Изобретение относится к области компьютерных систем. Более конкретно, изобретение относится к осуществлению операций с упакованными данными.
В обычных компьютерных системах процессоры создаются для выполнения операций с величинами, представляемыми большим количеством разрядов (например, 64) с использованием команд, которые формируют один результат. Например, выполнение команды сложения будет заключаться в сложении вместе первого 64-разрядного значения и второго 64-разрядного значения и запоминания результата, в виде третьего 64-разрядного значения. Однако, мультимедийные прикладные системы, например, системы, нацеленные на взаимодействие с компьютерной поддержкой (CSC--интеграция телеконференцсвязи со смешанной обработкой данных с носителей), средства двумерной/трехмерной графики, обработка изображений, сжатие/декомпрессия видеоданных, алгоритмы распознавания и обработка аудиосигналов) требуют обработки больших объемов данных, которые могут быть представлены небольшим количеством разрядов. Например, графические данные обычно требуют 8 или 16 разрядов и звуковые данные обычно требуют 8 или 16 разрядов. Для каждой из таких мультимедийных систем требуется один или более алгоритмов, причем каждый из них требует выполнения ряда операций. Например, для реализации алгоритма может потребоваться операция сложения, сравнения и сдвига.
Для повышения эффективности мультимедийных систем (а также других систем, имеющих такие же свойства) процессоры могут обеспечивать форматы упакованных данных. Формат упакованных данных - это формат, в котором разряды, обычно используемые для представления одного значения, разбиваются на ряд элементов данных фиксированного размера, причем каждый из них представляет отдельное значение. Например, 64-разрядный регистр может быть разбит на два 32-разрядных элемента, каждый из которых представляет отдельное 32-разрядное значение. Вдобавок эти процессоры в ответ на одну команду обеспечивают команды для раздельной обработки параллельно каждого элемента в этих типах упакованных данных. Например команда упакованного сложения обеспечивает суммирование соответствующих элементов данных из первых упакованных данных и вторых упакованных данных. Таким образом, если для мультимедийного алгоритма требуется цикл, содержаний пять операций, которые должны быть выполнены для большого количества элементов данных, желательно упаковать эти данные и выполнить эти операции параллельно, используя команды для упакованных данных. Таким образом эти процессоры могут более эффективно обрабатывать данные в мультимедийных системах.
Однако, если цикл операций содержит операцию, которая не может быть выполнена процессором с использованием упакованных данных (то есть, процессор не имеет соответствующей команды), то для выполнения такой операции данные должны быть распакованы. Например, если для мультимедийного алгоритма требуется операция сложения, а ранее описанной команды упакованного сложения не имеется, то программный блок должен распаковать как первые упакованные данные, так и вторые упакованные данные (то есть, разделить элементы, содержащие как первые упакованные данные, так и вторые упакованные данные), сложить по отдельности разделенные элементы, а затем упаковать результаты для получения упакованного результата используемого в дальнейшей обработке упакованных данных. Часто время обработки, необходимое для выполнения такого рода упаковки и распаковки сводит на нет преимущество в эффективности, ради которого создавались форматы упакованных данных. Следовательно, желательно включить в компьютерную систему набор команд для упакованных данных, которые обеспечивают все необходимые операции для типовых мультимедийных алгоритмов. Однако, из-за ограниченного пространства кристалла в современных микропроцессорах универсального назначения, количество команд, которые могут быть добавлены, ограничено. Следовательно, желательно создать команды, которые обеспечат как универсальность (то есть, команды, которые могут быть использованы в самых разнообразных мультимедийных алгоритмах), так и дадут преимущество в большей эффективности.
Один из способов обеспечения операций для использования в мультимедийных алгоритмах заключается в соединении отдельного процессора для цифровой обработки сигналов (ПЦС) с существующим универсальным процессором (например, IntelR 486, производимый Intel Corporation of Santa Clara, CA). Универсальный процессор направляет операции, которые могут выполняться с использованием упакованных данных (например, обработка видеоданных), на ПЦС.
Один такой ПЦС включает в себя команду умножения с накоплением, которая прибавляет к накопленному значению результаты перемножения двух значений (см. Kawakami, Yuchi et fl., "A Sing-Chip Digital Signal Processor for Voiceband Applications" IEEE International Solid-State Circiuts Conference, 1980, pp. 40-41). Пример операции умножения с накоплением для такого ПЦС показан ниже в таблице 1, в которой команда выполняется для значения данных A1 и B1, доступных в виде источника 1 и источника 2 соответственно.
Недостатком этой команды является ее ограниченная эффективность, то есть она работает только с двумя значениями и накопленным значением. Например, для умножения с накоплением двух наборов из 2-х значений требуется последовательное выполнение 2-х следующих команд: 1) умножение с накоплением первого значения из первого набора, первого значения из второго набора и накопленного значения О для генерации промежуточного накопленного значения; 2) умножение с накоплением второго значения из первого набора, второго значения из второго набора и промежуточного накопленного значения для генерации результата.
Другой ПЦС содержит команду умножения с накоплением, которая действует на двух наборах из двух значений и накопленном значении (патент 4 771470 на "Цифровой сигнальный процессор с параллельными умножителями"). Пример команды умножения с накоплением для этого ПЦС показан ниже в таблице 2, в которой команда выполняется со значениями данных A1, A2, B1 и B2, доступными в виде источников 1-4 соответственно.
При использовании этого способа два набора из 2-х значений перемножаются, а затем складываются с накопленным значением в одной команде.
Такая команда умножения с накоплением ограничивает универсальность, поскольку она всегда производит суммирование с накопленным значением. В результате такую команду трудно использовать для операций, отличных от умножения с накоплением. Например, в мультимедийных системах обычно используется умножение комплексных чисел. Умножение двух комплексных чисел (например, r1 i1 и r2 i2) выполняется согласно следующему выражению:
Действительная часть =r1•r2-i1•i2
Мнимая часть = r1•i2+r2•i1
Этот ПЦС не может выполнить операцию перемножения двух комплексных чисел с использованием одной команды умножения с накоплением.
Ограничения этой команды умножения с накоплением можно увидеть яснее, если результат такого вычисления необходим в последующей операции умножения, а не накопления. Например, если бы действительная часть была бы вычислена с использованием ПЦС, то накопленное значение необходимо было бы инициализировать на нуль, для того, чтобы правильно вычислить результат. Затем накопленное значение необходимо было бы инициализировать на нуль, для того, чтобы вычислить мнимую часть. Для выполнения другого комплексного умножения результирующего комплексного числа на третье комплексное число (например, r3, i3) должен быть изменен масштаб результирующего комплексного числа и его необходимо запомнить в подходящем формате памяти, а накопленное значение необходимо снова инициализировать на ноль. Затем комплексное умножение может выполняться, как было описано выше. В каждой из этих операций нет необходимости иметь арифметико-логическое устройство, которое отвечает за накопленное значение, но появляется необходимость в дополнительных командах для повторной инициализации этого накопленного значения. В противном случае в этих дополнительных командах нет необходимости.
Еще одним недостатком этого способа является то, что доступ к данным должен осуществляться через дорогостоящую многопортовую память. Это имеет место потому, что умножители соединены непосредственно с устройствами памяти данных. Следовательно, объем параллельных операций, который может быть использован, ограничивается небольшой величиной из-за затрат на межсоединения и из-за того, что эти межсоединения не развязаны с командой.
В вышеупомянутом патенте N 4771470 также указано, что альтернативным вариантом этим дорогостоящим межсоединениям является введение задержки для каждой последующей пары данных, подлежащих перемножению. Такое решение уменьшает преимущества, касающиеся эффективности обработки и сводит их к тому, что обеспечивает вариант решения, показанный в таблице 1.
Кроме того, идея использовать многопортовую память или конвейерный доступ к памяти влечет за собой использование многократных адресов. Такое явное использование одного адреса на единицу данных ясно показывает, что в этом способе не реализуется крайне важное понятие упакованных данных.
Заявлен процессор, содержащий первое и второе запоминающее устройство, имеющие первые и вторые упакованные данные соответственно. Каждые упакованные данные включают в себя первый, второй, третий и четвертый элемент данных.
Схема умножения-сложения соединена с первой и второй областями запоминающего устройства. Схема умножения-сложения включает в себя первый, второй, третий и четвертый умножитель, в которой каждый из умножителей получает соответствующий набор указанных элементов данных. Схема умножения-сложения, кроме того, включает в себя первый сумматор, соединенный с первым и вторым умножителями, и второй сумматор, соединенный с третьим и четвертым умножителями. Третья область запоминающего устройства соединена с сумматорами. Третья область запоминающего устройства включает в себя первое и второе поле для хранения выходных данных первого и второго сумматоров соответственно в виде первого и второго элементов данных третьих упакованных данных.
На фиг. 1 показана компьютерная система, соответствующая одному из вариантов осуществления изобретения.
Фиг. 2 - регистровый файл процессора согласно одному из вариантов осуществления изобретения.
Фиг. 3 - блок-схема, показывающая основные операции, используемые процессором для обработки данных согласно варианту осуществления изобретения.
Фиг. 4 - типы упакованных данных согласно варианту осуществления изобретения.
Фиг. 5a - представления в регистре упакованных данных согласно варианту осуществления изобретения.
Фиг. 5b - представления в регистре упакованных данных согласно варианту осуществления изобретения.
Фиг. 5c - представления в регистре упакованных данных согласно варианту осуществления изобретения.
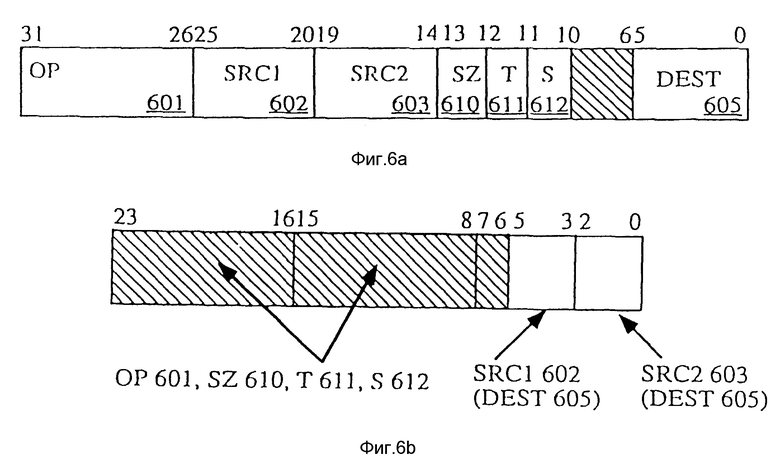
Фиг. 6a - формат управляющего сигнала, для указания использования упакованных данных, согласно варианту осуществления изобретения.
Фиг. 6b - второй формат управляющего сигнала для указания использования упакованных данных, согласно варианту осуществления изобретения.
