Область техники, к которой относится изобретение
[01] Настоящая технология относится к использованию нейросетевого ранжирования результатов поиска и, в частности, к двухступенчатой архитектуре нейронной сети на основе трансформера для персонализированного ранжирования результатов поиска.
Уровень техники
[02] Веб-поиск представляет собой важную задачу, связанную с ежедневной обработкой миллиардов пользовательских запросов. Современные системы веб-поиска обычно ранжируют результаты поиска по их релевантности поисковому запросу и другим критериям. Определение релевантности результатов поиска запросу часто предусматривает использование алгоритмов машинного обучения, обученных с использованием нескольких определенных вручную признаков для оценивания различных показателей релевантности. Такое определение релевантности можно рассматривать, по меньшей мере частично, как проблему понимания языка, поскольку релевантность документа поисковому запросу имеет по меньшей мере некоторое отношение к семантическому пониманию запроса и результатов поиска даже в случаях, когда запрос и результаты не содержат общих слов или когда результаты представляют собой изображения, музыку или другие нетекстовые результаты.
[03] Недавние разработки в области нейронной обработки естественного языка включают в себя использование трансформерных моделей машинного обучения, как описано в статье Vaswani et al. «Attention Is All You Need», Advances in neural information processing system, 2017, стр. 5998–6008. Трансформер представляет собой модель глубокого обучения (т.е. искусственную нейронную сеть или другую модель машинного обучения, содержащую несколько слоев), в которой для назначения некоторым частям входных данных большей значимости, чем другим, используется механизм внимания. При обработке естественного языка механизм внимания используется с целью определения контекста для слов из входных данных, поэтому одно и то же слово в разных контекстах может иметь различные значения. Трансформеры также способны параллельно обрабатывать множество слов или токенов естественного языка, что позволяет реализовать параллельное обучение.
[04] На трансформерах основаны и другие достижения в области обработки естественного языка, включая заранее обучаемые системы, которые могут заранее обучаться с использованием большого набора данных, а затем уточняться для использования в конкретных целях. Примеры таких систем включают в себя модель «Представления двунаправленного кодера из трансформеров» (BERT, Bidirectional Encoder Representations from Transformers), описанную в работе Devlin et al. «BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding», Proceedings of NAACL-HLT 2019, 2019, стр. 4171–4186.
[05] Благодаря успешности систем на основе трансформера, подобных модели BERT, в области обработки естественного языка, они стали использоваться при ранжировании результатов поиска. При этом возникли новые проблемы. Например, желательно, чтобы поисковые системы обеспечивали зависящее от пользователя ранжирование результатов поиска, поскольку наиболее релевантные результаты для одного пользователя поисковой системы могут отличаться от наиболее релевантных результатов для других пользователей даже в случае по существу схожего запроса. Кроме того, для «гладкой» работы поисковой системы ранжированные результаты должны предоставляться как можно быстрее. Таким образом, желательно обеспечить архитектуру нейронной сети на основе трансформера для быстрого предоставления персонализированных рейтинговых оценок для результатов поиска.
Раскрытие изобретения
[06] Различные варианты осуществления настоящей технологии обеспечивают способы формирования зависящей от пользователя рейтинговой оценки результатов поиска с использованием разделенной или двухступенчатой архитектуры нейронной сети, основанной на системе с использованием трансформера BERT. Такая двухступенчатая архитектура нейронной сети обеспечивает расчет рейтинговых оценок для результатов поиска с учетом зависящей от пользователя информации и зависящей от результатов информации. Двухступенчатая архитектура нейронной сети позволяет использовать выходные данные первой ступени в нескольких применениях второй ступени с целью формирования рейтинговых оценок для результатов поиска. Это позволяет сократить время и ресурсы, требуемые для предоставления персонализированных результатов поиска и, следовательно, повысить производительность и эффективность систем, ранжирующих результаты поиска. Поскольку такие системы могут обслуживать десятки миллионов активных пользователей и обрабатывать тысячи запросов в секунду, повышение эффективности таких систем ранжирования результатов поиска также позволяет обеспечить значительные преимущества с точки зрения размера, стоимости и энергопотребления центров обработки данных, в которых размещены поисковые системы.
[07] Согласно одному аспекту настоящей технологии реализован компьютерный способ формирования зависящей от пользователя рейтинговой оценки результатов поиска для документа. Способ включает в себя получение пользовательского журнала, содержащего историю поиска пользователя, получение поискового запроса от пользователя, предоставление пользовательского журнала и поискового запроса первой ступени кодера на основе искусственной нейронной сети и формирование с использованием первой ступени кодера на основе искусственной нейронной сети основанного на токенах пользовательского представления пользовательского журнала и поискового запроса, по меньшей мере частично, на основе определения взаимосвязи между пользовательским журналом и поисковым запросом. Способ дополнительно включает в себя получение документа из набора документов из результата поиска, связанных с поисковым запросом, предоставление основанного на токенах пользовательского представления и документа второй ступени кодера на основе искусственной нейронной сети и формирование с использованием второй ступени кодера на основе искусственной нейронной сети рейтинговой оценки для документа, по меньшей мере частично, на основе определения взаимосвязи между основанным на токенах пользовательским представлением и документом.
[08] В некоторых вариантах осуществления изобретения способ дополнительно включает в себя предоставление каждого документа из набора документов из результата поиска и основанного на токенах пользовательского представления второй ступени кодера на основе искусственной нейронной сети для формирования набора рейтинговых оценок, каждая из которых связана с соответствующим документом из набора документов из результата поиска. В этих вариантах осуществления изобретения способ также включает в себя использование набора рейтинговых оценок для ранжирования набора документов из результата поиска. В некоторых вариантах осуществления изобретения использование набора рейтинговых оценок для ранжирования набора документов из результата поиска включает в себя предоставление набора рейтинговых оценок и набора документов из результата поиска модели на основе машинного обучения для окончательного ранжирования.
[09] В некоторых вариантах осуществления изобретения предоставление пользовательского журнала и поискового запроса первой ступени кодера на основе искусственной нейронной сети дополнительно включает в себя предоставление токенов, представляющих пользовательский журнал и поисковый запрос. В некоторых вариантах осуществления изобретения предоставление пользовательского журнала и поискового запроса первой ступени кодера на основе искусственной нейронной сети дополнительно включает в себя предоставление информации о положении, связанной с токенами, представляющими пользовательский журнал и поисковый запрос.
[010] В некоторых вариантах осуществления изобретения первая ступень кодера на основе искусственной нейронной сети содержит механизм внимания. В некоторых вариантах осуществления изобретения первая ступень кодера на основе искусственной нейронной сети содержит кодер на основе трансформера. В некоторых вариантах осуществления изобретения первая ступень кодера на основе искусственной нейронной сети содержит кодер на основе архитектуры модели BERT. В некоторых вариантах осуществления изобретения основанное на токенах пользовательское представление содержит последовательность токенов классификатора.
[011] В некоторых вариантах осуществления изобретения предоставление основанного на токенах пользовательского представления и документа второй ступени кодера на основе искусственной нейронной сети дополнительно включает в себя предоставление токенов, представляющих документ. В некоторых вариантах осуществления изобретения предоставление основанного на токенах пользовательского представления и документа второй ступени кодера на основе искусственной нейронной сети дополнительно включает в себя предоставление информации о положении, связанной с токенами, представляющими документ.
[012] В некоторых вариантах осуществления изобретения вторая ступень кодера на основе искусственной нейронной сети содержит механизм внимания. В некоторых вариантах осуществления изобретения вторая ступень кодера на основе искусственной нейронной сети содержит кодер на основе трансформера. В некоторых вариантах осуществления изобретения вторая ступень кодера на основе искусственной нейронной сети содержит кодер на основе архитектуры модели BERT.
[013] В некоторых вариантах осуществления изобретения одно основанное на токенах пользовательское представление используется с целью формирования рейтинговых оценок для нескольких документов второй ступенью кодера на основе искусственной нейронной сети.
[014] Согласно другому аспекту настоящей технологии реализована система для формирования зависящей от пользователя рейтинговой оценки результатов поиска для документа. Система содержит процессор, память, связанную с процессором, и управляемый процессором кодер на основе искусственной нейронной сети. В памяти хранятся машиночитаемые команды, при исполнении которых процессор получает пользовательский журнал, содержащий историю поиска пользователя, получает поисковый запрос от пользователя, предоставляет пользовательский журнал и поисковый запрос первой ступени кодера на основе искусственной нейронной сети, использует первую ступень кодера на основе искусственной нейронной сети для формирования основанного на токенах пользовательского представления пользовательского журнала и поискового запроса, по меньшей мере частично, на основе определения взаимосвязи между пользовательским журналом и поисковым запросом, получает документ из набора документов из результата поиска, связанных с поисковым запросом, предоставляет основанное на токенах пользовательское представление и документ второй ступени кодера на основе искусственной нейронной сети и использует вторую ступень кодера на основе искусственной нейронной сети с целью формирования рейтинговой оценки для документа, по меньшей мере частично, на основе определения взаимосвязи между основанным на токенах пользовательским представлением и документом.
[015] В некоторых вариантах осуществления изобретения в памяти дополнительно хранятся машиночитаемые команды, при исполнении которых процессор предоставляет каждый документ из набора документов из результата поиска и основанное на токенах пользовательское представление второй ступени кодера на основе искусственной нейронной сети для формирования набора рейтинговых оценок, каждая из которых связана с соответствующим документом из набора документов из результата поиска, и использует набор рейтинговых оценок для ранжирования набора документов из результата поиска.
[016] В некоторых вариантах осуществления изобретения первая ступень кодера на основе искусственной нейронной сети содержит кодер на основе трансформера. В некоторых вариантах осуществления изобретения основанное на токенах пользовательское представление содержит последовательность токенов классификатора. В некоторых вариантах осуществления изобретения вторая ступень кодера на основе искусственной нейронной сети содержит кодер на основе трансформера.
