ПЕРЕКРЕСТНАЯ ССЫЛКА НА РОДСТВЕННЫЕ ЗАЯВКИ
Настоящая заявка испрашивает приоритет по дате подачи предварительной заявки на патент США №62/443495, поданной 6 января 2017 года, предварительной заявки на патент США №62/510228, поданной 23 мая 2017 года и предварительной заявки на патент США №62/589473, поданной 21 ноября 2017 года. Содержания каждой из этих заявок включены в данный документ посредством ссылки во всей полноте.
ПРЕДПОСЫЛКИ ИЗОБРЕТЕНИЯ
Терапевтические белки, например терапевтические антитела и белки слияния, содержащие Fc-домен, быстро стали клинически важным классом лекарственных средств для пациентов с иммунологическими и воспалительными заболеваниями, раком и инфекциями.
КРАТКОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Настоящее изобретение предусматривает биологически активные терапевтические конструкции, содержащие Fc-домен. Такие конструкции могут характеризоваться необходимым периодом полужизни в сыворотке и/или аффинностью связывания и/или авидностью к Fc-рецепторам.
В общем, изобретение предусматривает Fc-конструкции, содержащие 2-10 Fc-доменов, например, Fc-конструкции, содержащие 2, 3, 4, 5, 6, 7, 8, 9 или 10 Fc-доменов. В некоторых вариантах осуществления Fc-конструкция содержит 2-10 Fc-доменов, 2-5 Fc-доменов, 2-4 Fc-домена, 2-3 Fc-домена, 3-5 Fc-доменов, 2-8 Fc-доменов или 2-6 Fc-доменов. В некоторых вариантах осуществления Fc-конструкция содержит 2-4 Fc-домена. В некоторых вариантах осуществления Fc-конструкция содержит 5-10 Fc-доменов (например, 5-6, 5-7, 5-8, 5-9 или 5-10 Fc-доменов).
В некоторых вариантах осуществления конструкции (например, Fc-конструкции, содержащие 2-4 Fc-домена, например, 2, 3 или 4 Fc-домена) и гомогенные фармацевтические композиции (например, те, которые содержат Fc-конструкции, содержащие 2-4 Fc-домена, например, 2, 3 или 4 Fc-домена) по настоящему изобретению, применимы, например, для уменьшения воспаления у субъекта, для стимуляции клиренса аутоантител у субъекта, для подавления презентации антигена у субъекта, для блокирования иммунного ответа, например, для блокирования иммунокомплексной активации иммунного ответа у субъекта, и для лечения иммунологических и воспалительных заболеваний (например, аутоиммунных заболеваний) у субъекта. Описанные в данном документе Fc-конструкции можно применять для лечения пациентов с иммунологическими и воспалительными заболеваниями без значительной стимуляции иммунных клеток. В некоторых вариантах осуществления конструкции (например, Fc-конструкции, содержащие 5-10 Fc-доменов, например, 5, 6, 7, 8, 9 или 10 Fc-доменов) и гомогенные фармацевтические композиции (например, те, которые содержат Fc-конструкции, содержащие 5-10 Fc-доменов, например 5, 6, 7, 8, 9 или 10 Fc-доменов) по настоящему изобретению, применимы, например, для индуцирования активации иммунных клеток, обеспечивающих иммунный ответ у субъекта, для усиления фагоцитоза целевой клетки (т.е. раковой клетки или инфицированной клетки) у субъекта и для лечения таких заболеваний, как рак и инфекции у субъекта.
Свойства этих конструкций обеспечить эффективное получение по сути гомогенных композиций. Степень гомогенности композиции влияет на фармакокинетику и характеристику композиции in vivo. Такая гомогенность композиции необходима для обеспечения безопасности, эффективности, однородности и надежности композиции. Fc-конструкция по настоящему изобретению может находиться в композиции или совокупности, которая является по сути гомогенной (например, на по меньшей мере 85%, 90%, 95%, 98% или 99% гомогенной).
Как описано более подробно в данном документе, изобретение предусматривает по сути гомогенные композиции, содержащие Fc-конструкции, все из которых содержат одинаковое количество Fc-доменов, а также способы получения таких по сути гомогенных композиций.
В первом аспекте настоящее изобретение предусматривает Fc-конструкцию, содержащую а) первый полипептид, содержащий i) первый мономер Fc-домена; ii) второй мономер Fc-домена и iii) линкер, соединяющий первый мономер Fc-домена со вторым мономером Fc-домена; b) второй полипептид, содержащий i) третий мономер Fc-домена; ii) четвертый мономер Fc-домена и iii) линкер, соединяющий третий мономер Fc-домена с четвертым мономером Fc-домена; c) третий полипептид содержит пятый мономер Fc-домена и d) четвертый полипептид содержит шестой мономер Fc-домена; где первый мономер Fc-домена и пятый мономер Fc-домена соединены с образованием первого Fc-домена, второй мономер Fc-домена и четвертый мономер Fc-домена соединены с образованием второго Fc-домена, а третий мономер Fc-домена и шестой мономер Fc-домена соединены с образованием третьего Fc-домена, и где каждый из первого и второго полипептидов содержит последовательность DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 76), и каждый из третьего и четвертого полипептидов содержит последовательность DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 70).
В другом аспекте настоящее изобретение предусматривает Fc-конструкцию, содержащую а) первый полипептид, содержащий i) первый мономер Fc-домена; ii) второй мономер Fc-домена и iii) линкер, соединяющий первый мономер Fc-домена со вторым мономером Fc-домена; b) второй полипептид, содержащий i) третий мономер Fc-домена; ii) четвертый мономер Fc-домена и iii) линкер, соединяющий третий мономер Fc-домена с четвертым мономером Fc-домена; c) третий полипептид содержит пятый мономер Fc-домена и d) четвертый полипептид содержит шестой мономер Fc-домена; где первый мономер Fc-домена и пятый мономер Fc-домена соединены с образованием первого Fc-домена, второй мономер Fc-домена и четвертый мономер Fc-домена соединены с образованием второго Fc-домена, а третий мономер Fc-домена и шестой мономер Fc-домена соединены с образованием третьего Fc-домена, и где по меньшей мере один Fc-домен содержит аминокислотную модификацию в положении I253 (например, одну аминокислотную модификацию в положении I253). В другом аспекте настоящее изобретение предусматривает Fc-конструкцию, содержащую а) первый полипептид, содержащий i) первый мономер Fc-домена; ii) второй мономер Fc-домена и iii) линкер, соединяющий первый мономер Fc-домена со вторым мономером Fc-домена; b) второй полипептид, содержащий i) третий мономер Fc-домена; ii) четвертый мономер Fc-домена и iii) линкер, соединяющий третий мономер Fc-домена с четвертым мономером Fc-домена; c) третий полипептид содержит пятый мономер Fc-домена и d) четвертый полипептид содержит шестой мономер Fc-домена; где первый мономер Fc-домена и пятый мономер Fc-домена соединены с образованием первого Fc-домена, второй мономер Fc-домена и четвертый мономер Fc-домена соединены с образованием второго Fc-домена, а третий мономер Fc-домена и шестой мономер Fc-домена соединены с образованием третьего Fc-домена, и где по меньшей мере один мономер Fc-домена содержит аминокислотную замену в положении I253.
В некоторых случаях первый и второй полипептиды идентичны друг другу, а третий и четвертый полипептиды идентичны друг другу. В некоторых вариантах осуществления первый Fc-домен содержит аминокислотную модификацию в положении I253. В некоторых случаях один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену в положении I253. В некоторых вариантах осуществления второй Fc-домен содержит аминокислотную модификацию в положении I253. В некоторых вариантах осуществления один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену в положении I253. В некоторых вариантах осуществления третий Fc-домен содержит аминокислотную модификацию в положении I253. В некоторых вариантах осуществления один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену в положении I253. В некоторых вариантах осуществления каждая аминокислотная модификация (например, замена) в положении I253 независимо выбрана из группы, состоящей из I253A, I253C, I253D, I253E, I253F, I253G, I253H, I253I, I253K, I253L, I253M, I253N, I253P, I253Q, I253R, I253S, I253T, I253V, I253W и I253Y. В некоторых вариантах осуществления каждая аминокислотная модификация (например, замена) в положении I253 представляет собой I253A. В некоторых вариантах осуществления Fc-конструкция (например, по меньшей мере один мономер Fc-домена) содержит по меньшей мере одну аминокислотную модификацию в положении R292. В некоторых вариантах осуществления по меньшей мере один мономер Fc-домена содержит аминокислотную замену в положении R292. В некоторых вариантах осуществления первый Fc-домен содержит аминокислотную модификацию в положении R292. В некоторых вариантах осуществления первый Fc-домен (например, один или оба из первого мономера Fc-домена и пятого мономера Fc-домена) содержит аминокислотную замену в положении R292. В некоторых вариантах осуществления второй Fc-домен содержит аминокислотную модификацию в положении R292. В некоторых вариантах осуществления второй Fc-домен (например, один или оба из второго мономера Fc-домена и четвертого мономера Fc-домена) содержит аминокислотную замену в положении R292. В некоторых вариантах осуществления третий Fc-домен содержит аминокислотную модификацию в положении R292. В некоторых вариантах осуществления третий Fc-домен (например, один или оба из третьего мономера Fc-домена и шестого мономера Fc-домена) содержит аминокислотную замену в положении R292. В некоторых вариантах осуществления каждый из первого, второго и третьего Fc-домена содержит аминокислотную модификацию (например, замену) в положении R292. В некоторых случаях один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену в положении R292, один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену в положении R292 и один или более из третьего и шестого мономеров Fc-домена содержат аминокислотную замену в положении R292. В некоторых вариантах осуществления каждый из первого, второго и третьего Fc-домена содержит аминокислотную модификацию (например, замену) R292P. В некоторых вариантах осуществления каждая аминокислотная модификация (например, замена) в положении R292 независимо выбрана из группы, состоящей из R292D, R292E, R292L, R292P, R292Q, R292R, R292T и R292Y. В некоторых вариантах осуществления каждая аминокислотная модификация (например, замена) в положении R292 представляет собой R292P.
В некоторых вариантах осуществления всех аспектов каждый из Fc-доменов основан на Fc-последовательности IgG1 человека и содержит модификации, описанные в данном документе (т.е. представляет собой вариант Fc-последовательности IgG человека). В некоторых вариантах осуществления основная Fc-последовательность IgG1 представляет собой SEQ ID NO: 42 и содержит не более чем 10 одиночных аминокислотных модификаций. В некоторых вариантах осуществления каждый из Fc-доменов Fc-конструкций, описанных в данном документе, представляет собой Fc-последовательность IgG1 (например, SEQ ID NO: 42) с не более чем 10 одиночными аминокислотными модификациями. В некоторых вариантах осуществления Fc-последовательность IgG1 представляет собой SEQ ID NO: 42 и содержит модификации сконструированной полости, сконструированного выступа и/или модификации электростатического координирования для контроля сборки полипептидов и/или модификации мутаций, относящихся к связыванию, для модификации фармакокинетики конструкции, описанной в данном документе. Таким образом, не более чем 10 одиночных аминокислотных модификаций могут включать модификацию (например, замену) в одном или обоих из I253 (например, I253A) и R292 (например, R292P) и модификации (например, замены) для обеспечения: сконструированной полости и сконструированного выступа и/или модификации электростатического координирования для контроля сборки полипептидов. В некоторых случаях каждый мономер Fc-домена содержит не более чем 10, 9, 8, 7, 6, 5, 4, 3, 2 или 1 одиночную аминокислотную модификацию в дополнение к замене в одном или обоих из I253 и R292. Модификации для обеспечения сконструированной полости, сконструированного выступа и/или модификации электростатического координирования для контроля сборки полипептидов предпочтительно находятся в СН3-домене(-ах) Fc-домена.
В другом аспекте настоящее изобретение предусматривает Fc-конструкцию, содержащую а) первый полипептид, содержащий i) первый мономер Fc-домена; ii) второй мономер Fc-домена и iii) линкер, соединяющий первый мономер Fc-домена со вторым мономером Fc-домена; b) второй полипептид, содержащий i) третий мономер Fc-домена; ii) четвертый мономер Fc-домена и iii) линкер, соединяющий третий мономер Fc-домена с четвертым мономером Fc-домена; c) третий полипептид содержит пятый мономер Fc-домена и d) четвертый полипептид содержит шестой мономер Fc-домена; где первый мономер Fc-домена и пятый мономер Fc-домена соединены с образованием первого Fc-домена, второй мономер Fc-домена и четвертый мономер Fc-домена соединены с образованием второго Fc-домена, а третий мономер Fc-домена и шестой мономер Fc-домена соединены с образованием третьего Fc-домена, и где по меньшей мере один Fc-домен содержит аминокислотную модификацию в положении R292 (например, одну аминокислотную модификацию). В другом аспекте настоящее изобретение предусматривает Fc-конструкцию, содержащую а) первый полипептид, содержащий i) первый мономер Fc-домена; ii) второй мономер Fc-домена и iii) линкер, соединяющий первый мономер Fc-домена со вторым мономером Fc-домена; b) второй полипептид, содержащий i) третий мономер Fc-домена; ii) четвертый мономер Fc-домена и iii) линкер, соединяющий третий мономер Fc-домена с четвертым мономером Fc-домена; c) третий полипептид содержит пятый мономер Fc-домена и d) четвертый полипептид содержит шестой мономер Fc-домена; где первый мономер Fc-домена и пятый мономер Fc-домена соединены с образованием первого Fc-домена, второй мономер Fc-домена и четвертый мономер Fc-домена соединены с образованием второго Fc-домена, а третий мономер Fc-домена и шестой мономер Fc-домена соединены с образованием третьего Fc-домена, и где по меньшей мере один мономер Fc-домена содержит аминокислотную замену в положении R292.
В некоторых вариантах осуществления первый Fc-домен содержит аминокислотную модификацию в положении R292. В некоторых вариантах осуществления один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену в положении R292. В некоторых вариантах осуществления второй Fc-домен содержит аминокислотную модификацию в положении R292. В некоторых вариантах осуществления один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену в положении R292. В некоторых вариантах осуществления третий Fc-домен содержит аминокислотную модификацию в положении R292. В некоторых вариантах осуществления один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену в положении R292. В некоторых вариантах осуществления каждый из первого, второго и третьего Fc-домена содержит аминокислотную модификацию (например, замену) в положении R292. В некоторых вариантах осуществления каждый из первого, второго и третьего Fc-домена содержит аминокислотную модификацию (например, замену) R292P (т.е. каждый Fc-мономер имеет модификацию R292P, например, по сравнению с SEQ ID NO: 42). В некоторых вариантах осуществления один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену R292P, один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену R292P и один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену R292P.
В некоторых вариантах осуществления каждая аминокислотная модификация (например, замена) в положении R292 независимо выбрана из R292D, R292E, R292L, R292P, R292Q, R292R, R292T или R292Y. В некоторых вариантах осуществления каждая аминокислотная модификация (например, замена) в положении R292 представляет собой R292P. В некоторых вариантах осуществления каждый из первого и третьего Fc-доменов содержит аминокислотную модификацию (например, замену) I253A, и каждый из первого, второго и третьего Fc-доменов содержит аминокислотную модификацию (например, замену) R292P. В некоторых вариантах осуществления один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену I253A, один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену I253A, один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену R292P, один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену R292P, и один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену R292P. В некоторых вариантах осуществления каждый из первого, второго и третьего Fc-доменов содержит аминокислотную модификацию (например, замену) I253A и R292P. В некоторых вариантах осуществления один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену I253A, один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену I253A и один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену I253A, один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену R292P, один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену R292P и один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену R292P.
В некоторых вариантах осуществления последовательность каждого Fc-домена основана на последовательности Fc-домена IgG1 человека с не более чем десятью одиночными аминокислотными модификациями. В некоторых вариантах осуществления последовательность каждого Fc-домена основана на SEQ ID NO: 42 с не более чем десятью одиночными аминокислотными модификациями.
В некоторых вариантах осуществления каждый из первого Fc-домена и третьего Fc-домена содержит аминокислотные замены I253A и R292P, а второй Fc-домен содержит аминокислотную замену R292P. В некоторых случаях один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену I253A, один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену R292P, один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену I253A, один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену R292P, и один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену R292P.
В некоторых вариантах осуществления второй Fc-домен содержит аминокислотную замену в положении I253A. В некоторых вариантах осуществления один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену I253A. В некоторых вариантах осуществления каждый из первого Fc-домена и третьего Fc-домена содержит аминокислотную замену I253A. В некоторых вариантах осуществления один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену I253A, и один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену I253A. В некоторых вариантах осуществления каждый из первого Fc-домена, второго Fc-домена и третьего Fc-домена содержит аминокислотную замену I253A. В некоторых вариантах осуществления один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену I253A, один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену I253A и один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену I253A.
В некоторых вариантах осуществления второй Fc-домен содержит аминокислотную замену в положении R292P. В некоторых вариантах осуществления один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену R292P. В некоторых вариантах осуществления второй Fc-домен содержит аминокислотные замены I253A и R292P. В некоторых вариантах осуществления один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену I253A, и один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену R292P. В некоторых вариантах осуществления каждый из первого Fc-домена и третьего Fc-домена содержит аминокислотную замену I253A, а второй Fc-домен содержит аминокислотную замену R292P. В некоторых вариантах осуществления один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену I253A, один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену I253A и один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену R292P.
В некоторых вариантах осуществления каждый из первого Fc-домена и третьего Fc-домена содержит аминокислотную замену I253A, а второй Fc-домен содержит аминокислотную замену I253A и R292P. В некоторых вариантах осуществления один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену I253A, один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену I253A, один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену I253A, и один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену R292P. В некоторых вариантах осуществления каждый из первого Fc-домена и третьего Fc-домена содержит аминокислотную замену R292P. В некоторых вариантах осуществления один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену R292P, и один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену R292P.
В некоторых вариантах осуществления первый Fc-домен и третий Fc-домен содержат аминокислотную замену R292P, а второй Fc-домен содержит аминокислотную замену I253A. В некоторых вариантах осуществления один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену R292P, один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену R292P и один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену I253A. В некоторых вариантах осуществления каждый из первого Fc-домена и третьего Fc-домена содержит I253A и R292P (например, содержит аминокислотные замены I253A и R292P). В некоторых вариантах осуществления один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену I253A, один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену R292P, один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену I253A, и один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену R292P.
В некоторых вариантах осуществления каждый из первого Fc-домена и третьего Fc-домена содержит аминокислотные замены I253A и R292P, а второй Fc-домен содержит аминокислотную замену I253A. В некоторых вариантах осуществления один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену I253A, один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену R292P, один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену I253A, один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену R292P, и один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену I253A. В некоторых вариантах осуществления каждый из первого Fc-домена, второго Fc-домена и третьего Fc-домена содержит аминокислотную замену R292P. В некоторых вариантах осуществления один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену R292P, один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену R292P и один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену R292P.
В некоторых вариантах осуществления каждый из первого Fc-домена и третьего Fc-домена содержит аминокислотную замену R292P, а второй Fc-домен содержит аминокислотные замены I253A и R292P. В некоторых вариантах осуществления один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену R292P, один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену R292P, один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену I253A, и один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену R292P. В некоторых вариантах осуществления каждый из первого Fc-домена, второго Fc-домена и третьего Fc-домена содержит аминокислотные замены I253A и R292P. В некоторых вариантах осуществления один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену I253A, один или оба из первого и пятого мономеров Fc-домена содержат аминокислотную замену R292P и один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену I253A, один или оба из второго и четвертого мономеров Fc-домена содержат аминокислотную замену R292P, один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену I253A и один или оба из третьего и шестого мономеров Fc-домена содержат аминокислотную замену R292P.
В некоторых вариантах осуществления первый мономер Fc-домена и пятый мономер Fc-домена содержат модули селективности, обеспечивающие комплементарную димеризацию, которые способствуют осуществлению димеризации между первым мономером Fc-домена и пятым мономером Fc-домена. В некоторых вариантах осуществления второй мономер Fc-домена и четвертый мономер Fc-домена содержат модули селективности, обеспечивающие комплементарную димеризацию, которые способствуют осуществлению димеризации между вторым мономером Fc-домена и четвертым мономером Fc-домена. В некоторых вариантах осуществления третий мономер Fc-домена и шестой мономер Fc-домена содержат модули селективности, обеспечивающие комплементарную димеризацию, которые способствуют осуществлению димеризации между третьим мономером Fc-домена и шестым мономером Fc-домена. В некоторых вариантах осуществления первый полипептид и второй полипептид содержат, состоят из или состоят по сути из одной и той же аминокислотной последовательности, и при этом третий полипептид и четвертый полипептид содержат, состоят из или состоят по сути из одной и той же аминокислотной последовательности. В некоторых вариантах осуществления каждый из второго мономера Fc-домена и четвертого мономера Fc-домена содержит D399K и либо K409D, либо K409E. В некоторых вариантах осуществления каждый из второго мономера Fc-домена и четвертого мономера Fc-домена содержит K392D и D399K. В некоторых вариантах осуществления каждый из второго мономера Fc-домена и четвертого мономера Fc-домена содержит E357K и K370E. В некоторых вариантах осуществления каждый из второго мономера Fc-домена и четвертого мономера Fc-домена содержит D356K и K439D. В некоторых вариантах осуществления каждый из второго мономера Fc-домена и четвертого мономера Fc-домена содержит K392E и D399K. В некоторых вариантах осуществления каждый из второго мономера Fc-домена и четвертого мономера Fc-домена содержит E357K и K370D. В некоторых вариантах осуществления каждый из второго мономера Fc-домена и четвертого мономера Fc-домена содержит D356K и K439E. В некоторых вариантах осуществления каждый из первого мономера Fc-домена и третьего мономера Fc-домена содержит S354C и T366W, и каждый из пятого мономера Fc-домена и шестого мономера Fc-домена содержит Y349C, T366S, L368A и Y407V. В некоторых вариантах осуществления каждый из третьего и четвертого полипептидов содержит S354C и T366W, и каждый из первого мономера Fc-домена и третьего мономера Fc-домена содержит Y349C, T366S, L368A и Y407V. В некоторых вариантах осуществления каждый из первого мономера Fc-домена и третьего мономера Fc-домена содержит E357K или E357R, и каждый из пятого мономера Fc-домена и шестого мономера Fc-домена содержит K370D и K370E. В некоторых вариантах осуществления первый мономер Fc-домена и третий мономер Fc-домена содержат K370D или K370E, и каждый из пятого мономера Fc-домена и шестого мономера Fc-домена содержит E357K и E357R. В некоторых вариантах осуществления каждый из первого мономера Fc-домена и третьего мономера Fc-домена содержит K409D или K409E, и каждый из пятого мономера Fc-домена и шестого мономера Fc-домена содержит D399K и D399R. В некоторых вариантах осуществления первый мономер Fc-домена и третий мономер Fc-домена содержат D399K или D399R, и каждый из пятого мономера Fc-домена и шестого мономера Fc-домена содержит K409D и K409E.
В некоторых вариантах осуществления линкер (например, спейсер) содержит полипептид, имеющий последовательность GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23), GGGGS (SEQ ID NO: 1), GGSG (SEQ ID NO: 2), SGGG(SEQ ID NO: 3) , GSGS (SEQ ID NO: 4), GSGSGS (SEQ ID NO: 5), GSGSGSGS (SEQ ID NO: 6), GSGSGSGSGS (SEQ ID NO: 7), GSGSGSGSGSGS (SEQ ID NO: 8), GGSGGS (SEQ ID NO: 9), GGSGGSGGS (SEQ ID NO: 10), GGSGGSGGSGGS (SEQ ID NO: 11), GGSGGGSG (SEQ ID NO: 12), GGSGGGSGGGSG (SEQ ID NO: 13), GGSGGGSGGGSGGGSG (SEQ ID NO: 14), GGSGGGSGGGSGGGGGSGGGGSGGGGSGGGGS (SEQ ID NO: 80), GENLYFQSGG (SEQ ID NO: 28), SACYCELS (SEQ ID NO: 29), RSIAT (SEQ ID NO: 30), RPACKIPNDLKQKVMNH (SEQ ID NO: 31), GGSAGGSGSGSSGGSSGASGTGTAGGTGSGSGTGSG (SEQ ID NO: 32), AAANSSIDLISVPVDSR (SEQ ID NO: 33), GGSGGGSEGGGSEGGGSEGGGSEGGGSEGGGSGGGS (SEQ ID NO: 34), GGGSGGGSGGGS (SEQ ID NO: 35), SGGGSGGGSGGGSGGGSGGG (SEQ ID NO: 18), GGSGGGSGGGSGGGSGGS (SEQ ID NO: 36), GGGG (SEQ ID NO: 19), GGGGGGGG (SEQ ID NO: 20), GGGGGGGGGGGG (SEQ ID NO: 21) или GGGGGGGGGGGGGGGG (SEQ ID NO: 22). В других вариантах осуществления один или более линкеров в Fc-конструкции, описанной в данном документе, представляют собой спейсер, например аминокислотный спейсер из 2-200 аминокислот (например, 2-100, 3-200, 3-150, 3-100, 3-60, 3-50, 3-40, 3-30, 3-20, 3-10, 3-8, 3-5, 4-30, 5-30, 6-30, 8-30, 10-20, 10-30, 12-30, 14-30, 20-30, 15-25, 15-30, 18-22 и 20-30 аминокислот). В некоторых случаях аминокислотный спейсер содержит только глицин, только серин или только серин и глицин. В некоторых вариантах осуществления аминокислотный спейсер содержит только глицин.
В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEV
HNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 78). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 78) с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 78 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, вне подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO: 78 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 78 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 78 находится аланин, в положении 72 SEQ ID NO: 78 находится пролин, а в положении 319 SEQ ID NO: 78 находится пролин.
В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEV
HNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 49). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 49 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 49 с не более чем 10 одиночными аминокислотными модификациями, при условии, что ни одна из не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночных аминокислотных модификаций не находится в области вне линкера (например, вне подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO: 49 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 49 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 134 SEQ ID NO: 49 находится цистеин, в положении 137 SEQ ID NO: 49 находится лизин, в положении 146 SEQ ID NO: 49 находится триптофан, в положении 426 SEQ ID NO: 49 находится лизин, а в положении 436 SEQ ID NO: 49 находится аспарагиновая кислота.
В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPRE
EQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 62). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 62 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 62 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, вне подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO: 62 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 62 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 134 SEQ ID NO: 62 находится цистеин, в положении 137 SEQ ID NO: 62 находится лизин, в положении 146 SEQ ID NO: 62 находится триптофан, в положении 280 SEQ ID NO: 62 находится аланин, в положении 426 SEQ ID NO: 62 находится лизин, а в положении 436 SEQ ID NO: 62 находится аспарагиновая кислота.
В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 64). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 64 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 64 с не более чем 10 одиночными аминокислотными модификациями в области вне линкера (например, вне подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO: 64 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 64 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 64 находится аланин.
В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 65). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 65 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 65 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO: 65 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 65 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 65 находится аланин, в положении 134 SEQ ID NO: 65 находится цистеин, в положении 137 SEQ ID NO: 65 находится лизин, в положении 146 SEQ ID NO: 65 находится триптофан, в положении 280 SEQ ID NO: 65 находится аланин, в положении 426 SEQ ID NO: 65 находится лизин, а в положении 436 SEQ ID NO: 65 находится аспарагиновая кислота.
В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 66). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 66 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 66 с не более чем 10 одиночными аминокислотными модификациями в области вне линкера (например, вне подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO:66 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 66 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 134 SEQ ID NO: 66 находится цистеин, в положении 137 SEQ ID NO: 66 находится лизин, в положении 146 SEQ ID NO: 66 находится триптофан, в положении 319 SEQ ID NO: 66 находится пролин, в положении 426 SEQ ID NO: 66 находится лизин, а в положении 436 SEQ ID NO: 66 находится аспарагиновая кислота.
В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 67). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 67 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 67 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO: 67 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 67 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 134SEQ ID NO: 67 находится цистеин, в положении 137 SEQ ID NO: 67 находится лизин, в положении 146 SEQ ID NO: 67 находится триптофан, в положении 280 SEQ ID NO: 67 находится аланин, в положении 318 SEQ ID NO: 67 находится пролин, в положении 426 SEQ ID NO: 67 находится лизин, а в положении 436 SEQ ID NO: 67 находится аспарагиновая кислота.
В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 68). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 68 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 68 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO: 68 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 68 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33SEQ ID NO: 68 находится аланин, в положении 134 SEQ ID NO: 68 находится цистеин, в положении 137 SEQ ID NO: 68 находится лизин, в положении 146 SEQ ID NO: 68 находится триптофан, в положении 319 SEQ ID NO: 68 находится пролин, в положении 426 SEQ ID NO: 68 находится лизин, а в положении 436 SEQ ID NO: 68 находится аспарагиновая кислота.
В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQV
YTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 69). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 69 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 69 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO: 69 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 69 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 69 находится аланин, в положении 134 SEQ ID NO: 69 находится цистеин, в положении 137 SEQ ID NO: 69 находится лизин, в положении 146 SEQ ID NO: 69 находится триптофан, в положении 280 SEQ ID NO: 69 находится аланин, в положении 319 SEQ ID NO: 69 находится пролин, в положении 426 SEQ ID NO: 69 находится лизин, а в положении 436 SEQ ID NO: 69 находится аспарагиновая кислота.
В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 71). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 71 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 71 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO: 71 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 71 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 71SEQ ID NO: 71 находится пролин, в положении 134 SEQ ID NO: 71 находится цистеин, в положении 137 SEQ ID NO: 71 находится лизин, в положении 146 SEQ ID NO: 71 находится триптофан, в положении 426 SEQ ID NO: 71 находится лизин, а в положении 436 SEQ ID NO: 71 находится аспарагиновая кислота.
В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 72). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 72 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 72 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO: 72 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 72 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 72SEQ ID NO: 72 находится пролин, в положении 134 SEQ ID NO: 72 находится цистин, в положении 137 SEQ ID NO: 72 находится лизин, в положении 146 SEQ ID NO: 72 находится триптофан, в положении 426 SEQ ID NO: 72 находится лизин, а в положении 436 SEQ ID NO: 72 находится аспарагиновая кислота.
В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 74). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 74 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 74 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO: 74 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 74 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 74 находится аланин, в положении 72 SEQ ID NO: 74 находится пролин, в положении 134 SEQ ID NO: 74 находится цистеин, в положении 137 SEQ ID NO: 74 находится лизин, в положении 146 SEQ ID NO: 74 находится триптофан, в положении 426 SEQ ID NO: 74 находится лизин, а в положении 436 SEQ ID NO: 74 находится аспарагиновая кислота.
В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 75). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 75 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 75 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO: 75 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 75 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 75 находится аланин, в положении 72 SEQ ID NO: 75 находится пролин, в положении 134 SEQ ID NO: 75 находится цистеин, в положении 137 SEQ ID NO: 75 находится лизин, в положении 146 SEQ ID NO: 75 находится триптофан, в положении 280 SEQ ID NO: 75 находится аланин, в положении 426 SEQ ID NO: 75 находится лизин, а в положении 436 SEQ ID NO: 75 находится аспарагиновая кислота.
В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 76). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 76 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 76 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO: 76 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 76 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 72 SEQ ID NO: 76 находится пролин и в положении 319 SEQ ID NO: 76 находится пролин. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 77). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 77 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 77 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO: 77 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 77 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 72 SEQ ID NO: 77 находится пролин, в положении 134 SEQ ID NO: 77 находится цистеин, в положении 137 SEQ ID NO: 77 находится лизин, в положении 146 SEQ ID NO: 77 находится триптофан, в положении 280 SEQ ID NO: 77 находится аланин, в положении 319 SEQ ID NO: 77 находится пролин, в положении 426 SEQ ID NO: 77 находится лизин, а в положении 436 SEQ ID NO: 77 находится аспарагиновая кислота.
В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 79). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 79 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 79 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO: 79 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого полипептида и второго полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 79 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 79 находится аланин, в положении 72 SEQ ID NO: 79 находится пролин, в положении 280 SEQ ID NO: 79 находится аланин, а в положении 319 SEQ ID NO: 79 находится пролин.
В некоторых вариантах осуществления каждый из третьего полипептида и четвертого полипептида содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 73). В некоторых вариантах осуществления каждый из третьего полипептида и четвертого полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 73 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из третьего полипептида и четвертого полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 73 с не более чем 10одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 73 находится аланин, а в положении 72 SEQ ID NO: 73 находится пролин.
В некоторых вариантах осуществления каждый из третьего полипептида и четвертого полипептида содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 61). В некоторых вариантах осуществления каждый из третьего полипептида и четвертого полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 61 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из третьего полипептида и четвертого полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 61 с не более чем 10одиночными аминокислотными модификациями, при условии, что в положении 129 SEQ ID NO: 61 находится цистеин, в положении 146 SEQ ID NO: 61 находится серин, в положении 148 SEQ ID NO: 61 находится аланин, в положении 150 SEQ ID NO: 61 находится аспарагиновая кислота, а в положении 187 SEQ ID NO: 61 находится валин.
В некоторых вариантах осуществления каждый из третьего полипептида и четвертого полипептида содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 63). В некоторых вариантах осуществления каждый из третьего полипептида и четвертого полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 63 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из третьего полипептида и четвертого полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 63 с не более чем 10одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 63 находится аланин.
В некоторых вариантах осуществления каждый из третьего полипептида и четвертого полипептида содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 70). В некоторых вариантах осуществления каждый из третьего полипептида и четвертого полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 70 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из третьего полипептида и четвертого полипептида содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 70 с не более чем 10одиночными аминокислотными модификациями, при условии, что в положении 72 SEQ ID NO: 70 находится пролин.
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 78), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 73). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 78 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 73 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 78 с не более чем 10 одиночными аминокислотными модификациями, при условии, что ни одна из не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночных аминокислотных модификаций не находится в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). Линкер в SEQ ID NO: 78 может быть заменен альтернативным линкером. В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 78 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 78 находится аланин, в положении 72 SEQ ID NO: 78 находится пролин, а в положении 319 SEQ ID NO: 78 находится пролин, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 73 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 73 находится аланин, а в положении 72 SEQ ID NO: 73 находится пролин.
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 49), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 61). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 49 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 61 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 49 с не более чем (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23); линкер в SEQ ID NO: 76 может быть заменен альтернативным линкером) и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 61 с не более чем 10 одиночными аминокислотными модификациями. В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 49 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 134 SEQ ID NO: 49 находится цистеин, в положении 137 SEQ ID NO: 49 находится лизин, в положении 146 SEQ ID NO: 49 находится триптофан, в положении 426 SEQ ID NO: 49 находится лизин, а в положении 436 SEQ ID NO: 49 находится аспарагиновая кислота, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 61 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 129 SEQ ID NO: 61 находится цистеин, в положении 146 SEQ ID NO: 61 находится серин, в положении 148 SEQ ID NO: 61 находится аланин, в положении 150 SEQ ID NO: 61 находится аспарагиновая кислота, а в положении 187 SEQ ID NO: 61 находится валин.
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 62), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 61). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 62 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 61 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 62 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23); линкер в SEQ ID NO: 62 может быть заменен альтернативным линкером) и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 61 с не более чем 10 одиночными аминокислотными модификациями. В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 62 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 134 SEQ ID NO: 62 находится цистеин, в положении 137 SEQ ID NO: 62 находится лизин, в положении 146 SEQ ID NO: 62 находится триптофан, в положении 280 SEQ ID NO: 62 находится аланин, в положении 426 SEQ ID NO: 62 находится лизин, а в положении 436 SEQ ID NO: 62 находится аспарагиновая кислота, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 61 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 129 SEQ ID NO: 61 находится цистеин, в положении 146 SEQ ID NO: 61 находится серин, в положении 148 SEQ ID NO: 61 находится аланин, в положении 150 SEQ ID NO: 61 находится аспарагиновая кислота, а в положении 187 SEQ ID NO: 61 находится валин.
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 64), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 63). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 64 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 63 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 64 не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23); линкер в SEQ ID NO: 64 может быть заменен альтернативным линкером) и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 63 с не более чем 10 одиночными аминокислотными модификациями. В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 64 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 64 находится аланин, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 63 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 63 находится аланин.
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 65), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 63). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 65 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 63 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 65 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23); линкер в SEQ ID NO: 65 может быть заменен альтернативным линкером) и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 63 с не более чем 10 одиночными аминокислотными модификациями. В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 65 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 65 находится аланин, в положении 134 SEQ ID NO: 65 находится цистеин, в положении 137 SEQ ID NO: 65 находится лизин, в положении 146 SEQ ID NO: 65 находится триптофан, в положении 280 SEQ ID NO: 65 находится аланин, в положении 426 SEQ ID NO: 65 находится лизин, а в положении 436 SEQ ID NO: 65 находится аспарагиновая кислота, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 63 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 63 находится аланин.
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 66), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 61). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 66 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 61 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 66 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23); линкер в SEQ ID NO: 66 может быть заменен альтернативным линкером) и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 61 с не более чем 10 одиночными аминокислотными модификациями. В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 66 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 134 SEQ ID NO: 66 находится цистеин, в положении 137 SEQ ID NO: 66 находится лизин, в положении 146 SEQ ID NO: 66 находится триптофан, в положении 319 SEQ ID NO: 66 находится пролин, в положении 426 SEQ ID NO: 66 находится лизин, а в положении 436 SEQ ID NO: 66 находится аспарагиновая кислота, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 61 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 129 SEQ ID NO: 61 находится цистеин, в положении 146 SEQ ID NO: 61 находится серин, в положении 148 SEQ ID NO: 61 находится аланин, в положении 150 SEQ ID NO: 61 находится аспарагиновая кислота, а в положении 187 SEQ ID NO: 61 находится валин.
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 67), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 61). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 67 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 61 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 67 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23; линкер в SEQ ID NO: 67 может быть заменен альтернативным линкером) и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 61 с не более чем 10 одиночными аминокислотными модификациями. В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 67 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 134 SEQ ID NO: 67 находится цистеин, в положении 137 SEQ ID NO: 67 находится лизин, в положении 146 SEQ ID NO: 67 находится триптофан, в положении 280 SEQ ID NO: 67 находится аланин, в положении 318 SEQ ID NO: 67 находится пролин, в положении 426 SEQ ID NO: 67 находится лизин, а в положении 436 SEQ ID NO: 67 находится аспарагиновая кислота, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 61 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 129 SEQ ID NO: 61 находится цистеин, в положении 146 SEQ ID NO: 61 находится серин, в положении 148 SEQ ID NO: 61 находится аланин, в положении 150 SEQ ID NO: 61 находится аспарагиновая кислота, а в положении 187 SEQ ID NO: 61 находится валин.
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 68), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 63). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 68 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 63 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 68 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23); линкер в SEQ ID NO: 68 может быть заменен альтернативным линкером) и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 63 с не более чем 10 одиночными аминокислотными модификациями. В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 68 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 68 находится аланин, в положении 134 SEQ ID NO: 68 находится цистеин, в положении 137 SEQ ID NO: 68 находится лизин, в положении 146 SEQ ID NO: 68 находится триптофан, в положении 319 SEQ ID NO: 68 находится пролин, в положении 426 SEQ ID NO: 68 находится лизин, а в положении 436 SEQ ID NO: 68 находится аспарагиновая кислота, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 63 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 63 находится аланин.
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 69), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 63). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 69 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 63 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 69 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23); линкер в SEQ ID NO: 69 может быть заменен альтернативным линкером) и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 63 с не более чем 10 одиночными аминокислотными модификациями. В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 69 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 69 находится аланин, в положении 134 SEQ ID NO: 69 находится цистеин, в положении 137 SEQ ID NO: 69 находится лизин, в положении 146 SEQ ID NO: 69 находится триптофан, в положении 280 SEQ ID NO: 69 находится аланин, в положении 319 SEQ ID NO: 69 находится пролин, в положении 426 SEQ ID NO: 69 находится лизин, а в положении 436 SEQ ID NO: 69 находится аспарагиновая кислота, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 63 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 63 находится аланин.
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 71), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 70). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 71 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 70 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 71 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23); линкер в SEQ ID NO: 71 может быть заменен альтернативным линкером) и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 70 с не более чем 10 одиночными аминокислотными модификациями. В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 71 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 71 SEQ ID NO: 71 находится пролин, в 134 SEQ ID NO: 71 находится цистеин, в положении 137 SEQ ID NO: 71 находится лизин, в положении 146 SEQ ID NO: 71 находится триптофан, в положении 426 SEQ ID NO: 71 находится лизин, а в положении 436 SEQ ID NO: 71 находится аспарагиновая кислота, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 70 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 72 SEQ ID NO: 70 находится пролин.
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 72), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 70). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 72 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 70 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 72 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23); линкер в SEQ ID NO: 72 может быть заменен альтернативным линкером) и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 70 с не более чем 10 одиночными аминокислотными модификациями. В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 72 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 72 SEQ ID NO: 72 находится пролин, в положении 134 SEQ ID NO: 72 находится цистин, в положении 137 SEQ ID NO: 72 находится лизин, в положении 146 SEQ ID NO: 72 находится триптофан, в положении 426 SEQ ID NO: 72 находится лизин, а в положении 436 SEQ ID NO: 72 находится аспарагиновая кислота, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 70 с не более чем 10 одиночными аминокислотными модификациями, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 70 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 72 SEQ ID NO: 70 находится пролин.
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 74), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 73). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 74 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 73 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 74 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23); линкер в SEQ ID NO:74 может быть заменен альтернативным линкером) и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 73 с не более чем 10 одиночными аминокислотными модификациями. В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 74 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 74 находится аланин, в положении 72 SEQ ID NO: 74 находится пролин, в положении 134 SEQ ID NO: 74 находится цистеин, в положении 137 SEQ ID NO: 74 находится лизин, в положении 146 SEQ ID NO: 74 находится триптофан, в положении 426 SEQ ID NO: 74 находится лизин, а в положении 436 SEQ ID NO: 74 находится аспарагиновая кислота, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 73 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 73 находится аланин, а в положении 72 SEQ ID NO: 73 находится пролин.
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 75), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 73). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 75 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 73 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 75 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23); линкер в SEQ ID NO: 75 может быть заменен альтернативным линкером) и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 73 с не более чем 10 одиночными аминокислотными модификациями. В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 75 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 75 находится аланин, в положении 72 SEQ ID NO: 75 находится пролин, в положении 134 SEQ ID NO: 75 находится цистеин, в положении 137 SEQ ID NO: 75 находится лизин, в положении 146 SEQ ID NO: 75 находится триптофан, в положении 280 SEQ ID NO: 75 находится аланин, в положении 426 SEQ ID NO: 75 находится лизин, а в положении 436 SEQ ID NO: 75 находится аспарагиновая кислота, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 73 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 73 находится аланин, а в положении 72 SEQ ID NO: 73 находится пролин.
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 76), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 70). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 76 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 70 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 76 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23); линкер в SEQ ID NO: 76 может быть заменен альтернативным линкером) и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 70 с не более чем 10 одиночными аминокислотными модификациями. В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 76 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 72 SEQ ID NO: 76 находится пролин и в положении 319 SEQ ID NO: 76 находится пролин, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 70 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 72 SEQ ID NO: 70 находится пролин.
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 76), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 70).
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 77), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 70). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 77 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 70 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 77 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23); линкер в SEQ ID NO: 77 может быть заменен альтернативным линкером) и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 70 с не более чем 10 одиночными аминокислотными модификациями. В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 77 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 72 SEQ ID NO: 77 находится пролин, в положении 134 SEQ ID NO: 77 находится цистеин, в положении 137 SEQ ID NO: 77 находится лизин, в положении 146 SEQ ID NO: 77 находится триптофан, в положении 280 SEQ ID NO: 77 находится аланин, в положении 319 SEQ ID NO: 77 находится пролин, в положении 426 SEQ ID NO: 77 находится лизин, а в положении 436 SEQ ID NO: 77 находится аспарагиновая кислота, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 70 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 72 SEQ ID NO: 70 находится пролин.
В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 79), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 73). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 79 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами), и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности SEQ ID NO: 73 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 79 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями в области вне линкера (например, подпоследовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23); линкер в SEQ ID NO: 79 может быть заменен альтернативным линкером) и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 73 с не более чем 10 одиночными аминокислотными модификациями. В некоторых вариантах осуществления каждый из первого и второго полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 79 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 79 находится аланин, в положении 72 SEQ ID NO: 79 находится пролин, в положении 280 SEQ ID NO: 79 находится аланин, а в положении 319 SEQ ID NO: 79 находится пролин, и каждый из третьего и четвертого полипептидов содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 73 с не более чем 10 одиночными аминокислотными модификациями, при условии, что в положении 33 SEQ ID NO: 73 находится аланин, а в положении 72 SEQ ID NO: 73 находится пролин. В некоторых вариантах осуществления Fc-конструкция представляет собой конструкцию 4, конструкцию 5, конструкцию 6, конструкцию 7, конструкцию 8, конструкцию 9, конструкцию 10, конструкцию 11, конструкцию 12, конструкцию 13, конструкцию 14, конструкцию 15, конструкцию 16, конструкцию 17, конструкцию 18 или конструкцию 19.
В некоторых вариантах осуществления Fc-конструкция представляет собой конструкцию 5, конструкцию 6, конструкцию 7, конструкцию 9, конструкцию 10, конструкцию 11, конструкцию 13, конструкцию 14, конструкцию 15, конструкцию 16, конструкцию 17, конструкцию 18 или конструкцию 19.
В некоторых вариантах осуществления каждый из первого полипептида, второго полипептида, третьего полипептида и/или четвертого полипептида содержит N-концевую аминокислотную замену от D до Q.
Во втором аспекте Fc-конструкция по настоящему изобретению содержит (i) первый Fc-домен, содержащий первый мономер Fc-домена и второй мономер Fc-домена, и (ii) второй Fc-домен, содержащий третий мономер Fc-домена и четвертый мономер Fc-домена, где по меньшей мере один Fc-домен содержит аминокислотную модификацию в положении I253. Во другом аспекте Fc-конструкция по настоящему изобретению содержит (i) первый Fc-домен, содержащий первый мономер Fc-домена и второй мономер Fc-домена, и (ii) второй Fc-домен, содержащий третий мономер Fc-домена и четвертый мономер Fc-домена, где по меньшей мере один мономер Fc-домена содержит аминокислотную замену в положении I253. В некоторых вариантах осуществления каждая из аминокислотных модификаций (например, замен) в положении I253 независимо выбрана из группы, состоящей из I253A, I253C, I253D, I253E, I253F, I253G, I253H, I253I, I253K, I253L, I253M, I253N, I253P, I253Q, I253R, I253S, I253T, I253V, I253W и I253Y. В некоторых вариантах осуществления аминокислотная модификация (например, замена) в положении I253 представляет собой I253A. В некоторых вариантах осуществления Fc-конструкция содержит по меньшей мере одну аминокислотную модификацию (например, замену) в положении R292. В некоторых вариантах осуществления аминокислотная модификация (например, замена) в положении R292 выбрана из группы, состоящей из R292D, R292E, R292L, R292P, R292Q, R292R, R292T и R292Y. В некоторых вариантах осуществления аминокислотная модификация (например, замена) в положении R292 представляет собой R292P.
В некоторых вариантах осуществления первый мономер Fc-домена и третий мономер Fc-домена соединены посредством линкера (например, спейсера). В некоторых вариантах осуществления второй мономер Fc-домена и четвертый мономер Fc-домена соединены посредством линкера (например, спейсера). В некоторых вариантах осуществления каждый линкер (например, спейсер) независимо выбран из полипептида, имеющего последовательность GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23), GGGGS (SEQ ID NO: 1), GGSG (SEQ ID NO: 2), SGGG(SEQ ID NO: 3) , GSGS (SEQ ID NO: 4), GSGSGS (SEQ ID NO: 5), GSGSGSGS (SEQ ID NO: 6), GSGSGSGSGS (SEQ ID NO: 7), GSGSGSGSGSGS (SEQ ID NO: 8), GGSGGS (SEQ ID NO: 9), GGSGGSGGS (SEQ ID NO: 10), GGSGGSGGSGGS (SEQ ID NO: 11), GGSGGGSG (SEQ ID NO: 12), GGSGGGSGGGSG (SEQ ID NO: 13), GGSGGGSGGGSGGGSG (SEQ ID NO: 14), GGSGGGSGGGSGGGGGSGGGGSGGGGSGGGGS (SEQ ID NO: 80), GENLYFQSGG (SEQ ID NO: 28), SACYCELS (SEQ ID NO: 29), RSIAT (SEQ ID NO: 30), RPACKIPNDLKQKVMNH (SEQ ID NO: 31), GGSAGGSGSGSSGGSSGASGTGTAGGTGSGSGTGSG (SEQ ID NO: 32), AAANSSIDLISVPVDSR (SEQ ID NO: 33), GGSGGGSEGGGSEGGGSEGGGSEGGGSEGGGSGGGS (SEQ ID NO: 34), GGGSGGGSGGGS (SEQ ID NO: 35), SGGGSGGGSGGGSGGGSGGG (SEQ ID NO: 18), GGSGGGSGGGSGGGSGGS (SEQ ID NO: 36), GGGG (SEQ ID NO: 19), GGGGGGGG (SEQ ID NO: 20), GGGGGGGGGGGG (SEQ ID NO: 21) или GGGGGGGGGGGGGGGG (SEQ ID NO: 22).
В некоторых вариантах осуществления первый мономер Fc-домена и второй мономер Fc-домена содержат модули селективности, обеспечивающие комплементарную димеризацию, которые способствуют осуществлению димеризации между первым мономером Fc-домена и вторым мономером Fc-домена. В некоторых вариантах осуществления третий мономер Fc-домена и четвертый мономер Fc-домена содержат модули селективности, обеспечивающие комплементарную димеризацию, которые способствуют осуществлению димеризации между третьим мономером Fc-домена и четвертым мономером Fc-домена.
В другом аспекте настоящее изобретение предусматривает Fc-конструкцию, которая содержит (i) первый Fc-домен, содержащий первый мономер Fc-домена и второй мономер Fc-домена, и (ii) второй Fc-домен, содержащий третий мономер Fc-домена и четвертый мономер Fc-домена, где по меньшей мере один Fc-домен содержит аминокислотную модификацию в положении R292. В другом аспекте настоящее изобретение предусматривает Fc-конструкцию, которая содержит (i) первый Fc-домен, содержащий первый мономер Fc-домена и второй мономер Fc-домена, и (ii) второй Fc-домен, содержащий третий мономер Fc-домена и четвертый мономер Fc-домена, где по меньшей мере один мономер Fc-домена содержит аминокислотную замену в положении R292. В некоторых вариантах осуществления каждая из аминокислотных модификаций (например, замен) в положении R292 независимо выбрана из группы, состоящей из R292D, R292E, R292L, R292P, R292Q, R292R, R292T и R292Y. В некоторых вариантах осуществления аминокислотная модификация (например, замена) в положении R292 представляет собой R292P. В некоторых вариантах осуществления первый мономер Fc-домена и третий мономер Fc-домена соединены посредством линкера.
В некоторых вариантах осуществления второй мономер Fc-домена и четвертый мономер Fc-домена соединены посредством линкера. В некоторых вариантах осуществления каждый линкер независимо выбран из полипептида, имеющего последовательность GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23), GGGGS (SEQ ID NO: 1), GGSG (SEQ ID NO: 2), SGGG(SEQ ID NO: 3) , GSGS (SEQ ID NO: 4), GSGSGS (SEQ ID NO: 5), GSGSGSGS (SEQ ID NO: 6), GSGSGSGSGS (SEQ ID NO: 7), GSGSGSGSGSGS (SEQ ID NO: 8), GGSGGS (SEQ ID NO: 9), GGSGGSGGS (SEQ ID NO: 10), GGSGGSGGSGGS (SEQ ID NO: 11), GGSGGGSG (SEQ ID NO: 12), GGSGGGSGGGSG (SEQ ID NO: 13), GGSGGGSGGGSGGGSG (SEQ ID NO: 14), GGSGGGSGGGSGGGGGSGGGGSGGGGSGGGGS (SEQ ID NO: 80), GENLYFQSGG (SEQ ID NO: 28), SACYCELS (SEQ ID NO: 29), RSIAT (SEQ ID NO: 30), RPACKIPNDLKQKVMNH (SEQ ID NO: 31), GGSAGGSGSGSSGGSSGASGTGTAGGTGSGSGTGSG (SEQ ID NO: 32), AAANSSIDLISVPVDSR (SEQ ID NO: 33), GGSGGGSEGGGSEGGGSEGGGSEGGGSEGGGSGGGS (SEQ ID NO: 34), GGGSGGGSGGGS (SEQ ID NO: 35), SGGGSGGGSGGGSGGGSGGG (SEQ ID NO: 18), GGSGGGSGGGSGGGSGGS (SEQ ID NO: 36), GGGG (SEQ ID NO: 19), GGGGGGGG (SEQ ID NO: 20), GGGGGGGGGGGG (SEQ ID NO: 21) или GGGGGGGGGGGGGGGG (SEQ ID NO: 22). В некоторых вариантах осуществления линкер представляет собой GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23).
В некоторых вариантах осуществления первый мономер Fc-домена и второй мономер Fc-домена содержат модули селективности, обеспечивающие комплементарную димеризацию, которые способствуют осуществлению димеризации между первым мономером Fc-домена и вторым мономером Fc-домена. В некоторых вариантах осуществления третий мономер Fc-домена и четвертый мономер Fc-домена содержат модули селективности, обеспечивающие комплементарную димеризацию, которые способствуют осуществлению димеризации между третьим мономером Fc-домена и четвертым мономером Fc-домена.
В другом аспекте настоящее изобретение предусматривает способ получения Fc-конструкции, описанной в данном документе. Способ предусматривает: а) предоставление клетки-хозяина, содержащей полинуклеотиды, кодирующие полипептиды по настоящему изобретению; b) экспрессию полипептидов в клетке-хозяине в условиях, которые обеспечивают образование Fc-конструкции и c) извлечение Fc-конструкции.
