparvovirus, Protoparvovirus, Tetraparvovirus, Ambidensovirus, Brevidensovirus, Hepandensovirus, и Penstyldensovirus.
[466] E10. Молекула нуклеиновой кислоты согласно E8, где представителем семейства вирусов Parvoviridae является эритровирус, представляющий собой парвовирус B19 (вирус человека).
[467] E11. Молекула нуклеиновой кислоты согласно E8, где представитель семейства вирусов Parvoviridae представляет собой штамм парвовируса мускусных уток (MDPV).
[468] E12. Молекула нуклеиновой кислоты согласно E11, где штамм MDPV представляет собой аттенуированный штамм FZ91-30.
[469] E13. Молекула нуклеиновой кислоты согласно E11, где штамм MDPV представляет собой патогенный штамм YY.
[470] E14. Молекула нуклеиновой кислоты согласно E8, где Dependoparvovirus представляет собой штамм парвовируса гусей (GPV) из рода Dependovirus.
[471] E15. Молекула нуклеиновой кислоты согласно E14, где штамм GPV представляет собой аттенуированный штамм 82-0321V.
[472] E16. Молекула нуклеиновой кислоты согласно E14, где штамм GPV представляет собой патогенный штамм B.
[473] E17. Молекула нуклеиновой кислоты согласно E8, где представитель семейства вирусов Parvoviridae выбран из группы, состоящей из парвовируса свиней (U44978), мелкого вируса мышей (U34256), парвовируса собак (M19296) и вируса энтерита норок (D00765).
[474] E18. Молекула нуклеиновой кислоты согласно любому из E1-E17, которая дополнительно содержит промотор.
[475] E19. Молекула нуклеиновой кислоты согласно E18, где промотор представляет собой тканеспецифический промотор.
[476] E20. Молекула нуклеиновой кислоты согласно E18 или E19, где промотор управляет экспрессией терапевтического белка в гепатоцитах, эндотелиальных клетках, мышечных клетках, синусоидальных клетках или любой их комбинации.
[477] E21. Молекула нуклеиновой кислоты согласно E18 или E19, где промотор управляет экспрессией терапевтического белка в гепатоцитах.
[478] E22. Молекула нуклеиновой кислоты согласно любому из E18-E21, где промотор расположен в направлении 5' относительно последовательности нуклеиновой кислоты, кодирующей фактор свертывания крови.
[479] E23. Молекула нуклеиновой кислоты согласно любому из E18-E22, где промотор выбран из группы, состоящей из промотора гена тиретина мыши (mTTR), промотора гена эндогенного фактора VIII человека (F8), промотора гена альфа-1-антитрипсина человека (hAAT), минимального промотора гена альбумина человека, промотора гена альбумина мыши, промотора гена тристетрапролина (TTP), промотора CASI, промотора CAG, промотора цитомегаловируса (CMV), промотора гена α1-антитрипсина (AAT), мышечной креатинкиназы (MCK), тяжелой цепи миозина альфа (αMHC), миоглобина (MB), десмина (DES), SPc5-12, 2R5Sc5-12, dMCK, tMCK и фосфоглицераткиназы (PGK).
[480] E24. Молекула нуклеиновой кислоты согласно любому из E18-E23, где промотор включает в себя промотор TTP.
[481] E25. Молекула нуклеиновой кислоты согласно любому из E1-E24, где нуклеотидная последовательность дополнительно содержит интронную последовательность.
[482] E26. Молекула нуклеиновой кислоты согласно E25, где интронная последовательность расположена в направлении 5' относительно последовательности нуклеиновой кислоты, кодирующей фактор свертывания крови.
[483] E27. Молекула нуклеиновой кислоты согласно E25 или E26, где интронная последовательность расположена в направлении 3' относительно промотора.
[484] E28. Молекула нуклеиновой кислоты согласно любому из E25-E27, где интронная последовательность включает в себя синтетическую интронную последовательность.
[485] E29. Молекула нуклеиновой кислоты согласно любому из E25-E28, где интронная последовательность содержит SEQ ID NO: 115.
[486] E30. Молекула нуклеиновой кислоты согласно любому из E1-E29, где генная кассета дополнительно содержит посттранскрипционный регуляторный элемент.
[487] E31. Молекула нуклеиновой кислоты согласно E30, где посттранскрипционный регуляторный элемент расположен в направлении 3' относительно последовательности нуклеиновой кислоты, кодирующей фактор свертывания крови.
[488] E32. Молекула нуклеиновой кислоты согласно E30 или E31, где посттранскрипционный регуляторный элемент включает в себя мутантный посттранскрипционный регуляторный элемент вируса гепатита сурков (WPRE), сайт связывания microRNA, последовательность, направляющую ДНК к ядру, или любую их комбинацию.
[489] E33. Молекула нуклеиновой кислоты согласно E32, где сайт связывания microRNA включает в себя сайт связывания с miR142-3p.
[490] E34. Молекула нуклеиновой кислоты согласно любому из E1-E33, где генная кассета дополнительно содержит последовательность poly(A)-хвоста 3'-UTR.
[491] E35. Молекула нуклеиновой кислоты согласно E34, где последовательность poly(A)-хвоста 3'-UTR выбрана из группы, состоящей из poly(A) гена bGH, poly(A) гена актина, poly(A) гена гемоглобина и любой их комбинации.
[492] E36. Молекула нуклеиновой кислоты согласно E34 или E35, где последовательность poly(A)-хвоста 3'-UTR включает в себя poly(A) гена bGH.
[493] E37. Молекула нуклеиновой кислоты согласно любому из E1-E36, где генная кассета дополнительно содержит энхансерную последовательность.
[494] E38. Молекула нуклеиновой кислоты согласно E37, где энхансерная последовательность расположена между первым ITR и вторым ITR.
[495] E39. Молекула нуклеиновой кислоты согласно любому из E1-E38, где молекула нуклеиновой кислоты содержит в следующем порядке: первый ITR, генную кассету и второй ITR; где генная кассета содержит последовательность тканеспецифического промотора, интронную последовательность, последовательность нуклеиновой кислоты, кодирующую фактор свертывания крови, посттранскрипционный регуляторный элемент и последовательность poly(A)-хвоста 3'-UTR.
[496] E40. Молекула нуклеиновой кислоты согласно E39, где генная кассета содержит в следующем порядке: последовательность тканеспецифического промотора, интронную последовательность, последовательность нуклеиновой кислоты, кодирующую полипептид FVIII, посттранскрипционный регуляторный элемент и последовательность poly(A)-хвоста 3'-UTR.
[497] E41. Молекула нуклеиновой кислоты согласно E38 или E39, где
[498] (a) первый ITR представляет собой ITR вируса, отличного от AAV, являющегося представителем семейства Parvoviridae;
[499] (b) последовательность тканеспецифического промотора включает в себя промотор TTP;
[500] (c) интрон представляет собой синтетический интрон;
[501] (d) нуклеотидная последовательность кодирует фактор свертывания крови;
[502] (e) посттранскрипционный регуляторный элемент включает в себя WPRE;
[503] (f) последовательность poly(A)-хвоста 3'-UTR включает в себя bGHpA; и
[504] (g) второй ITR представляет собой ITR вируса, отличного от AAV, являющегося представителем семейства Parvoviridae.
[505] E42. Молекула нуклеиновой кислоты согласно любому из E1-E41, где генная кассета содержит однонитевую нуклеиновую кислоту.
[506] E43. Молекула нуклеиновой кислоты согласно любому из E1-E41, где генная кассета содержит двухнитевую нуклеиновую кислоту.
[507] E44. Молекула нуклеиновой кислоты согласно любому из E1-E43, где фактор свертывания крови экспрессируется гепатоцитами, эндотелиальными клетками, мышечными клетками, синусоидальными клетками или любой их комбинацией.
[508] E45. Молекула нуклеиновой кислоты согласно любому из E1-E44, где фактор свертывания крови включает в себя фактор I (FI), фактор II (FII), фактор V (FV), фактор VII (FVII), фактор VIII (FVIII), фактор IX (FIX), фактор X (FX), фактор XI (FXI), фактор XII (FXII), фактор XIII (FVIII), фактор фон Виллебранда (VWF), прекалликреин, высокомолекулярный кининоген, фибронектин, антитромбин III, кофактор гепарина II, белок C, белок S, белок Z, ингибитор протеаз, связанный с белком Z (ZPI), плазминоген, альфа-2-антиплазмин, тканевой активатор плазминогена (tPA), урокиназу, ингибитор активатора плазминогена-1 (PAI-1), ингибитор активатора плазминогена-2 (PAI2) или любую их комбинацию.
[509] E46. Молекула нуклеиновой кислоты согласно любому из E1-E45, где фактор свертывания крови представляет собой FVIII.
[510] E47. Молекула нуклеиновой кислоты согласно E46, где FVIII включает в себя полноразмерный зрелый FVIII.
[511] E48. Молекула нуклеиновой кислоты согласно E47, где FVIII содержит аминокислотную последовательность, которая на по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична аминокислотной последовательности, характеризующейся SEQ ID NO: 106.
[512] E49. Молекула нуклеиновой кислоты согласно E46, где FVIII содержит домен A1, домен A2, домен A3, домен C1, домен C2, а также содержит частичный домен B или вообще не содержит его.
[513] E50. Молекула нуклеиновой кислоты согласно E49, где FVIII содержит аминокислотную последовательность, которая на по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична аминокислотной последовательности под SEQ ID NO:109.
[514] E51. Молекула нуклеиновой кислоты согласно любому из E1-E50, где фактор свертывания крови содержит гетерологичный компонент.
[515] E52. Молекула нуклеиновой кислоты согласно E51, где гетерологичный компонент выбран из группы, состоящей из альбумина или его фрагмента, Fc-области иммуноглобулина, C-концевого пептида (CTP) β-субъединицы хорионического гонадотропина человека, последовательности PAS, последовательности HAP, трансферрина или его фрагмента, альбумин-связывающего компонента, их производного или любой их комбинации.
[516] E53. Молекула нуклеиновой кислоты согласно E51 или E52, где гетерологичный компонент связан с N-концом или C-концом FVIII или вставлен между двумя аминокислотами в FVIII.
[517] E54. Молекула нуклеиновой кислоты согласно E53, где гетерологичный компонент вставлен между двумя аминокислотами в одном или нескольких сайтах вставки, выбранных из сайтов вставки, перечисленных в таблице 5.
[518] E55. Молекула нуклеиновой кислоты согласно любому из E45-E54, где FVIII дополнительно содержит домен A1, домен A2, домен C1, домен C2, необязательный домен B и гетерологичный компонент, где гетерологичный компонент вставлен непосредственно ниже аминокислоты 745, соответствующей зрелому FVIII (SEQ ID NO:106).
[519] E56. Молекула нуклеиновой кислоты согласно любому из E53-55, где FVIII дополнительно содержит партнера по связыванию FcRn.
[520] E57. Молекула нуклеиновой кислоты согласно E56, где партнер по связыванию FcRn содержит Fc-область константного домена иммуноглобулина.
[521] E58. Молекула нуклеиновой кислоты согласно любому из E45-E57, где последовательность нуклеиновой кислоты, кодирующая FVIII, является кодон-оптимизированной.
[522] E59. Молекула нуклеиновой кислоты согласно любому из E45-E58, где последовательность нуклеиновой кислоты, кодирующая FVIII, является кодон-оптимизированной для экспрессии у человека.
[523] E60. Молекула нуклеиновой кислоты согласно E59, где последовательность нуклеиновой кислоты, кодирующая FVIII, содержит нуклеотидную последовательность, которая на по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или приблизительно 100% идентична нуклеотидной последовательности под SEQ ID NO: 107.
[524] E61. Молекула нуклеиновой кислоты согласно E59, где последовательность нуклеиновой кислоты, кодирующая FVIII, содержит нуклеотидную последовательность, которая на по меньшей мере приблизительно 60%, по меньшей мере приблизительно 65%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или приблизительно 100% идентична нуклеотидной последовательности под SEQ ID NO: 71.
[525] E62. Молекула нуклеиновой кислоты согласно любому из E1-61, где молекула нуклеиновой кислоты составлена со средством доставки.
[526] E63. Молекула нуклеиновой кислоты согласно E62, где средство доставки включает в себя липидную наночастицу.
[527] E64. Молекула нуклеиновой кислоты согласно E63, где средство доставки выбрано из группы, состоящей из липосом, нелипидных полимерных молекул, эндосом и любой их комбинации.
[528] E65. Молекула нуклеиновой кислоты согласно любому из E1-E64, где молекула нуклеиновой кислоты составлена для внутривенной, трансдермальной, внутрикожной, подкожной, пульмональной или пероральной доставки или любой их комбинации.
[529] E66. Молекула нуклеиновой кислоты согласно E65, где молекула нуклеиновой кислоты составлена для внутривенной доставки.
[530] E67. Вектор, содержащий молекулу нуклеиновой кислоты согласно любому из E1-E66.
[531] E68. Полипептид, кодируемый молекулой нуклеиновой кислоты согласно любому из E1-E66.
[532] E69. Клетка-хозяин, содержащая молекулу нуклеиновой кислоты согласно любому из E1-66.
[533] E70. Фармацевтическая композиция, содержащая (а) нуклеиновую кислоту согласно любому из E1-66, вектор согласно E67, полипептид согласно E68 или клетку-хозяина согласно E69; (b) LNP и (с) фармацевтически приемлемое вспомогательное вещество.
[534] E71. Набор, содержащий молекулу нуклеиновой кислоты согласно любому из E1-66 и инструкции по введению молекулы нуклеиновой кислоты нуждающемуся в этом субъекту.
[535] E72. Бакуловирусная система для получения молекулы нуклеиновой кислоты согласно любому из E1-E66.
[536] E73. Бакуловирусная система согласно E72, где молекулу нуклеиновой кислоты согласно любому из E1-66 получают в клетках насекомых.
[537] E74. Система доставки на основе наночастиц для экспрессионных конструкций, где экспрессионная конструкция содержит молекулу нуклеиновой кислоты согласно любому из Е1-Е66.
[538] E75. Способ получения полипептида со свертывающей активностью, включающий культивирование клетки-хозяина согласно E69 в подходящих условиях и извлечение полипептида со свертывающей активностью.
[539] E76. Способ обеспечения экспрессии фактора свертывания крови у нуждающегося в этом субъекта, включающий введение субъекту молекулы нуклеиновой кислоты согласно любому из E1-E66, вектора согласно E67, полипептида согласно E68 или фармацевтической композиции согласно E70.
[540] E77. Способ лечения субъекта, имеющего дефицит фактора свертывания крови, включающий введение субъекту молекулы нуклеиновой кислоты согласно любому из E1-E66, вектора согласно E67, полипептида согласно E68 или фармацевтической композиции согласно E70.
[541] E78. Способ согласно E76 или E77, где молекулу нуклеиновой кислоты вводят внутривенно, трансдермально, внутрикожно, подкожно, перорально, пульмонально или с помощью любой их комбинации.
[542] E79. Способ согласно E78, где молекулу нуклеиновой кислоты вводят внутривенно.
[543] E80. Способ согласно любому из E76-E79, дополнительно включающий введение субъекту второго средства.
[544] E81. Способ согласно любому из E76-E80, где субъектом является млекопитающее.
[545] E82. Способ согласно любому из E76-E81, где субъектом является человек.
[546] E83. Способ согласно любому из E76-E82, где введение молекулы нуклеиновой кислоты субъекту приводит к увеличению активности FVIII относительно активности FVIII у субъекта до введения, где активность FVIII увеличивается в по меньшей мере приблизительно 2 раза, по меньшей мере приблизительно 3 раза, по меньшей мере приблизительно 4 раза, по меньшей мере приблизительно 5 раз, по меньшей мере приблизительно 6 раз, по меньшей мере приблизительно 7 раз, по меньшей мере приблизительно 8 раз, по меньшей мере приблизительно 9 раз, по меньшей мере приблизительно 10 раз, по меньшей мере приблизительно 11 раз, по меньшей мере приблизительно 12 раз, по меньшей мере приблизительно 13 раз, по меньшей мере приблизительно 14 раз, по меньшей мере приблизительно 15 раз, по меньшей мере приблизительно 20 раз, по меньшей мере приблизительно 25 раз, по меньшей мере приблизительно 30 раз, по меньшей мере приблизительно 35 раз, по меньшей мере приблизительно 40 раз, по меньшей мере приблизительно 50 раз, по меньшей мере приблизительно 60 раз, по меньшей мере приблизительно 70 раз, по меньшей мере приблизительно 80 раз, по меньшей мере приблизительно 90 раз или по меньшей мере приблизительно 100 раз.
[547] E84. Способ согласно любому из E76-E83, где у субъекта имеется нарушение свертываемости крови.
[548] E85. Способ согласно E84, где нарушение свертываемости крови представляет собой гемофилию.
[549] E86. Способ согласно E84 или E85, где нарушение свертываемости крови представляет собой гемофилию A.
[550] E83. Способ согласно любому из E76-E82, E85 и E86, где введение молекулы нуклеиновой кислоты субъекту приводит к увеличению активности FVIII относительно активности FVIII у субъекта до введения, где активность FVIII увеличивается на по меньшей мере приблизительно 2%, по меньшей мере приблизительно 3%, по меньшей мере приблизительно 4%, по меньшей мере приблизительно 5%, по меньшей мере приблизительно 6%, по меньшей мере приблизительно 7%, по меньшей мере приблизительно 8%, по меньшей мере приблизительно 9%, по меньшей мере приблизительно 10%, по меньшей мере приблизительно 11%, по меньшей мере приблизительно 12%, по меньшей мере приблизительно 13%, по меньшей мере приблизительно 14%, по меньшей мере приблизительно 15%, по меньшей мере приблизительно 20%, по меньшей мере приблизительно 25%, по меньшей мере приблизительно 30%, по меньшей мере приблизительно 35%, по меньшей мере приблизительно 40%, по меньшей мере приблизительно 50%, по меньшей мере приблизительно 60%, по меньшей мере приблизительно 70%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 100%, по меньшей мере приблизительно 110%, по меньшей мере приблизительно 120%, по меньшей мере приблизительно 130%, по меньшей мере приблизительно 140%, по меньшей мере приблизительно 150% относительно нормальной активности FVIII.
Настоящая заявка испрашивает приоритет по предварительной заявке на патент США № 62/543297, поданной 9 августа 2017 г., которая включена в данный документ посредством ссылки во всей своей полноте.
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> BIOVERATIV THERAPEUTICS INC.
Seregin, Alexey
Liu, Tongyao
Patarroyo-White, Susannah
Drager, Douglas
Peters, Robert T.
Liu, Jiayun
<120> МОЛЕКУЛЫ НУКЛЕИНОВОЙ КИСЛОТЫ И ПУТИ ИХ ПРИМЕНЕНИЯ
<130> 4159.493PC01/C-K/BMD
<150> US 62/543,297
<151> 2017-08-09
<160> 184
<170> PatentIn версия 3.5
<210> 1
<211> 4374
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-5
<400> 1
atgcaaatcg aactgagcac ctgtttcttc ctctgcctgc tgagattctg tttctccgcg
60
acccgccgat actacctggg agcagtggag ctctcctggg attacatgca gagcgacctt
120
ggggagctgc ccgtggatgc caggttccct ccccgggtgc caaagtcgtt tccgttcaac
180
acctccgtgg tgtacaagaa aactctgttc gtggagttca ccgaccacct gttcaatatc
240
gccaagccca gacctccctg gatggggctg ttgggaccta ccatccaagc ggaggtgtac
300
gacactgtgg tcatcactct gaagaacatg gcctcgcatc ccgtgtccct gcacgccgtg
360
ggagtgtctt actggaaagc gtccgagggg gccgaatacg acgaccagac ctcgcagaga
420
gaaaaggaag atgacaaggt gttcccagga ggatcgcaca cctacgtgtg gcaagtgttg
480
aaggagaacg gcccaatggc ctccgacccg ctgtgcctga cctactcgta cctgtcccac
540
gtggacctcg tgaaggacct caactcggga ctgattggag ccctgctggt ctgcagggaa
600
ggctcactgg cgaaagaaaa gactcagacc ttgcacaagt tcattctgct gttcgctgtg
660
ttcgacgagg ggaagtcgtg gcacagcgag actaagaact ccctgatgca agatagagat
720
gccgcctccg cccgggcctg gcctaagatg cacaccgtga acggttacgt gaaccgctcc
780
ctccctggcc tgattggatg ccaccggaag tccgtgtact ggcacgtgat cgggatgggg
840
accacccccg aggtgcacag catcttcctg gaaggtcaca catttctcgt gcgcaaccac
900
cggcaggcct ccctggaaat cagccccatt accttcctca ctgcccagac tctgctgatg
960
gacctgggac agttcctgct gttctgccat atctcctccc accaacatga cggaatggag
1020
gcatacgtga aggtcgattc ctgccctgag gaaccccagc tccgcatgaa gaacaatgag
1080
gaagccgagg actacgacga cgacctgacg gatagcgaga tggatgtggt ccggttcgat
1140
gacgataaca gcccttcctt catccaaatt cgctcggtgg caaagaagca ccccaagacc
1200
tgggtgcatt acattgcggc ggaagaagag gactgggatt atgccccgct tgtcctcgct
1260
cctgacgacc ggagctacaa gagccagtac ctgaacaacg gtccacagag gatcggtaga
1320
aagtacaaga aggtccgctt catggcctat accgacgaaa ccttcaaaac tagagaggcc
1380
atccaacacg aatccggcat cctgggcccg ctcttgtacg gagaagtcgg cgacaccctt
1440
ctcattatct tcaagaacca ggcttcccgg ccgtacaaca tctatccgca tgggatcact
1500
gacgtgcgcc cactgtactc gcggcgcctg cccaagggtg tcaaacacct gaaggatttt
1560
ccgatccttc cgggagaaat cttcaagtac aagtggaccg tgaccgtgga agatggccca
1620
actaagtctg accctagatg cctcacccgc tactactcat ccttcgtcaa catggagcgc
1680
gacctggcca gcggactgat cggcccgctg ctgatttgct acaaggaatc agtggaccaa
1740
cggggaaacc agatcatgtc ggataagagg aacgtcatcc tcttctccgt gtttgacgaa
1800
aaccggtcgt ggtacctgac tgaaaacatc cagcggttcc tccccaaccc cgcgggcgtg
1860
cagctggaag atcctgagtt tcaggcatca aacatcatgc actccattaa cggctacgtg
1920
ttcgattcgc tgcagctgag cgtgtgtctg cacgaagtgg cctactggta catcctgtcc
1980
attggtgccc agactgactt cctgtccgtg tttttctccg gctacacgtt caagcacaag
2040
atggtgtacg aggacaccct gaccctcttc cctttttccg gcgaaactgt gtttatgagc
2100
atggagaatc ccggcctgtg gatcttgggc tgccacaaca gcgacttccg taacagagga
2160
atgactgcgc tgctcaaggt gtccagctgc gacaagaaca ccggagacta ttatgaggac
2220
tcatacgagg acatctccgc ctacctcctg tccaagaata acgccattga acctcggagc
2280
ttcagccaga acccacccgt gcttaagaga catcaacggg agatcactag gaccaccctg
2340
cagtcagacc aggaggaaat cgactacgat gacaccatct cggtcgagat gaagaaggag
2400
gactttgaca tctacgacga agatgaaaac cagagcccga ggtcgttcca aaagaaaacc
2460
cgccactact ttattgctgc tgtcgagcgg ctgtgggact acggaatgtc gtcctcgccg
2520
cacgtgctcc gcaaccgagc ccagagcggc tcggtgccgc aattcaagaa ggtcgtgttc
2580
caggagttca ctgacgggag cttcactcag cctttgtacc ggggagaact caatgaacat
2640
ctcggcctcc tcggacctta catcagagca gaagtggaag ataacatcat ggtcactttc
2700
cgtaaccaag ccagccgccc gtactcgttc tactcctccc tcatttctta cgaagaggac
2760
cagcggcagg gcgcagaacc gcgcaagaac ttcgtgaagc ccaacgaaac caagacctac
2820
ttctggaaag tgcagcatca tatggccccg actaaggacg agtttgactg caaagcctgg
2880
gcctacttct ccgatgtgga cttggagaag gacgtccact ccggcctcat cggtcccctg
2940
ctcgtgtgcc ataccaatac cctgaacccc gcacacggtc gccaggtcac cgtgcaggag
3000
ttcgctctgt tcttcactat cttcgacgaa actaagtcct ggtacttcac cgagaacatg
3060
gagaggaact gcagagcccc ctgtaacatc cagatggagg acccgacgtt caaggaaaac
3120
taccggttcc acgccattaa cggatacatc atggatacgc tgccgggtct tgtgatggcc
3180
caggatcaac ggatcagatg gtacttattg tcgatgggca gcaacgagaa catccactct
3240
attcacttct ccggtcatgt gttcactgtg cggaagaagg aagagtacaa gatggccctg
3300
tacaaccttt atcccggagt gttcgaaact gtggaaatgc tgccgtcgaa ggccggcatt
3360
tggcgcgtgg agtgtttgat tggagaacat ctccatgcgg ggatgtcaac cctgttcctg
3420
gtgtatagca acaagtgcca gactccgctt gggatggcgt caggacacat tagggatttc
3480
cagatcactg cgtccggcca gtacggccaa tgggccccta agctggcccg cctgcattac
3540
tccggatcca ttaacgcctg gtcaaccaag gagccattct cctggatcaa ggtggacctt
3600
ctggccccca tgattatcca cggaattaag acccaggggg cccggcagaa gttctcctca
3660
ctgtacatca gccagttcat aatcatgtac tccctggacg gaaagaagtg gcaaacctac
3720
agggggaaca gcaccggcac actgatggtc tttttcggaa atgtggactc ctccgggatt
3780
aagcataaca tcttcaaccc tccgattatc gctcggtaca ttagacttca ccctacccac
3840
tacagcattc gctccaccct gcggatggaa ctgatgggct gcgatctgaa ctcgtgcagc
3900
atgccgttgg gaatggagtc caaagcaatt tccgacgcgc agatcaccgc ctcgtcctac
3960
tttaccaaca tgttcgccac gtggtcaccg tccaaggccc ggctgcacct ccagggaaga
4020
tccaacgcat ggcggccaca ggtcaacaac cctaaggagt ggctccaggt ggacttccag
4080
aaaaccatga aggtcaccgg agtcacaacc cagggagtga agtcgctgct gacttctatg
4140
tacgtcaagg agttcctgat ctccagcagc caggacgggc accagtggac cctgttcttc
4200
caaaatggaa aggtcaaggt gtttcagggc aatcaggatt cattcacccc ggtggtgaac
4260
tcccttgatc cacccctcct gacccgctac cttcgcatcc acccacagtc ctgggtgcac
4320
cagatcgcgc tgaggatgga ggtcctggga tgcgaagccc aggacctgta ctga
4374
<210> 2
<211> 4374
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-4
<400> 2
atgcagatcg agctgagcac gtgcttcttc ctgtgcctgc tgaggttctg cttcagcgcc
60
accaggaggt actacctggg cgccgtggag ctgagctggg actacatgca gagcgacctg
120
ggcgagctgc ccgtggacgc caggttcccc cccagggtgc ccaagagctt ccccttcaac
180
acgagcgtgg tgtacaagaa gaccctgttc gtggagttca ccgaccatct gttcaatatc
240
gccaagccca ggcccccctg gatggggctg ctggggccca cgatccaggc cgaggtgtac
300
gacaccgtgg tcatcaccct gaagaacatg gccagccacc ccgtgagcct gcacgccgtg
360
ggcgtgagct actggaaggc cagcgagggc gccgagtacg acgaccagac cagccagagg
420
gagaaggagg acgacaaggt gttccccggc ggcagccaca cctacgtgtg gcaggtgctg
480
aaggagaatg ggcccatggc cagcgacccc ctgtgcctga cctactctta cctgagccac
540
gtggatctgg tgaaggacct gaacagcggc ctgatcggcg ccctgctggt gtgcagggag
600
ggcagcctgg ccaaggagaa gacccagacc ctgcacaagt tcatcctgct gttcgccgtg
660
ttcgacgagg gcaagagctg gcacagcgag accaagaaca gcctgatgca ggatagggac
720
gccgccagcg ccagggcctg gcccaagatg cacaccgtga acggctacgt gaacaggtct
780
ctgcccggcc tgatcggctg ccacaggaag agcgtgtact ggcacgtgat cggcatgggg
840
accacccccg aggtgcacag catcttcctg gagggccaca cgttcctggt gaggaatcac
900
aggcaggcca gcctggagat cagcccgatc accttcctga ccgcccagac cctgctgatg
960
gacctggggc agttcctgct gttctgccat atcagctctc accagcacga cggcatggag
1020
gcctacgtga aggtggatag ctgccccgag gagccccagc tgaggatgaa gaacaacgag
1080
gaggccgagg actacgacga cgacctgacc gacagcgaga tggacgtggt gaggttcgac
1140
gacgacaata gcccgagctt catccagatc aggagcgtgg ccaagaagca ccccaagacc
1200
tgggtgcatt acatcgccgc cgaggaggag gattgggact acgcccccct ggtgctggcc
1260
cccgacgaca ggtcttacaa gagccagtac ctgaacaacg ggccccagag gatcggcagg
1320
aagtacaaga aggtgaggtt catggcctac accgacgaga ccttcaagac cagggaggcg
1380
atccagcacg agagcgggat cctggggccc ctgctgtacg gcgaggtggg cgacacgctg
1440
ctgatcatct tcaagaacca ggccagcagg ccgtacaata tctaccccca cgggatcacc
1500
gacgtgaggc ccctgtactc taggaggctg cccaagggcg tgaagcacct gaaggacttc
1560
cccatcctgc ccggcgagat cttcaagtac aagtggaccg tgaccgtgga ggacgggccc
1620
acgaagagcg accccaggtg cctgaccagg tactacagct ctttcgtgaa catggagagg
1680
gacctggcca gcggcctgat cgggcccctg ctgatctgct acaaggagag cgtggatcag
1740
aggggcaacc agatcatgag cgacaagagg aacgtgatcc tgttcagcgt gttcgacgag
1800
aataggtctt ggtacctgac cgagaatatc cagaggttcc tgcccaaccc cgccggcgtg
1860
cagctggagg atcccgagtt ccaggccagc aacatcatgc acagcatcaa cggctacgtg
1920
ttcgacagcc tgcagctgag cgtgtgcctg cacgaggtgg cctactggta catcctgagc
1980
atcggcgccc agaccgactt cctgagcgtg ttcttcagcg gctacacctt caagcacaag
2040
atggtgtacg aggataccct gaccctgttc cccttcagcg gcgagaccgt gttcatgagc
2100
atggagaacc ccggcctgtg gatcctgggc tgccataact ccgacttcag gaataggggc
2160
atgaccgccc tgctgaaggt gagctcttgc gacaagaaca ccggcgacta ctacgaggat
2220
agctacgagg atatcagcgc ctacctgctg agcaagaaca acgccatcga gcccaggtct
2280
ttcagccaga acccccccgt gctgaagagg caccagaggg agatcaccag gacgaccctg
2340
cagagcgacc aggaggagat cgactacgac gacacgatca gcgtggagat gaagaaggag
2400
gatttcgaca tctacgacga ggacgagaat cagagcccca ggtctttcca gaagaagacc
2460
aggcattact tcatcgccgc cgtggagagg ctgtgggact acggcatgag cagctctccc
2520
cacgtgctga ggaatagggc ccagagcggc agcgtgcccc agttcaagaa ggtggtgttc
2580
caggagttca ccgacggcag cttcacccag cccctgtaca ggggcgagct gaacgagcac
2640
ctgggcctgc tggggcccta catcagggcc gaggtggagg ataacatcat ggtgaccttc
2700
aggaatcagg ccagcaggcc ctatagcttc tatagctctc tgatcagcta cgaggaggat
2760
cagaggcagg gcgccgagcc caggaagaac ttcgtgaagc ccaacgagac caagacctac
2820
ttctggaagg tgcagcacca catggccccc acgaaggacg agttcgactg caaggcctgg
2880
gcctacttca gcgacgtgga tctggagaag gacgtgcaca gcggcctgat cgggcccctg
2940
ctggtgtgcc acaccaacac cctgaacccc gcccacggca ggcaggtgac cgtgcaggag
3000
ttcgccctgt tcttcaccat cttcgacgag accaagagct ggtacttcac cgagaatatg
3060
gagaggaatt gcagggcccc ctgcaatatc cagatggagg acccgacctt caaggagaat
3120
tacaggttcc acgccatcaa cggctacatc atggacacgc tgcccggcct ggtcatggcc
3180
caggatcaga ggatcaggtg gtatctgctg agcatgggga gcaacgagaa tatccacagc
3240
atccacttca gcggccacgt gttcaccgtg aggaagaagg aggagtacaa gatggccctg
3300
tacaatctgt accccggcgt gttcgagacc gtggagatgc tgcccagcaa ggccgggatc
3360
tggagggtgg agtgcctgat cggcgagcac ctgcacgccg gcatgagcac gctgttcctg
3420
gtgtactcta acaagtgcca gacccccctg gggatggcca gcggccacat cagggacttc
3480
cagatcaccg ccagcggcca gtacggccag tgggccccca agctggccag gctgcactat
3540
tccggaagca tcaacgcctg gagcacgaag gagcccttca gctggatcaa ggtggatctg
3600
ctggccccca tgatcatcca cgggatcaag acccagggcg ccaggcagaa gttcagctct
3660
ctgtatatca gccagttcat catcatgtac tctctggacg gcaagaagtg gcagacctac
3720
aggggcaaca gcaccggcac gctgatggtg ttcttcggca acgtggactc tagcgggatc
3780
aagcacaata tcttcaaccc ccccatcatc gccaggtaca tcaggctgca ccccacccat
3840
tactctatca ggtctaccct gaggatggag ctgatgggct gcgacctgaa cagctgcagc
3900
atgcccctgg ggatggagag caaggccatc agcgacgccc agatcaccgc cagctcttac
3960
ttcaccaaca tgttcgccac ctggagcccg agcaaggcca ggctgcacct gcagggcagg
4020
tctaacgcct ggaggcccca ggtgaacaac cccaaggagt ggctgcaggt ggatttccag
4080
aagaccatga aggtgaccgg cgtgaccacg cagggcgtga agagcctgct gaccagcatg
4140
tacgtgaagg agttcctgat cagctctagc caggacggcc accagtggac cctgttcttc
4200
cagaacggca aggtgaaggt gttccagggc aaccaggata gcttcacccc cgtggtgaac
4260
agcctggacc cccccctgct gaccaggtat ctgaggatcc acccccagag ctgggtgcac
4320
cagatcgccc tgaggatgga ggtgctgggc tgcgaggccc aggatctgta ttga
4374
<210> 3
<211> 4374
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-52
<400> 3
atgcaaatcg aactgagcac ctgtttcttc ctctgcctgc tgagattctg tttctccgcg
60
acccgccgat actacctggg agcagtggag ctctcctggg attacatgca gagcgacctt
120
ggggagctgc ccgtggatgc caggttccct ccccgggtgc caaagtcgtt tccgttcaac
180
acctccgtgg tgtacaagaa aactctgttc gtggagttca ccgaccacct gttcaatatc
240
gccaagccca gacctccctg gatggggctg ttgggaccta ccatccaagc ggaggtgtac
300
gacactgtgg tcatcactct gaagaacatg gcctcgcatc ccgtgtccct gcacgccgtg
360
ggagtgtctt actggaaagc gtccgagggg gccgaatacg acgaccagac ctcgcagaga
420
gaaaaggaag atgacaaggt gttcccagga ggatcgcaca cctacgtgtg gcaagtgttg
480
aaggagaacg gcccaatggc ctccgacccg ctgtgcctga cctactcgta cctgtcccac
540
gtggacctcg tgaaggacct caactcggga ctgattggag ccctgctggt ctgcagggaa
600
ggctcactgg cgaaagaaaa gactcagacc ttgcacaagt tcattctgct gttcgctgtg
660
ttcgacgagg ggaagtcgtg gcacagcgag actaagaact ccctgatgca agatagagat
720
gccgcctccg cccgggcctg gcctaagatg cacaccgtga acggttacgt gaaccgctcc
780
ctccctggcc tgattggatg ccaccggaag tccgtgtact ggcacgtgat cgggatgggg
840
accacccccg aggtgcacag catcttcctg gaaggtcaca catttctcgt gcgcaaccac
900
cggcaggcct ccctggaaat cagccccatt accttcctca ctgcccagac tctgctgatg
960
gacctgggac agttcctgct gttctgccat atctcctccc accaacatga cggaatggag
1020
gcatacgtga aggtcgattc ctgccctgag gaaccccagc tccgcatgaa gaacaatgag
1080
gaagccgagg actacgacga cgacctgacg gatagcgaga tggatgtggt ccggttcgat
1140
gacgataaca gcccttcctt catccaaatt cgctcggtgg caaagaagca ccccaagacc
1200
tgggtgcatt acattgcggc ggaagaagag gactgggatt atgccccgct tgtcctcgct
1260
cctgacgacc ggagctacaa gagccagtac ctgaacaacg gtccacagag gatcggtaga
1320
aagtacaaga aggtccgctt catggcctat accgacgaaa ccttcaaaac tagagaggcc
1380
atccaacacg aatccggcat cctgggcccg ctcttgtacg gagaagtcgg cgacaccctt
1440
ctcattatct tcaagaacca ggcttcccgg ccgtacaaca tctatccgca tgggatcact
1500
gacgtgcgcc cactgtactc gcggcgcctg cccaagggtg tcaaacacct gaaggatttt
1560
ccgatccttc cgggagaaat cttcaagtac aagtggaccg tgaccgtgga agatggccca
1620
actaagtctg accctagatg cctcacccgc tactactcat ccttcgtcaa catggagcgc
1680
gacctggcca gcggactgat cggcccgctg ctgatttgct acaaggaatc agtggaccaa
1740
cggggaaacc agatcatgtc ggataagagg aacgtcatcc tcttctccgt gtttgacgaa
1800
aaccggtcgt ggtacctgac cgagaacatc cagaggttcc tgcccaaccc tgctggggtg
1860
cagctggagg accccgagtt ccaggccagc aacatcatgc acagcatcaa tggctacgtg
1920
ttcgacagcc tgcagctgag cgtgtgcctg cacgaggtgg cctactggta catcctgagc
1980
atcggcgccc agaccgactt cctgagcgtg ttcttctctg gctacacctt caagcacaag
2040
atggtgtatg aggacaccct gaccctgttc cccttcagcg gggagactgt cttcatgagc
2100
atggagaacc ctggcctgtg gatcctgggc tgccacaaca gcgacttcag gaacaggggc
2160
atgactgccc tgctgaaagt ctccagctgt gacaagaaca ccggggacta ctacgaggac
2220
agctacgagg acatcagcgc ctacctgctg agcaagaaca atgccatcga gcccaggagc
2280
ttctctcaga accccccagt gctgaagagg caccagaggg agatcaccag gaccaccctg
2340
cagtctgacc aggaggagat cgactatgat gacaccatca gcgtggagat gaagaaggag
2400
gacttcgaca tctacgacga ggacgagaac cagagcccca ggagcttcca gaagaagacc
2460
aggcactact tcattgctgc tgtggagagg ctgtgggact atggcatgtc cagcagcccc
2520
catgtgctga ggaacagggc ccagtctggc agcgtgcccc agttcaagaa agtcgtgttc
2580
caggagttca ccgacggcag cttcacccag cccctgtaca gaggggagct gaacgagcac
2640
ctgggcctgc tgggccccta catcagggcc gaggtggagg acaacatcat ggtgaccttc
2700
aggaaccagg ccagcaggcc ctacagcttc tacagcagcc tgatcagcta cgaggaggac
2760
cagaggcagg gggctgagcc caggaagaac tttgtgaagc ccaatgaaac caagacctac
2820
ttctggaagg tgcagcacca catggccccc accaaggacg agttcgactg caaggcctgg
2880
gcctacttct ctgacgtgga cctggagaag gacgtgcact ctggcctgat tggccccctg
2940
ctggtgtgcc acaccaacac cctgaaccct gcccatggca ggcaggtgac tgtgcaggag
3000
ttcgccctgt tcttcaccat cttcgatgaa accaagagct ggtacttcac tgagaacatg
3060
gagaggaact gcagggcccc ctgcaacatc cagatggagg accccacctt caaggagaac
3120
tacaggttcc atgccatcaa tggctacatc atggacaccc tgcctggcct ggtcatggcc
3180
caggaccaga ggatcaggtg gtatctgctg agcatgggca gcaacgagaa catccacagc
3240
atccacttct ctggccacgt gttcactgtg aggaagaagg aggagtacaa gatggccctg
3300
tacaacctgt accctggggt gttcgaaacc gtggagatgc tgcccagcaa ggccggcatc
3360
tggagggtgg agtgcctgat tggggagcac ctgcacgccg gcatgagcac cctgttcctg
3420
gtgtacagca acaagtgcca gacccccctg ggcatggcct ctggccacat cagggacttc
3480
cagatcactg cctctggcca gtacggccag tgggccccca agctggccag gctgcactac
3540
tccggaagca tcaatgcctg gagcaccaag gagcccttca gctggatcaa agtggacctg
3600
ctggccccca tgatcatcca cggcatcaag acccaggggg ccaggcagaa gttctccagc
3660
ctgtacatca gccagttcat catcatgtac agcctggacg gcaagaagtg gcagacctac
3720
aggggcaaca gcaccggcac cctgatggtg ttcttcggca acgtggacag cagcggcatc
3780
aagcacaaca tcttcaaccc ccccatcatc gccagataca tcaggctgca ccccacccac
3840
tacagcatca ggagcaccct gaggatggag ctgatgggct gtgacctgaa cagctgcagc
3900
atgcccctgg gcatggagag caaggccatc tctgacgccc agatcactgc ctccagctac
3960
ttcaccaaca tgtttgccac ctggagcccc agcaaggcca ggctgcacct gcagggcagg
4020
agcaatgcct ggaggcccca ggtcaacaac cccaaggagt ggctgcaggt ggacttccag
4080
aagaccatga aggtgactgg ggtgaccacc cagggggtga agagcctgct gaccagcatg
4140
tacgtgaagg agttcctgat ctccagcagc caggacggcc accagtggac cctgttcttc
4200
cagaatggca aggtgaaggt gttccagggc aaccaggaca gcttcacccc tgtggtcaac
4260
agcctggacc cccccctgct gaccagatac ctgaggatcc acccccagag ctgggtgcac
4320
cagatcgccc tgaggatgga ggtgctgggc tgtgaggccc aggacctgta ctga
4374
<210> 4
<211> 4374
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-62
<400> 4
atgcagattg agctgtccac ttgtttcttc ctgtgcctcc tgcgcttctg tttctccgcc
60
actcgccggt actaccttgg agccgtggag ctttcatggg actacatgca gagcgacctg
120
ggcgaactcc ccgtggatgc cagattcccc ccccgcgtgc caaagtcctt cccctttaac
180
acctccgtgg tgtacaagaa aaccctcttt gtcgagttca ctgaccacct gttcaacatc
240
gccaagccgc gcccaccttg gatgggcctc ctgggaccga ccattcaagc tgaagtgtac
300
gacaccgtgg tgatcaccct gaagaacatg gcgtcccacc ccgtgtccct gcatgcggtc
360
ggagtgtcct actggaaggc ctccgaagga gctgagtacg acgaccagac tagccagcgg
420
gaaaaggagg acgataaagt gttcccgggc ggctcgcata cttacgtgtg gcaagtcctg
480
aaggaaaacg gacctatggc atccgatcct ctgtgcctga cttactccta cctttcccat
540
gtggacctcg tgaaggacct gaacagcggg ctgattggtg cacttctcgt gtgccgcgaa
600
ggttcgctcg ctaaggaaaa gacccagacc ctccataagt tcatcctttt gttcgctgtg
660
ttcgatgaag gaaagtcatg gcattccgaa actaagaact cgctgatgca ggaccgggat
720
gccgcctcag cccgcgcctg gcctaaaatg catacagtca acggatacgt gaatcggtca
780
ctgcccgggc tcatcggttg tcacagaaag tccgtgtact ggcacgtcat cggcatgggc
840
actacgcctg aagtgcactc catcttcctg gaagggcaca ccttcctcgt gcgcaaccac
900
cgccaggcct ctctggaaat ctccccgatt acctttctga ccgcccagac tctgctcatg
960
gacctggggc agttccttct cttctgccac atctccagcc atcagcacga cggaatggag
1020
gcctacgtga aggtggactc atgcccggaa gaacctcagt tgcggatgaa gaacaacgag
1080
gaggccgagg actatgacga cgatttgact gactccgaga tggacgtcgt gcggttcgat
1140
gacgacaaca gccccagctt catccagatt cgcagcgtgg ccaagaagca ccccaaaacc
1200
tgggtgcact acatcgcggc cgaggaagaa gattgggact acgccccgtt ggtgctggca
1260
cccgatgacc ggtcgtacaa gtcccagtat ctgaacaatg gtccgcagcg gattggcaga
1320
aagtacaaga aagtgcggtt catggcgtac actgacgaaa cgtttaagac ccgggaggcc
1380
attcaacatg agagcggcat tctgggacca ctgctgtacg gagaggtcgg cgataccctg
1440
ctcatcatct tcaaaaacca ggcctcccgg ccttacaaca tctaccctca cggaatcacc
1500
gacgtgcggc cactctactc gcggcgcctg ccgaagggcg tcaagcacct gaaagacttc
1560
cctatcctgc cgggcgaaat cttcaagtat aagtggaccg tcaccgtgga ggacgggccc
1620
accaagagcg atcctaggtg tctgactcgg tactactcca gcttcgtgaa catggaacgg
1680
gacctggcat cgggactcat tggaccgctg ctgatctgct acaaagagtc ggtggatcaa
1740
cgcggcaacc agatcatgtc cgacaagcgc aacgtgatcc tgttctccgt gtttgatgaa
1800
aacagatcct ggtacctgac cgagaacatc cagaggttcc tgcccaaccc tgctggggtg
1860
cagctggagg accccgagtt ccaggccagc aacatcatgc acagcatcaa tggctacgtg
1920
ttcgacagcc tgcagctgag cgtgtgcctg cacgaggtgg cctactggta catcctgagc
1980
atcggcgccc agaccgactt cctgagcgtg ttcttctctg gctacacctt caagcacaag
2040
atggtgtatg aggacaccct gaccctgttc cccttcagcg gggagactgt cttcatgagc
2100
atggagaacc ctggcctgtg gatcctgggc tgccacaaca gcgacttcag gaacaggggc
2160
atgactgccc tgctgaaagt ctccagctgt gacaagaaca ccggggacta ctacgaggac
2220
agctacgagg acatcagcgc ctacctgctg agcaagaaca atgccatcga gcccaggagc
2280
ttctctcaga accccccagt gctgaagagg caccagaggg agatcaccag gaccaccctg
2340
cagtctgacc aggaggagat cgactatgat gacaccatca gcgtggagat gaagaaggag
2400
gacttcgaca tctacgacga ggacgagaac cagagcccca ggagcttcca gaagaagacc
2460
aggcactact tcattgctgc tgtggagagg ctgtgggact atggcatgtc cagcagcccc
2520
catgtgctga ggaacagggc ccagtctggc agcgtgcccc agttcaagaa agtcgtgttc
2580
caggagttca ccgacggcag cttcacccag cccctgtaca gaggggagct gaacgagcac
2640
ctgggcctgc tgggccccta catcagggcc gaggtggagg acaacatcat ggtgaccttc
2700
aggaaccagg ccagcaggcc ctacagcttc tacagcagcc tgatcagcta cgaggaggac
2760
cagaggcagg gggctgagcc caggaagaac tttgtgaagc ccaatgaaac caagacctac
2820
ttctggaagg tgcagcacca catggccccc accaaggacg agttcgactg caaggcctgg
2880
gcctacttct ctgacgtgga cctggagaag gacgtgcact ctggcctgat tggccccctg
2940
ctggtgtgcc acaccaacac cctgaaccct gcccatggca ggcaggtgac tgtgcaggag
3000
ttcgccctgt tcttcaccat cttcgatgaa accaagagct ggtacttcac tgagaacatg
3060
gagaggaact gcagggcccc ctgcaacatc cagatggagg accccacctt caaggagaac
3120
tacaggttcc atgccatcaa tggctacatc atggacaccc tgcctggcct ggtcatggcc
3180
caggaccaga ggatcaggtg gtatctgctg agcatgggca gcaacgagaa catccacagc
3240
atccacttct ctggccacgt gttcactgtg aggaagaagg aggagtacaa gatggccctg
3300
tacaacctgt accctggggt gttcgaaacc gtggagatgc tgcccagcaa ggccggcatc
3360
tggagggtgg agtgcctgat tggggagcac ctgcacgccg gcatgagcac cctgttcctg
3420
gtgtacagca acaagtgcca gacccccctg ggcatggcct ctggccacat cagggacttc
3480
cagatcactg cctctggcca gtacggccag tgggccccca agctggccag gctgcactac
3540
tccggaagca tcaatgcctg gagcaccaag gagcccttca gctggatcaa agtggacctg
3600
ctggccccca tgatcatcca cggcatcaag acccaggggg ccaggcagaa gttctccagc
3660
ctgtacatca gccagttcat catcatgtac agcctggacg gcaagaagtg gcagacctac
3720
aggggcaaca gcaccggcac cctgatggtg ttcttcggca acgtggacag cagcggcatc
3780
aagcacaaca tcttcaaccc ccccatcatc gccagataca tcaggctgca ccccacccac
3840
tacagcatca ggagcaccct gaggatggag ctgatgggct gtgacctgaa cagctgcagc
3900
atgcccctgg gcatggagag caaggccatc tctgacgccc agatcactgc ctccagctac
3960
ttcaccaaca tgtttgccac ctggagcccc agcaaggcca ggctgcacct gcagggcagg
4020
agcaatgcct ggaggcccca ggtcaacaac cccaaggagt ggctgcaggt ggacttccag
4080
aagaccatga aggtgactgg ggtgaccacc cagggggtga agagcctgct gaccagcatg
4140
tacgtgaagg agttcctgat ctccagcagc caggacggcc accagtggac cctgttcttc
4200
cagaatggca aggtgaaggt gttccagggc aaccaggaca gcttcacccc tgtggtcaac
4260
agcctggacc cccccctgct gaccagatac ctgaggatcc acccccagag ctgggtgcac
4320
cagatcgccc tgaggatgga ggtgctgggc tgtgaggccc aggacctgta ctga
4374
<210> 5
<211> 4374
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-25
<400> 5
atgcagattg agctgagcac ctgcttcttc ctgtgcctgc tgaggttctg cttctctgcc
60
accaggagat actacctggg cgccgtggag ctgagctggg actacatgca gtctgacctg
120
ggcgagctgc cagtggacgc caggttcccc cccagagtgc ccaagagctt ccccttcaac
180
accagcgtgg tgtacaagaa gaccctgttc gtggagttca ctgaccacct gttcaacatc
240
gccaagccca ggcccccctg gatgggcctg ctgggcccca ccatccaggc cgaggtgtac
300
gacaccgtgg tcatcaccct gaagaacatg gccagccacc ccgtctccct gcacgccgtg
360
ggggtgagct actggaaggc ctctgagggc gccgagtacg acgaccagac cagccagagg
420
gagaaggagg acgacaaggt gttccctggg ggcagccaca cctacgtgtg gcaggtcctg
480
aaggagaacg gccccatggc ctctgacccc ctgtgcctga cctacagcta cctgagccac
540
gtggacctgg tgaaggacct gaactctggc ctgattgggg ccctgctggt gtgcagggag
600
ggcagcctgg ccaaggagaa gacccagacc ctgcacaagt tcatcctgct gttcgccgtg
660
ttcgacgagg gcaagagctg gcactctgaa accaagaaca gcctgatgca ggacagggac
720
gccgcctctg ccagggcctg gcccaagatg cacaccgtca acggctacgt caacaggagc
780
ctgcctggcc tgattggctg ccacaggaag agcgtgtact ggcatgtgat cggcatgggc
840
accacccctg aggtgcacag catcttcctg gagggccaca ccttcctggt caggaaccac
900
aggcaggcca gcctggagat cagccccatc accttcctga ccgcccagac cctgctgatg
960
gacctgggcc agttcctgct gttctgccac atctccagcc accagcacga cggcatggag
1020
gcctacgtga aagtggacag ctgccctgag gagccccagc tgaggatgaa gaacaacgag
1080
gaggccgagg actatgatga cgacctgacc gacagcgaga tggacgtggt caggttcgac
1140
gacgacaaca gccccagctt catccagatc aggagcgtgg ccaagaagca ccccaagacc
1200
tgggtgcact acatcgctgc tgaggaggag gactgggact atgcccccct ggtgctggcc
1260
cctgatgaca ggagctacaa gagccagtac ctgaacaatg gcccccagag gattggcagg
1320
aagtacaaga aagtcaggtt catggcctac actgatgaaa ccttcaagac cagggaggcc
1380
atccagcatg agtctggcat cctgggcccc ctgctgtacg gggaggtggg ggacaccctg
1440
ctgatcatct tcaagaacca ggccagcagg ccctacaaca tctaccccca tggcatcacc
1500
gacgtgaggc ccctgtacag caggaggctg cctaaggggg tgaagcacct gaaagacttc
1560
cccatcctgc ctggggagat cttcaagtac aagtggactg tgactgtgga ggacggcccc
1620
accaagagcg accccaggtg cctgaccaga tactacagca gcttcgtcaa catggagagg
1680
gacctggcct ctggcctgat tggccccctg ctgatctgct acaaggagtc tgtggaccag
1740
aggggcaacc agatcatgag cgacaagagg aacgtgatcc tgttctctgt cttcgacgag
1800
aacaggagct ggtacctgac tgaaaacatc cagcggttcc tccccaaccc cgcgggcgtg
1860
cagctggaag atcctgagtt tcaggcatca aacatcatgc actccattaa cggctacgtg
1920
ttcgattcgc tgcagctgag cgtgtgtctg cacgaagtgg cctactggta catcctgtcc
1980
attggtgccc agactgactt cctgtccgtg tttttctccg gctacacgtt caagcacaag
2040
atggtgtacg aggacaccct gaccctcttc cctttttccg gcgaaactgt gtttatgagc
2100