Фиг. 7 - блок-схема, показывающая этапы выполнения операции умножения-сложения с упакованными данными согласно варианту осуществления изобретения.
Фиг. 8 - схема для выполнения операций умножения-сложения с упакованными данными согласно варианту осуществления изобретения.
Фиг. 9a-9e - дерево Wallace, выполняющее суммирование частичных произведений и сокращение для варианта осуществления настоящего изобретения.
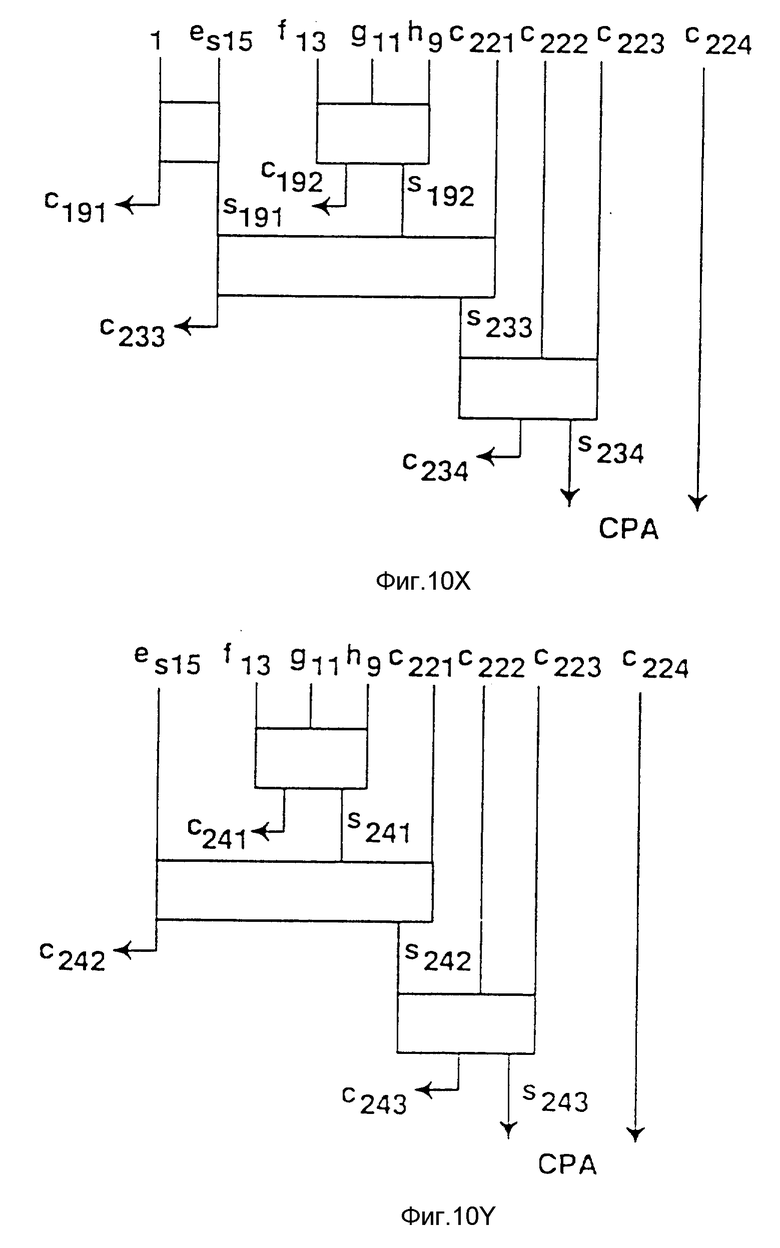
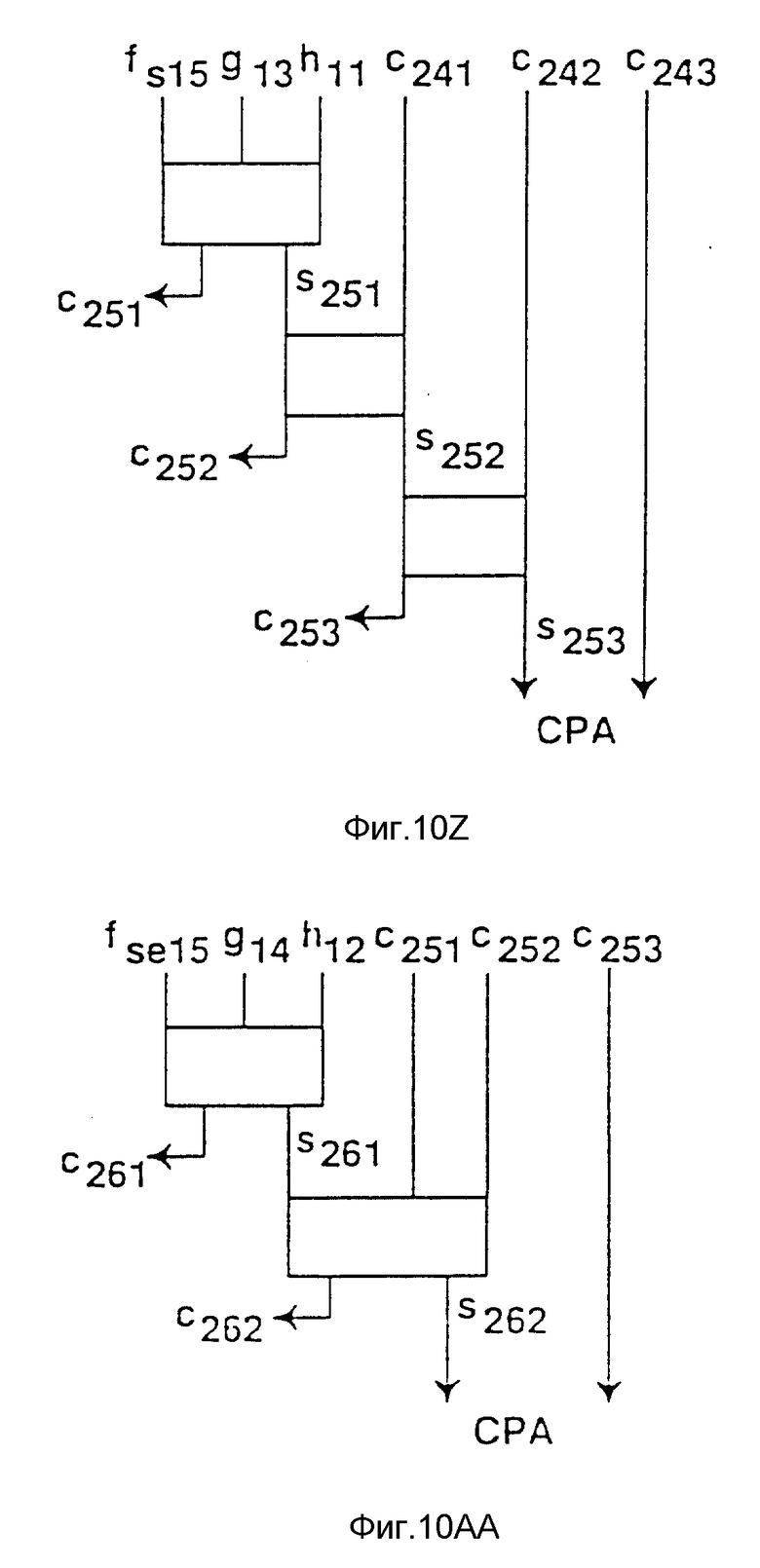
Фиг. 10a-10af - возможный вариант схемной реализации дерева Wallace по фиг. 9a-9e для варианта осуществления изобретения.
Фиг. 11 - схема для выполнения операций умножения-сложения с упакованными данными согласно варианту осуществления изобретения.
В последующем описании многочисленные конкретные детали приведены для обеспечения более ясного понимания изобретения. Однако понятно, что изобретение может быть реализовано на практике и без этих конкретных деталей. В других вариантах известные схемы, структуры и способы подробно не показаны, чтобы не затемнять сущность изобретения.
Для пояснения описания вариантов осуществления изобретения вводятся следующие определения.
Разряды с X по Y:
определяют субполе двоичного числа. Например, разряды с шестого по нулевой байта 001110102 (показывает основание два) представляют субполе 1110102. Цифра "2", следующая за двоичным числом, указывает основание 2. Следовательно 10002 равно 810 в то время как F16 равно 1510.
RX: регистр. Регистр - это любое устройство, способное запоминать и выдавать данные. Другие функции регистра описаны ниже. Регистр необязательно содержится в том же самом кристалле или в том же самом корпусе, что и процессор.
SRC1, SRC2 и DEST:
идентифицируют области памяти (например, адреса памяти, регистры и т.п. ).
источник 1-i и результат 1-i:
представляют данные.
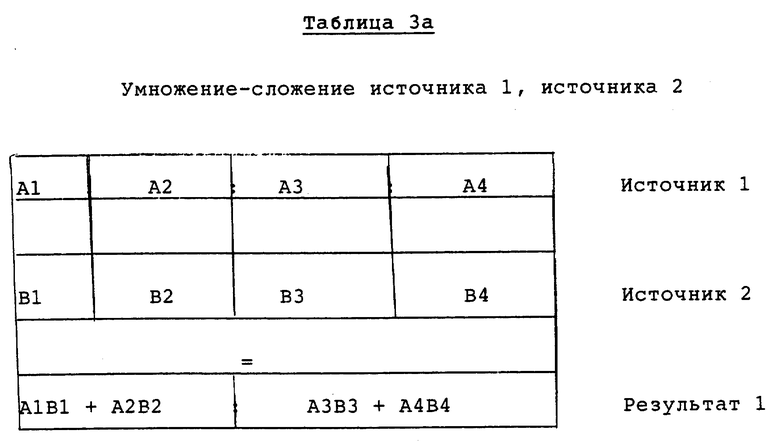
В данной заявке описано устройство в процессоре, выполняющем операции умножения-сложения с упакованными данными. В одном варианте выполняются две операции умножения-сложения с использованием одной команды умножения-сложения, как показано в таблице 3а и таблице 3b. Таблица 3а дает упрощенное представление раскрываемой операции умножения-сложения, в то время как таблица 3b показывает пример раскрываемой операции умножения- сложения на разрядном уровне.
Таким образом, описанный вариант операции умножения-сложения перемножает соответствующие 16-разрядные элементы данных источника 1 и источника 2, генерируя четыре 32-разрядных промежуточных результата. Эти 32-разрядные промежуточные результаты попарно суммируются, образуя два 32-разрядных результата, которые упаковываются в соответствующие элементы упакованного результата. Как описывается далее, в альтернативном варианте возможно изменение количества разрядов в элементах данных, промежуточных результатах и результатах. Вдобавок в альтернативном варианте возможно изменение количества используемых элементов данных, количества генерируемых промежуточных результатов и количества элементов данных в результирующих упакованных данных.