В другом аспекте настоящее изобретение предоставляет Fc-конструкцию, содержащую а) первый полипептид, содержащий i) первый мономер Fc-домена; ii) второй мономер Fc-домена и iii) линкер, соединяющий первый мономер Fc-домена со вторым мономером Fc-домена; b) второй полипептид, содержащий i) третий мономер Fc-домена; ii) четвертый мономер Fc-домена и iii) линкер, соединяющий третий мономер Fc-домена с четвертым мономером Fc-домена; c) третий полипептид содержит пятый мономер Fc-домена и d) четвертый полипептид содержит шестой мономер Fc-домена; где первый мономер Fc-домена и пятый мономер Fc-домена соединены с образованием первого Fc-домена, второй мономер Fc-домена и четвертый мономер Fc-домена соединены с образованием второго Fc-домена, а третий мономер Fc-домена и шестой мономер Fc-домена соединены с образованием третьего Fc-домена, и где по меньшей мере один Fc-домен содержит аминокислотную модификацию в положении I253, где каждый из первого и второго полипептидов содержит последовательность
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 78), и каждый из третьего и четвертого полипептидов содержит последовательность
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 73). В другом аспекте настоящее изобретение предоставляет Fc-конструкцию, содержащую а) первый полипептид, содержащий i) первый мономер Fc-домена; ii) второй мономер Fc-домена; и iii) линкер, соединяющий первый мономер Fc-домена со вторым мономером Fc-домена; b) второй полипептид, содержащий i) третий мономер Fc-домена; ii) четвертый мономер Fc-домена; и iii) линкер, соединяющий третий мономер Fc-домена с четвертым мономером Fc-домена; c) третий полипептид содержит пятый мономер Fc-домена; и d) четвертый полипептид содержит шестой мономер Fc-домена; где первый мономер Fc-домена и пятый мономер Fc-домена соединены с образованием первого Fc-домена, второй мономер Fc-домена и четвертый мономер Fc-домена соединены с образованием второго Fc-домена, а третий мономер Fc-домена и шестой мономер Fc-домена соединены с образованием третьего Fc-домена, где каждый из первого и второго полипептидов содержит последовательность
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 78), и каждый из третьего и четвертого полипептидов содержит последовательность
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 73).
В другом аспекте настоящее изобретение предоставляет Fc-конструкцию, содержащую а) первый полипептид, содержащий i) первый мономер Fc-домена; ii) второй мономер Fc-домена; и iii) линкер, соединяющий первый мономер Fc-домена со вторым мономером Fc-домена; b) второй полипептид, содержащий i) третий мономер Fc-домена; ii) четвертый мономер Fc-домена; и iii) линкер, соединяющий третий мономер Fc-домена с четвертым мономером Fc-домена; c) третий полипептид содержит пятый мономер Fc-домена; и d) четвертый полипептид содержит шестой мономер Fc-домена; где первый мономер Fc-домена и пятый мономер Fc-домена соединены с образованием первого Fc-домена, второй мономер Fc-домена и четвертый мономер Fc-домена соединены с образованием второго Fc-домена, а третий мономер Fc-домена и шестой мономер Fc-домена соединены с образованием третьего Fc-домена, и где по меньшей мере один Fc-домен содержит аминокислотную модификацию в положении I253, где каждый из первого и второго полипептидов содержит последовательность
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 79), и каждый из третьего и четвертого полипептидов содержит последовательность
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 73). В другом аспекте настоящее изобретение предоставляет Fc-конструкцию, содержащую а) первый полипептид, содержащий i) первый мономер Fc-домена; ii) второй мономер Fc-домена; и iii) линкер, соединяющий первый мономер Fc-домена со вторым мономером Fc-домена; b) второй полипептид, содержащий i) третий мономер Fc-домена; ii) четвертый мономер Fc-домена; и iii) линкер, соединяющий третий мономер Fc-домена с четвертым мономером Fc-домена; c) третий полипептид содержит пятый мономер Fc-домена; и d) четвертый полипептид содержит шестой мономер Fc-домена; где первый мономер Fc-домена и пятый мономер Fc-домена соединены с образованием первого Fc-домена, второй мономер Fc-домена и четвертый мономер Fc-домена соединены с образованием второго Fc-домена, а третий мономер Fc-домена и шестой мономер Fc-домена соединены с образованием третьего Fc-домена, где каждый из первого и второго полипептидов содержит последовательность
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 79), и каждый из третьего и четвертого полипептидов содержит последовательность
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMASRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 73).
В другом аспекте настоящее изобретение предоставляет Fc-конструкцию, содержащую: а) первый полипептид, содержащий i) первый мономер Fc-домена; ii) второй мономер Fc-домена; и iii) линкер, соединяющий первый мономер Fc-домена со вторым мономером Fc-домена; b) второй полипептид, содержащий i) третий мономер Fc-домена; ii) четвертый мономер Fc-домена; и iii) линкер, соединяющий третий мономер Fc-домена с четвертым мономером Fc-домена; c) третий полипептид содержит пятый мономер Fc-домена; и d) четвертый полипептид содержит шестой мономер Fc-домена; где первый мономер Fc-домена и пятый мономер Fc-домена соединены с образованием первого Fc-домена, второй мономер Fc-домена и четвертый мономер Fc-домена соединены с образованием второго Fc-домена, а третий мономер Fc-домена и шестой мономер Fc-домена соединены с образованием третьего Fc-домена, и где по меньшей мере один Fc-домен содержит аминокислотную модификацию в положении R292, где каждый из первого и второго полипептидов содержит последовательность
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 76), и каждый из третьего и четвертого полипептидов содержит последовательность
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 70). В другом аспекте настоящее изобретение предоставляет Fc-конструкцию, содержащую: а) первый полипептид, содержащий i) первый мономер Fc-домена; ii) второй мономер Fc-домена; и iii) линкер, соединяющий первый мономер Fc-домена со вторым мономером Fc-домена; b) второй полипептид, содержащий i) третий мономер Fc-домена; ii) четвертый мономер Fc-домена; и iii) линкер, соединяющий третий мономер Fc-домена с четвертым мономером Fc-домена; c) третий полипептид содержит пятый мономер Fc-домена; и d) четвертый полипептид содержит шестой мономер Fc-домена; где первый мономер Fc-домена и пятый мономер Fc-домена соединены с образованием первого Fc-домена, второй мономер Fc-домена и четвертый мономер Fc-домена соединены с образованием второго Fc-домена, а третий мономер Fc-домена и шестой мономер Fc-домена соединены с образованием третьего Fc-домена, где каждый из первого и второго полипептидов содержит последовательность
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGKGGGGGGGGGGGGGGGGGGGGDKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 76), и каждый из третьего и четвертого полипептидов содержит последовательность
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPPEEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG (SEQ ID NO: 70).
В некоторых вариантах осуществления в любой из Fc-конструкций, описанных в данном документе, каждый Fc-домен независимо представляет собой Fc-домен IgG1, Fc-домен IgG2, Fc-домен IgG3, Fc-домен IgG4 или их комбинацию. В некоторых вариантах осуществления в любой из Fc-конструкций, описанных в данном документе, каждый Fc-домен независимо представляет собой Fc-домен IgG1, Fc-домен IgG2, Fc-домен IgG3, Fc-домен IgG4 или их комбинацию с не более чем 10 (например, не более чем 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10) одиночными аминокислотными модификациями. В некоторых вариантах осуществления каждый Fc-домен представляет собой Fc-домен IgG1. В некоторых вариантах осуществления каждый Fc-домен представляет собой Fc-домен IgG2. В некоторых вариантах осуществления каждый Fc-домен представляет собой Fc-домен IgG3. В некоторых вариантах осуществления каждый из первого, второго и третьего Fc-доменов представляет собой Fc-домены IgG1. В некоторых вариантах осуществления каждый Fc-домен представляет собой Fc-домен IgG1 человека. В некоторых вариантах осуществления каждый Fc-домен содержит SEQ ID NO: 42 с не более чем 10 (например, не более 1, не более 2, не более 3, не более 4, не более 5, не более 6, не более 7, не более 8, не более чем 9) одиночными аминокислотными модификациями.
В некоторых вариантах осуществления в любой из Fc-конструкций, описанных в данном документе, один или более мономеров Fc-домена представляют собой мономер Fc-домена IgG человека, содержащий не более чем десять (например, не более чем 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10) аминокислотных модификаций. В некоторых вариантах осуществления в любой из Fc-конструкций, описанных в данном документе, каждый мономер Fc-домена имеет не более чем десять (например, не более 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10) аминокислотных модификаций. В некоторых вариантах осуществления в любой из Fc-конструкций, описанных в данном документе, каждый Fc-мономер содержит последовательность SEQ ID NO: 42 с не более чем десятью (например, не более чем 1, 2, 3, 4, 5, 6, 7, 8, 9 или 10) аминокислотными модификациями. В некоторых вариантах осуществления в любой из Fc-конструкций, описанных в данном документе, каждый Fc-мономер содержит последовательность SEQ ID NO: 42 с 5 аминокислотными модификациями. В некоторых вариантах осуществления в любой из Fc-конструкций, описанных в данном документе, каждый Fc-мономер содержит последовательность SEQ ID NO: 42 с 10 аминокислотными модификациями. В некоторых вариантах осуществления в любой из Fc-конструкций, описанных в данном документе, каждый Fc-мономер содержит последовательность SEQ ID NO: 42 с 8 аминокислотными модификациями. В каждом случае модификации могут включать одну или обе из аминокислотных замен I253A и R292P.
В другом аспекте настоящее изобретение предусматривает клетку-хозяина, которая экспрессирует Fc-конструкцию, описанную в данном документе. Клетка-хозяин содержит полинуклеотиды, кодирующие полипептиды по настоящему изобретению, где полинуклеотиды экспрессируются в клетке-хозяине.
В другом аспекте настоящее изобретение предусматривает полипептид, содержащий аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 43-79. В другом аспекте настоящее изобретение предусматривает полипептид, содержащий аминокислотную последовательность, выбранную из группы, состоящей из SEQ ID NO: 49 и SEQ ID NO: 61-79.
В другом аспекте настоящее изобретение предусматривает композицию, содержащую или состоящую из последовательности: SEQ ID NO: 78 и полипептид, содержащий или состоящий из последовательности: SEQ ID NO: 73. В другом аспекте настоящее изобретение предусматривает композицию, содержащую или состоящую из последовательности: SEQ ID NO: 49 и полипептид, содержащий или состоящий из последовательности: SEQ ID NO: 61. В другом аспекте настоящее изобретение предусматривает композицию, содержащую или состоящую из последовательности: SEQ ID NO: 62 и полипептид, содержащий или состоящий из последовательности: SEQ ID NO: 61. В другом аспекте настоящее изобретение предусматривает композицию, содержащую или состоящую из последовательности: SEQ ID NO: 64 и полипептид, содержащий или состоящий из последовательности: SEQ ID NO: 63. В другом аспекте настоящее изобретение предусматривает композицию, содержащую или состоящую из последовательности: SEQ ID NO: 65 и полипептид, содержащий или состоящий из последовательности: SEQ ID NO: 63. В другом аспекте настоящее изобретение предусматривает композицию, содержащую или состоящую из последовательности: SEQ ID NO: 67 и полипептид, содержащий или состоящий из последовательности: SEQ ID NO: 61. В другом аспекте настоящее изобретение предусматривает композицию, содержащую или состоящую из последовательности: SEQ ID NO: 68 и полипептид, содержащий или состоящий из последовательности: SEQ ID NO: 63. В другом аспекте настоящее изобретение предусматривает композицию, содержащую или состоящую из последовательности: SEQ ID NO: 69 и полипептид, содержащий или состоящий из последовательности: SEQ ID NO: 63. В другом аспекте настоящее изобретение предусматривает композицию, содержащую или состоящую из последовательности: SEQ ID NO: 72 и полипептид, содержащий или состоящий из последовательности: SEQ ID NO: 70. В другом аспекте настоящее изобретение предусматривает композицию, содержащую или состоящую из последовательности: SEQ ID NO: 74 и полипептид, содержащий или состоящий из последовательности: SEQ ID NO: 73. В другом аспекте настоящее изобретение предусматривает композицию, содержащую или состоящую из последовательности: SEQ ID NO: 75 и полипептид, содержащий или состоящий из последовательности: SEQ ID NO: 73. В другом аспекте настоящее изобретение предусматривает композицию, содержащую или состоящую из последовательности: SEQ ID NO: 77 и полипептид, содержащий или состоящий из последовательности: SEQ ID NO: 70. В другом аспекте настоящее изобретение предусматривает композицию, содержащую или состоящую из последовательности: SEQ ID NO: 79 и полипептид, содержащий или состоящий из последовательности: SEQ ID NO: 73. В другом аспекте настоящее изобретение предусматривает композицию, содержащую или состоящую из последовательности: SEQ ID NO: 76 и полипептид, содержащий или состоящий из последовательности: SEQ ID NO: 70.
В некоторых вариантах осуществления композиции содержат первый и второй перечисленные полипептиды, присутствующие в молярном соотношении от 1,1:1 до 1:1,1.
В другом аспекте настоящее изобретение предусматривает способ лечения пациента, включающий введение пациенту любой из композиций, описанных в данном документе.
В другом аспекте настоящее изобретение предусматривает фармацевтическую композицию, содержащую по сути гомогенную (например, на по меньшей мере 85%, 90%, 95%, 97%, 98%, 99% гомогенную) совокупность Fc-конструкций, описанных в данном документе (например, Fc-конструкции, содержащие три Fc-домена) или композицию, содержащую по сути гомогенную совокупность Fc-конструкций, описанных в данном документе (например, композицию, содержащую по сути гомогенную совокупность Fc-конструкций, содержащих три Fc-домена) и один или более фармацевтически приемлемых носителей или вспомогательных средств. Такие фармацевтические композиции могут быть получены без существенной агрегации или нежелательной мультимеризации Fc-конструкций.
В некоторых аспектах настоящее изобретение предусматривает композицию, содержащую полипептид, который содержит SEQ ID NO: 76, и полипептид, который содержит SEQ ID NO: 70. В некоторых аспектах настоящее изобретение предусматривает композицию, содержащую полипептид, который содержит SEQ ID NO: 78, и полипептид, который содержит SEQ ID NO: 73. В некоторых аспектах настоящее изобретение предусматривает композицию, содержащую полипептид, который содержит SEQ ID NO: 79, и полипептид, который содержит SEQ ID NO: 73.
В некоторых аспектах настоящее изобретение предусматривает способ лечения пациента, включающий введение пациенту любой из композиций, описанных в данном документе.
В некоторых аспектах настоящее изобретение предусматривает клетку, содержащую последовательность нуклеиновой кислоты, кодирующую SEQ ID NO: 76, и последовательность нуклеиновой кислоты, кодирующую SEQ ID NO: 70. В некоторых аспектах настоящее изобретение предусматривает клетку, содержащую последовательность нуклеиновой кислоты, кодирующую SEQ ID NO: 78, и последовательность нуклеиновой кислоты, кодирующую SEQ ID NO: 73. В некоторых аспектах настоящее изобретение предусматривает клетку, содержащую последовательность нуклеиновой кислоты, кодирующую SEQ ID NO: 79, и последовательность нуклеиновой кислоты, кодирующую SEQ ID NO: 73. В некоторых аспектах настоящее изобретение предусматривает клетку, содержащую последовательность нуклеиновой кислоты, кодирующую любую из Fc-конструкций, описанных в данном документе.
В другом аспекте настоящее изобретение предусматривает способ снижения активации иммунных клеток, обеспечивающих иммунный ответ у субъекта, включающий введение субъекту Fc-конструкции, описанной в данном документе (например, Fc-конструкции, содержащей три Fc-домена), или композиции, содержащей по сути гомогенную совокупность Fc-конструкций, описанных в данном документе (например, композиции, содержащей по сути гомогенную совокупность Fc-конструкций, содержащих три Fc-домена). В некоторых вариантах осуществления субъект имеет аутоиммунное заболевание.
В другом аспекте настоящее изобретение предусматривает способ лечения воспаления или воспалительного заболевания у субъекта, включающий введение субъекту Fc-конструкции, описанной в данном документе (например, Fc-конструкции, содержащей три Fc-домена), или композиции, содержащей по сути гомогенную совокупность Fc-конструкций, описанных в данном документе (например, композиции, содержащей по сути гомогенную совокупность Fc-конструкций, содержащих три Fc-домена).
В другом аспекте настоящее изобретение предусматривает способ стимулирования клиренса аутоантител и/или подавления презентации антигена у субъекта, включающий введение субъекту Fc-конструкции, описанной в данном документе (например, Fc-конструкции, содержащей три Fc-домена), или композиции, содержащей по сути гомогенную совокупность Fc-конструкций, описанных в данном документе (например, композиции, содержащей по сути гомогенную совокупность Fc-конструкций, содержащих три Fc-домена).
В некоторых вариантах осуществления иллюстративные заболевания, которые можно подвергать лечению путем введения Fc-конструкции, описанной в данном документе (например, Fc-конструкции, содержащей три Fc-домена), включают следующее: ревматоидный артрит (RA); системная красная волчанка (SLE); ANCA-ассоциированный васкулит; синдром антифосфолипидных антител; аутоиммунная гемолитическая анемия; хроническая воспалительная демиелинизирующая невропатия; клиренс аллоклеточных антигенов при трансплантации; аутореактивность при GVHD; заместительная терапия с помощью антител, терапевтических средств на основе IgG, парапротеинов на основе IgG, дерматомиозит; синдром Гудпасчера; синдромы гиперчувствительности типа II на уровне систем органов, опосредованные антителозависимой клеточно-опосредованной цитотоксичностью, например синдром Гийена-Барре, CIDP, дерматомиозит, синдром Фелти, опосредованное антителами отторжение, аутоиммунное заболевание щитовидной железы, язвенный колит, аутоиммунное заболевание печени; идиопатическая тромбоцитопеническая пурпура; миастения гравис, оптиконевромиелит; пузырчатка и другие аутоиммунные нарушения, сопровождающиеся образованием пузырей; синдром Шегрена; аутоиммунные цитопении и другие нарушения, опосредованные антителозависимым фагоцитозом; другие FcR-зависимые воспалительные синдромы, например синовит; дерматомиозит, системный васкулит, гломерулит и васкулит.
В некоторых вариантах осуществления Fc-конструкции, описанные в данном документе, не содержат область распознавания антигена, например вариабельный домен или область, определяющую комплементарность (CDR). В некоторых вариантах осуществления Fc-конструкция (или Fc-домен в Fc-конструкции) полностью или частично образуется путем ассоциации мономеров Fc-домена, которые присутствуют в разных полипептидах. В некоторых вариантах осуществления Fc-конструкции, описанные в данном документе, содержат область распознавания антигена, например вариабельный домен или CDR. В определенных вариантах осуществления Fc-конструкция не содержит дополнительный домен (например, хвостовую часть IgM или хвостовую часть IgA), который способствует ассоциации двух полипептидов. В других вариантах осуществления ковалентные связи присутствуют в Fc-конструкции только между двумя мономерами Fc-домена, которые соединяются, образуя Fc-домен. В других вариантах осуществления Fc-конструкция не содержит ковалентные связи между Fc-доменами. В других вариантах осуществления Fc-конструкция обеспечивает достаточную структурную гибкость, так что все или практически все Fc-домены в Fc-конструкции способны одновременно взаимодействовать с Fc-рецептором на поверхности клетки. В одном варианте осуществления мономеры домена отличаются по первичной последовательности от дикого типа или друг от друга тем, что они содержат модули селективности, обеспечивающие димеризацию.
Мономеры Fc-домена, принадлежащие Fc-домену Fc-конструкции, могут иметь одинаковую первичную аминокислотную последовательность. Например, оба мономера Fc-домена, принадлежащие Fc-домену, могут иметь одинаковый модуль селективности, обеспечивающий димеризацию, например, оба мономера Fc-домена, принадлежащие Fc-домену, могут иметь идентичные мутации, обеспечивающие изменение заряда на противоположный, по меньшей мере в двух положениях в кольце заряженных остатков на поверхности контакта между доменами CH3. В некоторых вариантах осуществления первый полипептид и второй полипептид имеют одинаковую аминокислотную последовательность. В некоторых вариантах осуществления третий и четвертый полипептиды имеют одинаковую аминокислотную последовательность. В некоторых вариантах осуществления последовательность первого мономера Fc-домена отличается от последовательности пятого мономера Fc-домена. В некоторых вариантах осуществления последовательность третьего мономера Fc-домена отличается от последовательности шестого мономера Fc-домена. В некоторых вариантах осуществления последовательность второго мономера Fc-домена такая же, как последовательность четвертого мономера Fc-домена.
В любой из Fc-конструкций, описанных в данном документе, мономеры Fc-домена, принадлежащие Fc-домену конструкции, могут иметь разные последовательности, например последовательности, которые отличаются не более чем 20 аминокислотами (например, не более чем 15, 10 аминокислотами), например, не более чем 20, 15, 10, 8, 7, 6, 5, 4, 3 или 2 аминокислотами между двумя мономерами Fc-домена (т.е. между мономером Fc-домена и другим мономером Fc-конструкции). Например, последовательности мономеров Fc-домена конструкции, описанной в данном документе, могут отличаться, поскольку модули селективности, обеспечивающие комплементарную димеризацию, любой из Fc-конструкций могут содержать сконструированную полость в константном домене CH3 антитела одного из мономеров домена и сконструированный выступ в константном домене CH3 антитела другого из мономеров Fc-домена, где сконструированная полость и сконструированный выступ расположены так, что образуют пару выступ-в-полость мономеров Fc-домена. В некоторых вариантах осуществления Fc-конструкции содержат аминокислотные модификации в домене CH3. В некоторых вариантах осуществления Fc-конструкции содержат аминокислотные модификации в домене CH3 мономеров Fc-домена (один или более мономеров Fc-домена) для селективной димеризации. Иллюстративные сконструированные полости и выступы показаны в таблице 1. В других вариантах осуществления модули селективности, обеспечивающие комплементарную димеризацию, содержат сконструированную (замещенную) отрицательно заряженную аминокислоту в константном домене CH3 антитела одного из мономеров домена и сконструированную (замещенную) положительно заряженную аминокислоту в константном домене CH3 антитела другого из мономеров Fc-домена, где отрицательно заряженная аминокислота и положительно заряженная аминокислота расположены так, чтобы способствовать образованию Fc-домена между комплементарными мономерами домена. Примерные комплементарные аминокислотные замены показаны в таблицах 2А-2С. В некоторых вариантах осуществления один или более мономеров Fc-домена имеют одинаковую последовательность. В некоторых вариантах осуществления один или более мономеров Fc-домена имеют одинаковые модификации. В некоторых вариантах осуществления только один, два, три или четыре мономера Fc-домена имеют одинаковые модификации.
В некоторых случаях Fc-домен содержит по меньшей мере одну аминокислотную модификацию, где аминокислотные модификации изменяют одно или более из следующего: (i) аффинность связывания с одним или более Fc-рецепторами, (ii) эффекторные функции, (iii) уровень сульфатирования Fc-домена, (iv) период полужизни, (v) устойчивость к протеазе, (vi) стабильность Fc-домена и/или (vii) подверженность разрушению (например, по сравнению с немодифицированным Fc-доменом). В некоторых случаях Fc-домен содержит не более 16 аминокислотных модификаций (например, не более чем 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 или 16 аминокислотных модификаций). В некоторых случаях Fc-домен содержит не более 16 аминокислотных модификаций (например, не более чем 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 или 16 аминокислотных модификаций в домене CH3).
Настоящее изобретение также предусматривает фармацевтическую композицию, которая содержит по сути гомогенную совокупность любой Fc-конструкций, описанных в данном документе. В одном варианте осуществления стерильный шприц или флакон, пригодный для фармацевтического применения, содержит фармацевтическую композицию, в которой единственный или первичный активный ингредиент представляет собой по сути гомогенную совокупность любой из Fc-конструкций, описанных в данном документе. Фармацевтическая композиция может содержать один или более неактивных ингредиентов, например, выбранных из солей, детергентов, поверхностно-активных веществ, наполнителей, полимеров, консервантов и других фармацевтических вспомогательных веществ.
В некоторых вариантах осуществления Fc-конструкция образована по меньшей мере частично путем ассоциации мономеров Fc-домена, которые присутствуют в разных полипептидах. В определенных вариантах осуществления Fc-конструкция образована путем ассоциации мономеров Fc-домена, которые присутствуют в разных полипептидах. В этих вариантах осуществления Fc-конструкция не содержит дополнительный домен, который способствует ассоциации двух полипептидов (например, хвостовой части IgM или хвостовой части IgA). В других вариантах осуществления ковалентные связи (например, дисульфидные мостики) присутствуют только между двумя мономерами Fc-домена, которые соединяются с образованием Fc-домена. В других вариантах осуществления Fc-конструкция не содержит ковалентные связи (например, дисульфидные мостики) между Fc-доменами. В других вариантах осуществления Fc-конструкция обеспечивает достаточную структурную гибкость, так что все или практически все Fc-домены в Fc-конструкции способны одновременно взаимодействовать с Fc-рецептором на поверхности клетки. В определенных примерах любого из этих вариантов осуществления Fc-конструкция содержит по меньшей мере два Fc-домена, соединенных посредством линкера (например, гибкого аминокислотного спейсера).
В другом аспекте настоящее изобретение предусматривает композиции и способы стимулирования селективной димеризации мономеров Fc-домена. Настоящее изобретение предоставляет Fc-домен, где два мономера Fc-домена, принадлежащие Fc-домену, содержат идентичные мутации по меньшей мере в двух положениях в кольце заряженных остатков на поверхности контакта между константными доменами CH3 антитела. Настоящее изобретение также предусматривает способ создания такого Fc-домена, включающий введение модуле селективности, обеспечивающих комплементарную димеризацию, имеющих идентичные мутации в двух последовательностях мономера Fc-домена по меньшей мере в двух положениях в кольце заряженных остатков на поверхности контакта между константными доменами CH3 антитела. Поверхность контакта между константными доменами CH3 антитела состоит из гидрофобного отрезка, окруженного кольцом заряженных остатков. Когда один константный домен CH3 антитела находится вместе с другим, эти заряженные остатки соединяются с остатками противоположного заряда. Путем изменения заряда на противоположный у обоих представителей двух или более комплементарных пар остатков, мутированные мономеры Fc-домена остаются комплементарными мономерам Fc-домена с той же мутированной последовательностью, но характеризуются меньшей комплементарностью в отношении мономеров Fc-домена без этих мутаций. В этом варианте осуществления идентичные модули селективности, обеспечивающие димеризацию, способствуют гомодимеризации. Такие Fc-домены содержат мономеры Fc-домена, содержащие двойные мутанты K409D/D399K, K392D/D399K, E357K/K370E, D356K/K439D, K409E/D399K, K392E/D399K, E357K/K370D или D356K/K439. В другом варианте осуществления Fc-домен содержит мономеры Fc-домена, в том числе четырехкратные мутанты, объединяющие любую пару двойных мутантов, например K409D/D399K/E357K/K370E.
В другом варианте осуществления, в дополнение к идентичным модулям селективности, обеспечивающим димеризацию, мономеры Fc-домена, принадлежащие Fc-домену содержат модули селективности, обеспечивающие комплементарную димеризацию, имеющие неидентичные мутации, которые способствуют специфической ассоциации (например, сконструированная полость и выступ). В результате два мономера Fc-домена содержат два модуля селективности, обеспечивающие димеризацию, и остаются комплементарными друг другу, но обладают пониженной комплементарностью по отношению к другим мономерам Fc-домена. В этом варианте осуществления обеспечивается гетеродимеризация между Fc-доменом, содержащим полость, и мономером Fc-домена, содержащим выступ. В одном примере модули селективности, обеспечивающие комплементарную димеризацию, имеющие неидентичные мутации в заряженной паре остатков обоих мономеров Fc-домена, объединяются с выступом на одном мономере Fc-домена и полостью на другом мономере Fc-домена.
В любой из Fc-конструкций, описанных в данном документе, видно, что порядок мономеров Fc-домена является взаимозаменяемым. Например, в полипептиде, имеющим первый мономер Fc-домена, соединенным со вторым мономером Fc-домена посредством линкера, карбокси-конец первого мономера Fc-домена может быть присоединен к амино-концу линкера, который, в свою очередь, присоединен своим карбокси-концом к амино-концу второго мономера Fc-домена. Альтернативно карбокси-конец второго мономера Fc-домена может быть присоединен к амино-концу линкера, который, в свою очередь, присоединен своим карбокси-концом к амино-концу первого мономера Fc-домена. Обе эти конфигурации охвачены настоящим изобретением.
Определения
Используемый в данном документе термин «мономер Fc-домена» относится к полипептидной цепи, которая содержит по меньшей мере шарнирный домен (или его часть) и второй и третий константные домены антитела (CH2 и CH3) или их функциональные фрагменты (например, фрагменты, которые способны (i) димеризоваться с другим мономером Fc-домена с образованием Fc-домена и (ii) связываться с Fc-рецептором). Мономер Fc-домена может иметь различное происхождение, например, происходить от человека, мыши или крысы. Мономер Fc-домена может представлять собой иммуноглобулин, представляющий собой антитело любого изотипа, в том числе IgG, IgE, IgM, IgA или IgD (например, IgG). Кроме того, мономер Fc-домена может быть подтипом IgG (например, IgG1, IgG2a, IgG2b, IgG3 или IgG4) (например, IgG1). Мономер Fc-домена не содержит какую-либо часть иммуноглобулина, которая способна действовать как область распознавания антигена, например вариабельный домен или область, определяющая комплементарность (CDR). Мономеры Fc-домена могут содержать до десяти изменений (например, одиночных аминокислотных модификаций) по сравнению с последовательностью мономера Fc-домена дикого типа (например, 1-10, 1-8, 1-6, 1-4 аминокислотных замен, добавлений или делеций), которые изменяют взаимодействие между Fc-доменом и Fc-рецептором. Примеры подходящих изменений известны из уровня техники.
Используемый в данном документе термин «Fc-домен» относится к димеру из двух мономеров Fc-домена, который способен связывать Fc-рецептор. В Fc-домене дикого типа два мономера Fc-домена димеризуются посредством взаимодействия между двумя константными доменами CH3 антитела, а также одной или более дисульфидных связей, которые образуются между шарнирными доменами двух димеризующихся мономеров Fc-домена.
В настоящем раскрытии термин «Fc-конструкция» относится к связанным полипептидным цепям, образующим Fc-домены, как описано в данном документе (например, Fc-конструкция, имеющая три Fc-домена). Описанные в данном документе Fc-конструкции могут содержать мономеры Fc-домена, которые имеют одинаковые или разные последовательности. Например, Fc-конструкция может иметь три Fc-домена, два из которых содержат мономеры Fc-домена, полученные из IgG1 или IgG1, а третий - мономеры Fc-домена, полученные из IgG2 или IgG2. В другом примере Fc-конструкция может иметь три Fc-домена, два из которых содержат «пару выступ-в-полость», а третий не содержит «пару выступ-в-полость». В настоящем изобретении Fc-домен не содержит вариабельную область антитела, например, VH, VL, CDR или HVR. Fc-домен образует минимальную структуру, которая связывается с Fc-рецептором, например, FcγRI, FcγRIIa, FcγRIIb, FcγRIIIa, FcγRIIIb, FcγRIV. В некоторых вариантах осуществления Fc-конструкции, описанные в данном документе, не содержат область распознавания антигена, например вариабельный домен или область, определяющую комплементарность (CDR). В некоторых вариантах осуществления Fc-конструкции, описанные в данном документе, содержат область распознавания антигена, например вариабельный домен или CDR.
Используемый в данном документе термин «константный домен антитела» относится к полипептиду, который соответствует домену константной области антитела (например, константному домену CL антитела, константному домену CH1 антитела, константному домену CH2 антитела или константному домену CH3 антитела).
Используемый в данном документе термин «способствовать» означает обеспечивать и благоприятствовать, например, благоприятствовать образованию Fc-домена из двух мономеров Fc-домена, которые имеют более высокую аффинность связывания друг с другом, чем для других, отличных мономеров Fc-домена. Как описано в данном документе, два мономера Fc-домена, которые объединяются с образованием Fc-домена, могут иметь совместимые аминокислотные модификации (например, сконструированные выступы и сконструированные полости) на поверхности контакта их соответствующих константных доменов CH3 антитела. Совместимые аминокислотные модификации способствуют или благоприятствуют селективному взаимодействию таких мономеров Fc-домена друг с другом по сравнению с другими мономерами Fc-домена, в которых отсутствуют такие аминокислотные модификации, или с несовместимыми аминокислотными модификациями. Это происходит потому, что из-за аминокислотных модификаций на поверхности контакта двух взаимодействующих константных доменов CH3 антитела мономеры Fc-домена имеют более высокую аффинность по отношению друг к другу, чем к другим мономерам Fc-домена, в которых отсутствуют аминокислотные модификации.
Используемый в данном документе термин «модуль селективности, обеспечивающий димеризацию» относится к последовательности мономера Fc-домена, которая способствует предпочтительному спариванию между двумя мономерами Fc-домена. Модули селективности, обеспечивающие «комплементарную» димеризацию, представляют собой модули селективности, обеспечивающие димеризацию, которые способствуют или благоприятствуют селективному взаимодействию двух мономеров Fc-домена друг с другом. Модули селективности, обеспечивающие комплементарную димеризацию, могут иметь одинаковые или разные последовательности. Иллюстративные модули селективности, обеспечивающие комплементарную димеризацию, описаны в данном документе.
Используемый в данном документе термин «сконструированная полость» относится к замене по меньшей мере одного из исходных аминокислотных остатков в константном домене CH3 антитела другим аминокислотным остатком, имеющим меньший объем боковой цепи, чем исходный аминокислотный остаток, с получением тем самым трехмерной полости в константном домене CH3 антитела. Термин «исходный аминокислотный остаток» относится к встречающемуся в природе аминокислотному остатку, кодируемому генетическим кодом константного домена CH3 антитела дикого типа.
Используемый в данном документе термин «сконструированный выступ» относится к замене по меньшей мере одного из исходных аминокислотных остатков в константном домене CH3 антитела другим аминокислотным остатком, имеющим больший объем боковой цепи, чем исходный аминокислотный остаток, с получением тем самым трехмерного выступа в константном домене CH3 антитела. Термин «исходные аминокислотные остатки» относится к встречающимся в природе аминокислотным остаткам, кодируемым генетическим кодом константного домена CH3 антитела дикого типа.
Используемый в данном документе термин «пара выступ-в-полость» описывает Fc-домен, содержащий два мономера Fc-домена, где первый мономер Fc-домена содержит сконструированную полость в своем константном домене CH3 антитела, в то время как второй мономер Fc-домена содержит сконструированный выступ в его константном домене CH3 антитела. В паре выступ-в-полость сконструированный выступ в константном домене CH3 антитела первого мономера Fc-домена расположен так, что он взаимодействует с сконструированной полостью константного домена CH3 антитела второго мономера Fc-домена без значительного нарушения нормальной ассоциации димера на поверхности контакта константного домена CH3 антитела.
Используемый в данном документе термин «гетеродимерный Fc-домен» относится к Fc-домену, который образован посредством гетеродимеризации двух мономеров Fc-домена, где два мономера Fc-домена содержат разные мутации, обеспечивающие изменение заряда на противоположный (см., например, мутации в таблице 2A), которые способствуют благоприятному образованию этих двух мономеров Fc-домена. Как показано на фиг. 1 и 2, в Fc-конструкции, содержащей три Fc-домена - один карбоксиконцевой Fc-домен «стебля» и два аминоконцевых Fc-домена «ветвей» - каждый из аминоконцевых Fc-доменов «ветвей» может представлять собой гетеродимерный Fc-домен (также называемый «гетеродимерный Fc-домен ветви») (например, гетеродимерный Fc-домен, образованный мономерами Fc-домена 106 и 114, или мономерами Fc-домена 112 и 116 на фиг. 1; гетеродимерный Fc-домен, образованный мономерами Fc-домена 206 и 214, или мономерами Fc-домена 212 и 216 на фиг. 2).
Используемый в данном документе термин «гомодимерный Fc-домен» относится к Fc-домену, который образован посредством гомодимеризации двух мономеров Fc-домена, где два мономера Fc-домена содержат одинаковые мутации, обеспечивающие изменение заряда на противоположный (см., например, мутации в таблице 2B и 2C). Как показано на фиг. 1 и 2, в Fc-конструкции, содержащей три Fc-домена - один карбоксиконцевой Fc-домен «стебля» и два аминоконцевых Fc-домена «ветвей» - карбоксиконцевой Fc-домен «стебля» может представлять собой гомодимерный Fc-домен (также называемый «гомодимерный Fc-домен стебля») (например, гомодимерный Fc-домен, образованный мономерами Fc-домена 104 и 110 на фиг. 1; гомодимерный Fc-домен, образованный мономерами Fc-домена 204 и 210 на фиг. 2).
Используемый в данном документе термин «модуль селективности, обеспечивающий гетеродимеризацию» относится к сконструированным выступам, сконструированным полостям и некоторым аминокислотным заменам, обеспечивающим изменение заряда на противоположный, которые могут быть сделаны в константных доменах CH3 антитела мономеров Fc-домена, с целью способствовать благоприятной гетеродимеризации двух мономеров Fc-домена, которые имеют совместимые модули селективности, обеспечивающие гетеродимеризацию. Мономеры Fc-домена, содержащие модули селективности, обеспечивающие гетеродимеризацию, могут объединяться с образованием гетеродимерного Fc-домена. Примеры модулей селективности, обеспечивающих гетеродимеризацию, показаны в таблицах 1 и 2А.
Используемый в данном документе термин «модуль селективности, обеспечивающий гетеродимеризацию» относится к мутациям, обеспечивающим изменение заряда на противоположный, в мономере Fc-домена по меньшей мере в двух положениях в кольце заряженных остатков на поверхности контакта между доменами CH3, которые способствуют гомодимеризации мономера Fc-домена с образованием гомодимерного Fc-домена. Примеры модулей селективности, обеспечивающих гомодимеризацию, показаны в таблицах 2A и 2B.
Используемый в данном документе термин «соединен» используется для описания комбинации или присоединения двух или больше элементов, компонентов или белковых доменов, например, полипептидов, посредством способов, в том числе химической конъюгации, рекомбинантных средств и химических связей, например дисульфидных связей и амидных связей. Например, два отдельных полипептида могут быть соединены с образованием одной смежной белковой структуры посредством химической конъюгации, химической связи, пептидного линкера или любых других способов обеспечения ковалентного связывания. В некоторых вариантах осуществления первый мономер Fc-домена присоединен ко второму мономеру Fc-домена посредством пептидного линкера, где N-конец пептидного линкера присоединен к C-концу первого мономера Fc-домена посредством химической связи, например, пептидной связи, и С-конец пептидного линкера присоединен к N-концу второго мономера Fc-домена посредством химической связи, например, пептидной связи. В других вариантах осуществления N-конец альбумин-связывающего пептида присоединен к C-концу константного домена CH3 антитела мономера Fc-домена посредством линкера таким же образом, как указано выше.
Используемый в данном документе термин «связанный» используется для описания взаимодействия, например водородного связывания, гидрофобного взаимодействия или ионного взаимодействия, между полипептидами (или последовательностями в пределах одного отдельного полипептида), таким образом, что полипептиды (или последовательности в пределах одного одиночного полипептида) расположены с образованием Fc-конструкции, описанной в данном документе (например, Fc-конструкции, содержащей три Fc-домена). Например, в некоторых вариантах осуществления четыре полипептида, например два полипептида, каждый из которых содержит два мономера Fc-домена, и два полипептида, каждый из которых содержит один мономер Fc-домена, связываются с образованием Fc-конструкции, которая имеет три Fc-домена (например, как показано на фиг. 1 и 2). Четыре полипептида могут связываться посредством соответствующих мономеров Fc-домена. Связывание между полипептидами не включает ковалентные взаимодействия.
Используемый в данном документе термин «линкер» относится к связи между двумя элементами, например белковыми доменами. Линкер может представлять собой ковалентную связь или спейсер. Термин «связь» относится к химической связи, например амидной связи или дисульфидной связи, или любому виду связи, создаваемой в результате химической реакции, например, химической конъюгации. Термин «спейсер» относится к фрагменту (например, полимер полиэтиленгликоля (PEG)) или аминокислотной последовательности (например, состоящей из 3-200 аминокислот, 3-150 аминокислот, 3-100 аминокислот, 3-60 аминокислота, 3-50 аминокислот, 3-40 аминокислот, 3-30 аминокислот, 3-20 аминокислот, 3-10 аминокислот, 3-8 аминокислот, 3-5 аминокислот, 4-30 аминокислот , 5-30 аминокислот, 6-30 аминокислот, 8-30 аминокислот, 10-20 аминокислот, 10-30 аминокислот, 12-30 аминокислот, 14-30 аминокислот, 20-30 аминокислот, 15-25 аминокислот, 15-30 аминокислот, 18-22 аминокислот и 20-30 аминокислотных последовательностей), находящихся между двумя полипептидами или доменами полипептида, для обеспечения пространства и/или гибкости между двумя полипептидами или доменами полипептида. Аминокислотный спейсер является частью первичной последовательности полипептида (например, присоединенного к разнесенным полипептидам или доменам полипептида через полипептидный остов). Образование дисульфидных связей, например, между двумя шарнирными областями или двумя мономерами Fc-домена, которые образуют Fc-домен, не считается линкером.
Используемый в данном документе термин «глициновый спейсер» относится к линкеру, содержащему только остатки глицина, который соединяет два мономера Fc-домена в тандемных последовательностях. Глициновый спейсер может содержать по меньшей мере 4, 8, 12, 14, 16, 18 или 20 остатков глицина (например, 4-30, 8-30, 12-30, 12-50, 12-100 или 12-200 остатков глицина, например, 12-30, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25 , 26, 27, 28, 29 или 30 остатков глицина). В некоторых вариантах осуществления глициновый спейсер содержит, состоит из или состоит по сути из последовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 27).
Используемый в данном документе термин «альбумин-связывающий пептид» относится к аминокислотной последовательности из 12-16 аминокислот, которая обладает сродством к альбумину и функционирует для связывания сывороточного альбумина. Альбумин-связывающий пептид может иметь различное происхождение, например, он может происходить от человека, мыши или крысы. В некоторых вариантах осуществления настоящего изобретения альбумин-связывающий пептид слит с С-концом мономера Fc-домена для увеличения периода полужизни в сыворотке Fc-конструкции. Альбумин-связывающий пептид может быть слит, либо непосредственно, либо посредством линкера, с N- или С-концом мономера Fc-домена.
Используемый в данном документе термин «пептид для очистки» относится к пептиду любой длины, который можно использовать для очистки, выделения или идентификации полипептида. Пептид для очистки может быть присоединен к полипептиду для способствования очистке полипептида и/или выделения полипептида, например, из смеси клеточных лизатов. В некоторых вариантах осуществления пептид для очистки связывается с другим фрагментом, который обладает специфическим сродством к пептиду для очистки. В некоторых вариантах осуществления такие фрагменты, которые специфически связываются с пептидом для очистки, прикрепляют к твердой подложке, такой как матрица, смола или агарозные шарики. Примеры пептидов для очистки, которые могут быть присоединены к Fc-конструкции, описаны более подробно в данном документе.
Используемый в данном документе термин «мультимер» относится к молекуле, содержащей по меньшей мере две связанные Fc-конструкции, описанные в данном документе.
Используемый в данном документе термин «область распознавания антигена» относится к частям легкой и тяжелой цепей антитела, которые отвечают за распознавание и связывание антитела с антигеном. Область распознавания антигена содержит вариабельные домены легкой и тяжелой цепей (Fab), которые содержат области, определяющие комплементарность (CDR, например, CDR L1, CDR L2, CDR L3, CDR H1, CDR H2 и CDR H3), и каркасные области (FR).
Используемое в данном документе выражение «активация иммунных клеток, обеспечивающих иммунный ответ» относится к иммунному ответу, который индуцируется или активируется посредством связывания иммунного комплекса или Fc-конструкции с рецептором Fcγ (FcγR) (например, активирующим FcγR, например, FcγRI, FcγRIIa, FcγRIIc, FcγRIIIa или FcγRIIIb) на клетке (например, иммунной клетке (например, моноците)). Иммунный комплекс представляет собой комплекс антиген-антитело, образованный в результате связывания антитела с антигеном. Иммунный комплекс часто имеет несколько Fc-доменов, которые агрегируют FcγR и ингибируют или активируют клеточные процессы, которые играют критическую роль в воспалении, инфекции и других заболеваниях. В некоторых вариантах осуществления Fc-конструкции по настоящему изобретению способны связываться с FcγR и индуцировать активацию передачи сигналов FcγR (например, FcγRI, FcγRIIa, FcγRIIc, FcγRIIIa или FcγRIIIb) на иммунные клетки (например, моноцит). Измерение определенных нижестоящих событий передачи сигнала, таких как фосфорилирование киназы (например, фосфорилирование Syk) и приток кальция в FcγR-экспрессирующую клетку, можно использовать для выявления активации иммунных клеток, обеспечивающих иммунный ответ, вызванный связыванием иммунного комплекса или Fc-конструкции. Например, активация иммунных клеток, обеспечивающих иммунный ответ, индуцируется, если уровень фосфорилирования киназы (например, фосфорилирования Syk) или уровень притока кальция в клетку в по меньшей мере 5 раз, например, в 5-100 раз (например, в 5-100, 10-95, 15-90, 20-85, 25-80, 30-75, 35-70, 40-65, 45-60 или 50-55 раз, например, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, в 91, 92, 93, 94, 95, 96, 97, 98, 99 или 100 раз выше, чем уровень фосфорилирования киназы (например, фосфорилирование Syk) или приток кальция из клетки без какой-либо активации со стороны иммунного комплекса или Fc-конструкции.
Используемый в данном документе термин «фагоцитоз» относится к форме эндоцитоза, при которой клетка, часто фагоцит (например, моноцит), поглощает другую клетку, частицу или патоген (например, микроб или паразит) с образованием фагосомы. В иммунной системе фагоцитоз является основным механизмом, используемым для удаления больных клеток (например, раковых клеток, инфицированных клеток или мертвых клеток), патогенов и клеточных остатков. Клетка, которая нацелена на фагоцитоз другой клеткой (например, фагоцитом (например, моноцитом)), называется клеткой-мишенью. Например, иммунная клетка (например, моноцит), активированная посредством связывания Fc-конструкции по настоящему изобретению с FcγRs (например, FcγRI, FcγRIIa, FcγRIIc, FcγRIIIa или FcγRIIIb) на иммунной клетке, может фагоцитировать клетку-мишень, которая может представлять собой раковую клетку или инфицированную клетку у субъекта.
Используемый в данном документе термин «увеличивать» или «увеличение» фагоцитоза клетки-мишени относится к увеличению фагоцитоза, вызванному связыванием Fc-конструкции по настоящему изобретению с FcγRs (например, FcγRI, FcγRIIa, FcγRIIc, FcγRIIIa или FcγRIIIb) на иммунной клетке (например, моноците) относительно уровня фагоцитоза, который происходит без индукции посредством Fc-конструкции. Например, фагоцитоз клетки-мишени увеличивается, если уровень фагоцитоза на по меньшей мере 10%, например, на 10-100% (например, 10-100%, 15-95%, 20-90%, 25-85%, 30-80%, 35-75%, 40-70%, 45-65% или 50-60%, например, 10%, 11%, 12%, 13%, 14%, 15%, 16%, 17%, 18%, 19%, 20%, 21%, 22%, 23%, 24%, 25%, 26%, 27%, 28%, 29%, 30%, 31%, 32%, 33%, 34%, 35%, 36%, 37%, 38%, 39%, 40%, 41%, 42%, 43%, 44%, 45%, 46%, 47%, 48%, 49%, 50% , 51%, 52%, 53%, 54%, 55%, 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% или 100% выше уровня фагоцитоза, который происходит без индукции посредством Fc-конструкции.
Используемый в данном документе термин «лечение рака» относится к терапевтическому лечению рака у субъекта. Терапевтическое лечение замедляет прогрессирование рака, улучшает итоговое состояние у субъекта и/или устраняет рак.
Используемый в данном документе термин «лечение инфекции» относится к терапевтическому лечению инфекции у субъекта. Терапевтическое лечение замедляет прогрессирование инфекции, улучшает итоговое состояние у субъекта и/или устраняет инфекцию.
Используемый в данном документе термин «инфекция» относится к проникновению в клетки, ткани и/или органы субъекта патогена, такого как бактерии, вирусы, грибки, гельминты, простейшие, членистоногие и другие микробы, паразиты и черви. В некоторых вариантах осуществления патоген может расти, размножаться и/или продуцировать токсины в клетках, тканях и/или органах субъекта. В некоторых вариантах осуществления у субъекта может развиться отрицательная реакция (т. е. аллергическая реакция или иммунный ответ) на патоген. Примеры инфекций включают без ограничения бактериальную инфекцию, вирусную инфекцию, грибковую инфекцию, гельминтозную инфекцию и протозойную инфекцию.
Используемый в данном документе термин «бактериальная инфекция» относится к инфекции, вызванной одним или более видами бактерий. Примеры бактерий, вызывающих инфекцию, хорошо известны в данной области техники и включают без ограничения бактерии рода Streptococcus (например, Streptococcus pyogenes), бактерии рода Escherichia (например, Escherichia coli), бактерии рода Vibrio (например, Vibrio cholerae), бактерии рода Enteritis (например, Enteritis salmonella), а также бактерии рода Salmonella (например, Salmonella typhi).
Используемый в данном документе термин «вирусная инфекция» относится к инфекции, вызванной одним или более видами вирусов. Примеры вызывающих инфекцию вирусов хорошо известны в данной области техники и включают без ограничения вирусы семейства Retroviridae (например, вирус иммунодефицита человека (HIV)), вирусы семейства Adenoviridae (например, аденовирус), вирусы семейства Herpesviridae (например, вирусы простого герпеса типов 1 и 2), вирусы семейства Papillomaviridae (например, вирус папилломы человека (HPV)), вирусы семейства Poxviridae (например, оспа), вирусы семейства Picornaviridae (например, вирус гепатита А, полиовирус, риновирус), вирусы семейства Hepadnaviridae (например, вирус гепатита В), вирусы семейства Flaviviridae (например, вирус гепатита С, вирус желтой лихорадки, вирус Западного Нила), вирусы семейства Togaviridae (например, вирус краснухи), вирусы семейства Orthomyxoviridae (например, вирус гриппа), вирусы семейства Filoviridae (например, вирус Эбола, вирус Марбурга) и вирусы семейства Paramyxoviridae (например, вирус кори, вирус эпидемического паротита).
Используемый в данном документе термин «грибковая инфекция» относится к инфекции, вызванной одним или более видами грибков. Примеры грибков, вызывающих инфекцию, хорошо известны в данной области техники и включают без ограничения грибы рода Aspergillus (например, Aspergillusfumigatus, A. flavus, A. terreus. A. niger, A. candidus, A. clavatus, A. ochraceus), грибы рода Candida (например, Candida albicans, C. parapsilosis, C. glabrata, C. guilliermondii, C. krusei, C. lusitaniae, C. tropicalis), грибы рода Cryptococcus (например, Cryptococcus neoformans), а также грибы рода Fusarium (например, Fusarium solani, F. verticillioides, F. oxysporum).
Используемый в данном документе термин «гельминтозная инфекция» относится к инфекции, вызванной одним или более видами гельминтов. Примеры гельминтов включают без ограничения ленточных червей (цестоды), круглых червей (нематоды), сосальщиков (трематоды) и моногенетических сосальщиков.
Используемый в данном документе термин «протозойная инфекция» относится к инфекции, вызванной одним или более видами простейших. Примеры простейших включают без ограничения простейших рода Entamoeba (например, Entamoeba histolytica), простейших рода Plasmodium (например, Plasmodiumfalciparum, P.malariae), простейших рода Giardia (например, Giardia lamblia), а также простейших рода Trypanosoma (например, Trypanosoma brucei).
Используемый в данном документе термин «полинуклеотид» относится к олигонуклеотиду или нуклеотиду и его фрагментам или частям, а также к ДНК или РНК геномного или синтетического происхождения, которые могут быть одноцепочечными или двухцепочечными и представляют собой смысловую или антисмысловую цепь. Один полинуклеотид транслируется в один полипептид.
Используемый в данном документе термин «полипептид» описывает один полимер, в котором мономеры представляют собой аминокислотные остатки, которые соединены вместе посредством амидных связей. Предполагается, что в полипептиде может быть охвачена любая аминокислотная последовательность, встречающаяся в природе, рекомбинантная или полученная синтетическим путем.
Используемый в данном документе термин «положения аминокислот» относится к номерам положений аминокислот в белке или белковом домене. Положения аминокислот для антител или Fc-конструкций нумеруются с использованием системы нумерации Kabat (Kabat et al., Sequences of Proteins of Immunological Interest, National Institutes of Health, Бетесда, Мэриленд, изд. 5, 1991 г.).
Используемые в данном документе термины «аминокислотная мутация», «аминокислотное замещение» и «аминокислотная модификация» используются взаимозаменяемо для обозначения изменения полипептида Fc-домена по сравнению с эталонным полипептидом Fc-домена (например, Fc-последовательностью дикого типа, немутированной или немодифицированной). Эталонный полипептид Fc-домена может представлять собой полипептид Fc-домена IgG1 человека дикого типа. Аминокислотная модификация включает аминокислотные замены, делеции и/или вставки. В некоторых вариантах осуществления аминокислотная модификация представляет собой модификацию одной аминокислоты. В другом варианте осуществления аминокислотная модификация представляет собой модификацию множества (например, более чем одной) аминокислот. Аминокислотная модификация может предусматривать комбинацию аминокислотных замен, делеций и/или вставок. В описание аминокислотных модификаций включены генетические (т.е. ДНК и РНК) изменения, такие как точечные мутации (например, замена одного нуклеотида на другой), вставки и делеции (например, добавление и/или удаление одного или более нуклеотидов) нуклеотидной последовательности, которая кодирует Fc-полипептид. Вставка, если не указано иное, представляет собой добавление одной или более аминокислот непосредственно после аминокислотного положения, в котором указана вставка. Аминокислотная модификация, например замена, вставка и/или делеция, если не указано иное, включена в оба мономера Fc-домена, которые составляют Fc-домен. В других вариантах осуществления Fc-домен, содержащий первый и второй мономеры Fc-домена, может содержать, например, одну или более (например, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или более) аминокислотных модификаций в первом мономере Fc-домена, которые отличаются от одной или более (например, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или более) аминокислотными модификациями во втором мономере Fc-домена. В некоторых вариантах осуществления Fc-домен может содержать мономеры Fc-домена, например, первый и второй мономеры Fc-домена, с гомогенными аминокислотными модификациями, например, в положении аминокислоты I253 и/или R292. В других вариантах осуществления Fc-домен может содержать мономеры Fc-домена, например, первый и второй мономеры Fc-домена, с гетерогенными аминокислотными модификациями, например, в положении аминокислоты I253 и/или R292. В определенных вариантах осуществления по меньшей мере один (например, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или более) Fc-домен в Fc-конструкции содержит аминокислотную модификацию. В некоторых случаях по меньшей мере один Fc-домен содержит одну или более (например, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 или больше) одиночных аминокислотных модификаций. В некоторых случаях Fc-домен содержит не более шестнадцати одиночных аминокислотных модификаций (например, не более одной, двух, трех, четырех, пяти, шести, семи, восьми, девяти, десяти, одиннадцати, двенадцати, тринадцати, четырнадцати, пятнадцати или шестнадцати аминокислотных модификаций). В некоторых случаях мономер Fc-домена содержит не более десяти одиночных аминокислотных модификаций. В некоторых случаях мономер Fc-домена содержит не более 12 одиночных аминокислотных модификаций. В некоторых случаях мономер Fc-домена содержит не более 14 одиночных аминокислотных модификаций.