atggagaatc ccggcctgtg gatcttgggc tgccacaaca gcgacttccg taacagagga
2160
atgactgcgc tgctcaaggt gtccagctgc gacaagaaca ccggagacta ttatgaggac
2220
tcatacgagg acatctccgc ctacctcctg tccaagaata acgccattga acctcggagc
2280
ttcagccaga acccacccgt gcttaagaga catcaacggg agatcactag gaccaccctg
2340
cagtcagacc aggaggaaat cgactacgat gacaccatct cggtcgagat gaagaaggag
2400
gactttgaca tctacgacga agatgaaaac cagagcccga ggtcgttcca aaagaaaacc
2460
cgccactact ttattgctgc tgtcgagcgg ctgtgggact acggaatgtc gtcctcgccg
2520
cacgtgctcc gcaaccgagc ccagagcggc tcggtgccgc aattcaagaa ggtcgtgttc
2580
caggagttca ctgacgggag cttcactcag cctttgtacc ggggagaact caatgaacat
2640
ctcggcctcc tcggacctta catcagagca gaagtggaag ataacatcat ggtcactttc
2700
cgtaaccaag ccagccgccc gtactcgttc tactcctccc tcatttctta cgaagaggac
2760
cagcggcagg gcgcagaacc gcgcaagaac ttcgtgaagc ccaacgaaac caagacctac
2820
ttctggaaag tgcagcatca tatggccccg actaaggacg agtttgactg caaagcctgg
2880
gcctacttct ccgatgtgga cttggagaag gacgtccact ccggcctcat cggtcccctg
2940
ctcgtgtgcc ataccaatac cctgaacccc gcacacggtc gccaggtcac cgtgcaggag
3000
ttcgctctgt tcttcactat cttcgacgaa actaagtcct ggtacttcac cgagaacatg
3060
gagaggaact gcagagcccc ctgtaacatc cagatggagg acccgacgtt caaggaaaac
3120
taccggttcc acgccattaa cggatacatc atggatacgc tgccgggtct tgtgatggcc
3180
caggatcaac ggatcagatg gtacttattg tcgatgggca gcaacgagaa catccactct
3240
attcacttct ccggtcatgt gttcactgtg cggaagaagg aagagtacaa gatggccctg
3300
tacaaccttt atcccggagt gttcgaaact gtggaaatgc tgccgtcgaa ggccggcatt
3360
tggcgcgtgg agtgtttgat tggagaacat ctccatgcgg ggatgtcaac cctgttcctg
3420
gtgtatagca acaagtgcca gactccgctt gggatggcgt caggacacat tagggatttc
3480
cagatcactg cgtccggcca gtacggccaa tgggccccta agctggcccg cctgcattac
3540
tccggatcca ttaacgcctg gtcaaccaag gagccattct cctggatcaa ggtggacctt
3600
ctggccccca tgattatcca cggaattaag acccaggggg cccggcagaa gttctcctca
3660
ctgtacatca gccagttcat aatcatgtac tccctggacg gaaagaagtg gcaaacctac
3720
agggggaaca gcaccggcac actgatggtc tttttcggaa atgtggactc ctccgggatt
3780
aagcataaca tcttcaaccc tccgattatc gctcggtaca ttagacttca ccctacccac
3840
tacagcattc gctccaccct gcggatggaa ctgatgggct gcgatctgaa ctcgtgcagc
3900
atgccgttgg gaatggagtc caaagcaatt tccgacgcgc agatcaccgc ctcgtcctac
3960
tttaccaaca tgttcgccac gtggtcaccg tccaaggccc ggctgcacct ccagggaaga
4020
tccaacgcat ggcggccaca ggtcaacaac cctaaggagt ggctccaggt ggacttccag
4080
aaaaccatga aggtcaccgg agtcacaacc cagggagtga agtcgctgct gacttctatg
4140
tacgtcaagg agttcctgat ctccagcagc caggacgggc accagtggac cctgttcttc
4200
caaaatggaa aggtcaaggt gtttcagggc aatcaggatt cattcacccc ggtggtgaac
4260
tcccttgatc cacccctcct gacccgctac cttcgcatcc acccacagtc ctgggtgcac
4320
cagatcgcgc tgaggatgga ggtcctggga tgcgaagccc aggacctgta ctga
4374
<210> 6
<211> 4374
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-26
<400> 6
atgcagattg agctgagcac ctgcttcttc ctgtgcctgc tgaggttctg cttctctgcc
60
accaggagat actacctggg cgccgtggag ctgagctggg actacatgca gtctgacctg
120
ggcgagctgc cagtggacgc caggttcccc cccagagtgc ccaagagctt ccccttcaac
180
accagcgtgg tgtacaagaa gaccctgttc gtggagttca ctgaccacct gttcaacatc
240
gccaagccca ggcccccctg gatgggcctg ctgggcccca ccatccaggc cgaggtgtac
300
gacaccgtgg tcatcaccct gaagaacatg gccagccacc ccgtctccct gcacgccgtg
360
ggggtgagct actggaaggc ctctgagggc gccgagtacg acgaccagac cagccagagg
420
gagaaggagg acgacaaggt gttccctggg ggcagccaca cctacgtgtg gcaggtcctg
480
aaggagaacg gccccatggc ctctgacccc ctgtgcctga cctacagcta cctgagccac
540
gtggacctgg tgaaggacct gaactctggc ctgattgggg ccctgctggt gtgcagggag
600
ggcagcctgg ccaaggagaa gacccagacc ctgcacaagt tcatcctgct gttcgccgtg
660
ttcgacgagg gcaagagctg gcactctgaa accaagaaca gcctgatgca ggacagggac
720
gccgcctctg ccagggcctg gcccaagatg cacaccgtca acggctacgt caacaggagc
780
ctgcctggcc tgattggctg ccacaggaag agcgtgtact ggcatgtgat cggcatgggc
840
accacccctg aggtgcacag catcttcctg gagggccaca ccttcctggt caggaaccac
900
aggcaggcca gcctggagat cagccccatc accttcctga ccgcccagac cctgctgatg
960
gacctgggcc agttcctgct gttctgccac atctccagcc accagcacga cggcatggag
1020
gcctacgtga aagtggacag ctgccctgag gagccccagc tgaggatgaa gaacaacgag
1080
gaggccgagg actatgatga cgacctgacc gacagcgaga tggacgtggt caggttcgac
1140
gacgacaaca gccccagctt catccagatc aggagcgtgg ccaagaagca ccccaagacc
1200
tgggtgcact acatcgctgc tgaggaggag gactgggact atgcccccct ggtgctggcc
1260
cctgatgaca ggagctacaa gagccagtac ctgaacaatg gcccccagag gattggcagg
1320
aagtacaaga aagtcaggtt catggcctac actgatgaaa ccttcaagac cagggaggcc
1380
atccagcatg agtctggcat cctgggcccc ctgctgtacg gggaggtggg ggacaccctg
1440
ctgatcatct tcaagaacca ggccagcagg ccctacaaca tctaccccca tggcatcacc
1500
gacgtgaggc ccctgtacag caggaggctg cctaaggggg tgaagcacct gaaagacttc
1560
cccatcctgc ctggggagat cttcaagtac aagtggactg tgactgtgga ggacggcccc
1620
accaagagcg accccaggtg cctgaccaga tactacagca gcttcgtcaa catggagagg
1680
gacctggcct ctggcctgat tggccccctg ctgatctgct acaaggagtc tgtggaccag
1740
aggggcaacc agatcatgag cgacaagagg aacgtgatcc tgttctctgt cttcgacgag
1800
aacaggagct ggtacctcac tgaaaacatc cagaggttcc tcccaaaccc cgcaggagtg
1860
caactggagg accctgagtt tcaggcctcg aatatcatgc actcgattaa cggttacgtg
1920
ttcgactcgc tgcagctgag cgtgtgcctc catgaagtcg cttactggta cattctgtcc
1980
atcggcgccc agactgactt cctgagcgtg ttcttttccg gttacacctt taagcacaag
2040
atggtgtacg aagataccct gaccctgttc cctttctccg gcgaaacggt gttcatgtcg
2100
atggagaacc cgggtctgtg gattctggga tgccacaaca gcgactttcg gaaccgcgga
2160
atgactgccc tgctgaaggt gtcctcatgc gacaagaaca ccggagacta ctacgaggac
2220
tcctacgagg atatctcagc ctacctcctg tccaagaaca acgcgatcga gccgcgcagc
2280
ttcagccaga acccgcctgt gctgaagagg caccagcgag aaattacccg gaccaccctc
2340
caatcggatc aggaggaaat cgactacgac gacaccatct cggtggaaat gaagaaggaa
2400
gatttcgata tctacgacga ggacgaaaat cagtcccctc gctcattcca aaagaaaact
2460
agacactact ttatcgccgc ggtggaaaga ctgtgggact atggaatgtc atccagccct
2520
cacgtccttc ggaaccgggc ccagagcgga tcggtgcctc agttcaagaa agtggtgttc
2580
caggagttca ccgacggcag cttcacccag ccgctgtacc ggggagaact gaacgaacac
2640
ctgggcctgc tcggtcccta catccgcgcg gaagtggagg ataacatcat ggtgaccttc
2700
cgtaaccaag catccagacc ttactccttc tattcctccc tgatctcata cgaggaggac
2760
cagcgccaag gcgccgagcc ccgcaagaac ttcgtcaagc ccaacgagac taagacctac
2820
ttctggaagg tccaacacca tatggccccg accaaggatg agtttgactg caaggcctgg
2880
gcctacttct ccgacgtgga ccttgagaag gatgtccatt ccggcctgat cgggccgctg
2940
ctcgtgtgtc acaccaacac cctgaaccca gcgcatggac gccaggtcac cgtccaggag
3000
tttgctctgt tcttcaccat ttttgacgaa actaagtcct ggtacttcac cgagaatatg
3060
gagcgaaact gtagagcgcc ctgcaatatc cagatggaag atccgacttt caaggagaac
3120
tatagattcc acgccatcaa cgggtacatc atggatactc tgccggggct ggtcatggcc
3180
caggatcaga ggattcggtg gtacttgctg tcaatgggat cgaacgaaaa cattcactcc
3240
attcacttct ccggtcacgt gttcactgtg cgcaagaagg aggagtacaa gatggcgctg
3300
tacaatctgt accccggggt gttcgaaact gtggagatgc tgccgtccaa ggccggcatc
3360
tggagagtgg agtgcctgat cggagagcac ctccacgcgg ggatgtccac cctcttcctg
3420
gtgtactcga ataagtgcca gaccccgctg ggcatggcct cgggccacat cagagacttc
3480
cagatcacag caagcggaca atacggccaa tgggcgccga agctggcccg cttgcactac
3540
tccggatcga tcaacgcatg gtccaccaag gaaccgttct cgtggattaa ggtggacctc
3600
ctggccccta tgattatcca cggaattaag acccagggcg ccaggcagaa gttctcctcc
3660
ctgtacatct cgcaattcat catcatgtac agcctggacg ggaagaagtg gcagacttac
3720
aggggaaact ccaccggcac cctgatggtc tttttcggca acgtggattc ctccggcatt
3780
aagcacaaca tcttcaaccc accgatcata gccagatata ttaggctcca ccccactcac
3840
tactcaatcc gctcaactct tcggatggaa ctcatggggt gcgacctgaa ctcctgctcc
3900
atgccgttgg ggatggaatc aaaggctatt agcgacgccc agatcaccgc gagctcctac
3960
ttcactaaca tgttcgccac ctggagcccc tccaaggcca ggctgcactt gcagggacgg
4020
tcaaatgcct ggcggccgca agtgaacaat ccgaaggaat ggcttcaagt ggatttccaa
4080
aagaccatga aagtgaccgg agtcaccacc cagggagtga agtcccttct gacctcgatg
4140
tatgtgaagg agttcctgat tagcagcagc caggacgggc accagtggac cctgttcttc
4200
caaaacggaa aggtcaaggt gttccagggg aaccaggact cgttcacacc cgtggtgaac
4260
tccctggacc ccccactgct gacgcggtac ttgaggattc atcctcagtc ctgggtccat
4320
cagattgcat tgcgaatgga agtcctgggc tgcgaggccc aggacctgta ctga
4374
<210> 7
<211> 1734
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-52-NT58
<400> 7
gcgacccgcc gatactacct gggagcagtg gagctctcct gggattacat gcagagcgac
60
cttggggagc tgcccgtgga tgccaggttc cctccccggg tgccaaagtc gtttccgttc
120
aacacctccg tggtgtacaa gaaaactctg ttcgtggagt tcaccgacca cctgttcaat
180
atcgccaagc ccagacctcc ctggatgggg ctgttgggac ctaccatcca agcggaggtg
240
tacgacactg tggtcatcac tctgaagaac atggcctcgc atcccgtgtc cctgcacgcc
300
gtgggagtgt cttactggaa agcgtccgag ggggccgaat acgacgacca gacctcgcag
360
agagaaaagg aagatgacaa ggtgttccca ggaggatcgc acacctacgt gtggcaagtg
420
ttgaaggaga acggcccaat ggcctccgac ccgctgtgcc tgacctactc gtacctgtcc
480
cacgtggacc tcgtgaagga cctcaactcg ggactgattg gagccctgct ggtctgcagg
540
gaaggctcac tggcgaaaga aaagactcag accttgcaca agttcattct gctgttcgct
600
gtgttcgacg aggggaagtc gtggcacagc gagactaaga actccctgat gcaagataga
660
gatgccgcct ccgcccgggc ctggcctaag atgcacaccg tgaacggtta cgtgaaccgc
720
tccctccctg gcctgattgg atgccaccgg aagtccgtgt actggcacgt gatcgggatg
780
gggaccaccc ccgaggtgca cagcatcttc ctggaaggtc acacatttct cgtgcgcaac
840
caccggcagg cctccctgga aatcagcccc attaccttcc tcactgccca gactctgctg
900
atggacctgg gacagttcct gctgttctgc catatctcct cccaccaaca tgacggaatg
960
gaggcatacg tgaaggtcga ttcctgccct gaggaacccc agctccgcat gaagaacaat
1020
gaggaagccg aggactacga cgacgacctg acggatagcg agatggatgt ggtccggttc
1080
gatgacgata acagcccttc cttcatccaa attcgctcgg tggcaaagaa gcaccccaag
1140
acctgggtgc attacattgc ggcggaagaa gaggactggg attatgcccc gcttgtcctc
1200
gctcctgacg accggagcta caagagccag tacctgaaca acggtccaca gaggatcggt
1260
agaaagtaca agaaggtccg cttcatggcc tataccgacg aaaccttcaa aactagagag
1320
gccatccaac acgaatccgg catcctgggc ccgctcttgt acggagaagt cggcgacacc
1380
cttctcatta tcttcaagaa ccaggcttcc cggccgtaca acatctatcc gcatgggatc
1440
actgacgtgc gcccactgta ctcgcggcgc ctgcccaagg gtgtcaaaca cctgaaggat
1500
tttccgatcc ttccgggaga aatcttcaag tacaagtgga ccgtgaccgt ggaagatggc
1560
ccaactaagt ctgaccctag atgcctcacc cgctactact catccttcgt caacatggag
1620
cgcgacctgg ccagcggact gatcggcccg ctgctgattt gctacaagga atcagtggac
1680
caacggggaa accagatcat gtcggataag aggaacgtca tcctcttctc cgtg
1734
<210> 8
<211> 2583
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-52-CT
<400> 8
tttgacgaaa accggtcgtg gtacctgacc gagaacatcc agaggttcct gcccaaccct
60
gctggggtgc agctggagga ccccgagttc caggccagca acatcatgca cagcatcaat
120
ggctacgtgt tcgacagcct gcagctgagc gtgtgcctgc acgaggtggc ctactggtac
180
atcctgagca tcggcgccca gaccgacttc ctgagcgtgt tcttctctgg ctacaccttc
240
aagcacaaga tggtgtatga ggacaccctg accctgttcc ccttcagcgg ggagactgtc
300
ttcatgagca tggagaaccc tggcctgtgg atcctgggct gccacaacag cgacttcagg
360
aacaggggca tgactgccct gctgaaagtc tccagctgtg acaagaacac cggggactac
420
tacgaggaca gctacgagga catcagcgcc tacctgctga gcaagaacaa tgccatcgag
480
cccaggagct tctctcagaa ccccccagtg ctgaagaggc accagaggga gatcaccagg
540
accaccctgc agtctgacca ggaggagatc gactatgatg acaccatcag cgtggagatg
600
aagaaggagg acttcgacat ctacgacgag gacgagaacc agagccccag gagcttccag
660
aagaagacca ggcactactt cattgctgct gtggagaggc tgtgggacta tggcatgtcc
720
agcagccccc atgtgctgag gaacagggcc cagtctggca gcgtgcccca gttcaagaaa
780
gtcgtgttcc aggagttcac cgacggcagc ttcacccagc ccctgtacag aggggagctg
840
aacgagcacc tgggcctgct gggcccctac atcagggccg aggtggagga caacatcatg
900
gtgaccttca ggaaccaggc cagcaggccc tacagcttct acagcagcct gatcagctac
960
gaggaggacc agaggcaggg ggctgagccc aggaagaact ttgtgaagcc caatgaaacc
1020
aagacctact tctggaaggt gcagcaccac atggccccca ccaaggacga gttcgactgc
1080
aaggcctggg cctacttctc tgacgtggac ctggagaagg acgtgcactc tggcctgatt
1140
ggccccctgc tggtgtgcca caccaacacc ctgaaccctg cccatggcag gcaggtgact
1200
gtgcaggagt tcgccctgtt cttcaccatc ttcgatgaaa ccaagagctg gtacttcact
1260
gagaacatgg agaggaactg cagggccccc tgcaacatcc agatggagga ccccaccttc
1320
aaggagaact acaggttcca tgccatcaat ggctacatca tggacaccct gcctggcctg
1380
gtcatggccc aggaccagag gatcaggtgg tatctgctga gcatgggcag caacgagaac
1440
atccacagca tccacttctc tggccacgtg ttcactgtga ggaagaagga ggagtacaag
1500
atggccctgt acaacctgta ccctggggtg ttcgaaaccg tggagatgct gcccagcaag
1560
gccggcatct ggagggtgga gtgcctgatt ggggagcacc tgcacgccgg catgagcacc
1620
ctgttcctgg tgtacagcaa caagtgccag acccccctgg gcatggcctc tggccacatc
1680
agggacttcc agatcactgc ctctggccag tacggccagt gggcccccaa gctggccagg
1740
ctgcactact ccggaagcat caatgcctgg agcaccaagg agcccttcag ctggatcaaa
1800
gtggacctgc tggcccccat gatcatccac ggcatcaaga cccagggggc caggcagaag
1860
ttctccagcc tgtacatcag ccagttcatc atcatgtaca gcctggacgg caagaagtgg
1920
cagacctaca ggggcaacag caccggcacc ctgatggtgt tcttcggcaa cgtggacagc
1980
agcggcatca agcacaacat cttcaacccc cccatcatcg ccagatacat caggctgcac
2040
cccacccact acagcatcag gagcaccctg aggatggagc tgatgggctg tgacctgaac
2100
agctgcagca tgcccctggg catggagagc aaggccatct ctgacgccca gatcactgcc
2160
tccagctact tcaccaacat gtttgccacc tggagcccca gcaaggccag gctgcacctg
2220
cagggcagga gcaatgcctg gaggccccag gtcaacaacc ccaaggagtg gctgcaggtg
2280
gacttccaga agaccatgaa ggtgactggg gtgaccaccc agggggtgaa gagcctgctg
2340
accagcatgt acgtgaagga gttcctgatc tccagcagcc aggacggcca ccagtggacc
2400
ctgttcttcc agaatggcaa ggtgaaggtg ttccagggca accaggacag cttcacccct
2460
gtggtcaaca gcctggaccc ccccctgctg accagatacc tgaggatcca cccccagagc
2520
tgggtgcacc agatcgccct gaggatggag gtgctgggct gtgaggccca ggacctgtac
2580
tga
2583
<210> 9
<211> 1734
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-62-NT58
<400> 9
gccactcgcc ggtactacct tggagccgtg gagctttcat gggactacat gcagagcgac
60
ctgggcgaac tccccgtgga tgccagattc cccccccgcg tgccaaagtc cttccccttt
120
aacacctccg tggtgtacaa gaaaaccctc tttgtcgagt tcactgacca cctgttcaac
180
atcgccaagc cgcgcccacc ttggatgggc ctcctgggac cgaccattca agctgaagtg
240
tacgacaccg tggtgatcac cctgaagaac atggcgtccc accccgtgtc cctgcatgcg
300
gtcggagtgt cctactggaa ggcctccgaa ggagctgagt acgacgacca gactagccag
360
cgggaaaagg aggacgataa agtgttcccg ggcggctcgc atacttacgt gtggcaagtc
420
ctgaaggaaa acggacctat ggcatccgat cctctgtgcc tgacttactc ctacctttcc
480
catgtggacc tcgtgaagga cctgaacagc gggctgattg gtgcacttct cgtgtgccgc
540
gaaggttcgc tcgctaagga aaagacccag accctccata agttcatcct tttgttcgct
600
gtgttcgatg aaggaaagtc atggcattcc gaaactaaga actcgctgat gcaggaccgg
660
gatgccgcct cagcccgcgc ctggcctaaa atgcatacag tcaacggata cgtgaatcgg
720
tcactgcccg ggctcatcgg ttgtcacaga aagtccgtgt actggcacgt catcggcatg
780
ggcactacgc ctgaagtgca ctccatcttc ctggaagggc acaccttcct cgtgcgcaac
840
caccgccagg cctctctgga aatctccccg attacctttc tgaccgccca gactctgctc
900
atggacctgg ggcagttcct tctcttctgc cacatctcca gccatcagca cgacggaatg
960
gaggcctacg tgaaggtgga ctcatgcccg gaagaacctc agttgcggat gaagaacaac
1020
gaggaggccg aggactatga cgacgatttg actgactccg agatggacgt cgtgcggttc
1080
gatgacgaca acagccccag cttcatccag attcgcagcg tggccaagaa gcaccccaaa
1140
acctgggtgc actacatcgc ggccgaggaa gaagattggg actacgcccc gttggtgctg
1200
gcacccgatg accggtcgta caagtcccag tatctgaaca atggtccgca gcggattggc
1260
agaaagtaca agaaagtgcg gttcatggcg tacactgacg aaacgtttaa gacccgggag
1320
gccattcaac atgagagcgg cattctggga ccactgctgt acggagaggt cggcgatacc
1380
ctgctcatca tcttcaaaaa ccaggcctcc cggccttaca acatctaccc tcacggaatc
1440
accgacgtgc ggccactcta ctcgcggcgc ctgccgaagg gcgtcaagca cctgaaagac
1500
ttccctatcc tgccgggcga aatcttcaag tataagtgga ccgtcaccgt ggaggacggg
1560
cccaccaaga gcgatcctag gtgtctgact cggtactact ccagcttcgt gaacatggaa
1620
cgggacctgg catcgggact cattggaccg ctgctgatct gctacaaaga gtcggtggat
1680
caacgcggca accagatcat gtccgacaag cgcaacgtga tcctgttctc cgtg
1734
<210> 10
<211> 2583
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-62-CT
<400> 10
tttgatgaaa acagatcctg gtacctgacc gagaacatcc agaggttcct gcccaaccct
60
gctggggtgc agctggagga ccccgagttc caggccagca acatcatgca cagcatcaat
120
ggctacgtgt tcgacagcct gcagctgagc gtgtgcctgc acgaggtggc ctactggtac
180
atcctgagca tcggcgccca gaccgacttc ctgagcgtgt tcttctctgg ctacaccttc
240
aagcacaaga tggtgtatga ggacaccctg accctgttcc ccttcagcgg ggagactgtc
300
ttcatgagca tggagaaccc tggcctgtgg atcctgggct gccacaacag cgacttcagg
360
aacaggggca tgactgccct gctgaaagtc tccagctgtg acaagaacac cggggactac
420
tacgaggaca gctacgagga catcagcgcc tacctgctga gcaagaacaa tgccatcgag
480
cccaggagct tctctcagaa ccccccagtg ctgaagaggc accagaggga gatcaccagg
540
accaccctgc agtctgacca ggaggagatc gactatgatg acaccatcag cgtggagatg
600
aagaaggagg acttcgacat ctacgacgag gacgagaacc agagccccag gagcttccag
660
aagaagacca ggcactactt cattgctgct gtggagaggc tgtgggacta tggcatgtcc
720
agcagccccc atgtgctgag gaacagggcc cagtctggca gcgtgcccca gttcaagaaa
780
gtcgtgttcc aggagttcac cgacggcagc ttcacccagc ccctgtacag aggggagctg
840
aacgagcacc tgggcctgct gggcccctac atcagggccg aggtggagga caacatcatg
900
gtgaccttca ggaaccaggc cagcaggccc tacagcttct acagcagcct gatcagctac
960
gaggaggacc agaggcaggg ggctgagccc aggaagaact ttgtgaagcc caatgaaacc
1020
aagacctact tctggaaggt gcagcaccac atggccccca ccaaggacga gttcgactgc
1080
aaggcctggg cctacttctc tgacgtggac ctggagaagg acgtgcactc tggcctgatt
1140
ggccccctgc tggtgtgcca caccaacacc ctgaaccctg cccatggcag gcaggtgact
1200
gtgcaggagt tcgccctgtt cttcaccatc ttcgatgaaa ccaagagctg gtacttcact
1260
gagaacatgg agaggaactg cagggccccc tgcaacatcc agatggagga ccccaccttc
1320
aaggagaact acaggttcca tgccatcaat ggctacatca tggacaccct gcctggcctg
1380
gtcatggccc aggaccagag gatcaggtgg tatctgctga gcatgggcag caacgagaac
1440
atccacagca tccacttctc tggccacgtg ttcactgtga ggaagaagga ggagtacaag
1500
atggccctgt acaacctgta ccctggggtg ttcgaaaccg tggagatgct gcccagcaag
1560
gccggcatct ggagggtgga gtgcctgatt ggggagcacc tgcacgccgg catgagcacc
1620
ctgttcctgg tgtacagcaa caagtgccag acccccctgg gcatggcctc tggccacatc
1680
agggacttcc agatcactgc ctctggccag tacggccagt gggcccccaa gctggccagg
1740
ctgcactact ccggaagcat caatgcctgg agcaccaagg agcccttcag ctggatcaaa
1800
gtggacctgc tggcccccat gatcatccac ggcatcaaga cccagggggc caggcagaag
1860
ttctccagcc tgtacatcag ccagttcatc atcatgtaca gcctggacgg caagaagtgg
1920
cagacctaca ggggcaacag caccggcacc ctgatggtgt tcttcggcaa cgtggacagc
1980
agcggcatca agcacaacat cttcaacccc cccatcatcg ccagatacat caggctgcac
2040
cccacccact acagcatcag gagcaccctg aggatggagc tgatgggctg tgacctgaac
2100
agctgcagca tgcccctggg catggagagc aaggccatct ctgacgccca gatcactgcc
2160
tccagctact tcaccaacat gtttgccacc tggagcccca gcaaggccag gctgcacctg
2220
cagggcagga gcaatgcctg gaggccccag gtcaacaacc ccaaggagtg gctgcaggtg
2280
gacttccaga agaccatgaa ggtgactggg gtgaccaccc agggggtgaa gagcctgctg
2340
accagcatgt acgtgaagga gttcctgatc tccagcagcc aggacggcca ccagtggacc
2400
ctgttcttcc agaatggcaa ggtgaaggtg ttccagggca accaggacag cttcacccct
2460
gtggtcaaca gcctggaccc ccccctgctg accagatacc tgaggatcca cccccagagc
2520
tgggtgcacc agatcgccct gaggatggag gtgctgggct gtgaggccca ggacctgtac
2580
tga
2583
<210> 11
<211> 1734
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-25-NT58
<400> 11
gccaccagga gatactacct gggcgccgtg gagctgagct gggactacat gcagtctgac
60
ctgggcgagc tgccagtgga cgccaggttc ccccccagag tgcccaagag cttccccttc
120
aacaccagcg tggtgtacaa gaagaccctg ttcgtggagt tcactgacca cctgttcaac
180
atcgccaagc ccaggccccc ctggatgggc ctgctgggcc ccaccatcca ggccgaggtg
240
tacgacaccg tggtcatcac cctgaagaac atggccagcc accccgtctc cctgcacgcc
300
gtgggggtga gctactggaa ggcctctgag ggcgccgagt acgacgacca gaccagccag
360
agggagaagg aggacgacaa ggtgttccct gggggcagcc acacctacgt gtggcaggtc
420
ctgaaggaga acggccccat ggcctctgac cccctgtgcc tgacctacag ctacctgagc
480
cacgtggacc tggtgaagga cctgaactct ggcctgattg gggccctgct ggtgtgcagg
540
gagggcagcc tggccaagga gaagacccag accctgcaca agttcatcct gctgttcgcc
600
gtgttcgacg agggcaagag ctggcactct gaaaccaaga acagcctgat gcaggacagg
660
gacgccgcct ctgccagggc ctggcccaag atgcacaccg tcaacggcta cgtcaacagg
720
agcctgcctg gcctgattgg ctgccacagg aagagcgtgt actggcatgt gatcggcatg
780
ggcaccaccc ctgaggtgca cagcatcttc ctggagggcc acaccttcct ggtcaggaac
840
cacaggcagg ccagcctgga gatcagcccc atcaccttcc tgaccgccca gaccctgctg
900
atggacctgg gccagttcct gctgttctgc cacatctcca gccaccagca cgacggcatg
960
gaggcctacg tgaaagtgga cagctgccct gaggagcccc agctgaggat gaagaacaac
1020
gaggaggccg aggactatga tgacgacctg accgacagcg agatggacgt ggtcaggttc
1080
gacgacgaca acagccccag cttcatccag atcaggagcg tggccaagaa gcaccccaag
1140
acctgggtgc actacatcgc tgctgaggag gaggactggg actatgcccc cctggtgctg
1200
gcccctgatg acaggagcta caagagccag tacctgaaca atggccccca gaggattggc
1260
aggaagtaca agaaagtcag gttcatggcc tacactgatg aaaccttcaa gaccagggag
1320
gccatccagc atgagtctgg catcctgggc cccctgctgt acggggaggt gggggacacc
1380
ctgctgatca tcttcaagaa ccaggccagc aggccctaca acatctaccc ccatggcatc
1440
accgacgtga ggcccctgta cagcaggagg ctgcctaagg gggtgaagca cctgaaagac
1500
ttccccatcc tgcctgggga gatcttcaag tacaagtgga ctgtgactgt ggaggacggc
1560
cccaccaaga gcgaccccag gtgcctgacc agatactaca gcagcttcgt caacatggag
1620
agggacctgg cctctggcct gattggcccc ctgctgatct gctacaagga gtctgtggac
1680
cagaggggca accagatcat gagcgacaag aggaacgtga tcctgttctc tgtc
1734
<210> 12
<211> 2583
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-25-CT
<400> 12
ttcgacgaga acaggagctg gtacctgact gaaaacatcc agcggttcct ccccaacccc
60
gcgggcgtgc agctggaaga tcctgagttt caggcatcaa acatcatgca ctccattaac
120
ggctacgtgt tcgattcgct gcagctgagc gtgtgtctgc acgaagtggc ctactggtac
180
atcctgtcca ttggtgccca gactgacttc ctgtccgtgt ttttctccgg ctacacgttc
240
aagcacaaga tggtgtacga ggacaccctg accctcttcc ctttttccgg cgaaactgtg
300
tttatgagca tggagaatcc cggcctgtgg atcttgggct gccacaacag cgacttccgt
360
aacagaggaa tgactgcgct gctcaaggtg tccagctgcg acaagaacac cggagactat
420
tatgaggact catacgagga catctccgcc tacctcctgt ccaagaataa cgccattgaa
480
cctcggagct tcagccagaa cccacccgtg cttaagagac atcaacggga gatcactagg
540
accaccctgc agtcagacca ggaggaaatc gactacgatg acaccatctc ggtcgagatg
600
aagaaggagg actttgacat ctacgacgaa gatgaaaacc agagcccgag gtcgttccaa
660
aagaaaaccc gccactactt tattgctgct gtcgagcggc tgtgggacta cggaatgtcg
720
tcctcgccgc acgtgctccg caaccgagcc cagagcggct cggtgccgca attcaagaag
780
gtcgtgttcc aggagttcac tgacgggagc ttcactcagc ctttgtaccg gggagaactc
840
aatgaacatc tcggcctcct cggaccttac atcagagcag aagtggaaga taacatcatg
900
gtcactttcc gtaaccaagc cagccgcccg tactcgttct actcctccct catttcttac
960
gaagaggacc agcggcaggg cgcagaaccg cgcaagaact tcgtgaagcc caacgaaacc
1020
aagacctact tctggaaagt gcagcatcat atggccccga ctaaggacga gtttgactgc
1080
aaagcctggg cctacttctc cgatgtggac ttggagaagg acgtccactc cggcctcatc
1140
ggtcccctgc tcgtgtgcca taccaatacc ctgaaccccg cacacggtcg ccaggtcacc
1200
gtgcaggagt tcgctctgtt cttcactatc ttcgacgaaa ctaagtcctg gtacttcacc
1260
gagaacatgg agaggaactg cagagccccc tgtaacatcc agatggagga cccgacgttc
1320
aaggaaaact accggttcca cgccattaac ggatacatca tggatacgct gccgggtctt
1380
gtgatggccc aggatcaacg gatcagatgg tacttattgt cgatgggcag caacgagaac
1440
atccactcta ttcacttctc cggtcatgtg ttcactgtgc ggaagaagga agagtacaag
1500
atggccctgt acaaccttta tcccggagtg ttcgaaactg tggaaatgct gccgtcgaag
1560
gccggcattt ggcgcgtgga gtgtttgatt ggagaacatc tccatgcggg gatgtcaacc
1620
ctgttcctgg tgtatagcaa caagtgccag actccgcttg ggatggcgtc aggacacatt
1680
agggatttcc agatcactgc gtccggccag tacggccaat gggcccctaa gctggcccgc
1740
ctgcattact ccggatccat taacgcctgg tcaaccaagg agccattctc ctggatcaag
1800
gtggaccttc tggcccccat gattatccac ggaattaaga cccagggggc ccggcagaag
1860
ttctcctcac tgtacatcag ccagttcata atcatgtact ccctggacgg aaagaagtgg
1920
caaacctaca gggggaacag caccggcaca ctgatggtct ttttcggaaa tgtggactcc
1980
tccgggatta agcataacat cttcaaccct ccgattatcg ctcggtacat tagacttcac
2040
cctacccact acagcattcg ctccaccctg cggatggaac tgatgggctg cgatctgaac
2100
tcgtgcagca tgccgttggg aatggagtcc aaagcaattt ccgacgcgca gatcaccgcc
2160
tcgtcctact ttaccaacat gttcgccacg tggtcaccgt ccaaggcccg gctgcacctc
2220
cagggaagat ccaacgcatg gcggccacag gtcaacaacc ctaaggagtg gctccaggtg
2280
gacttccaga aaaccatgaa ggtcaccgga gtcacaaccc agggagtgaa gtcgctgctg
2340
acttctatgt acgtcaagga gttcctgatc tccagcagcc aggacgggca ccagtggacc
2400
ctgttcttcc aaaatggaaa ggtcaaggtg tttcagggca atcaggattc attcaccccg
2460
gtggtgaact cccttgatcc acccctcctg acccgctacc ttcgcatcca cccacagtcc
2520
tgggtgcacc agatcgcgct gaggatggag gtcctgggat gcgaagccca ggacctgtac
2580
tga
2583
<210> 13
<211> 1734
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-26-NT58
<400> 13
gccaccagga gatactacct gggcgccgtg gagctgagct gggactacat gcagtctgac
60
ctgggcgagc tgccagtgga cgccaggttc ccccccagag tgcccaagag cttccccttc
120
aacaccagcg tggtgtacaa gaagaccctg ttcgtggagt tcactgacca cctgttcaac
180
atcgccaagc ccaggccccc ctggatgggc ctgctgggcc ccaccatcca ggccgaggtg
240
tacgacaccg tggtcatcac cctgaagaac atggccagcc accccgtctc cctgcacgcc
300
gtgggggtga gctactggaa ggcctctgag ggcgccgagt acgacgacca gaccagccag
360
agggagaagg aggacgacaa ggtgttccct gggggcagcc acacctacgt gtggcaggtc
420
ctgaaggaga acggccccat ggcctctgac cccctgtgcc tgacctacag ctacctgagc
480
cacgtggacc tggtgaagga cctgaactct ggcctgattg gggccctgct ggtgtgcagg
540
gagggcagcc tggccaagga gaagacccag accctgcaca agttcatcct gctgttcgcc
600
gtgttcgacg agggcaagag ctggcactct gaaaccaaga acagcctgat gcaggacagg
660
gacgccgcct ctgccagggc ctggcccaag atgcacaccg tcaacggcta cgtcaacagg
720
agcctgcctg gcctgattgg ctgccacagg aagagcgtgt actggcatgt gatcggcatg
780
ggcaccaccc ctgaggtgca cagcatcttc ctggagggcc acaccttcct ggtcaggaac
840
cacaggcagg ccagcctgga gatcagcccc atcaccttcc tgaccgccca gaccctgctg
900
atggacctgg gccagttcct gctgttctgc cacatctcca gccaccagca cgacggcatg
960
gaggcctacg tgaaagtgga cagctgccct gaggagcccc agctgaggat gaagaacaac
1020
gaggaggccg aggactatga tgacgacctg accgacagcg agatggacgt ggtcaggttc
1080
gacgacgaca acagccccag cttcatccag atcaggagcg tggccaagaa gcaccccaag
1140
acctgggtgc actacatcgc tgctgaggag gaggactggg actatgcccc cctggtgctg
1200
gcccctgatg acaggagcta caagagccag tacctgaaca atggccccca gaggattggc
1260
aggaagtaca agaaagtcag gttcatggcc tacactgatg aaaccttcaa gaccagggag
1320
gccatccagc atgagtctgg catcctgggc cccctgctgt acggggaggt gggggacacc
1380
ctgctgatca tcttcaagaa ccaggccagc aggccctaca acatctaccc ccatggcatc
1440
accgacgtga ggcccctgta cagcaggagg ctgcctaagg gggtgaagca cctgaaagac
1500
ttccccatcc tgcctgggga gatcttcaag tacaagtgga ctgtgactgt ggaggacggc
1560
cccaccaaga gcgaccccag gtgcctgacc agatactaca gcagcttcgt caacatggag
1620
agggacctgg cctctggcct gattggcccc ctgctgatct gctacaagga gtctgtggac
1680
cagaggggca accagatcat gagcgacaag aggaacgtga tcctgttctc tgtc
1734
<210> 14
<211> 2583
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-26-CT
<400> 14
ttcgacgaga acaggagctg gtacctcact gaaaacatcc agaggttcct cccaaacccc
60
gcaggagtgc aactggagga ccctgagttt caggcctcga atatcatgca ctcgattaac
120
ggttacgtgt tcgactcgct gcagctgagc gtgtgcctcc atgaagtcgc ttactggtac
180
attctgtcca tcggcgccca gactgacttc ctgagcgtgt tcttttccgg ttacaccttt
240
aagcacaaga tggtgtacga agataccctg accctgttcc ctttctccgg cgaaacggtg
300
ttcatgtcga tggagaaccc gggtctgtgg attctgggat gccacaacag cgactttcgg
360
aaccgcggaa tgactgccct gctgaaggtg tcctcatgcg acaagaacac cggagactac
420
tacgaggact cctacgagga tatctcagcc tacctcctgt ccaagaacaa cgcgatcgag
480
ccgcgcagct tcagccagaa cccgcctgtg ctgaagaggc accagcgaga aattacccgg
540
accaccctcc aatcggatca ggaggaaatc gactacgacg acaccatctc ggtggaaatg
600
aagaaggaag atttcgatat ctacgacgag gacgaaaatc agtcccctcg ctcattccaa
660
aagaaaacta gacactactt tatcgccgcg gtggaaagac tgtgggacta tggaatgtca
720
tccagccctc acgtccttcg gaaccgggcc cagagcggat cggtgcctca gttcaagaaa
780
gtggtgttcc aggagttcac cgacggcagc ttcacccagc cgctgtaccg gggagaactg
840
aacgaacacc tgggcctgct cggtccctac atccgcgcgg aagtggagga taacatcatg
900
gtgaccttcc gtaaccaagc atccagacct tactccttct attcctccct gatctcatac
960
gaggaggacc agcgccaagg cgccgagccc cgcaagaact tcgtcaagcc caacgagact
1020
aagacctact tctggaaggt ccaacaccat atggccccga ccaaggatga gtttgactgc
1080
aaggcctggg cctacttctc cgacgtggac cttgagaagg atgtccattc cggcctgatc
1140
gggccgctgc tcgtgtgtca caccaacacc ctgaacccag cgcatggacg ccaggtcacc
1200
gtccaggagt ttgctctgtt cttcaccatt tttgacgaaa ctaagtcctg gtacttcacc
1260
gagaatatgg agcgaaactg tagagcgccc tgcaatatcc agatggaaga tccgactttc
1320
aaggagaact atagattcca cgccatcaac gggtacatca tggatactct gccggggctg
1380
gtcatggccc aggatcagag gattcggtgg tacttgctgt caatgggatc gaacgaaaac
1440
attcactcca ttcacttctc cggtcacgtg ttcactgtgc gcaagaagga ggagtacaag
1500
atggcgctgt acaatctgta ccccggggtg ttcgaaactg tggagatgct gccgtccaag
1560
gccggcatct ggagagtgga gtgcctgatc ggagagcacc tccacgcggg gatgtccacc
1620
ctcttcctgg tgtactcgaa taagtgccag accccgctgg gcatggcctc gggccacatc
1680
agagacttcc agatcacagc aagcggacaa tacggccaat gggcgccgaa gctggcccgc
1740
ttgcactact ccggatcgat caacgcatgg tccaccaagg aaccgttctc gtggattaag
1800
gtggacctcc tggcccctat gattatccac ggaattaaga cccagggcgc caggcagaag
1860
ttctcctccc tgtacatctc gcaattcatc atcatgtaca gcctggacgg gaagaagtgg
1920
cagacttaca ggggaaactc caccggcacc ctgatggtct ttttcggcaa cgtggattcc
1980
tccggcatta agcacaacat cttcaaccca ccgatcatag ccagatatat taggctccac
2040
cccactcact actcaatccg ctcaactctt cggatggaac tcatggggtg cgacctgaac
2100
tcctgctcca tgccgttggg gatggaatca aaggctatta gcgacgccca gatcaccgcg
2160
agctcctact tcactaacat gttcgccacc tggagcccct ccaaggccag gctgcacttg
2220
cagggacggt caaatgcctg gcggccgcaa gtgaacaatc cgaaggaatg gcttcaagtg
2280
gatttccaaa agaccatgaa agtgaccgga gtcaccaccc agggagtgaa gtcccttctg
2340
acctcgatgt atgtgaagga gttcctgatt agcagcagcc aggacgggca ccagtggacc
2400
ctgttcttcc aaaacggaaa ggtcaaggtg ttccagggga accaggactc gttcacaccc
2460
gtggtgaact ccctggaccc cccactgctg acgcggtact tgaggattca tcctcagtcc
2520
tgggtccatc agattgcatt gcgaatggaa gtcctgggct gcgaggccca ggacctgtac
2580
tga
2583
<210> 15
<211> 2332
<212> БЕЛОК
<213> Homo sapiens
<400> 15
Ala Thr Arg Arg Tyr Tyr Leu Gly Ala Val Glu Leu Ser Trp Asp Tyr
1. 5 10 15
Met Gln Ser Asp Leu Gly Glu Leu Pro Val Asp Ala Arg Phe Pro Pro
20 25 30
Arg Val Pro Lys Ser Phe Pro Phe Asn Thr Ser Val Val Tyr Lys Lys
35 40 45
Thr Leu Phe Val Glu Phe Thr Asp His Leu Phe Asn Ile Ala Lys Pro
50 55 60
Arg Pro Pro Trp Met Gly Leu Leu Gly Pro Thr Ile Gln Ala Glu Val
65 70 75 80
Tyr Asp Thr Val Val Ile Thr Leu Lys Asn Met Ala Ser His Pro Val
85 90 95
Ser Leu His Ala Val Gly Val Ser Tyr Trp Lys Ala Ser Glu Gly Ala
100 105 110
Glu Tyr Asp Asp Gln Thr Ser Gln Arg Glu Lys Glu Asp Asp Lys Val
115 120 125
Phe Pro Gly Gly Ser His Thr Tyr Val Trp Gln Val Leu Lys Glu Asn
130 135 140
Gly Pro Met Ala Ser Asp Pro Leu Cys Leu Thr Tyr Ser Tyr Leu Ser
145 150 155 160
His Val Asp Leu Val Lys Asp Leu Asn Ser Gly Leu Ile Gly Ala Leu
165 170 175
Leu Val Cys Arg Glu Gly Ser Leu Ala Lys Glu Lys Thr Gln Thr Leu
180 185 190
His Lys Phe Ile Leu Leu Phe Ala Val Phe Asp Glu Gly Lys Ser Trp
195 200 205
His Ser Glu Thr Lys Asn Ser Leu Met Gln Asp Arg Asp Ala Ala Ser
210 215 220
Ala Arg Ala Trp Pro Lys Met His Thr Val Asn Gly Tyr Val Asn Arg
225 230 235 240
Ser Leu Pro Gly Leu Ile Gly Cys His Arg Lys Ser Val Tyr Trp His
245 250 255
Val Ile Gly Met Gly Thr Thr Pro Glu Val His Ser Ile Phe Leu Glu
260 265 270
Gly His Thr Phe Leu Val Arg Asn His Arg Gln Ala Ser Leu Glu Ile
275 280 285
Ser Pro Ile Thr Phe Leu Thr Ala Gln Thr Leu Leu Met Asp Leu Gly
290 295 300
Gln Phe Leu Leu Phe Cys His Ile Ser Ser His Gln His Asp Gly Met
305 310 315 320
Glu Ala Tyr Val Lys Val Asp Ser Cys Pro Glu Glu Pro Gln Leu Arg
325 330 335
Met Lys Asn Asn Glu Glu Ala Glu Asp Tyr Asp Asp Asp Leu Thr Asp
340 345 350
Ser Glu Met Asp Val Val Arg Phe Asp Asp Asp Asn Ser Pro Ser Phe
355 360 365
Ile Gln Ile Arg Ser Val Ala Lys Lys His Pro Lys Thr Trp Val His
370 375 380
Tyr Ile Ala Ala Glu Glu Glu Asp Trp Asp Tyr Ala Pro Leu Val Leu
385 390 395 400
Ala Pro Asp Asp Arg Ser Tyr Lys Ser Gln Tyr Leu Asn Asn Gly Pro
405 410 415
Gln Arg Ile Gly Arg Lys Tyr Lys Lys Val Arg Phe Met Ala Tyr Thr
420 425 430
Asp Glu Thr Phe Lys Thr Arg Glu Ala Ile Gln His Glu Ser Gly Ile
435 440 445
Leu Gly Pro Leu Leu Tyr Gly Glu Val Gly Asp Thr Leu Leu Ile Ile
450 455 460
Phe Lys Asn Gln Ala Ser Arg Pro Tyr Asn Ile Tyr Pro His Gly Ile
465 470 475 480
Thr Asp Val Arg Pro Leu Tyr Ser Arg Arg Leu Pro Lys Gly Val Lys
485 490 495
His Leu Lys Asp Phe Pro Ile Leu Pro Gly Glu Ile Phe Lys Tyr Lys
500 505 510
Trp Thr Val Thr Val Glu Asp Gly Pro Thr Lys Ser Asp Pro Arg Cys
515 520 525
Leu Thr Arg Tyr Tyr Ser Ser Phe Val Asn Met Glu Arg Asp Leu Ala
530 535 540
Ser Gly Leu Ile Gly Pro Leu Leu Ile Cys Tyr Lys Glu Ser Val Asp
545 550 555 560
Gln Arg Gly Asn Gln Ile Met Ser Asp Lys Arg Asn Val Ile Leu Phe
565 570 575
Ser Val Phe Asp Glu Asn Arg Ser Trp Tyr Leu Thr Glu Asn Ile Gln
580 585 590
Arg Phe Leu Pro Asn Pro Ala Gly Val Gln Leu Glu Asp Pro Glu Phe
595 600 605
Gln Ala Ser Asn Ile Met His Ser Ile Asn Gly Tyr Val Phe Asp Ser
610 615 620
Leu Gln Leu Ser Val Cys Leu His Glu Val Ala Tyr Trp Tyr Ile Leu
625 630 635 640
Ser Ile Gly Ala Gln Thr Asp Phe Leu Ser Val Phe Phe Ser Gly Tyr
645 650 655
Thr Phe Lys His Lys Met Val Tyr Glu Asp Thr Leu Thr Leu Phe Pro
660 665 670
Phe Ser Gly Glu Thr Val Phe Met Ser Met Glu Asn Pro Gly Leu Trp
675 680 685
Ile Leu Gly Cys His Asn Ser Asp Phe Arg Asn Arg Gly Met Thr Ala
690 695 700
Leu Leu Lys Val Ser Ser Cys Asp Lys Asn Thr Gly Asp Tyr Tyr Glu
705 710 715 720
Asp Ser Tyr Glu Asp Ile Ser Ala Tyr Leu Leu Ser Lys Asn Asn Ala
725 730 735
Ile Glu Pro Arg Ser Phe Ser Gln Asn Ser Arg His Pro Ser Thr Arg
740 745 750
Gln Lys Gln Phe Asn Ala Thr Thr Ile Pro Glu Asn Asp Ile Glu Lys
755 760 765
Thr Asp Pro Trp Phe Ala His Arg Thr Pro Met Pro Lys Ile Gln Asn
770 775 780
Val Ser Ser Ser Asp Leu Leu Met Leu Leu Arg Gln Ser Pro Thr Pro
785 790 795 800
His Gly Leu Ser Leu Ser Asp Leu Gln Glu Ala Lys Tyr Glu Thr Phe
805 810 815
Ser Asp Asp Pro Ser Pro Gly Ala Ile Asp Ser Asn Asn Ser Leu Ser
820 825 830
Glu Met Thr His Phe Arg Pro Gln Leu His His Ser Gly Asp Met Val
835 840 845
Phe Thr Pro Glu Ser Gly Leu Gln Leu Arg Leu Asn Glu Lys Leu Gly
850 855 860
Thr Thr Ala Ala Thr Glu Leu Lys Lys Leu Asp Phe Lys Val Ser Ser
865 870 875 880
Thr Ser Asn Asn Leu Ile Ser Thr Ile Pro Ser Asp Asn Leu Ala Ala
885 890 895
Gly Thr Asp Asn Thr Ser Ser Leu Gly Pro Pro Ser Met Pro Val His
900 905 910
Tyr Asp Ser Gln Leu Asp Thr Thr Leu Phe Gly Lys Lys Ser Ser Pro
915 920 925
Leu Thr Glu Ser Gly Gly Pro Leu Ser Leu Ser Glu Glu Asn Asn Asp
930 935 940
Ser Lys Leu Leu Glu Ser Gly Leu Met Asn Ser Gln Glu Ser Ser Trp
945 950 955 960
Gly Lys Asn Val Ser Ser Thr Glu Ser Gly Arg Leu Phe Lys Gly Lys
965 970 975
Arg Ala His Gly Pro Ala Leu Leu Thr Lys Asp Asn Ala Leu Phe Lys
980 985 990
Val Ser Ile Ser Leu Leu Lys Thr Asn Lys Thr Ser Asn Asn Ser Ala
995 1000 1005
Thr Asn Arg Lys Thr His Ile Asp Gly Pro Ser Leu Leu Ile Glu
1010 1015 1020
Asn Ser Pro Ser Val Trp Gln Asn Ile Leu Glu Ser Asp Thr Glu
1025 1030 1035
Phe Lys Lys Val Thr Pro Leu Ile His Asp Arg Met Leu Met Asp
1040 1045 1050
Lys Asn Ala Thr Ala Leu Arg Leu Asn His Met Ser Asn Lys Thr
1055 1060 1065
Thr Ser Ser Lys Asn Met Glu Met Val Gln Gln Lys Lys Glu Gly
1070 1075 1080
Pro Ile Pro Pro Asp Ala Gln Asn Pro Asp Met Ser Phe Phe Lys
1085 1090 1095
Met Leu Phe Leu Pro Glu Ser Ala Arg Trp Ile Gln Arg Thr His
1100 1105 1110
Gly Lys Asn Ser Leu Asn Ser Gly Gln Gly Pro Ser Pro Lys Gln
1115 1120 1125
Leu Val Ser Leu Gly Pro Glu Lys Ser Val Glu Gly Gln Asn Phe
1130 1135 1140
Leu Ser Glu Lys Asn Lys Val Val Val Gly Lys Gly Glu Phe Thr
1145 1150 1155
Lys Asp Val Gly Leu Lys Glu Met Val Phe Pro Ser Ser Arg Asn
1160 1165 1170
Leu Phe Leu Thr Asn Leu Asp Asn Leu His Glu Asn Asn Thr His
1175 1180 1185
Asn Gln Glu Lys Lys Ile Gln Glu Glu Ile Glu Lys Lys Glu Thr
1190 1195 1200
Leu Ile Gln Glu Asn Val Val Leu Pro Gln Ile His Thr Val Thr
1205 1210 1215
Gly Thr Lys Asn Phe Met Lys Asn Leu Phe Leu Leu Ser Thr Arg
1220 1225 1230
Gln Asn Val Glu Gly Ser Tyr Asp Gly Ala Tyr Ala Pro Val Leu
1235 1240 1245
Gln Asp Phe Arg Ser Leu Asn Asp Ser Thr Asn Arg Thr Lys Lys
1250 1255 1260
His Thr Ala His Phe Ser Lys Lys Gly Glu Glu Glu Asn Leu Glu
1265 1270 1275
Gly Leu Gly Asn Gln Thr Lys Gln Ile Val Glu Lys Tyr Ala Cys
1280 1285 1290
Thr Thr Arg Ile Ser Pro Asn Thr Ser Gln Gln Asn Phe Val Thr
1295 1300 1305
Gln Arg Ser Lys Arg Ala Leu Lys Gln Phe Arg Leu Pro Leu Glu
1310 1315 1320
Glu Thr Glu Leu Glu Lys Arg Ile Ile Val Asp Asp Thr Ser Thr
1325 1330 1335
Gln Trp Ser Lys Asn Met Lys His Leu Thr Pro Ser Thr Leu Thr
1340 1345 1350
Gln Ile Asp Tyr Asn Glu Lys Glu Lys Gly Ala Ile Thr Gln Ser
1355 1360 1365
Pro Leu Ser Asp Cys Leu Thr Arg Ser His Ser Ile Pro Gln Ala
1370 1375 1380
Asn Arg Ser Pro Leu Pro Ile Ala Lys Val Ser Ser Phe Pro Ser
1385 1390 1395
Ile Arg Pro Ile Tyr Leu Thr Arg Val Leu Phe Gln Asp Asn Ser
1400 1405 1410
Ser His Leu Pro Ala Ala Ser Tyr Arg Lys Lys Asp Ser Gly Val
1415 1420 1425
Gln Glu Ser Ser His Phe Leu Gln Gly Ala Lys Lys Asn Asn Leu
1430 1435 1440
Ser Leu Ala Ile Leu Thr Leu Glu Met Thr Gly Asp Gln Arg Glu
1445 1450 1455
Val Gly Ser Leu Gly Thr Ser Ala Thr Asn Ser Val Thr Tyr Lys
1460 1465 1470
Lys Val Glu Asn Thr Val Leu Pro Lys Pro Asp Leu Pro Lys Thr
1475 1480 1485
Ser Gly Lys Val Glu Leu Leu Pro Lys Val His Ile Tyr Gln Lys
1490 1495 1500
Asp Leu Phe Pro Thr Glu Thr Ser Asn Gly Ser Pro Gly His Leu
1505 1510 1515
Asp Leu Val Glu Gly Ser Leu Leu Gln Gly Thr Glu Gly Ala Ile
1520 1525 1530
Lys Trp Asn Glu Ala Asn Arg Pro Gly Lys Val Pro Phe Leu Arg
1535 1540 1545
Val Ala Thr Glu Ser Ser Ala Lys Thr Pro Ser Lys Leu Leu Asp
1550 1555 1560
Pro Leu Ala Trp Asp Asn His Tyr Gly Thr Gln Ile Pro Lys Glu
1565 1570 1575
Glu Trp Lys Ser Gln Glu Lys Ser Pro Glu Lys Thr Ala Phe Lys
1580 1585 1590
Lys Lys Asp Thr Ile Leu Ser Leu Asn Ala Cys Glu Ser Asn His
1595 1600 1605
Ala Ile Ala Ala Ile Asn Glu Gly Gln Asn Lys Pro Glu Ile Glu
1610 1615 1620
Val Thr Trp Ala Lys Gln Gly Arg Thr Glu Arg Leu Cys Ser Gln
1625 1630 1635
Asn Pro Pro Val Leu Lys Arg His Gln Arg Glu Ile Thr Arg Thr
1640 1645 1650
Thr Leu Gln Ser Asp Gln Glu Glu Ile Asp Tyr Asp Asp Thr Ile
1655 1660 1665
Ser Val Glu Met Lys Lys Glu Asp Phe Asp Ile Tyr Asp Glu Asp
1670 1675 1680
Glu Asn Gln Ser Pro Arg Ser Phe Gln Lys Lys Thr Arg His Tyr
1685 1690 1695
Phe Ile Ala Ala Val Glu Arg Leu Trp Asp Tyr Gly Met Ser Ser
1700 1705 1710
Ser Pro His Val Leu Arg Asn Arg Ala Gln Ser Gly Ser Val Pro
1715 1720 1725
Gln Phe Lys Lys Val Val Phe Gln Glu Phe Thr Asp Gly Ser Phe
1730 1735 1740
Thr Gln Pro Leu Tyr Arg Gly Glu Leu Asn Glu His Leu Gly Leu
1745 1750 1755
Leu Gly Pro Tyr Ile Arg Ala Glu Val Glu Asp Asn Ile Met Val
1760 1765 1770
Thr Phe Arg Asn Gln Ala Ser Arg Pro Tyr Ser Phe Tyr Ser Ser
1775 1780 1785
Leu Ile Ser Tyr Glu Glu Asp Gln Arg Gln Gly Ala Glu Pro Arg
1790 1795 1800
Lys Asn Phe Val Lys Pro Asn Glu Thr Lys Thr Tyr Phe Trp Lys
1805 1810 1815
Val Gln His His Met Ala Pro Thr Lys Asp Glu Phe Asp Cys Lys
1820 1825 1830
Ala Trp Ala Tyr Phe Ser Asp Val Asp Leu Glu Lys Asp Val His
1835 1840 1845
Ser Gly Leu Ile Gly Pro Leu Leu Val Cys His Thr Asn Thr Leu
1850 1855 1860
Asn Pro Ala His Gly Arg Gln Val Thr Val Gln Glu Phe Ala Leu
1865 1870 1875
Phe Phe Thr Ile Phe Asp Glu Thr Lys Ser Trp Tyr Phe Thr Glu
1880 1885 1890
Asn Met Glu Arg Asn Cys Arg Ala Pro Cys Asn Ile Gln Met Glu
1895 1900 1905
Asp Pro Thr Phe Lys Glu Asn Tyr Arg Phe His Ala Ile Asn Gly
1910 1915 1920
Tyr Ile Met Asp Thr Leu Pro Gly Leu Val Met Ala Gln Asp Gln
1925 1930 1935
Arg Ile Arg Trp Tyr Leu Leu Ser Met Gly Ser Asn Glu Asn Ile
1940 1945 1950
His Ser Ile His Phe Ser Gly His Val Phe Thr Val Arg Lys Lys
1955 1960 1965
Glu Glu Tyr Lys Met Ala Leu Tyr Asn Leu Tyr Pro Gly Val Phe
1970 1975 1980
Glu Thr Val Glu Met Leu Pro Ser Lys Ala Gly Ile Trp Arg Val
1985 1990 1995
Glu Cys Leu Ile Gly Glu His Leu His Ala Gly Met Ser Thr Leu
2000 2005 2010
Phe Leu Val Tyr Ser Asn Lys Cys Gln Thr Pro Leu Gly Met Ala
2015 2020 2025
Ser Gly His Ile Arg Asp Phe Gln Ile Thr Ala Ser Gly Gln Tyr
2030 2035 2040
Gly Gln Trp Ala Pro Lys Leu Ala Arg Leu His Tyr Ser Gly Ser
2045 2050 2055
Ile Asn Ala Trp Ser Thr Lys Glu Pro Phe Ser Trp Ile Lys Val
2060 2065 2070
Asp Leu Leu Ala Pro Met Ile Ile His Gly Ile Lys Thr Gln Gly
2075 2080 2085
Ala Arg Gln Lys Phe Ser Ser Leu Tyr Ile Ser Gln Phe Ile Ile
2090 2095 2100
Met Tyr Ser Leu Asp Gly Lys Lys Trp Gln Thr Tyr Arg Gly Asn
2105 2110 2115
Ser Thr Gly Thr Leu Met Val Phe Phe Gly Asn Val Asp Ser Ser
2120 2125 2130
Gly Ile Lys His Asn Ile Phe Asn Pro Pro Ile Ile Ala Arg Tyr
2135 2140 2145
Ile Arg Leu His Pro Thr His Tyr Ser Ile Arg Ser Thr Leu Arg
2150 2155 2160
Met Glu Leu Met Gly Cys Asp Leu Asn Ser Cys Ser Met Pro Leu
2165 2170 2175
Gly Met Glu Ser Lys Ala Ile Ser Asp Ala Gln Ile Thr Ala Ser
2180 2185 2190
Ser Tyr Phe Thr Asn Met Phe Ala Thr Trp Ser Pro Ser Lys Ala
2195 2200 2205
Arg Leu His Leu Gln Gly Arg Ser Asn Ala Trp Arg Pro Gln Val
2210 2215 2220
Asn Asn Pro Lys Glu Trp Leu Gln Val Asp Phe Gln Lys Thr Met
2225 2230 2235
Lys Val Thr Gly Val Thr Thr Gln Gly Val Lys Ser Leu Leu Thr
2240 2245 2250
Ser Met Tyr Val Lys Glu Phe Leu Ile Ser Ser Ser Gln Asp Gly
2255 2260 2265
His Gln Trp Thr Leu Phe Phe Gln Asn Gly Lys Val Lys Val Phe
2270 2275 2280
Gln Gly Asn Gln Asp Ser Phe Thr Pro Val Val Asn Ser Leu Asp
2285 2290 2295
Pro Pro Leu Leu Thr Arg Tyr Leu Arg Ile His Pro Gln Ser Trp
2300 2305 2310
Val His Gln Ile Ala Leu Arg Met Glu Val Leu Gly Cys Glu Ala
2315 2320 2325
Gln Asp Leu Tyr
2330
<210> 16
<211> 4371
<212> ДНК
<213> Искусственная последовательность
<220>
<223> BDD-FVIII (не оптимизированная; "родительская"), нуклеотидная
последовательность
<400> 16
atgcaaatag agctctccac ctgcttcttt ctgtgccttt tgcgattctg ctttagtgcc
60
accagaagat actacctggg tgcagtggaa ctgtcatggg actatatgca aagtgatctc
120
ggtgagctgc ctgtggacgc aagatttcct cctagagtgc caaaatcttt tccattcaac
180
acctcagtcg tgtacaaaaa gactctgttt gtagaattca cggatcacct tttcaacatc
240
gctaagccaa ggccaccctg gatgggtctg ctaggtccta ccatccaggc tgaggtttat
300
gatacagtgg tcattacact taagaacatg gcttcccatc ctgtcagtct tcatgctgtt
360
ggtgtatcct actggaaagc ttctgaggga gctgaatatg atgatcagac cagtcaaagg
420
gagaaagaag atgataaagt cttccctggt ggaagccata catatgtctg gcaggtcctg
480
aaagagaatg gtccaatggc ctctgaccca ctgtgcctta cctactcata tctttctcat
540
gtggacctgg taaaagactt gaattcaggc ctcattggag ccctactagt atgtagagaa
600
gggagtctgg ccaaggaaaa gacacagacc ttgcacaaat ttatactact ttttgctgta
