Изобретение касается передачи информации, а более конкретно - одновременной передачи информации между разными системами обработки данных, используя матричный коммутатор.
Системы обработки данных требуют передачи информации между компонентами системы обработки данных. Имеется несколько способов для осуществления передачи информации в системах обработки данных. Один способ, который является очень выгодным, состоит в одновременной передаче информации между несколькими элементами системы обработки данных путем использования матричного коммутатора. Пример матричного коммутатора приведен в патенте США N 4630045 под названием "Контроллер для матричного коммутатора". Матричный коммутатор обеспечивает одновременные коммутационные соединения между парами элементов системы обработки данных, так что несколько этих соединенных пар могут производить обмен информацией в одно и то же время через коммутатор. Матричный коммутатор в патенте США N 4630045 показывает реализацию матричного коммутатора предшествующего уровня техники, в результате чего порты матричного коммутатора, которые соединены с элементами обработки данных, соединены с коммутационной матрицей и централизованной управляющей схемой, которая управляет операциями портов и их соединениями через саму коммутационную матрицу.
Патент США N 4814762, озаглавленный "Управление схемой соединения треугольником матричного коммутатора" показывает другой вариант реализации матричного коммутатора, где фактические коммуникации между портами матричного коммутатора содержатся в схеме соединения треугольником. Согласно техническим решениями этого патента, когда порт пытается получить доступ к другому порту, он посылает сообщение запроса в отношении указанного соединения по схеме соединения треугольником. Эта коммуникация происходит снаружи самого матричного коммутатора. Настоящее изобретение направлено на создание коммуникаций через матричный коммутатор и тем самым образует коммуникацию внутри полосы частот не только для передачи данных, но и также для указания требуемых соединений между компонентами.
Патент США N 4752777, озаглавленный "Схема соединения треугольником матричного коммутатора", является продолжением предшествующей заявки на патент США N 4814762 и описывает схему соединения треугольником для управления портами матричного коммутатора.
В патенте США N 4695999 описывается многополосковый матричный коммутатор и управление портами, соединенными с матричным коммутатором.
Патент США N 4845722, озаглавленный "Компьютерный соединитель с использованием матричного коммутатора", описывает систему соединителя для соединения компонентов, которая включает в себя централизованную логическую схему коммутации для управления коммутационной матрицей.
Патент США N 4580011, озаглавленный "Распределительная обрабатывающая телефонная коммутационная система", описывает коммутационную систему, имеющую централизованный контроллер, который принимает управляющие сигналы от линейных соединителей, чтобы направить соединение через коммутационную матрицу.
В работе (Бюллетень технических решений IBM, том 28, N 2, июль 1985 г., с. 510-512), озаглавленной "Коммутатор схемы с быстрым установочным временем с распределенным управлением", описывается система управления коммутационной матрицей, имеющей порты, которые сообщаются с центральным управляющим контроллером для управления работой матричного коммутатора.
В работе (Бюллетень технических решений IBM, том 29, N 3, август 1986 г. , с. 1356-1360, озаглавленной "Динамически реконфигурируемый интегральный коммутатор", описывается реконфигурируемый коммутатор, предназначенный поддерживать многие схемы разных типов. Эта конфигурация включает в себя контроллер коммутатора, который управляет доступом портов к коммутатору.
В работе (Бюллетень технических решений IBM, том 32, N 1, июнь 1989 г, с. , 427-433), озаглавленной "Механизм управления в отношении контроллера коммуникации пакетной шины", описывается контроллер для пакетной шины. Пакетная шина разрешает только одну передачу информации за один раз в противоположность матричному коммутатору, который разрешает одновременные и непрерывные передачи информации между сообщающимися парами элементов системы.
В работе (Бюллетень технических решений IBM, том 20, N 2, июль 1977 г., с. 816-817), озаглавленной "Матричный коммутатор для АТС", описывается матричный коммутатор с контроллером, который регулирует доступ портов через матричный коммутатор.
В работе (Бюллетень технических решений IBM, том 29, N 4, сентябрь 1986 г., с. 1769-1771), озаглавленной "Разрешающая способность гонки в соединении трассы любого с любым с временным разделением в коммутаторе с пространственным разделением", описывается коммутатор, обеспечивающий возможность "пакетно-образной" коммуникации. Как сказано ранее, пакетная передача производит только одну пару связи за один раз.
В работе (Бюллетень технических решений IBM, том 27, N 4B, сентябрь 1984 г. , с. 2704-2708), озаглавленной "Переменной конфигурации гибридная пространственная и пакетная коммутационная сеть", описывается трехуровневое коммутационное устройство для сети пакетной передачи, используя центральное управление для установления соединений трассы".
В работе (Бюллетень технических решений IBM, том 24, N 7A, декабрь 1981 г. , с. 3352-3356), озаглавленной "Многотрассовый матричный коммутатор с адаптором канала с каналом", описывается с централизованным управлением коммутационное устройство, обеспечивающее межпроцессорные связи через каналы входа/выхода.
В работе (Бюллетень технических решений IBM, том 28, N 8, январь 1986 г. , с. 3272-3273), озаглавленной "Параллельная архитектура процессора для управления многочисленными независимыми телекоммуникационными узлами коммутации", описывается телекоммуникационная система, использующая распределенные параллельные процессоры для управления сетью распределения.