В определенных вариантах осуществления по меньшей мере один (например, один, два или три) Fc-домен в Fc-конструкции содержит аминокислотную модификацию. В некоторых случаях по меньшей мере один Fc-домен содержит одну или более (например, две, три, четыре, пять, шесть, семь, восемь, девять, десять или двадцать или более) аминокислотных модификаций. В некоторых случаях по меньшей мере один Fc-домен содержит не более десяти одиночных аминокислотных модификаций.
Используемый в данном документе термин «процент (%) идентичности» относится к проценту аминокислотных остатков (или остатков нуклеиновых кислот) кандидатной последовательности, например, последовательности мономера Fc-домена в Fc-конструкции, описанной в данном документе, которые идентичны аминокислотным остаткам (или остаткам нуклеиновых кислот) эталонной последовательности, например последовательности мономера Fc-домена дикого типа, после выравнивания последовательностей и введения гэпов, если необходимо, для достижения максимального процента идентичности (т.е. гэпы могут быть введены в одну или обе из кандидатной и эталонной последовательностей для оптимального выравнивания и негомологичные последовательности могут не учитываться для целей сравнения). Выравнивание в целях определения процента идентичности может быть достигнуто различными способами, которые известны специалисту в данной области техники, например с использованием общедоступного компьютерного программного обеспечения, такого как BLAST, ALIGN или Megalign (DNASTAR). Специалисты в данной области техники могут определять соответствующие параметры для оценки выравнивания, в том числе любые алгоритмы, необходимые для достижения максимального выравнивания по полной длине сравниваемых последовательностей. В некоторых вариантах осуществления процент идентичности аминокислотной (или нуклеиновой) последовательности данной кандидатной последовательности относительно данной эталонной последовательности или против нее (которую можно альтернативно сформулировать как данная кандидатная последовательность, которая имеет или содержит определенный процент идентичности аминокислотной (или нуклеиновой) последовательности, относительно или против данной эталонной последовательности) рассчитывают следующим образом:
100 x (фракция A/B)
где A - количество аминокислотных остатков (или остатков нуклеиновых кислот), оцененных как идентичные при выравнивании кандидатной последовательности и эталонной последовательности, и где B - общее количество аминокислотных остатков (или остатков нуклеиновых кислот) в эталонной последовательности. В некоторых вариантах осуществления, где длина кандидатной последовательности не равна длине эталонной последовательности, процент идентичности аминокислотной (или последовательности нуклеиновой кислоты) последовательности кандидатной последовательности относительно эталонной последовательности не будет равен проценту идентичности аминокислотной (или последовательности нуклеиновой кислоты) последовательности эталонной последовательности кандидатной последовательности.
В конкретных вариантах осуществления эталонная последовательность, выровненная для сравнения с кандидатной последовательностью, может показать, что кандидатная последовательность демонстрирует идентичность от 50% до 100% (например, от 50% до 100%, от 60% до 100%, от 70% до 100%, от 80% до 100%, от 90% до 100%, от 92% до 100%, от 95% до 100%, от 97% до 100%, от 99% до 100% или от 99,5% до 100%) по всей длине кандидатной последовательности или выбранной части смежных аминокислотных остатков (или остатков нуклеиновых кислот) кандидатной последовательности. Длина кандидатной последовательности, выровненной для целей сравнения, составляет по меньшей мере 30%, например, по меньшей мере 40%, например, по меньшей мере 50%, 60%, 70%, 80%, 90% или 100% длины эталонной последовательности. Когда положение в кандидатной последовательности занято тем же аминокислотным (или остатком нуклеиновой кислоты) остатком, что и соответствующее положение в эталонной последовательности, то молекулы в этом положении идентичны.
В некоторых вариантах осуществления мономер Fc-домена в Fc-конструкции, описанной в данном документе (например, Fc-конструкции, содержащей три Fc-домена), может содержать, состоять из или состоять по сути из последовательности, которая является на по меньшей мере 95% идентичной (например, идентичной на по меньшей мере 97%, 99% или 99,5%) последовательности мономера Fc-домена дикого типа (например, SEQ ID NO: 42). В некоторых вариантах осуществления мономер Fc-домена в Fc-конструкции, описанной в данном документе (например, Fc-конструкции, содержащей три Fc-домена), может содержать, состоять из или состоять по сути из последовательности, которая является на по меньшей мере 95% идентичной (например, идентичной на по меньшей мере 97%, 99% или 99,5%) последовательности под любым из SEQ ID NO: 44, 46, 48 и 50-53. В определенных вариантах осуществления мономер Fc-домена в Fc-конструкции может содержать, состоять из или состоять по сути из последовательности, которая является на по меньшей мере 95% идентичной (например, идентичной на по меньшей мере 97%, 99% или 99,5%) последовательности под SEQ ID NO: 48, 52 и 53.
В некоторых случаях мономер Fc-домена в Fc-конструкции, описанной в данном документе, может содержать, состоять из или состоять по сути из последовательности, которая является на по меньшей мере 95% идентичной (например, идентичной на по меньшей мере 97%, 99% или 99,5%) любой из последовательностей, описанных в данном документе. В некоторых случаях мономер Fc-домена в Fc-конструкции, описанной в данном документе, может содержать, состоять из или состоять по сути из последовательности, которая представляет собой любую из последовательностей, описанных в данном документе, с не более чем 10 (например, не более 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами).
В некоторых вариантах осуществления полипептид, характеризующийся двумя мономерами Fc-домена в Fc-конструкции, описанной в данном документе (например, полипептиды 102 и 108 на фиг. 1, полипептиды 202 и 208 на фиг. 2), может содержать, состоять из или состоять по сути из последовательности, которая является на по меньшей мере 95% идентичной (например, идентичной на по меньшей мере 97%, 99% или 99,5%) последовательности любой из SEQ ID NO: 43, 45, 47 и 49. В некоторых вариантах осуществления полипептид, содержащий два мономера Fc-домена в Fc-конструкции, описанной в данном документе, может содержать, состоять из или состоять по сути из последовательности, которая является на по меньшей мере 95% идентичной (например, идентичной на по меньшей мере 97%, 99% или 99,5%) последовательности под SEQ ID NO: 49.
В некоторых вариантах осуществления спейсер между двумя мономерами Fc-домена может содержать, состоять из или состоять по сути из последовательности, которая на по меньшей мере 75% идентична (например, на 75%, 77%, 79%, 81%, 83%, 85% (87%, 89%, 91%, 93%, 95%, 97%, 99%, 99,5% или 100% идентична) последовательности под любым из SEQ ID NO: 1-36 (например, SEQ ID NO: 17, 18, 26 и 27), дополнительно описанных в данном документе.
Используемый в данном документе термин «клетка-хозяин» относится к носителю, который содержит необходимые клеточные компоненты, например, органеллы, необходимые для экспрессии белков из их соответствующих нуклеиновых кислот. Нуклеиновые кислоты обычно включают в векторы на основе нуклеиновых кислот, которые можно вводить в клетку-хозяина посредством традиционных методик, известных в данной области техники (трансформация, трансфекция, электропорация, осаждение фосфатом кальция, прямая микроинъекция и т.д.). Клетка-хозяин может представлять собой прокариотическую клетку, например, бактериальную клетку или эукариотическую клетку, например клетку млекопитающего (например, клетку CHO). Как описано в данном документе, клетку-хозяина используют для экспрессии одного или более полипептидов, кодирующих необходимые домены, которые затем могут объединяться с образованием необходимой Fc-конструкции.
Используемый в данном документе термин «фармацевтическая композиция» относится к лекарственному или фармацевтическому составу, который содержит активный ингредиент, а также одно или более вспомогательных веществ и разбавителей, позволяющих активному ингредиенту быть приемлемым для способа введения. Фармацевтическая композиция по настоящему изобретению содержит фармацевтически приемлемые компоненты, которые совместимы с Fc-конструкцией. Фармацевтическая композиция обычно находится в водной форме для внутривенного или подкожного введения.
Используемый в данном документе термин «по сути гомогенная совокупность» полипептидов или Fc-конструкций представляет собой группу, в которой по меньшей мере 50% полипептидов или Fc-конструкций в композиции (например, среде для культивирования клеток или фармацевтической композиции) имеют одинаковое количество Fc-доменов, как определено посредством SDS гель-электрофореза в невосстанавливающих условиях или эксклюзионной хроматографии. По сути гомогенная совокупность полипептидов или Fc-конструкции может быть получена до очистки, или после очистки белка A или белка G, или только после любой Fab- или Fc-специфической аффинной хроматографии. В различных вариантах осуществления по меньшей мере 55%, 60%, 65%, 70%, 75%, 80% или 85% полипептидов или Fc-конструкций в композиции имеют одинаковое количество Fc-доменов. В других вариантах осуществления до 85%, 90%, 92% или 95% полипептидов или Fc-конструкций в композиции имеют одинаковое количество Fc-доменов. По сути гомогенная совокупность или композиция является на по меньшей мере 85% гомогенной (например, на по меньшей мере 85%, 90% или 95% гомогенной).
Используемый в данном документе термин «фармацевтически приемлемый носитель» относится к вспомогательному веществу или разбавителю в фармацевтической композиции. Фармацевтически приемлемый носитель должен быть совместим с другими ингредиентами состава и не причинять вреда реципиенту. В настоящем изобретении фармацевтически приемлемый носитель должен обеспечивать достаточную фармацевтическую стабильность Fc-конструкции. Природа носителя зависит от способа введения. Например, для перорального введения предпочтителен твердый носитель; для внутривенного введения обычно используют водный раствор-носитель (например, WFI и/или забуференный раствор).
Используемый в данном документе термин «терапевтически эффективное количество» относится к количеству, например, фармацевтической дозе, эффективному для индуцирования необходимого биологического эффекта у субъекта или пациента или при лечении пациента, имеющего состояние или нарушение, описанное в данном документе. Также следует понимать, что «терапевтически эффективное количество» можно интерпретировать как количество, обеспечивающее необходимый терапевтический эффект, либо в одной дозе, либо в любой дозировке или пути введения, взятых отдельно или в комбинации с другими терапевтическими средствами.
ОПИСАНИЕ ГРАФИЧЕСКИХ МАТЕРИАЛОВ
На фиг. 1 изображены Fc-конструкции (Fc-конструкция 1, Fc-конструкция 2 или Fc-конструкция 3), содержащие три Fc-домена, образованные из четырех полипептидов. Первый полипептид (102) содержит один мономер Fc-домена (104), содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, отличные от таковых у последовательности мономера Fc-домена дикого типа, соединенный в тандемную последовательность с мономером Fc-домена, содержащим выступ (106). Второй полипептид (108) содержит мономер Fc-домена (110), содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, отличные от таковых у последовательности мономера Fc-домена дикого типа, соединенный в тандемную последовательность с другим мономером Fc-домена, содержащим выступ (112). Каждый из третьего и четвертого полипептидов (114 и 116 соответственно) содержит мономер Fc-домена, содержащий полость.
На фиг. 2 изображена Fc-конструкция (Fc-конструкция 4), состоящая из трех Fc-доменов, образованных из четырех полипептидов. Первый полипептид (202) содержит один мономер Fc-домена (204), содержащий различно заряженные аминокислоты на поверхности контакта CH3-CH3, отличные от таковых у последовательности мономера Fc-домена дикого типа, соединенный в тандемную последовательность с другим мономером Fc-домена (206), содержащим различно заряженные аминокислоты и выступ. Второй полипептид (208) содержит мономер Fc-домена (210), содержащий различные заряженные аминокислоты на поверхности контакта CH3-CH3, отличные от таковых у последовательности мономера Fc-домена дикого типа, соединенный в тандемную последовательность с другим мономером Fc-домена (212), содержащим различно заряженные аминокислоты и выступ. Каждый из третьего и четвертого полипептидов (214 и 216 соответственно) содержит мономер Fc-домена, содержащий различно заряженные аминокислоты и полость.
На фиг. 3 показана идентификация O-ксилозилированного Ser в линкере Fc-конструкции 2 (SGGGSGGGSGGGSGGGSGGG (SEQ ID NO: 18)) с помощью LC-MS/MS.
На фиг. 4 показан уровень O-ксилозилирования линкера в Fc-конструкции, содержащей два Fc-домена (Fc-конструкция, показанная на фигуре 13), как определено с помощью LC-MS/MS.
На фиг. 5 показано образование мономерных молекул Fc из Fc-конструкций 2 и 4 при хранении при 45°C, как определено с помощью CE-SDS.
На фиг. 6 показаны продукты протеолиза Fc-конструкции 2 после двухнедельного хранения при 45°C, как определено посредством LC-MS.
На фиг. 7 показаны продукты протеолиза Fc-конструкции 4 после двухнедельного хранения при 45°C, как определено посредством LC-MS.
На фиг. 8 показано ингибирование высвобождения IL-8 клетками THP-1 посредством Fc-конструкции 2 с различной длиной линкера.
На фиг. 9 показано ингибирование потока кальция в нейтрофилах с помощью Fc-конструкции 2 с различной длиной линкера.
На фиг. 10 показано распределение по размеру с помощью SDS-PAGE в невосстанавливающих условиях Fc-конструкции 2 и Fc-конструкции 4 в неочищенной среде.
На фиг. 11 показана экспрессия и сборка Fc-конструкции 2 («с электростатическим координированием») и другой Fc-конструкции, содержащей три Fc-домена, но без мутаций электростатического координирования в субъединицах «стебля» («без электростатического координирования»).
На фиг. 12 показано, что удаление С-концевого лизина для получения Fc-конструкции 2 не индуцирует комплементзависимую цитотоксичность (CDC) in vitro.
На фиг. 13 изображена Fc-конструкция, состоящая из двух Fc-доменов, образованных из шести полипептидов.
На фиг. 14 изображена Fc-конструкция, состоящая из пяти Fc-доменов, образованных из шести полипептидов (Fc5X).
На фиг. 15 изображена Fc-конструкция, состоящая из пяти Fc-доменов, образованных из шести полипептидов (Fc5Y).
На фиг. 16 изображена Fc-конструкция, состоящая из пяти Fc-доменов, образованных из шести полипептидов (обратная Fc5Y-).
На фиг. 17 изображена Fc-конструкция, состоящая из трех Fc-доменов, образованных из двух полипептидов.
На фиг. 18A изображена Fc-конструкция (конструкция 5), состоящая из трех Fc-доменов, образованных из четырех полипептидов. Каждый из первого полипептида (502) и второго полипептида (508) содержит один мономер Fc-домена, содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, в отличие от последовательности дикого типа (506 и 512 соответственно), присоединенный посредством линкера к мономеру Fc-домена, содержащему выступ (504 и 510 соответственно). Каждый из третьего и четвертого полипептидов (514 и 516 соответственно) содержит мономер Fc-домена, содержащий полость. Каждый из первого полипептида (502) и второго полипептида (508) также содержит мутации, связанные с электростатическим координированием, например, E357K. Аналогично каждый из третьего и четвертого полипептидов (514 и 516 соответственно) содержит мутации, связанные с электростатическим координированием, например, K370D. Каждый из 506 и 512 содержит аминокислотную модификацию I253A, которая обозначена звездочкой. Каждый из 502 и 508 содержит аминокислотную последовательность под SEQ ID NO: 62. Каждый из 514 и 516 содержит аминокислотную последовательность под SEQ ID NO: 61.
На фиг. 18B изображена Fc-конструкция (конструкция 6), состоящая из трех Fc-доменов, образованных из четырех полипептидов. Каждый из первого полипептида (602) и второго полипептида (608) содержит один мономер Fc-домена, содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, в отличие от последовательности дикого типа (606 и 612 соответственно), присоединенный посредством линкера к мономеру Fc-домена, содержащему выступ (604 и 610 соответственно). Каждый из третьего и четвертого полипептидов (614 и 616 соответственно) содержит мономер Fc-домена, содержащий полость. Каждый из первого полипептида (602) и второго полипептида (608) также содержит мутации, связанные с электростатическим координированием, например, E357K. Аналогично каждый из третьего и четвертого полипептидов (614 и 616 соответственно) содержит мутации, связанные с электростатическим координированием, например, K370D. Каждый из 604, 610, 614 и 616 содержит аминокислотную модификацию I253A, которая обозначена звездочкой. Каждый из 602 и 608 содержит аминокислотную последовательность под SEQ ID NO: 64. Каждый из 614 и 616 содержит аминокислотную последовательность под SEQ ID NO: 63.
На фиг. 18С изображена Fc-конструкция (конструкция 7), состоящая из трех Fc-доменов, образованных из четырех полипептидов. Каждый из первого полипептида (702) и второго полипептида (708) содержит один мономер Fc-домена, содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, в отличие от последовательности дикого типа (706 и 712 соответственно), присоединенный посредством линкера к мономеру Fc-домена, содержащему выступ (704 и 710 соответственно). Каждый из третьего и четвертого полипептидов (714 и 716 соответственно) содержит мономер Fc-домена, содержащий полость. Каждый из первого полипептида (702) и второго полипептида (708) также содержит мутации, связанные с электростатическим координированием, например, E357K. Аналогично каждый из третьего и четвертого полипептидов (714 и 716 соответственно) содержит мутации, связанные с электростатическим координированием, например, K370D. Каждый из 704, 706, 710, 712, 714 и 716 содержит аминокислотную модификацию I253A, которая обозначена звездочкой. Каждый из 702 и 708 содержит аминокислотную последовательность под SEQ ID NO: 65. Каждый из 714 и 716 содержит аминокислотную последовательность под SEQ ID NO: 63.
На фиг. 18D изображена Fc-конструкция (конструкция 8), состоящая из трех Fc-доменов, образованных из четырех полипептидов. Каждый из первого полипептида (802) и второго полипептида (808) содержит один мономер Fc-домена, содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, в отличие от последовательности дикого типа (806 и 812 соответственно), присоединенный посредством линкера к мономеру Fc-домена, содержащему выступ (804 и 810 соответственно). Каждый из третьего и четвертого полипептидов (814 и 816 соответственно) содержит мономер Fc-домена, содержащий полость. Каждый из первого полипептида (802) и второго полипептида (808) также содержит мутации, связанные с электростатическим координированием, например, E357K. Аналогично каждый из третьего и четвертого полипептидов (814 и 816 соответственно) содержит мутации, связанные с электростатическим координированием, например, K370D. Каждый из 806 и 812 содержит аминокислотную модификацию R292P, которая обозначена в виде ромба. Каждый из 802 и 808 содержит аминокислотную последовательность под SEQ ID NO: 66. Каждый из 814 и 816 содержит аминокислотную последовательность под SEQ ID NO: 61.
На фиг. 18E изображена Fc-конструкция (конструкция 9), состоящая из трех Fc-доменов, образованных из четырех полипептидов. Каждый из первого полипептида (902) и второго полипептида (908) содержит один мономер Fc-домена, содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, в отличие от последовательности дикого типа (906 и 912 соответственно), присоединенный посредством линкера к мономеру Fc-домена, содержащему выступ (904 и 910 соответственно). Каждый из третьего и четвертого полипептидов (914 и 916 соответственно) содержит мономер Fc-домена, содержащий полость. Каждый из первого полипептида (902) и второго полипептида (908) также содержит мутации, связанные с электростатическим координированием, например, E357K. Аналогично каждый из третьего и четвертого полипептидов (914 и 916 соответственно) содержит мутации, связанные с электростатическим координированием, например, K370D. Каждый из 906 и 912 содержит аминокислотные модификации I253A, которые обозначены звездочкой, и R292P, обозначенную в виде ромба. Каждый из 902 и 908 содержит аминокислотную последовательность под SEQ ID NO: 67. Каждый из 914 и 916 содержит аминокислотную последовательность под SEQ ID NO: 61.
На фиг. 18F изображена Fc-конструкция (конструкция 10), состоящая из трех Fc-доменов, образованных из четырех полипептидов. Каждый из первого полипептида (1002) и второго полипептида (1008) содержит один мономер Fc-домена, содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, в отличие от последовательности дикого типа (1006 и 1012 соответственно), присоединенный посредством линкера к мономеру Fc-домена, содержащему выступ (1004 и 1010 соответственно). Каждый из третьего и четвертого полипептидов (1014 и 1016 соответственно) содержит мономер Fc-домена, содержащий полость. Каждый из первого полипептида (1002) и второго полипептида (1008) также содержит мутации, связанные с электростатическим координированием, например, E357K. Аналогично каждый из третьего и четвертого полипептидов (1014 и 1016 соответственно) содержит мутации, связанные с электростатическим координированием, например, K370D. Каждый из 1006 и 1012 содержит аминокислотную модификацию R292P, которая представлена в виде ромба, а каждый из 1004, 1010, 1014 и 1016 содержит аминокислотную модификацию I253A, которая представлена в виде звездочки. Каждый из 1002 и 1008 содержит аминокислотную последовательность под SEQ ID NO: 68. Каждый из 1014 и 1016 содержит аминокислотную последовательность под SEQ ID NO: 63.
На фиг. 18G изображена Fc-конструкция (конструкция 11), состоящая из трех Fc-доменов, образованных из четырех полипептидов. Каждый из первого полипептида (1102) и второго полипептида (1108) содержит один мономер Fc-домена, содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, в отличие от последовательности дикого типа (1106 и 1112 соответственно), присоединенный посредством линкера к мономеру Fc-домена, содержащему выступ (1104 и 1110 соответственно). Каждый из третьего и четвертого полипептидов (1114 и 1116 соответственно) содержит мономер Fc-домена, содержащий полость. Каждый из первого полипептида (1102) и второго полипептида (1108) также содержит мутации, связанные с электростатическим координированием, например, E357K. Аналогично каждый из третьего и четвертого полипептидов (1114 и 1116 соответственно) содержит мутации, связанные с электростатическим координированием, например, K370D. Каждый из 1106 и 1112 содержит аминокислотную модификацию R292P, которая представлена в виде ромба, а каждый из 1104, 1110, 1114 и 1116 содержит аминокислотную модификацию I253A, которая представлена в виде звездочки. Каждый из 1102 и 1108 содержит аминокислотную последовательность под SEQ ID NO: 69. Каждый из 1114 и 1116 содержит аминокислотную последовательность под SEQ ID NO: 63.
На фиг. 18H изображена Fc-конструкция (конструкция 12), состоящая из трех Fc-доменов, образованных из четырех полипептидов. Каждый из первого полипептида (1202) и второго полипептида (1208) содержит один мономер Fc-домена, содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, в отличие от последовательности дикого типа (1206 и 1212 соответственно), присоединенный посредством линкера к мономеру Fc-домена, содержащему выступ (1204 и 1210 соответственно). Каждый из третьего и четвертого полипептидов (1214 и 1216 соответственно) содержит мономер Fc-домена, содержащий полость. Каждый из первого полипептида (1202) и второго полипептида (1208) также содержит мутации, связанные с электростатическим координированием, например, E357K. Аналогично каждый из третьего и четвертого полипептидов (1214 и 1216 соответственно) содержит мутации, связанные с электростатическим координированием, например, K370D. Каждый из 1204, 1210, 1214 и 1216 содержит аминокислотную модификацию R292P, которая обозначена в виде ромба. Каждый из 1202 и 1208 содержит аминокислотную последовательность под SEQ ID NO: 71. Каждый из 1214 и 1216 содержит аминокислотную последовательность под SEQ ID NO: 70.
На фиг. 18I изображена Fc-конструкция (конструкция 13), состоящая из трех Fc-доменов, образованных из четырех полипептидов. Каждый из первого полипептида (1302) и второго полипептида (1308) содержит один мономер Fc-домена, содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, в отличие от последовательности дикого типа (1306 и 1312 соответственно), присоединенный посредством линкера к мономеру Fc-домена, содержащему выступ (1304 и 1310 соответственно). Каждый из третьего и четвертого полипептидов (1314 и 1316 соответственно) содержит мономер Fc-домена, содержащий полость. Каждый из первого полипептида (1302) и второго полипептида (1308) также содержит мутации, связанные с электростатическим координированием, например, E357K. Аналогично Каждый из третьего и четвертого полипептидов (1314 и 1316 соответственно) содержит мутации, связанные с электростатическим координированием, например, K370D. Каждый из 1304, 1310, 1314 и 1316 содержит аминокислотную модификацию R292P, которая представлена в виде ромба, а каждый из 1306 и 1132 содержит аминокислотную модификацию I253A, которая представлена в виде звездочки. Каждый из 1302 и 1308 содержит аминокислотную последовательность под SEQ ID NO: 72. Каждый из 1314 и 1316 содержит аминокислотную последовательность под SEQ ID NO: 70.
На фиг. 18J изображена Fc-конструкция (конструкция 14), состоящая из трех Fc-доменов, образованных из четырех полипептидов. Каждый из первого полипептида (1402) и второго полипептида (1408) содержит один мономер Fc-домена, содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, в отличие от последовательности дикого типа (1406 и 1412 соответственно), присоединенный посредством линкера к мономеру Fc-домена, содержащему выступ (1404 и 1410 соответственно). Каждый из третьего и четвертого полипептидов (1414 и 1416 соответственно) содержит мономер Fc-домена, содержащий полость. Каждый из первого полипептида (1402) и второго полипептида (1408) также содержит мутации, связанные с электростатическим координированием, например, E357K. Аналогично каждый из третьего и четвертого полипептидов (1414 и 1416 соответственно) содержит мутации, связанные с электростатическим координированием, например, K370D. Каждый из 1404, 1410, 1414 и 1416 содержит аминокислотные модификации R292P, которые обозначены в виде ромба, и I253A, обозначенную в виде звездочки. Каждый из 1402 и 1408 содержит аминокислотную последовательность под SEQ ID NO: 74. Каждый из 1414 и 1416 содержит аминокислотную последовательность под SEQ ID NO: 73.
На фиг. 18K изображена Fc-конструкция (конструкция 15), состоящая из трех Fc-доменов, образованных из четырех полипептидов. Каждый из первого полипептида (1502) и второго полипептида (1508) содержит один мономер Fc-домена, содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, в отличие от последовательности дикого типа (1506 и 1512 соответственно), присоединенный посредством линкера к мономеру Fc-домена, содержащему выступ (1504 и 1510 соответственно). Каждый из третьего и четвертого полипептидов (1514 и 1516 соответственно) содержит мономер Fc-домена, содержащий полость. Каждый из первого полипептида (1502) и второго полипептида (1508) также содержит мутации, связанные с электростатическим координированием, например, E357K. Аналогично каждый из третьего и четвертого полипептидов (1514 и 1516 соответственно) содержит мутации, связанные с электростатическим координированием, например, K370D. Каждый из 1504, 1510, 1514 и 1516 содержит аминокислотную модификацию R292P, которая представлена в виде ромба, а каждый из 1506 и 1512 содержит аминокислотную модификацию I253A, которая представлена в виде звездочки. Каждый из 1502 и 1508 содержит аминокислотную последовательность под SEQ ID NO: 75. Каждый из 1514 и 1516 содержит аминокислотную последовательность под SEQ ID NO: 73.
На фиг. 18L изображена Fc-конструкция (конструкция 16), состоящая из трех Fc-доменов, образованных из четырех полипептидов. Каждый из первого полипептида (1602) и второго полипептида (1608) содержит один мономер Fc-домена, содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, в отличие от последовательности дикого типа (1606 и 1612 соответственно), присоединенный посредством линкера к мономеру Fc-домена, содержащему выступ (1604 и 1610 соответственно). Каждый из третьего и четвертого полипептидов (1614 и 1616 соответственно) содержит мономер Fc-домена, содержащий полость. Каждый из первого полипептида (1602) и второго полипептида (1608) также содержит мутации, связанные с электростатическим координированием, например, E357K. Аналогично каждый из третьего и четвертого полипептидов (1614 и 1616 соответственно) содержит мутации, связанные с электростатическим координированием, например, K370D. Каждый из 1604, 1606, 1610, 1612, 1614 и 1616 содержит аминокислотную модификацию R292P, которая обозначена в виде ромба. Каждый из 1602 и 1608 содержит аминокислотную последовательность под SEQ ID NO: 76. Каждый из 1614 и 1616 содержит аминокислотную последовательность под SEQ ID NO: 70.
На фиг. 18M изображена Fc-конструкция (конструкция 17), состоящая из трех Fc-доменов, образованных из четырех полипептидов. Каждый из первого полипептида (1702) и второго полипептида (1708) содержит один мономер Fc-домена, содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, в отличие от последовательности дикого типа (1706 и 1712 соответственно), присоединенный посредством линкера к мономеру Fc-домена, содержащему выступ (1704 и 1710 соответственно). Каждый из третьего и четвертого полипептидов (1714 и 1716 соответственно) содержит мономер Fc-домена, содержащий полость. Каждый из первого полипептида (1702) и второго полипептида (1708) также содержит мутации, связанные с электростатическим координированием, например, E357K. Аналогично каждый из третьего и четвертого полипептидов (1714 и 1716 соответственно) содержит мутации, связанные с электростатическим координированием, например, K370D. Каждый из 1704, 1706, 1710, 1712, 1714 и 1716 содержит аминокислотную модификацию R292P, которая представлена в виде ромба, а каждый из 1706 и 1712 содержит аминокислотную модификацию I253A, которая представлена в виде звездочки. Каждый из 1702 и 1708 содержит аминокислотную последовательность под SEQ ID NO: 77. Каждый из 1714 и 1716 содержит аминокислотную последовательность под SEQ ID NO: 70.
На фиг. 18N изображена Fc-конструкция (конструкция 18), состоящая из трех Fc-доменов, образованных из четырех полипептидов. Каждый из первого полипептида (1802) и второго полипептида (1808) содержит один мономер Fc-домена, содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, в отличие от последовательности дикого типа (1806 и 1812 соответственно), присоединенный посредством линкера к мономеру Fc-домена, содержащему выступ (1804 и 1810 соответственно). Каждый из третьего и четвертого полипептидов (1814 и 1816 соответственно) содержит мономер Fc-домена, содержащий полость. Каждый из первого полипептида (1802) и второго полипептида (1808) также содержит мутации, связанные с электростатическим координированием, например, E357K. Аналогично каждый из третьего и четвертого полипептидов (1814 и 1816 соответственно) содержит мутации, связанные с электростатическим координированием, например, K370D. Каждый из 1804, 1806, 1810, 1812, 1814 и 1816 содержит аминокислотную модификацию R292P, которая представлена в виде ромба, а каждый 1804, 1810, 1814 и 1816 содержит аминокислотную модификацию I253A, которая представлена в виде звездочки. Каждый из 1802 и 1808 содержит аминокислотную последовательность под SEQ ID NO: 78. Каждый из 1814 и 1816 содержит аминокислотную последовательность под SEQ ID NO: 73.
На фиг. 18O изображена Fc-конструкция (конструкция 19), состоящая из трех Fc-доменов, образованных из четырех полипептидов. Каждый из первого полипептида (1902) и второго полипептида (1908) содержит один мономер Fc-домена, содержащий заряженные аминокислоты на поверхности контакта CH3-CH3, в отличие от последовательности дикого типа (1906 и 1912 соответственно), присоединенный посредством линкера к мономеру Fc-домена, содержащему выступ (1904 и 1910 соответственно). Каждый из третьего и четвертого полипептидов (1914 и 1916 соответственно) содержит мономер Fc-домена, содержащий полость. Каждый из первого полипептида (1902) и второго полипептида (1908) также содержит мутации, связанные с электростатическим координированием, например, E357K. Аналогично каждый из третьего и четвертого полипептидов (1914 и 1916 соответственно) содержит мутации, связанные с электростатическим координированием, например, K370D. Каждый из 1904, 1906, 1910, 1912, 1914 и 1916 содержит аминокислотные модификации R292P, которые обозначены в виде ромба, и I253A, обозначенную в виде звездочки. Каждый из 1902 и 1908 содержит аминокислотную последовательность под SEQ ID NO: 79. Каждый из 1914 и 1916 содержит аминокислотную последовательность под SEQ ID NO: 73.
На фиг. 18P представлен вестерн-блот, показывающий экспрессию конструкции 4, конструкции 5 и конструкции 7.
На фиг. 19А представлен график, показывающий клеточное связывание IgG1 и конструкции 4, конструкции 6, конструкции 16 и конструкции 18 с помощью TR-FRET с FcγRIIb (среднее ± стандартное отклонение, показанное для 3-8 повторностей).
На фиг. 19B представлен график, показывающий клеточное связывание IgG1 и конструкции 4, конструкции 6, конструкции 16 и конструкции 18 с помощью TR-FRET с FcγRI (среднее ± стандартное отклонение, показанное для 3-8 повторностей).
На фиг. 19C представлен график, показывающий клеточное связывание IgG1 и конструкции 4, конструкции 6, конструкции 16 и конструкции 18 с помощью TR-FRET с FcγRIIa (среднее ± стандартное отклонение, показанное для 3-8 повторностей).
На фиг. 19D представлен график, показывающий клеточное связывание IgG1 и конструкции 4, конструкции 6, конструкции 16 и конструкции 18 с помощью TR-FRET с FcγRIIIa (среднее ± стандартное отклонение, показанное для 3-8 повторностей).
На фиг. 20 представлен график, показывающий связывание конструкции 4, конструкции 7, конструкции 6, конструкции 16, конструкции 18 и конструкции 19 с FcRn при pH 6,0 посредством поверхностного плазмонного резонанса (SPR). Нормализованный максимальный уровень связывания пропорционален числу доменов, функционально связывающих FcRn.
На фиг. 21 представлен график сравнения фармакокинетики конструкции 4, конструкции 6, конструкции 16 и IVIg у мышей.
На фиг. 22 представлен график сравнения фармакокинетики конструкций 4, конструкции 5, конструкции 6 и конструкции 7 для оценки влияния количества доменов, характеризующихся пониженной степенью связывания с FcRn, например мутации I253A, на фармакокинетику у мышей.
На фиг. 23 представлен график сравнения фармакокинетики конструкции 20 (конструкции 4), конструкции 16, конструкции 18 и конструкции 19 у мышей.
На фиг. 24 представлен график сравнения ингибирования фагоцитоза в клетках THP-1, индуцированного посредством IVIg, конструкции 4, конструкции 6, конструкции 16 и конструкции 18.
На фиг. 25 представлен график сравнения ингибирования высвобождения IL-8 в моноцитах, индуцированного посредством меченых pacific-blue IgG1, конструкции 4, конструкции 6, конструкции 16 и конструкции 18.
На фиг. 26 представлен график сравнения ингибирования антителозависимой клеточно-опосредованной цитотоксичности (ADCC), индуцированного посредством конструкции 4, конструкции 5, конструкции 6, конструкции 7, конструкции 16, конструкции 18 и конструкции 19.
На фиг. 27 представлен график сравнения эффективности конструкции 4, конструкции 6, конструкции 16 и конструкции 18 при различных концентрациях в модели артрита, индуцированного антителами к коллагену (CAIA), измеренной по клиническим показателям в день 12.
На фиг. 28 представлен график сравнения эффективности конструкции 4 и конструкции 18 в модели CAIA, вводимых с профилактической целью в день 1, измеренной по клиническим показателям.
На фиг. 29 представлен график сравнения эффективности конструкции 4 и конструкции 18 в модели CAIA, вводимых с профилактической целью в день 3, измеренной по клиническим показателям.
На фиг. 30 представлен график сравнения эффективности конструкции 4 и конструкции 18 в модели CAIA, вводимых с профилактической целью в день 7, измеренной по клиническим показателям.
На фиг. 31 представлен график сравнения эффективности конструкции 4 и конструкции 18 в модели CAIA, вводимых с профилактической целью в день 10, измеренной по клиническим показателям.
На фиг. 32 представлен график сравнения эффективности конструкции 4 (AA: черные квадраты, сплошная линия), конструкции 18 (Q1: черные треугольники, штриховая линия), конструкции 19 (Q2: черные ромбы, точечная линия) или физиологического раствора (серые круги, штрихпунктирная линия) в дозе 100 мг/кг в день 1 на модели артрита, индуцированного антителами к коллагену (CAIA). Эквивалентный объем физиологического раствора (серые круги, штрихпунктирная линия) вводили в день 1. Среднее значение и стандартная ошибка среднего значения показаны для каждого момента времени.
На фиг. 33 представлен график сравнения эффективности конструкции 4 (AA: черные квадраты, сплошная линия), конструкции 18 (Q1: черные треугольники, штриховая линия) или конструкции 19 (Q2: черные ромбы, точечная линия) в дозе 100 мг/кг в день 3 на модели артрита, индуцированного антителами к коллагену (CAIA). Эквивалентный объем физиологического раствора (серые круги, штрихпунктирная линия) вводили в день 1. Среднее значение и стандартная ошибка среднего значения показаны для каждого момента времени.
На фиг. 34 представлен график сравнения эффективности конструкции 4 (AA: черные квадраты, сплошная линия), конструкции 18 (Q1: черные треугольники, штриховая линия) или конструкции 19 (Q2: черные ромбы, точечная линия) в дозе 100 мг/кг в день 7 на модели артрита, индуцированного антителами к коллагену (CAIA). Эквивалентный объем физиологического раствора (серые круги, штрихпунктирная линия) вводили в день 1. Среднее значение и стандартная ошибка среднего значения показаны для каждого момента времени.
На фиг. 35 представлен график сравнения эффективности конструкции 4 (AA: черные квадраты, сплошная линия), конструкции 18 (Q1: черные треугольники, штриховая линия) или конструкции 19 (Q2: черные ромбы, точечная линия) в дозе 100 мг/кг в день 10 на модели артрита, индуцированного антителами к коллагену (CAIA). Эквивалентный объем физиологического раствора (серые круги, штрихпунктирная линия) вводили в день 1. Среднее значение и стандартная ошибка среднего значения показаны для каждого момента времени.
На фиг. 36 представлен график сравнения профиля эксклюзионной хроматографии очищенных конструкций X1 (серый) и X2 (черный), нормализованных по максимумам пика.
На фиг. 37 представлен результат электрофореза в полиакриламидном геле с додецилсульфатом натрия в невосстанавливающих условиях для очищенной конструкции X1 (справа), очищенной конструкции X2 (в центре) и стандартов молекулярной массы (справа). Загружали равные массы двух конструкций.
На фиг. 38 представлен график сравнения фармакокинетики конструкции X1 (Fc-мультимер дикого типа) (черные круги, сплошная линия) и конструкции X2 (Fc-мультимер с мутациями I253A/R292P) (треугольники, штриховая линия) для оценки влияния снижения связывания с FcRn и FcγRIIb на фармакокинетику. Среднее значение и стандартное отклонение показаны для каждого момента времени.
На фиг. 39 представлен график, отображающий фармакокинетику конструкций 6 (круги; SEQ ID NO: 64 и 63), 16 (треугольники; SEQ ID NO: 76/70) и 18 (квадраты; SEQ ID NO: 78 и 73), в дозе 10 мг/кг у макак-крабоедов. Конструкцию 4 (перевернутые треугольники; SEQ ID NO: 49 и 48) вводили в дозе 20 мг/кг у макак-крабоедов.
На фиг. 40 представлен график, отображающий фармакокинетику конструкций 6 (серые круги; SEQ ID NO: 64 и 63), 16 (ромбы; SEQ ID NO: 76 и 70) и 18 (перевернутые треугольники; SEQ ID NO: 78 и 73) в дозе 30 мг/кг у макак-крабоедов. Конструкцию 4 (SEQ ID NO: 49 и 48) вводили в дозе 20 мг/кг (квадраты), 30 мг/кг (круги) и 50 мг/кг (треугольники) макакам-крабоедам.
ПОДРОБНОЕ ОПИСАНИЕ ИЗОБРЕТЕНИЯ
Терапевтические белки, которые содержат Fc-домены IgG, можно применять для лечения воспаления и иммунологических и воспалительных заболеваний, рака и инфекций. В настоящем изобретении описаны композиции и способы получения Fc-конструкций, содержащих Fc-домены (например, Fc-конструкций, имеющих 2-10 Fc-доменов, например Fc-конструкций, имеющих 2, 3, 4, 5, 6, 7, 8, 9 или 10 Fc-доменов). Описанные в данном документе Fc-конструкции облегчают получение гомогенных фармацевтических композиций путем включения структурных элементов (например, глициновых спейсеров), которые значительно улучшают результаты производства.
Соответственно, настоящее изобретение предусматривает фармацевтические композиции, которые содержат по сути гомогенную совокупность Fc-конструкций, описанных в данном документе (например, Fc-конструкцию, содержащую три Fc-домена). Гомогенность является важным аспектом фармацевтической композиции, поскольку она влияет на фармакокинетику и эффективность композиции in vivo. Традиционно при производстве фармацевтических продуктов существует проблема гетерогенности продукта, которая может быть вызвана несколькими факторами в зависимости от того, как производится продукт. Например, фармацевтический продукт может подвергаться случайному расщеплению, протеолизу, разрушению и/или агрегации продукта, нецелевой ассоциации субъединиц и/или неэффективному сворачиванию белка. Различные организмы, характеризующиеся разными способами биосинтеза или клеточные механизмы, которые используются для производства фармацевтического продукта, также могут вызывать гетерогенность в продукте. Зачастую исходная культура, содержащая необходимый фармацевтический продукт, должна подвергаться строгому процессу очистки для получения менее гетерогенной композиции, содержащей фармацевтический продукт.
Настоящее изобретение предусматривает, в одном аспекте, Fc-конструкции, имеющие структурные элементы, которые значительно улучшают эффективность сворачивания Fc-конструкций и минимизируют нецелевую ассоциацию субъединиц, с получением таким образом фармацевтических композиций, содержащих такие Fc-конструкции, с высокой гомогенностью. Высокая степень гомогенности обеспечивает безопасность, эффективность, однородность и надежность фармацевтической композиции. Наличие высокой степени гомогенности также минимизирует потенциальную агрегацию или разрушение фармацевтического продукта, вызванные нежелательными материалами (например, продуктами разложения и/или агрегированными продуктами или мультимерами), а также обеспечивает ограничение нежелательных и неблагоприятных побочных эффектов, вызванных нежелательными материалами.
Как описано подробно в данном документе, изобретение предусматривает по сути гомогенные композиции, содержащие Fc-конструкции, которые содержат такое же количество Fc-доменов, а также способы получения таких по сути гомогенных композиций.
Описанные в данном документе Fc-конструкции содержат глициновые спейсеры между Fc-доменами. Как хорошо известно в данной области техники, линкеры, содержащие как остатки серина, так и остатки глицина, обеспечивают структурную гибкость в белке и обычно используются для соединения двух полипептидов. В ходе экспериментов (см. пример 4) авторы настоящего изобретения наблюдали, что линкеры, содержащие как остатки серина, так и остатка глицина, подвергаются O-гликозилированию (например, O-ксилозилированию) по нескольким остаткам серина в линкере и протеолизу на N-концевой части серина. Авторы настоящего изобретения стремились оптимизировать последовательность и длину линкера для дальнейшего улучшения гомогенности Fc-конструкций. Авторы настоящего изобретения создали Fc-конструкции, в которых все линкеры в данных конструкциях представляют собой глициновые спейсеры, содержащие только остатки глицина (например, по меньшей мере 12 остатков глицина, например, 12-30 остатков глицина; SEQ ID NO: 27). Наличие полностью глициновых спейсеров в Fc-конструкциях дополнительно улучшало гомогенность Fc-конструкций посредством предотвращения O-гликозилирования по остаткам серина, а также уменьшения скорости протеолиза конструкций (см. пример 4). Следовательно, авторы смогли достичь более гомогенной совокупности Fc-конструкций посредством использования полностью глициновых спейсеров в Fc-конструкциях.
Гомогенность является результатом использования компонентов Fc-конструкции. Например, в первом подходе («подход (а)») можно использовать включение линкеров, содержащих только остатки глицина, для присоединения мономеров Fc-домена. Как наблюдали в ходе экспериментов, полностью глициновые спейсеры (например, по меньшей мере 12 остатков глицина, например, 12-30 остатков глицина; SEQ ID NO: 27) в Fc-конструкции не подвергаются O-гликозилированию и менее подвержены протеолизу по сравнению с традиционными линкерами, которые содержат остатки серина и глицина (см. пример 4).
Кроме того, в другом подходе («подход (b)») гомогенность композиции, содержащей Fc-конструкцию, описанную в данном документе (например, Fc-конструкцию, имеющую три Fc-домена), улучшается путем удаления C-концевых остатков лизина. Такие C-концевые остатки лизина высоко консервативны в иммуноглобулинах у многих видов и могут быть полностью или частично удалены посредством клеточного механизма во время выработки белка. Удаление С-концевых остатков лизина в Fc-конструкциях по настоящему изобретению улучшает гомогенность полученной композиции и позволяет получить более гомогенный препарат Fc-конструкции (см. пример 8). Например, в некоторых вариантах осуществления Fc-конструкций, описанных в данном документе (например, Fc-конструкции, содержащей три Fc-домена), кодон С-концевого лизина удаляется, с получением тем самым Fc-конструкции, содержащей полипептиды без С-концевых остатков лизина, и получением в результате гомогенной совокупности.
В дополнительном подходе («подход (с)») для улучшения гомогенности композиции, содержащей Fc-конструкцию, описанную в данном документе (например, Fc-конструкцию, имеющую три Fc-домена), использовали два набора модулей селективности, обеспечивающих гетеродимеризацию: (i) модули селективности, обеспечивающие гетеродимеризацию, имеющие различные мутации, обеспечивающие изменение заряда на противоположный, и (ii) модули селективности, обеспечивающие гетеродимеризацию, имеющие сконструированные полости и выступы. В ходе экспериментов, например, см. пример 6, авторы настоящего изобретения наблюдали, что при попытке образовать гетеродимерный Fc-домен в Fc-конструкции, при наличии как (i), так и (ii) дальнейшее улучшение гомогенности фармацевтической композиции достигалось путем уменьшения неконтролируемой ассоциации мономеров Fc-домена и, следовательно, нежелательных олигомеров и мультимеров. В конкретных примерах может быть получен мономер Fc-домена, содержащий (i) по меньшей мере одну мутацию, обеспечивающую изменение заряда на противоположный, и (ii) по меньшей мере одну сконструированную полость или по меньшей мере один сконструированный выступ, и он будет селективно объединяться с другим мономером Fc-домена, содержащим (i) по меньшей мере одну мутацию, обеспечивающую изменение заряда на противоположный, и (ii) по меньшей мере один сконструированный выступ или по меньшей мере одну сконструированную полость для образования Fc-домена. В другом примере мономер Fc-домена, содержащий, обеспечивающую изменение заряда на противоположный, K370D, и сконструированные полости Y349C, T366S, L368A и Y407V, и другой мономер Fc-домена, содержащий мутацию, обеспечивающую изменение заряда на противоположный, E357K, и сконструированные выступы S354C и T366W, могут быть получены и селективно объединены для образования Fc-домена.
Как подробно описано в данном документе, по сути гомогенная композиция, содержащая Fc-конструкцию по настоящему изобретению (например, Fc-конструкцию, имеющую три Fc-домена), может быть получена путем применения полностью глициновых спейсеров между двумя мономерами Fc-домена в Fc-конструкции (подход (a)), посредством применения полипептидов, в которых отсутствуют C-концевые остатки лизина в Fc-конструкции (подход (b)), и/или с применением двух наборов модулей селективности, обеспечивающих гетеродимеризацию, ((i) модули селективности, обеспечивающие гетеродимеризацию, имеющие различные мутации, обеспечивающие изменение заряда на противоположный, и (ii) модули селективности, обеспечивающие гетеродимеризацию, имеющие сконструированные полости и выступы), с целью способствовать образованию гетеродимерного Fc-домена некоторыми мономерами Fc-домена в Fc-конструкции (подход (с)).
В некоторых вариантах осуществления по сути гомогенная композиция, содержащая Fc-конструкцию, описанную в данном документе (например, Fc-конструкцию, имеющую три Fc-домена), может быть получена с помощью подхода (а).
В некоторых вариантах осуществления по сути гомогенная композиция, содержащая Fc-конструкцию, описанную в данном документе (например, Fc-конструкцию, имеющую три Fc-домена), может быть получена с помощью подхода (b).
В некоторых вариантах осуществления по сути гомогенная композиция, содержащая Fc-конструкцию, описанную в данном документе (например, Fc-конструкцию, имеющую три Fc-домена), может быть получена с помощью подхода (c).
В некоторых вариантах осуществления по сути гомогенная композиция, содержащая Fc--конструкцию, описанную в данном документе (например, Fc-конструкцию, имеющую три Fc-домена), может быть получена посредством комбинации подходов (a) и (b).
В некоторых вариантах осуществления по сути гомогенная композиция, содержащая Fc-конструкцию, описанную в данном документе (например, Fc-конструкцию, имеющую три Fc-домена), может быть получена посредством комбинации подходов (a) и (c).
В некоторых вариантах осуществления по сути гомогенная композиция, содержащая Fc-конструкцию, описанную в данном документе (например, Fc-конструкцию, имеющую три Fc-домена), может быть получена посредством комбинации подходов (b) и (c).
В некоторых вариантах осуществления по сути гомогенная композиция, содержащая Fc-конструкцию, описанную в данном документе (например, Fc-конструкцию, имеющую три Fc-домена), может быть получена посредством комбинации подходов (a), (b) и (c).
В некоторых вариантах осуществления для дополнительного улучшения гомогенности фармацевтической композиции, содержащей Fc-конструкцию, описанную в данном документе, N-концевой Asp в одном или более полипептидах в Fc-конструкции в композиции заменен на Gln в результате мутации. В некоторых вариантах осуществления композиции, содержащей по сути гомогенную совокупность Fc-конструкций, описанных в данном документе, N-концевой Asp в каждом из полипептидов в Fc-конструкции в композиции заменен на Gln в результате мутации.
Кроме того, в Fc-конструкциях по настоящему изобретению (например, Fc-конструкции, содержащей три Fc-домена), длина линкеров, которые соединяют мономеры Fc-домена, влияет на эффективность сворачивания Fc-конструкций. В некоторых вариантах осуществления линкер, содержащий по меньшей мере 4, 8 или 12 остатков глицина (например, 4-30, 8-30, 12-30 остатков глицина; SEQ ID NO: 26 и 27), можно использовать для соединения мономеров Fc-домена в Fc-конструкции по настоящему изобретению.
I. Мономеры Fc-домена
Мономер Fc-домена содержит шарнирный домен, константный домен CH2 антитела и константный домен CH3 антитела. Мономер Fc-домена может иметь различное происхождение, например, происходить от человека, мыши или крысы. Мономер Fc-домена может относиться к иммуноглобулину, представляющему собой антитело изотипа IgG, IgE, IgM, IgA или IgD. Мономер Fc-домена также может относиться к иммуноглобулину, представляющему собой антитело любого изотипа (например, IgG1, IgG2a, IgG2b, IgG3 или IgG4). Мономеры Fc-домена также могут представлять собой гибриды, например, с шарниром и CH2 из IgG1 и CH3 из IgA, или с шарниром и CH2 из IgG1, но с CH3 из IgG3. Димер мономеров Fc-домена представляет собой Fc-домен (дополнительно определенный в данном документе), который может связываться с Fc-рецептором, например, FcγRIIIa, который является рецептором, расположенным на поверхности лейкоцитов. В настоящем изобретении константный домен CH3 антитела мономера Fc-домена может содержать аминокислотные замены на поверхности контакта между константными доменами CH3-CH3 антитела с целью способствовать их ассоциации друг с другом. В других вариантах осуществления мономер Fc-домена содержит дополнительный фрагмент, например, альбумин-связывающий пептид или пептид для очистки, присоединенный к N- или C-концу. В настоящем изобретении мономер Fc-домена не содержит какого-либо типа вариабельной области антитела, например VH, VL, определяющей комплементарность области (CDR) или гипервариабельной области (HVR).
В некоторых вариантах осуществления мономер Fc-домена в Fc-конструкции, описанной в данном документе (например, Fc-конструкции, содержащей три Fc-домена), может содержать, состоять из или состоять по сути из последовательности, которая является на по меньшей мере 95% идентичной (например, идентичной на по меньшей мере 97%, 99% или 99,5%) последовательности мономера Fc-домена дикого типа (SEQ ID NO: 42). В некоторых вариантах осуществления мономер Fc-домена в Fc-конструкции, описанной в данном документе (например, Fc-конструкции, содержащей три Fc-домена), может содержать, состоять из или состоять по сути из последовательности, которая представляет собой мономер Fc-домена дикого типа (SEQ ID NO: 42) с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами). В некоторых вариантах осуществления мономер Fc-домена в Fc-конструкции, описанной в данном документе (например, Fc-конструкции, содержащей три Fc-домена), может содержать, состоять из или состоять по сути из последовательности, которая является на по меньшей мере 95% идентичной (например, идентичной на по меньшей мере 97%, 99% или 99,5%) последовательности под любым из SEQ ID NO: 44, 46, 48 и 50-53 (см. пример 1, таблицы 4 и 5). В некоторых вариантах осуществления мономер Fc-домена в Fc-конструкции, описанной в данном документе (например, Fc-конструкции, содержащей три Fc-домена), может содержать, состоять из или состоять по сути из последовательности, которая представляет собой последовательность под любым из SEQ ID NO: 44, 46, 48 и 50-53 (см. пример 1, таблицы 4 и 5) с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых случаях эти аминокислотные модификации являются дополнением к изменению длины глицинового спейсера, т. е. не более 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночных аминокислотных модификаций являются дополнением к изменениям длины всего глицинового спейсера (SEQ ID NO: 23). В определенных вариантах осуществления мономер Fc-домена в Fc-конструкции может содержать, состоять из или состоять по сути из последовательности, которая является на по меньшей мере 95% идентичной (например, идентичной на по меньшей мере 97%, 99% или 99,5%) последовательности под любым из SEQ ID NO: 48, 52 и 53. В определенных вариантах осуществления мономер Fc-домена в Fc-конструкции может содержать, состоять из или состоять по сути из последовательности, которая представляет собой последовательность под любым из SEQ ID NO: 48, 52 и 53 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами).
