Родственные заявки и включение при помощи ссылки
Данная заявка заявляет приоритет предварительных заявок на патент США 61/736527, 61/748427, 61/768959, 61/791409 и 61/835931 с общей ссылкой BI-2011/008/WSGR, номер в реестре 44063-701.101, BI-2011/008/WSGR, номер в реестре 44063-701.102, общей ссылкой BI-2011/008/VP, номер в реестре 44790.01.2003, BI-2011/008/VP, номер в реестре 44790.02.2003, и BI-2011/008/VP, номер в реестре 44790.03.2003, соответственно, все из которых озаглавлены "СИСТЕМЫ, СПОСОБЫ И КОМПОЗИЦИИ ДЛЯ МАНИПУЛЯЦИИ С ПОСЛЕДОВАТЕЛЬНОСТЯМИ" (SYSTEMS METHODS AND COMPOSITIONS FOR SEQUENCE MANIPULATION), поданных 12 декабря 2012 г., 2 января 2013 г., 25 февраля 2013 г., 15 марта 2013 г. и 17 июня 2013 г., соответственно.
Делается ссылка на предварительные заявки на патент США 61/758468; 61/769046; 61/802174; 61/806375; 61/814263; 61/819803 и 61/828130, каждая из которых озаглавлена "КОНСТРУИРОВАНИЕ И ОПТИМИЗАЦИЯ СИСТЕМ, СПОСОБОВ И КОМПОЗИЦИЙ ДЛЯ МАНИПУЛЯЦИИ С ПОСЛЕДОВАТЕЛЬНОСТЯМИ" (ENGINEERING AND OPTIMIZATION OF SYSTEMS, METHODS AND COMPOSITIONS FOR SEQUENCE MANIPULATION), поданные 30 января 2013 г.; 25 февраля 2013 г.; 15 марта 2013 г.; 28 марта 2013 г.; 20 апреля 2013 г.; 6 мая 2013 г. и 28 мая 2013 г., соответственно. Также делается ссылка на предварительные заявки на патенты США 61/835936, 61/836127, 61/836101, 61/836080, 61/836123 и 61/835973, каждая из которых подана 17 июня 2013 г. Также делается ссылка на предварительную заявку на патент США 61/842322 и заявку на патент США 14/054414, каждая с общей ссылкой BI-2011/008A, озаглавленные "СИСТЕМЫ CRISPR-CAS И СПОСОБЫ ДЛЯ ИЗМЕНЕНИЯ ЭКСПРЕССИИ ПРОДУКТОВ ГЕНА" (CRISPR-CAS SYSTEMS AND METHODS FOR ALTERING EXPRESSION OF GENE PRODUCTS), поданные 2 июля 2013 г. и 15 октября 2013 г., соответственно.
Вышеупомянутые заявки и все документы, упомянутые в них или во время их делопроизводства (“упомянутые в заявке документы”), и все документы, упомянутые или на которые ссылаются в упомянутых в заявке документах, и все документы, упомянутые или на которые ссылаются в данном документе (“документы, упомянутые в данном документе”), и все документы, упомянутые или на которые ссылаются в документах, упомянутых в данном документе, наравне с любыми инструкциями производителя, описаниями, характеристиками продуктов и описаниями продуктов для любых продуктов, упомянутых в данном документе или в любом документе, включенном при помощи ссылки в данный документ, таким образом, включены в данный документ при помощи ссылки и могут быть использованы при осуществлении на практике настоящего изобретения. Более конкретно, все документы, на которые ссылаются, включены при помощи ссылки в такой же мере, как если бы конкретно и отдельно было указано, что каждый отдельный документ включен при помощи ссылки.
Область техники
Настоящее изобретение в целом относится к системам, способам и композициям, применяемым для контроля экспрессии генов, включающего целенаправленное воздействие на последовательность, такое как внесение изменений в геном или редактирование гена, при котором можно использовать векторные системы, близкие к коротким палиндромным повторам, регулярно расположенным группами (CRISPR), и их компонентам.
Утверждение касательно финансируемого из федерального бюджета исследования
Настоящее изобретение было разработано при правительственной поддержке согласно NIH Pioneer Award DP1MH100706, выданному национальными институтами здравоохранения. Правительство обладает определенными правами на настоящее изобретение.
Предпосылки изобретения
Недавние достижения в технологиях секвенирования генома и способах анализа значительно ускорили возможность каталогизирования и картирования генетических факторов, ассоциированных с широким спектром биологических функций и заболеваний. Точные технологии целенаправленного воздействия на геном необходимы для обеспечения систематичного обратного конструирования казуальных генетических изменений путем обеспечения возможности селективного внесения изменений в отдельные генетические элементы, а также для продвижения применений в области синтетической биологии, биотехнологии и медицины. Несмотря на то, что технологии редактирования генома, такие как конструктор доменов "цинковые пальцы", подобные транскрипционным активаторам эффекторы (TALE) или хоминг мегануклеазы, доступны для осуществления внесений изменений в целевой геном, все еще существует необходимость в новых технологиях конструирования генома, которые являются доступными, простыми в осуществлении, масштабируемыми и поддающимися целенаправленному воздействию на несколько положений в эукариотическом геноме.
Краткое описание изобретения
Существует острая необходимость в альтернативных и функциональных системах и технологиях для целенаправленного воздействия на последовательности с широким спектром применений. Настоящее изобретение удовлетворяет этой необходимости и предусматривает связанные с этим преимущества. CRISPR/Cas или система CRISPR-Cas (оба выражения используют взаимозаменяемо по всей данной заявке) не предусматривает получение индивидуализированных белков для целенаправленного воздействия на конкретные последовательности, но скорее один фермент Cas может быть запрограммирован короткой молекулой РНК для узнавания специфичной ДНК-мишени, другими словами, фермент Cas может связываться со специфичной ДНК-мишенью при помощи указанной короткой молекулы РНК. Добавление системы CRISPR-Cas к спектру технологий секвенирования генома и способам анализа может значительно упростить методику и ускорить возможность каталогизирования и картирования генетических факторов, ассоциированных с широким спектром биологических функций и заболеваний. Для того, чтобы эффективно использовать систему CRISPR-Cas для редактирования генома без вредного действия, важно понимать аспекты конструирования и оптимизации этих средств для конструирования генома, которые являются аспектами заявленного изобретения.
В одном аспекте настоящее изобретение предусматривает векторную систему, содержащую один или несколько векторов. В некоторых вариантах осуществления система содержит (a) первый регуляторный элемент, функционально связанный с парной tracr-последовательностью и одним или несколькими сайтами встраивания для встраивания одной или нескольких направляющих последовательностей выше парной tracr-последовательности, где при экспрессии направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR с целевой последовательностью в эукариотической клетке, где комплекс CRISPR содержит фермент CRISPR, образующий комплекс с (1) направляющей последовательностью, которая гибридизируется с целевой последовательностью, и (2) парной tracr-последовательностью, которая гибридизируется с tracr-последовательностью; и (b) второй регуляторный элемент, функционально связанный с кодирующей фермент последовательностью, кодирующей указанный фермент CRISPR, содержащий последовательность ядерной локализации; где компоненты (a) и (b) находятся в одном и том же или в различных векторах системы. В некоторых вариантах осуществления компонент (a) дополнительно содержит tracr-последовательность ниже парной tracr-последовательности под контролем первого регуляторного элемента. В некоторых вариантах осуществления компонент (a) дополнительно содержит две или более направляющие последовательности, функционально связанные с первым регуляторным элементом, где при экспрессии каждая из двух или более направляющих последовательностей управляет специфичным к последовательности связыванием комплекса CRISPR со своей целевой последовательностью в эукариотической клетке. В некоторых вариантах осуществления система содержит tracr-последовательность под контролем третьего регуляторного элемента, такого как промотор полимеразы III. В некоторых вариантах осуществления tracr-последовательность характеризуется по меньшей мере 50%, 60%, 70%, 80%, 90%, 95% или 99% комплементарности последовательности по длине парной tracr-последовательности при оптимальном выравнивании. Определение оптимального выравнивания находится в компетенции специалиста в данной области. Например, существуют публично и коммерчески доступные алгоритмы и программы выравнивания, такие как, без ограничения, ClustalW, Smith-Waterman в matlab, Bowtie, Geneious, Biopython и SeqMan. В некоторых вариантах осуществления комплекс CRISPR содержит одну или несколько последовательностей ядерной локализации, достаточно эффективных, чтобы управлять накоплением указанного комплекса CRISPR в обнаруживаемом количестве в ядре эукариотической клетки. Не желая быть связанными теорией, полагают, что последовательность ядерной локализации не является необходимой для активности комплекса CRISPR у эукариот, но что включение таких последовательностей повышает активность системы, особенно в отношении нацеливания на молекулы нуклеиновых кислот в ядре. В некоторых вариантах осуществления фермент CRISPR является ферментом системы CRISPR II типа. В некоторых вариантах осуществления фермент CRISPR является ферментом Cas9. В некоторых вариантах осуществления фермент Cas9 представляет собой Cas9 S. pneumoniae, S. pyogenes или S. thermophilus и может включать мутированный Cas9, полученный из этих организмов. Фермент может быть гомологом или ортологом Cas9. В некоторых вариантах осуществления фермент CRISPR кодон-оптимизирован для экспрессии в эукариотической клетке. В некоторых вариантах осуществления фермент CRISPR управляет расщеплением одной или двух нитей в определенной точке целевой последовательности. В некоторых вариантах осуществления у фермента CRISPR отсутствует активность для расщепления нитей ДНК. В некоторых вариантах осуществления первый регуляторный элемент является промотором полимеразы III. В некоторых вариантах осуществления второй регуляторный элемент является промотором полимеразы II. В некоторых вариантах осуществления направляющая последовательность составляет по меньшей мере 15, 16, 17, 18, 19, 20, 25 нуклеотидов, или от 10 до 30, или от 15 до 25, или от 15 до 20 нуклеотидов в длину. В целом и по всему данному описанию выражение “вектор” относится к молекуле нуклеиновой кислоты, способной переносить другую нуклеиновую кислоту, с которой она была связана. Векторы включают, без ограничения, молекулы нуклеиновых кислот, которые являются одноцепочечными, двухцепочечными или частично двухцепочечными; молекулы нуклеиновых кислот, которые содержат один или несколько свободных концов, не содержат свободных концов (к примеру, кольцевые); молекулы нуклеиновых кислот, которые содержат ДНК, РНК или и ту, и другую; и другие разновидности полинуклеотидов, известных в уровне техники. Одним типом вектора является “плазмида”, которая означает кольцевую петлю двухцепочечной ДНК, в которую можно встраивать дополнительные сегменты ДНК, как, например, при помощи стандартных технологий молекулярного клонирования. Другим типом вектора является вирусный вектор, где полученные из вируса последовательности ДНК или РНК присутствуют в векторе для упаковки в вирус (к примеру, ретровирусы, ретровирусы с дефективной системой репликации, аденовирусы, аденовирусы с дефективной системой репликации и аденоассоциированные вирусы). Вирусные векторы также включают полинуклеотиды, переносимые вирусами для трансфекции клетки-хозяина. Определенные векторы способны к саморегулируемой репликации в клетке-хозяине, в которую они введены (к примеру, бактериальные векторы с бактериальной точкой начала репликации и эписомные векторы млекопитающих). Другие векторы (к примеру, неэписомные векторы млекопитающих) интегрируются в геном клетки-хозяина после введения в клетку-хозяина и, таким образом, реплицируются наряду с геномом хозяина. Более того, определенные векторы способны управлять экспрессией генов, с которыми они функционально связаны. Такие векторы в данном документе называют “векторами экспрессии”. Общепринятые пригодные в технологиях рекомбинантной ДНК векторы экспрессии часто находятся в форме плазмид.
Рекомбинантные векторы экспрессии могут содержать нуклеиновую кислоту согласно настоящему изобретению в форме, подходящей для экспрессии нуклеиновой кислоты в клетке-хозяине, что означает, что рекомбинантные векторы экспрессии включают один или несколько регуляторных элементов, которые могут быть выбраны с учетом клеток-хозяев, которые предполагается использовать для экспрессии, которые функционально связаны с последовательностью нуклеиновой кислоты, экспрессия которой предполагается. В контексте рекомбинантного вектора экспрессии выражение “функционально связанный” предназначено означать, что представляющая интерес нуклеотидная последовательность связана с регуляторным(и) элементом(ами) таким образом, при котором обеспечивается возможность экспрессии нуклеотидной последовательности (к примеру, в in vitro системе транскрипции/трансляции или в клетке-хозяине, когда вектор вводят в клетку-хозяина).
Выражение “регуляторный элемент” предназначено включать промоторы, энхансеры, внутренние сайты связывания рибосомы (IRES) и другие контролирующие экспрессию элементы (к примеру, сигналы терминации транскрипции, такие как сигналы полиаденилирования и поли-U-последовательности). Такие регуляторные элементы описаны, например, в Goeddel, GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990). Регуляторные элементы включают такие, которые управляют конститутивной экспрессией нуклеотидной последовательности во многих типах клеток-хозяев, и такие, которые управляют экспрессией нуклеотидной последовательности только в определенных клетках-хозяевах (к примеру, тканеспецифичные регуляторные последовательности). Тканеспецифичный промотор может управлять экспрессией преимущественно в представляющей интерес целевой ткани, такой как мышца, нейрон, кость, кожа, кровь, конкретных органах (к примеру, печени, поджелудочной железе) или определенных типах клеток (к примеру, лимфоцитах). Регуляторные элементы также могут управлять экспрессией зависимым от времени образом, как, например, зависимым от клеточного цикла или зависимым от стадии развития образом, который может быть или может не быть также тканеспецифичным или специфичным к типу клеток. В некоторых вариантах осуществления вектор содержит один или несколько промоторов pol III (к примеру, 1, 2, 3, 4, 5 или более промоторов pol III), один или несколько промоторов pol II (к примеру, 1, 2, 3, 4, 5 или более промоторов pol II), один или несколько промоторов pol I (к примеру, 1, 2, 3, 4, 5 или более промоторов pol I) или их комбинации. Примеры промоторов pol III включают, без ограничения, промоторы U6 и H1. Примеры промоторов pol II включают, без ограничения, ретровирусный промотор LTR вируса саркомы Рауса (RSV) (необязательно с энхансером RSV), промотор цитомегаловируса (CMV) (необязательно с энхансером CMV) [см., например, Boshart et al., Cell, 41:521-530 (1985)], промотор SV40, промотор дигидрофолатредуктазы, промотор β-актина, промотор глицерофосфаткиназы (PGK) и промотор EF1α. Также выражением “регуляторный элемент” охвачены энхансерные элементы, такие как WPRE; энхансеры CMV; сегмент R-U5’ в LTR HTLV-I (Mol. Cell. Biol., Vol. 8(1), p. 466-472, 1988); энхансер SV40; и интронная последовательность между экзонами 2 и 3 β-глобина кролика (Proc. Natl. Acad. Sci. USA., Vol. 78(3), p. 1527-31, 1981). Специалистам в данной области будет понятно, что структура вектора экспрессии может зависеть от таких факторов, как выбор клетки хозяина, подлежащей трансформации, желательный уровень экспрессии и т.п. Вектор можно вводить в клетки-хозяева с получением, таким образом, транскриптов, белков или пептидов, в том числе слитых белков или пептидов, кодируемых нуклеиновыми кислотами, которые описаны в данном документе (к примеру, транскриптов коротких палиндромных повторов, регулярно расположенных группами (CRISPR), белков, ферментов, их мутантных форм, их слитых белков и т.п.).
Преимущественные векторы включают лентивирусы и аденоассоциированные вирусы, и типы таких векторов также могут быть выбраны для целенаправленного воздействия на определенные типы клеток.
В одном аспекте настоящее изобретение предусматривает вектор, содержащий регуляторный элемент, функционально связанный с кодирующей фермент последовательностью, кодирующей фермент CRISPR, содержащий одну или несколько последовательностей ядерной локализации. В некоторых вариантах осуществления указанный регуляторный элемент управляет транскрипцией фермента CRISPR в эукариотической клетке, так что указанный фермент CRISPR накапливается в обнаруживаемом количестве в ядре эукариотической клетки. В некоторых вариантах осуществления регуляторный элемент является промотором полимеразы II. В некоторых вариантах осуществления фермент CRISPR является ферментом системы CRISPR II типа. В некоторых вариантах осуществления фермент CRISPR является ферментом Cas9. В некоторых вариантах осуществления фермент Cas9 представляет собой Cas9 S. pneumoniae, S. pyogenes или S. thermophilus и может включать мутированный Cas9, полученный из этих организмов. В некоторых вариантах осуществления фермент CRISPR кодон-оптимизирован для экспрессии в эукариотической клетке. В некоторых вариантах осуществления фермент CRISPR управляет расщеплением одной или двух нитей в определенной точке целевой последовательности. В некоторых вариантах осуществления у фермента CRISPR отсутствует активность для расщепления нитей ДНК.
В одном аспекте настоящее изобретение предусматривает фермент CRISPR, содержащий одну или несколько последовательностей ядерной локализации, достаточно эффективных, чтобы управлять накоплением указанного фермента CRISPR в обнаруживаемом количестве в ядре эукариотической клетки. В некоторых вариантах осуществления фермент CRISPR является ферментом системы CRISPR II типа. В некоторых вариантах осуществления фермент CRISPR является ферментом Cas9. В некоторых вариантах осуществления фермент Cas9 представляет собой Cas9 S. pneumoniae, S. pyogenes или S. thermophilus и может включать мутированный Cas9, полученный из этих организмов. Фермент может быть гомологом или ортологом Cas9. В некоторых вариантах осуществления у фермента CRISPR отсутствует способность расщеплять одну или несколько нитей целевой последовательности, с которой он связывается.
В одном аспекте настоящее изобретение предусматривает эукариотическую клетку-хозяина, содержащую (a) первый регуляторный элемент, функционально связанный с парной tracr-последовательностью и одним или несколькими сайтами встраивания для встраивания одной или нескольких направляющих последовательностей выше парной tracr-последовательности, где при экспрессии направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR с целевой последовательностью в эукариотической клетке, где комплекс CRISPR содержит фермент CRISPR, образующий комплекс с (1) направляющей последовательностью, которая гибридизируется с целевой последовательностью, и (2) парной tracr-последовательностью, которая гибридизируется с tracr-последовательностью; и/или (b) второй регуляторный элемент, функционально связанный с кодирующей фермент последовательностью, кодирующей указанный фермент CRISPR, содержащий последовательность ядерной локализации. В некоторых вариантах осуществления клетка-хозяин содержит компоненты (a) и (b). В некоторых вариантах осуществления компонент (a), компонент (b) или компоненты (a) и (b) стабильно интегрируются в геном эукариотической клетки-хозяина. В некоторых вариантах осуществления компонент (a) дополнительно содержит tracr-последовательность ниже парной tracr-последовательности под контролем первого регуляторного элемента. В некоторых вариантах осуществления компонент (a) дополнительно содержит две или более направляющие последовательности, функционально связанные с первым регуляторным элементом, где при экспрессии каждая из двух или более направляющих последовательностей управляет специфичным к последовательности связыванием комплекса CRISPR со своей целевой последовательностью в эукариотической клетке. В некоторых вариантах осуществления эукариотическая клетка-хозяин дополнительно содержит третий регуляторный элемент, такой как промотор полимеразы III, функционально связанный с указанной tracr-последовательностью. В некоторых вариантах осуществления tracr-последовательность характеризуется по меньшей мере 50%, 60%, 70%, 80%, 90%, 95% или 99% комплементарности последовательности по длине парной tracr-последовательности при оптимальном выравнивании. В некоторых вариантах осуществления фермент CRISPR содержит одну или несколько последовательностей ядерной локализации, достаточно эффективных, чтобы управлять накоплением указанного фермента CRISPR в обнаруживаемом количестве в ядре эукариотической клетки. В некоторых вариантах осуществления фермент CRISPR является ферментом системы CRISPR II типа. В некоторых вариантах осуществления фермент CRISPR является ферментом Cas9. В некоторых вариантах осуществления фермент Cas9 представляет собой Cas9 S. pneumoniae, S. pyogenes или S. thermophilus и может включать мутированный Cas9, полученный из этих организмов. Фермент может быть гомологом или ортологом Cas9. В некоторых вариантах осуществления фермент CRISPR кодон-оптимизирован для экспрессии в эукариотической клетке. В некоторых вариантах осуществления фермент CRISPR управляет расщеплением одной или двух нитей в определенной точке целевой последовательности. В некоторых вариантах осуществления у фермента CRISPR отсутствует активность для расщепления нитей ДНК. В некоторых вариантах осуществления первый регуляторный элемент является промотором полимеразы III. В некоторых вариантах осуществления второй регуляторный элемент является промотором полимеразы II. В некоторых вариантах осуществления направляющая последовательность составляет по меньшей мере 15, 16, 17, 18, 19, 20, 25 нуклеотидов, или от 10 до 30, или от 15 до 25, или от 15 до 20 нуклеотидов в длину. В одном аспекте настоящее изобретение предусматривает отличный от человека эукариотический организм, предпочтительно многоклеточный эукариотический организм, содержащий эукариотическую клетку-хозяина согласно любому из описанных вариантов осуществления. В других аспектах настоящее изобретение предусматривает эукариотический организм, предпочтительно многоклеточный эукариотический организм, содержащий эукариотическую клетку-хозяина согласно любому из описанных вариантов осуществления. Организм в некоторых вариантах осуществления данных аспектов может быть животным, например, млекопитающим. Также организмом может быть членистоногое, как, например, насекомое. Организмом также может быть растение. Кроме того, организмом может быть гриб.
В одном аспекте настоящее изобретение предусматривает набор, содержащий один или несколько компонентов, описанных в данном документе. В некоторых вариантах осуществления набор содержит векторную систему и инструкции по применению набора. В некоторых вариантах осуществления векторная система содержит (a) первый регуляторный элемент, функционально связанный с парной tracr-последовательностью и одним или несколькими сайтами встраивания для встраивания одной или нескольких направляющих последовательностей выше парной tracr-последовательности, где при экспрессии направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR с целевой последовательностью в эукариотической клетке, где комплекс CRISPR содержит фермент CRISPR, образующий комплекс с (1) направляющей последовательностью, которая гибридизируется с целевой последовательностью, и (2) парной tracr-последовательностью, которая гибридизируется с tracr-последовательностью; и/или (b) второй регуляторный элемент, функционально связанный с кодирующей фермент последовательностью, кодирующей указанный фермент CRISPR, содержащий последовательность ядерной локализации. В некоторых вариантах осуществления набор содержит компоненты (a) и (b), находящиеся в одном и том же или в различных векторах системы. В некоторых вариантах осуществления компонент (a) дополнительно содержит tracr-последовательность ниже парной tracr-последовательности под контролем первого регуляторного элемента. В некоторых вариантах осуществления компонент (a) дополнительно содержит две или более направляющие последовательности, функционально связанные с первым регуляторным элементом, где при экспрессии каждая из двух или более направляющих последовательностей управляет специфичным к последовательности связыванием комплекса CRISPR со своей целевой последовательностью в эукариотической клетке. В некоторых вариантах осуществления система дополнительно содержит третий регуляторный элемент, такой как промотор полимеразы III, функционально связанный с указанной tracr-последовательностью. В некоторых вариантах осуществления tracr-последовательность характеризуется по меньшей мере 50%, 60%, 70%, 80%, 90%, 95% или 99% комплементарности последовательности по длине парной tracr-последовательности при оптимальном выравнивании. В некоторых вариантах осуществления фермент CRISPR содержит одну или несколько последовательностей ядерной локализации, достаточно эффективных, чтобы управлять накоплением указанного фермента CRISPR в обнаруживаемом количестве в ядре эукариотической клетки. В некоторых вариантах осуществления фермент CRISPR является ферментом системы CRISPR II типа. В некоторых вариантах осуществления фермент CRISPR является ферментом Cas9. В некоторых вариантах осуществления фермент Cas9 представляет собой Cas9 S. pneumoniae, S. pyogenes или S. thermophilus и может включать мутированный Cas9, полученный из этих организмов. Фермент может быть гомологом или ортологом Cas9. В некоторых вариантах осуществления фермент CRISPR кодон-оптимизирован для экспрессии в эукариотической клетке. В некоторых вариантах осуществления фермент CRISPR управляет расщеплением одной или двух нитей в определенной точке целевой последовательности. В некоторых вариантах осуществления у фермента CRISPR отсутствует активность для расщепления нитей ДНК. В некоторых вариантах осуществления первый регуляторный элемент является промотором полимеразы III. В некоторых вариантах осуществления второй регуляторный элемент является промотором полимеразы II. В некоторых вариантах осуществления направляющая последовательность составляет по меньшей мере 15, 16, 17, 18, 19, 20, 25 нуклеотидов, или от 10 до 30, или от 15 до 25, или от 15 до 20 нуклеотидов в длину.
В одном аспекте настоящее изобретение предусматривает способ модификации целевого полинуклеотида в эукариотической клетке. В некоторых вариантах осуществления способ включает обеспечение связывания комплекса CRISPR с целевым полинуклеотидом для осуществления расщепления указанного целевого полинуклеотида с модификацией, таким образом, целевого полинуклеотида, где комплекс CRISPR содержит фермент CRISPR, образующий комплекс с направляющей последовательностью, гибридизирующейся с целевой последовательностью в указанном целевом полинуклеотиде, где указанная направляющая последовательность связана с парной tracr-последовательностью, которая, в свою очередь, гибридизируется с tracr-последовательностью. В некоторых вариантах осуществления указанное расщепление включает расщепление одной или двух нитей в определенной точке целевой последовательности указанным ферментом CRISPR. В некоторых вариантах осуществления указанное расщепление приводит к сниженной транскрипции целевого гена. В некоторых вариантах осуществления способ дополнительно включает репарацию указанного расщепленного целевого полинуклеотида при помощи гомологичной рекомбинации с экзогенным матричным полинуклеотидом, где указанная репарация приводит к мутации, включающей вставку, делецию или замену одного или нескольких нуклеотидов указанного целевого полинуклеотида. В некоторых вариантах осуществления указанная мутация приводит к одной или нескольким аминокислотным заменам в белке, экспрессируемом с гена, содержащего целевую последовательность. В некоторых вариантах осуществления способ дополнительно включает доставку одного или нескольких векторов в указанную эукариотическую клетку, где один или несколько векторов управляют экспрессией одного или нескольких из: фермента CRISPR, направляющей последовательности, связанной с парной tracr-последовательностью, и tracr-последовательности. В некоторых вариантах осуществления указанные векторы доставляют в эукариотическую клетку в субъекте. В некоторых вариантах осуществления указанная модификация имеет место в указанной эукариотической клетке в клеточной культуре. В некоторых вариантах осуществления способ дополнительно включает выделение указанной эукариотической клетки из субъекта перед указанной модификацией. В некоторых вариантах осуществления способ дополнительно включает возвращение указанной эукариотической клетки и/или клеток, полученных из субъекта, указанному субъекту.
В одном аспекте настоящее изобретение предусматривает способ модификации экспрессии полинуклеотида в эукариотической клетке. В некоторых вариантах осуществления способ включает обеспечение связывания комплекса CRISPR с полинуклеотидом так, что указанное связывание приводит к повышенной или пониженной экспрессии указанного полинуклеотида; где комплекс CRISPR содержит фермент CRISPR, образующий комплекс с направляющей последовательностью, гибридизирующейся с целевой последовательностью в указанном целевом полинуклеотиде, где указанная направляющая последовательность связана с парной tracr-последовательностью, которая, в свою очередь, гибридизируется с tracr-последовательностью. В некоторых вариантах осуществления способ дополнительно включает доставку одного или нескольких векторов в указанные эукариотические клетки, где один или несколько векторов управляют экспрессией одного или нескольких из: фермента CRISPR, направляющей последовательности, связанной с парной tracr-последовательностью, и tracr-последовательности.
В одном аспекте настоящее изобретение предусматривает способ получения модельной эукариотической клетки, содержащей мутированный ген, ответственный за развитие заболевания. В некоторых вариантах осуществления ген, ответственный за развитие заболевания, представляет собой любой ген, ассоциированный с повышением риска наличия или развития заболевания. В некоторых вариантах осуществления способ включает (a) введение одного или нескольких векторов в эукариотическую клетку, где один или несколько векторов управляют экспрессией одного или нескольких из: фермента CRISPR, направляющей последовательности, связанной с парной tracr-последовательностью, и tracr-последовательности; и (b) обеспечение связывания комплекса CRISPR с целевым полинуклеотидом для осуществления расщепления целевого полинуклеотида в указанном гене, ответственном за развитие заболевания, где комплекс CRISPR содержит фермент CRISPR, образующий комплекс с (1) направляющей последовательностью, которая гибридизируется с целевой последовательностью в целевом полинуклеотиде, и (2) парной tracr-последовательностью, которая гибридизируется с tracr-последовательностью, таким образом, получая модельную эукариотическую клетку, содержащую мутированный ген, ответственный за развитие заболевания. В некоторых вариантах осуществления указанное расщепление включает расщепление одной или двух нитей в определенной точке целевой последовательности указанным ферментом CRISPR. В некоторых вариантах осуществления указанное расщепление приводит к сниженной транскрипции целевого гена. В некоторых вариантах осуществления способ дополнительно включает репарацию указанного расщепленного целевого полинуклеотида при помощи гомологичной рекомбинации с экзогенным матричным полинуклеотидом, где указанная репарация приводит к мутации, включающей вставку, делецию или замену одного или нескольких нуклеотидов указанного целевого полинуклеотида. В некоторых вариантах осуществления указанная мутация приводит к одной или нескольким аминокислотным заменам при экспрессии белка с гена, содержащего целевую последовательность.
В одном аспекте настоящее изобретение предусматривает способ получения биологически активного средства, которое модулирует процесс передачи сигнала в клетке, ассоциированный с геном, ответственным за развитие заболевания. В некоторых вариантах осуществления ген, ответственный за развитие заболевания, представляет собой любой ген, ассоциированный с повышением риска наличия или развития заболевания. В некоторых вариантах осуществления способ включает (a) приведение тестового соединения в контакт с модельной клеткой по любому одному из описанных вариантов осуществления и (b) обнаружение изменения при считывании, которое свидетельствует об уменьшении или усилении процесса передачи сигнала в клетке, ассоциированного с указанной мутацией в указанном гене, ответственном за развитие заболевания, с получением, таким образом, указанного биологически активного средства, которое модулирует указанный процесс передачи сигнала в клетке, ассоциированный с указанным геном, ответственным за развитие заболевания.
В одном аспекте настоящее изобретение предусматривает рекомбинантный полинуклеотид, содержащий направляющую последовательность выше парной tracr-последовательности, где направляющая последовательность при экспрессии управляет специфичным к последовательности связыванием комплекса CRISPR с соответствующей целевой последовательностью, присутствующей в эукариотической клетке. В некоторых вариантах осуществления целевая последовательность является вирусной последовательностью, присутствующей в эукариотической клетке. В некоторых вариантах осуществления целевая последовательность является протоонкогеном или онкогеном.
В одном аспекте настоящее изобретение предусматривает способ отбора одной или нескольких прокариотических клеток путем введения одной или нескольких мутаций в ген в одной или нескольких прокариотических клетках, при этом способ включает введение одного или нескольких векторов в прокариотическую(ие) клетку(и), где один или несколько векторов управляют экспрессией одного или нескольких из: фермента CRISPR, направляющей последовательности, связанной с парной tracr-последовательностью, tracr-последовательности и матрицы редактирования; где матрица редактирования содержит одну или несколько мутаций, которые прекращают расщепление фермента CRISPR; обеспечение гомологичной рекомбинации матрицы редактирования с целевым полинуклеотидом в отбираемой(ых) клетке(ах); обеспечение связывания комплекса CRISPR с целевым полинуклеотидом для осуществления расщепления целевого полинуклеотида в указанном гене, где комплекс CRISPR содержит фермент CRISPR, образующий комплекс с (1) направляющей последовательностью, которая гибридизируется с целевой последовательностью в целевом полинуклеотиде, и (2) парной tracr-последовательностью, которая гибридизируется с tracr-последовательностью, где связывание комплекса CRISPR с целевым полинуклеотидом индуцирует гибель клеток, с обеспечением тем самым отбора одной или нескольких прокариотических клеток, в которые были введены одна или несколько мутаций. В предпочтительном варианте осуществления фермент CRISPR представляет собой Cas9. В другом аспекте настоящего изобретения отбираемая клетка может быть эукариотической клеткой. Аспекты настоящего изобретения обеспечивают возможность отбора конкретных клеток без необходимости наличия маркера отбора или двухстадийного способа, который может включать систему негативного отбора.
Соответственно, целью настоящего изобретения не является охват в пределах настоящего изобретения любого ранее известного продукта, способа получения продукта или способа применения продукта, так что заявители оставляют за собой право и настоящим раскрывают отказ от прав на любой ранее известный продукт, процесс или способ. Следует дополнительно отметить, что настоящее изобретение не предназначено охватывать в пределах объема настоящего изобретения любой продукт, способ получения продукта или способ применения продукта, который не соответствует письменному описанию и требованиям достаточного раскрытия сути изобретения USPTO (первый пункт § 112 статьи 35 USC) или EPO (статья 83 EPC), так что заявители оставляют за собой право и настоящим раскрывают отказ от прав на любой ранее описанный продукт, способ получения продукта или способ применения продукта.
Следует отметить, что в данном раскрытии и особенно в формуле изобретения и/или параграфах такие выражения, как "содержит", "содержащийся", "содержащий" и т.п., могут иметь значение, приписываемое им в патентном законодательстве США, например, они могут означать "включает", "включенный", "включающий" и т.п., и что такие выражения, как "состоящий, по сути, из" и "состоит, по сути, из" имеют значение, приписываемое им в патентном законодательстве США, например, они допускают не указанные прямо элементы, но исключают элементы, которые имеются в известном уровне техники или которые влияют на основные или новые характеристики настоящего изобретения. Эти и другие варианты осуществления раскрыты или являются очевидными, исходя из следующего подробного описания, и охвачены им.
Краткое описание графических материалов
Новые признаки настоящего изобретения изложены с характерными особенностями в прилагаемой формуле изобретения. Лучшее понимание признаков и преимуществ настоящего изобретения будет доступно благодаря ссылке на следующее подробное описание, в котором изложены показательные варианты осуществления, в которых используют принципы настоящего изобретения, и на сопутствующие графические материалы.
На фигуре 1 показана схематическая модель системы CRISPR. Нуклеаза Cas9 из Streptococcus pyogenes (желтый) нацелена на геномную ДНК при помощи синтетической направляющей РНК (sgRNA), состоящей из 20-нуклеотидной направляющей последовательности (голубой) и каркаса (красный). Направляющая последовательность образует пары оснований с ДНК-мишенью (голубой) непосредственно выше необходимого мотива, смежного с протоспейсером (PAM; пурпурный) 5’-NGG, и Cas9 опосредует двухцепочечный разрыв (DSB) на ~3 п.о. выше PAM (красный треугольник).
На фигурах 2A-F изображена показательная система CRISPR, возможный механизм действия, иллюстративная адаптация для экспрессии в эукариотических клетках и результаты тестов, оценивающих ядерную локализацию и активность CRISPR.
На фигуре 3 изображена показательная кассета экспрессии для экспрессии элементов системы CRISPR в эукариотических клетках, предсказанные структуры иллюстративных направляющих последовательностей и активность системы CRISPR, которая измерена в эукариотических и прокариотических клетках.
На фигурах 4A-D показаны результаты оценивания специфичности SpCas9 в отношении иллюстративной мишени.
На фигурах 5A-G изображена показательная векторная система и результаты ее применения при управлении гомологичной рекомбинацией в эукариотических клетках.
На фигуре 6 представлена таблица последовательностей протоспейсеров и обобщены результаты касательно эффективности модификаций для протоспейсеров-мишеней, разработанных на основе иллюстративных систем CRISPR S. pyogenes и S. thermophilus с соответствующими PAM к локусам в геномах человека и мыши. Клетки трансфицировали Cas9 и либо pre-crRNA/tracrRNA, либо химерной РНК и анализировали через 72 часа после трансфекции. Процент вставок/делеций рассчитывали на основе результатов анализа с помощью Surveyor с указанными линиями клеток (N=3 для всех протоспейсеров-мишеней, ошибки представляют собой стандартные ошибки среднего, N.D. означает "не обнаружено при помощи анализа с помощью Surveyor", и N.T. означает "не тестировали в данном исследовании").
На фигурах 7A-C показано сравнение различных транскриптов tracrRNA для опосредованного Cas9 целенаправленного воздействия на ген.
На фигуре 8 показано схематическое изображение анализа с помощью нуклеазы Surveyor для обнаружения индуцированных двухцепочечным разрывом микровставок и микроделеций.
На фигурах 9A-B изображены показательные бицистронные векторы экспрессии для экспрессии элементов системы CRISPR в эукариотических клетках.
На фигуре 10 показан анализ интерференции при трансформации бактериальной плазмидой, кассеты экспрессии и плазмиды, используемые в нем, и показатели эффективности трансформации клеток, используемых в нем.
На фигурах 11A-C показаны гистогораммы расстояний между смежными PAM (NGG) локуса 1 S. pyogenes SF370 (фигура 10A) и PAM (NNAGAAW) локуса 2 LMD9 S. thermophilus (фигура 10B) в геноме человека и расстояние для каждого PAM в хромосомах (Chr) (фигура 10C).
На фигурах 12A-C изображена показательная система CRISPR, иллюстративная адаптация для экспрессии в эукариотических клетках и результаты тестов, оценивающих активность CRISPR.
На фигурах 13A-C показаны иллюстративные манипуляции с системой CRISPR для целенаправленного воздействия на локусы генома в клетках млекопитающего.
На фигурах 14A-B показаны результаты анализа нозерн блоттинга процессинга crRNA в клетках млекопитающего.
На фигуре 15 изображен показательный отбор протоспейсеров в локусах PVALB человека и Th мыши.
На фигуре 16 показан иллюстративный протоспейсер и соответствующие представляющие собой мишени последовательности PAM системы CRISPR S. thermophilus в локусе EMX1 человека.
На фигуре 17 представлена таблица последовательностей для праймеров и зондов, используемых для Surveyor, RFLP, геномного секвенирования и анализов нозерн блоттинга.
На фигурах 18A-C показана иллюстративная манипуляция с системой CRISPR с химерными РНК и результаты анализов с помощью SURVEYOR в отношении активности системы в эукариотических клетках.
На фигурах 19A-B представлено графическое изображение результатов анализов с помощью SURVEYOR в отношении активности системы CRISPR в эукариотических клетках.
На фигуре 20 представлено показательное отображение некоторых целевых сайтов Cas9 S. pyogenes в геноме человека, полученное с использованием геномного браузера UCSC.
На фигуре 21 показаны предсказанные вторичные структуры для показательных химерных РНК, содержащих направляющую последовательность, парную tracr-последовательность и tracr-последовательность.
На фигуре 22 показаны иллюстративные бицистронные векторы экспрессии для экспрессии элементов системы CRISPR в эукариотических клетках.
На фигуре 23 показано, что активность нуклеазы Cas9 по отношению к эндогенным мишеням можно использовать для редактирования генома. (a) Концепция редактирования генома при помощи системы CRISPR. Конструкция CRISPR целенаправленного воздействия управляла расщеплением хромосомного локуса и была котрансформирована матрицей редактирования, которая рекомбинировала с мишенью для предотвращения расщепления. Устойчивые к канамицину трансформанты, которые выдерживали воздействие CRISPR, содержали модификации, введенные с помощью матрицы редактирования. tracr, трансактивирующую РНК CRISPR; aphA-3, ген устойчивости к кантамицину. (b) Трансформация ДНК crR6M в клетках R68232.5 без матрицы редактирования, srtA R6 дикого типа или матрицами редактирования R6370.1. Рекомбинация srtA либо R6, либо R6370.1 предотвращала расщепление с помощью Cas9. Эффективность трансформации подсчитывали как колониеобразующие единицы (cfu) на мкг ДНК crR6M; показаны средние значения со среднеквадратическими отклонениями от по меньшей мере трех независимых экспериментов. ПЦР анализ выполняли на 8 клонах при каждой трансформации. “Un.” означает нередактированный локус srtA штамма R68232.5; “Ed.” показывает матрицу редактирования. Мишени R68232.5 и R6370.1 различаются по рестрикции EaeI.
На фигуре 24 показан анализ PAM и затравочных последовательностей, которые исключают расщепление Cas9. (a) ПЦР-продуктами с рандомизированными последовательностями PAM или рандомизированными затравочными последовательностями трансформировали клетки crR6. Эти клетки экспрессировали Cas9, загруженную crRNA, которая была нацелена на хромосомный участок клеток R68232.5 (выделен розовым), отсутствующий в геноме R6. Более, чем 2×105 устойчивых к хлорамфениколу трансформантов, несущих неактивные PAM или затравочные последовательности, объединяли для амплификации и глубокого секвенирования целевого участка. (b) Относительная доля количества считываемых фрагментов после трансформации случайными конструкциями PAM клеток crR6 (по сравнению с количеством считываемых фрагментов в трансформантах R6). Показана относительная распространенность каждой 3-нуклеотидной последовательности PAM. Крайне недостаточно представленные последовательности (NGG) показаны красным; частично недостаточно представленные оранжевым (NAG). (c) Относительная доля количества считываемых фрагментов после трансформации конструкциями случайных затравочных последовательностей клеток crR6 (по сравнению с количеством считываемых фрагментов в трансформантах R6). Показана относительная распространенность каждого нуклеотида по каждому положению первых 20 нуклеотидов последовательности протоспейсера. Высокая распространенность указывает на отсутствие расщепления Cas9, т.e. CRISPR-инактивирующую мутацию. Серая линия показывает уровень последовательности WT. Пунктирная линия представляет уровень, выше которого мутация значительно нарушает расщепление (см. раздел “анализ данных глубокого секвенирования” в примере 5)
На фигуре 25 показано введение одиночной и множественных мутаций с применением системы CRISPR в S. pneumoniae. (a) Нуклеотидные и аминокислотные последовательности bgaA дикого типа и редактированного bgaA (зеленые нуклеотиды; подчеркнутые аминокислотные остатки). Показаны протоспейсер, PAM и сайты рестрикции. (b) Эффективность трансформации клеток, трансформированных конструкциями для целенаправленного воздействия, в присутствии матрицы редактирования или контроля. (c) ПЦР анализ 8 трансформантов каждого эксперимента редактирования с последующим расщеплением BtgZI (R→A) и TseI (NE→AA). Делеция bgaA была выявлена как ПЦР-продукт меньшего размера. (d) Анализ Миллера для измерения активности β-галактозидазы штаммов WT и редактированных. (e) Для одностадийной, двойной делеции конструкция для целенаправленного воздействия содержала два спейсера (в этом случае совпадающие srtA и bgaA), и ее котрансформировали двумя различными матрицами редактирования. (f) ПЦР анализ 8 трансформантов для выявления делеций в локусах srtA и bgaA. 6/8 трансформантов содержали делеции обоих генов.
На фигуре 26 представлены механизмы, лежащие в основе редактирования с применением системы CRISPR. (a) Стоп-кодон вводили в ген устойчивости к эритромицину ermAM для создания штамма JEN53. Последовательность дикого типа можно восстанавливать путем целенаправленного воздействия на стоп-кодон конструкцией CRISPR::ermAM(stop) и с использованием последовательности ermAM дикого типа в качестве матрицы редактирования. (b) Последовательности ermAM мутантные и дикого типа. (c) Фракция эритромицин-устойчивых (ermR) КОЕ, вычисленная по общим или устойчивым к канамицину (kanR) КОЕ. (d) Фракция общего количества клеток, получивших и конструкцию CRISPR, и матрицу редактирования. Котрансформация конструкцией CRISPR для целенаправленного воздействия обеспечивала больше трансформантов (t-тест, p=0,011). Во всех случаях значения показывают среднее ± среднеквадратическое отклонение для трех независимых экспериментов.
На фигуре 27 проиллюстрировано редактирование генома системой CRISPR в E. coli. (a) Плазмидой устойчивости к канамицину, несущей массив CRISPR (pCRISPR), целенаправленно воздействующий на ген с целью редактирования, можно трансформировать сконструированный штамм HME63, содержащий плазмиду устойчивости к хлорамфениколу, несущую cas9 и tracr (pCas9), совместно с олигонуклеотидом, определяющим мутацию. (b) Мутацию K42T, обеспечивающую устойчивость к стрептомицину, вводили в ген rpsL. (c) Фракцию устойчивых к стрептомицину (strepR) КОЕ подсчитывали по общим или устойчивым к канамицину (kanR) КОЕ. (d) Фракция всех клеток, получивших и плазмиду pCRISPR, и редактированный олигонуклеотид. Котрансформация плазмидой рCRISPR для целенаправленного воздействия обеспечивала больше трансформантов (t-тест, p=0,004). Во всех случаях значения показывают среднее ± среднеквадратическое отклонение для трех независимых экспериментов.
На фигуре 28 показано, что трансформация геномной ДНК crR6 приводит к редактированию локуса целенаправленного воздействия. (a) Элемент IS1167 R6 S. pneumoniae замещали локусом CRISPR01 SF370 S. pyogenes для создания штамма crR6. Этот локус кодирует для нуклеазы Cas9 массив CRISPR с шестью спейсерами, tracrRNA, необходимую для биогенеза crRNA, и белки Cas1, Cas2 и Csn2, которые не являются необходимыми для целенаправленного воздействия. Штамм crR6M содержит минимальную функциональную систему CRISPR без cas1, cas2 и csn2. Ген aphA-3 кодирует устойчивость к кантамицину. Протоспейсеры стрептококковых бактериофагов R68232.5 и R6370.1 гибридизировали с геном устойчивости к хлорамфениколу (cat) и интегрировали в ген srtA штамма R6 для создания штаммов R68232.5 и R6370.1. (b) Левая панель: трансформация геномной ДНК crR6 и crR6M в R68232.5 и R6370.1. В качестве контроля компетенции клеток также трансформировали геном устойчивости к стрептомицину. Правая панель: ПЦР анализ 8 трансформантов R68232.5 с геномной ДНК crR6. Для ПЦР использовали праймеры, обеспечивающие амплифицикацию локуса srtA. В 7/8 генотипированных колоний локус srtA R68232.5 был замещен локусом WT из геномной ДНК crR6.
На фигуре 29 представлены хроматограммы последовательностей ДНК редактированных клеток, полученных в этом исследовании. Во всех случаях выявляли последовательности дикого типа и мутантные последовательности протоспейсера и PAM (или их обратную комплементарную нить). В случае необходимости обеспечивается аминокислотная последовательность, кодируемая протоспейсером. Для каждого эксперимента редактирования секвенировали все штаммы, для которых ПЦР и рестрикционный анализы подтвердили введение желаемой модификации. Показана репрезентативная хроматограмма. (a) Хроматограмма введения мутации PAM в мишень R68232.5 (фигура 23d). (b) Хроматограммы введения мутаций R>A и NE>AA в ген β-галактозидазы (bgaA) (фигура 25c). (c) Хроматограмма введения делеции 6664 п.о. в ORF bgaA (фигуры 25c и 25f). Пунктирная линия указывает границы делеции. (d) Хроматограмма введения делеции 729 п.о. в ORF srtA (фигура 25f). Пунктирная линия указывает границы делеции. (e) Хроматограммы образования преждевременного стоп-кодона в ermAM (фигура 33). (f) Редактирование rpsL в E. coli (фигура 27).
На фигуре 30 проиллюстрирована устойчивость CRISPR к случайным мишеням S. pneumoniae, содержащим различные PAM. (a) Положение 10 случайных мишеней в геноме R6 S. pneumoniae. Выбранные мишени содержат различные PAM и находятся на обеих нитях. (b) Спейсеры, соответствующие мишеням, клонировали в минимальный массив CRISPR плазмиды pLZ12 и трансформировали ими штамм crR6Rc, который обеспечивает процессинг и механизм целенаправленного воздействия в трансформантах. (c) Эффективность трансформации различными плазмидами штаммов R6 и crR6Rc. Не было выделено колоний по трансформации pDB99-108 (T1-T10) в crR6Rc. Пунктирной линией представлен предел обнаружения анализа.
На фигуре 31 представлена общая схема целенаправленного редактирования генома. Для обеспечения целенаправленного редактирования генома crR6M дополнительно подвергали конструированию так, чтобы он содержал tracrRNA, Cas9 и только один повтор массива CRISPR, за которым находится маркер устойчивости к кантамицину (aphA-3), создавая штамм crR6Rk. ДНК этого штамма использовали в качестве матрицы для ПЦР с праймерами, сконструированными для введения нового спейсера (зеленый блок, обозначенный N). ПЦР с левыми и правыми праймерами объединяли с применением метода Гибсона для создания конструкции для целенаправленного воздействия. Конструкциями и для целенаправленного воздействия, и для редактирования затем трансформировали штамм crR6Rc, который является штаммом, эквивалентным crR6Rk, но содержит маркер устойчивости к кантамицину, замещенный маркером устойчивости к хлорамфениколу (cat). Приблизительно 90% устойчивых к канамицину трансформантов содержали желаемую мутацию.
На фигуре 32 проиллюстрировано распределение расстояний между PAM. NGG и CCN, которые считаются допустимыми PAM. Данные представлены по геному R6 S. pneumoniae, а также по случайным последовательностям такой же длины и с таким же содержанием GC (39,7%). Пунктирная линия представляет среднее расстояние (12) между PAM в геноме R6.
На фигуре 33 проиллюстрировано опосредованное CRISPR редактирование локуса ermAM с использованием геномной ДНК в качестве конструкции для целенаправленного воздействия. Для использования геномной ДНК в качестве конструкции для целенаправленного воздействия необходимо избегать аутоиммунной активности на CRISPR, и, таким образом, должен быть использован спейсер, соответствующий последовательности, не присутствующей в хромосоме (в этом случае ген устойчивости к эритромицину ermAM). (a) Нуклеотидная и аминокислотная последовательности гена ermAM дикого типа и мутированного (красные буквы). Приведены протоспейсер и последовательности PAM. (b) Схематическое изображение опосредованного CRISPR редактирования локуса ermAM с применением геномной ДНК. Конструкцию, несущую ermAM-целенаправленно воздействующий спейсер (голубой блок), получали с помощью ПЦР и сборки по методу Гибсона, трансформировали ею штамм crR6Rc, создавая штамм JEN37. Геномную ДНК JEN37 использовали в качестве конструкции для целенаправленного воздействия и ею вместе с матрицей редактирования котрансформировали JEN38, штамм, в котором ген srtA замещен копией ermAM дикого типа. Устойчивые к канамицину трансформанты содержат редактированный генотип (JEN43). (c) Количество устойчивых к канамицину клеток получали после котрансформации матрицами целенаправленного воздействия и редактирования или контрольными. В присутствии контрольной матрицы получали 5,4×103 КОЕ/мл и 4,3×105 КОЕ/мл при использовании матрицы редактирования. Это различие указывает на приблизительно 99% эффективность редактирования [(4,3×105-5,4×103)/4,3×105]. (d) Для проверки на наличие редактированных клеток семь устойчивых к канамицину клонов и JEN38 высевали штрихом на чашки с агаровой средой с эритромицином (erm+) или без (erm-) эритромицина. Только положительный контроль отображал устойчивость к эритромицину. Мутированный генотип ermAM одного из этих трансформантов также подтверждали путем секвенирования ДНК (фигура 29e).
На фигуре 34 проиллюстрировано последовательное введение мутаций путем опосредованного CRISPR редактирования генома. (a) Схематическое изображение последовательного введения мутаций путем опосредованного CRISPR редактирования генома. Прежде всего, R6 конструировали для создания crR6Rk. crR6Rk котрансформировали конструкцией для целенаправленного воздействия srtA, гибридизированной с cat для отбора по хлорамфениколу редактированных клеток, совместно с конструкцией для редактирования с делецией ΔsrtA внутри рамки считывания. Штамм ΔsrtA crR6 получали путем отбора по хлорамфениколу. Затем штамм ΔsrtA котрансформировали конструкцией для целенаправленного воздействия bgaA, гибридизированной с aphA-3 для отбора по канамицину редактированных клеток, и конструкцией для редактирования, содержащей делецию ΔbgaA внутри рамки считывания. И наконец, сконструированный локус CRISPR можно удалять из хромосомы путем сначала котрансформации ДНК R6, содержащей локус IS1167 дикого типа, и плазмидой, несущей протоспейсер bgaA (pDB97), а также отбором по спектиномицину. (b) ПЦР анализ 8 устойчивых к хлорамфениколу (Cam) трансформантов для выявления делеции в локусе srtA. (c) Активность β-галактозидазы, которую измеряли с помощью анализа Миллера. У S. pneumoniae этот фермент прикреплен к клеточной стенке сортазой A. Делеция гена srtA проявляется в высвобождении β-галактозидазы в супернатант. Мутанты ΔbgaA не проявляют активности. (d) ПЦР анализ 8 устойчивых к спектиномицину (Spec) трансформантов для выявления замещения локуса CRISPR IS1167 дикого типа.
На фигуре 35 показан фон частоты мутации CRISPR у S. pneumoniae. (a) Трансформация JEN53 конструкциями для целенаправленного воздействия CRISPR::∅ или CRISPR::erm(stop) с матрицей редактирования ermAM или без нее. Различие в kanR КОЕ между CRISPR::∅ и CRISPR::erm(stop) указывает на то, что расщепление Cas9 уничтожает нередактированные клетки. Мутантов, избегающих интерференции CRISPR при отсутствии матрицы редактирования, наблюдали с частотой 3×10-3. (b) ПЦР анализ локуса CRISPR клеток, избежавших воздействия, указывает на то, что 7/8 содержат делецию спейсера. (c) Клетка, избежавшая воздействия, № 2 несет точковую мутацию в cas9.
На фигуре 36 показано, что важные элементы локуса 1 CRISPR S. pyogenes воспроизводили в E. coli с применением pCas9. Плазмида содержала tracrRNA, Cas9, а также лидерную последовательность, управляющую массивом crRNA. Плазмиды pCRISPR содержали только лидерную последовательность и массив. Спейсеры могут быть вставлены в массив crRNA между сайтами BsaI с применением отожженных олигонуклеотидов. Структура олигонуклеотида показана внизу. pCas9 несет устойчивость к хлорамфениколу (CmR) и основана на остове низкокопийной плазмиды pACYC184. pCRISPR основана на большом количестве копий плазмиды pZE21. Требовалось две плазмиды, поскольку плaзмида pCRISPR, содержащая спейсер, целенаправленно воздействующий на хромосому E. coli, не может быть сконструирована с применением этого организма как хозяина для клонирования, если Cas9 также присутствует (это приведет к гибели хозяина).
На фигуре 37 показано редактирование в MG1655 E.coli под управлением CRISPR. Олигонуклеотидом (W542), несущим точковую мутацию, что и обеспечивает устойчивость к стрептомицину, и ликвидирует иммунную активность CRISPR, совместно с плазмидой, целенаправленно воздействующей на rpsL (pCRISPR::rpsL), или контрольной плазмидой (pCRISPR::∅) котрансформировали штамм дикого типа MG1655 E.coli, содержащий pCas9. Трансформантов отбирали на среде, содержащей либо стрептомицин, либо канамицин. Пунктирной линией указан предел детекции анализа трансформации.
На фигуре 38 показан фон частоты мутации CRISPR в HME63 E. coli. (a) Трансформация компетентных клеток HME63 плазмидами pCRISPR::∅ или pCRISPR::rpsL. Мутантов, избежавших интерференции CRISPR, наблюдали с частотой 2,6×10-4. (b) Амплификация массива CRISPR клеток, избежавших воздействия, показала, что у 8/8 спейсер был удален.
На фигуре 39A-D показано круговое изображение филогенетического анализа, выявляющего пять семейств Cas9, включая три группы больших Cas9 (~1400 аминокислот) и две малых Cas9 (~1100 аминокислот).
На фигуре 40A-F показано линейное отображение филогенетического анализа, выявляющего пять семейств Cas9, включая три группы больших Cas9 (~1400 аминокислот) и две малых Cas9 (~1100 аминокислот).
На фигуре 41A-M показаны последовательности, где точки мутаций расположены в гене SpCas9.
На фигуре 42 показано схематическое изображение конструкции, в которой домен активации транскрипции (VP64) слит с Cas9 с двумя мутациями в каталитических доменах (D10 и H840).
На фигуре 43A-D показано редактирование генома посредством гомологичной рекомбинации. (a) Схематическое изображение никазы SpCas9 с мутацией D10A в каталитическом домене RuvC I. (b) Схематическое представление гомологичной рекомбинации (HR) в локусе EMX1 человека при использовании смысловых или антисмысловых однонитевых олигонуклеотидов в качестве матриц для репарации. Красная стрелка вверху указывает на сайт расщепления для sgRNA; праймеры для ПЦР для генотипирования (таблицы J и K) обозначены стрелками в правой панели. (c) Последовательность участка, модифицированного с помощью HR. d, Анализ вставок/делеций в целевом локусе 1 EMX1 (n = 3), опосредованных SpCas9 дикого типа (wt) и никазой SpCas9 (D10A), с помощью SURVEYOR. Стрелки указывают положения фрагментов ожидаемого размера.
На фигуре 44A-B показаны одиночные векторные структуры для SpCas9.
На фигуре 45 показан количественный анализ расщепления конструкций NLS-Csn1, Csn1, Csn1-NLS, NLS-Csn1-NLS, NLS-Csn1-GFP-NLS и UnTFN.
На фигуре 46 показан индекс частоты NLS-Cas9, Cas9, Cas9-NLS и NLS-Cas9-NLS.
На фигуре 47 представлен анализ в геле, демонстрирующий, что SpCas9 с мутациями никазы (в отдельности) не индуцирует двухцепочечные разрывы.
На фигуре 48 показана структура олигонуклеотидной ДНК, используемой в качестве матрицы гомологичной рекомбинации (HR) в этом эксперименте, и сравнение эффективности HR, индуцированной различными комбинациями белка Cas9 и матрицы HR.
На фигуре 49A показана карта вектора для целенаправленного воздействия с зависимой от условий экспрессией Cas9, Rosa26.
На фигуре 49B показана карта вектора для целенаправленного воздействия с конститутивной экспрессией Cas9, Rosa26.
На фигуре 50A-H показаны последовательности для каждого элемента, присутствующего на картах векторов фигур 49A-B.
На фигуре 51 показано схематическое изображение важных элементов в конструкциях для конститутивной и зависимой от условий экспрессии Cas9.
На фигуре 52 показано подтверждение функции конструкций для конститутивной и зависимой от условий экспрессии Cas9.
На фигуре 53 показано подтверждение нуклеазной активности Cas9 с помощью Surveyor.
На фигуре 54 показан количественный анализ нуклеазной активности Cas9.
На фигуре 55 показана структура конструкции и стратегия гомологичной рекомбинации (HR).
На фигуре 56 показаны результаты ПЦР генотипирования генома конструкций для констутивной (правая) и зависимой от условий (левая) экспрессии при двух разных длительностях воздействия (верхний ряд в течение 3 мин и нижний ряд в течение 1 мин.).
На фигуре 57 показана активация Cas9 в mESC.
На фигуре 58 показано схематическое изображение стратегии, использованной для опосредования нокаута гена через NHEJ с применением никазного варианта Cas9 совместно с двумя направляющими РНК.
На фигуре 59 показано, как репарация двухцепочечного разрыва (DSB) ДНК способствует редактированию генов. В пути склонного к ошибкам негомологичного соединения концов (NHEJ) концы DSB подвергаются обработке посредством эндогенных механизмов репарации ДНК и соединяются вместе, что может приводить к случайным мутациям по типу вставки или делеции (вставки/делеции) в месте соединения. Мутации по типу вставки/делеции, имеющие место в кодирующем участке гена, могут обуславливать сдвиг рамки считывания и появление преждевременного стоп-кодона, что приводит к нокауту гена. Альтернативно, матрицу для репарации в форме плазмиды или однонитевых олигодезоксинуклеотидов (ssODN) можно предоставлять для эффективного использования пути репарации с участием гомологичной рекомбинации (HDR), что обеспечивает высокое качество и точное редактирование.
На фигуре 60 показаны временная шкала и общее описание экспериментов. Стадии разработки, создания, подтверждения реагента и размножения клеточной линии. Индивидуальные sgRNA (светло-голубые метки) для каждой мишени, а также праймеры для генотипирования конструировали in silico посредством онлайн-инструмента конструирования (доступен на веб-сайте genome-engineering.org/tools). Векторы экспрессии sgRNA затем клонировали в плазмиду, содержащую Cas9 (PX330), и проверяли посредством секвенирования ДНК. Готовыми плазмидами (pCRISPR) и необязательными матрицами для репарации для облегчения гомологично направленной репарации затем трансфицировали клетки и анализировали на возможность опосредовать целенаправленное расщепление. И наконец, можно осуществлять клональное размножение трансфицированных клеток для получения изогенных клеточных линий с определенными мутациями.
На фигуре 61A-C показан выбор мишени и приготовление реагентов. (a) Для Cas9 S. pyogenes, за мишенями из 20 п.о. (выделены голубым) должна находиться 5’-NGG, которая может встречаться в любой нити геномной ДНК. Рекомендовано использование онлайн-инструмента, описанного в этом протоколе для помощи в выборе мишени (www.genome-engineering.org/tools). (b) Схематическое изображение котрансфекции экспрессионной плазмиды Cas9 (PX165) и амплифицированной с помощью ПЦР управляемой U6 кассетой экспрессии sgRNA. С применением промотора U6, содержащего матрицу ПЦР и фиксированный прямой праймер (U6 Fwd), sgRNA-кодирующие ДНК могут присоединяться к обратному праймеру U6 (U6 Rev) и синтезироваться в виде удлиненного олигонуклеотида ДНК (Ultramer oligos от IDT). Следует отметить, что направляющая последовательность (голубые N) в U6 Rev является обратно-комплементарной фланкирующей целевой последовательностью 5’-NGG. (c) Схематическое изображение scarless-клонирования направляющей последовательности олигонуклеотидов в плазмиду, содержащую Cas9 и каркас sgRNA (PX330). Направляющие олигонуклеотиды (голубые N) содержат липкие концы для лигирования в пару сайтов BbsI в PS330 с ориентацией на верхнюю и нижнюю нить, совпадающие с данными мишенями генома (т.e. верхний олигонуклеотид находится на 20 п.о. перед последовательностью 5’-NGG в геномной ДНК). Расщепление PX330 BbsI обеспечивает замещение сайтов рестрикции типа IIs (голубой контур) с прямой вставкой отожженных олигонуклеотидов. Стоит отметить, что дополнительный G размещали перед первым основанием направляющей последовательности. Заявители обнаружили, что дополнительный G перед направляющей последовательностью не влияет отрицательно на эффективность целенаправленного воздействия. В случаях, когда выбранная 20-нт направляющая последовательность не начинается с гуанина, дополнительный гуанин обеспечит эффективное транскрибирование sgRNA с помощью промотора U6, для которого предпочтительным является гуанин в первом основании транскрипта.
На фигуре 62A-D показаны ожидаемые результаты мультиплексного NHEJ. (a) Схематическое изображение анализа с помощью SURVEYOR, использованного для определения процентной доли вставок/делеций. В первую очередь, геномную ДНК из гетерогенной популяции клеток с целенаправленно воздействующей Cas9 амплифицировали с помощью ПЦР. Затем ампликоны медленно повторно отжигали для создания гетеродуплексов. Повторно отожженные гетеродуплексы расщепляли с помощью нуклеазы SURVEYOR, в то время как гомодуплексы оставались интактными. Эффективность опосредованного Cas9 расщепления (% вставок/делеций) рассчитывали на основании фракции расщепленной ДНК, которую определяли с помощью интегральной интенсивности полос в геле. (b) Две sgRNA (оранжевая и голубая метки) конструировали для целенаправленного воздействия на локусы GRIN2B и DYRK1A человека. Анализ в геле с помощью SURVEYOR показывал модификации в обоих локусах в трансфицированных клетках. Цветные стрелки указывали на ожидаемые размеры фрагментов для каждого локуса. (c) Пару sgRNA (светло-голубая и зеленая метки) конструировали для вырезания экзона (темно-голубой) в локусе EMX1 человека. Целевые последовательности и PAM (красный) показаны соответствующими цветами, и сайты расщепления отмечены с помощью красного треугольника. Прогнозируемое место соединения показано ниже. Отдельные клоны выделяли из клеточных популяций, трансфицированных sgRNA, 3, 4 или и тот, и другой также анализировали с помощью ПЦР (OUT Fwd, OUT Rev), отображая делецию ~270 п.о. Показаны типичные клоны без модификации (12/23), с моноаллельными (10/23) и биаллельными (1/23) модификациями. IN Fwd и IN Rev праймеры использовали для отображения событий инверсии (фиг. 6d). (d) Количественный анализ клональных линий с делецией в экзоне EMX1. Две пары sgRNA (sgRNA 3.1, 3.2, фланкирующих слева; sgRNA 4.1, 4.2, фланкирующих справа) использовали для опосредования делеций различных размеров возле экзона EMX1. Трансфицированные клетки клонально выделяли и размножали для анализа генотипирования по событиям делеций и инверсий. Из 105 клонов, для которых проводили скрининг, 51 (49%) и 11 (10%) несли гетерозиготные и гомозиготные делеции, соответственно. Даны приблизительные размеры делеций, поскольку места соединения могут различаться.
На фигуре 63A-C показано применение ssODN и вектора для целенаправленного воздействия для опосредования HR и с Cas9 дикого типа, и с мутантной никазой Cas9 в клетках HEK293FT и HUES9 с эффективностями в диапазоне от 1,0 до 27%.
На фигуре 64 показано схематическое изображение способа на основе ПЦР для быстрого и эффективного целенаправленного воздействия CRISPR в клетках млекопитающих. Плазмиду, содержащую промотор U6 РНК-полимеразы III человека, амплифицировали с использованием ПЦР, применяя U6-специфичный прямой праймер и обратный праймер, несущий обратную комплементарную нить части промотора U6, каркас sgRNA(+85) с направляющей последовательностью и 7 T-нуклеотидов для терминации транскрипции. Полученный ПЦР-продукт очищали и доставляли совместно с плазмидой, несущей Cas9, управляемый промотором CBh.
На фигуре 65 показаны результаты использования набора для обнаружения мутаций SURVEYOR от Transgenomics для каждой направляющей РНК и соответствующие контроли. Положительный результат анализа с помощью SURVEYOR представляет собой одну большую полосу, соответствующую геномной ПЦР, и две полосы поменьше, которые являются продуктами нуклеазы SURVEYOR, производящей двухцепочечный разрыв в сайте мутации. Каждую направляющую РНК оценивали в клеточной линии мыши, Neuro-N2a, с помощью липосомальной неустойчивой котрансфекции hSpCas9. Через 72 часа после трансфекции геномную ДНК очищали с применением QuickExtract DNA от Epicentre. ПЦР выполняли для амплификации локуса, представляющего интерес.
На фигуре 66 показаны результаты анализа с помощью Surveyor для 38 живых детенышей (дорожки 1-38),1 мертвого детеныша (дорожка 39) и 1 детеныша дикого типа для сравнения (дорожка 40). Детенышам 1-19 инъецировали gRNA Chd8.2, а детенышам 20-38 инъецировали gRNA Chd8.3. Из 38 живых детенышей 13 были положительными по мутации. У одного мертвого детеныша также была мутация. В образце дикого типа не было обнаружено мутации. ПЦР секвенирование генома соответствовало данным анализа с помощью SURVEYOR.
На фигуре 67 показана структура различных конструкций Cas9-NLS. Все Cas9 представляли собой кодон-оптимизированный для человека вариант Sp Cas9. Последовательности NLS связаны с геном cas9 либо на N-конце, либо на С-конце. Все варианты Cas9 с различными структурами NLS клонировали в вектор, содержащий остов, так что он управлялся промотором EF1a. В этом же векторе находилась химерная РНК, целенаправленно воздействующая на локус EMX1 человека, управляемый промотором U6, формирующим вместе с ней двухкомпонентную систему.
На фигуре 68 показана эффективность расщепления генома, индуцированная вариантами Cas9, несущими различные структуры NLS. Процентная доля указывает часть геномной ДНК EMX1 человека, которая подвергалась расщеплению каждой конструкцией. Все эксперименты получены из 3 биологических повторностей. n = 3, ошибка означает стандартную ошибку среднего.
На фигуре 69A показана структура CRISPR-TF (фактора транскрипции), обладающего функцией активации транскрипции. Химерная РНК экспрессируется с помощью промотора U6, a кодон-оптимизированный для человека вариант двойного мутанта белка Cas9 (hSpCas9m), функционально связанного с трехкомпонентной NLS и функциональным доменом VP64, экспрессируется с помощью промотора EF1a. Двойные мутации, D10A и H840A, делают белок Cas9 неспособным вносить какое-либо расщепление, но поддерживают его способность связываться с целевой ДНК при направлении химерной РНК.
На фигуре 69B показана активация транскрипции гена SOX2 человека системой CRISPR-TF (химерная РНК и слитый белок Cas9-NLS-VP64). Клетки 293FT трансфицировали плазмидами, несущей два компонента: (1) управляемые U6 различные химерные РНК, целенаправленно воздействующие на последовательности из 20 п.о. в локусе генома человека SOX2 или рядом с ним, и (2) управляемый EF1 hSpCas9m (двойной мутант)-слитый белок NLS-VP64. Через 96 часа после трансфекции клетки 293FT собирали и измеряли уровень активации посредством индукции экспрессии мРНК с применением анализа qRT-PCR. Все уровни экспрессии нормированы по сравнению с контрольной группой (серый столбец), представляющей результаты клеток, трансфицированных плазмидой с остовом CRISPR-TF без химерной РНК. Зонды qRT-PCR использовали для выявления мРНК SOX2 при анализе экспрессии генов Taqman Human (Life Technologies). Представлены данные всех экспериментов 3 биологических повторностей, n=3, планки погрешностей показывают стандартную ошибку среднего.
На фигуре 70 изображена оптимизация строения NLS для SpCas9.
На фигуре 71 показана диаграмма "квантиль-квантиль" для последовательностей NGGNN.
На фигуре 72 показана гистограмма плотности данных с подобранным нормальным распределением (черная линия) и квантилем 0,99 (пунктирная линия).
На фигуре 73A-C показана РНК-направляемая репрессия экспрессии bgaA с помощью dgRNA::cas9**. a. Белок Cas9 связывается с tracrRNA и с предшественником РНК CRISPR, который подвергается процессингу РНКазой III с образованием crRNA. crRNA управляет связыванием Cas9 с промотором bgaA и репрессирует транскрипцию. b. Представлены мишени, использованные для направления Cas9** к промотору bgaA. Предполагаемые кодоны -35, -10, а также стартовый кодон bgaA представлены жирным шрифтом. c. Бета-галактозидазная активность как мера в анализе Миллера при отсутствии целенаправленного воздействия и для четырех различных мишеней.
На фигуре 74A-E показана характеристика опосредованной Cas9** репрессии. a. Ген gfpmut2 и его промотор, включающий сигналы -35 и -10, представлены совместно с положением различных целевых сайтов, использованных в данном исследовании. b. Относительная флюоресценция при целенаправленном воздействии на кодирующую нить. c. Относительная флюоресценция при целенаправленном воздействии на некодирующую нить. d. Нозерн-блоттинг с зондами B477 и B478 РНК, экстрагированной из T5, T10, B10 или контрольного штамма без мишени. e. Эффект увеличения количества мутаций на 5’-конце crRNA B1, T5 и B10.
Фигуры приведены в данном документе только в целях иллюстрации, и они не обязательно должны быть изображены в масштабе.
Пдробное описание изобретения
Выражения “полинуклеотид”, “нуклеотид”, “нуклеотидная последовательность”, “нуклеиновая кислота” и “олигонуклеотид” используют взаимозаменяемо. Они обозначают полимерную форму нуклеотидов любой длины, как дезоксирибонуклеотидов, так и рибонуклеотидов или их аналогов. Полинуклеотиды могут обладать любой пространственной структурой и могут выполнять любую функцию, известную или неизвестную. Неограничивающими примерами полинуклеотидов являются следующие: кодирующие или некодирующе участки гена или фрагмента гена, локусы (локус), определенные в результате анализа сцепления, экзоны, интроны, информационная РНК (иРНК), транспортная РНК, рибосомная РНК, короткая интерферирующая РНК (siRNA), короткая шпилечная РНК (shRNA), микроРНК (miRNA), рибозимы, кДНК, рекомбинантные полинуклеотиды, разветвленные полинуклеотиды, плазмиды, векторы, выделенные ДНК любой последовательности, выделенные РНК любой последовательности, зонды для нуклеиновых кислот и праймеры. Полинуклеотид может содержать один или несколько модифицированных нуклеотидов, как, например, метилированные нуклеотиды и аналоги нуклеотидов. При наличии, модификации в нуклеотидную структуру могут быть внесены до или после сборки полимера. Последовательность нуклеотидов может прерываться отличными от нуклеотидов компонентами. Полинуклеотид можно дополнительно модифицировать после полимеризации, как, например, путем конъюгации с компонентом для мечения.
В аспектах настоящего изобретения выражения “химерная РНК”, “химерная направляющая РНК”, “направляющая РНК”, “одиночная направляющая РНК” и “синтетическая направляющая РНК” используют взаимозаменяемо, и они обозначают полинуклеотидную последовательность, содержащую направляющую последовательность, tracr-последовательность и парную tracr-последовательность. Выражение “направляющая последовательность” обозначает последовательность из приблизительно 20 п.о. в пределах направляющей РНК, которая определяет целевой сайт, и ее можно использовать взаимозаменяемо с выражениями “гид” или “спейсер”. Выражение “парная tracr-последовательность” также можно использовать взаимозаменяемо с выражением “прямой(ые) повтор(ы)”.
Используемое в данном документе выражение “дикий тип” является выражением из данной области, понятным специалисту в данной области, и означает типичную форму организма, штамма, гена или характеристики, которые встречаются в природе в отличие от мутантных или вариантных форм.
Используемое в данном документе выражение “вариант” следует понимать как означающее проявление качеств, которые характеризуются паттерном, который отличается от такового, встречающегося в природе.
Выражение “не встречающийся в природе” или “сконструированный” используют взаимозаменяемо, и оно указывает на вмешательство человека. Выражения, в тех случаях, когда они касаются молекул нуклеиновых кислот или полипептидов, означают, что молекула нуклеиновой кислоты или полипептид по меньшей мере практически не содержат по меньшей мере один отличный компонент, с которым они естественным образом связаны в природе и встречаются в природе.
“Комплементарность” означает способность нуклеиновой кислоты образовывать водородную(ые) связь(и) с другой последовательностью нуклеиновой кислоты при помощи либо традиционного спаривания оснований по Уотсону-Крику, либо других нетрадиционных типов. Процент комплементарности показывает процентную долю остатков в молекуле нуклеиновой кислоты, которые могут образовывать водородные связи (к примеру, образование пар по Уотсону-Крику) со второй последовательностью нуклеиновой кислоты (к примеру, при этом 5, 6, 7, 8, 9, 10 из 10 будут на 50%, 60%, 70%, 80%, 90% и 100% комплементарны). “Точная комплементарность” означает, что все граничащие остатки последовательности нуклеиновой кислоты будут связаны водородными связями с тем же количеством граничащих остатков во второй последовательности нуклеиновой кислоты. Выражение “практически комплементарный”, используемое в данном документе, означает степень комплементарности, которая составляет по меньшей мере 60%, 65%, 70%, 75%, 80%, 85%, 90%, 95%, 97%, 98%, 99% или 100% в пределах участка из 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 30, 35, 40, 45, 50 или более нуклеотидов, или относится к двум нуклеиновым кислотам, которые гибиридизируются при жестких условиях.
Используемые в данном документе “жесткие условия” в отношении гибридизации означают условия, при которых нуклеиновая кислота с комплементарностью к целевой последовательности преимущественно гибридизируется с целевой последовательностью и практически не гибридизируется с нецелевыми последовательностями. Жесткие условия, как правило, являются зависимыми от последовательности и изменяются в зависимости от ряда факторов. В общем, чем длиннее последовательность, тем выше температура, при которой последовательность специфично гибридизируется с целевой последовательностью. Неограничивающие примеры жестких условий описаны подробно в Tijssen (1993), Laboratory Techniques In Biochemistry And Molecular Biology-Hybridization With Nucleic Acid Probes Part I, Second Chapter “Overview of principles of hybridization and the strategy of nucleic acid probe assay”, Elsevier, N.Y.
“Гибридизация” означает реакцию, при которой один или несколько полинуклеотидов реагируют с образованием комплекса, который стабилизируется посредством образования водородных связей между основаниями нуклеотидных остатков. Образование водородных связей может происходить по принципу образования пар по Уотсону-Крику, Хугстиновского связывания или любым другим специфичным к последовательности образом. Комплекс может содержать две нити, образующие дуплексную структуру, три или более нитей, образующих многонитевой комплекс, одиночную самогибридизирующуюся нить или любую их комбинацию. Реакция гибридизации может представлять собой стадию в более обширном способе, такую как начальная стадия ПЦР или расщепление полинуклеотида при помощи фермента. Последовательность, способную гибридизироваться с данной последовательностью, называют “комплементарной последовательностью” данной последовательности.
Используемое в данном документе выражение “экспрессия” означает процесс, при котором полинуклеотид транскрибируется с ДНК-матрицы (как, например, в иРНК или другой РНК-транскрипт), и/или способ, при помощи которого транскрибированная иРНК далее транслируется в пептиды, полипептиды или белки. Транскрипты и закодированные полипептиды можно в совокупности называть “продуктом гена”. Если полинуклеотид получен из геномной ДНК, то экспрессия может включать сплайсинг иРНК в эукариотической клетке.
Выражения “полипептид”, “пептид” и “белок” используют взаимозаменяемо в данном документе для обозначения полимеров из аминокислот любой длины. Полимер может быть линейным или разветвленным, он может содержать модифицированные аминокислоты, и его структура может прерываться отличными от аминокислот компонентами. Выражения также охватывают полимер из аминокислот, который был модифицирован; например, образованием дисульфидных связей, гликозилированием, липидизацией, ацетилированием, фосфорилированием или любой другой манипуляцией, такой как соединение с компонентом для мечения. Используемое в данном документе выражение “аминокислота” включает природные и/или неприродные или синтетические аминокислоты, в том числе глицин и как D-, так и L-оптические изомеры, и аналоги аминокислот, и пептидомиметики.
Выражения “субъект”, “индивидуум” и “пациент” используют взаимозаменяемо в данном документе для обозначения позвоночного, предпочтительно млекопитающего, более предпочтительно человека. Млекопитающие включают, без ограничения, мышей, обезьян, людей, сельскохозяйственных животных, животных для спорта и домашних животных. Также охватываются ткани, клетки и их потомство биологического организма, полученные in vivo или культивированные in vitro.
Выражения “терапевтическое средство”, “оказывающее терапевтический эффект средство” или “средство для лечения” используют взаимозаменяемо, и они означают молекулу или соединение, которые оказывают некоторое благоприятное воздействие при введении субъекту. Благоприятное воздействие включает осуществление диагностических определений; облегчение заболевания, симптома, нарушения или патологического состояния; ослабление или предупреждение начала проявления заболевания, симптома, нарушения или состояния; а также общее противодействие заболеванию, симптому, нарушению или патологическому состоянию.
Используемые в данном документе выражения “лечение”, или “осуществление лечения”, или “временное ослабление”, или “облегчение” используют взаимозаменяемо. Эти выражения означают подход для получения благоприятных или желательных результатов, в том числе, без ограничения, терапевтического эффекта и/или профилактического эффекта. Под терапевтическим эффектом понимают любые терапевтически значимые улучшение или действие в отношении одного или нескольких заболеваний, состояний или симптомов при лечении. Для профилактического эффекта композиции можно вводить субъекту с риском развития конкретного заболевания, состояния или симптома или субъекту, который сообщает об одном или нескольких физиологических симптомах заболевания, даже если заболевание, состояние или симптом могли еще не проявиться.
Выражение “эффективное количество” или “терапевтически эффективное количество” означает количество средства, которого достаточно для обеспечения благоприятных или желательных результатов. Терапевтически эффективное количество может изменяться в зависимости от одного или нескольких из: субъекта и болезненного состояния, которые подлежат лечению, веса и возраста субъекта, тяжести болезненного состояния, способа введения и подобного, что специалист в данной области легко может определить. Выражение также применимо к дозе, с помощью которой можно получить изображение для определения любым одним из способов визуализации, описанных в данном документе. Конкретная доза может изменяться в зависимости от одного или нескольких из: конкретного выбранного средства, режима дозирования, которому следуют, того, вводят ли его в комбинации с другими средствами, выбора времени введения, визуализируемой ткани и физической системы доставки, в которой оно заключено.
Практическое применение настоящего изобретения предусматривает, если не указано иное, традиционные методики иммунологии, биохимии, химии, молекулярной биологии, микробиологии, клеточной биологии, геномики и технологию рекомбинантной ДНК, которые находятся в пределах квалификации специалиста в данной области. См. Sambrook, Fritsch and Maniatis, MOLECULAR CLONING: A LABORATORY MANUAL, 2nd edition (1989); CURRENT PROTOCOLS IN MOLECULAR BIOLOGY (F. M. Ausubel, et al. eds., (1987)); серия METHODS IN ENZYMOLOGY (Academic Press, Inc.): PCR 2: A PRACTICAL APPROACH (M.J. MacPherson, B.D. Hames and G.R. Taylor eds. (1995)), Harlow and Lane, eds. (1988) ANTIBODIES, A LABORATORY MANUAL и ANIMAL CELL CULTURE (R.I. Freshney, ed. (1987)).
Некоторые аспекты настоящего изобретения касаются векторных систем, содержащих один или несколько векторов, или векторов как таковых. Векторы могут быть разработаны для экспрессии транскриптов CRISPR (к примеру, транскриптов нуклеиновых кислот, белков или ферментов) в прокариотических или эукариотических клетках. Например, транскрипты CRISPR могут экспрессироваться в бактериальных клетках, как, например, Escherichia coli, клетках насекомых (с использованием бакуловирусных векторов экспрессии), клетках дрожжей или клетках млекопитающих. Подходящие клетки-хозяева дополнительно рассматриваются в Goeddel, GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990). В качестве альтернативы рекомбинантный вектор экспрессии может транскрибироваться и транслироваться in vitro, например, при помощи регуляторных последовательностей промотора T7 и полимеразы T7.
Векторы можно вводить и размножать в прокариоте. В некоторых вариантах осуществления прокариота используют для амплификации копий вектора, который предполагается вводить в эукариотическую клетку, или в качестве промежуточного вектора при получении вектора, который предполагается вводить в эукариотическую клетку (к примеру, путем амплификации плазмиды как части системы упаковки вирусного вектора). В некоторых вариантах осуществления прокариота используют для амплификации копий вектора и экспрессии одной или нескольких нуклеиновых кислот, как, например, для обеспечения источника одного или нескольких белков для доставки в клетку-хозяина или организм-хозяин. Экспрессию белков в прокариотах наиболее часто осуществляют в Escherichia coli с векторами, содержащими конститутивные или индуцибельные промоторы, управляющие экспрессией либо слитых белков, либо отличных от слитых белков. Слитые векторы добавляют некоторое количество аминокислот к белку, закодированному в них, как, например, к амино-концу рекомбинантного белка. Такие слитые векторы могут служить для одной или нескольких целей, как например: (i) для повышения экспрессии рекомбинантного белка; (ii) для повышения растворимости рекомбинантного белка и (iii) для содействия очистке рекомбинантного белка путем функционирования в качестве лиганда при аффинной очистке. Часто в слитые векторы экспрессии сайт протеолитического расщепления вводят в место соединения фрагмента слияния и рекомбинантного белка для облегчения отделения рекомбинантного белка от фрагмента слияния после очистки слитого белка. Такие ферменты и их когнатные распознающие последовательности включают фактор Xa, тромбин и энтерокиназу. Иллюстративные слитые векторы экспрессии включают pGEX (Pharmacia Biotech Inc; Smith and Johnson, 1988. Gene 67: 31-40), pMAL (New England Biolabs, Беверли, Массачусетс) и pRIT5 (Pharmacia, Пискатауэй, Нью-Джерси), в которых глутатион-S-трансфераза (GST), мальтоза-связывающий белок E или белок A, соответственно, слиты с целевым рекомбинантным белком.
Примеры подходящих индуцибельных не являющихся слитыми векторов экспрессии E. coli включают pTrc (Amrann et al., (1988) Gene 69:301-315) и pET 11d (Studier et al., GENE EXPRESSION TECHNOLOGY: METHODS IN ENZYMOLOGY 185, Academic Press, San Diego, Calif. (1990) 60-89).
В некоторых вариантах осуществления вектор является дрожжевым вектором экспрессии. Примеры векторов для экспрессии в дрожжах Saccharomyces cerivisae включают pYepSec1 (Baldari, et al., 1987. EMBO J. 6: 229-234), pMFa (Kuijan and Herskowitz, 1982. Cell 30: 933-943), pJRY88 (Schultz et al., 1987. Gene 54: 113-123), pYES2 (Invitrogen Corporation, Сан-Диего, Калифорния) и picZ (InVitrogen Corp, Сан-Диего, Калифорния).
В некоторых вариантах осуществления вектор управляет экспрессией белка в клетках насекомых с помощью бакуловирусных векторов экспрессии. Бакуловирусные векторы, доступные для экспрессии белков в культивируемых клетках насекомых (к примеру, клетках SF9), включают группу pAc (Smith, et al., 1983. Mol. Cell. Biol. 3: 2156-2165) и группу pVL (Lucklow and Summers, 1989. Virology 170: 31-39).
В некоторых вариантах осуществления вектор способен управлять экспрессией одной или нескольких последовательностей в клетках млекопитающих при помощи вектора экспрессии млекопитающих. Примеры векторов экспрессии млекопитающих включают pCDM8 (Seed, 1987. Nature 329: 840) и pMT2PC (Kaufman, et al., 1987. EMBO J. 6: 187-195). При использовании клеток млекопитающих функции контроля вектора экспрессии, как правило, обеспечиваются одним или несколькими регуляторными элементами. Например, широко используемые промоторы получают из вируса полиомы, аденовируса 2, цитомегаловируса, вируса обезьян 40 и других, раскрыты в данном документе и известны в уровне техники. Что качается других подходящих систем экспрессии как для прокариотических, так и для эукариотических клеток, см., к примеру, главы 16 и 17 в Sambrook, et al., MOLECULAR CLONING: A LABORATORY MANUAL. 2nd ed., Cold Spring Harbor Laboratory, Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y., 1989.
В некоторых вариантах осуществления рекомбинантные векторы экспрессии млекопитающих способны управлять экспрессией нуклеиновой кислоты преимущественно в определенном типе клеток (к примеру, тканеспецифичные регуляторные элементы используют для экспрессии нуклеиновой кислоты). Тканеспецифичные регуляторные элементы известны в уровне техники. Неограничивающие примеры подходящих тканеспецифичных промоторов включают промотор гена альбумина (печень-специфичный; Pinkert, et al., 1987. Genes Dev. 1: 268-277), специфичные к лимфоидной ткани промоторы (Calame and Eaton, 1988. Adv. Immunol. 43: 235-275), в частности, промоторы рецепторов T-клеток (Winoto and Baltimore, 1989. EMBO J. 8: 729-733) и иммуноглобулины (Baneiji, et al., 1983. Cell 33: 729-740; Queen and Baltimore, 1983. Cell 33: 741-748), нейрон-специфичные промоторы (к примеру, промотор гена нейрофиламента; Byrne and Ruddle, 1989. Proc. Natl. Acad. Sci. USA 86: 5473-5477), специфичные к клеткам поджелудочной железы промоторы (Edlund, et al., 1985. Science 230: 912-916) и специфичные к клеткам молочной железы промоторы (к примеру, промотор молочной сыворотки; патент США № 4873316 и публикация европейской заявки № 264166). Регулируемые стадией развития промоторы также охвачены, к примеру, промоторы генов hox мыши (Kessel and Gruss, 1990. Science 249: 374-379) и промотор гена α-фетопротеина (Campes and Tilghman, 1989. Genes Dev. 3: 537-546).
В некоторых вариантах осуществления регуляторный элемент является функционально связанным с одним или несколькими элементами системы CRISPR с тем, чтобы управлять экспрессией одного или нескольких элементов системы CRISPR. В целом, CRISPR (короткие палиндромные повторы, регулярно расположенные группами), также известные как SPIDR (прерываемые спейсерами прямые повторы), составляют семейство локусов ДНК, которые, как правило, специфичны для определенного вида бактерий. Локус CRISPR включает определенный класс чередующихся коротких повторов последовательностей (SSR), которые были обнаружены у E. coli (Ishino et al., J. Bacteriol., 169:5429-5433 [1987]; and Nakata et al., J. Bacteriol., 171:3553-3556 [1989]), и ассоциированные гены. Подобные чередующиеся SSR были идентифицированы у Haloferax mediterranei, Streptococcus pyogenes, Anabaena и Mycobacterium tuberculosis (см., Groenen et al., Mol. Microbiol., 10:1057-1065 [1993]; Hoe et al., Emerg. Infect. Dis., 5:254-263 [1999]; Masepohl et al., Biochim. Biophys. Acta 1307:26-30 [1996]; и Mojica et al., Mol. Microbiol., 17:85-93 [1995]). Локусы CRISPR, как правило, отличаются от других SSR по структуре повторов, которые были названы короткими повторами с регулярными интервалами (SRSR) (Janssen et al., OMICS J. Integ. Biol., 6:23-33 [2002]; и Mojica et al., Mol. Microbiol., 36:244-246 [2000]). В целом, повторы являются короткими элементами, которые встречаются группами, которые регулярно разделены уникальными вставочными последовательностями с практически постоянной длинной (Mojica et al., [2000], выше). Несмотря на то, что последовательности повторов высоко консервативны между штаммами, некоторое количество чередующихся повторов и последовательностей спейсерных участков, как правило, отличаются от штамма к штамму (van Embden et al., J. Bacteriol., 182:2393-2401 [2000]). Локусы CRISPR были идентифицированы у более чем 40 видов прокариот (см., к примеру, Jansen et al., Mol. Microbiol., 43:1565-1575 [2002]; и Mojica et al., [2005]), в том числе, без ограничения, Aeropyrum, Pyrobaculum, Sulfolobus, Archaeoglobus, Halocarcula, Methanobacterium, Methanococcus, Methanosarcina, Methanopyrus, Pyrococcus, Picrophilus, Thermoplasma, Corynebacterium, Mycobacterium, Streptomyces, Aquifex, Porphyromonas, Chlorobium, Thermus, Bacillus, Listeria, Staphylococcus, Clostridium, Thermoanaerobacter, Mycoplasma, Fusobacterium, Azarcus, Chromobacterium, Neisseria, Nitrosomonas, Desulfovibrio, Geobacter, Myxococcus, Campylobacter, Wolinella, Acinetobacter, Erwinia, Escherichia, Legionella, Methylococcus, Pasteurella, Photobacterium, Salmonella, Xanthomonas, Yersinia, Treponema и Thermotoga.
В целом, “система CRISPR” означает в совокупности транскрипты и другие элементы, участвующие в экспрессии CRISPR-ассоциированных (“Cas”) генов или управлении их активностью, в том числе последовательности, кодирующие ген Cas, tracr (транс-активируемую CRISPR) последовательность (к примеру, tracrRNA или активную частичную tracrRNA), парную tracr-последовательность (охватывающую “прямой повтор” и tracrRNA-процессированный неполный прямой повтор в контексте эндогенной системы CRISPR), направляющую последовательность (также называемую “спейсером” в контексте эндогенной системы CRISPR) или другие последовательности и транскрипты с локуса CRISPR. В некоторых вариантах осуществления один или несколько элементов системы CRISPR получены из системы CRISPR I типа, II типа или III типа. В некоторых вариантах осуществления один или несколько элементов системы CRISPR получены из определенного организма, содержащего эндогенную систему CRISPR, как, например, Streptococcus pyogenes. В целом, система CRISPR характеризуется элементами, которые способствуют образованию комплекса CRISPR на сайте целевой последовательности (также называемой протоспейсером в контексте эндогенной системы CRISPR). В контексте образования комплекса CRISPR “целевая последовательность” означает последовательность, по отношению к которой направляющая последовательность разработана так, чтобы обладать комплементарностью, где гибридизация между целевой последовательностью и направляющей последовательностью способствует образованию комплекса CRISPR. Полная комплементарность не обязательна при условии, что имеет место достаточная комплементарность для осуществления гибридизации и способствования образованию комплекса CRISPR. Целевая последовательность может содержать любой полинуклеотид, как, например, ДНК- или РНК-полинуклеотиды. В некоторых вариантах осуществления целевая последовательность расположена в ядре или цитоплазме клетки. В некоторых вариантах осуществления целевая последовательность может находиться в органелле эукариотической клетки, например, митохондрии или хлоропласте. Последовательность или матрицу, которую можно применять для рекомбинации в целевом локусе, содержащем целевые последовательности, называют “матрицей редактирования”, или “полинуклеотидом для редактирования”, или “последовательностью для редактирования”. В аспекте настоящего изобретения экзогенный матричный полинуклеотид можно называть матрицей редактирования. В одном аспекте настоящего изобретения рекомбинация является гомологичной рекомбинацией.
Как правило, в контексте эндогенной системы CRISPR образование комплекса CRISPR (содержащего направляющую последовательность, гибридизирующуюся с целевой последовательностью и образующую комплекс с одним или несколькими белками Cas) приводит к расщеплению одной или обеих нитей в или около (к примеру, в пределах 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 20, 50 или более пар оснований от) целевой последовательности. Не желая быть связанными теорией, полагают, что tracr-последовательность, которая может содержать или состоять из всей или части tracr-последовательности дикого типа (к примеру, приблизительно или более чем приблизительно 20, 26, 32, 45, 48, 54, 63, 67, 85 или более нуклеотидов tracr-последовательности дикого типа), может также образовывать часть комплекса CRISPR, как, например, путем гибридизации вдоль по меньшей мере части tracr-последовательности со всей или частью парной tracr-последовательности, которая функционально связана с направляющей последовательностью. В некоторых вариантах осуществления tracr-последовательность обладает достаточной комплементарностью с парной tracr-последовательностью для гибридизации и участия в образовании комплекса CRISPR. Как и в случае с целевой последовательностью, полагают, что полная комплементарность не является необходимой при условии, что она является достаточной для выполнения функции. В некоторых вариантах осуществления tracr-последовательность характеризуется по меньшей мере 50%, 60%, 70%, 80%, 90%, 95% или 99% комплементарности последовательности по длине парной tracr-последовательности при оптимальном выравнивании. В некоторых вариантах осуществления один или несколько векторов, управляющих экспрессией одного или нескольких элементов системы CRISPR, вводят в клетку-хозяина, так что экспрессия элементов системы CRISPR управляет образованием комплекса CRISPR на одном или нескольких целевых сайтах. Например, каждое из фермента Cas, направляющей последовательности, связанной с парной tracr-последовательностью, и tracr-последовательности может быть функционально связано с отдельными регуляторными элементами в отдельных векторах. В качестве альтернативы, два или более элементов, экспрессируемых с одних и тех же или различных регуляторных элементов, можно объединять в одном векторе, с одним или несколькими дополнительными векторами, обеспечивая любые компоненты системы CRISPR, не включенные в первый вектор. Элементы системы CRISPR, которые объединены в один вектор, могут быть расположены в любой удобной ориентации, как, например, один элемент, расположенный 5’ (“выше”) относительно или 3’ (“ниже”) относительно второго элемента. Кодирующая последовательность одного элемента может быть расположена на той же или противоположной нити кодирующей последовательности второго элемента и направлена в том же или противоположном направлении. В некоторых вариантах осуществления один промотор управляет экспрессией транскрипта, кодирующего фермент CRISPR, и одной или нескольких из направляющей последовательности, парной tracr-последовательности (необязательно функционально связанной с направляющей последовательностью) и tracr-последовательности, встроенных в одну или несколько интронных последовательностей (к примеру, каждая в разном интроне, две или более по меньшей мере в одном интроне или все в одном интроне). В некоторых вариантах осуществления фермент CRISPR, направляющая последовательность, парная tracr-последовательность и tracr-последовательность функционально связаны с одним и тем же промотором и экспрессируются с него.
В некоторых вариантах осуществления вектор содержит один или несколько сайтов встраивания, как, например, последовательность узнавания рестрикционной эндонуклеазой (также называемая “сайтом клонирования”). В некоторых вариантах осуществления один или несколько сайтов встраивания (к примеру, приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или более сайтов встраивания) расположены выше и/или ниже одного или нескольких элементов последовательности одного или нескольких векторов. В некоторых вариантах осуществления вектор содержит сайт встраивания выше парной tracr-последовательности и необязательно ниже регуляторного элемента, функционально связанного с парной tracr-последовательностью, так что после встраивания направляющей последовательности в сайт встраивания и при экспрессии направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR с целевой последовательностью в эукариотической клетке. В некоторых вариантах осуществления вектор содержит два или более сайта встраивания, при этом каждый сайт встраивания расположен между двумя парными tracr-последовательностями с тем, чтобы обеспечить возможность встраивания направляющей последовательности в каждый сайт. В таком расположении две или более направляющие последовательности могут содержать две или более копий одной направляющей последовательности, две или более различных направляющих последовательностей или их комбинации. В тех случаях, когда применяют несколько различных направляющих последовательностей, может быть использована одна экспрессирующая конструкция для целенаправленного воздействия активности CRISPR на несколько различных соответствующих целевых последовательностей в клетке. Например, один вектор может содержать приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20 или более направляющих последовательностей. В некоторых вариантах осуществления приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или более таких содержащих направляющие последовательности векторов могут быть предусмотрены и необязательно доставлены в клетку.
В некоторых вариантах осуществления вектор содержит регуляторный элемент, функционально связанный с кодирующей фермент последовательностью, кодирующей фермент CRISPR, как, например, белок Cas. Неограничивающие примеры белков Cas включают Cas1, Cas1B, Cas2, Cas3, Cas4, Cas5, Cas6, Cas7, Cas8, Cas9 (также известный как Csn1 и Csx12), Cas10, Csy1, Csy2, Csy3, Cse1, Cse2, Csc1, Csc2, Csa5, Csn2, Csm2, Csm3, Csm4, Csm5, Csm6, Cmr1, Cmr3, Cmr4, Cmr5, Cmr6, Csb1, Csb2, Csb3, Csx17, Csx14, Csx10, Csx16, CsaX, Csx3, Csx1, Csx15, Csf1, Csf2, Csf3, Csf4, их гомологи или их модифицированные варианты. Эти ферменты известны; например, аминокислотную последовательность белка Cas9 S. pyogenes можно найти в базе данных SwissProt под номером доступа Q99ZW2. В некоторых вариантах осуществления немодифицированный фермент CRISPR обладает активностью для расщепления ДНК, как, например, Cas9. В некоторых вариантах осуществления фермент CRISPR представляет собой Cas9, и им может быть Cas9 из S. pyogenes или S. pneumoniae. В некоторых вариантах осуществления фермент CRISPR управляет расщеплением одной или обеих нитей в определенной точке целевой последовательности, как, например, в пределах целевой последовательности и/или в пределах комплементарной последовательности целевой последовательности. В некоторых вариантах осуществления фермент CRISPR управляет расщеплением одной или обеих нитей в пределах приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 15, 20, 25, 50, 100, 200, 500 или более пар оснований от первого или последнего нуклеотида целевой последовательности. В некоторых вариантах осуществления вектор кодирует фермент CRISPR, который является мутированным по отношению к соответствующему ферменту дикого типа, так что у мутированного фермента CRISPR отсутствует способность расщеплять одну или обе нити целевого полинуклеотида, содержащего целевую последовательность. Например, замена аспартата на аланин (D10A) в каталитическом домене RuvC I Cas9 из S. pyogenes трансформирует Cas9 из нуклеазы, которая расщепляет обе нити, в никазу (расщепляет одну нить). Другие примеры мутаций, которые превращают Cas9 в никазу, включают, без ограничения, H840A, N854A и N863A. В некоторых вариантах осуществления никазу Cas9 можно использовать в комбинации с направляющей(ими) последовательностью(ями), к примеру, двумя направляющими последовательностями, которые целенаправленно воздействуют, соответственно, на смысловую и антисмысловую нити ДНК-мишени. Эта комбинация позволяет надрезать обе нити и использовать их для индукции NHEJ. Авторы данной заявки показали (данные не показаны) эффективность двух мишеней для никаз (т.е. sgRNA, целенаправленно воздействующие на одну и ту же точку, но на различные нити ДНК) при индуцировании мутагенного NHEJ. Одиночная никаза (Cas9-D10A с одной sgRNA) не способна индуцировать NHEJ и создавать вставки/делеции, но авторы данной заявки показали, что двойная никаза (Cas9-D10A и две sgRNA, целенаправленно воздействующие на различные нити в одной и той же точке) способна делать это в эмбриональных стволовых клетках человека (hESC). Эффективность составляет приблизительно 50% таковой нуклеазы (т.е. нормального Cas9 без мутации D10) в hESC.
В качестве дополнительного примера два или более каталитических доменов Cas9 (RuvC I, RuvC II и RuvC III) можно подвергать мутациям с получением мутированного Cas9, у которого практически отсутствует вся активность для расщепления ДНК. В некоторых вариантах осуществления мутацию D10A объединяют с одной или несколькими из мутаций H840A, N854A или N863A с получением фермента Cas9, у которого практически отсутствует вся активность для расщепления ДНК. В некоторых вариантах осуществления фермент CRISPR рассматривают как такой, у которого практически отсутствует вся активность для расщепления ДНК, в случаях, когда активность для расщепления ДНК мутированного фермента составляет менее приблизительно 25%, 10%, 5%, 1%, 0,1%, 0,01% или меньше по отношению к его не мутированной форме. Могут быть целесообразными другие мутации; в тех случаях, когда Cas9 или другой фермент CRISPR получен из вида, отличного от S. pyogenes, могут быть произведены мутации в соответствующих аминокислотах для достижения подобных эффектов.
В некоторых вариантах осуществления кодирующая фермент последовательность, кодирующая фермент CRISPR, является кодон-оптимизированной для экспрессии в определенных клетках, как, например, эукариотических клетках. Эукариотические клетки могут быть клетками определенного организма или полученными из него, как, например, млекопитающего, в том числе, без ограничения, человека, мыши, крысы, кролика, собаки или отличного от человека примата. В целом, оптимизация кодонов означает способ модификации последовательности нуклеиновой кислоты для повышения экспрессии в представляющих интерес клетках-хозяевах путем замещения по меньшей мере одного кодона (к примеру, приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 10, 15, 20, 25, 50 или более кодонов) нативной последовательности кодонами, которые чаще или наиболее часто используют в генах этой клетки-хозяина, в то же время сохраняя нативную аминокислотную последовательность. Разные виды проявляют определенное "предпочтение" в отношении конкретных кодонов определенной аминокислоты. "Предпочтение" кодонов (различия в частоте использования кодонов между организмами) часто соотносят с эффективностью трансляции информационной РНК (иРНК), которая, в свою очередь, как полагают, зависит, среди прочего, от свойств кодонов, которые транслируются, и доступности конкретных молекул транспортной РНК (тРНК). Преобладание выбранных тРНК в клетке, как правило, является отражением кодонов, используемых наиболее часто при синтезе пептидов. Соответственно, гены могут быть приспособлены для оптимальной экспрессии генов в данном организме с использованием оптимизации кодонов. Таблицы частоты использования кодонов общедоступны, например, в "Базе данных частот использования кодонов" (“Codon Usage Database”), и эти таблицы можно адаптировать различными способами. См. Nakamura, Y., et al. “Codon usage tabulated from the international DNA sequence databases: status for the year 2000” Nucl. Acids Res. 28:292 (2000). Также доступны компьютерные алгоритмы для оптимизации кодонов определенной последовательности для экспрессии в определенной клетке-хозяине, как, например, также доступный Gene Forge (Aptagen; Джакобус, Пенсильвания). В некоторых вариантах осуществления один или несколько кодонов (к примеру, 1, 2, 3, 4, 5, 10, 15, 20, 25, 50 или более или все кодоны) в последовательности, кодирующей фермент CRISPR, соответствуют наиболее часто используемому кодону для определенной аминокислоты.
В некоторых вариантах осуществления вектор кодирует фермент CRISPR, содержащий одну или несколько последовательностей ядерной локализации (NLS), как, например, приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или более NLS. В некоторых вариантах осуществления фермент CRISPR содержит приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или более NLS на амино-конце или рядом с ним, приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или более NLS на карбокси-конце или рядом с ним или комбинацию этого (к примеру, одну или несколько NLS на амино-конце и одну или несколько NLS на карбокси-конце). В тех случаях, когда присутствуют несколько NLS, каждая может быть выбрана независимо от других, так что одна NLS может присутствовать в нескольких копиях и/или в комбинации с одной или несколькими другими NLS, присутствующими в одной или нескольких копиях. В предпочтительном варианте осуществления настоящего изобретения фермент CRISPR содержит самое большее 6 NLS. В некоторых вариантах осуществления считают, что NLS находится рядом с N- или C-концом в тех случаях, когда самая близкая аминокислота NLS находится в пределах приблизительно 1, 2, 3, 4, 5, 10, 15, 20, 25, 30, 40, 50 или более аминокислот вдоль полипетидной цепи от N- или C-конца. Обычно, NLS состоит из одной или нескольких коротких последовательностей положительно заряженных молекул лизина или аргинина, расположенных на поверхности белка, но известны другие типы NLS. Неограничивающие примеры NLS включают NLS-последовательности, полученные из: NLS из большого Т-антигена вируса SV40 с аминокислотной последовательностью PKKKRKV; NLS из нуклеоплазмина (к примеру, двойной NLS из нуклеоплазмина с последовательностью KRPAATKKAGQAKKKK); NLS из c-myc с аминокислотной последовательностью PAAKRVKLD или RQRRNELKRSP; NLS из hRNPA1 M9 с последовательностью NQSSNFGPMKGGNFGGRSSGPYGGGGQYFAKPRNQGGY; последовательность RMRIZFKNKGKDTAELRRRRVEVSVELRKAKKDEQILKRRNV домена IBB из импортина-альфа; последовательности VSRKRPRP и PPKKARED из Т-белка миомы; последовательность POPKKKPL из p53 человека; последовательность SALIKKKKKMAP из c-abl IV мыши; последовательности DRLRR и PKQKKRK из NS1 вируса гриппа; последовательность RKLKKKIKKL из дельта-антигена вируса гепатита; последовательность REKKKFLKRR из белка Mx1 мыши; последовательность KRKGDEVDGVDEVAKKKSKK из поли(АДФ-рибоза)-полимеразы человека и последовательность RKCLQAGMNLEARKTKK из рецепторов стероидных гормонов для глюкокортикоидов (человека).
В целом, одна или несколько NLS являются достаточно эффективными, чтобы управлять накоплением фермента CRISPR в обнаруживаемом количестве в ядре эукариотической клетки. В целом, степень проявления активности ядерной локализации может быть результатом следующего: количества NLS в ферменте CRISPR, конкретных(ой) используемых(ой) NLS или комбинации этих факторов. Обнаружение накопления в ядре можно выполнять при помощи любой подходящей методики. Например, детектируемый маркер может быть слит с ферментом CRISPR, так что расположение в клетке может быть визуализировано, как, например, в комбинации со средствами для обнаружения расположения ядра (к примеру, окрашивающим средством, специфичным к ядру, таким как DAPI). Примеры детектируемых маркеров включают флуоресцентные белки (такие как зеленые флуоресцентные белки или GFP; RFP; CFP) и эпитопные метки (HA-метку, flag-метку, SNAP-метку). Ядра клеток также можно выделять из клеток, содержимое которых можно затем анализировать при помощи любого подходящего способа для обнаружения белка, как, например, иммуногистохимии, вестерн-блоттинга или анализа на активность фермента. Накопление в ядре также можно определить опосредованно, как, например, при помощи анализа действия образования комплекса CRISPR (к примеру, анализа на расщепление ДНК или мутацию в целевой последовательности или анализа на измененную при помощи образования комплекса CRISPR и/или активности фермента CRISPR активность экспрессии генов) по сравнению с контролем, который не подвергали воздействию фермента или комплекса CRISPR или подвергали воздействию фермента CRISPR, у которого отсутствуют одна или несколько NLS.
В целом, направляющая последовательность представляет собой любую полинуклеотидную последовательностью, обладающую достаточной комплементарностью с целевой полинуклеотидной последовательностью для гибридизации с целевой последовательностью и управления специфичным к последовательности связыванием комплекса CRISPR с целевой последовательностью. В некоторых вариантах осуществления степень комплементарности между направляющей последовательностью и ее соответствующей целевой последовательностью при оптимальном выравнивании с использованием подходящего алгоритма выравнивания составляет приблизительно или более чем приблизительно 50%, 60%, 75%, 80%, 85%, 90%, 95%, 97,5%, 99% или более. Оптимальное выравнивание можно определять при помощи любого подходящего алгоритма для выравниваемых последовательностей, неограничивающие примеры которого включают алгоритм Смита-Ватермана, алгоритм Нидлмана-Вунша, алгоритмы, основанные на преобразовании Барроуза-Уилера (к примеру, Burrows Wheeler Aligner), ClustalW, Clustal X, BLAT, Novoalign (Novocraft Technologies), ELAND (Illumina, Сан-Диего, Калифорния), SOAP (доступный на soap.genomics.org.cn) и Maq (доступный на maq.sourceforge.net). В некоторых вариантах осуществления направляющая последовательность составляет приблизительно или более чем приблизительно 5, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 35, 40, 45, 50, 75 или более нуклеотидов в длину. В некоторых вариантах осуществления направляющая последовательность составляет менее чем приблизительно 75, 50, 45, 40, 35, 30, 25, 20, 15, 12 или менее нуклеотидов в длину. Способность направляющей последовательности управлять специфичным к последовательности связыванием комплекса CRISPR с целевой последовательностью можно оценить при помощи любого подходящего анализа. Например, компоненты системы CRISPR, достаточные для образования комплекса CRISPR, в том числе направляющая последовательность, которую необходимо исследовать, могут быть доставлены в клетку-хозяина с соответствующей целевой последовательностью, как, например, при помощи трансфекции векторами, кодирующими компоненты последовательности CRISPR, с последующей оценкой предпочтительного расщепления в пределах целевой последовательности, как, например, при помощи анализа с помощью Surveyor, который описан в данном документе. Подобным образом, расщепление целевой полинуклеотидной последовательности может быть установлено в пробирке путем обеспечения целевой последовательности, компонентов комплекса CRISPR, в том числе направляющей последовательности, которую необходимо исследовать, и контрольной направляющей последовательности, отличной от тестовой направляющей последовательности, и сравнения воздействий тестовой и контрольной направляющей последовательности на связывание или скорость расщепления целевой последовательности. Другие анализы возможны и будут очевидны специалисту в данной области.
Направляющая последовательность может быть выбрана для целенаправленного воздействия на любую целевую последовательность. В некоторых вариантах осуществления целевая последовательность является последовательностью в пределах генома клетки. Иллюстративные целевые последовательности включают те, которые являются уникальными в целевом геноме. Например, для Cas9 S. pyogenes уникальная целевая последовательность в геноме может включать целевой сайт для Cas9 в виде MMMMMMMMNNNNNNNNNNNNXGG, где NNNNNNNNNNNNXGG (N представляет собой A, G, T или C; и X может быть любым) характеризуется единичным появлением в геноме. Уникальная целевая последовательность в геноме может включать целевой сайт для Cas9 S. pyogenes в виде MMMMMMMMMNNNNNNNNNNNXGG, где NNNNNNNNNNNXGG (N представляет собой A, G, T или C; и X может быть любым) характеризуется единичным появлением в геноме. Для Cas9 CRISPR1 S. thermophilus уникальная целевая последовательность в геноме может включать целевой сайт для Cas9 в виде MMMMMMMMNNNNNNNNNNNNXXAGAAW, где NNNNNNNNNNNNXXAGAAW (N представляет собой A, G, T или C; X может быть любым; и W представляет собой A или T) характеризуется единичным появлением в геноме. Уникальная целевая последовательность в геноме может включать целевой сайт для Cas9 CRISPR1 S. thermophilus в виде MMMMMMMMMNNNNNNNNNNNXXAGAAW, где NNNNNNNNNNNXXAGAAW (N представляет собой A, G, T или C; X может быть любым; и W представляет собой A или T) характеризуется единичным появлением в геноме. Для Cas9 S. pyogenes уникальная целевая последовательность в геноме может включать целевой сайт для Cas9 в виде MMMMMMMMNNNNNNNNNNNNXGGXG, где NNNNNNNNNNNNXGGXG (N представляет собой A, G, T или C; и X может быть любым) характеризуется единичным появлением в геноме. Уникальная целевая последовательность в геноме может включать целевой сайт для Cas9 S. pyogenes в виде MMMMMMMMMNNNNNNNNNNNXGGXG, где NNNNNNNNNNNXGGXG (N представляет собой A, G, T или C; и X может быть любым) характеризуется единичным появлением в геноме. В каждой из этих последовательностей “M” может представлять собой A, G, T или C и не должен учитываться при идентификации последовательности как уникальной.
В некоторых вариантах осуществления направляющая последовательность выбрана для снижения доли вторичной структуры в направляющей последовательности. Вторичную структуру можно определить при помощи любого подходящего алгоритма сворачивания полинуклеотида. Некоторые программы основаны на вычислении минимальной свободной энергии Гиббса. Примером одного такого алгоритма является mFold, который описан Zuker и Stiegler (Nucleic Acids Res. 9 (1981), 133-148). Другим примером алгоритма сворачивания является доступный в режиме онлайн веб-сервер RNAfold, разработанный в Институте теоретической химии при Венском университете, использующий алгоритм прогнозирования структуры на основе центроидного метода (см., к примеру, A.R. Gruber et al., 2008, Cell 106(1): 23-24; and PA Carr and GM Church, 2009, Nature Biotechnology 27(12): 1151-62). Дополнительные алгоритмы можно найти в заявке на патент США с серийным номером TBA (номер дела у патентного поверенного 44790.11.2022; общая ссылка BI-2013/004A); включенной в данный документ при помощи ссылки.
В общем, парная tracr-последовательность включает любую последовательность, которая характеризуется достаточной комплементарностью с tracr-последовательностью для содействия одному или нескольким из: (1) вырезания направляющей последовательности, фланкированной парными tracr-последовательностями, в клетке, содержащей соответствующую tracr-последовательность; и (2) образования комплекса CRISPR на целевой последовательности, где комплекс CRISPR содержит парную tracr-последовательность, гибридизирующуюся с tracr-последовательностью. В общем, степень комплементарности указана на основании оптимального выравнивания парной tracr-последовательности и tracr-последовательности по длине более короткой из двух последовательностей. Оптимальное выравнивание можно определить при помощи любого подходящего алгоритма выравнивания и можно дополнительно высчитать для вторичных структур, как, например, самокомплементарность в пределах либо tracr-последовательности, либо парной tracr-последовательности. В некоторых вариантах осуществления степень комплементарности между tracr-последовательностью и парной tracr-последовательностью по длине более короткой из двух при оптимальном выравнивании составляет приблизительно или более чем приблизительно 25%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 95%, 97,5%, 99% или более. Примерные иллюстрации оптимального выравнивания между tracr-последовательностью и парной tracr-последовательностью представлены на фигурах 12B и 13B. В некоторых вариантах осуществления tracr-последовательность составляет приблизительно или более чем приблизительно 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 25, 30, 40, 50 или более нуклеотидов в длину. В некоторых вариантах осуществления tracr-последовательность и парная tracr-последовательность содержатся в одном транскрипте, так что гибридизация между ними двумя дает транскрипт со вторичной структурой, такой как "шпилька". Предпочтительные петлеобразующие последовательности для использования в "шпилечных" структурах составляют четыре нуклеотида в длину и наиболее предпочтительно имеют последовательность GAAA. Однако, можно использовать более короткие или длинные последовательности петли, а также альтернативные последовательности. Последовательности предпочтительно включают нуклеотидный триплет (например, AAA) и дополнительный нуклеотид (например, C или G). Примеры петлеобразующих последовательностей включают CAAA и AAAG. В одном варианте осуществления настоящего изобретения траснкрипт или транскрибированная полинуклеотидная последовательность характеризуются по меньшей мере двумя или более "шпильками". В предпочтительных вариантах осуществления транскрипт характеризуется двумя, тремя, четырьмя или пятью "шпильками". В дополнительном варианте осуществления настоящего изобретения транскрипт характеризуется самое большее пятью "шпильками". В некоторых вариантах осуществления один транскрипт дополнительно включает последовательность терминации транскрипции; предпочтительно она является полиТ-последовательностью, например, из шести нуклеотидов T. Примерная иллюстрация такой "шпилечной" структуры представлена в нижней части фигуры 13B, где часть последовательности в 5’ направлении по отношению к концевому “N” и выше петли соответствует парной tracr-последовательности, а часть последовательности в 3’ направлении по отношению к петле соответствует tracr-последовательности. Дополнительными неограничивающими примерами отдельных полинуклеотидов, содержащих направляющую последовательность, парную tracr-последовательность и tracr-последовательность, являются следующие (перечисленные от 5’ к 3’), где “N” представляет собой основание направляющей последовательности, первый блок букв нижнего регистра представляет собой парную tracr-последовательность, а второй блок букв нижнего регистра представляет собой tracr-последовательность, и конечная поли-T-последовательность представляет собой терминатор транскрипции: (1) NNNNNNNNNNNNNNNNNNNNgtttttgtactctcaagatttaGAAAtaaatcttgcagaagctacaaagataaggcttcatgccgaaatcaacaccctgtcattttatggcagggtgttttcgttatttaaTTTTTT; (2) NNNNNNNNNNNNNNNNNNNNgtttttgtactctcaGAAAtgcagaagctacaaagataaggcttcatgccgaaatcaacaccctgtcattttatggcagggtgttttcgttatttaaTTTTTT; (3) NNNNNNNNNNNNNNNNNNNNgtttttgtactctcaGAAAtgcagaagctacaaagataaggcttcatgccgaaatcaacaccctgtcattttatggcagggtgtTTTTTT; (4) NNNNNNNNNNNNNNNNNNNNgttttagagctaGAAAtagcaagttaaaataaggctagtccgttatcaacttgaaaaagtggcaccgagtcggtgcTTTTTT; (5) NNNNNNNNNNNNNNNNNNNNgttttagagctaGAAATAGcaagttaaaataaggctagtccgttatcaacttgaaaaagtgTTTTTTT и (6) NNNNNNNNNNNNNNNNNNNNgttttagagctagAAATAGcaagttaaaataaggctagtccgttatcaTTTTTTTT. В некоторых вариантах осуществления последовательности (1)-(3) используют в комбинации с Cas9 из CRISPR1 S. thermophilus. В некоторых вариантах осуществления последовательности (4)-(6) используют в комбинации с Cas9 из S. pyogenes. В некоторых вариантах осуществления tracr-последовательность является транскриптом, отдельным от транскрипта, содержащего парную tracr-последовательность (как, например, показанная в верхней части фигуры 13B).
В некоторых вариантах осуществления также предусмотрена матрица для рекомбинации. Матрица для рекомбинации может быть компонентом другого вектора, который описан в данном документе, может содержаться в отдельном векторе или предусматриваться в качестве отдельного полинуклеотида. В некоторых вариантах осуществления матрица для рекомбинации разработана так, чтобы служить в качестве матрицы при гомологичной рекомбинации, как, например, в пределах или рядом с целевой последовательностью, надрезанной или расщепленной ферментом CRISPR, в качестве части комплекса CRISPR. Матричный полинуклеотид может быть любой подходящей длины, как, например, приблизительно или более чем приблизительно 10, 15, 20, 25, 50, 75, 100, 150, 200, 500, 1000 или более нуклеотидов в длину. В некоторых вариантах осуществления матричный полинуклеотид комплементарен части полинуклеотида, содержащего целевую последовательность. При оптимальном выравнивании матричный полинуклеотид может перекрываться с одним или несколькими нуклеотидами целевых последовательностей (к примеру, с приблизительно или более чем приблизительно 1, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 60, 70, 80, 90, 100 или более нуклеотидами). В некоторых вариантах осуществления при оптимальном выравнивании матричных последовательности и полинуклеотида, содержащего целевую последовательность, наиболее близкий нуклеотид матричного полинуклеотида находится в пределах приблизительно 1, 5, 10, 15, 20, 25, 50, 75, 100, 200, 300, 400, 500, 1000, 5000, 10000 или более нуклеотидов от целевой последовательности.
В некоторых вариантах осуществления фермент CRISPR является частью слитого белка, содержащего один или несколько доменов гетерологичного белка (к примеру, приблизительно или более чем приблизительно 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или более доменов в дополнение к ферменту CRISPR). Слитый белок, содержащий фермент CRISPR, может содержать любую дополнительную последовательность белка и необязательно линкерную последовательность между любыми двумя доменами. Примеры белковых доменов, которые могут быть слиты с ферментом CRISPR, включают, без ограничения, эпитопные метки, последовательности генов-репортеров и белковые домены с одним или несколькими из следующих видов активности: метилазной активности, деметилазной активности, активности для активации транскрипции, активности для репрессии транскрипции, активности фактора освобождения при транскрипции, активности для модификации гистонов, активности для расщепления ДНК и активности для связывания нуклеиновой кислоты. Неограничивающие примеры эпитопных меток включают гистидиновые (His) метки, V5-метки, FLAG-метки, метки гемагглютинина вируса гриппа (HA), Myc-метки, VSV-G-метки и тиоредоксиновые (Trx) метки. Примеры генов-репортеров включают, без ограничения, глутатион-S-трансферазу (GST), пероксидазу хрена (HRP), хлорамфеникол-ацетилтрансферазу (CAT), бета-галактозидазу, бета-глюкуронидазу, люциферазу, зеленый флуоресцентный белок (GFP), HcRed, DsRed, голубой флуоресцентный белок (CFP), желтый флуоресцентный белок (YFP) и автофлуорисцирующие белки, в том числе синий флуоресцентный белок (BFP). Фермент CRISPR может быть слит с последовательностью гена, кодирующей белок или фрагмент белка, которые связываются с молекулой ДНК или связываются с другими клеточными молекулами, в том числе, без ограничения, связывающий мальтозу белок (MBP), S-метку, продукты слияния Lex A и ДНК-связывающего домена (DBD), продукты слияния GAL4 и ДНК-связывающего домена и продукты слияния белка BP16 вируса простого герпеса (HSV). Дополнительные домены, которые могут образовывать часть слитого белка, содержащего фермент CRISPR, описаны в US20110059502, включенном в данный документ при помощи ссылки. В некоторых вариантах осуществления меченный фермент CRISPR используют для идентификации расположения целевой последовательности.
В некоторых аспектах настоящее изобретение предусматривает способы, включающие доставку одного или нескольких полинуклеотидов, как, например, или одного, или нескольких векторов, которые описаны в данном документе, одного или нескольких их транскриптов и/или одного белка или белков, транскрибируемых с них, в клетку-хозяина. В некоторых аспектах настоящее изобретение дополнительно предусматривает клетки, полученные при помощи таких способов, и организмы (такие как животные, растения или грибы), содержащие такие клетки или полученные из них. В некоторых вариантах осуществления фермент CRISPR в комбинации с (и необязательно образующий комплекс с) направляющей последовательностью доставляют в клетку. Традиционные способы переноса генов с использованием вирусов и без использования вирусов можно применять для введения нуклеиновых кислот в клетки млекопитающих или целевые ткани. Такие способы можно использовать для введения нуклеиновых кислот, кодирующих компоненты системы CRISPR, в клетки в культуре и в организме-хозяине. Системы доставки на основе отличных от вирусных векторов включают ДНК-плазмиды, РНК (к примеру, транскрипт вектора, описанного в данном документе), "оголенную" нуклеиновую кислоту и нуклеиновую кислоту, образующую комплекс со средством доставки, как, например, липосому. Системы доставки на основе вирусного вектора включают ДНК- и РНК-вирусы, которые имеют либо эписомальный, либо интегрированный геномы после доставки в клетку. В отношении обзора процедур генной терапии см. Anderson, Science 256:808-813 (1992); Nabel & Felgner, TIBTECH 11:211-217 (1993); Mitani & Caskey, TIBTECH 11:162-166 (1993); Dillon, TIBTECH 11:167-175 (1993); Miller, Nature 357:455-460 (1992); Van Brunt, Biotechnology 6(10):1149-1154 (1988); Vigne, Restorative Neurology and Neuroscience 8:35-36 (1995); Kremer & Perricaudet, British Medical Bulletin 51(1):31-44 (1995); Haddada et al., в Current Topics in Microbiology and Immunology, Doerfler and  (eds) (1995); и Yu et al., Gene Therapy 1:13-26 (1994).
(eds) (1995); и Yu et al., Gene Therapy 1:13-26 (1994).
Способы отличной от вирусной доставки нуклеиновых кислот включают липофекцию, нуклеофекцию, микроинъекцию, баллистическую трансфекцию, виросомы, липосомы, иммунолипосомы, поликатион или конъюгаты липид:нуклеиновая кислота, "оголенную" ДНК, искусственные вирионы и повышенное средством поглощение ДНК. Липофекция описана, например, в патентах США №№ 5049386, 4946787 и 4897355), и реагенты для липофекции продают в промышленных масштабах (к примеру, Transfectam™ и Lipofectin™). Катионные и нейтральные липиды, которые подходят для эффективной липофекции с узнаванием рецептора полинуклеотидов, включают таковые из Felgner, WO 91/17424; WO 91/16024. Доставка может осуществляться в клетки (к примеру, in vitro или ex vivo введение) или целевые ткани (к примеру, in vivo введение).
Получение комплексов липид:нуклеиновая кислота, в том числе целенаправленно воздействующих липосом, как, например, иммунолипидных комплексов, хорошо известно специалистам в данной области (см., к примеру, Crystal, Science 270:404-410 (1995); Blaese et al., Cancer Gene Ther. 2:291-297 (1995); Behr et al., Bioconjugate Chem. 5:382-389 (1994); Remy et al., Bioconjugate Chem. 5:647-654 (1994); Gao et al., Gene Therapy 2:710-722 (1995); Ahmad et al., Cancer Res. 52:4817-4820 (1992); патенты США №№ 4186183, 4217344, 4235871, 4261975, 4485054, 4501728, 4774085, 4837028 и 4946787).
При применении систем на основе РНК- и ДНК-вирусов для доставки нуклеиновых кислот используют тщательно разработанные способы обеспечения целенаправленного воздействия вируса на конкретные клетки в организме и перемещения полезных последовательностей вируса в ядро. Вирусные векторы можно вводить непосредственно пациентам (in vivo) или их можно использовать для обработки клеток in vitro и модифицированные клетки можно необязательно вводить пациентам (ex vivo). Традиционные системы на основе вирусов могут включать ретровирусные, лентивирусные, аденовирусные векторы, векторы на основе аденоассоциированного вируса и вируса простого герпеса для переноса генов. Интеграция в геном хозяина возможна со способами переноса генов на основе ретровируса, лентивируса и аденоассоциированного вируса, что часто приводит к длительной экспрессии встроенного трансгена. Кроме того, высокие показатели эффективности трансдукции наблюдали у многих различных типов клеток и целевых тканей.
Тропизм ретровирусов может быть изменен путем включения чужеродных белков оболочки, расширяя возможную целевую популяцию целевых клеток. Лентивирусные векторы являются ретровирусными векторами, которые способны трансфицировать или инфицировать неделящиеся клетки и, как правило, дают высокие вирусные титры. Выбор системы переноса генов на основе ретровирусов, таким образом, будет зависеть от целевой ткани. Ретровирусные векторы состоят из действующих в цис-положении длинных концевых повторов с упаковывающей способностью до 6-10 п.о. чужеродной последовательности. Минимальных действующих в цис-положении LTR достаточно для репликации и упаковки векторов, которые затем используют для интеграции терапевтического гена в целевую клетку с получением постоянной экспрессии трансгена. Широко применяемые ретровирусные векторы включают такие, основанные на вирусе лейкоза (MuLV), вирусе лейкоза гиббонов (GaLV), вирусе иммунодефицита обезьян (SIV), вирусе иммунодефицита человека (HIV) и их комбинациях (см., к примеру, Buchscher et al., J. Virol. 66:2731-2739 (1992); Johann et al., J. Virol. 66:1635-1640 (1992); Sommnerfelt et al., Virol. 176:58-59 (1990); Wilson et al., J. Virol. 63:2374-2378 (1989); Miller et al., J. Virol. 65:2220-2224 (1991); PCT/US94/05700). В применениях, в которых транзиентная экспрессия является предпочтительной, можно применять системы на основе аденовирусов. Векторы на основе аденовирусов способны проявлять очень высокую эффективность трансдукции во многих типах клеток и не требуют деления клеток. С такими векторами были получены высокие титры и уровни экспрессии. Такой вектор можно получать в больших количествах в относительно простой системе. Векторы на основе аденоассоциированного вируса (“AAV”) также можно использовать для трансдукции в клетки целевых нуклеиновых кислот, к примеру, при получении in vitro нуклеиновых кислот и пептидов и для процедур генной терапии in vivo и ex vivo (см., к примеру, West et al., Virology 160:38-47 (1987); патент США № 4797368; WO 93/24641; Kotin, Human Gene Therapy 5:793-801 (1994); Muzyczka, J. Clin. Invest. 94:1351 (1994). Создание рекомбинантных AAV-векторов описано в ряде публикаций, в том числе в патенте США № 5173414; Tratschin et al., Mol. Cell. Biol. 5:3251-3260 (1985); Tratschin, et al., Mol. Cell. Biol. 4:2072-2081 (1984); Hermonat & Muzyczka, PNAS 81:6466-6470 (1984); и Samulski et al., J. Virol. 63:03822-3828 (1989).
Упаковывающие клетки, как правило, используют для получения вирусных частиц, которые способны инфицировать клетку-хозяина. Такие клетки включают клетки 293, которые упаковывают аденовирус, и клетки Ψ2 или клетки PA317, которые упаковывают ретровирус. Вирусные векторы, используемые в генной терапии, как правило, создают путем получения линии клеток, которые упаковывают вектор на основе нуклеиновой кислоты в вирусную частицу. Векторы обычно содержат минимальные вирусные последовательности, необходимые для упаковки и последующей интеграции в хозяина, при этом другие вирусные последовательности замещены на кассету экспрессии для экспрессии полинуклеотида(ов). Отсутствующие вирусные функции, как правило, обеспечивают во вспомогательном объекте при помощи линии упаковывающих клеток. Например, AAV-векторы, применяемые в генной терапии, как правило, имеют только ITR-последовательности из генома AAV, которые необходимы для упаковки и интеграции в геном хозяина. Вирусная ДНК упакована в линии клеток, которая содержит вспомогательную плазмиду, кодирующую другие гены AAV, а именно rep и cap, но без ITR-последовательностей. Линия клеток также может быть инфицирована аденовирусом в качестве вируса-помощника. Вирус-помощник способствует репликации AAV-вектора и экспрессии генов AAV из вспомогательной плазмиды. Вспомогательная плазмида не упакована в значительном количестве в связи с отсутствием ITR-последовательностей. Инфицирование аденовирусом может быть снижено, к примеру, при помощи тепловой обработки, к которой аденовирус более чувствителен, чем AAV. Дополнительные способы доставки нуклеиновых кислот в клетки известны специалистам в данной области. См., например, US20030087817, включенный в данный документ при помощи ссылки.
В некоторых вариантах осуществления клетка-хозяин транзиентно или не транзиентно трасфицирована одним или несколькими векторами, описанными в данном документе. В некоторых вариантах осуществления клетка трансфицирована так, как это в естественных условиях происходит у субъекта. В некоторых вариантах осуществления клетка, которую трансфицируют, взята из субъекта. В некоторых вариантах осуществления клетка получена из клеток, взятых из субъекта, как, например, линии клеток. Широкий спектр линий клеток для культуры тканей известен в уровне техники. Примеры линий клеток включают, без ограничения, C8161, CCRF-CEM, MOLT, mIMCD-3, NHDF, HeLa-S3, Huh1, Huh4, Huh7, HUVEC, HASMC, HEKn, HEKa, MiaPaCell, Panc1, PC-3, TF1, CTLL-2, C1R, Rat6, CV1, RPTE, A10, T24, J82, A375, ARH-77, Calu1, SW480, SW620, SKOV3, SK-UT, CaCo2, P388D1, SEM-K2, WEHI-231, HB56, TIB55, Jurkat, J45.01, LRMB, Bcl-1, BC-3, IC21, DLD2, Raw264.7, NRK, NRK-52E, MRC5, MEF, Hep G2, HeLa B, HeLa T4, COS, COS-1, COS-6, COS-M6A, эпителиальные клетки почки обезьяны BS-C-1, эмбриональные фибробласты мыши BALB/ 3T3, 3T3 Swiss, 3T3-L1, фетальные фибробласты человека 132-d5; фибробласты мыши 10.1, 293-T, 3T3, 721, 9L, A2780, A2780ADR, A2780cis, A172, A20, A253, A431, A-549, ALC, B16, B35, клетки BCP-1, BEAS-2B, bEnd.3, BHK-21, BR 293, BxPC3, C3H-10T1/2, C6/36, Cal-27, CHO, CHO-7, CHO-IR, CHO-K1, CHO-K2, CHO-T, CHO Dhfr -/-, COR-L23, COR-L23/CPR, COR-L23/5010, COR-L23/R23, COS-7, COV-434, CML T1, CMT, CT26, D17, DH82, DU145, DuCaP, EL4, EM2, EM3, EMT6/AR1, EMT6/AR10.0, FM3, H1299, H69, HB54, HB55, HCA2, HEK-293, HeLa, Hepa1c1c7, HL-60, HMEC, HT-29, Jurkat, клетки JY, клетки K562, Ku812, KCL22, KG1, KYO1, LNCap, Ma-Mel 1-48, MC-38, MCF-7, MCF-10A, MDA-MB-231, MDA-MB-468, MDA-MB-435, MDCK II, MDCK II, MOR/0.2R, MONO-MAC 6, MTD-1A, MyEnd, NCI-H69/CPR, NCI-H69/LX10, NCI-H69/LX20, NCI-H69/LX4, NIH-3T3, NALM-1, NW-145, линии клеток OPCN / OPCT, Peer, PNT-1A / PNT 2, RenCa, RIN-5F, RMA/RMAS, клетки Saos-2, Sf-9, SkBr3, T2, T-47D, T84, линия клеток THP1, U373, U87, U937, VCaP, клетки Vero, WM39, WT-49, X63, YAC-1, YAR и их трансгенные варианты. Линии клеток доступны из ряда источников, известных специалистам в данной области (см., к примеру, Американскую коллекцию типовых культур (ATCC) (Манассас, Вирджиния)). В некоторых вариантах осуществления клетку, трансфицированную одним или несколькими векторами, описанными в данном документе, используют для получения новой линии клеток, содержащей одну или несколько полученных из вектора последовательностей. В некоторых вариантах осуществления клетку, транзиентно трансфицированную компонентами системы CRISPR, которая описана в данном документе (как, например, путем транзиентной трансфекции одним или несколькими векторами или трансфекции РНК), и модифицированную при помощи активности комплекса CRISPR, используют для получения новой линии клеток, содержащей клетки, которые содержат модификацию, но у которых отсутствует любая другая экзогенная последовательность. В некоторых вариантах осуществления клетки, транзиентно или не транзиентно трансфицированные одним или несколькими векторами, описанными в данном документе, или линии клеток, полученные из таких клеток, использовали при оценивании одного или нескольких тестовых соединений.
В некоторых вариантах осуществления один или несколько векторов, описанных в данном документе, используют для получения отличного от человека трансгенного животного или трансгенного растения. В некоторых вариантах осуществления трансгенным животным является млекопитающее, как, например, мышь, крыса или кролик. В определенных вариантах осуществления организмом или субъектом является растение. В определенных вариантах осуществления организмом, или субъектом, или растением является водоросль. Способы получения трансгенных растений и животных известны в уровне техники и, как правило, начинаются со способа трансфекции клетки, такого как описанный в данном документе.
В одном аспекте настоящее изобретение предусматривает способы модификации целевого полинуклеотида в эукариотической клетке. В некоторых вариантах осуществления способ включает обеспечение связывания комплекса CRISPR с целевым полинуклеотидом для осуществления расщепления указанного целевого полинуклеотида с модификацией, таким образом, целевого полинуклеотида, где комплекс CRISPR содержит фермент CRISPR, образующий комплекс с направляющей последовательностью, гибридизирующейся с целевой последовательностью в указанном целевом полинуклеотиде, где указанная направляющая последовательность связана с парной tracr-последовательностью, которая, в свою очередь, гибридизируется с tracr-последовательностью.
В одном аспекте настоящее изобретение предусматривает способ модификации экспрессии полинуклеотида в эукариотической клетке. В некоторых вариантах осуществления способ включает обеспечение связывания комплекса CRISPR с полинуклеотидом так, что указанное связывание приводит к повышенной или пониженной экспрессии указанного полинуклеотида; где комплекс CRISPR содержит фермент CRISPR, образующий комплекс с направляющей последовательностью, гибридизирующейся с целевой последовательностью в указанном целевом полинуклеотиде, где указанная направляющая последовательность связана с парной tracr-последовательностью, которая, в свою очередь, гибридизируется с tracr-последовательностью.
С учетом недавних достижений в области геномики сельскохозяйственных культур возможность применения системы CRISPR-Cas для осуществления эффективных и экономичных редактирования генов и манипуляции с ними обеспечит возможность быстрого отбора и сравнения одиночных и мультиплексных генетических манипуляций для трансформирования таких геномов в отношении повышенного производства и улучшенных признаков. В связи с этим делается ссылка на патенты США и публикации патентов США: патент США № 6603061 - опосредованный агробактериями способ трансформации растений (Agrobacterium-Mediated Plant Transformation Method); патент США № 7868149 - последовательности генома растений и их применение (Plant Genome Sequences and Uses Thereof) и US 2009/0100536 - трансгенные растения с улучшенными агротехническими признаками (Transgenic Plants with Enhanced Agronomic Traits), все содержания и раскрытия каждого из которых включены в данный документ при помощи ссылки в полном объеме. При осуществлении на практике настоящего изобретения содержание и раскрытие Morrell et al., “Crop genomics:advances and applications” Nat Rev Genet. 2011 Dec 29;13(2):85-96 также включены в данный документ при помощи ссылки в полном объеме. В преимущественном варианте осуществления настоящего изобретения систему CRISPR/Cas9 используют для конструирования микроводорослей (пример 15). Соответственно, в данном документе ссылка на клетки животных также может быть применима, с учетом необходимых изменений, по отношению к клеткам растений, если явно не следует иное.
В одном аспекте настоящее изобретение предусматривает способы модификации целевого полинуклеотида в эукариотической клетке, что может происходить in vivo, ex vivo или in vitro. В некоторых вариантах осуществления способ включает забор клетки или популяции клеток из человека, или отличного от человека животного, или растения (в том числе микроскопических водорослей) и модификацию клетки или клеток. Культивирование можно осуществлять на любой стадии ex vivo. Клетку или клетки можно даже повторно вводить отличному от человека животному или в растение (в том числе микроскопические водоросли).
У растений патогены часто являются специфичными по отношению к хозяину. Например, Fusarium oxysporum f. sp. lycopersici вызывает фузариозный вилт томата, но поражает только томат, а F. oxysporum f. dianthii и Puccinia graminis f. sp. tritici поражают только пшеницу. Растения обладают присущими и индуцированными защитными реакциями, обеспечивающими устойчивость к большинству патогенов. Мутации и события рекомбинации в поколениях растений приводят к генетической изменчивости, которая обуславливает восприимчивость, тем более, что патогены размножаются с большей частотой, чем растения. У растений может наблюдаться устойчивость видов-нехозяев, например, хозяин и патоген являются несовместимыми. Также может наблюдаться горизонтальная устойчивость, например, частичная устойчивость ко всем расам патогена, обычно контролируемая многими генами, и вертикальная устойчивость, например, полная устойчивость к некоторым расам патогена, но не к другим расам, обычно контролируемая несколькими генами. На уровне взаимодействия генов растения и патогены эволюционируют совместно, а генетические изменения одного уравновешивают изменения другого. Соответственно, используя естественную изменчивость, селекционеры комбинируют наиболее полезные гены для урожайности, качества, однородности, выносливости, устойчивости. Источники генов устойчивости включают нативные или чужеродные сорта, старинные сорта, родственные дикорастущие растения и индуцированные мутации, например, при обработке растительного материала мутагенными средствами. Применяя настоящее изобретение, селекционеры растений получают новый инструмент для индукции мутаций. Соответственно, специалист в данной области может проанализировать геном источников генов устойчивости, а в отношении сортов, имеющих желаемые характеристики или признаки, использовать настоящее изобретение для индукции появления генов устойчивости с большей точностью, чем в случае применявшихся ранее мутагенных средств, и, следовательно, для ускорения и улучшения программ селекции растений.
В одном аспекте настоящее изобретение предусматривает наборы, содержащие любой один или несколько из элементов, раскрытых в приведенных выше способах и композициях. В некоторых вариантах осуществления набор содержит векторную систему и инструкции по применению набора. В некоторых вариантах осуществления векторная система содержит (a) первый регуляторный элемент, функционально связанный с парной tracr-последовательностью и одним или несколькими сайтами встраивания для встраивания направляющей последовательности выше парной tracr-последовательности, где при экспрессии направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR с целевой последовательностью в эукариотической клетке, где комплекс CRISPR содержит фермент CRISPR, образующий комплекс с (1) направляющей последовательностью, которая гибридизируется с целевой последовательностью, и (2) парной tracr-последовательностью, которая гибридизируется с tracr-последовательностью; и/или (b) второй регуляторный элемент, функционально связанный с кодирующей фермент последовательностью, кодирующей указанный фермент CRISPR, содержащий последовательность ядерной локализации. Элементы могут быть предоставлены отдельно или в комбинациях и могут быть предоставлены в любом подходящем контейнере, как, например, пузырьке, флаконе или пробирке. В некоторых вариантах осуществления набор включает инструкции на одном или нескольких языках, например, на более чем одном языке.