Краткое описание чертежей
[017] Эти и другие признаки, аспекты и преимущества настоящей технологии поясняются в дальнейшем описании, приложенной формуле изобретения и на следующих чертежах.
[018] На фиг. 1 представлена схема примера компьютерной системы для использования в некоторых вариантах реализации систем и/или способов согласно настоящей технологии.
[019] На фиг. 2 представлена блок-схема архитектуры модели машинного обучения на основе модели машинного обучения BERT согласно различным вариантам осуществления настоящей технологии.
[020] На фиг. 3 представлены данные о пользователе, которые могут быть доступными в различных вариантах осуществления настоящей технологии, и результаты поиска, подлежащие ранжированию.
[021] На фиг. 4 представлена блок-схема разделенной архитектуры модели машинного обучения на основе модели BERT согласно различным вариантам осуществления настоящей технологии.
[022] На фиг. 5 представлена блок-схема компьютерного способа формирования зависящей от пользователя рейтинговой оценки согласно различным вариантам осуществления настоящей технологии.
[023] На фиг. 6 представлена блок-схема компьютерного способа предоставления ранжированных результатов поиска согласно различным вариантам осуществления настоящей технологии.
Осуществление изобретения
[024] Различные иллюстративные варианты осуществления настоящей технологии более полно описаны ниже со ссылкой на приложенные чертежи. При этом настоящая технология может быть реализована во многих формах и не должна рассматриваться как ограниченная описанными здесь иллюстративными вариантами осуществления. Абсолютные и относительные размеры слоев и областей могут быть увеличенными на чертежах для ясности. Одинаковые числовые обозначения повсюду относятся к одинаковым элементам.
[025] Представленные здесь примеры и условный язык предназначены для обеспечения лучшего понимания принципов настоящей технологии, а не для ограничения ее объема до таких специально приведенных примеров и условий. Должно быть понятно, что специалисты в данной области техники способны разработать различные способы и устройства, которые явно не описаны и не показаны, но реализуют принципы настоящей технологии в пределах ее существа и объема.
[026] Кроме того, чтобы способствовать лучшему пониманию, последующее описание может содержать упрощенные варианты реализации настоящей технологии. Специалистам в данной области должно быть понятно, что другие варианты осуществления настоящей технологии могут быть значительно сложнее.
[027] В некоторых случаях приводятся полезные примеры модификаций настоящей технологии. Они способствуют пониманию, но также не определяют объема или границ настоящей технологии. Представленный перечень модификаций не является исчерпывающим и специалист в данной области может разработать другие модификации в пределах объема настоящей технологии. Кроме того, если в некоторых случаях модификации не описаны, это не означает, что они невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии.
[028] Должно быть понятно, что несмотря на использование здесь числительных «первый», «второй», «третий» и т.д. для описания различных элементов, такие элементы не должны ограничиваться этими числительными. Эти числительные используются для указания на различие между элементами. Таким образом, первый элемент можно было бы назвать вторым элементом без выхода за границы настоящей технологии. В контексте данного документа термин «и/или» соответствует любому элементу и всем сочетаниям элементов из числа соответствующих перечисленных элементов.
[029] Также должно быть понятно, что если указано на соединение или связь элемента с другим элементом, то он может быть непосредственно соединен или связан с другим элементом либо при этом могут присутствовать промежуточные элементы. Если же указано, что элемент непосредственно соединен или непосредственно связан с другим элементом, то промежуточные элементы отсутствуют. Другие слова, используемые для описания взаимосвязи между элементами, следует интерпретировать аналогичным образом (например, «между» и «непосредственно между», «примыкающий» и «непосредственно примыкающий» и т.д.).
[030] Используемая здесь терминология предназначена лишь для описания конкретных иллюстративных вариантов осуществления, но не для ограничения объема охраны настоящей технологии. Используемые здесь слова в единственном числе также подразумевают слова во множественном числе, если контекст явно не указывает на иное. Должно быть понятно, что используемые здесь термины «содержит» и/или «содержащий» соответствуют наличию указанных признаков, частей, шагов, операций, элементов и/или компонентов, но не исключают наличия или добавления одного или нескольких других признаков, частей, шагов, операций, элементов, компонентов и/или их групп.
[031] Функции различных элементов, показанных на чертежах, включая любой функциональный блок, обозначенный как «процессор», могут быть реализованы с использованием специализированных аппаратных средств, а также аппаратных средств, способных выполнять программное обеспечение. Если используется процессор, эти функции могут выполняться одним выделенным процессором, одним совместно используемым процессором или множеством отдельных процессоров, некоторые из которых могут использоваться совместно. В некоторых вариантах осуществления настоящей технологии процессор может представлять собой процессор общего назначения, такой как центральный процессор (CPU), или специализированный процессор, такой как цифровой сигнальный процессор (DSP). Кроме того, явное использование термина «процессор» не должно трактоваться как указание исключительно на аппаратные средства, способные выполнять программное обеспечение, и может, помимо прочего, подразумевать специализированную интегральную схему (ASIC), программируемую вентильную матрицу (FPGA), постоянное запоминающее устройство (ПЗУ) для хранения программного обеспечения, оперативное запоминающее устройство (ОЗУ) и энергонезависимое запоминающее устройство. Также могут подразумеваться другие аппаратные средства, общего назначения и/или заказные.
[032] Программные модули либо просто модули или блоки, реализация которых предполагается в виде программных средств, могут быть представлены здесь как любое сочетание элементов блок-схемы или других элементов, указывающих на выполнение шагов процесса и/или содержащих его текстовое описание. Такие модули могут выполняться аппаратными средствами, показанными явно или подразумеваемыми. Должно быть понятно, что модуль, помимо прочего, может содержать обеспечивающие требуемые возможности компьютерную программную логику, компьютерные программные команды, прикладное программное обеспечение, стек, встроенное программное обеспечение, цепи аппаратных средств либо их сочетание, но не ограничиваясь ими.
[033] В контексте настоящего описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, где реализован процесс, обеспечивающий хранение или использование информации, хранящейся в базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
[034] Настоящая технология может быть реализована в виде системы, способа и/или компьютерного продукта. Компьютерный программный продукт может содержать машиночитаемый носитель информации (или несколько носителей), хранящий машиночитаемые программные команды, при исполнении которых процессор обеспечивает реализацию аспектов настоящей технологии. Машиночитаемый носитель информации, например, может представлять собой электронное запоминающее устройство, магнитное запоминающее устройство, оптическое запоминающее устройство, электромагнитное запоминающее устройство, полупроводниковое запоминающее устройство или любое подходящее их сочетание. Неполный перечень более конкретных примеров машиночитаемого носителя информации включает в себя портативный компьютерный диск, жесткий диск, ОЗУ, ПЗУ, флэш-память, оптический диск, карту памяти, гибкий диск, носитель с механическим или визуальным кодированием (например, перфокарту или штрих-код) и/или любое их сочетание. В данном контексте машиночитаемый носитель информации должен рассматриваться как машиночитаемый физический носитель информации. Он не должен рассматриваться как изменяющийся сигнал, такой как радиоволны или другие свободно распространяющиеся электромагнитные волны, электромагнитные волны, распространяющиеся через волновод или другую среду передачи (например, световые импульсы, проходящие через волоконно-оптический кабель), или электрические сигналы, передаваемые по проводам.
[035] Должно быть понятно, что машиночитаемые программные команды могут быть загружены из машиночитаемого носителя информации в соответствующие вычислительные или обрабатывающие устройства либо во внешний компьютер или во внешнее запоминающее устройство через сеть, например, через сеть Интернет, локальную сеть, глобальную сеть и/или беспроводную сеть. Сетевой интерфейс в вычислительном или обрабатывающем устройстве может получать машиночитаемые программные команды через сеть и пересылать машиночитаемые программные команды для хранения на машиночитаемом носителе информации в соответствующем вычислительном или обрабатывающем устройстве.
[036] Машиночитаемые программные команды для выполнения операций согласно настоящей технологии могут представлять собой команды ассемблера, машинные команды, команды встроенного программного обеспечения, данные конфигурации для интегральных схем либо другой исходный или объектный код, написанный с использованием любого сочетания языков программирования. Машиночитаемые программные команды могут исполняться полностью на компьютере пользователя, частично на компьютере пользователя, как отдельный пакет программного обеспечения, частично на компьютере пользователя и частично на удаленном компьютере или полностью на удаленном компьютере либо сервере. В последнем случае удаленный компьютер может быть связан с компьютером пользователя через сеть любого вида.
[037] Описание принципов, аспектов и вариантов реализации настоящей технологии, а также их конкретные примеры предназначены для охвата их структурных и функциональных эквивалентов, независимо от того, известны они в настоящее время или будут разработаны в будущем. Например, специалистам в данной области техники должно быть понятно, что любые описанные здесь структурные схемы соответствуют концептуальным представлениям иллюстративных принципиальных схем, реализующих основы настоящей технологии. Также должно быть понятно, что любые блок-схемы, схемы процессов, диаграммы изменения состояния, псевдокоды и т.п. соответствуют различным процессам, которые могут быть представлены в машиночитаемых программных командах. Эти машиночитаемые программные команды могут быть предоставлены процессору или другому программируемому устройству обработки данных для формирования механизма так, чтобы команды, выполняемые процессором компьютера или другим программируемым устройством обработки данных, обеспечивали средства для реализации функций или действий, указанных в блок-схеме, и/или блока либо блоков блок-схемы. Эти машиночитаемые программные команды также могут быть сохранены на машиночитаемом носителе информации, который может предписывать компьютеру, программируемому устройству обработки данных и/или другим устройствам функционировать так, чтобы машиночитаемый носитель информации с хранящимися на нем командами содержал изделие, включая команды, реализующее аспекты функций или действий, указанных в блок-схемах, схемах процессов, диаграммах изменения состояния, псевдокодах и т.п.