SEQ ID NO: 42: аминокислотная последовательность мономера Fc-домена IgG1 человека дикого типа
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO: 44
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO: 46
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 48
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVCTLPPSRDELTKNQVSLSCAVDGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLVSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 50
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDELTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO: 51
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
SEQ ID NO: 52
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPSRDELTKNQVSLTCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLKSDGSFFLYSDLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPG
SEQ ID NO: 53
DKTHTCPPCPAPELLGGPSVFLFPPKPKDTLMISRTPEVTCVVVDVSHEDPEVKFNWYVDGVEVHNAKTKPREEQYNSTYRVVSVLTVLHQDWLNGKEYKCKVSNKALPAPIEKTISKAKGQPREPQVYTLPPCRDKLTKNQVSLWCLVKGFYPSDIAVEWESNGQPENNYKTTPPVLDSDGSFFLYSKLTVDKSRWQQGNVFSCSVMHEALHNHYTQKSLSLSPGK
II. Fc-домены
Как определено в данном документе, Fc-домен содержит два мономера Fc-домена, которые димеризуются в результате взаимодействия между константными доменами CH3 антитела. В настоящем изобретении Fc-домен не содержит вариабельную область антитела, например, VH, VL, CDR или HVR. Fc-домен образует минимальную структуру, которая связывается с Fc-рецептором, например, рецепторами Fc-гамма (т. е. рецепторами Fcγ (FcγR)), рецепторами Fc-альфа (т. е. рецепторами Fcα (FcαR)), рецепторами Fc-эпсилон (т.е., рецепторами Fcε (FcεR)) и/или неонатальным Fc-рецептором (FcRn). В некоторых вариантах осуществления Fc-домен по настоящему изобретению связывается с рецептором Fcγ (например, FcγRI (CD64), FcγRIIa (CD32), FcγRIIb (CD32), FcγRIIIa (CD16a), FcγRIIIb (CD16b)), и/или FcγRIV, и/или неонатальным Fc-рецептором (FcRn).
III. Модификации Fc-домена
Немодифицированный мономер Fc-домена может представлять собой природный мономер Fc-домена человека или мономер Fc-домена человека WT. Мономер Fc-домена может представлять собой природный мономер Fc-домена человека, содержащий шарнир, домен СН2 и домен СН3; или его вариант, имеющий не более чем 16 (например, до 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 или 16) аминокислотных модификаций (например, одиночных аминокислотных модификаций) для обеспечения или способствования направленной димеризации. Мономер Fc-домена может представлять собой Fc-домен IgG1, Fc-домен IgG2, Fc-домен IgG3, Fc-домен IgG4 или их комбинацию. Мономер Fc-домена может представлять собой Fc-домен IgG1, Fc-домен IgG2, Fc-домен IgG3, Fc-домен IgG4 или их комбинацию с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами). В некоторых случаях мономер Fc-домена представляет собой мономер Fc-домена IgG человека, имеющий до десяти аминокислотных модификаций (например, не более 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 или 16 аминокислотных модификаций). В некоторых случаях мономер Fc-домена содержит, состоит из или состоит по сути из последовательности под SEQ ID NO: 42 с не более чем десятью аминокислотными модификациями (например, не более чем 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 или 16 аминокислотных модификаций). В некоторых случаях Fc-домен содержит по меньшей мере одну аминокислотную модификацию, где аминокислотные модификации изменяют одно или более из следующего: (i) аффинность связывания с одним или более Fc-рецепторами, (ii) эффекторные функции, (iii) уровень сульфатирования Fc-домена, (iv) период полужизни, (v) устойчивость к протеазе, (vi) стабильность Fc-домена и/или (vii) подверженность разрушению (например, по сравнению с немодифицированным Fc-доменом). В некоторых случаях Fc-домен содержит не более 16 аминокислотных модификаций (например, не более чем 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15 или 16 аминокислотных модификаций в домене CH3).
По меньшей мере один Fc-домен Fc-конструкции по настоящему изобретению содержит аминокислотную модификацию в положении I253 (например, I253A, I253C, I253D, I253E, I253F, I253G, I253H, I253I, I253K, I253L, I253M, I253N, I253P, I253Q, I253R, I253S, I253T, I253V, I253W или I253Y) и/или в положении R292 (например, R292P, R292D, R292E, R292L, R292Q, R292R, R292T и R292Y). В некоторых случаях по меньшей мере один Fc-домен содержит аминокислотную модификацию в положении I253, например I253A. В некоторых случаях по меньшей мере один Fc-домен содержит аминокислотную модификацию в положении R292, например R292P. Fc-домен может содержать аминокислотную модификацию как в положении I253 (например, I253A), так и в положении R292 (например, R292P). Например, Fc-конструкция, имеющая три Fc-домена, может содержать аминокислотную модификацию в положении I253 (например, I253A) в одном, двух или всех трех Fc-доменах и может дополнительно или альтернативно содержать аминокислотную модификацию в положении R292 (например, R292P) в одном, двух или всех трех Fc-доменах. Типичные Fc-конструкции, имеющие аминокислотные модификации I253A и/или R292P, изображены на фиг. 2 и фиг. 18B-18O.
В некоторых вариантах осуществления модификации Fc-домена, которые изменяют период полужизни, могут уменьшать степень связывания модифицированного Fc-домена с FcRn, например, путем модификации Fc-домена в положении I253. Модификации в положении I253 могут включать аминокислотную замену, где аминокислота в положении I253 замещена природной или неприродной аминокислотой; делецию аминокислоты в положении I253; или вставку одного или более аминокислотных остатков в положение I253 Fc-домена. Аминокислотная модификация I253 может быть частью комбинации, включающей несколько модификаций (например, в других положениях остатка, например, R292), например, комбинацию одной или более аминокислотных замен, делеций и/или вставок. В конкретных вариантах осуществления Fc-конструкция может содержать, например, три Fc-домена, где по меньшей мере один Fc-домен содержит модификацию в положении I253. Например, аминокислотный остаток дикого типа, например изолейцин (I), в положении I253 может быть замещен природной или неприродной аминокислотой, например аланином (A). В некоторых случаях каждая аминокислотная модификация в положении I253 независимо выбрана из, например, I253A, I253C, I253D, I253E, I253F, I253G, I253H, I253I, I253K, I253L, I253M, I253N, I253P, I253Q, I253R, I253S, I253T, I253V, I253W и I253Y.
В других вариантах осуществления модификации Fc-домена, которые изменяют период полужизни, могут изменять степень связывания модифицированного Fc-домена с FcγRIIb, например, путем модификации Fc-домена в положении R292. Модификации в положении R292 могут включать аминокислотную замену, где аминокислота в положении R292 замещена природной или неприродной аминокислотой; делецию аминокислоты в положении R292; или вставку одного или более аминокислотных остатков в положение R292 Fc-домена. Модификация аминокислоты 292 может быть частью комбинации, включающей несколько модификаций (например, в других положениях остатка, например, I253), например, комбинацию одной или более аминокислотных замен, делеций и/или вставок. В конкретных вариантах осуществления Fc-конструкция может содержать, например, три Fc-домена, где по меньшей мере один Fc-домен содержит модификацию в положении R292. Например, аминокислотный остаток дикого типа, например аргинин (R), в положении 292 может быть замещен природной или неприродной аминокислотой, например пролином (P). В некоторых случаях каждая аминокислотная модификация в положении R292 независимо выбрана из, например, R292P, R292D, R292E, R292L, R292Q, R292R, R292T и R292Y.
Типичные Fc-домены с измененной аффинностью связывания с Fc-рецепторами включают Fc-мономеры, содержащие двойные мутанты S267E/L328F. Ранее было показано, что мутации S267E/L328F значительно и специфически усиливают связывание IgG1 с рецептором FcγRIIb (Chu et al. Molecular Immunology 45 2008).
Аминокислотная модификация, например для изменения периода полужизни, в положении I253, например I253A, может происходить по меньшей мере в одном (например, 1, 2, 3, 4 или 5) Fc-домене Fc-конструкции, например конструкции 4 (фиг. 2). В других вариантах осуществления аминокислотная модификация в положении R292, например R292P, может происходить по меньшей мере в одном (например, 1, 2, 3, 4 или 5) Fc-домене Fc-конструкции, например конструкции 4 (фиг. 2). В некоторых вариантах осуществления, например, аминокислотная модификация может происходить как в положении I253, например I253A, так и в положении R292, например R292P. Например, Fc-конструкция, например конструкция 4 (фиг. 2), может содержать один Fc-домен с аминокислотной модификацией в I253, например I253A, и содержать по меньшей мере один (например, 1, 2 или 3) Fc-домен с аминокислотной модификацией в R292, например R292P. В другом варианте осуществления Fc-конструкция, например конструкция 4 (фиг. 2), может содержать два Fc-домена с аминокислотной модификацией в I253, например I253A, и содержать по меньшей мере один (например, 1, 2 или 3) Fc-домен с аминокислотной модификацией в R292, например R292P. В другом варианте осуществления, Fc-конструкция, например конструкция 4, может содержать три Fc-домена с аминокислотной модификацией в I253, например I293A, и содержать по меньшей мере один (например, 1, 2 или 3) Fc-домен с аминокислотной модификацией в R292, например R292P. Типичные Fc-конструкции, имеющие модификации в положении аминокислоты I253 и/или R292, например I293A и/или R292P, соответственно, изображены на фиг. 18A-18O. Не показаны на фиг. 18A-18O, но раскрыты в данном описании Fc-конструкции, содержащие гетерогенные комбинации аминокислотных модификаций, например, в положениях аминокислот I253 и/или R292, в мономерах Fc-домена, составляющих Fc-домен.
IV. Модули селективности, обеспечивающие димеризацию
В настоящем изобретении модуль селективности, обеспечивающий димеризацию, представляет собой часть мономера Fc-домена, который способствует предпочтительному спариванию двух мономеров Fc-домена с образованием Fc-домена. В частности, модуль селективности, обеспечивающий димеризацию, представляет собой ту часть константного домена CH3 антитела мономера Fc-домена, которая содержит аминокислотные замены, расположенные на поверхности контакта между взаимодействующими константными доменами CH3 антитела двух мономеров Fc-домена. В модуле селективности, обеспечивающем димеризацию, аминокислотные замены благоприятствуют димеризации двух константных доменов CH3 антитела в результате совместимости аминокислот, выбранных для этих замен. Окончательное образование предпочтительного Fc-домена является селективным по сравнению с другими Fc-доменами, которые образуются из мономеров Fc-домена, в которых отсутствуют модули селективности, обеспечивающие димеризацию или есть несовместимые аминокислотные замены в модулях селективности, обеспечивающих димеризацию. Такой тип аминокислотной замены может быть осуществлен с применением общепринятых методик молекулярного клонирования, хорошо известных в данной области техники, таких как мутагенез QuikChange®.
В некоторых вариантах осуществления модуль селективности, обеспечивающий димеризацию, содержит сконструированную полость (описанную далее в настоящем документе) в константном домене CH3 антитела. В других вариантах осуществления модуль селективности, обеспечивающий димеризацию, содержит сконструированный выступ (описанный далее в настоящем документе) в константном домене CH3 антитела. Для селективного образования Fc-домена два мономера Fc-домена с совместимыми модулями селективности, обеспечивающими димеризацию, например, один константный домен CH3 антитела, содержащий сконструированную полость, и другой константный домен CH3 антитела, содержащий сконструированный выступ, объединяют с образованием пары мономеров Fc-домена типа «выступ-в-полость». Сконструированные выступы и сконструированные полости представляют собой примеры модулей селективности, обеспечивающих гетеродимеризацию, которые можно создавать в константных доменах CH3 антитела мономеров Fc-домена с целью способствовать благоприятной гетеродимеризации двух мономеров Fc-домена, которые имеют совместимые модули селективности, обеспечивающие гетеродимеризацию.
В других вариантах осуществления мономер Fc-домена с модулем селективности, обеспечивающим димеризацию, содержащим аминокислотные замены, обеспечивающие положительный заряд, и мономер Fc-домена с модулем селективности, обеспечивающим димеризацию, содержащим аминокислотные замены, обеспечивающие отрицательный заряд, могут селективно объединяться с образованием Fc-домена посредством способствующего этому электростатического координирования (описано далее в настоящем документе) заряженных аминокислот. В некоторых вариантах осуществления мономер Fc-домена может содержать одну из следующих аминокислотных замен, обеспечивающих положительный заряд, и аминокислотных замен, обеспечивающих отрицательный заряд: K392D, K392E, D399K, K409D, K409E, K439D и K439E. В одном примере мономер Fc-домена, содержащий аминокислотную замену, обеспечивающую положительный заряд, например D356K или E357K, и мономер Fc-домена, содержащий аминокислотную замену, обеспечивающую отрицательный заряд, например K370D или K370E, могут селективно объединяться с образованием Fc-домена посредством способствующего этому электростатического координирования заряженных аминокислот. В другом примере мономер Fc-домена, содержащий E357K, и мономер Fc-домена, содержащий K370D, могут селективно комбинироваться с образованием Fc-домена посредством способствующего этому электростатического координирования заряженных аминокислот. В некоторых вариантах осуществления аминокислотные замены, обеспечивающие изменение заряда на противоположный, можно применять в качестве модулей селективности, обеспечивающих гетеродимеризацию, при этом два мономера Fc-домена, содержащие различные, но совместимые аминокислотные замены, обеспечивающие изменение заряда на противоположный, объединяются с образованием гетеродимерного Fc-домена. Специфические модули селективности, обеспечивающие димеризацию дополнительно перечислены без ограничения в таблицах 1 и 2А, дополнительно описанных ниже.
В других вариантах осуществления два мономера Fc-домена включают модули селективности, обеспечивающие гомодимеризацию, содержащие идентичные мутации, обеспечивающие изменение заряда на противоположный, по меньшей мере в двух положениях в кольце заряженных остатков на поверхности контакта между доменами CH3. Модули селективности, обеспечивающие гомодимеризацию, представляют собой аминокислотные замены, обеспечивающие изменение заряда на противоположный, которые способствуют гомодимеризации мономеров Fc-домена с образованием гомодимерного Fc-домена. При изменении заряда на противоположный у обоих представителей двух или более комплементарных пар остатков в двух мономерах Fc-домена, мутированные мономеры Fc-домена остаются комплементарными мономерам Fc-домена с той же мутированной последовательностью, но характеризуются меньшей комплементарностью в отношении мономеров Fc-домена без этих мутаций. В одном варианте осуществления Fc-домен содержит мономеры Fc-домена, содержащие двойные мутанты K409D/D399K, K392D/D399K, E357K/K370E, D356K/K439D, K409E/D399K, K392E/D399K, E357K/K370D или D356K/K439E. В другом варианте осуществления Fc-домен содержит мономеры Fc-домена, в том числе четырехкратные мутанты, объединяющие любую пару двойных мутантов, например K409D/D399K/E357K/K370E. Примеры модулей селективности, обеспечивающих гомодимеризацию, дополнительно показаны в таблицах 2B и 2C.
В дополнительных вариантах осуществления мономер Fc-домена, содержащий (i) по меньшей мере одну мутацию, обеспечивающую изменение заряда на противоположный, и (ii) по меньшей мере одну сконструированную полость или по меньшей мере один сконструированный выступ, может селективно объединяться с другим мономером Fc-домена, содержащим (i) по меньшей мере одну мутацию, обеспечивающую изменение заряда на противоположный, и (ii) по меньшей мере один сконструированный выступ или по меньшей мере одну сконструированную полость, с образованием Fc-домена. Например, мономер Fc-домена, содержащий мутацию, обеспечивающую изменение заряда на противоположный, K370D, и сконструированные полости Y349C, T366S, L368A и Y407V, и другой мономер Fc-домена, содержащий мутацию, обеспечивающую изменение заряда на противоположный, E357K, и сконструированные выступы S354C и T366W, могут селективно объединяться с образованием Fc-домена.
Образованию таких Fc-доменов способствуют совместимые аминокислотные замены в константных доменах CH3 антитела. Два модуля селективности, обеспечивающие димеризацию, содержащие несовместимые аминокислотные замены, например, оба содержащие сконструированные полости, оба содержащие сконструированные выступы или оба содержащие одинаковые заряженные аминокислоты на поверхности контакта CH3-CH3, не будут способствовать образованию гетеродимерного Fc-домена.
Кроме того, другие способы, применяемые для способствования образованию Fc-доменов из определенных мономеров Fc-домена, включают без ограничения подход LUZ-Y (публикация заявки на патент США № WO 2011034605), который предусматривает С-концевое слияние мономерных α-спиралей лейциновой «молнии» с каждым из мономеров Fc-домена, с обеспечением образования гетеродимера, а также подход с применением домена, сконструированного путем обмена цепей (SEED) (Davis et al., Protein Eng Des Sel. 23: 195-202, 2010), с помощью которого получают Fc-домен из гетеродимерных мономеров Fc-домена, каждый из которых содержит чередующиеся сегменты последовательностей CH3 IgA и IgG.
V. Сконструированные полости и сконструированные выступы
Применение сконструированных полостей и сконструированных выступов (или стратегия «выступ-во-впадину») описано Картер и коллегами (Ridgway et al., Protein Eng. 9:617-612, 1996; Atwell et al., J Mol Biol. 270:26-35, 1997; Merchant et al., Nat Biotechnol. 16:677-681, 1998). Взаимодействие по типу «выступ-во-впадину» способствует образованию гетеродимера, тогда как взаимодействие по типу «выступ-выступ» и «впадина-впадина» препятствует образованию гомодимера из-за стерического столкновения и удаления благоприятных взаимодействий. Методика «выступ-во-впадину» также раскрыта в патенте США №5731168.
В настоящем изобретении сконструированные полости и сконструированные выступы применяют при получении Fc-конструкций, описанных в данном документе. Сконструированная полость представляет собой пустоту, которая создается, когда исходная аминокислота в белке заменяется другой аминокислотой, характеризующейся меньшим объемом боковой цепи. Сконструированный выступ представляет собой выступ, который создается, когда исходная аминокислота в белке заменяется другой аминокислотой, характеризующейся большим объемом боковой цепи. В частности, заменяемая аминокислота находится в константном домене CH3 антитела мономера Fc-домена и участвует в димеризации двух мономеров Fc-домена. В некоторых вариантах осуществления сконструированную полость в одном константном домене CH3 антитела создают для размещения сконструированного выступа в другом константном домене CH3 антитела, так что оба константных домена CH3 антитела действуют в качестве модулей селективности, обеспечивающих димеризацию (например, модулей селективности, обеспечивающих гетеродимеризацию) (описаны выше), которые способствуют или благоприятствуют димеризации двух мономеров Fc-домена. В других вариантах осуществления сконструированную полость в одном константном домене CH3 антитела создают для лучшего размещения исходной аминокислоты в другом константном домене CH3 антитела. В других вариантах осуществления сконструированный выступ в одном константном домене CH3 антитела создают для образования дополнительных взаимодействий с исходными аминокислотами в другом константном домене CH3 антитела.
Сконструированную полость можно сконструировать посредством замещения аминокислот, содержащих большие боковые цепи, таких как тирозин или триптофан, аминокислотами, содержащими меньшие боковые цепи, такими как аланин, валин или треонин. В частности, некоторые модули селективности, обеспечивающие димеризацию (например, модули селективности, обеспечивающие гетеродимеризацию) (более подробно описаны выше) содержат сконструированные полости, такие как мутация Y407V в константном домене CH3 антитела. Аналогично, сконструированный выступ можно сконструировать путем замены аминокислот, содержащих меньшие боковые цепи, аминокислотами, содержащими более крупные боковые цепи. В частности, некоторые модули селективности, обеспечивающие димеризацию (например, модули селективности, обеспечивающие гетеродимеризацию) (более подробно описаны выше) содержат сконструированные выступы, такие как мутация T366W в константном домене CH3 антитела. В настоящем изобретении сконструированные полости и сконструированные выступы также комбинируют с конструированием дисульфидных связей между CH3-доменами для улучшения образования гетеродимера. В одном примере мономер Fc-домена, содержащий сконструированные полости Y349C, T366S, L368A и Y407V, может селективно комбинироваться с другим мономером Fc-домена, содержащим сконструированные выступы S354C и T366W, с образованием Fc-домена. В другом примере мономер Fc-домена, содержащий сконструированную полость Y349C, и мономер Fc-домена, содержащий сконструированный выступ S354C, могут селективно объединяться с образованием Fc-домена. Другие сконструированные полости и сконструированные выступы в комбинации как с конструированием дисульфидных связей, так и со расчетами структуры (смешанный HA-TF), содержатся без ограничения в таблице 1.
Таблица 1
Замена исходного аминокислотного остатка в константном домене CH3 антитела другим аминокислотным остатком может быть достигнута путем изменения нуклеиновой кислоты, кодирующей исходный аминокислотный остаток. Верхний предел количества исходных аминокислотных остатков, которые могут быть заменены, представляет собой общее количество остатков на поверхности контакта между константными доменами CH3 антитела, при котором на поверхности контакта все еще сохраняется достаточное взаимодействие. В некоторых случаях константный домен СН3 антитела имеет не более 16 (например, не более 2, 4, 6, 8, 10, 12, 14 или 16) одиночных аминокислотных модификаций.
VI. Электростатическое координирование
Электростатическое координирование представляет собой использование благоприятных электростатических взаимодействий между противоположно заряженными аминокислотами в пептидах, белковых доменах и белках для контроля образования молекул белка более высокого порядка. Способ применения эффектов электростатического координирования для изменения взаимодействия доменов антител с целью уменьшения образования гомодимеров в пользу образования гетеродимеров при получении биспецифических антител раскрыт в публикации заявки на патент США №2014-0024111.
В настоящем изобретении электростатическое координирование используется для контроля димеризации мономеров Fc-домена и образования Fc-конструкций. В частности, для контроля димеризации мономеров Fc-домена с применением электростатического координирования один или более аминокислотных остатков, которые составляют поверхность контакта CH3-CH3, заменяют положительно или отрицательно заряженными аминокислотными остатками, так что взаимодействие становится электростатически благоприятным или неблагоприятным в зависимости от конкретных введенных заряженных аминокислот. В некоторых вариантах осуществления положительно заряженную аминокислоту на поверхности контакта, такую как лизин, аргинин или гистидин, заменяют отрицательно заряженной аминокислотой, такой как аспарагиновая кислота или глутаминовая кислота. В других вариантах осуществления отрицательно заряженную аминокислоту на поверхности контакта заменяют положительно заряженной аминокислотой. Заряженные аминокислоты можно вводить в один или оба из взаимодействующих константных доменов CH3 антитела. Путем введения заряженных аминокислот во взаимодействующие константные домены CH3 антител создают модули селективности, обеспечивающие димеризацию (более подробно описано выше), которые могут селективно образовывать димеры мономеров Fc-доменов что контролируется эффектами электростатического координирования, возникающими в результате взаимодействия между заряженными аминокислотами.
В некоторых вариантах осуществления для создания модуля селективности, обеспечивающего димеризацию, содержащего заряды, измененные на противоположные, который может селективно образовывать димеры мономеров Fc-домена, что контролируется эффектами электростатического координирования, два мономера Fc-домена могут быть селективно образованы посредством гетеродимеризации или гомодимеризации.
Гетеродимеризация мономеров Fc-домена
Гетеродимеризацию мономеров Fc-домена можно стимулировать путем введения различных, но совместимых мутаций в двух мономерах Fc-домена, таких как мутации, обеспечивающих образование пар остатков с совместимыми зарядами, содержащиеся без ограничения в таблице 2A. В некоторых вариантах осуществления мономер Fc-домена может содержать одну из следующих аминокислотных замен, обеспечивающих отрицательный заряд, и аминокислотных замен, обеспечивающих положительный заряд: D356K, D356R, E357K, E357R, K370D, K370E, K392D, K392E, D399K, K409D, K409E, K439D и K439E. В одном примере мономер Fc-домена, содержащий аминокислотную замену, обеспечивающую положительный заряд, например D356K или E357K, и мономер Fc-домена, содержащий аминокислотную замену, обеспечивающую отрицательный заряд, например K370D или K370E, могут селективно объединяться с образованием Fc-домена посредством способствующего этому электростатического координирования заряженных аминокислот. В другом примере мономер Fc-домена, содержащий E357K, и мономер Fc-домена, содержащий K370D, могут селективно комбинироваться с образованием Fc-домена посредством способствующего этому электростатического координирования заряженных аминокислот.
Например, в Fc-конструкции, содержащей три Fc-домена, два из трех Fc-доменов могут быть образованы путем гетеродимеризации двух мономеров Fc-домена, чему способствуют эффекты электростатического координирования. Термин «гетеродимерный Fc-домен» относится к Fc-домену, который образован посредством гетеродимеризации двух мономеров Fc-домена, где два мономера Fc-домена содержат разные мутации, обеспечивающие изменение заряда на противоположный (модули селективности, обеспечивающие гетеродимеризацию) (см., например, мутации в таблице 2A), которые способствуют благоприятному образованию этих двух мономеров Fc-домена. Как показано на фиг. 1 и 2, в Fc-конструкции, содержащей три Fc-домена - один карбоксиконцевой Fc-домен «стебля» и два аминоконцевых Fc-домена «ветвей» - каждый из аминоконцевых Fc-доменов «ветвей» может представлять собой гетеродимерный Fc-домен (также называемый «гетеродимерный Fc-домен ветви») (например, гетеродимерный Fc-домен, образованный мономерами Fc-домена 106 и 114, или мономерами Fc-домена 112 и 116 на фиг. 1; гетеродимерный Fc-домен, образованный мономерами Fc-домена 206 и 214, или мономерами Fc-домена 212 и 216 на фиг. 2). Гетеродимерный Fc-домен ветви может быть образован мономером Fc-домена, содержащим E357K, и другим мономером Fc-домена, содержащим K370D.
Таблица 2A
Гомодимеризация мономеров Fc-домена
Гомодимеризации мономеров Fc-домена может способствовать введение одинаковых мутаций, обеспечивающих электростатическое координирование (модулей селективности, обеспечивающих гомодимеризацию) в оба мономера Fc-домена симметричным образом. В некоторых вариантах осуществления два мономера Fc-домена содержат модули селективности, обеспечивающие гомодимеризацию, содержащие идентичные мутации, обеспечивающие изменение заряда на противоположный, по меньшей мере в двух положениях в кольце заряженных остатков на поверхности контакта между доменами CH3. При изменении заряда на противоположный у обоих представителей двух или более комплементарных пар остатков в двух мономерах Fc-домена мутированные мономеры Fc-домена остаются комплементарными мономерам Fc-домена с той же мутированной последовательностью, но характеризуются меньшей комплементарностью в отношении мономеров Fc-домена без этих мутаций. Мутации, обеспечивающие электростатическое координирование, которые можно вводить в мономер Fc-домена для стимулирования его гомодимеризации, приведены без ограничений в таблицах 2B и 2C. В одном варианте осуществления Fc-домен содержит два мономера Fc-домена, каждый из которых включает двойные мутанты по изменению заряда на противоположный (таблица 2B), например K409D/D399K. В другом варианте осуществления Fc-домен содержит два мономера Fc-домена, каждый из которых включает четырехкратные мутанты по изменению заряда на противоположный (таблица 2C), например K409D/D399K/K370D/E357K.
Например, в Fc-конструкции, содержащей три Fc-домена, один из трех Fc-доменов могут быть образованы путем гомодимеризации двух мономеров Fc-домена, чему способствуют эффекты электростатического координирования. «Гомодимерный Fc-домен» относится к Fc-домену, который образован посредством гомодимеризации двух мономеров Fc-домена, где два мономера Fc-домена содержат одинаковые мутации, обеспечивающие изменение заряда на противоположный (см., например, мутации в таблицах 2B и 2C). Как показано на фиг. 1 и 2, в Fc-конструкции, содержащей три Fc-домена - один карбоксиконцевой Fc-домен «стебля» и два аминоконцевых Fc-домена «ветвей» - карбоксиконцевой Fc-домен «стебля» может представлять собой гомодимерный Fc-домен (также называемый «гомодимерный Fc-домен стебля») (например, гомодимерный Fc-домен, образованный мономерами Fc-домена 104 и 110 на фиг. 1; гомодимерный Fc-домен, образованный мономерами Fc-домена 204 и 210 на фиг. 2). Гомодимерный Fc-домен стебля может быть образован двумя мономерами Fc-домена, каждый из которых содержит двойные мутанты K409D/D399K.
Таблица 2B
Таблица 2C
Замена исходного аминокислотного остатка в константном домене CH3 антитела другим аминокислотным остатком может быть достигнута путем изменения нуклеиновой кислоты, кодирующей исходный аминокислотный остаток. Верхний предел количества исходных аминокислотных остатков, которые могут быть заменены, представляет собой общее количество остатков на поверхности контакта между константными доменами CH3 антитела, при котором на поверхности контакта все еще сохраняется достаточное взаимодействие. В некоторых случаях константный домен СН3 антитела имеет не более 16 (например, не более 2, 4, 6, 8, 10, 12, 14 или 16) одиночных аминокислотных модификаций.
VII. Линкеры
В настоящем изобретении термин линкер используют для описания связи или соединения между полипептидами или белковыми доменами и/или ассоциированными небелковыми фрагментами. В некоторых вариантах осуществления линкер представляет собой связь или соединение между по меньшей мере двумя мономерами Fc-домена, при этом линкер соединяет C-конец константного домена CH3 антитела первого мономера Fc-домена с N-концом шарнирного домена второго мономера Fc-домена таким образом, что два мономера Fc-домена соединяются друг с другом в виде тандемной последовательности. В других вариантах осуществления линкер представляет собой связь между мономером Fc-домена и любыми другими белковыми доменами, которые к нему присоединены. Например, линкер может присоединять С-конец константного домена CH3 антитела мономера Fc-домена к N-концу альбумин-связывающего пептида.
Линкер может представлять собой простую ковалентную связь, например пептидную связь, синтетический полимер, например полимер полиэтиленгликоля (PEG), или любой вид связи, полученный в результате химической реакции, например химического конъюгирования. В случае, если линкер представляет собой пептидную связь, группа карбоновой кислоты на С-конце одного белкового домена может реагировать с аминогруппой на N-конце другого белкового домена в реакции конденсации с образованием пептидной связи. В частности, пептидная связь может быть образована из синтетических средств с помощью общепринятой в органической химии реакции, хорошо известной в данной области техники, или путем естественного получения из клетки-хозяина, при этом полинуклеотидная последовательность, кодирующая последовательности ДНК обоих белков, например, двух мономеров Fc-домена в виде тандемной последовательности, может непосредственно транскрибироваться и транслироваться в клетке-хозяине в непрерывный полипептид, кодирующий оба белка, с помощью необходимых молекулярных машин, например ДНК-полимеразы и рибосомы.
В случае, если линкер представляет собой синтетический полимер, например полимер PEG, полимер может быть функционализирован химически активными функциональными группами на каждом конце, для обеспечения реакции с концевыми аминокислотами на соединяющихся концах двух белков.
В случае, если линкер (кроме упомянутой выше пептидной связи) получают посредством химической реакции, химические функциональные группы, например, амин, карбоновая кислота, сложный эфир, азид или другие функциональные группы, обычно используемые в данной области техники, могут быть синтетически присоединены к С-концу одного белка и N-концу другого белка соответственно. Затем две функциональные группы могут вступать в реакцию с помощью средств синтетической химии с образованием химической связи, тем самым соединяя два белка друг с другом. Такие техники химического конъюгирования являются обычными для специалистов в данной области техники.
Спейсер
В настоящем изобретении линкер между двумя мономерами Fc-домена может представлять собой аминокислотный спейсер, содержащий 3-200 аминокислот (например, 3-200, 3-180, 3-160, 3-140, 3-120, 3-100, 3-90, 3-80, 3-70, 3-60, 3-50, 3-45, 3-40, 3-35, 3-30, 3-25, 3-20, 3-15, 3-10, 3-9, 3-8, 3-7, 3-6, 3-5, 3-4, 4-200, 5-200, 6-200, 7-200, 8-200, 9-200, 10-200, 15-200, 20-200, 25-200, 30-200, 35-200, 40-200, 45-200, 50-200, 60-200, 70-200, 80-200, 90-200, 100-200, 120-200, 140-200, 160-200 или 180-200 аминокислот) (например, 3-150, 3-100, 3-60, 3-50, 3-40, 3-30, 3-20, 3-10, 3-8, 3-5, 4-30, 5-30, 6-30, 8-30, 10-20, 10-30, 12-30, 14-30 20-30, 15-25, 15-30, 18-22 и 20-30 аминокислот). В некоторых вариантах осуществления линкер между двумя мономерами Fc-домена представляет собой аминокислотный спейсер, содержащий по меньшей мере 12 аминокислот, например 12-200 аминокислот (например, 12-200, 12-180, 12-160, 12-140, 12-120, 12-100, 12-90, 12-80, 12-70, 12-60, 12-50, 12-40, 12-30, 12-20, 12-19, 12-18, 12-17, 12-16, 12-15, 12-14 или 12-13 аминокислот) (например, 14-200, 16-200, 18-200, 20-200, 30-200, 40-200, 50-200, 60-200, 70-200, 80-200, 90-200, 100-200, 120-200, 140-200, 160-200, 180-200 или 190-200 аминокислот). В некоторых вариантах осуществления линкер между двумя мономерами Fc-домена представляет собой аминокислотный спейсер, содержащий 12-30 аминокислот (например, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29 или 30 аминокислот). Подходящие пептидные спейсеры известны в данной области техники и включают, например, пептидные линкеры, содержащие гибкие аминокислотные остатки, такие как глицин и серин. В определенных вариантах осуществления спейсер может содержать мотивы, например множественные или повторяющиеся мотивы, из GS, GGS, GGGGS (SEQ ID NO: 1), GGSG (SEQ ID NO: 2) или SGGG (SEQ ID NO: 3). В определенных вариантах осуществления спейсер может содержать от 2 до 12 аминокислот, в том числе мотивы из GS, например GS, GSGS (SEQ ID NO: 4), GSGSGS (SEQ ID NO: 5), GSGSGSGS (SEQ ID NO: 6), GSGSGSGSGS (SEQ ID NO: 7) или GSGSGSGSGSGS (SEQ ID NO: 8). В определенных других вариантах осуществления спейсер может содержать от 3 до 12 аминокислот, в том числе мотивы из GGS, например, GGS, GGSGGS (SEQ ID NO: 9), GGSGGSGGS (SEQ ID NO: 10) и GGSGGSGGSGGS (SEQ ID NO: 11). В еще других вариантах осуществления спейсер может содержать от 4 до 20 аминокислот, в том числе мотивы из GGSG (SEQ ID NO: 2), например, GGSGGGSG (SEQ ID NO: 12), GGSGGGSGGGSG (SEQ ID NO: 13), GGSGGGSGGGSGGGSG (SEQ ID NO: 14) или GGSGGGSGGGSGGGSGGGSG (SEQ ID NO: 15). В других вариантах осуществления спейсер может содержать мотивы из GGGGS (SEQ ID NO: 1), например GGGGSGGGGS (SEQ ID NO: 16) или GGGGSGGGGSGGGGS (SEQ ID NO: 17). В определенных вариантах осуществления спейсер представляет собой SGGGSGGGSGGGSGGGSGGG (SEQ ID NO: 18).
В некоторых вариантах осуществления спейсер между двумя мономерами Fc-домена содержит только остатки глицина, например, по меньшей мере 4 остатка глицина (например, 4-200, 4-180, 4-160, 4-140, 4-40, 4-100, 4-90, 4-80, 4-70, 4-60, 4-50, 4-40, 4-30, 4-20, 4-19, 4-18, 4-17, 4-16, 4-15, 4-14, 4-13, 4-12, 4-11, 4-10, 4-9, 4-8, 4-7, 4-6 или 4-5 остатков глицина) (например, 4-200, 6-200, 8-200, 10-200, 12-200, 14-200, 16-200, 18-200, 20-200, 30-200, 40-200, 50-200, 60-200, 70-200, 80-200, 90-200, 100-200, 120-200, 140-200, 160-200, 180-200 или 190-200 остатков глицина). В определенных вариантах осуществления спейсер содержит 4-30 остатков глицина (например, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29 или 30 остатков глицина). В некоторых вариантах осуществления спейсер, содержащий только остатки глицина, может не быть гликозилированным (например, для него не предусматривается О-связанное гликозилирование, также называемое О-гликозилированием) или может характеризоваться пониженным уровнем гликозилирования (например, пониженным уровнем О-гликозилирования) (например, пониженным уровнем O-гликозилирования с помощью гликанов, таких как ксилоза, манноза, сиаловые кислоты, фукоза (Fuc) и/или галактоза (Gal) (например, ксилоза)) по сравнению, например, со спейсером, содержащим один или более остатков серина (например, SGGGSGGGSGGGSGGGSGGG (SEQ ID NO: 18)) (см. пример 4).
В некоторых вариантах осуществления спейсер, содержащий только глициновые остатки, может не быть O-гликозилированным (например, для него не предусматривается O-ксилозилирование) или может характеризоваться пониженным уровнем O-гликозилирования (например, пониженным уровнем O-ксилозилирования) по сравнению, например, со спейсером, содержащим один или более остатков серина (например, SGGGSGGGSGGGSGGGSGGG (SEQ ID NO: 18)).
В некоторых вариантах осуществления спейсер, содержащий только остатки глицина, может не подвергаться протеолизу или может характеризоваться пониженным уровнем протеолиза по сравнению, например, со спейсером, содержащим один или более остатков серина (например, SGGGSGGGSGGGSGGGSGGG (SEQ ID NO: 18)) (см. пример 4).
В определенных вариантах осуществления спейсер может содержать мотивы из GGGG (SEQ ID NO: 19), например, GGGGGGGG (SEQ ID NO: 20), GGGGGGGGGGGG (SEQ ID NO: 21), GGGGGGGGGGGGGGGG (SEQ ID NO: 22) или GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23). В определенных вариантах осуществления спейсер может содержать мотивы из GGGGG (SEQ ID NO: 24), например, GGGGGGGGGG (SEQ ID NO: 25) или GGGGGGGGGGGGGGG (SEQ ID NO: 26). В определенных вариантах осуществления спейсер представляет собой GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 27).
В других вариантах осуществления спейсер также может содержать аминокислоты, отличные от глицина и серина, например, GENLYFQSGG (SEQ ID NO: 28), SACYCELS (SEQ ID NO: 29), RSIAT (SEQ ID NO: 30), RPACKIPNDLKQKVMNH (SEQ ID NO: 31), GGSAGGSGSGSSGGSSGASGTGTAGGTGSGSGTGSG (SEQ ID NO: 32), AAANSSIDLISVPVDSR (SEQ ID NO: 33) или GGSGGGSEGGGSEGGGSEGGGSEGGGSEGGGSGGGS (SEQ ID NO: 34).
В определенных вариантах осуществления настоящего изобретения пептидный спейсер из 12 или 20 аминокислот применяют для соединения двух мономеров Fc-домена в виде тандемной последовательности (например, полипептиды 102 и 108 на фиг. 1; полипептиды 202 и 208 на фиг. 2), при этом пептидные спейсеры из 12 и 20 аминокислот состоят из последовательностей GGGSGGGSGGGS (SEQ ID NO: 35) и SGGGSGGGSGGGSGGGSGGG (SEQ ID NO: 18) соответственно. В других вариантах осуществления может применяться пептидный спейсер из 18 аминокислот, состоящий из последовательности GGSGGGSGGGSGGGSGGS (SEQ ID NO: 36).
В некоторых вариантах осуществления спейсер между двумя мономерами Fc-домена может содержать, состоять из или состоять по сути из последовательности, которая на по меньшей мере 75% идентична (например, на по меньшей мере 77%, 79%, 81%, 83% (85%, 87%, 89%, 91%, 93%, 95%, 97%, 99% или 99,5% идентична) последовательности под любым из SEQ ID NO: 1-36, описанных выше. В некоторых вариантах осуществления спейсер между двумя мономерами Fc-домена может содержать, состоять из или состоять по сути из последовательности, которая представляет собой последовательность под любым из SEQ ID NO: 1-36, описанных в данном документе, с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В определенных вариантах осуществления спейсер между двумя мономерами Fc-домена может содержать, состоять из или состоять по сути из последовательности, которая на по меньшей мере 80% идентична (например, на по меньшей мере 82%, 85%, 87%, 90%, 92%, 95%, 97%, 99% или 99,5% идентична) последовательности под любым из SEQ ID NO: 17, 18, 26 и 27. В определенных вариантах осуществления спейсер между двумя мономерами Fc-домена может содержать, состоять из или состоять по сути из последовательности, которая представляет собой последовательность под любым из SEQ ID NO: 17, 18, 26 и 27, с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В определенных вариантах осуществления спейсер между двумя мономерами Fc-домена может содержать, состоять из или состоять по сути из последовательности, которая на по меньшей мере 80% (например, на по меньшей мере 82%, 85%, 87%, 90%, 92%, 95%, 97%, 99% или 99,5%) идентична последовательности под SEQ ID NO: 18 или 27. В определенных вариантах осуществления спейсер между двумя мономерами Fc-домена может содержать, состоять из или состоять по сути из последовательности, которая представляет собой последовательность под SEQ ID NO: 18 или 27, с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами).
VIII. Пептиды, связывающие сывороточные белки
Связываясь с сывороточными белками, пептиды, могут обеспечивать улучшение фармакокинетики белковых фармацевтических препаратов, и, в частности, описанные в данном документе Fc-конструкции можно сливать с пептидами, связывающимися с сывороточными белками.
В качестве одного примера, пептиды, связывающие альбумин, которые можно применять в способах и композициях, описанных в данном документе, общеизвестны в данной области техники. В одном варианте осуществления пептид, связывающий альбумин, содержит последовательность DICLPRWGCLW (SEQ ID NO: 37). В некоторых вариантах осуществления пептид, связывающий альбумин, содержит, состоит из или состоит по сути из последовательности, которая на по меньшей мере 80% идентична (например, на 80%, 90% или 100% идентична) последовательности под SEQ ID NO: 37. В некоторых вариантах осуществления пептид, связывающий альбумин, содержит, состоит из или состоит по сути из последовательности, которая представляет собой последовательность под SEQ ID NO: 37, с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами).
В настоящем изобретении пептиды, связывающие альбумин, могут быть присоединены к N- или С-концу определенных полипептидов в Fc-конструкции. В одном варианте осуществления пептид, связывающий альбумин, может быть присоединен к С-концу одного или более полипептидов в Fc-конструкциях 1-4 (фиг. 1 и 2). В другом варианте осуществления пептид, связывающий альбумин, может быть слит с С-концом полипептида, кодирующего два мономера Fc-домена, связанных в Fc-конструкциях 1-4 в виде тандемной последовательности (например, полипептиды 102 и 108 на фиг. 1 и полипептиды 202 и 208 на фиг. 2). В еще одном варианте осуществления пептид, связывающий альбумин, может быть присоединен к C-концу мономера Fc-домена (например, мономеры Fc-домена 114 и 116 на фиг. 1; мономеры Fc-домена 214 и 216 на фиг. 2), который присоединен ко второму мономеру Fc-домена в полипептиде, кодирующем два мономера Fc-домена, связанные в виде тандемной последовательности. Пептиды, связывающие альбумин, можно сливать с Fc-конструкциями на уровне генетической последовательности или присоединять к Fc-конструкциям химическими способами, например с помощью химического конъюгирования. При необходимости между Fc-конструкцией и пептидом, связывающим альбумин, можно вставлять спейсер. Не ограничиваясь какой-либо теорией, ожидают, что включение пептида, связывающего альбумин, в Fc-конструкцию по настоящему изобретению может привести к увеличению времени удержания терапевтического белка в организме за счет его связывания с сывороточным альбумином.
IX. Fc-конструкции
В целом, настоящее изобретение предусматривает Fc-конструкции, содержащие Fc-домены (например, Fc-конструкция, содержащая три Fc-домена). Они могут характеризоваться большей аффинностью и/или авидностью связывания с Fc-рецептором, например FcγRIIIa, чем одиночный Fc-домен дикого типа. В настоящем изобретении раскрыты способы конструирования аминокислот на поверхности контакта между двумя взаимодействующими константными доменами CH3 антитела, таких, что два мономера Fc-домена, принадлежащие Fc-домену, селективно образуют димер друг с другом, тем самым предотвращая образование нежелательных мультимеров или агрегатов. Fc-конструкция содержит четное количество мономеров Fc-домена, при этом каждая пара мономеров Fc-домена образует Fc-домен. Fc-конструкция содержит как минимум один функциональный Fc-домен, образованный из димера из двух мономеров Fc-домена. В некоторых вариантах осуществления Fc-конструкции, описанные в данном документе, не содержат область распознавания антигена, например вариабельный домен (например, VH, VL, гипервариабельную область (HVR)) или область, определяющую комплементарность (CDR). В некоторых вариантах осуществления Fc-конструкции, описанные в данном документе, содержат область распознавания антигена, например вариабельный домен (например, VH, VL, HVR) или CDR.
Fc-конструкция, содержащая три Fc-домена, может образовываться из четырех полипептидов (фиг. 1 и 2). Первый и второй полипептиды (например, полипептиды 102 и 108 на фиг. 1; полипептиды 202 и 208 на фиг. 2) могут быть одинаковыми или разными, как и третий и четвертый полипептиды (например, полипептиды 114 и 116 на фиг. 1; полипептиды 214 и 216 на фиг. 2). На фиг. 1 как в первом, так и во втором полипептиде закодировано по два мономера Fc-домена (например, мономеры Fc-домена 104, 106, 110 и 112), соединенных посредством линкера в виде тандемной последовательности, при этом один мономер Fc-домена содержит замены, представляющие собой заряженные аминокислоты, в константном домене CH3 антитела (например, мономеры Fc-домена 104 и 110), тогда как другой мономер Fc-домена содержит выступ в константном домене CH3 антитела (например, мономеры Fc-домена 106 и 112). Как в третьем, так и в четвертом полипептиде закодировано мономер Fc-домена с полостью (например, мономеры Fc-домена 114 и 116). Гомодимерный Fc-домен стебля может быть образован путем объединения мономеров Fc-домена 104 и 110, каждый из которых содержит одинаковые мутации, обеспечивающие изменение заряда на противоположный, в своем константном домене CH3 антитела (например, каждый из мономеров 104 и 110 Fc-домена содержит D399K и K409D. Гетеродимерный Fc-домен первой ветви может быть образован путем объединения мономеров 106 и 114 Fc-домена (например, мономер 106 Fc-домена содержит сконструированные выступы S354C и T366W, а мономер 114 Fc-домена содержит сконструированные полости Y349C, T366S, L368A и Y409V). Второй гетеродимерный Fc-домен может быть образован путем объединения мономеров 112 и 116 Fc-домена (например, мономер 112 Fc-домена содержит сконструированные выступы S354C и T366W, а мономер 116 Fc-домена содержит сконструированные полости Y349C, T366S, L368A и Y409V).
На фиг. 2 как в первом, так и во втором полипептидах закодировано по два мономера Fc-домена (например, мономеры Fc-домена 204, 206, 210 и 212), соединенных посредством линкера в виде тандемной последовательности, где один мономер Fc-домена содержит замены, представляющие собой заряженные аминокислоты, в константном домене CH3 антитела (например, мономеры Fc-домена 204 и 210), тогда как другой мономер Fc-домена содержит выступ и замены, представляющие собой заряженные аминокислоты, в константном домене CH3 антитела (например, мономеры Fc-домена 206 и 212). Как в третьем, так и в четвертом полипептидах закодирован мономер Fc-домена с полостью и заменами, представляющими собой заряженные аминокислоты (например, мономеры Fc-домена 214 и 216). Гомодимерный Fc-домен стебля может быть образован путем объединения мономеров Fc-домена 204 и 210, каждый из которых содержит одинаковые мутации, обеспечивающие изменение заряда на противоположный, в своем константном домене CH3 антитела (например, каждый из мономеров 204 и 210 Fc-домена содержит D399K и K409D. Гетеродимерный Fc-домен первой ветви может быть образован путем объединения мономеров 206 и 214 Fc-домена (например, мономер 206 Fc-домена содержит сконструированные выступы S354C и T366W и мутацию, обеспечивающую изменение заряда на противоположный, E357K, а мономер 214 Fc-домена содержит сконструированные полости Y349C, T366S, L368A и Y409V, а также мутацию, обеспечивающую изменение заряда на противоположный, K370D). Гетеродимерный Fc-домен второй ветви может быть образован путем объединения мономеров 212 и 216 Fc-домена (например, мономер 212 Fc-домена содержит сконструированные выступы S354C и T366W и мутацию, обеспечивающую изменение заряда на противоположный, E357K, а мономер 216 Fc-домена содержит сконструированные полости Y349C, T366S, L368A и Y409V, а также мутацию, обеспечивающую изменение заряда на противоположный, K370D).
В дополнительных вариантах осуществления мономер Fc-домена, содержащий (i) по меньшей мере одну мутацию, обеспечивающую изменение заряда на противоположный, и (ii) по меньшей мере одну сконструированную полость или по меньшей мере один сконструированный выступ, может селективно объединяться с другим мономером Fc-домена, содержащим (i) по меньшей мере одну мутацию, обеспечивающую изменение заряда на противоположный, и (ii) по меньшей мере один сконструированный выступ или по меньшей мере одну сконструированную полость, с образованием Fc-домена. Например, мономер Fc-домена, содержащий мутацию, обеспечивающую изменение заряда на противоположный, K370D, и сконструированные полости Y349C, T366S, L368A и Y407V, и другой мономер Fc-домена, содержащий мутацию, обеспечивающую изменение заряда на противоположный, E357K, и сконструированные выступы S354C и T366W, могут селективно объединяться с образованием Fc-домена.
В некоторых вариантах осуществления в Fc-конструкции, содержащей а) первый полипептид, имеющий формулу A-L-B; где i) A содержит первый мономер Fc-домена; ii) L представляет собой линкер; и iii) В содержит второй мономер Fc-домена; b) второй полипептид, имеющий формулу A'-L'-B'; где i) A' содержит третий мономер Fc-домена; ii) L' представляет собой линкер; и iii) B' содержит четвертый мономер Fc-домена; c) третий полипептид, который содержит пятый мономер Fc-домена; и d) четвертый полипептид, который содержит шестой мономер Fc-домена; где B и B' объединяются с образованием первого Fc-домена, A и пятый мономер Fc-домена объединяются с образованием второго Fc-домена, а A' и шестой мономер Fc-домена объединяются с образованием третьего Fc-домена, при этом примеры некоторых аминокислотных мутаций, которые могут быть включены в мономеры Fc-домена в Fc-конструкции, показаны в таблицах 3A-3D. В некоторых вариантах осуществления каждый из первого, второго, третьего и четвертого полипептидов в Fc-конструкции лишен С-концевого лизина. В некоторых вариантах осуществления N-концевой Asp в каждом из первого, второго, третьего и четвертого полипептидов в Fc-конструкции заменен на Gln в результате мутации. В некоторых вариантах осуществления каждый из L и L' содержит, состоит из или состоит по сути из последовательности GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 27).
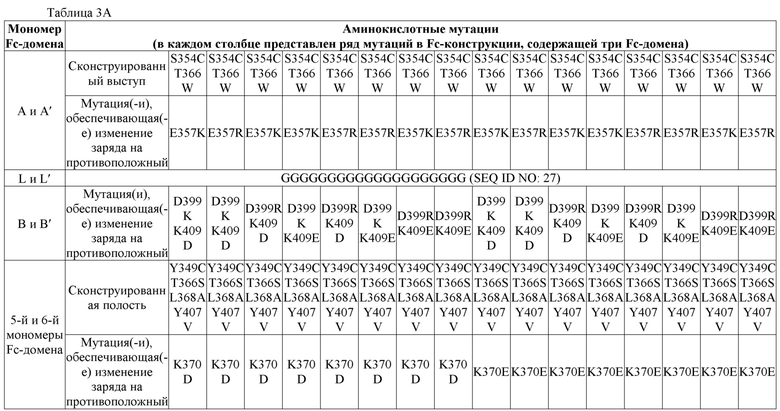
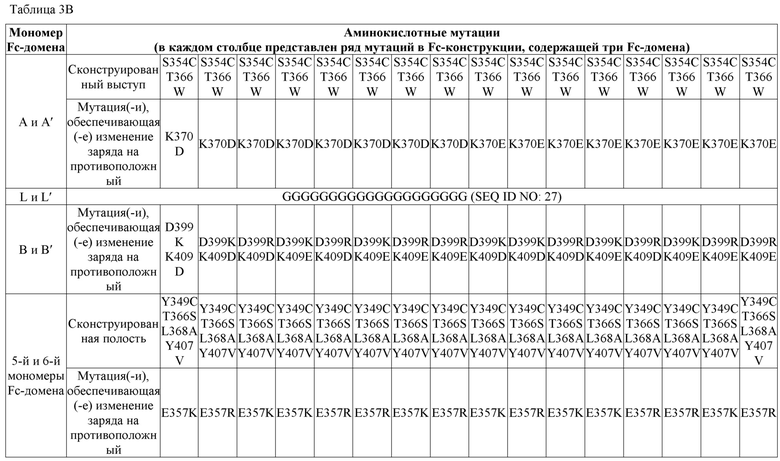
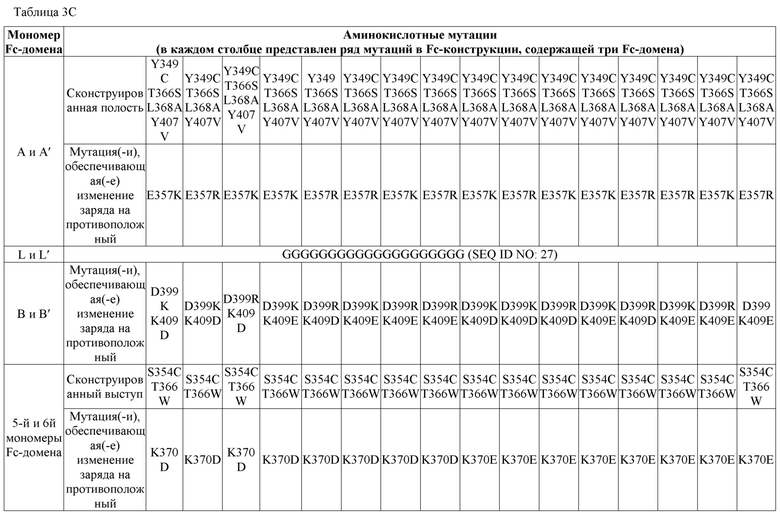
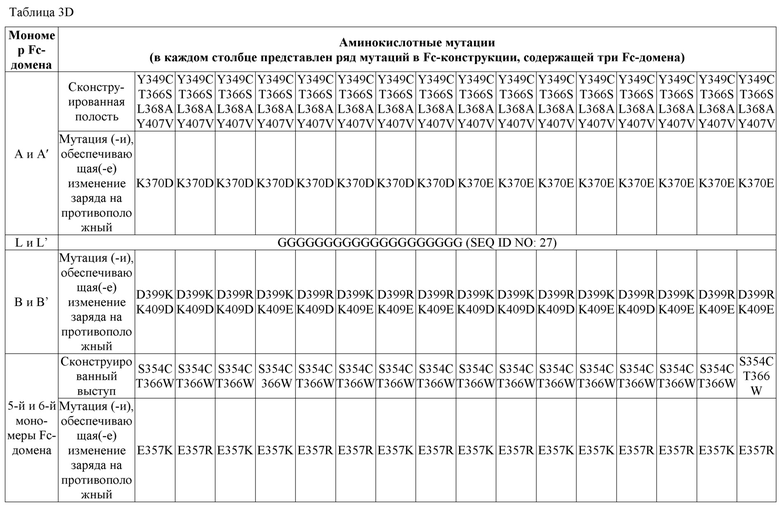
В некоторых вариантах осуществления Fc-конструкция содержит два Fc-домена, образованных из трех полипептидов. Первый полипептид содержит два мономера Fc-домена, соединенные в виде тандемной последовательности с соединением посредством линкера (например, глицинового спейсера; SEQ ID NO: 26 и 27), а второй и третий полипептиды содержат по одному мономеру Fc-домена. Второй и третий полипептиды могут представлять собой один и тот же полипептид или могут представлять собой разные полипептиды. На фиг. 13 изображен пример такой Fc-конструкции. Первый полипептид (1302) содержит два мономера Fc-домена (1304 и 1306), соединенных в виде тандемной последовательности посредством линкера (например, глицинового спейсера; SEQ ID NO: 26 и 27). Оба мономера Fc-домена 1304 и 1306 содержат сконструированные выступы в константных доменах CH3 антитела. Каждый из второго и третьего полипептидов (1308 и 1310) содержит один мономер Fc-домена, содержащий сконструированные полости в константном домене CH3 антитела. Один из мономеров Fc-домена (1304) в первом полипептиде образует первый гетеродимерный Fc-домен со вторым полипептидом (1308), тогда как другой мономер Fc-домена (1306) в первом полипептиде образует второй гетеродимерный Fc-домен с третьим полипептидом (1310). Второй и третий полипептиды не присоединены друг к другу или не связаны друг с другом. Сконструированная «выступ-в-полость» поверхность контакта CH3-CH3 благоприятствует образованию гетеродимеров из мономеров Fc-домена и предотвращает неконтролируемое образование нежелательных мультимеров. В некоторых вариантах осуществления каждый из мономеров Fc-домена может дополнительно содержать мутации, обеспечивающие изменение заряда на противоположный, для способствования гетеродимеризации. Например, мономер 1304 Fc-домена, содержащий сконструированные выступы и мутации, обеспечивающие изменение заряда на противоположный (например, E357K), может предпочтительно образовывать гетеродимерный Fc-домен с мономером 1308 Fc-домена, содержащего сконструированные полости и мутации, обеспечивающие изменение заряда на противоположный (например, K370D).