Как сказано ранее, были предложены другие способы передачи данных в предшествующем уровне техники. Один такой способ использует информационную шину, дающую возможность пропускать только одно сообщение за один раз. Пример этого способа шины приведен в патенте США N 4586175, озаглавленном "Способ функционирования пакетной шины для передачи асинхронных и псевдосинхронных сигналов". Этот патент описывает шину, управляемую двумя контрольными шинами. Патент США N 4363093, озаглавленный "Процессорная межкоммуникационная система", описывает межкоммуникационную систему между процессорами локальной зональной сети, по которой только одно сообщение может передаваться за один раз. Патент США N 4821170, озаглавленный "Система входа/выхода для мультиплексоров, также описывает систему, предусматривающую две шины системы, но не использующую коммутатор для облегчения внутрисистемной связи (связи между компонентами системы).
Другие примеры коммутации типа шины приведены в патенте США N 4704606, озаглавленном "Переменной длительности пакетная коммутационная система". Этот пакет описывает пакетную коммутационную систему для пакетов переменной длительности. Патент США N 4631534, озаглавленный "Распределенная пакетная коммутационная система", описывает пакетную коммутационную систему, где каждый порт включает в себя интеллект (логическую схему) для образования адресов порта назначения и станции в пакетах. Патент США N 4630258, озаглавленный "Коммутационный узел памяти 11 х M с пакетами коммутируемыми мультипортами и способ обработки", описывает пакетную коммутационную систему, использующую 11 х M коммутатор от 11 входных портов, соединяемых с M выходных портов. Коммутатор имеет центральное управление.
Патент США N 4773069, озаглавленный "Надежная трассируемая древовидная (разветвленная) схема", описывает схему передачи данных, включающую в себя модемы и имеющую по крайней мере два контроллера, соединенные с модемами.
Другие технические решения в области общей коммутации, иллюстрирующие коммутатор. В работе (Бюллетень технических решений IBM, том 25, N 7A, декабрь 1982 г., с. 3578-3582), озаглавленной "Система обработки и управления базой данных", описывается главный (ведущий) процессор, сообщающийся с множеством сателлитных (ретранслирующих) процессоров через коммутационную матрицу данных. Коммутатор и работа ретрансляторов управляются главным процессором. В работе (Бюллетень технических решений IBM, том 29, N 7, декабрь 1985 г., с. 3070-3072), озаглавленной "Вращающийся коммутатор", описывается вращающийся коммутатор. В работе (Бюллетень технических решений IBM, том 30, N1, июнь 1987 г., с. 403-405), озаглавленной "Архитектура динамического временного распределения щелей для цифрового телефонного коммутатора", описывается ординарный порт, обеспечивающий доступ к цифровой телефонной коммутационной системе. В работе (Бюллетень технических решений IBM, том 11, N 10, март 1969 г., с. 1231-1232), озаглавленной "Соединение управляющих схем", описывается многократно избыточное коммутационное устройство для цифрового компьютера.
