Настоящее изобретение относится к способу выбора опухолевых неоантигенов для применения в персонализированной вакцине. Настоящее изобретение также относится к способу конструирования несущего неоантигены вектора или коллекции векторов для персонализированной вакцины. Кроме того, настоящее изобретение относится к персонализированной вакцине, содержащей векторы или коллекцию векторов, и к применению указанных векторов для лечения рака.
Область техники, к которой относится настоящее изобретение
Некоторые опухолевые антигены были идентифицированы и классифицированы на различные категории: антигены зародышевой линии раковой опухоли, антигены тканевой дифференциации и неоантигены, происходящие из мутированных собственных белков (Anderson et al., 2012). Вопрос о том, влияют ли иммунные ответы против аутоантигенов на рост опухоли, является предметом споров (обзор в Anderson et al., 2012). Напротив, недавние убедительные доказательства подтверждают мнение о том, что неоантигены, образующиеся в опухоли в результате мутаций в кодирующих последовательностях экспрессируемых генов, представляют собой многообещающую мишень для вакцинации против рака (Fritsch et al., 2014).
Опухолевые неоантигены представляют собой антигены, присутствующие исключительно на опухолевых клетках, но не на нормальных клетках. Неоантигены возникают в результате мутаций ДНК в опухолевых клетках, и было показано, что они играют значительную роль в распознавании и уничтожении опухолевых клеток с помощью иммунного ответа, опосредованного Т-клетками, в основном Т-клетками CD8+ (Yarchoan et al., 2017). Благодаря способам массивно-параллельного секвенирования, обычно называемого секвенированием следующего поколения (NGS), которое позволяет определять полную последовательность ракового генома своевременным и недорогостоящим образом, был раскрыт спектр мутаций опухолей человека (Kandoth et al., 2013). Наиболее частым типом мутации является однонуклеотидный вариант, и среднее число однонуклеотидных вариантов, обнаруживаемых в опухолях, значительно варьируется в зависимости от их гистологии. Поскольку у пациентов обычно встречается очень мало общих мутаций, идентификация мутаций, приводящих к неоантигенам, требует персонализированного подхода.
Многие мутации действительно не обнаруживаются иммунной системой, либо так как потенциальные эпитопы не процессируются/презентуются опухолевыми клетками, либо так как иммунная толерантность приводит к устранению Т-клеток, реагирующих с мутантной последовательностью. Следовательно, среди всех потенциальных неоантигенов полезно выбирать те, которые имеют наибольшую вероятность быть иммуногенными, чтобы определить оптимальное количество, которое будет кодироваться вакциной, и, наконец, предпочтительную структуру вакцины для оптимизации иммуногенности. Кроме того, важное значение имеют не только неоантигены, создаваемые мутациями однонуклеотидного варианта, а также неоантигены, создаваемыми инсерционными/делеционными мутациями, которые приводят к пептиду со сдвигом рамки считывания, и последний, как ожидается, будет особенно иммуногенным. Недавно в клинических исследованиях фазы I были оценены два различных подхода к персонализированной вакцинации, основанные либо на РНК, либо на пептидах. Полученные данные показывают, что вакцинация действительно может как расширить уже существующие неоантиген-специфические Т-клетки, так и индуцировать более широкий репертуар новой Т-клеточной специфичности у пациентов, страдающих раком (Sahin et al., 2017). Основным ограничением обоих подходов является максимальное количество неоантигенов, на которые направлена вакцинация. Верхний предел для подхода на основе пептидов, основанный на опубликованных для них данных, составляет двадцать пептидов и не был достигнут у всех пациентов, потому что в некоторых случаях пептиды не могли быть синтезированы. Описанный верхний предел для подхода на основе РНК еще ниже, поскольку каждая вакцина включает только 10 мутаций (Sahin et al., 2017).
Задача противораковой вакцины при лечении рака состоит в том, чтобы индуцировать разнообразную популяцию иммунных Т-клеток, способных распознавать и уничтожать как можно большее количество раковых клеток одновременно, чтобы снизить вероятность того, что раковые клетки «ускользнут» от Т-клеточного ответа и останутся не распознанными иммунным ответом. Следовательно, желательно, чтобы вакцина кодировала большое количество опухоль-специфических антигенов, т.е. неоантигенов. Это особенно актуально для подхода к персонализированной генной вакцине на основе опухоль-специфических неоантигенов человека. Чтобы оптимизировать вероятность успеха вакцина должна быть нацелена на как можно больше неоантигенов. Более того, экспериментальные данные подтверждают представление о том, что эффективные иммуногенные неоантигены у пациентов охватывают широкий диапазон предсказанных аффинностей к аллелям МНС пациента (например, Gros et al., 2016). В большинстве существующих в настоящее время способов приоритизации вместо этого используется порог аффинности, например, часто используемый предел 500 нМ, что может ограничивать выбор иммуногенных неоантигенов. Следовательно, существует потребность в способе приоритизации, который позволяет избежать ограничений существующих в настоящее время способов (например, исключение из-за низкой предсказанной аффинности), и в подходе к вакцинации, который позволяет нацеливать персонализированную вакцину на большой и, следовательно, более широкий и более полный набор неоантигенов.
Краткое раскрытие настоящего изобретения
Согласно первому аспекту настоящее изобретение относится к способу выбора опухолевых неоантигенов для применения в персонализированной вакцине, предусматривающему стадии:
(a) определения неоантигенов в образце раковых клеток, взятом у индивидуума, где каждый неоантиген
- содержится в кодирующей последовательности,
- содержит по меньшей мере одну мутацию в кодирующей последовательности, приводящую к изменению кодируемой аминокислотной последовательности, которое не присутствует в образце нераковых клеток указанного индивидуума, и
- состоит из от 9 до 40, предпочтительно от 19 до 31, более предпочтительно от 23 до 25, наиболее предпочтительно 25 смежных аминокислот кодирующей последовательности в образце раковых клеток,
(b) определения для каждого неоантигена частоты мутантных аллелей каждой из указанных мутаций согласно стадии (а) в кодирующей последовательности,
(c) определения уровня экспрессии каждой кодирующей последовательности, содержащей по меньшей мере одну из указанных мутаций,
(i) в указанном образце раковых клеток или
(ii) на основании базы данных экспрессии рака того же типа, что и образец раковых клеток,
(d) предсказания аффинности связывания неоантигенов с МНС класса I, где
(I) аллели HLA класса I определяют в образце нераковых клеток указанного индивидуума,
(II) для каждого аллеля HLA класса I, определенного на стадии (I), предсказывают аффинность связывания с МНС класса I для каждого фрагмента, состоящего из от 8 до 15, предпочтительно от 9 до 10, более предпочтительно 9, смежных аминокислот неоантигена, где каждый фрагмент содержит по меньшей мере одно аминокислотное изменение, вызванное мутацией согласно стадии (а), и
(III) фрагмент с наивысшей аффинностью связывания с МНС класса I определяет аффинность связывания неоантигена с МНС класса I,
(e) ранжирования неоантигенов в соответствии с значениями, определенными на стадиях (b) - (d) для каждого неоантигена, от самого большого до самого маленького значения, с обеспечением первого, второго и третьего перечня рангов,
(f) вычисления ранговой суммы на основании первого, второго и третьего перечня рангов и распределения неоантигенов по увеличению ранговой суммы с получением ранжированного перечня неоантигенов,
(g) выбора 30-240, предпочтительно 40-80, более предпочтительно 60, неоантигенов из ранжированного перечня неоантигенов, полученного на стадии (f), начиная с самого низкого ранга.
Согласно второму аспекту настоящее изобретение относится к способу конструирования персонализированного вектора, кодирующего комбинацию неоантигенов согласно первому аспекту настоящего изобретения, для применения в виде вакцины, предусматривающему стадии:
(i) распределения перечня неоантигенов в по меньшей мере 10^5-10^8, предпочтительно 10^6 различные комбинации,
(ii) создания всех возможных пар сегментов соединения неоантигенов для каждой комбинации, где каждый сегмент соединения содержит 15 соседних смежных аминокислот с каждой стороны соединения,
(iii) предсказания аффинности связывания с МНС класса I и/или класса II для всех эпитопов в сегментах соединения, где тестируют только HLA аллели, которые присутствуют у индивидуума, для которого конструируют вектор, и
(iv) выбора комбинации неоантигенов с наименьшим числом соединенных эпитопов с IC50, равной ≤1500нМ, и где, если множество комбинаций имеют одно и то же наименьшее число соединенных эпитопов, выбирают первую встречающуюся комбинацию.
Согласно третьему аспекту настоящее изобретение относится к вектору, кодирующему перечень неоантигенов согласно первому аспекту настоящего изобретения или комбинацию неоантигенов согласно второму аспекту настоящего изобретения.
Согласно четвертому аспекту настоящее изобретение относится к коллекции векторов, где каждый кодирует различный набор неоантигенов согласно первому аспекту настоящего изобретения или комбинацию неоантигенов согласно второму аспекту настоящего изобретения, где коллекция содержит от 2 до 4, предпочтительно 2 вектора, и где предпочтительно векторные вставки, кодирующие часть перечня, имеют приблизительно равный размер по числу аминокислот.
Согласно пятому аспекту настоящее изобретение относится к вектору согласно третьему аспекту настоящего изобретения или коллекции векторов согласно четвертому аспекту настоящего изобретения для применения в вакцинации против рака.
Краткое описание чертежей
Далее следует описание чертежей, представленных в описании настоящего изобретения. В контексте чертежей также следует обратиться к подробному описанию настоящего изобретения, приведенному выше и/или ниже.
Фиг. 1. Создание неоантигенов, происходящих в результате SNV: (А) создание 25-ти мерных неоантигенов с мутацией, центрированной и фланкированной 12 аминокислотами дикого типа выше и ниже по ходу транскрипции, (В) создание 25-ти мерных неоантигенов, включающих более одной мутации, и (С) создание неоантигена, более короткого, чем 25-ти мерный, когда мутация находится близко к концу или началу последовательности белка.
Фиг. 2. Создание неоантигенов, происходящих из инсерционно/делеционных мутаций, приводящих к пептиду со сдвигом рамки считывания (FSP). Способ содержит расщепление пептидов FSP на два более маленьких фрагмента, предпочтительно на 25-ти мерные фрагменты.
Фиг. 3. Схематическое изображение создания ранжированного перечня RSUM на основании трех отдельных ранговых оценок.
Фиг. 4. Схематическое изображение методики оптимизации длины перекрывающихся неоантигенов, происходящих из FSP.
Фиг. 5. Схематическое изображение методики разделения К (предпочтительно 60) неоантигенов на два более маленьких перечня приблизительно равной общей длины.
Фиг. 6. Примеры слияния фрагментов FSP: Пример 1 относится к FSP, образованному делецией двух нуклеотидов chr11:1758971_АС.Четыре последовательности неоантигена (фрагменты FSP) слиты в один неоантиген длиной 30 аминокислот.Пример 2 относится к FSP, созданному однонуклеотидной вставкой chr6:168310205_-_Т. Две последовательности неоантигена (фрагменты FSP) слиты в один неоантиген длиной 31 аминокислота.
Фиг. 7. Валидация способа приоритизации: мутации, полученные для 14 пациентов, страдающих раком, ранжировали с применением способа приоритизации из Примера 1. На чертеже показана позиция в ранжированном перечне для мутаций, которые, как было экспериментально показано, индуцируют иммунный ответ. Ранги обозначены кружком (А) или квадратом (В) для ранжирования RSUM, включая данные NGS-PHK пациентов (А) или без данных NGS-PHK пациентов (В).
Фиг. 8. Иммуногенность одного вектора GAd или двух векторов GAd, кодирующих 62 неоантигена. Один вектор GAd, кодирующий все 62 неоантигена в одной экспрессионной кассете (GAd-CT26-1-62), вызывает более слабый иммунный ответ по сравнению с двумя совместно вводимыми векторами GAd, каждый из которых кодирует 31 неоантиген (GAd-CT26-1-31+GAd-CT26-32-62) или одним вектором GAd, кодирующим две кассеты по 31 неоантигену в каждой (GAd-CT26 двойной 1-31 и 32-62). Мышей BalbC (6 мышей в группе) иммунизировали внутримышечно (А) 5×10^8 вирусных частиц GAd-СТ26-1-62 или путем совместного введения двух векторов GAd-CT26-1-31+GAd-CT26-32-62 (5×10^8 вирусных частиц каждый) и (В) 5×10^8 вирусных частиц GAd-CT26-1-62 или 5×10^8 вирусных частиц двойного кассетного вектора GAd-CT26 двойной 1-31 и 32-62. Т-клеточные ответы измеряли на спленоцитах вакцинированных мышей на пике ответа (2 недели после вакцинации) с помощью ex vivo IFNγ ELISpot. Ответы оценивали с использованием 2 пулов пептидов, каждый из которых состоял из 31 пептида, кодируемого конструкциями вакцины (пул 1-31 - неоантигены 1-31, пул 32-62 - неоантигены 32-62). Каждый из полинеоантигенных векторов содержит энхансерную последовательность Т-клеток (TPА), добавленную на N-конце собранных полинеоантигенов, и метку вируса гриппа НА на С-конце для контроля экспрессии.
Подробное раскрытие настоящего изобретения
Прежде чем настоящее изобретение будет описано более подробно ниже, необходимо отметить, что настоящее изобретение не ограничено конкретными способами, протоколами и реагентами, описанными в настоящем документе, так как они могут варьироваться. Также должно быть понятно, что применяемая в настоящем документе терминология использована только в целях описания конкретных вариантов осуществления, и указанная терминология не предназначена для ограничения объема настоящего изобретения, который ограничивается только прилагаемой формулой изобретения. Если не указано иное, все технические и научные термины, используемые в настоящем документе, имеют значение, которое приписывается им специалистами в данной области техники.
Предпочтительно термины, используемые в настоящем документе, имеют определение, как описано в «А multilingual glossary of biotechnological terms: (IUPAC Recommendations)», Leuenberger, H.G.W, Nagel, B. and Klbl, H. eds. (1995), Helvetica Chimica Acta, CH-4010 Basel, Switzerland).
Во всем описании настоящего изобретения и формуле изобретения, которая следует за ним, если из контекста не следует иное, слово «содержать» и варианты, такие как «содержит» и «содержащий», следует понимать, как подразумевающие включение указанного целого или стадии, или группы целых или стадий, но не исключение любого другого целого или стадии, или группы целых или стадий. В следующих частях различные аспекты настоящего изобретения описаны более подробно. Каждый аспект, определенный таким образом, может быть объединен с любым другим аспектом или аспектами, если явно не указано иное. В частности, любой признак, указанный как необязательный, предпочтительный или преимущественный, может быть объединен с любым другим признаком или признаками, указанными как необязательные, предпочтительные или преимущественными.
В тексте описания настоящего изобретения процитированы несколько документов. Каждый из документов, процитированных в настоящем документе (включая все патенты, заявки на патенты, научные публикации, спецификации производителя, инструкции и т.д.), выше или ниже, включен в настоящий документ посредством ссылки во всей своей полноте. Ничто в описании не следует рассматривать как допущение, что изобретение не имеет права датировать такое раскрытие в соответствии с предшествующим изобретением. Некоторые из процитированных в настоящем документе документов охарактеризованы как «включены посредством ссылки». В случае противоречия между определениями или идеями таких включенных ссылочных источников и определениями или идеями, изложенными в настоящем описании, текст настоящего описания имеет преимущественную силу.
Далее следует описание элементов настоящего изобретения. Эти элементы перечислены с конкретными вариантами осуществления, однако, следует понимать, что они могут быть объединены любым образом и в любом числе с созданием дополнительных вариантов осуществления. Различные описанные примеры и предпочтительные варианты осуществления не должны толковаться как ограничивающие настоящее изобретение только явно описанными вариантами осуществления. Следует понимать, что настоящее описание поддерживает и охватывает варианты осуществления, которые объединяют явно описанные варианты осуществления с любым числом раскрытых и/или предпочтительных элементов. Кроме того, любые перестановки и комбинации всех описанных элементов в настоящей заявке следует рассматривать как раскрытые в описании настоящей заявки, если из контекста не следует иное.
Определения
Далее приведены некоторые определения терминов, часто используемых в настоящем описании. Эти термины в каждом случае их использования в оставшейся части описания будут иметь соответственно определенное значение и предпочтительные значения.
В контексте настоящего изобретения и в приложенной формуле изобретения форма единственного числа включает множественное число, если из контекста явно не следует иное.
Термин «приблизительно», при использовании вместе с числовым значением, предназначен для охвата числовых значений в пределах диапазона, имеющего нижний предел, который на 5% меньше указанного числового значения, и имеющего верхний предел, который на 5% больше указанного числового значения.
В контексте настоящего описания термин «главный комплекс гистосовместимости» (МНС) используется в его значении, известном в области клеточной биологии и иммунологии, и относится к молекуле клеточной поверхности, которая экспонирует специфическую фракцию (пептид), также называемую эпитопом, белка. Существует два основных класса молекул МНС: класс I и класс П. Внутри МНС класса I можно выделить две группы на основе их полиморфизма: а) классические (МНС-Iа) с соответствующими полиморфными генами HLA-A, HLA-B и HLA-C, и b) неклассические (МНС-Ib) с соответствующими менее полиморфными генами HLA-E, HLA-F, HLA-G и HLA-H.
Молекулы тяжелой цепи МНС класса I встречаются в виде альфа-цепи, связанной с единицей β2-микроглобулина молекулы, не относящейся к МНС. Альфа-цепь содержит в направлении от N-конца к С-концу сигнальный пептид, три внеклеточных домена (α1-3, при этом α1 находится на N-конце), трансмембранную область и С-концевой цитоплазматический хвост. Экспонируемый или презентируемый пептид удерживается пептид-связывающей полостью в центральной области доменов α1/α2.
Термин «домен β2-микроглобулина» относится к молекуле, не относящейся к МНС, которая является частью гетеродимерной молекулы МНС класса I. Другими словами, он составляет р цепь гетеродимера МНС класса I.
Основная функция классических молекул МНС-Iа состоит в презентации пептидов как части адаптивного иммунного ответа. Молекулы МНС-Iа представляют собой тримерные структуры, содержащие связанную с мембраной тяжелую цепь с тремя внеклеточными доменами (α1, α2 и α3), которая нековалентно связывается с β2-микроглобулином (β2m) и небольшим пептидом, который происходит из собственных белков, вирусов или бактерий. Домены α1 и α2 являются высокополиморфными и образуют платформу, которая дает начало пептид-связывающей полости. Рядом с консервативным доменом α3 находится трансмембранный домен, за которым следует внутриклеточный цитоплазматический хвост.
Чтобы инициировать иммунный ответ, классические молекулы МНС-Iа презентируют специфические пептиды, которые распознаются TCR (Т-клеточным рецептором), присутствующим на цитотоксических Т-лимфоцитах (CTL) CD8+, тогда как рецепторы NK-клеток, присутствующие в природных клетках-киллерах (NK), скорее распознают пептидные мотивы, чем отдельные пептиды. В нормальных физиологических условиях молекулы МНС-Ia существуют в виде гетеротримерных комплексов, отвечающих за представление пептидов клеткам CD8 и NK-клеткам.
Термин «лейкоцитарный антиген человека» (HLA) используется в его значении, известном в области клеточной биологии и биохимии, и относится к локусам генов, кодирующим белки МНС класса I человека. Тремя основными классическими генами МНС-Ia являются HLA-A, HLA-B и HLA-C, и все эти гены имеют варьирующееся число аллелей. Близкородственные аллели объединяются в подгруппы определенного аллеля. Полная или частичная последовательность всех известных генов HLA и их соответствующие аллели доступны специалисту в данной области техники в специализированных базах данных, таких как IMGT/HLA (http://www.ebi.ас.uk/ipd/imgt/hla/).
У людей есть молекулы МНС класса I, включающие классические молекулы (МНС-Ia) HLA-A, HLA-B и HLA-C, а также неклассические молекулы (MHC-Ib) HLA-E, HLA-F, HLA-G и HLA-H. Обе категории похожи по своим механизмам связывания пептидов, презентации и индуцированных Т-клеточных ответов. Наиболее существенным признаком классических МНС-Ia является их высокий полиморфизм, в то время как неклассические MHC-Ib обычно неполиморфны и, как правило, демонстрируют более ограниченный профиль экспрессии, чем их МНС-Ia аналоги.
Номенклатура HLA приводится в виде конкретного названия локуса гена (например, HLA-A), за которым следует серологический антиген семейства аллелей (например, HLA-А*02) и подтипы аллелей, обозначенные номерами и в порядке, в котором последовательности ДНК были определены (например, HLA-A*02:01). Аллели, которые отличаются только синонимичными нуклеотидными заменами (также называемыми молчащими или некодирующими заменами) в кодирующей последовательности различают использованием третьего набора цифр (например, HLA-A*02:01:01). Аллели, которые различаются только полиморфизмом последовательностей в интронах или в 5' или 3' нетранслируемых областях, которые фланкируют экзоны и интроны, различают с помощью четвертого набора цифр (например, HLA-A*02:01:01:02L).
Что касается предсказания аффинности связывания с МНС класса I и класса II, примерами способов, известных в данной области техники для предсказания эпитопов МНС класса I или II и для предсказания аффинности связывания с МНС класса I и II, являются Moutaftsi et al., 2006, Lundegaard et al., 2008, Hoof et al., 2009, Andreatta & Nielsen, 2016; Jurtz et al., 2017. Предпочтительно используют способ, описанный в Andreatta & Nielsen, 2016, и, если этот способ не охватывает один из аллелей МНС пациента, используют альтернативный способ, описанный Jurtz et al., 2017.
Гены и эпитопы, связанные с аутоиммунными реакциями человека и связанными аллелями МНС, можно идентифицировать в базе данных IEDB (https://www.iedb.org), применяя следующие критерии запроса: «Линейные эпитопы» для категории «Эпитоп», «Человек» для категория «Хозяин» и «Аутоиммунное заболевание» для категории «Заболевание».
Термин «энхансерный элемент Т-клеток» относится к полипептиду или полипептидной последовательности, которая при слиянии с антигенной последовательностью или пептидом увеличивает индукцию Т-клеток против неоантигенов в контексте генной вакцинации. Примерами энхансеров Т-клеток являются последовательность инвариантной цепи или ее фрагмент, лидерная последовательность тканевого активатора плазминогена, необязательно включающая шесть дополнительных аминокислотных остатков ниже по ходу транскрипции, последовательность PEST, коробка разрушения циклина, сигнал убиквитинирования, сигнал SUMOylation. Конкретными примерами энхансерных элементов Т-клеток являются элементы последовательностей SEQ ID NO 173-182.
Термин «кодирующая последовательность» относится к нуклеотидной последовательности, которая транскрибируется и транслируется в белок. Гены, кодирующие белки, являются конкретным примером кодирующих последовательностей.
