Область техники
Область техники относится в целом к способам представления данных секвенирования генома, полученных секвенатором, а в частности к реализуемым на компьютере способам сжатия таких данных секвенирования генома. В описании предложен способ сжатия на основе референсной последовательности, который обеспечивает быстрое сжатие и распаковку, в то же время исключая потерю информации, и который имеет высокий коэффициент сжатия.
Уровень техники
В настоящее время секвенаторы следующего поколения генерируют большие объемы данных секвенирования по доступной цене. Современные системы за один цикл продолжительностью 36 ч генерируют более 6 миллиардов последовательностей длиной 150 нуклеотидов, что достаточно для секвенирования 20 полных геномов человека. В результате этого открывается множество новых перспектив для диагностики генетических заболеваний или разработки персонализированной медицины, целью которой является адаптация лечения с учетом специфики генома человека.
Однако также возникают новые проблемы, в частности, связанные со стоимостью хранения больших объемов данных. Самым распространенным форматом файла для исходных (без выравнивания) данных последовательности является формат FASTQ, в котором хранятся данные последовательности (строка нуклеотидов А, С, Т, G, также называемая прочтением), значения качества (вероятности ошибки платформы секвенирования в последовательности для каждого нуклеотида) и названия последовательностей. Это обычный текстовой файл ASCII, который часто сжимают с помощью стандартного алгоритма сжатия LZ (алгоритм Lempel-Ziv, реализуемый в программном обеспечении gzip). Тем не менее использование таких способов сжатия сопряжено с рядом проблем:
- низкий коэффициент сжатия, поскольку не в полной мере используется повторяемость данных;
- медленное сжатие и распаковка.
Также существуют способы сжатия, специально разработанные для кодирования FASTQ, которые подразделяются на использующие референсную последовательность и не использующие ее. Тем не менее ни один из них в полной мере не удовлетворяет требованиям, поскольку а) способы на основе референсных последовательностей обеспечивают оптимальные коэффициенты сжатия, но они медленные, b) способы без референсных последовательностей быстрее, но имеют меньшие коэффициенты сжатия. Примером такого способа без референсных последовательностей является программное обеспечение SPRING, которое представляет собой программу сжатия без референсных последовательностей для файлов FASTQ (адрес в Интернете: github.com/shubhamchandak94/SPRING). Однако способ сжатия, предлагаемый программным обеспечением SPRING, имеет низкий коэффициент сжатия.
Предложен ряд способов, относящихся к способам сжатия с референсными последовательностями, где применяются выравнивания последовательностей и которые должны работать быстрее с хорошими коэффициентами сжатия. Однако такие способы имеют ряд проблем, причем особенно серьезной проблемой является то, что они не позволяют полностью исключить потери. Такой известный способ сжатия на основе референсной последовательности, например, описан в патентном документе WO 2018/068829 А1. В описанном способе после выравнивания с одной или более референсными последовательностями последовательности нуклеотидов классифицируются в соответствии со степенями точности соответствия (создавая таким образом классы выровненных прочтений), а затем кодируются в виде множества слоев элементов синтаксиса с использованием разных исходных моделей и энтропийных кодеров для каждого слоя, в которые осуществляется разделение данных. Таким образом, классы данных кодируются раздельно и структурируются в разные слои элементов синтаксиса, при этом каждый слой включает дескрипторы, которые уникальным образом отражают классифицированные и выровненные прочтения указанного слоя. Способ предназначен для того, чтобы получать источники четкой информации с пониженной энтропией информации, таким образом обеспечивая увеличение показателей сжатия, а также выборочный доступ к конкретным классам сжатых данных. Однако такой способ сжатия приводит к переупорядочению прочтений в таком порядке, который отличается от получаемого в конце стадии выравнивания прочтений (т.е. изменяется порядок прочтений в соответствии с их классами). Поэтому в процессе сжатия теряется определенная информация, в особенности порядок исходной последовательности. Таким образом, это может влиять на воспроизводимость некоторых результатов анализа, поскольку некоторые программы последующего анализа могут зависеть от порядка прочтений. Кроме того, распаковка данных в порядке, который отличается от исходного порядка прочтений, в значительной степени усложняет проверку идентичности распакованного файла с исходным файлом. Более того, такой способ сжатия является сравнительно медленным, в особенности в сравнении с существующими в данной области техники способами сжатия без референсной последовательности.
Краткое описание изобретения
Приведенные ниже признаки независимых пунктов формулы изобретения позволяют решить проблему существующих решений предшествующего уровня техники, предлагая способ сжатия данных последовательности генома. В одном аспекте реализуемый на компьютере способ сжатия данных последовательности генома, полученных с помощью секвенатора, причем указанные данные последовательности генома включают прочтения последовательностей нуклеотидов или оснований, которые были выровнены с референсной последовательностью, с формированием таким образом выровненных прочтений, при этом указанные выровненные прочтения хранятся в виде списка прочтений в исходном файле, и включает стадии, на которых:
- определяют для каждого выровненного прочтения, насколько точно или неточно указанное прочтение сопоставляется с указанной референсной последовательностью, или же указанное прочтение не сопоставляется с указанной референсной последовательностью,
- кодируют прочтения в соответствии с указанным определением, причем прочтения, которые определены как точно сопоставленные, кодируются в соответствии с первым процессом кодирования, а прочтения, которые определены как несопоставленные, кодируются в соответствии со вторым процессом кодирования,
- при этом стадия определения для каждого неточно сопоставленного прочтения включает сравнение количества несоответствий между указанным прочтением и указанной референсной последовательностью с учетом порогового значения,
- при этом на стадии кодирования прочтения, которые определены как неточно сопоставленные, кодируются в соответствии со вторым процессом кодирования или с третьим процессом кодирования, при этом неточно сопоставленные прочтения кодируются в соответствии со вторым процессом кодирования, если указанное количество несоответствий превышает пороговое значение, а если указанное количество несоответствий меньше порогового значения, то такие неточно сопоставленные прочтения кодируются в соответствии с третьим процессом кодирования,
- при этом в указанном втором процессе кодирования каждый нуклеотид или основание прочтения кодируются по отдельности,
- при этом указанные первый и третий процессы кодирования включают четко заданные наборы дескрипторов, и каждый набор дескрипторов уникальным образом представляет прочтения, связанные с соответствующим процессом кодирования, и каждый из указанных первого и третьего процессов кодирования представляет собой процесс кодирования с понижением энтропии источника информации.
Изобретение позволяет преодолеть недостатки способов сжатия предшествующего уровня техники, позволяя выполнять быстрое сжатие и распаковку и одновременно исключая потерю информации и обеспечивая высокий коэффициент сжатия. Более конкретно, в изобретении основное внимание уделяется кодированию наиболее часто встречающихся случаев наиболее компактным образом, даже если это означает применение режимов кодирования со сниженными характеристиками для редких наименее часто встречающихся случаев. Это обеспечивает значительное улучшение показателей сжатия. Более того, благодаря формату представления геномной информации, который используется в изобретении, сжатие, выполняемое по способу в соответствии с изобретением, является более быстрым. Не в последнюю очередь способ в соответствии с изобретением позволяет сохранить исходный порядок прочтений как таковой и не приводит к переупорядочению прочтений в соответствии с их классами. Следовательно, в ходе процесса не происходит потери информации, что упрощает последующий анализ, а также эффективные проверки конформации после стадии распаковки.
Эти и другие признаки и преимущества настоящего изобретения будут более очевидны из прилагаемых графических материалов и последующего подробного описания. Кроме того, несмотря на то что в настоящем документе могут упоминаться превышенные или не превышенные пороговые значения, следует понимать, что такие пороговые значения могут концептуально использоваться так, чтобы определить, удовлетворяется ли, соблюдается ли или регистрируется ли иным образом такое пороговое значение, независимо от того, описываются ли величины или значения, используемые для оценки таких пороговых значений, с использованием положительных или отрицательных значений.
В соответствии с одним инновационным аспектом настоящего описания раскрыт способ сжатия данных геномной последовательности. В одном аспекте способ может включать выполнение одной или более операций посредством исполнения инструкций программного обеспечения одним или более компьютерами, при этом операции включают получение одним или более компьютерами записи прочтения; определение одним или более компьютерами соответствия записи прочтения такому прочтению, которое точно сопоставляется с референсной последовательностью или неточно сопоставляется с референсной последовательностью; на основании определения одним или более компьютерами соответствия записи прочтения такому прочтению, которое неточно сопоставляется с референсной последовательностью, определение одним или более компьютерами того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий; и на основании определения того, что количество несоответствий удовлетворяет заданному пороговому количеству несоответствий, кодирование одним или более компьютерами каждого несоответствия неточно сопоставленного прочтения в запись размером 1 байт.
Другие аспекты включают соответствующие системы, аппарат и компьютерные программы для выполнения операций из способов, описанных в настоящем документе, согласно определению в инструкциях, закодированных на машиночитаемых устройствах хранения.
