Классификации:
C12Q 1/6869…методы секвенирования
C12Q 1/6876…продукты, используемые в анализе нуклеиновых кислот, например праймеры
C12Q 1/6888…для обнаружения или идентификации организмов
Область техники, к которой относится изобретение
Изобретение относится к области молекулярной биологии, биотехнологии, судебной медицины и криминалистики, генетическим исследованиям в области идентификации человека.
В настоящее время ДНК-анализ является наиболее доказательным методом анализа биологического материала при производстве судебно-медицинской идентификационной экспертизы. Идентификация личности по биологическим образцам почти всегда требует анализа полиморфизмов ДНК. ДНК-анализ позволяет исследовать специфичные для каждого человека участки генома, и получить, таким образом, уникальный генетический "паспорт" или генетически профиль индивида. Индивидуализирующие признаки, определяемые на уровне ДНК, характеризуются почти абсолютной устойчивостью, то есть сохраняются в организме человека неизменными на продолжении всей жизни. Анализ ДНК-профилей человека используется в криминалистике с 1985 года. В начале 1990-х годов короткие тандемные повторы (STR) были введены в качестве нового типа полиморфного ДНК-маркера и с тех пор стали золотым стандартом идентификации человека в базах данных ДНК, уголовных дел, анализа отцовства и родства, а также идентификации пропавших без вести лиц. Успехи в разработке больших мультиплексных STR-панелей значительно увеличили силу дискриминации, что помогает в принятии и исключении решений об идентификации человека.
К настоящему времени разработано и выпускается большое количество наборов для генотипирования по аутосомным STR-маркерам, которые используются для ДНК-идентификации неизвестного индивида и установления биологического родства. В мировой практике основными панелями маркеров являются система CODIS (система комбинированного индекса ДНК: D3S1358, D5S818, D7S820, D8S1179, D13S317, D16S539, D18S51, D21S11, CSF1PO, FGA, ТН01, ТРОХ, и VWA) и европейская система ESS (D1S1656, D2S441, D10S1248, D12S391 и D22S1045). Также широко распространена расширенная панель CODIS, с дополнительными маркерами: D10S1248, D12S391, D19S433, D21S11, D22S1045, D2S1338, D2S441. Основной методологический подход для получения маркеров - мультиплексная амплификация, а для типирования маркеров - метод капиллярного электрофореза с использованием автоматических генетических анализаторов с лазериндуцированной флуоресцентной детекцией.
Ниже приводится линейка наборов, которые выпускаются на мировом рынке продукции для ДНК-идентификации на основе аутосомных SRT- маркеров и генотипировании методом КЭ:
- «GlobalFiler» (Thermo Fisher (США)) содержат все маркеры, рекомендованные для внесения в американскую систему CODIS и европейскую систему ESS.
- Interpol (acceptable), USA (CODIS core-loci) Old фирма Standard Sets (США)
- Investigator 24plex, Investigator IDplex Plus (GO!) (Qiagen) (Германия)
- Powerplex 1.1, Powerplex 16, Powerplex 16, Powerplex 35GY 8C (Promega) (США)
- EX 16, EX20, EX 22 (AGCU ScienTech)(Китай)
Также в настоящее время существуют аналогичные наборы российского производства: CORDIS-9 и COrDIS Plus. Которые позволяют амплифицировать 7 и 19 локусов, содержащих короткие тандемные повторы (STR-локусы) в геномной ДНК человека. Для набора COrDIS Plus из 19-ти анализируемых STR-локусов 13 составляют стандартную панель CODIS, 5 локусов рекомендованы ENFSI (Европейской Сетью Институтов Криминалистики) для расширения европейских национальных баз данных и локус SE33 - наиболее полиморфный из известных STR-маркеров. Российскую базу данных формируют на основе исследования 20 STR-локусов и гена амелогенина для определения пола. Очественненные наборы адаптированы для использования стандартного метода капиллярного электрофореза (КЭ).
