УРОВЕНЬ ТЕХНИКИ
[0001] Настоящее изобретение относится к системам и способам автоматического перевода с естественного языка на искусственный машиночитаемый язык.
[0002] В последние годы все большее количество продуктов и сервисов полагаются на сбор и анализ больших объемов данных. Примеры охватывают практически все области человеческой деятельности, от производства до торговли, научных исследований, здравоохранения и обороны. К ним относятся, например, система розничной торговли, управляющая запасами, клиентами и продажами во множестве магазинов и складов, программное обеспечение для логистики для управления большим и разнообразным парком перевозчиков, а также служба интернет-рекламы, основанная на профилировании пользователей для нацеливания предложений на потенциальных клиентов. Управление большими объемами данных способствовало инновациям и развитию архитектуры баз данных, а также систем и способов взаимодействия с соответствующими данными. По мере увеличения размера и сложности баз данных использование людей-операторов для поиска, извлечения и анализа данных быстро становится непрактичным.
[0003] Параллельно наблюдается взрывной рост и диверсификация электронных устройств, широко известных как «Интернет вещи». Устройства от мобильных телефонов до бытовой техники, носимых устройств, развлекательных устройств, а также различных датчиков и устройств, встроенных в автомобили, дома и т.д., обычно подключаются к удаленным компьютерам и/или различным базам данных для выполнения своих функций. Очень желательной особенностью таких устройств и услуг является удобство использования. Коммерческое давление с целью сделать такие продукты и услуги доступными для широкой аудитории стимулирует исследования и разработки инновационных человеко-машинных интерфейсов. Некоторые примеры таких технологий включают личных помощников, таких как Apple Siri® и Echo® от Amazon®, помимо прочего.
[0004] Следовательно, существует значительный интерес к разработке систем и способов, которые облегчают взаимодействие между людьми и компьютерами, особенно в приложениях, которые включают доступ к базе данных и/или управление.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
[0005] Согласно одному аспекту, способ включает использование по меньшей мере одного аппаратного процессора компьютерной системы для выполнения кодера искусственного языка (AL) и декодера, соединенного с кодером AL, причем кодер AL конфигурирован для приема первого входного массива, содержащего представление входного предложения AL, сформулированного на искусственном языке, и в ответ, создания первого внутреннего массива. Декодер конфигурирован для приема первого внутреннего массива и, в ответ, создания первого выходного массива, содержащего представление первого выходного предложения AL, сформулированного на искусственном языке. Способ дополнительно включает в себя, в ответ на предоставление первого входного массива кодеру AL, определение первой оценки сходства, указывающей степень сходства между входным предложением AL и первым выходным предложением AL, и регулирование первого набора параметров декодера в соответствии с первой оценкой сходства, чтобы улучшить соответствие между входными данными кодера AL и выходными данными декодера. Способ дополнительно включает в себя, в ответ на определение, удовлетворяется ли условие завершения обучения первого этапа, в ответ, если условие завершения обучения первого этапа удовлетворено, исполнение кодера естественного языка (NL), конфигурированного для приема второго входного массива, содержащего представление входного предложения NL, сформулированного на естественном языке, и, в ответ, выведения второго внутреннего массива в декодер. Способ дополнительно включает в себя определение второго выходного массива, созданного декодером в ответ на прием второго внутреннего массива, причем второй выходной массив содержит представление второго выходного предложения AL, сформулированного на искусственном языке, и определение второй оценки сходства, указывающей степень сходства между вторым выходным предложением AL и целевым предложением AL, содержащим перевод входного предложения NL на искусственный язык. Способ дополнительно включает в себя регулирование второго набора параметров кодера NL в соответствии со второй оценкой сходства, чтобы улучшить соответствие между выходными данными декодера и целевыми выходными данными, представляющими соответствующие переводы на искусственный язык входных данных, полученных кодером NL.
[0006] Согласно другому аспекту, компьютерная система содержит по меньшей мере один аппаратный процессор и память, причем по меньшей мере один аппаратный процессор конфигурирован для исполнения кодера AL и декодера, связанного с кодером AL, причем кодер AL конфигурирован для приема первого входного массива, содержащего представление входного предложения AL, сформулированного на искусственном языке, и в ответ, создания первого внутреннего массива. Декодер конфигурирован для приема первого внутреннего массива и, в ответ, создания первого выходного массива, содержащего представление первого выходного предложения AL, сформулированного на искусственном языке. По меньшей мере один аппаратный процессор конфигурирован для, в ответ на предоставление первого входного массива кодеру AL, определения первой оценки сходства, указывающей степень сходства между входным предложением AL и первым выходным предложением AL, и регулирования первого набора параметров декодера в соответствии с первой оценкой сходства, чтобы улучшить соответствие между входными данными кодера AL и выходными данными декодера. По меньшей мере один аппаратный процессор дополнительно конфигурирован для определения, удовлетворяется ли условие завершения обучения первого этапа, и в ответ, если условие завершения обучения первого этапа удовлетворено, исполнения кодера NL, конфигурированного для приема второго входного массива, содержащего представление входного предложения NL, сформулированного на естественном языке, и, в ответ, выведения второго внутреннего массива в декодер. По меньшей мере один аппаратный процессор дополнительно конфигурирован для определения второго выходного массива, созданного декодером в ответ на прием второго внутреннего массива, причем второй выходной массив содержит представление второго выходного предложения AL, сформулированного на искусственном языке. По меньшей мере один аппаратный процессор дополнительно конфигурирован для определения второй оценки сходства, указывающей степень сходства между вторым выходным предложением AL и целевым предложением AL, содержащим перевод входного предложения NL на искусственный язык, и для регулирования второго набора параметров кодера NL в соответствии со второй оценкой сходства для улучшения соответствия между выходными данными декодера и целевыми выходными данными, представляющими соответствующие переводы на искусственный язык входных данных, полученных кодером NL.
[0007] Согласно другому аспекту невременный машиночитаемый носитель хранит инструкции, которые при исполнении первым аппаратным процессором первой компьютерной системы побуждают первую компьютерную систему формировать модуль обученного переводчика, содержащий кодер NL и декодер, соединенный с кодером NL, при этом обучение модуля переводчика включает использование второго аппаратного процессора второй компьютерной системы для соединения декодера с кодером AL, конфигурированным для приема первого входного массива, содержащего представление входного предложения AL, сформулированного на искусственном языке, и, в ответ, создания первого внутреннего массива. Кодер AL соединен с декодером, так что декодер принимает первый внутренний массив и, в ответ, создает первый выходной массив, содержащий представление первого выходного предложения AL, сформулированного на искусственном языке. Обучение модуля переводчика включает дополнительно включает в себя, в ответ на предоставление первого входного массива кодеру AL, определение первой оценки сходства, указывающей степень сходства между входным предложением AL и первым выходным предложением AL, и регулирование первого набора параметров декодера в соответствии с первой оценкой сходства, чтобы улучшить соответствие между входными данными кодера AL и выходными данными декодера. Обучение модуля переводчика дополнительно включает определение, удовлетворяется ли условие завершения обучения первого этапа, и, в ответ, если условие завершения обучения первого этапа удовлетворено, соединение кодера NL с декодером, так что кодер NL принимает второй входной массив, содержащий представление входного предложения NL, сформулированного на естественном языке, и, в ответ, выводит второй внутренний массив в декодер. Обучение модуля переводчика дополнительно включает определение второго выходного массива, созданного декодером в ответ на прием второго внутреннего массива, причем второй выходной массив содержит представление второго выходного предложения AL, сформулированного на искусственном языке, и определение второй оценки сходства, указывающей степень сходства между вторым выходным предложением AL и целевым предложением AL, содержащим перевод входного предложения NL на искусственный язык. Обучение модуля переводчика дополнительно включает регулирование второго набора параметров кодера NL в соответствии со второй оценкой сходства, чтобы улучшить соответствие между выходными данными декодера и целевыми выходными данными, представляющими соответствующие переводы на искусственный язык входных данных, полученных кодером NL.
[0008] Согласно другому аспекту компьютерная система содержит первый аппаратный процессор, конфигурированный для исполнения модуля обученного переводчика, содержащего кодер NL и декодер, соединенный с кодером NL, при этом обучение модуля переводчика включает использование второго аппаратного процессора второй компьютерной системы для соединения декодера с кодером AL, конфигурированным для приема первого входного массива, содержащего представление входного предложения AL, сформулированного на искусственном языке, и, в ответ, создания первого внутреннего массива. Кодер AL соединен с декодером, так что декодер принимает первый внутренний массив и, в ответ, создает первый выходной массив, содержащий представление первого выходного предложения AL, сформулированного на искусственном языке. Обучение модуля переводчика дополнительно включает, в ответ на предоставление первого входного массива кодеру AL, определение первой оценки сходства, указывающей степень сходства между входным предложением AL и первым выходным предложением AL, и регулирование первого набора параметров декодера в соответствии с первой оценкой сходства, чтобы улучшить соответствие между входными данными кодера AL и выходными данными декодера. Обучение модуля переводчика дополнительно включает определение, удовлетворяется ли условие завершения обучения первого этапа, и, в ответ, если условие завершения обучения первого этапа удовлетворено, соединение кодера NL с декодером, так что кодер NL принимает второй входной массив, содержащий представление входного предложения NL, сформулированного на естественном языке, и, в ответ, выводит второй внутренний массив в декодер. Обучение модуля переводчика дополнительно включает определение второго выходного массива, созданного декодером в ответ на прием второго внутреннего массива, причем второй выходной массив содержит представление второго выходного предложения AL, сформулированного на искусственном языке. Обучение модуля переводчика дополнительно включает определение второй оценки сходства, указывающей степень сходства между вторым выходным предложением AT и целевым предложением AT, содержащим перевод входного предложения NL на искусственный язык, и регулирование второго набора параметров кодера NL в соответствии со второй оценкой сходства для улучшения соответствия между выходными данными декодера и целевыми выходными данными, представляющими соответствующие переводы на искусственный язык входных данных, полученных кодером NL.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0009] Вышеупомянутые аспекты и преимущества настоящего изобретения станут более понятными после прочтения следующего ниже подробного описания, данного со ссылками на чертежи, на которых изображено следующее.
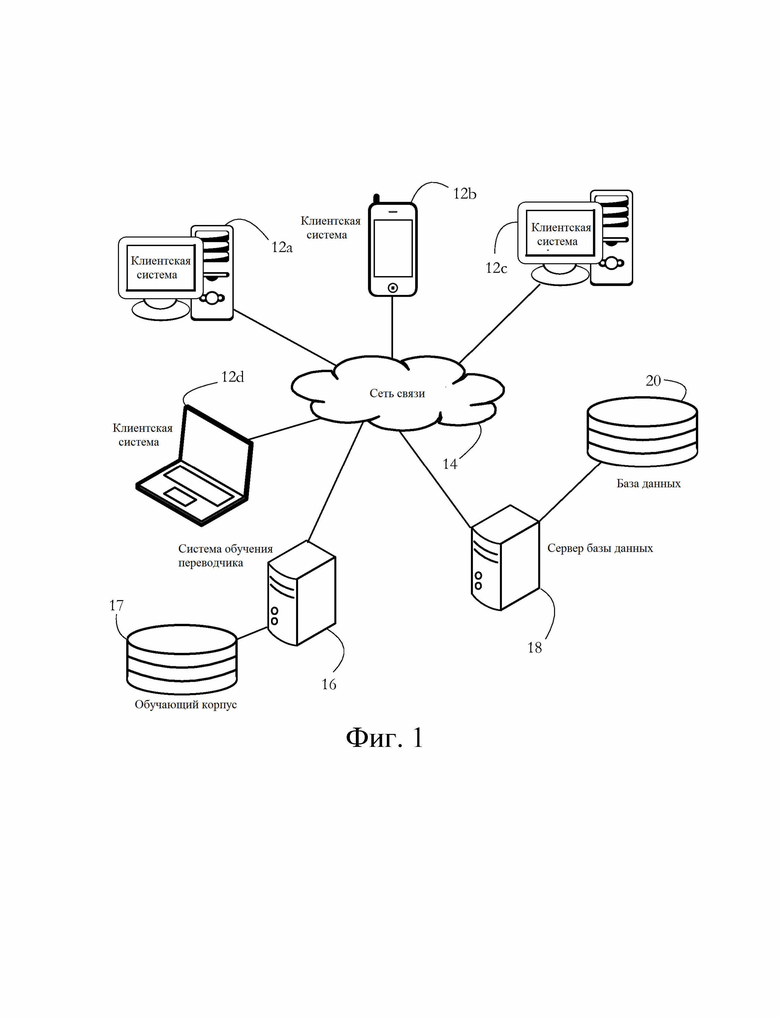
[0009] Фиг. 1 иллюстрирует примерную автоматизированную систему доступа к базе данных, в которой набор клиентов взаимодействует с системой обучения переводчика и сервером базы данных согласно некоторым вариантам осуществления настоящего изобретения.
