Уровень техники
[0001] Технология нейронной сети используется для выполнения сложных задач, таких как понимание чтения, перевод языка, распознавание изображения или распознавание речи. Службы машинного обучения, такие как службы, основанные на рекуррентных нейронных сетях (RNN), сверточных нейронных сетях (CNN), нейронных сетях с долгой краткосрочной памятью (LSTM) или рекуррентных блоках с импульсным управлением (GRU), были разработаны для выполнения таких сложных задач. В то время как эти типы нейронных сетей были разработаны, существует необходимость в непрерывном улучшении в лежащей в основе архитектуре и соответствующих инструкциях для выполнения таких сложных задач.
Сущность изобретения
[0002] В одном примере настоящее изобретение относится к процессору, содержащему набор регистров для хранения векторов, включающий в себя многопортовую память (например, двухпортовую память). Процессор может дополнительно включать в себя множество ячеек, сконфигурированных для обработки матрицы N×N элементов данных и вектора N×1 элементов данных, где N является целым числом, равным или более 8, и где каждая из множества ячеек конфигурируется для обработки N элементов данных. Набор регистров для хранения векторов может быть сконфигурирован, чтобы, в ответ на инструкцию записи, в течение одного тактового цикла сохранять N элементов данных в многопортовой памяти и в течение каждого цикла из P тактовых циклов предоставлять N элементов данных каждой схеме из P входных интерфейсных схем многопортовой памяти, где P является целым числом, равным N, разделенному на L, где L является целым числом, равным или более 2, и где каждая из P входных интерфейсных схем содержит входной тракт, сконфигурированный для передачи L элементов данных параллельно, и где в течение каждого цикла из P тактовых циклов многопортовая память сконфигурирована, чтобы принимать N элементов данных через выбранную по меньшей мере одну из P входных интерфейсных схем.
[0003] Набор регистров для хранения векторов может дополнительно быть сконфигурирован, чтобы, в ответ на инструкцию чтения, в течение одного тактового цикла извлекать N элементов данных из многопортовой памяти и в течение каждого цикла из Q тактовых циклов предоставлять L элементов данных из каждой схемы из Q выходных интерфейсных схем многопортовой памяти, где Q является целым числом, равным N, разделенному на L, и где каждая из Q выходных интерфейсных схем содержит выходной тракт, сконфигурированный для передачи L элементов данных параллельно, и где в течение каждого цикла из Q тактовых циклов многопортовая память сконфигурирована, чтобы предоставлять N элементов данных в выбранную по меньшей мере одну из Q выходных интерфейсных схем.
[0004] В другом примере настоящее изобретение относится к способу в системе, содержащей множество ячеек и набор регистров для хранения векторов, содержащий двухпортовую память, где каждая из множества ячеек сконфигурирована, чтобы обрабатывать матрицу N×N элементов данных и вектор N×1 элементов данных, где N является целым числом, равным или больше 8, и где каждая из множества ячеек сконфигурирована, чтобы обрабатывать N элементов данных.
[0005] Способ может включать в себя, в ответ на инструкцию записи, в течение одного тактового цикла сохранение N элементов данных в двухпортовой памяти и в течение каждого цикла из P тактовых циклов предоставление N элементов данных каждой схеме из P входных интерфейсных схем двухпортовой памяти, где P является целым числом, равным N, разделенному на L, где L является целым числом, равным или более 2, и где каждая из P входных интерфейсных схем содержит входной тракт, сконфигурированный для передачи L элементов данных параллельно, и где в течение каждого цикла из P тактовых циклов двухпортовая память сконфигурирована, чтобы принимать N элементов данных через выбранную по меньшей мере одну из P входных интерфейсных схем.
[0006] Способ может дополнительно включать в себя, в ответ на инструкцию чтения, в течение одного тактового цикла извлечение N элементов данных из двухпортовой памяти и в течение каждого из Q тактовых циклов предоставление L элементов данных из каждой из Q выходных интерфейсных схем двухпортовой памяти, где Q является целым числом, равным N, разделенному на L, и где каждая из Q выходных интерфейсных схем содержит выходной тракт, сконфигурированный для передачи L элементов данных параллельно, и где в течение каждого из Q тактовых циклов двухпортовая память сконфигурирована, чтобы предоставлять N элементов данных в выбранную по меньшей мере одну из Q выходных интерфейсных схем.
[0007] В еще одном примере настоящее изобретение относится к процессору, содержащему набор регистров для хранения векторов, содержащий двухпортовую память, включающую в себя один порт для чтения и один порт для записи. Процессор может дополнительно содержать множество ячеек, сконфигурированных, чтобы обрабатывать матрицу N×N и вектор N×1, где N является целым числом, равным или более 8, и где каждая из множества ячеек сконфигурирована, чтобы обрабатывать N элементов данных.
[0008] Набор регистров для хранения векторов может быть сконфигурирован, чтобы, в ответ на инструкцию записи, в течение одного тактового цикла сохранять N элементов данных в двухпортовой памяти через один порт для записи и в течение каждого цикла из P тактовых циклов предоставлять N элементов данных каждой схеме из P входных интерфейсных схем двухпортовой памяти, где P является целым числом, равным N, разделенному на L, где L является целым числом, равным или более 2, и где каждая из P входных интерфейсных схем содержит входной тракт, сконфигурированный для передачи L элементов данных параллельно, и где в течение каждого цикла из P тактовых циклов двухпортовая память сконфигурирована, чтобы принимать N элементов данных через выбранную схему из P входных интерфейсных схем.
[0009] Набор регистров для хранения векторов может дополнительно быть сконфигурирован, чтобы, в ответ на инструкцию чтения, в течение одного тактового цикла извлекать N элементов данных из двухпортовой памяти через один порт для чтения и в течение каждого цикла из Q тактовых циклов предоставлять L элементов данных из каждой схемы из Q выходных интерфейсных схем двухпортовой памяти, где Q является целым числом, равным N, разделенному на L, и где каждая из Q выходных интерфейсных схем содержит выходной тракт, сконфигурированный для передачи L элементов данных параллельно, и где в течение каждого цикла из Q тактовых циклов двухпортовая память сконфигурирована, чтобы предоставлять N элементов данных выбранной схеме из Q выходных интерфейсных схем.
[00010] Данная сущность предусмотрена для того, чтобы в упрощенной форме представить набор идей, которые дополнительно описываются ниже в подробном описании. Эта сущность не имеет намерением ни идентифицировать ключевые признаки или важнейшие признаки заявляемого предмета изобретения, ни использоваться так, чтобы ограничивать объем заявляемого предмета изобретения.
Краткое описание чертежей
[00011] Настоящее изобретение иллюстрируется в качестве примера и не ограничивается сопровождающими чертежами, на которых аналогичные ссылки указывают аналогичные элементы. Элементы на чертежах иллюстрируются для простоты и ясности и необязательно начерчены по масштабу.
[00012] Фиг. 1 - это блок-схема процессора в соответствии с одним примером;
[00013] Фиг. 2 - это блок-схема матрично-векторного умножителя в соответствии с одним примером;
[00014] Фиг. 3 - это блок-схема набора регистров для хранения векторов в соответствии с одним примером;
[00015] Фиг. 4 - это блок-схема набора регистров для хранения векторов в соответствии с другим примером; и
[00016] Фиг. 5 показывает блок-схему последовательности операции способа для обработки элементов векторных данных с помощью процессора на фиг. 1 и набора регистров для хранения векторов в соответствии с одним примером.
Подробное описание изобретения
[00017] Примеры, описанные в настоящем примере, относятся к процессору, включающему в себя матрично-векторный умножитель, имеющий набор регистров для хранения векторов. Набор регистров для хранения векторов может быть использован для чтения/записи данных из/в матрично-векторный умножитель. Некоторые примеры относятся к использованию многопортовой памяти, например, двухпортовой памяти, с входными интерфейсными схемами и выходными интерфейсными схемами, которые предоставляют возможность использования двухпортовой памяти, которая может иметь один порт для записи и один порт для чтения, быстрым и эффективным способом, чтобы выполнять вычисления с помощью нейронной сети.
[00018] Сверточные нейронные сети (CNN) и рекуррентные нейронные сети (RNN), и те, и другие широко используют вычислительные ядра в преобладающем машинном обучении. CNN и RNN могут быть эффективно выражены с точки зрения матрично-векторного умножителя, однако, параллелизм и структуры данных, характерные для каждой, значительно различаются. Следовательно, является трудным создавать единую компьютерную архитектуру терафлопс-масштаба, которая эффективно выполняет вычисления как для множества CNN, так и для множества RNN. Эта проблема усложняется, когда требования временной задержки в реальном времени накладываются на проект. В результате, предыдущие решения специализировались на множестве CNN или RNN без приоритезации сильной производительности для обеих. Некоторые примеры, раскрытые в данном описании изобретения, относятся к использованию системы, способов и компонентов, которые обеспечивают эффективное вычисление как для множества CNN, так и для множества RNN.
[00019] В качестве примера, настоящее изобретение описывает процессор, который эффективно использует параллелизм между отдельными выходными активациями в CNN, чтобы выполнять ограниченную форму матрично-матричного умножения в отдельной CNN-оценке. Этот параллелизм преобразуется в схему в форме массива квазинезависимых механизмов ячеек матрично-векторного умножения, которые принимают одинаковые матричные данные, но различные векторные данные. Этот подход предоставляет возможность высокого коэффициента использования в партии=1 для входных данных CNN, которые, в свою очередь, обеспечивают высокую пропускную способность с низким значением задержки. Одним из способов, которые предоставляют возможность такого подхода, является использование многопортового набора регистров для хранения векторов (VRF), который предоставляет возможность множества одновременных векторизованных считываний и записей в совместно используемое пространство памяти. Этот подход также разрешается посредством CNN-совместимой структуры набора команд (ISA), которая предоставляет информационно-насыщенное выражение множества CNN в одном и том же коде на уровне ассемблера, который может быть использован для выражения множества RNN.
[00020] Процессоры, описанные в этом описании изобретения, могут быть реализованы с помощью фрагментов или сочетаний программируемых пользователем вентильных матриц (FPGA), специализированных интегральных схем (ASIC), стираемых и/или сложных программируемых логических устройств (PLD), устройств программируемой матричной логики (PAL) и устройств типовой матричной логики (GAL). Файл образа может быть использован для конфигурирования или переконфигурирования процессоров, таких как FPGA. Файл образа или аналогичный файл или программа может быть предоставлен через сетевую линию связи или локальную линию связи (например, PCIe) от главного CPU. Информация, включенная в файл образа, может быть использована для программирования аппаратных блоков процессоров (например, логических блоков и переконфигурируемых межсоединений FPGA), чтобы реализовывать желаемую функциональность. Желаемая функциональность может быть реализована, чтобы поддерживать любую службу, которая может быть предложена посредством сочетания вычисления, сетевого взаимодействия и ресурсов хранения, например, через информационный центр или другую инфраструктуру для предоставления службы.