Эти и другие версии могут необязательно включать один или более из приведенных ниже признаков. Например, в некоторых вариантах реализации определение одним или более компьютерами того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий, может включать определение одним или более компьютерами того, превышает ли количество несоответствий неточно сопоставленных прочтений заданное пороговое количество несоответствий.
В некоторых вариантах реализации каждая запись прочтения может включать данные, указывающие на абсолютное положение начала выровненного прочтения по отношению к референсной последовательности, данные, указывающие на точное или неточное сопоставление прочтения, данные, указывающие на длину прочтения, данные, указывающие на точное или неточное сопоставление прочтения, данные, указывающие на количество несоответствий, выявленных в прочтении, и данные, указывающие на относительное положение каждого из указанных возможных несоответствий в прочтении.
В некоторых вариантах реализации кодирование каждого несоответствия неточно сопоставленного прочтения в запись размером 1 байт для каждого конкретного несоответствия включает: кодирование одним или более компьютерами первых двух битов байта, чтобы включить данные, представляющие альтернативный нуклеотид или основание, присутствующие в прочтении вместо соответствующего референсного нуклеотида или основания в референсной последовательности; и кодирование одним или более компьютерами шести остальных битов байта, чтобы включить данные, представляющие положение несоответствия в референсной последовательности, при этом указанное положение вычисляется в виде смещения относительно предыдущего несоответствия прочтения.
В некоторых вариантах реализации способ может дополнительно включать определение одним или более компьютерами того, превышает ли смещение максимальное кодируемое значение, и на основании определения того, что смещение превышает максимальное кодированное значение, вставку одним или более компьютерами по меньшей мере одного фиктивного несоответствия между конкретным несоответствием и предыдущим несоответствием.
В некоторых вариантах реализации на основании определения того, что количество несоответствий не удовлетворяет заданному пороговому количеству несоответствий, кодирование одним или более компьютерами списка положений референсной последовательности, соответствующих положению каждого из несоответствий относительно референсной последовательности, с использованием процесса кодирования с понижением энтропии информации.
В некоторых вариантах реализации на основании определения того, что запись прочтения соответствует прочтению, которое точно сопоставляется с референсной последовательностью, способ может дополнительно включать кодирование одним или более компьютерами по меньшей мере участка записи прочтения с использованием кодирования с понижением энтропии информации.
В некоторых вариантах реализации один или более компьютеров могут включать один или более аппаратных процессоров.
В некоторых вариантах реализации один или более аппаратных процессоров могут включать одну или более программируемых пользователем вентильных матриц (FPGA).
В некоторых вариантах реализации способ сжатия данных геномной последовательности может быть реализован с помощью одного или более аппаратных процессоров. В таких вариантах реализации аппаратные процессоры могут включать аппаратную систему обработки, которая выполнена с возможностью выполнения одной или более операций. В одном аспекте операции могут включают получение аппаратной системой обработки записи прочтения; определение аппаратной системой обработки соответствия записи прочтения такому прочтению, которое точно сопоставляется с референсной последовательностью или неточно сопоставляется с референсной последовательностью; на основании определения аппаратной системой обработки соответствия записи прочтения такому прочтению, которое неточно сопоставляется с референсной последовательностью, определение аппаратной системой обработки того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий; и на основании определения того, что количество несоответствий удовлетворяет заданному пороговому количеству несоответствий, кодирование аппаратной системой обработки каждого несоответствия неточно сопоставленного прочтения в запись размером 1 байт.
Эти и другие признаки и преимущества настоящего изобретения будут более очевидны из прилагаемых графических материалов и последующего подробного описания.
В некоторых вариантах реализации каждая запись прочтения может содержать данные, указывающие на абсолютное положение начала выровненного прочтения по отношению к референсной последовательности, данные, указывающие на точное или неточное сопоставление прочтения, данные, указывающие на длину прочтения, данные, указывающие на точное или неточное сопоставление прочтения, данные, указывающие на количество несоответствий, выявленных в прочтении, и данные, указывающие на относительное положение указанных возможных несоответствий в прочтении.
В некоторых вариантах реализации определение аппаратной системой обработки того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий, может включать определение аппаратной системой обработки того, превышает ли количество несоответствий неточно сопоставленных прочтений заданное пороговое количество несоответствий.
В некоторых вариантах реализации кодирование каждого несоответствия неточно сопоставленного прочтения в запись размером 1 байт для каждого конкретного несоответствия может включать кодирование аппаратной системой обработки первых двух битов байта, чтобы включить данные об альтернативном нуклеотиде или основании, присутствующем в прочтении вместо соответствующего референсного нуклеотида или основания референсной последовательности; и кодирование аппаратной системой обработки шести остальных битов байта, чтобы включить данные о положении несоответствия в референсной последовательности, при этом указанное положение вычисляется как смещение относительно предыдущего несоответствия прочтения.
В некоторых вариантах реализации аппаратная система обработки дополнительно выполнена с возможностью выполнения операций, которые включают определение аппаратной системой обработки, превышает ли смещение максимальное кодируемое значение, и на основании определения того, что смещение превышает максимальное кодированное значение, вставку аппаратной системой обработки по меньшей мере одного фиктивного несоответствия между конкретным несоответствием и предыдущим несоответствием.
В некоторых вариантах реализации на основании определения того, что количество несоответствий не удовлетворяет заданному пороговому количеству несоответствий, аппаратная система обработки дополнительно выполнена с возможностью выполнять операции, которые включают кодирование аппаратной системой обработки списка положений референсной последовательности, соответствующих положению каждого из несоответствий относительно референсной последовательности, с использованием процесса кодирования с понижением энтропии информации.
В некоторых вариантах реализации на основании определения того, что запись прочтения соответствует прочтению, которое точно сопоставляется с референсной последовательностью, аппаратная система обработки дополнительно выполнена с возможностью выполнять операции, которые включают кодирование аппаратной системой обработки по меньшей мере участка записи прочтения с использованием кодирования с понижением энтропии информации.
В некоторых вариантах реализации аппаратная система обработки включает одну или более программируемых пользователем вентильных матриц (FPGA).
В соответствии с другим инновационным аспектом настоящего описания реализуемый на компьютере способ сжатия данных последовательности генома, полученных с помощью секвенатора, причем указанные данные последовательности генома включают прочтения последовательностей нуклеотидов или оснований, которые были выровнены с референсной последовательностью, с формированием таким образом выровненных прочтений, при этом указанные выровненные прочтения хранятся в виде списка прочтений в исходном файле. В одном аспекте способ может включать действия для каждого выровненного прочтения, определение того, насколько точно или неточно указанное прочтение сопоставляется с указанной референсной последовательностью, или же установление того, что указанное прочтение не сопоставляется с указанной референсной последовательностью; кодирование прочтения в соответствии с указанным определением, при этом те прочтения, которые отнесены к точно сопоставленным, кодируются в соответствии с первым процессом кодирования, а те прочтения, которые отнесены к неточно сопоставленным, кодируется в соответствии со вторым процессом кодирования, при этом стадия определения для каждого неточно сопоставленного прочтения включает сравнение количества несоответствий между указанным прочтением и указанной референсной последовательностью с учетом порогового значения, при этом на стадии кодирования те прочтения, которые определены как неточно сопоставленные, кодируются в соответствии со вторым процессом кодирования или с третьим процессом кодирования, при этом неточно сопоставленные прочтения кодируются в соответствии со вторым процессом кодирования, если указанное количество несоответствий превышает пороговое значение, а если указанное количество несоответствий меньше порогового значения, то такие неточно сопоставленные прочтения кодируются в соответствии с третьим процессом кодирования, при этом в указанном втором процессе кодирования каждый нуклеотид или основание прочтения кодируются по отдельности, при этом указанные первый и третий процессы кодирования включают четко заданные наборы дескрипторов, и каждый набор дескрипторов уникальным образом представляет прочтения, связанные с соответствующим процессом кодирования, и каждый из указанных первого и третьего процессов кодирования представляет собой процесс кодирования с понижением энтропии источника информации.
Другие аспекты включают соответствующие системы, аппарат и компьютерные программы для выполнения операций из способов, описанных в настоящем документе, согласно определению в инструкциях, закодированных на машиночитаемых устройствах хранения.
Эти и другие версии могут необязательно включать один или более из приведенных ниже признаков. Например, в некоторых вариантах реализации, если прочтение отнесено к неточно сопоставленным с референсной последовательностью и его количество несоответствий меньше порогового значения, то стадия определения может включать определение того, насколько глобально или локально прочтение сопоставляется с указанной референсной последовательностью, и при этом третий процесс кодирования включает первый дополнительный процесс кодирования и второй дополнительный процесс кодирования, при этом те прочтения, которые определены как глобально сопоставленные, кодируются в соответствии с первым дополнительным процессом кодирования, а те прочтения, которые определены как локально сопоставленные, кодируются в соответствии со вторым дополнительным процессом, при этом указанные первый и второй дополнительные процессы кодирования включают четко заданные наборы дескрипторов, при этом каждый набор дескрипторов уникальным образом представляет прочтения, связанные с соответствующим дополнительным процессом кодирования.
