ОБЛАСТЬ ТЕХНИКИ
[1] Заявленное техническое решение в общем относится к области микропроцессоров, а в частности к устройству управления вычислительными ядрами ускорителя вывода нейронных сетей.
УРОВЕНЬ ТЕХНИКИ
[2] С развитием и внедрением во все сферы жизнедеятельности алгоритмов машинного обучения и искусственного интеллекта, в настоящий момент существенное развитие получили специализированные устройства, предназначенные для обучения и вывода нейронных сетей, например, ускорители вывода (инференса) нейронных сетей, нейронные процессоры и т.д.
[3] Разделяют несколько классов ускорителей, от которых зависит организация управления вычислительными ядрами указанных ускорителей. Так, существуют ускорители GPU-подобной архитектуры, содержащие, как правило, 2D-массив специализированных процессорных ядер с векторным ALU и ускорители не-GPU-подобной, (гетерогенной архитектуры), содержащие набор вычислительных ядер, оптимизированных и спроектированных для различных операций, например, в составе таких ускорителей, могут содержаться вычислительные ядра для матричных умножений (вычислительное устройство для матричных умножений), векторный процессор, устройства перестановок и сдвигов битов данных в микропроцессорах (патент РФ № RU 2488161 C1), вычислители специальных математических операций и т.д. Ускорители вывода нейронных сетей гетерогенной архитектуры более предпочтительны для таких задач, как вывод и обучение нейронных сетей, обработка изображений и т.д., т.к.. построены для выполнения параллельных обработок больших объемов данных.
[4] В подобных устройствах (гетерогенных ускорителях вывода нейронных сетей), как правило, наборы инструкций для вычислительных ядер (аппаратных вычислительных устройств, входящих в состав ускорителя) хранятся во внешней, относительного управляющего устройства, памяти, задержка чтения которой может составлять от десятков до сотен тактов в зависимости от организации самой памяти и доступа к ней. Нагрузка на каждое из вычислительных ядер (вычислительных устройств) устройств - количество исполняемых инструкций на один цикл инференса (профиль нагрузок на командный интерфейс), как правило, неравномерна и будет отличаться в зависимости от конкретной нейронной сети. Такая неравномерность, как правило, должна быть компенсирована в управляющем устройстве, которое осуществляет загрузку инструкций из внешней памяти и отправку вычислительным ядрам, которые могут быть объединены в вычислительные кластеры.
[5] Так, для компенсации задержек чтения внешней памяти в схемы управляющих устройств ускорителей добавляют буферы инструкций (очереди), арбитраж которых также производится управляющим устройством, например, как это раскрыто в известном уровне техники, в патенте США № US 11113101 B2 (CAVIUM LLC [US] et al.), опубл. 07.09.2021.
[6] К недостаткам такого подхода можно отнести существенные ограничения в организации хранения и арбитража инструкций к вычислительным устройствам ускорителя, ввиду того, что память для организации очередей имеет фиксированный размер и может быть недостаточна для компенсации задержек в случае недетерминированного времени доступа к внешней памяти инструкций и неравномерных нагрузок на вычислительные устройства (неравномерный поток инструкций в вычислительных ядрах). Кроме того, использование очередей одинакового размера в подобных условиях требует использования памяти большого объема при низкой утилизации этой памяти из-за неравномерной нагрузки, что, соответственно увеличивает площадь таких устройств управления на кристалле.
[7] Соответственно, целью настоящего технического решения является создание устройства управления вычислительными устройствами ускорителя вывода нейронных сетей, преодолевающего указанные выше недостатки, и обеспечивающего повышение производительности ускорителя за счет снижения простаивания вычислительных ядер такого ускорителя. Кроме того, заявленное устройство, за счет реализации двойной буферизации, обеспечивает возможность гибкой работы в соответствии с профилем нагрузок в условиях недетерминированного доступа к памяти при ограниченных ресурсах устройства, что также позволяет уменьшить суммарный объем памяти и сократить площадь устройства на кристалле.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[8] В заявленном техническом решении предлагается новый подход к архитектуре устройства управления вычислительными устройствами ускорителя вывода нейронных сетей, обеспечивающей уменьшение площади устройства управления, а также увеличение производительности ускорителя вывода нейронных сетей, за счет снижения времени простаивания вычислительных ядер указанного ускорителя, а также снижения суммарного объема памяти в устройстве управления.
[9] Техническим результатом, достигающимся при решении данной проблемы, является уменьшение площади устройства управления ускорителя вывода нейронных сетей на кристалле при сохранении производительности устройства управления.
[10] Указанный технический результат достигается благодаря устройству управления вычислительными устройствами ускорителя вывода нейронных сетей, содержащего, размещенные на кристалле, следующие элементы:
блок конфигурации параметров, связанный с внешним управляющим устройством, выполненный с возможностью получения данных, содержащих конфигурационные параметры для устройства управления;
сегментированную буферную память, соединенную с внешней памятью, выполненную с возможностью получения и хранения наборов инструкций, причем каждый сегмент обладает динамическим объемом памяти, устанавливаемый полученными конфигурационными параметрами, и выполнен с возможностью хранения набора инструкций для по меньшей мере одного вычислительного устройства ускорителя вывода нейронных сетей;
по меньшей мере два блока обработки потоков инструкций, связанных с по меньшей мере двумя вычислительными устройствами ускорителя вывода нейронных сетей, каждый из которых выполнен с возможностью:
осуществления буферизации потока инструкций, получаемых от сегментированной буферной памяти;
осуществления декодирования полученного потока инструкций;
синхронизацию потока инструкций;
отправку декодированного потока инструкций по меньшей мере одному вычислительному устройству ускорителя вывода нейронных сетей;
блок указателей дескрипторов, выполненный с возможностью получения указателей дескрипторов от внешнего управляющего устройства, причем, указатели дескрипторов содержат адрес расположения во внешней памяти и размер дескриптора набора инструкций для по меньшей мере одного вычислительного устройства;
блок управления запросами на чтение дескрипторов по указателям из блока указателей дескрипторов, выполненный с возможностью получения из внешней памяти дескрипторов набора инструкций для по меньшей мере одного вычислительного устройства на основе указателя дескрипторов;
блок обработки дескрипторов набора инструкций, выполненный с возможностью выделения адреса расположения и размера набора инструкций вычислительного устройства, а также параметров устройства управления для исполняемого вывода нейронной сети;
планировщик потоков инструкций, выполненный с возможностью осуществления загрузки набора инструкций, на основе обработанного дескриптора, из внешней памяти по меньшей мере в два сегмента сегментированной буферной памяти и контроля наполненности сегментов указанной памяти.