[00021] В одном примере процессоры (например, FPGA) или группы таких процессоров могут быть соединены друг с другом через сеть с низким временем задержки. Объединенная платформа, эффективно использующая от сотен до тысяч таких процессоров (например, FPGA), может преимущественно предлагать: (1) значительно уменьшенные времена обучения благодаря использованию параллелизма между сотнями тысяч узлов, (2) предоставление возможности новых сценариев обучения, таких как онлайн-обучение на месте по живым данным и (3) модели обучения беспрецедентного масштаба, в то же время эффективно использующие гибкие и взаимозаменяемые однородные FPGA-ресурсы в информационном центре гипермасштаба, охватывающем сотни тысяч серверов. В одном примере такие преимущества могут быть получены посредством использования нетрадиционных представлений данных, которые могут эффективно использовать архитектуру процессоров, таких как FPGA.
[00022] Описанные аспекты могут также быть реализованы в облачных вычислительных окружениях. Облачное вычисление может ссылаться на модель для предоставления возможности сетевого доступа по запросу к совместно используемому пулу конфигурируемых вычислительных ресурсов. Например, облачное вычисление может применяться на рынке, чтобы предлагать повсеместный и удобный доступ по требованию к совместно используемому пулу конфигурируемых вычислительных ресурсов. Совместно используемый пул конфигурируемых вычислительных ресурсов может быть быстро обеспечен посредством виртуализации и выпущен с низким объемом работ по управлению или взаимодействием с поставщиком услуги, и затем масштабирован соответствующим образом. Облачная вычислительная модель может состоять из различных характеристик, таких как, например, самообслуживание по запросу, широкополосный доступ к сети, объединение ресурсов в пул, способность быстро адаптироваться, измеримое обслуживание и т.д. Облачная вычислительная модель может использоваться, чтобы раскрывать различные модели обслуживания, такие как, например, аппаратные средства как услуга ("HaaS"), программное обеспечение как услуга ("SaaS"), платформа как услуга ("PaaS") и инфраструктура как услуга ("IaaS"). Облачная вычислительная модель может также быть развернута с помощью различных моделей развертывания, таких как частное облако, кооперативное облако, общедоступное облако, гибридное облако и т.д.
[00023] Службы машинного обучения, такие как службы, основанные на рекуррентных нейронных сетях (RNN), сверточных нейронных сетях (CNN), нейронных сетях с долгой краткосрочной памятью (LSTM) или рекуррентные блоки с импульсным управлением (GRU) могут быть реализованы с помощью процессоров, описанных в этом изобретении. В одном варианте осуществления связанный со службой контент или другая информация, такая как слова, предложения, изображения, видеозаписи или другой такой контент/информация могут быть переведены в векторное представление. Векторное представление может соответствовать таким методам как RNN, CNN, LSTM или GRU. Модели глубокого обучения могут быть подготовлены в оффлайн-режиме перед инициализацией службы и затем могут быть развернуты с помощью систем и процессоров, описанных в этом описании изобретения.
[00024] В одном примере модель нейронной сети может содержать множество слоев, и каждый слой может быть закодирован как матрицы или векторы весов, выраженных в форме коэффициентов или констант, которые были получены посредством оффлайн-обучения нейронной сети. Программируемые аппаратные логические блоки в узлах могут обрабатывать матрицы или векторы, чтобы выполнять различные операции, включающие в себя умножение, сложение и другие операции в отношении входных векторов, представляющих закодированную информацию, относящуюся к службе. В одном примере матрицы или векторы весов могут быть разделены и закреплены между множеством узлов с помощью таких методов как разбиение графа. Как часть этого процесса, большая нейронная сеть может быть преобразована в промежуточное представление (например, граф), и затем промежуточное представление может быть разделено на меньшие представления (например, подграфы), и каждая из матриц весов, соответствующих каждому подграфу, может быть закреплена за внутрикристальной памятью узла. В одном примере модели могут быть преобразованы в матрицы и векторы фиксированного размера. Таким образом, ресурсы узла могут работать по матрицам и векторам фиксированного размера параллельно.
[00025] Возьмем пример LSTM, LSTM-сеть может содержать последовательность повторяющихся RNN-слоев или другие типы слоев. Каждый слой LSTM-сети может потреблять входные данные в заданном временном такте, например, состояние слоя из предыдущего временного такта, и может создавать новый набор выходных данных или состояний. В случае использования LSTM, единственная порция контента может быть закодирована в единственный вектор или множество векторов. В качестве примера, слово или сочетание слов (например, фраза, предложение или параграф) могут быть закодированы как единственный вектор. Каждая порция может быть закодирована в отдельный слой (например, отдельный временной такт) LSTM-сети. LSTM-слой может быть описан с помощью набора уравнений, таких как уравнения ниже:
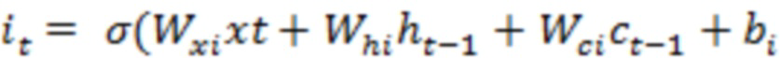
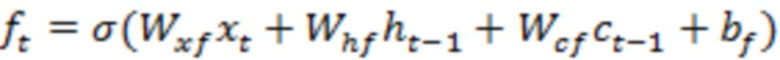
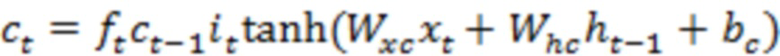
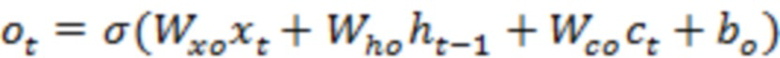
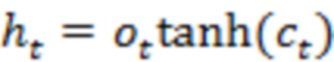
[00026] В этом примере, внутри каждого LSTM-слоя, входные данные и скрытые состояния могут быть обработаны с помощью сочетания векторных операций (например, скалярное произведение, внутреннее произведение или сложение векторов) и нелинейных функций (например, сигмоидальные кривые, гиперболы и касательные). В некоторых случаях, большинство требующих большого объема вычислений может возникать из скалярных произведений, которые могут быть реализованы с помощью интенсивных алгоритмов матрично-векторных и матрично-матричных умножений. В одном примере обработка векторных операций и нелинейных функций может выполняться параллельно.
[00027] В одном примере отдельные процессоры могут отправлять сообщения, содержащие пакеты, непосредственно друг другу, и, таким образом, это может предоставлять возможность разделения даже единой нейронной сети между множеством процессоров без причинения неприемлемых задержек. Для связи процессоры могут использовать легковесный протокол, включающий в себя, например, RDMA. Параллелизация может также выполняться в пределах слоя нейронной сети посредством распределения нейронных весов между множеством процессоров. В качестве примера, единая CNN- или RNN-модель (например, включающая в себя LSTM-весовые матрицы) может быть разделена и обработана с помощью процессоров.
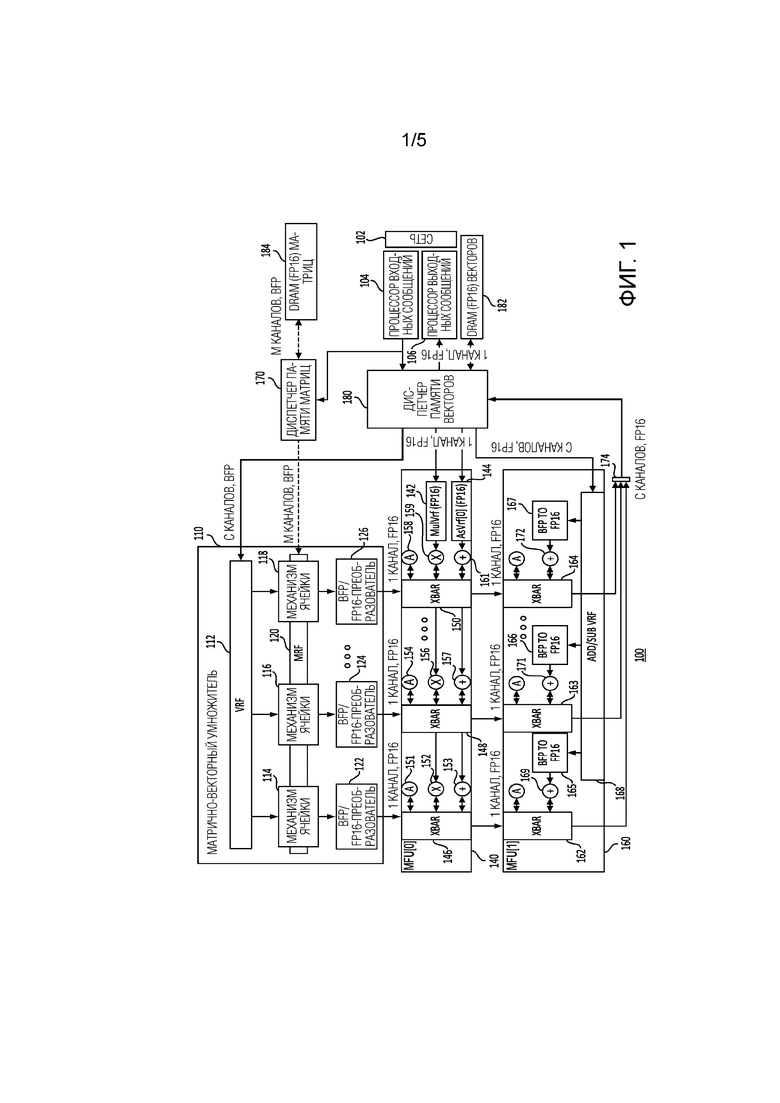
[00028] Фиг. 1 - это блок-схема процессора 100 в соответствии с одним примером. Каждый процессор 100 может включать в себя процессор входных сообщений (IMP) 104 для приема сообщений от других процессоров и процессор выходных сообщений (OMP) 106 для обработки исходящих сообщений другим процессорам или компонентам. Такие сообщения могут приниматься и передаваться по сети 102. Каждый процессор 100 может дополнительно включать в себя матрично-векторный умножитель (MVM) 110, два или более многофункциональных блоков (MFU) (например, MFU[0] 140 и MFU[1] 160). Каждый процессор 100 может дополнительно включать в себя диспетчер 170 матричной памяти, диспетчер 180 векторной памяти, векторное DRAM 182 и матричное DRAM 184. В этом примере процессор может принимать внекристальные сообщения, содержащие вспомогательную информацию, такую как управляющие и скалярные данные и данные полезной нагрузки (например, векторы, матрицы или другие многомерные структуры данных). В этом примере входящие сообщения могут быть обработаны посредством легковесного процессора входных сообщений (IMP) 104, который отправляет векторы диспетчеру 180 памяти векторов. IMP 104 может отправлять матрицы диспетчеру 170 памяти матриц.