В некоторых вариантах осуществления набор содержит один или несколько реагентов для применения в способе, в котором используется один или несколько элементов, описанных в данном документе. Реагенты могут быть предоставлены в любом подходящем контейнере. Например, набор может предусматривать один или несколько реакционных буферов или буферов для хранения. Реагенты могут быть предоставлены в форме, которая применима в конкретном анализе, или в форме, которая предусматривает добавление одного или нескольких других компонентов перед применением (к примеру, в форме концентрата или лиофилизированной форме). Буфер может быть любым буфером, в том числе без ограничения буфером с карбонатом натрия, буфером с бикарбонатом натрия, боратным буфером, Tris-буфером, буфером MOPS, буфером HEPES и их комбинациями. В некоторых вариантах осуществления буфер является щелочным. В некоторых вариантах осуществления буфер имеет значение pH от приблизительно 7 до приблизительно 10. В некоторых вариантах осуществления набор содержит один или несколько олигонуклеотидов, соответствующих направляющей последовательности, для встраивания в вектор для того, чтобы имела место функциональная связь направляющей последовательности и регуляторного элемента. В некоторых вариантах осуществления набор содержит матричный полинуклеотид для гомологичной рекомбинации.
В одном аспекте настоящее изобретение предусматривает способы применения одного или нескольких элементов системы CRISPR. Комплекс CRISPR по настоящему изобретению обеспечивает эффективное средство модификации целевого полинуклеотида. Комплекс CRISPR по настоящему изобретению характеризуется большим разнообразием полезных свойств, включая модификацию (например, делецию, вставку, транслокацию, инактивацию, активацию) целевого полинуклеотида во множестве типов клеток. Комплекс CRISPR по настоящему изобретению как таковой имеет широкий спектр применений, к примеру, в генной терапии, скрининге лекарственных средств, диагностике и прогнозировании заболеваний. Иллюстративный комплекс CRISPR содержит фермент CRISPR, образующий комплекс с направляющей последовательностью, которая гибридизируется с целевой последовательностью в целевом полинуклеотиде. Направляющая последовательность связана с парной tracr-последовательностью, которая, в свою очередь, гибридизируется с tracr-последовательностью.
Целевой полинуклеотид комплекса CRISPR может быть любым полинуклеотидом, эндогенным или экзогенным по отношению к эукариотической клетке. Например, целевой полинуклеотид может быть полинуклеотидом, находящимся в ядре эукариотической клетки. Целевой полинуклеотид может быть последовательностью, кодирующей продукт гена (к примеру, белок), или некодирующей последовательностью (к примеру, регуляторным полинуклеотидом или избыточной ДНК). Не желая быть связанными теорией, полагают, что целевая последовательность должна быть ассоциирована с PAM (мотивом, смежным с протоспейсером); то есть короткой последовательностью, узнаваемой комплексом CRISPR. Определенные требования в отношении последовательности и длины PAM различаются в зависимости от применяемого фермента CRISPR, но PAM, как правило, является последовательностью в 2-5 пары оснований, прилегающей к протоспейсеру (то есть целевой последовательности). Примеры последовательностей PAM приведены в разделе "Примеры" ниже, и специалист в данной области сможет выявить дополнительные последовательности PAM для применения с данным ферментом CRISPR.
Целевой полинуклеотид комплекса CRISPR может включать некоторое количество ассоциированных с заболеваниями генов и полинуклеотидов, а также ассоциированных с биохимическими путями проведения сигнала генов и полинуклеотидов, которые перечислены в предварительных заявках на патент США 61/736527 и 61/748427 с общей ссылкой BI-2011/008/WSGR, номер в реестре 44063-701.101, и BI-2011/008/WSGR, номер в реестре 44063-701.102, соответственно, обе озаглавленные "СИСТЕМЫ, СПОСОБЫ И КОМПОЗИЦИИ ДЛЯ МАНИПУЛЯЦИЯ С ПОСЛЕДОВАТЕЛЬНОСТЯМИ" (SYSTEMS METHODS AND COMPOSITIONS FOR SEQUENCE MANIPULATION), поданные 12 декабря 2012 г. и 2 января 2013 г., соответственно, содержания всех из которых включены в данный документ при помощи ссылки в полном объеме.
Примеры целевых полинуклеотидов включают последовательность, ассоциированную с биохимическими путями проведения сигнала, к примеру, ассоциированные с биохимическими путями проведения сигнала геном или полинуклеотидом. Примеры целевых полинуклеотидов включают ассоциированные с заболеваниями гены или полинуклеотиды. “Ассоциированный с заболеванием” ген или полинуклеотид означает любой ген или полинуклеотид, который обеспечивает продукты транскрипции или трансляции на отклоняющемся от нормы уровне или в отклоняющейся от нормы форме в клетках, полученных из пораженных заболеванием тканей, по сравнению с тканями или клетками контроля без заболевания. Это может быть ген, который начинает экспрессироваться при ненормально высоком уровне; это может быть ген, который начинает экспрессироваться при ненормально низком уровне, где измененная экспрессия коррелирует с появлением и/или развитием заболевания. Ассоциированный с заболеванием ген также означает ген, несущий мутацию(и) или генетическое изменение, который непосредственно ответственен или находится в неравновесном сцеплении с геном(ами), который(е) ответственен(ны) за этиологию заболевания. Транскрибируемые или транслируемые продукты могут быть известными или неизвестными и могут быть на нормальном уровне или на отклоняющемся от нормального уровне.
Примеры ассоциированных с заболеваниями генов и полинуклеотидов доступны от Института генетической медицины Маккьюсика-Натанса (McKusick-Nathans Institute of Genetic Medicine) при Университете Джонса Хопкинса (Johns Hopkins University) (Балтимор, Мэриленд) и Национального центра биотехнологической информации (National Center for Biotechnology Information) при Национальной библиотеке медицины (National Library of Medicine) (Бетесда, Мэриленд), доступных во всемирной сети Интернет.
Примеры ассоциированных с заболеваниями генов и полинуклеотидов перечислены в таблицах A и B. Конкретная информация в отношении заболеваний доступна от Института генетической медицины Маккьюсика-Натанса (McKusick-Nathans Institute of Genetic Medicine) при Университете Джонса Хопкинса (Johns Hopkins University) (Балтимор, Мэриленд) и Национального центра биотехнологической информации (National Center for Biotechnology Information), Национальной библиотеки медицины (National Library of Medicine) (Бетесда, Мэриленд), доступных во всемирной сети Интернет. Примеры ассоциированных с биохимическими путями проведения сигнала генов и полинуклеотидов перечислены в таблице C.
Мутации в этих генах и путях могут приводить к продуцированию неправильных белков или белков в несоответствующих количествах, которые воздействуют на функцию. Дополнительные примеры генов, заболеваний и белков, таким образом, включены при помощи ссылки из предварительной заявки на патент США 61/736527, поданной 12 декабря 2012 г., и 61/748427, поданной 2 февраля 2013 г. Такие гены, белки и пути могут быть целевым полинуклеотидом комплекса CRISPR.
Таблица A
Таблица B
Таблица C
Варианты осуществления настоящего изобретения также относятся к способам и композициям, связанным с нокаутированием генов, амплифицированием генов и репарацией конкретных мутаций, ассоциированных с нестабильностью ДНК-повторов и неврологическими нарушениями (Robert D. Wells, Tetsuo Ashizawa, Genetic Instabilities and Neurological Diseases, Second Edition, Academic Press, Oct 13, 2011 - Medical). Как было обнаружено, определенные аспекты последовательностей тандемных повторов ответственны за более двадцати заболеваний человека (New insights into repeat instability: role of RNA⋅DNA hybrids. McIvor EI, Polak U, Napierala M. RNA Biol. 2010 Sep-Oct;7(5):551-8). Система CRISPR-Cas может быть приспособлена для корректировки таких дефектов геномной нестабильности.
Дополнительный аспект настоящего изобретения относится к использованию системы CRISPR-Cas для корректирования дефектов в генах EMP2A и EMP2B, которые, как было обнаружено, ассоциированы с болезнью Лафора. Болезнь Лафора представляет собой аутосомно-рецессивное состояние, которое характеризуется прогрессирующей миоклонус-эпилепсией, которая может начинаться в виде эпелиптических приступов в подростковом возрасте. Некоторые случаи заболевания могут вызываться мутациями в генах, которые уже были выявлены. Заболевание вызывает приступы, мышечные спазмы, затрудненную ходьбу, слабоумие и, в конечном итоге, смерть. В настоящее время не существует терапии, которая показала эффективность против развития заболевания. На другие генетические расстройства, ассоциированные с эпилепсией, также можно целенаправленно воздействовать при помощи системы CRISPR-Cas, и лежащая в основе генетика дополнительно описана в Genetics of Epilepsy and Genetic Epilepsies, edited by Giuliano Avanzini, Jeffrey L. Noebels, Mariani Foundation Paediatric Neurology:20; 2009).
В еще одном аспекте настоящего изобретения систему CRISPR-Cas можно использовать для корректировки офтальмологических дефектов, которые являются результатом нескольких генетических мутаций, дополнительно описанных в Genetic Diseases of the Eye, Second Edition, edited by Elias I. Traboulsi, Oxford University Press, 2012.
Некоторые дополнительные аспекты настоящего изобретения связаны с корректированием дефектов, ассоциированных с широким спектром генетических заболеваний, которые дополнительно описаны на веб-сайте Национальных институтов здравоохранения (National Institutes of Health) в тематическом подразделе "Наследственные заболевания" ("Genetic Disorders") (веб-сайт по адресу health.nih.gov/topic/GeneticDisorders). Наследственные заболевания головного мозга могут включать, без ограничения, адренолейкодистрофию, агенезию мозолистого тела, синдром Айкарди, синдром Альперса, болезнь Альцгеймера, синдром Барта, болезнь Баттена, CADASIL, мозжечковую дегенерацию, болезнь Фабри, синдром Герстмана-Штраусслера-Шейнкера, болезнь Гентингтона и другие связанные с триплетным повтором нарушения, болезнь Лея, синдром Леша-Найхана, болезнь Менкеса, типы митохондриальной миопатии и кольпоцефалию по критериям NINDS. Такие заболевания дополнительно описаны на веб-сайте Национальных институтов здравоохранения (National Institutes of Health) в тематическом подразделе "Наследственные заболевания головного мозга" ("Genetic Brain Disorders").
В некоторых вариантах осуществления состоянием может быть неоплазия. В некоторых вариантах осуществления, где состоянием является неоплазия, гены, на которые целенаправленной воздействуют, являются любыми из перечисленных в таблице A (в данном случае PTEN и так далее). В некоторых вариантах осуществления состоянием может быть возрастная дегенерация желтого пятна. В некоторых вариантах осуществления состоянием может быть шизофреническое нарушение. В некоторых вариантах осуществления состоянием может быть связанное с тринуклеотидным повтором нарушение. В некоторых вариантах осуществления состоянием может быть синдром ломкой X-хромосомы. В некоторых вариантах осуществления состоянием может быть связанное с секретазой нарушение. В некоторых вариантах осуществления состоянием может быть связанное с прионами нарушение. В некоторых вариантах осуществления состоянием может быть ALS. В некоторых вариантах осуществления состоянием может быть привыкание к наркотическим средствам. В некоторых вариантах осуществления состоянием может быть аутизм. В некоторых вариантах осуществления состоянием может быть болезнь Альцгеймера. В некоторых вариантах осуществления состоянием может быть воспаление. В некоторых вариантах осуществления состоянием может быть болезнь Паркинсона.
Примеры белков, ассоциированных с болезнью Паркинсона, включают, без ограничения, α-синуклеин, DJ-1, LRRK2, PINK1, паркин, UCHL1, синфилин-1 и NURR1.
Примеры связанных с привыканием белков могут включать, например, ABAT.
Примеры связанных с воспалением белков могут включать, например, моноцитарный хемоаттрактантный белок-1 (monocyte chemoattractant protein-1) (MCP1), закодированный геном Ccr2, C-C рецептор хемокина 5 типа (C-C chemokine receptor type 5) (CCR5), закодированный геном Ccr5, IgG-рецептор IIB (IgG receptor IIB) (FCGR2b, также называемый CD32), закодированный геном Fcgr2b, или белок Fc-эпсилон-R1g (Fc epsilon R1g) (FCER1g), закодированный геном Fcer1g.
Примеры ассоциированных с заболеваниями сердечно-сосудистой системы белков могут включать, например, IL1B (интерлейкин 1, бета (interleukin 1, beta)), XDH (ксантиндегидрогеназу (xanthine dehydrogenase)), TP53 (опухолевый белок p53 (tumor protein p53)), PTGIS (простагландин-I2(простациклин)-синтазу (prostaglandin I2 (prostacyclin) synthase)), MB (миоглобин (myoglobin)), IL4 (интерлейкин 4 (interleukin 4)), ANGPT1 (ангиопоэтин 1 (angiopoietin 1)), ABCG8 (АТФ-связывающую кассету, подсемейство G (WHITE), представитель 8 (ATP-binding cassette, sub-family G (WHITE), member 8)) или CTSK (катепсин K (cathepsin K)).
Примеры ассоциированных с болезнью Альцгеймера белков могут включать, например, белок, представляющий собой рецептор липопротеинов очень низкой плотности (very low density lipoprotein receptor protein) (VLDLR), закодированный геном VLDLR, убиквитин-подобный модификатор-активирующий фермент 1 (ubiquitin-like modifier activating enzyme 1) (UBA1), закодированный геном UBA1, или белок, являющийся каталитической субъединицей NEDD8-активирующего фермента E1 (NEDD8-activating enzyme E1 catalytic subunit protein) (UBE1C), закодированный геном UBA3.
Примеры белков, ассоциированных с расстройствами аутистического спектра, могут включать, например, белок 1, ассоциированный с периферическим бензодиазепиновым рецептором (benzodiazapine receptor (peripheral) associated protein 1) (BZRAP1), закодированный геном BZRAP1, белок, представитель 2 семейства AF4/FMR2 (AF4/FMR2 family member 2 protein) (AFF2), закодированный геном AFF2 (также называемый MFR2), белок-аутосомный гомолог 1, ассоциированный с умственной отсталостью, связанной с ломкой X-хромосомой (fragile X mental retardation autosomal homolog 1 protein) (FXR1), закодированный геном FXR1, или белок-аутосомный гомлог 2, ассоциированный с умственной отсталостью, связанной с ломкой X-хромосомой (fragile X mental retardation autosomal homolog 2 protein) (FXR2), закодированный геном FXR2.
Примеры белков, ассоциированных с дегенерацией желтого пятна, могут включать, например, АТФ-связывающую кассету, белок-представитель 4 подсемейства A (ABC1) (ATP-binding cassette, sub-family A (ABC1) member 4 protein) (ABCA4), закодированный геном ABCR, белок-аполипротеин E (apolipoprotein E protein) (APOE), закодированный геном APOE, или белок-лиганд 2 хемокина (C-C мотив) (chemokine (C-C motif) Ligand 2 protein) (CCL2), закодированный геном CCL2.
Примеры белков, ассоциированных с шизофренией, могут включать NRG1, ErbB4, CPLX1, TPH1, TPH2, NRXN1, GSK3A, BDNF, DISC1, GSK3B и их комбинации.
Примеры белков, вовлеченных в подавление опухоли, могут включать, например, ATM (мутированный, атаксия-телеангиэктазия (ataxia telangiectasia mutated)), ATR (атаксия-телеангиэктазия- и Rad3-родственный (ataxia telangiectasia and Rad3 related)), EGFR (рецептор эпидермального фактора роста (epidermal growth factor receptor)), ERBB2 (гомолог 2 v-erb-b2 эритробластического лейкоза вирусного онкогена (v-erb-b2 erythroblastic leukemia viral oncogene homolog 2)), ERBB3 (гомолог 3 v-erb-b2 эритробластического лейкоза вирусного онкогена (v-erb-b2 erythroblastic leukemia viral oncogene homolog 3)), ERBB4 (гомолог 4 v-erb-b2 эритробластического лейкоза вирусного онкогена (v-erb-b2 erythroblastic leukemia viral oncogene homolog 4)), Notch 1, Notch2, Notch 3 или Notch 4.
Примеры белков, ассоциированных с нарушением, связанным с активностью секретазы, могут включать, например, PSENEN (presenilin enhancer 2 homolog (C. elegans)), CTSB (катепсин B (cathepsin B)), PSEN1 (пресенилин 1 (presenilin 1)), APP (белок-предшественник бета-амилоида (A4) (amyloid beta (A4) precursor protein)), APH1B (anterior pharynx defective 1 homolog B (C. elegans)), PSEN2 (пресенилин 2 (болезнь Альцгеймера 4) (presenilin 2 (Alzheimer disease 4)) или BACE1 (APP-расщепляющий фермент 1 по бета-сайту (beta-site APP-cleaving enzyme 1)).
Примеры белков, ассоциированных с амиотрофическим латеральным склерозом, могут включать, например, SOD1 (супероксиддисмутазу 1 (superoxide dismutase 1)), ALS2 (белок, ассоциированный с амиотрофическим латеральным склерозом 2 (amyotrophic lateral sclerosis 2)), FUS (РНК-связывающий белок FUS (fused in sarcoma)), TARDBP (TAR-ДНК связывающий белок (TAR DNA binding protein)), VAGFA (фактор роста эндотелия сосудов A (vascular endothelial growth factor A)), VAGFB (фактор роста эндотелия сосудов B (vascular endothelial growth factor B)) и VAGFC (фактор роста эндотелия сосудов C (vascular endothelial growth factor C)) и любую их комбинацию.
Примеры белков, ассоциированных с прионными болезнями, могут включать SOD1 (супероксиддисмутазу 1), ALS2 (белок, ассоциированный с амиотрофическим латеральным склерозом 2 (amyotrophic lateral sclerosis 2)), FUS (РНК-связывающий белок FUS (fused in sarcoma)), TARDBP (TAR-ДНК связывающий белок (TAR DNA binding protein)), VAGFA (фактор роста эндотелия сосудов A (vascular endothelial growth factor A)), VAGFB (фактор роста эндотелия сосудов B (vascular endothelial growth factor B)) и VAGFC (фактор роста эндотелия сосудов C (vascular endothelial growth factor C)) и любую их комбинацию.
Примеры белков, связанных с нейродегенеративными состояниями при прионных болезнях, могут включать, например, A2M (альфа-2-макроглобулин (Alpha-2-Macroglobulin)), AATF (фактор транскрипции, противодействующий апоптозу (Apoptosis antagonizing transcription factor)), ACPP (простатоспецифическую кислую фосфатазу (Acid phosphatase prostate)), ACTA2 (альфа-актин 2 гладкой мускулатуры аорты (Actin alpha 2 smooth muscle aorta)), ADAM22 (ADAM, металлопептидазный домен (ADAM metallopeptidase domain)), ADORA3 (аденозиновый рецептор A3 типа (Adenosine A3 receptor)) или ADRA1D (альфа-1D адренергический рецептор для альфа-1D адренорецептора (Alpha-1D adrenergic receptor for Alpha-1D adrenoreceptor)).
Примеры белков, ассоциированных с иммунодефицитом, могут включать, например, A2M [альфа-2-макроглобулин (alpha-2-macroglobulin)]; AANAT [арилалкиламин-N-ацетилтрансферазу (arylalkylamine N-acetyltransferase)]; ABCA1 [АТФ-связывающую кассету, подсемейство A (ABC1), представитель 1 (ATP-binding cassette, sub-family A (ABC1), member 1)]; ABCA2 [АТФ-связывающую кассету, подсемейство A (ABC1), представитель 2 (ATP-binding cassette, sub-family A (ABC1), member 2)] или ABCA3 [АТФ-связывающую кассету, подсемейство A (ABC1), представитель 3 (ATP-binding cassette, sub-family A (ABC1), member 3)].
Примеры белков, ассоциированных с нарушениями, связанными с тринуклеотидным повтором, включают, например, AR (андрогеновый рецептор (androgen receptor)), FMR1 (белок 1, ассоциированный с умственной отсталостью, связанной с ломкой X-хромосомой (fragile X mental retardation 1)), HTT (хантигтин (huntingtin)) или DMPK (протеинкиназу, ассоциированную с мышечной дистрофией (dystrophia myotonica-protein kinase)), FXN (фратаксин (frataxin)), ATXN2 (атаксин 2 (ataxin 2)).
Примеры белков, ассоциированных с нарушениями передачи нервных импульсов включают, например, SST (соматостатин (somatostatin)), NOS1 (синтазу оксида азота 1 (нейрональную) (nitric oxide synthase 1 (neuronal)), ADRA2A (адренергический, альфа-2A-, рецептор (adrenergic, alpha-2A-, receptor)), ADRA2C (адренергический, альфа-2C-, рецептор (adrenergic, alpha-2C-, receptor)), TACR1 (тахикининовый рецептор 1 (tachykinin receptor 1)) или HTR2c (5-гидрокситриптаминовый (серотониновый) рецептор 2C (5-hydroxytryptamine (serotonin) receptor 2C)).
Примеры последовательностей, ассоциированных с неврологическим развитием, включают, например, A2BP1 [атаксин 2-связывающий белок 1 (ataxin 2-binding protein 1)], AADAT [аминоадипатаминотрансферазу (aminoadipate aminotransferase)], AANAT [арилалкиламин-N-ацетилтрансферазу (arylalkylamine N-acetyltransferase)], ABAT [4-аминобутиратаминтрансферазу (4-aminobutyrate aminotransferase)], ABCA1 [АТФ-связывающую кассету, подсемейство A (ABC1), представитель 1 (ATP-binding cassette, sub-family A (ABC1), member 1)] или ABCA13 [АТФ-связывающую кассету, подсемейство A (ABC1), представитель 13 (ATP-binding cassette, sub-family A (ABC1), member 13)].
Дополнительные примеры предпочтительных состояний, которые подлежат лечению с помощью данной системы, включают те, которые могут быть выбраны из синдрома Айкарди-Гутьереса; болезни Александера; синдрома Аллана-Херндона-Дадли; связанных с геном POLG нарушений; альфа-маннозидоза (II и III тип); синдрома Альстрема; синдрома Ангельмана; атаксии-телеангиэктазии; нейронного высоковидного липофусциноза; бета-талассемии; двусторонней атрофии зрительного нерва и (инфантильной) атрофии зрительного нерва 1 типа; ретинобластомы (двусторонней); болезни Канавана; церебро-окуло-фацио-скелетного синдрома 1 [COFS1]; церебротендинального ксантоматоза; синдрома Корнелии де Ланге; связанных с геном MAPT нарушений; наследственных прионных болезней; синдрома Драве; семейной болезни Альцгеймера с ранним началом; атаксии Фридрейха [FRDA]; синдрома Фринса; фукозидоза; врожденной мышечной дистрофии Фукуямы; галактосиалидоза; болезни Гоше; органической ацидемии; гемофагоцитарного лимфогистиоцитоза; синдрома прогерии Гетчинсона-Гилфорда; муколипидоза II; инфантильной болезни накопления свободной сиаловой кислоты; ассоциированной с геном PLA2G6 нейродегенерации; синдрома Джервелла-Ланге-Нильсена; узелкового врожденного буллезного эпидермолиза; болезни Гентингтона; болезни Краббе (инфантильной); ассоциированного с митохондриальной ДНК синдрома Ли и NARP; синдрома Леша-Найхана; ассоциированной с геном LIS1 лиссэнцефалии; синдрома Лоу; болезни "кленового сиропа"; синдрома дупликации MECP2; связанных с геном ATP7A нарушений обмена меди; связанной с геном LAMA2 мышечной дистрофии; недостаточности арилсульфатазы А; мукополисахаридоза I, II или III типов; связанных с биогенезом пероксисом нарушений, спектра заболеваний по типу синдрома Цельвегера; нарушений по типу нейродегенерации с накоплением железа в головном мозге; недостаточности кислой сфингомиелиназы; болезни Ниманна-Пика C типа; глициновой энцефалопатии; связанных с геном ARX нарушений; нарушений орнитинового цикла; связанного с геном COL1A1/2 несовершенного остеогенеза; синдромов удаления митохондриальной ДНК; связанных с геном PLP1 нарушений; синдрома Перри; синдрома Фелана-МакДермида; болезни накопления гликогена II типа (болезни Помпе) (инфантильной); связанных с геном MAPT нарушений; связанных с геном MECP2 нарушений; эпифизарной точечной хондродисплазии 1 типа костей верхних конечностей или бедренной кости; синдрома Робертса; болезни Сандхоффа; болезни Шиндлера - 1 типа; аденозиндезаминазной недостаточности; синдрома Смита-Лемли-Опитца; спинальной мышечной атрофии; спинально-церебеллярной атаксии с возникновением в младенческом возрасте; недостаточности гексозаминидазы; танатофорной дисплазии 1 типа; связанных с геном коллагена VI типа нарушений; синдрома Ашера I типа; врожденной мышечной дистрофии; синдрома Вольфа-Хиршхорна; недостаточности лизосомной кислой липазы и пигментной ксеродермы.
Как будет понятно, предусматривается, что настоящую систему можно использовать для целенаправленного воздействия на любую представляющую интерес полинуклеотидную последовательность. Некоторые состояния или заболевания, которые можно эффективно лечить с использованием настоящей системы, включены в таблицы выше, и примеры известных на данный момент генов, ассоциированных с такими состояниями, также предоставлены в них. Тем не менее, гены, приведенные в качестве примеров, не являются исчерпывающими.
Примеры
Следующие примеры приведены с целью иллюстрации различных вариантов осуществления настоящего изобретения, и не предполагается, что они ограничивают настоящее изобретение каким-либо образом. Данные примеры совместно со способами, описанными в данном документе, в настоящее время отражают предпочтительные варианты осуществления, являются иллюстративными и не предназначены для ограничения объема настоящего изобретения. Изменения в данном документе и другие применения, которые охватываются сущностью настоящего изобретения, как определено формулой изобретения, будут очевидны специалистам в данной области.
Пример 1: активность комплекса CRISPR в ядре эукариотической клетки
Примером системы CRISPR II типа является локус CRISPR II типа из Streptococcus pyogenes SF370, который содержит группу из 4 генов Cas9, Cas1, Cas2 и Csn1, а также 2 некодирующих элемента РНК, tracrRNA и характерный массив повторяющихся последовательностей (прямых повторов), чередующихся с короткими фрагментами неповторяющихся последовательностей (спейсерами, примерно 30 п.о. каждый). В этой системе двухцепочечный разрыв (DSB) целевой ДНК образовывается в ходе четырех последовательных стадий (фигура 2A). Во-первых, две некодирующих РНК, массив pre-crRNA и tracrRNA, транскрибируются с локуса CRISPR. Во-вторых, tracrRNA гибридизируется с прямыми повторами pre-crRNA, которая затем процессируется в зрелые crRNA, содержащие индивидуальные спейсерные последовательности. В-третьих, комплекс зрелая crRNA:tracrRNA направляет Cas9 к ДНК-мишени, состоящей из протоспейсера и соответствующего PAM, посредством образования гетеродуплекса между спейсерным участком crRNA и протоспейсерной ДНК. И наконец, Cas9 опосредует расщепление целевой ДНК выше PAM с образованием DSB внутри протоспейсера (фигура 2A). В этом примере описывается иллюстративный способ приспособления этой РНК-программируемой нуклеазной системы к управлению активностью комплекса CRISPR в ядрах эукариотических клеток.
Клеточная культура и трансфекция
Линию клеток почки человеческого эмбриона (HEK), HEK 293FT (Life Technologies), поддерживали в среде Игла в модификации Дульбекко (DMEM), дополненной 10% фетальной бычьей сыворотки (HyClone), 2 мМ GlutaMAX (Life Technologies), 100 ед./мл пенициллина и 100 мкг/мл стрептомицина, при 37°C с инкубированием при 5% CO2. Линию мышиных клеток neuro2A (N2A) (ATCC) поддерживали в DMEM, дополненной 5% фетальной бычьей сывороткой (HyClone), 2 мМ GlutaMAX (Life Technologies), 100 ед./мл пенициллина и 100 мкг/мл стрептомицина, при 37°C с 5% CO2.
Клетки HEK 293FT или N2A высевали в 24-луночные планшеты (Corning) за один день до трансфекции с плотностью 200000 клеток на лунку. Клетки трансфицировали с применением Lipofectamine 2000 (Life Technologies), следуя рекомендованному производителем протоколу. Для каждой лунки 24-луночного планшета использовали в общей сложности 800 нг плазмид.
Анализ с помощью Surveyor и анализ с помощью секвенирования на предмет наличия модификации генома
Клетки HEK 293FT или N2A трансфицировали плазмидной ДНК, как описано выше. После трансфекции клетки инкубировали при 37°C в течение 72 часов перед экстракцией геномной ДНК. Геномную ДНК экстрагировали с помощью набора QuickExtract DNA extraction kit (Epicentre), следуя протоколу производителя. Вкратце, клетки ресуспендировали в растворе QuickExtract и инкубировали при 65°C в течение 15 минут и при 98°C в течение 10 минут. Экстрагированную геномную ДНК подвергали немедленной обработке или хранили при –20°C.
Геномный участок, окружающий целевой сайт CRISPR, для каждого гена подвергали ПЦР амплификации и продукты очищали с использованием колонки QiaQuick Spin Column (Qiagen), следуя протоколу производителя. В общей сложности 400 нг очищенных ПЦР-продуктов смешивали с 2 мкл 10X ПЦР-буфера для Taq-полимеразы (Enzymatics) и водой сверхвысокой чистоты до конечного объема 20 мкл и подвергали процессу повторного отжига для обеспечения образования гетеродуплекса: 95°C в течение 10 мин., линейное снижение температуры с 95°C до 85°C со скоростью 2°C/с, с 85°C до 25°C со скоростью 0,25°C/с и с выдерживанием при 25°C в течение 1 минуты. После повторного отжига продукты обрабатывали нуклеазой Surveyor и энхансером S Surveyor (Transgenomics), следуя рекомендованному производителем протоколу, и анализировали в 4-20% полиакриламидных гелях Novex TBE (Life Technologies). Гели окрашивали красителем ДНК SYBR Gold (Life Technologies) в течение 30 минут и получали изображение с помощью системы обработки изображений Gel Doc gel imaging system (Bio-rad). Количественный анализ основывался на относительных интенсивностях полос в качестве единицы измерения фракции расщепленной ДНК. На фигуре 8 представлена схематическая иллюстрация данного анализа с помощью Surveyor.
Анализ полиморфизма длины рестрикционных фрагментов для обнаружения гомологичной рекомбинации.
Клетки HEK 293FT и N2A трансфицировали плазмидной ДНК и инкубировали при 37°C в течение 72 часов перед экстракцией геномной ДНК, как описано выше. Целевой геномный участок подвергали ПЦР амплификации с использованием праймеров за пределами гомологичных плеч матрицы для гомологичной рекомбинации (HR). ПЦР-продукты разделяли в 1% агарозном геле и экстрагировали с помощью набора MinElute GelExtraction Kit (Qiagen). Очищенные продукты расщепляли с помощью HindIII (Fermentas) и анализировали в 6% полиакриламидном геле Novex TBE (Life Technologies).
Прогнозирование и анализ вторичной структуры РНК
Прогнозирование вторичной структуры РНК осуществляли с использованием доступного в режиме онлайн веб-сервера RNAfold, разработанного в Институте теоретической химии при Венском университете, использующего алгоритм прогнозирования структуры на основе центроидного метода (см., например, A.R. Gruber et al., 2008, Cell 106(1): 23-24; и PA Carr and GM Church, 2009, Nature Biotechnology 27(12): 1151-62).
Анализ интерференции при трансформации бактериальными плазмидами
Элементы локуса 1 CRISPR S. pyogenes, достаточные для активности CRISPR, воспроизводили у E. coli с применением плазмиды pCRISPR (схематически изображенной на фигуре 10A). pCRISPR содержала tracrRNA, SpCas9 и лидерную последовательность, запускающую массив crRNA. Как показано, спейсеры (также упоминаются как “направляющие последовательности”) встраивали в массив crRNA между сайтами BsaI с применением гибридизированных олигонуклеотидов. Контрольные плазмиды, применяемые в анализе интерференции, создавали путем встраивания протоспейсерной последовательности (также упоминающейся как “целевая последовательность”) совместно со смежной последовательностью мотива CRISPR (PAM) в pUC19 (см. фигуру 10B). Контрольная плазмида содержала гены устойчивости к ампициллину. На фигуре 10С представлено схематическое изображение анализа интерференции. Химически компетентные штаммы E. coli, уже несущие pCRISPR и соответствующий спейсер, трансформировали контрольной плазмидой, содержащей соответствующую последовательность протоспейсер-PAM. pUC19 применяли для оценки эффективности трансформации каждого компетентного штамма, несущего pCRISPR. Активность CRISPR приводила к расщеплению плазмиды pPSP, несущей протоспейсер, что устраняло устойчивость к ампициллину, в противном случае обеспечиваемую pUC19, не имеющему протоспейсера. На фигуре 10D представлена компетенция каждого штамма E. coli, несущего pCRISPR, применяемого в анализах, которые изображены на фигуре 4C.
Очистка РНК
Клетки HEK 293FT поддерживали и трансфицировали, как указано выше. Клетки собирали путем трипсинизации с последующим промыванием в фосфатно-солевом буфере (PBS). Общую клеточную РНК экстрагировали с помощью реагента TRI (Sigma), следуя протоколу производителя. Выполняли количественный анализ общей экстрагированной РНК с использованием Naonodrop (Thermo Scientific) и данные нормализовали к такой же концентрации.
Анализ экспрессии crRNA и tracrRNA в клетках млекопитающих с помощью нозерн-блоттинга
РНК смешивали с равными объемами 2X загрузочного буфера (Ambion), нагревали до 95°C в течение 5 мин., охлаждали на льду в течение 1 мин, а затем загружали в 8% денатурирующие полиакриламидные гели (SequaGel, National Diagnostics) после предварительного прогона геля в течение по меньшей мере 30 минут. Образцы подвергали электрофорезу в течение 1,5 часа при предельной мощности 40 Вт. После этого РНК переносили на мембрану Hybond N+ (GE Healthcare) при силе тока 300 мA в устройстве полусухого переноса (Bio-rad) при комнатной температуре в течение 1,5 часа. РНК сшивали с мембраной с использованием кнопки "автоматического сшивания" на приборе для автоматического сшивания с помощью ультрафиолета Stratagene UV Crosslinker the Stratalinker (Stratagene). Мембрану подвергали предварительной гибридизации в буфере для гибридизации ULTRAhyb-Oligo Hybridization Buffer (Ambion) в течение 30 мин с вращением при 42°C, а затем добавляли зонды и проводили гибридизацию в течение ночи. Зонды заказывали у IDT и метили [гамма-32P] ATP (Perkin Elmer) с использованием полинуклеотид-киназы T4 (New England Biolabs). Мембрану промывали один раз предварительно подогретым (42°C) 2xSSC, 0,5% SDS в течение 1 мин. с последующими двумя промываниями по 30 минут при 42°C. Мембрану экспонировали на люминесцентном экране в течение одного часа или в течение ночи при комнатной температуре, а затем сканировали с использованием устройства для формирования изображения на люминесцентном фосфорном покрытии (Typhoon).
Создание и оценка бактериальной системы CRISPR
Элементы локуса CRISPR, в том числе tracrRNA, Cas9 и лидерную последовательность, подвергали ПЦР амплификации из геномной ДНК Streptococcus pyogenes SF370 с фланкирующими гомологичными плечами для сборки по методу Гибсона. Два сайта BsaI типа IIS вводили между двумя прямыми повторами для обеспечения вставки спейсеров (фигура 9). ПЦР-продукты клонировали в расщепленный с помощью EcoRV pACYC184 ниже промотора tet с использованием мастер-микса для сборки по методу Гибсона Gibson Assembly Master Mix (NEB). Другие эндогенные элементы системы CRISPR пропускали, за исключением последних 50 п.о. Csn2. Олигонуклеотиды (Integrated DNA Technology), кодирующие спейсеры с комплементарными липкими концами клонировали в расщепленный с помощью BsaI вектор pDC000 (NEB), а затем лигировали с использованием лигазы T7 (Enzymatics) с получением плазмид pCRISPR. Контрольные плазмиды, содержащие спейсеры с последовательностями PAM (также называемыми в данном документе “последовательностями мотива CRISPR”), создавали путем лигирования гибридизированных олигонуклеотидов, несущих совместимые липкие концы (Integrated ДНК Technology), в расщепленный с помощью BamHI pUC19. Клонирование для всех конструкций выполняли в штамме JM109 E. coli (Zymo Research).
Клетки, несущие pCRISPR, делали компетентными с применением Z-Competent E. coli Transformation Kit и Buffer Set (Zymo Research, T3001) в соответствии с инструкциями производителя. При анализе трансформации производили оттаивание на льду 50 мкл аликвот компетентных клеток, несущих pCRISPR, и трансформировали 1 нг плазмиды со спейсером или pUC19 в течение 30 минут с последующим 45 секундами теплового шока при 42°C и 2 минутами на льду. Затем добавляли 250 мкл SOC (Invitrogen) с последующей инкубацией со встряхиванием при 37°C в течение 1 ч и высеивали 100 мкл клеток, полученных после SOC, на двойные планшеты для отбора (12,5 мкг/мл хлорамфеникола, 100 мкг/мл ампициллина). Для получения КОЕ/нг ДНК общее число колоний умножали на 3.
Для улучшения экспрессии компонентов CRISPR в клетках млекопитающих два гена из локуса 1 Streptococcus pyogenes SF370 (S. pyogenes) были кодон-оптимизированы, Cas9 (SpCas9) и РНКазы III (SpRNase III). Для обеспечения ядерной локализации клеточный сигнал ядерной локализации (NLS) включали в амино (N)- или карбоксильные (C)-терминальные области и SpCas9, и SpRNase III (фигура 2B). Для обеспечения визуализации экспрессии белков ген флуоресцентного белка в качестве маркера также включали в N- или C-терминальные области обоих белков (фигура 2B). Также был создан вариант SpCas9 с NLS, прикрепленной и к N-, и к C-терминальным областям (2xNLS-SpCas9). Конструкции, содержащие слитый с NLS SpCas9 и SpRNase III трансфицировали в клетки почки эмбриона человека (HEK) 293FT, и было обнаружено, что относительное положение NLS относительно SpCas9 и SpRNase III влияет на их эффективность ядерной локализации. Хотя C-терминальной NLS было достаточно для нацеливания SpRNase III в ядро, прикрепление одной копии этих конкретных NLS либо к N-, либо к C-терминальным областям SpCas9 не было способно обеспечить адекватную ядерную локализацию в этой системе. В этом примере C-терминальная NLS была из нуклеоплазмина (KRPAATKKAGQAKKKK), а C-терминальная NLS был из большого Т-антигена SV40 (PKKKRKV). Из тестируемых вариантов SpCas9 только 2xNLS-SpCas9 проявлял ядерную локализацию (фигура 2B).
tracrRNA из локуса CRISPR S. pyogenes SF370 содержал два сайта инициации транскрипции, дающие начало двум транскриптам из 89 нуклеотидов (нт) и 171 нт, которые затем подвергались процессингу в идентичные зрелые tracrRNA из 75 нт. Более короткие tracrRNA из 89 нт отбирали на предмет экспрессии в клетках млекопитающих (экспрессирующая конструкция изображена на фигуре 7A, с функциональностью, как определено по результатам анализа с помощью Surveyor, показанным на фигуре 7B). Сайты инициации транскрипции обозначены как +1, а также указаны терминатор транскрипции и последовательность, анализированная с помощью нозерн-блоттинга. Экспрессию подвергнутой процессингу tracrRNA также подтверждали с помощью нозерн-блоттинга. На фигуре 7C показаны результаты анализа с помощью нозерн-блоттинга общей РНК, экстрагированной из клеток 293FT, трансфицированных экспрессирующими конструкциями U6, несущими длинную или короткую tracrRNA, а также SpCas9 и DR-EMX1(1)-DR. Левая и правая секции получены с клетками 293FT, трансфицированными без SpRNase III или с таковой, соответственно. U6 являются показателем для контроля загрузки при блоттинге с зондом, нацеленным на малую ядерную РНК (snRNA) U6 человека. Трансфекция экспрессирующей конструкции с короткой tracrRNA приводила к высоким уровням подвергшейся процессингу формы tracrRNA (~75 п.о.). Очень низкие количества длинных tracrRNA обнаруживали при нозерн-блоттинге.
Для стимуляции точной инициации транскрипции промотор U6 на основе РНК-полимеразы III выбирали для управления экспрессией tracrRNA (фигура 2C). Подобным образом, конструкцию на основе промотора U6 разработали для экспрессии массива pre-crRNA, состоящего из одного спейсера, фланкированного двумя прямыми повторами (DR, также включены в выражение “парные tracr-последовательности”; фигура 2C). Исходный спейсер был разработан для нацеливания на целевой сайт из 33 пар оснований (п.о.) (протоспейсер из 30 п.о., а также последовательность мотива CRISPR (PAM) из 3 п.о., соответствующая мотиву узнавания NGG у Cas9) в локусе EMX1 человека (фигура 2C), ключевом гене в развитии коры головного мозга.
Клетки HEK 293FT трансфицировали комбинацией компонентов CRISPR для того, чтобы определить, можно ли при гетерологичной экспрессии системы CRISPR (SpCas9, SpRNase III, tracrRNA и pre-crRNA) в клетках млекопитающих достичь целенаправленного расщепления хромосом млекопитающего. Поскольку DSB в ядрах млекопитающих частично репарируются с помощью пути негомологичного соединения концов (NHEJ), которое приводит к формированию вставок/делеций, анализ с помощью SURVEYOR использовали для выявления потенциальной активности для расщепления в целевом локусе EMX1 (фигура 8) (см., например, Guschin et al., 2010, Methods Mol Biol 649: 247). Совместная трансфекция всех четырех компонентов CRISPR была способна индуцировать расщепление, составляющее до 5,0%, в протоспейсере (см. фигура 2D). Совместная трансфекция всех компонентов CRISPR, за исключением SpRNase III, также индуцировала образование вставок/делеций в протоспейсере на уровне до 4,7%, что указывало на то, что могут существовать эндогенные РНКазы млекопитающих, которые способны помогать созреванию crRNA, такие как, например, родственные ферменты Dicer и Drosha. Удаление любого из трех остальных компонентов ликвидировало активность системы CRISPR для расщепления генома (фигура 2D). Секвенирование по Сэнгеру ампликонов, содержащих целевой локус, подтверждало активность для расщепления: на 43 подвергшихся секвенированию клонов было обнаружено 5 мутированных аллелей (11,6%). В подобных экспериментах с использованием ряда направляющих последовательностей процентные значения содержания вставок/делеций составляли до 29% (см. фигуры 4-7, 12 и 13). Эти результаты определяют трехкомпонентную систему для эффективной опосредованной CRISPR модификации генома в клетках млекопитающих. Для оптимизации эффективности расщепления заявители также определяли, влияют ли различные изоформы tracrRNA на эффективность расщепления, и обнаружили, что в этой иллюстративной системе только короткая (89 п.о.) форма транскрипта была способна опосредовать расщепление локуса генома EMX1 человека (фигура 6B).
На фигуре 14 представлен дополнительный анализ процессинга crRNA в клетках млекопитающих с помощью нозерн-блоттинга. На фигуре 14A показано схематическое изображение вектора экспрессии для одного спейсера, фланкированного двумя прямыми повторами (DR-EMX1(1)-DR). Спейсер из 30 п.о., нацеленный на протоспейсер 1 локуса EMX1 человека (см. фигуру 6), и последовательности прямых повторов показаны в последовательности внизу фигуры 14A. Линия указывает на участок, обратно комплементарную последовательность которого использовали для создания зондов для нозерн-блоттинга для выявления crRNA EMX1(1). На фигуре 14B показаны результаты анализа с помощью нозерн-блоттинга общей РНК, экстрагированной из клеток 293FT, трансфицированных экспрессирующими конструкциями U6, несущими DR-EMX1(1)-DR. Левая и правая секции получены с клетками 293FT, трансфицированными без SpRNase III или с таковой, соответственно. DR-EMX1(1)-DR подвергался процессингу в зрелые crRNA только в присутствии SpCas9 и короткой tracrRNA и не зависел от присутствия SpRNase III. Зрелая crRNA, обнаруженная в общей РНК трансфицированных 293FT, имела длину ~33 п.о. и была короче, чем зрелая crRNA из S. pyogenes длиной 39-42 п.о. Эти результаты демонстрируют, что систему CRISPR можно переместить в эукариотические клетки и перепрограммировать для облегчения расщепления эндогенных целевых полинуклеотидов млекопитающих.
На фигуре 2 показана бактериальная система CRISPR, описанная в этом примере. На фигуре 2A показано схематическое изображение локуса 1 CRISPR из Streptococcus pyogenes SF370 и предполагаемый механизм опосредованного CRISPR расщепления ДНК с помощью этой системы. Зрелая crRNA, подвергшаяся процессингу из массива прямых повторов-спейсеров, направляет Cas9 к мишеням в геноме, состоящим из комплементарных протоспейсеров и протоспейсерного смежного мотива (PAM). При спаривании оснований мишень-спейсер Cas9 опосредует двухцепочечный разрыв в целевой ДНК. На фигуре 2B показано конструирование Cas9 S. pyogenes (SpCas9) и RNase III (SpRNase III) с клеточными сигналами ядерной локализации (NLS) для обеспечения импорта в ядро млекопитающих. На фигуре 2C показана экспрессия SpCas9 и SpRNase III у млекопитающих, управляемая конститутивным промотором EF1a, и массива tracrRNA и pre-crRNA (DR-спейсер-DR), управляемая промотором U6 РНК-полимеразы 3 для стимуляции точной инициации и терминации транскрипции. Протоспейсер из локуса EMX1 человека с удовлетворительной последовательностью PAM использовали в качестве спейсера в массиве pre-crRNA. На фигуре 2D показан анализ с помощью нуклеазы Surveyor для опосредованных SpCas9 минорных вставок и делеций. SpCas9 экспрессировался с SpRNase III, tracrRNA и массивом pre-crRNA, несущим целевой спейсер для EMX1, и без таковых. На фигуре 2E показано схематическое изображение спаривания оснований между целевым локусом и нацеленной на EMX1 crRNA, а также иллюстративная хроматограмма, на которой показана микроделеция, смежная по отношению к сайту расщепления SpCas9. На фигуре 2F показаны мутированные аллели, идентифицированные в результате анализа секвенирования 43 клональных ампликонов, показывающие разнообразие микровставок и микроделеций. Штрихами указаны удаленные основания, а невыровненные или несовпадающие основания указывают на вставки или мутации. Масштабная метка = 10 мкм.
Для дальнейшего упрощения трехкомпонентной системы адаптировали химерную crRNA-tracrRNA гибридную структуру, в которой зрелую crRNA (содержащую направляющую последовательность) сливали с частичной tracrRNA через структуру по типу стебель-петля для имитации естественного дуплекса crRNA:tracrRNA (фигура 3A). Для повышения эффективности совместной доставки создавали бицистронный вектор экспрессии для управления коэкспрессией химерной РНК и SpCas9 в трансфицированных клетках (фигуры 3A и 8). Параллельно, бицистронные векторы использовали для экспрессии pre-crRNA (DR-направляющая последовательность-DR) с SpCas9, чтобы индуцировать процессинг в crRNA с участием отдельно экспрессируемой tracrRNA (сравнение на фигуре 13B: верхняя часть и нижняя часть). На фигуре 9 представлены схематические иллюстрации бицистронных векторов экспрессии для массива pre-crRNA (фигура 9A) или химерных crRNA (представлено короткой линией ниже сайта встраивания направляющей последовательности и выше промотора EF1α на фигуре 9B) с hSpCas9, показывающие положение различных элементов и точки встраивания направляющей последовательности. Расширенная последовательность вокруг положения сайта встраивания направляющей последовательности на фигуре 9B также показывает частичную последовательность DR (GTTTAGAGCTA) и частичную последовательности tracrRNA (TAGCAAGTTAAAATAAGGCTAGTCCGTTTTT). Направляющие последовательности можно встроить между сайтами BbsI с использованием гибридизированных олигонуклеотидов. Структуры последовательностей для олигонуклеотидов показаны ниже схематических иллюстраций на фигуре 9 с указанными подходящими адаптерами лигирования. WPRE представляет собой посттранскрипционный регуляторный элемент вируса гепатита сурков. Эффективность опосредованного химерной РНК расщепления исследовали путем целенаправленного воздействия на тот же локус EMX1, описанный выше. С использованием как анализа с помощью Surveyor, так и секвенирования ампликонов по Сэнгеру авторы настоящего изобретения подтвердили, что химерная структура РНК облегчает расщепление локуса EMX1 человека со степенью модификации примерно 4,7% (фигура 4).
Генерализованность опосредованного CRISPR расщепления в эукариотических клетках исследовали путем целенаправленного воздействия на дополнительные локусы генома как в человеческих, так и мышиных клетках путем конструирования химерных РНК, целенаправленно воздействующих на множественные сайты в EMX1 и PVALB человека, а также на локусы Th мыши. На фигуре 15 показан выбор некоторых дополнительных служащих в качестве мишени протоспейсеров в локусах PVALB человека (фигура 15A) и Th мыши (фигура 15B). Приведены схематические изображения локусов генов и положения трех протоспейсеров в последнем экзоне каждого из них. Подчеркнутые последовательности включают последовательность протоспейсера из 30 п.о. и 3 п.о. на 3’-конце, соответствующую последовательностям PAM. Протоспейсеры на смысловой и антисмысловой нитях указаны выше и ниже последовательностей ДНК, соответственно. Степень модификации для локусов PVALB человека и Th мыши достигали 6,3% и 0,75%, соответственно, демонстрируя широкую применимость системы CRISPR при модификации различных локусов у многих организмов (фигуры 3B и 6). Хотя при использовании химерных конструкций расщепление обнаруживали только с одним из трех спейсеров для каждого локуса, все целевые последовательности расщеплялись с эффективностью получения вставок/делеций, достигающей 27%, при использовании схемы с коэкспрессируемой pre-crRNA (фигура 6).
На фигуре 13 представлена дополнительная иллюстрация того, что SpCas9 можно перепрограммировать для целенаправленного воздействия на множественные локусы генома в клетках млекопитающих. На фигуре 13A представлено схематическое изображение локуса EMX1 человека, на котором показано положение пяти протоспейсеров, указанных с помощью подчеркнутых последовательностей. На фигуре 13B представлено схематическое изображение комплекса pre-crRNA/trcrRNA, на котором показана гибридизация между участком прямого повтора в pre-crRNA и tracrRNA (вверху), и схематическое изображение химерной структуры РНК, содержащей направляющую последовательность из 20 п.о. и парную tracr-последовательность и tracr-последовательность, состоящие из неполного прямого повтора и последовательностей tracrRNA, гибридизованных в "шпилечную" структуру (внизу). Результаты анализа с помощью Surveyor со сравнением эффективности опосредованного Cas9 расщепления в пяти протоспейсерах в локусе EMX1 человека показаны на фигуре 13C. Целенаправленное воздействие на каждый протоспейсер осуществляли либо с использованием подвергнутого процессингу комплекса pre-crRNA/tracrRNA (crRNA), либо с использованием химерной РНК (chiRNA).
Поскольку вторичная структура РНК может быть важной для межмолекулярных взаимодействий, алгоритм предсказания структуры на основе минимальной свободной энергии и ансамбля взвешенных структур по Больцману использовали для сравнения предполагаемой вторичной структуры всех направляющих последовательностей, используемых в эксперименте с целенаправленным воздействием на геном (фигура 3B) (см., например, Gruber et al., 2008, Nucleic Acids Research, 36: W70). Анализ выявил, что в большинстве случаев эффективные направляющие последовательности в контексте химерной crRNA, по сути, не содержали мотивов вторичной структуры, тогда как неэффективные направляющие последовательности с большей вероятностью образовывали внутренние вторичные структуры, которые могут препятствовать спариванию оснований с ДНК целевого протоспейсера. Следовательно, возможно, что вариабельность во вторичной структуре спейсера может оказывать воздействие на эффективность опосредованной CRISPR интерференции при использовании химерной crRNA.
На фигуре 3 показан пример векторов экспрессии. На фигуре 3A представлено схематическое изображение бицистронного вектора для управления экспрессией химерной синтетической конструкции crRNA-tracrRNA (химерной РНК), а также SpCas9. Химерная направляющая РНК содержит направляющую последовательность из 20 п.о., соответствующую протоспейсеру в геномном целевом сайте. На фигуре 3B представлено схематическое изображение, на котором показаны направляющие последовательности, нацеленные на локусы EMX1, PVALB человека и Th мыши, а также их предсказанные вторичные структуры. Эффективность модификации в каждом целевом сайте указана ниже рисунка вторичной структуры РНК (EMX1, n = 216 считываемых фрагментов при секвенировании ампликонов; PVALB, n = 224 считываемых фрагментов; Th, n = 265 считываемых фрагментов). Представлены результаты по алгоритму укладки каждого основания, окрашенного соответственно его возможности принятия предсказанной вторичной структуры, как указано с помощью цветной шкалы, воспроизведенной на фигуре 3B в виде серой шкалы.
Структуры дополнительных векторов для SpCas9 показаны на фигуре 44, на которой показаны отдельные векторы экспрессии, включающие промотор U6, сцепленный с сайтом встраивания для направляющего олигонуклеотида, и промотор Cbh, сцепленный с кодирующей последовательностью SpCas9. Вектор, показанный на фигуре 44b, включает кодирующую последовательность tracrRNA, сцепленную с промотором H1.
Для того, чтобы определить, способны ли спейсеры со вторичными структурами функционировать в прокариотических клетках, где в естественных условиях функционируют CRISPR, интерференцию при трансформации плазмидами, несущими протоспейсеры, исследовали в штамме E. coli, гетерологично экспрессирующем локус 1 CRISPR S. pyogenes SF370 (фигура 10). Локус CRISPR клонировали в низкокопийный вектор экспрессии E. coli и массив crRNA замещали одним спейсером, фланкированным парой DR (pCRISPR). Штаммы E. coli, несущие разные плазмиды pCRISPR, трансформировали контрольными плазмидами, содержащими соответствующий протоспейсер и последовательности PAM (фигура 10C). При анализе у бактерий все спейсеры способствовали эффективной CRISPR-интерференции (фигура 4C). Эти результаты указывают на то, что могут существовать дополнительные факторы, влияющие на эффективность активности CRISPR в клетках млекопитающих.
Для исследования специфичности опосредованного CRISPR расщепления эффект однонуклеотидных мутаций в направляющей последовательности в отношении расщепления протоспейсера в геноме млекопитающих анализировали с использованием ряда целенаправленно воздействующих на EMX1 химерных crRNA с единичными точковыми мутациями (фигура 4A). На фигуре 4B показаны результаты анализа с помощью нуклеазы Surveyor со сравнением эффективности расщепления Cas9 при спаривании с различными мутантными химерными РНК. Несовпадение одного основания в участке вплоть до 12 п.о. с 5’ в PAM, по сути, прекращало расщепление генома SpCas9, тогда как спейсеры с мутациями в положениях, расположенных в более отдаленных положениях выше относительно хода транскрипции сохраняли активность в отношении исходного протоспейсера-мишени (фигура 4B). В дополнение к PAM, SpCas9 характеризуется специфичностью в отношении одного основания в последних 12 п.о. спейсера. Кроме того, CRISPR способен опосредовать расщепление генома столь же эффективно, как и пара нуклеаз TALE (TALEN), целенаправленно воздействующих на тот же протоспейсер EMX1. На фигуре 4C представлено схематическое изображение, на котором показана структура TALEN, целенаправленно воздействующих на EMX1, и на фигуре 4D показано сравнение эффективности TALEN и Cas9 (n=3) при разгонке в геле продуктов, полученных в результате анализа с помощью Surveyor.
Установив набор компонентов для достижения опосредованного CRISPR редактирования генов в клетках млекопитающих посредством подверженного ошибкам механизма NHEJ, исследовали способность CRISPR к стимуляции гомологичной рекомбинации (HR), высокоточный путь репарации генов для создания точных редакционных изменений в геноме. SpCas9 дикого типа способен опосредовать сайт-специфические DSB, которые могут репарироваться как с помощью NHEJ, так и HR. Кроме того, замену аспартат-на-аланин (D10A) в каталитическом домене RuvC I в SpCas9 конструировали для превращения нуклеазы в никазу (SpCas9n; проиллюстрировано на фигуре 5A) (см., например, Sapranausaks et al., 2011, Nucleic Acids Resch, 39: 9275; Gasiunas et al., 2012, Proc. Natl. Acad. Sci. USA, 109:E2579) так, чтобы надрезанная геномная ДНК подвергалась высокоточной репарации с участием гомологичной рекомбинации (HDR). Анализ с помощью Surveyor подтвердил, что SpCas9n не создает вставок/делеций в протоспейсере-мишени EMX1. Как показано на фигуре 5B, коэкспрессия целенаправленно воздействующей на EMX1 химерной crRNA с SpCas9 давала вставки/делеции в целевом сайте, тогда как коэкспрессия с SpCas9n - нет (n=3). Более того, секвенирование 327 ампликонов не обнаружило каких-либо вставок/делеций, индуцированных SpCas9n. Для исследования опосредованной CRISPR HR при совместной трансфекции клеток HEK 293FT химерной РНК, целенаправленно воздействующей на EMX1, hSpCas9 или hSpCas9n, выбирали тот же локус, также как и матрицу для HR для введения пары сайтов рестрикции (HindIII и NheI) возле протоспейсера. На фигуре 5C приведена схематическая иллюстрация стратегии HR с относительными положениями точек рекомбинации и последовательностей для гибридизации праймеров (стрелки). SpCas9 и SpCas9n действительно катализировали интеграцию матрицы HR в локус EMX1. ПЦР амплификация целевого участка с последующим рестрикционным расщеплением HindIII выявила продукты расщепления, соответствующие ожидаемым размерам фрагментов (стрелки на результатах анализа полиморфизма длин рестрикционных фрагментов с помощью гель-электрофореза, показанных на фигуре 5D), причем SpCas9 и SpCas9n опосредуют подобные уровни эффективности HR. Заявители дополнительно подтверждали HR с использованием секвенирования геномных ампликонов по Сэнгеру (фигура 5E). Эти результаты демонстрировали пригодность CRISPR для облегчения целенаправленной вставки генов в геном млекопитающего. С учетом специфичности целенаправленного воздействия в 14 п.о. (12 п.о. от спейсера и 2 п.о. от PAM) SpCas9 дикого типа, доступность никазы может значительно снизить вероятность нецелевых модификаций, поскольку одноцепочечные разрывы не являются субстратами для подверженного ошибкам пути NHEJ.
Экспрессирующие конструкции, имитирующие естественную архитектуру локусов CRISPR с собранными в массив спейсерами (фигура 2A), создавали для исследования возможности мультиплексного целенаправленного воздействия на последовательности. При использовании одного массива CRISPR, кодирующего пару спейсеров, нацеленных на EMX1 и PVALB, обнаруживали эффективное расщепление в обоих локусах (фигура 4F, на которой показаны как схематическая структура массива crRNA, так и блот, полученный после анализа с помощью Surveyor, показывающий эффективное опосредование расщепления). Также исследовали целенаправленную делецию геномных участков большего размера посредством одновременных DSB с использованием спейсеров против двух мишеней в EMX1, разделенных 119 п.о., и обнаруженная эффективность делеции составляла 1,6% (3 из 182 ампликонов; фигура 4G). Это демонстрирует, что система CRISPR может опосредовать мультиплексное редактирование в пределах одного генома.
Пример 2: модификации и альтернативы системы CRISPR
Возможность применения РНК для программирования специфичного к последовательности расщепления ДНК определяет новый класс инструментов для конструирования генома для разнообразных исследовательских и промышленных применений. Несколько аспектов системы CRISPR можно дополнительно улучшить для повышения эффективности и универсальности целенаправленного воздействия с помощью CRISPR. Оптимальная активность Cas9 может зависеть от доступности несвязанного Mg2+ на уровнях, которые превышают имеющиеся в ядре млекопитающего (см., например, Jinek et al., 2012, Science, 337:816), и предпочтение в отношении мотива NGG непосредственно ниже протоспейсера ограничивает способность к целенаправленному воздействию в среднем на каждые 12 п.о. в геноме человека (фигура 11, оценка как плюс-, так и минус-нитей в хромосомных последовательностях человека). Некоторые из этих затруднений можно преодолеть путем изучения разнообразия локусов CRISPR в микробном метагеноме (см., например, Makarova et al., 2011, Nat Rev Microbiol, 9:467). Другие локусы CRISPR можно переместить в микроокружение клетки млекопитающего с помощью способа, подобного описанному в примере 1. Например, на фигуре 12 показана адаптация системы CRISPR II типа из CRISPR 1 LMD-9 Streptococcus thermophilus для гетерологичной экспрессии в клетках млекопитающих, чтобы достичь опосредованного CRISPR редактирования генома. На фигуре 12A приведена схематическая иллюстрация CRISPR 1 из LMD-9 S. thermophilus. На фигуре 12B показана структура системы экспрессии для системы CRISPR S. thermophilus. Кодон-оптимизированный hStCas9 человека экспрессируется с помощью конститутивного промотора EF1α. Зрелые варианты tracrRNA и crRNA экспрессируются с помощью промотора U6 для стимуляции точной инициации транскрипции. Показаны последовательности из зрелых crRNA и tracrRNA. Одно основание, обозначенное буквой “a” в нижнем регистре в последовательности crRNA использовали для удаления последовательности polyU, которая служит в качестве терминатора транскрипции РНК polIII. На фигуре 12С представлено схематическое изображение, на котором показаны направляющие последовательности, нацеленные на локус EMX1 человека, а также их предсказанные вторичные структуры. Эффективность модификации в каждом целевом сайте указана ниже вторичных структур РНК. Алгоритм, генерирующий цвета структуры каждого основания соответственно его возможности принятия предсказанной вторичной структуры, которая указана с помощью цветной шкалы, воспроизведен на фигуре 12C в виде серой шкалы. На фигуре 12D показаны результаты опосредованного hStCas9 расщепления в целевом локусе с использованием анализа с помощью Surveyor. РНК направляющих спейсеров 1 и 2 индуцировали 14% и 6,4%, соответственно. Статистический анализ активности для расщепления по биологическим копиям в этих двух протоспейсерных сайтах также приведен на фигуре 6. На фигуре 16 приведено схематическое изображение дополнительного протоспейсера и соответствующих последовательностей PAM, являющихся мишенями для системы CRISPR S. thermophilus, в локусе EMX1 человека. Последовательности двух протоспейсеров выделены и их соответствующие последовательности PAM, удовлетворяющие мотиву NNAGAAW, обозначены путем подчеркивания в направлении 3’ относительно соответствующей выделенной последовательности. Оба протоспейсера нацелены на антисмысловую нить.
Пример 3: алгоритм выбора образцов целевой последовательности
Создали компьютерную программу для идентификации кандидатных целевых последовательностей CRISPR на обеих нитях вводимой последовательности ДНК на основе длины желаемой направляющей последовательности и последовательности мотива CRISPR (PAM) для определенного фермента CRISPR. Например, целевые сайты для Cas9 из S. pyogenes с последовательностями PAM NGG можно идентифицировать путем поиска в отношении 5’-Nx-NGG-3’ как на вводимой последовательности, так и на последовательности, обратно-комплементарной вводимой. Подобным образом, целевые сайты для Cas9 CRISPR1 S. thermophilus с последовательностью PAM NNAGAAW, можно идентифицировать путем поиска в отношении 5’-Nx-NNAGAAW-3’ как на вводимой последовательности, так и на последовательности, обратно-комплементарной вводимой. Подобным образом, целевые сайты для Cas9 CRISPR3 S. thermophilus с последовательностью PAM NGGNG можно идентифицировать путем поиска в отношении 5’-Nx-NGGNG-3’ как на вводимой последовательности, так и на последовательности, обратно-комплементарной вводимой. Значение “x” в Nx может фиксироваться программой или может быть определено пользователем, как, например, 20.
Поскольку несколько случаев появления целевого сайта ДНК в геноме могут приводить к неспецифическому редактированию генома, после идентификации всех возможных сайтов программа профильтровывает последовательности, исходя из количества раз, когда они встречаются в соответствующем эталонном геноме. Для тех ферментов CRISPR, для которых специфичность к последовательности определяется "затравочной" последовательностью, такой как находящаяся в 11-12 п.о. в направлении 5’ от последовательности PAM, в том числе сама последовательность PAM, стадия фильтрования может основываться на затравочной последовательности. Следовательно, во избежание редактирования в дополнительных локусах генома результаты фильтруют, исходя из числа случаев обнаружения последовательности затравки:PAM в подходящем геноме. Пользователь может иметь возможность выбора длины затравочной последовательности. Пользователь также может иметь возможность определять число случаев обнаружения последовательности затравки:PAM в геноме применительно к прохождению фильтра. По умолчанию установлен скрининг в отношении уникальных последовательностей. Уровень фильтрования изменяют путем изменения как длины затравочной последовательности, так и числа случаев обнаружения последовательности в геноме. В качестве дополнения или альтернативы, программа может обеспечивать последовательность направляющей последовательности, комплементарную сообщенной(ым) целевой(ым) последовательности(ям) путем обеспечения последовательности, обратно комплементарной идентифицированной(ым) целевой(ым) последовательности(ям).
Дальнейшие детали способов и алгоритмов для оптимизации выбора последовательности можно найти в заявке на патент США с серийным номером 61/836080 (номер дела у патентного поверенного 44790.11.2022); включенной в данный документ при помощи ссылки.
Пример 4: оценка гибридов нескольких химерных crRNA-tracrRNA
В данном примере описаны результаты, полученные для химерных РНК (chiRNA; содержащие направляющую последовательность, парную tracr-последовательность и tracr-последовательность в одном транскрипте), имеющих tracr-последовательности, которые включают фрагменты последовательности tracrRNA дикого типа с разной длиной. На фигуре 18a показано схематическое изображение бицистронного вектора экспрессии для химерной РНК и Cas9. Cas9 управляется промотором CBh, а химерная РНК управляется промотором U6. Химерная направляющая РНК состоит из направляющей последовательности (Ns) из 20 п.о., соединенной с tracr-последовательностью (проходящей от первого “U” в нижней нити к концу транскрипта), которая усечена в разных указанных положениях. Направляющие и tracr-последовательности разделены парной tracr-последовательностью GUUUUAGAGCUA, за которой следует последовательность петли GAAA. Результаты анализов с помощью SURVEYOR в отношении опосредованных Cas9 вставок/делеций в локусах EMX1 и PVALB человека показаны на фигурах 18b и 18c, соответственно. Стрелки указывают на ожидаемые фрагменты, полученные в результате расщепления с помощью SURVEYOR. ChiRNA показаны путем обозначения их “+n”, а crRNA относится к гибридной РНК, в которой направляющие и tracr-последовательности экспрессируются в виде раздельных транскриптов. Количественный анализ этих результатов, выполненный в трех повторностях, проиллюстрирован с помощью гистограмм на фигурах 19a и 19b, соответствующих фигурам 18b и 18c, соответственно (“N.D.” означает отсутствие обнаруженных вставок/делеций). ID (идентификационные данные) протоспейсеров и их соответствующей мишени в геноме, последовательность протоспейсера, последовательность PAM и положение нити приведены в таблице D. Направляющие последовательности разработаны так, чтобы они были комплементарны полной последовательности протоспейсера в случае отдельных транскриптов в гибридной системе или только подчеркнутой части в случае химерных РНК.
Таблица D:
протоспейсера
мишень
Клеточная культура и трансфекция
Линию клеток почки человеческого эмбриона (HEK) 293FT (Life Technologies) поддерживали в среде Игла в модификации Дульбекко (DMEM), дополненной 10% фетальной бычьей сыворотки (HyClone), 2 мМ GlutaMAX (Life Technologies), 100 ЕД/мл пенициллина и 100 мкг/мл стрептомицина, при 37°C с инкубированием при 5% CO2. Клетки 293FT засевали в 24-луночные планшеты (Corning) за 24 часа до трансфекции при плотности 150000 клеток на лунку. Клетки трансфицировали с применением Lipofectamine 2000 (Life Technologies), следуя рекомендованному производителем протоколу. Для каждой лунки 24-луночного планшета использовали в общей сложности 500 нг плазмид.
Анализ с помощью SURVEYOR на предмет наличия модификации генома
Клетки 293FT трансфицировали плазмидной ДНК, как описано выше. Клетки инкубировали при 37°C в течение 72 часов после трансфекции перед экстракцией геномной ДНК. Геномную ДНК экстрагировали с помощью раствора QuickExtract DNA Extraction Solution (Epicentre), следуя протоколу производителя. Вкратце, осажденные центрифугированием клетки ресуспендировали в растворе QuickExtract solution и инкубировали при 65°C в течение 15 минут и 98°C в течение 10 минут. Геномный участок, окружающий целевой сайт CRISPR, для каждого гена подвергали ПЦР амплификации (праймеры перечислены в таблице Е) и продукты очищали с использованием колонки QiaQuick Spin Column (Qiagen), следуя протоколу производителя. В общей сложности 400 нг очищенных ПЦР-продуктов смешивали с 2 мкл 10X ПЦР-буфера для ДНК-полимеразы Taq (Enzymatics) и воды сверхвысокой чистоты до конечного объема 20 мкл и подвергали процессу повторного отжига для обеспечения образования гетеродуплекса: 95°C в течение 10 мин., линейное снижение температуры с 95°C до 85°C со скоростью 2°C/с, с 85°C до 25°C со скоростью 0,25°C/с и с выдерживанием при 25°C в течение 1 минуты. После повторного отжига продукты обрабатывали нуклеазой SURVEYOR и энхансером S SURVEYOR (Transgenomics), следуя рекомендованному производителем протоколу, и анализировали в 4-20% полиакриламидных гелях Novex TBE (Life Technologies). Гели окрашивали красителем ДНК SYBR Gold (Life Technologies) в течение 30 минут и получали изображение с помощью системы обработки изображений Gel Doc gel imaging system (Bio-rad). Количественный анализ основывался на относительных интенсивностях полос.
Таблица E
Вычислительная идентификация уникальных целевых сайтов CRISPR
Для идентификации уникальных целевых сайтов для фермента Cas9 (SpCas9) S. pyogenes SF370 в геноме человека, мыши, крысы, данио, плодовой мухи и C. elegans был разработан пакет программ для сканирования обеих нитей последовательности ДНК и идентификации всех возможных целевых сайтов SpCas9. Для этого примера каждый целевой сайт SpCas9 был оперативно определен как последовательность из 20 п.о., за которой следует последовательность мотива, смежного с протоспейсером (PAM) NGG, при этом были определены все последовательности, удовлетворяющие определению 5’-N20-NGG-3’ на всех хромосомах. Для предотвращения неспецифического редактирования генома после идентификации всех потенциальных сайтов все целевые сайты фильтровали, исходя из количества раз, когда они встречаются в соответствующем эталонном геноме. Для того, чтобы извлечь пользу из специфичности к последовательности активности Cas9, обеспечиваемой "затравочной" последовательностью, которой может быть, например, последовательность из приблизительно 11-12 п.о. 5’ от последовательности PAM, при этом последовательности 5’-NNNNNNNNNN-NGG-3’ выбирали как уникальные в соответствующем геноме. Все геномные последовательности загружали из геномного браузера UCSC (геном человека hg19, геном мыши mm9, геном крысы rn5, геном данио danRer7, геном D. melanogaster dm4 и геном C. elegans ce10). Все результаты поиска доступны для просмотра с использованием информации из геномного браузера UCSC. Иллюстративная визуализация некоторых целевых сайтов в геноме человека представлена на фигуре 21.
Первоначально целенаправленному воздействию подвергали три сайта в пределах локуса EMX1 в клетках HEK 293FT человека. Эффективность модификации генома каждой chiРНК оценивали с использованием анализа с помощью нуклеазы SURVEYOR, который позволяет обнаруживать мутации, возникающие в результате двухцепочечных разрывов (DSB) ДНК и их последующей репарации с помощью пути репарации повреждения ДНК за счет негомологичного соединения концов (NHEJ). В конструкциях, обозначенных chiRNA(+n), указывается, что нуклеотиды в количестве до +n нуклеотида tracrRNA дикого типа включены в химерную РНК-конструкцию, при этом для n используются значения 48, 54, 67 и 85. Химерные РНК, содержащие более длинные фрагменты tracrRNA дикого типа (chiRNA(+67) и chiRNA(+85)), опосредовали расщепление ДНК во всех трех целевых сайтах EMX1, причем chiRNA(+85), в частности, демонстрировал значительно более высокие уровни расщепления ДНК, чем соответствующие гибриды crRNA/tracrRNA, у которых направляющие и tracr-последовательности экспрессируются в отдельных транскриптах (фигуры 18b и 19a). Два сайта в локусе PVALB, которые не давали обнаруживаемого расщепления с использованием гибридной системы (направляющая последовательность и tracr-последовательность, экспрессируемые в виде отдельных транскриптов), также подвергались целенаправленному воздействию с использованием chiRNA. СhiRNA(+67) и chiRNA(+85) были способны опосредовать значительное расщепление в двух протоспейсерах в PVALB (фигуры 18c и 19b).
Для всех пяти мишеней в локусах EMX1 и PVALB наблюдали соответствующее повышение эффективности модификации генома с увеличением длины tracr-последовательности. Не вдаваясь в какую-либо теорию, вторичная структура, формируемая 3’-концом tracrRNA, может играть роль в увеличении скорости образования комплекса CRISPR. Иллюстрация предсказанных вторичных структур для каждой химерной РНК, использованной в этом примере, представлена на фигуре 21. Вторичную структуру предсказывали с применением RNAfold (http://RNA.tbi.univie.ac.at/cgi-bin/RNAfold.cgi) с использованием минимальной свободной энергии и алгоритма функции распределения. Псевдоцвет для каждого основания (воспроизведен в серой шкале) указывает на возможность спаривания. По причине того, что chiRNA с более длинными tracr-последовательностями были способны расщеплять мишени, которые не были расщеплены нативными гибридами crRNA/tracrRNA CRISPR, возможно, что химерная РНК может загружаться на Cas9 более эффективно, чем ее нативный гибридный аналог. Для обеспечения применения Cas9 для сайт-специфического редактирования генома в эукариотических клетках и организмах все предсказанные уникальные целевые сайты для Cas9 S. pyogenes определяли путем вычислений в геномах человека, мыши, крысы, данио, C. elegans и D. melanogaster. Химерные РНК можно разрабатывать для ферментов Cas9 из других микроорганизмов для расширения целевого пространства CRISPR РНК-программируемых нуклеаз.
На фигуре 22 показан примерный бицистронный вектор экспрессии для экспрессии химерной РНК, включающий tracr-последовательность РНК дикого типа вплоть до нуклеотида +85 и SpCas9 с последовательностями ядерной локализации. SpCas9 экспрессируется с промотора CBh и терминируется polyA-сигналом bGH (bGH pA). Расширенная последовательность, показанная непосредственно под схематическим изображением, соответствует участку, окружающему направляющую последовательность сайта встраивания, и включает от 5’ дo 3’, 3’-часть промотора U6 (первый заштрихованный участок), сайты расщепления BbsI (стрелки), неполный прямой повтор (парная tracr-последовательность GTTTTAGAGCTA, подчеркнутая), последовательность петли GAAA и +85 tracr-последовательность (подчеркнутая последовательность, следующая за последовательностью петли). Иллюстративное встраивание направляющей последовательности изображено ниже сайта встраивания направляющей последовательности, при этом нуклеотиды направляющей последовательности для выбранной мишени представлены как “N”.
Последовательности, описанные в приведенных выше примерах, представляют собой следующие (полинуклеотидные последовательности представлены от 5' к 3'):
U6-короткая tracrRNA (Streptococcus pyogenes SF370):
GAGGGCCTATTTCCCATGATTCCTTCATATTTGCATATACGATACAAGGCTGTTAGAGAGATAATTGGAATTAATTTGACTGTAAACACAAAGATATTAGTACAAAATACGTGACGTAGAAAGTAATAATTTCTTGGGTAGTTTGCAGTTTTAAAATTATGTTTTAAAATGGACTATCATATGCTTACCGTAACTTGAAAGTATTTCGATTTCTTGGCTTTATATATCTTGTGGAAAGGACGAAACACCGGAACCATTCAAAACAGCATAGCAAGTTAAAATAAGGCTAGTCCGTTATCAACTTGAAAAAGTGGCACCGAGTCGGTGCTTTTT
T (жирный шрифт = последовательность tracrRNA; подчеркивание = терминаторная последовательность)
U6-длинная tracrRNA (Streptococcus pyogenes SF370):
GAGGGCCTATTTCCCATGATTCCTTCATATTTGCATATACGATACAAGGCTGTTAGAGAGATAATTGGAATTAATTTGACTGTAAACACAAAGATATTAGTACAAAATACGTGACGTAGAAAGTAATAATTTCTTGGGTAGTTTGCAGTTTTAAAATTATGTTTTAAAATGGACTATCATATGCTTACCGTAACTTGAAAGTATTTCGATTTCTTGGCTTTATATATCTTGTGGAAAGGACGAAACACCGGTAGTATTAAGTATTGTTTTATGGCTGATAAATTTCTTTGAATTTCTCCTTGATTATTTGTTATAAAAGTTATAAAATAATCTTGTTGGAACCATTCAAAACAGCATAGCAAGTTAAAATAAGGCTAGTCCGTTATCAACTTGAAAAAGTGGCACCGAGTCGGTGCTTTTTTT
U6-DR-BbsI-остов-DR (Streptococcus pyogenes SF370):
GAGGGCCTATTTCCCATGATTCCTTCATATTTGCATATACGATACAAGGCTGTTAGAGAGATAATTGGAATTAATTTGACTGTAAACACAAAGATATTAGTACAAAATACGTGACGTAGAAAGTAATAATTTCTTGGGTAGTTTGCAGTTTTAAAATTATGTTTTAAAATGGACTATCATATGCTTACCGTAACTTGAAAGTATTTCGATTTCTTGGCTTTATATATCTTGTGGAAAGGACGAAACACCGGGTTTTAGAGCTATGCTGTTTTGAATGGTCCCAAAACGGGTCTTCGAGAAGACGTTTTAGAGCTATGCTGTTTTGAATGGTCCCAAAAC
U6-химерная РНК-BbsI-остов (Streptococcus pyogenes SF370)
GAGGGCCTATTTCCCATGATTCCTTCATATTTGCATATACGATACAAGGCTGTTAGAGAGATAATTGGAATTAATTTGACTGTAAACACAAAGATATTAGTACAAAATACGTGACGTAGAAAGTAATAATTTCTTGGGTAGTTTGCAGTTTTAAAATTATGTTTTAAAATGGACTATCATATGCTTACCGTAACTTGAAAGTATTTCGATTTCTTGGCTTTATATATCTTGTGGAAAGGACGAAACACCGGGTCTTCGAGAAGACCTGTTTTAGAGCTAGAAATAGCAAGTTAAAATAAGGCTAGTCCG
NLS-SpCas9-EGFP:
MDYKDHDGDYKDHDIDYKDDDDKMAPKKKRKVGIHGVPAADKKYSIGLDIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKYKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRNFMQLIHDDSLTFKEDIQKAQVSGQGDSLHEHIANLAGSPAIKKGILQTVKVVDELVKVMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQLQNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIKRQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGKATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIMERSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGDAAAVSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTTGKLPVPWPTLVTTLTYGVQCFSRYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYIMADKQKNGIKVNFKIRHNIEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITLGMDELYK
SpCas9-EGFP-NLS:
MDKKYSIGLDIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKYKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRNFMQLIHDDSLTFKEDIQKAQVSGQGDSLHEHIANLAGSPAIKKGILQTVKVVDELVKVMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQLQNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIKRQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGKATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIMERSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGDAAAVSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTTGKLPVPWPTLVTTLTYGVQCFSRYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYIMADKQKNGIKVNFKIRHNIEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITLGMDELYKKRPAATKKAGQAKKKK
NLS-SpCas9-EGFP-NLS:
MDYKDHDGDYKDHDIDYKDDDDKMAPKKKRKVGIHGVPAADKKYSIGLDIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKYKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRNFMQLIHDDSLTFKEDIQKAQVSGQGDSLHEHIANLAGSPAIKKGILQTVKVVDELVKVMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQLQNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIKRQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGKATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIMERSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGDAAAVSKGEELFTGVVPILVELDGDVNGHKFSVSGEGEGDATYGKLTLKFICTTGKLPVPWPTLVTTLTYGVQCFSRYPDHMKQHDFFKSAMPEGYVQERTIFFKDDGNYKTRAEVKFEGDTLVNRIELKGIDFKEDGNILGHKLEYNYNSHNVYIMADKQKNGIKVNFKIRHNIEDGSVQLADHYQQNTPIGDGPVLLPDNHYLSTQSALSKDPNEKRDHMVLLEFVTAAGITLGMDELYKKRPAATKKAGQAKKKK
NLS-SpCas9-NLS:
MDYKDHDGDYKDHDIDYKDDDDKMAPKKKRKVGIHGVPAADKKYSIGLDIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKYKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRNFMQLIHDDSLTFKEDIQKAQVSGQGDSLHEHIANLAGSPAIKKGILQTVKVVDELVKVMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQLQNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIKRQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGKATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIMERSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGDKRPAATKKAGQAKKKK
NLS-mCherry-SpRNase3:
MFLFLSLTSFLSSSRTLVSKGEEDNMAIIKEFMRFKVHMEGSVNGHEFEIEGEGEGRPYEGTQTAKLKVTKGGPLPFAWDILSPQFMYGSKAYVKHPADIPDYLKLSFPEGFKWERVMNFEDGGVVTVTQDSSLQDGEFIYKVKLRGTNFPSDGPVMQKKTMGWEASSERMYPEDGALKGEIKQRLKLKDGGHYDAEVKTTYKAKKPVQLPGAYNVNIKLDITSHNEDYTIVEQYERAEGRHSTGGMDELYKGSKQLEELLSTSFDIQFNDLTLLETAFTHTSYANEHRLLNVSHNERLEFLGDAVLQLIISEYLFAKYPKKTEGDMSKLRSMIVREESLAGFSRFCSFDAYIKLGKGEEKSGGRRRDTILGDLFEAFLGALLLDKGIDAVRRFLKQVMIPQVEKGNFERVKDYKTCLQEFLQTKGDVAIDYQVISEKGPAHAKQFEVSIVVNGAVLSKGLGKSKKLAEQDAAKNALAQLSEV
SpRNase3-mCherry-NLS:
MKQLEELLSTSFDIQFNDLTLLETAFTHTSYANEHRLLNVSHNERLEFLGDAVLQLIISEYLFAKYPKKTEGDMSKLRSMIVREESLAGFSRFCSFDAYIKLGKGEEKSGGRRRDTILGDLFEAFLGALLLDKGIDAVRRFLKQVMIPQVEKGNFERVKDYKTCLQEFLQTKGDVAIDYQVISEKGPAHAKQFEVSIVVNGAVLSKGLGKSKKLAEQDAAKNALAQLSEVGSVSKGEEDNMAIIKEFMRFKVHMEGSVNGHEFEIEGEGEGRPYEGTQTAKLKVTKGGPLPFAWDILSPQFMYGSKAYVKHPADIPDYLKLSFPEGFKWERVMNFEDGGVVTVTQDSSLQDGEFIYKVKLRGTNFPSDGPVMQKKTMGWEASSERMYPEDGALKGEIKQRLKLKDGGHYDAEVKTTYKAKKPVQLPGAYNVNIKLDITSHNEDYTIVEQYERAEGRHSTGGMDELYKKRPAATKKAGQAKKKK
NLS-SpCas9n-NLS (D10A мутация никазы представлена в нижнем регистре):
MDYKDHDGDYKDHDIDYKDDDDKMAPKKKRKVGIHGVPAADKKYSIGLaIGTNSVGWAVITDEYKVPSKKFKVLGNTDRHSIKKNLIGALLFDSGETAEATRLKRTARRRYTRRKNRICYLQEIFSNEMAKVDDSFFHRLEESFLVEEDKKHERHPIFGNIVDEVAYHEKYPTIYHLRKKLVDSTDKADLRLIYLALAHMIKFRGHFLIEGDLNPDNSDVDKLFIQLVQTYNQLFEENPINASGVDAKAILSARLSKSRRLENLIAQLPGEKKNGLFGNLIALSLGLTPNFKSNFDLAEDAKLQLSKDTYDDDLDNLLAQIGDQYADLFLAAKNLSDAILLSDILRVNTEITKAPLSASMIKRYDEHHQDLTLLKALVRQQLPEKYKEIFFDQSKNGYAGYIDGGASQEEFYKFIKPILEKMDGTEELLVKLNREDLLRKQRTFDNGSIPHQIHLGELHAILRRQEDFYPFLKDNREKIEKILTFRIPYYVGPLARGNSRFAWMTRKSEETITPWNFEEVVDKGASAQSFIERMTNFDKNLPNEKVLPKHSLLYEYFTVYNELTKVKYVTEGMRKPAFLSGEQKKAIVDLLFKTNRKVTVKQLKEDYFKKIECFDSVEISGVEDRFNASLGTYHDLLKIIKDKDFLDNEENEDILEDIVLTLTLFEDREMIEERLKTYAHLFDDKVMKQLKRRRYTGWGRLSRKLINGIRDKQSGKTILDFLKSDGFANRNFMQLIHDDSLTFKEDIQKAQVSGQGDSLHEHIANLAGSPAIKKGILQTVKVVDELVKVMGRHKPENIVIEMARENQTTQKGQKNSRERMKRIEEGIKELGSQILKEHPVENTQLQNEKLYLYYLQNGRDMYVDQELDINRLSDYDVDHIVPQSFLKDDSIDNKVLTRSDKNRGKSDNVPSEEVVKKMKNYWRQLLNAKLITQRKFDNLTKAERGGLSELDKAGFIKRQLVETRQITKHVAQILDSRMNTKYDENDKLIREVKVITLKSKLVSDFRKDFQFYKVREINNYHHAHDAYLNAVVGTALIKKYPKLESEFVYGDYKVYDVRKMIAKSEQEIGKATAKYFFYSNIMNFFKTEITLANGEIRKRPLIETNGETGEIVWDKGRDFATVRKVLSMPQVNIVKKTEVQTGGFSKESILPKRNSDKLIARKKDWDPKKYGGFDSPTVAYSVLVVAKVEKGKSKKLKSVKELLGITIMERSSFEKNPIDFLEAKGYKEVKKDLIIKLPKYSLFELENGRKRMLASAGELQKGNELALPSKYVNFLYLASHYEKLKGSPEDNEQKQLFVEQHKHYLDEIIEQISEFSKRVILADANLDKVLSAYNKHRDKPIREQAENIIHLFTLTNLGAPAAFKYFDTTIDRKRYTSTKEVLDATLIHQSITGLYETRIDLSQLGGDKRPAATKKAGQAKKKK
hEMX1-HR-матрица-HindII-NheI:
GAATGCTGCCCTCAGACCCGCTTCCTCCCTGTCCTTGTCTGTCCAAGGAGAATGAGGTCTCACTGGTGGATTTCGGACTACCCTGAGGAGCTGGCACCTGAGGGACAAGGCCCCCCACCTGCCCAGCTCCAGCCTCTGATGAGGGGTGGGAGAGAGCTACATGAGGTTGCTAAGAAAGCCTCCCCTGAAGGAGACCACACAGTGTGTGAGGTTGGAGTCTCTAGCAGCGGGTTCTGTGCCCCCAGGGATAGTCTGGCTGTCCAGGCACTGCTCTTGATATAAACACCACCTCCTAGTTATGAAACCATGCCCATTCTGCCTCTCTGTATGGAAAAGAGCATGGGGCTGGCCCGTGGGGTGGTGTCCACTTTAGGCCCTGTGGGAGATCATGGGAACCCACGCAGTGGGTCATAGGCTCTCTCATTTACTACTCACATCCACTCTGTGAAGAAGCGATTATGATCTCTCCTCTAGAAACTCGTAGAGTCCCATGTCTGCCGGCTTCCAGAGCCTGCACTCCTCCACCTTGGCTTGGCTTTGCTGGGGCTAGAGGAGCTAGGATGCACAGCAGCTCTGTGACCCTTTGTTTGAGAGGAACAGGAAAACCACCCTTCTCTCTGGCCCACTGTGTCCTCTTCCTGCCCTGCCATCCCCTTCTGTGAATGTTAGACCCATGGGAGCAGCTGGTCAGAGGGGACCCCGGCCTGGGGCCCCTAACCCTATGTAGCCTCAGTCTTCCCATCAGGCTCTCAGCTCAGCCTGAGTGTTGAGGCCCCAGTGGCTGCTCTGGGGGCCTCCTGAGTTTCTCATCTGTGCCCCTCCCTCCCTGGCCCAGGTGAAGGTGTGGTTCCAGAACCGGAGGACAAAGTACAAACGGCAGAAGCTGGAGGAGGAAGGGCCTGAGTCCGAGCAGAAGAAGAAGGGCTCCCATCACATCAACCGGTGGCGCATTGCCACGAAGCAGGCCAATGGGGAGGACATCGATGTCACCTCCAATGACaagcttgctagcGGTGGGCAACCACAAACCCACGAGGGCAGAGTGCTGCTTGCTGCTGGCCAGGCCCCTGCGTGGGCCCAAGCTGGACTCTGGCCACTCCCTGGCCAGGCTTTGGGGAGGCCTGGAGTCATGGCCCCACAGGGCTTGAAGCCCGGGGCCGCCATTGACAGAGGGACAAGCAATGGGCTGGCTGAGGCCTGGGACCACTTGGCCTTCTCCTCGGAGAGCCTGCCTGCCTGGGCGGGCCCGCCCGCCACCGCAGCCTCCCAGCTGCTCTCCGTGTCTCCAATCTCCCTTTTGTTTTGATGCATTTCTGTTTTAATTTATTTTCCAGGCACCACTGTAGTTTAGTGATCCCCAGTGTCCCCCTTCCCTATGGGAATAATAAAAGTCTCTCTCTTAATGACACGGGCATCCAGCTCCAGCCCCAGAGCCTGGGGTGGTAGATTCCGGCTCTGAGGGCCAGTGGGGGCTGGTAGAGCAAACGCGTTCAGGGCCTGGGAGCCTGGGGTGGGGTACTGGTGGAGGGGGTCAAGGGTAATTCATTAACTCCTCTCTTTTGTTGGGGGACCCTGGTCTCTACCTCCAGCTCCACAGCAGGAGAAACAGGCTAGACATAGGGAAGGGCCATCCTGTATCTTGAGGGAGGACAGGCCCAGGTCTTTCTTAACGTATTGAGAGGTGGGAATCAGGCCCAGGTAGTTCAATGGGAGAGGGAGAGTGCTTCCCTCTGCCTAGAGACTCTGGTGGCTTCTCCAGTTGAGGAGAAACCAGAGGAAAGGGGAGGATTGGGGTCTGGGGGAGGGAACACCATTCACAAAGGCTGACGGTTCCAGTCCGAAGTCGTGGGCCCACCAGGATGCTCACCTGTCCTTGGAGAACCGCTGGGCAGGTTGAGACTGCAGAGACAGGGCTTAAGGCTGAGCCTGCAACCAGTCCCCAGTGACTCAGGGCCTCCTCAGCCCAAGAAAGAGCAACGTGCCAGGGCCCGCTGAGCTCTTGTGTTCACCTG
NLS-StCsn1-NLS:
MKRPAATKKAGQAKKKKSDLVLGLDIGIGSVGVGILNKVTGEIIHKNSRIFPAAQAENNLVRRTNRQGRRLARRKKHRRVRLNRLFEESGLITDFTKISINLNPYQLRVKGLTDELSNEELFIALKNMVKHRGISYLDDASDDGNSSVGDYAQIVKENSKQLETKTPGQIQLERYQTYGQLRGDFTVEKDGKKHRLINVFPTSAYRSEALRILQTQQEFNPQITDEFINRYLEILTGKRKYYHGPGNEKSRTDYGRYRTSGETLDNIFGILIGKCTFYPDEFRAAKASYTAQEFNLLNDLNNLTVPTETKKLSKEQKNQIINYVKNEKAMGPAKLFKYIAKLLSCDVADIKGYRIDKSGKAEIHTFEAYRKMKTLETLDIEQMDRETLDKLAYVLTLNTEREGIQEALEHEFADGSFSQKQVDELVQFRKANSSIFGKGWHNFSVKLMMELIPELYETSEEQMTILTRLGKQKTTSSSNKTKYIDEKLLTEEIYNPVVAKSVRQAIKIVNAAIKEYGDFDNIVIEMARETNEDDEKKAIQKIQKANKDEKDAAMLKAANQYNGKAELPHSVFHGHKQLATKIRLWHQQGERCLYTGKTISIHDLINNSNQFEVDHILPLSITFDDSLANKVLVYATANQEKGQRTPYQALDSMDDAWSFRELKAFVRESKTLSNKKKEYLLTEEDISKFDVRKKFIERNLVDTRYASRVVLNALQEHFRAHKIDTKVSVVRGQFTSQLRRHWGIEKTRDTYHHHAVDALIIAASSQLNLWKKQKNTLVSYSEDQLLDIETGELISDDEYKESVFKAPYQHFVDTLKSKEFEDSILFSYQVDSKFNRKISDATIYATRQAKVGKDKADETYVLGKIKDIYTQDGYDAFMKIYKKDKSKFLMYRHDPQTFEKVIEPILENYPNKQINEKGKEVPCNPFLKYKEEHGYIRKYSKKGNGPEIKSLKYYDSKLGNHIDITPKDSNNKVVLQSVSPWRADVYFNKTTGKYEILGLKYADLQFEKGTGTYKISQEKYNDIKKKEGVDSDSEFKFTLYKNDLLLVKDTETKEQQLFRFLSRTMPKQKHYVELKPYDKQKFEGGEALIKVLGNVANSGQCKKGLGKSNISIYKVRTDVLGNQHIIKNEGDKPKLDFKRPAATKKAGQAKKKK
U6-St_tracrRNA(7-97):
GAGGGCCTATTTCCCATGATTCCTTCATATTTGCATATACGATACAAGGCTGTTAGAGAGATAATTGGAATTAATTTGACTGTAAACACAAAGATATTAGTACAAAATACGTGACGTAGAAAGTAATAATTTCTTGGGTAGTTTGCAGTTTTAAAATTATGTTTTAAAATGGACTATCATATGCTTACCGTAACTTGAAAGTATTTCGATTTCTTGGCTTTATATATCTTGTGGAAAGGACGAAACACCGTTACTTAAATCTTGCAGAAGCTACAAAGATAAGGCTTCATGCCGAAATCAACACCCTGTCATTTTATGGCAGGGTGTTTTCGTTATTTAA
U6-DR-спейсер-DR (S. pyogenes SF370)
gagggcctatttcccatgattccttcatatttgcatatacgatacaaggctgttagagagataattggaattaatttgactgtaaacacaaagatattagtacaaaatacgtgacgtagaaagtaataatttcttgggtagtttgcagttttaaaattatgttttaaaatggactatcatatgcttaccgtaacttgaaagtatttcgatttcttggctttatatatcttgtggaaaggacgaaacaccgggttttagagctatgctgttttgaatggtcccaaaacNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNgttttagagctatgctgttttgaatggtcccaaaacTTTTTTT (нижний регистр, подчеркивание = прямой повтор; N = направляющая последовательность; жирный шрифт = терминатор)
Химерная РНК, содержащая +48 tracrRNA (S. pyogenes SF370)
gagggcctatttcccatgattccttcatatttgcatatacgatacaaggctgttagagagataattggaattaatttgactgtaaacacaaagatattagtacaaaatacgtgacgtagaaagtaataatttcttgggtagtttgcagttttaaaattatgttttaaaatggactatcatatgcttaccgtaacttgaaagtatttcgatttcttggctttatatatcttgtggaaaggacgaaacaccNNNNNNNNNNNNNNNNNNNNgttttagagctagaaatagcaagttaaaataaggctagtccgTTTTTTT (N = направляющая последовательность; первое подчеркивание = парная tracr-последовательность; второе подчеркивание = tracr-последовательность; жирный шрифт = терминатор)
Химерная РНК, содержащая +54 tracrRNA (S. pyogenes SF370)
gagggcctatttcccatgattccttcatatttgcatatacgatacaaggctgttagagagataattggaattaatttgactgtaaacacaaagatattagtacaaaatacgtgacgtagaaagtaataatttcttgggtagtttgcagttttaaaattatgttttaaaatggactatcatatgcttaccgtaacttgaaagtatttcgatttcttggctttatatatcttgtggaaaggacgaaacaccNNNNNNNNNNNNNNNNNNNNgttttagagctagaaatagcaagttaaaataaggctagtccgttatcaTTTTTTTT (N = направляющая последовательность; первое подчеркивание = парная tracr-последовательность; второе подчеркивание = tracr-последовательность; жирный шрифт = терминатор)
Химерная РНК, содержащая +67 tracrRNA (S. pyogenes SF370)
gagggcctatttcccatgattccttcatatttgcatatacgatacaaggctgttagagagataattggaattaatttgactgtaaacacaaagatattagtacaaaatacgtgacgtagaaagtaataatttcttgggtagtttgcagttttaaaattatgttttaaaatggactatcatatgcttaccgtaacttgaaagtatttcgatttcttggctttatatatcttgtggaaaggacgaaacaccNNNNNNNNNNNNNNNNNNNNgttttagagctagaaatagcaagttaaaataaggctagtccgttatcaacttgaaaaagtgTTTTTTT (N = направляющая последовательность; первое подчеркивание = парная tracr-последовательность; второе подчеркивание = tracr-последовательность; жирный шрифт = терминатор)
Химерная РНК, содержащая +85 tracrRNA (S. pyogenes SF370)
gagggcctatttcccatgattccttcatatttgcatatacgatacaaggctgttagagagataattggaattaatttgactgtaaacacaaagatattagtacaaaatacgtgacgtagaaagtaataatttcttgggtagtttgcagttttaaaattatgttttaaaatggactatcatatgcttaccgtaacttgaaagtatttcgatttcttggctttatatatcttgtggaaaggacgaaacaccNNNNNNNNNNNNNNNNNNNNgttttagagctagaaatagcaagttaaaataaggctagtccgttatcaacttgaaaaagtggcaccgagtcggtgcTTTTTTT (N = направляющая последовательность; первое подчеркивание = парная tracr-последовательность; второе подчеркивание = tracr-последовательность; жирный шрифт = терминатор)
CBh-NLS-SpCas9-NLS
CGTTACATAACTTACGGTAAATGGCCCGCCTGGCTGACCGCCCAACGACCCCCGCCCATTGACGTCAATAATGACGTATGTTCCCATAGTAACGCCAATAGGGACTTTCCATTGACGTCAATGGGTGGAGTATTTACGGTAAACTGCCCACTTGGCAGTACATCAAGTGTATCATATGCCAAGTACGCCCCCTATTGACGTCAATGACGGTAAATGGCCCGCCTGGCATTATGCCCAGTACATGACCTTATGGGACTTTCCTACTTGGCAGTACATCTACGTATTAGTCATCGCTATTACCATGGTCGAGGTGAGCCCCACGTTCTGCTTCACTCTCCCCATCTCCCCCCCCTCCCCACCCCCAATTTTGTATTTATTTATTTTTTAATTATTTTGTGCAGCGATGGGGGCGGGGGGGGGGGGGGGGCGCGCGCCAGGCGGGGCGGGGCGGGGCGAGGGGCGGGGCGGGGCGAGGCGGAGAGGTGCGGCGGCAGCCAATCAGAGCGGCGCGCTCCGAAAGTTTCCTTTTATGGCGAGGCGGCGGCGGCGGCGGCCCTATAAAAAGCGAAGCGCGCGGCGGGCGGGAGTCGCTGCGACGCTGCCTTCGCCCCGTGCCCCGCTCCGCCGCCGCCTCGCGCCGCCCGCCCCGGCTCTGACTGACCGCGTTACTCCCACAGGTGAGCGGGCGGGACGGCCCTTCTCCTCCGGGCTGTAATTAGCTGAGCAAGAGGTAAGGGTTTAAGGGATGGTTGGTTGGTGGGGTATTAATGTTTAATTACCTGGAGCACCTGCCTGAAATCACTTTTTTTCAGGTTGGaccggtgccaccATGGACTATAAGGACCACGACGGAGACTACAAGGATCATGATATTGATTACAAAGACGATGACGATAAGATGGCCCCAAAGAAGAAGCGGAAGGTCGGTATCCACGGAGTCCCAGCAGCCGACAAGAAGTACAGCATCGGCCTGGACATCGGCACCAACTCTGTGGGCTGGGCCGTGATCACCGACGAGTACAAGGTGCCCAGCAAGAAATTCAAGGTGCTGGGCAACACCGACCGGCACAGCATCAAGAAGAACCTGATCGGAGCCCTGCTGTTCGACAGCGGCGAAACAGCCGAGGCCACCCGGCTGAAGAGAACCGCCAGAAGAAGATACACCAGACGGAAGAACCGGATCTGCTATCTGCAAGAGATCTTCAGCAACGAGATGGCCAAGGTGGACGACAGCTTCTTCCACAGACTGGAAGAGTCCTTCCTGGTGGAAGAGGATAAGAAGCACGAGCGGCACCCCATCTTCGGCAACATCGTGGACGAGGTGGCCTACCACGAGAAGTACCCCACCATCTACCACCTGAGAAAGAAACTGGTGGACAGCACCGACAAGGCCGACCTGCGGCTGATCTATCTGGCCCTGGCCCACATGATCAAGTTCCGGGGCCACTTCCTGATCGAGGGCGACCTGAACCCCGACAACAGCGACGTGGACAAGCTGTTCATCCAGCTGGTGCAGACCTACAACCAGCTGTTCGAGGAAAACCCCATCAACGCCAGCGGCGTGGACGCCAAGGCCATCCTGTCTGCCAGACTGAGCAAGAGCAGACGGCTGGAAAATCTGATCGCCCAGCTGCCCGGCGAGAAGAAGAATGGCCTGTTCGGCAACCTGATTGCCCTGAGCCTGGGCCTGACCCCCAACTTCAAGAGCAACTTCGACCTGGCCGAGGATGCCAAACTGCAGCTGAGCAAGGACACCTACGACGACGACCTGGACAACCTGCTGGCCCAGATCGGCGACCAGTACGCCGACCTGTTTCTGGCCGCCAAGAACCTGTCCGACGCCATCCTGCTGAGCGACATCCTGAGAGTGAACACCGAGATCACCAAGGCCCCCCTGAGCGCCTCTATGATCAAGAGATACGACGAGCACCACCAGGACCTGACCCTGCTGAAAGCTCTCGTGCGGCAGCAGCTGCCTGAGAAGTACAAAGAGATTTTCTTCGACCAGAGCAAGAACGGCTACGCCGGCTACATTGACGGCGGAGCCAGCCAGGAAGAGTTCTACAAGTTCATCAAGCCCATCCTGGAAAAGATGGACGGCACCGAGGAACTGCTCGTGAAGCTGAACAGAGAGGACCTGCTGCGGAAGCAGCGGACCTTCGACAACGGCAGCATCCCCCACCAGATCCACCTGGGAGAGCTGCACGCCATTCTGCGGCGGCAGGAAGATTTTTACCCATTCCTGAAGGACAACCGGGAAAAGATCGAGAAGATCCTGACCTTCCGCATCCCCTACTACGTGGGCCCTCTGGCCAGGGGAAACAGCAGATTCGCCTGGATGACCAGAAAGAGCGAGGAAACCATCACCCCCTGGAACTTCGAGGAAGTGGTGGACAAGGGCGCTTCCGCCCAGAGCTTCATCGAGCGGATGACCAACTTCGATAAGAACCTGCCCAACGAGAAGGTGCTGCCCAAGCACAGCCTGCTGTACGAGTACTTCACCGTGTATAACGAGCTGACCAAAGTGAAATACGTGACCGAGGGAATGAGAAAGCCCGCCTTCCTGAGCGGCGAGCAGAAAAAGGCCATCGTGGACCTGCTGTTCAAGACCAACCGGAAAGTGACCGTGAAGCAGCTGAAAGAGGACTACTTCAAGAAAATCGAGTGCTTCGACTCCGTGGAAATCTCCGGCGTGGAAGATCGGTTCAACGCCTCCCTGGGCACATACCACGATCTGCTGAAAATTATCAAGGACAAGGACTTCCTGGACAATGAGGAAAACGAGGACATTCTGGAAGATATCGTGCTGACCCTGACACTGTTTGAGGACAGAGAGATGATCGAGGAACGGCTGAAAACCTATGCCCACCTGTTCGACGACAAAGTGATGAAGCAGCTGAAGCGGCGGAGATACACCGGCTGGGGCAGGCTGAGCCGGAAGCTGATCAACGGCATCCGGGACAAGCAGTCCGGCAAGACAATCCTGGATTTCCTGAAGTCCGACGGCTTCGCCAACAGAAACTTCATGCAGCTGATCCACGACGACAGCCTGACCTTTAAAGAGGACATCCAGAAAGCCCAGGTGTCCGGCCAGGGCGATAGCCTGCACGAGCACATTGCCAATCTGGCCGGCAGCCCCGCCATTAAGAAGGGCATCCTGCAGACAGTGAAGGTGGTGGACGAGCTCGTGAAAGTGATGGGCCGGCACAAGCCCGAGAACATCGTGATCGAAATGGCCAGAGAGAACCAGACCACCCAGAAGGGACAGAAGAACAGCCGCGAGAGAATGAAGCGGATCGAAGAGGGCATCAAAGAGCTGGGCAGCCAGATCCTGAAAGAACACCCCGTGGAAAACACCCAGCTGCAGAACGAGAAGCTGTACCTGTACTACCTGCAGAATGGGCGGGATATGTACGTGGACCAGGAACTGGACATCAACCGGCTGTCCGACTACGATGTGGACCATATCGTGCCTCAGAGCTTTCTGAAGGACGACTCCATCGACAACAAGGTGCTGACCAGAAGCGACAAGAACCGGGGCAAGAGCGACAACGTGCCCTCCGAAGAGGTCGTGAAGAAGATGAAGAACTACTGGCGGCAGCTGCTGAACGCCAAGCTGATTACCCAGAGAAAGTTCGACAATCTGACCAAGGCCGAGAGAGGCGGCCTGAGCGAACTGGATAAGGCCGGCTTCATCAAGAGACAGCTGGTGGAAACCCGGCAGATCACAAAGCACGTGGCACAGATCCTGGACTCCCGGATGAACACTAAGTACGACGAGAATGACAAGCTGATCCGGGAAGTGAAAGTGATCACCCTGAAGTCCAAGCTGGTGTCCGATTTCCGGAAGGATTTCCAGTTTTACAAAGTGCGCGAGATCAACAACTACCACCACGCCCACGACGCCTACCTGAACGCCGTCGTGGGAACCGCCCTGATCAAAAAGTACCCTAAGCTGGAAAGCGAGTTCGTGTACGGCGACTACAAGGTGTACGACGTGCGGAAGATGATCGCCAAGAGCGAGCAGGAAATCGGCAAGGCTACCGCCAAGTACTTCTTCTACAGCAACATCATGAACTTTTTCAAGACCGAGATTACCCTGGCCAACGGCGAGATCCGGAAGCGGCCTCTGATCGAGACAAACGGCGAAACCGGGGAGATCGTGTGGGATAAGGGCCGGGATTTTGCCACCGTGCGGAAAGTGCTGAGCATGCCCCAAGTGAATATCGTGAAAAAGACCGAGGTGCAGACAGGCGGCTTCAGCAAAGAGTCTATCCTGCCCAAGAGGAACAGCGATAAGCTGATCGCCAGAAAGAAGGACTGGGACCCTAAGAAGTACGGCGGCTTCGACAGCCCCACCGTGGCCTATTCTGTGCTGGTGGTGGCCAAAGTGGAAAAGGGCAAGTCCAAGAAACTGAAGAGTGTGAAAGAGCTGCTGGGGATCACCATCATGGAAAGAAGCAGCTTCGAGAAGAATCCCATCGACTTTCTGGAAGCCAAGGGCTACAAAGAAGTGAAAAAGGACCTGATCATCAAGCTGCCTAAGTACTCCCTGTTCGAGCTGGAAAACGGCCGGAAGAGAATGCTGGCCTCTGCCGGCGAACTGCAGAAGGGAAACGAACTGGCCCTGCCCTCCAAATATGTGAACTTCCTGTACCTGGCCAGCCACTATGAGAAGCTGAAGGGCTCCCCCGAGGATAATGAGCAGAAACAGCTGTTTGTGGAACAGCACAAGCACTACCTGGACGAGATCATCGAGCAGATCAGCGAGTTCTCCAAGAGAGTGATCCTGGCCGACGCTAATCTGGACAAAGTGCTGTCCGCCTACAACAAGCACCGGGATAAGCCCATCAGAGAGCAGGCCGAGAATATCATCCACCTGTTTACCCTGACCAATCTGGGAGCCCCTGCCGCCTTCAAGTACTTTGACACCACCATCGACCGGAAGAGGTACACCAGCACCAAAGAGGTGCTGGACGCCACCCTGATCCACCAGAGCATCACCGGCCTGTACGAGACACGGATCGACCTGTCTCAGCTGGGAGGCGACTTTCTTTTTCTTAGCTTGACCAGCTTTCTTAGTAGCAGCAGGACGCTTTAA
(подчеркивание = NLS-hSpCas9-NLS)
Иллюстративная химерная РНК для Cas9 из CRISPR1 LMD-9 S. thermophilus (с PAM NNAGAAW)
NNNNNNNNNNNNNNNNNNNNgtttttgtactctcaagatttaGAAAtaaatcttgcagaagctacaaagataaggcttcatgccgaaatcaacaccctgtcattttatggcagggtgttttcgttatttaaTTTTTT (N = направляющая последовательность; первое подчеркивание = парная tracr-последовательность; второе подчеркивание = tracr-последовательность; жирный шрифт = терминатор)
Иллюстративная химерная РНК для Cas9 из CRISPR1 LMD-9 S. thermophilus (с PAM NNAGAAW)
NNNNNNNNNNNNNNNNNNNNgtttttgtactctcaGAAAtgcagaagctacaaagataaggcttcatgccgaaatcaacaccctgtcattttatggcagggtgttttcgttatttaaTTTTTT (N = направляющая последовательность; первое подчеркивание = парная tracr-последовательность; второе подчеркивание = tracr-последовательность; жирный шрифт = терминатор)
Иллюстративная химерная РНК для Cas9 из CRISPR1 LMD-9 S. thermophilus (с PAM NNAGAAW)
NNNNNNNNNNNNNNNNNNNNgtttttgtactctcaGAAAtgcagaagctacaaagataaggcttcatgccgaaatcaacaccctgtcattttatggcagggtgtTTTTTT (N = направляющая последовательность; первое подчеркивание = парная tracr-последовательность; второе подчеркивание = tracr-последовательность; жирный шрифт = терминатор)
Иллюстративная химерная РНК для Cas9 из CRISPR1 LMD-9 S. thermophilus (с PAM NNAGAAW)
NNNNNNNNNNNNNNNNNNNNgttattgtactctcaagatttaGAAAtaaatcttgcagaagctacaaagataaggcttcatgccgaaatcaacaccctgtcattttatggcagggtgttttcgttatttaaTTTTTT (N = направляющая последовательность; первое подчеркивание = парная tracr-последовательность; второе подчеркивание = tracr-последовательность; жирный шрифт = терминатор)
Иллюстративная химерная РНК для Cas9 из CRISPR1 LMD-9 S. thermophilus (с PAM NNAGAAW)
NNNNNNNNNNNNNNNNNNNNgttattgtactctcaGAAAtgcagaagctacaaagataaggcttcatgccgaaatcaacaccctgtcattttatggcagggtgttttcgttatttaaTTTTTT (N = направляющая последовательность; первое подчеркивание = парная tracr-последовательность; второе подчеркивание = tracr-последовательность; жирный шрифт = терминатор)
Иллюстративная химерная РНК для Cas9 из CRISPR1 LMD-9 S. thermophilus (с PAM NNAGAAW)
NNNNNNNNNNNNNNNNNNNNgttattgtactctcaGAAAtgcagaagctacaaagataaggcttcatgccgaaatcaacaccctgtcattttatggcagggtgtTTTTTT (N = направляющая последовательность; первое подчеркивание = парная tracr-последовательность; второе подчеркивание = tracr-последовательность; жирный шрифт = терминатор)
Иллюстративная химерная РНК для Cas9 из CRISPR1 LMD-9 S. thermophilus (с PAM NNAGAAW)
NNNNNNNNNNNNNNNNNNNNgttattgtactctcaagatttaGAAAtaaatcttgcagaagctacaatgataaggcttcatgccgaaatcaacaccctgtcattttatggcagggtgttttcgttatttaaTTTTTT (N = направляющая последовательность; первое подчеркивание = парная tracr-последовательность; второе подчеркивание = tracr-последовательность; жирный шрифт = терминатор)
Иллюстративная химерная РНК для Cas9 из CRISPR1 LMD-9 S. thermophilus (с PAM NNAGAAW)
NNNNNNNNNNNNNNNNNNNNgttattgtactctcaGAAAtgcagaagctacaatgataaggcttcatgccgaaatcaacaccctgtcattttatggcagggtgttttcgttatttaaTTTTTT (N = направляющая последовательность; первое подчеркивание = парная tracr-последовательность; второе подчеркивание = tracr-последовательность; жирный шрифт = терминатор)
Иллюстративная химерная РНК для Cas9 из CRISPR1 LMD-9 S. thermophilus (с PAM NNAGAAW)
NNNNNNNNNNNNNNNNNNNNgttattgtactctcaGAAAtgcagaagctacaatgataaggcttcatgccgaaatcaacaccctgtcattttatggcagggtgtTTTTTT (N = направляющая последовательность; первое подчеркивание = парная tracr-последовательность; второе подчеркивание = tracr-последовательность; жирный шрифт = терминатор)
Иллюстративная химерная РНК для Cas9 из CRISPR3 LMD-9 S. thermophilus (с PAM NGGNG)
NNNNNNNNNNNNNNNNNNNNgttttagagctgtgGAAAcacagcgagttaaaataaggcttagtccgtactcaacttgaaaaggtggcaccgattcggtgtTTTTTT (N = направляющая последовательность; первое подчеркивание = парная tracr-последовательность; второе подчеркивание = tracr-последовательность; жирный шрифт = терминатор)
Кодон-оптимизированный вариант Cas9 из локуса CRISPR3 LMD-9 S. thermophilus (с NLS и на 5’- и на 3’-концах)
ATGAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGACCAAGCCCTACAGCATCGGCCTGGACATCGGCACCAATAGCGTGGGCTGGGCCGTGACCACCGACAACTACAAGGTGCCCAGCAAGAAAATGAAGGTGCTGGGCAACACCTCCAAGAAGTACATCAAGAAAAACCTGCTGGGCGTGCTGCTGTTCGACAGCGGCATTACAGCCGAGGGCAGACGGCTGAAGAGAACCGCCAGACGGCGGTACACCCGGCGGAGAAACAGAATCCTGTATCTGCAAGAGATCTTCAGCACCGAGATGGCTACCCTGGACGACGCCTTCTTCCAGCGGCTGGACGACAGCTTCCTGGTGCCCGACGACAAGCGGGACAGCAAGTACCCCATCTTCGGCAACCTGGTGGAAGAGAAGGCCTACCACGACGAGTTCCCCACCATCTACCACCTGAGAAAGTACCTGGCCGACAGCACCAAGAAGGCCGACCTGAGACTGGTGTATCTGGCCCTGGCCCACATGATCAAGTACCGGGGCCACTTCCTGATCGAGGGCGAGTTCAACAGCAAGAACAACGACATCCAGAAGAACTTCCAGGACTTCCTGGACACCTACAACGCCATCTTCGAGAGCGACCTGTCCCTGGAAAACAGCAAGCAGCTGGAAGAGATCGTGAAGGACAAGATCAGCAAGCTGGAAAAGAAGGACCGCATCCTGAAGCTGTTCCCCGGCGAGAAGAACAGCGGAATCTTCAGCGAGTTTCTGAAGCTGATCGTGGGCAACCAGGCCGACTTCAGAAAGTGCTTCAACCTGGACGAGAAAGCCAGCCTGCACTTCAGCAAAGAGAGCTACGACGAGGACCTGGAAACCCTGCTGGGATATATCGGCGACGACTACAGCGACGTGTTCCTGAAGGCCAAGAAGCTGTACGACGCTATCCTGCTGAGCGGCTTCCTGACCGTGACCGACAACGAGACAGAGGCCCCACTGAGCAGCGCCATGATTAAGCGGTACAACGAGCACAAAGAGGATCTGGCTCTGCTGAAAGAGTACATCCGGAACATCAGCCTGAAAACCTACAATGAGGTGTTCAAGGACGACACCAAGAACGGCTACGCCGGCTACATCGACGGCAAGACCAACCAGGAAGATTTCTATGTGTACCTGAAGAAGCTGCTGGCCGAGTTCGAGGGGGCCGACTACTTTCTGGAAAAAATCGACCGCGAGGATTTCCTGCGGAAGCAGCGGACCTTCGACAACGGCAGCATCCCCTACCAGATCCATCTGCAGGAAATGCGGGCCATCCTGGACAAGCAGGCCAAGTTCTACCCATTCCTGGCCAAGAACAAAGAGCGGATCGAGAAGATCCTGACCTTCCGCATCCCTTACTACGTGGGCCCCCTGGCCAGAGGCAACAGCGATTTTGCCTGGTCCATCCGGAAGCGCAATGAGAAGATCACCCCCTGGAACTTCGAGGACGTGATCGACAAAGAGTCCAGCGCCGAGGCCTTCATCAACCGGATGACCAGCTTCGACCTGTACCTGCCCGAGGAAAAGGTGCTGCCCAAGCACAGCCTGCTGTACGAGACATTCAATGTGTATAACGAGCTGACCAAAGTGCGGTTTATCGCCGAGTCTATGCGGGACTACCAGTTCCTGGACTCCAAGCAGAAAAAGGACATCGTGCGGCTGTACTTCAAGGACAAGCGGAAAGTGACCGATAAGGACATCATCGAGTACCTGCACGCCATCTACGGCTACGATGGCATCGAGCTGAAGGGCATCGAGAAGCAGTTCAACTCCAGCCTGAGCACATACCACGACCTGCTGAACATTATCAACGACAAAGAATTTCTGGACGACTCCAGCAACGAGGCCATCATCGAAGAGATCATCCACACCCTGACCATCTTTGAGGACCGCGAGATGATCAAGCAGCGGCTGAGCAAGTTCGAGAACATCTTCGACAAGAGCGTGCTGAAAAAGCTGAGCAGACGGCACTACACCGGCTGGGGCAAGCTGAGCGCCAAGCTGATCAACGGCATCCGGGACGAGAAGTCCGGCAACACAATCCTGGACTACCTGATCGACGACGGCATCAGCAACCGGAACTTCATGCAGCTGATCCACGACGACGCCCTGAGCTTCAAGAAGAAGATCCAGAAGGCCCAGATCATCGGGGACGAGGACAAGGGCAACATCAAAGAAGTCGTGAAGTCCCTGCCCGGCAGCCCCGCCATCAAGAAGGGAATCCTGCAGAGCATCAAGATCGTGGACGAGCTCGTGAAAGTGATGGGCGGCAGAAAGCCCGAGAGCATCGTGGTGGAAATGGCTAGAGAGAACCAGTACACCAATCAGGGCAAGAGCAACAGCCAGCAGAGACTGAAGAGACTGGAAAAGTCCCTGAAAGAGCTGGGCAGCAAGATTCTGAAAGAGAATATCCCTGCCAAGCTGTCCAAGATCGACAACAACGCCCTGCAGAACGACCGGCTGTACCTGTACTACCTGCAGAATGGCAAGGACATGTATACAGGCGACGACCTGGATATCGACCGCCTGAGCAACTACGACATCGACCATATTATCCCCCAGGCCTTCCTGAAAGACAACAGCATTGACAACAAAGTGCTGGTGTCCTCCGCCAGCAACCGCGGCAAGTCCGATGATGTGCCCAGCCTGGAAGTCGTGAAAAAGAGAAAGACCTTCTGGTATCAGCTGCTGAAAAGCAAGCTGATTAGCCAGAGGAAGTTCGACAACCTGACCAAGGCCGAGAGAGGCGGCCTGAGCCCTGAAGATAAGGCCGGCTTCATCCAGAGACAGCTGGTGGAAACCCGGCAGATCACCAAGCACGTGGCCAGACTGCTGGATGAGAAGTTTAACAACAAGAAGGACGAGAACAACCGGGCCGTGCGGACCGTGAAGATCATCACCCTGAAGTCCACCCTGGTGTCCCAGTTCCGGAAGGACTTCGAGCTGTATAAAGTGCGCGAGATCAATGACTTTCACCACGCCCACGACGCCTACCTGAATGCCGTGGTGGCTTCCGCCCTGCTGAAGAAGTACCCTAAGCTGGAACCCGAGTTCGTGTACGGCGACTACCCCAAGTACAACTCCTTCAGAGAGCGGAAGTCCGCCACCGAGAAGGTGTACTTCTACTCCAACATCATGAATATCTTTAAGAAGTCCATCTCCCTGGCCGATGGCAGAGTGATCGAGCGGCCCCTGATCGAAGTGAACGAAGAGACAGGCGAGAGCGTGTGGAACAAAGAAAGCGACCTGGCCACCGTGCGGCGGGTGCTGAGTTATCCTCAAGTGAATGTCGTGAAGAAGGTGGAAGAACAGAACCACGGCCTGGATCGGGGCAAGCCCAAGGGCCTGTTCAACGCCAACCTGTCCAGCAAGCCTAAGCCCAACTCCAACGAGAATCTCGTGGGGGCCAAAGAGTACCTGGACCCTAAGAAGTACGGCGGATACGCCGGCATCTCCAATAGCTTCACCGTGCTCGTGAAGGGCACAATCGAGAAGGGCGCTAAGAAAAAGATCACAAACGTGCTGGAATTTCAGGGGATCTCTATCCTGGACCGGATCAACTACCGGAAGGATAAGCTGAACTTTCTGCTGGAAAAAGGCTACAAGGACATTGAGCTGATTATCGAGCTGCCTAAGTACTCCCTGTTCGAACTGAGCGACGGCTCCAGACGGATGCTGGCCTCCATCCTGTCCACCAACAACAAGCGGGGCGAGATCCACAAGGGAAACCAGATCTTCCTGAGCCAGAAATTTGTGAAACTGCTGTACCACGCCAAGCGGATCTCCAACACCATCAATGAGAACCACCGGAAATACGTGGAAAACCACAAGAAAGAGTTTGAGGAACTGTTCTACTACATCCTGGAGTTCAACGAGAACTATGTGGGAGCCAAGAAGAACGGCAAACTGCTGAACTCCGCCTTCCAGAGCTGGCAGAACCACAGCATCGACGAGCTGTGCAGCTCCTTCATCGGCCCTACCGGCAGCGAGCGGAAGGGACTGTTTGAGCTGACCTCCAGAGGCTCTGCCGCCGACTTTGAGTTCCTGGGAGTGAAGATCCCCCGGTACAGAGACTACACCCCCTCTAGTCTGCTGAAGGACGCCACCCTGATCCACCAGAGCGTGACCGGCCTGTACGAAACCCGGATCGACCTGGCTAAGCTGGGCGAGGGAAAGCGTCCTGCTGCTACTAAGAAAGCTGGTCAAGCTAAGAAAAAGAAATAA
Пример 5: РНК-направляемое редактирование бактериальных геномов с применением систем CRISPR-Cas
Заявители использовали CRISPR-ассоциированную эндонуклеазу Cas9 для введения точных мутаций в геномы Streptococcus pneumoniae и Escherichia coli. Подход опирался на Cas9-направленное расщепление в целевом сайте для уничтожения немутированных клеток и устранял необходимость в селектируемых маркерах или системах негативного отбора. Специфичность Cas9 перепрограммировали путем изменения последовательности короткой CRISPR РНК (crRNA) для внесения одно- или многонуклеотидных изменений, переносимых на матрицах редактирования. Одновременное использование двух crRNA обеспечивало мультиплексный мутагенез. У S. pneumoniae около 100% клеток, выживших после расщепления Cas9, содержали желаемую мутацию, и 65% при использовании в комбинации с рекомбинационной инженерией в E. coli. Заявители тщательно анализировали плановые требования к Cas9 для определения диапазона последовательностей, представляющих собой мишени, и показали стратегии для редактирования сайтов, которые не отвечают данным требованиям, что указывает на универсальность этой методики для конструирования бактериального генома.
Понимание функции гена зависит от возможности изменения последовательностей ДНК в клетке контролируемым образом. Сайт-специфический мутагенез у эукариот достигается путем использования специфичных к последовательностям нуклеаз, которые активируют гомологичную рекомбинацию ДНК-матрицы, содержащей мутацию, представляющую интерес. Нуклеазы с "цинковыми пальцами" (ZFN), эффекторные нуклеазы, подобные активаторам транскрипции (TALEN), и хоминг-мегануклеазы можно программировать для расщепления геномов в конкретных местоположениях, но эти подходы требуют конструирования новых ферментов для каждой целевой последовательности. В прокариотических организмах способы мутагенеза или предусматривают введение маркера отбора в редактируемый локус, или требуют двухстадийного процесса, который включает систему негативного отбора. Совсем недавно для рекомбинационной инженерии использовали рекомбинантные белки фагов, методика, которая обеспечивает гомологичную рекомбинацию линейной ДНК или олигонуклеотидов. Однако, поскольку нет выбора мутаций, эффективность рекомбинационной инженерии может быть относительно низкой (от 0,1-10% для точковых мутаций вплоть до 10-5-10-6 для более обширных модификаций), во многих случаях требуя скрининга большего числа колоний. Таким образом, все еще требуются новые технологии, которые являются доступными, легкими в применении и эффективными для генетического конструирования как эукариотических, так и прокариотических организмов.
Недавние работы по CRISPR (коротким палиндромным повторам, регулярно расположенным группами) адаптивной иммунной системы прокариот привели к идентификации нуклеаз, у которых специфичность к последовательности программируется малыми РНК. Локусы CRISPR состоят из серий повторов, разделенных "спейсерными" последовательностями, которые соответствуют геномам бактериофагов и другим мобильным генетическим элементам. Массив повторов-спейсеров транскрибируется в виде длинного предшественника и подвергается процессингу в последовательностях повторов для создания малой crRNA, которая определяет целевые последовательности (также известные как протоспейсеры) расщепленных с помощью CRISPR систем. Важным для расщепления является наличие мотива последовательности непосредственно ниже целевого участка, известного как смежный с протоспейсером мотив (PAM). CRISPR-ассоциированные (cas) гены обычно фланкируют массив повторов-спейсеров и кодируют ферментативный механизм, ответственный за биогенез crRNA и целенаправленное воздействие. Cas9 является дцДНК-эндонуклеазой, которая использует crRNA-гид для определения сайта расщепления. Загрузка crRNA-гида на Cas9 происходит во время процессинга предшественника crRNA и требует наличия малой антисмысловой РНК на предшественнике, tracrRNA и RNAse III. В отличие от редактирования генома с помощью ZFN или TALEN, изменение специфичности целенаправленного воздействия Cas9 не требует конструирования белков, а только разработки короткой crRNA-гида.
Заявители в недавнее время показали на S. pneumoniae, что введение системы CRISPR, нацеленной на хромосомный локус, приводит к уничтожению трансформированных клеток. Было отмечено, что случайно выжившие клетки содержали мутации в целевом участке, что указывало на то, что эндонуклеазная активность, направленная на дцДНК, Cas9 по отношению к эндогенным мишеням может быть использована для редактирования генома. Заявители показали, что безмаркерные мутации можно вводить путем трансформации фрагмента ДНК-матрицы, который будет рекомбинировать в геноме и исключать распознавание мишеней Cas9. Управление специфичностью Cas9 с несколькими различными crRNA обеспечивает возможность введения многочисленных мутаций одновременно. Заявители также охарактеризовали в деталях требования к последовательности для направленного воздействия Cas9 и показали, что подход можно сочетать с рекомбинационной инженерией для редактирования генома у E. coli.
РЕЗУЛЬТАТЫ: редактирование генома с помощью расщепления Cas9 хромосомной мишени
Штамм crR6 S. Pneumoniae содержит систему CRISPR на основе Cas9, которая расщепляет целевую последовательность, присутствующую в бактериофаге R68232.5. Эту мишень интегрировали в хромосомный локус srtA второго штамма R68232.5. Измененную целевую последовательность, содержащую мутацию в участке PAM, интегрировали в локус srtA третьего штамма R6370.1, делая этот штамм "устойчивым" к расщеплению с помощью CRISPR (фигура 28a). Заявители трансформировали клетки R68232.5 и R6370.1 геномной ДНК из клеток crR6, ожидая, что успешная трансформация клеток R68232.5 должна привести к расщеплению целевого локуса и гибели клеток. Вопреки этому ожиданию, заявители выделили трансформантов R68232.5, хотя и с примерно в 10 раз меньшей эффективностью, чем трансформантов R6370.1 (фигура 28b). Генетический анализ восьми трансформантов R68232.5 (фигура 28) выявил, что подавляющее большинство представляют собой продукт явления двойной рекомбинации, исключающей токсичность целенаправленного воздействия Cas9 путем замещения мишени R68232.5 локусом дикого типа srtA генома crR6, который не содержит протоспейсер, требуемый для распознавания Cas9. Эти результаты были доказательством того, что одновременное введение системы CRISPR, нацеленной на локус генома (конструкция для целенаправленного воздействия), вместе с матрицей для рекомбинации в целевом локусе (матрица редактирования), приводило к целенаправленному редактированию генома (фигура 23a).
Для создания упрощенной системы для редактирования генома заявители модифицировали локус CRISPR в штамме crR6 путем делеции генов cas1, cas2 и csn2, которые, как было показано, являются необязательными для целенаправленного воздействия CRISPR, с получением штамма crR6M (фигура 28a). Этот штамм сохранял те же свойства, что и crR6 (фигура 28b). Для того, чтобы повысить эффективность редактирования на основе Cas9 и продемонстрировать, что выбранная ДНК-матрица может быть использована для контроля введенных мутаций, заявители котрансформировали клетки R68232.5 с ПЦР-продуктами гена srtA дикого типа или мутантной мишенью R6370.1, каждый из которых должен быть устойчивым к расщеплению Cas9. Это приводило к от 5- до 10-кратного повышения частоты трансформирования по сравнению с геномной ДНК crR6 в отдельности (фигура 23b). Эффективность редактирования также существенно увеличилась, при этом 8/8 тестированных трансформантов содержали копию srtA дикого типа, а 7/8 содержали PAM-мутацию, присутствующую в мишени R6370.1 (фигура 23b и фигура 29a). Взятые вместе, эти результаты свидетельствуют о возможности редактирования генома при помощи Cas9.
Анализа плановых требований для Cas9. Для введения специфичных изменений в геном нужно использовать матрицу редактирования, несущую мутации, которые прекращают расщепление, опосредованное Cas9, тем самым предотвращая гибель клеток. Этого легко достичь, когда необходима делеция мишени или ее замещение другой последовательностью (вставка гена). Если целью является создание слияний генов или создание однонуклеотидных мутаций, ликвидирование нуклеазной активности Cas9 будет возможно только путем введения мутаций в матрицу редактирования, которые изменяют последовательности либо PAM, либо протоспейсера. Для определения затруднений опосредованного CRISPR редактирования заявители выполняли исчерпывающий анализ мутаций PAM и протоспейсера, которые подавляют целенаправленное воздействие CRISPR.
Предыдущие исследования предполагали, что Cas9 S. pyogenes требует наличия PAM NGG непосредственно ниже протоспейсера. Однако по причине того, что на настоящий момент было описано только очень ограниченное количество мутаций, инактивирующих PAM, заявители провели систематический анализ для обнаружения всех 5-нуклеотидных последовательностей, расположенных после протоспейсера, которые исключают расщепление с помощью CRISPR. Заявители использовали рандомизированные олигонуклеотиды для создания всех возможных 1024 последовательностей PAM в гетерогенном ПЦР-продукте, который трансформировали в клетки crR6 или R6. Ожидалось, что конструкции, несущие функциональные PAM, будут распознаваться и разрушаться Cas9 в клетках crR6, но не в клетках R6 (фигура 24a). Более чем 2×105 колоний объединяли вместе с целью экстрагирования ДНК для использования в качестве матрицы для ко-амплификации всех мишеней. Поводили глубокое секвенирование ПЦР-продуктов, и было обнаружено, что они содержат все 1024 последовательности, с перекрыванием в диапазоне от 5 до 42472 считываемых фрагментов (см. раздел “Анализ данных глубокого секвенирования”). Функциональность каждого PAM оценивали по относительной доле его считываемых фрагментов в образце crR6 относительно образца R6. Анализ первых трех оснований PAM, усредненных по двум последним основаниям, ясно показал, что паттерн NGG был недостаточно представлен в трансформантах crR6 (фигура 24b). Кроме того, следующие два основания не имели заметного влияния на PAM NGG (см. раздел “Анализ данных глубокого секвенирования”), демонстрируя, что последовательность NGGNN была достаточной для разрешения проявления активности Cas9. Частичное целенаправленное воздействие наблюдалось для последовательностей PAM NAG (фигура 24b). Также паттерн NNGGN частично инактивировал целенаправленное воздействие CRISPR (таблица G), что указывало на то, что при сдвиге на 1 п.о. мотив NGG все еще мог узнаваться Cas9 с пониженной эффективностью. Эти данные пролили свет на молекулярный механизм распознавание мишеней Cas9, и было выявлено, что последовательности NGG (или CCN в комплементарной нити) являются достаточными для целенаправленного воздействия Cas9, и что следует избегать мутаций NGG на NAG или NNGGN в матрице редактирования. В связи с высокой частотой этих тринуклеотидных последовательностей (каждые 8 п.о.), это означает, что можно редактировать практически любое положение в геноме. Более того, заявители тестировали десять произвольно выбранных мишеней, несущих различные PAM, и было обнаружено, что все они являются функциональными (фигура 30).
Другим способом нарушения опосредованного Cas9 расщепления является введение мутаций в протоспейсерный участок матрицы редактирования. Известно, что точковые мутации в "затравочной последовательности" (от 8 дo 10 нуклеотидов протоспейсера, непосредственно смежных с PAM) могут прекращать расщепление с помощью нуклеаз CRISPR. Однако точная длина этого участка неизвестна, и не ясно, могут ли мутации в каком-либо нуклеотиде в затравке нарушать распознавание мишеней Cas9. Заявители следовали тому же подходу глубокого секвенирования, который описан выше, для рандомизирования целой протоспейсерной последовательности, участвующей в контактах пар оснований с crRNA, и для определения всех последовательностей, которые препятствуют целенаправленному воздействию. Каждое положение 20 совпадающих нуклеотидов (14) в мишени spc1, присутствующих в клетках R68232.5 (фигура 23a), рандомизировали и трансформировали в клетки crR6 и R6 (фигура 24a). В соответствии с наличием затравочной последовательности только мутации в 12 нуклеотидах непосредственно выше PAM подавляли расщепление с помощью Cas9 (фигура 24c). Тем не менее, различные мутации отображали весьма разные эффекты. Дистальные (от PAM) положения затравки (от 12 дo 7) выдерживали большинство мутаций, и только одно определенное замещение основания подавляло целенаправленное воздействие. В то же время, мутации в любом нуклеотиде в проксимальных положениях (от 6 до 1, за исключением 3) исключали активность Cas9, однако на разных уровнях для каждого конкретного замещения. В положении 3 только два замещения влияли на активность CRISPR и с разной силой. Заявители пришли к выводу, что хотя мутации затравочной последовательности могут предотвращать целенаправленное воздействие CRISPR, существуют ограничения в отношении изменений нуклеотидов, которые могут быть произведены в любом положении затравки. Более того, эти ограничения, наиболее вероятно, могут варьировать для разных спейсерных последовательностей. Таким образом, заявители полагают, что мутации в последовательности PAM, если это возможно, должны быть предпочтительной стратегией редактирования. Альтернативно, множественные мутации в затравочной последовательности можно вводить для предотвращения нуклеазной активности Cas9.
Опосредованное Cas9 редактирование генома у S. pneumonia. Для разработки быстрого и эффективного способа для целенаправленного редактирования генома заявители конструировали штамм crR6Rk, штамм, в котором спейсеры можно легко вводить с помощью ПЦР (фигура 33). Заявители решили редактировать ген β-галактозидазы (bgaA) S. pneumoniae, активность которого может быть легко измерена. Заявители вводили аминокислотные замены на аланин в активный сайт этого фермента: Мутации R481A (R→A) и N563A, E564A (NE→AA). Для иллюстрации различных стратегий редактирования заявители разрабатывали мутации как последовательности PAM, так и протоспейсера затравки. В обоих случаях использовали одну и ту же конструкцию для целенаправленного воздействия с crRNA, комплементарной участку гена β-галактозидазы, который является смежным с последовательностью PAM TGG (CCA в комплементарной нити, фигура 26). Матрица редактирования R→A производила трехнуклеотидное несовпадение в затравочной последовательности протоспейсера (CGT на GCA, также с введением сайта рестрикции BtgZI). В матрицу редактирования NE→AA заявители одновременно вводили синонимичную мутацию, которая производила неактивный PAM (TGG на TTG), совместно с мутациями, которые находились на 218 нуклеотидов ниже от участка протоспейсера (AAT GAA на GCT GCA, также с созданием сайта рестрикции TseI). Эта последняя стратегия редактирования демонстрировала возможность использования удаленного PAM для создания мутаций в местах, где подходящую мишень может быть сложно выбрать. Например, хотя геном R6 S. pneumoniae, который характеризуется содержанием GC 39,7%, содержит в среднем один мотив PAM на каждые 12 п.о., некоторые мотивы PAM разделены вплоть до 194 п.о. (фигура 33). К тому же заявители разработали делецию внутри рамки считывания ΔbgaA длиной 6664 п.о. Во всех трех случаях котрансформацией матриц целенаправленного воздействия и редактирования производили в 10 раз больше устойчивых к канамицину клеток, чем котрансформацией с контрольной матрицей редактирования, содержащей последовательности дикого типа bgaA (фигура 25b). Заявители генотипировали 24 трансформанта (8 для каждого эксперимента редактирования) и обнаружили, что все кроме одного включали желаемое изменение (фигура 25c). Секвенирование ДНК также подтверждало не только присутствие введенных мутаций, но и отсутствие вторичных мутаций в целевом участке (фигура 29b, c). И наконец, заявители измеряли активность β-галактозидазы для подтверждения того, что все редактированные клетки демонстрировали ожидаемый фенотип (фигура 25d).
Опосредованное Cas9 редактирование также может быть использовано для создания множественных мутаций для изучения биологических путей. Заявители решили проиллюстрировать это для сортаза-зависимого пути, посредством которого поверхностные белки прикрепляются к оболочке грамположительных бактерий. Заявители вводили делецию гена сортазы с помощью котрансформации устойчивой к хлорамфениколу конструкции для целенаправленного воздействия и матрицы редактирования ΔsrtA (фигура 33a, b) с последующей делецией ΔbgaA с применением устойчивой к канамицину конструкции для целенаправленного воздействия, которая замещала предыдущую. У S. pneumoniae β-галактозидаза ковалентно связывается с клеточной стенкой с помощью сортазы. Таким образом, делеция srtA приводит к высвобождению поверхностного белка в супернатант, в то время как двойная делеция не приводит к заметной активности β-галактозидазы (фигура 34c). Такой последовательный отбор можно повторять столько раз, сколько требуется для создания множественных мутаций.
Эти две мутации также можно вводить одновременно. Заявители разрабатывали конструкцию для целенаправленного воздействия, содержащую два спейсера, один, совпадающий с srtA, а другой, совпадающий с bgaA, и одновременно котрансформировали ее двумя матрицами редактирования (фигура 25e). Генетический анализ трансформантов показал, что редактирование происходило в 6/8 случаев (фигура 25f). В частности, каждый из двух оставшихся клонов содержал делецию ΔsrtA или ΔbgaA, что предполагало возможность выполнения комбинаторного мутагенеза с применением Cas9. И наконец, для ликвидации последовательностей CRISPR заявители вводили плазмиду, содержащую мишень bgaA и ген устойчивости к спектиномицину совместно с геномной ДНК из штамма дикого типа R6. Устойчивые к спектиномицину трансформанты, которые сохраняли плазмиду, ликвидировали последовательности CRISPR (фигура 34a, d).
Механизм и эффективность редактирования. Для понимания механизмов, лежащих в основе редактирования генома с помощью Cas9, заявители смоделировали эксперимент, в котором эффективность редактирования измеряли независимо от расщепления Cas9. Заявители интегрировали ген устойчивости к эритромицину ermAM в локус srtA и вводили преждевременный стоп-кодон с применением редактирования, опосредованного Cas9 (фигура 33). Полученный штамм (JEN53) содержит аллель ermAM(stop) и является чувствительным к эритромицину. Этот штамм можно использовать для оценки эффективности, с которой ген ermAM репарируется, с помощью количественного определения фракции клеток, у которых восстанавливается устойчивость к антибиотику с использованием или без использования расщепления Cas9. JEN53 трансформировали матрицей редактирования, которая восстанавливает аллель дикого типа, совместно либо с устойчивой к канамицину конструкцией CRISPR, нацеленной на аллель ermAM (stop) (CRISPR::ermAM(stop)), либо с контрольной конструкцией без спейсера (CRISPR::∅) (фигура 26a, b). При отсутствии отбора по канамицину фракция редактированных колоний составляла порядком 10-2 (устойчивые к эритромицину КОЕ/все КОЕ) (фигура 26c), что представляло базовую частоту рекомбинации без опосредованного Cas9 отбора против нередактированных клеток. Однако, если применяли отбор по канамицину и котрансформировали контрольную конструкцию CRISPR, фракция редактированных колоний возрастала до около 10-1 (устойчивые к канамицину и эритромицину КОЕ/устойчивые к канамицину КОЕ) (фигура 26c). Этот результат показывает,что отбор по рекомбинации локуса CRISPR проводили совместно с отбором по рекомбинации в локусе ermAM независимо от расщепления генома Cas9, что указывало на то, что субпопуляция клеток более подвержена трансформации и/или рекомбинации. Трансформация конструкции CRISPR::ermAM(stop) с последующим отбором по кантамицину приводила к увеличению фракции устойчивых к эритромицину редактированных клеток дo 99% (фигура 26c). Для определения, является ли это увеличение обусловленным нередактированными клетками, заявители сравнивали устойчивые к канамицину колониеобразующие единицы (КОЕ), полученные после котрансформации клеток JEN53 конструкциями CRISPR::ermAM(stop) или CRISPR::∅.
Заявители насчитывали в 5,3 раза меньше устойчивых к канамицину колоний после трансформации конструкцией ermAM(stop) (2,5×104/4,7×103, фигура 35a), результат, который подтверждает, что определенное целенаправленное воздействие Cas9 на хромосомный локус ведет к гибели нередактированных клеток. И наконец, поскольку введение разрывов дцДНК в бактериальную хромосому, как известно, запускает механизмы репарации, которые повышают уровень рекомбинации поврежденной ДНК, заявители исследовали, индуцирует ли расщепление с помощью Cas9 рекомбинацию матрицы редактирования. Заявители насчитывали в 2,2 раза больше колоний после котрансформации конструкцией CRISPR::erm(stop), чем конструкцией CRISPR::∅ (фигура 26d), что указывало на незначительную индукцию рекомбинации. Взятые вместе, эти результаты свидетельствуют о том, что и совместный отбор трансформируемых клеток, и индукция рекомбинации с помощью опосредованного Cas9 расщепления, и отбор против нередактированных клеток способствовали высокой эффективности редактирования генома у S. pneumoniae.
Поскольку расщепление генома с помощью Cas9 должно уничтожать нередактированные клетки, не ожидалось получение каких-либо клеток, получивших кассету устойчивости к канамицину, содержащую Cas9, но не матрицу редактирования. Однако при отсутствии матрицы редактирования заявители получали много устойчивых к канамицину колоний после трансформации конструкцией CRISPR::ermAM(stop) (фигура 35a). Эти клетки, которые "избежали" CRISPR-индуцированной гибели, создали фон, который определял предел способа. Эту фоновую частоту можно подсчитать в этом эксперименте как соотношение CRISPR::ermAM(stop)/CRISPR::∅ КОЕ, 2,6×10-3 (7,1×101/2,7×104), подразумевая, что если частота рекомбинации матрицы редактирования меньше этого значения, отбор с помощью CRISPR не может эффективно обеспечить получение желаемых мутантов в количестве, выше фонового. Для понимания происхождения этих клеток, заявители генотипировали 8 фоновых колоний и обнаружили, что 7 содержали делеции спейсера для целенаправленного воздействия (фигура 35b), и одна несла предположительно инактивирующую мутацию в Cas9 (фигура 35c).
Редактирование генома Cas9 у E. coli. Активация целенаправленного воздействия Cas9 через хромосомную интеграцию системы CRISPR-Cas является единственно возможной у организмов, у которых наблюдается высокая частота рекомбинации. Для разработки более общего способа, который является применимым к другим микроорганизмам, заявители решили выполнить редактирование генома у E. coli с применением системы на основе плазмиды CRISPR-Cas. Создавали две плазмиды: плазмиду pCas9, несущую tracrRNA, Cas9 и кассету устойчивости к хлорамфениколу (фигура 36), и плазмиду устойчивости к канамицину pCRISPR, несущую массив спейсеров CRISPR. Для оценки эффективности редактирования независимо от отбора с помощью CRISPR заявители стремились ввести трансверсию A на C в гене rpsL, вызывающую устойчивость к стрептомицину. Заявители создавали плазмиду pCRISPR::rpsL, несущую спейсер, который будет направлять расщепление Cas9 аллеля rpsL дикого типа, но не мутантного (фигура 27b). Сначала вводили плазмиду pCas9 E. coli MG1655 и полученный штамм котрансформировали плазмидой pCRISPR::rpsL и W542, олигонуклеотидом для редактирования, содержащим мутацию замены A на C. Устойчивые к стрептомицину колонии после трансформации плазмидой pCRISPR::rpsL были единственными полученными, что свидетельствует о том, что расщепление Cas9 индуцирует рекомбинацию данного олигонуклеотида (фигура 37). Однако количество устойчивых к стрептомицину колоний было на два порядка величины меньше, чем количество устойчивых к канамицину колоний, которые предположительно представляют собой клетки, избегающие расщепления с помощью Cas9. Таким образом, в данных условиях расщепление с помощью Cas9 облегчало введение мутации, но с эффективностью, которая была недостаточной для отбора мутантных клеток в количестве, выше фонового количества "клеток, избежавших воздействия".
Для повышения эффективности редактирования генома у E. coli, заявители применяли свою систему CRISPR с рекомбинационной инженерией с применением индуцированной Cas9 гибели клеток для отбора по желаемым мутациям. Плазмиду pCas9 вводили в штамм HME63 (31), который подвергали рекомбинационной инженерии, имеющего функции Gam, Exo и Beta фага □-red. Полученный штамм котрансформировали плазмидой pCRISPR::rpsL (или контрольной pCRISPR::∅) и олигонуклеотидом W542 (фигура 27a). Эффективность рекомбинационной инженерии, рассчитанная как фракция всех клеток, ставших устойчивыми к стрептомицину, при использовании контрольной плазмиды составляла 5,3×10-5 (фигура 27c). В то же время трансформация плазмидой pCRISPR::rpsL повысила процентную долю мутантных клеток до 65 ± 14% (фигуры 27c и 29f). Заявители наблюдали, что количество КОЕ после трансформации плазмидой pCRISPR::rpsL было приблизительно на три порядка величины ниже, чем после трансформации контрольной плазмидой (4,8×105/5,3×102, фигура 38a), что свидетельствовало о том, что отбор является следствием CRISPR-индуцированной смерти нередактированных клеток. Для измерения уровня, при котором инактивировалось расщепление Cas9, который является важным параметром способа заявителей, заявители трансформировали клетки либо pCRISPR::rpsL, либо контрольной плазмидой без олигонуклеотида для редактирования W542 (фигура 38a). Это фоновое количество "клеток, избежавших воздействия" CRISPR, которое измеряли как соотношение pCRISPR::rpsL/pCRISPR::∅ КОЕ, составляло 2,5×10-4 (1,2×102/4,8×105). Генотипирование восьми из этих клеток, избежавших воздействия, выявило, что во всех случаях присутствовала делеция спейсера для целенаправленного воздействия (фигура 38b). Этот фоновое количество было выше значения эффективности рекомбинационной инженерии для мутации rpsL, 5,3×10-5, что свидетельствовало о том, что для получения 65% редактированных клеток расщепление Cas9 должно индуцировать рекомбинацию олигонуклеотида. Для подтверждения этого заявители сравнили число устойчивых к канамицину и стрептомицину КОЕ после трансформации pCRISPR::rpsL или pCRISPR::∅ (фигура 27d). Как в случае для S. pneumoniae, заявители наблюдали незначительную индукцию рекомбинации, приблизительно 6,7-кратную (2,0×10-4/3,0×10-5). Взятые вместе, эти результаты свидетельствуют о том, что система CRISPR обеспечивала способ отбора мутаций, введенных путем рекомбинационной инженерии.
Заявители показали, что системы CRISPR-Cas можно использовать для целенаправленного редактирования генома у бактерий путем совместного введения конструкции для целенаправленного воздействия, которая уничтожала клетки дикого типа, и матрицы редактирования, которые совместно исключали расщепление с помощью CRISPR и обеспечивали введение желаемых мутаций. Можно создавать разные типы мутаций (вставки, делеции или scar-less однонуклеотидные замены). Множественные мутации можно вводить одновременно. Специфичность и универсальность редактирования с применением системы CRISPR основывались на нескольких уникальных свойствах эндонуклеазы Cas9: (i) ее специфичность целенаправленного воздействия можно программировать малыми РНК без необходимости конструировать фермент, (ii) специфичность целенаправленного воздействия, определенная с помощью взаимодействия РНК-ДНК на протяжении 20 п.о. с низкой вероятностью распознавания ложных мишеней, была очень высокой, (iii) практически любая последовательность может подвергаться целенаправленному воздействию, единственным требованием является наличие смежной последовательности NGG, (iv) практически любая мутация в последовательности NGG, а также мутации в затравочной последовательности протоспейсера исключают целенаправленное воздействие.
Заявители показали, что конструирование генома с применением системы CRISPR работало не только у бактерий, у которых наблюдается высокая частота рекомбинации, таких как S. pneumoniae, но также у E. coli. Результаты по E. coli свидетельствовали о том, что способ можно применять к другим микроорганизмам, которым можно вводить плазмиды. В E. coli данный подход дополняет рекомбинационную инженерию мутагенных олигонуклеотидов. Для использования этого метода в микроорганизмах, где рекомбинационная инженерия является невозможной, механизм гомологичной рекомбинации хозяина можно применять за счет обеспечения матрицы редактирования в плазмиде. К тому же, поскольку накопленные данные указывают на то, что опосредованное CRISPR расщепление приводит к гибели клеток многих бактерий и архей, можно предположить использование эндогенных систем CRISPR-Cas для целей редактирования.
И в S. pneumoniae, и в E. coli заявители наблюдали, что хотя редактированию способствовали совместный отбор трансформируемых клеток и незначительная индукция рекомбинации в целевом сайте за счет расщепления Cas9, механизмом, который способствовал редактированию в наибольшей степени, являлся отбор против нередактированных клеток. Таким образом, основным ограничением способа было наличие фона клеток, которые избежали CRISPR-индуцированной гибели клеток и не имели желаемой мутации. Заявители показали, что эти "клетки, избежавшие воздействия" возникли в основном путем делеции спейсера для целенаправленного воздействия, предположительно после рекомбинации последовательностей повторов, которые фланкируют спейсер для целенаправленного воздействия. Дальнейшее совершенствование можно сосредоточить на конструировании фланкирующих последовательностей для исключения рекомбинации, которые все еще могут поддерживать биогенез функциональных crRNA, но которые достаточно отличаются друг от друга. Альтернативно можно исследовать прямую трансформацию химерных crRNA. В частном случае E. coli создание системы CRISPR-Cas было невозможным, если этот организм также использовали в качестве хозяина для клонирования. Заявители решили эту проблему путем размещения Cas9 и tracrRNA на одной плазмиде, а CRISPR-массив на другой. Конструирование индуцибельной системы также может обойти это ограничение.
Хотя новые технологии синтеза ДНК обеспечивают возможность с оптимальными затратами создавать любую последовательность с высокой производительностью, остается проблема интегрирования синтетической ДНК в живые клетки для создания функциональных геномов. Недавно было показано, что стратегия совместного отбора MAGE повышает эффективность мутаций рекомбинационной инженерии путем отбора субпопуляции клеток, которые характеризуются повышенной вероятностью достижения рекомбинации в или возле данного локуса. В этом способе, введение селектируемых мутации используют для повышения вероятности создания расположенных поблизости неселектируемых мутаций. В отличие от непрямого отбора обеспечиваемого этой стратегией, использование системы CRISPR делает возможным производить прямой отбор по желаемой мутации и получать ее с высокой эффективностью. Эти технологии дополняют панель инструментов специалистов в области генной инженерии и совместно с синтезом ДНК они могут существенно увеличить как возможность расшифровки функции гена, так и осуществления манипуляции с организмами в биотехнологических целях. Два других исследования также относятся к конструированию с помощью CRISPR геномов млекопитающих. Ожидается, что эти crRNA-направленные технологии редактирования генома могут широко применяться в фундаментальных и медицинских науках.
Штаммы и условия культивирования. Штамм R6 S. pneumoniae был предоставлен д-ром Alexander Tomasz. Штамм crR6 получали в предыдущем исследовании. Культуры S. pneumoniae в жидкой среде выращивали в THYE (30 г/л агара Тодда-Хьюитта, 5 г/л дрожжевого экстракта). Клетки высевали на триптический соевый агар (TSA) с добавлением 5% дефибринированной овечьей крови. При необходимости добавляли следующие антибиотики: канамицин (400 мкг/мл), хлорамфеникол (5 мкг/мл), эритромицин (1 мкг/мл) стрептомицин (100 мкг/мл) или спектиномицин (100 мкг/мл). Измерения активности β-галактозидазы производили с применением анализа Миллера, как описано ранее.
Штаммы E. coli MG1655 и HME63 (полученные из MG1655, Δ(argF-lac) U169 λ cI857 Δcro-bioA galK tyr 145 UAG mutS<>amp) (31) были предоставлены Jeff Roberts и Donald Court, соответственно. Культуры E. coli в жидкой среде выращивали в среде LB (Difco). При необходимости добавляли следующие антибиотики: хлорамфеникол (25 мкг/мл), канамицин (25 мкг/мл) и стрептомицин (50 мкг/мл).
Трансформация S. pneumoniae. Компетентные клетки получали, как описано ранее (23). Для всех трансформаций для редактирования генома производили осторожное оттаивание клеток на льду и ресуспендировали их в 10 объемах среды M2 с добавлением 100 нг/мл стимулирующего компетенцию пептида CSP1(40) и с последующим добавлением конструкций для редактирования (конструкции для редактирования добавляли к клеткам при конечной концентрации от 0,7 нг/мкл дo 2,5 мкг/мкл). Клетки инкубировали 20 мин. при 37°C перед добавлением 2 мкл конструкций для целенаправленного воздействия и затем инкубировали 40 мин. при 37°C. Серийные разбавления клеток высевали на соответствующую среду для определения количества колониеобразующих единиц (КОЕ).
Рекомбинационная инженерия Lambda-red E. coli. Штамм HME63 использовали для всех экспериментов рекомбинационной инженерии. Клетки для рекомбинационной инженерии получали и обрабатывали в соответствии с ранее опубликованным протоколом (6). Кратко, 2 мл суточной культуры (среда LB), инокулированной из одной колонии, полученной из чашки, выращивали при 30°C. Суточную культуру разводили в 100 раз и выращивали при 30°C со встряхиванием (200 об/мин) до тех пор, пока OD600 не составляло 0,4-0,5 (приблизительно 3 часа). Для индукции Lambda-red культуру переносили на водяную баню при 42°C для встряхивания при 200 об/мин в течение 15 мин. Сразу же после индукции культуру перемешивали в суспензии ледяной воды и охлаждали на льду в течение 5-10 мин. Клетки затем промывали и аликвотировали в соответствии с протоколом. Для электротрансформации 50 мкл клеток смешивали с 1 мМ обессоленных олигонуклеотидов (IDT) или 100-150 нг плазмидной ДНК (полученной с помощью QIAprep Spin Miniprep Kit, Qiagen). Клетки электропорировали с использованием 1 мм кюветы Gene Pulser (Bio-rad) при 1,8 кВ и сразу же ресуспендировали в 1 мл среды LB комнатной температуры. Клетки извлекали при 30°C в течение 1-2 часов перед высеванием на агар LB с соответствующей устойчивостью к антибиотику и инкубировали при 32°C на протяжении ночи.
Получение геномной ДНК S. pneumoniae. В целях трансформации геномную ДНК S. pneumoniae выделяли с применением набора для очистки геномной ДНК Wizard, следуя инструкциям, предоставляемым производителем (Promega). В целях генотипирования 700 мкл суточных культур S. pneumoniae осаждали центрифугированием, ресуспендировали в 60 мкл раствора лизоцима (2 мг/мл) и инкубировали 30 мин при 37°C. Геномную ДНК экстрагировали с применением набора QIAprep Spin Miniprep Kit (Qiagen).
Создание штамма. Все праймеры, использованные в данном исследовании, представлены в таблице G. Для создания crR6M S. pneumoniae создавали промежуточный штамм LAM226. В этом штамме ген aphA-3 (обеспечивающий устойчивость к канамицину), смежный с массивом CRISPR штамма crR6 S. pneumoniae, замещали геном cat (обеспечивающим устойчивость к хлорамфениколу). Кратко, геномную ДНК crR6 амплифицировали с применением праймеров L448/L444 и L447/L481, соответственно. Ген cat амплифицировали из плазмиды pC194 с применением праймеров L445/L446. Каждый ПЦР-продукт очищали в геле и осуществляли слияние всех трех с помощью ПЦР с удлинением перекрывающихся фрагментов (SOEing PCR) с праймерами L448/L481. Полученным ПЦР-продуктом трансформировали компетентные клетки crR6 S. pneumoniae и отбирали устойчивые к хлорамфениколу трансформанты. Для создания crR6M S. pneumoniae геномную ДНК crR6 S. pneumoniae амплифицировали с помощью ПЦР с применением праймеров L409/L488 и L448/L481, соответственно. Каждый ПЦР-продукт очищали в геле и осуществляли их слияние с помощью ПЦР с удлинением перекрывающихся фрагментов (SOEing PCR) с праймерами L409/L481. Полученным ПЦР-продуктом трансформировали компетентные клетки LAM226 S. pneumoniae и отбирали устойчивые к канамицину трансформанты.
Для создания crR6Mc S. pneumoniae геномную ДНК crR6R S. pneumoniae амплифицировали с помощью ПЦР с применением праймеров L430/W286 и геномную ДНК LAM226 S. pneumoniae амплифицировали с помощью ПЦР с применением праймеров W288/L481. Каждый ПЦР-продукт очищали в геле и осуществляли их слияние с помощью ПЦР с удлинением перекрывающихся фрагментов (SOEing PCR) с праймерами L430/L481. Полученным ПЦР-продуктом трансформировали компетентные клетки crR6M S. pneumoniae и отбирали устойчивые к хлорамфениколу трансформанты.
Для создания crR6Rk S. pneumoniae геномную ДНК crR6M S. pneumoniae амплифицировали с помощью ПЦР с применением праймеров L430/W286 и W287/L481, соответственно. Каждый ПЦР-продукт очищали в геле и осуществляли их слияние с помощью ПЦР с удлинением перекрывающихся фрагментов (SOEing PCR) с праймерами L430/L481. Полученным ПЦР-продуктом трансформировали компетентные клетки crR6Rc S. pneumoniae и отбирали устойчивые к канамицину трансформанты.
Для создания JEN37 геномную ДНК crR6Rk S. pneumoniae амплифицировали с помощью ПЦР с применением праймеров L430/W356 и W357/L481, соответственно. Каждый ПЦР-продукт очищали в геле и осуществляли их слияние с помощью ПЦР с удлинением перекрывающихся фрагментов (SOEing PCR) с праймерами L430/L481. Полученным ПЦР-продуктом трансформировали компетентные клетки crR6Rc S. pneumoniae и отбирали устойчивые к канамицину трансформанты.
Для создания JEN38 геномную ДНК R6 амплифицировали с применением праймеров L422/L461 и L459/L426, соответственно. Ген ermAM (определяющий устойчивость к эритромицину) из плазмиды pFW1543 амплифицировали с применением праймеров L457/L458. Каждый ПЦР-продукт очищали в геле и осуществляли слияние всех трех с помощью ПЦР с удлинением перекрывающихся фрагментов (SOEing PCR) с праймерами L422/L426. Полученным ПЦР-продуктом трансформировали компетентные клетки crR6Rc S. pneumoniae и отбирали устойчивые к эритромицину трансформанты.
JEN53 S. pneumoniae создавали в две стадии. Сначала JEN43 создавали, как проиллюстрировано на фигуре 33. JEN53 создавали путем трансформирования компетентных клеток JEN43 геномной ДНК JEN25 и отбора, как по хлорамфениколу, так и по эритромицину.
Для создания JEN62 S. pneumoniae геномную ДНК crR6Rk S. pneumoniae амплифицировали с помощью ПЦР с применением праймеров W256/W365 и W366/L403, соответственно. Каждый ПЦР-продукт очищали и лигировали с помощью сборки по методу Гибсона. Продуктом сборки трансформировали компетентные клетки crR6Rc S. pneumoniae и отбирали устойчивые к канамицину трансформанты.
Создание плазмиды. pDB97 создавали посредством фосфорилирования и отжига олигонуклеотидов B296/B297 с последующим лигированием в pLZ12spec, расщепленный с помощью EcoRI/BamHI. Заявители полностью секвенировали pLZ12spec и депонировали его последовательность в Genbank (номер доступа: KC112384).
pDB98 получали после клонирования лидерной последовательности CRISPR совместно со структурной единицей повтор-спейсер-повтор в pLZ12spec. Этого достигали посредством амплификации ДНК crR6Rc с праймерами B298/B320 и B299/B321 с последующей ПЦР с удлинением перекрывающихся фрагментов (SOEing PCR) для обоих продуктов и клонированием в pLZ12spec с сайтами рестрикциии BamHI/EcoRI. Таким образом, последовательность спейсера в pDB98 конструировали так, чтобы она содержала два сайта рестрикции BsaI в противоположных направлениях, что обеспечивало возможность scar-less клонирования новых спейсеров.
От pDB99 до pDB108 создавали путем отжига олигонуклеотидов B300/B301 (pDB99), B302/B303 (pDB100), B304/B305 (pDB101), B306/B307 (pDB102), B308/B309 (pDB103), B310/B311 (pDB104), B312/B313 (pDB105), B314/B315 (pDB106), B315/B317 (pDB107), B318/B319 (pDB108) с последующим лигированием в pDB98, разрезанным с помощью BsaI.
Плазмиду pCas9 создавали следующим образом. Необходимые элементы CRISPR амплифицировали из геномной ДНК SF370 Streptococcus pyogenes с фланкирующими гомологичными плечами для сборки по методу Гибсона. tracrRNA и Cas9 амплифицировали с олигонуклеотидами HC008 и HC010. Лидерную последовательность и последовательности CRISPR амплифицировали с HC011/HC014 и HC015/HC009, так что два сайта BsaI типа IIS вводили между двумя прямыми повторами для обеспечения беспрепятственной вставки спейсеров.
pCRISPR создавали с помощью субклонирования массива CRISPR pCas9 в pZE21-MCS1 посредством амплификации с олигонуклеотидами B298+B299 и рестрикции EcoRI и BamHI. Спейсер для целенаправленного воздействия rpsL клонировали с помощью отжига олигонуклеотидов B352+B353 и клонирования в разрезанную BsaI pCRISPR с получением pCRISPR::rpsL.
Создание конструкций для целенаправленного воздействия и редактирования. Конструкций для целенаправленного воздействия, использованные для редактирования генома, получали с помощью сборки по методу Гибсона продуктов ПЦР с правыми и левыми праймерами (таблица G). Конструкции для редактирования получали посредством слияния ПЦР-продуктов A (ПЦР A), ПЦР-продуктов B (ПЦР B) и ПЦР-продуктов C (ПЦР C) при помощи ПЦР с удлинением перекрывающихся фрагментов (SOEing PCR), при необходимости (таблица G). Конструкции CRISPR::∅ и CRISPR::ermAM(stop) для целенаправленного воздействия получали с помощью ПЦР амплификации геномной ДНК JEN62 и crR6, соответственно, с олигонуклеотидами L409 и L481.
Получение мишеней с рандомизированными PAM или последовательностями протоспейсеров. 5 нуклеотидов, следующих за мишенью спейсера 1, рандомизировали посредством амплификации геномной ДНК R68232.5 с праймерами W377/ L426. Этот ПЦР-продукт затем собирали с геном cat и участком srtA, находящимся выше, которые амплифицировали с той же матрицы с праймерами L422/W376. 80 нг собранной ДНК использовали для трансформации штаммов R6 и crR6. Образцы для рандомизированных мишеней получали с использованием следующих праймеров: B280-B290/L426 для рандомизирования оснований 1-10 мишени и B269-B278/L426 для рандомизирования оснований 10-20. Праймеры L422/B268 и L422/B279 использовали для амплификации гена cat и находящегося выше участка srtA для сборки с первыми и последними 10 ПЦР-продуктами, соответственно. Собранные конструкции объединяли вместе и с помощью 30 нг трансформировали R6 и crR6. После трансформации клетки высевали для отбора по хлорамфениколу. Для каждого образца более чем 2×105 клеток объединяли вместе в 1 мл THYE и геномную ДНК экстрагировали с помощью набора Promega Wizard kit. Праймеры B250/B251 использовали для амплификации целевого участка. ПЦР-продукты метили и прогоняли на дорожке для секвенирования спаренных концов Illumina MiSeq с применением 300 циклов.
Анализ данных глубокого секвенирования
Рандомизированные PAM. Для эксперимента с рандомизированными PAM получали 3429406 считываемых фрагментов для crR6 и 3253998 для R6. Ожидалось, что только половина из них будет соответствовать мишени PAM, в то время как другая половина будет секвенировать другой конец ПЦР-продукта. 1623008 из считываемых фрагментов crR6 и 1537131 из считываемых фрагментов R6 несли лишенную ошибок целевую последовательность. Встречаемость каждого возможного PAM среди этих считываемых фрагментов показана в дополнительном файле. Для оценки функциональности PAM вычисляли его относительную долю в образце crR6 в сравнении с образцом R6 и обозначали rijklm, где I,j,k,l,m представляют собой одно из 4 возможных оснований. Создавали следующую статистическую модель:
log(rijklm) = μ + b2i + b3j + b4k + b2b3i,j+ b3b4j,k+ εijklm,
где ε представляет собой остаточную ошибку, b2 представляет собой эффект 2го основания PAM, b3 - третьего, b4 - четвертого, b2b3 представляет собой взаимодействие между вторым и третьим основаниями, b3b4 - между третьим и четвертым основаниями. Выполняли дисперсионный анализ:
Таблица дисперсионного анализа
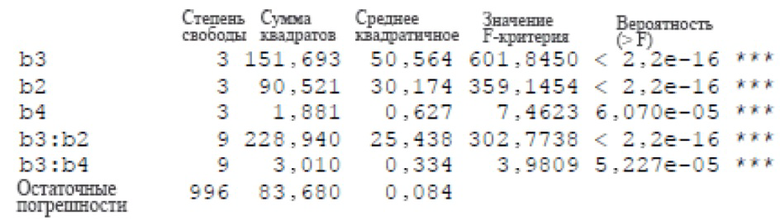
При добавлении в данную модель b1 или b5 оказываются незначимыми, и другие взаимодействия, кроме включенных, также можно исключать. Выбор модели осуществляли посредством последовательных сравнений более или менее полных моделей с применением метода дисперсионного анализа в R. Критерий подлинной значимости Тьюки использовали для определения, являются ли попарные различия между эффектами значимыми.
Паттерны NGGNN являлись достоверно отличными от всех других паттернов и имели самый сильный эффект (см. таблицу ниже).
Для того, чтобы показать, что положения 1, 4 или 5 не влияют на паттерн NGGNN, заявители рассматривали только эти последовательности. Оказывается, что их эффекты являются нормально распределенными (см. диаграмму "квантиль-квантиль" на фигуре 71), и сравнения моделей с применением метода дисперсионного анализа в R показывают, что нулевая модель является наилучшей, т. e. нет значимой роли b1, b4 и b5.
Сравнение моделей с применением метода дисперсионного анализа в R для последовательностей NGGNN