660
tttgatgaag ggaaaagttg gcactcagaa acaaagaact ccttgatgca ggatagggat
720
gctgcatctg ctcgggcctg gcctaaaatg cacacagtca atggttatgt aaacaggtct
780
ctgccaggtc tgattggatg ccacaggaaa tcagtctatt ggcatgtgat tggaatgggc
840
accactcctg aagtgcactc aatattcctc gaaggtcaca catttcttgt gaggaaccat
900
cgccaggcgt ccttggaaat ctcgccaata actttcctta ctgctcaaac actcttgatg
960
gaccttggac agtttctact gttttgtcat atctcttccc accaacatga tggcatggaa
1020
gcttatgtca aagtagacag ctgtccagag gaaccccaac tacgaatgaa aaataatgaa
1080
gaagcggaag actatgatga tgatcttact gattctgaaa tggatgtggt caggtttgat
1140
gatgacaact ctccttcctt tatccaaatt cgctcagttg ccaagaagca tcctaaaact
1200
tgggtacatt acattgctgc tgaagaggag gactgggact atgctccctt agtcctcgcc
1260
cccgatgaca gaagttataa aagtcaatat ttgaacaatg gccctcagcg gattggtagg
1320
aagtacaaaa aagtccgatt tatggcatac acagatgaaa cctttaagac tcgtgaagct
1380
attcagcatg aatcaggaat cttgggacct ttactttatg gggaagttgg agacacactg
1440
ttgattatat ttaagaatca agcaagcaga ccatataaca tctaccctca cggaatcact
1500
gatgtccgtc ctttgtattc aaggagatta ccaaaaggtg taaaacattt gaaggatttt
1560
ccaattctgc caggagaaat attcaaatat aaatggacag tgactgtaga agatgggcca
1620
actaaatcag atcctcggtg cctgacccgc tattactcta gtttcgttaa tatggagaga
1680
gatctagctt caggactcat tggccctctc ctcatctgct acaaagaatc tgtagatcaa
1740
agaggaaacc agataatgtc agacaagagg aatgtcatcc tgttttctgt atttgatgag
1800
aaccgaagct ggtacctcac agagaatata caacgctttc tccccaatcc agctggagtg
1860
cagcttgagg atccagagtt ccaagcctcc aacatcatgc acagcatcaa tggctatgtt
1920
tttgatagtt tgcagttgtc agtttgtttg catgaggtgg catactggta cattctaagc
1980
attggagcac agactgactt cctttctgtc ttcttctctg gatatacctt caaacacaaa
2040
atggtctatg aagacacact caccctattc ccattctcag gagaaactgt cttcatgtcg
2100
atggaaaacc caggtctatg gattctgggg tgccacaact cagactttcg gaacagaggc
2160
atgaccgcct tactgaaggt ttctagttgt gacaagaaca ctggtgatta ttacgaggac
2220
agttatgaag atatttcagc atacttgctg agtaaaaaca atgccattga accaagaagc
2280
ttctctcaaa acccaccagt cttgaaacgc catcaacggg aaataactcg tactactctt
2340
cagtcagatc aagaggaaat tgactatgat gataccatat cagttgaaat gaagaaggaa
2400
gattttgaca tttatgatga ggatgaaaat cagagccccc gcagctttca aaagaaaaca
2460
cgacactatt ttattgctgc agtggagagg ctctgggatt atgggatgag tagctcccca
2520
catgttctaa gaaacagggc tcagagtggc agtgtccctc agttcaagaa agttgttttc
2580
caggaattta ctgatggctc ctttactcag cccttatacc gtggagaact aaatgaacat
2640
ttgggactcc tggggccata tataagagca gaagttgaag ataatatcat ggtaactttc
2700
agaaatcagg cctctcgtcc ctattccttc tattctagcc ttatttctta tgaggaagat
2760
cagaggcaag gagcagaacc tagaaaaaac tttgtcaagc ctaatgaaac caaaacttac
2820
ttttggaaag tgcaacatca tatggcaccc actaaagatg agtttgactg caaagcctgg
2880
gcttatttct ctgatgttga cctggaaaaa gatgtgcact caggcctgat tggacccctt
2940
ctggtctgcc acactaacac actgaaccct gctcatggga gacaagtgac agtacaggaa
3000
tttgctctgt ttttcaccat ctttgatgag accaaaagct ggtacttcac tgaaaatatg
3060
gaaagaaact gcagggctcc ctgcaatatc cagatggaag atcccacttt taaagagaat
3120
tatcgcttcc atgcaatcaa tggctacata atggatacac tacctggctt agtaatggct
3180
caggatcaaa ggattcgatg gtatctgctc agcatgggca gcaatgaaaa catccattct
3240
attcatttca gtggacatgt gttcactgta cgaaaaaaag aggagtataa aatggcactg
3300
tacaatctct atccaggtgt ttttgagaca gtggaaatgt taccatccaa agctggaatt
3360
tggcgggtgg aatgccttat tggcgagcat ctacatgctg ggatgagcac actttttctg
3420
gtgtacagca ataagtgtca gactcccctg ggaatggctt ctggacacat tagagatttt
3480
cagattacag cttcaggaca atatggacag tgggccccaa agctggccag acttcattat
3540
tccggatcaa tcaatgcctg gagcaccaag gagccctttt cttggatcaa ggtggatctg
3600
ttggcaccaa tgattattca cggcatcaag acccagggtg cccgtcagaa gttctccagc
3660
ctctacatct ctcagtttat catcatgtat agtcttgatg ggaagaagtg gcagacttat
3720
cgaggaaatt ccactggaac cttaatggtc ttctttggca atgtggattc atctgggata
3780
aaacacaata tttttaaccc tccaattatt gctcgataca tccgtttgca cccaactcat
3840
tatagcattc gcagcactct tcgcatggag ttgatgggct gtgatttaaa tagttgcagc
3900
atgccattgg gaatggagag taaagcaata tcagatgcac agattactgc ttcatcctac
3960
tttaccaata tgtttgccac ctggtctcct tcaaaagctc gacttcacct ccaagggagg
4020
agtaatgcct ggagacctca ggtgaataat ccaaaagagt ggctgcaagt ggacttccag
4080
aagacaatga aagtcacagg agtaactact cagggagtaa aatctctgct taccagcatg
4140
tatgtgaagg agttcctcat ctccagcagt caagatggcc atcagtggac tctctttttt
4200
cagaatggca aagtaaaggt ttttcaggga aatcaagact ccttcacacc tgtggtgaac
4260
tctctagacc caccgttact gactcgctac cttcgaattc acccccagag ttgggtgcac
4320
cagattgccc tgaggatgga ggttctgggc tgcgaggcac aggacctcta c
4371
<210> 17
<211> 1438
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> BDD-FVIII (не оптимизированная; "родительская"),
аминокислотная последовательность
<400> 17
Ala Thr Arg Arg Tyr Tyr Leu Gly Ala Val Glu Leu Ser Trp Asp Tyr
1. 5 10 15
Met Gln Ser Asp Leu Gly Glu Leu Pro Val Asp Ala Arg Phe Pro Pro
20 25 30
Arg Val Pro Lys Ser Phe Pro Phe Asn Thr Ser Val Val Tyr Lys Lys
35 40 45
Thr Leu Phe Val Glu Phe Thr Asp His Leu Phe Asn Ile Ala Lys Pro
50 55 60
Arg Pro Pro Trp Met Gly Leu Leu Gly Pro Thr Ile Gln Ala Glu Val
65 70 75 80
Tyr Asp Thr Val Val Ile Thr Leu Lys Asn Met Ala Ser His Pro Val
85 90 95
Ser Leu His Ala Val Gly Val Ser Tyr Trp Lys Ala Ser Glu Gly Ala
100 105 110
Glu Tyr Asp Asp Gln Thr Ser Gln Arg Glu Lys Glu Asp Asp Lys Val
115 120 125
Phe Pro Gly Gly Ser His Thr Tyr Val Trp Gln Val Leu Lys Glu Asn
130 135 140
Gly Pro Met Ala Ser Asp Pro Leu Cys Leu Thr Tyr Ser Tyr Leu Ser
145 150 155 160
His Val Asp Leu Val Lys Asp Leu Asn Ser Gly Leu Ile Gly Ala Leu
165 170 175
Leu Val Cys Arg Glu Gly Ser Leu Ala Lys Glu Lys Thr Gln Thr Leu
180 185 190
His Lys Phe Ile Leu Leu Phe Ala Val Phe Asp Glu Gly Lys Ser Trp
195 200 205
His Ser Glu Thr Lys Asn Ser Leu Met Gln Asp Arg Asp Ala Ala Ser
210 215 220
Ala Arg Ala Trp Pro Lys Met His Thr Val Asn Gly Tyr Val Asn Arg
225 230 235 240
Ser Leu Pro Gly Leu Ile Gly Cys His Arg Lys Ser Val Tyr Trp His
245 250 255
Val Ile Gly Met Gly Thr Thr Pro Glu Val His Ser Ile Phe Leu Glu
260 265 270
Gly His Thr Phe Leu Val Arg Asn His Arg Gln Ala Ser Leu Glu Ile
275 280 285
Ser Pro Ile Thr Phe Leu Thr Ala Gln Thr Leu Leu Met Asp Leu Gly
290 295 300
Gln Phe Leu Leu Phe Cys His Ile Ser Ser His Gln His Asp Gly Met
305 310 315 320
Glu Ala Tyr Val Lys Val Asp Ser Cys Pro Glu Glu Pro Gln Leu Arg
325 330 335
Met Lys Asn Asn Glu Glu Ala Glu Asp Tyr Asp Asp Asp Leu Thr Asp
340 345 350
Ser Glu Met Asp Val Val Arg Phe Asp Asp Asp Asn Ser Pro Ser Phe
355 360 365
Ile Gln Ile Arg Ser Val Ala Lys Lys His Pro Lys Thr Trp Val His
370 375 380
Tyr Ile Ala Ala Glu Glu Glu Asp Trp Asp Tyr Ala Pro Leu Val Leu
385 390 395 400
Ala Pro Asp Asp Arg Ser Tyr Lys Ser Gln Tyr Leu Asn Asn Gly Pro
405 410 415
Gln Arg Ile Gly Arg Lys Tyr Lys Lys Val Arg Phe Met Ala Tyr Thr
420 425 430
Asp Glu Thr Phe Lys Thr Arg Glu Ala Ile Gln His Glu Ser Gly Ile
435 440 445
Leu Gly Pro Leu Leu Tyr Gly Glu Val Gly Asp Thr Leu Leu Ile Ile
450 455 460
Phe Lys Asn Gln Ala Ser Arg Pro Tyr Asn Ile Tyr Pro His Gly Ile
465 470 475 480
Thr Asp Val Arg Pro Leu Tyr Ser Arg Arg Leu Pro Lys Gly Val Lys
485 490 495
His Leu Lys Asp Phe Pro Ile Leu Pro Gly Glu Ile Phe Lys Tyr Lys
500 505 510
Trp Thr Val Thr Val Glu Asp Gly Pro Thr Lys Ser Asp Pro Arg Cys
515 520 525
Leu Thr Arg Tyr Tyr Ser Ser Phe Val Asn Met Glu Arg Asp Leu Ala
530 535 540
Ser Gly Leu Ile Gly Pro Leu Leu Ile Cys Tyr Lys Glu Ser Val Asp
545 550 555 560
Gln Arg Gly Asn Gln Ile Met Ser Asp Lys Arg Asn Val Ile Leu Phe
565 570 575
Ser Val Phe Asp Glu Asn Arg Ser Trp Tyr Leu Thr Glu Asn Ile Gln
580 585 590
Arg Phe Leu Pro Asn Pro Ala Gly Val Gln Leu Glu Asp Pro Glu Phe
595 600 605
Gln Ala Ser Asn Ile Met His Ser Ile Asn Gly Tyr Val Phe Asp Ser
610 615 620
Leu Gln Leu Ser Val Cys Leu His Glu Val Ala Tyr Trp Tyr Ile Leu
625 630 635 640
Ser Ile Gly Ala Gln Thr Asp Phe Leu Ser Val Phe Phe Ser Gly Tyr
645 650 655
Thr Phe Lys His Lys Met Val Tyr Glu Asp Thr Leu Thr Leu Phe Pro
660 665 670
Phe Ser Gly Glu Thr Val Phe Met Ser Met Glu Asn Pro Gly Leu Trp
675 680 685
Ile Leu Gly Cys His Asn Ser Asp Phe Arg Asn Arg Gly Met Thr Ala
690 695 700
Leu Leu Lys Val Ser Ser Cys Asp Lys Asn Thr Gly Asp Tyr Tyr Glu
705 710 715 720
Asp Ser Tyr Glu Asp Ile Ser Ala Tyr Leu Leu Ser Lys Asn Asn Ala
725 730 735
Ile Glu Pro Arg Ser Phe Ser Gln Asn Pro Pro Val Leu Lys Arg His
740 745 750
Gln Arg Glu Ile Thr Arg Thr Thr Leu Gln Ser Asp Gln Glu Glu Ile
755 760 765
Asp Tyr Asp Asp Thr Ile Ser Val Glu Met Lys Lys Glu Asp Phe Asp
770 775 780
Ile Tyr Asp Glu Asp Glu Asn Gln Ser Pro Arg Ser Phe Gln Lys Lys
785 790 795 800
Thr Arg His Tyr Phe Ile Ala Ala Val Glu Arg Leu Trp Asp Tyr Gly
805 810 815
Met Ser Ser Ser Pro His Val Leu Arg Asn Arg Ala Gln Ser Gly Ser
820 825 830
Val Pro Gln Phe Lys Lys Val Val Phe Gln Glu Phe Thr Asp Gly Ser
835 840 845
Phe Thr Gln Pro Leu Tyr Arg Gly Glu Leu Asn Glu His Leu Gly Leu
850 855 860
Leu Gly Pro Tyr Ile Arg Ala Glu Val Glu Asp Asn Ile Met Val Thr
865 870 875 880
Phe Arg Asn Gln Ala Ser Arg Pro Tyr Ser Phe Tyr Ser Ser Leu Ile
885 890 895
Ser Tyr Glu Glu Asp Gln Arg Gln Gly Ala Glu Pro Arg Lys Asn Phe
900 905 910
Val Lys Pro Asn Glu Thr Lys Thr Tyr Phe Trp Lys Val Gln His His
915 920 925
Met Ala Pro Thr Lys Asp Glu Phe Asp Cys Lys Ala Trp Ala Tyr Phe
930 935 940
Ser Asp Val Asp Leu Glu Lys Asp Val His Ser Gly Leu Ile Gly Pro
945 950 955 960
Leu Leu Val Cys His Thr Asn Thr Leu Asn Pro Ala His Gly Arg Gln
965 970 975
Val Thr Val Gln Glu Phe Ala Leu Phe Phe Thr Ile Phe Asp Glu Thr
980 985 990
Lys Ser Trp Tyr Phe Thr Glu Asn Met Glu Arg Asn Cys Arg Ala Pro
995 1000 1005
Cys Asn Ile Gln Met Glu Asp Pro Thr Phe Lys Glu Asn Tyr Arg
1010 1015 1020
Phe His Ala Ile Asn Gly Tyr Ile Met Asp Thr Leu Pro Gly Leu
1025 1030 1035
Val Met Ala Gln Asp Gln Arg Ile Arg Trp Tyr Leu Leu Ser Met
1040 1045 1050
Gly Ser Asn Glu Asn Ile His Ser Ile His Phe Ser Gly His Val
1055 1060 1065
Phe Thr Val Arg Lys Lys Glu Glu Tyr Lys Met Ala Leu Tyr Asn
1070 1075 1080
Leu Tyr Pro Gly Val Phe Glu Thr Val Glu Met Leu Pro Ser Lys
1085 1090 1095
Ala Gly Ile Trp Arg Val Glu Cys Leu Ile Gly Glu His Leu His
1100 1105 1110
Ala Gly Met Ser Thr Leu Phe Leu Val Tyr Ser Asn Lys Cys Gln
1115 1120 1125
Thr Pro Leu Gly Met Ala Ser Gly His Ile Arg Asp Phe Gln Ile
1130 1135 1140
Thr Ala Ser Gly Gln Tyr Gly Gln Trp Ala Pro Lys Leu Ala Arg
1145 1150 1155
Leu His Tyr Ser Gly Ser Ile Asn Ala Trp Ser Thr Lys Glu Pro
1160 1165 1170
Phe Ser Trp Ile Lys Val Asp Leu Leu Ala Pro Met Ile Ile His
1175 1180 1185
Gly Ile Lys Thr Gln Gly Ala Arg Gln Lys Phe Ser Ser Leu Tyr
1190 1195 1200
Ile Ser Gln Phe Ile Ile Met Tyr Ser Leu Asp Gly Lys Lys Trp
1205 1210 1215
Gln Thr Tyr Arg Gly Asn Ser Thr Gly Thr Leu Met Val Phe Phe
1220 1225 1230
Gly Asn Val Asp Ser Ser Gly Ile Lys His Asn Ile Phe Asn Pro
1235 1240 1245
Pro Ile Ile Ala Arg Tyr Ile Arg Leu His Pro Thr His Tyr Ser
1250 1255 1260
Ile Arg Ser Thr Leu Arg Met Glu Leu Met Gly Cys Asp Leu Asn
1265 1270 1275
Ser Cys Ser Met Pro Leu Gly Met Glu Ser Lys Ala Ile Ser Asp
1280 1285 1290
Ala Gln Ile Thr Ala Ser Ser Tyr Phe Thr Asn Met Phe Ala Thr
1295 1300 1305
Trp Ser Pro Ser Lys Ala Arg Leu His Leu Gln Gly Arg Ser Asn
1310 1315 1320
Ala Trp Arg Pro Gln Val Asn Asn Pro Lys Glu Trp Leu Gln Val
1325 1330 1335
Asp Phe Gln Lys Thr Met Lys Val Thr Gly Val Thr Thr Gln Gly
1340 1345 1350
Val Lys Ser Leu Leu Thr Ser Met Tyr Val Lys Glu Phe Leu Ile
1355 1360 1365
Ser Ser Ser Gln Asp Gly His Gln Trp Thr Leu Phe Phe Gln Asn
1370 1375 1380
Gly Lys Val Lys Val Phe Gln Gly Asn Gln Asp Ser Phe Thr Pro
1385 1390 1395
Val Val Asn Ser Leu Asp Pro Pro Leu Leu Thr Arg Tyr Leu Arg
1400 1405 1410
Ile His Pro Gln Ser Trp Val His Gln Ile Ala Leu Arg Met Glu
1415 1420 1425
Val Leu Gly Cys Glu Ala Gln Asp Leu Tyr
1430 1435
<210> 18
<211> 450
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Нуклеотидная последовательность XTEN
<400> 18
ggcgcgccaa catcagagag cgccacccct gaaagtggtc ccgggagcga gccagccaca
60
tctgggtcgg aaacgccagg cacaagtgag tctgcaactc ccgagtccgg acctggctcc
120
gagcctgcca ctagcggctc cgagactccg ggaacttccg agagcgctac accagaaagc
180
ggacccggaa ccagtaccga acctagcgag ggctctgctc cgggcagccc agccggctct
240
cctacatcca cggaggaggg cacttccgaa tccgccaccc cggagtcagg gccaggatct
300
gaacccgcta cctcaggcag tgagacgcca ggaacgagcg agtccgctac accggagagt
360
gggccaggga gccctgctgg atctcctacg tccactgagg aagggtcacc agcgggctcg
420
cccaccagca ctgaagaagg tgcctcgagc
450
<210> 19
<211> 4824
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-52-XTEN
<400> 19
atgcaaatcg aactgagcac ctgtttcttc ctctgcctgc tgagattctg tttctccgcg
60
acccgccgat actacctggg agcagtggag ctctcctggg attacatgca gagcgacctt
120
ggggagctgc ccgtggatgc caggttccct ccccgggtgc caaagtcgtt tccgttcaac
180
acctccgtgg tgtacaagaa aactctgttc gtggagttca ccgaccacct gttcaatatc
240
gccaagccca gacctccctg gatggggctg ttgggaccta ccatccaagc ggaggtgtac
300
gacactgtgg tcatcactct gaagaacatg gcctcgcatc ccgtgtccct gcacgccgtg
360
ggagtgtctt actggaaagc gtccgagggg gccgaatacg acgaccagac ctcgcagaga
420
gaaaaggaag atgacaaggt gttcccagga ggatcgcaca cctacgtgtg gcaagtgttg
480
aaggagaacg gcccaatggc ctccgacccg ctgtgcctga cctactcgta cctgtcccac
540
gtggacctcg tgaaggacct caactcggga ctgattggag ccctgctggt ctgcagggaa
600
ggctcactgg cgaaagaaaa gactcagacc ttgcacaagt tcattctgct gttcgctgtg
660
ttcgacgagg ggaagtcgtg gcacagcgag actaagaact ccctgatgca agatagagat
720
gccgcctccg cccgggcctg gcctaagatg cacaccgtga acggttacgt gaaccgctcc
780
ctccctggcc tgattggatg ccaccggaag tccgtgtact ggcacgtgat cgggatgggg
840
accacccccg aggtgcacag catcttcctg gaaggtcaca catttctcgt gcgcaaccac
900
cggcaggcct ccctggaaat cagccccatt accttcctca ctgcccagac tctgctgatg
960
gacctgggac agttcctgct gttctgccat atctcctccc accaacatga cggaatggag
1020
gcatacgtga aggtcgattc ctgccctgag gaaccccagc tccgcatgaa gaacaatgag
1080
gaagccgagg actacgacga cgacctgacg gatagcgaga tggatgtggt ccggttcgat
1140
gacgataaca gcccttcctt catccaaatt cgctcggtgg caaagaagca ccccaagacc
1200
tgggtgcatt acattgcggc ggaagaagag gactgggatt atgccccgct tgtcctcgct
1260
cctgacgacc ggagctacaa gagccagtac ctgaacaacg gtccacagag gatcggtaga
1320
aagtacaaga aggtccgctt catggcctat accgacgaaa ccttcaaaac tagagaggcc
1380
atccaacacg aatccggcat cctgggcccg ctcttgtacg gagaagtcgg cgacaccctt
1440
ctcattatct tcaagaacca ggcttcccgg ccgtacaaca tctatccgca tgggatcact
1500
gacgtgcgcc cactgtactc gcggcgcctg cccaagggtg tcaaacacct gaaggatttt
1560
ccgatccttc cgggagaaat cttcaagtac aagtggaccg tgaccgtgga agatggccca
1620
actaagtctg accctagatg cctcacccgc tactactcat ccttcgtcaa catggagcgc
1680
gacctggcca gcggactgat cggcccgctg ctgatttgct acaaggaatc agtggaccaa
1740
cggggaaacc agatcatgtc ggataagagg aacgtcatcc tcttctccgt gtttgacgaa
1800
aaccggtcgt ggtacctgac cgagaacatc cagaggttcc tgcccaaccc tgctggggtg
1860
cagctggagg accccgagtt ccaggccagc aacatcatgc acagcatcaa tggctacgtg
1920
ttcgacagcc tgcagctgag cgtgtgcctg cacgaggtgg cctactggta catcctgagc
1980
atcggcgccc agaccgactt cctgagcgtg ttcttctctg gctacacctt caagcacaag
2040
atggtgtatg aggacaccct gaccctgttc cccttcagcg gggagactgt cttcatgagc
2100
atggagaacc ctggcctgtg gatcctgggc tgccacaaca gcgacttcag gaacaggggc
2160
atgactgccc tgctgaaagt ctccagctgt gacaagaaca ccggggacta ctacgaggac
2220
agctacgagg acatcagcgc ctacctgctg agcaagaaca atgccatcga gcccaggagc
2280
ttctctcaga acggcgcgcc aacatcagag agcgccaccc ctgaaagtgg tcccgggagc
2340
gagccagcca catctgggtc ggaaacgcca ggcacaagtg agtctgcaac tcccgagtcc
2400
ggacctggct ccgagcctgc cactagcggc tccgagactc cgggaacttc cgagagcgct
2460
acaccagaaa gcggacccgg aaccagtacc gaacctagcg agggctctgc tccgggcagc
2520
ccagccggct ctcctacatc cacggaggag ggcacttccg aatccgccac cccggagtca
2580
gggccaggat ctgaacccgc tacctcaggc agtgagacgc caggaacgag cgagtccgct
2640
acaccggaga gtgggccagg gagccctgct ggatctccta cgtccactga ggaagggtca
2700
ccagcgggct cgcccaccag cactgaagaa ggtgcctcga gccccccagt gctgaagagg
2760
caccagaggg agatcaccag gaccaccctg cagtctgacc aggaggagat cgactatgat
2820
gacaccatca gcgtggagat gaagaaggag gacttcgaca tctacgacga ggacgagaac
2880
cagagcccca ggagcttcca gaagaagacc aggcactact tcattgctgc tgtggagagg
2940
ctgtgggact atggcatgtc cagcagcccc catgtgctga ggaacagggc ccagtctggc
3000
agcgtgcccc agttcaagaa agtcgtgttc caggagttca ccgacggcag cttcacccag
3060
cccctgtaca gaggggagct gaacgagcac ctgggcctgc tgggccccta catcagggcc
3120
gaggtggagg acaacatcat ggtgaccttc aggaaccagg ccagcaggcc ctacagcttc
3180
tacagcagcc tgatcagcta cgaggaggac cagaggcagg gggctgagcc caggaagaac
3240
tttgtgaagc ccaatgaaac caagacctac ttctggaagg tgcagcacca catggccccc
3300
accaaggacg agttcgactg caaggcctgg gcctacttct ctgacgtgga cctggagaag
3360
gacgtgcact ctggcctgat tggccccctg ctggtgtgcc acaccaacac cctgaaccct
3420
gcccatggca ggcaggtgac tgtgcaggag ttcgccctgt tcttcaccat cttcgatgaa
3480
accaagagct ggtacttcac tgagaacatg gagaggaact gcagggcccc ctgcaacatc
3540
cagatggagg accccacctt caaggagaac tacaggttcc atgccatcaa tggctacatc
3600
atggacaccc tgcctggcct ggtcatggcc caggaccaga ggatcaggtg gtatctgctg
3660
agcatgggca gcaacgagaa catccacagc atccacttct ctggccacgt gttcactgtg
3720
aggaagaagg aggagtacaa gatggccctg tacaacctgt accctggggt gttcgaaacc
3780
gtggagatgc tgcccagcaa ggccggcatc tggagggtgg agtgcctgat tggggagcac
3840
ctgcacgccg gcatgagcac cctgttcctg gtgtacagca acaagtgcca gacccccctg
3900
ggcatggcct ctggccacat cagggacttc cagatcactg cctctggcca gtacggccag
3960
tgggccccca agctggccag gctgcactac tccggaagca tcaatgcctg gagcaccaag
4020
gagcccttca gctggatcaa agtggacctg ctggccccca tgatcatcca cggcatcaag
4080
acccaggggg ccaggcagaa gttctccagc ctgtacatca gccagttcat catcatgtac
4140
agcctggacg gcaagaagtg gcagacctac aggggcaaca gcaccggcac cctgatggtg
4200
ttcttcggca acgtggacag cagcggcatc aagcacaaca tcttcaaccc ccccatcatc
4260
gccagataca tcaggctgca ccccacccac tacagcatca ggagcaccct gaggatggag
4320
ctgatgggct gtgacctgaa cagctgcagc atgcccctgg gcatggagag caaggccatc
4380
tctgacgccc agatcactgc ctccagctac ttcaccaaca tgtttgccac ctggagcccc
4440
agcaaggcca ggctgcacct gcagggcagg agcaatgcct ggaggcccca ggtcaacaac
4500
cccaaggagt ggctgcaggt ggacttccag aagaccatga aggtgactgg ggtgaccacc
4560
cagggggtga agagcctgct gaccagcatg tacgtgaagg agttcctgat ctccagcagc
4620
caggacggcc accagtggac cctgttcttc cagaatggca aggtgaaggt gttccagggc
4680
aaccaggaca gcttcacccc tgtggtcaac agcctggacc cccccctgct gaccagatac
4740
ctgaggatcc acccccagag ctgggtgcac cagatcgccc tgaggatgga ggtgctgggc
4800
tgtgaggccc aggacctgta ctga
4824
<210> 20
<211> 4824
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-1-XTEN
<400> 20
atgcagattg agctgtctac ttgctttttc ctgtgcctgc tgaggttttg cttttccgct
60
acacgaaggt attatctggg ggctgtggaa ctgtcttggg attacatgca gagtgacctg
120
ggagagctgc cagtggacgc aaggtttccc cctagagtcc ctaagtcatt ccccttcaac
180
actagcgtgg tctacaagaa aacactgttc gtggagttta ctgatcacct gttcaacatc
240
gcaaagccta ggccaccctg gatgggactg ctggggccaa caatccaggc cgaggtgtac
300
gacaccgtgg tcattacact taagaacatg gcctcacacc ccgtgagcct gcatgctgtg
360
ggcgtcagct actggaaggc ttccgaagga gcagagtatg acgatcagac ttcccagaga
420
gaaaaagagg acgataaggt gtttcctggc ggatctcata cctacgtgtg gcaggtcctg
480
aaagagaatg gccctatggc ctccgaccct ctgtgcctga cctactctta tctgagtcac
540
gtggacctgg tcaaggatct gaacagcggc ctgatcggag ccctgctggt gtgcagggaa
600
ggaagcctgg ctaaggagaa aacccagaca ctgcataagt tcattctgct gttcgccgtg
660
tttgacgaag ggaaatcatg gcacagcgag acaaagaata gtctgatgca ggacagggat
720
gccgcttcag ccagagcttg gcccaaaatg cacactgtga acggctacgt caatcgctca
780
ctgcctgggc tgatcggctg ccaccgaaag agcgtgtatt ggcatgtcat cgggatgggc
840
accacacctg aagtgcactc cattttcctg gagggacata cctttctggt ccgcaaccac
900
cgacaggctt ccctggagat ctctccaatt accttcctga cagcacagac tctgctgatg
960
gacctggggc agttcctgct gttttgccac atcagctccc accagcatga tggcatggag
1020
gcttacgtga aagtggactc ttgtcccgag gaacctcagc tgcggatgaa gaacaatgag
1080
gaagcagaag actatgacga tgacctgacc gactccgaga tggatgtggt ccgattcgat
1140
gacgataaca gcccctcctt tatccagatt agatctgtgg ccaagaaaca ccctaagaca
1200
tgggtccatt acatcgcagc cgaggaagag gactgggatt atgcaccact ggtgctggca
1260
ccagacgatc gctcctacaa atctcagtat ctgaacaatg ggccacagag gattggcaga
1320
aagtacaaga aagtgcggtt catggcatat accgatgaga ccttcaagac tcgcgaagcc
1380
atccagcacg agagcggcat cctgggacca ctgctgtacg gagaagtggg agacaccctg
1440
ctgatcattt tcaagaacca ggccagccgg ccttacaata tctatccaca tgggattaca
1500
gatgtgcgcc ctctgtacag caggagactg ccaaagggcg tcaaacacct gaaggacttc
1560
ccaatcctgc ccggagaaat cttcaagtac aagtggactg tcaccgtcga ggatggcccc
1620
actaagagcg accctcggtg cctgacccgc tactattcta gtttcgtgaa tatggaaaga
1680
gatctggcaa gcggactgat cggaccactg ctgatttgtt acaaagagag cgtggatcag
1740
agaggcaacc agatcatgtc cgacaagcgg aatgtgattc tgttcagtgt ctttgacgaa
1800
aacaggtcat ggtacctgac cgagaacatc cagagattcc tgcctaatcc agctggggtg
1860
cagctggaag atcctgagtt tcaggcatct aacatcatgc atagtattaa tggctacgtg
1920
ttcgacagtt tgcagctgag cgtgtgcctg cacgaggtcg cttactggta tatcctgagc
1980
attggggcac agacagattt cctgagcgtg ttcttttccg gctacacttt taagcataaa
2040
atggtctatg aggacacact gactctgttc cccttcagcg gcgaaaccgt gtttatgagc
2100
atggagaatc ccggactgtg gattctgggg tgccacaaca gcgatttcag aaatcgcgga
2160
atgactgccc tgctgaaagt gtcaagctgt gacaagaaca ccggggacta ctatgaagat
2220
tcatacgagg acatcagcgc atatctgctg tccaaaaaca atgccattga accccggtct
2280
tttagtcaga atggcgcgcc aacatcagag agcgccaccc ctgaaagtgg tcccgggagc
2340
gagccagcca catctgggtc ggaaacgcca ggcacaagtg agtctgcaac tcccgagtcc
2400
ggacctggct ccgagcctgc cactagcggc tccgagactc cgggaacttc cgagagcgct
2460
acaccagaaa gcggacccgg aaccagtacc gaacctagcg agggctctgc tccgggcagc
2520
ccagccggct ctcctacatc cacggaggag ggcacttccg aatccgccac cccggagtca
2580
gggccaggat ctgaacccgc tacctcaggc agtgagacgc caggaacgag cgagtccgct
2640
acaccggaga gtgggccagg gagccctgct ggatctccta cgtccactga ggaagggtca
2700
ccagcgggct cgcccaccag cactgaagaa ggtgcctcga gccctccagt gctgaagcgg
2760
caccagcgcg agatcacccg cactaccctg cagagtgatc aggaagagat cgactacgac
2820
gatacaattt ctgtggaaat gaagaaagag gacttcgata tctatgacga agatgagaac
2880
cagagtcctc gatcattcca gaagaaaacc aggcattact ttattgccgc agtggagcgg
2940
ctgtgggatt atggcatgtc ctctagtcct cacgtgctgc gaaatagggc ccagtcagga
3000
agcgtcccac agttcaagaa agtggtcttc caggagttta cagacgggtc ctttactcag
3060
ccactgtaca ggggcgaact gaacgagcac ctgggactgc tggggcccta tatcagagca
3120
gaagtggagg ataacattat ggtcaccttc agaaatcagg cctctcggcc ttacagtttt
3180
tattcaagcc tgatctctta cgaagaggac cagcgacagg gagctgaacc acgaaaaaac
3240
ttcgtgaagc ctaatgagac caaaacatac ttttggaagg tgcagcacca tatggcccca
3300
acaaaagacg agttcgattg caaggcatgg gcctattttt ctgacgtgga tctggagaag
3360
gacgtgcaca gtggcctgat tggcccactg ctggtgtgcc atactaacac cctgaatcca
3420
gcccacggcc ggcaggtcac tgtccaggag ttcgctctgt tctttaccat ctttgatgag
3480
acaaagagct ggtacttcac cgaaaacatg gagcgaaatt gcagggctcc atgtaacatt
3540
cagatggaag accccacatt caaggagaac taccgctttc atgctatcaa tggatacatc
3600
atggatactc tgcccgggct ggtcatggca caggaccaga gaatccggtg gtatctgctg
3660
agcatgggca gcaacgagaa tatccactca attcatttca gcgggcacgt gtttactgtc
3720
aggaagaaag aagagtacaa gatggccctg tacaacctgt atcccggcgt gttcgaaacc
3780
gtcgagatgc tgcctagcaa ggccggaatc tggagagtgg aatgcctgat tggagagcac
3840
ctgcatgctg ggatgtctac cctgtttctg gtgtacagta ataagtgtca gacacccctg
3900
ggaatggcat ccgggcatat cagggatttc cagattaccg catctggaca gtacggacag
3960
tgggcaccta agctggctag actgcactat tccggatcta tcaacgcttg gtccacaaaa
4020
gagcctttct cttggattaa ggtggacctg ctggccccaa tgatcattca tggcatcaaa
4080
actcagggag ctcggcagaa gttctcctct ctgtacatct cacagtttat catcatgtac
4140
agcctggatg ggaagaaatg gcagacatac cgcggcaata gcacaggaac tctgatggtg
4200
ttctttggca acgtggacag cagcggaatc aagcacaaca ttttcaatcc ccctatcatt
4260
gctagataca tccggctgca cccaacccat tattctattc gaagtacact gaggatggaa
4320
ctgatgggat gcgatctgaa cagttgttca atgcccctgg ggatggagtc caaggcaatc
4380
tctgacgccc agattaccgc cagctcctac ttcactaata tgtttgctac ctggagccct
4440
tccaaagcaa gactgcacct gcaaggccgc agcaacgcat ggcgaccaca ggtgaacaat
4500
cccaaggagt ggttgcaggt cgattttcag aaaactatga aggtgaccgg ggtcacaact
4560
cagggcgtga aaagtctgct gacctcaatg tacgtcaagg agttcctgat ctctagttca
4620
caggacggac atcagtggac actgttcttt cagaacggga aggtgaaagt cttccagggc
4680
aatcaggatt cctttacacc tgtggtcaac agtctagacc ctccactgct gaccagatac
4740
ctgagaatcc accctcagtc ctgggtgcac cagattgccc tgagaatgga agtgctggga
4800
tgcgaggccc aggatctgta ctga
4824
<210> 21
<211> 6
<212> ДНК
<213> Искусственная последовательность
<220>
<223> MAR/ARS
<400> 21
atattt
6
<210> 22
<211> 6
<212> ДНК
<213> Искусственная последовательность
<220>
<223> MAR/ARS
<400> 22
aaatat
6
<210> 23
<211> 5
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Дестабилизирующий элемент
<400> 23
attta
5
<210> 24
<211> 5
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Дестабилизирующий элемент
<400> 24
taaat
5
<210> 25
<211> 6
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Сайт poly-T
<400> 25
tttttt
6
<210> 26
<211> 7
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Сайт poly-A
<400> 26
aaaaaaa
7
<210> 27
<211> 6
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Сайт сплайсинга
<400> 27
ggtgat
6
<210> 28
<211> 5
<212> ДНК
<213> Искусственная последовательность
<220>
<223> TATA-бокс
<400> 28
tataa
5
<210> 29
<211> 5
<212> ДНК
<213> Искусственная последовательность
<220>
<223> TATA-бокс
<400> 29
ttata
5
<210> 30
<211> 8
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность богатых AU элементов
<400> 30
attttatt
8
<210> 31
<211> 8
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Последовательность богатых AU элементов
<400> 31
atttttaa
8
<210> 32
<211> 13
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Консенсусная последовательность Козак
<400> 32
gccgccacca tgc
13
<210> 33
<211> 32
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Пептид CTP
<400> 33
Asp Pro Arg Phe Gln Asp Ser Ser Ser Ser Lys Ala Pro Pro Pro Ser
1. 5 10 15
Leu Pro Ser Pro Ser Arg Leu Pro Gly Pro Ser Asp Thr Pro Ile Leu
20 25 30
<210> 34
<211> 28
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Пептид CTP
<400> 34
Ser Ser Ser Ser Lys Ala Pro Pro Pro Ser Leu Pro Ser Pro Ser Arg
1. 5 10 15
Leu Pro Gly Pro Ser Asp Thr Pro Ile Leu Pro Gln
20 25
<210> 35
<211> 11
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Коровая последовательность альбумин-связывающего пептида
<400> 35
Asp Ile Cys Leu Pro Arg Trp Gly Cys Leu Trp
1. 5 10
<210> 36
<211> 20
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Последовательность PAS
<400> 36
Ala Ser Pro Ala Ala Pro Ala Pro Ala Ser Pro Ala Ala Pro Ala Pro
1. 5 10 15
Ser Ala Pro Ala
20
<210> 37
<211> 20
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Последовательность PAS
<400> 37
Ala Ala Pro Ala Ser Pro Ala Pro Ala Ala Pro Ser Ala Pro Ala Pro
1. 5 10 15
Ala Ala Pro Ser
20
<210> 38
<211> 20
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Последовательность PAS
<400> 38
Ala Pro Ser Ser Pro Ser Pro Ser Ala Pro Ser Ser Pro Ser Pro Ala
1. 5 10 15
Ser Pro Ser Ser
20
<210> 39
<211> 19
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Последовательность PAS
<400> 39
Ala Pro Ser Ser Pro Ser Pro Ser Ala Pro Ser Ser Pro Ser Pro Ala
1. 5 10 15
Ser Pro Ser
<210> 40
<211> 20
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Последовательность PAS
<400> 40
Ser Ser Pro Ser Ala Pro Ser Pro Ser Ser Pro Ala Ser Pro Ser Pro
1. 5 10 15
Ser Ser Pro Ala
20
<210> 41
<211> 24
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Последовательность PAS
<400> 41
Ala Ala Ser Pro Ala Ala Pro Ser Ala Pro Pro Ala Ala Ala Ser Pro
1. 5 10 15
Ala Ala Pro Ser Ala Pro Pro Ala
20
<210> 42
<211> 20
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Последовательность PAS
<400> 42
Ala Ser Ala Ala Ala Pro Ala Ala Ala Ser Ala Ala Ala Ser Ala Pro
1. 5 10 15
Ser Ala Ala Ala
20
<210> 43
<211> 23
<212> ДНК
<213> Искусственная последовательность
<220>
<223> мишень miR142
<400> 43
tccataaagt aggaaacact aca
23
<210> 44
<211> 2332
<212> БЕЛОК
<213> Homo sapiens
<400> 44
Ala Thr Arg Arg Tyr Tyr Leu Gly Ala Val Glu Leu Ser Trp Asp Tyr
1. 5 10 15
Met Gln Ser Asp Leu Gly Glu Leu Pro Val Asp Ala Arg Phe Pro Pro
20 25 30
Arg Val Pro Lys Ser Phe Pro Phe Asn Thr Ser Val Val Tyr Lys Lys
35 40 45
Thr Leu Phe Val Glu Phe Thr Asp His Leu Phe Asn Ile Ala Lys Pro
50 55 60
Arg Pro Pro Trp Met Gly Leu Leu Gly Pro Thr Ile Gln Ala Glu Val
65 70 75 80
Tyr Asp Thr Val Val Ile Thr Leu Lys Asn Met Ala Ser His Pro Val
85 90 95
Ser Leu His Ala Val Gly Val Ser Tyr Trp Lys Ala Ser Glu Gly Ala
100 105 110
Glu Tyr Asp Asp Gln Thr Ser Gln Arg Glu Lys Glu Asp Asp Lys Val
115 120 125
Phe Pro Gly Gly Ser His Thr Tyr Val Trp Gln Val Leu Lys Glu Asn
130 135 140
Gly Pro Met Ala Ser Asp Pro Leu Cys Leu Thr Tyr Ser Tyr Leu Ser
145 150 155 160
His Val Asp Leu Val Lys Asp Leu Asn Ser Gly Leu Ile Gly Ala Leu
165 170 175
Leu Val Cys Arg Glu Gly Ser Leu Ala Lys Glu Lys Thr Gln Thr Leu
180 185 190
His Lys Phe Ile Leu Leu Phe Ala Val Phe Asp Glu Gly Lys Ser Trp
195 200 205
His Ser Glu Thr Lys Asn Ser Leu Met Gln Asp Arg Asp Ala Ala Ser
210 215 220
Ala Arg Ala Trp Pro Lys Met His Thr Val Asn Gly Tyr Val Asn Arg
225 230 235 240
Ser Leu Pro Gly Leu Ile Gly Cys His Arg Lys Ser Val Tyr Trp His
245 250 255
Val Ile Gly Met Gly Thr Thr Pro Glu Val His Ser Ile Phe Leu Glu
260 265 270
Gly His Thr Phe Leu Val Arg Asn His Arg Gln Ala Ser Leu Glu Ile
275 280 285
Ser Pro Ile Thr Phe Leu Thr Ala Gln Thr Leu Leu Met Asp Leu Gly
290 295 300
Gln Phe Leu Leu Phe Cys His Ile Ser Ser His Gln His Asp Gly Met
305 310 315 320
Glu Ala Tyr Val Lys Val Asp Ser Cys Pro Glu Glu Pro Gln Leu Arg
325 330 335
Met Lys Asn Asn Glu Glu Ala Glu Asp Tyr Asp Asp Asp Leu Thr Asp
340 345 350
Ser Glu Met Asp Val Val Arg Phe Asp Asp Asp Asn Ser Pro Ser Phe
355 360 365
Ile Gln Ile Arg Ser Val Ala Lys Lys His Pro Lys Thr Trp Val His
370 375 380
Tyr Ile Ala Ala Glu Glu Glu Asp Trp Asp Tyr Ala Pro Leu Val Leu
385 390 395 400
Ala Pro Asp Asp Arg Ser Tyr Lys Ser Gln Tyr Leu Asn Asn Gly Pro
405 410 415
Gln Arg Ile Gly Arg Lys Tyr Lys Lys Val Arg Phe Met Ala Tyr Thr
420 425 430
Asp Glu Thr Phe Lys Thr Arg Glu Ala Ile Gln His Glu Ser Gly Ile
435 440 445
Leu Gly Pro Leu Leu Tyr Gly Glu Val Gly Asp Thr Leu Leu Ile Ile
450 455 460
Phe Lys Asn Gln Ala Ser Arg Pro Tyr Asn Ile Tyr Pro His Gly Ile
465 470 475 480
Thr Asp Val Arg Pro Leu Tyr Ser Arg Arg Leu Pro Lys Gly Val Lys
485 490 495
His Leu Lys Asp Phe Pro Ile Leu Pro Gly Glu Ile Phe Lys Tyr Lys
500 505 510
Trp Thr Val Thr Val Glu Asp Gly Pro Thr Lys Ser Asp Pro Arg Cys
515 520 525
Leu Thr Arg Tyr Tyr Ser Ser Phe Val Asn Met Glu Arg Asp Leu Ala
530 535 540
Ser Gly Leu Ile Gly Pro Leu Leu Ile Cys Tyr Lys Glu Ser Val Asp
545 550 555 560
Gln Arg Gly Asn Gln Ile Met Ser Asp Lys Arg Asn Val Ile Leu Phe
565 570 575
Ser Val Phe Asp Glu Asn Arg Ser Trp Tyr Leu Thr Glu Asn Ile Gln
580 585 590
Arg Phe Leu Pro Asn Pro Ala Gly Val Gln Leu Glu Asp Pro Glu Phe
595 600 605
Gln Ala Ser Asn Ile Met His Ser Ile Asn Gly Tyr Val Phe Asp Ser
610 615 620
Leu Gln Leu Ser Val Cys Leu His Glu Val Ala Tyr Trp Tyr Ile Leu
625 630 635 640
Ser Ile Gly Ala Gln Thr Asp Phe Leu Ser Val Phe Phe Ser Gly Tyr
645 650 655
Thr Phe Lys His Lys Met Val Tyr Glu Asp Thr Leu Thr Leu Phe Pro
660 665 670
Phe Ser Gly Glu Thr Val Phe Met Ser Met Glu Asn Pro Gly Leu Trp
675 680 685
Ile Leu Gly Cys His Asn Ser Asp Phe Arg Asn Arg Gly Met Thr Ala
690 695 700
Leu Leu Lys Val Ser Ser Cys Asp Lys Asn Thr Gly Asp Tyr Tyr Glu
705 710 715 720
Asp Ser Tyr Glu Asp Ile Ser Ala Tyr Leu Leu Ser Lys Asn Asn Ala
725 730 735
Ile Glu Pro Arg Ser Phe Ser Gln Asn Ser Arg His Pro Ser Thr Arg
740 745 750
Gln Lys Gln Phe Asn Ala Thr Thr Ile Pro Glu Asn Asp Ile Glu Lys
755 760 765
Thr Asp Pro Trp Phe Ala His Arg Thr Pro Met Pro Lys Ile Gln Asn
770 775 780
Val Ser Ser Ser Asp Leu Leu Met Leu Leu Arg Gln Ser Pro Thr Pro
785 790 795 800
His Gly Leu Ser Leu Ser Asp Leu Gln Glu Ala Lys Tyr Glu Thr Phe
805 810 815
Ser Asp Asp Pro Ser Pro Gly Ala Ile Asp Ser Asn Asn Ser Leu Ser
820 825 830
Glu Met Thr His Phe Arg Pro Gln Leu His His Ser Gly Asp Met Val
835 840 845
Phe Thr Pro Glu Ser Gly Leu Gln Leu Arg Leu Asn Glu Lys Leu Gly
850 855 860
Thr Thr Ala Ala Thr Glu Leu Lys Lys Leu Asp Phe Lys Val Ser Ser
865 870 875 880
Thr Ser Asn Asn Leu Ile Ser Thr Ile Pro Ser Asp Asn Leu Ala Ala
885 890 895
Gly Thr Asp Asn Thr Ser Ser Leu Gly Pro Pro Ser Met Pro Val His
900 905 910
Tyr Asp Ser Gln Leu Asp Thr Thr Leu Phe Gly Lys Lys Ser Ser Pro
915 920 925
Leu Thr Glu Ser Gly Gly Pro Leu Ser Leu Ser Glu Glu Asn Asn Asp
930 935 940
Ser Lys Leu Leu Glu Ser Gly Leu Met Asn Ser Gln Glu Ser Ser Trp
945 950 955 960
Gly Lys Asn Val Ser Ser Thr Glu Ser Gly Arg Leu Phe Lys Gly Lys
965 970 975
Arg Ala His Gly Pro Ala Leu Leu Thr Lys Asp Asn Ala Leu Phe Lys
980 985 990
Val Ser Ile Ser Leu Leu Lys Thr Asn Lys Thr Ser Asn Asn Ser Ala
995 1000 1005
Thr Asn Arg Lys Thr His Ile Asp Gly Pro Ser Leu Leu Ile Glu
1010 1015 1020
Asn Ser Pro Ser Val Trp Gln Asn Ile Leu Glu Ser Asp Thr Glu
1025 1030 1035
Phe Lys Lys Val Thr Pro Leu Ile His Asp Arg Met Leu Met Asp
1040 1045 1050
Lys Asn Ala Thr Ala Leu Arg Leu Asn His Met Ser Asn Lys Thr
1055 1060 1065
Thr Ser Ser Lys Asn Met Glu Met Val Gln Gln Lys Lys Glu Gly
1070 1075 1080
Pro Ile Pro Pro Asp Ala Gln Asn Pro Asp Met Ser Phe Phe Lys
1085 1090 1095
Met Leu Phe Leu Pro Glu Ser Ala Arg Trp Ile Gln Arg Thr His
1100 1105 1110
Gly Lys Asn Ser Leu Asn Ser Gly Gln Gly Pro Ser Pro Lys Gln
1115 1120 1125
Leu Val Ser Leu Gly Pro Glu Lys Ser Val Glu Gly Gln Asn Phe
1130 1135 1140
Leu Ser Glu Lys Asn Lys Val Val Val Gly Lys Gly Glu Phe Thr
1145 1150 1155
Lys Asp Val Gly Leu Lys Glu Met Val Phe Pro Ser Ser Arg Asn
1160 1165 1170
Leu Phe Leu Thr Asn Leu Asp Asn Leu His Glu Asn Asn Thr His
1175 1180 1185
Asn Gln Glu Lys Lys Ile Gln Glu Glu Ile Glu Lys Lys Glu Thr
1190 1195 1200
Leu Ile Gln Glu Asn Val Val Leu Pro Gln Ile His Thr Val Thr
1205 1210 1215
Gly Thr Lys Asn Phe Met Lys Asn Leu Phe Leu Leu Ser Thr Arg
1220 1225 1230
Gln Asn Val Glu Gly Ser Tyr Asp Gly Ala Tyr Ala Pro Val Leu
1235 1240 1245
Gln Asp Phe Arg Ser Leu Asn Asp Ser Thr Asn Arg Thr Lys Lys
1250 1255 1260
His Thr Ala His Phe Ser Lys Lys Gly Glu Glu Glu Asn Leu Glu
1265 1270 1275
Gly Leu Gly Asn Gln Thr Lys Gln Ile Val Glu Lys Tyr Ala Cys
1280 1285 1290
Thr Thr Arg Ile Ser Pro Asn Thr Ser Gln Gln Asn Phe Val Thr
1295 1300 1305
Gln Arg Ser Lys Arg Ala Leu Lys Gln Phe Arg Leu Pro Leu Glu
1310 1315 1320
Glu Thr Glu Leu Glu Lys Arg Ile Ile Val Asp Asp Thr Ser Thr
1325 1330 1335
Gln Trp Ser Lys Asn Met Lys His Leu Thr Pro Ser Thr Leu Thr
1340 1345 1350
Gln Ile Asp Tyr Asn Glu Lys Glu Lys Gly Ala Ile Thr Gln Ser
1355 1360 1365
Pro Leu Ser Asp Cys Leu Thr Arg Ser His Ser Ile Pro Gln Ala
1370 1375 1380
Asn Arg Ser Pro Leu Pro Ile Ala Lys Val Ser Ser Phe Pro Ser
1385 1390 1395
Ile Arg Pro Ile Tyr Leu Thr Arg Val Leu Phe Gln Asp Asn Ser
1400 1405 1410
Ser His Leu Pro Ala Ala Ser Tyr Arg Lys Lys Asp Ser Gly Val
1415 1420 1425
Gln Glu Ser Ser His Phe Leu Gln Gly Ala Lys Lys Asn Asn Leu
1430 1435 1440
Ser Leu Ala Ile Leu Thr Leu Glu Met Thr Gly Asp Gln Arg Glu
1445 1450 1455
Val Gly Ser Leu Gly Thr Ser Ala Thr Asn Ser Val Thr Tyr Lys
1460 1465 1470
Lys Val Glu Asn Thr Val Leu Pro Lys Pro Asp Leu Pro Lys Thr
1475 1480 1485
Ser Gly Lys Val Glu Leu Leu Pro Lys Val His Ile Tyr Gln Lys
1490 1495 1500
Asp Leu Phe Pro Thr Glu Thr Ser Asn Gly Ser Pro Gly His Leu
1505 1510 1515
Asp Leu Val Glu Gly Ser Leu Leu Gln Gly Thr Glu Gly Ala Ile
1520 1525 1530
Lys Trp Asn Glu Ala Asn Arg Pro Gly Lys Val Pro Phe Leu Arg
1535 1540 1545
Val Ala Thr Glu Ser Ser Ala Lys Thr Pro Ser Lys Leu Leu Asp
1550 1555 1560
Pro Leu Ala Trp Asp Asn His Tyr Gly Thr Gln Ile Pro Lys Glu
1565 1570 1575
Glu Trp Lys Ser Gln Glu Lys Ser Pro Glu Lys Thr Ala Phe Lys
1580 1585 1590
Lys Lys Asp Thr Ile Leu Ser Leu Asn Ala Cys Glu Ser Asn His
1595 1600 1605
Ala Ile Ala Ala Ile Asn Glu Gly Gln Asn Lys Pro Glu Ile Glu
1610 1615 1620
Val Thr Trp Ala Lys Gln Gly Arg Thr Glu Arg Leu Cys Ser Gln
1625 1630 1635
Asn Pro Pro Val Leu Lys Arg His Gln Arg Glu Ile Thr Arg Thr
1640 1645 1650
Thr Leu Gln Ser Asp Gln Glu Glu Ile Asp Tyr Asp Asp Thr Ile
1655 1660 1665
Ser Val Glu Met Lys Lys Glu Asp Phe Asp Ile Tyr Asp Glu Asp
1670 1675 1680
Glu Asn Gln Ser Pro Arg Ser Phe Gln Lys Lys Thr Arg His Tyr
1685 1690 1695
Phe Ile Ala Ala Val Glu Arg Leu Trp Asp Tyr Gly Met Ser Ser
1700 1705 1710
Ser Pro His Val Leu Arg Asn Arg Ala Gln Ser Gly Ser Val Pro
1715 1720 1725
Gln Phe Lys Lys Val Val Phe Gln Glu Phe Thr Asp Gly Ser Phe
1730 1735 1740
Thr Gln Pro Leu Tyr Arg Gly Glu Leu Asn Glu His Leu Gly Leu
1745 1750 1755
Leu Gly Pro Tyr Ile Arg Ala Glu Val Glu Asp Asn Ile Met Val
1760 1765 1770
Thr Phe Arg Asn Gln Ala Ser Arg Pro Tyr Ser Phe Tyr Ser Ser
1775 1780 1785
Leu Ile Ser Tyr Glu Glu Asp Gln Arg Gln Gly Ala Glu Pro Arg
1790 1795 1800
Lys Asn Phe Val Lys Pro Asn Glu Thr Lys Thr Tyr Phe Trp Lys
1805 1810 1815
Val Gln His His Met Ala Pro Thr Lys Asp Glu Phe Asp Cys Lys
1820 1825 1830
Ala Trp Ala Tyr Phe Ser Asp Val Asp Leu Glu Lys Asp Val His
1835 1840 1845
Ser Gly Leu Ile Gly Pro Leu Leu Val Cys His Thr Asn Thr Leu
1850 1855 1860
Asn Pro Ala His Gly Arg Gln Val Thr Val Gln Glu Phe Ala Leu
1865 1870 1875
Phe Phe Thr Ile Phe Asp Glu Thr Lys Ser Trp Tyr Phe Thr Glu
1880 1885 1890
Asn Met Glu Arg Asn Cys Arg Ala Pro Cys Asn Ile Gln Met Glu
1895 1900 1905
Asp Pro Thr Phe Lys Glu Asn Tyr Arg Phe His Ala Ile Asn Gly
1910 1915 1920
Tyr Ile Met Asp Thr Leu Pro Gly Leu Val Met Ala Gln Asp Gln
1925 1930 1935
Arg Ile Arg Trp Tyr Leu Leu Ser Met Gly Ser Asn Glu Asn Ile
1940 1945 1950
His Ser Ile His Phe Ser Gly His Val Phe Thr Val Arg Lys Lys
1955 1960 1965
Glu Glu Tyr Lys Met Ala Leu Tyr Asn Leu Tyr Pro Gly Val Phe
1970 1975 1980
Glu Thr Val Glu Met Leu Pro Ser Lys Ala Gly Ile Trp Arg Val
1985 1990 1995
Glu Cys Leu Ile Gly Glu His Leu His Ala Gly Met Ser Thr Leu
2000 2005 2010
Phe Leu Val Tyr Ser Asn Lys Cys Gln Thr Pro Leu Gly Met Ala
2015 2020 2025
Ser Gly His Ile Arg Asp Phe Gln Ile Thr Ala Ser Gly Gln Tyr
2030 2035 2040
Gly Gln Trp Ala Pro Lys Leu Ala Arg Leu His Tyr Ser Gly Ser
2045 2050 2055
Ile Asn Ala Trp Ser Thr Lys Glu Pro Phe Ser Trp Ile Lys Val
2060 2065 2070
Asp Leu Leu Ala Pro Met Ile Ile His Gly Ile Lys Thr Gln Gly
2075 2080 2085
Ala Arg Gln Lys Phe Ser Ser Leu Tyr Ile Ser Gln Phe Ile Ile
2090 2095 2100
Met Tyr Ser Leu Asp Gly Lys Lys Trp Gln Thr Tyr Arg Gly Asn
2105 2110 2115
Ser Thr Gly Thr Leu Met Val Phe Phe Gly Asn Val Asp Ser Ser
2120 2125 2130
Gly Ile Lys His Asn Ile Phe Asn Pro Pro Ile Ile Ala Arg Tyr
2135 2140 2145
Ile Arg Leu His Pro Thr His Tyr Ser Ile Arg Ser Thr Leu Arg
2150 2155 2160
Met Glu Leu Met Gly Cys Asp Leu Asn Ser Cys Ser Met Pro Leu
2165 2170 2175
Gly Met Glu Ser Lys Ala Ile Ser Asp Ala Gln Ile Thr Ala Ser
2180 2185 2190
Ser Tyr Phe Thr Asn Met Phe Ala Thr Trp Ser Pro Ser Lys Ala
2195 2200 2205
Arg Leu His Leu Gln Gly Arg Ser Asn Ala Trp Arg Pro Gln Val
2210 2215 2220
Asn Asn Pro Lys Glu Trp Leu Gln Val Asp Phe Gln Lys Thr Met
2225 2230 2235
Lys Val Thr Gly Val Thr Thr Gln Gly Val Lys Ser Leu Leu Thr
2240 2245 2250
Ser Met Tyr Val Lys Glu Phe Leu Ile Ser Ser Ser Gln Asp Gly
2255 2260 2265
His Gln Trp Thr Leu Phe Phe Gln Asn Gly Lys Val Lys Val Phe
2270 2275 2280
Gln Gly Asn Gln Asp Ser Phe Thr Pro Val Val Asn Ser Leu Asp
2285 2290 2295
Pro Pro Leu Leu Thr Arg Tyr Leu Arg Ile His Pro Gln Ser Trp
2300 2305 2310
Val His Gln Ile Ala Leu Arg Met Glu Val Leu Gly Cys Glu Ala
2315 2320 2325
Gln Asp Leu Tyr
2330
<210> 45
<211> 4
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Аминокислоты 233-236 из человеческого IgG1
<400> 45
Glu Leu Leu Gly
1
<210> 46
<211> 42
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN AE42-4, последовательность белка
<400> 46
Gly Ala Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly
1. 5 10 15
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala
20 25 30
Thr Ser Gly Ser Glu Thr Pro Ala Ser Ser
35 40
<210> 47
<211> 126
<212> ДНК
<213> Искусственная последовательность
<220>
<223> XTEN AE42-4, последовательность ДНК
<400> 47
ggcgcgccag gttctcctgc tggctccccc acctcaacag aagaggggac aagcgaaagc
60
gctacgcctg agagtggccc tggctctgag ccagccacct ccggctctga aacccctgcc
120
tcgagc
126
<210> 48
<211> 144
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN AE144-2A, последовательность белка
<400> 48
Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Pro Ala Gly
1. 5 10 15
Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu Gly
20 25 30
Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
35 40 45
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu
50 55 60
Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu
65 70 75 80
Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly
85 90 95
Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu
100 105 110
Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu
115 120 125
Ser Gly Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly
130 135 140
<210> 49
<211> 450
<212> ДНК
<213> Искусственная последовательность
<220>
<223> XTEN AE144-2A, последовательность ДНК
<400> 49
ggcgcgccaa ccagtacgga gccgtccgag gggagcgcac caggaagccc ggctgggagc
60
ccgacttcta ccgaagaggg tacatctacc gaaccaagtg aaggttcagc accaggcacc
120
tcaacagaac cctctgaggg ctcggcgcct ggtacaagtg agtccgccac cccagaatcc
180
gggcctggga caagcacaga accttcggaa gggagtgccc ctggaacatc cgaatcggca
240
accccagaat cagggccagg atctgagccc gcgacttcgg gctccgagac gcctgggaca
300
tccaccgagc cctccgaagg atcagcccca ggcaccagca cggagccctc tgagggaagc
360
gcacctggta ccagcgaaag cgcaactccc gaatcaggtc ccggtacgag cgagtcggcg
420
accccggaga gcgggccagg tgcctcgagc
450
<210> 50
<211> 144
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN AE144-3B, последовательность белка
<400> 50
Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu Ser
1. 5 10 15
Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser
20 25 30
Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly
35 40 45
Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu
50 55 60
Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly
65 70 75 80
Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