[00029] С продолжающейся ссылкой на фиг. 1, каждая из матриц может иметь размер N×N, а каждый из векторов может иметь размер N×1. В этом примере все инструкции, соответствующие процессору 100, могут работать по данным собственного размера. Логические векторы и матрицы, соответствующие приложениям, обрабатываемым посредством процессора 100, могут часто быть больше собственного размера; в таких случаях, векторы и матрицы разбиваются на элементы собственного размера. В одном примере, для матрично-векторного умножения, матричные данные и векторные данные могут быть выражены в формате блока с плавающей запятой (BFP). В этом примере, размер блока данных BFP-формата может быть равен собственному размеру. Следовательно, каждый собственный вектор N×1 может иметь общий показатель степени, и каждая строка матрицы N×N может иметь общий показатель степени. Общий показатель степени может быть 5 битами. Каждые из векторных данных и матричных данных могут иметь фрагмент мантиссы поразрядного дополнения до двух, и размер мантиссы для векторных данных и матричных данных может быть различным.
[00030] MVM 110 может включать в себя набор регистров для хранения векторов (VRF) 112, набор регистров для хранения матриц (MRF) 120 и механизмы ячеек (например, механизмы 114, 116 и 118 ячеек). Механизмы ячеек могут принимать входные матричные и входные векторные данные от VRF 112. MVM 110 может дополнительно включать в себя преобразователи формата, при необходимости, включающие в себя преобразователи блока с плавающей запятой (BFP) в плавающую запятую (FP). В одном примере два внутренних BFP-формата могут быть использованы MVM 110 для выражения его входных и выходных данных: BFP-короткий, для хранения вектора и матрицы, и BFP-длинный для накопления. В одном примере MVM 110, BFP-короткий может использовать q1,15 значений с плавающей запятой с общим 5-битовым показателем степени, а BFP-длинный может использовать q34,40 значений с плавающей запятой с общим 5-битовым показателем степени. В этом примере, матрично-векторное умножение может приводить в результате к BFP-длинному, который может быть преобразован обратно в формат с плавающей запятой в качестве конечной выходной стадии. Таким образом, примерный MVM 110, показанный на фиг. 1, может включать в себя BFP/FP16-преобразователи 122, 124 и 126 на выходных стадиях. Механизмы 114, 116 и 118 ячеек могут, параллельно, предоставлять выходные данные соответствующим преобразователям, как показано в примере на фиг. 1. Дополнительные подробности, касающиеся MVM 110, предоставляются на фиг. 2, а дополнительные подробности для VRF 112 предоставляются на фиг. 3 и 4.
[00031] Обмен матричными данными может происходить между DRAM 184 для матриц и диспетчером 170 памяти матриц с помощью M числа каналов. Диспетчер памяти векторов может перемещать векторные данные по C числу каналов.
[00032] С продолжающейся ссылкой на фиг. 1, каждый MFU (например, MFU[0] 140 и MFU[1] 160) может включать в себя коммутаторы каналов (например, коммутаторы каналов, обозначенные как xbars). MFU[0] 140 может поддерживать векторные операции, такие как векторно-векторное умножение и сложение, сигмоидальную функцию, функцию TanH (гиперболического тангенса), многопеременную логистическую функцию, операцию блока линейной ректификации (ReLU), и/или операцию блока активизации. Таким образом, как показано на фиг. 1, MFU[0] 140 может включать в себя коммутаторы каналов (например, xbar 146, 148 и 150), которые могут передавать в потоковом режиме вектор со своей входной шины посредством конвейерной последовательности операций. Таким образом, вектор может быть принят через набор регистров, обозначенный как MulVrf 142, или другой набор регистров, обозначенный как AsVrf[0] 144, и такие векторы могут быть подвергнуты любой из операции умножения, операции сложения или некоторой другой операции. MFU[0] 140 может включать в себя несколько аппаратных блоков для выполнения сложения (например, 153, 157 и 161). MFU[0] 140 может также включать в себя несколько аппаратных блоков для выполнения умножения (например, 152, 156 и 159). MFU[0] 140 может также включать в себя несколько аппаратных блоков для выполнения активации (например, 151, 154 и 158).
[00033] Все еще обращаясь к фиг. 1, MFU[1] 160 может включать в себя коммутаторы каналов (например, xbar 162, 163 и 164), которые могут предоставлять возможность MFU[1] 160 принимать выходные данные от MFU[0] 140 и выполнять дополнительные операции по таким выходным данным и любые дополнительные входные данные, принимаемые через ADD/SUB VRF 168. MFU[1] 160 может включать в себя несколько аппаратных блоков для выполнения сложения (например, 169, 171 и 172). MFU[1] 160 может также включать в себя несколько аппаратных блоков для выполнения активации. Выходные данные от MFU[1] 160, принятые через C каналов, могут быть соединены посредством схемы 174 мультиплексирования для диспетчера 180 памяти векторов. Хотя фиг. 1 показывает некоторое число компонентов процессора 100, размещенных некоторым образом, может быть большее или меньшее число компонентов, размещенных по-другому.
[00034] Процессор 100 может быть использован для предоставления возможности выдачи инструкций, которые могут инициировать миллионы операций с помощью небольшого числа инструкций. В качестве примера, таблица 1 ниже показывает инструкции, соответствующие полностью параметризованной LSTM:
for (int t=0; t < steps; t++) {
v_rd (s , NeqQ, DONTCARE) ;
v_wr (s , InitialVrf , 1stm → ivrf_xt) ;
// xWF=xt * Wf+bf
v_rd (s, InitialVrf , 1stm → ivrf_xt);
mv_mul (s , 1stm → mrf_Wf) ;
vv_add (s , 1stm → asvrf_bf) ;
v_wr (s , AddSubVrf , 1stm → asvrf_xWf) ;
// xWi=xt * Wi+bi …
// xWf=xt * Wo+bo …
// xWc=xt * Wc+bc …
// f gate → multiply by c_prev
v_rd (s , InitialVrf , 1stm → ivrf_h_prev) ;
mv_mul (s , 1stm → mrf_Uf) ;
vv_add (s , 1stm → asvrf_xWf) ;
v_sigm (s) ; // ft
vv_mul (s , 1stm → mulvrf_c_prev) ;
v_wr (s , AddSubVrf , 1stm → asvrf_ft_mod) ;
// i gate …
// o gate …
// c gate → сохранить ct и c_prev
v_rd (s , InitialVrf , 1stm → ivrf_h_prev) ;
mv_mul (s , 1stm → mrf_Uc) ;
vv_add (s , 1stm → asvrf_xWc) ;
v_tanh (s) ;
vv_mul (s , 1stm → mulvrf_it) ;
vv_add (s , 1stm → asvrf_ft_mod) ; // ct
v_wr (s , MultiplyVrf , 1stm → mulvrf_c_prev) ;
v_wr (s , InitialVrf , 1stm → ivrf_ct) ;
// получить ht, сохранить и отправить в сеть
v_rd (s , InitialVrf , 1stm → ivrf_ct) ;
v_tanh (s) ;
vv_mul (s , 1stm → mulvrf_ot) ; // ht
v_wr (s , InitialVrf , 1stm → ivrf_h_prev) ;
v_wr (s , NetQ , DONTCARE) ;
}
}
Таблица 1
[00035] Хотя таблица 1 показывает некоторое число инструкций, имеющих некоторый формат, процессор 100 может выполнять больше или меньше инструкций, имеющих различный формат, чтобы достигать одних и тех же целей.
[00036] Таблица 2 ниже показывает, как вычислять свертку 1×1 как часть CNN-оценки.
SetRowsCols(bs, 1, args->cols);
// Вычислить
v_rd_inc(bs, ISA_Mem_MvmInitialVrf, mvuivrf_input, args->cols);
mv_mul(bs, mrf_weights);
vv_add_inc(bs, ISA_Mem_AddSubVrf_0, asvrf0_bias, 0);
vv_add_inc(bs, ISA_Mem_AddSubVrf_1, asvrf1_residual, 1);
v_relu(bs);
v_wr_inc(bs, ISA_Mem_NetOutputQ, DONTCARE, DONTCARE).
Таблица 2
[00037] Как показано в таблице выше, число итераций по всей цепочке инструкций для вычисления может быть точно определено. Далее, при необходимости, собственный размер каждой цепочки инструкций может быть масштабирован посредством коэффициента масштабирования столбца. И после считывания векторных данных из набора регистров для хранения векторов они могут быть перемножены с весами, извлеченными из набора регистров для хранения матриц. После выполнения дополнительных операций, которые требуются CNN-оценкой, выходные данные могут быть предоставлены. В качестве примера, поточечная операция блока линейной ректификации (ReLU) может быть выполнена для каждого элемента векторных данных.
[00038] Таблица 3 ниже показывает, как вычислять свертку N×N как часть CNN-оценки. Инструкции ниже, которые являются аналогичными свертке 1×1, не описываются снова. Инструкция Set2dWindows может быть использована, чтобы задавать итоговый размер окна, и затем инструкция SetIterations может быть использована, чтобы осуществлять скольжение этого окна по объему входных данных. *_inc instructions (например, v_rd_inc и v_add_inc) могут быть использованы для приращения адреса команды на основе шага по индексу. В качестве примера, шаг, равный 2, может приводить в результате к пропуску каждого второго вектора в наборе регистров для хранения векторов, который используется для хранения векторных данных для операций, таких как сложение.