В некоторых вариантах реализации указанные дескрипторы указанного первого дополнительного процесса кодирования могут включать стартовое положение выравнивания в референсной последовательности, длину прочтения и список несоответствий в виде замен символов, и при этом указанные дескрипторы указанного второго дополнительного процесса кодирования включают стартовое положение локального выравнивания в референсной последовательности, длину прочтения, список несоответствий в виде замен символов, а также длину отсеченных участков, которые не являются частью выравнивания.
В некоторых вариантах реализации на стадии кодирования отсеченные участки прочтения, которые должны кодироваться в соответствии со вторым дополнительным процессом кодирования, конкатенируются, при этом каждый нуклеотид или основание указанных отсеченных участков кодируются по отдельности.
В некоторых вариантах реализации на стадии кодирования каждое несоответствие неточно сопоставленного прочтения кодируется 1 байтом.
В некоторых вариантах реализации на стадии кодирования каждое несоответствие неточно сопоставленного прочтения кодирование выполняется следующим образом: два первых бита байта используются для кодирования альтернативного нуклеотида или основания, присутствующих в прочтении вместо соответствующего референсного нуклеотида или основания референсной последовательности; а шесть последних битов байта используются для кодирования положения несоответствия в референсной последовательности, при этом положение вычисляется как смещение относительно предыдущего несоответствия прочтения.
В некоторых вариантах реализации на стадии кодирования, если смещение, вычисляемое между определенным несоответствием и предшествующим несоответствием больше максимального кодируемого значения, то на стадии кодирования по меньшей мере одно фиктивное несоответствие вставляется между указанными двумя несоответствиями, до тех пор, пока каждое смещение между каждым из указанных несоответствий и указанным по меньшей мере одним фиктивным несоответствием не будет меньше указанного максимального кодируемого значения, при этом фиктивное несоответствие определяется как несоответствие, для которого биты байта используются для кодирования несоответствия или для кодирования нуклеотида или основания, которые идентичны соответствующему референсному нуклеотиду или основанию в референсной последовательности.
В некоторых вариантах осуществления начальная стадия разделения списка прочтений на блоки прочтений, при этом каждый блок начинается с заголовка, содержащего информацию, необходимую для декодирования блока, причем указанный способ сжатия реализуется поблочно.
В некоторых вариантах реализации блоки прочтений характеризуются одинаковым размером блока.
В некоторых вариантах реализации конечной стадией является формирование сжатого файла, содержащего список кодированных прочтений, при этом указанные кодированные прочтения хранятся в сжатом файле в том же порядке, что и прочтения, хранившиеся в исходном файле.
В некоторых вариантах реализации указанное пороговое значение составляет 31.
В некоторых вариантах реализации для каждого выровненного прочтения выполняется стадия определения того, включает ли указанное прочтение по меньшей мере одно несоответствие, соответствующее случаю, когда секвенатор не мог распознать какое-либо основание или нуклеотид.
В некоторых вариантах реализации для каждого прочтения, содержащего по меньшей мере одно несоответствие, соответствующее случаю, когда секвенатор не мог распознать какое-либо основание или нуклеотид, выполняется стадия определения количества таких несоответствий и стадия сопоставления указанного количества с референсным пороговым значением.
В некоторых вариантах реализации на стадии кодирования, если количество таких несоответствий больше референсного порогового значения, каждый нуклеотид или основание прочтения, которые должны кодироваться в соответствии со вторым процессом кодирования, индивидуальным образом кодируется в 4 битах, и если количество таких несоответствий меньше референсного порогового значения, каждый нуклеотид или основание прочтения, которые должны кодироваться в соответствии со вторым процессом кодирования, индивидуальным образом кодируется в 2 битах, а стадия кодирования дополнительно включает кодирование списка положений вдоль референсной последовательности, причем указанные положения соответствуют положениям таких несоответствий в референсной последовательности.
Краткое описание чертежей
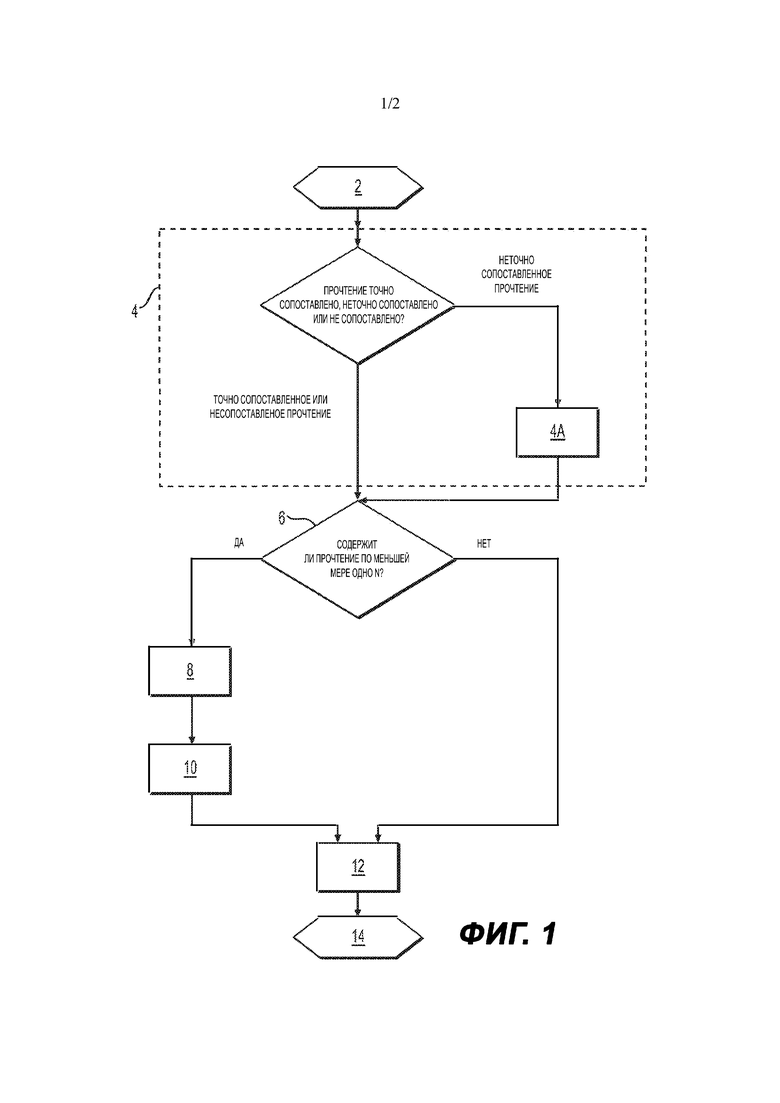
На Фиг. 1 представлена блок-схема, демонстрирующая стадии способа сжатия в соответствии с изобретением.
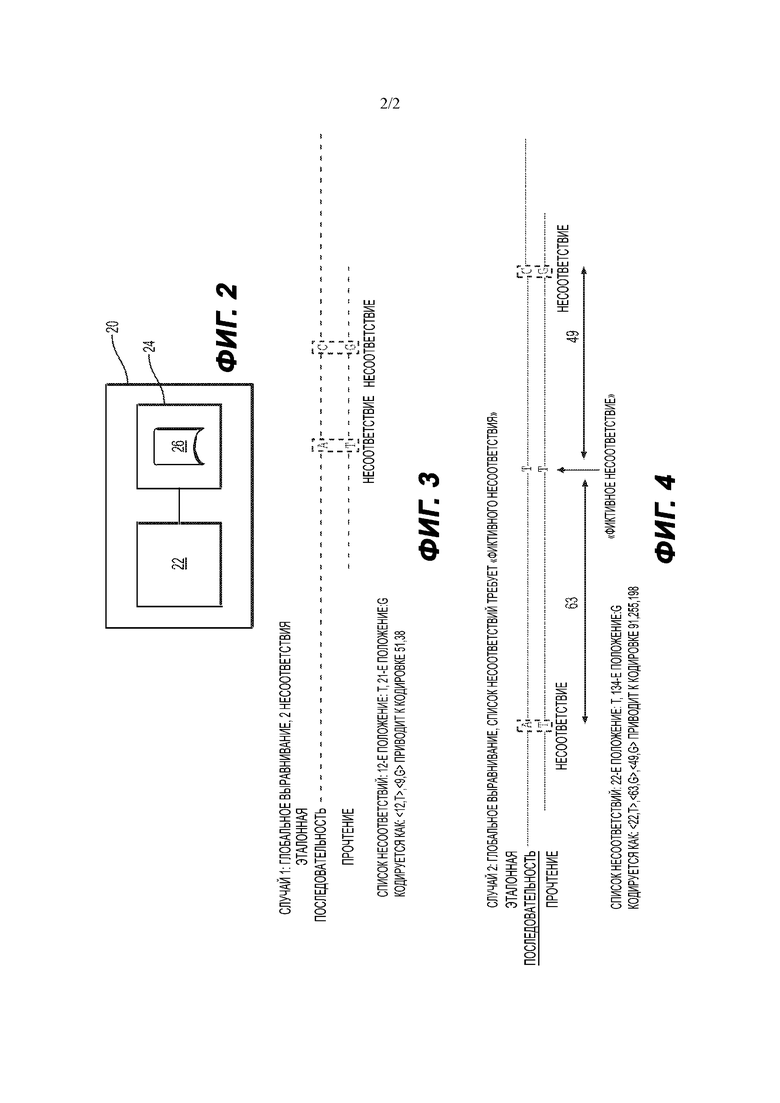
На Фиг. 2 представлена схема, демонстрирующая аппарат для реализации стадий способа сжатия в соответствии с изобретением.