Термин «частота аллелей» относится к относительной частоте конкретного аллеля в конкретном локусе в пределах множества элементов, как например, популяция или популяция клеток. Частота аллелей выражается в процентах или соотношении. Например, частота аллелей мутации в кодирующей последовательности будет определяться соотношением мутантных и немутантных прочтений в положении мутации. Частота мутантных аллелей, при которой в положении мутации 2 прочтения определяют мутантный аллель, а 18 прочтений показывают немутантный аллель, определяет частоту мутантных аллелей, равную 10%. Частота мутантных аллелей для неоантигенов, созданных из пептидов со сдвигом рамки считывания, представляет собой частоту инсерционной или делеционной мутации, приводящей к пептиду со сдвигом рамки считывания, т.е. все мутантные аминокислоты в FSP будут иметь одинаковую частоту мутантных аллелей, которая является частотой инсерционной/делеционной мутации, вызывающей сдвиг рамки считывания.
Термин «неоантиген» относится к рак-специфическим антигенам, которые не присутствуют в нормальных нераковых клетках.
Термин «противораковая вакцина» в контексте настоящего изобретения относится к вакцине, которая предназначена для индукции иммунного ответа против раковых клеток.
Термин «персонализированная вакцина» относится к вакцине, которая содержит антигенные последовательности, специфичные для конкретного индивидуума. Такая персонализированная вакцина представляет особый интерес для противораковой вакцины, в которой используются неоантигены, поскольку многие неоантигены специфичны для конкретных раковых клеток индивидуума.
Термин «мутация» в кодирующей последовательности в контексте настоящего изобретения к относится изменению в нуклеотидной последовательности кодирующей последовательности при сравнении нуклеотидной последовательности раковой клетки с нуклеотидной последовательностью нераковой клетки. Изменения в нуклеотидной последовательности, не приводящие к изменению аминокислотной последовательности кодируемого пептида, т.е. «молчащая» мутация, не рассматриваются как мутация в контексте настоящего изобретения. Типы мутаций, которые могут привести к изменению в аминокислотной последовательности, не ограничиваются несинонимичными однонуклеотидными вариантами (SNV), в которых один нуклеотид кодирующего триплета изменен, приводя к другой аминокислоте в транслируемой последовательности. Еще одним примером мутации, приводящей к изменению в аминокислотной последовательности, являются инсерционные/делеционные (вставка/делеция) мутации, в которых один или несколько нуклеотидов либо вставлены в кодирующую последовательность, либо удалены из нее. Особое значение имеют инсерционные/делеционные мутации, которые приводят к сдвигу рамки считывания, которое происходит, если вставлено или удалено несколько нуклеотидов, которые не делятся на три. Такая мутация вызывает значительное изменение в аминокислотной последовательности ниже по ходу транскрипции от мутации, что обозначается как пептид со сдвигом рамки считывания (FSP).
Термин «энтропия Шеннона» относится к энтропии, связанной с числом конформаций молекулы, например, белка. Способы, известные в данной области техники для вычисления энтропии Шеннона, представляют собой Strait & Dewey, 1996 и Shannon 1996. Для полипептида энтропия Шеннона (SE) может быть рассчитана как SE=(-Σ pc(aai)=log(pc(aai))) / N, где рс(ааi) представляет собой частоту встречаемости аминокислоты i в полипептиде, и сумму вычисляют по всем 20 различным аминокислотам, а N представляет собой длину полипептида.
Термин «экспрессионная кассета» в контексте настоящего изобретения означает молекулу нуклеиновой кислоты, которая содержит по меньшей мере одну последовательность нуклеиновой кислоты, которая подлежит экспрессии, например, нуклеиновой кислоты, кодирующей выбранные неоантигены согласно настоящему изобретению или их часть, функционально связанную с контрольными последовательностями транскрипции и трансляции. Предпочтительно экспрессионная кассета включает цис-регуляторные элементы для эффективной экспрессии данного гена, такие как промотор, сайт инициации и/или сайт полиаденилирования. Предпочтительно экспрессионная кассета содержит все дополнительные элементы, необходимые для экспрессии нуклеиновой кислоты в клетке пациента. Таким образом, типичная экспрессионная кассета содержит промотор, функционально связанный с экспрессируемой последовательностью нуклеиновой кислоты, и сигналы, необходимые для эффективного полиаденилирования транскрипта, сайты связывания рибосомы и терминацию трансляции. Дополнительные элементы кассеты могут включать, например, энхансеры. Экспрессионная кассета также предпочтительно содержит область терминации транскрипции ниже по ходу транскрипции от структурного гена для обеспечения эффективной терминации. Терминаторная область может быть получена из того же гена, что и промоторная последовательность, или может быть получена из другого гена.
Значение «IC50» относится к половине максимальной ингибирующей концентрации вещества и, таким образом, является мерой эффективности вещества при ингибировании конкретной биологической или биохимической функции. Значения обычно выражаются в виде молярной концентрации. IC50 молекулы может быть определена экспериментально в функциональных антагонистических анализах путем построения кривой зависимости ответа от дозы и изучения ингибирующего действия исследуемой молекулы при различных концентрациях. В качестве альтернативы могут быть выполнены анализы конкурентного связывания для определения значения IC50. Как правило, фрагменты неоантигена согласно настоящему изобретению демонстрируют значение IC50 от 1500 нМ до 1 пМ, более предпочтительно от 1000 нМ до 10 пМ и даже более предпочтительно от 500 нМ до 100 пМ.
Термин «массивно-параллельное секвенирование» относится к высокопроизводительным способам секвенирования нуклеиновых кислот. Массивно-параллельное секвенирование также называют секвенированием следующего поколения (NGS) или секвенированием второго поколения. В данной области техники известно много различных массивно-параллельных секвенирований, которые различаются по устанавливаемым параметрам и используемой химии. Однако все эти способы объединяет то, что они выполняют очень большое количество реакций секвенирования параллельным образом с увеличением скорости секвенирования.
Термин «Транскриптов на килобазу на миллион» (ТРМ) относится к ген-центрированной метрике, используемой при массивно-параллельном секвенирований образцов РНК, которая нормализует глубину секвенирования и длину гена. Ее вычисляют путем деления числа прочтений на длину каждого гена в тысячах пар нуклеотидов, в результате чего получают число прочтений на тысячу пар нуклеотидов (RPK). Деление количества всех значений RPK в образце на 1000000 приводит к коэффициенту масштабирования на миллион. Деление значений RPK на «коэффициент масштабирования на миллион» приводит к ТРМ для каждого гена.
Общий уровень экспрессии гена, несущего мутацию, выражается как ТРМ. Предпочтительно, «мутация-специфические» значения экспрессии (corrТРМ) затем определяют по числу мутантных и немутантных прочтений в положении мутации.
Скорректированное значение экспрессии corrТРМ вычисляют как corrТРМ=ТРМ * (М+с) / (М+W+с). М представляет собой число прочтений, охватывающих положение мутации, приводящей к неоантигену, a W представляет собой число прочтений без мутации, охватывающих положении мутации, приводящей к неоантигенам. Значение с является константой больше 0, предпочтительно 0,1. Значение с особенно важно, если М и/или W равны 0.
Варианты осуществления
Далее различные аспекты настоящего изобретения определены более подробно. Каждый аспект, определенный таким образом, может быть объединен с любым другим аспектом или аспектами, если ясно не указано иное. В частности, любой признак, указанный как предпочтительный или преимущественный, может быть определен с любым другим признаком или признаками, указанными как предпочтительные или преимущественные.
Согласно первому аспекту настоящее изобретение относится к способу выбора опухолевых неоантигенов для применения в персонализированной вакцине, предусматривающему стадии:
(а) определения неоантигенов в образце раковых клеток, взятом у индивидуума, где каждый неоантиген
- содержится в кодирующей последовательности,
- содержит по меньшей мере одну мутацию в кодирующей последовательности, приводящую к изменению кодируемой аминокислотной последовательности, которое не присутствует в образце нераковых клеток указанного индивидуума, и
- состоит из от 9 до 40, предпочтительно от 19 до 31, более предпочтительно от 23 до 25, наиболее предпочтительно 25 смежных аминокислот кодирующей последовательности в образце раковых клеток,
(b) определения для каждого неоантигена частоты мутантных аллелей каждой из указанных мутаций согласно стадии (а) в кодирующей последовательности,
(c) определения уровня экспрессии каждой кодирующей последовательности, содержащей по меньшей мере одну из указанных мутаций,
(i) в указанном образце раковых клеток или
(ii) на основании базы данных экспрессии рака того же типа, что и образец раковых клеток,
(d) предсказания аффинности связывания неоантигенов с МНС класса I, где
(I) аллели HLA класса I определяют в образце нераковых клеток указанного индивидуума,
(II) для каждого аллеля HLA класса I, определенного на стадии (I), предсказывают аффинность связывания с МНС класса I для каждого фрагмента, состоящего из от 8 до 15, предпочтительно от 9 до 10, более предпочтительно 9, смежных аминокислот неоантигена, где каждый фрагмент содержит по меньшей мере одно аминокислотное изменение, вызванное мутацией согласно стадии (а), и
(III) фрагмент с наивысшей аффинностью связывания с МНС класса I определяет аффинность связывания неоантигена с МНС класса I,
(e) ранжирования неоантигенов в соответствии с значениями, определенными на стадиях (b) - (d) для каждого неоантигена, от самого большого до самого маленького значения, с обеспечением первого, второго и третьего перечня рангов,
(f) вычисления ранговой суммы на основании первого, второго и третьего перечня рангов и распределения неоантигенов по увеличению ранговой суммы с получением ранжированного перечня неоантигенов,
(g) выбора 30-240, предпочтительно 40-80, более предпочтительно 60, неоантигенов из ранжированного перечня неоантигенов, полученного на стадии (f), начиная с самого низкого ранга.
Многие опухолевые неоантигены не «видны» иммунной системе, либо так как потенциальные эпитопы не процессируются/презентуются опухолевыми клетками, либо так как иммунная толерантность приводит к устранению Т-клеток, реагирующих с мутантной последовательностью. Следовательно, среди всех потенциальных неоантигенов целесообразно выбирать те, которые имеют наибольший шанс быть иммуногенными. В идеале неоантиген должен быть презентирован в большом числе раковых клеток, экспрессируясь в достаточных количествах и эффективно презентируясь иммунным клеткам.
Посредством выбора неоантигенов, содержащих специфические раковые мутации, которые имеют определенную частоту мутантных аллелей, обильно экспрессируются и, как предсказано, обладают высокой аффинностью связывания с молекулами МНС, вероятность индуцирования иммунного ответа значительно увеличивается. Авторы настоящего изобретения неожиданно обнаружили, что эти параметры могут быть наиболее эффективно использованы для выбора подходящих неоантигенов, вызывающих повышенный иммунный ответ, с использованием способа приоритизации, который учитывает различные параметры. Важно отметить, что в способе согласно настоящему изобретению также учитываются неоантигены, в которых частота аллелей, уровень экспрессии или предсказанная аффинность связывания с МНС не относятся к наивысшим среди наблюдаемых. Например, неоантиген с высоким уровнем экспрессии и высокой частотой мутантных аллелей, но относительно низкой предсказанной аффинностью связывания с МНС, все же может быть включен в перечень выбранных неоантигенов.
Следовательно, в способе согласно настоящему изобретению не используются критерии исключения, обычно используемые в способах выбора, но учитывается, что неоантигены с очень высокой предсказанной пригодностью по одному параметру просто не исключают из перечня из-за субоптимальной пригодности по другим параметрам. Это особенно актуально для неоантигенов, параметры которых лишь незначительно не удовлетворяют определенным критериям исключения.
Любая мутация в кодирующей последовательности (т.е. геномной последовательности нуклеиновой кислоты, которая транскрибируется и транслируется), которая присутствует только в раковых клетках индивидуума, но не в здоровых клетках того же индивидуума, потенциально представляет интерес как иммуногенные (т.е. способные индуцировать иммунный ответ) неоантигены. Мутация кодирующей последовательности также должна приводить к изменениям транслируемой аминокислотной последовательности, т.е. молчащая мутация, присутствующая только на уровне нуклеиновой кислоты, и поэтому не приводящая к изменению аминокислотной последовательности, не является подходящей. Существенным является то, что мутация, независимо от точного типа мутации (замена отдельных нуклеотидов, вставка или делеция одного или нескольких нуклеотидов и т.д.), приводит к измененным аминокислотным последовательностям транслированного белка. Каждая аминокислота, присутствующая только в измененной аминокислотной последовательности, но не в аминокислотной последовательности, полученной из кодирующего гена, присутствующего в нераковых клетках, рассматривается как мутантная аминокислота в контексте настоящего описания. Например, мутации кодирующей последовательности, такие как мутации вставки или делеции, приводящие к пептидам со сдвигом рамки считывания, будут приводить к пептиду, в котором каждая аминокислота, кодируемая сдвинутой рамкой считывания, должна рассматриваться как мутантная аминокислота.
Мутация кодирующей последовательности на самом деле может быть идентифицирована любым способом секвенирования ДНК образца, взятого у индивидуума. Предпочтительным способом получения последовательности ДНК, необходимой для идентификации мутации в кодирующей последовательности индивидуума, является способ массивно-параллельного секвенирования.
Частота аллелей мутации (т.е. соотношение немутантных и мутантных последовательностей в положении мутации) в кодирующей последовательности также является важным фактором для использования неоантигенов в вакцине. Неоантигены с высокой частотой аллелей присутствуют в значительном количестве раковых клеток, в следствие чего неоантигены, содержащие эти мутации, являются перспективной мишенью вакцины.
Подобным образом, важно, насколько изобильно неоантиген экспрессируется в раковых клетках. Чем выше экспрессия неоантигена в раковых клетках, тем более подходящим является неоантиген и тем выше вероятность достаточного иммунного ответа против таких клеток. Настоящее изобретение может быть реализовано с различными способами оценки уровней экспрессии неоантигенов. Экспрессию неоантигенов можно оценить непосредственно в образце раковых клеток. Экспрессию можно оценить различными способами, которые предпочтительно измеряют весь транскриптом, такие различные способы известны специалисту в данной области техники. Предпочтительно используют способ, обеспечивающий быстрый, надежный и экономичный способ измерения транскриптома. Одним из таких предпочтительных способов является массивно-параллельное секвенирование.
В качестве альтернативы, если прямое измерение не доступно, например, по техническим или экономическим причинам, можно использовать базы данных экспрессии. Специалисту в данной области техники известны доступные базы данных экспрессии, содержащие данные об экспрессии генов различных типов рака. Типичным неограничивающим примером такой базы данных является TCGA (https://portal.gdc.cancer.gov/). Экспрессию генов, содержащих мутацию, идентифицированную на стадии (а) способа, в опухоли того же типа, что и у индивидуума, для которого предназначена вакцина, можно искать в этих базах данных и использовать для определения значения экспрессии.
Кроме того, важно, чтобы выбранные неоантигены были эффективно представлены иммунным клеткам молекулами МНС на раковых клетках. В данной области техники известны различные способы предсказания аффинности связывания пептидов с молекулами МНС класса I (и класса II) (Moutaftsi et al., 2006, Lundegaard et al., 2008, Hoof et al., 2009, Andreatta & Nielsen, 2016, Jurtz et al., 2017). Поскольку молекулы МНС представляют собой высокополиморфную группу белков со значительными различиями между индивидуумами, важно определить аффинность связывания с МНС для типа молекул МНС, презентированных на клетках индивидуума. Молекулы МНС кодируются группой высокополиморфных генов HLA. Таким образом, в этом способе используют результаты секвенирования ДНК, использованные на стадии (а) для идентификации мутаций в кодирующих последовательностях, с идентификацией аллелей HLA, присутствующих у индивиддума. Для каждой молекулы МНС, соответствующей идентифицированным аллелям HLA у индивидуума, определяют аффинность связывания МНС с неоантигенами. Для этого аминокислотную последовательность неоантигена определяют посредством in silico трансляции кодирующей последовательности. Полученную в результате аминокислотную последовательность неоантигена затем разделяют на фрагменты, состоящие из 8-15, предпочтительно 9-10, более предпочтительно 9 смежных аминокислот, где фрагмент должен содержать по меньшей мере одну из мутантных аминокислот неоантигена. Размер фрагмента ограничен размером пептидов, которые может презентировать молекула МНС.Для каждого фрагмента предсказывают аффинность связывания с МНС.Аффинность связывания с МНС обычно измеряют как половину максимальной ингибирующей концентрации (IC50 в [нМ]). Следовательно, чем ниже значение IC50, тем выше аффинность связывания пептида с молекулой МНС.Фрагмент с наивысшей аффинностью связывания с МНС определяет аффинность связывания с МНС неоантигена, из которого получен фрагмент.
Затем в способе согласно настоящему изобретению используются параметры, определенные на стадиях (b) - (d), т.е. частоту мутантных аллелей, уровень экспрессии и предсказанную аффинность связывания неоантигена с МНС класса I, чтобы выбрать наиболее подходящие неоантигены посредством применения способа приоритизации для этих параметров. Поэтому параметры распределяют в ранжированный перечень. Неоантиген с наивысшей частотой мутантных аллелей получает первый ранг, т.е. ранг 1 в первом перечне рангов. Неоантигену со второй по величине частотой мутантных аллелей присваивают второй ранг в первом перечне рангов и т.д., до тех пор, пока всем идентифицированным неоантигенам не будет присвоен ранг в первом перечне рангов.
Подобным образом уровень экспрессии каждой кодирующей последовательности ранжируют от наивысшего к низшему, причем неоантигену с самым высоким значением экспрессии присваивают ранг 1, неоантигену со вторым по величине уровнем присваивают ранг 2 и т.д., до тех пор, пока всем идентифицированным неоантигенам не будет присвоен ранг во втором перечне рангов.
Аффинность связывания неоантигенов с МНС класса I ранжируют от самой высокой к самой маленькой аффинности связывания неоантигена, где самой высокой аффинности связывания с МНС класса I присваивают ранг 1, неоантигену со второй по величине аффинностью связывания присваивают ранг 2 и т.д., до тех пор, пока всем неоантигенам не будет присвоен ранг в третьем перечне рангов.
Если какой-либо из неоантигенов имеет такую же частоту мутантных аллелей, уровень экспрессии и/или аффинность связывания с МНС класса I, что и другой неоантиген, обоим антигенам присваивают один и тот же ранг в соответствующем перечне рангов.
Затем в способе используют способ приоритизации, который учитывает все три ранжирования путем вычислений ранговой суммы трех перечней рангов. Например, неоантиген, который имеет ранг 3 в первом перечне рангов, ранг 13 во втором перечне рангов и ранг 2 в третьем перечне рангов, имеет ранговую сумму 18 (3+13+2). После того, как ранговая сумма была вычислена для каждого неоантигена, ранговые суммы ранжируют в соответствии с их ранговой суммой, причем самой низкой ранговой сумме присваивают ранг 1 и т.д., получая ранжированный перечень неоантигенов. Неоантигены с одинаковой ранговой суммой получают одинаковые ранги в ранжированном перечне неоантигенов.
Окончательное число неоантигенов, присутствующих в перечне, зависит от количества мутаций, обнаруженных у каждого пациента. Число неоантигенов, используемых в вакцине, ограничено средством доставки или средствами доставки, используемыми для доставки вакцины. Например, если в качестве средства доставки используют один вирусный вектор, как это может быть в случае генной вакцины, максимальный размер вставки этого вектора будет ограничивать число неоантигенов, которые могут использоваться в каждом векторе.
Поэтому, согласно способу согласно настоящему изобретению выбирают 25-250, 30-240, 30-150, 35-80, предпочтительно 55-65, более предпочтительно 60 неоантигенов из перечня ранжированных неоантигенов, начиная с неоантигена, имеющего самый низкий ранг (т.е. самый низкий ранговый номер, ранг 1). В случае, если неоантигены выбраны для присутствия в одном наборе (например, одно средство доставки одновалентной вакцины), выбирают 25-80, 30-70, 35-70, 40-70, 55-65, предпочтительно 60 неоантигенов. Однако неоантигены, не включенные в первый набор, могут кодироваться дополнительными вирусными векторами для поливалентной вакцинации, основанной на совместном введении до 4 вирусных векторов.
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения стадии (а) и (d)(I) проводят с применением массивно-параллельного секвенирования ДНК образцов.
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения стадии (а) и (d)(I) проводят с применением массивно-параллельного секвенирования ДНК образцов, и число прочтений в хромосомном положении идентифицированной мутации составляет:
- в образце раковых клеток по меньшей мере 2, предпочтительно по меньшей мере 3, 4, 5 или 6,
- в образце нераковых клеток составляет 2 или менее, т.е. 2, 1 или 0, предпочтительно 0.
Согласно предпочтительному альтернативному варианту осуществления первого аспекта настоящего изобретен число прочтений в хромосомном положении идентифицированной мутации является более высоким в образце раковых клеток, чем в образце нераковых клеток, где различие между образцами является статистически значимым. Статистически значимая разница между двумя группами может быть определена с помощью ряда статистических тестов, известных специалисту в данной области техники. Одним из таких примеров подходящего статистического теста является точный тест Фишера. Согласно настоящему изобретению две группы рассматриваются отличными друг от друга, если значение р ниже 0,05.
Эти критерии применяют для дальнейшего выбора неоантигенов, в которых идентифицированная мутация обнаруживается с особенно высокой технической надежностью.
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения способ предусматривает стадию (d') в дополнение к стадии (d) или в качестве альтернативы ей, где стадия (d') содержит:
• определение аллелей HLA класса II в образце нераковых клеток указанного индивидуума,
• предсказание аффинности связывания неоантигена с МНС класса II, где
- для каждого определенного аллеля HLA класса II предсказывают аффинность связывания с МНС класса II для каждого фрагмента из от 11 до 30, предпочтительно 15, смежных аминокислот неоантигена, где каждый фрагмент содержит по меньшей мере одну мутантную аминокислоту, полученную посредством мутации согласно стадии (а), и
- фрагмент с самой высокой аффинностью связывания с МНС класса II определяет аффинность связывания неоантигена с МНС класса II,
где аффинность связывания с МНС класса II ранжируют от самой высокой до самой низкой аффинности связывания с МНС класса II с получением четвертого перечня рангов, который включают в ранговую сумму на стадии (f).
Согласно этому варианту осуществления добавлен альтернативный или дополнительный параметр выбора. Аффинность связывания с МНС класса II предсказывают в немного более крупных фрагментах из-за того, что пептиды, презентируемые молекулами МНС класса II, больше по размеру, чем пептиды МНС класса I. Аффинность связывания с МНС класса II также ранжируют от самой высокой к самой низкой аффинности связывания, причем неоантигену с наивысшей аффинностью связывания с МНС класса II присваивают ранг 1 и т.д., до тех пор, пока всем неоантигенам не будет присвоен ранг в четвертом перечне рангов.
В случае использования аффинности связывания с МНС класса II в качестве дополнительного параметра выбора, четвертый перечень дополнительно включают в вычисление ранговой суммы. В случае, если аффинность связывания с МНС класса II используют в качестве альтернативы аффинности связывания с МНС класса I на стадии (d), ранговую сумму на стадии (f) вычисляют только по первому, второму и четвертому перечням рангов.
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения по меньшей мере одна мутация на стадии (а) представляет собой однонуклеотидный вариант (SNV) или инсерционную/делеционную мутацию, приводящую к пептиду со сдвигом рамки считывания (FSP).
