Предшествующий уровень техники
Изобретение относится к устройству и способу функционирования компьютерной системы. В частности, описываются способ и устройство для управления сигналами разрешения запуска выходной буферной схемы на параллельно нагруженной шине.
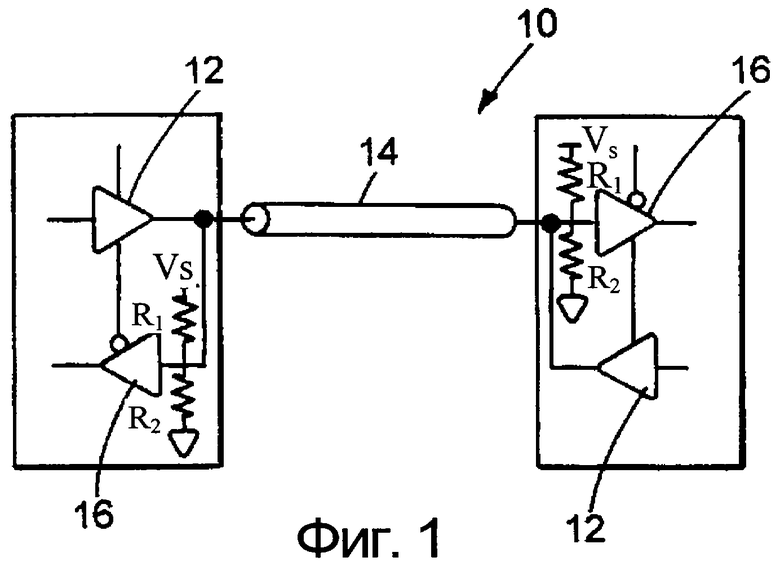
Фиг.1 изображает пример двунаправленной параллельно нагруженной (согласованной) шинной системы 10. Формирователи 12 имеют импеданс Zo и способны функционировать таким образом, чтобы выдавать сигналы на шину 14 к приемникам 16. Шина 14 нагружается в каждом приемнике 16, 18 резистором Ri, включенным между шиной и источником напряжения Vs питания, а также резистором R2, включенным между шиной и "землей". Следовательно, когда шина не получает сигналы с формирователя 12, она имеет смещение, равное половине напряжения. Такая конфигурация делает времена нарастания и спада сигналов на шине симметричными, что желательно в режиме работы с синхронными источниками. Параллельно согласованная шина может быть однонаправленной, двунаправленной или мультинаправленной.
Любой обмен данными между формирователями и приемниками двух модулей, такими, как, например, между процессором и устройством памяти, которые могут быть расположены на отдельных микросхемах (чипах), обычно выполняется синхронно.
То есть, чипы имеют внутренние тактовые генераторы, которые являются достаточно согласованными друг с другом, так, чтобы данные могли быть восприняты при переключениях тактовых сигналов. Кроме того, обмен данными может выполняться синхронно с источником, что означает, что обмен осуществляется при переключениях стробирующих сигналов, полученных из тактового сигнала и синхронизированных с соответствующими данными.
Протокол параллельного согласования был разработан для того, чтобы гарантировать правильное функционирование передачи сигналов данных для двух или более абонентов шины в пределах широкого диапазона функционирования. Протокол параллельного согласования также может быть подходящим для использования при работе с другими модулями, которые выдают и принимают данные в режиме параллельной обработки. Согласно протоколу параллельного согласования для того, чтобы предотвратить “плавание” сигнала к неопределенному логическому уровню, при воплощении необходимо, чтобы сигнал выдавался всегда. Если бы некоторым сигналам, например, таким, как стробирующие сигналы, было бы позволено “плавать”, то система стала бы ненадежной. Упомянутая ситуация может вызывать фатальную ошибку функционирования в системе вследствие ошибок при передаче данных. Для того, чтобы избежать возникновения подобных ситуаций, протокол параллельного согласования может задать условие, состоящее в том, что устройство шины, определенное в качестве главного устройства шины по умолчанию, будет синхронно устанавливать время выдачи точек отсечки, так, чтобы они возникали, когда другое устройство шины выдает сигналы на шину, например, для того, чтобы возвратить данные, запрошенные главным абонентом шины. Протокол параллельного согласования также может задать условие, состоящее в том, что определенное по умолчанию главное устройство шины должно синхронно с источником зафиксировать значение на шине, включить свои формирователи и выдать зафиксированное значение обратно на шину при поступлении последнего стробирующего сигнала для ответа, посланного кэш-памятью.