85 90 95
Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu
100 105 110
Pro Ser Glu Gly Ser Ala Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser
115 120 125
Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
130 135 140
<210> 51
<211> 450
<212> ДНК
<213> Искусственная последовательность
<220>
<223> XTEN AE144-3B, последовательность ДНК
<400> 51
ggcgcgccaa gtcccgctgg aagcccaact agcaccgaag aggggacctc agagtccgcc
60
acccccgagt ccggccctgg ctctgagcct gccactagcg gctccgagac tcctggcaca
120
tccgaaagcg ctacacccga gagtggaccc ggcacctcta ccgagcccag tgagggctcc
180
gcccctggaa caagcaccga gcccagcgaa ggcagcgccc cagggacctc cacagagccc
240
agtgaaggca gtgctcctgg caccagcacc gaaccaagcg agggctctgc acccgggacc
300
tccaccgagc caagcgaagg ctctgcccct ggcacttcca ccgagcccag cgaaggcagc
360
gcccctggga gccccgctgg ctctcccacc agcactgagg agggcacatc taccgaacca
420
agtgaaggct ctgcaccagg tgcctcgagc
450
<210> 52
<211> 144
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN AE144-4A, последовательность белка
<400> 52
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala
1. 5 10 15
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu
20 25 30
Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly
35 40 45
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu
50 55 60
Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu
65 70 75 80
Ser Gly Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly
85 90 95
Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Ser Pro Ala Gly
100 105 110
Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu Ser Ala Thr Pro Glu
115 120 125
Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
130 135 140
<210> 53
<211> 450
<212> ДНК
<213> Искусственная последовательность
<220>
<223> XTEN AE144-4A, последовательность ДНК
<400> 53
ggcgcgccaa cgtccgaaag tgctacccct gagtcaggcc ctggtagtga gcctgccaca
60
agcggaagcg aaactccggg gacctcagag tctgccactc ccgaatcggg gccaggctct
120
gaaccggcca cttcagggag cgaaacacca ggaacatcgg agagcgctac cccggagagc
180
gggccaggaa ctagtactga gcctagcgag ggaagtgcac ctggtacaag cgagtccgcc
240
acacccgagt ctggccctgg ctctccagcg ggctcaccca cgagcactga agagggctct
300
cccgctggca gcccaacgtc gacagaagaa ggatcaccag caggctcccc cacatcaaca
360
gaggagggta catcagaatc tgctactccc gagagtggac ccggtacctc cactgagccc
420
agcgagggga gtgcaccagg tgcctcgagc
450
<210> 54
<211> 144
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN AE144-5A, последовательность белка
<400> 54
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala
1. 5 10 15
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu
20 25 30
Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly
35 40 45
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu
50 55 60
Pro Ser Glu Gly Ser Ala Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser
65 70 75 80
Thr Glu Glu Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly
85 90 95
Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser
100 105 110
Ala Thr Pro Glu Ser Gly Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser
115 120 125
Thr Glu Glu Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly
130 135 140
<210> 55
<211> 450
<212> ДНК
<213> Искусственная последовательность
<220>
<223> XTEN AE144-5A, последовательность ДНК
<400> 55
ggcgcgccaa catcagagag cgccacccct gaaagtggtc ccgggagcga gccagccaca
60
tctgggtcgg aaacgccagg cacaagtgag tctgcaactc ccgagtccgg acctggctcc
120
gagcctgcca ctagcggctc cgagactccg ggaacttccg agagcgctac accagaaagc
180
ggacccggaa ccagtaccga acctagcgag ggctctgctc cgggcagccc agccggctct
240
cctacatcca cggaggaggg cacttccgaa tccgccaccc cggagtcagg gccaggatct
300
gaacccgcta cctcaggcag tgagacgcca ggaacgagcg agtccgctac accggagagt
360
gggccaggga gccctgctgg atctcctacg tccactgagg aagggtcacc agcgggctcg
420
cccaccagca ctgaagaagg tgcctcgagc
450
<210> 56
<211> 144
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN AE144-6B, последовательность белка
<400> 56
Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu Ser
1. 5 10 15
Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu
20 25 30
Ser Gly Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly
35 40 45
Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala
50 55 60
Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser
65 70 75 80
Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
85 90 95
Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Glu Pro Ala
100 105 110
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu
115 120 125
Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
130 135 140
<210> 57
<211> 450
<212> ДНК
<213> Искусственная последовательность
<220>
<223> XTEN AE144-6B, последовательность ДНК
<400> 57
ggcgcgccaa catctaccga gccttccgaa ggctctgccc ctgggacctc agaatctgca
60
acccctgaaa gcggccctgg aacctccgaa agtgccactc ccgagagcgg cccagggaca
120
agcgagtcag caacccctga gtctggaccc ggcagcgagc ctgcaacctc tggctcagag
180
actcccggct cagaacccgc tacctcaggc tccgagacac ccggctctcc tgctgggagt
240
cccacttcca ccgaggaagg aacatccact gagcctagtg agggctctgc ccctggaacc
300
agcacagagc caagtgaggg cagtgcacca ggatccgagc cagcaaccag cgggtccgag
360
actcccggga cctctgagtc tgccacccca gagagcggac ccggcacttc aaccgagccc
420
tccgaaggat cagcaccagg tgcctcgagc
450
<210> 58
<211> 144
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN AG144-1, последовательность белка
<400> 58
Pro Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Ser Ser
1. 5 10 15
Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Thr Pro Gly Ser Gly Thr
20 25 30
Ala Ser Ser Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser
35 40 45
Pro Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Ala Ser
50 55 60
Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Thr Pro Gly Ser Gly Thr
65 70 75 80
Ala Ser Ser Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser
85 90 95
Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ala Ser
100 105 110
Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser
115 120 125
Ser Thr Gly Ser Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser
130 135 140
<210> 59
<211> 450
<212> ДНК
<213> Искусственная последовательность
<220>
<223> XTEN AG144-1, последовательность ДНК
<400> 59
ggcgcgccac ccgggtcgtc cccgtcggcg tccaccggaa cagggccagg gtcatccccg
60
tcagcgtcga ctgggacggg acccgggaca cccggttcgg ggactgcatc ctcctcgcct
120
ggttcgtcca ccccgtcagg agccacgggt tcgccgggaa gcagcccaag cgcatccact
180
ggtacagggc ctggggcttc accgggtact tcatccacgg ggtcaccggg aacgcccgga
240
tcggggacgg cttcctcatc accaggatcg tcaacaccct cgggcgcaac gggcagcccc
300
ggaacccctg gttcgggtac ggcgtcgtcg agccccggtg cgagcccggg aacaagctcg
360
acaggatcgc ctggggcgtc acccggcacg tcgagcacag gcagccccgg aacccctgga
420
tcgggaaccg cgtcgtcaag cgcctcgagc
450
<210> 60
<211> 144
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN AG144-A, последовательность белка
<400> 60
Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ser Ser Pro
1. 5 10 15
Ser Ala Ser Thr Gly Thr Gly Pro Gly Ser Ser Pro Ser Ala Ser Thr
20 25 30
Gly Thr Gly Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro
35 40 45
Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Pro
50 55 60
Ser Ala Ser Thr Gly Thr Gly Pro Gly Ala Ser Pro Gly Thr Ser Ser
65 70 75 80
Thr Gly Ser Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro
85 90 95
Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Thr Pro Gly
100 105 110
Ser Gly Thr Ala Ser Ser Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser
115 120 125
Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
130 135 140
<210> 61
<211> 450
<212> ДНК
<213> Искусственная последовательность
<220>
<223> XTEN AG144-A, последовательность ДНК
<400> 61
ggcgcgccag gtgcctcgcc gggaacatca tcaactggtt cacccgggtc atccccctcg
60
gcctcaaccg ggacgggtcc cggctcatcc cccagcgcca gcactggaac aggtcctggc
120
actcctggtt ccggtacggc atcgtcatcc ccgggaagct caacaccgtc cggagcgaca
180
ggatcacctg gctcgtcacc ttcggcgtca actggaacgg ggccaggggc ctcacccgga
240
acgtcctcga ctgggtcgcc tggtacgccg ggatcaggaa cggcctcatc ctcgcctggg
300
tcctcaacgc cctcgggtgc gactggttcg ccgggaactc ctggctcggg gacggcctcg
360
tcgtcgcctg gggcatcacc ggggacgagc tccacggggt cccctggagc gtcaccgggg
420
acctcctcga caggtagccc ggcctcgagc
450
<210> 62
<211> 144
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN AG144-B, последовательность белка
<400> 62
Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser Thr
1. 5 10 15
Pro Ser Gly Ala Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser
20 25 30
Thr Gly Ser Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro
35 40 45
Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Pro
50 55 60
Ser Ala Ser Thr Gly Thr Gly Pro Gly Ser Ser Pro Ser Ala Ser Thr
65 70 75 80
Gly Thr Gly Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro
85 90 95
Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ala Ser Pro
100 105 110
Gly Thr Ser Ser Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser
115 120 125
Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
130 135 140
<210> 63
<211> 450
<212> ДНК
<213> Искусственная последовательность
<220>
<223> XTEN AG144-B, последовательность ДНК
<400> 63
ggcgcgccag gtacaccggg cagcggcacg gcttcgtcgt cacccggctc gtccacaccg
60
tcgggagcta cgggaagccc aggagcgtca ccgggaacgt cgtcaacggg gtcaccgggt
120
acgccaggta gcggcacggc cagcagctcg ccaggttcat cgaccccgtc gggagcgact
180
gggtcgcccg gatcaagccc gtcagcttcc actggaacag gacccgggtc gtcgccgtca
240
gcctcaacgg ggacaggacc tggttcatcg acgccgtcag gggcgacagg ctcgcccgga
300
tcgtcaacac cctcgggggc aacggggagc cctggtgcgt cgcctggaac ctcatccacc
360
ggaagcccgg gggcctcgcc gggtacgagc tccacgggat cgcccggagc gtcccccgga
420
acttcaagca cagggagccc tgcctcgagc
450
<210> 64
<211> 144
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN AG144-C, последовательность белка
<400> 64
Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ala Ser Pro
1. 5 10 15
Gly Thr Ser Ser Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser
20 25 30
Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
35 40 45
Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Thr Pro Gly
50 55 60
Ser Gly Thr Ala Ser Ser Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser
65 70 75 80
Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
85 90 95
Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ser Ser Thr
100 105 110
Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala
115 120 125
Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
130 135 140
<210> 65
<211> 450
<212> ДНК
<213> Искусственная последовательность
<220>
<223> XTEN AG144-C, последовательность ДНК
<400> 65
ggcgcgccag gtacacccgg atcgggtaca gcgtcatcga gccccggtgc gtcacctggt
60
acgtcgagca cggggtcgcc aggggcgtcc cctgggacgt cctcaacagg ctcgcccggt
120
gcgtcacccg gcacgtcgtc cacgggttca cctggtagct ccccttccgc gtccactggc
180
accgggcctg gaactccggg gagcggcaca gcgagctcgt cgccgggagc atcgcctggg
240
acatcgagca ccgggtcgcc aggagcatcg cccggaacat ccagcacagg aagccccggc
300
gcgtcgcccg ggacatcaag cacaggttcc ccgggatcga gcacgccgtc cggagccact
360
ggatcaccag ggagctcgac accttccggc gcaacgggat cgcccggagc cagcccgggt
420
acgtcaagca ctggctcccc tgcctcgagc
450
<210> 66
<211> 144
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN AG144-F, последовательность белка
<400> 66
Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Ser Ser Pro
1. 5 10 15
Ser Ala Ser Thr Gly Thr Gly Pro Gly Ala Ser Pro Gly Thr Ser Ser
20 25 30
Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
35 40 45
Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Pro
50 55 60
Ser Ala Ser Thr Gly Thr Gly Pro Gly Ala Ser Pro Gly Thr Ser Ser
65 70 75 80
Thr Gly Ser Pro Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro
85 90 95
Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser Thr
100 105 110
Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala
115 120 125
Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
130 135 140
<210> 67
<211> 450
<212> ДНК
<213> Искусственная последовательность
<220>
<223> XTEN AG144-F, последовательность ДНК
<400> 67
ggcgcgccag gctccagccc ctccgcgagc acgggaaccg gaccaggttc gtcaccctca
60
gcatcaacgg ggacgggacc gggggcgtca ccaggaacgt cctccaccgg ctcgccgggt
120
gcatcacccg gaacgtcatc gaccggatcg ccagggagct cgacgccatc aggcgcaaca
180
ggatcacctg gctcaagccc tagcgcgtca accggcacgg gtccgggtgc ctcccctggc
240
acgtccagca ccggatcacc cggatcgagc ccatccgcct caaccggaac cggacccggt
300
acaccagggt cgggaacagc ctcctcgtca ccaggctcct caaccccctc gggagccacg
360
ggttcgcccg gttcgtcaac gccttccgga gcaactggta gccccggagc atcgccagga
420
acttcgagca cggggtcgcc cgcctcgagc
450
<210> 68
<211> 4374
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-1 последовательность ДНК
<400> 68
atgcagattg agctgtctac ttgctttttc ctgtgcctgc tgaggttttg cttttccgct
60
acacgaaggt attatctggg ggctgtggaa ctgtcttggg attacatgca gagtgacctg
120
ggagagctgc cagtggacgc aaggtttccc cctagagtcc ctaagtcatt ccccttcaac
180
actagcgtgg tctacaagaa aacactgttc gtggagttta ctgatcacct gttcaacatc
240
gcaaagccta ggccaccctg gatgggactg ctggggccaa caatccaggc cgaggtgtac
300
gacaccgtgg tcattacact taagaacatg gcctcacacc ccgtgagcct gcatgctgtg
360
ggcgtcagct actggaaggc ttccgaagga gcagagtatg acgatcagac ttcccagaga
420
gaaaaagagg acgataaggt gtttcctggc ggatctcata cctacgtgtg gcaggtcctg
480
aaagagaatg gccctatggc ctccgaccct ctgtgcctga cctactctta tctgagtcac
540
gtggacctgg tcaaggatct gaacagcggc ctgatcggag ccctgctggt gtgcagggaa
600
ggaagcctgg ctaaggagaa aacccagaca ctgcataagt tcattctgct gttcgccgtg
660
tttgacgaag ggaaatcatg gcacagcgag acaaagaata gtctgatgca ggacagggat
720
gccgcttcag ccagagcttg gcccaaaatg cacactgtga acggctacgt caatcgctca
780
ctgcctgggc tgatcggctg ccaccgaaag agcgtgtatt ggcatgtcat cgggatgggc
840
accacacctg aagtgcactc cattttcctg gagggacata cctttctggt ccgcaaccac
900
cgacaggctt ccctggagat ctctccaatt accttcctga cagcacagac tctgctgatg
960
gacctggggc agttcctgct gttttgccac atcagctccc accagcatga tggcatggag
1020
gcttacgtga aagtggactc ttgtcccgag gaacctcagc tgcggatgaa gaacaatgag
1080
gaagcagaag actatgacga tgacctgacc gactccgaga tggatgtggt ccgattcgat
1140
gacgataaca gcccctcctt tatccagatt agatctgtgg ccaagaaaca ccctaagaca
1200
tgggtccatt acatcgcagc cgaggaagag gactgggatt atgcaccact ggtgctggca
1260
ccagacgatc gctcctacaa atctcagtat ctgaacaatg ggccacagag gattggcaga
1320
aagtacaaga aagtgcggtt catggcatat accgatgaga ccttcaagac tcgcgaagcc
1380
atccagcacg agagcggcat cctgggacca ctgctgtacg gagaagtggg agacaccctg
1440
ctgatcattt tcaagaacca ggccagccgg ccttacaata tctatccaca tgggattaca
1500
gatgtgcgcc ctctgtacag caggagactg ccaaagggcg tcaaacacct gaaggacttc
1560
ccaatcctgc ccggagaaat cttcaagtac aagtggactg tcaccgtcga ggatggcccc
1620
actaagagcg accctcggtg cctgacccgc tactattcta gtttcgtgaa tatggaaaga
1680
gatctggcaa gcggactgat cggaccactg ctgatttgtt acaaagagag cgtggatcag
1740
agaggcaacc agatcatgtc cgacaagcgg aatgtgattc tgttcagtgt ctttgacgaa
1800
aacaggtcat ggtacctgac cgagaacatc cagagattcc tgcctaatcc agctggggtg
1860
cagctggaag atcctgagtt tcaggcatct aacatcatgc atagtattaa tggctacgtg
1920
ttcgacagtt tgcagctgag cgtgtgcctg cacgaggtcg cttactggta tatcctgagc
1980
attggggcac agacagattt cctgagcgtg ttcttttccg gctacacttt taagcataaa
2040
atggtctatg aggacacact gactctgttc cccttcagcg gcgaaaccgt gtttatgagc
2100
atggagaatc ccggactgtg gattctgggg tgccacaaca gcgatttcag aaatcgcgga
2160
atgactgccc tgctgaaagt gtcaagctgt gacaagaaca ccggggacta ctatgaagat
2220
tcatacgagg acatcagcgc atatctgctg tccaaaaaca atgccattga accccggtct
2280
tttagtcaga atcctccagt gctgaagagg caccagaggg agatcacccg cactaccctg
2340
cagagtgatc aggaagagat cgactacgac gatacaattt ctgtggaaat gaagaaagag
2400
gacttcgata tctatgacga agatgagaac cagagtcctc gatcattcca gaagaaaacc
2460
aggcattact ttattgccgc agtggagcgg ctgtgggatt atggcatgtc ctctagtcct
2520
cacgtgctgc gaaatagggc ccagtcagga agcgtcccac agttcaagaa agtggtcttc
2580
caggagttta cagacgggtc ctttactcag ccactgtaca ggggcgaact gaacgagcac
2640
ctgggactgc tggggcccta tatcagagca gaagtggagg ataacattat ggtcaccttc
2700
agaaatcagg cctctcggcc ttacagtttt tattcaagcc tgatctctta cgaagaggac
2760
cagcgacagg gagctgaacc acgaaaaaac ttcgtgaagc ctaatgagac caaaacatac
2820
ttttggaagg tgcagcacca tatggcccca acaaaagacg agttcgattg caaggcatgg
2880
gcctattttt ctgacgtgga tctggagaag gacgtgcaca gtggcctgat tggcccactg
2940
ctggtgtgcc atactaacac cctgaatcca gcccacggcc ggcaggtcac tgtccaggag
3000
ttcgctctgt tctttaccat ctttgatgag acaaagagct ggtacttcac cgaaaacatg
3060
gagcgaaatt gcagggctcc atgtaacatt cagatggaag accccacatt caaggagaac
3120
taccgctttc atgctatcaa tggatacatc atggatactc tgcccgggct ggtcatggca
3180
caggaccaga gaatccggtg gtatctgctg agcatgggca gcaacgagaa tatccactca
3240
attcatttca gcgggcacgt gtttactgtc aggaagaaag aagagtacaa gatggccctg
3300
tacaacctgt atcccggcgt gttcgaaacc gtcgagatgc tgcctagcaa ggccggaatc
3360
tggagagtgg aatgcctgat tggagagcac ctgcatgctg ggatgtctac cctgtttctg
3420
gtgtacagta ataagtgtca gacacccctg ggaatggcat ccgggcatat cagggatttc
3480
cagattaccg catctggaca gtacggacag tgggcaccta agctggctag actgcactat
3540
tccggatcta tcaacgcttg gtccacaaaa gagcctttct cttggattaa ggtggacctg
3600
ctggccccaa tgatcattca tggcatcaaa actcagggag ctcggcagaa gttctcctct
3660
ctgtacatct cacagtttat catcatgtac agcctggatg ggaagaaatg gcagacatac
3720
cgcggcaata gcacaggaac tctgatggtg ttctttggca acgtggacag cagcggaatc
3780
aagcacaaca ttttcaatcc ccctatcatt gctagataca tccggctgca cccaacccat
3840
tattctattc gaagtacact gaggatggaa ctgatgggat gcgatctgaa cagttgttca
3900
atgcccctgg ggatggagtc caaggcaatc tctgacgccc agattaccgc cagctcctac
3960
ttcactaata tgtttgctac ctggagccct tccaaagcaa gactgcacct gcaaggccgc
4020
agcaacgcat ggcgaccaca ggtgaacaat cccaaggagt ggttgcaggt cgattttcag
4080
aaaactatga aggtgaccgg ggtcacaact cagggcgtga aaagtctgct gacctcaatg
4140
tacgtcaagg agttcctgat ctctagttca caggacggac atcagtggac actgttcttt
4200
cagaacggga aggtgaaagt cttccagggc aatcaggatt cctttacacc tgtggtcaac
4260
agtctagacc ctccactgct gaccagatac ctgagaatcc accctcagtc ctgggtgcac
4320
cagattgccc tgagaatgga agtgctggga tgcgaggccc aggatctgta ctga
4374
<210> 69
<211> 577
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Промотор ET, последовательность ДНК
<400> 69
ctcgaggtca attcacgcga gttaataatt accagcgcgg gccaaataaa taatccgcga
60
ggggcaggtg acgtttgccc agcgcgcgct ggtaattatt aacctcgcga atattgattc
120
gaggccgcga ttgccgcaat cgcgaggggc aggtgacctt tgcccagcgc gcgttcgccc
180
cgccccggac ggtatcgata agcttaggag cttgggctgc aggtcgaggg cactgggagg
240
atgttgagta agatggaaaa ctactgatga cccttgcaga gacagagtat taggacatgt
300
ttgaacaggg gccgggcgat cagcaggtag ctctagagga tccccgtctg tctgcacatt
360
tcgtagagcg agtgttccga tactctaatc tccctaggca aggttcatat ttgtgtaggt
420
tacttattct ccttttgttg actaagtcaa taatcagaat cagcaggttt ggagtcagct
480
tggcagggat cagcagcctg ggttggaagg agggggtata aaagcccctt caccaggaga
540
agccgtcaca cagatccaca agctcctgcc accatgg
577
<210> 70
<211> 4374
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-5
<400> 70
atgcaaatcg aactgagcac ctgtttcttc ctctgcctgc tgagattctg tttctccgcg
60
acccgccgat actacctggg agcagtggag ctctcctggg attacatgca gagcgacctt
120
ggggagctgc ccgtggatgc caggttccct ccccgggtgc caaagtcgtt tccgttcaac
180
acctccgtgg tgtacaagaa aactctgttc gtggagttca ccgaccacct gttcaatatc
240
gccaagccca gacctccctg gatggggctg ttgggaccta ccatccaagc ggaggtgtac
300
gacactgtgg tcatcactct gaagaacatg gcctcgcatc ccgtgtccct gcacgccgtg
360
ggagtgtctt actggaaagc gtccgagggg gccgaatacg acgaccagac ctcgcagaga
420
gaaaaggaag atgacaaggt gttcccagga ggatcgcaca cctacgtgtg gcaagtgttg
480
aaggagaacg gcccaatggc ctccgacccg ctgtgcctga cctactcgta cctgtcccac
540
gtggacctcg tgaaggacct caactcggga ctgattggag ccctgctggt ctgcagggaa
600
ggctcactgg cgaaagaaaa gactcagacc ttgcacaagt tcattctgct gttcgctgtg
660
ttcgacgagg ggaagtcgtg gcacagcgag actaagaact ccctgatgca agatagagat
720
gccgcctccg cccgggcctg gcctaagatg cacaccgtga acggttacgt gaaccgctcc
780
ctccctggcc tgattggatg ccaccggaag tccgtgtact ggcacgtgat cgggatgggg
840
accacccccg aggtgcacag catcttcctg gaaggtcaca catttctcgt gcgcaaccac
900
cggcaggcct ccctggaaat cagccccatt accttcctca ctgcccagac tctgctgatg
960
gacctgggac agttcctgct gttctgccat atctcctccc accaacatga cggaatggag
1020
gcatacgtga aggtcgattc ctgccctgag gaaccccagc tccgcatgaa gaacaatgag
1080
gaagccgagg actacgacga cgacctgacg gatagcgaga tggatgtggt ccggttcgat
1140
gacgataaca gcccttcctt catccaaatt cgctcggtgg caaagaagca ccccaagacc
1200
tgggtgcatt acattgcggc ggaagaagag gactgggatt atgccccgct tgtcctcgct
1260
cctgacgacc ggagctacaa gagccagtac ctgaacaacg gtccacagag gatcggtaga
1320
aagtacaaga aggtccgctt catggcctat accgacgaaa ccttcaaaac tagagaggcc
1380
atccaacacg aatccggcat cctgggcccg ctcttgtacg gagaagtcgg cgacaccctt
1440
ctcattatct tcaagaacca ggcttcccgg ccgtacaaca tctatccgca tgggatcact
1500
gacgtgcgcc cactgtactc gcggcgcctg cccaagggtg tcaaacacct gaaggatttt
1560
ccgatccttc cgggagaaat cttcaagtac aagtggaccg tgaccgtgga agatggccca
1620
actaagtctg accctagatg cctcacccgc tactactcat ccttcgtcaa catggagcgc
1680
gacctggcca gcggactgat cggcccgctg ctgatttgct acaaggaatc agtggaccaa
1740
cggggaaacc agatcatgtc ggataagagg aacgtcatcc tcttctccgt gtttgacgaa
1800
aaccggtcgt ggtacctgac tgaaaacatc cagcggttcc tccccaaccc cgcgggcgtg
1860
cagctggaag atcctgagtt tcaggcatca aacatcatgc actccattaa cggctacgtg
1920
ttcgattcgc tgcagctgag cgtgtgtctg cacgaagtgg cctactggta catcctgtcc
1980
attggtgccc agactgactt cctgtccgtg tttttctccg gctacacgtt caagcacaag
2040
atggtgtacg aggacaccct gaccctcttc cctttttccg gcgaaactgt gtttatgagc
2100
atggagaatc ccggcctgtg gatcttgggc tgccacaaca gcgacttccg taacagagga
2160
atgactgcgc tgctcaaggt gtccagctgc gacaagaaca ccggagacta ttatgaggac
2220
tcatacgagg acatctccgc ctacctcctg tccaagaata acgccattga acctcggagc
2280
ttcagccaga acccacccgt gcttaagaga catcaacggg agatcactag gaccaccctg
2340
cagtcagacc aggaggaaat cgactacgat gacaccatct cggtcgagat gaagaaggag
2400
gactttgaca tctacgacga agatgaaaac cagagcccga ggtcgttcca aaagaaaacc
2460
cgccactact ttattgctgc tgtcgagcgg ctgtgggact acggaatgtc gtcctcgccg
2520
cacgtgctcc gcaaccgagc ccagagcggc tcggtgccgc aattcaagaa ggtcgtgttc
2580
caggagttca ctgacgggag cttcactcag cctttgtacc ggggagaact caatgaacat
2640
ctcggcctcc tcggacctta catcagagca gaagtggaag ataacatcat ggtcactttc
2700
cgtaaccaag ccagccgccc gtactcgttc tactcctccc tcatttctta cgaagaggac
2760
cagcggcagg gcgcagaacc gcgcaagaac ttcgtgaagc ccaacgaaac caagacctac
2820
ttctggaaag tgcagcatca tatggccccg actaaggacg agtttgactg caaagcctgg
2880
gcctacttct ccgatgtgga cttggagaag gacgtccact ccggcctcat cggtcccctg
2940
ctcgtgtgcc ataccaatac cctgaacccc gcacacggtc gccaggtcac cgtgcaggag
3000
ttcgctctgt tcttcactat cttcgacgaa actaagtcct ggtacttcac cgagaacatg
3060
gagaggaact gcagagcccc ctgtaacatc cagatggagg acccgacgtt caaggaaaac
3120
taccggttcc acgccattaa cggatacatc atggatacgc tgccgggtct tgtgatggcc
3180
caggatcaac ggatcagatg gtacttattg tcgatgggca gcaacgagaa catccactct
3240
attcacttct ccggtcatgt gttcactgtg cggaagaagg aagagtacaa gatggccctg
3300
tacaaccttt atcccggagt gttcgaaact gtggaaatgc tgccgtcgaa ggccggcatt
3360
tggcgcgtgg agtgtttgat tggagaacat ctccatgcgg ggatgtcaac cctgttcctg
3420
gtgtatagca acaagtgcca gactccgctt gggatggcgt caggacacat tagggatttc
3480
cagatcactg cgtccggcca gtacggccaa tgggccccta agctggcccg cctgcattac
3540
tccggatcca ttaacgcctg gtcaaccaag gagccattct cctggatcaa ggtggacctt
3600
ctggccccca tgattatcca cggaattaag acccaggggg cccggcagaa gttctcctca
3660
ctgtacatca gccagttcat aatcatgtac tccctggacg gaaagaagtg gcaaacctac
3720
agggggaaca gcaccggcac actgatggtc tttttcggaa atgtggactc ctccgggatt
3780
aagcataaca tcttcaaccc tccgattatc gctcggtaca ttagacttca ccctacccac
3840
tacagcattc gctccaccct gcggatggaa ctgatgggct gcgatctgaa ctcgtgcagc
3900
atgccgttgg gaatggagtc caaagcaatt tccgacgcgc agatcaccgc ctcgtcctac
3960
tttaccaaca tgttcgccac gtggtcaccg tccaaggccc ggctgcacct ccagggaaga
4020
tccaacgcat ggcggccaca ggtcaacaac cctaaggagt ggctccaggt ggacttccag
4080
aaaaccatga aggtcaccgg agtcacaacc cagggagtga agtcgctgct gacttctatg
4140
tacgtcaagg agttcctgat ctccagcagc caggacgggc accagtggac cctgttcttc
4200
caaaatggaa aggtcaaggt gtttcagggc aatcaggatt cattcacccc ggtggtgaac
4260
tcccttgatc cacccctcct gacccgctac cttcgcatcc acccacagtc ctgggtgcac
4320
cagatcgcgc tgaggatgga ggtcctggga tgcgaagccc aggacctgta ctga
4374
<210> 71
<211> 4374
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-6
<400> 71
atgcagattg agctgtccac ttgtttcttc ctgtgcctcc tgcgcttctg tttctccgcc
60
actcgccggt actaccttgg agccgtggag ctttcatggg actacatgca gagcgacctg
120
ggcgaactcc ccgtggatgc cagattcccc ccccgcgtgc caaagtcctt cccctttaac
180
acctccgtgg tgtacaagaa aaccctcttt gtcgagttca ctgaccacct gttcaacatc
240
gccaagccgc gcccaccttg gatgggcctc ctgggaccga ccattcaagc tgaagtgtac
300
gacaccgtgg tgatcaccct gaagaacatg gcgtcccacc ccgtgtccct gcatgcggtc
360
ggagtgtcct actggaaggc ctccgaagga gctgagtacg acgaccagac tagccagcgg
420
gaaaaggagg acgataaagt gttcccgggc ggctcgcata cttacgtgtg gcaagtcctg
480
aaggaaaacg gacctatggc atccgatcct ctgtgcctga cttactccta cctttcccat
540
gtggacctcg tgaaggacct gaacagcggg ctgattggtg cacttctcgt gtgccgcgaa
600
ggttcgctcg ctaaggaaaa gacccagacc ctccataagt tcatcctttt gttcgctgtg
660
ttcgatgaag gaaagtcatg gcattccgaa actaagaact cgctgatgca ggaccgggat
720
gccgcctcag cccgcgcctg gcctaaaatg catacagtca acggatacgt gaatcggtca
780
ctgcccgggc tcatcggttg tcacagaaag tccgtgtact ggcacgtcat cggcatgggc
840
actacgcctg aagtgcactc catcttcctg gaagggcaca ccttcctcgt gcgcaaccac
900
cgccaggcct ctctggaaat ctccccgatt acctttctga ccgcccagac tctgctcatg
960
gacctggggc agttccttct cttctgccac atctccagcc atcagcacga cggaatggag
1020
gcctacgtga aggtggactc atgcccggaa gaacctcagt tgcggatgaa gaacaacgag
1080
gaggccgagg actatgacga cgatttgact gactccgaga tggacgtcgt gcggttcgat
1140
gacgacaaca gccccagctt catccagatt cgcagcgtgg ccaagaagca ccccaaaacc
1200
tgggtgcact acatcgcggc cgaggaagaa gattgggact acgccccgtt ggtgctggca
1260
cccgatgacc ggtcgtacaa gtcccagtat ctgaacaatg gtccgcagcg gattggcaga
1320
aagtacaaga aagtgcggtt catggcgtac actgacgaaa cgtttaagac ccgggaggcc
1380
attcaacatg agagcggcat tctgggacca ctgctgtacg gagaggtcgg cgataccctg
1440
ctcatcatct tcaaaaacca ggcctcccgg ccttacaaca tctaccctca cggaatcacc
1500
gacgtgcggc cactctactc gcggcgcctg ccgaagggcg tcaagcacct gaaagacttc
1560
cctatcctgc cgggcgaaat cttcaagtat aagtggaccg tcaccgtgga ggacgggccc
1620
accaagagcg atcctaggtg tctgactcgg tactactcca gcttcgtgaa catggaacgg
1680
gacctggcat cgggactcat tggaccgctg ctgatctgct acaaagagtc ggtggatcaa
1740
cgcggcaacc agatcatgtc cgacaagcgc aacgtgatcc tgttctccgt gtttgatgaa
1800
aacagatcct ggtacctcac tgaaaacatc cagaggttcc tcccaaaccc cgcaggagtg
1860
caactggagg accctgagtt tcaggcctcg aatatcatgc actcgattaa cggttacgtg
1920
ttcgactcgc tgcagctgag cgtgtgcctc catgaagtcg cttactggta cattctgtcc
1980
atcggcgccc agactgactt cctgagcgtg ttcttttccg gttacacctt taagcacaag
2040
atggtgtacg aagataccct gaccctgttc cctttctccg gcgaaacggt gttcatgtcg
2100
atggagaacc cgggtctgtg gattctggga tgccacaaca gcgactttcg gaaccgcgga
2160
atgactgccc tgctgaaggt gtcctcatgc gacaagaaca ccggagacta ctacgaggac
2220
tcctacgagg atatctcagc ctacctcctg tccaagaaca acgcgatcga gccgcgcagc
2280
ttcagccaga acccgcctgt gctgaagagg caccagcgag aaattacccg gaccaccctc
2340
caatcggatc aggaggaaat cgactacgac gacaccatct cggtggaaat gaagaaggaa
2400
gatttcgata tctacgacga ggacgaaaat cagtcccctc gctcattcca aaagaaaact
2460
agacactact ttatcgccgc ggtggaaaga ctgtgggact atggaatgtc atccagccct
2520
cacgtccttc ggaaccgggc ccagagcgga tcggtgcctc agttcaagaa agtggtgttc
2580
caggagttca ccgacggcag cttcacccag ccgctgtacc ggggagaact gaacgaacac
2640
ctgggcctgc tcggtcccta catccgcgcg gaagtggagg ataacatcat ggtgaccttc
2700
cgtaaccaag catccagacc ttactccttc tattcctccc tgatctcata cgaggaggac
2760
cagcgccaag gcgccgagcc ccgcaagaac ttcgtcaagc ccaacgagac taagacctac
2820
ttctggaagg tccaacacca tatggccccg accaaggatg agtttgactg caaggcctgg
2880
gcctacttct ccgacgtgga ccttgagaag gatgtccatt ccggcctgat cgggccgctg
2940
ctcgtgtgtc acaccaacac cctgaaccca gcgcatggac gccaggtcac cgtccaggag
3000
tttgctctgt tcttcaccat ttttgacgaa actaagtcct ggtacttcac cgagaatatg
3060
gagcgaaact gtagagcgcc ctgcaatatc cagatggaag atccgacttt caaggagaac
3120
tatagattcc acgccatcaa cgggtacatc atggatactc tgccggggct ggtcatggcc
3180
caggatcaga ggattcggtg gtacttgctg tcaatgggat cgaacgaaaa cattcactcc
3240
attcacttct ccggtcacgt gttcactgtg cgcaagaagg aggagtacaa gatggcgctg
3300
tacaatctgt accccggggt gttcgaaact gtggagatgc tgccgtccaa ggccggcatc
3360
tggagagtgg agtgcctgat cggagagcac ctccacgcgg ggatgtccac cctcttcctg
3420
gtgtactcga ataagtgcca gaccccgctg ggcatggcct cgggccacat cagagacttc
3480
cagatcacag caagcggaca atacggccaa tgggcgccga agctggcccg cttgcactac
3540
tccggatcga tcaacgcatg gtccaccaag gaaccgttct cgtggattaa ggtggacctc
3600
ctggccccta tgattatcca cggaattaag acccagggcg ccaggcagaa gttctcctcc
3660
ctgtacatct cgcaattcat catcatgtac agcctggacg ggaagaagtg gcagacttac
3720
aggggaaact ccaccggcac cctgatggtc tttttcggca acgtggattc ctccggcatt
3780
aagcacaaca tcttcaaccc accgatcata gccagatata ttaggctcca ccccactcac
3840
tactcaatcc gctcaactct tcggatggaa ctcatggggt gcgacctgaa ctcctgctcc
3900
atgccgttgg ggatggaatc aaaggctatt agcgacgccc agatcaccgc gagctcctac
3960
ttcactaaca tgttcgccac ctggagcccc tccaaggcca ggctgcactt gcagggacgg
4020
tcaaatgcct ggcggccgca agtgaacaat ccgaaggaat ggcttcaagt ggatttccaa
4080
aagaccatga aagtgaccgg agtcaccacc cagggagtga agtcccttct gacctcgatg
4140
tatgtgaagg agttcctgat tagcagcagc caggacgggc accagtggac cctgttcttc
4200
caaaacggaa aggtcaaggt gttccagggg aaccaggact cgttcacacc cgtggtgaac
4260
tccctggacc ccccactgct gacgcggtac ttgaggattc atcctcagtc ctgggtccat
4320
cagattgcat tgcgaatgga agtcctgggc tgcgaggccc aggacctgta ctga
4374
<210> 72
<211> 4824
<212> ДНК
<213> Искусственная последовательность
<220>
<223> coFVIII-6-XTEN
<400> 72
atgcagattg agctgtccac ttgtttcttc ctgtgcctcc tgcgcttctg tttctccgcc
60
actcgccggt actaccttgg agccgtggag ctttcatggg actacatgca gagcgacctg
120
ggcgaactcc ccgtggatgc cagattcccc ccccgcgtgc caaagtcctt cccctttaac
180
acctccgtgg tgtacaagaa aaccctcttt gtcgagttca ctgaccacct gttcaacatc
240
gccaagccgc gcccaccttg gatgggcctc ctgggaccga ccattcaagc tgaagtgtac
300
gacaccgtgg tgatcaccct gaagaacatg gcgtcccacc ccgtgtccct gcatgcggtc
360
ggagtgtcct actggaaggc ctccgaagga gctgagtacg acgaccagac tagccagcgg
420
gaaaaggagg acgataaagt gttcccgggc ggctcgcata cttacgtgtg gcaagtcctg
480
aaggaaaacg gacctatggc atccgatcct ctgtgcctga cttactccta cctttcccat
540
gtggacctcg tgaaggacct gaacagcggg ctgattggtg cacttctcgt gtgccgcgaa
600
ggttcgctcg ctaaggaaaa gacccagacc ctccataagt tcatcctttt gttcgctgtg
660
ttcgatgaag gaaagtcatg gcattccgaa actaagaact cgctgatgca ggaccgggat
720
gccgcctcag cccgcgcctg gcctaaaatg catacagtca acggatacgt gaatcggtca
780
ctgcccgggc tcatcggttg tcacagaaag tccgtgtact ggcacgtcat cggcatgggc
840
actacgcctg aagtgcactc catcttcctg gaagggcaca ccttcctcgt gcgcaaccac
900
cgccaggcct ctctggaaat ctccccgatt acctttctga ccgcccagac tctgctcatg
960
gacctggggc agttccttct cttctgccac atctccagcc atcagcacga cggaatggag
1020
gcctacgtga aggtggactc atgcccggaa gaacctcagt tgcggatgaa gaacaacgag
1080
gaggccgagg actatgacga cgatttgact gactccgaga tggacgtcgt gcggttcgat
1140
gacgacaaca gccccagctt catccagatt cgcagcgtgg ccaagaagca ccccaaaacc
1200
tgggtgcact acatcgcggc cgaggaagaa gattgggact acgccccgtt ggtgctggca
1260
cccgatgacc ggtcgtacaa gtcccagtat ctgaacaatg gtccgcagcg gattggcaga
1320
aagtacaaga aagtgcggtt catggcgtac actgacgaaa cgtttaagac ccgggaggcc
1380
attcaacatg agagcggcat tctgggacca ctgctgtacg gagaggtcgg cgataccctg
1440
ctcatcatct tcaaaaacca ggcctcccgg ccttacaaca tctaccctca cggaatcacc
1500
gacgtgcggc cactctactc gcggcgcctg ccgaagggcg tcaagcacct gaaagacttc
1560
cctatcctgc cgggcgaaat cttcaagtat aagtggaccg tcaccgtgga ggacgggccc
1620
accaagagcg atcctaggtg tctgactcgg tactactcca gcttcgtgaa catggaacgg
1680
gacctggcat cgggactcat tggaccgctg ctgatctgct acaaagagtc ggtggatcaa
1740
cgcggcaacc agatcatgtc cgacaagcgc aacgtgatcc tgttctccgt gtttgatgaa
1800
aacagatcct ggtacctcac tgaaaacatc cagaggttcc tcccaaaccc cgcaggagtg
1860
caactggagg accctgagtt tcaggcctcg aatatcatgc actcgattaa cggttacgtg
1920
ttcgactcgc tgcagctgag cgtgtgcctc catgaagtcg cttactggta cattctgtcc
1980
atcggcgccc agactgactt cctgagcgtg ttcttttccg gttacacctt taagcacaag
2040
atggtgtacg aagataccct gaccctgttc cctttctccg gcgaaacggt gttcatgtcg
2100
atggagaacc cgggtctgtg gattctggga tgccacaaca gcgactttcg gaaccgcgga
2160
atgactgccc tgctgaaggt gtcctcatgc gacaagaaca ccggagacta ctacgaggac
2220
tcctacgagg atatctcagc ctacctcctg tccaagaaca acgcgatcga gccgcgcagc
2280
ttcagccaga acggcgcgcc aacatcagag agcgccaccc ctgaaagtgg tcccgggagc
2340
gagccagcca catctgggtc ggaaacgcca ggcacaagtg agtctgcaac tcccgagtcc
2400
ggacctggct ccgagcctgc cactagcggc tccgagactc cgggaacttc cgagagcgct
2460
acaccagaaa gcggacccgg aaccagtacc gaacctagcg agggctctgc tccgggcagc
2520
ccagccggct ctcctacatc cacggaggag ggcacttccg aatccgccac cccggagtca
2580
gggccaggat ctgaacccgc tacctcaggc agtgagacgc caggaacgag cgagtccgct
2640
acaccggaga gtgggccagg gagccctgct ggatctccta cgtccactga ggaagggtca
2700
ccagcgggct cgcccaccag cactgaagaa ggtgcctcga gcccgcctgt gctgaagagg
2760
caccagcgag aaattacccg gaccaccctc caatcggatc aggaggaaat cgactacgac
2820
gacaccatct cggtggaaat gaagaaggaa gatttcgata tctacgacga ggacgaaaat
2880
cagtcccctc gctcattcca aaagaaaact agacactact ttatcgccgc ggtggaaaga
2940
ctgtgggact atggaatgtc atccagccct cacgtccttc ggaaccgggc ccagagcgga
3000
tcggtgcctc agttcaagaa agtggtgttc caggagttca ccgacggcag cttcacccag
3060
ccgctgtacc ggggagaact gaacgaacac ctgggcctgc tcggtcccta catccgcgcg
3120
gaagtggagg ataacatcat ggtgaccttc cgtaaccaag catccagacc ttactccttc
3180
tattcctccc tgatctcata cgaggaggac cagcgccaag gcgccgagcc ccgcaagaac
3240
ttcgtcaagc ccaacgagac taagacctac ttctggaagg tccaacacca tatggccccg
3300
accaaggatg agtttgactg caaggcctgg gcctacttct ccgacgtgga ccttgagaag
3360
gatgtccatt ccggcctgat cgggccgctg ctcgtgtgtc acaccaacac cctgaaccca
3420
gcgcatggac gccaggtcac cgtccaggag tttgctctgt tcttcaccat ttttgacgaa
3480
actaagtcct ggtacttcac cgagaatatg gagcgaaact gtagagcgcc ctgcaatatc
3540
cagatggaag atccgacttt caaggagaac tatagattcc acgccatcaa cgggtacatc
3600
atggatactc tgccggggct ggtcatggcc caggatcaga ggattcggtg gtacttgctg
3660
tcaatgggat cgaacgaaaa cattcactcc attcacttct ccggtcacgt gttcactgtg
3720
cgcaagaagg aggagtacaa gatggcgctg tacaatctgt accccggggt gttcgaaact
3780
gtggagatgc tgccgtccaa ggccggcatc tggagagtgg agtgcctgat cggagagcac
3840
ctccacgcgg ggatgtccac cctcttcctg gtgtactcga ataagtgcca gaccccgctg
3900
ggcatggcct cgggccacat cagagacttc cagatcacag caagcggaca atacggccaa
3960
tgggcgccga agctggcccg cttgcactac tccggatcga tcaacgcatg gtccaccaag
4020
gaaccgttct cgtggattaa ggtggacctc ctggccccta tgattatcca cggaattaag
4080
acccagggcg ccaggcagaa gttctcctcc ctgtacatct cgcaattcat catcatgtac
4140
agcctggacg ggaagaagtg gcagacttac aggggaaact ccaccggcac cctgatggtc
4200
tttttcggca acgtggattc ctccggcatt aagcacaaca tcttcaaccc accgatcata
4260
gccagatata ttaggctcca ccccactcac tactcaatcc gctcaactct tcggatggaa
4320
ctcatggggt gcgacctgaa ctcctgctcc atgccgttgg ggatggaatc aaaggctatt
4380
agcgacgccc agatcaccgc gagctcctac ttcactaaca tgttcgccac ctggagcccc
4440
tccaaggcca ggctgcactt gcagggacgg tcaaatgcct ggcggccgca agtgaacaat
4500
ccgaaggaat ggcttcaagt ggatttccaa aagaccatga aagtgaccgg agtcaccacc
4560
cagggagtga agtcccttct gacctcgatg tatgtgaagg agttcctgat tagcagcagc
4620
caggacgggc accagtggac cctgttcttc caaaacggaa aggtcaaggt gttccagggg
4680
aaccaggact cgttcacacc cgtggtgaac tccctggacc ccccactgct gacgcggtac
4740
ttgaggattc atcctcagtc ctgggtccat cagattgcat tgcgaatgga agtcctgggc
4800
tgcgaggccc aggacctgta ctga
4824
<210> 73
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AD
<400> 73
Gly Glu Ser Pro Gly Gly Ser Ser Gly Ser Glu Ser
1. 5 10
<210> 74
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AD
<400> 74
Gly Ser Glu Gly Ser Ser Gly Pro Gly Glu Ser Ser
1. 5 10
<210> 75
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AD
<400> 75
Gly Ser Ser Glu Ser Gly Ser Ser Glu Gly Gly Pro
1. 5 10
<210> 76
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AD
<400> 76
Gly Ser Gly Gly Glu Pro Ser Glu Ser Gly Ser Ser
1. 5 10
<210> 77
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AE, AM
<400> 77
Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu
1. 5 10
<210> 78
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AE, AM, AQ
<400> 78
Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
1. 5 10
<210> 79
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AE, AM, AQ
<400> 79
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro
1. 5 10
<210> 80
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AE, AM, AQ
<400> 80
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
1. 5 10
<210> 81
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AF, AM
<400> 81
Gly Ser Thr Ser Glu Ser Pro Ser Gly Thr Ala Pro
1. 5 10
<210> 82
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AF, AM
<400> 82
Gly Thr Ser Thr Pro Glu Ser Gly Ser Ala Ser Pro
1. 5 10
<210> 83
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AF, AM
<400> 83
Gly Thr Ser Pro Ser Gly Glu Ser Ser Thr Ala Pro
1. 5 10
<210> 84
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AF, AM
<400> 84
Gly Ser Thr Ser Ser Thr Ala Glu Ser Pro Gly Pro
1. 5 10
<210> 85
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AG, AM
<400> 85
Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro
1. 5 10
<210> 86
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AG, AM
<400> 86
Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro
1. 5 10
<210> 87
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AG, AM
<400> 87
Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro
1. 5 10
<210> 88
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AG, AM
<400> 88
Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
1. 5 10
<210> 89
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AQ
<400> 89
Gly Glu Pro Ala Gly Ser Pro Thr Ser Thr Ser Glu
1. 5 10
<210> 90
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AQ
<400> 90
Gly Thr Gly Glu Pro Ser Ser Thr Pro Ala Ser Glu
1. 5 10
<210> 91
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AQ
<400> 91
Gly Ser Gly Pro Ser Thr Glu Ser Ala Pro Thr Glu
1. 5 10
<210> 92
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AQ
<400> 92
Gly Ser Glu Thr Pro Ser Gly Pro Ser Glu Thr Ala
1. 5 10
<210> 93
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AQ
<400> 93
Gly Pro Ser Glu Thr Ser Thr Ser Glu Pro Gly Ala
1. 5 10
<210> 94
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив AQ
<400> 94
Gly Ser Pro Ser Glu Pro Thr Glu Gly Thr Ser Ala
1. 5 10
<210> 95
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив BD
<400> 95
Gly Ser Gly Ala Ser Glu Pro Thr Ser Thr Glu Pro
1. 5 10
<210> 96
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив BD
<400> 96
Gly Ser Glu Pro Ala Thr Ser Gly Thr Glu Pro Ser
1. 5 10
<210> 97
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив BD
<400> 97
Gly Thr Ser Glu Pro Ser Thr Ser Glu Pro Gly Ala
1. 5 10
<210> 98
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив BD
<400> 98
Gly Thr Ser Thr Glu Pro Ser Glu Pro Gly Ser Ala
1. 5 10
<210> 99
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив BD
<400> 99
Gly Ser Thr Ala Gly Ser Glu Thr Ser Thr Glu Ala
1. 5 10
<210> 100
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив BD
<400> 100
Gly Ser Glu Thr Ala Thr Ser Gly Ser Glu Thr Ala
1. 5 10
<210> 101
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив BD
<400> 101
Gly Thr Ser Glu Ser Ala Thr Ser Glu Ser Gly Ala
1. 5 10
<210> 102
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мотив BD
<400> 102
Gly Thr Ser Thr Glu Ala Ser Glu Gly Ser Ala Ser
1. 5 10
<210> 103
<211> 1607
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Последовательность белка coFVIII-6-XTEN
<400> 103
Met Gln Ile Glu Leu Ser Thr Cys Phe Phe Leu Cys Leu Leu Arg Phe
1. 5 10 15
Cys Phe Ser Ala Thr Arg Arg Tyr Tyr Leu Gly Ala Val Glu Leu Ser
20 25 30
Trp Asp Tyr Met Gln Ser Asp Leu Gly Glu Leu Pro Val Asp Ala Arg
35 40 45
Phe Pro Pro Arg Val Pro Lys Ser Phe Pro Phe Asn Thr Ser Val Val
50 55 60
Tyr Lys Lys Thr Leu Phe Val Glu Phe Thr Asp His Leu Phe Asn Ile
65 70 75 80
Ala Lys Pro Arg Pro Pro Trp Met Gly Leu Leu Gly Pro Thr Ile Gln
85 90 95
Ala Glu Val Tyr Asp Thr Val Val Ile Thr Leu Lys Asn Met Ala Ser
100 105 110
His Pro Val Ser Leu His Ala Val Gly Val Ser Tyr Trp Lys Ala Ser
115 120 125
Glu Gly Ala Glu Tyr Asp Asp Gln Thr Ser Gln Arg Glu Lys Glu Asp
130 135 140
Asp Lys Val Phe Pro Gly Gly Ser His Thr Tyr Val Trp Gln Val Leu
145 150 155 160
Lys Glu Asn Gly Pro Met Ala Ser Asp Pro Leu Cys Leu Thr Tyr Ser
165 170 175
Tyr Leu Ser His Val Asp Leu Val Lys Asp Leu Asn Ser Gly Leu Ile
180 185 190
Gly Ala Leu Leu Val Cys Arg Glu Gly Ser Leu Ala Lys Glu Lys Thr
195 200 205
Gln Thr Leu His Lys Phe Ile Leu Leu Phe Ala Val Phe Asp Glu Gly
210 215 220
Lys Ser Trp His Ser Glu Thr Lys Asn Ser Leu Met Gln Asp Arg Asp
225 230 235 240
Ala Ala Ser Ala Arg Ala Trp Pro Lys Met His Thr Val Asn Gly Tyr
245 250 255
Val Asn Arg Ser Leu Pro Gly Leu Ile Gly Cys His Arg Lys Ser Val
260 265 270
Tyr Trp His Val Ile Gly Met Gly Thr Thr Pro Glu Val His Ser Ile
275 280 285
Phe Leu Glu Gly His Thr Phe Leu Val Arg Asn His Arg Gln Ala Ser
290 295 300
Leu Glu Ile Ser Pro Ile Thr Phe Leu Thr Ala Gln Thr Leu Leu Met
305 310 315 320
Asp Leu Gly Gln Phe Leu Leu Phe Cys His Ile Ser Ser His Gln His
325 330 335
Asp Gly Met Glu Ala Tyr Val Lys Val Asp Ser Cys Pro Glu Glu Pro
340 345 350
Gln Leu Arg Met Lys Asn Asn Glu Glu Ala Glu Asp Tyr Asp Asp Asp
355 360 365
Leu Thr Asp Ser Glu Met Asp Val Val Arg Phe Asp Asp Asp Asn Ser
370 375 380
Pro Ser Phe Ile Gln Ile Arg Ser Val Ala Lys Lys His Pro Lys Thr
385 390 395 400
Trp Val His Tyr Ile Ala Ala Glu Glu Glu Asp Trp Asp Tyr Ala Pro
405 410 415
Leu Val Leu Ala Pro Asp Asp Arg Ser Tyr Lys Ser Gln Tyr Leu Asn
420 425 430
Asn Gly Pro Gln Arg Ile Gly Arg Lys Tyr Lys Lys Val Arg Phe Met
435 440 445
Ala Tyr Thr Asp Glu Thr Phe Lys Thr Arg Glu Ala Ile Gln His Glu
450 455 460
Ser Gly Ile Leu Gly Pro Leu Leu Tyr Gly Glu Val Gly Asp Thr Leu
465 470 475 480
Leu Ile Ile Phe Lys Asn Gln Ala Ser Arg Pro Tyr Asn Ile Tyr Pro
485 490 495
His Gly Ile Thr Asp Val Arg Pro Leu Tyr Ser Arg Arg Leu Pro Lys
500 505 510
Gly Val Lys His Leu Lys Asp Phe Pro Ile Leu Pro Gly Glu Ile Phe