[11] В одном из частных вариантов реализации вычислительное устройство ускорителя вывода нейронных сетей представляет собой вычислительное ядро ускорителя вывода нейронных сетей или кластер вычислительных ядер ускорителя вывода нейронных сетей.
[12] В другом частном варианте реализации конфигурационные параметры представляют собой по меньшей мере одно из: конфигурация сегментированной буферной памяти; конфигурация блока управления запросами на обработку дескрипторов; конфигурация блока обработки дескрипторов конфигурация каждого из блоков обработки потоков инструкций.
[13] В другом частном варианте реализации планировщик потоков инструкций выполнен с возможностью порционной загрузки набора инструкций.
[14] В другом частном варианте реализации порционная загрузка набора инструкций представляет собой последовательную загрузку отдельных частей набора инструкций в сегмент буферной памяти, размер которых не превышает свободный объем сегмента памяти в сегментированной буферной памяти.
[15] В другом частном варианте реализации каждая часть набора инструкций помечается тэгом, соответствующим номеру сегмента буферной памяти.
[16] В другом частном варианте реализации каждый сегмент буферной памяти представляет собой кольцевой буфер с конфигурируемым объемом памяти.
[17] В другом частном варианте реализации блок указателей дескрипторов представляет собой кольцевой буфер (FIFO).
[18] В другом частном варианте реализации указатель дескриптора содержит, по меньшей мере адрес расположения дескриптора набора инструкций для вычислительного устройства ускорителя вывода нейронных сетей во внешней памяти и размер указанного дескриптора.
[19] В другом частном варианте реализации набор инструкций содержит идентификатор получателя инструкции в ускорителе вывода нейронных сетей.
[20] В другом частном варианте реализации буферизация инструкций по меньшей мере в двух блоках обработки потоков инструкций осуществляется во внутреннем кольцевом буфере с шириной шины данных эквивалентной шине данных сегментированной буферной памяти.
[21] В другом частном варианте реализации отправка декодированного потока инструкций осуществляется в виде пакета данных.
[22] В другом частном варианте реализации при отправке декодированного потока инструкций, блок обработки потоков инструкций дополнительно выполнен с возможностью подсчета количества отправленных инструкций и детекции последней инструкции.
[23] В другом частном варианте реализации блок обработки потоков инструкций дополнительно содержит блок синхронизации, выполненный с возможностью приостановки и возобновления отправки инструкций при получении соответствующей команды о приостановке или возобновлении.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[24] Признаки заявленного технического решения и подробное описание приведено ниже в виде прилагаемых чертежей.
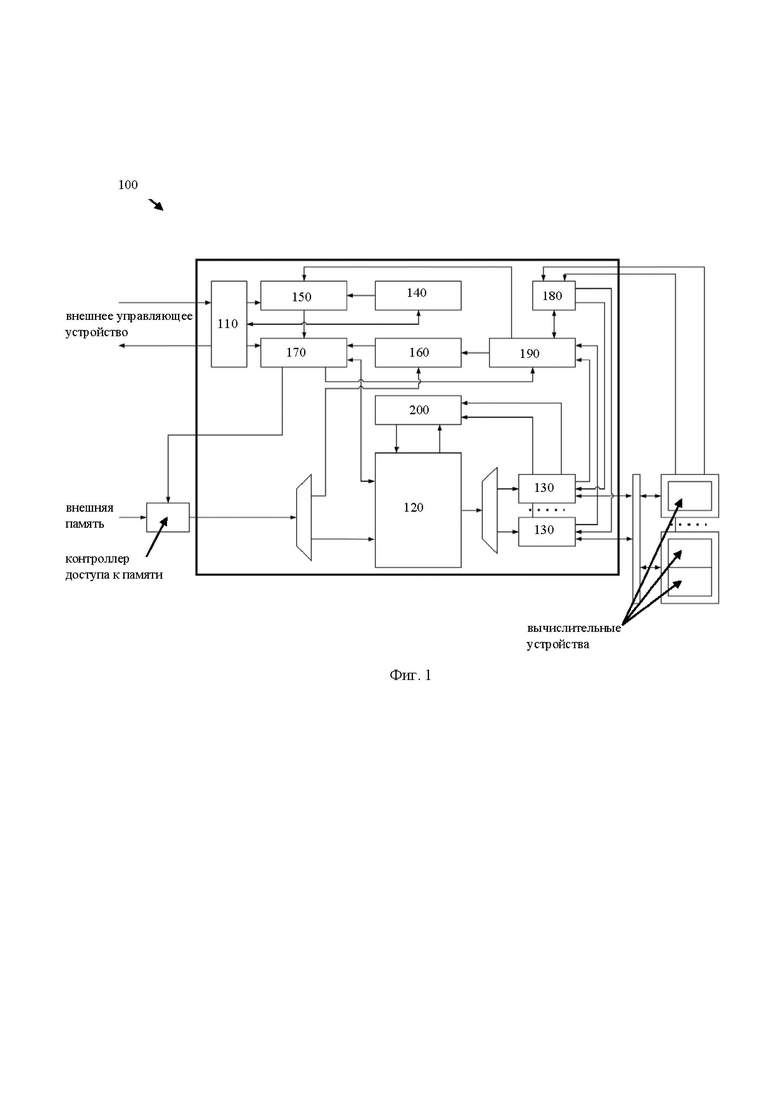
[25] Фиг. 1 иллюстрирует структурную схему устройства управления вычислительными устройствами ускорителя вывода нейронных сетей.