Частичная интерференция паттернов NAGNN и NNGGN
Паттерны NAGNN являются достоверно отличными от всех других паттернов, но несут намного меньший эффект, чем NGGNN (см. критерий подлинной значимости Тьюки ниже).
И наконец, паттерны NTGGN и NCGGN являются подобными и показывают значительно большую интерференцию CRISPR, чем паттерны NTGHN и NCGHN (где H представляет собой A,T или C), как показано с помощью парного критерия Стьюдента с поправкой Бониферрони.
Парные сравнения эффекта b4 на последовательности NYGNN с применением t-критериев с суммарным среднеквадратическим отклонением (SD)

Взятые вместе, эти результаты позволяют сделать вывод, что паттерны NNGGN в целом обеспечивают либо полную интерференцию, в случае NGGGN, либо частичную интерференцию, в случае NAGGN, NTGGN или NCGGN.
Множественные сравнения значений по Тьюки: уровень значимости с поправкой на эффект множественных сравнений 95%
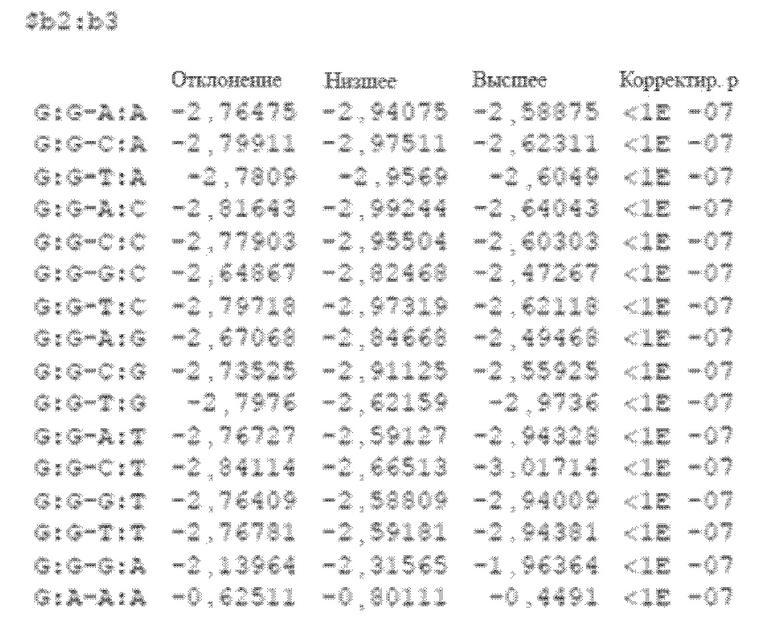
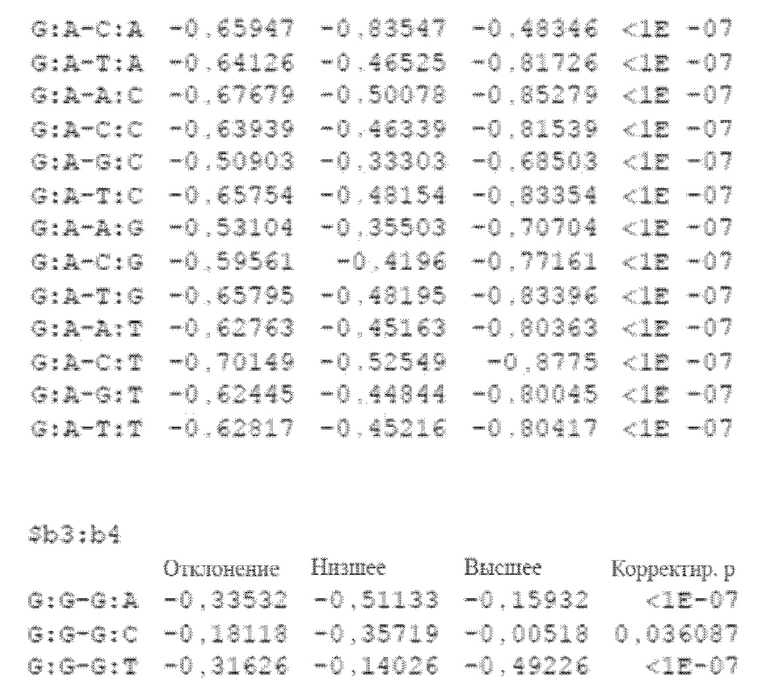
Рандомизированная мишень
Для эксперимента с рандомизированными мишенями для crR6 получали 540726 считываемых фрагментов и 753,570 для R6. Как и прежде, ожидалось, что только половина считываемых фрагментов будет секвенировать конец ПЦР-продукта, представляющий интерес. После фильтрования для считываемых фрагментов, которые несут мишень, являющуюся лишенной ошибок или с одноточечной мутацией, оставалось 217656 и 353141 считываемых фрагментов для crR6 и R6, соответственно. Вычисляли относительную долю каждого мутанта в образце crR6 в сравнении с образцом R6 (фигура 24c). Все мутации вне затравочной последовательности (13-20 оснований от PAM) проявляли полную интерференцию. Эти последовательности использовали как идентификатор для определения, можно ли сказать, что мутации в затравочной последовательности значимо нарушают интерференцию. Нормальное распределение подбирали для этих последовательностей с использованием выравнивания функции распределения пакета MASS R. Квантиль 0,99 подобранного распределения показан как пунктирная линия на фигуре 24c. На фигуре 72 показана гистограмма плотности данных с подобранным нормальным распределением (черная линия) и квантилем 0,99 (пунктирная линия).
Таблица F. Относительная распространенность последовательностей PAM в образцах crR6/R6, усредненная по основаниям 1 и 5
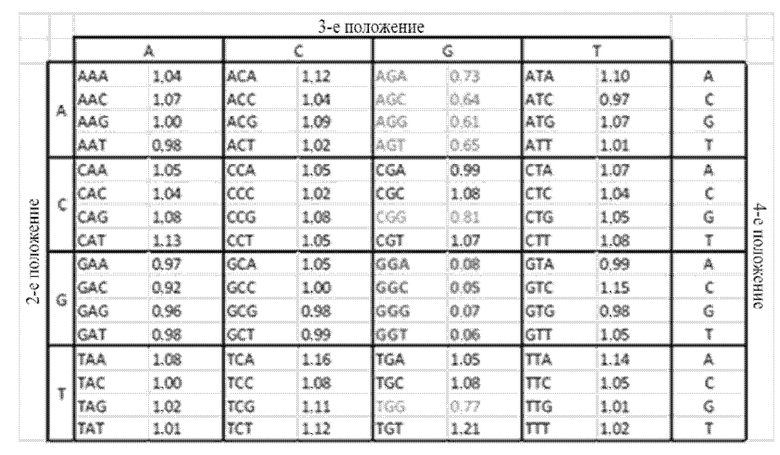
Таблица G. Праймеры, использованные в данном исследовании