Set2dWindow(bs, args->windowCols * args->volumeDepth, input_cols);
SetIterations(bs, output_cols);
for (unsigned imageRow=0; imageRow < output_rows; imageRow++)
{
for (unsigned filter=0; filter < args->filterCount; filter++)
{
v_rd_inc(bs, ISA_Mem_MvmInitialVrf, ivrf_input+imageRow * args->windowStride * input_cols, args->volumeDepth * args->windowStride);
mv_mul(bs, mrf_weights+filter * args->windowCols * args->windowCols * args->volumeDepth);
vv_add_inc(bs, ISA_Mem_AddSubVrf_0, asvrf0_bias+filter, 0);
v_relu(bs);
v_wr_inc(bs, ISA_Mem_Dram, dram_buffer_wr_ptr+filter, output_depth);
}
dram_buffer_wr_ptr += output_cols * output_depth;
}
Таблица 3
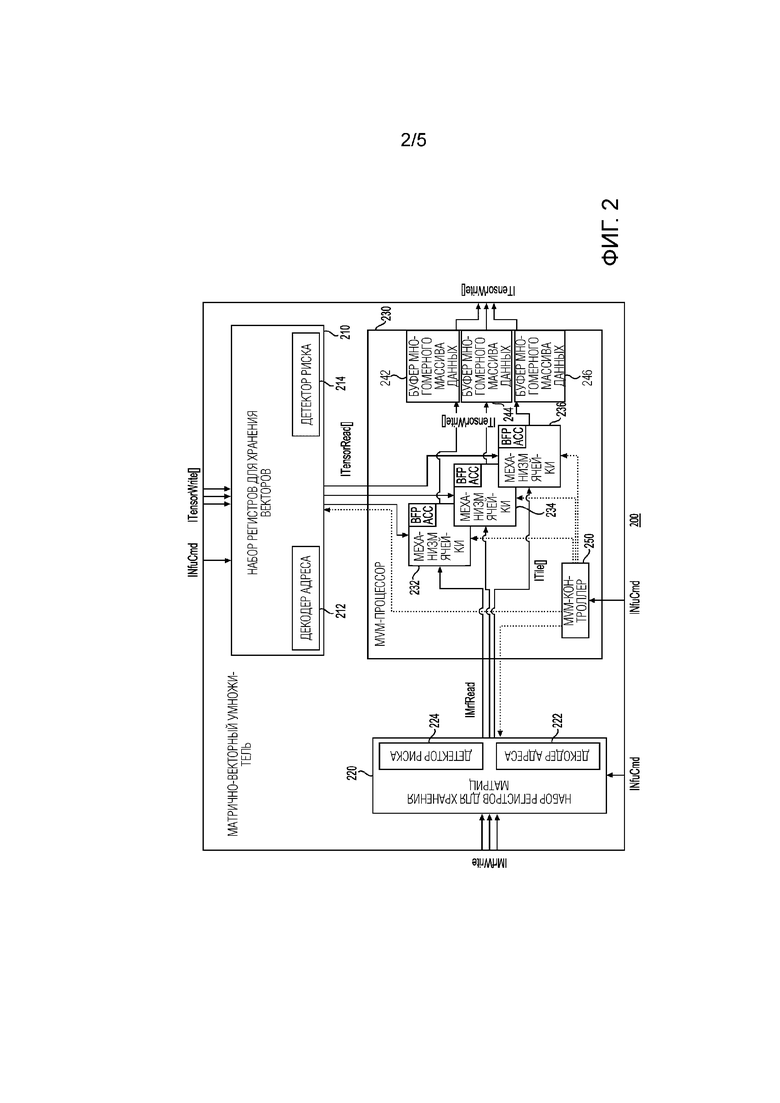
[00039] Фиг. 2 - это блок-схема матрично-векторного умножителя (MVM) 200 в соответствии с одним примером. В этом примере MVM 200 может быть использован для реализации MVM 110 на фиг. 1. MVM 200 может включать в себя набор регистров для хранения векторов (VRF) 210, набор регистров для хранения матриц (MRF) 220 и MVM-процессор 230. VRF 210 может дополнительно включать в себя декодер адреса 212 и декодер 214 паразитных импульсов. VRF 210 может принимать как команды, так и векторные данные, такие как многомерные массивы данных. MRF 220 может включать в себя декодер 222 адреса и декодер 224 паразитных импульсов. MRF 220 может принимать как команды, так и матричные данные. MVM-процессор 230 может включать в себя механизмы 232, 234 и 236 ячеек. MVM-процессор 230 может также включать в себя буферы для приема и предоставления многомерных массивов данных (например, буферы 242, 244 и 246 многомерных массивов данных). MVM-процессор 230 может дополнительно включать в себя MVM-контроллер 250. В этом примере, MVM 200 может реализовывать последовательность механизмов обработки элементов данных, каждый из которых может быть предназначен, чтобы ускорять имеющий собственный размер MVM. В этом примере каждый механизм обработки элементов данных создается из последовательности блоков скалярного произведения (DPU), так что каждый блок скалярного произведения может отвечать за вычисление скалярного произведения, которое соответствует одной собственной строке в ячейке матрицы. В одном примере, когда процессор 100 реализуется с помощью FPGA, небольшой набор BRAM и DSP может быть сконфигурирован, чтобы создавать механизм ячейки. В качестве примера, каждый может включать в себя блочные оперативные запоминающие устройства (BRAM) и логические блоки обработки (например, цифровые сигнальные процессоры (DSP)). Логические блоки обработки могут быть использованы для умножения входного вектора со строкой весов. Выходные данные логических блоков обработки могут быть сложены с помощью сумматора. Таким образом, в этом примере, каждая ячейка может выполнять поточечную операцию скалярного произведения. Блоки скалярного произведения могут состоять из трактов параллельных умножителей, которые могут вводить данные в дерево накопления. Эти тракты могут обеспечивать параллелизм в столбцах строки ячейки матрицы. Таким образом, MVM 200 может использовать, по меньшей мере, четыре измерения параллелизма: между MVM, разбиение MVM на ячейки, между строками ячейки и в столбцах строки. В этом примере, суммарная пропускная способность MVM может быть выражена как: ФЛОПс на цикл=2 * число ячеек * число DPU * число трактов.
[00040] MRF 220 может включать в себя несколько наборов регистров для хранения матриц, которые могут быть сконфигурированы, чтобы предоставлять матричные данные или элементы блокам скалярного произведения в каждой ячейке. Каждый множитель может принимать один векторный элемент от VRF 210 за цикл и один матричный элемент от одного набора регистров для хранения матриц за цикл. Матричные элементы могут быть предоставлены посредством выделенного порта набора регистров для хранения матриц, расположенного рядом с этим множителем. MRF 220 может быть организован следующим образом: сохраненные матрицы могут быть разделены на ячейки собственного размера, и каждая ячейка может быть сохранена только в одном механизме ячейки. Матрица, сохраненная в данном механизме ячейки, может рассматриваться как MRF-банк. Каждый блок скалярного произведения может быть ассоциирован с подбанком MRF, который удерживает одну строку каждой ячейки матрицы в этом MRF-банке. Строки могут быть статически назначены блокам скалярного произведения, так что первый блок скалярного произведения содержит первую строку каждой ячейки матрицы в MRF-банке. Наконец, элементы строки могут чередоваться в SRAM, так что порт считывания SRAM может быть непосредственно соединен с трактами множителя только проводами. Записи в набор регистров для хранения матриц могут обрабатываться по-разному, так как матричные данные для записи в MRF 220 могут приходить из внекристальной памяти, такой как DRAM. Хотя фиг. 2 показывает некоторое число компонентов MVM 200, размещенных некоторым образом, может быть большее или меньшее число компонентов, размещенных по-другому.
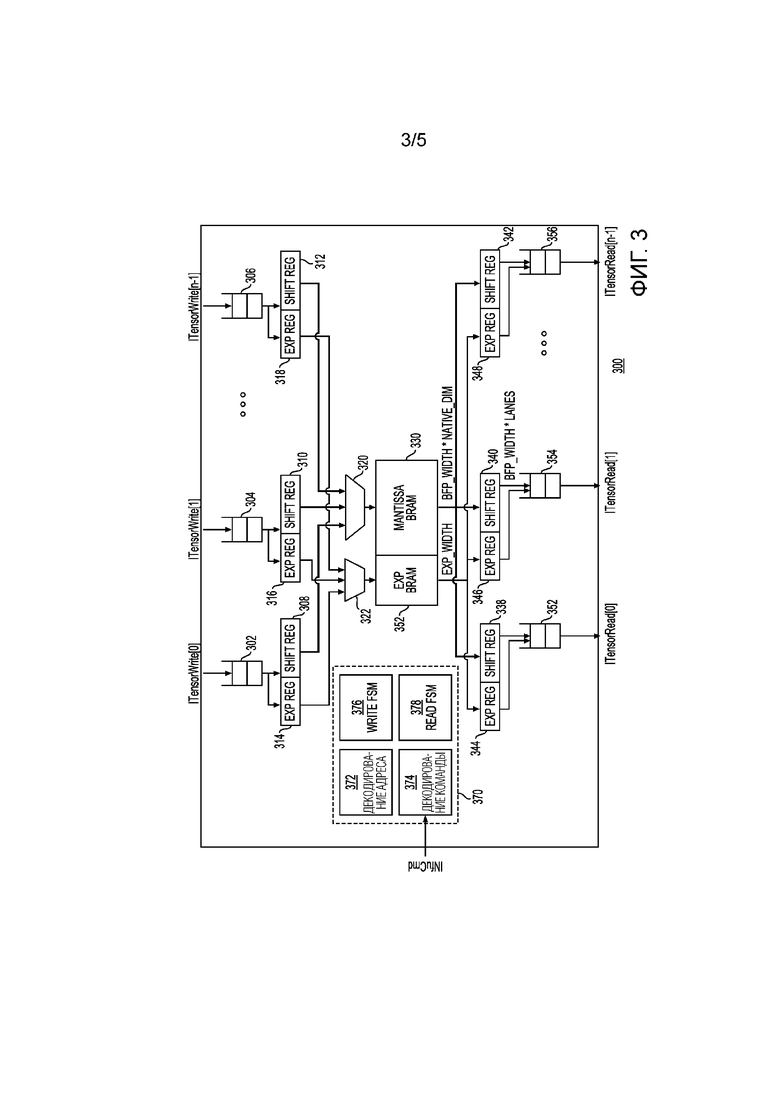
[00041] Фиг. 3 - это блок-схема набора регистров для хранения векторов (VRF) 300 в соответствии с одним примером. VRF 300 может быть использован для реализации, по меньшей мере, фрагмента VRF 112 на фиг. 1. VRF 300 может быть также использован для реализации, по меньшей мере, фрагмента VRF 210 на фиг. 2. В этом примере, интерфейсы считывания/записи данных в VRF 300 могут состоять из множества интерфейсов ITensorRead и ITensorWrite, каждый из которых может считывать/записывать ряды элементов данных за цикл. Каждый интерфейс может следовать протоколу многомерного массива данных и может независимо находиться под противодавлением. Интерфейсы чтения/записи VRF 300 могут включать в себя входные буферы 302, 304 и 306 и выходные буферы 352, 354 и 356. В ответ на операцию записи входные буферы могут быть использованы для приема многомерных массивов данных (например, входных векторных данных, соответствующих слою нейронной сети). В этом примере VRF 300 может обрабатывать векторные данные в формате блока с плавающей запятой (BFP). Показатель степени (например, общий показатель степени) может быть сохранен в регистрах показателей степени (например, EXP REG 314, 316 и 318), а мантисса может быть сохранена в сдвиговых регистрах (например, SHIFT REG 308, 310 и 312). Выходы регистров показателей степени могут быть соединены с мультиплексором 322, а выходы сдвиговых регистров могут быть соединены с мультиплексором 320, которые могут быть записаны в память (например, блочное RAM (BRAM)). Таким образом, показатель степени может быть записан в EXP BRAM 352, а мантисса может быть записана в MANTISAA BRAM 330. В ответ на считывание данные из памяти могут быть выведены в выходные интерфейсы. Таким образом, показатели степени могут быть выведены в регистры показателей степени (например, EXP REG 344, 346 и 348), а мантисса может быть выведена в сдвиговые регистры (например, SHIFT REG 338, 340 и 342). Из этих регистров BFP-векторные данные могут быть предоставлены в выходные буферы (например, буферы 352, 354 и 356). Управляющая логика 370 может управлять перемещением векторных данных через различные компоненты VRF 300, включающие в себя, например, мультиплексоры 320 и 322. Управляющая логика 370 может включать в себя декодирование адреса (например, ADDRESS DECODE 372), декодирование команд (например, через COMMAND DECODE 374) и управление чтением/записью (например, через READ FSM 378 и WRITE FSM 376). Таким образом, по приеме команды и адреса через шину INfuCmd, команда и адрес могут быть декодированы, чтобы определять схему доступа к адресу и выбор порта. Таблица 4 ниже показывает поля команды или параметры, которые могут быть декодированы посредством управляющей логики 370.