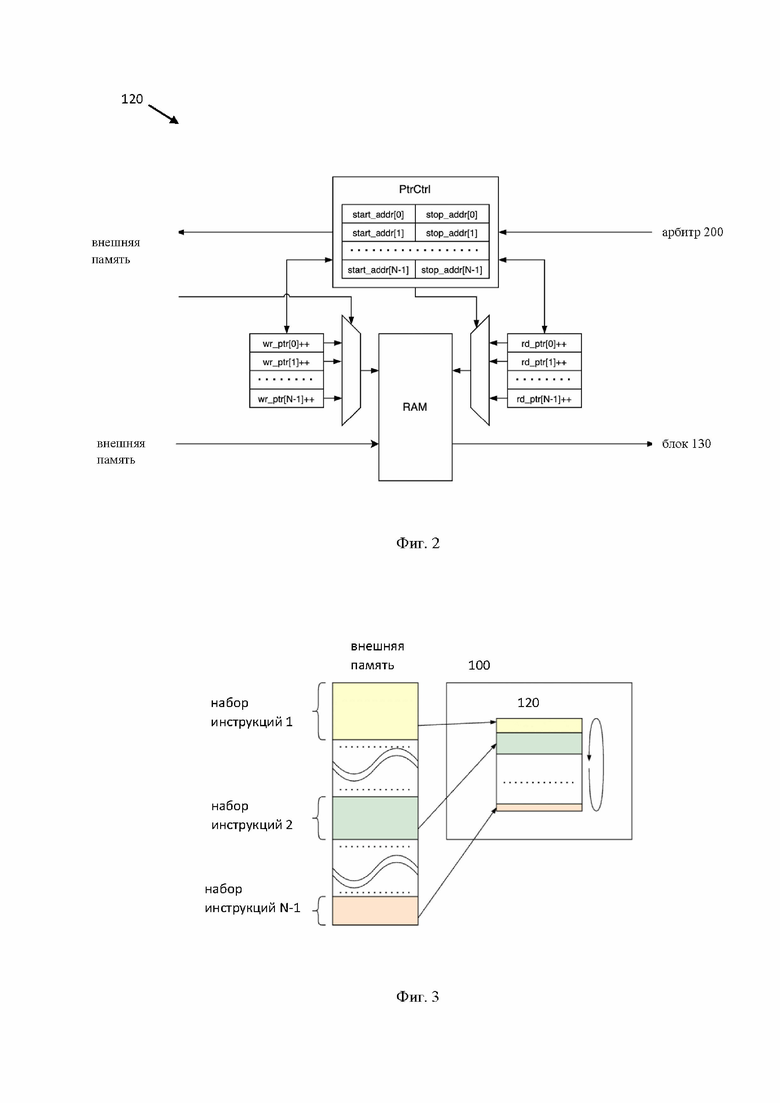
[26] Фиг. 2 иллюстрирует структурную схему сегментированной буферной памяти.
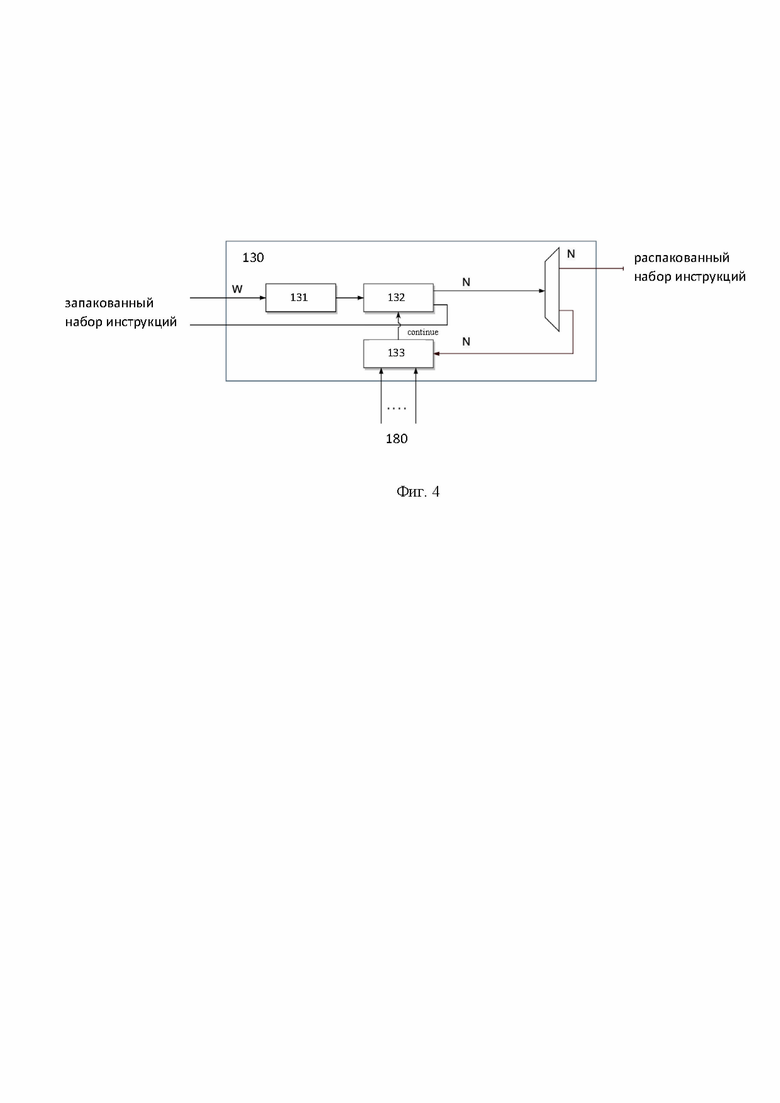
[27] Фиг. 3 иллюстрирует пример распределения наборов инструкций в сегментированной буферной памяти.
[28] Фиг. 4 иллюстрирует структурную схему блока обработки потоков инструкций.
ОСУЩЕСТВЛЕНИЕ ИЗОБРЕТЕНИЯ
[29] Ниже будут описаны понятия и термины, необходимые для понимания данного технического решения.
[30] Ускоритель вывода нейронных сетей - это специализированный класс аппаратных ускорителей, предназначенный для ускорения работы алгоритмов искусственных нейронных сетей, компьютерного зрения, распознавания голоса, машинного обучения и других методов искусственного интеллекта. Ускорители вывода нейронных сетей относятся к классу гетерогенной (не GPU-подобных) архитектуре в составе которой находятся вычислительные устройства (ядра) умножения матриц и устройства, предназначенные для векторных вычислений. Также, в дополнение к приведенным ядрам в системе могут присутствовать устройства, осуществляющее перестановку данных, такие как устройства перестановок и сдвигов битов данных в микропроцессорах, устройства, осуществляющие запись/чтение данных в память/из памяти, блоки специальных математических операций и другие. Управление ускорителем выполняется посредством устройства управления, расположенного в составе указанного ускорителя.
[31] Под термином вывод (инференс) нейронной сети в данном решении следует понимать непрерывный процесс работы обученной нейронной сети с получением логического вывода.
