1. Область техники, к которой относится изобретение
Варианты осуществления согласно настоящему изобретению относятся к аудиодекодеру.
Дополнительные варианты осуществления согласно настоящему изобретению относятся к устройству для определения набора значений, задающих характеристики фильтра.
Дополнительные варианты осуществления согласно изобретению относятся к способу для обеспечения декодированного аудиопредставления.
Дополнительные варианты осуществления согласно изобретению относятся к способу для определения набора значений, задающих характеристики фильтра.
Дополнительные варианты осуществления согласно изобретению относятся к соответствующим компьютерным программам.
Варианты осуществления согласно изобретению относятся к постфильтру на основе действительнозначной маски для повышения качества кодированной речи.
Варианты осуществления согласно настоящему изобретению, в общем, относятся к постфильтру для улучшения декодированного аудио аудиодекодера, определения набора значений, задающих характеристики фильтра на основе декодированного аудиопредставления.
2. Уровень техники
Ниже по тексту, предоставляется введение в некоторые традиционные решения.
С учетом этой ситуации, имеется потребность в концепции, которая предоставляет больший компромисс между скоростью передачи битов, качеством звучания и сложностью при декодировании аудиоконтента.
3. Сущность изобретения
Вариант осуществления согласно настоящему изобретению обеспечивает аудиодекодер (например, речевой декодер или общий аудиодекодер, или аудиодекодер, переключающийся между режимом декодирования речи, например, режимом декодирования на основе линейного прогнозирования и общим режимом декодирования аудио, например, режимом кодирования на основе представления в спектральной области с использованием коэффициентов масштабирования для масштабирования декодированных спектральных значений) для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления.
Аудиодекодер содержит фильтр (или "постфильтр") для обеспечения улучшенного аудиопредставления (например, 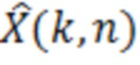 ) декодированного аудиопредставления (например,
) декодированного аудиопредставления (например, 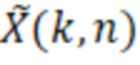 ), при этом входное аудиопредставление, которое используется посредством фильтра, может, например, обеспечиваться посредством ядра декодера для аудиодекодера.
), при этом входное аудиопредставление, которое используется посредством фильтра, может, например, обеспечиваться посредством ядра декодера для аудиодекодера.
Фильтр (или постфильтр) выполнен с возможностью получать множество значений масштабирования (например, значений маски, например, M(k, n)), которые, например, могут быть действительнозначными и которые, например, могут быть неотрицательными, и которые, например, могут быть ограничены предварительно определенным диапазоном, и которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами (например, имеющими индекс элемента разрешения по частоте или индекс k частотного диапазона), на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами (например, имеющими индекс элемента разрешения по частоте или индекс k частотного диапазона).
Фильтр (или постфильтр) выполнен с возможностью масштабировать спектральные значения декодированного представления аудиосигналов (например, 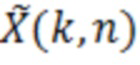 ) или их предварительно обработанную версию с использованием значений масштабирования (например, M(k, n)) для получения улучшенного аудиопредставления (например, ).
) или их предварительно обработанную версию с использованием значений масштабирования (например, M(k, n)) для получения улучшенного аудиопредставления (например, ).
Этот вариант осуществления основан на такой идее, что качество звучания может эффективно повышаться с использованием масштабирования спектральных значений декодированного представления аудиосигналов, при этом значения масштабирования извлекаются на основе спектральных значений декодированного аудиопредставления. Обнаружено, что фильтрация, которая осуществляется посредством масштабирования спектральных значений, может эффективно адаптироваться к характеристикам сигналов на основе спектральных значений декодированного аудиопредставления и может повышать качество декодированного аудиопредставления. Например, на основе спектральных значений декодированного аудиопредставления, настройка фильтра (которая может задаваться посредством значений масштабирования) может регулироваться таким образом, чтобы уменьшать влияние шума квантования. Например, регулирование значений масштабирования на основе спектральных значений декодированного аудиопредставления может использовать структуру на основе машинного обучения или нейронную сеть, которая может обеспечивать значения масштабирования вычислительно эффективным способом.
В частности, обнаружено, что извлечение значений масштабирования из спектральных значений декодированного аудиопредставления по-прежнему является преимущественным и возможным с хорошими результатами, даже если шум квантования, в общем, коррелируется с сигналом. Соответственно, концепция может применяться с очень хорошими результатами в этой ситуации.
В качестве вывода, вышеописанный аудиокодер предоставляет возможность улучшения достижимого качества звучания с использованием фильтра, характеристика которого регулируется на основе спектральных значений декодированного аудиопредставления, при этом операция фильтрации, например, может выполняться эффективным способом посредством масштабирования спектральных значений с использованием значений масштабирования. Таким образом, ощущение для слуха может улучшаться, при этом необязательно основываться на дополнительной вспомогательной информации для того, чтобы управлять регулированием фильтра. Наоборот, регулирование фильтра может быть основано только на декодированных спектральных значениях текущего обработанного кадра независимо от схемы кодирования, используемой для формирования кодированных и декодированных представлений аудиосигнала и возможно декодированных спектральных значений одного или более ранее декодированных кадров и/или одного или более последующих декодированных кадров.
В предпочтительном варианте осуществления аудиодекодера, фильтр выполнен с возможностью использовать конфигурируемую структуру обработки (например, структуру на основе "машинного обучения", как нейронная сеть), конфигурация которой основана на алгоритме машинного обучения, чтобы обеспечивать значения масштабирования.
Посредством использования конфигурируемой структуры обработки, такой как структура на основе машинного обучения или нейронная сеть, характеристики фильтра могут легко регулироваться на основе коэффициентов, задающих функциональность конфигурируемой структуры обработки. Соответственно, типично можно регулировать характеристики фильтра в широком диапазоне в зависимости от спектральных значений декодированного аудиопредставления. Следовательно, можно получать повышенное качество звука во множестве различных обстоятельств.
В предпочтительном варианте осуществления аудиодекодера, фильтр выполнен с возможностью определять значения масштабирования только на основе спектральных значений декодированного аудиопредставления во множестве элементов разрешения по частоте или частотных диапазонов (например, без использования дополнительной служебной информации при извлечении значений масштабирования из спектральных значений).
С использованием такой концепции, можно повышать качество звучания независимо от присутствия вспомогательной информации.
Вычислительная и структурная сложность может сохраняться достаточно низкой, поскольку используется когерентное и универсальное представление декодированного аудиосигнала (спектральных значений декодированного аудиопредставления), которое является агностическим относительно технологий кодирования, используемых для того, чтобы получать кодированное и декодированное представление. В этом случае, комплексные и специфические операции для конкретных вспомогательных информационных значений не допускаются. Помимо этого, в общем, можно извлекать значения масштабирования на основе спектральных значений декодированного аудиопредставления с использованием универсальной структуры обработки (такой как нейронная сеть), которая использует ограниченное число различных вычислительных функциональностей (таких как масштабированные суммирования и оценка функций активации).
В предпочтительном варианте осуществления аудиодекодера, фильтр выполнен с возможностью получать значения  абсолютной величины (которые, например, могут описывать абсолютное значение или амплитуду, или норму) улучшенного аудиопредставления согласно следующему:
абсолютной величины (которые, например, могут описывать абсолютное значение или амплитуду, или норму) улучшенного аудиопредставления согласно следующему:
 ,
,
при этом M(k, n) является значением масштабирования, при этом k является частотным индексом (например, обозначающим различные элементы разрешения по частоте или частотные диапазоны), при этом n является временным индексом (например, обозначающим различные перекрывающиеся или неперекрывающиеся кадры), и при этом 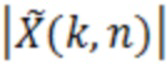 является значением абсолютной величины спектрального значения декодированного аудиопредставления. Значение абсолютной величины может быть абсолютной величиной, абсолютным значением или любой нормой спектрального значения, полученного посредством применения частотно-временного преобразования, такого как как STFT (кратковременное преобразование Фурье), FFT или MDCT, к декодированному аудиосигналу.
является значением абсолютной величины спектрального значения декодированного аудиопредставления. Значение абсолютной величины может быть абсолютной величиной, абсолютным значением или любой нормой спектрального значения, полученного посредством применения частотно-временного преобразования, такого как как STFT (кратковременное преобразование Фурье), FFT или MDCT, к декодированному аудиосигналу.
Альтернативно, фильтр может быть выполнен с возможностью получать значения улучшенного аудиопредставления согласно следующему:
 ,
,
при этом M(k, n) является значением масштабирования, при этом k является частотным индексом (например, обозначающим различные элементы разрешения по частоте или частотные диапазоны), при этом n является временным индексом (например, обозначающим различные перекрывающиеся или неперекрывающиеся кадры), и при этом является спектральным значением декодированного аудиопредставления.
Обнаружено, что такое простое извлечение значения абсолютной величины улучшенного аудиопредставления или (типично комплекснозначных) значений улучшенного аудиопредставления может выполняться с хорошей эффективностью и по-прежнему приводит к значительному улучшению качества звучания.
В предпочтительном варианте осуществления аудиодекодера, фильтр выполнен с возможностью получать значения масштабирования таким образом, что значения масштабирования вызывают масштабирование (или, в некоторых случаях, усиление) для одного или более спектральных значений декодированного представления аудиосигналов или для одного или более предварительно обработанных спектральных значений, которые основаны на спектральных значениях декодированного представления аудиосигналов.
Посредством выполнения такого масштабирования, которое может предпочтительно, но не обязательно, вызывать усиление или затухание, по меньшей мере, для одного спектрального значения (и которое типично может также приводить к затуханию, по меньшей мере, одного спектрального значения), спектр декодированного аудиопредставления может формироваться эффективным способом. Например, посредством предоставления возможности как усиления, так и затухания посредством масштабирования, артефакты, которые могут вызываться посредством ограниченной точности представления чисел, также могут уменьшаться в некоторых случаях. Кроме того, регулирование значений масштабирования необязательно содержит дополнительную степень свободы посредством недопущения ограничения значений масштабирования значениями, меньшими единицы. Соответственно, хорошее улучшение качества звучания может достигаться.
В предпочтительном варианте осуществления аудиодекодера, фильтр содержит нейронную сеть или структуру на основе машинного обучения, выполненную с возможностью обеспечивать значения масштабирования на основе множества спектральных значений, описывающих декодированное аудиопредставление (например, описывающих абсолютные величины преобразованного представления декодированного аудиопредставления), при этом спектральные значения ассоциированы с различными элементами разрешения по частоте или частотными диапазонами.
Обнаружено, что использование нейронной сети или структуры на основе машинного обучения в таком фильтре способствует сравнительно высокой эффективности. Также обнаружено, что нейронная сеть или структура на основе машинного обучения может легко обрабатывать спектральные значения декодированного аудиопредставления входной величины, в случаях, в которых число спектральных значений, введенных в нейронную сеть или структуру на основе машинного обучения, является сравнительно высоким. Обнаружено, что нейронные сети или структуры на основе машинного обучения могут хорошо обрабатывать такое высокое число входных сигналов или входных величин, и они также могут предлагать большое количество различных значений масштабирования в качестве выходных величин. Другими словами, обнаружено, что нейронные сети или структуры на основе машинного обучения оптимально подходят для того, чтобы извлекать сравнительно большое число значений масштабирования на основе сравнительно большого числа спектральных значений, без необходимости чрезмерных вычислительных ресурсов. Таким образом, значения масштабирования могут регулироваться до спектральных значений декодированного аудиопредставления очень точным способом без чрезмерной вычислительной нагрузки, при этом подробности спектра декодированного аудиопредставления могут рассматриваться при регулировании характеристики фильтрации. Кроме того, обнаружено, что коэффициенты нейронной сети или структуры на основе машинного обучения, предоставляющей значения масштабирования, могут определяться с обоснованным усилием, и что нейронная сеть или структура на основе машинного обучения предоставляет достаточные степени свободы для того, чтобы достигать точного определения значений масштабирования.
В предпочтительном варианте осуществления аудиодекодера, входные сигналы нейронной сети или структуры на основе машинного обучения представляют логарифмические абсолютные величины, амплитуду или норму спектральных значений декодированного аудиопредставления, при этом спектральные значения ассоциированы с различными элементами разрешения по частоте или частотными диапазонами.
Обнаружено, что предпочтительно обеспечивать логарифмические абсолютные величины спектральных значений, амплитуды спектральных значений или нормы спектральных значений в качестве входных сигналов нейронной сети или структуры на основе машинного обучения. Обнаружено, что знак или фаза спектральных значений имеет второстепенную важность для регулирования фильтра, т.е. для определения значений масштабирования. В частности, обнаружено, что логарифмизация абсолютных величин спектральных значений декодированного аудиопредставления, в частности, является предпочтительной, поскольку динамический диапазон может уменьшаться. Обнаружено, что нейронная сеть или структура на основе машинного обучения типично может лучше обрабатывать логарифмизированные абсолютные величины спектральных значений по сравнению с самими спектральными значениями, поскольку спектральные значения типично имеют расширенный динамический диапазон. Посредством использования логарифмизированных значений, также можно использовать упрощенное представление чисел в (искусственной) нейронной сети или в структуре на основе машинного обучения, поскольку зачастую не требуется использовать представление чисел с плавающей запятой. Наоборот, можно проектировать нейронную сеть или структуру на основе машинного обучения с использованием представления чисел с фиксированной запятой, что значительно сокращает усилия по реализации.
В предпочтительном варианте осуществления аудиодекодера, выходные сигналы нейронной сети или структуры на основе машинного обучения представляют значения масштабирования (например, значения маски).
Посредством предоставления значений масштабирования в качестве выходных сигналов (или выходных величин) нейронной сети или структуры на основе машинного обучения, усилия по реализации могут поддерживаться достаточно низкими. Например, нейронную сеть или структуру на основе машинного обучения, предлагающую сравнительно большое количество значений масштабирования, легко реализовывать. Например, может использоваться однородная структура, что уменьшает усилия по реализации.
В предпочтительном варианте осуществления аудиодекодера, нейронная сеть или структура на основе машинного обучения обучается, чтобы ограничивать, уменьшать или минимизировать отклонение (например, среднеквадратическую ошибку; например, MSEMA) между множеством целевых значений масштабирования (например, IRM(k, n)) и множеством значений масштабирования (например, M(k, n)), полученных с использованием нейронной сети или с использованием структуры на основе машинного обучения.
Посредством обучения нейронной сети или структура на основе машинного обучения таким способом, может достигаться то, что улучшенное аудиопредставление, которое получается посредством масштабирования спектральных значений декодированного представления аудиосигналов (или их предварительно обработанной версии) с использованием значений масштабирования, предоставляет хорошее ощущение для слуха. Например, целевые значения масштабирования могут легко определяться, например, на основе знаний обработки с потерями на стороне кодера. Таким образом, может определяться с небольшими усилиями то, какие значения масштабирования лучше всего аппроксимируют спектральные значения декодированного аудиопредставления в идеальное улучшенное аудиопредставление (которое, например, может быть равным входному аудиопредставлению аудиокодера). Другими словами, посредством обучения нейронной сети или структуры на основе машинного обучения, чтобы ограничивать, уменьшать или минимизировать отклонение между множеством целевых значений масштабирования и множеством значений масштабирования, полученных с использованием нейронной сети или с использованием структуры на основе машинного обучения, например, для множества различного аудиоконтента или типов аудиоконтента, может достигаться то, что нейронная сеть или структура на основе машинного обучения предоставляет соответствующие значения масштабирования даже для различного аудиоконтента или различных типов аудиоконтента. Кроме того, посредством использования извлечения между целевыми значениями масштабирования и значениями масштабирования, полученными с использованием нейронной сети или с использованием структуры на основе машинного обучения в качестве величины оптимизации, сложность процесса обучения может поддерживаться небольшой, и числовые проблемы могут не допускаться.
В предпочтительном варианте осуществления аудиодекодера, нейронная сеть или структура на основе машинного обучения обучается, чтобы ограничивать, уменьшать или минимизировать отклонение (например, MSESA) между целевым спектром абсолютной величины, целевым амплитудным спектром, целевым абсолютным спектром или целевым норменным спектром (например, 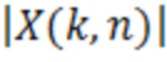 , например, исходным спектром обучающего аудиосигнала) и (улучшенным) спектром абсолютной величины, амплитудным спектром, абсолютным спектром или норменным спектром, полученным с использованием масштабирования (например, частотно-зависимого масштабирования) обработанного (например, декодированного, например, квантованного, кодированного и декодированного) спектра (который, например, основан на целевом спектре абсолютной величины и/или на обучающем аудиосигнале), который использует значения масштабирования, которые обеспечиваются посредством нейронной сети, или посредством структуры на основе машинного обучения (при этом входные сигналы нейронной сети, например, основаны на декодированном спектре).
, например, исходным спектром обучающего аудиосигнала) и (улучшенным) спектром абсолютной величины, амплитудным спектром, абсолютным спектром или норменным спектром, полученным с использованием масштабирования (например, частотно-зависимого масштабирования) обработанного (например, декодированного, например, квантованного, кодированного и декодированного) спектра (который, например, основан на целевом спектре абсолютной величины и/или на обучающем аудиосигнале), который использует значения масштабирования, которые обеспечиваются посредством нейронной сети, или посредством структуры на основе машинного обучения (при этом входные сигналы нейронной сети, например, основаны на декодированном спектре).
Посредством использования такого подхода на основе обучения, типично может обеспечиваться хорошее качество улучшенного аудиопредставления. В частности, обнаружено, что нейронные сети или структуры на основе машинного обучения также обеспечивают соответствующие коэффициенты масштабирования, если декодированное аудиопредставление представляет различный аудиоконтент по сравнению с аудиоконтентом, используемым для обучения. Кроме того, обнаружено, что улучшенное аудиопредставление воспринимается как хорошего качества, если спектр абсолютной величины или амплитудный спектр, или абсолютный спектр, или норменный спектр находится в достаточно хорошем соответствии с требуемым (целевым) спектром абсолютной величины или (целевым) амплитудным спектром, или (целевым) абсолютным спектром, или (целевым) норменным спектром.
В предпочтительном варианте осуществления аудио, нейронная сеть или структура на основе машинного обучения обучается таким образом, что масштабирование для одного или более спектральных значений спектрального разложения декодированного представления аудиосигналов или для одного или более предварительно обработанных спектральных значений, которые основаны на спектральных значениях спектрального разложения декодированного представления аудиосигналов, находится в диапазоне между 0 и предварительно определенным максимальным значением.
Обнаружено, что ограничение масштабирования (или значений масштабирования) является полезным, чтобы не допускать чрезмерного усиления спектральных значений. Обнаружено, что очень высокое усиление (или масштабирование) одного или более спектральных значений может приводить к слышимым артефактам. Кроме того, обнаружено, что чрезмерно большие значения масштабирования могут достигаться во время обучения, например, если спектральные значения декодированного аудиопредставления являются очень небольшими или даже равными нулю. Таким образом, качество улучшенного аудиопредставления может повышаться посредством использования такого подхода на основе ограничения.
В предпочтительном варианте осуществления аудиодекодера, максимальное значение превышает 1 (и, например, может быть равным 2, 5 или 10).
Обнаружено, что такое ограничение для масштабирования (или для значений масштабирования) способствует очень хорошим результатам. Например, посредством предоставления возможности усиления (например, посредством предоставления возможности масштабирования или значения масштабирования, большего единицы), артефакты, которые вызываются посредством "спектральных дыр", также могут частично компенсироваться. Одновременно, избыточный шум может быть ограничен посредством затухания (например, с использованием масштабирования или значений масштабирования, меньших единицы). Следовательно, очень гибкое улучшение сигнала может получаться посредством масштабирования.
В предпочтительном варианте осуществления аудиодекодера, нейронная сеть или структура на основе машинного обучения обучается таким образом, что масштабирование (или значения масштабирования) для одного или более спектральных значений спектрального разложения декодированного представления аудиосигналов или для одного или более предварительно обработанных спектральных значений, которые основаны на спектральных значениях спектрального разложения декодированного представления аудиосигналов, ограничиваются 2, или ограничиваются 5, или ограничиваются 10, или ограничиваются предварительно определенным значением, большим 1.
Посредством использования такого подхода, артефакты могут поддерживаться достаточно небольшими, в то время как усиление разрешается (что, например, может помогать не допускать "спектральных дыр"). Таким образом, может получаться хорошее ощущение для слуха.
В предпочтительном варианте осуществления аудиодекодера, нейронная сеть или структура на основе машинного обучения обучается таким образом, что значения масштабирования ограничены 2 или ограничены 5, или ограничены 10, или ограничены предварительно определенным значением, большим 1.
Посредством ограничения значений масштабирования таким диапазоном, может достигаться очень хорошее качество улучшенного аудиопредставления.
В предпочтительном варианте осуществления аудиодекодера, число входных признаков нейронной сети или структуры на основе машинного обучения (например, 516 или 903) больше, по меньшей мере, на коэффициент 2 числа выходных значений (например, 129) нейронной сети или структуры на основе машинного обучения.
Обнаружено, что использование сравнительно большого числа входных признаков для нейронной сети или структуры на основе машинного обучения, которое больше числа выходных значений (или выходных сигналов) нейронной сети или структуры на основе машинного обучения, приводит к конкретным надежным значениям масштабирования. В частности, посредством выбора сравнительно высокого числа входных признаков нейронной сети, можно рассматривать информацию из предыдущих кадров и/или из следующих кадров, при этом обнаружено, что рассмотрение таких дополнительных входных признаков типично повышает качество значений масштабирования и в силу этого качество улучшенного аудиопредставления.
В предпочтительном варианте осуществления аудиодекодера, фильтр выполнен с возможностью нормализовать входные признаки (например, представленные посредством входных сигналов) нейронной сети или структуры на основе машинного обучения (например, абсолютные величины спектральных значений, полученных с использованием кратковременного преобразования Фурье) до предварительно определенного среднего значения (например, до среднего значения в нуль) и/или до предварительно определенной дисперсии (например, до единичной дисперсии) или среднеквадратического отклонения.