Хотя протокол параллельного согласования для высокоскоростных процессорных систем может быть легко установлен, существует потребность в способах и устройстве, предназначенных для того, чтобы реализовать протокол в более широком диапазоне рабочих частот с более четкими переходами сигналов.
Краткое описание чертежей
В дальнейшем изобретение поясняется описанием конкретных вариантов его воплощения со ссылками на чертежи, на которых:
фиг.1 изображает упрощенную схему, иллюстрирующую параллельно нагруженную шинную систему,
фиг.2 изображает упрощенную блок-схему параллельно нагруженной шинной системы согласно изобретению,
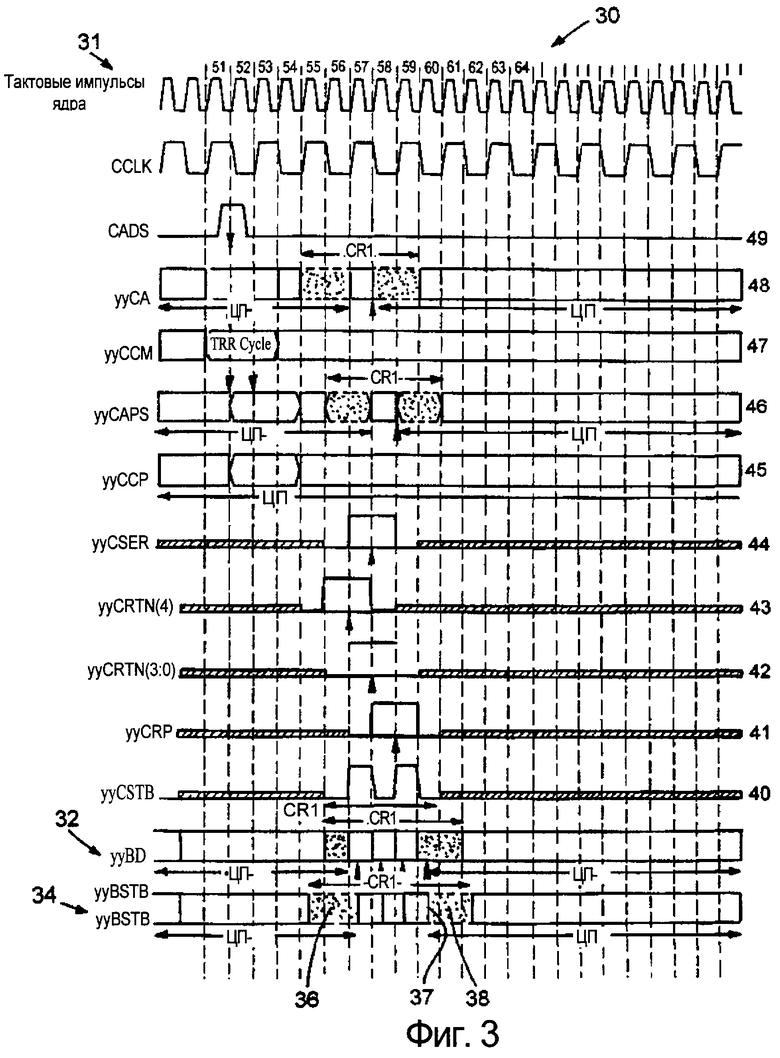