[32] Заявленное техническое решение предлагает новый подход в создании устройства управления вычислительными устройствами ускорителя вывода нейронных сетей, обладающего высокой скоростью управления вычислительными ядрами ускорителя и имеющего малую площадь на кристалле. Архитектура заявленного технического решения обеспечивает уменьшение объема памяти устройства управления, и, как следствие, сокращение площади устройства на кристалле, за счет двойной буферизации очередей инструкций и применения сегментированной буферной памяти. Также, указанные особенности, дополнительно позволяют подстраиваться под профиль нагрузок в условиях недетерминированного доступа к памяти при ограниченных ресурсах устройства.
[33] Термин «инструкции», используемый в этой заявке, может относиться, в общем, к программным инструкциям или программным командам, которые написаны на заданном языке программирования для осуществления конкретной функции, такой как, например, выполнение вычислений в вычислительных ядрах ускорителя, буферизация данных в памяти устройства управления и т. п. Инструкции могут быть осуществлены множеством способов, включающих в себя, например, потоковую конфигурацию машинных команд, объектно-ориентированные методы и т.д. Инструкции, осуществляющие процессы, описанные в этом решении, могут передаваться по проводным каналам от внешних устройств (хостов) в устройство управления, например, устройства управления ускорителем инференса и обучения нейронных сетей, а также из устройства управления в вычислительные ядра ускорителя.
[34] На Фиг. 1 представлена блок схема устройства управления вычислительными устройствами ускорителя вывода нейронных сетей 100. Указанное устройство 100 включает в себя блок конфигурации параметров 110, сегментированную буферную память 120, по меньшей мере два блока обработки потоков инструкций 130, блок указателей дескрипторов 140, блок управления запросами на чтение дескрипторов 150, блок обработки дескрипторов набора инструкций 160, планировщик потоков инструкций 170, модуль счетчиков исполненных инструкций вычислительными устройствами 180, блок контроля исполнения наборов инструкций 190, арбитр запросов инструкций 200.
[35] Устройство 100, преимущественно, является частью ускорителей вывода нейронных сетей. Так, устройство 100 выполнено с возможностью предоставления внешнему (по отношению к ускорителю и устройству 100) управляющему устройству регистрового интерфейса для управления ускорителем и чтения статусных регистров; обработки дескрипторов, представляющих собой указание на адрес и размер наборов инструкций для вычислительных устройств ускорителя или кластеров вычислительных устройств; чтение из внешней памяти наборов инструкций вычислительных устройств по описанию из дескрипторов, их буферизацию, обработку и отправку по командным интерфейсам вычислительным устройствам; обработку команд для контроля зависимостей исполнения (остановка подачи командных пакетов в вычислительные устройства и ожидание событий); обеспечения работы режимов покомандной отладки, выгрузки отладочной информации, счётчиков производительности и ошибок, обработки прерываний.
[36] Стоит отметить, что в данном решении термин вычислительные устройства ускорителя вывода нейронных сетей является эквивалентным термину вычислительные ядра ускорителя вывода нейронных сетей и может применяться взаимозаменяемо.
[37] Также, в еще одном частном варианте осуществления устройство 100 выполнено с возможностью отправки набора инструкций группе вычислительных устройств ускорителя вывода нейронной сети, объединенных в единый кластер.
[38] Элементы устройства 100 расположены на кристалле интегральной схемы (ИС). В одном частном варианте осуществления кристалл ИС может являться частью другого кристалла ИС, например, ускорителя нейросетей, который также содержит другие компоненты, связанные с устройством 100 (векторный процессор, устройство матричных вычислений, устройство перестановки данных и т.д.).
[39] Блок конфигурации параметров 110 представляет собой аппаратный блок, состоящий из простейших вычислительных элементов. Указанный блок 110 связан с внешним управляющим устройством и выполнен с возможностью получения данных, содержащих конфигурационные параметры для устройства управления. Указанный блок 110 предназначен для получения и пересылки в соответствующие элементы устройства 100 конфигурационных параметров устройства 100. Т.е. указанный блок 110 предназначен для получения массива контрольных и статусных регистров для задания режимов работы элементов устройства 100. Так, конфигурационные параметры могут поступать от внешнего устройства управления, например, в виде файла данных, набора инструкций и т.д. Конфигурационные параметры представляют собой по меньшей мере одно из: параметры конфигурации сегментированной буферной памяти 130; параметры конфигурации блока управления запросами на обработку дескрипторов 150; параметры конфигурации блока обработки дескрипторов 160; параметры конфигурации каждого из блоков обработки потоков инструкций 130. Так, например, параметры конфигурации памяти 130 могут представлять собой выделяемые размеры сегментов памяти до начала работы устройства 100, например, посредством указания в конфигурационных параметрах адреса выделяемого сегмента памяти для соответствующего вычислительного устройства. Параметры блока 150 могут представлять приоритет очередности считывания дескрипторов из внешней памяти и т.д.
[40] Стоит отметить, что в зависимости от типа исполняемой нейронной сети, может меняться профиль нагрузки каждого вычислительного устройства ускорителя. Соответственно, конфигурационные параметры предназначены для предварительной подготовки устройства 100 на работу в определенном режиме, например, в режиме, соответствующим типу нейронной сети. Частота получения конфигурационных параметров может зависеть от исполняемых действий вычислительных устройств ускорителя. Так, например, конфигурационные параметры могут быть получены единожды перед выполнением операции вывода нейронной сети ускорителем. В еще одном частном варианте осуществления, конфигурационные параметры могут быть изменены в соответствии со сменой исполняемых операций вычислительными устройствами, например, при выполнении нового типа нейронной сети устройством матричных вычислений или векторным процессором, устройство 100 получит новые конфигурационные параметры, соответствующие указанной нейронной сети. Получение конфигурационных параметров выполняется, посредством интерфейса связи с внешним управляющим устройством, например, хостом.
[41] Сегментированная буферная память 120 представляет собой память SRAM фиксированного размера с одним портом чтения и одним портом записи. Более подробно указанная память 120 раскрыта на Фиг. 2. Соответственно, все сегменты реализованы на указанной памяти 120. Размер каждого сегмента задается посредством конфигурационных параметров и зависит от профиля нагрузки вычислительного устройства ускорителя, которому предназначается поток инструкций. Под профилем нагрузки может пониматься частота поступления и объем инструкций, адресованных определенному вычислительному устройству ускорителя. Так, в зависимости от исполняемой нейронной сети определенные вычислительные устройства задействуются по-разному. Профиль нагрузки на устройстве 100 будет пропорционален степени нагрузки вычислительного устройства.