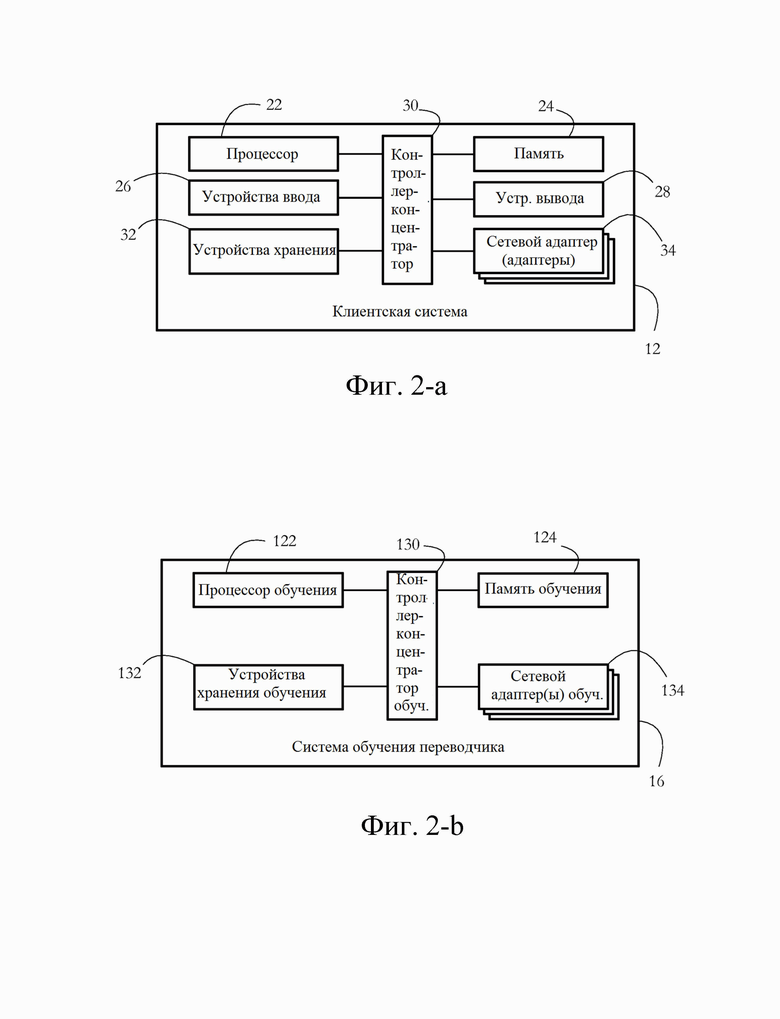
[0011] Фиг. 2-А иллюстрирует примерную конфигурацию аппаратного обеспечения клиентской системы согласно некоторым вариантам осуществления настоящего изобретения.
[0012] Фиг. 2-В иллюстрирует примерную конфигурацию оборудования системы обучения переводчика согласно некоторым вариантам осуществления настоящего изобретения.
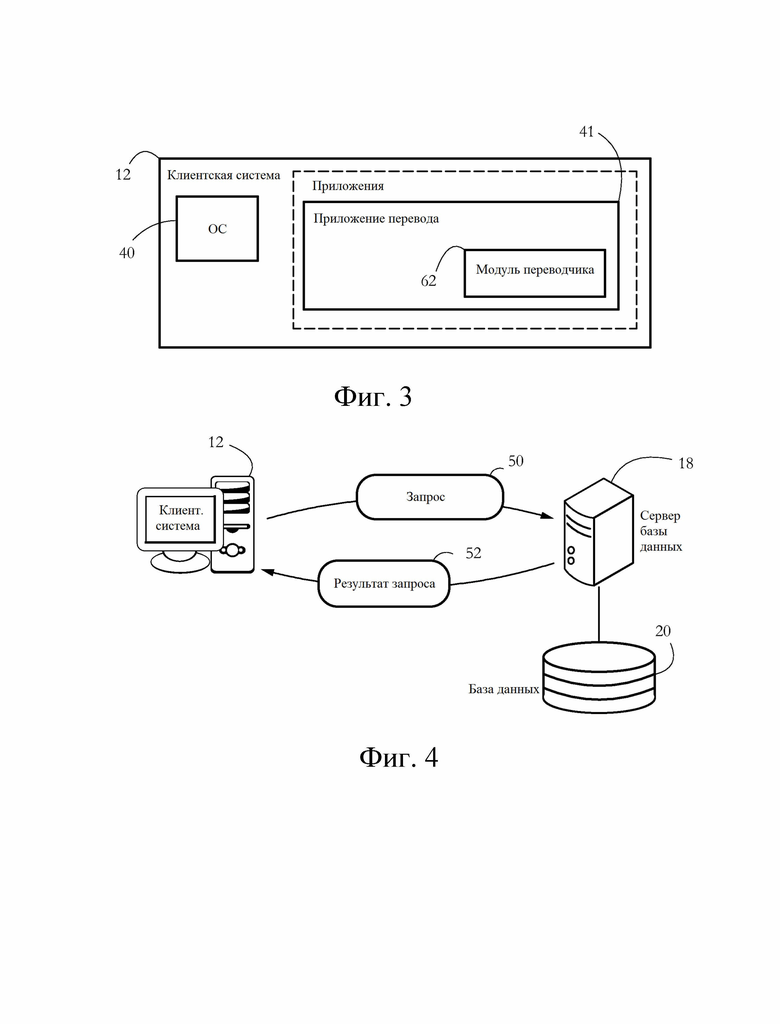
[0013] Фиг. 3 иллюстрирует набор примерных программных компонентов, исполняемых в клиентской системе согласно некоторым вариантам осуществления настоящего изобретения.
[0014] Фиг. 4 иллюстрирует примерный обмен данными между клиентской системой и сервером базы данных согласно некоторым вариантам осуществления настоящего изобретения.
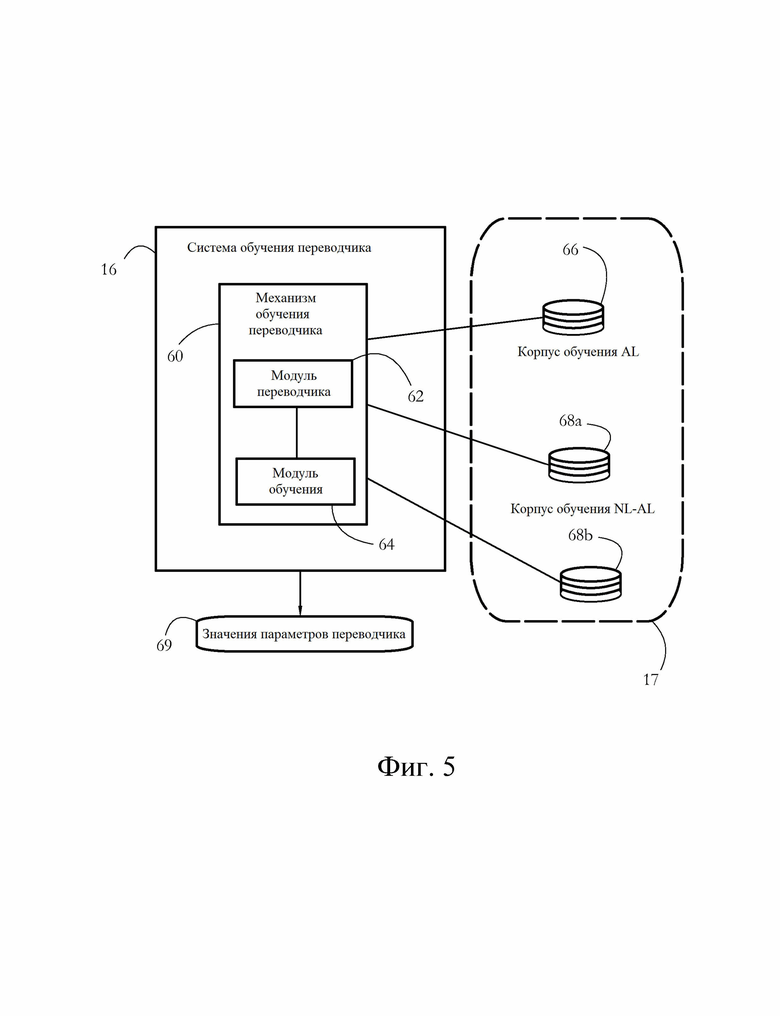
[0015] Фиг. 5 иллюстрирует примерные компоненты системы обучения переводчика согласно некоторым вариантам осуществления настоящего изобретения.
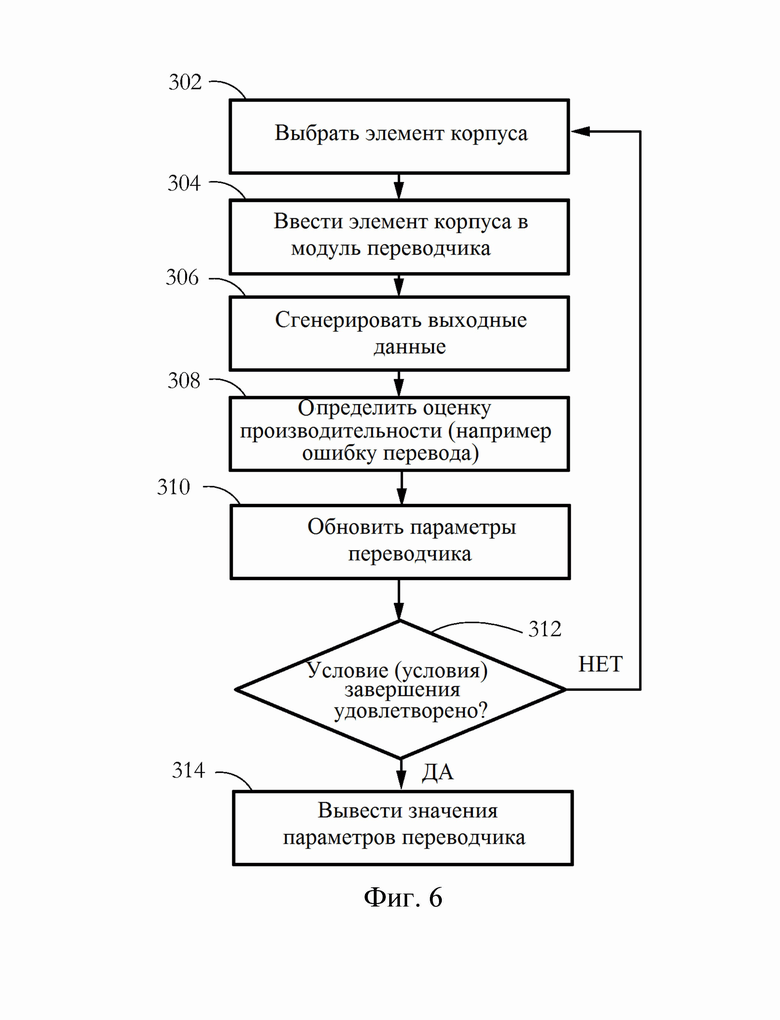
[0016] Фиг. 6 иллюстрирует примерную процедуру обучения переводчика согласно некоторым вариантам осуществления настоящего изобретения.