Существенным недостатком импортных наборов для ДНК-идентификации является их значительная дороговизна, обусловленная необходимостью использования дорогостоящих расходных материалов (специфических ДНК-полимераз, растворов для ПЦР, буферных растворов). Для устранения указанных недостатков необходимым условием является повышение информативности предлагаемого набора и его экономичности.
Кроме того, на данном этапе развития технологий молекулярно-генетического анализа для исследования различных видов генетического полиморфизма, важное место в занимает технология широкомасштабного секвенирования - "массовое параллельное секвенирование" (NGS). Учитывая ускоренный прогресс в мире в оптимизации технологий секвенирования нового поколения для целей ДНК-идентификации, является целесообразным сосредоточение усилий в разработке наборов реагентов для анализа с помощью NGS технологий.
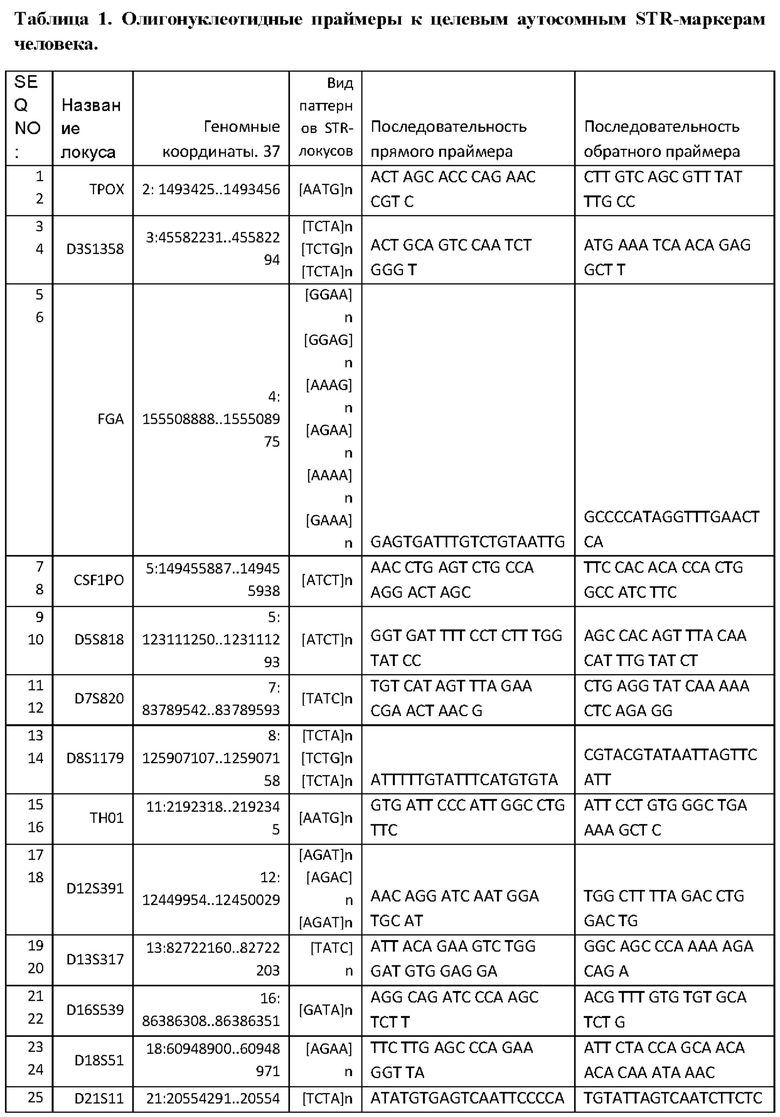
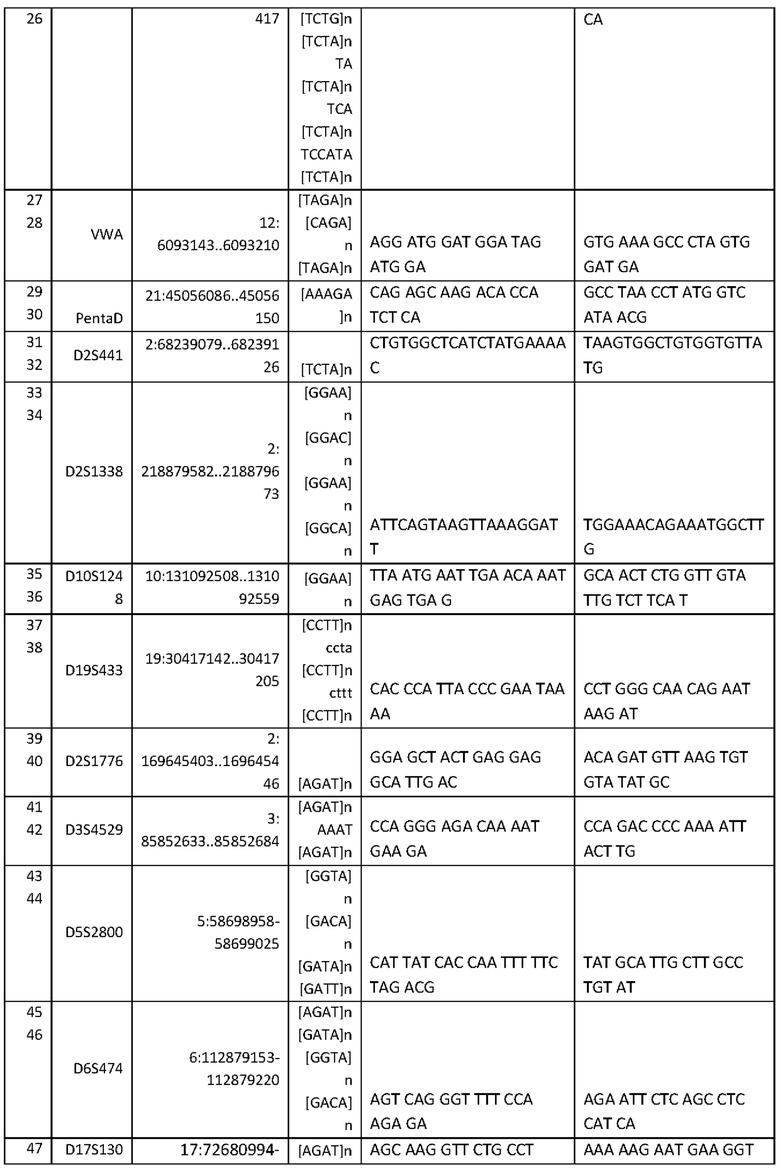
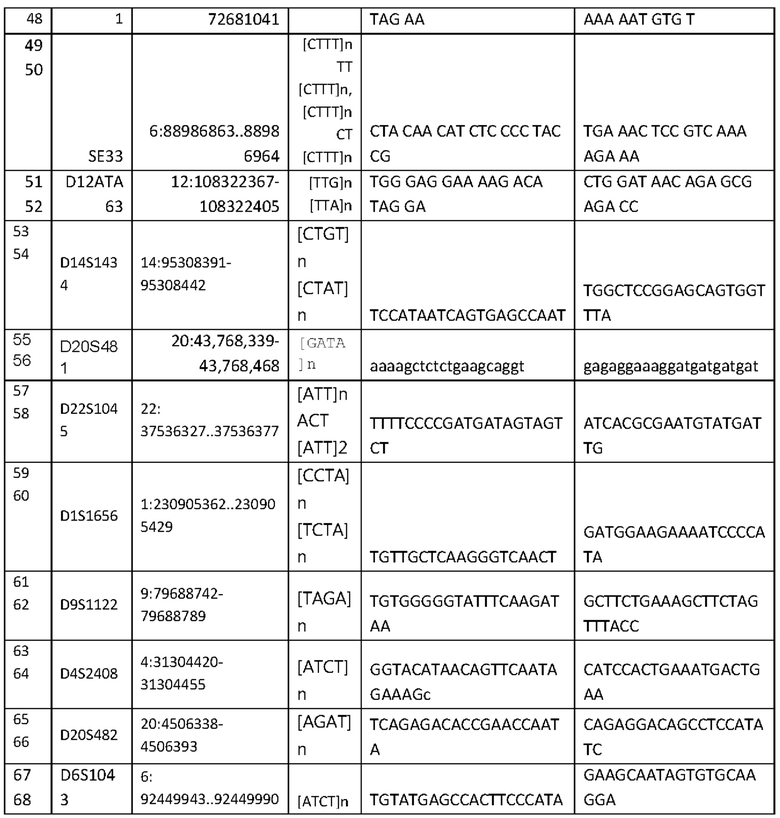
Для решения поставленной задачи авторами предложен набор из 34 пар синтетических олигонуклеотидных праймеров, комплементарных фланкирующим участкам локусов аутосомных STR-маркеров. При этом авторами были учтены некоторые моменты, ограничивающие использование аутосомных STR-маркеров применительно к методу "массового параллельного секвенирования" (NGS-секвенирование), а именно - размер ампликона, содержащего STR-маркер. Поэтому, авторами были подобраны олигонуклеотдные праймеры для успешной амплификации ПЦР-продукта