[42] Сегменты буферной памяти 120 представляют собой динамически выделяемый физический объем памяти из общего объема памяти 120. Использование одной физической памяти 120 с динамическими конфигурируемыми сегментами по сравнению с применением нескольких физических памятей для каждого сегмента обусловлено тем, что память большого объема имеет более плотную компоновку (бит/um2), что значительно снижает требуемую площадь по сравнению с несколькими памятями меньшего объема (при одинаковом суммарном объеме).
[43] Каждый сегмент имеет следующие программно-задаваемые параметры: адрес начала сегмента в общей сегментированной памяти, адрес конца сегмента в общей сегментированной памяти. Эти адреса используются для построения кольцевого буфера типа FIFO. Каждый пакет инструкций, который приходит из внешнего управляющего устройства в сегментированную память 120 помечается тэгом-идентификатором сегмента, которому этот пакет предназначен. По этому тэгу происходит инкрементирование указателей записи, указывающих на адреса SRAM, в которые происходит запись. Запрос на выгрузку инструкций в блоки обработки потоков инструкций также помечается идентификатором сегмента, по которому происходит инкрементирование указателей адресов чтения из общей SRAM.
[44] Память 120 предназначена для получения и хранения наборов инструкций для вычислительных устройств ускорителя. Пример загрузки наборов инструкций в память 120 показан на Фиг. 3. Так, каждый сегмент памяти 120 предназначен для хранения набора инструкций для одного вычислительного устройства ускорителя. Т.е. количество сегментов памяти 120 равно количеству управляемых устройств в ускорителе, либо числу кластеров вычислительных устройств, если они объединены в кластер, например, 4 сегмента, 8 сегментов, 4 кластера, 8 кластеров и т.д. Так, например, ускоритель вывода нейронных сетей может содержать следующие элементы: два устройства матричных вычислений, устройство перестановок данных, векторный вычислитель. Соответственно для управления каждым вычислительным устройством или группой вычислительных устройств (устройства матричных вычислений) устройство 100 будет иметь соответствующее количество сегментов в памяти 120. Как упоминалось выше, в одном частном варианте осуществления, сегмент может соответствовать нескольким вычислительным устройствам, объединенным в группу (кластер). Т.е. устройства могут быть подключены как в индивидуальном порядке, так и группой (кластером). В обоих случаях, что индивидуальному устройству, что группе устройств, ставится в соответствие один блок 130, соответственно, с одним командным интерфейсом. При этом каждому блоку 130 ставится в соответствие один сегмент сегментированной памяти 120. В свою очередь, память 120 соединена с внешней памятью посредством шины данных.
[45] Загрузка наборов инструкций в память 120 выполняется после обработки дескриптора блоком обработки дескрипторов 160. После получения запрошенного дескриптора блоком 160, указанный блок 160 осуществляет выделение адреса расположения и размера набора инструкций вычислительного устройства или группы вычислительных устройств, и служебную информацию, например, параметры устройства 100, применимые к конкретному инференсу.
[46] Из полученных адресов и размеров наборов инструкций в планировщике потоков инструкций 170 формируются запросы на чтение самого набора инструкций для каждого из вычислительных устройств или группы вычислительных устройств, объединенных в группу и управляемых одним набором инструкций. Набор инструкций, в свою очередь, содержит размер и идентификатор получателя инструкции, если инструкция предназначена для кластера вычислительных ядер.
[47] Запросы на чтение наборов команд планировщиком 170 формируются на основе свободного объема памяти 120 и программно-задаваемых максимальных размеров запроса для каждого из сегментов (один сегмент памяти 120 хранит набор инструкций для одного вычислительного ядра или группы вычислительных ядер). В случае одновременного запроса от нескольких сегментов планировщик 170 осуществляет арбитраж запросов. Так как весь набор инструкций может не поместиться в памяти 120, указанный набор может загружаться в память 120 через множество отдельных запросов, размер которых не превышает свободный объем памяти 120 в соответствующем сегменте. Каждый запрос на чтение помечается тэгом – соответствующим id-сегмента памяти 120. Запрошенный набор инструкций поступает на входной демультиплексор и из него в память 120, где по возвращенному с набором инструкций тэгом происходит адресация к тому или иному сегменту памяти 120. Как видно из Фиг. 2, каждый из сегментов представляет собой кольцевой буфер с динамическим (программно-задаваемым) объемом памяти (например, посредством команд start_addr[x]/stop_addr[x]), и блоком указателей на чтение, например, вида rd_ptr[x] и запись, например, вида wr_ptr[x]. Так, команды Start_addr[x]/stop_addr[x] могут являться командами для присвоения адреса каждого сегмента, т.е. указанные команды, по сути, определяют объем каждого сегмента. Указатели управляются блоком контроля указателей (PtrCtrl), который принимает запросы на чтение инструкций из памяти 120 и управляет адресами записи инструкций в память 120 и чтения их из памяти 120.
[48] Каждый из по меньшей мере двух блоков 130 может представлять собой аппаратный блок, состоящий из простейших вычислительных элементов. Структурная схема блока 130 представлена на Фиг. 4. Так, каждый из поменьше мере двух блоков 130 состоит из следующих элементов: буферная память 131, блок декодирования 132, блок синхронизации 133.
[49] Память 131 представляет собой буферную память, такую как FIFO с шириной шины данных эквивалентной шине данных памяти 120. Такая особенность повышает пропускную способность устройства 100. Глубина буферной памяти 131 может выбираться исходя из количества подключенных к устройству 100 командных интерфейсов и компенсации задержки на обработку запросов от других блоков 130.
[50] Блок 132 предназначен для декодирования инструкций. Декодирование может осуществляться посредством получения на вход упакованной инструкции и формировании распакованной инструкции и отправки ее вычислительным устройствам в виде пакета данных. Каждая упакованная инструкция имеет преамбулу – в частном случае 32 бита, которая содержит длину инструкции в байтах, идентификатор (адрес) устройства назначения, а также флаг последней инструкции (LAST) и флаг команды синхронизации (WAIT). В общем случае, по информации о длине команды, блок декодирования 132 формирует пакет инструкции без преамбулы и отправляет его по адресу, указанному в идентификаторе. Ширина выходной шины (которая связывает вычислительное устройство с блоком 130) может быть произвольной и выбирается исходя из требований трассировки и пропускной способности командного интерфейса.
