Клаудины - это интегрированные в мембрану белки, расположенные в плотных контактах эпителия и эндотелия. Предполагается, что клаудины имеют четыре трансмембранных сегмента с двумя внеклеточными петлями и N- и С-концами, расположенными в цитоплазме. Семейство трансмембранных белков клаудинов (CLDN) играет критическую роль в поддержании эпителиальных и эндотелиальных плотных контактов и может также играть роль в поддержании цитоскелета и в передаче клеточных сигналов.
CLDN18 существует в двух различных сплайс-вариантах, которые описаны у мышей и человека (Niimi, Mol. Cell. Biol. 21:7380-90, 2001). Сплайс-варианты (учетный номер Genbank: сплайс-вариант 1 (CLDN18.1): NP_057453, NM_016369 и сплайс-вариант 2 (CLDN18.2): NM_001002026, NP_001002026) имеют молекулярную массу приблизительно 27,9/27,72 кДа. Сплайс-варианты CLDN18.1 и CLDN18.2 отличаются по N-концевой части, которая включает первую трансмембранную (TM) область и петлю 1, тогда как первичная белковая последовательность C-конца идентична.
В нормальных тканях не обнаруживается экспрессии CLDN18.2, за исключением желудка, где CLDN18.2 экспрессируется исключительно на короткоживущих дифференцированных эпителиальных клетках желудка. CLDN18.2 поддерживается в ходе злокачественной трансформации и, таким образом, часто презентируется на поверхности клеток рака желудка человека. Кроме того, этот пан-опухолевый антиген эктопически активируется на значительных уровнях при аденокарциномах пищевода, поджелудочной железы и легких. Белок CLDN18.2 также локализуется в метастазах лимфатических узлов при аденокарциноме рака желудка и в отдаленных метастазах, особенно в яичнике (так называемых опухолях Крукенберга).
CLDN6 экспрессируется в ряде различных раковых клеток человека, тогда как экспрессия в нормальных тканях ограничена плацентой.
Дифференциальная экспрессия клаудинов, таких как CLDN18.2 и CLDN6, между раковыми и нормальными клетками, их локализация в мембране и их отсутствие в подавляющем большинстве нормальных тканей делает эти молекулы привлекательными мишенями для иммунотерапии рака и применения терапевтических средств на основе антител для направленного воздействия на клаудины при лечении онкологических заболеваний обещает высокий уровень терапевтической специфичности.
Целью изобретения было создание новых агентов и способов для лечения онкологических заболеваний.
Решение проблемы, лежащее в основе изобретения, основано на концепции создания связывающего агента, который включает два связывающих домена, которые специфичны для молекулы клаудина, ассоциированной с опухолью, то есть раковыми клетками. Связывающий агент также включает связывающий домен, который является специфическим для антигена, специфичного для Т-клеток, такого как CD3, позволяющего связываться с Т-клетками и собрать Т-клетки в комплекс, таким образом делая возможным целевой цитотоксический эффект Т-клеток по отношению к раковым клеткам. Образование этого комплекса может индуцировать передачу сигналов в цитотоксических Т-клетках либо самостоятельно, либо в сочетании с дополнительными клетками, что приводит к высвобождению цитотоксических медиаторов.
Мы впервые сообщаем, что связывающие агенты, включающие два связывающих домена, нацеленных на клаудин, и другой связывающий домен, нацеленный на Т-клеточный специфический антиген, такой как CD3, могут индуцировать мощный лизис, опосредованный Т-клетками, и эффективны при лечении опухолевых заболеваний.
Сущность изобретения
Изобретение обеспечивает связывающий агент, включающий, по меньшей мере, три связывающих домена, причем первый связывающий домен связывается с Т-клеточным специфическим антигеном, а второй связывающий домен и третий связывающий домен связываются с клаудином. Связывающий агент по изобретению может связываться с Т-клеткой (например, путем вовлечения CD3-рецептора) и раковой клеткой, экспрессирующей клаудин, которая должна быть уничтожена как мишень.
В одном воплощении связывающий агент включает шесть вариабельных доменов антитела, по меньшей мере, с тремя связывающими доменами, где, по меньшей мере, два связывающих домена связываются с клаудином и, по меньшей мере, один связывающий домен связывается с Т-клеточным специфическим антигеном.
В одном воплощении каждый из первого, второго и третьего связывающих доменов включает вариабельный домен тяжелой цепи иммуноглобулина (VH) и вариабельный домен легкой цепи иммуноглобулина (VL).
В одном воплощении первый связывающий домен включает вариабельный домен тяжелой цепи иммуноглобулина (VH) со специфичностью к Т-клеточному специфическому антигену (VH(T)) и вариабельный домен легкой цепи иммуноглобулина (VL) со специфичностью к Т-клеточному специфическому антигену (VL(T)) и второй связывающий домен и третий связывающий домен, каждый включает вариабельный домен тяжелой цепи иммуноглобулина (VH) со специфичностью к антигену клаудина (VH(CLDN)) и вариабельный домен легкой цепи иммуноглобулина (VL) со специфичностью к антигену клаудина (VL (CLDN)).
В одном воплощении указанный вариабельный домен тяжелой цепи (VH) и соответствующий вариабельный домен легкой цепи (VL) одного или нескольких связывающих доменов связаны через пептидный линкер, в частности гибкий пептидный линкер, такой как глицин-сериновый пептидный линкер. В одном воплощении пептидный линкер включает аминокислотную последовательность (G4S)x, где x равно 3, 4, 5 или 6.
В одном воплощении указанный вариабельный домен тяжелой цепи (VH) и соответствующий вариабельный домен легкой цепи (VL) одного или нескольких связывающих доменов имеют формат молекулы Fab и/или молекулы scFv.
В одном воплощении первый связывающий домен имеет формат молекулы Fab и/или второй связывающий домен, а третий связывающий домен имеет формат молекулы scFv.
В одном воплощении связывающий агент по изобретению представляет собой димер, состоящий из двух полипептидных цепей, в котором первый полипептид включает scFv, связанный с дополнительным доменом VL через константный домен легкой цепи иммуноглобулина (CL), и второй полипептид включает scFv, связанный с дополнительным доменом VH через константный домен 1 тяжелой цепи иммуноглобулина (CH1). Две полипептидные цепи предпочтительно связаны друг с другом дисульфидным мостиком. Дисульфидный мостик предпочтительно образуется между остатком Cys в домене CL и остатком Cys в домене CH1, так что дополнительный домен VL первого полипептида ассоциируется с дополнительным доменом VH второго полипептида в антигенсвязывающей конфигурации, так что связывающий агент в целом включает три антигенсвязывающих домена. Согласно изобретению домены VH и VL в фрагментах scFv предпочтительно связаны пептидными линкерами, такими как пептидный линкер, содержащий аминокислотную последовательность (G4S)x, где x равен 3, 4, 5 или 6, и Fab-цепи и scFv предпочтительно связаны пептидными линкерами, такими как пептидный линкер, содержащий аминокислотную последовательность DVPG2S или SGPG3RS(G4S)2. В одном воплощении scFv-фрагменты связываются с клаудином, а Fab-фрагмент связывается с Т-клеточным специфическим антигеном.
В одном воплощении первый связывающий домен состоит из фрагмента Fab, а второй и третий связывающие домены каждый состоит из scFv, где каждая цепь фрагмента Fab связана с одним scFv, и scFv предпочтительно связаны на С-концами с фрагментом Fab.
В одном воплощении связывающий агент включает первый и второй полипептид, причем указанные первый и второй полипептиды включают домен VH со специфичностью к Т-клеточному специфическому антигену (VH(T)), домен VL со специфичностью к Т-клеточному специфическому антигену (VL(T)), первый домен VH со специфичностью к клаудину (VH(CLDN)), второй домен VH со специфичностью к клаудину (VH(CLDN)), первый домен VL со специфичностью к клаудину (VL (CLDN)) и второй домен VL со специфичностью к клаудину (VL (CLDN)), где первый полипептид и второй полипептид связаны с образованием связывающего агента.
В одном воплощении связывающий агент включает
(а) первый полипептид, включающий домен VH со специфичностью к Т-клеточному специфическому антигену (VH(T)), домен VH со специфичностью к клаудину (VH(CLDN)) и домен VL со специфичностью к клаудину (VL (CLDN)); и
(b) второй полипептид, включающий домен VL со специфичностью к Т-клеточному специфическому антигену (VL(T)), домен VH со специфичностью к клаудину (VH(CLDN)) и домен VL со специфичностью к клаудину (VL (CLDN)),
где первый полипептид и второй полипептид связаны так, что образуют связывающий агент.
В одном воплощении первый полипептид дополнительно включает константный домен 1 тяжелой цепи иммуноглобулина (CH1), а второй полипептид дополнительно включает константный домен легкой цепи иммуноглобулина (CL), где оба домена способны связываться.
В одном воплощении первый полипептид и второй полипептид ковалентно связаны через дисульфидный мостик между доменом CH1 и доменом CL.
В одном воплощении связывающего агента по изобретению в первом полипептиде и втором полипептиде расположены домен(ы) VH, домен(ы) VL, домен CH1 и домен CL от N-конца к C -концу, в порядке
- VH(T) -CH1-VH (CLDN) -VL (CLDN) и VL(T) -CL-VH (CLDN) -VL (CLDN); или
- VH(T) -CH1-VL (CLDN) -VH (CLDN) и VL(T) -CL-VL (CLDN) -VH (CLDN); или
- VH(T) -CH1-VH (CLDN) -VL- (CLDN) и VL(T) -CL-VL (CLDN) -VH- (CLDN); или
- VH(T) -CH1-VL (CLDN) -VH- (CLDN) и VL(T) -CL-VH (CLDN) -VL- (CLDN); или
- VH (CLDN) -CH1-VH(T) -VL(T) и VL (CLDN) -CL-VH (CLDN) -VL (CLDN); или
- VH (CLDN) -CH1-VL(T) -VH(T) и VL (CLDN) -CL-VL (CLDN) -VH (CLDN); или
- VH (CLDN) -CH1-VL(T) -VH(T) и VL (CLDN) -CL-VH (CLDN) -VL (CLDN); или
- VH (CLDN) -CH1-VH(T) -VL(T) и VL (CLDN) -CL-VL (CLDN) -VH (CLDN); или
- VH (CLDN) -CH1-VH (CLDN) -VL (CLDN) и VL (CLDN) -CL-VH(T) -VL(T); или
- VH (CLDN) -CH1-VL (CLDN) -VH (CLDN) и VL (CLDN) -CL-VL(T) -VH(T); или
- VH (CLDN) -CH1-VL (CLDN) -VH (CLDN) и VL (CLDN) -CL-VH(T) -VL(T); или
- VH (CLDN) -CH1-VH (CLDN) -VL (CLDN) и VL (CLDN) -CL-VL(T) -VH(T).
В одном воплощении большая часть N-концевого домена VH одной цепи ассоциируется с большей частью N-концевого домена VL другой цепи, чтобы образовать связывающий домен, и каждый из доменов VH-VL или VL-VH в одной цепи образуют связующий домен.
В одном воплощении домены VH-VL или VL-VH связаны с доменом CH1 или доменом CL через пептидный линкер, такой как пептидный линкер, содержащий аминокислотную последовательность DVPG2S или SGPG3RS(G4S)2.
В одном воплощении домены VH и VL связаны через пептидный линкер с образованием доменов VH-VL или VL-VH, таких как пептидный линкер, содержащий аминокислотную последовательность (G4S)x, где x равно 3, 4, 5 или 6.
В связывающем агенте по изобретению домен VH со специфичностью к Т-клеточному антигену (VH(T)) и домен VL со специфичностью к Т-клеточному специфическому антигену (VL(T)) способны связываться с тем, чтобы образовать связывающий домен, связывающийся с Т-клеточным специфическим антигеном.
Кроме того, в связывающем агенте по изобретению домен VH со специфичностью к клаудину (VH (CLDN)) и домен VL со специфичностью к клаудину (VL (CLDN)) способны связываться так, чтобы образовывать связывающий домен, который связывается с клаудином. Согласно изобретению домены VH со специфичностью к клаудину (VH (CLDN)) и домены VL со специфичностью к клаудину (VL (CLDN)) могут быть одинаковыми или разными. В случае, если связывающий агент по изобретению включает разные домены VH со специфичностью к клаудину (VH (CLDN), VH (CLDN)*) и/или разные домены VL со специфичностью к клаудину (VL (CLDN), VL (CLDN)*), VH (CLDN) и VL (CLDN) способны связываться так, чтобы сформировать первую привязку домена, связывающегося с клаудином, а VH (CLDN)* и VL (CLDN)* могут связываться, чтобы сформировать второй связывающий домен, связывающийся с клаудином.
В одном воплощении связывающий агент по изобретению представляет собой биспецифический димерный связывающий агент.
В одном воплощении Т-клеточный специфический антиген экспрессируется на поверхности Т-клетки.
В одном воплощении связывание связывающего агента с Т-клеточным специфическим антигеном на Т-клетках приводит к пролиферации и/или активации Т-клеток.
В одном воплощении Т-клеточный специфический антиген представляет собой CD3.
В одном воплощении первый связывающий домен связывается с эпсилон-цепью CD3.
В одном воплощении CD3 экспрессируется на поверхности Т-клетки. В одном воплощении связывание связывающего агента с CD3 на Т-клетках приводит к пролиферации и/или активации Т-клеток, где указанные Т-клетки предпочтительно высвобождают цитотоксические факторы, например, перфорины и гранзимы, и инициируют цитолиз и апоптоз раковых клеток.
В одном воплощении клаудин экспрессируется на поверхности раковой клетки.
В одном воплощении клаудин выбран из группы, состоящей из клаудина 6 и клаудина 18.2.
В одном воплощении связывающий агент связывается с внеклеточным доменом клаудина.
В одном воплощении связывающий агент по изобретению связывается с нативными эпитопами клаудина, присутствующими на поверхности живых клеток. В одном воплощении связывающий агент связывается с первой внеклеточной петлей клаудина.
В одном воплощении связывание с Т-клеточным специфическим антигеном и/или связывание с клаудином является специфическим связыванием.
В одном воплощении связывающий агент индуцирует опосредованную Т-клетками цитотоксичность в отношении раковых клеток, экспрессирующих клаудин.
В одном воплощении связывающий агент индуцирует опосредованную Т-клетками цитотоксичность в отношении раковых клеток, экспрессирующих клаудин, с ЕС50<10 нМ или <1 нМ или <500 пМ, или <250 пМ, или <100 пМ, или <50 пМ.
В одном воплощении изобретения клаудин представляет собой клаудин 6, а раковая(ые) клетка(и) являются клетками или происходит от клеток рака, выбранного из группы, состоящей из рака мочевого пузыря, рака яичника, в частности аденокарциномы яичника и тератокарциномы яичника, рака легкого, включая мелкоклеточный рак легкого (SCLC) и немелкоклеточный рак легкого (NSCLC), в частности плоскоклеточного рак легкого и аденокарциномы, рака желудка, рака молочной железы, рака печени, рака поджелудочной железы, рака кожи, в частности базальноклеточной карциномы и плоскоклеточной карциномы, злокачественной меланомы, рака головы и шеи, в частности злокачественной плеоморфной аденомы, саркомы, в частности синовиальной саркомы и карциносаркомы, рака желчных протоков, рака мочевого пузыря, в частности переходно-клеточной карциномы и папиллярной карциномы, рака почки, в частности почечно-клеточной карциномы, включая светлоклеточную почечно-клеточную карциному и папиллярную почечно-клеточную карциному, рака толстой кишки, рака тонкой кишки, включая рак подвздошной кишки, в частности аденокарциномы тонкой кишки и аденокарциномы подвздошной кишки, эмбриональной карциномы яичка, плацентарной хориокарциномы, рака шейки матки, рака яичка, в частности семиномы яичка, тератомы яичка и эмбрионального рака яичка, рака матки, опухолей половых клеток, таких как тератокарцинома или эмбриональная карцинома, в частности герминомы яичка, и их метастатических форм.
В одном воплощении изобретения клаудин представляет собой клаудин 18.2, и раковая(ые) клетка(и) происходит из рака, выбранного из группы, состоящей из рака желудка, рака пищевода, рака поджелудочной железы, рака легкого, такого как немелкоклеточный рак легкого (NSCLC), рака молочной железы, рака яичника, рака толстой кишки, рака печени, рака головы и шеи, рака желчного пузыря и их метастатических форм, опухоли Крукенберга, метастазов в брюшной полости и/или метастазов в лимфатические узлы.
В одном воплощении Т-клеточный специфический антиген представляет собой CD3, и VH(T) включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 5, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента и/или VL (T) включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 6, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента.
В одном воплощении изобретения клаудин представляет собой клаудин 6, и VH (CLDN) включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 8, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента, и/или VL (CLDN) включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 10, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента.
В одном воплощении Т-клеточный специфический антиген представляет собой CD3, клаудин представляет собой клаудин 6 и
- первый полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 14, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента, и второй полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO. 16 или ее фрагмента, или варианта аминокислотной последовательности или фрагмента;
- первый полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 15, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента, и второй полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO. 16 или ее фрагмента, или варианта аминокислотной последовательности или фрагмента;
- первый полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 17, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента, и второй полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO. 19 или ее фрагмента, или варианта аминокислотной последовательности или фрагмента; или
- первый полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 18, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента, и второй полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO. 19 или ее фрагмента, или варианта аминокислотной последовательности или фрагмента.
В одном воплощении изобретения клаудин представляет собой клаудин 18.2, и (i) VH (CLDN) включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 20, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента и/или VL (CLDN) включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 22, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента, или (ii) VH (CLDN) включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 21 или ее фрагмента, или варианта аминокислотной последовательности или фрагмента и/или VL (CLDN) включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 23, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента.
В одном воплощении Т-клеточный специфический антиген представляет собой CD3, клаудин представляет собой клаудин 18.2 и
- первый полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 30, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента, и второй полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 32 или ее фрагмента, или варианта аминокислотной последовательности или фрагмента;
- первый полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 31, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента, и второй полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 32 или ее фрагмента, или варианта аминокислотной последовательности или фрагмента;
- первый полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 33, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента, и второй полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO. 35 или ее фрагмента, или варианта аминокислотной последовательности или фрагмента;
- первый полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 34, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента, и второй полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO. 35 или ее фрагмента, или варианта аминокислотной последовательности или фрагмента;
- первый полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 36, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента, и второй полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO. 37 или ее фрагмента, или варианта аминокислотной последовательности или фрагмента;
- первый полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 38, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента, и второй полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO. 39 или ее фрагмента, или варианта аминокислотной последовательности или фрагмента;
- первый полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 40, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента, и второй полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 41 или ее фрагмента, или варианта аминокислотной последовательности или фрагмента;
- первый полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 42, или ее фрагмента, или варианта аминокислотной последовательности или фрагмента, и второй полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 43 или ее фрагмента, или варианта аминокислотной последовательности или фрагмента.
В различных воплощениях связывающий агент по изобретению или одна или несколько полипептидных цепей связывающего агента по изобретению включают или не включают сигналы секреции, такие как N-концевые сигналы секреции, в частности иммуноглобулина, такие как сигналы секреции IgG, такие как последовательность MGWSCIILFLVATATGVHS и/или включает или не включает метки, в частности C-концевые метки, такие как His-метки, в частности последовательность Gly-Gly-Ser-(His)6 или (His)6, или Strep-метка.
Изобретение также обеспечивает нуклеиновую кислоту, кодирующую связывающий агент по изобретению.
Изобретение также относится к нуклеиновой кислоте, кодирующей первый полипептид и/или второй полипептид, как определено в данном документе.
В одном воплощении нуклеиновая кислота по изобретению находится в форме вектора или в форме РНК.
В одном воплощении нуклеиновая кислота по изобретению представляет собой рекомбинантную нуклеиновую кислоту.
Изобретение также относится к клетке-хозяину, содержащей нуклеиновую кислоту по изобретению.
Изобретение также обеспечивает связывающий агент по изобретению, нуклеиновую кислоту по изобретению или клетку-хозяина по изобретению для применения в качестве лекарственного средства.
Изобретение также обеспечивает связывающий агент по изобретению, нуклеиновую кислоту по изобретению или клетку-хозяина по изобретению для применения в лечении или профилактике онкологического заболевания.
Изобретение также относится к фармацевтической композиции, включающей связывающий агент по изобретению, нуклеиновую кислоту по изобретению или клетку-хозяина по изобретению.
В одном воплощении фармацевтическая композиция дополнительно включает фармацевтически приемлемый носитель и/или наполнитель.
Изобретение также предлагает способ лечения заболевания, включающий введение связывающего агента по изобретению, нуклеиновой кислоты по изобретению, клетки-хозяина по изобретению или фармацевтической композиции по изобретению объекту, нуждающемуся в этом. В одном воплощении заболевание представляет собой онкологическое заболевание.
Изобретение также предлагает способ лечения или профилактики рака, включающий введение связывающего агента по изобретению, нуклеиновой кислоты по изобретению, клетки-хозяина по изобретению или фармацевтической композиции по изобретению объекту, нуждающемуся в этом.
Изобретение также предусматривает применение связующего агента по изобретению, нуклеиновой кислоты по изобретению, клетки-хозяина по изобретению или фармацевтической композиции по изобретению для изготовления лекарственного средства. В одном воплощении лекарственное средство предназначено для лечения рака.
В одном воплощении клетки указанного рака экспрессируют клаудин, с которым указанный связывающий агент способен связываться.
В одном воплощении указанный клаудин представляет собой клаудин 6, и указанный рак выбран из группы, состоящей из рака мочевого пузыря, рака яичника, в частности аденокарциномы яичника и тератокарциномы яичника, рака легкого, включая мелкоклеточный рак легкого (SCLC) и немелкоклеточный рак легкого (NSCLC), в частности плоскоклеточного рака легкого и аденокарциномы, рака желудка, рака молочной железы, рака печени, рака поджелудочной железы, рака кожи, в частности базальноклеточной карциномы и плоскоклеточной карциномы, злокачественной меланомы, рака головы и шеи, в частности злокачественной плеоморфной аденомы, саркомы, в частности синовиальной саркомы и карциносаркомы, рака желчного протока, рака мочевого пузыря, в частности переходно-клеточной карциномы и папиллярной карциномы, рака почки, в частности почечно-клеточной карциномы, включая светлоклеточную почечно-клеточную карциному и светлоклеточную почечно-клеточную карциному, рака толстой кишки, рака тонкой кишки, включая рак подвздошной кишки, в частности, аденокарциному тонкой кишки и аденокарциному подвздошной кишки, эмбриональной карциномы яичка, плацентарной хориокарциномы, рака шейки матки, рака яичка, в частности семиномы яичка, тератомы яичка и эмбрионального рака яичка, рака матки, опухолей половых клеток, таких как тератокарцинома или эмбриональная карцинома, в частности герминомы яичка, и их метастатических форм.
В одном воплощении указанный клаудин представляет собой клаудин 18.2, и указанный рак выбран из группы, состоящей из рака желудка, рака пищевода, рака поджелудочной железы, рака легких, такого как немелкоклеточный рак легкого (NSCLC), рака молочной железы, рака яичника, рака толстой кишки, рака печени, рака головы и шеи, рака желчного пузыря, и их метастатических форм, опухоли Крукенберга, метастазов в брюшную полость и/или метастазов в лимфатические узлы.
Изобретение также относится к связывающему агенту, нуклеиновой кислоте или клетке-хозяину, как описано в данном документе, для применения в способах лечения, описанных в данном документе. В одном воплощении изобретение предоставляет фармацевтическую композицию, как описано в настоящем документе, для применения в способах лечения, описанных в данном документе.
Согласно изобретению клаудин 18.2 предпочтительно имеет аминокислотную последовательность согласно SEQ ID NO: 1, а клаудин 6 предпочтительно имеет аминокислотную последовательность согласно SEQ ID NO: 2 или 3.
Другие признаки и преимущества настоящего изобретения будут очевидны из следующего подробного описания и формулы изобретения.
Краткое описание чертежей
Фиг. 1. Модульные схемы, иллюстрирующие ДНК-конструкции и белок bstb, нацеленный на TAA CLDN6.
(А) Дизайн цепей bstb на уровне ДНК. (B) Схематическая модель молекулы bstb.
CH 1 получен из IgG1 в bstb_369/367 и из IgG2 в bstb_371/367.
С обозначает константную область; CMV, цитомегаловирусный промотор; Fd, гидролизуемый фрагмент/часть тяжелой цепи Fab (антигенсвязывающий фрагмент); Н, тяжелая цепь; His, 6xHis-метка; L - легкая цепь; L1, линкер SGPG3RS(G4S)2; L2, линкер DVPG2S; L3, линкер (G4S)4; S-S, дисульфидный мостик; scFv, одноцепочечный вариабельный фрагмент; Sec, сигнал секреции; Strp, Strep- метка; V, вариабельный домен.
Фиг. 2. Очистка меченых и немеченых белков bstb из надосадочной жидкости клеточной культуры.
Клетки Expi293FТМ транзиторно трансфицировали соответствующими конструкциями bstb. Надосадочную жидкость собирали через семь дней после трансфекции и подвергали очистке. (A) Хроматограммы, показывающие первую стадию очистки меченых bstb с помощью аффинной хроматографии Ni-NTA (аффинная хроматография с иммобилизованными ионами металлов - IMAC). mAU (миллиабсорбционные единицы) на оси Y нанесены в зависимости от объема в мл на оси X. Слева, пики IMAC bstb_369/367, справа, пики IMAC bstb_371/367. Соответствующий правый пик включает ВМВ-соединения, а соответствующий средний пик - мономерные соединения. Соответствующий левый пик показывает примеси. 1) указывает фракции, объединенные в качестве основного пика, содержащие в основном мономерные соединения, 2) фракции, объединенные в виде ВМВ-соединений. (B) Хроматограммы, показывающие вторую стадию очистки меченых bstb. Пулы основных пиков IMAC подвергали аффинной хроматографии Strep- Tactin®. График слева, пик bstb_369/367, график справа, пик bstb_371/367. (C) Разделение ВМВ-соединений и мономерных соединений bstb_369/367 эксклюзионной хроматографией (SEC). Фракции пула ВМВ и пула мономеров указаны в квадратных скобках. (D) SE-HPLC анализ немеченного bstb_5726/5725 после очистки. Величины mAU (миллиабсорбционные единицы) на оси у обозначены относительно времени в минутах на оси х.
Bstb обозначает биспецифичный TriMAB; ВМВ, высокомолекулярные соединения; LMW, низкомолекулярные соединения.
Фиг. 3. SDS-PAGE-анализ белка CLDN6 x CD3 bstb_369/367.
Надосадочную жидкость клеток Expi293FTM, транзиторно экспрессирующих bstb_369/367, очищали с помощью IMAC. ВМВ-соединения были отдельно элюированы из основного пика. Соединения основного пика были впоследствии подвергнуты аффинной хроматографии на Strep- Tactin®. Элюированный пул был далее разделен SEC для сбора в высокой степени мономерного bstb. Аликвоты надосадочной жидкости клеточной культуры, эталонную и различные стадии очистки загружали в невосстанавливающих (слева) и восстанавливающих (справа) условиях на 4–15% трис-глициновом неокрашенный гель. (A) Полосы визуализировали на неокрашенном геле с помощью флуоресценции. (B) Вестерн-блот-анализ с использованием анти-His-детектирующего антитела (верхний блот) или детектирующего антитела StrepMAB. Стрелки слева обозначают невосстановленный мономер и ВМВ, стрелки справа - восстановленные цепи bstb. Fd обозначает гидролизуемый фрагмент/часть тяжелой цепи Fab (антигенсвязывающий фрагмент); ВМВ, высокомолекулярные соединения; His, 6xHis -метка; IMAC, аффинная хроматография с иммобилизованным металлом; L - легкая цепь; scFv, одноцепочечный вариабельный фрагмент; SEC, эксклюзионная хроматография; Strp, Strep-метка.
Фиг. 4. Анализ цитотоксичности in vitro для определения специфического лизиса, опосредованного белками CLDN6 x CD3 bstb_369/367 и bstb_371/367.
PBMC человека в качестве эффекторных клеток и клетки человека, стабильно трансдуцированные люциферазой, в качестве клеток-мишеней использовали в соотношении эффектор/мишень 5:1 в анализах цитотоксичности на основе люциферазы для определения специфического лизиса, зависимого от концентрации. Клеточные линии CLDN6+ PA-1 (тератокарцинома яичника) и/или OV-90 (рак яичника) служили в качестве положительных мишеней, а CDLN6- клеточная линия MDA-MB-231 (рак молочной железы) в качестве отрицательной мишени. Показаны средние значения в трех повторах, включая стандартное отклонение. Полумаксимальные значения лизиса (EC50) указаны под соответствующими графиками. (A) Специфический лизис (стандартный наклон), опосредованный bstb_369/367 и bstb_371/367, клеток CLDN6 + карциномы яичника OV-90 после 48 ч инкубации. (B) Сравнение специфического лизиса (стандартный наклон), опосредованного bstb_369/367 и CDLN6 x CD3-специфическим эталонным белком би-(scFv)2. Клеточные линии и время инкубации указаны на отдельных графиках. (C) Специфический лизис (вариабельный наклон) bstb_369/367 и влияние 5% ВМВ на активность bstb_369/367. Слева: инкубация с PA-1 в течение 16 ч; справа: инкубация с OV-90 в течение 48 часов. Сплошные линии обозначают кривую лизиса мономерного bstb_369/367, пунктирные линии - кривую лизиса мономерного bstb_369/367 с добавлением 5% ВМВ-соединений. (D) Специфический лизис (стандартный наклон) OV-90 после 48 ч инкубации. Левый график: лизис опосредован bstb_369/367 и немеченным аналогом bstb_5726/5725 в виде мономера и включает 5% ВМВ. Правый график: лизис опосредован bstb_369/367 в качестве эталона и CH1 (IgG2)-несущим вариантом bstb_5727/5725 в виде мономера, и включает 5% ВМВ.
Bstb обозначает биспецифичный TriMAB; би-(scFv)2, биспецифический одноцепочечный вариабельный фрагмент; ЕС50, полумаксимальная эффективная концентрация; ВМВ, высокомолекулярные соединения.
Фиг. 5. Таргетно-зависимая модуляция Т-клеток, опосредованная белками CLDN6 x CD3 bstb_369/367 и bstb_371/367
В качестве клеток-мишеней использовали линии раковых клеток CLDN6+ OV-90 и PA-1 и CLDN6- MDA-MB-231. РВМС человека служили эффекторными клетками в соотношении E:T 5:1. Анти-CD3 IgG2a ОКТ3 применяли в концентрации 100 нг/мл в качестве контроля активации. Ложные образцы инкубировали с DPBS для вычитания фоновых сигналов из значений анализируемых образцов. PBMC без клеток-мишеней использовали в качестве дополнительного контроля специфичности. Все образцы были созданы в двух экземплярах в 24-луночном формате. Повышение концентрации белков bstb bstb_369/367 или bstb_371/367 (0,005–5000 нг/мл). (A) Активация Т-клеток: PBMC собирали после 48 ч совместной инкубации и метили анти-CD5-PE-Cy7, анти-CD25-PE, анти-CD69-APC и eFluor506 для анализа активации жизнеспособных Т-клеток путем проточной цитометрии. (B) пролиферация Т-клеток: PBMC человека окрашивали CFSE до проведения анализа. PBMC собирали после 72 ч совместной инкубации и метили анти-CD5-APC и eFluor506 для исключения не-лимфоцитов и мертвых клеток. Снижение сигнала CFSE, указывающего на пролиферацию Т-клеток, анализировали с помощью проточной цитометрии.
Bstb обозначает биспецифичное TriMAB; Ctrl, контроль.
Фиг. 6. Связывание различных биспецифичных антител CLDN6 x CD3 с опухолеспецифическим антигеном CLDN6.
(A) Относительную аффинность связывания эталона би-(scFv)2, bstb_369/367 и bstb_5726/5725 исследовали с помощью проточной цитометрии на эндогенно экспрессирующих CLDN6 клетках человека PA-1, в диапазоне концентраций 9,77 нг/мл до 10 мкг/мл. Первичные антитела детектировали с помощью протеина-L-FITC (4 мкг/мл). Данные представлены как среднее значение ± стандартное отклонение (n = 2 повторения). (B) Влияние высокомолекулярных (ВМВ) соединений на связывание мономера bstb_5726/5725 анализировали с помощью проточной цитометрии либо с мономерным bstb_5726/5725, либо с мономерным bstb_5726/5725 с добавкой ~3% или 5% ВМВ-соединений (диапазон концентраций от 9,77 нг/мл до 10 мкг/мл). Первичные антитела детектировали с помощью протеина-L-FITC (4 мкг/мл). Данные представлены как среднее значение ± стандартное отклонение (n = 2 повторения). Bstb обозначает биспецифичный TriMAB; MFI, средняя интенсивность флуоресценции.
Фиг. 7. Эффективность белка CLDN6 x CD3 bstb_369/367 in vivo на мышиной модели ксенотрансплантата опухоли.
Использовали самцов и самок иммунодефицитных мышей NSG. (А) Схема графика инъекций. Мышей инокулировали подкожно клетками карциномы яичника человека OV-90 CLDN6+ в качестве клеток-мишеней и приживляли внутрибрюшинно (i.p.) PBMC человека в качестве эффекторных клеток. Обработка начиналась со среднего объема опухоли ~ 35 мм3 на группу и проводилось внутрибрюшинно 3 раза в неделю. Группа 1 (G1) получала буферный буфер DPBS, группа 2 (G2) - низкая доза bstb_369/367, равная 31 мкг/кг, и группа 3 (G3) - более высокая доза, равная 308 мкг/кг. (В) Рост опухоли у всех мышей и групп с течением времени. Обработка применялось в течение периода времени, выделенного границей. Вверху, группа с носителем G1; внизу слева, группа G2 bstb_369/367 с низкой дозой; справа внизу, группа G3 bstb_369/367 с более высокой дозой. Каждая строка представляет отдельную мышь. (C) График выживаемости Каплана-Мейера для всех групп со дня начала обработки до дня эвтаназии. В таблице ниже указаны средние дни выживания на группу и значимость выживания G2 и G3 по сравнению с G1 по логранговому критерию (Кокса-Мантеля).
Bstb обозначает биспецифичный TriMAB; d, дни; G, группа; GVHD, болезнь трансплантат против хозяина; i.p., внутрибрюшинно; PBMC, мононуклеарные клетки периферической крови; s.c., подкожно.
Фиг. 8. Оценка фармакокинетики in vivo белка CLDN6 x CD3 bstb_369/367.
5 мг/кг bstb_369/367 вводили внутрибрюшинно самкам мышей NSG с иммунодефицитом в день 0. Инъекция DPBS («0 ч») служила контролем перед инъекцией. Плазму собирали через 0,25 ч, 1 ч, 2 ч, 3 ч, 6 ч и 8 ч после введения. Концентрация Bstb_369/367 в плазме была обнаружена с помощью ELISA. Концентрация представлена в логарифмическом масштабе по оси Y. Каждая точка представляет собой среднее значение по трем мышам со стандартным отклонением.
i.p. обозначает внутрибрюшинно.
Фиг. 9. Определение дозы in vivo с белком CLDN6 x CD3-bstb bstb_5726/5725 на мышиной модели ксенотрансплантата опухоли.
Самцов и самок иммунодефицитных мышей NSG инокулировали подкожно клетками карциномы яичника человека OV-90 CLDN6+ в качестве клеток-мишеней и приживляли внутрибрюшинно (i.p.) PBMC человека в качестве эффекторных клеток. Лечение начиналось со среднего объема опухоли ~150 мм3 на группу и проводилось внутрибрюшинно 3 раза в неделю. (А) Схема графика инъекций. (B) Графики роста опухолей. Дозирование групп (n = 6) было таким, как указано на отдельных графиках. Контрольная группа G7 (n = 8) получила DPBS. Графики показывают рост всех мышей и групп с течением времени. Период обработки выделяется границей. Каждая строка представляет отдельную мышь (ID мыши = BIO - ####).
Bstb обозначает биспецифичный TriMAB; DPBS, физиологический раствор Дульбекко с фосфатным буфером; i.p., внутрибрюшинно; PBMC, мононуклеарные клетки периферической крови; s.c., подкожно.
Фиг. 10. Модульные схемы, иллюстрирующие ДНК-конструкции и белок bstb, нацеленный на TAA CLDN18.2.
(A) Дизайн цепей bstb на уровне ДНК. Анти-CLDN18.2-scFv ориентируется либо в порядке VH-VL (верхняя схема), либо в порядке VL-VH (нижняя схема). Были разработаны конструкции с (+/-) дисульфидными мостиками (SS) и без них. (B) Теоретические модели представленных в качестве примера молекул bstb с scFv против CLDN18.2 в порядке VH-VL или VL-VH с метками, но без дисульфидных мостиков (S-S) в фрагментах scFv (вверху) и без меток, но с S-S (внизу). CH1 получен из IgG1 или IgG2.
С обозначает константную область; CMV, цитомегаловирусный промотор; Fd, гидролизуемый фрагмент/часть тяжелой цепи Fab (антигенсвязывающий фрагмент); Н, тяжелая цепь; His, 6xHis-метка; L - легкая цепь; L1, SGPG3RS(G4S)2 линкер; L2, DVPG2S линкер; L3, (G4S)4 линкер; L4, (G4S)5 линкер; S-S, дисульфидный мостик; scFv, одноцепочечный вариабельный фрагмент; Sec, сигнал секреции; Strp, Strep-метка; V, вариабельный домен.
Фиг. 11. Анализ цитотоксичности in vitro для сравнения специфического лизиса, опосредованного белками CLDN18,2 × CD3-bstb.
РВМС человека в качестве эффекторных клеток и клетки человека, стабильно трансдуцированные люциферазой, в качестве клеток-мишеней, использовали в соотношении эффектор к мишени 5: 1 в анализе цитотоксичности на основе люциферазы. IMAC и Strep- Tactin® очищенные тестовые образцы bstb использовали без дальнейшего обогащения мономерных частиц посредством SEC. Левый график: специфический и зависимый от концентрации лизис клеток рака желудка CLDN18.2+, NUGC-4_hCLDN18.2, опосредованный bstb_5730/5728, bstb_5731/5729, bstb_5732/5728 и bstb_5733/5729 после 48 ч инкубации. Правый график: лизис CDLN18.2- контрольной клеточной линии MDA-MB-231. Показаны средние значения в трех повторах, включая стандартное отклонение.
Bstb обозначает биспецифичный TriMAB.
Фиг. 12. Анализ SE-HPLC различных белков CLDN18,2 x CD3-bstb после очистки.
Клетки Expi293FТМ транзиторно трансфицировали конструкциями bstb_5745/5747, bstb_5749/5751, bstb_5746/5748 или bstb_5750/5752. Надосадочную жидкость собирали через семь дней после трансфекции и подвергали очистке. (A) Анализ SE-HPLC bstb_5745/5747 (верхний график) и bstb_5749/5751 (нижний график) после очистки (нижний график). Величины mAU (миллиабсорбционные единицы) на оси у обозначены относительно времени в минутах на оси х. Содержание мономера сильно увеличено в bstb_5749/5751, который включает дополнительные дисульфидные связи в фрагментах scFv против CLDN18.2. (B) SE-HPLC анализ bstb_5746/5748 (верхний график) и bstb_5750/5752 (нижний график) после очистки (нижний график). Величины mAU (миллиабсорбционные единицы) на оси у обозначены относительно времени в минутах на оси х. Содержание мономера сильно увеличено в bstb_5749/5751, который включает дополнительные дисульфидные связи в анти-CLDN18.2 scFv-фрагментах.
Bstb обозначает биспецифичный TriMAB; ВМВ, высокомолекулярные соединения; LMW, низкомолекулярные соединения.
Фиг. 13. Анализ цитотоксичности in vitro для сравнения специфического лизиса, опосредованного высокомономерным дисульфидным мостиком, содержащим белки CLDN18,2 × CD3-bstb и би-(scFv)2.
Использовали РВМС человека в качестве эффекторных клеток и стабильно трансдуцированные люциферазой человеческие клетки рака желудка CLDN18.2+ NUGC-4_hCLDN18.2 в качестве клеток-мишеней в отношении эффектор к мишени 5:1 в анализе цитотоксичности на основе люциферазы. Мономерные тестируемые образцы bstb, разделенные SEC, и их белковые аналоги (scFv)2 использовали в 10-точечных 5-кратных серийных разведениях. (A) Специфический и зависимый от концентрации лизис, опосредованный bstb_5749/5751 и bstb_5750/5752 (левый график) и bi-scFv_5506 и bi-scFv_5538 (правый график) после 48 ч инкубации. Значения EC50 приведены в таблицах ниже. Значения ЕС50 «эталонного образца» служили для нормализации. (B) Кратное различие двухвалентного bstb по сравнению с родственными аналогами би-(scFv)2 после нормализации к «эталону планшета». Для расчетов связанные значения EC50 для би-(scFv)2 были приняты равными 1.
Bi-scFv обозначает биспецифический одноцепочечный вариабельный фрагмент; bstb, биспецифичный TriMAB; EC50, полумаксимальная эффективная концентрация.
Фиг. 14. Модульные схемы, иллюстрирующие РНК-конструкции, кодирующие CLDN6 x CD3 bstb.
Дизайн bstb Fd (вверху) и L-цепи (внизу) на уровне РНК.
С обозначает константную область; CMV, цитомегаловирусный промотор; Fd, гидролизуемый фрагмент/часть тяжелой цепи Fab (антигенсвязывающий фрагмент); Н, тяжелая цепь; His, 6xHis-метка; L - легкая цепь; L1, линкер SGPG3RS(G4S)2; L2, линкер DVPG2S; L3, линкер (G4S)4; S-S, дисульфидный мостик; scFv, одноцепочечный вариабельный фрагмент; Sec, сигнал секреции; Strp, Strep-метка; V, вариабельный домен.
Фиг. 15. Вестерн-блот-анализ IVT-мРНК, кодирующей CLDN6 x CD3 bstb_435/434 и bstb_436/434, в клетках-продуцентах.
Клеточную линию хронического миелоидного лейкоза человека K-562 транзиторно трансфицировали посредством электропорации с равными количествами IVT-мРНК Fd- и L-цепи или только с помощью H2O (пустой контроль). Надосадочные жидкости К-562 собирали через 48 ч после электропорации и получали клеточные лизаты. В качестве эталона очищенные белковые аналоги bstb_369/367 (A) или bstb_371/367 (B) загружали в виде мономерного препарата и препарата ВМВ на гели. Градиентный SDS-PAGE и Вестерн-блот анализ были выполнены для обнаружения транслированных и очищенных белковых продуктов.
Оба варианта bstb ((A) bstb_435/434, (B) bstb_436/434) были обнаружены в надосадочной жидкости K-562 и лизате клеток с помощью анти-6xHis HRP (Fd-часть) и анти-Strep-MAB-HRP (L-часть). Анти-β-актин иммуноблоттинг служил в качестве контроля загрузки клеточных лизатов. Образцы загружали, как указано в прилагаемых таблицах загрузки образцов в невосстанавливающих и восстанавливающих условиях. Стрелки указывают на представляющие интерес полосы белка. (A) bstb_435/434, (B) bstb_436/434. В (C) оба варианта bstb были обнаружены в восстанавливающих условиях смесью анти-6xHis-HRP и анти-Strep-MAB-HRP для визуализации гетеродимерного состояния производных антител.
Bstb обозначает биспецифичный TriMAB; Fd, гидролизуемый фрагмент/часть тяжелой цепи Fab (антигенсвязывающий фрагмент); His, 6xHis-метка; ВМВ, высокомолекулярные соединения; HRP, пероксидаза хрена; L, часть легкой цепи bstb; scFv, одноцепочечный вариабельный фрагмент; SN, надосадочная жидкость.
Фиг. 16. Анализ цитотоксичности in vitro для определения специфического лизиса, опосредованного CLDN6 x CD3 bstb_435/434 и bstb_436/434.
РВМС человека в качестве эффекторных клеток и клетки человека, стабильно трансдуцированные люциферазой, в качестве клеток-мишеней использовали в соотношении эффектор к мишени 5:1 в анализе цитотоксичности на основе люциферазы. SN из K-562, содержащих кодируемую РНК bstb_435/434 или bstb_436/434, применяли в 7-точечном 5-кратном серийном разведении. Показан специфически зависимый от концентрации лизис, опосредованный bstb_435/434 и bstb_436/434 клеток CLDN6+ рака яичника OV-90 после 48 ч инкубации. CDLN6- клетки карциномы молочной железы MDA-MB-231 служили отрицательным контролем. Показаны средние значения трех повторов, включая стандартное отклонение.
Bstb обозначает биспецифичный TriMAB; EC50, полумаксимальная эффективная концентрация.
Фиг. 17. Сравнение in vivo эффективности CLDN6 x CD3 РНК и белка bstb и би-(scFv)2 на мышиной модели ксенотрансплантата опухоли.
Использовали самцов (черные символы) и самок (белые символы) иммунодефицитных мышей NSG. (А) Схема графика инъеций. Мышей инокулировали подкожно (s.c.) клетками карциномы яичника человека OV-90 CLDN6+ в качестве клеток-мишеней и приживляли внутрибрюшинно (i.p.) PBMC человека в качестве эффекторных клеток. Обработка начиналась при среднем объеме опухоли ~250 мм3 на группу и проводилось внутривенно (i.v.) один раз в неделю. Группа 1 (G1) получала контрольный комплекс РНК (люциферазную РНК в TransIT), G2, РНК-комплекс bstb, и G3, РНК-комплекс би-(scFv)2. Каждая инъекция содержала всего 3 мкг РНК. G4-6 служили контрольными/эталонными группами белка: G4 получали буфер-носитель (буфер для белкового состава), G5 получали 100 мкг/кг эталонного bstb и G6 получали 200 мкг/кг эталонного би-(scFv)2. (В) Рост опухоли у всех мышей и групп в зависимости от времени. Обработка применялась внутривенно, как указано стрелками. Обработки на группу указаны в заголовках графиков. Каждая строка представляет отдельную мышь. (C) Проточный цитометрический анализ Т-клеток человека, которые инфильтрировали опухолевую ткань ксенотрансплантата мышей, обработанную контрольной РНК (G1), bstb РНК (G2) или би-(scFv)2 РНК (G3). Каждый символ представляет отдельную мышь, а линии - среднее значение для каждой группы. Символы в соответствии с (B).
Bi-scFv обозначает биспецифический одноцепочечный фрагмент; bstb, биспецифичный TriMAB; d, дни; G, группа; GVHD, болезнь трансплантат против хозяина; i.p., внутрибрюшинно; i.v., внутривенно; PBMC, мононуклеарные клетки периферической крови; s.c., подкожно.
Фиг. 18. Аминокислотные последовательности VH и VL согласно номенклатуре IMGT.
Показаны аминокислотные последовательности в стандартном однобуквенном коде доменов VH и VL, которые использовались в описанных в данном документе молекулах bstb. A) VH и VL последовательности анти-CLDN18.2 и анти-CLDN6, B) VH и VL последовательности анти-CD3.
CDR указывает область, определяющую комплементарность; FR, каркасная область; IMGT, международная информационная система ImMunoGeneTics; VH, переменная тяжелая цепь; VL, переменная легкая цепь.
Подробное описание изобретения
Хотя настоящее изобретение подробно описано ниже, следует понимать, что это изобретение не ограничено конкретными методологиями, протоколами и реагентами, описанными в данном документе, поскольку они могут различаться. Кроме того, следует понимать, что терминология, используемая в настоящем документе, предназначена для целей описания только конкретных воплощений, и не предназначена для ограничения, поскольку объем настоящего изобретения будет ограничен только прилагаемой формулой изобретения. Если не указано иное, все технические и научные термины, используемые в данном документе, имеют те же значения, которые обычно понимаются специалистом в данной области техники.
Ниже будут описаны элементы настоящего изобретения. Эти элементы перечислены в конкретных воплощениях, однако следует понимать, что они могут быть объединены любым способом и любым числом для создания дополнительных воплощений. Различные описанные примеры и предпочтительные воплощения не должны толковаться как ограничивающие настоящее изобретение только явно описанными воплощениями. Это описание следует понимать как поддерживающее и охватывающее воплощения, которые объединяют явно описанные воплощения с любым количеством раскрытых и/или предпочтительных элементов. Кроме того, любые перестановки и комбинации всех описанных элементов в этом приложении должны рассматриваться раскрытыми описанием настоящей заявки, если контекст не указывает иное.
Предпочтительно термины, используемые в данном документе, определяются в соответствии с описанием «Многоязычного глоссария биотехнологических терминов: (Рекомендации IUPAC)», HGW Leuenberger, B. Nagel и H. Kölbl, Eds., Helvetica Chimica Acta, CH-4010 Basel, Швейцария, (1995).
Практическое осуществление настоящего изобретения будет использовать, если не указано иное, традиционные способы химии, биохимии, клеточной биологии, иммунологии и рекомбинантных ДНК, которые объясняются в литературе в данной области (см., например, Molecular Cloning: A Laboratory Manual, 2nd Edition, J. Sambrook et al. eds., Cold Spring Harbor Laboratory Press, Cold Spring Harbor 1989).
Всюду по этому описанию и последующей формуле изобретения, если контекст не требует иного, слово «содержать», и варианты, такие как «содержит» и «содержащий», будут подразумеваться как включение заявленного элемента, целого или стадии или группы членов, целых или стадий, но не исключение любого члена, целого или стадии или группы членов, целых или стадий, хотя в некоторых воплощениях может быть исключен такой другой элемент, целое или стадия или группу членов, целых или стадий, т.е. объект изобретения заключается во включении указанного члена, целого или стадии или группы членов, целых или стадий. Термины в единственном числе должны толковаться как охватывающие как единственное, так и множественное число, если иное не указано в данном документе или нет явного противоречия контексту. Изложение диапазонов значений в данном документе просто предназначено для применения в качестве сокращенного способа обращения индивидуально к каждому отдельному значению, входящему в диапазон. Если не указано иное, каждое индивидуальное значение включается в описание, как если бы оно было индивидуально описано в данном документе. Все описанные в данном документе способы могут быть выполнены в любом подходящем порядке, если в данном документе не указано иное или иное явно противоречит контексту. Использование любых и всех примеров или примерной формулировки (например, «такой как»), приведенных в данном документе, предназначено просто для лучшей иллюстрации изобретения и не представляет собой ограничение объема заявленного изобретения. Ни одна формулировка в описании не должна быть истолкована как указание на любой незаявленный элемент как существенный при практическом осуществлении изобретения.
В тексте этого описания приводятся несколько документов. Каждый из документов, процитированных в данном документе (включая все патенты, заявки на патент, научные публикации, спецификации производителей, инструкции и т.д.), независимо от того, находятся они выше или ниже, полностью включены в настоящее описание ссылкой. Никакую часть настоящего документа не следует считать признанием того, что изобретение не может претендовать на более раннюю дату настоящего описания в силу предшествующего создания изобретения.
Клаудины - это семейство белков, которые являются наиболее важными компонентами плотных контактов, в которых они устанавливают парацеллюлярный барьер, контролирующий поток молекул в межклеточном пространстве между клетками эпителия. Клаудины - трансмембранные белки, пересекающие мембрану 4 раза, с N- и C-концами, расположенными в цитоплазме. Первая внеклеточная петля, называемая EC1 или ECL1, состоит в среднем из 53 аминокислот, а вторая внеклеточная петля, называемая EC2 или ECL2, состоит из примерно 24 аминокислот. Белки клеточной поверхности семейства клаудинов, такие как CLDN6 и CLDN18.2, экспрессируются в опухолях различного происхождения и особенно подходят в качестве структур-мишеней в случае антитело-опосредуемой иммунотерапии рака из-за их избирательной экспрессии (отсутствие экспрессии в релевантной по токсичности нормальной ткани) и локализации в плазматической мембране.
В контексте настоящего изобретения предпочтительными клаудинами являются CLDN6 и CLDN18.2. CLDN6 и CLDN18.2 были идентифицированы как дифференциально экспрессированные в опухолевых тканях, при этом единственными нормальными тканями, экспрессирующими CLDN18.2, являются желудок, а единственной нормальной тканью, экспрессирующей CLDN6, является плацента.
CLDN18.2 избирательно экспрессируется в нормальных тканях в дифференцированных эпителиальных клетках слизистой оболочки желудка. CLDN18.2 экспрессируется в раках различного происхождения, таких как карцинома поджелудочной железы, карцинома пищевода, карцинома желудка, бронхиальная карцинома, карцинома молочной железы и ЛОР-опухоли. CLDN18.2 является ценной мишенью для профилактики и/или лечения первичных опухолей, таких как рак желудка, рак пищевода, рак поджелудочной железы, рак легкого, такой как немелкоклеточный рак легкого (NSCLC), рак яичника, рак толстой кишки, рак печени, рак головы и шеи, рак желчного пузыря и метастазы, в частности метастазы рака желудка, такие как опухоли Крукенберга, перитонеальные метастазы и метастазы в лимфатические узлы.
Было обнаружено, что CLDN6 экспрессируется, например, при раке яичника, раке легкого, раке желудка, раке молочной железы, раке печени, раке поджелудочной железы, раке кожи, меланомах, раке шеи головы, саркомах, раке желчных протоков, раке почечных клеток и раке мочевого пузыря. CLDN6 является особенно предпочтительной мишенью для профилактики и/или лечения рака яичника, в частности аденокарциномы яичника и тератокарциномы яичника, рака легкого, включая мелкоклеточный рак легкого (SCLC), и немелкоклеточный рак легкого (NSCLC), в частности плоскоклеточный клеточный рак легкого и аденокарцинома, рака желудка, рака молочной железы, рака печени, рака поджелудочной железы, рака кожи, в частности базальноклеточной карциномы и плоскоклеточного рака, злокачественной меланомы, рака головы и шеи, в частности злокачественной плеоморфной аденомы, саркомы, в частности синовиальной саркомы и карциносаркомы, рака желчных протоков, рака мочевого пузыря, в частности, переходно-клеточной карциномы и папиллярной карциномы, рака почки, в частности почечно-клеточной карциномы, включая светлоклеточный почечно-клеточную карциному и светлоклеточную почечно-клеточную карциному, рака толстой кишки, рака тонкой кишки, включая рак подвздошной кишки, в частности, аденокарциномы тонкой кишки и аденокарциномы подвздошной кишки, эмбриональной карциномы яичка, плацентарной хориокарциномы, рака шейки матки, рака яичка, в частности семиномы яичка, тератомы яичка и эмбрионального рака яичка, рака матки, опухолей половых клеток, таких как тератокарцинома или эмбриональная карцинома, в частности герминомы яичка, и их метастатических форм. В одном воплощении раковое заболевание, связанное с экспрессией CLDN6, выбрано из группы, состоящей из рака яичника, рака легкого, метастатического рака яичника и метастатического рака легкого. Предпочтительно, рак яичника представляет собой карциному или аденокарциному. Предпочтительно рак легкого представляет собой карциному или аденокарциному и, предпочтительно, представляет собой бронхиолярный рак, такой как бронхиальная карцинома или бронхиолярная аденокарцинома.
Термин «клаудин» или «CLDN» включает CLDN18.2 и CLDN6. Предпочтительно клаудин является клаудином человека.
Термин «клаудин 18» или «CLDN18» включает любые варианты, включая сплайс-вариант 1 клаудина 18 (клаудин 18.1 (CLDN18.1)) и сплайс-вариант 2 клаудина 18 (клаудин 18.2 (CLDN18.2)).
Термин «клаудин 18.2» или «CLDN18.2» предпочтительно относится к CLDN18.2 человека и, в частности, к белку, включающему, предпочтительно состоящему из аминокислотной последовательности в соответствии с SEQ ID NO: 1 перечня последовательностей или варианта указанной аминокислотной последовательности. Первая внеклеточная петля CLDN18.2 предпочтительно включает аминокислоты 27-81, более предпочтительно аминокислоты 29-78 аминокислотной последовательности, показанной в SEQ ID NO: 1. Вторая внеклеточная петля CLDN18.2 предпочтительно включает аминокислоты с 140 по 180 или с 144 по 167 аминокислотной последовательности, показанной в SEQ ID NO: 1. Указанные первая и вторая внеклеточные петли предпочтительно образуют внеклеточную часть CLDN18.2.
Термин «клаудин 6» или «CLDN6» предпочтительно относится к человеческому CLDN6 и, в частности, к белку, включающему, предпочтительно состоящему из аминокислотной последовательности SEQ ID NO: 2 или SEQ ID NO: 3 из перечня последовательностей или варианта указанной аминокислотной последовательности. Первая внеклеточная петля CLDN6 предпочтительно включает аминокислоты с 28 по 80 или с 29 по 81, более предпочтительно аминокислоты с 28 по 76 аминокислотной последовательности, представленной в SEQ ID NO: 2 или аминокислотной последовательности, представленной в SEQ ID NO: 3. Вторая внеклеточная петля CLDN6 предпочтительно включает аминокислоты с 138 по 160, предпочтительно аминокислоты с 141 по 159, более предпочтительно аминокислоты с 145 по 157 аминокислотной последовательности, представленной в SEQ ID NO: 2, или аминокислотной последовательности, представленной в SEQ ID NO: 3. Указанные первая и вторая внеклеточные петли предпочтительно образуют внеклеточную часть CLDN6.
Термин «вариант» согласно изобретению относится, в частности, к мутантам, вариантам сплайсинга, конформациям, изоформам, аллельным вариантам, видам и гомологам видов, в частности к тем, которые встречаются в природе. Аллельный вариант относится к изменению нормальной последовательности гена, значение которого часто неясно. Секвенирование полного гена часто идентифицирует многочисленные аллельные варианты для данного гена. Гомолог вида представляет собой нуклеиновую кислоту или аминокислотную последовательность вида другого происхождения, полученным из данной последовательности нуклеиновой кислоты или аминокислотной последовательности. Термин «вариант» должен охватывать любые посттрансляционно модифицированные варианты и конформационные варианты.
Вторая целевая молекула связывающих агентов, описанных в настоящем документе, представляет собой Т-клеточный специфический антиген. T-клеточный специфический антиген является антигеном на поверхности Т-клеток. Предпочтительным воплощением такого Т-клеточного специфического антигена является комплекс CD3 (кластер дифференцировки 3).
Комплекс CD3 обозначает антиген, который экспрессируется на зрелых человеческих Т-клетках, тимоцитах и подгруппе естественных клеток-киллеров как часть многомолекулярного комплекса Т-клеточных рецепторов (TCR). Т-клеточный корецептор представляет собой белковый комплекс и состоит из четырех отдельных цепей. У млекопитающих комплекс включает цепь CD3γ, цепь CD3δ и две цепи CD3ε. Эти цепи связываются с молекулой, известной как Т-клеточный рецептор (TCR), и ζ-цепь генерирует сигнал активации в Т-лимфоцитах. Молекулы TCR, ζ-цепь и CD3 вместе составляют комплекс TCR.
CD3 эпсилон человека имеет учетный номер GenBank NM_000733 и включен в SEQ ID NO: 4. CD3 гамма человека имеет учетный номер GenBank NM_ 000073. CD3 дельта человека имеет учетный номер GenBank NM_000732. CD3 отвечает за передачу сигнала TCR. Как описано Lin and Weiss, Journal of Cell Science 114, 243-244 (2001), активация комплекса TCR путем связывания специфических антигенных эпитопов, представленных MHC, приводит к фосфорилированию иммунорецепторных мотивов активации на основе тирозина (ITAM) с помощью киназ семейства Src, запускающих рекрутирование дополнительных киназ, что приводит к активации T- клеток, включая высвобождение Ca2+. Кластеризация CD3 на Т-клетках, например, с помощью иммобилизованных анти-CD3-антител, приводит к активации Т-клеток, сходной с активацией Т-клеточного рецептора, но не зависит от клон-типичной специфичности.
Используемый в данном документе термин «CD3» включает CD3 человека и обозначает антиген, который экспрессируется на Т-клетках человека как часть мультимолекулярного комплекса Т-клеточного рецептора.
Что касается CD3, связывающий агент по изобретению предпочтительно распознает эпсилон-цепь CD3, в частности, он распознает эпитоп, который соответствует первым 27 N-концевым аминокислотам CD3-эпсилон или функциональным фрагментам этого 27-аминокислотного участка.
Согласно изобретению термин «клаудин-положительный рак» или подобные термины означают рак, вовлекающий раковые клетки, экспрессирующие клаудин, предпочтительно на поверхности указанных раковых клеток.
«Клеточная поверхность» используется в соответствии с ее нормальным значением в данной области техники и, таким образом, включает внешнюю поверхность клетки, которая доступна для связывания белками и другими молекулами.
Клаудин экспрессируется на поверхности клеток, если он расположен на поверхности указанных клеток и доступен для связывания с помощью клаудин-специфических антител, добавляемых к клеткам.
Термин «внеклеточная часть» в контексте настоящего изобретения относится к части молекулы, такой как белок, которая обращена к внеклеточному пространству клетки и предпочтительно доступна извне указанной клетки, например, антиген-связывающим молекулам, таким как антитела, расположенные вне клетки. Предпочтительно, термин относится к одной или нескольким внеклеточным петлям или доменам или их фрагменту.
Термины «часть» или «фрагмент» используются в данном документе взаимозаменяемо и относятся к непрерывному элементу. Например, часть структуры, такая как аминокислотная последовательность или белок, относится к непрерывному элементу указанной структуры. Доля, часть или фрагмент структуры предпочтительно включает одно или несколько функциональных свойств указанной структуры. Например, доля, часть или фрагмент эпитопа или пептида предпочтительно иммунологически эквивалентны эпитопу или пептиду, из которого они получены. Часть или фрагмент белковой последовательности предпочтительно включает последовательность, по меньшей мере, 4, в частности, по меньшей мере, 6, по меньшей мере, 8, по меньшей мере, 12, по меньшей мере, 15, по меньшей мере, 20, по меньшей мере, 30, по меньшей мере, 50 или, по меньшей мере, 100 последовательных аминокислот белковой последовательности.
Согласно изобретению CLDN18.2 существенно не экспрессируется в клетке, если уровень экспрессии ниже по сравнению с экспрессией в клетках желудка или ткани желудка. Предпочтительно уровень экспрессии составляет менее 10%, предпочтительно менее 5%, 3%, 2%, 1%, 0,5%, 0,1% или 0,05% от экспрессии в клетках желудка или в тканях желудка или даже ниже. Предпочтительно, CLDN18.2 существенно не экспрессируется в клетке, если уровень экспрессии превышает уровень экспрессии в нераковой ткани, отличной от желудка, не более чем в 2 раза, предпочтительно в 1,5 раза, и предпочтительно не превышает уровень экспрессии в указанной нераковой ткани. Предпочтительно CLDN18.2 по существу не экспрессируется в клетке, если уровень экспрессии ниже предела обнаружения и/или если уровень экспрессии слишком мал, чтобы позволить связывание CLDN18.2-специфическими антителами, добавленными к клеткам.
Согласно изобретению CLDN18.2 экспрессируется в клетке, если уровень экспрессии превышает уровень экспрессии в нераковой ткани, отличной от желудка, предпочтительно более чем в 2 раза, предпочтительно в 10 раз, в 100 раз, 1000 или 10000 раз. Предпочтительно CLDN18.2 экспрессируется в клетке, если уровень экспрессии выше предела обнаружения и/или если уровень экспрессии достаточно высок, чтобы позволить связывание с CLDN18.2-специфическими антителами, добавленными к клеткам. Предпочтительно CLDN18.2, экспрессируемый в клетке, экспрессируется или экспонируется на поверхности указанной клетки.
Согласно изобретению CLDN6 по существу не экспрессируется в клетке, если уровень экспрессии ниже по сравнению с экспрессией в клетках плаценты или ткани плаценты. Предпочтительно уровень экспрессии составляет менее 10%, предпочтительно менее 5%, 3%, 2%, 1%, 0,5%, 0,1% или 0,05% от экспрессии в клетках плаценты или в ткани плаценты или даже ниже. Предпочтительно, CLDN6 существенно не экспрессируется в клетке, если уровень экспрессии превышает уровень экспрессии в нераковой ткани, отличной от плаценты, не более чем в 2 раза, предпочтительно в 1,5 раза, и предпочтительно не превышает уровень экспрессии в указанной нераковой ткани. Предпочтительно CLDN6 по существу не экспрессируется в клетке, если уровень экспрессии ниже предела обнаружения и/или если уровень экспрессии слишком низок, чтобы позволить связывание CLDN6-специфическими антителами, добавленными к клетке.
Согласно изобретению CLDN6 экспрессируется в клетке, если уровень экспрессии превышает уровень экспрессии в нераковой ткани, отличной от желудка, предпочтительно более чем в 2 раза, предпочтительно в 10 раз, в 100 раз, 1000 или 10000 раз. Предпочтительно CLDN6 экспрессируется в клетке, если уровень экспрессии выше предела обнаружения и/или если уровень экспрессии достаточно высок, чтобы позволить связывание CLDN6-специфическими антителами, добавленными к клетке. Предпочтительно CLDN6, экспрессируемый в клетке, экспрессируется или экспонируется на поверхности указанной клетки.