фиг.3 изображает временную диаграмму протокола цикла считывания шины процессор-вторичная кэш-память (ПВКП) (BSB), на которую подано смещение со среднего отвода (СТТ), в режиме работы с нулевой задержкой линии передачи,
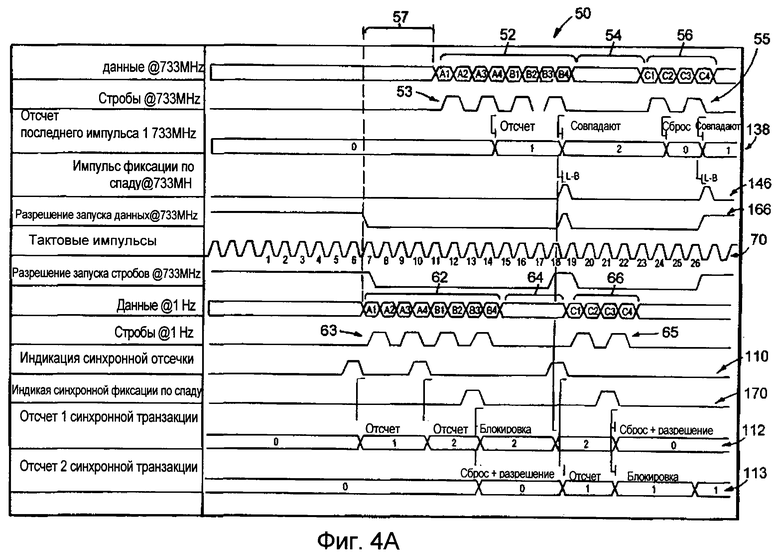
фиг.4А изображает временную диаграмму, иллюстрирующую операцию СТТ отсечки и фиксации и обратной выдачи согласно изобретению,
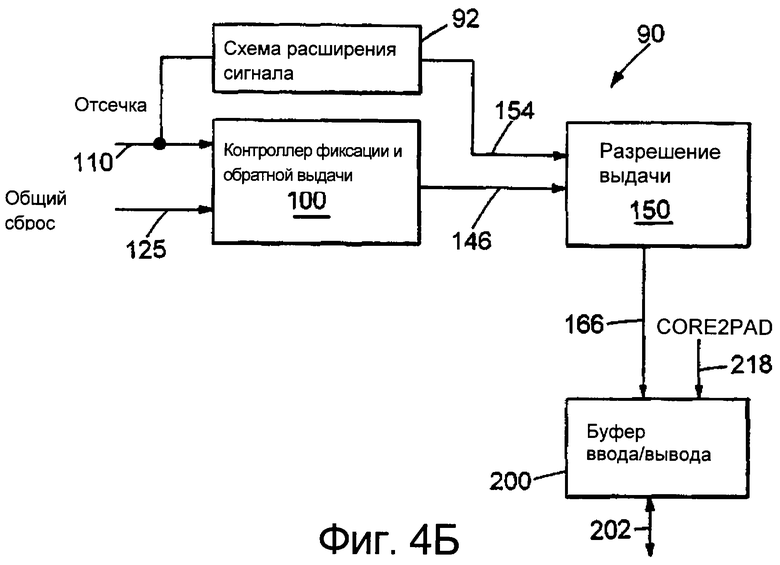
фиг.4Б изображает блок-схему системы для выдачи сигнала на ПВКП (BSB) шину согласно изобретению,
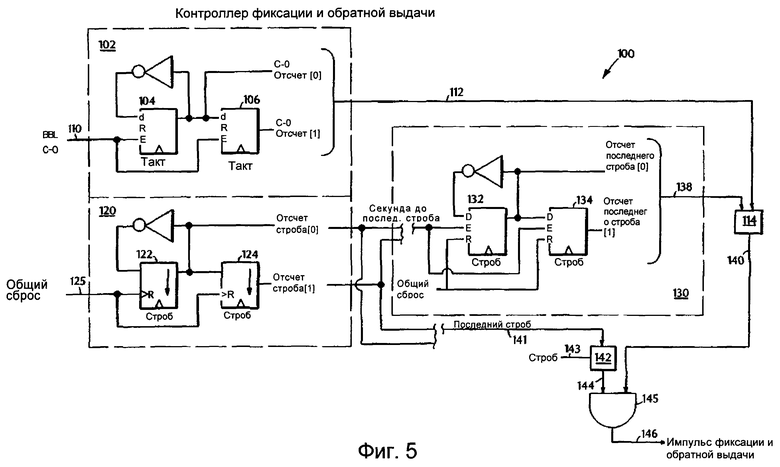
фиг.5 изображает блок-схему контроллера фиксации и обратной выдачи согласно изобретению,
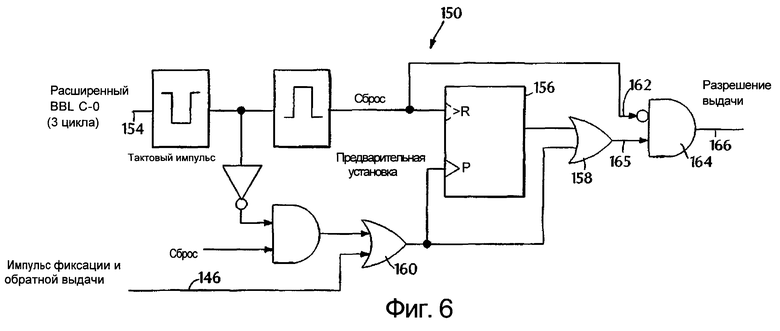
фиг.6 изображает блок-схему схемы разрешения выдачи сигналов согласно изобретению,