На фиг. 1 показана в качестве примера компьютерная система 100 согласно варианту осуществления изобретения.
Компьютерная система 100 включает в себя шину 101, или другие аппаратные и программные средства обмена информацией, для обмена информацией и процессор 109, соединенный с шиной 101, для обработки информации. Процессор 109 представляет собой центральный блок обработки с архитектурой любого типа, включая тип архитектуры CISC (компьютер с полной системой команд) или RISC (компьютер с сокращенным набором команд). Компьютерная система 100, кроме того, включает в себя запоминающее устройство с произвольной выборкой (ОЗУ) или другое динамическое запоминающее устройство (называемое основной памятью 104), подсоединенное к шине 101, для запоминания информации и команд, подлежащих выполнению процессором 109. Основная память 104 может быть также использована для запоминания временных переменных или другой промежуточной информации во время выполнения команд процессором 109. Компьютерная система 100 включает в себя также постоянное запоминающее устройство (ПЗУ) 106 и/или другое статическое запоминающее устройство, подсоединенное к шине 101, для запоминания статической информации и команд для процессора 109. Запоминающее устройство для данных 107 подсоединено к шине 101 для хранения информации и команд.
Согласно фиг. 1, процессор 109 содержит исполнительный блок 130, блок умножения-сложения 145, регистровый файл 150, кэш-память 160, декодер 165 и внутреннюю шину 170. Конечно, процессор 109 содержит и другие схемы, не являющиеся необходимыми для понимания сущности изобретения.
Исполнительный блок 130 используется для выполнения команд, получаемых процессором 109. Вдобавок к распознаванию команд, что обычно реализуется в процессорах общего назначения, исполнительный блок 130 распознает команды 142 в наборе упакованных команд (команд, поддерживающих операции с упакованными данными) 140 для выполнения операций с форматами упакованных данных. Набор упакованных команд включает в себя команды для поддержания операций умножения-сложения. Вдобавок набор упакованных команд 140 может также включать в себя команды для поддержки операции упаковки, операции распаковки, операции упакованного сложения, операции упакованного вычитания, операции упакованного умножения, операции упакованного сдвига, операции упакованного сравнения, операции подсчета совокупности и набора упакованных логических операций (включая упакованную операцию И, упакованную операцию И- НЕ, упакованную операцию ИЛИ и упакованную операцию "исключающее ИЛИ"), как описано в заявке на ("Набор команд для работы с упакованными данными"). Исполнительный блок 130, кроме того включает в себя блок умножения-сложения 145 для выполнения операций умножения-сложения.
Исполнительный блок 130 подсоединен к регистровому файлу 150 с помощью внутренней шины 170. Регистровый файл 150 представляет область памяти в процессоре 109 для запоминания информации, включающей данные. Исполнительный блок 130 кроме того, подсоединен к кэш-памяти 160 и декодеру 165. Кэш-память 160 используется для помещения в нее данных и/или управляющих сигналов, например, из основной памяти 104. Декодер 165 используется для декодирования команд, принимаемых процессором 109, и получения управляющих, сигналов и/или точек входа микрокода. В ответ на эти управляющие сигналы и/или точки входа микрокода исполнительный блок 130 выполняет соответствующие операции. Например, если принята команда сложения, то декодер 165 заставляет исполнительный блок 130 выполнять необходимое сложение. Декодер 165 может быть реализован с использованием любого числа различных средств (например, таблицы преобразования, аппаратных средств, программируемой логической матрицы и т.п.). Таким образом, хотя выполнение различных команд декодером и исполнительным блоком представляется последовательностью условных операторов ("если/тогда"), понятно, что выполнение одной команды не требует последовательной обработки этих условных операторов. Подразумевается, что любое средство для логического выполнения этой процедуры обработки "если/тогда" должно входить в объем настоящего изобретения.
На фиг.1 дополнительно показано устройство запоминания данных 107, такое как магнитный диск или оптический диск и соответствующий дисковод, которое может быть подсоединено к компьютерной системе 100. Компьютерная система 100 через шину 101 также может быть подсоединена к устройству отображения 121 для отображения информации пользователю компьютера. Устройство отображения 121 может включать в себя буфер кадров, специализированные устройства графической визуализации, электронно-лучевую трубку (ЭЛТ) и/или дисплей с плоским экраном. Буквенно-цифровое устройство ввода 122, содержащее буквенно-цифровые и другие клавиши, обычно подсоединяются к шине 101 для передачи информации в процессор 109 и выбора команд. Другим типом входного устройства пользователя является устройство управления курсором 123, такое как мышь, шаровой манипулятор, перо, сенсорный экран или клавиши управления курсором для передачи управляющей информации и выбранных команд на процессор 109 и для управления перемещением курсора по устройству отображения 121. Это входное устройство обычно имеет две степени свободы по двум осям, первой оси (например, х) и второй оси (например, y), что позволяет устройству определять координаты местоположения на плоскости. Однако это изобретение не следует ограничивать входными устройствами только с двумя степенями свободы.
Другим устройством, которое может быть подсоединено к шине 101, является устройство выдачи документальных копий 124, которое может быть использовано для распечатки команд, данных или другой информации на таком носителе, как бумага, пленка, или каком-либо подобном носителе. Дополнительно компьютерная система 100 может быть подсоединена к устройству для записи и/или воспроизведения звука 125, такому как аудиодигитайзер, подсоединенному к микрофону, для записи информации. Кроме того, это устройство может включать в себя громкоговоритель, который подсоединяется к цифроаналоговому преобразователю (ЦАП) для воспроизведения оцифрованного звукового сигнала.
Компьютерная система 100 может также представлять собой терминал в компьютерной сети (например, в LAN - локальной вычислительной сети). Тогда компьютерная система 100 является компьютерной подсистемой компьютерной сети. Компьютерная система 100 может также дополнительно включать устройство оцифровки видеосигналов 126. Устройство оцифровки видеосигналов 126 может быть использовано для сбора видеоизображений, которые могут передаваться на другие устройства в компьютерной сети.
В одном варианте процессор 109 дополнительно поддерживает набор команд, который совместим с набором команд x86, используемым существующими процессорами (такими, как процессор PentiumR), выпускаемыми Intel Corporation, Santa Clara, California. Таким образом в одном варианте процессор 109 поддерживает все операции, поддерживаемые в архитектуре IATM - Intel, определенной Intel Corporation (см. Microprocessors, Intel Data Books, volume 1 and volume 2, 1992 and 1993, предоставляемые компанией Intel. В результате процессор 109, помимо операций согласно изобретению, может поддерживать существующие операции x86. Хотя данное изобретение описывается как включенное в набор команд x86, альтернативные варианты могут включать изобретение в другие наборы команд. Например, изобретение может быть включено в 64-разрядный процессор, использующий иной набор команд.
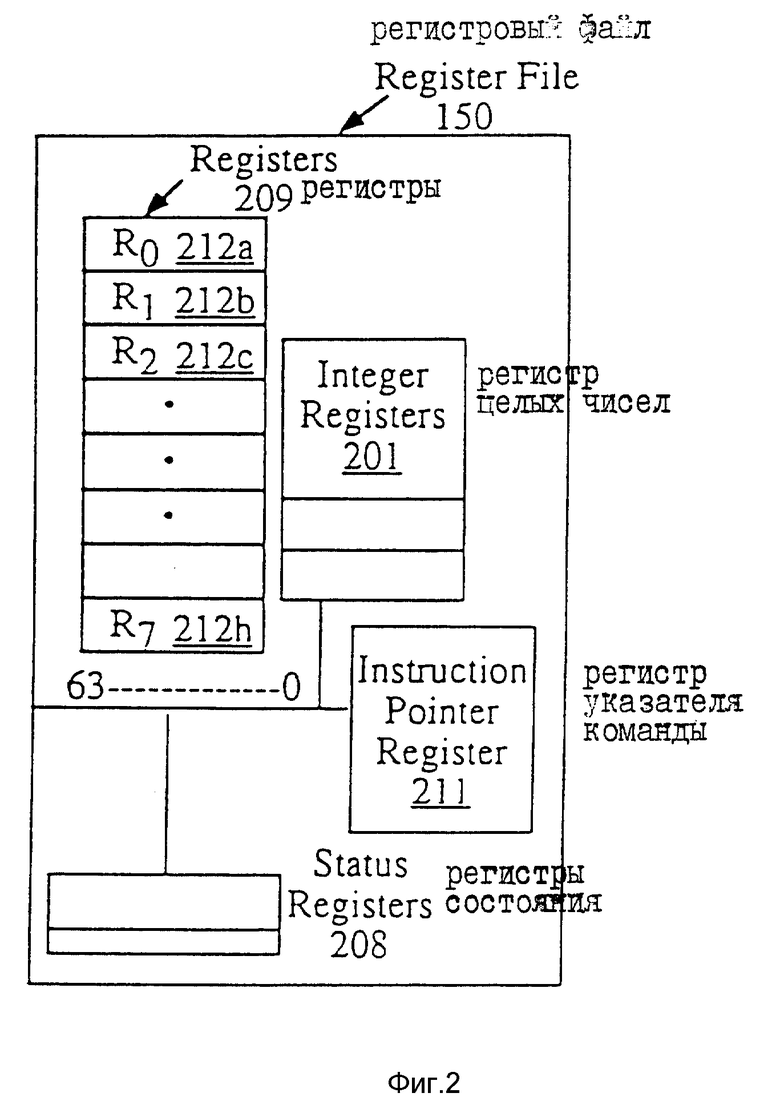
На фиг. 2 показан регистровый файл процессора согласно возможному варианту осуществления изобретения. Регистровый файл 150 используется для запоминания информации, включающей управляющую информацию/информацию о состоянии, целочисленные данные, данные с плавающей запятой и упакованные данные. В варианте, показанном на фиг. 2 регистровый файл 150 включает в себя регистры целых чисел 201, регистры 209, регистры состояния 208 и регистр указателя команды 211. Регистры состояния 208 показывают состояние процессора 109. Регистр указателя команды 211 запоминает адрес следующей команды, подлежащей выполнению. Регистры целых чисел 201, регистры 209, регистры состояния 208 и регистр указателя команды 211 подсоединены все к внутренней шине 170. К внутренней шине 170 могут быть также подсоединены любые дополнительные регистры.
В одном из вариантов регистры 209 используются как для упакованных данных, так и для данных с плавающей запятой. В одном таком варианте процессор 109 в любой данный момент должен обрабатывать регистры 209, обращаясь к ним как к стековым регистрам с плавающей запятой, либо как к нестековым регистрам упакованных данных. В этом варианте имеется механизм, позволяющий процессору 109 переключаться на работу с регистрами 209 либо как со стековыми регистрами данных с плавающей запятой или как с нестековыми регистрами с упакованными данными. В другом подобном варианте процессор 109 может одновременно работать с регистрами 209 как с нестековыми регистрами с плавающей запятой и регистрами упакованных данных. В еще одном варианте те же самые регистры могут использоваться для запоминания целочисленных данных.