Обнаружено, что нормализация входных признаков нейронной сети или структуры на основе машинного обучения делает предоставление значений масштабирования независимым от громкости или уровня громкости либо от интенсивности декодированного аудиопредставления. Соответственно, нейронная сеть или структура на основе машинного обучения может "фокусироваться" на структурных характеристиках спектра декодированного аудиопредставления и не затрагивается (или не затрагиваются в значительной степени) посредством изменений громкости. Кроме того, посредством выполнения такой нормализации, можно не допускать того, что узлы нейронной сети чрезмерно насыщаются. Кроме того, уменьшается динамический диапазон, что является полезным, чтобы поддерживать представление чисел, используемое в нейронной сети или в структуре на основе машинного обучения, эффективным.
В предпочтительном варианте осуществления аудиодекодера, нейронная сеть содержит входной слой, один или более скрытых слоев и выходной слой.
Такая структура нейронной сети оказалась предпочтительной для настоящей заявки.
В предпочтительном варианте осуществления аудиодекодера, один или более скрытых слоев используют блоки линейной ректификации в качестве функций активации.
Обнаружено, что использование блоков линейной ректификации в качестве функций активации обеспечивает возможность предоставления масштабирующих векторов на основе спектральных значений декодированного аудиопредставления с хорошей надежностью.
В предпочтительном варианте осуществления аудиодекодера, выходной слой использует (неограниченные) блоки линейной ректификации или ограниченные блоки линейной ректификации, или сигмоидальные функции (например, масштабированные сигмоидальные функции) в качестве функций активации.
Посредством использования блоков линейной ректификации или ограниченных блоков линейной ректификации, или сигмоидальных функций в качестве функций активации в выходном слое, значения масштабирования могут получаться надежным способом. В частности, использование ограниченных блоков линейной ректификации или сигмоидальных функций предоставляет возможность ограничения значений масштабирования требуемым диапазоном, как пояснено выше. Таким образом, значения масштабирования могут получаться эффективным и надежным способом.
В предпочтительном варианте осуществления аудиодекодера, фильтр выполнен с возможностью получать коэффициенты кратковременного преобразования Фурье (например, ), которые представляют спектральные значения декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами.
Обнаружено, что коэффициенты кратковременного преобразования Фурье составляют, в частности, значимое представление декодированного аудиопредставления. Например, следует признавать то, что коэффициенты кратковременного преобразования Фурье лучше применяются посредством нейронной сети или посредством структуры на основе машинного обучения, чем MDCT-коэффициенты в некоторых случаях (даже если MDCT-коэффициенты могут использоваться посредством аудиодекодера для восстановления декодированного спектрального представления).
В предпочтительном варианте осуществления аудиодекодера, фильтр выполнен с возможностью извлекать логарифмическую абсолютную величину, амплитуду, абсолютные или норменные значения (например, на основе коэффициентов кратковременного преобразования Фурье) и определять значения масштабирования на основе логарифмической абсолютной величины, амплитуды, абсолютных или норменных значений.
Обнаружено, что извлечение значений масштабирования на основе неотрицательных значений, таких как логарифмические значения абсолютной величины, значения амплитуды, абсолютные значения или норменные значения, является эффективным, поскольку рассмотрение фазы должно значительно увеличивать вычислительную нагрузку без результирующего существенного улучшения значений масштабирования. Таким образом, удаление знака и типично также фазы спектральных значений (например, полученных посредством кратковременного преобразования Фурье) способствует хорошему компромиссу между сложностью и качеством звучания.
В предпочтительном варианте осуществления аудиодекодера, фильтр выполнен с возможностью определять множество значений масштабирования, ассоциированных с текущим кадром (например, с текущим кадром декодированного аудиопредставления или с текущим кадром кратковременного преобразования Фурье) на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами текущего кадра, и на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами одного или более кадров, предшествующих текущему кадру (например, предыдущих контекстных кадров).
Тем не менее, обнаружено, что рассмотрение спектральных значений одного или более кадров, предшествующих текущему кадру, помогает улучшать масштабирующие векторы. Это обусловлено тем фактом, что множество типов аудиоконтента содержат временную корреляцию между последующими кадрами. Таким образом, нейронная сеть или структура на основе машинного обучения, например, может рассматривать временную эволюцию спектральных значений при определении значений масштабирования. Например, нейронная сеть или структура на основе машинного обучения может регулировать значения масштабирования, чтобы не допускать (или противодействовать) чрезмерных изменений масштабированных спектральных значений (например, в улучшенном аудиопредставлении) со временем.
В предпочтительном варианте осуществления аудиодекодера, фильтр выполнен с возможностью определять множество значений масштабирования, ассоциированных с текущим кадром (например, с текущим кадром декодированного аудиопредставления или с текущим кадром кратковременного преобразования Фурье) на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами одного или более кадров после текущего кадра (например, будущих контекстных кадров).
Посредством рассмотрения спектральных значений декодированного аудиопредставления одного или более кадров после текущих кадров, также могут быть использованы корреляции между последующими кадрами, и качество значений масштабирования типично может повышаться.
Вариант осуществления согласно настоящему изобретению обеспечивает устройство для определения набора значений (например, коэффициентов нейронной сети или коэффициентов другой структуры на основе машинного обучения), задающих характеристики фильтра (например, фильтра на основе нейронной сети или фильтра на основе другой структуры на основе машинного обучения) для обеспечения улучшенного аудиопредставления (например, ) на основе декодированного аудиопредставления (которое, например, может обеспечиваться посредством декодирования аудио).
Устройство выполнено с возможностью получать спектральные значения (например, абсолютные величины или фазы, или MDCT-коэффициенты, например, представленные посредством значений абсолютной величины, например, ) декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами.
Устройство выполнено с возможностью определять набор значений, задающих характеристики фильтра, так что значения масштабирования, обеспеченные посредством фильтра на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, аппроксимируют целевые значения масштабирования (которые могут вычисляться на основе сравнения требуемого улучшенного аудиопредставления и декодированного аудиопредставления).
Альтернативно, устройство выполнено с возможностью определять набор значений, задающих характеристики фильтра, так что спектр, полученный посредством фильтра на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и с использованием значений масштабирования, полученных на основе декодированного аудиопредставления, аппроксимирует целевой спектр (который может соответствовать требуемому улучшенному аудиопредставлению и который может быть равным входному сигналу аудиокодера в цепочке обработки, содержащей аудиокодер и аудиодекодер, включающий в себя фильтр).
С использованием такого устройства, набор значений, задающих характеристики фильтра, который используется в вышеуказанном аудиодекодере, может получаться с небольшими усилиями. В частности, набор значений, которые могут представлять собой коэффициенты нейронной сети или коэффициенты другой структуры на основе машинного обучения, задающие характеристики фильтра, может определяться таким образом, что фильтр использует значения масштабирования, которые приводят к хорошему качеству звука и приводят к улучшению улучшенного аудиопредставления по сравнению с декодированным аудиопредставлением. Например, определение набора значений, задающих характеристики фильтра, может выполняться на основе множества обучающего аудиоконтента или опорного аудиоконтента, при этом целевые значения масштабирования или целевой спектр могут извлекаться из опорного аудиоконтента. Тем не менее, обнаружено, что набор значений, задающих характеристики фильтра, типично также является подходящим для аудиоконтента, который отличается от опорного аудиоконтента, при условии, что опорный аудиоконтент, по меньшей мере, до некоторой степени представляет аудиоконтент, который должен декодироваться посредством аудиодекодера, упомянутого выше. Кроме того, обнаружено, что использование значений масштабирования, предоставленных посредством фильтра или с использованием спектра, полученного посредством фильтра в качестве величины оптимизации, приводит к надежному набору значений, задающих характеристики фильтра.
В предпочтительном варианте осуществления устройства, устройство выполнено с возможностью обучать структуру на основе машинного обучения (например, нейронную сеть), которая является частью фильтра и которая обеспечивает значения масштабирования для масштабирования значений абсолютной величины декодированного аудиосигнала или спектральных значений декодированного аудиосигнала, чтобы уменьшать или минимизировать отклонение (например, среднеквадратическую ошибку; например, MSEMA) между множеством целевых значений масштабирования (например, IRM(k, n)) и множеством значений масштабирования (например, M(k, n)), полученных с использованием нейронной сети, на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами.
Посредством обучения структуры на основе машинного обучения с использованием целевых значений масштабирования, которые, например, могут извлекаться на основе исходного аудиоконтента, который кодируется и декодируется в цепочке обработки, содержащей аудиодекодер (который извлекает декодированное аудиопредставление), структура на основе машинного обучения может проектироваться (или конфигурироваться) с возможностью, по меньшей мере, частично компенсировать ухудшение характеристик сигнала в цепочке обработки. Например, целевые значения масштабирования могут определяться таким образом, что целевые значения масштабирования масштабируют декодированное аудиопредставление таким образом, что декодированное аудиопредставление аппроксимирует (исходное) аудиопредставление, вводимое в цепочку обработки (например, вводимое в аудиокодер). Таким образом, значения масштабирования, обеспеченные посредством структуры на основе машинного обучения, могут иметь высокую степень надежности и могут быть выполнены с возможностью улучшать восстановление аудиоконтента, которое подвергается цепочке обработки.
В предпочтительном варианте осуществления, устройство выполнено с возможностью обучать структуру на основе машинного обучения (например, нейронную сеть), с тем чтобы уменьшать или минимизировать отклонение (например, MSESA) между целевым спектром (абсолютной величины) (например, , например, исходным спектром обучающего аудиосигнала) и (улучшенным) спектром (или спектром абсолютной величины), полученным с использованием масштабирования (например, частотно-зависимого масштабирования) обработанного (например, декодированного, например, квантованного, кодированного и декодированного) спектра (который, например, основан на целевом спектре абсолютной величины и/или на обучающем аудиосигнале), который использует значения масштабирования, которые обеспечиваются посредством структуры на основе машинного обучения (например, нейронной сети). Например, входные сигналы структуры на основе машинного обучения или нейронной сети основаны на декодированном спектре.
Обнаружено, что такое обучение структуры на основе машинного обучения также приводит к значениям масштабирования, которые обеспечивают возможность компенсации ухудшения характеристик сигнала в цепочке обработки сигналов (которая может содержать кодирование аудио и декодирование аудио). Например, целевой спектр может представлять собой спектр опорного аудиоконтента или обучающего аудиоконтента, который вводится в цепочке обработки, содержащей аудиокодер (с потерями) и аудиодекодер, предоставляющий декодированное аудиопредставление. Таким образом, структура на основе машинного обучения может обучаться таким образом, что значения масштабирования масштабируют декодированное аудиопредставление, чтобы аппроксимировать опорный аудиоконтент, вводимый в аудиокодер. Следовательно, структура на основе машинного обучения может обучаться, чтобы обеспечивать значения масштабирования, которые помогают преодолевать ухудшение характеристик в цепочке обработки (с потерями).
В предпочтительном варианте осуществления, устройство выполнено с возможностью обучать структуру на основе машинного обучения (например, нейронную сеть) таким образом, что масштабирование (или значение масштабирования) для спектральных значений декодированного представления аудиосигналов или для одного или более предварительно обработанных спектральных значений, которые основаны на спектральных значениях декодированного представления аудиосигналов, находится в диапазоне между 0 и 2 или находится в диапазоне между 0 и 5, или находится в диапазоне между 0 и 10, или находится в диапазоне между 0 и максимальным значением (которое, например, может быть больше 1).
Посредством ограничения масштабирования предварительно определенным диапазоном (например, между нулем и предварительно определенным значением, которое типично может быть больше единицы), можно не допускать артефактов, которые могут вызываться, например, посредством чрезмерно больших значений масштабирования. Кроме того, следует отметить, что ограничение значений масштабирования (которое может обеспечиваться в качестве выходных сигналов нейронной сети или структуры на основе машинного обучения) предоставляет возможность сравнительно простой реализации выходных каскадов (например, выходных узлов) нейронной сети или структуры на основе машинного обучения.
В предпочтительном варианте осуществления устройства, устройство выполнено с возможностью обучать структуру на основе машинного обучения (например, нейронную сеть) таким образом, что масштабирование абсолютной величины (или значения масштабирования) для спектральных значений декодированного представления аудиосигналов или для одного или более предварительно обработанных спектральных значений, которые основаны на спектральных значениях декодированного представления аудиосигналов, ограничено таким образом, что они находятся в диапазоне между 0 и предварительно определенным максимальным значением.
Посредством ограничения масштабирования абсолютной величины (или значений масштабирования) таким образом, что они находятся в диапазоне между нулем и предварительно определенным максимумом, переключение ухудшения характеристик, вызываемое посредством чрезмерно сильного масштабирования абсолютной величины, не допускается.
В предпочтительном варианте осуществления аудиодекодера, максимальное значение превышает 1 (и, например, может быть равным 2, 5 или 10).
Посредством предоставления возможности того, что максимальное значение масштабирования абсолютной величины больше единицы, затухание и усиление могут достигаться посредством масштабирования с использованием значений масштабирования. Показано, что такая концепция является очень гибкой и способствует очень хорошему ощущению для слуха.
Вариант осуществления изобретения обеспечивает способ для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления.
Способ содержит предоставление улучшенного аудиопредставления (например, ) декодированного аудиопредставления (например, ), при этом входное аудиопредставление, которое используется посредством фильтра, предоставляющего улучшенное аудиопредставление, например, может обеспечиваться посредством ядра декодера для аудиодекодера.
Способ содержит получение множества значений масштабирования (например, значений маски, например, M(k, n)), которые, например, могут быть действительнозначными и которые, например, могут быть неотрицательными, и которые, например, может быть ограничены предварительно определенным диапазоном, и которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами (например, имеющими индекс элемента разрешения по частоте или индекс k частотного диапазона), на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами (например, имеющими индекс элемента разрешения по частоте или индекс k частотного диапазона).
Способ содержит масштабирование спектральных значений декодированного представления аудиосигналов (например, ) или их предварительно обработанной версии с использованием значений масштабирования (например, M(k, n)) для получения улучшенного аудиопредставления (например, ).
Этот способ основан на подходыподходах, идентичных подходыподходам для вышеописанного устройства. Кроме того, следует отметить, что способ может дополняться посредством любых из признаков, функциональностей и подробностей, описанных в данном документе, также относительно устройства. Кроме того, следует отметить, что способ может дополняться посредством любых из этих признаков, функциональностей и подробностей как отдельно, так и в комбинации.
Вариант осуществления обеспечивает способ для определения набора значений (например, коэффициентов нейронной сети или коэффициентов другой структуры на основе машинного обучения), задающих характеристики фильтра (например, фильтра на основе нейронной сети или фильтра на основе другой структуры на основе машинного обучения) для обеспечения улучшенного аудиопредставления (например, ) на основе декодированного аудиопредставления (которое, например, может обеспечиваться посредством декодирования аудио).
Способ содержит получение спектральных значений (например, абсолютных величин или фаз, или MDCT-коэффициентов, представленных посредством значений абсолютной величины, например, ) декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами.
Способ содержит определение набора значений, задающих характеристики фильтра, так что значения масштабирования, обеспеченные посредством фильтра на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, аппроксимируют целевые значения масштабирования (которые могут вычисляться на основе сравнения требуемого улучшенного аудиопредставления и декодированного аудиопредставления).
Альтернативно, способ содержит определение набора значений, задающих характеристики фильтра, так что спектр, полученный посредством фильтра на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и с использованием значений масштабирования, полученных на основе декодированного аудиопредставления, аппроксимирует целевой спектр (который может соответствовать требуемому улучшенному аудиопредставлению и который может быть равным входному сигналу аудиокодера в цепочке обработки, содержащей аудиокодер и аудиодекодер, включающий в себя фильтр).
Этот способ основан на подходыподходах, идентичных подходыподходам для вышеописанного устройства. Тем не менее, следует отметить, что способ может дополняться посредством любых из признаков, функциональностей и подробностей, описанных в данном документе, также относительно устройства. Кроме того, способ может дополняться посредством признаков, функциональностей и подробностей как отдельно, так и в комбинации.
Вариант осуществления согласно изобретению обеспечивает компьютерную программу для осуществления способа, описанного в данном документе, когда компьютерная программа работает на компьютере.
4. Краткое описание чертежей
Далее описываются варианты осуществления согласно настоящему изобретению со ссылкой на прилагаемые чертежи, на которых:
Фиг. 1 показывает принципиальную блок-схему аудиодекодера, согласно варианту осуществления настоящего изобретения;
Фиг. 2 показывает принципиальную блок-схему устройства для определения набора значений, задающих характеристики фильтра, согласно варианту осуществления настоящего изобретения;
Фиг. 3 показывает принципиальную блок-схему аудиодекодера, согласно варианту осуществления настоящего изобретения;
Фиг. 4 показывает принципиальную блок-схему устройства для определения набора значений, задающих характеристики фильтра, согласно варианту осуществления настоящего изобретения;
Фиг. 5 показывает принципиальную блок-схему устройства для определения набора значений, задающих характеристики фильтра, согласно варианту осуществления настоящего изобретения;
Таблица 1 показывает представление процентной доли от значений маски, которые находятся в интервале (0, 1) для различного отношения "сигнал-шум" (SNR);
Таблица 2 показывает представление процентной доли от значений маски в различных пороговых областях, измеренных при наименьших трех скоростях передачи битов AMR-WB;
Фиг. 6 показывает схематичное представление полностью соединенной нейронной сети (FCNN), которая преобразует логарифмическую абсолютную величину в действительнозначные маски;
Фиг. 7 показывает графическое представление средних количественных PESQ- и POLQA-показателей, оценивающих эксперимент по принципу оракула с различными пределами маски при 6,65 Кбит/с;
Фиг. 8 показывает графическое представление средних количественных PESQ- и POLQA-показателей, оценивающих производительность предложенных способов и EVS-постпроцессора;
Фиг. 9 показывает блок-схему последовательности операций способа, согласно варианту осуществления настоящего изобретения; и
Фиг. 10 показывает блок-схему последовательности операций способа, согласно варианту осуществления настоящего изобретения.
5. Подробное описание вариантов осуществления
1. Аудиодекодер согласно фиг. 1
Фиг. 1 показывает принципиальную блок-схему аудиодекодера 100, согласно варианту осуществления настоящего изобретения. Аудиодекодер 100 выполнен с возможностью принимать кодированное аудиопредставление 110 и обеспечивать, на его основе, улучшенное аудиопредставление 112, которое может представлять собой улучшенную форму декодированного аудиопредставления.
Аудиодекодер 100 необязательно содержит ядро 120 декодера, которое может принимать кодированное аудиопредставление 110 и обеспечивать, на его основе, декодированное аудиопредставление 122. Аудиодекодер дополнительно содержит фильтр 130, который выполнен с возможностью обеспечивать улучшенное аудиопредставление 112 на основе декодированного аудиопредставления 122. Фильтр 130, который может рассматриваться как постфильтр, выполнен с возможностью получать множество значений 136 масштабирования, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, на основе спектральных значений 132 декодированного аудиопредставления, которые также ассоциированы с различными элементами разрешения по частоте или частотными диапазонами. Например, фильтр 130 может содержать определение значений масштабирования или модуль 134 определения значений масштабирования, который принимает спектральные значения 132 декодированного аудиопредставления и который обеспечивает значения 136 масштабирования. Фильтр 130 дополнительно выполнен с возможностью масштабировать спектральные значения декодированного представления аудиосигналов или их предварительно обработанную версию с использованием значений 136 масштабирования для получения улучшенного аудиопредставления 112.
Следует отметить, что спектральные значения декодированного аудиопредставления, которые используются для того, чтобы получать значения масштабирования, могут быть идентичными спектральным значениям, которые фактически масштабируются (например, посредством масштабирования или модуля 138 масштабирования), или могут отличаться от спектральных значений, которые фактически масштабируются. Например, первый поднабор спектральных значений декодированного аудиопредставления может использоваться для определения значений масштабирования, и второй поднабор спектральных значений спектра или амплитудного спектра, или абсолютного спектра, или норменного спектра может фактически масштабироваться. Первый поднабор и второй поднабор могут быть равными или могут перекрываться частично, или могут даже полностью отличаться (вообще без общих спектральных значений).
Относительно функциональности аудиодекодера 100 можно сказать, что аудиодекодер 100 предоставляет декодированное аудиопредставление 122 на основе кодированного аудиопредставления. Поскольку кодирование (т.е. предоставление кодированного аудиопредставления) типично выполняется с потерями, декодированное аудиопредставление 122, предоставляемое, например, посредством ядра декодера может содержать некоторое ухудшение характеристик по сравнению с исходным аудиоконтентом (который может подаваться в аудиокодер, предоставляющий кодированное аудиопредставление 110). Следует отметить, что декодированное аудиопредставление 122, предоставляемое, например, посредством ядра декодера, может принимать любую форму, и, например, может обеспечиваться посредством ядра декодера в форме представления во временной области или в форме представления в спектральной области. Представление в спектральной области, например, может содержать коэффициенты (дискретного) преобразования Фурье или (дискретные) MDCT-коэффициенты и т.п.
Фильтр 130, например, может получать (или принимать) спектральные значения, представляющие декодированное аудиопредставление. Тем не менее, спектральные значения, используемые посредством фильтра 130, например, могут иметь другой тип по сравнению со спектральными значениями, предоставленными посредством ядра декодера. Например, фильтр 130 может использовать коэффициенты Фурье в качестве спектральных значений, в то время как ядро 120 декодера первоначально только предоставляет MDCT-коэффициенты. Кроме того, фильтр 130 может, необязательно, извлекать спектральные значения из представления во временной области декодированного аудиопредставления 120, например, посредством преобразования Фурье или MDCT-преобразования и т.п. (например, кратковременного преобразования Фурье (STFT)).