минимального размера к стандартным маркерам из расширенной панели CODIS и панели ESS, так же были добавлены дополнительные новые апробированные маркеры меньшего размера для увеличения достоверности при использования метода NGS. Список выбранных аутосомных STR-маркеров: ТРОХ, D3S1358, FGA, D5S818, ТН01 D12S391, D13S317, D16S539, D18S51, D21S11, VWA, PentaD, D2S441, D10S1248, D19S433, D2S1776, D3S4529, D5S2800, D6S474, D17S1301, SE33, D12ATA63, D14S1434, D7S820, D8S1179, D2S1338, CSF1PO, D1S1656, D22S1045, D9S1122, D4S2408, D20S482, D6S1043, D20S481.
Изобретение раскрывает разработанные синтетические оригинальные олигонуклеотидные праймеры, позволяющие амплифицировать локусы, содержащие целевые молекулярно-генетические маркеры для последующего секвенирования с помощью метода «массового параллельного секвенирования». Набор для генотипирования включает композицию, образованную 34 парами синтетическими оригинальными олигонуклеотидными праймерами для локусов в геноме человека, включающих выбранных 34 аутосомных STR-маркеров, позволяющую проводить мультиплексную ПЦР (нуклеотидная последовательность праймеров SEQ ID NO: 1- SEQ ID NO 68 приведена в таблице 1). Преимущества данного набора состоит в том, что авторами изобретения разработана система олигонуклеотидных праймеров с минимальным размером ПЦР-продуктов, позволяющая одновременно анализировать множество образцов методом "массового параллельного секвенирования" и включающая аутосомные STR-маркеры человека.
Осуществление изобретения
Пример генотипирования биологического образца.