Конечно, могут быть реализованы альтернативные варианты, содержащие большие или меньшие наборы регистров. Например, альтернативный вариант может включать в себя отдельный набор регистров с плавающей запятой для запоминания данных с плавающей запятой, в другом альтернативном варианте может содержаться, например, первый набор регистров, каждый из которых запоминает управляющую информацию/информацию о состоянии и второй набор регистров, каждый из которых способен запоминать целочисленные данные, данные с плавющей запятой и упакованные данные. Ясно, что регистры одного варианта не должны быть ограничены по своему назначению конкретным типом схемы. Просто регистр варианта должен быть способен запоминать и выдавать данные и выполнять описанные здесь функции.
Различные наборы регистров (например, регистры целых чисел 201, регистры 209) могут быть реализованы с включением разного числа регистров и/или регистров различных размеров. Например, в одном варианте регистры целых чисел 201 реализуются для запоминания тридцати двух разрядов, в то время как регистры 209 реализуются для запоминания восьмидесяти разрядов (все восемьдесят разрядов используются для запоминания данных с плавающей запятой, в то время как для упакованных данных используется только шестьдесят четыре разряда). Регистры 209 содержат, кроме того, восемь регистров с R0 212a по R7 212 h. R1 212a, R2 212b и R3 212с, являются примерами отдельных регистров в регистрах 209. Тридцать два разряда регистра в регистрах 209 могут быть перенесены в регистр целых чисел в регистрах целых чисел 201. Подобным же образом значение в регистре целого числа может быть перенесено в тридцать два разряда регистра в регистрах 209. В другом варианте регистры целых чисел 201 содержат каждый 64 разряда данных, могут переноситься между регистром целых чисел 201 и регистрами 209.
На фиг. 3 показана блок-схема, представляющая основные этапы, которые используются процессором для обработки данных согласно возможному варианту осуществления изобретения. То есть, фиг. 3 показывает этапы, которые реализует процессор 109 при выполнении операции с упакованными данными, выполнении операции с распакованными данными или выполнении какой-нибудь другой операции. Например, такие операции включают в себя операцию загрузки для загрузки регистра в регистровом файле 150 данными из кэш-памяти 106, основной памяти 104, постоянного запоминающего устройства (ПЗУ) 106 или запоминающего устройства для данных 107.
На этапе 301 декодер 165 получает управляющий сигнал либо из кэш-памяти 160, либо из шины 101. Декодер 165 декодирует управляющий сигнал, чтобы определить операции, подлежащие выполнению. На этапе 302 декодер 165 осуществляет доступ к регистровому файлу 150 или ячейке памяти. Доступ к регистрам в регистровом файле 150 или к ячейкам в памяти осуществляется в зависимости от адреса регистра, определенного в управляющем сигнале. Например, для операции с упакованными данными управляющий сигнал может включать в себя адреса регистров SRC1, SRC2 и DEST. SRC1 - это адрес регистра первого источника. SRC2 - адрес регистра второго источника. В некоторых случаях, адрес SRC2 необязателен, так как не во всех операциях требуются адреса двух источников. Если адрес SRC2 для операции не требуется, то тогда используется только адрес SRC1. DEST - это адрес регистра результата, где запоминаются данные результата. В одном варианте SRC1 или SRC2 используется также в качестве DEST. Более подробно SRC1, SRC2 и DEST описаны в связи с фиг. 6a и фиг. 6b. Данные, запоминаемые в соответствующих регистрах, называются источник 1, источник 2 и результат соответственно. Каждые из этих данных имеют длину шестьдесят четыре разряда.
В другом варианте осуществления изобретения либо один, либо все SRC1, SRC2 и DEST могут определять ячейку памяти в адресуемом пространстве памяти процессора 109. Например, SRC1 может идентифицировать ячейку в основной памяти 104, в то время как SRC2 идентифицирует первый регистр в целочисленных регистрах 201, а DEST идентифицирует второй регистр в регистрах 209. Для простоты описания изобретение раскрывается здесь в связи с обращением к регистровому файлу 150. Однако вместо этого эти обращения могут выполняться к памяти.
На этапе 303 исполнительному блоку 130 разрешается выполнять операцию с выбранными данными. На этапе 304 результат запоминается обратно в регистровом файле 150 в соответствии с требованиями управляющего сигнала.
На фиг. 4 показаны типы упакованных данных согласно возможному варианту осуществления изобретения. Здесь показаны три формата упакованных данных: упакованный байт 401, упакованное слово 402 и упакованное двойное слово 403. Упакованный байт в одном варианте изобретения имеет шестьдесят четыре разряда в длину и содержит восемь элементов данных. Каждый элемент данных имеет в длину один байт. Обычно элемент данных представляет собой отдельную порцию данных, которая хранится в одном регистре (или ячейке памяти) вместе с другими элементами данных такой же длины. В одном из вариантов изобретения количество элементов данных, запоминаемых в регистре, составляет шестьдесят четыре разряда, поделенных на длину в разрядах элемента данных.
Упакованное слово 402 имеет длину шестьдесят четыре разряда и содержит четыре элемента данных слова 402. Каждый элемент данных слова 402 содержит шестнадцать информационных разрядов.
Упакованное двойное слово 403 имеет в длину шестьдесят четыре разряда и содержит два элемента данных двойного слова 403. Каждый элемент данных двойного слова 403 содержит тридцать два информационных разряда.
На фигурах с 5a по 5c показано представление запоминания упакованных в регистре данных согласно одному варианту изобретения. Представление 510 упакованного в регистре байта без знака показывает запоминание упакованного без знака байта 401 в одном из регистров от R0 212a до R7212h. Информация для каждого элемента данных байта запоминается для байта ноль с разряда семь по разряд ноль, для байта один с разряда пятнадцать по разряд восемь, для байта два с разряда двадцать три по разряд шестнадцать, для байта три с разряда тридцать один по разряд двадцать четыре, для байта четыре с разряда тридцать девять по разряд тридцать два, для байта пять с разряда сорок семь по разряд сорок, для байта шесть с разряда пятьдесят пять по разряд сорок восемь и для байта семь с разряда шестьдесят три по разряд пятьдесят шесть. Таким образом, в регистре используются все имеющиеся разряды. Такая организация запоминания повышает эффективность запоминания процессора. Также, если доступны восемь элементов данных, то тогда одна операция может выполняться одновременно с восемью элементами данных. Представление 511 упакованного в регистре байта со знаком показывает запоминание упакованного байта 401 со знаком. Отметим, что восьмой разряд каждого байтого элемента данных представляет собой индикатор знака.
Регистровое представление 512 упакованного слова без знака показывает, как слова от слова три до слова ноль запоминаются в одном регистре регистров 209. Разряды с разряда пятнадцать по разряд ноль содержат информацию элементов данных для слова ноль, разряды с разряда тридцать один по разряд шестнадцать содержат информацию для слова один элементов данных, разряды с разряда сорок семь по разряд тридцать два содержат информацию для слова два элементов данных и разряды с разряда шестьдесят три по разряд сорок восемь содержат информацию для слова три элементов данных. Регистровое представление 513 упакованного со знаком слова подобно регистровому представлению 512 упакованного без знака слова. Заметим, что шестнадцатый разряд каждого словного элемента данных представляет собой индикатор знака.
Регистровое представление 514 упакованного без знака двойного слова показывает, как регистры 209 запоминают два элемента данных двойного слова. Двойное слово ноль запоминается в разрядах с разряда тридцать один по разряд ноль регистра. Двойное слово один запоминается в разрядах с разряда шестьдесят три по разряд тридцать два регистра. Регистровое представление 515 упакованного со знаком двойного слова подобно регистровому представлению 514 упакованного без знака двойного слова. Заметим, что необходимым разрядом знака является тридцать второй разряд элемента данных двойного слова.
Как упоминалось ранее, регистры 209 могут быть использованы как для упакованных данных, так и для данных с плавающей запятой. В этом варианте изобретения может потребоваться отдельный программирующий процессор 109 для отслеживания того, запоминает ли адресуемый регистр, например R0 212a, упакованные данные, либо данные с плавающей запятой. В альтернативном варианте процессор 109 может отслеживать тип данных, запоминаемых в отдельных регистрах среди регистров 209. Тогда в этом альтернативном варианте могут появиться ошибки, если, например, была предпринята попытка выполнить операцию упакованного сложения с данными с плавающей запятой.
Далее описывается вариант форматов управляющего сигнала, используемых процессором 109 для обработки упакованных данных. В одном из вариантов изобретения управляющие сигналы представляются тридцатью двумя разрядами. Декодер 165 может получать управляющий сигнал из шины 101. В другом варианте декодер 165 может получать такие управляющие сигналы, из кэш-памяти 160.
На фиг. 6a показан формат управляющего сигнала, указывающего, как использовать упакованные данные, согласно одному варианту изобретения. Рабочее поле OP 601, с разряда тридцать один по разряд двадцать шесть, обеспечивает информацию для операции, подлежащей выполнению процессором 109; например, упакованное сложение и т. п. SRC 602, с разряда двадцать пять по разряд двадцать, обеспечивает адрес регистра источника в регистрах 209. Этот регистр источника содержит первые упакованные данные, Источник 1, подлежащие использованию при исполнении управляющего сигнала. Подобным же образом SRC2 603, с разряда девятнадцать по разряд четырнадцать, содержит адрес регистра в регистрах 209. Этот регистр второго источника содержит упакованные данные, Источник 2, подлежащие использованию во время выполнения операции. DEST 605, с разряда пять по разряд ноль содержит адрес регистра в регистрах 209. Этот регистр результата будет запоминать упакованные данные результата. Результат, операции с упакованными данными.
Управляющие разряды SZ 610, разряд двенадцать и разряд тринадцать указывают длину элементов данных в первом и втором регистрах источников упакованных данных. Если SZ 610 равно 012, то тогда упакованные данные форматируются в виде упакованного байта 401. Если SZ 610 равно 102, то тогда упакованные данные форматируются в виде упакованного слова 402. SZ 610, равное 002 или 112 зарезервировано, однако в другом варианте одно из этих значений может быть использовано для указания упакованного двойного слова 403.
Управляющий разряд T 611, разряд одиннадцать, указывает, должна ли операция выполняться в режиме насыщения. Если T 611 равен единице, то тогда выполняется операция с насыщением. Если T 611 равен нулю, то тогда, выполняется операция без насыщения. Операции с насыщением будут описаны ниже. Управляющий разряд S 612, разряд десять, указывает на использование операции со знаком. Если S 612 равен единице, то тогда выполняется операция со знаком. Если S 612 равен нулю, то тогда выполняется операция без знака.