Определение 134 значений масштабирования извлекает значения 136 масштабирования из множества спектральных значений декодированного аудиопредставления (например, извлекаемых из декодированного аудиопредставления). Например, определение 134 значений масштабирования может содержать нейронную сеть или структуру на основе машинного обучения, которая принимает спектральные значения 132 и извлекает значения 136 масштабирования. Кроме того, спектральные значения улучшенного аудиопредставления 112 могут получаться посредством масштабирования спектральных значений декодированного аудиопредставления (которое может быть равным или отличающимся от спектральных значений, используемых посредством определения 134 значений масштабирования) в соответствии со значениями 136 масштабирования. Например, значения 136 масштабирования могут задавать масштабирование спектральных значений в различных элементах разрешения по частоте или частотных диапазонах. Кроме того, следует отметить, что масштабирование 136 может работать с комплекснозначными спектральными значениями или с действительнозначными спектральными значениями (например, значениями амплитуды или значениями абсолютной величины, или норменными значениями).
Соответственно, при использовании соответствующего определения значений 136 масштабирования на основе спектральных значений 132 декодированного аудиопредставления, масштабирование 138 может противодействовать ухудшению качества звучания, вызываемому посредством кодирования с потерями, используемого для того, чтобы обеспечивать кодированное аудиопредставление 110.
Например, масштабирование 138 может уменьшать шум квантования, например, посредством избирательного ослабления спектральных элементов разрешения или спектральных диапазонов, содержащих высокий шум квантования. Альтернативно или помимо этого, масштабирование 138 также может приводить к сглаживанию спектра во времени и/или по частоте, что также может помогать уменьшать шум квантования и/или улучшать перцепционное ощущение.
Тем не менее, следует отметить, что аудиодекодер 100 согласно фиг. 1 необязательно может дополняться посредством любых из признаков, функциональностей и подробностей раскрытых в данном документе, как отдельно, так и в комбинации.
2. Устройство согласно фиг. 2
Фиг. 2 показывает принципиальную блок-схему устройства 200 для определения набора значений (например, коэффициентов нейронной сети или коэффициентов другой структуры на основе машинного обучения), задающих характеристики фильтра (например, фильтра на основе нейронной сети или фильтра на основе другой структуры на основе машинного обучения).
Устройство 200 согласно фиг. 2 выполнено с возможностью принимать декодированное аудиопредставление 210 и обеспечивать, на его основе, набор 212 значений, задающих фильтр, при этом набор 212 значений, задающих фильтр, например, может содержать коэффициенты нейронной сети или коэффициенты другой структуры на основе машинного обучения. Необязательно, устройство 200 может принимать целевые значения 214 масштабирования и/или информацию 216 целевого спектра. Тем не менее, устройство 200 может, необязательно, непосредственно формировать целевые значения масштабирования и/или информацию 216 целевого спектра.
Следует отметить, что целевые значения масштабирования, например, могут описывать значения масштабирования, которые серьезно приближают (или приближают) декодированное аудиопредставление 210 к идеальному (неискаженному) состоянию. Например, целевые значения масштабирования могут определяться на основе знаний опорного аудиопредставления, из которого декодированное аудиопредставление 210 извлекается посредством кодирования и декодирования. Например, из знаний спектральных значений опорного аудиопредставления и из знаний спектральных значений декодированного аудиопредставления может извлекаться то, какое масштабирование вызывает улучшенное аудиопредставление (которое получается на основе спектральных значений декодированного аудиопредставления с использованием масштабирования), с тем чтобы аппроксимировать опорное аудиопредставление.
Кроме того, информация 216 целевого спектра, например, может быть основана на знаниях опорного аудиопредставления, из которого декодированное аудиопредставление извлекается посредством кодирования и декодирования. Например, информация целевого спектра может принимать форму спектральных значений опорного аудиопредставления.
Как можно видеть на фиг. 2, устройство 200 необязательно может содержать определение спектрального значения, в котором спектральные значения декодированного аудиопредставления 210 извлекаются из декодированного аудиопредставления 210. Определение спектральных значений обозначается с помощью 220, и спектральные значения декодированного аудиопредставления обозначаются с помощью 222. Тем не менее, следует отметить, что определение 220 спектральных значений должно считаться необязательным, поскольку декодированное аудиопредставление 210 может непосредственно обеспечиваться в форме спектральных значений.
Устройство 200 также содержит определение 230 набора значений, задающих фильтр. Определение 230 может принимать или получать спектральные значения 222 декодированного аудиопредставления и обеспечивать, на их основе, набор 212 значений, задающих фильтр. Определение 230 необязательно может использовать целевые значения 214 масштабирования и/или информацию 216 целевого спектра.
Относительно функциональности устройства 200 следует отметить, что устройство 200 выполнено с возможностью получать спектральные значения 222 декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами. Кроме того, определение 230 может быть выполнено с возможностью определять набор 212 значений, задающих характеристики фильтра, так что значения масштабирования, обеспеченные посредством фильтра на основе спектральных значений 222 декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, аппроксимируют целевые значения масштабирования (например, целевые значения 214 масштабирования). Как упомянуто выше, целевые значения масштабирования могут вычисляться на основе сравнения требуемого улучшенного аудиопредставления и декодированного аудиопредставления, при этом требуемое улучшенное аудиопредставление может соответствовать опорному аудиопредставлению, упомянутому выше. Иными словами, определение 230 может определять и/или оптимизировать набор значений (например, набор коэффициентов нейронной сети или набор коэффициентов другой структуры на основе машинного обучения), задающих характеристики фильтра (например, фильтра на основе нейронной сети или фильтра на основе другой структуры на основе машинного обучения), таким образом, что этот фильтр обеспечивает значения масштабирования на основе спектральных значений декодированного аудиопредставления, которые аппроксимируют целевые значения 214 масштабирования. Определение набора 214 значений, задающих фильтр, может осуществляться с использованием однопроходного прямого вычисления, но типично может выполняться с использованием итеративной оптимизации. Тем не менее, могут использоваться любые известные процедуры обучения для нейронных сетей или для структур на основе компьютерного обучения.
Альтернативно, определение 230 набора 212 значений, задающих фильтр, может быть выполнено с возможностью определять набор 212 значений, задающих характеристики фильтра, так что спектр, полученный посредством фильтра на основе спектральных значений декодированного аудиопредставления (которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами), и с использованием значений масштабирования, полученных на основе декодированного аудиопредставления, аппроксимирует целевой спектр (который, например, может описываться посредством целевой информации спектра 216). Другими словами, определение 230 может выбирать набор 212 значений, задающих фильтр таким образом, что фильтрованная версия спектральных значений декодированного аудиопредставления 210 аппроксимирует спектральные значения, описанные посредством целевой информации спектра 216. В качестве вывода, устройство 200 может определять набор 212 значений, задающих фильтр таким образом, что фильтр, по меньшей мере, частично аппроксимирует спектральные значения декодированного аудиопредставления как "идеальные" или "опорные", или "целевые" спектральные значения. С этой целью, устройство типично использует декодированные аудиопредставления, представляющие различный аудиоконтент. Посредством определения набора 212 значений, задающих фильтр на основе различного аудиоконтента (или различных типов аудиоконтента), набор 212 значений, задающих фильтр, может выбираться таким образом, что фильтр работает достаточно хорошо для аудиоконтента, который отличается от опорного аудиоконтента, используемого для обучения набора 212 значений, задающих фильтр.
Таким образом, может достигаться то, что набор 212 значений, задающих фильтр, оптимально подходит для улучшения декодированного аудиопредставления, полученного в аудиодекодере, например, в аудиодекодере 100 согласно фиг. 1. Другими словами, набор 212 значений, задающих фильтр, может использоваться, например, в аудиодекодере 100, чтобы задавать операцию определения 134 значений масштабирования (и в силу этого задавать операцию фильтра 130).
Тем не менее, следует отметить, что устройство 200 согласно фиг. 2 необязательно может дополняться посредством любых из признаков, функциональностей и подробностей, описанных в данном документе, как отдельно, так и в комбинации.
3. Аудиодекодер 300 согласно фиг. 3
Фиг. 3 показывает принципиальную блок-схему аудиодекодера 300, согласно другому варианту осуществления настоящего изобретения. Аудиодекодер 300 выполнен с возможностью принимать кодированное аудиопредставление 310, которое может соответствовать кодированному аудиопредставлению 110, и обеспечивать, на его основе, улучшенное аудиопредставление 312, которое может соответствовать улучшенному аудиопредставлению 112. Аудиодекодер 300 содержит ядро 320 декодера, которое может соответствовать ядру 120 декодера. Ядро 320 декодера предоставляет декодированное аудиопредставление 322 (которое может соответствовать декодированному аудиопредставлению 122) на основе кодированного аудиопредставления 310. Декодированное аудиопредставление может находиться в представлении во временной области, но также может находиться в представлении в спектральной области.
Необязательно, аудиодекодер 300 может содержать преобразование 324, которое может принимать декодированное аудиопредставление 322 и обеспечивать представление 326 в спектральной области на основе декодированного аудиопредставления 322. Это преобразование 324, например, может быть полезным, если декодированное аудиопредставление не принимает форму спектральных значений, ассоциированных с различными элементами разрешения по частоте или частотными диапазонами. Например, преобразование 324 может преобразовывать декодированное аудиопредставление 322 во множество спектральных значений, если декодированное аудиопредставление 322 находится в представлении во временной области. Тем не менее, преобразование 324 также может выполнять преобразование из первого типа представления в спектральной области во второй тип представления в спектральной области в случае, если ядро 320 декодера не предоставляет спектральные значения, применимые посредством стадий последующей обработки. Представление 326 в спектральной области, например, может содержать спектральные значения 132, как показано в аудиодекодере 100 по фиг. 1.
Кроме того, аудиодекодер 300 содержит определение 334 значений масштабирования, которое, например, содержит определение 360 абсолютных значений, логарифмическое вычисление 370 и нейронную сеть или структуру 380 на основе машинного обучения. Определение 334 значений масштабирования обеспечивает значения 336 масштабирования на основе спектральных значений 326, которые могут соответствовать спектральным значениям 132.
Аудиодекодер 300 также содержит масштабирование 338, которое может соответствовать масштабированию 138. При масштабировании, спектральные значения декодированного аудиопредставления или их предварительно обработанная версия масштабируются в зависимости от значений 336 масштабирования, предоставленных посредством нейронной сети/структуры 380 на основе машинного обучения. Соответственно, масштабирование 338 предоставляет улучшенное аудиопредставление.
Определение 334 значений масштабирования и масштабирование 338 могут рассматриваться как фильтр или "постфильтр".
Далее описываются некоторые дополнительные подробности.
Определение 334 значений масштабирования содержит определение 360 абсолютных значений. Определение 360 абсолютных значений может принимать представление 326 в спектральной области декодированного аудиопредставления, например, 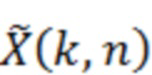 . Определение 360 абсолютных значений затем может обеспечивать абсолютные значения 362 представления 326 в спектральной области декодированного аудиопредставления. Абсолютные значения 362, например, могут быть обозначаться с помощью
. Определение 360 абсолютных значений затем может обеспечивать абсолютные значения 362 представления 326 в спектральной области декодированного аудиопредставления. Абсолютные значения 362, например, могут быть обозначаться с помощью 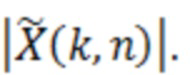
Определение значений масштабирования также содержит логарифмическое вычисление 370, которое принимает абсолютные значения 362 представления в спектральной области декодированного аудиопредставления (например, множество абсолютных значений спектральных значений) и предоставляет, на их основе, логарифмизированные абсолютные значения 372 представления в спектральной области декодированного аудиопредставления. Например, логарифмизированные абсолютные значения 372 могут быть обозначаться с помощью log10 
Следует отметить, что определение 360 абсолютных значений, например, может определять абсолютные значения или значения абсолютной величины, или норменные значения для множества спектральных значений представления 326 в спектральной области, так что, например, знаки или фазы спектральных значений удаляются. Логарифмические вычисления, например, вычисляют обыкновенный логарифм (с основанием 10) или натуральный логарифм, или любой другой логарифм, который может быть подходящим. Кроме того, следует отметить, что логарифмическое вычисление необязательно может заменяться посредством любого другого вычисления, которое уменьшает динамический диапазон спектральных значений 362. Кроме того, известно, что логарифмическое вычисление 370 может содержать ограничение отрицательных и/или положительных значений таким образом, что логарифмизированные абсолютные значения 372 могут быть ограничены обоснованным диапазоном значений.
Определение 334 значений масштабирования также содержит нейронную сеть или структуру 380 на основе машинного обучения, которая принимает логарифмизированные абсолютные значения 372 и которая предоставляет, на их основе, значения 332 масштабирования. Нейронная сеть или структура 380 на основе машинного обучения, например, может параметризоваться посредством набора 382 значений, задающих характеристики фильтра. Набор значений, например, может содержать коэффициенты структуры на основе машинного обучения или коэффициенты нейронной сети. Например, набор 382 значений может содержать весовые коэффициенты ветвей нейронной сети и необязательно также параметры функции активации. Набор 382 значений, например, может определяться посредством устройства 200, и набор 382 значений, например, может соответствовать набору 212 значений.
Кроме того, нейронная сеть или структура 380 на основе машинного обучения необязательно может также содержать логарифмизированные абсолютные значения представления в спектральной области декодированного аудиопредставления для одного или более кадров, предшествующих текущему кадру, и/или для одного или более кадров после текущего кадра. Другими словами, нейронная сеть или структура 380 на основе машинного обучения может не только использовать логарифмизированные абсолютные значения спектральных значений, ассоциированных с текущим обработанным кадром (для которого значения масштабирования применяются), но также может рассматривать логарифмизированные абсолютные значения спектральных значений одного или более предшествующих кадров и/или одного или более последующих кадров. Таким образом, значения масштабирования, ассоциированные с данным (текущим обработанным) кадром, могут быть основаны на спектральных значениях данного (текущего обработанного) кадра, а также на спектральных значениях одного или более предшествующих кадров и/или одного или более последующих кадров.
Например, логарифмизированные абсолютные значения представления в спектральной области декодированного аудиопредставления (обозначенные с помощью 372) могут применяться к вводам (например, входным нейронам) нейронной сети или структуры 380 на основе машинного обучения. Значения 336 масштабирования могут обеспечиваться посредством выводов нейронной сети или структуры 380 на основе машинного обучения (например, посредством выходных нейронов). Кроме того, нейронная сеть или структура на основе машинного обучения может выполнять обработку в соответствии с набором 382 значений, задающих характеристики фильтра.
Масштабирование 338 может принимать значения 336 масштабирования, которые также могут обозначаться "как значения маскирования" и которые, например, могут быть обозначаться с помощью M(k, n), а также спектральные значения или предварительно обработанные спектральные значения представления в спектральной области декодированного аудиопредставления. Например, спектральные значения, которые вводятся в масштабирование 338 и которые масштабируются в соответствии со значениями 336 масштабирования, могут быть основаны на представлении 326 в спектральной области или могут быть основаны на абсолютных значениях 362, при этом, необязательно, предварительная обработка может применяться до того, как масштабирование 338 выполняется. Предварительная обработка, например, может содержать фильтрацию, например, в форме фиксированного масштабирования или масштабирования, определенного посредством вспомогательной информации кодированной аудиоинформации. Тем не менее, предварительная обработка также может быть фиксированной, может быть независимой от вспомогательной информации кодированного аудиопредставления. Кроме того, следует отметить, что спектральные значения, которые вводятся в масштабирование 338 и которые масштабируются с использованием значений 336 масштабирования, не обязательно должны быть идентичными спектральным значениям, которые используются для извлечения значений 336 масштабирования.
Соответственно, масштабирование 338, например, может умножать спектральные значения, которые вводятся в масштабирование 338, на значения масштабирования, при этом различные значения масштабирования ассоциированы с различными элементами разрешения по частоте или частотными диапазонами. Соответственно, получается улучшенное аудиопредставление 312, при этом улучшенное аудиопредставление, например, может содержать масштабированное представление в спектральной области (например, 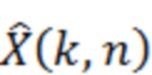 ) или масштабированные абсолютные значения такого представления в спектральной области (например,
) или масштабированные абсолютные значения такого представления в спектральной области (например,  ). Таким образом, масштабирование 338, например, может выполняться с использованием простого умножения между спектральными значениями, ассоциированными с декодированным аудиопредставлением 322, и ассоциированными значениями масштабирования, предоставленными посредством нейронной сети или структуры 380 на основе машинного обучения.
). Таким образом, масштабирование 338, например, может выполняться с использованием простого умножения между спектральными значениями, ассоциированными с декодированным аудиопредставлением 322, и ассоциированными значениями масштабирования, предоставленными посредством нейронной сети или структуры 380 на основе машинного обучения.
В качестве вывода, устройство 300 предоставляет улучшенное аудиопредставление 312 на основе кодированного аудиопредставления 310, при этом масштабирование 338 применяется к спектральным значениям, которые основаны на декодированном аудиопредставлении 322, предоставленном посредством ядра 320 декодера. Значения 336 масштабирования, которые используются при масштабировании 338, обеспечиваются посредством нейронной сети или посредством структуры на основе машинного обучения, при этом входные сигналы нейронной сети или структуры 380 на основе машинного обучения предпочтительно получаются посредством логарифмизации абсолютных значений спектральных значений, которые основаны на декодированном аудиопредставлении 322. Тем не менее, посредством соответствующего варианта выбора набора 382 значений, задающих характеристики фильтра, нейронная сеть или структура на основе машинного обучения может обеспечивать значения масштабирования таким образом, что масштабирование 338 улучшает ощущение для слуха улучшенного аудиопредставления по сравнению с декодированным аудиопредставлением.
Кроме того, следует отметить, что аудиодекодер 300 необязательно может дополняться посредством любых из признаков, функциональностей и подробностей, описанных в данном документе.
4. Устройство согласно фиг. 4
Фиг. 4 показывает принципиальную блок-схему устройства 400 для определения набора значений (например, коэффициентов нейронной сети или коэффициентов другой структуры на основе машинного обучения), задающих характеристики фильтра. Устройство 400 выполнено с возможностью принимать обучающее аудиопредставление 410 и обеспечивать, на его основе, набор 412 значений, задающих характеристики фильтра. Следует отметить, что обучающее аудиопредставление 410, например, может содержать различный аудиоконтент, который используется для определения набора 412 значений.
Устройство 400 содержит аудиокодер 420, который выполнен с возможностью кодировать обучающее аудиопредставление 410, чтобы за счет этого получать кодированное обучающее аудиопредставление 422. Устройство 400 также содержит ядро 430 декодера, которое принимает кодированное обучающее аудиопредставление 422 и предоставляет, на его основе, декодированное аудиопредставление 432. Следует отметить, что ядро 420 декодера, например, может быть идентичным ядру 320 декодера и ядру 120 декодера. Декодированное аудиопредставление 432 также может соответствовать декодированному аудиопредставлению 210.
Устройство 400 также содержит, необязательно, преобразование 442, которое преобразует декодированное аудиопредставление 432, которое основано на обучающем аудиопредставлении 410, в представление 446 в спектральной области. Преобразование 442, например, может соответствовать преобразованию 324, и представление 446 в спектральной области, например, может соответствовать представлению 326 в спектральной области. Устройство 400 также содержит определение 460 абсолютных значений, которое принимает представление 446 в спектральной области и предоставляет, на его основе, абсолютные значения 462 представления в спектральной области. Определение 460 абсолютных значений, например, может соответствовать определению 360 абсолютных значений. Устройство 400 также содержит логарифмическое вычисление 470, которое принимает абсолютные значения 462 представления в спектральной области и предоставляет, на их основе, логарифмизированные абсолютные значения 472 представления в спектральной области декодированного аудиопредставления. Логарифмическое вычисление 470 может соответствовать логарифмическому вычислению 370.
Кроме того, устройство 400 также содержит нейронную сеть или структуру 480 на основе машинного обучения, которая соответствует нейронной сети или структуре 380 на основе машинного обучения. Тем не менее, коэффициенты структуры на основе машинного обучения или нейронной сети 480, которые обозначаются с помощью 482, обеспечиваются посредством тренировки 490 нейронной сети/тренировки машинного обучения. Здесь следует отметить, что нейронная сеть/структура 480 на основе машинного обучения обеспечивает значения масштабирования, которые нейронная сеть/структура на основе машинного обучения извлекает на основе логарифмизированных абсолютных значений 372, в тренировку 490 нейронной сети/тренировку машинного обучения.
Устройство 400 также содержит вычисление 492 целевых значений масштабирования, которое также обозначается в качестве "вычисления масок соотношений". Например, вычисление 492 целевых значений масштабирования принимает обучающее аудиопредставление 410 и абсолютные значения 462 представления в спектральной области декодированного аудиопредставления 432. Соответственно, вычисление 492 целевых значений масштабирования предоставляет информацию 494 целевых значений масштабирования, которая описывает требуемые значения масштабирования, которые должны обеспечиваться посредством нейронной сети/структуры 480 на основе машинного обучения. Соответственно, тренировка 490 нейронной сети/тренировка машинного обучения сравнивает значения 484 масштабирования, обеспеченные посредством нейронной сети/структуры 480 на основе машинного обучения, с целевыми значениями 494 масштабирования, предоставленными посредством масштабирования 492 целевых вычислений значения, и регулирует значения 482 (т.е. коэффициенты структуры на основе машинного обучения или нейронной сети), чтобы уменьшать (или минимизировать) отклонение между значениями 484 масштабирования и целевыми значениями 494 масштабирования.