Все вышеупомянутые прототипы описывают использование централизованного управления для коммутационной схемы. Цель настоящего изобретения состоит в создании распределенного управления по портам, соединенным с коммутатором, чтобы более эффективно регулировать соединения портов с коммутатором, и тем самым коммуникацию через коммутатор.
В соответствии с настоящим изобретением предусматривается коммуникационная сеть, которая включает в себя множество портов, каждый из которых соединен по крайней мере с одним элементом системы обработки данных. Предусмотрена шина, которая соединяет порты между собой. Предусмотрен матричный коммутатор, который соединен с портами и шиной, соединяющей порты. Матричный коммутатор создает возможность соединять коммутационные каналы между любыми двумя портами. Каждый из портов содержит управляющую логику, соединенную с шиной для связи с другими портами, и матричный коммутатор для регулирования установления коммуникационных каналов между портами.
Вышеприведенные и другие цели, отличительные признаки и преимущества изобретения будут лучше поняты из нижеследующего подробного описания наилучшего варианта реализации изобретения со ссылкой на приведенные ниже чертежи.
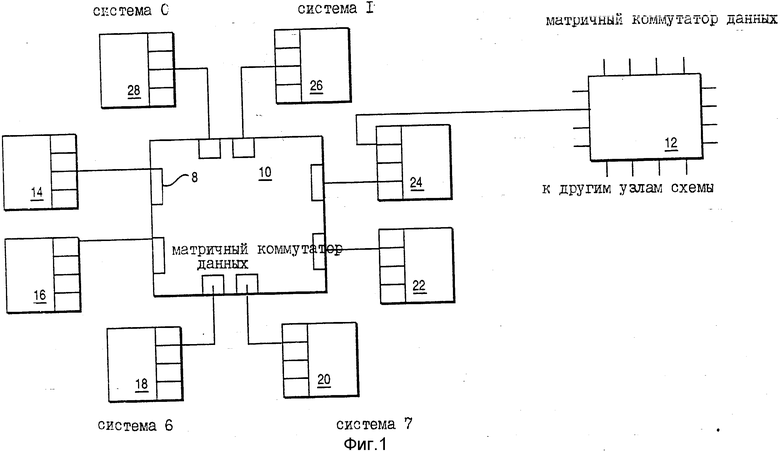
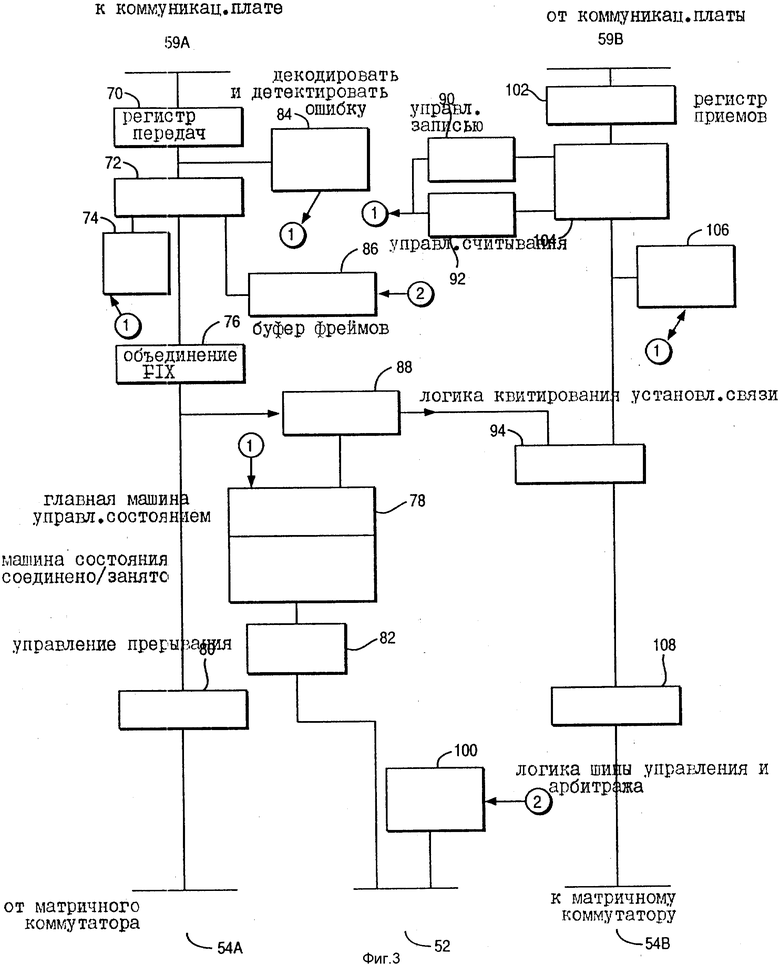
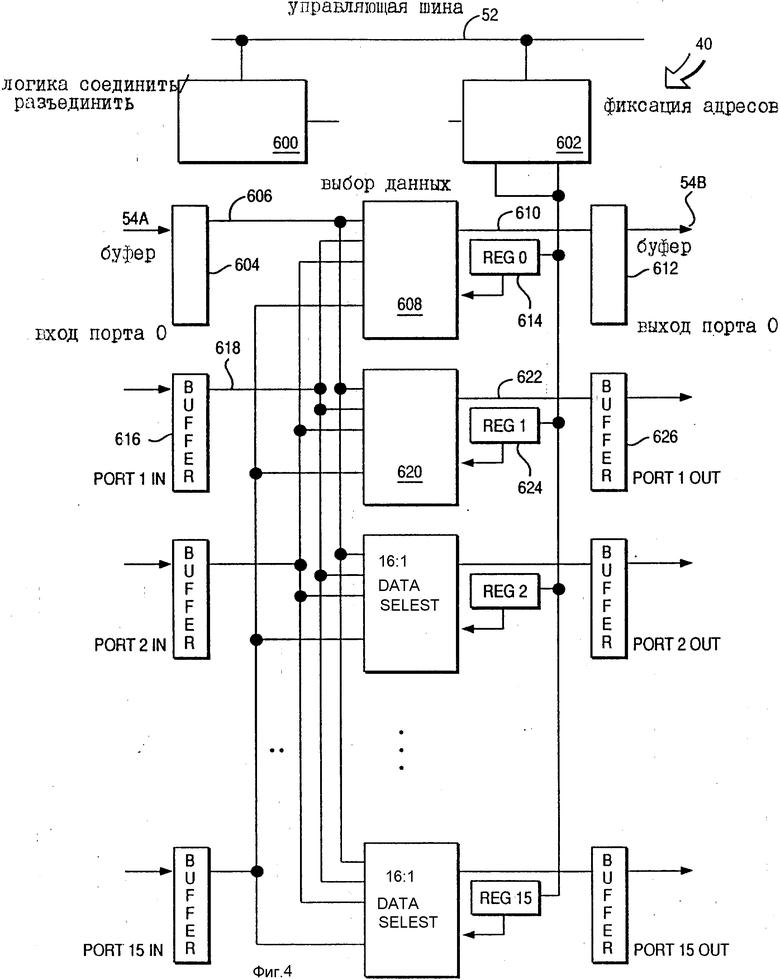
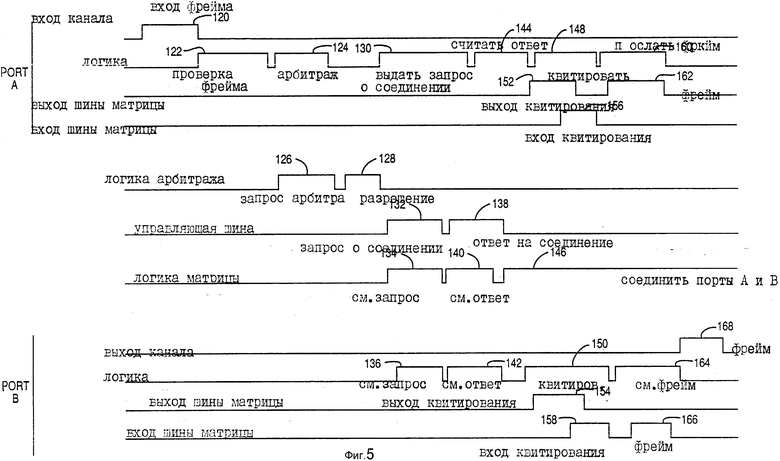
На фиг. 1 дана блок-схема, показывающая восемь систем, соединенных с первым матричным коммутатором, и одну, соединенную со вторым матричным коммутатором; на фиг. 2 - блок-схема, показывающая содержание матричного коммутатора; на фиг. 3 - блок-схема, показывающая содержание схемы портов матричного коммутатора; на фиг. 4 - блок-схема матричного коммутатора; на фиг. 5 - схема событий, показывающая события между портом A, портом B и матричным коммутатором при установке связи между портом A и портом B; на фиг. 6 - схема событий, показывающая разъединения между портом A и портом B; на фиг. 7 - блок-схема порядка действий, показывающая управление порта, когда коммуникационный фрейм принят от его канала связи ("фрейм" здесь и далее это служебное кодовое управляющее слово, представляющее собой информационный блок кодирования команд, используемых в общении между компонентами системы); на фиг. 8 - блок-схема порядка действий, показывающая управление порта, когда принят запрос от коммуникационной шины; на фиг. 9 - блок-схема порядка действий, показывающая окончание коммуникации портом; на фиг. 10 - блок-схема порядка действий, показывающая управление матричного коммутатора во время коммуникации порта с портом.