На Фиг. 3 представлен первый пример прочтения, которое глобально сопоставляется с референсной последовательностью.
На Фиг. 4 представлен второй пример прочтения, которое глобально сопоставляется с референсной последовательностью, в том случае, когда требуется вставка фиктивного несоответствия.
Подробное описание изобретения
К геномным последовательностям, указанным в настоящем изобретении, относятся, для примера и без ограничений, нуклеотидные последовательности, последовательности дезоксирибонуклеиновой кислоты (ДНК), рибонуклеиновой кислоты (РНК) и аминокислотные последовательности. Несмотря на приведенное в настоящем документе достаточно подробное описание геномной информации в форме нуклеотидной последовательности, следует понимать, что способ сжатия в соответствии с изобретением может быть реализован также и для других геномных последовательностей, хотя и с рядом изменений, которые будут очевидны специалисту в данной области.
Информацию о секвенировании генома получают с помощью секвенаторов в форме последовательностей нуклеотидов (или, в более общем случае, оснований), представленной в виде строки букв из определенного набора терминов. Наименьший набор терминов представлен пятью символами: {А, С, G, Т, N}, которые представляют собой 4 типа нуклеотидов, присутствующих в ДНК, а именно аденин, цитозин, гуанин и тимин. В РНК тимин заменен на урацил (U). N указывает на то, что секвенатор не мог распознать какое-либо основание, поэтому истинная природа положения остается неопределенной.
Нуклеотидные последовательности, получаемые секвенаторами, называются «прочтениями». Прочтения последовательностей могут иметь длину от нескольких десятков до нескольких тысяч нуклеотидов. Некоторые технологии позволяют получать прочтения последовательностей в парах, при этом одно прочтение относится к одной цепочке ДНК, а второе прочтение относится к другой цепочке. Во всем тексте настоящего описания термин «референсная последовательность» означает любую последовательность, относительно которой выполняется выравнивание/сопоставление последовательностей нуклеотидов или оснований, полученных секвенатором. Одним из примеров такой референсной последовательности фактически может быть референсный геном, т.е. последовательность, построенная учеными в качестве репрезентативного примера набора генов того или иного вида. Однако референсная последовательность может также состоять из синтетической последовательности, сконструированной лишь для того, чтобы улучшить степень сжатия прочтений в связи с их последующей обработкой. Секвенаторы могут вносить ошибки в прочтения последовательностей, и в частности использовать неверный символ (т.е. представляющий другую нуклеиновую кислоту) для обозначения нуклеиновой кислоты или основания, в действительности присутствующего в секвенируемом образце; это обычно называют ошибкой замены, или «несоответствием».
Предметом изобретения является способ сжатия на основе референсной последовательности, входные данные которого представляют собой прочтения нуклеотидов или оснований, и такие прочтения предварительно выравнивались относительно референсной последовательности, формируя таким образом выровненные прочтения. Затем выровненные прочтения хранятся в виде списка прочтений в исходном файле. Способ выравнивания прочтений и их хранения в исходном файле после выравнивания не имеет критического значения для изобретения и не входит в цель настоящего описания. После этого каждое прочтение кодируется в виде положения на референсной последовательности и в виде списка различий с указанной референсной последовательностью. Затем каждое прочтение может реконструироваться на основе кодированной информации выравнивания и референсной последовательности с использованием надлежащего программного обеспечения для распаковки, выполненного в соответствии с настоящим изобретением.
Предпочтительно, чтобы программное обеспечение для выравнивания, которое обрабатывает прочтения и выравнивает их относительно референсной последовательности до их передачи в качестве входных данных в программное обеспечение для сжатия и аппарат, не учитывало определенные виды ошибок, вносимых в прочтения последовательностей, такие как, например, ошибки вставок или ошибки делеций. Ошибка вставки проявляется в виде вставки в одно прочтение последовательности одного или более дополнительных символов, которые не относятся к какой-либо фактически присутствующей нуклеиновой кислоте. Ошибка делеции проявляется в виде удаления из одного прочтения последовательности одного или более символов, относящихся к нуклеиновым кислотам, которые фактически присутствуют в секвенированном образце. Точнее, в случае ошибки вставки или ошибки делеции в заданном прочтении последовательности программное обеспечение для выравнивания будет рассматривать полученные ошибочные нуклеиновые кислоты как ошибки замены, также называемые «несоответствиями». Такой предпочтительный выбор для конфигурации программного обеспечения для выравнивания позволяет выполнять более быстрое последующее кодирование, обеспечивая существенно более взвешенный компромисс между скоростью и коэффициентом сжатия.
Для каждого прочтения программное обеспечение для выравнивания передает соответствующую запись прочтения в программное обеспечение для сжатия и аппарат. Каждая запись прочтения содержит по меньшей мере следующую информацию: абсолютное положение начала выровненного прочтения относительно референсной последовательности, длина прочтения, тип выравнивания прочтения, количество несоответствий, выявленных в прочтении, и относительное положение указанных возможных несоответствий в прочтении (в соответствующих случаях).
Способ сжатия в соответствии с настоящим изобретением будет описан со ссылкой на Фиг. 1. Например, способ может выполняться аппаратом 20, приведенным на Фиг. 2. Аппарат содержит по меньшей мере один процессор 22 и одно запоминающее устройство 24, функционально связанное с процессором 22, чтобы образовать вычислительное устройство. В запоминающем устройстве 24 может храниться код компьютерной программы или программное обеспечение 26, содержащее исполняемые на компьютере инструкции, которые при их исполнении процессором 22 приводят к тому, что процессор 22 выполняет операции, включающие стадии способа сжатия в соответствии с изобретением.
Исходный файл, в котором находятся выровненные прочтения в виде списка прочтений, например, хранится в аппарате 20. Как показано на Фиг. 1, способ предпочтительно включает начальную стадию 2, причем исходный список выровненных прочтений подразделяется на блоки прочтений. Как правило, список выровненных прочтений подразделяется на блоки по 50000 прочтений, при этом это конкретное значение не следует толковать как ограничивающее объем настоящего изобретение, которое может применяться таким же образом и к другим значениям. Предпочтительно блоки прочтений характеризуются одинаковым размером блока. Каждый блок прочтений начинается с заголовка, содержащего информацию, необходимую для декодирования блока, такую как, например, размер содержания блока в байтах, и/или идентификатор блока или его содержания, и/или количество прочтений, содержащихся в блоке. Таким образом обеспечивается поддержка конкатенации сжатого файла, а также возможностей передачи (каждый блок прочтений содержит всю информацию, необходимую для декодирования прочтений блока). Кроме того, поскольку способ сжатия может осуществляться поблочно, это также позволяет выполнять многопоточную обработку блоков прочтений, таким образом обеспечивая распараллеливание и в результате этого определенный выигрыш по времени обработки. При одинаковой длине всех прочтений заданного блока длина прочтения также сохраняется в заголовке, в противном случае при выполнении способа сжатия в явной форме сохраняется список значений длины каждого прочтения.
Каждая запись прочтения содержит информацию о типе выравнивания прочтения. Как правило, можно выделить два основных типа выравнивания: точное выравнивание и неточное выравнивание, а также дополнительный тип, соответствующий «несопоставленному» выравниванию. «Неточное выравнивание» означает, что выравнивание содержит по меньшей мере одно несоответствие, отличное от N, тогда как по меньшей мере участок прочтения соответствует участку референсной последовательности (согласно этому определению, неточно сопоставленное прочтение может содержать одно или более N, при условии, что оно также содержит одно или более других несоответствий). В одном примере осуществления каждая запись прочтения начинается со следующих битовых флагов, при этом каждый битовый флаг принимает одно значение из двух возможных значений:
- первый битовый флаг указывает на прямую или обратную ориентацию относительно референсной последовательности,
- второй битовый флаг указывает на то, является ли выравнивание точным,
- третий битовый флаг указывает на то, содержит ли прочтение по меньшей мере одно N,
- четвертый битовый флаг указывает на разрядность кодирования данных о положении - 16 битов или 32 бита.