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения, в котором мутацией является SNV, и неоантиген имеет общий размер, определенный на стадии (а), и состоит из аминокислоты, вызванной мутацией, фланкированной с каждой стороны рядом соседних смежных аминокислот, причем число на каждой стороне не отличается более чем на одну, кроме тех случаев, когда кодирующая последовательность не содержит достаточного количества аминокислот на каждой стороне, где неоантиген имеет общий размер, определенный на стадии (а). Предпочтительно мутантная аминокислота, полученная в результате SNV, расположена внутри «среднего» неоантигена (т.е. фланкируется равным числом аминокислот). Это обеспечивает равные шансы присутствия мутации в конце или начале эпитопа. Таким образом, выбирают неоантиген с приблизительно равным (т.е. отличаются не более чем на одну) числом окружающих аминокислот, полученных из кодирующей последовательности, на каждой стороне мутантной аминокислоты.
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения мутация приводит к FSP, и каждое одно аминокислотное изменение, вызванное мутацией, приводит к неоантигену, который имеет общий размер, определенный на стадии (а), и состоит из:
(i) указанного одного аминокислотного изменения, вызванного мутацией, и от 7 до 14, предпочтительно 8 N-концевых соседних смежных аминокислот, и
(ii) числа смежных аминокислот, примыкающих к фрагменту согласно стадии (i) с каждой стороны, причем число аминокислот с каждой стороны отличается не более чем на одну, кроме тех случаев, когда кодирующая последовательность не содержит достаточного количества аминокислот на каждой стороне,
где аффинность связывания с МНС класса I на стадии (d) и/или аффинность связывания с МНС класса II на стадии (d') предсказывают для фрагмента согласно стадии (i).
Каждая мутантная аминокислота FSP определяет один отдельный неоантиген. Каждый неоантиген состоит из мутантной аминокислоты и ряда аминокислот, которые на одну аминокислоту короче, чем размер фрагмента, используемого для определения аффинности связывания с МНС класса I (т.е. 7-14), которые расположены на N-конце мутантной аминокислоты. Неоантиген, кроме того, состоит из ряда смежных аминокислот, происходящих из кодирующей последовательности, которые образуют с последовательностью фрагмента неоантигена стадии (i) непрерывную последовательность в кодирующей последовательности. Число аминокислот, окружающих фрагмент неоантигена стадии (i) с обеих сторон, отличается только на одну, при этом общий размер неоантигена такой же, как определено на стадии (а). Фрагмент неоантигена стадии (i) используют для определения аффинности связывания с МНС класса I и/или класса II.
Например, мутантная аминокислота в относительном положении 20 транслируемой кодирующей последовательности будет определять фрагмент неоантигена, включающий непрерывную аминокислотную последовательность из 8 смежных аминокислот (т.е. фрагмент стадии (i)) в диапазоне от положения 12 до 20. Полная последовательность неоантигена из 25 аминокислот согласно стадии (ii) будет состоять из аминокислот 4-28. Фрагмент неоантигена в диапазоне от положения 12 до 20, состоящий из 9 аминокислот, будет использовать для определения аффинности связывания с МНС.
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения частота мутантных аллелей неоантигена, определенная на стадии (b) в образце раковых клеток, составляет по меньшей мере 2%, предпочтительно по меньшей мере 5%, более предпочтительно по меньшей мере 10%.
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения стадия (g) дополнительно содержит удаление из ранжированного перечня неоантигенов неоантигены из генов, связанных с аутоиммунным заболеванием. Специалисту в данной области техники известны неоантигены, связанные с аутоиммунными заболеваниями, из общедоступных баз данных. Одним из примеров таких баз данных является база данных IEDB (www.iedb.org). Исключение неоантигена-кандидата может быть выполнено как на уровне гена, если ген, несущий мутацию, принадлежит к одному из тех генов, которые связаны с аутоиммунным заболеванием согласно базе данных IEDB, или, менее строгим образом, не только в том случае, если у пациента есть мутация в гене, о котором известно, что он вовлечен в аутоиммунитет, но и когда один из аллелей МНС пациента также идентичен аллелю, описанному в базе данных IEDB для эпитопа аутоиммунного заболевания человека в связи с описанным аутоиммунным явлением.
Согласно предпочтительному варианту осуществления неоантигены, связанные с аутоиммунным заболеванием, не удаляют из ранжированного перечня неоантигенов, если в базе данных указан определенный аллель МНС класса I для этой взаимосвязи, и соответствующий аллель HLA не был обнаружен у индивидуума на стадии (d) (I).
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения на стадии (g) дополнительно удаляют из указанного ранжированного перечня неоантигенов неоантигены со значением энтропии Шеннона для их аминокислотной последовательности ниже 0,1.
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения уровень экспрессии указанных кодирующих генов на стадии (c)(i) определяют посредством массивно-параллельного секвенирования транскриптома.
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения уровень экспрессии, определенный на стадии (c)(i), использует скорректированное значение транскриптов на килобазу на миллион (corrТРМ), вычисленное согласно следующей формуле:
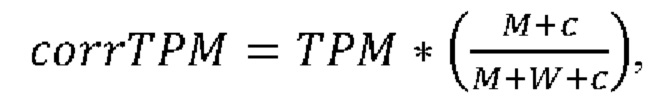
где М представляет собой число прочтений, охватывающих положение мутации согласно стадии (а), которые содержат мутацию, и W представляет собой число прочтений, охватывающих положение мутации согласно стадии (а), без мутации, и ТРМ представляет собой значение транскриптов на килобазу на миллион гена, содержащего мутацию, и с является константой больше 0, предпочтительно с равно 0,1.
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения ранговая сумма на стадии (f) представляет собой взвешенную ранговую сумму, где число неоантигенов, определенное на стадии (а), добавляют к значению ранга каждого неоантигена:
• в третьем перечне рангов, для которого предсказанная аффинность связывания с МНС класса I согласно стадии (d) привела к значению IC50 выше 1000 нМ и/или
• в четвертом перечне рангов, для которого предсказанная аффинность связывания с МНС класса II на стадии (d') привела к значению IC50 выше 1000 нМ.
Такое взвешивание аффинности связывания с МНС исключает очень низкую аффинность связывания с МНС класса I и/или класса II посредством добавления рангов.
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения ранговая сумма на стадии (f) представляет собой взвешенную ранговую сумму, причем, в случае выполнения стадии (с) (i) путем массивно-параллельного секвенирования транскриптома, ранговую сумма на стадии (f) умножают на фактор взвешивания (WF), где WF равен
• 1, если число картированных прочтений транскриптома для мутации равно >0,
• 2, если число картированных прочтений транскриптома для мутации равно 0, и число картированных прочтений немутантной последовательности равно 0, и значение транскриптов на миллион (ТРМ) равно по меньшей мере 0,5,
• 3, если число картированных прочтений транскриптома для мутации равно 0, и число картированных прочтений немутантной последовательности равно>0, и значение транскриптов на миллион (ТРМ) равно по меньшей мере 0,5,
• 4, если число картированных прочтений транскриптома для мутации равно 0, и число картированных прочтений немутантной последовательности равно 0, и значение транскриптов на миллион (ТРМ) равно <0,5, или
• 5, если число картированных прочтений транскриптома для мутации равно 0, и число картированных прочтений немутантной последовательности равно >0, и значение транскриптов на миллион (ТРМ) равно <0,5.
Матрица взвешивания исключает определенные неоантигены, для которых результаты секвенирования имеют плохое качество (т.е. число картированных прочтений является низким), и/или значение экспрессии (т.е. значение ТРМ) ниже определенного порога. Этот режим взвешивания (т.е. приоритизации) определенных параметров обеспечивает неоантигены с лучшей иммуногенностью, чем использование пороговых значений для отдельных параметров, что устраняет определенные неоантигены из-за низкой пригодности по одному параметру, даже если другой параметр квалифицирует неоантиген как подходящий.
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения стадия (g) содержит альтернативный способ выбора, где неоантигены выбирают из ранжированного перечня неоантигенов начиная с самого низкого ранга, до тех пор, пока не будет достигнут установленный максимальный размер в общей полной длине в аминокислотах для всех выбранных неоантигенов, где максимальный размер составляет от 1200 до 1800, предпочтительно 1500 аминокислот для каждого вектора. Способ можно повторить в случае поливалентной вакцинации, где максимальный размер, указанный выше, применяется для каждого средства доставки, используемого в поливалентном подходе. Например, поливалентный подход, основанный на 4 векторах, может, например, позволить общий предел, составляющий 6000 аминокислот.В этом варианте осуществления учитывается максимальный размер неоантигенов, разрешенный определенным рассматриваемым средством доставки. Следовательно, число неоантигенов, выбранных из ранжированного перечня, не определяется числом неоантигенов, а учитывается размер неоантигенов. Число небольших неоантигенов в ранжированном перечне антигенов позволит включить больше антигенов в перечень выбранных антигенов.
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения два или несколько неоантигенов сливают в один новый неоантиген, если они содержат перекрывающиеся сегменты аминокислотных последовательностей. В некоторых случаях неоантигены могут содержать перекрывающиеся аминокислотные последовательности. Особенно часто это происходит с неоантигенами, происходящими из FSP. Чтобы избежать избыточных перекрывающихся последовательностей, неоантигены сливают в один новый неоантиген, который состоит из неизбыточных частей слитых неоантигенов. Слитый новый неоантиген может иметь размер больше, чем определено на стадии (а) первого аспекта настоящего изобретения, в зависимости от числа слитых неоантигенов и степени перекрытия.
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения персонализированная вакцина представляет собой персонализированную генную вакцину. Термин «генная вакцина» используется как синоним термину «ДНК-вакцина» и относится к использованию генетической информации в качестве вакцины, когда клетки вакцинированного субъекта продуцируют антиген, против которого направлена вакцинация.
Согласно предпочтительному варианту осуществления первого аспекта настоящего изобретения персонализированная вакцина представляет собой персонализированную противораковую вакцину.
Согласно второму аспекту настоящее изобретение относится к способу конструирования персонализированного вектора, кодирующего комбинацию неоантигенов согласно первому аспекту настоящего изобретения, для применения в виде вакцины, предусматривающему стадии:
(i) распределения перечня неоантигенов в по меньшей мере 10^5-10^8, предпочтительно 10^6 различные комбинации,
(ii) создания всех возможных пар сегментов соединения неоантигенов для каждой комбинации, где каждый сегмент соединения содержит 15 соседних смежных аминокислот с каждой стороны соединения,
(iii) предсказания аффинности связывания с МНС класса I и/или класса II для всех эпитопов в сегментах соединения, где тестируют только HLA аллели, которые присутствуют у индивидуума, для которого конструируют вектор, и
(iv) выбора комбинации неоантигенов с наименьшим числом соединенных эпитопов с IC50, равной ≤1500нМ, и где, если множество комбинаций имеют одно и то же наименьшее число соединенных эпитопов, выбирают первую встречающуюся комбинацию.
Перечень выбранных неоантигенов согласно первому аспекту настоящего изобретения может быть объединен в один объединенный неоантиген. Сегменты соединения, в которых соединяются отдельные неоантигены, могут приводить к новым эпитопам, которые могут приводить к нежелательным ненаправленным действиям, не связанным с эпитопами, присутствующими на раковых клетках. Следовательно, желательно, чтобы эпитопы, созданные соединением отдельных неоантигенов, имели низкую иммуногенность. С этой целью неоантигены располагают в различных порядках, что приводит к разным соединенным эпитопам, и предсказывают аффинность связывания с МНС класса I и класса II этих соединенных эпитопов. Выбирают комбинацию с наименьшим числом соединенных эпитопов со значением IC50 ≤1500нМ. Число комбинаций выбранных неоантигенов ограничено в первую очередь доступной вычислительной мощностью. Компромисс между используемыми вычислительными ресурсами и необходимой точностью заключается в том, что используются 10^5-10^8, предпочтительно 10^6 различных комбинаций неоантигенов, где предсказывают аффинность связывания с МНС класса I и/или класса II соединенных эпитопов каждого сегмента соединения неоантигена.
Согласно альтернативному второму аспекту настоящее изобретение относится к способу конструирования персонализированного вектора, кодирующего комбинацию неоантигенов, для применения в виде вакцины, предусматривающему стадии:
(i) распределения перечня неоантигенов в по меньшей мере 10^5-10^8, предпочтительно 10^6 различные комбинации,
(ii) создания всех возможных пар сегментов соединения неоантигенов для каждой комбинации, где каждый сегмент соединения содержит 15 соседних смежных аминокислот с каждой стороны соединения,
(iii) предсказания аффинности связывания с МНС класса I и/или класса II для всех эпитопов сегментов соединения, где тестируют только HLA аллели, которые присутствуют у индивидуума, для которого конструируют вектор, и
(iv) выбора комбинации неоантигенов с наименьшим числом соединенных эпитопов с IC50, равной ≤1500нМ, и где, если множество комбинаций имеют одно и то же наименьшее число соединенных эпитопов, выбирают первую встречающуюся комбинацию.
Перечень неоантигенов можно расположить в единый комбинированный неоантиген. Сегменты соединения, в которых соединяются отдельные неоантигены, могут приводить к новым эпитопам, которые могут приводить к нежелательным ненаправленным действиям, не связанным с эпитопами, присутствующими на раковых клетках. Следовательно, желательно, чтобы эпитопы, созданные соединением отдельных неоантигенов, имели низкую иммуногенность. С этой целью неоантигены располагают в разных порядках, что приводит к разным соединенным эпитопам, и предсказывают аффинность связывания МНС класса I и класса II этих соединенных эпитопов. Выбирают комбинация с наименьшим числом соединенных эпитопов со значением IC50 ≤1500нМ. Количество комбинаций выбранных неоантигенов ограничено в первую очередь доступной вычислительной мощностью. Компромисс между используемыми вычислительными ресурсами и необходимой точностью заключается в том, что используются 10^5-10^8, предпочтительно 10^6 различных комбинаций неоантигенов, где предсказывают аффинность связывания с МНС класса I и/или класса II соединенных эпитопов каждого сегмента соединения неоантигена.
Согласно третьему аспекту настоящее изобретение относится к вектору, кодирующему перечень неоантигенов согласно первому аспекту настоящего изобретения, или комбинацию неоантигенов согласно второму аспекту настоящего изобретения.
Предпочтительно вектор содержит один или несколько элементов, усиливающих иммуногенность экспрессионного вектора. Предпочтительно такие элементы экспрессируются в виде слияния с полипептидом неоантигенов или комбинации неоантигенов или кодируются другой нуклеиновой кислотой, содержащейся в векторе, предпочтительно в экспрессионной кассете.
Согласно предпочтительному варианту осуществления третьего аспекта настоящего изобретения вектор дополнительно содержит энхансерный элемент Т-клеток, предпочтительно (SEQ ID NO: 173 - 182), более предпочтительно SEQ ID NO: 175, который слит с N-концом первого неоантигена в перечне.
Вектор согласно третьему аспекту или коллекция векторов согласно четвертому аспекту, где вектор в каждом случае независимо выбран из группы, состоящей из плазмиды, космиды, липосомальной частицы, вирусного вектора или вирусоподобной частицы, в частности, альфавирусного вектора, вектора на основе вируса венесуэльского энцефалита лошадей (VEE), вектора на основе вируса Синдбис (SIN), вектора на основе вируса леса Семлики (SFV), вектора на основе обезьяньего или человеческого цитомегаловируса (CMV), вектора на основе вируса лимфоцитарного хориоменингита (LCMV), ретровирусного вектора, лентивирусного вектора, аденовирусного вектора, аденоассоциированного вирусного вектора, поксвирусного вектора, вектора на основе вируса осповакцины или вектора на основе модифицированного вируса осповакцины Анкара (MVA). Предпочтительна коллекция векторов, в которой каждый член коллекции содержит полинуклеотид, кодирующий различный антиген или его фрагменты, и которая, таким образом, обычно вводится одновременно, используя один и тот же тип вектора, например, вектор, полученный из аденовируса.
Наиболее предпочтительными экспрессионными векторами являются аденовирусные векторы, в частности аденовирусные векторы, происходящие из человека или не относящихся к человеку человекообразных обезьян. Предпочтительными человекообразными обезьянами, из которых происходят аденовирусы, являются шимпанзе (Pan), горилла (Gorilla) и орангутаны (Pongo), предпочтительно бонобо (Pan paniscu) и обыкновенный шимпанзе (Pan troglodytes). Обычно встречающиеся в природе аденовирусы не относящихся к человеку человекообразных обезьян выделяют из образцов кала соответствующей обезьяны. Наиболее предпочтительными векторами являются нереплицирующиеся аденовирусные векторы на основе hAd5, hAd11, hAd26, hAd35, hAd49, ChAd3, ChAd4, ChAd5, ChAd6, ChAd7, ChAd8, ChAd9, ChAd10, ChAd11, ChAd16, ChAd17, ChAd19, ChAd20, ChAd22, ChAd24, ChAd26, ChAd30, ChAd31, ChAd37, ChAd38, ChAd44, ChAd55, ChAd63, ChAd73, ChAd82, ChAd83, ChAd146, ChAd147, PanAd1, PanAd2 и PanAd3 или репликационно-компетентные векторы на основе Ad4 и Ad7. Аденовирусы человека hAd4, hAd5, hAd7, hAd11, hAd26, hAd35 и hAd49 хорошо известны в данной области техники. Векторы на основе встречающихся в природе ChAd3, ChAd4, ChAd5, ChAd6, ChAd7, ChAd8, ChAd9, ChAd10, ChAd11, ChAd16, ChAd17, ChAd19, ChAd20, ChAd22, ChAd24, ChAd26, ChAd30, ChAd31, ChAd37, ChAd38, ChAd44, ChAd63 и ChAd82 подробно описаны в WO 2005/071093. Векторы на основе встречающихся в природе PanAd1, PanAd2, PanAd3, ChAd55, ChAd73, ChAd83, ChAd146 и ChAd147 подробно описаны в WO 2010/086189.
Согласно предпочтительному варианту осуществления третьего аспекта настоящего изобретения вектор содержит две независимые экспрессионные кассеты, где каждая экспрессионная кассета кодирует часть перечня неоантигенов согласно первому аспекту настоящего изобретения или комбинацию неоантигенов согласно второму аспекту настоящего изобретения. Предпочтительно, части перечня, кодируемые экспрессионными кассетами, имеют приблизительно равный размер по числу аминокислот.
Согласно предпочтительному варианту осуществления третьего аспекта настоящего изобретения вектор содержит экспрессионную кассету, кодирующую выбранные неоантигены ранжированного перечня неоантигенов согласно первому аспекту настоящего изобретения, где перечень выбранных неоантигенов разделяют на две части приблизительно равной длины, где две части разделяют посредством элемента внутреннего участка посадки рибосомы (IRES) или вирусной области 2А (Luke et al., 2008), например вирусной областью 2А афтовируса афтозной лихорадки (SEQ ID NO: 184 APVKQTLNFDLLKLAGDVESNPGP), которая опосредует процессинг полибелка посредством трансляционного эффекта, известного как рибосомный проскок (Donnelly et al., J. Gen. Virology 2001). Необязательно в каждой из двух частей энхансерный элемент Т-клетки, предпочтительно (SEQ ID NO: 173-182), более предпочтительно SEQ ID NO: 175, слит с N-концом первого неоантигена в перечне.
Согласно четвертому аспекту настоящее изобретение относится к коллекции векторов, кодирующей каждую часть перечня неоантигенов согласно первому аспекту настоящего изобретения, или комбинацию неоантигенов согласно второму аспекту настоящего изобретения, где коллекция содержит 2-4, предпочтительно 2 вектора, и где векторные вставки, кодирующие часть перечня, предпочтительно имеют приблизительно равный размер по числу аминокислот.
Согласно пятому аспекту настоящее изобретение относится к вектору согласно третьему аспекту настоящего изобретения или коллекции векторов согласно четвертому аспекту настоящего изобретения для применения в вакцинации против рака.
Вектор согласно третьему аспекту настоящего изобретения или коллекция векторов согласно четвертому аспекту настоящего изобретения для применения в вакцинации против рака, где рак выбран из группы, состоящей из злокачественных новообразований губы, ротовой полости, глотки, органа пищеварительного тракта, органа дыхания, орган грудной полости, кости, суставного хряща, кожи, мезотелиальной ткани, мягкой ткани, груди, женских половых органов, мужских половых органов, мочевыводящего пути, головного мозга и других частей центральной нервной системы, щитовидной железы, эндокринной железы, лимфоидной ткани и кроветворной ткани.
Согласно предпочтительному варианту осуществления пятого аспекта настоящего изобретения режим вакцинации представляет собой гетерологичный режим примирования/стимулирования с использованием двух разных вирусных векторов. Предпочтительными комбинациями являются аденовирусный вектор, происходящий из человекообразных обезьян, для примирования, и поксвирусный вектор, вектор на основе вируса осповакцины или вектор на основе модифицированного вируса осповакцины Анкара (MVA) для стимулирования. Предпочтительно их вводят последовательно с интервалом по меньшей мере 1 неделя, предпочтительно 6 недель.
Примеры
В настоящем изобретении описан способ оценки раковых мутаций по их вероятности вызывать иммуногенные неоантигены. Этот подход анализирует данные секвенирования ДНК следующего поколения (NGS-ДНК), и необязательно данные секвенирования РНК следующего поколения (NGS-PHK) образца опухоли, и данные NGS-ДНК нормального образца, полученного у того же пациента, как описано ниже.
Персонализированный подход основан на данных NGS, полученных путем анализа образцов, взятых у пациента, страдающего раком. Для каждого пациента данные NGS-ДНК экзома для ДНК опухоли сравнивают с данными, полученными для нормальной ДНК, чтобы идентифицировать соматические мутации, надежно присутствующие в опухоли, но не в нормальном образце, которые вызывают изменения в аминокислотной последовательности белка.
Далее анализировали нормальная ДНК экзома для определения аллелей HLA класса I и класса II пациента. Данные NGS-PHK для образца опухоли, если они доступны, анализировали для определения экспрессии генов, несущих мутации.
Приведенные ниже примеры относятся к следующим аспектам настоящего изобретения:
Пример 1: Описание способа приоритизации
Пример 2: Применение способа приоритизации к раскрытому в литературе набору данных NGS
Пример 3: Валидация способа приоритизации
Валидацию способа приоритизации проводили путем измерения его эффективности относительно набора данных (опубликованные исследования), где описаны как данные NGS, так и иммуногенные неоантигены. В примере использовали способ приоритизации а и b. Этот пример показывает, что при выборе 60 лучших неоантигенов в вакцину включали очень большую часть известных иммуногенных неоантигенов, как при использовании способа а (с данными NGS-PHK пациента), так и при использовании способа b (без данных NGS-PHK пациента).
Пример 4: Оптимизация расположения неоантигена для синтетических генов, кодирующих неоантигены, доставляемые вектором генной вакцины.
Показали, что разделение 62 выбранных неоантигенов, полученных на модели мыши, на два синтетических гена (всего 31+31=62 неоантигена) приводит к улучшенной иммуногенности по сравнению с использованием одного синтетического гена, кодирующего 62 неоантигена.