Ниже по тексту предоставляется общее представление функциональности устройства 400. Посредством кодирования и декодирования обучающего аудиопредставления (которое, например, может содержать различный аудиоконтент) в аудиокодере 420 и в аудиодекодере 430, получается декодированное аудиопредставление 432, которое типично содержит некоторое ухудшение характеристик по сравнению с обучающим аудиопредставлением вследствие потерь в кодировании с потерями. Вычисление 492 целевых значений масштабирования определяет то, какое масштабирование (например, какие значения масштабирования) должно применяться к спектральным значениям декодированного аудиопредставления 432, так что масштабированные спектральные значения декодированного аудиопредставления 432 хорошо аппроксимируют спектральные значения обучающего аудиопредставления. Предполагается, что артефакты, введенные посредством кодирования с потерями, могут, по меньшей мере, частично компенсироваться посредством применения масштабирования в спектральные значения декодированного аудиопредставления 432. Следовательно, нейронная сеть или структура 480 на основе машинного обучения обучается посредством тренировки нейронной сети/тренировки машинного обучения таким образом, что значения 482 масштабирования, обеспеченные посредством нейронной сети/структуры 480 на основе машинного обучения на основе декодированного аудиопредставления 432, аппроксимируют целевые значения 494 масштабирования. Необязательное преобразование 442, определение 460 абсолютных значений и логарифмическое вычисление 470 составляют только (необязательные) этапы предварительной обработки, чтобы извлекать входные значения 472 (которые представляют собой логарифмизированные абсолютные значения спектральных значений декодированного аудиопредставления) для нейронной сети или структуры 480 на основе машинного обучения.
Тренировка 490 нейронной сети/тренировка машинного обучения может использовать соответствующий механизм обучения (например, процедуру оптимизации), чтобы регулировать коэффициенты 482 структуры на основе машинного обучения или нейронной сети таким образом, что разность (например, взвешенная разность) между значениями 484 масштабирования и целевыми значениями 494 масштабирования минимизируется или опускается ниже порогового значения либо, по меньшей мере, уменьшается.
Соответственно, коэффициенты 482 структуры на основе машинного обучения или нейронной сети (или, вообще говоря, набор значений, задающих характеристики фильтра) обеспечиваются посредством устройства 400. Эти значения могут использоваться в фильтре 130 (чтобы регулировать определение 134 значений масштабирования) или в устройстве 300 (чтобы регулировать нейронную сеть/структуру 380 на основе машинного обучения).
Тем не менее, следует отметить, что устройство 400 необязательно может дополняться посредством любых из признаков, функциональностей и подробностей, описанных в данном документе.
5. Устройство согласно фиг. 5
Фиг. 5 показывает принципиальную блок-схему устройства 500 для определения набора 512 значений, задающих фильтр, при этом значения 512, например, могут представлять собой коэффициенты структуры на основе машинного обучения или нейронной сети.
Следует отметить, что устройство 500 является аналогичным устройству 400, так что идентичные признаки, функциональности и подробности не приводятся снова. Вместо этого, следует обратиться к вышеприведенным пояснениям.
Устройство 500 принимает обучающее аудиопредставление 510, которое, например, может соответствовать обучающему аудиопредставлению 410. Устройство 500 содержит аудиокодер 520, который соответствует аудиокодеру 420 и который предоставляет кодированное обучающее аудиопредставление 522, которое соответствует кодированному обучающему аудиопредставлению 422. Устройство 500 также содержит ядро 530 декодера, которое соответствует ядру 430 декодера и предоставляет декодированное аудиопредставление 532.
Устройство 500 необязательно содержит преобразование 542, которое соответствует преобразованию 442 и которое предоставляет представление в спектральной области (например, в форме спектральных значений) декодированного аудиопредставления 552. Представление в спектральной области обозначается с помощью 546 и соответствует представлению 446 в спектральной области. Кроме того, устройство 500 содержит определение 560 абсолютных значений, которое соответствует определению 460 абсолютных значений. Устройство 500 также содержит логарифмическое вычисление 570, которое соответствует логарифмическому вычислению 470. Кроме того, устройство 500 содержит нейронную сеть или структуру 580 на основе машинного обучения, которая соответствует структуре 480 на основе машинного обучения. Тем не менее, устройство 500 также содержит масштабирование 590, которое выполнено с возможностью принимать спектральные значения 546 декодированного аудиопредставления или абсолютные значения 562 спектральных значений декодированного аудиопредставления. Масштабирование также принимает значения 584 масштабирования, обеспеченные посредством нейронной сети 580. Соответственно, масштабирование 590 масштабирует спектральные значения декодированного аудиопредставления или абсолютные значения спектральных значений аудиопредставления, чтобы за счет этого получать улучшенное аудиопредставление 592. Улучшенное аудиопредставление 592, например, может содержать масштабированные спектральные значения (например, 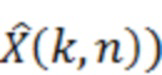 или масштабированные абсолютные значения спектральных значений (например,
или масштабированные абсолютные значения спектральных значений (например,  ). В принципе, улучшенное аудиопредставление 592 может соответствовать улучшенному аудиопредставлению 112, предоставленному посредством устройства 100, и улучшенному аудиопредставлению 312, предоставленному посредством устройства 300. До такой степени, функциональность устройства 500 может соответствовать функциональности устройства 100 и/или функциональности устройства 300, за исключением того факта, что коэффициенты нейронной сети или структуры 580 на основе машинного обучения, которые обозначаются с помощью 594, регулируются посредством тренировки 596 нейронной сети/тренировки машинного обучения. Например, тренировка 596 нейронной сети/тренировка машинного обучения может принимать обучающее аудиопредставление 510, а также улучшенное аудиопредставление 592 и может регулировать коэффициенты 594 таким образом, что улучшенное аудиопредставление 592 аппроксимирует обучающее аудиопредставление.
). В принципе, улучшенное аудиопредставление 592 может соответствовать улучшенному аудиопредставлению 112, предоставленному посредством устройства 100, и улучшенному аудиопредставлению 312, предоставленному посредством устройства 300. До такой степени, функциональность устройства 500 может соответствовать функциональности устройства 100 и/или функциональности устройства 300, за исключением того факта, что коэффициенты нейронной сети или структуры 580 на основе машинного обучения, которые обозначаются с помощью 594, регулируются посредством тренировки 596 нейронной сети/тренировки машинного обучения. Например, тренировка 596 нейронной сети/тренировка машинного обучения может принимать обучающее аудиопредставление 510, а также улучшенное аудиопредставление 592 и может регулировать коэффициенты 594 таким образом, что улучшенное аудиопредставление 592 аппроксимирует обучающее аудиопредставление.
Здесь следует отметить, что, если улучшенное аудиопредставление 592 аппроксимирует обучающее аудиопредставление 510 с хорошей точностью, ухудшение характеристик сигнала, вызываемое посредством кодирования с потерями, по меньшей мере, частично компенсируется посредством масштабирования 590. Иными словами, тренировка 596 нейронной сети, например, может определять (взвешенную) разность между обучающим аудиопредставлением 510 и улучшенным аудиопредставлением 592 и регулировать коэффициенты 594 структуры на основе машинного обучения или нейронной сети 580, чтобы уменьшать или минимизировать эту разность. Регулирование коэффициентов 594, например, может выполняться в итеративной процедуре.
Соответственно, можно добиваться того, что коэффициенты 594 нейронной сети или структуры 580 на основе машинного обучения адаптируются таким образом, что в нормальном режиме работы, структура на основе машинного обучения или нейронная сеть 380 с использованием определенных коэффициентов 594 может обеспечивать значения 336 масштабирования, которые приводят к улучшенному аудиопредставлению 312 хорошего качества.
Иными словами, коэффициенты 482, 594 нейронной сети или структуры 480 на основе машинного обучения либо нейронной сети или структуры 580 на основе машинного обучения могут использоваться в нейронной сети 380 устройства 300, и можно ожидать, что устройство 300 предоставляет высококачественное улучшенное аудиопредставление 312 в этой ситуации. Конечно, эта функциональность основана на таком допущении, что нейронная сеть/структура 380 на основе машинного обучения является аналогичной или даже является идентичной нейронной сети/структуре 480 на основе машинного обучения или нейронной сети/структуре 580 на основе машинного обучения.
Кроме того, следует отметить, что коэффициенты 482, 412 или коэффициенты 594, 512 также могут использоваться в определении 134 значений масштабирования аудиодекодера 100.
Кроме того, следует отметить, что устройство 500 необязательно может дополняться посредством любых из признаков, функциональностей и подробностей, описанных в данном документе, как отдельно, так и в комбинации.
6. Подробности и варианты осуществления
Ниже по тексту поясняются некоторые подходы, лежащие в основе настоящего изобретения, и описываются несколько решений. В частности, раскрывается определенное число подробностей, которое необязательно могут вводиться в любой из вариантов осуществления, раскрытых в данном документе.
6.1. Формулирование проблемы
6.1.1. Идеальная маска соотношений (IRM)
С очень упрощенной математической точки зрения, можно описывать кодированную речь  , например, декодированную речь, предоставленную посредством ядра декодера (например, ядра 120 декодера либо ядра 320 декодера, либо ядра 430 декодера, либо ядра 530 декодера), следующим образом:
, например, декодированную речь, предоставленную посредством ядра декодера (например, ядра 120 декодера либо ядра 320 декодера, либо ядра 430 декодера, либо ядра 530 декодера), следующим образом:
 (1)
(1)
- где x(n) является вводом в кодер (например, в аудиокодер 410, 510), и δ(n) является шумом квантования. Шум δ(n) квантования коррелируется с входной речью, поскольку ACELP использует перцепционные модели во время процесса квантования. Это свойство корреляции шума квантования делает проблему постфильтрации уникальной для проблемы улучшения речи, которая допускает то, что шум должен декоррелироваться. Чтобы уменьшать шум квантования, оценивается действительнозначная маска в расчете на элемент разрешения по частоте и времени, и эта маска умножается на маску абсолютной величины кодированной речи для этого элемента разрешения по частоте и времени.
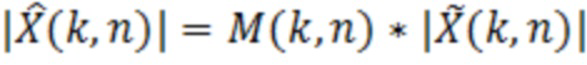 (2)
(2)
- где M(k, n) является действительнозначной маской, является абсолютной величиной кодированной речи, является абсолютной величиной улучшенной речи, k является частотным индексом, и n является временным индексом. Если маска является идеальной (например, если значения M(k, n) масштабирования являются идеальными), можно восстанавливать чистую речь из кодированной речи.
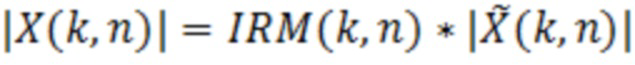 (3)
(3)
- где  является абсолютной величиной чистой речи.
является абсолютной величиной чистой речи.
При сравнении уравнения 2 и 3, получается идеальная маска соотношений (IRM) (например, идеальное значение значений M(k, n) масштабирования), которая задается следующим образом:
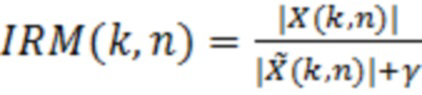 (4)
(4)
- где 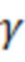 является очень небольшим постоянным коэффициентом с тем, чтобы предотвращать деление на нуль. Поскольку значения абсолютной величины находятся в диапазоне
является очень небольшим постоянным коэффициентом с тем, чтобы предотвращать деление на нуль. Поскольку значения абсолютной величины находятся в диапазоне 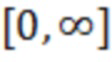 , значения IRM также находятся в диапазоне .
, значения IRM также находятся в диапазоне .
Иными словами, например, улучшенное аудиопредставление 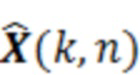 может извлекаться на основе декодированного аудио
может извлекаться на основе декодированного аудио 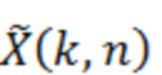 с использованием масштабирования, при этом коэффициенты масштабирования могут описываться посредством M(k, n). Кроме того, например, коэффициенты M(k, n) масштабирования могут извлекаться из декодированного аудиопредставления, поскольку типично существует корреляция между шумом (который, по меньшей мере, частично компенсируется посредством масштабирования с использованием коэффициентов масштабирования M(k, n)) и декодированным аудиопредставлением
с использованием масштабирования, при этом коэффициенты масштабирования могут описываться посредством M(k, n). Кроме того, например, коэффициенты M(k, n) масштабирования могут извлекаться из декодированного аудиопредставления, поскольку типично существует корреляция между шумом (который, по меньшей мере, частично компенсируется посредством масштабирования с использованием коэффициентов масштабирования M(k, n)) и декодированным аудиопредставлением 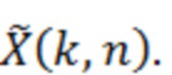 Например, масштабирование, как задано в уравнении (2), может выполняться посредством масштабирования 138, при этом определение 134 значений масштабирования может, например, обеспечивать значения M(k, n) масштабирования, которые аппроксимируют идеальные масштабирующие векторы IRM(k, n), как описано, например, посредством уравнения (4).
Например, масштабирование, как задано в уравнении (2), может выполняться посредством масштабирования 138, при этом определение 134 значений масштабирования может, например, обеспечивать значения M(k, n) масштабирования, которые аппроксимируют идеальные масштабирующие векторы IRM(k, n), как описано, например, посредством уравнения (4).
Таким образом, желательно, если определение 134 значений масштабирования определяет значения масштабирования, которые аппроксимируют IRM(k, n).
Это, например, может достигаться посредством соответствующего проектирования определения 134 значений масштабирования или определения 334 значений масштабирования, при этом, например, коэффициенты структуры на основе машинного обучения или нейронной сети, используемые для того, чтобы реализовывать блок 380, могут определяться так, как указано ниже по тексту.
6.1.2. MMSE-оптимизации
Например, два различных типа оптимизации на основе минимальной среднеквадратической ошибки (MMSE) могут использоваться для того, чтобы обучать нейронную сеть (например, нейронную сеть 380): аппроксимация масок (MA) (например, как показано на фиг. 4) и аппроксимация сигналов (SA) [10] (например, как показано на фиг. 5). Подход на основе MA-оптимизации пытается минимизировать среднеквадратическую ошибку (MSE) между целевой маской (например, целевыми значениями масштабирования) и оцененной маской (например, значениями 484 масштабирования, предоставленными посредством нейронной сети).
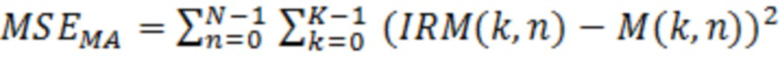 (5)
(5)
- где IRM(k, n) является целевой маской, M(k, n) является оцененной маской.
Подход на основе SA-оптимизации пытается минимизировать среднеквадратическую ошибку (MSE) между целевым спектром абсолютной величины 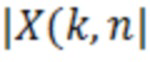 (например, спектром абсолютной величины обучающего аудиопредставления 510) и улучшенным спектром абсолютной величины
(например, спектром абсолютной величины обучающего аудиопредставления 510) и улучшенным спектром абсолютной величины  (например, спектром абсолютной величины улучшенного аудиопредставления 592).
(например, спектром абсолютной величины улучшенного аудиопредставления 592).
 (6)
(6)
- где улучшенный спектр абсолютной величины задается посредством уравнения 2.
Иными словами, нейронная сеть, используемая в определении 134 значений масштабирования или в определении 334 значений масштабирования, может обучаться, например, как показано на фиг. 4 и 5. Как видно из фиг. 4, тренировка 490 нейронной сети/тренировка машинного обучения оптимизирует коэффициенты нейронной сети или коэффициенты 482 структуры на основе машинного обучения в соответствии с критерием, заданным в уравнении (5).
Как показано на фиг. 5, тренировка 596 нейронной сети/тренировка машинного обучения оптимизирует коэффициенты нейронной сети/коэффициенты 594 структуры машинного обучения в соответствии с критерием, показанным в уравнении (6).
6.1.3. Анализ значений маски
В большинстве предложенных подходов на основе маски для улучшения речи и дереверберации, значения маски ограничены единицей [9]-[10]. Это обусловлено тем, что, традиционно, если значения маски не ограничены единицей, ошибки оценки могут вызывать усиление шумовых или музыкальных тонов [15]. Следовательно, эти подходы используют сигмоиду в качестве выходных активаций, чтобы ограничивать значения маски 1.
Таблица 1 показывает процентную долю от значений маски, которые находятся в интервале (0,1) для различного отношения "сигнал-шум" (SNR). Эти значения маски вычисляются посредством добавления белого шума при различных SNR в чистую речь. Из таблицы 1 можно логически выводить то, что большинство значений маски находятся в интервале [0,1], и в силу этого ограничение значениями маски в 1 не имеет отрицательного эффекта на системы улучшения речи на основе нейронной сети.
Затем вычислено распределение значений маски при более низких трех скоростях передачи битов (6,65 Кбит/с, 8,85 Кбит/с и 12,65 Кбит/с) AMR-WB. Таблица 2 показывает вычисленное распределение. Одно существенное отличие для таблицы 1 заключается в процентной доле от значений маски, которые находятся в диапазоне [0,1]. Хотя 39% значений находятся в этом диапазоне при 6,65 Кбит/с, при 12,65 Кбит/с, это значение увеличивается до 44%. Почти 30-36% значений маски находятся в диапазоне (1,2]. Почти 95% значений маски находятся в диапазоне [0,5]. Следовательно, для проблемы постфильтрации, нельзя просто ограничивать значение маски 1. Это предотвращает использование сигмоидальных активаций (или простых, немасштабированных сигмоидальных активаций) в выходном слое.
Другими словами, обнаружено, что предпочтительно использовать значения маски (также обозначенные в качестве значений масштабирования), которые больше единицы в вариантах осуществления согласно изобретению. Кроме того, обнаружено, что предпочтительно ограничивать значения маски или значения масштабирования предварительно определенным значением, которое должно быть больше единицы и которое, например, может находиться в области между 1 и 10 или в области между 1,5 и 10. Посредством ограничения значения маски или значения масштабирования, может не допускаться чрезмерное масштабирование, которое может приводить к артефактам. Например, соответствующий диапазон значений деления шкалы может достигаться посредством использования масштабированной сигмоидальной активации в выходном слое нейронной сети или посредством использования (например, выпрямленной) ограниченной линейной функции активации в качестве выходного слоя нейронной сети.
6.2. Экспериментальная компоновка
Ниже по тексту описываются некоторые подробности относительно экспериментальной компоновки. Тем не менее, следует отметить, что функциональности признаков и подробности, описанные в данном документе, необязательно могут перениматься в любом из вариантов осуществления, раскрытых в данном документе.
Предложенный постфильтр вычисляет кратковременное преобразование Фурье (STFT) кадров с длиной 16 мс с 50%-м перекрытием (8 мс) на частоте дискретизации в 16 кГц (например, в блоке 324). Временные кадры кодируются со взвешиванием с функцией кодирования со взвешиванием Хана, до того, как быстрое преобразование Фурье (FFT) длины 256 вычисляется, приводя к 129 элементам разрешения по частоте (например, представление в пространственной области 326). Из FFT вычисляются значения логарифмической абсолютной величины, чтобы сжимать очень расширенный динамический диапазон значений абсолютной величины (например, логарифмизированных абсолютных значений 372). Поскольку речь имеет временную зависимость, использованы контекстные кадры вокруг обработанного временного кадра (например, обозначенные с помощью 373). Предложенная модель протестирована при двух условиях: a) использованы только предыдущие контекстные кадры, и b) использованы предыдущие и будущие контекстные кадры. Это осуществлено, поскольку будущие контекстные кадры способствуют задержке предложенного постфильтра, и необходимо тестировать преимущество использования будущих контекстных кадров. Контекстная функция кодирования со взвешиванием в 3 выбрана для экспериментов с продвижением задержки всего в один кадр (16 мс), когда рассматриваются только предыдущие контекстные кадры. Когда рассматриваются предыдущие и будущие контекстные кадры, задержка предложенного постфильтра равна 4 кадрам (64 мс).
Размерность по входным признакам (например, значений 373 и 373) для предложенной нейронной сети при тестировании только с предыдущими 3 контекстными кадрами и текущим обработанным кадром составляет 516 (4*129). При тестировании с предыдущими и будущими контекстными кадрами, размерность по входным признакам составляет 903 (7*129). Входные признаки (например, значения 372 и 373) нормализуются к нулевому среднему и единичной дисперсии. Тем не менее, цель, либо действительнозначная маска (например, значения 494), либо спектр абсолютной величины некодированной речи (например, абсолютная величина значений 410), не нормализуется.
Фиг. 6 показывает FCNN 600, которая тренируется для того, чтобы обучать функцию fθ преобразования между логарифмической абсолютной величиной и действительнозначной маской.
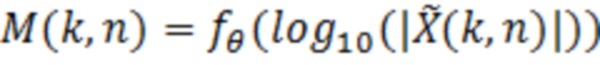 (7)
(7)
FCNN представляет собой простую нейронную сеть, которая имеет входной слой 610, один или более скрытых слоев 612a-612d и выходной слой 614. FCNN реализована на Python с помощью работы Keras [16], и использован Tensorflow [17] в качестве внутреннего интерфейса. В экспериментах, использовано 4 скрытых слоя с 2048 единицами. Все 4 скрытых слоя используют блоки линейной ректификации (ReLU) в качестве функций активации [18]. Вывод скрытых слоев нормализован с использованием пакетной нормализации [19]. Чтобы предотвращать сверхподгонку, выпадение сигнала [20] задается равным 0,2. Чтобы обучать FCNN, использован оптимизатор Адама [21] с темпом обучения 0,01, и используемый размер пакета равен 32.
Размерность выходного слоя 614 равна 129. Поскольку FCNN оценивает действительнозначную (или действительнозначную) маску, и эти маски могут принимать любое значение между , тестирование выполняется как с ограничением значений маски, так и без ограничения. Когда значения маски являются неограниченными, использована ReLU-активация в выходном слое. Когда значения маски являются ограниченными, использована либо ограниченная ReLU-активация, либо сигмоидальная функция, и вывод сигмоидальной активации масштабирован на определенный коэффициент N масштабирования.
Чтобы обучать FCNN, использованы две функции потерь (MSEMA и MSESA), заданные в разделе 6.1.2. Нормы отсечения использованы для того, чтобы обеспечивать сходимость модели, когда ограниченная ReLU или неограниченная ReLU используется в качестве активации выходного слоя.