На фиг. 1 показана блок-схема коммуникационной системы, которая включает в себя несколько систем 14, 16, 18, 20, 22, 24, 26 и 28, каждая из которых соединена с матричным коммутатором 10. Каждая из этих систем, такая как система 14, соединена с матричным коммутатором 10 через порт 8. Следует отметить, что каждая система, такая как система 24, может быть альтернативно соединена с дополнительными матричными коммутаторами (таким как матричный коммутатор 12) для резервной возможности или возможности соединения. В предпочтительном варианте реализации система 14 и система 24 являются системой RISC/6000 - автоматизированными рабочими местами (APM), которые соединены посредством последовательного световодного канала с матричным коммутатором 10. В этом предпочитаемом варианте реализации каждый компонент системы RISC/6000 может включать в себя четыре порта для реализации соединений последовательной связи. Пример протокола, используемого с соединителем последовательной связи, представляет ESCON (соединение предпринимательской системы для последовательного канала входа/выхода предпринимательской системы IBM 3090). Должно быть понято, что в этом предпочитаемом варианте реализации, когда система должна соединяться с другой системой для предоставления информации другой системе, вся информация подается через этот световодный канал последовательной связи. Исходная система будет посылать фрейм информации до 32 байтов для первоначального установления связи с принимающей системой. После того, как первый фрейм был послан и принят, установление соединения через матричный коммутатор 10 производится, и это соединение поддерживается, так что исходная система может постоянно пропускать дополнительные фреймы информации на принимающую систему, пока не будет послан фрейм о разъединении, чтобы известить принимающую систему и коммутатор 10, что связь прекращается (разъединяется). В предпочитаемом варианте реализации матричный коммутатор является коммутатором 11 х 11, поддерживающим 11 х 11 портов для обеспечения одновременной коммуникации между соединенными портами и системами, соединенными с портами.
На фиг. 2 представлена блок-схема матричного коммутатора данных 10. В предпочитаемом варианте реализации используется коммутатор 16 х 16. Только для цели описания показано восемь портов из 16. Каждый порт 30 соединен с арбитражной шиной портов 50, управляющей шиной портов 52 и линиями передачи данных (такими как линии 54 и 55 для портов 30 и 42 соответственно). Каждый из портов соединен через эти линии данных с матричным коммутатором 16 х 16. Матричный коммутатор 40 может быть готовым (выпускаемым промышленностью) изделием, таким как ГИГАБИТ Ложик 100051, который образует соединение точек пересечения между портами (за исключением Ложик 600 и фиксации адресов 602, фиг. 4).
В предпочтительном варианте реализации каждый порт производит оптико-электрическое преобразование, чтобы информация пропускалась электрически между портами через матрицу 40 16 х 16. Первоначально порт, такой как 30, может попытаться соединиться с другим портом, таким как порт 32. Сначала порт 30 запросит арбитраж. Иначе говоря, порт 30 запросит разрешение по арбитражной шине 50 в арбитре шины 38. После получения разрешения по управляющей шине 52 будет передан запрос о соединении на порт 32. Затем происходит прием состояния. На фиг. 2 приведен пример, когда порт 32 пытается соединиться с портом 30 путем посылки запроса, символически обозначенного стрелкой 58. Порт 30 посылает сигнал занятости (занято), обозначенный символически пунктирной стрелкой 56, обратно на порт 32, отклоняя запрос о передаче. Следует отметить, что во время этой первоначальной попытки в соединении порта с портом матрица 16 х 16 не имела доступа. Это возможно благодаря наличию управления коммутационного устройства, которое (управление) распределено между портами. Иначе говоря, только после приема подтверждения, что передача данных может иметь место, коммутатор 40 включается в соединение между портами.
Матричный коммутатор 40 соединен с управляющей шиной 52. Это может возбуждать матричный коммутатор 40 для ответа на команды, направленные ему. В предпочитаемом варианте реализации только команды, которые направлены матричному коммутатору 40, являются командами диагностического характера. Во время нормального функционирования матричный коммутатор 40 просто контролирует управляющую шину 52 и управляющую коммуникацию между портами, чтобы определить когда соединения должны быть произведены или прекращены. Когда соединения произведены, линии, такие как 54, соединены с линиями, такими как 55, для возможности передачи данных между портами, такими как порт 30 и порт 42, без запроса явных команд для коммутаторов от портов или другого управляющего устройства.