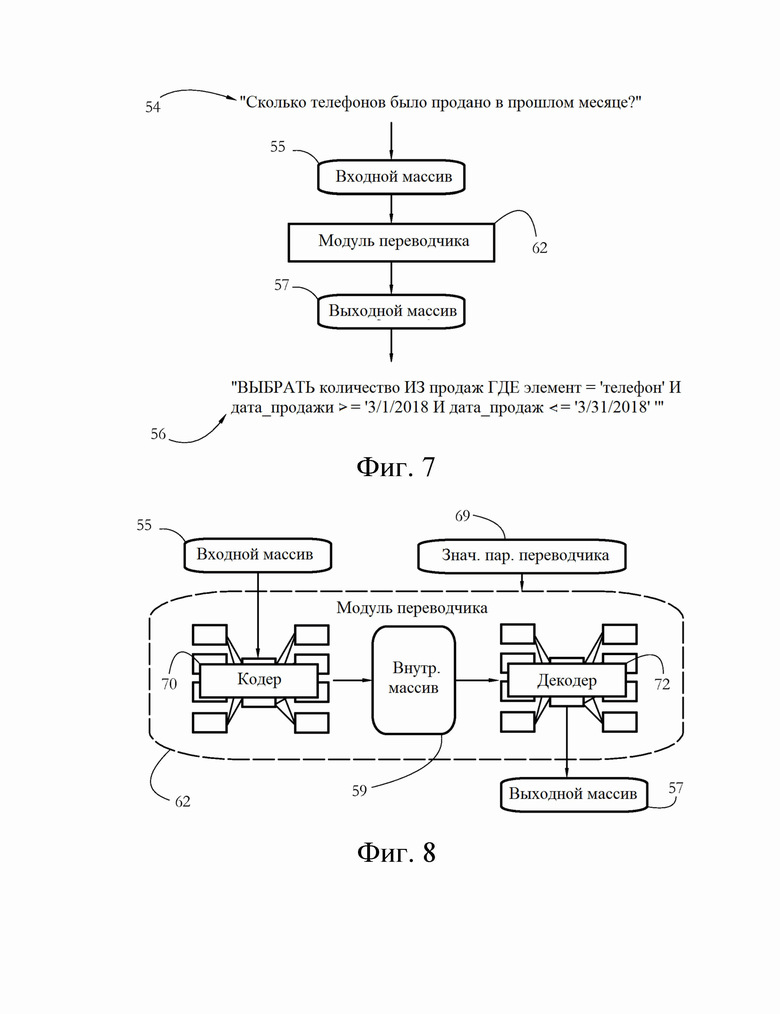
[0017] Фиг. 7 иллюстрирует примерную работу модуля переводчика согласно некоторым вариантам осуществления настоящего изобретения.
[0018] Фиг. 8 иллюстрирует примерные компоненты и работу модуля переводчика согласно некоторым вариантам осуществления настоящего изобретения.
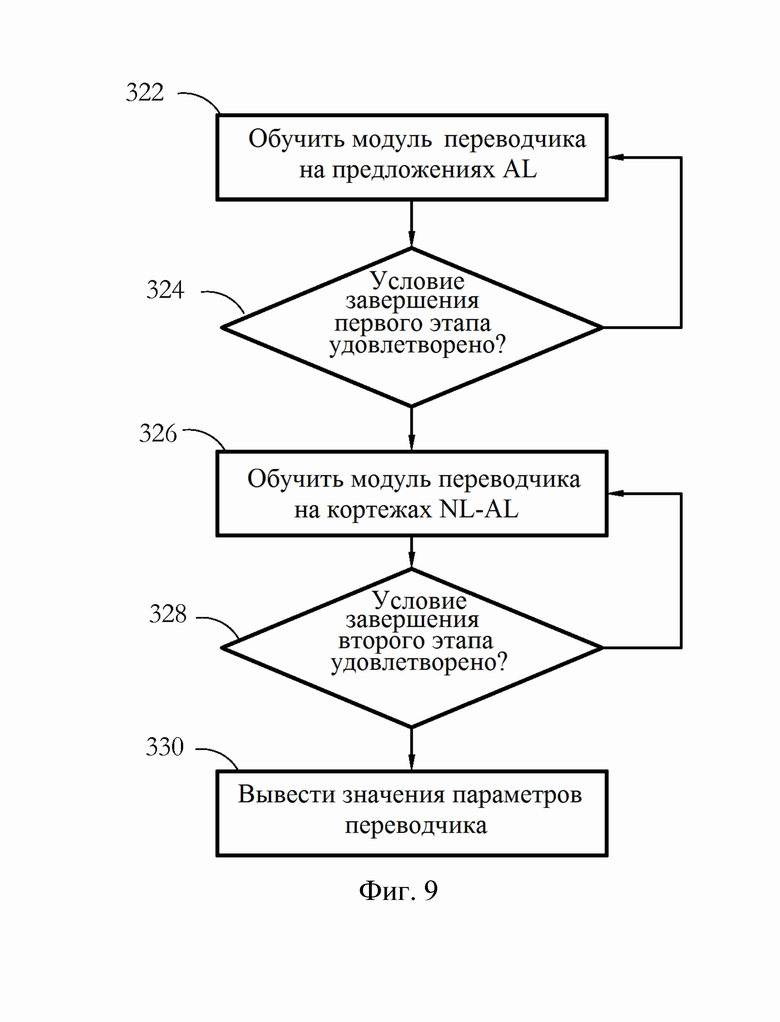
[0019] Фиг. 9 иллюстрирует примерную последовательность этапов, выполняемых системой обучения переводчика согласно одному варианту осуществления настоящего изобретения.
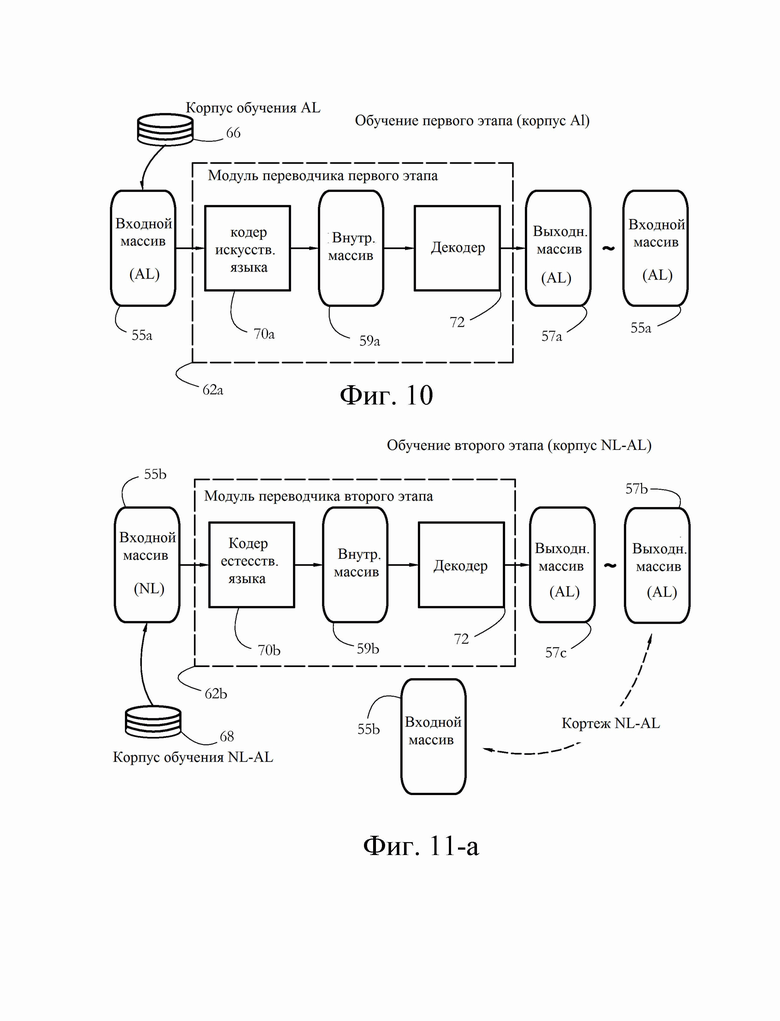
[0020] Фиг. 10 иллюстрирует примерный первый этап обучения модуля переводчика согласно некоторым вариантам осуществления настоящего изобретения.
[0021] Фиг. 11-А иллюстрирует примерный второй этап обучения модуля переводчика согласно некоторым вариантам осуществления настоящего изобретения.
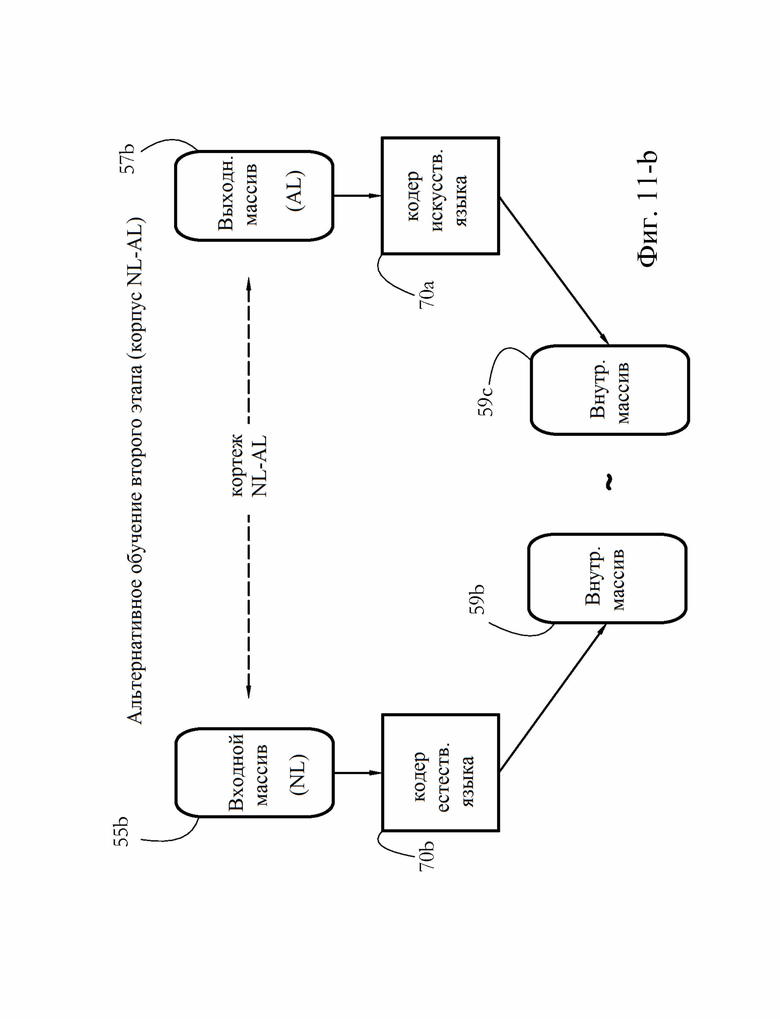
[0022] Фиг. 11-В иллюстрирует альтернативный примерный второй этап обучения модуля переводчика согласно некоторым вариантам осуществления настоящего изобретения.