Градиенты в выходном слое, когда ограниченная или неограниченная ReLU используется, являются следующими:
 (8)
(8)
- где tar является либо спектром абсолютной величины (например, абсолютной величиной аудиопредставления 510), либо IRM (например, значениями 494), out является либо улучшенной абсолютной величиной (например, значениями 542), либо оцененной маской (например, значениями 484), которая принимает любое значение между 0 и пороговое значение, и h является выводом скрытого модуля, который задается как ввод в выходной модуль. Когда ограниченная ReLU используется, уравнение 8 равно нулю за пределами ограниченного значения.
Градиенты в выходном слое, когда масштабированная сигмоида используется, являются следующими:
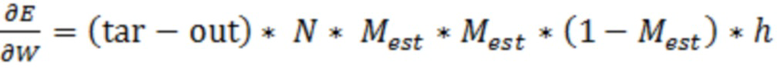 (9)
(9)
- где tar является либо спектром абсолютной величины, либо IRM (например, значениями 494), out является либо улучшенной абсолютной величиной, либо оцененной маской Mest, которая принимает любое значение между 0 и 1, и h является выводом скрытого модуля, который задается как ввод в выходной модуль.
Для обучения проверки достоверности и тестирования, использована NTT-база данных [22]. Также выполнено перекрестное тестирование баз данных для TIMIT-базы данных [23], чтобы подтверждать независимость модели от обучающей базы данных. NTT- и TIMIT-базы данных представляют собой базу данных с чистой речью. TIMIT-база данных состоит из файлов с моноречью на частоте дискретизации в 16 кГц. NTT-база данных состоит из файлов со стереоречью, дискретизированных при 48 кГц. Чтобы получать файлы с моноречью при 16 кГц, выполнено пассивное понижающее сведение и повторная дискретизация для NTT-база данных. NTT-база данных состоит из 3960 файлов, из которых 3612 файлов использованы для обучения, 198 файлов использованы для проверки достоверности, и 150 файлов использованы для тестирования. База данных NT состоит из говорящих мужского пола и женского пола, а также состоит из таких языков, как американский английский и британский английский, немецкий, китайский, французский и японский язык.
Улучшенная речь временной области получается с использованием обратного кратковременного преобразования Фурье (iSTFT). iSTFT использует фазу кодированной речи вообще без обработки.
В качестве вывода, полностью соединенная нейронная сеть 600, как показано на фиг. 6 используется в вариантах осуществления согласно изобретению, чтобы реализовывать определение 134 значений масштабирования или нейронную сеть 380. Кроме того, нейронная сеть 600 может обучаться посредством устройства 200 или посредством устройства 400, или посредством устройства 500.
Как можно видеть, нейронная сеть 600 принимает логарифмизированные значения абсолютной величины (например, логарифмизированные абсолютные значения спектральных значений 132, 372, 472, 572) во входном слое 610. Например, логарифмизированные абсолютные значения спектральных значений текущего обработанного кадра и одного или более предшествующих кадров, и одного или более последующих кадров могут приниматься во входном слое 610. Входной слой, например, может принимать логарифмизированные абсолютные значения спектральных значений. Значения, принятые посредством входного слоя, затем могут перенаправляться, масштабированным способом, в искусственные нейроны первых скрытых слоев 612a. Масштабирование входных значений входного слоя 612, например, может задаваться посредством набора значений, задающих характеристики фильтра. Затем, искусственные нейроны первого скрытого слоя 612, который может реализовываться с использованием нелинейных функций, обеспечивают выходные значения первого скрытого слоя 612a. Выходные значения первого скрытого слоя 612a затем обеспечиваются, масштабированным способом, во вводы искусственных нейронов последующего (второго) скрытого слоя 612b. С другой стороны, масштабирование задается посредством набора значений, задающих характеристики фильтра. Дополнительные скрытые слои, содержащие аналогичную функциональность, могут включаться. В завершение, выходные сигналы последнего скрытого слоя (например, четвертого скрытого слоя 612d) обеспечиваются, масштабированным способом, во вводы искусственных нейронов выходного слоя 614. Функциональность искусственных нейронов выходного слоя 614, например, может задаваться посредством функции активации выходного слоя. Соответственно, выходные значения нейронной сети могут определяться с использованием оценки функции активации выходного слоя.
Кроме того, следует отметить, что нейронная сеть может быть "полностью соединенной", что означает, например, то, что все входные сигналы нейронной сети могут способствовать входным сигналам всех искусственных нейронов первого скрытого слоя, и то, что выходные сигналы всех искусственных нейронов данного скрытого слоя могут способствовать входным сигналам всех искусственных нейронов последующего скрытого слоя. Тем не менее, фактические доли могут определяться посредством набора значений, задающих характеристики фильтра, который типично определяется посредством тренировки 490, 596 нейронной сети.
Кроме того, следует отметить, что тренировка 490, 596 нейронной сети, например, может использовать градиенты, как предусмотрено в уравнениях (8) и (9), при определении коэффициентов нейронной сети.
Следует отметить, что любые из признаков, функциональностей и подробностей, описанных в этом разделе, необязательно могут вводиться в любые из вариантов осуществления, раскрытых в данном документе, как отдельно, так и в комбинации.
6.3. Эксперименты и результаты
Чтобы оценивать предел значений маски, проведен эксперимент по принципу оракула. При этом оценивается IRM и ограничивается IRM с различными пороговыми значениями, как показано на фиг. 7. Использованы объективные показатели, такие как перцепционная оценка качества речи (PESQ) [24][25][26] и перцепционная объективная оценка качества прослушивания (POLQA) [27] для оценки. Из фиг. 7 можно сделать вывод, что задание порогового значения равным 1 не работает настолько хорошо, как задание порогового значения равным 2, 4 или 10. Имеются очень незначительные разности между пороговыми значениями 2, 4 и 10. Следовательно, выбрано ограничение значения маски 2 в дополнительных экспериментах.
Кроме того, фиг. 8 показывает средние количественные PESQ- и POLQA-показатели, оценивающие производительность предложенных способов и EVS-постпроцессора. Можно видеть, что применение концепций, описанных в данном документе, приводит к повышению качества речи, как для случая, в котором аппроксимация сигналов (например, как показано на фиг. 5), так и для случая, в котором маскированная аппроксимация (например, как показано на фиг. 4) используется для обучения искусственной нейронной сети.
7. Заключения
Обнаружено, что качество кодированной речи существенно страдает на более низких скоростях передачи битов вследствие высокого шума квантования. Постфильтры обычно используются на низких скоростях передачи битов, чтобы смягчать эффект шума квантования. В этом раскрытии сущности, предлагается постфильтр на основе действительнозначной маски для того, чтобы повышать качество декодированной речи при более низких скоростях передачи битов. Чтобы оценивать эту действительнозначную маску, используется, например, полностью соединенная нейронная сеть, которая работает с нормализованными логарифмическими абсолютными величинами. Данное предложение протестировано на кодеке на основе стандарта широкополосного адаптивного многоскоростного кодирования (AMR-WB) в более низких 3 режимах (6,65 Кбит/с, 8,85 Кбит/с и 12,65 Кбит/с). Эксперимент показывает улучшение в PESQ, POLQA и субъективных тестах на основе прослушивания.
Другими словами, варианты осуществления согласно изобретению относятся к концепции, которая использует полностью соединенную сеть в контексте кодирования речи и/или декодирования речи. Варианты осуществления согласно изобретению относятся к улучшению кодированной речи. Варианты осуществления согласно изобретению относятся к постфильтрации. Варианты осуществления согласно изобретению относятся к концепции, которая решает проблемы, связанные с шумом квантования (или, более точно, с уменьшением шума квантования).
В вариантах осуществления согласно изобретению, CNN (сверточная нейронная сеть) используется в качестве функции преобразования в кепстральной области. Работа [14] предлагает статистический контекстный постфильтр в области логарифмической абсолютной величины.
В этой работе, проблема улучшения кодированной речи формулируется как проблема регрессии. Полностью соединенная нейронная сеть (FCNN) тренируется для того, чтобы обучать функцию fθ преобразования между вводом (логарифмической абсолютной величиной) и выводом (действительнозначной маской). Оцененная действительнозначная маска затем умножается на входную абсолютную величину, чтобы улучшать кодированную речь. Работа оценивается для AMR-WB-кодека на скоростях передачи битов в 6,65 Кбит/с, 8,85 Кбит/с и 12,65 Кбит/с. В вариантах осуществления, постфильтр может использоваться в EVS [4][3] в качестве опорного постфильтра. Для получения дальнейшей информации, следует обратиться к разделам 6.1 и 6.2. Как можно видеть, вербальные результаты тестирования на основе прослушивания обеспечиваются. Например, предпочтительные количественные PESQ- и POLQA-показатели могут достигаться с использованием вариантов осуществления согласно изобретению.
Ниже по тексту описываются некоторые дополнительные важные моменты.
Согласно первому аспекту, постфильтр на основе маски, чтобы повышать качество кодированной речи, используется в вариантах осуществления согласно изобретению.
Маска является действительнозначной (либо значения масштабирования являются действительнозначными). Она оценивается для каждого элемента разрешения по частоте посредством алгоритма машинного обучения (или посредством нейронной сети) из входных признаков:
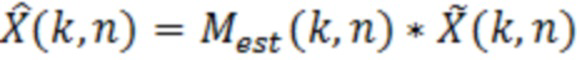
- где 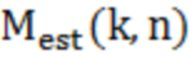 является оцененной маской,
является оцененной маской, 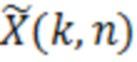 является значением абсолютной величины кодированной речи, и
является значением абсолютной величины кодированной речи, и  является постобработанной речью в элементе k разрешения по частоте и временном индексе n.
является постобработанной речью в элементе k разрешения по частоте и временном индексе n.
Входные признаки, используемые в данный момент, представляют собой спектр логарифмической абсолютной величины, но также могут представлять собой любую производную спектра абсолютной величины.
Согласно второму аспекту, необязательно может быть предусмотрено ограничение значений маски или значений масштабирования.
Значения оцененной маски находятся, например, в диапазоне [0,  ]. Чтобы предотвращать такой большой диапазон, пороговое значение необязательно может задаваться. В традиционных алгоритмах улучшения речи, маска является ограниченной 1. В отличие от них, здесь она ограничивается пороговым значением, которое превышает 1. Это пороговое значение определяется посредством анализа распределения масок. Полезные пороговые значения, например, могут составлять между 2 и 10.
]. Чтобы предотвращать такой большой диапазон, пороговое значение необязательно может задаваться. В традиционных алгоритмах улучшения речи, маска является ограниченной 1. В отличие от них, здесь она ограничивается пороговым значением, которое превышает 1. Это пороговое значение определяется посредством анализа распределения масок. Полезные пороговые значения, например, могут составлять между 2 и 10.
a. Поскольку значения оцененной маски, например, ограничены пороговым значением, и поскольку оцененное пороговое значение превышает 1, выходной слой может представлять собой либо ограниченные блоки линейной ректификации (ReLU), либо масштабированную сигмоиду.
b. Когда алгоритм машинного обучения оптимизируется с использованием способа на основе MMSE (оптимизации оценки минимального среднеквадратического значения) для аппроксимации масок, целевая маска (например, целевые значения масштабирования) необязательно может модифицироваться либо посредством задания значений маски (например, целевых значений масштабирования) выше порогового значения в целевой маске равным 1, либо может задаваться равной пороговому значению.
Согласно третьему аспекту, алгоритм машинного обучения может использоваться в качестве полностью соединенной нейронной сети. Долгое кратковременное запоминающее устройство (LSTM) также может использоваться в качестве альтернативы.
a. Полностью соединенная нейронная сеть состоит, например, из 4 скрытых слоев. Каждый скрытый слой, например, состоит из 2048 или 2500 активаций блоков линейной ректификации (ReLU).
b. Входная размерность полностью соединенной нейронной сети зависит от контекстных кадров и размера FFT. Задержка системы также зависит от контекстных кадров и размера кадра.
c. Размер контекстных кадров, например, может составлять любое значение между 3 и 5. Для экспериментов, использовано, например, 256 (16 мс 16 кГц) в качестве размера кадра и FFT-размера. Размер контекстных кадров задан равным 3, поскольку получается очень небольшое преимущество при выходе за пределы 3. Также тест выполнен как с будущими+предыдущими контекстными кадрами, так и только с предыдущими контекстными кадрами.
Согласно четвертому аспекту, полностью соединенная сеть обучена со следующей MMSE (оптимизацией оценки минимального среднеквадратического значения): аппроксимация масок и аппроксимация сигналов.
a. При аппроксимации масок, среднеквадратическая ошибка между целевой маской (например, целевыми значениями масштабирования) и оцененной маской (например, значениями масштабирования значений масштабирования, определенными с использованием нейронной сети) минимизируется. Целевая маска модифицируется, например, как указано в (2.b) (например, в аспекте 2, подраздел b).
b. При аппроксимации сигналов, среднеквадратическая ошибка между улучшенной абсолютной величиной (например, улучшенным спектром 592 абсолютной величины) и целевой абсолютной величиной (например, спектром абсолютной величины аудиопредставления 510) минимизируется. Улучшенная абсолютная величина получается посредством умножения оцененной маски из DNN (например, из нейронной сети) на оцененную маску кодированной абсолютной величины. Целевая абсолютная величина представляет собой некодированную речевую абсолютную величину.
В качестве вывода, варианты осуществления, описанные в данном документе, могут необязательно дополняться посредством любого из важных моментов или аспектов, описанных здесь. Тем не менее, следует отметить, что важные моменты и аспекты, описанные здесь, могут использоваться отдельно или в комбинации и могут вводиться в любой из вариантов осуществления, описанных в данном документе, как отдельно, так и в комбинации.
8. Способ согласно фиг. 9
Фиг. 9 показывает принципиальную блок-схему способа 900 для обеспечения улучшенного аудиопредставления на основе кодированного аудиопредставления, согласно варианту осуществления настоящего изобретения.
Способ содержит предоставление 910 декодированного аудиопредставления ().
Кроме того, способ содержит получение 920 множества значений (M(k, n)) масштабирования, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и способ содержит масштабирование 930 спектральных значений декодированного представления () аудиосигналов или их предварительно обработанной версии, с использованием значений (M(k, n)) масштабирования для получения улучшенного аудиопредставления ().
Способ 900 необязательно может дополняться посредством любых из признаков, функциональностей и подробностей, описанных в данном документе, как отдельно, так и в комбинации.
9. Способ согласно фиг. 10
Фиг. 10 показывает принципиальную блок-схему способа 1000 для определения набора значений, задающих характеристики фильтра для обеспечения улучшенного аудиопредставления () на основе декодированного аудиопредставления, согласно варианту осуществления настоящего изобретения.
Способ содержит получение 1010 спектральных значений () декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами.
Способ также содержит определение 1020 набора значений, задающих характеристики фильтра таким образом, что значения масштабирования, обеспеченные посредством фильтра на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, аппроксимируют целевые значения масштабирования.
Альтернативно, способ содержит определение 1030 набора значений, задающих характеристики фильтра таким образом, что спектр, полученный посредством фильтра на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и с использованием значений масштабирования, полученных на основе декодированного аудиопредставления, аппроксимирует целевой спектр.
10. Альтернативы реализации
Хотя некоторые аспекты описаны в контексте устройства, очевидно, что эти аспекты также представляют описание соответствующего способа, при этом блок или устройство соответствует этапу способа либо признаку этапа способа. Аналогично, аспекты, описанные в контексте этапа способа, также представляют описание соответствующего блока или элемента, или признака соответствующего устройства. Некоторые или все этапы способа могут выполняться посредством (или с использованием) аппаратного устройства, такого как, например, микропроцессор, программируемый компьютер либо электронная схема. В некоторых вариантах осуществления, один или более из самых важных этапов способа могут выполняться посредством этого устройства.
Изобретаемый кодированный аудиосигнал может сохраняться на цифровом носителе хранения данных либо может передаваться по среде передачи, такой как беспроводная среда передачи или проводная среда передачи, к примеру, Интернет.
В зависимости от определенных требований к реализации, варианты осуществления изобретения могут реализовываться в аппаратных средствах или в программном обеспечении. Реализация может выполняться с использованием цифрового носителя хранения данных, например, гибкого диска, DVD, Blu-Ray, CD, ROM, PROM, EPROM, EEPROM или флэш-памяти, имеющего сохраненные электронно считываемые управляющие сигналы, которые взаимодействуют (или допускают взаимодействие) с программируемой компьютерной системой таким образом, что осуществляется соответствующий способ. Следовательно, цифровой носитель хранения данных может быть машиночитаемым.
Некоторые варианты осуществления согласно изобретению содержат носитель данных, имеющий электронночитаемые управляющие сигналы, которые допускают взаимодействие с программируемой компьютерной системой таким образом, что осуществляется один из способов, описанных в данном документе.
В общем, варианты осуществления настоящего изобретения могут реализовываться как компьютерный программный продукт с программным кодом, при этом программный код выполнен с возможностью осуществления одного из способов, когда компьютерный программный продукт работает на компьютере. Программный код, например, может сохраняться на машиночитаемом носителе.
Другие варианты осуществления содержат компьютерную программу для осуществления одного из способов, описанных в данном документе, сохраненную на машиночитаемом носителе.
Другими словами, вариант осуществления изобретаемого способа в силу этого представляет собой компьютерную программу, имеющую программный код для осуществления одного из способов, описанных в данном документе, когда компьютерная программа работает на компьютере.
Следовательно, дополнительный вариант осуществления изобретаемых способов представляет собой носитель хранения данных (цифровой носитель хранения данных или машиночитаемый носитель), содержащий записанную компьютерную программу для осуществления одного из способов, описанных в данном документе. Носитель данных, цифровой носитель хранения данных или носитель с записанными данными типично является материальным и/или энергонезависимым.
Следовательно, дополнительный вариант осуществления изобретаемого способа представляет собой поток данных или последовательность сигналов, представляющих компьютерную программу для осуществления одного из способов, описанных в данном документе. Поток данных или последовательность сигналов, например, может быть выполнена с возможностью передачи через соединение для передачи данных, например, через Интернет.
Дополнительный вариант осуществления содержит средство обработки, например, компьютер или программируемое логическое устройство, выполненное с возможностью осуществлять один из способов, описанных в данном документе.
Дополнительный вариант осуществления содержит компьютер, имеющий установленную компьютерную программу для осуществления одного из способов, описанных в данном документе.
Дополнительный вариант осуществления согласно изобретению содержит устройство или систему, выполненную с возможностью передавать (например, электронно или оптически) компьютерную программу для осуществления одного из способов, описанных в данном документе, в приемное устройство. Приемное устройство, например, может представлять собой компьютер, мобильное устройство, запоминающее устройство и т.п. Устройство или система, например, может содержать файловый сервер для передачи компьютерной программы в приемное устройство.
В некоторых вариантах осуществления, программируемое логическое устройство (например, программируемая пользователем вентильная матрица) может использоваться для того, чтобы выполнять часть или все из функциональностей способов, описанных в данном документе. В некоторых вариантах осуществления, программируемая пользователем вентильная матрица может взаимодействовать с микропроцессором, чтобы осуществлять один из способов, описанных в данном документе. В общем, способы предпочтительно осуществляются посредством любого аппаратного устройства.
Устройство, описанное в данном документе, может реализовываться с использованием аппаратного устройства либо с использованием компьютера, либо с использованием комбинации аппаратного устройства и компьютера.
Устройство, описанное в данном документе, или любые компоненты устройства, описанного в данном документе, могут реализовываться, по меньшей мере, частично в аппаратных средствах и/или в программном обеспечении.
Способы, описанные в данном документе, могут осуществляться с использованием аппаратного устройства либо с использованием компьютера, либо с использованием комбинации аппаратного устройства и компьютера.
Способы, описанные в данном документе, или любые компоненты устройства, описанного в данном документе, могут выполняться, по меньшей мере, частично посредством аппаратных средств и/или посредством программного обеспечения.
Вышеописанные варианты осуществления являются просто иллюстративными в отношении принципов настоящего изобретения. Следует понимать, что модификации и изменения компоновок и подробностей, описанных в данном документе, должны быть очевидными для специалистов в данной области техники. Следовательно, они подразумеваются как ограниченные только посредством объема нижеприведенной формулы изобретения, а не посредством конкретных подробностей, представленных посредством описания и пояснения вариантов осуществления в данном документе.
11. Библиографический список
1. 3GPP "Speech codec speech processing functions; Adaptive Multi-Rate - Wideband (AMR-WB) speech codec; Transcoding functions", 3rd Generation Partnership Project (3GPP), TS 26.190, 12 2009. [онлайн]. По адресу: http://www.3gpp.org/ftp/Specs/html-info/26190.htm
2. M. Dietz, M. Multrus, V. Eksler, V. Malenovsky, E. Norvell, H. Pobloth, L. Miao, Z. Wang, L. Laaksonen, A. Vasilache, Y. Kamamoto, K. Kikuiri, S. Ragot, J. Faure, H. Ehara, V. Rajendran, V. Atti, H. Sung, E. Oh, H. Yuan и C. Zhu "Overview of the EVS codec architecture", IEEE, 2015 год, стр. 5698-5702.
3. 3GPP "TS 26.445, EVS Codec Detailed Algorithmic Description; 3GPP Technical Specification (Release 12)", 3rd Generation Partnership Project (3GPP), TS 26.445, 12 2014. [онлайн]. По адресу: http://www.3gpp.org/ftp/Specs/html-info/26445.htm
4. T. Vaillancourt, R. Salami и M. Jelnek "New post-processing techniques for low bit rate celp codecs", in ICASSP, 2015 год.
5. J.-H. Chen и A. Gersho "Adaptive postfiltering for quality enhancement of coded speech", издание 3, номер 1, стр. 59-71, 1995 год.
6. T. Bäckström, Speech Coding with Code-Excited Linear Prediction. Springer, 2017 год. [онлайн]. По адресу: http://www.springer.com/gp/book/9783319502021
7. K. Han, Y. Wang, D. Wang, W. S. Woods, I. Merks и T. Zhang "Learning spectral mapping for speech dereverberation and denoising".