[51] Блок синхронизации 133 дополнительно осуществляет приостановку отправки инструкций по командному интерфейсу при получении команды WAIT, условие продолжения отправки инструкций может быть указано в теле команды и может включать как условную или безусловную задержку в тактах системной частоты, так и одно или несколько событий от модуля 180, который подсчитывает количество исполненных инструкций вычислительных ядер. При выполнении условия продолжения работы блок 133 выставляет сигнал continue в модуль декодирования.
[52] Каждый из по меньшей мере двух блоков 130 связан с вычислительным устройством ускорителя или группой вычислительных устройств ускорителя и выполнен с возможностью: осуществления буферизации потока инструкций, получаемых от сегментированной буферной памяти; осуществления декодирования полученного потока инструкций; синхронизации потока инструкций; отправки декодированного потока инструкций по меньшей мере одному вычислительному устройству ускорителя вывода нейронных сетей.
[53] В одном частном варианте осуществления для избегания блокировки канала чтения (когда память 120 ожидает готовности принимающего блока 130), размер запроса на чтение не должен превышать свободный объем памяти в блоке 130, размер минимального запроса и максимального запроса также может конфигурироваться в зависимости от профиля нагрузок.
[54] Для отправки потока инструкций на вычислительные устройства арбитр 200 (арбитража) принимает запросы от блоков 130, производит арбитраж по алгоритму round-robin и отправляет их в память 120 c указанием количества запрошенных инструкций и идентификатора конкретного блока 130, который выставил запрос. Прочитанные из памяти 120 инструкции проходят через демультиплексор и отправляются в соответствующий блок 130, который осуществляет дополнительную буферизацию инструкций, декодирование инструкций, синхронизацию инструкций по запрограммированному событию и отправку декодированных инструкций вычислительным ядрам или кластерам вычислительных ядер. При отправке инструкций, блок 130 инкрементирует счетчики отправленных инструкций и детектирует последнюю инструкцию, которая помечается флагом LAST.
[55] Стоит отметить, что наличие памяти 131 в блоке 130 обеспечивает снижение задержек на чтение наборов инструкций из памяти 120. Так, поскольку каждое вычислительное устройство ускорителя управляется своим набором инструкций, то для исключения задержек в момент одновременного обращения вычислительных устройств к памяти 120, наборы инструкций буферизируются в соответствующих блоках 130. Соответственно, исполнение памяти 120 как единой физической памяти с динамическими сегментами, в свою очередь, компенсирует задержку на чтение из внешней памяти. Т.е. такой подход позволяет сократить общий объем памяти, сохранив при этом высокую скорость чтения инструкций командным интерфейсом.
[56] Блок указателей дескрипторов 140 предназначен для получения указателей дескрипторов от внешнего управляющего устройства. Указатели дескрипторов содержат адрес расположения во внешней памяти и размер дескриптора набора инструкций для по меньшей мере одного вычислительного устройства.
[57] Параметры конфигурации блока 140 задаются посредством потоков конфигураций, получаемых от блока 110. Параметры блока 140 задаются посредством конфигурации, получаемой от блока 110. Так, параметры блока 140 могут представлять собой указатели кольцевого буфера адресов дескрипторов и т.д. В одном частном варианте осуществления блок 140 может представлять собой кольцевой буфер (FIFO), реализованный на памяти SRAM, имеющий один порт чтения и один порт записи. Каждая запись в блоке 140 содержит адрес и размер дескриптора. Стоит отметить, что сам дескриптор хранится во внешней памяти, так как его размер может достигать несколько Кбайт, что значительно превышает размер памяти устройства 100. Также, такая особенность позволяет уменьшить необходимый объем памяти на кристалле. После записи внешним управляющим устройством (хостом) дескрипторов во внешнюю память, хост записывает указатели (адрес и размер дескрипторов) на дескрипторы в блок 140.
[58] Блок управления запросами на чтение дескрипторов 150 по указателям из блока указателей дескрипторов 140, выполнен с возможностью получения из внешней памяти дескрипторов набора инструкций для по меньшей мере одного вычислительного устройства на основе указателя дескрипторов.
[59] Блок 150 предназначен для контроля наполненности блока 140 и отправки запросов на чтение дескриптора по указателю из блока 140. Так, запрос на чтение мультиплексируется с запросами на чтение наборов инструкций в планировщике 170 и отправляется в контроллер доступа к памяти. Запрошенный дескриптор поступает на входной демультиплексор и из него в блок обработки дескрипторов 160, который выделяет адреса расположения и размер наборов инструкций вычислительных ядер и служебную информацию – настройки устройства 100, применимые к конкретному инференсу.
[60] Блок обработки дескрипторов набора инструкций 160 предназначен для выделения адреса расположения и размера набора инструкций вычислительного устройства, а также параметров устройства управления для исполняемого вывода нейронной сети.
[61] Указанный блок 160 осуществляет прием дескриптора, выделение адресов и размеров потоков программ, а также осуществляет отправку указанных данных в блок 170.
[62] Планировщик потоков инструкций 170 выполнен с возможностью осуществления загрузки набора инструкций, на основе обработанного дескриптора, из внешней памяти по меньшей мере в два сегмента сегментированной буферной памяти и контроля наполненности сегментов указанной памяти.
[63] Так, на основе полученных данных из блока 160 (из полученных адресов и размеров наборов инструкций) в планировщик 170 формирует запросы на чтение потока инструкций для каждого из вычислительных ядер или группы вычислительных ядер. Набор инструкций представляет собой упакованный набор инструкций, каждая из которых содержит размер и идентификатор получателя инструкции, если инструкция предназначена для кластера вычислительных ядер.
[64] Так, в одном частном варианте осуществления, планировщик 170 выполнен с возможностью порционной загрузки части набора инструкций в память 120 в соответствии с свободным объемом памяти каждого сегмента. Так, после получения данных от блока 160, планировщик, на основе известного объема памяти сегмента и размера потока инструкций может выполнять порционную загрузку (т.е. загрузку не всего набора инструкций, а его части) в память 120. Соответственно после отправки такой части инструкций в память 120, планировщик выставляет команду на загрузку следующей части инструкций. В еще одном частном варианте осуществления, запрос на загрузку части инструкций может быть направлен при опустошении сегмента памяти до определенного порога, например, до 80% от объема сегмента и т.д.
[65] Модуль счетчиков исполненных инструкций вычислительными устройствами 180.
[66] Указанный модуль 180 предназначен для подсчета количества исполненных инструкций вычислительных ядер. Модуль 180 выполнен с возможностью получения от каждого вычислительного устройства или группы вычислительных устройств сигнала об исполнении отправленных инструкций и подсчета указанных исполненных инструкций.