На приведенных ниже стадиях 4-12 выполняется поочередная обработка блоков прочтений и поочередная обработка прочтений внутри блоков.
Способ включает следующую стадию 4 определения для каждого выровненного прочтения того, насколько точно или неточно указанное прочтение сопоставляется с референсной последовательностью, или же того, что указанное прочтение не сопоставляется с референсной последовательностью. Такая стадия 4 определения для каждого неточно сопоставленного прочтения включает сравнение 4А количества несоответствий между указанным прочтением и референсной последовательностью с учетом порогового значения. В предпочтительном варианте осуществления, который не следует толковать как ограничивающий объем настоящего изобретения, указанное пороговое значение составляет 31. Это конкретное значение было выбрано специально, чтобы обеспечить наилучший возможный компромисс для хранения количества несоответствий в достаточно компактной форме, что станет более понятно ниже в отношении стадии 12. Действительно, статистика наблюдений показывает, что в подавляющем большинстве случаев неточно сопоставленные прочтения включают менее 31 несоответствия. Принцип, лежащий в основе такого выбора, заключается в кодировании в наиболее компактной форме наиболее часто встречающихся случаев, оставляя пространство для ряда очень незначительного количества случаев с низким качеством. Если было установлено, что прочтение неточно сопоставлено с количеством несоответствий меньше порогового значения, стадия 4 определения включает дополнительное определение того, насколько глобально или локально прочтение сопоставляется с референсной последовательностью. «Глобально сопоставленное прочтение» представляет собой неточно сопоставленное прочтение, полная последовательность которого, включая начало и конец прочтения, неточно сопоставляется с референсной последовательностью. «Локально сопоставленное прочтение» представляет собой неточно сопоставленное прочтение, содержащее сегмент нуклеотидов или оснований, которые неточно сопоставлены с референсной последовательностью. Таким образом, указанный сегмент нуклеотидов или оснований соответствует участку исходного прочтения.
Предпочтительно для каждого выровненного прочтения способ дополнительно включает стадию 6 определения того, включает ли указанное прочтение по меньшей мере одно N, т.е. включает ли указанное прочтение по меньшей мере одно несоответствие, соответствующее случаю, когда секвенатор не мог распознать какое-либо основание или нуклеотид. Затем для каждого прочтения, содержащего по меньшей мере один N, способ включает стадию 8 определения количества таких N несоответствий и стадию 10 сравнения указанного количества N несоответствий с референсным пороговым значением. В предпочтительном варианте осуществления, который не следует толковать как ограничивающий объем настоящего изобретения, указанное референсное пороговое значение составляет 31.
Независимо от результатов стадии 4 определения способ включает следующую стадию 12 кодирования прочтений по меньшей мере в соответствии с указанным определением. Точнее, прочтения, которые отнесены к точно сопоставленным с референсной последовательностью, независимо от того, нет ли в них ни одного N или количество N в них меньше референсного порогового значения, кодируются в соответствии с первым процессом кодирования. Прочтения, которые отнесены к несопоставленным, или прочтения, которые отнесены к точно сопоставленным, но в которых количество N больше референсного порогового значения, кодируются в соответствии со вторым процессом кодирования, где каждый нуклеотид или основание кодируются отдельно, независимо от того, были ли выровнены указанный нуклеотид или основание или нет. Прочтения, которые отнесены к неточно сопоставленным, кодируются в соответствии со вторым процессом кодирования или третьим процессом кодирования. Точнее, прочтения, которые отнесены к неточно сопоставленным с количеством несоответствий больше порогового значения, кодируются в соответствии со вторым процессом кодирования. Если установлено, что прочтение неточно сопоставлено с количеством несоответствий меньше порогового значения, и если указанное прочтение не содержит ни одного N или количество N в таком прочтении меньше референсного порогового значения, то указанное прочтение кодируется в соответствии с третьим процессом кодирования. В противном случае, т.е. если количество N в таком прочтении больше референсного порогового значения, то указанное прочтение кодируется в соответствии со вторым процессом кодирования.
Независимо от того, отнесено ли конкретное прочтение к точно сопоставленным, неточно сопоставленным или несопоставленным, если указанное прочтение содержит по меньшей мере одно N, но количество N меньше референсного порогового значения, то стадия 12 кодирования включает кодирование списка положений вдоль референсной последовательности, при этом указанные положения соответствуют положениям N в референсной последовательности. Затем список положений сохраняется в запоминающем устройстве вычислительного устройства, при этом указанное устройство осуществляет способ сжатия. Если прочтение содержит по меньшей мере одно значение N, но количество N меньше референсного порогового значения, и оно должно кодироваться по второму процессу кодирования, то каждый нуклеотид или основание прочтения отдельно кодируется 2 битами.
Если прочтение содержит по меньшей мере одно значение N, но количество N больше референсного порогового значения, то указанное прочтение во всех случаях кодируется по второму процессу кодирования, а каждый нуклеотид или основание прочтения отдельно кодируется 4 битами. В этом случае стадия 12 кодирования не включает кодирования и хранения списка положений N в референсной последовательности. Действительно, после этого каждое несоответствие N напрямую кодируется в соответствии со вторым процессом кодирования точно таким же образом, как и другие нуклеотиды или основания прочтения.
Первый и третий процессы кодирования включают четко заданные наборы дескрипторов. Каждый набор дескрипторов уникальным образом представляет прочтения, связанные с соответствующим процессом кодирования, и каждый из первого и третьего процессов кодирования представляет собой процесс кодирования с понижением энтропии информации. Точнее, третий процесс кодирования включает первый дополнительный процесс кодирования и второй дополнительный процесс кодирования. Неточно сопоставленные прочтения, которые на стадии 4 отнесены к глобально сопоставленным, кодируются в соответствии с первым дополнительным процессом кодирования. Неточно сопоставленные прочтения, которые на стадии 4 отнесены к локально сопоставленным, кодируются в соответствии со вторым дополнительным процессом кодирования. Первый и второй дополнительные процессы кодирования включают четко заданные наборы дескрипторов, уникальным образом представляющие прочтения, связанные с соответствующим дополнительным процессом кодирования.
Таким образом, информация выравнивания, которая кодируется для каждого прочтения и которая позволяет восстанавливать полную последовательность прочтения в ходе распаковки данных, зависит от соответствующего процесса или дополнительного процесса кодирования, который использовался для указанного прочтения. Например, дескрипторами, используемыми в первом процессе кодирования, могут быть:
 абсолютное положение начала точно сопоставленного прочтения относительно референсной последовательности (в 16- или 32-битовой кодировке) и
абсолютное положение начала точно сопоставленного прочтения относительно референсной последовательности (в 16- или 32-битовой кодировке) и
длина прочтения (кодируемая посредством дифференциального кодирования относительно длины предыдущего прочтения с кодом переменной длины от 2 битов до 34 битов).
Дескрипторами, используемыми в первом дополнительном процессе кодирования, могут быть:
абсолютное положение начала неточно сопоставленного прочтения относительно референсной последовательности (в 16- или 32-битовой кодировке),
длина прочтения (кодируемая посредством дифференциального кодирования относительно длины предыдущего прочтения с кодом переменной длины от 2 битов до 34 битов) и
список несоответствий прочтения.
Дескрипторами, используемыми во втором дополнительном процессе кодирования, могут быть:
абсолютное положение начала неточно сопоставленного участка прочтения относительно референсной последовательности, также называемое положением начала локального выравнивания (в 16- или 32-битовой кодировке),
длина прочтения (кодируемая посредством дифференциального кодирования относительно длины предыдущего прочтения с кодом переменной длины от 2 битов до 34 битов),
список несоответствий прочтения и
длина отсеченных участков прочтения, которые не являются частью выравнивания (8-битовое кодирование для каждого отсеченного участка).
Предпочтительно список несоответствий, который кодируется в первом и втором дополнительных процессах, включает заголовок (битовый флаг, кодируемый 1 байтом). Первые пять битов байта используются для кодирования количества несоответствий, содержащихся в прочтении (в предпочтительном варианте осуществления, где пороговое значение составляет 31, указанное количество находится в диапазоне [0-31]). Затем один бит используется для кодирования информации о том, является ли неточно сопоставленное прочтение глобально или локально сопоставленным. Другой бит используется для кодирования информации о том, активирован ли 2-битовый режим для второго процесса кодирования. Последний бит используется для кодирования информации о том, активирован ли 4-битовый режим для второго процесса кодирования. Предпочтительно для каждого прочтения, кодируемого в соответствии со вторым дополнительным процессом кодирования на стадии 12 кодирования, выполняется конкатенация отсеченных участков указанного прочтения (т.е. тех участков, которые не являются частью локального выравнивания), и каждый нуклеотид или основание указанных отсеченных участков кодируется отдельно. В предпочтительном варианте осуществления каждый нуклеотид или основание таких отсеченных участков прочтения кодируется отдельно 2 битами.