Таблица H. Структура конструкций для целенаправленного воздействия и редактирования, использованных в данном исследовании


Пример 6: оптимизация направляющей РНК для Cas9 Streptococcus pyogenes (называемого SpCas9)
Заявители вносили мутации в tracrRNA и последовательности прямых повторов или вносили мутации в химерную направляющую РНК для повышения экспрессии РНК в клетках.
Оптимизация основана на наблюдении, что присутствовали фрагменты тимина (Ts) в tracrRNA и направляющей РНК, которые могли приводить к ранней терминации транскрипции посредством промотора pol 3. Таким образом заявители создавали следующие оптимизированные последовательности. Оптимизированная tracrRNA и соответствующий оптимизированный прямой повтор представлены в парах.
Оптимизированная tracrRNA 1 (мутация подчеркнута):
GGAACCATTCAtAACAGCATAGCAAGTTAtAATAAGGCTAGTCCGTTATCAACTTGAAAAAGTGGCACCGAGTCGGTGCTTTTT
Оптимизированный прямой повтор 1 (мутация подчеркнута):
GTTaTAGAGCTATGCTGTTaTGAATGGTCCCAAAAC
Оптимизированная tracrRNA 2 (мутация подчеркнута):
GGAACCATTCAAtACAGCATAGCAAGTTAAtATAAGGCTAGTCCGTTATCAACTTGAAAAAGTGGCACCGAGTCGGTGCTTTTT
Оптимизированный прямой повтор 2 (мутация подчеркнута):
GTaTTAGAGCTATGCTGTaTTGAATGGTCCCAAAAC
Заявители также оптимизировали химерную направляющую РНК для оптимальной активности в эукариотических клетках.
Исходная направляющая РНК:
NNNNNNNNNNNNNNNNNNNNGTTTTAGAGCTAGAAATAGCAAGTTAAAATAAGGCTAGTCCGTTATCAACTTGAAAAAGTGGCACCGAGTCGGTGCTTTTTTT
Оптимизированная химерная направляющая последовательность РНК 1:
NNNNNNNNNNNNNNNNNNNNGTATTAGAGCTAGAAATAGCAAGTTAATATAAGGCTAGTCCGTTATCAACTTGAAAAAGTGGCACCGAGTCGGTGCTTTTTTT
Оптимизированная химерная направляющая последовательность РНК 2:
NNNNNNNNNNNNNNNNNNNNGTTTTAGAGCTATGCTGTTTTGGAAACAAAACAGCATAGCAAGTTAAAATAAGGCTAGTCCGTTATCAACTTGAAAAAGTGGCACCGAGTCGGTGCTTTTTTT
Оптимизированная химерная направляющая последовательность РНК 3:
NNNNNNNNNNNNNNNNNNNNGTATTAGAGCTATGCTGTATTGGAAACAATACAGCATAGCAAGTTAATATAAGGCTAGTCCGTTATCAACTTGAAAAAGTGGCACCGAGTCGGTGCTTTTTTT
Заявители показали, что оптимизированная химерная направляющая РНК работает лучше, как показано на фигуре 3. Эксперимент проводили путем котрансфекции клеток 293FT Cas9 и ДНК-кассетой с U6-направляющей РНК для экспрессии одной из четырех форм РНК, показанных выше. Мишень направляющей РНК является таким же целевым сайтом в локусе EMX1 человека: “GTCACCTCCAATGACTAGGG”.
Пример 7: оптимизация Cas9 из CRISPR1 LMD-9 Streptococcus thermophiles (называемого St1Cas9)
Заявители разрабатывали направляющие химерные РНК, как показано на фигуре 4.
Направляющие РНК St1Cas9 можно подвергать такому же типу оптимизации, как и направляющие РНК SpCas9, путем разрушения политиминовых фрагментов (Ts).
Пример 8: разнообразие и мутации Cas9
Система CRISPR-Cas является адаптивным иммунным механизмом в отношении внедряющейся экзогенной ДНК, используемым разнообразными видами из числа бактерий и архей. Система CRISPR-Cas9 II типа состоит из набора генов, кодирующих белки, ответственные за “захват” чужеродной ДНК в локус CRISPR, а также из набора генов, кодирующих “выполнение” механизма расщепления ДНК; они включают ДНК-нуклеазу (Cas9), некодирующую транс-активирующую cr-RNA (tracrRNA) и массив полученных из чужеродной ДНК спейсеров, фланкированных прямыми повторами (crRNA). При созревании под действием Cas9 дуплекс tracRNA и crRNA направляет нуклеазу Cas9 к целевой последовательности ДНК, определенной спейсерными направляющими последовательностями и опосредует двухцепочечные разрывы в ДНК вблизи короткого мотива последовательности в целевой ДНК, которые требуются для расщепления и являются специфичными для каждой системы CRISPR-Cas. Системы CRISPR-Cas II типа обнаруживаются повсеместно в царстве бактерий и являются очень разнообразными по последовательности и размеру белка Cas9, последовательности прямого повтора tracrRNA и crRNA, организации этих элементов в геноме и требованиям к мотиву для целенаправленного расщепления. Один вид может иметь несколько отдельных систем CRISPR-Cas.
Заявители оценивали 207 предполагаемых Cas9 из видов бактерий, идентифицированных на основании гомологии последовательности с известными Cas9 и структурами, ортологичными известным субдоменам, в том числе домену эндонуклеазы HNH и доменам эндонуклеазы RuvC [информация от Eugene Koonin и Kira Makarova]. Филогенетический анализ, основанный на консервативности последовательности белка в этом наборе, позволил выявить пять семейств Cas9, включая три группы больших Cas9 (~1400 аминокислот) и две малых Cas9 (~1100 аминокислот) (фигуры 39 и 40A-F).
В этом примере заявители показали, что следующие мутации могут превратить SpCas9 в надрезающий фермент: D10A, E762A, H840A, N854A, N863A, D986A.
Заявителями представлены последовательности, в которых показано, где локализованы точки мутаций в гене SpCas9 (фигура 41). Заявители также показывают, что никазы все еще могут опосредовать гомологичную рекомбинацию (анализ, указанный на фигуре 2). Более того, заявители показали, что SpCas9 с этими мутациями (отдельно) не индуцировал двухцепочечный разрыв (фигура 47).
Пример 9: дополнение специфичности целенаправленного воздействия в отношении ДНК РНК-направляемой нуклеазы Cas9
Клеточная культура и трансфекция
Линию клеток почки человеческого эмбриона (HEK) 293FT (Life Technologies) поддерживали в среде Игла в модификации Дульбекко (DMEM), дополненной 10% фетальной бычьей сыворотки (HyClone), 2 мМ GlutaMAX (Life Technologies), 100 ЕД/мл пенициллина и 100 мкг/мл стрептомицина, при 37°C с инкубированием при 5% CO2.
Клетки 293FT засевали или на 6-луночные планшеты, 24-луночные планшеты, или на 96-луночные планшеты (Corning) за 24 часа до трансфекции. Клетки трансфицировали с применением Lipofectamine 2000 (Life Technologies) при 80-90% конфлуентности, следуя рекомендованному производителем протоколу. На каждую лунку 6-луночного планшета использовали в общей сложности 1 мкг плазмиды Cas9+sgRNA. На каждую лунку 24-луночного планшета использовали, если не указано иное, в общей сложности 500 нг плазмиды Cas9+sgRNA. На каждую лунку 96-луночного планшета использовали 65 нг плазмиды Cas9 при молярном соотношении ПЦР-продукта U6-sgRNA 1:1.
Клеточную линию эмбриональных стволовых клеток человека HUES9 (Harvard Stem Cell Institute core) поддерживали в условиях без подслоя на GelTrex (Life Technologies) в среде mTesR (Stemcell Technologies) с добавлением 100 мкг/мл Normocin (InvivoGen). Клетки HUES9 трансфицировали с помощью набора Amaxa P3 Primary Cell 4-D Nucleofector Kit (Lonza), следуя протоколу производителя.
Анализ с помощью SURVEYOR на предмет наличия модификации генома
Клетки 293FT трансфицировали плазмидной ДНК, как описано выше. Клетки инкубировали при 37°C в течение 72 часов после трансфекции перед экстракцией геномной ДНК. Геномную ДНК экстрагировали с помощью раствора QuickExtract DNA Extraction Solution (Epicentre), следуя протоколу производителя. Вкратце, осажденные центрифугированием клетки ресуспендировали в растворе QuickExtract solution и инкубировали при 65°C в течение 15 минут и 98°C в течение 10 минут.
Геномный участок, фланкирующий целевой сайт CRISPR каждого гена, амплифицировали с помощью ПЦР (праймеры перечислены в таблицах J и K) и продукты очищали с применением колонки QiaQuick Spin Column (Qiagen), следуя протоколу производителя. В общей сложности 400 нг очищенных ПЦР-продуктов смешивали с 2 мкл 10X ПЦР-буфера для ДНК-полимеразы Taq (Enzymatics) и воды сверхвысокой чистоты до конечного объема 20 мкл и подвергали процессу повторного отжига для обеспечения образования гетеродуплекса: 95°C в течение 10 мин., линейное снижение температуры с 95°C до 85°C со скоростью 2°C/с, с 85°C до 25°C со скоростью 0,25°C/с и с выдерживанием при 25°C в течение 1 минуты. После повторного отжига продукты обрабатывали нуклеазой SURVEYOR и энхансером S SURVEYOR (Transgenomics), следуя рекомендованному производителем протоколу, и анализировали в 4-20% полиакриламидных гелях Novex TBE (Life Technologies). Гели окрашивали красителем ДНК SYBR Gold (Life Technologies) в течение 30 минут и получали изображение с помощью системы обработки изображений Gel Doc gel imaging system (Bio-rad). Количественный анализ основывался на относительных интенсивностях полос.
Анализ экспрессии tracrRNA в клетках человека с помощью нозерн-блоттинга
Анализы нозерн-блоттинга выполняли, как описано ранее 1. Кратко, молекулы РНК нагревали до 95°C в течение 5 мин перед погружением в 8% денатурирующие полиакриламидные гели (SequaGel, National Diagnostics). После этого РНК переносили на предварительно гибридизированную мембрану Hybond N+ (GE Healthcare) и сшивали с помощью прибора для автоматического сшивания с помощью ультрафиолета Stratagene UV Crosslinker (Stratagene). Зонды метили [гамма-32P] АТФ (Perkin Elmer) с полинуклеотидкиназой T4 (New England Biolabs). После промывания мембрану экспонировали на люминисцентном экране в течение одного часа и сканировали с использованием устройства для формирования изображения на люминесцентном фосфорном покрытии (Typhoon).
Бисульфитное секвенирование для оценки статуса метилирования ДНК
Клетки HEK 293FT трансфицировали Cas9, как описано выше. Геномную ДНК выделяли с помощью набора DNeasy Blood & Tissue Kit (Qiagen) и подвергали бисульфитной модификации с помощью набора EZ DNA Methylation-Lightning Kit (Zymo Research). Бисульфитную ПЦР проводили с применением ДНК-полимеразы KAPA2G Robust HotStart (KAPA Biosystems) с праймерами, разработанными с применением Bisulfite Primer Seeker (Zymo Research, таблицы J и K). Полученные ПЦР-ампликоны очищали в геле, расщепляли EcoRI и HindIII и лигировали в остов pUC19 перед трансформацией. Отдельные клоны затем секвенровали по Сэнгеру для оценки статуса метилирования ДНК.
In vitro транскрипция и анализ расщепления
Клетки HEK 293FT трансфицировали Cas9, как описано выше. Цельноклеточные лизаты затем получали с применением лизирующего буфера (20 мМ HEPES, 100 мМ KCl, 5 мМ MgCl2, 1 мМ DTT, 5% глицерина, 0,1% Triton X-100) с добавлением смеси ингибиторов протеаз (Roche). Управляемые T7 sgRNA транскрибировали in vitro с применением специальных олигонуклеотидов (пример 10) и набора для транскрипции in vitro HiScribe T7 (NEB), следуя рекомендованному производителем протоколу. Для получения метилированных целевых сайтов плазмиду pUC19 метилировали с помощью M.SssI и затем проводили линеаризацию с помощью NheI. Анализ расщепления in vitro выполняли следующим образом: для реакции расщепления 20 мкл 10 мкл клеточного лизата инкубировали с 2 мкл буфера для расщепления (100 мМ HEPES, 500 мМ KCl, 25 мМ MgCl2, 5 мМ DTT, 25% глицерина), транскрибированной in vitro РНК и 300 нг ДНК плазмиды pUC19.
Глубокое секвенирование для оценки специфичности целенаправленного воздействия
Клетки HEK 293FT, которые высевали в 96-луночные планшеты, трансфицировали ПЦР кассетой с плазмидной ДНК Cas9 и одиночной направляющей РНК (sgRNA) за 72 часа до экстракции геномной ДНК (фиг. 72). Геномный участок, фланкирующий целевой сайт CRISPR каждого гена, амплифицировали (фиг. 74, фиг. 80, (пример 10)) с помощью метода ПЦР с перекрывающимися праймерами для присоединения адаптеров Illumina P5, а также уникальных специфичных для каждого образца штрихкодов к целевым ампликонам (схематическое изображение, описанное на фиг. 73). ПЦР-продукты очищали с применением 96-луночных планшетов для фильтрования EconoSpin (Epoch Life Sciences), следуя рекомендованному производителем протоколу.
Очищенные образцы ДНК со штрихкодами количественно определяли с помощью набора для анализа Quant-iT PicoGreen dsDNA или Qubit 2.0 Fluorometer (Life Technologies) и объединяли в эквимолярном соотношении. С библиотеками секвенирования затем проводили глубокое секвенирование с использованием секвенсера Illumina MiSeq Personal Sequencer (Life Technologies).
Анализ данных секвенирования и обнаружение вставок/делеций
Считываемые фрагменты MiSeq фильтровали с требуемым средним качеством Phred (оценка Q), по меньшей мере 23, а также полными соответствиями последовательностей к штрихкодам и прямым праймерам ампликона. Считываемые фрагменты из целевых и нецелевых локусов анализировали сначала с помощью выполнения выравниваний Смита-Ватермана против последовательностей ампликонов, которые включали 50 нуклеотидов выше и ниже целевого сайта (в общей сложности 120 п.о.). При этом выравнивания анализировали по вставкам/делециям от 5 нуклеотидов выше до 5 нуклеотидов ниже целевого сайта (в общей сложности 30 п.о.). Анализированные целевые участки исключали, если часть их выравнивания выходила за пределы самого считываемого фрагмента MiSeq или если совпавшие пары оснований содержали меньше 85% их общей длины.
Отрицательные контроли для каждого образца представляли эталон включения или исключения вставок/делеций как предполагаемых событий разрезания. Для каждого образца вставку/делецию учитывали, только если ее показатель качества превышал  , где
, где  представляло собой средний показатель качества отрицательного контроля, соответствующего образцу, и
представляло собой средний показатель качества отрицательного контроля, соответствующего образцу, и  представляло собой его среднеквадратическое отклонение. Это дало соотношения всех вставок/делеций целевых участков, как для отрицательных контролей, так и их соответствующих образцов. С применением соотношений ошибок отрицательного контроля на-целевой-участок-на-считываемый фрагмент,
представляло собой его среднеквадратическое отклонение. Это дало соотношения всех вставок/делеций целевых участков, как для отрицательных контролей, так и их соответствующих образцов. С применением соотношений ошибок отрицательного контроля на-целевой-участок-на-считываемый фрагмент, 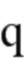 , наблюдаемое количество вставок/делеций образцов
, наблюдаемое количество вставок/делеций образцов  и его количество считываемых фрагментов
и его количество считываемых фрагментов  , оценку максимального правдоподобия для фракции считываемых фрагментов, содержащих целевые участки с верными вставками/делециями,
, оценку максимального правдоподобия для фракции считываемых фрагментов, содержащих целевые участки с верными вставками/делециями,  , выявляли с помощью применения бионормальной модели ошибок, указанной ниже.
, выявляли с помощью применения бионормальной модели ошибок, указанной ниже.
Допустив, что (неизвестное) количество считываемых фрагментов в образце, содержащих целевые участки, неправильно подсчитанные как такие, которые имеют по меньшей мере 1 вставку/делецию, равно 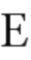 , можно написать (без внесения каких-либо предположений о количестве верных вставок/делеций)
, можно написать (без внесения каких-либо предположений о количестве верных вставок/делеций)
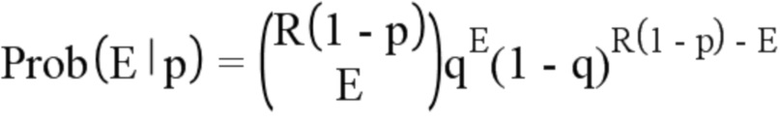
поскольку  представляет собой количество считываемых фрагментов, содержащих целевые участки без верных вставок/делеций. При этом, поскольку количество считываемых фрагментов, наблюдаемых, как такие, которые содержат вставки/делеции, равно ,
представляет собой количество считываемых фрагментов, содержащих целевые участки без верных вставок/делеций. При этом, поскольку количество считываемых фрагментов, наблюдаемых, как такие, которые содержат вставки/делеции, равно , 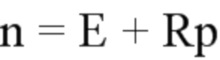 , другими словами, количество считываемых фрагментов, содержащих целевые участки с ошибками, но без верных вставок/делеций, плюс количество считываемых фрагментов, чьи целевые участки содержат правильные вставки/делеции. Можно переписать указанное выше:
, другими словами, количество считываемых фрагментов, содержащих целевые участки с ошибками, но без верных вставок/делеций, плюс количество считываемых фрагментов, чьи целевые участки содержат правильные вставки/делеции. Можно переписать указанное выше:
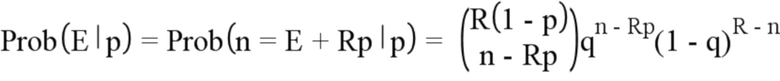
Принимая, что все значения частоты целевых участков с верными вставками/делециями априори являются равновероятными, 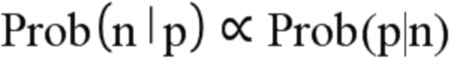 . Оценка максимального правдоподобия (MLE) частоты целевых участков с верными вставками/делециями, таким образом, устанавливали как величину , которая максимизировала
. Оценка максимального правдоподобия (MLE) частоты целевых участков с верными вставками/делециями, таким образом, устанавливали как величину , которая максимизировала  . Это оценивали в числовом отношении.
. Это оценивали в числовом отношении.
Для размещения границ ошибки относительно частот фрагментов считывания с верными вставками/делециями в их библиотеках секвенирования для каждого образца рассчитывали доверительные интервалы Вильсона (2), предоставляющие MLE-оценку целевых участков с верными вставками/делециями,  , и количество считываемых фрагментов . Конкретно, нижнюю границу
, и количество считываемых фрагментов . Конкретно, нижнюю границу  и верхнюю границу
и верхнюю границу  рассчитывали как
рассчитывали как
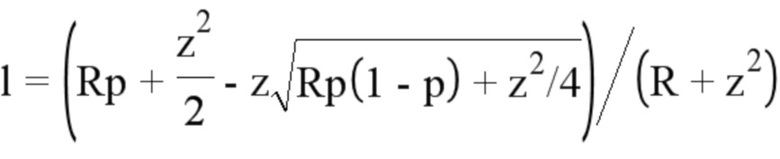
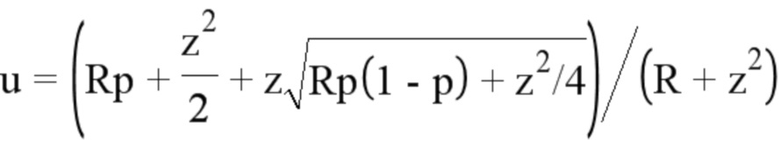
где  , стандартный показатель достоверности, требуемый для нормального распределения дисперсии 1, устанавливали на 1,96, что означало достоверность 95%. Максимальные верхние границы и минимальные нижние границы для каждой биологической повторности перечислены на фигурах 80-83.
, стандартный показатель достоверности, требуемый для нормального распределения дисперсии 1, устанавливали на 1,96, что означало достоверность 95%. Максимальные верхние границы и минимальные нижние границы для каждой биологической повторности перечислены на фигурах 80-83.
Анализ qRT-PCR относительной экспрессии Cas9 и sgRNA
Клетки 293FT, высеянные в 24-луночные планшеты, трансфицировали, как описано выше. Через 72 часа после трансфекции общую РНК собирали с помощью набора miRNeasy Micro Kit (Qiagen). Синтез минус-нити sgRNA выполняли c помощью набора qScript Flex cDNA kit (VWR) и специальных праймеров для синтеза первой нити (таблицы J и K). Анализ количественной ПЦР выполняли с использованием Fast SYBR Green Master Mix (Life Technologies) и специальных праймеров (таблицы J и K) с применением GAPDH в качестве эндогенного контроля. Относительный количественный анализ производили с помощью способа ΔCT.
Таблица I | Последовательности целевого сайта. Тестируемые целевые сайты для системы CRISPR II типа S. pyogenes с соответствующим PAM. Клетки трансфицировали Cas9 и либо crRNA-tracrRNA, либо химерной sgRNA для каждой мишени.
Таблица J | Последовательности праймеров
Анализ с помощью SURVEYOR
Анализ qRT-PCR экспрессии Cas9 и sgRNA
Бисульфитная ПЦР и секвенирование
(локус SERPINB5)
Таблица K | Последовательности праймеров для проверки строения sgRNA. Праймеры гибридизируют с минус-нитью промотора U6, если не указано иное. Праймирующий сайт U6 обозначен курсивом, направляющая последовательность обозначена как фрагмент Ns, последовательность прямого повтора выделена жирным шрифтом, а последовательность tracrRNA подчеркнута. Вторичная структура каждого строения sgRNA показана на фиг. 43.
Таблица L | Целевые сайты с альтернативными PAM для тестирования специфичности Cas9 в отношении PAM. Все целевые сайты для тестирования специфичности в отношении PAM найдены в локусе EMX1 человека.
Пример 10: дополнительные последовательности
Все последовательности представлены в направлении от 5’ к 3’. Для транскрипции U6 черта подчеркнутого целевого сайта (Ts) выступает как терминатор транскрипции.
U6 с короткой tracrRNA (Streptococcus pyogenes SF370):
gagggcctatttcccatgattccttcatatttgcatatacgatacaaggctgttagagagataattggaattaatttgactgtaaacacaaagatattagtacaaaatacgtgacgtagaaagtaataatttcttgggtagtttgcagttttaaaattatgttttaaaatggactatcatatgcttaccgtaacttgaaagtatttcgatttcttggctttatatatcttgtggaaaggacgaaacaccGGAACCATTCAAAACAGCATAGCAAGTTAAAATAAGGCTAGTCCGTTATCAACTTGAAAAAGTGGCACCGAGTCGGTGCTTTTTTT
(последовательность tracrRNA представлена жирным шрифтом)
>U6-DR-направляющая последовательность-DR (SF370 Streptococcus pyogenes)
gagggcctatttcccatgattccttcatatttgcatatacgatacaaggctgttagagagataattggaattaatttgactgtaaacacaaagatattagtacaaaatacgtgacgtagaaagtaataatttcttgggtagtttgcagttttaaaattatgttttaaaatggactatcatatgcttaccgtaacttgaaagtatttcgatttcttggctttatatatcttgtggaaaggacgaaacaccgggttttagagctatgctgttttgaatggtcccaaaacNNNNNNNNNNNNNNNNNNNNNNNNNNNNNNgttttagagctatgctgttttgaatggtcccaaaacTTTTTTT
(прямой повтор последовательности выделен серым, а направляющая последовательность N представлена жирным шрифтом)
> sgRNA, содержащая +48 tracrRNA (SF370 Streptococcus pyogenes)
gagggcctatttcccatgattccttcatatttgcatatacgatacaaggctgttagagagataattggaattaatttgactgtaaacacaaagatattagtacaaaatacgtgacgtagaaagtaataatttcttgggtagtttgcagttttaaaattatgttttaaaatggactatcatatgcttaccgtaacttgaaagtatttcgatttcttggctttatatatcttgtggaaaggacgaaacaccNNNNNNNNNNNNNNNNNNNNgttttagagctagaaatagcaagttaaaataaggctagtccgTTTTTTT
(направляющая последовательность представлена жирным шрифтом N, и фрагмент tracrRNA представлен жирным шрифтом)
> sgRNA, содержащая +54 tracrRNA (SF370 Streptococcus pyogenes)
gagggcctatttcccatgattccttcatatttgcatatacgatacaaggctgttagagagataattggaattaatttgactgtaaacacaaagatattagtacaaaatacgtgacgtagaaagtaataatttcttgggtagtttgcagttttaaaattatgttttaaaatggactatcatatgcttaccgtaacttgaaagtatttcgatttcttggctttatatatcttgtggaaaggacgaaacaccNNNNNNNNNNNNNNNNNNNNgttttagagctagaaatagcaagttaaaataaggctagtccgttatcaTTTTTTTT
(направляющая последовательность представлена жирным шрифтом N, и фрагмент tracrRNA представлен жирным шрифтом)
> sgRNA, содержащая +67 tracrRNA (SF370 Streptococcus pyogenes)
gagggcctatttcccatgattccttcatatttgcatatacgatacaaggctgttagagagataattggaattaatttgactgtaaacacaaagatattagtacaaaatacgtgacgtagaaagtaataatttcttgggtagtttgcagttttaaaattatgttttaaaatggactatcatatgcttaccgtaacttgaaagtatttcgatttcttggctttatatatcttgtggaaaggacgaaacaccNNNNNNNNNNNNNNNNNNNNgttttagagctagaaatagcaagttaaaataaggctagtccgttatcaacttgaaaaagtgTTTTTTT
(направляющая последовательность представлена жирным шрифтом N, и фрагмент tracrRNA представлен жирным шрифтом)
> sgRNA, содержащая +85 tracrRNA (SF370 Streptococcus pyogenes)
gagggcctatttcccatgattccttcatatttgcatatacgatacaaggctgttagagagataattggaattaatttgactgtaaacacaaagatattagtacaaaatacgtgacgtagaaagtaataatttcttgggtagtttgcagttttaaaattatgttttaaaatggactatcatatgcttaccgtaacttgaaagtatttcgatttcttggctttatatatcttgtggaaaggacgaaacaccNNNNNNNNNNNNNNNNNNNNgttttagagctagaaatagcaagttaaaataaggctagtccgttatcaacttgaaaaagtggcaccgagtcggtgcTTTTTTT
(направляющая последовательность представлена жирным шрифтом N, и фрагмент tracrRNA представлен жирным шрифтом)
> CBh-NLS-SpCas9-NLS
cgttacataacttacggtaaatggcccgcctggctgaccgcccaacgacccccgcccattgacgtcaataatgacgtatgttcccatagtaacgccaatagggactttccattgacgtcaatgggtggagtatttacggtaaactgcccacttggcagtacatcaagtgtatcatatgccaagtacgccccctattgacgtcaatgacggtaaatggcccgcctggcattatgcccagtacatgaccttatgggactttcctacttggcagtacatctacgtattagtcatcgctattaccatggtcgaggtgagccccacgttctgcttcactctccccatctcccccccctccccacccccaattttgtatttatttattttttaattattttgtgcagcgatgggggcggggggggggggggggcgcgcgccaggcggggcggggcggggcgaggggcggggcggggcgaggcggagaggtgcggcggcagccaatcagagcggcgcgctccgaaagtttccttttatggcgaggcggcggcggcggcggccctataaaaagcgaagcgcgcggcgggcgggagtcgctgcgacgctgccttcgccccgtgccccgctccgccgccgcctcgcgccgcccgccccggctctgactgaccgcgttactcccacaggtgagcgggcgggacggcccttctcctccgggctgtaattagctgagcaagaggtaagggtttaagggatggttggttggtggggtattaatgtttaattacctggagcacctgcctgaaatcactttttttcaggttGGaccggtgccaccATGGACTATAAGGACCACGACGGAGACTACAAGGATCATGATATTGATTACAAAGACGATGACGATAAGATGGCCCCAAAGAAGAAGCGGAAGGTCGGTATCCACGGAGTCCCAGCAGCCGACAAGAAGTACAGCATCGGCCTGGACATCGGCACCAACTCTGTGGGCTGGGCCGTGATCACCGACGAGTACAAGGTGCCCAGCAAGAAATTCAAGGTGCTGGGCAACACCGACCGGCACAGCATCAAGAAGAACCTGATCGGAGCCCTGCTGTTCGACAGCGGCGAAACAGCCGAGGCCACCCGGCTGAAGAGAACCGCCAGAAGAAGATACACCAGACGGAAGAACCGGATCTGCTATCTGCAAGAGATCTTCAGCAACGAGATGGCCAAGGTGGACGACAGCTTCTTCCACAGACTGGAAGAGTCCTTCCTGGTGGAAGAGGATAAGAAGCACGAGCGGCACCCCATCTTCGGCAACATCGTGGACGAGGTGGCCTACCACGAGAAGTACCCCACCATCTACCACCTGAGAAAGAAACTGGTGGACAGCACCGACAAGGCCGACCTGCGGCTGATCTATCTGGCCCTGGCCCACATGATCAAGTTCCGGGGCCACTTCCTGATCGAGGGCGACCTGAACCCCGACAACAGCGACGTGGACAAGCTGTTCATCCAGCTGGTGCAGACCTACAACCAGCTGTTCGAGGAAAACCCCATCAACGCCAGCGGCGTGGACGCCAAGGCCATCCTGTCTGCCAGACTGAGCAAGAGCAGACGGCTGGAAAATCTGATCGCCCAGCTGCCCGGCGAGAAGAAGAATGGCCTGTTCGGCAACCTGATTGCCCTGAGCCTGGGCCTGACCCCCAACTTCAAGAGCAACTTCGACCTGGCCGAGGATGCCAAACTGCAGCTGAGCAAGGACACCTACGACGACGACCTGGACAACCTGCTGGCCCAGATCGGCGACCAGTACGCCGACCTGTTTCTGGCCGCCAAGAACCTGTCCGACGCCATCCTGCTGAGCGACATCCTGAGAGTGAACACCGAGATCACCAAGGCCCCCCTGAGCGCCTCTATGATCAAGAGATACGACGAGCACCACCAGGACCTGACCCTGCTGAAAGCTCTCGTGCGGCAGCAGCTGCCTGAGAAGTACAAAGAGATTTTCTTCGACCAGAGCAAGAACGGCTACGCCGGCTACATTGACGGCGGAGCCAGCCAGGAAGAGTTCTACAAGTTCATCAAGCCCATCCTGGAAAAGATGGACGGCACCGAGGAACTGCTCGTGAAGCTGAACAGAGAGGACCTGCTGCGGAAGCAGCGGACCTTCGACAACGGCAGCATCCCCCACCAGATCCACCTGGGAGAGCTGCACGCCATTCTGCGGCGGCAGGAAGATTTTTACCCATTCCTGAAGGACAACCGGGAAAAGATCGAGAAGATCCTGACCTTCCGCATCCCCTACTACGTGGGCCCTCTGGCCAGGGGAAACAGCAGATTCGCCTGGATGACCAGAAAGAGCGAGGAAACCATCACCCCCTGGAACTTCGAGGAAGTGGTGGACAAGGGCGCTTCCGCCCAGAGCTTCATCGAGCGGATGACCAACTTCGATAAGAACCTGCCCAACGAGAAGGTGCTGCCCAAGCACAGCCTGCTGTACGAGTACTTCACCGTGTATAACGAGCTGACCAAAGTGAAATACGTGACCGAGGGAATGAGAAAGCCCGCCTTCCTGAGCGGCGAGCAGAAAAAGGCCATCGTGGACCTGCTGTTCAAGACCAACCGGAAAGTGACCGTGAAGCAGCTGAAAGAGGACTACTTCAAGAAAATCGAGTGCTTCGACTCCGTGGAAATCTCCGGCGTGGAAGATCGGTTCAACGCCTCCCTGGGCACATACCACGATCTGCTGAAAATTATCAAGGACAAGGACTTCCTGGACAATGAGGAAAACGAGGACATTCTGGAAGATATCGTGCTGACCCTGACACTGTTTGAGGACAGAGAGATGATCGAGGAACGGCTGAAAACCTATGCCCACCTGTTCGACGACAAAGTGATGAAGCAGCTGAAGCGGCGGAGATACACCGGCTGGGGCAGGCTGAGCCGGAAGCTGATCAACGGCATCCGGGACAAGCAGTCCGGCAAGACAATCCTGGATTTCCTGAAGTCCGACGGCTTCGCCAACAGAAACTTCATGCAGCTGATCCACGACGACAGCCTGACCTTTAAAGAGGACATCCAGAAAGCCCAGGTGTCCGGCCAGGGCGATAGCCTGCACGAGCACATTGCCAATCTGGCCGGCAGCCCCGCCATTAAGAAGGGCATCCTGCAGACAGTGAAGGTGGTGGACGAGCTCGTGAAAGTGATGGGCCGGCACAAGCCCGAGAACATCGTGATCGAAATGGCCAGAGAGAACCAGACCACCCAGAAGGGACAGAAGAACAGCCGCGAGAGAATGAAGCGGATCGAAGAGGGCATCAAAGAGCTGGGCAGCCAGATCCTGAAAGAACACCCCGTGGAAAACACCCAGCTGCAGAACGAGAAGCTGTACCTGTACTACCTGCAGAATGGGCGGGATATGTACGTGGACCAGGAACTGGACATCAACCGGCTGTCCGACTACGATGTGGACCATATCGTGCCTCAGAGCTTTCTGAAGGACGACTCCATCGACAACAAGGTGCTGACCAGAAGCGACAAGAACCGGGGCAAGAGCGACAACGTGCCCTCCGAAGAGGTCGTGAAGAAGATGAAGAACTACTGGCGGCAGCTGCTGAACGCCAAGCTGATTACCCAGAGAAAGTTCGACAATCTGACCAAGGCCGAGAGAGGCGGCCTGAGCGAACTGGATAAGGCCGGCTTCATCAAGAGACAGCTGGTGGAAACCCGGCAGATCACAAAGCACGTGGCACAGATCCTGGACTCCCGGATGAACACTAAGTACGACGAGAATGACAAGCTGATCCGGGAAGTGAAAGTGATCACCCTGAAGTCCAAGCTGGTGTCCGATTTCCGGAAGGATTTCCAGTTTTACAAAGTGCGCGAGATCAACAACTACCACCACGCCCACGACGCCTACCTGAACGCCGTCGTGGGAACCGCCCTGATCAAAAAGTACCCTAAGCTGGAAAGCGAGTTCGTGTACGGCGACTACAAGGTGTACGACGTGCGGAAGATGATCGCCAAGAGCGAGCAGGAAATCGGCAAGGCTACCGCCAAGTACTTCTTCTACAGCAACATCATGAACTTTTTCAAGACCGAGATTACCCTGGCCAACGGCGAGATCCGGAAGCGGCCTCTGATCGAGACAAACGGCGAAACCGGGGAGATCGTGTGGGATAAGGGCCGGGATTTTGCCACCGTGCGGAAAGTGCTGAGCATGCCCCAAGTGAATATCGTGAAAAAGACCGAGGTGCAGACAGGCGGCTTCAGCAAAGAGTCTATCCTGCCCAAGAGGAACAGCGATAAGCTGATCGCCAGAAAGAAGGACTGGGACCCTAAGAAGTACGGCGGCTTCGACAGCCCCACCGTGGCCTATTCTGTGCTGGTGGTGGCCAAAGTGGAAAAGGGCAAGTCCAAGAAACTGAAGAGTGTGAAAGAGCTGCTGGGGATCACCATCATGGAAAGAAGCAGCTTCGAGAAGAATCCCATCGACTTTCTGGAAGCCAAGGGCTACAAAGAAGTGAAAAAGGACCTGATCATCAAGCTGCCTAAGTACTCCCTGTTCGAGCTGGAAAACGGCCGGAAGAGAATGCTGGCCTCTGCCGGCGAACTGCAGAAGGGAAACGAACTGGCCCTGCCCTCCAAATATGTGAACTTCCTGTACCTGGCCAGCCACTATGAGAAGCTGAAGGGCTCCCCCGAGGATAATGAGCAGAAACAGCTGTTTGTGGAACAGCACAAGCACTACCTGGACGAGATCATCGAGCAGATCAGCGAGTTCTCCAAGAGAGTGATCCTGGCCGACGCTAATCTGGACAAAGTGCTGTCCGCCTACAACAAGCACCGGGATAAGCCCATCAGAGAGCAGGCCGAGAATATCATCCACCTGTTTACCCTGACCAATCTGGGAGCCCCTGCCGCCTTCAAGTACTTTGACACCACCATCGACCGGAAGAGGTACACCAGCACCAAAGAGGTGCTGGACGCCACCCTGATCCACCAGAGCATCACCGGCCTGTACGAGACACGGATCGACCTGTCTCAGCTGGGAGGCGACTTTCTTTTTCTTAGCTTGACCAGCTTTCTTAGTAGCAGCAGGACGCTTTAA
(NLS-hSpCas9-NLS выделена жирным шрифтом)
> Ампликон секвенирования для гидов EMX1 1.1, 1.14, 1.17
CCAATGGGGAGGACATCGATGTCACCTCCAATGACTAGGGTGGGCAACCACAAACCCACGAGGGCAGAGTGCTGCTTGCTGCTGGCCAGGCCCCTGCGTGGGCCCAAGCTGGACTCTGGCCAC
> Ампликон секвенирования для гидов EMX1 1.2, 1.16
CGAGCAGAAGAAGAAGGGCTCCCATCACATCAACCGGTGGCGCATTGCCACGAAGCAGGCCAATGGGGAGGACATCGATGTCACCTCCAATGACTAGGGTGGGCAACCACAAACCCACGAG
> Ампликон секвенирования для гидов EMX1 1.3, 1.13, 1.15
GGAGGACAAAGTACAAACGGCAGAAGCTGGAGGAGGAAGGGCCTGAGTCCGAGCAGAAGAAGAAGGGCTCCCATCACATCAACCGGTGGCGCATTGCCACGAAGCAGGCCAATGGGGAGGACATCGAT
> Ампликон секвенирования для гидов EMX1 1.6
AGAAGCTGGAGGAGGAAGGGCCTGAGTCCGAGCAGAAGAAGAAGGGCTCCCATCACATCAACCGGTGGCGCATTGCCACGAAGCAGGCCAATGGGGAGGACATCGATGTCACCTCCAATGACTAGGGTGG
> Ампликон секвенирования для гидов EMX1 1.10
CCTCAGTCTTCCCATCAGGCTCTCAGCTCAGCCTGAGTGTTGAGGCCCCAGTGGCTGCTCTGGGGGCCTCCTGAGTTTCTCATCTGTGCCCCTCCCTCCCTGGCCCAGGTGAAGGTGTGGTTCCA
> Ампликон секвенирования для гидов EMX1 1.11, 1.12
TCATCTGTGCCCCTCCCTCCCTGGCCCAGGTGAAGGTGTGGTTCCAGAACCGGAGGACAAAGTACAAACGGCAGAAGCTGGAGGAGGAAGGGCCTGAGTCCGAGCAGAAGAAGAAGGGCTCCCATCACA
> Ампликон секвенирования для гидов EMX1 1.18, 1.19
CTCCAATGACTAGGGTGGGCAACCACAAACCCACGAGGGCAGAGTGCTGCTTGCTGCTGGCCAGGCCCCTGCGTGGGCCCAAGCTGGACTCTGGCCACTCCCTGGCCAGGCTTTGGGGAGGCCTGGAGT
> Ампликон секвенирования для гидов EMX1 1.20
CTGCTTGCTGCTGGCCAGGCCCCTGCGTGGGCCCAAGCTGGACTCTGGCCACTCCCTGGCCAGGCTTTGGGGAGGCCTGGAGTCATGGCCCCACAGGGCTTGAAGCCCGGGGCCGCCATTGACAGAG
> Промотор T7 праймера F для отжига с целевой нитью
gaaatTAATACGACTCACTATAGGG
>Олигонуклеотид, содержащий целевой сайт 1 pUC19 для метилирования (обратный T7)
aaaaaagcaccgactcggtgccactttttcaagttgataacggactagccttattttaacttgctatttctagctctaaaacaacgacgagcgtgacaccaccctatagtgagtcgtattaatttc
>Олигонуклеотид, содержащий целевой сайт 2 pUC19 для метилирования (обратный T7)
aaaaaagcaccgactcggtgccactttttcaagttgataacggactagccttattttaacttgctatttctagctctaaaacgcaacaattaatagactggacctatagtgagtcgtattaatttc
Пример 11: опосредованная олигонуклеотидами Cas9-индуцированная гомологичная рекомбинация
Тест олигонуклеотидной гомологичной рекомбинации представляет собой сравнение эффективности всех различных вариантов Cas9 и различных матриц HR (олигонуклеотид по сравнению с плазмидой).
Использовали клетки 293FT. SpCas9 = Cas9 дикого типа и SpCas9n = никаза Cas9 (D10A). Мишень химерной РНК представляет собой такую же протоспейсер-мишень 1 EMX1, как в примерах 5, 9 и 10, и олигонуклеотиды синтезированы с помощью IDT с применением очистки PAGE.
На фигуре 44 изображена структура олигонуклеотидной ДНК, использованной как матрица гомологичной рекомбинации (HR) в этом эксперименте. Длинные олигонуклеотиды содержат гомологичность 100 п.о. к локусу EMX1 и сайт рестрикции HindIII. Клетки 293FT котрансфицировали: во-первых, плазмидой, содержащей целевой локус EMX1 человека, химерную РНК и белок cas9 дикого типа, и, во-вторых, олигонуклеотидной ДНК в качестве матрицы HR. Образцы получены из клеток 293FT, собранных через 96 часов после трансфекции Lipofectamine 2000. Все продукты амплифицировали с праймером EMX1 HR Primer, очищали на геле с последующим расщеплением HindIII для выявления эффективности интеграции матрицы HR в геном человека.
На фигурах 45 и 46 изображено сравнение эффективности HR, индуцированной с помощью разных комбинаций белка Cas9 и матрицы HR. Использованной конструкцией Cas9 были или Cas9 дикого типа, или вариант никазы Cas9 (Cas9n). Использованной матрицей HR были: антисмысловая олигонуклеотидная ДНК (антисмысловой олигонуклеотид на фигуре выше), или смысловая олигонуклеотидная ДНК (смысловой олигонуклеотид на фигуре выше), или матрица HR плазмиды (матрица HR на фигуре выше). Определение "смысловая/антисмысловая" означает, что активно транскрибируемая нить с последовательностью, соответствующей транскрибированной мРНК, определяется как смысловая нить в геноме. Эффективность HR показана как процентная доля группы расщепления HindIII от всего амплифицированного с помощью ПЦР продукта генома (числа внизу).
Пример 12: мышь-аутист
Недавние широкомасштабные проекты по секвенированию представили большое количество генов, ассоциированных с заболеваниями. Выявление генов является только началом понимания, что делает ген и как это приводит к фенотипу заболеваний. Существующие технологии и подходы для изучения генов-кандидатов медленные и трудоемкие. Золотые стандарты, целенаправленное воздействие на ген и генные нокауты, требуют значительных инвестиций времени и ресурсов, как денежных, так и относительно исследовательского персонала. Заявители поставили задачу использовать нуклеазу hSpCas9 для целенаправленного воздействия на многие гены и сделать это с более высокой эффективностью и более низкой оборотностью по сравнению с любой другой технологией. По причине высокой эффективности hSpCas9 заявители могут производить инъекцию РНК в зиготы мышей и сразу же получать животных с модифицированным геномом без потребности в производстве каких-либо предварительных генов, целенаправленно воздействующих в mESC.
Ген хромодомен хеликазы ДНК-связывающего белка 8 (CHD8) является важнейшим геном, вовлеченным в раннее развитие позвоночных и морфогенез. Мыши без CHD8 умирают в ходе эмбрионального развития. Мутации в CHD8 ассоциировали с расстройством аутического спектра у людей. Эту ассоциацию проводили в трех разных статьях, опубликованных одновременно в Nature. В тех же трех исследованиях идентифицировали множество генов, ассоциированных с расстройством аутического спектра. Целью заявителей было создание нокаутных мышей по четырем генам, которые были обнаружены во всех статьях, Chd8, Katnal2, Kctd13 и Scn2a. К тому же заявители выбрали два других гена, ассоциированных с расстройством аутического спектра, шизофренией и ADHD, GIT1, CACNA1C и CACNB2. И наконец, в качестве положительного контроля заявители решили задать MeCP2.
Для каждого гена заявители разрабатывали три gRNA, которые, вероятно, нокаутировали бы гены. Нокаутирование происходило бы после того, как нуклеаза hSpCas9 произведет двухцепочечный разрыв, и подверженный ошибкам путь репарации ДНК, негомологичное соединение концов, устранит разрыв, создавая мутацию. Наиболее вероятным результатом является мутация со сдвигом рамки считывания, которая произвела бы нокаут гена. Стратегия целенаправленного воздействия включала нахождение протоспейсеров в экзонах гена, содержащего последовательность PAM, NGG, являющегося уникальным в геноме. Предпочтение отдавали протоспейсерам в первом экзоне, которые были бы наиболее разрушительными для гена.
Каждую gRNA оценивали в клеточной линии мыши, Neuro-N2a, с помощью липосомальной неустойчивой котрансфекции hSpCas9. Через 72 часа после трансфекции геномную ДНК очищали с применением QuickExtract DNA от Epicentre. ПЦР выполняли для амплификации локуса, представляющего интерес. Затем следовало использование набора для обнаружения мутаций SURVEYOR от Transgenomics. Результаты анализа с помощью SURVEYOR для каждой gRNA и соответствующие контроли показаны на фигуре A1. Положительный результат анализа с помощью SURVEYOR представляет собой одну большую полосу, соответствующую геномной ПЦР, и две полосы поменьше, которые являются продуктами нуклеазы SURVEYOR, производящей двухцепочечный разрыв в сайте мутации. Среднюю эффективность разрезания каждой gRNA также определяли для каждой gRNA. gRNA, которую выбирали для инъекции, представляла собой gRNA наивысшей эффективности, которая была наиболее уникальной в геноме.
РНК (hSpCas9+gRNA РНК) инъецировали в пронуклеус зиготы и позже пересаживали приемной матери. Матерей позволяли проходить полный срок беременности, а у детенышей отбирали пробы путем надреза хвоста через 10 дней после рождения. ДНК выделяли и использовали как матрицу для ПЦР, которую затем подвергали процессингу с помощью SURVEYOR. Кроме того, ПЦР-продукты отправляли на секвенирование. ПЦР-продукты генома животных, которых определяли как положительные либо при анализе с помощью SURVEYOR, либо при ПЦР секвенировании, клонировали в вектор pUC19 и секвенировали для определения предполагаемых мутаций каждого аллеля.
На сегодняшний день детенышей мышей из эксперимента целенаправленного воздействия Chd8 полностью подвергали обработке, до самого секвенирования аллеля. Результаты анализа с помощью Surveyor для 38 живых детенышей (дорожки 1-38), 1 мертвого детеныша (дорожка 39) и 1 детеныша дикого типа для сравнения (дорожка 40) показаны на фигуре A2. Детенышам 1-19 инъецировали gRNA Chd8.2, а детенышам 20-38 инъецировали gRNA Chd8.3. Из 38 живых детенышей 13 были положительными по мутации. У одного мертвого детеныша также была мутация. В образце дикого типа не было обнаружено мутации. ПЦР секвенирование генома соответствовало данным анализа с помощью SURVEYOR.
Пример 13: опосредованная CRISPR/Cas модуляция транскрипции
На фигуре 67 изображенa структура CRISPR-TF (транскрипционного фактора), обладающего функцией активации транскрипции. Химерная РНК экспрессируется с помощью промотора U6, a кодон-оптимизированный для человека вариант двойного мутанта белка Cas9 (hSpCas9m), функционально связанного с трехкомпонентной NLS и функциональным доменом VP64, экспрессируется с помощью промотора EF1a. Двойные мутации, D10A и H840A, делают белок Cas9 неспособным вносить какое-либо расщепление, но поддерживают его способность связываться с целевой ДНК при направлении химерной РНК.
На фигуре 68 изображена активация транскрипции гена SOX2 человека с помощью системы CRISPR-TF (химерная РНК и слитый белок Cas9-NLS-VP64). Клетки 293FT трансфицировали плазмидами, несущей два компонента: (1) управляемые U6 различные химерные РНК, целенаправленно воздействующие на последовательности из 20 п.о. в локусе генома человека SOX2 или рядом с ним, и (2) управляемый EF1 hSpCas9m (двойной мутант)-слитый белок NLS-VP64. Через 96 часа после трансфекции клетки 293FT собирали и измеряли уровень активации посредством индукции экспрессии мРНК с применением анализа qRT-PCR. Все уровни экспрессии нормированы по сравнению с контрольной группой (серый столбец), представляющей результаты клеток, трансфицированных плазмидой с остовом CRISPR-TF без химерной РНК. Зонды qRT-PCR использовали для выявления мРНК SOX2 при анализе экспрессии генов Taqman Human (Life Technologies). Представлены данные всех экспериментов 3 биологических повторностей, n=3, планки погрешностей показывают стандартную ошибку среднего.
Пример 14: NLS: Cas9-NLS
Клетки 293FT трансфицировали плазмидой, содержащей два компонента: (1) промотор EF1, управляющий экспрессией Cas9 (Sp Cas9 дикого типа, кодон-оптимизированный для человека) с различными структурами NLS, (2) промотор U6, управляющий тем же локусом EMX1 человека, подвергающимся целенаправленному воздействию химерной РНК.
Клетки собирали в момент времени 72 часа после трансфекции и затем экстрагировали 50 мкл раствора для экстракции геномной ДНК QuickExtract, следуя протоколу производителя. Целевую геномную ДНК EMX1 амплифицировали с помощью ПЦР и затем очищали в геле с 1% агарозного геля. Геномный ПЦР-продукт вторично отжигали и подвергали анализу с помощью SURVEYOR, следуя протоколу производителя. Эффективность расщепления различных конструкций генома измеряли с применением SDS-PAGE в 4-12% геле TBE-PAGE (Life Technologies), анализировали и количественно определяли с использованием программного обеспечения ImageLab (Bio-rad), следуя протоколу производителя.
На фигуре 69 изображена структура различных конструкций Cas9-NLS. Все Cas9 представляли собой кодон-оптимизированный для человека вариант Sp Cas9. Последовательности NLS связаны с геном cas9 либо на N-конце, либо на С-конце. Все варианты Cas9 с различными структурами NLS клонировали в вектор, содержащий остов, так что он управлялся промотором EF1a. В этом же векторе находилась химерная РНК, целенаправленно воздействующая на локус EMX1 человека, управляемый промотором U6, формирующим вместе с ней двухкомпонентную систему.
Таблица M. Результаты исследования структуры Cas9-NLS. Количественный анализ геномного расщепления различных конструкций cas9-nls посредством анализа с помощью Surveyor.
(%)
На фигуре 70 изображена эффективность геномного расщепления, индуцированного вариантами Cas9, несущими разные структуры NLS. Процентная доля указывает часть геномной ДНК EMX1 человека, которая подвергалась расщеплению каждой конструкцией. Все эксперименты получены из 3 биологических повторностей. n = 3, ошибка означает S.E.M.
Пример 15: конструирование микроводорослей с использованием Cas9
Способы доставки Cas9
Способ 1: заявители доставляли Cas9 и направляющую РНК с использованием вектора, который экспрессирует Cas9 под контролем конститутивного промотора, такого как промотор Hsp70A-Rbc S2 или бета-2-тубулиновый промотор.
Способ 2: заявители доставляли Cas9 и полимеразу T7 с использованием векторов, которые экспрессируют Cas9 и полимеразу T7 под контролем конститутивного промотора, такого как промотор Hsp70A-Rbc S2 или бета-2-тубулиновый промотор. Направляющая РНК будет доставляться с использованием вектора, содержащего промотор T7, управляющий экспрессией направляющей РНК.
Способ 3: заявители доставляли мРНК Cas9 и in vitro транскрибировали направляющую РНК в клетках водорослей. РНК можно транскрибировать in vitro. мРНК Cas9 будет состоять из кодирующего участка для Cas9, а также 3’UTR из Cop1, чтобы обеспечивать стабилизацию мРНК Cas9.
Для гомологичной рекомбинации заявители обеспечивали дополнительную матрицу для репарации с участием гомологичной рекомбинации.
Последовательность для кассеты, управляющей экспрессией Cas9 под контролем бета-2-тубулинового промотора, за которой следует 3’ UTR Cop1.
TCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACATGTACCCATACGATGTTCCAGATTACGCTTCGCCGAAGAAAAAGCGCAAGGTCGAAGCGTCCGACAAGAAGTACAGCATCGGCCTGGACATCGGCACCAACTCTGTGGGCTGGGCCGTGATCACCGACGAGTACAAGGTGCCCAGCAAGAAATTCAAGGTGCTGGGCAACACCGACCGGCACAGCATCAAGAAGAACCTGATCGGAGCCCTGCTGTTCGACAGCGGCGAAACAGCCGAGGCCACCCGGCTGAAGAGAACCGCCAGAAGAAGATACACCAGACGGAAGAACCGGATCTGCTATCTGCAAGAGATCTTCAGCAACGAGATGGCCAAGGTGGACGACAGCTTCTTCCACAGACTGGAAGAGTCCTTCCTGGTGGAAGAGGATAAGAAGCACGAGCGGCACCCCATCTTCGGCAACATCGTGGACGAGGTGGCCTACCACGAGAAGTACCCCACCATCTACCACCTGAGAAAGAAACTGGTGGACAGCACCGACAAGGCCGACCTGCGGCTGATCTATCTGGCCCTGGCCCACATGATCAAGTTCCGGGGCCACTTCCTGATCGAGGGCGACCTGAACCCCGACAACAGCGACGTGGACAAGCTGTTCATCCAGCTGGTGCAGACCTACAACCAGCTGTTCGAGGAAAACCCCATCAACGCCAGCGGCGTGGACGCCAAGGCCATCCTGTCTGCCAGACTGAGCAAGAGCAGACGGCTGGAAAATCTGATCGCCCAGCTGCCCGGCGAGAAGAAGAATGGCCTGTTCGGCAACCTGATTGCCCTGAGCCTGGGCCTGACCCCCAACTTCAAGAGCAACTTCGACCTGGCCGAGGATGCCAAACTGCAGCTGAGCAAGGACACCTACGACGACGACCTGGACAACCTGCTGGCCCAGATCGGCGACCAGTACGCCGACCTGTTTCTGGCCGCCAAGAACCTGTCCGACGCCATCCTGCTGAGCGACATCCTGAGAGTGAACACCGAGATCACCAAGGCCCCCCTGAGCGCCTCTATGATCAAGAGATACGACGAGCACCACCAGGACCTGACCCTGCTGAAAGCTCTCGTGCGGCAGCAGCTGCCTGAGAAGTACAAAGAGATTTTCTTCGACCAGAGCAAGAACGGCTACGCCGGCTACATTGACGGCGGAGCCAGCCAGGAAGAGTTCTACAAGTTCATCAAGCCCATCCTGGAAAAGATGGACGGCACCGAGGAACTGCTCGTGAAGCTGAACAGAGAGGACCTGCTGCGGAAGCAGCGGACCTTCGACAACGGCAGCATCCCCCACCAGATCCACCTGGGAGAGCTGCACGCCATTCTGCGGCGGCAGGAAGATTTTTACCCATTCCTGAAGGACAACCGGGAAAAGATCGAGAAGATCCTGACCTTCCGCATCCCCTACTACGTGGGCCCTCTGGCCAGGGGAAACAGCAGATTCGCCTGGATGACCAGAAAGAGCGAGGAAACCATCACCCCCTGGAACTTCGAGGAAGTGGTGGACAAGGGCGCTTCCGCCCAGAGCTTCATCGAGCGGATGACCAACTTCGATAAGAACCTGCCCAACGAGAAGGTGCTGCCCAAGCACAGCCTGCTGTACGAGTACTTCACCGTGTATAACGAGCTGACCAAAGTGAAATACGTGACCGAGGGAATGAGAAAGCCCGCCTTCCTGAGCGGCGAGCAGAAAAAGGCCATCGTGGACCTGCTGTTCAAGACCAACCGGAAAGTGACCGTGAAGCAGCTGAAAGAGGACTACTTCAAGAAAATCGAGTGCTTCGACTCCGTGGAAATCTCCGGCGTGGAAGATCGGTTCAACGCCTCCCTGGGCACATACCACGATCTGCTGAAAATTATCAAGGACAAGGACTTCCTGGACAATGAGGAAAACGAGGACATTCTGGAAGATATCGTGCTGACCCTGACACTGTTTGAGGACAGAGAGATGATCGAGGAACGGCTGAAAACCTATGCCCACCTGTTCGACGACAAAGTGATGAAGCAGCTGAAGCGGCGGAGATACACCGGCTGGGGCAGGCTGAGCCGGAAGCTGATCAACGGCATCCGGGACAAGCAGTCCGGCAAGACAATCCTGGATTTCCTGAAGTCCGACGGCTTCGCCAACAGAAACTTCATGCAGCTGATCCACGACGACAGCCTGACCTTTAAAGAGGACATCCAGAAAGCCCAGGTGTCCGGCCAGGGCGATAGCCTGCACGAGCACATTGCCAATCTGGCCGGCAGCCCCGCCATTAAGAAGGGCATCCTGCAGACAGTGAAGGTGGTGGACGAGCTCGTGAAAGTGATGGGCCGGCACAAGCCCGAGAACATCGTGATCGAAATGGCCAGAGAGAACCAGACCACCCAGAAGGGACAGAAGAACAGCCGCGAGAGAATGAAGCGGATCGAAGAGGGCATCAAAGAGCTGGGCAGCCAGATCCTGAAAGAACACCCCGTGGAAAACACCCAGCTGCAGAACGAGAAGCTGTACCTGTACTACCTGCAGAATGGGCGGGATATGTACGTGGACCAGGAACTGGACATCAACCGGCTGTCCGACTACGATGTGGACCATATCGTGCCTCAGAGCTTTCTGAAGGACGACTCCATCGACAACAAGGTGCTGACCAGAAGCGACAAGAACCGGGGCAAGAGCGACAACGTGCCCTCCGAAGAGGTCGTGAAGAAGATGAAGAACTACTGGCGGCAGCTGCTGAACGCCAAGCTGATTACCCAGAGAAAGTTCGACAATCTGACCAAGGCCGAGAGAGGCGGCCTGAGCGAACTGGATAAGGCCGGCTTCATCAAGAGACAGCTGGTGGAAACCCGGCAGATCACAAAGCACGTGGCACAGATCCTGGACTCCCGGATGAACACTAAGTACGACGAGAATGACAAGCTGATCCGGGAAGTGAAAGTGATCACCCTGAAGTCCAAGCTGGTGTCCGATTTCCGGAAGGATTTCCAGTTTTACAAAGTGCGCGAGATCAACAACTACCACCACGCCCACGACGCCTACCTGAACGCCGTCGTGGGAACCGCCCTGATCAAAAAGTACCCTAAGCTGGAAAGCGAGTTCGTGTACGGCGACTACAAGGTGTACGACGTGCGGAAGATGATCGCCAAGAGCGAGCAGGAAATCGGCAAGGCTACCGCCAAGTACTTCTTCTACAGCAACATCATGAACTTTTTCAAGACCGAGATTACCCTGGCCAACGGCGAGATCCGGAAGCGGCCTCTGATCGAGACAAACGGCGAAACCGGGGAGATCGTGTGGGATAAGGGCCGGGATTTTGCCACCGTGCGGAAAGTGCTGAGCATGCCCCAAGTGAATATCGTGAAAAAGACCGAGGTGCAGACAGGCGGCTTCAGCAAAGAGTCTATCCTGCCCAAGAGGAACAGCGATAAGCTGATCGCCAGAAAGAAGGACTGGGACCCTAAGAAGTACGGCGGCTTCGACAGCCCCACCGTGGCCTATTCTGTGCTGGTGGTGGCCAAAGTGGAAAAGGGCAAGTCCAAGAAACTGAAGAGTGTGAAAGAGCTGCTGGGGATCACCATCATGGAAAGAAGCAGCTTCGAGAAGAATCCCATCGACTTTCTGGAAGCCAAGGGCTACAAAGAAGTGAAAAAGGACCTGATCATCAAGCTGCCTAAGTACTCCCTGTTCGAGCTGGAAAACGGCCGGAAGAGAATGCTGGCCTCTGCCGGCGAACTGCAGAAGGGAAACGAACTGGCCCTGCCCTCCAAATATGTGAACTTCCTGTACCTGGCCAGCCACTATGAGAAGCTGAAGGGCTCCCCCGAGGATAATGAGCAGAAACAGCTGTTTGTGGAACAGCACAAGCACTACCTGGACGAGATCATCGAGCAGATCAGCGAGTTCTCCAAGAGAGTGATCCTGGCCGACGCTAATCTGGACAAAGTGCTGTCCGCCTACAACAAGCACCGGGATAAGCCCATCAGAGAGCAGGCCGAGAATATCATCCACCTGTTTACCCTGACCAATCTGGGAGCCCCTGCCGCCTTCAAGTACTTTGACACCACCATCGACCGGAAGAGGTACACCAGCACCAAAGAGGTGCTGGACGCCACCCTGATCCACCAGAGCATCACCGGCCTGTACGAGACACGGATCGACCTGTCTCAGCTGGGAGGCGACAGCCCCAAGAAGAAGAGAAAGGTGGAGGCCAGCTAAGGATCCGGCAAGACTGGCCCCGCTTGGCAACGCAACAGTGAGCCCCTCCCTAGTGTGTTTGGGGATGTGACTATGTATTCGTGTGTTGGCCAACGGGTCAACCCGAACAGATTGATACCCGCCTTGGCATTTCCTGTCAGAATGTAACGTCAGTTGATGGTACT
Последовательность для кассеты, управляющей экспрессией полимеразы T7 под контролем бета-2-тубулинового промотора, за которой следует 3’ UTR Cop1:
TCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACatgcctaagaagaagaggaaggttaacacgattaacatcgctaagaacgacttctctgacatcgaactggctgctatcccgttcaacactctggctgaccattacggtgagcgtttagctcgcgaacagttggcccttgagcatgagtcttacgagatgggtgaagcacgcttccgcaagatgtttgagcgtcaacttaaagctggtgaggttgcggataacgctgccgccaagcctctcatcactaccctactccctaagatgattgcacgcatcaacgactggtttgaggaagtgaaagctaagcgcggcaagcgcccgacagccttccagttcctgcaagaaatcaagccggaagccgtagcgtacatcaccattaagaccactctggcttgcctaaccagtgctgacaatacaaccgttcaggctgtagcaagcgcaatcggtcgggccattgaggacgaggctcgcttcggtcgtatccgtgaccttgaagctaagcacttcaagaaaaacgttgaggaacaactcaacaagcgcgtagggcacgtctacaagaaagcatttatgcaagttgtcgaggctgacatgctctctaagggtctactcggtggcgaggcgtggtcttcgtggcataaggaagactctattcatgtaggagtacgctgcatcgagatgctcattgagtcaaccggaatggttagcttacaccgccaaaatgctggcgtagtaggtcaagactctgagactatcgaactcgcacctgaatacgctgaggctatcgcaacccgtgcaggtgcgctggctggcatctctccgatgttccaaccttgcgtagttcctcctaagccgtggactggcattactggtggtggctattgggctaacggtcgtcgtcctctggcgctggtgcgtactcacagtaagaaagcactgatgcgctacgaagacgtttacatgcctgaggtgtacaaagcgattaacattgcgcaaaacaccgcatggaaaatcaacaagaaagtcctagcggtcgccaacgtaatcaccaagtggaagcattgtccggtcgaggacatccctgcgattgagcgtgaagaactcccgatgaaaccggaagacatcgacatgaatcctgaggctctcaccgcgtggaaacgtgctgccgctgctgtgtaccgcaaggacaaggctcgcaagtctcgccgtatcagccttgagttcatgcttgagcaagccaataagtttgctaaccataaggccatctggttcccttacaacatggactggcgcggtcgtgtttacgctgtgtcaatgttcaacccgcaaggtaacgatatgaccaaaggactgcttacgctggcgaaaggtaaaccaatcggtaaggaaggttactactggctgaaaatccacggtgcaaactgtgcgggtgtcgacaaggttccgttccctgagcgcatcaagttcattgaggaaaaccacgagaacatcatggcttgcgctaagtctccactggagaacacttggtgggctgagcaagattctccgttctgcttccttgcgttctgctttgagtacgctggggtacagcaccacggcctgagctataactgctcccttccgctggcgtttgacgggtcttgctctggcatccagcacttctccgcgatgctccgagatgaggtaggtggtcgcgcggttaacttgcttcctagtgaaaccgttcaggacatctacgggattgttgctaagaaagtcaacgagattctacaagcagacgcaatcaatgggaccgataacgaagtagttaccgtgaccgatgagaacactggtgaaatctctgagaaagtcaagctgggcactaaggcactggctggtcaatggctggcttacggtgttactcgcagtgtgactaagcgttcagtcatgacgctggcttacgggtccaaagagttcggcttccgtcaacaagtgctggaagataccattcagccagctattgattccggcaagggtctgatgttcactcagccgaatcaggctgctggatacatggctaagctgatttgggaatctgtgagcgtgacggtggtagctgcggttgaagcaatgaactggcttaagtctgctgctaagctgctggctgctgaggtcaaagataagaagactggagagattcttcgcaagcgttgcgctgtgcattgggtaactcctgatggtttccctgtgtggcaggaatacaagaagcctattcagacgcgcttgaacctgatgttcctcggtcagttccgcttacagcctaccattaacaccaacaaagatagcgagattgatgcacacaaacaggagtctggtatcgctcctaactttgtacacagccaagacggtagccaccttcgtaagactgtagtgtgggcacacgagaagtacggaatcgaatcttttgcactgattcacgactccttcggtacgattccggctgacgctgcgaacctgttcaaagcagtgcgcgaaactatggttgacacatatgagtcttgtgatgtactggctgatttctacgaccagttcgctgaccagttgcacgagtctcaattggacaaaatgccagcacttccggctaaaggtaacttgaacctccgtgacatcttagagtcggacttcgcgttcgcgtaaGGATCCGGCAAGACTGGCCCCGCTTGGCAACGCAACAGTGAGCCCCTCCCTAGTGTGTTTGGGGATGTGACTATGTATTCGTGTGTTGGCCAACGGGTCAACCCGAACAGATTGATACCCGCCTTGGCATTTCCTGTCAGAATGTAACGTCAGTTGATGGTACT
Последовательность направляющей РНК, управляемая промотором T7 (промотор T7, N представляют нацеливающую последовательность):
gaaatTAATACGACTCACTATANNNNNNNNNNNNNNNNNNNNgttttagagctaGAAAtagcaagttaaaataaggctagtccgttatcaacttgaaaaagtggcaccgagtcggtgcttttttt
Доставка генов
Штаммы CC-124 и CC-125 Chlamydomonas reinhardtii из Ресурсного центра Chlamydomonas (Chlamydomonas Resource Center) будут использоваться для электропорации. Протокол электропорации соответствует стандартному рекомендованному протоколу для набора GeneArt Chlamydomonas Engineering kit.
Заявители также получали линию Chlamydomonas reinhardtii, которая экспрессирует Cas9 конститутивно. Это можно выполнить при помощи pChlamy1 (линеаризованная с использованием PvuI) и отбора в отношении устойчивых к гигромицину колоний. Последовательность для pChlamy1, содержащая Cas9, приведена ниже. В данном пути для достижения нокаутирования гена необходимо просто доставить РНК для направляющей РНК. Для гомологичной рекомбинации заявители доставляли направляющую РНК, а также линеаризованную матрицу для гомологичной рекомбинации.
pChlamy1-Cas9:
TGCGGTATTTCACACCGCATCAGGTGGCACTTTTCGGGGAAATGTGCGCGGAACCCCTATTTGTTTATTTTTCTAAATACATTCAAATATGTATCCGCTCATGAGATTATCAAAAAGGATCTTCACCTAGATCCTTTTAAATTAAAAATGAAGTTTTAAATCAATCTAAAGTATATATGAGTAAACTTGGTCTGACAGTTACCAATGCTTAATCAGTGAGGCACCTATCTCAGCGATCTGTCTATTTCGTTCATCCATAGTTGCCTGACTCCCCGTCGTGTAGATAACTACGATACGGGAGGGCTTACCATCTGGCCCCAGTGCTGCAATGATACCGCGAGACCCACGCTCACCGGCTCCAGATTTATCAGCAATAAACCAGCCAGCCGGAAGGGCCGAGCGCAGAAGTGGTCCTGCAACTTTATCCGCCTCCATCCAGTCTATTAATTGTTGCCGGGAAGCTAGAGTAAGTAGTTCGCCAGTTAATAGTTTGCGCAACGTTGTTGCCATTGCTACAGGCATCGTGGTGTCACGCTCGTCGTTTGGTATGGCTTCATTCAGCTCCGGTTCCCAACGATCAAGGCGAGTTACATGATCCCCCATGTTGTGCAAAAAAGCGGTTAGCTCCTTCGGTCCTCCGATCGTTGTCAGAAGTAAGTTGGCCGCAGTGTTATCACTCATGGTTATGGCAGCACTGCATAATTCTCTTACTGTCATGCCATCCGTAAGATGCTTTTCTGTGACTGGTGAGTACTCAACCAAGTCATTCTGAGAATAGTGTATGCGGCGACCGAGTTGCTCTTGCCCGGCGTCAATACGGGATAATACCGCGCCACATAGCAGAACTTTAAAAGTGCTCATCATTGGAAAACGTTCTTCGGGGCGAAAACTCTCAAGGATCTTACCGCTGTTGAGATCCAGTTCGATGTAACCCACTCGTGCACCCAACTGATCTTCAGCATCTTTTACTTTCACCAGCGTTTCTGGGTGAGCAAAAACAGGAAGGCAAAATGCCGCAAAAAAGGGAATAAGGGCGACACGGAAATGTTGAATACTCATACTCTTCCTTTTTCAATATTATTGAAGCATTTATCAGGGTTATTGTCTCATGACCAAAATCCCTTAACGTGAGTTTTCGTTCCACTGAGCGTCAGACCCCGTAGAAAAGATCAAAGGATCTTCTTGAGATCCTTTTTTTCTGCGCGTAATCTGCTGCTTGCAAACAAAAAAACCACCGCTACCAGCGGTGGTTTGTTTGCCGGATCAAGAGCTACCAACTCTTTTTCCGAAGGTAACTGGCTTCAGCAGAGCGCAGATACCAAATACTGTTCTTCTAGTGTAGCCGTAGTTAGGCCACCACTTCAAGAACTCTGTAGCACCGCCTACATACCTCGCTCTGCTAATCCTGTTACCAGTGGCTGTTGCCAGTGGCGATAAGTCGTGTCTTACCGGGTTGGACTCAAGACGATAGTTACCGGATAAGGCGCAGCGGTCGGGCTGAACGGGGGGTTCGTGCACACAGCCCAGCTTGGAGCGAACGACCTACACCGAACTGAGATACCTACAGCGTGAGCTATGAGAAAGCGCCACGCTTCCCGAAGGGAGAAAGGCGGACAGGTATCCGGTAAGCGGCAGGGTCGGAACAGGAGAGCGCACGAGGGAGCTTCCAGGGGGAAACGCCTGGTATCTTTATAGTCCTGTCGGGTTTCGCCACCTCTGACTTGAGCGTCGATTTTTGTGATGCTCGTCAGGGGGGCGGAGCCTATGGAAAAACGCCAGCAACGCGGCCTTTTTACGGTTCCTGGCCTTTTGCTGGCCTTTTGCTCACATGTTCTTTCCTGCGTTATCCCCTGATTCTGTGGATAACCGTATTACCGCCTTTGAGTGAGCTGATACCGCTCGCCGCAGCCGAACGACCGAGCGCAGCGAGTCAGTGAGCGAGGAAGCGGTCGCTGAGGCTTGACATGATTGGTGCGTATGTTTGTATGAAGCTACAGGACTGATTTGGCGGGCTATGAGGGCGGGGGAAGCTCTGGAAGGGCCGCGATGGGGCGCGCGGCGTCCAGAAGGCGCCATACGGCCCGCTGGCGGCACCCATCCGGTATAAAAGCCCGCGACCCCGAACGGTGACCTCCACTTTCAGCGACAAACGAGCACTTATACATACGCGACTATTCTGCCGCTATACATAACCACTCAGCTAGCTTAAGATCCCATCAAGCTTGCATGCCGGGCGCGCCAGAAGGAGCGCAGCCAAACCAGGATGATGTTTGATGGGGTATTTGAGCACTTGCAACCCTTATCCGGAAGCCCCCTGGCCCACAAAGGCTAGGCGCCAATGCAAGCAGTTCGCATGCAGCCCCTGGAGCGGTGCCCTCCTGATAAACCGGCCAGGGGGCCTATGTTCTTTACTTTTTTACAAGAGAAGTCACTCAACATCTTAAAATGGCCAGGTGAGTCGACGAGCAAGCCCGGCGGATCAGGCAGCGTGCTTGCAGATTTGACTTGCAACGCCCGCATTGTGTCGACGAAGGCTTTTGGCTCCTCTGTCGCTGTCTCAAGCAGCATCTAACCCTGCGTCGCCGTTTCCATTTGCAGGAGATTCGAGGTACCATGTACCCATACGATGTTCCAGATTACGCTTCGCCGAAGAAAAAGCGCAAGGTCGAAGCGTCCGACAAGAAGTACAGCATCGGCCTGGACATCGGCACCAACTCTGTGGGCTGGGCCGTGATCACCGACGAGTACAAGGTGCCCAGCAAGAAATTCAAGGTGCTGGGCAACACCGACCGGCACAGCATCAAGAAGAACCTGATCGGAGCCCTGCTGTTCGACAGCGGCGAAACAGCCGAGGCCACCCGGCTGAAGAGAACCGCCAGAAGAAGATACACCAGACGGAAGAACCGGATCTGCTATCTGCAAGAGATCTTCAGCAACGAGATGGCCAAGGTGGACGACAGCTTCTTCCACAGACTGGAAGAGTCCTTCCTGGTGGAAGAGGATAAGAAGCACGAGCGGCACCCCATCTTCGGCAACATCGTGGACGAGGTGGCCTACCACGAGAAGTACCCCACCATCTACCACCTGAGAAAGAAACTGGTGGACAGCACCGACAAGGCCGACCTGCGGCTGATCTATCTGGCCCTGGCCCACATGATCAAGTTCCGGGGCCACTTCCTGATCGAGGGCGACCTGAACCCCGACAACAGCGACGTGGACAAGCTGTTCATCCAGCTGGTGCAGACCTACAACCAGCTGTTCGAGGAAAACCCCATCAACGCCAGCGGCGTGGACGCCAAGGCCATCCTGTCTGCCAGACTGAGCAAGAGCAGACGGCTGGAAAATCTGATCGCCCAGCTGCCCGGCGAGAAGAAGAATGGCCTGTTCGGCAACCTGATTGCCCTGAGCCTGGGCCTGACCCCCAACTTCAAGAGCAACTTCGACCTGGCCGAGGATGCCAAACTGCAGCTGAGCAAGGACACCTACGACGACGACCTGGACAACCTGCTGGCCCAGATCGGCGACCAGTACGCCGACCTGTTTCTGGCCGCCAAGAACCTGTCCGACGCCATCCTGCTGAGCGACATCCTGAGAGTGAACACCGAGATCACCAAGGCCCCCCTGAGCGCCTCTATGATCAAGAGATACGACGAGCACCACCAGGACCTGACCCTGCTGAAAGCTCTCGTGCGGCAGCAGCTGCCTGAGAAGTACAAAGAGATTTTCTTCGACCAGAGCAAGAACGGCTACGCCGGCTACATTGACGGCGGAGCCAGCCAGGAAGAGTTCTACAAGTTCATCAAGCCCATCCTGGAAAAGATGGACGGCACCGAGGAACTGCTCGTGAAGCTGAACAGAGAGGACCTGCTGCGGAAGCAGCGGACCTTCGACAACGGCAGCATCCCCCACCAGATCCACCTGGGAGAGCTGCACGCCATTCTGCGGCGGCAGGAAGATTTTTACCCATTCCTGAAGGACAACCGGGAAAAGATCGAGAAGATCCTGACCTTCCGCATCCCCTACTACGTGGGCCCTCTGGCCAGGGGAAACAGCAGATTCGCCTGGATGACCAGAAAGAGCGAGGAAACCATCACCCCCTGGAACTTCGAGGAAGTGGTGGACAAGGGCGCTTCCGCCCAGAGCTTCATCGAGCGGATGACCAACTTCGATAAGAACCTGCCCAACGAGAAGGTGCTGCCCAAGCACAGCCTGCTGTACGAGTACTTCACCGTGTATAACGAGCTGACCAAAGTGAAATACGTGACCGAGGGAATGAGAAAGCCCGCCTTCCTGAGCGGCGAGCAGAAAAAGGCCATCGTGGACCTGCTGTTCAAGACCAACCGGAAAGTGACCGTGAAGCAGCTGAAAGAGGACTACTTCAAGAAAATCGAGTGCTTCGACTCCGTGGAAATCTCCGGCGTGGAAGATCGGTTCAACGCCTCCCTGGGCACATACCACGATCTGCTGAAAATTATCAAGGACAAGGACTTCCTGGACAATGAGGAAAACGAGGACATTCTGGAAGATATCGTGCTGACCCTGACACTGTTTGAGGACAGAGAGATGATCGAGGAACGGCTGAAAACCTATGCCCACCTGTTCGACGACAAAGTGATGAAGCAGCTGAAGCGGCGGAGATACACCGGCTGGGGCAGGCTGAGCCGGAAGCTGATCAACGGCATCCGGGACAAGCAGTCCGGCAAGACAATCCTGGATTTCCTGAAGTCCGACGGCTTCGCCAACAGAAACTTCATGCAGCTGATCCACGACGACAGCCTGACCTTTAAAGAGGACATCCAGAAAGCCCAGGTGTCCGGCCAGGGCGATAGCCTGCACGAGCACATTGCCAATCTGGCCGGCAGCCCCGCCATTAAGAAGGGCATCCTGCAGACAGTGAAGGTGGTGGACGAGCTCGTGAAAGTGATGGGCCGGCACAAGCCCGAGAACATCGTGATCGAAATGGCCAGAGAGAACCAGACCACCCAGAAGGGACAGAAGAACAGCCGCGAGAGAATGAAGCGGATCGAAGAGGGCATCAAAGAGCTGGGCAGCCAGATCCTGAAAGAACACCCCGTGGAAAACACCCAGCTGCAGAACGAGAAGCTGTACCTGTACTACCTGCAGAATGGGCGGGATATGTACGTGGACCAGGAACTGGACATCAACCGGCTGTCCGACTACGATGTGGACCATATCGTGCCTCAGAGCTTTCTGAAGGACGACTCCATCGACAACAAGGTGCTGACCAGAAGCGACAAGAACCGGGGCAAGAGCGACAACGTGCCCTCCGAAGAGGTCGTGAAGAAGATGAAGAACTACTGGCGGCAGCTGCTGAACGCCAAGCTGATTACCCAGAGAAAGTTCGACAATCTGACCAAGGCCGAGAGAGGCGGCCTGAGCGAACTGGATAAGGCCGGCTTCATCAAGAGACAGCTGGTGGAAACCCGGCAGATCACAAAGCACGTGGCACAGATCCTGGACTCCCGGATGAACACTAAGTACGACGAGAATGACAAGCTGATCCGGGAAGTGAAAGTGATCACCCTGAAGTCCAAGCTGGTGTCCGATTTCCGGAAGGATTTCCAGTTTTACAAAGTGCGCGAGATCAACAACTACCACCACGCCCACGACGCCTACCTGAACGCCGTCGTGGGAACCGCCCTGATCAAAAAGTACCCTAAGCTGGAAAGCGAGTTCGTGTACGGCGACTACAAGGTGTACGACGTGCGGAAGATGATCGCCAAGAGCGAGCAGGAAATCGGCAAGGCTACCGCCAAGTACTTCTTCTACAGCAACATCATGAACTTTTTCAAGACCGAGATTACCCTGGCCAACGGCGAGATCCGGAAGCGGCCTCTGATCGAGACAAACGGCGAAACCGGGGAGATCGTGTGGGATAAGGGCCGGGATTTTGCCACCGTGCGGAAAGTGCTGAGCATGCCCCAAGTGAATATCGTGAAAAAGACCGAGGTGCAGACAGGCGGCTTCAGCAAAGAGTCTATCCTGCCCAAGAGGAACAGCGATAAGCTGATCGCCAGAAAGAAGGACTGGGACCCTAAGAAGTACGGCGGCTTCGACAGCCCCACCGTGGCCTATTCTGTGCTGGTGGTGGCCAAAGTGGAAAAGGGCAAGTCCAAGAAACTGAAGAGTGTGAAAGAGCTGCTGGGGATCACCATCATGGAAAGAAGCAGCTTCGAGAAGAATCCCATCGACTTTCTGGAAGCCAAGGGCTACAAAGAAGTGAAAAAGGACCTGATCATCAAGCTGCCTAAGTACTCCCTGTTCGAGCTGGAAAACGGCCGGAAGAGAATGCTGGCCTCTGCCGGCGAACTGCAGAAGGGAAACGAACTGGCCCTGCCCTCCAAATATGTGAACTTCCTGTACCTGGCCAGCCACTATGAGAAGCTGAAGGGCTCCCCCGAGGATAATGAGCAGAAACAGCTGTTTGTGGAACAGCACAAGCACTACCTGGACGAGATCATCGAGCAGATCAGCGAGTTCTCCAAGAGAGTGATCCTGGCCGACGCTAATCTGGACAAAGTGCTGTCCGCCTACAACAAGCACCGGGATAAGCCCATCAGAGAGCAGGCCGAGAATATCATCCACCTGTTTACCCTGACCAATCTGGGAGCCCCTGCCGCCTTCAAGTACTTTGACACCACCATCGACCGGAAGAGGTACACCAGCACCAAAGAGGTGCTGGACGCCACCCTGATCCACCAGAGCATCACCGGCCTGTACGAGACACGGATCGACCTGTCTCAGCTGGGAGGCGACAGCCCCAAGAAGAAGAGAAAGGTGGAGGCCAGCTAACATATGATTCGAATGTCTTTCTTGCGCTATGACACTTCCAGCAAAAGGTAGGGCGGGCTGCGAGACGGCTTCCCGGCGCTGCATGCAACACCGATGATGCTTCGACCCCCCGAAGCTCCTTCGGGGCTGCATGGGCGCTCCGATGCCGCTCCAGGGCGAGCGCTGTTTAAATAGCCAGGCCCCCGATTGCAAAGACATTATAGCGAGCTACCAAAGCCATATTCAAACACCTAGATCACTACCACTTCTACACAGGCCACTCGAGCTTGTGATCGCACTCCGCTAAGGGGGCGCCTCTTCCTCTTCGTTTCAGTCACAACCCGCAAACATGACACAAGAATCCCTGTTACTTCTCGACCGTATTGATTCGGATGATTCCTACGCGAGCCTGCGGAACGACCAGGAATTCTGGGAGGTGAGTCGACGAGCAAGCCCGGCGGATCAGGCAGCGTGCTTGCAGATTTGACTTGCAACGCCCGCATTGTGTCGACGAAGGCTTTTGGCTCCTCTGTCGCTGTCTCAAGCAGCATCTAACCCTGCGTCGCCGTTTCCATTTGCAGCCGCTGGCCCGCCGAGCCCTGGAGGAGCTCGGGCTGCCGGTGCCGCCGGTGCTGCGGGTGCCCGGCGAGAGCACCAACCCCGTACTGGTCGGCGAGCCCGGCCCGGTGATCAAGCTGTTCGGCGAGCACTGGTGCGGTCCGGAGAGCCTCGCGTCGGAGTCGGAGGCGTACGCGGTCCTGGCGGACGCCCCGGTGCCGGTGCCCCGCCTCCTCGGCCGCGGCGAGCTGCGGCCCGGCACCGGAGCCTGGCCGTGGCCCTACCTGGTGATGAGCCGGATGACCGGCACCACCTGGCGGTCCGCGATGGACGGCACGACCGACCGGAACGCGCTGCTCGCCCTGGCCCGCGAACTCGGCCGGGTGCTCGGCCGGCTGCACAGGGTGCCGCTGACCGGGAACACCGTGCTCACCCCCCATTCCGAGGTCTTCCCGGAACTGCTGCGGGAACGCCGCGCGGCGACCGTCGAGGACCACCGCGGGTGGGGCTACCTCTCGCCCCGGCTGCTGGACCGCCTGGAGGACTGGCTGCCGGACGTGGACACGCTGCTGGCCGGCCGCGAACCCCGGTTCGTCCACGGCGACCTGCACGGGACCAACATCTTCGTGGACCTGGCCGCGACCGAGGTCACCGGGATCGTCGACTTCACCGACGTCTATGCGGGAGACTCCCGCTACAGCCTGGTGCAACTGCATCTCAACGCCTTCCGGGGCGACCGCGAGATCCTGGCCGCGCTGCTCGACGGGGCGCAGTGGAAGCGGACCGAGGACTTCGCCCGCGAACTGCTCGCCTTCACCTTCCTGCACGACTTCGAGGTGTTCGAGGAGACCCCGCTGGATCTCTCCGGCTTCACCGATCCGGAGGAACTGGCGCAGTTCCTCTGGGGGCCGCCGGACACCGCCCCCGGCGCCTGATAAGGATCCGGCAAGACTGGCCCCGCTTGGCAACGCAACAGTGAGCCCCTCCCTAGTGTGTTTGGGGATGTGACTATGTATTCGTGTGTTGGCCAACGGGTCAACCCGAACAGATTGATACCCGCCTTGGCATTTCCTGTCAGAATGTAACGTCAGTTGATGGTACT
Для всех модифицированных клеток Chlamydomonas reinhardtii заявители использовали ПЦР, анализ с помощью нуклеазы SURVEYOR и секвенирование ДНК для подтверждения успешной модификации.
Пример 16: использование Cas9 как репрессора транскрипции у бактерий
Возможность искусственно контролировать транскрипцию является важной как для изучения функции гена, так и для создания синтетических генных сетей с желаемыми свойствами. Заявители описывают в данном документе использование РНК-направляемого белка Cas9 как программируемого репрессора транскрипции.
Заявители ранее продемонстрировали, как белок Cas9 SF370 Streptococcus pyogenes можно использовать для направленного редактирования генома у Streptococcus pneumoniae. В данном исследовании заявители конструировали штамм crR6Rk, содержащий минимальную систему CRISPR, состоящую из cas9, tracrRNA и повтора. В этом штамме мутации D10A-H840 вводили в cas9 с получением штамма crR6Rk**. Четыре спейсера, целенаправленно воздействующие на различные положения промотора bgaA гена β-галактозидазы, клонировали в массив CRISPR, переносимый ранее описанной плазмидой pDB98. Заявители наблюдали X-Y-кратное снижение активности β-галактозидазы, зависящее от положения целенаправленного воздействия, демонстрирующее потенциал Cas9 как программируемого репрессора (фигура 73).
С целью обеспечения репрессии Cas9** у Escherichia coli конструировали репортерную плазмиду (pDB127) с зеленым флуоресцентным белком (GFP) для экспрессии гена gfpmut2 с конститутивного промотора. Разрабатывали промотор, несущий несколько NPP PAM на обеих нитях, для измерения эффекта Cas9**, связывающегося в разных положениях. Заявители вводили мутации D10A-H840 в pCas9, при этом плазмиду, описанную как несущую tracrRNA, cas9 и минимальный массив CRISPR, разрабатывали для удобного клонирования новых спейсеров. Двадцать два различных спейсера разрабатывали для целенаправленного воздействия на различные участки промотора gfpmut2 и открытой рамки считывания. Приблизительно 20-кратное снижение флюоресценции наблюдали при целенаправленном воздействии на участки, перекрывающиеся или смежные по отношению к -35 и -10 элементам промотора и к последовательности Шайна-Дальгарно. Мишени на обеих нитях показывали подобные уровни репрессии. Эти результаты предполагают, что связывание Cas9** с каким-либо положением участка промотора предотвращает инициацию транскрипции предположительно посредством стерического ингибирования связывания RNAP.
Для определения того, может ли Cas9** предотвращать элонгацию транскрипции, заявители направляли ее к рамке считывания gpfmut2. Снижение флюоресценции наблюдали при целенаправленном воздействии и на кодирующие, и на некодирующие нити, что указывало на то, что связывание Cas9 действительно достаточно сильное, чтобы представлять собой препятствие для прохождения RNAP. Тем не менее в то время как 40% снижение экспрессии наблюдали, когда кодирующая нить являлась мишенью, 20-кратное снижение наблюдали для некодирующей нити (фиг. 21b, сравнение T9, T10 и T11 с B9, B10 и B11). Для непосредственного определения эффектов связывания Cas9**при транскрипции заявители выделяли РНК из штаммов, несущих либо T5, T10, B10, либо контрольную конструкцию, которая не воздействует целенаправленно на pDB127, и подвергали ее нозерн-блоттингу с применением зонда, связывающегося либо до (B477), либо после (B510) целевых сайтов B10 и T10. В соответствии с флюоресцентными методами заявителей, не было обнаружено транскрипции gfpmut2 при направлении Cas9** к промоторному участку (мишень T5), и транскрипцию наблюдали после целенаправленного воздействия на участок T10. Интересно, что меньший транскрипт наблюдали с зондом B477. Эта полоса соответствует ожидаемому размеру транскрипта, который будет прерываться Cas9**, и является непосредственной индикацией терминации транскрипции, вызванной dgRNA::Cas9**, связывающейся с кодирующей нитью. На удивление, заявители не обнаружили транскрипт при целенаправленном воздействии на некодирующую нить (B10). Поскольку связывание Cas9** с участком B1 маловероятно препятствует инициации транскрипции, эти результаты предполагают, что мРНК была разрушена. Было показано, что DgRNA::Cas9 связывает ssРНК in vitro. Заявители предполагают, что связывание может запускать разрушение мРНК нуклеазами хозяина. Действительно, остановка рибосом может индуцировать расщепление на транслированной мРНК у E. coli.
Некоторые применения требуют точного регулирования экспрессии генов, а не ее абсолютной репрессии. Заявители стремились к достижению промежуточных уровней репрессии за счет введения несовпадений, которые ослабили бы взаимодействия crRNA/мишень. Заявители создавали серии спейсеров на основе конструкций B1, T5 и B10 с увеличением количества мутаций на 5’-конце crRNA. До 8 мутаций включительно в B1 и T5 не влияли на уровень репрессии, и прогрессивное повышение флюоресценции наблюдали для дополнительных мутации.
Наблюдаемая репрессия с совпадением только 8 нт между crRNA и ее мишенью ставит вопрос эффектов нецелевого воздействия при использовании Cas9** как регулятора транскрипции. Поскольку подходящий PAM (NGG) также требуется для связывания Cas9, количество нуклеотидов в соответствии с получением определенного уровня рестрикции составляет 10. Совпадение в 10 нт встречается случайным образом каждый ~1 м.п.о., и такие сайты, таким образом, вероятно, можно найти даже в небольших бактериальных геномах. Однако для эффективной репрессии транскрипции необходимо, чтоб такие сайты находились в промоторном участке гена, который осуществляет нецелевое воздействие с намного меньшей вероятностью. Заявители также показали, что экспрессия генов может быть нарушена, если некодирующая нить гена подвергается целенаправленному воздействию. Для того, чтобы это произошло, произвольная мишень должна находиться в правильной ориентации, но эти события происходят с относительно большей вероятностью. Фактически, в ходе этого исследования заявители не смогли сконструировать один из разработанных спейсеров в pCas9**. Заявители позже обнаружили этот спейсер, характеризующийся совпадением 12 п.о., рядом с соответствующим PAM в ключевом гене murC. Такого нецелевого воздействия можно легко избежать путем систематического повреждения разработанных спейсеров.
Аспекты настоящего изобретения дополнительно описаны в следующих пронумерованных параграфах.
1. Векторная система, содержащая один или несколько векторов, где система содержит
a. первый регуляторный элемент, функционально связанный с парной traer-последовательностью и одним или несколькими сайтами встраивания для встраивания направляющей последовательности выше парной traer-последовательности, где при экспрессии направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR с целевой последовательностью в эукариотической клетке, где комплекс CRISPR содержит фермент CRISPR, образующий комплекс с (1) направляющей последовательностью, которая гибридизируется с целевой последовательностью, и (2) парной traer-последовательностью, которая гибридизируется с traer-последовательностью; и
b. второй регуляторный элемент, функционально связанный с кодирующей фермент последовательностью, кодирующей указанный фермент CRISPR, содержащий последовательность ядерной локализации;
где компоненты (a) и (b) находятся в одном и том же или в различных векторах системы.
2. Векторная система по параграфу 1, где компонент (a) дополнительно содержит traer-последовательность ниже парной traer-последовательности под контролем первого регуляторного элемента.
3. Векторная система по параграфу 1, где компонент (a) дополнительно содержит две или более направляющие последовательности, функционально связанные с первым регуляторным элементом, где при экспрессии каждая из двух или более направляющих последовательностей управляет специфичным к последовательности связыванием комплекса CRISPR со своей целевой последовательностью в эукариотической клетке.
4. Векторная система по параграфу 1, где система содержит traer-последовательность под контролем третьего регуляторного элемента.
5. Векторная система по параграфу 1, где traer-последовательность характеризуется по меньшей мере 50% комплементарности последовательности по длине парной traer-последовательности при оптимальном выравнивании.
6. Векторная система по параграфу 1, где фермент CRISPR содержит одну или несколько последовательностей ядерной локализации, достаточно эффективных, чтобы управлять накоплением указанного фермента CRISPR в обнаруживаемом количестве в ядре эукариотической клетки.
7. Векторная система по параграфу 1, где фермент CRISPR является ферментом системы CRISPR II типа.
8. Векторная система по параграфу 1, где фермент CRISPR является ферментом Cas9.
9. Векторная система по параграфу 1, где фермент CRISPR кодон-оптимизирован для экспрессии в эукариотической клетке.
10. Векторная система по параграфу 1, где фермент CRISPR управляет расщеплением одной или двух нитей в определенной точке целевой последовательности.
11. Векторная система по параграфу 1, где у фермента CRISPR отсутствует активность для расщепления нитей ДНК.
12. Векторная система по параграфу 1, где первый регуляторный элемент является промотором полимеразы III.
13. Векторная система по параграфу 1, где второй регуляторный элемент является промотором полимеразы II.
14. Векторная система по параграфу 4, где третий регуляторный элемент является промотором полимеразы III.
15. Векторная система по параграфу 1, где направляющая последовательность составляет по меньшей мере 15 нуклеотидов в длину.
16. Векторная система по параграфу 1, где менее 50% нуклеотидов направляющей последовательности участвует в самокомплементарном спаривании оснований при оптимальном сворачивании.
17. Вектор, содержащий регуляторный элемент, функционально связанный с кодирующей фермент последовательностью, кодирующей фермент CRISPR, содержащий одну или несколько последовательностей ядерной локализации, где указанный регуляторный элемент управляет транскрипцией фермента CRISPR в эукариотической клетке так, что указанный фермент CRISPR накапливается в обнаруживаемом количестве в ядре эукариотической клетки.
18. Вектор по параграфу 17, где указанный регуляторный элемент является промотором полимеразы II.
19. Вектор по параграфу 17, где указанный фермент CRISPR является ферментом системы CRISPR II типа.
20. Вектор по параграфу 17, где указанный фермент CRISPR является ферментом Cas9.
21. Вектор по параграфу 17, где у указанного фермента CRISPR отсутствует способность расщеплять одну или несколько нитей целевой последовательности, с которой он связывается.
22. Фермент CRISPR, содержащий одну или несколько последовательностей ядерной локализации, достаточно эффективных, чтобы управлять накоплением указанного фермента CRISPR в обнаруживаемом количестве в ядре эукариотической клетки.
23. Фермент CRISPR по параграфу 22, где указанный фермент CRISPR является ферментом системы CRISPR II типа.
24. Фермент CRISPR по параграфу 22, где указанный фермент CRISPR является ферментом Cas9.
25. Фермент CRISPR по параграфу 22, где у указанного фермента CRISPR отсутствует способность расщеплять одну или несколько нитей целевой последовательности, с которой он связывается.
26. Эукариотическая клетка-хозяин, содержащая
a. первый регуляторный элемент, функционально связанный с парной traer-последовательностью и одним или несколькими сайтами встраивания для встраивания направляющей последовательности выше парной traer-последовательности, где при экспрессии направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR с целевой последовательностью в эукариотической клетке, где комплекс CRISPR содержит фермент CRISPR, образующий комплекс с (1) направляющей последовательностью, которая гибиридизируется с целевой последовательностью, и (2) парной traсr-последовательность, которая гибиридизируется с traer-последовательностью; и/или
b. второй регуляторный элемент, функционально связанный с кодирующей фермент последовательностью, кодирующей указанный фермент CRISPR, содержащий последовательность ядерной локализации.
27. Эукариотическая клетка-хозяин по параграфу 26, где указанная клетка-хозяин содержит компоненты (a) и (b).
28. Эукариотическая клетка-хозяин по параграфу 26, где компонент (a), компонент (b) или компоненты (a) и (b) стабильно интегрируются в геном эукариотической клетки-хозяина.
29. Эукариотическая клетка-хозяин по параграфу 26, где компонент (a) дополнительно содержит traer-последовательность ниже парной traer-последовательности под контролем первого регуляторного элемента.
30. Эукариотическая клетка-хозяин по параграфу 26, где компонент (a) дополнительно содержит две или более направляющие последовательности, функционально связанные с первым регуляторным элементом, где при экспрессии каждая из двух или более направляющих последовательностей управляет специфичным к последовательности связыванием комплекса CRISPR со своей целевой последовательностью в эукариотической клетке.
31. Эукариотическая клетка-хозяин по параграфу 26, дополнительно содержащая третий регуляторный элемент, функционально связанный с указанной traer-последовательностью.
32. Эукариотическая клетка-хозяин по параграфу 26, где traer-последовательность характеризуется по меньшей мере 50% комплементарности последовательности по длине парной traer-последовательности при оптимальном выравнивании.
33. Эукариотическая клетка-хозяин по параграфу 26, где фермент CRISPR содержит одну или несколько последовательностей ядерной локализации, достаточно эффективных, чтобы управлять накоплением указанного фермента CRISPR в обнаруживаемом количестве в ядре эукариотической клетки.
34. Эукариотическая клетка-хозяин по параграфу 26, где фермент CRISPR является ферментом системы CRISPR II типа.
35. Эукариотическая клетка-хозяин по параграфу 26, где фермент CRISPR является ферментом Cas9.
36. Эукариотическая клетка-хозяин по параграфу 26, где фермент CRISPR кодон-оптимизирован для экспрессии в эукариотической клетке.
37. Эукариотическая клетка-хозяин по параграфу 26, где фермент CRISPR управляет расщеплением одной или двух нитей в определенной точке целевой последовательности.
38. Эукариотическая клетка-хозяин по параграфу 26, где у фермента CRISPR отсутствует активность для расщепления нитей ДНК.
39. Эукариотическая клетка-хозяин по параграфу 26, где первый регуляторный элемент является промотором полимеразы III.
40. Эукариотическая клетка-хозяин по параграфу 26, где второй регуляторный элемент является промотором полимеразы II.
41. Эукариотическая клетка-хозяин по параграфу 31, где третий регуляторный элемент является промотором полимеразы III.
42. Эукариотическая клетка-хозяин по параграфу 26, где направляющая последовательность составляет по меньшей мере 15 нуклеотидов в длину.
43. Эукариотическая клетка-хозяин по параграфу 26, где менее 50% нуклеотидов направляющей последовательности участвует в самокомплементарном спаривании оснований при оптимальном сворачивании.
44. Отличное от человека животное, содержащее эукариотическую клетку-хозяина по любому одному из параграфов 26-43.
45. Набор, содержащий векторную систему и инструкции по применению указанного набора, при этом векторная система содержит
a. первый регуляторный элемент, функционально связанный с парной traer-последовательностью и одним или несколькими сайтами встраивания для встраивания направляющей последовательности выше парной traer-последовательности, где при экспрессии направляющая последовательность управляет специфичным к последовательности связыванием комплекса CRISPR с целевой последовательностью в эукариотической клетке, где комплекс CRISPR содержит фермент CRISPR, образующий комплекс с (1) направляющей последовательностью, которая гибиридизируется с целевой последовательностью, и (2) парной traсr-последовательность, которая гибиридизируется с traer-последовательностью; и/или
b. второй регуляторный элемент, функционально связанный с кодирующей фермент последовательностью, кодирующей указанный фермент CRISPR, содержащий последовательность ядерной локализации.
46. Набор по параграфу 45, где указанный набор содержит компоненты (a) и (b), находящиеся в одном и том же или в различных векторах системы.
47. Набор по параграфу 45, где компонент (a) дополнительно содержит traer-последовательность ниже парной traer-последовательности под контролем первого регуляторного элемента.
48. Набор по параграфу 45, где компонент (a) дополнительно содержит две или более направляющие последовательности, функционально связанные с первым регуляторным элементом, где при экспрессии каждая из двух или более направляющих последовательностей управляет специфичным к последовательности связыванием комплекса CRISPR со своей целевой последовательностью в эукариотической клетке.
49. Набор по параграфу 45, где система содержит traer-последовательность под контролем третьего регуляторного элемента.
50. Набор по параграфу 45, где traer-последовательность характеризуется по меньшей мере 50% комплементарности последовательности по длине парной traer-последовательности при оптимальном выравнивании.
51. Набор по параграфу 45, где фермент CRISPR содержит одну или несколько последовательностей ядерной локализации, достаточно эффективных, чтобы управлять накоплением указанного фермента CRISPR в определяемом количестве в ядре эукариотической клетки.
52. Набор по параграфу 45, где фермент CRISPR является ферментом системы CRISPR II типа.
53. Набор по параграфу 45, где фермент CRISPR является ферментом Cas9.
54. Набор по параграфу 45, где фермент CRISPR кодон-оптимизирован для экспрессии в эукариотической клетке.
55. Набор по параграфу 45, где фермент CRISPR управляет расщеплением одной или двух нитей в определенной точке целевой последовательности.
56. Набор по параграфу 45, где у фермента CRISPR отсутствует активность для расщепления нитей ДНК.
57. Набор по параграфу 45, где первый регуляторный элемент является промотором полимеразы III.
58. Набор по параграфу 45, где второй регуляторный элемент является промотором полимеразы II.
59. Набор по параграфу 49, где третий регуляторный элемент является промотором полимеразы III.
60. Набор по параграфу 45, где направляющая последовательность составляет по меньшей мере 15 нуклеотидов в длину.
61. Набор по параграфу 45, где менее 50% нуклеотидов направляющей последовательности участвует в самокомплементарном спаривании оснований при оптимальном сворачивании.
62. Компьютерная система для отбора кандидатной целевой последовательности в пределах последовательности нуклеиновой кислоты в эукариотической клетке для целенаправленного воздействия комплекса CRISPR, при этом система содержит
a. блок памяти, выполненный с возможностью получения и/или хранения указанной последовательности нуклеиновой кислоты; и
b. один или несколько процессоров отдельно или в комбинации, запрограммированных с возможностью (i) определения местонахождения последовательности мотива CRISPR в пределах указанной последовательности нуклеиновой кислоты и (ii) выбора последовательности, смежной с указанной последовательностью мотива CRISPR с определенным местонахождением, в качестве кандидатной целевой последовательности, с которой связывается комплекс CRISPR.
63. Компьютерная система по параграфу 62, где указанная стадия определения местонахождения включает идентификацию последовательности мотива CRISPR, расположенной менее чем приблизительно в 500 нуклеотидах от указанной целевой последовательности.
64. Компьютерная система по параграфу 62, где указанная кандидатная целевая последовательность составляет по меньшей мере 10 нуклеотидов в длину.
65. Компьютерная система по параграфу 62, где нуклеотид на 3’-конце кандидатной целевой последовательности расположен не более чем приблизительно в 10 нуклеотидах выше последовательности мотива CRISPR.
66. Компьютерная система по параграфу 62, где последовательность нуклеиновой кислоты в эукариотической клетке является эндогенной по отношению к эукариотическому геному.
67. Компьютерная система по пункту 62, где последовательность нуклеиновой кислоты в эукариотической клетке является экзогенной по отношению к эукариотическому геному.
68. Машиночитаемый носитель, содержащий коды, которые при выполнении одним или несколькими процессорами реализуют способ выбора кандидатной целевой последовательности в пределах последовательности нуклеиновой кислоты в эукариотической клетке для целенаправленного воздействия комплекса CRISPR, при этом указанный способ включает (a) определение местонахождения последовательности мотива CRISPR в пределах указанной последовательности нуклеиновой кислоты и (b) выбор последовательности, смежной с указанной последовательностью мотива CRISPR с определенным местонахождением, в качестве кандидатной целевой последовательности, с которой связывается комплекс CRISPR.
69. Машиночитаемый носитель по параграфу 68, где указанное определение местонахождения включает определение местонахождения последовательности мотива CRISPR, которая находится менее чем приблизительно в 500 нуклеотидах от указанной целевой последовательности.
70. Машиночитаемый по параграфу 68, где указанная кандидатная целевая последовательность составляет по меньшей мере 10 нуклеотидов в длину.
71. Машиночитаемый по параграфу 68, где нуклеотид на 3’-конце кандидатной целевой последовательности расположен не более чем приблизительно в 10 нуклеотидах выше последовательности мотива CRISPR.
72. Машиночитаемый по параграфу 68, где последовательность нуклеиновой кислоты в эукариотической клетке является эндогенной по отношению к эукариотическому геному.
73. Машиночитаемый по параграфу 68, где последовательность нуклеиновой кислоты в эукариотической клетке является экзогенной по отношению к эукариотическому геному.
74. Способ модификации целевого полинуклеотида в эукариотической клетке, при этом способ включает обеспечение связывания комплекса CRISPR с целевым полинуклеотидом для осуществления расщепления указанного целевого полинуклеотида с модификацией, таким образом, целевого полинуклеотида, где комплекс CRISPR содержит фермент CRISPR, образующий комплекс с направляющей последовательностью, гибридизирующейся с целевой последовательностью в указанном целевом полинуклеотиде, где указанная направляющая последовательность связана с парной traer-последовательностью, которая, в свою очередь, гибридизируется с traer-последовательностью.
75. Способ по параграфу 74, где указанное расщепление включает расщепление одной или двух нитей в определенной точке целевой последовательности указанным ферментом CRISPR.
76. Способ по параграфу 74, где указанное расщепление приводит к сниженной транскрипции целевого гена.
77. Способ по параграфу 74, дополнительно включающий репарацию указанного расщепленного целевого полинуклеотида при помощи гомологичной рекомбинации с экзогенным матричным полинуклеотидом, где указанная репарация приводит к мутации, включающей вставку, делецию или замену одного или нескольких нуклеотидов указанного целевого полинуклеотида.
78. Способ по параграфу 77, где указанная мутация приводит к одной или нескольким аминокислотным заменам в белке, экспрессируемом с гена, содержащего целевую последовательность.
79. Способ по параграфу 74, дополнительно включающий доставку одного или нескольких векторов в указанную эукариотическую клетку, где один или несколько векторов управляют экспрессией одного или нескольких из следующих: фермента CRISPR, направляющей последовательности, связанной с парной traer-последовательностью, и traer-последовательности.
80. Способ по параграфу 79, где указанные векторы доставляют в эукариотическую клетку в субъекте.
81. Способ по параграфу 74, где указанная модификация имеет место в указанной эукариотической клетке в клеточной культуре.
82. Способ по параграфу 74, дополнительно включающий выделение указанной эукариотической клетки из субъекта перед указанной модификацией.
83. Способ по параграфу 82, дополнительно включающий возвращение указанной эукариотической клетки и/или клеток, полученных из субъекта, указанному субъекту.
84. Способ модификации экспрессии полинуклеотида в эукариотической клетке, при этом способ включает обеспечение связывания комплекса CRISPR с полинуклеотидом так, что указанное связывание приводит к повышенной или пониженной экспрессии указанного полинуклеотида; где комплекс CRISPR содержит фермент CRISPR, образующий комплекс с направляющей последовательностью, гибридизирующейся с целевой последовательностью в указанном полинуклеотиде, где указанная направляющая последовательность связана с парной traer-последовательностью, которая, в свою очередь, гибридизируется с traer-последовательностью.
85. Способ по параграфу 74, дополнительно включающий доставку одного или нескольких векторов в указанные эукариотические клетки, где один или несколько векторов управляют экспрессией одного или нескольких из следующих: фермента CRISPR, направляющей последовательности, связанной с парной traer-последовательностью, и traer-последовательности.
86. Способ получения модельной эукариотической клетки, содержащей мутантный ген, ответственный за развитие заболевания, при этом способ включает
a. введение одного или нескольких векторов в эукариотическую клетку, где один или несколько векторов управляют экспрессией одного или нескольких из: фермента CRISPR, направляющей последовательности, связанной с парной traer-последовательностью, и traer-последовательности; и
b. обеспечение связывания комплекса CRISPR с целевым полинуклеотидом для осуществления расщепления целевого полинуклеотида в указанном гене, ответственном за развитие заболевания, где комплекс CRISPR содержит фермент CRISPR, образующий комплекс с (1) направляющей последовательностью, которая гибридизируется с целевой последовательностью в целевом полинуклеотиде, и (2) парной traer-последовательностью, которая гибридизируется с traer-последовательностью, с получением, таким образом, модельной эукариотической клетки, содержащей мутантный ген, ответственный за развитие заболевания.
87. Способ по параграфу 86, где указанное расщепление включает расщепление одной или двух нитей в определенной точке целевой последовательности указанным ферментом CRISPR.
88. Способ по параграфу 86, где указанное расщепление приводит к сниженной транскрипции целевого гена.
89. Способ по параграфу 86, дополнительно включающий репарацию указанного расщепленного целевого полинуклеотида при помощи гомологичной рекомбинации с экзогенным матричным полинуклеотидом, где указанная репарация приводит к мутации, включающей вставку, делецию или замену одного или нескольких нуклеотидов указанного целевого полинуклеотида.
90. Способ по параграфу 89, где указанная мутация приводит к одной или нескольким аминокислотным заменам в белке, экспрессируемом с гена, содержащего целевую последовательность.
91. Способ получения биологически активного средства, которое модулирует процесс передачи сигнала в клетке, ассоциированный с геном, ответственным за развитие заболевания, включающий
a. приведение тестового соединения в контакт с модельной клеткой по любому из параграфов 86-90 и
b. обнаружение изменения при считывании, которое свидетельствует об уменьшении или усилении процесса передачи сигнала в клетке, ассоциированного с указанной мутацией в указанном гене, ответственном за развитие заболевания, с получением, таким образом, указанного биологически активного средства, которое модулирует указанный процесс передачи сигнала в клетке, ассоциированный с указанным геном, ответственным за развитие заболевания.
92. Рекомбинантный полинуклеотид, содержащий направляющую последовательность выше парной traer-последовательности, где направляющая последовательность при экспрессии управляет специфичным к последовательности связыванием комплекса CRISPR с соответствующей целевой последовательностью, присутствующей в эукариотической клетке.
93. Рекомбинантный полинуклеотид по параграфу 89, где целевая последовательность является вирусной последовательностью, присутствующей в эукариотической клетке.
94. Рекомбинантный полинуклеотид по параграфу 89, где целевая последовательность является протоонкогеном или онкогеном.
Несмотря на то, что предпочтительные варианты осуществления настоящего изобретения были показаны и описаны в данном документе, для специалиста в данной области будет очевидно, что такие варианты осуществления предоставлены только в качестве примера. Многочисленные вариации, изменения и замены теперь будут очевидны для специалиста в данной области без отступления от сути настоящего изобретения. Следует понимать, что различные альтернативные варианты вариантов осуществления настоящего изобретения, раскрытые в данном документе, можно применять при практическом осуществлении настоящего изобретения. Предполагают, что следующая формула изобретения определяет объем настоящего изобретения, и что, таким образом, охвачены способы и структуры в пределах объема данной формулы изобретения и их эквиваленты.
Библиографические ссылки
1. Urnov, F.D., Rebar, E.J., Holmes, M.C., Zhang, H.S. & Gregory, P.D. Genome editing with engineered zinc finger nucleases. Nat. Rev. Genet. 11, 636-646 (2010).
2. Bogdanove, A.J. & Voytas, D.F. TAL effectors: customizable proteins for DNA targeting. Science 333, 1843-1846 (2011).
3. Stoddard, B.L. Homing endonuclease structure and function. Q. Rev. Biophys. 38, 49-95 (2005).
4. Bae, T. & Schneewind, O. Allelic replacement in Staphylococcus aureus with inducible counter-selection. Plasmid 55, 58-63 (2006).
5. Sung, C.K., Li, H., Claverys, J.P. & Morrison, D.A. An rpsL cassette, janus, for gene replacement through negative selection in Streptococcus pneumoniae. Appl. Environ. Microbiol. 67, 5190-5196 (2001).
6. Sharan, S.K., Thomason, L.C., Kuznetsov, S.G. & Court, D.L. Recombineering: a homologous recombination-based method of genetic engineering. Nat. Protoc. 4, 206-223 (2009).
7. Jinek, M. et al. A programmable dual-RNA-guided DNA endonuclease in adaptive bacterial immunity. Science 337, 816-821 (2012).
8. Deveau, H., Garneau, J.E. & Moineau, S. CRISPR/Cas system and its role in phage-bacteria interactions. Annu. Rev. Microbiol. 64, 475-493 (2010).
9. Horvath, P. & Barrangou, R. CRISPR/Cas, the immune system of bacteria and archaea. Science 327, 167-170 (2010).
10. Terns, M.P. & Terns, R.M. CRISPR-based adaptive immune systems. Curr. Opin. Microbiol. 14, 321-327 (2011).
11. van der Oost, J., Jore, M.M., Westra, E.R., Lundgren, M. & Brouns, S.J. CRISPR-based adaptive and heritable immunity in prokaryotes. Trends. Biochem. Sci. 34, 401-407 (2009).
12. Brouns, S.J. et al. Small CRISPR RNAs guide antiviral defense in prokaryotes. Science 321, 960-964 (2008).
13. Carte, J., Wang, R., Li, H., Terns, R.M. & Terns, M.P. Cas6 is an endoribonuclease that generates guide RNAs for invader defense in prokaryotes. Genes Dev. 22, 3489-3496 (2008).
14. Deltcheva, E. et al. CRISPR RNA maturation by trans-encoded small RNA and host factor RNase III. Nature 471, 602-607 (2011).
15. Hatoum-Aslan, A., Maniv, I. & Marraffini, L.A. Mature clustered, regularly interspaced, short palindromic repeats RNA (crRNA) length is measured by a ruler mechanism anchored at the precursor processing site. Proc. Natl. Acad. Sci. U.S.A. 108, 21218-21222 (2011).
16. Haurwitz, R.E., Jinek, M., Wiedenheft, B., Zhou, K. & Doudna, J.A. Sequence- and structure-specific RNA processing by a CRISPR endonuclease. Science 329, 1355-1358 (2010).
17. Deveau, H. et al. Phage response to CRISPR-encoded resistance in Streptococcus thermophilus. J. Bacteriol. 190, 1390-1400 (2008).
18. Gasiunas, G., Barrangou, R., Horvath, P. & Siksnys, V. Cas9-crRNA ribonucleoprotein complex mediates specific DNA cleavage for adaptive immunity in bacteria. Proc. Natl. Acad. Sci. U.S.A. (2012).
19. Makarova, K.S., Aravind, L., Wolf, Y.I. & Koonin, E.V. Unification of Cas protein families and a simple scenario for the origin and evolution of CRISPR-Cas systems. Biol. Direct. 6, 38 (2011).
20. Barrangou, R. RNA-mediated programmable DNA cleavage. Nat. Biotechnol. 30, 836-838 (2012).
21. Brouns, S.J. Molecular biology. A Swiss army knife of immunity. Science 337, 808-809 (2012).
22. Carroll, D. A CRISPR Approach to Gene Targeting. Mol. Ther. 20, 1658-1660 (2012).
23. Bikard, D., Hatoum-Aslan, A., Mucida, D. & Marraffini, L.A. CRISPR interference can prevent natural transformation and virulence acquisition during in vivo bacterial infection. Cell Host Microbe 12, 177-186 (2012).
24. Sapranauskas, R. et al. The Streptococcus thermophilus CRISPR/Cas system provides immunity in Escherichia coli. Nucleic Acids Res. (2011).
25. Semenova, E. et al. Interference by clustered regularly interspaced short palindromic repeat (CRISPR) RNA is governed by a seed sequence. Proc. Natl. Acad. Sci. U.S.A. (2011).
26. Wiedenheft, B. et al. RNA-guided complex from a bacterial immune system enhances target recognition through seed sequence interactions. Proc. Natl. Acad. Sci. U.S.A. (2011).
27. Zahner, D. & Hakenbeck, R. The Streptococcus pneumoniae beta-galactosidase is a surface protein. J. Bacteriol. 182, 5919-5921 (2000).
28. Marraffini, L.A., Dedent, A.C. & Schneewind, O. Sortases and the art of anchoring proteins to the envelopes of gram-positive bacteria. Microbiol. Mol. Biol. Rev. 70, 192-221 (2006).
29. Motamedi, M.R., Szigety, S.K. & Rosenberg, S.M. Double-strand-break repair recombination in Escherichia coli: physical evidence for a DNA replication mechanism in vivo. Genes Dev. 13, 2889-2903 (1999).
30. Hosaka, T. et al. The novel mutation K87E in ribosomal protein S12 enhances protein synthesis activity during the late growth phase in Escherichia coli. Mol. Genet. Genomics 271, 317-324 (2004).
31. Costantino, N. & Court, D.L. Enhanced levels of lambda Red-mediated recombinants in mismatch repair mutants. Proc. Natl. Acad. Sci. U.S.A. 100, 15748-15753 (2003).
32. Edgar, R. & Qimron, U. The Escherichia coli CRISPR system protects from lambda lysogenization, lysogens, and prophage induction. J. Bacteriol. 192, 6291-6294 (2010).
33. Marraffini, L.A. & Sontheimer, E.J. Self versus non-self discrimination during CRISPR RNA-directed immunity. Nature 463, 568-571 (2010).
34. Fischer, S. et al. An archaeal immune system can detect multiple Protospacer Adjacent Motifs (PAMs) to target invader DNA. J. Biol. Chem. 287, 33351-33363 (2012).
35. Gudbergsdottir, S. et al. Dynamic properties of the Sulfolobus CRISPR/Cas and CRISPR/Cmr systems when challenged with vector-borne viral and plasmid genes and protospacers. Mol. Microbiol. 79, 35-49 (2011).
36. Wang, H.H. et al. Genome-scale promoter engineering by coselection MAGE. Nat Methods 9, 591-593 (2012).
37. Cong, L. et al. Multiplex Genome Engineering Using CRISPR/Cas Systems. Science в печати (2013).
38. Mali, P. et al. RNA-Guided Human Genome Engineering via Cas9. Science в печати (2013).
39. Hoskins, J. et al. Genome of the bacterium Streptococcus pneumoniae strain R6. J. Bacteriol. 183, 5709-5717 (2001).
40. Havarstein, L.S., Coomaraswamy, G. & Morrison, D.A. An unmodified heptadecapeptide pheromone induces competence for genetic transformation in Streptococcus pneumoniae. Proc. Natl. Acad. Sci. U.S.A. 92, 11140-11144 (1995).
41. Horinouchi, S. & Weisblum, B. Nucleotide sequence and functional map of pC194, a plasmid that specifies inducible chloramphenicol resistance. J. Bacteriol. 150, 815-825 (1982).
42. Horton, R.M. In Vitro Recombination and Mutagenesis of DNA : SOEing Together Tailor-Made Genes. Methods Mol. Biol. 15, 251-261 (1993).
43. Podbielski, A., Spellerberg, B., Woischnik, M., Pohl, B. & Lutticken, R. Novel series of plasmid vectors for gene inactivation and expression analysis in group A streptococci (GAS). Gene 177, 137-147 (1996).
44. Husmann, L.K., Scott, J.R., Lindahl, G. & Stenberg, L. Expression of the Arp protein, a member of the M protein family, is not sufficient to inhibit phagocytosis of Streptococcus pyogenes. Infection and immunity 63, 345-348 (1995).
45. Gibson, D.G. et al. Enzymatic assembly of DNA molecules up to several hundred kilobases. Nat Methods 6, 343-345 (2009).
--->
СПИСОК ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> THE BROAD INSTITUTE, INC.