В еще других вариантах осуществления Fc-конструкции могут содержать пять Fc-доменов, образованных из шести полипептидов. Два примера изображены на фиг. 14 и 15. Хотя эти изображенные Fc-конструкции состоят из шести полипептидов, четыре из этих полипептидов могут кодироваться одной и той же нуклеиновой кислотой, и остальные два полипептида также могут кодироваться одной и той же нуклеиновой кислотой. В результате эти Fc-конструкции можно получить путем экспрессии двух нуклеиновых кислот в подходящей клетке-хозяине.
На фиг. 14 изображена Fc-конструкция, содержащая пять Fc-доменов, образованных из шести полипептидов. Каждый из первого и второго полипептидов (1402 и 1410) содержит по три мономера Fc-домена (1404, 1406, 1408 и 1412, 1414, 1416 соответственно), соединенные в виде тандемной последовательности посредством линкера (например, глицинового спейсера; SEQ ID NO: 26 и 27). В частности, в полипептиде 1402 или 1410 первый мономер Fc-домена, содержащий выступ (1404 или 1412), соединен со вторым мономером Fc-домена, содержащим различно заряженные аминокислоты на поверхности контакта CH3-CH3 (1406 или 1414), в отличие от последовательности дикого типа, который связан с третьим мономером Fc-домена, содержащим выступ (1408 или 1416). Каждый из мономеров Fc-домена 1406 и 1414 может содержать одинаковые мутации, обеспечивающие изменение заряда на противоположный (например, D399K/K409D), которые способствуют образованию гомодимерного Fc-домена. Каждый полипептид с третьего по шестой (1418, 1420, 1422 и 1424) содержит мономер Fc-домена, содержащий полость, и образует гетеродимерный Fc-домен с каждым из мономеров Fc-домена 1404, 1408, 1412 и 1416 соответственно. В некоторых вариантах осуществления каждый из мономеров Fc-домена 1404, 1408, 1412, 1416, 1418, 1420, 1422 и 1424 может дополнительно содержать мутации, обеспечивающие изменение заряда на противоположный, для способствования гетеродимеризации. Например, мономер 1408 Fc-домена, содержащий сконструированные выступы и мутации, обеспечивающие изменение заряда на противоположный (например, E357K), может предпочтительно образовывать гетеродимерный Fc-домен с мономером 1420 Fc-домена, содержащим сконструированные полости и мутации, обеспечивающие изменение заряда на противоположный (например, K370D).
На фиг. 15 изображена Fc-конструкция, содержащая пять Fc-доменов, образованных из шести полипептидов. Каждый из первого и второго полипептидов (1502 и 1510) содержит по три мономера Fc-домена (1504, 1506, 1508 и 1512, 1514, 1516 соответственно), соединенные в виде тандемной последовательности посредством линкера (например, глицинового спейсера; SEQ ID NO: 26 и 27). В частности, в полипептиде 1502 или 1510 первый мономер Fc-домена, содержащий выступ (1504 или 1512), соединен со вторым мономером Fc-домена, содержащим выступ (1506 или 1514), который связан с третьим мономером Fc-домена, содержащим различно заряженные аминокислоты на поверхности контакта CH3-CH3 (1508 или 1516), в отличие от последовательности дикого типа. Каждый из мономеров Fc-домена 1508 и 1516 может содержать одинаковые мутации, обеспечивающие изменение заряда на противоположный (например, D399K/K409D), которые способствуют образованию гомодимерного Fc-домена. Каждый полипептид с третьего по шестой (1518, 1520, 1522 и 1524) содержит мономер Fc-домена, содержащий полость, и образует гетеродимерный Fc-домен с каждым из мономеров Fc-домена 1504, 1506, 1512 и 1514 соответственно. В некоторых вариантах осуществления каждый из мономеров Fc-домена 1504, 1506, 1512, 1514, 1518, 1520, 1522 и 1524 может дополнительно содержать мутации, обеспечивающие изменение заряда на противоположный, для способствования гетеродимеризации. Например, мономер 1504 Fc-домена, содержащий сконструированные выступы и мутации, обеспечивающие изменение заряда на противоположный (например, E357K), может предпочтительно образовывать гетеродимерный Fc-домен с мономером 1518 Fc-домена, содержащим сконструированные полости и мутации, обеспечивающие изменение заряда на противоположный (например, K370D).
На фиг. 16 изображена еще одна Fc-конструкция, состоящая из пяти Fc-доменов, образованных из шести полипептидов. Каждый из первого и второго полипептидов (1602 и 1610) содержит по три мономера Fc-домена (1604, 1606, 1608 и 1612, 1614, 1616 соответственно), соединенные в виде тандемной последовательности посредством линкера (например, глицинового спейсера; SEQ ID NO: 26 и 27). В частности, в полипептиде 1602 или 1610 первый мономер Fc-домена, содержащий различно заряженные аминокислоты на поверхности контакта CH3-CH3 (1604 или 1612), связан со вторым мономером Fc-домена, содержащим выступ (1606 или 1614), который связан с третьим мономером Fc-домена, содержащим выступ (1608 или 1616), в отличие от последовательности дикого типа. Каждый из мономеров Fc-домена 1604 и 1612 может содержать одинаковые мутации, обеспечивающие изменение заряда на противоположный (например, D399K/K409D), которые способствуют образованию гомодимерного Fc-домена. Каждый полипептид с третьего по шестой (1618, 1620, 1622 и 1624) содержит мономер Fc-домена, содержащий полость, и образует гетеродимерный Fc-домен с каждым из мономеров Fc-домена 1606, 1608, 1614 и 1616 соответственно. В некоторых вариантах осуществления каждый из мономеров Fc-домена 1606, 1608, 1614, 1616, 1618, 1620, 1622 и 1624 может дополнительно содержать мутации, обеспечивающие изменение заряда на противоположный, для способствования гетеродимеризации. Например, мономер 1608 Fc-домена, содержащий сконструированные выступы и мутации, обеспечивающие изменение заряда на противоположный (например, E357K), может предпочтительно образовывать гетеродимерный Fc-домен с мономером 1620 Fc-домена, содержащим сконструированные полости и мутации, обеспечивающие изменение заряда на противоположный (например, K370D).
В другом варианте осуществления Fc-конструкция, содержащая два или более Fc-доменов, может быть образована из двух полипептидов, имеющих одинаковую первичную последовательность. Такая конструкция может быть образована путем экспрессии одной полипептидной последовательности в клетке-хозяине. Пример показан на фиг. 17. В этом примере одной нуклеиновой кислоты достаточно для кодирования Fc-конструкции, содержащей три Fc-домена. Два мономера Fc-домена, которые являются частью одного и того же полипептида, могут образовывать гетеродимерный Fc-домен посредством включения гибкого линкера достаточной длины и гибкости. Этот же полипептид также содержит третий мономер Fc-домена, присоединенный посредством гибкого линкера (например, глицинового спейсера; SEQ ID NO: 26 и 27). Этот третий мономер Fc-домена (1708) может соединяться с другим мономером Fc-домена (1716) с образованием гомодимерного Fc-домена и получением Y-образной Fc-конструкции, изображенной на фиг. 17. Образование Fc-доменов можно контролировать с помощью модулей селективности, обеспечивающих димеризацию, как также показано на фиг. 17. В некоторых вариантах осуществления каждый из мономеров Fc-домена 1704, 1706, 1712 и 1714 может дополнительно содержать мутации, обеспечивающие изменение заряда на противоположный, для способствования гетеродимеризации. Например, мономер 1704 Fc-домена, содержащий сконструированные выступы и мутации, обеспечивающие изменение заряда на противоположный (например, E357K), может предпочтительно образовывать гетеродимерный Fc-домен с мономером 1706 Fc-домена, содержащим сконструированные полости и мутации, обеспечивающие изменение заряда на противоположный (например, K370D).
В некоторых вариантах осуществления один или более Fc-полипептидов в Fc-конструкции (например, Fc-конструкции 1-3 на фиг. 1; Fc-конструкции 4 на фиг. 2) лишены С-концевого остатка лизина. В некоторых вариантах осуществления все Fc-полипептиды в Fc-конструкции лишены С-концевого остатка лизина. В некоторых вариантах осуществления отсутствие С-концевого лизина в одном или более Fc-полипептидах в Fc-конструкции может улучшить гомогенность совокупности Fc-конструкций (например, Fc-конструкций, содержащих три Fc-домена), например, совокупности Fc-конструкций, содержащих три Fc-домена, которая является по сути гомогенной (см. пример 8). В одном примере C-концевой остаток лизина в Fc-полипептиде, имеющем последовательность под любым из SEQ ID NO: 43 и 44 (см. пример 1, таблица 6), может быть удален для получения соответствующего Fc-полипептида, который не содержит C-концевого остатка лизина.
В некоторых вариантах осуществления мономер Fc-домена в Fc-конструкции, описанной в данном документе (например, Fc-конструкции, содержащей три Fc-домена), может содержать, состоять из или состоять по сути из последовательности, которая является на по меньшей мере 95% идентичной (например, идентичной на по меньшей мере 97%, 99% или 99,5%) последовательности мономера Fc-домена дикого типа (например, SEQ ID NO: 42). В некоторых вариантах осуществления мономер Fc-домена в Fc-конструкции, описанной в данном документе (например, Fc-конструкции, содержащей три Fc-домена), может содержать, состоять из или состоять по сути из последовательности, которая представляет собой последовательность мономера Fc-домена дикого типа (SEQ ID NO: 42) с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например, консервативными заменами). В некоторых вариантах осуществления мономер Fc-домена в Fc-конструкции, описанной в данном документе (например, Fc-конструкции, содержащей три Fc-домена), может содержать, состоять из или состоять по сути из последовательности, которая является на по меньшей мере 95% идентичной (например, идентичной на по меньшей мере 97%, 99% или 99,5%) последовательности под любым из SEQ ID NO: 44, 46, 48 и 50-53. В некоторых вариантах осуществления мономер Fc-домена в Fc-конструкции, описанной в данном документе (например, Fc-конструкции, содержащей три Fc-домена), может содержать, состоять из или состоять по сути из последовательности, которая представляет собой последовательность под любым из SEQ ID NO: 44, 46, 48 и 50-53 с не более чем 10 (9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В определенных вариантах осуществления мономер Fc-домена в Fc-конструкции может содержать, состоять из или состоять по сути из последовательности, которая является на по меньшей мере 95% идентичной (например, идентичной на по меньшей мере 97%, 99% или 99,5%) последовательности под SEQ ID NO: 48, 52 и 53. В определенных вариантах осуществления мономер Fc-домена в Fc-конструкции может содержать, состоять из или состоять по сути из последовательности, которая представляет собой последовательность под SEQ ID NO: 48, 52 и 53 с не более чем 10 (не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами).
В некоторых вариантах осуществления полипептид, содержащий два мономера Fc-домена в Fc-конструкции, описанной в данном документе (например, полипептиды 102 и 108 на фиг. 1, полипептиды 202 и 208 на фиг. 2), может содержать, состоять из или состоять по сути из последовательности, которая является на по меньшей мере 95% идентичной (например, идентичной на по меньшей мере 97%, 99% или 99,5%) последовательности под любым из SEQ ID NO: 43, 45, 47 и 49 (см. пример 1, таблица 6). В некоторых вариантах осуществления полипептид, содержащий два мономера Fc-домена в Fc-конструкции, описанной в данном документе (например, полипептиды 102 и 108 на фиг. 1, полипептиды 202 и 208 на фиг. 2), может содержать, состоять из или состоять по сути из последовательности, которая представляет собой последовательность под любым из SEQ ID NO: 43, 45, 47 и 49 (см. пример 1, таблица 6) с не более чем 10 (не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В определенных вариантах осуществления полипептид, содержащий два мономера Fc-домена в Fc-конструкции, описанной в данном документе, может содержать, состоять из или состоять по сути из последовательности, которая является на по меньшей мере 95% идентичной (например, идентичной на по меньшей мере 97%, 99% или 99,5%) последовательности под SEQ ID NO: 49. В определенных вариантах осуществления полипептид, содержащий два мономера Fc-домена в Fc-конструкции, описанной в данном документе, может содержать, состоять из или состоять по сути из последовательности, которая представляет собой последовательность под SEQ ID NO: 49 с не более чем 10 (например, не более чем 9, 8, 7, 6, 5, 4, 3, 2 или 1) одиночными аминокислотными модификациями (например, заменами, например консервативными заменами). В некоторых вариантах осуществления аминокислотные мутации в полипептиде, содержащем два мономера Fc-домена в Fc-конструкции, описанной в данном документе (например, полипептиды 102 и 108 на фиг.1; полипептиды 202 и 208 на фиг.2), встречаются только в мономерах Fc-домена (например, мономерах Fc-домена 104, 106, 110 и 112 на фиг. 1; мономерах Fc-домена 204, 206, 210 и 212 на фиг. 2) и не встречаются в спейсере. Например, в полипептидах, показанных в таблице 8, дополнительные аминокислотные мутации можно вносить в мономеры Fc-домена, имеющие последовательности под SEQ ID NO: 50-53, тогда как спейсеры, имеющие последовательности под SEQ ID NO: 18, 26 и 27, остаются неизменными.
В некоторых вариантах осуществления N-концевой Asp в одном или более из первого, второго, третьего и четвертого полипептидов в Fc-конструкции, описанной в данном документе (например, полипептиды 102, 108, 114 и 116 на фиг. 1; 202, 208, 214 и 216 на фиг.2) может быть заменен на Gln в результате мутации. В некоторых вариантах осуществления N-концевой Asp в каждом из первого, второго, третьего и четвертого полипептидов в Fc-конструкции, описанной в данном документе, заменен на Gln в результате мутации. В других вариантах осуществления Fc-конструкция, описанная в настоящем документе (например, Fc-конструкция, содержащая три Fc-домена), может содержать один или более мономеров Fc-домена, в которых N-концевой Asp заменен на Gln в результате мутации. В некоторых вариантах осуществления замена N-концевого Asp на Gln в результате мутации в одном или более из первого, второго, третьего и четвертого полипептидов в Fc-конструкции, описанной в данном документе, может улучшать гомогенность совокупности Fc-конструкций (например, Fc-конструкций, содержащих три Fc-домена), например, совокупности Fc-конструкций, содержащих три Fc-домена, которая является по сути гомогенной. Например, в таблице 4 показаны аминокислотные последовательности первого, второго, третьего и четвертого полипептидов, в которых N-концевой Asp в Fc-конструкции, содержащей три Fc-домена, заменен на Gln в результате мутации.
Таблица 4
X. Клетки-хозяева и продуцирование белка
В настоящем изобретении клетка-хозяин относится к носителю, который содержит необходимые клеточные компоненты, например, органеллы, необходимые для экспрессии описанных в данном документе полипептидов и конструкций на основе их соответствующих нуклеиновых кислот. Нуклеиновые кислоты можно включать в векторы на основе нуклеиновой кислоты, которые можно вводить в клетку-хозяина посредством традиционных методик, известных в данной области техники (трансформация, трансфекция, электропорация, осаждение фосфатом кальция, прямая микроинъекция и т. д.). Клетки-хозяева могут происходить от млекопитающего, бактерии, грибка или насекомого. Клетки-хозяева млекопитающих включают без ограничения СНО (или клеточные штаммы, полученные на основе СНО, например, CHO-K1, CHO-DXB11 CHO-DG44), клетки-хозяева мыши (например, NS0, Sp2/0), VERY, HEK (например, HEK293), клетки BHK, HeLa, COS, MDCK, 293, 3T3, W138, BT483, Hs578T, HTB2, BT20 и T47D, CRL7O3O и HsS78Bst. Также могут быть выбраны клетки-хозяева, которые модулируют экспрессию белковых конструкций или модифицируют и процессируют белковый продукт необходимым специфическим образом. Различные клетки-хозяева имеют характерные и специфические механизмы посттрансляционного процессинга и модификации белковых продуктов. Можно выбрать подходящие линии клеток или системы экспрессии в хозяине для обеспечения правильной модификации и процессинга экспрессируемого белка.
Для экспрессии и секреции белковых продуктов с соответствующих конструкций на основе плазмидной ДНК клетки-хозяева можно трансфицировать или трансформировать с помощью ДНК под контролем соответствующих элементов контроля экспрессии, известных в данной области техники, в том числе последовательностей промотора, энхансера, терминаторов транскрипции, сайтов полиаденилирования и селектируемых маркеров. Способы экспрессии терапевтических белков известны в данной области техники. См., например, Paulina Balbas, Argelia Lorence (ред.) Recombinant Gene Expression: Reviews and Protocols (Methods in Molecular Biology), Humana Press; 2-е изд издание 2004 г. (20 июля, 2004 г.); Vladimir Voynov and Justin A. Caravella (ред.) Therapeutic Proteins: Methods and Protocols (Methods in Molecular Biology) Humana Press; 2-е изд. издание 2012 г. (28 июня, 2012 г.).
XI. Очистка
Fc-конструкцию можно очищать любым способом, известным в области очистки белка, например, с помощью хроматографии (например, ионнообменной, аффинной (например, аффинной с белком A) и эксклюзионной колоночной хроматографии), центрифугирования, дифференциальной растворимости или с помощью любой другой стандартной методики очистки белков. Например, Fc-конструкцию можно выделить и очистить путем правильного выбора и комбинирования аффинных колонок, таких как колонка с белком A, с хроматографическими колонками, фильтрацией, ультрафильтрацией, высаливанием и диализом (см., например, Process Scale Purification of Antibodies, Uwe Gottschalk (ред.) John Wiley & Sons, Inc., 2009; и Subramanian (ред.) Antibodies-Volume I-Production and Purification, Kluwer Academic/Plenum Publishers, New York (2004)).
В некоторых случаях Fc-конструкцию можно конъюгировать с одним или более пептидами для очистки для облегчения очистки и выделения Fc-конструкции, например, из смеси лизатов, полученных из целых клеток. В некоторых вариантах осуществления пептид для очистки связывается с другим фрагментом, который обладает специфическим сродством к пептиду для очистки. В некоторых вариантах осуществления такие фрагменты, которые специфически связываются с пептидом для очистки, прикрепляют к твердой подложке, такой как матрица, смола или агарозные шарики. Примеры пептидов для очистки, которые могут быть присоединены к Fc-конструкции, включают без ограничения пептид гексагистидин, пептид FLAG, пептид myc и пептид гемагглютинин (HA). Гексагистидиновый пептид (HHHHHH (SEQ ID NO: 38)) связывается с колонкой для аффинной хроматографии с агарозой, функционализированной никелем, с микромолярной аффинностью. В некоторых вариантах осуществления пептид FLAG включает последовательность DYKDDDDK (SEQ ID NO: 39). В некоторых вариантах осуществления пептид FLAG содержит целочисленные кратные количества последовательности DYKDDDDK, расположенные в виде тандемной последовательности, например 3xDYKDDDDK. В некоторых вариантах осуществления пептид myc содержит последовательность EQKLISEEDL (SEQ ID NO: 40). В некоторых вариантах осуществления пептид myc содержит целочисленные кратные количества последовательности EQKLISEEDL, расположенные в виде тандемной последовательности, например 3xEQKLISEEDL. В некоторых вариантах осуществления пептид HA содержит последовательность YPYDVPDYA (SEQ ID NO: 41). В некоторых вариантах осуществления пептид HA содержит целочисленные кратные количества последовательности YPYDVPDYA, в расположенные в виде тандемной последовательности, например 3xYPYDVPDYA. Антитела, которые специфически распознают и связываются с пептидом для очистки, представляющим собой FLAG, myc или HA, хорошо известны в данной области техники и часто коммерчески доступны. Твердую подложку (например, матрица, смола или агарозные шарики), функционализированную посредством таких антител, можно применять для очистки Fc-конструкции, которая содержит пептид FLAG, myc или HA.
Для Fc-конструкций в качестве способа очистки можно применять колоночную хроматографию с белком А. Лиганды белка А взаимодействуют с Fc-конструкциями через Fc-область, что делает хроматографию на основе связывания с белком А высокоселективным способом захвата, посредством которого можно удалять большинство белков клетки-хозяина. В настоящем изобретении Fc-конструкции могут быть очищены с применением колоночной хроматографии с белком А, как описано в примере 2.
XII. Фармацевтические композиции/препараты
В настоящем изобретении предусмотрены фармацевтические композиции, которые содержат одну или более Fc-конструкций, описанных в данном документе. В одном варианте осуществления фармацевтическая композиция содержит по сути гомогенную совокупность Fc-конструкций. В различных примерах фармацевтическая композиция содержит по сути гомогенную совокупность любой из Fc-конструкций 1-4.
Конструкция терапевтического белка, например, Fc-конструкция, описанная в настоящем документе (например, Fc-конструкция, содержащая три Fc-домена) по настоящему изобретению, может быть включена в фармацевтическую композицию. Фармацевтические композиции, содержащие терапевтические белки, могут быть составлены с помощью способов, известных специалистам в данной области техники. Фармацевтическую композицию можно вводить парентерально в форме инъекционного состава, в том числе стерильного раствора или суспензии в воде или другой фармацевтически приемлемой жидкости. Например, фармацевтическая композиция может быть составлена путем подходящего комбинирования Fc-конструкции с фармацевтически приемлемыми носителями или средами-носителями, такими как стерильная вода для инъекций (WFI), физиологический раствор, эмульгатор, суспендирующее средство, поверхностно-активное вещество, стабилизатор, разбавитель, связующее, вспомогательное вещество, с последующим смешиванием с получением дозированной лекарственной формы, требуемой для общепринятой фармацевтической практики. Количество активного ингредиента, включенного в фармацевтические препараты, таково, что обеспечивается подходящая доза, находящаяся в указанном диапазоне.
Стерильная композиция для инъекций может быть составлена в соответствии с общепринятой фармацевтической практикой, с применением дистиллированной воды для инъекций в качестве носителя. Например, физиологический раствор или изотонический раствор, содержащий глюкозу и другие добавки, такие как D-сорбит, D-манноза, D-маннит и хлорид натрия, можно применять в качестве водного раствора для инъекций, необязательно в комбинации с подходящим солюбилизирующим средством, например, спиртом, таким как этанол, и многоатомным спиртом, таким как пропиленгликоль или полиэтиленгликоль, и неионогенным поверхностно-активным веществом, таким как полисорбат 80™, HCO-50, и подобными средствами, общеизвестными в данной области техники. Способы составления продуктов на основе терапевтических белков известны в данной области техники, см., например, Banga (ред.) Therapeutic Peptides and Proteins: Formulation, Processing and Delivery Systems (2-е изд.) Taylor & Francis Group, CRC Press (2006 г.).
XIII. Дозировка
Фармацевтические композиции вводят посредством способа, совместимого с дозированным составом, и в таком количестве, которое является терапевтически эффективным для улучшения или устранения симптомов. Фармацевтические композиции вводят в виде различных лекарственных форм, например лекарственных форм для внутривенного введения, лекарственных форм для подкожного введения, лекарственных форм для перорального введения, таких как принимаемые внутрь растворы, капсулы для высвобождения лекарственного средства и тому подобное. Подходящая дозировка для отдельного субъекта зависит от терапевтических целей, пути введения и состояния пациента. Обычно рекомбинантные белки вводят в дозе 1-200 мг/кг, например 1-100 мг/кг, например 20-100 мг/кг. Соответственно, для получения оптимального терапевтического эффекта для поставщика медицинских услуг будет необходимо подбирать и титровать дозировку и модифицировать путь введения.
XIV. Показания
Фармацевтические композиции по настоящему изобретению (например, содержащие Fc-конструкции, содержащие 2, 3 или 4 Fc-домена) применимы для уменьшения воспаления у субъекта, для стимуляции клиренса аутоантител у субъекта, для подавления презентации антигена у субъекта, для снижения иммунного ответа, например, блокирования иммунокомплексной активации иммунного ответа у субъекта, и лечения иммунологических и воспалительных состояний или заболеваний у субъекта. Иллюстративные состояния и заболевания включают следующее: ревматоидный артрит (RA); системная красная волчанка (SLE); ANCA-ассоциированный васкулит; синдром антифосфолипидных антител; аутоиммунная гемолитическая анемия; хроническая воспалительная демиелинизирующая невропатия; клиренс антител к чужеродным клеткам при трансплантации; аутореактивность при GVHD; заместительная терапия с помощью антител, терапевтических средств на основе IgG, парапротеинов на основе IgG, дерматомиозит; синдром Гудпасчера; синдромы гиперчувствительности типа II на уровне систем органов, опосредованные антителозависимой клеточно-опосредованной цитотоксичностью, например синдром Гийена-Барре, CIDP, дерматомиозит, синдром Фелти, опосредованное антителами отторжение, аутоиммунное заболевание щитовидной железы, язвенный колит, аутоиммунное заболевание печени; идиопатическая тромбоцитопеническая пурпура; миастения гравис, оптиконевромиелит; пузырчатка и другие аутоиммунные нарушения, сопровождающиеся образованием пузырей; синдром Шегрена; аутоиммунные цитопении и другие нарушения, опосредованные антителозависимым фагоцитозом; другие FcR-зависимые воспалительные синдромы; синовит; дерматомиозит, системный васкулит, гломерулит и васкулит.
В некоторых вариантах осуществления фармацевтические композиции по настоящему изобретению, содержащие Fc-конструкции, содержащие 5-10 Fc-доменов, также применимы, например, для индукции иммунноклеточной активации иммунного ответа у субъекта, для усиления фагоцитоза клетки-мишени (т.е. раковой клетки или инфицированной клетки) у субъекта и для лечения таких заболеваний, как рак и инфекции у субъекта. Fc-конструкции и гомогенные фармацевтические композиции по настоящему изобретению могут связываться с активирующими Fcγ-рецепторами (например, FcγRI, FcγRIIa, FcγRIIc, FcγRIIIa и FcγRIIIb) для индукции иммунного ответа. Fc-конструкции и гомогенные фармацевтические композиции по настоящему изобретению могут активировать фосфорилирование Syk и поток кальция из первичных моноцитов THP-1. Активированные моноциты и происходящие от них дифференцированные макрофаги обладают способностью к фагоцитозу или уничтожению клеток-мишеней. Таким образом, в настоящем изобретении предусмотрены способы лечения, которые можно применять для лечения субъектов, страдающих от заболеваний и нарушений, таких как рак и инфекции. В некоторых вариантах осуществления Fc-конструкции и гомогенные фармацевтические композиции, описанные в данном документе, можно вводить субъекту в терапевтически эффективном количестве для обеспечения фагоцитоза или уничтожения раковых клеток или инфицированных клеток у субъекта.
Виды рака, которые поддаются лечению в соответствии со способами по настоящему изобретению, включают без ограничения рак мочевого пузыря, рак поджелудочной железы, рак легкого, рак печени, рак яичника, рак толстой кишки, рак желудка, рак молочной железы, рак простаты, рак почки, рак яичка, рак щитовидной железы, рак матки, рак прямой кишки, рак дыхательной системы, рак мочевыделительной системы, рак полости рта, рак кожи, лейкоз, саркому, карциному, базальноклеточный рак, неходжкинскую лимфому, острый миелоидный лейкоз (AML), хронический лимфоцитарный лейкоз (CLL), В-клеточный хронический лимфолейкоз (B-CLL), множественную миелому (ММ), эритролейкоз, почечно-клеточную карциному, астроцитому, олигоастроцитому, рак желчных путей, хориокарциному, рак ЦНС, рак гортани, мелкоклеточный рак легкого, аденокарциному, гигантоклеточную (или овсяноклеточную) карциному, плоскоклеточный рак, анапластическую крупноклеточную лимфому, немелкоклеточный рак легкого, нейробластому, рабдомиосаркому, нейроэктодермальный рак, глиобластому, карциному молочной железы, меланому, воспалительную миофибробластическую опухоль и опухоль мягких тканей.
Инфекции, которые поддаются лечению в соответствии со способами по настоящему изобретению, включают без ограничения бактериальную инфекцию, вирусную инфекцию, грибковую инфекцию, глистную инфекцию и протозойную инфекцию.
Примеры бактерий, вызывающих инфекцию, хорошо известны в данной области техники и включают без ограничения бактерии рода Streptococcus (например, Streptococcus pyogenes), бактерии рода Escherichia (например, Escherichia coli), бактерии рода Vibrio (например, Vibrio cholerae), бактерии рода Enteritis (например, Enteritis salmonella), а также бактерии рода Salmonella (например, Salmonella typhi).
Примеры вызывающих инфекцию вирусов хорошо известны в данной области техники и включают без ограничения вирусы семейства Retroviridae (например, вирус иммунодефицита человека (HIV)), вирусы семейства Adenoviridae (например, аденовирус), вирусы семейства Herpesviridae (например, вирусы простого герпеса типов 1 и 2), вирусы семейства Papillomaviridae (например, вирус папилломы человека (HPV)), вирусы семейства Poxviridae (например, оспа), вирусы семейства Picornaviridae (например, вирус гепатита А, полиовирус, риновирус), вирусы семейства Hepadnaviridae (например, вирус гепатита В), вирусы семейства Flaviviridae (например, вирус гепатита С, вирус желтой лихорадки, вирус Западного Нила), вирусы семейства Togaviridae (например, вирус краснухи), вирусы семейства Orthomyxoviridae (например, вирус гриппа), вирусы семейства Filoviridae (например, вирус Эбола, вирус Марбурга) и вирусы семейства Paramyxoviridae (например, вирус кори, вирус эпидемического паротита).
Примеры грибков, вызывающих инфекцию, хорошо известны в данной области техники и включают без ограничения грибы рода Aspergillus (например, Aspergillusfumigatus, A. flavus, A. terreus. A. niger, A. candidus, A. clavatus, A. ochraceus), грибы рода Candida (например, Candida albicans, C. parapsilosis, C. glabrata, C. guilliermondii, C. krusei, C. lusitaniae, C. tropicalis), грибы рода Cryptococcus (например, Cryptococcus neoformans), а также грибы рода Fusarium (например, Fusarium solani, F. verticillioides, F. oxysporum).
Примеры гельминтов включают без ограничения ленточных червей (цестоды), круглых червей (нематоды), сосальщиков (трематоды) и моногенетических сосальщиков.
Примеры простейших включают без ограничения простейших рода Entamoeba (например, Entamoeba histolytica), простейших рода Plasmodium (например, Plasmodiumfalciparum, P.malariae), простейших рода Giardia(например, Giardia lamblia), а также простейших рода Trypanosoma (например, Trypanosoma brucei).
ПРИМЕРЫ
Пример 1. Разработка Fc-конструкций
Целью разработки Fc-конструкций является повышение эффективности сворачивания, минимизация неконтролируемой ассоциации субъединиц, которые могут создавать нежелательные высокомолекулярные олигомеры и мультимеры, и получение композиций, которые являются по сути гомогенными. С учетом этих целей авторы разработали четыре Fc-конструкции (фиг. 1 и 2), каждая из которых содержит длинный полипептид, содержащий два мономера Fc-домена, разделенных спейсером (полипептиды 102 и 108 на фиг. 1 и полипептиды 202 и 208 на фиг. 2), и короткий полипептид, содержащий один мономер Fc-домена (полипептиды 114 и 116 на фиг. 1 и полипептиды 214 и 216 на фиг. 2). Каждая из них создана на основе последовательности Fc IgG1, в которую для контроля сборки полипептидов включали модификации, обеспечивающие образование сконструированной полости, сконструированного выступа и/или электростатическое координирование. Последовательности ДНК, кодирующие длинные и короткие полипептиды, оптимизировали для экспрессии в клетках млекопитающих и клонировали в вектор экспрессии pcDNA3.4 млекопитающих. Конструкции на основе плазмидной ДНК трансфицировали с помощью липосом в эмбриональные клетки почки человека (HEK) 293. Всего применяли восемь конструкций на основе плазмидной ДНК для сборки четырех Fc-конструкций, каждая из которых содержала три Fc-домена.
В случае каждой Fc-конструкции при совместной экспрессии длинных и коротких полипептидов получают разветвленную молекулу, содержащую три Fc-домена, при этом C-концевые Fc-мономеры длинных полипептидов специфически ассоциируют друг с другом с образованием одного C-концевого Fc-домена, и N-концевые Fc-мономеры длинных полипептидов специфически ассоциируют с короткими полипептидами с образованием двух N-концевых Fc-доменов. Fc-конструкции 1-4 и их разработка описаны в таблице 5 и на фиг. 1 и 2. Последовательности, применяемые в каждой Fc-конструкции, показаны в таблице 6. В таблице 7 ниже дополнительно кратко описаны характеристики длинных и коротких полипептидов в каждой из конструкций 1-4.
Таблица 5
Таблица 6
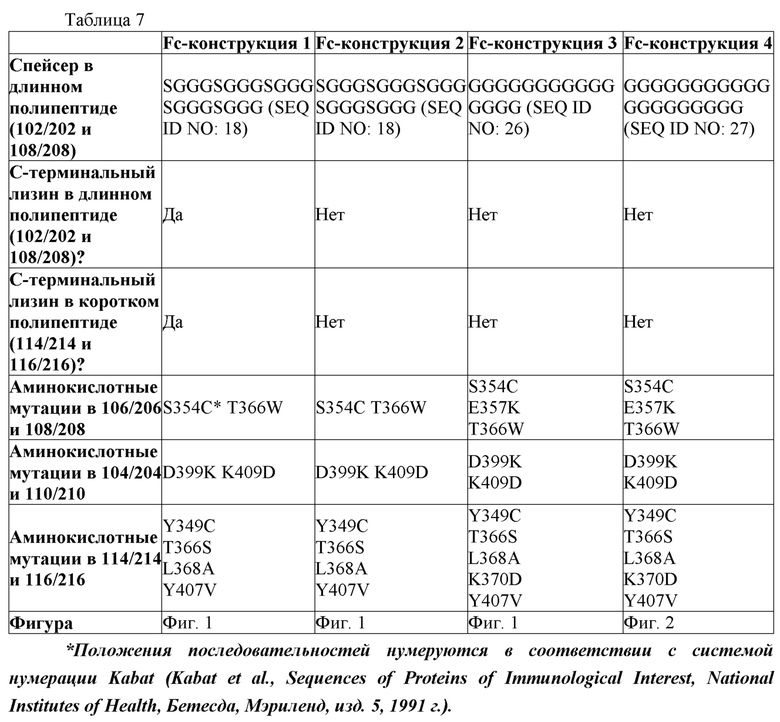
Каждый из длинных полипептидов 102 и 108 в Fc-конструкциях 1-3 (фиг. 1) и длинных полипептидов 202 и 208 в Fc-конструкции 4 (фиг. 2) содержат два мономера Fc-домена, соединенные в виде тандемной последовательности посредством спейсера. В приведенной ниже таблице 8 представлены последовательности мономеров Fc-домена в длинных полипептидах и спейсеров в Fc-конструкциях 1-4.
Таблица 8
Пример 2. Экспрессия Fc-конструкций
Экспрессированные белки очищали от надосадочной жидкости культуры клеток с помощью аффинной колоночной хроматографии на основе связывания с белком A с применением колонки Poros MabCapture A (LifeTechnologies). Захваченные Fc-конструкции промывали фосфатно-солевым буфером (промывка с низким содержанием соли) и элюировали с помощью 100 мМ глицина, рН 3. Элюат быстро нейтрализовали путем добавления 1 М TRIS pH 7,4 и фильтровали в стерильных условиях через 0,2 мкм фильтр.
Далее белки фракционировали с помощью ионообменной хроматографии с применением смолы Poros XS (Applied Biosciences). Колонку предварительно уравновешивали с помощью 50 мМ MES, pH 6 (буфер A), и образец элюировали с использованием ступенчатого градиента с применением 50 мМ MES, 400 мМ хлорида натрия, pH 6 (буфер B) в качестве буфера для элюирования.
После проведения ионного обмена буфер целевой фракции заменяли на PBS-буфер с применением полиэфирсульфонового (PES) мембранного картриджа с границей отсечки 10 кДа на системе тангенциальной поточной фильтрации. Образцы концентрировали до приблизительно 30 мг/мл и фильтровали в стерильных условиях через 0,2 мкм фильтр.
Пример 3. Экспериментальные анализы, применяемые для определения характеристик Fc-конструкций
Жидкостная хроматография-MS/MS для анализа пептидов и гликопептидов
Белки разбавляли до 1 мкг/мкл в 6 М гуанидине (Sigma). Дитиотреитол (DTT) добавляли до достижения концентрации 10 мМ, чтобы снизить количество дисульфидных связей в условиях денатурирования при 65°C в течение 30 минут. После охлаждения на льду образцы инкубировали с 30 мМ йодацетамидом (IAM) в течение 1 ч. в темноте для алкилирования (карбамидометилирования) свободных тиолов. Затем белок подвергали диализу через мембрану 10 кДа в 25 мМ буфер с бикарбонатом аммония (рН 7,8) для удаления IAM, DTT и гуанидина. Белок расщепляли трипсином в Barocycler (NEP 2320; Pressure Biosciences, Inc.). Давление циклически изменяли с 20000 фунт/кв. дюйм до давления окружающей среды при 37°С в ходе 30 циклов в течение 1 ч. Анализ пептидов с помощью LC-MS/MS проводили на хроматографической системе Ultimate 3000 (Dionex) и масс-спектрометре Q-Exactive (Thermo Fisher Scientific). Пептиды разделяли на колонке BEH PepMap (Waters) с применением 0,1% FA в воде и 0,1% FA в ацетонитриле в качестве подвижных фаз. Линкерный пептид, ксилозилированый по одному остатку, распознавали по двухзарядному иону (z=2) m/z 842,5 при ширине окна выделения квадруполя, составляющем ± 1,5 Да.
Интактная масс-спектрометрия
Белок разбавляли до концентрации 2 мкг/мкл в подвижном буфере, состоящем из 78,98% воды, 20% ацетонитрила, 1% муравьиной кислоты (FA) и 0,02% трифторуксусной кислоты. Разделение посредством эксклюзионной хроматографии проводили на двух колонках Zenix-C SEC-300 (Sepax Technologies, Ньюарк, Делавэр) 2,1×350 мм, расположенных последовательно друг за другом таким образом, что общая длина колонок составляла 700 мм. Белки элюировали из колонки SEC с применением подвижного буфера, описанного выше, при скорости потока 80 мкл/мин. Масс-спектры получали на масс-спектрометре Q-ToF QSTAR Elite (Applied Biosystems), работающем в положительном режиме. Значения массы нейтральных частиц в отдельных фракциях при разделении по размеру частиц подвергали деконволюции с применением байесовской деконволюции пика путем суммирования спектров по всей ширине хроматографического пика.
Анализ методом капиллярного электрофореза с додецилсульфатом натрия (CE-SDS)
Образцы разбавляли до 1 мг/мл и смешивали с денатурирующим буфером HT Protein Express (PerkinElmer). Смесь инкубировали при 40°С в течение 20 мин. Образцы разбавляли с помощью 70 мкл воды и переносили в 96-луночный планшет. Образцы анализировали с помощью прибора Caliper GXII (PerkinElmer), оборудованного HT Protein Express LabChip (PerkinElmer). Для расчета относительного содержания каждого варианта по размеру использовали интенсивность флуоресценции.
SDS-PAGE в невосстанавливающих условиях
Образцы денатурировали в буфере для образцов Laemmli (4% SDS, Bio-Rad) при 95°C в течение 10 мин. Образцы прогоняли на геле Criterion TGX без окрашивания (4-15% полиакриламид, Bio-Rad). Пятна белков визуализировали с помощью УФ-излучения или окрашивания Кумасси синим. Гели визуализировали с помощью ChemiDoc MP Imaging System (Bio-Rad). Количественное определение пятен проводили с применением программного обеспечения Imagelab 4.0.1 (Bio-Rad).
Комплементзависимая цитотоксичность (CDC)
CDC оценивали с помощью колориметрического анализа, в котором клетки линии Raji (ATCC) покрывали серийными разведениями ритуксимаба, Fc-конструкции 4 или IVIg. Комплемент сыворотки человека (Quidel) добавляли во все лунки в количестве 25% об./об. и инкубировали в течение 2 ч. при 37°С. Клетки инкубировали в течение 12 ч. при 37°С после добавления реагента для пролиферации клеток WST-1 (Roche Applied Science). Планшеты помещали на шейкер на 2 мин. и измеряли поглощение при 450 нм.
Пример 4. О-гликозилирование и протеолиз сериновых остатков линкера
O-гликозилирование сериновых остатков линкера
Как описано в примере 1, авторы настоящего изобретения осуществляли разработку в отношении Fc-конструкции с целью увеличения эффективности сворачивания, минимизации неконтролируемой ассоциации субъединиц и создания композиций для фармацевтического применения, которые являются по сути гомогенными. В попытке достичь этих целей авторы исследовали различные линкеры между двумя мономерами Fc-домена в длинном полипептиде (102 и 108 на фиг. 1; 202 и 208 на фиг. 2). Каждая из Fc-конструкции 1 и Fc-конструкции 2 содержит серин-глициновый линкер (SGGGSGGGSGGGSGGGSGGG (SEQ ID NO: 18)) между двумя мономерами Fc-домена в длинном полипептиде.
При анализе Fc-конструкции 2, которая содержит линкер SGGGSGGGSGGGSGGGSGGG (SEQ ID NO: 18) между двумя мономерами Fc-домена в длинном полипептиде, с помощью LC-MS/MS для анализа пептидов обнаружили наличие O-ксилозилирования (фиг. 3). Однако, поскольку фрагменты с y2 по y9 не содержат ксилозу, пятый серин в линкере не является O-ксилозилированным. Может быть несколько сайтов, которые являются O-ксилозилированными, но каждый пептид является O-ксилозилированным только по одному остатку. Распространенность и расположение этой посттрансляционной модификации могут зависеть как от последовательности, так и от системы экспрессии.
Аналогично, O-ксилозилирование обнаружили в Fc-конструкции, содержащей два Fc-домена (Fc-конструкция, показанная на фиг. 13), содержащей тот же линкер (SG3)5 (фиг. 4). Модификацию обнаружили в разных положениях, причем в каждом линкере присутствовало не более двух модификаций ксилозы. Кроме того, степень распространенности модификации варьировал между сериями.
После обнаружения O-ксилозилирования по сериновым остаткам в серин-глициновом линкере авторы настоящего изобретения исследовали альтернативные линкеры, которые содержали только глициновые остатки, чтобы дополнительно оптимизировать последовательность линкера и улучшить гомогенность Fc-конструкции. В результате был выбран полностью глициновый спейсер для применения в Fc-конструкции 3 и Fc-конструкции 4. Fc-конструкция 3 содержит 15-мерный полностью глициновый спейсер (GGGGGGGGGGGGGGG (SEQ ID NO: 26)) между двумя мономерами Fc-домена в длинном полипептиде. Fc-конструкция 4 содержит 20-мерный полностью глициновый спейсер (GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 27)) между двумя мономерами Fc-домена в длинном полипептиде.
Протеолиз по сериновым остаткам линкера
В некоторых вариантах осуществления было обнаружено, что Fc-конструкции подвергаются протеолизу по линкерам при инкубации при 45°C в фосфатно-солевом буфере с образованием мономерных Fc-продуктов. Скорость образования мономеров в случае Fc-конструкции 2 (которая содержит линкер SGGGSGGGSGGGSGGGSGGG в каждом из полипептидов 102 и 108) была выше, чем в случае Fc-конструкции 4 (которая содержит полностью глициновый спейсер GGGGGGGGGGGGGGGGGGGG в каждом из полипептидов 202 и 208) (фиг. 5), что указывает на то, что полностью глициновый спейсер подвержен протеолизу в меньшей степени. Было обнаружено, что этот эффект является общим для разветвленных Fc-конструкций, содержащих три Fc-домена, при разных длинах линкеров; протеолиз полностью глициновых спейсеров происходит медленнее, чем серин-глициновых линкеров (таблица 9).
Таблица 9
Кроме того, анализы посредством масс-спектрометрии мономерных продуктов Fc в случае Fc-конструкции 2 с линкером (SG3)5 в каждом из полипептидов 102 и 108 показали, что доминантные продукты расщеплялись по серину N-концевой стороны, при этом к протеолизу были восприимчивыми все остатки серина, кроме первого (фиг. 6). Напротив, в случае продуктов расщепления Fc-конструкции 4 со спейсером G20 в каждом из полипептидов 202 и 208 не наблюдали сильной специфичности в отношении какого-либо конкретного остатка спейсера (фиг.7). Вместе эти результаты показали, что полностью глициновый спейсер характеризовался пониженной восприимчивостью к протеолизу. Для ограничения протеолиза можно применять не содержащий серина спейсер, такой как спейсер G20, используемый в Fc-конструкции 4. Применение такого глицинового спейсера обеспечивает существенное улучшение в отношении гомогенности конечной композиции на основе Fc-конструкции.
Пример 5. Оптимизация длины линкера
Для обеспечения еще большей оптимизации в отношении гомогенности исследовали длину линкера с помощью получения вариаций в последовательности Fc-конструкции 2, в которой линкер (SG3)5 заменяли спейсером G8, G15 или G20. Анализы с помощью анализов in vitro показали, что длина линкера влияла на биологическую активность, предположительно за счет изменения способности Fc-конструкции взаимодействовать с Fcγ-рецепторами.
Было обнаружено, что ингибирование высвобождения IL-8 клетками THP-1, стимулируемое связанным на планшете IgG, зависело от длины линкера (фиг. 8). При низких концентрациях Fc-конструкции степень ингибирования следовала порядку G8 < G15 < G20, при этом высвобождение IL-8 клетками THP-1 наиболее сильно ингибировалось Fc-конструкцией 2, содержащей спейсер G20.
Кроме того, было обнаружено, что ингибирование потока кальция в нейтрофилах зависит от длины линкера (фиг. 9). Степень ингибирования следовала порядку G8 < G15 < G20, при этом Fc-конструкция 2, содержащая спейсер G20, демонстрировала наибольшую степень ингибирования потока кальция в нейтрофилах.
Пример 6. Оптимизация гетеродимеризации по технологии выступ-во-впадину
Плазмиды, экспрессирующие длинные и короткие полипептиды Fc-конструкции 2 (полипептиды 102, 108, 114 и 116 на фиг. 1) или длинные и короткие полипептиды Fc-конструкции 4 (полипептиды 202, 208, 214 и 216 на фиг. 2) трансфицировали в клетки линии HEK293. После семи дней культивирования клетки очищали посредством центрифугирования и надосадочную жидкость с неочищенной среды разделяли с помощью SDS-PAGE в невосстанавливающих условиях (фиг. 10). Денситометрический анализ визуализированных белковых пятен показал, что Fc-конструкция 2, содержащая три Fc-домена, и Fc-конструкция 4, содержащая три Fc-домена (Fc3), экспрессировались на сходных уровнях. Однако в случае Fc-конструкции 2 для конструкций были показаны значительно более высокие уровни загрязняющих молекул, представляющих собой димер (Fc2) (фиг. 10). Оба ряда конструкций экспрессировали сходные уровни содержания мономерных молекул (Fc1). Дополнительные пятна, присутствующие на изображении, представляют компоненты среды, которые присутствуют в ложно-трансфицированных контролях.
Эти результаты указывают на то, что наличие как мутаций, обеспечивающих электростатическое координирование, которые способствуют гетеродимеризации, так и мутаций, обеспечивающих формирование структуры «выступ-во-впадину», которые способствуют гетеродимеризации в субъединицах «ветви» (например, мономеры Fc-домена 106, 114, 112 и 116 на фиг. 1; мономеры Fc-домена 206, 214, 212 и 216 на фиг.2), обеспечивает улучшение в отношении образования гетеродимерного Fc-домена в Fc-конструкции, оптимизацию сборки Fc-конструкции, содержащей три Fc-домена, и улучшение в отношении гомогенности композиции, содержащей Fc-конструкцию.
Пример 7. Электростатическое координирование для контроля гомодимеризации
Чтобы минимизировать ассоциацию субъединиц непредусмотренным образом, в результате которой образуются нежелательные высокомолекулярные олигомеры и мультимеры, в субъединицы «ветви» (например, мономеры Fc-домена 106, 112, 114, и 116 на фиг. 1; мономеры Fc-домена 206, 212, 214 и 216 на фиг. 2) вводили мутации, которые способствуют гетеродимеризации (например, выступы и впадины). Эти аминокислотные замены обеспечивают сохранение сродства субъединиц с выступами (например, мономеры Fc-домена 106 и 112 на фиг. 1; мономеры Fc-домена 206 и 212 на фиг. 2) с их аналогами со впадинами (например, мономерами Fc-домена 114 и 116 на фиг. 1; мономерами Fc-домена 214 и 216 на фиг. 2) и в то же время препятствуют ассоциации субъединиц с выступами. Поскольку мутации, обеспечивающие образование выступов, также ингибируют сборку с последовательностями Fc дикого типа, это ставит под сомнение необходимость включения дополнительных мутаций для дальнейшего снижения аффинности Fc-субъединиц «стебля» (например, мономеров Fc-домена 104 и 110 на фиг. 1; мономеров Fc-домена 204 и 210 на фиг. 2) в отношении субъединиц «ветви», содержащих выступы и впадины. Для решения этого вопроса был создан длинный полипептид Fc-конструкции, который содержал последовательность мономера Fc-домена дикого типа в карбоксиконцевой субъединице «стебля», и мономер Fc-домена, несущий мутации, обеспечивающие образование выступа, в аминоконцевой субъединице «ветви». Соответствующий короткий полипептид представлял собой мономер Fc-домена, несущий мутации, обеспечивающие образование впадины. Такая Fc-конструкция создана на основе последовательностей полипептидов в Fc-конструкции 2, но содержит последовательность мономера Fc-домена дикого типа в карбоксиконцевой субъединице «стебля» в каждом из длинных полипептидов.
Клетки HEK293 совместно трансфицировали плазмидами, экспрессирующими Fc-конструкцию 2 (которая содержит мутации, обеспечивающие гомодимеризацию за счет электростатического координирования, в мономере Fc-домена в карбоксиконцевой субъединице «стебля» в каждом из длинных полипептидов; см. таблицы 5 и 6 в примере 1), или Fc-конструкцию на основе Fc-конструкции 2, в которой мономер Fc-домена в карбоксиконцевой субъединице «стебля» в каждом из длинных полипептидов был заменен последовательностью мономера Fc-домена дикого типа (SEQ ID NO: 42) (как описано выше). После семи дней культивирования клетки очищали посредством центрифугирования и надосадочную жидкость с неочищенной среды разделяли с помощью SDS-PAGE в невосстанавливающих условиях. Визуализация окрашенных белков показала, что Fc-конструкция без мутаций, обеспечивающих электростатическое координирование, в субъединицах «стебля» (обозначено как «без электростатического координирования» (дорожки 1-3) на фиг. 11) содержала гораздо более высокие уровни мономера (Fc1) и димера (Fc2), чем аналог Fc-конструкции 2 (обозначенный как «с электростатическим координированием» (дорожки 4 и 5) на фиг. 11). Кроме того, может быть обнаружено гораздо большее количество пятен с более высокой молекулярной массой, чем у тримера (дорожки 1-3 на фиг. 11).
Эти результаты указывают на то, что наличие мутаций, обеспечивающих электростатическое координирование, которые способствуют гомодимеризации в субъединицах «стебля» (например, мономеры Fc-домена 104 и 110 на фиг. 1; мономеры Fc-домена 204 и 210 на фиг.2) дополнительно обеспечивает улучшение в отношении образования гомодимерного Fc-домена в Fc-конструкции, оптимизацию сборки Fc-конструкции, содержащей три Fc-домена, и улучшение в отношении гомогенности композиции, содержащей Fc-конструкцию.
Пример 8. Оптимизация гомогенности композиции путем удаления С-концевых остатков лизина
С-концевой остаток лизина иммуноглобулинов является высококонсервативным у многих видов. В некоторых случаях остатки С-концевого лизина в полипептидах удаляются посредством клеточных механизмов в ходе продуцирования белка. Авторы настоящего изобретения стремились дополнительно улучшить однородность Fc-конструкций в композиции и получить композицию, содержащую Fc-конструкцию, описанную в данном документе, характеризующуюся большей степенью гомогенности, путем удаления C-концевого лизина из каждого из полипептидов в Fc-конструкции. Fc-конструкция 2 не содержит С-концевых остатков лизина ни в своих длинных полипептидах (102 и 108; см. пример 1, таблицы 5-7; фиг. 1), ни в коротких полипептидах (114 и 116). На фиг.12 показано, что удаление С-концевого лизина для получения Fc-конструкции 2 не индуцирует комплементзависимую цитотоксичность (CDC) in vitro. Таким образом, путем удаления С-концевого остатка лизина авторы настоящего изобретения смогли улучшить гомогенность фармацевтической композиции Fc-конструкции, не вызывая неблагоприятных иммунологических побочных эффектов.