515 520 525
Lys Tyr Lys Trp Thr Val Thr Val Glu Asp Gly Pro Thr Lys Ser Asp
530 535 540
Pro Arg Cys Leu Thr Arg Tyr Tyr Ser Ser Phe Val Asn Met Glu Arg
545 550 555 560
Asp Leu Ala Ser Gly Leu Ile Gly Pro Leu Leu Ile Cys Tyr Lys Glu
565 570 575
Ser Val Asp Gln Arg Gly Asn Gln Ile Met Ser Asp Lys Arg Asn Val
580 585 590
Ile Leu Phe Ser Val Phe Asp Glu Asn Arg Ser Trp Tyr Leu Thr Glu
595 600 605
Asn Ile Gln Arg Phe Leu Pro Asn Pro Ala Gly Val Gln Leu Glu Asp
610 615 620
Pro Glu Phe Gln Ala Ser Asn Ile Met His Ser Ile Asn Gly Tyr Val
625 630 635 640
Phe Asp Ser Leu Gln Leu Ser Val Cys Leu His Glu Val Ala Tyr Trp
645 650 655
Tyr Ile Leu Ser Ile Gly Ala Gln Thr Asp Phe Leu Ser Val Phe Phe
660 665 670
Ser Gly Tyr Thr Phe Lys His Lys Met Val Tyr Glu Asp Thr Leu Thr
675 680 685
Leu Phe Pro Phe Ser Gly Glu Thr Val Phe Met Ser Met Glu Asn Pro
690 695 700
Gly Leu Trp Ile Leu Gly Cys His Asn Ser Asp Phe Arg Asn Arg Gly
705 710 715 720
Met Thr Ala Leu Leu Lys Val Ser Ser Cys Asp Lys Asn Thr Gly Asp
725 730 735
Tyr Tyr Glu Asp Ser Tyr Glu Asp Ile Ser Ala Tyr Leu Leu Ser Lys
740 745 750
Asn Asn Ala Ile Glu Pro Arg Ser Phe Ser Gln Asn Gly Ala Pro Thr
755 760 765
Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr
770 775 780
Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser
785 790 795 800
Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr
805 810 815
Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro
820 825 830
Ser Glu Gly Ser Ala Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr
835 840 845
Glu Glu Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser
850 855 860
Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala
865 870 875 880
Thr Pro Glu Ser Gly Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr
885 890 895
Glu Glu Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Ala
900 905 910
Ser Ser Pro Pro Val Leu Lys Arg His Gln Arg Glu Ile Thr Arg Thr
915 920 925
Thr Leu Gln Ser Asp Gln Glu Glu Ile Asp Tyr Asp Asp Thr Ile Ser
930 935 940
Val Glu Met Lys Lys Glu Asp Phe Asp Ile Tyr Asp Glu Asp Glu Asn
945 950 955 960
Gln Ser Pro Arg Ser Phe Gln Lys Lys Thr Arg His Tyr Phe Ile Ala
965 970 975
Ala Val Glu Arg Leu Trp Asp Tyr Gly Met Ser Ser Ser Pro His Val
980 985 990
Leu Arg Asn Arg Ala Gln Ser Gly Ser Val Pro Gln Phe Lys Lys Val
995 1000 1005
Val Phe Gln Glu Phe Thr Asp Gly Ser Phe Thr Gln Pro Leu Tyr
1010 1015 1020
Arg Gly Glu Leu Asn Glu His Leu Gly Leu Leu Gly Pro Tyr Ile
1025 1030 1035
Arg Ala Glu Val Glu Asp Asn Ile Met Val Thr Phe Arg Asn Gln
1040 1045 1050
Ala Ser Arg Pro Tyr Ser Phe Tyr Ser Ser Leu Ile Ser Tyr Glu
1055 1060 1065
Glu Asp Gln Arg Gln Gly Ala Glu Pro Arg Lys Asn Phe Val Lys
1070 1075 1080
Pro Asn Glu Thr Lys Thr Tyr Phe Trp Lys Val Gln His His Met
1085 1090 1095
Ala Pro Thr Lys Asp Glu Phe Asp Cys Lys Ala Trp Ala Tyr Phe
1100 1105 1110
Ser Asp Val Asp Leu Glu Lys Asp Val His Ser Gly Leu Ile Gly
1115 1120 1125
Pro Leu Leu Val Cys His Thr Asn Thr Leu Asn Pro Ala His Gly
1130 1135 1140
Arg Gln Val Thr Val Gln Glu Phe Ala Leu Phe Phe Thr Ile Phe
1145 1150 1155
Asp Glu Thr Lys Ser Trp Tyr Phe Thr Glu Asn Met Glu Arg Asn
1160 1165 1170
Cys Arg Ala Pro Cys Asn Ile Gln Met Glu Asp Pro Thr Phe Lys
1175 1180 1185
Glu Asn Tyr Arg Phe His Ala Ile Asn Gly Tyr Ile Met Asp Thr
1190 1195 1200
Leu Pro Gly Leu Val Met Ala Gln Asp Gln Arg Ile Arg Trp Tyr
1205 1210 1215
Leu Leu Ser Met Gly Ser Asn Glu Asn Ile His Ser Ile His Phe
1220 1225 1230
Ser Gly His Val Phe Thr Val Arg Lys Lys Glu Glu Tyr Lys Met
1235 1240 1245
Ala Leu Tyr Asn Leu Tyr Pro Gly Val Phe Glu Thr Val Glu Met
1250 1255 1260
Leu Pro Ser Lys Ala Gly Ile Trp Arg Val Glu Cys Leu Ile Gly
1265 1270 1275
Glu His Leu His Ala Gly Met Ser Thr Leu Phe Leu Val Tyr Ser
1280 1285 1290
Asn Lys Cys Gln Thr Pro Leu Gly Met Ala Ser Gly His Ile Arg
1295 1300 1305
Asp Phe Gln Ile Thr Ala Ser Gly Gln Tyr Gly Gln Trp Ala Pro
1310 1315 1320
Lys Leu Ala Arg Leu His Tyr Ser Gly Ser Ile Asn Ala Trp Ser
1325 1330 1335
Thr Lys Glu Pro Phe Ser Trp Ile Lys Val Asp Leu Leu Ala Pro
1340 1345 1350
Met Ile Ile His Gly Ile Lys Thr Gln Gly Ala Arg Gln Lys Phe
1355 1360 1365
Ser Ser Leu Tyr Ile Ser Gln Phe Ile Ile Met Tyr Ser Leu Asp
1370 1375 1380
Gly Lys Lys Trp Gln Thr Tyr Arg Gly Asn Ser Thr Gly Thr Leu
1385 1390 1395
Met Val Phe Phe Gly Asn Val Asp Ser Ser Gly Ile Lys His Asn
1400 1405 1410
Ile Phe Asn Pro Pro Ile Ile Ala Arg Tyr Ile Arg Leu His Pro
1415 1420 1425
Thr His Tyr Ser Ile Arg Ser Thr Leu Arg Met Glu Leu Met Gly
1430 1435 1440
Cys Asp Leu Asn Ser Cys Ser Met Pro Leu Gly Met Glu Ser Lys
1445 1450 1455
Ala Ile Ser Asp Ala Gln Ile Thr Ala Ser Ser Tyr Phe Thr Asn
1460 1465 1470
Met Phe Ala Thr Trp Ser Pro Ser Lys Ala Arg Leu His Leu Gln
1475 1480 1485
Gly Arg Ser Asn Ala Trp Arg Pro Gln Val Asn Asn Pro Lys Glu
1490 1495 1500
Trp Leu Gln Val Asp Phe Gln Lys Thr Met Lys Val Thr Gly Val
1505 1510 1515
Thr Thr Gln Gly Val Lys Ser Leu Leu Thr Ser Met Tyr Val Lys
1520 1525 1530
Glu Phe Leu Ile Ser Ser Ser Gln Asp Gly His Gln Trp Thr Leu
1535 1540 1545
Phe Phe Gln Asn Gly Lys Val Lys Val Phe Gln Gly Asn Gln Asp
1550 1555 1560
Ser Phe Thr Pro Val Val Asn Ser Leu Asp Pro Pro Leu Leu Thr
1565 1570 1575
Arg Tyr Leu Arg Ile His Pro Gln Ser Trp Val His Gln Ile Ala
1580 1585 1590
Leu Arg Met Glu Val Leu Gly Cys Glu Ala Gln Asp Leu Tyr
1595 1600 1605
<210> 104
<211> 16
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Rep-связывающий сайт (RBS) для AAV2
<400> 104
gcgcgctcgc tcgctc
16
<210> 105
<211> 6
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Сайт концевого разрешения (TRS) для AAV2
<400> 105
agttgg
6
<210> 106
<211> 2328
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Зрелый полноразмерный FVIII
<400> 106
Ala Thr Arg Arg Tyr Tyr Leu Gly Ala Val Glu Leu Ser Trp Asp Tyr
1. 5 10 15
Met Gln Ser Asp Leu Gly Glu Leu Pro Val Asp Ala Arg Phe Pro Pro
20 25 30
Arg Val Pro Lys Ser Phe Pro Phe Asn Thr Ser Val Val Tyr Lys Lys
35 40 45
Thr Leu Phe Val Glu Phe Thr Asp His Leu Phe Asn Ile Ala Lys Pro
50 55 60
Arg Pro Pro Trp Met Gly Leu Leu Gly Pro Thr Ile Gln Ala Glu Val
65 70 75 80
Tyr Asp Thr Val Val Ile Thr Leu Lys Asn Met Ala Ser His Pro Val
85 90 95
Ser Leu His Ala Val Gly Val Ser Tyr Trp Lys Ala Ser Glu Gly Ala
100 105 110
Glu Tyr Asp Asp Gln Thr Ser Gln Arg Glu Lys Glu Asp Asp Lys Val
115 120 125
Phe Pro Gly Gly Ser His Thr Tyr Val Trp Gln Val Leu Lys Glu Asn
130 135 140
Gly Pro Met Ala Ser Asp Pro Leu Cys Leu Thr Tyr Ser Tyr Leu Ser
145 150 155 160
His Val Asp Leu Val Lys Asp Leu Asn Ser Gly Leu Ile Gly Ala Leu
165 170 175
Leu Val Cys Arg Glu Gly Ser Leu Ala Lys Glu Lys Thr Gln Thr Leu
180 185 190
His Lys Phe Ile Leu Leu Phe Ala Val Phe Asp Glu Gly Lys Ser Trp
195 200 205
His Ser Glu Thr Lys Asn Ser Leu Met Gln Asp Arg Asp Ala Ala Ser
210 215 220
Ala Arg Ala Trp Pro Lys Met His Thr Val Asn Gly Tyr Val Asn Arg
225 230 235 240
Ser Leu Pro Gly Leu Ile Gly Cys His Arg Lys Ser Val Tyr Trp His
245 250 255
Val Ile Gly Met Gly Thr Thr Pro Glu Val His Ser Ile Phe Leu Glu
260 265 270
Gly His Thr Phe Leu Val Arg Asn His Arg Gln Ala Ser Leu Glu Ile
275 280 285
Ser Pro Ile Thr Phe Leu Thr Ala Gln Thr Leu Leu Met Asp Leu Gly
290 295 300
Gln Phe Leu Leu Phe Cys His Ile Ser Ser His Gln His Asp Gly Met
305 310 315 320
Glu Ala Tyr Val Lys Val Asp Ser Cys Pro Glu Glu Pro Gln Leu Arg
325 330 335
Met Lys Asn Asn Glu Glu Ala Glu Asp Tyr Asp Asp Asp Leu Thr Asp
340 345 350
Ser Glu Met Asp Val Val Arg Phe Asp Asp Asp Asn Ser Pro Ser Phe
355 360 365
Ile Gln Ile Arg Ser Val Ala Lys Lys His Pro Lys Thr Trp Val His
370 375 380
Tyr Ile Ala Ala Glu Glu Glu Asp Trp Asp Tyr Ala Pro Leu Val Leu
385 390 395 400
Ala Pro Asp Asp Arg Ser Tyr Lys Ser Gln Tyr Leu Asn Asn Gly Pro
405 410 415
Gln Arg Ile Gly Arg Lys Tyr Lys Lys Val Arg Phe Met Ala Tyr Thr
420 425 430
Asp Glu Thr Phe Lys Thr Arg Glu Ala Ile Gln His Glu Ser Gly Ile
435 440 445
Leu Gly Pro Leu Leu Tyr Gly Glu Val Gly Asp Thr Leu Leu Ile Ile
450 455 460
Phe Lys Asn Gln Ala Ser Arg Pro Tyr Asn Ile Tyr Pro His Gly Ile
465 470 475 480
Thr Asp Val Arg Pro Lys Arg Arg Leu Pro Lys Gly Val Lys His Leu
485 490 495
Lys Asp Phe Pro Ile Leu Pro Gly Glu Ile Phe Lys Tyr Lys Trp Thr
500 505 510
Val Thr Val Glu Asp Gly Pro Thr Lys Ser Asp Pro Arg Cys Leu Thr
515 520 525
Arg Tyr Tyr Ser Ser Phe Val Asn Met Glu Arg Asp Leu Ala Ser Gly
530 535 540
Leu Ile Gly Pro Leu Leu Ile Cys Tyr Lys Glu Ser Val Asp Gln Arg
545 550 555 560
Gly Asn Gln Ile Met Ser Asp Lys Arg Asn Val Ile Leu Phe Ser Val
565 570 575
Phe Asp Glu Asn Arg Ser Trp Tyr Leu Thr Glu Asn Ile Gln Arg Phe
580 585 590
Leu Pro Asn Pro Ala Gly Val Gln Leu Glu Asp Pro Glu Phe Gln Ala
595 600 605
Ser Asn Ile Met His Ser Ile Asn Gly Tyr Val Phe Asp Ser Leu Gln
610 615 620
Leu Ser Val Cys Leu His Glu Val Ala Tyr Trp Tyr Ile Leu Ser Ile
625 630 635 640
Gly Ala Gln Thr Asp Phe Leu Ser Val Phe Phe Ser Gly Tyr Thr Phe
645 650 655
Lys His Lys Met Val Tyr Glu Asp Thr Leu Thr Leu Phe Pro Phe Ser
660 665 670
Gly Glu Thr Val Phe Met Ser Met Glu Asn Pro Gly Leu Trp Ile Leu
675 680 685
Gly Cys His Asn Ser Asp Phe Arg Asn Arg Gly Met Thr Ala Leu Leu
690 695 700
Lys Val Ser Ser Cys Asp Lys Asn Thr Gly Asp Tyr Tyr Glu Asp Ser
705 710 715 720
Tyr Glu Asp Ile Ser Ala Tyr Leu Leu Ser Lys Asn Asn Ala Ile Glu
725 730 735
Pro Arg Ser Phe Ser Gln Asn Ser Arg His Pro Ser Thr Arg Gln Lys
740 745 750
Gln Phe Asn Ala Thr Thr Ile Pro Glu Asn Asp Ile Glu Lys Thr Asp
755 760 765
Pro Trp Phe Ala His Arg Thr Pro Met Pro Lys Ile Gln Asn Val Ser
770 775 780
Ser Ser Asp Leu Leu Met Leu Leu Arg Gln Ser Pro Thr Pro His Gly
785 790 795 800
Leu Ser Leu Ser Asp Leu Gln Glu Ala Lys Tyr Glu Thr Phe Ser Asp
805 810 815
Asp Pro Ser Pro Gly Ala Ile Asp Ser Asn Asn Ser Leu Ser Glu Met
820 825 830
Thr His Phe Arg Pro Gln Leu His His Ser Gly Asp Met Val Phe Thr
835 840 845
Pro Glu Ser Gly Leu Gln Leu Arg Leu Asn Glu Lys Leu Gly Thr Thr
850 855 860
Ala Ala Thr Glu Leu Lys Lys Leu Asp Phe Lys Val Ser Ser Thr Ser
865 870 875 880
Asn Asn Leu Ile Ser Thr Ile Pro Ser Asp Asn Leu Ala Ala Gly Thr
885 890 895
Asp Asn Thr Ser Ser Leu Gly Pro Pro Ser Met Pro Val His Tyr Asp
900 905 910
Ser Gln Leu Asp Thr Thr Leu Phe Gly Lys Lys Ser Ser Pro Leu Thr
915 920 925
Glu Ser Gly Gly Pro Leu Ser Leu Ser Glu Glu Asn Asn Asp Ser Lys
930 935 940
Leu Leu Glu Ser Gly Leu Met Asn Ser Gln Glu Ser Ser Trp Gly Lys
945 950 955 960
Asn Val Ser Ser Thr Glu Ser Gly Arg Leu Phe Lys Gly Lys Arg Ala
965 970 975
His Gly Pro Ala Leu Leu Thr Lys Asp Asn Ala Leu Phe Lys Val Ser
980 985 990
Ile Ser Leu Leu Lys Thr Asn Lys Thr Ser Asn Asn Ser Ala Thr Asn
995 1000 1005
Arg Lys Thr His Ile Asp Gly Pro Ser Leu Leu Ile Glu Asn Ser
1010 1015 1020
Pro Ser Val Trp Gln Asn Ile Ser Asp Thr Glu Phe Lys Lys Val
1025 1030 1035
Thr Pro Leu Ile His Asp Arg Met Leu Met Asp Lys Asn Ala Thr
1040 1045 1050
Ala Leu Arg Leu Asn His Met Ser Asn Lys Thr Thr Ser Ser Lys
1055 1060 1065
Asn Met Glu Met Val Gln Gln Lys Lys Glu Gly Pro Ile Pro Pro
1070 1075 1080
Asp Ala Gln Asn Pro Asp Met Ser Phe Phe Lys Met Leu Phe Leu
1085 1090 1095
Pro Glu Ser Ala Arg Trp Ile Gln Arg Thr His Gly Lys Asn Ser
1100 1105 1110
Leu Asn Ser Gly Gln Gly Pro Ser Pro Lys Gln Leu Val Ser Leu
1115 1120 1125
Gly Pro Glu Lys Ser Val Glu Gly Gln Asn Phe Leu Ser Glu Lys
1130 1135 1140
Asn Lys Val Val Val Gly Lys Gly Glu Phe Thr Lys Asp Val Gly
1145 1150 1155
Leu Lys Glu Met Val Phe Pro Ser Ser Arg Asn Leu Phe Leu Thr
1160 1165 1170
Asn Leu Asp Asn Leu His Glu Asn Asn Thr His Asn Gln Glu Lys
1175 1180 1185
Lys Ile Gln Glu Glu Ile Glu Lys Lys Glu Thr Leu Ile Gln Glu
1190 1195 1200
Asn Val Val Leu Pro Gln Ile His Thr Val Thr Gly Thr Lys Asn
1205 1210 1215
Phe Met Lys Asn Leu Phe Leu Leu Ser Thr Arg Gln Asn Val Glu
1220 1225 1230
Gly Ser Tyr Asp Gly Ala Tyr Ala Pro Val Leu Gln Asp Phe Arg
1235 1240 1245
Ser Leu Asn Asp Ser Thr Asn Arg Thr Lys Lys His Thr Ala His
1250 1255 1260
Phe Ser Lys Lys Gly Glu Glu Glu Asn Leu Glu Gly Leu Gly Asn
1265 1270 1275
Gln Thr Lys Gln Ile Val Glu Lys Tyr Ala Cys Thr Thr Arg Ile
1280 1285 1290
Ser Pro Asn Thr Ser Gln Gln Asn Phe Val Thr Gln Arg Ser Lys
1295 1300 1305
Arg Ala Leu Lys Gln Phe Arg Leu Pro Leu Glu Glu Thr Glu Leu
1310 1315 1320
Glu Lys Arg Ile Ile Val Asp Asp Thr Ser Thr Gln Trp Ser Lys
1325 1330 1335
Asn Met Lys His Leu Thr Pro Ser Thr Leu Thr Gln Ile Asp Tyr
1340 1345 1350
Asn Glu Lys Glu Lys Gly Ala Ile Thr Gln Ser Pro Leu Ser Asp
1355 1360 1365
Cys Leu Thr Arg Ser His Ser Ile Pro Gln Ala Asn Arg Ser Pro
1370 1375 1380
Leu Pro Ile Ala Lys Val Ser Ser Phe Pro Ser Ile Arg Pro Ile
1385 1390 1395
Tyr Leu Thr Arg Val Leu Phe Gln Asp Asn Ser Ser His Leu Pro
1400 1405 1410
Ala Ala Ser Tyr Arg Lys Lys Asp Ser Gly Val Gln Glu Ser Ser
1415 1420 1425
His Phe Leu Gln Gly Ala Lys Lys Asn Asn Leu Ser Leu Ala Ile
1430 1435 1440
Leu Thr Leu Glu Met Thr Gly Asp Gln Arg Glu Val Gly Ser Leu
1445 1450 1455
Gly Thr Ser Ala Thr Asn Ser Val Thr Tyr Lys Lys Val Glu Asn
1460 1465 1470
Thr Val Leu Pro Lys Pro Asp Leu Pro Lys Thr Ser Gly Lys Val
1475 1480 1485
Glu Leu Leu Pro Lys Val His Ile Tyr Gln Lys Asp Leu Phe Pro
1490 1495 1500
Thr Glu Thr Ser Asn Gly Ser Pro Gly His Leu Asp Leu Val Glu
1505 1510 1515
Gly Ser Leu Leu Gln Gly Thr Glu Gly Ala Ile Lys Trp Asn Glu
1520 1525 1530
Ala Asn Arg Pro Gly Lys Val Pro Phe Leu Arg Val Ala Thr Glu
1535 1540 1545
Ser Ser Ala Lys Thr Pro Ser Lys Leu Leu Asp Pro Leu Ala Trp
1550 1555 1560
Asp Asn His Tyr Gly Thr Gln Ile Pro Lys Glu Glu Trp Lys Ser
1565 1570 1575
Gln Glu Lys Ser Pro Glu Lys Thr Ala Phe Lys Lys Lys Asp Thr
1580 1585 1590
Ile Leu Ser Leu Asn Ala Cys Glu Ser Asn His Ala Ile Ala Ala
1595 1600 1605
Ile Asn Glu Gly Gln Asn Lys Pro Glu Ile Glu Val Thr Trp Ala
1610 1615 1620
Lys Gln Gly Arg Thr Glu Arg Leu Cys Ser Gln Asn Pro Pro Val
1625 1630 1635
Leu Lys Arg His Gln Arg Glu Ile Thr Arg Thr Thr Leu Gln Ser
1640 1645 1650
Asp Gln Glu Glu Ile Asp Tyr Asp Asp Thr Ile Ser Val Glu Met
1655 1660 1665
Lys Lys Glu Asp Phe Asp Ile Tyr Asp Glu Asp Glu Asn Gln Ser
1670 1675 1680
Pro Arg Ser Phe Gln Lys Lys Thr Arg His Tyr Phe Ile Ala Ala
1685 1690 1695
Val Glu Arg Leu Trp Asp Tyr Gly Met Ser Ser Ser Pro His Val
1700 1705 1710
Leu Arg Asn Arg Ala Gln Ser Gly Ser Val Pro Gln Phe Lys Lys
1715 1720 1725
Val Val Phe Gln Glu Phe Thr Asp Gly Ser Phe Thr Gln Pro Leu
1730 1735 1740
Tyr Arg Gly Glu Leu Asn Glu His Leu Gly Leu Leu Gly Pro Tyr
1745 1750 1755
Ile Arg Ala Glu Val Glu Asp Asn Ile Met Val Thr Phe Arg Asn
1760 1765 1770
Gln Ala Ser Arg Pro Tyr Ser Phe Tyr Ser Ser Leu Ile Ser Tyr
1775 1780 1785
Glu Glu Asp Gln Arg Gln Gly Ala Glu Pro Arg Lys Asn Phe Val
1790 1795 1800
Lys Pro Asn Glu Thr Lys Thr Tyr Phe Trp Lys Val Gln His His
1805 1810 1815
Met Ala Pro Thr Lys Asp Glu Phe Asp Cys Lys Ala Trp Ala Tyr
1820 1825 1830
Phe Ser Asp Val Asp Leu Glu Lys Asp Val His Ser Gly Leu Ile
1835 1840 1845
Gly Pro Leu Leu Val Cys His Thr Asn Thr Leu Asn Pro Ala His
1850 1855 1860
Gly Arg Gln Val Thr Val Gln Glu Phe Ala Leu Phe Phe Thr Ile
1865 1870 1875
Phe Asp Glu Thr Lys Ser Trp Tyr Phe Thr Glu Asn Met Glu Arg
1880 1885 1890
Asn Cys Arg Ala Pro Cys Asn Ile Gln Met Glu Asp Pro Thr Phe
1895 1900 1905
Lys Glu Asn Tyr Arg Phe His Ala Ile Asn Gly Tyr Ile Met Asp
1910 1915 1920
Thr Leu Pro Gly Leu Val Met Ala Gln Asp Gln Arg Ile Arg Trp
1925 1930 1935
Tyr Leu Leu Ser Met Gly Ser Asn Glu Asn Ile His Ser Ile His
1940 1945 1950
Phe Ser Gly His Val Phe Thr Val Arg Lys Lys Glu Glu Tyr Lys
1955 1960 1965
Met Ala Leu Tyr Asn Leu Tyr Pro Gly Val Phe Glu Thr Val Glu
1970 1975 1980
Met Leu Pro Ser Lys Ala Gly Ile Trp Arg Val Glu Cys Leu Ile
1985 1990 1995
Gly Glu His Leu His Ala Gly Met Ser Thr Leu Phe Leu Val Tyr
2000 2005 2010
Ser Asn Lys Cys Gln Thr Pro Leu Gly Met Ala Ser Gly His Ile
2015 2020 2025
Arg Asp Phe Gln Ile Thr Ala Ser Gly Gln Tyr Gly Gln Trp Ala
2030 2035 2040
Pro Lys Leu Ala Arg Leu His Tyr Ser Gly Ser Ile Asn Ala Trp
2045 2050 2055
Ser Thr Lys Glu Pro Phe Ser Trp Ile Lys Val Asp Leu Leu Ala
2060 2065 2070
Pro Met Ile Ile His Gly Ile Lys Thr Gln Gly Ala Arg Gln Lys
2075 2080 2085
Phe Ser Ser Leu Tyr Ile Ser Gln Phe Ile Ile Met Tyr Ser Leu
2090 2095 2100
Asp Gly Lys Lys Trp Gln Thr Tyr Arg Gly Asn Ser Thr Gly Thr
2105 2110 2115
Leu Met Val Phe Phe Gly Asn Val Asp Ser Ser Gly Ile Lys His
2120 2125 2130
Asn Ile Phe Asn Pro Pro Ile Ile Ala Arg Tyr Ile Arg Leu His
2135 2140 2145
Pro Thr His Tyr Ser Ile Arg Ser Thr Leu Arg Met Glu Leu Met
2150 2155 2160
Gly Cys Asp Leu Asn Ser Cys Ser Met Pro Leu Gly Met Glu Ser
2165 2170 2175
Lys Ala Ile Ser Asp Ala Gln Ile Thr Ala Ser Ser Tyr Phe Thr
2180 2185 2190
Asn Met Phe Ala Thr Trp Ser Pro Ser Lys Ala Arg Leu His Leu
2195 2200 2205
Gln Gly Arg Ser Asn Ala Trp Arg Pro Gln Val Asn Asn Pro Lys
2210 2215 2220
Glu Trp Leu Gln Val Asp Phe Gln Lys Thr Met Lys Val Thr Gly
2225 2230 2235
Val Thr Thr Gln Gly Val Lys Ser Leu Leu Thr Ser Met Tyr Val
2240 2245 2250
Lys Glu Phe Leu Ile Ser Ser Ser Gln Asp Gly His Gln Trp Thr
2255 2260 2265
Leu Phe Phe Gln Asn Gly Lys Val Lys Val Phe Gln Gly Asn Gln
2270 2275 2280
Asp Ser Phe Thr Pro Val Val Asn Ser Leu Asp Pro Pro Leu Leu
2285 2290 2295
Thr Arg Tyr Leu Arg Ile His Pro Gln Ser Trp Val His Gln Ile
2300 2305 2310
Ala Leu Arg Met Glu Val Leu Gly Cys Glu Ala Gln Asp Leu Tyr
2315 2320 2325
<210> 107
<211> 7053
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Зрелый полноразмерный FVIII
<400> 107
atgcaaatag agctctccac ctgcttcttt ctgtgccttt tgcgattctg ctttagtgcc
60
accagaagat actacctggg tgcagtggaa ctgtcatggg actatatgca aagtgatctc
120
ggtgagctgc ctgtggacgc aagatttcct cctagagtgc caaaatcttt tccattcaac
180
acctcagtcg tgtacaaaaa gactctgttt gtagaattca cggatcacct tttcaacatc
240
gctaagccaa ggccaccctg gatgggtctg ctaggtccta ccatccaggc tgaggtttat
300
gatacagtgg tcattacact taagaacatg gcttcccatc ctgtcagtct tcatgctgtt
360
ggtgtatcct actggaaagc ttctgaggga gctgaatatg atgatcagac cagtcaaagg
420
gagaaagaag atgataaagt cttccctggt ggaagccata catatgtctg gcaggtcctg
480
aaagagaatg gtccaatggc ctctgaccca ctgtgcctta cctactcata tctttctcat
540
gtggacctgg taaaagactt gaattcaggc ctcattggag ccctactagt atgtagagaa
600
gggagtctgg ccaaggaaaa gacacagacc ttgcacaaat ttatactact ttttgctgta
660
tttgatgaag ggaaaagttg gcactcagaa acaaagaact ccttgatgca ggatagggat
720
gctgcatctg ctcgggcctg gcctaaaatg cacacagtca atggttatgt aaacaggtct
780
ctgccaggtc tgattggatg ccacaggaaa tcagtctatt ggcatgtgat tggaatgggc
840
accactcctg aagtgcactc aatattcctc gaaggtcaca catttcttgt gaggaaccat
900
cgccaggcgt ccttggaaat ctcgccaata actttcctta ctgctcaaac actcttgatg
960
gaccttggac agtttctact gttttgtcat atctcttccc accaacatga tggcatggaa
1020
gcttatgtca aagtagacag ctgtccagag gaaccccaac tacgaatgaa aaataatgaa
1080
gaagcggaag actatgatga tgatcttact gattctgaaa tggatgtggt caggtttgat
1140
gatgacaact ctccttcctt tatccaaatt cgctcagttg ccaagaagca tcctaaaact
1200
tgggtacatt acattgctgc tgaagaggag gactgggact atgctccctt agtcctcgcc
1260
cccgatgaca gaagttataa aagtcaatat ttgaacaatg gccctcagcg gattggtagg
1320
aagtacaaaa aagtccgatt tatggcatac acagatgaaa cctttaagac tcgtgaagct
1380
attcagcatg aatcaggaat cttgggacct ttactttatg gggaagttgg agacacactg
1440
ttgattatat ttaagaatca agcaagcaga ccatataaca tctaccctca cggaatcact
1500
gatgtccgtc ctttgtattc aaggagatta ccaaaaggtg taaaacattt gaaggatttt
1560
ccaattctgc caggagaaat attcaaatat aaatggacag tgactgtaga agatgggcca
1620
actaaatcag atcctcggtg cctgacccgc tattactcta gtttcgttaa tatggagaga
1680
gatctagctt caggactcat tggccctctc ctcatctgct acaaagaatc tgtagatcaa
1740
agaggaaacc agataatgtc agacaagagg aatgtcatcc tgttttctgt atttgatgag
1800
aaccgaagct ggtacctcac agagaatata caacgctttc tccccaatcc agctggagtg
1860
cagcttgagg atccagagtt ccaagcctcc aacatcatgc acagcatcaa tggctatgtt
1920
tttgatagtt tgcagttgtc agtttgtttg catgaggtgg catactggta cattctaagc
1980
attggagcac agactgactt cctttctgtc ttcttctctg gatatacctt caaacacaaa
2040
atggtctatg aagacacact caccctattc ccattctcag gagaaactgt cttcatgtcg
2100
atggaaaacc caggtctatg gattctgggg tgccacaact cagactttcg gaacagaggc
2160
atgaccgcct tactgaaggt ttctagttgt gacaagaaca ctggtgatta ttacgaggac
2220
agttatgaag atatttcagc atacttgctg agtaaaaaca atgccattga accaagaagc
2280
ttctcccaga attcaagaca ccctagcact aggcaaaagc aatttaatgc caccacaatt
2340
ccagaaaatg acatagagaa gactgaccct tggtttgcac acagaacacc tatgcctaaa
2400
atacaaaatg tctcctctag tgatttgttg atgctcttgc gacagagtcc tactccacat
2460
gggctatcct tatctgatct ccaagaagcc aaatatgaga ctttttctga tgatccatca
2520
cctggagcaa tagacagtaa taacagcctg tctgaaatga cacacttcag gccacagctc
2580
catcacagtg gggacatggt atttacccct gagtcaggcc tccaattaag attaaatgag
2640
aaactgggga caactgcagc aacagagttg aagaaacttg atttcaaagt ttctagtaca
2700
tcaaataatc tgatttcaac aattccatca gacaatttgg cagcaggtac tgataataca
2760
agttccttag gacccccaag tatgccagtt cattatgata gtcaattaga taccactcta
2820
tttggcaaaa agtcatctcc ccttactgag tctggtggac ctctgagctt gagtgaagaa
2880
aataatgatt caaagttgtt agaatcaggt ttaatgaata gccaagaaag ttcatgggga
2940
aaaaatgtat cgtcaacaga gagtggtagg ttatttaaag ggaaaagagc tcatggacct
3000
gctttgttga ctaaagataa tgccttattc aaagttagca tctctttgtt aaagacaaac
3060
aaaacttcca ataattcagc aactaataga aagactcaca ttgatggccc atcattatta
3120
attgagaata gtccatcagt ctggcaaaat atattagaaa gtgacactga gtttaaaaaa
3180
gtgacacctt tgattcatga cagaatgctt atggacaaaa atgctacagc tttgaggcta
3240
aatcatatgt caaataaaac tacttcatca aaaaacatgg aaatggtcca acagaaaaaa
3300
gagggcccca ttccaccaga tgcacaaaat ccagatatgt cgttctttaa gatgctattc
3360
ttgccagaat cagcaaggtg gatacaaagg actcatggaa agaactctct gaactctggg
3420
caaggcccca gtccaaagca attagtatcc ttaggaccag aaaaatctgt ggaaggtcag
3480
aatttcttgt ctgagaaaaa caaagtggta gtaggaaagg gtgaatttac aaaggacgta
3540
ggactcaaag agatggtttt tccaagcagc agaaacctat ttcttactaa cttggataat
3600
ttacatgaaa ataatacaca caatcaagaa aaaaaaattc aggaagaaat agaaaagaag
3660
gaaacattaa tccaagagaa tgtagttttg cctcagatac atacagtgac tggcactaag
3720
aatttcatga agaacctttt cttactgagc actaggcaaa atgtagaagg ttcatatgac
3780
ggggcatatg ctccagtact tcaagatttt aggtcattaa atgattcaac aaatagaaca
3840
aagaaacaca cagctcattt ctcaaaaaaa ggggaggaag aaaacttgga aggcttggga
3900
aatcaaacca agcaaattgt agagaaatat gcatgcacca caaggatatc tcctaataca
3960
agccagcaga attttgtcac gcaacgtagt aagagagctt tgaaacaatt cagactccca
4020
ctagaagaaa cagaacttga aaaaaggata attgtggatg acacctcaac ccagtggtcc
4080
aaaaacatga aacatttgac cccgagcacc ctcacacaga tagactacaa tgagaaggag
4140
aaaggggcca ttactcagtc tcccttatca gattgcctta cgaggagtca tagcatccct
4200
caagcaaata gatctccatt acccattgca aaggtatcat catttccatc tattagacct
4260
atatatctga ccagggtcct attccaagac aactcttctc atcttccagc agcatcttat
4320
agaaagaaag attctggggt ccaagaaagc agtcatttct tacaaggagc caaaaaaaat
4380
aacctttctt tagccattct aaccttggag atgactggtg atcaaagaga ggttggctcc
4440
ctggggacaa gtgccacaaa ttcagtcaca tacaagaaag ttgagaacac tgttctcccg
4500
aaaccagact tgcccaaaac atctggcaaa gttgaattgc ttccaaaagt tcacatttat
4560
cagaaggacc tattccctac ggaaactagc aatgggtctc ctggccatct ggatctcgtg
4620
gaagggagcc ttcttcaggg aacagaggga gcgattaagt ggaatgaagc aaacagacct
4680
ggaaaagttc cctttctgag agtagcaaca gaaagctctg caaagactcc ctccaagcta
4740
ttggatcctc ttgcttggga taaccactat ggtactcaga taccaaaaga agagtggaaa
4800
tcccaagaga agtcaccaga aaaaacagct tttaagaaaa aggataccat tttgtccctg
4860
aacgcttgtg aaagcaatca tgcaatagca gcaataaatg agggacaaaa taagcccgaa
4920
atagaagtca cctgggcaaa gcaaggtagg actgaaaggc tgtgctctca aaacccacca
4980
gtcttgaaac gccatcaacg ggaaataact cgtactactc ttcagtcaga tcaagaggaa
5040
attgactatg atgataccat atcagttgaa atgaagaagg aagattttga catttatgat
5100
gaggatgaaa atcagagccc ccgcagcttt caaaagaaaa cacgacacta ttttattgct
5160
gcagtggaga ggctctggga ttatgggatg agtagctccc cacatgttct aagaaacagg
5220
gctcagagtg gcagtgtccc tcagttcaag aaagttgttt tccaggaatt tactgatggc
5280
tcctttactc agcccttata ccgtggagaa ctaaatgaac atttgggact cctggggcca
5340
tatataagag cagaagttga agataatatc atggtaactt tcagaaatca ggcctctcgt
5400
ccctattcct tctattctag ccttatttct tatgaggaag atcagaggca aggagcagaa
5460
cctagaaaaa actttgtcaa gcctaatgaa accaaaactt acttttggaa agtgcaacat
5520
catatggcac ccactaaaga tgagtttgac tgcaaagcct gggcttattt ctctgatgtt
5580
gacctggaaa aagatgtgca ctcaggcctg attggacccc ttctggtctg ccacactaac
5640
acactgaacc ctgctcatgg gagacaagtg acagtacagg aatttgctct gtttttcacc
5700
atctttgatg agaccaaaag ctggtacttc actgaaaata tggaaagaaa ctgcagggct
5760
ccctgcaata tccagatgga agatcccact tttaaagaga attatcgctt ccatgcaatc
5820
aatggctaca taatggatac actacctggc ttagtaatgg ctcaggatca aaggattcga
5880
tggtatctgc tcagcatggg cagcaatgaa aacatccatt ctattcattt cagtggacat
5940
gtgttcactg tacgaaaaaa agaggagtat aaaatggcac tgtacaatct ctatccaggt
6000
gtttttgaga cagtggaaat gttaccatcc aaagctggaa tttggcgggt ggaatgcctt
6060
attggcgagc atctacatgc tgggatgagc acactttttc tggtgtacag caataagtgt
6120
cagactcccc tgggaatggc ttctggacac attagagatt ttcagattac agcttcagga
6180
caatatggac agtgggcccc aaagctggcc agacttcatt attccggatc aatcaatgcc
6240
tggagcacca aggagccctt ttcttggatc aaggtggatc tgttggcacc aatgattatt
6300
cacggcatca agacccaggg tgcccgtcag aagttctcca gcctctacat ctctcagttt
6360
atcatcatgt atagtcttga tgggaagaag tggcagactt atcgaggaaa ttccactgga
6420
accttaatgg tcttctttgg caatgtggat tcatctggga taaaacacaa tatttttaac
6480
cctccaatta ttgctcgata catccgtttg cacccaactc attatagcat tcgcagcact
6540
cttcgcatgg agttgatggg ctgtgattta aatagttgca gcatgccatt gggaatggag
6600
agtaaagcaa tatcagatgc acagattact gcttcatcct actttaccaa tatgtttgcc
6660
acctggtctc cttcaaaagc tcgacttcac ctccaaggga ggagtaatgc ctggagacct
6720
caggtgaata atccaaaaga gtggctgcaa gtggacttcc agaagacaat gaaagtcaca
6780
ggagtaacta ctcagggagt aaaatctctg cttaccagca tgtatgtgaa ggagttcctc
6840
atctccagca gtcaagatgg ccatcagtgg actctctttt ttcagaatgg caaagtaaag
6900
gtttttcagg gaaatcaaga ctccttcaca cctgtggtga actctctaga cccaccgtta
6960
ctgactcgct accttcgaat tcacccccag agttgggtgc accagattgc cctgaggatg
7020
gaggttctgg gctgcgaggc acaggacctc tac
7053
<210> 108
<400> 108
000
<210> 109
<211> 1718
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> BIVV001 BDD-FVIII(XTEN) последовательность (без Fc)
<400> 109
Ala Thr Arg Arg Tyr Tyr Leu Gly Ala Val Glu Leu Ser Trp Asp Tyr
1. 5 10 15
Met Gln Ser Asp Leu Gly Glu Leu Pro Val Asp Ala Arg Phe Pro Pro
20 25 30
Arg Val Pro Lys Ser Phe Pro Phe Asn Thr Ser Val Val Tyr Lys Lys
35 40 45
Thr Leu Phe Val Glu Phe Thr Asp His Leu Phe Asn Ile Ala Lys Pro
50 55 60
Arg Pro Pro Trp Met Gly Leu Leu Gly Pro Thr Ile Gln Ala Glu Val
65 70 75 80
Tyr Asp Thr Val Val Ile Thr Leu Lys Asn Met Ala Ser His Pro Val
85 90 95
Ser Leu His Ala Val Gly Val Ser Tyr Trp Lys Ala Ser Glu Gly Ala
100 105 110
Glu Tyr Asp Asp Gln Thr Ser Gln Arg Glu Lys Glu Asp Asp Lys Val
115 120 125
Phe Pro Gly Gly Ser His Thr Tyr Val Trp Gln Val Leu Lys Glu Asn
130 135 140
Gly Pro Met Ala Ser Asp Pro Leu Cys Leu Thr Tyr Ser Tyr Leu Ser
145 150 155 160
His Val Asp Leu Val Lys Asp Leu Asn Ser Gly Leu Ile Gly Ala Leu
165 170 175
Leu Val Cys Arg Glu Gly Ser Leu Ala Lys Glu Lys Thr Gln Thr Leu
180 185 190
His Lys Phe Ile Leu Leu Phe Ala Val Phe Asp Glu Gly Lys Ser Trp
195 200 205
His Ser Glu Thr Lys Asn Ser Leu Met Gln Asp Arg Asp Ala Ala Ser
210 215 220
Ala Arg Ala Trp Pro Lys Met His Thr Val Asn Gly Tyr Val Asn Arg
225 230 235 240
Ser Leu Pro Gly Leu Ile Gly Cys His Arg Lys Ser Val Tyr Trp His
245 250 255
Val Ile Gly Met Gly Thr Thr Pro Glu Val His Ser Ile Phe Leu Glu
260 265 270
Gly His Thr Phe Leu Val Arg Asn His Arg Gln Ala Ser Leu Glu Ile
275 280 285
Ser Pro Ile Thr Phe Leu Thr Ala Gln Thr Leu Leu Met Asp Leu Gly
290 295 300
Gln Phe Leu Leu Phe Cys His Ile Ser Ser His Gln His Asp Gly Met
305 310 315 320
Glu Ala Tyr Val Lys Val Asp Ser Cys Pro Glu Glu Pro Gln Leu Arg
325 330 335
Met Lys Asn Asn Glu Glu Ala Glu Asp Tyr Asp Asp Asp Leu Thr Asp
340 345 350
Ser Glu Met Asp Val Val Arg Phe Asp Asp Asp Asn Ser Pro Ser Phe
355 360 365
Ile Gln Ile Arg Ser Val Ala Lys Lys His Pro Lys Thr Trp Val His
370 375 380
Tyr Ile Ala Ala Glu Glu Glu Asp Trp Asp Tyr Ala Pro Leu Val Leu
385 390 395 400
Ala Pro Asp Asp Arg Ser Tyr Lys Ser Gln Tyr Leu Asn Asn Gly Pro
405 410 415
Gln Arg Ile Gly Arg Lys Tyr Lys Lys Val Arg Phe Met Ala Tyr Thr
420 425 430
Asp Glu Thr Phe Lys Thr Arg Glu Ala Ile Gln His Glu Ser Gly Ile
435 440 445
Leu Gly Pro Leu Leu Tyr Gly Glu Val Gly Asp Thr Leu Leu Ile Ile
450 455 460
Phe Lys Asn Gln Ala Ser Arg Pro Tyr Asn Ile Tyr Pro His Gly Ile
465 470 475 480
Thr Asp Val Arg Pro Lys Arg Arg Leu Pro Lys Gly Val Lys His Leu
485 490 495
Lys Asp Phe Pro Ile Leu Pro Gly Glu Ile Phe Lys Tyr Lys Trp Thr
500 505 510
Val Thr Val Glu Asp Gly Pro Thr Lys Ser Asp Pro Arg Cys Leu Thr
515 520 525
Arg Tyr Tyr Ser Ser Phe Val Asn Met Glu Arg Asp Leu Ala Ser Gly
530 535 540
Leu Ile Gly Pro Leu Leu Ile Cys Tyr Lys Glu Ser Val Asp Gln Arg
545 550 555 560
Gly Asn Gln Ile Met Ser Asp Lys Arg Asn Val Ile Leu Phe Ser Val
565 570 575
Phe Asp Glu Asn Arg Ser Trp Tyr Leu Thr Glu Asn Ile Gln Arg Phe
580 585 590
Leu Pro Asn Pro Ala Gly Val Gln Leu Glu Asp Pro Glu Phe Gln Ala
595 600 605
Ser Asn Ile Met His Ser Ile Asn Gly Tyr Val Phe Asp Ser Leu Gln
610 615 620
Leu Ser Val Cys Leu His Glu Val Ala Tyr Trp Tyr Ile Leu Ser Ile
625 630 635 640
Gly Ala Gln Thr Asp Phe Leu Ser Val Phe Phe Ser Gly Tyr Thr Phe
645 650 655
Lys His Lys Met Val Tyr Glu Asp Thr Leu Thr Leu Phe Pro Phe Ser
660 665 670
Gly Glu Thr Val Phe Met Ser Met Glu Asn Pro Gly Leu Trp Ile Leu
675 680 685
Gly Cys His Asn Ser Asp Phe Arg Asn Arg Gly Met Thr Ala Leu Leu
690 695 700
Lys Val Ser Ser Cys Asp Lys Asn Thr Gly Asp Tyr Tyr Glu Asp Ser
705 710 715 720
Tyr Glu Asp Ile Ser Ala Tyr Leu Leu Ser Lys Asn Asn Ala Ile Glu
725 730 735
Pro Arg Ser Phe Ser Gln Asn Gly Thr Ser Glu Ser Ala Thr Pro Glu
740 745 750
Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly
755 760 765
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala
770 775 780
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu
785 790 795 800
Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
805 810 815
Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu Ser
820 825 830
Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser
835 840 845
Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly
850 855 860
Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Ser Pro Ala Gly
865 870 875 880
Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu Gly
885 890 895
Ser Ala Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly
900 905 910
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Glu Ser
915 920 925
Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser
930 935 940
Glu Thr Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly
945 950 955 960
Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Thr Glu
965 970 975
Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly
980 985 990
Ser Ala Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly
995 1000 1005
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr
1010 1015 1020
Glu Pro Ser Glu Gly Ser Ala Pro Ala Ser Ser Glu Ile Thr Arg
1025 1030 1035
Thr Thr Leu Gln Ser Asp Gln Glu Glu Ile Asp Tyr Asp Asp Thr
1040 1045 1050
Ile Ser Val Glu Met Lys Lys Glu Asp Phe Asp Ile Tyr Asp Glu
1055 1060 1065
Asp Glu Asn Gln Ser Pro Arg Ser Phe Gln Lys Lys Thr Arg His
1070 1075 1080
Tyr Phe Ile Ala Ala Val Glu Arg Leu Trp Asp Tyr Gly Met Ser
1085 1090 1095
Ser Ser Pro His Val Leu Arg Asn Arg Ala Gln Ser Gly Ser Val
1100 1105 1110
Pro Gln Phe Lys Lys Val Val Phe Gln Glu Phe Thr Asp Gly Ser
1115 1120 1125
Phe Thr Gln Pro Leu Tyr Arg Gly Glu Leu Asn Glu His Leu Gly
1130 1135 1140
Leu Leu Gly Pro Tyr Ile Arg Ala Glu Val Glu Asp Asn Ile Met
1145 1150 1155
Val Thr Phe Arg Asn Gln Ala Ser Arg Pro Tyr Ser Phe Tyr Ser
1160 1165 1170
Ser Leu Ile Ser Tyr Glu Glu Asp Gln Arg Gln Gly Ala Glu Pro
1175 1180 1185
Arg Lys Asn Phe Val Lys Pro Asn Glu Thr Lys Thr Tyr Phe Trp
1190 1195 1200
Lys Val Gln His His Met Ala Pro Thr Lys Asp Glu Phe Asp Cys
1205 1210 1215
Lys Ala Trp Ala Tyr Phe Ser Asp Val Asp Leu Glu Lys Asp Val
1220 1225 1230
His Ser Gly Leu Ile Gly Pro Leu Leu Val Cys His Thr Asn Thr
1235 1240 1245
Leu Asn Pro Ala His Gly Arg Gln Val Thr Val Gln Glu Phe Ala
1250 1255 1260
Leu Phe Phe Thr Ile Phe Asp Glu Thr Lys Ser Trp Tyr Phe Thr
1265 1270 1275
Glu Asn Met Glu Arg Asn Cys Arg Ala Pro Cys Asn Ile Gln Met
1280 1285 1290
Glu Asp Pro Thr Phe Lys Glu Asn Tyr Arg Phe His Ala Ile Asn
1295 1300 1305
Gly Tyr Ile Met Asp Thr Leu Pro Gly Leu Val Met Ala Gln Asp
1310 1315 1320
Gln Arg Ile Arg Trp Tyr Leu Leu Ser Met Gly Ser Asn Glu Asn
1325 1330 1335
Ile His Ser Ile His Phe Ser Gly His Val Phe Thr Val Arg Lys
1340 1345 1350
Lys Glu Glu Tyr Lys Met Ala Leu Tyr Asn Leu Tyr Pro Gly Val
1355 1360 1365
Phe Glu Thr Val Glu Met Leu Pro Ser Lys Ala Gly Ile Trp Arg
1370 1375 1380
Val Glu Cys Leu Ile Gly Glu His Leu His Ala Gly Met Ser Thr
1385 1390 1395
Leu Phe Leu Val Tyr Ser Asn Lys Cys Gln Thr Pro Leu Gly Met
1400 1405 1410
Ala Ser Gly His Ile Arg Asp Phe Gln Ile Thr Ala Ser Gly Gln
1415 1420 1425
Tyr Gly Gln Trp Ala Pro Lys Leu Ala Arg Leu His Tyr Ser Gly
1430 1435 1440
Ser Ile Asn Ala Trp Ser Thr Lys Glu Pro Phe Ser Trp Ile Lys
1445 1450 1455
Val Asp Leu Leu Ala Pro Met Ile Ile His Gly Ile Lys Thr Gln
1460 1465 1470
Gly Ala Arg Gln Lys Phe Ser Ser Leu Tyr Ile Ser Gln Phe Ile
1475 1480 1485
Ile Met Tyr Ser Leu Asp Gly Lys Lys Trp Gln Thr Tyr Arg Gly
1490 1495 1500
Asn Ser Thr Gly Thr Leu Met Val Phe Phe Gly Asn Val Asp Ser
1505 1510 1515
Ser Gly Ile Lys His Asn Ile Phe Asn Pro Pro Ile Ile Ala Arg
1520 1525 1530
Tyr Ile Arg Leu His Pro Thr His Tyr Ser Ile Arg Ser Thr Leu
1535 1540 1545
Arg Met Glu Leu Met Gly Cys Asp Leu Asn Ser Cys Ser Met Pro
1550 1555 1560
Leu Gly Met Glu Ser Lys Ala Ile Ser Asp Ala Gln Ile Thr Ala
1565 1570 1575
Ser Ser Tyr Phe Thr Asn Met Phe Ala Thr Trp Ser Pro Ser Lys
1580 1585 1590
Ala Arg Leu His Leu Gln Gly Arg Ser Asn Ala Trp Arg Pro Gln
1595 1600 1605
Val Asn Asn Pro Lys Glu Trp Leu Gln Val Asp Phe Gln Lys Thr
1610 1615 1620
Met Lys Val Thr Gly Val Thr Thr Gln Gly Val Lys Ser Leu Leu
1625 1630 1635
Thr Ser Met Tyr Val Lys Glu Phe Leu Ile Ser Ser Ser Gln Asp
1640 1645 1650
Gly His Gln Trp Thr Leu Phe Phe Gln Asn Gly Lys Val Lys Val
1655 1660 1665
Phe Gln Gly Asn Gln Asp Ser Phe Thr Pro Val Val Asn Ser Leu
1670 1675 1680
Asp Pro Pro Leu Leu Thr Arg Tyr Leu Arg Ile His Pro Gln Ser
1685 1690 1695
Trp Val His Gln Ile Ala Leu Arg Met Glu Val Leu Gly Cys Glu
1700 1705 1710
Ala Gln Asp Leu Tyr
1715
<210> 110
<211> 6526
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Конструкция NB15.1v32 (AAV-FVIIIco6XTEN-ssDNA)
<400> 110
ctgcgcgctc gctcgctcac tgaggccgcc cgggcaaagc ccgggcgtcg ggcgaccttt
60
ggtcgcccgg cctcagtgag cgagcgagcg cgcagagagg gagtggccaa ctccatcact
120
aggggttcct gcggcaattc agtcgataac tataacggtc ctaaggtagc gatttaaata
180
cgcgctctct taaggtagcc ccgggacgcg tcaattgaga tctggatccg gtaccgaatt
240
cgcggccgcc tcgacgacta gcgtttaatt aaacgcgtgt ctgtctgcac atttcgtaga
300
gcgagtgttc cgatactcta atctccctag gcaaggttca tatttgtgta ggttacttat
360
tctccttttg ttgactaagt caataatcag aatcagcagg tttggagtca gcttggcagg
420
gatcagcagc ctgggttgga aggagggggt ataaaagccc cttcaccagg agaagccgtc
480
acacagatcc acaagctcct gaggtaagtg ccgtgtgtgg ttcccgcggg cctggcctct
540
ttacgggtta tggcccttgc gtgccttgaa ttactgacac tgacatccac tttttctttt
600
tctccacagc tagcgccacc atgcagattg agctgtccac ttgtttcttc ctgtgcctcc
660
tgcgcttctg tttctccgcc actcgccggt actaccttgg agccgtggag ctttcatggg
720
actacatgca gagcgacctg ggcgaactcc ccgtggatgc cagattcccc ccccgcgtgc
780
caaagtcctt cccctttaac acctccgtgg tgtacaagaa aaccctcttt gtcgagttca
840
ctgaccacct gttcaacatc gccaagccgc gcccaccttg gatgggcctc ctgggaccga
900
ccattcaagc tgaagtgtac gacaccgtgg tgatcaccct gaagaacatg gcgtcccacc
960
ccgtgtccct gcatgcggtc ggagtgtcct actggaaggc ctccgaagga gctgagtacg
1020
acgaccagac tagccagcgg gaaaaggagg acgataaagt gttcccgggc ggctcgcata
1080
cttacgtgtg gcaagtcctg aaggaaaacg gacctatggc atccgatcct ctgtgcctga
1140
cttactccta cctttcccat gtggacctcg tgaaggacct gaacagcggg ctgattggtg
1200
cacttctcgt gtgccgcgaa ggttcgctcg ctaaggaaaa gacccagacc ctccataagt
1260
tcatcctttt gttcgctgtg ttcgatgaag gaaagtcatg gcattccgaa actaagaact
1320
cgctgatgca ggaccgggat gccgcctcag cccgcgcctg gcctaaaatg catacagtca
1380
acggatacgt gaatcggtca ctgcccgggc tcatcggttg tcacagaaag tccgtgtact
1440
ggcacgtcat cggcatgggc actacgcctg aagtgcactc catcttcctg gaagggcaca
1500
ccttcctcgt gcgcaaccac cgccaggcct ctctggaaat ctccccgatt acctttctga
1560
ccgcccagac tctgctcatg gacctggggc agttccttct cttctgccac atctccagcc
1620
atcagcacga cggaatggag gcctacgtga aggtggactc atgcccggaa gaacctcagt
1680
tgcggatgaa gaacaacgag gaggccgagg actatgacga cgatttgact gactccgaga
1740
tggacgtcgt gcggttcgat gacgacaaca gccccagctt catccagatt cgcagcgtgg
1800
ccaagaagca ccccaaaacc tgggtgcact acatcgcggc cgaggaagaa gattgggact
1860
acgccccgtt ggtgctggca cccgatgacc ggtcgtacaa gtcccagtat ctgaacaatg
1920
gtccgcagcg gattggcaga aagtacaaga aagtgcggtt catggcgtac actgacgaaa
1980
cgtttaagac ccgggaggcc attcaacatg agagcggcat tctgggacca ctgctgtacg
2040
gagaggtcgg cgataccctg ctcatcatct tcaaaaacca ggcctcccgg ccttacaaca
2100
tctaccctca cggaatcacc gacgtgcggc cactctactc gcggcgcctg ccgaagggcg
2160
tcaagcacct gaaagacttc cctatcctgc cgggcgaaat cttcaagtat aagtggaccg
2220
tcaccgtgga ggacgggccc accaagagcg atcctaggtg tctgactcgg tactactcca
2280
gcttcgtgaa catggaacgg gacctggcat cgggactcat tggaccgctg ctgatctgct
2340
acaaagagtc ggtggatcaa cgcggcaacc agatcatgtc cgacaagcgc aacgtgatcc
2400
tgttctccgt gtttgatgaa aacagatcct ggtacctcac tgaaaacatc cagaggttcc
2460
tcccaaaccc cgcaggagtg caactggagg accctgagtt tcaggcctcg aatatcatgc
2520
actcgattaa cggttacgtg ttcgactcgc tgcaactgag cgtgtgcctc catgaagtcg
2580
cttactggta cattctgtcc atcggcgccc agactgactt cctgagcgtg ttcttttccg
2640
gttacacctt taagcacaag atggtgtacg aagataccct gaccctgttc cctttctccg
2700
gcgaaacggt gttcatgtcg atggagaacc cgggtctgtg gattctggga tgccacaaca
2760
gcgactttcg gaaccgcgga atgactgccc tgctgaaggt gtcctcatgc gacaagaaca
2820
ccggagacta ctacgaggac tcctacgagg atatctcagc ctacctcctg tccaagaaca
2880
acgcgatcga gccgcgcagc ttcagccaga acggcgcgcc aacatcagag agcgccaccc
2940
ctgaaagtgg tcccgggagc gagccagcca catctgggtc ggaaacgcca ggcacaagtg
3000
agtctgcaac tcccgagtcc ggacctggct ccgagcctgc cactagcggc tccgagactc
3060
cgggaacttc cgagagcgct acaccagaaa gcggacccgg aaccagtacc gaacctagcg
3120
agggctctgc tccgggcagc ccagccggct ctcctacatc cacggaggag ggcacttccg
3180
aatccgccac cccggagtca gggccaggat ctgaacccgc tacctcaggc agtgagacgc
3240
caggaacgag cgagtccgct acaccggaga gtgggccagg gagccctgct ggatctccta
3300
cgtccactga ggaagggtca ccagcgggct cgcccaccag cactgaagaa ggtgcctcga
3360
gcccgcctgt gctgaagagg caccagcgag aaattacccg gaccaccctc caatcggatc
3420
aggaggaaat cgactacgac gacaccatct cggtggaaat gaagaaggaa gatttcgata
3480
tctacgacga ggacgaaaat cagtcccctc gctcattcca aaagaaaact agacactact
3540
ttatcgccgc ggtggaaaga ctgtgggact atggaatgtc atccagccct cacgtccttc
3600
ggaaccgggc ccagagcgga tcggtgcctc agttcaagaa agtggtgttc caggagttca
3660
ccgacggcag cttcacccag ccgctgtacc ggggagaact gaacgaacac ctgggcctgc
3720
tcggtcccta catccgcgcg gaagtggagg ataacatcat ggtgaccttc cgtaaccaag
3780
catccagacc ttactccttc tattcctccc tgatctcata cgaggaggac cagcgccaag
3840
gcgccgagcc ccgcaagaac ttcgtcaagc ccaacgagac taagacctac ttctggaagg
3900
tccaacacca tatggccccg accaaggatg agtttgactg caaggcctgg gcctacttct
3960
ccgacgtgga ccttgagaag gatgtccatt ccggcctgat cgggccgctg ctcgtgtgtc
4020
acaccaacac cctgaaccca gcgcatggac gccaggtcac cgtccaggag tttgctctgt
4080
tcttcaccat ttttgacgaa actaagtcct ggtacttcac cgagaatatg gagcgaaact
4140
gtagagcgcc ctgcaatatc cagatggaag atccgacttt caaggagaac tatagattcc
4200
acgccatcaa cgggtacatc atggatactc tgccggggct ggtcatggcc caggatcaga
4260
ggattcggtg gtacttgctg tcaatgggat cgaacgaaaa cattcactcc attcacttct
4320
ccggtcacgt gttcactgtg cgcaagaagg aggagtacaa gatggcgctg tacaatctgt
4380
accccggggt gttcgaaact gtggagatgc tgccgtccaa ggccggcatc tggagagtgg
4440
agtgcctgat cggagagcac ctccacgcgg ggatgtccac cctcttcctg gtgtactcga
4500
ataagtgcca gaccccgctg ggcatggcct cgggccacat cagagacttc cagatcacag
4560
caagcggaca atacggccaa tgggcgccga agctggcccg cttgcactac tccggatcga
4620
tcaacgcatg gtccaccaag gaaccgttct cgtggattaa ggtggacctc ctggccccta
4680
tgattatcca cggaattaag acccagggcg ccaggcagaa gttctcctcc ctgtacatct
4740
cgcaattcat catcatgtac agcctggacg ggaagaagtg gcagacttac aggggaaact
4800
ccaccggcac cctgatggtc tttttcggca acgtggattc ctccggcatt aagcacaaca
4860
tcttcaaccc accgatcata gccagatata ttaggctcca ccccactcac tactcaatcc
4920
gctcaactct tcggatggaa ctcatggggt gcgacctgaa ctcctgctcc atgccgttgg
4980
ggatggaatc aaaggctatt agcgacgccc agatcaccgc gagctcctac ttcactaaca
5040
tgttcgccac ctggagcccc tccaaggcca ggctgcactt gcagggacgg tcaaatgcct
5100
ggcggccgca agtgaacaat ccgaaggaat ggcttcaagt ggatttccaa aagaccatga
5160
aagtgaccgg agtcaccacc cagggagtga agtcccttct gacctcgatg tatgtgaagg
5220
agttcctgat tagcagcagc caggacgggc accagtggac cctgttcttc caaaacggaa
5280
aggtcaaggt gttccagggg aaccaggact cgttcacacc cgtggtgaac tccctggacc
5340
ccccactgct gacgcggtac ttgaggattc atcctcagtc ctgggtccat cagattgcat
5400
tgcgaatgga agtcctgggc tgcgaggccc aggacctgta ctgaatcagc ctgagctcgc
5460
tgatcataat caacctctgg attacaaaat ttgtgaaaga ttgactggta ttcttaacta
5520
tgttgctcct tttacgctat gtggatacgc tgctttaatg cctttgtatc atgctattgc
5580
ttcccgtatg gctttcattt tctcctcctt gtataaatcc tggttgctgt ctctttatga
5640
ggagttgtgg cccgttgtca ggcaacgtgg cgtggtgtgc actgtgtttg ctgacgcaac
5700
ccccactggt tggggcattg ccaccacctg tcagctcctt tccgggactt tcgctttccc
5760
cctccctatt gccacggcgg aactcatcgc cgcctgcctt gcccgctgct ggacaggggc
5820
tcggctgttg ggcactgaca attccgtggt gttgtcgggg aaatcatcgt cctttccttg
5880
gctgctcgcc tgtgttgcca cctggattct gcgcgggacg tccttctgct acgtcccttc
5940
ggccctcaat ccagcggacc ttccttcccg cggcctgctg ccggctctgc ggcctcttcc
6000
gcgtcttcgc cttcgccctc agacgagtcg gatctccctt tgggccgcct ccccgctgat
6060
cagcctcgac tgtgccttct agttgccagc catctgttgt ttgcccctcc cccgtgcctt
6120