- vrf_addr: предоставляет адрес первого собственного вектора для считывания
- increment: число адресов для приращения в каждой итерации (это значение может быть определено посредством инструкций v_rd_inc, v_wr_inc или vv_add_inc).
- batch: указывает число последовательных собственных векторов для чтения или записи, формирующих логический вектор (в одном примере это может быть указано через параметры tileRows или tileCols).
- iterations: указывает число раз, которое цепочка команд выполняется.
- window_cols: указывает число собственных векторов в одной строке 2D-окна.
- window_offset: предоставляет смещение адреса в следующей строке в окне.
Таблица 4
[00042] В одном примере управляющая логика, ассоциированная с процессором 100, может декодировать параметры, указанные в таблице 2, чтобы определять адрес собственного вектора и интерфейс для чтения или записи. Модули, соединенные с VRF 300, могут требоваться, чтобы декодировать команды и такие параметры одним и тем же способом, так что эти модули могут считывать/записывать данные в соответствующем интерфейсе и в соответствующем порядке в или из VRF 300.
[00043] В одном примере это может быть выполнено с помощью иерархической архитектуры декодирования и диспетчеризации. Таким образом, в случае, когда процессор 100 реализуется на основе FPGA, управляющий процессор может быть реализован с помощью готового для использования Nios II/f процессора, который идет в паре со специально разработанным кодом. Планировщик верхнего уровня, ассоциированный с управляющим процессором, может принимать поток инструкций, которые могут быть сгруппированы в цепочки. После декодирования инструкций планировщик верхнего уровня может выполнять диспетчеризацию распространяемых управляющих сигналов набору планировщиков второго уровня и другому набору декодеров второго уровня. Эти планировщики и декодеры второго уровня могут выполнять диспетчеризацию дополнительных распространяемых управляющих сигналов декодерам самого низшего уровня. В примерной реализации, использующей процессор Nios, процессор Nios может передавать в потоковом режиме T итераций для N инструкций в планировщик верхнего уровня. Далее, планировщик верхнего уровня может выполнять диспетчеризацию MVM-характерного фрагмента инструкций планировщику второго уровня, который может расширять операции по N строкам и N столбцам целевой матрицы. Эти планы MVM могут быть преобразованы в E матрично-векторных механизмов ячеек, и операции могут быть отправлены набору из E декодеров, каждая для механизмов ячеек и их ассоциированных наборов регистров для хранения векторов и блоков накопления. Набор из E декодеров может формировать управляющие сигналы, которые рассеиваются в плоскость данных, при этом каждый диспетчер механизма ячейки разветвляется на сотни блоков скалярного произведения, которые могут считывать векторные данные из набора регистров для хранения векторов и записывать векторные данные обратно в набор регистров для хранения векторов.
[00044] С точки зрения операций чтения/записи, в этом примере, VRF 300 может внутренне использовать многопортовую память (например, двухпортовое BRAM) с разрядностью данных NATIVE_DIM * BFP_WIDTH+EXP_WIDTH. В одном примере двухпортовая память (например, BRAM) может чередоваться, чтобы обслуживать данные в различной интерфейсной схеме в каждом цикле. Таким образом, в этом примере, в устойчивом состоянии, VRF 300 может добиваться полной пропускной способности чтения/записи без конфликтов портов. Хотя фиг. 3 показывает некоторое число компонентов VRF 300, размещенных некоторым образом, может быть большее или меньшее число компонентов, размещенных по-другому. В качестве примера, хотя двухпортовая память описывается в качестве BRAM, другие типы памяти в других типах процессоров также могут быть использованы. В качестве примера, SRAM или другие типы двухпортовой памяти во множестве GPU, CPU или других типах процессоров могут также быть использованы. Кроме того, хотя фиг. 3 описывает двухпортовую память (один порт для чтения и один порт для записи), память с дополнительными портами также может быть использована; например, память с двумя портами для чтения и двумя портами для записи может быть использована.
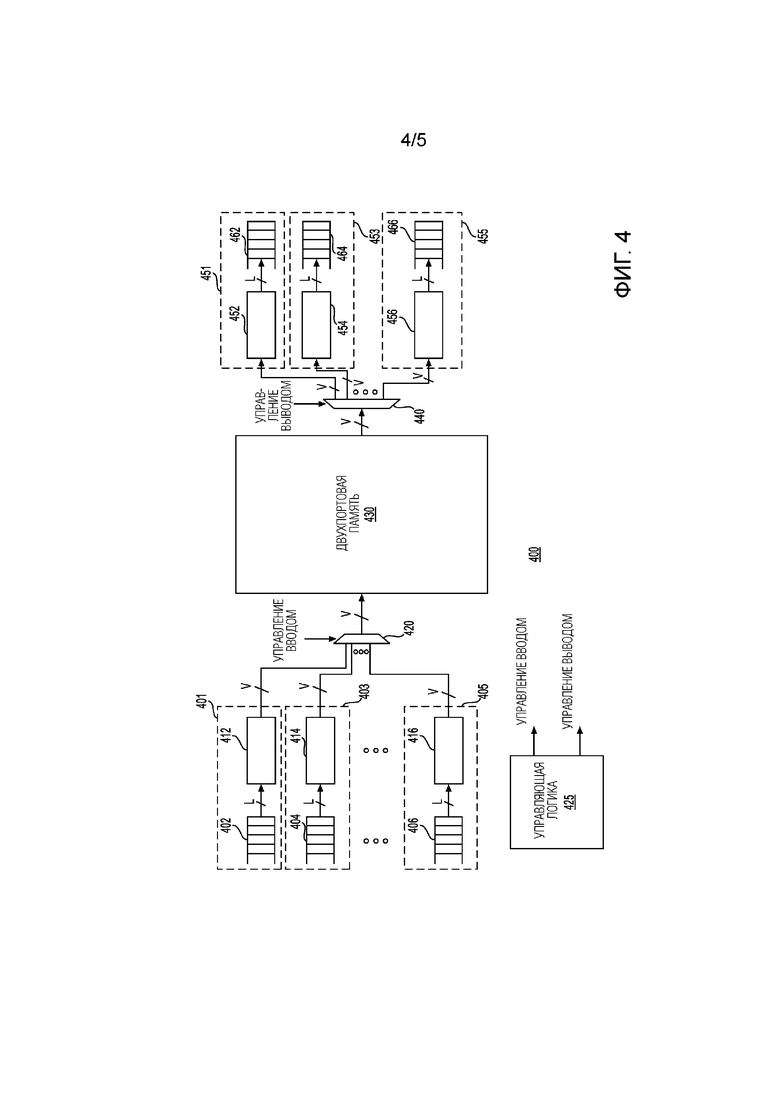
[00045] Фиг. 4 - это блок-схема набора 400 регистров для хранения векторов в соответствии с другим примером. Этот пример был упрощен, чтобы объяснять работу набора регистров для хранения векторов (например, VRF 300 на фиг. 3), включающего в себя двухпортовую память 430. Этот пример предполагает, что собственный размер N вектора или матрицы равен 128 слов. Таким образом, матрично-векторный умножитель может умножать матрицу N×N с вектором N×1 как часть обработки нейронной сети. Этот пример дополнительно предполагает, что каждый элемент является словом, которое имеет разрядность W бит. Этот пример дополнительно предполагает, что каждый блок скалярного произведения может обрабатывать L слов (или L элементов) векторных и матричных данных, которые будут создавать частичное скалярное произведение. MVM может включать в себя дерево добавления-уменьшения для накопления частичных скалярных произведений. Выходные данные добавления-уменьшения могут затем быть предоставлены в сумматор, который суммирует все частичные суммы, чтобы предоставлять конечное скалярное произведение для всей строки матрицы. VRF 400 может принимать векторные данные через восемь интерфейсов, где каждый интерфейс имеет L трактов. Интерфейс записи VRF 400 может иметь входные интерфейсные схемы, включающие в себя, например, входную интерфейсную схему 401, входную интерфейсную схему 403 и входную интерфейсную схему 405. Интерфейс чтения VRF 400 может иметь выходные интерфейсные схемы, включающие в себя, например, выходную интерфейсную схему 451, выходную интерфейсную схему 453 и выходную интерфейсную схему 455. Каждая входная интерфейсная схема может включать в себя входной буфер (например, входные буферы 402, 404 и 406), и каждая выходная интерфейсная схема может включать в себя выходной буфер (например, выходные буферы 462, 464 и 466). Входные буферы могут дополнительно быть соединены с дополнительными интерфейсными элементами (например, интерфейсными элементами 412, 414 и 416). Выходные буферы могут дополнительно быть соединены с дополнительными выходными интерфейсными элементами (например, выходными интерфейсными элементами 452, 454 и 456). Интерфейс записи может дополнительно содержать мультиплексор 420, который может быть присоединен для приема выходных данных от каждой из входных интерфейсных схем. Выход мультиплексора 420 может быть соединен с портом чтения двухпортовой памяти 430. Интерфейс чтения может дополнительно содержать демультиплексор 440, который может быть присоединен для приема выходных данных из двухканальной памяти 430. Выходы из демультиплексора могут быть присоединены к выходным интерфейсным схемам.