<120> CRISPR-CAS COMPONENT SYSTEMS, METHODS AND COMPOSITIONS FOR
SEQUENCE MANIPULATION
<130> 44790.99.2003
<140> PCT/US2013/074611
<141> 2013-12-12
<150> 61/835,931
<151> 2013-06-17
<150> 61/791,409
<151> 2013-03-15
<150> 61/768,959
<151> 2013-02-25
<150> 61/748,427
<151> 2013-01-02
<150> 61/736,527
<151> 2012-12-12
<160> 529
<170> PatentIn version 3.5
<210> 1
<211> 7
<212> PRT
<213> Simian virus 40
<400> 1
Pro Lys Lys Lys Arg Lys Val
1 5
<210> 2
<211> 16
<212> PRT
<213> Unknown
<220>
<221> source
<223> /note="Description of Unknown:
Nucleoplasmin bipartite NLS sequence"
<400> 2
Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1 5 10 15
<210> 3
<211> 9
<212> PRT
<213> Unknown
<220>
<221> source
<223> /note="Description of Unknown:
C-myc NLS sequence"
<400> 3
Pro Ala Ala Lys Arg Val Lys Leu Asp
1 5
<210> 4
<211> 11
<212> PRT
<213> Unknown
<220>
<221> source
<223> /note="Description of Unknown:
C-myc NLS sequence"
<400> 4
Arg Gln Arg Arg Asn Glu Leu Lys Arg Ser Pro
1 5 10
<210> 5
<211> 38
<212> PRT
<213> Homo sapiens
<400> 5
Asn Gln Ser Ser Asn Phe Gly Pro Met Lys Gly Gly Asn Phe Gly Gly
1 5 10 15
Arg Ser Ser Gly Pro Tyr Gly Gly Gly Gly Gln Tyr Phe Ala Lys Pro
20 25 30
Arg Asn Gln Gly Gly Tyr
35
<210> 6
<211> 42
<212> PRT
<213> Unknown
<220>
<221> source
<223> /note="Description of Unknown:
IBB domain from importin-alpha sequence"
<400> 6
Arg Met Arg Ile Glx Phe Lys Asn Lys Gly Lys Asp Thr Ala Glu Leu
1 5 10 15
Arg Arg Arg Arg Val Glu Val Ser Val Glu Leu Arg Lys Ala Lys Lys
20 25 30
Asp Glu Gln Ile Leu Lys Arg Arg Asn Val
35 40
<210> 7
<211> 8
<212> PRT
<213> Unknown
<220>
<221> source
<223> /note="Description of Unknown:
Myoma T protein sequence"
<400> 7
Val Ser Arg Lys Arg Pro Arg Pro
1 5
<210> 8
<211> 8
<212> PRT
<213> Unknown
<220>
<221> source
<223> /note="Description of Unknown:
Myoma T protein sequence"
<400> 8
Pro Pro Lys Lys Ala Arg Glu Asp
1 5
<210> 9
<211> 8
<212> PRT
<213> Homo sapiens
<400> 9
Pro Gln Pro Lys Lys Lys Pro Leu
1 5
<210> 10
<211> 12
<212> PRT
<213> Mus musculus
<400> 10
Ser Ala Leu Ile Lys Lys Lys Lys Lys Met Ala Pro
1 5 10
<210> 11
<211> 5
<212> PRT
<213> Influenza virus
<400> 11
Asp Arg Leu Arg Arg
1 5
<210> 12
<211> 7
<212> PRT
<213> Influenza virus
<400> 12
Pro Lys Gln Lys Lys Arg Lys
1 5
<210> 13
<211> 10
<212> PRT
<213> Hepatitus delta virus
<400> 13
Arg Lys Leu Lys Lys Lys Ile Lys Lys Leu
1 5 10
<210> 14
<211> 10
<212> PRT
<213> Mus musculus
<400> 14
Arg Glu Lys Lys Lys Phe Leu Lys Arg Arg
1 5 10
<210> 15
<211> 20
<212> PRT
<213> Homo sapiens
<400> 15
Lys Arg Lys Gly Asp Glu Val Asp Gly Val Asp Glu Val Ala Lys Lys
1 5 10 15
Lys Ser Lys Lys
20
<210> 16
<211> 17
<212> PRT
<213> Homo sapiens
<400> 16
Arg Lys Cys Leu Gln Ala Gly Met Asn Leu Glu Ala Arg Lys Thr Lys
1 5 10 15
Lys
<210> 17
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t or g
<220>
<221> modified_base
<222> (21)..(22)
<223> a, c, t, g, unknown or other
<400> 17
nnnnnnnnnn nnnnnnnnnn nnagaaw 27
<210> 18
<211> 19
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(12)
<223> a, c, t or g
<220>
<221> modified_base
<222> (13)..(14)
<223> a, c, t, g, unknown or other
<400> 18
nnnnnnnnnn nnnnagaaw 19
<210> 19
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t or g
<220>
<221> modified_base
<222> (21)..(22)
<223> a, c, t, g, unknown or other
<400> 19
nnnnnnnnnn nnnnnnnnnn nnagaaw 27
<210> 20
<211> 18
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(11)
<223> a, c, t or g
<220>
<221> modified_base
<222> (12)..(13)
<223> a, c, t, g, unknown or other
<400> 20
nnnnnnnnnn nnnagaaw 18
<210> 21
<211> 137
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 21
nnnnnnnnnn nnnnnnnnnn gtttttgtac tctcaagatt tagaaataaa tcttgcagaa 60
gctacaaaga taaggcttca tgccgaaatc aacaccctgt cattttatgg cagggtgttt 120
tcgttattta atttttt 137
<210> 22
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 22
nnnnnnnnnn nnnnnnnnnn gtttttgtac tctcagaaat gcagaagcta caaagataag 60
gcttcatgcc gaaatcaaca ccctgtcatt ttatggcagg gtgttttcgt tatttaattt 120
ttt 123
<210> 23
<211> 110
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 23
nnnnnnnnnn nnnnnnnnnn gtttttgtac tctcagaaat gcagaagcta caaagataag 60
gcttcatgcc gaaatcaaca ccctgtcatt ttatggcagg gtgttttttt 110
<210> 24
<211> 102
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 24
nnnnnnnnnn nnnnnnnnnn gttttagagc tagaaatagc aagttaaaat aaggctagtc 60
cgttatcaac ttgaaaaagt ggcaccgagt cggtgctttt tt 102
<210> 25
<211> 88
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 25
nnnnnnnnnn nnnnnnnnnn gttttagagc tagaaatagc aagttaaaat aaggctagtc 60
cgttatcaac ttgaaaaagt gttttttt 88
<210> 26
<211> 76
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 26
nnnnnnnnnn nnnnnnnnnn gttttagagc tagaaatagc aagttaaaat aaggctagtc 60
cgttatcatt tttttt 76
<210> 27
<211> 12
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 27
gttttagagc ta 12
<210> 28
<211> 31
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 28
tagcaagtta aaataaggct agtccgtttt t 31
<210> 29
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(22)
<223> a, c, t, g, unknown or other
<400> 29
nnnnnnnnnn nnnnnnnnnn nnagaaw 27
<210> 30
<211> 12
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 30
guuuuagagc ua 12
<210> 31
<211> 33
<212> DNA
<213> Homo sapiens
<400> 31
ggacatcgat gtcacctcca atgactaggg tgg 33
<210> 32
<211> 33
<212> DNA
<213> Homo sapiens
<400> 32
cattggaggt gacatcgatg tcctccccat tgg 33
<210> 33
<211> 33
<212> DNA
<213> Homo sapiens
<400> 33
ggaagggcct gagtccgagc agaagaagaa ggg 33
<210> 34
<211> 33
<212> DNA
<213> Homo sapiens
<400> 34
ggtggcgaga ggggccgaga ttgggtgttc agg 33
<210> 35
<211> 33
<212> DNA
<213> Homo sapiens
<400> 35
atgcaggagg gtggcgagag gggccgagat tgg 33
<210> 36
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 36
aaaaccaccc ttctctctgg c 21
<210> 37
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 37
ggagattgga gacacggaga g 21
<210> 38
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 38
ctggaaagcc aatgcctgac 20
<210> 39
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 39
ggcagcaaac tccttgtcct 20
<210> 40
<211> 335
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 40
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccg gaaccattca aaacagcata gcaagttaaa ataaggctag tccgttatca 300
acttgaaaaa gtggcaccga gtcggtgctt ttttt 335
<210> 41
<211> 423
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 41
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccg gtagtattaa gtattgtttt atggctgata aatttctttg aatttctcct 300
tgattatttg ttataaaagt tataaaataa tcttgttgga accattcaaa acagcatagc 360
aagttaaaat aaggctagtc cgttatcaac ttgaaaaagt ggcaccgagt cggtgctttt 420
ttt 423
<210> 42
<211> 339
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 42
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccg ggttttagag ctatgctgtt ttgaatggtc ccaaaacggg tcttcgagaa 300
gacgttttag agctatgctg ttttgaatgg tcccaaaac 339
<210> 43
<211> 309
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 43
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccg ggtcttcgag aagacctgtt ttagagctag aaatagcaag ttaaaataag 300
gctagtccg 309
<210> 44
<211> 1648
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 44
Met Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
1 5 10 15
Tyr Lys Asp Asp Asp Asp Lys Met Ala Pro Lys Lys Lys Arg Lys Val
20 25 30
Gly Ile His Gly Val Pro Ala Ala Asp Lys Lys Tyr Ser Ile Gly Leu
35 40 45
Asp Ile Gly Thr Asn Ser Val Gly Trp Ala Val Ile Thr Asp Glu Tyr
50 55 60
Lys Val Pro Ser Lys Lys Phe Lys Val Leu Gly Asn Thr Asp Arg His
65 70 75 80
Ser Ile Lys Lys Asn Leu Ile Gly Ala Leu Leu Phe Asp Ser Gly Glu
85 90 95
Thr Ala Glu Ala Thr Arg Leu Lys Arg Thr Ala Arg Arg Arg Tyr Thr
100 105 110
Arg Arg Lys Asn Arg Ile Cys Tyr Leu Gln Glu Ile Phe Ser Asn Glu
115 120 125
Met Ala Lys Val Asp Asp Ser Phe Phe His Arg Leu Glu Glu Ser Phe
130 135 140
Leu Val Glu Glu Asp Lys Lys His Glu Arg His Pro Ile Phe Gly Asn
145 150 155 160
Ile Val Asp Glu Val Ala Tyr His Glu Lys Tyr Pro Thr Ile Tyr His
165 170 175
Leu Arg Lys Lys Leu Val Asp Ser Thr Asp Lys Ala Asp Leu Arg Leu
180 185 190
Ile Tyr Leu Ala Leu Ala His Met Ile Lys Phe Arg Gly His Phe Leu
195 200 205
Ile Glu Gly Asp Leu Asn Pro Asp Asn Ser Asp Val Asp Lys Leu Phe
210 215 220
Ile Gln Leu Val Gln Thr Tyr Asn Gln Leu Phe Glu Glu Asn Pro Ile
225 230 235 240
Asn Ala Ser Gly Val Asp Ala Lys Ala Ile Leu Ser Ala Arg Leu Ser
245 250 255
Lys Ser Arg Arg Leu Glu Asn Leu Ile Ala Gln Leu Pro Gly Glu Lys
260 265 270
Lys Asn Gly Leu Phe Gly Asn Leu Ile Ala Leu Ser Leu Gly Leu Thr
275 280 285
Pro Asn Phe Lys Ser Asn Phe Asp Leu Ala Glu Asp Ala Lys Leu Gln
290 295 300
Leu Ser Lys Asp Thr Tyr Asp Asp Asp Leu Asp Asn Leu Leu Ala Gln
305 310 315 320
Ile Gly Asp Gln Tyr Ala Asp Leu Phe Leu Ala Ala Lys Asn Leu Ser
325 330 335
Asp Ala Ile Leu Leu Ser Asp Ile Leu Arg Val Asn Thr Glu Ile Thr
340 345 350
Lys Ala Pro Leu Ser Ala Ser Met Ile Lys Arg Tyr Asp Glu His His
355 360 365
Gln Asp Leu Thr Leu Leu Lys Ala Leu Val Arg Gln Gln Leu Pro Glu
370 375 380
Lys Tyr Lys Glu Ile Phe Phe Asp Gln Ser Lys Asn Gly Tyr Ala Gly
385 390 395 400
Tyr Ile Asp Gly Gly Ala Ser Gln Glu Glu Phe Tyr Lys Phe Ile Lys
405 410 415
Pro Ile Leu Glu Lys Met Asp Gly Thr Glu Glu Leu Leu Val Lys Leu
420 425 430
Asn Arg Glu Asp Leu Leu Arg Lys Gln Arg Thr Phe Asp Asn Gly Ser
435 440 445
Ile Pro His Gln Ile His Leu Gly Glu Leu His Ala Ile Leu Arg Arg
450 455 460
Gln Glu Asp Phe Tyr Pro Phe Leu Lys Asp Asn Arg Glu Lys Ile Glu
465 470 475 480
Lys Ile Leu Thr Phe Arg Ile Pro Tyr Tyr Val Gly Pro Leu Ala Arg
485 490 495
Gly Asn Ser Arg Phe Ala Trp Met Thr Arg Lys Ser Glu Glu Thr Ile
500 505 510
Thr Pro Trp Asn Phe Glu Glu Val Val Asp Lys Gly Ala Ser Ala Gln
515 520 525
Ser Phe Ile Glu Arg Met Thr Asn Phe Asp Lys Asn Leu Pro Asn Glu
530 535 540
Lys Val Leu Pro Lys His Ser Leu Leu Tyr Glu Tyr Phe Thr Val Tyr
545 550 555 560
Asn Glu Leu Thr Lys Val Lys Tyr Val Thr Glu Gly Met Arg Lys Pro
565 570 575
Ala Phe Leu Ser Gly Glu Gln Lys Lys Ala Ile Val Asp Leu Leu Phe
580 585 590
Lys Thr Asn Arg Lys Val Thr Val Lys Gln Leu Lys Glu Asp Tyr Phe
595 600 605
Lys Lys Ile Glu Cys Phe Asp Ser Val Glu Ile Ser Gly Val Glu Asp
610 615 620
Arg Phe Asn Ala Ser Leu Gly Thr Tyr His Asp Leu Leu Lys Ile Ile
625 630 635 640
Lys Asp Lys Asp Phe Leu Asp Asn Glu Glu Asn Glu Asp Ile Leu Glu
645 650 655
Asp Ile Val Leu Thr Leu Thr Leu Phe Glu Asp Arg Glu Met Ile Glu
660 665 670
Glu Arg Leu Lys Thr Tyr Ala His Leu Phe Asp Asp Lys Val Met Lys
675 680 685
Gln Leu Lys Arg Arg Arg Tyr Thr Gly Trp Gly Arg Leu Ser Arg Lys
690 695 700
Leu Ile Asn Gly Ile Arg Asp Lys Gln Ser Gly Lys Thr Ile Leu Asp
705 710 715 720
Phe Leu Lys Ser Asp Gly Phe Ala Asn Arg Asn Phe Met Gln Leu Ile
725 730 735
His Asp Asp Ser Leu Thr Phe Lys Glu Asp Ile Gln Lys Ala Gln Val
740 745 750
Ser Gly Gln Gly Asp Ser Leu His Glu His Ile Ala Asn Leu Ala Gly
755 760 765
Ser Pro Ala Ile Lys Lys Gly Ile Leu Gln Thr Val Lys Val Val Asp
770 775 780
Glu Leu Val Lys Val Met Gly Arg His Lys Pro Glu Asn Ile Val Ile
785 790 795 800
Glu Met Ala Arg Glu Asn Gln Thr Thr Gln Lys Gly Gln Lys Asn Ser
805 810 815
Arg Glu Arg Met Lys Arg Ile Glu Glu Gly Ile Lys Glu Leu Gly Ser
820 825 830
Gln Ile Leu Lys Glu His Pro Val Glu Asn Thr Gln Leu Gln Asn Glu
835 840 845
Lys Leu Tyr Leu Tyr Tyr Leu Gln Asn Gly Arg Asp Met Tyr Val Asp
850 855 860
Gln Glu Leu Asp Ile Asn Arg Leu Ser Asp Tyr Asp Val Asp His Ile
865 870 875 880
Val Pro Gln Ser Phe Leu Lys Asp Asp Ser Ile Asp Asn Lys Val Leu
885 890 895
Thr Arg Ser Asp Lys Asn Arg Gly Lys Ser Asp Asn Val Pro Ser Glu
900 905 910
Glu Val Val Lys Lys Met Lys Asn Tyr Trp Arg Gln Leu Leu Asn Ala
915 920 925
Lys Leu Ile Thr Gln Arg Lys Phe Asp Asn Leu Thr Lys Ala Glu Arg
930 935 940
Gly Gly Leu Ser Glu Leu Asp Lys Ala Gly Phe Ile Lys Arg Gln Leu
945 950 955 960
Val Glu Thr Arg Gln Ile Thr Lys His Val Ala Gln Ile Leu Asp Ser
965 970 975
Arg Met Asn Thr Lys Tyr Asp Glu Asn Asp Lys Leu Ile Arg Glu Val
980 985 990
Lys Val Ile Thr Leu Lys Ser Lys Leu Val Ser Asp Phe Arg Lys Asp
995 1000 1005
Phe Gln Phe Tyr Lys Val Arg Glu Ile Asn Asn Tyr His His Ala
1010 1015 1020
His Asp Ala Tyr Leu Asn Ala Val Val Gly Thr Ala Leu Ile Lys
1025 1030 1035
Lys Tyr Pro Lys Leu Glu Ser Glu Phe Val Tyr Gly Asp Tyr Lys
1040 1045 1050
Val Tyr Asp Val Arg Lys Met Ile Ala Lys Ser Glu Gln Glu Ile
1055 1060 1065
Gly Lys Ala Thr Ala Lys Tyr Phe Phe Tyr Ser Asn Ile Met Asn
1070 1075 1080
Phe Phe Lys Thr Glu Ile Thr Leu Ala Asn Gly Glu Ile Arg Lys
1085 1090 1095
Arg Pro Leu Ile Glu Thr Asn Gly Glu Thr Gly Glu Ile Val Trp
1100 1105 1110
Asp Lys Gly Arg Asp Phe Ala Thr Val Arg Lys Val Leu Ser Met
1115 1120 1125
Pro Gln Val Asn Ile Val Lys Lys Thr Glu Val Gln Thr Gly Gly
1130 1135 1140
Phe Ser Lys Glu Ser Ile Leu Pro Lys Arg Asn Ser Asp Lys Leu
1145 1150 1155
Ile Ala Arg Lys Lys Asp Trp Asp Pro Lys Lys Tyr Gly Gly Phe
1160 1165 1170
Asp Ser Pro Thr Val Ala Tyr Ser Val Leu Val Val Ala Lys Val
1175 1180 1185
Glu Lys Gly Lys Ser Lys Lys Leu Lys Ser Val Lys Glu Leu Leu
1190 1195 1200
Gly Ile Thr Ile Met Glu Arg Ser Ser Phe Glu Lys Asn Pro Ile
1205 1210 1215
Asp Phe Leu Glu Ala Lys Gly Tyr Lys Glu Val Lys Lys Asp Leu
1220 1225 1230
Ile Ile Lys Leu Pro Lys Tyr Ser Leu Phe Glu Leu Glu Asn Gly
1235 1240 1245
Arg Lys Arg Met Leu Ala Ser Ala Gly Glu Leu Gln Lys Gly Asn
1250 1255 1260
Glu Leu Ala Leu Pro Ser Lys Tyr Val Asn Phe Leu Tyr Leu Ala
1265 1270 1275
Ser His Tyr Glu Lys Leu Lys Gly Ser Pro Glu Asp Asn Glu Gln
1280 1285 1290
Lys Gln Leu Phe Val Glu Gln His Lys His Tyr Leu Asp Glu Ile
1295 1300 1305
Ile Glu Gln Ile Ser Glu Phe Ser Lys Arg Val Ile Leu Ala Asp
1310 1315 1320
Ala Asn Leu Asp Lys Val Leu Ser Ala Tyr Asn Lys His Arg Asp
1325 1330 1335
Lys Pro Ile Arg Glu Gln Ala Glu Asn Ile Ile His Leu Phe Thr
1340 1345 1350
Leu Thr Asn Leu Gly Ala Pro Ala Ala Phe Lys Tyr Phe Asp Thr
1355 1360 1365
Thr Ile Asp Arg Lys Arg Tyr Thr Ser Thr Lys Glu Val Leu Asp
1370 1375 1380
Ala Thr Leu Ile His Gln Ser Ile Thr Gly Leu Tyr Glu Thr Arg
1385 1390 1395
Ile Asp Leu Ser Gln Leu Gly Gly Asp Ala Ala Ala Val Ser Lys
1400 1405 1410
Gly Glu Glu Leu Phe Thr Gly Val Val Pro Ile Leu Val Glu Leu
1415 1420 1425
Asp Gly Asp Val Asn Gly His Lys Phe Ser Val Ser Gly Glu Gly
1430 1435 1440
Glu Gly Asp Ala Thr Tyr Gly Lys Leu Thr Leu Lys Phe Ile Cys
1445 1450 1455
Thr Thr Gly Lys Leu Pro Val Pro Trp Pro Thr Leu Val Thr Thr
1460 1465 1470
Leu Thr Tyr Gly Val Gln Cys Phe Ser Arg Tyr Pro Asp His Met
1475 1480 1485
Lys Gln His Asp Phe Phe Lys Ser Ala Met Pro Glu Gly Tyr Val
1490 1495 1500
Gln Glu Arg Thr Ile Phe Phe Lys Asp Asp Gly Asn Tyr Lys Thr
1505 1510 1515
Arg Ala Glu Val Lys Phe Glu Gly Asp Thr Leu Val Asn Arg Ile
1520 1525 1530
Glu Leu Lys Gly Ile Asp Phe Lys Glu Asp Gly Asn Ile Leu Gly
1535 1540 1545
His Lys Leu Glu Tyr Asn Tyr Asn Ser His Asn Val Tyr Ile Met
1550 1555 1560
Ala Asp Lys Gln Lys Asn Gly Ile Lys Val Asn Phe Lys Ile Arg
1565 1570 1575
His Asn Ile Glu Asp Gly Ser Val Gln Leu Ala Asp His Tyr Gln
1580 1585 1590
Gln Asn Thr Pro Ile Gly Asp Gly Pro Val Leu Leu Pro Asp Asn
1595 1600 1605
His Tyr Leu Ser Thr Gln Ser Ala Leu Ser Lys Asp Pro Asn Glu
1610 1615 1620
Lys Arg Asp His Met Val Leu Leu Glu Phe Val Thr Ala Ala Gly
1625 1630 1635
Ile Thr Leu Gly Met Asp Glu Leu Tyr Lys
1640 1645
<210> 45
<211> 1625
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 45
Met Asp Lys Lys Tyr Ser Ile Gly Leu Asp Ile Gly Thr Asn Ser Val
1 5 10 15
Gly Trp Ala Val Ile Thr Asp Glu Tyr Lys Val Pro Ser Lys Lys Phe
20 25 30
Lys Val Leu Gly Asn Thr Asp Arg His Ser Ile Lys Lys Asn Leu Ile
35 40 45
Gly Ala Leu Leu Phe Asp Ser Gly Glu Thr Ala Glu Ala Thr Arg Leu
50 55 60
Lys Arg Thr Ala Arg Arg Arg Tyr Thr Arg Arg Lys Asn Arg Ile Cys
65 70 75 80
Tyr Leu Gln Glu Ile Phe Ser Asn Glu Met Ala Lys Val Asp Asp Ser
85 90 95
Phe Phe His Arg Leu Glu Glu Ser Phe Leu Val Glu Glu Asp Lys Lys
100 105 110
His Glu Arg His Pro Ile Phe Gly Asn Ile Val Asp Glu Val Ala Tyr
115 120 125
His Glu Lys Tyr Pro Thr Ile Tyr His Leu Arg Lys Lys Leu Val Asp
130 135 140
Ser Thr Asp Lys Ala Asp Leu Arg Leu Ile Tyr Leu Ala Leu Ala His
145 150 155 160
Met Ile Lys Phe Arg Gly His Phe Leu Ile Glu Gly Asp Leu Asn Pro
165 170 175
Asp Asn Ser Asp Val Asp Lys Leu Phe Ile Gln Leu Val Gln Thr Tyr
180 185 190
Asn Gln Leu Phe Glu Glu Asn Pro Ile Asn Ala Ser Gly Val Asp Ala
195 200 205
Lys Ala Ile Leu Ser Ala Arg Leu Ser Lys Ser Arg Arg Leu Glu Asn
210 215 220
Leu Ile Ala Gln Leu Pro Gly Glu Lys Lys Asn Gly Leu Phe Gly Asn
225 230 235 240
Leu Ile Ala Leu Ser Leu Gly Leu Thr Pro Asn Phe Lys Ser Asn Phe
245 250 255
Asp Leu Ala Glu Asp Ala Lys Leu Gln Leu Ser Lys Asp Thr Tyr Asp
260 265 270
Asp Asp Leu Asp Asn Leu Leu Ala Gln Ile Gly Asp Gln Tyr Ala Asp
275 280 285
Leu Phe Leu Ala Ala Lys Asn Leu Ser Asp Ala Ile Leu Leu Ser Asp
290 295 300
Ile Leu Arg Val Asn Thr Glu Ile Thr Lys Ala Pro Leu Ser Ala Ser
305 310 315 320
Met Ile Lys Arg Tyr Asp Glu His His Gln Asp Leu Thr Leu Leu Lys
325 330 335
Ala Leu Val Arg Gln Gln Leu Pro Glu Lys Tyr Lys Glu Ile Phe Phe
340 345 350
Asp Gln Ser Lys Asn Gly Tyr Ala Gly Tyr Ile Asp Gly Gly Ala Ser
355 360 365
Gln Glu Glu Phe Tyr Lys Phe Ile Lys Pro Ile Leu Glu Lys Met Asp
370 375 380
Gly Thr Glu Glu Leu Leu Val Lys Leu Asn Arg Glu Asp Leu Leu Arg
385 390 395 400
Lys Gln Arg Thr Phe Asp Asn Gly Ser Ile Pro His Gln Ile His Leu
405 410 415
Gly Glu Leu His Ala Ile Leu Arg Arg Gln Glu Asp Phe Tyr Pro Phe
420 425 430
Leu Lys Asp Asn Arg Glu Lys Ile Glu Lys Ile Leu Thr Phe Arg Ile
435 440 445
Pro Tyr Tyr Val Gly Pro Leu Ala Arg Gly Asn Ser Arg Phe Ala Trp
450 455 460
Met Thr Arg Lys Ser Glu Glu Thr Ile Thr Pro Trp Asn Phe Glu Glu
465 470 475 480
Val Val Asp Lys Gly Ala Ser Ala Gln Ser Phe Ile Glu Arg Met Thr
485 490 495
Asn Phe Asp Lys Asn Leu Pro Asn Glu Lys Val Leu Pro Lys His Ser
500 505 510
Leu Leu Tyr Glu Tyr Phe Thr Val Tyr Asn Glu Leu Thr Lys Val Lys
515 520 525
Tyr Val Thr Glu Gly Met Arg Lys Pro Ala Phe Leu Ser Gly Glu Gln
530 535 540
Lys Lys Ala Ile Val Asp Leu Leu Phe Lys Thr Asn Arg Lys Val Thr
545 550 555 560
Val Lys Gln Leu Lys Glu Asp Tyr Phe Lys Lys Ile Glu Cys Phe Asp
565 570 575
Ser Val Glu Ile Ser Gly Val Glu Asp Arg Phe Asn Ala Ser Leu Gly
580 585 590
Thr Tyr His Asp Leu Leu Lys Ile Ile Lys Asp Lys Asp Phe Leu Asp
595 600 605
Asn Glu Glu Asn Glu Asp Ile Leu Glu Asp Ile Val Leu Thr Leu Thr
610 615 620
Leu Phe Glu Asp Arg Glu Met Ile Glu Glu Arg Leu Lys Thr Tyr Ala
625 630 635 640
His Leu Phe Asp Asp Lys Val Met Lys Gln Leu Lys Arg Arg Arg Tyr
645 650 655
Thr Gly Trp Gly Arg Leu Ser Arg Lys Leu Ile Asn Gly Ile Arg Asp
660 665 670
Lys Gln Ser Gly Lys Thr Ile Leu Asp Phe Leu Lys Ser Asp Gly Phe
675 680 685
Ala Asn Arg Asn Phe Met Gln Leu Ile His Asp Asp Ser Leu Thr Phe
690 695 700
Lys Glu Asp Ile Gln Lys Ala Gln Val Ser Gly Gln Gly Asp Ser Leu
705 710 715 720
His Glu His Ile Ala Asn Leu Ala Gly Ser Pro Ala Ile Lys Lys Gly
725 730 735
Ile Leu Gln Thr Val Lys Val Val Asp Glu Leu Val Lys Val Met Gly
740 745 750
Arg His Lys Pro Glu Asn Ile Val Ile Glu Met Ala Arg Glu Asn Gln
755 760 765
Thr Thr Gln Lys Gly Gln Lys Asn Ser Arg Glu Arg Met Lys Arg Ile
770 775 780
Glu Glu Gly Ile Lys Glu Leu Gly Ser Gln Ile Leu Lys Glu His Pro
785 790 795 800
Val Glu Asn Thr Gln Leu Gln Asn Glu Lys Leu Tyr Leu Tyr Tyr Leu
805 810 815
Gln Asn Gly Arg Asp Met Tyr Val Asp Gln Glu Leu Asp Ile Asn Arg
820 825 830
Leu Ser Asp Tyr Asp Val Asp His Ile Val Pro Gln Ser Phe Leu Lys
835 840 845
Asp Asp Ser Ile Asp Asn Lys Val Leu Thr Arg Ser Asp Lys Asn Arg
850 855 860
Gly Lys Ser Asp Asn Val Pro Ser Glu Glu Val Val Lys Lys Met Lys
865 870 875 880
Asn Tyr Trp Arg Gln Leu Leu Asn Ala Lys Leu Ile Thr Gln Arg Lys
885 890 895
Phe Asp Asn Leu Thr Lys Ala Glu Arg Gly Gly Leu Ser Glu Leu Asp
900 905 910
Lys Ala Gly Phe Ile Lys Arg Gln Leu Val Glu Thr Arg Gln Ile Thr
915 920 925
Lys His Val Ala Gln Ile Leu Asp Ser Arg Met Asn Thr Lys Tyr Asp
930 935 940
Glu Asn Asp Lys Leu Ile Arg Glu Val Lys Val Ile Thr Leu Lys Ser
945 950 955 960
Lys Leu Val Ser Asp Phe Arg Lys Asp Phe Gln Phe Tyr Lys Val Arg
965 970 975
Glu Ile Asn Asn Tyr His His Ala His Asp Ala Tyr Leu Asn Ala Val
980 985 990
Val Gly Thr Ala Leu Ile Lys Lys Tyr Pro Lys Leu Glu Ser Glu Phe
995 1000 1005
Val Tyr Gly Asp Tyr Lys Val Tyr Asp Val Arg Lys Met Ile Ala
1010 1015 1020
Lys Ser Glu Gln Glu Ile Gly Lys Ala Thr Ala Lys Tyr Phe Phe
1025 1030 1035
Tyr Ser Asn Ile Met Asn Phe Phe Lys Thr Glu Ile Thr Leu Ala
1040 1045 1050
Asn Gly Glu Ile Arg Lys Arg Pro Leu Ile Glu Thr Asn Gly Glu
1055 1060 1065
Thr Gly Glu Ile Val Trp Asp Lys Gly Arg Asp Phe Ala Thr Val
1070 1075 1080
Arg Lys Val Leu Ser Met Pro Gln Val Asn Ile Val Lys Lys Thr
1085 1090 1095
Glu Val Gln Thr Gly Gly Phe Ser Lys Glu Ser Ile Leu Pro Lys
1100 1105 1110
Arg Asn Ser Asp Lys Leu Ile Ala Arg Lys Lys Asp Trp Asp Pro
1115 1120 1125
Lys Lys Tyr Gly Gly Phe Asp Ser Pro Thr Val Ala Tyr Ser Val
1130 1135 1140
Leu Val Val Ala Lys Val Glu Lys Gly Lys Ser Lys Lys Leu Lys
1145 1150 1155
Ser Val Lys Glu Leu Leu Gly Ile Thr Ile Met Glu Arg Ser Ser
1160 1165 1170
Phe Glu Lys Asn Pro Ile Asp Phe Leu Glu Ala Lys Gly Tyr Lys
1175 1180 1185
Glu Val Lys Lys Asp Leu Ile Ile Lys Leu Pro Lys Tyr Ser Leu
1190 1195 1200
Phe Glu Leu Glu Asn Gly Arg Lys Arg Met Leu Ala Ser Ala Gly
1205 1210 1215
Glu Leu Gln Lys Gly Asn Glu Leu Ala Leu Pro Ser Lys Tyr Val
1220 1225 1230
Asn Phe Leu Tyr Leu Ala Ser His Tyr Glu Lys Leu Lys Gly Ser
1235 1240 1245
Pro Glu Asp Asn Glu Gln Lys Gln Leu Phe Val Glu Gln His Lys
1250 1255 1260
His Tyr Leu Asp Glu Ile Ile Glu Gln Ile Ser Glu Phe Ser Lys
1265 1270 1275
Arg Val Ile Leu Ala Asp Ala Asn Leu Asp Lys Val Leu Ser Ala
1280 1285 1290
Tyr Asn Lys His Arg Asp Lys Pro Ile Arg Glu Gln Ala Glu Asn
1295 1300 1305
Ile Ile His Leu Phe Thr Leu Thr Asn Leu Gly Ala Pro Ala Ala
1310 1315 1320
Phe Lys Tyr Phe Asp Thr Thr Ile Asp Arg Lys Arg Tyr Thr Ser
1325 1330 1335
Thr Lys Glu Val Leu Asp Ala Thr Leu Ile His Gln Ser Ile Thr
1340 1345 1350
Gly Leu Tyr Glu Thr Arg Ile Asp Leu Ser Gln Leu Gly Gly Asp
1355 1360 1365
Ala Ala Ala Val Ser Lys Gly Glu Glu Leu Phe Thr Gly Val Val
1370 1375 1380
Pro Ile Leu Val Glu Leu Asp Gly Asp Val Asn Gly His Lys Phe
1385 1390 1395
Ser Val Ser Gly Glu Gly Glu Gly Asp Ala Thr Tyr Gly Lys Leu
1400 1405 1410
Thr Leu Lys Phe Ile Cys Thr Thr Gly Lys Leu Pro Val Pro Trp
1415 1420 1425
Pro Thr Leu Val Thr Thr Leu Thr Tyr Gly Val Gln Cys Phe Ser
1430 1435 1440
Arg Tyr Pro Asp His Met Lys Gln His Asp Phe Phe Lys Ser Ala
1445 1450 1455
Met Pro Glu Gly Tyr Val Gln Glu Arg Thr Ile Phe Phe Lys Asp
1460 1465 1470
Asp Gly Asn Tyr Lys Thr Arg Ala Glu Val Lys Phe Glu Gly Asp
1475 1480 1485
Thr Leu Val Asn Arg Ile Glu Leu Lys Gly Ile Asp Phe Lys Glu
1490 1495 1500
Asp Gly Asn Ile Leu Gly His Lys Leu Glu Tyr Asn Tyr Asn Ser
1505 1510 1515
His Asn Val Tyr Ile Met Ala Asp Lys Gln Lys Asn Gly Ile Lys
1520 1525 1530
Val Asn Phe Lys Ile Arg His Asn Ile Glu Asp Gly Ser Val Gln
1535 1540 1545
Leu Ala Asp His Tyr Gln Gln Asn Thr Pro Ile Gly Asp Gly Pro
1550 1555 1560
Val Leu Leu Pro Asp Asn His Tyr Leu Ser Thr Gln Ser Ala Leu
1565 1570 1575
Ser Lys Asp Pro Asn Glu Lys Arg Asp His Met Val Leu Leu Glu
1580 1585 1590
Phe Val Thr Ala Ala Gly Ile Thr Leu Gly Met Asp Glu Leu Tyr
1595 1600 1605
Lys Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys
1610 1615 1620
Lys Lys
1625
<210> 46
<211> 1664
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 46
Met Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
1 5 10 15
Tyr Lys Asp Asp Asp Asp Lys Met Ala Pro Lys Lys Lys Arg Lys Val
20 25 30
Gly Ile His Gly Val Pro Ala Ala Asp Lys Lys Tyr Ser Ile Gly Leu
35 40 45
Asp Ile Gly Thr Asn Ser Val Gly Trp Ala Val Ile Thr Asp Glu Tyr
50 55 60
Lys Val Pro Ser Lys Lys Phe Lys Val Leu Gly Asn Thr Asp Arg His
65 70 75 80
Ser Ile Lys Lys Asn Leu Ile Gly Ala Leu Leu Phe Asp Ser Gly Glu
85 90 95
Thr Ala Glu Ala Thr Arg Leu Lys Arg Thr Ala Arg Arg Arg Tyr Thr
100 105 110
Arg Arg Lys Asn Arg Ile Cys Tyr Leu Gln Glu Ile Phe Ser Asn Glu
115 120 125
Met Ala Lys Val Asp Asp Ser Phe Phe His Arg Leu Glu Glu Ser Phe
130 135 140
Leu Val Glu Glu Asp Lys Lys His Glu Arg His Pro Ile Phe Gly Asn
145 150 155 160
Ile Val Asp Glu Val Ala Tyr His Glu Lys Tyr Pro Thr Ile Tyr His
165 170 175
Leu Arg Lys Lys Leu Val Asp Ser Thr Asp Lys Ala Asp Leu Arg Leu
180 185 190
Ile Tyr Leu Ala Leu Ala His Met Ile Lys Phe Arg Gly His Phe Leu
195 200 205
Ile Glu Gly Asp Leu Asn Pro Asp Asn Ser Asp Val Asp Lys Leu Phe
210 215 220
Ile Gln Leu Val Gln Thr Tyr Asn Gln Leu Phe Glu Glu Asn Pro Ile
225 230 235 240
Asn Ala Ser Gly Val Asp Ala Lys Ala Ile Leu Ser Ala Arg Leu Ser
245 250 255
Lys Ser Arg Arg Leu Glu Asn Leu Ile Ala Gln Leu Pro Gly Glu Lys
260 265 270
Lys Asn Gly Leu Phe Gly Asn Leu Ile Ala Leu Ser Leu Gly Leu Thr
275 280 285
Pro Asn Phe Lys Ser Asn Phe Asp Leu Ala Glu Asp Ala Lys Leu Gln
290 295 300
Leu Ser Lys Asp Thr Tyr Asp Asp Asp Leu Asp Asn Leu Leu Ala Gln
305 310 315 320
Ile Gly Asp Gln Tyr Ala Asp Leu Phe Leu Ala Ala Lys Asn Leu Ser
325 330 335
Asp Ala Ile Leu Leu Ser Asp Ile Leu Arg Val Asn Thr Glu Ile Thr
340 345 350
Lys Ala Pro Leu Ser Ala Ser Met Ile Lys Arg Tyr Asp Glu His His
355 360 365
Gln Asp Leu Thr Leu Leu Lys Ala Leu Val Arg Gln Gln Leu Pro Glu
370 375 380
Lys Tyr Lys Glu Ile Phe Phe Asp Gln Ser Lys Asn Gly Tyr Ala Gly
385 390 395 400
Tyr Ile Asp Gly Gly Ala Ser Gln Glu Glu Phe Tyr Lys Phe Ile Lys
405 410 415
Pro Ile Leu Glu Lys Met Asp Gly Thr Glu Glu Leu Leu Val Lys Leu
420 425 430
Asn Arg Glu Asp Leu Leu Arg Lys Gln Arg Thr Phe Asp Asn Gly Ser
435 440 445
Ile Pro His Gln Ile His Leu Gly Glu Leu His Ala Ile Leu Arg Arg
450 455 460
Gln Glu Asp Phe Tyr Pro Phe Leu Lys Asp Asn Arg Glu Lys Ile Glu
465 470 475 480
Lys Ile Leu Thr Phe Arg Ile Pro Tyr Tyr Val Gly Pro Leu Ala Arg
485 490 495
Gly Asn Ser Arg Phe Ala Trp Met Thr Arg Lys Ser Glu Glu Thr Ile
500 505 510
Thr Pro Trp Asn Phe Glu Glu Val Val Asp Lys Gly Ala Ser Ala Gln
515 520 525
Ser Phe Ile Glu Arg Met Thr Asn Phe Asp Lys Asn Leu Pro Asn Glu
530 535 540
Lys Val Leu Pro Lys His Ser Leu Leu Tyr Glu Tyr Phe Thr Val Tyr
545 550 555 560
Asn Glu Leu Thr Lys Val Lys Tyr Val Thr Glu Gly Met Arg Lys Pro
565 570 575
Ala Phe Leu Ser Gly Glu Gln Lys Lys Ala Ile Val Asp Leu Leu Phe
580 585 590
Lys Thr Asn Arg Lys Val Thr Val Lys Gln Leu Lys Glu Asp Tyr Phe
595 600 605
Lys Lys Ile Glu Cys Phe Asp Ser Val Glu Ile Ser Gly Val Glu Asp
610 615 620
Arg Phe Asn Ala Ser Leu Gly Thr Tyr His Asp Leu Leu Lys Ile Ile
625 630 635 640
Lys Asp Lys Asp Phe Leu Asp Asn Glu Glu Asn Glu Asp Ile Leu Glu
645 650 655
Asp Ile Val Leu Thr Leu Thr Leu Phe Glu Asp Arg Glu Met Ile Glu
660 665 670
Glu Arg Leu Lys Thr Tyr Ala His Leu Phe Asp Asp Lys Val Met Lys
675 680 685
Gln Leu Lys Arg Arg Arg Tyr Thr Gly Trp Gly Arg Leu Ser Arg Lys
690 695 700
Leu Ile Asn Gly Ile Arg Asp Lys Gln Ser Gly Lys Thr Ile Leu Asp
705 710 715 720
Phe Leu Lys Ser Asp Gly Phe Ala Asn Arg Asn Phe Met Gln Leu Ile
725 730 735
His Asp Asp Ser Leu Thr Phe Lys Glu Asp Ile Gln Lys Ala Gln Val
740 745 750
Ser Gly Gln Gly Asp Ser Leu His Glu His Ile Ala Asn Leu Ala Gly
755 760 765
Ser Pro Ala Ile Lys Lys Gly Ile Leu Gln Thr Val Lys Val Val Asp
770 775 780
Glu Leu Val Lys Val Met Gly Arg His Lys Pro Glu Asn Ile Val Ile
785 790 795 800
Glu Met Ala Arg Glu Asn Gln Thr Thr Gln Lys Gly Gln Lys Asn Ser
805 810 815
Arg Glu Arg Met Lys Arg Ile Glu Glu Gly Ile Lys Glu Leu Gly Ser
820 825 830
Gln Ile Leu Lys Glu His Pro Val Glu Asn Thr Gln Leu Gln Asn Glu
835 840 845
Lys Leu Tyr Leu Tyr Tyr Leu Gln Asn Gly Arg Asp Met Tyr Val Asp
850 855 860
Gln Glu Leu Asp Ile Asn Arg Leu Ser Asp Tyr Asp Val Asp His Ile
865 870 875 880
Val Pro Gln Ser Phe Leu Lys Asp Asp Ser Ile Asp Asn Lys Val Leu
885 890 895
Thr Arg Ser Asp Lys Asn Arg Gly Lys Ser Asp Asn Val Pro Ser Glu
900 905 910
Glu Val Val Lys Lys Met Lys Asn Tyr Trp Arg Gln Leu Leu Asn Ala
915 920 925
Lys Leu Ile Thr Gln Arg Lys Phe Asp Asn Leu Thr Lys Ala Glu Arg
930 935 940
Gly Gly Leu Ser Glu Leu Asp Lys Ala Gly Phe Ile Lys Arg Gln Leu
945 950 955 960
Val Glu Thr Arg Gln Ile Thr Lys His Val Ala Gln Ile Leu Asp Ser
965 970 975
Arg Met Asn Thr Lys Tyr Asp Glu Asn Asp Lys Leu Ile Arg Glu Val
980 985 990
Lys Val Ile Thr Leu Lys Ser Lys Leu Val Ser Asp Phe Arg Lys Asp
995 1000 1005
Phe Gln Phe Tyr Lys Val Arg Glu Ile Asn Asn Tyr His His Ala
1010 1015 1020
His Asp Ala Tyr Leu Asn Ala Val Val Gly Thr Ala Leu Ile Lys
1025 1030 1035
Lys Tyr Pro Lys Leu Glu Ser Glu Phe Val Tyr Gly Asp Tyr Lys
1040 1045 1050
Val Tyr Asp Val Arg Lys Met Ile Ala Lys Ser Glu Gln Glu Ile
1055 1060 1065
Gly Lys Ala Thr Ala Lys Tyr Phe Phe Tyr Ser Asn Ile Met Asn
1070 1075 1080
Phe Phe Lys Thr Glu Ile Thr Leu Ala Asn Gly Glu Ile Arg Lys
1085 1090 1095
Arg Pro Leu Ile Glu Thr Asn Gly Glu Thr Gly Glu Ile Val Trp
1100 1105 1110
Asp Lys Gly Arg Asp Phe Ala Thr Val Arg Lys Val Leu Ser Met
1115 1120 1125
Pro Gln Val Asn Ile Val Lys Lys Thr Glu Val Gln Thr Gly Gly
1130 1135 1140
Phe Ser Lys Glu Ser Ile Leu Pro Lys Arg Asn Ser Asp Lys Leu
1145 1150 1155
Ile Ala Arg Lys Lys Asp Trp Asp Pro Lys Lys Tyr Gly Gly Phe
1160 1165 1170
Asp Ser Pro Thr Val Ala Tyr Ser Val Leu Val Val Ala Lys Val
1175 1180 1185
Glu Lys Gly Lys Ser Lys Lys Leu Lys Ser Val Lys Glu Leu Leu
1190 1195 1200
Gly Ile Thr Ile Met Glu Arg Ser Ser Phe Glu Lys Asn Pro Ile
1205 1210 1215
Asp Phe Leu Glu Ala Lys Gly Tyr Lys Glu Val Lys Lys Asp Leu
1220 1225 1230
Ile Ile Lys Leu Pro Lys Tyr Ser Leu Phe Glu Leu Glu Asn Gly
1235 1240 1245
Arg Lys Arg Met Leu Ala Ser Ala Gly Glu Leu Gln Lys Gly Asn
1250 1255 1260
Glu Leu Ala Leu Pro Ser Lys Tyr Val Asn Phe Leu Tyr Leu Ala
1265 1270 1275
Ser His Tyr Glu Lys Leu Lys Gly Ser Pro Glu Asp Asn Glu Gln
1280 1285 1290
Lys Gln Leu Phe Val Glu Gln His Lys His Tyr Leu Asp Glu Ile
1295 1300 1305
Ile Glu Gln Ile Ser Glu Phe Ser Lys Arg Val Ile Leu Ala Asp
1310 1315 1320
Ala Asn Leu Asp Lys Val Leu Ser Ala Tyr Asn Lys His Arg Asp
1325 1330 1335
Lys Pro Ile Arg Glu Gln Ala Glu Asn Ile Ile His Leu Phe Thr
1340 1345 1350
Leu Thr Asn Leu Gly Ala Pro Ala Ala Phe Lys Tyr Phe Asp Thr
1355 1360 1365
Thr Ile Asp Arg Lys Arg Tyr Thr Ser Thr Lys Glu Val Leu Asp
1370 1375 1380
Ala Thr Leu Ile His Gln Ser Ile Thr Gly Leu Tyr Glu Thr Arg
1385 1390 1395
Ile Asp Leu Ser Gln Leu Gly Gly Asp Ala Ala Ala Val Ser Lys
1400 1405 1410
Gly Glu Glu Leu Phe Thr Gly Val Val Pro Ile Leu Val Glu Leu
1415 1420 1425
Asp Gly Asp Val Asn Gly His Lys Phe Ser Val Ser Gly Glu Gly
1430 1435 1440
Glu Gly Asp Ala Thr Tyr Gly Lys Leu Thr Leu Lys Phe Ile Cys
1445 1450 1455
Thr Thr Gly Lys Leu Pro Val Pro Trp Pro Thr Leu Val Thr Thr
1460 1465 1470
Leu Thr Tyr Gly Val Gln Cys Phe Ser Arg Tyr Pro Asp His Met
1475 1480 1485
Lys Gln His Asp Phe Phe Lys Ser Ala Met Pro Glu Gly Tyr Val
1490 1495 1500
Gln Glu Arg Thr Ile Phe Phe Lys Asp Asp Gly Asn Tyr Lys Thr
1505 1510 1515
Arg Ala Glu Val Lys Phe Glu Gly Asp Thr Leu Val Asn Arg Ile
1520 1525 1530
Glu Leu Lys Gly Ile Asp Phe Lys Glu Asp Gly Asn Ile Leu Gly
1535 1540 1545
His Lys Leu Glu Tyr Asn Tyr Asn Ser His Asn Val Tyr Ile Met
1550 1555 1560
Ala Asp Lys Gln Lys Asn Gly Ile Lys Val Asn Phe Lys Ile Arg
1565 1570 1575
His Asn Ile Glu Asp Gly Ser Val Gln Leu Ala Asp His Tyr Gln
1580 1585 1590
Gln Asn Thr Pro Ile Gly Asp Gly Pro Val Leu Leu Pro Asp Asn
1595 1600 1605
His Tyr Leu Ser Thr Gln Ser Ala Leu Ser Lys Asp Pro Asn Glu
1610 1615 1620
Lys Arg Asp His Met Val Leu Leu Glu Phe Val Thr Ala Ala Gly
1625 1630 1635
Ile Thr Leu Gly Met Asp Glu Leu Tyr Lys Lys Arg Pro Ala Ala
1640 1645 1650
Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1655 1660
<210> 47
<211> 1423
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 47
Met Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
1 5 10 15
Tyr Lys Asp Asp Asp Asp Lys Met Ala Pro Lys Lys Lys Arg Lys Val
20 25 30
Gly Ile His Gly Val Pro Ala Ala Asp Lys Lys Tyr Ser Ile Gly Leu
35 40 45
Asp Ile Gly Thr Asn Ser Val Gly Trp Ala Val Ile Thr Asp Glu Tyr
50 55 60
Lys Val Pro Ser Lys Lys Phe Lys Val Leu Gly Asn Thr Asp Arg His
65 70 75 80
Ser Ile Lys Lys Asn Leu Ile Gly Ala Leu Leu Phe Asp Ser Gly Glu
85 90 95
Thr Ala Glu Ala Thr Arg Leu Lys Arg Thr Ala Arg Arg Arg Tyr Thr
100 105 110
Arg Arg Lys Asn Arg Ile Cys Tyr Leu Gln Glu Ile Phe Ser Asn Glu
115 120 125
Met Ala Lys Val Asp Asp Ser Phe Phe His Arg Leu Glu Glu Ser Phe
130 135 140
Leu Val Glu Glu Asp Lys Lys His Glu Arg His Pro Ile Phe Gly Asn
145 150 155 160
Ile Val Asp Glu Val Ala Tyr His Glu Lys Tyr Pro Thr Ile Tyr His
165 170 175
Leu Arg Lys Lys Leu Val Asp Ser Thr Asp Lys Ala Asp Leu Arg Leu
180 185 190
Ile Tyr Leu Ala Leu Ala His Met Ile Lys Phe Arg Gly His Phe Leu
195 200 205
Ile Glu Gly Asp Leu Asn Pro Asp Asn Ser Asp Val Asp Lys Leu Phe
210 215 220
Ile Gln Leu Val Gln Thr Tyr Asn Gln Leu Phe Glu Glu Asn Pro Ile
225 230 235 240
Asn Ala Ser Gly Val Asp Ala Lys Ala Ile Leu Ser Ala Arg Leu Ser
245 250 255
Lys Ser Arg Arg Leu Glu Asn Leu Ile Ala Gln Leu Pro Gly Glu Lys
260 265 270
Lys Asn Gly Leu Phe Gly Asn Leu Ile Ala Leu Ser Leu Gly Leu Thr
275 280 285
Pro Asn Phe Lys Ser Asn Phe Asp Leu Ala Glu Asp Ala Lys Leu Gln
290 295 300
Leu Ser Lys Asp Thr Tyr Asp Asp Asp Leu Asp Asn Leu Leu Ala Gln
305 310 315 320
Ile Gly Asp Gln Tyr Ala Asp Leu Phe Leu Ala Ala Lys Asn Leu Ser
325 330 335
Asp Ala Ile Leu Leu Ser Asp Ile Leu Arg Val Asn Thr Glu Ile Thr
340 345 350
Lys Ala Pro Leu Ser Ala Ser Met Ile Lys Arg Tyr Asp Glu His His
355 360 365
Gln Asp Leu Thr Leu Leu Lys Ala Leu Val Arg Gln Gln Leu Pro Glu
370 375 380
Lys Tyr Lys Glu Ile Phe Phe Asp Gln Ser Lys Asn Gly Tyr Ala Gly
385 390 395 400
Tyr Ile Asp Gly Gly Ala Ser Gln Glu Glu Phe Tyr Lys Phe Ile Lys
405 410 415
Pro Ile Leu Glu Lys Met Asp Gly Thr Glu Glu Leu Leu Val Lys Leu
420 425 430
Asn Arg Glu Asp Leu Leu Arg Lys Gln Arg Thr Phe Asp Asn Gly Ser
435 440 445
Ile Pro His Gln Ile His Leu Gly Glu Leu His Ala Ile Leu Arg Arg
450 455 460
Gln Glu Asp Phe Tyr Pro Phe Leu Lys Asp Asn Arg Glu Lys Ile Glu
465 470 475 480
Lys Ile Leu Thr Phe Arg Ile Pro Tyr Tyr Val Gly Pro Leu Ala Arg
485 490 495
Gly Asn Ser Arg Phe Ala Trp Met Thr Arg Lys Ser Glu Glu Thr Ile
500 505 510
Thr Pro Trp Asn Phe Glu Glu Val Val Asp Lys Gly Ala Ser Ala Gln
515 520 525
Ser Phe Ile Glu Arg Met Thr Asn Phe Asp Lys Asn Leu Pro Asn Glu
530 535 540
Lys Val Leu Pro Lys His Ser Leu Leu Tyr Glu Tyr Phe Thr Val Tyr
545 550 555 560
Asn Glu Leu Thr Lys Val Lys Tyr Val Thr Glu Gly Met Arg Lys Pro
565 570 575
Ala Phe Leu Ser Gly Glu Gln Lys Lys Ala Ile Val Asp Leu Leu Phe
580 585 590
Lys Thr Asn Arg Lys Val Thr Val Lys Gln Leu Lys Glu Asp Tyr Phe
595 600 605
Lys Lys Ile Glu Cys Phe Asp Ser Val Glu Ile Ser Gly Val Glu Asp
610 615 620
Arg Phe Asn Ala Ser Leu Gly Thr Tyr His Asp Leu Leu Lys Ile Ile
625 630 635 640
Lys Asp Lys Asp Phe Leu Asp Asn Glu Glu Asn Glu Asp Ile Leu Glu
645 650 655
Asp Ile Val Leu Thr Leu Thr Leu Phe Glu Asp Arg Glu Met Ile Glu
660 665 670
Glu Arg Leu Lys Thr Tyr Ala His Leu Phe Asp Asp Lys Val Met Lys
675 680 685
Gln Leu Lys Arg Arg Arg Tyr Thr Gly Trp Gly Arg Leu Ser Arg Lys
690 695 700
Leu Ile Asn Gly Ile Arg Asp Lys Gln Ser Gly Lys Thr Ile Leu Asp
705 710 715 720
Phe Leu Lys Ser Asp Gly Phe Ala Asn Arg Asn Phe Met Gln Leu Ile
725 730 735
His Asp Asp Ser Leu Thr Phe Lys Glu Asp Ile Gln Lys Ala Gln Val
740 745 750
Ser Gly Gln Gly Asp Ser Leu His Glu His Ile Ala Asn Leu Ala Gly
755 760 765
Ser Pro Ala Ile Lys Lys Gly Ile Leu Gln Thr Val Lys Val Val Asp
770 775 780
Glu Leu Val Lys Val Met Gly Arg His Lys Pro Glu Asn Ile Val Ile
785 790 795 800
Glu Met Ala Arg Glu Asn Gln Thr Thr Gln Lys Gly Gln Lys Asn Ser
805 810 815
Arg Glu Arg Met Lys Arg Ile Glu Glu Gly Ile Lys Glu Leu Gly Ser
820 825 830
Gln Ile Leu Lys Glu His Pro Val Glu Asn Thr Gln Leu Gln Asn Glu
835 840 845
Lys Leu Tyr Leu Tyr Tyr Leu Gln Asn Gly Arg Asp Met Tyr Val Asp
850 855 860
Gln Glu Leu Asp Ile Asn Arg Leu Ser Asp Tyr Asp Val Asp His Ile
865 870 875 880
Val Pro Gln Ser Phe Leu Lys Asp Asp Ser Ile Asp Asn Lys Val Leu
885 890 895
Thr Arg Ser Asp Lys Asn Arg Gly Lys Ser Asp Asn Val Pro Ser Glu
900 905 910
Glu Val Val Lys Lys Met Lys Asn Tyr Trp Arg Gln Leu Leu Asn Ala
915 920 925
Lys Leu Ile Thr Gln Arg Lys Phe Asp Asn Leu Thr Lys Ala Glu Arg
930 935 940
Gly Gly Leu Ser Glu Leu Asp Lys Ala Gly Phe Ile Lys Arg Gln Leu
945 950 955 960
Val Glu Thr Arg Gln Ile Thr Lys His Val Ala Gln Ile Leu Asp Ser
965 970 975
Arg Met Asn Thr Lys Tyr Asp Glu Asn Asp Lys Leu Ile Arg Glu Val
980 985 990
Lys Val Ile Thr Leu Lys Ser Lys Leu Val Ser Asp Phe Arg Lys Asp
995 1000 1005
Phe Gln Phe Tyr Lys Val Arg Glu Ile Asn Asn Tyr His His Ala
1010 1015 1020
His Asp Ala Tyr Leu Asn Ala Val Val Gly Thr Ala Leu Ile Lys
1025 1030 1035
Lys Tyr Pro Lys Leu Glu Ser Glu Phe Val Tyr Gly Asp Tyr Lys
1040 1045 1050
Val Tyr Asp Val Arg Lys Met Ile Ala Lys Ser Glu Gln Glu Ile
1055 1060 1065
Gly Lys Ala Thr Ala Lys Tyr Phe Phe Tyr Ser Asn Ile Met Asn
1070 1075 1080
Phe Phe Lys Thr Glu Ile Thr Leu Ala Asn Gly Glu Ile Arg Lys
1085 1090 1095
Arg Pro Leu Ile Glu Thr Asn Gly Glu Thr Gly Glu Ile Val Trp
1100 1105 1110
Asp Lys Gly Arg Asp Phe Ala Thr Val Arg Lys Val Leu Ser Met
1115 1120 1125
Pro Gln Val Asn Ile Val Lys Lys Thr Glu Val Gln Thr Gly Gly
1130 1135 1140
Phe Ser Lys Glu Ser Ile Leu Pro Lys Arg Asn Ser Asp Lys Leu
1145 1150 1155
Ile Ala Arg Lys Lys Asp Trp Asp Pro Lys Lys Tyr Gly Gly Phe
1160 1165 1170
Asp Ser Pro Thr Val Ala Tyr Ser Val Leu Val Val Ala Lys Val
1175 1180 1185
Glu Lys Gly Lys Ser Lys Lys Leu Lys Ser Val Lys Glu Leu Leu
1190 1195 1200
Gly Ile Thr Ile Met Glu Arg Ser Ser Phe Glu Lys Asn Pro Ile
1205 1210 1215
Asp Phe Leu Glu Ala Lys Gly Tyr Lys Glu Val Lys Lys Asp Leu
1220 1225 1230
Ile Ile Lys Leu Pro Lys Tyr Ser Leu Phe Glu Leu Glu Asn Gly
1235 1240 1245
Arg Lys Arg Met Leu Ala Ser Ala Gly Glu Leu Gln Lys Gly Asn
1250 1255 1260
Glu Leu Ala Leu Pro Ser Lys Tyr Val Asn Phe Leu Tyr Leu Ala
1265 1270 1275
Ser His Tyr Glu Lys Leu Lys Gly Ser Pro Glu Asp Asn Glu Gln
1280 1285 1290
Lys Gln Leu Phe Val Glu Gln His Lys His Tyr Leu Asp Glu Ile
1295 1300 1305
Ile Glu Gln Ile Ser Glu Phe Ser Lys Arg Val Ile Leu Ala Asp
1310 1315 1320
Ala Asn Leu Asp Lys Val Leu Ser Ala Tyr Asn Lys His Arg Asp
1325 1330 1335
Lys Pro Ile Arg Glu Gln Ala Glu Asn Ile Ile His Leu Phe Thr
1340 1345 1350
Leu Thr Asn Leu Gly Ala Pro Ala Ala Phe Lys Tyr Phe Asp Thr
1355 1360 1365
Thr Ile Asp Arg Lys Arg Tyr Thr Ser Thr Lys Glu Val Leu Asp
1370 1375 1380
Ala Thr Leu Ile His Gln Ser Ile Thr Gly Leu Tyr Glu Thr Arg
1385 1390 1395
Ile Asp Leu Ser Gln Leu Gly Gly Asp Lys Arg Pro Ala Ala Thr
1400 1405 1410
Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1415 1420
<210> 48
<211> 483
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 48
Met Phe Leu Phe Leu Ser Leu Thr Ser Phe Leu Ser Ser Ser Arg Thr
1 5 10 15
Leu Val Ser Lys Gly Glu Glu Asp Asn Met Ala Ile Ile Lys Glu Phe
20 25 30
Met Arg Phe Lys Val His Met Glu Gly Ser Val Asn Gly His Glu Phe
35 40 45
Glu Ile Glu Gly Glu Gly Glu Gly Arg Pro Tyr Glu Gly Thr Gln Thr
50 55 60
Ala Lys Leu Lys Val Thr Lys Gly Gly Pro Leu Pro Phe Ala Trp Asp
65 70 75 80
Ile Leu Ser Pro Gln Phe Met Tyr Gly Ser Lys Ala Tyr Val Lys His
85 90 95
Pro Ala Asp Ile Pro Asp Tyr Leu Lys Leu Ser Phe Pro Glu Gly Phe
100 105 110
Lys Trp Glu Arg Val Met Asn Phe Glu Asp Gly Gly Val Val Thr Val
115 120 125
Thr Gln Asp Ser Ser Leu Gln Asp Gly Glu Phe Ile Tyr Lys Val Lys
130 135 140
Leu Arg Gly Thr Asn Phe Pro Ser Asp Gly Pro Val Met Gln Lys Lys
145 150 155 160
Thr Met Gly Trp Glu Ala Ser Ser Glu Arg Met Tyr Pro Glu Asp Gly
165 170 175
Ala Leu Lys Gly Glu Ile Lys Gln Arg Leu Lys Leu Lys Asp Gly Gly
180 185 190
His Tyr Asp Ala Glu Val Lys Thr Thr Tyr Lys Ala Lys Lys Pro Val
195 200 205
Gln Leu Pro Gly Ala Tyr Asn Val Asn Ile Lys Leu Asp Ile Thr Ser
210 215 220
His Asn Glu Asp Tyr Thr Ile Val Glu Gln Tyr Glu Arg Ala Glu Gly
225 230 235 240
Arg His Ser Thr Gly Gly Met Asp Glu Leu Tyr Lys Gly Ser Lys Gln
245 250 255
Leu Glu Glu Leu Leu Ser Thr Ser Phe Asp Ile Gln Phe Asn Asp Leu
260 265 270
Thr Leu Leu Glu Thr Ala Phe Thr His Thr Ser Tyr Ala Asn Glu His
275 280 285
Arg Leu Leu Asn Val Ser His Asn Glu Arg Leu Glu Phe Leu Gly Asp
290 295 300
Ala Val Leu Gln Leu Ile Ile Ser Glu Tyr Leu Phe Ala Lys Tyr Pro
305 310 315 320
Lys Lys Thr Glu Gly Asp Met Ser Lys Leu Arg Ser Met Ile Val Arg
325 330 335
Glu Glu Ser Leu Ala Gly Phe Ser Arg Phe Cys Ser Phe Asp Ala Tyr
340 345 350
Ile Lys Leu Gly Lys Gly Glu Glu Lys Ser Gly Gly Arg Arg Arg Asp
355 360 365
Thr Ile Leu Gly Asp Leu Phe Glu Ala Phe Leu Gly Ala Leu Leu Leu
370 375 380
Asp Lys Gly Ile Asp Ala Val Arg Arg Phe Leu Lys Gln Val Met Ile
385 390 395 400
Pro Gln Val Glu Lys Gly Asn Phe Glu Arg Val Lys Asp Tyr Lys Thr
405 410 415
Cys Leu Gln Glu Phe Leu Gln Thr Lys Gly Asp Val Ala Ile Asp Tyr
420 425 430
Gln Val Ile Ser Glu Lys Gly Pro Ala His Ala Lys Gln Phe Glu Val
435 440 445
Ser Ile Val Val Asn Gly Ala Val Leu Ser Lys Gly Leu Gly Lys Ser
450 455 460
Lys Lys Leu Ala Glu Gln Asp Ala Ala Lys Asn Ala Leu Ala Gln Leu
465 470 475 480
Ser Glu Val
<210> 49
<211> 483
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 49
Met Lys Gln Leu Glu Glu Leu Leu Ser Thr Ser Phe Asp Ile Gln Phe
1 5 10 15
Asn Asp Leu Thr Leu Leu Glu Thr Ala Phe Thr His Thr Ser Tyr Ala
20 25 30
Asn Glu His Arg Leu Leu Asn Val Ser His Asn Glu Arg Leu Glu Phe
35 40 45
Leu Gly Asp Ala Val Leu Gln Leu Ile Ile Ser Glu Tyr Leu Phe Ala
50 55 60
Lys Tyr Pro Lys Lys Thr Glu Gly Asp Met Ser Lys Leu Arg Ser Met
65 70 75 80
Ile Val Arg Glu Glu Ser Leu Ala Gly Phe Ser Arg Phe Cys Ser Phe
85 90 95
Asp Ala Tyr Ile Lys Leu Gly Lys Gly Glu Glu Lys Ser Gly Gly Arg
100 105 110
Arg Arg Asp Thr Ile Leu Gly Asp Leu Phe Glu Ala Phe Leu Gly Ala
115 120 125
Leu Leu Leu Asp Lys Gly Ile Asp Ala Val Arg Arg Phe Leu Lys Gln
130 135 140
Val Met Ile Pro Gln Val Glu Lys Gly Asn Phe Glu Arg Val Lys Asp
145 150 155 160
Tyr Lys Thr Cys Leu Gln Glu Phe Leu Gln Thr Lys Gly Asp Val Ala
165 170 175
Ile Asp Tyr Gln Val Ile Ser Glu Lys Gly Pro Ala His Ala Lys Gln
180 185 190
Phe Glu Val Ser Ile Val Val Asn Gly Ala Val Leu Ser Lys Gly Leu
195 200 205
Gly Lys Ser Lys Lys Leu Ala Glu Gln Asp Ala Ala Lys Asn Ala Leu
210 215 220
Ala Gln Leu Ser Glu Val Gly Ser Val Ser Lys Gly Glu Glu Asp Asn
225 230 235 240
Met Ala Ile Ile Lys Glu Phe Met Arg Phe Lys Val His Met Glu Gly
245 250 255
Ser Val Asn Gly His Glu Phe Glu Ile Glu Gly Glu Gly Glu Gly Arg
260 265 270
Pro Tyr Glu Gly Thr Gln Thr Ala Lys Leu Lys Val Thr Lys Gly Gly
275 280 285
Pro Leu Pro Phe Ala Trp Asp Ile Leu Ser Pro Gln Phe Met Tyr Gly
290 295 300
Ser Lys Ala Tyr Val Lys His Pro Ala Asp Ile Pro Asp Tyr Leu Lys
305 310 315 320
Leu Ser Phe Pro Glu Gly Phe Lys Trp Glu Arg Val Met Asn Phe Glu
325 330 335
Asp Gly Gly Val Val Thr Val Thr Gln Asp Ser Ser Leu Gln Asp Gly
340 345 350
Glu Phe Ile Tyr Lys Val Lys Leu Arg Gly Thr Asn Phe Pro Ser Asp
355 360 365
Gly Pro Val Met Gln Lys Lys Thr Met Gly Trp Glu Ala Ser Ser Glu
370 375 380
Arg Met Tyr Pro Glu Asp Gly Ala Leu Lys Gly Glu Ile Lys Gln Arg
385 390 395 400
Leu Lys Leu Lys Asp Gly Gly His Tyr Asp Ala Glu Val Lys Thr Thr
405 410 415
Tyr Lys Ala Lys Lys Pro Val Gln Leu Pro Gly Ala Tyr Asn Val Asn
420 425 430
Ile Lys Leu Asp Ile Thr Ser His Asn Glu Asp Tyr Thr Ile Val Glu
435 440 445
Gln Tyr Glu Arg Ala Glu Gly Arg His Ser Thr Gly Gly Met Asp Glu
450 455 460
Leu Tyr Lys Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys
465 470 475 480
Lys Lys Lys
<210> 50
<211> 1423
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 50
Met Asp Tyr Lys Asp His Asp Gly Asp Tyr Lys Asp His Asp Ile Asp
1 5 10 15
Tyr Lys Asp Asp Asp Asp Lys Met Ala Pro Lys Lys Lys Arg Lys Val
20 25 30
Gly Ile His Gly Val Pro Ala Ala Asp Lys Lys Tyr Ser Ile Gly Leu
35 40 45
Ala Ile Gly Thr Asn Ser Val Gly Trp Ala Val Ile Thr Asp Glu Tyr
50 55 60
Lys Val Pro Ser Lys Lys Phe Lys Val Leu Gly Asn Thr Asp Arg His
65 70 75 80
Ser Ile Lys Lys Asn Leu Ile Gly Ala Leu Leu Phe Asp Ser Gly Glu
85 90 95
Thr Ala Glu Ala Thr Arg Leu Lys Arg Thr Ala Arg Arg Arg Tyr Thr
100 105 110
Arg Arg Lys Asn Arg Ile Cys Tyr Leu Gln Glu Ile Phe Ser Asn Glu
115 120 125
Met Ala Lys Val Asp Asp Ser Phe Phe His Arg Leu Glu Glu Ser Phe
130 135 140
Leu Val Glu Glu Asp Lys Lys His Glu Arg His Pro Ile Phe Gly Asn
145 150 155 160
Ile Val Asp Glu Val Ala Tyr His Glu Lys Tyr Pro Thr Ile Tyr His
165 170 175
Leu Arg Lys Lys Leu Val Asp Ser Thr Asp Lys Ala Asp Leu Arg Leu
180 185 190
Ile Tyr Leu Ala Leu Ala His Met Ile Lys Phe Arg Gly His Phe Leu
195 200 205
Ile Glu Gly Asp Leu Asn Pro Asp Asn Ser Asp Val Asp Lys Leu Phe
210 215 220
Ile Gln Leu Val Gln Thr Tyr Asn Gln Leu Phe Glu Glu Asn Pro Ile
225 230 235 240
Asn Ala Ser Gly Val Asp Ala Lys Ala Ile Leu Ser Ala Arg Leu Ser
245 250 255
Lys Ser Arg Arg Leu Glu Asn Leu Ile Ala Gln Leu Pro Gly Glu Lys
260 265 270
Lys Asn Gly Leu Phe Gly Asn Leu Ile Ala Leu Ser Leu Gly Leu Thr
275 280 285
Pro Asn Phe Lys Ser Asn Phe Asp Leu Ala Glu Asp Ala Lys Leu Gln
290 295 300
Leu Ser Lys Asp Thr Tyr Asp Asp Asp Leu Asp Asn Leu Leu Ala Gln
305 310 315 320
Ile Gly Asp Gln Tyr Ala Asp Leu Phe Leu Ala Ala Lys Asn Leu Ser
325 330 335
Asp Ala Ile Leu Leu Ser Asp Ile Leu Arg Val Asn Thr Glu Ile Thr
340 345 350
Lys Ala Pro Leu Ser Ala Ser Met Ile Lys Arg Tyr Asp Glu His His
355 360 365
Gln Asp Leu Thr Leu Leu Lys Ala Leu Val Arg Gln Gln Leu Pro Glu
370 375 380
Lys Tyr Lys Glu Ile Phe Phe Asp Gln Ser Lys Asn Gly Tyr Ala Gly
385 390 395 400
Tyr Ile Asp Gly Gly Ala Ser Gln Glu Glu Phe Tyr Lys Phe Ile Lys
405 410 415
Pro Ile Leu Glu Lys Met Asp Gly Thr Glu Glu Leu Leu Val Lys Leu
420 425 430
Asn Arg Glu Asp Leu Leu Arg Lys Gln Arg Thr Phe Asp Asn Gly Ser
435 440 445
Ile Pro His Gln Ile His Leu Gly Glu Leu His Ala Ile Leu Arg Arg
450 455 460
Gln Glu Asp Phe Tyr Pro Phe Leu Lys Asp Asn Arg Glu Lys Ile Glu
465 470 475 480
Lys Ile Leu Thr Phe Arg Ile Pro Tyr Tyr Val Gly Pro Leu Ala Arg
485 490 495
Gly Asn Ser Arg Phe Ala Trp Met Thr Arg Lys Ser Glu Glu Thr Ile
500 505 510
Thr Pro Trp Asn Phe Glu Glu Val Val Asp Lys Gly Ala Ser Ala Gln
515 520 525
Ser Phe Ile Glu Arg Met Thr Asn Phe Asp Lys Asn Leu Pro Asn Glu
530 535 540
Lys Val Leu Pro Lys His Ser Leu Leu Tyr Glu Tyr Phe Thr Val Tyr
545 550 555 560
Asn Glu Leu Thr Lys Val Lys Tyr Val Thr Glu Gly Met Arg Lys Pro
565 570 575
Ala Phe Leu Ser Gly Glu Gln Lys Lys Ala Ile Val Asp Leu Leu Phe
580 585 590
Lys Thr Asn Arg Lys Val Thr Val Lys Gln Leu Lys Glu Asp Tyr Phe
595 600 605
Lys Lys Ile Glu Cys Phe Asp Ser Val Glu Ile Ser Gly Val Glu Asp
610 615 620
Arg Phe Asn Ala Ser Leu Gly Thr Tyr His Asp Leu Leu Lys Ile Ile
625 630 635 640
Lys Asp Lys Asp Phe Leu Asp Asn Glu Glu Asn Glu Asp Ile Leu Glu
645 650 655
Asp Ile Val Leu Thr Leu Thr Leu Phe Glu Asp Arg Glu Met Ile Glu
660 665 670
Glu Arg Leu Lys Thr Tyr Ala His Leu Phe Asp Asp Lys Val Met Lys
675 680 685
Gln Leu Lys Arg Arg Arg Tyr Thr Gly Trp Gly Arg Leu Ser Arg Lys
690 695 700
Leu Ile Asn Gly Ile Arg Asp Lys Gln Ser Gly Lys Thr Ile Leu Asp
705 710 715 720
Phe Leu Lys Ser Asp Gly Phe Ala Asn Arg Asn Phe Met Gln Leu Ile
725 730 735
His Asp Asp Ser Leu Thr Phe Lys Glu Asp Ile Gln Lys Ala Gln Val
740 745 750
Ser Gly Gln Gly Asp Ser Leu His Glu His Ile Ala Asn Leu Ala Gly
755 760 765
Ser Pro Ala Ile Lys Lys Gly Ile Leu Gln Thr Val Lys Val Val Asp
770 775 780
Glu Leu Val Lys Val Met Gly Arg His Lys Pro Glu Asn Ile Val Ile
785 790 795 800
Glu Met Ala Arg Glu Asn Gln Thr Thr Gln Lys Gly Gln Lys Asn Ser
805 810 815
Arg Glu Arg Met Lys Arg Ile Glu Glu Gly Ile Lys Glu Leu Gly Ser
820 825 830
Gln Ile Leu Lys Glu His Pro Val Glu Asn Thr Gln Leu Gln Asn Glu
835 840 845
Lys Leu Tyr Leu Tyr Tyr Leu Gln Asn Gly Arg Asp Met Tyr Val Asp
850 855 860
Gln Glu Leu Asp Ile Asn Arg Leu Ser Asp Tyr Asp Val Asp His Ile
865 870 875 880
Val Pro Gln Ser Phe Leu Lys Asp Asp Ser Ile Asp Asn Lys Val Leu
885 890 895
Thr Arg Ser Asp Lys Asn Arg Gly Lys Ser Asp Asn Val Pro Ser Glu
900 905 910
Glu Val Val Lys Lys Met Lys Asn Tyr Trp Arg Gln Leu Leu Asn Ala
915 920 925
Lys Leu Ile Thr Gln Arg Lys Phe Asp Asn Leu Thr Lys Ala Glu Arg
930 935 940
Gly Gly Leu Ser Glu Leu Asp Lys Ala Gly Phe Ile Lys Arg Gln Leu
945 950 955 960
Val Glu Thr Arg Gln Ile Thr Lys His Val Ala Gln Ile Leu Asp Ser
965 970 975
Arg Met Asn Thr Lys Tyr Asp Glu Asn Asp Lys Leu Ile Arg Glu Val
980 985 990
Lys Val Ile Thr Leu Lys Ser Lys Leu Val Ser Asp Phe Arg Lys Asp
995 1000 1005
Phe Gln Phe Tyr Lys Val Arg Glu Ile Asn Asn Tyr His His Ala
1010 1015 1020
His Asp Ala Tyr Leu Asn Ala Val Val Gly Thr Ala Leu Ile Lys
1025 1030 1035
Lys Tyr Pro Lys Leu Glu Ser Glu Phe Val Tyr Gly Asp Tyr Lys
1040 1045 1050
Val Tyr Asp Val Arg Lys Met Ile Ala Lys Ser Glu Gln Glu Ile
1055 1060 1065
Gly Lys Ala Thr Ala Lys Tyr Phe Phe Tyr Ser Asn Ile Met Asn
1070 1075 1080
Phe Phe Lys Thr Glu Ile Thr Leu Ala Asn Gly Glu Ile Arg Lys
1085 1090 1095
Arg Pro Leu Ile Glu Thr Asn Gly Glu Thr Gly Glu Ile Val Trp
1100 1105 1110
Asp Lys Gly Arg Asp Phe Ala Thr Val Arg Lys Val Leu Ser Met
1115 1120 1125
Pro Gln Val Asn Ile Val Lys Lys Thr Glu Val Gln Thr Gly Gly
1130 1135 1140
Phe Ser Lys Glu Ser Ile Leu Pro Lys Arg Asn Ser Asp Lys Leu
1145 1150 1155
Ile Ala Arg Lys Lys Asp Trp Asp Pro Lys Lys Tyr Gly Gly Phe
1160 1165 1170
Asp Ser Pro Thr Val Ala Tyr Ser Val Leu Val Val Ala Lys Val
1175 1180 1185
Glu Lys Gly Lys Ser Lys Lys Leu Lys Ser Val Lys Glu Leu Leu
1190 1195 1200
Gly Ile Thr Ile Met Glu Arg Ser Ser Phe Glu Lys Asn Pro Ile
1205 1210 1215
Asp Phe Leu Glu Ala Lys Gly Tyr Lys Glu Val Lys Lys Asp Leu
1220 1225 1230
Ile Ile Lys Leu Pro Lys Tyr Ser Leu Phe Glu Leu Glu Asn Gly
1235 1240 1245
Arg Lys Arg Met Leu Ala Ser Ala Gly Glu Leu Gln Lys Gly Asn
1250 1255 1260
Glu Leu Ala Leu Pro Ser Lys Tyr Val Asn Phe Leu Tyr Leu Ala
1265 1270 1275
Ser His Tyr Glu Lys Leu Lys Gly Ser Pro Glu Asp Asn Glu Gln
1280 1285 1290
Lys Gln Leu Phe Val Glu Gln His Lys His Tyr Leu Asp Glu Ile
1295 1300 1305
Ile Glu Gln Ile Ser Glu Phe Ser Lys Arg Val Ile Leu Ala Asp
1310 1315 1320
Ala Asn Leu Asp Lys Val Leu Ser Ala Tyr Asn Lys His Arg Asp
1325 1330 1335
Lys Pro Ile Arg Glu Gln Ala Glu Asn Ile Ile His Leu Phe Thr
1340 1345 1350
Leu Thr Asn Leu Gly Ala Pro Ala Ala Phe Lys Tyr Phe Asp Thr
1355 1360 1365
Thr Ile Asp Arg Lys Arg Tyr Thr Ser Thr Lys Glu Val Leu Asp
1370 1375 1380
Ala Thr Leu Ile His Gln Ser Ile Thr Gly Leu Tyr Glu Thr Arg
1385 1390 1395
Ile Asp Leu Ser Gln Leu Gly Gly Asp Lys Arg Pro Ala Ala Thr
1400 1405 1410
Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1415 1420
<210> 51
<211> 2012
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 51
gaatgctgcc ctcagacccg cttcctccct gtccttgtct gtccaaggag aatgaggtct 60
cactggtgga tttcggacta ccctgaggag ctggcacctg agggacaagg ccccccacct 120
gcccagctcc agcctctgat gaggggtggg agagagctac atgaggttgc taagaaagcc 180
tcccctgaag gagaccacac agtgtgtgag gttggagtct ctagcagcgg gttctgtgcc 240
cccagggata gtctggctgt ccaggcactg ctcttgatat aaacaccacc tcctagttat 300
gaaaccatgc ccattctgcc tctctgtatg gaaaagagca tggggctggc ccgtggggtg 360
gtgtccactt taggccctgt gggagatcat gggaacccac gcagtgggtc ataggctctc 420
tcatttacta ctcacatcca ctctgtgaag aagcgattat gatctctcct ctagaaactc 480
gtagagtccc atgtctgccg gcttccagag cctgcactcc tccaccttgg cttggctttg 540
ctggggctag aggagctagg atgcacagca gctctgtgac cctttgtttg agaggaacag 600
gaaaaccacc cttctctctg gcccactgtg tcctcttcct gccctgccat ccccttctgt 660
gaatgttaga cccatgggag cagctggtca gaggggaccc cggcctgggg cccctaaccc 720
tatgtagcct cagtcttccc atcaggctct cagctcagcc tgagtgttga ggccccagtg 780
gctgctctgg gggcctcctg agtttctcat ctgtgcccct ccctccctgg cccaggtgaa 840
ggtgtggttc cagaaccgga ggacaaagta caaacggcag aagctggagg aggaagggcc 900
tgagtccgag cagaagaaga agggctccca tcacatcaac cggtggcgca ttgccacgaa 960
gcaggccaat ggggaggaca tcgatgtcac ctccaatgac aagcttgcta gcggtgggca 1020
accacaaacc cacgagggca gagtgctgct tgctgctggc caggcccctg cgtgggccca 1080
agctggactc tggccactcc ctggccaggc tttggggagg cctggagtca tggccccaca 1140
gggcttgaag cccggggccg ccattgacag agggacaagc aatgggctgg ctgaggcctg 1200
ggaccacttg gccttctcct cggagagcct gcctgcctgg gcgggcccgc ccgccaccgc 1260
agcctcccag ctgctctccg tgtctccaat ctcccttttg ttttgatgca tttctgtttt 1320
aatttatttt ccaggcacca ctgtagttta gtgatcccca gtgtccccct tccctatggg 1380
aataataaaa gtctctctct taatgacacg ggcatccagc tccagcccca gagcctgggg 1440
tggtagattc cggctctgag ggccagtggg ggctggtaga gcaaacgcgt tcagggcctg 1500
ggagcctggg gtggggtact ggtggagggg gtcaagggta attcattaac tcctctcttt 1560
tgttggggga ccctggtctc tacctccagc tccacagcag gagaaacagg ctagacatag 1620
ggaagggcca tcctgtatct tgagggagga caggcccagg tctttcttaa cgtattgaga 1680
ggtgggaatc aggcccaggt agttcaatgg gagagggaga gtgcttccct ctgcctagag 1740
actctggtgg cttctccagt tgaggagaaa ccagaggaaa ggggaggatt ggggtctggg 1800
ggagggaaca ccattcacaa aggctgacgg ttccagtccg aagtcgtggg cccaccagga 1860
tgctcacctg tccttggaga accgctgggc aggttgagac tgcagagaca gggcttaagg 1920
ctgagcctgc aaccagtccc cagtgactca gggcctcctc agcccaagaa agagcaacgt 1980
gccagggccc gctgagctct tgtgttcacc tg 2012
<210> 52
<211> 1153
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polypeptide"
<400> 52
Met Lys Arg Pro Ala Ala Thr Lys Lys Ala Gly Gln Ala Lys Lys Lys
1 5 10 15
Lys Ser Asp Leu Val Leu Gly Leu Asp Ile Gly Ile Gly Ser Val Gly
20 25 30
Val Gly Ile Leu Asn Lys Val Thr Gly Glu Ile Ile His Lys Asn Ser
35 40 45
Arg Ile Phe Pro Ala Ala Gln Ala Glu Asn Asn Leu Val Arg Arg Thr
50 55 60
Asn Arg Gln Gly Arg Arg Leu Ala Arg Arg Lys Lys His Arg Arg Val
65 70 75 80
Arg Leu Asn Arg Leu Phe Glu Glu Ser Gly Leu Ile Thr Asp Phe Thr
85 90 95
Lys Ile Ser Ile Asn Leu Asn Pro Tyr Gln Leu Arg Val Lys Gly Leu
100 105 110
Thr Asp Glu Leu Ser Asn Glu Glu Leu Phe Ile Ala Leu Lys Asn Met
115 120 125
Val Lys His Arg Gly Ile Ser Tyr Leu Asp Asp Ala Ser Asp Asp Gly
130 135 140
Asn Ser Ser Val Gly Asp Tyr Ala Gln Ile Val Lys Glu Asn Ser Lys
145 150 155 160
Gln Leu Glu Thr Lys Thr Pro Gly Gln Ile Gln Leu Glu Arg Tyr Gln
165 170 175
Thr Tyr Gly Gln Leu Arg Gly Asp Phe Thr Val Glu Lys Asp Gly Lys
180 185 190
Lys His Arg Leu Ile Asn Val Phe Pro Thr Ser Ala Tyr Arg Ser Glu
195 200 205
Ala Leu Arg Ile Leu Gln Thr Gln Gln Glu Phe Asn Pro Gln Ile Thr
210 215 220
Asp Glu Phe Ile Asn Arg Tyr Leu Glu Ile Leu Thr Gly Lys Arg Lys
225 230 235 240
Tyr Tyr His Gly Pro Gly Asn Glu Lys Ser Arg Thr Asp Tyr Gly Arg
245 250 255
Tyr Arg Thr Ser Gly Glu Thr Leu Asp Asn Ile Phe Gly Ile Leu Ile
260 265 270
Gly Lys Cys Thr Phe Tyr Pro Asp Glu Phe Arg Ala Ala Lys Ala Ser
275 280 285
Tyr Thr Ala Gln Glu Phe Asn Leu Leu Asn Asp Leu Asn Asn Leu Thr
290 295 300
Val Pro Thr Glu Thr Lys Lys Leu Ser Lys Glu Gln Lys Asn Gln Ile
305 310 315 320
Ile Asn Tyr Val Lys Asn Glu Lys Ala Met Gly Pro Ala Lys Leu Phe
325 330 335
Lys Tyr Ile Ala Lys Leu Leu Ser Cys Asp Val Ala Asp Ile Lys Gly
340 345 350
Tyr Arg Ile Asp Lys Ser Gly Lys Ala Glu Ile His Thr Phe Glu Ala
355 360 365
Tyr Arg Lys Met Lys Thr Leu Glu Thr Leu Asp Ile Glu Gln Met Asp
370 375 380
Arg Glu Thr Leu Asp Lys Leu Ala Tyr Val Leu Thr Leu Asn Thr Glu
385 390 395 400
Arg Glu Gly Ile Gln Glu Ala Leu Glu His Glu Phe Ala Asp Gly Ser
405 410 415
Phe Ser Gln Lys Gln Val Asp Glu Leu Val Gln Phe Arg Lys Ala Asn
420 425 430
Ser Ser Ile Phe Gly Lys Gly Trp His Asn Phe Ser Val Lys Leu Met
435 440 445
Met Glu Leu Ile Pro Glu Leu Tyr Glu Thr Ser Glu Glu Gln Met Thr
450 455 460
Ile Leu Thr Arg Leu Gly Lys Gln Lys Thr Thr Ser Ser Ser Asn Lys
465 470 475 480
Thr Lys Tyr Ile Asp Glu Lys Leu Leu Thr Glu Glu Ile Tyr Asn Pro
485 490 495
Val Val Ala Lys Ser Val Arg Gln Ala Ile Lys Ile Val Asn Ala Ala
500 505 510
Ile Lys Glu Tyr Gly Asp Phe Asp Asn Ile Val Ile Glu Met Ala Arg
515 520 525
Glu Thr Asn Glu Asp Asp Glu Lys Lys Ala Ile Gln Lys Ile Gln Lys
530 535 540
Ala Asn Lys Asp Glu Lys Asp Ala Ala Met Leu Lys Ala Ala Asn Gln
545 550 555 560
Tyr Asn Gly Lys Ala Glu Leu Pro His Ser Val Phe His Gly His Lys
565 570 575
Gln Leu Ala Thr Lys Ile Arg Leu Trp His Gln Gln Gly Glu Arg Cys
580 585 590
Leu Tyr Thr Gly Lys Thr Ile Ser Ile His Asp Leu Ile Asn Asn Ser
595 600 605
Asn Gln Phe Glu Val Asp His Ile Leu Pro Leu Ser Ile Thr Phe Asp
610 615 620
Asp Ser Leu Ala Asn Lys Val Leu Val Tyr Ala Thr Ala Asn Gln Glu
625 630 635 640
Lys Gly Gln Arg Thr Pro Tyr Gln Ala Leu Asp Ser Met Asp Asp Ala
645 650 655
Trp Ser Phe Arg Glu Leu Lys Ala Phe Val Arg Glu Ser Lys Thr Leu
660 665 670
Ser Asn Lys Lys Lys Glu Tyr Leu Leu Thr Glu Glu Asp Ile Ser Lys
675 680 685
Phe Asp Val Arg Lys Lys Phe Ile Glu Arg Asn Leu Val Asp Thr Arg
690 695 700
Tyr Ala Ser Arg Val Val Leu Asn Ala Leu Gln Glu His Phe Arg Ala
705 710 715 720
His Lys Ile Asp Thr Lys Val Ser Val Val Arg Gly Gln Phe Thr Ser
725 730 735
Gln Leu Arg Arg His Trp Gly Ile Glu Lys Thr Arg Asp Thr Tyr His
740 745 750
His His Ala Val Asp Ala Leu Ile Ile Ala Ala Ser Ser Gln Leu Asn
755 760 765
Leu Trp Lys Lys Gln Lys Asn Thr Leu Val Ser Tyr Ser Glu Asp Gln
770 775 780
Leu Leu Asp Ile Glu Thr Gly Glu Leu Ile Ser Asp Asp Glu Tyr Lys
785 790 795 800
Glu Ser Val Phe Lys Ala Pro Tyr Gln His Phe Val Asp Thr Leu Lys
805 810 815
Ser Lys Glu Phe Glu Asp Ser Ile Leu Phe Ser Tyr Gln Val Asp Ser
820 825 830
Lys Phe Asn Arg Lys Ile Ser Asp Ala Thr Ile Tyr Ala Thr Arg Gln
835 840 845
Ala Lys Val Gly Lys Asp Lys Ala Asp Glu Thr Tyr Val Leu Gly Lys
850 855 860
Ile Lys Asp Ile Tyr Thr Gln Asp Gly Tyr Asp Ala Phe Met Lys Ile
865 870 875 880
Tyr Lys Lys Asp Lys Ser Lys Phe Leu Met Tyr Arg His Asp Pro Gln
885 890 895
Thr Phe Glu Lys Val Ile Glu Pro Ile Leu Glu Asn Tyr Pro Asn Lys
900 905 910
Gln Ile Asn Glu Lys Gly Lys Glu Val Pro Cys Asn Pro Phe Leu Lys
915 920 925
Tyr Lys Glu Glu His Gly Tyr Ile Arg Lys Tyr Ser Lys Lys Gly Asn
930 935 940
Gly Pro Glu Ile Lys Ser Leu Lys Tyr Tyr Asp Ser Lys Leu Gly Asn
945 950 955 960
His Ile Asp Ile Thr Pro Lys Asp Ser Asn Asn Lys Val Val Leu Gln
965 970 975
Ser Val Ser Pro Trp Arg Ala Asp Val Tyr Phe Asn Lys Thr Thr Gly
980 985 990
Lys Tyr Glu Ile Leu Gly Leu Lys Tyr Ala Asp Leu Gln Phe Glu Lys
995 1000 1005
Gly Thr Gly Thr Tyr Lys Ile Ser Gln Glu Lys Tyr Asn Asp Ile
1010 1015 1020
Lys Lys Lys Glu Gly Val Asp Ser Asp Ser Glu Phe Lys Phe Thr
1025 1030 1035
Leu Tyr Lys Asn Asp Leu Leu Leu Val Lys Asp Thr Glu Thr Lys
1040 1045 1050
Glu Gln Gln Leu Phe Arg Phe Leu Ser Arg Thr Met Pro Lys Gln
1055 1060 1065
Lys His Tyr Val Glu Leu Lys Pro Tyr Asp Lys Gln Lys Phe Glu
1070 1075 1080
Gly Gly Glu Ala Leu Ile Lys Val Leu Gly Asn Val Ala Asn Ser
1085 1090 1095
Gly Gln Cys Lys Lys Gly Leu Gly Lys Ser Asn Ile Ser Ile Tyr
1100 1105 1110
Lys Val Arg Thr Asp Val Leu Gly Asn Gln His Ile Ile Lys Asn
1115 1120 1125
Glu Gly Asp Lys Pro Lys Leu Asp Phe Lys Arg Pro Ala Ala Thr
1130 1135 1140
Lys Lys Ala Gly Gln Ala Lys Lys Lys Lys
1145 1150
<210> 53
<211> 340
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 53
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccg ttacttaaat cttgcagaag ctacaaagat aaggcttcat gccgaaatca 300
acaccctgtc attttatggc agggtgtttt cgttatttaa 340
<210> 54
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (288)..(317)
<223> a, c, t, g, unknown or other
<400> 54
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccg ggttttagag ctatgctgtt ttgaatggtc ccaaaacnnn nnnnnnnnnn 300
nnnnnnnnnn nnnnnnngtt ttagagctat gctgttttga atggtcccaa aacttttttt 360
<210> 55
<211> 318
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (250)..(269)
<223> a, c, t, g, unknown or other
<400> 55
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccn nnnnnnnnnn nnnnnnnnng ttttagagct agaaatagca agttaaaata 300
aggctagtcc gttttttt 318
<210> 56
<211> 325
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (250)..(269)
<223> a, c, t, g, unknown or other
<400> 56
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccn nnnnnnnnnn nnnnnnnnng ttttagagct agaaatagca agttaaaata 300
aggctagtcc gttatcattt ttttt 325
<210> 57
<211> 337
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (250)..(269)
<223> a, c, t, g, unknown or other
<400> 57
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccn nnnnnnnnnn nnnnnnnnng ttttagagct agaaatagca agttaaaata 300
aggctagtcc gttatcaact tgaaaaagtg ttttttt 337
<210> 58
<211> 352
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (250)..(269)
<223> a, c, t, g, unknown or other
<400> 58
gagggcctat ttcccatgat tccttcatat ttgcatatac gatacaaggc tgttagagag 60
ataattggaa ttaatttgac tgtaaacaca aagatattag tacaaaatac gtgacgtaga 120
aagtaataat ttcttgggta gtttgcagtt ttaaaattat gttttaaaat ggactatcat 180
atgcttaccg taacttgaaa gtatttcgat ttcttggctt tatatatctt gtggaaagga 240
cgaaacaccn nnnnnnnnnn nnnnnnnnng ttttagagct agaaatagca agttaaaata 300
aggctagtcc gttatcaact tgaaaaagtg gcaccgagtc ggtgcttttt tt 352
<210> 59
<211> 5101
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 59
cgttacataa cttacggtaa atggcccgcc tggctgaccg cccaacgacc cccgcccatt 60
gacgtcaata atgacgtatg ttcccatagt aacgccaata gggactttcc attgacgtca 120
atgggtggag tatttacggt aaactgccca cttggcagta catcaagtgt atcatatgcc 180
aagtacgccc cctattgacg tcaatgacgg taaatggccc gcctggcatt atgcccagta 240
catgacctta tgggactttc ctacttggca gtacatctac gtattagtca tcgctattac 300
catggtcgag gtgagcccca cgttctgctt cactctcccc atctcccccc cctccccacc 360
cccaattttg tatttattta ttttttaatt attttgtgca gcgatggggg cggggggggg 420
gggggggcgc gcgccaggcg gggcggggcg gggcgagggg cggggcgggg cgaggcggag 480
aggtgcggcg gcagccaatc agagcggcgc gctccgaaag tttcctttta tggcgaggcg 540
gcggcggcgg cggccctata aaaagcgaag cgcgcggcgg gcgggagtcg ctgcgacgct 600
gccttcgccc cgtgccccgc tccgccgccg cctcgcgccg cccgccccgg ctctgactga 660
ccgcgttact cccacaggtg agcgggcggg acggcccttc tcctccgggc tgtaattagc 720
tgagcaagag gtaagggttt aagggatggt tggttggtgg ggtattaatg tttaattacc 780
tggagcacct gcctgaaatc actttttttc aggttggacc ggtgccacca tggactataa 840
ggaccacgac ggagactaca aggatcatga tattgattac aaagacgatg acgataagat 900
ggccccaaag aagaagcgga aggtcggtat ccacggagtc ccagcagccg acaagaagta 960
cagcatcggc ctggacatcg gcaccaactc tgtgggctgg gccgtgatca ccgacgagta 1020
caaggtgccc agcaagaaat tcaaggtgct gggcaacacc gaccggcaca gcatcaagaa 1080
gaacctgatc ggagccctgc tgttcgacag cggcgaaaca gccgaggcca cccggctgaa 1140
gagaaccgcc agaagaagat acaccagacg gaagaaccgg atctgctatc tgcaagagat 1200
cttcagcaac gagatggcca aggtggacga cagcttcttc cacagactgg aagagtcctt 1260
cctggtggaa gaggataaga agcacgagcg gcaccccatc ttcggcaaca tcgtggacga 1320
ggtggcctac cacgagaagt accccaccat ctaccacctg agaaagaaac tggtggacag 1380
caccgacaag gccgacctgc ggctgatcta tctggccctg gcccacatga tcaagttccg 1440
gggccacttc ctgatcgagg gcgacctgaa ccccgacaac agcgacgtgg acaagctgtt 1500
catccagctg gtgcagacct acaaccagct gttcgaggaa aaccccatca acgccagcgg 1560
cgtggacgcc aaggccatcc tgtctgccag actgagcaag agcagacggc tggaaaatct 1620
gatcgcccag ctgcccggcg agaagaagaa tggcctgttc ggcaacctga ttgccctgag 1680
cctgggcctg acccccaact tcaagagcaa cttcgacctg gccgaggatg ccaaactgca 1740
gctgagcaag gacacctacg acgacgacct ggacaacctg ctggcccaga tcggcgacca 1800
gtacgccgac ctgtttctgg ccgccaagaa cctgtccgac gccatcctgc tgagcgacat 1860
cctgagagtg aacaccgaga tcaccaaggc ccccctgagc gcctctatga tcaagagata 1920
cgacgagcac caccaggacc tgaccctgct gaaagctctc gtgcggcagc agctgcctga 1980
gaagtacaaa gagattttct tcgaccagag caagaacggc tacgccggct acattgacgg 2040
cggagccagc caggaagagt tctacaagtt catcaagccc atcctggaaa agatggacgg 2100
caccgaggaa ctgctcgtga agctgaacag agaggacctg ctgcggaagc agcggacctt 2160
cgacaacggc agcatccccc accagatcca cctgggagag ctgcacgcca ttctgcggcg 2220
gcaggaagat ttttacccat tcctgaagga caaccgggaa aagatcgaga agatcctgac 2280
cttccgcatc ccctactacg tgggccctct ggccagggga aacagcagat tcgcctggat 2340
gaccagaaag agcgaggaaa ccatcacccc ctggaacttc gaggaagtgg tggacaaggg 2400
cgcttccgcc cagagcttca tcgagcggat gaccaacttc gataagaacc tgcccaacga 2460
gaaggtgctg cccaagcaca gcctgctgta cgagtacttc accgtgtata acgagctgac 2520
caaagtgaaa tacgtgaccg agggaatgag aaagcccgcc ttcctgagcg gcgagcagaa 2580
aaaggccatc gtggacctgc tgttcaagac caaccggaaa gtgaccgtga agcagctgaa 2640
agaggactac ttcaagaaaa tcgagtgctt cgactccgtg gaaatctccg gcgtggaaga 2700
tcggttcaac gcctccctgg gcacatacca cgatctgctg aaaattatca aggacaagga 2760
cttcctggac aatgaggaaa acgaggacat tctggaagat atcgtgctga ccctgacact 2820
gtttgaggac agagagatga tcgaggaacg gctgaaaacc tatgcccacc tgttcgacga 2880
caaagtgatg aagcagctga agcggcggag atacaccggc tggggcaggc tgagccggaa 2940
gctgatcaac ggcatccggg acaagcagtc cggcaagaca atcctggatt tcctgaagtc 3000
cgacggcttc gccaacagaa acttcatgca gctgatccac gacgacagcc tgacctttaa 3060
agaggacatc cagaaagccc aggtgtccgg ccagggcgat agcctgcacg agcacattgc 3120
caatctggcc ggcagccccg ccattaagaa gggcatcctg cagacagtga aggtggtgga 3180
cgagctcgtg aaagtgatgg gccggcacaa gcccgagaac atcgtgatcg aaatggccag 3240
agagaaccag accacccaga agggacagaa gaacagccgc gagagaatga agcggatcga 3300
agagggcatc aaagagctgg gcagccagat cctgaaagaa caccccgtgg aaaacaccca 3360
gctgcagaac gagaagctgt acctgtacta cctgcagaat gggcgggata tgtacgtgga 3420
ccaggaactg gacatcaacc ggctgtccga ctacgatgtg gaccatatcg tgcctcagag 3480
ctttctgaag gacgactcca tcgacaacaa ggtgctgacc agaagcgaca agaaccgggg 3540
caagagcgac aacgtgccct ccgaagaggt cgtgaagaag atgaagaact actggcggca 3600
gctgctgaac gccaagctga ttacccagag aaagttcgac aatctgacca aggccgagag 3660
aggcggcctg agcgaactgg ataaggccgg cttcatcaag agacagctgg tggaaacccg 3720
gcagatcaca aagcacgtgg cacagatcct ggactcccgg atgaacacta agtacgacga 3780
gaatgacaag ctgatccggg aagtgaaagt gatcaccctg aagtccaagc tggtgtccga 3840
tttccggaag gatttccagt tttacaaagt gcgcgagatc aacaactacc accacgccca 3900
cgacgcctac ctgaacgccg tcgtgggaac cgccctgatc aaaaagtacc ctaagctgga 3960
aagcgagttc gtgtacggcg actacaaggt gtacgacgtg cggaagatga tcgccaagag 4020
cgagcaggaa atcggcaagg ctaccgccaa gtacttcttc tacagcaaca tcatgaactt 4080
tttcaagacc gagattaccc tggccaacgg cgagatccgg aagcggcctc tgatcgagac 4140
aaacggcgaa accggggaga tcgtgtggga taagggccgg gattttgcca ccgtgcggaa 4200
agtgctgagc atgccccaag tgaatatcgt gaaaaagacc gaggtgcaga caggcggctt 4260
cagcaaagag tctatcctgc ccaagaggaa cagcgataag ctgatcgcca gaaagaagga 4320
ctgggaccct aagaagtacg gcggcttcga cagccccacc gtggcctatt ctgtgctggt 4380
ggtggccaaa gtggaaaagg gcaagtccaa gaaactgaag agtgtgaaag agctgctggg 4440
gatcaccatc atggaaagaa gcagcttcga gaagaatccc atcgactttc tggaagccaa 4500
gggctacaaa gaagtgaaaa aggacctgat catcaagctg cctaagtact ccctgttcga 4560
gctggaaaac ggccggaaga gaatgctggc ctctgccggc gaactgcaga agggaaacga 4620
actggccctg ccctccaaat atgtgaactt cctgtacctg gccagccact atgagaagct 4680
gaagggctcc cccgaggata atgagcagaa acagctgttt gtggaacagc acaagcacta 4740
cctggacgag atcatcgagc agatcagcga gttctccaag agagtgatcc tggccgacgc 4800
taatctggac aaagtgctgt ccgcctacaa caagcaccgg gataagccca tcagagagca 4860
ggccgagaat atcatccacc tgtttaccct gaccaatctg ggagcccctg ccgccttcaa 4920
gtactttgac accaccatcg accggaagag gtacaccagc accaaagagg tgctggacgc 4980
caccctgatc caccagagca tcaccggcct gtacgagaca cggatcgacc tgtctcagct 5040
gggaggcgac tttctttttc ttagcttgac cagctttctt agtagcagca ggacgcttta 5100
a 5101
<210> 60
<211> 137
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 60
nnnnnnnnnn nnnnnnnnnn gttattgtac tctcaagatt tagaaataaa tcttgcagaa 60
gctacaaaga taaggcttca tgccgaaatc aacaccctgt cattttatgg cagggtgttt 120
tcgttattta atttttt 137
<210> 61
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 61
nnnnnnnnnn nnnnnnnnnn gttattgtac tctcagaaat gcagaagcta caaagataag 60
gcttcatgcc gaaatcaaca ccctgtcatt ttatggcagg gtgttttcgt tatttaattt 120
ttt 123
<210> 62
<211> 110
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 62
nnnnnnnnnn nnnnnnnnnn gttattgtac tctcagaaat gcagaagcta caaagataag 60
gcttcatgcc gaaatcaaca ccctgtcatt ttatggcagg gtgttttttt 110
<210> 63
<211> 137
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 63
nnnnnnnnnn nnnnnnnnnn gttattgtac tctcaagatt tagaaataaa tcttgcagaa 60
gctacaatga taaggcttca tgccgaaatc aacaccctgt cattttatgg cagggtgttt 120
tcgttattta atttttt 137
<210> 64
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 64
nnnnnnnnnn nnnnnnnnnn gttattgtac tctcagaaat gcagaagcta caatgataag 60
gcttcatgcc gaaatcaaca ccctgtcatt ttatggcagg gtgttttcgt tatttaattt 120
ttt 123
<210> 65
<211> 110
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 65
nnnnnnnnnn nnnnnnnnnn gttattgtac tctcagaaat gcagaagcta caatgataag 60
gcttcatgcc gaaatcaaca ccctgtcatt ttatggcagg gtgttttttt 110
<210> 66
<211> 107
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 66
nnnnnnnnnn nnnnnnnnnn gttttagagc tgtggaaaca cagcgagtta aaataaggct 60
tagtccgtac tcaacttgaa aaggtggcac cgattcggtg ttttttt 107
<210> 67
<211> 4263
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 67
atgaaaaggc cggcggccac gaaaaaggcc ggccaggcaa aaaagaaaaa gaccaagccc 60
tacagcatcg gcctggacat cggcaccaat agcgtgggct gggccgtgac caccgacaac 120
tacaaggtgc ccagcaagaa aatgaaggtg ctgggcaaca cctccaagaa gtacatcaag 180
aaaaacctgc tgggcgtgct gctgttcgac agcggcatta cagccgaggg cagacggctg 240
aagagaaccg ccagacggcg gtacacccgg cggagaaaca gaatcctgta tctgcaagag 300
atcttcagca ccgagatggc taccctggac gacgccttct tccagcggct ggacgacagc 360
ttcctggtgc ccgacgacaa gcgggacagc aagtacccca tcttcggcaa cctggtggaa 420
gagaaggcct accacgacga gttccccacc atctaccacc tgagaaagta cctggccgac 480
agcaccaaga aggccgacct gagactggtg tatctggccc tggcccacat gatcaagtac 540
cggggccact tcctgatcga gggcgagttc aacagcaaga acaacgacat ccagaagaac 600
ttccaggact tcctggacac ctacaacgcc atcttcgaga gcgacctgtc cctggaaaac 660
agcaagcagc tggaagagat cgtgaaggac aagatcagca agctggaaaa gaaggaccgc 720
atcctgaagc tgttccccgg cgagaagaac agcggaatct tcagcgagtt tctgaagctg 780
atcgtgggca accaggccga cttcagaaag tgcttcaacc tggacgagaa agccagcctg 840
cacttcagca aagagagcta cgacgaggac ctggaaaccc tgctgggata tatcggcgac 900
gactacagcg acgtgttcct gaaggccaag aagctgtacg acgctatcct gctgagcggc 960
ttcctgaccg tgaccgacaa cgagacagag gccccactga gcagcgccat gattaagcgg 1020
tacaacgagc acaaagagga tctggctctg ctgaaagagt acatccggaa catcagcctg 1080
aaaacctaca atgaggtgtt caaggacgac accaagaacg gctacgccgg ctacatcgac 1140
ggcaagacca accaggaaga tttctatgtg tacctgaaga agctgctggc cgagttcgag 1200
ggggccgact actttctgga aaaaatcgac cgcgaggatt tcctgcggaa gcagcggacc 1260
ttcgacaacg gcagcatccc ctaccagatc catctgcagg aaatgcgggc catcctggac 1320
aagcaggcca agttctaccc attcctggcc aagaacaaag agcggatcga gaagatcctg 1380
accttccgca tcccttacta cgtgggcccc ctggccagag gcaacagcga ttttgcctgg 1440
tccatccgga agcgcaatga gaagatcacc ccctggaact tcgaggacgt gatcgacaaa 1500
gagtccagcg ccgaggcctt catcaaccgg atgaccagct tcgacctgta cctgcccgag 1560
gaaaaggtgc tgcccaagca cagcctgctg tacgagacat tcaatgtgta taacgagctg 1620
accaaagtgc ggtttatcgc cgagtctatg cgggactacc agttcctgga ctccaagcag 1680
aaaaaggaca tcgtgcggct gtacttcaag gacaagcgga aagtgaccga taaggacatc 1740
atcgagtacc tgcacgccat ctacggctac gatggcatcg agctgaaggg catcgagaag 1800
cagttcaact ccagcctgag cacataccac gacctgctga acattatcaa cgacaaagaa 1860
tttctggacg actccagcaa cgaggccatc atcgaagaga tcatccacac cctgaccatc 1920
tttgaggacc gcgagatgat caagcagcgg ctgagcaagt tcgagaacat cttcgacaag 1980
agcgtgctga aaaagctgag cagacggcac tacaccggct ggggcaagct gagcgccaag 2040
ctgatcaacg gcatccggga cgagaagtcc ggcaacacaa tcctggacta cctgatcgac 2100
gacggcatca gcaaccggaa cttcatgcag ctgatccacg acgacgccct gagcttcaag 2160
aagaagatcc agaaggccca gatcatcggg gacgaggaca agggcaacat caaagaagtc 2220
gtgaagtccc tgcccggcag ccccgccatc aagaagggaa tcctgcagag catcaagatc 2280
gtggacgagc tcgtgaaagt gatgggcggc agaaagcccg agagcatcgt ggtggaaatg 2340
gctagagaga accagtacac caatcagggc aagagcaaca gccagcagag actgaagaga 2400
ctggaaaagt ccctgaaaga gctgggcagc aagattctga aagagaatat ccctgccaag 2460
ctgtccaaga tcgacaacaa cgccctgcag aacgaccggc tgtacctgta ctacctgcag 2520
aatggcaagg acatgtatac aggcgacgac ctggatatcg accgcctgag caactacgac 2580
atcgaccata ttatccccca ggccttcctg aaagacaaca gcattgacaa caaagtgctg 2640
gtgtcctccg ccagcaaccg cggcaagtcc gatgatgtgc ccagcctgga agtcgtgaaa 2700
aagagaaaga ccttctggta tcagctgctg aaaagcaagc tgattagcca gaggaagttc 2760
gacaacctga ccaaggccga gagaggcggc ctgagccctg aagataaggc cggcttcatc 2820
cagagacagc tggtggaaac ccggcagatc accaagcacg tggccagact gctggatgag 2880
aagtttaaca acaagaagga cgagaacaac cgggccgtgc ggaccgtgaa gatcatcacc 2940
ctgaagtcca ccctggtgtc ccagttccgg aaggacttcg agctgtataa agtgcgcgag 3000
atcaatgact ttcaccacgc ccacgacgcc tacctgaatg ccgtggtggc ttccgccctg 3060
ctgaagaagt accctaagct ggaacccgag ttcgtgtacg gcgactaccc caagtacaac 3120
tccttcagag agcggaagtc cgccaccgag aaggtgtact tctactccaa catcatgaat 3180
atctttaaga agtccatctc cctggccgat ggcagagtga tcgagcggcc cctgatcgaa 3240
gtgaacgaag agacaggcga gagcgtgtgg aacaaagaaa gcgacctggc caccgtgcgg 3300
cgggtgctga gttatcctca agtgaatgtc gtgaagaagg tggaagaaca gaaccacggc 3360
ctggatcggg gcaagcccaa gggcctgttc aacgccaacc tgtccagcaa gcctaagccc 3420
aactccaacg agaatctcgt gggggccaaa gagtacctgg accctaagaa gtacggcgga 3480
tacgccggca tctccaatag cttcaccgtg ctcgtgaagg gcacaatcga gaagggcgct 3540
aagaaaaaga tcacaaacgt gctggaattt caggggatct ctatcctgga ccggatcaac 3600
taccggaagg ataagctgaa ctttctgctg gaaaaaggct acaaggacat tgagctgatt 3660
atcgagctgc ctaagtactc cctgttcgaa ctgagcgacg gctccagacg gatgctggcc 3720
tccatcctgt ccaccaacaa caagcggggc gagatccaca agggaaacca gatcttcctg 3780
agccagaaat ttgtgaaact gctgtaccac gccaagcgga tctccaacac catcaatgag 3840
aaccaccgga aatacgtgga aaaccacaag aaagagtttg aggaactgtt ctactacatc 3900
ctggagttca acgagaacta tgtgggagcc aagaagaacg gcaaactgct gaactccgcc 3960
ttccagagct ggcagaacca cagcatcgac gagctgtgca gctccttcat cggccctacc 4020
ggcagcgagc ggaagggact gtttgagctg acctccagag gctctgccgc cgactttgag 4080
ttcctgggag tgaagatccc ccggtacaga gactacaccc cctctagtct gctgaaggac 4140
gccaccctga tccaccagag cgtgaccggc ctgtacgaaa cccggatcga cctggctaag 4200
ctgggcgagg gaaagcgtcc tgctgctact aagaaagctg gtcaagctaa gaaaaagaaa 4260
taa 4263
<210> 68
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 68
tcctagcagg atttctgata ttactgtcac gttttagagc tatgctgttt tga 53
<210> 69
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 69
gtgacagtaa tatcagaaat cctgctagga gttttgggac cattcaaaac agc 53
<210> 70
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 70
gggtttcaag tctttgtagc aagag 25
<210> 71
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 71
gccaatgaac gggaaccctt ggtc 24
<210> 72
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (1)..(4)
<223> a, c, t, g, unknown or other
<400> 72
nnnngacgag gcaatggctg aaatc 25
<210> 73
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (1)..(4)
<223> a, c, t, g, unknown or other
<400> 73
nnnnttattt ggctcatatt tgctg 25
<210> 74
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 74
ctttacacca atcgctgcaa cagac 25
<210> 75
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 75
caaaatttct agtcttcttt gcctttcccc ataaaaccct cctta 45
<210> 76
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 76
agggttttat ggggaaaggc aaagaagact agaaattttg atacc 45
<210> 77
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 77
cttacggtgc ataaagtcaa tttcc 25
<210> 78
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 78
tggctcgatt tcagccattg c 21
<210> 79
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (33)..(33)
<223> a, c, t, g, unknown or other
<400> 79
ctttgacgag gcaatggctg aaatcgagcc aanaaagcgc aag 43
<210> 80
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (34)..(34)
<223> a, c, t, g, unknown or other
<400> 80
ctttgacgag gcaatggctg aaatcgagcc aaanaagcgc aag 43
<210> 81
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (35)..(35)
<223> a, c, t, g, unknown or other
<400> 81
ctttgacgag gcaatggctg aaatcgagcc aaaanagcgc aag 43
<210> 82
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (36)..(36)
<223> a, c, t, g, unknown or other
<400> 82
ctttgacgag gcaatggctg aaatcgagcc aaaaangcgc aag 43
<210> 83
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (37)..(37)
<223> a, c, t, g, unknown or other
<400> 83
ctttgacgag gcaatggctg aaatcgagcc aaaaaancgc aag 43
<210> 84
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (38)..(38)
<223> a, c, t, g, unknown or other
<400> 84
ctttgacgag gcaatggctg aaatcgagcc aaaaaagngc aag 43
<210> 85
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (39)..(39)
<223> a, c, t, g, unknown or other
<400> 85
ctttgacgag gcaatggctg aaatcgagcc aaaaaagcnc aagaag 46
<210> 86
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (40)..(40)
<223> a, c, t, g, unknown or other
<400> 86
ctttgacgag gcaatggctg aaatcgagcc aaaaaagcgn aagaag 46
<210> 87
<211> 46
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (41)..(41)
<223> a, c, t, g, unknown or other
<400> 87
ctttgacgag gcaatggctg aaatcgagcc aaaaaagcgc nagaag 46
<210> 88
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 88
gcgctttttt ggctcgattt cag 23
<210> 89
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (31)..(31)
<223> a, c, t, g, unknown or other
<400> 89
caatggctga aatcgagcca aaaaagcgca ngaagaaatc 40
<210> 90
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (32)..(32)
<223> a, c, t, g, unknown or other
<400> 90
caatggctga aatcgagcca aaaaagcgca anaagaaatc 40
<210> 91
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (33)..(33)
<223> a, c, t, g, unknown or other
<400> 91
caatggctga aatcgagcca aaaaagcgca agnagaaatc 40
<210> 92
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (34)..(34)
<223> a, c, t, g, unknown or other
<400> 92
caatggctga aatcgagcca aaaaagcgca agangaaatc 40
<210> 93
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (35)..(35)
<223> a, c, t, g, unknown or other
<400> 93
caatggctga aatcgagcca aaaaagcgca agaanaaatc 40
<210> 94
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (36)..(36)
<223> a, c, t, g, unknown or other
<400> 94
caatggctga aatcgagcca aaaaagcgca agaagnaatc aacc 44
<210> 95
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (37)..(37)
<223> a, c, t, g, unknown or other
<400> 95
caatggctga aatcgagcca aaaaagcgca agaaganatc aacc 44
<210> 96
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (38)..(38)
<223> a, c, t, g, unknown or other
<400> 96
caatggctga aatcgagcca aaaaagcgca agaagaantc aacc 44
<210> 97
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (39)..(39)
<223> a, c, t, g, unknown or other
<400> 97
caatggctga aatcgagcca aaaaagcgca agaagaaanc aacc 44
<210> 98
<211> 47
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (40)..(40)
<223> a, c, t, g, unknown or other
<400> 98
caatggctga aatcgagcca aaaaagcgca agaagaaatn aaccagc 47
<210> 99
<211> 47
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (41)..(41)
<223> a, c, t, g, unknown or other
<400> 99
caatggctga aatcgagcca aaaaagcgca agaagaaatc naccagc 47
<210> 100
<211> 31
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 100
gatcctccat ccgtacaacc cacaaccctg g 31
<210> 101
<211> 31
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 101
aattccaggg ttgtgggttg tacggatgga g 31
<210> 102
<211> 34
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 102
catggatcct atttcttaat aactaaaaat atgg 34
<210> 103
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 103
catgaattca actcaacaag tctcagtgtg ctg 33
<210> 104
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 104
aaacattttt tctccattta ggaaaaagga tgctg 35
<210> 105
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 105
aaaacagcat cctttttcct aaatggagaa aaaat 35
<210> 106
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 106
aaaccttaaa tcagtcacaa atagcagcaa aattg 35
<210> 107
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 107
aaaacaattt tgctgctatt tgtgactgat ttaag 35
<210> 108
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 108
aaacttttca tcatacgacc aatctgcttt atttg 35
<210> 109
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 109
aaaacaaata aagcagattg gtcgtatgat gaaaa 35
<210> 110
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 110
aaactcgtcc agaagttatc gtaaaagaaa tcgag 35
<210> 111
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 111
aaaactcgat ttcttttacg ataacttctg gacga 35
<210> 112
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 112
aaacaatctc tccaaggttt ccttaaaaat ctctg 35
<210> 113
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 113
aaaacagaga tttttaagga aaccttggag agatt 35
<210> 114
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 114
aaacgccatc gtcaggaaga agctatgctt gagtg 35
<210> 115
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 115
aaaacactca agcatagctt cttcctgacg atggc 35
<210> 116
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 116
aaacatctct atacttattg aaatttcttt gtatg 35
<210> 117
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 117
aaaacataca aagaaatttc aataagtata gagat 35
<210> 118
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 118
aaactagctg tgatagtccg caaaaccagc cttcg 35
<210> 119
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 119
aaaacgaagg ctggttttgc ggactatcac agcta 35
<210> 120
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 120
aaacatcgga aggtcgagca agtaattatc ttttg 35
<210> 121
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 121
aaaacaaaag ataattactt gctcgacctt ccgat 35
<210> 122
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 122
aaacaagatg gtatcgcaaa gtaagtgaca ataag 35
<210> 123
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 123
aaaacttatt gtcacttact ttgcgatacc atctt 35
<210> 124
<211> 52
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 124
gagacctttg agcttccgag actggtctca gttttgggac cattcaaaac ag 52
<210> 125
<211> 52
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 125
tgagaccagt ctcggaagct caaaggtctc gttttagagc tatgctgttt tg 52
<210> 126
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 126
aaactacttt acgcagcgcg gagttcggtt ttttg 35
<210> 127
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 127
aaaacaaaaa accgaactcc gcgctgcgta aagta 35
<210> 128
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 128
atgccggtac tgccgggcct cttgcgggat tacgaaatca tcctg 45
<210> 129
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 129
gtgactggcg atgctgtcgg aatggacgat cacactactc ttctt 45
<210> 130
<211> 50
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 130
ttaagaaata atcttcatct aaaatatact tcagtcacct cctagctgac 50
<210> 131
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 131
attgatttga gtcagctagg aggtgactga agtatatttt agatgaag 48
<210> 132
<211> 85
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 132
gagacctttg agcttccgag actggtctca gttttgggac cattcaaaac agcatagctc 60
taaaacctcg tagactattt ttgtc 85
<210> 133
<211> 84
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 133
gagaccagtc tcggaagctc aaaggtctcg ttttagagct atgctgtttt gaatggtccc 60
aaaacttcag cacactgaga cttg 84
<210> 134
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 134
agtcatccca gcaacaaatg g 21
<210> 135
<211> 31
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 135
cgtggtaaat cggataacgt tccaagtgaa g 31
<210> 136
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 136
tgctcttctt cacaaacaag gg 22
<210> 137
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 137
aagccaaagt ttggcaccac c 21
<210> 138
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 138
gtagcttatt cagtcctagt gg 22
<210> 139
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 139
cgtttgttga actaatgggt gcaaattacg aatcttctcc tgacg 45
<210> 140
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 140
cgtcaggaga agattcgtaa tttgcaccca ttagttcaac aaacg 45
<210> 141
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 141
gatattatgg agcctatttt tgtgggtttt taggcataaa actatatg 48
<210> 142
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 142
catatagttt tatgcctaaa aacccacaaa aataggctcc ataatatc 48
<210> 143
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 143
attatttctt aataactaaa aatatgg 27
<210> 144
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 144
cgtgtacaat tgctagcgta cggc 24
<210> 145
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 145
gcaccggtga tcactagtcc tagg 24
<210> 146
<211> 47
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 146
cctaggacta gtgatcaccg gtgcaaatat gagccaaata aatatat 47
<210> 147
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 147
gccgtacgct agcaattgta cacgtttgtt gaactaatgg gtgc 44
<210> 148
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 148
ttcaaatttt cccatttgat tctcc 25
<210> 149
<211> 47
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 149
ccatattttt agttattaag aaataatacc agccatcagt cacctcc 47
<210> 150
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 150
agacgattca atagacaata agg 23
<210> 151
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 151
gttttgggac cattcaaaac agcatagctc taaaacctcg tagac 45
<210> 152
<211> 50
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 152
gctatgctgt tttgaatggt cccaaaacca ttattttaac acacgaggtg 50
<210> 153
<211> 50
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 153
gctatgctgt tttgaatggt cccaaaacgc acccattagt tcaacaaacg 50
<210> 154
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 154
aattcttttc ttcatcatcg gtc 23
<210> 155
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 155
aagaaagaat gaagattgtt catg 24
<210> 156
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 156
ggtactaatc aaaatagtga ggagg 25
<210> 157
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 157
gtttttcaaa atctgcggtt gcg 23
<210> 158
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 158
aaaaattgaa aaaatggtgg aaacac 26
<210> 159
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 159
atttcgtaaa cggtatcggt ttcttttaaa gttttgggac cattcaaaac agc 53
<210> 160
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 160
tttaaaagaa accgataccg tttacgaaat gttttagagc tatgctgttt tga 53
<210> 161
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 161
aaacggtatc ggtttctttt aaattcaatt gttttgggac cattcaaaac agc 53
<210> 162
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 162
aattgaattt aaaagaaacc gataccgttt gttttagagc tatgctgttt tga 53
<210> 163
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 163
gttccttaaa ccaaaacggt atcggtttct tttaaattc 39
<210> 164
<211> 47
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 164
gaaaccgata ccgttttggt ttaaggaaca ggtaaagggc atttaac 47
<210> 165
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 165
cgatttcagc cattgcctcg tc 22
<210> 166
<211> 56
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (29)..(33)
<223> a, c, t, g, unknown or other
<400> 166
gcctttgacg aggcaatggc tgaaatcgnn nnnaaaaagc gcaagaagaa atcaac 56
<210> 167
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 167
tccgtacaac ccacaaccct gctagtgagc gttttgggac cattcaaaac agc 53
<210> 168
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 168
gctcactagc agggttgtgg gttgtacgga gttttagagc tatgctgttt tga 53
<210> 169
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 169
ttgttgccac tcttccttct ttc 23
<210> 170
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 170
cagggttgtg ggttgttgcg atggagttaa ctcccatctc c 41
<210> 171
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 171
gggagttaac tccatcgcaa caacccacaa ccctgctagt g 41
<210> 172
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 172
gtggtatcta tcgtgatgtg ac 22
<210> 173
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 173
ttaccgaaac ggaatttatc tgc 23
<210> 174
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 174
aaagctagag ttccgcaatt gg 22
<210> 175
<211> 37
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 175
gtgggttgta cggattgagt taactcccat ctccttc 37
<210> 176
<211> 38
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 176
gatgggagtt aactcaatcc gtacaaccca caaccctg 38
<210> 177
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 177
gcttcaccta ttgcagcacc aattgaccac atgaagatag 40
<210> 178
<211> 41
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 178
gtggtcaatt ggtgctgcaa taggtgaagc taatggtgat g 41
<210> 179
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 179
ctgatttgta ttaattttga gacattatgc ttcaccttc 39
<210> 180
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 180
gcataatgtc tcaaaattaa tacaaatcag tgaaatcatg 40
<210> 181
<211> 52
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 181
gttttgggac cattcaaaac agcatagctc taaaacgtga cagtaatatc ag 52
<210> 182
<211> 53
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 182
gttttagagc tatgctgttt tgaatggtcc caaaacgctc actagcaggg ttg 53
<210> 183
<211> 59
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 183
atactttacg cagcgcggag ttcggttttg taggagtggt agtatataca cgagtacat 59
<210> 184
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 184
gctcactagc agggttgtgg gttgtacgga tgg 33
<210> 185
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 185
tcctagcagg atttctgata ttactgtcac tgg 33
<210> 186
<211> 33
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 186
tttaaaagaa accgataccg tttacgaaat tgg 33
<210> 187
<211> 84
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 187
ggaaccattc ataacagcat agcaagttat aataaggcta gtccgttatc aacttgaaaa 60
agtggcaccg agtcggtgct tttt 84
<210> 188
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 188
gttatagagc tatgctgtta tgaatggtcc caaaac 36
<210> 189
<211> 84
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 189
ggaaccattc aatacagcat agcaagttaa tataaggcta gtccgttatc aacttgaaaa 60
agtggcaccg agtcggtgct tttt 84
<210> 190
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 190
gtattagagc tatgctgtat tgaatggtcc caaaac 36
<210> 191
<211> 103
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 191
nnnnnnnnnn nnnnnnnnnn gttttagagc tagaaatagc aagttaaaat aaggctagtc 60
cgttatcaac ttgaaaaagt ggcaccgagt cggtgctttt ttt 103
<210> 192
<211> 103
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 192
nnnnnnnnnn nnnnnnnnnn gtattagagc tagaaatagc aagttaatat aaggctagtc 60
cgttatcaac ttgaaaaagt ggcaccgagt cggtgctttt ttt 103
<210> 193
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 193
nnnnnnnnnn nnnnnnnnnn gttttagagc tatgctgttt tggaaacaaa acagcatagc 60
aagttaaaat aaggctagtc cgttatcaac ttgaaaaagt ggcaccgagt cggtgctttt 120
ttt 123
<210> 194
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 194
nnnnnnnnnn nnnnnnnnnn gtattagagc tatgctgtat tggaaacaat acagcatagc 60
aagttaatat aaggctagtc cgttatcaac ttgaaaaagt ggcaccgagt cggtgctttt 120
ttt 123
<210> 195
<211> 20
<212> DNA
<213> Homo sapiens
<400> 195
gtcacctcca atgactaggg 20
<210> 196
<211> 23
<212> DNA
<213> Homo sapiens
<400> 196
gacatcgatg tcctccccat tgg 23
<210> 197
<211> 23
<212> DNA
<213> Homo sapiens
<400> 197
gagtccgagc agaagaagaa ggg 23
<210> 198
<211> 23
<212> DNA
<213> Homo sapiens
<400> 198
gcgccaccgg ttgatgtgat ggg 23
<210> 199
<211> 23
<212> DNA
<213> Homo sapiens
<400> 199
ggggcacaga tgagaaactc agg 23
<210> 200
<211> 23
<212> DNA
<213> Homo sapiens
<400> 200
gtacaaacgg cagaagctgg agg 23
<210> 201
<211> 23
<212> DNA
<213> Homo sapiens
<400> 201
ggcagaagct ggaggaggaa ggg 23
<210> 202
<211> 23
<212> DNA
<213> Homo sapiens
<400> 202
ggagcccttc ttcttctgct cgg 23
<210> 203
<211> 23
<212> DNA
<213> Homo sapiens
<400> 203
gggcaaccac aaacccacga ggg 23
<210> 204
<211> 23
<212> DNA
<213> Homo sapiens
<400> 204
gctcccatca catcaaccgg tgg 23
<210> 205
<211> 23
<212> DNA
<213> Homo sapiens
<400> 205
gtggcgcatt gccacgaagc agg 23
<210> 206
<211> 23
<212> DNA
<213> Homo sapiens
<400> 206
ggcagagtgc tgcttgctgc tgg 23
<210> 207
<211> 23
<212> DNA
<213> Homo sapiens
<400> 207
gcccctgcgt gggcccaagc tgg 23
<210> 208
<211> 23
<212> DNA
<213> Homo sapiens
<400> 208
gagtggccag agtccagctt ggg 23
<210> 209
<211> 23
<212> DNA
<213> Homo sapiens
<400> 209
ggcctcccca aagcctggcc agg 23
<210> 210
<211> 23
<212> DNA
<213> Homo sapiens
<400> 210
ggggccgaga ttgggtgttc agg 23
<210> 211
<211> 23
<212> DNA
<213> Homo sapiens
<400> 211
gtggcgagag gggccgagat tgg 23
<210> 212
<211> 23
<212> DNA
<213> Homo sapiens
<400> 212
gagtgccgcc gaggcggggc ggg 23
<210> 213
<211> 23
<212> DNA
<213> Homo sapiens
<400> 213
ggagtgccgc cgaggcgggg cgg 23
<210> 214
<211> 23
<212> DNA
<213> Homo sapiens
<400> 214
ggagaggagt gccgccgagg cgg 23
<210> 215
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 215
ccatcccctt ctgtgaatgt 20
<210> 216
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 216
ggagattgga gacacggaga 20
<210> 217
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 217
aagcaccgac tcggtgccac 20
<210> 218
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 218
tcacctccaa tgactagggg 20
<210> 219
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 219
caagttgata acggactagc ct 22
<210> 220
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 220
agtccgagca gaagaagaag ttt 23
<210> 221
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 221
tttcaagttg ataacggact agcct 25
<210> 222
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 222
aaacagcaga ttcgcctgga 20
<210> 223
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 223
tcatccgctc gatgaagctc 20
<210> 224
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 224
tccaaaatca agtggggcga 20
<210> 225
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 225
tgatgaccct tttggctccc 20
<210> 226
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 226
gaggaattct ttttttgtty gaatatgttg gaggtttttt ggaag 45
<210> 227
<211> 42
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 227
gagaagctta aataaaaaac racaatactc aacccaacaa cc 42
<210> 228
<211> 17
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 228
caggaaacag ctatgac 17
<210> 229
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 229
gcctctagag gtacctgagg gcctatttcc catgattcc 39
<210> 230
<211> 133
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (92)..(111)
<223> a, c, t, g, unknown or other
<400> 230
acctctagaa aaaaagcacc gactcggtgc cactttttca agttgataac ggactagcct 60
tattttaact tgctatttct agctctaaaa cnnnnnnnnn nnnnnnnnnn nggtgtttcg 120
tcctttccac aag 133
<210> 231
<211> 133
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (92)..(111)
<223> a, c, t, g, unknown or other
<400> 231
acctctagaa aaaaagcacc gactcggtgc cactttttca agttgataac ggactagcct 60
tatattaact tgctatttct agctctaata cnnnnnnnnn nnnnnnnnnn nggtgtttcg 120
tcctttccac aag 133
<210> 232
<211> 153
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (112)..(131)
<223> a, c, t, g, unknown or other
<400> 232
acctctagaa aaaaagcacc gactcggtgc cactttttca agttgataac ggactagcct 60
tattttaact tgctatgctg ttttgtttcc aaaacagcat agctctaaaa cnnnnnnnnn 120
nnnnnnnnnn nggtgtttcg tcctttccac aag 153
<210> 233
<211> 153
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<220>
<221> modified_base
<222> (112)..(131)
<223> a, c, t, g, unknown or other
<400> 233
acctctagaa aaaaagcacc gactcggtgc cactttttca agttgataac ggactagcct 60
tatattaact tgctatgctg tattgtttcc aatacagcat agctctaata cnnnnnnnnn 120
nnnnnnnnnn nggtgtttcg tcctttccac aag 153
<210> 234
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 234
aggccccagt ggctgctctn aa 22
<210> 235
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 235
acatcaaccg gtggcgcatn at 22
<210> 236
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 236
aaggtgtggt tccagaaccn ac 22
<210> 237
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 237
ccatcacatc aaccggtggn ag 22
<210> 238
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 238
aaacggcaga agctggaggn ta 22
<210> 239
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 239