[67] Так, каждому исполнительному вычислительному устройству, отдельному или объединенному в кластер, присвоен свой номер-идентификатор. При исполнении инструкции устройства выдают строб-сигнал (done) длительностью один такт системной частоты, который подсчитывается в блоке 180. Таким образом блок 180 содержит информацию о количестве исполненных инструкций каждого вычислительного устройства. После исполнения всего инференса, счетчики исполненных инструкций в блоке 180 сбрасываются в исходное состояние.
[68] Блок контроля исполнения наборов инструкций 190 предназначен для контроля исполнения текущих инструкций.
[69] Указанный блок предназначен для определения корректности исполнения набора инструкций на каждом вычислительном устройстве.
[70] Так, значения счетчиков отправленных и исполненных инструкций (модуль 180) и флаги последних инструкций каждого из блоков 130 поступают в блок 190. Указанный блок 190 осуществляет контроль исполнения текущего набора инструкций и после того, как инструкции будут исполнены, формирует запрос на чтение нового указателя дескриптора. При такой реализации также становится возможна дополнительная буферизация дескриптора для компенсации задержки чтения из внешней памяти.
[71] Арбитр запросов инструкций 200 предназначен для получения запросов от блоков 130, выполнения арбитража, например, по алгоритму round-robin, и отправки запросов память 120 c указанием количества запрошенных инструкций и идентификатора блока 130, который выставил запрос.
[72] Таким образом, в представленных материалах заявки были описаны различные варианты исполнения управления вычислительными устройствами ускорителя вывода нейронных сетей.
[73] Конкретный выбор элементов устройства 100 для реализации различных программно-аппаратных и/или архитектурных решений может варьироваться с сохранением обеспечиваемого требуемого функционала.
[74] Представленные материалы заявки раскрывают предпочтительные примеры реализации технического решения и не должны трактоваться как ограничивающие иные, частные примеры его воплощения, не выходящие за пределы испрашиваемой правовой охраны, которые являются очевидными для специалистов соответствующей области техники. Таким образом, объем настоящего технического решения ограничен только объемом прилагаемой формулы.
| название | год | авторы | номер документа |
|---|---|---|---|
| УСТРОЙСТВО МАТРИЧНЫХ ВЫЧИСЛЕНИЙ | 2025 |
|
RU2838831C1 |
| Программируемые устройства для обработки запросов передачи данных памяти | 2016 |
|
RU2690751C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПАРАЛЛЕЛЬНОЙ ОБРАБОТКИ ЦИФРОВОЙ ИНФОРМАЦИИ В ВЫЧИСЛИТЕЛЬНОЙ СИСТЕМЕ | 2014 |
|
RU2571376C1 |
| СИСТЕМЫ И СПОСОБЫ ПРЕДОТВРАЩЕНИЯ НЕСАНКЦИОНИРОВАННОГО ПЕРЕМЕЩЕНИЯ СТЕКА | 2014 |
|
RU2629442C2 |
| ВЕКТОРНОЕ ВЫЧИСЛИТЕЛЬНОЕ УСТРОЙСТВО | 2024 |
|
RU2830044C1 |
| ИЗМЕРИТЕЛЬНОЕ СРЕДСТВО ДЛЯ ФУНКЦИЙ АДАПТЕРА | 2010 |
|
RU2523194C2 |
| УСТРОЙСТВО ДЛЯ ПРИЕМА И ПЕРЕДАЧИ ДАННЫХ С ВОЗМОЖНОСТЬЮ ОСУЩЕСТВЛЕНИЯ ВЗАИМОДЕЙСТВИЯ С OpenFlow КОНТРОЛЛЕРОМ | 2014 |
|
RU2584471C1 |
| ИНСТРУКЦИЯ И ЛОГИКА ДЛЯ ДОСТУПА К ПАМЯТИ В КЛАСТЕРНОЙ МАШИНЕ ШИРОКОГО ИСПОЛНЕНИЯ | 2013 |
|
RU2662394C2 |
| АКТИВАЦИЯ/ДЕАКТИВАЦИЯ АДАПТЕРОВ ВЫЧИСЛИТЕЛЬНОЙ СРЕДЫ | 2010 |
|
RU2562372C2 |
| ИНСТРУКЦИЯ И ЛОГИКА ДЛЯ ИДЕНТИФИКАЦИИ ИНСТРУКЦИЙ ДЛЯ УДАЛЕНИЯ В МНОГОПОТОЧНОМ ПРОЦЕССОРЕ С ИЗМЕНЕНИЕМ ПОСЛЕДОВАТЕЛЬНОСТИ | 2013 |
|
RU2644528C2 |
Изобретение относится к области вычислительных средств, а именно к микропроцессорам, а в частности к устройству управления вычислительными ядрами ускорителя вывода нейронных сетей. Технический результат заключается в повышении производительности ускорителя за счет снижения времени простаивания вычислительных ядер. Устройство управления вычислительными устройствами ускорителя вывода нейронных сетей, содержащее размещенные на кристалле следующие элементы: блок конфигурации параметров, связанный с внешним управляющим устройством; сегментированную буферную память, соединенную с внешней памятью; по меньшей мере два блока обработки потоков инструкций, каждый из которых выполнен с возможностью: осуществления буферизации потока инструкций, получаемых от сегментированной буферной памяти; осуществления декодирования и синхронизации потока инструкций; блок указателей дескрипторов, выполненный с возможностью получения указателей дескрипторов от внешнего управляющего устройства; блок управления запросами на чтение дескрипторов по указателям из блока указателей дескрипторов; блок обработки дескрипторов набора инструкций; планировщик потоков инструкций, выполненный с возможностью осуществления загрузки набора инструкций и контроля наполненности сегментов указанной памяти. 13 з.п. ф-лы, 4 ил.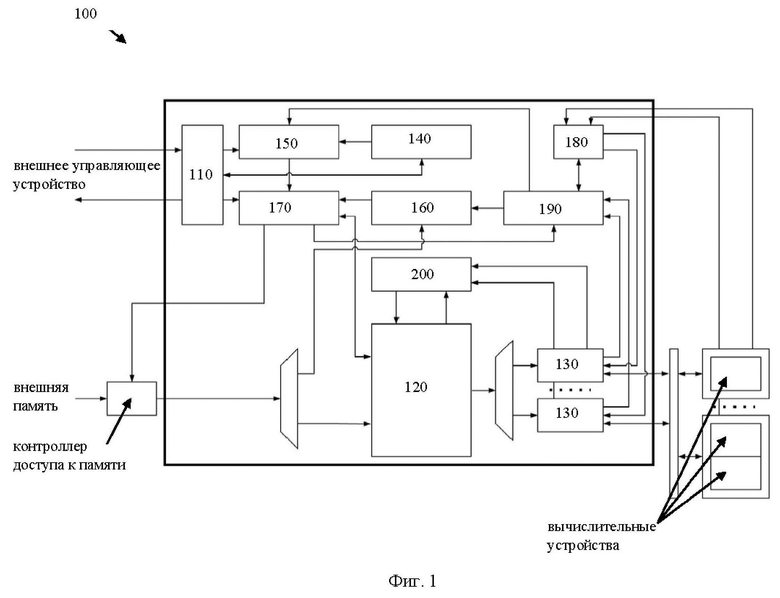
1. Устройство управления вычислительными устройствами ускорителя вывода нейронных сетей, содержащее размещенные на кристалле следующие элементы:
• блок конфигурации параметров, связанный с внешним управляющим устройством, выполненный с возможностью получения данных, содержащих конфигурационные параметры для устройства управления;