[038] Эти машиночитаемые программные команды также могут быть загружены в компьютер, иное программируемое устройство обработки данных или другие устройства, чтобы инициировать последовательность рабочих шагов, подлежащих выполнению в компьютере, ином программируемом устройстве или других устройствах, с целью формирования вычислительного процесса так, чтобы команды, исполняемые в компьютере, ином программируемом устройстве или других устройствах, реализовывали функции или действия, указанные в блок-схемах, схемах процессов, диаграммах изменения состояния, псевдокодах и т.п.
[039] В некоторых альтернативных вариантах осуществления изобретения функции, указанные на блок-схемах, схемах процессов, диаграммах изменения состояния, в псевдокодах и т.п., могут реализовываться в порядке, отличном от указанного на чертежах. Например, два блока, представленные на блок-схеме как последовательные, фактически могут выполняться одновременно или эти блоки иногда могут выполняться в обратном порядке – в зависимости от реализуемой функции. Также следует отметить, что каждая функция, указанная на чертежах, и сочетания таких функций могут быть реализованы системами на основе специализированных аппаратных средств, выполняющих указанные функции или действия, либо сочетаниями специализированных аппаратных средств и компьютерных команд.
[040] Далее с учетом вышеизложенных принципов рассмотрены некоторые не имеющие ограничительного характера примеры, иллюстрирующие различные варианты реализации аспектов настоящей технологии.
Компьютерная система
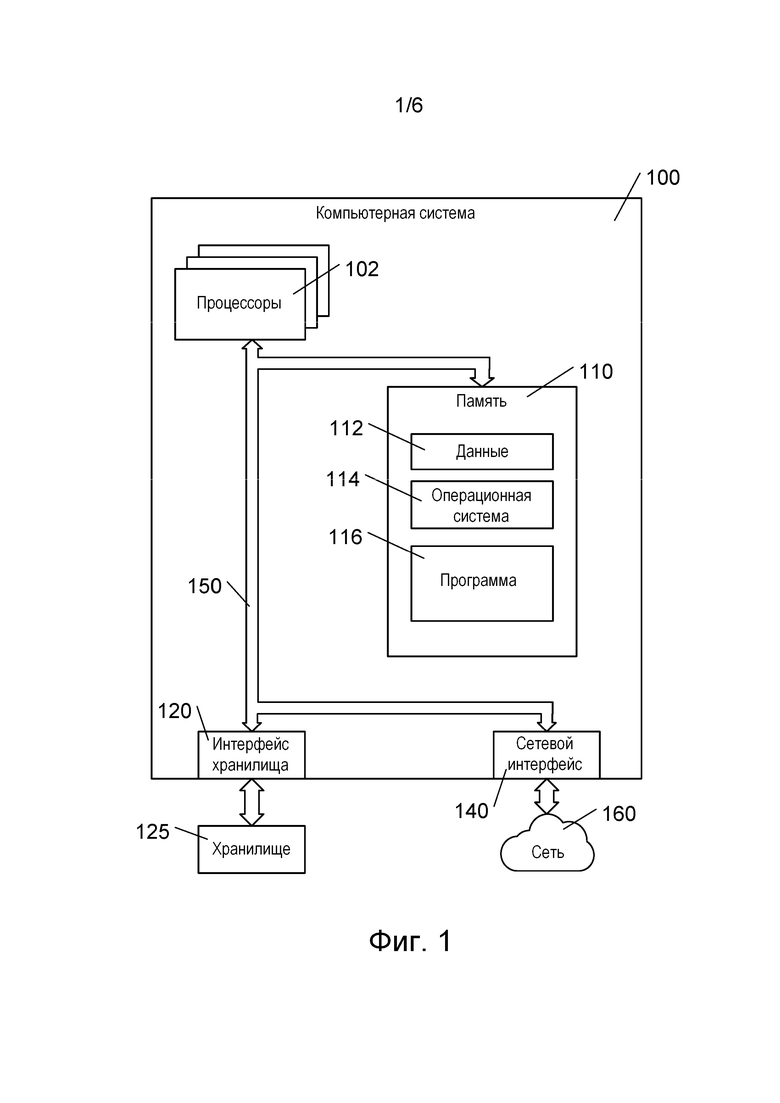
[041] На фиг. 1 представлена компьютерная система 100. Компьютерная система 100 может представлять собой многопользовательский компьютер, однопользовательский компьютер, ноутбук, планшетный компьютер, смартфон, встроенную систему управления или любую другую компьютерную систему, которая известна в настоящее время или будет разработана в будущем. Кроме того, следует понимать, что некоторые или все элементы компьютерной системы 100 могут быть виртуализированы и/или основаны на облачных вычислениях. Как показано на фиг. 1, компьютерная система 100 содержит один или несколько процессоров 102, память 110, интерфейс 120 хранилища данных и сетевой интерфейс 140. Эти элементы системы связаны через шину 150, которая может содержать одну или несколько внутренних и/или внешних шин (не показаны), таких как шина PCI, шина USB, шина FireWire стандарта IEEE 1394, шина SCSI, шина Serial-ATA и т.д., с которыми различные аппаратные элементы соединены электронными средствами.
[042] Память 110 может представлять собой ОЗУ или память любого другого вида и может содержать данные 112, операционную систему 114 и программу 116. Данные 112 могут представлять собой любые данные, соответствующие входным или выходным данным любой программы в компьютерной системе 100. Операционная система 114 представляет собой операционную систему, такую как Microsoft Windows или Linux. Программа 116 может представлять собой любую программу или набор программ, содержащих запрограммированные команды, которые могут исполняться процессором для управления действиями, выполняемыми компьютерной системой 100. Например, программа 116 может представлять собой обучающий модуль машинного обучения, который обучает модель машинного обучения, как описано ниже. Программа 116 также может представлять собой систему, использующую обученную модель машинного обучения для ранжирования результатов поиска, как описано ниже.
[043] Интерфейс 120 хранилища данных используется для подключения к компьютерной системе 100 запоминающих устройств, таких как хранилище 125. Хранилище 125 одного вида представляет собой твердотельный накопитель, который может использовать блок интегральных схем для постоянного хранения данных. Хранилище 125 другого вида представляет собой накопитель на жестких дисках, такой как электромеханическое устройство, использующее магнитное запоминающее устройство для хранения и извлечения цифровых данных. Хранилище 125 также может представлять собой накопитель на оптических дисках, устройство для считывания карт памяти, таких как SD-карта, или устройство флэш-памяти, которое может быть подключено к компьютерной системе 100, например, через универсальную последовательную шину (USB).
[044] В некоторых вариантах реализации изобретения в компьютерной системе 100 могут использоваться хорошо известные механизмы виртуальной памяти, позволяющие программам компьютерной системы 100 работать так, как если бы они имели доступ к большому непрерывному адресному пространству, а не обращались к нескольким областям памяти меньшего размера, таким как память 110 и хранилище 125. Таким образом, несмотря на то, что данные 112, операционная система 114 и программы 116 показаны как размещенные в памяти 110, специалисту в данной области техники должно быть понятно, что эти элементы не обязательно должны одновременно полностью содержаться в памяти 110.
[045] Процессоры 102 могут содержать один или несколько микропроцессоров и/или других интегральных схем. Процессоры 102 исполняют программные команды, хранящиеся в памяти 110. При запуске компьютерной системы 100 процессоры 102 могут сначала выполнять процедуру загрузки и/или исполнять программные команды, формирующие операционную систему 114.
[046] Сетевой интерфейс 140 используется для подключения компьютерной системы 100 к другим компьютерным системам или сетевым устройствам (не показаны) через сеть 160. Сетевой интерфейс 140 может содержать сочетание аппаратных и программных средств, обеспечивающих связь через сеть 160. В некоторых вариантах реализации изобретения сетевой интерфейс 140 может представлять собой беспроводной сетевой интерфейс. Программное обеспечение сетевого интерфейса 140 может содержать программное обеспечение, использующее один или несколько сетевых протоколов для связи через сеть 160. Например, сетевые протоколы могут включать в себя протокол управления передачей/интернет-протокол (TCP/IP, Transmission Control Protocol/Internet Protocol).
[047] Должно быть понятно, что компьютерная система 100 представляет собой лишь пример и что описанная технология может быть использована с компьютерными системами или другими компьютерными устройствами другой конфигурации.
Архитектура BERT
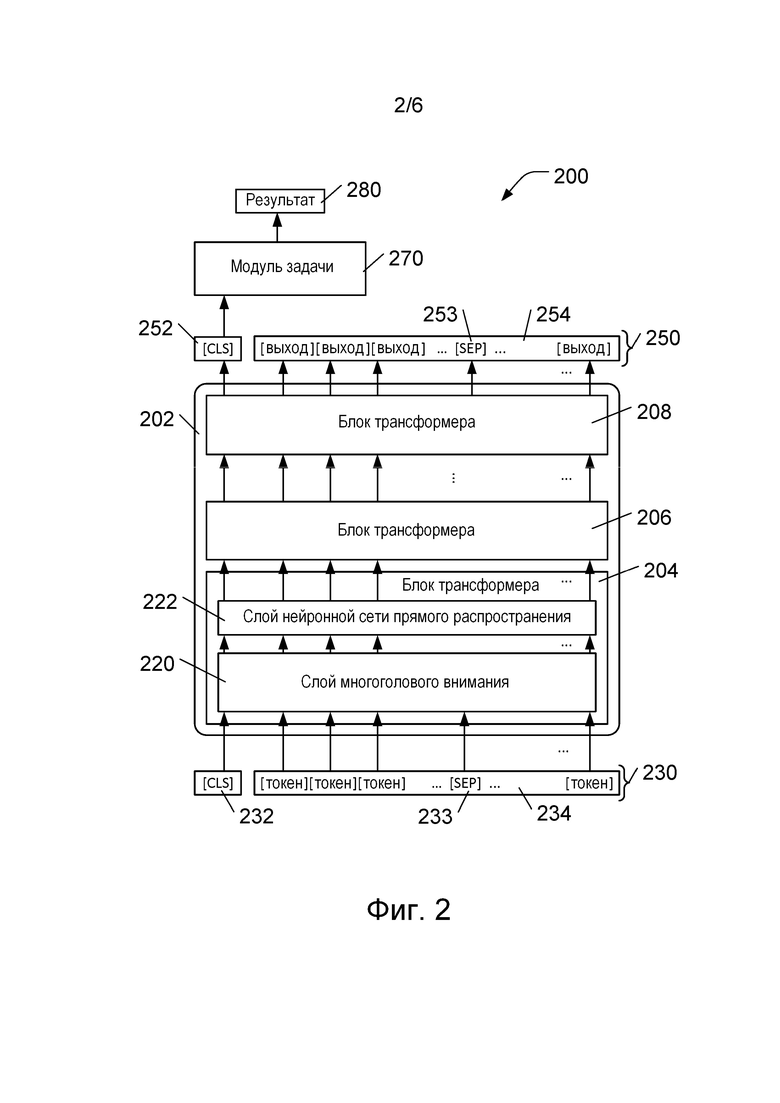
[048] На фиг. 2 представлена блок-схема архитектуры 200 модели машинного обучения на основе модели машинного обучения BERT, описанной, например, в указанной выше работе Devlin et al. Архитектура 200 модели машинного обучения содержит стек 202 трансформеров, состоящий из блоков трансформеров, включая, например, блоки 204, 206 и 208 трансформеров.