Согласно изобретению термин «заболевание» относится к любому патологическому состоянию, включая рак, в частности к таким формам рака, которые описаны в данном документе. Любая ссылка в данном документе на рак или конкретные формы рака также включает метастазы рака. В предпочтительном воплощении заболевание, подлежащее лечению в соответствии с настоящей заявкой, включает клетки, экспрессирующие клаудин (CLDN), такой как CLDN18.2 и/или CLDN6.
«Заболевания, связанные с клетками, экспрессирующими клаудин» или подобные выражения означают в соответствии с изобретением, что клаудин экспрессируется в клетках больных ткани или органа. В одном воплощении экспрессия опухолевого антигена в клетках больных ткани или органа увеличивается по сравнению с состоянием в здоровых ткани или органе. Увеличение относится к увеличению, по меньшей мере, на 10%, в частности, по меньшей мере, на 20%, по меньшей мере, на 50%, по меньшей мере, на 100%, по меньшей мере, на 200%, по меньшей мере, на 500%, по меньшей мере, на 1000%, по меньшей мере, на 10000% или даже больше. В одном воплощении экспрессия обнаруживается только в пораженной ткани, тогда как экспрессия в здоровой ткани репрессируется. Согласно изобретению заболевания, связанные с клетками, экспрессирующими клаудин, включают онкологические заболевания. Кроме того, согласно изобретению онкологические заболевания предпочтительно представляют собой заболевания, при которых раковые клетки экспрессируют клаудин.
Используемый в данном документе термин «онкологическое заболевание» или «рак» включает заболевание, характеризующееся аберрантно регулируемыми ростом клеток, пролиферацией, дифференцировкой, адгезией и/или миграцией. Под «раковой клеткой» подразумевается аномальная клетка, которая быстро и неконтролируемо пролиферирует и продолжает расти после того, как стимулы, которые положили начало новому росту, прекратились. Предпочтительно «онкологическое заболевание» характеризуется клетками, экспрессирующими клаудин, и раковая клетка экспрессирует клаудин. Клетка, экспрессирующая клаудин, предпочтительно представляет собой раковую клетку, предпочтительно из рака, описанного в данном документе.
Термин «рак» согласно изобретению включает лейкозы, семиномы, меланомы, тератомы, лимфомы, нейробластомы, глиомы, рак прямой кишки, рак эндометрия, рак почки, рак надпочечников, рак щитовидной железы, гемобластоз, рак кожи, рак головного мозга, рак шейки матки, рак кишечника, рак печени, рак толстой кишки, рак желудка, рак кишечника, рак головы и шеи, рак желудочно-кишечного тракта, рак лимфатических узлов, рак пищевода, рак толстой кишки, рак поджелудочной железы, рак уха, носа и горла (ЛОР), рак молочной железы, рак предстательной железы, рак матки, рак яичника и рак легкого, и их метастазы. Примерами этого являются рак легкого, рак молочной железы, рак предстательной железы, рак толстой кишки, почечно-клеточная карцинома, рак шейки матки или метастазы описанных выше типов раков или опухолей. Термин рак по изобретению также включает метастазы рака.
Согласно изобретению, «карцинома» представляет собой раковую опухоль, полученную из эпителиальных клеток. Эта группа представляет собой наиболее распространенные виды рака, включая распространенные формы рака молочной железы, предстательной железы, легких и толстой кишки.
«Аденокарцинома» - это рак, которое возникает в железистой ткани. Эта ткань также является частью более широкой категории тканей, известной как эпителиальная ткань. Эпителиальная ткань включает кожу, железы и множество других тканей, которые выстилают полости и органы тела. Эпителий эмбриологически получается из эктодермы, эндодермы и мезодермы. Чтобы быть классифицированными как аденокарцинома, клетки не обязательно должны быть частью железы, если они обладают секреторными свойствами. Эта форма карциномы может встречаться у некоторых высших млекопитающих, включая людей. Хорошо дифференцированные аденокарциномы имеют тенденцию напоминать железистую ткань, из которой они происходят, тогда как плохо дифференцированные могут не напоминать. Путем окрашивания клеток биопсии патологоанатом определит, является ли опухоль аденокарциномой или другим типом рака. Аденокарциномы могут возникать во многих тканях тела из-за вездесущей природы желез в организме. Хотя каждая железа не может выделять одно и то же вещество, при наличии экзокринной функции в клетке она считается железистой, поэтому ее злокачественная форма называется аденокарциномой. Злокачественные аденокарциномы вторгаются в другие ткани и часто метастазируют, если у них достаточно времени. Аденокарцинома яичника является наиболее распространенным типом карциномы яичника. Она включает серозную и муциновую аденокарциному, светлоклеточную карциному и эндометриоидную аденокарциному.
Под «метастазами» подразумевается распространение клеток рака из исходного места в другую часть организма. Образование метастазов является очень сложным процессом и зависит от отделения раковых клеток от первичной опухоли, инвазии внеклеточного матрикса, проникновения через эндотелиальные базальные мембраны в полость тела и сосудов, а затем, после транспортировки кровью, инфильтрации в органы-мишени. Наконец, рост новой опухоли на целевом участке зависит от ангиогенеза. Опухолевые метастазы часто возникают даже после удаления первичной опухоли, потому что опухолевые клетки или компоненты могут оставаться и развивать метастатический потенциал. В одном воплощении термин «метастаз» в соответствии с изобретением относится к «отдаленному метастазированию», которая относится к метастазированию, удаленному от первичной опухоли и региональной системы лимфатических узлов. В одном воплощении термин «метастаз» в соответствии с изобретением относится к метастазированию в лимфатические узлы. Одна конкретная форма метастазов, которая поддается лечению с использованием терапии по изобретению, представляет собой метастаз, происходящий из рака желудка в качестве первичного сайта. В предпочтительных вариантах такой метастаз рака желудка представляет собой опухоли Крукенберга, перитонеальный метастаз и/или метастаз в лимфатические узлы.
Опухоль Крукенберга - необычная метастатическая опухоль яичника, составляющая от 1% до 2% всех опухолей яичника. Прогноз опухоли Крукенберга по-прежнему очень плохой, и нет никакого лечения опухолей Крукенберга. Опухоль Крукенберга представляет собой метастазирующую аденокарциному перстевидных клеток яичника. Желудок является основным участком в большинстве случаев опухолей Крукенберга (70%). Карциномы толстой кишки, аппендикса и молочной железы (преимущественно инвазивная дольковая карцинома) являются наиболее распространенными первичными участками. Сообщалось о редких случаях опухоли Крукенберга, происходящих от карцином желчного пузыря, желчных путей, поджелудочной железы, тонкой кишки, фатеровой ампулы, шейки матки и мочевого пузыря/урахуса.
Под «лечить» подразумевается введение соединения или композиции или комбинации соединений или композиций объекту с целью предотвращения или устранения заболевания, включая уменьшение размера опухоли или количества опухолей у объекта; остановки или замедления заболевания у объекта; торможения или замедления развития нового заболевания у объекта; уменьшения частоты или серьезности симптомов и/или рецидивов у объекта, который в настоящее время страдает или у кого ранее было заболевание; и/или продления, т.е. увеличения продолжительность жизни объекта.
В частности, термин «лечение заболевания» включает излечение, сокращение продолжительности, улучшение, предотвращение, замедление или замедление прогрессирования или ухудшения, или предотвращение или задержку начала заболевания или его симптомов.
В контексте настоящего изобретения такие термины, как «защищать», «предотвращать», «профилактический», «превентивный» или «защитный», относятся к предупреждению или лечению или к тому и другому возникновения и/или распространения заболевания у объекта и, в частности, для минимизации вероятности того, что у объекта разовьется заболевание, или для задержки развития заболевания. Например, объект, подверженный риску рака, будет кандидатом на терапию профилактики рака.
Под «находящимся под угрозой» подразумевается объект, который идентифицируется как имеющий более высокий, чем обычно, шанс развития заболевания, в частности рака, по сравнению с общей популяцией. Кроме того, объект, который имел или у которого в настоящее время есть заболевание, в частности рак, представляет собой объект, у которого повышен риск развития заболевания, поскольку у такого объекта может продолжить развиваться заболевание. Объекты, которые в настоящее время имеют или у которых было рак, также имеют повышенный риск развития метастазов рака.
Термин «пациент» в соответствии с изобретением означает объект для лечения, в частности больного объекта, включая людей, не являющихся человеком приматов или других животных, в частности млекопитающих, таких как коровы, лошади, свиньи, овцы, козы, собаки, кошки или грызуны, такие как мыши и крысы. В особенно предпочтительном воплощении пациентом является человек.
«Клетка-мишень» означает любую нежелательную клетку, такую как клетка рака. В предпочтительных воплощениях клетка-мишень экспрессирует клаудин.
Термин «антиген» относится к молекуле, такой как белок или пептид, содержащей эпитоп, против которого направлен и/или должен быть направлен агент, предпочтительно для индукции иммунного ответа. В предпочтительном воплощении антиген представляет собой ассоциированный с опухолью антиген, такой как CLDN18.2 или CLDN6, то есть элемент раковых клеток, который может быть получен из цитоплазмы, поверхности клетки и клеточного ядра, в частности тех антигенов, которые продуцируются, предпочтительно в большом количестве, внутриклеточно или в качестве поверхностных антигенов на клетках рака.
В контексте настоящего изобретения термин «ассоциированный с опухолью антиген» предпочтительно относится к белкам, которые в нормальных условиях специфически экспрессируются в ограниченном количестве тканей и/или органов или на определенных стадиях развития и экспрессируются или аберрантно экспрессируются в одной или нескольких опухолевых или раковых тканей. В контексте настоящего изобретения ассоциированный с опухолью антиген предпочтительно связывается с клеточной поверхностью раковой клетки и предпочтительно не экспрессируется или редко экспрессируется в нормальных тканях.
Термин «эпитоп» относится к антигенной детерминанте в молекуле, т.е. к части молекулы, которая распознается иммунной системой, например, которая распознается антителом. Например, эпитопы представляют собой дискретные трехмерные участки на антигене, которые распознаются иммунной системой. Эпитопы обычно состоят из химически активных поверхностных групп молекул, таких как аминокислоты или сахарные боковые цепи, и обычно имеют специфические трехмерные структурные характеристики, и специфические характеристики заряда. Конформационные и неконформационные эпитопы отличаются тем, что связывание с первым, но не с последним, теряется в присутствии денатурирующих растворителей. Эпитоп белка предпочтительно включает непрерывную или прерывистую часть указанного белка и предпочтительно составляет от 5 до 100, предпочтительно от 5 до 50, более предпочтительно от 8 до 30, наиболее предпочтительно от 10 до 25 аминокислот в длину, например, эпитоп может быть предпочтительно 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24 или 25 аминокислот в длину.
Термин «связывающий агент», используемый в данном документе, относится к любому агенту, способному связываться с искомыми антигенами. В определенных воплощениях изобретения связывающий агент представляет собой антитело, фрагмент антитела или их конструкцию. Связывающий агент также может содержать синтетические, модифицированные или не встречающиеся в природе фрагменты, в частности непептидные фрагменты. Такие фрагменты могут, например, связывать искомые антигенсвязывающие функционалы или области, как антитела или фрагменты антител. В одном воплощении связывающий агент представляет собой синтетическую конструкцию, содержащую антигенсвязывающие CDR или вариабельные области.
Термин «иммуноглобулин» относится к белкам суперсемейства иммуноглобулинов, предпочтительно к антигенным рецепторам, таким как антитела или B-клеточный рецептор (BCR). Иммуноглобулины характеризуются структурным доменом, то есть доменом иммуноглобулина, имеющим характерную иммуноглобулиновую складку (Ig). Термин охватывает мембраносвязанные иммуноглобулины, и растворимые иммуноглобулины. Растворимые иммуноглобулины обычно называют антителами. Иммуноглобулины обычно содержат несколько цепей, обычно две идентичные тяжелые цепи и две идентичные легкие цепи, которые связаны через дисульфидные связи. Эти цепи в основном состоят из доменов иммуноглобулина, таких как домен VL (вариабельный легкой цепи), Домен CL (константный легкой цепи) и домены CH (константный тяжелой цепи) CH1, CH2, CH3 и CH4. Существует пять типов тяжелых цепей иммуноглобулинов млекопитающих, а именно, α, δ, ε, γ и µ, которые обуславливают различные классы антител, т.е. IgA, IgD, IgE, IgG и IgM. В отличие от тяжелых цепей растворимых иммуноглобулинов, тяжелые цепи мембранных или поверхностных иммуноглобулинов содержат трансмембранный домен и короткий цитоплазматический домен на своем карбокси-конце. У млекопитающих есть два типа легких цепей, а именно, лямбда и каппа. Цепи иммуноглобулинов содержат вариабельную область и константную область. Константная область, по существу, консервативна в различных изотипах иммуноглобулинов, а вариабельная часть сильно отличается и определяет распознавание антигена.
Термин «антитело» относится к иммуноглобулину, содержащему, по меньшей мере, две тяжелые (Н) цепи и две легкие (L) цепи, соединенные дисульфидными связями, или их антигенсвязывающую часть. Термин «антитело» включает моноклональные антитела, рекомбинантные антитела, антитела человека, гуманизированные антитела и химерные антитела. Каждая тяжелая цепь состоит из вариабельной области тяжелой цепи (сокращенно обозначенной в данном документе как VH) и константной области тяжелой цепи. Каждая легкая цепь состоит из вариабельной области легкой цепи (сокращенно обозначенной в данном документе как VL) и константной области легкой цепи. Термин «область» и термин «домен» используются в данном документе взаимозаменяемо. Области VH и VL можно далее подразделить на области гипервариабельности, которые называются областями определения комплементарности (CDR), чередующимися с областями, которые более консервативны, и называются каркасными областями (FR). Каждый VH и VL состоит из трех CDR и четырех FR, расположенных от аминоконца до карбоксиконца в следующем порядке: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4. Вариабельные области тяжелой и легкой цепей содержат связывающий домен, который взаимодействует с антигеном. Константные области антител могут опосредовать связывание иммуноглобулина с тканями или факторами хозяина, включая различные клетки иммунной системы (например, эффекторные клетки) и первый компонент (Clq) классической системы комплемента.
Используемый в данном документе термин «моноклональное антитело» относится к препарату молекул антител с одним молекулярным составом. Моноклональное антитело проявляет единственную связывающую специфичность и аффинность. В одном воплощении моноклональные антитела получают из гибридомы, которая состоит из В-клетки, полученной от не являющегося человеком животного, например мыши, слитой с иммортализованной клеткой.
Используемый в данном документе термин «рекомбинантное антитело» включает все антитела, которые были получены, экспрессированы, созданы или выделены рекомбинантными средствами, такими как (а) антитела, выделенные из животного (например, мыши), которое является трансгенным или трансхромосомным в отношении генов иммуноглобулинов, или полученной из них гибридомы, (b) антитела, выделенные из клетки-хозяина, трансформированной для экспрессии антитела, например, из трансфектомы, (с) антитела, выделенные из библиотеки рекомбинантных комбинаторных антител, и (d) антитела, полученные, экспрессированные, созданные или выделенные любыми другими способами, которые включают сплайсинг последовательностей генов иммуноглобулинов с другими последовательностями ДНК.
Используемый в данном документе термин «человеческое антитело» предназначен для включения антител, имеющих вариабельные и константные области, полученные из последовательностей иммуноглобулина человека зародышевой линии. Человеческие антитела могут включать аминокислотные остатки, не кодируемые последовательностями иммуноглобулина человека зародышевой линии (например, мутации, введенные случайным или сайтоспецифическим мутагенезом in vitro или соматической мутацией in vivo).
Термин «гуманизированное антитело» относится к молекуле, имеющей сайт связывания антигена, который по существу получен из иммуноглобулина не являющихся человеком видов, в которой оставшаяся структура иммуноглобулина молекулы основана на структуре и/или последовательности человеческого иммуноглобулина. Участок связывания антигена может либо содержать полные вариабельные домены, слитые с константными доменами, либо только области, определяющие комплементарность (CDR), привитые в соответствующие каркасные области в вариабельных доменах. Сайты связывания антигена могут быть дикого типа или могут быть модифицированы одной или несколькими аминокислотными заменами, например, модифицированы так, чтобы более точно напоминать человеческие иммуноглобулины. Некоторые формы гуманизированных антител сохраняют все последовательности CDR (например, гуманизированное мышиное антитело, которое включает все шесть CDR из мышиного антитела). Другие формы имеют одну или несколько CDR, которые изменяются относительно исходного антитела.
Термин «химерное антитело» относится к тем антителам, где одна часть каждой из аминокислотных последовательностей тяжелых и легких цепей гомологична соответствующим последовательностям в антителах, полученных из одного вида или принадлежащих к определенному классу, тогда как оставшийся сегмент цепи гомологичен соответствующим последовательностям в другом виде или классе. Обычно вариабельная область как легкой, так и тяжелой цепей имитирует вариабельные области антител, полученных от одного вида млекопитающих, тогда как константные части гомологичны последовательностям антител, полученных из другого организма. Одним явным преимуществом таких химерных форм является то, что вариабельная область может быть удобно получена из известных в настоящее время источников с использованием легко доступных В-клеток или гибридом из организмов-хозяев не являющихся человеком в комбинации с константными областями, полученными, например, из препаратов клеток человека. Хотя вариабельная область имеет преимущество легкости получения, и на специфичность не оказывает влияние источник, константная область человека с меньшей вероятностью вызывает иммунный ответ у человека при введении антитела, чем константная область из источника, не являющегося человеком. Однако это определение не ограничивается этим конкретным примером.
Антитела могут быть получены из разных видов, включая, без ограничения указанным, мышей, крыс, кроликов, морских свинок и человека.
Антитела, описанные в данном документе, включают антитела IgA, такие как IgA1 или IgA2, IgG1, IgG2, IgG3, IgG4, IgE, IgM и IgD. В различных воплощениях изобретения антитело представляет собой антитело IgG1, более конкретно IgG1, каппа или IgG1, лямбда - изотипа (то есть IgG1, κ, λ), IgG2a антитела (например, IgG2a, κ, λ), антитело IgG2b (например, IgG2b, κ, λ), IgG3, антитело (например, IgG 3, κ, λ) или IgG4 - антитело (например, IgG4, κ, λ).
Используемый в данном документе термин «гетерологичное антитело» определяется по отношению к трансгенному организму, продуцирующему такое антитело. Этот термин относится к антителу, имеющему аминокислотную последовательность или кодируемому нуклеотидной последовательностью, соответствующей той, которая обнаружена в организме, не совпадающем с трансгенным организмом, и обычно получена из вида, отличного от трансгенного организма.
Используемый в данном документе термин «гетерогибридное антитело» относится к антителу, имеющему легкие и тяжелые цепи с происхождением из различных организмов. Например, антитело, имеющее тяжелую цепь человека, связанную с легкой цепью мыши, представляет собой гетерогибридное антитело.
Связывающие агенты, такие как антитела, описанные в данном документе, предпочтительно являются выделенными. Термин «выделенный», при использовании в данном документе, предназначен для обозначения связывающего агента, который по существу не включает других агентов, имеющих различные антигенные специфичности (например, выделенное антитело, которое специфически связывается с CLDN18.2, по существу не включает антител, которые специфически связывают антигены, отличные от CLDN18.2). Выделенный связывающий агент, который специфически связывается с эпитопом, изоформой или вариантом CLDN18.2 человека, может, однако, иметь перекрестную реактивность к другим родственным антигенам, например, из других видов (например, видовых гомологов CLDN18.2). Кроме того, выделенный связывающий агент может быть по существу свободным от других клеточных материалов и/или химических веществ.
Термины «антигенсвязывающая часть» антитела (или просто «связывающая часть») или «антигенсвязывающий фрагмент» антитела (или просто «связывающий фрагмент») или сходные термины относятся к одному или нескольким фрагментам антитела, которые сохраняют способность специфически связываться с антигеном. Было показано, что антигенсвязывающая функция антитела может быть выполнена фрагментами полноразмерного антитела. Примеры связывающих фрагментов, включенных в термин «антигенсвязывающая часть» антитела, включают (i) Fab-фрагменты, моновалентные фрагменты, состоящие из доменов VL, VH, CL и CH; (ii) фрагменты F(ab')2, двухвалентные фрагменты, содержащие два Fab-фрагмента, соединенных дисульфидным мостиком в шарнирной области; (iii) фрагменты Fd, состоящие из доменов VH и CH; (iv) фрагменты Fv, состоящие из доменов VL и VH одного плеча антитела, (v) фрагменты dAb (Ward et al., (1989) Nature 341: 544-546), которые состоят из домена VH; (vi) выделенные области определения комплементарности (CDR) и (vii) комбинации двух или более выделенных CDR, которые могут быть необязательно соединены синтетическим линкером. Кроме того, хотя две области фрагмента Fv, VL и VH кодируются отдельными генами, их можно объединить, используя рекомбинантные способы, синтетическим линкером, который позволяет получить одиночную белковую цепь, в которой VL- и VH-пары образуют одновалентные молекулы (известные как одноцепочечные Fv (scFv), см., например, Bird et al. (1988) Science 242: 423-426; and Huston et al. (1988) Proc. Natl. Acad. Sci. USA 85: 5879-5883). Такие одноцепочечные антитела предназначены для включения в термин «антигенсвязывающий фрагмент» антитела. Другим примером являются слитые белки иммуноглобулина и связывающего домена, содержащие (i) полипептид связывающего домена, который слит с полипептидом шарнирной области иммуноглобулина, (ii) константную область CH2 тяжелой цепи иммуноглобулина, слитую с шарнирной областью, и (iii) константная область CH3 тяжелой цепи иммуноглобулина, слитую с константной областью CH2. Полипептид связывающего домена может быть вариабельной областью тяжелой цепи или вариабельной областью легкой цепи. Слитые белки связывающего домена и иммуноглобулина далее описаны в US 2003/0118592 и US 2003/0133939. Эти фрагменты антител получают обычными методами, известными специалистам в данной области, и фрагменты подвергают скринингу на предмет полезности таким же образом, как и интактные антитела.
Одноцепочечный вариабельный фрагмент (scFv) представляет собой гибридный белок вариабельных областей тяжелой (VH) и легкой цепей (VL) иммуноглобулинов, связанных с коротким линкерным пептидом, обычно из 10-30 аминокислот. Линкер обычно богат глицином для гибкости, и серином или треонином для растворимости и может либо соединять N-конец VH с C-концом VL, либо наоборот. Двухвалентные (или бивалентные) одноцепочечные вариабельные фрагменты (ди-scFv, би-scFv) могут быть получены путем связывания двух scFv. Это можно сделать путем получения одной пептидной цепи с двумя областями VH и двумя областями VL, в результате чего образуются тандемные scFv. Изобретение также включает полиспецифичные молекулы, содержащие более двух связывающих доменов scFv. Одним общим гибким связывающим пептидом является (Gly4Ser)x, где x может составлять 3, 4, 5 или 6. Необязательно, ассоциация VH и VL может быть стабилизирована одной или несколькими межмолекулярными дисульфидными связями.
Используемый в данном документе термин «связывающий домен» или «антигенсвязывающий домен» относится к сайту, например, антитела, который связывается с антигеном и включает антигенсвязывающую часть антитела. связывающий домен может состоять из вариабельных доменов тяжелой цепи и легкой цепи (VH и VL), каждый из которых включает четыре консервативных каркасных области (FR) и три CDR. CDR различаются по последовательности и определяют специфичность к определенному антигену. Домены VH и VL вместе могут образовывать сайт, который специфически связывает определенный антиген.
Fab (антигенсвязывающий фрагмент)-фрагменты антитела представляют собой иммунореактивные полипептиды, содержащие одновалентные антигенсвязывающие домены антитела, состоящие из полипептида, состоящего из вариабельной области тяжелой цепи (VH) и константной области 1 тяжелой цепи (CH1), и полипептида, состоящего из вариабельной области легкой цепи (VL) и константной области легкой цепи (в которой участки CL и CH1 связаны вместе, предпочтительно дисульфидной связью между остатками Cys). Предпочтительно в описанных в данном документе фрагментах Fab область CH1 и область CL имеют человеческое происхождение. В одном воплощении область CL представляет собой область CL каппа-типа. В одном воплощении область CH1 происходит от IgG1 или IgG2.
Все антитела и производные антител, таких как фрагменты антител, как описано в данном документе для целей изобретения, охватываются термином «антитело». Термин «производные антитела» относится к любой модифицированной форме антитела, например, к конъюгату антитела и другого агента или антитела или фрагмента антитела. Кроме того, антитела и производные антител, как описано в данном документе, полезны для получения связывающих агентов по изобретению, таких как фрагменты антител.
Естественно встречающиеся антитела, как правило, моноспецифичны, то есть они связываются с одним антигеном. Настоящее изобретение обеспечивает связывающие агенты, связывающиеся с цитотоксической клеткой, такой как Т-клетка (например, путем вовлечения CD3-рецептора) и клеткой-мишенью, такой как раковая клетка (путем вовлечения клаудина). Связывающие агенты по настоящему изобретению связываются, по меньшей мере, с двумя различными типами антигена и являются, по меньшей мере, биспецифичными или мультиспецифичными, такими как триспецифичные, тетраспецифичные и так далее.
Связывающий агент по настоящему изобретению может быть, по меньшей мере, трехвалентным. Используемый в данном документе термин «валентный», «валентность», «валентности» или другие их грамматические варианты означают количество сайтов связывания антигена или связывающих доменов в связывающем агенте. Сайты связывания антигена, связывающиеся с одним и тем же антигеном, могут распознавать один и тот же эпитоп или разные эпитопы. Трехвалентные биспецифичные антитела и четырехвалентные биспецифичные антитела известны в данной области. Связывающий агент по настоящему изобретению также может иметь валентность выше 4.
Связывающий агент, описанный в данном документе, предпочтительно, представляет собой искусственный белок (в том числе белковые комплексы), который может быть составлен из фрагментов, по меньшей мере, двух различных антител (указанные фрагменты, по меньшей мере, двух различных антител, образующих, по меньшей мере, два различных связывающих домена) и, следовательно, связывающихся, по меньшей мере, с двумя разными типами антигенов. Связывающий агент по изобретению разработан для одновременного связывания с иммунной клеткой, такой как иммунная эффекторная клетка, в частности с Т-клеткой, такой как цитотоксическая клетка (например, путем связывания с CD3), и клеткой-мишенью, подлежащей уничтожению, такой как раковая клетка (путем связывания с опухолевым антигеном (клаудином).
Было разработано несколько типов трехвалентных антител, и все типы находятся в пределах объема настоящего изобретения. TRIPLEBODY или одноцепочечные тройные антитела (sctb) состоят из трех отдельных областей scFv, соединенных линкерными последовательностями. Кроме того, естественная гетеродимеризация in vivo тяжелой цепи (домен CH1) и легкой цепи (домен CL) может быть использована для образования каркаса, на который можно добавить несколько scFv. Так, например, ScFv специфичный для одного антигена может быть связан с доменом CH1, который также связан с определенной ScFv с другим антигеном, и эта цепь может взаимодействовать с другой цепью, содержащей ScFv специфичной для любого антигена, связанного с доменом CL (scFv3 -CH1/CL). Другой пример трехвалентной конструкции включает использование Fab-фрагмента, специфичного для одного эпитопа, С-конца связанного с двумя scFv, специфичными для другого эпитопа, по одному на каждую цепь (Fab-scFv2). Еще один пример трехвалентной (или четырехвалентной) молекулы включает множество форматов, которые содержат дополнительные связывающие объекты, присоединенные к N- или C-концам антител. Например, один формат состоит из молекулы интактного антитела, специфичного к одному антигену, с одноцепочечным Fab (scFab), связанным с C- концом молекулы (IgG-scFab). Подход Dock-and-Lock (DNL) также использовался для получения трехвалентных антител (DNL- F (ab) 3) (Chang, C.-H. et al. In: Bispecific Antibodies. Kontermann R.E. (ed.), Springer Гейдельберг Dordrecht London New York, pp. 199-216 (2011)). Каждое из вышеупомянутых антител входит в объем настоящего изобретения.
Также были сконструированы четырехвалентные антитела, и все типы находятся в пределах объема настоящего изобретения. Примеры четырехвалентных антител включают, без ограничения указанным, молекулы scFv2-Fc, F (ab') 2-scFv2, scFv2-H/L и scFv-dhlx-scFv. Биспецифичные конструкции scFv2-Fc имеют домен Fc с двумя scFv, специфичными к одной молекуле, связанный с N-концом цепей Fc, и двумя другими scFv, специфичными к другой молекуле, связанной с С-концом цепи Fc. Биспецифичные конструкции F (ab') 2-scFv2 включают фрагменты scFv, связанные с C-концом фрагмента F (ab')2. Конструкции scFv2-H/L имеют scFv, специфичные к одной молекуле, связанной с тяжелыми цепями, тогда как scFv, специфичные к другой молекуле, связаны с легкими цепями. Наконец, конструкции scFv-dhlx-scFv содержат один тип scFv, связанный с спиральным доменом димеризации, за которым следует другой тип scFv. Две цепи этого типа могут димеризоваться, образуя четырехвалентное антитело.
Связывающий агент по изобретению может быть в форме молекулы антитела или молекулы, подобной антителу, или белкового каркаса с антителоподобными свойствами, или циклического пептида, по меньшей мере, с двумя специфичностями связывания. Таким образом, связывающий агент может содержать одно или несколько антител, описанных в данном документе, или их фрагменты.
В одном воплощении связывающий агент по изобретению включает тяжелую цепь (фрагмент Fd) и легкую цепь (L) фрагмента Fab, которые способны к гетеродимеризации и с помощью которых могут быть привнесены дополнительные функции или связывающие домены. Такие дополнительные связывающие домены могут быть независимо выбраны из группы, состоящей из связывающих доменов, содержащих две вариабельные области антитела, такие как scFv-связывающие домены, т.е. VH-VL или VL-VH, и связывающих доменов, содержащих одну вариабельную область антитела, такую как VH-связывающие домены и VHH-связывающие домены.
В одном воплощении связывающий агент по изобретению находится в формате конструкции Fab-scFv2, то есть фрагмент Fab, снабженный двумя фрагментами scFv, предпочтительно на С-конце константных областей фрагмента Fab. В одном воплощении связывающий агент по изобретению представляет собой димер, состоящий из двух полипептидных цепей, предпочтительно связанных вместе дисульфидным мостиком, в котором первый полипептид включает scFv, связанный с дополнительным доменом VL через полипептидную цепь CL, и второй полипептид включает scFv, связанный с дополнительным доменом VH через полипептидную цепь CH1. Дисульфидный мостик предпочтительно образуется между остатком Cys в CL и остатком Cys в CH1, так что дополнительный VL первого полипептида ассоциируется с дополнительным VH второго полипептида в антигенсвязывающей конфигурации, так что связывающий агент в целом включает три антигенсвязывающих домена. Таким образом, в одном воплощении связывающий агент по изобретению включает тяжелую цепь (фрагмент Fd) и легкую цепь (L) фрагмента Fab, которые способны гетеродимеризоваться и в которые включены scFv-связывающие домены (предпочтительно на С-конце) в Fd/L). Согласно изобретению домены VH и VL в фрагментах scFv предпочтительно соединены пептидными линкерами и/или цепями Fab, а scFv предпочтительно соединены пептидными линкерами. Согласно изобретению домены VH и VL в фрагментах scFv предпочтительно связаны пептидными линкерами, имеющими аминокислотную последовательность (G4S)x, где x равно 3, 4, 5 или 6. Цепи Fab и scFv предпочтительно связаны пептидным линкером, имеющим аминокислотную последовательность DVPG2S или SGPG3RS(G4S)2. В одном воплощении линкер, содержащий аминокислотную последовательность SGPG3RS(G4S)2, соединяет связывающий домен scFv с Fd-фрагментом, и линкер, содержащий аминокислотную последовательность DVPG2S, соединяет связывающий домен scFv с L-фрагментом. В одном воплощении scFv-фрагменты связываются с клаудином, а Fab-фрагмент связывается с Т-клеточным специфическим антигеном.
В одном воплощении связывающий агент по изобретению включает первый и второй полипептид, где первый полипептид и второй полипептид включают от N-конца до C-конца следующие домены:
VH-CH1-scFv и VL-CL-scFv,
где VH и VL связаны с образованием связывающего домена.
В одном воплощении связывающий агент по изобретению включает первый и второй полипептид, где в первом полипептиде и втором полипептиде домен(ы) VH, домен(ы) VL, домен CH1 и домен CL расположены от N-конца к C-концу в порядке
- VH(T) -CH1-VH (CLDN) -VL (CLDN) и VL(T) -CL-VH (CLDN) -VL (CLDN); или
- VH(T) -CH1-VL (CLDN) -VH (CLDN) и VL(T) -CL-VL (CLDN) -VH (CLDN); или
- VH(T) -CH1-VH (CLDN) -VL- (CLDN) и VL(T) -CL-VL (CLDN) -VH- (CLDN); или
- VH(T) -CH1-VL (CLDN) -VH- (CLDN) и VL(T) -CL-VH (CLDN) -VL- (CLDN); или
- VH (CLDN) -CH1-VH(T) -VL(T) и VL (CLDN) -CL-VH (CLDN) -VL (CLDN); или
- VH (CLDN) -CH1-VL(T) -VH(T) и VL (CLDN) -CL-VL (CLDN) -VH (CLDN); или
- VH (CLDN) -CH1-VL(T) -VH(T) и VL (CLDN) -CL-VH (CLDN) -VL (CLDN); или
- VH (CLDN) -CH1-VH(T) -VL(T) и VL (CLDN) -CL-VL (CLDN) -VH (CLDN); или
- VH (CLDN) -CH1-VH (CLDN) -VL (CLDN) и VL (CLDN) -CL-VH(T) -VL(T); или
- VH (CLDN) -CH1-VL (CLDN) -VH (CLDN) и VL (CLDN) -CL-VL(T) -VH(T); или
- VH (CLDN) -CH1-VL (CLDN) -VH (CLDN) и VL (CLDN) -CL-VH(T) -VL(T); или
-VH(CLDN)-CH1-VH(CLDN)-VL(CLDN) and VL(CLDN)-CL-VL(T)-VH(T).
Термин «линкер» относится к любым средствам, которые служат для соединения двух различных функциональных единиц (например, антигенсвязывающих фрагментов). Типы линкеров включают, без ограничения указанным, химические линкеры и полипептидные линкеры. Последовательности полипептидных линкеров не ограничены. Полипептидные линкеры предпочтительно являются неиммуногенными и гибкими, такими как линкеры, содержащие последовательности серина и глицина. В зависимости от конкретной конструкции линкеры могут быть длинными или короткими.
Согласно изобретению линкер, соединяющий домены VH и VL с образованием доменов scFv VH-VL или VL-VH, предпочтительно включает гибкий пептидный линкер, такой как глицин-сериновый пептидный линкер. В одном воплощении линкер включает аминокислотную последовательность (GSx, где x равно 3, 4, 5 или 6. В случае домена scFv, содержащего домены VH и VL в ориентации VH-VL, линкер предпочтительно включает аминокислотную последовательность (G4S)4. В случае домена scFv, содержащего домены VH и VL в ориентации VL-VH, линкер предпочтительно включает аминокислотную последовательность (G4S)5.
Согласно изобретению линкер, соединяющий домен scFv и домен Fd, предпочтительно на С-конце CH1, предпочтительно включает аминокислотную последовательность DVPG2S или SGPG3RS(G4S)2, предпочтительно SGPG3RS(G4S)2. Согласно изобретению линкер, соединяющий домен scFv и домен L, предпочтительно на С-конце CL, предпочтительно включает аминокислотную последовательность DVPG2S или SGPG3RS(G4S)2, предпочтительно DVPG2S.
Связывающие агенты согласно изобретению могут также содержать аминокислотную последовательность для облегчения секреции молекулы, такую как N-концевой сигнал секреции, и/или одну или несколько эпитопных меток, облегчающих связывание, очистку или обнаружение молекулы.
Предпочтительно сигнал секреции представляет собой сигнальную последовательность (например, аминокислотную последовательность MGWSCIILFLVATATGVHS), которая обеспечивает достаточный проход через секреторный путь и/или секрецию связывающего агента или его полипептидных цепей во внеклеточную среду. Предпочтительно сигнальная последовательность секреции является расщепляемой и удаляется из зрелого связывающего агента. Сигнальная последовательность секреции предпочтительно выбирается с учетом клетки или организма, в которых продуцируется связывающий агент.
Аминокислотная последовательность эпитопной метки может быть введена в любое положение в аминокислотной последовательности связывающего агента и может принимать форму петли в структуре кодируемого белка, или она может быть слитой с N-концом или С-концом связывающего агента. Предпочтительно эпитопная метка соединена со связующим агентом на С-конце. Эпитопная метка может включать сайт расщепления, который позволяет удалить метку из связывающего агента. Указанная эпитопная метка может быть любым типом эпитопной метки, которая функционирует в нативных и/или денатурирующих условиях, предпочтительно гистидиновой меткой, наиболее предпочтительно меткой, содержащей шесть гистидинов.
Связывающий агент по изобретению может содержать, помимо указанных первого, второго и третьего связывающих доменов, один или несколько дополнительных связывающих доменов, которые служат, например, для повышения селективности в отношении опухолевых клеток. Это может быть достигнуто, например, путем предоставления связывающих доменов, которые связываются с другими антигенами, экспрессированными на опухолевых клетках.
В контексте настоящего изобретения полученные связывающие агенты предпочтительно способны вызывать иммунные эффекторные функции, как описано в данном документе. Предпочтительно указанные иммунные эффекторные функции направлены против клеток, несущих ассоциированный с опухолью антиген клаудин на своей поверхности.
Термин «функции иммунного эффектора» в контексте настоящего изобретения включает любые функции, опосредованные компонентами иммунной системы, которые приводят, например, к ингибированию роста опухоли и/или ингибированию развития опухоли, включая ингибирование распространения опухолей и метастазов. Предпочтительно, функции иммунного эффектора приводят к уничтожению опухолевых клеток. Такие функции включают комплементарно-зависимую цитотоксичность (CDC), антителозависимую клеточно-опосредованную цитотоксичность (ADCC), антителозависимый клеточно-опосредованный фагоцитоз (ADCP), индукцию апоптоза в клетках, несущих опухолевый антиген, цитолиз клеток, несущих опухолевый антиген и/или ингибирование пролиферации клеток, несущих опухолевый антиген. Связывающие агенты могут также оказывать действие просто путем связывания с опухолевыми антигенами на поверхности раковой клетки. Например, антитела могут блокировать функцию опухолевого антигена или индуцировать апоптоз только путем связывания с опухолевым антигеном на поверхности раковой клетки.
Описываемые в данном документе связывающие агенты могут быть конъюгированы с терапевтическим фрагментом или агентом, таким как цитотоксин, лекарственное средство (например, иммунодепрессант) или радиоизотоп. Цитотоксин или цитотоксический агент включает любой агент, который вреден для клетки и, в частности, убивает клетки. Примеры включают таксол, цитохалазин В, грамицидин D, этидиумбромид, эметин, митомицин, этопозид, тенопозид, винкристин, винбластин, колхицин, доксорубицин, даунорубицин, дигидроксиантрациндион, митоксантрон, митрамицин, актиномицин D, аманитин, 1-дегидротестостерон, глюкокортикоиды, прокаин, тетракаин, лидокаин, пропранолол и пуромицин, и их аналоги или гомологи. Подходящие терапевтические агенты для образования конъюгатов антител включают, без ограничения указанным, антиметаболиты (например, метотрексат, 6-меркаптопурин, 6-тиогуанин, цитарабин, флударабин, 5-фторурацилдекарбазин), алкилирующие агенты (например, мехлорэтамин, тиоэпа хлорамбуцил, мелфалан, кармустин (BSNU) и ломустин (CCNU), циклофосфамид, бусульфан, дибромманнитол, стрептозотоцин, митомицин С и ис-Диамминдихлороплатина (II) (DDP) цисплатин), антрациклины (например, даунорубицин (ранее дауномицин) и доксорубицин), антибиотики (например, дактиномицин (ранее актиномицин), блеомицин, митрамицин и антрамицин (АМС) и антимитотические агенты (например, винкристин и винбластин). В предпочтительном воплощении терапевтический агент представляет собой цитотоксический агент или радиотоксический агент. В другом воплощении терапевтический агент представляет собой иммунодепрессант. В еще одном варианте терапевтический агент представляет собой GM-CSF. В предпочтительном воплощении терапевтический агент представляет собой доксорубицин, цисплатин, блеомицин, сульфат, кармустин, хлорамбуцил, циклофосфамид или рицин А.
Связывающие агенты могут быть конъюгированы с радиоизотопом, например иодом-131, иттрием-90 или индием-111, для получения цитотоксических радиофармацевтических препаратов.
Способы конъюгирования такого терапевтического фрагмента с антителами хорошо известны, см., например, Arnon et al., "Monoclonal Antibodies For Immunotargeting Of Drugs In Cancer Therapy", in Monoclonal Antibodies And Cancer Therapy, Reisfeld et al. (eds.), pp. 243-56 (Alan R. Liss, Inc. 1985); Hellstrom et al., "Antibodies For Drug Delivery", in Controlled Drug Delivery (2nd Ed.), Robinson et al. (eds.), pp. 623-53 (Marcel Dekker, Inc. 1987); Thorpe, "Antibody Carriers Of Cytotoxic Agents In Cancer Therapy: A Review", in Monoclonal Antibodies '84: Biological And Clinical Applications, Pincheraet al. (eds.), pp. 475-506 (1985); "Analysis, Results, And Future Prospective Of The Therapeutic Use Of Radiolabeled Antibody In Cancer Therapy", in Monoclonal Antibodies For Cancer Detection And Therapy, Baldwin et al. (eds.), pp. 303-16 (Academic Press 1985), и Thorpe et al., "The Preparation And Cytotoxic Properties Of Antibody-Toxin Conjugates", Immunol. Rev., 62: 119-58 (1982).
Термин «связывание» согласно изобретению предпочтительно относится к специфическому связыванию.
Согласно настоящему изобретению агент, такой как антитело, способен связываться с заранее определенной мишенью, если он обладает значительным сродством к указанной заранее определенной мишени и связывается с указанной предварительно определенной мишенью в стандартных анализах. «Аффинность» или «аффинность связывания» часто измеряют по равновесной константе диссоциации (KD). Предпочтительно термин «значительная аффинность» относится к связыванию с заданной мишенью с константой диссоциации (KD) 10-5 М или ниже, 10-6 М или ниже, 10-7 М или ниже, 10-8 М или ниже, 10-9 М или ниже, 10-10 М или ниже, 10-11 М или ниже, или 10-12 М или ниже.
Агент (по существу) не способен связываться с мишенью, если он не имеет значительного аффинности к указанной мишени и не связывается значительно, в частности, не связывается детектируемым образом с указанной мишенью в стандартных анализах. Предпочтительно антитело не обнаруживает связи с указанной мишенью, если оно присутствует в концентрации до 2, предпочтительно 10, более предпочтительно 20, в частности 50 или 100 мкг/мл или выше. Предпочтительно, если агент не имеет существенной аффинности к мишени, если он связывается с указанной мишенью с KD, которое, по меньшей мере, в 10 раз, 100 раз, 103 - раз, 104 - раз, 105 - раз, или 106 раз выше, чем KD для связывания с предопределенной мишенью, с которой антитело способно связываться. Например, если KD для связывания антитела с мишенью, с которой антитело способно связываться, составляет 10-7 М, KD для связывания с мишенью, с которым антитело не имеет значимой аффинности, будет составлять, по меньшей мере, 10-6 М, 10-5 М, 10-4 М, 10-3 М, 10-2 М или 10-1 М.
Агент специфичен для заданной мишени, если он способен связываться с указанной предопределенной мишенью, и в то же время не способен связываться с другими мишенями, то есть не имеет существенного аффинности к другим мишеням и не может существенно связываться с другими мишенями в стандартных анализах. Согласно изобретению агент специфичен для клаудина, если он способен связываться с клаудином, но (по существу) не способен связываться с другими мишенями. Предпочтительно, агент является специфичным для клаудина, если аффинность и связывание с такими другими мишенями значительно не превышают аффинность или связывание с не родственными с клаудином белками, такими как бычий сывороточный альбумин (BSA), казеин, человеческий сывороточный альбумин (HSA)) или с неклаудиновыми трансмембранными белками, такими как молекулы МНС или рецептор трансферрина, или любым другим указанным полипептидом. Предпочтительно, агент является специфическим для предварительно определенной мишени, если он связывается с указанным объектом с KD, которое, по меньшей мере, в 10 раз, 100 раз, 103 - раз, 104 - раз, 105 - раз или 106 -раз меньше, чем KD связывания с мишенью, для которой оно не является специфическим. Например, если KD для связывания агента с мишенью, для которой он специфичен, составляет 10-7 M, KD для связывания с мишенью, для которой он не является специфическим, будет составлять, по меньшей мере, 10-6 М, 10-5 М, 10-4 М, 10-3 М, 10-2 М или 10-1 М.
Связывание агента с мишенью может быть определено экспериментально с использованием любого подходящего способа; см., например, Berzofsky et al., "Antibody-Antigen Interactions" In Fundamental Immunology, Paul, W. E., Ed., Raven Press New York, N Y (1984), Kuby, Janis Immunology, W. H. Freeman and Company New York, N Y (1992), и способы, описанные в данном документе. Аффинности могут быть легко определены с использованием обычных методов, таких как равновесный диализ; с помощью прибора BIAcore 2000, используя общие процедуры, указанные производителем; путем радиоиммунологического анализа с использованием радиоактивно меченного антигена; или другим способом, известным специалисту в данной области техники. Данные о аффинности могут быть проанализированы, например, способом Scatchard et al., Ann NY Acad. ScL, 51:660 (1949). Измеренная аффинность конкретного взаимодействия антитело-антиген может изменяться, если измерять ее в разных условиях, например, концентрации соли, рН. Таким образом, измерения аффинности и других антигенсвязывающих параметров, например KD, IC50, предпочтительно производятся со стандартизованными растворами антител и антигена и стандартизованным буфером.
Термин «конкурирует» относится к конкуренции между двумя антителами за связывание с антигеном-мишенью. Если два антитела не блокируют друг друга за связывание с антигеном-мишенью, такие антитела не являются конкурирующими, и это указывает на то, что указанные антитела не связываются с одной и той же частью, т.е. эпитопом антигена-мишени. Специалисту в данной области хорошо известно, как тестировать конкуренцию антител за связывание с антигеном-мишенью. Примером такого способа является так называемый анализ перекрестной конкуренции, который может, например, быть выполнен в виде ELISA или с помощью проточной цитометрии.
Например, анализ на основе ELISA можно проводить, проведя покрытие лунки планшета для ELISA каждым из антител; добавление конкурирующего антитела и His-меченого внеклеточного домена антигена/мишени и инкубирование; определение того, ингибирует ли добавленное антитело связывание His-меченого белка с нанесенным в виде покрытия антителом может быть выполнено путем добавления биотинилированного анти-His-антитела с последующим добавлением стрептавидин-поли-HRP и дальнейшим проявлением реакции с помощью ABTS и измерением поглощения при 405 нм. Например, анализ проточной цитометрией может быть выполнен путем инкубации клеток, экспрессирующих антиген/мишень с избытком немеченого антитела, инкубации клеток с субоптимальной концентрацией меченного биотином антитела с последующей инкубацией с флуоресцентно меченным стрептавидином и анализом путем проточной цитометрии.
Два антитела имеют «одинаковую специфичность», если они связываются с одним и тем же антигеном и одним и тем же эпитопом. Распознает ли антитело, подлежащее тестированию, тот же эпитоп, что и определенное антигенсвязывающее антитело, т.е. антитела, связываются с одним и тем же эпитопом, может быть проанализировано на основе их конкуренции за один и тот же эпитоп. Конкуренция между антителами может быть обнаружена с помощью анализа перекрестного блокирования. Например, конкурентный анализ ELISA может использоваться в качестве анализа перекрестного блокирования. Например, целевой антиген может быть нанесен в лунки планшета для микротитрования, и может быть добавлено антигенсвязывающее антитело и возможное конкурирующее тестируемое антитело. Количество антигенсвязывающего антитела, связанного с антигеном в лунке, косвенно коррелирует со способностью связывания потенциального конкурирующего тестируемого антитела, которое конкурирует с ним за связывание с тем же эпитопом. В частности, чем больше аффинность потенциального конкурирующего тестируемого антитела к тому же эпитопу, тем меньше количество антигенсвязывающего антитела, связанного с лункой, покрытой антигеном. Количество антигенсвязывающего антитела, связанного с лункой, можно измерить, помечая антитело детектируемыми или измеряемыми метящими веществами.
Антитело, конкурирующее за связывание с антигеном с другим антителом, например антитело, содержащее вариабельные области тяжелой и легкой цепи, как описано в данном документе, или антитело, обладающее специфичностью к антигену другого антитела, например антитело, содержащее вариабельную тяжелую и легкую цепь области, как описано в данном документе, может представлять собой антитело, содержащее варианты указанных вариабельных областей тяжелой и/или легкой цепи, как описано в данном документе, например, модификации CDR и/или определенную степень идентичности, как описано в данном документе.
Используемый в данном документе термин «изотип» относится к классу антител (например, IgM или IgG1), который кодируется генами константной области тяжелой цепи.
Используемый в данном документе термин «переключение изотипа» относится к феномену, с помощью которого класс или изотип антитела изменяется от одного класса Ig к одному из других классов Ig.
Термин «встречающийся в природе», используемый в данном документе для применения к объекту, относится к тому факту, что объект можно найти в природе. Например, полипептидная или полинуклеотидная последовательность, присутствующая в организме (включая вирусы), которая может быть выделена из источника в природе и которая не была намеренно модифицирована человеком в лаборатории является встречающейся в природе.
Используемый в данном документе термин «перегруппированный» относится к конфигурации локуса иммуноглобулина тяжелой цепи или легкой цепи, где V-сегмент расположен непосредственно рядом с сегментом D-J или J в конформации, кодирующей, по существу, полный домен VH или VL, соответственно. Перестроенный локус гена иммуноглобулина (антитела) может быть идентифицирован путем сравнения с ДНК зародышевой линии; перестроенный локус будет иметь, по меньшей мере, один рекомбинированный элемент гомологии гептамера/нонамера.
Термин «неперестроенный» или «конфигурация зародышевой линии», при использовании в данном документе в отношении V-сегмента, относится к конфигурации, в которой V-сегмент не рекомбинирован, чтобы быть непосредственно смежным с сегментом D или J.
В одном воплощении связывающий агент по изобретению обладает способностью связываться с CLDN18.2, то есть способностью связываться с эпитопом, присутствующим в CLDN18.2, предпочтительно с эпитопом, расположенным внутри внеклеточных доменов CLDN18.2, в частности с первой внеклеточной петлей, предпочтительно аминокислотными положениями 29-78 в CLDN18.2. В конкретных воплощениях агент, обладающий способностью связываться с CLDN18.2, связывается с эпитопом на CLDN18.2, который отсутствует на CLDN18.1.
Агент, имеющий способность связываться с CLDN18.2, предпочтительно связывается с CLDN18.2, но не с CLDN18.1. Предпочтительно, агент, обладающий способностью связываться с CLDN18.2, является специфичным к CLDN18.2. Предпочтительно, агент, обладающий способностью связываться с CLDN18.2, связывается с CLDN18.2, экспрессируемым на клеточной поверхности. В предпочтительных воплощениях агент, обладающий способностью связываться с CLDN18.2, связывается с нативными эпитопами CLDN18.2, присутствующими на поверхности живых клеток.
В предпочтительном воплощении связывающий домен, связывающий с CLDN18.2, из связывающего агента по изобретению, включает вариабельную область тяжелой цепи (VH), содержащую аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 20, 21, 24 или ее фрагмента, или варианта аминокислотной последовательности или фрагмента.
В предпочтительном воплощении связывающий домен, связывающийся с CLDN18.2 связывающего агента по изобретению, включает вариабельную область легкой цепи (VL), содержащую аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 22, 23, 25 или ее фрагмента, или варианта аминокислотной последовательности или фрагмента.
В некоторых предпочтительных воплощениях связывающий домен, связывающий с CLDN18.2, из связывающего агента по изобретению, включает комбинацию вариабельной области тяжелой цепи (VH) и вариабельной области легкой цепи (VL), выбранную из следующих возможностей:
(i) VH включает аминокислотную последовательность, представленную SEQ ID NO: 20 или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 22, или ее фрагмент или вариант аминокислотной последовательности или фрагмента,
(ii) VH включает аминокислотную последовательность, представленную SEQ ID NO: 20, или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 23, или ее фрагмент или вариант аминокислотной последовательности или фрагмента,
(iii) VH включает аминокислотную последовательность, представленную SEQ ID NO: 21 или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 22, или ее фрагмент или вариант аминокислотной последовательности или фрагмента,
(iv) VH включает аминокислотную последовательность, представленную SEQ ID NO: 21 или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 23, или ее фрагмент или вариант аминокислотной последовательности или фрагмента,
(v) VH включает аминокислотную последовательность, представленную SEQ ID NO: 24, или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 25, или ее фрагмент или вариант аминокислотной последовательности или фрагмента.
В особенно предпочтительном воплощении связывающий домен, связывающий с CLDN18.2, из связывающего агента по изобретению, включает следующую комбинацию вариабельной области тяжелой цепи (VH) и вариабельной области легкой цепи (VL):
VH включает аминокислотную последовательность, представленную SEQ ID NO: 20, или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 22, или ее фрагмент, или вариант аминокислотной последовательности или фрагмента.
В особенно предпочтительном воплощении связывающий домен, связывающий с CLDN18.2, из связывающего агента по изобретению, включает следующую комбинацию вариабельной области тяжелой цепи (VH) и вариабельной области легкой цепи (VL):
VH включает аминокислотную последовательность, представленную SEQ ID NO: 21 или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 23, или ее фрагмент, или вариант аминокислотной последовательности или фрагмента.
Термин «фрагмент» относится, в частности, к одной или нескольким из определяющих комплементарность областей (CDR), предпочтительно, по меньшей мере, вариабельной области CDR3 вариабельной области тяжелой цепи (VH) и/или вариабельной области легкой цепи (VL). В одном воплощении указанная одна или несколько областей, определяющих комплементарность (CDR), выбираются из набора областей, определяющих комплементарность CDR1, CDR2 и CDR3. В особенно предпочтительном воплощении термин «фрагмент» относится к областям, определяющим комплементарность CDR1, CDR2 и CDR3 вариабельной области тяжелой цепи (VH) и/или вариабельной области легкой цепи (VL).
В одном воплощении связывающий домен, содержащий одну или несколько CDR, набор CDR или комбинацию наборов CDR, как описано в настоящем документе, включает указанные CDR вместе с их промежуточными каркасными областями. Предпочтительно, эта часть также будет включать, по меньшей мере, около 50% одной или обеих из первой и четвертой каркасных областей, причем 50% являются С-концевой 50% первой каркасной области и N-концевой 50% четвертой каркасной области. Конструирование связывающих агентов, полученных методами рекомбинантных ДНК, может привести к введению остатков N- или C-конца в вариабельные области, кодируемых линкерами, которые введены для облегчения клонирования или других стадий обработки, включая введение линкеров для соединения вариабельных областей по изобретению с дополнительными последовательностями белка, включая тяжелые цепи иммуноглобулина, другие вариабельные домены или белковые метки.
В одном воплощении связывающий домен, содержащий одну или несколько CDR, набор CDR или комбинацию наборов CDR, как описано в настоящем документе, включает указанные CDR в каркасе человеческого антитела.
В предпочтительном воплощении связывающий домен, связывающий с CLDN18.2, из связывающего агента по изобретению, включает следующую комбинацию вариабельной области тяжелой цепи (VH) и вариабельной области легкой цепи (VL):
VH включает область 3, определяющую комплементарность тяжелой цепи (HCDR3), содержащую последовательность, представленную в SEQ ID NO: 58, и
VL включает область 3, определяющую комплементарность легкой цепи (LCDR3), содержащую последовательность, представленную в SEQ ID NO: 64.
В одном воплощении VH дополнительно включает HCDR1, содержащую последовательность, представленную в SEQ ID NO: 56, и/или HCDR2, содержащую последовательность, представленную в SEQ ID NO: 57, и/или VL дополнительно включает LCDR1, содержащую последовательность, представленную в SEQ ID NO: 62, и/или LCDR2, содержащую последовательность, представленную в SEQ ID NO: 63.
В предпочтительном воплощении связывающий домен, связывающий с CLDN18.2, из связывающего агента по изобретению, включает следующую комбинацию вариабельной области тяжелой цепи (VH) и вариабельной области легкой цепи (VL):
VH включает HCDR1, содержащую последовательность, представленную в SEQ ID NO: 56, HCDR2, содержащую последовательность, представленную в SEQ ID NO: 57, и HCDR3, содержащую последовательность, представленную в SEQ ID NO: 58, и VL включает LCDR1, содержащую последовательность, представленную в SEQ ID NO: 62, LCDR2, содержащую последовательность, представленную в SEQ ID NO: 63, и LCDR3, содержащую последовательность, представленную в SEQ ID NO: 64.
В предпочтительном воплощении связывающий домен, связывающий с CLDN18.2, из связывающего агента по изобретению, включает следующую комбинацию вариабельной области тяжелой цепи (VH) и вариабельной области легкой цепи (VL):
VH включает область 3, определяющую комплементарность тяжелой цепи (HCDR3), содержащую последовательность, представленную в SEQ ID NO: 61, и
VL включает область 3, определяющую комплементарность легкой цепи (LCDR3), содержащую последовательность, представленную в SEQ ID NO: 65.
В одном воплощении VH дополнительно включает HCDR1, содержащую последовательность, представленную в SEQ ID NO: 59, и/или HCDR2, содержащую последовательность, представленную в SEQ ID NO: 60, и/или VL дополнительно включает LCDR1, содержащую последовательность, представленную в SEQ ID NO: 62, и/или LCDR2, содержащую последовательность, представленную в SEQ ID NO: 63.
В предпочтительном воплощении связывающий домен, связывающий с CLDN18.2, из связывающего агента по изобретению, включает следующую комбинацию вариабельной области тяжелой цепи (VH) и вариабельной области легкой цепи (VL):
VH включает HCDR1, содержащую последовательность, представленную в SEQ ID NO: 59, HCDR2, содержащую последовательность, представленную в SEQ ID NO: 60, и HCDR3, содержащую последовательность, представленную в SEQ ID NO: 61, и VL включает LCDR1 содержащую последовательность, представленную в SEQ ID NO: 62, LCDR2, содержащую последовательность, представленную в SEQ ID NO: 63, и LCDR3, содержащую последовательность, представленную в SEQ ID NO: 65.
В одном воплощении указанные вариабельные области тяжелой и легкой цепи содержат указанные области, определяющие комплементарность, вставленные в каркасные области. В одном воплощении каждая вариабельная область включает три определяющие комплементарность области (CDR1, 2 и 3) и четыре каркасных области (FR1, 2, 3 и 4). В одном воплощении указанные определяющие комплементарность области и указанные каркасные области расположены от аминоконца до карбоксиконца в следующем порядке: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4.
В других воплощениях связывающий домен, связывающий с CLDN18.2, из связывающего агента по изобретению, включает вариабельные области тяжелой и легкой цепи антитела, которое (i) конкурирует за связывание CLDN18.2 с антителом, содержащим вариабельные области тяжелой и легкой цепи, как описано выше, и/или (ii) имеет специфичность к CLDN18.2 антитела, содержащего вариабельные области тяжелой и легкой цепи, как описано выше.
В одном воплощении вариабельная область тяжелой цепи (VH) и вариабельная область легкой цепи (VL) связывающего домена, связывающегося с CLDN18.2, связывающего агента по изобретению, имеют формат молекулы scFv. В этом воплощении связывающий домен, связывающийся с CLDN18.2 связывающего агента по изобретению, включает аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 26, 27, 28, 29 или их фрагмента, или варианта аминокислотной последовательности или фрагмента.
Следует понимать, что связывающие домены, связывающиеся с CLDN18.2 связывающего агента по изобретению, могут быть идентичными или по существу идентичными или разными и, таким образом, могут связываться с идентичными или по существу идентичными эпитопами или различными эпитопами. Таким образом, оба домена связывания, связывающиеся с CLDN18.2 связывающего агента по изобретению, могут соответствовать или по существу соответствовать одному из связывающих доменов, связывающихся с CLDN18.2 связывающего агента по изобретению, описанному в данном документе, или они могут быть независимо выбраны из связывающих доменов, связывающихся с CLDN18.2 связывающего агента по изобретению, описанного в данном документе.
В одном воплощении связывающий агент по изобретению обладает способностью связываться с CLDN6, то есть способностью связываться с эпитопом, присутствующим в CLDN6, предпочтительно эпитопом, расположенным внутри внеклеточных доменов CLDN6, в частности первой внеклеточной петли, предпочтительно аминокислотные положения 28-76 или 29-81 в CLDN6 или второй внеклеточной петли, предпочтительно аминокислотные положения 141-159 в CLDN6. В конкретных воплощениях агент, обладающий способностью связываться с CLDN6, связывается с эпитопом на CLDN6, который не присутствует на CLDN9. Предпочтительно агент, обладающий способностью связываться с CLDN6, связывается с эпитопом на CLDN6, который не присутствует на CLDN4 и/или CLDN3. Наиболее предпочтительно, агент, обладающий способностью связываться с CLDN6, связывается с эпитопом на CLDN6, который не присутствует на белке клаудина, отличном от CLDN6.
Агент, обладающий способностью связываться с CLDN6, предпочтительно связывается с CLDN6, но не с CLDN9 и предпочтительно не связывается с CLDN4 и/или CLDN3. Предпочтительно агент, обладающий способностью связываться с CLDN6, является специфичным для CLDN6. Предпочтительно агент, обладающий способностью связываться с CLDN6, связывается с CLDN6, экспрессируемым на клеточной поверхности. В конкретных предпочтительных воплощениях агент, обладающий способностью связываться с CLDN6, связывается с нативными эпитопами CLDN6, присутствующими на поверхности живых клеток.
В предпочтительном воплощении связывание связывающего домена с CLDN6 связывающего агента по изобретению включает вариабельную область тяжелой цепи (VH), содержащую аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 7, 8, 11 или ее фрагмента или варианта аминокислотной последовательности или фрагмента.
В предпочтительном воплощении связывание связывающего домена с CLDN6 связывающего агента по изобретению включает вариабельную область легкой цепи (VL), содержащую аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 9, 10, 12 или ее фрагмента или варианта аминокислотной последовательности или фрагмента.
В некоторых предпочтительных воплощениях связывание связывающего домена с CLDN6 связывающего агента по изобретению включает комбинацию вариабельной области тяжелой цепи (VH) и вариабельной области легкой цепи (VL), выбранную из следующих возможностей:
(i) VH включает аминокислотную последовательность, представленную SEQ ID NO: 7 или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 9, или ее фрагмент или вариант аминокислотной последовательности или фрагмента,
(ii) VH включает аминокислотную последовательность, представленную SEQ ID NO: 7 или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 10, или ее фрагмент или вариант аминокислотной последовательности или фрагмента,
(iii) VH включает аминокислотную последовательность, представленную SEQ ID NO: 8 или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 9, или ее фрагмент или вариант аминокислотной последовательности или фрагмента,
(iv) VH включает аминокислотную последовательность, представленную SEQ ID NO: 8 или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 10, или ее фрагмент или вариант аминокислотной последовательности или фрагмента,
(v) VH включает аминокислотную последовательность, представленную SEQ ID NO: 11 или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 12, или ее фрагмент или вариант аминокислотной последовательности или фрагмента,
(vi) VH включает аминокислотную последовательность, представленную SEQ ID NO: 7 или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 12, или ее фрагмент или вариант аминокислотной последовательности или фрагмента,
(vii) VH включает аминокислотную последовательность, представленную SEQ ID NO: 8 или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 12, или ее фрагмент или вариант аминокислотной последовательности или фрагмента.
В особенно предпочтительном воплощении связывание связывающего домена с CLDN6 связывающего агента по изобретению включает следующую комбинацию вариабельной области тяжелой цепи (VH) и вариабельной области легкой цепи (VL):
VH включает аминокислотную последовательность, представленную SEQ ID NO: 8 или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 10, или ее фрагмент, или вариант аминокислотной последовательности или фрагмента.
В особенно предпочтительном воплощении связывание связывающего домена с CLDN6 связывающего агента по изобретению включает следующую комбинацию вариабельной области тяжелой цепи (VH) и вариабельной области легкой цепи (VL):
VH включает аминокислотную последовательность, представленную SEQ ID NO: 7 или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 12, или ее фрагмент, или вариант аминокислотной последовательности или фрагмента.
Термин «фрагмент» относится, в частности, к одной или нескольким из определяющих комплементарность областей (CDR), предпочтительно, по меньшей мере, вариабельной области CDR3 вариабельной области тяжелой цепи (VH) и/или вариабельной области легкой цепи (VL). В одном воплощении указанная одна или несколько областей, определяющих комплементарность (CDR), выбираются из набора областей, определяющих комплементарность CDR1, CDR2 и CDR3. В особенно предпочтительном воплощении термин «фрагмент» относится к областям, определяющим комплементарность CDR1, CDR2 и CDR3 вариабельной области тяжелой цепи (VH) и/или вариабельной области легкой цепи (VL).