ggcagaagct ggaggaggan tt 22
<210> 240
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 240
ggtgtggttc cagaaccggn tc 22
<210> 241
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 241
aaccggagga caaagtacan tg 22
<210> 242
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 242
ttccagaacc ggaggacaan ca 22
<210> 243
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 243
gtgtggttcc agaaccggan ct 22
<210> 244
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 244
tccagaaccg gaggacaaan cc 22
<210> 245
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 245
cagaagctgg aggaggaagn cg 22
<210> 246
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 246
catcaaccgg tggcgcattn ga 22
<210> 247
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 247
gcagaagctg gaggaggaan gt 22
<210> 248
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 248
cctccctccc tggcccaggn gc 22
<210> 249
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 249
tcatctgtgc ccctccctcn aa 22
<210> 250
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 250
gggaggacat cgatgtcacn at 22
<210> 251
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 251
caaacggcag aagctggagn ac 22
<210> 252
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 252
gggtgggcaa ccacaaaccn ag 22
<210> 253
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 253
ggtgggcaac cacaaacccn ta 22
<210> 254
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 254
ggctcccatc acatcaaccn tt 22
<210> 255
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 255
gaagggcctg agtccgagcn tc 22
<210> 256
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 256
caaccggtgg cgcattgccn tg 22
<210> 257
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 257
aggaggaagg gcctgagtcn ca 22
<210> 258
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 258
agctggagga ggaagggccn ct 22
<210> 259
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 259
gcattgccac gaagcaggcn cc 22
<210> 260
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 260
attgccacga agcaggccan cg 22
<210> 261
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 261
agaaccggag gacaaagtan ga 22
<210> 262
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 262
tcaaccggtg gcgcattgcn gt 22
<210> 263
<211> 22
<212> DNA
<213> Homo sapiens
<220>
<221> modified_base
<222> (20)..(20)
<223> a, c, t, g, unknown or other
<400> 263
gaagctggag gaggaagggn gc 22
<210> 264
<211> 123
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 264
ccaatgggga ggacatcgat gtcacctcca atgactaggg tgggcaacca caaacccacg 60
agggcagagt gctgcttgct gctggccagg cccctgcgtg ggcccaagct ggactctggc 120
cac 123
<210> 265
<211> 121
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 265
cgagcagaag aagaagggct cccatcacat caaccggtgg cgcattgcca cgaagcaggc 60
caatggggag gacatcgatg tcacctccaa tgactagggt gggcaaccac aaacccacga 120
g 121
<210> 266
<211> 128
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 266
ggaggacaaa gtacaaacgg cagaagctgg aggaggaagg gcctgagtcc gagcagaaga 60
agaagggctc ccatcacatc aaccggtggc gcattgccac gaagcaggcc aatggggagg 120
acatcgat 128
<210> 267
<211> 130
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 267
agaagctgga ggaggaaggg cctgagtccg agcagaagaa gaagggctcc catcacatca 60
accggtggcg cattgccacg aagcaggcca atggggagga catcgatgtc acctccaatg 120
actagggtgg 130
<210> 268
<211> 125
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 268
cctcagtctt cccatcaggc tctcagctca gcctgagtgt tgaggcccca gtggctgctc 60
tgggggcctc ctgagtttct catctgtgcc cctccctccc tggcccaggt gaaggtgtgg 120
ttcca 125
<210> 269
<211> 129
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 269
tcatctgtgc ccctccctcc ctggcccagg tgaaggtgtg gttccagaac cggaggacaa 60
agtacaaacg gcagaagctg gaggaggaag ggcctgagtc cgagcagaag aagaagggct 120
cccatcaca 129
<210> 270
<211> 129
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 270
ctccaatgac tagggtgggc aaccacaaac ccacgagggc agagtgctgc ttgctgctgg 60
ccaggcccct gcgtgggccc aagctggact ctggccactc cctggccagg ctttggggag 120
gcctggagt 129
<210> 271
<211> 127
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 271
ctgcttgctg ctggccaggc ccctgcgtgg gcccaagctg gactctggcc actccctggc 60
caggctttgg ggaggcctgg agtcatggcc ccacagggct tgaagcccgg ggccgccatt 120
gacagag 127
<210> 272
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 272
gaaattaata cgactcacta taggg 25
<210> 273
<211> 126
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 273
aaaaaagcac cgactcggtg ccactttttc aagttgataa cggactagcc ttattttaac 60
ttgctatttc tagctctaaa acaacgacga gcgtgacacc accctatagt gagtcgtatt 120
aatttc 126
<210> 274
<211> 126
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 274
aaaaaagcac cgactcggtg ccactttttc aagttgataa cggactagcc ttattttaac 60
ttgctatttc tagctctaaa acgcaacaat taatagactg gacctatagt gagtcgtatt 120
aatttc 126
<210> 275
<211> 4677
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 275
tctttcttgc gctatgacac ttccagcaaa aggtagggcg ggctgcgaga cggcttcccg 60
gcgctgcatg caacaccgat gatgcttcga ccccccgaag ctccttcggg gctgcatggg 120
cgctccgatg ccgctccagg gcgagcgctg tttaaatagc caggcccccg attgcaaaga 180
cattatagcg agctaccaaa gccatattca aacacctaga tcactaccac ttctacacag 240
gccactcgag cttgtgatcg cactccgcta agggggcgcc tcttcctctt cgtttcagtc 300
acaacccgca aacatgtacc catacgatgt tccagattac gcttcgccga agaaaaagcg 360
caaggtcgaa gcgtccgaca agaagtacag catcggcctg gacatcggca ccaactctgt 420
gggctgggcc gtgatcaccg acgagtacaa ggtgcccagc aagaaattca aggtgctggg 480
caacaccgac cggcacagca tcaagaagaa cctgatcgga gccctgctgt tcgacagcgg 540
cgaaacagcc gaggccaccc ggctgaagag aaccgccaga agaagataca ccagacggaa 600
gaaccggatc tgctatctgc aagagatctt cagcaacgag atggccaagg tggacgacag 660
cttcttccac agactggaag agtccttcct ggtggaagag gataagaagc acgagcggca 720
ccccatcttc ggcaacatcg tggacgaggt ggcctaccac gagaagtacc ccaccatcta 780
ccacctgaga aagaaactgg tggacagcac cgacaaggcc gacctgcggc tgatctatct 840
ggccctggcc cacatgatca agttccgggg ccacttcctg atcgagggcg acctgaaccc 900
cgacaacagc gacgtggaca agctgttcat ccagctggtg cagacctaca accagctgtt 960
cgaggaaaac cccatcaacg ccagcggcgt ggacgccaag gccatcctgt ctgccagact 1020
gagcaagagc agacggctgg aaaatctgat cgcccagctg cccggcgaga agaagaatgg 1080
cctgttcggc aacctgattg ccctgagcct gggcctgacc cccaacttca agagcaactt 1140
cgacctggcc gaggatgcca aactgcagct gagcaaggac acctacgacg acgacctgga 1200
caacctgctg gcccagatcg gcgaccagta cgccgacctg tttctggccg ccaagaacct 1260
gtccgacgcc atcctgctga gcgacatcct gagagtgaac accgagatca ccaaggcccc 1320
cctgagcgcc tctatgatca agagatacga cgagcaccac caggacctga ccctgctgaa 1380
agctctcgtg cggcagcagc tgcctgagaa gtacaaagag attttcttcg accagagcaa 1440
gaacggctac gccggctaca ttgacggcgg agccagccag gaagagttct acaagttcat 1500
caagcccatc ctggaaaaga tggacggcac cgaggaactg ctcgtgaagc tgaacagaga 1560
ggacctgctg cggaagcagc ggaccttcga caacggcagc atcccccacc agatccacct 1620
gggagagctg cacgccattc tgcggcggca ggaagatttt tacccattcc tgaaggacaa 1680
ccgggaaaag atcgagaaga tcctgacctt ccgcatcccc tactacgtgg gccctctggc 1740
caggggaaac agcagattcg cctggatgac cagaaagagc gaggaaacca tcaccccctg 1800
gaacttcgag gaagtggtgg acaagggcgc ttccgcccag agcttcatcg agcggatgac 1860
caacttcgat aagaacctgc ccaacgagaa ggtgctgccc aagcacagcc tgctgtacga 1920
gtacttcacc gtgtataacg agctgaccaa agtgaaatac gtgaccgagg gaatgagaaa 1980
gcccgccttc ctgagcggcg agcagaaaaa ggccatcgtg gacctgctgt tcaagaccaa 2040
ccggaaagtg accgtgaagc agctgaaaga ggactacttc aagaaaatcg agtgcttcga 2100
ctccgtggaa atctccggcg tggaagatcg gttcaacgcc tccctgggca cataccacga 2160
tctgctgaaa attatcaagg acaaggactt cctggacaat gaggaaaacg aggacattct 2220
ggaagatatc gtgctgaccc tgacactgtt tgaggacaga gagatgatcg aggaacggct 2280
gaaaacctat gcccacctgt tcgacgacaa agtgatgaag cagctgaagc ggcggagata 2340
caccggctgg ggcaggctga gccggaagct gatcaacggc atccgggaca agcagtccgg 2400
caagacaatc ctggatttcc tgaagtccga cggcttcgcc aacagaaact tcatgcagct 2460
gatccacgac gacagcctga cctttaaaga ggacatccag aaagcccagg tgtccggcca 2520
gggcgatagc ctgcacgagc acattgccaa tctggccggc agccccgcca ttaagaaggg 2580
catcctgcag acagtgaagg tggtggacga gctcgtgaaa gtgatgggcc ggcacaagcc 2640
cgagaacatc gtgatcgaaa tggccagaga gaaccagacc acccagaagg gacagaagaa 2700
cagccgcgag agaatgaagc ggatcgaaga gggcatcaaa gagctgggca gccagatcct 2760
gaaagaacac cccgtggaaa acacccagct gcagaacgag aagctgtacc tgtactacct 2820
gcagaatggg cgggatatgt acgtggacca ggaactggac atcaaccggc tgtccgacta 2880
cgatgtggac catatcgtgc ctcagagctt tctgaaggac gactccatcg acaacaaggt 2940
gctgaccaga agcgacaaga accggggcaa gagcgacaac gtgccctccg aagaggtcgt 3000
gaagaagatg aagaactact ggcggcagct gctgaacgcc aagctgatta cccagagaaa 3060
gttcgacaat ctgaccaagg ccgagagagg cggcctgagc gaactggata aggccggctt 3120
catcaagaga cagctggtgg aaacccggca gatcacaaag cacgtggcac agatcctgga 3180
ctcccggatg aacactaagt acgacgagaa tgacaagctg atccgggaag tgaaagtgat 3240
caccctgaag tccaagctgg tgtccgattt ccggaaggat ttccagtttt acaaagtgcg 3300
cgagatcaac aactaccacc acgcccacga cgcctacctg aacgccgtcg tgggaaccgc 3360
cctgatcaaa aagtacccta agctggaaag cgagttcgtg tacggcgact acaaggtgta 3420
cgacgtgcgg aagatgatcg ccaagagcga gcaggaaatc ggcaaggcta ccgccaagta 3480
cttcttctac agcaacatca tgaacttttt caagaccgag attaccctgg ccaacggcga 3540
gatccggaag cggcctctga tcgagacaaa cggcgaaacc ggggagatcg tgtgggataa 3600
gggccgggat tttgccaccg tgcggaaagt gctgagcatg ccccaagtga atatcgtgaa 3660
aaagaccgag gtgcagacag gcggcttcag caaagagtct atcctgccca agaggaacag 3720
cgataagctg atcgccagaa agaaggactg ggaccctaag aagtacggcg gcttcgacag 3780
ccccaccgtg gcctattctg tgctggtggt ggccaaagtg gaaaagggca agtccaagaa 3840
actgaagagt gtgaaagagc tgctggggat caccatcatg gaaagaagca gcttcgagaa 3900
gaatcccatc gactttctgg aagccaaggg ctacaaagaa gtgaaaaagg acctgatcat 3960
caagctgcct aagtactccc tgttcgagct ggaaaacggc cggaagagaa tgctggcctc 4020
tgccggcgaa ctgcagaagg gaaacgaact ggccctgccc tccaaatatg tgaacttcct 4080
gtacctggcc agccactatg agaagctgaa gggctccccc gaggataatg agcagaaaca 4140
gctgtttgtg gaacagcaca agcactacct ggacgagatc atcgagcaga tcagcgagtt 4200
ctccaagaga gtgatcctgg ccgacgctaa tctggacaaa gtgctgtccg cctacaacaa 4260
gcaccgggat aagcccatca gagagcaggc cgagaatatc atccacctgt ttaccctgac 4320
caatctggga gcccctgccg ccttcaagta ctttgacacc accatcgacc ggaagaggta 4380
caccagcacc aaagaggtgc tggacgccac cctgatccac cagagcatca ccggcctgta 4440
cgagacacgg atcgacctgt ctcagctggg aggcgacagc cccaagaaga agagaaaggt 4500
ggaggccagc taaggatccg gcaagactgg ccccgcttgg caacgcaaca gtgagcccct 4560
ccctagtgtg tttggggatg tgactatgta ttcgtgtgtt ggccaacggg tcaacccgaa 4620
cagattgata cccgccttgg catttcctgt cagaatgtaa cgtcagttga tggtact 4677
<210> 276
<211> 3150
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 276
tctttcttgc gctatgacac ttccagcaaa aggtagggcg ggctgcgaga cggcttcccg 60
gcgctgcatg caacaccgat gatgcttcga ccccccgaag ctccttcggg gctgcatggg 120
cgctccgatg ccgctccagg gcgagcgctg tttaaatagc caggcccccg attgcaaaga 180
cattatagcg agctaccaaa gccatattca aacacctaga tcactaccac ttctacacag 240
gccactcgag cttgtgatcg cactccgcta agggggcgcc tcttcctctt cgtttcagtc 300
acaacccgca aacatgccta agaagaagag gaaggttaac acgattaaca tcgctaagaa 360
cgacttctct gacatcgaac tggctgctat cccgttcaac actctggctg accattacgg 420
tgagcgttta gctcgcgaac agttggccct tgagcatgag tcttacgaga tgggtgaagc 480
acgcttccgc aagatgtttg agcgtcaact taaagctggt gaggttgcgg ataacgctgc 540
cgccaagcct ctcatcacta ccctactccc taagatgatt gcacgcatca acgactggtt 600
tgaggaagtg aaagctaagc gcggcaagcg cccgacagcc ttccagttcc tgcaagaaat 660
caagccggaa gccgtagcgt acatcaccat taagaccact ctggcttgcc taaccagtgc 720
tgacaataca accgttcagg ctgtagcaag cgcaatcggt cgggccattg aggacgaggc 780
tcgcttcggt cgtatccgtg accttgaagc taagcacttc aagaaaaacg ttgaggaaca 840
actcaacaag cgcgtagggc acgtctacaa gaaagcattt atgcaagttg tcgaggctga 900
catgctctct aagggtctac tcggtggcga ggcgtggtct tcgtggcata aggaagactc 960
tattcatgta ggagtacgct gcatcgagat gctcattgag tcaaccggaa tggttagctt 1020
acaccgccaa aatgctggcg tagtaggtca agactctgag actatcgaac tcgcacctga 1080
atacgctgag gctatcgcaa cccgtgcagg tgcgctggct ggcatctctc cgatgttcca 1140
accttgcgta gttcctccta agccgtggac tggcattact ggtggtggct attgggctaa 1200
cggtcgtcgt cctctggcgc tggtgcgtac tcacagtaag aaagcactga tgcgctacga 1260
agacgtttac atgcctgagg tgtacaaagc gattaacatt gcgcaaaaca ccgcatggaa 1320
aatcaacaag aaagtcctag cggtcgccaa cgtaatcacc aagtggaagc attgtccggt 1380
cgaggacatc cctgcgattg agcgtgaaga actcccgatg aaaccggaag acatcgacat 1440
gaatcctgag gctctcaccg cgtggaaacg tgctgccgct gctgtgtacc gcaaggacaa 1500
ggctcgcaag tctcgccgta tcagccttga gttcatgctt gagcaagcca ataagtttgc 1560
taaccataag gccatctggt tcccttacaa catggactgg cgcggtcgtg tttacgctgt 1620
gtcaatgttc aacccgcaag gtaacgatat gaccaaagga ctgcttacgc tggcgaaagg 1680
taaaccaatc ggtaaggaag gttactactg gctgaaaatc cacggtgcaa actgtgcggg 1740
tgtcgacaag gttccgttcc ctgagcgcat caagttcatt gaggaaaacc acgagaacat 1800
catggcttgc gctaagtctc cactggagaa cacttggtgg gctgagcaag attctccgtt 1860
ctgcttcctt gcgttctgct ttgagtacgc tggggtacag caccacggcc tgagctataa 1920
ctgctccctt ccgctggcgt ttgacgggtc ttgctctggc atccagcact tctccgcgat 1980
gctccgagat gaggtaggtg gtcgcgcggt taacttgctt cctagtgaaa ccgttcagga 2040
catctacggg attgttgcta agaaagtcaa cgagattcta caagcagacg caatcaatgg 2100
gaccgataac gaagtagtta ccgtgaccga tgagaacact ggtgaaatct ctgagaaagt 2160
caagctgggc actaaggcac tggctggtca atggctggct tacggtgtta ctcgcagtgt 2220
gactaagcgt tcagtcatga cgctggctta cgggtccaaa gagttcggct tccgtcaaca 2280
agtgctggaa gataccattc agccagctat tgattccggc aagggtctga tgttcactca 2340
gccgaatcag gctgctggat acatggctaa gctgatttgg gaatctgtga gcgtgacggt 2400
ggtagctgcg gttgaagcaa tgaactggct taagtctgct gctaagctgc tggctgctga 2460
ggtcaaagat aagaagactg gagagattct tcgcaagcgt tgcgctgtgc attgggtaac 2520
tcctgatggt ttccctgtgt ggcaggaata caagaagcct attcagacgc gcttgaacct 2580
gatgttcctc ggtcagttcc gcttacagcc taccattaac accaacaaag atagcgagat 2640
tgatgcacac aaacaggagt ctggtatcgc tcctaacttt gtacacagcc aagacggtag 2700
ccaccttcgt aagactgtag tgtgggcaca cgagaagtac ggaatcgaat cttttgcact 2760
gattcacgac tccttcggta cgattccggc tgacgctgcg aacctgttca aagcagtgcg 2820
cgaaactatg gttgacacat atgagtcttg tgatgtactg gctgatttct acgaccagtt 2880
cgctgaccag ttgcacgagt ctcaattgga caaaatgcca gcacttccgg ctaaaggtaa 2940
cttgaacctc cgtgacatct tagagtcgga cttcgcgttc gcgtaaggat ccggcaagac 3000
tggccccgct tggcaacgca acagtgagcc cctccctagt gtgtttgggg atgtgactat 3060
gtattcgtgt gttggccaac gggtcaaccc gaacagattg atacccgcct tggcatttcc 3120
tgtcagaatg taacgtcagt tgatggtact 3150
<210> 277
<211> 125
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (23)..(42)
<223> a, c, t, g, unknown or other
<400> 277
gaaattaata cgactcacta tannnnnnnn nnnnnnnnnn nngttttaga gctagaaata 60
gcaagttaaa ataaggctag tccgttatca acttgaaaaa gtggcaccga gtcggtgctt 120
ttttt 125
<210> 278
<211> 8452
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 278
tgcggtattt cacaccgcat caggtggcac ttttcgggga aatgtgcgcg gaacccctat 60
ttgtttattt ttctaaatac attcaaatat gtatccgctc atgagattat caaaaaggat 120
cttcacctag atccttttaa attaaaaatg aagttttaaa tcaatctaaa gtatatatga 180
gtaaacttgg tctgacagtt accaatgctt aatcagtgag gcacctatct cagcgatctg 240
tctatttcgt tcatccatag ttgcctgact ccccgtcgtg tagataacta cgatacggga 300
gggcttacca tctggcccca gtgctgcaat gataccgcga gacccacgct caccggctcc 360
agatttatca gcaataaacc agccagccgg aagggccgag cgcagaagtg gtcctgcaac 420
tttatccgcc tccatccagt ctattaattg ttgccgggaa gctagagtaa gtagttcgcc 480
agttaatagt ttgcgcaacg ttgttgccat tgctacaggc atcgtggtgt cacgctcgtc 540
gtttggtatg gcttcattca gctccggttc ccaacgatca aggcgagtta catgatcccc 600
catgttgtgc aaaaaagcgg ttagctcctt cggtcctccg atcgttgtca gaagtaagtt 660
ggccgcagtg ttatcactca tggttatggc agcactgcat aattctctta ctgtcatgcc 720
atccgtaaga tgcttttctg tgactggtga gtactcaacc aagtcattct gagaatagtg 780
tatgcggcga ccgagttgct cttgcccggc gtcaatacgg gataataccg cgccacatag 840
cagaacttta aaagtgctca tcattggaaa acgttcttcg gggcgaaaac tctcaaggat 900
cttaccgctg ttgagatcca gttcgatgta acccactcgt gcacccaact gatcttcagc 960
atcttttact ttcaccagcg tttctgggtg agcaaaaaca ggaaggcaaa atgccgcaaa 1020
aaagggaata agggcgacac ggaaatgttg aatactcata ctcttccttt ttcaatatta 1080
ttgaagcatt tatcagggtt attgtctcat gaccaaaatc ccttaacgtg agttttcgtt 1140
ccactgagcg tcagaccccg tagaaaagat caaaggatct tcttgagatc ctttttttct 1200
gcgcgtaatc tgctgcttgc aaacaaaaaa accaccgcta ccagcggtgg tttgtttgcc 1260
ggatcaagag ctaccaactc tttttccgaa ggtaactggc ttcagcagag cgcagatacc 1320
aaatactgtt cttctagtgt agccgtagtt aggccaccac ttcaagaact ctgtagcacc 1380
gcctacatac ctcgctctgc taatcctgtt accagtggct gttgccagtg gcgataagtc 1440
gtgtcttacc gggttggact caagacgata gttaccggat aaggcgcagc ggtcgggctg 1500
aacggggggt tcgtgcacac agcccagctt ggagcgaacg acctacaccg aactgagata 1560
cctacagcgt gagctatgag aaagcgccac gcttcccgaa gggagaaagg cggacaggta 1620
tccggtaagc ggcagggtcg gaacaggaga gcgcacgagg gagcttccag ggggaaacgc 1680
ctggtatctt tatagtcctg tcgggtttcg ccacctctga cttgagcgtc gatttttgtg 1740
atgctcgtca ggggggcgga gcctatggaa aaacgccagc aacgcggcct ttttacggtt 1800
cctggccttt tgctggcctt ttgctcacat gttctttcct gcgttatccc ctgattctgt 1860
ggataaccgt attaccgcct ttgagtgagc tgataccgct cgccgcagcc gaacgaccga 1920
gcgcagcgag tcagtgagcg aggaagcggt cgctgaggct tgacatgatt ggtgcgtatg 1980
tttgtatgaa gctacaggac tgatttggcg ggctatgagg gcgggggaag ctctggaagg 2040
gccgcgatgg ggcgcgcggc gtccagaagg cgccatacgg cccgctggcg gcacccatcc 2100
ggtataaaag cccgcgaccc cgaacggtga cctccacttt cagcgacaaa cgagcactta 2160
tacatacgcg actattctgc cgctatacat aaccactcag ctagcttaag atcccatcaa 2220
gcttgcatgc cgggcgcgcc agaaggagcg cagccaaacc aggatgatgt ttgatggggt 2280
atttgagcac ttgcaaccct tatccggaag ccccctggcc cacaaaggct aggcgccaat 2340
gcaagcagtt cgcatgcagc ccctggagcg gtgccctcct gataaaccgg ccagggggcc 2400
tatgttcttt acttttttac aagagaagtc actcaacatc ttaaaatggc caggtgagtc 2460
gacgagcaag cccggcggat caggcagcgt gcttgcagat ttgacttgca acgcccgcat 2520
tgtgtcgacg aaggcttttg gctcctctgt cgctgtctca agcagcatct aaccctgcgt 2580
cgccgtttcc atttgcagga gattcgaggt accatgtacc catacgatgt tccagattac 2640
gcttcgccga agaaaaagcg caaggtcgaa gcgtccgaca agaagtacag catcggcctg 2700
gacatcggca ccaactctgt gggctgggcc gtgatcaccg acgagtacaa ggtgcccagc 2760
aagaaattca aggtgctggg caacaccgac cggcacagca tcaagaagaa cctgatcgga 2820
gccctgctgt tcgacagcgg cgaaacagcc gaggccaccc ggctgaagag aaccgccaga 2880
agaagataca ccagacggaa gaaccggatc tgctatctgc aagagatctt cagcaacgag 2940
atggccaagg tggacgacag cttcttccac agactggaag agtccttcct ggtggaagag 3000
gataagaagc acgagcggca ccccatcttc ggcaacatcg tggacgaggt ggcctaccac 3060
gagaagtacc ccaccatcta ccacctgaga aagaaactgg tggacagcac cgacaaggcc 3120
gacctgcggc tgatctatct ggccctggcc cacatgatca agttccgggg ccacttcctg 3180
atcgagggcg acctgaaccc cgacaacagc gacgtggaca agctgttcat ccagctggtg 3240
cagacctaca accagctgtt cgaggaaaac cccatcaacg ccagcggcgt ggacgccaag 3300
gccatcctgt ctgccagact gagcaagagc agacggctgg aaaatctgat cgcccagctg 3360
cccggcgaga agaagaatgg cctgttcggc aacctgattg ccctgagcct gggcctgacc 3420
cccaacttca agagcaactt cgacctggcc gaggatgcca aactgcagct gagcaaggac 3480
acctacgacg acgacctgga caacctgctg gcccagatcg gcgaccagta cgccgacctg 3540
tttctggccg ccaagaacct gtccgacgcc atcctgctga gcgacatcct gagagtgaac 3600
accgagatca ccaaggcccc cctgagcgcc tctatgatca agagatacga cgagcaccac 3660
caggacctga ccctgctgaa agctctcgtg cggcagcagc tgcctgagaa gtacaaagag 3720
attttcttcg accagagcaa gaacggctac gccggctaca ttgacggcgg agccagccag 3780
gaagagttct acaagttcat caagcccatc ctggaaaaga tggacggcac cgaggaactg 3840
ctcgtgaagc tgaacagaga ggacctgctg cggaagcagc ggaccttcga caacggcagc 3900
atcccccacc agatccacct gggagagctg cacgccattc tgcggcggca ggaagatttt 3960
tacccattcc tgaaggacaa ccgggaaaag atcgagaaga tcctgacctt ccgcatcccc 4020
tactacgtgg gccctctggc caggggaaac agcagattcg cctggatgac cagaaagagc 4080
gaggaaacca tcaccccctg gaacttcgag gaagtggtgg acaagggcgc ttccgcccag 4140
agcttcatcg agcggatgac caacttcgat aagaacctgc ccaacgagaa ggtgctgccc 4200
aagcacagcc tgctgtacga gtacttcacc gtgtataacg agctgaccaa agtgaaatac 4260
gtgaccgagg gaatgagaaa gcccgccttc ctgagcggcg agcagaaaaa ggccatcgtg 4320
gacctgctgt tcaagaccaa ccggaaagtg accgtgaagc agctgaaaga ggactacttc 4380
aagaaaatcg agtgcttcga ctccgtggaa atctccggcg tggaagatcg gttcaacgcc 4440
tccctgggca cataccacga tctgctgaaa attatcaagg acaaggactt cctggacaat 4500
gaggaaaacg aggacattct ggaagatatc gtgctgaccc tgacactgtt tgaggacaga 4560
gagatgatcg aggaacggct gaaaacctat gcccacctgt tcgacgacaa agtgatgaag 4620
cagctgaagc ggcggagata caccggctgg ggcaggctga gccggaagct gatcaacggc 4680
atccgggaca agcagtccgg caagacaatc ctggatttcc tgaagtccga cggcttcgcc 4740
aacagaaact tcatgcagct gatccacgac gacagcctga cctttaaaga ggacatccag 4800
aaagcccagg tgtccggcca gggcgatagc ctgcacgagc acattgccaa tctggccggc 4860
agccccgcca ttaagaaggg catcctgcag acagtgaagg tggtggacga gctcgtgaaa 4920
gtgatgggcc ggcacaagcc cgagaacatc gtgatcgaaa tggccagaga gaaccagacc 4980
acccagaagg gacagaagaa cagccgcgag agaatgaagc ggatcgaaga gggcatcaaa 5040
gagctgggca gccagatcct gaaagaacac cccgtggaaa acacccagct gcagaacgag 5100
aagctgtacc tgtactacct gcagaatggg cgggatatgt acgtggacca ggaactggac 5160
atcaaccggc tgtccgacta cgatgtggac catatcgtgc ctcagagctt tctgaaggac 5220
gactccatcg acaacaaggt gctgaccaga agcgacaaga accggggcaa gagcgacaac 5280
gtgccctccg aagaggtcgt gaagaagatg aagaactact ggcggcagct gctgaacgcc 5340
aagctgatta cccagagaaa gttcgacaat ctgaccaagg ccgagagagg cggcctgagc 5400
gaactggata aggccggctt catcaagaga cagctggtgg aaacccggca gatcacaaag 5460
cacgtggcac agatcctgga ctcccggatg aacactaagt acgacgagaa tgacaagctg 5520
atccgggaag tgaaagtgat caccctgaag tccaagctgg tgtccgattt ccggaaggat 5580
ttccagtttt acaaagtgcg cgagatcaac aactaccacc acgcccacga cgcctacctg 5640
aacgccgtcg tgggaaccgc cctgatcaaa aagtacccta agctggaaag cgagttcgtg 5700
tacggcgact acaaggtgta cgacgtgcgg aagatgatcg ccaagagcga gcaggaaatc 5760
ggcaaggcta ccgccaagta cttcttctac agcaacatca tgaacttttt caagaccgag 5820
attaccctgg ccaacggcga gatccggaag cggcctctga tcgagacaaa cggcgaaacc 5880
ggggagatcg tgtgggataa gggccgggat tttgccaccg tgcggaaagt gctgagcatg 5940
ccccaagtga atatcgtgaa aaagaccgag gtgcagacag gcggcttcag caaagagtct 6000
atcctgccca agaggaacag cgataagctg atcgccagaa agaaggactg ggaccctaag 6060
aagtacggcg gcttcgacag ccccaccgtg gcctattctg tgctggtggt ggccaaagtg 6120
gaaaagggca agtccaagaa actgaagagt gtgaaagagc tgctggggat caccatcatg 6180
gaaagaagca gcttcgagaa gaatcccatc gactttctgg aagccaaggg ctacaaagaa 6240
gtgaaaaagg acctgatcat caagctgcct aagtactccc tgttcgagct ggaaaacggc 6300
cggaagagaa tgctggcctc tgccggcgaa ctgcagaagg gaaacgaact ggccctgccc 6360
tccaaatatg tgaacttcct gtacctggcc agccactatg agaagctgaa gggctccccc 6420
gaggataatg agcagaaaca gctgtttgtg gaacagcaca agcactacct ggacgagatc 6480
atcgagcaga tcagcgagtt ctccaagaga gtgatcctgg ccgacgctaa tctggacaaa 6540
gtgctgtccg cctacaacaa gcaccgggat aagcccatca gagagcaggc cgagaatatc 6600
atccacctgt ttaccctgac caatctggga gcccctgccg ccttcaagta ctttgacacc 6660
accatcgacc ggaagaggta caccagcacc aaagaggtgc tggacgccac cctgatccac 6720
cagagcatca ccggcctgta cgagacacgg atcgacctgt ctcagctggg aggcgacagc 6780
cccaagaaga agagaaaggt ggaggccagc taacatatga ttcgaatgtc tttcttgcgc 6840
tatgacactt ccagcaaaag gtagggcggg ctgcgagacg gcttcccggc gctgcatgca 6900
acaccgatga tgcttcgacc ccccgaagct ccttcggggc tgcatgggcg ctccgatgcc 6960
gctccagggc gagcgctgtt taaatagcca ggcccccgat tgcaaagaca ttatagcgag 7020
ctaccaaagc catattcaaa cacctagatc actaccactt ctacacaggc cactcgagct 7080
tgtgatcgca ctccgctaag ggggcgcctc ttcctcttcg tttcagtcac aacccgcaaa 7140
catgacacaa gaatccctgt tacttctcga ccgtattgat tcggatgatt cctacgcgag 7200
cctgcggaac gaccaggaat tctgggaggt gagtcgacga gcaagcccgg cggatcaggc 7260
agcgtgcttg cagatttgac ttgcaacgcc cgcattgtgt cgacgaaggc ttttggctcc 7320
tctgtcgctg tctcaagcag catctaaccc tgcgtcgccg tttccatttg cagccgctgg 7380
cccgccgagc cctggaggag ctcgggctgc cggtgccgcc ggtgctgcgg gtgcccggcg 7440
agagcaccaa ccccgtactg gtcggcgagc ccggcccggt gatcaagctg ttcggcgagc 7500
actggtgcgg tccggagagc ctcgcgtcgg agtcggaggc gtacgcggtc ctggcggacg 7560
ccccggtgcc ggtgccccgc ctcctcggcc gcggcgagct gcggcccggc accggagcct 7620
ggccgtggcc ctacctggtg atgagccgga tgaccggcac cacctggcgg tccgcgatgg 7680
acggcacgac cgaccggaac gcgctgctcg ccctggcccg cgaactcggc cgggtgctcg 7740
gccggctgca cagggtgccg ctgaccggga acaccgtgct caccccccat tccgaggtct 7800
tcccggaact gctgcgggaa cgccgcgcgg cgaccgtcga ggaccaccgc gggtggggct 7860
acctctcgcc ccggctgctg gaccgcctgg aggactggct gccggacgtg gacacgctgc 7920
tggccggccg cgaaccccgg ttcgtccacg gcgacctgca cgggaccaac atcttcgtgg 7980
acctggccgc gaccgaggtc accgggatcg tcgacttcac cgacgtctat gcgggagact 8040
cccgctacag cctggtgcaa ctgcatctca acgccttccg gggcgaccgc gagatcctgg 8100
ccgcgctgct cgacggggcg cagtggaagc ggaccgagga cttcgcccgc gaactgctcg 8160
ccttcacctt cctgcacgac ttcgaggtgt tcgaggagac cccgctggat ctctccggct 8220
tcaccgatcc ggaggaactg gcgcagttcc tctgggggcc gccggacacc gcccccggcg 8280
cctgataagg atccggcaag actggccccg cttggcaacg caacagtgag cccctcccta 8340
gtgtgtttgg ggatgtgact atgtattcgt gtgttggcca acgggtcaac ccgaacagat 8400
tgatacccgc cttggcattt cctgtcagaa tgtaacgtca gttgatggta ct 8452
<210> 279
<211> 102
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 279
gttttagagc tatgctgttt tgaatggtcc caaaacggaa gggcctgagt ccgagcagaa 60
gaagaagttt tagagctatg ctgttttgaa tggtcccaaa ac 102
<210> 280
<211> 100
<212> DNA
<213> Homo sapiens
<400> 280
cggaggacaa agtacaaacg gcagaagctg gaggaggaag ggcctgagtc cgagcagaag 60
aagaagggct cccatcacat caaccggtgg cgcattgcca 100
<210> 281
<211> 50
<212> DNA
<213> Homo sapiens
<400> 281
agctggagga ggaagggcct gagtccgagc agaagaagaa gggctcccac 50
<210> 282
<211> 30
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 282
gaguccgagc agaagaagaa guuuuagagc 30
<210> 283
<211> 49
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 283
agctggagga ggaagggcct gagtccgagc agaagagaag ggctcccat 49
<210> 284
<211> 53
<212> DNA
<213> Homo sapiens
<400> 284
ctggaggagg aagggcctga gtccgagcag aagaagaagg gctcccatca cat 53
<210> 285
<211> 52
<212> DNA
<213> Homo sapiens
<400> 285
ctggaggagg aagggcctga gtccgagcag aagagaaggg ctcccatcac at 52
<210> 286
<211> 54
<212> DNA
<213> Homo sapiens
<400> 286
ctggaggagg aagggcctga gtccgagcag aagaaagaag ggctcccatc acat 54
<210> 287
<211> 50
<212> DNA
<213> Homo sapiens
<400> 287
ctggaggagg aagggcctga gtccgagcag aagaagggct cccatcacat 50
<210> 288
<211> 47
<212> DNA
<213> Homo sapiens
<400> 288
ctggaggagg aagggcctga gcccgagcag aagggctccc atcacat 47
<210> 289
<211> 66
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> source
<223> /note="Description of Combined DNA/RNA Molecule: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, t, g, unknown or other
<400> 289
nnnnnnnnnn nnnnnnnnnn guuuuagagc uagaaauagc aaguuaaaau aaggctagtc 60
cguuuu 66
<210> 290
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 290
gaguccgagc agaagaagaa 20
<210> 291
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 291
gacaucgaug uccuccccau 20
<210> 292
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 292
gucaccucca augacuaggg 20
<210> 293
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 293
auuggguguu cagggcagag 20
<210> 294
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 294
guggcgagag gggccgagau 20
<210> 295
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 295
ggggccgaga uuggguguuc 20
<210> 296
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 296
gugccauuag cuaaaugcau 20
<210> 297
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 297
guaccaccca caggugccag 20
<210> 298
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 298
gaaagccucu gggccaggaa 20
<210> 299
<211> 48
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 299
ctggaggagg aagggcctga gtccgagcag aagaagaagg gctcccat 48
<210> 300
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 300
gaguccgagc agaagaagau 20
<210> 301
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 301
gaguccgagc agaagaagua 20
<210> 302
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 302
gaguccgagc agaagaacaa 20
<210> 303
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 303
gaguccgagc agaagaugaa 20
<210> 304
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 304
gaguccgagc agaaguagaa 20
<210> 305
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 305
gaguccgagc agaugaagaa 20
<210> 306
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 306
gaguccgagc acaagaagaa 20
<210> 307
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 307
gaguccgagg agaagaagaa 20
<210> 308
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 308
gaguccgugc agaagaagaa 20
<210> 309
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 309
gagucggagc agaagaagaa 20
<210> 310
<211> 20
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 310
gagaccgagc agaagaagaa 20
<210> 311
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 311
aatgacaagc ttgctagcgg tggg 24
<210> 312
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 312
aaaacggaag ggcctgagtc cgagcagaag aagaagttt 39
<210> 313
<211> 39
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 313
aaacaggggc cgagattggg tgttcagggc agaggtttt 39
<210> 314
<211> 38
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 314
aaaacggaag ggcctgagtc cgagcagaag aagaagtt 38
<210> 315
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 315
aacggaggga ggggcacaga tgagaaactc agggttttag 40
<210> 316
<211> 38
<212> DNA
<213> Homo sapiens
<400> 316
agcccttctt cttctgctcg gactcaggcc cttcctcc 38
<210> 317
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 317
cagggaggga ggggcacaga tgagaaactc aggaggcccc 40
<210> 318
<211> 80
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 318
ggcaatgcgc caccggttga tgtgatggga gcccttctag gaggccccca gagcagccac 60
tggggcctca acactcaggc 80
<210> 319
<211> 23
<212> DNA
<213> Homo sapiens
<400> 319
gtcacctcca atgactaggg tgg 23
<210> 320
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (6)..(25)
<223> a, c, t, g, unknown or other
<400> 320
caccgnnnnn nnnnnnnnnn nnnnn 25
<210> 321
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (5)..(24)
<223> a, c, t, g, unknown or other
<400> 321
aaacnnnnnn nnnnnnnnnn nnnnc 25
<210> 322
<211> 33
<212> DNA
<213> Homo sapiens
<400> 322
catcgatgtc ctccccattg gcctgcttcg tgg 33
<210> 323
<211> 33
<212> DNA
<213> Homo sapiens
<400> 323
ttcgtggcaa tgcgccaccg gttgatgtga tgg 33
<210> 324
<211> 33
<212> DNA
<213> Homo sapiens
<400> 324
tcgtggcaat gcgccaccgg ttgatgtgat ggg 33
<210> 325
<211> 33
<212> DNA
<213> Homo sapiens
<400> 325
tccagcttct gccgtttgta ctttgtcctc cgg 33
<210> 326
<211> 33
<212> DNA
<213> Homo sapiens
<400> 326
ggagggaggg gcacagatga gaaactcagg agg 33
<210> 327
<211> 33
<212> DNA
<213> Homo sapiens
<400> 327
aggggccgag attgggtgtt cagggcagag agg 33
<210> 328
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 328
aacaccgggt cttcgagaag acctgtttta gagctagaaa tagcaagtta aaat 54
<210> 329
<211> 54
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 329
caaaacgggt cttcgagaag acgttttaga gctatgctgt tttgaatggt ccca 54
<210> 330
<211> 33
<212> DNA
<213> Mus musculus
<400> 330
caagcactga gtgccattag ctaaatgcat agg 33
<210> 331
<211> 33
<212> DNA
<213> Mus musculus
<400> 331
aatgcatagg gtaccaccca caggtgccag ggg 33
<210> 332
<211> 33
<212> DNA
<213> Mus musculus
<400> 332
acacacatgg gaaagcctct gggccaggaa agg 33
<210> 333
<211> 37
<212> DNA
<213> Homo sapiens
<400> 333
ggaggaggta gtatacagaa acacagagaa gtagaat 37
<210> 334
<211> 37
<212> DNA
<213> Homo sapiens
<400> 334
agaatgtaga ggagtcacag aaactcagca ctagaaa 37
<210> 335
<211> 98
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 335
ggacgaaaca ccggaaccat tcaaaacagc atagcaagtt aaaataaggc tagtccgtta 60
tcaacttgaa aaagtggcac cgagtcggtg cttttttt 98
<210> 336
<211> 186
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 336
ggacgaaaca ccggtagtat taagtattgt tttatggctg ataaatttct ttgaatttct 60
ccttgattat ttgttataaa agttataaaa taatcttgtt ggaaccattc aaaacagcat 120
agcaagttaa aataaggcta gtccgttatc aacttgaaaa agtggcaccg agtcggtgct 180
tttttt 186
<210> 337
<211> 95
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 337
gggttttaga gctatgctgt tttgaatggt cccaaaacgg gtcttcgaga agacgtttta 60
gagctatgct gttttgaatg gtcccaaaac ttttt 95
<210> 338
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (5)..(34)
<223> a, c, t, g, unknown or other
<400> 338
aaacnnnnnn nnnnnnnnnn nnnnnnnnnn nnnngt 36
<210> 339
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (7)..(36)
<223> a, c, t, g, unknown or other
<400> 339
taaaacnnnn nnnnnnnnnn nnnnnnnnnn nnnnnn 36
<210> 340
<211> 84
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 340
gtggaaagga cgaaacaccg ggtcttcgag aagacctgtt ttagagctag aaatagcaag 60
ttaaaataag gctagtccgt tttt 84
<210> 341
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (6)..(24)
<223> a, c, t, g, unknown or other
<400> 341
caccgnnnnn nnnnnnnnnn nnnn 24
<210> 342
<211> 24
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (5)..(23)
<223> a, c, t, g, unknown or other
<400> 342
aaacnnnnnn nnnnnnnnnn nnnc 24
<210> 343
<211> 88
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 343
gttttagagc tatgctgttt tgaatggtcc caaaactgag accaaaggtc tcgttttaga 60
gctatgctgt tttgaatggt cccaaaac 88
<210> 344
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 344
aaacggaagg gcctgagtcc gagcagaaga agaag 35
<210> 345
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 345
aaaacttctt cttctgctcg gactcaggcc cttcc 35
<210> 346
<211> 46
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(19)
<223> a, c, u, g, unknown or other
<400> 346
nnnnnnnnnn nnnnnnnnng uuauuguacu cucaagauuu auuuuu 46
<210> 347
<211> 91
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 347
guuacuuaaa ucuugcagaa gcuacaaaga uaaggcuuca ugccgaaauc aacacccugu 60
cauuuuaugg caggguguuu ucguuauuua a 91
<210> 348
<211> 70
<212> DNA
<213> Homo sapiens
<400> 348
ttttctagtg ctgagtttct gtgactcctc tacattctac ttctctgtgt ttctgtatac 60
tacctcctcc 70
<210> 349
<211> 122
<212> DNA
<213> Homo sapiens
<400> 349
ggaggaaggg cctgagtccg agcagaagaa gaagggctcc catcacatca accggtggcg 60
cattgccacg aagcaggcca atggggagga catcgatgtc acctccaatg actagggtgg 120
gc 122
<210> 350
<211> 48
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (3)..(32)
<223> a, c, u, g, unknown or other
<400> 350
acnnnnnnnn nnnnnnnnnn nnnnnnnnnn nnguuuuaga gcuaugcu 48
<210> 351
<211> 67
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> source
<223> /note="Description of Combined DNA/RNA Molecule: Synthetic
oligonucleotide"
<400> 351
agcauagcaa guuaaaauaa ggctaguccg uuaucaacuu gaaaaagugg caccgagucg 60
gugcuuu 67
<210> 352
<211> 62
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, u, g, unknown or other
<400> 352
nnnnnnnnnn nnnnnnnnnn guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cg 62
<210> 353
<211> 73
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 353
tgaatggtcc caaaacggaa gggcctgagt ccgagcagaa gaagaagttt tagagctatg 60
ctgttttgaa tgg 73
<210> 354
<211> 69
<212> DNA
<213> Homo sapiens
<400> 354
ctggtcttcc acctctctgc cctgaacacc caatctcggc ccctctcgcc accctcctgc 60
atttctgtt 69
<210> 355
<211> 138
<212> DNA
<213> Mus musculus
<400> 355
acccaagcac tgagtgccat tagctaaatg catagggtac cacccacagg tgccaggggc 60
ctttcccaaa gttcccagcc ccttctccaa cctttcctgg cccagaggct ttcccatgtg 120
tgtggctgga ccctttga 138
<210> 356
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 356
gtgctttgca gaggcctacc 20
<210> 357
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 357
cctggagcgc atgcagtagt 20
<210> 358
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 358
accttctgtg tttccaccat tc 22
<210> 359
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 359
ttggggagtg cacagacttc 20
<210> 360
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 360
ggctccctgg gttcaaagta 20
<210> 361
<211> 21
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 361
agaggggtct ggatgtcgta a 21
<210> 362
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
probe"
<400> 362
tagctctaaa acttcttctt ctgctcggac 30
<210> 363
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
probe"
<400> 363
ctagccttat tttaacttgc tatgctgttt 30
<210> 364
<211> 99
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (1)..(20)
<223> a, c, u, g, unknown or other
<400> 364
nnnnnnnnnn nnnnnnnnnn guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuu 99
<210> 365
<211> 12
<212> DNA
<213> Homo sapiens
<400> 365
tagcgggtaa gc 12
<210> 366
<211> 12
<212> DNA
<213> Homo sapiens
<400> 366
tcggtgacat gt 12
<210> 367
<211> 12
<212> DNA
<213> Homo sapiens
<400> 367
actccccgta gg 12
<210> 368
<211> 12
<212> DNA
<213> Homo sapiens
<400> 368
actgcgtgtt aa 12
<210> 369
<211> 12
<212> DNA
<213> Homo sapiens
<400> 369
acgtcgcctg at 12
<210> 370
<211> 12
<212> DNA
<213> Homo sapiens
<400> 370
taggtcgacc ag 12
<210> 371
<211> 12
<212> DNA
<213> Homo sapiens
<400> 371
ggcgttaatg at 12
<210> 372
<211> 12
<212> DNA
<213> Homo sapiens
<400> 372
tgtcgcatgt ta 12
<210> 373
<211> 12
<212> DNA
<213> Homo sapiens
<400> 373
atggaaacgc at 12
<210> 374
<211> 12
<212> DNA
<213> Homo sapiens
<400> 374
gccgaattcc tc 12
<210> 375
<211> 12
<212> DNA
<213> Homo sapiens
<400> 375
gcatggtacg ga 12
<210> 376
<211> 12
<212> DNA
<213> Homo sapiens
<400> 376
cggtactctt ac 12
<210> 377
<211> 12
<212> DNA
<213> Homo sapiens
<400> 377
gcctgtgccg ta 12
<210> 378
<211> 12
<212> DNA
<213> Homo sapiens
<400> 378
tacggtaagt cg 12
<210> 379
<211> 12
<212> DNA
<213> Homo sapiens
<400> 379
cacgaaatta cc 12
<210> 380
<211> 12
<212> DNA
<213> Homo sapiens
<400> 380
aaccaagata cg 12
<210> 381
<211> 12
<212> DNA
<213> Homo sapiens
<400> 381
gagtcgatac gc 12
<210> 382
<211> 12
<212> DNA
<213> Homo sapiens
<400> 382
gtctcacgat cg 12
<210> 383
<211> 12
<212> DNA
<213> Homo sapiens
<400> 383
tcgtcgggtg ca 12
<210> 384
<211> 12
<212> DNA
<213> Homo sapiens
<400> 384
actccgtagt ga 12
<210> 385
<211> 12
<212> DNA
<213> Homo sapiens
<400> 385
caggacgtcc gt 12
<210> 386
<211> 12
<212> DNA
<213> Homo sapiens
<400> 386
tcgtatccct ac 12
<210> 387
<211> 12
<212> DNA
<213> Homo sapiens
<400> 387
tttcaaggcc gg 12
<210> 388
<211> 12
<212> DNA
<213> Homo sapiens
<400> 388
cgccggtgga at 12
<210> 389
<211> 12
<212> DNA
<213> Homo sapiens
<400> 389
gaacccgtcc ta 12
<210> 390
<211> 12
<212> DNA
<213> Homo sapiens
<400> 390
gattcatcag cg 12
<210> 391
<211> 12
<212> DNA
<213> Homo sapiens
<400> 391
acaccggtct tc 12
<210> 392
<211> 12
<212> DNA
<213> Homo sapiens
<400> 392
atcgtgccct aa 12
<210> 393
<211> 12
<212> DNA
<213> Homo sapiens
<400> 393
gcgtcaatgt tc 12
<210> 394
<211> 12
<212> DNA
<213> Homo sapiens
<400> 394
ctccgtatct cg 12
<210> 395
<211> 12
<212> DNA
<213> Homo sapiens
<400> 395
ccgattcctt cg 12
<210> 396
<211> 12
<212> DNA
<213> Homo sapiens
<400> 396
tgcgcctcca gt 12
<210> 397
<211> 12
<212> DNA
<213> Homo sapiens
<400> 397
taacgtcgga gc 12
<210> 398
<211> 12
<212> DNA
<213> Homo sapiens
<400> 398
aaggtcgccc at 12
<210> 399
<211> 12
<212> DNA
<213> Homo sapiens
<400> 399
gtcggggact at 12
<210> 400
<211> 12
<212> DNA
<213> Homo sapiens
<400> 400
ttcgagcgat tt 12
<210> 401
<211> 12
<212> DNA
<213> Homo sapiens
<400> 401
tgagtcgtcg ag 12
<210> 402
<211> 12
<212> DNA
<213> Homo sapiens
<400> 402
tttacgcaga gg 12
<210> 403
<211> 12
<212> DNA
<213> Homo sapiens
<400> 403
aggaagtatc gc 12
<210> 404
<211> 12
<212> DNA
<213> Homo sapiens
<400> 404
actcgatacc at 12
<210> 405
<211> 12
<212> DNA
<213> Homo sapiens
<400> 405
cgctacatag ca 12
<210> 406
<211> 12
<212> DNA
<213> Homo sapiens
<400> 406
ttcataaccg gc 12
<210> 407
<211> 12
<212> DNA
<213> Homo sapiens
<400> 407
ccaaacggtt aa 12
<210> 408
<211> 12
<212> DNA
<213> Homo sapiens
<400> 408
cgattccttc gt 12
<210> 409
<211> 12
<212> DNA
<213> Homo sapiens
<400> 409
cgtcatgaat aa 12
<210> 410
<211> 12
<212> DNA
<213> Homo sapiens
<400> 410
agtggcgatg ac 12
<210> 411
<211> 12
<212> DNA
<213> Homo sapiens
<400> 411
cccctacggc ac 12
<210> 412
<211> 12
<212> DNA
<213> Homo sapiens
<400> 412
gccaacccgc ac 12
<210> 413
<211> 12
<212> DNA
<213> Homo sapiens
<400> 413
tgggacaccg gt 12
<210> 414
<211> 12
<212> DNA
<213> Homo sapiens
<400> 414
ttgactgcgg cg 12
<210> 415
<211> 12
<212> DNA
<213> Homo sapiens
<400> 415
actatgcgta gg 12
<210> 416
<211> 12
<212> DNA
<213> Homo sapiens
<400> 416
tcacccaaag cg 12
<210> 417
<211> 12
<212> DNA
<213> Homo sapiens
<400> 417
gcaggacgtc cg 12
<210> 418
<211> 12
<212> DNA
<213> Homo sapiens
<400> 418
acaccgaaaa cg 12
<210> 419
<211> 12
<212> DNA
<213> Homo sapiens
<400> 419
cggtgtattg ag 12
<210> 420
<211> 12
<212> DNA
<213> Homo sapiens
<400> 420
cacgaggtat gc 12
<210> 421
<211> 12
<212> DNA
<213> Homo sapiens
<400> 421
taaagcgacc cg 12
<210> 422
<211> 12
<212> DNA
<213> Homo sapiens
<400> 422
cttagtcggc ca 12
<210> 423
<211> 12
<212> DNA
<213> Homo sapiens
<400> 423
cgaaaacgtg gc 12
<210> 424
<211> 12
<212> DNA
<213> Homo sapiens
<400> 424
cgtgccctga ac 12
<210> 425
<211> 12
<212> DNA
<213> Homo sapiens
<400> 425
tttaccatcg aa 12
<210> 426
<211> 12
<212> DNA
<213> Homo sapiens
<400> 426
cgtagccatg tt 12
<210> 427
<211> 12
<212> DNA
<213> Homo sapiens
<400> 427
cccaaacggt ta 12
<210> 428
<211> 12
<212> DNA
<213> Homo sapiens
<400> 428
gcgttatcag aa 12
<210> 429
<211> 12
<212> DNA
<213> Homo sapiens
<400> 429
tcgatggtaa ac 12
<210> 430
<211> 12
<212> DNA
<213> Homo sapiens
<400> 430
cgactttttg ca 12
<210> 431
<211> 12
<212> DNA
<213> Homo sapiens
<400> 431
tcgacgactc ac 12
<210> 432
<211> 12
<212> DNA
<213> Homo sapiens
<400> 432
acgcgtcaga ta 12
<210> 433
<211> 12
<212> DNA
<213> Homo sapiens
<400> 433
cgtacggcac ag 12
<210> 434
<211> 12
<212> DNA
<213> Homo sapiens
<400> 434
ctatgccgtg ca 12
<210> 435
<211> 12
<212> DNA
<213> Homo sapiens
<400> 435
cgcgtcagat at 12
<210> 436
<211> 12
<212> DNA
<213> Homo sapiens
<400> 436
aagatcggta gc 12
<210> 437
<211> 12
<212> DNA
<213> Homo sapiens
<400> 437
cttcgcaagg ag 12
<210> 438
<211> 12
<212> DNA
<213> Homo sapiens
<400> 438
gtcgtggact ac 12
<210> 439
<211> 12
<212> DNA
<213> Homo sapiens
<400> 439
ggtcgtcatc aa 12
<210> 440
<211> 12
<212> DNA
<213> Homo sapiens
<400> 440
gttaacagcg tg 12
<210> 441
<211> 12
<212> DNA
<213> Homo sapiens
<400> 441
tagctaaccg tt 12
<210> 442
<211> 12
<212> DNA
<213> Homo sapiens
<400> 442
agtaaaggcg ct 12
<210> 443
<211> 12
<212> DNA
<213> Homo sapiens
<400> 443
ggtaatttcg tg 12
<210> 444
<211> 69
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 444
gucaccucca augacuaggg guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuuuuuu 69
<210> 445
<211> 69
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 445
gacaucgaug uccuccccau guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuuuuuu 69
<210> 446
<211> 69
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 446
gaguccgagc agaagaagaa guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuuuuuu 69
<210> 447
<211> 69
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 447
ggggccgaga uuggguguuc guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuuuuuu 69
<210> 448
<211> 69
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 448
guggcgagag gggccgagau guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuuuuuu 69
<210> 449
<211> 76
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 449
gucaccucca augacuaggg guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucauu uuuuuu 76
<210> 450
<211> 76
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 450
gacaucgaug uccuccccau guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucauu uuuuuu 76
<210> 451
<211> 76
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 451
gaguccgagc agaagaagaa guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucauu uuuuuu 76
<210> 452
<211> 76
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 452
ggggccgaga uuggguguuc guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucauu uuuuuu 76
<210> 453
<211> 76
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 453
guggcgagag gggccgagau guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucauu uuuuuu 76
<210> 454
<211> 88
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 454
gucaccucca augacuaggg guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu guuuuuuu 88
<210> 455
<211> 88
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 455
gacaucgaug uccuccccau guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu guuuuuuu 88
<210> 456
<211> 88
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 456
gaguccgagc agaagaagaa guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu guuuuuuu 88
<210> 457
<211> 88
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 457
ggggccgaga uuggguguuc guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu guuuuuuu 88
<210> 458
<211> 88
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 458
guggcgagag gggccgagau guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu guuuuuuu 88
<210> 459
<211> 103
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 459
gucaccucca augacuaggg guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu uuu 103
<210> 460
<211> 103
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 460
gacaucgaug uccuccccau guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu uuu 103
<210> 461
<211> 103
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 461
gaguccgagc agaagaagaa guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu uuu 103
<210> 462
<211> 103
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 462
ggggccgaga uuggguguuc guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu uuu 103
<210> 463
<211> 103
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 463
guggcgagag gggccgagau guuuuagagc uagaaauagc aaguuaaaau aaggcuaguc 60
cguuaucaac uugaaaaagu ggcaccgagu cggugcuuuu uuu 103
<210> 464
<211> 120
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 464
gtggaaagga cgaaacaccg ggtcttcgag aagacctgtt ttagagctag aaatagcaag 60
ttaaaataag gctagtccgt tatcaacttg aaaaagtggc accgagtcgg tgcttttttt 120
<210> 465
<211> 40
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 465
tcggtgcgct ggttgatttc ttcttgcgct tttttggctt 40
<210> 466
<211> 26
<212> RNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 466
gauuucuucu ugcgcuuuuu guuuua 26
<210> 467
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (22)..(26)
<223> a, c, t, g, unknown or other
<400> 467
tgatttcttc ttgcgctttt tnnnnn 26
<210> 468
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (21)..(21)
<223> a, c, t, g, unknown or other
<400> 468
tgatttcttc ttgcgctttt ntggct 26
<210> 469
<211> 26
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (2)..(2)
<223> a, c, t, g, unknown or other
<400> 469
tnatttcttc ttgcgctttt ttggct 26
<210> 470
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 470
gatttcttct tgcgcttttt tgg 23
<210> 471
<211> 34
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> CDS
<222> (1)..(33)
<400> 471
tcc atc cgt aca acc cac aac cct gct agt gag c 34
Ser Ile Arg Thr Thr His Asn Pro Ala Ser Glu
1 5 10
<210> 472
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 472
Ser Ile Arg Thr Thr His Asn Pro Ala Ser Glu
1 5 10
<210> 473
<211> 34
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> CDS
<222> (1)..(33)
<400> 473
tcc atc gca aca acc cac aac cct gct agt gag c 34
Ser Ile Ala Thr Thr His Asn Pro Ala Ser Glu
1 5 10
<210> 474
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 474
Ser Ile Ala Thr Thr His Asn Pro Ala Ser Glu
1 5 10
<210> 475
<211> 34
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> CDS
<222> (1)..(33)
<400> 475
tca atc cgt aca acc cac aac cct gct agt gag c 34
Ser Ile Arg Thr Thr His Asn Pro Ala Ser Glu
1 5 10
<210> 476
<211> 42
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (1)..(36)
<400> 476
caa ttg aat tta aaa gaa acc gat acc gtt ttg gtt taagga 42
Gln Leu Asn Leu Lys Glu Thr Asp Thr Val Leu Val
1 5 10
<210> 477
<211> 12
<212> PRT
<213> Homo sapiens
<400> 477
Gln Leu Asn Leu Lys Glu Thr Asp Thr Val Leu Val
1 5 10
<210> 478
<211> 42
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (1)..(42)
<400> 478
caa ttg aat tta aaa gaa acc gat acc gtt tac gaa att gga 42
Gln Leu Asn Leu Lys Glu Thr Asp Thr Val Tyr Glu Ile Gly
1 5 10
<210> 479
<211> 14
<212> PRT
<213> Homo sapiens
<400> 479
Gln Leu Asn Leu Lys Glu Thr Asp Thr Val Tyr Glu Ile Gly
1 5 10
<210> 480
<211> 34
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (2)..(34)
<400> 480
t cct aaa aaa ccg aac tcc gcg ctg cgt aaa gta 34
Pro Lys Lys Pro Asn Ser Ala Leu Arg Lys Val
1 5 10
<210> 481
<211> 11
<212> PRT
<213> Homo sapiens
<400> 481
Pro Lys Lys Pro Asn Ser Ala Leu Arg Lys Val
1 5 10
<210> 482
<211> 34
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (2)..(34)
<400> 482
t cct aca aaa ccg aac tcc gcg ctg cgt aaa gta 34
Pro Thr Lys Pro Asn Ser Ala Leu Arg Lys Val
1 5 10
<210> 483
<211> 11
<212> PRT
<213> Homo sapiens
<400> 483
Pro Thr Lys Pro Asn Ser Ala Leu Arg Lys Val
1 5 10
<210> 484
<211> 33
<212> DNA
<213> Homo sapiens
<400> 484
tgcgctggtt gatttcttct tgcgcttttt tgg 33
<210> 485
<211> 33
<212> DNA
<213> Homo sapiens
<400> 485
tacgctggtt gatttcttct tgcgcttttt ttg 33
<210> 486
<211> 27
<212> DNA
<213> Homo sapiens
<400> 486
ggagggtttt atggggaaag gccattg 27
<210> 487
<211> 29
<212> DNA
<213> Homo sapiens
<400> 487
gtaaaaaaga agactagaaa ttttgatac 29
<210> 488
<211> 46
<212> DNA
<213> Homo sapiens
<400> 488
ggagggtttt atggggaaag gcaaagaaga ctagaaattt tgatac 46
<210> 489
<211> 27
<212> DNA
<213> Homo sapiens
<400> 489
aggtgaagca taatgtctca aaaaata 27
<210> 490
<211> 29
<212> DNA
<213> Homo sapiens
<400> 490
attttattaa tacaaatcag tgaaatcat 29
<210> 491
<211> 46
<212> DNA
<213> Homo sapiens
<400> 491
aggtgaagca taatgtctca aaattaatac aaatcagtga aatcat 46
<210> 492
<211> 36
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (1)..(36)
<400> 492
aat tta aaa gaa acc gat acc gtt tac gaa att gga 36
Asn Leu Lys Glu Thr Asp Thr Val Tyr Glu Ile Gly
1 5 10
<210> 493
<211> 12
<212> PRT
<213> Homo sapiens
<400> 493
Asn Leu Lys Glu Thr Asp Thr Val Tyr Glu Ile Gly
1 5 10
<210> 494
<211> 36
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (1)..(30)
<400> 494
aat tta aaa gaa acc gat acc gtt ttg gtt taagga 36
Asn Leu Lys Glu Thr Asp Thr Val Leu Val
1 5 10
<210> 495
<211> 10
<212> PRT
<213> Homo sapiens
<400> 495
Asn Leu Lys Glu Thr Asp Thr Val Leu Val
1 5 10
<210> 496
<211> 36
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (1)..(36)
<400> 496
tgg gat cca aaa aaa tat ggt ggt ttt gat agt cca 36
Trp Asp Pro Lys Lys Tyr Gly Gly Phe Asp Ser Pro
1 5 10
<210> 497
<211> 12
<212> PRT
<213> Homo sapiens
<400> 497
Trp Asp Pro Lys Lys Tyr Gly Gly Phe Asp Ser Pro
1 5 10
<210> 498
<211> 36
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> CDS
<222> (1)..(36)
<400> 498
tgg gat cca aaa aaa tat tgt ggt ttt gat agt cca 36
Trp Asp Pro Lys Lys Tyr Cys Gly Phe Asp Ser Pro
1 5 10
<210> 499
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
peptide"
<400> 499
Trp Asp Pro Lys Lys Tyr Cys Gly Phe Asp Ser Pro
1 5 10
<210> 500
<211> 35
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 500
aaactacttt acgcagcgcg gagttcggtt ttttg 35
<210> 501
<211> 4104
<212> DNA
<213> Homo sapiens
<220>
<221> CDS
<222> (1)..(4104)
<400> 501
atg gac aag aag tac agc atc ggc ctg gac atc ggc acc aac tct gtg 48
Met Asp Lys Lys Tyr Ser Ile Gly Leu Asp Ile Gly Thr Asn Ser Val
1 5 10 15
ggc tgg gcc gtg atc acc gac gag tac aag gtg ccc agc aag aaa ttc 96
Gly Trp Ala Val Ile Thr Asp Glu Tyr Lys Val Pro Ser Lys Lys Phe
20 25 30
aag gtg ctg ggc aac acc gac cgg cac agc atc aag aag aac ctg atc 144
Lys Val Leu Gly Asn Thr Asp Arg His Ser Ile Lys Lys Asn Leu Ile
35 40 45
gga gcc ctg ctg ttc gac agc ggc gaa aca gcc gag gcc acc cgg ctg 192
Gly Ala Leu Leu Phe Asp Ser Gly Glu Thr Ala Glu Ala Thr Arg Leu
50 55 60
aag aga acc gcc aga aga aga tac acc aga cgg aag aac cgg atc tgc 240
Lys Arg Thr Ala Arg Arg Arg Tyr Thr Arg Arg Lys Asn Arg Ile Cys
65 70 75 80
tat ctg caa gag atc ttc agc aac gag atg gcc aag gtg gac gac agc 288
Tyr Leu Gln Glu Ile Phe Ser Asn Glu Met Ala Lys Val Asp Asp Ser
85 90 95
ttc ttc cac aga ctg gaa gag tcc ttc ctg gtg gaa gag gat aag aag 336
Phe Phe His Arg Leu Glu Glu Ser Phe Leu Val Glu Glu Asp Lys Lys
100 105 110
cac gag cgg cac ccc atc ttc ggc aac atc gtg gac gag gtg gcc tac 384
His Glu Arg His Pro Ile Phe Gly Asn Ile Val Asp Glu Val Ala Tyr
115 120 125
cac gag aag tac ccc acc atc tac cac ctg aga aag aaa ctg gtg gac 432
His Glu Lys Tyr Pro Thr Ile Tyr His Leu Arg Lys Lys Leu Val Asp
130 135 140
agc acc gac aag gcc gac ctg cgg ctg atc tat ctg gcc ctg gcc cac 480
Ser Thr Asp Lys Ala Asp Leu Arg Leu Ile Tyr Leu Ala Leu Ala His
145 150 155 160
atg atc aag ttc cgg ggc cac ttc ctg atc gag ggc gac ctg aac ccc 528
Met Ile Lys Phe Arg Gly His Phe Leu Ile Glu Gly Asp Leu Asn Pro
165 170 175
gac aac agc gac gtg gac aag ctg ttc atc cag ctg gtg cag acc tac 576
Asp Asn Ser Asp Val Asp Lys Leu Phe Ile Gln Leu Val Gln Thr Tyr
180 185 190
aac cag ctg ttc gag gaa aac ccc atc aac gcc agc ggc gtg gac gcc 624
Asn Gln Leu Phe Glu Glu Asn Pro Ile Asn Ala Ser Gly Val Asp Ala
195 200 205
aag gcc atc ctg tct gcc aga ctg agc aag agc aga cgg ctg gaa aat 672
Lys Ala Ile Leu Ser Ala Arg Leu Ser Lys Ser Arg Arg Leu Glu Asn
210 215 220
ctg atc gcc cag ctg ccc ggc gag aag aag aat ggc ctg ttc ggc aac 720
Leu Ile Ala Gln Leu Pro Gly Glu Lys Lys Asn Gly Leu Phe Gly Asn
225 230 235 240
ctg att gcc ctg agc ctg ggc ctg acc ccc aac ttc aag agc aac ttc 768
Leu Ile Ala Leu Ser Leu Gly Leu Thr Pro Asn Phe Lys Ser Asn Phe
245 250 255
gac ctg gcc gag gat gcc aaa ctg cag ctg agc aag gac acc tac gac 816
Asp Leu Ala Glu Asp Ala Lys Leu Gln Leu Ser Lys Asp Thr Tyr Asp
260 265 270
gac gac ctg gac aac ctg ctg gcc cag atc ggc gac cag tac gcc gac 864
Asp Asp Leu Asp Asn Leu Leu Ala Gln Ile Gly Asp Gln Tyr Ala Asp
275 280 285
ctg ttt ctg gcc gcc aag aac ctg tcc gac gcc atc ctg ctg agc gac 912
Leu Phe Leu Ala Ala Lys Asn Leu Ser Asp Ala Ile Leu Leu Ser Asp
290 295 300
atc ctg aga gtg aac acc gag atc acc aag gcc ccc ctg agc gcc tct 960
Ile Leu Arg Val Asn Thr Glu Ile Thr Lys Ala Pro Leu Ser Ala Ser
305 310 315 320
atg atc aag aga tac gac gag cac cac cag gac ctg acc ctg ctg aaa 1008
Met Ile Lys Arg Tyr Asp Glu His His Gln Asp Leu Thr Leu Leu Lys
325 330 335
gct ctc gtg cgg cag cag ctg cct gag aag tac aaa gag att ttc ttc 1056
Ala Leu Val Arg Gln Gln Leu Pro Glu Lys Tyr Lys Glu Ile Phe Phe
340 345 350
gac cag agc aag aac ggc tac gcc ggc tac att gac ggc gga gcc agc 1104
Asp Gln Ser Lys Asn Gly Tyr Ala Gly Tyr Ile Asp Gly Gly Ala Ser
355 360 365
cag gaa gag ttc tac aag ttc atc aag ccc atc ctg gaa aag atg gac 1152
Gln Glu Glu Phe Tyr Lys Phe Ile Lys Pro Ile Leu Glu Lys Met Asp
370 375 380
ggc acc gag gaa ctg ctc gtg aag ctg aac aga gag gac ctg ctg cgg 1200
Gly Thr Glu Glu Leu Leu Val Lys Leu Asn Arg Glu Asp Leu Leu Arg
385 390 395 400
aag cag cgg acc ttc gac aac ggc agc atc ccc cac cag atc cac ctg 1248
Lys Gln Arg Thr Phe Asp Asn Gly Ser Ile Pro His Gln Ile His Leu
405 410 415
gga gag ctg cac gcc att ctg cgg cgg cag gaa gat ttt tac cca ttc 1296
Gly Glu Leu His Ala Ile Leu Arg Arg Gln Glu Asp Phe Tyr Pro Phe
420 425 430
ctg aag gac aac cgg gaa aag atc gag aag atc ctg acc ttc cgc atc 1344
Leu Lys Asp Asn Arg Glu Lys Ile Glu Lys Ile Leu Thr Phe Arg Ile
435 440 445
ccc tac tac gtg ggc cct ctg gcc agg gga aac agc aga ttc gcc tgg 1392
Pro Tyr Tyr Val Gly Pro Leu Ala Arg Gly Asn Ser Arg Phe Ala Trp
450 455 460
atg acc aga aag agc gag gaa acc atc acc ccc tgg aac ttc gag gaa 1440
Met Thr Arg Lys Ser Glu Glu Thr Ile Thr Pro Trp Asn Phe Glu Glu
465 470 475 480
gtg gtg gac aag ggc gct tcc gcc cag agc ttc atc gag cgg atg acc 1488
Val Val Asp Lys Gly Ala Ser Ala Gln Ser Phe Ile Glu Arg Met Thr
485 490 495
aac ttc gat aag aac ctg ccc aac gag aag gtg ctg ccc aag cac agc 1536
Asn Phe Asp Lys Asn Leu Pro Asn Glu Lys Val Leu Pro Lys His Ser
500 505 510
ctg ctg tac gag tac ttc acc gtg tat aac gag ctg acc aaa gtg aaa 1584
Leu Leu Tyr Glu Tyr Phe Thr Val Tyr Asn Glu Leu Thr Lys Val Lys
515 520 525
tac gtg acc gag gga atg aga aag ccc gcc ttc ctg agc ggc gag cag 1632
Tyr Val Thr Glu Gly Met Arg Lys Pro Ala Phe Leu Ser Gly Glu Gln
530 535 540
aaa aag gcc atc gtg gac ctg ctg ttc aag acc aac cgg aaa gtg acc 1680
Lys Lys Ala Ile Val Asp Leu Leu Phe Lys Thr Asn Arg Lys Val Thr
545 550 555 560
gtg aag cag ctg aaa gag gac tac ttc aag aaa atc gag tgc ttc gac 1728
Val Lys Gln Leu Lys Glu Asp Tyr Phe Lys Lys Ile Glu Cys Phe Asp
565 570 575
tcc gtg gaa atc tcc ggc gtg gaa gat cgg ttc aac gcc tcc ctg ggc 1776
Ser Val Glu Ile Ser Gly Val Glu Asp Arg Phe Asn Ala Ser Leu Gly
580 585 590
aca tac cac gat ctg ctg aaa att atc aag gac aag gac ttc ctg gac 1824
Thr Tyr His Asp Leu Leu Lys Ile Ile Lys Asp Lys Asp Phe Leu Asp
595 600 605
aat gag gaa aac gag gac att ctg gaa gat atc gtg ctg acc ctg aca 1872
Asn Glu Glu Asn Glu Asp Ile Leu Glu Asp Ile Val Leu Thr Leu Thr
610 615 620
ctg ttt gag gac aga gag atg atc gag gaa cgg ctg aaa acc tat gcc 1920
Leu Phe Glu Asp Arg Glu Met Ile Glu Glu Arg Leu Lys Thr Tyr Ala
625 630 635 640
cac ctg ttc gac gac aaa gtg atg aag cag ctg aag cgg cgg aga tac 1968
His Leu Phe Asp Asp Lys Val Met Lys Gln Leu Lys Arg Arg Arg Tyr
645 650 655
acc ggc tgg ggc agg ctg agc cgg aag ctg atc aac ggc atc cgg gac 2016
Thr Gly Trp Gly Arg Leu Ser Arg Lys Leu Ile Asn Gly Ile Arg Asp
660 665 670
aag cag tcc ggc aag aca atc ctg gat ttc ctg aag tcc gac ggc ttc 2064
Lys Gln Ser Gly Lys Thr Ile Leu Asp Phe Leu Lys Ser Asp Gly Phe
675 680 685
gcc aac aga aac ttc atg cag ctg atc cac gac gac agc ctg acc ttt 2112
Ala Asn Arg Asn Phe Met Gln Leu Ile His Asp Asp Ser Leu Thr Phe
690 695 700
aaa gag gac atc cag aaa gcc cag gtg tcc ggc cag ggc gat agc ctg 2160
Lys Glu Asp Ile Gln Lys Ala Gln Val Ser Gly Gln Gly Asp Ser Leu
705 710 715 720
cac gag cac att gcc aat ctg gcc ggc agc ccc gcc att aag aag ggc 2208
His Glu His Ile Ala Asn Leu Ala Gly Ser Pro Ala Ile Lys Lys Gly
725 730 735
atc ctg cag aca gtg aag gtg gtg gac gag ctc gtg aaa gtg atg ggc 2256
Ile Leu Gln Thr Val Lys Val Val Asp Glu Leu Val Lys Val Met Gly
740 745 750
cgg cac aag ccc gag aac atc gtg atc gcc atg gcc aga gag aac cag 2304
Arg His Lys Pro Glu Asn Ile Val Ile Ala Met Ala Arg Glu Asn Gln
755 760 765
acc acc cag aag gga cag aag aac agc cgc gag aga atg aag cgg atc 2352
Thr Thr Gln Lys Gly Gln Lys Asn Ser Arg Glu Arg Met Lys Arg Ile
770 775 780
gaa gag ggc atc aaa gag ctg ggc agc cag atc ctg aaa gaa cac ccc 2400
Glu Glu Gly Ile Lys Glu Leu Gly Ser Gln Ile Leu Lys Glu His Pro
785 790 795 800
gtg gaa aac acc cag ctg cag aac gag aag ctg tac ctg tac tac ctg 2448
Val Glu Asn Thr Gln Leu Gln Asn Glu Lys Leu Tyr Leu Tyr Tyr Leu
805 810 815
cag aat ggg cgg gat atg tac gtg gac cag gaa ctg gac atc aac cgg 2496
Gln Asn Gly Arg Asp Met Tyr Val Asp Gln Glu Leu Asp Ile Asn Arg
820 825 830
ctg tcc gac tac gat gtg gac gcc atc gtg cct cag agc ttt ctg aag 2544
Leu Ser Asp Tyr Asp Val Asp Ala Ile Val Pro Gln Ser Phe Leu Lys
835 840 845
gac gac tcc atc gac gcc aag gtg ctg acc aga agc gac aag gcc cgg 2592
Asp Asp Ser Ile Asp Ala Lys Val Leu Thr Arg Ser Asp Lys Ala Arg
850 855 860
ggc aag agc gac aac gtg ccc tcc gaa gag gtc gtg aag aag atg aag 2640
Gly Lys Ser Asp Asn Val Pro Ser Glu Glu Val Val Lys Lys Met Lys
865 870 875 880
aac tac tgg cgg cag ctg ctg aac gcc aag ctg att acc cag aga aag 2688
Asn Tyr Trp Arg Gln Leu Leu Asn Ala Lys Leu Ile Thr Gln Arg Lys
885 890 895
ttc gac aat ctg acc aag gcc gag aga ggc ggc ctg agc gaa ctg gat 2736
Phe Asp Asn Leu Thr Lys Ala Glu Arg Gly Gly Leu Ser Glu Leu Asp
900 905 910
aag gcc ggc ttc atc aag aga cag ctg gtg gaa acc cgg cag atc aca 2784
Lys Ala Gly Phe Ile Lys Arg Gln Leu Val Glu Thr Arg Gln Ile Thr
915 920 925
aag cac gtg gca cag atc ctg gac tcc cgg atg aac act aag tac gac 2832
Lys His Val Ala Gln Ile Leu Asp Ser Arg Met Asn Thr Lys Tyr Asp
930 935 940
gag aat gac aag ctg atc cgg gaa gtg aaa gtg atc acc ctg aag tcc 2880
Glu Asn Asp Lys Leu Ile Arg Glu Val Lys Val Ile Thr Leu Lys Ser
945 950 955 960
aag ctg gtg tcc gat ttc cgg aag gat ttc cag ttt tac aaa gtg cgc 2928
Lys Leu Val Ser Asp Phe Arg Lys Asp Phe Gln Phe Tyr Lys Val Arg
965 970 975
gag atc aac aac tac cac cac gcc cac gcc gcc tac ctg aac gcc gtc 2976
Glu Ile Asn Asn Tyr His His Ala His Ala Ala Tyr Leu Asn Ala Val
980 985 990
gtg gga acc gcc ctg atc aaa aag tac cct aag ctg gaa agc gag ttc 3024
Val Gly Thr Ala Leu Ile Lys Lys Tyr Pro Lys Leu Glu Ser Glu Phe
995 1000 1005
gtg tac ggc gac tac aag gtg tac gac gtg cgg aag atg atc gcc 3069
Val Tyr Gly Asp Tyr Lys Val Tyr Asp Val Arg Lys Met Ile Ala
1010 1015 1020
aag agc gag cag gaa atc ggc aag gct acc gcc aag tac ttc ttc 3114
Lys Ser Glu Gln Glu Ile Gly Lys Ala Thr Ala Lys Tyr Phe Phe
1025 1030 1035
tac agc aac atc atg aac ttt ttc aag acc gag att acc ctg gcc 3159
Tyr Ser Asn Ile Met Asn Phe Phe Lys Thr Glu Ile Thr Leu Ala
1040 1045 1050
aac ggc gag atc cgg aag cgg cct ctg atc gag aca aac ggc gaa 3204
Asn Gly Glu Ile Arg Lys Arg Pro Leu Ile Glu Thr Asn Gly Glu
1055 1060 1065
acc ggg gag atc gtg tgg gat aag ggc cgg gat ttt gcc acc gtg 3249
Thr Gly Glu Ile Val Trp Asp Lys Gly Arg Asp Phe Ala Thr Val
1070 1075 1080
cgg aaa gtg ctg agc atg ccc caa gtg aat atc gtg aaa aag acc 3294
Arg Lys Val Leu Ser Met Pro Gln Val Asn Ile Val Lys Lys Thr
1085 1090 1095
gag gtg cag aca ggc ggc ttc agc aaa gag tct atc ctg ccc aag 3339
Glu Val Gln Thr Gly Gly Phe Ser Lys Glu Ser Ile Leu Pro Lys
1100 1105 1110
agg aac agc gat aag ctg atc gcc aga aag aag gac tgg gac cct 3384
Arg Asn Ser Asp Lys Leu Ile Ala Arg Lys Lys Asp Trp Asp Pro
1115 1120 1125
aag aag tac ggc ggc ttc gac agc ccc acc gtg gcc tat tct gtg 3429
Lys Lys Tyr Gly Gly Phe Asp Ser Pro Thr Val Ala Tyr Ser Val
1130 1135 1140
ctg gtg gtg gcc aaa gtg gaa aag ggc aag tcc aag aaa ctg aag 3474
Leu Val Val Ala Lys Val Glu Lys Gly Lys Ser Lys Lys Leu Lys
1145 1150 1155
agt gtg aaa gag ctg ctg ggg atc acc atc atg gaa aga agc agc 3519
Ser Val Lys Glu Leu Leu Gly Ile Thr Ile Met Glu Arg Ser Ser
1160 1165 1170
ttc gag aag aat ccc atc gac ttt ctg gaa gcc aag ggc tac aaa 3564
Phe Glu Lys Asn Pro Ile Asp Phe Leu Glu Ala Lys Gly Tyr Lys
1175 1180 1185
gaa gtg aaa aag gac ctg atc atc aag ctg cct aag tac tcc ctg 3609
Glu Val Lys Lys Asp Leu Ile Ile Lys Leu Pro Lys Tyr Ser Leu
1190 1195 1200
ttc gag ctg gaa aac ggc cgg aag aga atg ctg gcc tct gcc ggc 3654
Phe Glu Leu Glu Asn Gly Arg Lys Arg Met Leu Ala Ser Ala Gly
1205 1210 1215
gaa ctg cag aag gga aac gaa ctg gcc ctg ccc tcc aaa tat gtg 3699
Glu Leu Gln Lys Gly Asn Glu Leu Ala Leu Pro Ser Lys Tyr Val
1220 1225 1230
aac ttc ctg tac ctg gcc agc cac tat gag aag ctg aag ggc tcc 3744
Asn Phe Leu Tyr Leu Ala Ser His Tyr Glu Lys Leu Lys Gly Ser
1235 1240 1245
ccc gag gat aat gag cag aaa cag ctg ttt gtg gaa cag cac aag 3789
Pro Glu Asp Asn Glu Gln Lys Gln Leu Phe Val Glu Gln His Lys
1250 1255 1260
cac tac ctg gac gag atc atc gag cag atc agc gag ttc tcc aag 3834
His Tyr Leu Asp Glu Ile Ile Glu Gln Ile Ser Glu Phe Ser Lys
1265 1270 1275
aga gtg atc ctg gcc gac gct aat ctg gac aaa gtg ctg tcc gcc 3879
Arg Val Ile Leu Ala Asp Ala Asn Leu Asp Lys Val Leu Ser Ala
1280 1285 1290
tac aac aag cac cgg gat aag ccc atc aga gag cag gcc gag aat 3924
Tyr Asn Lys His Arg Asp Lys Pro Ile Arg Glu Gln Ala Glu Asn
1295 1300 1305
atc atc cac ctg ttt acc ctg acc aat ctg gga gcc cct gcc gcc 3969
Ile Ile His Leu Phe Thr Leu Thr Asn Leu Gly Ala Pro Ala Ala
1310 1315 1320
ttc aag tac ttt gac acc acc atc gac cgg aag agg tac acc agc 4014
Phe Lys Tyr Phe Asp Thr Thr Ile Asp Arg Lys Arg Tyr Thr Ser
1325 1330 1335
acc aaa gag gtg ctg gac gcc acc ctg atc cac cag agc atc acc 4059
Thr Lys Glu Val Leu Asp Ala Thr Leu Ile His Gln Ser Ile Thr
1340 1345 1350
ggc ctg tac gag aca cgg atc gac ctg tct cag ctg gga ggc gac 4104
Gly Leu Tyr Glu Thr Arg Ile Asp Leu Ser Gln Leu Gly Gly Asp
1355 1360 1365
<210> 502
<211> 1368
<212> PRT
<213> Homo sapiens
<400> 502
Met Asp Lys Lys Tyr Ser Ile Gly Leu Asp Ile Gly Thr Asn Ser Val
1 5 10 15
Gly Trp Ala Val Ile Thr Asp Glu Tyr Lys Val Pro Ser Lys Lys Phe
20 25 30
Lys Val Leu Gly Asn Thr Asp Arg His Ser Ile Lys Lys Asn Leu Ile
35 40 45
Gly Ala Leu Leu Phe Asp Ser Gly Glu Thr Ala Glu Ala Thr Arg Leu
50 55 60
Lys Arg Thr Ala Arg Arg Arg Tyr Thr Arg Arg Lys Asn Arg Ile Cys
65 70 75 80
Tyr Leu Gln Glu Ile Phe Ser Asn Glu Met Ala Lys Val Asp Asp Ser
85 90 95
Phe Phe His Arg Leu Glu Glu Ser Phe Leu Val Glu Glu Asp Lys Lys
100 105 110
His Glu Arg His Pro Ile Phe Gly Asn Ile Val Asp Glu Val Ala Tyr
115 120 125
His Glu Lys Tyr Pro Thr Ile Tyr His Leu Arg Lys Lys Leu Val Asp
130 135 140
Ser Thr Asp Lys Ala Asp Leu Arg Leu Ile Tyr Leu Ala Leu Ala His
145 150 155 160
Met Ile Lys Phe Arg Gly His Phe Leu Ile Glu Gly Asp Leu Asn Pro
165 170 175
Asp Asn Ser Asp Val Asp Lys Leu Phe Ile Gln Leu Val Gln Thr Tyr
180 185 190
Asn Gln Leu Phe Glu Glu Asn Pro Ile Asn Ala Ser Gly Val Asp Ala
195 200 205
Lys Ala Ile Leu Ser Ala Arg Leu Ser Lys Ser Arg Arg Leu Glu Asn
210 215 220
Leu Ile Ala Gln Leu Pro Gly Glu Lys Lys Asn Gly Leu Phe Gly Asn
225 230 235 240
Leu Ile Ala Leu Ser Leu Gly Leu Thr Pro Asn Phe Lys Ser Asn Phe
245 250 255
Asp Leu Ala Glu Asp Ala Lys Leu Gln Leu Ser Lys Asp Thr Tyr Asp
260 265 270
Asp Asp Leu Asp Asn Leu Leu Ala Gln Ile Gly Asp Gln Tyr Ala Asp
275 280 285
Leu Phe Leu Ala Ala Lys Asn Leu Ser Asp Ala Ile Leu Leu Ser Asp
290 295 300
Ile Leu Arg Val Asn Thr Glu Ile Thr Lys Ala Pro Leu Ser Ala Ser
305 310 315 320
Met Ile Lys Arg Tyr Asp Glu His His Gln Asp Leu Thr Leu Leu Lys
325 330 335
Ala Leu Val Arg Gln Gln Leu Pro Glu Lys Tyr Lys Glu Ile Phe Phe
340 345 350
Asp Gln Ser Lys Asn Gly Tyr Ala Gly Tyr Ile Asp Gly Gly Ala Ser
355 360 365
Gln Glu Glu Phe Tyr Lys Phe Ile Lys Pro Ile Leu Glu Lys Met Asp
370 375 380
Gly Thr Glu Glu Leu Leu Val Lys Leu Asn Arg Glu Asp Leu Leu Arg
385 390 395 400
Lys Gln Arg Thr Phe Asp Asn Gly Ser Ile Pro His Gln Ile His Leu
405 410 415
Gly Glu Leu His Ala Ile Leu Arg Arg Gln Glu Asp Phe Tyr Pro Phe
420 425 430
Leu Lys Asp Asn Arg Glu Lys Ile Glu Lys Ile Leu Thr Phe Arg Ile
435 440 445
Pro Tyr Tyr Val Gly Pro Leu Ala Arg Gly Asn Ser Arg Phe Ala Trp
450 455 460
Met Thr Arg Lys Ser Glu Glu Thr Ile Thr Pro Trp Asn Phe Glu Glu
465 470 475 480
Val Val Asp Lys Gly Ala Ser Ala Gln Ser Phe Ile Glu Arg Met Thr
485 490 495
Asn Phe Asp Lys Asn Leu Pro Asn Glu Lys Val Leu Pro Lys His Ser
500 505 510
Leu Leu Tyr Glu Tyr Phe Thr Val Tyr Asn Glu Leu Thr Lys Val Lys
515 520 525
Tyr Val Thr Glu Gly Met Arg Lys Pro Ala Phe Leu Ser Gly Glu Gln
530 535 540
Lys Lys Ala Ile Val Asp Leu Leu Phe Lys Thr Asn Arg Lys Val Thr
545 550 555 560
Val Lys Gln Leu Lys Glu Asp Tyr Phe Lys Lys Ile Glu Cys Phe Asp
565 570 575
Ser Val Glu Ile Ser Gly Val Glu Asp Arg Phe Asn Ala Ser Leu Gly
580 585 590
Thr Tyr His Asp Leu Leu Lys Ile Ile Lys Asp Lys Asp Phe Leu Asp
595 600 605
Asn Glu Glu Asn Glu Asp Ile Leu Glu Asp Ile Val Leu Thr Leu Thr
610 615 620
Leu Phe Glu Asp Arg Glu Met Ile Glu Glu Arg Leu Lys Thr Tyr Ala
625 630 635 640
His Leu Phe Asp Asp Lys Val Met Lys Gln Leu Lys Arg Arg Arg Tyr
645 650 655
Thr Gly Trp Gly Arg Leu Ser Arg Lys Leu Ile Asn Gly Ile Arg Asp
660 665 670
Lys Gln Ser Gly Lys Thr Ile Leu Asp Phe Leu Lys Ser Asp Gly Phe
675 680 685
Ala Asn Arg Asn Phe Met Gln Leu Ile His Asp Asp Ser Leu Thr Phe
690 695 700
Lys Glu Asp Ile Gln Lys Ala Gln Val Ser Gly Gln Gly Asp Ser Leu
705 710 715 720
His Glu His Ile Ala Asn Leu Ala Gly Ser Pro Ala Ile Lys Lys Gly
725 730 735
Ile Leu Gln Thr Val Lys Val Val Asp Glu Leu Val Lys Val Met Gly
740 745 750
Arg His Lys Pro Glu Asn Ile Val Ile Ala Met Ala Arg Glu Asn Gln
755 760 765
Thr Thr Gln Lys Gly Gln Lys Asn Ser Arg Glu Arg Met Lys Arg Ile
770 775 780
Glu Glu Gly Ile Lys Glu Leu Gly Ser Gln Ile Leu Lys Glu His Pro
785 790 795 800
Val Glu Asn Thr Gln Leu Gln Asn Glu Lys Leu Tyr Leu Tyr Tyr Leu
805 810 815
Gln Asn Gly Arg Asp Met Tyr Val Asp Gln Glu Leu Asp Ile Asn Arg
820 825 830
Leu Ser Asp Tyr Asp Val Asp Ala Ile Val Pro Gln Ser Phe Leu Lys
835 840 845
Asp Asp Ser Ile Asp Ala Lys Val Leu Thr Arg Ser Asp Lys Ala Arg
850 855 860
Gly Lys Ser Asp Asn Val Pro Ser Glu Glu Val Val Lys Lys Met Lys
865 870 875 880
Asn Tyr Trp Arg Gln Leu Leu Asn Ala Lys Leu Ile Thr Gln Arg Lys
885 890 895
Phe Asp Asn Leu Thr Lys Ala Glu Arg Gly Gly Leu Ser Glu Leu Asp
900 905 910
Lys Ala Gly Phe Ile Lys Arg Gln Leu Val Glu Thr Arg Gln Ile Thr
915 920 925
Lys His Val Ala Gln Ile Leu Asp Ser Arg Met Asn Thr Lys Tyr Asp
930 935 940
Glu Asn Asp Lys Leu Ile Arg Glu Val Lys Val Ile Thr Leu Lys Ser
945 950 955 960
Lys Leu Val Ser Asp Phe Arg Lys Asp Phe Gln Phe Tyr Lys Val Arg
965 970 975
Glu Ile Asn Asn Tyr His His Ala His Ala Ala Tyr Leu Asn Ala Val
980 985 990
Val Gly Thr Ala Leu Ile Lys Lys Tyr Pro Lys Leu Glu Ser Glu Phe
995 1000 1005
Val Tyr Gly Asp Tyr Lys Val Tyr Asp Val Arg Lys Met Ile Ala
1010 1015 1020
Lys Ser Glu Gln Glu Ile Gly Lys Ala Thr Ala Lys Tyr Phe Phe
1025 1030 1035
Tyr Ser Asn Ile Met Asn Phe Phe Lys Thr Glu Ile Thr Leu Ala
1040 1045 1050
Asn Gly Glu Ile Arg Lys Arg Pro Leu Ile Glu Thr Asn Gly Glu
1055 1060 1065
Thr Gly Glu Ile Val Trp Asp Lys Gly Arg Asp Phe Ala Thr Val
1070 1075 1080
Arg Lys Val Leu Ser Met Pro Gln Val Asn Ile Val Lys Lys Thr
1085 1090 1095
Glu Val Gln Thr Gly Gly Phe Ser Lys Glu Ser Ile Leu Pro Lys
1100 1105 1110
Arg Asn Ser Asp Lys Leu Ile Ala Arg Lys Lys Asp Trp Asp Pro
1115 1120 1125
Lys Lys Tyr Gly Gly Phe Asp Ser Pro Thr Val Ala Tyr Ser Val
1130 1135 1140
Leu Val Val Ala Lys Val Glu Lys Gly Lys Ser Lys Lys Leu Lys
1145 1150 1155
Ser Val Lys Glu Leu Leu Gly Ile Thr Ile Met Glu Arg Ser Ser
1160 1165 1170
Phe Glu Lys Asn Pro Ile Asp Phe Leu Glu Ala Lys Gly Tyr Lys
1175 1180 1185
Glu Val Lys Lys Asp Leu Ile Ile Lys Leu Pro Lys Tyr Ser Leu
1190 1195 1200
Phe Glu Leu Glu Asn Gly Arg Lys Arg Met Leu Ala Ser Ala Gly
1205 1210 1215
Glu Leu Gln Lys Gly Asn Glu Leu Ala Leu Pro Ser Lys Tyr Val
1220 1225 1230
Asn Phe Leu Tyr Leu Ala Ser His Tyr Glu Lys Leu Lys Gly Ser
1235 1240 1245
Pro Glu Asp Asn Glu Gln Lys Gln Leu Phe Val Glu Gln His Lys
1250 1255 1260
His Tyr Leu Asp Glu Ile Ile Glu Gln Ile Ser Glu Phe Ser Lys
1265 1270 1275
Arg Val Ile Leu Ala Asp Ala Asn Leu Asp Lys Val Leu Ser Ala
1280 1285 1290
Tyr Asn Lys His Arg Asp Lys Pro Ile Arg Glu Gln Ala Glu Asn
1295 1300 1305
Ile Ile His Leu Phe Thr Leu Thr Asn Leu Gly Ala Pro Ala Ala
1310 1315 1320
Phe Lys Tyr Phe Asp Thr Thr Ile Asp Arg Lys Arg Tyr Thr Ser
1325 1330 1335
Thr Lys Glu Val Leu Asp Ala Thr Leu Ile His Gln Ser Ile Thr
1340 1345 1350
Gly Leu Tyr Glu Thr Arg Ile Asp Leu Ser Gln Leu Gly Gly Asp
1355 1360 1365
<210> 503
<211> 15
<212> DNA
<213> Homo sapiens
<400> 503
cagaagaaga agggc 15
<210> 504
<211> 51
<212> DNA
<213> Homo sapiens
<400> 504
ccaatgggga ggacatcgat gtcacctcca atgactaggg tggtgggcaa c 51
<210> 505
<211> 15
<212> DNA
<213> Homo sapiens
<400> 505
ctctggccac tccct 15
<210> 506
<211> 52
<212> DNA
<213> Homo sapiens
<400> 506
acatcgatgt cacctccaat gacaagcttg ctagcggtgg gcaaccacaa ac 52
<210> 507
<211> 1733
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 507
ccgtttaaac aattctgcag gaatctagtt attaatagta atcaattacg gggtcattag 60
ttcatagccc atatatggag ttccgcgtta cataacttac ggtaaatggc ccgcctggct 120
gaccgcccaa cgacccccgc ccattgacgt caataatgac gtatgttccc atagtaacgc 180
caatagggac tttccattga cgtcaatggg tggagtattt acggtaaact gcccacttgg 240
cagtacatca agtgtatcat atgccaagta cgccccctat tgacgtcaat gacggtaaat 300
ggcccgcctg gcattatgcc cagtacatga ccttatggga ctttcctact tggcagtaca 360
tctacgtatt agtcatcgct attaccatgg tcgaggtgag ccccacgttc tgcttcactc 420
tccccatctc ccccccctcc ccacccccaa ttttgtattt atttattttt taattatttt 480
gtgcagcgat gggggcgggg gggggggggg ggcgcgcgcc aggcggggcg gggcggggcg 540
aggggcgggg cggggcgagg cggagaggtg cggcggcagc caatcagagc ggcgcgctcc 600
gaaagtttcc ttttatggcg aggcggcggc ggcggcggcc ctataaaaag cgaagcgcgc 660
ggcgggcgga agtcgctgcg cgctgccttc gccccgtgcc ccgctccgcc gccgcctcgc 720
gccgcccgcc ccggctctga ctgaccgcgt tactcccaca ggtgagcggg cgggacggcc 780
cttctcctcc gggctgtaat tagcgcttgg tttaatgacg gcttgtttct tttctgtggc 840
tgcgtgaaag ccttgagggg ctccgggagg gccctttgtg cggggggagc ggctcggggg 900
gtgcgtgcgt gtgtgtgtgc gtggggagcg ccgcgtgcgg ctccgcgctg cccggcggct 960
gtgagcgctg cgggcgcggc gcggggcttt gtgcgctccg cagtgtgcgc gaggggagcg 1020
cggccggggg cggtgccccg cggtgcgggg ggggctgcga ggggaacaaa ggctgcgtgc 1080
ggggtgtgtg cgtggggggg tgagcagggg gtgtgggcgc gtcggtcggg ctgcaacccc 1140
ccctgcaccc ccctccccga gttgctgagc acggcccggc ttcgggtgcg gggctccgta 1200
cggggcgtgg cgcggggctc gccgtgccgg gcggggggtg gcggcaggtg ggggtgccgg 1260
gcggggcggg gccgcctcgg gccggggagg gctcggggga ggggcgcggc ggcccccgga 1320
gcgccggcgg ctgtcgaggc gcggcgagcc gcagccattg ccttttatgg taatcgtgcg 1380
agagggcgca gggacttcct ttgtcccaaa tctgtgcgga gccgaaatct gggaggcgcc 1440
gccgcacccc ctctagcggg cgcggggcga agcggtgcgg cgccggcagg aaggaaatgg 1500
gcggggaggg ccttcgtgcg tcgccgcgcc gccgtcccct tctccctctc cagcctcggg 1560
gctgtccgcg gggggacggc tgccttcggg ggggacgggg cagggcgggg ttcggcttct 1620
ggcgtgtgac cggcggctct agagcctctg ctaaccatgt tcatgccttc ttctttttcc 1680
tacagctcct gggcaacgtg ctggttattg tgctgtctca tcattttggc aaa 1733
<210> 508
<211> 4269
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 508
atggactata aggaccacga cggagactac aaggatcatg atattgatta caaagacgat 60
gacgataaga tggccccaaa gaagaagcgg aaggtcggta tccacggagt cccagcagcc 120
gacaagaagt acagcatcgg cctggacatc ggcaccaact ctgtgggctg ggccgtgatc 180
accgacgagt acaaggtgcc cagcaagaaa ttcaaggtgc tgggcaacac cgaccggcac 240
agcatcaaga agaacctgat cggagccctg ctgttcgaca gcggcgaaac agccgaggcc 300
acccggctga agagaaccgc cagaagaaga tacaccagac ggaagaaccg gatctgctat 360
ctgcaagaga tcttcagcaa cgagatggcc aaggtggacg acagcttctt ccacagactg 420
gaagagtcct tcctggtgga agaggataag aagcacgagc ggcaccccat cttcggcaac 480
atcgtggacg aggtggccta ccacgagaag taccccacca tctaccacct gagaaagaaa 540
ctggtggaca gcaccgacaa ggccgacctg cggctgatct atctggccct ggcccacatg 600
atcaagttcc ggggccactt cctgatcgag ggcgacctga accccgacaa cagcgacgtg 660
gacaagctgt tcatccagct ggtgcagacc tacaaccagc tgttcgagga aaaccccatc 720
aacgccagcg gcgtggacgc caaggccatc ctgtctgcca gactgagcaa gagcagacgg 780
ctggaaaatc tgatcgccca gctgcccggc gagaagaaga atggcctgtt cggaaacctg 840
attgccctga gcctgggcct gacccccaac ttcaagagca acttcgacct ggccgaggat 900
gccaaactgc agctgagcaa ggacacctac gacgacgacc tggacaacct gctggcccag 960
atcggcgacc agtacgccga cctgtttctg gccgccaaga acctgtccga cgccatcctg 1020
ctgagcgaca tcctgagagt gaacaccgag atcaccaagg cccccctgag cgcctctatg 1080
atcaagagat acgacgagca ccaccaggac ctgaccctgc tgaaagctct cgtgcggcag 1140
cagctgcctg agaagtacaa agagattttc ttcgaccaga gcaagaacgg ctacgccggc 1200
tacattgacg gcggagccag ccaggaagag ttctacaagt tcatcaagcc catcctggaa 1260
aagatggacg gcaccgagga actgctcgtg aagctgaaca gagaggacct gctgcggaag 1320
cagcggacct tcgacaacgg cagcatcccc caccagatcc acctgggaga gctgcacgcc 1380
attctgcggc ggcaggaaga tttttaccca ttcctgaagg acaaccggga aaagatcgag 1440
aagatcctga ccttccgcat cccctactac gtgggccctc tggccagggg aaacagcaga 1500
ttcgcctgga tgaccagaaa gagcgaggaa accatcaccc cctggaactt cgaggaagtg 1560
gtggacaagg gcgcttccgc ccagagcttc atcgagcgga tgaccaactt cgataagaac 1620
ctgcccaacg agaaggtgct gcccaagcac agcctgctgt acgagtactt caccgtgtat 1680
aacgagctga ccaaagtgaa atacgtgacc gagggaatga gaaagcccgc cttcctgagc 1740
ggcgagcaga aaaaggccat cgtggacctg ctgttcaaga ccaaccggaa agtgaccgtg 1800
aagcagctga aagaggacta cttcaagaaa atcgagtgct tcgactccgt ggaaatctcc 1860
ggcgtggaag atcggttcaa cgcctccctg ggcacatacc acgatctgct gaaaattatc 1920
aaggacaagg acttcctgga caatgaggaa aacgaggaca ttctggaaga tatcgtgctg 1980
accctgacac tgtttgagga cagagagatg atcgaggaac ggctgaaaac ctatgcccac 2040
ctgttcgacg acaaagtgat gaagcagctg aagcggcgga gatacaccgg ctggggcagg 2100
ctgagccgga agctgatcaa cggcatccgg gacaagcagt ccggcaagac aatcctggat 2160
ttcctgaagt ccgacggctt cgccaacaga aacttcatgc agctgatcca cgacgacagc 2220
ctgaccttta aagaggacat ccagaaagcc caggtgtccg gccagggcga tagcctgcac 2280
gagcacattg ccaatctggc cggcagcccc gccattaaga agggcatcct gcagacagtg 2340
aaggtggtgg acgagctcgt gaaagtgatg ggccggcaca agcccgagaa catcgtgatc 2400
gaaatggcca gagagaacca gaccacccag aagggacaga agaacagccg cgagagaatg 2460
aagcggatcg aagagggcat caaagagctg ggcagccaga tcctgaaaga acaccccgtg 2520
gaaaacaccc agctgcagaa cgagaagctg tacctgtact acctgcagaa tgggcgggat 2580
atgtacgtgg accaggaact ggacatcaac cggctgtccg actacgatgt ggaccatatc 2640
gtgcctcaga gctttctgaa ggacgactcc atcgacaaca aggtgctgac cagaagcgac 2700
aagaaccggg gcaagagcga caacgtgccc tccgaagagg tcgtgaagaa gatgaagaac 2760
tactggcggc agctgctgaa cgccaagctg attacccaga gaaagttcga caatctgacc 2820
aaggccgaga gaggcggcct gagcgaactg gataaggccg gcttcatcaa gagacagctg 2880
gtggaaaccc ggcagatcac aaagcacgtg gcacagatcc tggactcccg gatgaacact 2940
aagtacgacg agaatgacaa gctgatccgg gaagtgaaag tgatcaccct gaagtccaag 3000
ctggtgtccg atttccggaa ggatttccag ttttacaaag tgcgcgagat caacaactac 3060
caccacgccc acgacgccta cctgaacgcc gtcgtgggaa ccgccctgat caaaaagtac 3120
cctaagctgg aaagcgagtt cgtgtacggc gactacaagg tgtacgacgt gcggaagatg 3180
atcgccaaga gcgagcagga aatcggcaag gctaccgcca agtacttctt ctacagcaac 3240
atcatgaact ttttcaagac cgagattacc ctggccaacg gcgagatccg gaagcggcct 3300
ctgatcgaga caaacggcga aaccggggag atcgtgtggg ataagggccg ggattttgcc 3360
accgtgcgga aagtgctgag catgccccaa gtgaatatcg tgaaaaagac cgaggtgcag 3420
acaggcggct tcagcaaaga gtctatcctg cccaagagga acagcgataa gctgatcgcc 3480
agaaagaagg actgggaccc taagaagtac ggcggcttcg acagccccac cgtggcctat 3540
tctgtgctgg tggtggccaa agtggaaaag ggcaagtcca agaaactgaa gagtgtgaaa 3600
gagctgctgg ggatcaccat catggaaaga agcagcttcg agaagaatcc catcgacttt 3660
ctggaagcca agggctacaa agaagtgaaa aaggacctga tcatcaagct gcctaagtac 3720
tccctgttcg agctggaaaa cggccggaag agaatgctgg cctctgccgg cgaactgcag 3780
aagggaaacg aactggccct gccctccaaa tatgtgaact tcctgtacct ggccagccac 3840
tatgagaagc tgaagggctc ccccgaggat aatgagcaga aacagctgtt tgtggaacag 3900
cacaagcact acctggacga gatcatcgag cagatcagcg agttctccaa gagagtgatc 3960
ctggccgacg ctaatctgga caaagtgctg tccgcctaca acaagcaccg ggataagccc 4020
atcagagagc aggccgagaa tatcatccac ctgtttaccc tgaccaatct gggagcccct 4080
gccgccttca agtactttga caccaccatc gaccggaaga ggtacaccag caccaaagag 4140
gtgctggacg ccaccctgat ccaccagagc atcaccggcc tgtacgagac acggatcgac 4200
ctgtctcagc tgggaggcga caaaaggccg gcggccacga aaaaggccgg ccaggcaaaa 4260
aagaaaaag 4269
<210> 509
<211> 780
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 509
ggaagcggag ccactaactt ctccctgttg aaacaagcag gggatgtcga agagaatccc 60
gggccagtga gcaagggcga ggagctgttc accggggtgg tgcccatcct ggtcgagctg 120
gacggcgacg taaacggcca caagttcagc gtgtccggcg agggcgaggg cgatgccacc 180
tacggcaagc tgaccctgaa gttcatctgc accaccggca agctgcccgt gccctggccc 240
accctcgtga ccaccctgac ctacggcgtg cagtgcttca gccgctaccc cgaccacatg 300
aagcagcacg acttcttcaa gtccgccatg cccgaaggct acgtccagga gcgcaccatc 360
ttcttcaagg acgacggcaa ctacaagacc cgcgccgagg tgaagttcga gggcgacacc 420
ctggtgaacc gcatcgagct gaagggcatc gacttcaagg aggacggcaa catcctgggg 480
cacaagctgg agtacaacta caacagccac aacgtctata tcatggccga caagcagaag 540
aacggcatca aggtgaactt caagatccgc cacaacatcg aggacggcag cgtgcagctc 600
gccgaccact accagcagaa cacccccatc ggcgacggcc ccgtgctgct gcccgacaac 660
cactacctga gcacccagtc cgccctgagc aaagacccca acgagaagcg cgatcacatg 720
gtcctgctgg agttcgtgac cgccgccggg atcactctcg gcatggacga gctgtacaag 780
<210> 510
<211> 597
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 510
cgataatcaa cctctggatt acaaaatttg tgaaagattg actggtattc ttaactatgt 60
tgctcctttt acgctatgtg gatacgctgc tttaatgcct ttgtatcatg ctattgcttc 120
ccgtatggct ttcattttct cctccttgta taaatcctgg ttgctgtctc tttatgagga 180
gttgtggccc gttgtcaggc aacgtggcgt ggtgtgcact gtgtttgctg acgcaacccc 240
cactggttgg ggcattgcca ccacctgtca gctcctttcc gggactttcg ctttccccct 300
ccctattgcc acggcggaac tcatcgccgc ctgccttgcc cgctgctgga caggggctcg 360
gctgttgggc actgacaatt ccgtggtgtt gtcggggaaa tcatcgtcct ttccttggct 420
gctcgcctgt gttgccacct ggattctgcg cgggacgtcc ttctgctacg tcccttcggc 480
cctcaatcca gcggaccttc cttcccgcgg cctgctgccg gctctgcggc ctcttccgcg 540
tcttcgcctt cgccctcaga cgagtcggat ctccctttgg gccgcctccc cgcatcg 597
<210> 511
<211> 210
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 511
cgacctcgac tgtgccttct agttgccagc catctgttgt ttgcccctcc cccgtgcctt 60
ccttgaccct ggaaggtgcc actcccactg tcctttccta ataaaatgag gaaattgcat 120
cgcattgtct gagtaggtgt cattctattc tggggggtgg ggtggggcag gacagcaagg 180
gggaggattg ggaagacaat ggcaggcatg 210
<210> 512
<211> 906
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (109)..(109)
<223> a, c, t, g, unknown or other
<220>
<221> modified_base
<222> (135)..(135)
<223> a, c, t, g, unknown or other
<400> 512
ataacttcgt ataatgtatg ctatacgaag ttattcgcga tgaataaatg aaagcttgca 60
gatctgcgac tctagaggat ctgcgactct agaggatcat aatcagccnt accacatttt 120
gtagaggttt tactngcttt aaaaaacctc ccacacctcc ccctgaacct gaaacataaa 180
atgaatgcaa ttgttgttgt taacttgttt attgcagctt ataatggtta caaataaagc 240
aatagcatca caaatttcac aaataaagca tttttttcac tgcattctag ttgtggtttg 300
tccaaactca tcaatgtatc ttatcatgtc tggatctgcg actctagagg atcataatca 360
gccataccac atttgtagag gttttacttg ctttaaaaaa cctcccacac ctccccctga 420
acctgaaaca taaaatgaat gcaattgttg ttgttaactt gtttattgca gcttataatg 480
gttacaaata aagcaatagc atcacaaatt tcacaaataa agcatttttt tcactgcatt 540
ctagttgtgg tttgtccaaa ctcatcaatg tatcttatca tgtctggatc tgcgactcta 600
gaggatcata atcagccata ccacatttgt agaggtttta cttgctttaa aaaacctccc 660
acacctcccc ctgaacctga aacataaaat gaatgcaatt gttgttgtta acttgtttat 720
tgcagcttat aatggttaca aataaagcaa tagcatcaca aatttcacaa ataaagcatt 780
tttttcactg cattctagtt gtggtttgtc caaactcatc aatgtatctt atcatgtctg 840
gatccccatc aagctgatcc ggaaccctta atataacttc gtataatgta tgctatacga 900
agttat 906
<210> 513
<211> 1079
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 513
caggccctcc gagcgtggtg gagccgttct gtgagacagc cgggtacgag tcgtgacgct 60
ggaaggggca agcgggtggt gggcaggaat gcggtccgcc ctgcagcaac cggaggggga 120
gggagaaggg agcggaaaag tctccaccgg acgcggccat ggctcggggg ggggggggca 180
gcggaggagc gcttccggcc gacgtctcgt cgctgattgg cttcttttcc tcccgccgtg 240
tgtgaaaaca caaatggcgt gttttggttg gcgtaaggcg cctgtcagtt aacggcagcc 300
ggagtgcgca gccgccggca gcctcgctct gcccactggg tggggcggga ggtaggtggg 360
gtgaggcgag ctggacgtgc gggcgcggtc ggcctctggc ggggcggggg aggggaggga 420
gggtcagcga aagtagctcg cgcgcgagcg gccgcccacc ctccccttcc tctgggggag 480
tcgttttacc cgccgccggc cgggcctcgt cgtctgattg gctctcgggg cccagaaaac 540
tggcccttgc cattggctcg tgttcgtgca agttgagtcc atccgccggc cagcgggggc 600
ggcgaggagg cgctcccagg ttccggccct cccctcggcc ccgcgccgca gagtctggcc 660
gcgcgcccct gcgcaacgtg gcaggaagcg cgcgctgggg gcggggacgg gcagtagggc 720
tgagcggctg cggggcgggt gcaagcacgt ttccgacttg agttgcctca agaggggcgt 780
gctgagccag acctccatcg cgcactccgg ggagtggagg gaaggagcga gggctcagtt 840
gggctgtttt ggaggcagga agcacttgct ctcccaaagt cgctctgagt tgttatcagt 900
aagggagctg cagtggagta ggcggggaga aggccgcacc cttctccgga ggggggaggg 960
gagtgttgca atacctttct gggagttctc tgctgcctcc tggcttctga ggaccgccct 1020
gggcctggga gaatcccttc cccctcttcc ctcgtgatct gcaactccag tctttctag 1079
<210> 514
<211> 4336
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 514
agatgggcgg gagtcttctg ggcaggctta aaggctaacc tggtgtgtgg gcgttgtcct 60
gcaggggaat tgaacaggtg taaaattgga gggacaagac ttcccacaga ttttcggttt 120
tgtcgggaag ttttttaata ggggcaaata aggaaaatgg gaggataggt agtcatctgg 180
ggttttatgc agcaaaacta caggttatta ttgcttgtga tccgcctcgg agtattttcc 240
atcgaggtag attaaagaca tgctcacccg agttttatac tctcctgctt gagatcctta 300
ctacagtatg aaattacagt gtcgcgagtt agactatgta agcagaattt taatcatttt 360
taaagagccc agtacttcat atccatttct cccgctcctt ctgcagcctt atcaaaaggt 420
attttagaac actcatttta gccccatttt catttattat actggcttat ccaaccccta 480
gacagagcat tggcattttc cctttcctga tcttagaagt ctgatgactc atgaaaccag 540
acagattagt tacatacacc acaaatcgag gctgtagctg gggcctcaac actgcagttc 600
ttttataact ccttagtaca ctttttgttg atcctttgcc ttgatcctta attttcagtg 660
tctatcacct ctcccgtcag gtggtgttcc acatttgggc ctattctcag tccagggagt 720
tttacaacaa tagatgtatt gagaatccaa cctaaagctt aactttccac tcccatgaat 780
gcctctctcc tttttctcca tttataaact gagctattaa ccattaatgg tttccaggtg 840
gatgtctcct cccccaatat tacctgatgt atcttacata ttgccaggct gatattttaa 900
gacattaaaa ggtatatttc attattgagc cacatggtat tgattactgc ttactaaaat 960
tttgtcattg tacacatctg taaaaggtgg ttccttttgg aatgcaaagt tcaggtgttt 1020
gttgtctttc ctgacctaag gtcttgtgag cttgtatttt ttctatttaa gcagtgcttt 1080
ctcttggact ggcttgactc atggcattct acacgttatt gctggtctaa atgtgatttt 1140
gccaagcttc ttcaggacct ataattttgc ttgacttgta gccaaacaca agtaaaatga 1200
ttaagcaaca aatgtatttg tgaagcttgg tttttaggtt gttgtgttgt gtgtgcttgt 1260
gctctataat aatactatcc aggggctgga gaggtggctc ggagttcaag agcacagact 1320
gctcttccag aagtcctgag ttcaattccc agcaaccaca tggtggctca caaccatctg 1380
taatgggatc tgatgccctc ttctggtgtg tctgaagacc acaagtgtat tcacattaaa 1440
taaataaatc ctccttcttc ttcttttttt tttttttaaa gagaatactg tctccagtag 1500
aatttactga agtaatgaaa tactttgtgt ttgttccaat atggtagcca ataatcaaat 1560
tactctttaa gcactggaaa tgttaccaag gaactaattt ttatttgaag tgtaactgtg 1620
gacagaggag ccataactgc agacttgtgg gatacagaag accaatgcag actttaatgt 1680
cttttctctt acactaagca ataaagaaat aaaaattgaa cttctagtat cctatttgtt 1740
taaactgcta gctttactta acttttgtgc ttcatctata caaagctgaa agctaagtct 1800
gcagccatta ctaaacatga aagcaagtaa tgataatttt ggatttcaaa aatgtagggc 1860
cagagtttag ccagccagtg gtggtgcttg cctttatgcc tttaatccca gcactctgga 1920
ggcagagaca ggcagatctc tgagtttgag cccagcctgg tctacacatc aagttctatc 1980
taggatagcc aggaatacac acagaaaccc tgttggggag gggggctctg agatttcata 2040
aaattataat tgaagcattc cctaatgagc cactatggat gtggctaaat ccgtctacct 2100
ttctgatgag atttgggtat tattttttct gtctctgctg ttggttgggt cttttgacac 2160
tgtgggcttt ctttaaagcc tccttcctgc catgtggtct cttgtttgct actaacttcc 2220
catggcttaa atggcatggc tttttgcctt ctaagggcag ctgctgagat ttgcagcctg 2280
atttccaggg tggggttggg aaatctttca aacactaaaa ttgtccttta attttttttt 2340
taaaaaatgg gttatataat aaacctcata aaatagttat gaggagtgag gtggactaat 2400
attaaatgag tccctcccct ataaaagagc tattaaggct ttttgtctta tacttaactt 2460
tttttttaaa tgtggtatct ttagaaccaa gggtcttaga gttttagtat acagaaactg 2520
ttgcatcgct taatcagatt ttctagtttc aaatccagag aatccaaatt cttcacagcc 2580
aaagtcaaat taagaatttc tgacttttaa tgttaatttg cttactgtga atataaaaat 2640
gatagctttt cctgaggcag ggtctcacta tgtatctctg cctgatctgc aacaagatat 2700
gtagactaaa gttctgcctg cttttgtctc ctgaatacta aggttaaaat gtagtaatac 2760
ttttggaact tgcaggtcag attcttttat aggggacaca ctaagggagc ttgggtgata 2820
gttggtaaat gtgtttaagt gatgaaaact tgaattatta tcaccgcaac ctacttttta 2880
aaaaaaaaag ccaggcctgt tagagcatgc ttaagggatc cctaggactt gctgagcaca 2940
caagagtagt tacttggcag gctcctggtg agagcatatt tcaaaaaaca aggcagacaa 3000
ccaagaaact acagttaagg ttacctgtct ttaaaccatc tgcatataca cagggatatt 3060
aaaatattcc aaataatatt tcattcaagt tttcccccat caaattggga catggatttc 3120
tccggtgaat aggcagagtt ggaaactaaa caaatgttgg ttttgtgatt tgtgaaattg 3180
ttttcaagtg atagttaaag cccatgagat acagaacaaa gctgctattt cgaggtctct 3240
tggtttatac tcagaagcac ttctttgggt ttccctgcac tatcctgatc atgtgctagg 3300
cctaccttag gctgattgtt gttcaaataa acttaagttt cctgtcaggt gatgtcatat 3360
gatttcatat atcaaggcaa aacatgttat atatgttaaa catttgtact taatgtgaaa 3420
gttaggtctt tgtgggtttg atttttaatt ttcaaaacct gagctaaata agtcattttt 3480
acatgtctta catttggtgg aattgtataa ttgtggtttg caggcaagac tctctgacct 3540
agtaacccta cctatagagc actttgctgg gtcacaagtc taggagtcaa gcatttcacc 3600
ttgaagttga gacgttttgt tagtgtatac tagtttatat gttggaggac atgtttatcc 3660
agaagatatt caggactatt tttgactggg ctaaggaatt gattctgatt agcactgtta 3720
gtgagcattg agtggccttt aggcttgaat tggagtcact tgtatatctc aaataatgct 3780
ggcctttttt aaaagccctt gttctttatc accctgtttt ctacataatt tttgttcaaa 3840
gaaatacttg tttggatctc cttttgacaa caatagcatg ttttcaagcc atattttttt 3900
tccttttttt tttttttttt ggtttttcga gacagggttt ctctgtatag ccctggctgt 3960
cctggaactc actttgtaga ccaggctggc ctcgaactca gaaatccgcc tgcctctgcc 4020
tcctgagtgc cgggattaaa ggcgtgcacc accacgcctg gctaagttgg atattttgtt 4080
atataactat aaccaatact aactccactg ggtggatttt taattcagtc agtagtctta 4140
agtggtcttt attggccctt cattaaaatc tactgttcac tctaacagag gctgttggta 4200
ctagtggcac ttaagcaact tcctacggat atactagcag attaagggtc agggatagaa 4260
actagtctag cgttttgtat acctaccagc tttatactac cttgttctga tagaaatatt 4320
tcaggacatc tagctt 4336
<210> 515
<211> 1846
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 515
aattctaccg ggtaggggag gcgcttttcc caaggcagtc tggagcatgc gctttagcag 60
ccccgctggg cacttggcgc tacacaagtg gcctctggcc tcgcacacat tccacatcca 120
ccggtaggcg ccaaccggct ccgttctttg gtggcccctt cgcgccacct tctactcctc 180
ccctagtcag gaagttcccc cccgccccgc agctcgcgtc gtgcaggacg tgacaaatgg 240
aagtagcacg tctcactagt ctcgtgcaga tggacagcac cgctgagcaa tggaagcggg 300
taggcctttg gggcagcggc caatagcagc tttgctcctt cgctttctgg gctcagaggc 360
tgggaagggg tgggtccggg ggcgggctca ggggcgggct caggggcggg gcgggcgccc 420
gaaggtcctc cggaggcccg gcattctgca cgcttcaaaa gcgcacgtct gccgcgctgt 480
tctcctcttc ctcatctccg ggcctttcga cctgcaatcg ccgctagcga agttcctatt 540
ctctagaaag tataggaact tcgccaccat gggatcggcc attgaacaag atggattgca 600
cgcaggttct ccggccgctt gggtggagag gctattcggc tatgactggg cacaacagac 660
aatcggctgc tctgatgccg ccgtgttccg gctgtcagcg caggggcgcc cggttctttt 720
tgtcaagacc gacctgtccg gtgccctgaa tgaactgcag gacgaggcag cgcggctatc 780
gtggctggcc acgacgggcg ttccttgcgc agctgtgctc gacgttgtca ctgaagcggg 840
aagggactgg ctgctattgg gcgaagtgcc ggggcaggat ctcctgtcat ctcaccttgc 900
tcctgccgag aaagtatcca tcatggctga tgcaatgcgg cggctgcata cgcttgatcc 960
ggctacctgc ccattcgacc accaagcgaa acatcgcatc gagcgagcac gtactcggat 1020
ggaagccggt cttgtcgatc aggatgatct ggacgaagag catcaggggc tcgcgccagc 1080
cgaactgttc gccaggctca aggcgcgcat gcccgacggc gatgatctcg tcgtgaccca 1140
tggcgatgcc tgcttgccga atatcatggt ggaaaatggc cgcttttctg gattcatcga 1200
ctgtggccgg ctgggtgtgg cggaccgcta tcaggacata gcgttggcta cccgtgatat 1260
tgctgaagag cttggcggcg aatgggctga ccgcttcctc gtgctttacg gtatcgccgc 1320
tcccgattcg cagcgcatcg ccttctatcg ccttcttgac gagttcttct gaggggatcc 1380
gctgtaagtc tgcagaaatt gatgatctat taaacaataa agatgtccac taaaatggaa 1440
gtttttcctg tcatactttg ttaagaaggg tgagaacaga gtacctacat tttgaatgga 1500
aggattggag ctacgggggt gggggtgggg tgggattaga taaatgcctg ctctttactg 1560
aaggctcttt actattgctt tatgataatg tttcatagtt ggatatcata atttaaacaa 1620
gcaaaaccaa attaagggcc agctcattcc tcccactcat gatctataga tctatagatc 1680
tctcgtggga tcattgtttt tctcttgatt cccactttgt ggttctaagt actgtggttt 1740
ccaaatgtgt cagtttcata gcctgaagaa cgagatcagc agcctctgtt ccacatacac 1800
ttcattctca gtattgtttt gccaagttct aattccatca gaaagc 1846
<210> 516
<211> 1519
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<400> 516
taccgggtag gggaggcgct tttcccaagg cagtctggag catgcgcttt agcagccccg 60
ctgggcactt ggcgctacac aagtggcctc tggcctcgca cacattccac atccaccggt 120
aggcgccaac cggctccgtt ctttggtggc cccttcgcgc caccttctac tcctccccta 180
gtcaggaagt tcccccccgc cccgcagctc gcgtcgtgca ggacgtgaca aatggaagta 240
gcacgtctca ctagtctcgt gcagatggac agcaccgctg agcaatggaa gcgggtaggc 300
ctttggggca gcggccaata gcagctttgc tccttcgctt tctgggctca gaggctggga 360
aggggtgggt ccgggggcgg gctcaggggc gggctcaggg gcggggcggg cgcccgaagg 420
tcctccggag gcccggcatt ctgcacgctt caaaagcgca cgtctgccgc gctgttctcc 480
tcttcctcat ctccgggcct ttcgacctgc aggtcctcgc catggatcct gatgatgttg 540
ttgattcttc taaatctttt gtgatggaaa acttttcttc gtaccacggg actaaacctg 600
gttatgtaga ttccattcaa aaaggtatac aaaagccaaa atctggtaca caaggaaatt 660
atgacgatga ttggaaaggg ttttatagta ccgacaataa atacgacgct gcgggatact 720
ctgtagataa tgaaaacccg ctctctggaa aagctggagg cgtggtcaaa gtgacgtatc 780
caggactgac gaaggttctc gcactaaaag tggataatgc cgaaactatt aagaaagagt 840
taggtttaag tctcactgaa ccgttgatgg agcaagtcgg aacggaagag tttatcaaaa 900
ggttcggtga tggtgcttcg cgtgtagtgc tcagccttcc cttcgctgag gggagttcta 960
gcgttgaata tattaataac tgggaacagg cgaaagcgtt aagcgtagaa cttgagatta 1020
attttgaaac ccgtggaaaa cgtggccaag atgcgatgta tgagtatatg gctcaagcct 1080
gtgcaggaaa tcgtgtcagg cgatctcttt gtgaaggaac cttacttctg tggtgtgaca 1140
taattggaca aactacctac agagatttaa agctctaagg taaatataaa atttttaagt 1200
gtataatgtg ttaaactact gattctaatt gtttgtgtat tttagattcc aacctatgga 1260
actgatgaat gggagcagtg gtggaatgca gatcctagag ctcgctgatc agcctcgact 1320
gtgccttcta gttgccagcc atctgttgtt tgcccctccc ccgtgccttc cttgaccctg 1380
gaaggtgcca ctcccactgt cctttcctaa taaaatgagg aaattgcatc gcattgtctg 1440
agtaggtgtc attctattct ggggggtggg gtggggcagg acagcaaggg ggaggattgg 1500
gaagacaata gcaggcatg 1519
<210> 517
<211> 23
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
primer"
<400> 517
gagggcctat ttcccatgat tcc 23
<210> 518
<211> 22
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 518
cttgtggaaa ggacgaaaca cc 22
<210> 519
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<220>
<221> modified_base
<222> (4)..(23)
<223> a, c, t, g, unknown or other
<400> 519
aacnnnnnnn nnnnnnnnnn nnnggtgttt cgtcctttcc acaag 45
<210> 520
<211> 28
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 520
cctgagtgtt gaggccccag tggctgct 28
<210> 521
<211> 37
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 521
acgagggcag agtgctgctt gctgctggcc aggcccc 37
<210> 522
<211> 68
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 522
catcaggctc tcagctcagc ctgagtgttg aggccctgct ggccaggccc ctgcgtgggc 60
ccaagctg 68
<210> 523
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 523
gagggcctat ttcccatgat tccttca 27
<210> 524
<211> 125
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (84)..(103)
<223> a, c, t, g, unknown or other
<400> 524
aaaaaaagca ccgactcggt gccacttttt caagttgata acggactagc cttattttaa 60
cttgctattt ctagctctaa aacnnnnnnn nnnnnnnnnn nnnggtgttt cgtcctttcc 120
acaag 125
<210> 525
<211> 111
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
polynucleotide"
<220>
<221> modified_base
<222> (9)..(28)
<223> a, c, t, g, unknown or other
<400> 525
gaaacaccnn nnnnnnnnnn nnnnnnnngt tttagagcta gaaatagcaa gttaaaataa 60
ggctagtccg ttatcaactt gaaaaagtgg caccgagtcg gtgctttttt t 111
<210> 526
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 526
agctgtttta ctggtcggct 20
<210> 527
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 527
aatggataca cctggtcgaa 20
<210> 528
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<221> source
<223> /note="Description of Artificial Sequence: Synthetic
oligonucleotide"
<400> 528
caatggatac acctggtcga 20
<210> 529
<211> 68
<212> DNA
<213> Homo sapiens
<400> 529
accatgtata ccacttgggc tttggcagta gctaactgca ctaaatataa tataaggagg 60
gttttatg 68
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| КОНСТРУИРОВАНИЕ СИСТЕМ, СПОСОБЫ И ОПТИМИЗИРОВАННЫЕ НАПРАВЛЯЮЩИЕ КОМПОЗИЦИИ ДЛЯ МАНИПУЛЯЦИИ С ПОСЛЕДОВАТЕЛЬНОСТЯМИ | 2013 |
|
RU2796017C2 |
| НОВЫЕ ФЕРМЕНТЫ И СИСТЕМЫ CRISPR | 2016 |
|
RU2777988C2 |
| НОВЫЕ ФЕРМЕНТЫ CRISPR И СИСТЕМЫ | 2016 |
|
RU2771826C2 |
| ДОСТАВКА, КОНСТРУИРОВАНИЕ И ОПТИМИЗАЦИЯ СИСТЕМ, СПОСОБОВ И КОМПОЗИЦИЙ ДЛЯ МАНИПУЛЯЦИИ С ПОСЛЕДОВАТЕЛЬНОСТЯМИ И ПРИМЕНЕНИЯ В ТЕРАПИИ | 2013 |
|
RU2721275C2 |
| ГИБРИДНЫЕ БЕЛКИ ВАРИАНТА sPD-1—FC | 2019 |
|
RU2785993C2 |
| Антитела против CXCR2 и их применение | 2019 |
|
RU2807067C2 |
| НОВЫЕ ФЕРМЕНТЫ И СИСТЕМЫ CRISPR | 2023 |
|
RU2832308C2 |
| КОМПОЗИЦИИ Т-КЛЕТОК С НЕДОСТАТОЧНОСТЬЮ РЕЦЕПТОРОВ Т-КЛЕТОК | 2013 |
|
RU2781979C2 |
| НАПРАВЛЯЕМАЯ РНК РЕГУЛЯЦИЯ ТРАНСКРИПЦИИ | 2014 |
|
RU2756865C2 |
| СИСТЕМА РЕДАКТИРОВАНИЯ ГЕНОМА CRISPR/CAS9 II ТИПА И ЕЕ ПРИМЕНЕНИЕ | 2022 |
|
RU2794774C1 |