[049] Каждый из блоков 204, 206 и 208 трансформеров содержит блок кодера трансформера, например, как описано в указанной выше работе Vaswani et al. Каждый из блоков 204, 206 и 208 трансформеров содержит слой 220 многоголового внимания (на фиг. 2 показан для иллюстрации только в блоке 204 трансформера) и слой 222 нейронной сети прямого распространения (также для иллюстрации показан только в блоке 204 трансформера). Блоки 204, 206 и 208 обычно имеют одинаковую структуру, но имеют различные веса (после обучения). В слое 220 многоголового внимания реализованы зависимости между входными данными блока трансформера, которые, например, могут использоваться с целью предоставления контекстной информации для каждого элемента входных данных на основе каждого другого элемента входных данных блока трансформера. В слое 222 нейронной сети прямого распространения эти зависимости обычно отсутствуют, поэтому входные данные слоя 222 нейронной сети прямого распространения могут обрабатываться параллельно. Должно быть понятно, что несмотря на то, что на фиг. 2 показано лишь три блока трансформеров (блоки 204, 206 и 208 трансформеров), в практических вариантах реализации настоящей технологии стек 202 трансформеров может содержать намного больше таких блоков трансформеров. Например, в некоторых вариантах реализации изобретения в стеке 202 трансформеров может использоваться 12 блоков трансформеров.
[050] Входные данные 230 стека 202 трансформеров содержат токены, такие как токен 232 [CLS], токен 233 [SEP] и токены 234. Токены 234 могут, например, представлять слова или части слов. Токен 232 [CLS] является токеном классификации и используется в качестве представления для классификации всего набора токенов. Токен 233 [SEP] используется для разделения последовательностей токенов, если входные данные 230 содержат несколько последовательностей. Например, если входные данные 230 содержат два предложения, то токен 233 [SEP] может использоваться, чтобы отделить токены первого предложения от токенов второго предложения.
[051] Каждый токен 234, токен 232 [CLS] и токен 233 [SEP] представлен вектором. В некоторых вариантах осуществления изобретения длина каждого из этих векторов может, например, соответствовать 768 значениям с плавающей запятой. Должно быть понятно, что для эффективного уменьшения размеров токенов может использоваться множество способов сжатия. В различных вариантах осуществления изобретения в качестве входных данных 230 стека 202 трансформеров может использоваться фиксированное количество токенов. Например, в некоторых вариантах осуществления изобретения могут использоваться 1024 токена (помимо токена 232 [CLS]), а в других вариантах осуществления изобретения стек 202 трансформеров может получать 512 токенов (помимо токена 232 [CLS]). Входные данные 230, которые оказываются короче этого фиксированного количества токенов 234, могут быть дополнены до фиксированной длины путем добавления дополнительных токенов.
[052] Токены во входных данных 230 могут содержать информацию нескольких видов, включая информацию токена (не показано), информацию о положении (не показано) и информацию о сегменте (не показано). Информация токена кодирует входной текст с использованием заранее созданного словаря токенов, подходящих для текста на естественном языке. В некоторых вариантах осуществления изобретения это может быть реализовано путем использования известной схемы кодирования пар байтов WordPiece с достаточно большим размером словаря. Например, в некоторых вариантах осуществления изобретения размер словаря может быть приблизительно равен 30 000 токенов, представляющих самые распространенные слова и части слов, например, обнаруженные в английском языке. В некоторых вариантах осуществления изобретения может использоваться больший размер словаря, например, 120 000 токенов, чтобы обеспечить токены для специализированного словаря или чтобы представить информацию, отличную от слов и/или частей слов естественного языка. Токены обычно представлены в числовом виде. Схема кодирования пар байтов WordPiece, которая может быть использована в некоторых вариантах осуществления изобретения для построения словаря токенов, описана, например, в работе Rico Sennrich et al. «Neural Machine Translation of Rare Words with Subword Units», Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), 2016, стр. 1715–1725.
[053] Информация о положении кодирует положение токена в последовательности входных данных 230. Например, токен 232 [CLS] обычно находится в позиции 0, а токены 234 – в позициях 1, 2, 3 и т.д. Благодаря кодированию информации о положении во входных данных 230 модель может учитывать позиции слов.
[054] Информация о последовательности, содержащаяся в токене, кодирует последовательность, с которой связан токен. Например, если входные данные 230 содержат два предложения, каждое из которых обрабатывается как последовательность, то информация о последовательности из токена кодирует информацию о том, с каким предложением связан токен.
[055] Выходные данные 250 стека 202 трансформеров содержат выходные данные 252 [CLS] и векторные выходные данные 254, включая векторные выходные данные для каждого токена 234 из входных данных 230 стека 202 трансформеров. Если входные данные 230 содержат токен 233 [SEP], то выходные данные 250 также могут содержать выходные данные 253 [SEP].
[056] Выходные данные 250 могут быть отправлены модулю 270 задачи. В некоторых вариантах осуществления изобретения, как показано на фиг. 2, модуль 270 задачи использует только выходные данные 252 [CLS], представляющие весь набор выходных данных 254. Это наиболее полезно, когда модуль 270 задачи используется для задачи классификации либо для вывода метки или значения, характеризующего все входные данные. В некоторых вариантах осуществления изобретения (не показано на фиг. 2) все или некоторые выходные данные 254 и, возможно, выходные данные 252 [CLS] могут использоваться в качестве входных данных для модуля 270 задачи. Это наиболее полезно, когда модуль 270 задачи используется с целью формирования меток или значений для отдельных входных токенов 234, например, для прогнозирования замаскированного или отсутствующего токена либо для распознавания заданного объекта. В некоторых вариантах осуществления изобретения модуль 270 задачи может содержать нейронную сеть прямого распространения (не показана), формирующую зависящий от задачи результат 280, такой как оценка релевантности. В модуле 270 задачи также могут использоваться другие модели. Например, модуль 270 задачи может представлять собой трансформер или нейронную сеть другого вида.
[057] В некоторых вариантах осуществления изобретения обучение модели BERT включает в себя два этапа – предварительное обучение и точную настройку. Предварительное обучение используется для обучения стека 202 трансформеров обнаружению общих лингвистических паттернов в тексте с использованием большого неразмеченного обучающего корпуса. В некоторых вариантах осуществления изобретения этот неразмеченный обучающий корпус может, например, представлять собой контент свободной энциклопедии Wikipedia или текст тысяч книг. Во время точной настройки предварительно обученная модель используется в качестве основы для обучения модуля 270 задачи и стека 202 трансформеров выполнению конкретных задач, таких как ранжирование результатов поиска или классификация текста, с использованием намного меньшего размеченного обучающего набора данных.
[058] Модель BERT предварительно обучается с использованием двух задач обучения без учителя. Первая из них представляет собой маскированное языковое моделирование (MLM, Masked Language Modeling). Для предварительного обучения с использованием задачи MLM один или несколько токенов из входных данных модели машинного обучения маскируются путем замены их на специальный токен [MASK] (не показано). Модель машинного обучения обучается прогнозированию вероятностей соответствия замаскированного токена токенам из словаря токенов. Это выполняется на основе соответствующих замаскированным токенам выходных данных 250 (каждый элемент которых представляет собой вектор) последнего слоя стека 202 трансформеров. Поскольку фактические замаскированные токены известны (т.е. имеется контрольная информация), потери кросс-энтропии, представляющие меру отклонения прогнозируемых вероятностей от фактических замаскированных токенов (здесь называются потерями MLM), рассчитываются и используются для корректировки весов в модели машинного обучения с целью уменьшения этих потерь.
[059] В некоторых вариантах осуществления изобретения для маскирования случайным образом выбирается заранее заданная часть входных токенов 234, например, 15%. Заранее заданная часть этих выбранных случайным образом токенов, например, 80% заменяется токеном [MASK], а вторая заранее заданная часть, например, 10% заменяется случайными токенами, выбранными из словаря. Оставшиеся выбранные токены (10% в данном примере) не изменяются.
[060] Вторая задача обучения без учителя, используемая при предварительном обучении модели BERT, представляет собой задачу предсказания следующего предложения (NSP, Next Sentence Prediction). Для предварительного обучения модели с использованием задачи NSP в качестве входных данных 230 используются пары предложений (обычно разделенных токеном [SEP]). Во время предварительного обучения модели половина входных данных представляет собой пару предложений, в которых второе предложение следует за первым предложением в обучающем корпусе. В другой половине входных данных второе предложение случайным образом выбрано из обучающего корпуса и поэтому не связано с первым предложением. Модель обучается определению вероятности того, что второе предложение следует за первым предложением. Обычно при этом используется слой классификации (не показан), который получает выходные данные 252 [CLS] в качестве входных данных и определяет вероятность того, что второе предложение следует за первым предложением (например, с использованием многопеременной логистической функции (softmax)). Поскольку системе известна контрольная информация для любой пары предложений, потери (потери NSP) могут быть рассчитаны и использованы для корректировки весов в модели машинного обучения с целью уменьшения этих потерь.