В одном воплощении связывающий домен, содержащий одну или несколько CDR, набор CDR или комбинацию наборов CDR, как описано в настоящем документе, включает указанные CDR вместе с их промежуточными каркасными областями. Предпочтительно, эта часть также будет включать, по меньшей мере, около 50% одной или обеих из первой и четвертой каркасных областей, причем 50% являются С-концевой, 50% первой каркасной области и 50% N-концевой четвертой каркасной области. Конструирование связывающих агентов, полученных методами рекомбинантной ДНК, может привести к введению остатков N- или C-конца в вариабельные области, кодируемых линкерами, введенными для облегчения клонирования или других стадий обработки, включая введение линкеров для соединения вариабельных областей по изобретению для дополнительных последовательностей белка, включая тяжелые цепи иммуноглобулина, другие вариабельные домены или белковые метки.
В одном воплощении связывающий домен, содержащий одну или несколько CDR, набор CDR или комбинацию наборов CDR, как описано в настоящем документе, включает указанные CDR в каркасе человеческого антитела.
В предпочтительном воплощении связывание связывающего домена с CLDN6 связывающего агента по изобретению включает следующую комбинацию вариабельной области тяжелой цепи (VH) и вариабельной области легкой цепи (VL):
VH включает область 3, определяющую комплементарность тяжелой цепи (HCDR3), содержащую последовательность Ala Arg Asp Xaa1 Gly Xaa2 Val Xaa3 Asp Tyr, где Xaa1 представляет собой любую аминокислоту, предпочтительно ароматическую аминокислоту, более предпочтительно Phe или Tyr, наиболее предпочтительно Tyr, Xaa2 представляет собой любую аминокислоту, предпочтительно ароматическую аминокислоту, более предпочтительно Phe или Tyr, наиболее предпочтительно Tyr, и Xaa3 представляет собой любую аминокислоту, предпочтительно Leu или Phe, более предпочтительно Leu. В одном воплощении HCDR3 включает последовательность, представленную в SEQ ID NO: 46 или 47, и
VL включает область 3, определяющую комплементарность легкой цепи (LCDR3), содержащую последовательность Gln Gln Arg Xaa1 Xaa2 Xaa3 Pro Pro Trp Thr, где Xaa1 представляет собой любую аминокислоту, предпочтительно Ser или Asn, наиболее предпочтительно Ser, Xaa2 представляет собой любую аминокислоту, предпочтительно Tyr, Ser, Ile, Asn или Thr, более предпочтительно Ile, Asn или Thr, наиболее предпочтительно Ile или Asn, и Xaa3 представляет собой любую аминокислоту, предпочтительно Ser или Tyr, более предпочтительно Tyr. В одном воплощении LCDR3 включает последовательность, представленную в SEQ ID NO: 52 или 53.
В одном воплощении VH дополнительно включает HCDR1, содержащую последовательность, указанную в SEQ ID NO: 44, и/или HCDR2, содержащую последовательность, указанную в SEQ ID NO: 48, где Xaa представляет собой любую аминокислоту, предпочтительно Thr, Ser или Ile, наиболее предпочтительно Thr, такой как последовательность, указанная в SEQ ID NO: 45, и/или VL дополнительно включает LCDR1, включающий последовательность, указанную в SEQ ID NO: 54, где Xaa представляет собой любую аминокислоту, предпочтительно Ser или Asn, наиболее предпочтительно Ser, такой как последовательность, изложенная в SEQ ID NO: 50, и/или LCDR2, содержащая последовательность, представленную в SEQ ID NO: 51.
В предпочтительном воплощении связывание связывающего домена с CLDN6 связывающего агента по изобретению включает следующую комбинацию вариабельной области тяжелой цепи (VH) и вариабельной области легкой цепи (VL):
VH включает HCDR1, содержащую последовательность, представленную в SEQ ID NO: 44, HCDR2, содержащую последовательность, представленную в SEQ ID NO: 45, и HCDR3, содержащую последовательность, представленную в SEQ ID NO: 46, и VL включает LCDR1 содержащую последовательность, представленную в SEQ ID NO: 50, LCDR2, содержащую последовательность, представленную в SEQ ID NO: 51, и LCDR3, содержащую последовательность, представленную в SEQ ID NO: 52.
В предпочтительном воплощении связывание связывающего домена с CLDN6 связывающего агента по изобретению включает следующую комбинацию вариабельной области тяжелой цепи (VH) и вариабельной области легкой цепи (VL):
VH включает HCDR1, содержащую последовательность, представленную в SEQ ID NO: 44, HCDR2, содержащую последовательность, представленную в SEQ ID NO: 45, и HCDR3, содержащую последовательность, представленную в SEQ ID NO: 47, и VL включает LCDR1 содержащую последовательность, представленную в SEQ ID NO: 50, LCDR2, содержащую последовательность, представленную в SEQ ID NO: 51, и LCDR3, содержащую последовательность, представленную в SEQ ID NO: 53.
В предпочтительном воплощении связывание связывающего домена с CLDN6 связывающего агента по изобретению включает следующую комбинацию вариабельной области тяжелой цепи (VH) и вариабельной области легкой цепи (VL):
VH включает HCDR1, содержащую последовательность, представленную в SEQ ID NO: 44, HCDR2, содержащую последовательность, представленную в SEQ ID NO: 45, и HCDR3, содержащую последовательность, представленную в SEQ ID NO: 46, и VL включает LCDR1 содержащую последовательность, представленную в SEQ ID NO: 50, LCDR2, содержащую последовательность, представленную в SEQ ID NO: 51, и LCDR3, содержащую последовательность, представленную в SEQ ID NO: 53.
В одном воплощении указанные вариабельные области тяжелой и легкой цепи содержат указанные области, определяющие комплементарность, включенные в каркасные области. В одном воплощении каждая вариабельная область включает три определяющие комплементарность области (CDR1, 2 и 3) и четыре каркасных области (FR1, 2, 3 и 4). В одном воплощении указанные определяющие комплементарность области и указанные каркасные области расположены от аминоконца до карбоксиконца в следующем порядке: FR1, CDR1, FR2, CDR2, FR3, CDR3, FR4.
В других воплощениях связывание связывающего домена с CLDN6 связывающего агента по изобретению включает вариабельные области тяжелой и легкой цепи антитела, которое (i) конкурирует за связывание CLDN6 с антителом, содержащим вариабельные области тяжелой и легкой цепи, как описано выше, и/или (ii) обладает специфичностью к CLDN6 антитела, содержащего вариабельные области тяжелой и легкой цепи, как описано выше.
В одном воплощении вариабельная область тяжелой цепи (VH) и вариабельная область легкой цепи (VL) связывающего домена, связывающегося с CLDN6, связывающего агента по изобретению, имеют формат молекулы scFv. В этом воплощении связывающий домен, связывающийся с CLDN6 связывающего агента по изобретению, включает аминокислотную последовательность, представленную в SEQ ID NO: 13, или ее фрагмент, или вариант аминокислотной последовательности или фрагмента.
Следует понимать, что связывающие домены, связывающиеся с CLDN6 связывающего агента по изобретению, могут быть идентичными или по существу идентичными или разными и, таким образом, могут связываться с идентичными или по существу идентичными эпитопами или различными эпитопами. Таким образом, оба домена связывания, связывающихся с CLDN6 связывающего агента по изобретению, могут соответствовать или по существу соответствовать одному из связывающих доменов, связывающихся с CLDN6 связывающего агента по изобретению, описанному в данном документе, или они могут быть независимо выбраны из связывающих доменов, связывающихся с CLDN6 связующего агента по изобретению, описанного в данном документе.
Антитела против CD3, которые полезны для обеспечения связывающих агентов по изобретению, включают, без ограничения указанным, UCHT1-HS (гуманизированное mAb), UCHT1-MM (мышиное mAb), CLB-T3, TR66, 145-2C11.
UCHT1 представляет собой моноклональное анти-CD3 моноклональное антитело IgG1, которое обнаруживает CD3 в образцах человека и приматов. CLB-T3 является мышиным моноклональным анти-CD3 антителом, которое направлено против антигена CD3 и реагирует с 80-90% человеческими периферическим Т-лимфоцитами и медуллярные тимоцитами. TR66 представляет собой мышиное моноклональное анти-CD3-антитело IgG1, которое распознает эпсилон-цепь CD3 человека. 145-2C11 представляет собой моноклональное антитело серого хомячка против CD3 мыши.
Предпочтительно, области VH и VL CD3-связывающего домена получены из молекул антитела/антитела и антителоподобных молекул, которые способны специфически распознавать CD3 человека в контексте других субъединиц TCR, присутствующих в активированных первичных Т-клетках человека, экспрессирующих TCR в его родной конфигурации. Области VH и VL, полученные из антител, специфичных для цепи CD3-эпсилон, являются наиболее предпочтительными, и указанные (родительские) антитела должны быть способны специфически связывать эпитопы, отражающие нативную или почти нативную структуру, или конформационный эпитоп CD3 человека, представленный в контекст комплекса TCR. В предпочтительном воплощении изобретения области VH и VL CD3-связывающего домена получены из CD3-специфического антитела, выбранного из группы, состоящей из UCHT1-HS, UCHT1-MM, CLB-T3 и TR66, предпочтительно TR66.
В предпочтительном воплощении связывающий домен, связывающийся с CD3 связывающего агента по изобретению, включает вариабельную область тяжелой цепи (VH), содержащую аминокислотную последовательность, представленную в SEQ ID NO: 5, или ее фрагмент, или вариант аминокислотной последовательности или фрагмента.
В предпочтительном воплощении связывающий домен, связывающийся с CD3 связывающего агента по изобретению, включает вариабельную область легкой цепи (VL), содержащую аминокислотную последовательность, представленную в SEQ ID NO: 6, или ее фрагмент, или варианте аминокислотной последовательности или фрагмента.
В предпочтительном воплощении связывание связывающего домена с CD3 связывающего агента по изобретению включает следующую комбинацию вариабельной области тяжелой цепи (VH) и вариабельной области легкой цепи (VL):
VH включает аминокислотную последовательность, представленную SEQ ID NO: 5, или ее фрагмент, или вариант аминокислотной последовательности или фрагмента, и VL включает аминокислотную последовательность, представленную SEQ ID NO: 6, или ее фрагмент, или варианта аминокислотной последовательности или фрагмента.
Термин «фрагмент» относится, в частности, к одной или нескольким из определяющих комплементарность областей (CDR), предпочтительно, по меньшей мере, вариабельной области CDR3 вариабельной области тяжелой цепи (VH) и/или вариабельной области легкой цепи (VL). В одном воплощении указанная одна или несколько областей, определяющих комплементарность (CDR), выбираются из набора областей, определяющих комплементарность CDR1, CDR2 и CDR3. В особенно предпочтительном воплощении термин «фрагмент» относится к областям, определяющим комплементарность, CDR1, CDR2 и CDR3 вариабельной области тяжелой цепи (VH) и/или вариабельной области легкой цепи (VL).
В одном воплощении связывающий домен, содержащий одну или несколько CDR, набор CDR или комбинацию наборов CDR, как описано в настоящем документе, включает указанные CDR вместе с их промежуточными каркасными областями. Предпочтительно, эта часть также будет включать, по меньшей мере, около 50% одной или обеих из первой и четвертой каркасных областей, причем 50% являются С-концевой 50% первой каркасной области и N-концевой 50% четвертой каркасной области. Конструирование связывающих агентов, полученных методами рекомбинантной ДНК, может привести к введению остатков N- или C-конца в вариабельные области, кодируемые линкерами, введенными для облегчения клонирования или других стадий обработки, включая введение линкеров для соединения вариабельных областей по изобретению с дополнительными последовательностями белка, включая тяжелые цепи иммуноглобулина, другие вариабельные домены или белковые метки.
В одном воплощении связывающий домен, содержащий одну или несколько CDR, набор CDR или комбинацию наборов CDR, как описано в настоящем документе, включает указанные CDR в каркасе человеческого антитела.
Следует понимать, что описанные в данном документе связывающие агенты могут быть доставлены пациенту путем введения нуклеиновой кислоты, такой как РНК, кодирующая антитело, и/или путем введения клетки-хозяина, содержащей нуклеиновую кислоту, такую как РНК, кодирующую антитело. Если связывающий агент включает более одной полипептидной цепи, разные полипептидные цепи могут кодироваться в одной и той же нуклеиновой кислоте или в разных нуклеиновых кислотах. Таким образом, нуклеиновая кислота для введения может представлять собой смесь различных молекул нуклеиновых кислот. Нуклеиновая кислота, кодирующая связывающий агент при введении в организм пациента, может присутствовать в обнаженном виде или в подходящем носителе для доставки, например, в виде липосом или наночастиц или вирусных частиц, или в клетке-хозяине. Предоставляемая нуклеиновая кислота может продуцировать агент в течение длительных периодов времени устойчивым образом, уменьшая нестабильность, по меньшей мере, частично, наблюдаемую для терапевтических антител. Нуклеиновые кислоты, которые должны быть доставлены пациенту, могут быть получены рекомбинантными средствами. Если нуклеиновую кислоту вводят пациенту без присутствия в клетке-хозяине, то она предпочтительно захватывается клетками пациента для экспрессии связывающего агента, кодируемого нуклеиновой кислотой. Если нуклеиновую кислоту вводят пациенту в клетке-хозяине, она предпочтительно экспрессируется клеткой-хозяином внутри пациента, с получением связывающего агента, кодируемого нуклеиновой кислотой.
Термин «рекомбинантный» в контексте настоящего изобретения означает «полученный посредством генной инженерии». Предпочтительно, «рекомбинантный объект», такой как рекомбинантная нуклеиновая кислота в контексте настоящего изобретения, не встречается в природе.
Используемый в данном документе термин «встречающийся в природе» относится к тому факту, что объект можно найти в природе. Например, пептид или нуклеиновая кислота, которые присутствуют в организме (включая вирусы), могут быть выделены из природного источника, не были преднамеренно изменены человеком в лаборатории, являются встречающимися в природе.
Используемый в данном документе термин «нуклеиновая кислота» предназначен для включения ДНК и РНК, таких как геномная ДНК, кДНК, мРНК, рекомбинантно продуцируемые и химически синтезированные молекулы. Нуклеиновая кислота может быть одноцепочечной или двухцепочечной. РНК включает транскрибированную in vitro РНК (IVT RNA) или синтетическую РНК.
Нуклеиновые кислоты могут быть включены в вектор. Используемый в данном документе термин «вектор» включает любые векторы, известные специалисту в данной области, включая плазмидные векторы, космидные векторы, фаговые векторы, такие как лямбда-фаг, вирусные векторы, такие как аденовирусные или бакуловирусные векторы, или векторы-искусственные хромосомы, такие как бактериальные искусственные хромосомы (BAC), дрожжевые искусственные хромосомы (YAC) или искусственные хромосомы P1 (PAC). Указанные векторы включают как экспрессирующие, так и клонирующие векторы. Экспрессирующие векторы включают плазмиды, и вирусные векторы и обычно содержат искомую кодирующую последовательность и соответствующие последовательности ДНК, необходимые для экспрессии функционально связанной кодирующей последовательности в конкретном организме-хозяине (например, бактерии, дрожжах, растении, насекомом или млекопитающем) или в системах экспрессии in vitro. Клонирующие векторы обычно используются для обработки и амплификации определенного искомого фрагмента ДНК и могут не иметь функциональных последовательностей, необходимых для экспрессии искомых фрагментов ДНК.
В контексте настоящего изобретения термин «РНК» относится к молекуле, которая включает рибонуклеотидные остатки и предпочтительно полностью или по существу состоит из рибонуклеотидных остатков. «Рибонуклеотид» относится к нуклеотиду с гидроксильной группой в 2'-положении β-D-рибофуранозильной группы. Термин включает двухцепочечную РНК, одноцепочечную РНК, выделенную РНК, такую как частично очищенная РНК, по существу очищенная РНК, синтетическую РНК, рекомбинантно продуцируемую РНК, и модифицированную РНК, которая отличается от естественной РНК добавлением, делецией, замещением и/или заменой одного или нескольких нуклеотидов. Такие изменения могут включать добавление ненуклеотидного материала, например, к концу(ам) РНК или внутрь, например, в одном или нескольких нуклеотидах РНК. Нуклеотиды в молекулах РНК могут также содержать нестандартные нуклеотиды, такие как неприродные нуклеотиды или химически синтезированные нуклеотиды или дезоксинуклеотиды. Эти измененные РНК можно назвать аналогами или аналогами природной РНК.
Согласно настоящему изобретению термин «РНК» включает и предпочтительно относится к «мРНК», что означает «информационную РНК» и относится к «транскрипту», который может быть получен с использованием ДНК в качестве матрицы и который кодирует пептид или белок. мРНК обычно включает 5'-нетранслируемую область (5'-UTR), область кодирования белка или пептида и 3'-нетранслируемую область (3'-UTR). мРНК имеет ограниченный период полужизни в клетках и in vitro. Предпочтительно, мРНК получают путем транскрипции in vitro с использованием матрицы ДНК. В одном воплощении изобретения РНК получают путем транскрипции in vitro или химического синтеза. Методология транскрипции in vitro известна специалисту. Например, существует множество коммерчески доступных наборов транскрипции in vitro.
В одном воплощении настоящего изобретения РНК представляет собой самореплицирующуюся РНК, такую как одноцепочечная самореплицирующаяся РНК. В одном воплощении самореплицирующаяся РНК представляет собой положительно-полярную одноцепочечную РНК. В одном воплощении самореплицирующаяся РНК представляет собой вирусную РНК или РНК, полученную из вирусной РНК. В одном воплощении самореплицирующаяся РНК представляет собой альфа-вирусную геномную РНК или происходит из альфа-вирусной геномной РНК. В одном воплощении самореплицирующаяся РНК представляет собой вектор, экспрессирующий вирусный ген. В одном воплощении вирус представляет собой вирус леса Семлики. В одном воплощении самореплицирующаяся РНК включает один или несколько трансгенов, по меньшей мере, один из указанных трансгенов, кодирующих связывающий агент, описанный в данном документе. В одном воплощении, если РНК представляет собой вирусную РНК или происходит из вирусной РНК, трансгены могут частично или полностью заменять вирусные последовательности, такие как вирусные последовательности, кодирующие структурные белки. В одном воплощении самореплицирующаяся РНК представляет собой транскрибированную РНК in vitro.
Геном альфа-вирусов представляет собой положительно-полярную одноцепочечную РНК (ssRNA (+)), которая кодирует две открытые рамки считывания (ORF) для больших полипротеинов. ORF на 5'-конце генома кодирует неструктурные белки с nSP1 по nSP4 (nsP1-4), которые транслируются и процессируются в РНК-зависимую РНК-полимеразу (репликазу); ORF на 3'- конце кодирует структурные белки капсида и гликопротеины. Обе ORF разделены так называемым субгеномным промотором (SGP), который управляет транскрипцией структурной ORF. При использовании в качестве генных векторов структурные белки за SGP обычно заменяются трансгенами. Чтобы упаковать такие векторы в вирусные частицы, структурные белки обычно экспрессируются в транс-клетках со вспомогательными конструкциями. Альфавирусы реплицируются в цитоплазме инфицированных клеток исключительно на уровне РНК. После заражения геном ssRNA (+) действует как мРНК для трансляции предшественника полипептида nsP1234, который на ранних стадиях жизненного цикла вируса самопроизвольно обрабатывается до фрагментов nsP123 и nsP4. Фрагменты nsP123 и nsP4 образуют репликазный комплекс для (-) цепей, который транскрибирует (-) нитевую РНК из матрицы геномной РНК. На более поздних стадиях полипротеин nsP1234 полностью расщепляется на отдельные белки, которые собираются в (+) нитевой репликазный комплекс, который синтезирует новые (+) нитевые геномы, и субгеномные транскрипты, которые кодируют структурные белки или трансгены. Субгеномная РНК, и новая геномная РНК кэпированы и полиаденилированы и, таким образом, распознаются как мРНК после инфекции клеток-мишеней. Только новая геномная РНК включает сигнал упаковки, который обеспечивает эксклюзивную упаковку геномной РНК в зарождающиеся вирионы. Привлекательность альфа-вирусных репликонов для векторологии основана на положительной ориентации генома кэпированной и полиаденилированной РНК. Транслируемую репликоновую РНК можно легко синтезировать in vitro, в результате чего может быть достигнуто кэппирование с помощью кэп-аналогов, добавленных в реакцию транскрипции in vitro, а хвосты поли-A могут кодироваться как поли-T-треки на плазмидных матрицах. Репликоны, транскрибированные in vitro (IVT), трансфицируют обычными методами трансфекции, и даже небольшие количества исходной IVT-РНК быстро преумножаются. В течение нескольких часов после переноса трансгены, которые располагаются ниже SGP, транскрибируются с очень высоким числом копий, примерно от 40 000 до 200 000 копий субгеномной РНК на клетку, поэтому неудивительно, что рекомбинантные белки сильно экспрессируются. В зависимости от конкретной цели, репликоны IVT могут быть трансфицированы непосредственно в клетки-мишени или упакованы в альфа-вирусные частицы с помощью вспомогательных векторов, которые обеспечивают структурные гены in trans. Перенос в кожу или мышцы приводит к высокой и устойчивой локальной экспрессии, сопровождаемой сильной индукцией гуморального и клеточного иммунного ответа.
Чтобы увеличить экспрессию и/или стабильность РНК, используемой согласно настоящему изобретению, она может быть модифицирована, предпочтительно без изменения последовательности экспрессированного пептида или белка.
Термин «модификация» в контексте РНК, используемый в соответствии с настоящим изобретением, включает любую модификацию РНК, которая в природе не присутствует в указанной РНК.
В одном воплощении изобретения РНК, используемая согласно изобретению, не имеет некэпированных 5'-трифосфатов. Удаление таких некэпированных 5'-трифосфатов может быть достигнуто путем обработки РНК фосфатазой.
РНК по изобретению может иметь модифицированные природные или синтетические рибонуклеотиды, чтобы повысить ее стабильность и/или уменьшить цитотоксичность и/или иммуногенность. Например, в одном воплощении в РНК, используемой согласно изобретению, 5-метилцитидин замещен частично или полностью, предпочтительно полностью, для цитидина. Альтернативно или дополнительно в одном воплощении в РНК, используемой согласно изобретению, псевдоуридин замещен частично или полностью, предпочтительно полностью, на уридин.
В одном воплощении термин «модификация» относится к обеспечению РНК структурой 5'-кэп или аналогом 5'-кэп структуры. Термин «5'-кэп» относится к кэп-структуре, обнаруженной на 5'-конце молекулы мРНК, и обычно состоит из нуклеотида гуанозина, связанного с мРНК, посредством необычной 5'-5'-трифосфатной связи. В одном воплощении этот гуанозин метилирован в 7-положении. Термин «традиционный 5'-кэп» относится к природной 5'-кэп РНК, предпочтительно к кэпу на основе 7-метилгуанозина (m7G). В контексте настоящего изобретения термин «5'-кэп» включает аналог 5'-кэпа, который напоминает структуру РНК-кэп и является модифицированной, чтобы обладать способностью стабилизировать РНК, если она присоединена к ней, предпочтительно in vivo и/или в клетке.
Обеспечение РНК с 5'-кэпом или аналогом 5'-кэпа может быть достигнуто путем транскрипции ДНК-матрицы in vitro в присутствии указанного 5'-кэпа или аналога 5'-кэпа, где указанный 5'-кэп котранскрипционно включается в сгенерированную цепь РНК, или РНК может быть сгенерирована, например, путем транскрипции in vitro, и 5'-кэп может быть присоединен к РНК посттранскрипционно с использованием ферментов кэппинга, например, ферментов кэппинга вируса коровьей оспы.
РНК может включать дополнительные модификации. Например, дальнейшая модификация РНК, используемой в настоящем изобретении, может быть удлинением или усечением встречающегося в природе поли (А) хвоста или изменением 5'- или 3'-нетранслируемых областей (UTR), такая как введение UTR, который не связан с кодирующей областью указанной РНК, например, вставка одной или нескольких, предпочтительно двух копий 3'-UTR, происходящего из гена глобина, такого как альфа-2-глобин, альфа-1-глобин, бета-глобин, предпочтительно бета-глобин, более предпочтительно бета-глобин человека.
Следовательно, чтобы повысить стабильность и/или экспрессию РНК, используемой согласно настоящему изобретению, ее можно модифицировать так, чтобы она присутствовала в сочетании с последовательностью поли-А, предпочтительно имеющей длину от 10 до 500, более предпочтительно от 30 до 300, еще более предпочтительно от 65 до 200 и особенно от 100 до 150 остатков аденозина. В особенно предпочтительном воплощении последовательность поли-А имеет длину приблизительно 120 остатков аденозина. Кроме того, включение двух или более 3'-нетранслируемых областей (UTR) в 3'-нетранслированную область молекулы РНК может привести к повышению эффективности трансляции. В одном конкретном воплощении 3'-UTR происходит из гена β-глобина человека.
Предпочтительно, чтобы РНК, если она доставляется, т.е. трансфицируется в клетку, в частности клетку, присутствующую in vivo, экспрессировала белок или пептид, который она кодирует.
Термин «трансфекция» относится к введению нуклеиновых кислот, конкретно РНК, в клетку. Для целей настоящего изобретения термин «трансфекция» также включает введение нуклеиновой кислоты в клетку или поглощение нуклеиновой кислоты такой клеткой, в которой клетка может присутствовать у объекта, например пациента. Таким образом, согласно настоящему изобретению клетка для трансфекции нуклеиновой кислоты, описанная в данном документе, может присутствовать in vitro или in vivo, например, клетка может составлять часть органа, ткани и/или организма пациента. Согласно изобретению трансфекция может быть транзиторной или стабильной. Для некоторых применений трансфекции достаточно, чтобы трансфицированный генетический материал был экспрессирован лишь транзиторно. Так как нуклеиновая кислота, вводимая в процесс трансфекции, обычно не интегрируется в ядерный геном, то чужеродная нуклеиновая кислота будет разведена через митоз или деградирована. Клетки, допускающие эписомную амплификацию нуклеиновых кислот, значительно снижают степень разведения. Если желательно, чтобы трансфицированная нуклеиновая кислота фактически оставалась в геноме клетки и в ее дочерних клетках, то должна иметь место стабильная трансфекция. РНК может быть трансфицирована в клетки для транзиторной экспрессии кодируемого белка.
Термин «стабильность» РНК относится к «периоду полужизни» РНК. «Период полужизни» относится к периоду времени, необходимому для устранения половины активности, количества или числа молекул. В контексте настоящего изобретения период полужизни РНК является показателем стабильности указанной РНК. Период полужизни РНК может влиять на «продолжительность экспрессии» РНК. Можно ожидать, что РНК, имеющая длительный период полужизни, будет экспрессироваться в течение длительного периода времени.
В контексте настоящего изобретения термин «транскрипция» относится к процессу, в котором генетический код в последовательности ДНК транскрибируется в РНК. Впоследствии РНК может быть транслирована в белок. Согласно настоящему изобретению термин «транскрипция» включает «транскрипцию in vitro», где термин «транскрипция in vitro» относится к способу, в котором РНК, конкретно, мРНК, синтезируется in vitro в бесклеточной системе, предпочтительно, с использованием подходящих клеточных экстрактов. Предпочтительно клонирующие векторы применяются для генерации транскриптов. Эти клонирующие векторы обычно обозначаются как векторы транскрипции и согласно настоящему изобретению охватываются термином «вектор».
Термин «трансляция» согласно изобретению относится к процессу в рибосомах клетки, посредством которого цепь матричной РНК направляет сборку последовательности аминокислот с получением пептида или белка.
Термин «экспрессия» используется согласно изобретению в его наиболее общем значении и включает продуцирование РНК и/или пептидов или белков, например, путем транскрипции и/или трансляции. Что касается РНК, то термин «экспрессия» или «трансляция» относится, в частности, к образованию пептидов или белков. Он также включает частичную экспрессию нуклеиновых кислот. Более того, экспрессия может быть транзиторной или стабильной. Согласно изобретению термин экспрессия также включает «аберрантную экспрессию» или «аномальную экспрессию».
«Аберрантная экспрессия» или «аномальная экспрессия» означает согласно изобретению, что экспрессия изменяется, предпочтительно повышается, по сравнению с эталонной, например, при состоянии объекта, не имеющего заболевания, связанного с аберрантной или аномальной экспрессией определенного белка, например, опухолевого антигена. Повышение экспрессии относится к повышению, по меньшей мере, на 10%, конкретно, по меньшей мере, на 20%, по меньшей мере, на 50% или, по меньшей мере, на 100% или более. В одном воплощении экспрессия обнаруживается только в пораженной ткани, тогда как экспрессия в здоровой ткани репрессируется.
Термин «специфично экспрессированный» означает, что белок по существу экспрессируется только в определенной ткани или органе. Например, опухолевый антиген, специфично экспрессированный в слизистой оболочке желудка, означает, что указанный белок в основном экспрессируется в слизистой оболочке желудка и не экспрессируется в других тканях или не экспрессируется в значительной степени в других тканях или органах. Таким образом, белок, который экспрессируется исключительно в клетках слизистой оболочки желудка и в значительно меньшей степени в любой другой ткани, такой как яичко, будет специфично экспрессироваться в клетках слизистой оболочки желудка. В некоторых воплощениях опухолевый антиген может быть также специфично экспрессирован в нормальных условиях более чем в одном типе ткани или органе, как например, в 2 или 3 типах тканей или органов, но предпочтительно не более чем в 3 разных типах тканей или органов. В этом случае опухолевый антиген затем специфично экспрессируется в этих органах. Например, если опухолевый антиген экспрессируется в нормальных условиях, предпочтительно примерно в равной степени в легких и желудке, то указанный опухолевый антиген специфически экспрессируется в легких и желудке.
Согласно изобретению термин «РНК, кодирующая» означает, что РНК, если она присутствует в соответствующей среде, предпочтительно внутри клетки, может быть экспрессирована для получения белка или пептида, который она кодирует.
Некоторые аспекты изобретения основаны на адоптивном переносе клеток-хозяев, которые трансфицируются in vitro нуклеиновой кислотой, такой как РНК, кодирующая антитело, описанное в данном документе, и переносятся реципиентам, таким как пациенты, предпочтительно после ex vivo наработки, начиная от низко представленных предшественников до клинически значимых количеств клеток. Клетки-хозяева, используемые для лечения согласно изобретению, могут быть аутологичными, аллогенными или сингенными для подвергнутого лечению реципиента.
Термин «аутологичный» используется для описания всего, что происходит от одного и того же объекта. Например, «аутологичная трансплантация» относится к трансплантации ткани или органов, полученных от одного и того же объекта. Такие процедуры являются выгодными, поскольку они преодолевают иммунологический барьер, который в противном случае приводит к отторжению.
Термин «аллогенный» используется для описания всего, что происходит от разных особей одного и того же вида. Говорят, что два или более индивидуумов являются аллогенными по отношению друг к другу, когда гены в одном или нескольких локусах не идентичны.
Термин «сингенный» используется для описания всего, что происходит от индивидуумов или тканей, имеющих идентичные генотипы, т.е. идентичных близнецов или животных одного и того же инбредного штамма или их тканей.
Термин «гетерологичный» используется для описания того, что состоит из нескольких разных элементов. В качестве примера перенос костного мозга одного человека другому человеку представляет собой гетерологичную трансплантацию. Гетерологичный ген представляет собой ген, полученный из источника, отличного от объекта.
Термин «пептид» согласно изобретению включает олиго- и полипептиды и относится к веществам, содержащим два или более, предпочтительно 3 или более, предпочтительно 4 или более, предпочтительно 6 или более, предпочтительно 8 или более, предпочтительно 9 или более, предпочтительно 10 или более, предпочтительно 13 или более, предпочтительно еще 16, предпочтительно 21 или более и предпочтительно до 8, 10, 20, 30, 40 или 50, в частности 100 аминокислот, ковалентно соединенных пептидными связями. Термин «белок» относится к большим пептидам, предпочтительно к пептидам с более чем 100 аминокислотными остатками, но в целом термины «пептиды» и «белки» являются синонимами и используются в данном документе взаимозаменяемо.
Руководство, приведенное в данном документе в отношении конкретных аминокислотных последовательностей, например, представленных в списке последовательностей, должно быть истолковано так, что оно также относится к вариантам указанных конкретных последовательностей, приводя к получению последовательностей, которые функционально эквивалентны указанным конкретным последовательностям, например аминокислотные последовательности, обладающие свойствами, идентичными или сходными с характеристиками конкретных аминокислотных последовательностей. Одним из важных свойств является сохранение связывания с мишенью или сохранение эффекторных функций. Предпочтительно, последовательность, которая является вариантом по отношению к определенной последовательности, когда она заменяет конкретную последовательность в антителе, сохраняет связывание указанного антитела с его мишенью и предпочтительно функции указанного антитела, как описано в данном документе, например, опосредованный CDC лизис или опосредованный ADCC лизис. Кроме того, предпочтительно, последовательность, которая является вариантом по отношению к конкретной последовательности, когда она заменяет конкретную последовательность в связывающем агенте, сохраняет связывание указанного связывающего агента с клаудином и/или CD3 и предпочтительно выполняет функции указанного связывающего агента, как описано в настоящем документе, например, цитотоксический лизис, опосредованный Т-клетками.
Например, последовательности, показанные в перечне последовательностей, могут быть изменены таким образом, чтобы удалить один или несколько, предпочтительно все свободные остатки цистеина, в частности, путем замены остатков цистеина на аминокислоты, отличные от цистеина, предпочтительно серин, аланин, треонин, глицин, тирозин, триптофан, лейцин или метионин.
Специалистам в данной области будет понятно, что, в частности, последовательности CDR, гипервариабельные и вариабельные области могут быть модифицированы без потери способности связывать клаудин и/или CD3. Например, области CDR будут либо идентичны, либо высоко гомологичны областям, указанным в данном документе. Под «высоко гомологичным» подразумевается, что в CDR могут быть сделаны замены в количестве от 1 до 5, предпочтительно от 1 до 4, например, от 1 до 3 или 1 или 2 замены. Кроме того, гипервариабельные и вариабельные области могут быть модифицированы так, чтобы они демонстрировали существенную гомологию с областями антител, конкретно раскрытых в данном документе. В одном воплощении последовательности вариабельной области отклоняются только в последовательностях каркаса от последовательностей вариабельной области, конкретно раскрытых в данном документе.
Для целей настоящего изобретения «варианты» аминокислотной последовательности включают варианты с аминокислотными вставками, варианты с добавлением аминокислот, варианты с делецией аминокислот и/или варианты с заменой аминокислот. Варианты делеции аминокислот, которые включают делецию на N-конце и/или С-конце белка, также называются N-концевыми и/или С-концевыми укороченными вариантами.
Варианты аминокислотных вставок включают вставки одной или двух или более аминокислот в конкретной аминокислотной последовательности. В случае вариантов аминокислотной последовательности, имеющих вставку, один или несколько аминокислотных остатков вводят в конкретный участок в аминокислотной последовательности, хотя также возможна случайная вставка с соответствующим скринингом полученного продукта.
Варианты добавления аминокислот включают амино- и/или карбокси-концевые слияния одной или нескольких аминокислот, как например, 1, 2, 3, 5, 10, 20, 30, 50 или более аминокислот.
Варианты аминокислотных делеций характеризуются удалением одной или нескольких аминокислот из последовательности, как например, удаление 1, 2, 3, 5, 10, 20, 30, 50 или более аминокислот. Делеции могут быть в любом положении белка.
Варианты аминокислот характеризуются, по меньшей мере, одним остатком в удаляемой последовательности и другим остатком, вставленным на его место. Предпочтение отдается модификациям, которые находятся в положениях аминокислотной последовательности, которые не консервативны между гомологичными белками или пептидами и/или заменам аминокислот на другие, обладающие сходными свойствами. Предпочтительно, аминокислотные замены в вариантах белка представляют собой консервативные аминокислотные замены, то есть замены одинаково заряженных или незаряженных аминокислот. Консервативная аминокислотная замена включает замену на одну из семейства аминокислот, которые родственны по их боковым цепям. Природные аминокислоты обычно делятся на четыре семейства: кислотные (аспартат, глутамат), основные (лизин, аргинин, гистидин), неполярные (аланин, валин, лейцин, изолейцин, пролин, фенилаланин, метионин, триптофан) и незаряженные полярные (глицин, аспарагин, глутамин, цистеин, серин, треонин, тирозин) аминокислоты. Фенилаланин, триптофан и тирозин иногда классифицируют как ароматические аминокислоты.
Предпочтительно, степень сходства, предпочтительно идентичности между данной аминокислотной последовательностью и аминокислотной последовательностью, которая является вариантом указанной указанной аминокислотной последовательности, будет составлять, по меньшей мере, около 60%, 65%, 70%, 80%, 81%, 82 %, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98% или 99%. Степень сходства или идентичности дается предпочтительно для аминокислотной области, которая составляет, по меньшей мере, около 10%, по меньшей мере, около 20%, по меньшей мере, около 30%, по меньшей мере, около 40%, по меньшей мере, около 50%, по меньшей мере, около 60%, по меньшей мере, около 70%, по меньшей мере, около 80%, по меньшей мере, около 90% или около 100% всей длины эталонной аминокислотной последовательности. Например, если эталонная аминокислотная последовательность состоит из 200 аминокислот, степень сходства или идентичности дается предпочтительно для, по меньшей мере, около 20, по меньшей мере, для около 40, по меньшей мере, для около 60, по меньшей мере, для около 80, по меньшей мере, для около 100, по меньшей мере, для около 120, по меньшей мере, для около 140, по меньшей мере, для около 160, по меньшей мере, для около 180 или для около 200 аминокислот, предпочтительно непрерывных аминокислот. В предпочтительных воплощениях степень сходства или идентичности дается для всей длины эталонной аминокислотной последовательности. Выравнивание для определения сходства последовательностей, предпочтительно идентичности последовательности, может быть выполнено с помощью известных инструментов, предпочтительно с использованием наилучшего выравнивания последовательностей, например, с использованием Align, с использованием стандартных настроек, предпочтительно EMBOSS: needle, Матрица: Blosum62, штраф за пропуск 10,0, штраф за удлинение 0,5.
«Сходство последовательностей» указывает на процент аминокислот, которые либо идентичны, либо представляют консервативные аминокислотные замены. «Идентичность последовательности» между двумя аминокислотными последовательностями указывает процент аминокислот, которые являются идентичными между последовательностями.
Термин «процентная идентичность» предназначен для обозначения процента аминокислотных остатков, которые идентичны между двумя последовательностями, которые следует сравнить, полученного после наилучшего выравнивания, причем этот процент является чисто статистическим, а различия между двумя последовательностями распределяются случайным образом и по всей длине. Сравнения последовательностей между двумя аминокислотными последовательностями обычно выполняются путем сравнения этих последовательностей после их оптимального выравнивания, причем указанное сравнение проводят с помощью сегмента или «окна сравнения» для идентификации и сравнения локальных областей сходства последовательностей. Оптимальное выравнивание последовательностей для сравнения может быть получено, кроме того, вручную с помощью алгоритма локальной гомологии Smith and Waterman, 1981, Ads App. Math. 2, 482, с помощью локального алгоритма гомологии Neddleman and Wunsch, 1970, J. Mol. Biol. 48, 443, с помощью метода поиска подобия Pearson and Lipman, 1988, Proc. Natl Acad. Sci. USA 85, 2444 или с помощью компьютерных программ, которые используют эти алгоритмы (GAP, BESTFIT, FASTA, BLAST P, BLAST N и TFASTA в программном пакете Wisconsin Genetics, Genetics Computer Group, 575 Science Drive, Мэдисон, штат Висконсин).
Процент идентичности вычисляется путем определения количества идентичных положений между двумя сравниваемыми последовательностями, деля это количество на количество сравниваемых положений и умножая полученный результат на 100, с получением процентного выражения идентичности между этими двумя последовательностями.
Связывающие агенты по изобретению могут быть получены либо внутриклеточно (например, в цитозоле, в периплазме или в тельцах включения), а затем выделены из клеток-хозяев и необязательно дополнительно очищены; или они могут быть получены внеклеточно (например, в среде, в которой культивируются клетки-хозяева), а затем выделены из культуральной среды и, возможно, дополнительно очищены. Способы и реагенты, используемые для рекомбинантного получения полипептидов, такие как специфические подходящие экспрессирующие векторы, способы трансформации или трансфекции, маркеры селекции, способы индукции экспрессии белка, условия культивирования и тому подобное, известны в данной области. Аналогично, способы выделения и очистки белка хорошо известны специалисту в данной области.
Термин «клетка» или «клетка-хозяин» предпочтительно относится к интактной клетке, то есть к клетке с интактной мембраной, которая не высвобождает ее нормальные внутриклеточные компоненты, такие как ферменты, органеллы или генетический материал. Интактная клетка предпочтительно представляет собой жизнеспособную клетку, то есть живую клетку, способную выполнять свои нормальные метаболические функции. Предпочтительно указанный термин относится в соответствии с изобретением к любой клетке, которая может быть трансфицирована экзогенной нуклеиновой кислотой. Предпочтительно клетка, трансфицированная экзогенной нуклеиновой кислотой и переносимая реципиенту, может экспрессировать нуклеиновую кислоту у реципиента. Термин «клетка» включает бактериальные клетки; другими полезными клетками являются дрожжевые клетки, грибные клетки или клетки млекопитающих. Подходящие бактериальные клетки включают клетки из грамотрицательных бактериальных штаммов, таких как штаммы Escherichia coli, Proteus и Pseudomonas, и грамположительные бактериальные штаммы, такие как штаммы Bacillus, Streptomyces, Staphylococcus и Lactococcus. Подходящие грибные клетки включают клетки из видов Trichoderma, Neurospora и Aspergillus. Подходящие дрожжевые клетки включают клетки из видов Saccharomyces (например, Saccharomyces cerevisiae), Schizosaccharomyces (например, Schizo saccharomyces pombe), Pichia (например, Pichia pastoris и Pichia methanolicd) и Hansenula. Подходящие клетки млекопитающих включают, например, клетки СНО, клетки BHK, клетки HeLa, клетки COS, 293 HEK и тому подобное. Однако также можно использовать клетки амфибий, клетки насекомых, растительные клетки и любые другие клетки, используемые в данной области для экспрессии гетерологичных белков. Клетки млекопитающих особенно предпочтительны для адоптивного переноса, такие как клетки людей, мышей, хомяков, свиней, коз и приматов. Клетки могут быть получены из большого количества типов тканей и включают первичные клетки и клеточные линии, такие как клетки иммунной системы, в частности антиген-презентирующие клетки, такие как дендритные клетки и Т-клетки, стволовые клетки, такие как гемопоэтические стволовые клетки и мезенхимальные стволовые клетки и другие типы клеток. Антиген-презентирующая клетка представляет собой клетку, которая презентирует антиген в контексте главного комплекса гистосовместимости на его поверхности. Т-клетки могут распознавать этот комплекс, используя их Т-клеточный рецептор (TCR).
«Снизить», «уменьшить» или «ингибировать», при использовании в данном документе, означает общее уменьшение или способность вызвать общее уменьшение, предпочтительно на 5% или более, на 10% или более, на 20% или более, более предпочтительно на 50% или более и наиболее предпочтительно на 75% или более, уровня, например, уровня экспрессии или уровня пролиферации клеток.
Такие термины, как «увеличение» или «повышение», предпочтительно относятся к увеличению или повышению на около 10%, предпочтительно, по меньшей мере, на 20%, предпочтительно, по меньшей мере, на 30%, более предпочтительно, по меньшей мере, на 40%, более предпочтительно, по меньшей мере, на 50%, еще более предпочтительно, по меньшей мере, на 80% и наиболее предпочтительно, по меньшей мере, на 100%, по меньшей мере, на 200%, по меньшей мере, на 500%, по меньшей мере, на 1000%, по меньшей мере, на 10000% или даже более.
Антителозависимая клеточно-опосредованная цитотоксичность
ADCC описывает способность эффекторных клеток уничтожать клетки, как описано в данном документе, в частности лимфоциты, что предпочтительно требует, чтобы клетка-мишень была маркирована антителом.
ADCC предпочтительно возникает, когда антитела связываются с антигенами на опухолевых клетках, а Fc-домены антитела взаимодействуют с Fc-рецепторами (FcR) на поверхности иммунных эффекторных клеток. Было идентифицировано несколько семейств Fc-рецепторов, а специфические клеточные популяции характерно экспрессируют определенные Fc-рецепторы. ADCC можно рассматривать как механизм, позволяющий непосредственно индуцировать вариабельную степень немедленного разрушения опухоли, что приводит к представлению антигена и индукции опухоль-индуцируемых Т-клеточных реакций. Предпочтительно in vivo индукция ADCC приведет к опухоль-индуцируемым Т-клеточным ответам и антительным ответам хозяина.
Комплементзависимая цитотоксичность
CDC - еще один способ уничтожения клеток, который может быть управляться антителами. IgM является наиболее эффективным изотипом активации комплемента. IgG1 и IgG3 также очень эффективны при управлении CDC через классический путь активации комплемента. Предпочтительно в этом каскаде образование комплексов антиген-антитело приводит к оголению множественных сайтов связывания C1q в непосредственной близости от доменов CH2 участвующих молекул антитела, таких как молекулы IgG (C1q является одним из трех подкомпонентов комплемента C1). Предпочтительно, эти оголенные сайты связывания C1q превращают ранее низкоаффинное взаимодействие C1q-IgG во взаимодействие с высокой авидностью, которая запускает каскад событий, включающих ряд других белков комплемента, и приводит к протеолитическому высвобождению хемотаксисических/активирующих агентов эффекторной клетки C3a и C5a. Предпочтительно каскад комплемента заканчивается образованием комплекса мембранной атаки, который создает поры в клеточной мембране, облегчающих свободный проход воды и растворенных веществ в клетку и из нее.
Антитела, описанные в настоящем документе, например, для обеспечения областей VL и VH, могут быть получены различными способами, включая обычную методологию моноклональных антител, например стандартную методику гибридизации соматических клеток Kohler and Milstein, Nature 256: 495 (1975). Хотя предпочтительны процедуры гибридизации соматических клеток, в принципе могут быть использованы другие способы получения моноклональных антител, например, вирусная или онкогенная трансформация B-лимфоцитов или методы фагового дисплея с использованием библиотек генов антител.
Предпочтительной животной системой для продуцирования гибридом, которые секретируют моноклональные антитела, является мышиная система. Продуцирование гибридомы у мышей - очень хорошо зарекомендовавшая себя процедура. Протоколы иммунизации и способы выделения иммунизированных спленоцитов для слияния известны в данной области. Также известны партнеры по слиянию (например, мышиные клетки миеломы) и процедуры слияния.
Другими предпочтительными животными системами для получения гибридом, которые секретируют моноклональные антитела, являются крысиная и кроличья система (например, описанная в Spieker-Polet et al., Proc. Natl. Acad. Sci. U.S.A. 92:9348 (1995), см. также Rossi et al., Am. J. Clin. Pathol. 124: 295 (2005)).
В еще одном предпочтительном воплощении человеческие моноклональные антитела могут быть получены с использованием трансгенных или трансхромосомных мышей, несущих части иммунной системы человека, а не с использованием мышиной системы. Эти трансгенные и трансхромосомные мыши включают мышей, известных как мыши HuMAb и мыши KM, соответственно, и все вместе упоминаются в данном документе как «трансгенные мыши». Продуцирование человеческих антител у таких трансгенных мышей может быть осуществлено, как подробно описано для CD20 в WO 2004 035607.
Еще одна стратегия получения моноклональных антител заключается в прямом выделении генов, кодирующих антитела из лимфоцитов, продуцирующих антитела определенной специфичности, например, см. Babcock et al., 1996; Новая стратегия получения моноклональных антител из одиночных выделенных лимфоцитов, продуцирующих антитела определенных специфичностей. Подробные сведения о разработке рекомбинантных антител см. также Welschof and Kraus, Recombinant antibodes for cancer therapy ISBN-0-89603-918-8 и Benny K.C. Lo Antibody Engineering ISBN 1-58829-092-1.
Для получения антител мыши могут быть иммунизированы конъюгированными с носителем пептидами, полученными из последовательности антигена, то есть последовательности, на которую должны быть нацелены антитела обогащенного препарата рекомбинантно экспрессированного антигена или его фрагментов и/или клеток, экспрессирующих антиген, как описано. Альтернативно, мыши могут быть иммунизированы с помощью ДНК, кодирующей антиген или его фрагменты. В том случае, если иммунизация с использованием очищенного или обогащенного препарата антигена не приводит к получению антител, мышей также можно иммунизировать клетками, экспрессирующими антиген, например клеточной линией, для стимулирования иммунных реакций.
Иммунный ответ можно контролировать в течение курса иммунизации с помощью образцов плазмы и сыворотки, получаемых из хвостовой вены или ретроорбитальными кровопусканиями. Мыши с достаточным титром иммуноглобулина могут быть использованы для слияния. Мышей можно стимулировать внутрибрюшинно или внутривенно с помощью клеток, экспрессирующих антиген, за 3 дня до умервщления и удаления селезенки, чтобы увеличить процент гибридом, секретирующих специфические антитела.
Для получения гибридом, продуцирующих моноклональные антитела, спленоциты и клетки лимфатических узлов могут быть выделены из иммунизированных мышей и слиты с соответствующей иммортализованной клеточной линией, такой как клеточная линия мышиной миеломы. Полученные гибридомы затем могут быть скринированы для получения антигенспецифических антител. Затем индивидуальные лунки можно подвергнуть скринингу с помощью ELISA на предмет гибридом, секретирующих антитела. При иммунофлуоресцентном анализе и FACS с использованием клеток, экспрессирующих антиген, можно идентифицировать антитела со специфичностью к антигену. Гибридомы, секретирующие антитела, могут быть реплицированы, снова скринированы и, если они еще положительны для моноклональных антител, то могут быть субклонированы путем лимитирующего разведения. Затем стабильные субклоны можно культивировать in vitro для получения антител в тканевой культуральной среде для характеризации.
Антитела могут быть получены в трансфектоме клетки-хозяина, используя, например, комбинацию методов рекомбинантной ДНК и методов трансфекции генов, которые хорошо известны в данной области (Morrison, S. (1985) Science 229: 1202).
Например, в одном воплощении представляющий интерес ген (гены), например гены антитела, можно лигировать в экспрессирующий вектор, такой как эукариотическая экспрессирующая плазмида, например, используемая системой экспрессии гена GS, раскрытая в WO 87/04462, WO 89/01036 и ЕР 338 841 или другие системы экспрессии, хорошо известные в данной области. Очищенную плазмиду с клонированными генами антитела можно вводить в эукариотические клетки-хозяева, такие как клетки СНО, NS/0 клетки, клетки HEK293T или клетки HEK293 или, альтернативно, другие эукариотические клетки, такие как клетки, полученные из растений, грибов или дрожжей. Способ, используемый для введения этих генов, может быть способом, описанным в данной области, таким как электропорация, использование липофектина, липофектамина или другие. После введения этих генов антител в клетки-хозяева, клетки, экспрессирующие антитело, могут быть идентифицированы и отобраны. Эти клетки представляют собой трансфектомы, которые затем могут быть амплифицированы для их уровня экспрессии и наработаны для получения антител. Рекомбинантные антитела можно выделить и очистить из этих культуральных надосадочных жидкостей и/или клеток.
Альтернативно, клонированные гены антитела могут быть экспрессированы в других экспрессирующих системах, включая прокариотические клетки, такие как микроорганизмы, например E. coli. Кроме того, антитела могут быть продуцированы в трансгенных животных, не относящихся к человеку, как, например, в молоке овец и кроликов или в яйцах кур или в трансгенных растениях; См., например, Verma, R., et al. (1998) J. Immunol. Meth. 216: 165-181; Pollock, et al. (1999) J. Immunol. Meth. 231: 147-157; and Fischer, R., et al. (1999) Biol. Chem. 380: 825-839.
Химеризация
Немеченые мышиные антитела являются высокоиммуногенными для человека при многократном применении, что приводит к снижению терапевтического эффекта. Основная иммуногенность опосредована константными областями тяжелой цепи. Иммуногенность мышиных антител у человека может быть уменьшена или полностью исключена, если соответствующие антитела подвергаются химеризации или гуманизации. Химерные антитела представляют собой антитела, различные части которых получены из разных видов животных, таких как те, которые имеют вариабельную область, полученную из мышиного антитела, и константные области иммуноглобулина человека. Химеризация антител достигается путем соединения вариабельных областей тяжелой и легкой цепи мышиного антитела с константной областью тяжелой и легкой цепи человека (например, как описано Kraus et al., in Methods in Molecular Biology series, Recombinant antibodies for cancer therapy ISBN-0-89603-918-8). В предпочтительном воплощении химерные антитела образуются путем соединения константной области легкой цепи каппа человека с вариабельной областью легкой цепи мыши. В также предпочтительном воплощении химерные антитела могут быть получены путем соединения константной области цепи легкой цепи лямбда человека с вариабельной областью легкой цепи мыши. Предпочтительными константными областями тяжелой цепи для получения химерных антител являются IgG1, IgG3 и IgG4. Другими предпочтительными константными областями тяжелой цепи для получения химерных антител являются IgG2, IgA, IgD и IgM.
Гуманизация
Антитела взаимодействуют с целевыми антигенами преимущественно через аминокислотные остатки, которые расположены в шести областях, определяющих комплементарность, тяжелой и легкой цепей (CDR). По этой причине аминокислотные последовательности внутри CDR более разнообразны между индивидуальными антителами, чем последовательности вне CDR. Поскольку последовательности CDR отвечают за большинство взаимодействий антитело-антиген, можно экспрессировать рекомбинантные антитела, которые имитируют свойства специфических встречающихся в природе антител, путем конструирования экспрессирующих векторов, которые включают CDR-последовательности из специфического встречающегося в природе антитела, привитого на каркасные последовательности из другого антитела с другими свойствами (см., например, Riechmann, L. et al. (1998) Nature 332: 323-327; Jones, P. et al. (1986) Nature 321: 522-525; и Queen, C. et al. (1989) Proc. Natl. Acad. Sci. U. S. A. 86: 10029-10033). Такие каркасные последовательности могут быть получены из общедоступных баз данных ДНК, которые включают зародышевые последовательности генов антител. Эти зародышевые последовательности будут отличаться от последовательностей генов зрелого антитела, поскольку они не будут включать полностью собранные вариабельные гены, которые образуются путем соединения V(D)J во время созревания В-клеток. Зародышевые последовательности гена также будут отличаться от последовательностей антител с высокой аффинностью к вторичному репертуару при индивидуальном равномерном распределении по вариабельной области.
Способность антител и других связывающих агентов связывать антиген может быть определена с использованием стандартных анализов связывания (например, ELISA, Вестерн-блот, иммунофлуоресцентный и проточный цитометрический анализ).
Для очистки антител отобранные клеточные линии-продуценты можно выращивать в двухлитровых вращающихся колбах для очистки рекомбинантных антител. Альтернативно, антитела могут быть получены в биореакторах на основе диализа. Надосадочные жидкости могут быть отфильтрованы и, если необходимо, сконцентрированы перед аффинной хроматографией с сефарозой с L-протеином. Элюированный IgG можно проверить с помощью гель-электрофореза и высокоэффективной жидкостной хроматографии для обеспечения чистоты. Буферный раствор можно заменить на PBS, и концентрацию можно определить с помощью OD280 с использованием соответствующего коэффициента поглощения. Рекомбинантные антитела можно аликвотировать и хранить при температуре от -65 до -85°С.
Для демонстрации связывание моноклональных антител с живыми клетками, экспрессирующими антиген, можно использовать проточную цитометрию. Клеточные линии, экспрессирующие естественно или после трансфекции антиген, и отрицательные контроли, лишенные экспрессии антигена (выращенные в стандартных ростовых условиях), можно смешивать с различными концентрациями моноклональных антител в надосадочных жидкостях гибридомы или в PBS, содержащем 1% FBS, и инкубировать при 4°С в течение 30 минут. После промывки флуоресцентно-меченный детектирующий реагент (такой как флуоресцентно-конъюгированное анти-IgG-антитело, анти-Fab-антитело или протеин-L) может связываться с антигенсвязанным моноклональным антителом в тех же условиях, что и условия для окрашивания первичного антитела. Образцы могут быть проанализированы с помощью проточной цитометрии с помощью прибора FACS с использованием свойств света и бокового рассеяния с пропусканием одиночных живых клеток. Чтобы отличить антигенспецифические моноклональные антитела от неспецифических связующих компонентов при единичном измерении, можно использовать способ котрансфекции. Клетки, транзиторно трансфицированные плазмидами, кодирующими антиген и флуоресцентный маркер, могут быть окрашены, как описано выше. Трансфицированные клетки могут быть обнаружены в другом канале флуоресценции, чем клетки, окрашенные антителами. Поскольку большинство трансфицированных клеток экспрессируют оба трансгена, антигенспецифические моноклональные антитела связываются преимущественно с клетками, экспрессирующими маркер флуоресценции, тогда как неспецифические антитела связываются в сопоставимом соотношении с нетрансфицированными клетками. Альтернативный анализ с использованием флуоресцентной микроскопии может быть использован в дополнение или вместо анализа проточной цитометрии. Клетки могут быть окрашены точно так, как описано выше, и исследованы с помощью флуоресцентной микроскопии.
Чтобы продемонстрировать связывание моноклональных антител с живыми клетками, экспрессирующими антиген, можно использовать иммунофлуоресцентный микроскопический анализ. Например, клеточные линии, экспрессирующие либо спонтанно, либо после трансфекции антиген и отрицательные контрольные образцы, лишенные экспрессии антигена, выращивают на стеклах с камерами в стандартных условиях роста в среде DMEM/F12, дополненной 10% фетальной телячьей сывороткой (FCS), 2 мМ L-глутамином, 100 МЕ/мл пенициллина и 100 мкг/мл стрептомицина. Затем клетки могут быть зафиксированы метанолом или параформальдегидом или оставлены необработанными. Затем клетки могут вступать в реакцию с моноклональными антителами против антигена в течение 30 мин при 25°С. После промывания клетки могут вступать в реакцию с Alexa555-меченным антителом против мышиного IgG (Molecular Probes) в тех же условиях. Затем клетки могут быть исследованы с помощью флуоресцентной микроскопии.
Клеточные экстракты из клеток, экспрессирующих антиген, и соответствующие отрицательные контрольные образцы, могут быть получены и подвергнуты электрофорезу в полиакриламидном геле с додецилсульфатом натрия (SDS). После электрофореза разделенные антигены переносят на нитроцеллюлозные мембраны, блокируют и исследуют моноклональные антитела, подлежащие тестированию. Связывание IgG может быть детектировано с использованием пероксидазы IgG против мышиного белка и проявлено с помощью ECL-субстрата.
Антитела могут быть дополнительно протестированы на реакционную способность с антигеном методом иммуногистохимии, хорошо известным специалисту, например, с использованием криосрезов, фиксированных параформальдегидом или ацетоном, или срезов тканей, фиксированных параформальдегидом и залитых в парафин, из образцов неопухолевой ткани или опухолевой ткани, полученных от пациентов во время обычной хирургической процедуры, или от мышей, несущих ксенотрансформированные опухоли, инокулированные клеточными линиями, экспрессирующими антиген спонтанно или после трансфекции. Для иммуноокрашивания антитела, реакционноспособные к антигену, могут быть затем инкубированы с козьими антимышиными антителами или козими антикроличьими антителами, конъюгированными с пероксидазой хрена (DAKO), в соответствии с инструкциями поставщика.
Доклинические исследования
Связывающие агенты, описанные в данном документе, также могут быть протестированы на модели in vivo (например, у мышей с иммунодефицитом, несущих ксенотрансплантированные опухоли, инокулированные клеточными линиями, экспрессирующими клаудин), чтобы определить их эффективность в контроле роста экспрессирующих клаудин опухолевых клеток.
Исследования in vivo после ксенотрансплантации опухолевых клеток, экспрессирующих клаудин, мышам с ослабленным иммунитетом или другим животным могут быть выполнены с использованием связывающих агентов, описанных в данном документе. Связывающие агенты можно вводить мышам без опухолей с последующей инъекцией опухолевых клеток для измерения эффектов связывающих агентов для предотвращения образования опухолей или связанных с опухолями симптомов. Связывающие агенты можно вводить мышам с опухолями для определения терапевтической эффективности соответствующих связывающих агентов для уменьшения роста опухоли, метастазирования или связанных с опухолью симптомов. Применение связывающих агентов может сочетаться с применением других веществ в качестве цистостатических лекарств, ингибиторов факторов роста, блокаторов клеточного цикла, ингибиторов ангиогенеза или антител для определения синергетической эффективности и потенциальной токсичности комбинаций. Для анализа токсических побочных эффектов, опосредованных связывающими агентами, животных можно инокулировать связывающими агентами или контрольными реагентами и тщательно исследовать на предмет симптомов, возможно связанных с терапией клаудин-связывающим агентом.
Может быть выполнено картирование эпитопов, распознаваемых связывающими агентами, что подробно описано в "Epitope Mapping Protocols (Methods in Molecular Biology) by Glenn E. Morris ISBN-089603-375-9 и в "Epitope Mapping: A Practical Approach" Practical Approach Series, 248 by ISBN-089603-375-9 и в "Epitope Mapping: A Practical Approach" Practical Approach Series, 248 by Olwyn M. R. Westwood, Frank C. Hay.
Соединения и агенты, описанные в данном документе, могут вводиться в форме любой подходящей фармацевтической композиции.
Фармацевтические композиции по изобретению предпочтительно являются стерильными и содержат эффективное количество связывающих агентов, описанных в данном документе, и, необязательно, дополнительных агентов, как описано в данном документе, для создания искомой реакции искомого эффекта.
Фармацевтические композиции обычно предоставляются в единой лекарственной форме и могут быть приготовлены известным образом. Фармацевтическая композиция может быть, например, представлена в форме раствора или суспензии.
Фармацевтическая композиция может содержать соли, буферные вещества, консерванты, носители, разбавители и/или вспомогательные вещества, каждое из которых предпочтительно является фармацевтически приемлемым. Термин «фармацевтически приемлемый» относится к нетоксичности материала, который не взаимодействует с действием активного компонента фармацевтической композиции.
Соли, которые не являются фармацевтически приемлемыми, могут быть использованы для получения фармацевтически приемлемых солей и включены в изобретение. Фармацевтически приемлемые соли этого типа включают без ограничения указанным, соли, которые получены из следующих кислот: соляной, бромистоводородной, серной, азотной, фосфорной, малеиновой, уксусной, салициловой, лимонной, муравьиной, малоновой, янтарной кислот и т.п. Фармацевтически приемлемые соли также могут быть получены в виде солей щелочных металлов или солей щелочноземельных металлов, таких как соли натрия, соли калия или соли кальция.
Подходящие буферные вещества для применения в фармацевтической композиции включают уксусную кислоту в соли, лимонную кислоту в соли, борную кислоту в соли и фосфорную кислоту в соли.
Подходящие консерванты для применения в фармацевтической композиции включают хлорид бензалкония, хлорбутанол, парабен и тимеросал.
Состав для инъекций может включать фармацевтически приемлемое вспомогательное вещество, такое как Рингер лактат.
Термин «носитель» относится к органическому или неорганическому компоненту природного или синтетического характера, в котором активный компонент комбинирован для облегчения, усиления или возможности применения. Согласно изобретению термин «носитель» также включает один или несколько совместимых твердых или жидких наполнителей, разбавителей или инкапсулирующих веществ, которые подходят для введения пациенту.
Возможными веществами-носителями для парентерального введения являются, например, стерильная вода, раствор Рингера, Рингер лактат, стерильный раствор хлорида натрия, полиалкиленгликоли, гидрированные нафталины и, в частности, биосовместимые лактидные полимеры, лактид-гликолидные сополимеры или полиоксиэтилен/полиоксипропиленовые сополимеры.
Используемый в данном документе термин «вспомогательное вещество» предназначен для обозначения всех веществ, которые могут присутствовать в фармацевтической композиции и которые не являются активными ингредиентами, такие как, например, носители, связующие, смазывающие вещества, загустители, поверхностно-активные агенты, консерванты, эмульгаторы, буферы, ароматизаторы или красители.
Агенты и композиции, описанные в данном документе, могут вводиться любым обычным способом, таким как парентеральное введение, в том числе путем инъекции или инфузии. Введение предпочтительно является парентеральным, например, внутривенным, внутриартериальным, подкожным, внутрикожным или внутримышечным.
Композиции, подходящие для парентерального введения, обычно содержат стерильный водный или неводный препарат активного соединения, которое предпочтительно является изотоническим по отношению к крови реципиента. Примерами совместимых носителей и растворителей являются раствор Рингера и изотонический раствор хлорида натрия. Кроме того, обычно в качестве раствора или суспензионной среды используются стерильные, жирные масла.
Агенты и композиции, описанные в данном документе, вводят в эффективных количествах. «Эффективное количество» относится к количеству, которое достигает желаемой реакции искомого эффекта индивидуально или вместе с дополнительными дозами. В случае лечения конкретного заболевания или конкретного состояния желаемая реакция предпочтительно относится к ингибированию течения заболевания. Это включает замедление прогресса заболевания и, в частности, прекращение или отмену прогресса заболевания. Желаемая реакция при лечении заболевания или состояния может также представлять собой задержку начала или предотвращения начала заболевания или указанного состояния.