8. Y. Zhao, D. Wang, I. Merks и T. Zhang "DNN-based enhancement of noisy and reverberant speech", in 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2016 год.
9. Y. Wang, A. Narayanan и D. Wang "On training targets for supervised speech separation", IEEE/ACM Transactions on Audio, Speech and Language Processing, издание 22, стр. 1849-1858, 2014 год.
10. F. Weninger, J. R. Hershey, J. L. Roux и B. Schuller "Discriminatively trained recurrent neural networks for single-channel speech separation", in IEEE Global Conference on Signal and Information Processing (GlobalSIP), 2014 год.
[11. D. S. Williamson и D. Wang "Time-frequency masking in the complex domain for speech dereverberation and denoising".
12. Z. Zhao, S. Elshamy, H. Liu и T. Fingscheidt "A CNN postprocessor to enhance coded speech", in 16th International Workshop on Acoustic Signal Enhancement (IWAENC), 2018 год.
13. Z. Zhao, H. Liu и T. Fingscheidt "Convolutional neural networks to enhance coded speech", IEEE/ACM Transactions on Au-dio, Speech and Language Processing, издание 27, номер 4, стр. 663-678, апрель 2019 года.
14. S. Das и T. Bäckström "Postfiltering using log-magnitude spectrum for speech and audio coding", in Proc. Inter-speech 2018, 2018 год, стр. 3543-3547. [онлайн]. По адресу: http://dx.doi.org/10.21437/Interspeech.2018-1027
15. W. Mack, S. Chakrabarty, F.-R. Stöter, S. Braun, B. Edler и E. Habets "Single-channel dereverberation using direct MMSE optimization and bidirectional LSTM networks", in Proc. Interspeech 2018, 2018 год, стр. 1314-1318. [онлайн]. По адресу: http://dx.doi.org/10.21437/Interspeech.2018-1296
16. F. Chollet и др. "Keras", https://keras.io, 2015 год.
17. M. Abadi, A. Agarwal, P. Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, S. Ghemawat, I. Goodfellow, A. Harp, G. Irving, M. Isard, Y. Jia, R. Jozefowicz, L. Kaiser, M. Kudlur, J. Levenberg, D. Mane´, R. Monga, S. Moore, D. Murray, C. Olah, M. Schuster, J. Shlens, B. Steiner, I. Sutskever, K. Talwar, P. Tucker, V. Vanhoucke, V. Vasudevan, F. Vie´gas, O. Vinyals, P. Warden, M. Wattenberg, M. Wicke, Y. Yu и X. Zheng "TensorFlow: Large-scale machine learning on heterogeneous systems", 2015 год, программное обеспечение доступно для скачивания с tensorflow.org. [онлайн]. По адресу: http://tensorflow.org/
X. Glorot, A. Bordes и Y. Bengio "Deep sparse rectifier neural networks", in ^ International Conference on Artificial Intelligence and Statistics, 2011 год, стр. 315-323.
S. Ioffe и C. Szegedy "Batch normalization: Accelerating deep network training by reducing internal covariate shift", in International Conference on Machine Learning, издание 37, 2015 год, стр. 448- 456.
N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever и R. Salakhutdinov "Dropout: A simple way to prevent neural networks from overfitting", J. Mach. Learn. Res., издание 15, номер 1, стр. 1929-1958, январь 2014 года. [онлайн]. По адресу: http://dl.acm.org/citation.cfm?id=2627435.2670313
D. Kingma и J. Ba "Adam: A method for stochastic optimization", in arXiv preprint arXiv:1412.6980, 2014 год.
NTT-AT, "Super wideband stereo speech database", http://www.ntt-at.com/product/widebandspeech, обращение: 09.09.2014. [онлайн]. По адресу: http://www.ntt-at.com/product/widebandspeech
J. S. Garofolo, L. D. Consortium и другие "TIMIT: acoustic-phonetic continuous speech corpus", Linguistic Data Consortium, 1993 год.
A. Rix, J. Beerends, M. Hollier и A. Hekstra "Perceptual evaluation of speech quality (PESQ) - the new method for speech quality assessment of telephone networks and codecs", in 2001 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2001 год.
ITU-T "P.862.1: Mapping Function for Transforming P.862 Raw Result Scores to MOS-LQO", (International Telecommunication Union), Tech. Rep. P.862.1, ноябрь 2003 года.
"P.862.2: Wideband Extension to Recommendation P.862 for the Assessment of Wideband Telephone Networks and Speech Codecs", (International Telecommunication Union), Tech. Rep. P.862.2, ноябрь 2005 года.
27. Perceptual objective listening quality assessment (POLQA), ITU-T Recommendation P.863, 2011. [онлайн]. По адресу: http://www.itu.int/rec/T-REC-P.863/en
28. Recommendation BS.1534, Method for the subjective assessment of intermediate quality levels of coding systems, ITU-R, 2003 год.
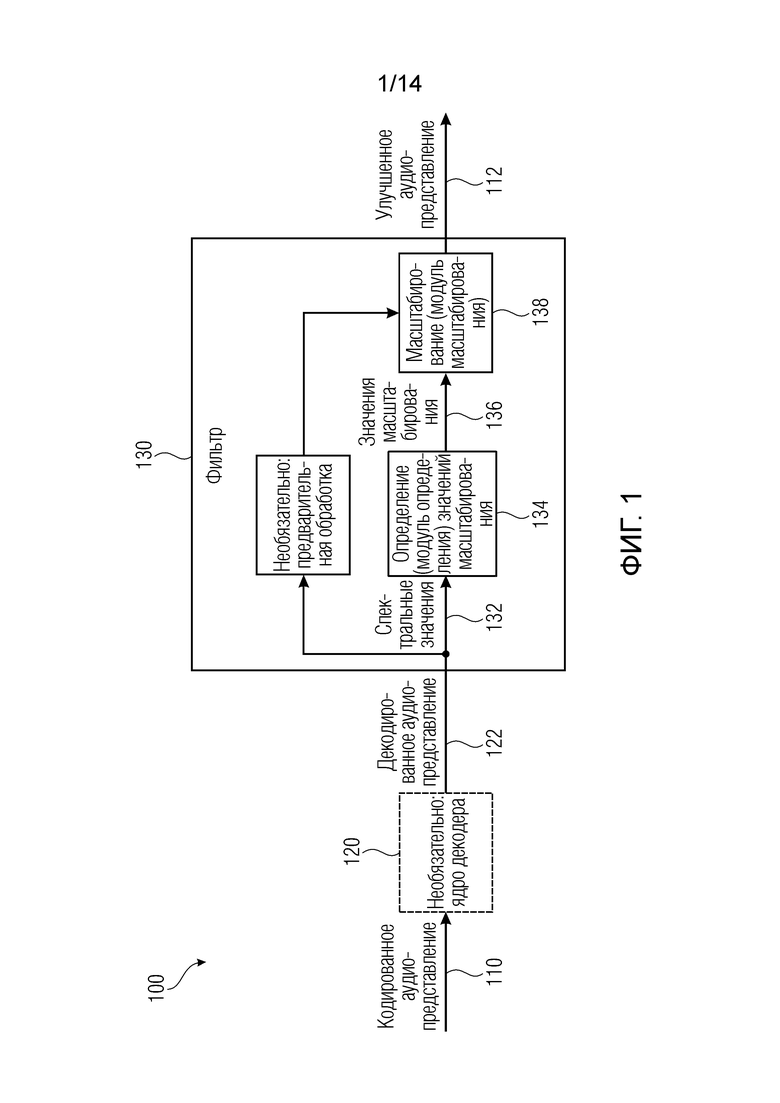

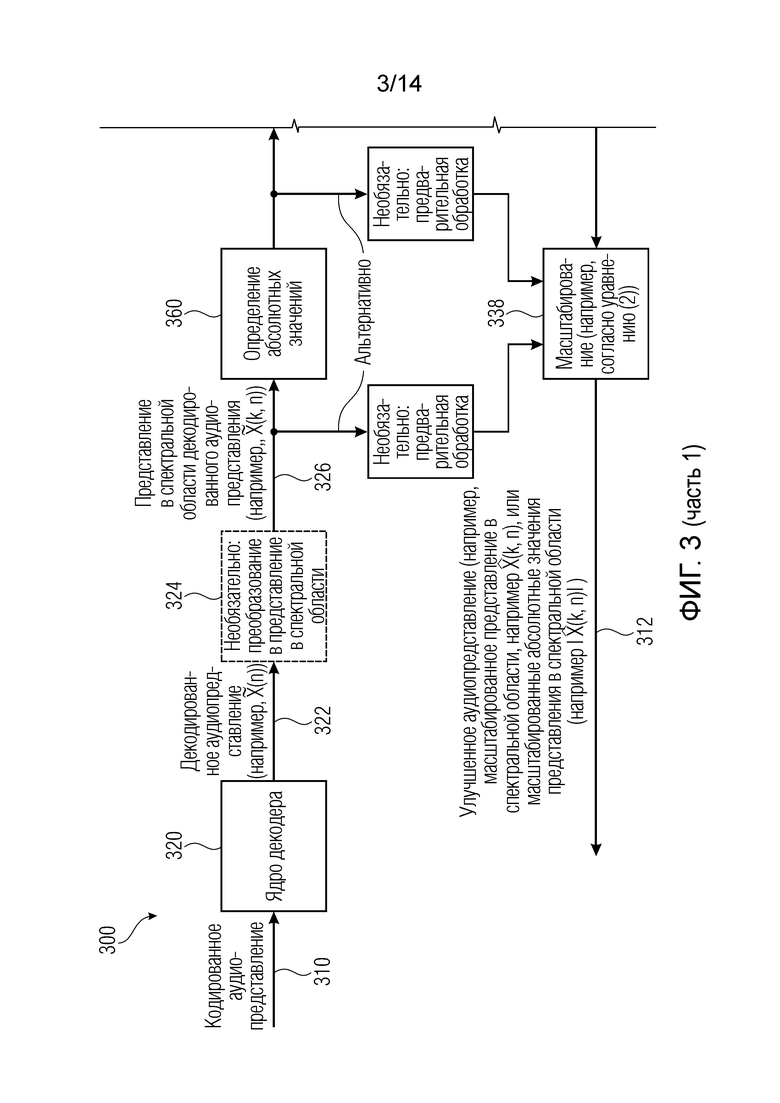


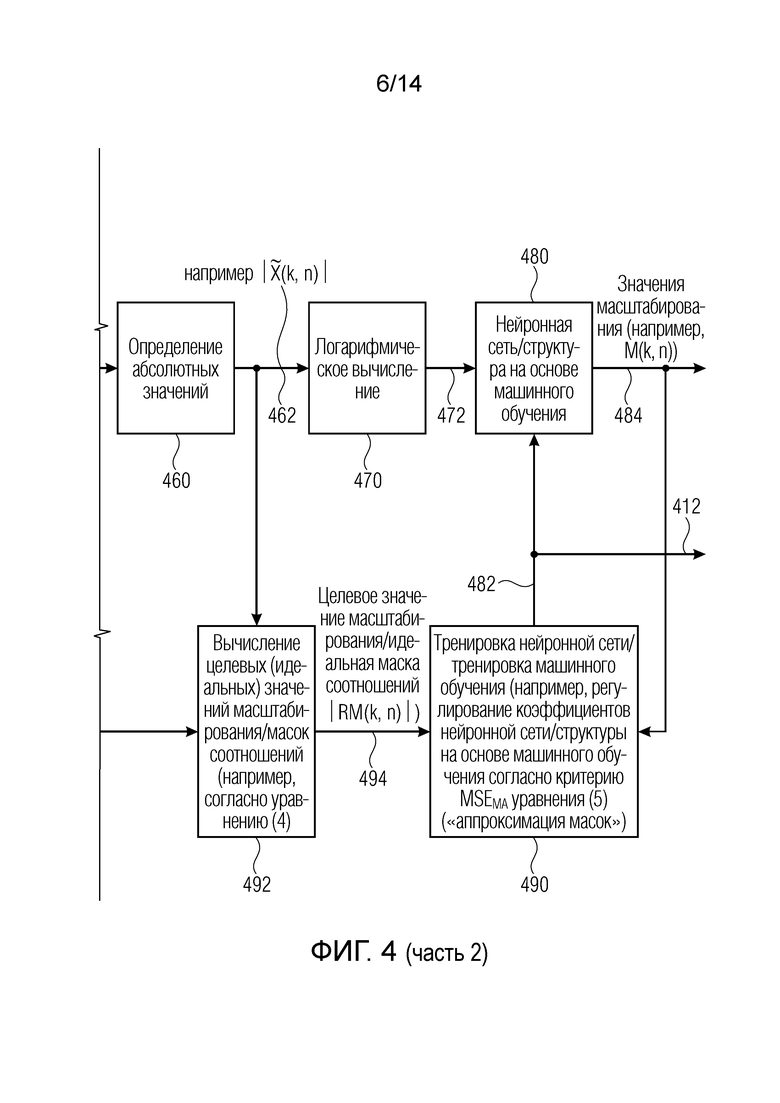

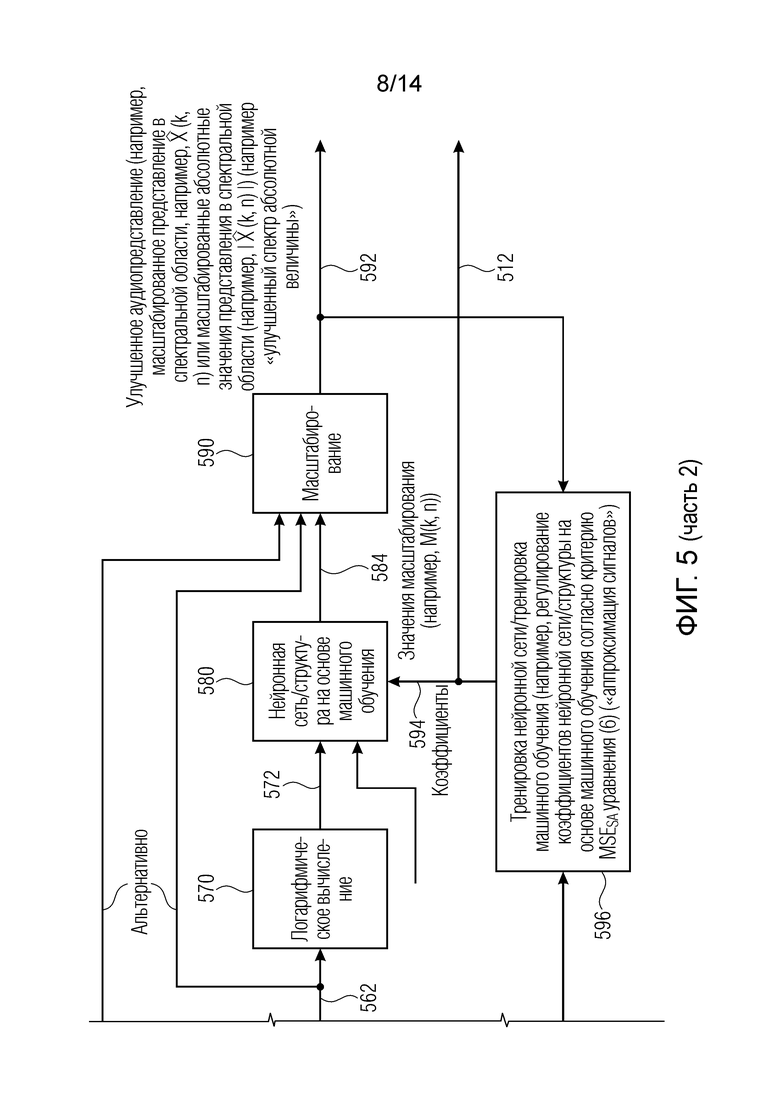
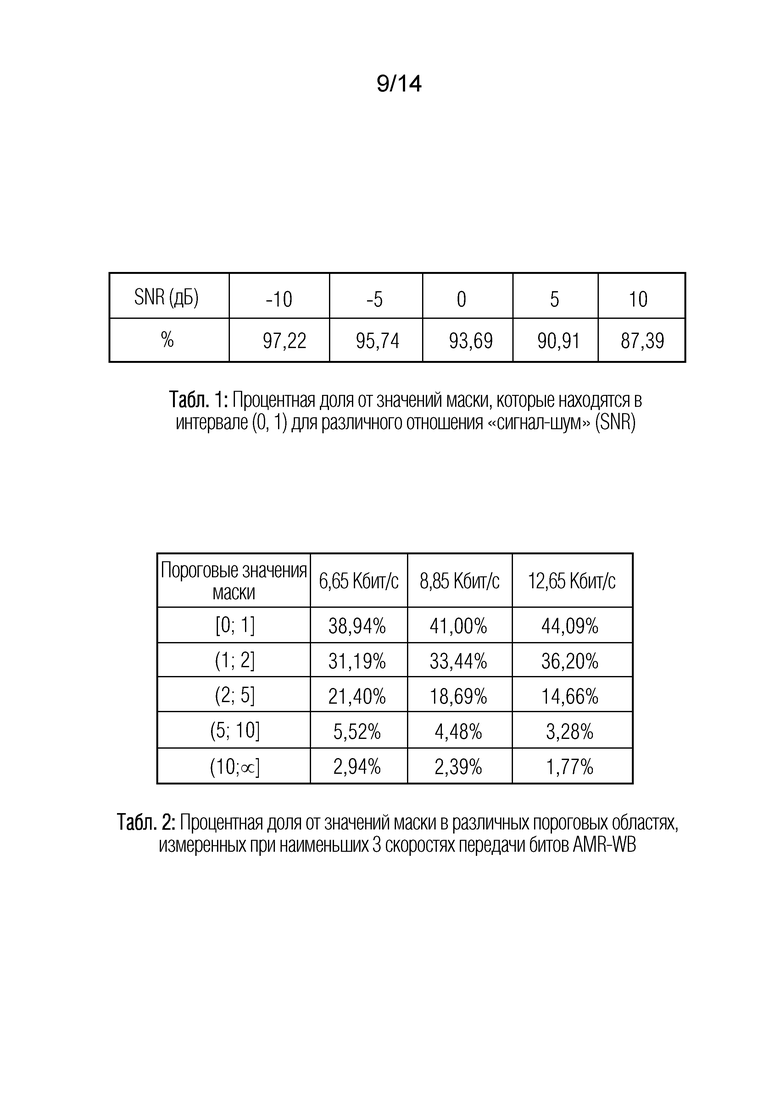
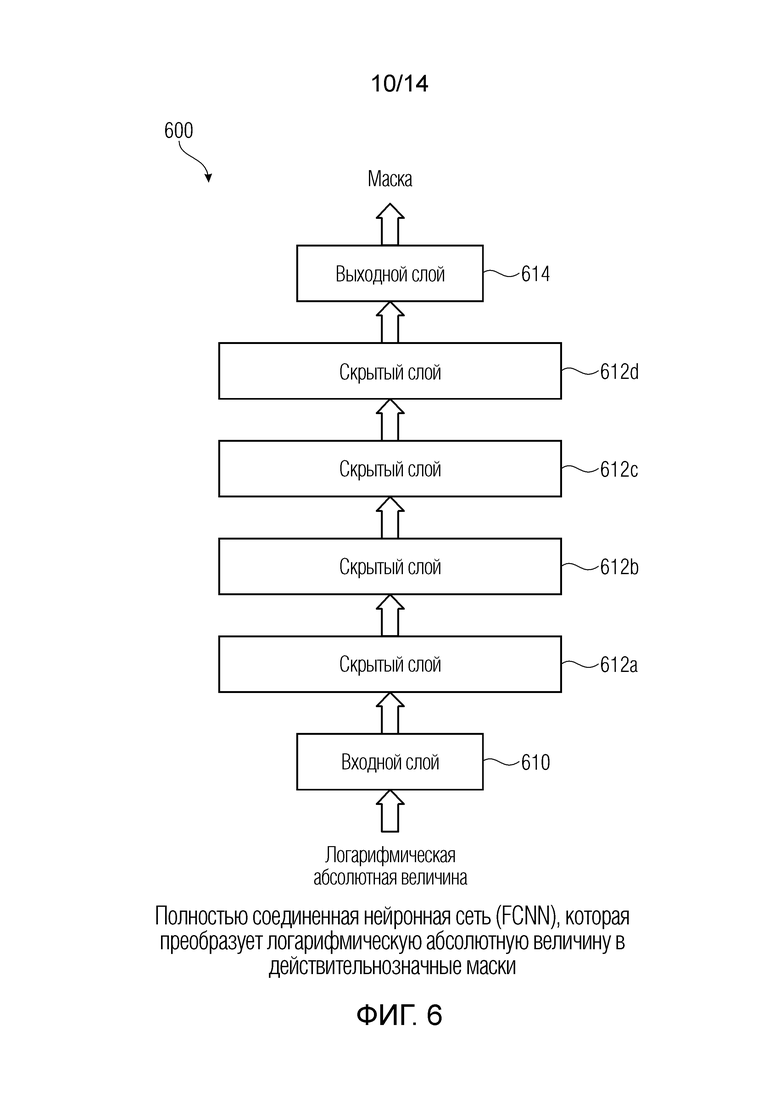
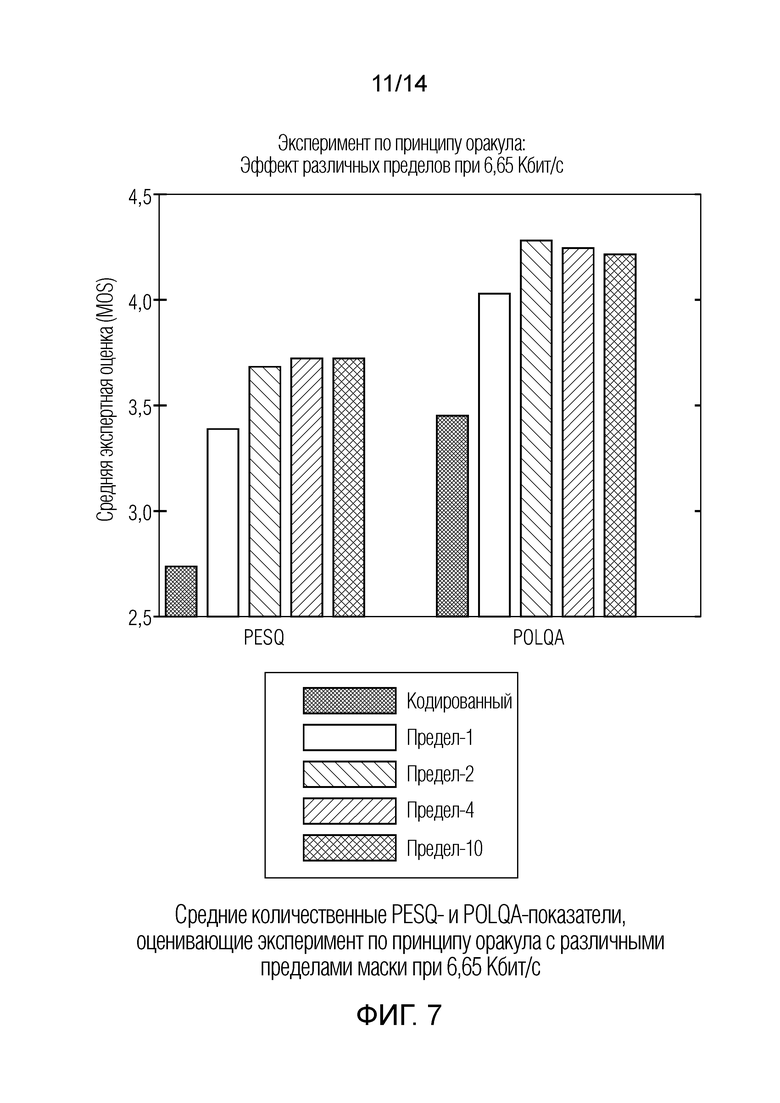
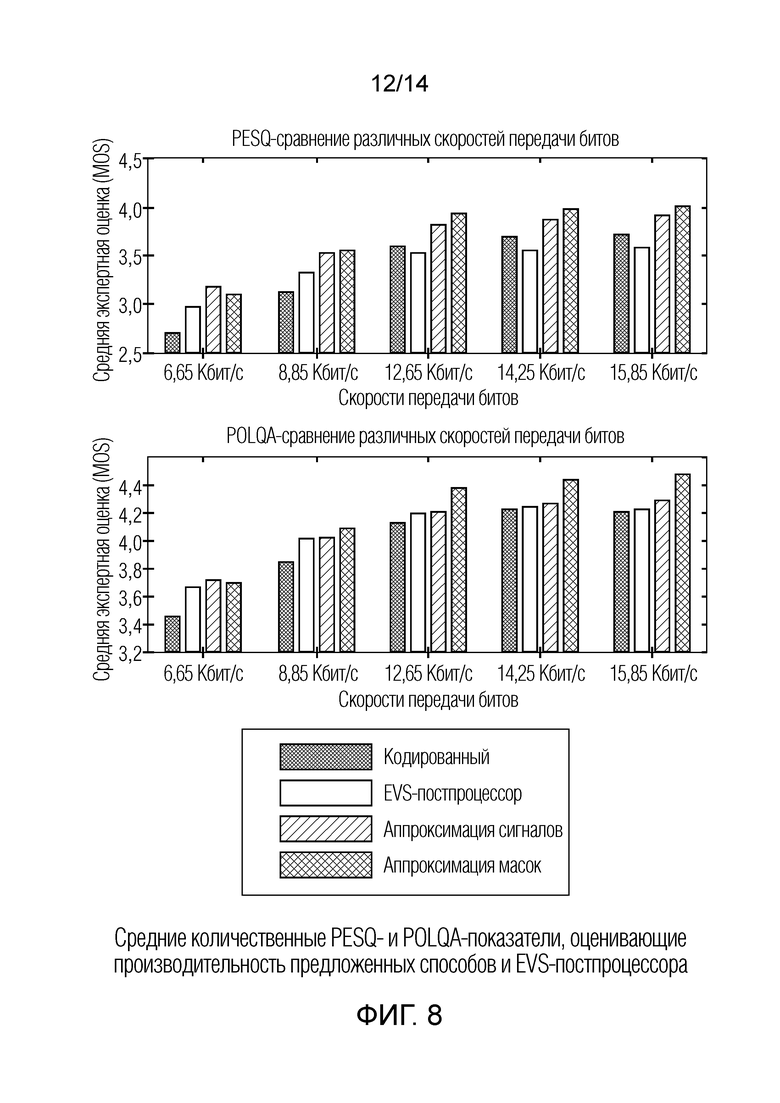
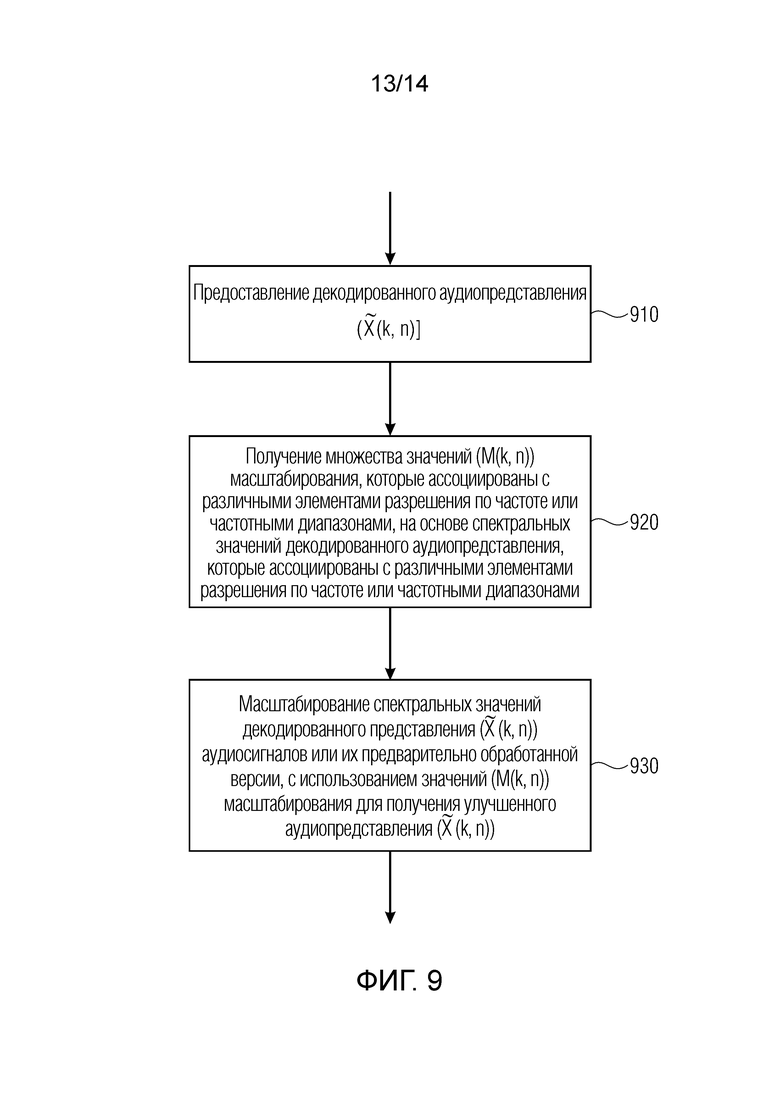
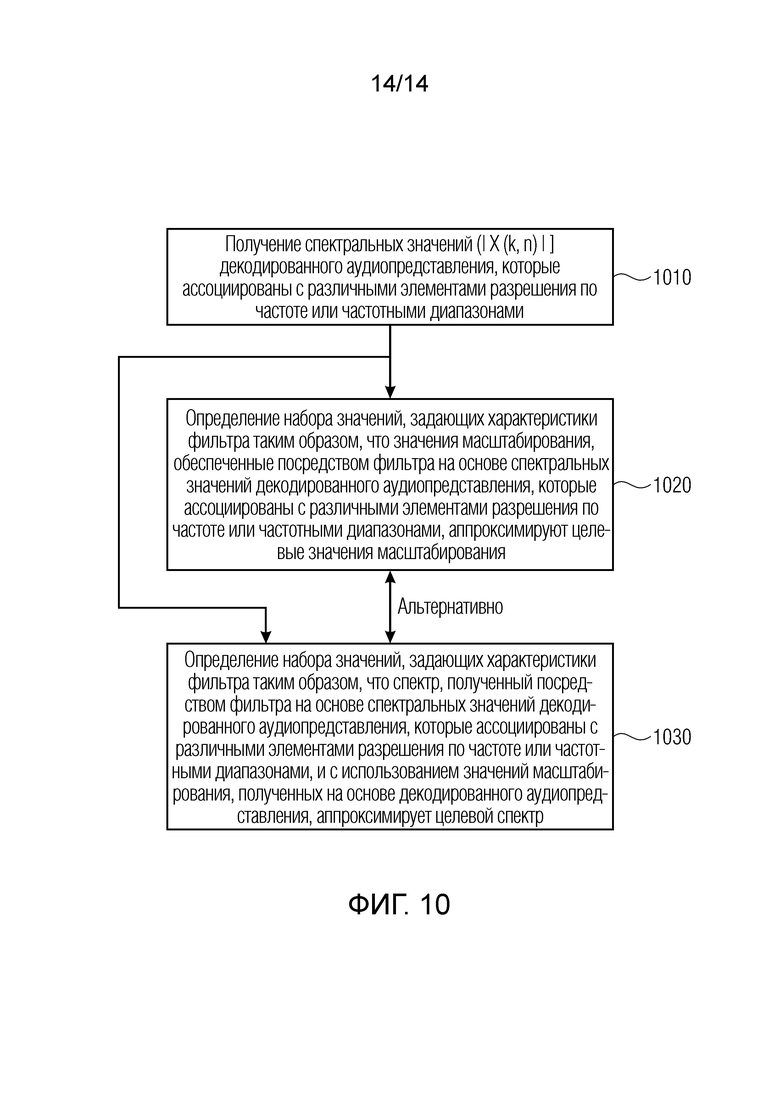
Изобретение относится к области вычислительной техники для обработки аудиоданных. Технический результат заключается в повышении качества воспроизведения аудиоданных с сохранением скорости передачи битов. Технический результат достигается за счет аудиодекодера для обеспечения декодированного аудиопредставления на основе кодированного аудиопредставления, который содержит фильтр для обеспечения улучшенного аудиопредставления декодированного аудиопредставления. Фильтр выполнен с возможностью получать множество значений масштабирования, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и фильтр выполнен с возможностью масштабировать спектральные значения декодированного представления аудиосигналов или их предварительно обработанную версию с использованием значений масштабирования для получения улучшенного аудиопредставления. Также описывается устройство для определения набора значений, задающих характеристики фильтра для обеспечения улучшенного аудиопредставления на основе декодированного аудиопредставления. 17 н. 27 з.п. ф-лы, 14 ил.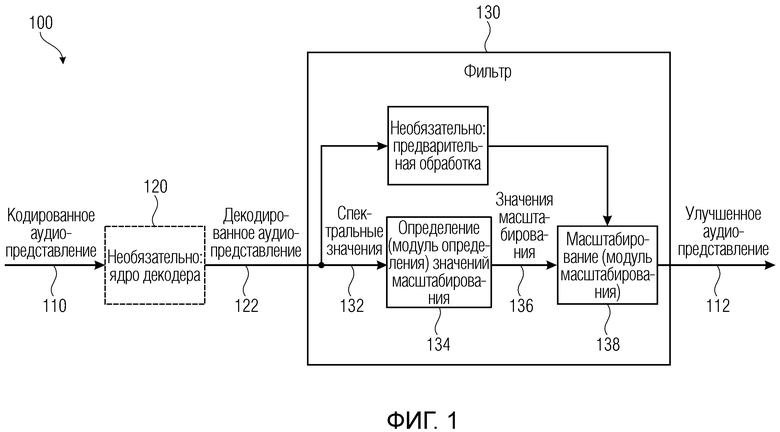
1. Аудиодекодер (100; 300) для обеспечения декодированного аудиопредставления (122; 322; 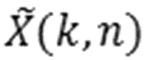 ) на основе кодированного аудиопредставления (110; 310),
) на основе кодированного аудиопредставления (110; 310),
при этом аудиодекодер содержит фильтр (130; 360, 370, 380, 338) для обеспечения улучшенного аудиопредставления (112; 312; 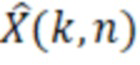 ) декодированного аудиопредставления (122; 322; ),
) декодированного аудиопредставления (122; 322; ),
при этом фильтр выполнен с возможностью получать множество значений (136; 336; M(k, n)) масштабирования, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, на основе спектральных значений (132; 326; ) декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и
при этом фильтр выполнен с возможностью масштабировать спектральные значения декодированного представления () аудиосигналов или их предварительно обработанную версию с использованием значений (136; 336; M(k, n)) масштабирования для получения улучшенного аудиопредставления (122; 312;  ).
).
2. Аудиодекодер (100; 300) по п. 1,
в котором фильтр (130; 360, 370, 380, 338) выполнен с возможностью использовать конфигурируемую структуру обработки, конфигурация которой основана на алгоритме машинного обучения, чтобы обеспечивать значения (136; 336; M(k, n)) масштабирования.
3. Аудиодекодер (100; 300) по п. 1 или 2,
в котором фильтр (130; 360, 370, 380, 338), выполнен с возможностью определять значения (136; 336; M(k, n)) масштабирования только на основе спектральных значений (132; 326; ) декодированного аудиопредставления (122; 322; ) во множестве элементов разрешения по частоте или частотных диапазонов.
4. Аудиодекодер (100; 300) по одному из пп. 1-3,
в котором фильтр (130; 360, 370, 380, 338) выполнен с возможностью получать значения абсолютной величины 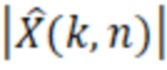 улучшенного аудиопредставления согласно следующему:
улучшенного аудиопредставления согласно следующему:
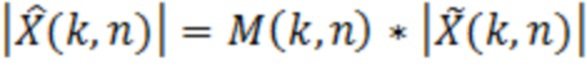 ,
,
при этом M(k, n) является значением масштабирования,
при этом k является частотным индексом,
при этом n является временным индексом,
при этом 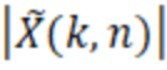 ] является значением абсолютной величины спектрального значения декодированного аудиопредставления; или