Операция отсоединения производится матричным коммутатором 40 без команды со стороны портов. Матричный коммутатор 40 производит перехват (подслушивание) по командной шине 52, чтобы определить, когда разъединение должно быть произведено путем изучения команд о разъединении на управляющей шине 52. Когда фрейм об окончании связи послан по одной системе другой, матричный коммутатор 40 путем контроля управляющей шины 52 автоматически определяет, какое соединение должно быть разъединено, тем самым экономя время в том, что не запрашивается отдельный протокол команды, чтобы сказать матричному коммутатору произвести разъединение. Это является важным, потому что операция разъединения производит на базе высокого приоритета, так как дальнейшее соединение с любым из портов может быть происходит только в случае, когда происходит это разъединение.
На фиг. 3 представлена блок-схема логики, содержащейся в каждом порте, таком как порт 30. Основная машина управления состоянием и машина состояния соединить/занято 78 управляет функционированием логики порта. Логика состояния 78 соединена с прерывающим управляющим устройством 82, которое производит прерывание в случае условий ошибок на и от управляющей шины 52. Логика состояния 78 далее соединена с логикой 88 квитирования установления связи. Функционирование логики квитирования установления связи является типом, который описан в Бюллетене технических решений IBM, том 32, N 6A, ноябрь 1989, с. 21-22, в работе, озаглавленной "Способ оценки динамических трасс данных в коммутационном блоке данных". Когда фрейм сначала принят от системы, он принимается по шине 598, где первоначально фиксируется символ, в момент времени в принимающем регистре 102. Содержание этого регистра затем загружается в буфер 104 соединение/синхронизации, где логика управления записью или логика управления считыванием 90 и 92 соответственно с логикой состояния 78 определяют, будет ли буфер 104 действовать как пропускающий первый входящий/первый выходящий буфер или накапливающий буфер. Управление записью 92 определяет, когда в буфере 104 данные должны быть записаны. Логика управления считыванием 90 определяет, с какого мета в буфере 104 должен считываться следующий символ. Логика 106 декодирования и определения ошибки также соединена с логикой состояния 78, чтобы обозначить любое условие ошибки. Если фрейм должен быть пропущен на другой порт, запрос о соединении пропускается по управляющей шине. Как сказано ранее, арбитр посылает запрос арбитру шины 38 по шине 50 через интерфейс 100 арбитражной и управляющей шин. После разрешения машина состояния порта 78 посылает запрос о соединении и оценивает состояние, принятое по управляющей шине 52 от порта, предполагаемого для соединения. Если соединяемый порт не занят, тогда соединение устанавливается автоматически матрицей 40 и данные из буфера соединения/синхронизации 104 пропускаются через регистр 108 по линии данных 54B на матричный коммутатор. Принимающий мультиплексор 94 определяет загружены ли данные из линии 59B или логики квитирования установления связи 88 в регистр 108. Аналогичным образом данные, принимаемые от матричного коммутатора по линии 54A, проходят через регистр 80 через совмещенную логическую схему 76, который предотвращает проход кодовых ошибок блока через передающий мультиплексор 72 на передающий регистр 70 по шине 59A. Следует отметить, что в передающей стороне логика 74 занятости и отклонения, а также логика 84 декодирования и детектирования ошибки предусмотрены для условий ошибки. Логика 74 занятости/отклонения определяет, когда принята индикация о занятости от управляющей шины 52, и образует фрейм занятости по линии 59A. Буфер 96 фрейма предназначен для передачи ранее указанных фреймов, указывающих специфические условия ошибок.
На фиг. 5 представлена схема событий, показывающая соединение между портом A и портом B. На фиг. 5 фрейм сначала принимается портом по шине (такой как 59B) в событии 120. В событии 122 логика порта изучает фрейм и определяет установление соединения, в событии 124 решает конфликт в отношении управляющей шины. Арбитр 38 шины принимает запрос о событии 126 и разрешает (предоставляет) запрос в событии 128. В это время логика порта A выдает запрос о соединении 130, который включает в себя соответствующие адреса портов, по управляющей шине 52, обозначенной под событием 132. Логика матрицы 600 (фиг. 4) наблюдает за этим запросом в событии 134 и фиксирует адреса портов, которые фиксированы в фиксаторах 602, тогда как логика порта B рассматривает этот запрос о событии 136. Логика порта B затем посылает ответ 142, который рассматривается логикой матрицы 600 в событии 140, по управляющей шине 52, как показано под событием 138. Этот ответ считывается логикой порта A в событии 144. В этом примере приводится последовательное соединение. Поэтому логика матрицы 600 загружает адрес порта из фиксаторов 602 в регистры, такие как 614 и 624, чтобы дать возможность схемам выборки данных 608 и 620 соединить внутреннюю шину 606 с внутренней шиной 622. Логика порта A тогда образует сигнал квитирования установления связи с портом B по шине матрицы, такой как 54A и 54B. Сначала происходят события 152 и 154 передачи квитирования установления связи из обоих портов, а затем из обоих портов квитирование установления связи в событиях 156 и 158 передается обратно на противоположные порты. Следует отметить, что логика матрицы автоматически соединяет порты A и B через матричный коммутатор 40. В конечном счете фрейм посылается в событии 160 по шине матрицы в событии 162 на матрицу в линии на порт B 166, где логика порта изучает фрейм в событии 164. Этот фрейм затем подается на выход линии связи на соединенное устройство в событии 168.