[061] Точная настройка модели на основе технологии BERT для выполнения конкретной задачи обычно предусматривает использование предварительно обученного стека 202 трансформеров и добавление модуля 270 задачи для конкретной задачи. Для большинства задач модуль 270 задачи может быть намного меньше стека 202 трансформеров и может быть обучен с использованием значительно меньшего размеченного обучающего набора данных.
[062] В некоторых вариантах осуществления изобретения предварительное обучение стека 202 трансформеров может представлять собой процесс, требующий относительно длительного времени, например, нескольких суток. Точная настройка может быть значительно более быстрой. В некоторых вариантах осуществления изобретения предварительное обучение может выполняться только один раз, а его результат впоследствии может использоваться многократно для многих применений путем замены модуля 270 задачи и точной настройки для конкретного применения.
[063] Должно быть понятно, что архитектура модели, описанная со ссылкой на фиг. 2, упрощена для лучшего понимания. Например, в фактических вариантах реализации архитектуры 200 модели машинного обучения каждый из блоков 204, 206 и 208 трансформеров может содержать операции нормализации слоя, модуль 270 задачи может содержать функцию нормализации softmax и т.д. Специалистам в данной области должно быть понятно, что эти операции широко используются в нейронных сетях и моделях глубокого обучения, таких как архитектура 200 модели машинного обучения.
Персонализированное ранжирование результатов поиска
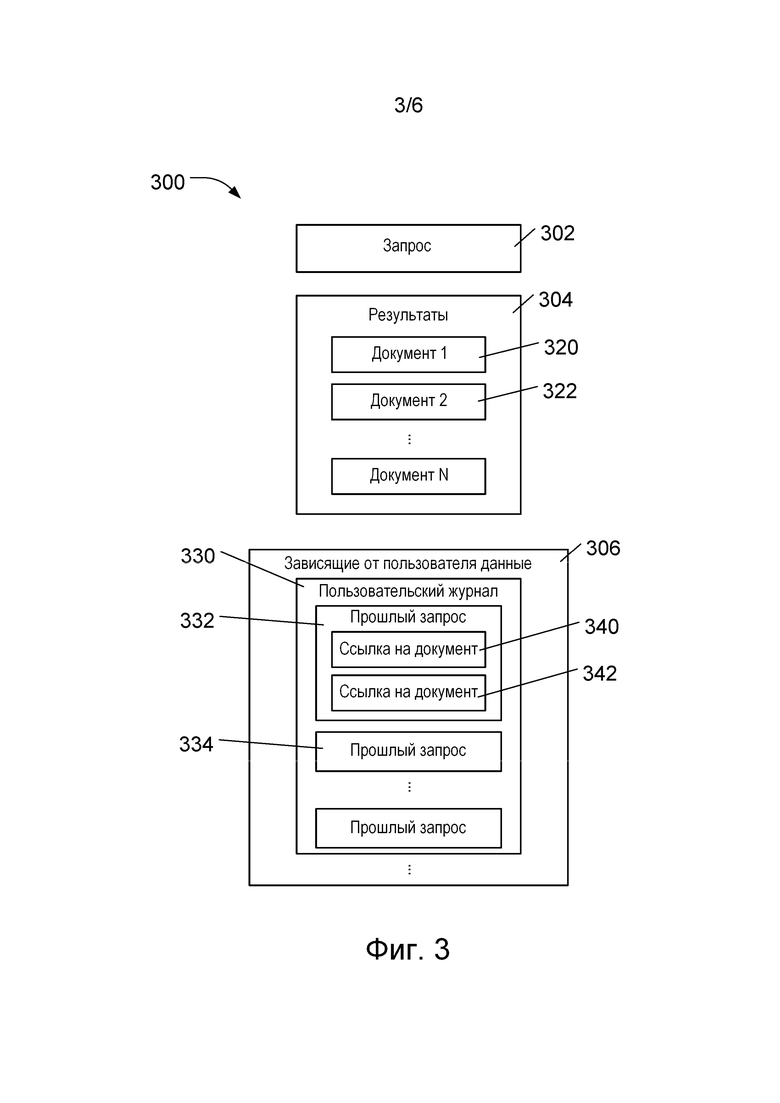
[064] Согласно различным вариантам осуществления настоящей технологии, архитектура модели машинного обучения на основе технологии BERT, например, описанная со ссылкой на фиг. 2, может использоваться с целью предоставления рейтинговых оценок для результатов поиска. Эти результаты могут быть персонализированы для пользователя в соответствии с информацией о пользователе, доступной системе ранжирования. На фиг. 3 представлены данные 300 о пользователе, которые могут быть доступными в различных вариантах осуществления настоящей технологии, и результаты поиска, подлежащие ранжированию.
[065] Данные содержат запрос 302 текущего поиска, результаты которого подлежат ранжированию. Данные также содержат набор 304 результатов, подлежащих ранжированию системой. Набор 304 результатов обычно содержит множество документов, таких как документы 320 и 322, представляющих собой результаты, сформированные поисковой системой (не показана) на основе запроса 302.
[066] Кроме того, данные содержат зависящие от пользователя данные 306. В некоторых вариантах осуществления изобретения зависящие от пользователя данные 306 могут содержать данные 330 пользовательского журнала, содержащие прошлые запросы пользователя, такие как прошлые запросы 332 и 334. В некоторых вариантах осуществления изобретения информация о результатах прошлого запроса может содержать результаты прошлого запроса и/или документы из результатов, просмотренных пользователем. Например, для прошлого запроса 332 данные 330 пользовательского журнала содержат ссылки 340 и 342 на документы, просмотренные пользователем из результатов прошлого запроса 332. Должно быть понятно, что содержимое зависящих от пользователя данных 306 может отличаться в разных вариантах осуществления изобретения, но обычно они содержат зарегистрированные данные, такие как данные 330 пользовательского журнала.
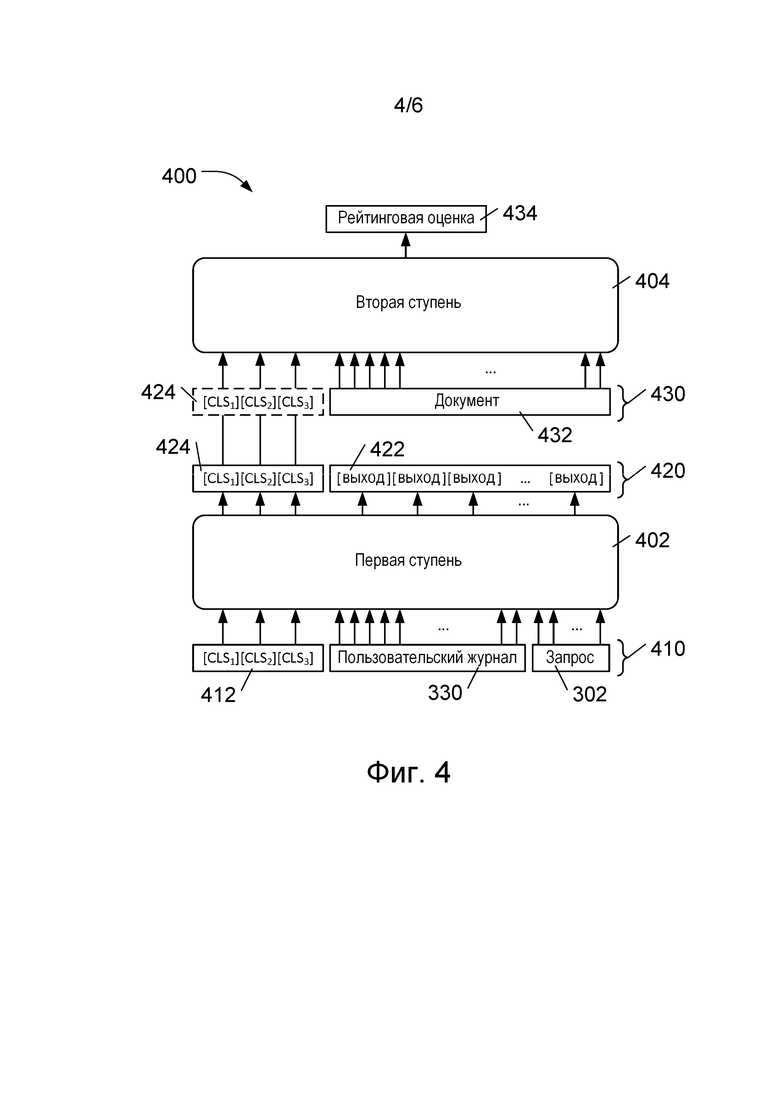
[067] На фиг. 4 представлена блок-схема разделенной архитектуры 400 модели машинного обучения на основе модели BERT согласно некоторым вариантам осуществления настоящей технологии. Разделенная архитектура 400 модели машинного обучения на основе технологии BERT включает в себя первую ступень 402 кодера на основе нейронной сети и вторую ступень 404 кодера на основе нейронной сети. Первая ступень 402 содержит стек трансформеров (не показан) с архитектурой предварительно обученной модели на основе технологии BERT, например, согласно представленному выше со ссылкой на фиг. 2 описанию, в котором используется последовательность токенов классификатора ([CLS]), а не один токен классификатора (на фиг. 4 показано три таких токена, но может использоваться и другое количество токенов классификатора). Входные данные 410 первой ступени 402 содержат данные 330 пользовательского журнала, запрос 302 и первоначальные значения в последовательности токенов 412 классификатора. Данные 330 пользовательского журнала и запрос 302 обеспечивают зависящую от пользователя информацию. Данные 330 пользовательского журнала обычно содержат прошлые запросы пользователя, а запрос 302 представляет собой текущий запрос пользователя. Как описано выше со ссылкой на фиг. 2, в некоторых вариантах осуществления изобретения входные данные 410 могут быть токенизированы и могут также содержать информацию о положении и о последовательности (не показано).