Пример 1. Описание способа приоритизации
Стадия 1. Идентификация мутаций, которые создают неоантиген Мутации, определенные как надежно присутствующие в опухоли, в идеале, но не исключительно, соответствуют следующим критериям:
• частота мутантных аллелей (MF) в образце ДНК опухоли>=10%,
• соотношение MF между образцом ДНК опухоли и контрольным образцом ДНК>=5,
• число мутантных прочтений в хромосомном положении соматического варианта в ДНК опухоли>2,
• число мутантных прочтений в хромосомном положении соматического варианта в нормальной ДНК<2,
В способе согласно настоящему изобретению рассматриваются два типа соматических мутаций: однонуклеотидные варианты (SNV), приводящие к несинонимичной замене кодона с получением мутантной аминокислоты в белке, и инсерционные/делеционные (вставка/делеция) мутации, которые приводят к пептидам со сдвигом рамки считывания (FSP) путем изменения рамки считывания мРНК, кодирующей белок.
Стадия 2. Создание структуры каждого неоантигена Стадия 2.1
Для каждой мутации последовательность пептида неоантигена создавали следующим образом.
a) Однонуклеотидные варианты SNV
Создавали последовательность длиной 25 аминокислот с мутантной аминокислотой, расположенной в центре и фланкированной с обеих сторон предположительно А=12 немутантными аминокислотами (Фиг. 1). В случаях, когда мутация локализована близко к N-концу или С-концу белка, включали менее А=12 немутантных аминокислот.Минимальное количество из 8 немутантных аминокислот добавляли либо выше, либо ниже по ходу транскрипции от мутации. Это гарантировало, что неоантиген может содержать 9-ти мерный неоэпитоп с по меньшей мере 1 мутантной аминокислотой. Добавление, например, 4 немутантных аминокислот выше и 2 ниже по ходу транскрипции невозможно, так как соответствует очень короткому белку.
Иногда две (или даже больше) мутации, SNV и/или вставки/делеции, присутствуют на небольшом расстоянии (расстояние, меньшее или равное А аминокислот) в белке. В этих случаях сегмент А немутантных аминокислот, который добавлен на N-конце или С-конце, модифицировали таким образом, что дополнительная мутация (мутации) присутствует (присутствуют) (Фиг. 1).
Для каждого неоантигена затем выполняли предсказание 9-ти мерного эпитопа МНС класса I с использованием аллелей HLA пациента, идентифицированных из данных NGS-ДНК экзома. Затем значение IC50, связанное с неоантигеном, выбирали как значение с самым низким значением IC50 для всех предсказанных эпитопов, которые содержат по меньшей мере 1 мутантную аминокислоту, и для всех аллелей класса I пациента.
b) Пептиды со сдвигом рамки считывания (FSP)
Для FSP максимальное количество N=12 немутантных аминокислот добавляли на N-конце FSP (Фиг. 2А), если выше по ходу транскрипции от FSP присутствует менее 12 немутантных аминокислот, добавляли только их. В случае, если SNV, ведущий к мутантной аминокислоте, присутствует в добавленном немутантном сегменте, включали мутантную аминокислоту. Это создает расширенную пептидную последовательность FSP.
Полученную в результате расширенную пептидную последовательность FSP затем разделяли на фрагменты длиной 9 аминокислот, и выполняли предсказание 9-ти мерного эпитопа МНС класса I (с помощью аллелей HLA пациента) для всех фрагментов, содержащих по меньшей мере 1 мутантную аминокислоту. Затем значение IC50, связанное с каждым фрагментом, выбирали как наименьшее предсказанное значение IC50 для всех исследованных аллелей.
Каждый фрагмент из 9 аминокислот затем расширяли до последовательности неоантигена длиной 25 аминокислот путем добавления 8 расположенных выше и 8 расположенных ниже по ходу транскрипции аминокислот к N-концу и С-концу фрагмента, соответственно (Фиг. 2В). Для фрагментов длинной 9 аминокислот, близких к N- или С-концу расширенного FSP, добавляли меньше аминокислот.
Полученные последовательности неоантигенов со связанными с ними IC50 затем добавляли в перечень последовательностей неоантигенов, полученных в результате SNV.
Стадия 2.2 (необязательная)
Затем выполняли необязательный контрольный фильтр для ранжированного списка RSUM неоантигенов, чтобы удалить те неоантигены, которые представляют потенциальный риск индукции аутоиммунитета. Фильтр проверяет, входит ли ген, кодирующий неоантиген, в перечень нежелательных генов (например, извлеченный из базы данных IEDB), содержащий известные эпитопы МНС класса I и класса II, связанные с аутоиммунным заболеванием. Если доступно, перечень также содержит аллель HLA эпитопа.
Неоантигены удаляли, если приводящая к ним мутация происходит из одного из генов в перечне нежелательных генов, и в то же время один из аллелей HLA пациента соответствует HLA, связанному с геном аутоиммунного заболевания.
Для генов из перечня нежелательных генов, для которых нет информации об аллеле HLA эпитопа, неоантиген удаляли независимо от аллелей HLA пациента.
Стадия 2.3 (необязательная)
Перечень кандидатных неоантигенов затем фильтровали, чтобы удалить неоантигены, которые кодируют пептиды с аминокислотной последовательностью низкой сложности (присутствие сегментов в последовательности, где одна или несколько аминокислот повторяются множество раз).
Сразу после преобразования в нуклеотидные последовательности эти сегменты, вероятно, будут представлять собой области с высоким содержанием нуклеотидов G или С. Следовательно, эти области могут создавать проблемы в ходе первоначального конструирования/синтеза экспрессионной кассеты вакцины, и/или они также могут отрицательно влиять на экспрессию кодируемых полипептидов.
Идентификацию аминокислотных последовательностей низкой сложности выполняли путем оценки энтропии Шеннона последовательности неоантигена, поделенной на ее длину в аминокислотах. Энтропия Шеннона представляет собой показатель, обычно используемый в теории передачи информации, который измеряет среднее минимальное количество битов, необходимых для кодирования строки символов, в зависимости от размера алфавита и частоты символов.
В способе согласно настоящему изобретению метрику применяли к строке аминокислот, присутствующих в последовательности неоантигена. Неоантигены, у которых значение энтропии Шеннона ниже 0,10, удаляли из перечня.
Стадия 3
Описание способа приоритизации неоантигенов пациента
Данные, необходимые для выполнения приоритизации:
- перечень М неоантигенов (полученных в результате несинонимичных SNV или вставок/делеций со сдвигом рамки считывания) со стадии 2,
- данные по частоте мутантных аллелей для каждого неоантигена со стадии 1,
- данные по экспрессии для каждого неоантигена: из данных секвенирования РНК (стадия 1) или, в качестве альтернативного способа (В) (если данные NGS-PHK недоступны из образца опухоли), из общей базы данных экспрессии на уровне генов того же типа опухоли
- предсказанная аффинность связывания с МНС класса I для лучшего мутантного 9-ти мерного эпитопа для каждого неоантигена (со стадии 3).
Стратегия приоритизации основана на общей оценке, полученной путем комбинации трех отдельных независимых значений ранговых оценок (RFREQ, REXPR, RIC50). Три значения ранговых оценок получали путем независимого упорядочивания перечня М неоантигенов в соответствии с одним из следующих параметров (таким образом, результатом будут три различных упорядоченных перечня неоантигенов, каждый из которых, таким образом, обеспечивает ранговую оценку).
Стадия 3.1. Ранговая оценка частоты аллелей (RFREQ)
Каждый неоантиген связан с наблюдаемой частотой аллеля опухоли для мутации, создающей неоантиген. Список М неоантигенов упорядочивали от самой высокой частоты аллеля до самой низкой частоты аллеля. Неоантиген с наивысшей частотой аллеля имеет ранговую оценку RFREQ, равную 1, второй по величине имеет ранговую оценку RFREQ=2 и т.д. Если присутствуют неоантигены с одинаковой частотой аллелей, им присваивается одинаковая ранговая оценка RFREQ, т.е. самая низкая ранговая оценка может быть меньше М (Таблица 1)

Стадия 3.2. Ранговая оценка экспрессии РНК (REXPR)
Уровень экспрессии каждого неоантигена определяли на основании данных NGS-PHK опухоли посредством вычисления ген-центрированного значения Транскриптов на килобазу на миллион (ТРМ) (Li & Dewey, 2011), рассматривая все картированные прочтения. Затем значение ТРМ модифицировали с учетом числа прочтений мутантного и дикого типа, охватывающих положение мутации, в данных NGS-PHK транскриптома (corrТРМ):
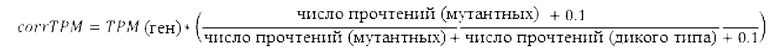
Предпочтительное значение 0,1 добавляли как к нумератору, так и к энумератору, чтобы включить также случаи, когда нет прочтений в положении мутации.
Если данные NGS-PHK секвенирования опухоли пациента недоступны, corrТРМ заменяли для каждого неоантигена средним значением ТРМ соответствующего гена, которое присутствует в базе данных экспрессии для того же типа опухоли.
Затем неоантигены ранжировали в соответствии с уровнем экспрессии, как определено посредством значения corrТРМ. Упорядочение проводили от самой высокой экспрессии (оценка REXP равна 1) до самой низкой экспрессии. Неоантигены с одинаковым значением соггТРМ получали одну и ту же оценку REXPR (Таблица 2).
Стадия 3.3. Предсказание связывания HLA класса-I (RIC50)
Для каждого пептида неоантигена, полученного в результате SNV или FSP, вероятность связывания с МНС класса I определяли как наилучшее предсказанное (самое низкое) значение IC50 среди всех предсказанных 9-ти мерных эпитопов, которые включают мутантную аминокислоту (аминокислоты) или включают одну мутантную аминокислоту из FSP. Предсказание выполняли только в отношении аллелей МНС класса I, присутствующих у пациента, определенных путем анализа нормального образца ДНК.
Перечень неоантигенов затем упорядочивали от самого низкого предсказанного значения IC50 (оценка RIC50, равная 1) до самого высокого предсказанного значения IC50. Неоантигены с одинаковым значением IC50 получали одну и ту же ранговую оценку RIC50 (Таблица 3).

Стадия 3.4.
Затем выполняли окончательную приоритизацию (ранжирование) неоантигенов путем вычисления взвешенной суммы (RSUM) трех индивидуальных ранговых оценок и ранжирования неоантигенов от самого низкого до самого высокого значения RSUM (Фиг. 3). Взвешивание проводили следующим образом:
Формула (I):
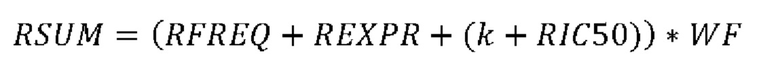
В формуле (I) к представляет собой константное значение, которое добавляют к значению RIC50 в случае, если предсказанный эпитоп имеет значение IC50 выше 1000 нМ (это исключает неоантигены с высоким значением оценки RIC50, т.е. с высоким значением IC50).
Значение к определяют следующим образом:

Иногда данные NGS-PHK по техническим причинам не обеспечивают охват положения мутации, ни для немутантных аминокислот, ни для мутантных аминокислот, в гене, экспрессирующемся иным образом. WF представляет собой понижающий фактор взвешивания (понижающий взвешивание, потому что полученное значение RSUM увеличивается, а неоантиген ранжируется ниже в перечне) с учетом случаев, когда в данных NGS-PHK транскриптома не наблюдается мутантных прочтений.

Таким образом получали ранжированный перечень RSUM неоантигенов.
Неоантигены с одинаковой оценкой RSUM получали дальнейший приоритет в соответствии с их оценкой RIC50 (Фиг. 3). Если как оценка RSUM, так и оценка RIC50 идентичны, неоантигены получали дальнейший приоритет в соответствии с их оценкой REXPR. В случае, если оценка RSUM, оценка RIC50 и оценка REXPR идентичны, неоантигены получали дальнейший приоритет в соответствии с их оценкой RFREQ. В случае, если оценка RSUM, оценка RIC50, оценка REXPR и оценка RFREQ идентичны, неоантигены получали дальнейший приоритет в соответствии с нескорректированным значением ТРМ на уровне гена.
Стадия 4
Стадия 4.1
Окончательный перечень из М ранжированных неоантигенов затем анализировали способом, определяющим, какие и сколько неоантигенов могут быть включены в вектор вакцины.
Способ работает на основе итеративной методики. На каждой итерации создается перечень из N лучших ранжированных неоантигенов, необходимых для достижения максимального размера вставки L аминокислот (предпочтительно 1500 аминокислот). Если перечень N неоантигенов содержит более одного частичного перекрытия неоантигенов, полученных в результате одного и того же FSP, выполняется стадия слияния, чтобы избежать включения избыточного участка одной и той же аминокислотной последовательности (Фиг. 4). Если после стадии слияния общая длина включенных неоантигенов все еще не достигает максимального желаемого размера вставки, выполняется новая итерация путем добавления следующего неоантигена из ранжированного перечня.
Методику останавливают, когда добавление следующего неоантигена к уже выбранному перечню N неоантигенов превышает максимальный желаемый размер вставки L.
Таким образом, точное значение N может уменьшаться из-за присутствия слитых неоантигенов, происходящих из FSP (длина больше 25-ти мера), или увеличиваться из-за присутствия неоантигенов, содержащих мутации, близкие к N- или С-концу белка (эти неоантигены будет короче 25-ти мера).
Результатом является перечень из N неоантигенов с общей длиной, меньшей или равной L=1500 аминокислот.
Стадия 4.2
Затем упорядоченный перечень делили на две части примерно равной длины (Фиг. 5). Специалисту в данной области техники известно, что существует несколько возможных различных способов разделения перечня на две части.
Стадия 4.3
Перечень N выбранных последовательностей неоантигенов затем перераспределяли в соответствии со способом, который минимизирует образование предсказанных соединенных эпитопов, которые могут быть созданы путем совмещения двух соседних пептидов неоантигена в собранном полипептиде полинеоантигена. Создавали один миллион скремблированных структур собранного полинеоантигена, каждая с разным порядком неоантигенов. Затем каждую структуру анализировали, чтобы определить количество предсказанных соединенных эпитопов с IC50<=1500 нМ для одного из аллелей HLA пациента. При циклическом просмотре всего миллиона структур записывали структуру с минимальным количеством предсказанных соединенных эпитопов, встреченных до этого момента. Если позже будет обнаружена вторая структура с таким же минимальным количеством предсказанных соединенных эпитопов, сохраняется первая обнаруженная структура.
Пример 2. Применение способа приоритизации к одному существующему в литературе набору данных
Способ приоритизации, описанный в примере 1, применяли к набору данных NGS для образца рака поджелудочной железы (Pat_3942; Tran et al. 2015), для которого сообщалось об одной экспериментально подтвержденной иммуногенной реактивности. Исходные данные NGS опухолевого/нормального экзома и транскриптома опухоли загружали из базы данных NCBI SRA [SRA ID: SRR2636946; SRR2636947; SRR4176783] и анализировали с помощью конвейера, который характеризует мутацию пациента.
Используемый конвейер обнаружения информации состоял из 8 стадий:
a) контроль качества и оптимизация прочтений
Предварительный контроль качества необработанных данных последовательности выполняли с помощью FastQC 0.11.5 (Andrews, https://www.bioinformatics.babraham.ac.uk/projects/fastqc/). Парные прочтения длиной менее 50 пар оснований отфильтровывали. После визуальной оценки оставшиеся прочтения необязательно обрезали на концах 5' и 3' с использованием Trimmomatic-0.33 (Bolger et al., 2014) для удаления секвенированных оснований с низким качеством и повышения качества подходящих прочтений (прочтения с фильтрацией QC) для выравнивания с эталонным геномом.
b) Выравнивание прочтения относительно эталонного генома
Затем полученные с помощью QC-фильтрации прочтения ДНК выравнивали с версией эталонного генома человека GRCh38/hg38 с использованием алгоритма BWA-mem (Li & Durbin, 2009) с параметрами по умолчанию. Прочтения РНК с QC-фильтрацией выравнивали с помощью программного обеспечения Hisat2 2.2.0.4 (Kim et al., 2015), сохраняя все параметры по умолчанию. Пары прочтений, для которых было выровнено только одно прочтение, и парные прочтения, которые выровнены по более чем одному геномному локусу с одинаковой оценкой картирования, были отфильтрованы с помощью Samtools 1.4 (Li et al., 2009).
c) Оптимизация выравнивания
Выравнивания прочтений ДНК дополнительно обрабатывали посредством методики, которая оптимизировала локальное выравнивание вокруг небольших вставок или делеций (вставки/делеции), помечала повторяющиеся прочтения и повторно откалибровывала окончательную базовую оценку качества в повторно выровненных областях. Повторное выравнивание вставки/делеции выполняли с использованием инструментов RealignerTargetCreator и IndelRealigner из программного обеспечения GATK version 3.7 (McKenna et al., 2010). Дублированные прочтения обнаруживали и помечали с помощью MarkDuplicates из Picard version 2.12 (http://broadinstitute.github.io/picard). Пере калибровку базовой оценки качества выполняли с использованием BaseRecalibrator и PrintReads version GATK 3.7 (McKenna et al., 2010). Полиморфизмы, аннотированные в версии dbSNP138 человека (https://www.ncbi.nlm.nih.gov/projects/SNP/snp_summary.cgi?view+summary=view+summary&build_id=138), использовали в качестве перечня известных сайтов по порядку для создания базовой модели перекалибровки.
d) Определение HLA
Оценку типа специфического для пациента HLA класса I выполняли путем сопоставления QC-отфильтрованных прочтений ДНК для нормального образца на участке генома hg38, который кодирует гаплотипы человека класса I, с BWA-mem (Li & Durbin, 2009). Пары прочтений, для которых было выровнено только одно прочтение, и пары прочтений, выровненные по более чем одному локусу с одинаковой оценкой картирования, фильтровали с помощью Samtools 1.4 (Li et al., 2009). Наконец, определение наиболее вероятных гаплотипов пациента выполняли с помощью программного обеспечения optytipe (Szolek et al., 2014). Оценку типа HLA класса II выполняли путем сопоставления QC-фильтрованных прочтений ДНК для нормального образца на участке генома hg38, который кодирует гаплотипы человека класса II, с BWA-mem (li & Durbin, 2009). Определение наиболее вероятных гаплотипов класса II пациента проводили с помощью программы HLAminer (Warren et al., 2012).
e) Определение вариантов
Определение соматических вариантов однонуклеотидных вариантов (SNV) и небольших вставок/делеций выполняли на повторно откалиброванных данных прочтения ДНК с помощью mutect2 (Cibulskis et al., 2012), включенного в GATK version 3.7 [25], и Varscan2 2.3.9 (Koboldt et al., 2012), путем явного сравнения образца опухоли с нормальным контрольным образцом. Все параметры оставлены по умолчанию. SCALPEL (Fang et al., 2014) с параметрами по умолчанию использовали как дополнительный инструмент для определения вариантов вставок/делеций. Значимые соматические варианты, обнаруженные по меньшей мере одним из алгоритмов, затем картировали на транскриптом человека Refseq с помощью программного обеспечения Annovar (Wang et al., 2010) и дополнительно фильтровали. Были сохранены только SNV, которые вызывают несинонимичные (миссенс) изменения в кодоне, или вставки/делеции, которые вызывают изменение рамки считывания в кодирующей последовательности генов, кодирующих белок (вставки/делеции со сдвигом рамки считывания). SNV, которые генерируют преждевременные стоп-кодоны, исключали. Для каждого обнаруженного варианта количество мутантных прочтений и прочтений дикого типа, наблюдаемых в выровненных данных NGS для образцов ДНК и РНК, затем определяли с помощью специального инструмента, который использует Samtools 1.4 (Li et al., 2009).
f) Создание неоантигена
Каждый соматический вариант транслировали в пептид, содержащий мутантную аминокислоту. Для вариантов SNV пептиды неоантигена получали путем добавления 12 аминокислот дикого типа выше и ниже по ходу транскрипции от мутантной аминокислоты. Исключения по длине имели место для 5 мутаций, для которых мутантная аминокислота была картирована на расстоянии менее 12 аминокислот от N-конца или от С-конца. Множество 25-ти мерных пептидов получали в 3 случаях, когда SNV индуцировал аминокислотную замену во множестве альтернативных изоформ сплайсинга с различными последовательностями белка. Для вставок/делеций, генерирующих FSP, выше по ходу транскрипции от первой новой аминокислоты добавляли 12 аминокислот дикого типа. Сохраняли модифицированные FSP, которые имеют конечную длину, равную по меньшей мере девять аминокислот.
g) Предсказания связывания HLA-I неоантигенов
Вероятность связывания с MHC-I определяли, как наилучшее предсказанное (самое низкое) значение IC50 среди всех предсказанных 9-ти мерных эпитопов, которые включают мутантную аминокислоту (аминокислоты). Предсказания выполняли с использованием рекомендованного IEDB способа на основе программного обеспечения IEDB (Moutaftsi et al., 2006). Способ netMHCpan (Hoof et al., 2009) использовали в случае, если гаплотип МНС-I не был охвачен способом, рекомендованным IEDB (Moutaftsi et al., 2006).
h) Окончательный выбор надежных вариантов
Первоначальный перечень вариантов SNV и вставок/делеций, вызывающих сдвиг рамки считывания, затем сокращали путем выбора только мутаций, которые удовлетворяют следующим критериям
• частота мутантных аллелей (MF) в образце ДНК опухоли>=10%
• соотношение MF в образце ДНК опухоли и контрольном образце ДНК>=5
• мутантные прочтения в хромосомном положении соматического варианта в ДНК опухоли>2
• мутантные прочтения в хромосомном положении соматического варианта в нормальной ДНК<2
Окончательный перечень из 129 мутаций, кодирующих неоантиген, надежно обнаруженных у пациента Pat 3942, включал 4 вставки/делеции, создающие сдвиг рамки считывания, и 125 вариантов SNV. 125 вариантов SNV генерируют 128 неоантигенов, 3 из которых происходят из мутаций, картированных на множестве альтернативных изоформ сплайсинга. 4 вставки/делеции со сдвигом рамки считывания создают 4 FSP с общей длиной 307 аминокислот и в общей сложности 260 последовательностей неоантигенов. Общая длина всех 388 неоантигенов, полученных либо из вариантов SNV, либо из вставок/делеций, приводящих к сдвигу рамки считывания, составляла 3942 аминокислоты.
Максимальный размер вставки (включая контрольные элементы экспрессии), которые могут быть использованы для генных вакцин, например, на основе аденовирусных векторов, ограничен, таким образом, приводя к максимальному размеру кодируемого полинеоантигена, равному L-аминокислот.Типичные значения L для аденовирусных векторов составляют порядка 1500 аминокислот, что меньше совокупной длины 3942 аминокислот для всех неоантигенов. Поэтому стратегию приоритизации, описанную в Примере 1, применяли для выбора оптимального подмножества ранжированных неоантигенов, совместимого с пределом в 3942 аминокислот.