] является значением абсолютной величины спектрального значения декодированного аудиопредставления; или
при этом фильтр выполнен с возможностью получать значения улучшенного аудиопредставления согласно следующему:
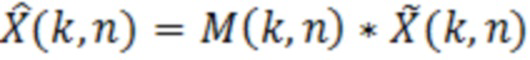 ,
,
при этом M(k, n) является значением масштабирования,
при этом k является частотным индексом,
при этом n является временным индексом,
при этом является спектральным значением декодированного аудиопредставления.
5. Аудиодекодер (100; 300) по одному из пп. 1-4,
в котором фильтр (130; 360, 370, 380, 338) выполнен с возможностью получать значения (136; 336; M(k, n)) масштабирования таким образом, что значения масштабирования вызывают масштабирование или усиление для одного или более спектральных значений (132; 326; ) декодированного представления (122; 322; ) аудиосигналов или для одного или более предварительно обработанных спектральных значений, которые основаны на спектральных значениях (132; 326; ) декодированного представления (122; 322; ) аудиосигналов.
6. Аудиодекодер (100; 300) по одному из пп. 1-5,
в котором фильтр (130; 360, 370, 380, 338) содержит нейронную сеть (380; 600) или структуру на основе машинного обучения, выполненную с возможностью обеспечивать значения (136; 336; M(k, n)) масштабирования на основе множества спектральных значений (132; 326; ), описывающих декодированное аудиопредставление (122; 322; ), причем спектральные значения ассоциированы с различными элементами разрешения по частоте или частотными диапазонами.
7. Аудиодекодер (100; 300) по п. 6,
в котором входные сигналы (372) нейронной сети (380; 600) или структуры на основе машинного обучения представляют логарифмические абсолютные величины, амплитуду или норму спектральных значений декодированного аудиопредставления, причем спектральные значения ассоциированы с различными элементами разрешения по частоте или частотными диапазонами.
8. Аудиодекодер (100; 300) по одному из пп. 6, 7,
в котором выходные сигналы (336) нейронной сети (380; 600) или структуры на основе машинного обучения представляют значения (136; 336; M(k, n)) масштабирования.
9. Аудиодекодер (100; 300) по одному из пп. 6-8,
в котором нейронная сеть (380; 600) или структура на основе машинного обучения обучается, чтобы ограничивать, уменьшать или минимизировать отклонение (MSEMA) между множеством целевых значений (494, IRM(k, n)) масштабирования и множеством значений (484, M(k, n)) масштабирования, полученных с использованием нейронной сети (380; 580; 600) или с использованием структуры на основе машинного обучения.
10. Аудиодекодер (100; 300) по одному из пп. 6-9,
в котором нейронная сеть (380; 600) или структура на основе машинного обучения обучается, чтобы ограничивать, уменьшать или минимизировать отклонение (MSESA) между целевым спектром (510) абсолютной величины, целевым амплитудным спектром, целевым абсолютным спектром или целевым норменным спектром (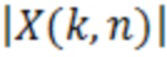 ) и спектром (592) абсолютной величины, амплитудным спектром, абсолютным спектром или норменным спектром, полученным с использованием масштабирования обработанного спектра, который использует значения (584) масштабирования, которые обеспечиваются посредством нейронной сети (380; 580; 600) или посредством структуры на основе машинного обучения.
) и спектром (592) абсолютной величины, амплитудным спектром, абсолютным спектром или норменным спектром, полученным с использованием масштабирования обработанного спектра, который использует значения (584) масштабирования, которые обеспечиваются посредством нейронной сети (380; 580; 600) или посредством структуры на основе машинного обучения.
11. Аудиодекодер (100; 300) по одному из пп. 6-10,
в котором нейронная сеть (380; 600) или структура на основе машинного обучения обучена таким образом, что масштабирование для одного или более спектральных значений (132; 326; ) спектрального разложения декодированного представления (122; 322; ) аудиосигналов или для одного или более предварительно обработанных спектральных значений, которые основаны на спектральных значениях спектрального разложения декодированного представления аудиосигналов, находится в диапазоне между 0 и предварительно определенным максимальным значением.
12. Аудиодекодер (100; 300) по п. 11, в котором максимальное значение превышает 1.
13. Аудиодекодер (100; 300) по одному из пп. 6-12,
в котором нейронная сеть (380; 600) или структура на основе машинного обучения обучена таким образом, что масштабирование для одного или более спектральных значений спектрального разложения декодированного представления аудиосигналов или для одного или более предварительно обработанных спектральных значений, которые основаны на спектральных значениях спектрального разложения декодированного представления аудиосигналов, ограничено 2 или ограничено 5, или ограничено 10, или ограничено предварительно определенным значением, большим 1.
14. Аудиодекодер (100; 300) по одному из пп. 6-13,
в котором нейронная сеть (380; 600) или структура на основе машинного обучения обучена таким образом, что значения масштабирования ограничены 2 или ограничены 5, или ограничены 10, или ограничены предварительно определенным значением, большим 1.
15. Аудиодекодер (100; 300) по одному из пп. 6-14,
в котором число входных признаков нейронной сети (380; 600) или структуры на основе машинного обучения больше по меньшей мере на коэффициент 2 числа выходных значений нейронной сети или структуры на основе машинного обучения.
16. Аудиодекодер (100; 300) по одному из пп. 6-15,
в котором фильтр (130; 360, 370, 380, 338) выполнен с возможностью нормализовать входные признаки нейронной сети или структуры на основе машинного обучения до предварительно определенного среднего значения и/или до предварительно определенной дисперсии или среднеквадратического отклонения.
17. Аудиодекодер (100; 300) по одному из пп. 1-16,
в котором нейронная сеть (380; 600) содержит входной слой (610), один или более скрытых слоев (612a-612d) и выходной слой (614).
18. Аудиодекодер (100; 300) по п. 17,
в котором один или более скрытых слоев (612a-612d) используют блоки линейной ректификации в качестве функций активации.
19. Аудиодекодер (100; 300) по одному из пп. 17, 18,
в котором выходной слой (614) использует блоки линейной ректификации или ограниченные блоки линейной ректификации или сигмоидальные функции в качестве функций активации.
20. Аудиодекодер (100; 300) по одному из пп. 1-19,
в котором фильтр (130; 360, 370, 380, 338) выполнен с возможностью получать коэффициенты ( ) кратковременного преобразования Фурье, которые представляют спектральные значения декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами.
) кратковременного преобразования Фурье, которые представляют спектральные значения декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами.
21. Аудиодекодер (100; 300) по одному из пп. 1-19,
в котором фильтр (130; 360, 370, 380, 338) выполнен с возможностью извлекать логарифмическую абсолютную величину, амплитуду, абсолютное или норменное значения (372) и определять значения (136; 336; M(k, n)) масштабирования на основе логарифмической абсолютной величины, амплитуды, абсолютного или норменного значений.
22. Аудиодекодер (100; 300) по одному из пп. 1-20,
в котором фильтр (130; 360, 370, 380, 338) выполнен с возможностью определять множество значений (136; 336; M(k, n)) масштабирования, ассоциированных с текущим кадром на основе спектральных значений (132; 326; ) декодированного аудиопредставления (122; 322; ), которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами текущего кадра, и на основе спектральных значений (132; 326; 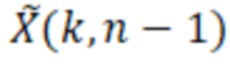 ) декодированного аудиопредставления (122; 322; ), которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами одного или более кадров, предшествующих текущему кадру.
) декодированного аудиопредставления (122; 322; ), которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами одного или более кадров, предшествующих текущему кадру.