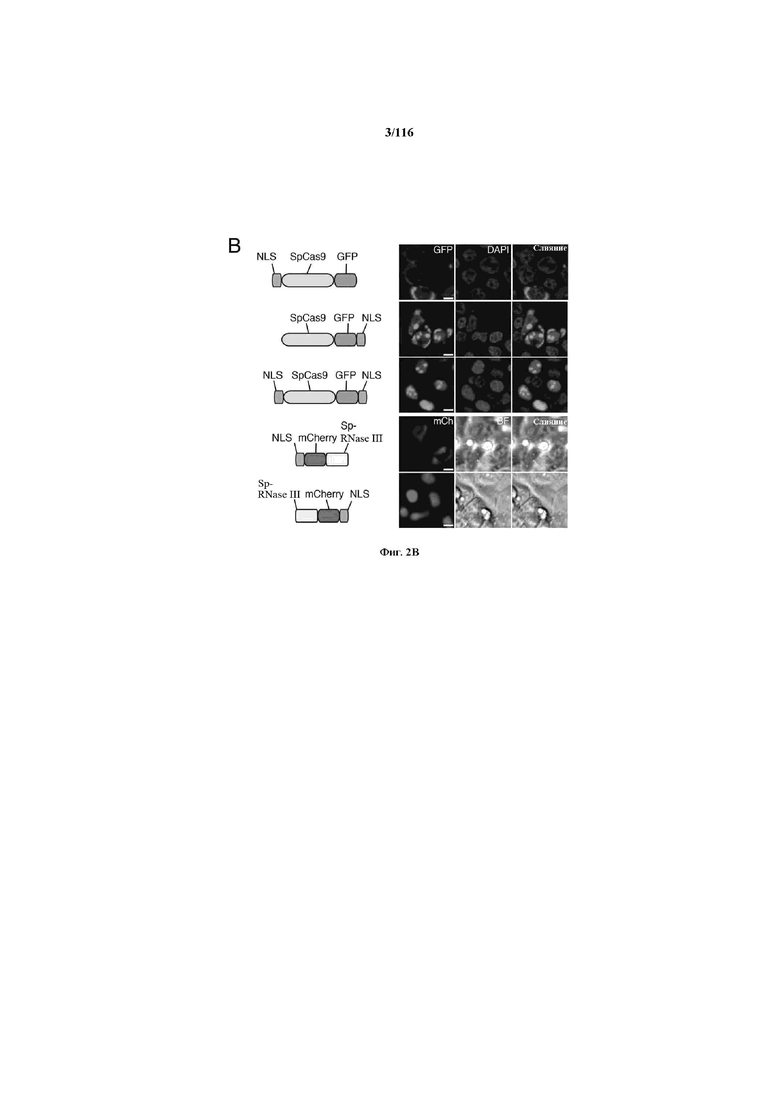

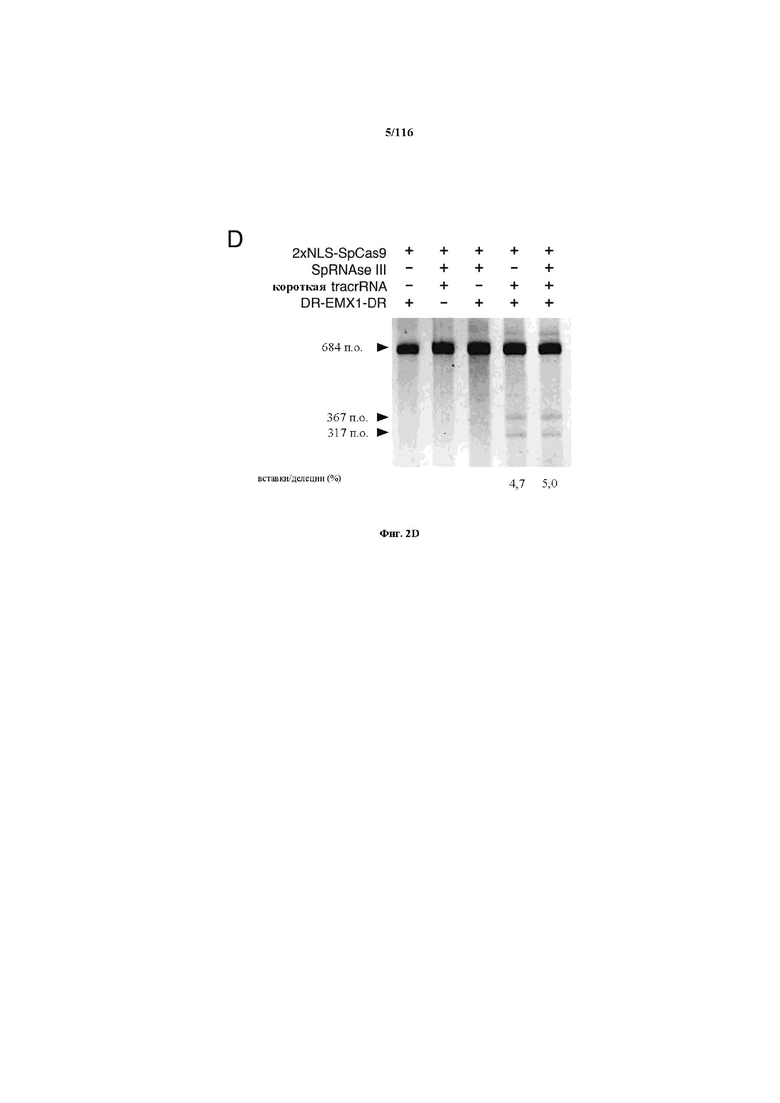

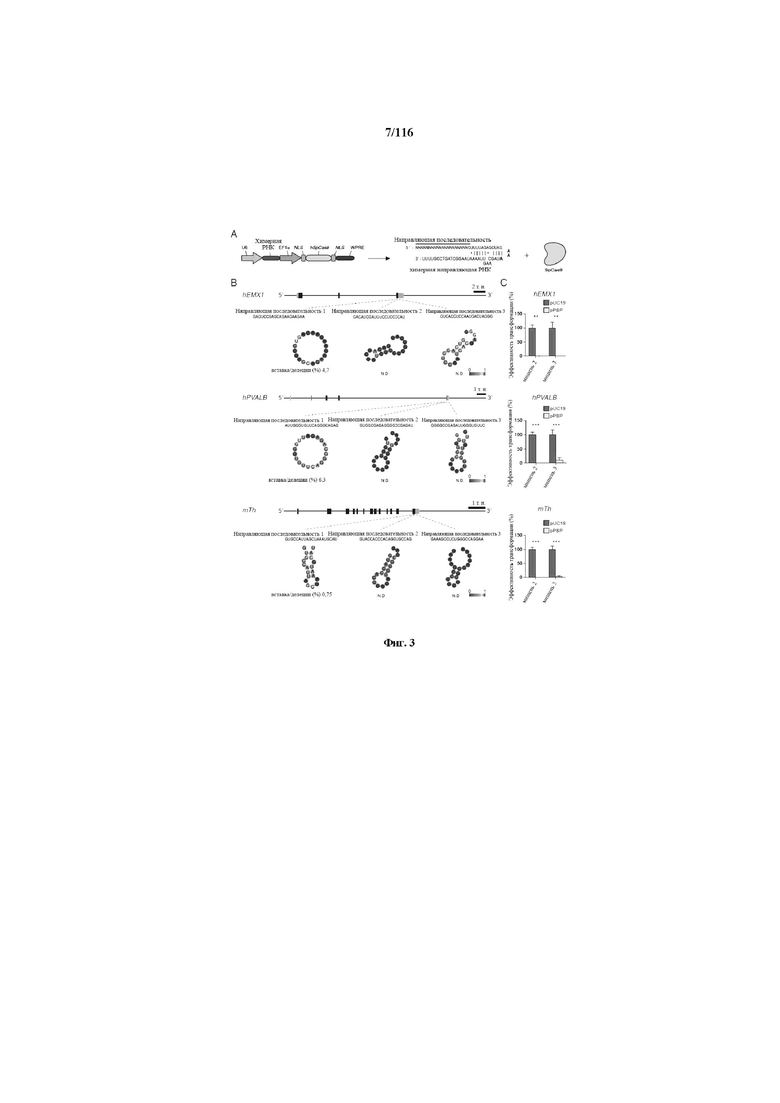
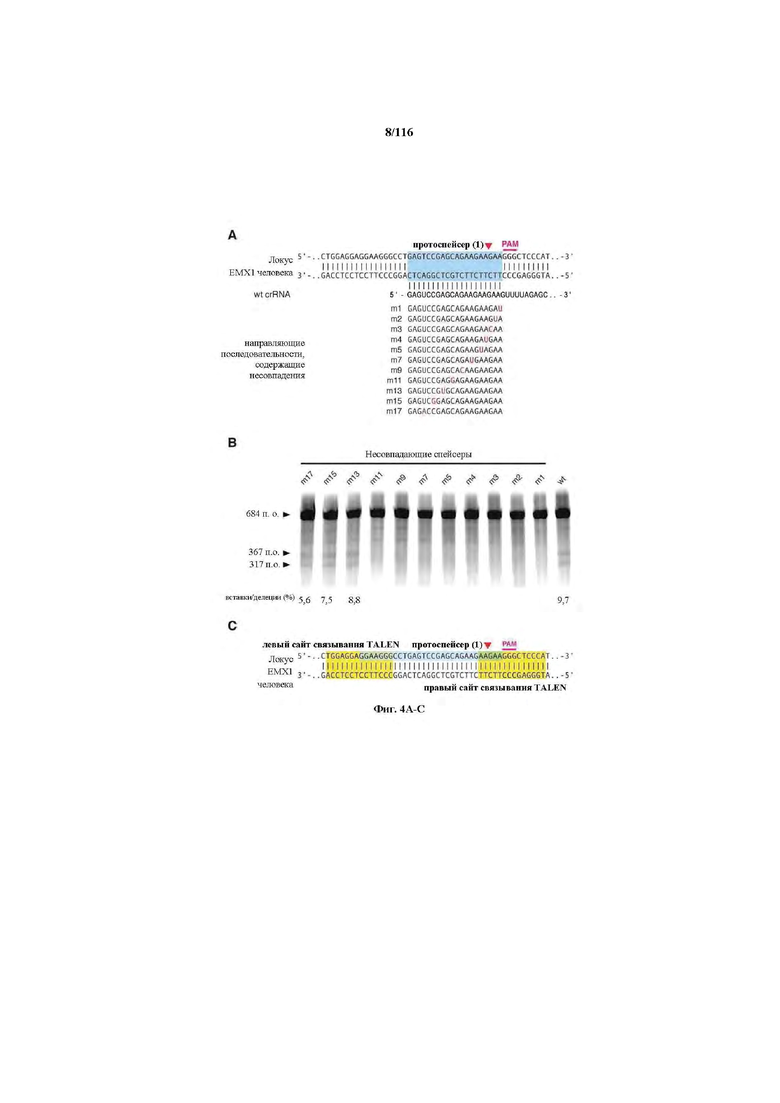