В предпочтительном варианте осуществления каждое несоответствие, кодированное в списке несоответствий неточно сопоставленного прочтения (т.е. кодированное в соответствии с первым или вторым дополнительным процессом кодирования), кодируется 1 байтом. Более конкретно, каждое несоответствие неточно сопоставленного прочтения, которое должно кодироваться в соответствии с первым или вторым дополнительным процессом кодирования, может кодироваться следующим образом:
первые два бита байта используются для кодирования альтернативного нуклеотида или основания, присутствующего в прочтении вместо соответствующего референсного нуклеотида или основания референсной последовательности,
шесть последних битов используются для кодирования положения несоответствия в референсной последовательности, причем указанное положение вычисляется как смещение относительно предыдущего несоответствия прочтения (относительное положение несоответствия, исключая первое несоответствие прочтения, для которого кодируется абсолютное положение). Таким образом, диапазон такого смещения, которое кодируется 6 битами, составляет [0-63].
На Фиг. 3 представлен пример кодирования несоответствий прочтения с использованием первого дополнительного процесса кодирования. Прочтение представляет собой неточно сопоставленное прочтение, которое глобально сопоставляется с референсной последовательностью. Прочтение содержит два несоответствия:
первое несоответствие, находящееся в 12-м положении прочтения, которое представляет собой замену нуклеотида А в референсной последовательности на нуклеотид Т в прочтении, и
второе несоответствие, находящееся в 21-м положении прочтения, которое представляет собой замену нуклеотида С в референсной последовательности на нуклеотид G в прочтении.
Затем список несоответствий кодируется следующим образом:
<12, Т>, значение «12», соответствующее абсолютному положению первого несоответствия в прочтении, и
<9, G>, значение «9», соответствующее относительному положению второго несоответствия в прочтении, т.е. смещению между вторым несоответствием и первым несоответствием.
<12, Т>может быть, например, преобразовано в значение «51» (кодируемое 1 байтом), а <9, G>может быть преобразовано в значение «38» (кодируемое 1 байтом). Такое байтовое кодирование получают следующим образом:
положение смещения х 4+ код нуклеотида (при А=0, С=1, G=2, Т=3)
Предпочтительно для каждого неточно сопоставленного прочтения, которое должно кодироваться в соответствии с первым или вторым дополнительным процессом кодирования, если смещение, вычисленное между заданным несоответствием прочтения и предшествующим несоответствием прочтения, больше максимального кодируемого значения, то по меньшей мере одно «фиктивное» несоответствие вставляется между указанными двумя несоответствиями, до тех пор, пока каждое смещение между каждым из указанных несоответствий и по меньшей мере одно «фиктивное» несоответствие не окажутся меньше указанного максимального кодируемого значения. «Фиктивное» несоответствие определяется как несоответствие, для которого биты байта, используемые для кодирования несоответствия, кодируют нуклеотид или основание, которые эквивалентны соответствующим референсным нуклеотиду или основанию в референсной последовательности. В предпочтительном варианте осуществления, который не следует толковать как ограничивающий объем настоящего изобретения, максимальное кодируемое значение составляет 63, что соответствует максимальному значению, которое может кодироваться 6 битами.
На Фиг. 4 представлен пример кодирования несоответствий прочтения с использованием первого дополнительного процесса кодирования в случае, когда требуется вставка «фиктивного» несоответствия. Прочтение представляет собой неточно сопоставленное прочтение, которое глобально сопоставляется с референсной последовательностью. Прочтение содержит два несоответствия:
первое несоответствие, находящееся в 22-м положении прочтения, которое представляет собой замену нуклеотида А в референсной последовательности на нуклеотид Т в прочтении, и
второе несоответствие, находящееся в 134-м положении прочтения, которое представляет собой замену нуклеотида С в референсной последовательности на нуклеотид G в прочтении.
Положение смещения между вторым и первым несоответствием составляет 112, что превышает максимальное кодируемое значение, равное 63. Таким образом, между двумя несоответствиями необходимо вставить «фиктивное» несоответствие, так чтобы каждое смещение между каждым из несоответствий и «фиктивным» несоответствием было меньше, чем указанное максимальное кодируемое значение. «Фиктивное» несоответствие с нуклеотидом Т (соответствующее «настоящему» нуклеотиду Т в референсной последовательности), например, вводится в 85-е положение прочтения. Положение смещения, вычисляемое между «фиктивным» несоответствием и первым несоответствием, составляет 63, что совпадает с максимальным кодируемым значением. Положение смещения, вычисляемое между вторым несоответствием и «фиктивным» несоответствием, составляет 49, что меньше 63.
Затем список несоответствий кодируется следующим образом:
<22, Т>, значение «22», соответствующее абсолютному положению первого несоответствия в прочтении,
<63, Т>, значение «63», соответствующее относительному положению «фиктивного» несоответствия в прочтении, т.е. смещению между «фиктивным» несоответствием и первым несоответствием, и
<49, Т>, значение «49», соответствующее относительному положению второго несоответствия в считывании, т.е. смещению между вторым несоответствием и «фиктивным» несоответствием.
Например, <22, Т> может быть преобразовано в значение «91» (кодируется 1 байтом), <63, Т> может быть преобразовано в значение «255» (кодируется 1 байтом), а <49, G> может быть преобразовано в значение «198» (кодируется 1 байтом). Такое байтовое кодирование получают следующим образом:
положение смещения х 4+ код нуклеотида (при А=0, С=1, G=2, Т=3)
Способ включает конечную стадию 14 формирования сжатого файла, содержащего список кодированных прочтений. Кодированные прочтения хранятся в сжатом файле в том же порядке, что и прочтения, хранившиеся в исходном файле без сжатия. Затем каждое прочтение может реконструироваться на основе кодированной информации выравнивания и референсной последовательности с использованием надлежащего программного обеспечения для распаковки и/или способа, выполненного в соответствии с настоящим изобретением.
Несмотря на то что обладающие признаками изобретения методики, раскрываемые в настоящем документе, описаны со ссылкой на пример архитектуры вычислительного устройства 20 (показано на Фиг. 2 для целей иллюстрации), они могут быть реализованы в аппаратном обеспечении, программном обеспечении, микропрограммном обеспечении или в любой их комбинации. При реализации в программном обеспечении код компьютерной программы может храниться на машиночитаемом носителе или исполняться аппаратным блоком обработки, включающим один или более процессоров, как в случае с устройством 20 на Фиг. 2. Следует понимать, что термин «процессор» при использовании в настоящем документе включает одно или более устройств обработки, включая сигнальный процессор, микропроцессор, микроконтроллер, специализированную интегральную схему (ASIC), программируемую пользователем вентильную матрицу (FPGA) или систему обработки другого типа, а также участки или комбинации таких элементов системы. Также термин «запоминающее устройство» при использовании в настоящем документе включает электронное запоминающее устройство, связанное с процессором, такое как оперативное запоминающее устройство (ОЗУ), постоянное запоминающее устройство (ПЗУ) или запоминающие устройства другого типа, в любой комбинации.
Соответственно, инструкции программного обеспечения или код для реализации методологий и протоколов, описанных в настоящем документе, могут храниться в одном или более из связанных запоминающих устройств, например ОЗУ, встроенное или съемное запоминающее устройство, а затем, при готовности к использованию, загружаться в ОЗУ и исполняться процессором.
Методики настоящего описания могут быть реализованы в широком разнообразии устройств или аппаратов, включая, например, мобильные телефоны, компьютеры, сервера, планшетные компьютеры и аналогичные устройства.
Несмотря на то что представленные для иллюстрации варианты осуществления настоящего изобретения были описаны в настоящем документе со ссылкой на приложенные графические материалы, следует понимать, что изобретение не ограничено этими вариантами осуществления и что различные другие изменения и модификации могут быть реализованы специалистом в данной области, не выходя за рамки объема или сущности изобретения.
Статистические и численные примеры способа сжатия в соответствии с изобретением
Приведенный ниже сравнительный пример был реализован для файла данных без сжатия, который содержал 48 миллионов прочтений или последовательностей нуклеотидов:
размер файла данных без сжатия: 35 770 Мб (мегабайт)
размер файла, сжатого с использованием программного обеспечения gzip: 6649 Мб
размер файла, сжатого с использованием программного обеспечения без референсной последовательности SPRING: 1402 Мб
размер файла, сжатого использованием способа сжатия на основе референсной последовательности в соответствии с настоящим изобретением: 1179 Мб
время сжатия с использованием программного обеспечение без референсной последовательности SPRING: 1722 с
время сжатия с использованием способа сжатия на основе референсной последовательности в соответствии с настоящим изобретением: 181 с
средний размер битов/нуклеотидов в файле данных без сжатия (кодирование ASCII): 8 битов/нуклеотид о средний размер битов/нуклеотидов в файле, который был сжат с кодированием, адаптированным для 4 возможных символов А, Т, С, G: 2 бита/нуклеотид
средний размер битов/нуклеотидов в файле, который был сжат с использованием способа сжатия на основе референсной последовательности в соответствии с настоящим изобретением: 0,33 бита/нуклеотид
Приведенные выше численные примеры показывают, что настоящее изобретение обеспечивает быстрое сжатие и распаковку, обеспечивая высокий коэффициент сжатия.