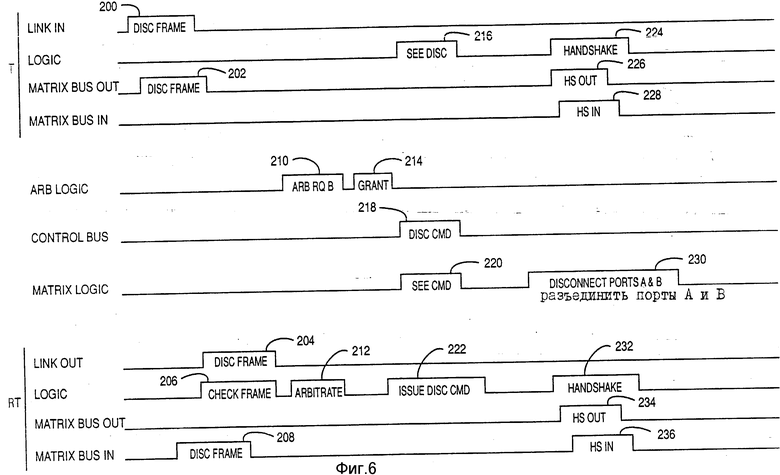
На фиг. 6 представлена схема событий, показывающая операцию разъединения. В этом примере порт A принимает фрейм о разъединении от своего соединенного устройства в событии 200. Это пропускается на выходную шину матрицы в событии 202. Это принимается портом B по входной шине матрицы в событии 208, где логика проверяет фрейм в событии 206, и фрейм распределяется по соединенным устройствам в событии 204. Логика в порте B затем определяет вопрос об арбитраже в отношении управляющей шины в событии 212 и принимается арбитром шины 38 в событии 210, что разрешает подать запрос в событии 214. Логика порта B затем посылает команду о разъединении в событии 222, которая рассматривается на управляющей шине в событии 218, посредством логики матрицы в событии 220 и логикой порта B в событии 216. Затем квитирование установления связи проводится через управляющую шину в событии 232 и 224 портами B и A соответственно, через входную и выходную линии матрицы для соответствующих портов в событиях 226, 228, 234 и 236 соответственно. Важное событие состоит в том, когда логика матрицы 40 автоматически отсоединяет порты A и B в событии 230 путем перехвата на управляющей шине и изучения команды о разъединении, затем посланную.
Должно быть понятно специалистам в данной области техники, что путем перехвата по шине, чтобы рассмотреть команды о разъединении, дальнейших циклов шин не требуется для управления коммутатором, даже если коммутатор работает с тем, чтобы поддерживать автономные отношения между портами.
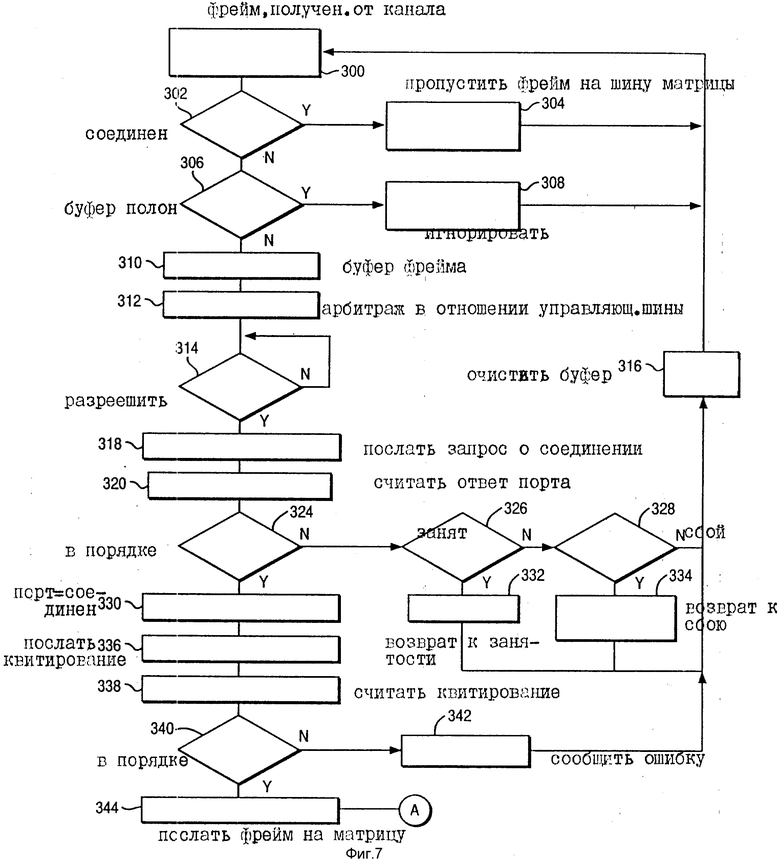
На фиг. 7 представлена блок-схема порядка действий, показывающая логику состояния 78 порта, когда она принимает фрейм. В блоке 300 фрейм принимается от устройства, соединенного со стороной связи порта. Логика сначала определяет, относится ли фрейм к существующему соединению. Это относится к случаю, когда прежний фрейм установил соединение, и этот существующий фрейм просто является одним из фреймов в последовательности фреймов, который пропускается через существующее соединение. На стадии 304 фрейм пропускается через существующее соединение по шине матрицы на матричный коммутатор. Управляющая логика затем возвращается к стадии 300 в ожидании следующего фрейма. Однако на стадии 302 соединение не было ранее установлено, управляющая логика определяет, полон ли буфер 104. Если да, фрейм игнорируется на стадии 308, и управляющая логика возвращается к ожиданию следующего фрейма. Если буфер фреймов не был заполнен, фрейм помещается в буфер на стадии 310, и управляющая логика решает конфликт в отношении управляющей шины на стадии 312. На стадии 314 логика ждет получения разрешения. В это время она приступает к выдаче запроса о соединении на стадии 318. На стадии 320 управляющая логика считывает записанный ответ порта. Ответ изучается на стадии 324 для определения, занят ли он или нет (стадия 326), в это время подается сообщение о занятости или, если порт указывает, что у него сбой (стадия 328), в этот момент посылается сообщение о сбое на стадии 334. Возвращение к стадии 324, если ответ успешный, порт маркирован как соединенный на стадии 330, и отправление квитирования об установлении связи начинается на стадии 336 через матрицу. Когда принимаемое квитирование установления связи принято на стадии 338, оно изучается на стадии 340. Если оно не в порядке, выдается сообщение об ошибке на стадии 342, и в это время буфер 104 очищается на стадии 316. Возвращение к стадии 340, если квитирование установления связи завершено успешно, фрейм посылается на матричный коммутатор 40 на стадии 324, и логика приступает к узлу A, показанному на фиг. 9 ( о чем будет сказано ниже).