[00046] В ответ на операцию записи входные интерфейсные схемы могут быть использованы для приема многомерных массивов данных, а в ответ на операцию чтения выходные интерфейсные схемы могут предоставлять векторные данные. В этом примере, в ответ на инструкцию записи, в течение одного тактового цикла, N элементов данных могут быть сохранены в двухканальной памяти через интерфейс с большой разрядностью (обозначенный V на фиг. 4). В течение каждого цикла из P (N/L) тактовых циклов VRF 400 может принимать через каждый входной интерфейс один из многомерных массивов данных (например, один вектор N×1). В примере, показанном на фиг. 4, P=8, N=128 и L=16. Предположим, что каждый элемент данных является словом, которое имеет W бит, каждые восемь тактовых циклов каждая входная интерфейсная схема может принимать N×W бит (V бит). В этом примере N равно 128, и предположим, что размер слова равен 4 бит, каждый тактовый цикл VRF 400 может сохранять 512 бит. В течение каждого тактового цикла L (например, 16 в этом случае) входных трактов, которые являются частью входных интерфейсных схем, могут передавать L элементов данных (например, L слов) параллельно. Сдвиговые регистры (например, сдвиговые регистры 412, 414 и 416), которые являются частью входных интерфейсных схем, могут предоставлять 512 бит в каждом тактовом цикле мультиплексору 420.
[00047] Аналогично, в ответ на инструкцию чтения, каждые восемь тактовых циклов VRF 400 может предоставлять V бит (512 бит), через порт для чтения разрядностью V-бит по меньшей мере одной из выходных интерфейсных схем через мультиплексор 440. Сдвиговые регистры (например, сдвиговые регистры 452, 454 и 456) могут предоставлять L элементов данных в каждом тактовом цикле в соответствующий выходной буфер. Инструкции чтения и записи могут быть запланированы для выполнения одновременно. Таким образом, "чередуя" двухпортовую память 430 от интерфейса к интерфейсу, в каждом тактовом цикле полный вектор с собственным размером, равным N, может быть считан из и записан в VRF 400. Это может преимущественно предоставлять возможность процессору 100 основываться на FPGA или другом типе аппаратного узла, который имеет ограниченный объем SRAM, такой как ограниченный объем BRAM в FPGA. Это может быть полезным, так как матрично-векторное умножение может быть предназначено для масштабирования до большинства ресурсов FPGA и без растрачивания ресурсов FPGA, чтобы предусматривать выделенные многопортовые BRAM. Управляющая логика 425 может предоставлять управляющие сигналы, такие как INPUT CONTROL и OUTPUT CONTROL. Больше подробностей, касающихся аспекта управления для VRF 400, предоставляются относительно фиг. 3 и другого описания. Хотя фиг. 4 описывает работу VRF 400 с помощью 2D-матриц размером N×N и 1D-векторов длиной N, VRF 400 может работать также с использованием других размеров. Выбор размера вектора может зависеть от целевого набора моделей - выбор вектора слишком большим может вызывать неоптимальное добавление битов заполнителя, тогда как выбор вектора слишком маленьким может увеличивать непроизводительные издержки управления для процессора. Кроме того, хотя фиг. 4 описывает работу VRF 400 с помощью двухпортовой памяти, память может иметь дополнительные порты для чтения/записи.
[00048] Фиг. 5 показывает блок-схему последовательности операций способа для обработки элементов векторных данных с помощью процессора и набора регистров для хранения векторов в соответствии с одним примером. В этом примере этап 510 может включать в себя декодирование команды набора регистров для хранения векторов (VRF), чтобы определять схему доступа к адресу и выбор порта. Декодер 374 команд может выполнять этот этап. Как описано ранее, в одном примере, это может быть осуществлено с помощью иерархической архитектуры декодирования и диспетчеризации. Таким образом, в случае, когда процессор 100 реализуется на основе FPGA, управляющий процессор может быть реализован с помощью готового для использования Nios II/f процессора, который идет в паре со специально разработанным кодом. Планировщик верхнего уровня, ассоциированный с управляющим процессором, может принимать поток инструкций, которые могут быть сгруппированы в цепочки. После декодирования инструкций планировщик верхнего уровня может выполнять диспетчеризацию распределяемых управляющих сигналов набору планировщиков второго уровня и другому набору декодеров второго уровня. Эти планировщики и декодеры второго уровня могут выполнять диспетчеризацию дополнительных распространяемых управляющих сигналов декодерам самого низшего уровня. В примерной реализации, использующей процессор Nios, процессор Nios может передавать в потоковом режиме T итераций для N инструкций в планировщик верхнего уровня. Далее, планировщик верхнего уровня может выполнять диспетчеризацию MVM-характерного фрагмента инструкций планировщику второго уровня, который может расширять операции по N строкам и N столбцам целевой матрицы. Эти планы MVM могут быть преобразованы в E матрично-векторных механизмов ячеек, и операции могут быть отправлены набору из E декодеров, каждая для механизмов ячеек и их ассоциированных наборов регистров для хранения векторов и блоков накопления. Набор из E декодеров может формировать управляющие сигналы, которые рассеиваются в плоскость данных, при этом каждый диспетчер механизма ячейки разветвляется на сотни блоков скалярного произведения, которые могут считывать векторные данные из набора регистров для хранения векторов и записывать векторные данные обратно в набор регистров для хранения векторов.
[00049] Кроме того, так как является возможным иметь паразитные импульсы чтения после записи (RAW) и записи после чтения (WAR) в наборе регистров для хранения векторов, обнаружение паразитного импульса может быть использовано. Таким образом, в одном примере, детектор паразитных импульсов (например, 214 на фиг. 2) может отслеживать адреса, по которым осуществляется доступ по инструкциям чтения или записи, и когда инструкция чтения прибывает, и существует действующая запись, детектор паразитных импульсов может проверять, перекрываются ли адреса, к которым осуществляется доступ посредством входящей инструкции чтения, с адресами, к которым осуществляется доступ посредством текущей инструкции записи. В одном примере детектор паразитных импульсов может осуществлять работу, сохраняя пару регистров для отслеживания некоторого числа адресов, к которым осуществляется доступ посредством этих инструкций.
[00050] Этап 520 может включать в себя помещение по меньшей мере одного декодированного VRF-адреса в очередь. В этом примере декодер 372 адреса может выполнять этот этап.
[00051] Этап 530 может включать в себя удаление из очереди по прибытии векторных данных, имеющих собственный размер, равный N. Управляющая логика 370, ассоциированная с VRF 370, может выполнять этот этап.
[00052] Этап 540 может включать в себя, в ответ на инструкцию записи, в течение одного тактового цикла сохранение N элементов данных в двухпортовой памяти и в течение каждого цикла из P тактовых циклов предоставление N элементов данных каждой схеме из P входных интерфейсных схем двухпортовой памяти, где P является целым числом, равным N, разделенному на L, и где каждая из P входных интерфейсных схем содержит входной тракт, сконфигурированный для передачи L элементов данных параллельно, и где в течение каждого цикла из P тактовых циклов двухпортовая память сконфигурирована, чтобы принимать N элементов данных через выбранную схему из P входных интерфейсных схем. В этом примере конечный автомат (например, WRITE FSM 376) может выполнять этот этап. Дополнительные подробности, касающиеся этого этапа, предоставляются относительно фиг. 4.
[00053] Этап 550 может включать в себя, в ответ на инструкцию чтения, в течение одного тактового цикла извлечение N элементов данных из двухпортовой памяти и в течение каждого цикла из P тактовых циклов предоставление L элементов данных из каждой схемы из P выходных интерфейсных схем двухпортовой памяти, где каждая из P выходных интерфейсных схем содержит выходной тракт, сконфигурированный для передачи L элементов данных параллельно, и где в течение каждого цикла из P тактовых циклов двухпортовая память сконфигурирована, чтобы предоставлять N элементов данных выбранной схеме из P выходных интерфейсных схем. В этом примере конечный автомат (например, READ FSM 378) может выполнять этот этап. Дополнительные подробности, касающиеся этого этапа, предоставляются относительно фиг. 4. Хотя фиг. 5 описывает некоторое число этапов, выполняемых в некотором порядке, дополнительные или меньшее количество этапов в другом порядке могут выполняться. Кроме того, хотя фиг. 5 описывает способ относительно двухпортовой памяти, память с дополнительными портами может быть использована. В качестве примера, память с двумя портами для чтения и двумя портами для записи может быть использована.
[00054] В заключение, настоящее изобретение относится к процессору, содержащему набор регистров для хранения векторов, включающий в себя многопортовую память (например, двухпортовую память). Процессор может дополнительно включать в себя множество ячеек, сконфигурированных для обработки матрицы N×N элементов данных и вектора N×1 элементов данных, где N является целым числом, равным или более 8, и где каждая из множества ячеек конфигурируется для обработки N элементов данных. Набор регистров для хранения векторов может быть сконфигурирован, чтобы, в ответ на инструкцию записи, в течение одного тактового цикла сохранять N элементов данных в многопортовой памяти и в течение каждого цикла из P тактовых циклов предоставлять N элементов данных каждой схеме из P входных интерфейсных схем многопортовой памяти, где P является целым числом, равным N, разделенному на L, где L является целым числом, равным или более 2, и где каждая из P входных интерфейсных схем содержит входной тракт, сконфигурированный для передачи L элементов данных параллельно, и где в течение каждого цикла из P тактовых циклов многопортовая память сконфигурирована, чтобы принимать N элементов данных через выбранную по меньшей мере одну из P входных интерфейсных схем.
[00055] Набор регистров для хранения векторов может дополнительно быть сконфигурирован, чтобы, в ответ на инструкцию чтения, в течение одного тактового цикла извлекать N элементов данных из многопортовой памяти и в течение каждого цикла из Q тактовых циклов предоставлять L элементов данных из каждой схемы из Q выходных интерфейсных схем многопортовой памяти, где Q является целым числом, равным N, разделенному на L, и где каждая из Q выходных интерфейсных схем содержит выходной тракт, сконфигурированный для передачи L элементов данных параллельно, и где в течение каждого цикла из Q тактовых циклов многопортовая память сконфигурирована, чтобы предоставлять N элементов данных в выбранную по меньшей мере одну из Q выходных интерфейсных схем.
[00056] В одном примере многопортовая память может быть сконфигурирована как двухпортовая память, и двухпортовая память может содержать один порт для чтения и один порт для записи. В этом примере инструкция чтения может быть обработана по существу одновременно с инструкцией записи.