В примере показан способ получения выбранных аутосомных STR-маркеров человека из биологических образцов, содержащих геномную ДНК человека, путем проведения мультиплексного ПЦР-анализа с последующим "массовым параллельным секвенированием" полученных мультиплексных ПЦР-продуктов и генотипированием выбранных маркеров с использованием адаптированной программы STRinNGS [8].
Получение ДНК
ДНК может быть получена из любого биологического материала человека, любой ткани человека, содержащей клеточные ядра, например, лейкоцитов, волосяных фолликулов, клеток буккального эпителия и др. Пригодная для проведения ПЦР ДНК может быть выделена из образа при помощи любого ранее широко применяемого метода выделения ДНК. Авторы рекомендуют использовать готовые наборы для выделения ДНК из различных тканей человека (например, представленных фирмой Qiagen)
Получение молекулярных аутосомных STR-маркеров включает в себя четыре этапа:
- Мультиплексная ПЦР геномной ДНК с использованием смеси специфических олигонуклеотидных праймеров;
- Приготовление фрагментных библиотек из полученных ПЦР-продуктов для секвенирования на платформе Illumina;
- Проведение широкомасштабного параллельного секвенирования полученных библиотек;
Набор олигонуклеотидных праймеров адаптирован для использования ДНК в количестве от 10 нг до 1 нг ДНК. При необходимости образец ДНК следует развести в буфере ЕВ. Также необходимо проводить параллельно контрольную реакцию (отрицательный контроль), где вместо ДНК добавляется деионизированная вода.