На фиг. 6b показан второй формат управляющего сигнала, указывающий на то, как использовать упакованные данные, согласно одному варианту изобретения. Этот формат соответствует общему формату кода целочисленной операции, описанному в "Pentium Processor Family User's Manual", Intel Corporation, Literature Sales, P.O. Box 7641, Mt prospect, IL, 60056-7641. Заметим, что OP 601, SZ 610, T 611 и S 612 объединены в одном большом поле. Для некоторых управляющих сигналов разряды с разряда три по разряд пять представляют собой SRCI 602. В одном варианте, если имеется адрес SRCI 602, то разряды с разряда три по разряд пять соответствуют также DEST 605. В альтернативном варианте, если есть адрес SRC2 603, то разряды с разряда ноль по разряд два соответствуют также DEST 605. Для других управляющих сигналов, типа промежуточной операции упакованного сдвига, разряды с разряда три по разряд пять представляют расширение к полю кода операции. В одном варианте это расширение позволяет программному блоку ввести промежуточное значение вместе с управляющим сигналом, такое как значение отсчета сдвига. В одном из вариантов это промежуточное значение следует за управляющим сигналом. Более подробно это описание в "Pentium Processor Family User's Manual", приложение F, страницы с F-l по F-3. Разряды с разрядов ноль по разряд два представляют SRC2 603. Этот общий формат допускает адресацию регистр - регистр, память - регистр, регистр - памятью, регистр - регистром, регистр непосредственно, регистр - память. Также в одном из вариантов этот общий формат может поддерживать адресацию регистр - целочисленный регистр.
Как указывалось ранее, Т 611 указывает, обязательны ли операции с насыщением. Если результат операции, при разрешении насыщения, приводит к переполнению или потере значимости диапазона данных, то результат будет зафиксирован. Фиксация означает установку результата на максимальное или минимальное значение, если результат превышает максимальное или минимальное значение диапазона. В случае потери значимости насыщение фиксирует результат на самом нижнем значении диапазона, а в случае переполнения - на самом верхнем значении. Допускаемый диапазон для каждого формата данных показан в таблице 4.
Как упоминалось выше, T 611 указывает, выполняются ли операции с насыщением. Следовательно, при использовании формата данных "байт без знака", если результат операции = 258 и насыщение было разрешено, то тогда результат будет зафиксирован на 255, прежде чем он будет сохранен в регистре результата операции. Подобным же образом, если результат операции = -32999 и процессор 109 использовал формат данных "слово со знаком", причем насыщение разрешено, то тогда результат будет зафиксирован на -32768, прежде чем он будет записан в регистр результата операции.
В одном из вариантов осуществления изобретения регистр SRC1 содержит упакованные данные (Источник 1), регистр SRC2 содержит упакованные данные (Источник 2), а регистр DEST будет содержать результат (Результат) выполнения операции умножения-сложения с Источником 1 и Источником 2. На первом этапе операции умножения-сложения Источник 1 будет содержать каждый элемент данных, умножаемый независимо на соответствующий элемент данных Источника 2, для генерации набора соответствующих промежуточных результатов. Эти промежуточные результаты попарно суммируются, генерируя результат для операции умножения-сложения.
В одном из вариантов операция умножения-сложения осуществляется с упакованными со знаком данными и с усечением результата во избежание любых переполнений. Кроме того, операция осуществляется с данными упакованного слова, а результат представляет собой упакованное двойное слово. Однако в альтернативных вариантах может поддерживаться операция и для других типов упакованных данных.
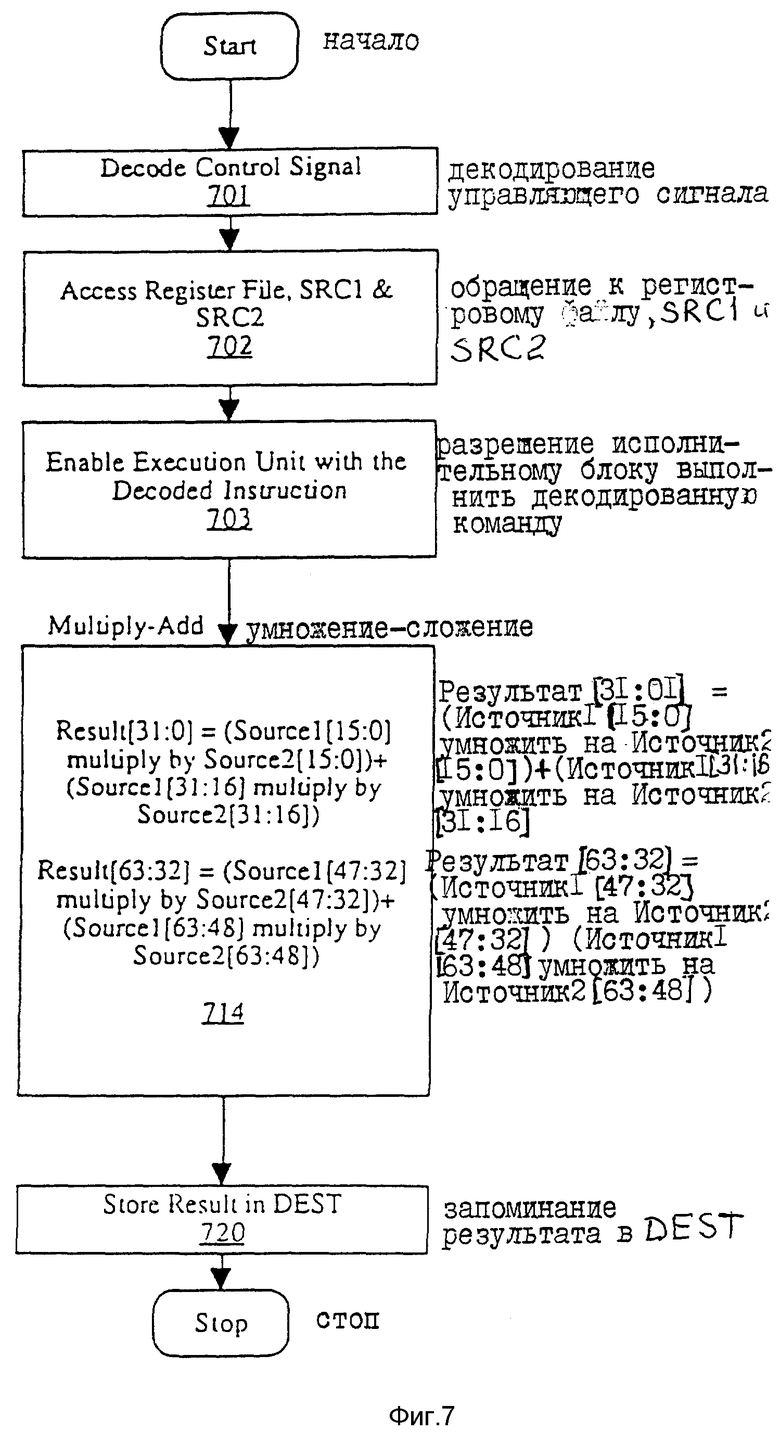
На фиг. 7 представлена блок-схема, показывающая этапы выполнения операций умножения-сложения с упакованными данными согласно одному варианту изобретения.
На этапе 701 декодер 165 декодирует управляющий сигнал, получаемый процессором 109. Таким образом, декодер 165 декодирует код операции для операции умножения-сложения.
На этапе 702 через внутреннюю шину 170 декодер 165 осуществляет доступ к регистрам 209 в регистровом файле 150, задавая адреса SRC1 602 и SRC2 603. Регистры 209 обеспечивают исполнительный блок 130 упакованными данными, хранящимися в регистре SRC1 602 (Источник 1), и упакованными данными, хранящимися в регистре SRC2 603 (источник 2). То есть, регистры 209 передают упакованные данные в исполнительный блок 130 через внутреннюю шину 170.
На этапе 703 декодер 165 позволяет блоку умножения-сложения 145 исполнительного блока 130 выполнить команду. На этапе 714 выполняется следующее. Разряды с разряда пятнадцать по разряд ноль Источника 1 умножаются на разряды с пятнадцатого по нулевой Источника 2, генерируя первый 32-разрядный промежуточный результат (промежуточный результат 1). Разряды Источника 1 с тридцать первого по шестнадцатый умножаются на разряды с разряда тридцать один по разряд шестнадцать Источника 2, генерируя второй 32-разрядный промежуточный результат (промежуточный результат 1). Разряды Источника 1 с разряда сорок семь по разряд тридцать два умножаются на разряды с разряда сорок семь по разряд тридцать два Источника 2, генерируя третий 32- разрядный промежуточный результат (промежуточный результат 3). Разряды Источника 1 с разряда шестьдесят три по разряд сорок восемь умножаются на разряды с разряда шестьдесят три по разряд сорок восемь Источника 2, генерируя четвертый 32-разрядный промежуточный результат (Промежуточный результат 4). Промежуточный результат 1 складывается с промежуточным результатом 2, генерируя разряды результата с разрядов тридцать один по разряд 0, а промежуточный результат 3 складывается с промежуточным результатом 4, генерируя разряды результата с разряда шестьдесят три по разряд тридцать два.
В различных вариантах воплощения изобретения умножения и сложения могут выполняться последовательно, параллельно, либо в некоторой комбинации из последовательных и параллельных операций.
На шаге 720 результат запоминается в регистре DEST.
В одном из вариантов операции умножения-сложения могут выполняться на множестве элементов данных в том же самом количестве периодов тактовых импульсов, что и одно умножение в упакованных данных. Чтобы достичь выполнения в том же самом количестве периодов тактовых импульсов, используется параллельная работа. То есть, на регистры одновременно подается команда на выполнение операций умножения-сложения с элементами данных.
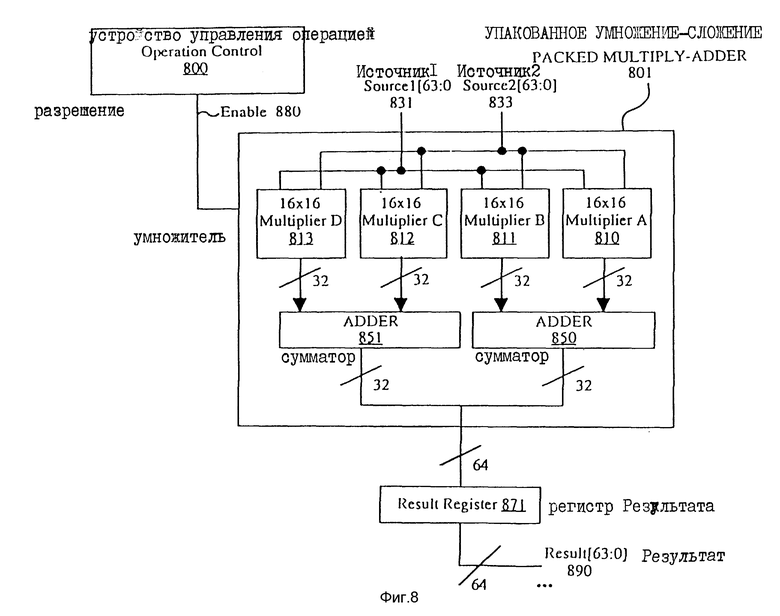
Фиг. 8 иллюстрирует в сжатом виде схему для выполнения операций умножения-сложения с упакованными данными согласно одному варианту изобретения. Устройство управления операцией 800 обрабатывает управляющий сигнал для команд умножения-сложения. Устройство управления операцией 800 выдает сигналы на вход разрешения 880, чтобы управлять упакованным умножителем-сумматором 801.