Эффективное количество агента или композиции, описанных в данном документе, будет зависеть от состояния, подлежащего лечению, тяжести заболевания, индивидуальных параметров пациента, включая возраст, физиологическое состояние, размер и вес, продолжительность лечения, типа сопутствующей терапии (если имеется), конкретного пути введения и аналогичных факторов. Соответственно, дозы, вводимые агентами, описанными в данном документе, могут зависеть от различных таких параметров. В случае если реакция у пациента недостаточна при использовании начальной дозы, могут использоваться более высокие дозы (или эффективные более высокие дозы, достигаемые другим, более локализованным способом введения).
Агенты и композиции, описанные в данном документе, могут вводиться пациентам, например in vivo, для лечения или предотвращения различных нарушений, таких как описанные в данном документе. Предпочтительные пациенты включают пациентов, страдающих расстройствами, которые могут быть исправлены или облегчены путем введения агентов и композиций, описанных в данном документе. Это включает расстройства с участием клеток, характеризующихся измененным паттерном экспрессии клаудина, такого как CLDN18.2 и/или CLDN6.
Например, в одном воплощении агенты, описанные в настоящем документе, можно использовать для лечения пациента с онкологическим заболеванием, например раком, описанным в настоящем документе, которое характеризуется наличием раковых клеток, экспрессирующих клаудин.
Фармацевтические композиции и способы лечения, описанные в соответствии с изобретением, также могут быть использованы для иммунизации или вакцинации для предотвращения описанного в данном документе заболевания.
Фармацевтическую композицию по изобретению можно вводить вместе с дополнительными веществами, усиливающими иммунитет, такими как один или несколько адъювантов, и могут содержать одно или несколько веществ, усиливающих иммунитет, для дальнейшего повышения ее эффективности, предпочтительно для достижения синергетического эффекта иммуностимуляции. Термин «адъювант» относится к соединениям, которые продлевают или усиливают или ускоряют иммунный ответ. В этом отношении возможны различные механизмы в зависимости от различных типов адъювантов. Например, соединения, которые обеспечивают созревание DC, например липополисахариды или лиганд CD40, образуют первый класс подходящих адъювантов. Как правило, любой агент, который влияет на иммунную систему по типу «сигнал опасности» (LPS, GP96, дцРНК и т.д.) или цитокины, такие как GM-CSF, можно использовать в качестве адъюванта, который позволяет интенсифицировать и/или контролируемым образом усилить иммунный ответ. Также необязательно в этом контексте могут использоваться олигодезоксинуклеотиды CpG, хотя должны быть рассмотрены их побочные эффекты, которые возникают при определенных обстоятельствах, как объяснено выше. Особенно предпочтительными адъювантами являются цитокины, такие как монокины, лимфокины, интерлейкины или хемокины, например, IL-1, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-8, IL -9, IL-10, IL-12, INFα, INF-γ, GM-CSF, LT-α или факторы роста, например, hGH. Другими известными адъювантами являются гидроксид алюминия, адъювант Фрейнда или масло, такое как Montanide®, наиболее предпочтительно Montanide® ISA51. Липопептиды, такие как Pam3Cys, также подходят для применения в качестве адъювантов в фармацевтической композиции по настоящему изобретению.
Агенты и композиции, представленные в данном документе, могут использоваться индивидуально или в комбинации с традиционными терапевтическими схемами, такими как операция, облучение, химиотерапия и/или трансплантация костного мозга (аутологичная, изогенная, аллогенная или неродственная).
Лечение рака представляет собой область, где комбинированные стратегии особенно желательны, поскольку часто комбинированное действие двух, трех, четырех или даже более противоопухолевых лекарственных/терапевтических средств создает синергические эффекты, которые значительно сильнее, чем воздействие монотерапевтического подхода. Таким образом, в другом воплощении настоящего изобретения, лечение онкологических заболеваний, в котором используются механизмы на основе иммунизации или вакцинации, такие как способы и фармацевтические композиции по настоящему изобретению, можно эффективно комбинировать с различными другими лекарственными средствами и/или способами, нацеленными на сходные или другие специфические механизмы. К ним относятся, например, комбинации с обычными противоопухолевыми терапиями, стратегиями множественных эпитопов, дополнительной иммунотерапией и подходами к лечению, нацеленными на ангиогенез или апоптоз (обзор см., например, Andersen et al. 2008: Cancer treatment: the combination of vaccination with other therapies. Cancer Immunology Immunotherapy, 57(11): 1735-1743). Последовательное введение различных агентов может ингибировать рост раковых клеток в разных контрольных точках, тогда как другие агенты могут, например, ингибировать неоангиогенез, выживаемость раковых клеток или метастазов, потенциально превращая рак в хроническое заболевание. В следующем перечне приведены некоторые неограничивающие примеры противораковых лекарственных средств и методов лечения, которые можно использовать в сочетании с настоящим изобретением:
1. Химиотерапия
Химиотерапия является стандартом лечения нескольких видов онкологических заболеваний. Наиболее распространенные химиотерапевтические агенты действуют, убивая клетки, которые быстро делятся, что является одним из основных свойств раковых клеток. Таким образом, комбинация с обычными химиотерапевтическими лекарственными средствами, такими как, например, алкилирующие агенты, антиметаболиты, антрациклины, растительные алкалоиды, ингибиторы топоизомеразы и другие противоопухолевые агенты, которые влияют на деление клеток или синтез ДНК, могут значительно улучшить терапевтические эффекты настоящего изобретения путем очистки клеток-супрессоров, перезагрузки иммунной системы, придания опухолевым клеткам восприимчивости к иммуноопосредованному уничтожению, или дополнительной активации клеток иммунной системы. Синергическое противоопухолевое действие химиотерапевтических и иммунотерапевтических препаратов на основе вакцинации было продемонстрировано в нескольких исследованиях (см., Например, Quoix et al. 2011: Therapeutic vaccination with TG4010 and first-line chemotherapy in advanced non-small-cell lung cancer: a controlled phase 2B trial. Lancet Oncol. 12 (12): 1125-33.; см. также Liseth et al. 2010: Combination of intensive chemotherapy and anticancer vaccines in the treatment of human malignancies: the hematological experience. J Biomed Biotechnol. 2010: 6920979; см. также Hirooka et al. 2009: A combination therapy of gemcitabine with immunotherapy for patients with inoperable locally advanced pancreatic cancer. Pancreas 38(3): e69-74). Существуют сотни химиотерапевтических препаратов, которые в основном подходят для комбинированной терапии. Некоторыми (не ограничивающими) примерами химиотерапевтических препаратов, которые можно комбинировать с настоящим изобретением, являются карбоплатин (параплатин), цисплатин (платинол, платинол-AQ), циклофосфамид (цитоксан, неосар), доцетаксел (таксотер), доксорубицин (адриамицин), эрлотиниб (Tarceva), этопозид (VePesid), фторурацил (5-FU), гемцитабин (Gemzar), мезилат иматиниба (Gleevec), иринотекан (Camptosar), метотрексат (Folex, мексат, аметоптерин), паклитаксраксол (налог) (Nexavar), сунитиниб (Sutent), топотекан (Hycamtin), винкристин (Oncovin, Vincasar PFS) и винбластин (Velban).
2. Хирургия
Операция по удалению рака - операция по удалению опухоли - остается основой лечения онкологических заболеваний. Операция может быть объединена с другими методами лечения онкологических заболеваний для того, чтобы удалить любые оставшиеся опухолевые клетки. Сочетание хирургических подходов с последующим иммунотерапевтическим лечением является многообещающим подходом, который был продемонстрирован бесчисленное количество раз.
3. Облучение
Лучевая терапия остается важным компонентом лечения онкологических заболеваний, при этом примерно 50% всех онкологических больных получают лучевую терапию в ходе заболевания. Основная цель лучевой терапии - лишить раковые клетки их потенциала размножения (деления клеток). Типы излучения, используемые для лечения онкологических заболеваний - это излучение фотонов (рентгеновское и гамма-излучение) и излучение частиц (пучки электронов, протонов и нейтронов). Есть два способа доставки облучения в расположение рака. Наружное направленное облучение доставляется извне тела, направляя высокоэнергетические лучи (фотоны, протоны или излучение частиц) в расположение опухоли. Внутреннее облучение или брахитерапия доставляется изнутри организма радиоактивными источниками, запечатанными в катетеры или имплантируемые источники излучения непосредственно в область опухоли. Методы лучевой терапии, которые применимы в сочетании с настоящим изобретением, включают, например, фракционирование (лучевую терапию, проводимую во фракционированном режиме, например, ежедневные фракции от 1,5 до 3 Гр, проводимые в течение нескольких недель), трехмерную конформную лучевую терапию (3DCRT; доставка излучения в макроскопический объём опухоли), лучевая терапия с модуляцией интенсивности (IMRT; управляемая компьютером модуляция интенсивности нескольких пучков излучения), лучевая терапия с визуальным контролем (IGRT; метод, включающий визуализацию перед лучевой терапией, которая допускает коррекцию) и стереотаксическая лучевая терапия тела (SRBT, обеспечивает очень высокие индивидуальные дозы радиации только на несколько фракциях лечения). Для обзора лучевой терапии см. Baskar et al., 2012: Cancer and radiation therapy: current advances and future directions. Int. J Med Sci. 9(3): 193–199.
4. Антитела
Антитела (предпочтительно моноклональные антитела) достигают своего терапевтического эффекта против раковых клеток посредством различных механизмов. Они могут оказывать непосредственное влияние на апоптоз или запрограммированную гибель клеток. Они могут блокировать компоненты путей передачи сигнала, такие как, например, рецепторы факторов роста, эффективно задерживая пролиферацию опухолевых клеток. В клетках, которые экспрессируют моноклональные антитела, они могут вызывать образование антиидиотипических антител. Косвенные эффекты включают рекрутирование клеток, обладающих цитотоксичностью, таких как моноциты и макрофаги. Этот тип антителопосредованного уничтожения клеток называется антителозависимой клеточно-опосредованной цитотоксичностью (ADCC). Антитела также связывают комплемент, приводя к прямой клеточной токсичности, известной как комплемент-зависимая цитотоксичность (CDC). Объединение хирургических методов с иммунотерапевтическими препаратами или способами является успешным подходом, как, например, продемонстрировано в Gadri et al. 2009: Synergistic effect of dendritic cell vaccination and anti-CD20 antibody treatment in the therapy of murine lymphoma. J Immunother. 32(4): 333-40. В следующем перечне приведены некоторые неограничивающие примеры противоопухолевых антител и потенциальных антител-мишеней (в скобках), которые можно использовать в сочетании с настоящим изобретением: абаговомаб (CA-125), абциксимаб (CD41), адекатумумаб (EpCAM), афутузумаб (CD20), алацизумаб пигол (VEGFR2), алтумомаб пентетат (CEA), аматуксимаб (MORAb-009), анатумомаб мафенатокс (TAG-72), аполизумаб (HLA-DR), арцитумомаб (CEA), бавитуксимаб (фосфатидилсерин), бектумомаб (CD22), белимумаб (BAFF), бевацизумаб (VEGF-A), биватузумаб мертанзин (CD44 v6), блинатумомаб (CD19), брентуксимаб ведотин (CD30 TNFRSF8), кантузумаб мертансин (mucin CanAg), кантузумаб равтансин (MUC1), капромаб пендетид (клетки карциномы предстательной железы), (CNTO888), катумаксомаб (EpCAM, CD3), цетуксимаб (EGFR), цитатузумаб богатокс (EpCAM), циксутумумаб (рецептор IGF-1), клаудиксимаб (клаудин), кливатузумаб тетраксетан (MUC1), конатумумаб (TRAIL-R2), дацетузумаб (CD40), далотузумаб (инсулиноподобный рецептор фактора роста I), деносумаб (RANKL), Детумомаб (клетка В-лимфомы), дрозитумаб (DR5), экромексимаб (ганглиозид GD3), эдреколомаб (EpCAM), элотузумаб (SLAMF7), энаватузумаб (PDL192), энситуксимаб (NPC-1C), эпратузумаб (CD22), эртумаксомаб (HER2/neu, CD3), этарацизумаб (интегрин αvβ3), фарлетузумаб (фолатный рецептор 1), FBTA05 (CD20), фиклатузумаб (SCH 900105), фигитумумаб (рецептор IGF-1), фланвотумаб (гликопротеин 75), фрезолимумаб (TGF -β), галиксимаб (CD80), ганитумаб (IGF-I), гемтузумаб озогамицин (CD33), гевокизумаб (IL-1β), гирентуксимаб (карбоангидраза 9 (CA-IX)), глембатумумаб ведотин (GPNMB), ибритумумаб тиуксетан (CD20), икрукумаб (VEGFR-1), иговома (CA-125), индатуксимаб равтансин (SDC1), интетумумаб (CD51), инотузумаб озогамицин (CD22), ипилимумаб (CD152), иратумумаб (CD30), лабетузумаб (CEA), лексатумумаб (TRAIL-R2), либивирумаб (поверхностный антиген гепатита В), линтузумаб (CD33), лорвотузумаб мертанзин (CD56), лукатумумаб (CD40), люмиксимаб (CD23), мапатумумаб (TRAIL-R1), матузумаб (EGFR), меполизумаб (IL-5), милатузумаб (CD74), митумомаб (GD3 ганглиозид), могамулизумаб (CCR4), моксетумомаб пасудотокс (CD22), наколомаб тафенатокс (антиген С242), наптумомаб эстафенатокс (5T4) нарнатумаб (RON), нецитумумаб (EGFR), нимотузумаб (EGFR), ниволумаб (IgG4), офатумумаб (CD20), оларатумаб (PDGF-Rα), онартузумаб (киназа рецептора фактора рассеяния человека), опортузумаб монатокс (EpCAM), Ореговомаб (CA-125), Окселумаб (OX-40), панитумумаб (EGFR), патритумаб (HER3), пемтумома (MUC1), пертузумаб (HER2/neu), пинтумомаб (антиген аденокарциномы), притумумаб (вименин), ракотумомаб (N-гликонейраминовая кислота), радретумаб (экстрадомен В-фибронектина), рафивирумаб (гликопротеин вируса бешенства), рамуцирумаб (VEGFR2), рилотумумаб (HGF), ритуксимаб (CD20), робатумумаб (рецептор IGF-1), самализумаб (CD200), сибротузумаб (FAP), силтуксимаб (IL-6), табалумаб (BAFF), такатузумаб тетраксетан (альфа-фетопротеин), таплитумомаб паптокс (CD19), тенатумомаб (тенасцин С), тепротумумаб (CD221), тицилимумаб (CTLA-4), тигатузумаб (TRAIL-R2), TNX-650 (IL-13), тозитумомаб (CD20), трастузумаб (HER2/neu), TRBS07 (GD2), тремелимумаб (CTLA-4), тукотузумаб целмолейкин (EpCAM), ублитуксимаб (MS4A1), урелумаб (4-1BB), волоцикимаб (интегрин α5β1), вотумумаб (опухолевый антиген CTAA16.88), залутумумаб (EGFR), занолимумаб (CD4).
5. Цитокины, хемокины, костимулирующие молекулы, гибридные белки
Комбинированное применение антиген-кодирующих фармацевтических композиций по настоящему изобретению с цитокинами, хемокинами, костимулирующими молекулами и/или их гибридными белками для индукции полезных эффектов иммунной модуляции или ингибирования опухоли представляет собой другое воплощение настоящего изобретения. Чтобы увеличить инфильтрацию иммунных клеток в опухоль и облегчить перемещение антиген-презентирующих клеток в лимфатические узлы, дренирующих опухоль, могут быть использованы различные хемокины со структурами C, CC, CXC и CX3C. Некоторые из наиболее перспективных хемокинов - это, например, CCR7 и его лиганды CCL19 и CCL21, и CCL2, CCL3, CCL5 и CCL16. Другими примерами являются CXCR4, CXCR7 и CXCL12. Кроме того, полезны костимулирующие или регуляторные молекулы, такие как, например, лиганды B7 (B7.1 и B7.2). Также могут быть использованы другие цитокины, такие как, например, интерлейкины, особенно (например, IL-1 до IL17), интерфероны (например, IFNальфа1 к IFNальфа8, IFNальфа10, IFNальфа13, IFNальфа14, IFNальфа16, IFNальфа17, IFNальфа21, IFNбета1, IFNW, IFNE1 и IFNK), гемопоэтические факторы, TGF (например, TGF-α, TGF-β и другие члены семейства TGF), наконец, члены семейства рецепторов фактора некроза опухоли и их лигандов, и другие стимулирующие молекулы, содержащие, без ограничения указанным, 4-1BB, 4 -1BB-L, CD137, CD137L, CTLA-4GITR, GITRL, Fas, Fas-L, TNFR1, TRAIL-R1, TRAIL-R2, p75NGF-R, DR6, LT.beta.R, RANK, EDAR1, XEDAR, Fn114, Troy/Trade, TAJ, TNFRII, HVEM, CD27, CD30, CD40, 4-1BB, OX40, GITR, GITRL, TACI, BAFF-R, BCMA, RELT и CD95 (Fas/APO-1), глюкокортикоид-индуцированный TNFR-родственный белок, апоптоз-опосредующий белок, родственный рецептору TNF (TRAMP) и рецептор смерти-6 (DR6). CD40/CD40L и OX40/OX40L являются особенно важными мишенями для комбинированной иммунотерапии из-за их прямого воздействия на выживание и пролиферацию Т-клеток. Для обзора см. Lechner et al. 2011: Chemokines, costimulatory molecules and fusion proteins for the immunotherapy of solid tumors. Immunotherapy 3 (11), 1317-1340.
6. Бактериальные обработки
Исследователи используют анаэробные бактерии, такие как Clostridium novyi, для уничтожения внутренней части опухолей с низким содержанием кислорода. Затем бактерии должны умереть при контакте с оксигенированными сторонами опухоли, что означает, что они будут безвредны для остальной части организма. Другая стратегия заключается в использовании анаэробных бактерий, которые были трансформированы ферментом, способным превращать нетоксичное пролекарство в токсичное лекарство. При размножении бактерий в некротических и гипоксических областях опухоли фермент экспрессируется исключительно в опухоли. Таким образом, системно применяемое пролекарство метаболизируется до токсического препарата только в опухоли. Была продемонстрирована эффективность с непатогенными анаэробами Clostridium sporogenes.
7. Ингибиторы киназ
Другая большая группа потенциальных мишеней для копмплементарной терапии онкологических заболеваний включает ингибиторы киназ, потому что рост и выживание раковых клетках тесно взаимосвязаны с дерегуляцией активности киназ. Для восстановления нормальной активности киназ и, следовательно, для уменьшения роста опухоли используют широкий спектр ингибиторов. Группа целевых киназ включает рецепторные тирозинкиназы, например, BCR-ABL, B-Raf, EGFR, HER-2/ErbB2, IGF-IR, PDGFR-α, PDGFR-β, c-Kit, Flt-4, Flt3, FGFR1, FGFR3, FGFR4, CSF1R, c-Met, RON, c-Ret, ALK, цитоплазматические тирозинкиназы, например, c-SRC, c-YES, Abl, JAK-2, серин/треониновые киназы, например, ATM, Aurora A & B, CDK, mTOR, PKCi, PLKs, b-Raf, S6K, STK11/LKB1 и липидкиназы, например, PI3K, SK1. К низкомолекулярным ингибиторам киназ относятся, например, PHA-739358, нилотиниб, дазатиниб и PD166326, NSC 743411, лапатиниб (GW-572016), канертиниб (CI-1033), семаксиниб (SU5416), ваталаниб (PTK787/ZK222584), Сутент (SU11248), Сорафениб (BAY 43-9006) и лефлуномид (SU101). Для получения дополнительной информации см., Например, Zhang et al., 2009: Targeting cancer with small molecule kinase inhibitors. Nature Reviews Cancer 9, 28-39.
8. Toll-подобные рецепторы
Представители семейства Toll-подобных рецепторов (TLR) являются важной связью между врожденным и адаптивным иммунитетом, а действие многих адъювантов зависит от активации TLR. Большое количество известных вакцин против раков включают лиганды для TLR для усиления реакции на вакцины. Помимо TLR2, TLR3, TLR4, главным образом TLR7 и TLR8 были исследованы на предмет онкотерапии в подходах пассивной иммунотерапии. Близкородственные TLR7 и TLR8 вносят вклад в противоопухолевые ответы, воздействуя на иммунные клетки, опухолевые клетки и микроокружение опухоли, и могут активироваться структурами нуклеозидных аналогов. Все TLR были использованы в качестве самостоятельных иммунотерапевтических средств или адъювантов противоопухолевых вакцин и могут быть синергетически объединены с составами и способами по настоящему изобретению. Для получения дополнительной информации см. Van Duin et al., 2005: Triggering TLR signaling in vaccination. Trends in Immunology, 27(1):49-55.
9. Ингибиторы ангиогенеза
В дополнение к терапии, которая нацелена на иммуномодулирующие рецепторы, затронутые опосредованными опухолью механизмами ухода и подавления иммунитета, существуют способы лечения, которые нацелены на окружение опухоли. Ингибиторы ангиогенеза предотвращают обширный рост кровеносных сосудов (ангиогенез), который необходим опухолям для выживания. Например, ангиогенез, стимулируемый опухолевыми клетками для удовлетворения их растущей потребности в питательных веществах и кислороде, может блокироваться путем направленного воздействия на разные молекулы. Неограничивающими примерами молекул, опосредующих ангиогенез, или ингибиторов ангиогенеза, которые можно комбинировать с настоящим изобретением, являются растворимый VEGF (VEGF-изоформы VEGF121 и VEGF165, рецепторы VEGFR1, VEGFR2 и корецепторы нейрофилилна-1 и нейрофилилина-2) 1 и NRP-1, ангиопоэтин 2, TSP-1 и TSP-2, ангиостатин и родственные молекулы, эндостатин, вазостатин, кальретикулин, фактор тромбоцитов-4, TIMP и CDAI, Meth-1 и Meth-2, IFN-α, -β и -γ, CXCL10, IL-4, -12 и -18, протромбин ("kringle"-домен 2), фрагмент антитромбина III, пролактин, VEGI, SPARC, остеопонтин, маспин, канстатин, пролиферин-родственный белок, рестин и лекарственные средства, такие как, например, бевацизумаб, итраконазол, карбоксиамидотриазол, TNP-470, CM101, IFN-α, тромбоцитарный фактор-4, сурамин, SU5416, тромбоспондин, антагонисты VEGFR, ангиостатические стероиды + гепарин, хрящевой фактор ингибирования ангиогенеза, ингибиторы матриксных металлопротеиназ, 2-метоксиэстрадиол, текогалан, тетратиомоибдат, талисомид, тромбоспондин, ингибиторы пролактина Vβ3, линомид, тасквинимод, см., например, Schoenfeld and Dranoff 2011: Anti-angiogenesis immunotherapy. Hum Vaccin. (9):976-81.
10. Низкомолекулярные лекарственные средства для направленной терапии
Низкомолекулярные лекарственные средства для направленной терапии, как правило, являются ингибиторами ферментативных доменов мутантных, сверхэкспрессированных или других критически важных белков в раковой клетке. Яркими и неограничивающими примерами являются ингибиторы тирозинкиназы иматиниб (Gleevec/Glivec) и гефитиниб (Iressa). Использование малых молекул, например сунитиниб малата и/или торалата сорафениба, нацеленных на некоторые киназы, в сочетании с вакцинами для лечения онкологических заболеваний, также описано в предшествующей патентной заявке US2009004213.
11. Вирусные вакцины
Существует ряд вакцин на основе вирусов, доступных или находящихся в стадии разработки, которые можно использовать в комбинированном терапевтическом подходе вместе с составами по настоящему изобретению. Одним из преимуществ использования таких вирусных векторов является их собственная способность инициировать иммунные реакции, причем воспалительные реакции, возникающие в результате вирусной инфекции, создают сигнал опасности, необходимый для иммунной активации. Идеальный вирусный вектор должен быть безопасным и не вызывать иммунный ответ против вектора для усиления специфических противоопухолевых ответов. Рекомбинантные вирусы, такие как вирусы коровьей оспы, вирусы простого герпеса, аденовирусы, аденоассоциированные вирусы, ретровирусы и вирусы птичьей оспы, были использованы в моделях опухолей на животных, и на основании их обнадеживающих результатов были начаты клинические испытания на людях. Особенно важными вакцинами на основе вируса являются вирусоподобные частицы (VLP), мелкие частицы, которые содержат определенные белки из внешней оболочки вируса. Вирусоподобные частицы не содержат никакого генетического материала от вируса и не могут вызвать инфекцию, но они могут быть сконструированы так, чтобы представлять опухолевые антигены на своей оболочке. VLP могут быть получены из различных вирусов, таких как, например, вирус гепатита B, или других семейств вирусов, включая Parvoviridae (например, аденоассоциированный вирус), Retroviridae (например, HIV) и Flaviviridae (например, вирус гепатита C). Обзорный анализ см. в Sorensen and Thompsen 2007: Virus-based immunotherapy of cancer: what do we know and where are we going? APMIS 115 (11): 1177-93; вирусоподобные частицы против рака рассмотрены в Buonaguro et al. 2011: Developments in virus-like particle-based vaccines for infectious diseases and cancer. Expert Rev Vaccines 10(11):1569-83; и в Guillén et al. 2010: Virus-like particles as vaccine antigens and adjuvants: application to chronic disease, cancer immunotherapy and infectious disease preventive strategies. Procedia in Vaccinology 2 (2), 128–133.
12. Мультиэпитопные стратегии
Использование мультиэпитопов показывает многообещающие результаты для вакцинации. Технологии быстрого секвенирования в сочетании с системами интеллектуальных алгоритмов позволяют эксплуатировать опухолевый мутаном и могут обеспечить множественные эпитопы для индивидуализированных вакцин, которые можно комбинировать с настоящим изобретением. Для получения дополнительной информации см. 2007: Vaccination of metastatic colorectal cancer patients with matured dendritic cells loaded with multiple major histocompatibility complex class I peptides. J Immunother 30: 762–772; furthermore Castle et al. 2012: Exploiting the mutanome for tumor vaccination. Cancer Res 72 (5):1081-91.
13. Адоптивный перенос T-клеток
Например, комбинация вакцинации против опухолевого антигена и переноса Т-клеток описана в: Rapoport et al. 2011: Combination immunotherapy using adoptive T-cell transfer and tumor antigen vaccination on the basis of hTERT and survivin after ASCT for myeloma. Blood 117(3):788-97.
14. Таргетные терапии на основе пептидов
Пептиды могут связываться с рецепторами клеточной поверхности или поврежденным внеклеточным матриксом, окружающим опухоль. Радионуклиды, которые присоединены к этим пептидам (например, RGD), в конечном итоге убивают раковые клетки, если нуклид распадается в непосредственной близости от клетки. Особенно интересны олиго- или мультимеры этих связывающих мотивов, поскольку это может привести к повышенной специфичности и авидности опухоли. Неограничивающие примеры см. В Yamada 2011: Peptide-based cancer vaccine therapy for prostate cancer, bladder cancer, and malignant glioma. Nihon Rinsho 69(9): 1657-61.
15. Другие способы лечения
Существует множество других способов лечения онкологических заболеваний, которые можно комбинировать с составами и способами по настоящему изобретению для создания синергетических эффектов. Неограничивающими примерами являются способы лечения, нацеленные на апоптоз, гипертермию, гормональную терапию, теломеразную терапию, потенцированную инсулиновую терапию, генную терапию и фотодинамическую терапию.
Настоящее изобретение дополнительно иллюстрируется следующими примерами, которые не могут быть истолкованы как ограничивающие объем изобретения.
ПРИМЕРЫ
Пример 1. Получение, очистка и анализ производных биспецифичных антител, нацеленных на CLDN6 и CD3 (CLDN6 x CD3).
а. Происхождение последовательностей, дизайн конструкций bstb и клонирование в экспрессирующие векторы
Биспецифичные химерные конструкции TriMAB (bstb) конструировали в виде антигенсвязывающих фрагментов (Fab), снабженных двумя одноцепочечными вариабельными фрагментами (scFv) на С-конце константных областей. Fab-связывающий домен специфичен для компонента Т-клеточного рецептора человека CD3. Анти-CD3 вариабельная область тяжелой цепи (VH) и соответствующие домены вариабельной области легкой цепи (VL) получены из мышиного IgG TR66 (Lanzavecchia und Scheidegger 1987). Цистеин в положении 114 (согласно номенклатуре IMGT) был заменен серином. Константная область тяжелой цепи (CH1) и константная область легкой цепи (CL) имеют человеческое происхождение. Для наших конструкций мы выбрали константную область легкой цепи каппа-типа. Две scFv-связывающие части специфичны для CLDN6, ассоциированного с опухолевым антигеном человека (TAA). Соответствующие области VH и VL получены из химерного IgG1 IMAB206-SUBW (Ganymed Pharmaceuticals AG, Майнц, Германия). На фиг. 18 показаны аминокислотные последовательности доменов VH и VL, которые были использованы в изобретении.
Были получены две молекулы bstb, различающиеся по своей области CH1. Bstb_369/367 включает область CH1, полученную из человеческого IgG1, тогда как bstb_371/367 включает область CH1 из человеческого IgG2. Рациональным было сравнение образования гетеродимера из-за образования различных дисульфидных связей CH1 и CL разных подклассов (Röthlisberger et al. 2005). Поскольку последовательность для каппа-типа CL является консервативной в IgG1 и IgG2, одну и ту же конструкцию CL использовали для получения двух конструкций. Следующие молекулы были получены на уровне белка для образования молекул bstb:
Bstb_369/367:
Bstb_371/367:
C = C-конец, CH = константная область тяжелой цепи, CL = константная область легкой цепи, Fd = гидролизуемый фрагмент (часть тяжелой цепи Fab), L = часть легкой цепи Fab, N = N-конец, VH = вариабельный домен тяжелой цепи, VL = вариабельный домен легкой цепи.
Таблица 1 суммирует информацию о конструкциях bstb, специфичных для TAA CLDN6, которые были получены в ходе изобретения. Фрагменты конструкции bstb были получены путем синтеза генов в GeneArt AG (GeneArt/Thermo Fisher Scientific, Регенсбург, Германия) с использованием последовательностей VH и VL соответствующих антител IgG и консервативных последовательностей CH и CL человека в качестве GeneArt Strings. Оптимизация кодонов CHO была реализована с помощью программного обеспечения GeneArt GeneOptimizer®. Информация о специфичности, происхождении последовательностей из моноклональных антител (mAB), параметре для оптимизации использования кодонов и дополнительных характеристиках последовательностей приведена в таблице 1. Последовательности, кодирующие вариабельные домены фрагментов, связывающих клетки-мишени, были первоначально получены из Ganymed Pharmaceuticals AG.
Конструирование вектора клонирования и экспрессии ДНК осуществляли с использованием набора для клонирования и сборки Seamless PLUS (GeneArt/Thermo Fisher Scientific), известного специалистам в данной области. Сигнальная последовательность секреции человеческого IgG, кодирующая MGWSCIILFLVATATGVHS, была введена на 5'-конце выше последовательностей V-области Fd- и L-bstb для секреции белка в культуральную среду. Последовательность, кодирующая гибкий аминокислотный пептидный линкер (GS) из 20 аминокислот (AК) ((GGGGS)4), была вставлена для объединения доменов VH и VL для композиции анти-TAA scFv. В каждый из доменов VH и VL вводили одну замену на цистеин для образования scFv-стабилизирующего дисульфидного мостика. Одна последовательность домена scFv была соединена с Fd-частью (C-конец CH1) с помощью последовательности, кодирующей линкер 18 АК (SGPGGGRS(GGGGS)2), а другая scFv была присоединена к L-части (C -конец CL) с помощью последовательности, кодирующей линкер с шестью AA (DVPGGS). Различные длины линкера позволили различить Fd- и L-часть по размеру. Последовательность 6xHis-метки добавляли к 3'-концу фрагмента Fd-scFv и Strep- метку к 3'-концу фрагмента L-scFv для облегчения очистки чистого гетеродимерного bstb первого поколения. В таблице 2 приведены полные последовательности ДНК, кодирующие белок bstb. В таблице 3 показана последовательность ДНК, кодирующая би-(scFv)2, которая использовалась в качестве эталона.
Конструкции антител bstb клонировали в стандартный экспрессирующий вектор на основе pCEP4 млекопитающих (Invitrogen/Thermo Fisher Scientific, Дармштадт, Германия), расщепленный Nae I и Pml I, в результате чего образовалась линейная плазмида с тупыми концами. С-концевая 6xHis-метка и Strep- метка служили для очистки белков аффинной хроматографией и для целей обнаружения. Также были получены конструкты без меток. Все конструкции были проверены внешней службой секвенирования. Конструкция и белковые схемы показаны на фиг. 1.
Таблица 1. Краткое описание признаков антител CLDN6 x CD3-bstb
области VH -VL
(SEQ ID NO: 14/16)
(SEQ ID NO: 15/16)
(SEQ ID NO: 17/19)
(SEQ ID NO: 18/19)
Bstb обозначает биспецифичный TriMAB; С, цистеин; CH1, константная тяжелая область 1; CG, Cricetulus griseus; IMAB, идеальное моноклональное антитело; His, 6xHis-метка; HS, Homo Sapiens; IgG, иммуноглобулин G; S, серин; Strp, Strep-метка; W, триптофан.
Таблица 2. Последовательности ДНК, кодирующие CLDN6 x CD3-bstb
L bstb_371/367
L bstb_5727/5725
Таблица 3. Последовательности ДНК, кодирующие CLDN6 x CD3-bi- (scFv)2
би-(scFv)2
b. Транзиторная трансфекция и продукция
Для транзиторного продуцирования CLDN6-специфичных белков bstb была использована система экспрессии Expi293TM (Thermo Fisher Scientific, Дармштадт, Германия) - производная линии эмбриональных клеток почки человека HEK293 - в соответствии с руководством производителя. Для этого клетки Expi293FTM предварительно культивировали до плотности 2,0×106 на мл среды для экспрессии Expi293TM в суспензионных колбах для культивирования клеток в течение двух дней. В день трансфекции 2,5×106 клеток Expi293TM на мл свежей среды экспрессии Expi293TM переносили в стерильные стеклянные колбы Эрленмейера с емкостью в 5-кратном объеме. В содержащихся в плазмидах рСЕР4 Fd- и L-фрагменты были смешаны в соотношении 1:1 в Opti-MEM (Gibco/Термо Fisher Scientific). На мл клеточной суспензии 1 мкг смеси ДНК предварительно разводили в 50 мкл Opti-MEM и 2,7 мкл реагента ExpiFectamineTM 293 на мл клеточной суспензии в 50 мкл Opti-MEM в отдельных пробирках и инкубировали в течение 5 минут при комнатной температуре. Затем предварительно разбавленную смесь ДНК добавляли к предварительно разбавленному реагенту ExpiFectamineTM 293, перемешивали и инкубировали в течение 20 минут при комнатной температуре перед добавлением к суспензии клеток. Колбу для культивирования клеток перемешивали при 125 об/мин в 8% CO2, 37°C в увлажненном шейкере Multitron Cell (Infors HT, Боттминген, Швейцария) в течение 16-18 часов. Затем на мл клеточной суспензии добавляли 3,9 мкл Enhancer 1 и 39 мкл Enhancer 2 и дополнительно инкубировали колбы для культивирования клеток. Белоксодержащую надосадочную жидкость собирали через семь дней после трансфекции. Надосадочные жидкости фильтровали с 0,22 мкм фильтрующие блоки Nalgene Rapid Flow 90 мм, с низким связыванием белка (Thermo Fisher Scientific). Содержание секретируемого белка оценивали путем количественного определения BLItz с использованием биосенсоров с протеином L (Pall/ForteBio, Драйайх, Германия) в соответствии с протоколом производителя. Надосадочную жидкость хранили при 2–8°С до очистки.
c. Очистка меченых белков bstb_369/367 и bstb_371/367
Надосадочную жидкость клеточной культуры транзиторно трансфицированных клеток Expi293TM, содержащий белок bstb_369/367 или bstb_371/367 (описанный в примере 1b), подвергали аффинной хроматографии с иммобилизованным металлом (IMAC) с использованием стандартных процедур (Coligan et al. 2001b). Вкратце, надосадочную жидкость клеточной культуры с добавлением 10 мМ имидазола загружали в 1 мл колонку HisTrap HP, подключенную к системе ÄKTA pure 25 FPLC (обе из GE Healthcare Life Sciences, Фрайбург, Германия), и уравновешивали промывочным буфером (20 мМ NaH2PO4)., 500 мМ NaCl, 10 мМ имидазол, рН 7,5). Образец загружали со скоростью 1 мл/мин. Элюирующий буфер отличался от промывочного буфера концентрацией имидазола 500 мМ. После промывания десятью колоночными объемами (CV) белок элюировали с использованием линейного градиента 0–100% буфера для элюции. Элюат собирали фракциями по 1 мл со скоростью 1 мл/мин. Собирали высокомолекулярные (ВМВ) и мономерные соединения (основной пик) (фиг. 2А). Элюированный белок bstb объединяли и немедленно диализовали с использованием диализной кассеты Slide-A-Lyzer G2 10K MWCO (Pierce/Thermo Fisher Scientific, Рокфорд, Иллинойс, США) против буфера для связывания DPBS Strep-Tactin® (фосфатно-буферный солевой раствор Дульбекко, Gibco/Thermo Fisher Scientific), содержащий 137 мМ NaCl, 2,7 мМ KCl, 10 мМ Na2HPO4, 2 мМ KH2PO4, рН 7,4. Диализованный белок bstb из основного пика IMAC очищали дальнейшей аффинной хроматографией Strep-Tactin® (GE Healthcare Life Sciences). Все последующие стадии очистки Strep-Tactin® проводились при скорости потока 1 мл/мин.
Колонка Strep-Tactin® уравновешивали буфером для связывания перед внесением белка bstb. Элюирование белка bstb проводили линейным градиентом 0–100% с 2,5 мM дестиобиотина (SigmaAldrich, Тауфкирхен, Германия), содержащим связывающий буфер, после стадии промывки пятью CV связывающего буфера (фиг. 2B). Элюированный белок bstb во фракциях по 1 мл объединяли и суб-инъецировали в эксклюзионную хроматографическую колонку (SEC) HiLoad 16/600 Superdex 200 pg (GE Healthcare Life Sciences) с последующей изократической элюцией одним CV DPBS. Элюированные ВМВ и мономерные соединения bstb собирали во фракции по 1 мл (фиг. 2C) и объединяли.
Концентрацию Bstb определяли путем измерения при 280 нм на NanoDrop 2000c с учетом коэффициента экстинкции и теоретической молекулярной массы, определенной с помощью инструмента ProtParam (http://web.expasy.org/protparam/). Очищенный белок разделяли на аликвоты и хранили при 2–8°C.
d. Очистка не содержащих метку белков bstb_5726/5725 и bstb_5727/5725
Надосадочную жидкость клеточной культуры транзиторно трансфицированных клеток Expi293TM, содержащих белок bstb_5726/5725 и bstb_5727/5725 (описанных в примере 1b) - оба без меток - фильтровали с использованием капсул глубокой фильтрации SupracapTM 50 (Pall corporation, Крайльсхайм, Германия) и затем осуществляли процесс очистки белка. Очищенный белок bstb анализировали методом высокоэффективной эксклюзионной жидкостной хроматографии, короткая SE-HPLC (фиг. 2D).
SE-HPLC выполняли с использованием Dionex Ultimate 3000 (Thermo Scientific) с помощью эксклюзионной колонки TSKgel G3000SWxl (300 × 7,8 мм, Tosoh Bioscience, Грисхайм, Германия). Инъецировали вплоть до 100 мкл. Колонку промывали буфером SE-HPLC (0,3 М Na2HPO4, рН 7,2) и белок bstb отделяли изократическим элюированием.
И bstb_5726/5725, и bstb_5727/5725 (данные не показаны) могут быть эффективно очищены с помощью разработанного процесса, и содержание мономера увеличится до >93% после процесса очистки (фиг. 2D). Чтобы дополнительно обогатить мономерную фракцию до ~100%, образцы, диализированные против PBS, наконец, подвергали препаративной SEC с использованием колонки HiLoad 26/600 Superdex 200 pg (GE Healthcare Life Sciences).
C этим может быть показана стратегия очистки bstb без меток.
e. Анализ меченых белков bstb_369/367 и bstb_371/367
Качество и чистоту белков bstb с метками проверяли с помощью электрофореза в полиакриламидном геле с использованием 4–15% геля Criterion™ TGX Stain-Free™ (Bio-Rad Laboratories, Драйайх, Германия), после которого использовали безокрасочный гель (фиг. 3А) и вестерн блот-анализ (фиг. 3B) в соответствии со стандартными процедурами, хорошо известными специалисту в данной области. Антитела, используемые для вестерн-блот анализа, представляли собой антитело против 6xHis tag® (HRP) (1:10, 000, Abcam, Кембридж, Массачусетс, США) и Strep MAB-Classic, конъюгат HRP (1:10, 000, IBA GmbH, Геттинген, Германия). Мембраны геля и вестерн-блота фиксировали с помощью системы визуализации Chemidoc MP от Bio-Rad. Сигналы белков bstb детектировали при 50–55 кДа в восстанавливающих условиях (добавление DTT) и при ~100 кДа в невосстанавливающих условиях по сравнению с внутренним стандартом молекулярной массы (фиг. 3). Гетеродимерный состав bstb становится очевидным в восстанавливающих условиях при разделении Fd- и L-фрагмента в безокрасочном геле.
Состояние агрегации очищенных белков определяли аналитической SE-HPLC в зависимости от времени. SE-HPLC проводили с использованием системы Agilent 1260 Infinity (Agilent Technologies, Вальдброн, Германия) с помощью эксклюзионной колонки TSKgel G3000SWXL (300 × 7,8 мм, Tosoh Bioscience). Инъецировали вплоть до 100 мкл. Колонку промывали буфером SE-HPLC (0,3 М Na2HPO4, рН 7,2) и белок bstb отделяли изократическим элюированием. Как показано в таблице 4, очищенный белок bstb_369/367 был протестирован в течение более шести месяцев с помощью аналитической SE-HPLC и показал высокую стабильность при 2–8°C в DPBS без каких-либо признаков агрегации или деградации.
Таблица 4. Стабильность bstb_369/367 по данным SE-HPLC
2–8°C в DPBS [дни]
[%]
[%]
[%]
При этом может быть продемонстрирована высокая стабильность молекулы bstb. Более поздние очистки дали даже 100% мономерный белок bstb_369/367.
Пример 2. Определение удельной лизисной активности bstb_369/367 и bstb_371/367 в анализах цитотоксичности in vitro.
Для определения специфических эффектов лизиса мы использовали люциферазный анализ цитотоксичности in vitro. В качестве линий клеток-мишеней использовали клеточные линии рака яичника человека OV-90 (ATCC CRL-11732), стабильно экспрессирующие люциферазу и эндогенно экспрессирующие CLDN6, и клеточную линию тератокарциномы PA-1 (ATCC CRL-1572). CLDN6-отрицательная клеточная линия рака молочной железы человека MDA-MB-231 (ATCC HTB-26), также стабильно экспрессирующая люциферазу, служила контролем специфичности (нецелевым).
В качестве эффекторных клеток были выбраны мононуклеарные клетки периферической крови человека (РВМС), выделенные из крови здоровых доноров (Университетский медицинский центр JGU Mainz, Центр переливания крови, Майнц, Германия) в соответствии со стандартными процедурами (Coligan et al. 2001a).
а. Определение EC50
Для определения половины максимальной эффективной концентрации (ЕС50) высокомономерного bstb_369/367 ряд титрования белка тестировали в люциферазном анализе цитотоксичности in vitro.
В описанном примере эффекторные (E) и целевые (T) клетки смешивали в соотношении E:T 5:1 и высевали в белые 96-луночные планшеты для клеточных культур (Nunclon® Delta Surface, Thermo Scientific, Брауншвейг, Германия) с конечным числом клеток на лунку 1×104 клеток-мишеней и 5×104 эффекторных клеток. Клетки инкубировали с 10-точечным, 10-кратным рядом последовательных разведений белка bstb_369/367 или bstb_371/367 в диапазоне концентраций от 4,85 до 48,50 нМ. Лунки, служащие в качестве значений Lmin и Lmax (см. ниже), были дополнены DPBS вместо белка bstb.
Микропланшеты для клеточных культур инкубировали в течение 48 ч при 37°С, 5% СО2. Для анализа 50 мкл водного раствора, содержащего 1 мг/мл люциферина (BD Monolight, BD Biosciences, Гейдельберг, Германия) и 50 мМ HEPES, добавляли в каждую лунку и планшеты затем инкубировали в течение 30 мин в темноте при 37°С. Люминесценцию, возникающую в результате окисления люциферина жизнеспособными клетками, экспрессирующими люциферазу, измеряли с помощью устройства для считывания микропланшетов Infinite M200 Tecan (Tecan, Меннедорф, Швейцария). Процент специфического лизиса клеток-мишеней рассчитывали по следующей формуле:
% специфического лизиса = [1 - (люминесция тестовый образец - L max)/(Lmin - Lmax)] x 100, где «L» обозначает лизис. Lmin относится к люминесценции при минимальном лизисе в отсутствие bstb, а Lmax - к люминесценции при максимальном лизисе (равном количеству спонтанной люминесценции) в отсутствие bstb, достигаемом путем добавления Triton X-100 (2% конечная концентрация).
Значение EC50 рассчитывали с использованием сигмоидального алгоритма доза-ответ (логарифм (агонист) против ответа (три параметра)), интегрированного в программное обеспечение PRISM 6 (GraphPad Software, Сан-Диего, Калифорния, США).
Определяемое значение EC50 для bstb_369/367 составляло 39,71 пМ, и в три раза ниже, чем значение EC50 для bstb_371/367 с 117,00 пМ (фиг. 4A) для CLDN6-положительных клеток OV-90. С CLDN6-отрицательной контрольной клеточной линией MDA-MB-231 лизис не наблюдался. Результат этого анализа сильно зависит от активности PBMC человека, которая варьирует в зависимости от иммунного статуса донора, о чем также сообщали другие (см., например, Lutterbuese et al. 2010). Таким образом, используя восемь различных доноров РВМС, мы определили диапазон значений EC50 белка bstb_369/367, который составляет от 0,98 до 39,71 пМ (данные не показаны).
b. Сравнение bstb_369/367 и CLDN6 x CD3 bi- (scFv)2
Двухвалентный CLDN6-связывающий bstb_369/367 сравнивали с высоко мономерным (99,5%) CDLN6 x CD3 би-(scFv)2 собственного изготовления, (BioNTech AG, Stadler et al. 2015) для того, чтобы исследовать благоприятные эффекты авидности двухвалентного противоопухолевого агента, направленно воздействующего на эффективность лизиса.
Для этой цели bstb и би-(scFv)2 использовали в эквимолярных концентрациях, а эффекты лизиса тестировали на PA-1, OV-90 и MDA-MB-231 в анализе цитотоксичности (фиг. 4B) в основном так, как описано в Примере 2а. Клетки PA-1 совместно инкубировали только в течение 24 часов, потому что эта клеточная линия более чувствительна к уничтожению, вызванному эффекторными клетками, чем OV-90. Белки разводили в 9-точечных, 5- кратных (PA-1) или 8-точечных, 10-кратных (OV-90, MDA-MB-231) рядах последовательных разведений. Поразительно, что bstb_369/367 опосредовал уничтожение клеток PA-1 на 58% только с 0,24 пМ, самой низкой концентрацией, используемой для PA-1, тогда как эталон би-(scFv)2 показал кривую лизиса, начинающуюся с уничтожения 0%. В случае OV-90 более высокая эффективность bstb_369/367 по сравнению с bi- (scFv)2 становится очевидной в 55 раз более низкой EC50 bstb. Обе молекулы не оказывают влияния на эффекты лизиса мишени.
Следовательно, двухвалентное связывание CLDN6 молекулой bstb сильно повышает потенциал уничтожения клеток-мишеней по сравнению с моновалентной CLDN6-связывающей молекулой би-(scFv)2.
c. Изучение влияния высокомолекулярных соединений bstb_369/367 на лизисную активность.
ВМВ-соединения, такие как димеры или мультимеры, могут проявлять другую активность по сравнению с мономерными соединениями из-за их многовалентности к соответствующим антигенам. Даже если было показано, что молекулы стабильны в своем мономерном состоянии, влияние ВМВ-соединений на активность была проверена с точки зрения будущих аспектов безопасности.
Для этого ВМВ-соединения собирали во время процедуры очистки, обогащали с помощью SEC и добавляли в мономерный препарат до определенного количества 5%. Впоследствии 99,3% мономера и 94,3% мономера, дополненного 5% ВМВ, сравнивали в анализе цитотоксичности, как описано в примере 2а, но в 15-точечных 20-кратных последовательных разведениях. PA-1 и OV-90 служили клетками-мишенями. Совместную инкубацию с bstb_369/367 проводили в течение 16 часов с довольно чувствительной линией клеток PA-1 и в течение 48 часов с более устойчивой линией клеток OV-90. Значения EC50 рассчитывали с использованием сигмоидального алгоритма доза-ответ (логарифм (агонист) в зависимости от реакции - переменный наклон (четыре параметра)), интегрированного в программное обеспечение PRISM 6 (GraphPad Software), как показано на фиг. 4C. Расчетный EC50 для образца 5% ВМВ bstb_369/367 был в случае PA-1 в 1,5 раза выше, а в случае OV-90 в 2,3 раза ниже. Следовательно, небольшое снижение активности наблюдалось с PA-1 и небольшое увеличение активности с OV-90. В целом, влияние 5% ВМВ-соединений на активность является низкой и может зависеть от целевой клеточной линии и/или времени инкубации. Что касается стабильности белка bstb и низкого влияния довольно высокого процента ВМВ-соединений, то молекула bstb подходит для разработки терапевтического продукта.
d. Сравнение bstb_369/367 с вариантами bstb_5726/5725 и bstb_5727/5725 без меток
Варианты bstb без меток оценивали в анализе цитотоксичности и сравнивали с bstb_369/367. Кроме того, было проверено влияние ВМВ-соединений на активность. Схема проведения анализа была такой же, как описано в Примере 2с, но испытуемые элементы наносились в 10-точечных 5-кратных серийных разведениях только на OV-90 в качестве CLDN6+ клеток-мишеней.
Bstb_369/367 и его аналог без метки bstb_5726/5725 (99,9% мономерный) продемонстрировали равную эффективность лизиса со значением EC50 ~9,3 пМ. (фиг. 4D, левый график). 5% ВМВ привели к 1,4-кратному снижению значения EC50. EC50 CH1 (IgG2)-несущего варианта bstb_5727/5725 (100% мономер), был в ~1,6 раза выше, чем эталонный bstb_369/367, подтверждая немного более низкую активность этого варианта, что также показано для варианта без метки в Примере 2а. В случае bstb_5727/5725, 5% ВМВ едва влияют на эффективность (фиг. 4D, правый график). ЕС50 при добавлении ВМВ был только в 1,1 раза ниже, чем с мономером в этом примерном исследовании.
В заключение надо отметить, что меченые и не меченые CH1 (IgG1)-содержащие bstb одинаковы по своей функциональности и проявляют несколько более высокую активность по сравнению с CH1 (IgG2)-содержащими bstb. Влияние ВМВ-соединений низкое для обоих вариантов.
Пример 3. Модуляция Т-клеток, опосредованная bstb_369/367 и bstb_371/367
Модуляция Т-клеток, а именно активация и пролиферация Т-клеток, опосредованная bstb_369/367 и bstb_371/367, была исследована в аналогичной схеме, как описано в примере 2, с теми же линиями клеток-мишеней. Вкратце, CLDN6+ клетки-мишени OV-90 и PA-1, и CLDN6- контрольные клетки MDA-MB-231 сеяли с РВМС человека в 0,5 мл полной среды в 24-луночные планшеты в соотношении E:Т 5:1. Для дальнейшего подтверждения целевой зависимости, PBMC без клеток-мишеней подвергали ко-инкубации с белками bstb. Белки Bstb bstb_369/367 и bstb_371/367 добавляли в диапазоне концентраций 0,005–5000 нг/мл в 4-точечном 100-кратном ряду серийных разведений. В качестве положительного контроля использовали 100 нг/мл человеческого анти-CD3 IgG2a клона OKT3 (BioXCell, Западный Ливан, Нью-Гэмпшир, США), мишень-независимые мышиные IgG, активирующие Т-клетки. В качестве отрицательного контроля мы добавили DPBS, буфер bstb.
а. Т-клеточная активация
Эффекторные и целевые клетки совместно инкубировали с bstb в течение 48 часов. РВМС собирали, переносили в круглодонные 96-луночные (Fisher Scientific, Шверте, Германия), центрифугировали и промывали. Клетки окрашивали флуоресцентно-меченными антителами против белка человека, анти-CD5-PE-Cy7 (Abcam), CD69-APC, CD25-PE (BD Biosciences) и красителем для живых/неживых клеток eFluor506 (eBioscience, Франкфурт-на-Майне, Германия). Образцы измеряли с помощью BD FACSCantoII и регистрировали 10000 CD5+ жизнеспособных синглетных лимфоцитов. Данные были проанализированы с помощью программного обеспечения FlowJo V10 (Tree Star, Сан-Карлос, Калифорния, США) и Microsoft Excel 2010 (Microsoft Deutschland GmbH, Унтершлайсхайм, Германия). Вычитали фоновые сигналы образцов отрицательных контролей.
Как показано на фиг. 5А, оба bstb опосредуют сильную CLDN6-зависимую активацию Т-клеток. После 48 ч клетки находились на промежуточной стадии активации, что определялось высоким процентом двойной положительности для маркера ранней активации CD69 и маркера поздней активации CD25 и отсутствием Т-клеток, положительных только по CD25. Более того, данные показывают, что чем ниже концентрация bstb, тем раньше наступало состояние активации. Только при высокой концентрации 5000 нг/мл белки bstb приводили к поддающейся измерению мишень-независимой активации Т-клеток, которая была ниже 5,5%. Bstb_369/367 демонстрирует слабую, но незначительную более высокую активность, чем bstb_371/367, при опосредовании мишень-зависимой активации Т-клеток (см. также таблицу 5).
Таблица 5. Активация Т-клеток bstb_369/367 и bstb_371/367
линия
мишеней
CLDN6
элемент
активация [%]
b. Пролиферация Т-клеток
PBMC метили с помощью набора для клеточной пролиферации CellTraceTM CFSE (Thermo Fisher Scientific, Дармштадт, Германия) в соответствии с протоколом производителя перед организацией анализа. Эффекторные клетки и клетки-мишени совместно инкубировали с bstb в течение 72 часов. PBMC собирали, как описано выше в примере 3a. Клетки окрашивали анти-CD5-APC антителами, меченными флуоресцентными антителами человека (BD Biosciences) и красителем живых/мертвых клеток eFluor506 (eBioscience). Образцы измеряли с помощью BD FACSCantoII и регистрировали 10000 CD5+ жизнеспособных синглетных лимфоцитов. Данные были проанализированы с помощью программного обеспечения FlowJo V10 от Tree Star и Microsoft Excel 2010.
Как показано на фиг. 5B, оба bstb опосредуют сильную CLDN6-зависимую пролиферацию Т-клеток, что определяется по угасанию позитивности CFSE, указывающей на деление клеток. Четкое различие в эффективности двух молекул bstb с точки зрения более сильной пролиферации не определялось в присутствии PA-1. Как также видно для активации T-клеток в присутствии OV-90, bstb_369/367 опосредуют более сильные эффекты, чем bstb_371/367. Никакой неспецифической или независимой от мишени пролиферации Т-клеток не обнаружено.
Таким образом, обе молекулы bstb обеспечивают сильную модуляцию Т-клеток в строгой зависимости от мишени.
Пример 4. Связывание bstb_369/367 и bstb_5726/5725 с CLDN6
Относительную аффинность связывания эталонного белка би-(scFv)2, bstb_369/367 и его аналога без метки bstb_5726/5725 определяли с помощью анализа проточной цитометрией. Клетки PA-1, эндогенно экспрессирующие CLDN6, собирали с 0,05% трипсином/EDTA, промывали PBS и ресуспендировали в буфере FACS (PBS, содержащем 2% FCS и 0,1% азида натрия) в концентрации 2×106 клеток/мл. 100 мкл клеточной суспензии инкубировали с сериями концентраций различных соответствующих антител, разведенных в буфере FACS (11-точечная серия 2-кратных разведений 9,77–10 000 нг/мл), и инкубировали в течение 45 мин при 4°C. Затем клетки трижды промывали буфером FACS и инкубировали в течение 45 мин при 4°С с протеином L (Pierce/Thermo Scientific), конъюгированным с FITC Squarix (Squarix Biotechnology, Марл, Германия), в концентрации 4 мкг/мл. Затем клетки дважды промывали и ресуспендировали в 100 мкл буфера FACS. Связывание анализировали с помощью проточной цитометрии с использованием BD FACSArray (BD Biosciences). Значение EC50 для полумаксимального связывания определяли с использованием GraphPad Prism 6 Один Сайт - Специфическое связывание.
Белок би-(scFv)2, который обладает одновалентным сайтом связывания CLDN6, проявлял низкую относительную аффинность связывания (EC50: ~ 8,3 мкг/мл, что соответствует ~150 нМ). Для сравнения, bstb_369/367 и bstb_5726/5725 продемонстрировали половинное максимальное связывание при концентрации ~1,9 мкг/мл, соответствующей ~ 19 нМ, таким образом, относительная аффинность связывания была примерно в 8 раз выше по сравнению с эталонным белком би- (scFv)2 (фиг. 6А). Это указывает на то, что связывание с целевым CLDN6 может быть значительно улучшено путем использования двухвалентных сайтов связывания, таким образом, увеличивая аффинность связывания путем реализации эффектов авидности. Следует отметить, что кривые связывания bstb с метками и без меток являются конгруэнтными.
Мы также проанализировали влияние ВМВ-соединений на свойства связывания мономеров bstb_5726/5725 в проточной цитометрии с использованием белка L-FITC в концентрации 4 мкг/мл или PE-конъюгированного мышиного антитела против человеческого IgG (область Fab) (antikoerper-online, Аахен, Германия) в концентрации 6 мкг/мл в качестве вторичных реагентов для обнаружения. ЕС50 с половинным максимальным связыванием не различался между 100% мономером, 97% мономером/3% ВМВ и 95% мономером/5% ВМВ (варьировал от 28 нМ до 31–34 нМ в зависимости от реагента вторичного обнаружения). На фиг. 6B показано только обнаружение с помощью протеина L- FITC. Эти данные согласуются с данными анализов цитотоксичности (см. Пример 2с), которые ясно демонстрируют, что 5% ВМВ не оказывают соответствующего влияния на активность молекулы bstb_369/367, таким образом, благоприятствуя этому формату для разработки продукта.
Пример 5. Эффективность на мышиной модели ксенотрансплантата
Для исследования терапевтического потенциала белка bstb_369/367 in vivo была выбрана иммунодефицитная мышиная линия NOD.Cg-Prkdscid IL2rgtm1Wjl/SzJ или short NSG (Jackson laboratory, Бар-Харбор, Мэн, США). Все мыши были использованы в соответствии с рекомендациями Комитета по содержанию лабораторных животных Университета им. Йоханнеса Гутенберга, Майнц, Германия.
а. Лечение прогрессирующих CLDN6-экспрессирующих опухолей у мышей с помощью белка bstb_369/367
В приведенном в качестве примера исследовании использовали самцов и самок мышей NSG в возрасте восьми недель и с массой тела 21-36 г. CLDN6-положительные клетки OV-90 служили опухолевыми клетками, а PBMC - эффекторными клетками.
5×106 опухолевых клеток инокулировали подкожно (подкожно) и 1×107 РВМС вводили внутрибрюшинно (внутрибрюшинно) через восемь дней после этого. Только мыши с привитыми привитые PBMC - что было проанализировано в периферической крови через пять дней после инъекции PBMC - были разделены на группы по объему опухоли и полу (оба пола во всех группах). Обработку начинали при среднем объеме опухоли ~30 мм3 на группу. Мышей обрабатывали три раза в неделю (с понедельника по среду) носителем (DPBS), 31 мкг/кг bstb (низкая доза) или 308 мкг/кг bstb (высокая доза) путем внутрибрюшинных инъекций. Группа «G1 - Носитель» включала четырех мышей (n = 4), «G2 - bstb_369/367 (низкая доза)», восемь мышей (n = 8) и «G3 - bstb_369/367 (высокая доза)», девять мышей (n = 9). Группы обработки приведены в таблице 6. Введение проводилось внутрибрюшинно в течение пяти (G1), шести (G2) или четырех (G3) последовательных недель в зависимости от показаний объема опухоли (фиг. 7А). Два раза в неделю размеры опухоли измеряли с помощью цифрового калиброванного штангенциркуля и объем опухоли рассчитывали по формуле: объем опухоли [мм3] = длина [мм] × (ширина [мм]) 2/2. Мышей умерщвляли смещением шейных позвонков, когда объем опухоли достигал 1500 мм3 или в случае тяжелой заболеваемости (главным образом, симптомов «трансплантат против хозяина» (GVHD)).
На фиг. 7В показано ингибирование роста опухоли у всех мышей из групп, обработанных bstb, G2 и G3. Противоопухолевую эффективность измеряли как ингибирование/элиминацию роста опухоли и выживаемость по сравнению с контрольным носителем G1. Обработка с помощью тестового элемента bstb_369/367 привела к удалению опухоли в обеих группах дозирования в отличие от контрольной группы. Все девять мышей в группе с более высокой дозой bstb_369/367 (G3) не имели опухолей после семи инъекций. Все восемь мышей в группе с более низкой дозой bstb_369/367 (G2) не имели опухолей после 15 инъекций. У мышей без опухолей наблюдали рецидив опухоли до появления симптомов GVHD. В этот период времени не было зарегистрировано случаев рецидива опухоли.
Для построения графика выживания Каплана-Мейера (фиг. 7C) днем начала обработки считался день 0. Выживание был значительно продлено в случае обоих обработанных bstb_369/367 групп по сравнению с контрольной группой G1, что определялось по статистике выживаемости Каплана-Мейера, объединенной с логарифмическим ранговым критерием Кокса-Мантеля для парного сравнения. Сравнение G2 с G1 привело к p-значению p <0,0001, а сравнение G3 с G1 - к p=0,0043. Медиана выживаемости составила 31 день в контрольной группе G1 против 52 и 42 дней в группах обработки G2 и G3, соответственно. Таким образом, bstb_369/367 продемонстрировал высокую эффективность с точки зрения элиминации опухоли и, кроме того, полезен с точки зрения выживания на этой мышиной модели с ограничением GVHD.
Таблица 6. Группы обработки
группа (G)
n
Белок
[мкг/кг]
b. Определение влияния терапии на массу тела
Массу тела каждой мыши исследовали два раза в неделю с использованием лабораторных весов. Ни у одной мыши, ни в одной группе не наблюдалось значительной потери массы за время обработки (данные не показаны).
c. Выделение спленоцитов
После эвтаназии мышей иссекали селезенки для выявления приживления клеток человека методом проточной цитометрии. Выделение спленоцитов проводили сразу же после вскрытия селезенки путем протирания селезенки через сито для клеток диаметром 70 мкм, помещенное в реакционную пробирку на 50 мл со стерильным поршнем шприца на 3–5 мл, и повторной промывки сита для клеток RT DPBS. Выделенные спленоциты центрифугировали, DPBS декантировали и гранулы спленоцитов ресуспендировали в 1 мл инактивированной нагреванием фетальной бычьей сыворотки с добавлением 10% ДМСО. Образцы немедленно замораживали при температуре от -65 до -85°С и хранили до тех пор, пока образцы спленоцитов всех мышей не были готовы.
d. Анализ приживления человеческих Т-лимфоцитов в селезенке мыши
Полный набор образцов спленоцитов оттаивали за один раз, все клетки дважды промывали теплым DPBS и 1 × 106 спленоцитов на образец инкубировали с антителами, конъюгированными с флуоресцентным красителем (BD Biosciences), в течение 20 минут при 4°C в темноте для детекции приживления человеческих клеток с помощью окрашивания анти-hCD45-APC и процента Т-клеток человека с помощью окрашивания анти-hCD3-FITC. Проточный цитометрический анализ был проведен с помощью FACSCanto II (BD Biosciences). Приживление Т-клеток человека может быть подтверждено процентами 50–95% двойных положительных синглетных спленоцитов hCD45/hCD3 (данные не показаны).
Пример 6. Оценка фармакокинетического поведения у иммунодефицитных мышей
Чтобы определить приблизительный период полувыведения и клиренс белка bstb_369/367 у мышей, мы использовали самок мышей NSG в возрасте 9–49 недель. 5 мг/кг высокомономерного (100%) bstb_369/367 в DPBS вводили внутрибрюшинно на мышь. Размеры групп составили три мыши, каждая из которых соответствовала одному моменту времени забора крови. В качестве базового значения («время после введения» = 0 ч) одной группе вводили только буфер-носитель (DPBS). Дальнейшие моменты времени для забора крови были установлены на 15 минут, 1 час, 2 часа, 3 часа, 6 часов и 8 часов. Кровь собирали непосредственно в пробирки Li-Heparin (Microvette 300 LH, Sarstedt, Нюмбрехт, Германия) и плазму отделяли центрифугированием, как известно специалисту в данной области. Плазму собирали, немедленно замораживали в жидком азоте и хранили при -65 до -85°С до использования.