Амплификация участков генома, содержащих исследуемые маркеры
Амплификация участков генома, содержащих исследуемые маркеры, может быть осуществлена с помощью любого набора, предназначенного для проведения мультиплексной ПЦР, авторы использовали набор Multiplex PCR kit компании «Qiagen». Мультиплексную ПЦР проводили на приборе GeneAmp PCR System 9700 Thermal Cycler компании «Applied Biosystems».
Состав реакционной смеси для мультиплексной ПЦР:
- Раствор олигонуклеотидов для мультиплексной ПЦР (в конечной концентрации от 1 нМ до 0,5 мкМ
- Смесь полимеразы и буфера
- Деионизированная вода
- исследуемая ДНК
Амплификацию следует проводить в пробирках, стрипах, или планшетах предназначенных для ПЦР.
В отдельной стерильной пробирке смешать из расчета на одну реакцию все необходимые компоненты, согласно расчетной таблице (пробирка с раствором MasterMix).
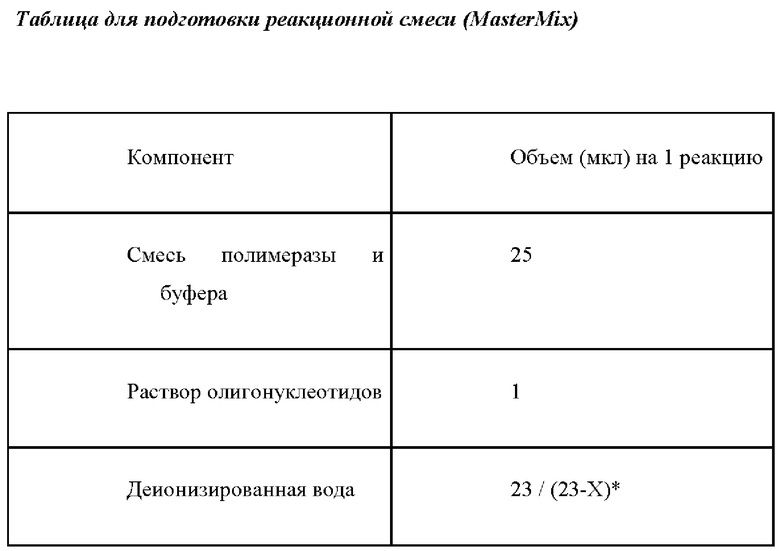
* Предлагаемый расчет для подготовки реакционной смеси подходит для работ с образцами ДНК с концентрацией выше 10 нг/мкл. При работе с образцами ДНК с меньшей концентрацией расчет количества вносимой в реакционную смесь деионизированной воды следует проводить по формуле (23-Х), где X - объем анализируемого препарата ДНК, который обеспечивает необходимое количества ДНК в реакционной смеси. Например, образец ДНК с концентрацией 250 пг/мкл. Необходимо внести в реакционную смесь минимум 4 мкл препарата ДНК (суммарно 1 нг) и 19 мкл деионизированной воды.
При использовании такой системы для амплификации (2-х смесь буфера и полимеразы), минимальная возможная для использования концентрация ДНК составляет 40 пг/мкл. После приготовления, смесь для амплификации помещают в амплификатор и выставляется программа:

Наличие продуктов амплификации исследуемой ДНК и отсутствие продуктов амплификации в отрицательном контроле проверяют с помощью электрофореза в агарозном геле. Продукты амплификации очищают с помощью соответствующих мини-колонок (например, Qiagen MinElute system) в соответствии с инструкцией к используемому набору реагентов. Полученные в результате мультиплексной амплификации очищенные ПЦР продукты, содержащие аутосомные STR-маркеры используются в качестве матрицы для приготовления фрагментных геномных библиотек для секвенирования.