В таблице 4 приведены все 60 выбранных неоантигена, отобранные для достижения совокупной длины 1485 аминокислот.Способ выбора включал 6 последовательностей неоантигенов, полученных из FSP chr11:1758971_АС_- (делеция 2 нуклеотидов), 2 последовательности неоантигена, полученные из FSP chr6:168310205_-_Т (вставка 1 нуклеотида) и 1 последовательность неоантигена, полученную из FSP chr16_3757295_GATAGCTGTAGTAGGCAGCАТС_- (делеция 22 нуклеотидов, SEQ ID NO: 185). В ходе выбора несколько перекрывающихся последовательностей неоантигенов, происходящих из FSP, были объединены, чтобы удалить повторяющиеся сегменты последовательностей (Таблица 5). Детали слитых последовательностей неоантигенов показаны на Фиг. 6.
Все последовательности неоантигенов, созданные 129 надежно обнаруженными мутациями в Pat_3942, перечислены в Таблице 6, включая связанные значения трех параметров (частота мутантных аллелей MFREQ, скорректированное значение экспрессии corrТРМ, наилучшее предсказанное значение IC50 для 9-ти мерных эпитопов МНС класса I MIC50), полученные в результате три независимые ранговые оценки (RFREQ, REXPR, RIC50), фактор взвешивания WF, взвешенное значение RSUM и результирующий ранг RSUM.
Важно отметить, все три последовательности неоантигенов, указанные как индуцирующие реакционную способность Т-клеток у пациента (Tran et al., 2015), были выбраны среди лучших 60 неоантигенов посредством стратегии приоритизации.
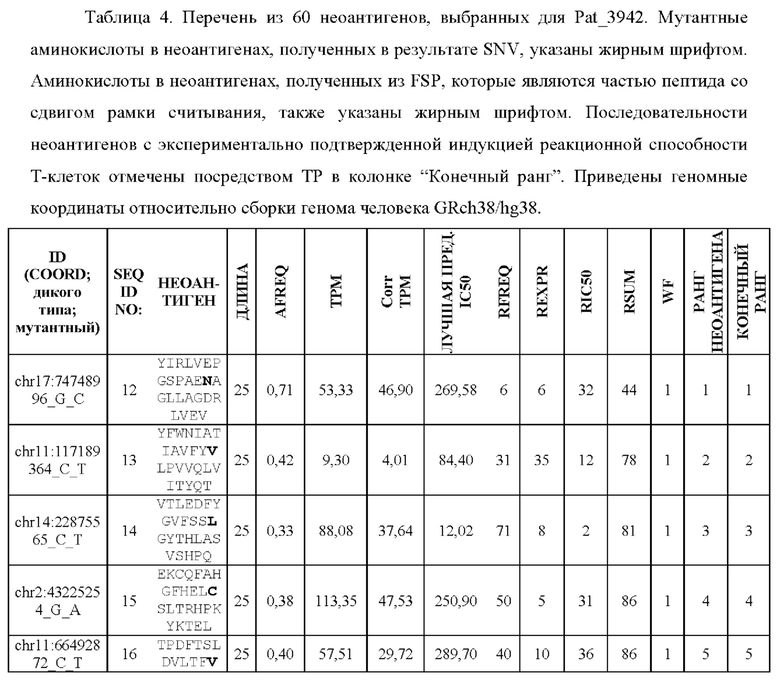
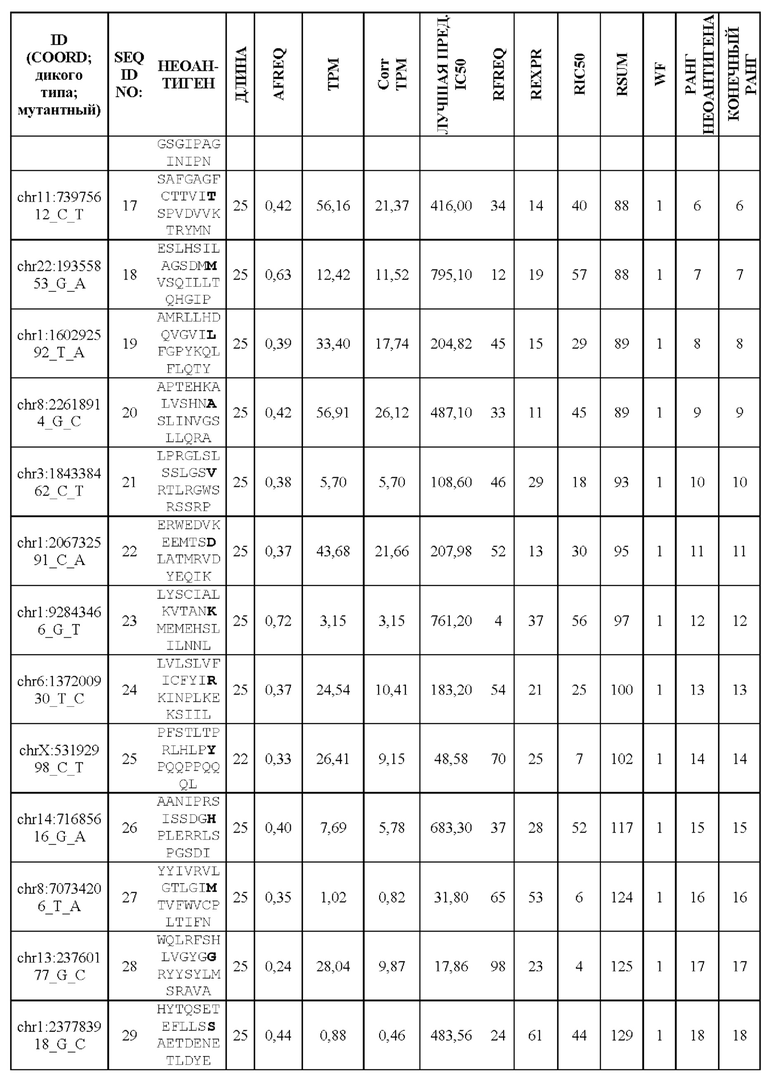
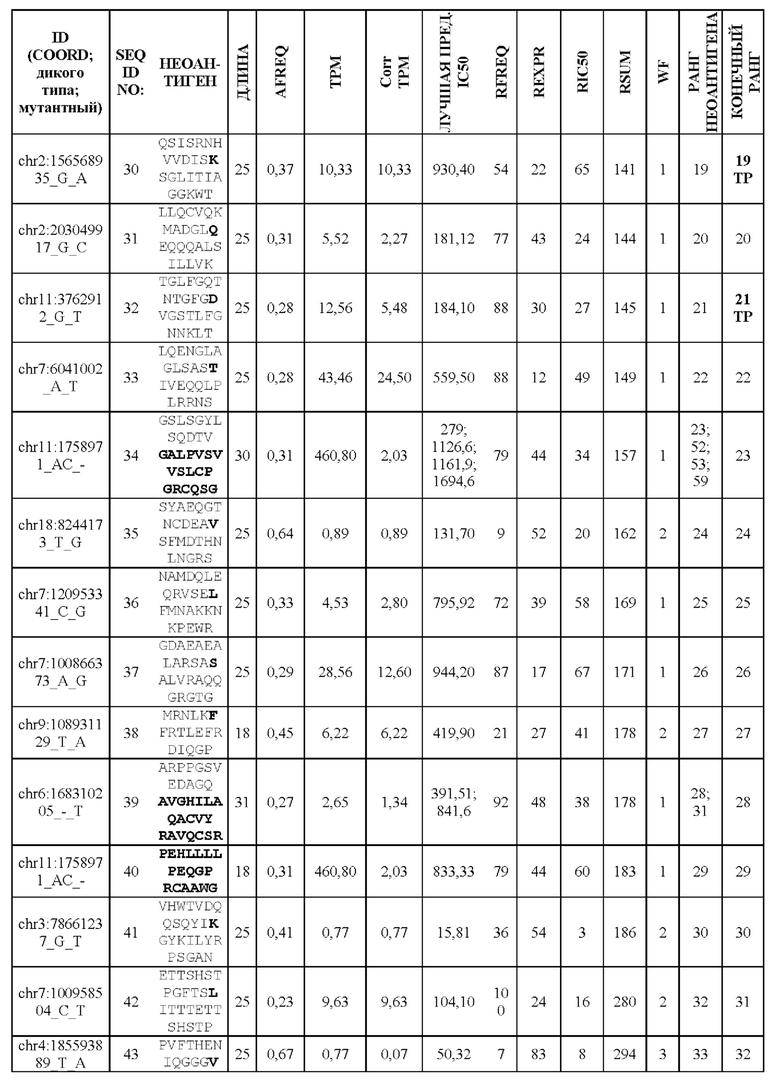
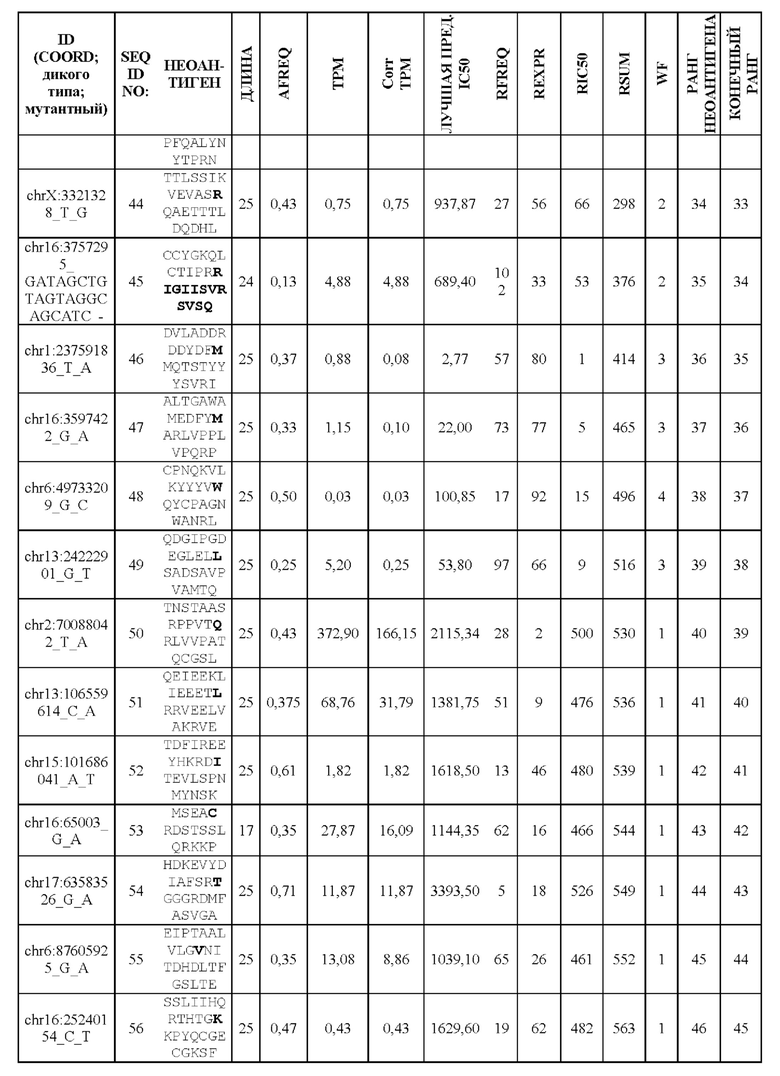
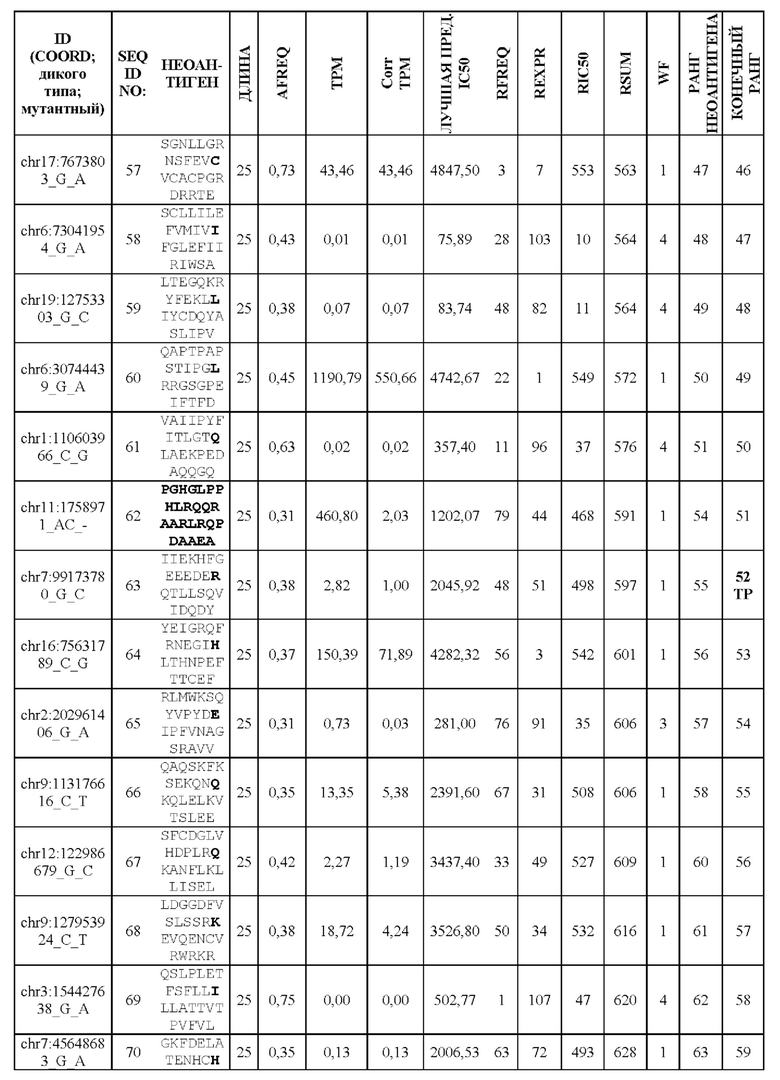
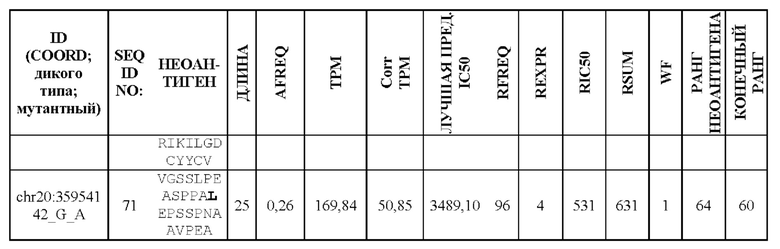
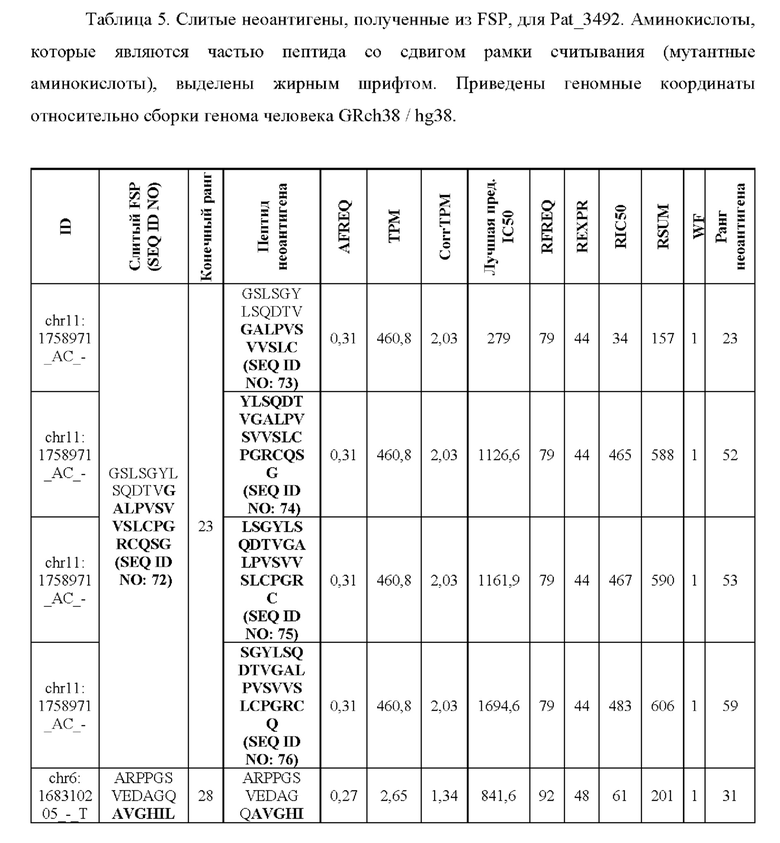



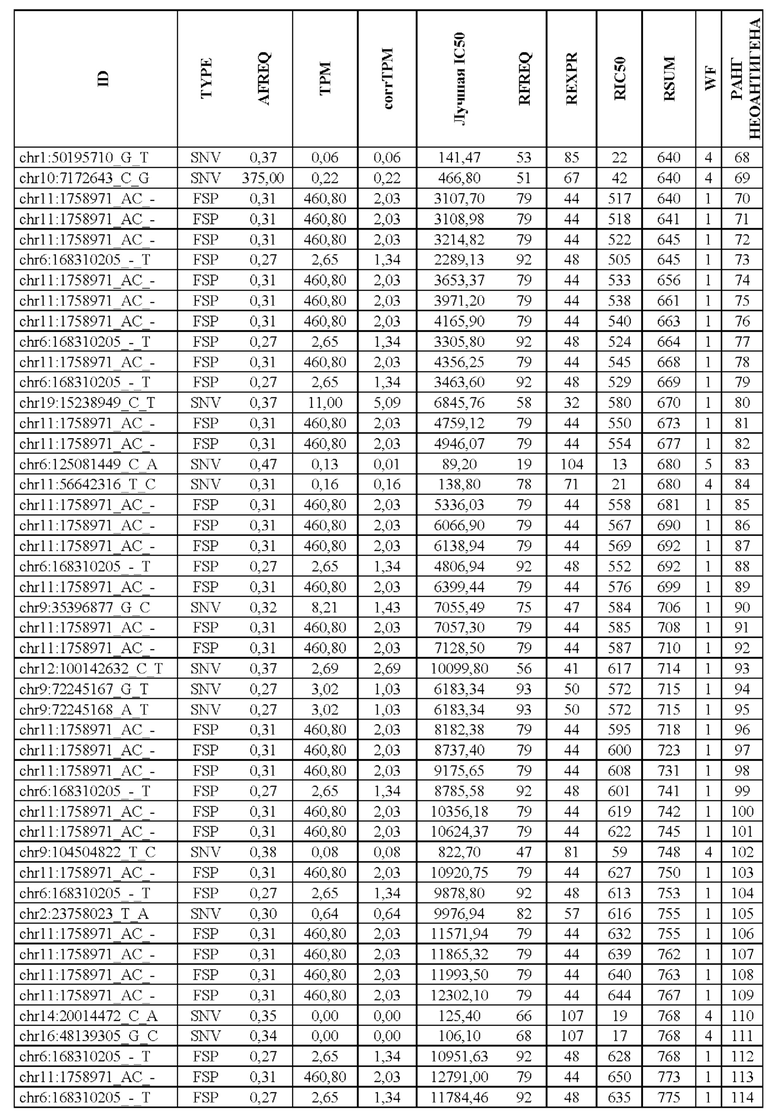
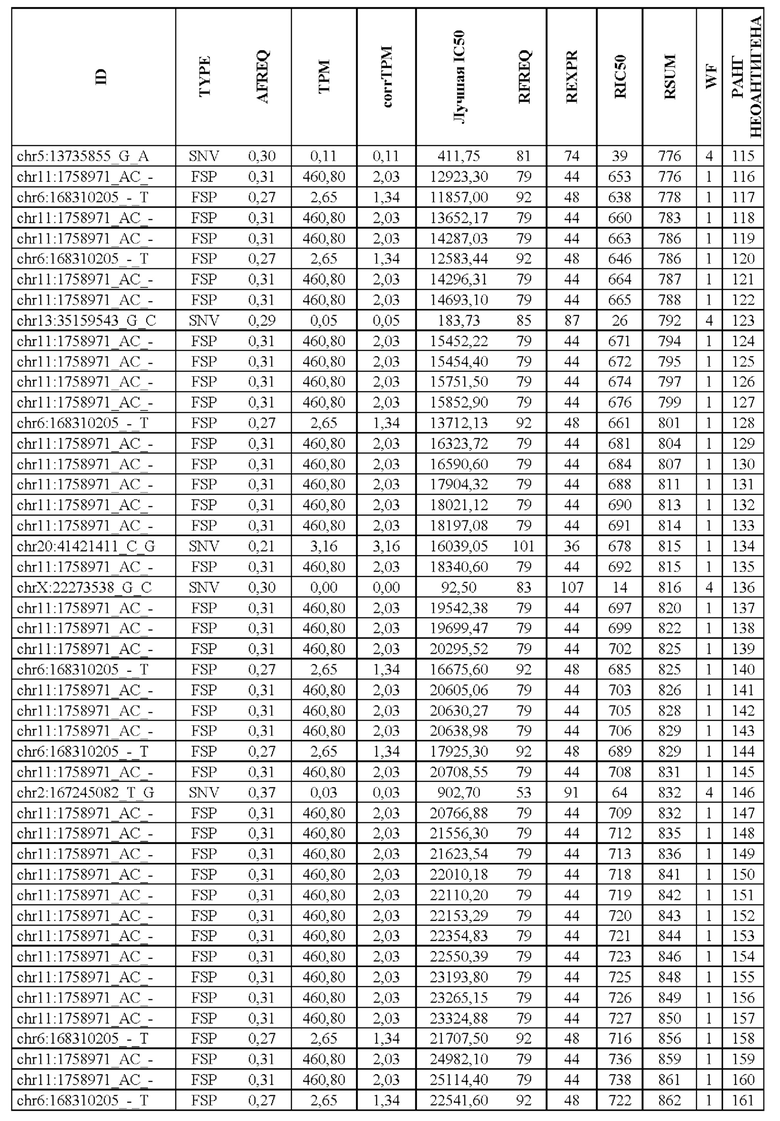
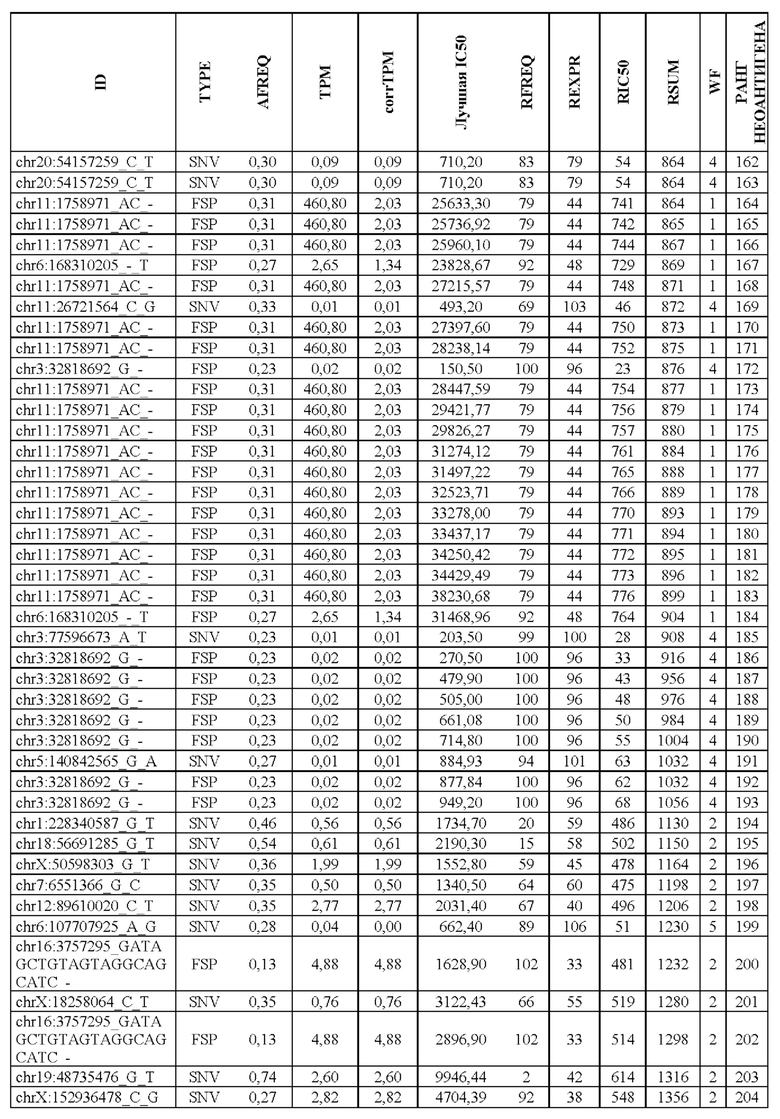
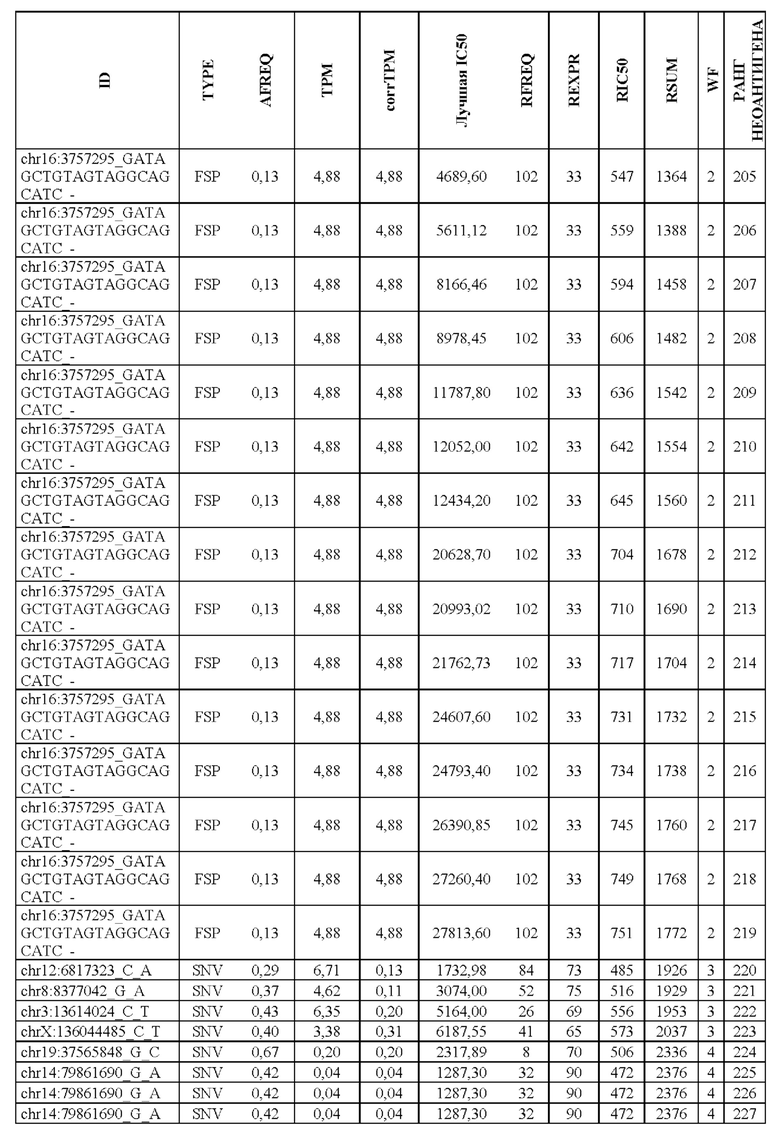
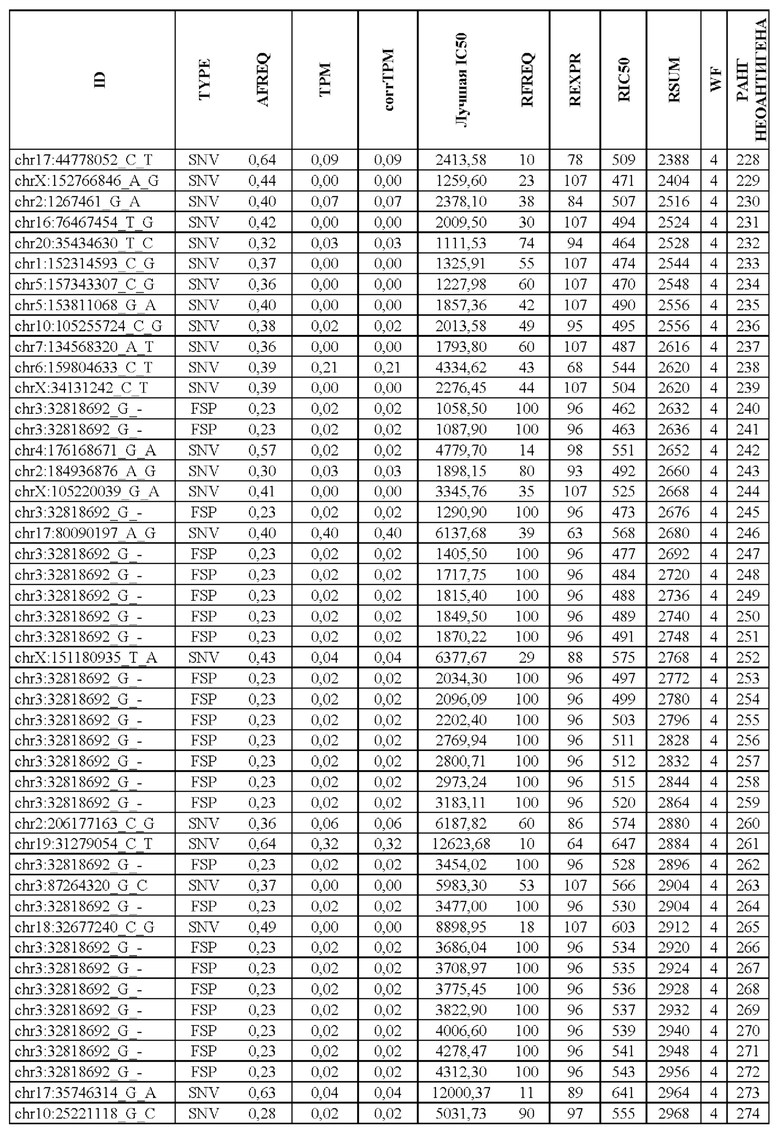

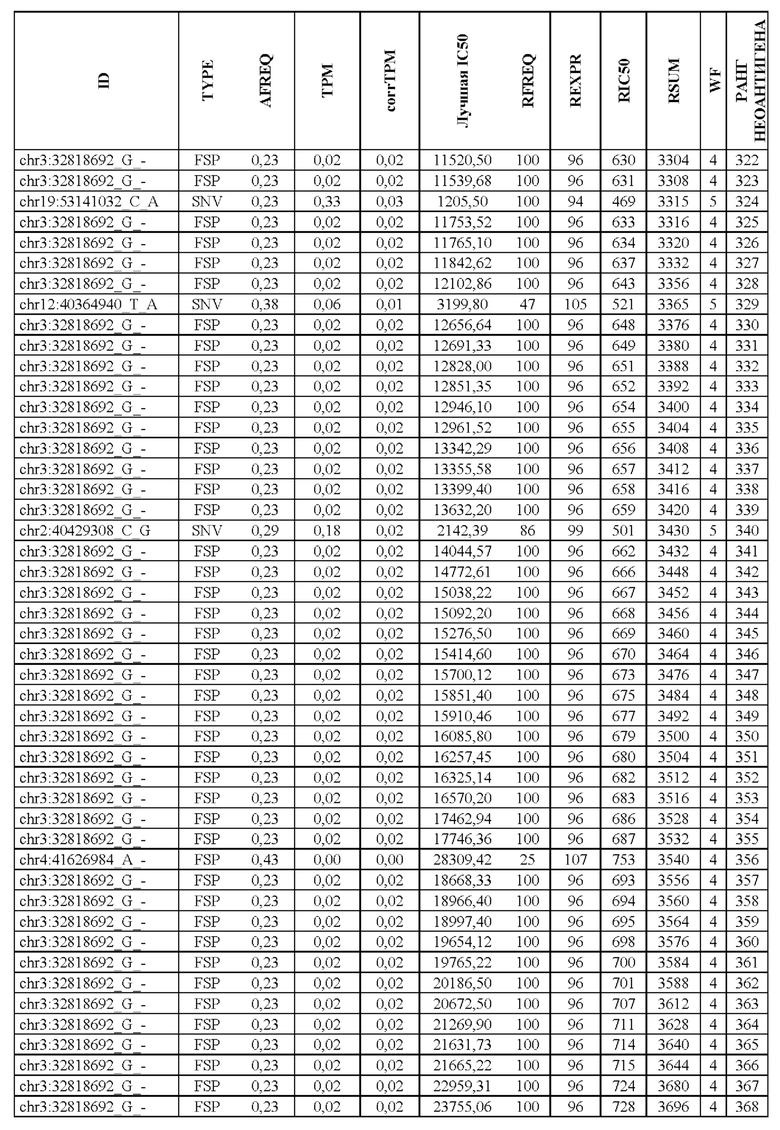
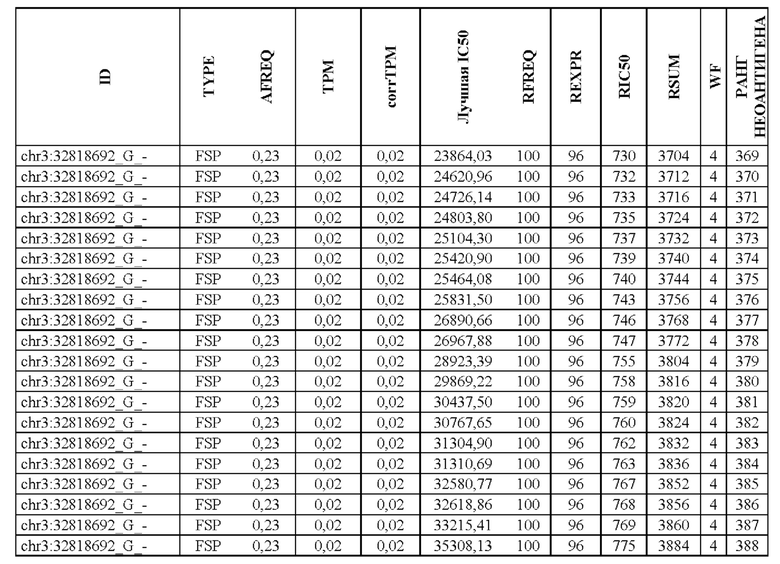
Пример 3. Валидация способа приоритизации
Для валидации способа приоритизации анализировали наборы данных с в общем 30 экспериментально подтвержденными иммуногенными неоантигенами с реакционной способностью Т-клеток CD8+(Таблица 7). Наборы данных включали биопсии, взятые у 13 пациентов, страдающих раком, с 5 различными типами опухолей, для которых доступны исходные данные NGS (NGS-ДНК нормального/опухолевого экзома и NGS-PHK транскриптома опухоли).
Данные NGS загружали с веб-сайта NCBI SRA и обрабатывали с помощью того же конвейера обработки NGS, который использовали в Примере 1. Мутации для 28 из 30 экспериментально подтвержденных неоантигенов идентифицировали посредством применения конвейера обработки NGS, описанного в Примере 2 (две мутации не были обнаружены из-за очень низкого числа мутантных прочтений). Для каждого образца пациента общий перечень всех идентифицированных неоантигенов затем ранжировали в соответствии со способом, описанным на стадии 3 в примере 1, исходя из того, что максимальный размер целевого полипептида (полинеоантигена) составляет 1500 аминокислот.
В Таблице 8 приведены предсказанные значения IC50 в отношении МНС класса I для 28 неоантигенов, для только предсказанного 9-ти мерного эпитопа или для предсказанных эпитопов из от 8 до 11 аминокислот.В обоих случаях присутствует несколько неоантигенов, для которых наилучшие (самые низкие) значения IC50 намного выше (более высокие) порогового значения 500 нМ, часто применяемого в данной области техники для выбора кандидатных неоантигенов для вакцины, и, следовательно, они были бы исключены из персонализированной вакцины.