[068] На основе входных данных 410 первая ступень 402 формирует выходные данные 420, содержащие выходные токены 422 и последовательность выходных токенов 424 классификатора. Выходные токены 424 классификатора кодируют информацию о взаимосвязях (по меньшей мере об основанных на контексте лингвистических взаимосвязях, фиксируемых моделью BERT) внутри и между данными 330 пользовательского журнала и запросом 302. Благодаря двунаправленности модели машинного обучения на основе технологии BERT последовательность выходных токенов 424 классификатора кодирует информацию, относящуюся ко всем входным данным 410 и взаимосвязям во входных данных 410.
[069] Использование последовательности токенов классификатора обеспечивает кодирование увеличенного объема информации, касающейся данных 330 пользовательского журнала и запроса 302, в последовательности выходных токенов 424 классификатора. Количество выходных токенов классификатора в последовательности выходных токенов 424 классификатора может отличаться в разных вариантах осуществления изобретения и может рассматриваться как проектное решение, обеспечивающее оптимальное соотношение между скоростью и качеством персонализированного ранжирования.
[070] Последовательность выходных токенов 424 классификатора может рассматриваться как компактное представление зависящей от пользователя информации в данных 330 пользовательского журнала с учетом их связи с запросом 302. Поскольку она содержит зависящую от пользователя информацию, которая может быть использована для формирования персонализированных рейтинговых оценок результатов поиска по запросу 302 для пользователя, последовательность выходных токенов 424 классификатора эффективно обеспечивает основанное на токенах пользовательское представление, которое может быть рассчитано один раз для каждого поиска, а затем может быть использовано с каждым документом из набора 304 результатов.
[071] Первая ступень 402 кодера на основе нейронной сети может быть предварительно обучена с использованием задачи MLM и задачи NSP, как описано выше, с применением нескольких токенов классификатора вместо одного токена классификатора. Как и в случае модели BERT, для этого обучения без учителя может использоваться большой обучающий корпус текстов, преимущественно подобных текстам, встречающимся в поисковых запросах и пользовательских журналах поиска. Вследствие относительно медленной сходимости трансформеров, обучаемых на задачах MLM и NSP, ожидается, что для предварительного обучения может потребоваться относительно длительный период времени, возможно, до нескольких суток. Предварительное обучение может выполняться в автономном режиме.
[072] Вторая ступень 404 кодера на основе нейронной сети включает в себя архитектуру предварительно обученной модели на основе технологии BERT, например, согласно описанию, представленному выше со ссылкой на фиг. 2. Входные данные 430 второй ступени 404 содержат последовательность выходных токенов 424 классификатора из первой ступени 402, представляющих данные 330 пользовательского журнала и запрос 302. Входные данные 430 также содержат документ 432 из набора 304 результатов поиска по запросу 302 (не показано на фиг. 4). Документ 432 может быть токенизирован, как описано выше, а токены могут содержать информацию о положении и о последовательности.
[073] Вторая ступень 404 содержит модуль задачи (не показан), точно настроенный для формирования рейтинговой оценки 434 для документа 432, которая обеспечивает персонализированное ранжирование на основе документа 432 и информации основанного на токенах пользовательского представления, закодированной в последовательности выходных токенов 424 классификатора из первой ступени 402.
[074] Подобно первой ступени 402 кодера, вторая ступень 404 кодера на основе нейронной сети предварительно обучена с использованием задач MLM и NSP, как и в случае предварительно обученной модели BERT. После предварительного обучения, которое может выполняться в автономном режиме, вторая ступень 404 подвергается точной настройке с использованием заранее размеченного набора оценок документов. В некоторых вариантах осуществления изобретения во время точной настройки обучается модуль задачи (не показан), связанный со второй ступенью 404. В некоторых вариантах осуществления изобретения во время точной настройки обучается модуль задачи (не показан), а также вторая ступень 404, а в некоторых вариантах осуществления изобретения – первая ступень 402 кодера на основе нейронной сети.
[075] Во время обработки поискового запроса модель в реальном времени получает от поисковой системы (не показана) набор результатов, содержащий N документов. N документов из набора результатов поиска подлежат ранжированию для пользователя с использованием предыдущей истории поиска пользователя и запроса для персонализированного ранжирования. Первая ступень 402 кодера на основе нейронной сети формирует одну последовательность выходных токенов 424 классификатора. Затем вторая ступень 404 используется для формирования N рейтинговых оценок – по одной рейтинговой оценке для каждого из N документов в наборе результатов поиска. На основе набора из N рейтинговых оценок отдельная модель (не показана) может сформировать окончательный ранжированный набор из N документов.
[076] Одно из преимуществ описанной разделенной архитектуры 400 модели машинного обучения на основе технологии BERT заключается в том, что на множестве итераций второй ступени 404 кодера на основе нейронной сети может использоваться последовательность выходных токенов 424 классификатора, сформированных первой ступенью 402. В результате повышается эффективность формирования персонализированных рангов результатов поиска.
[077] Должно быть понятно, что несмотря на описание первой ступени 402 и второй ступени 404 кодера на основе нейронной сети как основанных на технологии BERT, в некоторых вариантах осуществления изобретения могут использоваться другие архитектуры модели на основе трансформера или на основе нейронной сети. Например, в некоторых вариантах осуществления изобретения две ступени кодера на основе нейронной сети могут содержать стеки трансформеров, которые сходны с частью архитектуры модели BERT или используют количество блоков трансформеров, отличное от обычно используемого в модели BERT. Также возможно много других модификаций или вариантов. Например, как описано выше, количество токенов классификатора в последовательности выходных токенов классификатора может отличаться в разных вариантах осуществления изобретения.
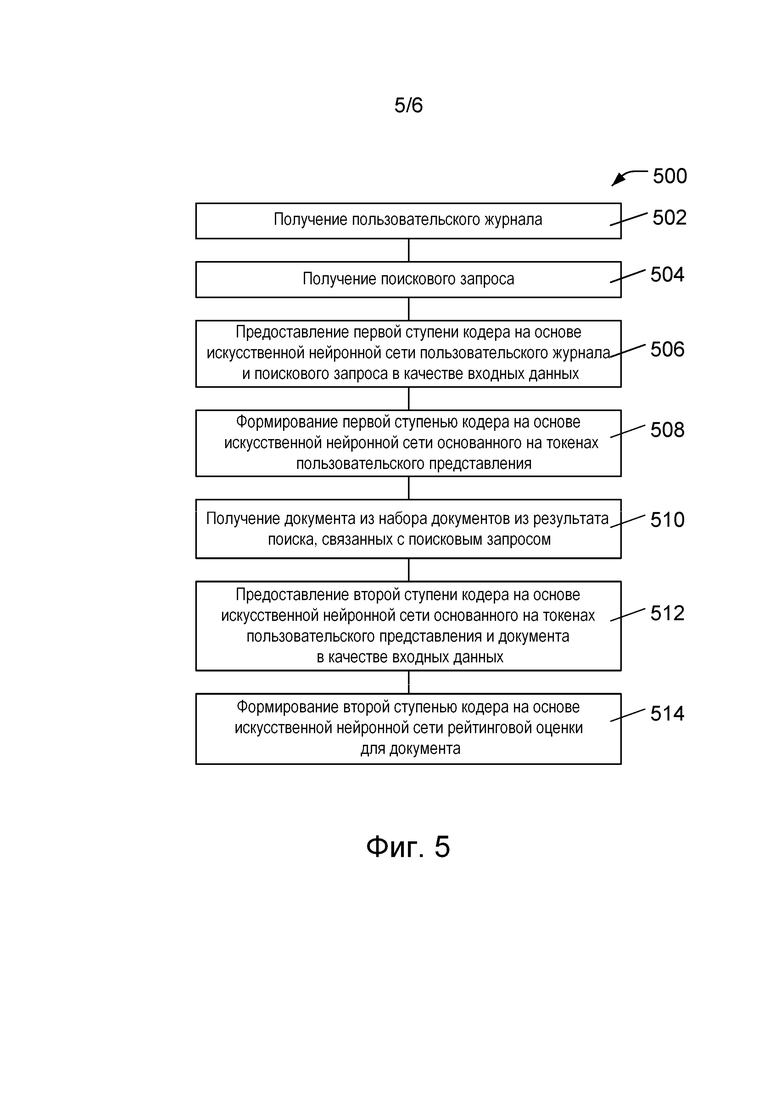
[078] На фиг. 5 представлена блок-схема 500 компьютерного способа формирования зависящей от пользователя рейтинговой оценки согласно различным вариантам осуществления настоящей технологии.
[079] В блоке 502 процессор получает пользовательский журнал, содержащий историю поиска пользователя. Такие журналы или записи прошлых поисков для пользователя обычно сохраняются интерактивными поисковыми системами или службами. Для целей ранжирования результатов поиска поисковая система, формирующая результаты, должна быть способной предоставлять эту информацию процессу ранжирования результатов поиска.
[080] В блоке 504 процессор получает поисковый запрос от пользователя. Поисковый запрос определяет поиск, который выполняется поисковой системой или службой, и может быть отправлен процессору через поисковую систему или службу, которая в ответ на запрос формирует результаты поиска, подлежащие ранжированию.
[081] В блоке 506 процессор предоставляет первой ступени кодера на основе искусственной нейронной сети пользовательский журнал и поисковый запрос в качестве входных данных. Как описано выше, эти входные данные могут быть токенизированы и токены могут также кодировать информацию о положении и о последовательности каждого токена. В некоторых вариантах осуществления изобретения первая ступень кодера на основе искусственной нейронной сети может представлять собой модель на основе трансформера, которая, например, содержит множество блоков трансформеров, каждый из которых может содержать механизм внимания, такой как слой многоголового внимания. В некоторых вариантах осуществления изобретения первая ступень кодера на основе искусственной нейронной сети может основываться на архитектуре модели BERT.