На фиг. 8 блок-схема порядка действий показывает функционирование управляющей логики порта, когда запрос принят от управляющей шины. Это происходит на стадии 400. В это время порт определяет будет или нет он соединен на стадии 402. Если да, порт отвечает на стадии 404 сигналом занято. Если нет, на стадии 406 порт отвечает, что он может произвести соединение. На стадии 408 порт запоминает индикацию, что он соединен, и на стадии 410 производит квитирование об установлении связи. Ответ о квитировании установления связи принимается на стадии 412 и изучается на стадии 414, чтобы определить, в порядке ли оно. Если нет, тогда на стадии 416 посылается сообщение об ошибке, и порт маркирует себя как отсоединенный на стадии 418, возвращаясь к стадии 400. Если, однако, на стадии 414 ответ о квитировании установления связи в порядке, тогда управляющая логика приступает к узлу A.
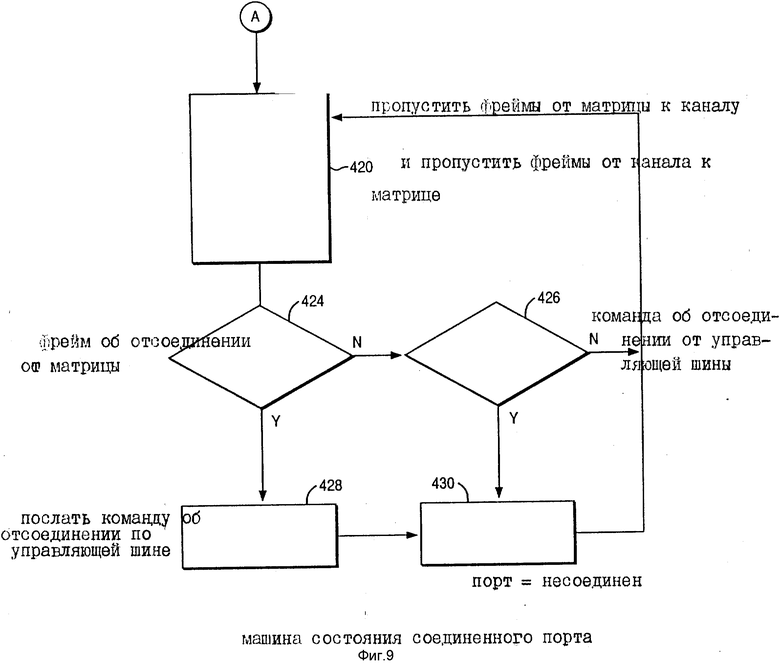
Узел A показан на фиг. 9 как соединяющий логику на фиг. 5 и 7 с каналом связи. Фреймы могут также посылаться от канала связи на матрицу, если это необходимо. На стадии 424 логика порта определяет, принят ли фрейм о разъединении от матричного коммутатора. Если нет, тогда логика порта определяет на стадии 426, принята ли команда о разъединении от управляющей шины. Если нет, тогда логика порта возвращается к стадии 420, чтобы продолжать посылать фреймы. Возвращение к стадии 424, если фрейм о разъединении был получен через матричный коммутатор, и затем на стадии 428 происходит выдача команды о разъединении по управляющей шине. Порт затем маркируется как отсоединенный на стадии 430. Аналогичным образом на стадии 426, если команда об отсоединении принята от управляющей шины, порт маркируется отсоединенным на стадии 430.