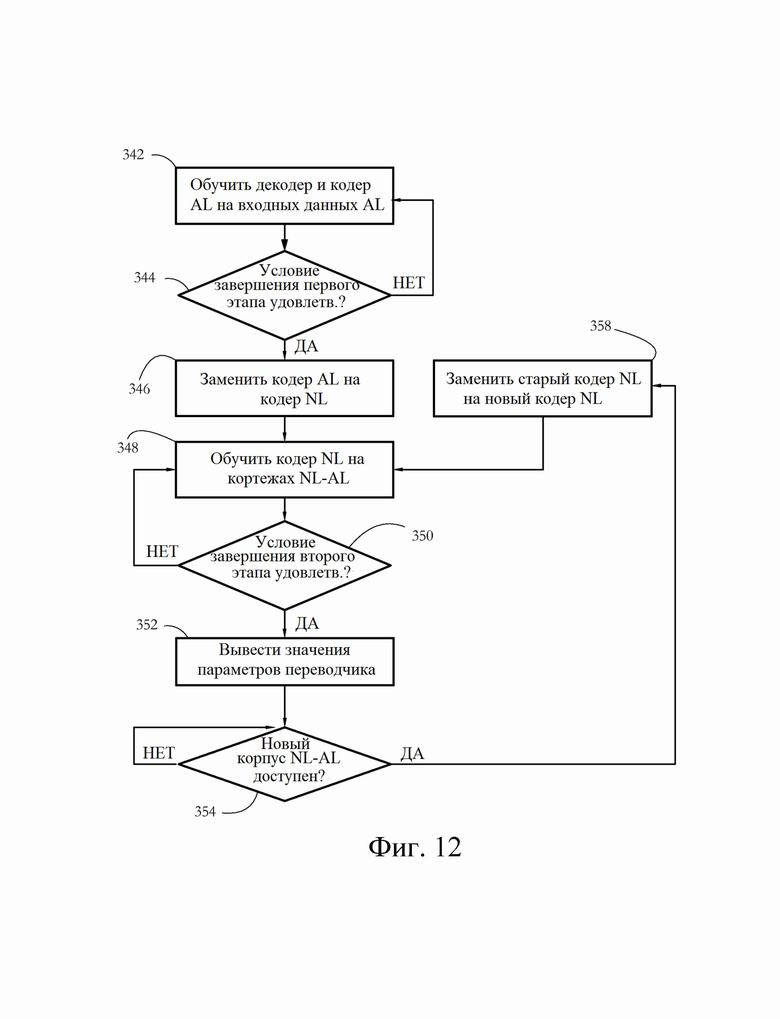
[0023] Фиг. 12 иллюстрирует примерную последовательность этапов для обучения модуля переводчика на множестве обучающих корпусов согласно некоторым вариантам осуществления настоящего изобретения.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[0024] Следует понимать, что в нижеследующем описании все перечисленные соединения между структурами могут быть прямыми функциональными соединениями или непрямыми функциональными соединениями через промежуточные структуры. Набор элементов включает в себя один или более элементов. Считается, что любое упоминание элемента относится по меньшей мере к одному элементу. Множество элементов включает по меньшей мере два элемента. Если не требуется иное, любые описанные этапы способа не обязательно должны выполняться в конкретном проиллюстрированном порядке. Первый элемент (например, данные), полученный из второго элемента, включает в себя первый элемент, равный второму элементу, а также первый элемент, сгенерированный путем обработки второго элемента и, опционально, других данных. Принятие определения или решения в соответствии с параметром включает в себя принятие определения или решения в соответствии с параметром и, опционально, в соответствии с другими данными. Если не указано иное, индикатором некоторого количества/данных может быть само количество/данные или индикатор, отличный от самого количества/данных. Компьютерная программа - это последовательность инструкций процессора, выполняющих задачу. Компьютерные программы, описанные в некоторых вариантах осуществления настоящего изобретения, могут быть автономными программными объектами или подобъектами (например, подпрограммами, библиотеками) других компьютерных программ. Термин «база данных» используется здесь для обозначения любого организованного набора данных. Если не указано иное, предложение представляет собой последовательность слов и/или лексем, сформулированных на естественном или искусственном языке. Два предложения, сформулированные на разных языках, здесь считаются переводами друг друга, когда два предложения являются семантическими эквивалентами друг друга, т.е. два предложения имеют одинаковое или очень похожее значение. Машиночитаемые носители включают невременные носители, такие как магнитные, оптические и полупроводниковые носители данных (например, жесткие диски, оптические диски, флэш-память, DRAM), а также каналы связи, такие как проводящие кабели и оптоволоконные линии. Согласно некоторым вариантам осуществления настоящее изобретение обеспечивает, среди прочего, компьютерные системы, содержащие аппаратные средства (например, один или более процессоров), запрограммированные для выполнения описанных здесь способов, а также машиночитаемые инструкции кодирования мультимедиа для выполнения способов, описанных в данном документе.
[0025] Нижеследующее описание иллюстрирует варианты осуществления изобретения в качестве примера, а не обязательно в качестве ограничения.
[0026] Фиг. 1 иллюстрирует примерную систему доступа к базе данных и управления ею в соответствии с некоторыми вариантами осуществления настоящего изобретения. Множество клиентских систем 12a-d может взаимодействовать с сервером 18 базы данных, например, для исполнения запроса, тем самым осуществляя доступ/извлечение/запись набора данных из базы данных 20 и в нее. Примерные базы данных 20 включают в себя, среди прочего, реляционную базу данных, базу данных расширяемого языка разметки (XML), электронную таблицу и хранилище значений ключей.
[0027] Примерные клиентские системы 12a-d включают в себя персональные компьютерные системы, мобильные вычислительные платформы (портативные компьютеры, планшеты, мобильные телефоны), развлекательные устройства (телевизоры, игровые консоли), носимые устройства (умные часы, фитнес-браслеты), бытовую технику и любые другие электронные устройства, содержащие процессор, память и интерфейс связи. Клиентские системы 12a-d соединены с сервером 18 через сеть 14 связи, например, Интернет. Части сети 14 могут включать в себя локальную сеть (LAN), такую как домашняя или корпоративная сеть. Сервер 18 базы данных в общем описывает набор вычислительных систем, коммуникативно связанных с базой 20 данных и конфигурированных для доступа к базе 20 данных для выполнения вставления данных, извлечения данных и/или других операций управления базой данных.
[0028] В одном примерном применении проиллюстрированной системы клиентские системы 12a-d представляют отдельные компьютеры, используемые сотрудниками компании электронной коммерции, а база 20 данных представляет собой реляционную базу данных, в которой хранятся записи о продуктах, которые продает соответствующая компания. Сотрудники могут использовать проиллюстрированную систему, например, чтобы узнать, сколько единиц определенного продукта в настоящее время имеется в наличии на конкретном складе.
[0029] В некоторых вариантах осуществления доступу к базе 20 данных способствует программное обеспечение, исполняемое в клиентских системах 12a-d и/или сервере 18 базы данных, соответствующее программное обеспечение содержит компонент переводчика, обеспечивающий автоматический перевод предложения, сформулированного на естественном языке (например, английском, китайском), в набор предложений, сформулированных на искусственном формальном языке, таком как язык структурированных запросов (SQL), язык программирования (например, С ++, Java®, байт-код) и/или язык разметки (например, XML, язык разметки гипертекста - HTML). В некоторых вариантах осуществления соответствующий переводчик содержит систему искусственного интеллекта, такую как набор нейронных сетей, обученных системой 16 обучения переводчика, также подключенной к сети 14. Работа системы 16 обучения переводчика, а также самого переводчика будет описана более подробно ниже.
[0030] Фиг. 2-А иллюстрирует примерную конфигурацию оборудования клиентской системы 12. Клиентская система 12 может представлять любую из клиентских систем 12a-d с фиг. 1. Без потери общности, проиллюстрированная клиентская система представляет собой компьютерную систему. Аппаратная конфигурация других клиентских систем (например, мобильных телефонов, умных часов) может несколько отличаться от конфигурации, показанной на фиг. 2-А. Клиентская система 12 содержит набор физических устройств, включая аппаратный процессор 22 и блок 24 памяти. Процессор 22 содержит физическое устройство (например, микропроцессор, многоядерную интегральную схему, сформированную на полупроводниковой подложке и т.д.), конфигурированное для исполнения вычислительных и/или логических операций с набором сигналов и/или данных. В некоторых вариантах осуществления такие операции доставляются процессору 22 в форме последовательности инструкций процессора (например, машинного кода или другого типа кодирования). Блок 24 памяти может содержать энергозависимый машиночитаемый носитель (например, DRAM, SRAM), на котором хранятся инструкции и/или данные, к которым осуществляется доступ, или которые генерируются процессором 22.
[0031] Устройства 26 ввода могут включать в себя компьютерные клавиатуры, мыши и микрофоны, среди прочего, включая соответствующие аппаратные интерфейсы и/или адаптеры, позволяющие пользователю вводить данные и/или инструкции в клиентскую систему 12. Устройства 28 вывода могут включать в себя устройства отображения, такие как мониторы и динамики, среди прочего, а также аппаратные интерфейсы/адаптеры, такие как графические карты, позволяющие клиентской системе 12 передавать данные пользователю. В некоторых вариантах осуществления устройства 26 ввода и устройства 28 вывода могут совместно использовать общее оборудование, как в случае устройств с сенсорным экраном. Устройства 32 хранения включают в себя машиночитаемые носители, обеспечивающие долговременное хранение, чтение и запись программных инструкций и/или данных. Примерные устройства 32 хранения включают в себя магнитные и оптические диски и устройства флэш-памяти, а также съемные носители, такие как CD и/или DVD диски и приводы. Набор сетевых адаптеров 34 позволяет клиентской системе 12 подключаться к компьютерной сети и/или другим устройствам/компьютерным системам. Контроллер-концентратор 30 представляет собой множество системных, периферийных шин и/или шин набора микросхем и/или всех других схем, обеспечивающих связь между процессором 22 и устройствами 24, 26, 28, 32 и 34. Например, контроллер-концентратор 30 может включать в себя, среди прочего, контроллер памяти, контроллер ввода/вывода (I/O) и контроллер прерываний. В другом примере контроллер-концентратор 30 может содержать процессор 22 подключения северного моста к памяти 24 и/или процессор 22 подключения южного моста к устройствам 26, 28, 32 и 34.
[0032] Фиг. 2-В иллюстрирует примерную конфигурацию оборудования системы обучения переводчика согласно некоторым вариантам осуществления настоящего изобретения. Проиллюстрированная система обучения включает в себя компьютер, содержащий по меньшей мере процессор 122 обучения (например, микропроцессор, многоядерную интегральную схему), физическую память 124, набор устройств 132 хранения обучения и набор сетевых адаптеров 134 обучения. Устройства 132 хранения включают в себя машиночитаемые носители, обеспечивающие долговременное хранение, чтение и запись программных инструкций и/или данных. Адаптеры 134 могут включать в себя сетевые карты и другие интерфейсы связи, позволяющие системе 16 обучения подключаться к сети 14 связи. В некоторых вариантах осуществления система 16 обучения переводчика дополнительно содержит устройства ввода и вывода, которые могут быть аналогичны по функциям устройствам 26 и 28 ввода и вывода клиентской системы 12 соответственно.
[0033] Фиг. 3 иллюстрирует примерные компьютерные программы, исполняемые в клиентской системе 12 согласно некоторым вариантам осуществления настоящего изобретения. Такое программное обеспечение может включать в себя операционную систему (ОС) 40, которая может включать любую широко доступную операционную систему, такую как Microsoft Windows®, MacOS®, Finux®, iOS® или Android™, среди других. ОС 40 обеспечивает связь между аппаратным обеспечением клиентской системы 12 и набором приложений, включая, например, приложение 41 перевода. В некоторых вариантах осуществления приложение 41 конфигурировано для автоматического перевода предложений на естественном языке (NF) в предложения на искусственном языке (AF), например, в набор SQL-запросов и/или в последовательность программных инструкций (кода). Приложение 41 перевода включает в себя модуль 62 переводчика, выполняющий фактический перевод, и может дополнительно включать, среди прочего, компоненты, которые принимают соответствующие предложения на естественном языке от пользователя (например, в виде текста или речи через устройства 26 ввода), компоненты, которые разбирают и анализируют соответствующие входные данные NL (например, синтаксический анализатор речи, токенизатор, различные словари и т.д.), компоненты, передающие переведенные выходные данные AL на сервер 18 базы данных, и компоненты, отображающие содержимое ответа от сервера 18 пользователю. Модуль 62 переводчика содержит экземпляр системы искусственного интеллекта (например, набор нейронных сетей), обученный системой 16 обучения переводчика выполнять преобразования NL в AL, как дополнительно описано ниже. Такое обучение может привести к созданию набора оптимальных значений параметров переводчика 62, то есть значений, которые могут быть переданы из системы 16 обучения клиенту 12 и/или серверу 18 базы данных, например, посредством периодических обновлений программного обеспечения или обновлений программного обеспечения по запросу. Термин «обученный переводчик» в данном документе относится к модулю переводчика, экземпляр которого создан с такими оптимальными значениями параметров, полученными из системы 16 обучения переводчика.
[0034] Для ясности нижеследующее описание будет сфокусировано на примерном приложении, в котором модуль 62 переводчика выводит запрос к базе данных, то есть набору предложений, сформулированных на языке запросов, таком как SQL. Таким образом, проиллюстрированные системы и способы направлены на то, чтобы позволить оператору-человеку выполнять запросы к базе данных. Однако специалисту в данной области техники понятно, что описанные системы и способы могут быть изменены и адаптированы к другим приложениям, в которых переводчик конфигурирован для создания компьютерного кода (например, Java®), байт-код и т.д.), данных разметки (например, XML) или выходных данных, сформулированных на любом другом искусственном языке.
[0035] Фиг. 4 иллюстрирует примерный обмен данными между клиентской системой 12 и сервером 18 базы данных согласно некоторым вариантам осуществления настоящего изобретения. Клиентская система 12 отправляет запрос 50 на сервер 18 базы данных и в ответ получает результат 52 запроса, содержащий результат выполнения запроса 50. Запрос 50 содержит кодирование набора инструкций, которые при исполнении сервером 18 побуждают сервер 18 выполнять определенные манипуляции с базой 20 данных, например, путем выборочного вставления или извлечения данных в базы 20 данных или из них, соответственно. Результат 52 запроса может содержать, например, кодирование набора записей базы данных, выборочно извлеченных из базы 20 данных согласно запросу 50.