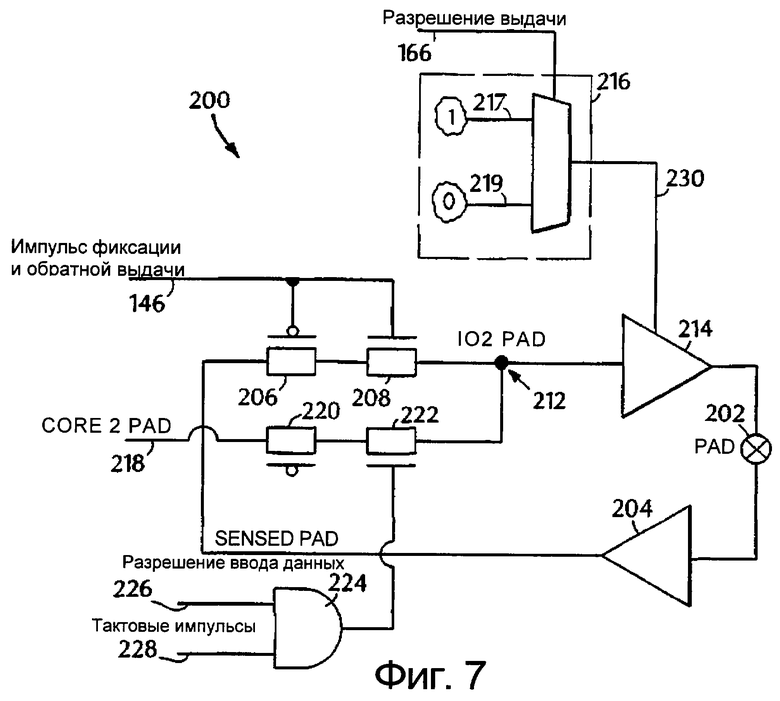
фиг.7 изображает блок-схему схемы буфера ввода/вывода согласно изобретению,
фиг.8 изображает принципиальную схему варианта воплощения СТТ контроллера,
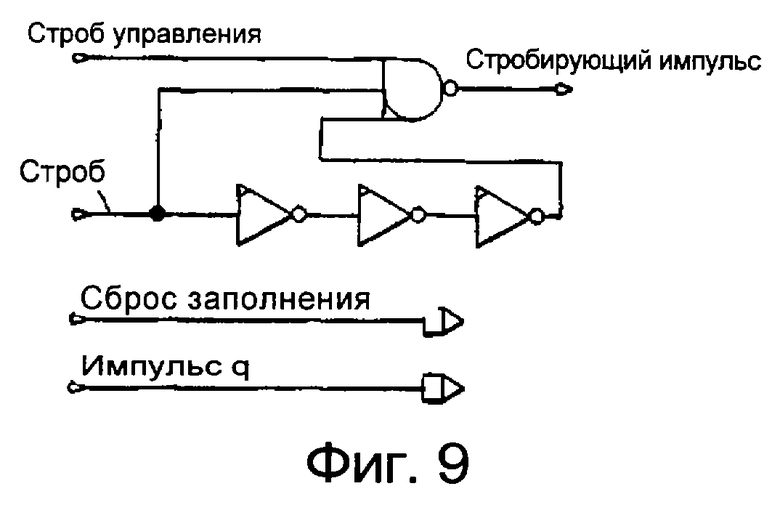
фиг.9 изображает схему генерацию стробирующих импульсов,
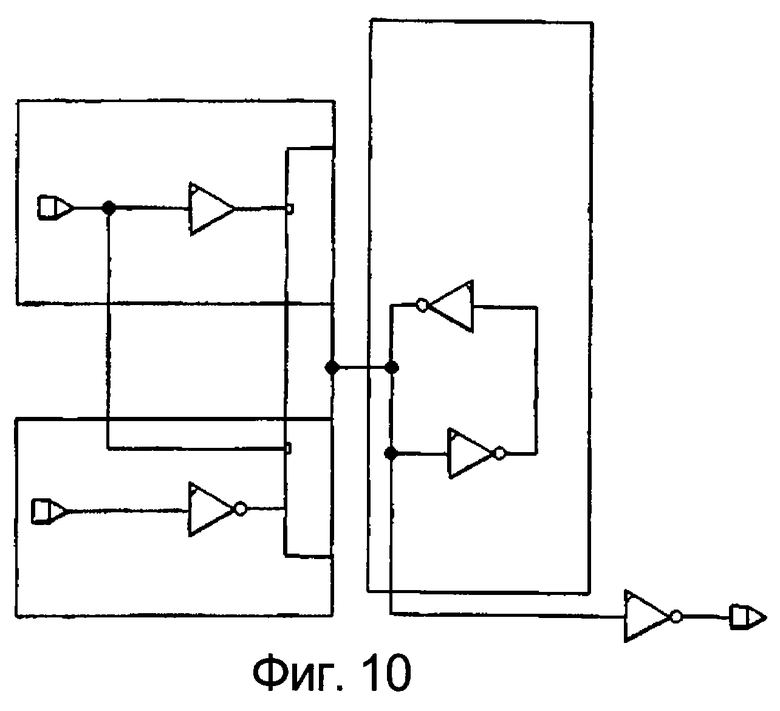
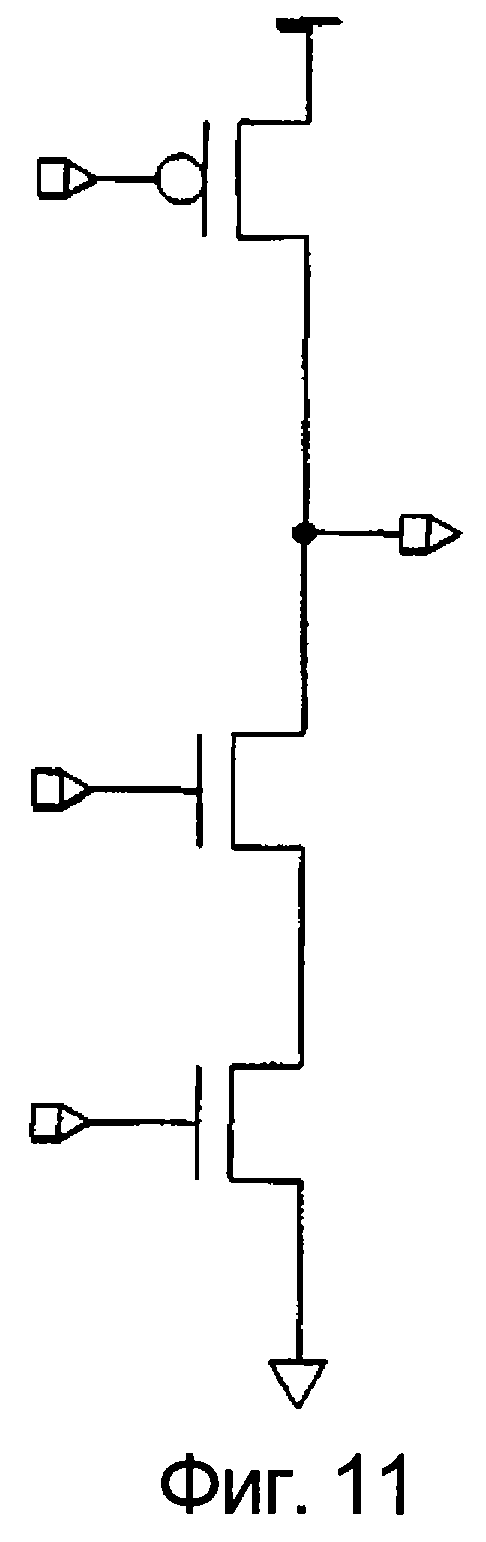
фиг.10 и 11 иллюстрируют варианты воплощений и приоритетность триггера с раздельной установкой 0 и 1,
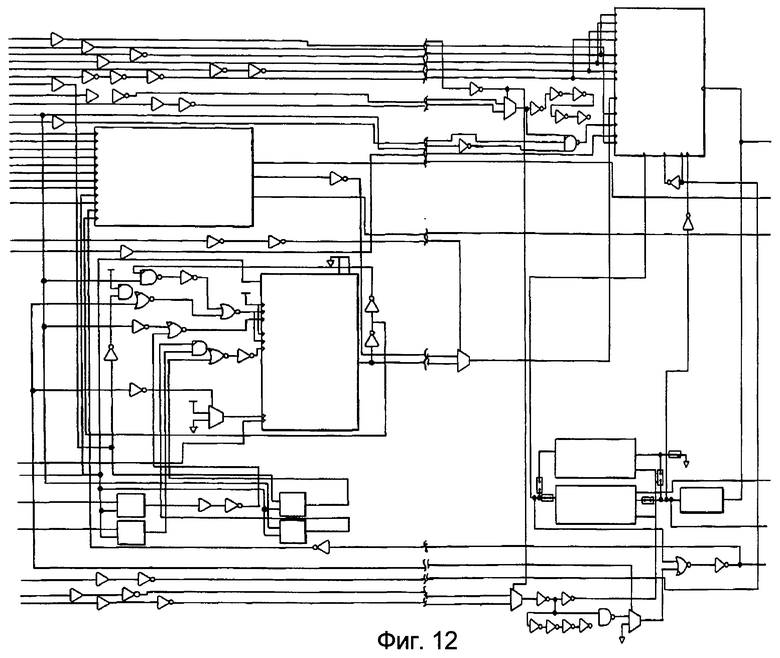
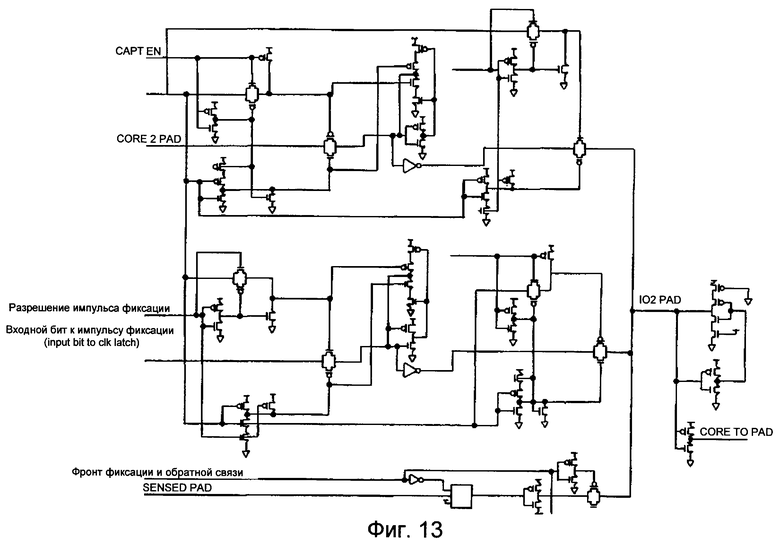
фиг.12 и 13 изображают принципиальные схемы варианта воплощения схемы управления буфером ввода/вывода, а также схемы управления логикой,