Для количественного определения bstb_369/367 в плазме проводили ELISA. Для этого аликвоту плазмы каждой группы оттаивали при комнатной температуре и разводили в PBS/0,2% BSA. Разбавленную bstb_369/367-содержащую плазму и белок bstb_369/367 в качестве стандартного ряда (от 0,39 нг/мл до 3,41 мкг/мл) добавляли в планшеты MaxiSorp™ (Thermo Scientific), покрытые козьим антителом против IgG F(ab')2 человека (Abd Serotec, Оксфорд, Великобритания) и блокировали 3% молоком. После стадии промывки инкубировали мышиный IgG, специфичный для сайта связывания анти-CLDN6 bstb_369/367 (Ganymed Pharmaceuticals AG) в концентрации 3,5 мкг/мл, после чего следовала стадия промывки и инкубации с козьим антителом против IgG (Fc) мыши, конъюгированным с щелочной фосфатазой (Дианова, Гамбург, Германия) в разведении 1:500. Наконец, 6-гидрат 4-нитрофенилфосфата динатриевой соли, короткий PNPP (PanReac AppliChem, Дармштадт, Германия), добавляли в качестве субстрата для щелочной фосфатазы и через 30 мин реакцию останавливали 3 М гидроксидом калия. ELISA измеряли с помощью устройства для считывания микропланшетов M200 Pro (Tecan) при 405/492 нм. На основе стандартной кривой bstb_369/367 измеренные значения поглощения были преобразованы в значения концентрации.
Как показано на фиг. 8, максимальная концентрация bstb_369/367 в плазме 34 мкг/мл была достигнута через 1 ч после внутрибрюшинной инъекции. В конечной точке анализа, через 8 ч после внутрибрюшинной инъекции, белок bstb_369/367 все еще обнаруживался в сыворотке (8 нг/мл).
Принимая во внимание связывание с опухолью-мишенью и Т-клетками у пациентов, которое обеспечивает длительная циркуляция, возможны циклы инъекции молекул bstb от одного до двух раз в неделю.
Пример 7. Исследование нахождения дозы in vivo bstb_5726/5725 без метки
Модель ксенотрансплантата была устроена так, как описано в Примере 5, в соответствии с графиком, проиллюстрированным на фиг. 9A. Вкратце, 44 самцам и самкам NSG в возрасте 10–36 недель были имплантированы OV-90 (s.c.) и человеческие PBMC (i.p.). Мышей рандомизировали на семь групп с шестью группами обработки - по шесть мышей и одной контрольной группой PBS - из восьми мышей. Для определения оптимальной дозы bstb_5726/5725 были выбраны концентрации выше и ниже эффективных доз bstb_369/367, использованных в примере 5 (~300 и 30 мкг/кг), точно 1000 мкг/кг, 300 мкг/кг, 100 мкг/кг, 30 мкг/кг, 10 мкг/кг и 3 мкг/кг. В день начала обработки средний объем опухоли в рандомизированных группах составил ~ 150 мм3. Обработку применяли внутрибрюшинно три раза в неделю, начиная с 28 дня после инокуляции опухолевых клеток. Всего было сделано 11 инъекций на группу. Опухоли измеряли два раза в неделю с помощью цифрового штангенциркуля.
Как показано на фиг. 9B, скорость уменьшения опухоли коррелирует с дозой. Кажется, что объем опухоли ~400 мм3 в начале обработки имеет критический размер, который устраняется только при дозах bstb>30 мкг/кг. Интересно, что даже 3 мкг/кг приводили к уменьшению роста опухоли и ее размера с течением времени, предполагая накопление эффекта bstb в массе опухоли.
В этом случае 100 мкг/кг были определены как высокоэффективная и безопасная доза. В группе с максимальной дозой 1000 мкг/кг мы наблюдали неблагоприятные эффекты, такие как изменение цвета кожи на желтый и потеря массы.
Пример 8. Получение, очистка и анализ производных биспецифичных антител, нацеленных на CLDN18.2 и CD3.
а. Происхождение последовательности, дизайн конструкций bstb и клонирование в экспрессирующие векторы
Биспецифичные химерные конструкции TriMAB (bstb) конструировали в виде антигенсвязывающих фрагментов (Fab), снабженных двумя одноцепочечными вариабельными фрагментами (scFv) на С-конце константных областей. Fab-связывающий домен специфичен для компонента Т-клеточного рецептора человека CD3. Вариабельная область тяжелой цепи (VH) анти-CD3 и соответствующие домены вариабельной области легкой цепи (VL) получали из IgG TR66 (Lanzavecchia und Scheidegger 1987). Цистеин в положении 114 был заменен серином. Константная область тяжелой цепи (CH1) и константная область легкой цепи (CL) имеют человеческое происхождение. Мы выбрали область константную легкую область каппа для наших конструкций. Два ScFv-связывающих фрагмента являются специфическими к опухоль-ассоциированному антигену (ТАА) человека, CLDN18.2. Соответствующие области VH и VL получены из химерного IgG1 IMAB362 (Ganymed Pharmaceuticals AG, Майнц, Германия) (например, Woll et al. 2014), который в настоящее время проходит клинические испытания, такие как NCT01630083 и NCT01671774. Ориентация областей VH и VL и выбор линкеров в фрагментах scFv коррелируют с би-(scFv)2 молекулами 5506 и 5538, описанными в патентной заявке PCT/EP2013/003399. На фиг. 18 показаны аминокислотные последовательности доменов VH и VL, которые были использованы в ходе изобретения.
Четыре молекулы bstb, полученные в первом поколении, отличались своей областью CH1 и частью scFv IMAB362. Bstb_5730/5728 и bstb_5731/5729 содержат область CH1, полученную из человеческого IgG1, bstb_5732/5728 и bstb_5733/5729 область CH1, полученную из человеческого IgG2. Кроме того, bstb_5730/5728 и bstb_5732/5728 несут scFv-фрагмент IMAB362 в ориентации VH-VL, тогда как bstb_5731/5729 и bstb_5733/5728 несут scFv-фрагмент IMAB362 в ориентации VL-VH. Следующие молекулы были получены на уровне белка для получения молекул bstb:
Bstb_5730/5728:
Bstb_5732/5728:
Bstb_5731/5729:
Bstb_5733/5729:
C = C-конец, CH = константная область тяжелой цепи, CL = константная область легкой цепи, Fd = гидролизуемый фрагмент (часть тяжелой цепи Fab), L = часть легкой цепи Fab, N = N-конец, VH = вариабельный домен тяжелой цепи, VL = вариабельный домен легкой цепи.
Таблица 7 суммирует информацию о конструкциях bstb, специфичных для TAA CLDN18.2, которые были созданы в ходе изобретения. Приведена информация о специфичности, происхождении последовательности от моноклональных антител (mAB), использовании кодонов и дополнительных характеристиках последовательности. Последовательности, кодирующие вариабельные домены фрагментов, связывающих клетки-мишени, были первоначально получены от Ganymed Pharmaceuticals AG.
Клонирование ДНК и конструирование экспрессирующего вектора pCEP4 осуществляли с помощью GeneArt (GeneArt/Thermo Fisher Scientific). Сигнальная последовательность секреции человеческого IgG, кодирующая MGWSCIILFLVATATGVHS, была введена на 5'-конце выше последовательностей V-области Fd- и L-bstb для секреции белка в культуральную среду. Последовательность, кодирующая гибкий аминокислотный глицин-серин (GS) пептид из 20 аминокислот (AК) ((GGGGS)4), была вставлена для присоединения доменов VH и VL для композиции анти-TAA scFv в ориентации VH-VL, в то время как гибкий 25-АК пептидный линкер (GGGGS)5 был вставлен для композиции анти-TAA scFv в ориентации VL-VH. Одна последовательность домена scFv была соединена с Fd-частью (C-конец CH1) с помощью последовательности, кодирующей линкер из 18 АК (SGPGGGRS(GGGGS)2), а другая scFv была соединена с L-частью (C-конец CL) с помощью последовательности, кодирующей линкер из шести AК (DVPGGS). Различные длины линкера позволили различить Fd- и L-части по размеру. Последовательность 6xHis-метки добавляли к 3'-концу фрагмента Fd-scFv, а Strep-метку к 3'-концу фрагмента L-scFv для облегчения очистки чистого гетеродимерного bstb первого поколения. В Таблице 8 перечислены полные последовательности ДНК, кодирующие белок bstb. В Таблице 9 перечислены последовательности ДНК, кодирующие белок родительского би-(scFv)2 и эталонного би-(scFv)2, использованные для исследований in vitro.
С-концевые 6xHis-метка и Strep-метка служили для аффинной очистки белка и для анализа детекции. Все конструкции были проверены внешней службой секвенирования. Схемы конструкции проиллюстрированы на фиг. 10А. Bstb второго поколения были сконструированы без меток, а в фрагменты scFv были введены дисульфидные мостики.
Таблица 7. Сводка характеристик антител CLDN18.2 x CD3-bstb
области VH-VL
би-(scFv)2
(SEQ ID NO: 76)
(SEQ ID NO: 31/32)
(SEQ ID NO: 76)
(SEQ ID NO: 33/35)
(SEQ ID NO: 77)
(SEQ ID NO: 34/35)
(SEQ ID NO: 77)
(SEQ ID NO: 36/37)
(SEQ ID NO: 76)
(SEQ ID NO: 38/39)
(SEQ ID NO: 77)
(SEQ ID NO: 40/41)
(SEQ ID NO: 76)
(SEQ ID NO: 42/43)
(SEQ ID NO: 77)
CH1 обозначает константную тяжелую область 1; CG, Cricetulus griseus; ds, дисульфид; IMAB, идеальное моноклональное антитело; His, 6xHis-метка; HS, Homo Sapiens; IgG, иммуноглобулин G; Strp, Strep-метка.
Таблица 8. Последовательности ДНК, кодирующие CLDN18.2 x CD3-bstb
L bstb_5732/5728
L bstb_5733/5729
Таблица 9. Последовательности ДНК, кодирующие CLDN18.2 x CD3-би-(scFv)2
плазмиды
би-(scFv)2
Пример 9. Сравнение удельной лизисной активности четырех CLDN18,2 x CD3-bstb в анализах цитотоксичности in vitro.
Белки bstb_5730/5728, bstb_5731/5729, bstb_5732/5728 и bstb_5733/5729 (все, включая метки, но без дисульфидных мостиков в фрагментах scFv) были получены и очищены, как описано в Примере 1b и c. Перед разделением высокомономерных соединений с помощью SEC функциональность белков (50–77% мономерных соединений) исследовали в анализе цитотоксичности люциферазы in vitro, в основном, как описано в примере 2а. Отклонения описаны ниже.
В этом примере в качестве линии клеток-мишеней использовали клеточную линию рака желудка человека NUGC-4_hCLDN18.2, стабильно экспрессирующую люциферазу и CLDN18.2. CLDN18.2-отрицательная клеточная линия карциномы молочной железы человека MDA-MB-231 служила в качестве контроля специфичности. Эффекторные клетки РВМС и клетки-мишени инкубировали с 10-точечным, 10-кратным рядом последовательных разведений белков bstb в диапазоне концентраций от 47,44 до 47,44 нМ.
Как показано на фиг. 11, все четыре молекулы CLDN18.2 x CD3-bstb (фиг. 10B) приводили к эффективному лизису клеток NUGC-4_hCLDN18.2 через 48 ч совместной инкубации в примерном исследовании. Было лизировано максимум 93% клеток-мишеней. С CLDN18.2-отрицательной контрольной клеточной линией MDA-MB-231 не наблюдалось лизиса. Что касается содержания мономера до SEC и эффективности в анализе цитотоксичности, два варианта bstb bstb_5730/5728 и bstb_5731/5729, несущие CH1-фрагмент IgG1, были отобраны для дальнейших исследований без меток и с или без дисульфидных мостиков в фрагментах scFv.
Пример 10. Сравнение физико-химических свойств очищенных CLDN18.2 x CD3-bstb без меток.
Надосадочные жидкости клеточных культур транзиторно трансфицированных клеток Expi293TM, содержащих белки bstb_5745/5747, bstb_5746/5748, bstb_5749/5751 или bstb_5750/5752, фильтровали с использованием капсул глубокой фильтрации SupracapTM 50 (Pall Corporation, Порт-Вашингтон, Нью-Йорк, США) и затем подвергали очистке белка.
Чтобы проанализировать состояние агрегации различных очищенных белков CLDN18.2 x CD3-bstb, мы проводили эксклюзионную высокоэффективную жидкостную хроматографию (SE-HPLC) с использованием Dionex Ultimate 3000 (Thermo Scientific) с эксклюзионной колонкой TSKgel G3000SWxl (300 × 7,8) мм, Tosoh Bioscience). Колонку промывали буфером SE-HPLC (0,3 М Na2HPO4, рН 7,2) и белок bstb отделяли изократическим элюированием. В то время как bstb_5745/5747 и bstb_5746/5748 продемонстрировали относительно низкое количество мономерных белков (~60% и ~40%, соответственно), bstb_5749/5751 и bstb_5750/5752 были высоко мономерными после очистки (~ 96% и ~89% соответственно)) (фиг. 12 А и В). Кроме того, кратковременное хранение bstb_5745/5747 и bstb_5746/5748 при комнатной температуре привело к образованию видимых агрегатов.
Bstb_5745/5747 и bstb_5749/5751, и bstb_5746/5748 и bstb_5750/5752 каждое отличаются только двумя аминокислотами соответствующего анти-CLDN18.2 фрагмента scFv, что позволяет образовывать дисульфидный мостик в анти-CLDN18.2 фрагментах scFv из bstb_5749/5751 и bstb_5750/5752. Такое введение дополнительного дисульфидного мостика в анти-CLDN18.2 фрагменты scFv способствует образованию мономерного белка, таким образом, улучшает физико-химические свойства соответствующего bstb.
Все варианты bstb после начальной очистки подвергали диализу в PBS и, наконец, подвергали препаративной SEC с использованием колонки HiLoad 26/600 Superdex 200 pg (GE Healthcare Life Sciences) для обогащения мономерной фракции до ~100% для дальнейшей характеристики активности и связывания,
Пример 11. Непосредственное сравнение активности белков CLDN18.2 х CD3 bstb и би-(scFv)2
Мономерные белки bstb_5749/5751 и bstb_5750/5752 (все, включая дисульфидные мостики в фрагментах scFv) и их соответствующие би-(scFv)2 аналоги bi-scFv_5506 и bi-scFv_5538 (без дисульфидных мостиков) были исследованы в анализе цитотоксичности in vitro с люциферазой также, как описано в Примере 9. Помимо описанного ранее, применяли 10-точечный 5-кратный ряд серийных разведений в диапазоне концентраций от 24,64 фМ до 48,11 нМ. Кроме того, был включен эталон на каждом планшете для нормализации. Белки Bstb и би-(scFv)2 использовали в эквимолярных концентрациях.
Bstb_5750/5752 показывает в 1,8 раза более низкий EC50 (40,63 пМ), чем bstb_5749/5751 (70,94 пМ) (фиг. 13А, левый график), тем самым указывая немного более высокую активность первого bstb. Оба белка bstb привели к эффективному лизису ~95% клеток-мишеней в самой высокой концентрации. Лизиса с CLDN18.2-отрицательной контрольной клеточной линией MDA-MB-231 не наблюдалось (данные не показаны). Интересно, что соответствующие аналоги би-(scFv)2 би-scFv_5506 и би-scFv_5538 (фиг. 13А, правый график) представляют значительную разницу в значениях EC50, равную 9,99 пМ и 777,20 пМ, соответственно. Впоследствии значения EC50 нормализовали к эталону на планшете (bi-scFv_5376), а кратная разность, рассчитанная с EC50 би-(scFv)2, была принята за 1. Удивительно, но EC50 bstb_5749/5751 в 6 раз выше по сравнению с би-scFv_5506, что указывает на потерю активности ~80% от первого (фиг. 13B, левый график). С другой стороны, EC50 bstb_5750/5752 в 23 раза ниже по сравнению с би-scFv_5538, что подразумевает увеличение активности >2000% при использовании формата bstb (фиг. 13B, правый график).
В совокупности, переход от моновалентности к бивалентности в зависимости от используемых связывающих доменов, и их ориентации может улучшить активность биспецифического антитела, что демонстрируется резким увеличением активности bstb_5750/5752 по сравнению с би-scFv_5538. Кроме того, характеристики белка в формате bstb могут превосходить формат би-(scFv)2 по стабильности.
Пример 12. Получение производных биспецифичных антител на основе IVT-мРНК, нацеленных на CLDN6 и CD3.
а. Клонирование векторов с матрицей bstb IVT-мРНК и синтез IVT-мРНК
Для создания CLDN6 x CD3 биспецифических химерных TriMAB (bstb) в качестве транскрибируемой in vitro мессенджерной РНК (IVT-мРНК) мы субклонировали ДНК-последовательности bstb_369/367 и bstb_371/367 (описанные в примере 1) в вектор с матрицей IVT-мРНК pST1-TEV-MCS-FI (BioNTech AG, Майнц, Германия) с использованием стандартных методик. Лидерная последовательность TEV была описана в другом месте (Zeenko und Gallie 2005; Weingarten-Gabbay et al. 2016; Gallie et al. 1995), а последовательность FI описана в заявке на патент «Последовательности 3'UTR для стабилизации РНК» (PCT/EP2015/073180). Следующие конструкции были получены для получения молекул bstb:
Bstb_435/434:
Bstb_436/434:
A = аденин, Fd = гидролизуемый фрагмент (часть тяжелой цепи Fab), FI = 3'UTR-последовательность, L = часть легкой цепи Fab, Sec = сигнал секреции, 5'TEV = 5'UTR от вируса гравировки табака.
Таблица 10 суммирует информацию о конструкциях bstb, специфичных для TAA CLDN6, которые были получены в ходе изобретения. Перечислены информация о специфичности, происхождение последовательности из моноклональных антител (Mab), использование кодонов, дополнительные функции последовательностей. Последовательности, кодирующие вариабельные домены фрагментов, связывающих клетки-мишени, были первоначально получены от Ganymed Pharmaceuticals AG.
Таблица 10. Сводная информация об особенностях антител к CLDN6 x CD3-bstb
области VH-VL
(SEQ ID NO: 79/78)
(SEQ ID NO: 80/78)
Bstb обозначает биспецифичные TriMAB; С, цистеин; CH1, константная область тяжелой цепи 1; CG, Cricetulus griseus; IMAB, идеальное моноклональное антитело; His, 6xHis-метка; HS, Homo Sapiens; IgG, иммуноглобулин G; S, серин; Strp, Strep-метка; W, триптофан.
b. Синтез IVT-мРНК
Для создания матриц для транскрипции in vitro плазмидные ДНК линеаризовали ниже от области, кодирующей хвост поли (А), используя эндонуклеазу рестрикции класса II, таким образом получая матрицу для транскрипции РНК без дополнительных нуклеотидов после поли(А)-хвоста (Holtkamp et al. 2006). Линеаризованные матричные ДНК очищали, спектрофотометрически определяли количество и затем подвергали транскрипции in vitro с использованием РНК-полимеразы Т7, по существу, как описано ранее (Grudzien-Nogalska et al. 2013), в присутствии 7,5 мМ каждого из ATP, CTP, UTP, 1,5 мМ GTP и 6 мМ кэп-аналог бета-S-ARCA (D2) (Kuhn et al. 2010). РНК очищали с использованием магнитных частиц (Berensmeier 2006). Для исследований in vivo использовали неиммуногенную РНК. С этой целью вместо UTP включали N1-метилпсевдуридин-5'-трифосфат (TriLink Biotechnologies, Сан-Диего, Калифорния, США), и удаляли двухцепочечную РНК. РНК ферментативно кэпировали с помощью системы ScriptCap m7G Capping System и 2'-метилтрансферазы (CellScript, Мэдисон, Висконсин, США). Концентрацию и качество РНК оценивали с помощью спектрофотометрии и анализа на 2100 Bioanalyzer (Agilent, Санта-Клара, Калифорния, США). Эскиз двух IVT-мРНК, необходимых для образования полной молекулы bstb, представлен на фиг. 14.
Пример 13. Определение удельной лизисной активности bstb_435/434 и bstb_436/434 в анализах цитотоксичности in vitro
а. Электропорация клеток-продуцентов
Для получения белка bstb из IVT-мРНК 4×106 клеток K-562 (ATCC CCL-243, LGC Standards GmbH, Wesel, Германия) на мл, растущих в лог-фазе, подвергали электропорации с H2O (отрицательный контроль) или с 25 мкг/мл IVT-мРНК на цепь bstb в кюветах 0,4 мм с использованием GenePulser MXCell (Bio-Rad Laboratories Драйайх, Германия) со следующими настройками: 200 В, 2 импульса, 8 мс. Затем клетки высевали в полную культуральную среду с плотностью 5×105/мл в 6-луночные планшеты для тканевых культур. После 48 ч инкубации надосадочную жидкость собирали центрифугированием и стерильно фильтровали с помощью 0,2 мкм шприцевых фильтров Minisart NML (Sartorius, Геттинген, Германия).
b. Количественное определение bstb в надосадочной жидкости клеток-продуцентов с помощью ELISA
Надосадочные жидкости электропорированных K-562 подвергали анализу ELISA собственной разработки для количественного определения. Вкратце, 96-луночные планшеты MaxiSorp™ (Thermo Scientific, Брауншвейг, Германия) покрывали 4,5 мкг/мл козьего антитела против человеческого IgG F (ab ') 2 (Abd Serotec, Пуххайм, Германия) в DPBS в течение 1 часа при 37°C, трижды промывали (промывочный буфер: PBS/0,05% Tween-20) и блокировали при 2–8°C 3% сухого молока в DPBS в течение ночи. После стадии промывки серийное разбавление белков bstb_369/367 и bstb_371/367 в качестве эталона и серийное разбавление надосадочных жидкостей K-562, содержащих bstb_435/434 и bstb_436/434 (разбавитель: 0,2% BSA), добавляли в планшет с покрытием в трехкратном повторе. После 2 ч при комнатной температуре планшет промывали три раза. Для обнаружения bstb, связанного с анти-F(ab')2, добавляли 3,5 мкг/мл мышиного анти-IMAB206 (Ganymed Pharmaceuticals AG, Майнц, Германия), инкубировали в течение 1 часа при комнатной температуре и планшет снова промывали три раза. AP-конъюгированное козье антитело против IgG-Fc мыши (Jackson ImmunoResearch, Ньюмаркет, Великобритания) в разведении 1: 500 инкубировали в течение 1 часа при комнатной температуре. Для визуализации планшет инкубировали с самодельным раствором субстрата pNPP в течение 30 минут при комнатной температуре в темноте и, наконец, реакцию прекращали с 3 М КОН. Анализ проводили в устройстве для считывания микропланшетов Tecan M200 (Tecan, Меннедорф, Швейцария) при 405/492 нм. Данные анализировали с помощью программного обеспечения GraphPad Prism 6 и Microsoft Excel 2010 (данные не показаны).
Концентрация 253 нг/мл bstb_435/434 и 427 нг/мл bstb_436/434 может быть определена в надосадочной жидкости K-562. Соответственно, оба bstb были транслированы и секретированы, но в разных количествах. Количество получаемого белка сильно зависит от электропорации и меняется от раза к разу. В ходе различных экспериментов было произведено 1,0-1,7-кратное bstb_436/434 по сравнению с bstb_435/434.
c. Вестерн- блот анализ лизата клеток-продуцентов и надосадочной жидкости
Надосадочную жидкость и клеточный лизат клеток K-562 (пример 13 а.) использовали для анализа трансляции и секреции белков bstb. Клеточные лизаты получали инкубацией 1×106 отмытых клеток в 200 мкл 4х буфера Лэмли (Bio-Rad Laboratories), включающего 20 единиц бензоназы (Merck Millipore, Дармштадт, Германия). Затем образцы нагревали до 95°С в течение 10 мин с (восстанавливающие условия) или без (невосстановливающие условия) 1М дитиотреитола (DTT, конечная концентрация 0,1М). Надосадочные жидкости также обрабатывали буфером Лэммли. Подготовленные клеточные лизаты и надосадочные жидкости и соответствующие очищенные белки bstb разделяли электрофорезом в полиакриламидном геле с использованием 4–15% геля Criterion™ TGX Stain-Free™ (Bio-Rad Laboratories) с последующим анализом вестерн-блоттингом (фиг. 15) в соответствии со стандартными процедурами, известными специалисту в данной области. Для Вестерн-блоттинга были использованы антитела против 6xHis-метки, конъюгированные с пероксидазой хрена (HRP) (1:10, 000, Abcam, Кембридж, Массачусетс, США), Strep MAB-Classic (1:10000, IBA GmbH, Гёттинген, Германия) и против бета-актина (1:25, 000, Abcam). Мембраны вестерн-блоттинга регистрировали с помощью системы визуализации Chemidoc MP от Bio-Rad. Сигналы белков bstb были обнаружены при 50–55 кДа в восстанавливающих условиях и при ~100 кДа в невосстанавливающих условиях по сравнению с внутренним стандартом молекулярной массы. Bstb_435/436 (фиг. 15A) и bstb_436/434 (фиг. 15B) были в основном обнаружены в надоссадочной жидкости, но также и в клеточном лизате, что указывает на неполную секрецию в момент сбора. Гетеродимерный состав белков bstb становится очевидным в восстанавливающих условиях и детекции смесью анти-6xHis-метка HRP и Strep MAB-Classic HRP (фиг. 15C): Fd- и L-фрагмент различаются на ~2 кДа размер (~51 кДа и ~49 кДа соответственно). Посредством количественного определения полос белка, соответствующих ВМВ и мономерному bstb, обнаруженным в невосстанавливающих условиях, мы определили 3% ВМВ и 88% мономерных соединений bstb_435/434 и 1,4% ВМВ и 92% мономерных соединений bstb_436/434. Было обнаружено только несколько более мелких полос (всего ~8% и ~6%, соответственно), указывающих на незначительную деградацию в ходе культивирования клеток.
Таким образом, оба bstb могут эффективно транслироваться с IVT-мРНК и секретироваться в надосадочную жидкость клеточной культуры. В Bstb_436/434 показана несколько более благоприятная структура белка в отношении ВМВ-соединений и продуктов распада, но процент ВМВ-соединений является низким для обеих молекул bstb.
d. Анализ цитотоксичности с люциферазой и определение EC50
Анализ цитотоксичности в принципе проводили, как описано в Примере 2а. Белки Bstb использовали в качестве эталона. К-562 надосадочной жидкости образца из примера 1, 3 разводили в К-562 макете надосадочной жидкости (электропорация без IVT-мРНК). Lmin и Lmax образцов надосадочной жидкости K-562 были дополнены надосадочной жидкостью ложно-трансфицированных K-562.
20 мкл bstb в надосадочной жидкости наносили в 7-точечном 5-кратном ряду серийных разведений от 33,1 фМ до 516,5 пМ для раковых клеток OV-90 и MDA-MB-231 (стабильно трансдуцированных люциферазой), которые высевали вместе с РВМС в качестве эффекторных клеток (E:T 5:1). После 48 ч совместной инкубации добавляли раствор люциферазы для измерения и считывали данные с планшета.
Как показано на фиг. 16, оба bstb обеспечивают эффективный лизис CLDN6+ OV-90, но не CLDN6- MDA-MB-231. Максимальный лизис ок. 77–80% был достигнут при 516,5 пМ bstb_436/434 и bstb_435/434, соответственно. Значения EC50 показывают в 1,3 раза более высокую активность в случае bstb_435/434. Значения ЕС50 для РНК-транслированных bstb были в 4 раза и в 7,5 раз ниже по сравнению с соответствующими белковыми элементами bstb_369/367 и bstb_371/367, соответственно. Этот эффект может происходить из-за более высокой активности белка из-за отсутствия каких-либо дальнейших манипуляций с белком, из-за влияния ВМВ-соединений, из-за отклонений в количественном определении или их комбинации.
Таким образом, подход с РНК является осуществимым, высокоэффективным и экономящим время в отношении упущений экспрессии, очистки, стабильности и анализа белка.
Пример 14. Эффективность IVT-РНК, кодирующей биспецифичные антитела, в сравнении с эталонными белками в мышиной модели ксенотрансплантата.
Для исследования терапевтического потенциала IVT-мРНК, кодирующей биспецифичные антитела bstb и би-(scFv)2, по сравнению с эталонными белками in vivo, снова была выбрана иммунодефицитная линия мышей NOD.Cg-PrkdscidIL2rgtm1Wjl/SzJ или short NSG (Jackson laboratory, Бар Харбор, Мэн, США). Все мыши были использованы в соответствии с рекомендациями Комитета по содержанию лабораторных животных Университета Йоханнеса Гутенберга, Майнц, Германия.
а. Обработка прогрессирующих CLDN6-экспрессирующих опухолей у мышей с помощью bstb и би-(scFv)2-кодирующих IVT-РНК, по сравнению с белком
В приведенном в качестве примера исследовании использовались самцы и самки мышей NSG в возрасте 6–25 недель и с массой тела 18–38 г. CLDN6-положительные клетки OV-90 служили опухолевыми клетками, а PBMC - эффекторными клетками.
5×106 опухолевых клеток инокулировали подкожно (s.c.) и 1×107 РВМС вводили внутрибрюшинно (i.p.) через 19 дней после этого. Мыши с прививкой PBMC - что было проанализировано в периферической крови через шесть дней после инъекции PBMC - были разделены на группы по объему опухоли и полу (оба пола во всех группах). Обработка была начата через восемь дней после введения РВМС на довольно поздней стадии опухоли, со средним объемом опухоли ~250 мм3 на группу. Мышей обрабатывали один раз в неделю внутривенными (i.v.) инъекциями (схема инъекций, фиг. 17А) в ретроорбитальное венозное сплетение. Группы «G1 - РНК-контроль», «G2 - bstb РНК» и «G3 - bi-scFv РНК» получили 3 мкг IVT-мРНК в комплексе с TransIT®-мРНК Transfection Kit (Mirus Bio, Мэдисон, Висконсин, США) в объеме 200 мкл на мышь. В качестве контроля использовали IVT-мРНК люциферазы, bstb-кодирующие РНК, представляющие собой CDLN6 x CD3 bstb Fd и LCT-цепи IVT-мРНК 435 и 434 (смешанные 1:1), а би- (scFv)2-кодирующие РНК представляющие собой CDLN6 x CD3 би-(scFv)2 IVT-РНК 123r. Все IVT-РНК были синтезированы в соответствии с примером 1 2b in vivo. «G4 - контроль носителя» включал шесть мышей, обработанных DPBS, и шесть мышей, обработанных 10 мМ NaOAc-буфером, pH 5,5 (буферы для приготовления bstb и би-(scFv)2, соответственно). «Белок G5 - bstb» и «белок G6 - biscFF» обрабатывали белковыми аналогами элементов IVT-мРНК. Белком Bstb был bstb_369/367 (доза 100 мкг/кг, 5 мкл/г массы тела) и би-(scFv)2 белок bi-scFv_123 (доза 200 мкг/кг, 5 мкл/г массы тела). Группы обработки приведены в таблице 11. Введение проводилось четыре недели подряд. Два раза в неделю размеры опухоли измеряли с помощью цифрового калиброванного штангенциркуля и объем опухоли рассчитывали по формуле: объем опухоли [мм3] = Длина [мм] × (ширина [мм]) 2/2. Мышей забивали смещением шейных позвонков, когда объем опухоли достигал 1500 мм3 или в случае тяжелой заболеваемости (в основном симптомов трансплантат против хозяина (GVHD)).
Фиг. 17B иллюстрирует эффекты обработки на рост опухоли. Противоопухолевую эффективность измеряли как ингибирование/уменьшение роста опухоли и выживаемость по сравнению с контрольной группой РНК G1 или контрольным носителем G4. Обработка тестируемым элементом bstb_435/434 (G2) привела к уменьшению опухоли у 8/9 мышей, а тестируемым элементом bi-scFv_123r (G3) у 9/9 мышей в отличие от контрольной группы G1, в которой 0/10 мышей имели уменьшенный рост опухоли. Обработка белковыми аналогами (G5, G6) была аналогичной для bstb, но менее эффективной для би-(scFv)2. Важно отметить, что белки вводили в соответствии со схемой инъекции РНК (один раз в неделю, в.в., что подразумевает ретроорбитально) для прямого сравнения, а не с установленным графиком лечения белком три раза в неделю, i.p. Более высокая эффективность РНК, вероятно, вызвана более длительной трансляцией и секрецией белка в течение нескольких дней, тогда как введенный белок быстро удаляется. Концентрации белка в крови in vivo после введения РНК неизвестны. Три мыши G1-G3 были забиты ранее для исследования инфильтрирующих опухоль лимфоцитов (TIL) методом проточной цитометрии. Для этого суспензию отдельных клеток опухолей окрашивали флуоресцентно-меченными антителами против CD45 и CD3 человека (BD Biosciences, Гейдельберг, Германия) и синглетными клетками общих опухолей, анализируемыми с помощью проточного цитометра BD FACS CantoII. В контрольной группе РНК были обнаружены <3% инфильтрованных человеческих Т-клеток, тогда как >7% и >12% человеческих Т-клеток были обнаружены в группе bstb- и би-(scFv)2-РНК, соответственно (фиг. 17C). Эти данные показывают направленную инфильтрацию человеческих Т-клеток, вовлеченных биспецифическими РНК-кодированными антителами.
b. Определение влияния терапии на массу тела
Массу тела каждой мыши исследовали один раз в неделю с использованием лабораторных весов. Потеря массы, связанная с лечением, не наблюдалась (данные не показаны).
Список литературы
Berensmeier, Sonja (2006): Magnetic particles for the separation and purification of nucleic acids. In: Applied microbiology and biotechnology 73 (3), S. 495–504. DOI: 10.1007/s00253-006-0675-0.
Coligan, John E.; Bierer, Barbara E.; Margulies, David H.; Shevach, Ethan M.; Strober, Warren (2001a): Current Protocols in Immunology. Hoboken, NJ, USA: John Wiley & Sons, Inc.
Coligan, John E.; Dunn, Ben M.; Speicher, David W.; Wingfield, Paul T. (2001b): Current Protocols in Protein Science. Hoboken, NJ, USA: John Wiley & Sons, Inc.
Gallie, D. R.; Tanguay, R. L.; Leathers, V. (1995): The tobacco etch viral 5' leader and poly(A) tail are functionally synergistic regulators of translation. In: Gene 165 (2), S. 233–238. DOI: 10.1016/0378-1119(95)00521-7.
Grudzien-Nogalska, Ewa; Kowalska, Joanna; Su, Wei; Kuhn, Andreas N.; Slepenkov, Sergey V.; Darzynkiewicz, Edward et al. (2013): Synthetic mRNAs with superior translation and stability properties. In: Methods in molecular biology (Clifton, N.J.) 969, S. 55–72. DOI: 10.1007/978-1-62703-260-5_4.
Holtkamp, S.; Kreiter, S.; Selmi, A.; Simon, P.; Koslowski, M.; Huber, C. et al. (2006): Modification of antigen-encoding RNA increases stability, translational efficacy, and T-cell stimulatory capacity of dendritic cells. In: Blood 108 (13), S. 4009–4017. DOI: 10.1182/blood-2006-04-015024.
Kuhn, A. N.; Diken, M.; Kreiter, S.; Selmi, A.; Kowalska, J.; Jemielity, J. et al. (2010): Phosphorothioate cap analogs increase stability and translational efficiency of RNA vaccines in immature dendritic cells and induce superior immune responses in vivo. In: Gene Ther 17 (8), S. 961–971. DOI: 10.1038/gt.2010.52.
Lanzavecchia, A.; Scheidegger, D. (1987): The use of hybrid hybridomas to target human cytotoxic T lymphocytes. In: Eur. J. Immunol. 17 (1), S. 105–111. DOI: 10.1002/eji.1830170118.
Lutterbuese, Ralf; Raum, Tobias; Kischel, Roman; Hoffmann, Patrick; Mangold, Susanne; Rattel, Benno et al. (2010): T cell-engaging BiTE antibodies specific for EGFR potently eliminate KRAS- and BRAF-mutated colorectal cancer cells. In: Proceedings of the National Academy of Sciences of the United States of America 107 (28), S. 12605–12610. DOI: 10.1073/pnas.1000976107.
Röthlisberger, Daniela; Honegger, Annemarie; Plückthun, Andreas (2005): Domain interactions in the Fab fragment: a comparative evaluation of the single-chain Fv and Fab format engineered with variable domains of different stability. In: Journal of molecular biology 347 (4), S. 773–789. DOI: 10.1016/j.jmb.2005.01.053.
Stadler, Christiane R.; Bähr-Mahmud, Hayat; Plum, Laura M.; Schmoldt, Kathrin; Kölsch, Anne C.; Türeci, Özlem; Sahin, Ugur (2015): Characterization of the first-in-class T-cell-engaging bispecific single-chain antibody for targeted immunotherapy of solid tumors expressing the oncofetal protein claudin 6. In: OncoImmunology 5 (3), S. e1091555. DOI: 10.1080/2162402X.2015.1091555.
Weingarten-Gabbay, Shira; Elias-Kirma, Shani; Nir, Ronit; Gritsenko, Alexey A.; Stern-Ginossar, Noam; Yakhini, Zohar et al. (2016): Comparative genetics. Systematic discovery of cap-independent translation sequences in human and viral genomes. In: Science (New York, N.Y.) 351 (6270). DOI: 10.1126/science.aad4939.
Woll, Stefan; Schlitter, Anna Melissa; Dhaene, Karl; Roller, Marc; Esposito, Irene; Sahin, Ugur; Tureci, Ozlem (2014): Claudin 18.2 is a target for IMAB362 antibody in pancreatic neoplasms. In: International journal of cancer 134 (3), S. 731–739. DOI: 10.1002/ijc.28400.
Zeenko, Vladimir; Gallie, Daniel R. (2005): Cap-independent translation of tobacco etch virus is conferred by an RNA pseudoknot in the 5'-leader. In: The Journal of biological chemistry 280 (29), S. 26813–26824. DOI: 10.1074/jbc.M503576200.
--->
СПИСОК ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> BioNTech AG et al.
<120> AGENTS FOR TREATMENT OF CLAUDIN EXPRESSING CANCER DISEASES
<130> 674-180 PCT2
<150> PCT/EP2016/072688
<151> 2016-09-23
<160> 101
<170> PatentIn version 3.5
<210> 1
<211> 261
<212> PRT
<213> Homo sapiens
<400> 1
Met Ala Val Thr Ala Cys Gln Gly Leu Gly Phe Val Val Ser Leu Ile
1 5 10 15
Gly Ile Ala Gly Ile Ile Ala Ala Thr Cys Met Asp Gln Trp Ser Thr
20 25 30
Gln Asp Leu Tyr Asn Asn Pro Val Thr Ala Val Phe Asn Tyr Gln Gly
35 40 45
Leu Trp Arg Ser Cys Val Arg Glu Ser Ser Gly Phe Thr Glu Cys Arg
50 55 60
Gly Tyr Phe Thr Leu Leu Gly Leu Pro Ala Met Leu Gln Ala Val Arg
65 70 75 80
Ala Leu Met Ile Val Gly Ile Val Leu Gly Ala Ile Gly Leu Leu Val
85 90 95
Ser Ile Phe Ala Leu Lys Cys Ile Arg Ile Gly Ser Met Glu Asp Ser
100 105 110
Ala Lys Ala Asn Met Thr Leu Thr Ser Gly Ile Met Phe Ile Val Ser
115 120 125
Gly Leu Cys Ala Ile Ala Gly Val Ser Val Phe Ala Asn Met Leu Val
130 135 140
Thr Asn Phe Trp Met Ser Thr Ala Asn Met Tyr Thr Gly Met Gly Gly
145 150 155 160
Met Val Gln Thr Val Gln Thr Arg Tyr Thr Phe Gly Ala Ala Leu Phe
165 170 175
Val Gly Trp Val Ala Gly Gly Leu Thr Leu Ile Gly Gly Val Met Met
180 185 190
Cys Ile Ala Cys Arg Gly Leu Ala Pro Glu Glu Thr Asn Tyr Lys Ala
195 200 205
Val Ser Tyr His Ala Ser Gly His Ser Val Ala Tyr Lys Pro Gly Gly
210 215 220
Phe Lys Ala Ser Thr Gly Phe Gly Ser Asn Thr Lys Asn Lys Lys Ile
225 230 235 240
Tyr Asp Gly Gly Ala Arg Thr Glu Asp Glu Val Gln Ser Tyr Pro Ser
245 250 255
Lys His Asp Tyr Val
260
<210> 2
<211> 220
<212> PRT
<213> Homo sapiens
<400> 2
Met Ala Ser Ala Gly Met Gln Ile Leu Gly Val Val Leu Thr Leu Leu
1 5 10 15
Gly Trp Val Asn Gly Leu Val Ser Cys Ala Leu Pro Met Trp Lys Val
20 25 30
Thr Ala Phe Ile Gly Asn Ser Ile Val Val Ala Gln Val Val Trp Glu
35 40 45
Gly Leu Trp Met Ser Cys Val Val Gln Ser Thr Gly Gln Met Gln Cys
50 55 60
Lys Val Tyr Asp Ser Leu Leu Ala Leu Pro Gln Asp Leu Gln Ala Ala
65 70 75 80
Arg Ala Leu Cys Val Ile Ala Leu Leu Val Ala Leu Phe Gly Leu Leu
85 90 95
Val Tyr Leu Ala Gly Ala Lys Cys Thr Thr Cys Val Glu Glu Lys Asp
100 105 110
Ser Lys Ala Arg Leu Val Leu Thr Ser Gly Ile Val Phe Val Ile Ser
115 120 125
Gly Val Leu Thr Leu Ile Pro Val Cys Trp Thr Ala His Ala Ile Ile
130 135 140
Arg Asp Phe Tyr Asn Pro Leu Val Ala Glu Ala Gln Lys Arg Glu Leu
145 150 155 160
Gly Ala Ser Leu Tyr Leu Gly Trp Ala Ala Ser Gly Leu Leu Leu Leu
165 170 175
Gly Gly Gly Leu Leu Cys Cys Thr Cys Pro Ser Gly Gly Ser Gln Gly
180 185 190
Pro Ser His Tyr Met Ala Arg Tyr Ser Thr Ser Ala Pro Ala Ile Ser
195 200 205
Arg Gly Pro Ser Glu Tyr Pro Thr Lys Asn Tyr Val
210 215 220
<210> 3
<211> 220
<212> PRT
<213> Homo sapiens
<400> 3
Met Ala Ser Ala Gly Met Gln Ile Leu Gly Val Val Leu Thr Leu Leu
1 5 10 15
Gly Trp Val Asn Gly Leu Val Ser Cys Ala Leu Pro Met Trp Lys Val
20 25 30
Thr Ala Phe Ile Gly Asn Ser Ile Val Val Ala Gln Val Val Trp Glu
35 40 45
Gly Leu Trp Met Ser Cys Val Val Gln Ser Thr Gly Gln Met Gln Cys
50 55 60
Lys Val Tyr Asp Ser Leu Leu Ala Leu Pro Gln Asp Leu Gln Ala Ala
65 70 75 80
Arg Ala Leu Cys Val Ile Ala Leu Leu Val Ala Leu Phe Gly Leu Leu
85 90 95
Val Tyr Leu Ala Gly Ala Lys Cys Thr Thr Cys Val Glu Glu Lys Asp
100 105 110
Ser Lys Ala Arg Leu Val Leu Thr Ser Gly Ile Val Phe Val Ile Ser
115 120 125
Gly Val Leu Thr Leu Ile Pro Val Cys Trp Thr Ala His Ala Val Ile
130 135 140
Arg Asp Phe Tyr Asn Pro Leu Val Ala Glu Ala Gln Lys Arg Glu Leu
145 150 155 160
Gly Ala Ser Leu Tyr Leu Gly Trp Ala Ala Ser Gly Leu Leu Leu Leu
165 170 175
Gly Gly Gly Leu Leu Cys Cys Thr Cys Pro Ser Gly Gly Ser Gln Gly
180 185 190
Pro Ser His Tyr Met Ala Arg Tyr Ser Thr Ser Ala Pro Ala Ile Ser
195 200 205
Arg Gly Pro Ser Glu Tyr Pro Thr Lys Asn Tyr Val
210 215 220
<210> 4
<211> 207
<212> PRT
<213> Homo sapiens
<400> 4
Met Gln Ser Gly Thr His Trp Arg Val Leu Gly Leu Cys Leu Leu Ser
1 5 10 15
Val Gly Val Trp Gly Gln Asp Gly Asn Glu Glu Met Gly Gly Ile Thr
20 25 30
Gln Thr Pro Tyr Lys Val Ser Ile Ser Gly Thr Thr Val Ile Leu Thr
35 40 45
Cys Pro Gln Tyr Pro Gly Ser Glu Ile Leu Trp Gln His Asn Asp Lys
50 55 60
Asn Ile Gly Gly Asp Glu Asp Asp Lys Asn Ile Gly Ser Asp Glu Asp
65 70 75 80
His Leu Ser Leu Lys Glu Phe Ser Glu Leu Glu Gln Ser Gly Tyr Tyr
85 90 95
Val Cys Tyr Pro Arg Gly Ser Lys Pro Glu Asp Ala Asn Phe Tyr Leu
100 105 110
Tyr Leu Arg Ala Arg Val Cys Glu Asn Cys Met Glu Met Asp Val Met
115 120 125
Ser Val Ala Thr Ile Val Ile Val Asp Ile Cys Ile Thr Gly Gly Leu
130 135 140
Leu Leu Leu Val Tyr Tyr Trp Ser Lys Asn Arg Lys Ala Lys Ala Lys
145 150 155 160
Pro Val Thr Arg Gly Ala Gly Ala Gly Gly Arg Gln Arg Gly Gln Asn
165 170 175
Lys Glu Arg Pro Pro Pro Val Pro Asn Pro Asp Tyr Glu Pro Ile Arg
180 185 190
Lys Gly Gln Arg Asp Leu Tyr Ser Gly Leu Asn Gln Arg Arg Ile
195 200 205
<210> 5
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 5
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Arg Tyr
20 25 30
Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Tyr Asp Asp His Tyr Ser Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Leu Thr Val Ser Ser
115
<210> 6
<211> 106
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 6
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Arg Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Val Ala Ser Gly Val Pro Tyr Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Leu Thr
85 90 95
Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
100 105
<210> 7
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 7
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Met Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
20 25 30
Thr Met Asn Trp Val Lys Gln Ser His Gly Lys Asn Leu Glu Trp Ile
35 40 45
Gly Leu Ile Asn Pro Tyr Asn Gly Gly Thr Ile Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Leu Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Tyr Gly Phe Val Leu Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Leu Thr Val Ser Ser
115
<210> 8
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 8
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Met Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
20 25 30
Thr Met Asn Trp Val Lys Gln Ser His Gly Lys Cys Leu Glu Trp Ile
35 40 45
Gly Leu Ile Asn Pro Tyr Asn Gly Gly Thr Ile Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Leu Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Tyr Gly Phe Val Leu Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Leu Thr Val Ser Ser
115
<210> 9
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 9
Gln Ile Val Leu Thr Gln Ser Pro Ser Ile Met Ser Val Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Ile Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
His Trp Phe Gln Gln Lys Pro Gly Thr Ser Pro Lys Leu Cys Ile Tyr
35 40 45
Ser Thr Ser Asn Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Arg
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Arg Val Ala Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Arg Ser Asn Tyr Pro Pro Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 10
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 10
Gln Ile Val Leu Thr Gln Ser Pro Ser Ile Met Ser Val Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Ile Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
His Trp Phe Gln Gln Lys Pro Gly Thr Ser Pro Lys Leu Trp Ile Tyr
35 40 45
Ser Thr Ser Asn Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Arg
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Arg Val Ala Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Arg Ser Asn Tyr Pro Pro Trp
85 90 95
Thr Phe Gly Cys Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 11
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 11
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Met Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
20 25 30
Thr Met Asn Trp Val Lys Gln Ser His Gly Lys Asn Leu Glu Trp Ile
35 40 45
Gly Leu Ile Asn Pro Tyr Asn Gly Gly Thr Ser Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Ile Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Leu Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Tyr Gly Tyr Val Leu Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Leu Thr Val Ser Ser
115
<210> 12
<211> 107
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 12
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Ile Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Leu
20 25 30
His Trp Phe Gln Gln Lys Pro Gly Thr Ser Pro Lys Leu Trp Val Tyr
35 40 45
Ser Thr Ser Asn Leu Pro Ser Gly Val Pro Ala Arg Phe Gly Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Arg Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Arg Ser Ile Tyr Pro Pro Trp
85 90 95
Thr Phe Gly Gly Gly Thr Lys Leu Glu Ile Lys
100 105
<210> 13
<211> 244
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 13
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
1 5 10 15
Ser Met Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
20 25 30
Thr Met Asn Trp Val Lys Gln Ser His Gly Lys Cys Leu Glu Trp Ile
35 40 45
Gly Leu Ile Asn Pro Tyr Asn Gly Gly Thr Ile Tyr Asn Gln Lys Phe
50 55 60
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Glu Leu Leu Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Asp Tyr Gly Phe Val Leu Asp Tyr Trp Gly Gln Gly Thr Thr
100 105 110
Leu Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
115 120 125
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Ile Val Leu Thr Gln Ser
130 135 140
Pro Ser Ile Met Ser Val Ser Pro Gly Glu Lys Val Thr Ile Thr Cys
145 150 155 160
Ser Ala Ser Ser Ser Val Ser Tyr Met His Trp Phe Gln Gln Lys Pro
165 170 175
Gly Thr Ser Pro Lys Leu Trp Ile Tyr Ser Thr Ser Asn Leu Ala Ser
180 185 190
Gly Val Pro Ala Arg Phe Ser Gly Arg Gly Ser Gly Thr Ser Tyr Ser
195 200 205
Leu Thr Ile Ser Arg Val Ala Ala Glu Asp Ala Ala Thr Tyr Tyr Cys
210 215 220
Gln Gln Arg Ser Asn Tyr Pro Pro Trp Thr Phe Gly Cys Gly Thr Lys
225 230 235 240
Leu Glu Ile Lys