ccttgaccct ggaaggtgcc actcccactg tcctttccta ataaaatgag gaaattgcat
6180
cgcattgtct gagtaggtgt cattctattc tggggggtgg ggtggggcag gacagcaagg
6240
gggaggattg ggaagacaat agcaggcatg ctggggatgc ggtgggctct atggcttctg
6300
aggcggaaag aacgggctcg agaagcttct agatatcctc tcttaaggta gcatcgagat
6360
ttaaattagg gataacaggg taatggcgcg ggccgcagga acccctagtg atggagttgg
6420
ccactccctc tctgcgcgct cgctcgctca ctgaggccgg gcgaccaaag gtcgcccgac
6480
gcccgggctt tgcccgggcg gcctcagtga gcgagcgagc gcgcag
6526
<210> 111
<211> 130
<212> ДНК
<213> Искусственная последовательность
<220>
<223> 5'-ITR (инвертированный концевой повтор AAV2 на 5'-конце)
<400> 111
ctgcgcgctc gctcgctcac tgaggccgcc cgggcaaagc ccgggcgtcg ggcgaccttt
60
ggtcgcccgg cctcagtgag cgagcgagcg cgcagagagg gagtggccaa ctccatcact
120
aggggttcct
130
<210> 112
<211> 142
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Каркасная последовательность плазмиды (PBS)-1
<400> 112
gcggcaattc agtcgataac tataacggtc ctaaggtagc gatttaaata cgcgctctct
60
taaggtagcc ccgggacgcg tcaattgaga tctggatccg gtaccgaatt cgcggccgcc
120
tcgacgacta gcgtttaatt aa
142
<210> 113
<211> 229
<212> ДНК
<213> Искусственная последовательность
<220>
<223> TTPp (специфический для печени промотор)
<400> 113
acgcgtgtct gtctgcacat ttcgtagagc gagtgttccg atactctaat ctccctaggc
60
aaggttcata tttgtgtagg ttacttattc tccttttgtt gactaagtca ataatcagaa
120
tcagcaggtt tggagtcagc ttggcaggga tcagcagcct gggttggaag gagggggtat
180
aaaagcccct tcaccaggag aagccgtcac acagatccac aagctcctg
229
<210> 114
<211> 2
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Каркасная последовательность плазмиды (PBS)-2
<400> 114
ag
2
<210> 115
<211> 106
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Синтетический интрон
<400> 115
gtaagtgccg tgtgtggttc ccgcgggcct ggcctcttta cgggttatgg cccttgcgtg
60
ccttgaatta ctgacactga catccacttt ttctttttct ccacag
106
<210> 116
<211> 11
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Каркасная последовательность плазмиды (PBS)-3
<400> 116
ctagcgccac c
11
<210> 117
<211> 4824
<212> ДНК
<213> Искусственная последовательность
<220>
<223> FVIIIco6XTEN (открытая рамка считывания для оптимизированного
по кодонам FVIII варианта 6, содержащего XTEN144)
<400> 117
atgcagattg agctgtccac ttgtttcttc ctgtgcctcc tgcgcttctg tttctccgcc
60
actcgccggt actaccttgg agccgtggag ctttcatggg actacatgca gagcgacctg
120
ggcgaactcc ccgtggatgc cagattcccc ccccgcgtgc caaagtcctt cccctttaac
180
acctccgtgg tgtacaagaa aaccctcttt gtcgagttca ctgaccacct gttcaacatc
240
gccaagccgc gcccaccttg gatgggcctc ctgggaccga ccattcaagc tgaagtgtac
300
gacaccgtgg tgatcaccct gaagaacatg gcgtcccacc ccgtgtccct gcatgcggtc
360
ggagtgtcct actggaaggc ctccgaagga gctgagtacg acgaccagac tagccagcgg
420
gaaaaggagg acgataaagt gttcccgggc ggctcgcata cttacgtgtg gcaagtcctg
480
aaggaaaacg gacctatggc atccgatcct ctgtgcctga cttactccta cctttcccat
540
gtggacctcg tgaaggacct gaacagcggg ctgattggtg cacttctcgt gtgccgcgaa
600
ggttcgctcg ctaaggaaaa gacccagacc ctccataagt tcatcctttt gttcgctgtg
660
ttcgatgaag gaaagtcatg gcattccgaa actaagaact cgctgatgca ggaccgggat
720
gccgcctcag cccgcgcctg gcctaaaatg catacagtca acggatacgt gaatcggtca
780
ctgcccgggc tcatcggttg tcacagaaag tccgtgtact ggcacgtcat cggcatgggc
840
actacgcctg aagtgcactc catcttcctg gaagggcaca ccttcctcgt gcgcaaccac
900
cgccaggcct ctctggaaat ctccccgatt acctttctga ccgcccagac tctgctcatg
960
gacctggggc agttccttct cttctgccac atctccagcc atcagcacga cggaatggag
1020
gcctacgtga aggtggactc atgcccggaa gaacctcagt tgcggatgaa gaacaacgag
1080
gaggccgagg actatgacga cgatttgact gactccgaga tggacgtcgt gcggttcgat
1140
gacgacaaca gccccagctt catccagatt cgcagcgtgg ccaagaagca ccccaaaacc
1200
tgggtgcact acatcgcggc cgaggaagaa gattgggact acgccccgtt ggtgctggca
1260
cccgatgacc ggtcgtacaa gtcccagtat ctgaacaatg gtccgcagcg gattggcaga
1320
aagtacaaga aagtgcggtt catggcgtac actgacgaaa cgtttaagac ccgggaggcc
1380
attcaacatg agagcggcat tctgggacca ctgctgtacg gagaggtcgg cgataccctg
1440
ctcatcatct tcaaaaacca ggcctcccgg ccttacaaca tctaccctca cggaatcacc
1500
gacgtgcggc cactctactc gcggcgcctg ccgaagggcg tcaagcacct gaaagacttc
1560
cctatcctgc cgggcgaaat cttcaagtat aagtggaccg tcaccgtgga ggacgggccc
1620
accaagagcg atcctaggtg tctgactcgg tactactcca gcttcgtgaa catggaacgg
1680
gacctggcat cgggactcat tggaccgctg ctgatctgct acaaagagtc ggtggatcaa
1740
cgcggcaacc agatcatgtc cgacaagcgc aacgtgatcc tgttctccgt gtttgatgaa
1800
aacagatcct ggtacctcac tgaaaacatc cagaggttcc tcccaaaccc cgcaggagtg
1860
caactggagg accctgagtt tcaggcctcg aatatcatgc actcgattaa cggttacgtg
1920
ttcgactcgc tgcaactgag cgtgtgcctc catgaagtcg cttactggta cattctgtcc
1980
atcggcgccc agactgactt cctgagcgtg ttcttttccg gttacacctt taagcacaag
2040
atggtgtacg aagataccct gaccctgttc cctttctccg gcgaaacggt gttcatgtcg
2100
atggagaacc cgggtctgtg gattctggga tgccacaaca gcgactttcg gaaccgcgga
2160
atgactgccc tgctgaaggt gtcctcatgc gacaagaaca ccggagacta ctacgaggac
2220
tcctacgagg atatctcagc ctacctcctg tccaagaaca acgcgatcga gccgcgcagc
2280
ttcagccaga acggcgcgcc aacatcagag agcgccaccc ctgaaagtgg tcccgggagc
2340
gagccagcca catctgggtc ggaaacgcca ggcacaagtg agtctgcaac tcccgagtcc
2400
ggacctggct ccgagcctgc cactagcggc tccgagactc cgggaacttc cgagagcgct
2460
acaccagaaa gcggacccgg aaccagtacc gaacctagcg agggctctgc tccgggcagc
2520
ccagccggct ctcctacatc cacggaggag ggcacttccg aatccgccac cccggagtca
2580
gggccaggat ctgaacccgc tacctcaggc agtgagacgc caggaacgag cgagtccgct
2640
acaccggaga gtgggccagg gagccctgct ggatctccta cgtccactga ggaagggtca
2700
ccagcgggct cgcccaccag cactgaagaa ggtgcctcga gcccgcctgt gctgaagagg
2760
caccagcgag aaattacccg gaccaccctc caatcggatc aggaggaaat cgactacgac
2820
gacaccatct cggtggaaat gaagaaggaa gatttcgata tctacgacga ggacgaaaat
2880
cagtcccctc gctcattcca aaagaaaact agacactact ttatcgccgc ggtggaaaga
2940
ctgtgggact atggaatgtc atccagccct cacgtccttc ggaaccgggc ccagagcgga
3000
tcggtgcctc agttcaagaa agtggtgttc caggagttca ccgacggcag cttcacccag
3060
ccgctgtacc ggggagaact gaacgaacac ctgggcctgc tcggtcccta catccgcgcg
3120
gaagtggagg ataacatcat ggtgaccttc cgtaaccaag catccagacc ttactccttc
3180
tattcctccc tgatctcata cgaggaggac cagcgccaag gcgccgagcc ccgcaagaac
3240
ttcgtcaagc ccaacgagac taagacctac ttctggaagg tccaacacca tatggccccg
3300
accaaggatg agtttgactg caaggcctgg gcctacttct ccgacgtgga ccttgagaag
3360
gatgtccatt ccggcctgat cgggccgctg ctcgtgtgtc acaccaacac cctgaaccca
3420
gcgcatggac gccaggtcac cgtccaggag tttgctctgt tcttcaccat ttttgacgaa
3480
actaagtcct ggtacttcac cgagaatatg gagcgaaact gtagagcgcc ctgcaatatc
3540
cagatggaag atccgacttt caaggagaac tatagattcc acgccatcaa cgggtacatc
3600
atggatactc tgccggggct ggtcatggcc caggatcaga ggattcggtg gtacttgctg
3660
tcaatgggat cgaacgaaaa cattcactcc attcacttct ccggtcacgt gttcactgtg
3720
cgcaagaagg aggagtacaa gatggcgctg tacaatctgt accccggggt gttcgaaact
3780
gtggagatgc tgccgtccaa ggccggcatc tggagagtgg agtgcctgat cggagagcac
3840
ctccacgcgg ggatgtccac cctcttcctg gtgtactcga ataagtgcca gaccccgctg
3900
ggcatggcct cgggccacat cagagacttc cagatcacag caagcggaca atacggccaa
3960
tgggcgccga agctggcccg cttgcactac tccggatcga tcaacgcatg gtccaccaag
4020
gaaccgttct cgtggattaa ggtggacctc ctggccccta tgattatcca cggaattaag
4080
acccagggcg ccaggcagaa gttctcctcc ctgtacatct cgcaattcat catcatgtac
4140
agcctggacg ggaagaagtg gcagacttac aggggaaact ccaccggcac cctgatggtc
4200
tttttcggca acgtggattc ctccggcatt aagcacaaca tcttcaaccc accgatcata
4260
gccagatata ttaggctcca ccccactcac tactcaatcc gctcaactct tcggatggaa
4320
ctcatggggt gcgacctgaa ctcctgctcc atgccgttgg ggatggaatc aaaggctatt
4380
agcgacgccc agatcaccgc gagctcctac ttcactaaca tgttcgccac ctggagcccc
4440
tccaaggcca ggctgcactt gcagggacgg tcaaatgcct ggcggccgca agtgaacaat
4500
ccgaaggaat ggcttcaagt ggatttccaa aagaccatga aagtgaccgg agtcaccacc
4560
cagggagtga agtcccttct gacctcgatg tatgtgaagg agttcctgat tagcagcagc
4620
caggacgggc accagtggac cctgttcttc caaaacggaa aggtcaaggt gttccagggg
4680
aaccaggact cgttcacacc cgtggtgaac tccctggacc ccccactgct gacgcggtac
4740
ttgaggattc atcctcagtc ctgggtccat cagattgcat tgcgaatgga agtcctgggc
4800
tgcgaggccc aggacctgta ctga
4824
<210> 118
<211> 450
<212> ДНК
<213> Искусственная последовательность
<220>
<223> XTEN144
<400> 118
ggcgcgccaa catcagagag cgccacccct gaaagtggtc ccgggagcga gccagccaca
60
tctgggtcgg aaacgccagg cacaagtgag tctgcaactc ccgagtccgg acctggctcc
120
gagcctgcca ctagcggctc cgagactccg ggaacttccg agagcgctac accagaaagc
180
ggacccggaa ccagtaccga acctagcgag ggctctgctc cgggcagccc agccggctct
240
cctacatcca cggaggaggg cacttccgaa tccgccaccc cggagtcagg gccaggatct
300
gaacccgcta cctcaggcag tgagacgcca ggaacgagcg agtccgctac accggagagt
360
gggccaggga gccctgctgg atctcctacg tccactgagg aagggtcacc agcgggctcg
420
cccaccagca ctgaagaagg tgcctcgagc
450
<210> 119
<211> 19
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Каркасная последовательность плазмиды (PBS)-4
<400> 119
atcagcctga gctcgctga
19
<210> 120
<211> 595
<212> ДНК
<213> Искусственная последовательность
<220>
<223> WPRE (мутантный посттранскрипционный регуляторный элемент
вируса гепатита сурков)
<400> 120
tcataatcaa cctctggatt acaaaatttg tgaaagattg actggtattc ttaactatgt
60
tgctcctttt acgctatgtg gatacgctgc tttaatgcct ttgtatcatg ctattgcttc
120
ccgtatggct ttcattttct cctccttgta taaatcctgg ttgctgtctc tttatgagga
180
gttgtggccc gttgtcaggc aacgtggcgt ggtgtgcact gtgtttgctg acgcaacccc
240
cactggttgg ggcattgcca ccacctgtca gctcctttcc gggactttcg ctttccccct
300
ccctattgcc acggcggaac tcatcgccgc ctgccttgcc cgctgctgga caggggctcg
360
gctgttgggc actgacaatt ccgtggtgtt gtcggggaaa tcatcgtcct ttccttggct
420
gctcgcctgt gttgccacct ggattctgcg cgggacgtcc ttctgctacg tcccttcggc
480
cctcaatcca gcggaccttc cttcccgcgg cctgctgccg gctctgcggc ctcttccgcg
540
tcttcgcctt cgccctcaga cgagtcggat ctccctttgg gccgcctccc cgctg
595
<210> 121
<211> 8
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Каркасная последовательность плазмиды (PBS)-5
<400> 121
atcagcct
8
<210> 122
<211> 211
<212> ДНК
<213> Искусственная последовательность
<220>
<223> bGHpA (сигнал полиаденилирования бычьего гормона роста)
<400> 122
cgactgtgcc ttctagttgc cagccatctg ttgtttgccc ctcccccgtg ccttccttga
60
ccctggaagg tgccactccc actgtccttt cctaataaaa tgaggaaatt gcatcgcatt
120
gtctgagtag gtgtcattct attctggggg gtggggtggg gcaggacagc aagggggagg
180
attgggaaga caatagcagg catgctgggg a
211
<210> 123
<211> 119
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Каркасная последовательность плазмиды (PBS)-6
<400> 123
tgcggtgggc tctatggctt ctgaggcgga aagaacgggc tcgagaagct tctagatatc
60
ctctcttaag gtagcatcga gatttaaatt agggataaca gggtaatggc gcgggccgc
119
<210> 124
<211> 130
<212> ДНК
<213> Искусственная последовательность
<220>
<223> 3'-ITR (инвертированный концевой повтор AAV2 на 3'-конце)
<400> 124
aggaacccct agtgatggag ttggccactc cctctctgcg cgctcgctcg ctcactgagg
60
ccgggcgacc aaaggtcgcc cgacgcccgg gctttgcccg ggcggcctca gtgagcgagc
120
gagcgcgcag
130
<210> 125
<211> 415
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Зрелый полипептид FIX
<400> 125
Tyr Asn Ser Gly Lys Leu Glu Glu Phe Val Gln Gly Asn Leu Glu Arg
1. 5 10 15
Glu Cys Met Glu Glu Lys Cys Ser Phe Glu Glu Ala Arg Glu Val Phe
20 25 30
Glu Asn Thr Glu Arg Thr Thr Glu Phe Trp Lys Gln Tyr Val Asp Gly
35 40 45
Asp Gln Cys Glu Ser Asn Pro Cys Leu Asn Gly Gly Ser Cys Lys Asp
50 55 60
Asp Ile Asn Ser Tyr Glu Cys Trp Cys Pro Phe Gly Phe Glu Gly Lys
65 70 75 80
Asn Cys Glu Leu Asp Val Thr Cys Asn Ile Lys Asn Gly Arg Cys Glu
85 90 95
Gln Phe Cys Lys Asn Ser Ala Asp Asn Lys Val Val Cys Ser Cys Thr
100 105 110
Glu Gly Tyr Arg Leu Ala Glu Asn Gln Lys Ser Cys Glu Pro Ala Val
115 120 125
Pro Phe Pro Cys Gly Arg Val Ser Val Ser Gln Thr Ser Lys Leu Thr
130 135 140
Arg Ala Glu Thr Val Phe Pro Asp Val Asp Tyr Val Asn Ser Thr Glu
145 150 155 160
Ala Glu Thr Ile Leu Asp Asn Ile Thr Gln Ser Thr Gln Ser Phe Asn
165 170 175
Asp Phe Thr Arg Val Val Gly Gly Glu Asp Ala Lys Pro Gly Gln Phe
180 185 190
Pro Trp Gln Val Val Leu Asn Gly Lys Val Asp Ala Phe Cys Gly Gly
195 200 205
Ser Ile Val Asn Glu Lys Trp Ile Val Thr Ala Ala His Cys Val Glu
210 215 220
Thr Gly Val Lys Ile Thr Val Val Ala Gly Glu His Asn Ile Glu Glu
225 230 235 240
Thr Glu His Thr Glu Gln Lys Arg Asn Val Ile Arg Ile Ile Pro His
245 250 255
His Asn Tyr Asn Ala Ala Ile Asn Lys Tyr Asn His Asp Ile Ala Leu
260 265 270
Leu Glu Leu Asp Glu Pro Leu Val Leu Asn Ser Tyr Val Thr Pro Ile
275 280 285
Cys Ile Ala Asp Lys Glu Tyr Thr Asn Ile Phe Leu Lys Phe Gly Ser
290 295 300
Gly Tyr Val Ser Gly Trp Gly Arg Val Phe His Lys Gly Arg Ser Ala
305 310 315 320
Leu Val Leu Gln Tyr Leu Arg Val Pro Leu Val Asp Arg Ala Thr Cys
325 330 335
Leu Arg Ser Thr Lys Phe Thr Ile Tyr Asn Asn Met Phe Cys Ala Gly
340 345 350
Phe His Glu Gly Gly Arg Asp Ser Cys Gln Gly Asp Ser Gly Gly Pro
355 360 365
His Val Thr Glu Val Glu Gly Thr Ser Phe Leu Thr Gly Ile Ile Ser
370 375 380
Trp Gly Glu Glu Cys Ala Met Lys Gly Lys Tyr Gly Ile Tyr Thr Lys
385 390 395 400
Val Ser Arg Tyr Val Asn Trp Ile Lys Glu Lys Thr Lys Leu Thr
405 410 415
<210> 126
<211> 415
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Зрелый полипептид Padua(R338L)FIX
<400> 126
Tyr Asn Ser Gly Lys Leu Glu Glu Phe Val Gln Gly Asn Leu Glu Arg
1. 5 10 15
Glu Cys Met Glu Glu Lys Cys Ser Phe Glu Glu Ala Arg Glu Val Phe
20 25 30
Glu Asn Thr Glu Arg Thr Thr Glu Phe Trp Lys Gln Tyr Val Asp Gly
35 40 45
Asp Gln Cys Glu Ser Asn Pro Cys Leu Asn Gly Gly Ser Cys Lys Asp
50 55 60
Asp Ile Asn Ser Tyr Glu Cys Trp Cys Pro Phe Gly Phe Glu Gly Lys
65 70 75 80
Asn Cys Glu Leu Asp Val Thr Cys Asn Ile Lys Asn Gly Arg Cys Glu
85 90 95
Gln Phe Cys Lys Asn Ser Ala Asp Asn Lys Val Val Cys Ser Cys Thr
100 105 110
Glu Gly Tyr Arg Leu Ala Glu Asn Gln Lys Ser Cys Glu Pro Ala Val
115 120 125
Pro Phe Pro Cys Gly Arg Val Ser Val Ser Gln Thr Ser Lys Leu Thr
130 135 140
Arg Ala Glu Thr Val Phe Pro Asp Val Asp Tyr Val Asn Ser Thr Glu
145 150 155 160
Ala Glu Thr Ile Leu Asp Asn Ile Thr Gln Ser Thr Gln Ser Phe Asn
165 170 175
Asp Phe Thr Arg Val Val Gly Gly Glu Asp Ala Lys Pro Gly Gln Phe
180 185 190
Pro Trp Gln Val Val Leu Asn Gly Lys Val Asp Ala Phe Cys Gly Gly
195 200 205
Ser Ile Val Asn Glu Lys Trp Ile Val Thr Ala Ala His Cys Val Glu
210 215 220
Thr Gly Val Lys Ile Thr Val Val Ala Gly Glu His Asn Ile Glu Glu
225 230 235 240
Thr Glu His Thr Glu Gln Lys Arg Asn Val Ile Arg Ile Ile Pro His
245 250 255
His Asn Tyr Asn Ala Ala Ile Asn Lys Tyr Asn His Asp Ile Ala Leu
260 265 270
Leu Glu Leu Asp Glu Pro Leu Val Leu Asn Ser Tyr Val Thr Pro Ile
275 280 285
Cys Ile Ala Asp Lys Glu Tyr Thr Asn Ile Phe Leu Lys Phe Gly Ser
290 295 300
Gly Tyr Val Ser Gly Trp Gly Arg Val Phe His Lys Gly Arg Ser Ala
305 310 315 320
Leu Val Leu Gln Tyr Leu Arg Val Pro Leu Val Asp Arg Ala Thr Cys
325 330 335
Leu Leu Ser Thr Lys Phe Thr Ile Tyr Asn Asn Met Phe Cys Ala Gly
340 345 350
Phe His Glu Gly Gly Arg Asp Ser Cys Gln Gly Asp Ser Gly Gly Pro
355 360 365
His Val Thr Glu Val Glu Gly Thr Ser Phe Leu Thr Gly Ile Ile Ser
370 375 380
Trp Gly Glu Glu Cys Ala Met Lys Gly Lys Tyr Gly Ile Tyr Thr Lys
385 390 395 400
Val Ser Arg Tyr Val Asn Trp Ile Lys Glu Lys Thr Lys Leu Thr
405 410 415
<210> 127
<211> 46
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> FIX сигнальный полипептид и пропептид
<400> 127
Met Gln Arg Val Asn Met Ile Met Ala Glu Ser Pro Gly Leu Ile Thr
1. 5 10 15
Ile Cys Leu Leu Gly Tyr Leu Leu Ser Ala Glu Cys Thr Val Phe Leu
20 25 30
Asp His Glu Asn Ala Asn Lys Ile Leu Asn Arg Pro Lys Arg
35 40 45
<210> 128
<211> 8442
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Человеческий VWF
<400> 128
atgattcctg ccagatttgc cggggtgctg cttgctctgg ccctcatttt gccagggacc
60
ctttgtgcag aaggaactcg cggcaggtca tccacggccc gatgcagcct tttcggaagt
120
gacttcgtca acacctttga tgggagcatg tacagctttg cgggatactg cagttacctc
180
ctggcagggg gctgccagaa acgctccttc tcgattattg gggacttcca gaatggcaag
240
agagtgagcc tctccgtgta tcttggggaa ttttttgaca tccatttgtt tgtcaatggt
300
accgtgacac agggggacca aagagtctcc atgccctatg cctccaaagg gctgtatcta
360
gaaactgagg ctgggtacta caagctgtcc ggtgaggcct atggctttgt ggccaggatc
420
gatggcagcg gcaactttca agtcctgctg tcagacagat acttcaacaa gacctgcggg
480
ctgtgtggca actttaacat ctttgctgaa gatgacttta tgacccaaga agggaccttg
540
acctcggacc cttatgactt tgccaactca tgggctctga gcagtggaga acagtggtgt
600
gaacgggcat ctcctcccag cagctcatgc aacatctcct ctggggaaat gcagaagggc
660
ctgtgggagc agtgccagct tctgaagagc acctcggtgt ttgcccgctg ccaccctctg
720
gtggaccccg agccttttgt ggccctgtgt gagaagactt tgtgtgagtg tgctgggggg
780
ctggagtgcg cctgccctgc cctcctggag tacgcccgga cctgtgccca ggagggaatg
840
gtgctgtacg gctggaccga ccacagcgcg tgcagcccag tgtgccctgc tggtatggag
900
tataggcagt gtgtgtcccc ttgcgccagg acctgccaga gcctgcacat caatgaaatg
960
tgtcaggagc gatgcgtgga tggctgcagc tgccctgagg gacagctcct ggatgaaggc
1020
ctctgcgtgg agagcaccga gtgtccctgc gtgcattccg gaaagcgcta ccctcccggc
1080
acctccctct ctcgagactg caacacctgc atttgccgaa acagccagtg gatctgcagc
1140
aatgaagaat gtccagggga gtgccttgtc actggtcaat cccacttcaa gagctttgac
1200
aacagatact tcaccttcag tgggatctgc cagtacctgc tggcccggga ttgccaggac
1260
cactccttct ccattgtcat tgagactgtc cagtgtgctg atgaccgcga cgctgtgtgc
1320
acccgctccg tcaccgtccg gctgcctggc ctgcacaaca gccttgtgaa actgaagcat
1380
ggggcaggag ttgccatgga tggccaggac atccagctcc ccctcctgaa aggtgacctc
1440
cgcatccagc atacagtgac ggcctccgtg cgcctcagct acggggagga cctgcagatg
1500
gactgggatg gccgcgggag gctgctggtg aagctgtccc ccgtctatgc cgggaagacc
1560
tgcggcctgt gtgggaatta caatggcaac cagggcgacg acttccttac cccctctggg
1620
ctggcrgagc cccgggtgga ggacttcggg aacgcctgga agctgcacgg ggactgccag
1680
gacctgcaga agcagcacag cgatccctgc gccctcaacc cgcgcatgac caggttctcc
1740
gaggaggcgt gcgcggtcct gacgtccccc acattcgagg cctgccatcg tgccgtcagc
1800
ccgctgccct acctgcggaa ctgccgctac gacgtgtgct cctgctcgga cggccgcgag
1860
tgcctgtgcg gcgccctggc cagctatgcc gcggcctgcg cggggagagg cgtgcgcgtc
1920
gcgtggcgcg agccaggccg ctgtgagctg aactgcccga aaggccaggt gtacctgcag
1980
tgcgggaccc cctgcaacct gacctgccgc tctctctctt acccggatga ggaatgcaat
2040
gaggcctgcc tggagggctg cttctgcccc ccagggctct acatggatga gaggggggac
2100
tgcgtgccca aggcccagtg cccctgttac tatgacggtg agatcttcca gccagaagac
2160
atcttctcag accatcacac catgtgctac tgtgaggatg gcttcatgca ctgtaccatg
2220
agtggagtcc ccggaagctt gctgcctgac gctgtcctca gcagtcccct gtctcatcgc
2280
agcaaaagga gcctatcctg tcggcccccc atggtcaagc tggtgtgtcc cgctgacaac
2340
ctgcgggctg aagggctcga gtgtaccaaa acgtgccaga actatgacct ggagtgcatg
2400
agcatgggct gtgtctctgg ctgcctctgc cccccgggca tggtccggca tgagaacaga
2460
tgtgtggccc tggaaaggtg tccctgcttc catcagggca aggagtatgc ccctggagaa
2520
acagtgaaga ttggctgcaa cacttgtgtc tgtcgggacc ggaagtggaa ctgcacagac
2580
catgtgtgtg atgccacgtg ctccacgatc ggcatggccc actacctcac cttcgacggg
2640
ctcaaatacc tgttccccgg ggagtgccag tacgttctgg tgcaggatta ctgcggcagt
2700
aaccctggga cctttcggat cctagtgggg aataagggat gcagccaccc ctcagtgaaa
2760
tgcaagaaac gggtcaccat cctggtggag ggaggagaga ttgagctgtt tgacggggag
2820
gtgaatgtga agaggcccat gaaggatgag actcactttg aggtggtgga gtctggccgg
2880
tacatcattc tgctgctggg caaagccctc tccgtggtct gggaccgcca cctgagcatc
2940
tccgtggtcc tgaagcagac ataccaggag aaagtgtgtg gcctgtgtgg gaattttgat
3000
ggcatccaga acaatgacct caccagcagc aacctccaag tggaggaaga ccctgtggac
3060
tttgggaact cctggaaagt gagctcgcag tgtgctgaca ccagaaaagt gcctctggac
3120
tcatcccctg ccacctgcca taacaacatc atgaagcaga cgatggtgga ttcctcctgt
3180
agaatcctta ccagtgacgt cttccaggac tgcaacaagc tggtggaccc cgagccatat
3240
ctggatgtct gcatttacga cacctgctcc tgtgagtcca ttggggactg cgcctgcttc
3300
tgcgacacca ttgctgccta tgcccacgtg tgtgcccagc atggcaaggt ggtgacctgg
3360
aggacggcca cattgtgccc ccagagctgc gaggagagga atctccggga gaacgggtat
3420
gagtgtgagt ggcgctataa cagctgtgca cctgcctgtc aagtcacgtg tcagcaccct
3480
gagccactgg cctgccctgt gcagtgtgtg gagggctgcc atgcccactg ccctccaggg
3540
aaaatcctgg atgagctttt gcagacctgc gttgaccctg aagactgtcc agtgtgtgag
3600
gtggctggcc ggcgttttgc ctcaggaaag aaagtcacct tgaatcccag tgaccctgag
3660
cactgccaga tttgccactg tgatgttgtc aacctcacct gtgaagcctg ccaggagccg
3720
ggaggcctgg tggtgcctcc cacagatgcc ccggtgagcc ccaccactct gtatgtggag
3780
gacatctcgg aaccgccgtt gcacgatttc tactgcagca ggctactgga cctggtcttc
3840
ctgctggatg gctcctccag gctgtccgag gctgagtttg aagtgctgaa ggcctttgtg
3900
gtggacatga tggagcggct gcgcatctcc cagaagtggg tccgcgtggc cgtggtggag
3960
taccacgacg gctcccacgc ctacatcggg ctcaaggacc ggaagcgacc gtcagagctg
4020
cggcgcattg ccagccaggt gaagtatgcg ggcagccagg tggcctccac cagcgaggtc
4080
ttgaaataca cactgttcca aatcttcagc aagatcgacc gccctgaagc ctcccgcatc
4140
gccctgctcc tgatggccag ccaggagccc caacggatgt cccggaactt tgtccgctac
4200
gtccagggcc tgaagaagaa gaaggtcatt gtgatcccgg tgggcattgg gccccatgcc
4260
aacctcaagc agatccgcct catcgagaag caggcccctg agaacaaggc cttcgtgctg
4320
agcagtgtgg atgagctgga gcagcaaagg gacgagatcg ttagctacct ctgtgacctt
4380
gcccctgaag cccctcctcc tactctgccc cccgacatgg cacaagtcac tgtgggcccg
4440
gggctcttgg gggtttcgac cctggggccc aagaggaact ccatggttct ggatgtggcg
4500
ttcgtcctgg aaggatcgga caaaattggt gaagccgact tcaacaggag caaggagttc
4560
atggaggagg tgattcagcg gatggatgtg ggccaggaca gcatccacgt cacggtgctg
4620
cagtactcct acatggtgac cgtggagtac cccttcagcg aggcacagtc caaaggggac
4680
atcctgcagc gggtgcgaga gatccgctac cagggcggca acaggaccaa cactgggctg
4740
gccctgcggt acctctctga ccacagcttc ttggtcagcc agggtgaccg ggagcaggcg
4800
cccaacctgg tctacatggt caccggaaat cctgcctctg atgagatcaa gaggctgcct
4860
ggagacatcc aggtggtgcc cattggagtg ggccctaatg ccaacgtgca ggagctggag
4920
aggattggct ggcccaatgc ccctatcctc atccaggact ttgagacgct cccccgagag
4980
gctcctgacc tggtgctgca gaggtgctgc tccggagagg ggctgcagat ccccaccctc
5040
tcccctgcac ctgactgcag ccagcccctg gacgtgatcc ttctcctgga tggctcctcc
5100
agtttcccag cttcttattt tgatgaaatg aagagtttcg ccaaggcttt catttcaaaa
5160
gccaatatag ggcctcgtct cactcaggtg tcagtgctgc agtatggaag catcaccacc
5220
attgacgtgc catggaacgt ggtcccggag aaagcccatt tgctgagcct tgtggacgtc
5280
atgcagcggg agggaggccc cagccaaatc ggggatgcct tgggctttgc tgtgcgatac
5340
ttgacttcag aaatgcatgg tgccaggccg ggagcctcaa aggcggtggt catcctggtc
5400
acggacgtct ctgtggattc agtggatgca gcagctgatg ccgccaggtc caacagagtg
5460
acagtgttcc ctattggaat tggagatcgc tacgatgcag cccagctacg gatcttggca
5520
ggcccagcag gcgactccaa cgtggtgaag ctccagcgaa tcgaagacct ccctaccatg
5580
gtcaccttgg gcaattcctt cctccacaaa ctgtgctctg gatttgttag gatttgcatg
5640
gatgaggatg ggaatgagaa gaggcccggg gacgtctgga ccttgccaga ccagtgccac
5700
accgtgactt gccagccaga tggccagacc ttgctgaaga gtcatcgggt caactgtgac
5760
cgggggctga ggccttcgtg ccctaacagc cagtcccctg ttaaagtgga agagacctgt
5820
ggctgccgct ggacctgccc ctgygtgtgc acaggcagct ccactcggca catcgtgacc
5880
tttgatgggc agaatttcaa gctgactggc agctgttctt atgtcctatt tcaaaacaag
5940
gagcaggacc tggaggtgat tctccataat ggtgcctgca gccctggagc aaggcagggc
6000
tgcatgaaat ccatcgaggt gaagcacagt gccctctccg tcgagstgca cagtgacatg
6060
gaggtgacgg tgaatgggag actggtctct gttccttacg tgggtgggaa catggaagtc
6120
aacgtttatg gtgccatcat gcatgaggtc agattcaatc accttggtca catcttcaca
6180
ttcactccac aaaacaatga gttccaactg cagctcagcc ccaagacttt tgcttcaaag
6240
acgtatggtc tgtgtgggat ctgtgatgag aacggagcca atgacttcat gctgagggat
6300
ggcacagtca ccacagactg gaaaacactt gttcaggaat ggactgtgca gcggccaggg
6360
cagacgtgcc agcccatcct ggaggagcag tgtcttgtcc ccgacagctc ccactgccag
6420
gtcctcctct taccactgtt tgctgaatgc cacaaggtcc tggctccagc cacattctat
6480
gccatctgcc agcaggacag ttgccaccag gagcaagtgt gtgaggtgat cgcctcttat
6540
gcccacctct gtcggaccaa cggggtctgc gttgactgga ggacacctga tttctgtgct
6600
atgtcatgcc caccatctct ggtctacaac cactgtgagc atggctgtcc ccggcactgt
6660
gatggcaacg tgagctcctg tggggaccat ccctccgaag gctgtttctg ccctccagat
6720
aaagtcatgt tggaaggcag ctgtgtccct gaagaggcct gcactcagtg cattggtgag
6780
gatggagtcc agcaccagtt cctggaagcc tgggtcccgg accaccagcc ctgtcagatc
6840
tgcacatgcc tcagcgggcg gaaggtcaac tgcacaacgc agccctgccc cacggccaaa
6900
gctcccacgt gtggcctgtg tgaagtagcc cgcctccgcc agaatgcaga ccagtgctgc
6960
cccgagtatg agtgtgtgtg tgacccagtg agctgtgacc tgcccccagt gcctcactgt
7020
gaacgtggcc tccagcccac actgaccaac cctggcgagt gcagacccaa cttcacctgc
7080
gcctgcagga aggaggagtg caaaagagtg tccccaccct cctgcccccc gcaccgtttg
7140
cccacccttc ggaagaccca gtgctgtgat gagtatgagt gtgcctgcaa ctgtgtcaac
7200
tccacagtga gctgtcccct tgggtacttg gcctcaaccg ccaccaatga ctgtggctgt
7260
accacaacca cctgccttcc cgacaaggtg tgtgtccacc gaagcaccat ctaccctgtg
7320
ggccagttct gggaggaggg ctgcgatgtg tgcacctgca ccgacatgga ggatgccgtg
7380
atgggcctcc gcgtggccca gtgctcccag aagccctgtg aggacagctg tcggtcgggc
7440
ttcacttacg ttctgcatga aggcgagtgc tgtggaaggt gcctgccatc tgcctgtgag
7500
gtggtgactg gctcaccgcg gggggactcc cagtcttcct ggaagagtgt cggctcccag
7560
tgggcctccc cggagaaccc ctgcctcatc aatgagtgtg tccgagtgaa ggaggaggtc
7620
tttatacaac aaaggaacgt ctcctgcccc cagctggagg tccctgtctg cccctcgggc
7680
tttcagctga gctgtaagac ctcagcgtgc tgcccaagct gtcgctgtga gcgcatggag
7740
gcctgcatgc tcaatggcac tgtcattggg cccgggaaga ctgtgatgat cgatgtgtgc
7800
acgacctgcc gctgcatggt gcaggtgggg gtcatctctg gattcaagct ggagtgcagg
7860
aagaccacct gcaacccctg ccccctgggt tacaaggaag aaaataacac aggtgaatgt
7920
tgtgggagat gtttgcctac ggcttgcacc attcagctaa gaggaggaca gatcatgaca
7980
ctgaagcgtg atgagacgct ccaggatggc tgtgatactc acttctgcaa ggtcaatgag
8040
agaggagagt acttctggga gaagagggtc acaggctgcc caccctttga tgaacacaag
8100
tgtcttgctg agggaggtaa aattatgaaa attccaggca cctgctgtga cacatgtgag
8160
gagcctgagt gcaacgacat cactgccagg ctgcagtatg tcaaggtggg aagctgtaag
8220
tctgaagtag aggtggatat ccactactgc cagggcaaat gtgccagcaa agccatgtac
8280
tccattgaca tcaacgatgt gcaggaccag tgctcctgct gctctccgac acggacggag
8340
cccatgcagg tggccctgca ctgcaccaat ggctctgttg tgtaccatga ggttctcaat
8400
gccatggagt gcaaatgctc ccccaggaag tgcagcaagt ga
8442
<210> 129
<211> 2809
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Человеческий VWF
<220>
<221> другой_признак
<222> (540)..(540)
<223> Xaa может представлять собой любую втречающуюся в природе
аминокислоту
<220>
<221> другой_признак
<222> (1944)..(1944)
<223> Xaa может представлять собой любую втречающуюся в природе
аминокислоту
<220>
<221> другой_признак
<222> (2012)..(2012)
<223> Xaa может представлять собой любую втречающуюся в природе
аминокислоту
<400> 129
Met Ile Pro Ala Arg Phe Ala Gly Val Leu Leu Ala Leu Ala Leu Ile
1. 5 10 15
Leu Pro Gly Thr Leu Cys Ala Glu Gly Thr Arg Gly Arg Ser Ser Thr
20 25 30
Ala Arg Cys Ser Leu Phe Gly Ser Asp Phe Val Asn Thr Phe Asp Gly
35 40 45
Ser Met Tyr Ser Phe Ala Gly Tyr Cys Ser Tyr Leu Leu Ala Gly Gly
50 55 60
Cys Gln Lys Arg Ser Phe Ser Ile Ile Gly Asp Phe Gln Asn Gly Lys
65 70 75 80
Arg Val Ser Leu Ser Val Tyr Leu Gly Glu Phe Phe Asp Ile His Leu
85 90 95
Phe Val Asn Gly Thr Val Thr Gln Gly Asp Gln Arg Val Ser Met Pro
100 105 110
Tyr Ala Ser Lys Gly Leu Tyr Leu Glu Thr Glu Ala Gly Tyr Tyr Lys
115 120 125
Leu Ser Gly Glu Ala Tyr Gly Phe Val Ala Arg Ile Asp Gly Ser Gly
130 135 140
Asn Phe Gln Val Leu Leu Ser Asp Arg Tyr Phe Asn Lys Thr Cys Gly
145 150 155 160
Leu Cys Gly Asn Phe Asn Ile Phe Ala Glu Asp Asp Phe Met Thr Gln
165 170 175
Glu Gly Thr Leu Thr Ser Asp Pro Tyr Asp Phe Ala Asn Ser Trp Ala
180 185 190
Leu Ser Ser Gly Glu Gln Trp Cys Glu Arg Ala Ser Pro Pro Ser Ser
195 200 205
Ser Cys Asn Ile Ser Ser Gly Glu Met Gln Lys Gly Leu Trp Glu Gln
210 215 220
Cys Gln Leu Leu Lys Ser Thr Ser Val Phe Ala Arg Cys His Pro Leu
225 230 235 240
Val Asp Pro Glu Pro Phe Val Cys Glu Lys Thr Leu Cys Glu Cys Ala
245 250 255
Gly Gly Leu Glu Cys Ala Cys Pro Ala Leu Leu Glu Tyr Ala Arg Thr
260 265 270
Cys Ala Gln Glu Gly Met Val Leu Tyr Gly Trp Thr Asp His Ser Ala
275 280 285
Cys Ser Pro Val Cys Pro Ala Gly Met Glu Tyr Arg Gln Cys Val Ser
290 295 300
Pro Cys Ala Arg Thr Cys Gln Ser Leu His Ile Asn Glu Met Cys Gln
305 310 315 320
Glu Arg Cys Val Asp Gly Cys Ser Cys Pro Glu Gly Gln Leu Leu Asp
325 330 335
Glu Gly Leu Cys Val Glu Ser Thr Glu Cys Pro Cys Val His Ser Gly
340 345 350
Lys Arg Tyr Pro Pro Gly Thr Ser Leu Ser Arg Asp Cys Asn Thr Cys
355 360 365
Ile Cys Arg Asn Ser Gln Trp Ile Cys Ser Asn Glu Glu Cys Pro Gly
370 375 380
Glu Cys Leu Val Thr Gly Gln Ser His Phe Lys Ser Phe Asp Asn Arg
385 390 395 400
Tyr Phe Thr Phe Ser Gly Ile Cys Gln Tyr Leu Leu Ala Arg Asp Cys
405 410 415
Gln Asp His Ser Phe Ser Ile Val Ile Glu Thr Val Gln Cys Ala Asp
420 425 430
Asp Arg Asp Ala Val Cys Thr Arg Ser Val Thr Val Arg Leu Pro Gly
435 440 445
Leu His Asn Ser Leu Val Lys Leu Lys His Gly Ala Gly Val Ala Met
450 455 460
Asp Gly Gln Asp Ile Gln Leu Pro Leu Leu Lys Gly Asp Leu Arg Ile
465 470 475 480
Gln His Thr Val Thr Ala Ser Val Arg Leu Ser Tyr Gly Glu Asp Leu
485 490 495
Gln Met Asp Trp Asp Gly Arg Gly Arg Leu Leu Val Lys Leu Ser Pro
500 505 510
Val Tyr Ala Gly Lys Thr Cys Gly Leu Cys Gly Asn Tyr Asn Gly Asn
515 520 525
Gln Gly Asp Asp Phe Leu Thr Pro Ser Gly Leu Xaa Glu Pro Arg Val
530 535 540
Glu Asp Phe Gly Asn Ala Trp Lys Leu His Gly Asp Cys Gln Asp Leu
545 550 555 560
Gln Lys Gln His Ser Asp Pro Cys Ala Leu Asn Pro Arg Met Thr Arg
565 570 575
Phe Ser Glu Glu Ala Cys Ala Val Leu Thr Ser Pro Thr Phe Glu Ala
580 585 590
Cys His Arg Ala Val Ser Pro Leu Pro Tyr Leu Arg Asn Cys Arg Tyr
595 600 605
Asp Val Cys Ser Cys Ser Asp Gly Arg Glu Cys Leu Cys Gly Ala Ser
610 615 620
Tyr Ala Ala Ala Cys Ala Gly Arg Gly Val Arg Val Ala Trp Arg Glu
625 630 635 640
Pro Gly Arg Cys Glu Leu Asn Cys Pro Lys Gly Gln Val Tyr Leu Gln
645 650 655
Cys Gly Thr Pro Cys Asn Leu Thr Cys Arg Ser Leu Ser Tyr Pro Asp
660 665 670
Glu Glu Cys Asn Glu Ala Cys Leu Glu Gly Cys Phe Cys Pro Pro Gly
675 680 685
Leu Tyr Met Asp Glu Arg Gly Asp Cys Val Pro Lys Ala Gln Cys Pro
690 695 700
Cys Tyr Tyr Asp Gly Glu Ile Phe Gln Pro Glu Asp Ile Phe Ser Asp
705 710 715 720
His His Thr Met Cys Tyr Cys Glu Asp Gly Phe Met His Cys Thr Met
725 730 735
Ser Gly Val Pro Gly Ser Leu Leu Pro Asp Ala Val Leu Ser Ser Pro
740 745 750
Leu Ser His Arg Ser Lys Arg Ser Leu Ser Cys Arg Pro Pro Met Val
755 760 765
Lys Leu Val Cys Pro Ala Asp Asn Leu Arg Ala Glu Gly Leu Glu Cys
770 775 780
Thr Lys Thr Cys Gln Asn Tyr Asp Leu Glu Cys Met Ser Met Gly Cys
785 790 795 800
Val Ser Gly Cys Leu Cys Pro Pro Gly Met Val Arg His Glu Asn Arg
805 810 815
Cys Val Ala Leu Glu Arg Cys Pro Cys Phe His Gln Gly Lys Glu Tyr
820 825 830
Ala Pro Gly Glu Thr Val Lys Ile Gly Cys Asn Thr Cys Val Cys Arg
835 840 845
Asp Arg Lys Trp Asn Cys Thr Asp His Val Cys Asp Ala Thr Cys Ser
850 855 860
Thr Ile Gly Met Ala His Tyr Leu Thr Phe Asp Gly Leu Lys Tyr Leu
865 870 875 880
Phe Pro Gly Glu Cys Gln Tyr Val Leu Val Gln Asp Tyr Cys Gly Ser
885 890 895
Asn Pro Gly Thr Phe Arg Ile Leu Val Gly Asn Lys Gly Cys Ser His
900 905 910
Pro Ser Val Lys Cys Lys Lys Arg Val Thr Ile Leu Val Glu Gly Gly
915 920 925
Glu Ile Glu Leu Phe Asp Gly Glu Val Asn Val Lys Arg Pro Met Lys
930 935 940
Asp Glu Thr His Phe Glu Val Val Glu Ser Gly Arg Tyr Ile Ile Leu
945 950 955 960
Leu Leu Gly Lys Ala Leu Ser Val Val Trp Asp Arg His Leu Ser Ile
965 970 975
Ser Val Val Leu Lys Gln Thr Tyr Gln Glu Lys Val Cys Gly Leu Cys
980 985 990
Gly Asn Phe Asp Gly Ile Gln Asn Asn Asp Leu Thr Ser Ser Asn Leu
995 1000 1005
Gln Val Glu Glu Asp Pro Val Asp Phe Gly Asn Ser Trp Lys Val
1010 1015 1020
Ser Ser Gln Cys Ala Asp Thr Arg Lys Val Pro Leu Asp Ser Ser
1025 1030 1035
Pro Ala Thr Cys His Asn Asn Ile Met Lys Gln Thr Met Val Asp
1040 1045 1050
Ser Ser Cys Arg Ile Leu Thr Ser Asp Val Phe Gln Asp Cys Asn
1055 1060 1065
Lys Leu Val Asp Pro Glu Pro Tyr Leu Asp Val Cys Ile Tyr Asp
1070 1075 1080
Thr Cys Ser Cys Glu Ser Ile Gly Asp Cys Ala Cys Phe Cys Asp
1085 1090 1095
Thr Ile Ala Ala Tyr Ala His Val Cys Ala Gln His Gly Lys Val
1100 1105 1110
Val Thr Trp Arg Thr Ala Thr Leu Cys Pro Gln Ser Cys Glu Glu
1115 1120 1125
Arg Asn Leu Arg Glu Asn Gly Tyr Glu Cys Glu Trp Arg Tyr Asn
1130 1135 1140
Ser Cys Ala Pro Ala Cys Gln Val Thr Cys Gln His Pro Glu Pro
1145 1150 1155
Leu Ala Cys Pro Val Gln Cys Val Glu Gly Cys His Ala His Cys
1160 1165 1170
Pro Pro Gly Lys Ile Leu Asp Glu Leu Leu Gln Thr Cys Val Asp
1175 1180 1185
Pro Glu Asp Cys Pro Val Cys Glu Val Ala Gly Arg Arg Phe Ala
1190 1195 1200
Ser Gly Lys Lys Val Thr Leu Asn Pro Ser Asp Pro Glu His Cys
1205 1210 1215
Gln Ile Cys His Cys Asp Val Val Asn Leu Thr Cys Glu Ala Cys
1220 1225 1230
Gln Glu Pro Gly Gly Leu Val Val Pro Pro Thr Asp Ala Pro Val
1235 1240 1245
Ser Pro Thr Thr Leu Tyr Val Glu Asp Ile Ser Glu Pro Pro Leu
1250 1255 1260
His Asp Phe Tyr Cys Ser Arg Leu Leu Asp Leu Val Phe Leu Leu
1265 1270 1275
Asp Gly Ser Ser Arg Leu Ser Glu Ala Glu Phe Glu Val Leu Lys
1280 1285 1290
Ala Phe Val Val Asp Met Met Glu Arg Leu Arg Ile Ser Gln Lys
1295 1300 1305
Trp Val Arg Val Ala Val Val Glu Tyr His Asp Gly Ser His Ala
1310 1315 1320
Tyr Ile Gly Leu Lys Asp Arg Lys Arg Pro Ser Glu Leu Arg Arg
1325 1330 1335
Ile Ala Ser Gln Val Lys Tyr Ala Gly Ser Gln Val Ala Ser Thr
1340 1345 1350
Ser Glu Val Leu Lys Tyr Thr Leu Phe Gln Ile Phe Ser Lys Ile
1355 1360 1365
Asp Arg Pro Glu Ala Ser Arg Ile Ala Leu Leu Leu Met Ala Ser
1370 1375 1380
Gln Glu Pro Gln Arg Met Ser Arg Asn Phe Val Arg Tyr Val Gln
1385 1390 1395
Gly Leu Lys Lys Lys Lys Val Ile Val Ile Pro Val Gly Ile Gly
1400 1405 1410
Pro His Ala Asn Leu Lys Gln Ile Arg Leu Ile Glu Lys Gln Ala
1415 1420 1425
Pro Glu Asn Lys Ala Phe Val Leu Ser Ser Val Asp Glu Leu Glu
1430 1435 1440
Gln Gln Arg Asp Glu Ile Val Ser Tyr Leu Cys Asp Leu Ala Pro
1445 1450 1455
Glu Ala Pro Pro Pro Thr Leu Pro Pro Asp Met Ala Gln Val Thr
1460 1465 1470
Val Gly Pro Gly Leu Leu Gly Val Ser Thr Leu Gly Pro Lys Arg
1475 1480 1485
Asn Ser Met Val Leu Asp Val Ala Phe Val Leu Glu Gly Ser Asp
1490 1495 1500
Lys Ile Gly Glu Ala Asp Phe Asn Arg Ser Lys Glu Phe Met Glu
1505 1510 1515
Glu Val Ile Gln Arg Met Asp Val Gly Gln Asp Ser Ile His Val
1520 1525 1530
Thr Val Leu Gln Tyr Ser Tyr Met Val Thr Val Glu Tyr Pro Phe
1535 1540 1545
Ser Glu Ala Gln Ser Lys Gly Asp Ile Leu Gln Arg Val Arg Glu
1550 1555 1560
Ile Arg Tyr Gln Gly Gly Asn Arg Thr Asn Thr Gly Leu Ala Leu
1565 1570 1575
Arg Tyr Leu Ser Asp His Ser Phe Leu Val Ser Gln Gly Asp Arg
1580 1585 1590
Glu Gln Ala Pro Asn Leu Val Tyr Met Val Thr Gly Asn Pro Ala
1595 1600 1605
Ser Asp Glu Ile Lys Arg Leu Pro Gly Asp Ile Gln Val Val Pro
1610 1615 1620
Ile Gly Val Gly Pro Asn Ala Asn Val Gln Glu Leu Glu Arg Ile
1625 1630 1635
Gly Trp Pro Asn Ala Pro Ile Leu Ile Gln Asp Phe Glu Thr Leu
1640 1645 1650
Pro Arg Glu Ala Pro Asp Leu Val Leu Gln Arg Cys Cys Ser Gly
1655 1660 1665
Glu Gly Leu Gln Ile Pro Thr Leu Ser Pro Ala Pro Asp Cys Ser
1670 1675 1680
Gln Pro Leu Asp Val Ile Leu Leu Leu Asp Gly Ser Ser Ser Phe
1685 1690 1695
Pro Ala Ser Tyr Phe Asp Glu Met Lys Ser Phe Ala Lys Ala Phe
1700 1705 1710
Ile Ser Lys Ala Asn Ile Gly Pro Arg Leu Thr Gln Val Ser Val
1715 1720 1725
Leu Gln Tyr Gly Ser Ile Thr Thr Ile Asp Val Pro Trp Asn Val
1730 1735 1740
Val Pro Glu Lys Ala His Leu Leu Ser Leu Val Asp Val Met Gln
1745 1750 1755
Arg Glu Gly Gly Pro Ser Gln Ile Gly Asp Ala Leu Gly Phe Ala
1760 1765 1770
Val Arg Tyr Leu Thr Ser Glu Met His Gly Ala Arg Pro Gly Ala
1775 1780 1785
Ser Lys Ala Val Val Ile Leu Val Thr Asp Val Ser Val Asp Ser
1790 1795 1800
Val Asp Ala Ala Ala Asp Ala Ala Arg Ser Asn Arg Val Thr Val
1805 1810 1815
Phe Pro Ile Gly Ile Gly Asp Arg Tyr Asp Ala Ala Gln Leu Arg
1820 1825 1830
Ile Leu Ala Gly Pro Ala Gly Asp Ser Asn Val Val Lys Leu Gln
1835 1840 1845
Arg Ile Glu Asp Leu Pro Thr Met Val Thr Leu Gly Asn Ser Phe
1850 1855 1860
Leu His Lys Leu Cys Ser Gly Phe Val Arg Ile Cys Met Asp Glu
1865 1870 1875
Asp Gly Asn Glu Lys Arg Pro Gly Asp Val Trp Thr Leu Pro Asp
1880 1885 1890
Gln Cys His Thr Val Thr Cys Gln Pro Asp Gly Gln Thr Leu Leu
1895 1900 1905
Lys Ser His Arg Val Asn Cys Asp Arg Gly Leu Arg Pro Ser Cys
1910 1915 1920
Pro Asn Ser Gln Ser Pro Val Lys Val Glu Glu Thr Cys Gly Cys
1925 1930 1935
Arg Trp Thr Cys Pro Xaa Val Cys Thr Gly Ser Ser Thr Arg His
1940 1945 1950
Ile Val Thr Phe Asp Gly Gln Asn Phe Lys Leu Thr Gly Ser Cys
1955 1960 1965
Ser Tyr Val Leu Phe Gln Asn Lys Glu Gln Asp Leu Glu Val Ile
1970 1975 1980
Leu His Asn Gly Ala Cys Ser Pro Gly Ala Arg Gln Gly Cys Met
1985 1990 1995
Lys Ser Ile Glu Val Lys His Ser Ala Leu Ser Val Glu Xaa His
2000 2005 2010
Ser Asp Met Glu Val Thr Val Asn Gly Arg Leu Val Ser Val Pro
2015 2020 2025
Tyr Val Gly Gly Asn Met Glu Val Asn Val Tyr Gly Ala Ile Met
2030 2035 2040
His Glu Val Arg Phe Asn His Leu Gly His Ile Phe Thr Phe Thr
2045 2050 2055
Pro Gln Asn Asn Glu Phe Gln Leu Gln Leu Ser Pro Lys Thr Phe
2060 2065 2070
Ala Ser Lys Thr Tyr Gly Leu Cys Gly Ile Cys Asp Glu Asn Gly
2075 2080 2085
Ala Asn Asp Phe Met Leu Arg Asp Gly Thr Val Thr Thr Asp Trp
2090 2095 2100
Lys Thr Leu Val Gln Glu Trp Thr Val Gln Arg Pro Gly Gln Thr
2105 2110 2115
Cys Gln Pro Ile Leu Glu Glu Gln Cys Leu Val Pro Asp Ser Ser
2120 2125 2130
His Cys Gln Val Leu Leu Leu Pro Leu Phe Ala Glu Cys His Lys
2135 2140 2145
Val Leu Ala Pro Ala Thr Phe Tyr Ala Ile Cys Gln Gln Asp Ser
2150 2155 2160
Cys His Gln Glu Gln Val Cys Glu Val Ile Ala Ser Tyr Ala His
2165 2170 2175
Leu Cys Arg Thr Asn Gly Val Cys Val Asp Trp Arg Thr Pro Asp
2180 2185 2190
Phe Cys Ala Met Ser Cys Pro Pro Ser Leu Val Tyr Asn His Cys
2195 2200 2205
Glu His Gly Cys Pro Arg His Cys Asp Gly Asn Val Ser Ser Cys
2210 2215 2220
Gly Asp His Pro Ser Glu Gly Cys Phe Cys Pro Pro Asp Lys Val
2225 2230 2235
Met Leu Glu Gly Ser Cys Val Pro Glu Glu Ala Cys Thr Gln Cys
2240 2245 2250
Ile Gly Glu Asp Gly Val Gln His Gln Phe Leu Glu Ala Trp Val
2255 2260 2265
Pro Asp His Gln Pro Cys Gln Ile Cys Thr Cys Leu Ser Gly Arg
2270 2275 2280
Lys Val Asn Cys Thr Thr Gln Pro Cys Pro Thr Ala Lys Ala Pro
2285 2290 2295
Thr Cys Gly Leu Cys Glu Val Ala Arg Leu Arg Gln Asn Ala Asp
2300 2305 2310
Gln Cys Cys Pro Glu Tyr Glu Cys Val Cys Asp Pro Val Ser Cys
2315 2320 2325
Asp Leu Pro Pro Val Pro His Cys Glu Arg Gly Leu Gln Pro Thr
2330 2335 2340
Leu Thr Asn Pro Gly Glu Cys Arg Pro Asn Phe Thr Cys Ala Cys
2345 2350 2355
Arg Lys Glu Glu Cys Lys Arg Val Ser Pro Pro Ser Cys Pro Pro
2360 2365 2370
His Arg Leu Pro Thr Leu Arg Lys Thr Gln Cys Cys Asp Glu Tyr
2375 2380 2385
Glu Cys Ala Cys Asn Cys Val Asn Ser Thr Val Ser Cys Pro Leu
2390 2395 2400
Gly Tyr Leu Ala Ser Thr Ala Thr Asn Asp Cys Gly Cys Thr Thr
2405 2410 2415
Thr Thr Cys Leu Pro Asp Lys Val Cys Val His Arg Ser Thr Ile
2420 2425 2430
Tyr Pro Val Gly Gln Phe Trp Glu Glu Gly Cys Asp Val Cys Thr
2435 2440 2445
Cys Thr Asp Met Glu Asp Ala Val Met Gly Leu Arg Val Ala Gln
2450 2455 2460
Cys Ser Gln Lys Pro Cys Glu Asp Ser Cys Arg Ser Gly Phe Thr
2465 2470 2475
Tyr Val Leu His Glu Gly Glu Cys Cys Gly Arg Cys Leu Pro Ser
2480 2485 2490
Ala Cys Glu Val Val Thr Gly Ser Pro Arg Gly Asp Ser Gln Ser
2495 2500 2505
Ser Trp Lys Ser Val Gly Ser Gln Trp Ala Ser Pro Glu Asn Pro
2510 2515 2520
Cys Leu Ile Asn Glu Cys Val Arg Val Lys Glu Glu Val Phe Ile
2525 2530 2535
Gln Gln Arg Asn Val Ser Cys Pro Gln Leu Glu Val Pro Val Cys
2540 2545 2550
Pro Ser Gly Phe Gln Leu Ser Cys Lys Thr Ser Ala Cys Cys Pro
2555 2560 2565
Ser Cys Arg Cys Glu Arg Met Glu Ala Cys Met Leu Asn Gly Thr
2570 2575 2580
Val Ile Gly Pro Gly Lys Thr Val Met Ile Asp Val Cys Thr Thr
2585 2590 2595
Cys Arg Cys Met Val Gln Val Gly Val Ile Ser Gly Phe Lys Leu
2600 2605 2610
Glu Cys Arg Lys Thr Thr Cys Asn Pro Cys Pro Leu Gly Tyr Lys
2615 2620 2625
Glu Glu Asn Asn Thr Gly Glu Cys Cys Gly Arg Cys Leu Pro Thr
2630 2635 2640
Ala Cys Thr Ile Gln Leu Arg Gly Gly Gln Ile Met Thr Leu Lys
2645 2650 2655
Arg Asp Glu Thr Leu Gln Asp Gly Cys Asp Thr His Phe Cys Lys
2660 2665 2670
Val Asn Glu Arg Gly Glu Tyr Phe Trp Glu Lys Arg Val Thr Gly
2675 2680 2685
Cys Pro Pro Phe Asp Glu His Lys Cys Leu Ala Glu Gly Gly Lys
2690 2695 2700
Ile Met Lys Ile Pro Gly Thr Cys Cys Asp Thr Cys Glu Glu Pro
2705 2710 2715
Glu Cys Asn Asp Ile Thr Ala Arg Leu Gln Tyr Val Lys Val Gly
2720 2725 2730
Ser Cys Lys Ser Glu Val Glu Val Asp Ile His Tyr Cys Gln Gly
2735 2740 2745
Lys Cys Ala Ser Lys Ala Met Tyr Ser Ile Asp Ile Asn Asp Val
2750 2755 2760
Gln Asp Gln Cys Ser Cys Cys Ser Pro Thr Arg Thr Glu Pro Met
2765 2770 2775
Gln Val Ala Leu His Cys Thr Asn Gly Ser Val Val Tyr His Glu
2780 2785 2790
Val Leu Asn Ala Met Glu Cys Lys Cys Ser Pro Arg Lys Cys Ser
2795 2800 2805
Lys
<210> 130
<211> 36
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AE36
<400> 130
Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu
1. 5 10 15
Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly
20 25 30
Ser Glu Thr Pro
35
<210> 131
<211> 42
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AE42
<400> 131
Gly Ala Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly
1. 5 10 15
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala
20 25 30
Thr Ser Gly Ser Glu Thr Pro Ala Ser Ser
35 40
<210> 132
<211> 78
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AE72
<400> 132
Gly Ala Pro Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser
1. 5 10 15
Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala
20 25 30
Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu
35 40 45
Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr
50 55 60
Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Ala Ser Ser
65 70 75
<210> 133
<211> 78
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AE78
<400> 133
Gly Ala Pro Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser
1. 5 10 15
Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala
20 25 30
Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu
35 40 45
Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr
50 55 60
Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Ala Ser Ser
65 70 75
<210> 134
<211> 143
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AE144
<400> 134
Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu
1. 5 10 15
Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly
20 25 30
Ser Glu Thr Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu
35 40 45
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Glu Pro
50 55 60
Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala Thr Ser Gly
65 70 75 80
Ser Glu Thr Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