Приготовление фрагментных библиотек
Предварительно необходимо провести измерение концентрации очищенных ПЦР-фрагментов, полученных на предыдущем этапе мультиплексной амплификации на приборах NanoDrop или Qubit (ThermoFisher) в соответствии с инструкцией к прибору. Для приготовления фрагментных библиотек оптимально использовать около 300 нг ДНК очищенных ПЦР-продуктов мультиплексной амплификации. Приготовление фрагментных геномных библиотек проводят с использованием наборов реагентов Illumina®. TruSeq® DNA PCR-Free library prep kit в соответствии с инструкцией к набору. Для секвенирования нескольких образцов фрагментных библиотек одновременно необходимо использовать индексированные адаптеры (например, Dual index adaptors Illumina). Для каждого образца библиотеки используется отдельный индексируемый адаптер, который необходимо записать в таблицу для дальнейшего учета при анализе результатов секвенирования нескольких образцов фрагментных библиотек. Для приготовления фрагментных библиотек рекомендуется/возможно использовать 1/2 от объема всех реагентов, входящих в набор Illumina®. TruSeq® DNA PCR-Free library prep kit, прописанного в инструкции к набору.
Этапы 1-3 являются рекомендованными, но не обязательными.
1 Очистка фрагментных библиотек: необходимо нанести весь объем элюата в одну лунку 2% агарозного геля с красителем SYBR Gold (например, с использованием готового 2%-ного E-gel (Invitrogen)). Провести электрофорез с использованием маркера молекулярных весов 50 bp Ladder в течение 10 минут (в случае использования системы e-gel (Invitrigen)).
2 с использованием стерильного одноразового скальпеля вырезать кусочки геля, с фрагментами библиотеки от 220 п. н. и больше. Светящиеся фрагменты длиной меньше 150 п. н. соответствуют димерам адаптеров и не должны быть использованы для дальнейшего анализа.
3 Провести очистку вырезанных фрагментов ДНК с использованием набора реагентов MinElute gele extraction kit (Qiagen). Эллюировать в 20-22 мкл буфера ЕВ (Qiagen).
Приготовленные описанным выше способом фрагментные библиотеки можно напрямую использовать для секвенирования на технологической платформе Illumina, предварительно проведя оценку качества полученных фрагментных библиотек.
Качественную и количественную оценку фрагментных библиотек можно проводить стандартными методами, рекомендованными фирмой производителем платформ для секвенирования Illumina. Для оптимизации рабочего процесса рекомендуем использовать следующие этапы: измерить концентрации фрагментных библиотек на приборе Qubit с использованием набора реагентов HS. Для дальнейшего секвенирования рекомендуется использовать фрагментные библиотеки с концентрацией не менее 2 нМ/мкл.
Перед секвенированием необходимо провести мультиплексирование библиотек в эквимолярных количествах (объединение библиотек для нескольких образцов). Не допускается объединение в один пул библиотек с одинаковыми индексами.
Приготовленные фрагментные библиотеки секвенируют методом параллельного широкомасштабного секвенирования на технологической платформе Illumina в режиме одноконцевого секвенирования с длинной прочтения не менее 350 п.о. Рекомендуемый прибор настольный секвенатор MiSeq (Illumina). Определение генотипов проводили с помощью адаптированной программы STRinNGS [8].
Авторами были проанализированы 10 образцов ДНК индивидов и контрольная ДНК М2800 (Promega) в различных разведениях ДНК. В результате работы, у всех исследованных образцов были амплифицированные все выбранные локусы. Генотипы локусов аутосомных STR-маркеров для контрольной ДНК М2800 (Promega), определенные с помощью адаптированной программы STRinNGS совпали.