[00057] В одном примере, каждая схема из P входных интерфейсных схем содержит входной буфер, сконфигурированный для хранения N×1 векторов, и каждая схема из Q выходных интерфейсных схем содержит выходной буфер, сконфигурированный для хранения N×1 векторов. В этом примере, каждая из P входных интерфейсных схем содержит по меньшей мере один сдвиговый регистр, присоединенный для приема N×1 векторов из входного буфера, и каждая из Q выходных интерфейсных схем содержит по меньшей мере один сдвиговый регистр, присоединенный для предоставления N×1 векторов в выходной буфер.
[00058] В другом примере настоящее изобретение относится к способу в системе, содержащей множество ячеек и набор регистров для хранения векторов, содержащий двухпортовую память, где каждая из множества ячеек сконфигурирована, чтобы обрабатывать матрицу N×N элементов данных и вектор N×1 элементов данных, где N является целым числом, равным или больше 8, и где каждая из множества ячеек сконфигурирована, чтобы обрабатывать N элементов данных.
[00059] Способ может включать в себя, в ответ на инструкцию записи, в течение одного тактового цикла сохранение N элементов данных в двухпортовой памяти и в течение каждого цикла из P тактовых циклов предоставление N элементов данных каждой схеме из P входных интерфейсных схем двухпортовой памяти, где P является целым числом, равным N, разделенному на L, где L является целым числом, равным или более 2, и где каждая схема из P входных интерфейсных схем содержит входной тракт, сконфигурированный для передачи L элементов данных параллельно, и где в течение каждого цикла из P тактовых циклов двухпортовая память сконфигурирована, чтобы принимать N элементов данных через выбранную по меньшей мере одну из P входных интерфейсных схем.
[00060] Способ может дополнительно включать в себя, в ответ на инструкцию чтения, в течение одного тактового цикла извлечение N элементов данных из двухпортовой памяти и в течение каждого цикла из Q тактовых циклов предоставление L элементов данных из каждой схемы из Q выходных интерфейсных схем двухпортовой памяти, где Q является целым числом, равным N, разделенному на L, и где каждая из Q выходных интерфейсных схем содержит выходной тракт, сконфигурированный для передачи L элементов данных параллельно, и где в течение каждого цикла из Q тактовых циклов двухпортовая память сконфигурирована, чтобы предоставлять N элементов данных выбранной схеме из Q выходных интерфейсных схем.
[00061] В одном примере двухпортовая память может содержать один порт для чтения и один порт для записи. В этом примере инструкция чтения может быть обработана по существу одновременно с инструкцией записи.
[00062] В одном примере, каждая схема из P входных интерфейсных схем содержит входной буфер, сконфигурированный для хранения N×1 векторов, и каждая схема из Q выходных интерфейсных схем содержит выходной буфер, сконфигурированный для хранения N×1 векторов. В этом примере, каждая из P входных интерфейсных схем содержит по меньшей мере один сдвиговый регистр, присоединенный для приема N×1 векторов из входного буфера, и каждая из Q выходных интерфейсных схем содержит по меньшей мере один сдвиговый регистр, присоединенный для предоставления N×1 векторов в выходной буфер.
[00063] В еще одном примере настоящее изобретение относится к процессору, содержащему набор регистров для хранения векторов, содержащий двухпортовую память, включающую в себя один порт для чтения и один порт для записи. Процессор может дополнительно содержать множество ячеек, сконфигурированных, чтобы обрабатывать матрицу N×N и вектор N×1, где N является целым числом, равным или более 8, и где каждая из множества ячеек сконфигурирована, чтобы обрабатывать N элементов данных.
[00064] Набор регистров для хранения векторов может быть сконфигурирован, чтобы, в ответ на инструкцию записи, в течение одного тактового цикла сохранять N элементов данных в двухпортовой памяти через один порт для записи и в течение каждого цикла из P тактовых циклов предоставлять N элементов данных каждой схеме из P входных интерфейсных схем двухпортовой памяти, где P является целым числом, равным N, разделенному на L, где L является целым числом, равным или более 2, и где каждая из P входных интерфейсных схем содержит входной тракт, сконфигурированный для передачи L элементов данных параллельно, и где в течение каждого цикла из P тактовых циклов двухпортовая память сконфигурирована, чтобы принимать N элементов данных через выбранную схему из P входных интерфейсных схем.
[00065] Набор регистров для хранения векторов может дополнительно быть сконфигурирован, чтобы, в ответ на инструкцию чтения, в течение одного тактового цикла извлекать N элементов данных из двухпортовой памяти через один порт для чтения и в течение каждого цикла из Q тактовых циклов предоставлять L элементов данных из каждой схемы из Q выходных интерфейсных схем двухпортовой памяти, где Q является целым числом, равным N, разделенному на L, и где каждая из Q выходных интерфейсных схем содержит выходной тракт, сконфигурированный для передачи L элементов данных параллельно, и где в течение каждого цикла из Q тактовых циклов двухпортовая память сконфигурирована, чтобы предоставлять N элементов данных выбранной схеме из Q выходных интерфейсных схем.
[00066] В одном примере, каждая схема из P входных интерфейсных схем содержит входной буфер, сконфигурированный для хранения N×1 векторов, и каждая схема из Q выходных интерфейсных схем содержит выходной буфер, сконфигурированный для хранения N×1 векторов. В этом примере, каждая из P входных интерфейсных схем содержит по меньшей мере один сдвиговый регистр, присоединенный для приема N×1 векторов из входного буфера, и каждая из Q выходных интерфейсных схем содержит по меньшей мере один сдвиговый регистр, присоединенный для предоставления N×1 векторов в выходной буфер. В этом примере инструкция чтения может быть обработана по существу одновременно с инструкцией записи.
[00067] Следует понимать, что способы, модули и компоненты, изображенные в данном документе, являются просто примерными. Альтернативно, или в дополнение, функциональность, описанная в данном документе, может быть выполнена, по меньшей мере, частично, посредством одного или более аппаратных логических компонентов. Например, и без ограничения, иллюстративные типы аппаратных логических компонентов, которые могут быть использованы, включают в себя программируемые пользователем вентильные матрицы (FPGA), программно-зависимые интегральные схемы (ASIC), программно-зависимые стандартные продукты (ASSP), системы в виде системы на кристалле (SOC), сложные программируемые логические устройства (CPLD) и т.д. В абстрактном, но все еще определенном, смысле любая компоновка компонентов, чтобы добиваться одной и той же функциональности, эффективно "ассоциируется", так что желаемая функциональность достигается. Следовательно, любые два компонента в данном документе, объединенные, чтобы добиваться конкретной функциональности, могут рассматриваться как "ассоциированные" друг с другом так, что желаемая функциональность достигается, независимо от архитектур или связующих компонентов. Также, любые два компонента, ассоциированные таким образом, могут также рассматриваться как "функционально соединенные", или "связанные" друг с другом, чтобы достигать желаемой функциональности.
[00068] Функциональность, ассоциированная с некоторыми примерами, описанными в этом описании изобретения, может также включать в себя инструкции, сохраненные на долговременных носителях. Термин "долговременные носители", когда используется в данном документе, ссылается на любые носители, хранящие данные и/или инструкции, которые инструктируют машине работать конкретным образом. Примерные долговременные носители включают в себя энергонезависимые носители и/или энергозависимые носители. Энергонезависимые носители включают в себя, например, жесткий диск, твердотельный накопитель, магнитный диск или ленту, оптический диск или ленту, флеш-память, EPROM, NVRAM, PRAM или другие такие носители, или сетевые версии таких носителей. Энергозависимые носители включают в себя, например, динамическую память, такую как DRAM, SRAM, кэш-память, или другие такие носители. Долговременные носители отличаются, но могут быть использованы совместно, со средой передачи данных. Среда передачи данных используется для передачи данных и/или инструкции к или от машины. Примерная среда передачи данных включает в себя коаксиальные кабели, волоконно-оптические кабели, медные провода и беспроводную среду, такую как радиоволны.
[00069] Кроме того, специалисты в области техники поймут, что границы между функциональностью вышеописанных операций являются просто иллюстративными. Функциональность множества операций может быть объединена в одну операцию, и/или функциональность одной операции может быть распределена в дополнительных операциях. Кроме того, альтернативные варианты осуществления могут включать в себя множество экземпляров конкретной операции, и порядок операций может быть изменен в различных других вариантах осуществления.
[00070] Хотя описание предоставляет конкретные примеры, различные модификации и изменения могут быть выполнены без отступления от рамок изобретения, которые изложены в формуле изобретения ниже. Соответственно, спецификация и чертежи должны рассматриваться скорее в иллюстративном, а не ограничительном смысле, и все подобные модификации предназначены для того, чтобы быть включенными в рамки настоящего изобретения. Любые выгоды, преимущества или решения проблем, которые описываются в данном документе в отношении конкретного примера, не предполагают толкования в качестве критического, требуемого или неотъемлемого признака или элемента какого-либо или всех пунктов формулы изобретения.
[00071] Кроме того, термины в единственном числе, когда используются в данном документе, определяются как один или более, чем один. Также, использование вводных фраз, таких как "по меньшей мере один" и "один или более" в формуле изобретения, не должно толковаться как подразумевающее, что введение другого элемента формулы изобретения без использования терминов "упомянутый" или "указанный" ограничивает какой-либо конкретный пункт формулы изобретения, содержащий такой вступительный элемент пункта формулы, изобретениями, содержащими только один такой элемент, даже когда тот же пункт формулы включает в себя вступительные фразы "один или более" или "по меньшей мере один" и термины "упомянутый" или "указанный" не используются. То же справедливо при использования терминов "упомянутый" или "указанный".