Пример 9. Разработка Fc-конструкций, содержащих аминокислотные модификации I253 и/или R292
Fc-конструкции, характеризующиеся измененным (например, увеличенным) периодом полужизни, были разработаны на основе конструкции 4 (M230) и содержали аминокислотные модификации (например, одиночные мутации или комбинации мутаций), которые изменяют аффинность связывания с FcRn (например, снижают степень связывания с FcRn например, путем включения аминокислотной модификации в положении I253, например I253A) и/или которые изменяют аффинность связывания с FcRIIb (например, снижают степень связывания с FcRIIb, например, путем включения аминокислотной модификации в положении R292, например, R292P) (фиг. 18A-18O).
Получили шесть Fc-конструкций (фиг. 2, 18B, 18C, 18L, 18N и 18O), каждая из которых включает длинный полипептид, содержащий два мономера Fc-домена, разделенных спейсером, например, полностью глициновым линкером, например, GGGGGGGGGGGGGGGGGGGG (SEQ ID NO: 23) и короткий полипептид, содержащий один мономер Fc-домена и характеризующийся различной валентностью аминокислотных модификаций в положениях I253 (например, I253A) и/или R292 (например, R292P). Каждую Fc-конструкцию создавали на основе последовательности Fc IgG1, в которую для контроля сборки полипептидов включали модификации, обеспечивающие образование сконструированной полости, сконструированного выступа и/или электростатическое координирование. Последовательности ДНК, кодирующие длинные и короткие полипептиды, оптимизировали для экспрессии в клетках млекопитающих и клонировали в вектор экспрессии pcDNA3.4 млекопитающих. Конструкции на основе плазмидной ДНК трансфицировали с помощью липосом в эмбриональные клетки почки человека (HEK) 293.
В случае каждой Fc-конструкции при совместной экспрессии длинных и коротких полипептидов получают разветвленную молекулу, содержащую три Fc-домена, при этом C-концевые Fc-мономеры длинных полипептидов специфически ассоциируют друг с другом с образованием одного C-концевого Fc-домена, и N-концевые Fc-мономеры длинных полипептидов специфически ассоциируют с короткими полипептидами с образованием двух N-концевых Fc-доменов. Fc-конструкции 12-15, 24, 26 и 27 и их разработка описаны в таблице 10 и на фиг. 2 и 18B-18O. Последовательности, применяемые в каждой Fc-конструкции, показаны в таблице 11, где каждая аминокислотная модификация I253A и/или R292P выделена жирным шрифтом и подчеркнута.
В конструкции 4 каждый из длинных полипептидов содержит один мономер Fc-домена, содержащий заряженные аминокислоты (D399K и K409D) на поверхности контакта CH3-CH3, соединенный посредством линкера с содержащим выступ (образованным модификациями S354C и T366W) мономером Fc-домена. Содержащий выступ мономер Fc-домена содержит аминокислотную модификацию (E357K), которая обеспечивает улучшение сборки Fc-домена. Каждый из коротких полипептидов содержит мономер Fc-домена, содержащий полость (образованную с помощью модификаций Y349C/T366S/L368A/Y407V). Короткие полипептиды также содержат аминокислотную модификацию (K370D), которая обеспечивает улучшение сборки Fc-доменов. Конструкция 4 образуется путем экспрессии первого и второго полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 49, а также третьего и четвертого полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 61.
Конструкции 13-27 (фиг. 18A-18O) идентичны конструкции 4, за исключением определенных модификаций в положениях I253 и/или R292, описанных в данном документе. Конструкция 5 образуется путем экспрессии первого и второго полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 62, а также третьего и четвертого полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 61. Конструкция 6 образуется путем экспрессии первого и второго полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 64, а также третьего и четвертого полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 57. Конструкция 7 образуется путем экспрессии первого и второго полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 65, а также третьего и четвертого полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 57. Конструкция 8 образуется путем экспрессии первого и второго полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 66, а также третьего и четвертого полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 61. Конструкция 9 образуется путем экспрессии первого и второго полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 67, а также третьего и четвертого полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 61. Конструкция 10 образуется путем экспрессии первого и второго полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 68, а также третьего и четвертого полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 57. Конструкция 11 образуется путем экспрессии первого и второго полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 69, а также третьего и четвертого полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 57. Конструкция 12 образуется путем экспрессии первого и второго полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 71, а также третьего и четвертого полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 70. Конструкция 13 образуется путем экспрессии первого и второго полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 72, а также третьего и четвертого полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 70. Конструкция 14 образуется путем экспрессии первого и второго полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 74, а также третьего и четвертого полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 73. Конструкция 15 образуется путем экспрессии первого и второго полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 75, а также третьего и четвертого полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 73. Конструкция 16 образуется путем экспрессии первого и второго полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 76, а также третьего и четвертого полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 70. Конструкция 17 образуется путем экспрессии первого и второго полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 77, а также третьего и четвертого полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 70. Конструкция 18 образуется путем экспрессии первого и второго полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 78, а также третьего и четвертого полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 73. Конструкция 19 образуется путем экспрессии первого и второго полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 79, а также третьего и четвертого полипептидов, имеющих аминокислотную последовательность под SEQ ID NO: 73.
Таблица 10. Fc-конструкции, содержащие аминокислотные модификации I253 и/или R292
2 мутация I253A
Таблица 11. Аминокислотные последовательности
Пример 10. Оценка влияния аминокислотных модификаций I253A и R292P на специфичность связывания с Fc-рецептором
Анализ связывания с участием клеток использовали для подтверждения того, что аминокислотные модификации в положениях I253, например I253A, и R292, например R292P, специфичны для предполагаемых рецепторов, например, сниженная аффинность связывания с рецептором FcRn и рецептором FcγRIIb, соответственно. Относительное связывание Fc-конструкций и контролей с Fc-гамма рецепторами (FcγRs) измеряли с использованием гомогенных конкурентных анализов с участием клеток с переносом энергии флуоресцентного резонанса с временным разрешением (TR-FRET) (CISBIO®) для наборов FcγRI, FcγRIIa H131, FcγRIIb и FcγRIIIa V158. Реагенты для анализа готовили в соответствии с инструкциями производителя. С помощью автоматического манипулятора с жидкостью (Freedom EVOware 150, TECAN®) была получена серия из 3-кратных серийных разведений с 10 точками, плюс один холостой контроль на образец. Планшеты для анализа считывали на флуоресцентном ридере PHERAstar (BMG Labtech GmbH) при 665 и 620 нм. Образец IgG1 использовали в качестве контроля. На фиг.19 A-D показано, что мутации R292P в конструкции 16 и конструкции 18 резко снижают степень связывания с FcγRIIb-экспрессирующими клетками по сравнению с контролем IgG1, и в то же время оказывают минимальное влияние на связывание FcγRI, FcγRIIa и FcγRIIIa. Однако мутации I253A оказывали минимальное влияние на связывание с любым Fc-гамма-рецептором, о чем свидетельствует сходство профилей связывания конструкции 6 и конструкции 4 и сходство профилей связывания конструкции 18 и конструкции 16.
Чтобы оценить влияние аминокислотных модификаций в положении I253, например I253A и R292, например R292P, на связывание FcRn, был разработан эксперимент по изучению связывания с помощью поверхностного плазмонного резонанса (SPR) для измерения аффинности и нормализованного уровня связывания жидкофазного FcRn человека со связанными с сенсором Fc-конструкциями при рН 6,0. Антитело козы к человеческому IgG иммобилизовали на поверхностях контрольного и исследуемого сенсоров с применением химических принципов реакции иммобилизации по амину. Fc-конструкции захватывались на поверхности исследуемого сенсора. Рекомбинантный FcRn человека пропускали по поверхности сенсора в серии разведений с максимальной концентрацией 1,0 мкМ. Поверхность сенсора восстанавливали в конце каждого цикла с применением 10 мМ глицина при рН 1,7. Сенсограммы с вычитанием двух контрольных значений подвергали анализу равновесного связывания; оценивали максимальный уровень связывания (RMax) и константу равновесной диссоциации (KD). Нормализованный максимальный уровень связывания рассчитывали путем деления RMax на уровень захвата FC-конструкции. Конструкция 16 подвергалась захвату на том же уровне, что и конструкция 4, что указывало на отсутствие потери связывания с FcRn, как ожидалось (фиг. 20). Конструкция 6 и конструкция 18 показали значительно сниженные уровни захвата, что согласуется с тем, что два Fc-домена теряют аффинность к FcRn, как предполагалось (фиг. 20). Аналогично, конструкция 7 и конструкция 19, которые имели мутации во всех трех доменах для ограничения связывания FcRn, не связывались с FcRn (фиг. 20).
Вместе эти данные демонстрируют, что мутация для уменьшения связывания с FcγRIIb (например, аминокислотная модификация в положении R292, например, R292P) имела предполагаемый эффект с небольшим влиянием на связывание с другими Fc-гамма рецепторами и минимальным влиянием на связывание FcRn. Аналогично, мутация для уменьшения связывания с FcRn (например, аминокислотная модификация в положении I253, например, I253A) имела необходимый эффект с минимальным воздействием на связывание Fc-гамма рецептора. Кроме того, две мутации (например, мутации I253 и R292, такие как I253A и R292P) могут быть объединены для достижения уменьшенного связывания Fc-конструкции как с FcγRIIb, так и с FcRn.
Пример 11. Оценка влияния аминокислотных модификаций I253A и R292P на фармакокинетику Fc-рецепторов у мышей
Влияние относящихся к связыванию мутаций на фармакокинетику первоначально оценивали путем сравнения конструкции 4, конструкции 16, которые обуславливали снижение степени связывания с FcγRIIb во всех трех Fc-доменах, и конструкции 6, которая обуславливала снижение степени связывания с FcRn в двух Fc-доменах. IVIg включали в качестве образца сравнения, демонстрирующего типичное для IgG поведение. Самкам мышей C57BL/6 (n=12, 8-10 недель) вводили внутривенно (в/в) по 0,1 г/кг каждой из конструкции 4, конструкции 6, конструкции 16 или IVIg. Образцы крови (50 мкл) собирали из подкожных вен, от четырех мышей на момент времени, в чередующиеся промежутки времени 15 минут, 30 минут, 1 час, 2 часа, 4 часа, 6 часов, 8 часов, 1 день, 2 дня, 3 дня, 4 дня и 5 дней. У всех мышей кровь отбирали на 7, 9, 11, 14, 16, 21 и 23 день. Концентрации Fc-конструкции и IVIg в сыворотке определяли с помощью Fc-специфического ELISA с IgG1 человека. Как показано на фиг. 21, и Fc-конструкция 6, и Fc-конструкция 16 характеризовались более длительной персистенцией in vivo и обуславливали увеличение среднего времени удерживания (MRT) в 1,2-1,5 раза (ранее значения увеличения (например, в три-четыре раза) измеряли по площади под кривой (AUC)).
Для дальнейшего изучения влияния аминокислотной модификации I253A, обуславливающей изменение валентность в отношении FcRn, на фармакокинетику сравнивали три соединения с одним, двумя или тремя доменами с пониженной аффинностью в отношении FcRn, как описано выше. Как видно на фиг. 22, все мутанты персистировали дольше, чем исходное соединение. Среднее время удерживания (MRT) последовательно увеличивалось с каждым Fc-доменом, модифицированным для снижения аффинности к FcRn. Экспозицию лекарственного средства также можно измерять с помощью AUC.
Также изучали влияние объединения мутаций (фиг. 23). Включение мутаций в оба рецептора увеличивало MRT в три раза по сравнению с двукратным увеличением, достигнутым в этом исследовании за счет уменьшения связывания с FcγRIIb. Воздействие лекарственного средства также можно измерять с помощью AUC, например, шестикратное увеличение.
Пример 12. Оценка влияния аминокислотных модификаций I253A и R292P на эффективность in vitro
Воздействие мутаций, влияющих на связывание, на эффективность in vitro оценивали с применением анализов, для которых ранее было показано, что они являются чувствительными в отношении определения валентности в отношении Fc-гамма-рецепторов. Ингибирование фагоцитоза в клетках THP-1 было сопоставимым для всех Fc-конструкций (фиг. 24). Клетки THP-1 высевали в 96-луночные планшеты. Fc-конструкции подвергали 10-кратному серийному разбавлению и добавляли к клеткам. Инкубацию продолжали в течение 15 мин. при 37°С; затем к клеткам добавляли латексные шарики, покрытые IgG кролика, меченными с помощью FITC (Cayman Chemical). Инкубацию продолжали в течение 3 ч. при 37°С. Клетки дважды промывали и ресуспендировали в 100 мкл буфера FACS (PBS/2% FBS); для гашения сигнала FITC на клеточной поверхности добавляли трипановый синий и образцы считывали на проточном цитометре BD Canto. Данные представлены в виде процента FITC-положительных клеток по сравнению с общей популяцией клеток в отсутствие ингибитора (100% фагоцитоз).
Высвобождение IL-8 связанными с планшетами IgG-стимулированными моноцитами ингибировалось всеми Fc-конструкциями с сопоставимой эффективностью (фиг. 25). РВМС выделяли из лейкоцитарных пленок доноров, представляющих собой здоровых людей (Research Blood Components), с помощью центрифугирования в градиенте плотности на среде Ficoll-Paque Plus (GE Healthcare Life Sciences). Моноциты выделяли путем негативного отбора с применением набора для обогащения моноцитов человека без истощения CD16 (StemCell Technologies). Опосредованную FcγR выработку цитокинов стимулировали с применением 96-луночных планшетов, покрытых на ночь с помощью 50 мкл 100 мкг/мл IgG1 человека (SouthernBiotech). IVIg или каждую Fc-конструкцию подвергали серийному разведению в культуральном планшете при концентрации, в два раза превышающей конечную концентрацию в данном анализе. Добавляли очищенные моноциты (1,5×105 клеток/лунку), инкубировали в течение 24 ч. и надосадочные жидкости с культур анализировали в отношении концентрации IL-8 (специальный набор цитокинов человека для IL-8 с высокой концентрацией, Meso Scale Discovery).
Аналогично, ингибирование ADCC было сопоставимым для всех Fc-конструкций (фиг. 26). NK-клетки (Hemacare) размораживали и оставляли на ночь в среде LGM-3 (Lonza). Культивируемые клетки линии Raji инкубировали в присутствии различных концентраций каждого исследуемого соединения и ритуксимаба (2 мкг/мл) в течение 30 минут перед добавлением NK-клеток при соотношении эффектор:клетка-мишень 50K:10K. Клетки NK и клетки линии Raji также высевали в присутствии отдельно зондов. Клетки инкубировали в течение 6 часов. В качестве средства для считывания показаний применяли Cytotox-Glo.
Во всех анализах мутации вызывали пренебрежимо малое снижение эффективности.
Пример 13. Оценка влияния аминокислотных модификаций I253A и R292P на эффективность in vivo
Для дальнейшей оценки воздействия мутаций, влияющих на связывание с рецептором, на активность Fc-конструкции исследовали in vivo с применением модели артрита, индуцированного антителами к коллагену (CAIA). Самцам мышей C57BL/6 вводили внутрибрюшинно коктейль артритогенных моноклональных антител, состоящий из четырех антител к коллагену II (ArthritoMab, MDBiosciences; 8 мг). В день 4 животным вводили в/б липополисахарид (100 мкг). При введении доз с целью лечения в день 6 животных рандомизировали на основании тяжести заболевания с получением исследуемых групп, при этом исключали животных с плохой индукцией заболевания (оценка 0 в день рандомизации), и вводили в/в носитель или исследуемое вещество. При введении доз с целью профилактики животным вводили в/в дозу носителя или исследуемого соединения один раз, в день в промежутке времени от дня 1 до дня 14 (дни были пронумерованы без нулевого). Клиническая балльная оценка параметров была следующей: 0 = нормальный, нет отеков, покраснений или деформации; полная гибкость суставов. 1 = легкий артрит: легкая припухлость и/или деформация; полная гибкость суставов. 2 = умеренный артрит: умеренный отек и/или деформация; уменьшенная гибкость сустава или сила захвата. 3 = тяжелый артрит: сильный отек и/или деформация; сильно сниженная гибкость сустава или сила захвата. 4 = анкилозированные суставы; нет гибкости суставов и сильно нарушенные движения; терминальный период. Животных умерщвляли через 12 дней.
Как показано на фиг. 27, уменьшение связывания с FcγRIIb (конструкция 16), FcRn (конструкция 6) или обоими (конструкция 18) оказывало минимальное влияние на эффективность по сравнению с исходной молекулой (конструкция 4).
Пример 14. Оценка влияния аминокислотных модификаций I253A и R292P на продолжительность ответа in vivo
В случае модели CAIA мышей подвергали профилактической обработке в течение не более чем 14 дней до инъекции артритогенных антител. Как видно на фиг. 28, профилактическая обработка в день 1 была более эффективной при применении Q1 с более медленным выведением (конструкция 18), чем при применении конструкции 4, вероятно из-за большего периода воздействия лекарственного средства в течение всей многодневной индукции заболевания. Соединение конструкции 4 теряет эффективность при введении дозы за 3 дня до индукции заболевания (фиг. 29), тогда как Q1 (конструкция 18) обеспечивает защиту даже при введении дозы за 7 дней до индукции заболевания (фиг. 30). Обе конструкции были неэффективны при введении доз за 10 дней до индукции заболевания (фиг. 31). Эти результаты показывают, что в случае фармакокинетического профиля конструкции 18, охватывающего более продолжительный период времени, по сравнению с конструкцией 4 обеспечивается большая стойкость ответа.