Изобретение относится к области вычислительной техники, а именно к способу сжатия данных последовательности генома. Технический результат направлен на снижение потерь при сжатии данных. Способ сжатия данных геномной последовательности включает получение одним или более компьютерами записи прочтения, определение одним или более компьютерами соответствия записи прочтений тому прочтению, которое точно сопоставляется с референсной последовательностью или неточно сопоставляется с референсной последовательностью, на основании определения одним или более компьютерами того, что запись прочтения соответствует прочтению, которое неточно сопоставляется с референсной последовательностью, определение одним или более компьютерами того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий, и на основании определения того, что количество несоответствий удовлетворяет заданному пороговому количеству несоответствий (i) получение одним или более компьютерами смещения относительно предыдущего несоответствия, которое меньше максимального кодируемого значения смещения, и (ii) кодирование одним или более компьютерами каждого несоответствия неточно сопоставленного прочтения и смещения относительно предыдущего несоответствия прочтения в запись размером 1 байт. 4 н. и 27 з.п. ф-лы, 4 ил.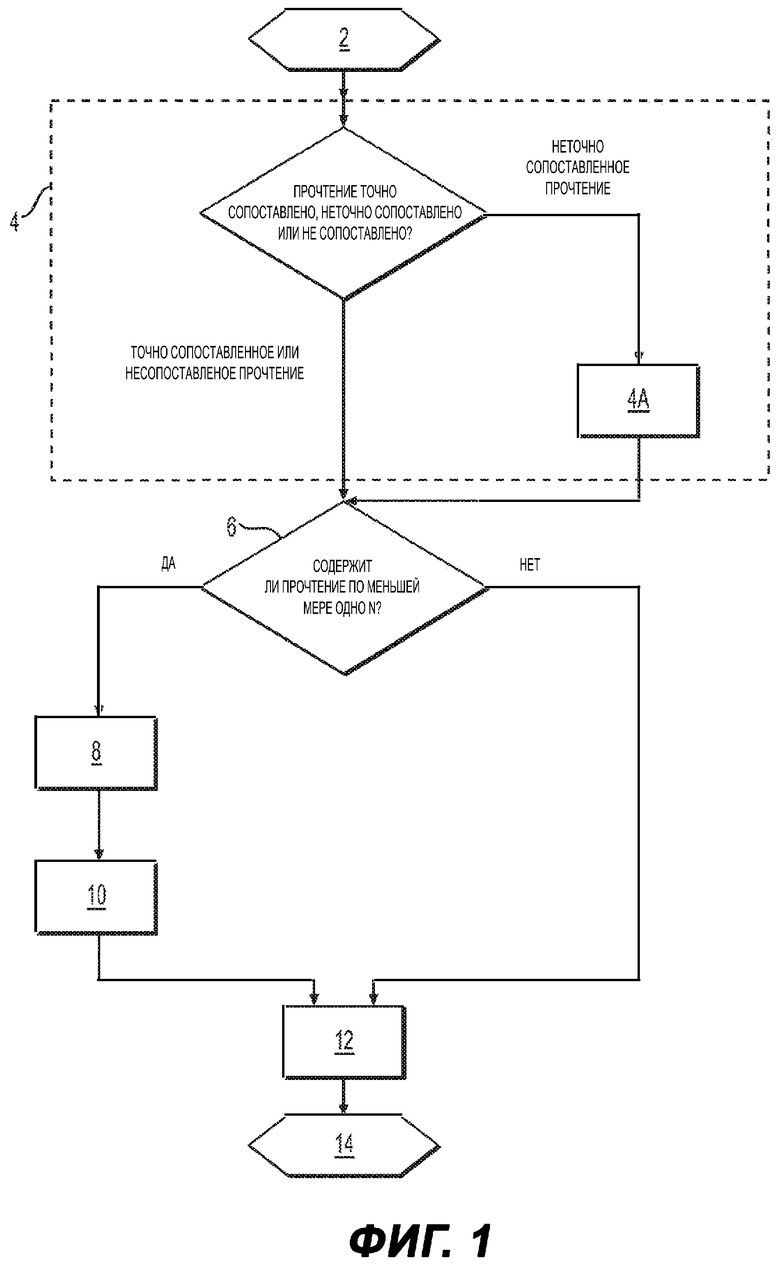
1. Способ сжатия данных геномной последовательности, включающий:
получение одним или более компьютерами записи прочтения;
определение одним или более компьютерами соответствия записи прочтений тому прочтению, которое точно сопоставляется с референсной последовательностью или неточно сопоставляется с референсной последовательностью;
на основании определения одним или более компьютерами того, что запись прочтения соответствует прочтению, которое неточно сопоставляется с референсной последовательностью, определение одним или более компьютерами того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий; и
на основании определения того, что количество несоответствий удовлетворяет заданному пороговому количеству несоответствий, (i) получение одним или более компьютерами смещения относительно предыдущего несоответствия, которое меньше максимального кодируемого значения смещения, и (ii) кодирование одним или более компьютерами каждого несоответствия неточно сопоставленного прочтения и смещения относительно предыдущего несоответствия прочтения в запись размером 1 байт.
2. Способ по п. 1, в котором определение одним или более компьютерами того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий, включает
определение одним или более компьютерами того, превышает ли количество несоответствий неточно сопоставленного прочтения заданное пороговое количество несоответствий.
3. Способ по п. 1, в котором каждая запись прочтения содержит:
данные, указывающие на абсолютное положение начала выровненного прочтения по отношению к референсной последовательности;
данные, указывающие на длину прочтения;
данные, указывающие на точное или неточное сопоставление прочтения;
данные, указывающие на количество несоответствий, выявленных в прочтении; и
данные, указывающие на относительное положение каждого из указанных возможных несоответствий в прочтении.
4. Способ по п. 1, в котором кодирование каждого несоответствия неточно сопоставленного прочтения в запись размером 1 байт для каждого конкретного несоответствия включает:
кодирование одним или более компьютерами первых двух битов байта для включения данных, отражающих альтернативный нуклеотид или основание, присутствующие в прочтении вместо соответствующего референсного нуклеотида или основания в референсной последовательности; и
кодирование одним или более компьютерами шести последних битов байта для включения данных, отражающих смещение.
5. Способ по п. 4, дополнительно включающий:
определение одним или более компьютерами того, превышает ли смещение максимальное кодируемое значение; и
на основании определения того, что смещение превышает максимальное кодируемое значение, вставку одним или более компьютерами по меньшей мере одного фиктивного несоответствия между конкретным несоответствием и предыдущим несоответствием.
6. Способ по п. 1, дополнительно включающий
на основании определения того, что количество несоответствий не удовлетворяет заданному пороговому количеству несоответствий, кодирование одним или более компьютерами списка положений референсной последовательности, соответствующих положению каждого из несоответствий относительно референсной последовательности, с использованием процесса кодирования с понижением энтропии информации.
7. Способ по п. 1, дополнительно включающий
на основании определения того, что запись прочтения соответствует прочтению, которое точно сопоставляется с референсной последовательностью, кодирование одним или более компьютерами по меньшей мере участка записи прочтения с использованием процесса кодирования с понижением энтропии информации.
8. Способ по п. 1, в котором один или более компьютеров содержат один или более аппаратных процессоров.
9. Способ по п. 8, в котором один или более аппаратных процессоров содержат одну или более программируемых пользователем вентильных матриц (FPGA).
10. Аппаратный процессор, который содержит аппаратную систему обработки, которая выполнена с возможностью выполнения одной или более операций, причем одна или более операций включают:
получение записи прочтения аппаратной системой обработки;
определение аппаратной системой обработки того, что запись прочтения соответствует прочтению, которое точно сопоставляется с референсной последовательностью или неточно сопоставляется с референсной последовательностью;
на основании определения аппаратной системой обработки того, что запись прочтения соответствует прочтению, которое неточно сопоставляется с референсной последовательностью, определение одним или более компьютерами того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий; и
на основании определения того, что количество несоответствий удовлетворяет заданному пороговому количеству несоответствий, (i) получение аппаратной системой обработки смещения относительно предыдущего несоответствия, которое меньше максимального кодируемого значения смещения, и (ii) кодирование аппаратной системой обработки каждого несоответствия неточно сопоставленного прочтения и смещения относительно предыдущего несоответствия прочтения в запись размером 1 байт.