[0036] В некоторых вариантах осуществления запрос 50 сформулирован на искусственном языке, таком как SQL. В альтернативном варианте осуществления запрос 50 может быть сформулирован как набор предложений естественного языка. В таких вариантах осуществления модуль переводчика, описанный в данном документе, может исполняться на сервере 18 базы данных.
[0037] Фиг. 5 иллюстрирует примерные компоненты системы обучения переводчика согласно некоторым вариантам осуществления настоящего изобретения. Система 16 обучения может исполнять механизм 60 обучения переводчика, содержащий экземпляр модуля 62 переводчика и модуль 64 обучения, подключенный к модулю 62 переводчика. В некоторых вариантах осуществления настоящего изобретения механизм 60 коммуникативно связан с набором обучающих корпусов 17, используемых модулем 64 обучения для обучения модуля 62 переводчика. Корпус 17 может содержать по меньшей мере один корпус 66 обучения искусственному языку (AL) и/или набор корпусов 68а-b обучения преобразованию естественного языка в искусственный язык (NL-AL).
[0038] В некоторых вариантах осуществления корпус 66 обучения AL содержит множество записей, причем все записи сформулированы на одном и том же искусственном языке. В одном примере каждая запись состоит из по меньшей мере одного оператора AL, генерированного автоматически или оператором-человеком. Некоторые записи могут включать множество операторов AL, некоторые из которых считаются синонимами или семантическими эквивалентами друг друга. В примере, в котором соответствующий AL является языком запросов к базе данных, два оператора AL могут считаться синонимами, когда они вызывают извлечение одних и тех же данных из базы данных. Аналогично, в примере языка программирования два оператора AL (то есть части кода) могут быть синонимами/семантическими эквивалентами, если они производят одинаковый результат вычислений.
[0039] В некоторых вариантах осуществления корпус 68a-b NL-AL содержит множество записей, каждая запись состоит из кортежа (например, пары) предложений, причем по меньшей мере одно предложение сформулировано на искусственном языке, а другое предложение сформулировано на естественном языке. В некоторых вариантах осуществления сторона AL кортежа содержит перевод стороны NL соответствующего кортежа на искусственный язык. Другими словами, соответствующая сторона AL кортежа имеет то же или очень похожее значение, что и сторона NL соответствующего кортежа. Некоторые кортежи NL-AL могут состоять из одного предложения NL и множества синонимичных предложений AL. Другие кортежи NL-AL могут иметь множество предложений NL, соответствующих одному предложению AL. Отдельные корпуса 68а-b NL-AL могут соответствовать различным естественным языкам (например, английскому и китайскому). В другом примере отдельные корпуса NL-AL могут содержать различные наборы предложений NL, сформулированных на одном и том же естественном языке (например, английском). В одном из таких примеров один корпус NL-AL используется для обучения переводчика, который будет использоваться англоговорящим торговым представителем, в то время как другой корпус NL-AL может использоваться для обучения переводчика для использования англоязычным администратором базы данных.
[0040] Обучающий модуль 64 конфигурирован для обучения модуля 62 переводчика для получения требуемого результата, например, для правильного перевода предложений на естественном языке в предложения на искусственном языке, как более подробно изложено ниже. Здесь обучение в целом означает процесс регулирования набора параметров модуля 62 переводчика в попытке получить требуемый результат (например, правильный перевод). Примерная последовательность этапов, иллюстрирующая обучение, показана на фиг. 6. Последовательность этапов 302-304 может выбрать элемент корпуса (например, предложение на естественном языке) и ввести соответствующий элемент корпуса в модуль 62 переводчика. Модуль 62 может затем генерировать выходные данные в соответствии с принятыми входными данными. На этапе 308 соответствующие выходные данные сравниваются с требуемыми выходными данными, и определяется оценка производительности, например ошибка перевода, указывающая степень сходства между фактическими выходными данными модуля 62 и требуемыми выходными данными. В ответ на определение оценки производительности на этапе 310 модуль 64 обучения может обновить параметры модуля 62 таким образом, чтобы повысить производительность модуля 62 переводчика, например, за счет уменьшения ошибки перевода. Такая регулировка параметров может осуществляться любым способом, известным в данной области техники. Некоторые примеры включают обратное распространение с использованием градиентного спуска, симуляции восстановления и генетических алгоритмов. В некоторых вариантах осуществления обучение заканчивается, когда какое-либо условие завершения (этап 312) удовлетворено. Более подробная информация об условиях завершения приведена ниже.
[0041] В некоторых вариантах осуществления после завершения обучения на этапе 314 система 16 обучения переводчика выводит набор значений 69 параметров переводчика. Когда модуль 62 содержит искусственные нейронные сети, значения 69 параметров переводчика могут включать в себя, например, набор весов синапсов и/или набор значений параметров сетевой архитектуры (например, количество слоев, количество нейронов на слой, карты связности и т.д.). Значения 69 параметров могут быть затем переданы в клиентские системы 12a-d и/или сервер 18 базы данных и использованы для создания экземпляров соответствующих модулей локального переводчика, выполняющих автоматический перевод с естественного языка на искусственный.
[0042] Фиг. 7 иллюстрирует примерную работу модуля 62 переводчика согласно некоторым вариантам осуществления настоящего изобретения. Модуль 62 конфигурирован для автоматического перевода предложения естественного языка (NL), такого как примерное предложение 54, в предложение искусственного языка (AL), такое как примерное предложение 56. Термин «предложение» используется здесь для обозначения любой последовательности слов/лексем, сформулированных на естественном или искусственном языке. Примеры естественных языков включают, среди прочего, английский, немецкий и китайский. Искусственный язык содержит набор токенов (например, ключевые слова, идентификаторы, операторы) вместе с набором правил для объединения соответствующих токенов. Правила обычно известны как грамматика или синтаксис и обычно зависят от языка. Примеры искусственных языков включают формальные компьютерные языки, такие как языки запросов (например, SQL), языки программирования (например, С ++, Perl, Java®, байт-код) и языки разметки (например, XML, HTML). Примеры предложений NL включают, среди прочего, утверждение, вопрос и команду. Примеры предложений AL включают в себя, например, часть компьютерного кода и SQL-запрос.
[0043] В некоторых вариантах осуществления модуль 62 переводчика принимает входной массив 55, содержащий машиночитаемое представление предложения NL, и создает выходной массив 57, содержащий кодирование предложения (й) AL, полученного в результате перевода входного предложения NL. Входные и/или выходные массивы могут содержать массив числовых значений, вычисленных с использованием любого метода, известного в данной области техники, например однократного кодирования. В одном из таких примеров каждому слову словаря NL присвоена отдельная числовая метка. Например, «как» может иметь метку 2, а «много» может иметь метку 37. Затем однократное представление слова «как» может содержать двоичный вектор размером N×1, где N - размер словаря, а все элементы равны 0, кроме второго элемента, который имеет значение 1. Между тем, слово «много» может быть представлено как двоичный вектор А×1, в котором все элементы равны 0, кроме 37-го. В некоторых вариантах осуществления входной массив 55, кодирующий последовательность слов, такую как входное предложение 54, содержит двоичный массив N×М, где М обозначает количество слов входного предложения, при этом каждый столбец входного массива 55 представляет отдельное слово входного предложения. Последовательные столбцы входного массива 55 могут соответствовать последовательным словам входного предложения. Выходной массив 57 может использовать аналогичную стратегию однократного кодирования, хотя словари, используемые для кодирования входных и выходных данных, могут отличаться друг от друга. Поскольку входной массив 55 и выходной массив 57 представляют собой входное предложение 54 и выходное предложение 56, соответственно, выходной массив 57 будет здесь считаться переводом входного массива 55.
[0044] Преобразование предложения 54 NL во входной массив 55, а также преобразование выходного массива 57 в предложение (я) 56 AL может включать в себя такие операции, как синтаксический анализ, токенизация и т.д., которые могут выполняться программными компонентами отдельно от модуля 62 переводчика.
[0045] В некоторых вариантах осуществления модуль 62 содержит систему искусственного интеллекта, такую как искусственная нейронная сеть, обученная выполнять проиллюстрированный перевод. Такие системы искусственного интеллекта могут быть созданы с использованием любого метода, известного в данной области техники. В предпочтительном варианте осуществления с фиг. 8 модуль 62 включает в себя кодер 70 и декодер 72, подключенные к кодеру 70. Каждый из кодера 70 и декодера 72 может содержать нейронную сеть, например рекуррентную нейронную сеть (RNN). RNN образуют особый класс искусственных нейронных сетей, в которых соединения между узлами сети образуют ориентированный граф. Примеры рекуррентных нейронных сетей включают, среди прочего, сети долгой краткосрочной памяти (LSTM).
[0046] Кодер 70 принимает входной массив 55 и выводит внутренний массив 59, содержащий собственное внутреннее представление входного предложения 54 модуля переводчика. На практике внутренний массив 59 содержит математическое преобразование входного массива 55 посредством набора операций, специфичных для кодера 70 (например, умножение матриц, применение функций активации и т.д.). В некоторых вариантах осуществления размер внутреннего массива 59 является фиксированным, в то время как размер входного массива 55 может варьироваться в зависимости от входного предложения. Например, длинные входные предложения могут быть представлены с использованием относительно больших входных массивов по сравнению с короткими входными предложениями. С этой точки зрения можно сказать, что в некоторых вариантах осуществления кодер 70 преобразует входные данные переменного размера в кодирование фиксированного размера соответствующих входных данных. В некоторых вариантах осуществления декодер 72 принимает внутренний массив 59 в качестве входных данных и создает выходной массив 57 с помощью второго набора математических операций. Размер выходного массива 57 может изменяться в зависимости от содержимого внутреннего массива 59 и, следовательно, в соответствии с входным предложением.
[0047] Фиг. 9 иллюстрирует примерный процесс обучения модуля 62 переводчика для выполнения автоматизированных преобразований NL в AL. В некоторых вариантах осуществления обучение включает по меньшей мере два этапа. Первый этап, представленный этапами 322-324, включает обучение экземпляра модуля 62 переводчика на корпусе искусственного языка (например, корпус 66 AL на фиг. 5). В некоторых вариантах осуществления этап 322 содержит модуль 62 обучения переводчика для создания выходных данных AL при подаче входных данных AL. В одном из таких примеров модуль 62 переводчика обучен воспроизводить ввод, сформулированный на соответствующем искусственном языке. В другом примере модуль 62 обучается, при подаче входных данных AL, производить синоним/семантический эквивалент соответствующих входных данных. В еще одном примере модуль 62 обучен так, чтобы его выходные данные были по меньшей мере грамматически правильными, то есть чтобы выходные данные соответствовали правилам грамматики/синтаксиса соответствующего искусственного языка.
[0048] В некоторых вариантах осуществления первый этап обучения продолжается до тех пор, пока не будет удовлетворен набор условий завершения (этап 324). Условия завершения могут включать в себя критерии производительности, например, является ли среднее отклонение от ожидаемых выходных данных модуля 62 (то есть ошибка перевода) меньше, чем предварительно определенный порог. Другой примерный критерий производительности состоит в том, являются ли выходные данные модуля 62 перевода в основном грамматически правильным, например, по меньшей мере, в 90% случаев. В варианте осуществления, в котором выходные данные модуля 62 сформулированы на языке программирования, проверка грамматической правильности может включать в себя попытку скомпилировать соответствующие выходные данные и определение того, что соответствующие выходные данные являются правильными, при отсутствии ошибок компиляции. Другие примерные условия завершения включают в себя критерии вычислительной стоимости, например, обучение может продолжаться до тех пор, пока не будет превышен предварительно определенный предел времени или количество итераций.