• сегментированную буферную память, соединенную с внешней памятью, выполненную с возможностью получения и хранения наборов инструкций, причем каждый сегмент обладает динамическим объемом памяти, устанавливаемым полученными конфигурационными параметрами, и выполнен с возможностью хранения набора инструкций для по меньшей мере одного вычислительного устройства ускорителя вывода нейронных сетей;
• по меньшей мере два блока обработки потоков инструкций, связанных с по меньшей мере двумя вычислительными устройствами ускорителя вывода нейронных сетей, каждый из которых выполнен с возможностью:
- осуществления буферизации потока инструкций, получаемых от сегментированной буферной памяти;
- осуществления декодирования полученного потока инструкций;
- синхронизации потока инструкций;
- отправки декодированного потока инструкций по меньшей мере одному вычислительному устройству ускорителя вывода нейронных сетей;
• блок указателей дескрипторов, выполненный с возможностью получения указателей дескрипторов от внешнего управляющего устройства, причем указатели дескрипторов содержат адрес расположения во внешней памяти и размер дескриптора набора инструкций для по меньшей мере одного вычислительного устройства;
• блок управления запросами на чтение дескрипторов по указателям из блока указателей дескрипторов, выполненный с возможностью получения из внешней памяти дескрипторов набора инструкций для по меньшей мере одного вычислительного устройства на основе указателя дескрипторов;
• блок обработки дескрипторов набора инструкций, выполненный с возможностью выделения адреса расположения и размера набора инструкций вычислительного устройства, а также параметров устройства управления для исполняемого вывода нейронной сети;
• планировщик потоков инструкций, выполненный с возможностью осуществления загрузки набора инструкций, на основе обработанного дескриптора, из внешней памяти по меньшей мере в два сегмента сегментированной буферной памяти и контроля наполненности сегментов указанной памяти.
2. Устройство по п. 1, характеризующееся тем, что вычислительное устройство ускорителя вывода нейронных сетей представляет собой вычислительное ядро ускорителя вывода нейронных сетей или кластер вычислительных ядер ускорителя вывода нейронных сетей.
3. Устройство по п. 1, характеризующееся тем, что конфигурационные параметры представляют собой по меньшей мере одно из: конфигурация сегментированной буферной памяти; конфигурация блока управления запросами на обработку дескрипторов; конфигурация блока обработки дескрипторов, конфигурация каждого из блоков обработки потоков инструкций.
4. Устройство по п. 1, характеризующееся тем, что планировщик потоков инструкций выполнен с возможностью порционной загрузки набора инструкций.
5. Устройство по п. 4, характеризующееся тем, что порционная загрузка набора инструкций представляет собой последовательную загрузку отдельных частей набора инструкций в сегмент буферной памяти, размер которых не превышает свободный объем сегмента памяти в сегментированной буферной памяти.
6. Устройство по пп. 4, 5, характеризующееся тем, что каждая часть набора инструкций помечается тэгом, соответствующим номеру сегмента буферной памяти.
7. Устройство по п. 1, характеризующееся тем, что каждый сегмент буферной памяти представляет собой кольцевой буфер с конфигурируемым объемом памяти.
8. Устройство по п. 1, характеризующееся тем, что блок указателей дескрипторов представляет собой кольцевой буфер (FIFO).
9. Устройство по п. 1, характеризующееся тем, что указатель дескриптора содержит, по меньшей мере, адрес расположения дескриптора набора инструкций для вычислительного устройства ускорителя вывода нейронных сетей во внешней памяти и размер указанного дескриптора.
10. Устройство по п. 1, характеризующееся тем, что набор инструкций содержит идентификатор получателя инструкции в ускорителе вывода нейронных сетей.
11. Устройство по п. 1, характеризующееся тем, что буферизация инструкций по меньшей мере в двух блоках обработки потоков инструкций осуществляется во внутреннем кольцевом буфере с шириной шины данных эквивалентной шине данных сегментированной буферной памяти.
12. Устройство по п. 1, характеризующееся тем, что отправка декодированного потока инструкций осуществляется в виде пакета данных.
13. Устройство по п. 1, характеризующееся тем, что при отправке декодированного потока инструкций блок обработки потоков инструкций дополнительно выполнен с возможностью подсчета количества отправленных инструкций и детекции последней инструкции.
14. Устройство по п. 13, характеризующееся тем, что блок обработки потоков инструкций дополнительно содержит блок синхронизации, выполненный с возможностью приостановки и возобновления отправки инструкций при получении соответствующей команды о приостановке или возобновлении.
| Двухосный автомобиль | 1924 |
|
SU2024A1 |
| Способ получения продуктов конденсации фенолов с формальдегидом | 1924 |
|
SU2022A1 |
| US 11113101 B2, 07.09.2021 | |||
| Двухосный автомобиль | 1924 |
|
SU2024A1 |
| КОМПАУНД НА ОСНОВЕ ЭПОКСИДНОГО ДИАНОВОГО ОЛИГОМЕРА | 0 |
|
SU212411A1 |
| УСТРОЙСТВО ПЕРЕСТАНОВОК И СДВИГОВ БИТОВ ДАННЫХ В МИКРОПРОЦЕССОРАХ | 2011 |
|
RU2488161C1 |