Введение доз с целью профилактики в модели CAIA проводили с применением 100 мг/кг конструкции 4 (исходная молекула), конструкции 18 (I253A в двух доменах и R292P в трех доменах) (Q1) или конструкции 19 (I253A и R292P во всех трех доменах) (Q2) в день 1 (фиг. 32), день 3 (фиг. 33), день 7 (фиг. 34) или день 10 (фиг. 35). Контроль носителя (физиологический раствор) вводили только в день 1.
На фиг. 32 представлен график сравнения эффективности конструкции 4 (AA: черные квадраты, сплошная линия), конструкции 18 (Q1: черные треугольники, штриховая линия), конструкции 19 (Q2: черные ромбы, точечная линия) или физиологического раствора (серые круги, штрихпунктирная линия) в дозе 100 мг/кг в день 1 на модели артрита, индуцированного антителами к коллагену (CAIA). На фиг. 33 представлен график сравнения конструкции 4 (AA: черные квадраты, сплошная линия), конструкции 18 (Q1: черные треугольники, штриховая линия) или конструкции 19 (Q2: черные ромбы, точечная линия), которые вводили в дозе 100 мг/ кг в день 3. На фиг. 34 представлен график сравнения конструкции 4 (AA: черные квадраты, сплошная линия), конструкции 18 (Q1: черные треугольники, штриховая линия) или конструкции 19 (Q2: черные ромбы, точечная линия), которые вводили в дозе 100 мг/ кг в день 7. На фиг. 35 представлен график сравнения конструкции 4 (AA: черные квадраты, сплошная линия), конструкции 18 (Q1: черные треугольники, штриховая линия) или конструкции 19 (Q2: черные ромбы, точечная линия), которые вводили в дозе 100 мг/ кг в день 10. В каждом случае эквивалентный объем физиологического раствора (серые круги, штрихпунктирная линия) вводили в день 1. Среднее значение и стандартная ошибка среднего значения показаны для каждого момента времени.
Пример 15. Оценка влияния аминокислотных модификаций I253A и R292P на Fc-мультимеры
Fc-мультимеры получали как описано в (Strome et al, US 2010/0239633 A1; Jain et al, Arthritis Res. Ther. 14, R192 (2012)). В частности, Fc IgG1 сливали на С-конце с шарнирной последовательностью IgG2. ДНК-конструкции получали с применением последовательности Fc IgG1 дикого типа (конструкция X1) и с применением двойного мутанта I253A/R292P (конструкция X2). Конструкции на основе плазмидной ДНК трансфицировали посредством липосом в клетки линии HEK293. После семи дней культивирования клетки очищали посредством центрифугирования.
Экспрессированные белки очищали от надосадочной жидкости с клеточной культуры с помощью аффинной колоночной хроматографии на основе связывания с белком A с применением колонки Poros MabCapture A. Захваченные конструкции промывали фосфатно-солевым буфером (промывка с низким содержанием соли) и элюировали с применением 100 мМ глицина, рН 3. Элюат быстро нейтрализовали путем добавления 1 М TRIS pH 7,4 и фильтровали в стерильных условиях через 0,2 мкм фильтр.
Далее белки фракционировали с помощью ионообменной хроматографии с применением смолы Poros XS. Колонку предварительно уравновешивали с помощью 50 мМ MES, pH 6 (буфер A) и образец разбавляли в уравновешивающем буфере перед загрузкой. Образец элюировали с применением многоступенчатого градиента с 50 мМ MES, 400 мМ хлорида натрия, pH 6 (буфер B) в качестве буфера для элюирования. Стадии градиента включали изменение концентрации В от 0 до 40% в течение прогона 2 объемов колонки (CV) для удаления низкомолекулярных частиц, стадию выдерживания при 40% B (4 CV), затем изменение концентрации В от 40 до 80% (4 CV) для выделения целевых молекул и затем линейное увеличение до 100% В. Все белоксодержащие фракции подвергали скринингу с помощью аналитической эксклюзионной хроматографии и осуществляли количественное определение компонентов по поглощению при 280 нм. Фракции с общим содержанием Fc (приблизительно 50 кДа) вместе с Fc-димерами (приблизительно 100 кДа), составляющим более 8%, исключали. В случае конструкции X1 все оставшиеся фракции объединяли. Из-за сдвига в распределении молекулярной массы между конструкциями X1 и X2 фракции конструкции X2 выбрали для имитации распределения молекулярной массы конструкции X1.
После проведения ионного обмена буфер целевой фракции заменяли на PBS-буфер с применением полиэфирсульфонового (PES) мембранного картриджа с границей отсечки 30 кДа на системе тангенциальной поточной фильтрации. Образцы концентрировали до приблизительно 30 мг/мл и фильтровали в стерильных условиях через 0,2 мкм фильтр.
Значения распределения молекулярных масс для конструкции 4 и конструкции X1 сравнивали с помощью аналитической эксклюзионной хроматографии (фиг. 36) (очищенные конструкции X1 (серый) и X2 (черный), нормализованные по максимумам пиков) и электрофореза в полиакриламидном геле в присутствии додецилсульфата натрия (фигура 37) (очищенная конструкция X1 (справа), очищенная конструкция X2 (в центре) и стандарты молекулярной массы (справа). Загружали равные массы двух конструкций). Конструкции X1 и X2 состоят из разных молекул в диапазоне от ~ 100 кДа (два Fc-доменами), при этом большое количество пятен находятся выше значения 250 кДа, и при этом ни один из компонентов не является преобладающим. Распределение по размерам для конструкции X2 аналогично таковому для конструкции X1, но немного шире с большим количеством компонентов как с самой высокой, так и с самой низкой молекулярной массой.
Самкам мышей C57BL/6 (n=15, 8 недель) вводили внутривенно (в/в) по 0,1 г/кг каждой из конструкции X1 или конструкции 4. Кровь (25 мкл) собирали из подчелюстной вены и обрабатывали для получения сыворотки. У пяти мышей из каждой группы кровь отбирали в разные моменты времени в течение дня 5, тогда как во всех остальных моментах времени кровь отбирали у всех пятнадцати мышей в каждой группе. Моменты времени, в которые осуществляли отбор, включали 15 и 30 минут; 1, 2, 4, 6, 8, 24 ч.; 2 дня. Концентрации Fc-мультимеров в сыворотке определяли с помощью ELISA на основе антител к IgG человека с помощью идентифицирующего антитела, специфического к Fc.
Как показано на фиг. 38, в каждый момент времени уровни содержания конструкции X1 в сыворотке ниже, чем уровни содержания конструкции X2. Введение мутаций I253A и R292P в конструкцию X2 задерживало клиренс Fc-мультимеров по сравнению с соответствующим материалом дикого типа (конструкция X1).
Пример 16. Оценка влияния аминокислотных модификаций I253A и R292P на фармакокинетику Fc-рецепторов у макак-крабоедов
Влияние относящихся к связыванию мутаций на фармакокинетику у макак-крабоедов оценивали путем сравнения конструкций 6, 16 и 18. Данные за прошлые периоды для конструкции 4 получены из исследования на макаках-крабоедах, выполненного при различных уровнях дозы, в отличие от исследования, посредством которого проводили сравнение конструкции 6, 16 и 18. Самцам макак-крабоедов (N=3) вводили в/в по 10 или 30 мг/кг каждой из конструкций 6, 16 и 18. Образцы крови собирали в течение 44 дней. Концентрации Fc-конструкции определяли с помощью ELISA с применением антител, специфичных к Fc-конструкциям на основе IgG1 человека, в том числе конструкциям 4, 6, 16 и 18.
Как показано на фиг. 39, конструкция 16, которую вводили в дозе 10 мг/кг, дольше персистирует in vivo, чем конструкция 4, которую вводили в дозе 20 мг/кг. Конструкция 18, которую вводили в дозе 10 мг/кг, характеризуется такой же персистенцией in vivo, что и конструкция 4, которую вводили в дозе 20 мг/кг. Конструкция 6, которую вводили в дозе 10 мг/кг, не персистирует так долго, как конструкция 4, которую вводили в дозе 20 мг/кг.
Как показано на фиг. 40, конструкция 16, которую вводили в дозе 30 мг/кг, персистирует in vivo дольше, чем конструкция 4, которую вводили в дозе 20 или 50 мг/кг. Значение персистенции конструкции 18, которую вводили в дозе 30 мг/кг, является промежуточным между значением персистенции конструкции 4, которую вводили в дозе 20 или 50 мг/кг. Конструкция 6, которую вводили в дозе 30 мг/кг, не персистирует in vivo так долго, как конструкция 4, которую вводили в дозе 20 или 50 мг/кг.
Примечательно, что фармакокинетические свойства в случае макак-крабоедов отличаются от таковых в случае мышей. У мышей уменьшение связывания как FcRn, так и Fc-гамма-RIIb, приводило к увеличению персистенции, а комбинация обоих приводила к дальнейшему увеличению персистенции. У макак-крабоедов уменьшение в отношении FcRn приводило к снижению персистенции, уменьшение в отношении Fc-гамма-RIIb приводило к увеличению персистенции, а их комбинация обеспечивала небольшое суммарное изменение персистенции по сравнению с исходной молекулой (конструкция 4).
Другие варианты осуществления
Все публикации, патенты и заявки на патенты, упоминаемые В настоящем изобретении, включены в данный документ посредством ссылки в такой же степени, как если бы каждая отдельная публикация или заявка на патент была конкретно и отдельно указана как включенная посредством ссылки.
Несмотря на то, что настоящее изобретение было описано в связи с конкретными вариантами его осуществления, будет понятно, что существует возможность дополнительных изменений, и предполагается, что данная заявка охватывает любые варианты, применения или адаптации настоящего раскрытия, следующие, в целом, идеям настоящего раскрытия и включающие такие отступления от настоящего раскрытия, которые относятся к известной или обычной практике в пределах области техники, к которой принадлежит настоящее изобретение, и которые можно применять по отношению к основным признакам, изложенным в данном документе выше.
Другие варианты осуществления находятся в пределах формулы изобретения.
--->
ПЕРЕЧЕНЬ ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> Момента Фармасьютикалс, Инк.
<120> КОМПОЗИЦИИ И СПОСОБЫ, СВЯЗАННЫЕ СО СКОНСТРУИРОВАННЫМИ
Fc-КОНСТРУКЦИЯМИ
<130> 14131-0150WO1
<150> US 62/589,473
<151> 2017-11-21
<150> US 62/510,228
<151> 2017-05-23
<150> US 62/443,495
<151> 2017-01-06
<160> 80
<170> PatentIn версия 3.5
<210> 1
<211> 5
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 1
Gly Gly Gly Gly Ser
1 5
<210> 2
<211> 4
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 2
Gly Gly Ser Gly
1
<210> 3
<211> 4
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 3
Ser Gly Gly Gly
1
<210> 4
<211> 4
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 4
Gly Ser Gly Ser
1
<210> 5
<211> 6
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 5
Gly Ser Gly Ser Gly Ser
1 5
<210> 6
<211> 8
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 6
Gly Ser Gly Ser Gly Ser Gly Ser
1 5
<210> 7
<211> 10
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 7
Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser
1 5 10
<210> 8
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 8
Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser Gly Ser
1 5 10
<210> 9
<211> 6
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 9
Gly Gly Ser Gly Gly Ser
1 5
<210> 10
<211> 9
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 10
Gly Gly Ser Gly Gly Ser Gly Gly Ser
1 5
<210> 11
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 11
Gly Gly Ser Gly Gly Ser Gly Gly Ser Gly Gly Ser
1 5 10
<210> 12
<211> 8
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 12
Gly Gly Ser Gly Gly Gly Ser Gly
1 5
<210> 13
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 13
Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly
1 5 10
<210> 14
<211> 16
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 14
Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly
1 5 10 15
<210> 15
<211> 20
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 15
Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Ser Gly
20
<210> 16
<211> 10
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 16
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10
<210> 17
<211> 15
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 17
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 18
<211> 20
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 18
Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly
1 5 10 15
Ser Gly Gly Gly
20
<210> 19
<211> 4
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 19
Gly Gly Gly Gly
1
<210> 20
<211> 8
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 20
Gly Gly Gly Gly Gly Gly Gly Gly
1 5
<210> 21
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 21
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10
<210> 22
<211> 16
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 22
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
<210> 23
<211> 20
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 23
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Gly
20
<210> 24
<211> 5
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 24
Gly Gly Gly Gly Gly
1 5
<210> 25
<211> 10
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 25
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10
<210> 26
<211> 15
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 26
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
<210> 27
<211> 20
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 27
Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Gly Gly Gly
20
<210> 28
<211> 10
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 28
Gly Glu Asn Leu Tyr Phe Gln Ser Gly Gly
1 5 10
<210> 29
<211> 8
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 29
Ser Ala Cys Tyr Cys Glu Leu Ser
1 5
<210> 30
<211> 5
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 30
Arg Ser Ile Ala Thr
1 5
<210> 31
<211> 17
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 31
Arg Pro Ala Cys Lys Ile Pro Asn Asp Leu Lys Gln Lys Val Met Asn
1 5 10 15
His
<210> 32
<211> 36
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 32
Gly Gly Ser Ala Gly Gly Ser Gly Ser Gly Ser Ser Gly Gly Ser Ser
1 5 10 15
Gly Ala Ser Gly Thr Gly Thr Ala Gly Gly Thr Gly Ser Gly Ser Gly
20 25 30
Thr Gly Ser Gly
35
<210> 33
<211> 17
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 33
Ala Ala Ala Asn Ser Ser Ile Asp Leu Ile Ser Val Pro Val Asp Ser
1 5 10 15
Arg
<210> 34
<211> 36
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 34
Gly Gly Ser Gly Gly Gly Ser Glu Gly Gly Gly Ser Glu Gly Gly Gly
1 5 10 15
Ser Glu Gly Gly Gly Ser Glu Gly Gly Gly Ser Glu Gly Gly Gly Ser
20 25 30
Gly Gly Gly Ser
35
<210> 35
<211> 12
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 35
Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser
1 5 10
<210> 36
<211> 18
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 36
Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly
1 5 10 15
Gly Ser
<210> 37
<211> 11
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Альбумин-связывающий пептид
<400> 37
Asp Ile Cys Leu Pro Arg Trp Gly Cys Leu Trp
1 5 10
<210> 38
<211> 6
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Пептид гексагистидин
<400> 38
His His His His His His
1 5
<210> 39
<211> 8
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Пептид FLAG
<400> 39
Asp Tyr Lys Asp Asp Asp Asp Lys
1 5
<210> 40
<211> 10
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Пептид Myc
<400> 40
Glu Gln Lys Leu Ile Ser Glu Glu Asp Leu
1 5 10
<210> 41
<211> 9
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Пептид HA
<400> 41
Tyr Pro Tyr Asp Val Pro Asp Tyr Ala
1 5
<210> 42
<211> 227
<212> БЕЛОК
<213> Homo sapiens
<400> 42
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys
225
<210> 43
<211> 474
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинноцепочечный полипептид
<400> 43
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser
225 230 235 240
Gly Gly Gly Ser Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
465 470
<210> 44
<211> 227
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мономер Fc-домена, короткоцепочечный полипептид
<400> 44
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Cys Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Ser Cys Ala Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Val Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys
225
<210> 45
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинноцепочечный полипептид
<400> 45
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser
225 230 235 240
Gly Gly Gly Ser Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 46
<211> 226
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мономер Fc-домена, короткоцепочечный полипептид
<400> 46
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Cys Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Ser Cys Ala Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Val Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly
225
<210> 47
<211> 468
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинноцепочечный полипептид
<400> 47
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
245 250 255
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
260 265 270
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
275 280 285
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
290 295 300
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
305 310 315 320
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
325 330 335
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
340 345 350
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
355 360 365
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
370 375 380
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
385 390 395 400
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
405 410 415
Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe Leu Tyr Ser Asp Leu
420 425 430
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
435 440 445
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
450 455 460
Leu Ser Pro Gly
465
<210> 48
<211> 226
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мономер Fc-домена, короткоцепочечный полипептид
<400> 48
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Cys Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Ser Cys Ala Val Asp Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Val Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly
225
<210> 49
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинный полипептид, конструкция 4/AA
<400> 49
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 50
<211> 227
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мономер Fc-домена, короткоцепочечный полипептид
<400> 50
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys
225
<210> 51
<211> 227
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мономер Fc-домена, короткоцепочечный полипептид
<400> 51
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Lys Ser Asp Gly Ser Phe Phe Leu Tyr Ser Asp Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys
225
<210> 52
<211> 225
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мономер Fc-домена, короткоцепочечный полипептид
<400> 52