[0049] В некоторых вариантах осуществления второй этап обучения, проиллюстрированный этапами 326-328 на фиг. 9, содержит модуль 62 обучения переводчика на корпусе с естественного языка на искусственный язык, то есть с использованием кортежей NL-AL. В одном таком примере модуль 62 обучается при подаче NL-стороны кортежа в качестве входных данных для вывода соответствующей AL-стороны кортежа. В альтернативном варианте осуществления модуль 62 можно обучить выводить по меньшей мере синоним AL-стороны соответствующего кортежа. Второй этап обучения может продолжаться до тех пор, пока не будут удовлетворены критерии завершения (например, пока не будет достигнут желаемый процент правильных преобразований NL в AL). Затем, на этапе 330, система 16 обучения переводчика может выводить значения 69 параметров переводчика, полученные в результате обучения. В примерном варианте осуществления, в котором модуль 62 переводчика использует нейронные сети, значения 69 параметров могут включать в себя значения весов синапсов, полученные посредством обучения.
[0050] Фиг. 10 дополнительно иллюстрирует тренировку первого этапа в предпочтительном варианте осуществления настоящего изобретения. Проиллюстрированный модуль 62а переводчика первой этапа содержит кодер 70а искусственного языка, подключенный к декодеру 72. Кодер 70а AL принимает входной массив 55а и выводит внутренний массив 59а, который, в свою очередь, преобразуется декодером 72 в выходной массив 57а. В некоторых вариантах осуществления обучение на первом этапе включает обеспечение модуля 62а переводчика множеством входов AL и настройку параметров модуля 62а для генерации выходных данных AL, которые аналогичны соответствующим представленным входным данным. Другими словами, в некоторых вариантах осуществления цель обучения на первом этапе может состоять в том, чтобы сделать выходные данные более похожими на входные данные. В альтернативных вариантах осуществления цель обучения может заключаться в том, чтобы выходные данные были по меньшей мере, синонимами соответствующих входных данных, или чтобы выходные данные были грамматически правильными на соответствующем искусственном языке.
[0051] В одном примере обучения первого этапа для каждой пары входных/выходных массивов обучающий модуль 64 может вычислять оценку сходства, указывающую степень сходства между выходными и входными массивами (57а и 55а на фиг. 10, соответственно). Оценка сходства может быть вычислена с использованием любого метода, известного в данной области техники, например, в соответствии с расстоянием Манхэттена или Левенштейна между входными и выходными массивами. Обучающий модуль 64 может затем отрегулировать параметры кодера 70а AL и/или декодера 72 для увеличения сходства между выходными данными декодера 72 и входными данными кодера 70а AL, например, чтобы уменьшить среднее манхэттенское расстояние между массивами 55а и 57а.
[0052] Обучение на первом этапе может продолжаться до тех пор, пока не будут выполнены условия завершения первого этапа (например, пока не будет достигнут предварительно определенный уровень производительности, пока все элементы корпуса 66 AL не будут использованы в обучении, и т.д.).
[0053] Фиг. 11-А иллюстрирует примерный процесс обучения второго этапа, который включает обучение переводу между естественным языком и искусственным языком, используемым в обучении первого этапа. В некоторых вариантах осуществления переход от первого ко второму этапу включает переключение на модуль 62b переводчика второго этапа, полученный заменой кодера 70а AL кодером 70b естественного языка, при сохранении уже обученного декодера 72. Иначе говоря, декодер 72 сохраняет экземпляры со значениями параметров, полученными в результате обучения на первом этапе. Архитектура и/или значения параметров кодера 70b NL могут существенно отличаться от кодера 70а AL. Одна причина такого различия состоит в том, что словари искусственных и естественных языков обычно отличаются друг от друга, поэтому входные массивы, представляющие предложения NL, могут отличаться по меньшей мере по размеру от входных массивов, представляющих предложения AL. Другая причина, по которой кодеры 70а-b могут иметь разные архитектуры, заключается в том, что грамматика/синтаксис искусственных языков обычно существенно отличается от грамматики/синтаксиса естественных языков.
[0054] Кодер 70b NL принимает входной массив 55b, представляющий предложение NL, и выводит внутренний массив 59b. В некоторых вариантах осуществления внутренний массив 59b имеет тот же размер и/или структуру, что и внутренний массив 59а, выводимый кодером 59а AL модуля 62а перевода (см. Фиг. 10). Затем внутренний массив 59b подается в качестве входных данных в декодер 72, который, в свою очередь, создает выходной массив 57 с, представляющий предложение AL.
[0055] В некоторых вариантах осуществления, обучение на втором этапе использует кортежи NL-AL, причем AL-сторона кортежа представляет перевод в целевую AL-NL сторону соответствующего кортежа. Обучение на втором этапе может включать предоставление кодеру 70b NL множества входных данных NL, при этом каждые входные данные NL содержат NL-сторону кортежа NL-AL, и настройку параметров модуля 62b переводчика так, чтобы выходные данные декодера 72 был подобны AL-стороне соответствующего кортежа NL-AL. Иначе говоря, цель обучения на втором этапе состоит в том, чтобы сделать выходные данные декодера 72 более похожими на переводы в целевой AL соответствующих входов NL.
[0056] В одном примерном варианте осуществления, в ответ на подачу NL-стороны каждого кортежа (представленного как массив 55b на фиг. 11-А) в кодер 70b NL, модуль 64 обучения может сравнивать выходные данные декодера 72 (массив 57с) с AL-стороны соответствующего кортежа (массив 57b). Сравнение может включать в себя вычисление оценки сходства, указывающей степень сходства между массивами 57b и 57с. Обучающий модуль 64 может отрегулировать параметры кодера 70b NL и/или декодера 72 в направлении увеличения сходства между массивами 57b и 57с.
[0057] Альтернативный сценарий для второго этапа тренировки проиллюстрирован на фиг. 11-В. В данном альтернативном сценарии используются (обученный) кодер AL, полученный путем обучения на первом этапе (например, кодер 70а AL на фиг. 10, конкретизированный со значениями параметров, полученными в результате обучения на первом этапе), так и кодер 70b NL. В некоторых вариантах осуществления в кодер 70b NL подается входной массив 55b, представляющий NL-сторону кортежа NL-AL, в то время как в кодер AL подается выходной массив 57b, представляющий AL-сторону соответствующего кортежа. Способ основан на наблюдении, что кодер 70а AL уже конфигурирован во время первого этапа обучения для преобразования входных данных AL в «правильный» внутренний массив 59с, который декодер 72 может затем преобразовать обратно в соответствующие входные данные AL. Иначе говоря, для того, чтобы декодер 72 сформировал выходной массив 57а, его входные данные должен быть как можно ближе к выходным данным (уже обученного) кодера 70а AL. Следовательно, в варианте осуществления с фиг. 11-В модуль 64 обучения может сравнивать выходные данные кодера 72 NL (то есть внутренний массив 59b) с внутренним массивом 59с и количественно определять разницу как оценку сходства. Модуль 64 обучения может регулировать параметры кодера 70b NL и/или декодера 72 в направлении увеличения сходства между массивами 59b и 59 с.
[0058] Фиг. 12 иллюстрирует примерную последовательность этапов для обучения модуля 62 переводчика на множестве обучающих корпусов согласно некоторым вариантам осуществления настоящего изобретения. Проиллюстрированный способ основан на наблюдении, что декодер 72 может быть обучен только один раз для каждого целевого искусственного языка (см. первый этап обучения выше), а затем повторно использован в уже обученной форме для получения множества модулей переводчика, например, модулей, которые могут переводить с множества исходных естественных языков (например, английского, немецкого и т.д.) на соответствующий целевой искусственный язык (например, SQL).
[0059] В другом примере каждый отдельный модуль переводчика можно обучить на отдельном наборе предложений NL, сформулированных на одном и том же естественном языке (например, английском). Данный конкретный вариант осуществления основан на наблюдении, что язык обычно является специализированным и специфичным для конкретной задачи, то есть предложения/команды, которые люди-операторы используют для решения определенных проблем, отличаются от предложений/команд, используемых при других обстоятельствах. Следовательно, в некоторых вариантах осуществления используется один корпус (то есть набор предложений NL) для обучения переводчика, который будет использоваться продавцом, и другой корпус, чтобы обучить переводчика, который будет использоваться техническим персоналом.
[0060] Этапы 342-344 на фиг. 12 иллюстрируют процесс обучения первого этапа, содержащий обучение кодера 70а AL и/или декодера 72. В ответ на успешное обучение первого этапа этап 346 заменяет кодер 70а AL на кодер NL. В некоторых вариантах осуществления затем выполняется второй этап обучения кодера NL для каждого доступного корпуса NL-AL. При переключении с одного корпуса NL-AL на другой (например, при переключении с английского на испанский или с «коммерческого английского» на «технический английский») некоторые варианты осуществления заменяют существующий кодер NL на новый кодер NL, подходящий для текущего NL-AL корпуса (этап 358) с сохранением уже обученного декодера 72. Такие оптимизации могут существенно облегчить и ускорить обучение автоматических переводчиков.
[0061] В некоторых вариантах осуществления, обучение второго этапа только регулирует параметры кодера 70b NL (см. фиг. 11-А-В), сохраняя при этом параметры декодера 72 фиксированными на значении (значениях), полученном посредством обучения первого этапа. Такая стратегия обучения направлена на сохранение производительности декодера 72 на уровне, достигаемом посредством обучения первого этапа, независимо от выбора исходного естественного языка или корпуса NL-AL. В других вариантах осуществления, в которых обучение включает регулирование параметров как кодера 70b NL, так и декодера 72, этап 358 может дополнительно содержать сброс параметров декодера 72 до значений, полученных по завершении обучения первого этапа.
[0062] Примерные системы и способы, описанные выше, обеспечивают автоматический перевод с исходного естественного языка, такого как английский, на целевой искусственный язык (например, SQL, язык программирования, язык разметки и т.д.). Одно примерное применение некоторых вариантов осуществления настоящего изобретения позволяет непрофессионалу выполнять запросы к базе данных с использованием простых вопросов, сформулированных на естественном языке, без необходимости знания языка запросов, такого как SQL. Например, оператор по продажам может спросить клиентскую машину: «Сколько у нас клиентов младше 30 лет в Колорадо?». В ответ машина может преобразовать соответствующий вопрос в запрос к базе данных и выполнить соответствующий запрос, чтобы получить ответ на вопрос оператора.
[0063] В некоторых вариантах осуществления используется модуль переводчика для перевода последовательности слов NL в предложение AL, например, в действительный запрос, используемый для выборочного извлечения данных из базы данных. Модуль переводчика может содержать набор искусственных нейронных сетей, таких как сеть кодера и сеть декодера. Кодер и декодер могут быть созданы с использованием рекуррентных нейронных сетей (RNN) или любой другой технологии искусственного интеллекта.
[0064] В некоторых вариантах осуществления обучение модуля переводчика включает, по меньшей мере, два этапа. На первом этапе модуль переводчика обучается формировать выходные данные AL в ответ на входные данные AL. Например, первый этап обучения может включать обучение модуля переводчика воспроизводить входные данные AL. В альтернативном варианте осуществления переводчик обучается создавать грамматически правильные предложения AL в ответ на ввод AL. Используя удобную метафору, можно сказать, что обучение первого этапа учит модуль переводчика «говорить» на соответствующем искусственном языке. На практике обучение первого этапа включает в себя представление переводчику обширного корпуса предложений AL (например, SQT-запросов). Для каждого входного предложения выходные данные переводчика оцениваются для определения оценки производительности, а параметры переводчика регулируются для повышения производительности переводчика при обучении.
[0065] Последующий второй этап включает обучение модуля переводчика для создания выходных данных AL в ответ на входные данные NT, сформулированные на исходном языке. На втором этапе обучения может использоваться корпус NL-AL, содержащий множество кортежей предложений (например, пар), каждый кортеж имеет по меньшей мере NL-сторону и AL-сторону. В примерном варианте осуществления каждая AL-сторона кортежа может представлять перевод соответствующей NL-стороны, то есть желаемый результат переводчика, когда он представлен соответствующей NL-стороной кортежа. Примерное обучение второго этапа происходит следующим образом: для каждого кортежа NL-AL переводчик принимает NL-сторону в качестве входных данных. Выходные данные переводчика сравниваются с AL-стороной кортежа для определения ошибки перевода, и параметры переводчика регулируются для уменьшения ошибки переводчика.
[0066] Традиционные автоматические переводчики обычно обучаются с использованием пар элементов, в которых один член пары сформулирован на исходном языке, а другой член пары сформулирован на целевом языке. Одним из технических препятствий, с которыми сталкивается такое традиционное обучение, является размер учебного корпуса. В данной области хорошо известно, что более крупные и разнообразные корпуса производят более надежных и производительных переводчиков. Для достижения приемлемой производительности перевода могут потребоваться десятки тысяч кортежей NL-AL или больше. Но поскольку кортежи NL-AL, как правило, не могут быть созданы автоматически, объем квалифицированного человеческого труда, необходимый для создания таких больших корпусов, непрактичен.