11. Аппаратный процессор по п. 10, в котором каждая запись прочтения содержит:
данные, указывающие на абсолютное положение начала выровненного прочтения по отношению к референсной последовательности;
данные, указывающие на длину прочтения;
данные, указывающие на точное или неточное сопоставление прочтения;
данные, указывающие на количество несоответствий, выявленных в прочтении; и
данные, указывающие на относительное положение указанных возможных несоответствий в прочтении.
12. Аппаратный процессор по п. 10, в котором кодирование каждого несоответствия неточно сопоставленного прочтения в запись размером 1 байт для каждого конкретного несоответствия включает:
кодирование аппаратной системой обработки первых двух битов байта для включения данных, отражающих альтернативный нуклеотид или основание, присутствующие в прочтении вместо соответствующего референсного нуклеотида или основания в референсной последовательности; и
кодирование аппаратной системой обработки шести последних битов байта для включения данных, отражающих смещение.
13. Аппаратный процессор по п. 12, в котором аппаратная система обработки дополнительно выполнена с возможностью выполнения операций, включающих:
определение аппаратной системой обработки того, превышает ли смещение максимальное кодируемое значение;
на основании определения того, что смещение превышает максимальное кодируемое значение, вставку аппаратной системой обработки по меньшей мере одного фиктивного несоответствия между конкретным несоответствием и предыдущим несоответствием.
14. Аппаратный процессор по п. 10, в котором аппаратная система обработки дополнительно выполнена с возможностью выполнения операций, включающих:
на основании определения того, что количество несоответствий не удовлетворяет заданному пороговому количеству несоответствий, кодирование аппаратной системой обработки списка положений референсной последовательности, соответствующих положению каждого из несоответствий относительно референсной последовательности, с использованием процесса кодирования с понижением энтропии информации.
15. Аппаратный процессор по п. 10, причем аппаратная система обработки дополнительно выполнена с возможностью выполнения операций, включающих
на основании определения того, что запись прочтения соответствует прочтению, которое точно сопоставляется с референсной последовательностью, кодирование аппаратной системой обработки по меньшей мере участка записи прочтения с использованием кодирования с понижением энтропии информации.
16. Аппаратный процессор по п. 10, в котором аппаратная система обработки содержит одну или более программируемых пользователем вентильных матриц (FPGA).
17. Аппаратный процессор по п. 10, в котором определение аппаратной системой обработки того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий, включает
определение аппаратной системой обработки того, превышает ли количество несоответствий неточно сопоставленного прочтения заданное пороговое количество несоответствий.
18. Система сжатия данных последовательности генома, содержащая:
один или более компьютеров и одно или более устройств хранения, на которых хранятся инструкции, при исполнении которых одним или более компьютерами один или более компьютеров выполняют операции, включающие:
получение одним или более компьютерами записи прочтения;
определение одним или более компьютерами соответствия записи прочтений тому прочтению, которое точно сопоставляется с референсной последовательностью или неточно сопоставляется с референсной последовательностью;
на основании определения одним или более компьютерами того, что запись прочтения соответствует прочтению, которое неточно сопоставляется с референсной последовательностью, определение одним или более компьютерами того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий; и
на основании определения того, что количество несоответствий удовлетворяет заданному пороговому количеству несоответствий, (i) получение одним или более компьютерами смещения относительно предыдущего несоответствия, которое меньше максимального кодируемого значения смещения, и (ii) кодирование одним или более компьютерами каждого несоответствия неточно сопоставленного прочтения и смещения относительно предыдущего несоответствия прочтения в запись размером 1 байт.
19. Система по п. 18, в которой каждая запись прочтения содержит:
данные, указывающие на абсолютное положение начала выровненного прочтения по отношению к референсной последовательности;
данные, указывающие на длину прочтения;
данные, указывающие на точное или неточное сопоставление прочтения;
данные, указывающие на количество несоответствий, выявленных в прочтении; и
данные, указывающие на относительное положение каждого из указанных возможных несоответствий в прочтении.
20. Система по п. 18, в которой кодирование каждого несоответствия неточно сопоставленного прочтения в запись размером 1 байт включает для каждого конкретного несоответствия:
кодирование одним или более компьютерами первых двух битов байта для включения данных, отражающих альтернативный нуклеотид или основание, присутствующие в прочтении вместо соответствующего референсного нуклеотида или основания в референсной последовательности; и
кодирование одним или более компьютерами шести последних битов байта для включения данных, отражающих смещение.
21. Система по п. 20, в которой операции дополнительно включают:
определение одним или более компьютерами того, превышает ли смещение максимальное кодируемое значение; и
на основании определения того, что смещение превышает максимальное кодируемое значение, вставку одним или более компьютерами по меньшей мере одного фиктивного несоответствия между конкретным несоответствием и предыдущим несоответствием.
22. Система по п. 18, в которой операции дополнительно включают
на основании определения того, что количество несоответствий не удовлетворяет заданному пороговому количеству несоответствий, кодирование одним или более компьютерами списка положений референсной последовательности, соответствующих положению каждого из несоответствий относительно референсной последовательности, с использованием процесса кодирования с понижением энтропии информации.
23. Система по п. 18, в которой операции дополнительно включают
на основании определения того, что запись прочтения соответствует прочтению, которое точно сопоставляется с референсной последовательностью, кодирование одним или более компьютерами по меньшей мере участка записи прочтения с использованием кодирования с понижением энтропии информации.
24. Система по п. 18, в которой один или более компьютеров содержат один или более аппаратных процессоров.
25. Система по п. 24, в которой один или более аппаратных процессоров содержат одну или более программируемых пользователем вентильных матриц (FPGA).
26. Машиночитаемое устройство хранения, имеющее хранящиеся в нем инструкции, которые при их исполнении аппаратом для обработки данных приводят к тому, что аппарат для обработки данных выполняет операции сжатия данных геномной последовательности, включающие:
получение записи прочтения;
определение соответствия записи прочтения такому прочтению, которое точно сопоставляется с референсной последовательностью или неточно сопоставляется с референсной последовательностью;
на основании определения того, что запись прочтения соответствует прочтению, которое неточно сопоставляется с референсной последовательностью, определение того, насколько количество несоответствий неточно сопоставленного прочтения удовлетворяет заданному пороговому количеству несоответствий; и
на основании определения того, что количество несоответствий удовлетворяет заданному пороговому количеству несоответствий, (i) получение смещения относительно предыдущего несоответствия, которое меньше максимального кодируемого значения смещения, и (ii) кодирование каждого несоответствия неточно сопоставленного прочтения и смещения относительно предыдущего несоответствия прочтения в запись размером 1 байт.
27. Машиночитаемое устройство хранения по п. 26, в котором каждая запись прочтения содержит:
данные, указывающие на абсолютное положение начала выровненного прочтения по отношению к референсной последовательности;
данные, указывающие на длину прочтения;
данные, указывающие на точное или неточное сопоставление прочтения;
данные, указывающие на количество несоответствий, выявленных в прочтении; и
данные, указывающие на относительное положение каждого из указанных возможных несоответствий в прочтении.
28. Машиночитаемое устройство хранения по п. 26, в котором кодирование каждого несоответствия неточно сопоставленного прочтения в запись размером 1 байт для каждого конкретного несоответствия включает:
кодирование одним или более компьютерами первых двух битов байта для включения данных, отражающих альтернативный нуклеотид или основание, присутствующие в прочтении вместо соответствующего референсного нуклеотида или основания в референсной последовательности; и
кодирование одним или более компьютерами шести последних битов байта, для включения данных, отражающих смещение.
29. Машиночитаемое устройство хранения по п. 28, в котором операции дополнительно включают:
определение одним или более компьютерами того, превышает ли смещение максимальное кодируемое значение; и
на основании определения того, что смещение превышает максимальное кодируемое значение, вставку одним или более компьютерами по меньшей мере одного фиктивного несоответствия между конкретным несоответствием и предыдущим несоответствием.
30. Машиночитаемое устройство хранения по п. 26, причем операции дополнительно включают:
на основании определения того, что количество несоответствий не удовлетворяет заданному пороговому количеству несоответствий, кодирование списка положений референсной последовательности, соответствующих положению каждого из несоответствий относительно референсной последовательности, с использованием процесса кодирования с понижением энтропии информации.
31. Машиночитаемое устройство хранения по п. 26, причем операции дополнительно включают
на основании определения того, что запись прочтения соответствует прочтению, которое точно сопоставляется с референсной последовательностью, кодирование по меньшей мере участка записи прочтения с использованием кодирования с понижением энтропии информации.
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| ЗЮЗИН Н.А | |||
| и др "ПОДХОД К СЖАТИЮ ПОСЛЕДОВАТЕЛЬНОСТЕЙ ДНК С ПОМОЩЬЮ АЛГОРИТМА "БИНАРНЫЙ АРХИВАТОР"" материалы научно-практической internet-конференции | |||
| Ответственный редактор Ю.C | |||
| Нагорнов; редакционная коллегия сборника: Мельников Б.Ф., Крашенинников | |||