<210> 14
<211> 493
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 14
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Arg Tyr
20 25 30
Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Tyr Asp Asp His Tyr Ser Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Leu Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Ser Gly
210 215 220
Pro Gly Gly Gly Arg Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
225 230 235 240
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
245 250 255
Ser Met Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
260 265 270
Thr Met Asn Trp Val Lys Gln Ser His Gly Lys Cys Leu Glu Trp Ile
275 280 285
Gly Leu Ile Asn Pro Tyr Asn Gly Gly Thr Ile Tyr Asn Gln Lys Phe
290 295 300
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
305 310 315 320
Met Glu Leu Leu Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
325 330 335
Ala Arg Asp Tyr Gly Phe Val Leu Asp Tyr Trp Gly Gln Gly Thr Thr
340 345 350
Leu Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
355 360 365
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Ile Val Leu Thr Gln Ser
370 375 380
Pro Ser Ile Met Ser Val Ser Pro Gly Glu Lys Val Thr Ile Thr Cys
385 390 395 400
Ser Ala Ser Ser Ser Val Ser Tyr Met His Trp Phe Gln Gln Lys Pro
405 410 415
Gly Thr Ser Pro Lys Leu Trp Ile Tyr Ser Thr Ser Asn Leu Ala Ser
420 425 430
Gly Val Pro Ala Arg Phe Ser Gly Arg Gly Ser Gly Thr Ser Tyr Ser
435 440 445
Leu Thr Ile Ser Arg Val Ala Ala Glu Asp Ala Ala Thr Tyr Tyr Cys
450 455 460
Gln Gln Arg Ser Asn Tyr Pro Pro Trp Thr Phe Gly Cys Gly Thr Lys
465 470 475 480
Leu Glu Ile Lys Gly Gly Ser His His His His His His
485 490
<210> 15
<211> 493
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 15
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Arg Tyr
20 25 30
Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Tyr Asp Asp His Tyr Ser Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Leu Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Lys Ser Thr Ser Glu Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Pro Lys Ser Ala Ser Gly
210 215 220
Pro Gly Gly Gly Arg Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
225 230 235 240
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
245 250 255
Ser Met Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
260 265 270
Thr Met Asn Trp Val Lys Gln Ser His Gly Lys Cys Leu Glu Trp Ile
275 280 285
Gly Leu Ile Asn Pro Tyr Asn Gly Gly Thr Ile Tyr Asn Gln Lys Phe
290 295 300
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
305 310 315 320
Met Glu Leu Leu Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
325 330 335
Ala Arg Asp Tyr Gly Phe Val Leu Asp Tyr Trp Gly Gln Gly Thr Thr
340 345 350
Leu Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
355 360 365
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Ile Val Leu Thr Gln Ser
370 375 380
Pro Ser Ile Met Ser Val Ser Pro Gly Glu Lys Val Thr Ile Thr Cys
385 390 395 400
Ser Ala Ser Ser Ser Val Ser Tyr Met His Trp Phe Gln Gln Lys Pro
405 410 415
Gly Thr Ser Pro Lys Leu Trp Ile Tyr Ser Thr Ser Asn Leu Ala Ser
420 425 430
Gly Val Pro Ala Arg Phe Ser Gly Arg Gly Ser Gly Thr Ser Tyr Ser
435 440 445
Leu Thr Ile Ser Arg Val Ala Ala Glu Asp Ala Ala Thr Tyr Tyr Cys
450 455 460
Gln Gln Arg Ser Asn Tyr Pro Pro Trp Thr Phe Gly Cys Gly Thr Lys
465 470 475 480
Leu Glu Ile Lys Gly Gly Ser His His His His His His
485 490
<210> 16
<211> 473
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 16
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Arg Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Val Ala Ser Gly Val Pro Tyr Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Leu Thr
85 90 95
Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Arg Thr Val Ala Ala Pro
100 105 110
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr
115 120 125
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys
130 135 140
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu
145 150 155 160
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
165 170 175
Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala
180 185 190
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe
195 200 205
Asn Arg Gly Glu Cys Asp Val Pro Gly Gly Ser Glu Val Gln Leu Gln
210 215 220
Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala Ser Met Lys Ile Ser
225 230 235 240
Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr Thr Met Asn Trp Val
245 250 255
Lys Gln Ser His Gly Lys Cys Leu Glu Trp Ile Gly Leu Ile Asn Pro
260 265 270
Tyr Asn Gly Gly Thr Ile Tyr Asn Gln Lys Phe Lys Gly Lys Ala Thr
275 280 285
Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met Glu Leu Leu Ser
290 295 300
Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala Arg Asp Tyr Gly
305 310 315 320
Phe Val Leu Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
325 330 335
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
340 345 350
Gly Gly Gly Ser Gln Ile Val Leu Thr Gln Ser Pro Ser Ile Met Ser
355 360 365
Val Ser Pro Gly Glu Lys Val Thr Ile Thr Cys Ser Ala Ser Ser Ser
370 375 380
Val Ser Tyr Met His Trp Phe Gln Gln Lys Pro Gly Thr Ser Pro Lys
385 390 395 400
Leu Trp Ile Tyr Ser Thr Ser Asn Leu Ala Ser Gly Val Pro Ala Arg
405 410 415
Phe Ser Gly Arg Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Arg
420 425 430
Val Ala Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Arg Ser Asn
435 440 445
Tyr Pro Pro Trp Thr Phe Gly Cys Gly Thr Lys Leu Glu Ile Lys Ser
450 455 460
Ala Trp Ser His Pro Gln Phe Glu Lys
465 470
<210> 17
<211> 484
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 17
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Arg Tyr
20 25 30
Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Tyr Asp Asp His Tyr Ser Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Leu Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Ser Gly
210 215 220
Pro Gly Gly Gly Arg Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
225 230 235 240
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
245 250 255
Ser Met Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
260 265 270
Thr Met Asn Trp Val Lys Gln Ser His Gly Lys Cys Leu Glu Trp Ile
275 280 285
Gly Leu Ile Asn Pro Tyr Asn Gly Gly Thr Ile Tyr Asn Gln Lys Phe
290 295 300
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
305 310 315 320
Met Glu Leu Leu Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
325 330 335
Ala Arg Asp Tyr Gly Phe Val Leu Asp Tyr Trp Gly Gln Gly Thr Thr
340 345 350
Leu Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
355 360 365
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Ile Val Leu Thr Gln Ser
370 375 380
Pro Ser Ile Met Ser Val Ser Pro Gly Glu Lys Val Thr Ile Thr Cys
385 390 395 400
Ser Ala Ser Ser Ser Val Ser Tyr Met His Trp Phe Gln Gln Lys Pro
405 410 415
Gly Thr Ser Pro Lys Leu Trp Ile Tyr Ser Thr Ser Asn Leu Ala Ser
420 425 430
Gly Val Pro Ala Arg Phe Ser Gly Arg Gly Ser Gly Thr Ser Tyr Ser
435 440 445
Leu Thr Ile Ser Arg Val Ala Ala Glu Asp Ala Ala Thr Tyr Tyr Cys
450 455 460
Gln Gln Arg Ser Asn Tyr Pro Pro Trp Thr Phe Gly Cys Gly Thr Lys
465 470 475 480
Leu Glu Ile Lys
<210> 18
<211> 484
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 18
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Arg Tyr
20 25 30
Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Tyr Asp Asp His Tyr Ser Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Leu Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Lys Ser Thr Ser Glu Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Pro Lys Ser Ala Ser Gly
210 215 220
Pro Gly Gly Gly Arg Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
225 230 235 240
Glu Val Gln Leu Gln Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala
245 250 255
Ser Met Lys Ile Ser Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr
260 265 270
Thr Met Asn Trp Val Lys Gln Ser His Gly Lys Cys Leu Glu Trp Ile
275 280 285
Gly Leu Ile Asn Pro Tyr Asn Gly Gly Thr Ile Tyr Asn Gln Lys Phe
290 295 300
Lys Gly Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
305 310 315 320
Met Glu Leu Leu Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
325 330 335
Ala Arg Asp Tyr Gly Phe Val Leu Asp Tyr Trp Gly Gln Gly Thr Thr
340 345 350
Leu Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
355 360 365
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Ile Val Leu Thr Gln Ser
370 375 380
Pro Ser Ile Met Ser Val Ser Pro Gly Glu Lys Val Thr Ile Thr Cys
385 390 395 400
Ser Ala Ser Ser Ser Val Ser Tyr Met His Trp Phe Gln Gln Lys Pro
405 410 415
Gly Thr Ser Pro Lys Leu Trp Ile Tyr Ser Thr Ser Asn Leu Ala Ser
420 425 430
Gly Val Pro Ala Arg Phe Ser Gly Arg Gly Ser Gly Thr Ser Tyr Ser
435 440 445
Leu Thr Ile Ser Arg Val Ala Ala Glu Asp Ala Ala Thr Tyr Tyr Cys
450 455 460
Gln Gln Arg Ser Asn Tyr Pro Pro Trp Thr Phe Gly Cys Gly Thr Lys
465 470 475 480
Leu Glu Ile Lys
<210> 19
<211> 463
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 19
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Arg Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Val Ala Ser Gly Val Pro Tyr Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Leu Thr
85 90 95
Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Arg Thr Val Ala Ala Pro
100 105 110
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr
115 120 125
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys
130 135 140
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu
145 150 155 160
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
165 170 175
Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala
180 185 190
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe
195 200 205
Asn Arg Gly Glu Cys Asp Val Pro Gly Gly Ser Glu Val Gln Leu Gln
210 215 220
Gln Ser Gly Pro Glu Leu Val Lys Pro Gly Ala Ser Met Lys Ile Ser
225 230 235 240
Cys Lys Ala Ser Gly Tyr Ser Phe Thr Gly Tyr Thr Met Asn Trp Val
245 250 255
Lys Gln Ser His Gly Lys Cys Leu Glu Trp Ile Gly Leu Ile Asn Pro
260 265 270
Tyr Asn Gly Gly Thr Ile Tyr Asn Gln Lys Phe Lys Gly Lys Ala Thr
275 280 285
Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met Glu Leu Leu Ser
290 295 300
Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala Arg Asp Tyr Gly
305 310 315 320
Phe Val Leu Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
325 330 335
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
340 345 350
Gly Gly Gly Ser Gln Ile Val Leu Thr Gln Ser Pro Ser Ile Met Ser
355 360 365
Val Ser Pro Gly Glu Lys Val Thr Ile Thr Cys Ser Ala Ser Ser Ser
370 375 380
Val Ser Tyr Met His Trp Phe Gln Gln Lys Pro Gly Thr Ser Pro Lys
385 390 395 400
Leu Trp Ile Tyr Ser Thr Ser Asn Leu Ala Ser Gly Val Pro Ala Arg
405 410 415
Phe Ser Gly Arg Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Arg
420 425 430
Val Ala Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Arg Ser Asn
435 440 445
Tyr Pro Pro Trp Thr Phe Gly Cys Gly Thr Lys Leu Glu Ile Lys
450 455 460
<210> 20
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 20
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Ile Asn Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Asn Ile Tyr Pro Ser Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Pro Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Ser Trp Arg Gly Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Thr Leu Thr Val Ser Ser
115
<210> 21
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 21
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Ile Asn Trp Val Lys Gln Arg Pro Gly Gln Cys Leu Glu Trp Ile
35 40 45
Gly Asn Ile Tyr Pro Ser Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Pro Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Ser Trp Arg Gly Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Thr Leu Thr Val Ser Ser
115
<210> 22
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 22
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser
20 25 30
Gly Asn Gln Lys Asn Tyr Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile
100 105 110
Lys
<210> 23
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 23
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser
20 25 30
Gly Asn Gln Lys Asn Tyr Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Phe Thr Phe Gly Cys Gly Thr Lys Leu Glu Ile
100 105 110
Lys
<210> 24
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 24
Gln Ile Gln Leu Val Gln Ser Gly Pro Glu Leu Lys Lys Pro Gly Glu
1 5 10 15
Thr Val Lys Ile Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Asn Tyr
20 25 30
Gly Met Asn Trp Val Lys Gln Ala Pro Gly Lys Gly Leu Lys Trp Met
35 40 45
Gly Trp Ile Asn Thr Asn Thr Gly Glu Pro Thr Tyr Ala Glu Glu Phe
50 55 60
Lys Gly Arg Phe Ala Phe Ser Leu Glu Thr Ser Ala Ser Thr Ala Tyr
65 70 75 80
Leu Gln Ile Asn Asn Leu Lys Asn Glu Asp Thr Ala Thr Tyr Phe Cys
85 90 95
Ala Arg Leu Gly Phe Gly Asn Ala Met Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Ser Val Thr Val
115
<210> 25
<211> 113
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 25
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser
20 25 30
Gly Asn Gln Lys Asn Tyr Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Leu Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu
100 105 110
Lys
<210> 26
<211> 251
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 26
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Ile Asn Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Asn Ile Tyr Pro Ser Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Pro Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Ser Trp Arg Gly Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Thr Leu Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Val Met Thr Gln
130 135 140
Ser Pro Ser Ser Leu Thr Val Thr Ala Gly Glu Lys Val Thr Met Ser
145 150 155 160
Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser Gly Asn Gln Lys Asn Tyr
165 170 175
Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile
180 185 190
Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val Pro Asp Arg Phe Thr Gly
195 200 205
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Val Gln Ala
210 215 220
Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn Asp Tyr Ser Tyr Pro Phe
225 230 235 240
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
245 250
<210> 27
<211> 256
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 27
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser
20 25 30
Gly Asn Gln Lys Asn Tyr Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile
100 105 110
Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln
130 135 140
Pro Gly Ala Glu Leu Val Arg Pro Gly Ala Ser Val Lys Leu Ser Cys
145 150 155 160
Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Trp Ile Asn Trp Val Lys
165 170 175
Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile Gly Asn Ile Tyr Pro Ser
180 185 190
Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr Leu
195 200 205
Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Pro
210 215 220
Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Thr Arg Ser Trp Arg Gly
225 230 235 240
Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
245 250 255
<210> 28
<211> 251
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 28
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Ile Asn Trp Val Lys Gln Arg Pro Gly Gln Cys Leu Glu Trp Ile
35 40 45
Gly Asn Ile Tyr Pro Ser Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Pro Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Ser Trp Arg Gly Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Thr Leu Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Val Met Thr Gln
130 135 140
Ser Pro Ser Ser Leu Thr Val Thr Ala Gly Glu Lys Val Thr Met Ser
145 150 155 160
Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser Gly Asn Gln Lys Asn Tyr
165 170 175
Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile
180 185 190
Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val Pro Asp Arg Phe Thr Gly
195 200 205
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Val Gln Ala
210 215 220
Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn Asp Tyr Ser Tyr Pro Phe
225 230 235 240
Thr Phe Gly Cys Gly Thr Lys Leu Glu Ile Lys
245 250
<210> 29
<211> 256
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 29
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser
20 25 30
Gly Asn Gln Lys Asn Tyr Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Phe Thr Phe Gly Cys Gly Thr Lys Leu Glu Ile
100 105 110
Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln
130 135 140
Pro Gly Ala Glu Leu Val Arg Pro Gly Ala Ser Val Lys Leu Ser Cys
145 150 155 160
Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Trp Ile Asn Trp Val Lys
165 170 175
Gln Arg Pro Gly Gln Cys Leu Glu Trp Ile Gly Asn Ile Tyr Pro Ser
180 185 190
Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr Leu
195 200 205
Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Pro
210 215 220
Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Thr Arg Ser Trp Arg Gly
225 230 235 240
Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
245 250 255
<210> 30
<211> 500
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 30
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Arg Tyr
20 25 30
Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Tyr Asp Asp His Tyr Ser Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Leu Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Ser Gly
210 215 220
Pro Gly Gly Gly Arg Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
225 230 235 240
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Ala
245 250 255
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
260 265 270
Trp Ile Asn Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
275 280 285
Gly Asn Ile Tyr Pro Ser Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe
290 295 300
Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
305 310 315 320
Met Gln Leu Ser Ser Pro Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
325 330 335
Thr Arg Ser Trp Arg Gly Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr
340 345 350
Thr Leu Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
355 360 365
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Val Met Thr Gln
370 375 380
Ser Pro Ser Ser Leu Thr Val Thr Ala Gly Glu Lys Val Thr Met Ser
385 390 395 400
Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser Gly Asn Gln Lys Asn Tyr
405 410 415
Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile
420 425 430
Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val Pro Asp Arg Phe Thr Gly
435 440 445
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Val Gln Ala
450 455 460
Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn Asp Tyr Ser Tyr Pro Phe
465 470 475 480
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Gly Gly Ser His His
485 490 495
His His His His
500
<210> 31
<211> 500
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 31
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Arg Tyr
20 25 30
Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Tyr Asp Asp His Tyr Ser Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Leu Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Lys Ser Thr Ser Glu Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Pro Lys Ser Ala Ser Gly
210 215 220
Pro Gly Gly Gly Arg Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
225 230 235 240
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Ala
245 250 255
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
260 265 270
Trp Ile Asn Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
275 280 285
Gly Asn Ile Tyr Pro Ser Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe
290 295 300
Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
305 310 315 320
Met Gln Leu Ser Ser Pro Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
325 330 335
Thr Arg Ser Trp Arg Gly Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr
340 345 350
Thr Leu Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
355 360 365
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Val Met Thr Gln
370 375 380
Ser Pro Ser Ser Leu Thr Val Thr Ala Gly Glu Lys Val Thr Met Ser
385 390 395 400
Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser Gly Asn Gln Lys Asn Tyr
405 410 415
Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile
420 425 430
Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val Pro Asp Arg Phe Thr Gly
435 440 445
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Val Gln Ala
450 455 460
Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn Asp Tyr Ser Tyr Pro Phe
465 470 475 480
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Gly Gly Ser His His
485 490 495
His His His His
500
<210> 32
<211> 480
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 32
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Arg Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Val Ala Ser Gly Val Pro Tyr Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Leu Thr
85 90 95
Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Arg Thr Val Ala Ala Pro
100 105 110
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr
115 120 125
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys
130 135 140
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu
145 150 155 160
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
165 170 175
Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala
180 185 190
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe
195 200 205
Asn Arg Gly Glu Cys Asp Val Pro Gly Gly Ser Gln Val Gln Leu Gln
210 215 220
Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Ala Ser Val Lys Leu Ser
225 230 235 240
Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Trp Ile Asn Trp Val
245 250 255
Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile Gly Asn Ile Tyr Pro
260 265 270
Ser Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr
275 280 285
Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser
290 295 300
Pro Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Thr Arg Ser Trp Arg
305 310 315 320
Gly Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser
325 330 335
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
340 345 350
Gly Gly Gly Gly Ser Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu
355 360 365
Thr Val Thr Ala Gly Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln
370 375 380
Ser Leu Leu Asn Ser Gly Asn Gln Lys Asn Tyr Leu Thr Trp Tyr Gln
385 390 395 400
Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr
405 410 415
Arg Glu Ser Gly Val Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr
420 425 430
Asp Phe Thr Leu Thr Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val
435 440 445
Tyr Tyr Cys Gln Asn Asp Tyr Ser Tyr Pro Phe Thr Phe Gly Ser Gly
450 455 460
Thr Lys Leu Glu Ile Lys Ser Ala Trp Ser His Pro Gln Phe Glu Lys
465 470 475 480
<210> 33
<211> 503
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 33
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Arg Tyr
20 25 30
Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Tyr Asp Asp His Tyr Ser Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Leu Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Ser Gly
210 215 220
Pro Gly Gly Gly Arg Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
225 230 235 240
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly
245 250 255
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser
260 265 270
Gly Asn Gln Lys Asn Tyr Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
275 280 285
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
290 295 300
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
305 310 315 320
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn
325 330 335
Asp Tyr Ser Tyr Pro Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile
340 345 350
Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
355 360 365
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln
370 375 380
Pro Gly Ala Glu Leu Val Arg Pro Gly Ala Ser Val Lys Leu Ser Cys
385 390 395 400
Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Trp Ile Asn Trp Val Lys
405 410 415
Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile Gly Asn Ile Tyr Pro Ser
420 425 430
Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr Leu
435 440 445
Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Pro
450 455 460
Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Thr Arg Ser Trp Arg Gly
465 470 475 480
Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
485 490 495
Ser His His His His His His
500
<210> 34
<211> 503
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 34
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Arg Tyr
20 25 30
Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Tyr Asp Asp His Tyr Ser Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Leu Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Cys Ser Lys Ser Thr Ser Glu Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Asn Phe Gly Thr Gln Thr Tyr Thr Cys Asn Val Asp His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Thr Val Glu Pro Lys Ser Ala Ser Gly
210 215 220
Pro Gly Gly Gly Arg Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
225 230 235 240
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly
245 250 255
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser
260 265 270
Gly Asn Gln Lys Asn Tyr Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
275 280 285
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
290 295 300
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
305 310 315 320
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn
325 330 335
Asp Tyr Ser Tyr Pro Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile
340 345 350
Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
355 360 365
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln
370 375 380
Pro Gly Ala Glu Leu Val Arg Pro Gly Ala Ser Val Lys Leu Ser Cys
385 390 395 400
Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Trp Ile Asn Trp Val Lys
405 410 415
Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile Gly Asn Ile Tyr Pro Ser
420 425 430
Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr Leu
435 440 445
Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Pro
450 455 460
Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Thr Arg Ser Trp Arg Gly
465 470 475 480
Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
485 490 495
Ser His His His His His His
500
<210> 35
<211> 485
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 35
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Arg Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Val Ala Ser Gly Val Pro Tyr Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Leu Thr
85 90 95
Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Arg Thr Val Ala Ala Pro
100 105 110
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr
115 120 125
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys
130 135 140
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu
145 150 155 160
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
165 170 175
Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala
180 185 190
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe
195 200 205
Asn Arg Gly Glu Cys Asp Val Pro Gly Gly Ser Asp Ile Val Met Thr
210 215 220
Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly Glu Lys Val Thr Met
225 230 235 240
Ser Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser Gly Asn Gln Lys Asn
245 250 255
Tyr Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu
260 265 270
Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val Pro Asp Arg Phe Thr
275 280 285
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Val Gln
290 295 300
Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn Asp Tyr Ser Tyr Pro
305 310 315 320
Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly
325 330 335
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
340 345 350
Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu
355 360 365
Val Arg Pro Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr
370 375 380
Thr Phe Thr Ser Tyr Trp Ile Asn Trp Val Lys Gln Arg Pro Gly Gln
385 390 395 400
Gly Leu Glu Trp Ile Gly Asn Ile Tyr Pro Ser Asp Ser Tyr Thr Asn
405 410 415
Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser
420 425 430
Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Pro Thr Ser Glu Asp Ser
435 440 445
Ala Val Tyr Tyr Cys Thr Arg Ser Trp Arg Gly Asn Ser Phe Asp Tyr
450 455 460
Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser Ser Ala Trp Ser His
465 470 475 480
Pro Gln Phe Glu Lys
485
<210> 36
<211> 491
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 36
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Arg Tyr
20 25 30
Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Tyr Asp Asp His Tyr Ser Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Leu Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Ser Gly
210 215 220
Pro Gly Gly Gly Arg Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
225 230 235 240
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Ala
245 250 255
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
260 265 270
Trp Ile Asn Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
275 280 285
Gly Asn Ile Tyr Pro Ser Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe
290 295 300
Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
305 310 315 320
Met Gln Leu Ser Ser Pro Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
325 330 335
Thr Arg Ser Trp Arg Gly Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr
340 345 350
Thr Leu Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
355 360 365
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Val Met Thr Gln
370 375 380
Ser Pro Ser Ser Leu Thr Val Thr Ala Gly Glu Lys Val Thr Met Ser
385 390 395 400
Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser Gly Asn Gln Lys Asn Tyr
405 410 415
Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile
420 425 430
Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val Pro Asp Arg Phe Thr Gly
435 440 445
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Val Gln Ala
450 455 460
Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn Asp Tyr Ser Tyr Pro Phe
465 470 475 480
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys
485 490
<210> 37
<211> 470
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 37
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Arg Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Val Ala Ser Gly Val Pro Tyr Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Leu Thr
85 90 95
Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Arg Thr Val Ala Ala Pro
100 105 110
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr
115 120 125
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys
130 135 140
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu
145 150 155 160
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
165 170 175
Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala
180 185 190
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe
195 200 205
Asn Arg Gly Glu Cys Asp Val Pro Gly Gly Ser Gln Val Gln Leu Gln
210 215 220
Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Ala Ser Val Lys Leu Ser
225 230 235 240
Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Trp Ile Asn Trp Val
245 250 255
Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile Gly Asn Ile Tyr Pro
260 265 270
Ser Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr
275 280 285
Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser
290 295 300
Pro Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Thr Arg Ser Trp Arg
305 310 315 320
Gly Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser
325 330 335
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
340 345 350
Gly Gly Gly Gly Ser Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu
355 360 365
Thr Val Thr Ala Gly Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln
370 375 380
Ser Leu Leu Asn Ser Gly Asn Gln Lys Asn Tyr Leu Thr Trp Tyr Gln
385 390 395 400
Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr
405 410 415
Arg Glu Ser Gly Val Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr
420 425 430
Asp Phe Thr Leu Thr Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val
435 440 445
Tyr Tyr Cys Gln Asn Asp Tyr Ser Tyr Pro Phe Thr Phe Gly Ser Gly
450 455 460
Thr Lys Leu Glu Ile Lys
465 470
<210> 38
<211> 496
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 38
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Arg Tyr
20 25 30
Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Tyr Asp Asp His Tyr Ser Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Leu Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Ser Gly
210 215 220
Pro Gly Gly Gly Arg Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
225 230 235 240
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly
245 250 255
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser
260 265 270
Gly Asn Gln Lys Asn Tyr Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
275 280 285
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
290 295 300
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
305 310 315 320
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn
325 330 335
Asp Tyr Ser Tyr Pro Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile
340 345 350
Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
355 360 365
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln
370 375 380
Pro Gly Ala Glu Leu Val Arg Pro Gly Ala Ser Val Lys Leu Ser Cys
385 390 395 400
Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Trp Ile Asn Trp Val Lys
405 410 415
Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile Gly Asn Ile Tyr Pro Ser
420 425 430
Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr Leu
435 440 445
Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Pro
450 455 460
Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Thr Arg Ser Trp Arg Gly
465 470 475 480
Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
485 490 495
<210> 39
<211> 475
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 39
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Arg Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Val Ala Ser Gly Val Pro Tyr Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Leu Thr
85 90 95
Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Arg Thr Val Ala Ala Pro
100 105 110
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr
115 120 125
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys
130 135 140
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu
145 150 155 160
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
165 170 175
Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala
180 185 190
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe
195 200 205
Asn Arg Gly Glu Cys Asp Val Pro Gly Gly Ser Asp Ile Val Met Thr
210 215 220
Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly Glu Lys Val Thr Met
225 230 235 240
Ser Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser Gly Asn Gln Lys Asn
245 250 255
Tyr Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu
260 265 270
Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val Pro Asp Arg Phe Thr
275 280 285
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Val Gln
290 295 300
Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn Asp Tyr Ser Tyr Pro
305 310 315 320
Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly
325 330 335
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
340 345 350
Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu
355 360 365
Val Arg Pro Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr
370 375 380
Thr Phe Thr Ser Tyr Trp Ile Asn Trp Val Lys Gln Arg Pro Gly Gln
385 390 395 400
Gly Leu Glu Trp Ile Gly Asn Ile Tyr Pro Ser Asp Ser Tyr Thr Asn
405 410 415
Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser
420 425 430
Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Pro Thr Ser Glu Asp Ser
435 440 445
Ala Val Tyr Tyr Cys Thr Arg Ser Trp Arg Gly Asn Ser Phe Asp Tyr
450 455 460
Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
465 470 475
<210> 40
<211> 491
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 40
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Arg Tyr
20 25 30
Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Tyr Asp Asp His Tyr Ser Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Leu Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Ser Gly
210 215 220
Pro Gly Gly Gly Arg Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
225 230 235 240
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Ala
245 250 255
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
260 265 270
Trp Ile Asn Trp Val Lys Gln Arg Pro Gly Gln Cys Leu Glu Trp Ile
275 280 285
Gly Asn Ile Tyr Pro Ser Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe
290 295 300
Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
305 310 315 320
Met Gln Leu Ser Ser Pro Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
325 330 335
Thr Arg Ser Trp Arg Gly Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr
340 345 350
Thr Leu Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
355 360 365
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Val Met Thr Gln
370 375 380
Ser Pro Ser Ser Leu Thr Val Thr Ala Gly Glu Lys Val Thr Met Ser
385 390 395 400
Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser Gly Asn Gln Lys Asn Tyr
405 410 415
Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile
420 425 430
Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val Pro Asp Arg Phe Thr Gly
435 440 445
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Val Gln Ala
450 455 460
Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn Asp Tyr Ser Tyr Pro Phe
465 470 475 480
Thr Phe Gly Cys Gly Thr Lys Leu Glu Ile Lys
485 490
<210> 41
<211> 470
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 41
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Arg Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Val Ala Ser Gly Val Pro Tyr Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Leu Thr
85 90 95
Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Arg Thr Val Ala Ala Pro
100 105 110
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr
115 120 125
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys
130 135 140
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu
145 150 155 160
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
165 170 175
Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala
180 185 190
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe
195 200 205
Asn Arg Gly Glu Cys Asp Val Pro Gly Gly Ser Gln Val Gln Leu Gln
210 215 220
Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Ala Ser Val Lys Leu Ser
225 230 235 240
Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Trp Ile Asn Trp Val
245 250 255
Lys Gln Arg Pro Gly Gln Cys Leu Glu Trp Ile Gly Asn Ile Tyr Pro
260 265 270
Ser Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr
275 280 285
Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser
290 295 300
Pro Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Thr Arg Ser Trp Arg
305 310 315 320
Gly Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser
325 330 335
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
340 345 350
Gly Gly Gly Gly Ser Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu
355 360 365
Thr Val Thr Ala Gly Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln
370 375 380
Ser Leu Leu Asn Ser Gly Asn Gln Lys Asn Tyr Leu Thr Trp Tyr Gln
385 390 395 400
Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr
405 410 415
Arg Glu Ser Gly Val Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr
420 425 430
Asp Phe Thr Leu Thr Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val
435 440 445
Tyr Tyr Cys Gln Asn Asp Tyr Ser Tyr Pro Phe Thr Phe Gly Cys Gly
450 455 460
Thr Lys Leu Glu Ile Lys
465 470
<210> 42
<211> 496
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 42
Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Arg Tyr
20 25 30
Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Tyr Asp Asp His Tyr Ser Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Leu Thr Val Ser Ser Ala Ser Thr Lys Gly Pro Ser Val Phe
115 120 125
Pro Leu Ala Pro Ser Ser Lys Ser Thr Ser Gly Gly Thr Ala Ala Leu
130 135 140
Gly Cys Leu Val Lys Asp Tyr Phe Pro Glu Pro Val Thr Val Ser Trp
145 150 155 160
Asn Ser Gly Ala Leu Thr Ser Gly Val His Thr Phe Pro Ala Val Leu
165 170 175
Gln Ser Ser Gly Leu Tyr Ser Leu Ser Ser Val Val Thr Val Pro Ser
180 185 190
Ser Ser Leu Gly Thr Gln Thr Tyr Ile Cys Asn Val Asn His Lys Pro
195 200 205
Ser Asn Thr Lys Val Asp Lys Arg Val Glu Pro Lys Ser Cys Ser Gly
210 215 220
Pro Gly Gly Gly Arg Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
225 230 235 240
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly
245 250 255
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser
260 265 270
Gly Asn Gln Lys Asn Tyr Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
275 280 285
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
290 295 300
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
305 310 315 320
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn
325 330 335
Asp Tyr Ser Tyr Pro Phe Thr Phe Gly Cys Gly Thr Lys Leu Glu Ile
340 345 350
Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
355 360 365
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln
370 375 380
Pro Gly Ala Glu Leu Val Arg Pro Gly Ala Ser Val Lys Leu Ser Cys
385 390 395 400
Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Trp Ile Asn Trp Val Lys
405 410 415
Gln Arg Pro Gly Gln Cys Leu Glu Trp Ile Gly Asn Ile Tyr Pro Ser
420 425 430
Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr Leu
435 440 445
Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Pro
450 455 460
Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Thr Arg Ser Trp Arg Gly
465 470 475 480
Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
485 490 495
<210> 43
<211> 475
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 43
Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly
1 5 10 15
Glu Lys Val Thr Met Thr Cys Arg Ala Ser Ser Ser Val Ser Tyr Met
20 25 30
Asn Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr
35 40 45
Asp Thr Ser Lys Val Ala Ser Gly Val Pro Tyr Arg Phe Ser Gly Ser
50 55 60
Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu
65 70 75 80
Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Leu Thr
85 90 95
Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Arg Thr Val Ala Ala Pro
100 105 110
Ser Val Phe Ile Phe Pro Pro Ser Asp Glu Gln Leu Lys Ser Gly Thr
115 120 125
Ala Ser Val Val Cys Leu Leu Asn Asn Phe Tyr Pro Arg Glu Ala Lys
130 135 140
Val Gln Trp Lys Val Asp Asn Ala Leu Gln Ser Gly Asn Ser Gln Glu
145 150 155 160
Ser Val Thr Glu Gln Asp Ser Lys Asp Ser Thr Tyr Ser Leu Ser Ser
165 170 175
Thr Leu Thr Leu Ser Lys Ala Asp Tyr Glu Lys His Lys Val Tyr Ala
180 185 190
Cys Glu Val Thr His Gln Gly Leu Ser Ser Pro Val Thr Lys Ser Phe
195 200 205
Asn Arg Gly Glu Cys Asp Val Pro Gly Gly Ser Asp Ile Val Met Thr
210 215 220
Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly Glu Lys Val Thr Met
225 230 235 240
Ser Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser Gly Asn Gln Lys Asn
245 250 255
Tyr Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu
260 265 270
Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val Pro Asp Arg Phe Thr
275 280 285
Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Val Gln
290 295 300
Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn Asp Tyr Ser Tyr Pro
305 310 315 320
Phe Thr Phe Gly Cys Gly Thr Lys Leu Glu Ile Lys Gly Gly Gly Gly
325 330 335
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
340 345 350
Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu
355 360 365
Val Arg Pro Gly Ala Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr
370 375 380
Thr Phe Thr Ser Tyr Trp Ile Asn Trp Val Lys Gln Arg Pro Gly Gln
385 390 395 400
Cys Leu Glu Trp Ile Gly Asn Ile Tyr Pro Ser Asp Ser Tyr Thr Asn
405 410 415
Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser
420 425 430
Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Pro Thr Ser Glu Asp Ser
435 440 445
Ala Val Tyr Tyr Cys Thr Arg Ser Trp Arg Gly Asn Ser Phe Asp Tyr
450 455 460
Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
465 470 475
<210> 44
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 44
Gly Tyr Ser Phe Thr Gly Tyr Thr
1 5
<210> 45
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 45
Ile Asn Pro Tyr Asn Gly Gly Thr
1 5
<210> 46
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 46
Ala Arg Asp Tyr Gly Phe Val Leu Asp Tyr
1 5 10
<210> 47
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 47
Ala Arg Asp Tyr Gly Tyr Val Leu Asp Tyr
1 5 10
<210> 48
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<220>
<221> MISC_FEATURE
<222> (8)..(8)
<223> Any amino acid, preferably Thr, Ser or Ile, most preferably Thr
<400> 48
Ile Asn Pro Tyr Asn Gly Gly Xaa
1 5
<210> 49
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<220>
<221> MISC_FEATURE
<222> (4)..(4)
<223> Any amino acid, preferably an aromatic amino acid, more
preferably Phe or Tyr, most preferably Tyr
<220>
<221> MISC_FEATURE
<222> (6)..(6)
<223> Any amino acid, preferably an aromatic amino acid, more
preferably Phe or Tyr, most preferably Tyr
<220>
<221> MISC_FEATURE
<222> (8)..(8)
<223> Any amino acid, preferably Leu or Phe, more preferably Leu
<400> 49
Ala Arg Asp Xaa Gly Xaa Val Xaa Asp Tyr
1 5 10
<210> 50
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 50
Ser Ser Val Ser Tyr
1 5
<210> 51
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 51
Ser Thr Ser
1
<210> 52
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 52
Gln Gln Arg Ser Asn Tyr Pro Pro Trp Thr
1 5 10
<210> 53
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 53
Gln Gln Arg Ser Ile Tyr Pro Pro Trp Thr
1 5 10
<210> 54
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<220>
<221> MISC_FEATURE
<222> (4)..(4)
<223> Any amino acid, preferably Ser or Asn, most preferably Ser
<400> 54
Ser Ser Val Xaa Tyr
1 5
<210> 55
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<220>
<221> MISC_FEATURE
<222> (4)..(4)
<223> Any amino acid, preferably Ser or Asn, most preferably Ser
<220>
<221> MISC_FEATURE
<222> (5)..(5)
<223> Any amino acid, preferably Tyr, Ser, Ile, Asn or Thr, more
preferably Ile, Asn or Thr, most preferably Ile or Asn
<220>
<221> MISC_FEATURE
<222> (6)..(6)
<223> Any amino acid, preferably Ser or Tyr, more preferably Tyr
<400> 55
Gln Gln Arg Xaa Xaa Xaa Pro Pro Trp Thr
1 5 10
<210> 56
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 56
Gly Tyr Thr Phe Thr Ser Tyr Trp
1 5
<210> 57
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 57
Ile Tyr Pro Ser Asp Ser Tyr Thr
1 5
<210> 58
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 58
Thr Arg Ser Trp Arg Gly Asn Ser Phe Asp Tyr
1 5 10
<210> 59
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 59
Gly Tyr Thr Phe Thr Asn Tyr Gly
1 5
<210> 60
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 60
Ile Asn Thr Asn Thr Gly Glu Pro
1 5
<210> 61
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 61
Ala Arg Leu Gly Phe Gly Asn Ala Met Asp Tyr
1 5 10
<210> 62
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 62
Gln Ser Leu Leu Asn Ser Gly Asn Gln Lys Asn Tyr
1 5 10
<210> 63
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 63
Trp Ala Ser
1
<210> 64
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 64
Gln Asn Asp Tyr Ser Tyr Pro Phe Thr
1 5
<210> 65
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR sequence
<400> 65
Gln Asn Asp Tyr Ser Tyr Pro Leu Thr
1 5
<210> 66
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker sequence
<400> 66
Ser Gly Pro Gly Gly Gly Arg Ser Gly Gly Gly Gly Ser Gly Gly Gly
1 5 10 15
Gly Ser
<210> 67
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker sequence
<400> 67
Asp Val Pro Gly Gly Ser
1 5
<210> 68
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker sequence
<400> 68
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser
20
<210> 69
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker sequence
<400> 69
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser
20 25
<210> 70
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker sequence
<220>
<221> REPEAT
<222> (1)..(5)
<223> Sequence repeated x times, wherein x is 3, 4, 5 or 6
<400> 70
Gly Gly Gly Gly Ser
1 5
<210> 71
<211> 19
<212> PRT
<213> Artificial Sequence
<220>
<223> Secretion signal
<400> 71
Met Gly Trp Ser Cys Ile Ile Leu Phe Leu Val Ala Thr Ala Thr Gly
1 5 10 15
Val His Ser
<210> 72
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> His tag
<400> 72
Gly Gly Ser His His His His His His
1 5
<210> 73
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> His tag
<400> 73
His His His His His His
1 5
<210> 74
<211> 494
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 74
Asp Ile Lys Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Met Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Arg Tyr
20 25 30
Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Tyr Tyr Asp Asp His Tyr Ser Leu Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Thr Leu Thr Val Ser Ser Val Glu Gly Gly Ser Gly Gly Ser Gly
115 120 125
Gly Ser Gly Gly Ser Gly Gly Val Asp Asp Ile Gln Leu Thr Gln Ser
130 135 140
Pro Ala Ile Met Ser Ala Ser Pro Gly Glu Lys Val Thr Met Thr Cys
145 150 155 160
Arg Ala Ser Ser Ser Val Ser Tyr Met Asn Trp Tyr Gln Gln Lys Ser
165 170 175
Gly Thr Ser Pro Lys Arg Trp Ile Tyr Asp Thr Ser Lys Val Ala Ser
180 185 190
Gly Val Pro Tyr Arg Phe Ser Gly Ser Gly Ser Gly Thr Ser Tyr Ser
195 200 205
Leu Thr Ile Ser Ser Met Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys
210 215 220
Gln Gln Trp Ser Ser Asn Pro Leu Thr Phe Gly Ala Gly Thr Lys Leu
225 230 235 240
Glu Leu Lys Ser Gly Gly Gly Gly Ser Glu Val Gln Leu Gln Gln Ser
245 250 255
Gly Pro Glu Leu Val Lys Pro Gly Ala Ser Met Lys Ile Ser Cys Lys
260 265 270
Ala Ser Gly Tyr Ser Phe Thr Gly Tyr Thr Met Asn Trp Val Lys Gln
275 280 285
Ser His Gly Lys Asn Leu Glu Trp Ile Gly Leu Ile Asn Pro Tyr Asn
290 295 300
Gly Gly Thr Ile Tyr Asn Gln Lys Phe Lys Gly Lys Ala Thr Leu Thr
305 310 315 320
Val Asp Lys Ser Ser Ser Thr Ala Tyr Met Glu Leu Leu Ser Leu Thr
325 330 335
Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala Arg Asp Tyr Gly Phe Val
340 345 350
Leu Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser Gly Gly
355 360 365
Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Val
370 375 380
Leu Thr Gln Ser Pro Ser Ile Met Ser Val Ser Pro Gly Glu Lys Val
385 390 395 400
Thr Ile Thr Cys Ser Ala Ser Ser Ser Val Ser Tyr Met His Trp Phe
405 410 415
Gln Gln Lys Pro Gly Thr Ser Pro Lys Leu Leu Ile Tyr Ser Thr Ser
420 425 430
Asn Leu Ala Ser Gly Val Pro Ala Arg Phe Ser Gly Arg Gly Ser Gly
435 440 445
Thr Ser Tyr Ser Leu Thr Ile Ser Arg Val Ala Ala Glu Asp Ala Ala
450 455 460
Thr Tyr Tyr Cys Gln Gln Arg Ser Asn Tyr Pro Pro Trp Thr Phe Gly
465 470 475 480
Gly Gly Thr Lys Leu Glu Ile Lys His His His His His His
485 490
<210> 75
<211> 495
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 75
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Ile Asn Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Asn Ile Tyr Pro Ser Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Pro Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Ser Trp Arg Gly Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Thr Leu Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu
130 135 140
Thr Val Thr Ala Gly Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln
145 150 155 160
Ser Leu Leu Asn Ser Gly Asn Gln Lys Asn Tyr Leu Thr Trp Tyr Gln
165 170 175
Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr
180 185 190
Arg Glu Ser Gly Val Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr
195 200 205
Asp Phe Thr Leu Thr Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val
210 215 220
Tyr Tyr Cys Gln Asn Asp Tyr Ser Tyr Pro Phe Thr Phe Gly Ser Gly
225 230 235 240
Thr Lys Leu Glu Ile Lys Ser Gly Gly Gly Gly Ser Asp Ile Lys Leu
245 250 255
Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly Ala Ser Val Lys Met
260 265 270
Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Arg Tyr Thr Met His Trp
275 280 285
Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile Gly Tyr Ile Asn
290 295 300
Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala
305 310 315 320
Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser
325 330 335
Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Ala Arg Tyr Tyr
340 345 350
Asp Asp His Tyr Ser Leu Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr
355 360 365
Val Ser Ser Val Glu Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly
370 375 380
Ser Gly Gly Val Asp Asp Ile Gln Leu Thr Gln Ser Pro Ala Ile Met
385 390 395 400
Ser Ala Ser Pro Gly Glu Lys Val Thr Met Thr Cys Arg Ala Ser Ser
405 410 415
Ser Val Ser Tyr Met Asn Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro
420 425 430
Lys Arg Trp Ile Tyr Asp Thr Ser Lys Val Ala Ser Gly Val Pro Tyr
435 440 445
Arg Phe Ser Gly Ser Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser
450 455 460
Ser Met Glu Ala Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser
465 470 475 480
Ser Asn Pro Leu Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys
485 490 495
<210> 76
<211> 511
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 76
Gln Val Gln Leu Gln Gln Pro Gly Ala Glu Leu Val Arg Pro Gly Ala
1 5 10 15
Ser Val Lys Leu Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr
20 25 30
Trp Ile Asn Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile
35 40 45
Gly Asn Ile Tyr Pro Ser Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe
50 55 60
Lys Asp Lys Ala Thr Leu Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr
65 70 75 80
Met Gln Leu Ser Ser Pro Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys
85 90 95
Thr Arg Ser Trp Arg Gly Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr
100 105 110
Thr Leu Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Asp Ile Val Met Thr Gln
130 135 140
Ser Pro Ser Ser Leu Thr Val Thr Ala Gly Glu Lys Val Thr Met Ser
145 150 155 160
Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser Gly Asn Gln Lys Asn Tyr
165 170 175
Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln Pro Pro Lys Leu Leu Ile
180 185 190
Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val Pro Asp Arg Phe Thr Gly
195 200 205
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Val Gln Ala
210 215 220
Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn Asp Tyr Ser Tyr Pro Phe
225 230 235 240
Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile Lys Ser Gly Gly Gly Gly
245 250 255
Ser Gln Val Gln Leu Gln Gln Ser Gly Ala Glu Leu Ala Arg Pro Gly
260 265 270
Ala Ser Val Lys Met Ser Cys Lys Thr Ser Gly Tyr Thr Phe Thr Arg
275 280 285
Tyr Thr Met His Trp Val Lys Gln Arg Pro Gly Gln Gly Leu Glu Trp
290 295 300
Ile Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr Asn Tyr Asn Gln Lys
305 310 315 320
Phe Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys Ser Ser Ser Thr Ala
325 330 335
Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp Ser Ala Val Tyr Tyr
340 345 350
Cys Ala Arg Tyr Tyr Asp Asp His Tyr Ser Leu Asp Tyr Trp Gly Gln
355 360 365
Gly Thr Thr Leu Thr Val Ser Ser Gly Gly Gly Gly Ser Gly Gly Gly
370 375 380
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Ile Val Leu
385 390 395 400
Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro Gly Glu Lys Val Thr
405 410 415
Met Thr Cys Arg Ala Ser Ser Ser Val Ser Tyr Met Asn Trp Tyr Gln
420 425 430
Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile Tyr Asp Thr Ser Lys
435 440 445
Val Ala Ser Gly Val Pro Tyr Arg Phe Ser Gly Ser Gly Ser Gly Thr
450 455 460
Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala Glu Asp Ala Ala Thr
465 470 475 480
Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Leu Thr Phe Gly Ala Gly
485 490 495
Thr Lys Leu Glu Leu Lys Gly Gly Ser His His His His His His
500 505 510
<210> 77
<211> 516
<212> PRT
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 77
Asp Ile Val Met Thr Gln Ser Pro Ser Ser Leu Thr Val Thr Ala Gly
1 5 10 15
Glu Lys Val Thr Met Ser Cys Lys Ser Ser Gln Ser Leu Leu Asn Ser
20 25 30
Gly Asn Gln Lys Asn Tyr Leu Thr Trp Tyr Gln Gln Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Tyr Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Thr Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Ser Ser Val Gln Ala Glu Asp Leu Ala Val Tyr Tyr Cys Gln Asn
85 90 95
Asp Tyr Ser Tyr Pro Phe Thr Phe Gly Ser Gly Thr Lys Leu Glu Ile
100 105 110
Lys Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
115 120 125
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln
130 135 140
Pro Gly Ala Glu Leu Val Arg Pro Gly Ala Ser Val Lys Leu Ser Cys
145 150 155 160
Lys Ala Ser Gly Tyr Thr Phe Thr Ser Tyr Trp Ile Asn Trp Val Lys
165 170 175
Gln Arg Pro Gly Gln Gly Leu Glu Trp Ile Gly Asn Ile Tyr Pro Ser
180 185 190
Asp Ser Tyr Thr Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr Leu
195 200 205
Thr Val Asp Lys Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Pro
210 215 220
Thr Ser Glu Asp Ser Ala Val Tyr Tyr Cys Thr Arg Ser Trp Arg Gly
225 230 235 240
Asn Ser Phe Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser
245 250 255
Ser Gly Gly Gly Gly Ser Gln Val Gln Leu Gln Gln Ser Gly Ala Glu
260 265 270
Leu Ala Arg Pro Gly Ala Ser Val Lys Met Ser Cys Lys Thr Ser Gly
275 280 285
Tyr Thr Phe Thr Arg Tyr Thr Met His Trp Val Lys Gln Arg Pro Gly
290 295 300
Gln Gly Leu Glu Trp Ile Gly Tyr Ile Asn Pro Ser Arg Gly Tyr Thr
305 310 315 320
Asn Tyr Asn Gln Lys Phe Lys Asp Lys Ala Thr Leu Thr Thr Asp Lys
325 330 335
Ser Ser Ser Thr Ala Tyr Met Gln Leu Ser Ser Leu Thr Ser Glu Asp
340 345 350
Ser Ala Val Tyr Tyr Cys Ala Arg Tyr Tyr Asp Asp His Tyr Ser Leu
355 360 365
Asp Tyr Trp Gly Gln Gly Thr Thr Leu Thr Val Ser Ser Gly Gly Gly
370 375 380
Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly
385 390 395 400
Ser Gln Ile Val Leu Thr Gln Ser Pro Ala Ile Met Ser Ala Ser Pro
405 410 415
Gly Glu Lys Val Thr Met Thr Cys Arg Ala Ser Ser Ser Val Ser Tyr
420 425 430
Met Asn Trp Tyr Gln Gln Lys Ser Gly Thr Ser Pro Lys Arg Trp Ile
435 440 445
Tyr Asp Thr Ser Lys Val Ala Ser Gly Val Pro Tyr Arg Phe Ser Gly
450 455 460
Ser Gly Ser Gly Thr Ser Tyr Ser Leu Thr Ile Ser Ser Met Glu Ala
465 470 475 480
Glu Asp Ala Ala Thr Tyr Tyr Cys Gln Gln Trp Ser Ser Asn Pro Leu
485 490 495
Thr Phe Gly Ala Gly Thr Lys Leu Glu Leu Lys Gly Gly Ser His His
500 505 510
His His His His
515
<210> 78
<211> 1479
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 78
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactctcag 60
atcgtgctga cccagtctcc cgccatcatg tctgctagcc ctggcgagaa agtgacaatg 120
acctgccggg cctcctcctc cgtgtcctac atgaactggt atcagcagaa gtccggcacc 180
tcccccaagc ggtggatcta cgacacctcc aaggtggcct ctggcgtgcc ctacagattc 240
tccggctctg gctctggcac ctcctacagc ctgaccatct ccagcatgga agccgaggat 300
gccgccacct actactgcca gcagtggtcc tccaaccccc tgacctttgg cgctggcacc 360
aagctggaac tgaagcggac cgtggccgct ccttccgtgt tcatcttccc tccctccgac 420
gagcagctga agtccggcac cgcctccgtg gtgtgcctgc tgaacaactt ctaccctcgg 480
gaggccaagg tgcagtggaa ggtggacaac gccctgcagt ccggcaactc ccaggaaagc 540
gtcaccgagc aggactccaa ggacagcacc tactccctgt cctccaccct gaccctgtcc 600
aaggccgact acgagaagca caaggtgtac gcctgcgagg tgacccacca gggcctgtcc 660
agccctgtga ccaagtcctt caaccggggc gagtgtgacg tgcctggtgg tagcgaagtg 720
cagctgcagc agagcggccc tgagctggtg aaacccggcg ctagcatgaa gatcagctgc 780
aaggccagcg gctacagctt caccggctac accatgaact gggtgaaaca gagccacggc 840
aagtgcctgg aatggatcgg cctgatcaac ccctacaacg gcggcaccat ctacaaccag 900
aagttcaagg gcaaggccac actgaccgtg gacaagagca gcagcaccgc ctacatggaa 960
ctgctgagcc tgaccagcga ggacagcgcc gtgtactact gcgccagaga ctacggcttc 1020
gtgctggact actggggcca gggcaccacc ctgacagtgt ctagcggagg cggaggatct 1080
ggtggtggcg gatctggcgg cggtggaagt ggcggaggtg gtagccagat cgtgctgacc 1140
cagtccccct ccatcatgtc cgtgtctccc ggcgagaaag tgacaattac ctgctccgcc 1200
tcctcctccg tgtcctacat gcactggttc cagcagaagc ccggcacctc ccccaagctg 1260
tggatctact ccacctccaa cctggcctcc ggcgtgcccg ccagattctc cggaagaggc 1320
tccggcacca gctactccct gaccatctcc agagtggccg ccgaggacgc cgccacctac 1380
tactgccagc agcggtccaa ctaccccccc tggacctttg gctgcggcac caagctggaa 1440
atcaagtctg cctggagcca cccacagttc gagaagtga 1479
<210> 79
<211> 1539
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 79
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactcccag 60
gtgcagctgc agcagtctgg cgctgagctg gctagacctg gcgcctccgt gaagatgtcc 120
tgcaagacct ccggctacac cttcacccgg tacaccatgc actgggtcaa gcagaggcct 180
ggacagggcc tggaatggat cggctacatc aacccctccc ggggctacac caactacaac 240
cagaagttca aggacaaggc caccctgaca accgacaagt cctcctccac cgcctacatg 300
cagctgtcct ccctgacctc cgaggactcc gccgtgtact actgcgcccg gtactacgac 360
gaccactact ccctggacta ctggggccag ggcaccacac tgacagtgtc tagcgcctcc 420
accaagggcc cttccgtgtt ccctctggcc ccttcctcca agtccacctc cggcggcacc 480
gccgctctgg gctgcctggt gaaggactac ttccctgagc ctgtgaccgt gagctggaac 540
tctggcgccc tgaccagcgg cgtgcacacc ttccctgccg tgctgcagtc ctccggcctg 600
tactccctgt cctccgtggt gaccgtgcct tcctcctccc tgggcaccca gacctacatc 660
tgcaacgtga accacaagcc ttccaacacc aaggtggaca agcgggtgga gcctaagtcc 720
tgctccggcc ctgggggcgg acgcagcggc ggaggcggat ccggcggagg aggctctgaa 780
gtgcagctgc agcagagcgg ccctgagctg gtgaaacccg gcgctagcat gaagatcagc 840
tgcaaggcca gcggctacag cttcaccggc tacaccatga actgggtgaa acagagccac 900
ggcaagtgcc tggaatggat cggcctgatc aacccctaca acggcggcac catctacaac 960
cagaagttca agggcaaggc cacactgacc gtggacaaga gcagcagcac cgcctacatg 1020
gaactgctga gcctgaccag cgaggacagc gccgtgtact actgcgccag agactacggc 1080
ttcgtgctgg actactgggg ccagggcacc accctgacag tgtctagcgg aggcggagga 1140
tctggtggtg gcggatctgg cggcggtgga agtggcggag gtggtagcca gatcgtgctg 1200
acccagtccc cctccatcat gtccgtgtct cccggcgaga aagtgacaat tacctgctcc 1260
gcctcctcct ccgtgtccta catgcactgg ttccagcaga agcccggcac ctcccccaag 1320
ctgtggatct actccacctc caacctggcc tccggcgtgc ccgccagatt ctccggaaga 1380
ggctccggca ccagctactc cctgaccatc tccagagtgg ccgccgagga cgccgccacc 1440
tactactgcc agcagcggtc caactacccc ccctggacct ttggctgcgg caccaagctg 1500
gaaatcaagg gcggctccca ccaccaccat caccactga 1539
<210> 80
<211> 1539
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 80
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactcccag 60
gtgcagctgc agcagtctgg cgctgagctg gctagacctg gcgcctccgt gaagatgtcc 120
tgcaagacct ccggctacac cttcacccgg tacaccatgc actgggtcaa gcagaggcct 180
ggacagggcc tggaatggat cggctacatc aacccctccc ggggctacac caactacaac 240
cagaagttca aggacaaggc caccctgaca accgacaagt cctcctccac cgcctacatg 300
cagctgtcct ccctgacctc cgaggactcc gccgtgtact actgcgcccg gtactacgac 360
gaccactact ccctggacta ctggggccag ggcaccacac tgacagtgtc tagcgcctcc 420
accaagggcc cttccgtgtt ccctctggcc ccttgctcca agtccacctc cgaaggcacc 480
gccgctctgg gctgcctggt gaaggactac ttccctgagc ctgtgaccgt gagctggaac 540
tctggcgccc tgaccagcgg cgtgcacacc ttccctgccg tgctgcagtc ctccggcctg 600
tactccctgt cctccgtggt gaccgtgcct tcctccaact tcggcaccca gacctacacc 660
tgcaacgtgg accacaagcc ttccaacacc aaggtggaca agaccgtgga gcctaagtcc 720
gcctccggcc ctgggggcgg acgcagcggc ggaggcggat ccggcggagg aggctctgaa 780
gtgcagctgc agcagagcgg ccctgagctg gtgaaacccg gcgctagcat gaagatcagc 840
tgcaaggcca gcggctacag cttcaccggc tacaccatga actgggtgaa acagagccac 900
ggcaagtgcc tggaatggat cggcctgatc aacccctaca acggcggcac catctacaac 960
cagaagttca agggcaaggc cacactgacc gtggacaaga gcagcagcac cgcctacatg 1020
gaactgctga gcctgaccag cgaggacagc gccgtgtact actgcgccag agactacggc 1080
ttcgtgctgg actactgggg ccagggcacc accctgacag tgtctagcgg aggcggagga 1140
tctggtggtg gcggatctgg cggcggtgga agtggcggag gtggtagcca gatcgtgctg 1200
acccagtccc cctccatcat gtccgtgtct cccggcgaga aagtgacaat tacctgctcc 1260
gcctcctcct ccgtgtccta catgcactgg ttccagcaga agcccggcac ctcccccaag 1320
ctgtggatct actccacctc caacctggcc tccggcgtgc ccgccagatt ctccggaaga 1380
ggctccggca ccagctactc cctgaccatc tccagagtgg ccgccgagga cgccgccacc 1440
tactactgcc agcagcggtc caactacccc ccctggacct ttggctgcgg caccaagctg 1500
gaaatcaagg gcggctccca ccaccaccat caccactga 1539
<210> 81
<211> 1449
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 81
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactctcag 60
atcgtgctga cccagtctcc cgccatcatg tctgctagcc ctggcgagaa agtgacaatg 120
acctgccggg cctcctcctc cgtgtcctac atgaactggt atcagcagaa gtccggcacc 180
tcccccaagc ggtggatcta cgacacctcc aaggtggcct ctggcgtgcc ctacagattc 240
tccggctctg gctctggcac ctcctacagc ctgaccatct ccagcatgga agccgaggat 300
gccgccacct actactgcca gcagtggtcc tccaaccccc tgacctttgg cgctggcacc 360
aagctggaac tgaagcggac cgtggccgct ccttccgtgt tcatcttccc tccctccgac 420
gagcagctga agtccggcac cgcctccgtg gtgtgcctgc tgaacaactt ctaccctcgg 480
gaggccaagg tgcagtggaa ggtggacaac gccctgcagt ccggcaactc ccaggaaagc 540
gtcaccgagc aggactccaa ggacagcacc tactccctgt cctccaccct gaccctgtcc 600
aaggccgact acgagaagca caaggtgtac gcctgcgagg tgacccacca gggcctgtcc 660
agccctgtga ccaagtcctt caaccggggc gagtgtgacg tgcctggtgg tagcgaagtg 720
cagctgcagc agagcggccc tgagctggtg aaacccggcg ctagcatgaa gatcagctgc 780
aaggccagcg gctacagctt caccggctac accatgaact gggtgaaaca gagccacggc 840
aagtgcctgg aatggatcgg cctgatcaac ccctacaacg gcggcaccat ctacaaccag 900
aagttcaagg gcaaggccac actgaccgtg gacaagagca gcagcaccgc ctacatggaa 960
ctgctgagcc tgaccagcga ggacagcgcc gtgtactact gcgccagaga ctacggcttc 1020
gtgctggact actggggcca gggcaccacc ctgacagtgt ctagcggagg cggaggatct 1080
ggtggtggcg gatctggcgg cggtggaagt ggcggaggtg gtagccagat cgtgctgacc 1140
cagtccccct ccatcatgtc cgtgtctccc ggcgagaaag tgacaattac ctgctccgcc 1200
tcctcctccg tgtcctacat gcactggttc cagcagaagc ccggcacctc ccccaagctg 1260
tggatctact ccacctccaa cctggcctcc ggcgtgcccg ccagattctc cggaagaggc 1320
tccggcacca gctactccct gaccatctcc agagtggccg ccgaggacgc cgccacctac 1380
tactgccagc agcggtccaa ctaccccccc tggacctttg gctgcggcac caagctggaa 1440
atcaagtga 1449
<210> 82
<211> 1512
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 82
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactcccag 60
gtgcagctgc agcagtctgg cgctgagctg gctagacctg gcgcctccgt gaagatgtcc 120
tgcaagacct ccggctacac cttcacccgg tacaccatgc actgggtcaa gcagaggcct 180
ggacagggcc tggaatggat cggctacatc aacccctccc ggggctacac caactacaac 240
cagaagttca aggacaaggc caccctgaca accgacaagt cctcctccac cgcctacatg 300
cagctgtcct ccctgacctc cgaggactcc gccgtgtact actgcgcccg gtactacgac 360
gaccactact ccctggacta ctggggccag ggcaccacac tgacagtgtc tagcgcctcc 420
accaagggcc cttccgtgtt ccctctggcc ccttcctcca agtccacctc cggcggcacc 480
gccgctctgg gctgcctggt gaaggactac ttccctgagc ctgtgaccgt gagctggaac 540
tctggcgccc tgaccagcgg cgtgcacacc ttccctgccg tgctgcagtc ctccggcctg 600
tactccctgt cctccgtggt gaccgtgcct tcctcctccc tgggcaccca gacctacatc 660
tgcaacgtga accacaagcc ttccaacacc aaggtggaca agcgggtgga gcctaagtcc 720
tgctccggcc ctgggggcgg acgcagcggc ggaggcggat ccggcggagg aggctctgaa 780
gtgcagctgc agcagagcgg ccctgagctg gtgaaacccg gcgctagcat gaagatcagc 840
tgcaaggcca gcggctacag cttcaccggc tacaccatga actgggtgaa acagagccac 900
ggcaagtgcc tggaatggat cggcctgatc aacccctaca acggcggcac catctacaac 960
cagaagttca agggcaaggc cacactgacc gtggacaaga gcagcagcac cgcctacatg 1020
gaactgctga gcctgaccag cgaggacagc gccgtgtact actgcgccag agactacggc 1080
ttcgtgctgg actactgggg ccagggcacc accctgacag tgtctagcgg aggcggagga 1140
tctggtggtg gcggatctgg cggcggtgga agtggcggag gtggtagcca gatcgtgctg 1200
acccagtccc cctccatcat gtccgtgtct cccggcgaga aagtgacaat tacctgctcc 1260
gcctcctcct ccgtgtccta catgcactgg ttccagcaga agcccggcac ctcccccaag 1320
ctgtggatct actccacctc caacctggcc tccggcgtgc ccgccagatt ctccggaaga 1380
ggctccggca ccagctactc cctgaccatc tccagagtgg ccgccgagga cgccgccacc 1440
tactactgcc agcagcggtc caactacccc ccctggacct ttggctgcgg caccaagctg 1500
gaaatcaagt ga 1512
<210> 83
<211> 1512
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 83
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactcccag 60
gtgcagctgc agcagtctgg cgctgagctg gctagacctg gcgcctccgt gaagatgtcc 120
tgcaagacct ccggctacac cttcacccgg tacaccatgc actgggtcaa gcagaggcct 180
ggacagggcc tggaatggat cggctacatc aacccctccc ggggctacac caactacaac 240
cagaagttca aggacaaggc caccctgaca accgacaagt cctcctccac cgcctacatg 300
cagctgtcct ccctgacctc cgaggactcc gccgtgtact actgcgcccg gtactacgac 360
gaccactact ccctggacta ctggggccag ggcaccacac tgacagtgtc tagcgcctcc 420
accaagggcc cttccgtgtt ccctctggcc ccttgctcca agtccacctc cgaaggcacc 480
gccgctctgg gctgcctggt gaaggactac ttccctgagc ctgtgaccgt gagctggaac 540
tctggcgccc tgaccagcgg cgtgcacacc ttccctgccg tgctgcagtc ctccggcctg 600
tactccctgt cctccgtggt gaccgtgcct tcctccaact tcggcaccca gacctacacc 660
tgcaacgtgg accacaagcc ttccaacacc aaggtggaca agaccgtgga gcctaagtcc 720
gcctccggcc ctgggggcgg acgcagcggc ggaggcggat ccggcggagg aggctctgaa 780
gtgcagctgc agcagagcgg ccctgagctg gtgaaacccg gcgctagcat gaagatcagc 840
tgcaaggcca gcggctacag cttcaccggc tacaccatga actgggtgaa acagagccac 900
ggcaagtgcc tggaatggat cggcctgatc aacccctaca acggcggcac catctacaac 960
cagaagttca agggcaaggc cacactgacc gtggacaaga gcagcagcac cgcctacatg 1020
gaactgctga gcctgaccag cgaggacagc gccgtgtact actgcgccag agactacggc 1080
ttcgtgctgg actactgggg ccagggcacc accctgacag tgtctagcgg aggcggagga 1140
tctggtggtg gcggatctgg cggcggtgga agtggcggag gtggtagcca gatcgtgctg 1200
acccagtccc cctccatcat gtccgtgtct cccggcgaga aagtgacaat tacctgctcc 1260
gcctcctcct ccgtgtccta catgcactgg ttccagcaga agcccggcac ctcccccaag 1320
ctgtggatct actccacctc caacctggcc tccggcgtgc ccgccagatt ctccggaaga 1380
ggctccggca ccagctactc cctgaccatc tccagagtgg ccgccgagga cgccgccacc 1440
tactactgcc agcagcggtc caactacccc ccctggacct ttggctgcgg caccaagctg 1500
gaaatcaagt ga 1512
<210> 84
<211> 1542
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 84
atgggctggt cctgcatcat cctgtttctg gtggccaccg ccaccggcgt gcacagcgac 60
atcaagctgc agcagagcgg agccgagctg gccagacctg gggccagcgt gaagatgagc 120
tgcaagacca gcggctacac cttcacccgg tacaccatgc actgggtgaa acagcggcct 180
ggacagggcc tggaatggat cggctacatc aaccccagcc ggggctacac caactacaac 240
cagaagttca aggacaaggc caccctgacc accgacaaga gcagcagcac cgcctacatg 300
cagctgagca gcctgaccag cgaggacagc gccgtgtact actgcgcccg gtactacgac 360
gaccactaca gcctggacta ctggggccag ggcaccaccc tgacagtgtc tagcgtggaa 420
ggaggaagcg gaggatctgg cggctctggg ggaagcggtg gcgtggacga catccagctg 480
acccagagcc ccgccatcat gtctgccagc cctggcgaga aagtgaccat gacctgccgg 540
gccagcagca gcgtgtccta catgaactgg tatcagcaga agtccggcac cagccccaag 600
cggtggatct acgacaccag caaggtggca agcggcgtgc cctacagatt cagcggcagc 660
ggctccggca cctcctactc cctgaccatc agcagcatgg aagccgagga cgccgccacc 720
tactactgcc agcagtggtc cagcaacccc ctgaccttcg gagccggcac caagctggaa 780
ctgaagtctg gcgggggagg atccgaggtg cagctgcagc agtccggccc tgagctggtg 840
aaacccggcg ctagcatgaa gatctcttgc aaggcctccg gctacagctt taccggctac 900
acaatgaatt gggtgaagca gagccacggc aagaatctgg aatggattgg cctgatcaac 960
ccttacaacg gcggcacaat ctataatcag aagtttaaag ggaaggccac actgacagtg 1020
gacaagtcca gctccacagc ctacatggaa ctgctgagcc tgacctccga ggactctgcc 1080
gtgtattact gtgccagaga ctacggcttc gtgctggatt attggggaca gggaacaaca 1140
ctgaccgtgt cctccggggg agggggatca ggtgggggag gtagtggggg tggcggctct 1200
gatatcgtgc tgacccagtc ccctagcatc atgagcgtgt ccccaggcga aaaagtgaca 1260
atcacttgca gcgccagctc ctccgtgtct tatatgcatt ggttccagca gaagcctggc 1320
acatccccca aactgttaat ctacagcacc tccaacctgg cttccggcgt gcccgccaga 1380
ttttctggca gaggcagcgg caccagctac agcctgacaa tcagccgggt ggccgccgaa 1440
gatgccgcca catattattg tcagcagcgg agcaactacc ccccctggac attcggggga 1500
ggaacaaagc tggaaatcaa gcaccaccac caccaccact ga 1542
<210> 85
<211> 1500
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 85
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactctcag 60
atcgtgctga cccagtctcc cgccatcatg tctgctagcc ctggcgagaa agtgacaatg 120
acctgccggg cctcctcctc cgtgtcctac atgaactggt atcagcagaa gtccggcacc 180
tcccccaagc ggtggatcta cgacacctcc aaggtggcct ctggcgtgcc ctacagattc 240
tccggctctg gctctggcac ctcctacagc ctgaccatct ccagcatgga agccgaggat 300
gccgccacct actactgcca gcagtggtcc tccaaccccc tgacctttgg cgctggcacc 360
aagctggaac tgaagcggac cgtggccgct ccttccgtgt tcatcttccc tccctccgac 420
gagcagctga agtccggcac cgcctccgtg gtgtgcctgc tgaacaactt ctaccctcgg 480
gaggccaagg tgcagtggaa ggtggacaac gccctgcagt ccggcaactc ccaggaaagc 540
gtcaccgagc aggactccaa ggacagcacc tactccctgt cctccaccct gaccctgtcc 600
aaggccgact acgagaagca caaggtgtac gcctgcgagg tgacccacca gggcctgtcc 660
agccctgtga ccaagtcctt caaccggggc gagtgtgacg tgcctggtgg tagccaggtg 720
cagctgcagc agcctggcgc tgaactggtc cgacctggcg cctccgtgaa gctgtcctgc 780
aaggcctccg gctacacctt caccagctac tggatcaact gggtcaagca gcggcctggc 840
cagggcctgg aatggatcgg caacatctac ccctccgact cctacaccaa ctacaaccag 900
aagttcaagg acaaggccac cctgaccgtg gacaagtcct cctccaccgc ctacatgcag 960
ctgtccagcc ccacctccga ggactccgcc gtgtactact gcacccggtc ctggcggggc 1020
aactccttcg actattgggg ccagggcacc accctgacag tgtcctctgg aggcggagga 1080
tctggtggtg gcggatctgg cggcggtgga agtggcggag gtggtagcga catcgtgatg 1140
acccagtccc cctccagcct gaccgtgacc gctggcgaga aagtgaccat gagctgcaag 1200
tcctcccagt ccctgctgaa ctccggcaac cagaagaact acctgacctg gtatcagcag 1260
aagcccggcc agccccccaa gctgctgatc tactgggcct ccacccgcga gtctggcgtg 1320
cccgatagat tcaccggctc cggcagcggc accgacttta ccctgaccat ctccagcgtg 1380
caggccgagg acctggccgt gtattactgt cagaacgact actcctaccc cttcaccttc 1440
ggctctggca ccaagctgga aatcaagtct gcctggagcc acccacagtt cgagaagtga 1500
<210> 86
<211> 1515
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 86
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactctcag 60
atcgtgctga cccagtctcc cgccatcatg tctgctagcc ctggcgagaa agtgacaatg 120
acctgccggg cctcctcctc cgtgtcctac atgaactggt atcagcagaa gtccggcacc 180
tcccccaagc ggtggatcta cgacacctcc aaggtggcct ctggcgtgcc ctacagattc 240
tccggctctg gctctggcac ctcctacagc ctgaccatct ccagcatgga agccgaggat 300
gccgccacct actactgcca gcagtggtcc tccaaccccc tgacctttgg cgctggcacc 360
aagctggaac tgaagcggac cgtggccgct ccttccgtgt tcatcttccc tccctccgac 420
gagcagctga agtccggcac cgcctccgtg gtgtgcctgc tgaacaactt ctaccctcgg 480
gaggccaagg tgcagtggaa ggtggacaac gccctgcagt ccggcaactc ccaggaaagc 540
gtcaccgagc aggactccaa ggacagcacc tactccctgt cctccaccct gaccctgtcc 600
aaggccgact acgagaagca caaggtgtac gcctgcgagg tgacccacca gggcctgtcc 660
agccctgtga ccaagtcctt caaccggggc gagtgtgacg tgcctggtgg tagcgacatc 720
gtgatgaccc agtccccctc cagcctgacc gtgaccgctg gcgagaaagt gaccatgagc 780
tgcaagtcct cccagtccct gctgaactcc ggcaaccaga agaactacct gacctggtat 840
cagcagaagc ccggccagcc ccccaagctg ctgatctact gggcctccac ccgcgagtct 900
ggcgtgcccg atagattcac cggctccggc agcggcaccg actttaccct gaccatctcc 960
agcgtgcagg ccgaggacct ggccgtgtat tactgtcaga acgactactc ctaccccttc 1020
accttcggct ctggcaccaa gctggaaatc aagggaggcg gtggttcagg cggcggaggc 1080
agcggtggag gtggtagtgg cggtggcggt tcagggggag gtggctcgca ggtgcagctg 1140
cagcagcctg gcgctgaact ggtccgacct ggcgcctccg tgaagctgtc ctgcaaggcc 1200
tccggctaca ccttcaccag ctactggatc aactgggtca agcagcggcc tggccagggc 1260
ctggaatgga tcggcaacat ctacccctcc gactcctaca ccaactacaa ccagaagttc 1320
aaggacaagg ccaccctgac cgtggacaag tcctcctcca ccgcctacat gcagctgtcc 1380
agccccacct ccgaggactc cgccgtgtac tactgcaccc ggtcctggcg gggcaactcc 1440
ttcgactatt ggggccaggg caccaccctg acagtgtcct cttctgcctg gagccaccca 1500
cagttcgaga agtga 1515
<210> 87
<211> 1560
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 87
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactcccag 60
gtgcagctgc agcagtctgg cgctgagctg gctagacctg gcgcctccgt gaagatgtcc 120
tgcaagacct ccggctacac cttcacccgg tacaccatgc actgggtcaa gcagaggcct 180
ggacagggcc tggaatggat cggctacatc aacccctccc ggggctacac caactacaac 240
cagaagttca aggacaaggc caccctgaca accgacaagt cctcctccac cgcctacatg 300
cagctgtcct ccctgacctc cgaggactcc gccgtgtact actgcgcccg gtactacgac 360
gaccactact ccctggacta ctggggccag ggcaccacac tgacagtgtc tagcgcctcc 420
accaagggcc cttccgtgtt ccctctggcc ccttcctcca agtccacctc cggcggcacc 480
gccgctctgg gctgcctggt gaaggactac ttccctgagc ctgtgaccgt gagctggaac 540
tctggcgccc tgaccagcgg cgtgcacacc ttccctgccg tgctgcagtc ctccggcctg 600
tactccctgt cctccgtggt gaccgtgcct tcctcctccc tgggcaccca gacctacatc 660
tgcaacgtga accacaagcc ttccaacacc aaggtggaca agcgggtgga gcctaagtcc 720
tgctccggcc ctgggggcgg acgcagcggc ggaggcggat ccggcggagg aggctctcag 780
gtgcagctgc agcagcctgg cgctgaactg gtccgacctg gcgcctccgt gaagctgtcc 840
tgcaaggcct ccggctacac cttcaccagc tactggatca actgggtcaa gcagcggcct 900
ggccagggcc tggaatggat cggcaacatc tacccctccg actcctacac caactacaac 960
cagaagttca aggacaaggc caccctgacc gtggacaagt cctcctccac cgcctacatg 1020
cagctgtcca gccccacctc cgaggactcc gccgtgtact actgcacccg gtcctggcgg 1080
ggcaactcct tcgactattg gggccagggc accaccctga cagtgtcctc tggaggcgga 1140
ggatctggtg gtggcggatc tggcggcggt ggaagtggcg gaggtggtag cgacatcgtg 1200
atgacccagt ccccctccag cctgaccgtg accgctggcg agaaagtgac catgagctgc 1260
aagtcctccc agtccctgct gaactccggc aaccagaaga actacctgac ctggtatcag 1320
cagaagcccg gccagccccc caagctgctg atctactggg cctccacccg cgagtctggc 1380
gtgcccgata gattcaccgg ctccggcagc ggcaccgact ttaccctgac catctccagc 1440
gtgcaggccg aggacctggc cgtgtattac tgtcagaacg actactccta ccccttcacc 1500
ttcggctctg gcaccaagct ggaaatcaag ggcggctccc accaccacca tcaccactga 1560
<210> 88
<211> 1569
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 88
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactcccag 60
gtgcagctgc agcagtctgg cgctgagctg gctagacctg gcgcctccgt gaagatgtcc 120
tgcaagacct ccggctacac cttcacccgg tacaccatgc actgggtcaa gcagaggcct 180
ggacagggcc tggaatggat cggctacatc aacccctccc ggggctacac caactacaac 240
cagaagttca aggacaaggc caccctgaca accgacaagt cctcctccac cgcctacatg 300
cagctgtcct ccctgacctc cgaggactcc gccgtgtact actgcgcccg gtactacgac 360
gaccactact ccctggacta ctggggccag ggcaccacac tgacagtgtc tagcgcctcc 420
accaagggcc cttccgtgtt ccctctggcc ccttcctcca agtccacctc cggcggcacc 480
gccgctctgg gctgcctggt gaaggactac ttccctgagc ctgtgaccgt gagctggaac 540
tctggcgccc tgaccagcgg cgtgcacacc ttccctgccg tgctgcagtc ctccggcctg 600
tactccctgt cctccgtggt gaccgtgcct tcctcctccc tgggcaccca gacctacatc 660
tgcaacgtga accacaagcc ttccaacacc aaggtggaca agcgggtgga gcctaagtcc 720
tgctccggcc ctgggggcgg acgcagcggc ggaggcggat ccggcggagg aggctctgac 780
atcgtgatga cccagtcccc ctccagcctg accgtgaccg ctggcgagaa agtgaccatg 840
agctgcaagt cctcccagtc cctgctgaac tccggcaacc agaagaacta cctgacctgg 900
tatcagcaga agcccggcca gccccccaag ctgctgatct actgggcctc cacccgcgag 960
tctggcgtgc ccgatagatt caccggctcc ggcagcggca ccgactttac cctgaccatc 1020
tccagcgtgc aggccgagga cctggccgtg tattactgtc agaacgacta ctcctacccc 1080
ttcaccttcg gctctggcac caagctggaa atcaagggag gcggtggttc aggcggcgga 1140
ggcagcggtg gaggtggtag tggcggtggc ggttcagggg gaggtggctc gcaggtgcag 1200
ctgcagcagc ctggcgctga actggtccga cctggcgcct ccgtgaagct gtcctgcaag 1260
gcctccggct acaccttcac cagctactgg atcaactggg tcaagcagcg gcctggccag 1320
ggcctggaat ggatcggcaa catctacccc tccgactcct acaccaacta caaccagaag 1380
ttcaaggaca aggccaccct gaccgtggac aagtcctcct ccaccgccta catgcagctg 1440
tccagcccca cctccgagga ctccgccgtg tactactgca cccggtcctg gcggggcaac 1500
tccttcgact attggggcca gggcaccacc ctgacagtgt cctcttctca ccaccaccat 1560
caccactga 1569
<210> 89
<211> 1560
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 89
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactcccag 60
gtgcagctgc agcagtctgg cgctgagctg gctagacctg gcgcctccgt gaagatgtcc 120
tgcaagacct ccggctacac cttcacccgg tacaccatgc actgggtcaa gcagaggcct 180
ggacagggcc tggaatggat cggctacatc aacccctccc ggggctacac caactacaac 240
cagaagttca aggacaaggc caccctgaca accgacaagt cctcctccac cgcctacatg 300
cagctgtcct ccctgacctc cgaggactcc gccgtgtact actgcgcccg gtactacgac 360
gaccactact ccctggacta ctggggccag ggcaccacac tgacagtgtc tagcgcctcc 420
accaagggcc cttccgtgtt ccctctggcc ccttgctcca agtccacctc cgaaggcacc 480
gccgctctgg gctgcctggt gaaggactac ttccctgagc ctgtgaccgt gagctggaac 540
tctggcgccc tgaccagcgg cgtgcacacc ttccctgccg tgctgcagtc ctccggcctg 600
tactccctgt cctccgtggt gaccgtgcct tcctccaact tcggcaccca gacctacacc 660
tgcaacgtgg accacaagcc ttccaacacc aaggtggaca agaccgtgga gcctaagtcc 720
gcctccggcc ctgggggcgg acgcagcggc ggaggcggat ccggcggagg aggctctcag 780
gtgcagctgc agcagcctgg cgctgaactg gtccgacctg gcgcctccgt gaagctgtcc 840
tgcaaggcct ccggctacac cttcaccagc tactggatca actgggtcaa gcagcggcct 900
ggccagggcc tggaatggat cggcaacatc tacccctccg actcctacac caactacaac 960
cagaagttca aggacaaggc caccctgacc gtggacaagt cctcctccac cgcctacatg 1020
cagctgtcca gccccacctc cgaggactcc gccgtgtact actgcacccg gtcctggcgg 1080
ggcaactcct tcgactattg gggccagggc accaccctga cagtgtcctc tggaggcgga 1140
ggatctggtg gtggcggatc tggcggcggt ggaagtggcg gaggtggtag cgacatcgtg 1200
atgacccagt ccccctccag cctgaccgtg accgctggcg agaaagtgac catgagctgc 1260
aagtcctccc agtccctgct gaactccggc aaccagaaga actacctgac ctggtatcag 1320
cagaagcccg gccagccccc caagctgctg atctactggg cctccacccg cgagtctggc 1380
gtgcccgata gattcaccgg ctccggcagc ggcaccgact ttaccctgac catctccagc 1440
gtgcaggccg aggacctggc cgtgtattac tgtcagaacg actactccta ccccttcacc 1500
ttcggctctg gcaccaagct ggaaatcaag ggcggctccc accaccacca tcaccactga 1560
<210> 90
<211> 1569
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 90
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactcccag 60
gtgcagctgc agcagtctgg cgctgagctg gctagacctg gcgcctccgt gaagatgtcc 120
tgcaagacct ccggctacac cttcacccgg tacaccatgc actgggtcaa gcagaggcct 180
ggacagggcc tggaatggat cggctacatc aacccctccc ggggctacac caactacaac 240
cagaagttca aggacaaggc caccctgaca accgacaagt cctcctccac cgcctacatg 300
cagctgtcct ccctgacctc cgaggactcc gccgtgtact actgcgcccg gtactacgac 360
gaccactact ccctggacta ctggggccag ggcaccacac tgacagtgtc tagcgcctcc 420
accaagggcc cttccgtgtt ccctctggcc ccttgctcca agtccacctc cgaaggcacc 480
gccgctctgg gctgcctggt gaaggactac ttccctgagc ctgtgaccgt gagctggaac 540
tctggcgccc tgaccagcgg cgtgcacacc ttccctgccg tgctgcagtc ctccggcctg 600
tactccctgt cctccgtggt gaccgtgcct tcctccaact tcggcaccca gacctacacc 660
tgcaacgtgg accacaagcc ttccaacacc aaggtggaca agaccgtgga gcctaagtcc 720
gcctccggcc ctgggggcgg acgcagcggc ggaggcggat ccggcggagg aggctctgac 780
atcgtgatga cccagtcccc ctccagcctg accgtgaccg ctggcgagaa agtgaccatg 840
agctgcaagt cctcccagtc cctgctgaac tccggcaacc agaagaacta cctgacctgg 900
tatcagcaga agcccggcca gccccccaag ctgctgatct actgggcctc cacccgcgag 960
tctggcgtgc ccgatagatt caccggctcc ggcagcggca ccgactttac cctgaccatc 1020
tccagcgtgc aggccgagga cctggccgtg tattactgtc agaacgacta ctcctacccc 1080
ttcaccttcg gctctggcac caagctggaa atcaagggag gcggtggttc aggcggcgga 1140
ggcagcggtg gaggtggtag tggcggtggc ggttcagggg gaggtggctc gcaggtgcag 1200
ctgcagcagc ctggcgctga actggtccga cctggcgcct ccgtgaagct gtcctgcaag 1260
gcctccggct acaccttcac cagctactgg atcaactggg tcaagcagcg gcctggccag 1320
ggcctggaat ggatcggcaa catctacccc tccgactcct acaccaacta caaccagaag 1380
ttcaaggaca aggccaccct gaccgtggac aagtcctcct ccaccgccta catgcagctg 1440
tccagcccca cctccgagga ctccgccgtg tactactgca cccggtcctg gcggggcaac 1500
tccttcgact attggggcca gggcaccacc ctgacagtgt cctcttctca ccaccaccat 1560
caccactga 1569
<210> 91
<211> 1533
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 91
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactcccag 60
gtgcagctgc agcagtctgg cgctgagctg gctagacctg gcgcctccgt gaagatgtcc 120
tgcaagacct ccggctacac cttcacccgg tacaccatgc actgggtcaa gcagaggcct 180
ggacagggcc tggaatggat cggctacatc aacccctccc ggggctacac caactacaac 240
cagaagttca aggacaaggc caccctgaca accgacaagt cctcctccac cgcctacatg 300
cagctgtcct ccctgacctc cgaggactcc gccgtgtact actgcgcccg gtactacgac 360
gaccactact ccctggacta ctggggccag ggcaccacac tgacagtgtc tagcgcctcc 420
accaagggcc cttccgtgtt ccctctggcc ccttcctcca agtccacctc cggcggcacc 480
gccgctctgg gctgcctggt gaaggactac ttccctgagc ctgtgaccgt gagctggaac 540
tctggcgccc tgaccagcgg cgtgcacacc ttccctgccg tgctgcagtc ctccggcctg 600
tactccctgt cctccgtggt gaccgtgcct tcctcctccc tgggcaccca gacctacatc 660
tgcaacgtga accacaagcc ttccaacacc aaggtggaca agcgggtgga gcctaagtcc 720
tgctccggcc ctgggggcgg acgcagcggc ggaggcggat ccggcggagg aggctctcag 780
gtgcagctgc agcagcctgg cgctgaactg gtccgacctg gcgcctccgt gaagctgtcc 840
tgcaaggcct ccggctacac cttcaccagc tactggatca actgggtcaa gcagcggcct 900
ggccagggcc tggaatggat cggcaacatc tacccctccg actcctacac caactacaac 960
cagaagttca aggacaaggc caccctgacc gtggacaagt cctcctccac cgcctacatg 1020
cagctgtcca gccccacctc cgaggactcc gccgtgtact actgcacccg gtcctggcgg 1080
ggcaactcct tcgactattg gggccagggc accaccctga cagtgtcctc tggaggcgga 1140
ggatctggtg gtggcggatc tggcggcggt ggaagtggcg gaggtggtag cgacatcgtg 1200
atgacccagt ccccctccag cctgaccgtg accgctggcg agaaagtgac catgagctgc 1260
aagtcctccc agtccctgct gaactccggc aaccagaaga actacctgac ctggtatcag 1320
cagaagcccg gccagccccc caagctgctg atctactggg cctccacccg cgagtctggc 1380
gtgcccgata gattcaccgg ctccggcagc ggcaccgact ttaccctgac catctccagc 1440
gtgcaggccg aggacctggc cgtgtattac tgtcagaacg actactccta ccccttcacc 1500
ttcggctctg gcaccaagct ggaaatcaag tga 1533
<210> 92
<211> 1548
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 92
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactcccag 60
gtgcagctgc agcagtctgg cgctgagctg gctagacctg gcgcctccgt gaagatgtcc 120
tgcaagacct ccggctacac cttcacccgg tacaccatgc actgggtcaa gcagaggcct 180
ggacagggcc tggaatggat cggctacatc aacccctccc ggggctacac caactacaac 240
cagaagttca aggacaaggc caccctgaca accgacaagt cctcctccac cgcctacatg 300
cagctgtcct ccctgacctc cgaggactcc gccgtgtact actgcgcccg gtactacgac 360
gaccactact ccctggacta ctggggccag ggcaccacac tgacagtgtc tagcgcctcc 420
accaagggcc cttccgtgtt ccctctggcc ccttcctcca agtccacctc cggcggcacc 480
gccgctctgg gctgcctggt gaaggactac ttccctgagc ctgtgaccgt gagctggaac 540
tctggcgccc tgaccagcgg cgtgcacacc ttccctgccg tgctgcagtc ctccggcctg 600
tactccctgt cctccgtggt gaccgtgcct tcctcctccc tgggcaccca gacctacatc 660
tgcaacgtga accacaagcc ttccaacacc aaggtggaca agcgggtgga gcctaagtcc 720
tgctccggcc ctgggggcgg acgcagcggc ggaggcggat ccggcggagg aggctctgac 780
atcgtgatga cccagtcccc ctccagcctg accgtgaccg ctggcgagaa agtgaccatg 840
agctgcaagt cctcccagtc cctgctgaac tccggcaacc agaagaacta cctgacctgg 900
tatcagcaga agcccggcca gccccccaag ctgctgatct actgggcctc cacccgcgag 960
tctggcgtgc ccgatagatt caccggctcc ggcagcggca ccgactttac cctgaccatc 1020
tccagcgtgc aggccgagga cctggccgtg tattactgtc agaacgacta ctcctacccc 1080
ttcaccttcg gctctggcac caagctggaa atcaagggag gcggtggttc aggcggcgga 1140
ggcagcggtg gaggtggtag tggcggtggc ggttcagggg gaggtggctc gcaggtgcag 1200
ctgcagcagc ctggcgctga actggtccga cctggcgcct ccgtgaagct gtcctgcaag 1260
gcctccggct acaccttcac cagctactgg atcaactggg tcaagcagcg gcctggccag 1320
ggcctggaat ggatcggcaa catctacccc tccgactcct acaccaacta caaccagaag 1380
ttcaaggaca aggccaccct gaccgtggac aagtcctcct ccaccgccta catgcagctg 1440
tccagcccca cctccgagga ctccgccgtg tactactgca cccggtcctg gcggggcaac 1500