[0067] Напротив, предложения AL могут производиться автоматически в большом количестве. В некоторых вариантах осуществления настоящего изобретения это понимание используется для повышения производительности, облегчения обучения и сокращения времени вывода модуля переводчика на рынок. Первый этап обучения может проводиться на относительно большом, автоматически генерируемом корпусе AL, в результате чего частично обученный переводчик способен надежно создавать грамматически правильные предложения AL на целевом искусственном языке. Затем второй этап обучения может быть проведен на корпусе NL-AL меньшего размера.
[0068] Другое преимущество двухэтапного обучения, как описано в данном документе, состоит в том, что множество переводчиков NL-AL могут быть разработаны независимо друг от друга, без необходимости повторения первого этапа обучения. Таким образом, часть декодера модуля переводчика может быть повторно использована как есть (т.е. без переобучения) во множестве переводчиков, что может существенно снизить их затраты на разработку и время вывода на рынок. Каждый такой отдельный переводчик может соответствовать, например, отдельному исходному естественному языку, такому как английский, немецкий и китайский. В другом примере каждый отдельный переводчик может быть обучен разному набору предложений одного и того же естественного языка (например, английского). Такие ситуации могут возникнуть, когда каждый переводчик используется для отдельной задачи/приложения, например, один переводчик используется в продажах, а другой - в управлении базой данных.
[0069] Хотя основная часть настоящего описания была направлена на обучение автоматическому переводу с естественного языка на язык запросов, такой как SQL, специалисту в данной области техники понятно, что описанные системы и способы могут быть адаптированы для других приложений и искусственных языков. Альтернативные языки запросов включают SPARQL и другие языки запросов формата описания ресурсов (RDF). Примеры применения таких переводов включают облегчение доступа к данным, представленным в RDF, например, для извлечения информации из всемирной паутины и/или разнородных баз знаний, таких как Wikipedia®. Другим примерным применением некоторых вариантов осуществления настоящего изобретения является автоматическая генерация кода RDF, например, для автоматической организации/структурирования разнородных данных или для ввода данных в базу знаний без специальных знаний в области программирования или языков запросов.
[0070] Приложения некоторых вариантов осуществления, в которых целевой язык является языком программирования, могут включать, среди прочего, автоматическое создание кода (например, сценария оболочки), обеспечивающего взаимодействие человека с машиной. Например, пользователь может попросить машину выполнить действие (например, позвонить по телефонному номеру, получить доступ к веб-странице, получить объект и т.д.). Автоматический переводчик может преобразовывать соответствующую команду NL в набор машиночитаемых инструкций, которые могут выполняться в ответ на получение команды пользователя. Другие примерные приложения включают в себя автоматический перевод кода между двумя разными языками программирования (например, с Python на Java(№) и автоматическую обработку мультимедийных данных (например, аннотирование изображений и видео).
[0071] В еще одном примере некоторые поставщики услуг компьютерной безопасности, специализирующиеся на обнаружении вредоносного программного обеспечения, используют специальный язык программирования (версию байт-кода) для кодирования процедур обнаружения вредоносных программ и/или сигнатур, указывающих на наличие вредоносных программ. Некоторые варианты осуществления настоящего изобретения могут облегчить такие исследования и разработки в области защиты от вредоносных программ, позволяя оператору без специальных знаний о байт-коде автоматически генерировать подпрограммы байт-кода.
[0072] Специалисту в данной области техники понятно, что вышеупомянутые варианты осуществления могут быть различным образом изменены, без выхода при этом за рамки объема правовой охраны настоящего изобретения. Соответственно, объем правовой охраны настоящего изобретения определен следующей ниже формулой изобретения и ее юридическими эквивалентами.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ ПЕРЕВОДУ | 2020 |
|
RU2770569C2 |
| Компьютерная система и способ для обнаружения вредоносных программ с использованием машинного обучения | 2021 |
|
RU2802860C1 |
| СПОСОБ И СИСТЕМА МАШИННОГО ОБУЧЕНИЯ ИЕРАРХИЧЕСКИ ОРГАНИЗОВАННОМУ ЦЕЛЕНАПРАВЛЕННОМУ ПОВЕДЕНИЮ | 2019 |
|
RU2755935C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБУЧЕНИЯ МОДЕЛИ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПЕРЕВОДА | 2023 |
|
RU2835121C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ВЫПОЛНЕНИЯ ПРОБЛЕМНО-ОРИЕНТИРОВАННОГО ПЕРЕВОДА | 2021 |
|
RU2820953C2 |
| Способ и сервер для выполнения контекстно-зависимого перевода | 2021 |
|
RU2812301C2 |
| ОПТИЧЕСКОЕ РАСПОЗНАВАНИЕ СИМВОЛОВ ПОСРЕДСТВОМ КОМБИНАЦИИ МОДЕЛЕЙ НЕЙРОННЫХ СЕТЕЙ | 2020 |
|
RU2768211C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ НЕЙРОННОЙ СЕТИ ФОРМИРОВАНИЮ ТЕКСТОВОЙ ВЫХОДНОЙ ПОСЛЕДОВАТЕЛЬНОСТИ | 2020 |
|
RU2798362C2 |
| СИСТЕМЫ И СПОСОБЫ ДЕТЕКТИРОВАНИЯ ПОВЕДЕНЧЕСКИХ УГРОЗ | 2019 |
|
RU2772549C1 |
| СИСТЕМЫ И СПОСОБЫ ДЕТЕКТИРОВАНИЯ ПОВЕДЕНЧЕСКИХ УГРОЗ | 2019 |
|
RU2803399C2 |
Изобретение относится к способу, системам и машиночитаемому носителю для автоматического перевода с естественного языка на искусственный машиночитаемый язык. Технический результат заключается в повышении точности перевода на искусственный машиночитаемый язык за счет применения двух стадий обучения на различных типах данных. В способе выполняют первый этап, на котором исполняют кодер искусственного языка (AL) и декодер, связанный с кодером AL, причем кодер AL конфигурирован для приема первого входного массива, содержащего представление входного предложения AL, сформулированного на искусственном языке, и, в ответ, создания первого внутреннего массива, причем декодер конфигурирован для приема первого внутреннего массива и, в ответ, создания первого выходного массива, содержащего представление первого выходного предложения AL, сформулированного на искусственном языке; в ответ на предоставление первого входного массива кодеру AL, определяют первую оценку сходства, указывающую степень сходства между входным предложением AL и первым выходным предложением AL; регулируют первый набор параметров декодера в соответствии с первой оценкой сходства, чтобы улучшить соответствие между входными данными кодера AL и выходными данными декодера; определяют, удовлетворяется ли условие завершения обучения первого этапа; в ответ на определение, удовлетворяется ли условие завершения обучения первого этапа, если условие завершения обучения первого этапа удовлетворено, выполняют второй этап, на котором исполняют кодер естественного языка (NL), конфигурированный для приема второго входного массива, содержащего представление входного предложения NL, сформулированного на естественном языке, и, в ответ, выведения второго внутреннего массива в декодер; определяют второй выходной массив, созданный декодером в ответ на прием второго внутреннего массива, причем второй выходной массив содержит представление второго выходного предложения AL, сформулированного на искусственном языке; определяют вторую оценку сходства, указывающую степень сходства между вторым выходным предложением AL и целевым предложением AL, содержащим перевод входного предложения NL на искусственный язык; и регулируют второй набор параметров кодера NL в соответствии со второй оценкой сходства, чтобы улучшить соответствие между выходными данными декодера и целевыми выходными данными, представляющими соответствующие переводы на искусственный язык входных данных, полученных кодером NL. 4 н. и 14 з.п. ф-лы, 14 ил.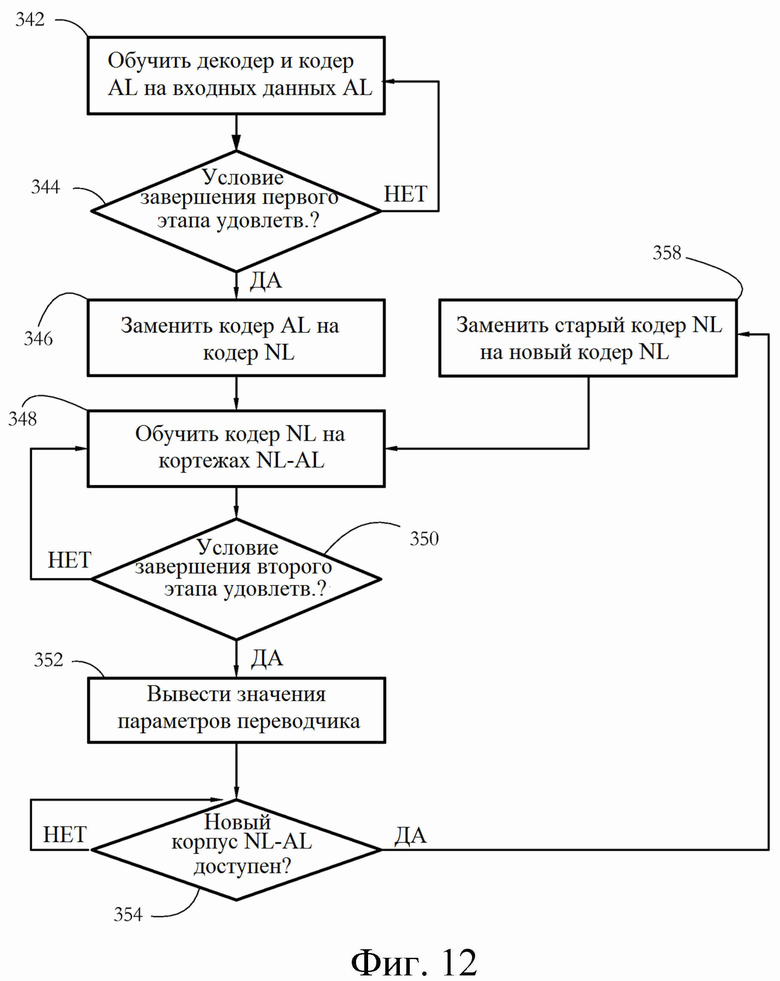
1. Способ автоматического перевода с естественного языка на искусственный машиночитаемый язык, включающий использование по меньшей мере одного аппаратного процессора компьютерной системы, чтобы:
выполнять первый этап, на котором:
исполняют кодер искусственного языка (AL) и декодер, связанный с кодером AL, причем кодер AL конфигурирован для приема первого входного массива, содержащего представление входного предложения AL, сформулированного на искусственном языке, и, в ответ, создания первого внутреннего массива, причем декодер конфигурирован для приема первого внутреннего массива и, в ответ, создания первого выходного массива, содержащего представление первого выходного предложения AL, сформулированного на искусственном языке; в ответ на предоставление первого входного массива кодеру AL, определяют первую оценку сходства, указывающую степень сходства между входным предложением AL и первым выходным предложением AL;
регулируют первый набор параметров декодера в соответствии с первой оценкой сходства, чтобы улучшить соответствие между входными данными кодера AL и выходными данными декодера; определяют, удовлетворяется ли условие завершения обучения первого этапа;
в ответ на определение, удовлетворяется ли условие завершения обучения первого этапа, если условие завершения обучения первого этапа удовлетворено, выполнять второй этап, на котором:
исполняют кодер естественного языка (NL), конфигурированный для приема второго входного массива, содержащего представление входного предложения NL, сформулированного на естественном языке, и, в ответ, выведения второго внутреннего массива в декодер;
определяют второй выходной массив, созданный декодером в ответ на прием второго внутреннего массива, причем второй выходной массив содержит представление второго выходного предложения AL, сформулированного на искусственном языке;
определяют вторую оценку сходства, указывающую степень сходства между вторым выходным предложением AL и целевым предложением AL, содержащим перевод входного предложения NL на искусственный язык; и
регулируют второй набор параметров кодера NL в соответствии со второй оценкой сходства, чтобы улучшить соответствие между выходными данными декодера и целевыми выходными данными, представляющими соответствующие переводы на искусственный язык входных данных, полученных кодером NL.
2. Способ по п. 1, в котором искусственный язык содержит элемент, выбранный из группы, включающей в себя язык запросов к базе данных, язык программирования и язык разметки.