“Способ получения молекулярных маркеров для идентификации личности на
основе аутосомных STR- маркеров методом мультиплексной амплификации”
Перечень нуклеотидных последовательностей
SEQ ID NO:1
ACTAGCACCCAGAACCGTC
SEQ ID NO:2
CTTGTCAGCGTTTATTTGCC
SEQ ID NO:3
ACTGCAGTCCAATCTGGGT
SEQ ID NO:4
ATGAAATCAACAGAGGCTT
SEQ ID NO:5
GAGTGATTTGTCTGTAATTG
SEQ ID NO:6
GCCCCATAGGTTTGAACTCA
SEQ ID NO:7
AACCTGAGTCTGCCAAGGACTAGC
SEQ ID NO:8
TTCCACACACCACTGGCCATCTTC
SEQ ID NO:9
GGTGATTTTCCTCTTTGGTATCC
SEQ ID NO:10
AGCCACAGTTTACAACATTTGTATCT
SEQ ID NO:11
TGTCATAGTTTAGAACGAACTAACG
SEQ ID NO:12
CTGAGGTATCAAAAACTCAGAGG
SEQ ID NO:13
ATTTTTGTATTTCATGTGTA
SEQ ID NO:14
CGTACGTATAATTAGTTCATT
SEQ ID NO:15
GTGATTCCCATTGGCCTGTTC
SEQ ID NO:16
ATTCCTGTGGGCTGAAAAGCTC
SEQ ID NO:17
AACAGGATCAATGGATGCAT
SEQ ID NO:18
TGGCTTTTAGACCTGGACTG
SEQ ID NO:19
ATTACAGAAGTCTGGGATGTGGAGGA
SEQ ID NO:20
GGCAGCCCAAAAAGACAGA
SEQ ID NO:21
AGGCAGATCCCAAGCTCTT
SEQ ID NO:22
ACGTTTGTGTGTGCATCTG
SEQ ID NO:23
TTCTTGAGCCCAGAAGGTTA
SEQ ID NO:24
ATTCTACCAGCAACAACACAAATAAAC
SEQ ID NO:25
ATATGTGAGTCAATTCCCCA
SEQ ID NO:26
TGTATTAGTCAATCTTCTCCA
SEQ ID NO:27
AGGATGGATGGATAGATGGA
SEQ ID NO:28
GTGAAAGCCCTAGTGGATGA
SEQ ID NO:29
CAGAGCAAGACACCATCTCA
SEQ ID NO:30
GCCTAACCTATGGTCATAACG
SEQ ID NO:31
CTGTGGCTCATCTATGAAAAC
SEQ ID NO:32
TAAGTGGCTGTGGTGTTATG
SEQ ID NO:33
ATTCAGTAAGTTAAAGGATT
SEQ ID NO:34
TGGAAACAGAAATGGCTTG
SEQ ID NO:35
TTAATGAATTGAACAAATGAGTGAG
SEQ ID NO:36
GCAACTCTGGTTGTATTGTCTTCAT
SEQ ID NO:37
CACCCATTACCCGAATAAAA
SEQ ID NO:38
CCTGGGCAACAGAATAAGAT
SEQ ID NO:39
GGAGCTACTGAGGAGGCATTGAC
SEQ ID NO:40
ACAGATGTTAAGTGTGTATATGC
SEQ ID NO:41
CCAGGGAGACAAAATGAAGA
SEQ ID NO:42
CCAGACCCCAAAATTACTTG
SEQ ID NO:43
CATTATCACCAATTTTTCTAGACG
SEQ ID NO:44
TATGCATTGCTTGCCTGTAT
SEQ ID NO:45
AGTCAGGGTTTTCCAAGAGA
SEQ ID NO:46
AGAATTCTCAGCCTCCATCA
SEQ ID NO:47
AGCAAGGTTCTGCCTTAGAA
SEQ ID NO:48
AAAAAGAATGAAGGTAAAAATGTGT
SEQ ID NO:49
CTACAACATCTCCCCTACCG
SEQ ID NO:50
TGAAACTCCGTCAAAAGAAA
SEQ ID NO:51
TGGGAGGAAAAGACATAGGA
SEQ ID NO:52
CTGGATAACAGAGCGAGACC
SEQ ID NO:53
TCCATAATCAGTGAGCCAAT
SEQ ID NO:54
TGGCTCCGGAGCAGTGGTTTA
SEQ ID NO:55
AAAAGCTCTCTGAAGCAGGT
SEQ ID NO:56
GAGAGGAAAGGATGATGATGAT
SEQ ID NO:57
TTTTCCCCGATGATAGTAGTCT
SEQ ID NO:58
ATCACGCGAATGTATGATTG
SEQ ID NO:59
TGTTGCTCAAGGGTCAACT
SEQ ID NO:60
GATGGAAGAAAATCCCCATA
SEQ ID NO:61
TGTGGGGGTATTTCAAGATAA
SEQ ID NO:62
GCTTCTGAAAGCTTCTAGTTTACC
SEQ ID NO:63
GGTACATAACAGTTCAATAGAAAGC
SEQ ID NO:64
CATCCACTGAAATGACTGAA
SEQ ID NO:65
TCAGAGACACCGAACCAATA
SEQ ID NO:66
CAGAGGACAGCCTCCATATC
SEQ ID NO:67
TGTATGAGCCACTTCCCATA
SEQ ID NO:68
GAAGCAATAGTGTGCAAGGA