[082] В блоке 508 первая ступень кодера на основе искусственной нейронной сети формирует основанное на токенах пользовательское представление или закодированное представление пользовательского журнала и поискового запроса. В некоторых вариантах осуществления изобретения основанное на токенах пользовательское представление может быть реализовано в виде последовательности токенов классификации, таких как токены [CLS], используемые в модели BERT. Как описано выше, последовательность токенов классификации содержит информацию о пользовательском журнале и поисковом запросе, а также кодирует информацию о взаимосвязях внутри и между пользовательским журналом и поисковым запросом.
[083] В блоке 510 процессор получает документ из набора документов из результата поиска, связанных с поисковым запросом. Набор документов из результата поиска представляет собой соответствующие запросу документы, обнаруженные поисковой системой или службой. Набор документов из результата поиска может быть отправлен поисковой системой или службой для ранжирования этих документов.
[084] В блоке 512 основанное на токенах пользовательское представление, сформированное первой ступенью кодера на основе искусственной нейронной сети, и документ из набора документов из результата поиска предоставляется второй ступени кодера на основе искусственной нейронной сети. Как и первая ступень, вторая ступень кодера на основе искусственной нейронной сети может представлять собой модель на основе трансформера, которая, например, содержит множество блоков трансформеров, каждый из которых может содержать механизм внимания, такой как слой многоголового внимания. В некоторых вариантах осуществления изобретения вторая ступень кодера на основе искусственной нейронной сети может основываться на архитектуре модели BERT. В некоторых вариантах осуществления изобретения вторая ступень может содержать модуль задачи, точно настроенный для определения рейтинговой оценки.
[085] В блоке 514 вторая ступень кодера на основе искусственной нейронной сети формирует рейтинговую оценку для документа. Рейтинговая оценка представляет собой зависящую от пользователя рейтинговую оценку, основанную на зависящей от пользователя информации, закодированной в основанном на токенах пользовательском представлении, на документе из набора документов из результата поиска, а также на взаимосвязях внутри и между этими входными данными второй ступени.
[086] Должно быть понятно, что блоки 502–508, обеспечивающие работу первой ступени кодера на основе искусственной нейронной сети, требуется выполнить лишь один раз для каждого поиска, поскольку основанное на токенах пользовательское представление неизменно для всех документов из набора документов из результата поиска. Блоки 510–514, предназначенные для работы второй ступени кодера на основе искусственной нейронной сети, выполняются для каждого документа из набора документов из результата поиска с целью формирования рейтинговой оценки для каждого документа.
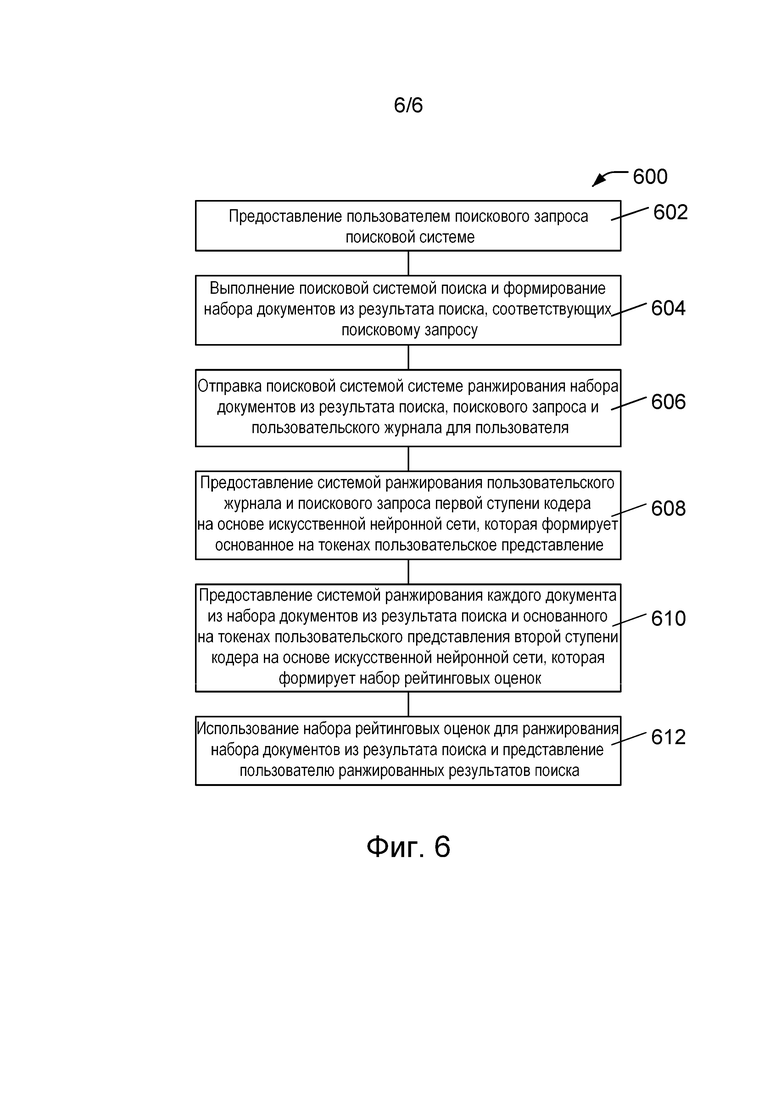
[087] На фиг. 6 представлена блок-схема 600 способа предоставления ранжированных результатов поиска с использованием способа, описанного выше со ссылкой на фиг. 5.
[088] В блоке 602 пользователь предоставляет поисковый запрос поисковой системе или службе. В блоке 604 поисковая система выполняет запрошенный поиск и формирует набор документов из результата поиска, соответствующих поисковому запросу.
[089] В блоке 606 поисковая система отправляет системе ранжирования набор документов из результата поиска, поисковый запрос и пользовательский журнал, содержащий историю поиска пользователя. В блоке 608 система ранжирования предоставляет пользовательский журнал и поисковый запрос первой ступени кодера на основе искусственной нейронной сети, как описано выше со ссылкой на блоки 502–508, представленные на фиг. 5. Первая ступень кодера на основе искусственной нейронной сети формирует основанное на токенах пользовательское представление.
[090] В блоке 610 система ранжирования предоставляет каждый документ из набора документов из результата поиска и основанное на токенах пользовательское представление второй ступени кодера на основе искусственной нейронной сети, как описано выше со ссылкой на блоки 510–514, представленные на фиг. 5. Вторая ступень кодера на основе искусственной нейронной сети формирует набор рейтинговых оценок, каждая из которых связана с соответствующим документом из набора документов из результата поиска.
[091] В блоке 612 набор рейтинговых оценок используется для ранжирования набора документов из результата поиска и ранжированные результаты поиска представляются пользователю. В некоторых вариантах осуществления изобретения набор рейтинговых оценок может использоваться для ранжирования документов путем сортировки набора документов из результата поиска согласно их рейтинговым оценкам. В некоторых вариантах осуществления изобретения процесс ранжирования документов может быть более сложным и может, например, предусматривать использование модели на основе машинного обучения, ранжирующей документы на основе набора рейтинговых оценок и набора документов из результата поиска.