На Фиг. 7А показан ранг RSUM, полученный способом приоритизации для 28 обнаруженных экспериментально подтвержденных неоантигенов. Пунктирная линия (Фиг. 5А) показывает максимальное число 25-ти меров неоантигенов (60), которое может быть размещено в аденовирусном векторе для персонализированной вакцины с емкостью вставки (исключая контрольные элементы экспрессии) приблизительно 1500 аминокислот.
27 из 30 экспериментально подтвержденных неоантигенов (90%) присутствуют среди лучших 60 неоантигенов и, следовательно, должны быть включены в вектор персонализированной вакцины. Затем приоритизацию повторяли, принимая, что данные по экспрессии NGS-PHK для опухоли пациента не доступны. Значение экспрессии соггТРМ для каждого неоантигена оценивали, как среднее значение ТРМ соответствующего гена в данных экспрессии TCGA для этого конкретного типа опухоли [номер доступа NCBI GEO: GSE62944]. На Фиг. 7В показано, что и в этом случае большая часть (25 из 30=83%) экспериментально подтвержденных неоантигенов должна быть включена в вектор вакцины. Важно отметить, что для каждого из исследованных наборов данных имелся по меньшей мере один подтвержденный неоантиген, который мог бы быть включен в вектор персонализированной вакцины. Дополнительные детали, включая результаты ранжирования RSUM с данными NGS-RNA и без них для 28 подтвержденных неоантигенов, перечислены в Таблице 7.
Таким образом, оба результата подтвердили, что посредством способа приоритизации можно выбрать, в присутствии, а также в отсутствии данных транскриптома опухоли пациента, перечень неоантигенов, который включает наиболее релевантные неоантигены, т.е. неоантигены с экспериментально подтвержденной иммуногенностью, которые должны быть включены в вектор персонализированной вакцины.


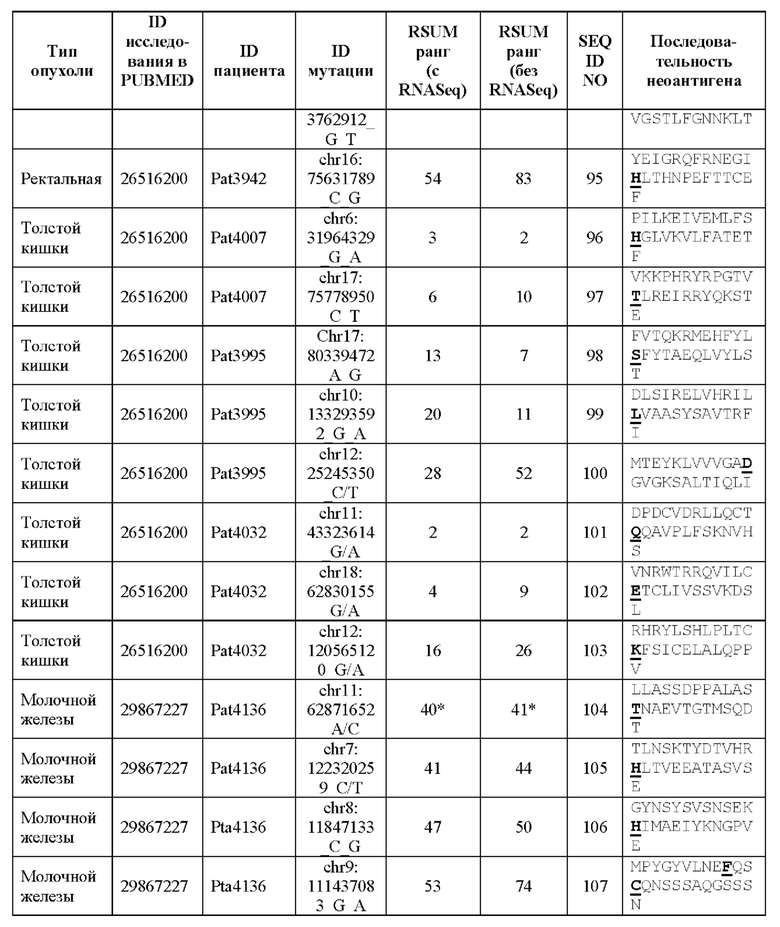
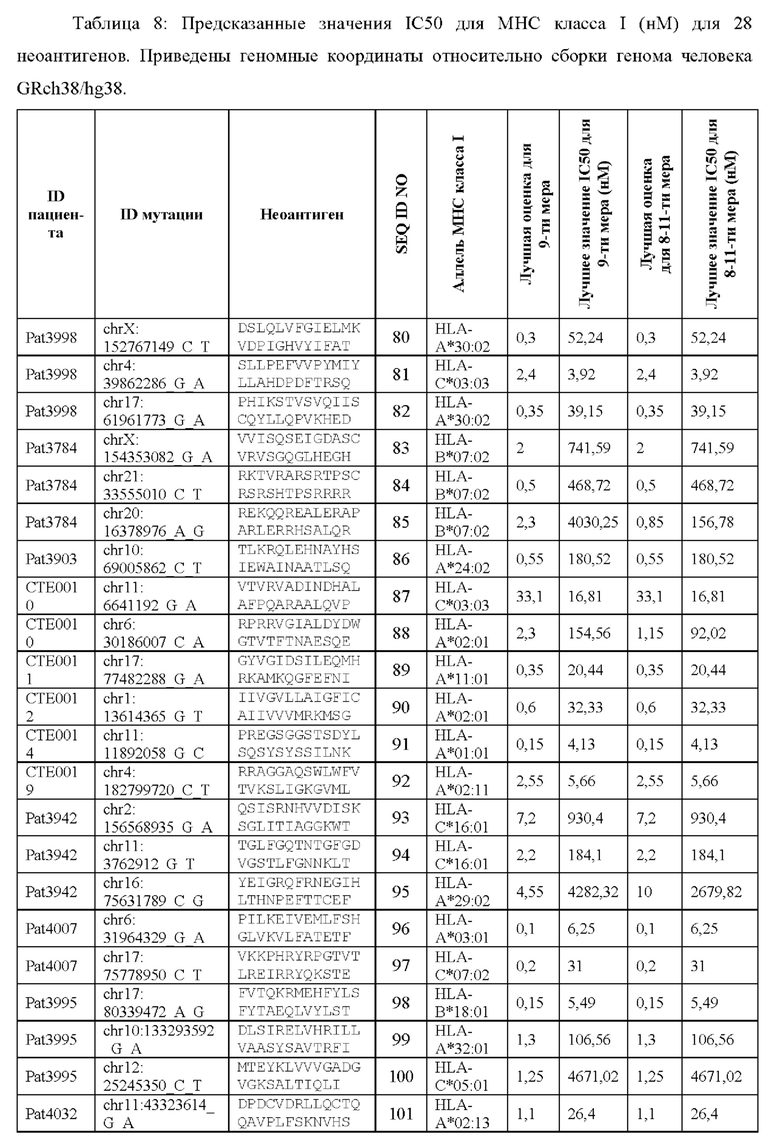
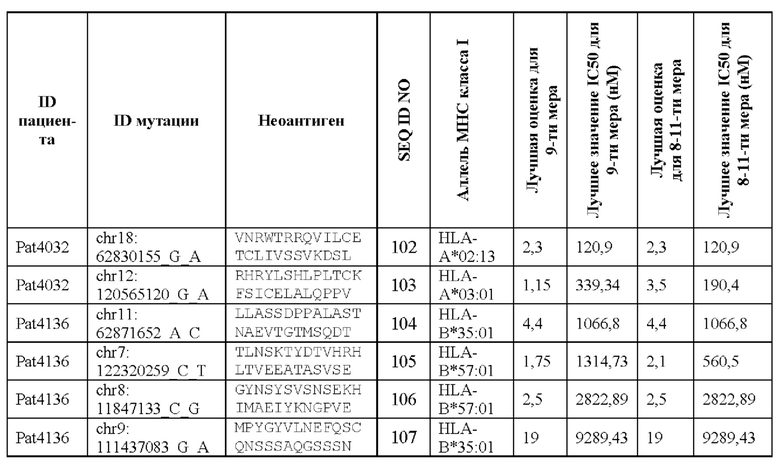
Пример 4. Оптимизация структуры неоантигенов для синтетических генов, кодирующих неоантигены, которые доставляются вектором генной вакцины
Полинеоантиген, содержащий 60 неоантигенов, приводит к созданию искусственного белка с общей длиной приблизительно 1500 аминокислот, который необходимо кодировать с помощью экспрессионной кассеты, вставленной в вектор генной вакцины. Экспрессия таких длинных искусственных белков может быть субоптимальной, что влияет на уровень иммуногенности, индуцированной против кодируемых неоантигенов. Таким образом, разделение полинеоантигена на две части может способствовать получению более высоких уровней индуцированной иммуногенности.
Полинеоантиген, состоящий из 62 неоантигенов (Таблица 9), полученный из линии мышиных опухолевых клеток СТ26, поэтому протестировали с использованием аденовирусного вектора GAd20 в различных структурах (Фиг. 8А и 8В) на его способность вызывать иммуногенность in vivo: в структуре одного вектора со всеми 62 неоантигенами, кодируемыми одним полинеоантигеном (GAd20-CT26-62, SEQ ID NO: 170), в структуре из двух векторов, каждый из которых кодирует половину из 62 неоантигенов (GAd-CT26-1-31+GAd-CT26-32-62, SEQ ID NO: 171, 172), и в третьей структуре с теми же двумя отдельными экспрессионными кассетами, присутствующими в одном векторе (GAd-CT26 двойной 1-31 и 32-62). Один энхансерный элемент Т-клеток ТРА (SEQ ID NO: 173) присутствовал на N-конце полинеоантигена, содержащего 62 неоантигена, и один энхансерный элемент Т-клеток ТРА присутствовал на N-конце каждой из двух конструкций по 31 неоантигену. Последовательность пептида НА (SEQ ID NO: 183) добавляли на С-конце собранных неоантигенов с целью контроля экспрессии.
Иммуногенность определяли in vivo путем иммунизации групп (n=6) наивных мышей BalbC однократно внутримышечно дозой 5×10^8 вирусных частиц (vp). Ответы Т-клеток измеряли через 2 недели после иммунизации на спленоцитах с помощью INFγ ELISpot для распознавания пулов пептидов, содержащих 25-ти мерные неоантигены.