85 90 95
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu
100 105 110
Ser Ala Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser
115 120 125
Glu Thr Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
130 135 140
<210> 135
<211> 144
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AE144_6B
<400> 135
Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu Ser
1. 5 10 15
Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu
20 25 30
Ser Gly Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly
35 40 45
Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala
50 55 60
Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser
65 70 75 80
Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
85 90 95
Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Glu Pro Ala
100 105 110
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu
115 120 125
Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
130 135 140
<210> 136
<211> 144
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AG144
<400> 136
Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser Thr
1. 5 10 15
Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Pro Ser Ala Ser Thr
20 25 30
Gly Thr Gly Pro Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro
35 40 45
Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ala Ser Pro
50 55 60
Gly Thr Ser Ser Thr Gly Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala
65 70 75 80
Thr Gly Ser Pro Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro
85 90 95
Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ser Ser Pro
100 105 110
Ser Ala Ser Thr Gly Thr Gly Pro Gly Thr Pro Gly Ser Gly Thr Ala
115 120 125
Ser Ser Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro
130 135 140
<210> 137
<211> 144
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AG144_A
<400> 137
Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ser Ser Pro
1. 5 10 15
Ser Ala Ser Thr Gly Thr Gly Pro Gly Ser Ser Pro Ser Ala Ser Thr
20 25 30
Gly Thr Gly Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro
35 40 45
Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Pro
50 55 60
Ser Ala Ser Thr Gly Thr Gly Pro Gly Ala Ser Pro Gly Thr Ser Ser
65 70 75 80
Thr Gly Ser Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro
85 90 95
Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Thr Pro Gly
100 105 110
Ser Gly Thr Ala Ser Ser Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser
115 120 125
Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
130 135 140
<210> 138
<211> 288
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AE288
<400> 138
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro
1. 5 10 15
Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro
20 25 30
Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
35 40 45
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr
50 55 60
Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Pro Ala Gly Ser Pro Thr
65 70 75 80
Ser Thr Glu Glu Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro
85 90 95
Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu
100 105 110
Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Pro Ala Gly Ser Pro Thr
115 120 125
Ser Thr Glu Glu Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu
130 135 140
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu
145 150 155 160
Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Glu Ser Ala Thr Pro
165 170 175
Glu Ser Gly Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro
180 185 190
Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro
195 200 205
Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly Ser Pro Thr
210 215 220
Ser Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
225 230 235 240
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Glu Pro
245 250 255
Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro
260 265 270
Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
275 280 285
<210> 139
<211> 288
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AE288_2
<400> 139
Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu
1. 5 10 15
Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly
20 25 30
Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro
35 40 45
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr
50 55 60
Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu
65 70 75 80
Gly Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
85 90 95
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr
100 105 110
Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Pro Ala Gly Ser Pro Thr
115 120 125
Ser Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
130 135 140
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro
145 150 155 160
Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro
165 170 175
Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
180 185 190
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr
195 200 205
Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu Ser Ala Thr Pro
210 215 220
Glu Ser Gly Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu
225 230 235 240
Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Ser Pro Ala
245 250 255
Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu Ser Ala Thr Pro
260 265 270
Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
275 280 285
<210> 140
<211> 288
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AG288
<400> 140
Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ala Ser
1. 5 10 15
Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Thr Pro Gly Ser Gly Thr
20 25 30
Ala Ser Ser Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser
35 40 45
Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser
50 55 60
Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Thr Pro Gly Ser Gly Thr
65 70 75 80
Ala Ser Ser Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser
85 90 95
Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser
100 105 110
Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Ser Ser Pro Ser Ala Ser
115 120 125
Thr Gly Thr Gly Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser
130 135 140
Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser
145 150 155 160
Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Pro Ser Ala Ser
165 170 175
Thr Gly Thr Gly Pro Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly
180 185 190
Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ala Ser
195 200 205
Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ser Ser Thr Pro Ser Gly
210 215 220
Ala Thr Gly Ser Pro Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly
225 230 235 240
Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ser Ser
245 250 255
Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Thr Pro Gly Ser Gly Thr
260 265 270
Ala Ser Ser Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser
275 280 285
<210> 141
<211> 576
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AE576
<400> 141
Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu
1. 5 10 15
Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu
20 25 30
Gly Ser Ala Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu
35 40 45
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr
50 55 60
Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu Ser Ala Thr Pro
65 70 75 80
Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
85 90 95
Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala
100 105 110
Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu Ser Ala Thr Pro
115 120 125
Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
130 135 140
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Pro Ala
145 150 155 160
Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu
165 170 175
Gly Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
180 185 190
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr
195 200 205
Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu Ser Ala Thr Pro
210 215 220
Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
225 230 235 240
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr
245 250 255
Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu Ser Ala Thr Pro
260 265 270
Glu Ser Gly Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro
275 280 285
Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu
290 295 300
Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly
305 310 315 320
Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro
325 330 335
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr
340 345 350
Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu
355 360 365
Gly Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
370 375 380
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr
385 390 395 400
Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Pro Ala Gly Ser Pro Thr
405 410 415
Ser Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
420 425 430
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro
435 440 445
Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro
450 455 460
Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
465 470 475 480
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr
485 490 495
Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu Ser Ala Thr Pro
500 505 510
Glu Ser Gly Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu
515 520 525
Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Ser Pro Ala
530 535 540
Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu Ser Ala Thr Pro
545 550 555 560
Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
565 570 575
<210> 142
<211> 576
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AG576
<400> 142
Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser
1. 5 10 15
Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Pro Ser Ala Ser
20 25 30
Thr Gly Thr Gly Pro Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly
35 40 45
Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser
50 55 60
Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser
65 70 75 80
Ser Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser
85 90 95
Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Thr Pro
100 105 110
Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ala Ser Pro Gly Thr Ser
115 120 125
Ser Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser
130 135 140
Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ser Ser
145 150 155 160
Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Thr Pro Gly Ser Gly Thr
165 170 175
Ala Ser Ser Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser
180 185 190
Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ala Ser
195 200 205
Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ser Ser Thr Pro Ser Gly
210 215 220
Ala Thr Gly Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser
225 230 235 240
Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Thr Pro
245 250 255
Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser Thr Pro Ser Gly
260 265 270
Ala Thr Gly Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser
275 280 285
Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser
290 295 300
Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Ala Ser Pro Gly Thr Ser
305 310 315 320
Ser Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser
325 330 335
Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ala Ser
340 345 350
Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser
355 360 365
Ser Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser
370 375 380
Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Thr Pro
385 390 395 400
Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser Thr Pro Ser Gly
405 410 415
Ala Thr Gly Ser Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser
420 425 430
Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Thr Pro
435 440 445
Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser Thr Pro Ser Gly
450 455 460
Ala Thr Gly Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser
465 470 475 480
Pro Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Ser Ser
485 490 495
Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Ala Ser Pro Gly Thr Ser
500 505 510
Ser Thr Gly Ser Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser
515 520 525
Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser
530 535 540
Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Ser Ser Pro Ser Ala Ser
545 550 555 560
Thr Gly Thr Gly Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser
565 570 575
<210> 143
<211> 864
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AE864
<400> 143
Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu
1. 5 10 15
Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu
20 25 30
Gly Ser Ala Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu
35 40 45
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr
50 55 60
Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu Ser Ala Thr Pro
65 70 75 80
Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
85 90 95
Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala
100 105 110
Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu Ser Ala Thr Pro
115 120 125
Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
130 135 140
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Pro Ala
145 150 155 160
Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu
165 170 175
Gly Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
180 185 190
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr
195 200 205
Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu Ser Ala Thr Pro
210 215 220
Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
225 230 235 240
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr
245 250 255
Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu Ser Ala Thr Pro
260 265 270
Glu Ser Gly Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro
275 280 285
Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu
290 295 300
Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly
305 310 315 320
Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro
325 330 335
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr
340 345 350
Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu
355 360 365
Gly Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
370 375 380
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr
385 390 395 400
Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Pro Ala Gly Ser Pro Thr
405 410 415
Ser Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
420 425 430
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro
435 440 445
Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro
450 455 460
Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
465 470 475 480
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr
485 490 495
Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu Ser Ala Thr Pro
500 505 510
Glu Ser Gly Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu
515 520 525
Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Ser Pro Ala
530 535 540
Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu Ser Ala Thr Pro
545 550 555 560
Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
565 570 575
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro
580 585 590
Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro
595 600 605
Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
610 615 620
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr
625 630 635 640
Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Pro Ala Gly Ser Pro Thr
645 650 655
Ser Thr Glu Glu Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro
660 665 670
Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu
675 680 685
Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Pro Ala Gly Ser Pro Thr
690 695 700
Ser Thr Glu Glu Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu
705 710 715 720
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu
725 730 735
Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Glu Ser Ala Thr Pro
740 745 750
Glu Ser Gly Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro
755 760 765
Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro
770 775 780
Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly Ser Pro Thr
785 790 795 800
Ser Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
805 810 815
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Glu Pro
820 825 830
Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro
835 840 845
Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
850 855 860
<210> 144
<211> 864
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AG864
<400> 144
Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ser Ser Pro
1. 5 10 15
Ser Ala Ser Thr Gly Thr Gly Pro Gly Ser Ser Pro Ser Ala Ser Thr
20 25 30
Gly Thr Gly Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro
35 40 45
Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Pro
50 55 60
Ser Ala Ser Thr Gly Thr Gly Pro Gly Ala Ser Pro Gly Thr Ser Ser
65 70 75 80
Thr Gly Ser Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro
85 90 95
Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Thr Pro Gly
100 105 110
Ser Gly Thr Ala Ser Ser Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser
115 120 125
Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
130 135 140
Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser Thr
145 150 155 160
Pro Ser Gly Ala Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser
165 170 175
Thr Gly Ser Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro
180 185 190
Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Pro
195 200 205
Ser Ala Ser Thr Gly Thr Gly Pro Gly Ser Ser Pro Ser Ala Ser Thr
210 215 220
Gly Thr Gly Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro
225 230 235 240
Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ala Ser Pro
245 250 255
Gly Thr Ser Ser Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser
260 265 270
Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
275 280 285
Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ala Ser Pro
290 295 300
Gly Thr Ser Ser Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser
305 310 315 320
Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
325 330 335
Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Thr Pro Gly
340 345 350
Ser Gly Thr Ala Ser Ser Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser
355 360 365
Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
370 375 380
Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ser Ser Thr
385 390 395 400
Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala
405 410 415
Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
420 425 430
Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser Thr
435 440 445
Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala
450 455 460
Thr Gly Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro
465 470 475 480
Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Ala Ser Pro
485 490 495
Gly Thr Ser Ser Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser
500 505 510
Thr Gly Ser Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro
515 520 525
Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ala Ser Pro
530 535 540
Gly Thr Ser Ser Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser
545 550 555 560
Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
565 570 575
Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser Thr
580 585 590
Pro Ser Gly Ala Thr Gly Ser Pro Gly Thr Pro Gly Ser Gly Thr Ala
595 600 605
Ser Ser Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro
610 615 620
Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser Thr
625 630 635 640
Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala
645 650 655
Thr Gly Ser Pro Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro
660 665 670
Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Ala Ser Pro
675 680 685
Gly Thr Ser Ser Thr Gly Ser Pro Gly Thr Pro Gly Ser Gly Thr Ala
690 695 700
Ser Ser Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro
705 710 715 720
Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Ser Ser Pro
725 730 735
Ser Ala Ser Thr Gly Thr Gly Pro Gly Ala Ser Pro Gly Thr Ser Ser
740 745 750
Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
755 760 765
Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Pro
770 775 780
Ser Ala Ser Thr Gly Thr Gly Pro Gly Ala Ser Pro Gly Thr Ser Ser
785 790 795 800
Thr Gly Ser Pro Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro
805 810 815
Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser Thr
820 825 830
Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala
835 840 845
Thr Gly Ser Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
850 855 860
<210> 145
<211> 72
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN_AE72_2A_1
<400> 145
Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Pro Ala Gly
1. 5 10 15
Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu Gly
20 25 30
Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
35 40 45
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu
50 55 60
Pro Ser Glu Gly Ser Ala Pro Gly
65 70
<210> 146
<211> 72
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN_AE72_2A_2
<400> 146
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala
1. 5 10 15
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly
20 25 30
Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
35 40 45
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Glu Ser
50 55 60
Ala Thr Pro Glu Ser Gly Pro Gly
65 70
<210> 147
<211> 72
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN_AE72_3B_1
<400> 147
Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu Ser
1. 5 10 15
Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser
20 25 30
Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly
35 40 45
Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu
50 55 60
Pro Ser Glu Gly Ser Ala Pro Gly
65 70
<210> 148
<211> 72
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN_AE72_3B_2
<400> 148
Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu
1. 5 10 15
Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly
20 25 30
Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
35 40 45
Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Thr Glu
50 55 60
Pro Ser Glu Gly Ser Ala Pro Gly
65 70
<210> 149
<211> 72
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN_AE72_4A_2
<400> 149
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Pro Ala Gly
1. 5 10 15
Ser Pro Thr Ser Thr Glu Glu Gly Ser Pro Ala Gly Ser Pro Thr Ser
20 25 30
Thr Glu Glu Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly
35 40 45
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu
50 55 60
Pro Ser Glu Gly Ser Ala Pro Gly
65 70
<210> 150
<211> 72
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN_AE72_5A_2
<400> 150
Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu Ser
1. 5 10 15
Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser
20 25 30
Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly
35 40 45
Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Ser Pro Ala Gly
50 55 60
Ser Pro Thr Ser Thr Glu Glu Gly
65 70
<210> 151
<211> 72
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN_AE72_6B_1
<400> 151
Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu Ser
1. 5 10 15
Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu
20 25 30
Ser Gly Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly
35 40 45
Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala
50 55 60
Thr Ser Gly Ser Glu Thr Pro Gly
65 70
<210> 152
<211> 72
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN_AE72_6B_2
<400> 152
Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Thr Glu
1. 5 10 15
Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly
20 25 30
Ser Ala Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly
35 40 45
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu
50 55 60
Pro Ser Glu Gly Ser Ala Pro Gly
65 70
<210> 153
<211> 72
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN_AE72_1A_1
<400> 153
Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu Ser
1. 5 10 15
Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly
20 25 30
Ser Ala Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly
35 40 45
Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu
50 55 60
Pro Ser Glu Gly Ser Ala Pro Gly
65 70
<210> 154
<211> 72
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN_AE72_1A_2
<400> 154
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala
1. 5 10 15
Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser
20 25 30
Glu Thr Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly
35 40 45
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu
50 55 60
Pro Ser Glu Gly Ser Ala Pro Gly
65 70
<210> 155
<211> 144
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> XTEN_AE144_1A
<400> 155
Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu Ser
1. 5 10 15
Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly
20 25 30
Ser Ala Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly
35 40 45
Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu
50 55 60
Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu
65 70 75 80
Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly
85 90 95
Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly
100 105 110
Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu Ser Ala Thr Pro Glu
115 120 125
Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
130 135 140
<210> 156
<211> 150
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AE150
<400> 156
Gly Ala Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly
1. 5 10 15
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala
20 25 30
Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly Ser Pro Thr Ser
35 40 45
Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
50 55 60
Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala
65 70 75 80
Thr Ser Gly Ser Glu Thr Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser
85 90 95
Glu Thr Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
100 105 110
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala
115 120 125
Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly
130 135 140
Ser Ala Pro Ala Ser Ser
145 150
<210> 157
<211> 150
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> G150
<400> 157
Gly Ala Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro Gly
1. 5 10 15
Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Pro Ser
20 25 30
Ala Ser Thr Gly Thr Gly Pro Gly Ser Ser Pro Ser Ala Ser Thr Gly
35 40 45
Thr Gly Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly
50 55 60
Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ser Ser Thr Pro
65 70 75 80
Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Pro Ser Ala Ser Thr Gly
85 90 95
Thr Gly Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly
100 105 110
Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Thr Pro Gly Ser
115 120 125
Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr
130 135 140
Gly Ser Pro Ala Ser Ser
145 150
<210> 158
<211> 294
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AE294
<400> 158
Gly Ala Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly
1. 5 10 15
Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser
20 25 30
Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser
35 40 45
Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly
50 55 60
Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Ser Pro Ala Gly
65 70 75 80
Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu Ser Ala Thr Pro Glu
85 90 95
Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly
100 105 110
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Pro Ala Gly
115 120 125
Ser Pro Thr Ser Thr Glu Glu Gly Ser Pro Ala Gly Ser Pro Thr Ser
130 135 140
Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
145 150 155 160
Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Glu Ser
165 170 175
Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu
180 185 190
Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly
195 200 205
Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Ser Pro Ala Gly
210 215 220
Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu Gly
225 230 235 240
Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly
245 250 255
Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser
260 265 270
Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly
275 280 285
Ser Ala Pro Ala Ser Ser
290
<210> 159
<211> 294
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> AG294
<400> 159
Gly Ala Pro Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
1. 5 10 15
Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Thr Pro Gly
20 25 30
Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala
35 40 45
Thr Gly Ser Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro
50 55 60
Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Thr Pro Gly
65 70 75 80
Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala
85 90 95
Thr Gly Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro
100 105 110
Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Ser Ser Pro
115 120 125
Ser Ala Ser Thr Gly Thr Gly Pro Gly Ala Ser Pro Gly Thr Ser Ser
130 135 140
Thr Gly Ser Pro Gly Thr Pro Gly Ser Gly Thr Ala Ser Ser Ser Pro
145 150 155 160
Gly Ser Ser Thr Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Pro
165 170 175
Ser Ala Ser Thr Gly Thr Gly Pro Gly Ser Ser Pro Ser Ala Ser Thr
180 185 190
Gly Thr Gly Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
195 200 205
Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro Gly Ser Ser Thr
210 215 220
Pro Ser Gly Ala Thr Gly Ser Pro Gly Ser Ser Pro Ser Ala Ser Thr
225 230 235 240
Gly Thr Gly Pro Gly Ala Ser Pro Gly Thr Ser Ser Thr Gly Ser Pro
245 250 255
Gly Ser Ser Pro Ser Ala Ser Thr Gly Thr Gly Pro Gly Thr Pro Gly
260 265 270
Ser Gly Thr Ala Ser Ser Ser Pro Gly Ser Ser Thr Pro Ser Gly Ala
275 280 285
Thr Gly Ser Ala Ser Ser
290
<210> 160
<211> 1016
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> FIX-линкер-альбумин
<400> 160
Tyr Asn Ser Gly Lys Leu Glu Glu Phe Val Gln Gly Asn Leu Glu Arg
1. 5 10 15
Glu Cys Met Glu Glu Lys Cys Ser Phe Glu Glu Ala Arg Glu Val Phe
20 25 30
Glu Asn Thr Glu Arg Thr Thr Glu Phe Trp Lys Gln Tyr Val Asp Gly
35 40 45
Asp Gln Cys Glu Ser Asn Pro Cys Leu Asn Gly Gly Ser Cys Lys Asp
50 55 60
Asp Ile Asn Ser Tyr Glu Cys Trp Cys Pro Phe Gly Phe Glu Gly Lys
65 70 75 80
Asn Cys Glu Leu Asp Val Thr Cys Asn Ile Lys Asn Gly Arg Cys Glu
85 90 95
Gln Phe Cys Lys Asn Ser Ala Asp Asn Lys Val Val Cys Ser Cys Thr
100 105 110
Glu Gly Tyr Arg Leu Ala Glu Asn Gln Lys Ser Cys Glu Pro Ala Val
115 120 125
Pro Phe Pro Cys Gly Arg Val Ser Val Ser Gln Thr Ser Lys Leu Thr
130 135 140
Arg Ala Glu Thr Val Phe Pro Asp Val Asp Tyr Val Asn Ser Thr Glu
145 150 155 160
Ala Glu Thr Ile Leu Asp Asn Ile Thr Gln Ser Thr Gln Ser Phe Asn
165 170 175
Asp Phe Thr Arg Val Val Gly Gly Glu Asp Ala Lys Pro Gly Gln Phe
180 185 190
Pro Trp Gln Val Val Leu Asn Gly Lys Val Asp Ala Phe Cys Gly Gly
195 200 205
Ser Ile Val Asn Glu Lys Trp Ile Val Thr Ala Ala His Cys Val Glu
210 215 220
Thr Gly Val Lys Ile Thr Val Val Ala Gly Glu His Asn Ile Glu Glu
225 230 235 240
Thr Glu His Thr Glu Gln Lys Arg Asn Val Ile Arg Ile Ile Pro His
245 250 255
His Asn Tyr Asn Ala Ala Ile Asn Lys Tyr Asn His Asp Ile Ala Leu
260 265 270
Leu Glu Leu Asp Glu Pro Leu Val Leu Asn Ser Tyr Val Thr Pro Ile
275 280 285
Cys Ile Ala Asp Lys Glu Tyr Thr Asn Ile Phe Leu Lys Phe Gly Ser
290 295 300
Gly Tyr Val Ser Gly Trp Gly Arg Val Phe His Lys Gly Arg Ser Ala
305 310 315 320
Leu Val Leu Gln Tyr Leu Arg Val Pro Leu Val Asp Arg Ala Thr Cys
325 330 335
Leu Arg Ser Thr Lys Phe Thr Ile Tyr Asn Asn Met Phe Cys Ala Gly
340 345 350
Phe His Glu Gly Gly Arg Asp Ser Cys Gln Gly Asp Ser Gly Gly Pro
355 360 365
His Val Thr Glu Val Glu Gly Thr Ser Phe Leu Thr Gly Ile Ile Ser
370 375 380
Trp Gly Glu Glu Cys Ala Met Lys Gly Lys Tyr Gly Ile Tyr Thr Lys
385 390 395 400
Val Ser Arg Tyr Val Asn Trp Ile Lys Glu Lys Thr Lys Leu Thr Pro
405 410 415
Val Ser Gln Thr Ser Lys Leu Thr Arg Ala Glu Thr Val Phe Pro Asp
420 425 430
Val Asp Ala His Lys Ser Glu Val Ala His Arg Phe Lys Asp Leu Gly
435 440 445
Glu Glu Asn Phe Lys Ala Leu Val Leu Ile Ala Phe Ala Gln Tyr Leu
450 455 460
Gln Gln Cys Pro Phe Glu Asp His Val Lys Leu Val Asn Glu Val Thr
465 470 475 480
Glu Phe Ala Lys Thr Cys Val Ala Asp Glu Ser Ala Glu Asn Cys Asp
485 490 495
Lys Ser Leu His Thr Leu Phe Gly Asp Lys Leu Cys Thr Val Ala Thr
500 505 510
Leu Arg Glu Thr Tyr Gly Glu Met Ala Asp Cys Cys Ala Lys Gln Glu
515 520 525
Pro Glu Arg Asn Glu Cys Phe Leu Gln His Lys Asp Asp Asn Pro Asn
530 535 540
Leu Pro Arg Leu Val Arg Pro Glu Val Asp Val Met Cys Thr Ala Phe
545 550 555 560
His Asp Asn Glu Glu Thr Phe Leu Lys Lys Tyr Leu Tyr Glu Ile Ala
565 570 575
Arg Arg His Pro Tyr Phe Tyr Ala Pro Glu Leu Leu Phe Phe Ala Lys
580 585 590
Arg Tyr Lys Ala Ala Phe Thr Glu Cys Cys Gln Ala Ala Asp Lys Ala
595 600 605
Ala Cys Leu Leu Pro Lys Leu Asp Glu Leu Arg Asp Glu Gly Lys Ala
610 615 620
Ser Ser Ala Lys Gln Arg Leu Lys Cys Ala Ser Leu Gln Lys Phe Gly
625 630 635 640
Glu Arg Ala Phe Lys Ala Trp Ala Val Ala Arg Leu Ser Gln Arg Phe
645 650 655
Pro Lys Ala Glu Phe Ala Glu Val Ser Lys Leu Val Thr Asp Leu Thr
660 665 670
Lys Val His Thr Glu Cys Cys His Gly Asp Leu Leu Glu Cys Ala Asp
675 680 685
Asp Arg Ala Asp Leu Ala Lys Tyr Ile Cys Glu Asn Gln Asp Ser Ile
690 695 700
Ser Ser Lys Leu Lys Glu Cys Cys Glu Lys Pro Leu Leu Glu Lys Ser
705 710 715 720
His Cys Ile Ala Glu Val Glu Asn Asp Glu Met Pro Ala Asp Leu Pro
725 730 735
Ser Leu Ala Ala Asp Phe Val Glu Ser Lys Asp Val Cys Lys Asn Tyr
740 745 750
Ala Glu Ala Lys Asp Val Phe Leu Gly Met Phe Leu Tyr Glu Tyr Ala
755 760 765
Arg Arg His Pro Asp Tyr Ser Val Val Leu Leu Leu Arg Leu Ala Lys
770 775 780
Thr Tyr Glu Thr Thr Leu Glu Lys Cys Cys Ala Ala Ala Asp Phe Cys
785 790 795 800
Tyr Ala Lys Val Phe Asp Glu Phe Lys Pro Leu Val Glu Glu Pro Gln
805 810 815
Asn Leu Ile Lys Gln Asn Cys Glu Leu Phe Glu Gln Leu Gly Glu Tyr
820 825 830
Lys Phe Gln Asn Ala Leu Leu Val Arg Tyr Thr Lys Lys Val Pro Gln
835 840 845
Val Ser Thr Pro Thr Leu Val Glu Val Ser Arg Asn Leu Gly Lys Val
850 855 860
Gly Ser Lys Cys Cys Lys His Pro Glu Ala Lys Arg Met Pro Cys Ala
865 870 875 880
Glu Asp Tyr Leu Ser Val Val Leu Asn Gln Leu Cys Val Leu His Glu
885 890 895
Lys Thr Pro Val Ser Asp Arg Val Thr Lys Cys Cys Thr Glu Ser Leu
900 905 910
Val Asn Arg Arg Pro Cys Phe Ser Ala Leu Glu Val Asp Glu Thr Tyr
915 920 925
Val Pro Lys Glu Phe Asn Ala Glu Thr Phe Thr Phe His Ala Asp Ile
930 935 940
Cys Thr Leu Ser Glu Lys Glu Arg Gln Ile Lys Lys Gln Thr Ala Leu
945 950 955 960
Val Glu Leu Val Lys His Lys Pro Lys Ala Thr Lys Glu Gln Leu Lys
965 970 975
Ala Val Met Asp Asp Phe Ala Ala Phe Val Glu Lys Cys Cys Lys Ala
980 985 990
Asp Asp Lys Glu Thr Cys Phe Ala Glu Glu Gly Lys Lys Leu Val Ala
995 1000 1005
Ala Ser Gln Ala Ala Leu Gly Leu
1010 1015
<210> 161
<211> 424
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> FIX
<400> 161
Tyr Asn Ser Gly Lys Leu Glu Glu Phe Val Gln Gly Asn Leu Glu Arg
1. 5 10 15
Glu Cys Met Glu Glu Lys Cys Ser Phe Glu Glu Ala Arg Glu Val Phe
20 25 30
Glu Asn Thr Glu Arg Thr Thr Glu Phe Trp Lys Gln Tyr Val Asp Gly
35 40 45
Asp Gln Cys Glu Ser Asn Pro Cys Leu Asn Gly Gly Ser Cys Lys Asp
50 55 60
Asp Ile Asn Ser Tyr Glu Cys Trp Cys Pro Phe Gly Phe Glu Gly Lys
65 70 75 80
Asn Cys Glu Leu Asp Val Thr Cys Asn Ile Lys Asn Gly Arg Cys Glu
85 90 95
Gln Phe Cys Lys Asn Ser Ala Asp Asn Lys Val Val Cys Ser Cys Thr
100 105 110
Glu Gly Tyr Arg Leu Ala Glu Asn Gln Lys Ser Cys Glu Pro Ala Val
115 120 125
Pro Phe Pro Cys Gly Arg Val Ser Val Ser Gln Thr Ser Lys Leu Thr
130 135 140
Arg Ala Glu Thr Val Phe Pro Asp Val Asp Tyr Val Asn Ser Thr Glu
145 150 155 160
Ala Glu Thr Ile Leu Asp Asn Ile Thr Gln Ser Thr Gln Ser Phe Asn
165 170 175
Asp Phe Thr Arg Val Val Gly Gly Glu Asp Ala Lys Pro Gly Gln Phe
180 185 190
Pro Trp Gln Val Val Leu Asn Gly Lys Val Asp Ala Phe Cys Gly Gly
195 200 205
Ser Ile Val Asn Glu Lys Trp Ile Val Thr Ala Ala His Cys Val Glu
210 215 220
Thr Gly Val Lys Ile Thr Val Val Ala Gly Glu His Asn Ile Glu Glu
225 230 235 240
Thr Glu His Thr Glu Gln Lys Arg Asn Val Ile Arg Ile Ile Pro His
245 250 255
His Asn Tyr Asn Ala Ala Ile Asn Lys Tyr Asn His Asp Ile Ala Leu
260 265 270
Leu Glu Leu Asp Glu Pro Leu Val Leu Asn Ser Tyr Val Thr Pro Ile
275 280 285
Cys Ile Ala Asp Lys Glu Tyr Thr Asn Ile Phe Leu Lys Phe Gly Ser
290 295 300
Gly Tyr Val Ser Gly Trp Gly Arg Val Phe His Lys Gly Arg Ser Ala
305 310 315 320
Leu Val Leu Gln Tyr Leu Arg Val Pro Leu Val Asp Arg Ala Thr Cys
325 330 335
Leu Arg Ser Thr Lys Phe Thr Ile Tyr Asn Asn Met Phe Cys Ala Gly
340 345 350
Phe His Glu Gly Gly Arg Asp Ser Cys Gln Gly Asp Ser Gly Gly Pro
355 360 365
His Val Thr Glu Val Glu Gly Thr Ser Phe Leu Thr Gly Ile Ile Ser
370 375 380
Trp Gly Glu Glu Cys Ala Met Lys Gly Lys Tyr Gly Ile Tyr Thr Lys
385 390 395 400
Val Ser Arg Tyr Val Asn Trp Ile Lys Glu Lys Thr Lys Leu Thr Pro
405 410 415
Val Ser Gln Thr Ser Lys Leu Thr
420
<210> 162
<211> 9
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкер
<400> 162
Arg Ala Glu Thr Val Phe Pro Asp Val
1. 5
<210> 163
<211> 585
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Альбумин
<400> 163
Asp Ala His Lys Ser Glu Val Ala His Arg Phe Lys Asp Leu Gly Glu
1. 5 10 15
Glu Asn Phe Lys Ala Leu Val Leu Ile Ala Phe Ala Gln Tyr Leu Gln
20 25 30
Gln Cys Pro Phe Glu Asp His Val Lys Leu Val Asn Glu Val Thr Glu
35 40 45
Phe Ala Lys Thr Cys Val Ala Asp Glu Ser Ala Glu Asn Cys Asp Lys
50 55 60
Ser Leu His Thr Leu Phe Gly Asp Lys Leu Cys Thr Val Ala Thr Leu
65 70 75 80
Arg Glu Thr Tyr Gly Glu Met Ala Asp Cys Cys Ala Lys Gln Glu Pro
85 90 95
Glu Arg Asn Glu Cys Phe Leu Gln His Lys Asp Asp Asn Pro Asn Leu
100 105 110
Pro Arg Leu Val Arg Pro Glu Val Asp Val Met Cys Thr Ala Phe His
115 120 125
Asp Asn Glu Glu Thr Phe Leu Lys Lys Tyr Leu Tyr Glu Ile Ala Arg
130 135 140
Arg His Pro Tyr Phe Tyr Ala Pro Glu Leu Leu Phe Phe Ala Lys Arg
145 150 155 160
Tyr Lys Ala Ala Phe Thr Glu Cys Cys Gln Ala Ala Asp Lys Ala Ala
165 170 175
Cys Leu Leu Pro Lys Leu Asp Glu Leu Arg Asp Glu Gly Lys Ala Ser
180 185 190
Ser Ala Lys Gln Arg Leu Lys Cys Ala Ser Leu Gln Lys Phe Gly Glu
195 200 205
Arg Ala Phe Lys Ala Trp Ala Val Ala Arg Leu Ser Gln Arg Phe Pro
210 215 220
Lys Ala Glu Phe Ala Glu Val Ser Lys Leu Val Thr Asp Leu Thr Lys
225 230 235 240
Val His Thr Glu Cys Cys His Gly Asp Leu Leu Glu Cys Ala Asp Asp
245 250 255
Arg Ala Asp Leu Ala Lys Tyr Ile Cys Glu Asn Gln Asp Ser Ile Ser
260 265 270
Ser Lys Leu Lys Glu Cys Cys Glu Lys Pro Leu Leu Glu Lys Ser His
275 280 285
Cys Ile Ala Glu Val Glu Asn Asp Glu Met Pro Ala Asp Leu Pro Ser
290 295 300
Leu Ala Ala Asp Phe Val Glu Ser Lys Asp Val Cys Lys Asn Tyr Ala
305 310 315 320
Glu Ala Lys Asp Val Phe Leu Gly Met Phe Leu Tyr Glu Tyr Ala Arg
325 330 335
Arg His Pro Asp Tyr Ser Val Val Leu Leu Leu Arg Leu Ala Lys Thr
340 345 350
Tyr Glu Thr Thr Leu Glu Lys Cys Cys Ala Ala Ala Asp Pro His Glu
355 360 365
Cys Tyr Ala Lys Val Phe Asp Glu Phe Lys Pro Leu Val Glu Glu Pro
370 375 380
Gln Asn Leu Ile Lys Gln Asn Cys Glu Leu Phe Glu Gln Leu Gly Glu
385 390 395 400
Tyr Lys Phe Gln Asn Ala Leu Leu Val Arg Tyr Thr Lys Lys Val Pro
405 410 415
Gln Val Ser Thr Pro Thr Leu Val Glu Val Ser Arg Asn Leu Gly Lys
420 425 430
Val Gly Ser Lys Cys Cys Lys His Pro Glu Ala Lys Arg Met Pro Cys
435 440 445
Ala Glu Asp Tyr Leu Ser Val Val Leu Asn Gln Leu Cys Val Leu His
450 455 460
Glu Lys Thr Pro Val Ser Asp Arg Val Thr Lys Cys Cys Thr Glu Ser
465 470 475 480
Leu Val Asn Arg Arg Pro Cys Phe Ser Ala Leu Glu Val Asp Glu Thr
485 490 495
Tyr Val Pro Lys Glu Phe Asn Ala Glu Thr Phe Thr Phe His Ala Asp
500 505 510
Ile Cys Thr Leu Ser Glu Lys Glu Arg Gln Ile Lys Lys Gln Thr Ala
515 520 525
Leu Val Glu Leu Val Lys His Lys Pro Lys Ala Thr Lys Glu Gln Leu
530 535 540
Lys Ala Val Met Asp Asp Phe Ala Ala Phe Val Glu Lys Cys Cys Lys
545 550 555 560
Ala Asp Asp Lys Glu Thr Cys Phe Ala Glu Glu Gly Lys Lys Leu Val
565 570 575
Ala Ala Ser Gln Ala Ala Leu Gly Leu
580 585
<210> 164
<211> 763
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> FIX(XTEN)-Fc
<400> 164
Met Gln Arg Val Asn Met Ile Met Ala Glu Ser Pro Gly Leu Ile Thr
1. 5 10 15
Ile Cys Leu Leu Gly Tyr Leu Leu Ser Ala Glu Cys Thr Val Phe Leu
20 25 30
Asp His Glu Asn Ala Asn Lys Ile Leu Asn Arg Pro Lys Arg Tyr Asn
35 40 45
Ser Gly Lys Leu Glu Glu Phe Val Gln Gly Asn Leu Glu Arg Glu Cys
50 55 60
Met Glu Glu Lys Cys Ser Phe Glu Glu Ala Arg Glu Val Phe Glu Asn
65 70 75 80
Thr Glu Arg Thr Thr Glu Phe Trp Lys Gln Tyr Val Asp Gly Asp Gln
85 90 95
Cys Glu Ser Asn Pro Cys Leu Asn Gly Gly Ser Cys Lys Asp Asp Ile
100 105 110
Asn Ser Tyr Glu Cys Trp Cys Pro Phe Gly Phe Glu Gly Lys Asn Cys
115 120 125
Glu Leu Asp Val Thr Cys Asn Ile Lys Asn Gly Arg Cys Glu Gln Phe
130 135 140
Cys Lys Asn Ser Ala Asp Asn Lys Val Val Cys Ser Cys Thr Glu Gly
145 150 155 160
Tyr Arg Leu Ala Glu Asn Gln Lys Ser Cys Glu Pro Ala Val Pro Phe
165 170 175
Pro Cys Gly Arg Val Ser Val Ser Gln Thr Ser Lys Leu Thr Arg Ala
180 185 190
Glu Thr Val Phe Pro Asp Val Asp Tyr Val Asn Ser Thr Glu Ala Glu
195 200 205
Thr Ile Leu Asp Gly Pro Ser Pro Gly Ser Pro Thr Ser Thr Glu Glu
210 215 220
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro
225 230 235 240
Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro
245 250 255
Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
260 265 270
Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro Gly Ala Ser Ser
275 280 285
Asn Ile Thr Gln Ser Thr Gln Ser Phe Asn Asp Phe Thr Arg Val Val
290 295 300
Gly Gly Glu Asp Ala Lys Pro Gly Gln Phe Pro Trp Gln Val Val Leu
305 310 315 320
Asn Gly Lys Val Asp Ala Phe Cys Gly Gly Ser Ile Val Asn Glu Lys
325 330 335
Trp Ile Val Thr Ala Ala His Cys Val Glu Thr Gly Val Lys Ile Thr
340 345 350
Val Val Ala Gly Glu His Asn Ile Glu Glu Thr Glu His Thr Glu Gln
355 360 365
Lys Arg Asn Val Ile Arg Ile Ile Pro His His Asn Tyr Asn Ala Ala
370 375 380
Ile Asn Lys Tyr Asn His Asp Ile Ala Leu Leu Glu Leu Asp Glu Pro
385 390 395 400
Leu Val Leu Asn Ser Tyr Val Thr Pro Ile Cys Ile Ala Asp Lys Glu
405 410 415
Tyr Thr Asn Ile Phe Leu Lys Phe Gly Ser Gly Tyr Val Ser Gly Trp
420 425 430
Gly Arg Val Phe His Lys Gly Arg Ser Ala Leu Val Leu Gln Tyr Leu
435 440 445
Arg Val Pro Leu Val Asp Arg Ala Thr Cys Leu Leu Ser Thr Lys Phe
450 455 460
Thr Ile Tyr Asn Asn Met Phe Cys Ala Gly Phe His Glu Gly Gly Arg
465 470 475 480
Asp Ser Cys Gln Gly Asp Ser Gly Gly Pro His Val Thr Glu Val Glu
485 490 495
Gly Thr Ser Phe Leu Thr Gly Ile Ile Ser Trp Gly Glu Glu Cys Ala
500 505 510
Met Lys Gly Lys Tyr Gly Ile Tyr Thr Lys Val Ser Arg Tyr Val Asn
515 520 525
Trp Ile Lys Glu Lys Thr Lys Leu Thr Asp Lys Thr His Thr Cys Pro
530 535 540
Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe
545 550 555 560
Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val
565 570 575
Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe
580 585 590
Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro
595 600 605
Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr
610 615 620
Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val
625 630 635 640
Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala
645 650 655
Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg
660 665 670
Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly
675 680 685
Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro
690 695 700
Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp Ser Asp Gly Ser
705 710 715 720
Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser Arg Trp Gln Gln
725 730 735
Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His
740 745 750
Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly
755 760
<210> 165
<211> 712
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> FIX-FXIa-AE288
<400> 165
Tyr Asn Ser Gly Lys Leu Glu Glu Phe Val Gln Gly Asn Leu Glu Arg
1. 5 10 15
Glu Cys Met Glu Glu Lys Cys Ser Phe Glu Glu Ala Arg Glu Val Phe
20 25 30
Glu Asn Thr Glu Arg Thr Thr Glu Phe Trp Lys Gln Tyr Val Asp Gly
35 40 45
Asp Gln Cys Glu Ser Asn Pro Cys Leu Asn Gly Gly Ser Cys Lys Asp
50 55 60
Asp Ile Asn Ser Tyr Glu Cys Trp Cys Pro Phe Gly Phe Glu Gly Lys
65 70 75 80
Asn Cys Glu Leu Asp Val Thr Cys Asn Ile Lys Asn Gly Arg Cys Glu
85 90 95
Gln Phe Cys Lys Asn Ser Ala Asp Asn Lys Val Val Cys Ser Cys Thr
100 105 110
Glu Gly Tyr Arg Leu Ala Glu Asn Gln Lys Ser Cys Glu Pro Ala Val
115 120 125
Pro Phe Pro Cys Gly Arg Val Ser Val Ser Gln Thr Ser Lys Leu Thr
130 135 140
Arg Ala Glu Thr Val Phe Pro Asp Val Asp Tyr Val Asn Ser Thr Glu
145 150 155 160
Ala Glu Thr Ile Leu Asp Asn Ile Thr Gln Ser Thr Gln Ser Phe Asn
165 170 175
Asp Phe Thr Arg Val Val Gly Gly Glu Asp Ala Lys Pro Gly Gln Phe
180 185 190
Pro Trp Gln Val Val Leu Asn Gly Lys Val Asp Ala Phe Cys Gly Gly
195 200 205
Ser Ile Val Asn Glu Lys Trp Ile Val Thr Ala Ala His Cys Val Glu
210 215 220
Thr Gly Val Lys Ile Thr Val Val Ala Gly Glu His Asn Ile Glu Glu
225 230 235 240
Thr Glu His Thr Glu Gln Lys Arg Asn Val Ile Arg Ile Ile Pro His
245 250 255
His Asn Tyr Asn Ala Ala Ile Asn Lys Tyr Asn His Asp Ile Ala Leu
260 265 270
Leu Glu Leu Asp Glu Pro Leu Val Leu Asn Ser Tyr Val Thr Pro Ile
275 280 285
Cys Ile Ala Asp Lys Glu Tyr Thr Asn Ile Phe Leu Lys Phe Gly Ser
290 295 300
Gly Tyr Val Ser Gly Trp Gly Arg Val Phe His Lys Gly Arg Ser Ala
305 310 315 320
Leu Val Leu Gln Tyr Leu Arg Val Pro Leu Val Asp Arg Ala Thr Cys
325 330 335
Leu Arg Ser Thr Lys Phe Thr Ile Tyr Asn Asn Met Phe Cys Ala Gly
340 345 350
Phe His Glu Gly Gly Arg Asp Ser Cys Gln Gly Asp Ser Gly Gly Pro
355 360 365
His Val Thr Glu Val Glu Gly Thr Ser Phe Leu Thr Gly Ile Ile Ser
370 375 380
Trp Gly Glu Glu Cys Ala Met Lys Gly Lys Tyr Gly Ile Tyr Thr Lys
385 390 395 400
Val Ser Arg Tyr Val Asn Trp Ile Lys Glu Lys Thr Lys Leu Thr Gly
405 410 415
Lys Leu Thr Arg Ala Glu Thr Gly Gly Thr Ser Glu Ser Ala Thr Pro
420 425 430
Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
435 440 445
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro
450 455 460
Ala Thr Ser Gly Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro
465 470 475 480
Glu Ser Gly Pro Gly Thr Ser Thr Glu Pro Ser Glu Gly Ser Ala Pro
485 490 495
Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Glu
500 505 510
Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly
515 520 525
Ser Glu Thr Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro
530 535 540
Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Ser Pro Ala
545 550 555 560
Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Thr Glu Pro Ser Glu
565 570 575
Gly Ser Ala Pro Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro
580 585 590
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Glu
595 600 605
Ser Ala Thr Pro Glu Ser Gly Pro Gly Ser Glu Pro Ala Thr Ser Gly
610 615 620
Ser Glu Thr Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
625 630 635 640
Gly Ser Pro Ala Gly Ser Pro Thr Ser Thr Glu Glu Gly Thr Ser Thr
645 650 655
Glu Pro Ser Glu Gly Ser Ala Pro Gly Thr Ser Thr Glu Pro Ser Glu
660 665 670
Gly Ser Ala Pro Gly Ser Glu Pro Ala Thr Ser Gly Ser Glu Thr Pro
675 680 685
Gly Thr Ser Glu Ser Ala Thr Pro Glu Ser Gly Pro Gly Thr Ser Thr
690 695 700
Glu Pro Ser Glu Gly Ser Ala Pro
705 710
<210> 166
<211> 944
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> FIX-Fc-Fc
<400> 166
Met Gln Arg Val Asn Met Ile Met Ala Glu Ser Pro Gly Leu Ile Thr
1. 5 10 15
Ile Cys Leu Leu Gly Tyr Leu Leu Ser Ala Glu Cys Thr Val Phe Leu
20 25 30
Asp His Glu Asn Ala Asn Lys Ile Leu Asn Arg Pro Lys Arg Tyr Asn
35 40 45
Ser Gly Lys Leu Glu Glu Phe Val Gln Gly Asn Leu Glu Arg Glu Cys
50 55 60
Met Glu Glu Lys Cys Ser Phe Glu Glu Ala Arg Glu Val Phe Glu Asn
65 70 75 80
Thr Glu Arg Thr Thr Glu Phe Trp Lys Gln Tyr Val Asp Gly Asp Gln
85 90 95
Cys Glu Ser Asn Pro Cys Leu Asn Gly Gly Ser Cys Lys Asp Asp Ile
100 105 110
Asn Ser Tyr Glu Cys Trp Cys Pro Phe Gly Phe Glu Gly Lys Asn Cys
115 120 125
Glu Leu Asp Val Thr Cys Asn Ile Lys Asn Gly Arg Cys Glu Gln Phe
130 135 140
Cys Lys Asn Ser Ala Asp Asn Lys Val Val Cys Ser Cys Thr Glu Gly
145 150 155 160
Tyr Arg Leu Ala Glu Asn Gln Lys Ser Cys Glu Pro Ala Val Pro Phe
165 170 175
Pro Cys Gly Arg Val Ser Val Ser Gln Thr Ser Lys Leu Thr Arg Ala
180 185 190
Glu Thr Val Phe Pro Asp Val Asp Tyr Val Asn Ser Thr Glu Ala Glu
195 200 205
Thr Ile Leu Asp Asn Ile Thr Gln Ser Thr Gln Ser Phe Asn Asp Phe
210 215 220
Thr Arg Val Val Gly Gly Glu Asp Ala Lys Pro Gly Gln Phe Pro Trp
225 230 235 240
Gln Val Val Leu Asn Gly Lys Val Asp Ala Phe Cys Gly Gly Ser Ile
245 250 255
Val Asn Glu Lys Trp Ile Val Thr Ala Ala His Cys Val Glu Thr Gly
260 265 270
Val Lys Ile Thr Val Val Ala Gly Glu His Asn Ile Glu Glu Thr Glu
275 280 285
His Thr Glu Gln Lys Arg Asn Val Ile Arg Ile Ile Pro His His Asn
290 295 300
Tyr Asn Ala Ala Ile Asn Lys Tyr Asn His Asp Ile Ala Leu Leu Glu
305 310 315 320
Leu Asp Glu Pro Leu Val Leu Asn Ser Tyr Val Thr Pro Ile Cys Ile
325 330 335
Ala Asp Lys Glu Tyr Thr Asn Ile Phe Leu Lys Phe Gly Ser Gly Tyr
340 345 350
Val Ser Gly Trp Gly Arg Val Phe His Lys Gly Arg Ser Ala Leu Val
355 360 365
Leu Gln Tyr Leu Arg Val Pro Leu Val Asp Arg Ala Thr Cys Leu Arg
370 375 380
Ser Thr Lys Phe Thr Ile Tyr Asn Asn Met Phe Cys Ala Gly Phe His
385 390 395 400
Glu Gly Gly Arg Asp Ser Cys Gln Gly Asp Ser Gly Gly Pro His Val
405 410 415
Thr Glu Val Glu Gly Thr Ser Phe Leu Thr Gly Ile Ile Ser Trp Gly
420 425 430
Glu Glu Cys Ala Met Lys Gly Lys Tyr Gly Ile Tyr Thr Lys Val Ser
435 440 445
Arg Tyr Val Asn Trp Ile Lys Glu Lys Thr Lys Leu Thr Asp Lys Thr
450 455 460
His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
465 470 475 480
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
485 490 495
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
500 505 510
Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
515 520 525
Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
530 535 540
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
545 550 555 560
Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
565 570 575
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
580 585 590
Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys
595 600 605
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
610 615 620
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
625 630 635 640
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
645 650 655
Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
660 665 670
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
675 680 685
Arg Arg Arg Arg Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
690 695 700
Gly Gly Gly Ser Gly Gly Gly Gly Ser Arg Arg Arg Arg Asp Lys Thr
705 710 715 720
His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser
725 730 735
Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met Ile Ser Arg
740 745 750
Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His Glu Asp Pro
755 760 765
Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val His Asn Ala
770 775 780
Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val
785 790 795 800
Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly Lys Glu Tyr
805 810 815
Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr
820 825 830
Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu
835 840 845
Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser Leu Thr Cys
850 855 860
Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu Trp Glu Ser
865 870 875 880
Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro Val Leu Asp
885 890 895
Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val Asp Lys Ser
900 905 910
Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met His Glu Ala
915 920 925
Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
930 935 940
<210> 167
<211> 383
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Парвовирус B19 KY940273.1
<400> 167
ccaaatcaga tgccgccggt cgccgccggt aggcgggact tccggtacaa gatggcggac
60
aattacgtca tttcctgtga cgtcatttcc tgtgacgtca cttccggtgg gcgggacttc
120
cggaattagg gttggctctg ggccagcttg cttggggttg ccttgacact aagacaagcg
180
gcgcgccgct tgatcttagt ggcacgtcaa ccccaagcgc tggcccagag ccaaccctaa
240
ttccggaagt cccgcccacc ggaagtgacg tcacaggaaa tgacgtcaca ggaaatgacg
300
taattgtccg ccatcttgta ccggaagtcc cgcctaccgg cggcgaccgg cggcatctga
360
tttggtgtct tcttttaaat ttt
383
<210> 168
<211> 248
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Парвовирус B19 d135
<400> 168
ctctgggcca gcttgcttgg ggttgccttg acactaagac aagcggcgcg ccgcttgatc
60
ttagtggcac gtcaacccca agcgctggcc cagagccaac cctaattccg gaagtcccgc
120
ccaccggaag tgacgtcaca ggaaatgacg tcacaggaaa tgacgtaatt gtccgccatc
180
ttgtaccgga agtcccgcct accggcggcg accggcggca tctgatttgg tgtcttcttt
240
taaatttt
248
<210> 169
<211> 129
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Парвовирус v1 AAV2
<400> 169
cggcgcgccg cttgatctta gtggcacgtc aaccagcgct ggcccagagc caaccctaat
60
tccggaagtc ctcagtccgc catcttgccc gcctaccggc ggcgaccggc ggcatcattt
120
ggtgttctt
129
<210> 170
<211> 113
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Парвовирус V2
<400> 170
ctctgggcca gcttgcttgg ggttgccttg acactaagac aagcggcgcg ccgcttgatc
60
ttagtggcac gtcaacccca agcgctggcc cagagtgtct tcttttaaat ttt
113
<210> 171
<211> 340
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Парвовирус V3
<400> 171
caaatcagat gccgccggtc gccgccggta ggcgggactt ccggtacaag atggcggaca
60
attacgtcat ttcctgtgac gtatttcctg tgacgtactt ccggtggcgg gacttccgga
120
attttggctc tgggccagct tgcttggggt tgccttgacc aagcgcgcgc cgcttgatca
180
ccccaagcgc tggcccagag ccacctaacc ggaagtcccc ccaccggaag tgacgtcaca
240
ggaaagacgt cacaggaagt aattgtccgc catcttgtac cggaagtccc gcaccggcgg
300
cgaccggcgg catctgattt ggtgtcttct tttaaatttt
340
<210> 172
<211> 444
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Парвовирус U25749.1
<400> 172
ctcattggag ggttcgttcg ttcgaaccag ccaatcaggg gagggggaag tgacgcaagt
60
tccggtcaca tgcttccggt gacgcacatc cggtgacgta gttccggtca cgtgcttcct
120
gtcacgtgtt tccggtcacg tgacttccgg tcatgtgact tccggtgacg tgtttccggc
180
tgttaggttg accacgcgca tgccgcgcgg tcagcccaat agttaagccg gaaacacgtc
240
accggaagtc acatgaccgg aagtcacgtg accggaaaca cgtgacagga agcacgtgac
300
cggaactacg tcaccggatg tgcgtcaccg gaagcatgtg accggaactt gcgtcacttc
360
cccctcccct gattggctgg ttcgaacgaa cgaaccctcc aatgagactc aaggacaaga
420
ggatattttg cgcgccagga agtg
444
<210> 173
<211> 282
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Парвовирус GPV AAV2 V1
<400> 173
cggtgacgtg tttccggctg ttaggttgac cacgcgcatg ccgcgcggtc agcccaatag
60
ttaagccgga aacacgtcac cggaagtcac atgaccggaa gtcacgtgac cggaaacacg
120
tgacaggaag cacgtgaccg gaactacgtc accggatgtg cgtcaccgga agcatgtgac
180
cggaacttgc gtcacttccc cctcccctga ttggctggtt cgaacgaacg aaccctccaa
240
tgagactcaa ggacaagagg atattttgcg cgccaggaag tg
282
<210> 174
<211> 145
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Парвовирус GPV AAV2 V1
<400> 174
ttgaccacgc gcatgccgcg cggtcagccc aatagttaag ccgggtgacc acacgtgaca
60
ggaagcacgg gatgtgcgtc accggaagca gtgaccgggc tggttcgaac gaacgaaccc
120
tccaactcaa ggacaagagg atatt
145
<210> 175
<211> 120
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Парвовирус GPV V2
<400> 175
cggtgacgtg tttccggctg ttaggttgac cacgcgcatg ccgcgcggtc agcccaatag
60
ttaagccgga aacacgtcac cgactcaagg acaagaggat attttgcgcg ccaggaagtg
120
<210> 176
<211> 102
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Парвовирус GPV V3
<400> 176
gggaacaatc aggggaagtg accggtgacg tcatgtaact tgcgtcactt cccgttcgaa
60
cgaacgaacg agactcaagg acaagaggcg cgccaggaag tg
102
<210> 177
<211> 145
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Парвовирус AAV2 NC_001401.2
<400> 177
ttggccactc cctctctgcg cgctcgctcg ctcactgagg ccgggcgacc aaaggtcgcc
60
cgacgcccgg gctttgcccg ggcggcctca gtgagcgagc gagcgcgcag agagggagtg
120
gccaactcca tcactagggg ttcct
145
<210> 178
<211> 130
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Парвовирус Gtx
<400> 178
ctgcgcgctc gctcgctcac tgaggccgcc cgggcaaagc ccgggcgtcg ggcgaccttt
60
ggtcgcccgg cctcagtgag cgagcgagcg cgcagagagg gagtggccaa ctccatcact
120
aggggttcct
130
<210> 179
<211> 6762
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Конструкция B19-FVIII
<400> 179
ctctgggcca gcttgcttgg ggttgccttg acactaagac aagcggcgcg ccgcttgatc
60
ttagtggcac gtcaacccca agcgctggcc cagagccaac cctaattccg gaagtcccgc
120
ccaccggaag tgacgtcaca ggaaatgacg tcacaggaaa tgacgtaatt gtccgccatc
180
ttgtaccgga agtcccgcct accggcggcg accggcggca tctgatttgg tgtcttcttt
240
taaattttgc ggcaattcag tcgataacta taacggtcct aaggtagcga tttaaatacg
300
cgctctctta aggtagcccc gggacgcgtc aattgagatc tggatccggt accgaattcg
360
cggccgcctc gacgactagc gtttaattaa acgcgtgtct gtctgcacat ttcgtagagc
420
gagtgttccg atactctaat ctccctaggc aaggttcata tttgtgtagg ttacttattc
480
tccttttgtt gactaagtca ataatcagaa tcagcaggtt tggagtcagc ttggcaggga
540
tcagcagcct gggttggaag gagggggtat aaaagcccct tcaccaggag aagccgtcac
600
acagatccac aagctcctga ggtaagtgcc gtgtgtggtt cccgcgggcc tggcctcttt
660
acgggttatg gcccttgcgt gccttgaatt actgacactg acatccactt tttctttttc
720
tccacagcta gcgccaccat gcagattgag ctgtccactt gtttcttcct gtgcctcctg
780
cgcttctgtt tctccgccac tcgccggtac taccttggag ccgtggagct ttcatgggac
840
tacatgcaga gcgacctggg cgaactcccc gtggatgcca gattcccccc ccgcgtgcca
900
aagtccttcc cctttaacac ctccgtggtg tacaagaaaa ccctctttgt cgagttcact
960
gaccacctgt tcaacatcgc caagccgcgc ccaccttgga tgggcctcct gggaccgacc
1020
attcaagctg aagtgtacga caccgtggtg atcaccctga agaacatggc gtcccacccc
1080
gtgtccctgc atgcggtcgg agtgtcctac tggaaggcct ccgaaggagc tgagtacgac
1140
gaccagacta gccagcggga aaaggaggac gataaagtgt tcccgggcgg ctcgcatact
1200
tacgtgtggc aagtcctgaa ggaaaacgga cctatggcat ccgatcctct gtgcctgact
1260
tactcctacc tttcccatgt ggacctcgtg aaggacctga acagcgggct gattggtgca
1320
cttctcgtgt gccgcgaagg ttcgctcgct aaggaaaaga cccagaccct ccataagttc
1380
atccttttgt tcgctgtgtt cgatgaagga aagtcatggc attccgaaac taagaactcg
1440
ctgatgcagg accgggatgc cgcctcagcc cgcgcctggc ctaaaatgca tacagtcaac
1500
ggatacgtga atcggtcact gcccgggctc atcggttgtc acagaaagtc cgtgtactgg
1560
cacgtcatcg gcatgggcac tacgcctgaa gtgcactcca tcttcctgga agggcacacc
1620
ttcctcgtgc gcaaccaccg ccaggcctct ctggaaatct ccccgattac ctttctgacc
1680
gcccagactc tgctcatgga cctggggcag ttccttctct tctgccacat ctccagccat
1740
cagcacgacg gaatggaggc ctacgtgaag gtggactcat gcccggaaga acctcagttg
1800
cggatgaaga acaacgagga ggccgaggac tatgacgacg atttgactga ctccgagatg
1860
gacgtcgtgc ggttcgatga cgacaacagc cccagcttca tccagattcg cagcgtggcc
1920
aagaagcacc ccaaaacctg ggtgcactac atcgcggccg aggaagaaga ttgggactac
1980
gccccgttgg tgctggcacc cgatgaccgg tcgtacaagt cccagtatct gaacaatggt
2040
ccgcagcgga ttggcagaaa gtacaagaaa gtgcggttca tggcgtacac tgacgaaacg
2100
tttaagaccc gggaggccat tcaacatgag agcggcattc tgggaccact gctgtacgga
2160
gaggtcggcg ataccctgct catcatcttc aaaaaccagg cctcccggcc ttacaacatc
2220
taccctcacg gaatcaccga cgtgcggcca ctctactcgc ggcgcctgcc gaagggcgtc
2280
aagcacctga aagacttccc tatcctgccg ggcgaaatct tcaagtataa gtggaccgtc
2340
accgtggagg acgggcccac caagagcgat cctaggtgtc tgactcggta ctactccagc
2400
ttcgtgaaca tggaacggga cctggcatcg ggactcattg gaccgctgct gatctgctac
2460
aaagagtcgg tggatcaacg cggcaaccag atcatgtccg acaagcgcaa cgtgatcctg
2520
ttctccgtgt ttgatgaaaa cagatcctgg tacctcactg aaaacatcca gaggttcctc
2580
ccaaaccccg caggagtgca actggaggac cctgagtttc aggcctcgaa tatcatgcac
2640
tcgattaacg gttacgtgtt cgactcgctg caactgagcg tgtgcctcca tgaagtcgct
2700
tactggtaca ttctgtccat cggcgcccag actgacttcc tgagcgtgtt cttttccggt
2760
tacaccttta agcacaagat ggtgtacgaa gataccctga ccctgttccc tttctccggc
2820
gaaacggtgt tcatgtcgat ggagaacccg ggtctgtgga ttctgggatg ccacaacagc
2880
gactttcgga accgcggaat gactgccctg ctgaaggtgt cctcatgcga caagaacacc
2940
ggagactact acgaggactc ctacgaggat atctcagcct acctcctgtc caagaacaac
3000
gcgatcgagc cgcgcagctt cagccagaac ggcgcgccaa catcagagag cgccacccct
3060
gaaagtggtc ccgggagcga gccagccaca tctgggtcgg aaacgccagg cacaagtgag
3120
tctgcaactc ccgagtccgg acctggctcc gagcctgcca ctagcggctc cgagactccg
3180
ggaacttccg agagcgctac accagaaagc ggacccggaa ccagtaccga acctagcgag
3240
ggctctgctc cgggcagccc agccggctct cctacatcca cggaggaggg cacttccgaa
3300
tccgccaccc cggagtcagg gccaggatct gaacccgcta cctcaggcag tgagacgcca
3360
ggaacgagcg agtccgctac accggagagt gggccaggga gccctgctgg atctcctacg
3420
tccactgagg aagggtcacc agcgggctcg cccaccagca ctgaagaagg tgcctcgagc
3480
ccgcctgtgc tgaagaggca ccagcgagaa attacccgga ccaccctcca atcggatcag
3540
gaggaaatcg actacgacga caccatctcg gtggaaatga agaaggaaga tttcgatatc
3600
tacgacgagg acgaaaatca gtcccctcgc tcattccaaa agaaaactag acactacttt
3660
atcgccgcgg tggaaagact gtgggactat ggaatgtcat ccagccctca cgtccttcgg
3720
aaccgggccc agagcggatc ggtgcctcag ttcaagaaag tggtgttcca ggagttcacc
3780
gacggcagct tcacccagcc gctgtaccgg ggagaactga acgaacacct gggcctgctc
3840
ggtccctaca tccgcgcgga agtggaggat aacatcatgg tgaccttccg taaccaagca
3900
tccagacctt actccttcta ttcctccctg atctcatacg aggaggacca gcgccaaggc
3960
gccgagcccc gcaagaactt cgtcaagccc aacgagacta agacctactt ctggaaggtc
4020
caacaccata tggccccgac caaggatgag tttgactgca aggcctgggc ctacttctcc
4080
gacgtggacc ttgagaagga tgtccattcc ggcctgatcg ggccgctgct cgtgtgtcac
4140
accaacaccc tgaacccagc gcatggacgc caggtcaccg tccaggagtt tgctctgttc
4200
ttcaccattt ttgacgaaac taagtcctgg tacttcaccg agaatatgga gcgaaactgt
4260
agagcgccct gcaatatcca gatggaagat ccgactttca aggagaacta tagattccac
4320
gccatcaacg ggtacatcat ggatactctg ccggggctgg tcatggccca ggatcagagg
4380
attcggtggt acttgctgtc aatgggatcg aacgaaaaca ttcactccat tcacttctcc
4440
ggtcacgtgt tcactgtgcg caagaaggag gagtacaaga tggcgctgta caatctgtac
4500
cccggggtgt tcgaaactgt ggagatgctg ccgtccaagg ccggcatctg gagagtggag
4560
tgcctgatcg gagagcacct ccacgcgggg atgtccaccc tcttcctggt gtactcgaat
4620
aagtgccaga ccccgctggg catggcctcg ggccacatca gagacttcca gatcacagca
4680
agcggacaat acggccaatg ggcgccgaag ctggcccgct tgcactactc cggatcgatc
4740
aacgcatggt ccaccaagga accgttctcg tggattaagg tggacctcct ggcccctatg
4800
attatccacg gaattaagac ccagggcgcc aggcagaagt tctcctccct gtacatctcg
4860
caattcatca tcatgtacag cctggacggg aagaagtggc agacttacag gggaaactcc
4920
accggcaccc tgatggtctt tttcggcaac gtggattcct ccggcattaa gcacaacatc
4980
ttcaacccac cgatcatagc cagatatatt aggctccacc ccactcacta ctcaatccgc
5040
tcaactcttc ggatggaact catggggtgc gacctgaact cctgctccat gccgttgggg
5100
atggaatcaa aggctattag cgacgcccag atcaccgcga gctcctactt cactaacatg
5160
ttcgccacct ggagcccctc caaggccagg ctgcacttgc agggacggtc aaatgcctgg
5220
cggccgcaag tgaacaatcc gaaggaatgg cttcaagtgg atttccaaaa gaccatgaaa
5280
gtgaccggag tcaccaccca gggagtgaag tcccttctga cctcgatgta tgtgaaggag
5340
ttcctgatta gcagcagcca ggacgggcac cagtggaccc tgttcttcca aaacggaaag
5400
gtcaaggtgt tccaggggaa ccaggactcg ttcacacccg tggtgaactc cctggacccc
5460
ccactgctga cgcggtactt gaggattcat cctcagtcct gggtccatca gattgcattg
5520
cgaatggaag tcctgggctg cgaggcccag gacctgtact gaatcagcct gagctcgctg
5580
atcataatca acctctggat tacaaaattt gtgaaagatt gactggtatt cttaactatg
5640
ttgctccttt tacgctatgt ggatacgctg ctttaatgcc tttgtatcat gctattgctt
5700
cccgtatggc tttcattttc tcctccttgt ataaatcctg gttgctgtct ctttatgagg
5760
agttgtggcc cgttgtcagg caacgtggcg tggtgtgcac tgtgtttgct gacgcaaccc
5820
ccactggttg gggcattgcc accacctgtc agctcctttc cgggactttc gctttccccc
5880
tccctattgc cacggcggaa ctcatcgccg cctgccttgc ccgctgctgg acaggggctc
5940
ggctgttggg cactgacaat tccgtggtgt tgtcggggaa atcatcgtcc tttccttggc
6000
tgctcgcctg tgttgccacc tggattctgc gcgggacgtc cttctgctac gtcccttcgg
6060
ccctcaatcc agcggacctt ccttcccgcg gcctgctgcc ggctctgcgg cctcttccgc
6120
gtcttcgcct tcgccctcag acgagtcgga tctccctttg ggccgcctcc ccgctgatca
6180
gcctcgactg tgccttctag ttgccagcca tctgttgttt gcccctcccc cgtgccttcc
6240
ttgaccctgg aaggtgccac tcccactgtc ctttcctaat aaaatgagga aattgcatcg
6300
cattgtctga gtaggtgtca ttctattctg gggggtgggg tggggcagga cagcaagggg
6360
gaggattggg aagacaatag caggcatgct ggggatgcgg tgggctctat ggcttctgag
6420
gcggaaagaa cgggctcgag aagcttctag atatcctctc ttaaggtagc atcgagattt
6480
aaattaggga taacagggta atggcgcggg ccgcaaaatt taaaagaaga caccaaatca
6540
gatgccgccg gtcgccgccg gtaggcggga cttccggtac aagatggcgg acaattacgt
6600
catttcctgt gacgtcattt cctgtgacgt cacttccggt gggcgggact tccggaatta
6660
gggttggctc tgggccagcg cttggggttg acgtgccact aagatcaagc ggcgcgccgc
6720
ttgtcttagt gtcaaggcaa ccccaagcaa gctggcccag ag
6762
<210> 180
<211> 248
<212> ДНК
<213> Искусственная последовательность
<220>
<223> 5'-ITR
<400> 180
ctctgggcca gcttgcttgg ggttgccttg acactaagac aagcggcgcg ccgcttgatc
60
ttagtggcac gtcaacccca agcgctggcc cagagccaac cctaattccg gaagtcccgc
120
ccaccggaag tgacgtcaca ggaaatgacg tcacaggaaa tgacgtaatt gtccgccatc
180
ttgtaccgga agtcccgcct accggcggcg accggcggca tctgatttgg tgtcttcttt
240
taaatttt
248
<210> 181
<211> 248
<212> ДНК
<213> Искусственная последовательность
<220>
<223> 3'-ITR инвертированный концевой повтор
<400> 181
ctctgggcca gcttgcttgg ggttgccttg acactaagac aagcggcgcg ccgcttgatc
60
ttagtggcac gtcaacccca agcgctggcc cagagccaac cctaattccg gaagtcccgc
120
ccaccggaag tgacgtcaca ggaaatgacg tcacaggaaa tgacgtaatt gtccgccatc
180
ttgtaccgga agtcccgcct accggcggcg accggcggca tctgatttgg tgtcttcttt
240
taaatttt
248
<210> 182
<211> 6830
<212> ДНК
<213> Искусственная последовательность
<220>
<223> Конструкция GPV-FVIII
<400> 182
cggtgacgtg tttccggctg ttaggttgac cacgcgcatg ccgcgcggtc agcccaatag
60
ttaagccgga aacacgtcac cggaagtcac atgaccggaa gtcacgtgac cggaaacacg
120
tgacaggaag cacgtgaccg gaactacgtc accggatgtg cgtcaccgga agcatgtgac
180
cggaacttgc gtcacttccc cctcccctga ttggctggtt cgaacgaacg aaccctccaa
240
tgagactcaa ggacaagagg atattttgcg cgccaggaag tggcggcaat tcagtcgata
300
actataacgg tcctaaggta gcgatttaaa tacgcgctct cttaaggtag ccccgggacg
360
cgtcaattga gatctggatc cggtaccgaa ttcgcggccg cctcgacgac tagcgtttaa
420
ttaaacgcgt gtctgtctgc acatttcgta gagcgagtgt tccgatactc taatctccct
480
aggcaaggtt catatttgtg taggttactt attctccttt tgttgactaa gtcaataatc
540
agaatcagca ggtttggagt cagcttggca gggatcagca gcctgggttg gaaggagggg
600
gtataaaagc cccttcacca ggagaagccg tcacacagat ccacaagctc ctgaggtaag
660
tgccgtgtgt ggttcccgcg ggcctggcct ctttacgggt tatggccctt gcgtgccttg
720
aattactgac actgacatcc actttttctt tttctccaca gctagcgcca ccatgcagat
780
tgagctgtcc acttgtttct tcctgtgcct cctgcgcttc tgtttctccg ccactcgccg
840
gtactacctt ggagccgtgg agctttcatg ggactacatg cagagcgacc tgggcgaact
900
ccccgtggat gccagattcc ccccccgcgt gccaaagtcc ttccccttta acacctccgt
960
ggtgtacaag aaaaccctct ttgtcgagtt cactgaccac ctgttcaaca tcgccaagcc
1020
gcgcccacct tggatgggcc tcctgggacc gaccattcaa gctgaagtgt acgacaccgt
1080
ggtgatcacc ctgaagaaca tggcgtccca ccccgtgtcc ctgcatgcgg tcggagtgtc
1140
ctactggaag gcctccgaag gagctgagta cgacgaccag actagccagc gggaaaagga
1200
ggacgataaa gtgttcccgg gcggctcgca tacttacgtg tggcaagtcc tgaaggaaaa
1260
cggacctatg gcatccgatc ctctgtgcct gacttactcc tacctttccc atgtggacct
1320
cgtgaaggac ctgaacagcg ggctgattgg tgcacttctc gtgtgccgcg aaggttcgct
1380
cgctaaggaa aagacccaga ccctccataa gttcatcctt ttgttcgctg tgttcgatga
1440
aggaaagtca tggcattccg aaactaagaa ctcgctgatg caggaccggg atgccgcctc
1500
agcccgcgcc tggcctaaaa tgcatacagt caacggatac gtgaatcggt cactgcccgg
1560
gctcatcggt tgtcacagaa agtccgtgta ctggcacgtc atcggcatgg gcactacgcc
1620
tgaagtgcac tccatcttcc tggaagggca caccttcctc gtgcgcaacc accgccaggc
1680
ctctctggaa atctccccga ttacctttct gaccgcccag actctgctca tggacctggg
1740
gcagttcctt ctcttctgcc acatctccag ccatcagcac gacggaatgg aggcctacgt
1800
gaaggtggac tcatgcccgg aagaacctca gttgcggatg aagaacaacg aggaggccga
1860
ggactatgac gacgatttga ctgactccga gatggacgtc gtgcggttcg atgacgacaa
1920
cagccccagc ttcatccaga ttcgcagcgt ggccaagaag caccccaaaa cctgggtgca
1980
ctacatcgcg gccgaggaag aagattggga ctacgccccg ttggtgctgg cacccgatga
2040
ccggtcgtac aagtcccagt atctgaacaa tggtccgcag cggattggca gaaagtacaa
2100
gaaagtgcgg ttcatggcgt acactgacga aacgtttaag acccgggagg ccattcaaca
2160
tgagagcggc attctgggac cactgctgta cggagaggtc ggcgataccc tgctcatcat
2220
cttcaaaaac caggcctccc ggccttacaa catctaccct cacggaatca ccgacgtgcg
2280
gccactctac tcgcggcgcc tgccgaaggg cgtcaagcac ctgaaagact tccctatcct
2340
gccgggcgaa atcttcaagt ataagtggac cgtcaccgtg gaggacgggc ccaccaagag
2400
cgatcctagg tgtctgactc ggtactactc cagcttcgtg aacatggaac gggacctggc
2460
atcgggactc attggaccgc tgctgatctg ctacaaagag tcggtggatc aacgcggcaa
2520
ccagatcatg tccgacaagc gcaacgtgat cctgttctcc gtgtttgatg aaaacagatc
2580
ctggtacctc actgaaaaca tccagaggtt cctcccaaac cccgcaggag tgcaactgga
2640
ggaccctgag tttcaggcct cgaatatcat gcactcgatt aacggttacg tgttcgactc
2700
gctgcaactg agcgtgtgcc tccatgaagt cgcttactgg tacattctgt ccatcggcgc
2760
ccagactgac ttcctgagcg tgttcttttc cggttacacc tttaagcaca agatggtgta
2820
cgaagatacc ctgaccctgt tccctttctc cggcgaaacg gtgttcatgt cgatggagaa
2880
cccgggtctg tggattctgg gatgccacaa cagcgacttt cggaaccgcg gaatgactgc
2940
cctgctgaag gtgtcctcat gcgacaagaa caccggagac tactacgagg actcctacga
3000
ggatatctca gcctacctcc tgtccaagaa caacgcgatc gagccgcgca gcttcagcca
3060
gaacggcgcg ccaacatcag agagcgccac ccctgaaagt ggtcccggga gcgagccagc
3120
cacatctggg tcggaaacgc caggcacaag tgagtctgca actcccgagt ccggacctgg
3180
ctccgagcct gccactagcg gctccgagac tccgggaact tccgagagcg ctacaccaga
3240
aagcggaccc ggaaccagta ccgaacctag cgagggctct gctccgggca gcccagccgg
3300
ctctcctaca tccacggagg agggcacttc cgaatccgcc accccggagt cagggccagg
3360
atctgaaccc gctacctcag gcagtgagac gccaggaacg agcgagtccg ctacaccgga
3420
gagtgggcca gggagccctg ctggatctcc tacgtccact gaggaagggt caccagcggg
3480
ctcgcccacc agcactgaag aaggtgcctc gagcccgcct gtgctgaaga ggcaccagcg
3540
agaaattacc cggaccaccc tccaatcgga tcaggaggaa atcgactacg acgacaccat
3600
ctcggtggaa atgaagaagg aagatttcga tatctacgac gaggacgaaa atcagtcccc
3660
tcgctcattc caaaagaaaa ctagacacta ctttatcgcc gcggtggaaa gactgtggga
3720
ctatggaatg tcatccagcc ctcacgtcct tcggaaccgg gcccagagcg gatcggtgcc
3780
tcagttcaag aaagtggtgt tccaggagtt caccgacggc agcttcaccc agccgctgta
3840
ccggggagaa ctgaacgaac acctgggcct gctcggtccc tacatccgcg cggaagtgga
3900
ggataacatc atggtgacct tccgtaacca agcatccaga ccttactcct tctattcctc
3960
cctgatctca tacgaggagg accagcgcca aggcgccgag ccccgcaaga acttcgtcaa
4020
gcccaacgag actaagacct acttctggaa ggtccaacac catatggccc cgaccaagga
4080
tgagtttgac tgcaaggcct gggcctactt ctccgacgtg gaccttgaga aggatgtcca
4140
ttccggcctg atcgggccgc tgctcgtgtg tcacaccaac accctgaacc cagcgcatgg
4200
acgccaggtc accgtccagg agtttgctct gttcttcacc atttttgacg aaactaagtc
4260
ctggtacttc accgagaata tggagcgaaa ctgtagagcg ccctgcaata tccagatgga
4320
agatccgact ttcaaggaga actatagatt ccacgccatc aacgggtaca tcatggatac
4380
tctgccgggg ctggtcatgg cccaggatca gaggattcgg tggtacttgc tgtcaatggg
4440
atcgaacgaa aacattcact ccattcactt ctccggtcac gtgttcactg tgcgcaagaa
4500
ggaggagtac aagatggcgc tgtacaatct gtaccccggg gtgttcgaaa ctgtggagat
4560
gctgccgtcc aaggccggca tctggagagt ggagtgcctg atcggagagc acctccacgc
4620
ggggatgtcc accctcttcc tggtgtactc gaataagtgc cagaccccgc tgggcatggc
4680
ctcgggccac atcagagact tccagatcac agcaagcgga caatacggcc aatgggcgcc
4740
gaagctggcc cgcttgcact actccggatc gatcaacgca tggtccacca aggaaccgtt
4800
ctcgtggatt aaggtggacc tcctggcccc tatgattatc cacggaatta agacccaggg
4860
cgccaggcag aagttctcct ccctgtacat ctcgcaattc atcatcatgt acagcctgga
4920
cgggaagaag tggcagactt acaggggaaa ctccaccggc accctgatgg tctttttcgg
4980
caacgtggat tcctccggca ttaagcacaa catcttcaac ccaccgatca tagccagata
5040
tattaggctc caccccactc actactcaat ccgctcaact cttcggatgg aactcatggg
5100
gtgcgacctg aactcctgct ccatgccgtt ggggatggaa tcaaaggcta ttagcgacgc
5160
ccagatcacc gcgagctcct acttcactaa catgttcgcc acctggagcc cctccaaggc
5220
caggctgcac ttgcagggac ggtcaaatgc ctggcggccg caagtgaaca atccgaagga
5280
atggcttcaa gtggatttcc aaaagaccat gaaagtgacc ggagtcacca cccagggagt
5340
gaagtccctt ctgacctcga tgtatgtgaa ggagttcctg attagcagca gccaggacgg
5400
gcaccagtgg accctgttct tccaaaacgg aaaggtcaag gtgttccagg ggaaccagga
5460
ctcgttcaca cccgtggtga actccctgga ccccccactg ctgacgcggt acttgaggat
5520
tcatcctcag tcctgggtcc atcagattgc attgcgaatg gaagtcctgg gctgcgaggc
5580
ccaggacctg tactgaatca gcctgagctc gctgatcata atcaacctct ggattacaaa
5640
atttgtgaaa gattgactgg tattcttaac tatgttgctc cttttacgct atgtggatac
5700
gctgctttaa tgcctttgta tcatgctatt gcttcccgta tggctttcat tttctcctcc
5760
ttgtataaat cctggttgct gtctctttat gaggagttgt ggcccgttgt caggcaacgt
5820
ggcgtggtgt gcactgtgtt tgctgacgca acccccactg gttggggcat tgccaccacc
5880
tgtcagctcc tttccgggac tttcgctttc cccctcccta ttgccacggc ggaactcatc
5940
gccgcctgcc ttgcccgctg ctggacaggg gctcggctgt tgggcactga caattccgtg
6000
gtgttgtcgg ggaaatcatc gtcctttcct tggctgctcg cctgtgttgc cacctggatt
6060
ctgcgcggga cgtccttctg ctacgtccct tcggccctca atccagcgga ccttccttcc
6120
cgcggcctgc tgccggctct gcggcctctt ccgcgtcttc gccttcgccc tcagacgagt
6180
cggatctccc tttgggccgc ctccccgctg atcagcctcg actgtgcctt ctagttgcca
6240
gccatctgtt gtttgcccct cccccgtgcc ttccttgacc ctggaaggtg ccactcccac
6300
tgtcctttcc taataaaatg aggaaattgc atcgcattgt ctgagtaggt gtcattctat
6360
tctggggggt ggggtggggc aggacagcaa gggggaggat tgggaagaca atagcaggca
6420
tgctggggat gcggtgggct ctatggcttc tgaggcggaa agaacgggct cgagaagctt
6480
ctagatatcc tctcttaagg tagcatcgag atttaaatta gggataacag ggtaatggcg
6540
cgggccgcca cttcctggcg cgcaaaatat cctcttgtcc ttgagtctca ttggagggtt
6600
cgttcgttcg aaccagccaa tcaggggagg gggaagtgac gcaagttccg gtcacatgct
6660
tccggtgacg cacatccggt gacgtagttc cggtcacgtg cttcctgtca cgtgtttccg
6720
gtcacgtgac ttccggtcat gtgacttccg gtgacgtgtt tccggcttaa ctattgggct
6780
gaccgcgcgg catgcgcgtg gtcaacctaa cagccggaaa cacgtcaccg
6830
<210> 183
<211> 282
<212> ДНК
<213> Искусственная последовательность
<220>
<223> 5'-ITR
<400> 183
cggtgacgtg tttccggctg ttaggttgac cacgcgcatg ccgcgcggtc agcccaatag
60
ttaagccgga aacacgtcac cggaagtcac atgaccggaa gtcacgtgac cggaaacacg
120
tgacaggaag cacgtgaccg gaactacgtc accggatgtg cgtcaccgga agcatgtgac
180
cggaacttgc gtcacttccc cctcccctga ttggctggtt cgaacgaacg aaccctccaa
240
tgagactcaa ggacaagagg atattttgcg cgccaggaag tg
282
<210> 184
<211> 282
<212> ДНК
<213> Искусственная последовательность
<220>
<223> 3'-ITR инвертированный концевой повтор
<400> 184
cggtgacgtg tttccggctg ttaggttgac cacgcgcatg ccgcgcggtc agcccaatag
60
ttaagccgga aacacgtcac cggaagtcac atgaccggaa gtcacgtgac cggaaacacg
120
tgacaggaag cacgtgaccg gaactacgtc accggatgtg cgtcaccgga agcatgtgac
180
cggaacttgc gtcacttccc cctcccctga ttggctggtt cgaacgaacg aaccctccaa
240
tgagactcaa ggacaagagg atattttgcg cgccaggaag tg
282
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| МОЛЕКУЛЫ НУКЛЕИНОВОЙ КИСЛОТЫ И ПУТИ ИХ ПРИМЕНЕНИЯ ДЛЯ НЕВИРУСНОЙ ГЕННОЙ ТЕРАПИИ | 2019 |
|
RU2834625C2 |
| ПРИМЕНЕНИЕ ЛЕНТИВИРУСНЫХ ВЕКТОРОВ, ЭКСПРЕССИРУЮЩИХ ФАКТОР VIII | 2019 |
|
RU2803163C2 |
| ГЕННАЯ ТЕРАПИЯ ДЛЯ ЛЕЧЕНИЯ ГЕМОФИЛИИ A | 2017 |
|
RU2762257C2 |
| Выделенная нуклеиновая кислота, которая кодирует слитый белок на основе FVIII-BDD и гетерологичного сигнального пептида, и ее применение | 2022 |
|
RU2818229C2 |
| СПОСОБЫ ВЫЯВЛЕНИЯ AAV | 2017 |
|
RU2771622C2 |
| ВЫСОКОГЛИКОЗИЛИРОВАННЫЙ СЛИТЫЙ БЕЛОК НА ОСНОВЕ ФАКТОРА СВЕРТЫВАНИЯ КРОВИ ЧЕЛОВЕКА VIII, СПОСОБ ЕГО ПОЛУЧЕНИЯ И ЕГО ПРИМЕНЕНИЕ | 2016 |
|
RU2722374C1 |
| УЛУЧШЕНИЕ КЛИНИЧЕСКИХ ПАРАМЕТРОВ ПОСРЕДСТВОМ ЭКСПРЕССИИ ФАКТОРА VIII | 2019 |
|
RU2799048C2 |
| УЛУЧШЕННЫЙ БЕЛОК СЛИЯНИЯ FVIII И ЕГО ПРИМЕНЕНИЕ | 2019 |
|
RU2789085C2 |
| СПОСОБЫ ЛЕЧЕНИЯ ГЕМОФИЛИИ A | 2019 |
|
RU2812863C2 |
| МОДУЛЯЦИЯ АКТИВНОСТИ REP БЕЛКА ПРИ ПОЛУЧЕНИИ ДНК С ЗАМКНУТЫМИ КОНЦАМИ (ЗКДНК) | 2020 |
|
RU2812850C2 |
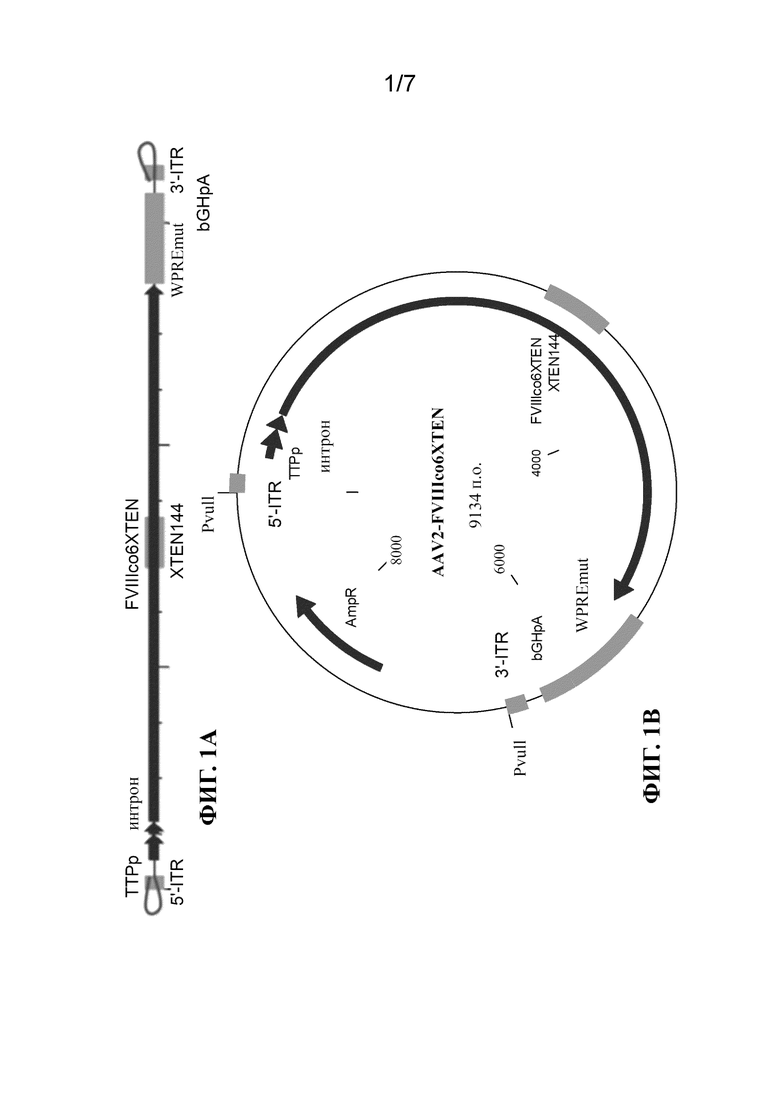
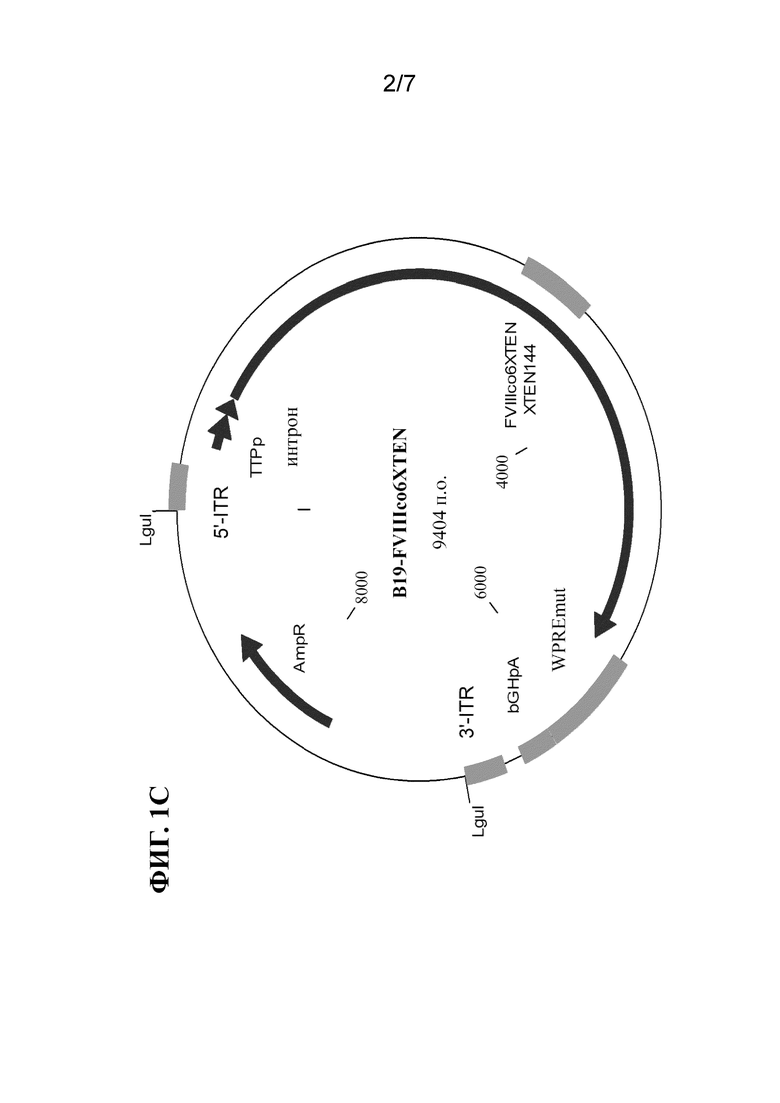
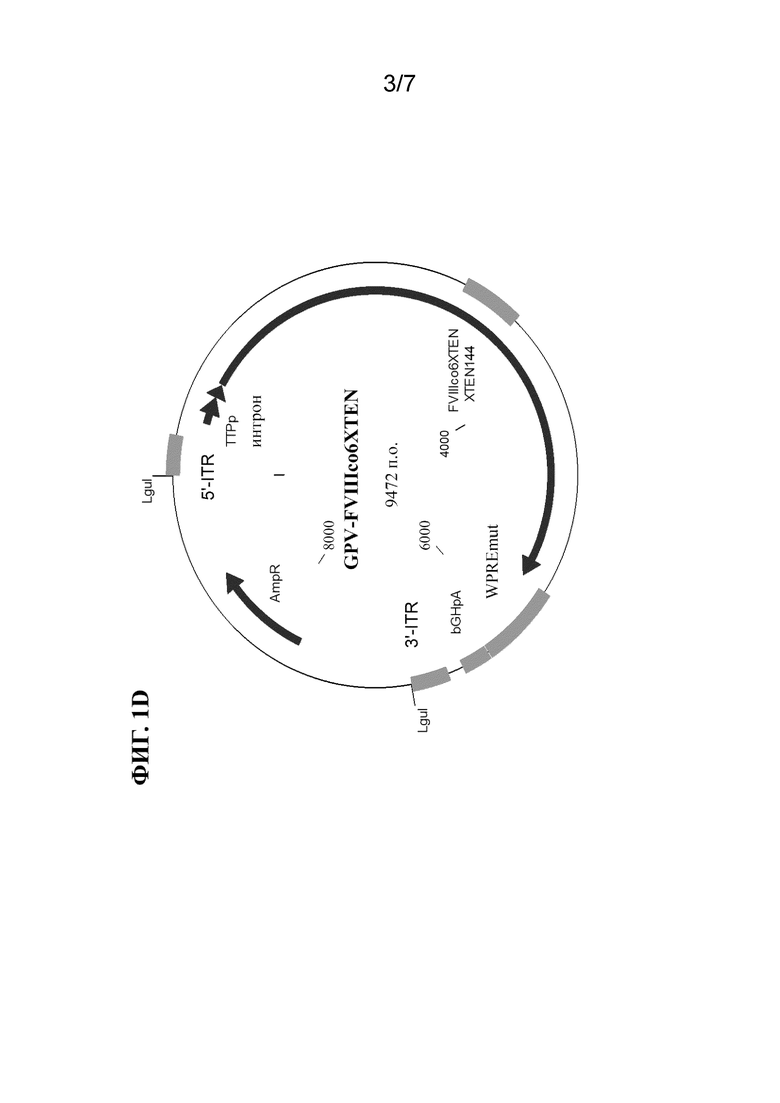
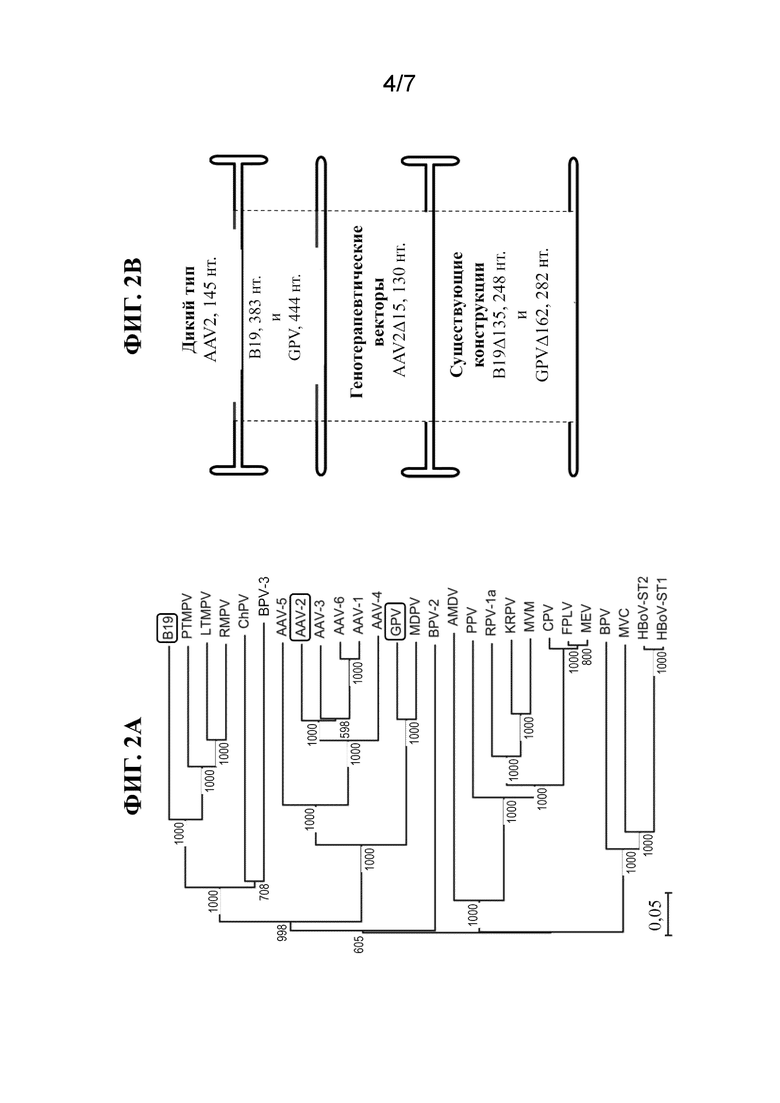
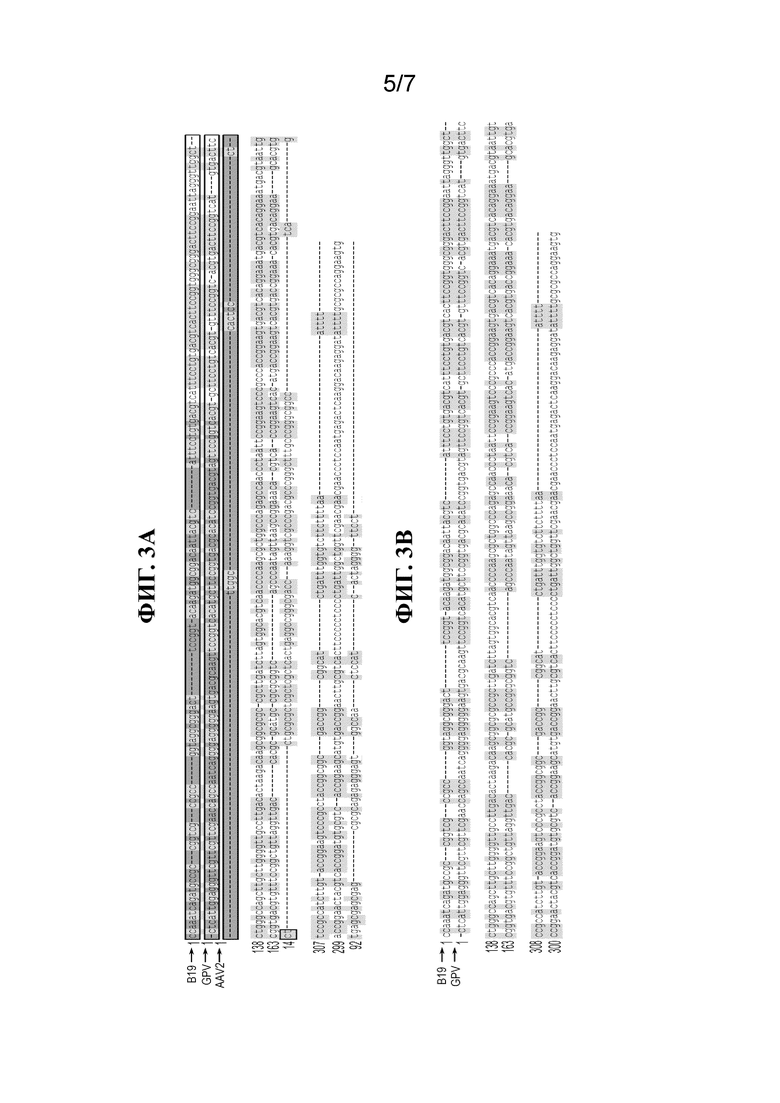
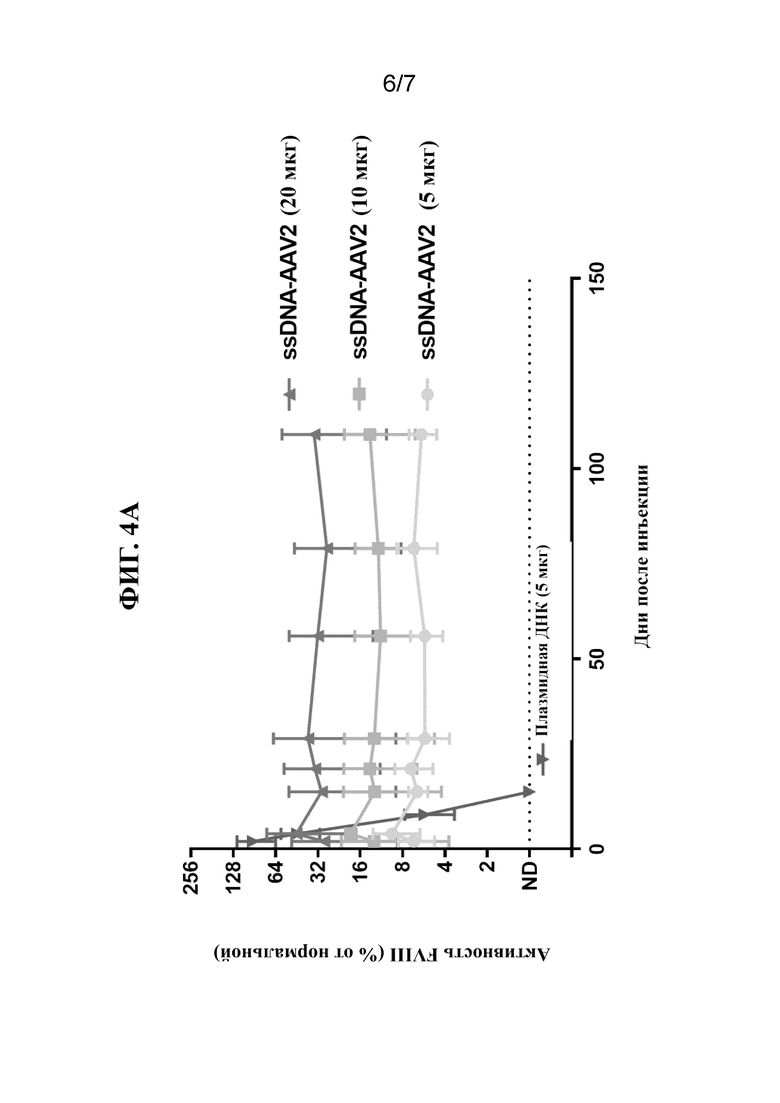
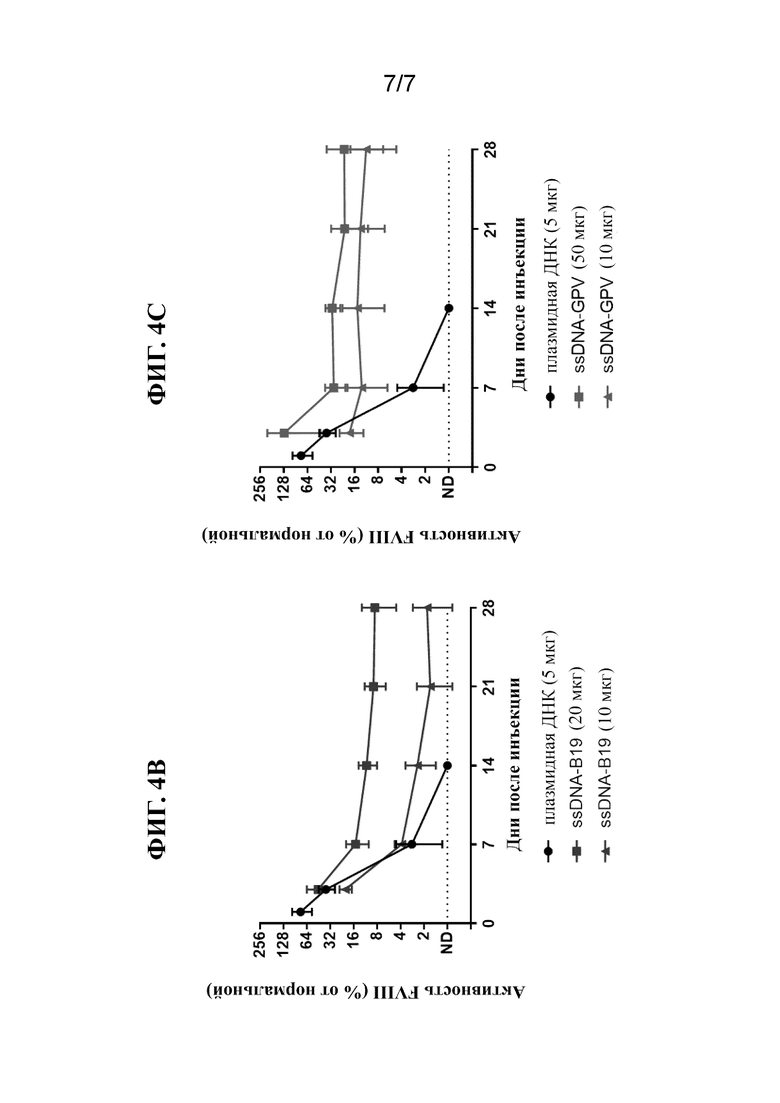
Изобретение относится к области биотехнологии. Описана группа изобретений, включающая молекулу нуклеиновой кислоты для экспрессии терапевтического белка у субъекта, фармацевтическую композицию для лечения заболевания, дефицита, нарушения или состояния, связанного с фактором коагуляции, и способ обеспечения экспрессии фактора свертывания крови у пациента. В одном из вариантов реализации молекула нуклеиновой кислоты содержит в направлении от 5' к 3': первый ITR, генную кассету, содержащую нуклеотид, кодирующий терапевтический белок, и второй ITR. Изобретение расширяет арсенал средств для экспрессии фактора свертывания крови у пациента. 3 н. и 15 з.п. ф-лы, 4 ил., 9 табл., 7 пр.
1. Молекула нуклеиновой кислоты для экспрессии терапевтического белка у субъекта, содержащая в направлении от 5' к 3':
(а) первый инвертированный концевой повтор (ITR),
(b) генную кассету, содержащую нуклеотид, кодирующий терапевтический белок, и
(с) второй ITR;
где первый ITR и/или второй ITR представляют собой ITR вируса, отличного от аденоассоциированного вируса (вируса, отличного от AAV),
где первый ITR и/или второй ITR содержит последовательность, выбранную из группы, состоящей из SEQ ID NO: 167-176, и
где молекула нуклеиновой кислоты не имеет капсида.
2. Молекула нуклеиновой кислоты по п.1, где терапевтический белок включает фактор свертывания крови.
3. Молекула нуклеиновой кислоты по п.1 или 2, где первый ITR и/или второй ITR происходит из эритровируса, представляющего собой парвовирус B19 (вирус человека).
4. Молекула нуклеиновой кислоты по п.1 или 2, где первый ITR и/или второй ITR происходит изпарвовируса гусей (GPV).
5. Молекула нуклеиновой кислоты по любому из пп. 1-4, которая дополнительно содержит тканеспецифический промотор.
6. Молекула нуклеиновой кислоты по п.5, где промотор управляет экспрессией терапевтического белка в гепатоцитах, эндотелиальных клетках, мышечных клетках, синусоидальных клетках или любой их комбинации.
7. Молекула нуклеиновой кислоты по п.5 или 6, где промотор выбран из группы, состоящей из промотора тиретина мыши (mTTR), эндогенного промотора фактора VIII человека (F8), промотора альфа-1-антитрипсина человека (hAAT), минимального промотора альбумина человека, промотора альбумина мыши, промотора тристетрапролина (TTP), промотора CASI, промотора CAG, промотора цитомегаловируса (CMV), промотора α1-антитрипсина (AAT), мышечной креатинкиназы (MCK), тяжелой цепи миозина альфа (αMHC), миоглобина (MB), десмина (DES), SPc5-12, 2R5Sc5-12, dMCK, tMCK и фосфоглицераткиназы (PGK).
8. Молекула нуклеиновой кислоты по любому из пп. 1-7, где нуклеотидная последовательность дополнительно содержит:
(a) интронную последовательность,
(b) посттранскрипционный регуляторный элемент,
(c) последовательность poly(А)-хвоста 3'-UTR,
(d) энхансерную последовательность или
(e) любую комбинацию (a)-(d).
9. Молекула нуклеиновой кислоты по п.8, где
(a) интронная последовательность расположена в направлении 5' относительно последовательности нуклеиновой кислоты, кодирующей фактор свертывания крови;
(b) посттранскрипционный регуляторный элемент содержит мутантный посттранскрипционный регуляторный элемент вируса гепатита сурков (WPRE), сайт связывания microRNA, последовательность, направляющую ДНК к ядру, или любую их комбинацию;
(c) последовательность poly(А)-хвоста 3'-UTR выбрана из группы, состоящей из poly(A) bGH, poly(A) актина, poly(A) гемоглобина и любой их комбинации; или
(d) любая комбинация (a)-(c).
10. Молекула нуклеиновой кислоты по п.9, где
(a) интронная последовательность содержит SEQ ID NO: 115;
(b) сайт связывания microRNA содержит сайт связывания с miR142-3p;
(c) последовательность poly(А)-хвоста 3'-UTR содержит poly(A) bGH; или
(d) любая комбинация (a)-(c).
11. Молекула нуклеиновой кислоты по любому из пп. 1-10, где молекула нуклеиновой кислоты содержит в следующем порядке:
(a) первый ITR, который представляет собой ITR вируса, отличного от AAV, являющегося представителем семейства Parvoviridae;
(b) последовательность тканеспецифического промотора, которая содержит промотор TTP;
(c) интрон, который представляет собой синтетический интрон;
(d) нуклеотидную последовательность, которая кодирует фактор свертывания крови;
(e) посттранскрипционный регуляторный элемент, который содержит WPRE;
(f) последовательность poly(А)-хвоста 3'-UTR, которая содержит bGHpA; и
(g) второй ITR, который представляет собой ITR вируса, отличного от AAV, являющегося представителем семейства Parvoviridae.
12. Молекула нуклеиновой кислоты по любому из пп. 2-11, где фактор свертывания крови включает фактор I (FI), фактор II (FII), фактор V (FV), фактор VII (FVII), фактор VIII (FVIII), фактор IX (FIX), фактор X (FX), фактор XI (FXI), фактор XII (FXII), фактор XIII (FVIII), фактор фон Виллебранда (VWF), прекалликреин, высокомолекулярный кининоген, фибронектин, антитромбин III, кофактор гепарина II, белок C, белок S, белок Z, ингибитор белок Z-подобной протеазы (ZPI), плазминоген, альфа-2-антиплазмин, тканевой активатор плазминогена (tPA), урокиназу, ингибитор активатора плазминогена 1 (PAI-1), ингибитор активатора плазминогена 2 (PAI2) или любую их комбинацию.
13. Молекула нуклеиновой кислоты по п.12, где FVIII содержит аминокислотную последовательность, которая на по меньшей мере приблизительно 70%, по меньшей мере приблизительно 75%, по меньшей мере приблизительно 80%, по меньшей мере приблизительно 85%, по меньшей мере приблизительно 90%, по меньшей мере приблизительно 95%, по меньшей мере приблизительно 96%, по меньшей мере приблизительно 97%, по меньшей мере приблизительно 98%, по меньшей мере приблизительно 99% или 100% идентична аминокислотной последовательности, представленной последовательностью, выбранной из SEQ ID NO: 71, 106, 107 и 109.
14. Молекула нуклеиновой кислоты по любому из пп. 1-13, где фактор свертывания крови содержит гетерологичный компонент, выбранный из группы, состоящей из альбумина или его фрагмента, Fc-области иммуноглобулина, C-концевого пептида (CTP) β-субъединицы хорионического гонадотропина человека, последовательности PAS, последовательности HAP, трансферрина или его фрагмента, альбуминсвязывающего компонента, их производного или любой их комбинации.
15. Молекула нуклеиновой кислоты по любому из пп. 12-14, где FVIII дополнительно содержит партнера по связыванию FcRn.
16. Молекула нуклеиновой кислоты по любому из пп. 1-15, где молекула нуклеиновой кислоты составлена со средством доставки, включающим липидную наночастицу.
17. Фармацевтическая композиция для лечения заболевания, дефицита, нарушения или состояния, связанного с фактором коагуляции, содержащая молекулу нуклеиновой кислоты по любому из пп. 1-16 и фармацевтически приемлемый носитель.
18. Способ обеспечения экспрессии фактора свертывания крови у пациента, включающий введение пациенту молекулы нуклеиновой кислоты по любому из пп. 1-16 или фармацевтической композиции по п.17.
| Maxwell I | |||
| H., Terrell K | |||
| L., Maxwell F., Autonomous parvovirus vectors, Methods, 2002, Т | |||
| Видоизменение прибора с двумя приемами для рассматривания проекционные увеличенных и удаленных от зрителя стереограмм | 1919 |
|
SU28A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Приспособление, заменяющее сигнальную веревку | 1921 |
|
SU168A1 |
| Chen M | |||
| et al | |||
| Vector-based siRNA delivery strategies for high-throughput screening of novel target genes, Journal of RNAi and gene silencing: an international journal of RNA and gene targeting research, 2005, Т | |||
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| Кипятильник для воды | 1921 |
|
SU5A1 |