tccttcgact attggggcca gggcaccacc ctgacagtgt cctcttga 1548
<210> 93
<211> 1470
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 93
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactctcag 60
atcgtgctga cccagtctcc cgccatcatg tctgctagcc ctggcgagaa agtgacaatg 120
acctgccggg cctcctcctc cgtgtcctac atgaactggt atcagcagaa gtccggcacc 180
tcccccaagc ggtggatcta cgacacctcc aaggtggcct ctggcgtgcc ctacagattc 240
tccggctctg gctctggcac ctcctacagc ctgaccatct ccagcatgga agccgaggat 300
gccgccacct actactgcca gcagtggtcc tccaaccccc tgacctttgg cgctggcacc 360
aagctggaac tgaagcggac cgtggccgct ccttccgtgt tcatcttccc tccctccgac 420
gagcagctga agtccggcac cgcctccgtg gtgtgcctgc tgaacaactt ctaccctcgg 480
gaggccaagg tgcagtggaa ggtggacaac gccctgcagt ccggcaactc ccaggaaagc 540
gtcaccgagc aggactccaa ggacagcacc tactccctgt cctccaccct gaccctgtcc 600
aaggccgact acgagaagca caaggtgtac gcctgcgagg tgacccacca gggcctgtcc 660
agccctgtga ccaagtcctt caaccggggc gagtgtgacg tgcctggtgg tagccaggtg 720
cagctgcagc agcctggcgc tgaactggtc cgacctggcg cctccgtgaa gctgtcctgc 780
aaggcctccg gctacacctt caccagctac tggatcaact gggtcaagca gcggcctggc 840
cagggcctgg aatggatcgg caacatctac ccctccgact cctacaccaa ctacaaccag 900
aagttcaagg acaaggccac cctgaccgtg gacaagtcct cctccaccgc ctacatgcag 960
ctgtccagcc ccacctccga ggactccgcc gtgtactact gcacccggtc ctggcggggc 1020
aactccttcg actattgggg ccagggcacc accctgacag tgtcctctgg aggcggagga 1080
tctggtggtg gcggatctgg cggcggtgga agtggcggag gtggtagcga catcgtgatg 1140
acccagtccc cctccagcct gaccgtgacc gctggcgaga aagtgaccat gagctgcaag 1200
tcctcccagt ccctgctgaa ctccggcaac cagaagaact acctgacctg gtatcagcag 1260
aagcccggcc agccccccaa gctgctgatc tactgggcct ccacccgcga gtctggcgtg 1320
cccgatagat tcaccggctc cggcagcggc accgacttta ccctgaccat ctccagcgtg 1380
caggccgagg acctggccgt gtattactgt cagaacgact actcctaccc cttcaccttc 1440
ggctctggca ccaagctgga aatcaagtga 1470
<210> 94
<211> 1485
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 94
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactctcag 60
atcgtgctga cccagtctcc cgccatcatg tctgctagcc ctggcgagaa agtgacaatg 120
acctgccggg cctcctcctc cgtgtcctac atgaactggt atcagcagaa gtccggcacc 180
tcccccaagc ggtggatcta cgacacctcc aaggtggcct ctggcgtgcc ctacagattc 240
tccggctctg gctctggcac ctcctacagc ctgaccatct ccagcatgga agccgaggat 300
gccgccacct actactgcca gcagtggtcc tccaaccccc tgacctttgg cgctggcacc 360
aagctggaac tgaagcggac cgtggccgct ccttccgtgt tcatcttccc tccctccgac 420
gagcagctga agtccggcac cgcctccgtg gtgtgcctgc tgaacaactt ctaccctcgg 480
gaggccaagg tgcagtggaa ggtggacaac gccctgcagt ccggcaactc ccaggaaagc 540
gtcaccgagc aggactccaa ggacagcacc tactccctgt cctccaccct gaccctgtcc 600
aaggccgact acgagaagca caaggtgtac gcctgcgagg tgacccacca gggcctgtcc 660
agccctgtga ccaagtcctt caaccggggc gagtgtgacg tgcctggtgg tagcgacatc 720
gtgatgaccc agtccccctc cagcctgacc gtgaccgctg gcgagaaagt gaccatgagc 780
tgcaagtcct cccagtccct gctgaactcc ggcaaccaga agaactacct gacctggtat 840
cagcagaagc ccggccagcc ccccaagctg ctgatctact gggcctccac ccgcgagtct 900
ggcgtgcccg atagattcac cggctccggc agcggcaccg actttaccct gaccatctcc 960
agcgtgcagg ccgaggacct ggccgtgtat tactgtcaga acgactactc ctaccccttc 1020
accttcggct ctggcaccaa gctggaaatc aagggaggcg gtggttcagg cggcggaggc 1080
agcggtggag gtggtagtgg cggtggcggt tcagggggag gtggctcgca ggtgcagctg 1140
cagcagcctg gcgctgaact ggtccgacct ggcgcctccg tgaagctgtc ctgcaaggcc 1200
tccggctaca ccttcaccag ctactggatc aactgggtca agcagcggcc tggccagggc 1260
ctggaatgga tcggcaacat ctacccctcc gactcctaca ccaactacaa ccagaagttc 1320
aaggacaagg ccaccctgac cgtggacaag tcctcctcca ccgcctacat gcagctgtcc 1380
agccccacct ccgaggactc cgccgtgtac tactgcaccc ggtcctggcg gggcaactcc 1440
ttcgactatt ggggccaggg caccaccctg acagtgtcct cttga 1485
<210> 95
<211> 1533
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 95
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactcccag 60
gtgcagctgc agcagtctgg cgctgagctg gctagacctg gcgcctccgt gaagatgtcc 120
tgcaagacct ccggctacac cttcacccgg tacaccatgc actgggtcaa gcagaggcct 180
ggacagggcc tggaatggat cggctacatc aacccctccc ggggctacac caactacaac 240
cagaagttca aggacaaggc caccctgaca accgacaagt cctcctccac cgcctacatg 300
cagctgtcct ccctgacctc cgaggactcc gccgtgtact actgcgcccg gtactacgac 360
gaccactact ccctggacta ctggggccag ggcaccacac tgacagtgtc tagcgcctcc 420
accaagggcc cttccgtgtt ccctctggcc ccttcctcca agtccacctc cggcggcacc 480
gccgctctgg gctgcctggt gaaggactac ttccctgagc ctgtgaccgt gagctggaac 540
tctggcgccc tgaccagcgg cgtgcacacc ttccctgccg tgctgcagtc ctccggcctg 600
tactccctgt cctccgtggt gaccgtgcct tcctcctccc tgggcaccca gacctacatc 660
tgcaacgtga accacaagcc ttccaacacc aaggtggaca agcgggtgga gcctaagtcc 720
tgctccggcc ctgggggcgg acgcagcggc ggaggcggat ccggcggagg aggctctcag 780
gtgcagctgc agcagcctgg cgctgaactg gtccgacctg gcgcctccgt gaagctgtcc 840
tgcaaggcct ccggctacac cttcaccagc tactggatca actgggtcaa gcagcggcct 900
ggccagtgcc tggaatggat cggcaacatc tacccctccg actcctacac caactacaac 960
cagaagttca aggacaaggc caccctgacc gtggacaagt cctcctccac cgcctacatg 1020
cagctgtcca gccccacctc cgaggactcc gccgtgtact actgcacccg gtcctggcgg 1080
ggcaactcct tcgactattg gggccagggc accaccctga cagtgtcctc tggaggcgga 1140
ggatctggtg gtggcggatc tggcggcggt ggaagtggcg gaggtggtag cgacatcgtg 1200
atgacccagt ccccctccag cctgaccgtg accgctggcg agaaagtgac catgagctgc 1260
aagtcctccc agtccctgct gaactccggc aaccagaaga actacctgac ctggtatcag 1320
cagaagcccg gccagccccc caagctgctg atctactggg cctccacccg cgagtctggc 1380
gtgcccgata gattcaccgg ctccggcagc ggcaccgact ttaccctgac catctccagc 1440
gtgcaggccg aggacctggc cgtgtattac tgtcagaacg actactccta ccccttcacc 1500
ttcggctgcg gcaccaagct ggaaatcaag tga 1533
<210> 96
<211> 1548
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 96
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactcccag 60
gtgcagctgc agcagtctgg cgctgagctg gctagacctg gcgcctccgt gaagatgtcc 120
tgcaagacct ccggctacac cttcacccgg tacaccatgc actgggtcaa gcagaggcct 180
ggacagggcc tggaatggat cggctacatc aacccctccc ggggctacac caactacaac 240
cagaagttca aggacaaggc caccctgaca accgacaagt cctcctccac cgcctacatg 300
cagctgtcct ccctgacctc cgaggactcc gccgtgtact actgcgcccg gtactacgac 360
gaccactact ccctggacta ctggggccag ggcaccacac tgacagtgtc tagcgcctcc 420
accaagggcc cttccgtgtt ccctctggcc ccttcctcca agtccacctc cggcggcacc 480
gccgctctgg gctgcctggt gaaggactac ttccctgagc ctgtgaccgt gagctggaac 540
tctggcgccc tgaccagcgg cgtgcacacc ttccctgccg tgctgcagtc ctccggcctg 600
tactccctgt cctccgtggt gaccgtgcct tcctcctccc tgggcaccca gacctacatc 660
tgcaacgtga accacaagcc ttccaacacc aaggtggaca agcgggtgga gcctaagtcc 720
tgctccggcc ctgggggcgg acgcagcggc ggaggcggat ccggcggagg aggctctgac 780
atcgtgatga cccagtcccc ctccagcctg accgtgaccg ctggcgagaa agtgaccatg 840
agctgcaagt cctcccagtc cctgctgaac tccggcaacc agaagaacta cctgacctgg 900
tatcagcaga agcccggcca gccccccaag ctgctgatct actgggcctc cacccgcgag 960
tctggcgtgc ccgatagatt caccggctcc ggcagcggca ccgactttac cctgaccatc 1020
tccagcgtgc aggccgagga cctggccgtg tattactgtc agaacgacta ctcctacccc 1080
ttcaccttcg gctgcggcac caagctggaa atcaagggag gcggtggttc aggcggcgga 1140
ggcagcggtg gaggtggtag tggcggtggc ggttcagggg gaggtggctc gcaggtgcag 1200
ctgcagcagc ctggcgctga actggtccga cctggcgcct ccgtgaagct gtcctgcaag 1260
gcctccggct acaccttcac cagctactgg atcaactggg tcaagcagcg gcctggccag 1320
tgcctggaat ggatcggcaa catctacccc tccgactcct acaccaacta caaccagaag 1380
ttcaaggaca aggccaccct gaccgtggac aagtcctcct ccaccgccta catgcagctg 1440
tccagcccca cctccgagga ctccgccgtg tactactgca cccggtcctg gcggggcaac 1500
tccttcgact attggggcca gggcaccacc ctgacagtgt cctcttga 1548
<210> 97
<211> 1470
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 97
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactctcag 60
atcgtgctga cccagtctcc cgccatcatg tctgctagcc ctggcgagaa agtgacaatg 120
acctgccggg cctcctcctc cgtgtcctac atgaactggt atcagcagaa gtccggcacc 180
tcccccaagc ggtggatcta cgacacctcc aaggtggcct ctggcgtgcc ctacagattc 240
tccggctctg gctctggcac ctcctacagc ctgaccatct ccagcatgga agccgaggat 300
gccgccacct actactgcca gcagtggtcc tccaaccccc tgacctttgg cgctggcacc 360
aagctggaac tgaagcggac cgtggccgct ccttccgtgt tcatcttccc tccctccgac 420
gagcagctga agtccggcac cgcctccgtg gtgtgcctgc tgaacaactt ctaccctcgg 480
gaggccaagg tgcagtggaa ggtggacaac gccctgcagt ccggcaactc ccaggaaagc 540
gtcaccgagc aggactccaa ggacagcacc tactccctgt cctccaccct gaccctgtcc 600
aaggccgact acgagaagca caaggtgtac gcctgcgagg tgacccacca gggcctgtcc 660
agccctgtga ccaagtcctt caaccggggc gagtgtgacg tgcctggtgg tagccaggtg 720
cagctgcagc agcctggcgc tgaactggtc cgacctggcg cctccgtgaa gctgtcctgc 780
aaggcctccg gctacacctt caccagctac tggatcaact gggtcaagca gcggcctggc 840
cagtgcctgg aatggatcgg caacatctac ccctccgact cctacaccaa ctacaaccag 900
aagttcaagg acaaggccac cctgaccgtg gacaagtcct cctccaccgc ctacatgcag 960
ctgtccagcc ccacctccga ggactccgcc gtgtactact gcacccggtc ctggcggggc 1020
aactccttcg actattgggg ccagggcacc accctgacag tgtcctctgg aggcggagga 1080
tctggtggtg gcggatctgg cggcggtgga agtggcggag gtggtagcga catcgtgatg 1140
acccagtccc cctccagcct gaccgtgacc gctggcgaga aagtgaccat gagctgcaag 1200
tcctcccagt ccctgctgaa ctccggcaac cagaagaact acctgacctg gtatcagcag 1260
aagcccggcc agccccccaa gctgctgatc tactgggcct ccacccgcga gtctggcgtg 1320
cccgatagat tcaccggctc cggcagcggc accgacttta ccctgaccat ctccagcgtg 1380
caggccgagg acctggccgt gtattactgt cagaacgact actcctaccc cttcaccttc 1440
ggctgcggca ccaagctgga aatcaagtga 1470
<210> 98
<211> 1485
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 98
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactctcag 60
atcgtgctga cccagtctcc cgccatcatg tctgctagcc ctggcgagaa agtgacaatg 120
acctgccggg cctcctcctc cgtgtcctac atgaactggt atcagcagaa gtccggcacc 180
tcccccaagc ggtggatcta cgacacctcc aaggtggcct ctggcgtgcc ctacagattc 240
tccggctctg gctctggcac ctcctacagc ctgaccatct ccagcatgga agccgaggat 300
gccgccacct actactgcca gcagtggtcc tccaaccccc tgacctttgg cgctggcacc 360
aagctggaac tgaagcggac cgtggccgct ccttccgtgt tcatcttccc tccctccgac 420
gagcagctga agtccggcac cgcctccgtg gtgtgcctgc tgaacaactt ctaccctcgg 480
gaggccaagg tgcagtggaa ggtggacaac gccctgcagt ccggcaactc ccaggaaagc 540
gtcaccgagc aggactccaa ggacagcacc tactccctgt cctccaccct gaccctgtcc 600
aaggccgact acgagaagca caaggtgtac gcctgcgagg tgacccacca gggcctgtcc 660
agccctgtga ccaagtcctt caaccggggc gagtgtgacg tgcctggtgg tagcgacatc 720
gtgatgaccc agtccccctc cagcctgacc gtgaccgctg gcgagaaagt gaccatgagc 780
tgcaagtcct cccagtccct gctgaactcc ggcaaccaga agaactacct gacctggtat 840
cagcagaagc ccggccagcc ccccaagctg ctgatctact gggcctccac ccgcgagtct 900
ggcgtgcccg atagattcac cggctccggc agcggcaccg actttaccct gaccatctcc 960
agcgtgcagg ccgaggacct ggccgtgtat tactgtcaga acgactactc ctaccccttc 1020
accttcggct gcggcaccaa gctggaaatc aagggaggcg gtggttcagg cggcggaggc 1080
agcggtggag gtggtagtgg cggtggcggt tcagggggag gtggctcgca ggtgcagctg 1140
cagcagcctg gcgctgaact ggtccgacct ggcgcctccg tgaagctgtc ctgcaaggcc 1200
tccggctaca ccttcaccag ctactggatc aactgggtca agcagcggcc tggccagtgc 1260
ctggaatgga tcggcaacat ctacccctcc gactcctaca ccaactacaa ccagaagttc 1320
aaggacaagg ccaccctgac cgtggacaag tcctcctcca ccgcctacat gcagctgtcc 1380
agccccacct ccgaggactc cgccgtgtac tactgcaccc ggtcctggcg gggcaactcc 1440
ttcgactatt ggggccaggg caccaccctg acagtgtcct cttga 1485
<210> 99
<211> 1593
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 99
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactctcag 60
gtgcagctgc agcagcctgg cgctgaactg gtccgacctg gcgcctccgt gaagctgtcc 120
tgcaaggcct ccggctacac cttcaccagc tactggatca actgggtcaa gcagcggcct 180
ggccagggcc tggaatggat cggcaacatc tacccctccg actcctacac caactacaac 240
cagaagttca aggacaaggc caccctgacc gtggacaagt cctcctccac cgcctacatg 300
cagctgtcca gccccacctc cgaggactcc gccgtgtact actgcacccg gtcctggcgg 360
ggcaactcct tcgactattg gggccagggc accaccctga cagtgtcctc tggaggcgga 420
ggatctggtg gtggcggatc tggcggcggt ggaagtggcg gaggtggtag cgacatcgtg 480
atgacccagt ccccctccag cctgaccgtg accgctggcg agaaagtgac catgagctgc 540
aagtcctccc agtccctgct gaactccggc aaccagaaga actacctgac ctggtatcag 600
cagaagcccg gccagccccc caagctgctg atctactggg cctccacccg cgagtctggc 660
gtgcccgata gattcaccgg ctccggcagc ggcaccgact ttaccctgac catctccagc 720
gtgcaggccg aggacctggc cgtgtattac tgtcagaacg actactccta ccccttcacc 780
ttcggctctg gcaccaagct ggaaatcaag tctggcggag gcggatccca ggtgcagctg 840
cagcagtctg gcgctgagct ggctagacct ggcgcctccg tgaagatgtc ctgcaagacc 900
tccggctaca ccttcacccg gtacaccatg cactgggtca agcagaggcc tggacagggc 960
ctggaatgga tcggctacat caacccctcc cggggctaca ccaactacaa ccagaagttc 1020
aaggacaagg ccaccctgac aaccgacaag tcctcctcca ccgcctacat gcagctgtcc 1080
tccctgacct ccgaggactc cgccgtgtac tactgcgccc ggtactacga cgaccactac 1140
tccctggact actggggcca gggcaccaca ctgacagtgt ctagcggtgg tggaggaagc 1200
ggagggggtg gtagcggtgg tggaggctct ggcgggggag ggagtcagat cgtgctgacc 1260
cagtctcccg ccatcatgtc tgctagccct ggcgagaaag tgacaatgac ctgccgggcc 1320
tcctcctccg tgtcctacat gaactggtat cagcagaagt ccggcacctc ccccaagcgg 1380
tggatctacg acacctccaa ggtggcctct ggcgtgccct acagattctc cggctctggc 1440
tctggcacct cctacagcct gaccatctcc agcatggaag ccgaggatgc cgccacctac 1500
tactgccagc agtggtcctc caaccccctg acctttggcg ctggcaccaa gctggaactg 1560
aagggcggct ctcaccacca ccatcaccac tga 1593
<210> 100
<211> 1608
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 100
atgggctggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcactctgac 60
atcgtgatga cccagtcccc ctccagcctg accgtgaccg ctggcgagaa agtgaccatg 120
agctgcaagt cctcccagtc cctgctgaac tccggcaacc agaagaacta cctgacctgg 180
tatcagcaga agcccggcca gccccccaag ctgctgatct actgggcctc cacccgcgag 240
tctggcgtgc ccgatagatt caccggctcc ggcagcggca ccgactttac cctgaccatc 300
tccagcgtgc aggccgagga cctggccgtg tattactgtc agaacgacta ctcctacccc 360
ttcaccttcg gctctggcac caagctggaa atcaagggag gcggtggttc aggcggcgga 420
ggcagcggtg gaggtggtag tggcggtggc ggttcagggg gaggtggctc gcaggtgcag 480
ctgcagcagc ctggcgctga actggtccga cctggcgcct ccgtgaagct gtcctgcaag 540
gcctccggct acaccttcac cagctactgg atcaactggg tcaagcagcg gcctggccag 600
ggcctggaat ggatcggcaa catctacccc tccgactcct acaccaacta caaccagaag 660
ttcaaggaca aggccaccct gaccgtggac aagtcctcct ccaccgccta catgcagctg 720
tccagcccca cctccgagga ctccgccgtg tactactgca cccggtcctg gcggggcaac 780
tccttcgact attggggcca gggcaccacc ctgacagtgt cctcttctgg cggaggcgga 840
tcccaggtgc agctgcagca gtctggcgct gagctggcta gacctggcgc ctccgtgaag 900
atgtcctgca agacctccgg ctacaccttc acccggtaca ccatgcactg ggtcaagcag 960
aggcctggac agggcctgga atggatcggc tacatcaacc cctcccgggg ctacaccaac 1020
tacaaccaga agttcaagga caaggccacc ctgacaaccg acaagtcctc ctccaccgcc 1080
tacatgcagc tgtcctccct gacctccgag gactccgccg tgtactactg cgcccggtac 1140
tacgacgacc actactccct ggactactgg ggccagggca ccacactgac agtgtctagc 1200
ggaggcggag gatctggtgg tggcggatct ggcggcggtg gaagtggcgg aggtggtagc 1260
cagatcgtgc tgacccagtc tcccgccatc atgtctgcta gccctggcga gaaagtgaca 1320
atgacctgcc gggcctcctc ctccgtgtcc tacatgaact ggtatcagca gaagtccggc 1380
acctccccca agcggtggat ctacgacacc tccaaggtgg cctctggcgt gccctacaga 1440
ttctccggct ctggctctgg cacctcctac agcctgacca tctccagcat ggaagccgag 1500
gatgccgcca cctactactg ccagcagtgg tcctccaacc ccctgacctt tggcgctggc 1560
accaagctgg aactgaaggg cggctctcac caccaccatc accactga 1608
<210> 101
<211> 1545
<212> DNA
<213> Artificial Sequence
<220>
<223> Antibody-derived sequence
<400> 101
atgggatggt cctgcatcat cctgtttctg gtggctaccg ccaccggcgt gcacagccag 60
gtgcagctgc agcagcctgg agctgaactg gtgcggcctg gagccagcgt gaagctgtcc 120
tgcaaggcca gcggctacac cttcaccagc tactggatca actgggtgaa gcagcggcct 180
ggacagggcc tggaatggat cggcaacatc taccccagcg acagctacac caactacaac 240
cagaagttca aggacaaggc caccctgacc gtggacaaga gcagcagcac cgcctacatg 300
cagctgtcca gccccacctc cgaggacagc gccgtgtact actgcaccag aagctggcgg 360
ggcaacagct tcgactactg gggccagggc accacactga cagtcagcag cggaggaggg 420
ggatctggcg ggggaggaag cggagggggg ggaagcgaca tcgtgatgac ccagagcccc 480
agcagcctga ccgtgacagc cggggaaaag gtgaccatga gctgcaagag cagccagagc 540
ctgctgaaca gcggcaacca gaagaactac ctgacctggt atcagcagaa gcccggccag 600
ccccccaagc tgctgatcta ctgggccagc acccgggaga gcggcgtgcc cgaccggttt 660
accggctccg gctccggcac cgacttcacc ctgaccatca gcagcgtgca ggccgaggac 720
ctggccgtgt attactgtca gaacgactac agctacccct tcaccttcgg cagcggcacc 780
aagctggaaa tcaagagcgg agggggagga tccgatatca agctgcagca gagcggagct 840
gaactggcta ggccaggcgc ctccgtgaag atgagctgta agacctccgg ctataccttt 900
acccggtaca ccatgcactg ggtgaaacag aggcccggac aggggctgga atggattggc 960
tatatcaacc cctcccgggg ctacacaaat tacaatcaga aattcaaaga taaagccaca 1020
ctgacaaccg acaagtccag ctccacagcc tatatgcagc tgtcctccct gaccagcgag 1080
gactctgccg tgtactattg cgcccggtac tacgacgacc actacagcct ggattattgg 1140
gggcagggga caacactgac agtctccagc gtggagggcg gcagcggagg atctggcggg 1200
agcggcggct ctgggggcgt cgacgacatc cagctgaccc agtcccccgc catcatgagc 1260
gccagccctg gcgagaaggt gacaatgacc tgccgggcca gcagcagcgt gagctacatg 1320
aattggtatc agcagaaaag cggcaccagc cccaagcggt ggatctacga caccagcaag 1380
gtggcctccg gcgtgcccta cagattctcc ggctccggct ctggcaccag ctacagcctg 1440
acaatttcta gcatggaagc cgaggacgcc gccacctact actgccagca gtggagcagc 1500
aaccccctga cctttggcgc cggaacaaag ctggaactga agtga 1545
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| АГЕНТЫ ДЛЯ ЛЕЧЕНИЯ ЭКСПРЕССИРУЮЩИХ КЛАУДИН РАКОВЫХ ЗАБОЛЕВАНИЙ | 2013 |
|
RU2798990C2 |
| АНТИТЕЛА ПРОТИВ КЛАУДИНА И ИХ ПРИМЕНЕНИЕ | 2019 |
|
RU2815926C2 |
| АНТИТЕЛО ПРОТИВ КЛАУДИНА 18.2 И ЕГО ПРИМЕНЕНИЕ | 2020 |
|
RU2822550C2 |
| КОНЪЮГАТЫ ЛЕКАРСТВЕННЫХ СРЕДСТВ, СОДЕРЖАЩИЕ АНТИТЕЛА ПРОТИВ КЛАУДИНА 18.2 | 2016 |
|
RU2841168C2 |
| КОМБИНИРОВАННАЯ ТЕРАПИЯ С ИСПОЛЬЗОВАНИЕМ АНТИТЕЛ ПРОТИВ КЛАУДИНА 18.2 ДЛЯ ЛЕЧЕНИЯ РАКА | 2014 |
|
RU2792932C2 |
| ПОЛИСПЕЦИФИЧЕСКИЕ СВЯЗЫВАЮЩИЕ БЕЛКИ, НАЦЕЛЕННЫЕ НА CAIX, ANO1, МЕЗОТЕЛИН, TROP2, СEA ИЛИ КЛАУДИН-18.2 | 2018 |
|
RU2792671C2 |
| АНТИТЕЛА ДЛЯ ЛЕЧЕНИЯ РАКОВЫХ ЗАБОЛЕВАНИЙ, ПРИ КОТОРЫХ ЭКСПРЕССИРУЕТСЯ КЛАУДИН 6 | 2012 |
|
RU2816850C2 |
| АНТИТЕЛО ПРОТИВ КЛАУДИНА 18A2 И ЕГО ПРИМЕНЕНИЕ | 2020 |
|
RU2811431C2 |
| ТЕРАПИЯ ДЛЯ ЛЕЧЕНИЯ РАКА, ВКЛЮЧАЮЩАЯ АНТИТЕЛА ПРОТИВ КЛАУДИНА 18.2 | 2014 |
|
RU2832015C2 |
| Модифицированные клетки с химерным антигеновым рецептором для лечения рака, экспрессирующего CLDN6 | 2020 |
|
RU2826058C2 |

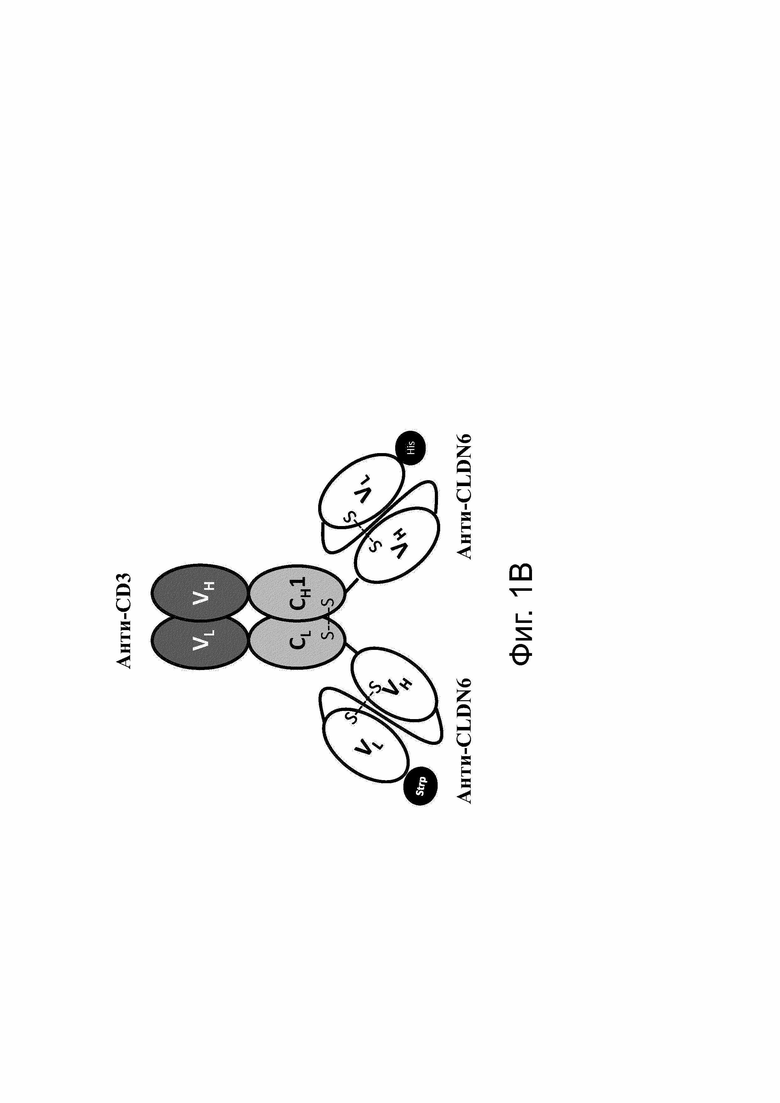

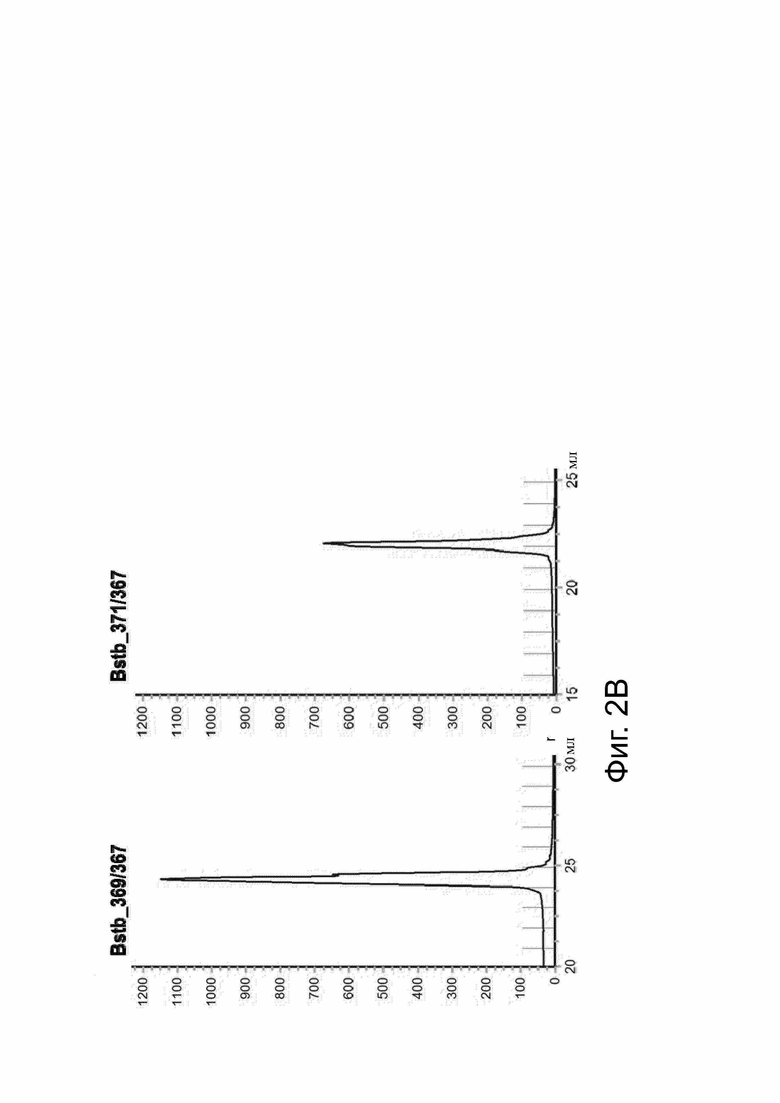

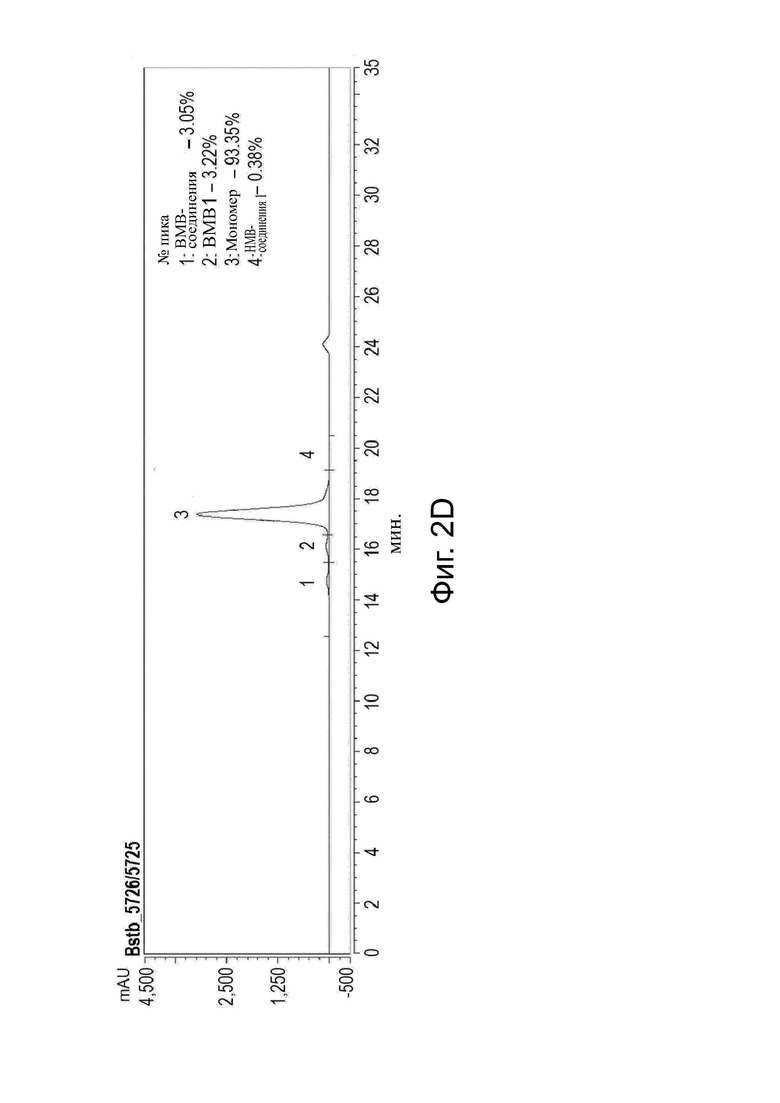

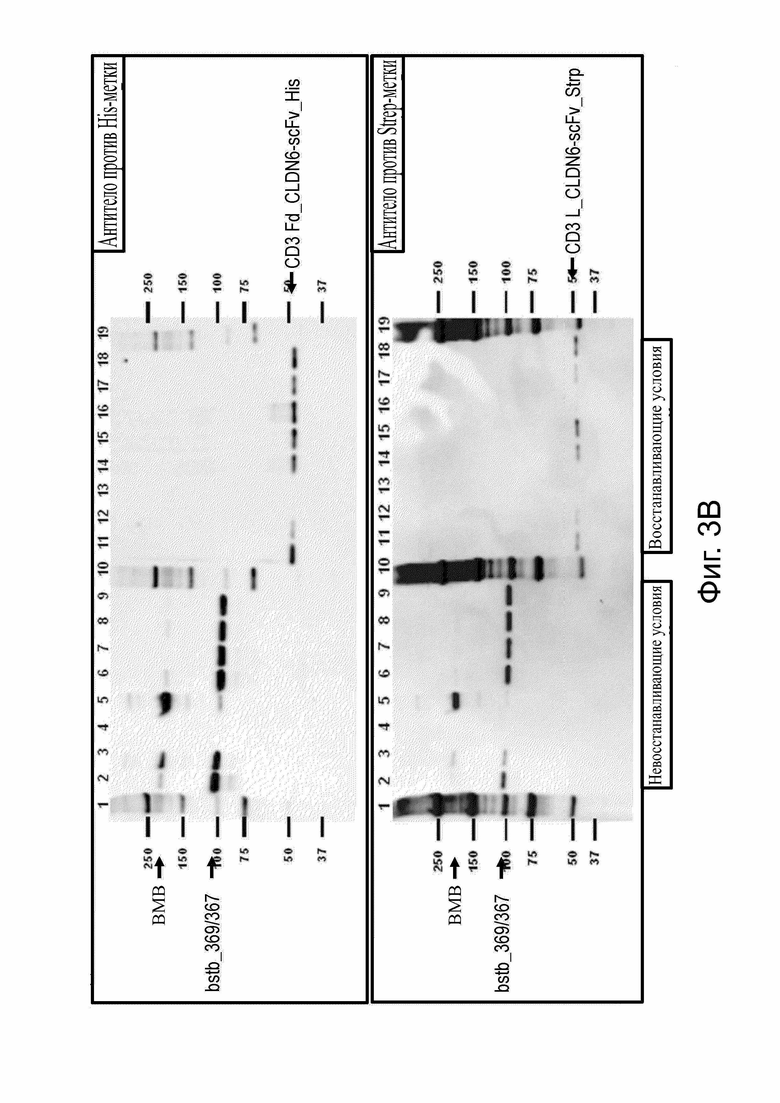
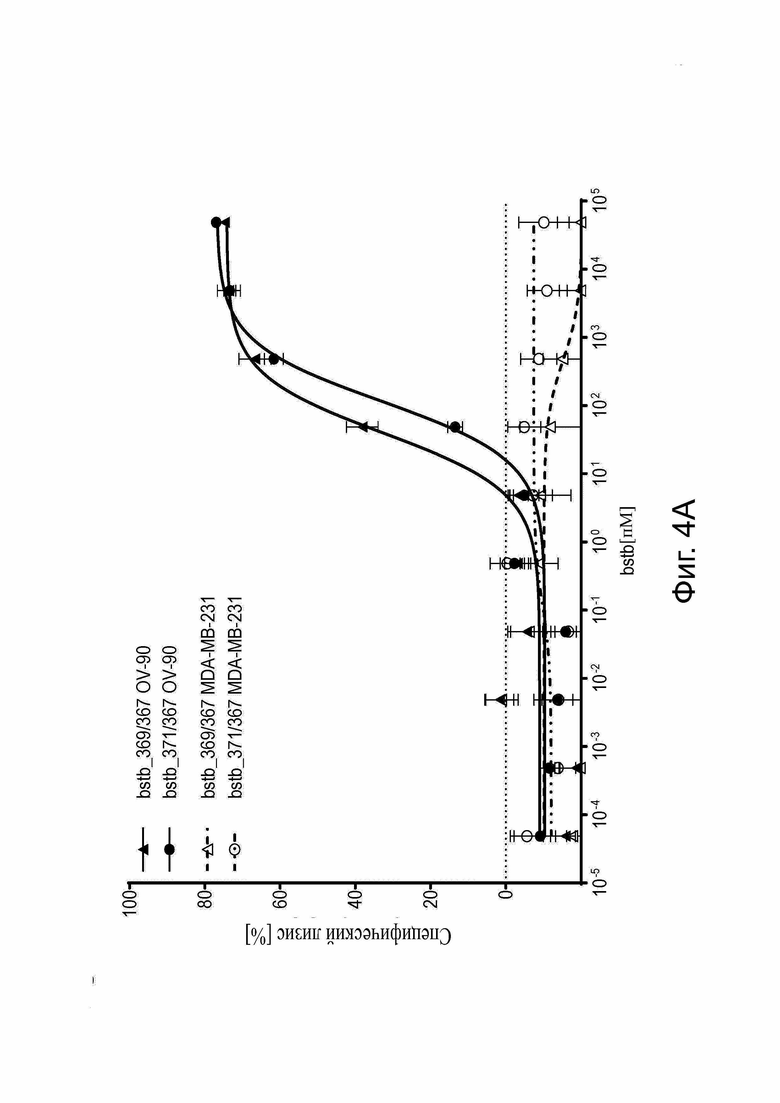

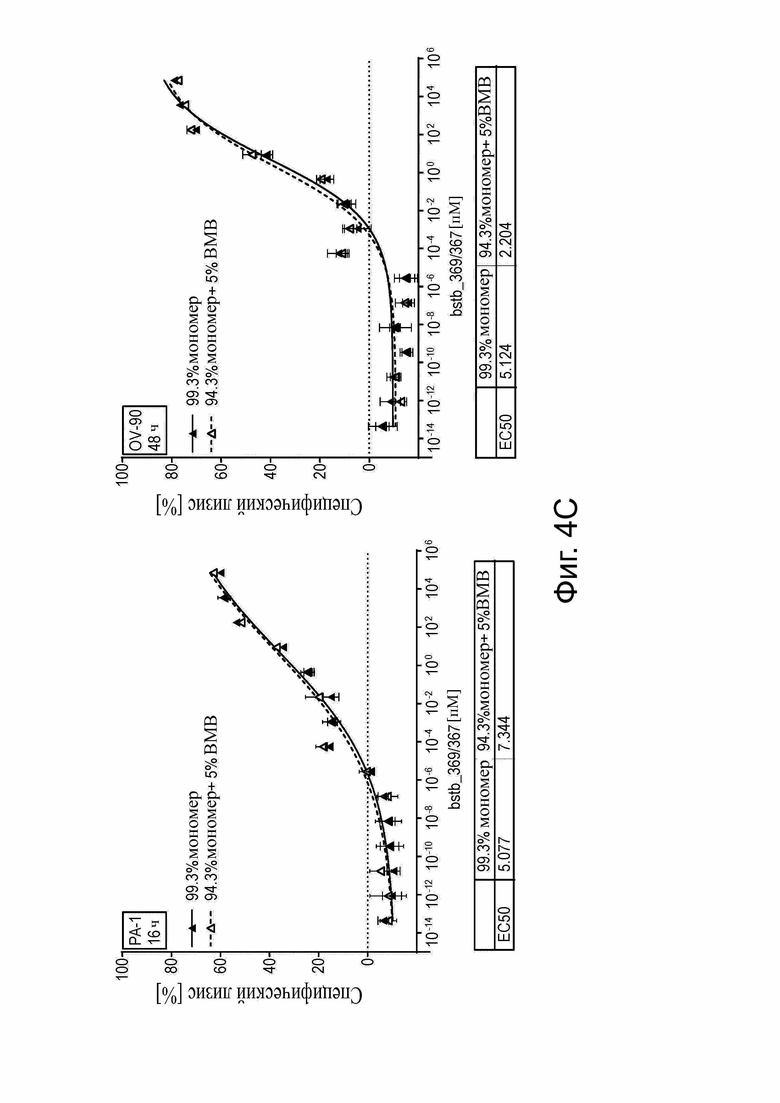
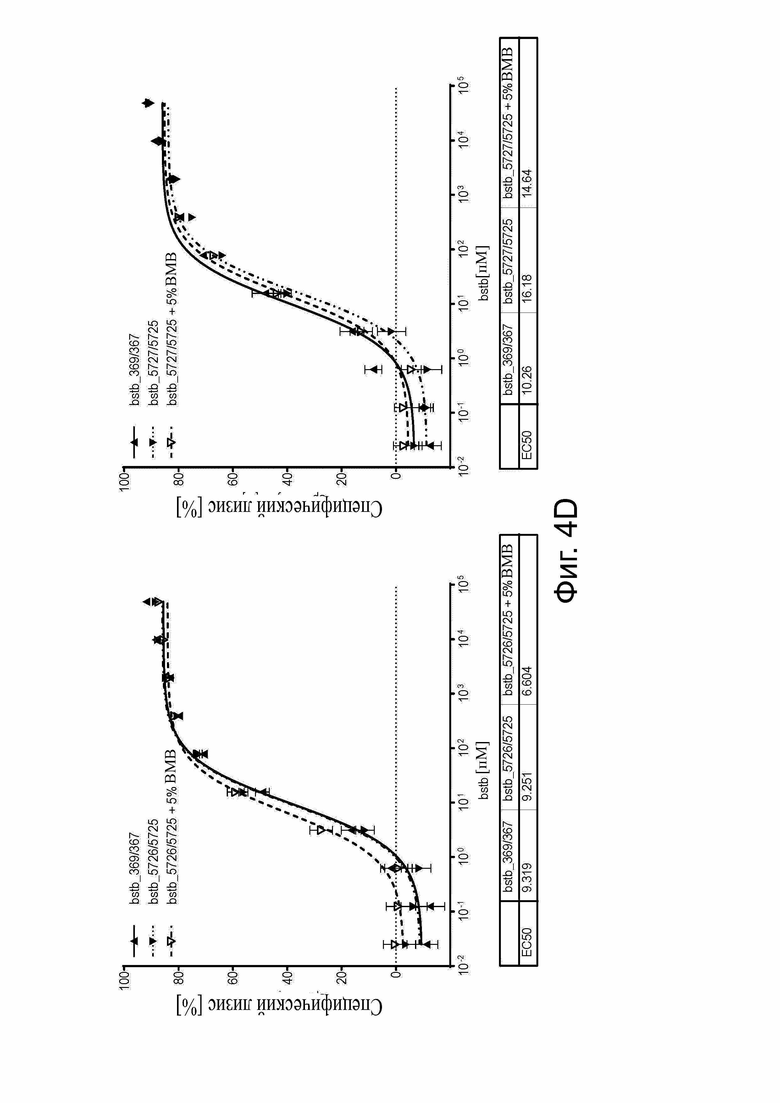

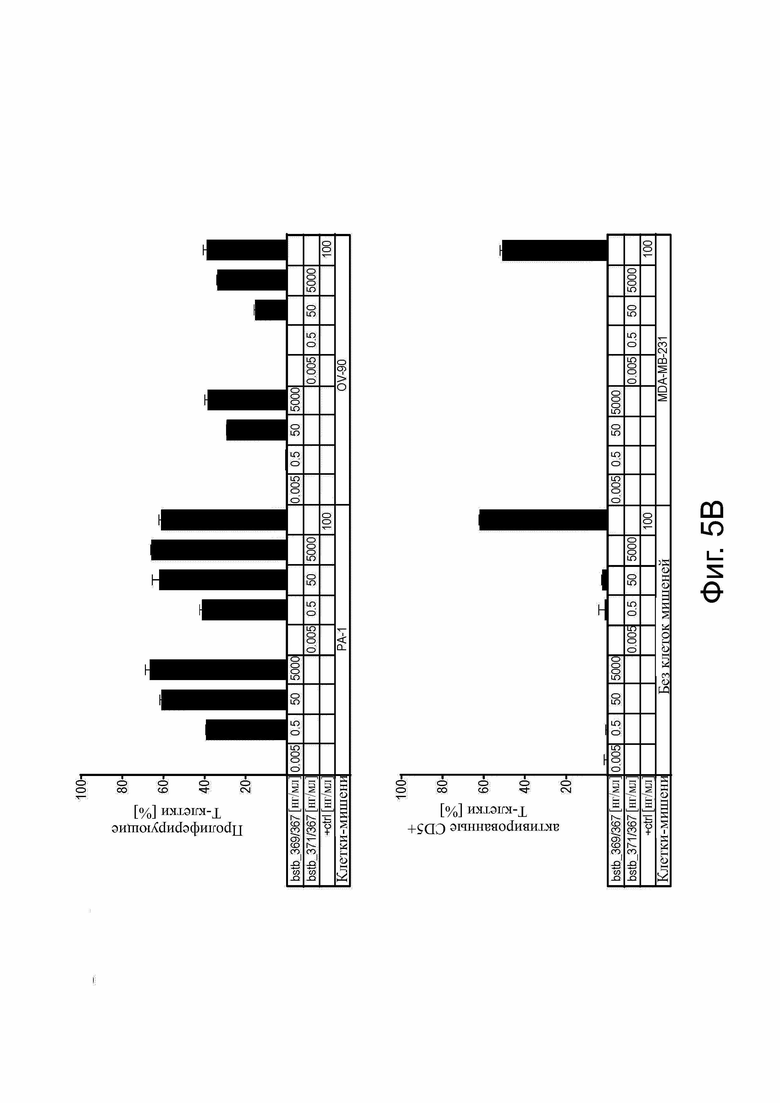
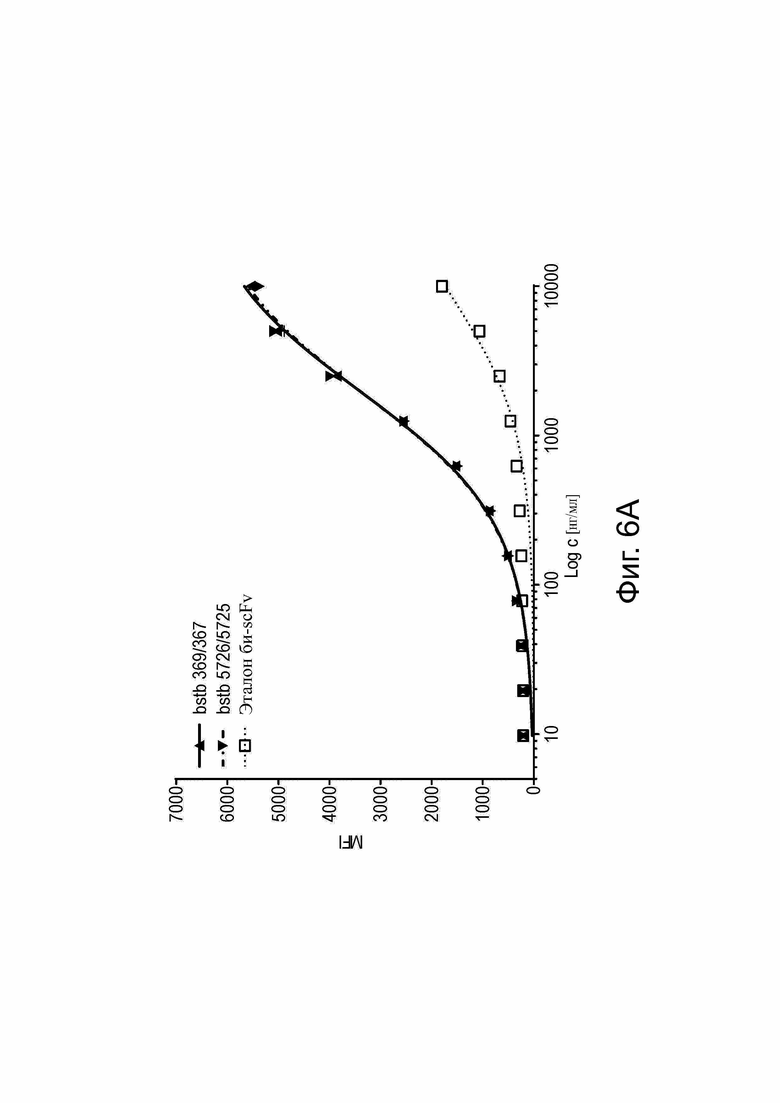
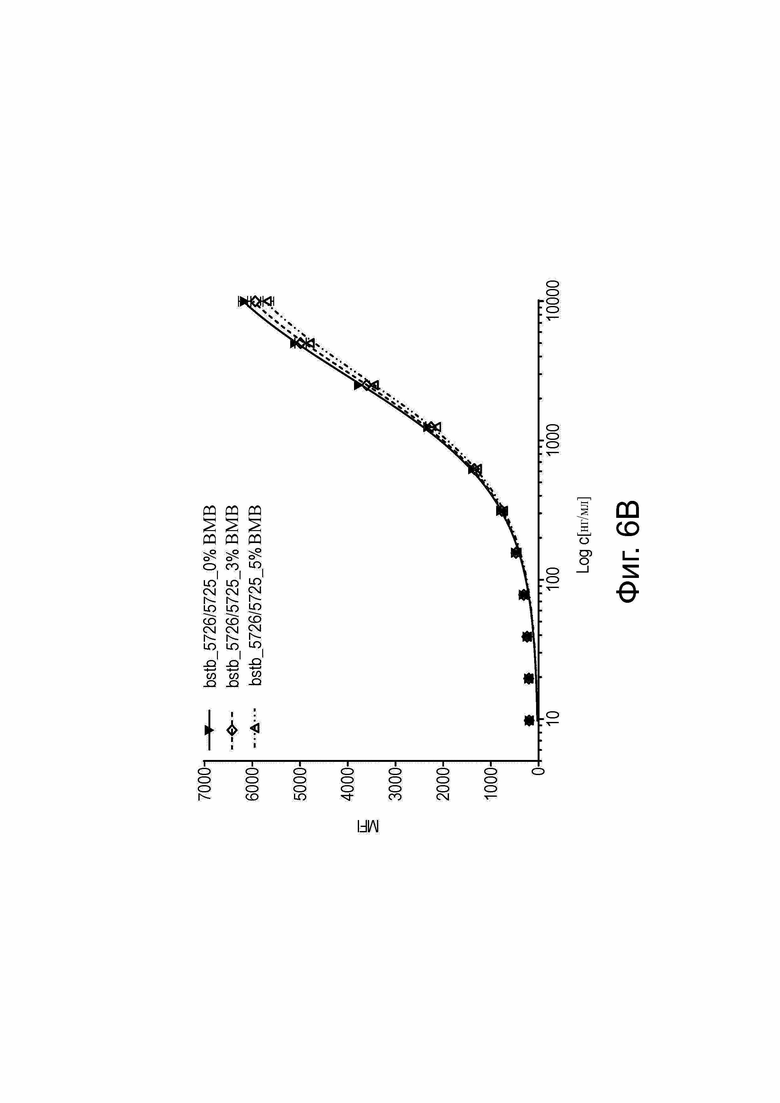
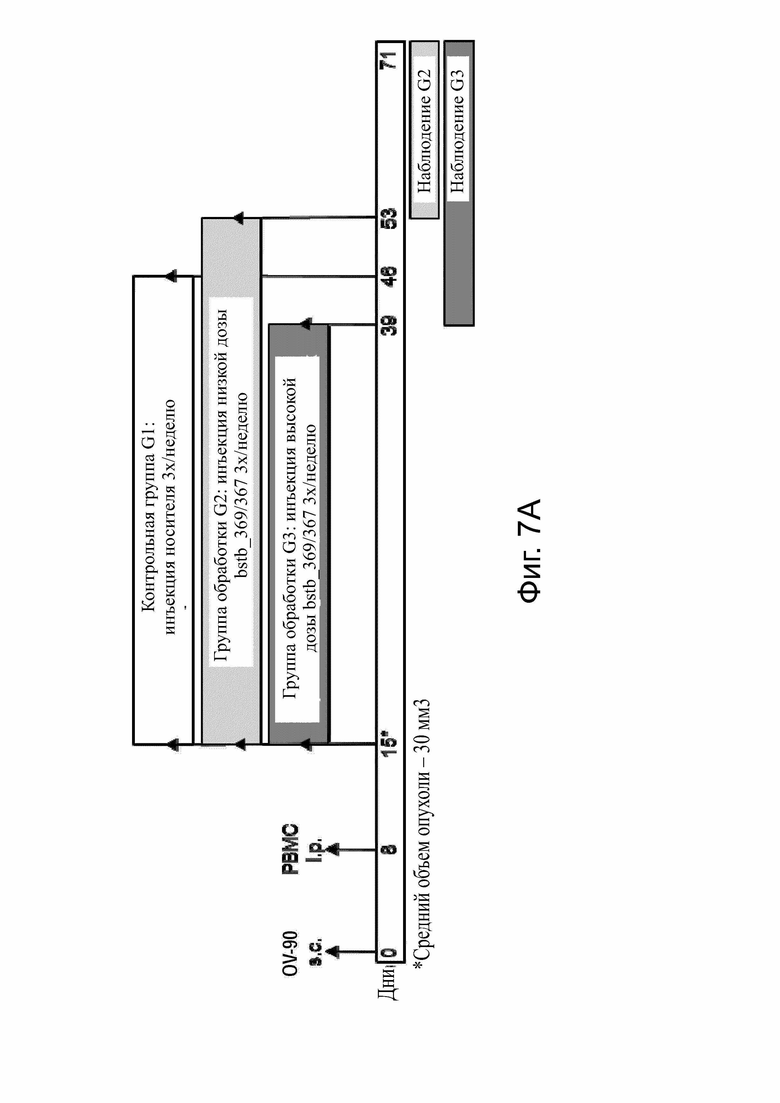
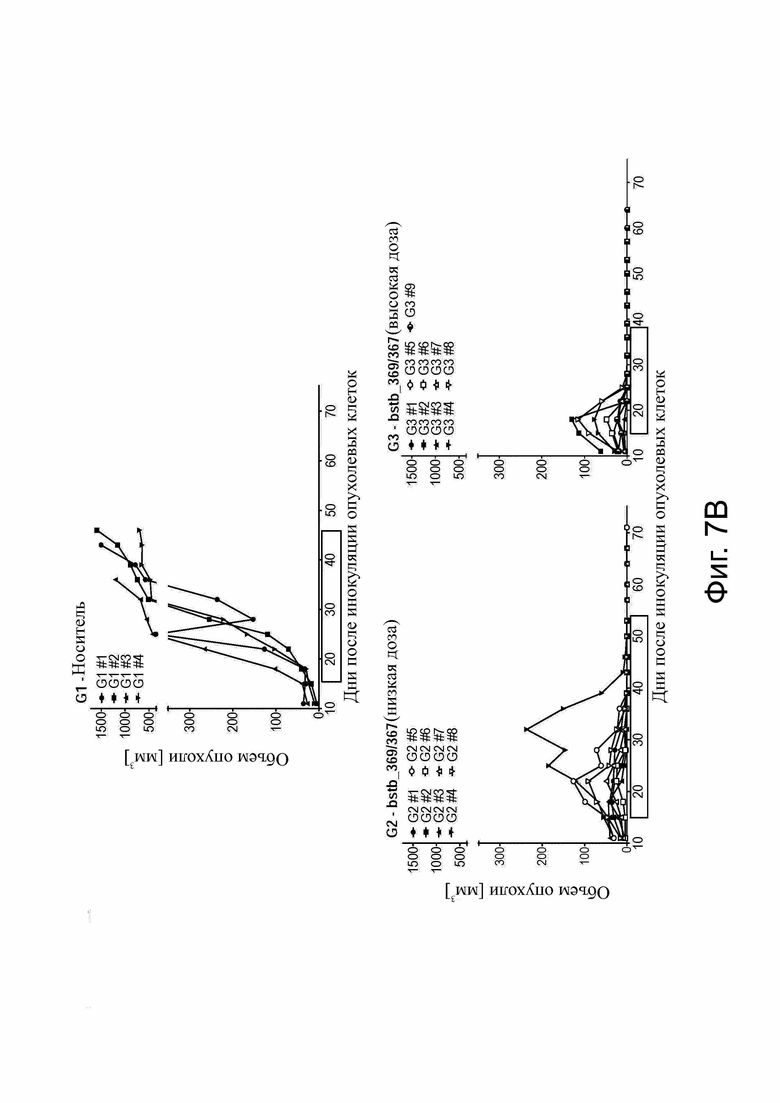
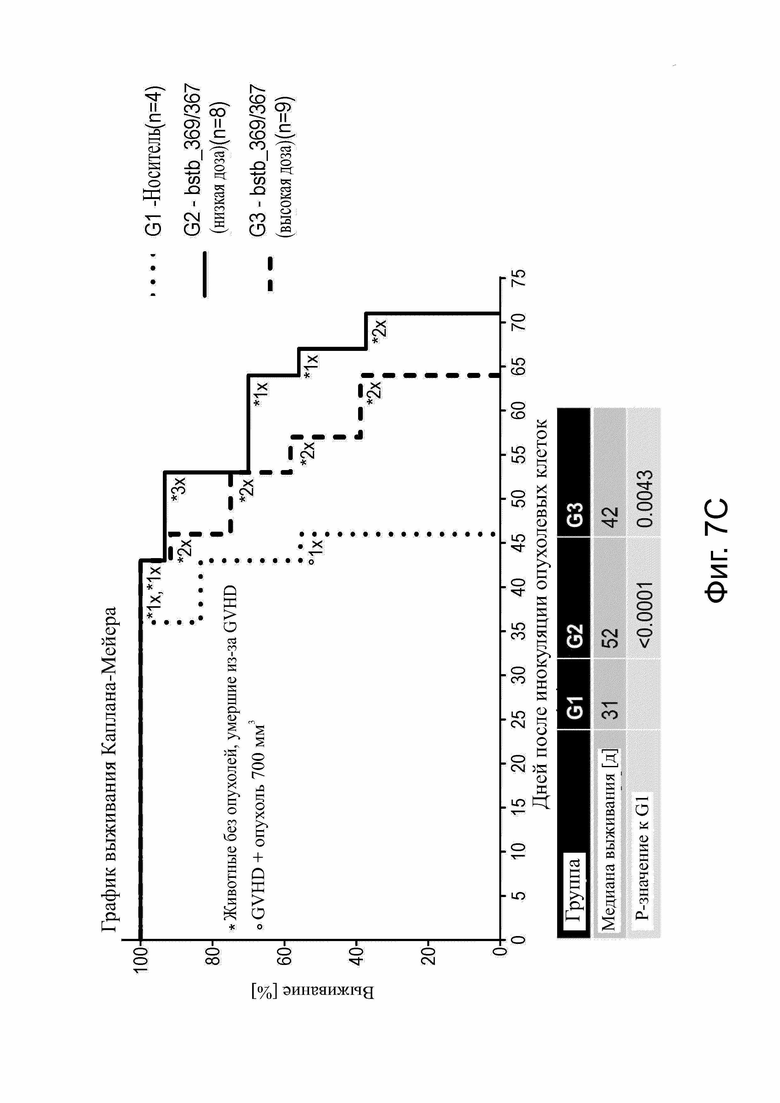
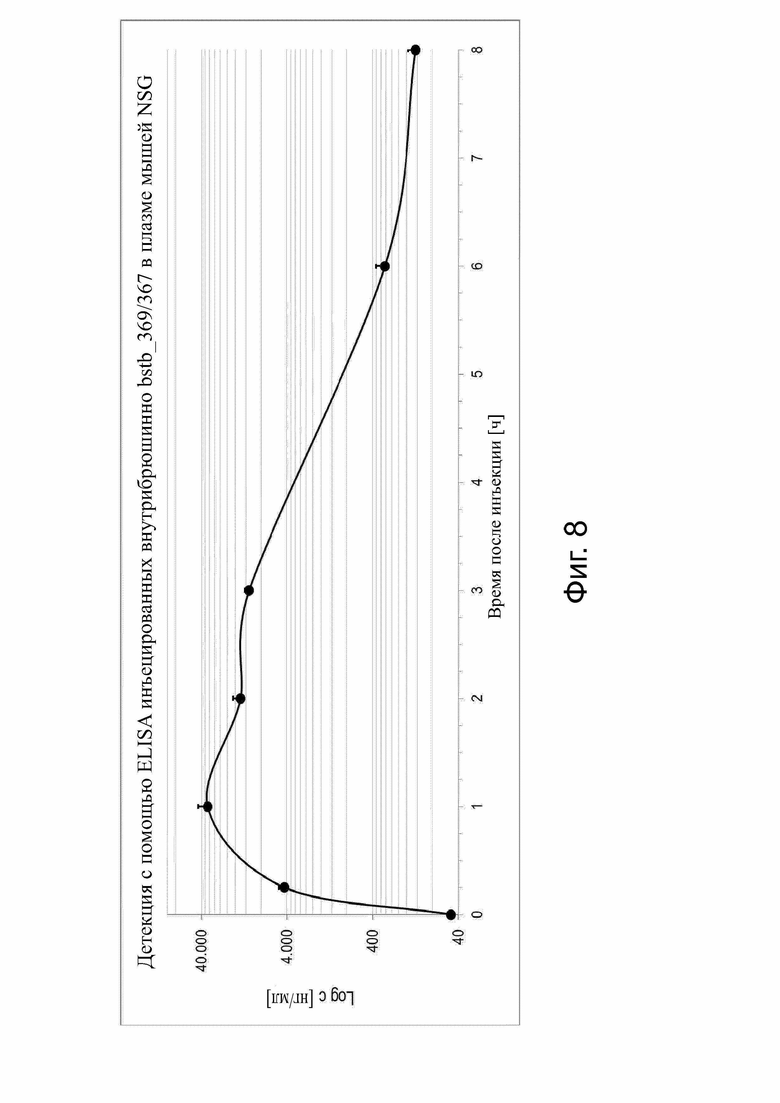
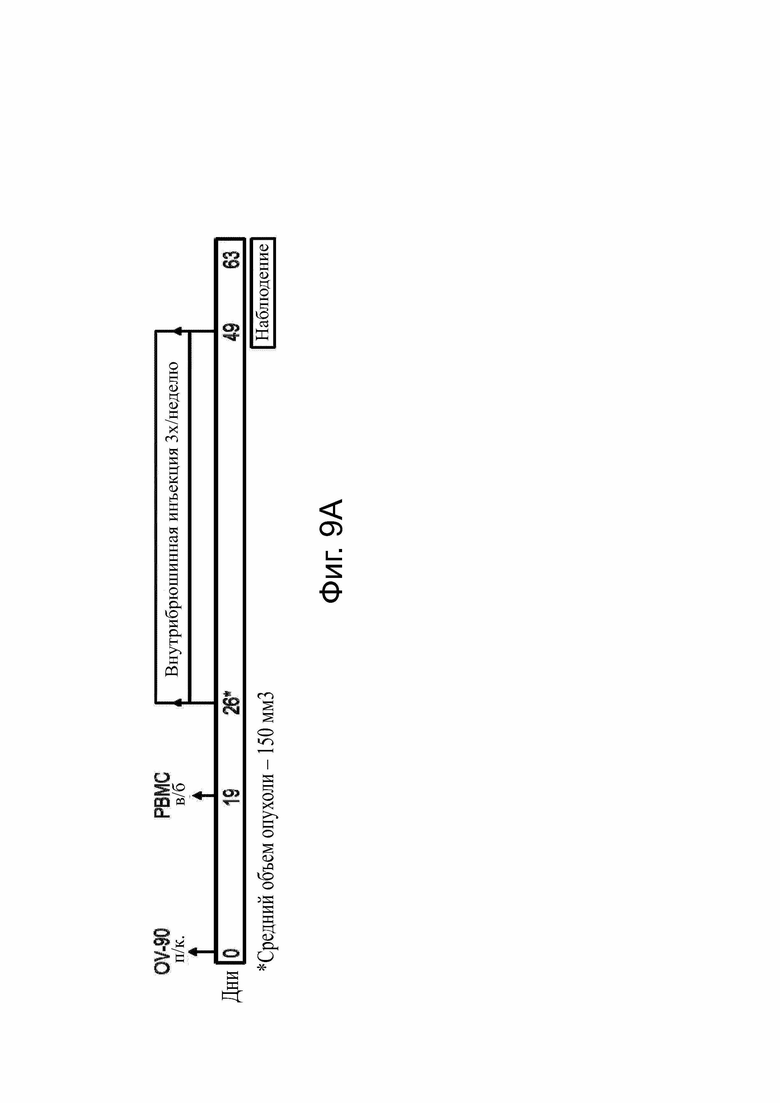
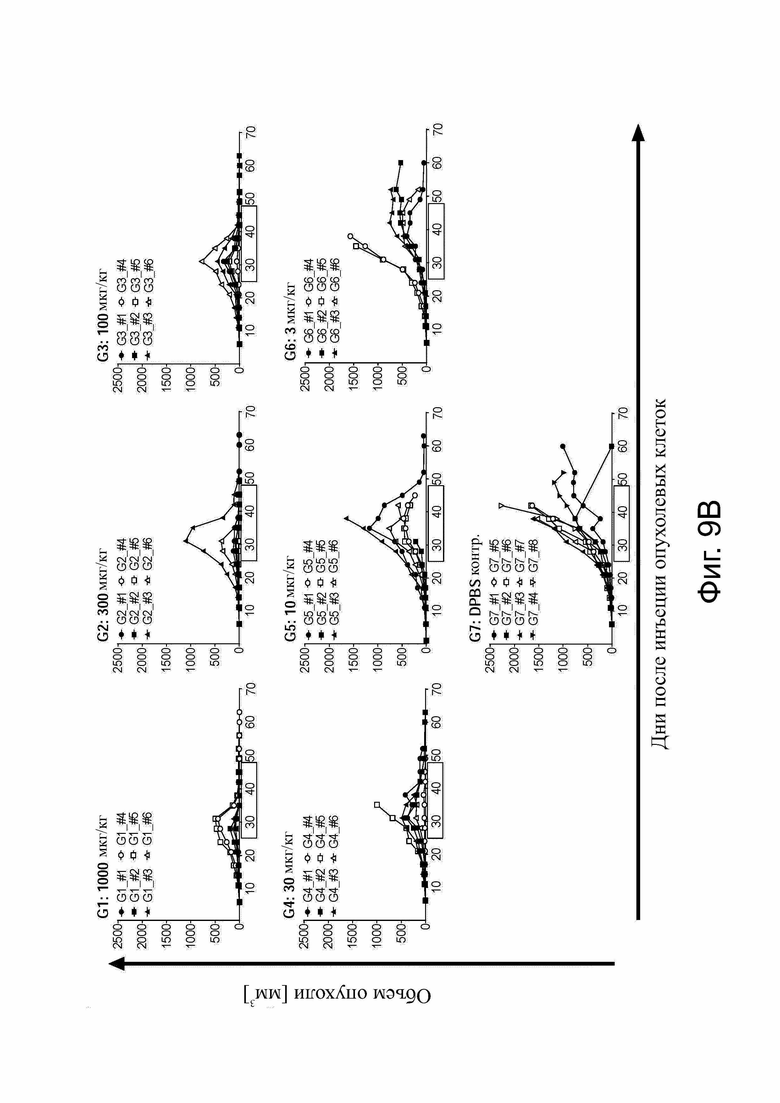
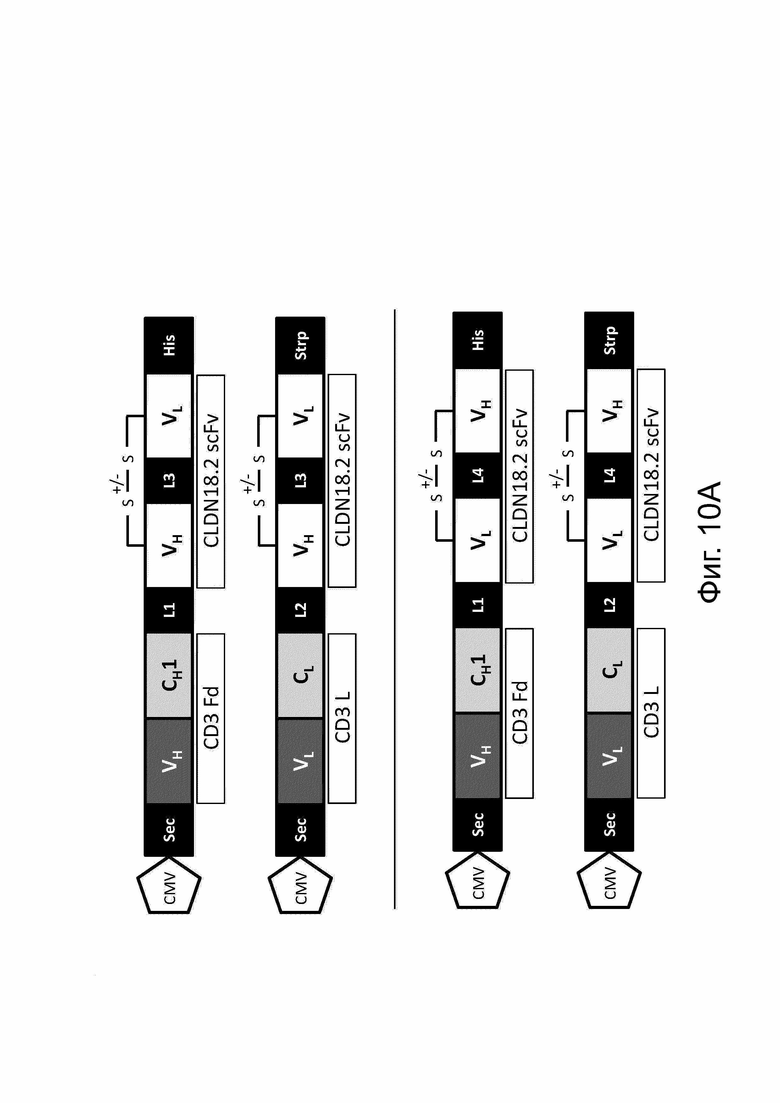
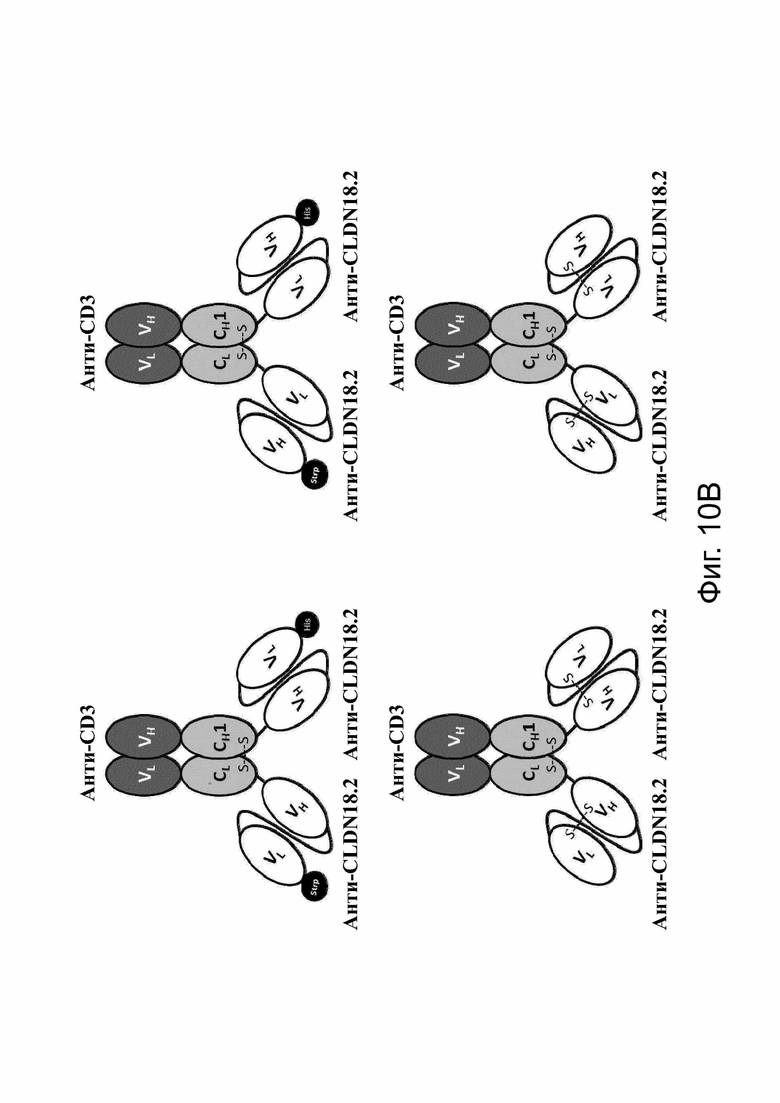

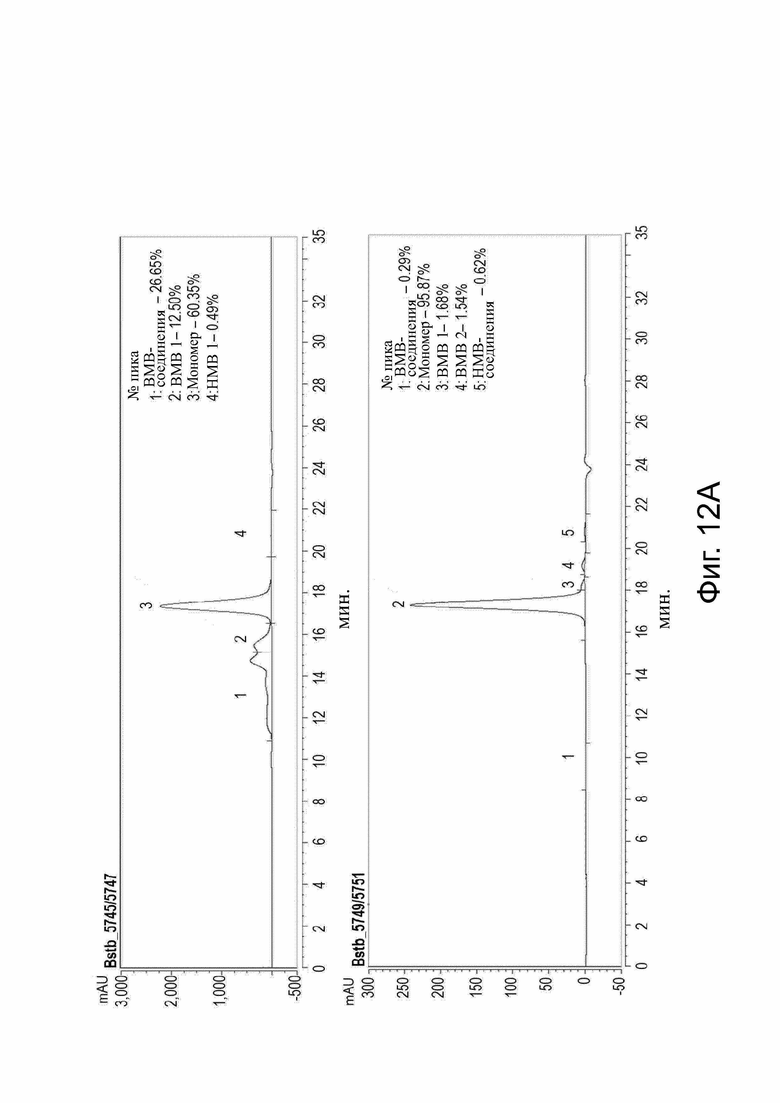
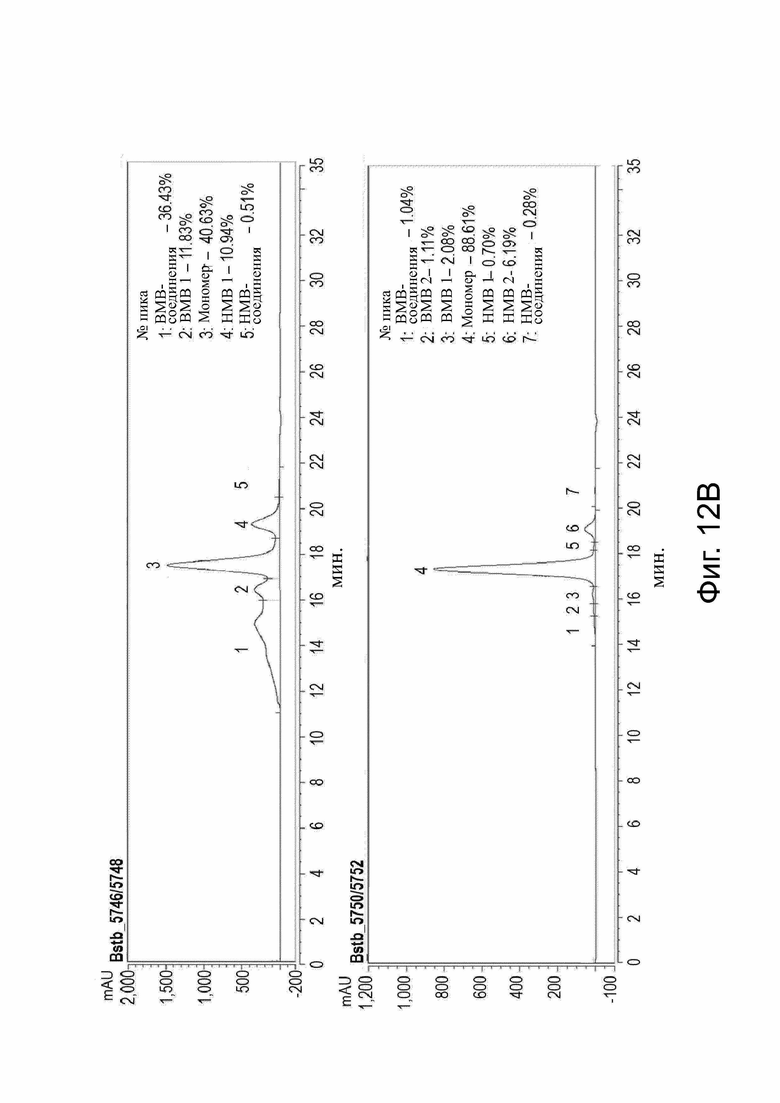
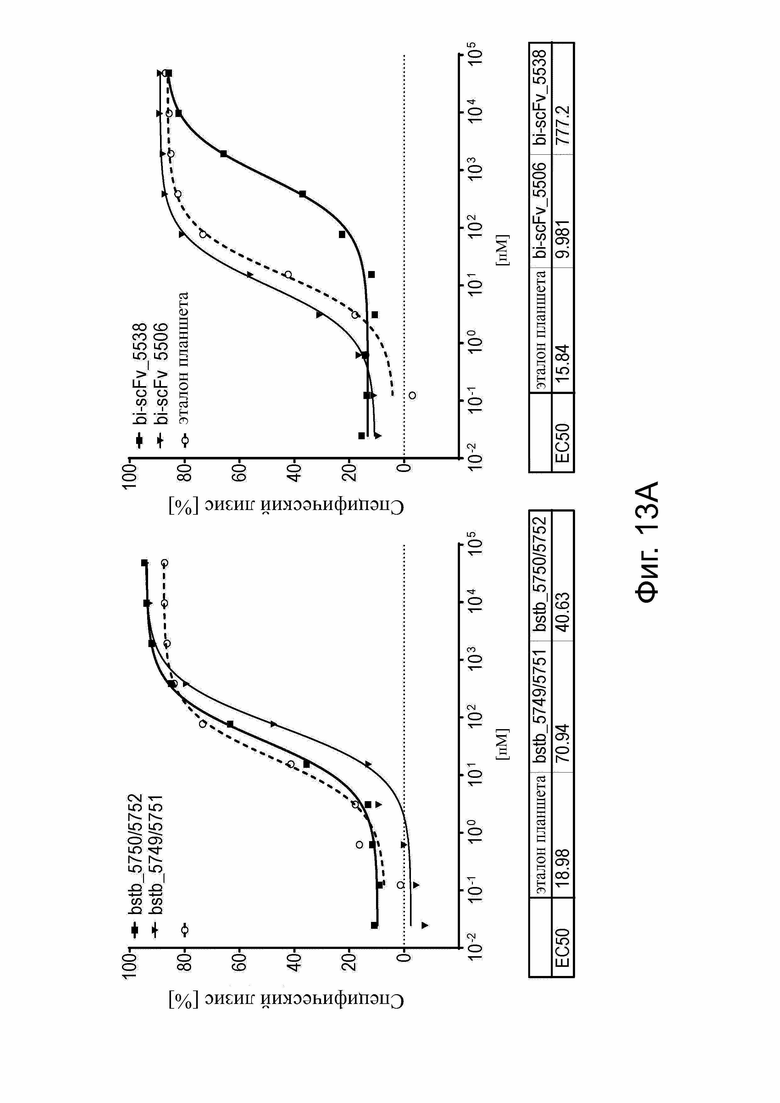
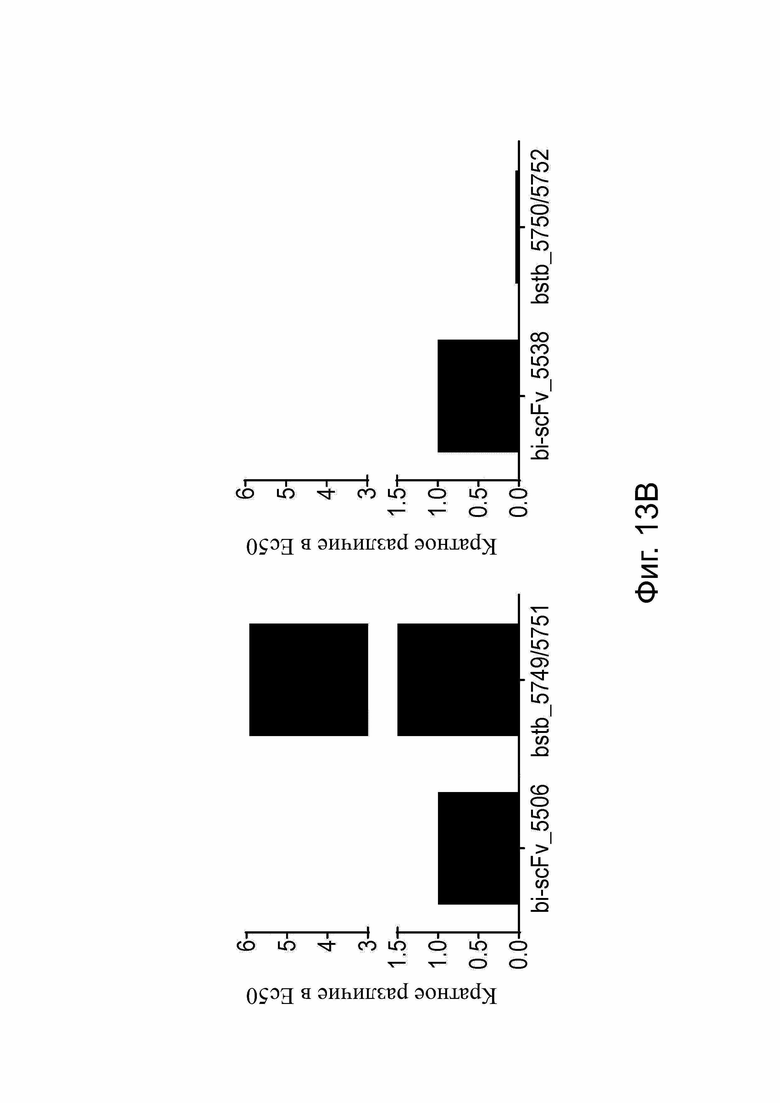
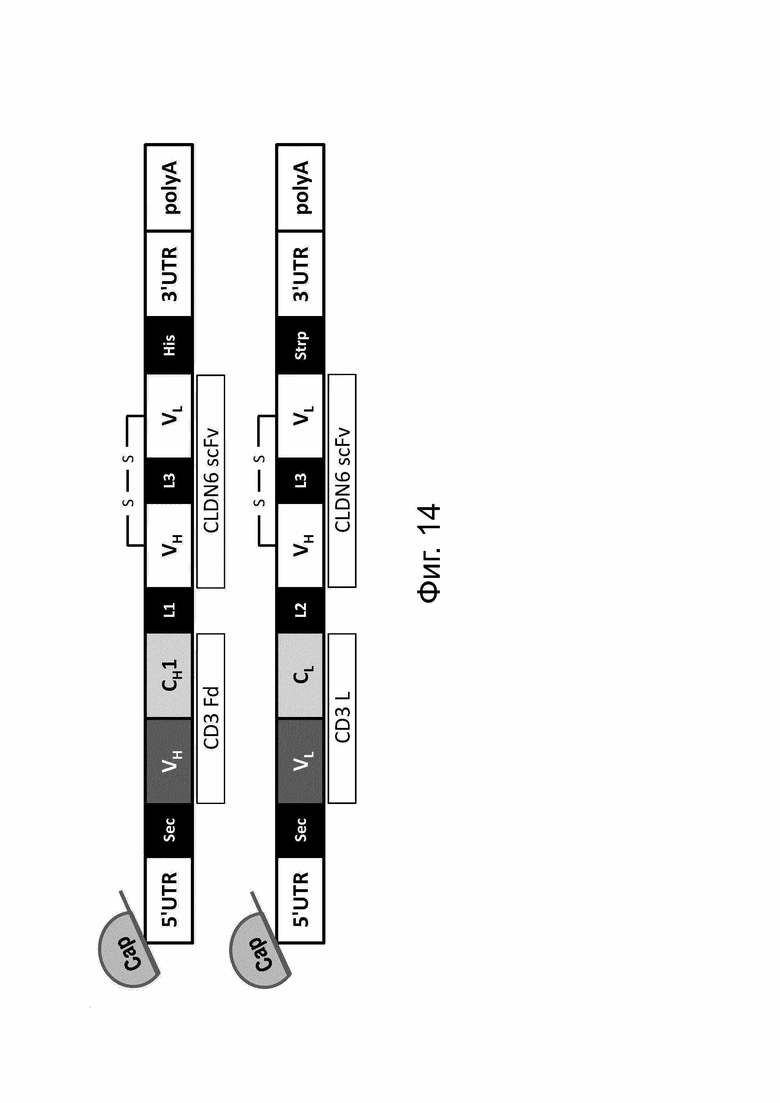



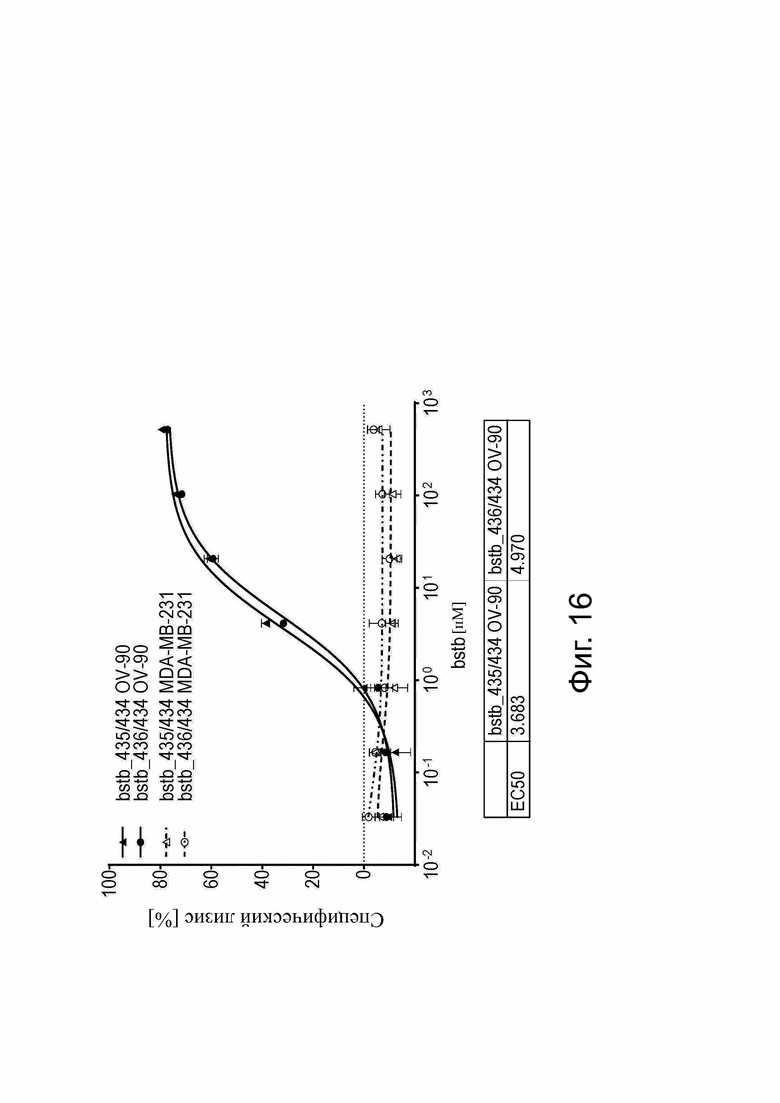

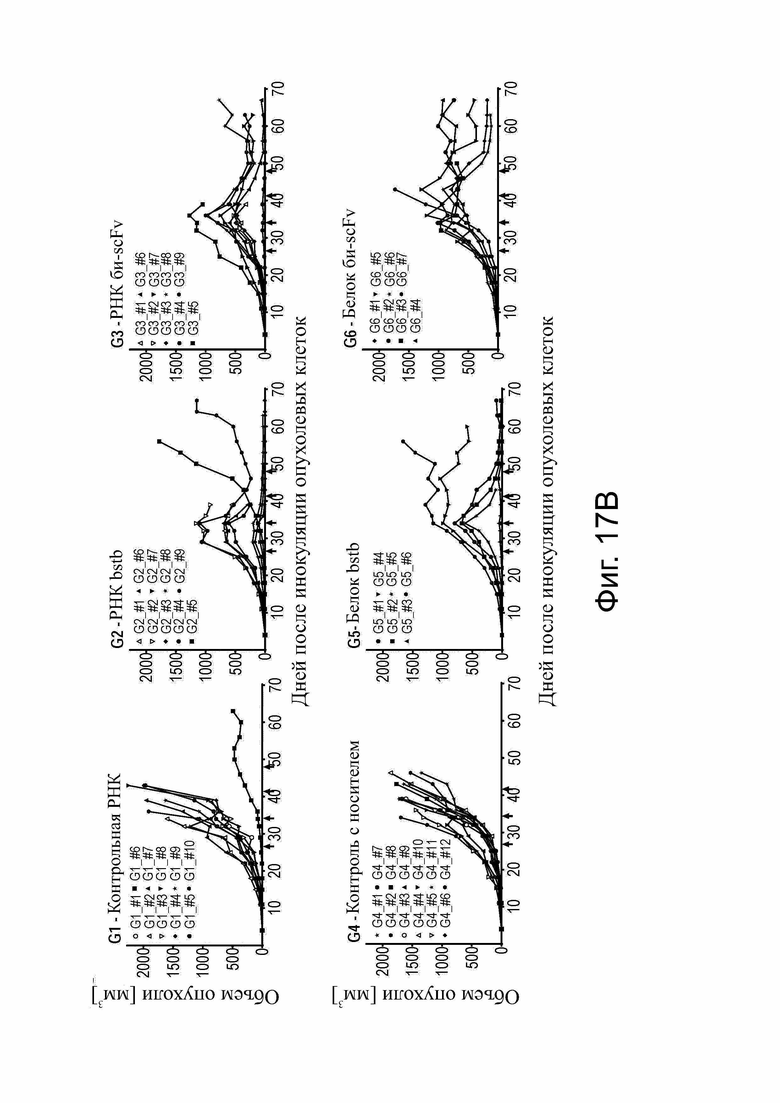
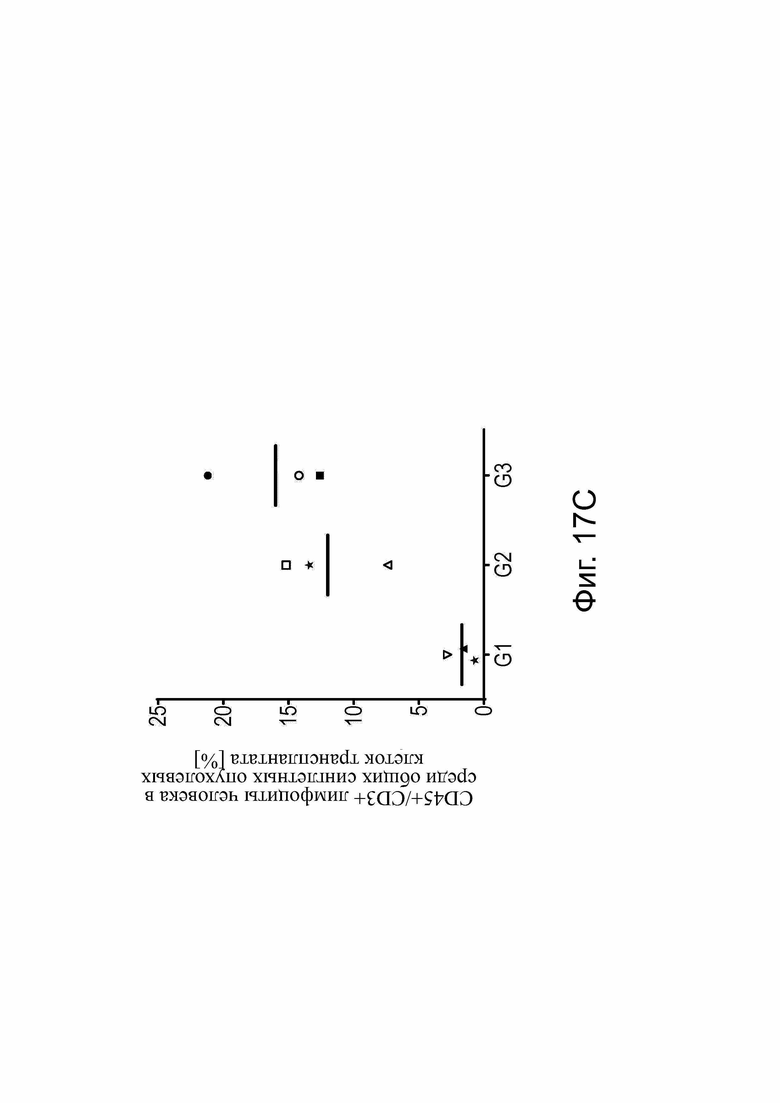


Изобретение относится к области биохимии, в частности к связывающему агенту, который связывается с Т-клеточным специфическим антигеном CD3 и клаудином 6 (CLDN6). Также раскрыты нуклеиновая кислота или смесь нуклеиновых кислот, кодирующих указанный агент; клетка-хозяин, содержащая указанную нуклеиновую кислоту; вектор или композиция векторов, содержащих указанную нуклеиновую кислоту; клетка-хозяин, содержащая указанную нуклеиновую кислоту; фармацевтическая композиция, содержащая указанный агент. Раскрыты применение указанного связывающего агента в качестве лекарственного средства, способ лечения или профилактики рака, с помощью указанного агента. Изобретение позволяет эффективно лечить заболевания, ассоциированные с экспрессией клаудина 6. 12 н. и 22 з.п. ф-лы, 14 пр., 10 табл., 18 ил.
1. Связывающий агент, который связывается с Т-клеточным специфическим антигеном CD3 и клаудином 6 (CLDN6), где связывающий агент содержит три связывающих домена, где первый связывающий домен связывается с Т-клеточным специфическим антигеном CD3, а второй связывающий домен и третий связывающий домен связываются с клаудином 6,
где первый связывающий домен имеет формат молекулы Fab, и второй связывающий домен и третий связывающий домен имеют формат молекулы scFv, где связывающий агент содержит
(а) первый полипептид, включающий вариабельный домен тяжелой цепи иммуноглобулина (VH) со специфичностью к Т-клеточному специфическому антигену CD3 (VH(CD3)), домен VH со специфичностью к клаудину 6 (VH(CLDN6)) и вариабельный домен легкой цепи иммуноглобулина (VL) со специфичностью к клаудину 6 (VL(CLDN6)); и
(b) второй полипептид, включающий домен VL со специфичностью к Т-клеточному антигену CD3 (VL(CD3)), домен VH со специфичностью к клаудину 6 (VH(CLDN6)) и домен VL со специфичностью к клаудину 6 (VL(CLDN6)),
где первый полипептид и второй полипептид связаны так, что образуют связывающий агент,
где
каждый VH(CD3) содержит:
HCDR1 имеющий аминокислотную последовательность GYTFTRYT,
HCDR2 имеющий аминокислотную последовательность INPSRGYT, и
HCDR3 имеющий аминокислотную последовательность ARYYDDHYSLDY;
а каждый VL(CD3) содержит:
LCDR1 имеющий аминокислотную последовательность SSVSY,
LCDR2 имеющий аминокислотную последовательность DTS, и
LCDR3 имеющий аминокислотную последовательность QQWSSNPLT,
и
где
каждый VH(CLDN6) содержит:
HCDR1 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 44,
HCDR2 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 45, и
HCDR3 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 46;
и каждый VL(CLDN6) содержит:
LCDR1 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 50,
LCDR2 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 51, и
LCDR3 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 52.
2. Связывающий агент по п. 1, отличающийся тем, что первый полипептид дополнительно включает константный домен 1 тяжелой цепи иммуноглобулина (CH1), а второй полипептид дополнительно включает константный домен легкой цепи иммуноглобулина (CL), где оба домена обладают способностью к ассоциации.
3. Связывающий агент по п. 2, отличающийся тем, что первый полипептид и второй полипептид ковалентно связаны через дисульфидный мостик между доменом CH1 и доменом CL.
4. Связывающий агент по п. 2 или 3, отличающийся тем, что в первом полипептиде и втором полипептиде домен(ы) VH, домен(ы) VL, домен CH1 и домен CL расположены от N-конца до C -конец, в порядке
-VH(CD3)-CH1-VH(CLDN6)-VL(CLDN6) и VL(CD3)-CL-VH(CLDN6)-VL(CLDN6); или
VH(CD3)-CH1-VL(CLDN6)-VH(CLDN6) и VL(CD3)-CL-VL(CLDN6)-VH(CLDN6).
5. Связывающий агент по п. 4, отличающийся тем, что домены VH-VL или VL-VH связаны с доменом CH1 или доменом CL через пептидный линкер, например, пептидный линкер, содержащий аминокислотную последовательность DVPG2S или SGPG3RS(G4S)2.
6. Связывающий агент по п. 4 или 5, отличающийся тем, что домены VH и VL связаны через пептидный линкер с образованием доменов VH-VL или VL-VH, таких как пептидный линкер, содержащий аминокислотную последовательность (G4S)x, где х равен 3, 4, 5 или 6.
7. Связывающий агент по любому из пп. 1-6, отличающийся тем, что Т-клеточный специфический антиген экспрессируется на поверхности Т-клетки.
8. Связывающий агент по любому из пп. 1-7, отличающийся тем, что связывание связывающего агента с Т-клеточным специфическим антигеном CD3 на Т-клетках приводит к пролиферации и/или активации Т-клеток.
9. Связывающий агент по п. 1, отличающийся тем, что первый связывающий домен связывается с эпсилон-цепью CD3.
10. Связывающий агент по любому из пп. 1-9, отличающийся тем, что клаудин 6 экспрессируется на поверхности раковой клетки.
11. Связывающий агент по любому из пп. 1-10, отличающийся тем, что связывающий агент связывается с внеклеточным доменом клаудина 6.
12. Связывающий агент по любому из пп. 1-11, отличающийся тем, что связывание с Т-клеточным специфическим антигеном CD3 и/или связывание с клаудином 6 является специфическим связыванием.
13. Связывающий агент по любому из пп. 1-12, отличающийся тем, что связывающий агент индуцирует опосредованную Т-клетками цитотоксичность в отношении раковых клеток, экспрессирующих клаудин 6.
14. Связывающий агент по п. 13, отличающийся тем, что связывающий агент индуцирует опосредованную Т-клетками цитотоксичность против раковых клеток, экспрессирующих клаудин 6, с ЕС50 < 10 нМ или < 1 нМ или < 500 пМ, или < 250 пМ, или < 100 пМ, или < 50 пМ.
15. Связывающий агент по любому из пп. 10-14, отличающийся тем, что раковая(ые) клетка(и) являются клетками или получены из клеток рака, выбранного из группы, состоящей из: рака мочевого пузыря, рака яичника, в частности аденокарциномы яичника и тератокарциномы яичника, рака легкого, включая мелкоклеточный рак легкого (SCLC) и немелкоклеточный рак легкого (NSCLC), в частности плоскоклеточный рак легкого и аденокарцинома, рака желудка, рака молочной железы, рака печени, рака поджелудочной железы, рака кожи, в частности базальноклеточной карциномы и плоскоклеточной карциномы, злокачественной меланомы, рака головы и шеи, в частности злокачественной плеоморфной аденомы, саркомы, в частности синовиальной саркомы и карциносаркомы, рака желчных протоков, рака мочевого пузыря, в частности переходно-клеточной карциномы и папиллярной кациномы, рака почки, в частности почечно-клеточной карциномы, включая светлоклеточную почечно-клеточную карциному и папиллярную почечно-клеточную карциному, рака толстой кишки, рака тонкой кишки, включая рак подвздошной кишки, в частности аденокарциномы тонкой кишки и аденокарциномы подвздошной кишки, эмбриональной карциномы яичка, плацентарной хориокарциномы, рака шейки матки, рака яичка, в частности семиномы яичка, тератомы яичка и эмбрионального рака яичка, рака матки, опухолей половых клеток, таких как тератокарцинома или эмбриональная карцинома, в частности герминомы яичка, и их метастатических форм.
16. Связывающий агент по любому из пп. 1-15, отличающийся тем, что VH(CD3) включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 5 или варианта аминокислотной последовательности, где данный вариант по меньшей мере на 95% идентичен аминокислотной последовательности, представленной SEQ ID NO: 5 по всей длине, или где указанный вариант содержит максимум одну замену аминокислоты в аминокислотной последовательности, представленной SEQ ID NO: 5 и/или
VL(CD3) включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 6, или варианта аминокислотной последовательности, где вариант по меньшей мере на 95% идентичен аминокислотной последовательности, представленной SEQ ID NO: 6 по всей длине, или где вариант содержит максимум одну замену аминокислоты в аминокислотной последовательности, представленной SEQ ID NO: 6.
17. Связывающий агент по любому из пп. 1-16, в котором VH (CLDN6) включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 8, или варианта аминокислотной последовательности, где вариант по меньшей мере на 95% идентичен аминокислотной последовательности, представленной SEQ ID NO: 8 по всей длине, или где вариант содержит максимум одну замену аминокислоты в аминокислотной последовательности, представленной SEQ ID NO: 8, и/или
VL(CLDN6) включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 10, или варианта аминокислотной последовательности, где вариант по меньшей мере на 95% идентичен аминокислотной последовательности, представленной SEQ ID NO: 10 по всей длине, или где вариант содержит максимум одну замену аминокислоты в аминокислотной последовательности, представленной SEQ ID NO: 10.
18. Связывающий агент по любому из пп. 1-17, отличающийся тем, что первый полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 14, или варианта аминокислотной последовательности где вариант по меньшей мере на 95% идентичен аминокислотной последовательности, представленной SEQ ID NO: 14 по всей длине, или где вариант содержит максимум одну замену аминокислоты в аминокислотной последовательности, представленной SEQ ID NO: 14, и
второй полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO. 16, или варианта аминокислотной последовательности, где вариант по меньшей мере на 95% идентичен аминокислотной последовательности, представленной SEQ ID NO: 16 по всей длине, или где вариант содержит максимум одну замену аминокислоты в аминокислотной последовательности, представленной SEQ ID NO: 16;
- первый полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 15, или варианта аминокислотной последовательности, где вариант по меньшей мере на 95% идентичен аминокислотной последовательности, представленной SEQ ID NO: 15 по всей длине, или где вариант содержит максимум одну замену аминокислоты в аминокислотной последовательности, представленной SEQ ID NO: 15, и
второй полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO. 16, или варианта аминокислотной последовательности, где вариант по меньшей мере на 95% идентичен аминокислотной последовательности, представленной SEQ ID NO: 16 по всей длине, или где вариант содержит максимум одну замену аминокислоты в аминокислотной последовательности, представленной SEQ ID NO: 16;
- первый полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 17, или варианта аминокислотной последовательности, где вариант по меньшей мере на 95% идентичен аминокислотной последовательности, представленной SEQ ID NO: 17 по всей длине, или где вариант содержит максимум одну замену аминокислоты в аминокислотной последовательности, представленной SEQ ID NO: 17, и
второй полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO. 19, или варианта аминокислотной последовательности, где вариант по меньшей мере на 95% идентичен аминокислотной последовательности, представленной SEQ ID NO: 19 по всей длине, или где вариант содержит максимум одну замену аминокислоты в аминокислотной последовательности, представленной SEQ ID NO: 19; или
- первый полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO: 18, или варианта аминокислотной последовательности, где вариант по меньшей мере на 95% идентичен аминокислотной последовательности, представленной SEQ ID NO: 18 по всей длине, или где вариант содержит максимум одну замену аминокислоты в аминокислотной последовательности, представленной SEQ ID NO: 18, и
второй полипептид включает или состоит из аминокислотной последовательности, представленной SEQ ID NO. 19, или варианта аминокислотной последовательности, где вариант по меньшей мере на 95% идентичен аминокислотной последовательности, представленной SEQ ID NO: 19 по всей длине, или где вариант содержит максимум одну замену аминокислоты в аминокислотной последовательности, представленной SEQ ID NO: 19.
19. Нуклеиновая кислота, кодирующая связывающий агент по любому из пп. 1-18, где связывающий агент содержит, по меньшей мере, три связывающих домена, где первый связывающий домен связывается с Т-клеточным специфическим антигеном CD3, а второй связывающий домен и третий связывающий домен связываются с клаудином 6,
где первый связывающий домен имеет формат молекулы Fab, и второй связывающий домен и третий связывающий домен имеют формат молекулы scFv, где связывающий агент содержит
(а) первый полипептид, включающий вариабельный домен тяжелой цепи иммуноглобулина (VH) со специфичностью к Т-клеточному специфическому антигену CD3 (VH(CD3)), домен VH со специфичностью к клаудину 6 (VH(CLDN6)) и вариабельный домен легкой цепи иммуноглобулина (VL) со специфичностью к клаудину 6 (VL(CLDN6)); и
(b) второй полипептид, включающий домен VL со специфичностью к Т-клеточному антигену CD3 (VL(CD3)), домен VH со специфичностью к клаудину 6 (VH(CLDN6)) и домен VL со специфичностью к клаудину 6 (VL(CLDN6)),
каждый VH(CD3) содержит:
HCDR1 имеющий аминокислотную последовательность GYTFTRYT,
HCDR2 имеющий аминокислотную последовательность INPSRGYT, и
HCDR3 имеющий аминокислотную последовательность ARYYDDHYSLDY;
а каждый VL(CD3) содержит:
LCDR1 имеющий аминокислотную последовательность SSVSY,
LCDR2 имеющий аминокислотную последовательность DTS, и
LCDR3 имеющий аминокислотную последовательность QQWSSNPLT,
и
каждый VH(CLDN6) содержит:
HCDR1 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 44,
HCDR2 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 45, и
HCDR3 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 46;
и каждый VL(CLDN6) содержит:
LCDR1 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 50,
LCDR2 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 51, и
LCDR3 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 52.
20. Нуклеиновая кислота по п. 19, которая находится в форме РНК.
21. Вектор, который содержит нуклеиновую кислоту по любому из пп.19-20, где вектор является экспессирующим вектором.
22. Клетка-хозяин для экспрессии связывающего агента, закодированного нуклеиновой кислотой, где клетка-хозяин содержит нуклеиновую кислоту по любому из пп. 19-20 или вектор по п. 21.
23. Смесь нуклеиновых кислот, кодирующая связывающий агент по любому из пп. 1-18, где смесь содержит:
(а) нуклеиновую кислоту или нуклеиновые кислоты, кодирующие первый полипептид, содержащийся в связывающем агенте, как определено в любом из пп. 1-18, гле первая полипептидная цепь включает вариабельный домен тяжелой цепи иммуноглобулина (VH) со специфичностью к Т-клеточному специфическому антигену CD3 (VH(CD3)), домен VH со специфичностью к клаудину 6 (VH(CLDN6)) и вариабельный домен легкой цепи иммуноглобулина (VL) со специфичностью к клаудину 6 (VL(CLDN6)); и/или
(b) нуклеиновую кислоту или нуклеиновые кислоты, кодирующие второй полипептид, содержащийся в связывающем агенте, как определено в любому из пп. 1-18, где второй полипептид включает домен VL со специфичностью к Т-клеточному антигену CD3 (VL(CD3)), домен VH со специфичностью к клаудину 6 (VH(CLDN6)) и домен VL со специфичностью к клаудину 6 (VL(CLDN6)),
каждый VH(CD3) содержит:
HCDR1 имеющий аминокислотную последовательность GYTFTRYT,
HCDR2 имеющий аминокислотную последовательность INPSRGYT, и
HCDR3 имеющий аминокислотную последовательность ARYYDDHYSLDY;
а каждый VL(CD3) содержит:
LCDR1 имеющий аминокислотную последовательность SSVSY,
LCDR2 имеющий аминокислотную последовательность DTS, и
LCDR3 имеющий аминокислотную последовательность QQWSSNPLT,
и
каждый VH(CLDN6) содержит:
HCDR1 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 44,
HCDR2 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 45, и
HCDR3 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 46;
и каждый VL(CLDN6) содержит:
LCDR1 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 50,
LCDR2 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 51, и
LCDR3 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 52.
24. Смесь нуклеиновых кислот кодирующая связывающий агент по любому из пп. 1-18, где смесь содержит нуклеиновые кислоты, кодирующие связывающий агент по любому из пп. 1-18, где связывающий агент содержит по меньшей мере три связывающих домена, где первый связывающий домен связывается с Т-клеточным специфическим антигеном CD3, а второй связывающий домен и третий связывающий домен связываются с клаудином 6,
где первый связывающий домен имеет формат молекулы Fab, и второй связывающий домен и третий связывающий домен имеют формат молекулы scFv, где связывающий агент содержит
(а) первый полипептид, включающий вариабельный домен тяжелой цепи иммуноглобулина (VH) со специфичностью к Т-клеточному специфическому антигену CD3 (VH(CD3)), домен VH со специфичностью к клаудину 6 (VH(CLDN6)) и вариабельный домен легкой цепи иммуноглобулина (VL) со специфичностью к клаудину 6 (VL(CLDN6)); и
(b) второй полипептид, включающий домен VL со специфичностью к Т-клеточному антигену CD3 (VL(CD3)), домен VH со специфичностью к клаудину 6 (VH(CLDN6)) и домен VL со специфичностью к клаудину 6 (VL(CLDN6)),
где первый полипептид и второй полипептид связаны так, что образуют связывающий агент,
где
каждый VH(CD3) содержит:
HCDR1 имеющий аминокислотную последовательность GYTFTRYT,
HCDR2 имеющий аминокислотную последовательность INPSRGYT, и
HCDR3 имеющий аминокислотную последовательность ARYYDDHYSLDY;
а каждый VL(CD3) содержит:
LCDR1 имеющий аминокислотную последовательность SSVSY,
LCDR2 имеющий аминокислотную последовательность DTS, и
LCDR3 имеющий аминокислотную последовательность QQWSSNPLT,
и
где
каждый VH(CLDN6) содержит:
HCDR1 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 44,
HCDR2 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 45, и
HCDR3 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 46;
и каждый VL(CLDN6) содержит:
LCDR1 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 50,
LCDR2 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 51, и
LCDR3 имеющий аминокислотную последовательность приведенную в SEQ ID NO: 52.
25. Смесь нуклеиновых кислот по п. 23 или 24, где нуклеиновые кислоты находятся в форме РНК.
26. Композиция векторов для экспрессии связывающего агента, где композиция содержит смесь нуклеиновых кислот по любому из пп. 23-25, где нуклеиновые кислоты в смеси нуклеиновых кислот находятся в форме векторов.
27. Клетка-хозяин для экспрессии связывающего агента, закодированного нуклеиновыми кислотами, где клетка-хозяин содержит смесь нуклеиновых кислот по любому из пп. 23-26.
28. Применение связывающего агента по любому из пп. 1-18, нуклеиновой кислоты по любому из пп. 19-20, вектора по п. 21, клетки-хозяина по п. 22 или 27, смеси нуклеиновых кислот по любому из пп. 23 - 25, или композиции по п. 26 в качестве лекарственного средства для лечения или профилактики рака, характеризующегося экспрессией клаудина 6.
29. Применение связывающего агента по любому из пп. 1-18, нуклеиновой кислоты по любому из пп. 19-20, вектора по п. 21, клетки-хозяина по п. 22 или 27, смеси нуклеиновых кислот по любому из пп. 23 - 25, или композиции по п. 26 в лечении или профилактике рака, характеризующегося тем, что раковые клетки экспрессируют клаудин, с которым способен связываться связывающий агент.
30. Применение по п. 28 или 29, отличающееся тем, что рак выбран из группы, состоящей из рака мочевого пузыря, рака яичника, в частности аденокарциномы яичника и тератокарциномы яичника, рака легкого, включая мелкоклеточный рак легкого (SCLC) и немелкоклеточный рак легкого (NSCLC), в частности плоскоклеточный рак легкого и аденокарцинома, рака желудка, рака молочной железы, рака печени, рака поджелудочной железы, рака кожи, в частности базальноклеточной карциномы и плоскоклеточной карциномы, злокачественной меланомы, рака головы и шеи, в частности злокачественной плеоморфной аденомы, саркомы, в частности синовиальной саркомы и карциносаркомы, рака желчных протоков, рака мочевого пузыря, в частности переходно-клеточной карциномы и папиллярной кациномы, рака почки, в частности почечно-клеточной карциномы, включая светлоклеточную почечно-клеточную карциному и папиллярную почечно-клеточную карциному, рака толстой кишки, рака тонкой кишки, включая рак подвздошной кишки, в частности аденокарциномы тонкой кишки и аденокарциномы подвздошной кишки, эмбриональной карциномы яичка, плацентарной хориокарциномы, рака шейки матки, рака яичка, в частности семиномы яичка, тератомы яичка и эмбрионального рака яичка, рака матки, опухолей половых клеток, таких как тератокарцинома или эмбриональная карцинома, в частности герминомы яичка, и их метастатических форм.
31. Фармацевтическая композиция для лечения рака, характеризующегося тем, что раковые клетки экспрессируют клаудин 6, где фармацевтическая композиция включает связывающий агент по любому из пп. 1-18, нуклеиновую кислоту по любому из пп. 19-20, вектор по п. 21, клетку-хозяина по п. 22 или 27, смесь нуклеиновых кислот по любому из пп. 23-25, или композицию по п. 26, где связывающий агент способен связываться с указанным клаудином 6.
32. Фармацевтическая композиция по п. 31, отличающаяся тем, что рак выбран из группы, состоящей из рака мочевого пузыря, рака яичника, в частности аденокарциномы яичника и тератокарциномы яичника, рака легкого, включая мелкоклеточный рак легкого (SCLC) и немелкоклеточный рак легкого (NSCLC), в частности плоскоклеточный рак легкого и аденокарцинома, рака желудка, рака молочной железы, рака печени, рака поджелудочной железы, рака кожи, в частности базальноклеточной карциномы и плоскоклеточной карциномы, злокачественной меланомы, рака головы и шеи, в частности злокачественной плеоморфной аденомы, саркомы, в частности синовиальной саркомы и карциносаркомы, рака желчных протоков, рака мочевого пузыря, в частности переходно-клеточной карциномы и папиллярной кациномы, рака почки, в частности почечно-клеточной карциномы, включая светлоклеточную почечно-клеточную карциному и папиллярную почечно-клеточную карциному, рака толстой кишки, рака тонкой кишки, включая рак подвздошной кишки, в частности аденокарциномы тонкой кишки и аденокарциномы подвздошной кишки, эмбриональной карциномы яичка, плацентарной хориокарциномы, рака шейки матки, рака яичка, в частности семиномы яичка, тератомы яичка и эмбрионального рака яичка, рака матки, опухолей половых клеток, таких как тератокарцинома или эмбриональная карцинома, в частности герминомы яичка, и их метастатических форм.
33. Способ лечения или профилактики рака, характеризующегося тем, что раковые клетки экспрессируют клаудин 6, включающий введение нуждающегося в этом субъекту связывающегося агента по п. 1 по 18, нуклеиновой кислоты по любому из пп. 19-20, вектора по п. 21 для экспрессии связывающего агента, закодированного нуклеиновой кислотой, клетки-хозяина по п. 22 или 27 для продукции связывающего агента, закодированного нуклеиновой кислотой, смеси нуклеиновых кислот по любому из пп. 23-25, или композиции векторов по п. 26 для экспрессии связывающего агента, закодированного нуклеиновой кислотой или фармацевтической композиции по п. 31 или 32, где связывающий агент способен связываться с указанным клаудином.
34. Способ лечения или профилактики рака по п. 33, отличающийся тем, что рак выбран из группы, состоящей из рака мочевого пузыря, рака яичника, в частности аденокарциномы яичника и тератокарциномы яичника, рака легкого, включая мелкоклеточный рак легкого (SCLC) и немелкоклеточный рак легкого (NSCLC), в частности плоскоклеточный рак легкого и аденокарцинома, рака желудка, рака молочной железы, рака печени, рака поджелудочной железы, рака кожи, в частности базальноклеточной карциномы и плоскоклеточной карциномы, злокачественной меланомы, рака головы и шеи, в частности злокачественной плеоморфной аденомы, саркомы, в частности синовиальной саркомы и карциносаркомы, рака желчных протоков, рака мочевого пузыря, в частности переходно-клеточной карциномы и папиллярной кациномы, рака почки, в частности почечно-клеточной карциномы, включая светлоклеточную почечно-клеточную карциному и папиллярную почечно-клеточную карциному, рака толстой кишки, рака тонкой кишки, включая рак подвздошной кишки, в частности аденокарциномы тонкой кишки и аденокарциномы подвздошной кишки, эмбриональной карциномы яичка, плацентарной хориокарциномы, рака шейки матки, рака яичка, в частности семиномы яичка, тератомы яичка и эмбрионального рака яичка, рака матки, опухолей половых клеток, таких как тератокарцинома или эмбриональная карцинома, в частности герминомы яичка, и их метастатических форм.
| RU 2012123995 A, 20.12.2013 | |||
| WO 2014075697 A1, 22.05.2014 | |||
| WO 2015113576 A1, 06.08.2015 | |||
| WO 2014075788 A1, 22.05.2014 | |||
| WO 2016087416 A1, 09.06.2016. |