GAd20-CT26-62, экспрессирующий длинный полинеоантиген, продемонстрировал субоптимальную индукцию неоантиген-специфических Т-клеточных ответов по сравнению с совместно вводимыми двумя структурами векторов GAd-CT26-1-31 / GAd-СТ26-32-62 (Фиг. 8А). Следовательно, разделение длинного полинеоантигена на два более коротких полинеоантигена примерно равной длины обеспечивало значительно улучшенный иммуногенный ответ.Важно отметить, что также двойной кассетный вектор GAd-CT26 двойной 1-31 и 32-62 (Фиг. 8В) индуцировал уровень иммуногенности, который был значительно выше, чем у GAd-CT26-1-62 и сопоставимым с уровнем, наблюдаемым для комбинации двух аденовирусных векторов GAd-CT26-1-31+GAd-CT26-31-62 (Фиг. 8А и В).
Разделение длинного полиантигена на два полинеоантигена приблизительно равного меньшего размера, таким образом, обеспечивает композицию вектора вакцины (один двойной кассетный вектор или два отдельных вектора) с превосходными иммуногенными свойствами.
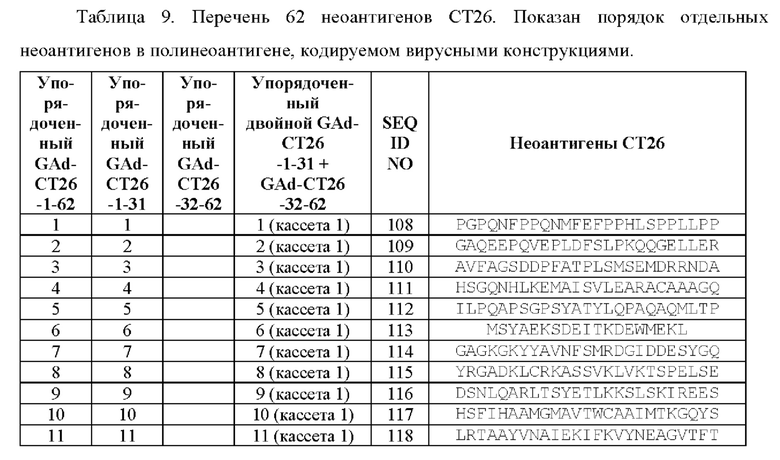

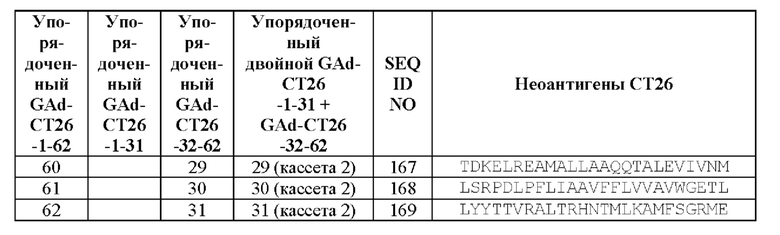
Ссылочные источники
Andersen RS, Kvistborg P, Frasig TM, Pedersen NW, Lyngaa R, Bakker AH, Shu CJ, Straten Pt, Schumacher TN, Hadrup SR. (2012). Parallel detection of antigen-specific T cell responses by combinatorial encoding of MHC multimers. Nat Protoc, 7(5), 891-902. doi: 10.1038/nprot.2012.037
Andreatta M & Nielsen M. (2016). Gapped sequence alignment using artificial neural networks: application to the MHC class I system. Bioinformatics, 32(4), 511-517. doi: 10.1093/bioinformatics/btv639
Andrews, S. FastQC A Quality Control tool for High Throughput Sequence Data. Available online at: http://www.bioinformatics.babraham.ac.uk/projects/fastqc.
Bolger AM, Lohse M, Usadel B. (2014). Trimmomatic: a flexible trimmer for Illumina sequence data. Bioinformatics, 30(15), 2114-2120. doi:10.1093/bioinformatics/btul70
Cibulskis Kl, Lawrence MS, Carter SL, Sivachenko A, Jaffe D, Sougnez C, Gabriel S, Meyerson M, Lander ES, Getz G. (2013). Sensitive detection of somatic point mutations in impure and heterogeneous cancer samples. Nat Biotechnol, 31(3), 213-219. doi: 10.1038/nbt.2514
Donnelly ML, Hughes LE, Luke G, Mendoza H, ten Dam E, Gani D, Ryan MD.(2001) The 'cleavage' activities of foot-and-mouth disease virus 2A site-directed mutants and naturally occurring '2A-like' sequences. J Gen Virol. 2001 82(Pt 5): 1027-41.
Fang H, Wu Y, Narzisi G, O'Rawe JA, Barron LT, Rosenbaum J, Ronemus M, Iossifov I, Schatz MC, Lyon GJ. (2014). Reducing INDEL calling errors in whole genome and exome sequencing data. Genome Med, 6(10), 89. doi:10.1186/sl3073-014-0089-z
Fritsch EF, Rajasagi M, Ott PA, Brusic V, Hacohen N, Wu CJ. (2014). HLA-binding properties of tumor neoepitopes in humans. Cancer Immunol Res, 2(6), 522-529. doi:10.1158/2326-6066.CIR-13-0227
Gros A, Parkhurst MR, Tran E, Pasetto A, Robbins PF, Ilyas S, Prickett TD, Gartner JJ, Crystal JS, Roberts IM, Trebska-McGowan K, Wunderlich JR, Yang JC1, Rosenberg SA. (2016). Prospective identification of neoantigen-specific lymphocytes in the peripheral blood of melanoma patients. Nat Med. 22(4):433-8. doi: 10.1038/nm.4051.
Hoof I, Peters B, Sidney J, Pedersen LE, Sette A, Lund O, Buus S, Nielsen M. (2009). NetMHCpan, a method for MHC class I binding prediction beyond humans, hnmunogenetics, 61(1), 1-13. doi:10.1007/s00251-008-0341-z
Jurtz V, Paul S, Andreatta M, Marcatili P, Peters B, Nielsen M. (2017). NetMHCpan-4.0: Improved Peptide-МНС Class I Interaction Predictions Integrating Eluted Ligand and Peptide Binding Affinity Data. J Immunol, 199(9), 3360-3368. doi: 10.4049/jimmunol. 1700893
Kandoth C, McLellan MD, Vandin F, Ye K, Niu B, Lu C, Xie M, Zhang Q, McMichael JF, Wyczalkowski MA, Leiserson MDM, Miller CA, Welch JS, Walter MJ, Wendl MC, Ley TJ, Wilson RK, Raphael BJ, Ding L. (2013). Mutational landscape and significance across 12 major cancer types. Nature, 502(7471), 333-339. doi:10.1038/naturel2634
Kim D, Langmead B, Salzberg SL. (2015). HISAT: a fast spliced aligner with low memory requirements. Nat Methods, 12(4), 357-360. doi:10.1038/nmeth.3317
Koboldt DC, Zhang Q, Larson DE, Shen D, McLellan MD, Lin L, Miller CA, Mardis ER, Ding L, Wilson RK. (2012). VarScan 2: somatic mutation and copy number alteration discovery in cancer by exome sequencing. Genome Res, 22(3), 568-576. doi: 10.1101/gr. 129684.111
Li В & Dewey CN. (2011). RSEM: accurate transcript quantification from RNA-Seq data with or without a reference genome. BMC Bioinformatics, 12, 323. doi:10.1186/1471-2105-12-323
Li H & Durbin R. (2009). Fast and accurate short read alignment with Burrows-Wheeler transform. Bioinformatics, 25(14), 1754-1760. doi:10.1093/bioinformatics/btp324
Li H, Handsaker B, Wysoker A, Fennell T, Ruan J, Homer N, Marth G, Abecasis G, Durbin R; 1000 Genome Project Data Processing Subgroup.Genome Project Data Processing, S. (2009). The Sequence Alignment/Map format and SAMtools. Bioinformatics, 25(16), 2078-2079. doi: 10.1093/bioinformatics/btp352
Luke GA, de Felipe P, Lukashev A, Kallioinen SE, Bruno EA, Ryan MD. (2008) Occurrence, function and evolutionary origins of '2A-like' sequences in virus genomes.J Gen Virol. 2008 89(Pt 4): 1036-42. doi: 10.1099/vir.0.83428-0.
Lundegaard C, Lamberth K, Harndahl M, Buus S, Lund O, Nielsen M. (2008). NetMHC-3.0: accurate web accessible predictions of human, mouse and monkey MHC class I affinities for peptides of length 8-11. Nucleic Acids Res, 36(Web Server issue), W509-512. doi:10.1093/nar/gkn202
McKenna A, Hanna M, Banks E, Sivachenko A, Cibulskis K, Kernytsky A, Garimella K, Altshuler D, Gabriel S, Daly M, DePristo MA. (2010). The Genome Analysis Toolkit: a Map Reduce framework for analyzing next-generation DNA sequencing data. Genome Res, 20(9), 1297-1303. doi: 10.1101/gr. 107524.110
Moutaftsi M, Peters В, Pasquetto V, Tscharke DC, Sidney J, Bui HH, Grey H, Sette A. (2006). A consensus epitope prediction approach identifies the breadth of murine T(CD8+)-cell responses to vaccinia virus. Nat Biotechnol, 24(7), 817-819. doi:10.1038/nbtl215
Sahin U, Derhovanessian E, Miller M, Kloke BP, Simon P,  Bukur V, Tadmor AD, Luxemburger U,
Bukur V, Tadmor AD, Luxemburger U,  Omokoko T, Vormehr M, Albrecht C, Paruzynski A, Kuhn AN, Buck J, Heesch S, Schreeb KH,
Omokoko T, Vormehr M, Albrecht C, Paruzynski A, Kuhn AN, Buck J, Heesch S, Schreeb KH,  Ortseifer I, Vogler I, Godehardt E, Attig S, Rae R, Breitkreuz A, Tolliver C, Suchan M, Martic G, Hohberger A, Sorn P, Diekmann J, Ciesla J, Waksmann O,
Ortseifer I, Vogler I, Godehardt E, Attig S, Rae R, Breitkreuz A, Tolliver C, Suchan M, Martic G, Hohberger A, Sorn P, Diekmann J, Ciesla J, Waksmann O,  Witt M, Zillgen M, Rothermel A, Kasemann B, Langer D, Bolte S, Diken M, Kreiter S, Nemecek R, Gebhardt C, Grabbe S,
Witt M, Zillgen M, Rothermel A, Kasemann B, Langer D, Bolte S, Diken M, Kreiter S, Nemecek R, Gebhardt C, Grabbe S,  Utikal J, Huber C, Loquai C,
Utikal J, Huber C, Loquai C,  Personalized RNA mutanome vaccines mobilize poly-specific therapeutic immunity against cancer. Nature, 547(7662), 222-226. doi:10.1038/nature23003
Personalized RNA mutanome vaccines mobilize poly-specific therapeutic immunity against cancer. Nature, 547(7662), 222-226. doi:10.1038/nature23003
Shannon, С.E. (1997). The mathematical theory of communication. 1963. MD Comput, 14(4), 306-317.
Strait & Dewey. (1996). The Shannon information entropy of protein sequences. Biophys. J. 1996 Biophys J. 71(l),148-55.
Szolek A, Schubert B, Mohr C, Sturm M, Feldhahn M, Kohlbacher O. (2014). OptiType: precision HLA typing from next-generation sequencing data. Bioinformatics, 30(23), 3310-3316. doi: 10.1093/bioinformatics/btu548
Tran E, Ahmadzadeh M, Lu YC, Gros A, Turcotte S, Robbins PF, Gartner JJ, Zheng Z, Li YF, Ray S, Wunderlich JR, Somerville RP, Rosenberg SA. (2015). knmunogenicity of somatic mutations in human gastrointestinal cancers. Science, 350(6266), 1387-1390. doi: 10.1126/science.aadl253
Wang K, Li M, Hakonarson H. (2010). ANNOVAR: functional annotation of genetic variants from high-throughput sequencing data. Nucleic Acids Res, 38(16), el64. doi:10.1093/nar/gkq603
Warren RL, Choe G, Freeman DJ, Castellarin M, Munro S, Moore R, Holt RA. (2012). Derivation of HLA types from shotgun sequence datasets. Genome Med, 4(12), 95. doi:10.1186/gm396
Yarchoan M, Johnson BA3rd, Lutz ER, Laheru DA, Jaffee EM. (2017). Targeting neoantigens to augment antitumour immunity. Nat Rev Cancer, 17(9), 569. doi: 10.1038/nrc.2017.74.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ отбора неоэпитопов | 2019 |
|
RU2826184C2 |
| СПОСОБ ЛЕЧЕНИЯ РАКА | 2016 |
|
RU2770447C2 |
| ИДЕНТИФИКАЦИЯ, ПРОИЗВОДСТВО И ПРИМЕНЕНИЕ НЕОАНТИГЕНОВ | 2016 |
|
RU2729116C2 |
| НЕОАНТИГЕННЫЕ КОМПОЗИЦИИ И ИХ ИСПОЛЬЗОВАНИЕ | 2020 |
|
RU2832574C2 |
| ПРЕДСКАЗАНИЕ ИММУНОГЕННОСТИ Т-КЛЕТОЧНЫХ ЭПИТОПОВ | 2014 |
|
RU2724370C2 |
| ВАКЦИННАЯ КОМПОЗИЦИЯ ДЛЯ ЛЕЧЕНИЯ РАКА | 2018 |
|
RU2782261C2 |
| СПОСОБЫ ПРОГНОЗИРОВАНИЯ ПРИМЕНИМОСТИ СПЕЦИФИЧНЫХ ДЛЯ ЗАБОЛЕВАНИЯ АМИНОКИСЛОТНЫХ МОДИФИКАЦИЙ ДЛЯ ИММУНОТЕРАПИИ | 2018 |
|
RU2799341C2 |
| НЕОАНТИГЕННЫЕ ВЕКТОРЫ НА ОСНОВЕ АЛЬФАВИРУСА | 2018 |
|
RU2803566C2 |
| СОСТАВЫ ВАКЦИН ПРОТИВ НЕОПЛАЗИИ И СПОСОБЫ ИХ ПОЛУЧЕНИЯ | 2016 |
|
RU2753246C2 |
| СПОСОБ И СИСТЕМЫ ДЛЯ ПРОГНОЗИРОВАНИЯ СПЕЦИФИЧЕСКИХ ДЛЯ HLA КЛАССА II ЭПИТОПОВ И ОХАРАКТЕРИЗАЦИИ CD4+ T-КЛЕТОК | 2019 |
|
RU2826261C2 |
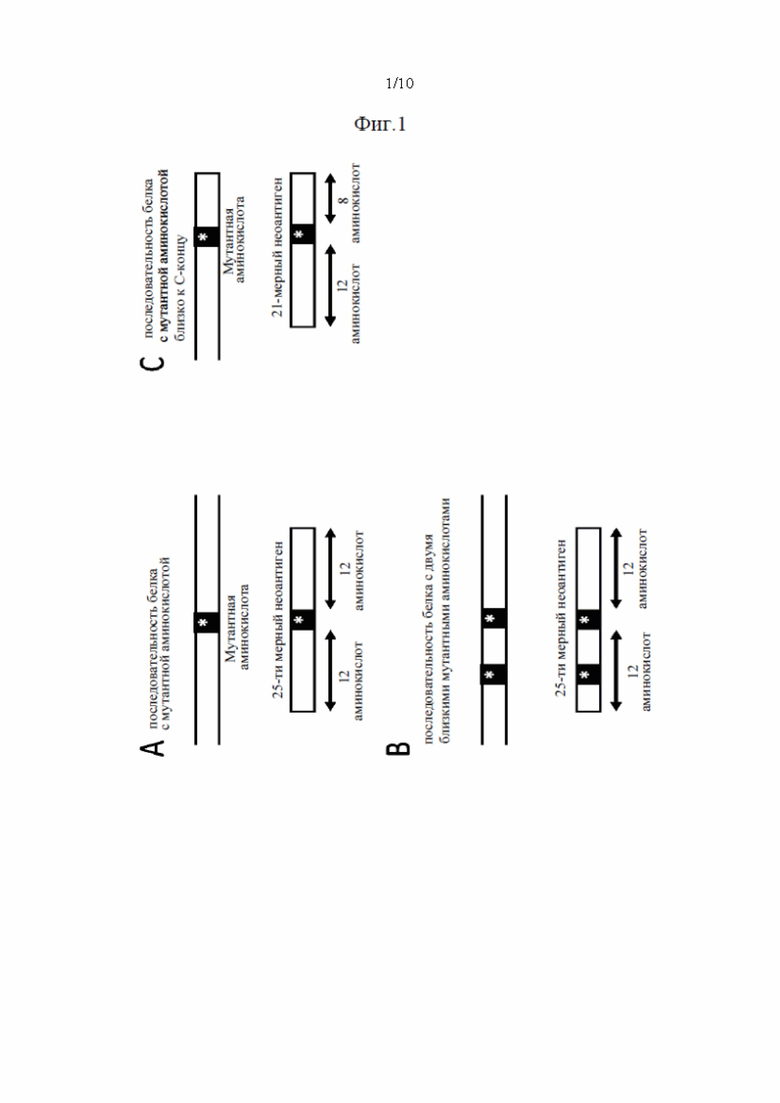

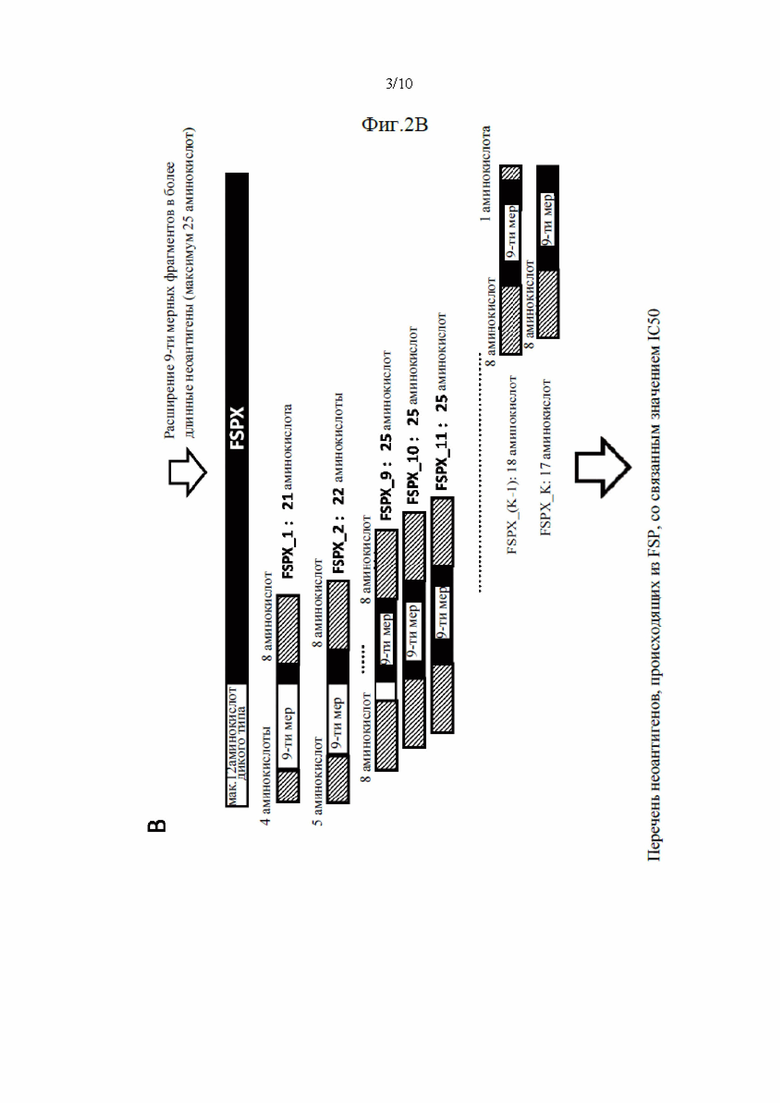
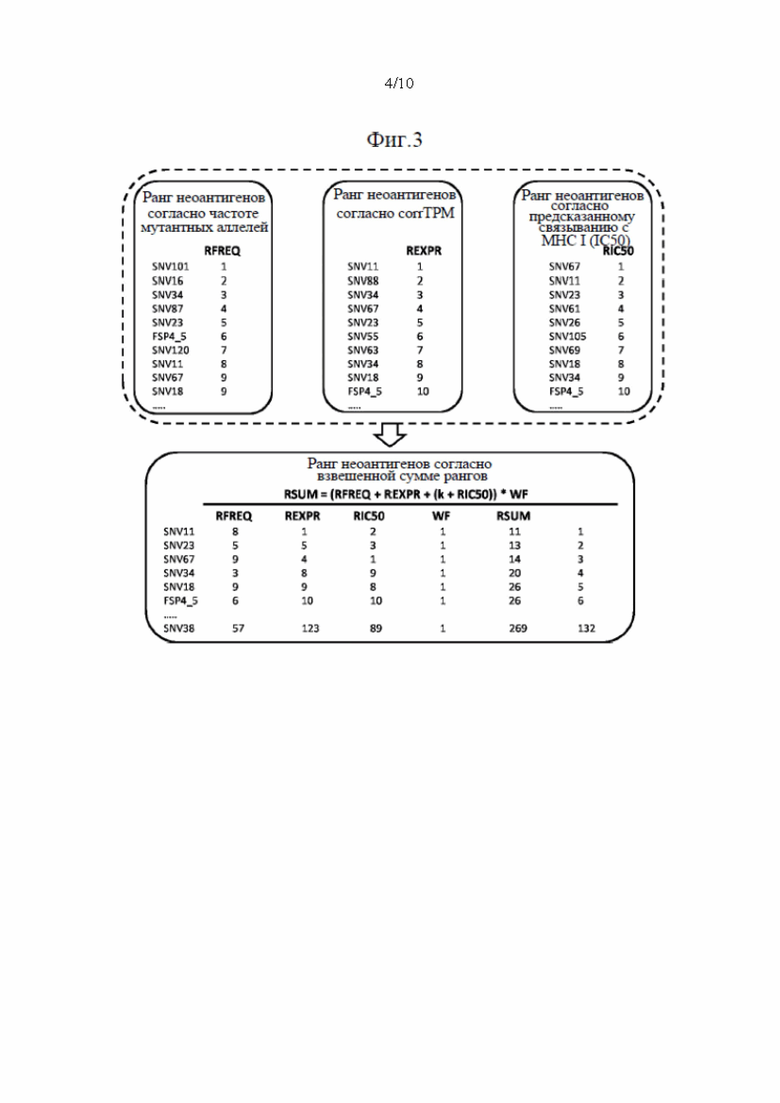
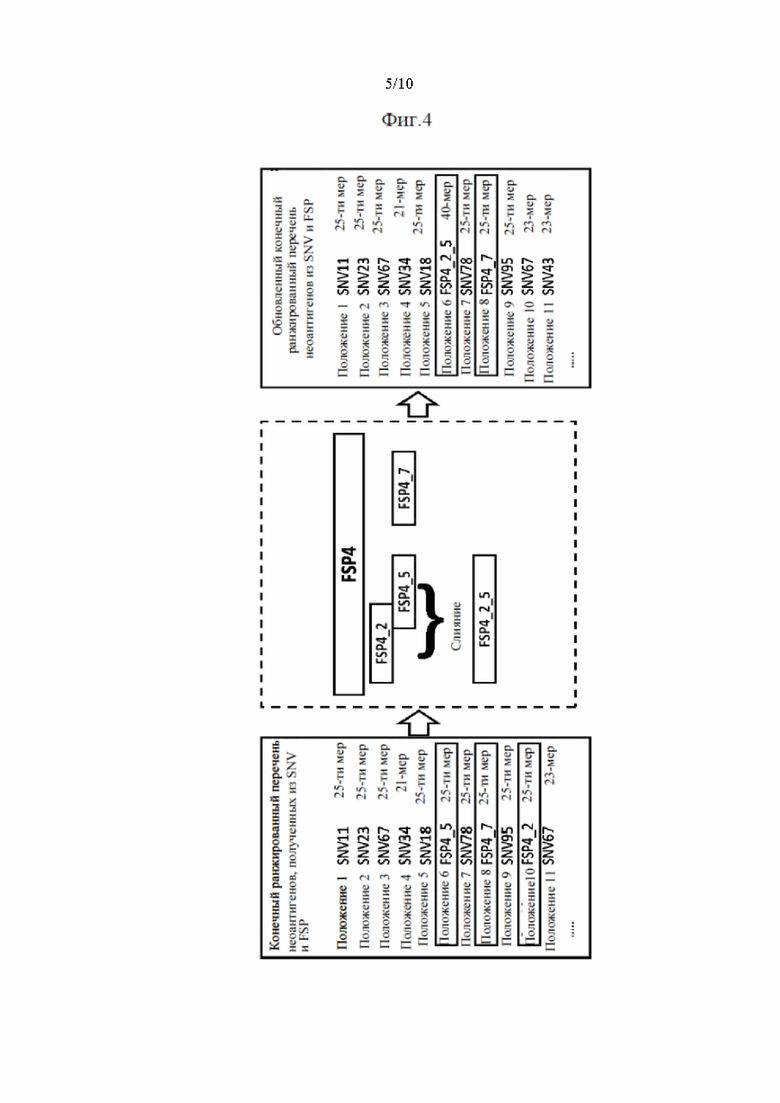
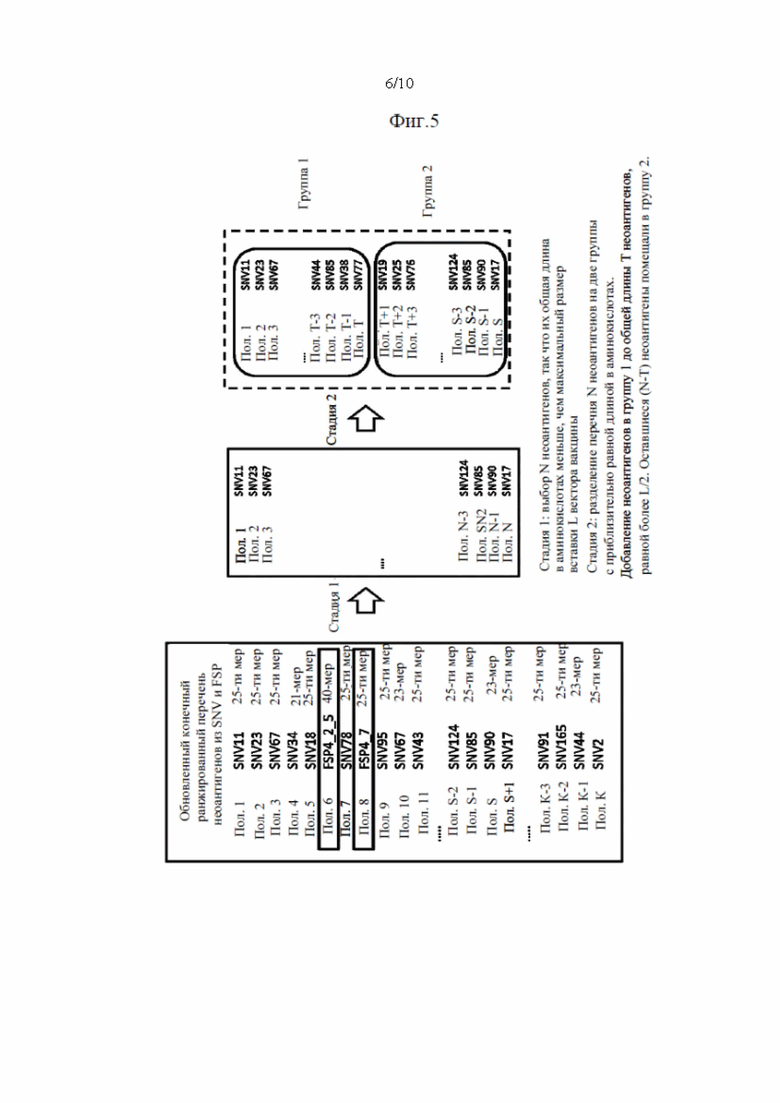

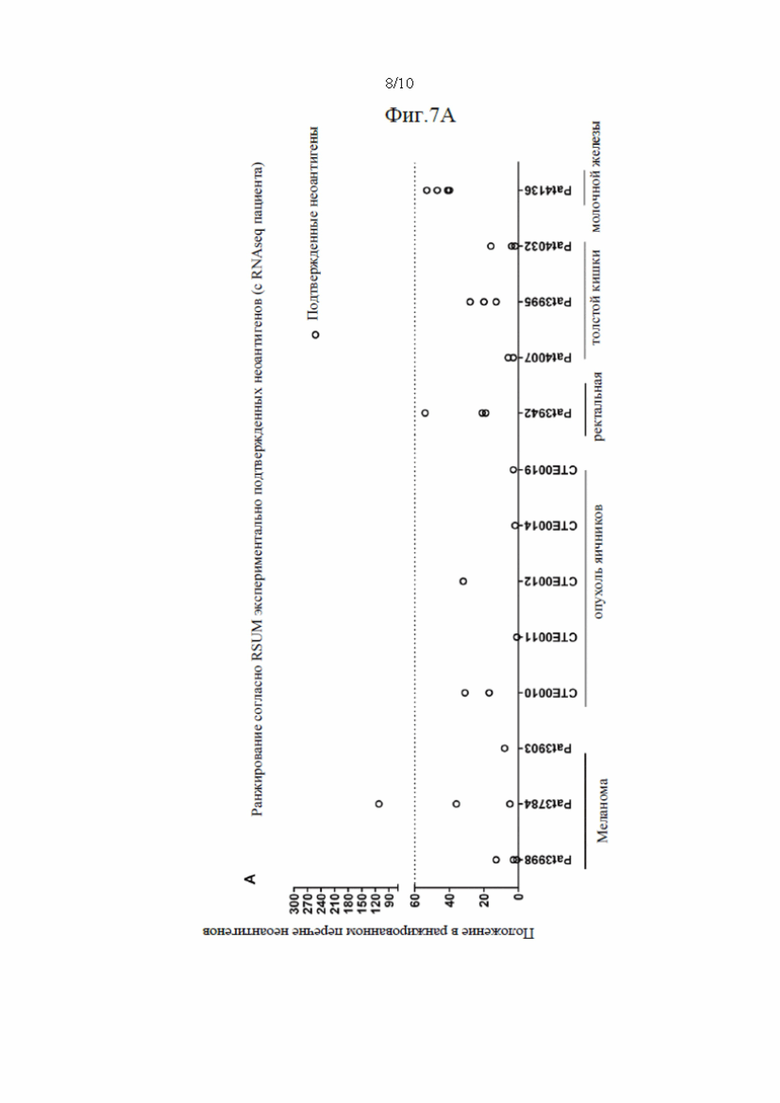

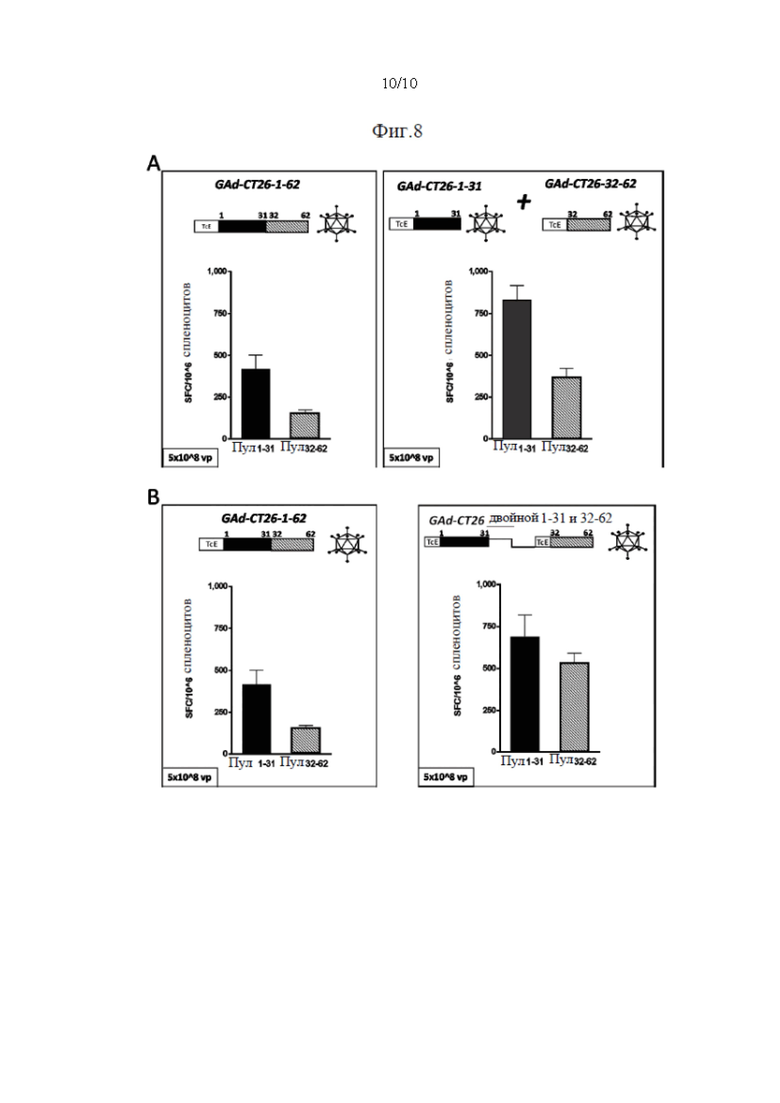
Изобретение относится к области молекулярной биологии. Описан способ выбора опухолевых неоантигенов для применения в персонализированной вакцине. Определяют неоантигены в образце раковых клеток, взятом у индивидуума, где каждый неоантиген содержится в кодирующей последовательности, содержит по меньшей мере одну мутацию в кодирующей последовательности, приводящую к изменению кодируемой аминокислотной последовательности, которое не присутствует в образце нераковых клеток указанного индивидуума, и состоит из от 9 до 40 смежных аминокислот кодирующей последовательности в образце раковых клеток. Определяют для каждого неоантигена частоты мутантных аллелей каждой из указанных мутаций в кодирующей последовательности. Определяют уровень экспрессии каждой кодирующей последовательности в образце раковых клеток или на основании базы данных экспрессии рака того же типа, что и образец раковых клеток. Предсказывают аффинность связывания неоантигенов с MHC класса I. Ранжируют неоантигены в соответствии со значениями, определенными ранее, для каждого неоантигена, от самого большого до самого маленького значения, с обеспечением первого, второго и третьего перечня рангов. Вычисляют ранговую сумму на основании первого, второго и третьего перечня рангов и распределения неоантигенов по увеличению ранговой суммы с получением ранжированного перечня неоантигенов, причем ранговая сумма представляет собой взвешенную ранговую сумму, где число неоантигенов добавляют к значению ранга каждого неоантигена. Выбор 30-240 неоантигенов из ранжированного перечня неоантигенов, начиная с самого низкого ранга. Также описан способ конструирования персонализированного вектора, кодирующего перечень неоантигенов, выбранных способом, для применения в виде вакцины. Представлен экспрессионный вектор, кодирующий перечень неоантигенов. Представлена коллекция экспрессионных векторов, каждый из которых кодирует часть перечня неоантигенов. Заявленное изобретение расширяет арсенал средств для лечения рака. 4 н. и 11 з.п. ф-лы, 8 ил., 9 табл., 4 пр.