Изобретение относится к области молекулярной биологии, биотехнологии, судебной медицины и криминалистики, генетическим исследованиям в области идентификации человека. Представлен способ получения молекулярных аутосомных STR-маркеров человека для идентификации неизвестного индивида и набор синтетических олигонуклеотидных праймеров для проведения мультиплексной полимеразной цепной реакции (ПЦР). Набор для генотипирования включает композицию, образованную 34 парами синтетических оригинальных олигонуклеотидных праймеров для локусов в геноме человека, включающих выбранные 34 аутосомных STR-маркера, что позволяет проводить мультиплексную ПЦР с последовательностями праймеров SEQ ID NO: 1 - SEQ ID NO: 68. Синтетические олигонуклеотидные праймеры подобраны таким образом, чтобы успешно амплифицировать выбранные локусы в ходе одной мультиплексной реакции и последующего секвенирования методом «массового параллельного секвенирования» (NGS). Представлен способ идентификации неизвестного индивида. Изобретение может быть использовано для исследования ДНК с целью идентификации неизвестного индивида и определения биологического родства в российской популяции с высокой чувствительностью, специфичностью и точностью по сравнению с существующими аналогами. 3 н. и 3 з.п. ф-лы, 1 табл., 1 пр.
1. Способ получения молекулярных аутосомных STR-маркеров человека для идентификации неизвестного индивида, характеризующийся тем, что для генотипирования используют композицию, образованную 34 парами синтетических оригинальных олигонуклеотидных праймеров для проведения мультиплексной полимеразной цепной реакции (ПЦР) с нуклеотидными последовательностями SEQ ID NO: 1 - SEQ ID NO: 68, специфичных для локусов в геноме человека, включающих выбранные 34 аутосомных STR-мapкepa; ПЦР-продукты, соответствующие выбранным праймерам, представляют собой маркеры.
2. Способ по п. 1, отличающийся тем, что полученные в результате мультиплексной амплификации ПЦР-продукты, содержащие маркеры для идентификации неизвестного индивида, используют в качестве матрицы для приготовления геномных библиотек для определения нуклеотидной последовательности.
3. Способ по п. 1, где определение нуклеотидной последовательности продуктов амплификации (ПЦР-продуктов) проводят секвенированием по методу "массового параллельного секвенирования" (NGS).
4. Способ по п. 1 для идентификации неизвестного индивида, происходящего из популяций Российской Федерации.
5. Способ идентификации неизвестного индивида, включающий генетическое исследование биологического образца, содержащего ДНК, с использованием мультиплексной полимеразно-цепной реакции (мультиплексной ПЦР) и последующего определения нуклеотидной последовательности продуктов амплификации, содержащих специфичные для локусов в геноме человека аутосомные STR-маркеры, полученные способом по п. 1.
6. Набор олигонуклеотидов для осуществления способа по п. 1, используемый для детектирования присутствия аутосомных STR-локусов человека, предназначенных для идентификации неизвестного индивида, включающий оригинальные синтетические олигонуклеотидные праймеры с нуклеотидными последовательностями SEQ ID NO: 1 - SEQ ID NO: 68.
| GlobalFiler™ and GlobalFiler™ IQC PCR Amplification Kits - PCR Amplification and CE, август 2019, 4 с., https://assets.thermofisher.com/TFS-Assets/LSG/manuals/4477593.pdf | |||
| MARTIN G., et al., The PowerPlex® 16 HS System, март 2009, 3 с., |