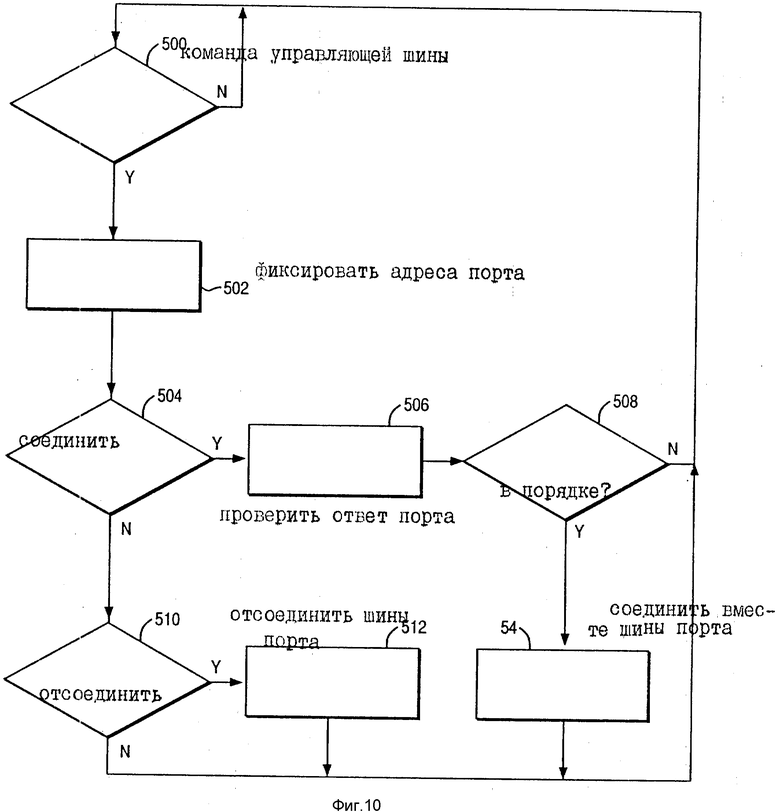
На фиг. 10 блок-схема порядка действий показывает управляющую логику матричного коммутатора 40. Следует отметить, что матричный коммутатор 40 является исполнительным устройством, которое перехватывает по управляющей шине и управляет соответственно соединениями коммутатора. На стадии 500 управляющая логика коммутатора определяет, послана ли команда по управляющей шине. Если нет, она продолжает ждать. Если команда есть, тогда адреса портов фиксируются на стадии 502. На стадии 504 команда изучается, чтобы определить, является ли это командой о соединении. Если да, на стадии 506 ответ порта контролируется и проверяется. Если ответ в порядке на стадии 508, тогда соединение шины между портами происходит на стадии 504. Аналогичным образом, на стадии 510 команда изучается, чтобы определить, является ли это командой о разъединении, и если да, тогда соединения порта разъединяются на стадии 512.
Специалисту в этой области техники должно быть понятным, что логика перехвата матричного коммутатора может также использоваться для управления иными функциями, чем просто соединение или разъединение устройств. Например, логика перехвата матричного коммутатора может использоваться для определения, когда произошло указанное событие, путем изучения информации, связанной с соединением двух портов, и для контроля операции автономных устройств, таких как предотвращение двух последовательных соединений с одним и тем же портом, или операции разъединения с несоединенным портом.
Хотя это изобретение описано со ссылкой на показанный вариант реализации, оно не предназначено толковаться в ограничительном смысле. Разные модификации показанного варианта реализации, а также другие варианты реализации изобретения станут очевидны специалистам в этой области техники после ознакомления с описанием. Поэтому считается, что прилагаемая формула изобретения будет охватывать любые такие модификации или варианты реализации, как входящие в действительный объем изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СИСТЕМА СВЯЗИ | 1991 |
|
RU2110839C1 |
| СИСТЕМА СВЯЗИ | 1991 |
|
RU2117405C1 |
| ПАРАЛЛЕЛЬНАЯ ПРОЦЕССОРНАЯ СИСТЕМА | 1991 |
|
RU2084953C1 |
| УСТРОЙСТВО ДЛЯ ОПТИМИЗАЦИИ ОРГАНИЗАЦИИ ДОСТУПА К ОБЩЕЙ ШИНЕ ВО ВРЕМЯ ПЕРЕДАЧИ ДАННЫХ С ПРЯМЫМ ДОСТУПОМ К ПАМЯТИ | 1991 |
|
RU2110838C1 |
| ПЕРСОНАЛЬНАЯ КОМПЬЮТЕРНАЯ СИСТЕМА | 1991 |
|
RU2068578C1 |
| ЗАПОМИНАЮЩЕЕ УСТРОЙСТВО ПРЯМОГО ДОСТУПА (DASD) ЕМКОСТЬЮ БОЛЬШЕ 528 МЕГАБАЙТ И СПОСОБ ЕГО ВОПЛОЩЕНИЯ ДЛЯ ПЕРСОНАЛЬНЫХ КОМПЬЮТЕРОВ | 1994 |
|
RU2155369C2 |
| ПЕРСОНАЛЬНАЯ КОМПЬЮТЕРНАЯ СИСТЕМА | 1991 |
|
RU2072553C1 |
| СИСТЕМА ОБРАБОТКИ И СПОСОБ ЕЕ ФУНКЦИОНИРОВАНИЯ | 1994 |
|
RU2150738C1 |
| СХЕМНОЕ УСТРОЙСТВО ДЛЯ ПАРАЛЛЕЛЬНОЙ ОБРАБОТКИ ДВУХ ИЛИ БОЛЕЕ КОМАНД В ЦИФРОВОМ КОМПЬЮТЕРЕ | 1991 |
|
RU2111531C1 |
| СПОСОБ ФУНКЦИОНИРОВАНИЯ СИСТЕМЫ ОБРАБОТКИ | 1994 |
|
RU2142157C1 |


Изобретение относится к вычислительной технике и предназначено для передачи информации между разными системами обработки данных. Система связи содержит N портов, матричный коммутатор и средство арбитра шины. Порты соединены друг с другом посредством шин. Дополнительно порты соединены с матричным коммутатором. 9 з.п. ф-лы, 10 ил.