Упакованный умножитель-сумматор 801 имеет следующие входы: Источник 1 [63: 0] 831, Источник 2 [63:0] 833 и разрешение 880. Упакованный умножитель-сумматор 801 включает в себя четыре схемы умножителя 16х16: 16х16 умножитель A 810, 16х16 умножитель В 811, 16х16 умножитель С 812 и 16х16 умножитель D 813. 16х16 умножитель А 810 имеет в качестве входов Источник 1 [15:0] и Источник 2 [15:0]. 16х16 умножитель В 811 имеет в качестве входов Источник 1 [31: 16] и Источник 2 [31:16]. 16х16 умножитель C 812 имеет в качестве входов источник 1 [47:32] и Источник 2 [47:32]. 16х16 умножитель D 813 имеет в качестве входов Источник 1 [63:48] и Источник 2 [63: 48]. 32-разрядные промежуточные результаты, генерируемые 16х 16 умножителем А 810 и 16х16х умножителем В 811 принимаются сумматором 1350, в то время как 32-разрядные промежуточные результаты, генерируемые 16х16 умножителем С 812 и 16х16 умножителем D 813, принимаются сумматором 851.
Сумматор 850 и сумматор 851 складывают соответствующие 32-разрядные входные данные. Выходные данные сумматора 850 (то есть, разряды результата от разряда 31 до разряда ноль) и выходные данные сумматора 851 (то есть, разряды результата с 63 по 32) объединяются в 64-разрядный результат и передаются в регистр результата 871.
В одном варианте осуществления изобретения каждый из сумматоров 851 и 850 состоит из 32-разрядного сумматора с соответствующими задержками на распространение сигнала. Однако, в альтернативных вариантах сумматор 851 и сумматор 850 могут быть реализованы любым количеством способов.
Выполнение эквивалента этой команды умножения-сложения с использованием известного процессора ПЦС, описанного со ссылками на таблицу 1, требует одну команду, чтобы обнулить накопленное значение и четыре команды умножения с накоплением. Выполнение эквивалента этой команды умножения-сложения с использованием известного процессора. ПЦС, описанного со ссылками на таблицу 2, требует одну команду, чтобы обнулить накопленное значение и две команды накопления.
В одном варианте блока умножения-сложения 145 настоящего изобретения каждый 16-разрядный умножитель, используемый для операций упакованного умножения, в настоящем изобретении реализуется с использованием 2-разрядного алгоритма Booth. Основное назначение алгоритма Booth в умножителях - сократить количество частичных произведений, подлежащих суммированию. Меньшее количество частичных произведений уменьшает объем аппаратуры и снижает потребность в пространстве для умножителя. В приведенной таблице 5 описывается известный процесс 16- разрядного умножения, когда генерируются 16 частичных произведений. Каждое частичное произведение сдвигается влево на один разряд и содержит либо все "0", либо точную копию множимого в зависимости от того, равен ли соответствующий разряд множителя "1" или "0", 32-разрядный результат генерируется посредством суммирования всех 16 частичных произведений, вырезка за вырезкой.
С другой стороны, 2-разрядный умножитель Booth, показанный в таблице 6, работает по-другому. В этом случае имеет всего 8 частичных произведений и каждое частичное произведение имеет длину 17 разрядов. Каждое частичное произведение имеет свой собственный кодер Booth, который и задает содержимое соответствующего частичного произведения. В альтернативных вариантах для выбора частичных произведений могут быть использованы другие схемы кодера Booth.
Обычный 2-разрядный кодер Booth имеет пять выходов, для операций ноль, плюс 1, плюс 2, минус 1 и минус 2. Их таблица истинности представлена в таблице 6.
Как установлено в таблице 6, yk+l, yk и yk-l являются разрядами смежных сомножителей в порядке убывания значимости. В приведенной таблице 7 кроме того описывается форма частичных произведений в соответствии с выходными данными кодера Booth.
Для сокращения количества одинаковых адресов переноса (CSA), необходимых для сокращения частичных произведений, вместо знакового расширения частичных произведений используется способ генерации знака. Таблица 8 показывает способ генерации знака. Дополнение знакового разряда частичного произведения подвешивается перед частичным произведением. Затем перед дополнением знакового разряда подвешивают два единичных разряда.
В приведенной таблице 9 показан процесс 16-разрядного умножения в одном варианте настоящего изобретения с использованием 2-разрядного кодера Booth и способ генерации знака для генерирования 8 частичных произведений.
В одном варианте каждый кодер Booth содержит 3 разряда смежных сомножителей (yO - младший значащий разряд и y15 - старший значащий разряд из разрядов множителя). Форма частичного произведения определяется 17 селекторами и схемой отрицания, подсоединенной к определенному кодеру Booth. Разряды данных селекторов содержат 2 разряда смежных сомножителей, их дополнения и Vcc (для операции обнуления). Затем выбранные выходные данные проходят через лабиринт дерева сокращений частичных произведений, обычно называемого деревом Wallace.
Как только выбраны все частичные произведения, начинается суммирование частичных произведений. Дерево Wallace выполняется на полных сумматорах и половинных сумматорах. На фиг. 9a-9e показано дерево Wallace, выполняющее суммирование и сокращение частичных произведений для одного из вариантов осуществления настоящего изобретения, реализуемое каждым из четырех 16-разрядных умножителей в блоке умножения-сложения 145. Как показано на чертежах 8 частичных произведений сокращаются до 6 частичных произведений, затем до 4 частичных произведений, затем до 3 частичных произведений и, в конце концов, до 2 частичных произведений.
В частности, как показано на фигурах 9a-9e, нижние индексы в каждом ряду представляют разряды частичного произведения (ase15, аs15, а14 - а0). Каждый ряд представляет отдельное частичное произведение. Negh - nega представляет часть +1 дополнения до 2 для каждого частичного произведения. В результате, если некоторый закодированный по Booth разряд множителя отрицательный, то соответствующий разряд "neg" частичного произведения равен 1, представленной в следующем ряду.
Кроме того, как показано далее на фиг. 9a-9e, S "позиция" "номер сумматора" представляет часть суммы сумматора с запоминанием переноса, "номер сумматора" указывает, к какому ряду сумматоров принадлежит сумма. Сумматоры на фиг. 9a-9e пронумерованы сверху вниз. "Позиция" указывает, с какой разрядной позицией (0...31) работает этот сумматор. Например, S42 - это сумма сумматора с запоминанием переноса 2, которая соответствует разрядной позиции 4.
С "позиция" "уровень" представляет часть переноса сумматора с запоминанием переноса. "Уровень" указывает соответствующий ряд адресов для переноса. "Позиция" указывает, с какой разрядной позицией (0...31) работает этот сумматор. Сумматор с запоминанием переноса может быть полным сумматором или полусумматором. Полный сумматор складывает вместе 3 разряда. Полусумматор складывает 2 разряда.
На фиг. 9a-9e, кроме того, показана реализация ранее описанного способа генерации знака. Как показано на чертежах, способ генерации знака создает 1 на разрядной позиции 16 в ряду над рядом первого частичного произведения. В ряду последнего частичного произведения, если старшее значащее кодированное по Booth число является отрицательным, то в ряду под ним создается 1, поскольку частичное произведение является дополнением до 2. Этот процесс обычно требует 10 рядов вместо 8. Чем больше рядов имеется при умножении, тем больший объем аппаратуры требуется для сокращения частичных произведений до 2-х чисел, которые сумматор с передачей переноса может сложить.
Однако, двоичное умножение выполняется посредством сложения. Когда складываются два числа, то порядок чисел не имеет значения. Результат также не зависит от того, какое число было первым. Этот принцип используется по всему дереву Wallace для сокращения количества необходимых запоминаний переноса. В частности, в одном варианте 1 в разрядной позиции 16 первого ряда на фиг. 9a передвигается вниз на разрядную позицию 16 в последнем ряду фиг. 9, который также содержит negh. В результате для сокращения потребуется меньший объем аппаратуры, поскольку используется меньшее количество рядов.
На фиг. 9b показан результат первого уровня сокращения. В прямоугольниках показано, с какими разрядами работают сумматоры с запоминанием переноса. Количество разрядов передвигается по кругу, чтобы уложить все в 6 рядов. Например, разряд dse15 перемещается в первый ряд. Cse15 перемещается в пятый ряд. Однако, разряд должен перемещаться вверх или вниз только в одной и той же разрядной позиции. От фиг. 9b к фиг. 9c количество рядов уменьшается до 4. От фиг. 9c к фиг. 9e количество рядов уменьшается до 3. И наконец, как показано на фиг. 9e, еще один ряд сумматоров с запоминанием переноса сокращает количество рядов до 2.
На фиг. 10a-10f показан один вариант схемы, состоящей из полных сумматоров и полусумматоров, реализующих диаграмму дерева Wallace, показанную на фигурах 9a-9e.
На фиг. 11 показан один вариант блок-схемы данного блока. Здесь показаны 2 одинаковых 16-разрядных умножителя. Умножители могут выполнять операцию умножения-сложения либо с разрядами 0-31, либо с разрядами 32-63. Также могут быть предусмотрены 2 16-разрядных умножителя, очень похожих по структуре на показанные умножители, для завершения блока умножения-сложения 145. Как показано на фигуре, каждый умножитель выполняет 16-разрядное умножение, дающее в результате 2 частичных произведения за 1,5 периода тактовых импульсов. В следующей половине периода тактового импульса с низким уровнем (34-й такт), 4 частичных произведения, генерируемые умножителями 1110 и 1120, снова суммируются сумматором СЗП 4:2 1130. Управляющий сигнал 1150 выбирает либо частичное произведение умножителя 1110, либо частичное произведение, генерируемое на выходе СЗП 4:2 1130 (sumres или coutres). Выбранные данные фиксируются вместе с частичными произведениями умножителя 1120. На отрезке с высоким уровнем на 35-м такте СПП 1140 генерирует 32- разрядный результат путем суммирования результирующих частичных произведений. Окончательное разбиение 32-разрядной, суммы выполняется мультиплексорами - защелкой и выбранные данные записываются снова на отрезке с низким уровнем 35-го периода тактовых импульсов.