Должно быть понятно, что несмотря на то, что представленные здесь варианты осуществления изобретения описаны со ссылкой на конкретные признаки и структуры, без выхода за границы таких описаний могут быть реализованы их различные модификации и сочетания. Например, различные оптимизации, применяемые в нейронных сетях, включая трансформеры и/или модель BERT, могут подобным образом применяться и в настоящей технологии. Соответственно, описание и чертежи следует рассматривать просто как иллюстрацию обсуждаемых вариантов реализации или осуществления изобретения, принципы которого определенны приложенной формулой изобретения, которая охватывает все модификации, изменения, сочетания или эквиваленты в пределах объема настоящего изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| МНОГОЭТАПНОЕ ОБУЧЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2021 |
|
RU2824338C2 |
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2832419C2 |
| МНОГОЭТАПНОЕ ОБУЧЕНИЕ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ | 2021 |
|
RU2831678C2 |
| СИСТЕМА И СПОСОБ ОБУЧЕНИЯ МОДЕЛЕЙ МАШИННОГО ОБУЧЕНИЯ ДЛЯ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА | 2023 |
|
RU2829065C1 |
| СПОСОБ И СИСТЕМА ОБУЧЕНИЯ СИСТЕМЫ ЧАТ-БОТА | 2023 |
|
RU2820264C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ОТВЕТА НА ПОИСКОВЫЙ ЗАПРОС | 2024 |
|
RU2834217C1 |
| СПОСОБЫ И ЭЛЕКТРОННЫЕ УСТРОЙСТВА ДЛЯ ПАКЕТИРОВАНИЯ ЗАПРОСОВ, ПРЕДНАЗНАЧЕННЫХ ДЛЯ ОБРАБОТКИ ОБРАБАТЫВАЮЩИМ БЛОКОМ | 2021 |
|
RU2810916C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ПРОВЕРКИ МЕДИАКОНТЕНТА | 2022 |
|
RU2815896C2 |
| Способ и система для формирования карточки объекта | 2018 |
|
RU2739554C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ НЕЙРОННОЙ СЕТИ ФОРМИРОВАНИЮ ТЕКСТОВОЙ ВЫХОДНОЙ ПОСЛЕДОВАТЕЛЬНОСТИ | 2020 |
|
RU2798362C2 |
Изобретение относится к области ранжирования результатов поиска. Технический результат заключается в обеспечении возможности формирования зависящей от пользователя рейтинговой оценки результатов поиска для повышения эффективности систем ранжирования результатов. Способ включает в себя получение пользовательского журнала, содержащего историю поиска пользователя, получение запроса от пользователя, предоставление пользовательского журнала и запроса первой ступени кодера на основе искусственной нейронной сети для формирования основанного на токенах пользовательского представления пользовательского журнала и поискового запроса, по меньшей мере частично, на основе определения взаимосвязи между пользовательским журналом и поисковым запросом. Способ также включает в себя получение документа из набора документов из результата поиска, связанных с запросом, и предоставление основанного на токенах пользовательского представления и документа второй ступени кодера на основе искусственной нейронной сети с целью формирования рейтинговой оценки для документа, по меньшей мере частично, на основе определения взаимосвязи между основанным на токенах пользовательским представлением и документом. 2 н. и 16 з.п. ф-лы, 6 ил.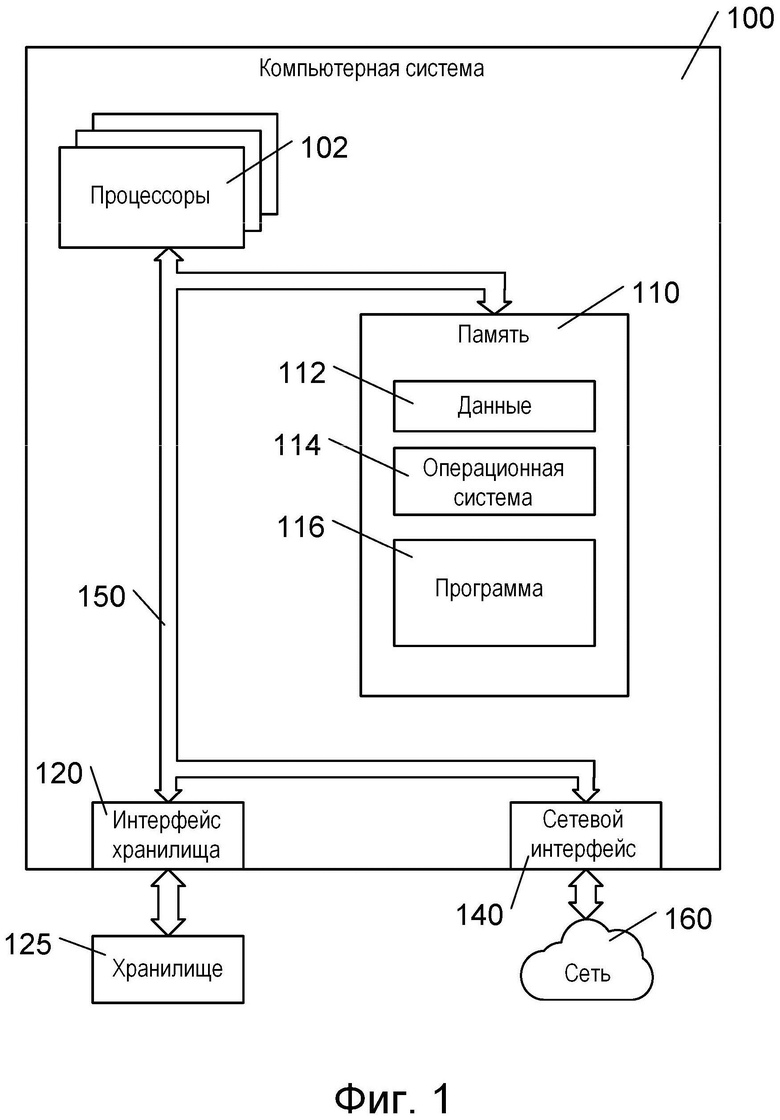
1. Компьютерный способ ранжирования набора документов из результата поиска, включающий в себя:
- получение пользовательского журнала, содержащего историю поиска пользователя;
- получение поискового запроса от пользователя;
- предоставление пользовательского журнала и поискового запроса первой ступени кодера на основе искусственной нейронной сети с двухступенчатой архитектурой;
- формирование с использованием первой ступени кодера на основе искусственной нейронной сети с двухступенчатой архитектурой основанного на токенах пользовательского представления пользовательского журнала и поискового запроса, по меньшей мере частично, на основе определения взаимосвязи между пользовательским журналом и поисковым запросом;
- получение документа из набора документов из результата поиска, связанных с поисковым запросом;
- предоставление основанного на токенах пользовательского представления и документа второй ступени кодера на основе искусственной нейронной сети; и
- формирование с использованием второй ступени кодера на основе искусственной нейронной сети с двухступенчатой архитектурой рейтинговой оценки для документа, по меньшей мере частично, на основе определения взаимосвязи между основанным на токенах пользовательским представлением и документом;
- формирование с использованием второй ступени кодера на основе искусственной нейронной сети набора рейтинговых оценок, каждая из которых связана с соответствующим документом из набора документов из результата поиска;
- использование набора рейтинговых оценок для ранжирования набора документов из результата поиска.
2. Компьютерный способ по п. 1, отличающийся тем, что использование набора рейтинговых оценок для ранжирования набора документов из результата поиска включает в себя предоставление набора рейтинговых оценок и набора документов из результата поиска модели на основе машинного обучения для окончательного ранжирования.
3. Компьютерный способ по п. 1, отличающийся тем, что предоставление пользовательского журнала и поискового запроса первой ступени кодера на основе искусственной нейронной сети дополнительно включает в себя предоставление токенов, представляющих пользовательский журнал и поисковый запрос.
4. Компьютерный способ по п. 3, отличающийся тем, что предоставление пользовательского журнала и поискового запроса первой ступени кодера на основе искусственной нейронной сети дополнительно включает в себя предоставление информации о положении, связанной с токенами, представляющими пользовательский журнал и поисковый запрос.
5. Компьютерный способ по п. 1, отличающийся тем, что первая ступень кодера на основе искусственной нейронной сети содержит механизм внимания.
6. Компьютерный способ по п. 1, отличающийся тем, что первая ступень кодера на основе искусственной нейронной сети содержит кодер на основе трансформера.
7. Компьютерный способ по п. 6, отличающийся тем, что первая ступень кодера на основе искусственной нейронной сети содержит кодер на основе архитектуры модели BERT.
8. Компьютерный способ по п. 6, отличающийся тем, что основанное на токенах пользовательское представление содержит последовательность токенов классификатора.
9. Компьютерный способ по п. 1, отличающийся тем, что предоставление основанного на токенах пользовательского представления и документа второй ступени кодера на основе искусственной нейронной сети дополнительно включает в себя предоставление токенов, представляющих документ.
10. Компьютерный способ по п. 9, отличающийся тем, что предоставление основанного на токенах пользовательского представления и документа второй ступени кодера на основе искусственной нейронной сети дополнительно включает в себя предоставление информации о положении, связанной с токенами, представляющими документ.
11. Компьютерный способ по п. 1, отличающийся тем, что вторая ступень кодера на основе искусственной нейронной сети содержит механизм внимания.
12. Компьютерный способ по п. 1, отличающийся тем, что вторая ступень кодера на основе искусственной нейронной сети содержит кодер на основе трансформера.
13. Компьютерный способ по п. 12, отличающийся тем, что вторая ступень кодера на основе искусственной нейронной сети содержит кодер на основе архитектуры модели BERT.
14. Компьютерный способ по п. 1, отличающийся тем, что одно основанное на токенах пользовательское представление используется с целью формирования рейтинговых оценок для нескольких документов второй ступенью кодера на основе искусственной нейронной сети.
15. Система ранжирования набора документов из результата поиска, содержащая:
- процессор;
- память, связанную с процессором; и
- управляемый процессором кодер на основе искусственной нейронной сети с двухступенчатой архитектурой,
при этом в памяти хранятся машиночитаемые команды, при исполнении которых процессор выполняет следующие действия:
- получение пользовательского журнала, содержащего историю поиска пользователя;
- получение поискового запроса от пользователя;
- предоставление пользовательского журнала и поискового запроса первой ступени кодера на основе искусственной нейронной сети с двухступенчатой архитектурой;
- использование первой ступени кодера на основе искусственной нейронной сети с двухступенчатой архитектурой для формирования основанного на токенах пользовательского представления пользовательского журнала и поискового запроса, по меньшей мере частично, на основе определения взаимосвязи между пользовательским журналом и поисковым запросом;
- получение документа из набора документов из результата поиска, связанных с поисковым запросом;
- предоставление основанного на токенах пользовательского представления и документа второй ступени кодера на основе искусственной нейронной сети; и
- использование второй ступени кодера на основе искусственной нейронной сети с двухступенчатой архитектурой с целью формирования рейтинговой оценки для документа, по меньшей мере частично, на основе определения взаимосвязи между основанным на токенах пользовательским представлением и документом;
- формирование с использованием второй ступени кодера на основе искусственной нейронной сети набора рейтинговых оценок, каждая из которых связана с соответствующим документом из набора документов из результата поиска;
- использование набора рейтинговых оценок для ранжирования набора документов из результата поиска.
16. Система ранжирования по п. 15, отличающаяся тем, что первая ступень кодера на основе искусственной нейронной сети содержит кодер на основе трансформера.
17. Система ранжирования по п. 16, отличающаяся тем, что основанное на токенах пользовательское представление содержит последовательность токенов классификатора.
18. Система ранжирования по п. 15, отличающаяся тем, что вторая ступень кодера на основе искусственной нейронной сети содержит кодер на основе трансформера.
| СПОСОБ И СИСТЕМА ВЫБОРА ДЛЯ РАНЖИРОВАНИЯ ПОИСКОВЫХ РЕЗУЛЬТАТОВ С ПОМОЩЬЮ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2731658C2 |
| СПОСОБ И СИСТЕМА РАНЖИРОВАНИЯ МНОЖЕСТВА ДОКУМЕНТОВ НА СТРАНИЦЕ РЕЗУЛЬТАТОВ ПОИСКА | 2017 |
|
RU2677380C2 |
| US 20190251422 A1, 15.08.2019 | |||
| US 8812493 B2, 19.08.2014 | |||
| US 7664735 B2, 16.02.2010. | |||