3. Способ по п. 2, в котором искусственный язык представляет собой язык структурированных запросов (SQL).
4. Способ по п. 1, дополнительно включающий определение второй оценки сходства в соответствии со степенью сходства между вторым выходным массивом и целевым массивом, содержащим представление целевого предложения AL.
5. Способ по п. 1, в котором определение второй оценки сходства включает использование по меньшей мере одного аппаратного процессора компьютерной системы для:
введения представления целевого предложения AL в кодер AL;
определения третьего внутреннего массива, содержащего выходные данные кодера А в ответ на получение представления целевого предложения AL в качестве входных данных; и
определения второй оценки сходства в соответствии со степенью сходства между вторым и третьим внутренними массивами.
6. Способ по п. 1, в котором дополнительно, в ответ на определение, удовлетворяется ли условие завершения обучения на первом этапе, если условие завершения обучения на первом этапе не удовлетворено, используют по меньшей мере один аппаратный процессор компьютерной системы для:
предоставления кодеру AL третьего входного массива, причем третий входной массив содержит представление третьего предложения AL, сформулированного на искусственном языке;
определения третьего выходного массива, содержащего выходные данные декодера в ответ на прием кодером AL третьего входного массива, причем третий выходной массив содержит представление третьего выходного предложения AL;
определения третьей оценки сходства, указывающей степень сходства между третьим входным предложением AL и третьим выходным предложением AL;
регулирования первого набора параметров декодера в соответствии с третьей оценкой сходства, чтобы улучшить соответствие между входными данными кодера AL и выходными данными декодера.
7. Способ по п. 1, в котором дополнительно, в ответ на регулирование второго набора параметров кодера NL, используют по меньшей мере один аппаратный процессор компьютерной системы для:
исполнения другого кодера NL, конфигурированного для приема третьего входного массива, содержащего представление другого предложения NL, и, в ответ, для вывода третьего внутреннего массива в декодер, при этом другое предложение NL сформулировано на другом естественном языке, отличном от естественного языка;
определения третьего выходного массива, созданного декодером в ответ на прием третьего внутреннего массива, причем третий выходной массив содержит представление третьего выходного предложения AL;
определения третьей оценки сходства, указывающей степень сходства между третьим выходным предложением AL и третьим целевым предложением AL, содержащим перевод другого предложения NL на искусственный язык; и
регулирования третьего набора параметров другого кодера NL в соответствии с третьей оценкой сходства, чтобы улучшить соответствие между выходными данными декодера и другим набором целевых выходных данных, представляющих соответствующие переводы на искусственный язык входных данных, принятых другим декодером NL.
8. Способ по п. 1, в котором кодер NL содержит рекуррентную нейронную сеть.
9. Компьютерная система для автоматического перевода с естественного языка на искусственный машиночитаемый язык, содержащая по меньшей мере один аппаратный процессор и память, причем по меньшей мере один аппаратный процессор конфигурирован, чтобы:
выполнять первый этап, включающий:
исполнение кодера AL и декодера, связанного с кодером AL, причем кодер AL конфигурирован для приема первого входного массива, содержащего представление входного предложения AL, сформулированного на искусственном языке, и, в ответ, создания первого внутреннего массива, при этом декодер конфигурирован для приема первого внутреннего массива и, в ответ, создания первого выходного массива, содержащего представление первого выходного предложения AL, сформулированного на искусственном языке;
в ответ на предоставление первого входного массива кодеру AL, определение первой оценки сходства, указывающей степень сходства между входным предложением AL и первым выходным предложением AL;
регулирование первого набора параметров декодера в соответствии с первой оценкой сходства, чтобы улучшить соответствие между входными данными кодера AL и выходными данными декодера; определение, удовлетворяется ли условие завершения обучения первого этапа;
в ответ на определение, удовлетворяется ли условие завершения обучения первого этапа, если условие завершения обучения первого этапа удовлетворено, выполнять второй этап, включающий:
исполнение кодера NL, конфигурированного для приема второго входного массива, содержащего представление входного предложения NL, сформулированного на естественном языке, и, в ответ, выведения второго внутреннего массива в декодер;
определение второго выходного массива, созданного декодером в ответ на прием второго внутреннего массива, причем второй выходной массив содержит представление второго выходного предложения AL, сформулированного на искусственном языке;
определение второй оценки сходства, указывающей степень сходства между вторым выходным предложением AL и целевым предложением AL, содержащим перевод входного предложения NL на искусственный язык; и
регулирование второго набора параметров кодера NL в соответствии со второй оценкой сходства, чтобы улучшить соответствие между выходными данными декодера и целевыми выходными данными, представляющими соответствующие переводы на искусственный язык входных данных, полученных кодером NL.
10. Компьютерная система по п. 9, причем искусственный язык содержит элемент, выбранный из группы, включающей в себя язык запросов к базе данных, язык программирования и язык разметки.
11. Компьютерная система по п. 10, причем искусственный язык является языком структурированных запросов (SQL).
12. Компьютерная система по п. 9, причем по меньшей мере один аппаратный процессор дополнительно конфигурирован для определения второй оценки сходства в соответствии со степенью сходства между вторым выходным массивом и целевым массивом, содержащим представление целевого предложения AL.
13. Компьютерная система по п. 9, причем определение второй оценки сходства включает использование по меньшей мере одного аппаратного процессора компьютерной системы для:
введения представления целевого предложения AL в кодер AL;
определения третьего внутреннего массива, содержащего выходные данные кодера AL в ответ на получение представления целевого предложения AL в качестве входных данных; и
определения второй оценки сходства в соответствии со степенью сходства между вторым и третьим внутренними массивами.
14. Компьютерная система по п. 9, причем по меньшей мере один аппаратный процессор дополнительно конфигурирован, в ответ на определение, удовлетворяется ли первое условие завершения, если первое условие завершения не удовлетворено, для:
предоставления третьего входного массива кодеру AL, причем третий входной массив содержит представление третьего предложения AL, сформулированного на искусственном языке;
определения третьего выходного массива, содержащего выходные данные декодера в ответ на прием кодером AL третьего входного массива, причем третий выходной массив содержит представление третьего выходного предложения AL;
определения третьей оценки сходства, указывающей степень сходства между третьим входным предложением AL и третьим выходным предложением AL;
регулирования первого набора параметров декодера в соответствии с третьей оценкой сходства, чтобы улучшить соответствие между входными данными кодера AL и выходными данными декодера.
15. Компьютерная система по п. 9, причем по меньшей мере один аппаратный процессор дополнительно конфигурирован, в ответ на регулирование второго набора параметров кодера NL, для:
исполнения другого кодера NL, конфигурированного для приема третьего входного массива и, в ответ, выведения третьего внутреннего массива в декодер, при этом другое предложение NL сформулировано на другом естественном языке, отличном от естественного языка;
определения третьего выходного массива, созданного декодером в ответ на прием третьего внутреннего массива, причем третий выходной массив содержит представление третьего выходного предложения AL;
определения третьей оценки сходства, указывающей степень сходства между третьим выходным предложением AL и третьим целевым предложением AL, содержащим перевод другого предложения NL на искусственный язык;
и регулирования третьего набора параметров другого кодера NL в соответствии с третьей оценкой сходства, чтобы улучшить соответствие между выходными данными декодера и другим набором целевых выходных данных, представляющих соответствующие переводы на искусственный язык входных данных, принятых другим декодером NL.
16. Компьютерная система по п. 9, в которой кодер NL содержит рекуррентную нейронную сеть.
17. Невременный машиночитаемый носитель, хранящий инструкции, которые при исполнении первым аппаратным процессором первой компьютерной системы побуждают первую компьютерную систему формировать модуль обученного переводчика, содержащий кодер NL и декодер, соединенный с кодером NL, при этом обучение модуля переводчика включает использование второго аппаратного процессора второй компьютерной системы, чтобы:
выполнять первый этап, включающий:
соединение декодера с кодером AL, конфигурированным для приема первого входного массива, содержащего представление входного предложения AL, сформулированного на искусственном языке, и, в ответ, создания первого внутреннего массива, причем кодер AL соединен с декодером так, чтобы декодер принимал первый внутренний массив и, в ответ, создавал первый выходной массив, содержащий представление первого выходного предложения AL, сформулированного на искусственном языке;
в ответ на предоставление первого входного массива кодеру AL, определение первой оценки сходства, указывающей степень сходства между входным предложением AL и первым выходным предложением AL;
регулирование первого набора параметров декодера в соответствии с первой оценкой сходства, чтобы улучшить соответствие между входными данными кодера AL и выходными данными декодера;
определение, удовлетворяется ли условие завершения обучения первого этапа;
в ответ на определение, удовлетворяется ли условие завершения обучения первого этапа, если условие завершения обучения первого этапа удовлетворено, выполнять второй этап, включающий:
соединение кодера NL с декодером так, что кодер NL принимает второй входной массив, содержащий представление входного предложения NL, сформулированного на естественном языке, и, в ответ, выводит второй внутренний массив в декодер;
определение второго выходного массива, созданного декодером в ответ на прием второго внутреннего массива, причем второй выходной массив содержит представление второго выходного предложения AL, сформулированного на искусственном языке;
определение второй оценки сходства, указывающей степень сходства между вторым выходным предложением AL и целевым предложением AL, содержащим перевод входного предложения NL на искусственный язык; и
регулирование второго набора параметров кодера NL в соответствии со второй оценкой сходства, чтобы улучшить соответствие между выходными данными декодера и целевыми выходными данными, представляющими соответствующие переводы на искусственный язык входных данных, полученных кодером NL.
18. Компьютерная система для автоматического перевода с естественного языка на искусственный машиночитаемый язык, содержащая первый аппаратный процессор, конфигурированный для исполнения обученного модуля переводчика, содержащего кодер NL и декодер, соединенный с кодером NL, при этом обучение модуля переводчика включает использование второго аппаратного процессора второй компьютерной системы, чтобы:
выполнять первый этап, включающий:
соединение декодера с кодером AL, конфигурированным для приема первого входного массива, содержащего представление входного предложения AL, сформулированного на искусственном языке, и, в ответ, создания первого внутреннего массива, причем кодер AL соединен с декодером так, что декодер принимает первый внутренний массив и, в ответ, создает первый выходной массив, содержащий представление первого выходного предложения AL, сформулированного на искусственном языке;
в ответ на предоставление первого входного массива кодеру AL, определение первой оценки сходства, указывающей степень сходства между входным предложением AL и первым выходным предложением AL;
регулирование первого набора параметров декодера в соответствии с первой оценкой сходства, чтобы улучшить соответствие между входными данными кодера AL и выходными данными декодера; определение, удовлетворяется ли условие завершения обучения первого этапа;
в ответ на определение, удовлетворяется ли условие завершения обучения первого этапа, если условие завершения обучения первого этапа удовлетворено, выполнять второй этап, включающий:
соединение кодера NL с декодером так, что кодер принимает второй входной массив, содержащий представление входного предложения NL, сформулированного на естественном языке, и, в ответ, выводит второй внутренний массив в декодер;
определение второго выходного массива, созданного декодером в ответ на прием второго внутреннего массива, причем второй выходной массив содержит представление второго выходного предложения AL, сформулированного на искусственном языке;
определение второй оценки сходства, указывающей степень сходства между вторым выходным предложением AL и целевым предложением AL, содержащим перевод входного предложения NL на искусственный язык; и
регулирование второго набора параметров кодера NL в соответствии со второй оценкой сходства, чтобы улучшить соответствие между выходными данными декодера и целевыми выходными данными, представляющими соответствующие переводы на искусственный язык входных данных, полученных кодером NL.
| Srinivasan Iyer и др., "Learning a Neural Semantic Parser from User Feedback", 27.04.2017, URL: https://arxiv.org/pdf/1704.08760 | |||
| Maxim Rabinovich и др., "Abstract Syntax Networks for Code Generation and Semantic Parsing", 25.04.2017, URL: https://arxiv.org/pdf/1704.07535 | |||
| СПОСОБ ИЗВЛЕЧЕНИЯ ФАКТОВ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2016 |
|
RU2637992C1 |
| ПРЕДЛОЖЕНИЕ РОДСТВЕННЫХ ТЕРМИНОВ ДЛЯ МНОГОСМЫСЛОВОГО ЗАПРОСА | 2005 |
|
RU2393533C2 |
| Токарный резец | 1924 |
|
SU2016A1 |