В одном варианте блок умножения-сложения 145 работает по правилу "задержка на 3 такта на 1 загрузку". В противном случае, блок 145 требует 3 тактовых цикла для завершения задачи каждый раз, когда на его входы подается прерываемый поток данных. Все входы блока 145 буферизируются, что позволяет использовать малую емкость для внешних данных.
Даже если имеются данные на входах блока 145 в начале 32L (низкий уровень 33 такта), данные не могут стать действительными, пока не начнется интервал 33 H (высокий уровень 33 такта). Следовательно предполагается, что умножение начинается с начала 33H. Во время 33H действительные и стабильные данные на входах множимого проходят через элементы задержки и фиксируются защелками 1160 и 1170 соответственно. В это же время данные на входах множителя проходят через входные буферы и кодеры Booth 1165 и 1175 и фиксируются защелками 1180 и 1182. В этот момент данные в трактах как множителя, так и множимого точно синхронизированы друг с другом. Во время 33L данные проходят через матрицу выбора разрядов и набор полных сумматоров, который формирует первую часть дерева Wallace и становятся действительными перед моментом установки для защелок 1180 и 1182. Количество частичных произведений в этот момент уменьшается с 8 до 4. Во время 34H данные проходят через другой набор полных сумматоров, которые образуют остальную часть дерева Wallace и становятся действительными и стабильными в конце 34H перед фиксацией в защелках 1184 и 1186.
Как объяснялось ранее, во время 34 данные проходят через устройство сжатия 4:2 1130 (два полных сумматора, соединенных последовательно) и мультиплексора 2-1 1135 для окончательного отбора частичных произведений. Данные становятся действительными в конце 34L перед их фиксацией защелкой 1190. Во время 35H два частичных произведения на выходе защелки 1190 окончательно сокращаются до одного вектора суммы. Этот вектор суммы расчленяется на составляющие и фиксируется защелкой 1195 вне блока 145. На отрезке 35L имеются в наличии данные для операции обратной записи.
Как было сказано ниже, использовавшиеся ранее команды умножения с накоплением всегда суммировали результаты своих умножений с накопленным значением. Это накопленное значение становилось узким местом для выполнения операций, отличных от умножения и накопления (например, накопленное значение должно каждый раз обнуляться, когда требуется новый набор операций, который не требует иметь ранее накопленное значение). Это накопленное значение также становилось узким местом, если перед накоплением необходимо выполнить такие операции, как округление.
В противоположность этому, раскрытая здесь операция умножения-сложения не выполняет перенос накопленного значения. В результате эти команды легче использовать в самых разнообразных алгоритмах. Кроме того, для достижения сравнимой производительности может быть использована программная конвейерная обработка. Чтобы показать универсальность команды умножения-сложения, ниже описывается несколько примеров мультимедийных алгоритмов. Некоторые из этих мультимедийных алгоритмов используют дополнительные команды для упакованных данных. Работа этих дополнительных команд для упакованных данных демонстрируется в связи с описываемыми алгоритмами. Дальнейшее описание этих команд для упакованных данных представлено в заявке на "Набор команд для работы с упакованными данными". Конечно, можно использовать и другие команды для упакованных данных. Кроме того, ряд этапов, требующих использования команд универсального процессора для управления перемещением данных, организации циклов и разветвления по условию, в последующих примерах опущены.
1) Умножение комплексных чисел
Представленная команда умножения-сложения может быть использована для умножения двух комплексных чисел в одной команде, как показано в таблице 10a. Как описывалось ранее, умножение двух комплексных чисел (например, r1 i1 и r2 i2) выполняется согласно следующему выражению:
Действительная часть = r1•r2 -i1•i2
Мнимая часть = k1•i2+r2•i1
Если эта команда должна завершаться каждый период тактовых импульсов, то изобретение может перемножить два комплексных числа на каждом периоде тактового импульса.
Другой пример. В таблице 10b показаны команды, используемые для перемножения трех комплексных чисел.
2) Операции умножения с накоплением
Рассмотренные команды умножения-сложения могут также быть использованы для умножения с накоплением значений. Например, два набора из четырех элементов данных (A1-4 и B1-4) могут быть перемножены с накоплением, как показано в таблице 11. В одном варианте каждая из команд, показанных в таблице 6, реализуется таким образом, чтобы завершить каждый период тактового импульса.
Если количество элементов данных в каждом наборе превышает 8 и кратно 4, то умножение с накоплением этих наборов требует меньшего количества команд, если его выполнять, как показано в приведенной таблице 12.
В таблице 13 показан еще один пример, где производится отдельное умножение с накоплением наборов A и B и наборов C и D, причем каждый из этих наборов включает в себя 2 элемента данных.
В таблице 14 представлен еще один пример, демонстрирующий отдельное умножение с накоплением наборов А и В и наборов С и D, где каждый из этих наборов включает в себя 4 элемента данных.
3) Алгоритмы скалярного произведения
Скалярное произведение (называемое также внутренним произведением) используется в операциях обработки сигналов и операциях с матрицами. Например, скалярное произведение используется при вычислении произведения матриц, в операциях цифровой фильтрации (таких как фильтрация с конечной импульсной характеристикой (FIR) и фильтрация с бесконечной импульсной характеристикой (IIR)) и вычислении корреляционных последовательностей. Поскольку во многих алгоритмах речевого сжатия (например, GSM, G.728, CELP и VSELP) и алгоритмах Hi-Fi сжатия (например, MPEG и субполосного кодирования) широко используются вычисления для цифровой фильтрации и корреляции, повышение эффективности скалярного произведения повышает эффективность этих алгоритмов.
Скалярное, произведение двух последовательностей длины NA и В определяется как:
Вычисление скалярного произведения связано с широким использованием операции умножения-сложения, когда соответствующие элементы каждой последовательности перемножаются, а результаты накапливаются, образуя результат скалярного произведения.
Вычисление скалярного произведения может быть выполнено с использованием команды умножения-сложения. Например, если используется тип упакованных данных, содержащий четыре шестнадцатиразрядных элемента, то скалярное произведение может быть выполнено с двумя последовательностями, каждая из которых содержит четыре уровня, путем:
1) обращения к четырем шестнадцатиразрядным значениям из A последовательности для генерации Источника 1 с использованием команды пересылки;
2) обращения к четырем шестнадцатиразрядным значениям из В последовательности для генерации Источника 2 с использованием команды пересылки; и
3) выполнения умножения с накоплением, как описано выше, с использованием команд умножения-сложения, упакованного сложения и сдвига.
Для векторов, имеющих достаточно большое число элементов, используется способ, показанный в таблице 9, а окончательные результаты суммируются вместе в конце. Другие команды поддержки включают в себя команды упакованного ИЛИ и "исключающего ИЛИ" для инициализации регистра накопления, команду упакованного сдвига для избавления от нежелательных значений на финальном этапе вычислений. Операции управления циклом осуществляются с использованием команд, уже существующих в наборе команд процессора 109.
4) Алгоритмы дискретного косинусного преобразования
Дискретное косинусное преобразование (ДКП) - хорошо известная функция, используемая во многих алгоритмах обработки сигналов. В частности, это преобразование широко используется в алгоритмах сжатия видеосигналов и изображений.
В алгоритмах сжатия видеосигналов и изображений ДКП используется для преобразования блока пикселей из пространственного представления в частотное представление. При частотном представлении информация об изображении делится на частотные составляющие, некоторые из которых более важны, чем другие. Алгоритм сжатия избирательно квантифицирует, или отбрасывает частотные составляющие, которые неблагоприятно воздействуют на компоненты восстанавливаемого изображения. Таким образом достигается сжатие.
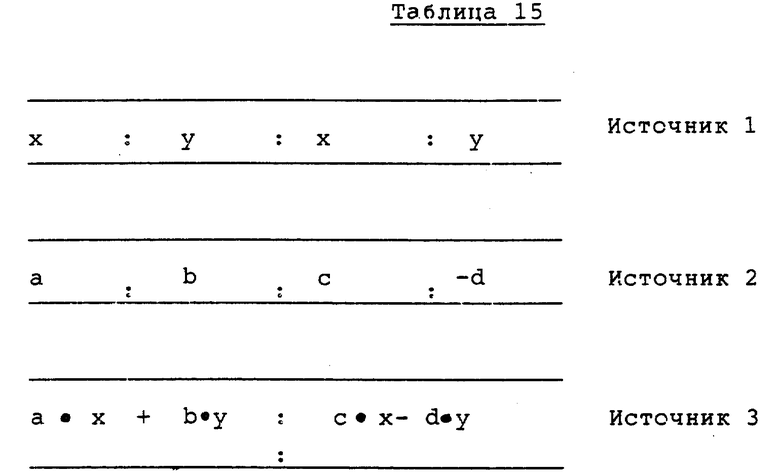
Существует много вариантов реализации ДКП, причем наиболее распространенным является вариант метода быстрого преобразования, моделируемый на основе последовательности операций быстрого преобразования Фурье (БПФ). При быстром преобразовании преобразование порядка N разбивается на комбинацию преобразований порядка N/2 и рекомбинированного результата. Эта декомпозиция может выполняться, пока не будет достигнуто преобразование самого маленького порядка 2. Ядро элементарного преобразования порядка 2 часто называют операцией "бабочка" (butterfly). Операция "бабочка" описывается следующим образом:
X = a•x + b•y
Y = c•x -d•y
где a, b, c - коэффициенты, x и y - входные данные и X и Y - выходные данные преобразования.
Умножение-сложение дает возможность вычисления ДКП, подлежащего выполнению, с использованием упакованных данных следующим образом:
1) обращение к двум 16-разрядным значениям, представляющим x и y, для генерации Источника 1 (смотри таблицу 10) с использованием команд пересылки и распаковки;
2) генерация Источника 2, как показано в таблице 10. Заметим, что Источник 2 может быть использован повторно в ряде операций "бабочка"; и
3) выполнение команды умножения-сложения с использованием Источника 1 и Источника 2 для генерации результата (смотри таблицу 15).
В некоторых ситуациях коэффициенты операции "бабочка" равны 1. В этих случаях операция "бабочка" вырождается просто в сложения и вычитания, которые могут быть выполнены с использованием команд упакованного сложения и упакованного вычитания.
Документация IEEE определяет точность, с которой может выполняться обратное ДКП для видеоконференций. (Смотри Circuits and Systems Society, "IEEE Standard Shtcifications for the Implantations of 8х8 Inverse Discrete Cosine Tranform", IEEE Std. 1180-1990. IEEE Inc. 345 East 47th St., NY, NY 10017, USA, March 18, 1991). Требуемая точность удовлетворяется раскрытой командой умножения-сложения, поскольку она использует 16-разрядные входные данные для генерации 32- разрядных выходных данных.