1. Способ выбора опухолевых неоантигенов для применения в персонализированной вакцине, предусматривающий стадии:
(a) определения неоантигенов в образце раковых клеток, взятом у индивидуума, где каждый неоантиген
- содержится в кодирующей последовательности,
- содержит по меньшей мере одну мутацию в кодирующей последовательности, приводящую к изменению кодируемой аминокислотной последовательности, которое не присутствует в образце нераковых клеток указанного индивидуума, и
- состоит из от 9 до 40 смежных аминокислот кодирующей последовательности в образце раковых клеток,
(b) определения для каждого неоантигена частоты мутантных аллелей каждой из указанных мутаций согласно стадии (a) в кодирующей последовательности,
(c) определения уровня экспрессии каждой кодирующей последовательности, содержащей по меньшей мере одну из указанных мутаций,
(i) в указанном образце раковых клеток или
(ii) на основании базы данных экспрессии рака того же типа, что и образец раковых клеток,
(d) предсказания аффинности связывания неоантигенов с MHC класса I, где
(I) аллели HLA класса I определяют в образце нераковых клеток указанного индивидуума,
(II) для каждого аллеля HLA класса I, определенного на стадии (I), предсказывают аффинность связывания с MHC класса I для каждого фрагмента, состоящего из от 8 до 15 смежных аминокислот неоантигена, где каждый фрагмент содержит по меньшей мере одно аминокислотное изменение, вызванное мутацией согласно стадии (a), и
(III) фрагмент с наивысшей аффинностью связывания с MHC класса I определяет аффинность связывания неоантигена с MHC класса I,
(e) ранжирования неоантигенов в соответствии со значениями, определенными на стадиях (b) - (d), для каждого неоантигена, от самого большого до самого маленького значения, с обеспечением первого, второго и третьего перечня рангов,
(f) вычисления ранговой суммы на основании первого, второго и третьего перечня рангов и распределения неоантигенов по увеличению ранговой суммы с получением ранжированного перечня неоантигенов,
причем ранговая сумма представляет собой взвешенную ранговую сумму, где
- число неоантигенов, определенное на стадии (а), добавляют к значению ранга каждого неоантигена:
● в третьем перечне рангов, для которого предсказанная аффинность связывания с MНC класса I согласно стадии (d) привела к значению IC50 выше 1000 нМ и/или
● в четвертом перечне рангов, для которого предсказанная аффинность связывания с MНC класса II на стадии (d’) привела к значению IC50 выше 1000 нМ;
и/или
- в случае выполнения стадии (c) (i) путем массивно-параллельного секвенирования транскриптома ранговую сумму на стадии (f) умножают на фактор взвешивания (WF), где WF равен
● 1, если число картированных прочтений транскриптома для мутации равно > 0;
● 2, если число картированных прочтений транскриптома для мутации равно 0, и число картированных прочтений немутантной последовательности равно 0, и значение транскриптов на миллион (TPM) равно по меньшей мере 0,5;
● 3, если число картированных прочтений транскриптома для мутации равно 0, и число картированных прочтений немутантной последовательности равно > 0, и значение транскриптов на миллион (TPM) равно по меньшей мере 0,5;
● 4, если число картированных прочтений транскриптома для мутации равно 0, и число картированных прочтений немутантной последовательности равно 0, и значение транскриптов на миллион (TPM) равно < 0,5; или
● 5, если число картированных прочтений транскриптома для мутации равно 0, и число картированных прочтений немутантной последовательности равно > 0, и значение транскриптов на миллион (TPM) равно < 0,5;
(g) выбора 30-240 неоантигенов из ранжированного перечня неоантигенов, полученного на стадии (f), начиная с самого низкого ранга.
2. Способ по п. 1, в котором стадии (a) и (d) (I) проводят с применением массивно-параллельного секвенирования ДНК образцов, и где число прочтений, содержащих мутацию в хромосомном положении идентифицированной мутации, составляет:
- в образце раковых клеток по меньшей мере 2,
- в образце нераковых клеток составляет 2 или менее.
3. Способ по любому из предшествующих пунктов, где способ предусматривает стадию (d’) в дополнение к стадии (d) или в качестве альтернативы ей, где стадия (d’) содержит:
● определение аллелей HLA класса II в образце нераковых клеток указанного индивидуума,
● предсказание аффинности связывания неоантигена с MHC класса II, где
- для каждого определенного аллеля HLA класса II предсказывают аффинность связывания с MHC класса II для каждого фрагмента из от 11 до 30 смежных аминокислот неоантигена, где каждый фрагмент содержит по меньшей мере одну мутантную аминокислоту, полученную посредством мутации согласно стадии (a), и
фрагмент с самой высокой аффинностью связывания с MHC класса II определяет аффинность связывания неоантигена с MHC класса II,
где аффинность связывания с MHC класса II ранжируют от самой высокой до самой низкой аффинности связывания с MHC класса II, с получением четвертого перечня рангов, который включают в ранговую сумму на стадии (f).
4. Способ по любому из пп. 1-3, где по меньшей мере одна мутация согласно стадии (a) представляет собой однонуклеотидный вариант (SNV) или инсерционную/делеционную мутацию, приводящую к пептиду со сдвигом рамки считывания (FSP).
5. Способ по п. 4, где мутацией является SNV, и неоантиген имеет общий размер, определенный на стадии (a), и состоит из аминокислоты, вызванной мутацией, фланкированной с каждой стороны рядом соседних смежных аминокислот, причем число на каждой стороне не отличается более чем на одну, кроме тех случаев, когда кодирующая последовательность не содержит достаточного количества аминокислот на каждой стороне, где неоантиген имеет общий размер, определенный на стадии (а).
6. Способ по п. 4, где мутация приводит к FSP и каждое одно аминокислотное изменение, вызванное мутацией, приводит к неоантигену, который имеет общий размер, определенный на стадии (а), и состоит из:
(i) указанного одного аминокислотного изменения, вызванного мутацией, и от 7 до 14 N-концевых соседних смежных аминокислот, и
(ii) числа смежных аминокислот, примыкающих к фрагменту согласно стадии (i) с каждой стороны, причем число аминокислот с каждой стороны отличается не более чем на одну, кроме тех случаев, когда кодирующая последовательность не содержит достаточного количества аминокислот на каждой стороне,
где аффинность связывания с MНC класса I на стадии (d) и/или аффинность связывания с MНC класса II на стадии (d’) предсказывают для фрагмента согласно стадии (i).
7. Способ по любому из предшествующих пунктов, где частота мутантных аллелей неоантигена, определенная на стадии (b) в образце раковых клеток, составляет по меньшей мере 2%.
8. Способ по любому из предшествующих пунктов, где на стадии (g) дополнительно удаляют из указанного ранжированного перечня неоантигенов неоантигены из генов, связанных с аутоиммунным заболеванием, и/или неоантигены со значением энтропии Шеннона для их аминокислотной последовательности ниже 0,1.
9. Способ по любому из предшествующих пунктов, где уровень экспрессии указанных кодирующих генов на стадии (c) (i) определяют посредством массивно-параллельного секвенирования транскриптома, и причем уровень экспрессии, определенный на стадии (c) (i) использует скорректированное значение транскриптов на килобазу на миллион (corrTPM), вычисленное согласно следующей формуле:
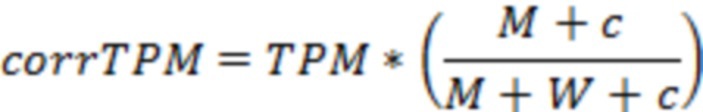 ,
,
где M представляет собой число прочтений, охватывающих положение мутации согласно стадии (а), которые содержат мутацию, и W представляет собой число прочтений, охватывающих положение мутации согласно стадии (а), без мутации, и TPM представляет собой значение транскриптов на килобазу на миллион гена, содержащего мутацию, и c является константой больше 0.
10. Способ по любому из предшествующих пунктов, где стадия (g) содержит альтернативный способ выбора, где неоантигены выбирают из ранжированного перечня неоантигенов начиная с самого низкого ранга, до тех пор, пока не будет достигнут установленный максимальный размер в общей полной длине в аминокислотах для всех выбранных неоантигенов, где максимальный размер составляет от 1200 до 1800, аминокислот для каждого вектора одновалентной или поливалентной вакцины, и необязательно где два или несколько неоантигена сливают в один новый неоантиген, если они содержат перекрывающиеся сегменты аминокислотных последовательностей.
11. Способ конструирования персонализированного вектора, кодирующего перечень неоантигенов, выбранных способом по любому из пп. 1-10, для применения в виде вакцины, предусматривающий стадии:
(i) распределения перечня неоантигенов в по меньшей мере 10^5-10^8 различные комбинации,
(ii) создания всех возможных пар сегментов соединения неоантигенов для каждой комбинации, где каждый сегмент соединения содержит 15 соседних смежных аминокислот с каждой стороны соединения,
(iii) предсказания аффинности связывания с MHC класса I и/или класса II для всех эпитопов в сегментах соединения, где тестируют только HLA аллели, которые присутствуют у индивидуума, для которого конструируют вектор, и
(iv) выбора комбинации неоантигенов с наименьшим числом соединенных эпитопов с IC50, равной ≤ 1500 нМ, и где, если множество комбинаций имеют одно и то же наименьшее число соединенных эпитопов, выбирают первую встречающуюся комбинацию.
12. Экспрессионный вектор, кодирующий перечень неоантигенов, выбранных способом по любому из пп. 1-10, дополнительно содержащий энхансерный элемент T-клеток, слитый с N-концом первого неоантигена в перечне, и где необязательно вектор содержит две независимые экспрессионные кассеты, где каждая экспрессионная кассета кодирует часть перечня неоантигенов, выбранных способом по любому из пп. 1-10, и где части перечня, кодируемые экспрессионными кассетами, имеют приблизительно равный размер по числу аминокислот.
13. Коллекция экспрессионных векторов, каждый из которых кодирует часть перечня неоантигенов, выбранных способом по любому из пп. 1-10, где коллекция содержит 2-4 вектора.
14. Коллекция экспрессионных векторов по п. 13, где вставки в эти векторы, кодирующие часть перечня, имеют приблизительно равный размер по числу аминокислот.
15. Вектор по п. 12 или коллекция векторов по любому из пп. 13 и 14 для применения в вакцинации против рака.
| US 2017016075 A1, 19.01.2017 | |||
| WO 2017106638 A1, 22.06.2017 | |||
| WO 2018098362 А1, 31.05.2018 | |||
| LUIGI AURISICCHIO ET AL, "The perfect personalized cancer therapy: cancer vaccines against neoantigens", JOURNAL OF EXPERIMENTAL AND CLINICAL CANCER RESEARCH.,Vol | |||
| Пишущая машина | 1922 |
|
SU37A1 |
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| OTT PATRICK A ET AL, "An immunogenic personal neoantigen vaccine for | |||