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Lys Ser Asp Gly Ser Phe Phe Leu Tyr Ser Asp Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro
225
<210> 53
<211> 227
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Мономер Fc-домена, короткоцепочечный полипептид
<400> 53
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys
225
<210> 54
<211> 474
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Fc-конструкция длинного полипептида с N-концевой заменой Asp
на Gln
<400> 54
Gln Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser
225 230 235 240
Gly Gly Gly Ser Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly Lys
465 470
<210> 55
<211> 227
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Fc-конструкция короткого полипептида с N-концевой заменой Asp
на Gln
<400> 55
Gln Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Cys Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Ser Cys Ala Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Val Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys
225
<210> 56
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Fc-конструкция длинного полипептида с N-концевой заменой Asp
на Gln
<400> 56
Gln Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser
225 230 235 240
Gly Gly Gly Ser Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 57
<211> 226
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Fc-конструкция короткого полипептида с N-концевой заменой Asp
на Gln
<400> 57
Gln Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Cys Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Ser Cys Ala Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Val Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly
225
<210> 58
<211> 468
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Fc-конструкция длинного полипептида с N-концевой заменой Asp
на Gln
<400> 58
Gln Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu
245 250 255
Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr
260 265 270
Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val
275 280 285
Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val
290 295 300
Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser
305 310 315 320
Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu
325 330 335
Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala
340 345 350
Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro
355 360 365
Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln
370 375 380
Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala
385 390 395 400
Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr
405 410 415
Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe Leu Tyr Ser Asp Leu
420 425 430
Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser
435 440 445
Val Met His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser
450 455 460
Leu Ser Pro Gly
465
<210> 59
<211> 226
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Fc-конструкция короткого полипептида с N-концевой заменой Asp
на Gln
<400> 59
Gln Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Cys Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Ser Cys Ala Val Asp Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Val Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly
225
<210> 60
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Fc-конструкция длинного полипептида с N-концевой заменой Asp
на Gln
<400> 60
Gln Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 61
<211> 226
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Короткий полипептид
<400> 61
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Cys Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Ser Cys Ala Val Asp Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Val Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly
225
<210> 62
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинный полипептид
<400> 62
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ala Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 63
<211> 226
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Короткий полипетид, конструкция 6/A1
<400> 63
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ala Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Cys Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Ser Cys Ala Val Asp Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Val Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly
225
<210> 64
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинный пептид, конструкция 6/A1
<400> 64
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ala Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 65
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинный полипептид
<400> 65
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ala Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ala Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 66
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинный полипептид
<400> 66
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Pro Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 67
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинный полипептид
<400> 67
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ala Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Pro Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 68
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинный белок
<400> 68
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ala Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Pro Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 69
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинный полипептид
<400> 69
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ala Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Arg Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ala Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Pro Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 70
<211> 226
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Короткий полипептид, конструкция 16/CC
<400> 70
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Pro Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Cys Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Ser Cys Ala Val Asp Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Val Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly
225
<210> 71
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинный белок
<400> 71
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Pro Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 72
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинный белок
<400> 72
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Pro Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ala Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 73
<211> 226
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Короткий полипептид, конструкция 18/Q1
<400> 73
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ala Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Pro Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Cys Thr Leu Pro Pro Ser Arg Asp Glu Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Ser Cys Ala Val Asp Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Val Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly
225
<210> 74
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинный полипептид
<400> 74
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ala Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Pro Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 75
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинный полипептид
<400> 75
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ala Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Pro Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ala Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Arg Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 76
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинный полипептид
<400> 76
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Pro Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Pro Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 77
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинный полипептид
<400> 77
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ile Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Pro Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ala Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Pro Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 78
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинный полипептид Конструкция 18/Q1
<400> 78
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ala Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Pro Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ile Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Pro Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 79
<211> 473
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Длинный полипептид конструкция 19/Q2
<400> 79
Asp Lys Thr His Thr Cys Pro Pro Cys Pro Ala Pro Glu Leu Leu Gly
1 5 10 15
Gly Pro Ser Val Phe Leu Phe Pro Pro Lys Pro Lys Asp Thr Leu Met
20 25 30
Ala Ser Arg Thr Pro Glu Val Thr Cys Val Val Val Asp Val Ser His
35 40 45
Glu Asp Pro Glu Val Lys Phe Asn Trp Tyr Val Asp Gly Val Glu Val
50 55 60
His Asn Ala Lys Thr Lys Pro Pro Glu Glu Gln Tyr Asn Ser Thr Tyr
65 70 75 80
Arg Val Val Ser Val Leu Thr Val Leu His Gln Asp Trp Leu Asn Gly
85 90 95
Lys Glu Tyr Lys Cys Lys Val Ser Asn Lys Ala Leu Pro Ala Pro Ile
100 105 110
Glu Lys Thr Ile Ser Lys Ala Lys Gly Gln Pro Arg Glu Pro Gln Val
115 120 125
Tyr Thr Leu Pro Pro Cys Arg Asp Lys Leu Thr Lys Asn Gln Val Ser
130 135 140
Leu Trp Cys Leu Val Lys Gly Phe Tyr Pro Ser Asp Ile Ala Val Glu
145 150 155 160
Trp Glu Ser Asn Gly Gln Pro Glu Asn Asn Tyr Lys Thr Thr Pro Pro
165 170 175
Val Leu Asp Ser Asp Gly Ser Phe Phe Leu Tyr Ser Lys Leu Thr Val
180 185 190
Asp Lys Ser Arg Trp Gln Gln Gly Asn Val Phe Ser Cys Ser Val Met
195 200 205
His Glu Ala Leu His Asn His Tyr Thr Gln Lys Ser Leu Ser Leu Ser
210 215 220
Pro Gly Lys Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly Gly
225 230 235 240
Gly Gly Gly Gly Gly Gly Gly Asp Lys Thr His Thr Cys Pro Pro Cys
245 250 255
Pro Ala Pro Glu Leu Leu Gly Gly Pro Ser Val Phe Leu Phe Pro Pro
260 265 270
Lys Pro Lys Asp Thr Leu Met Ala Ser Arg Thr Pro Glu Val Thr Cys
275 280 285
Val Val Val Asp Val Ser His Glu Asp Pro Glu Val Lys Phe Asn Trp
290 295 300
Tyr Val Asp Gly Val Glu Val His Asn Ala Lys Thr Lys Pro Pro Glu
305 310 315 320
Glu Gln Tyr Asn Ser Thr Tyr Arg Val Val Ser Val Leu Thr Val Leu
325 330 335
His Gln Asp Trp Leu Asn Gly Lys Glu Tyr Lys Cys Lys Val Ser Asn
340 345 350
Lys Ala Leu Pro Ala Pro Ile Glu Lys Thr Ile Ser Lys Ala Lys Gly
355 360 365
Gln Pro Arg Glu Pro Gln Val Tyr Thr Leu Pro Pro Ser Arg Asp Glu
370 375 380
Leu Thr Lys Asn Gln Val Ser Leu Thr Cys Leu Val Lys Gly Phe Tyr
385 390 395 400
Pro Ser Asp Ile Ala Val Glu Trp Glu Ser Asn Gly Gln Pro Glu Asn
405 410 415
Asn Tyr Lys Thr Thr Pro Pro Val Leu Lys Ser Asp Gly Ser Phe Phe
420 425 430
Leu Tyr Ser Asp Leu Thr Val Asp Lys Ser Arg Trp Gln Gln Gly Asn
435 440 445
Val Phe Ser Cys Ser Val Met His Glu Ala Leu His Asn His Tyr Thr
450 455 460
Gln Lys Ser Leu Ser Leu Ser Pro Gly
465 470
<210> 80
<211> 32
<212> БЕЛОК
<213> Искусственная последовательность
<220>
<223> Линкерная последовательность
<400> 80
Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Ser Gly Gly Gly Gly Gly
1 5 10 15
Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
20 25 30
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| КОНСТРУКЦИИ, ИМЕЮЩИЕ SIRP-АЛЬФА ДОМЕН ИЛИ ЕГО ВАРИАНТ | 2016 |
|
RU2740672C2 |
| Гетеродимерные слитые белки ИЛ-15/ИЛ-15Рα - Fc и их применение | 2019 |
|
RU2827796C2 |
| АНТИТЕЛА ПРОТИВ СИГНАЛ-РЕГУЛЯТОРНОГО БЕЛКА АЛЬФА И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2017 |
|
RU2771964C2 |
| СЛИТЫЕ СЕРПИНОВЫЕ ПОЛИПЕПТИДЫ И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2019 |
|
RU2728861C1 |
| СЛИТЫЕ СЕРПИНОВЫЕ ПОЛИПЕПТИДЫ И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2015 |
|
RU2746550C2 |
| АНТАГОНИСТЫ NGF ДЛЯ МЕДИЦИНСКОГО ИСПОЛЬЗОВАНИЯ | 2020 |
|
RU2829812C2 |
| СЛИТЫЕ СЕРПИНОВЫЕ ПОЛИПЕПТИДЫ И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2012 |
|
RU2698655C2 |
| БИСПЕЦИФИЧЕСКИЕ 2+1 КОНТОРСТЕЛА | 2018 |
|
RU2797305C2 |
| КОНСТРУКЦИИ СЛИТОГО БЕЛКА ДЛЯ ЗАБОЛЕВАНИЯ, СВЯЗАННОГО С КОМПЛЕМЕНТОМ | 2019 |
|
RU2824402C2 |
| Новые гибридные ActRIIB белки-ловушки лигандов для лечения заболеваний, связанных с мышечной атрофией | 2016 |
|
RU2834707C1 |
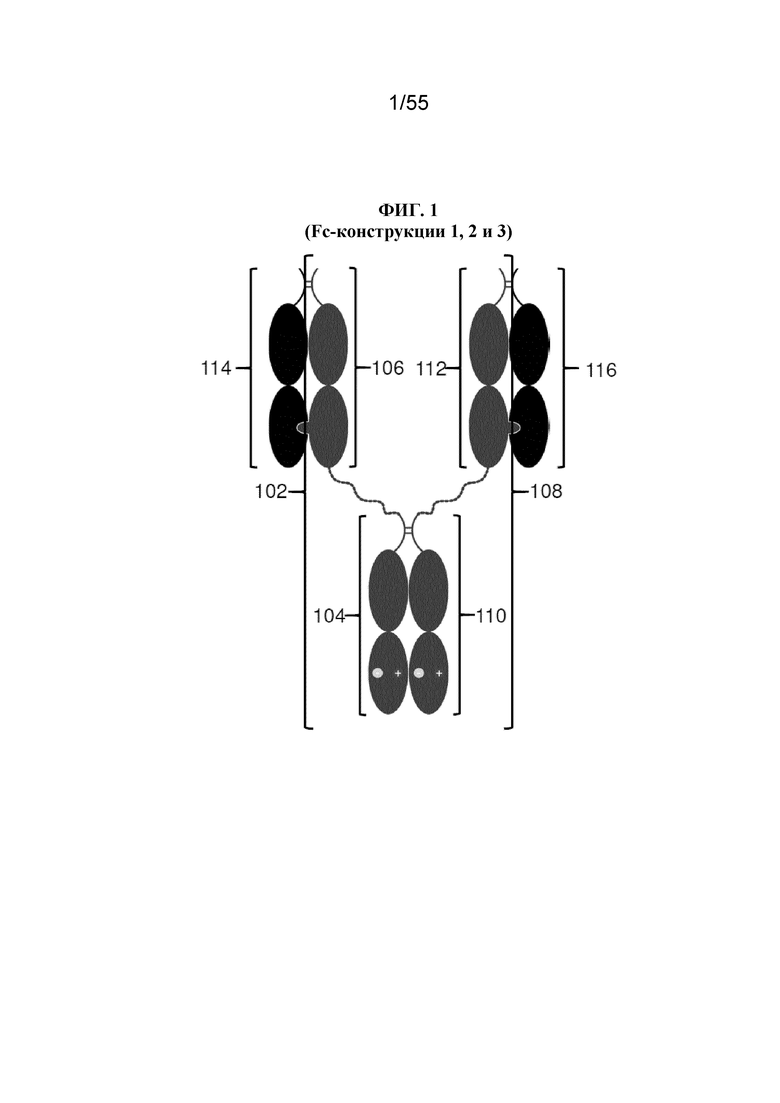
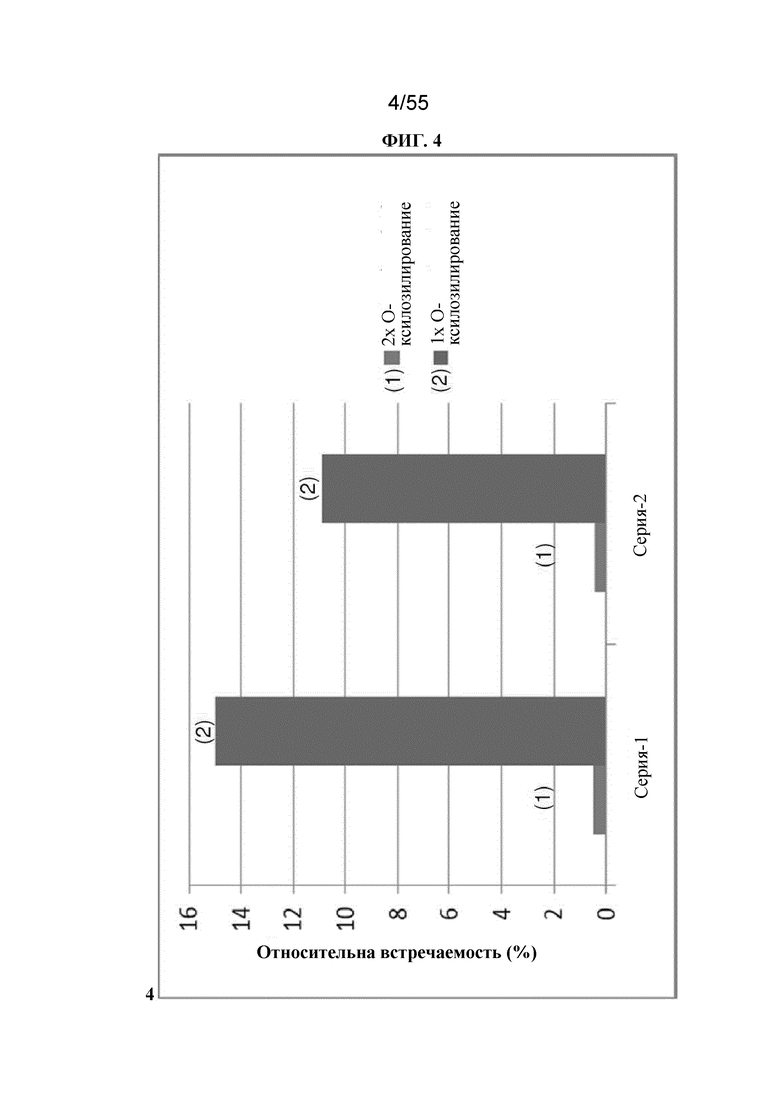
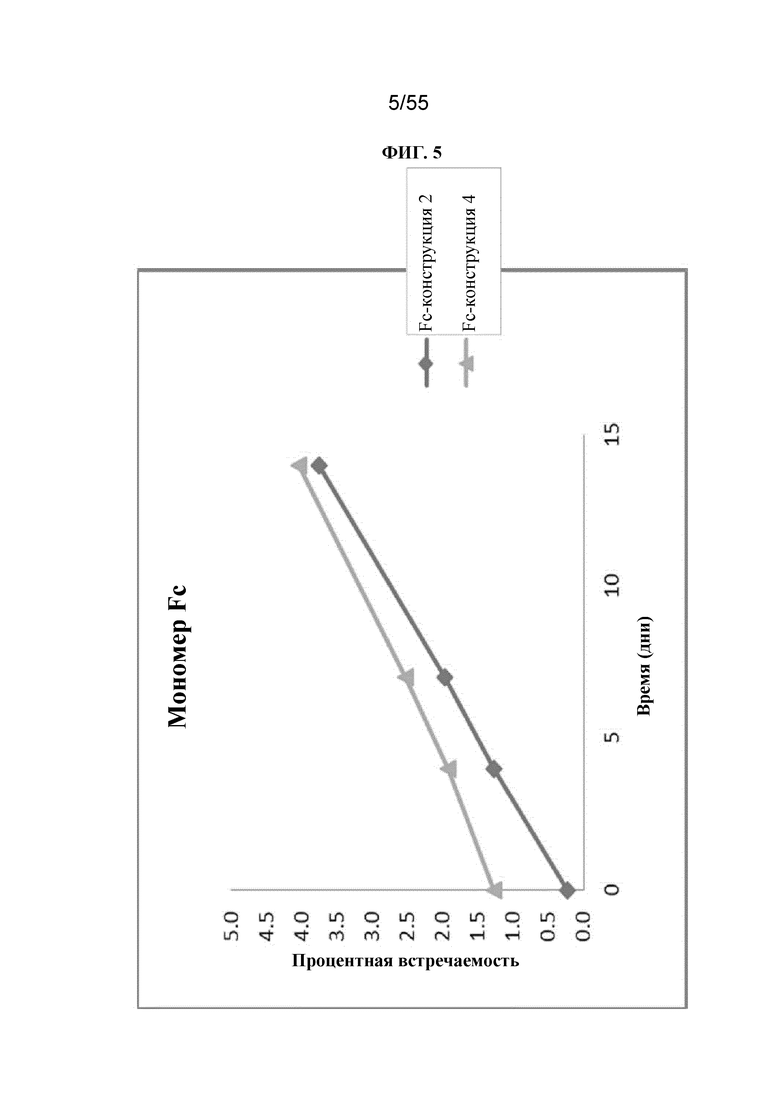
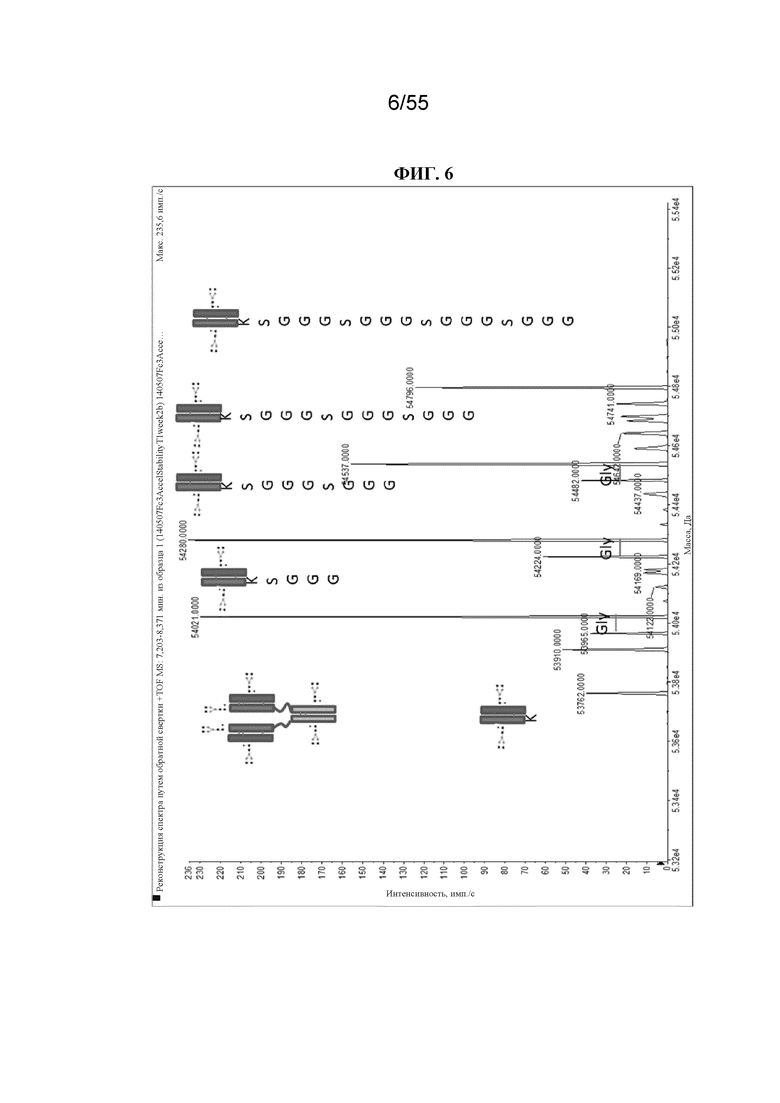
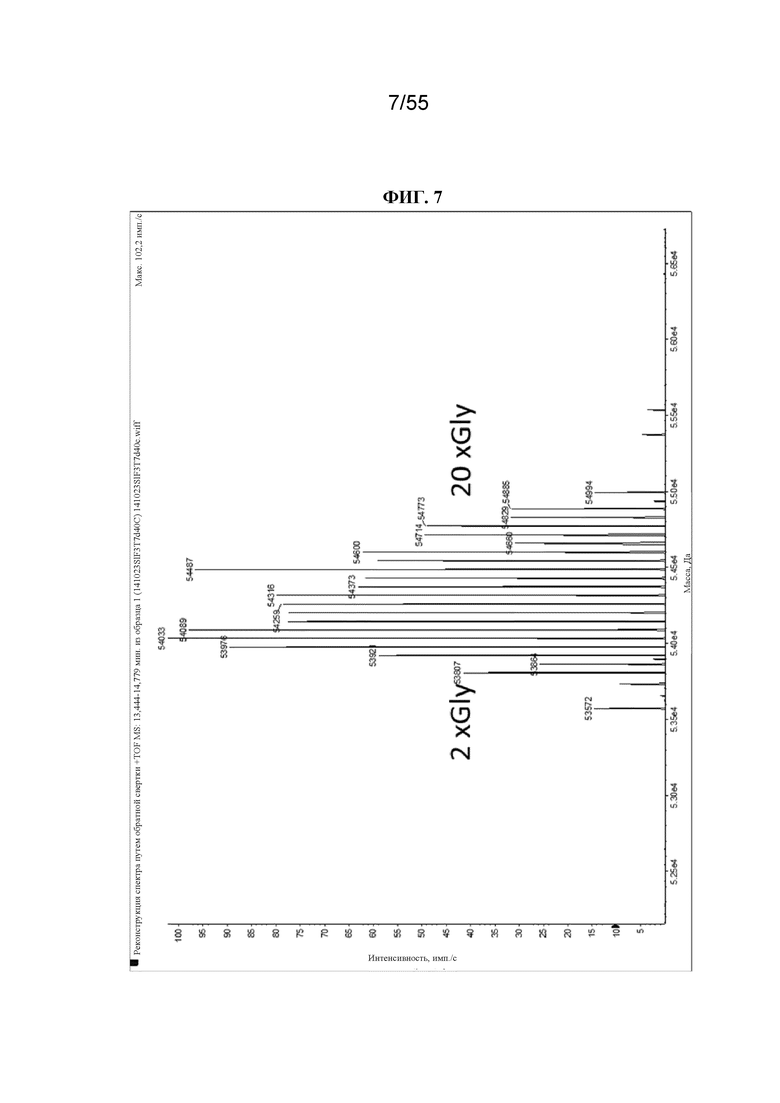
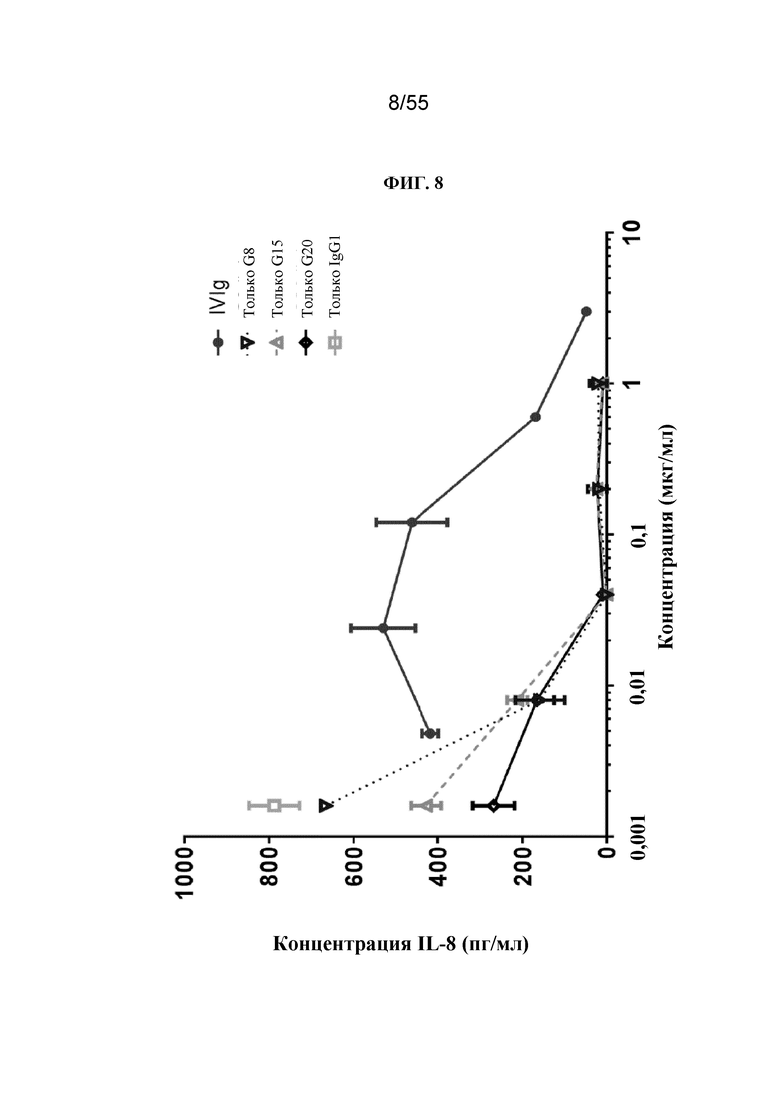
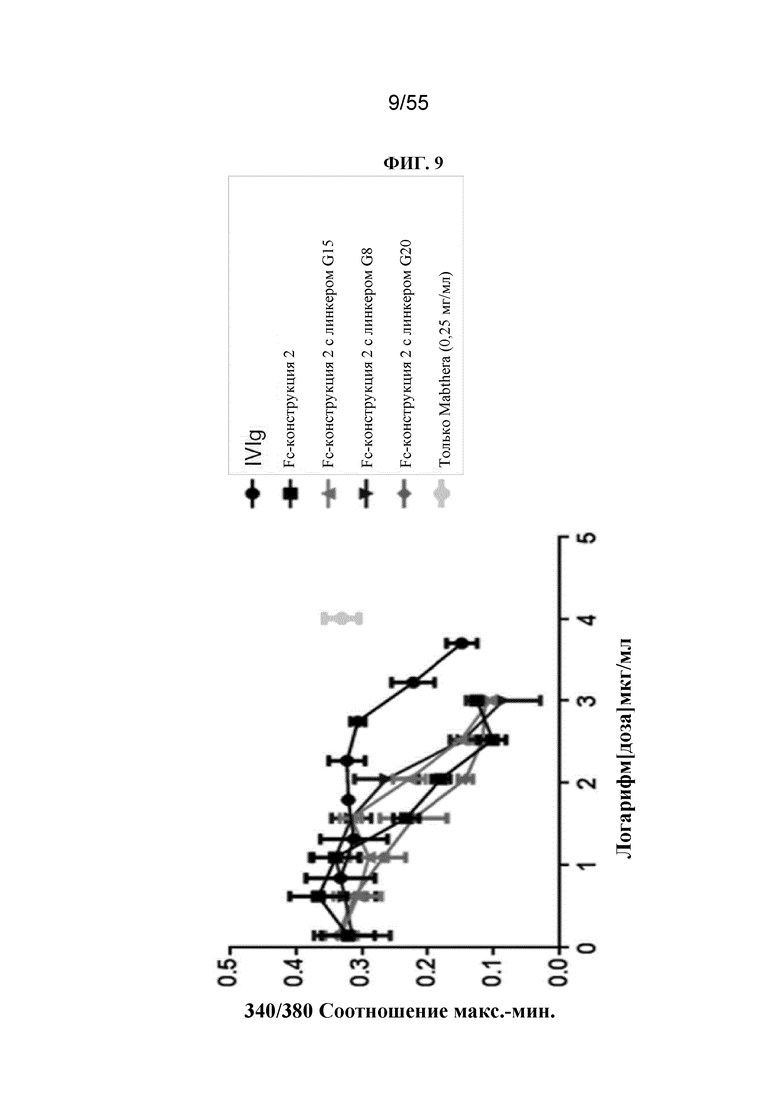
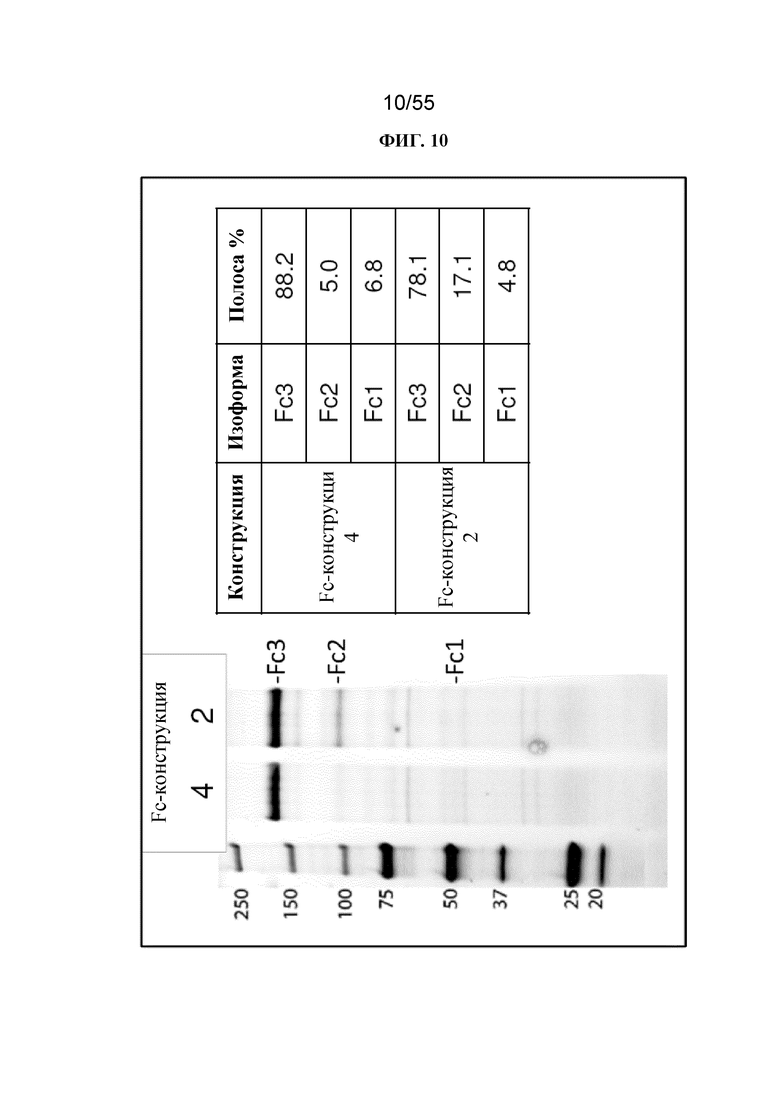
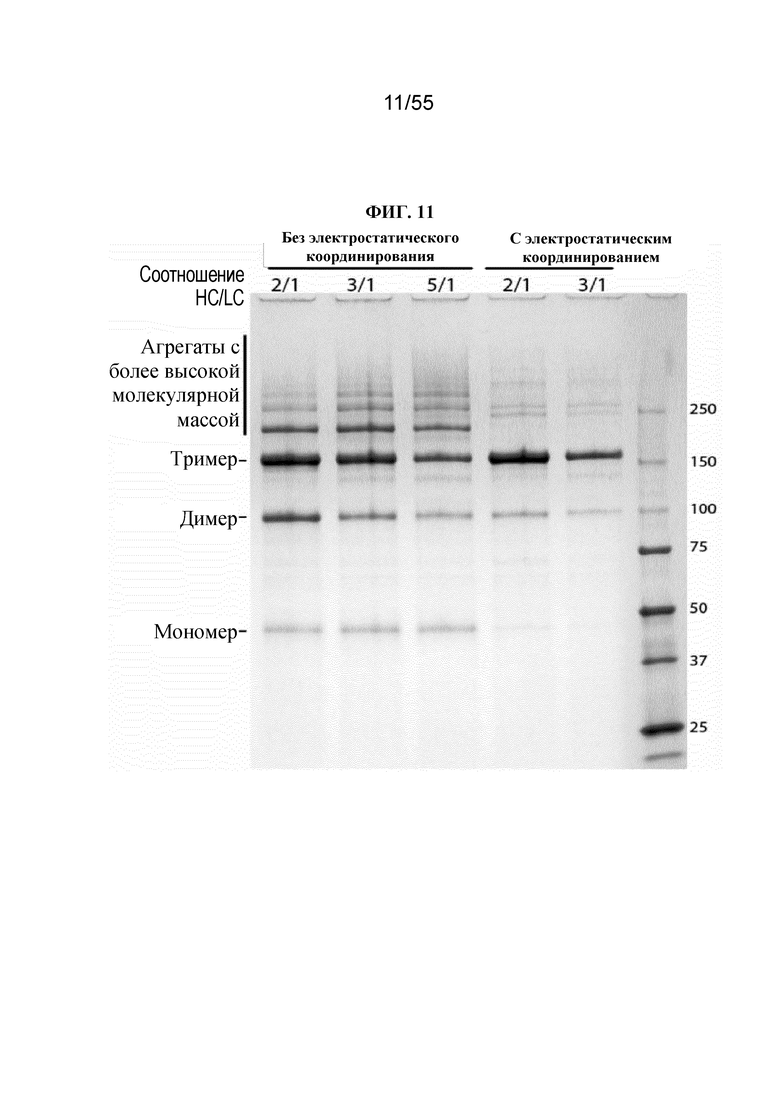
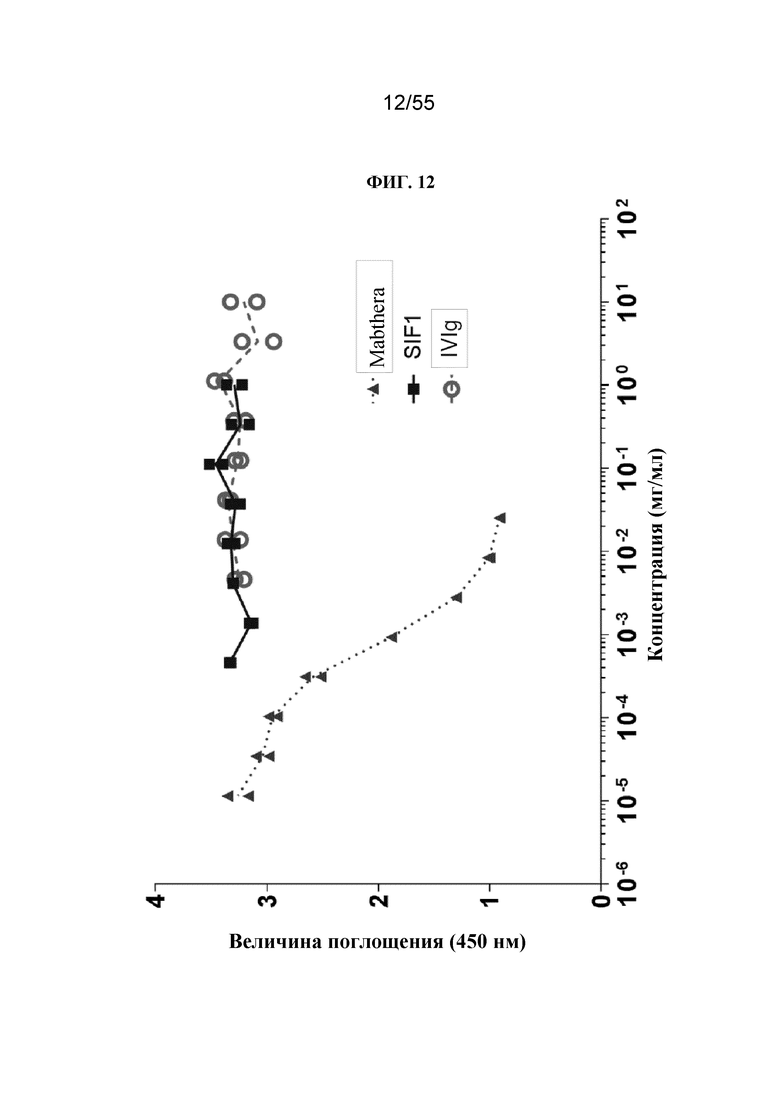
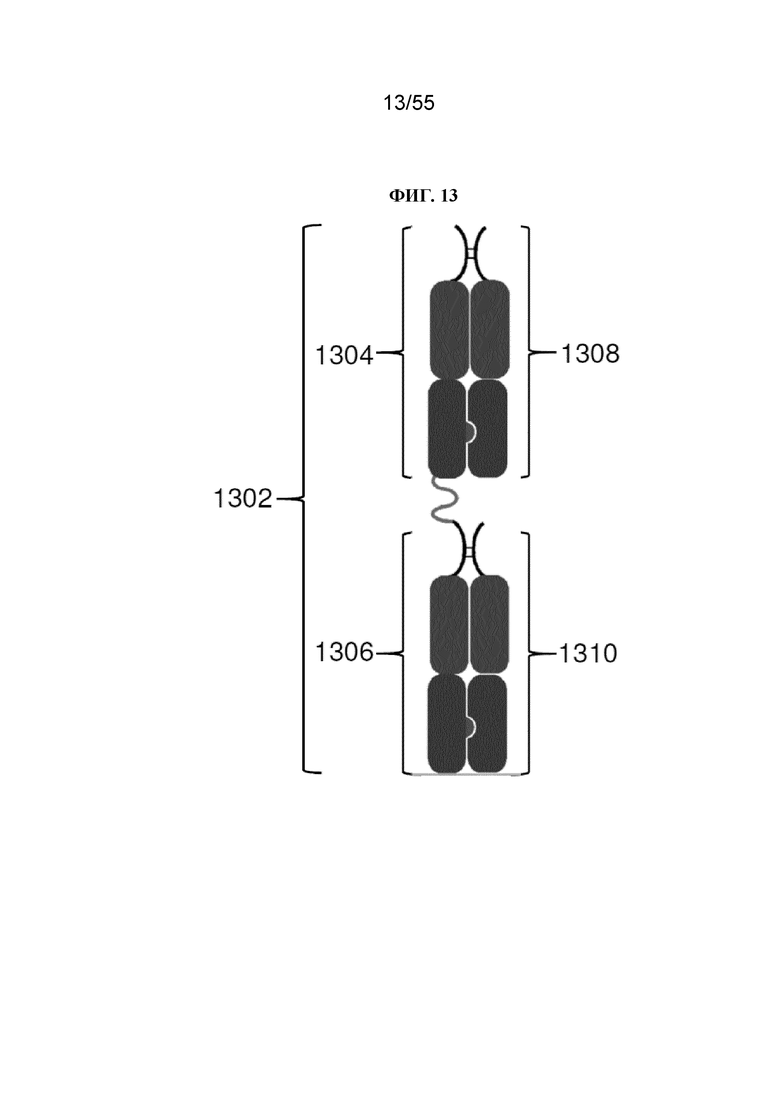
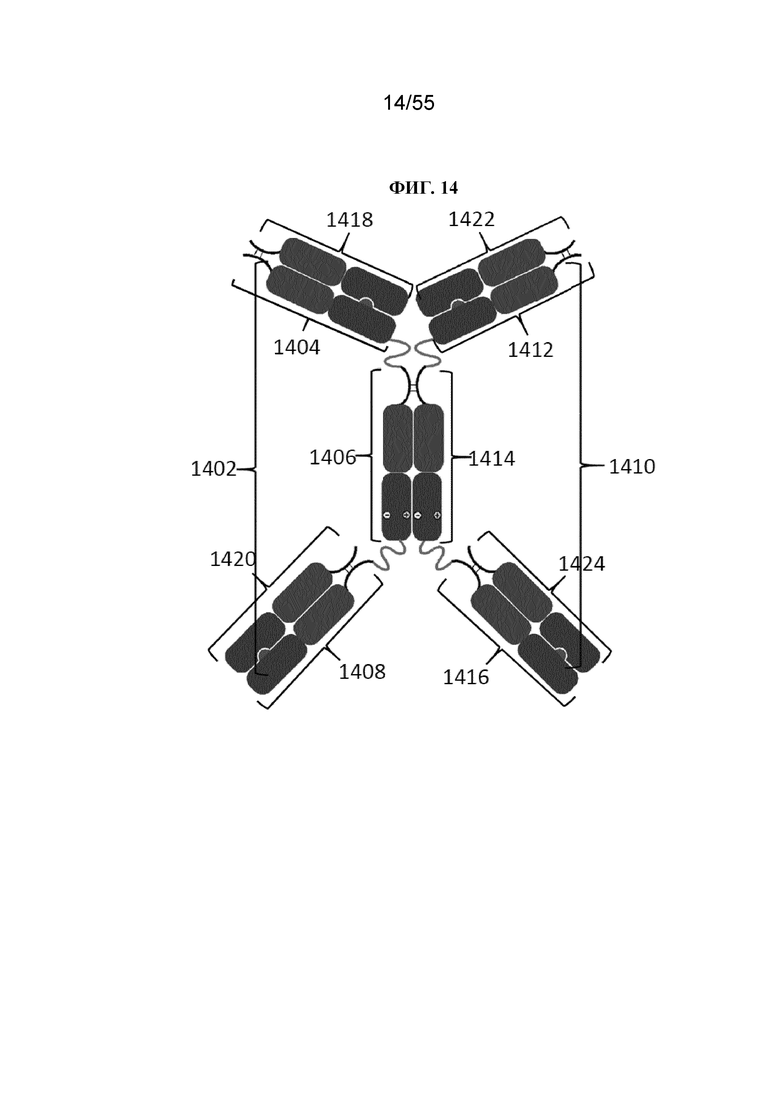
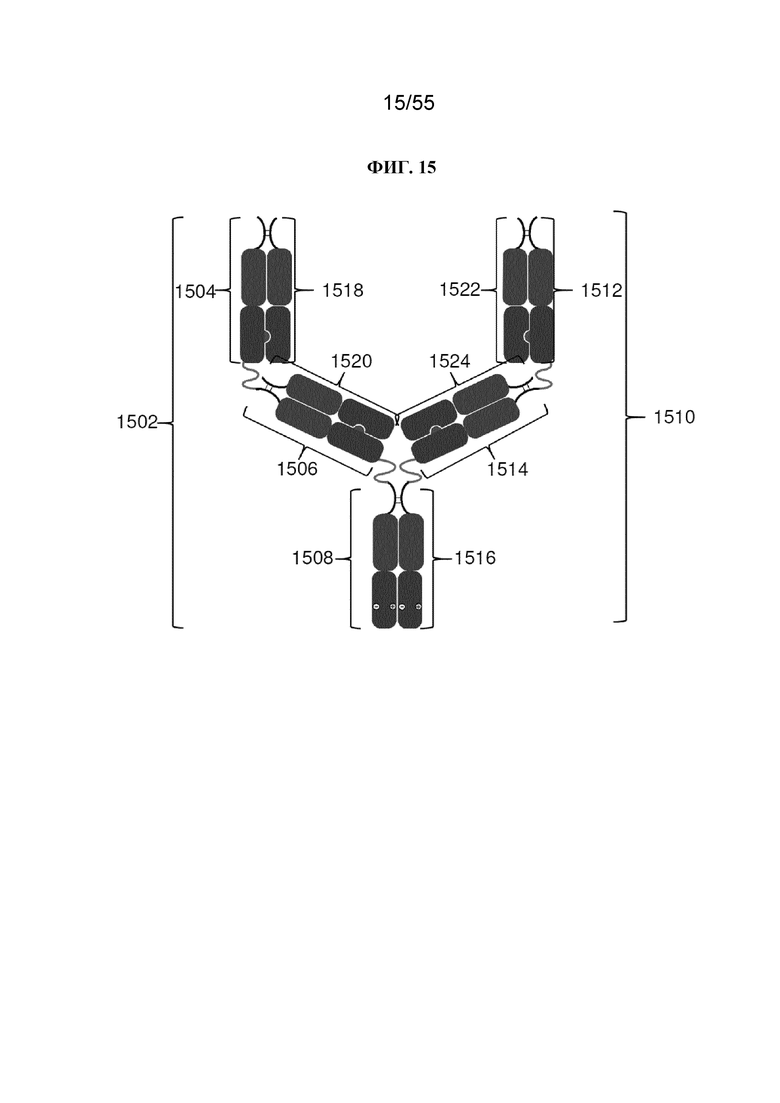
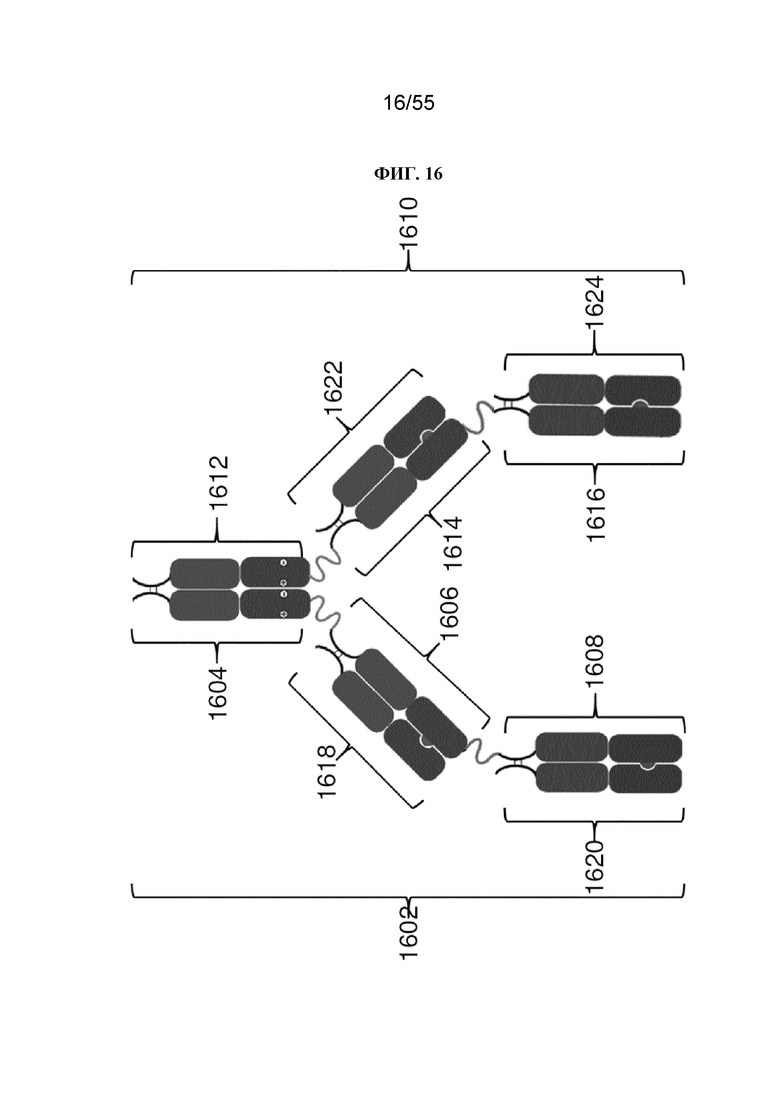
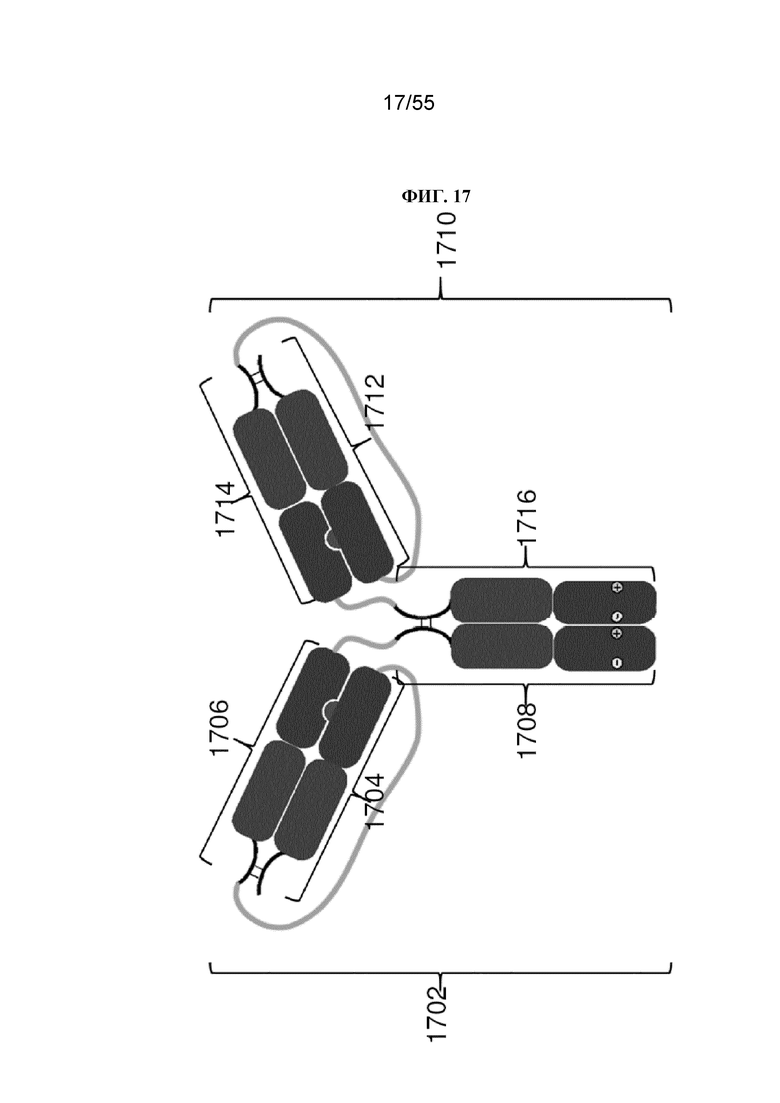
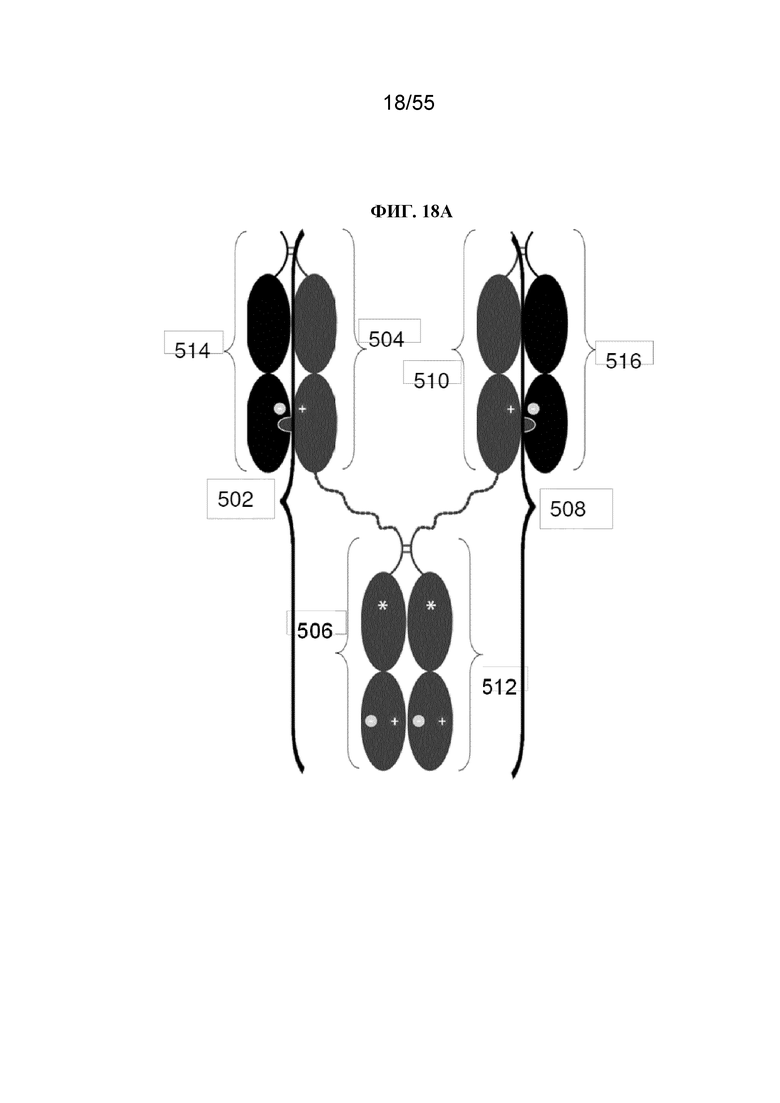
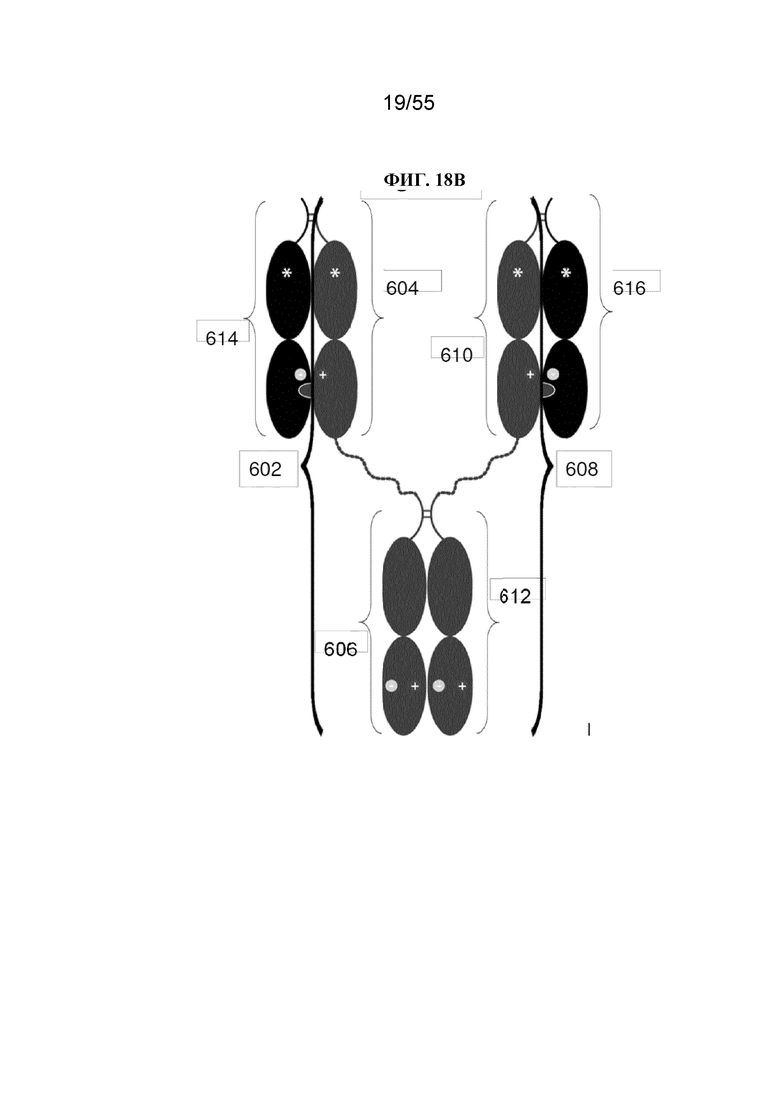
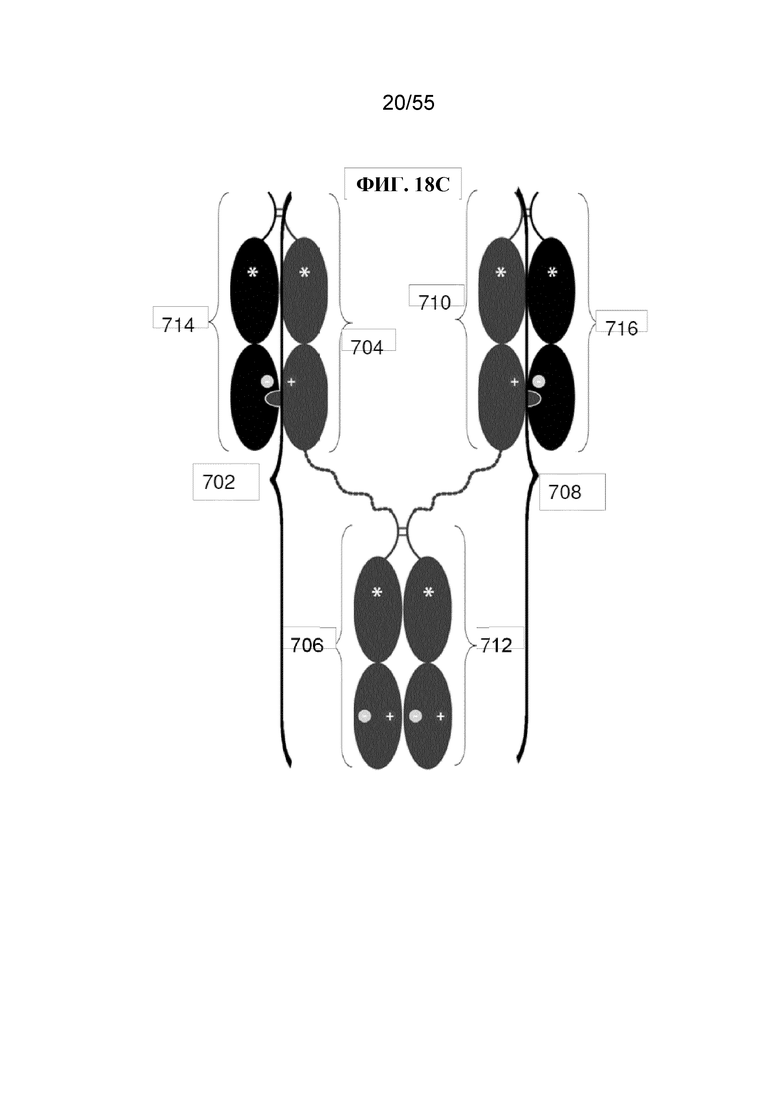
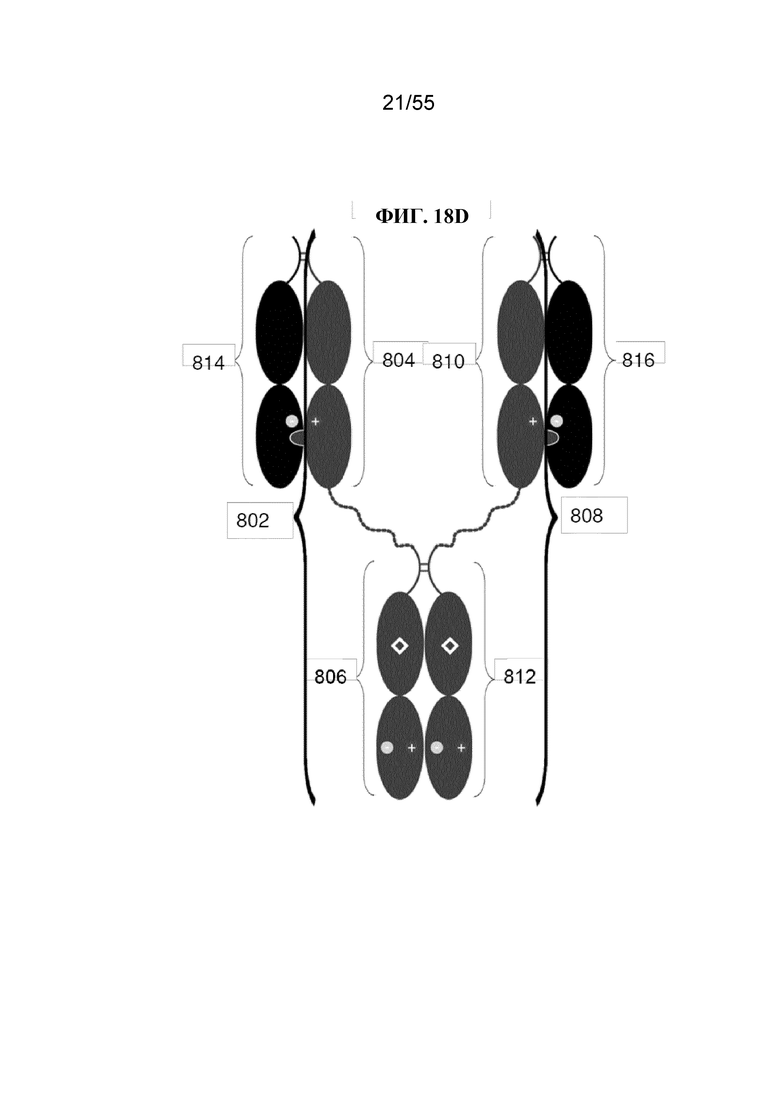
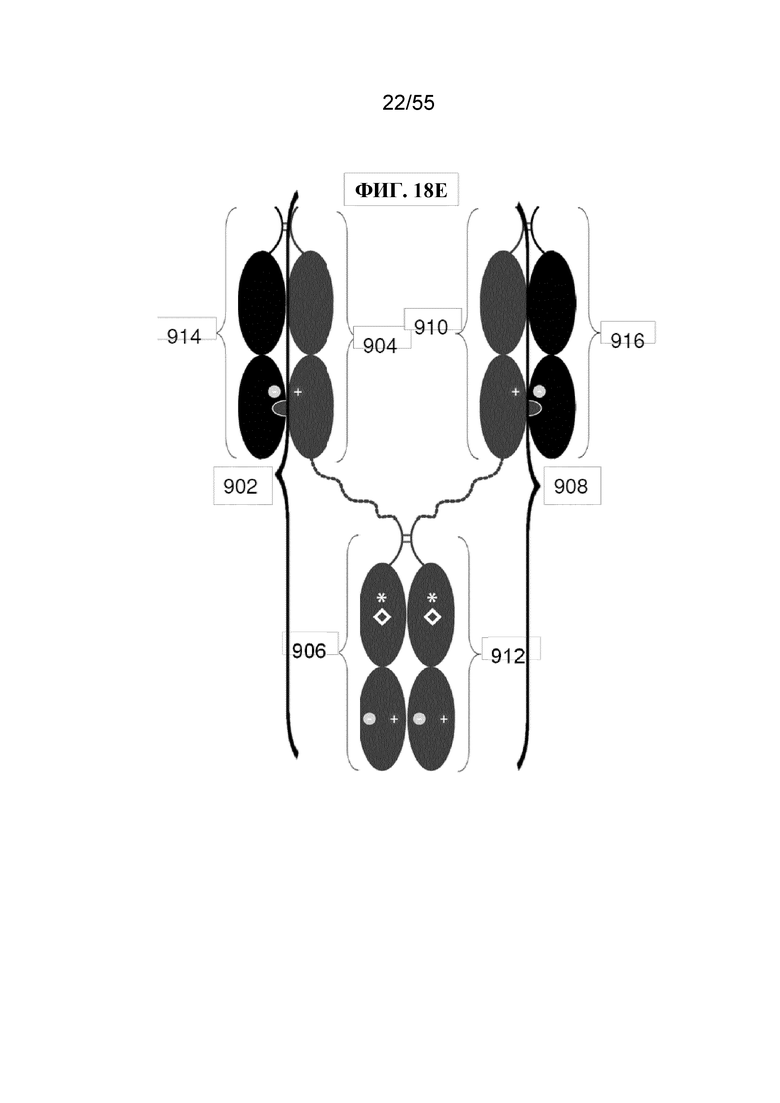
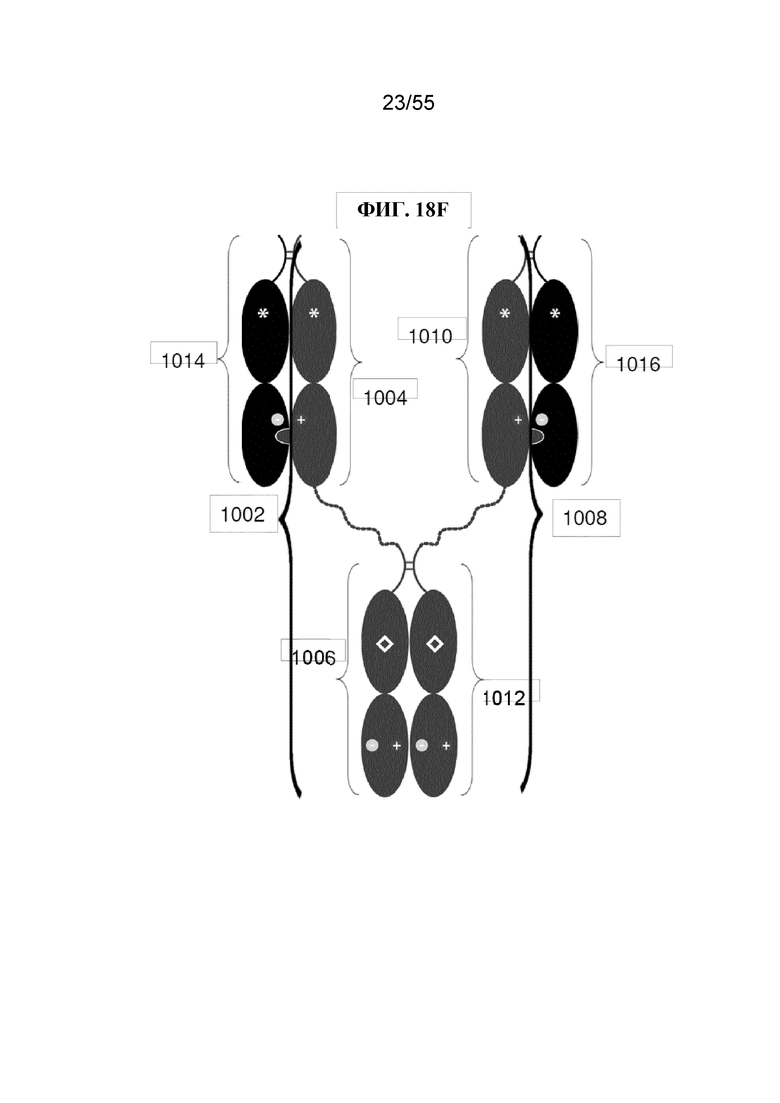
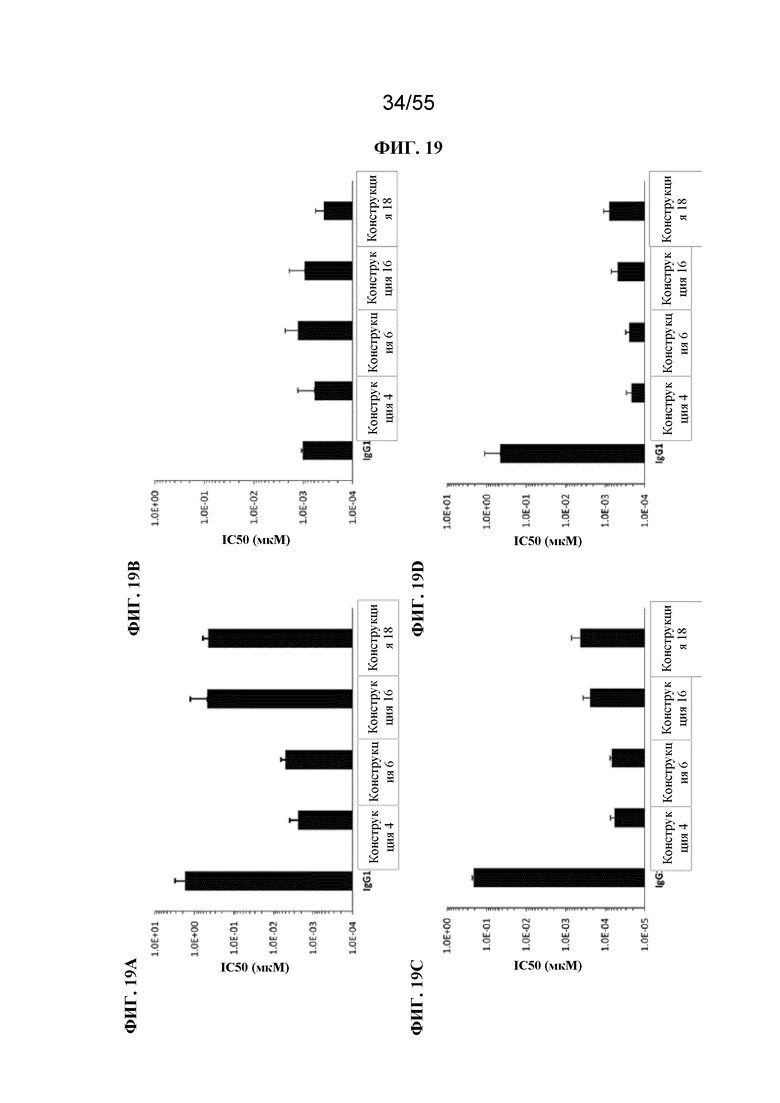
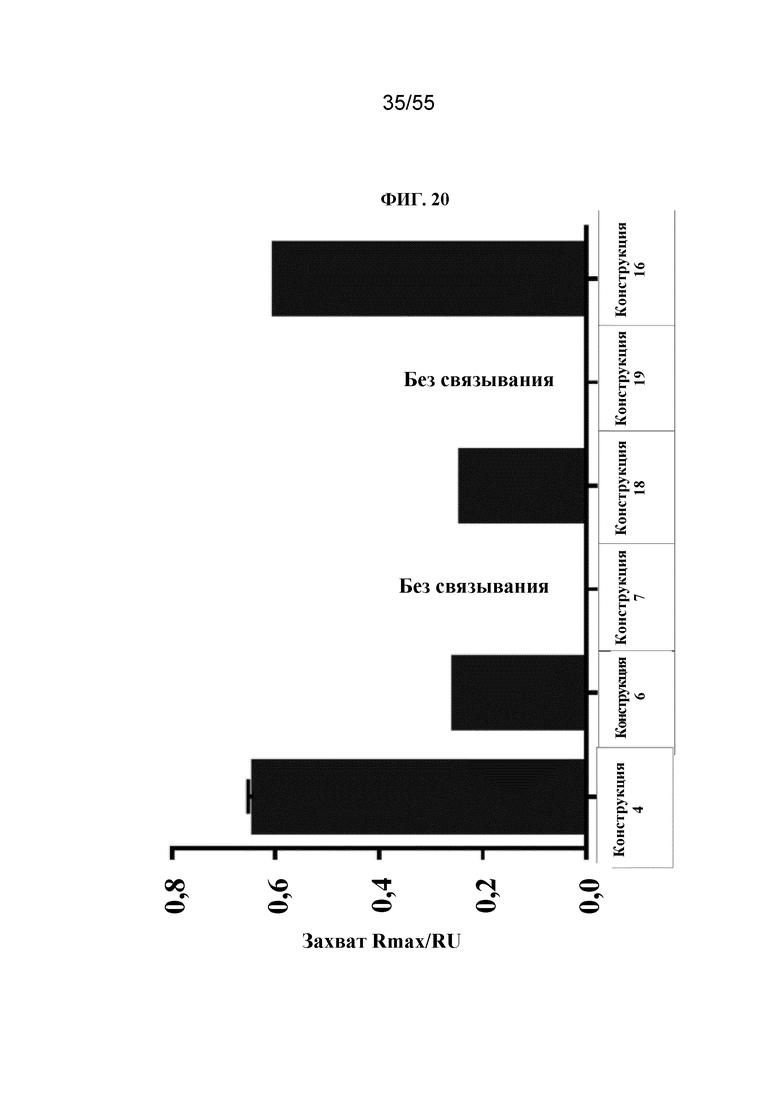
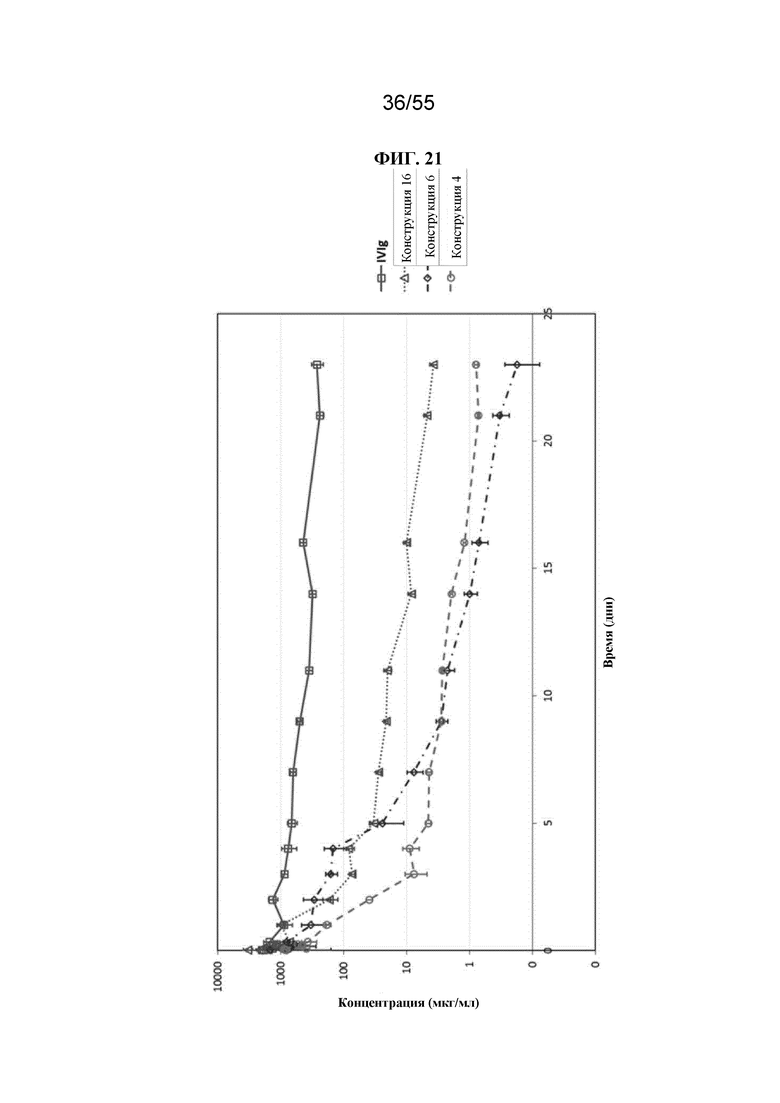
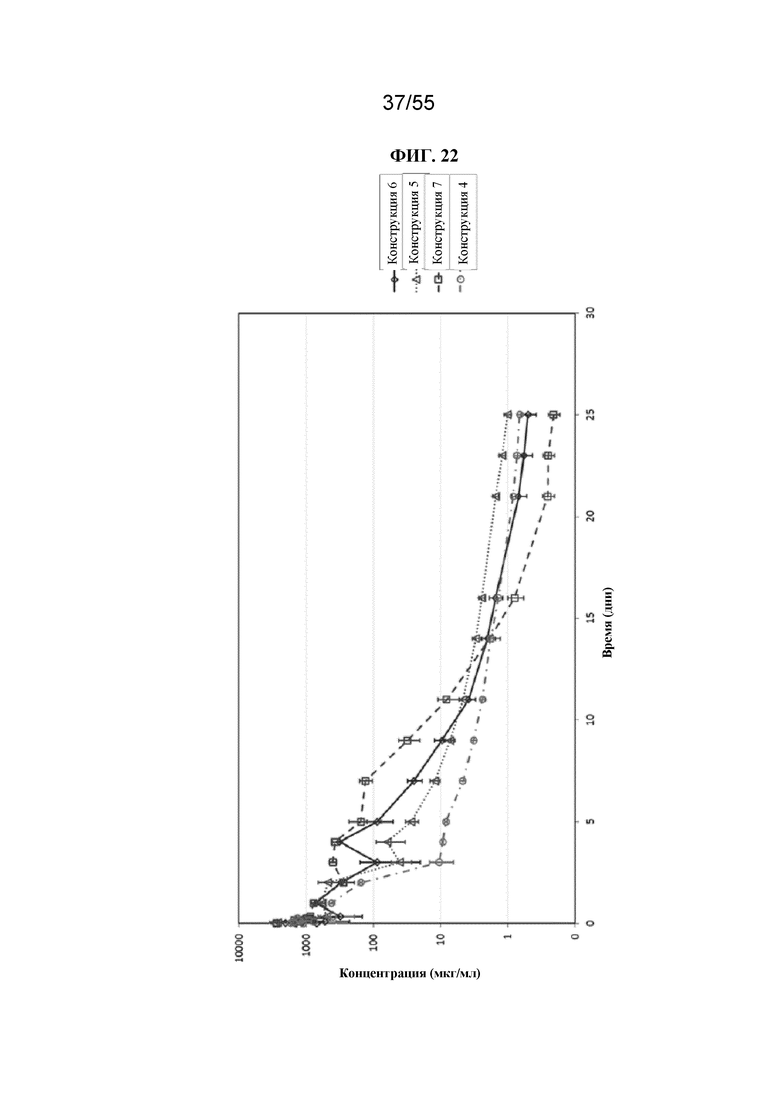
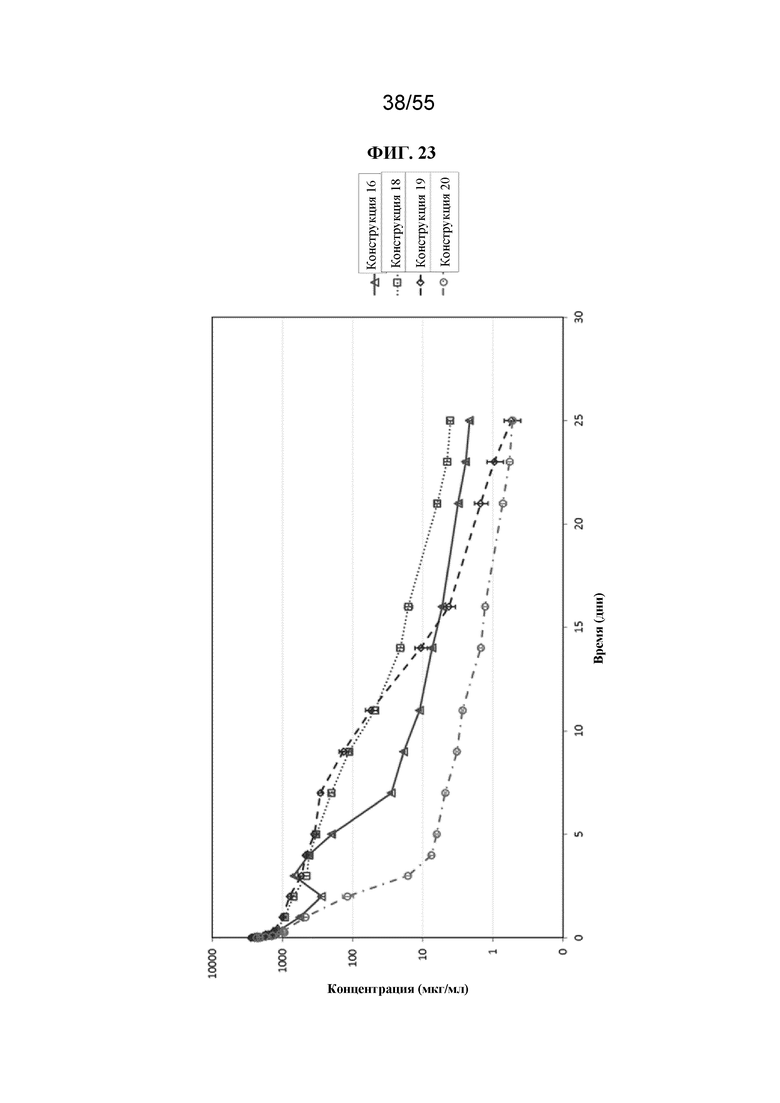
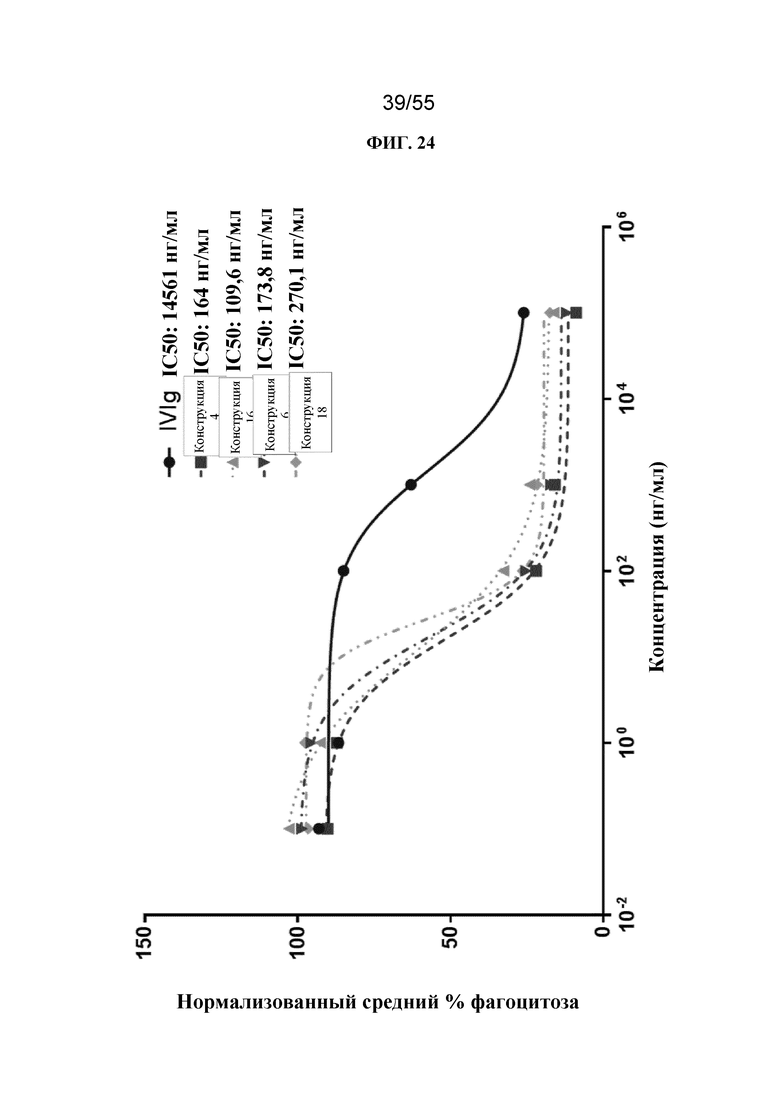
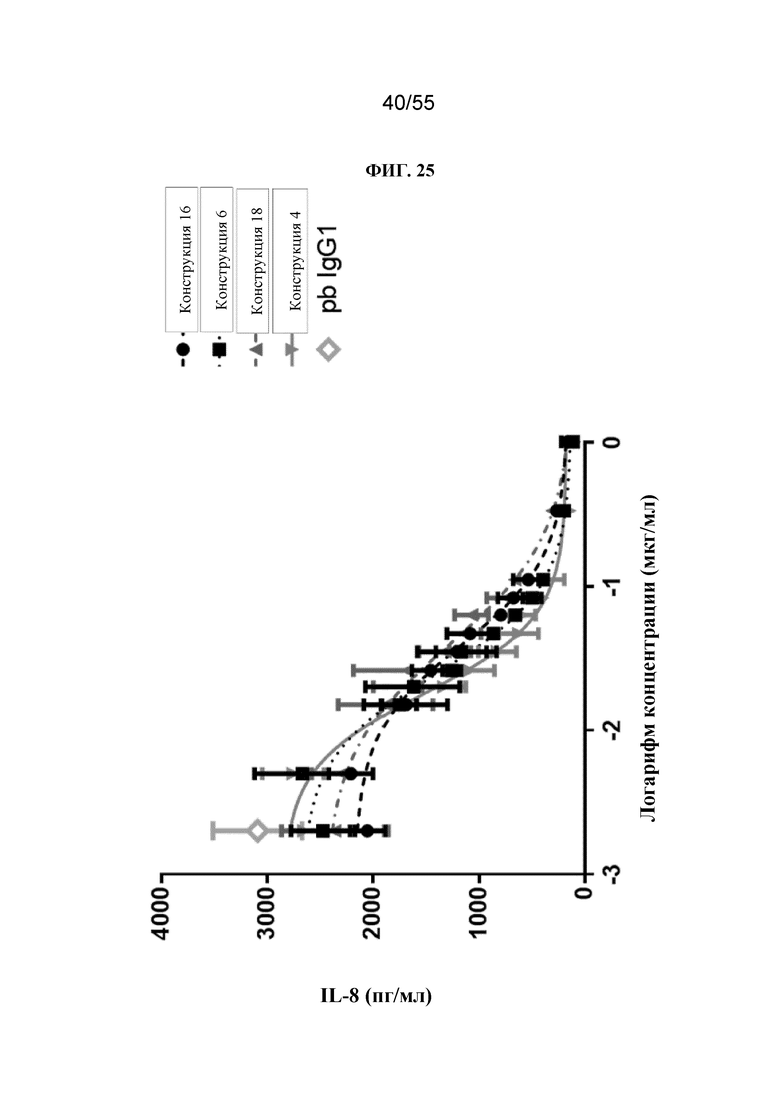
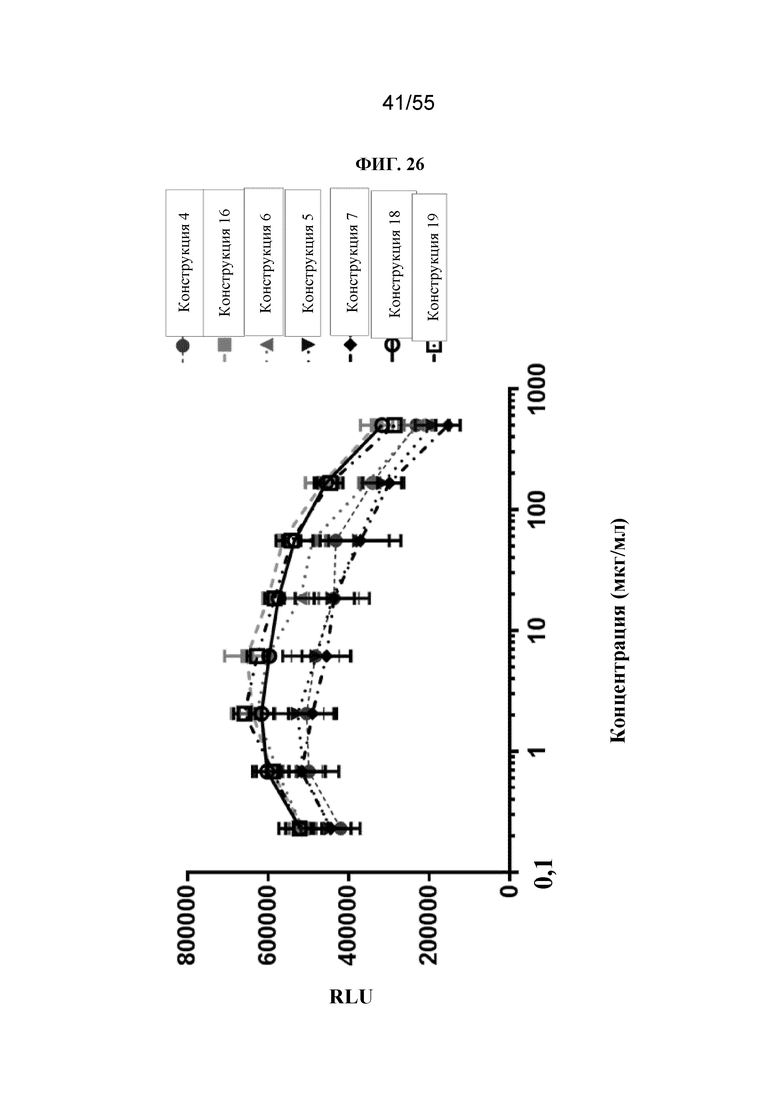
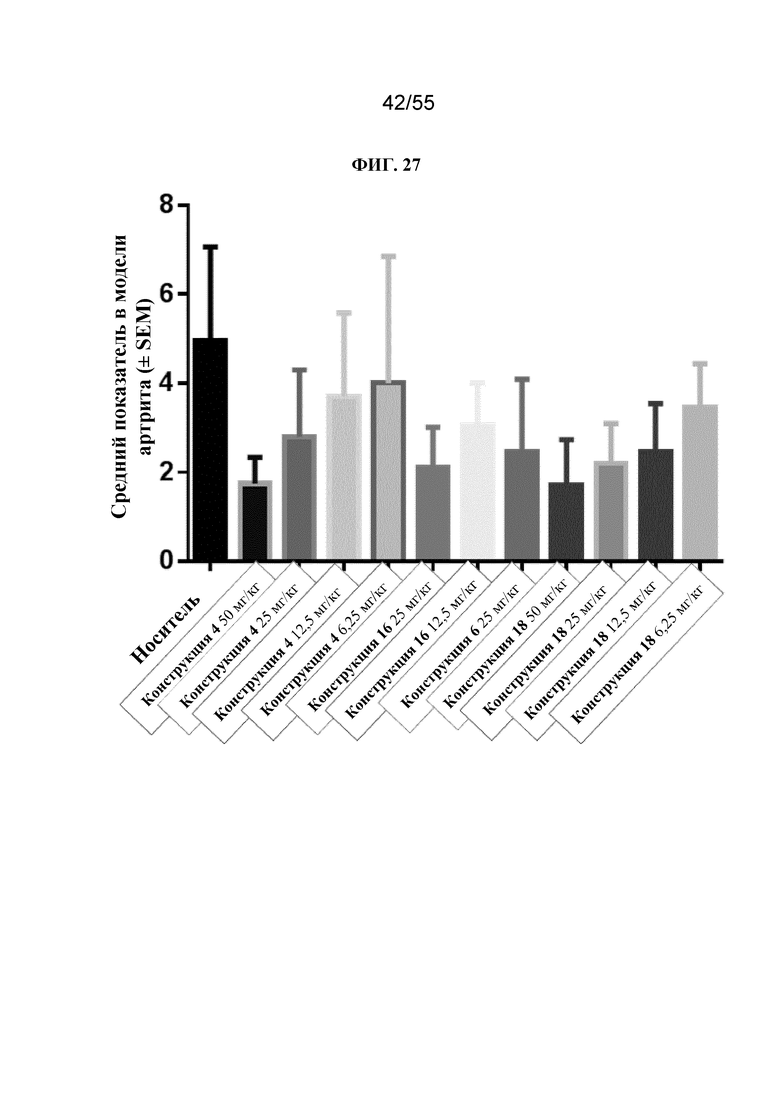
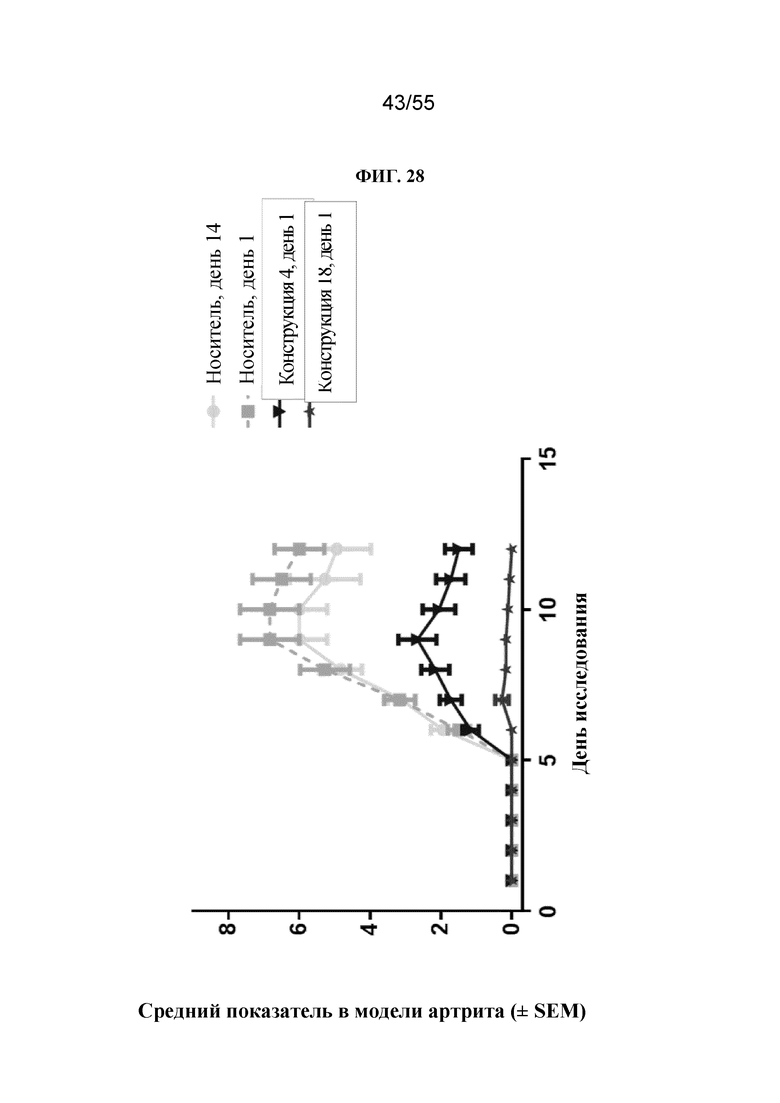
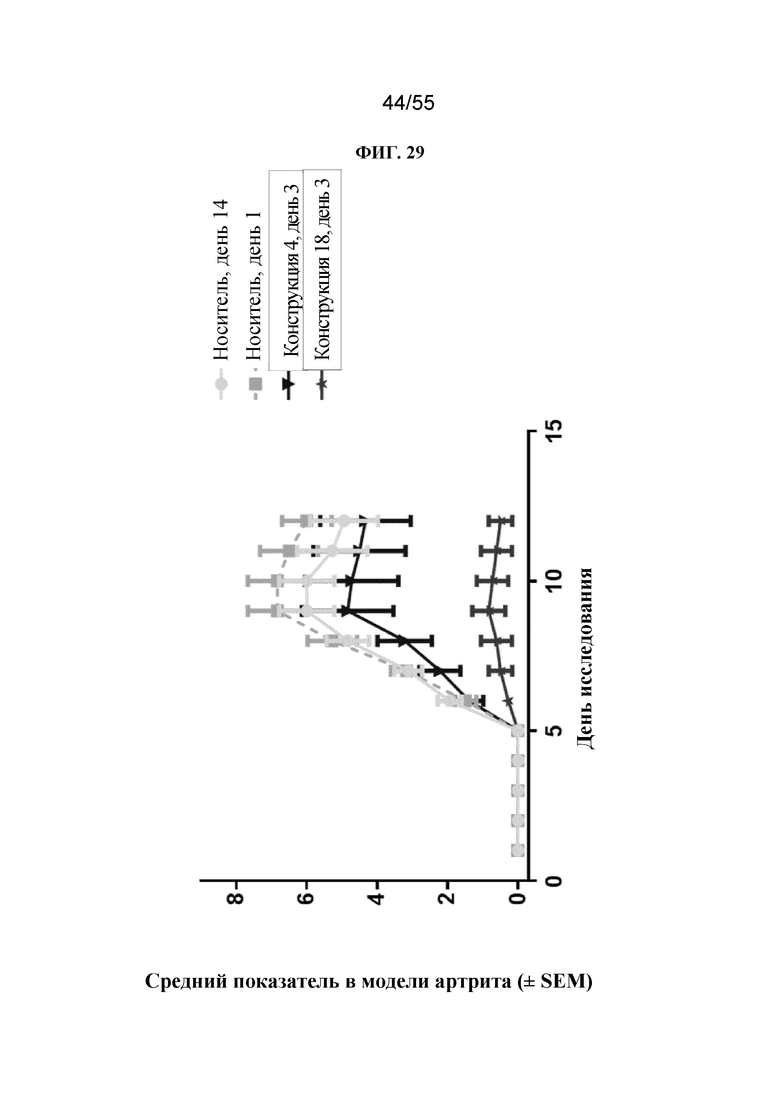
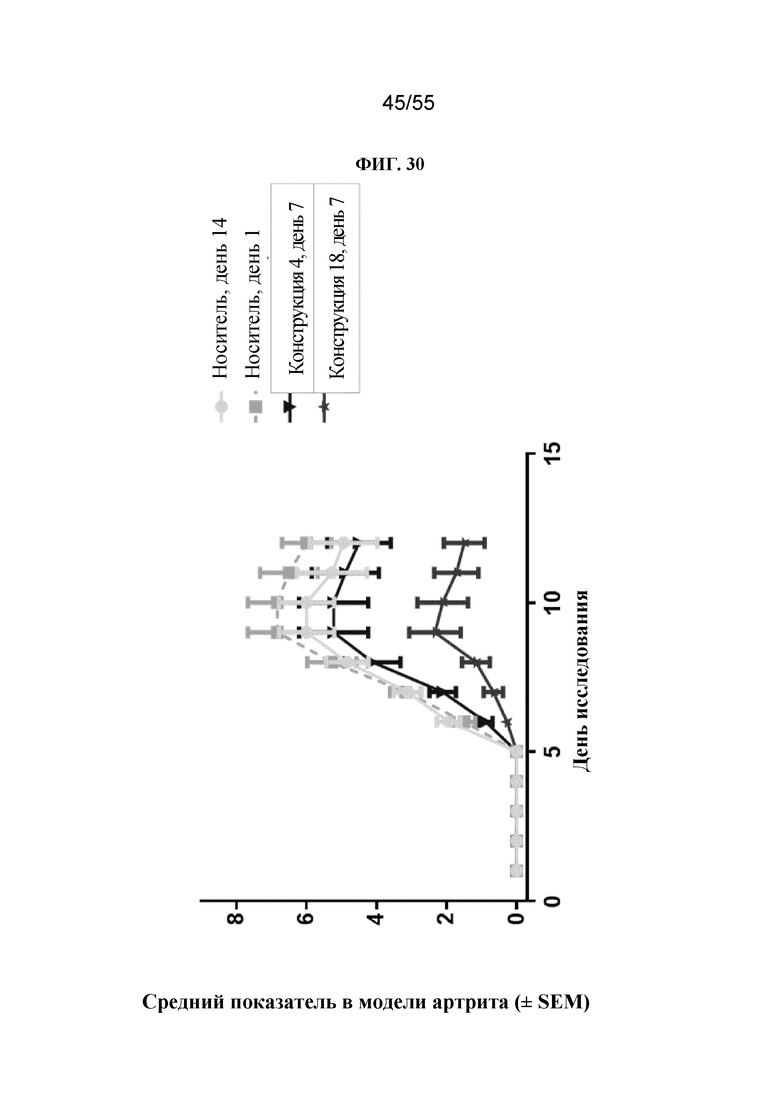
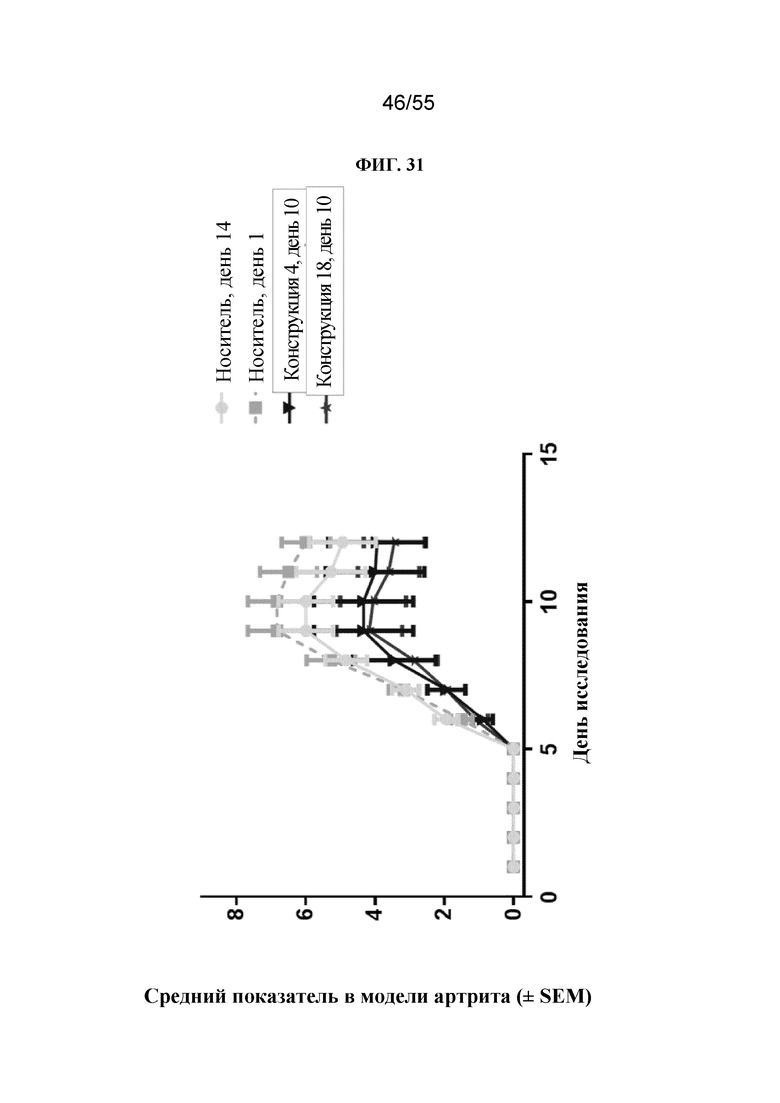
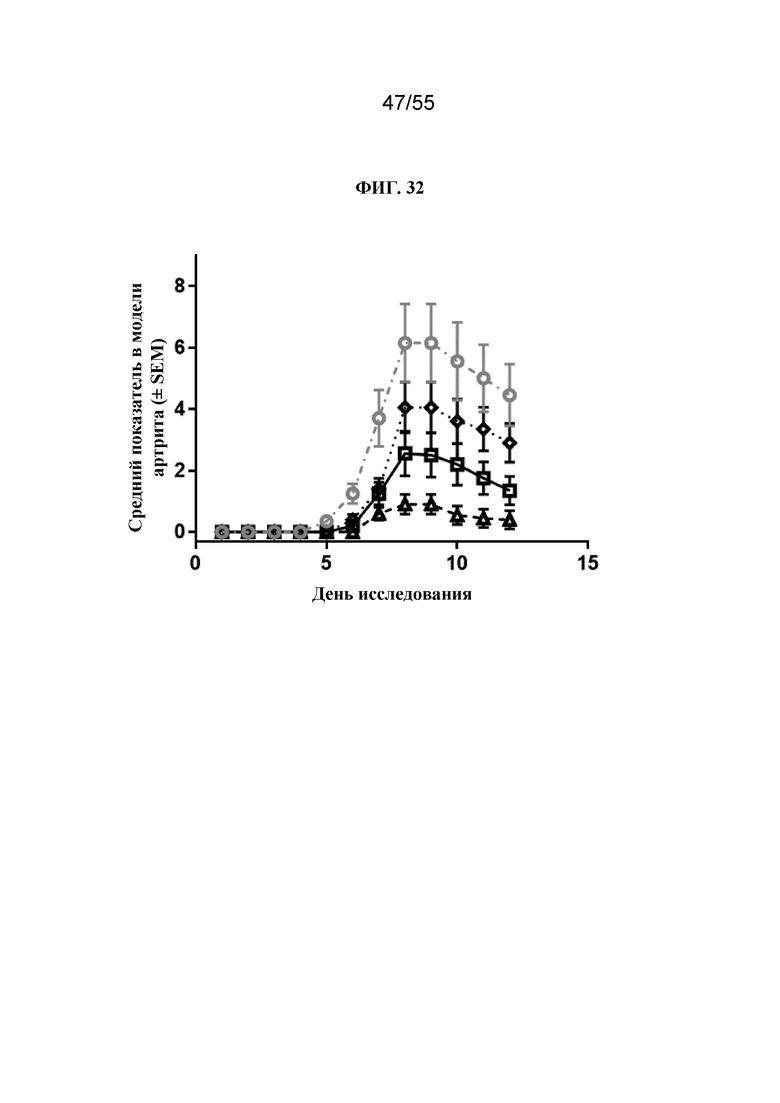
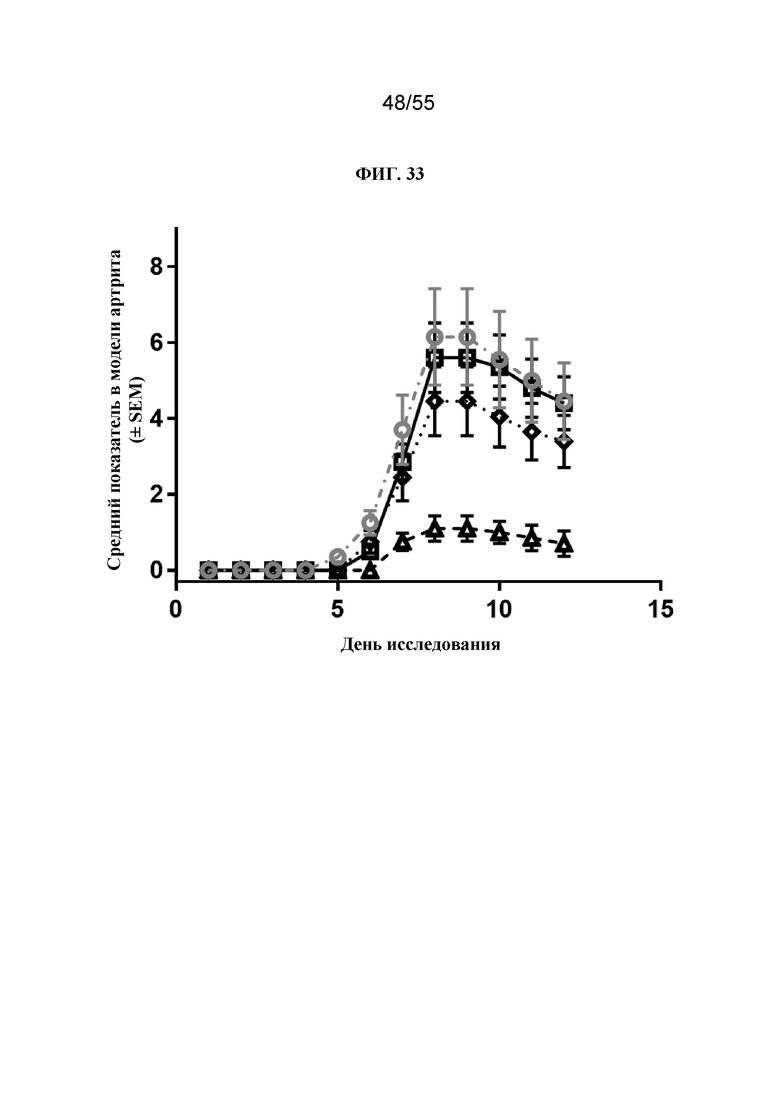
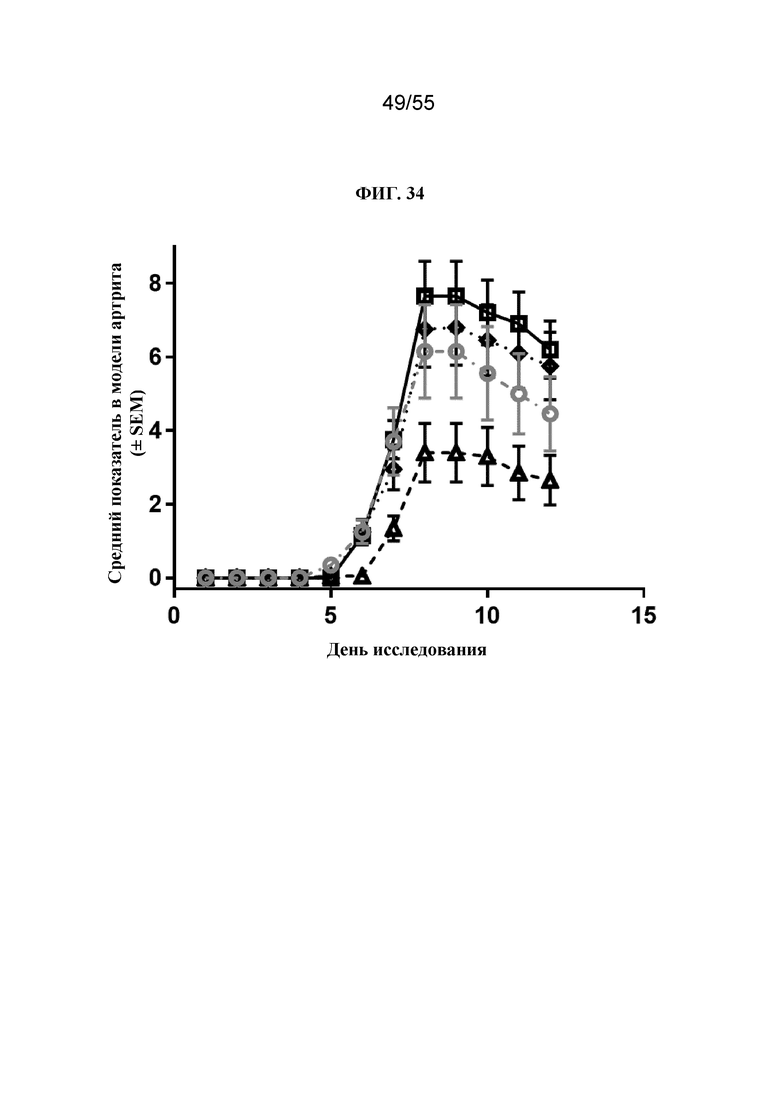
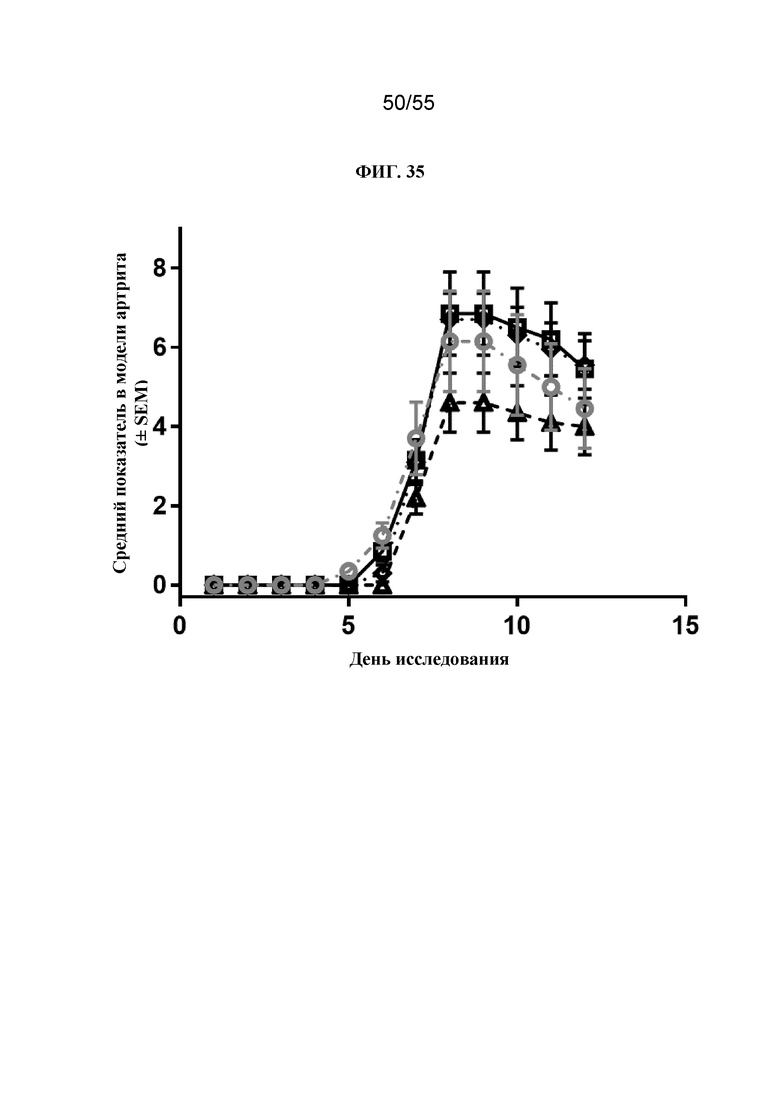
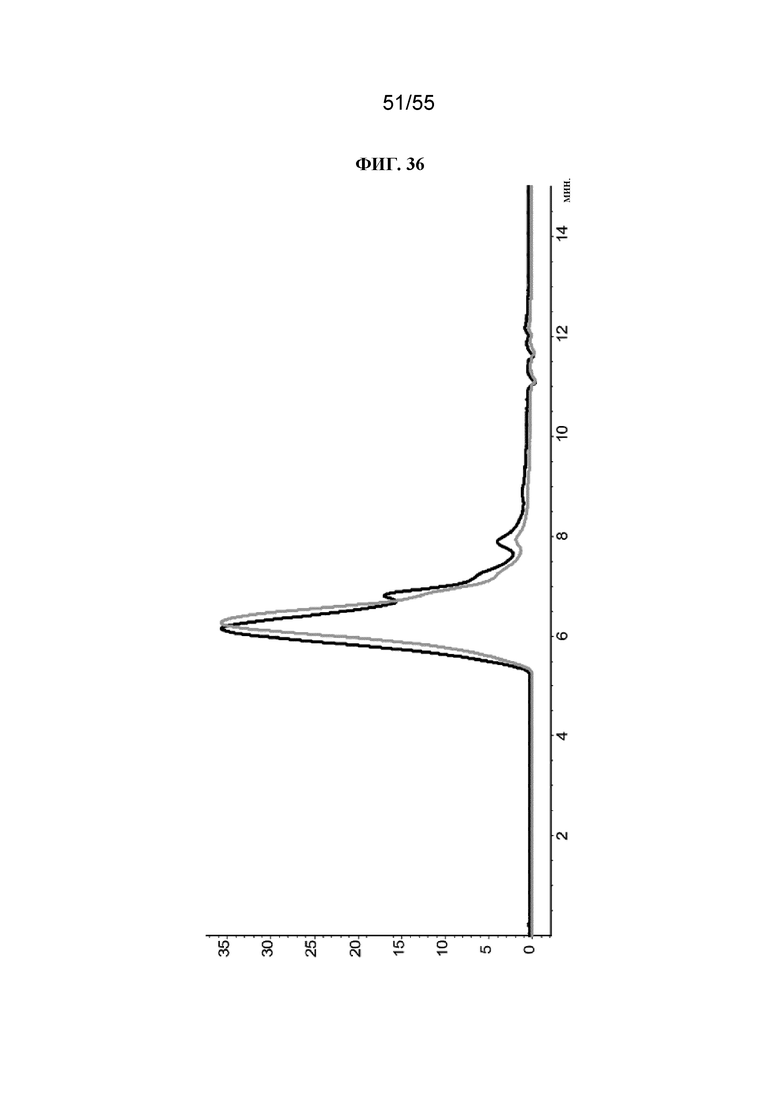
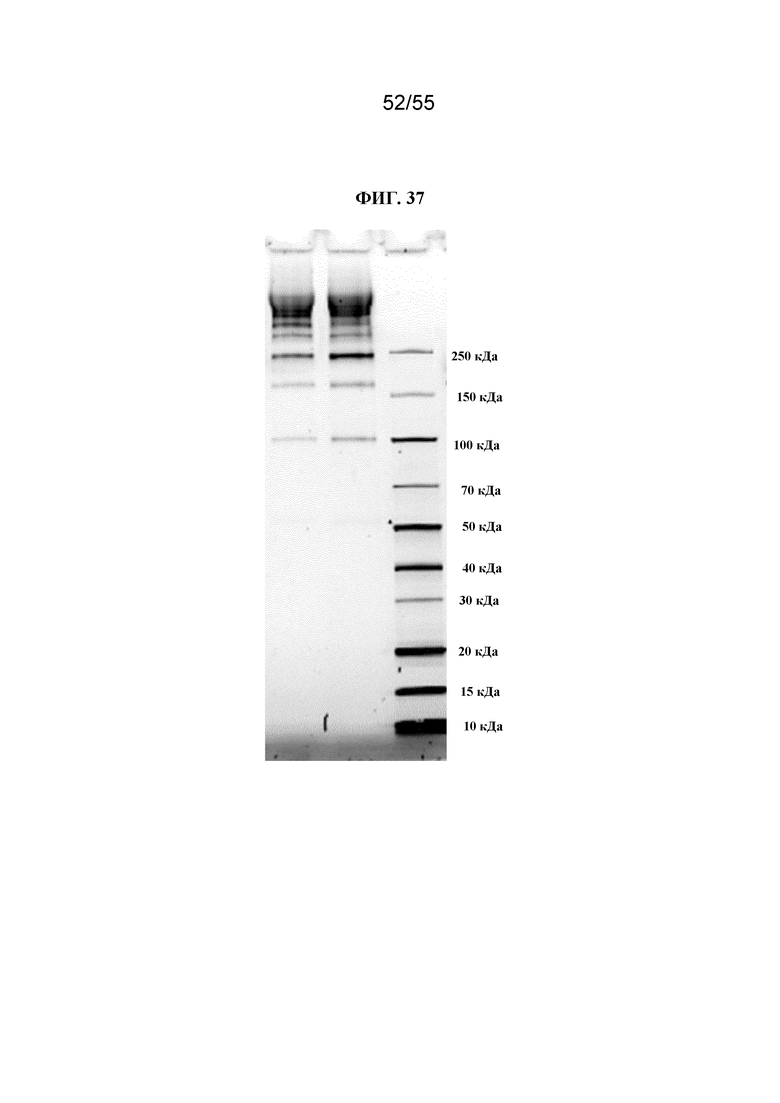
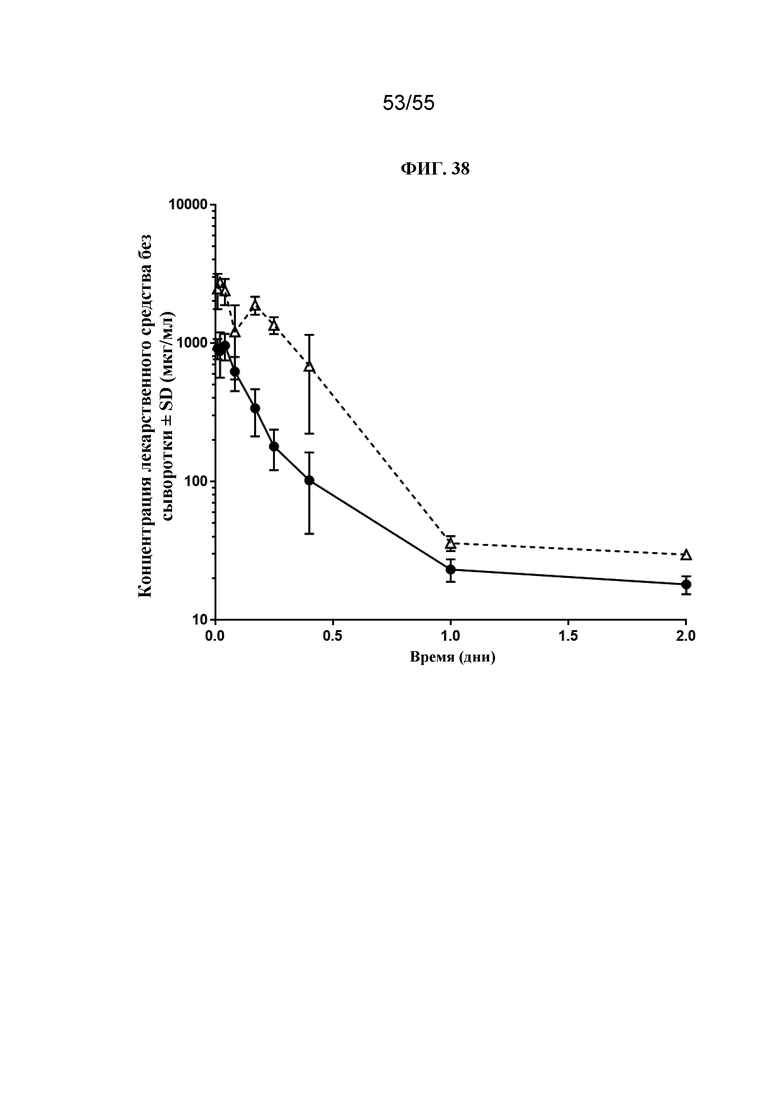
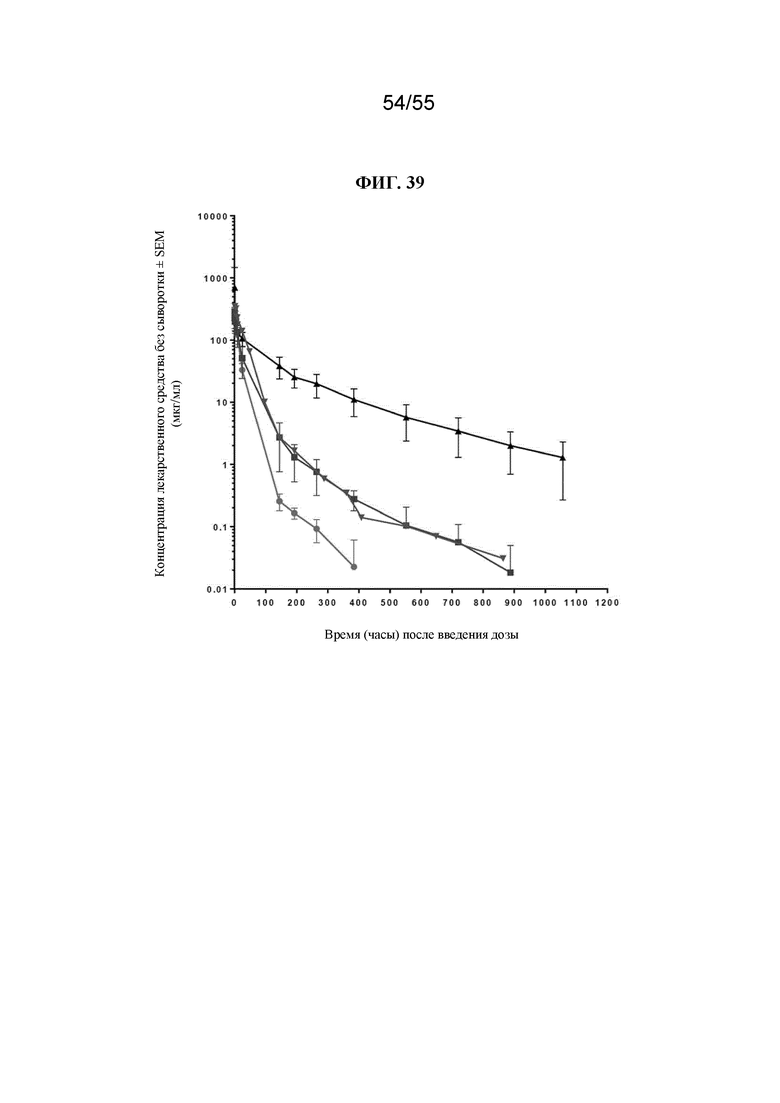
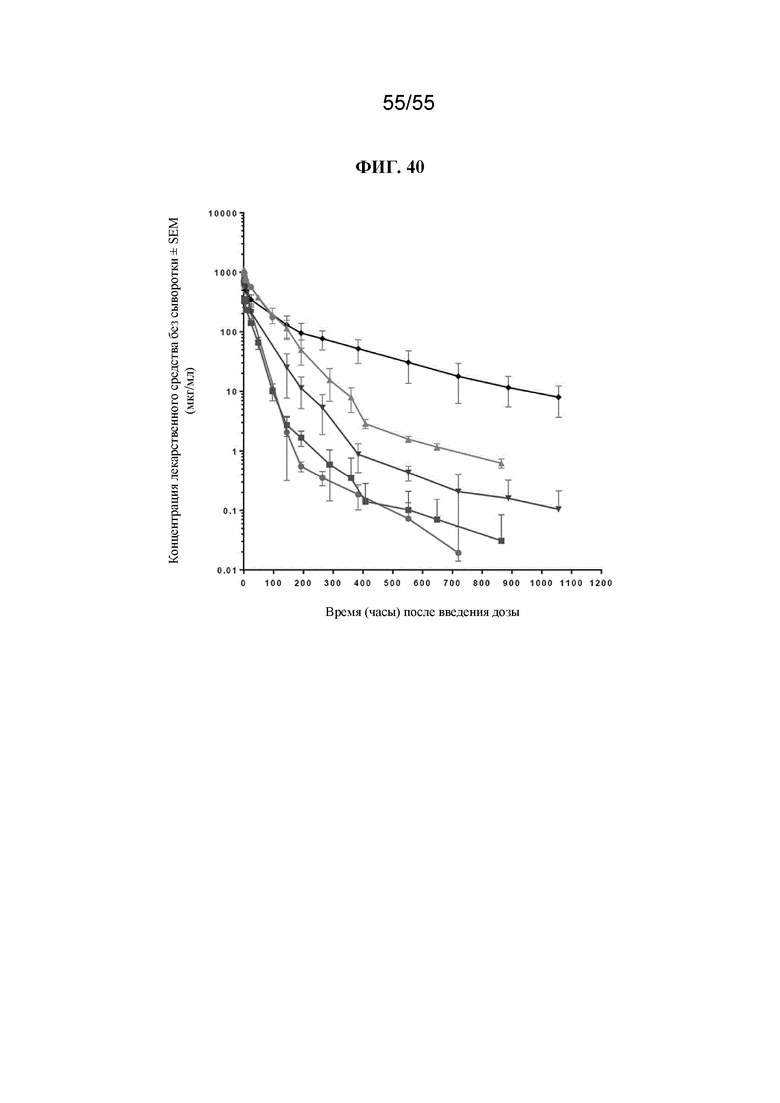
Изобретение относится к области биотехнологии, конкретно к рекомбинантному получению Fc-конструкций, и может быть использовано в медицине для снижения иммунного ответа при лечении воспалительного, аутоиммунного или иммунного заболевания. Предложена Fc-конструкция, содержащая a) первый полипептид, содержащий первый и второй мономеры Fc-домена, соединенные линкером; b) второй полипептид, содержащий третий и четвертый мономеры Fc-домена, соединенные линкером; c) третий полипептид, содержащий пятый мономер Fc-домена; и d) четвертый полипептид, содержащий шестой мономер Fc-домена. При этом первый и пятый мономеры Fc-домена объединяются с образованием первого Fc-домена; второй и четвертый мономеры Fc-домена объединяются с образованием второго Fc-домена; третий и шестой мономеры Fc-домена объединяются с образованием третьего Fc-домена. Изобретение обеспечивает получение Fc-конструкции со сниженным связыванием с Fc-рецептором. 2 н. и 2 з.п. ф-лы, 40 ил., 11 табл., 16 пр.
1. Fc-конструкция для снижения иммунного ответа у субъекта, содержащая:
a) первый полипептид, содержащий
i) первый мономер Fc-домена,
ii) второй мономер Fc-домена и
iii) линкер, соединяющий первый мономер Fc-домена со вторым мономером Fc-домена;
b) второй полипептид, содержащий
i) третий мономер Fc-домена,
ii) четвертый мономер Fc-домена и
iii) линкер, соединяющий третий мономер Fc-домена с четвертым мономером Fc-домена;
c) третий полипептид, содержащий пятый мономер Fc-домена; и
d) четвертый полипептид, содержащий шестой мономер Fc-домена;
при этом первый мономер Fc-домена и пятый мономер Fc-домена объединяются с образованием первого Fc-домена;
второй мономер Fc-домена и четвертый мономер Fc-домена объединяются с образованием второго Fc-домена;
и третий мономер Fc-домена и шестой мономер Fc-домена объединяются с образованием третьего Fc-домена;
причем каждый из первого и второго полипептидов содержит последовательность

и каждый из третьего и четвертого полипептидов содержит последовательность

2. Fc-конструкция по п. 1, в которой каждый из первого и второго полипептидов состоит из последовательности

и каждый из третьего и четвертого полипептидов состоит из последовательности

3. Применение Fc-конструкции по п. 1 или 2 для снижения иммунного ответа у субъекта, нуждающегося в этом.
4. Применение Fc-конструкции по п. 3 для снижения иммунного ответа при лечении воспалительного, аутоиммунного или иммунного заболевания, выбранного из ревматоидного артрита (RA); системной красной волчанки (SLE); ANCA-ассоциированного васкулита; синдрома антифосфолипидных антител; аутоиммунной гемолитической анемии; хронической воспалительной демиелинизирующей невропатии; трансплантации органа; GVHD; дерматомиозита; синдрома Гудпасчера; синдромов гиперчувствительности типа II на уровне систем органов, опосредованных антителозависимой клеточно-опосредованной цитотоксичностью, например синдрома Гийена-Барре, CIDP, синдрома Фелти, опосредованного антителами отторжения, аутоиммунного заболевания щитовидной железы, язвенного колита, аутоиммунного заболевания печени; идиопатической тромбоцитопенической пурпуры; миастении гравис, оптиконевромиелита; пузырчатки и других аутоиммунных нарушений, сопровождающихся образованием пузырей; синдрома Шегрена; аутоиммунных цитопений и других нарушений, опосредованных антителозависимым фагоцитозом; вызванной гепарином тромбоцитопении (HIT); миозита; полимиозита; антителозависимого усиления; синдрома мышечной скованности; болезни Кавасаки; миозита с тельцами-включениями; системного склероза; IgA-нефропатии; заболевания, связанного с IgG4; болезни Грейвса; аутоиммунного заболевания внутреннего уха (AIED); антифосфолипидного синдрома (APS); пузырчатки обыкновенной; пузырчатки эксфолиативной; пузырчатки беременных; паранеопластической пузырчатки; неврита зрительного нерва, синдрома Парри-Ромберга; FcR-зависимых воспалительных синдромов; синовита; гломерулита и васкулита.
| US 20160229913 A1, 11.08.2016, RU 2583298 C2, 10.05.2016, MIMOTO F | |||
| et al., Novel asymmetrically engineered antibody Fc variant with superior FcγR binding affinity and specificity compared with afucosylated Fc variant, MAbs, 2013, v | |||
| Кипятильник для воды | 1921 |
|
SU5A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| L | |||
| et al., Differential binding to human FcγRIIa and FcγRIIb receptors by human IgG | |||