При таком способе описанная команда умножения-сложения может быть использована, для повышения эффективности различных алгоритмов, включая алгоритмы, которые требуют перемножений комплексных чисел, алгоритмы, которые требуют преобразований и алгоритмы, которые требуют операции умножения с накоплением. В результате данная команда умножения-сложения может быть использована в процессоре общего назначения для повышения эффективности большего числа алгоритмов, чем описанные предыдущие команды.
Хотя изобретение было описано применительно к нескольким вариантам его осуществления, специалисты в данной области поймут, что изобретение не ограничивается описанными вариантами. Способ и устройство изобретения могут быть реализованы на практике с модификациями и заменами, лежащими в рамках сущности и объема прилагаемой формулы изобретения. Таким образом данное описание следует рассматривать как иллюстрацию, а не ограничение на изобретение.















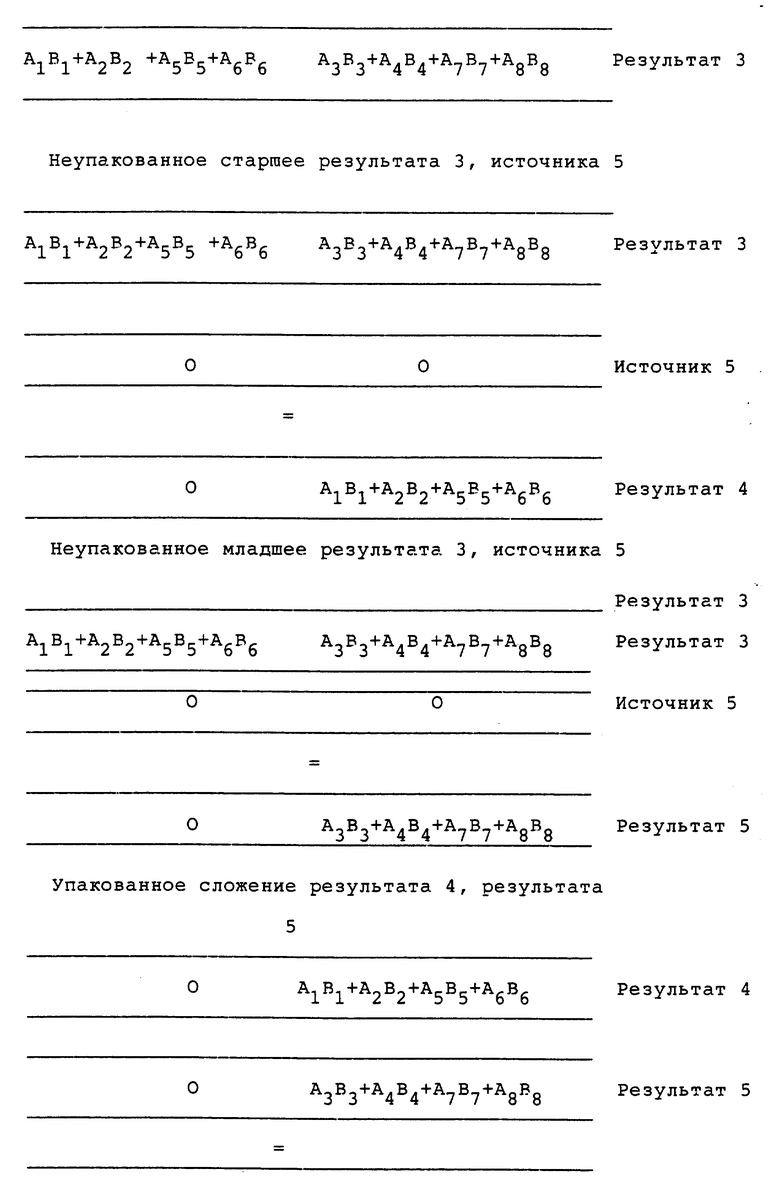












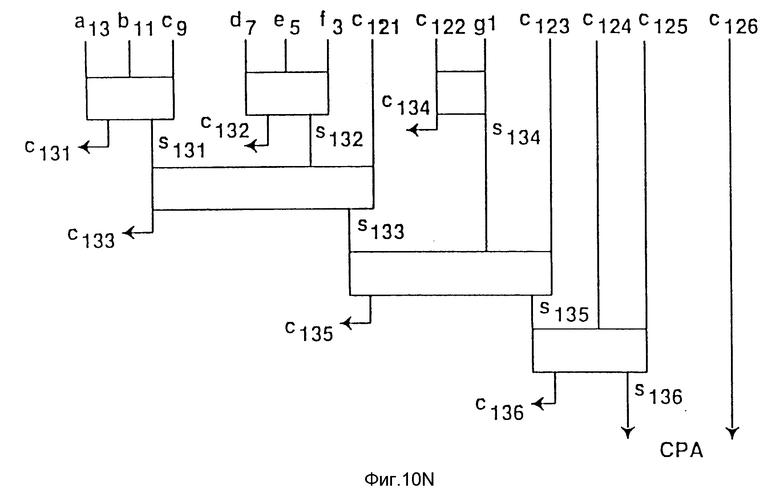


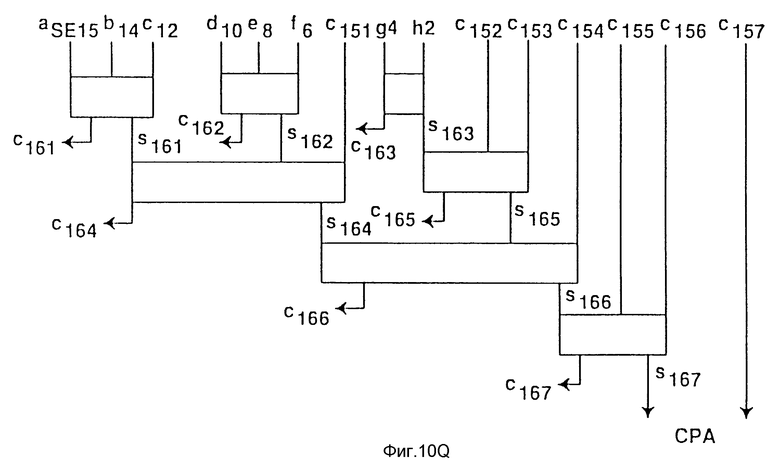
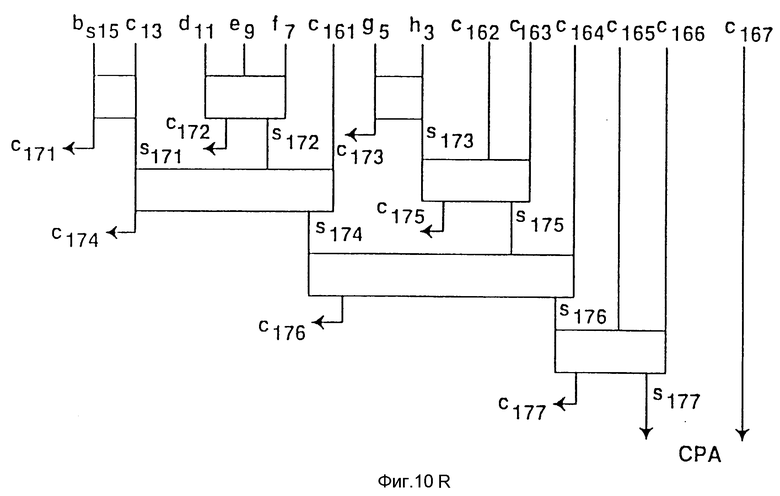
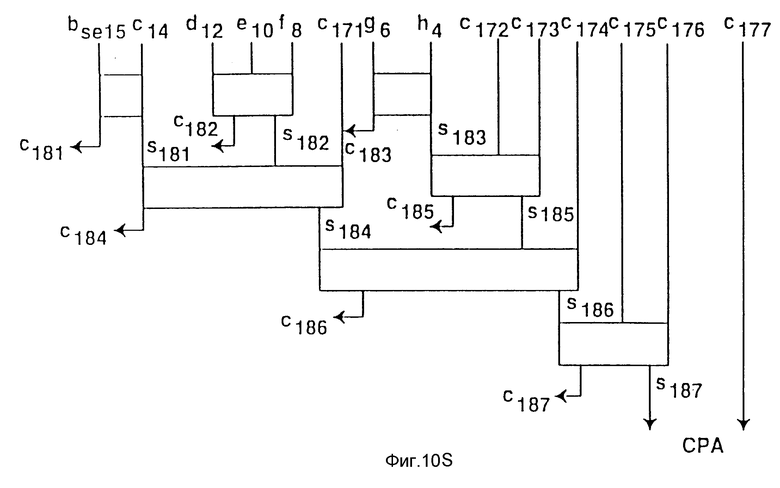





Процессор содержит первое и второе запоминающие устройства, имеющие соответственно первые и вторые упакованные данные. Каждые упакованные данные включают в себя первый-четвертый элементы данных. Схема умножения-сложения связана с первой и второй областями памяти. Схема умножения-сложения включает в себя первый-четвертый умножители, причем каждый из умножителей получает соответствующий набор элементов данных. Схема умножения-сложения также содержит первый сумматор, подсоединенный к первому и второму умножителям и второй сумматор, подсоединенный к третьему и четвертому умножителям. Третья область памяти связана с сумматорами и включает в себя первое и второе поля для запоминания выходных данных первого и второго сумматоров соответственно в качестве первого и второго элементов данных третьих упакованных данных. Достигаемым техническим результатом является повышение эффективности при увеличении числа используемых алгоритмов. 5 с. и 32 з.п. ф-лы, 15 табл., 11 ил.
| US 4771379 A, 13.09.88 | |||
| US 4769780 A, 06.09.88 | |||
| US 4799183 A, 17.01.89 | |||
| US 5442799 A, 15.08.95 | |||
| Устройство для выпрямления опрокинувшихся на бок и затонувших у берега судов | 1922 |
|
SU85A1 |
| Способ размножения копий рисунков, текста и т.п. | 1921 |
|
SU89A1 |
| US 5047973 A, 10.09.91 | |||
| ОДНОТАКТНЫЙ УМНОЖИТЕЛЬ ДВОИЧНЫХ ЧИСЕЛ | 1988 |
|
RU2012039C1 |
| УСТРОЙСТВО ДЛЯ УМНОЖЕНИЯ ЧИСЕЛ | 1991 |
|
RU2021633C1 |
| МНОЖИТЕЛЬНОЕ УСТРОЙСТВО | 1992 |
|
RU2022339C1 |