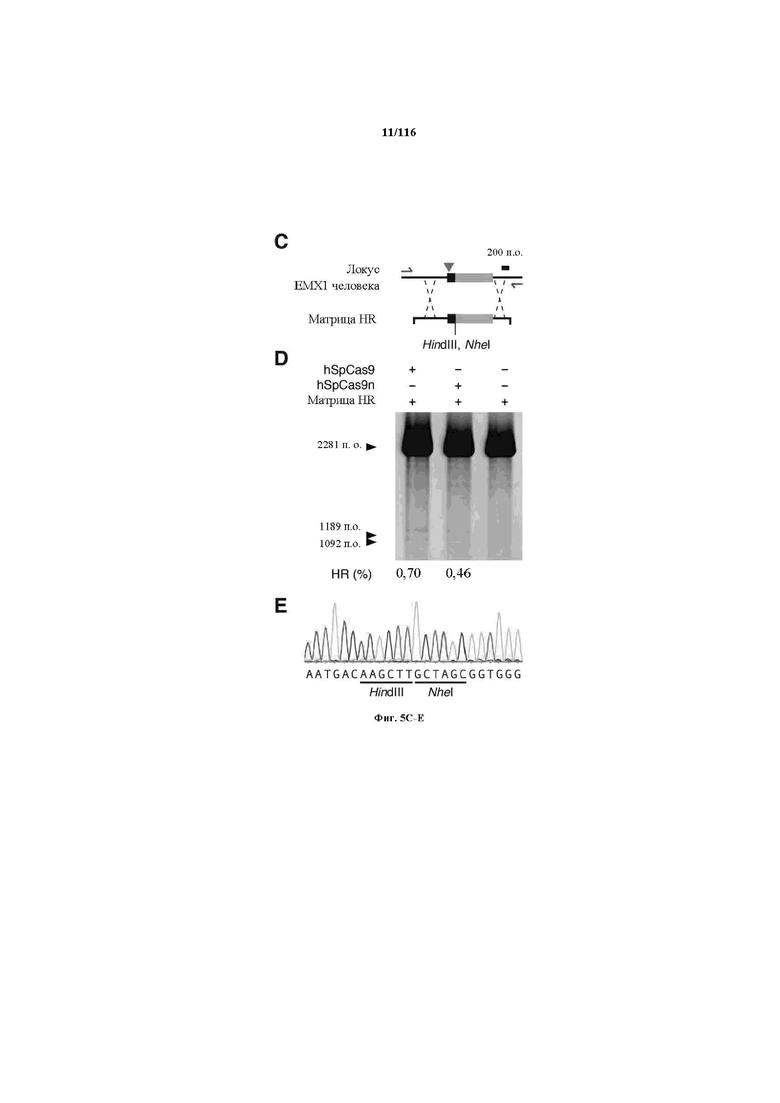



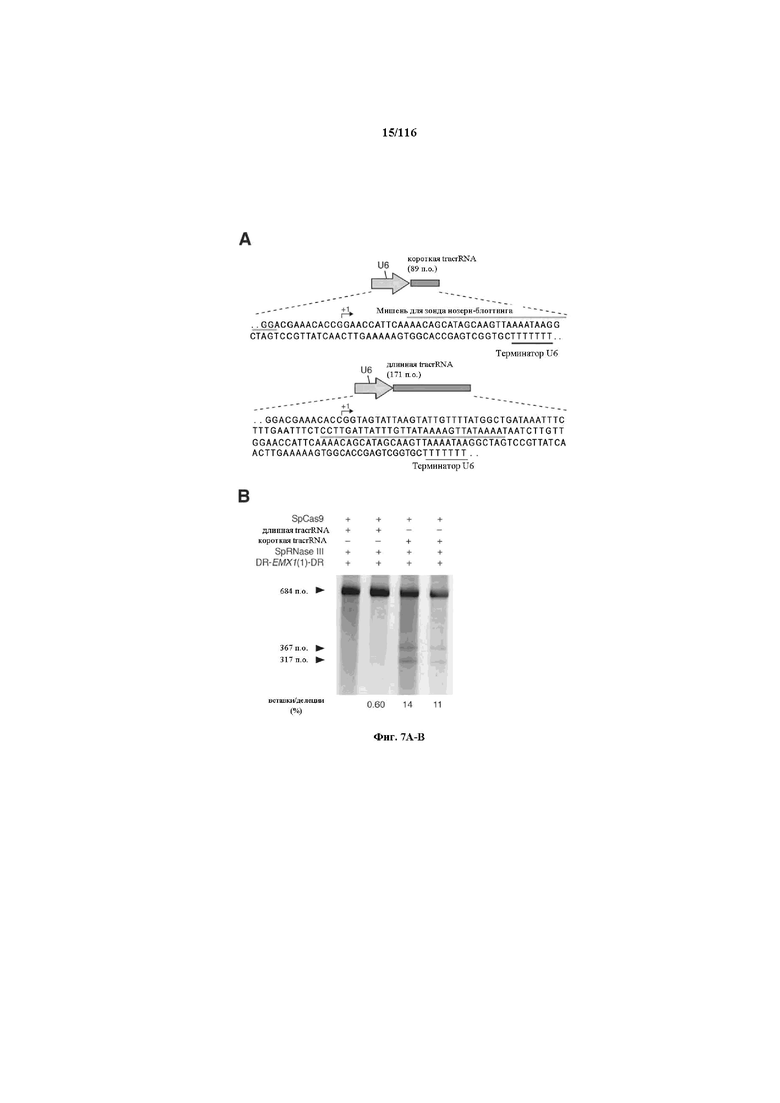


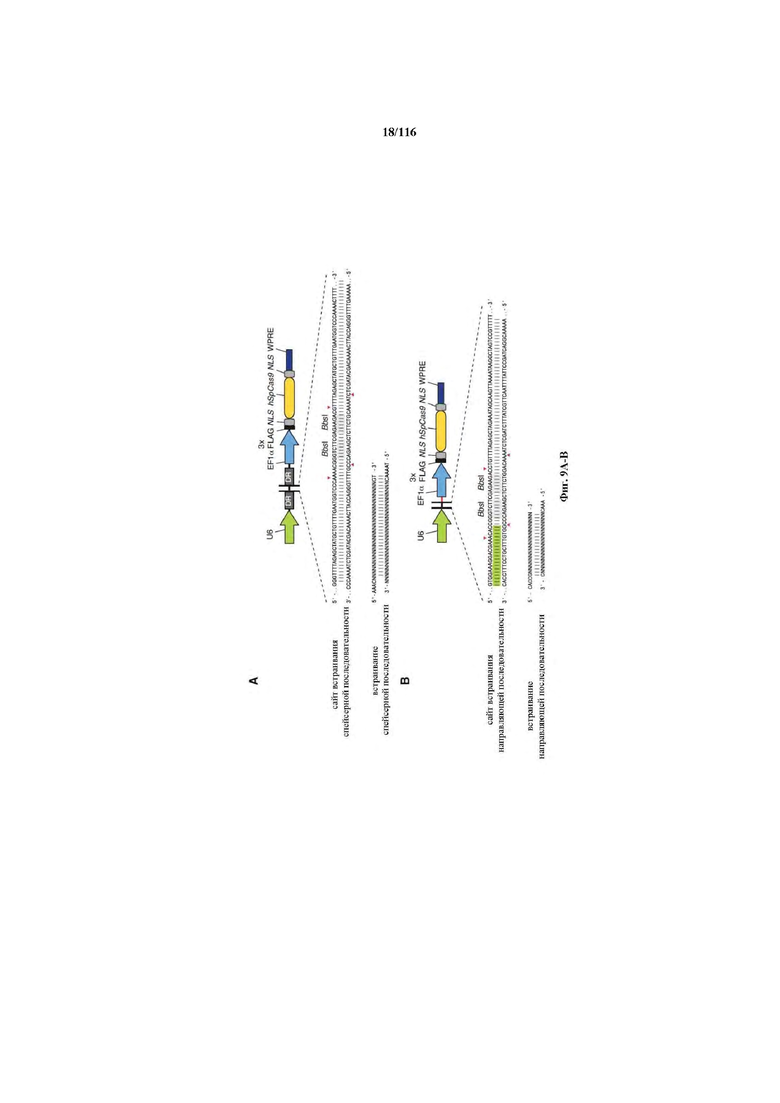
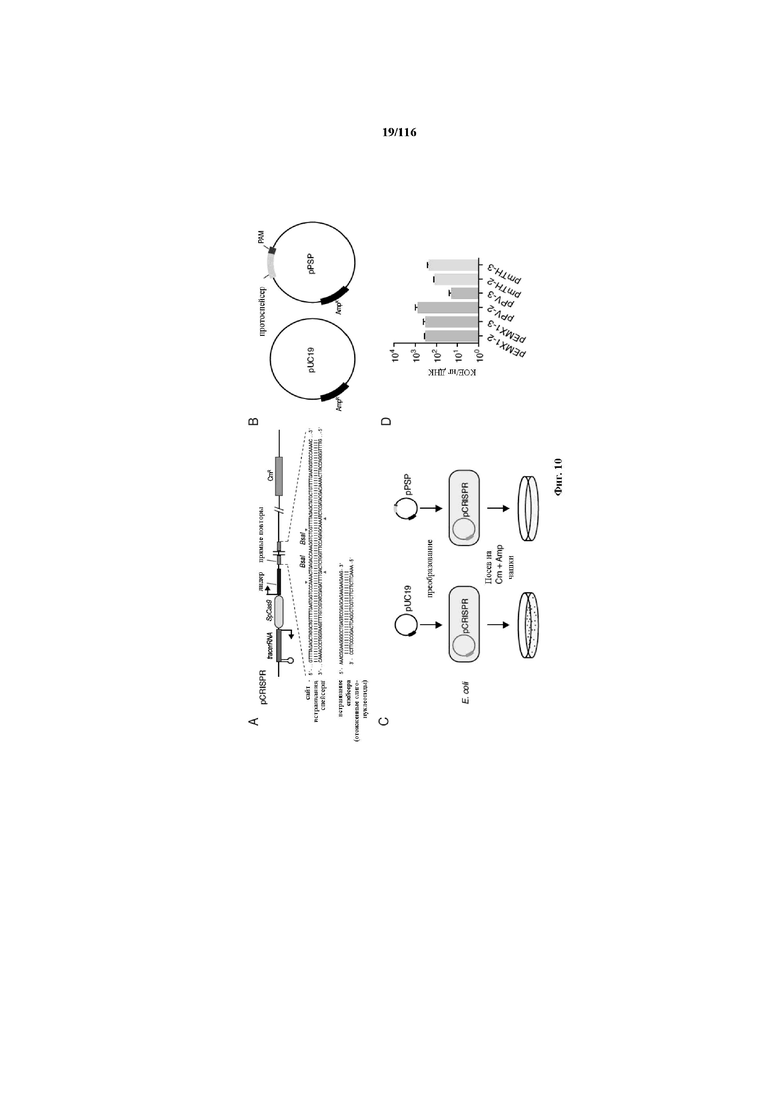
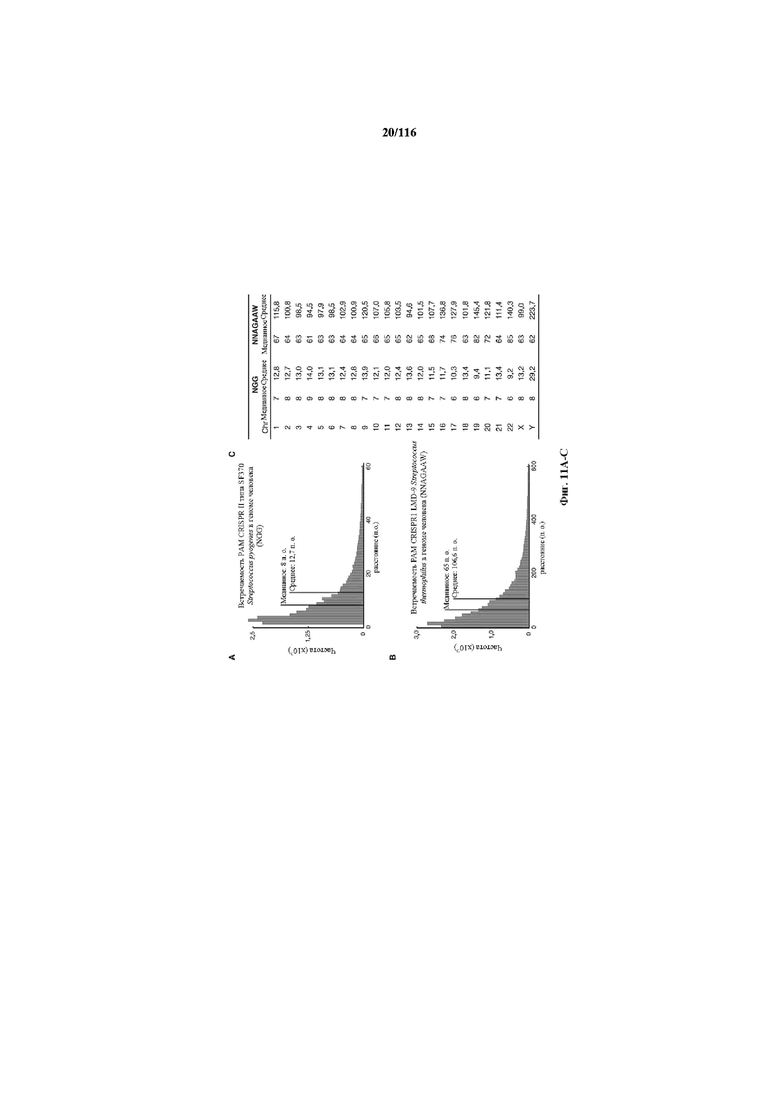


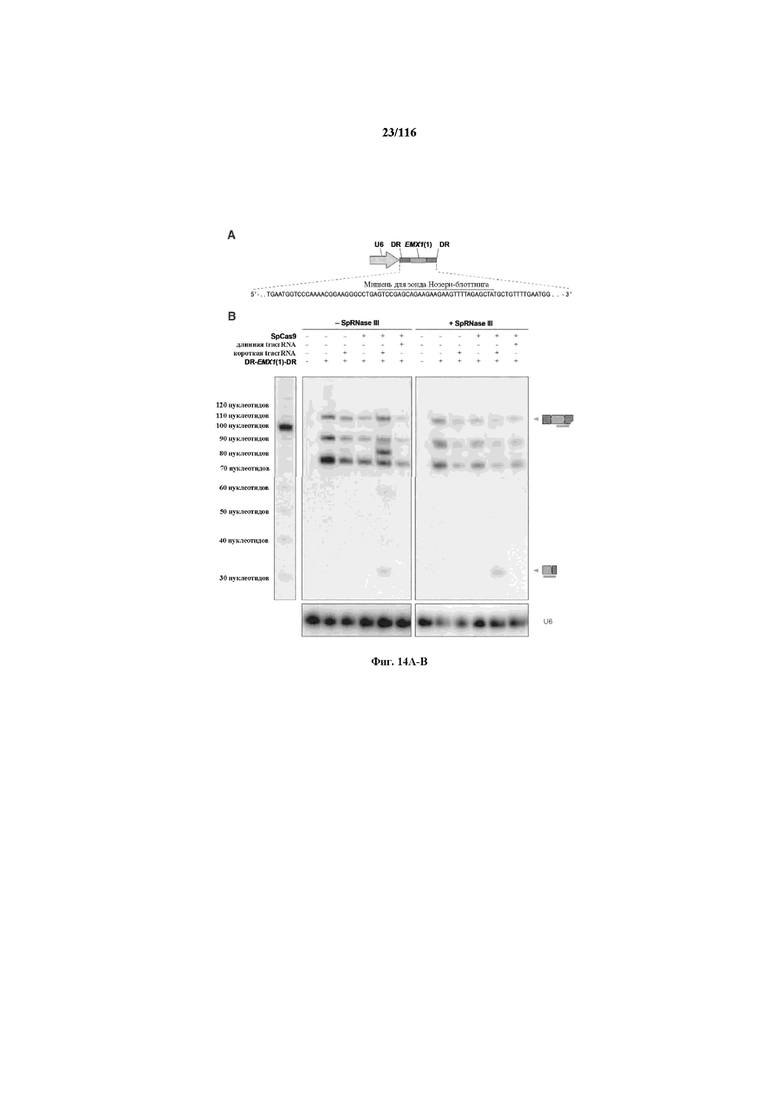


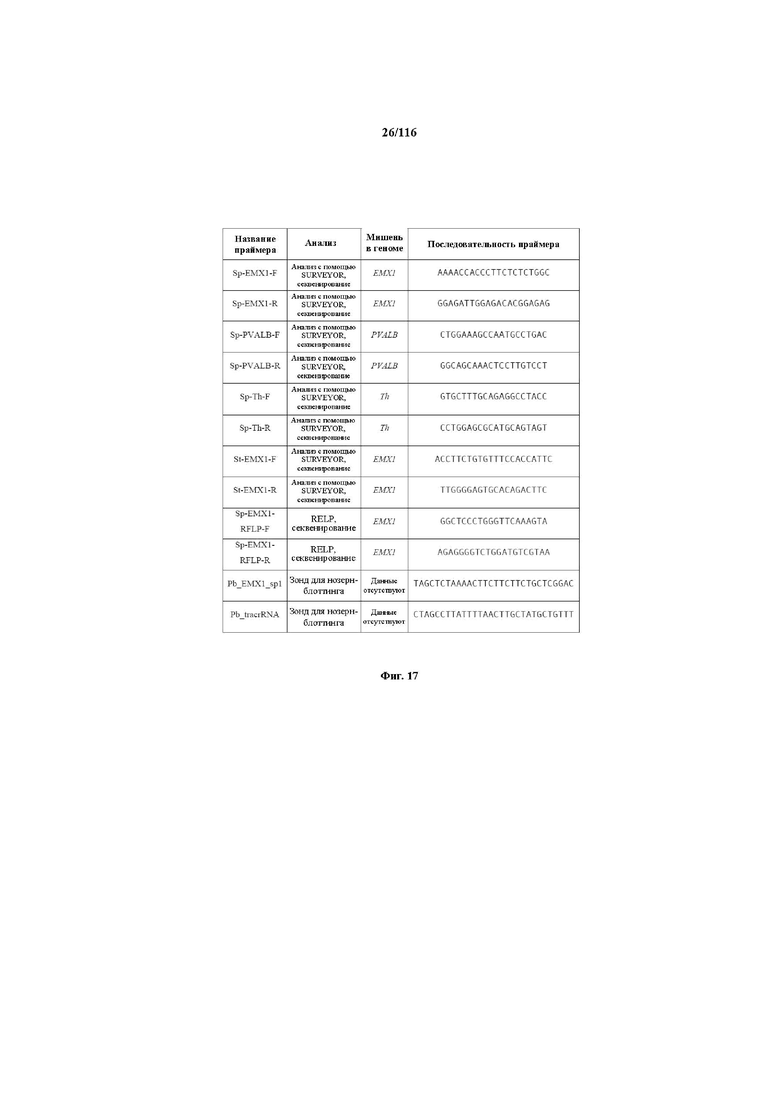







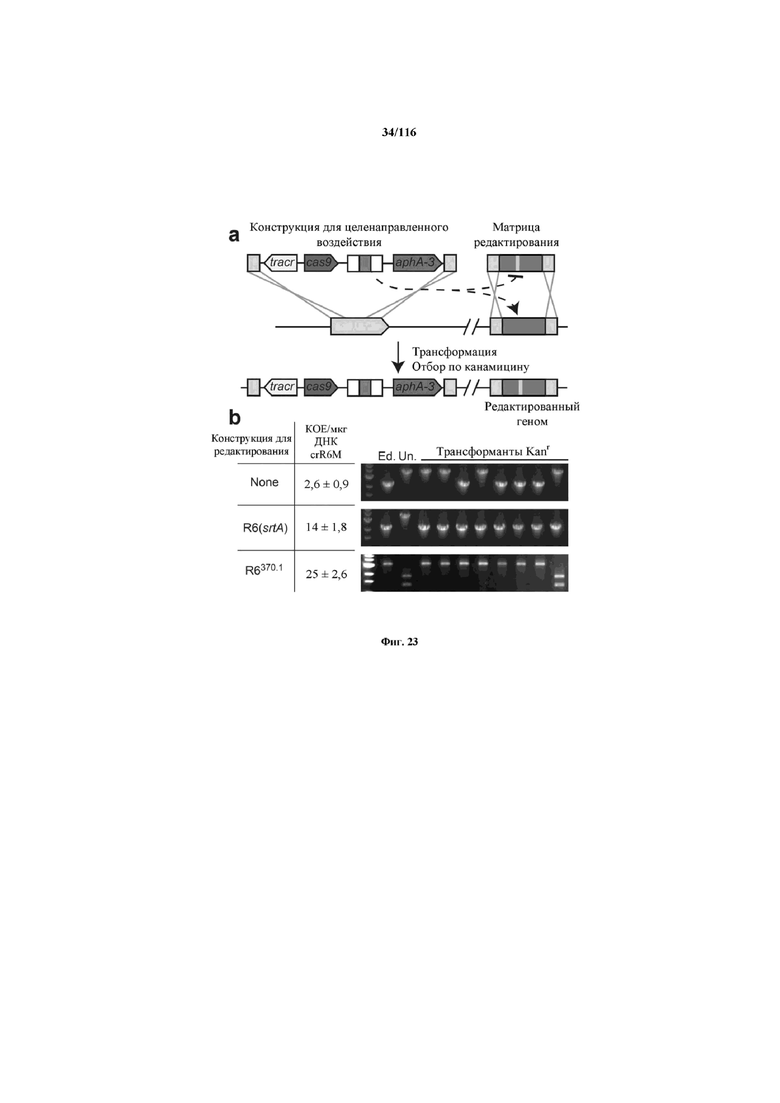



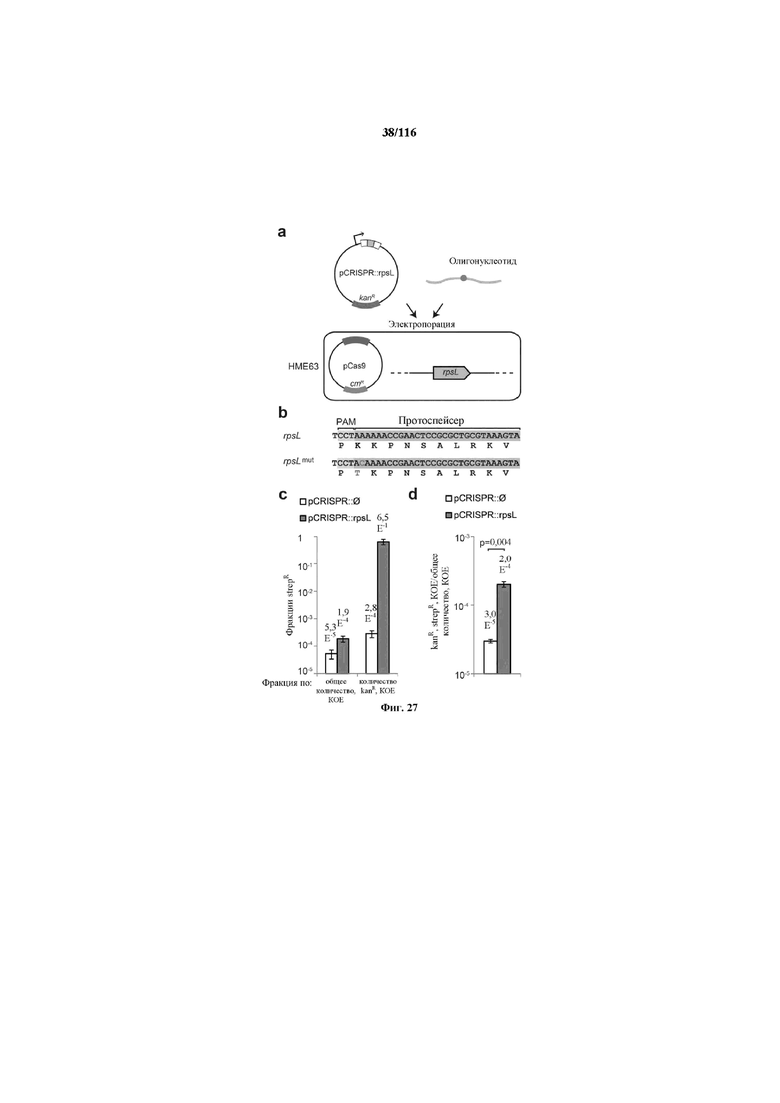
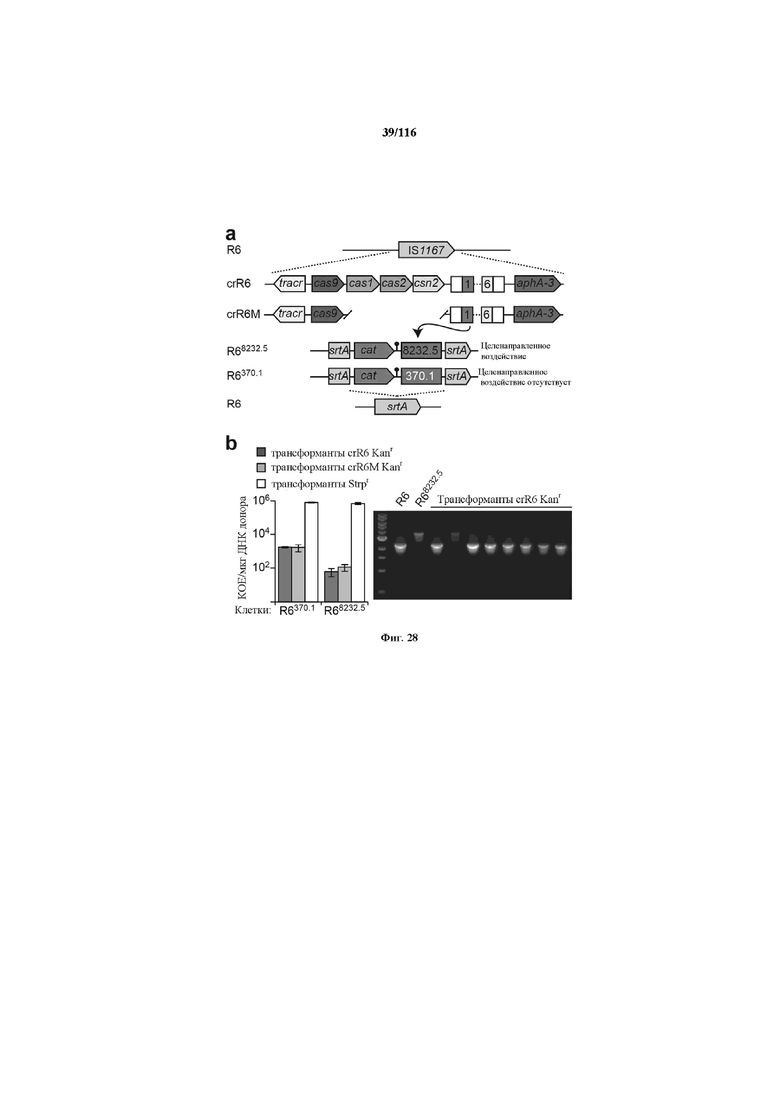

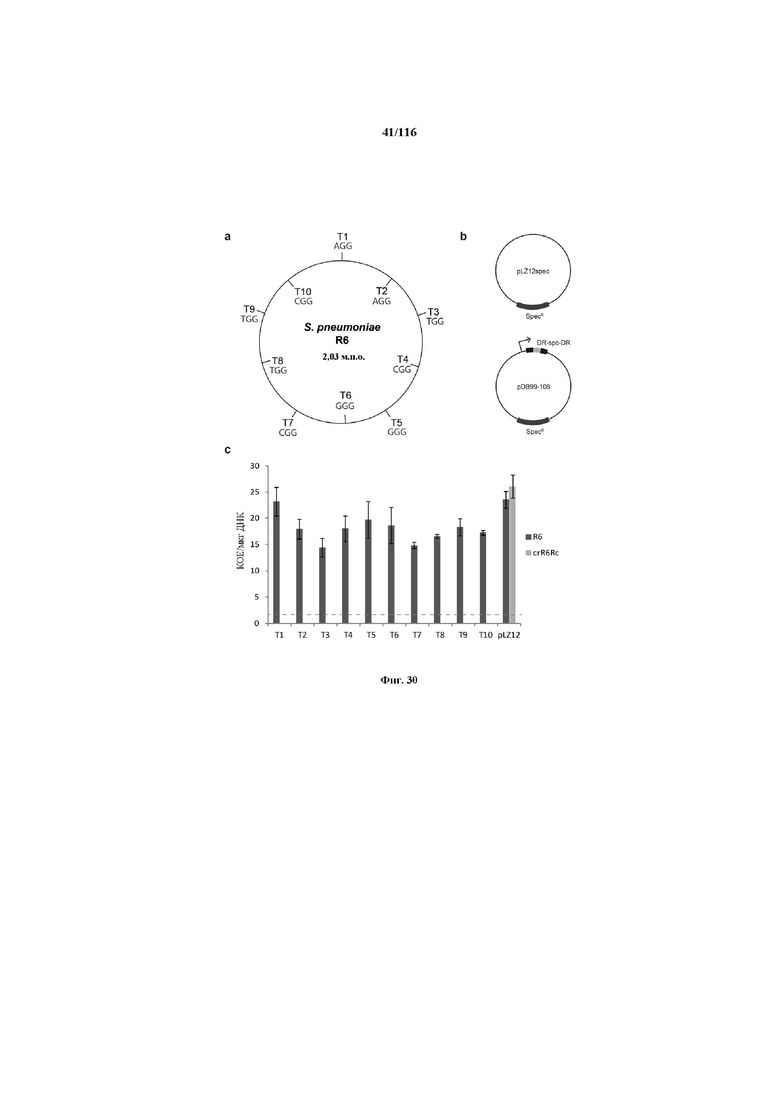
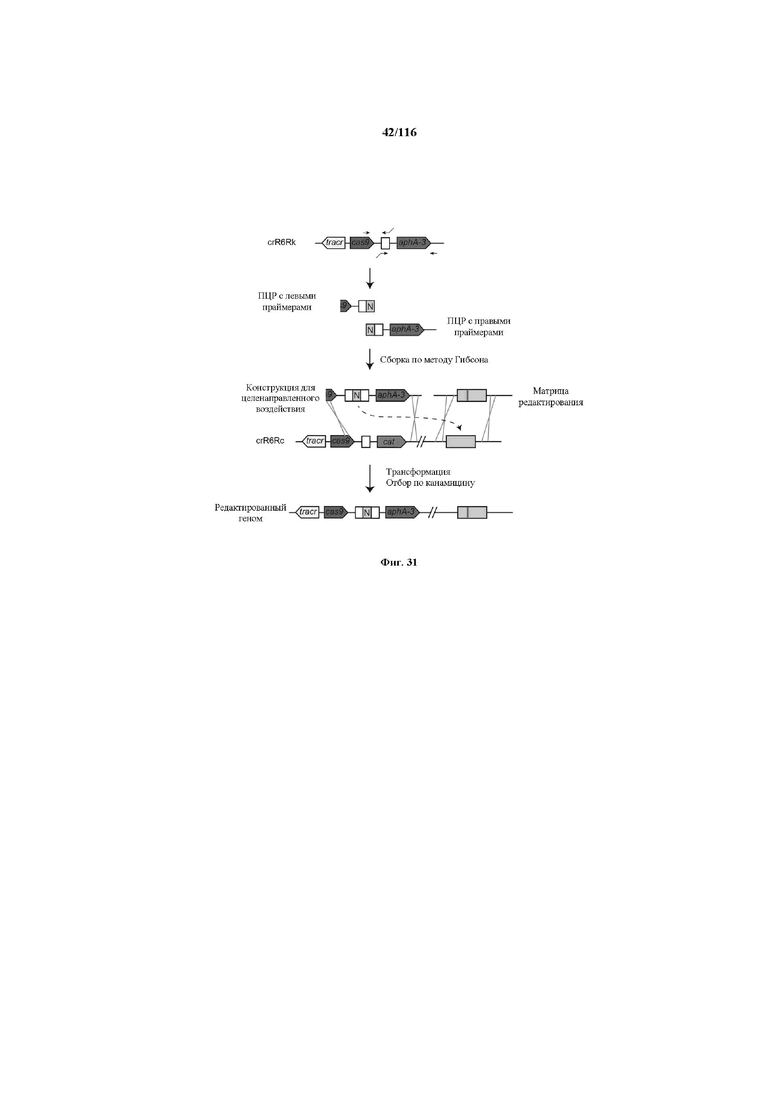
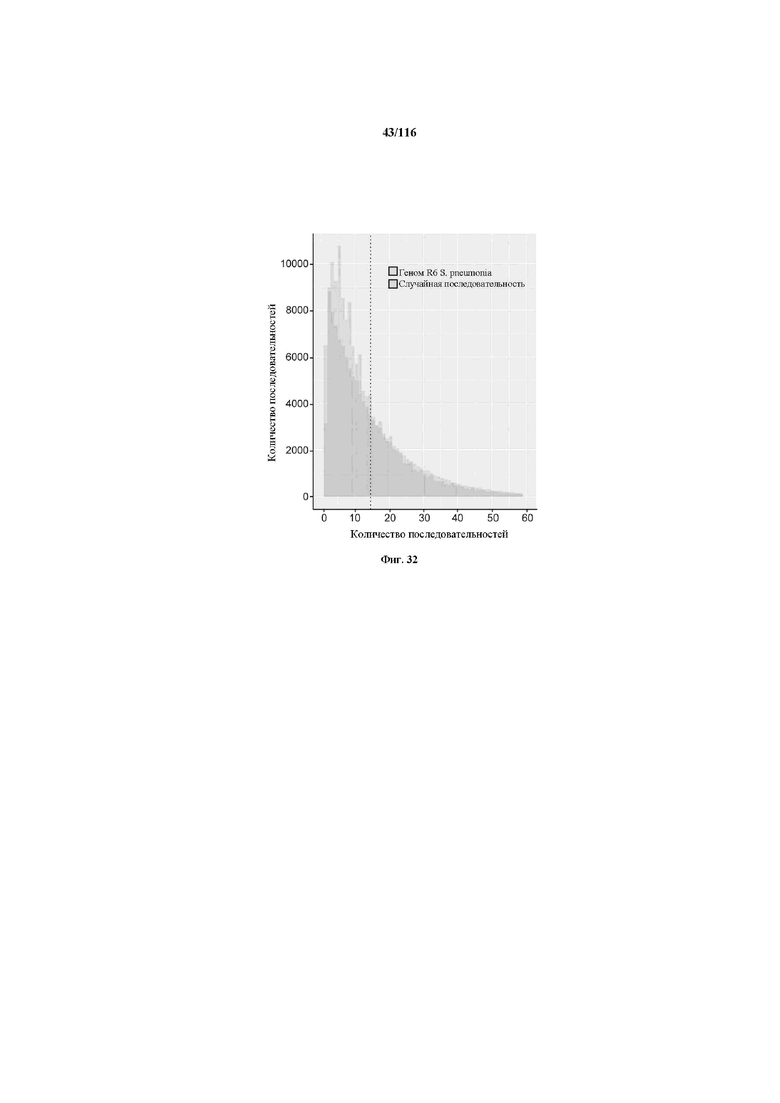
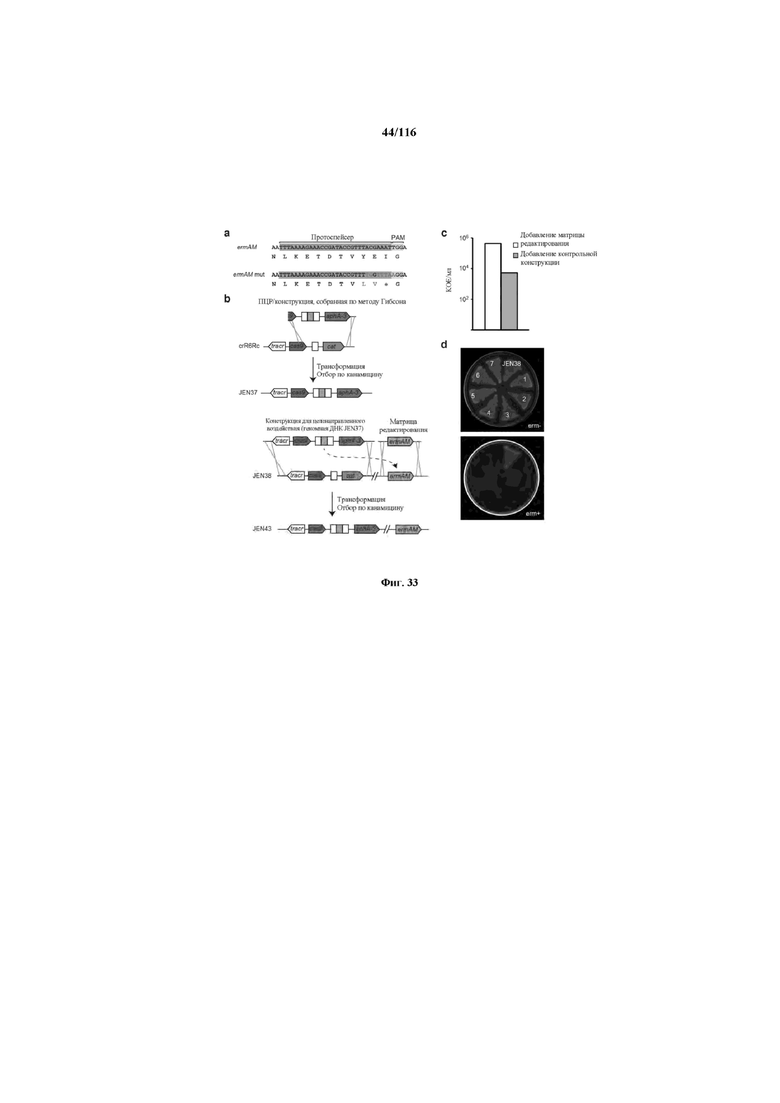

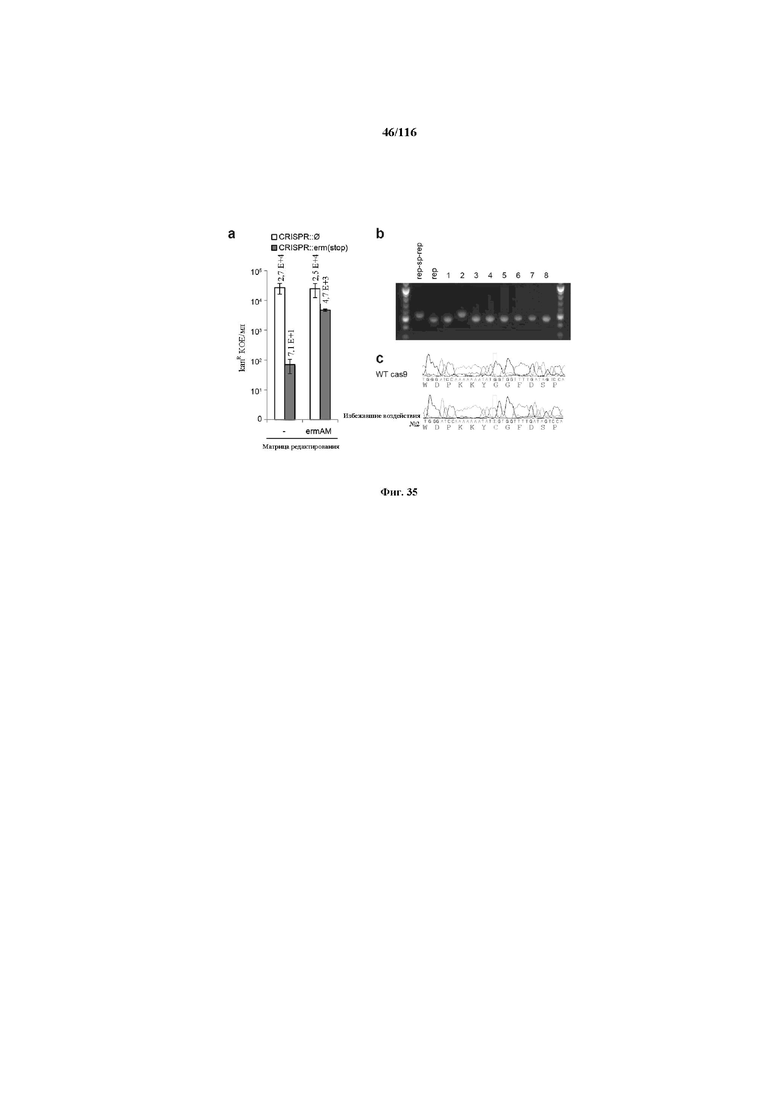

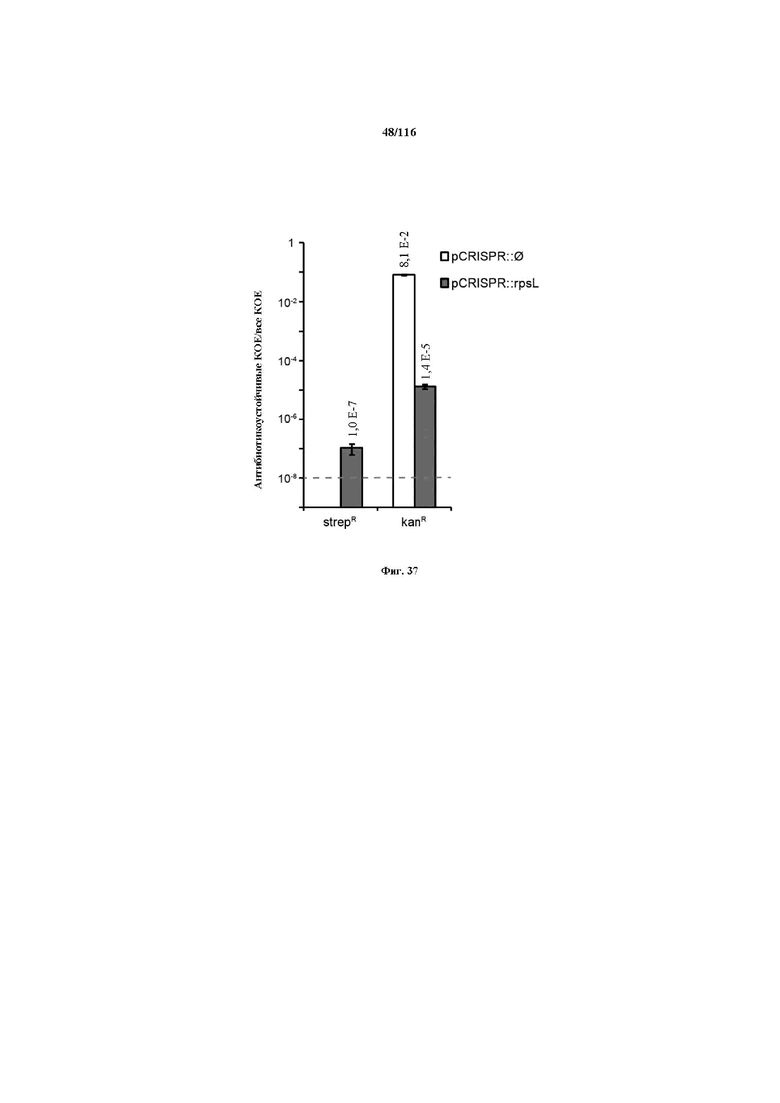









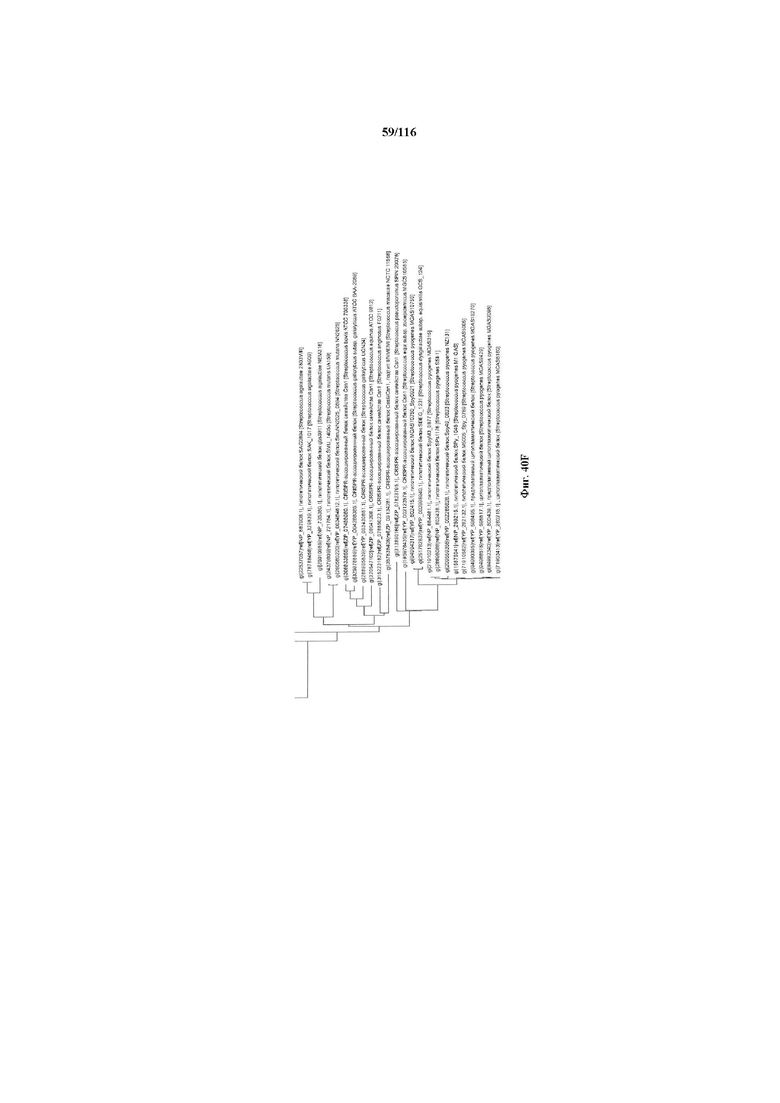














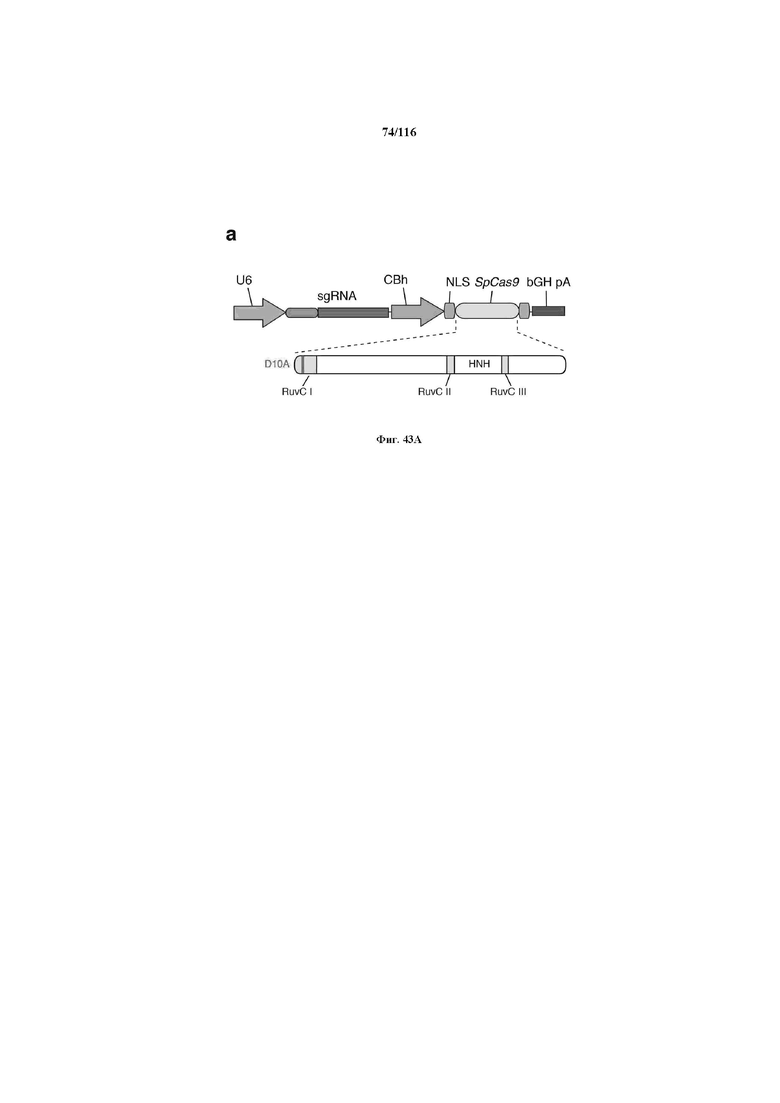


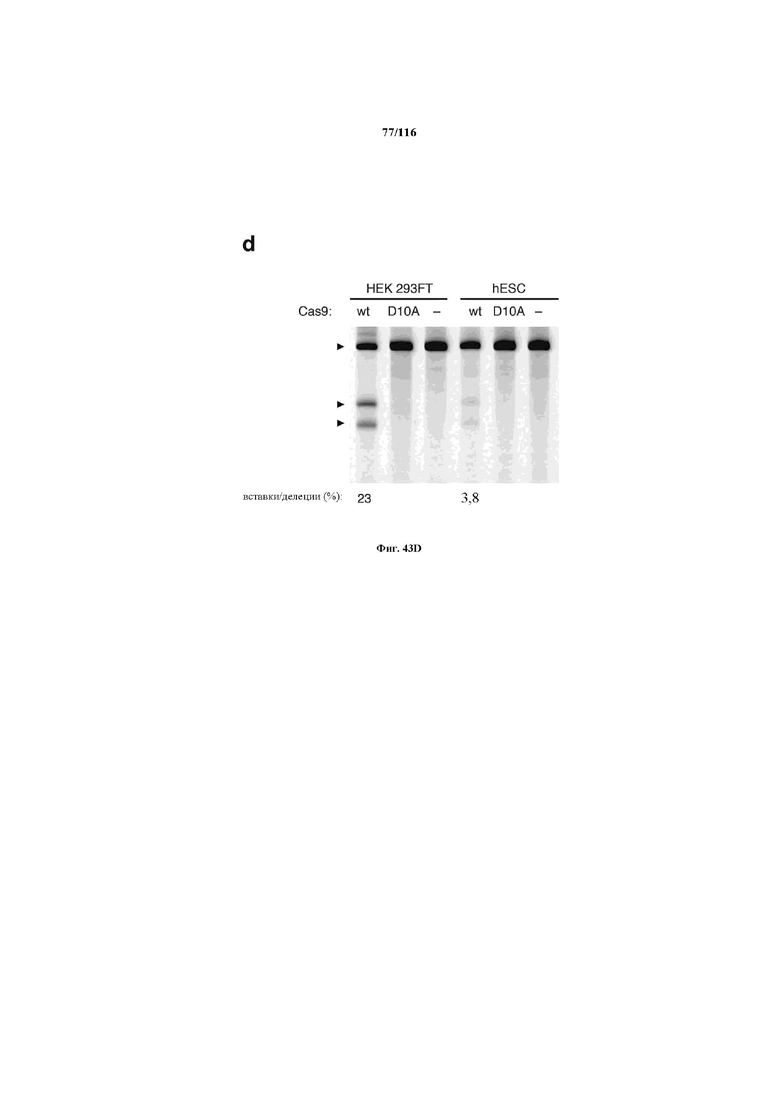
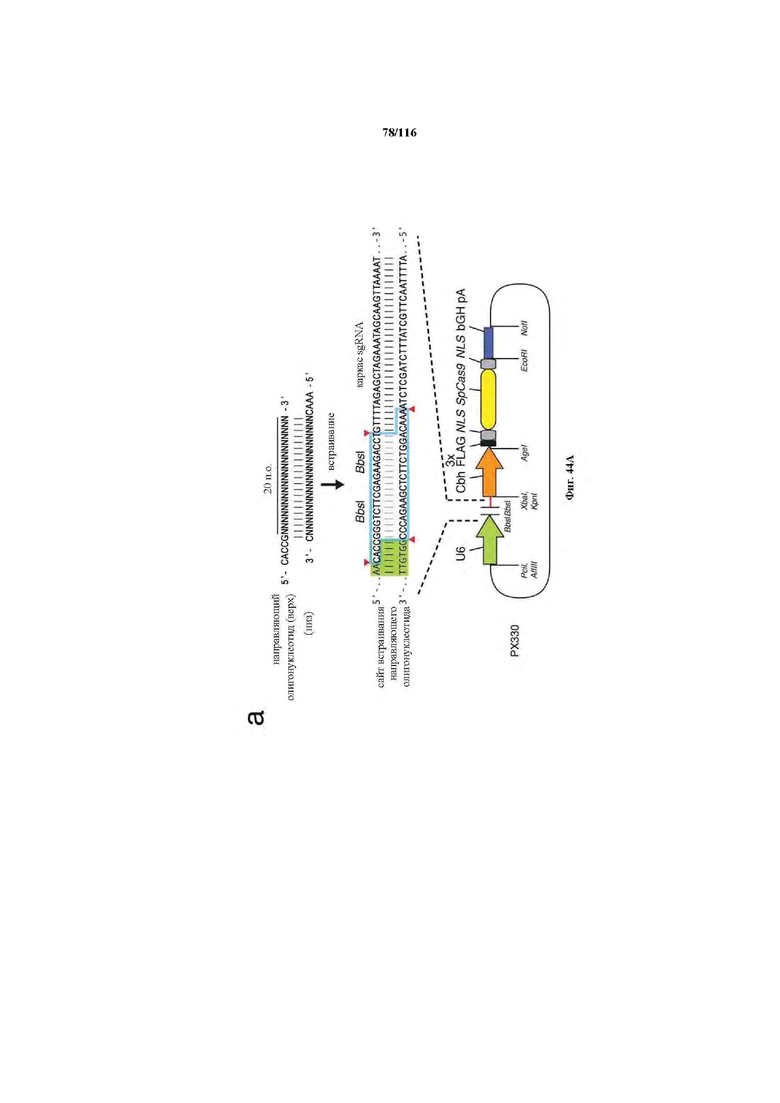
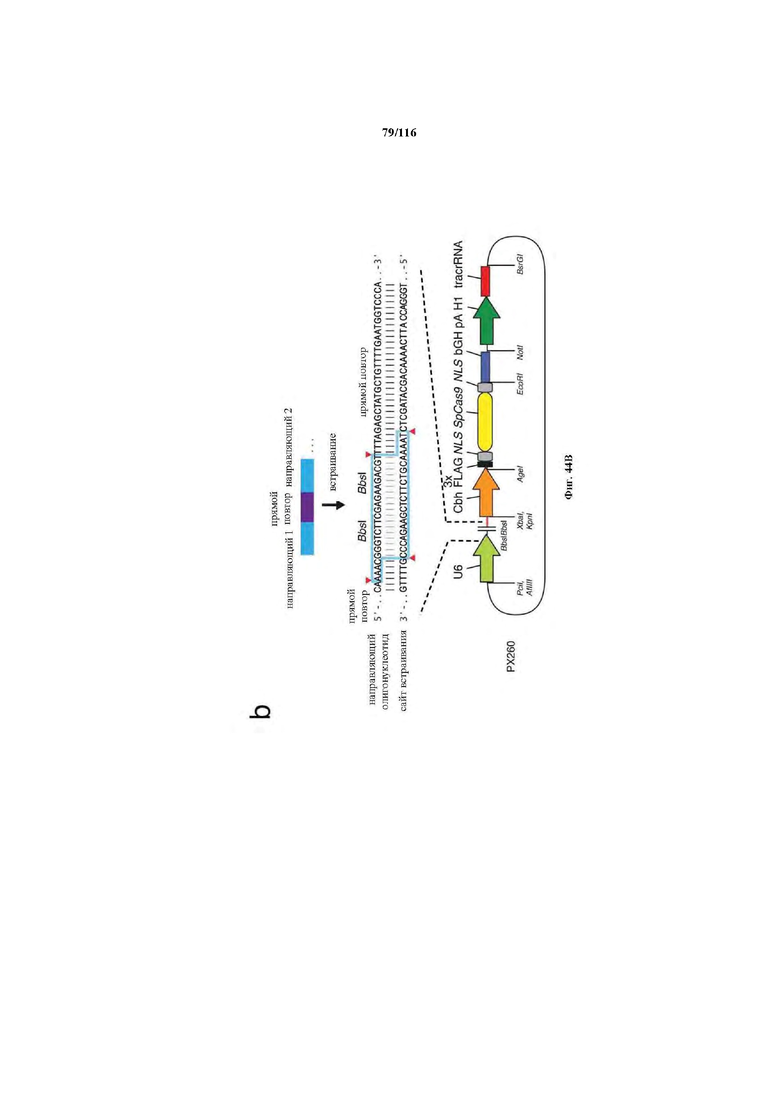

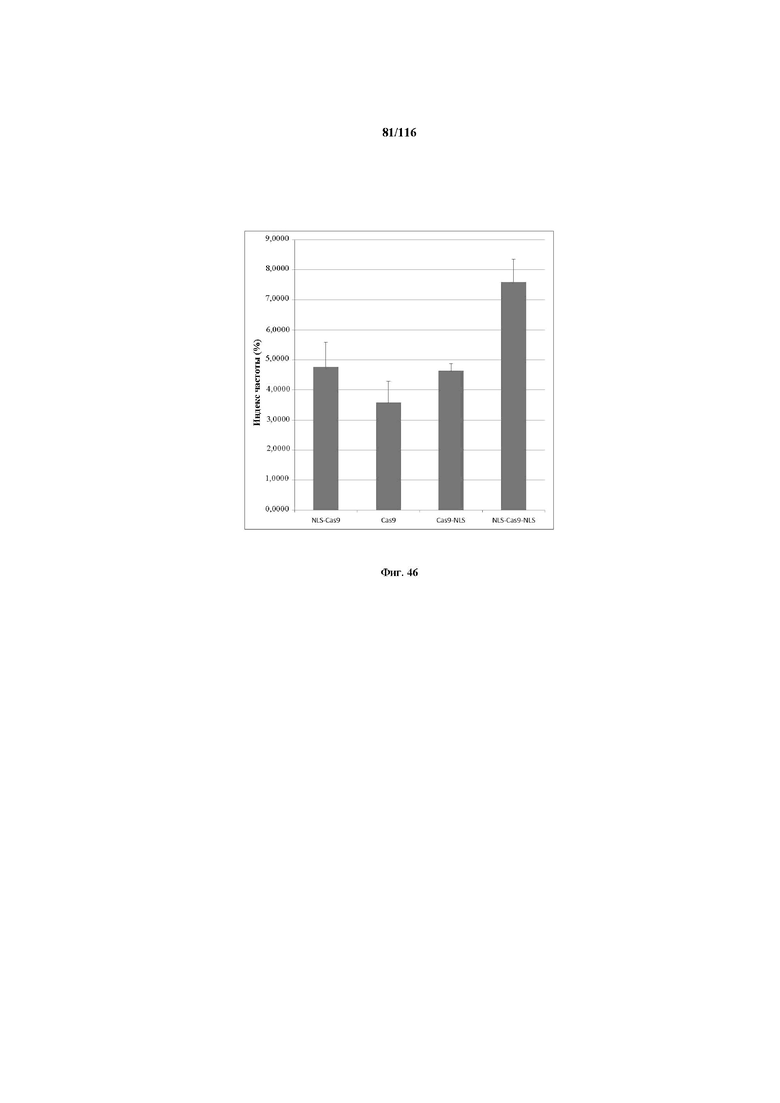
















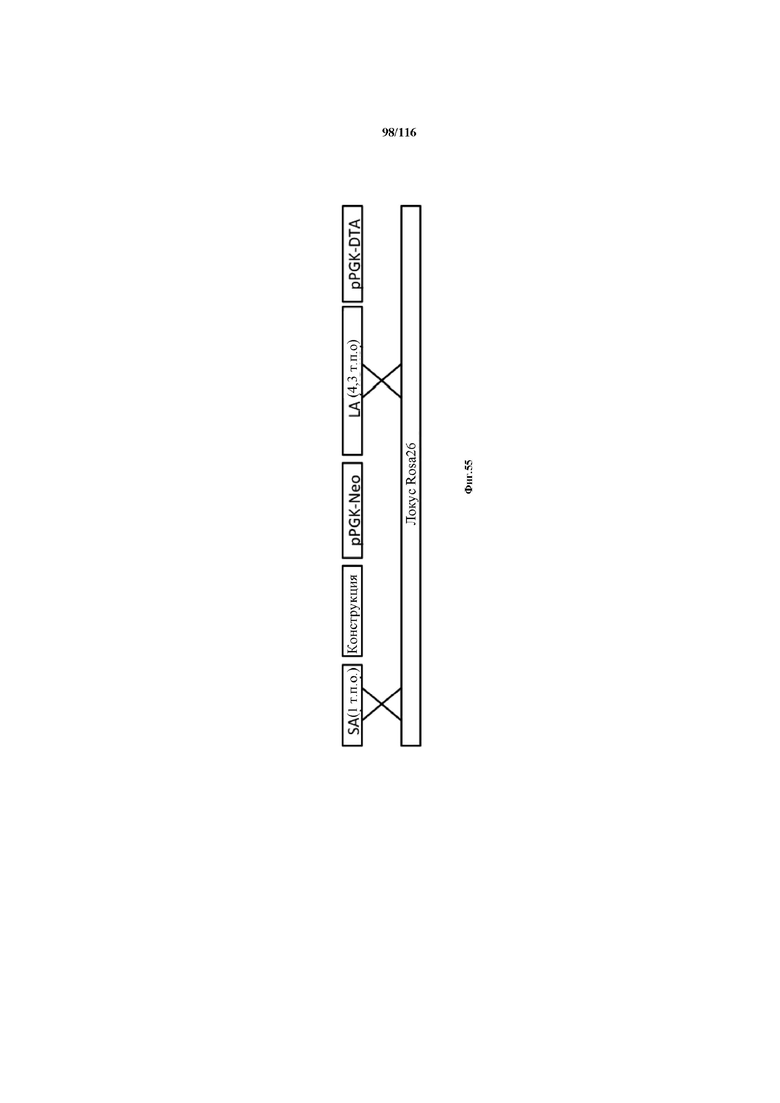

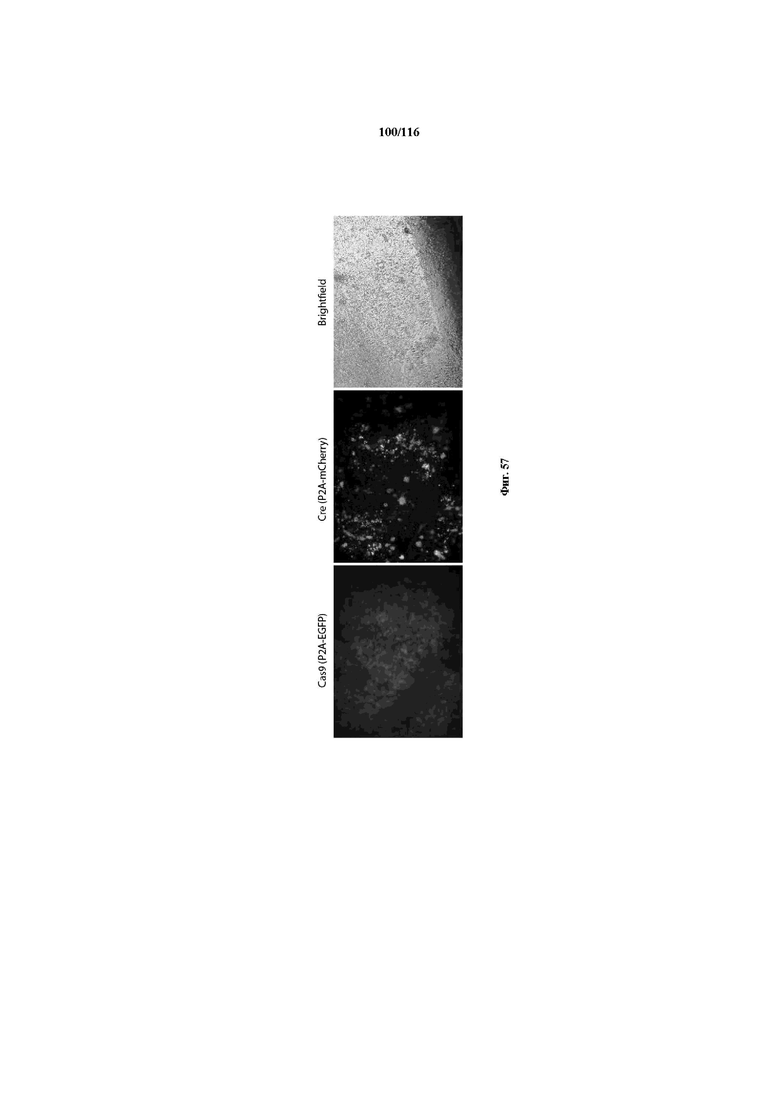

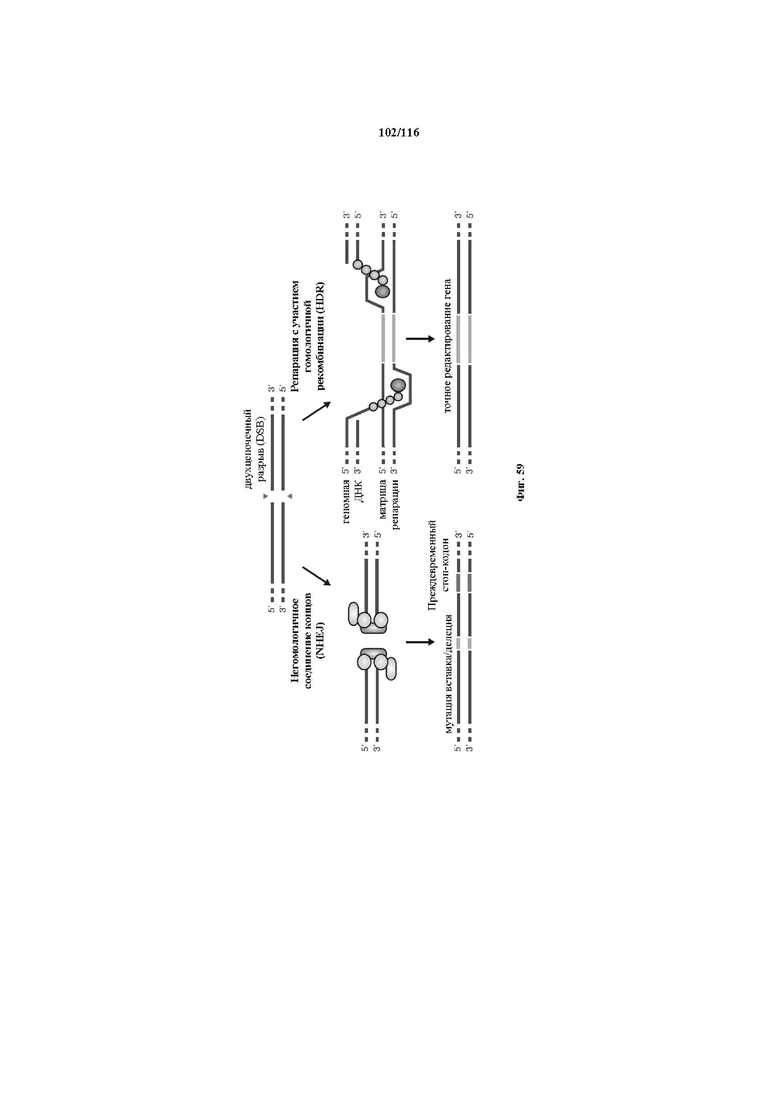

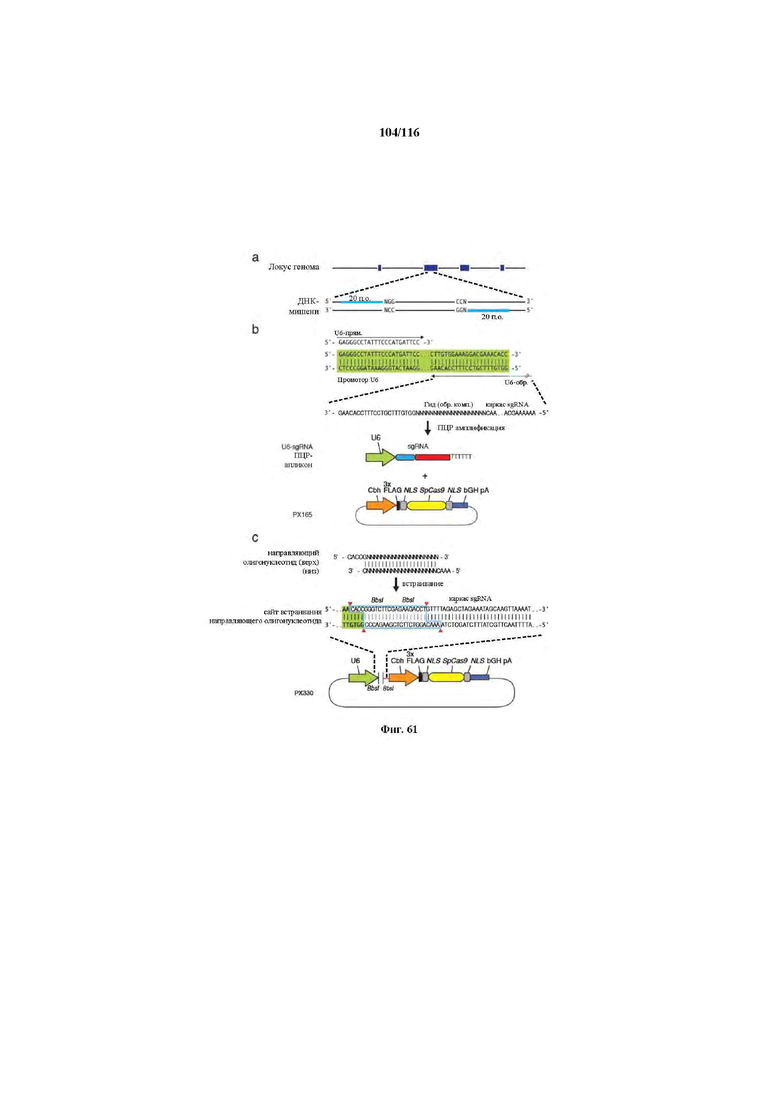






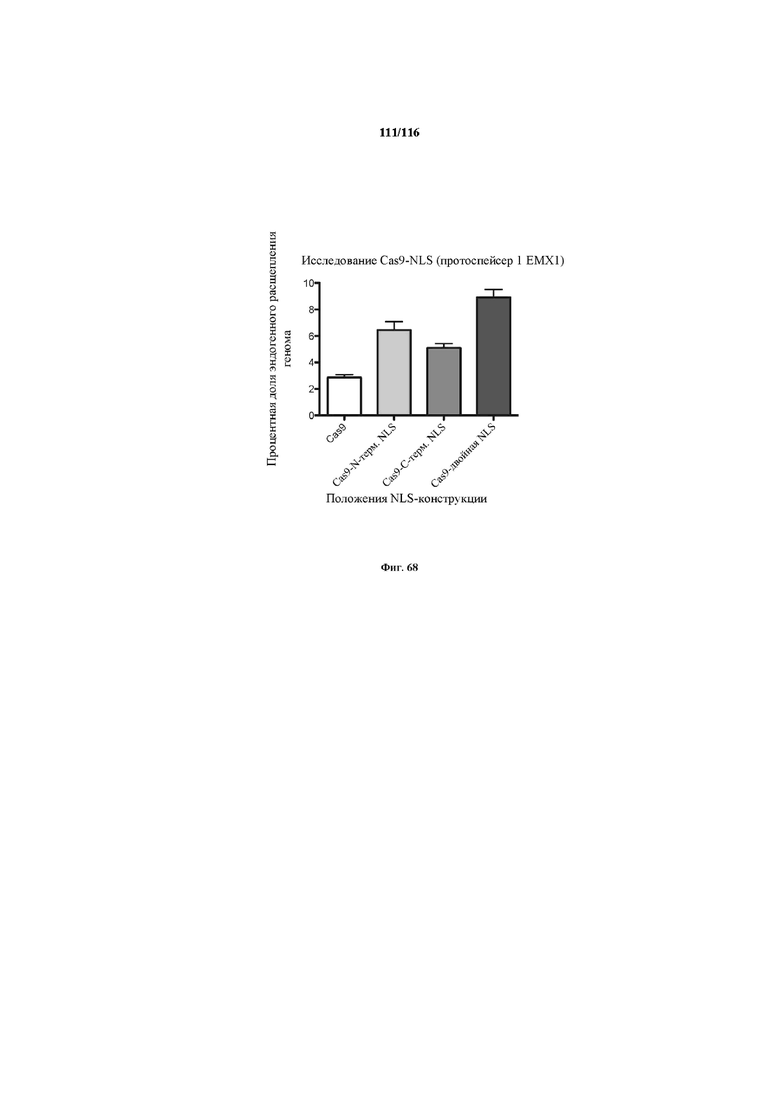
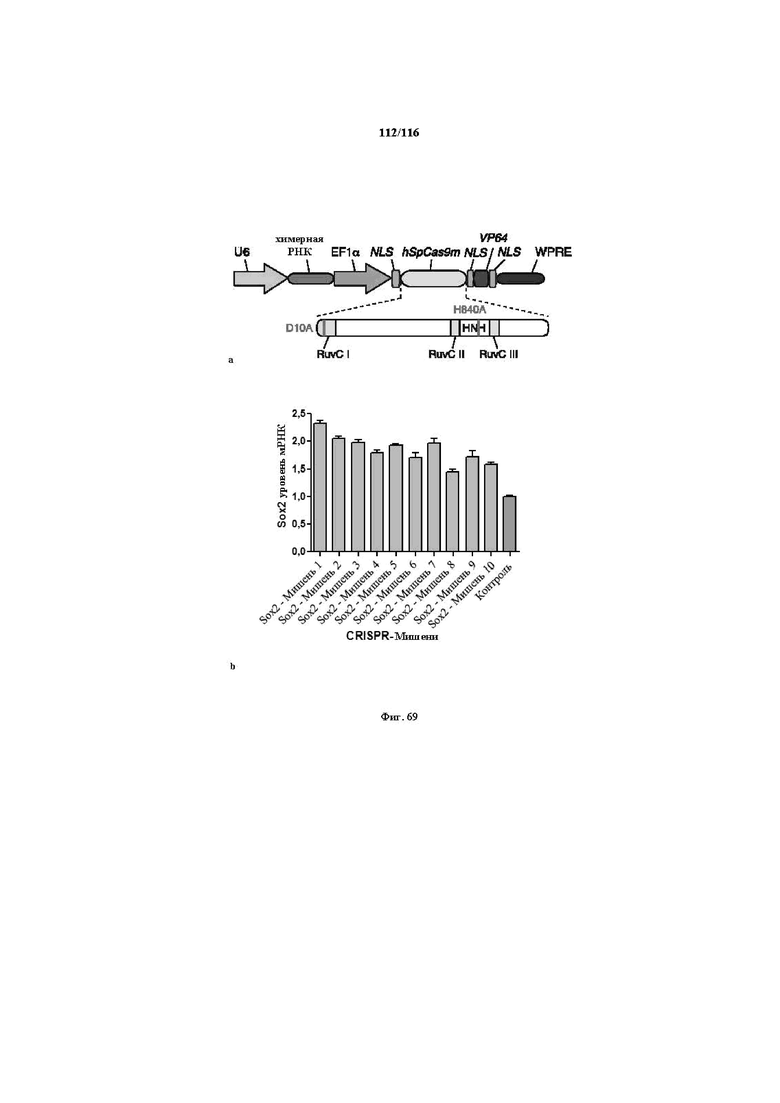
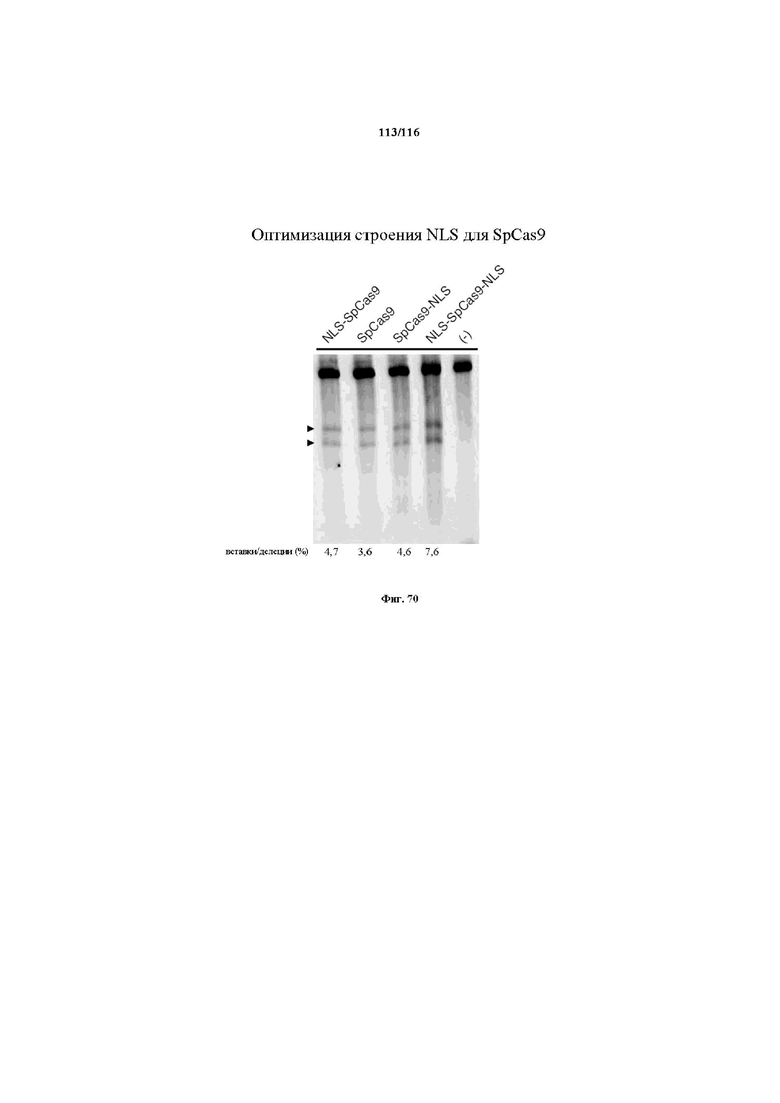
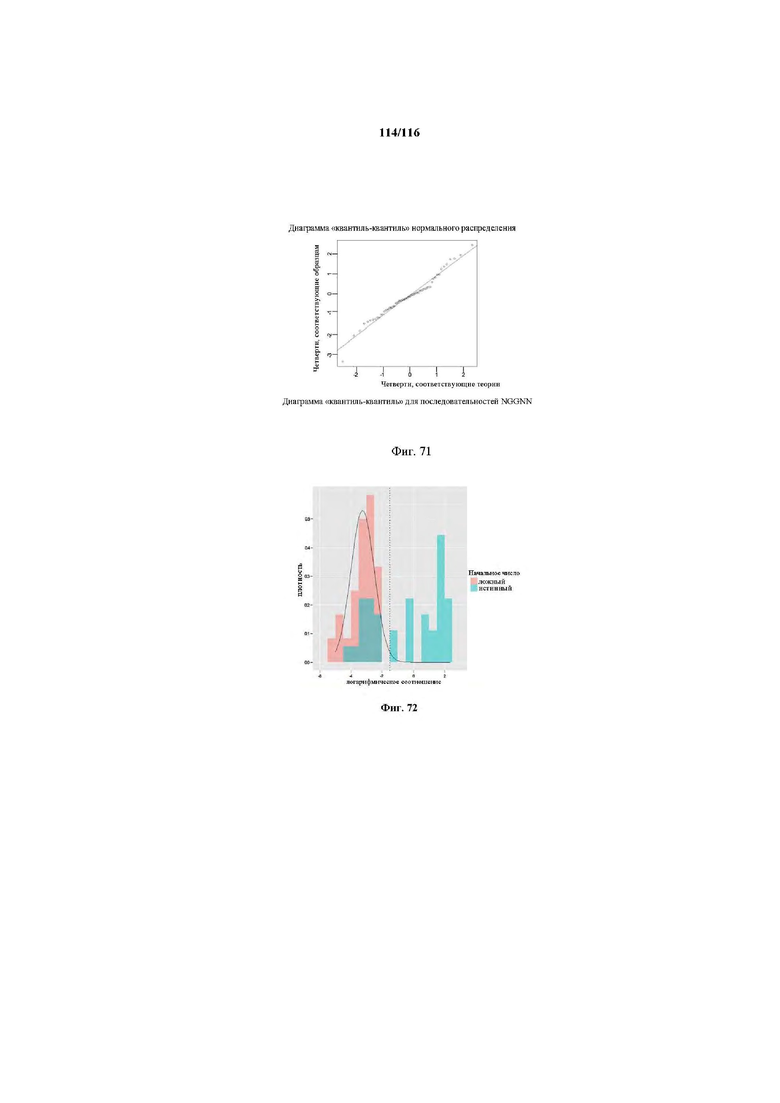


Изобретение относится к области биотехнологии, в частности к вариантам сконструированной системы CRISPR-Cas, содержащей слитый белок, содержащий белок Cas9, слитый с по меньшей мере одним сигналом ядерной локализации (NLS), или одну или более молекул нуклеиновой кислоты, кодирующих этот слитый белок, и РНК системы CRISPR-Cas или одну или более молекул нуклеиновой кислоты, кодирующих РНК системы CRISPR-Cas. Изобретение эффективно для модификации эукариотической клетки. 2 н. и 42 з.п. ф-лы, 74 ил., 15 табл., 16 пр.
1. Сконструированная система CRISPR-Cas для модификации эукариотической клетки, содержащая:
(a) слитый белок, содержащий белок Cas9, слитый с по меньшей мере одним сигналом ядерной локализации (NLS), или одну или более молекул нуклеиновой кислоты, кодирующих этот слитый белок, и
(b) РНК системы CRISPR-Cas или одну или более молекул нуклеиновой кислоты, кодирующих РНК системы CRISPR-Cas, где РНК системы CRISPR-Cas содержит направляющую последовательность, способную гибридизоваться с целевой последовательностью, примыкающей к мотиву, смежному с протоспейсером, (PAM) в эукариотической клетке, парную tracr-последовательность, способную гибридизоваться с tracr-последовательностью, и tracr-последовательность,
при этом Cas9 содержит по меньшей мере одну мутацию в каталитическом домене и представляет собой никазу, не обладающую способностью расщеплять одну цепь ДНК,
где РНК системы CRISPR-Cas способна формировать комплекс CRISPR с белком Cas9 и направлять белок Cas9 к целевой последовательности в эукариотической клетке.
2. Система по п.1, отличающаяся тем, что фермент Cas9 слит с по меньшей мере двумя NLS.
3. Система по п.2, в которой белок Cas9 слит с первым NLS на С-конце Cas9 или рядом с ним и со вторым NLS на N-конце Cas9 или рядом с ним.
4. Система по любому из пп.1-3, в которой NLS независимо выбирают из группы, состоящей из PKKKRKV, KRPAATKKAGQAKKKK, PAAKRVKLD, RQRRNELKRSP, NQSSNFGPMKGGNFGGRSSGPYGGGGQYFAKPRNQGGY, RMRIZFKNKGKDTAELRRRRVEVSVELRKAKKDEQILKRRNV, VSRKRPRP, PPKKARED, POPKKKPL, SALIKKKKKMAP, DRLRR, PKQKKRK, RKLKKKIKKL, REKKKFLKRR, KRKGDEVDGVDEVAKKKSKK и RKCLQAGMNLEARKTKK.
5. Система по любому из пп.1-4, в которой Cas9 представляет собой Cas9 S. pyogenes, а PAM включает NGG; или где Cas9 представляет собой S. thermophilus Cas9, а PAM включает NNAGAAW.
6. Система по любому из пп.1-5, отличающаяся тем, что Cas9 содержит по меньшей мере одну мутацию, соответствующую D10A, H840A, N854A или N863A Cas9 S. pyogenes.
7. Система по любому из пп.1-6, в которой Cas9 слит по меньшей мере с одним доменом гетерологичного белка.
8. Система по п. 7, отличающаяся тем, что домен гетерологичного белка содержит эпитопную метку, репортерный домен или домен белка, обладающий одной или несколькими из следующих активностей: метилазная активность, деметилазная активность, активность активации транскрипции, активность подавления транскрипции, активность фактора освобождения при транскрипции, активность для модификации гистонов, активность для расщепления РНК и активность для связывания нуклеиновой кислоты.
9. Система по любому из пп.1-8, отличающаяся тем, что РНК системы CRISPR-Cas содержит: crRNA, содержащую направляющую последовательность и парную tracr-последовательность, и tracrRNA, содержащую tracr-последовательность.
10. Система по любому из пп.1-8, отличающаяся тем, что РНК системы CRISPR-Cas представляет собой химерную РНК, содержащую в направлении от 5' к 3' направляющую последовательность, парную tracr-последовательность и tracr-последовательность.
11. Система по п.10, отличающаяся тем, что tracr-последовательность составляет по меньшей мере 30 нуклеотидов в длину.
12. Система по п.10, в которой tracr-последовательность содержит по меньшей мере 40 нуклеотидов в длину.
13. Система по п.10, в которой tracr-последовательность содержит по меньшей мере 50 нуклеотидов в длину.
14. Система по любому из пп.1-13, где РНК системы CRISPR-Cas содержит один или несколько модифицированных нуклеотидов.
15. Система по любому из пп.1-14, где система содержит РНК системы CRISPR-Cas и слитый белок.
16. Система по любому из пп. 1-14, отличающаяся тем, что система содержит РНК системы CRISPR-Cas и мРНК, кодирующую слитый белок, которая является кодон-оптимизированной для экспрессии в эукариотической клетке.
17. Система по любому из пп.1-14, где указанные одна или более молекул нуклеиновой кислоты, кодирующих этот слитый белок, и указанные одна или более молекул нуклеиновой кислоты, кодирующих РНК системы CRISPR-Cas, содержатся в одном или нескольких векторах.
18. Система по п.17, отличающаяся тем, что указанные одна или более молекул нуклеиновой кислоты, кодирующих этот слитый белок, и указанные одна или более молекул нуклеиновой кислоты, кодирующих РНК системы CRISPR-Cas, содержатся в одном и том же векторе.
19. Система по п.17 или 18, в которой векторы представляют собой вирусные векторы.
20. Система по п.19, в которой вирусные векторы представляют собой ретровирусные, лентивирусные, аденовирусные, аденоассоциированные или векторы вируса простого герпеса.
21. Система по любому из пп.1-20, в которой эукариотическая клетка представляет собой клетку млекопитающего или клетку человека.
22. Сконструированная система CRISPR-Cas для модификации эукариотической клетки, содержащая:
(a) слитый белок, содержащий белок Cas9, слитый с по меньшей мере одним сигналом ядерной локализации (NLS) и с по меньшей мере одним доменом гетерологичного белка, или одну или более молекул нуклеиновой кислоты, кодирующих этот слитый белок, и
(b) РНК системы CRISPR-Cas или одну или более молекул нуклеиновой кислоты, кодирующих РНК системы CRISPR-Cas, где РНК системы CRISPR-Cas содержит направляющую последовательность, способную гибридизоваться с целевой последовательностью, примыкающей к мотиву, смежному с протоспейсером (PAM) в эукариотической клетке, парную tracr-последовательность, способную гибридизоваться с tracr-последовательностью, и tracr-последовательность,
при этом РНК способна образовывать комплекс CRISPR с белком Cas9 и направлять белок Cas9 к целевой последовательности в эукариотической клетке.
23. Система по п.22, отличающаяся тем, что Cas9 слит с по меньшей мере двумя NLS.
24. Система по п.23, в которой белок Cas9 слит с первым NLS на С-конце Cas9 или рядом с ним и со вторым NLS на N-конце Cas9 или рядом с ним.
25. Система по любому из пп.22-24, в которой NLS независимо выбирают из группы, состоящей из PKKKRKV, KRPAATKKAGQAKKKK, PAAKRVKLD, RQRRNELKRSP, NQSSNFGPMKGGNFGGRSSGPYGGGGQYFAKPRNQGGY, RMRIZFKNKGKDTAELRRRRVEVSVELRKAKKDEQILKRRNV, VSRKRPRP, PPKKARED, POPKKKPL, SALIKKKKKMAP, DRLRR, PKQKKRK, RKLKKKIKKL, REKKKFLKRR, KRKGDEVDGVDEVAKKKSKK и RKCLQAGMNLEARKTKK.
26. Система по любому из пп.22-25, в которой Cas9 представляет собой Cas9 S. pyogenes, а PAM включает NGG; или где Cas9 представляет собой S. thermophilus Cas9, а PAM включает NNAGAAW.
27. Система по любому из пп.22-26, отличающаяся тем, что Cas9 содержит по меньшей мере одну мутацию в каталитическом домене и представляет собой никазу, не способную расщеплять одну цепь ДНК.
28. Система по п.27, отличающаяся тем, что Cas9 содержит по меньшей мере одну мутацию, соответствующую D10A, H840A, N854A или N863A Cas9 S. pyogenes.
29. Система по любому из пп.22-26, отличающаяся тем, что Cas9 содержит по меньшей мере одну мутацию в двух или более каталитических доменах и, по существу, лишен всей активности расщепления ДНК.
30. Система по п.29, отличающаяся тем, что Cas9 содержит мутацию, соответствующую D10A Cas9 S. pyogenes, и дополнительно содержит по меньшей мере одну мутацию, соответствующую H840A, N854A или N863A Cas9 S. pyogenes.
31. Система по любому из пп. 22-30, отличающаяся тем, что гетерологичный белковый домен содержит эпитопную метку, репортерный домен или белковый домен, обладающий одной или несколькими из следующих активностей: метилазная активность, деметилазная активность, активность активации транскрипции, активность подавления транскрипции, активность фактора высвобождения при транскрипции, активность модификации гистонов, активность расщепления РНК и активность связывания нуклеиновой кислоты.
32. Система по любому из пп.22-31, отличающаяся тем, что РНК системы CRISPR-Cas содержит: crRNA, содержащую направляющую последовательность и парную tracr-последовательность, и tracrRNA, содержащую tracr-последовательность.
33. Система по любому из пп.22-31, где РНК системы CRISPR-Cas представляет собой химерную РНК, содержащую в направлении от 5' к 3' направляющую последовательность, парную tracr-последовательность и tracr-последовательность.
34. Система по п.33, в которой tracr-последовательность содержит по меньшей мере 30 нуклеотидов в длину.
35. Система по п.33, в которой tracr-последовательность содержит по меньшей мере 40 нуклеотидов в длину.
36. Система по п.33, в которой tracr-последовательность содержит по меньшей мере 50 нуклеотидов в длину.
37. Система по любому из пп.22-36, где РНК системы CRISPR-Cas содержит один или несколько модифицированных нуклеотидов.
38. Система по любому из пп.22-37, где система содержит РНК системы CRISPR-Cas и слитый белок.
39. Система по любому из пп.22-37, где система содержит РНК системы CRISPR-Cas и мРНК, кодирующую слитый белок, которая кодон-оптимизирована для экспрессии в эукариотической клетке.
40. Система по любому из пп.22-37, где указанные одна или более молекул нуклеиновой кислоты, кодирующих этот слитый белок, и указанные одна или более молекул нуклеиновой кислоты, кодирующих РНК системы CRISPR-Cas,содержатся в одном или нескольких векторах.
41. Система по п.40, отличающаяся тем, что указанные одна или более молекул нуклеиновой кислоты, кодирующих этот слитый белок, и указанные одна или более молекул нуклеиновой кислоты, кодирующих РНК системы CRISPR-Cas, содержатся в одном и том же векторе.
42. Система по п.40 или 41, где векторы представляют собой вирусные векторы.
43. Система по п.42, в которой вирусные векторы представляют собой ретровирусные, лентивирусные, аденовирусные, аденоассоциированные или векторы вируса простого герпеса.
44. Система по любому из пп.22-43, где эукариотическая клетка представляет собой клетку млекопитающего или клетку человека.
| JINEK M | |||
| et al., A programmable dual-RNA-guided DNA endonuclease in adaptive bacterial immunity, Science, AUGUST 2012, 337(6096): 816-821 | |||
| GASIUNAS G | |||
| et al., Cas9-crRNA ribonucleoprotein complex mediates specific DNA cleavage for adaptive immunity in bacteria, Proceedings of the National Academy of Scieces, 2012 (published online September 4, |