23. Аудиодекодер (100; 300) по одному из пп. 1-22,
в котором фильтр (130; 360, 370, 380, 338) выполнен с возможностью определять множество значений масштабирования, ассоциированных с текущим кадром на основе спектральных значений (132; 326;  ) декодированного аудиопредставления (122; 322; ), которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами одного или более кадров после текущего кадра.
) декодированного аудиопредставления (122; 322; ), которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами одного или более кадров после текущего кадра.
24. Устройство (200; 400; 500) для определения набора значений, задающих характеристики фильтра (130; 360, 370, 380, 338) для обеспечения улучшенного аудиопредставления (112; 312; ) на основе декодированного аудиопредставления (122; 322),
при этом упомянутое устройство выполнено с возможностью получать спектральные значения (132; 326; 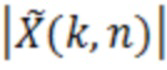 ) декодированного аудиопредставления (122; 322), которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и
) декодированного аудиопредставления (122; 322), которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и
при этом упомянутое устройство выполнено с возможностью определять набор (382; 412; 512) значений, задающих характеристики фильтра (130; 360, 370, 380, 338), так что значения (136; 336; 484; 584) масштабирования, обеспеченные посредством фильтра на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, аппроксимируют целевые значения (494) масштабирования, или
при этом упомянутое устройство выполнено с возможностью определять набор (382; 412; 512) значений, задающих характеристики фильтра (130; 360, 370, 380, 338), так что спектр, полученный посредством фильтра на основе спектральных значений (132; 326; ) декодированного аудиопредставления (122; 322), которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и с использованием значений (136; 336; 484; 584) масштабирования, полученных на основе декодированного аудиопредставления (122; 322), аппроксимирует целевой спектр (510).
25. Устройство (200; 400) по п. 24,
при этом упомянутое устройство выполнено с возможностью обучать структуру (380; 480; 580) на основе машинного обучения, которая является частью фильтра (130; 360, 370, 380, 338) и которая обеспечивает значения (136; 336; 484; 584; M(k, n)) масштабирования для масштабирования значений (362, 372; 462, 472; 562) абсолютной величины декодированного аудиосигнала (122; 322; 432; 532) или спектральных значений (326; 446; 546) декодированного аудиосигнала, чтобы уменьшать или минимизировать отклонение (MSEMA) между множеством целевых значений (494; IRM(k, n)) масштабирования и множеством значений (136; 336; 484; 584; M(k, n)) масштабирования, полученных с использованием нейронной сети, на основе спектральных значений (326; 446; 546) декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами.
26. Устройство (200; 500) по п. 24,
при этом упомянутое устройство выполнено с возможностью обучать структуру (380; 480; 580) на основе машинного обучения уменьшать или минимизировать отклонение (MSESA) между целевым спектром (510; 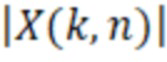 ) и спектром (592; ), полученным с использованием масштабирования обработанного спектра (532; 546), который использует значения (584) масштабирования, которые обеспечиваются посредством структуры на основе машинного обучения.
) и спектром (592; ), полученным с использованием масштабирования обработанного спектра (532; 546), который использует значения (584) масштабирования, которые обеспечиваются посредством структуры на основе машинного обучения.
27. Устройство (200; 400; 500) по одному из пп. 24-26,
при этом упомянутое устройство выполнено с возможностью обучать структуру (380; 480; 580) на основе машинного обучения таким образом, что масштабирование для спектральных значений декодированного представления аудиосигналов или для одного или более предварительно обработанных спектральных значений, которые основаны на спектральных значениях декодированного представления аудиосигналов, находится в диапазоне между 0 и 2 или находится в диапазоне между 0 и 5, или находится в диапазоне между 0 и 10.
28. Устройство (200; 400; 500) по одному из пп. 24-27,
при этом упомянутое устройство выполнено с возможностью обучать структуру (380; 480; 580) на основе машинного обучения таким образом, что масштабирование абсолютной величины для спектральных значений декодированного представления аудиосигналов или для одного или более предварительно обработанных спектральных значений, которые основаны на спектральных значениях декодированного представления аудиосигналов, ограничено нахождением в диапазоне между 0 и предварительно определенным максимальным значением.
29. Аудиодекодер (200; 400; 500) по п. 28, в котором максимальное значение превышает 1.
30. Способ (900) для обеспечения улучшенного аудиопредставления на основе кодированного аудиопредставления,
при этом упомянутый способ содержит этап, на котором обеспечивают (910) декодированное аудиопредставление ( ) кодированного аудиопредставления,
) кодированного аудиопредставления,
при этом упомянутый способ содержит этап, на котором получают (920) множество значений (M(k, n)) масштабирования, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и
при этом упомянутый способ содержит этап, на котором масштабируют (930) спектральные значения декодированного представления () аудиосигналов или их предварительно обработанную версию с использованием значений (M(k, n)) масштабирования для получения улучшенного аудиопредставления ().
31. Способ (1000) для определения набора значений, задающих характеристики фильтра для обеспечения улучшенного аудиопредставления () на основе декодированного аудиопредставления,
при этом упомянутый способ содержит этап, на котором получают (1010) спектральные значения () декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и
при этом упомянутый способ содержит этап, на котором определяют (1020) набор значений, задающих характеристики фильтра, так что значения масштабирования, обеспеченные посредством фильтра на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, аппроксимируют целевые значения масштабирования, или
при этом упомянутый способ содержит этап, на котором определяют (1030) набор значений, задающих характеристики фильтра, так что спектр, полученный посредством фильтра на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и с использованием значений масштабирования, полученных на основе декодированного аудиопредставления, аппроксимирует целевой спектр.
32. Цифровой носитель хранения, содержащий хранящиеся на нем исполняемые компьютером инструкции, которые при выполнении компьютером заставляют компьютер выполнять способ по п. 30.
33. Аудиодекодер (100; 300) для обеспечения декодированного аудиопредставления (122; 322; ) на основе кодированного аудиопредставления (110; 310),
при этом аудиодекодер содержит фильтр (130; 360, 370, 380, 338) для обеспечения улучшенного аудиопредставления (112; 312; ) декодированного аудиопредставления (122; 322; ),
при этом фильтр выполнен с возможностью получать множество значений (136; 336; M(k, n)) масштабирования, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, на основе спектральных значений (132; 326; ) декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и
при этом фильтр выполнен с возможностью масштабировать спектральные значения декодированного представления () аудиосигналов или их предварительно обработанную версию с использованием значений (136; 336; M(k, n)) масштабирования для получения улучшенного аудиопредставления (122; 312; );
при этом фильтр (130; 360, 370, 380, 338) содержит нейронную сеть (380; 600) или структуру на основе машинного обучения, выполненную с возможностью обеспечивать значения (136; 336; M(k, n)) масштабирования на основе множества спектральных значений (132; 326; ), описывающих декодированное аудиопредставление (122; 322; ), причем спектральные значения ассоциированы с различными элементами разрешения по частоте или частотными диапазонами;
при этом нейронная сеть (380; 600) или структура на основе машинного обучения обучена таким образом, что масштабирование для одного или более спектральных значений (132; 326; ) спектрального разложения декодированного представления (122; 322; ) аудиосигналов или для одного или более предварительно обработанных спектральных значений, которые основаны на спектральных значениях спектрального разложения декодированного представления аудиосигналов, находится в диапазоне между 0 и предварительно определенным максимальным значением,
при этом максимальное значение превышает 1.
34. Аудиодекодер (100; 300) для обеспечения декодированного аудиопредставления (122; 322; ) на основе кодированного аудиопредставления (110; 310),
при этом аудиодекодер содержит фильтр (130; 360, 370, 380, 338) для обеспечения улучшенного аудиопредставления (112; 312; ) декодированного аудиопредставления (122; 322; ),
при этом фильтр выполнен с возможностью получать множество значений (136; 336; M(k, n)) масштабирования, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, на основе спектральных значений (132; 326; ) декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и
при этом фильтр выполнен с возможностью масштабировать спектральные значения декодированного представления () аудиосигналов или их предварительно обработанную версию с использованием значений (136; 336; M(k, n)) масштабирования для получения улучшенного аудиопредставления (122; 312; );
при этом фильтр (130; 360, 370, 380, 338) содержит нейронную сеть (380; 600) или структуру на основе машинного обучения, выполненную с возможностью обеспечивать значения (136; 336; M(k, n)) масштабирования на основе множества спектральных значений (132; 326; ), описывающих декодированное аудиопредставление (122; 322; ), причем спектральные значения ассоциированы с различными элементами разрешения по частоте или частотными диапазонами;
при этом нейронная сеть (380; 600) или структура на основе машинного обучения обучена таким образом, что масштабирование для одного или более спектральных значений спектрального разложения декодированного представления аудиосигналов или для одного или более предварительно обработанных спектральных значений, которые основаны на спектральных значениях спектрального разложения декодированного представления аудиосигналов, ограничено 2 или ограничено 5, или ограничено 10, или ограничено предварительно определенным значением, большим 1.
35. Аудиодекодер (100; 300) для обеспечения декодированного аудиопредставления (122; 322; ) на основе кодированного аудиопредставления (110; 310),
при этом аудиодекодер содержит фильтр (130; 360, 370, 380, 338) для обеспечения улучшенного аудиопредставления (112; 312; ) декодированного аудиопредставления (122; 322; ),
при этом фильтр выполнен с возможностью получать множество значений (136; 336; M(k, n)) масштабирования, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, на основе спектральных значений (132; 326; ) декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и
при этом фильтр выполнен с возможностью масштабировать спектральные значения декодированного представления () аудиосигналов или их предварительно обработанную версию с использованием значений (136; 336; M(k, n)) масштабирования для получения улучшенного аудиопредставления (122; 312; );
при этом фильтр (130; 360, 370, 380, 338) содержит нейронную сеть (380; 600) или структуру на основе машинного обучения, выполненную с возможностью обеспечивать значения (136; 336; M(k, n)) масштабирования на основе множества спектральных значений (132; 326; ), описывающих декодированное аудиопредставление (122; 322; ), причем спектральные значения ассоциированы с различными элементами разрешения по частоте или частотными диапазонами;
при этом нейронная сеть (380; 600) или структура на основе машинного обучения обучена таким образом, что значения масштабирования ограничены 2 или ограничены 5, или ограничены 10, или ограничены предварительно определенным значением, большим 1.
36. Аудиодекодер (100; 300) для обеспечения декодированного аудиопредставления (122; 322; ) на основе кодированного аудиопредставления (110; 310),
при этом аудиодекодер содержит фильтр (130; 360, 370, 380, 338) для обеспечения улучшенного аудиопредставления (112; 312; ) декодированного аудиопредставления (122; 322; ),
при этом фильтр выполнен с возможностью получать множество значений (136; 336; M(k, n)) масштабирования, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, на основе спектральных значений (132; 326; ) декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и
при этом фильтр выполнен с возможностью масштабировать спектральные значения декодированного представления () аудиосигналов или их предварительно обработанную версию с использованием значений (136; 336; M(k, n)) масштабирования для получения улучшенного аудиопредставления (122; 312; );
при этом фильтр (130; 360, 370, 380, 338) содержит нейронную сеть (380; 600) или структуру на основе машинного обучения, выполненную с возможностью обеспечивать значения (136; 336; M(k, n)) масштабирования на основе множества спектральных значений (132; 326; ), описывающих декодированное аудиопредставление (122; 322; ), причем спектральные значения ассоциированы с различными элементами разрешения по частоте или частотными диапазонами;
при этом фильтр (130; 360, 370, 380, 338) выполнен с возможностью нормализовать входные признаки нейронной сети или структуры на основе машинного обучения до предварительно определенного среднего значения и/или до предварительно определенной дисперсии или среднеквадратического отклонения.
37. Аудиодекодер (100; 300) для обеспечения декодированного аудиопредставления (122; 322; ) на основе кодированного аудиопредставления (110; 310),
при этом аудиодекодер содержит фильтр (130; 360, 370, 380, 338) для обеспечения улучшенного аудиопредставления (112; 312; ) декодированного аудиопредставления (122; 322; ),
при этом фильтр выполнен с возможностью получать множество значений (136; 336; M(k, n)) масштабирования, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, на основе спектральных значений (132; 326; ) декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и
при этом фильтр выполнен с возможностью масштабировать спектральные значения декодированного представления () аудиосигналов или их предварительно обработанную версию с использованием значений (136; 336; M(k, n)) масштабирования для получения улучшенного аудиопредставления (122; 312; );
при этом фильтр (130; 360, 370, 380, 338) содержит нейронную сеть (380; 600) или структуру на основе машинного обучения, выполненную с возможностью обеспечивать значения (136; 336; M(k, n)) масштабирования на основе множества спектральных значений (132; 326; ), описывающих декодированное аудиопредставление (122; 322; ), причем спектральные значения ассоциированы с различными элементами разрешения по частоте или частотными диапазонами;
при этом входные сигналы (372) нейронной сети (380; 600) или структуры на основе машинного обучения представляют логарифмические абсолютные величины спектральных значений декодированного аудиопредставления, причем спектральные значения ассоциированы с различными элементами разрешения по частоте или частотными диапазонами.
38. Аудиодекодер (100; 300) для обеспечения декодированного аудиопредставления (122; 322; ) на основе кодированного аудиопредставления (110; 310),
при этом аудиодекодер содержит фильтр (130; 360, 370, 380, 338) для обеспечения улучшенного аудиопредставления (112; 312; ) декодированного аудиопредставления (122; 322; ),
при этом фильтр выполнен с возможностью получать множество значений (136; 336; M(k, n)) масштабирования, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, на основе спектральных значений (132; 326; ) декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и
при этом фильтр выполнен с возможностью масштабировать спектральные значения декодированного представления () аудиосигналов или их предварительно обработанную версию с использованием значений (136; 336; M(k, n)) масштабирования для получения улучшенного аудиопредставления (122; 312; );
при этом фильтр (130; 360, 370, 380, 338) содержит нейронную сеть (380; 600) или структуру на основе машинного обучения, выполненную с возможностью обеспечивать значения (136; 336; M(k, n)) масштабирования на основе множества спектральных значений (132; 326; ), описывающих декодированное аудиопредставление (122; 322; ), причем спектральные значения ассоциированы с различными элементами разрешения по частоте или частотными диапазонами;
при этом нейронная сеть (380; 600) содержит входной слой (610), один или более скрытых слоев (612a-612d) и выходной слой (614);
при этом один или более скрытых слоев (612a-612d) используют блоки линейной ректификации в качестве функций активации.
39. Аудиодекодер (100; 300) для обеспечения декодированного аудиопредставления (122; 322; ) на основе кодированного аудиопредставления (110; 310),
при этом аудиодекодер содержит фильтр (130; 360, 370, 380, 338) для обеспечения улучшенного аудиопредставления (112; 312; ) декодированного аудиопредставления (122; 322; );
при этом фильтр выполнен с возможностью получать множество значений (136; 336; M(k, n)) масштабирования, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, на основе спектральных значений (132; 326; ) декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и
при этом фильтр выполнен с возможностью масштабировать спектральные значения декодированного представления () аудиосигналов или их предварительно обработанную версию с использованием значений (136; 336; M(k, n)) масштабирования для получения улучшенного аудиопредставления (122; 312; );
при этом фильтр (130; 360, 370, 380, 338) содержит нейронную сеть (380; 600) или структуру на основе машинного обучения, выполненную с возможностью обеспечивать значения (136; 336; M(k, n)) масштабирования на основе множества спектральных значений (132; 326; ), описывающих декодированное аудиопредставление (122; 322; ), причем спектральные значения ассоциированы с различными элементами разрешения по частоте или частотными диапазонами;
при этом нейронная сеть (380; 600) содержит входной слой (610), один или более скрытых слоев (612a-612d) и выходной слой (614);
при этом выходной слой (614) использует блоки линейной ректификации или ограниченные блоки линейной ректификации или сигмоидальные функции в качестве функций активации.
40. Аудиодекодер (100; 300) для обеспечения декодированного аудиопредставления (122; 322; ) на основе кодированного аудиопредставления (110; 310),
при этом аудиодекодер содержит фильтр (130; 360, 370, 380, 338) для обеспечения улучшенного аудиопредставления (112; 312; ) декодированного аудиопредставления (122; 322; ),
при этом фильтр выполнен с возможностью получать множество значений (136; 336; M(k, n)) масштабирования, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, на основе спектральных значений (132; 326; ) декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и
при этом фильтр выполнен с возможностью масштабировать спектральные значения декодированного представления () аудиосигналов или их предварительно обработанную версию с использованием значений (136; 336; M(k, n)) масштабирования для получения улучшенного аудиопредставления (122; 312; );
при этом фильтр (130; 360, 370, 380, 338) выполнен с возможностью извлекать логарифмические значения (372) абсолютной величины и определять значения (136; 336; M(k, n)) масштабирования на основе логарифмических значений абсолютной величины.
41. Устройство (200; 400; 500) для определения набора значений, задающих характеристики фильтра (130; 360, 370, 380, 338) для обеспечения улучшенного аудиопредставления (112; 312; ) на основе декодированного аудиопредставления (122; 322),
при этом фильтр выполнен с возможностью масштабировать спектральные значения декодированного представления () аудиосигналов или их предварительно обработанную версию с использованием значений (136; 336; M(k, n)) масштабирования для получения улучшенного аудиопредставления (122; 312; ),
при этом упомянутое устройство выполнено с возможностью получать спектральные значения (132; 326; ) декодированного аудиопредставления (122; 322), которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и
при этом упомянутое устройство выполнено с возможностью определять набор (382; 412; 512) значений, задающих характеристики фильтра (130; 360, 370, 380, 338), так что значения (136; 336; 484; 584) масштабирования, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и которые обеспечиваются посредством фильтра на основе спектральных значений декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, аппроксимируют целевые значения (494) масштабирования, или
при этом упомянутое устройство выполнено с возможностью определять набор (382; 412; 512) значений, задающих характеристики фильтра (130; 360, 370, 380, 338), так что спектр, полученный посредством фильтра на основе спектральных значений (132; 326; ) декодированного аудиопредставления (122; 322), которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и с использованием значений (136; 336; 484; 584) масштабирования, полученных на основе декодированного аудиопредставления (122; 322), аппроксимирует целевой спектр (510).
42. Аудиодекодер (100; 300) для обеспечения декодированного аудиопредставления (122; 322; ) на основе кодированного аудиопредставления (110; 310),
при этом аудиодекодер содержит фильтр (130; 360, 370, 380, 338) для обеспечения улучшенного аудиопредставления (112; 312; ) декодированного аудиопредставления (122; 322; ),
при этом фильтр выполнен с возможностью получать множество значений (136; 336; M(k, n)) масштабирования, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, на основе спектральных значений (132; 326; ) декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и
при этом фильтр выполнен с возможностью масштабировать спектральные значения декодированного представления () аудиосигналов или их предварительно обработанную версию с использованием значений (136; 336; M(k, n)) масштабирования для получения улучшенного аудиопредставления (122; 312; );
при этом фильтр (130; 360, 370, 380, 338) выполнен с возможностью получать значения (136; 336; M(k, n)) масштабирования таким образом, что значения масштабирования вызывают усиление для одного или более спектральных значений (132; 326; ) декодированного представления (122; 322; ) аудиосигналов или для одного или более предварительно обработанных спектральных значений, которые основаны на спектральных значениях (132; 326; ) декодированного представления (122; 322; ) аудиосигналов.
43. Аудиодекодер (100; 300) для обеспечения декодированного аудиопредставления (122; 322; ) на основе кодированного аудиопредставления (110; 310),
при этом аудиодекодер содержит фильтр (130; 360, 370, 380, 338) для обеспечения улучшенного аудиопредставления (112; 312; ) декодированного аудиопредставления (122; 322; ),
при этом фильтр выполнен с возможностью получать множество значений (136; 336; M(k, n)) масштабирования, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, на основе спектральных значений (132; 326; ) декодированного аудиопредставления, которые ассоциированы с различными элементами разрешения по частоте или частотными диапазонами, и
при этом фильтр выполнен с возможностью масштабировать спектральные значения декодированного представления () аудиосигналов или их предварительно обработанную версию с использованием значений (136; 336; M(k, n)) масштабирования для получения улучшенного аудиопредставления (122; 312; );
при этом фильтр (130; 360, 370, 380, 338) выполнен с возможностью получать значения (136; 336; M(k, n)) масштабирования таким образом, что значения масштабирования обеспечивают возможность и усиления и затухания посредством масштабирования.
44. Цифровой носитель хранения, содержащий хранящиеся на нем исполняемые компьютером инструкции, которые при выполнении компьютером заставляют компьютер выполнять способ по п. 31.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Станок для изготовления деревянных ниточных катушек из цилиндрических, снабженных осевым отверстием, заготовок | 1923 |
|
SU2008A1 |
| Токарный резец | 1924 |
|
SU2016A1 |
| МНОГОРЕЖИМНЫЙ ДЕКОДИРОВЩИК АУДИО СИГНАЛА, МНОГОРЕЖИМНЫЙ КОДИРОВЩИК АУДИО СИГНАЛОВ, СПОСОБЫ И КОМПЬЮТЕРНЫЕ ПРОГРАММЫ С ИСПОЛЬЗОВАНИЕМ КОДИРОВАНИЯ С ЛИНЕЙНЫМ ПРЕДСКАЗАНИЕМ НА ОСНОВЕ ОГРАНИЧЕНИЯ ШУМА | 2010 |
|
RU2591661C2 |
| УСТРОЙСТВО И СПОСОБ ДЛЯ КОДИРОВАНИЯ И ДЕКОДИРОВАНИЯ КОДИРОВАННОГО АУДИОСИГНАЛА С ИСПОЛЬЗОВАНИЕМ ВРЕМЕННОГО ФОРМИРОВАНИЯ ШУМА/НАЛОЖЕНИЙ | 2014 |
|
RU2607263C2 |