[00072] Пока не установлено иное, термины, такие как "первый" и "второй", используются для произвольного различения между элементами, которые такие термины описывают. Таким образом, эти термины необязательно предназначаются, чтобы указывать временной или другой приоритет таких элементов.
| название | год | авторы | номер документа |
|---|---|---|---|
| ВЕКТОРНОЕ ВЫЧИСЛИТЕЛЬНОЕ ЯДРО | 2023 |
|
RU2819403C1 |
| ВЕКТОРНОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО | 2024 |
|
RU2830044C1 |
| СКАЛЯРНО-ВЕКТОРНЫЙ ПРОЦЕССОР | 2021 |
|
RU2781355C1 |
| УСТРОЙСТВО МАТРИЧНЫХ ВЫЧИСЛЕНИЙ | 2025 |
|
RU2838831C1 |
| Устройство для отображения векторных диаграмм на экране электронно-лучевой трубки | 1985 |
|
SU1316027A1 |
| РАСШИРЕНИЕ БЛОКА СТЕКОВЫХ РЕГИСТРОВ С ПОМОЩЬЮ ТЕНЕВЫХ РЕГИСТРОВ | 2006 |
|
RU2405189C2 |
| ВЫЧИСЛИТЕЛЬНЫЙ МОДУЛЬ ДЛЯ МНОГОСТАДИЙНОЙ МНОГОПОТОЧНОЙ ОБРАБОТКИ ЦИФРОВЫХ ДАННЫХ И СПОСОБ ОБРАБОТКИ С ИСПОЛЬЗОВАНИЕМ ДАННОГО МОДУЛЯ | 2018 |
|
RU2681365C1 |
| Центральный процессор | 1991 |
|
SU1804645A3 |
| ВЕКТОРНЫЙ УСКОРИТЕЛЬ | 1992 |
|
RU2042980C1 |
| Пакетная сеть для мультипроцессорных систем и способ коммутации с использованием такой сети | 2018 |
|
RU2703231C1 |
Настоящее техническое решение относится к области вычислительной техники. Технический результат заключается в повышении пропускной способности процессора. Технический результат достигается за счёт того, что процессор может содержать ячейки для обработки матрицы NxN элементов данных и вектора Nx1 элементов данных. VRF может, в ответ на инструкцию записи, сохранять N элементов данных в многопортовой памяти и во время каждого цикла из P тактовых циклов предоставлять N элементов данных каждой схеме из P входных интерфейсных схем многопортовой памяти, содержащей входной тракт, сконфигурированный для передачи L элементов данных параллельно. В течение каждого цикла из P тактовых циклов многопортовая память может быть сконфигурирована, чтобы принимать N элементов данных через выбранную по меньшей мере одну из P входных интерфейсных схем. VRF может включать в себя выходные интерфейсные схемы для предоставления N элементов данных в ответ на инструкцию чтения. 3 н. и 12 з.п. ф-лы, 5 ил., 4 табл.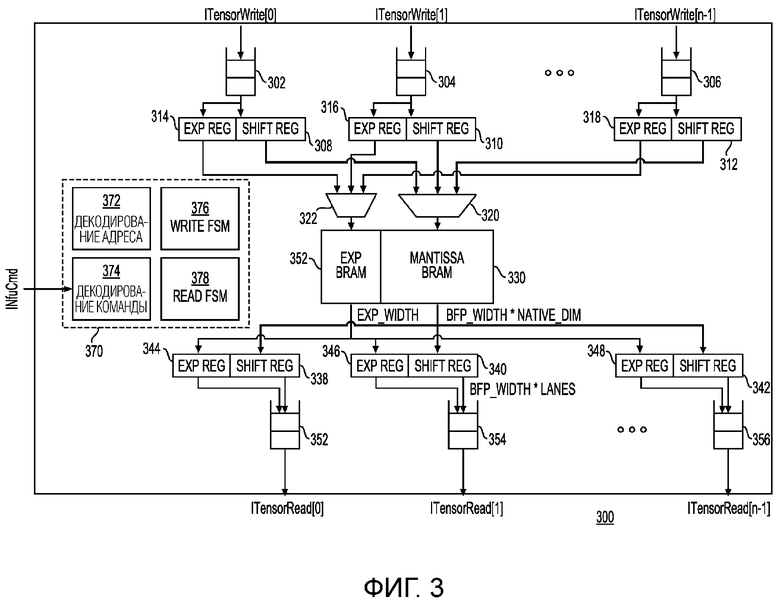
1. Процессор, содержащий:
набор регистров для хранения векторов, содержащий многопортовую память; и
множество ячеек, сконфигурированных для обработки матрицы NxN элементов данных и вектора Nx1 элементов данных, при этом N является целым числом, равным или более 8, и при этом каждая из множества ячеек сконфигурирована, чтобы обрабатывать N элементов данных, и при этом набор регистров для хранения векторов сконфигурирован, чтобы:
в ответ на инструкцию записи, в течение одного тактового цикла сохранять N элементов данных в многопортовой памяти и в течение каждого цикла из P тактовых циклов предоставлять N элементов данных каждой схеме из P входных интерфейсных схем многопортовой памяти, при этом P является целым числом, равным N, разделенному на L, при этом L является целым числом, равным или более 2, и при этом каждая из P входных интерфейсных схем содержит входной тракт, сконфигурированный для передачи L элементов данных параллельно, и при этом в течение каждого цикла из P тактовых циклов многопортовая память сконфигурирована, чтобы принимать N элементов данных через выбранную по меньшей мере одну из P входных интерфейсных схем, и
в ответ на инструкцию чтения, в течение одного тактового цикла извлекать N элементов данных из многопортовой памяти и в течение каждого цикла из Q тактовых циклов предоставлять L элементов данных из каждой схемы из Q выходных интерфейсных схем многопортовой памяти, при этом Q является целым числом, равным N, разделенному на L, и при этом каждая из Q выходных интерфейсных схем содержит выходной тракт, сконфигурированный для передачи L элементов данных параллельно, и при этом в течение каждого цикла из Q тактовых циклов многопортовая память сконфигурирована, чтобы предоставлять N элементов данных в выбранную по меньшей мере одну из Q выходных интерфейсных схем.
2. Процессор по п. 1, при этом многопортовая память является двухпортовой памятью, и при этом двухпортовая память содержит один порт для чтения и один порт для записи.
3. Процессор по п. 1, при этом инструкция чтения обрабатывается по существу одновременно с инструкцией записи.
4. Процессор по п. 1, при этом каждая схема из P входных интерфейсных схем содержит входной буфер, сконфигурированный для хранения векторов Nx1.
5. Процессор по п. 1, при этом каждая схема из Q выходных интерфейсных схем содержит выходной буфер, сконфигурированный для хранения векторов Nx1.
6. Процессор по п. 4, при этом каждая из P входных интерфейсных схем содержит по меньшей мере один сдвиговый регистр, присоединенный для приема векторов Nx1 из входного буфера.
7. Процессор по п. 5, при этом каждая из Q выходных интерфейсных схем содержит по меньшей мере один сдвиговый регистр, присоединенный, чтобы предоставлять векторы Nx1 в выходной буфер.
8. Способ для обработки элементов данных в системе, содержащей множество ячеек и набор регистров для хранения векторов, содержащий двухпортовую память, при этом каждая из множества ячеек сконфигурирована, чтобы обрабатывать матрицу NxN элементов данных и вектор Nx1 элементов данных, при этом N является целым числом, равным или больше 8, и при этом каждая из множества ячеек сконфигурирована, чтобы обрабатывать N элементов данных, причем способ содержит этапы, на которых:
в ответ на инструкцию записи, в течение одного тактового цикла сохраняют N элементов данных в двухпортовой памяти и в течение каждого цикла из P тактовых циклов предоставляют N элементов данных каждой схеме из P входных интерфейсных схем двухпортовой памяти, при этом P является целым числом, равным N, разделенному на L, при этом L является целым числом, равным или более 2, и при этом каждая из P входных интерфейсных схем содержит входной тракт, сконфигурированный для передачи L элементов данных параллельно, и при этом в течение каждого цикла из P тактовых циклов двухпортовая память сконфигурирована, чтобы принимать N элементов данных через выбранную схему из P входных интерфейсных схем; и
в ответ на инструкцию чтения, в течение одного тактового цикла извлекают N элементов данных из двухпортовой памяти и в течение каждого цикла из Q тактовых циклов предоставляют L элементов данных из каждой схемы из Q выходных интерфейсных схем двухпортовой памяти, при этом Q является целым числом, равным N, разделенному на L, и при этом каждая из Q выходных интерфейсных схем содержит выходной тракт, сконфигурированный для передачи L элементов данных параллельно, и при этом в течение каждого цикла из Q тактовых циклов двухпортовая память сконфигурирована, чтобы предоставлять N элементов данных выбранной схеме из Q выходных интерфейсных схем.
9. Способ по п. 8, при этом двухпортовая память содержит один порт для чтения и один порт для записи.
10. Способ по п. 8, при этом инструкция чтения обрабатывается по существу одновременно с инструкцией записи.
11. Способ по п. 8, при этом каждая схема из P входных интерфейсных схем содержит входной буфер, сконфигурированный для хранения векторов Nx1.
12. Способ по п. 8, при этом каждая схема из Q выходных интерфейсных схем содержит выходной буфер, сконфигурированный для хранения векторов Nx1.
13. Способ по п. 11, при этом каждая из P входных интерфейсных схем содержит по меньшей мере один сдвиговый регистр, присоединенный для приема векторов Nx1 из входного буфера.
14. Способ по п. 12, при этом каждая из Q выходных интерфейсных схем содержит по меньшей мере один сдвиговый регистр, присоединенный, чтобы предоставлять векторы Nx1 в выходной буфер.
15. Процессор, содержащий:
набор регистров для хранения векторов, содержащий двухпортовую память, включающую в себя один порт для чтения и один порт для записи; и
множество ячеек, сконфигурированных для обработки матрицы NxN и вектора Nx1, при этом N является целым числом, равным или более 8, и при этом каждая из множества ячеек сконфигурирована, чтобы обрабатывать N элементов данных, и при этом набор регистров для хранения векторов сконфигурирован, чтобы:
в ответ на инструкцию записи, в течение одного тактового цикла сохранять N элементов данных в двухпортовой памяти через один порт для записи и в течение каждого цикла из P тактовых циклов предоставлять N элементов данных каждой схеме из P входных интерфейсных схем двухпортовой памяти, при этом P является целым числом, равным N, разделенному на L, при этом L является целым числом, равным или более 2, и при этом каждая из P входных интерфейсных схем содержит входной тракт, сконфигурированный для передачи L элементов данных параллельно, и при этом в течение каждого цикла из P тактовых циклов двухпортовая память сконфигурирована, чтобы принимать N элементов данных через выбранную схему из P входных интерфейсных схем, и
в ответ на инструкцию чтения, в течение одного тактового цикла извлекать N элементов данных из двухпортовой памяти через один порт для чтения и в течение каждого цикла из Q тактовых циклов предоставлять L элементов данных из каждой схемы из Q выходных интерфейсных схем двухпортовой памяти, при этом Q является целым числом, равным N, разделенному на L, и при этом каждая из Q выходных интерфейсных схем содержит выходной тракт, сконфигурированный для передачи L элементов данных параллельно, и при этом в течение каждого цикла из Q тактовых циклов двухпортовая память сконфигурирована, чтобы предоставлять N элементов данных выбранной схеме из Q выходных интерфейсных схем.
| US 5475631 A, 12.12.1995 | |||
| ПАРАЛЛЕЛЬНАЯ ПРОЦЕССОРНАЯ СИСТЕМА | 1991 |
|
RU2084953C1 |
| US 6718429 B1, 06.04.2004 | |||
| KR 20120113777 A, 15.10.2012 | |||
| US 8335878 B2, 18.12.2012. | |||