фиг.13 иллюстрирует как оптимальная логика управляет потоком данных из "Core2Pad" и "SensedPad" к ″I02Pad″.
Подробное описание
Фиг.2 изображает упрощенную блок-схему согласованной (нагруженной) системы 20, на которую подано смещение от среднего отвода, включающей в себя первое устройство 22, подключенное ко второму устройству 26 через параллельно согласованную шину 24. Первое и второе устройства способны выдавать сигналы данных, управления, адреса, стробов и другие сигналы на шину и компонуются таким образом, чтобы захватывать различные сигналы данных. По меньшей мере стробирующие сигналы непрерывно выдаются на шину 24 формирователями (не показаны), связанными либо с первым устройством 22, либо со вторым устройством 26. Вообще говоря, когда от первого устройства принимается последний стробирующий сигнал, второе устройство приступает к включению формирователя в режиме синхронных источников. Когда от второго устройства ожидаются сигналы данных или стробирующие сигналы, формирователи первого устройства должны быть синхронно выключены.
В одном варианте воплощения первое устройство 22 может быть процессором, второе устройство 26 может быть кэш-памятью, а шина 24 может быть шиной процессор-вторичная кэш-память (ПВКП, BSB). Указанные компоненты могут быть включены в один корпус интегральной схемы или же могут быть отдельными компонентами, расположенными на различных микросхемах. И процессор, и кэш-память включают в себя формирователи и приемники для выдачи и приема сигналов на шине ПВКП. Однако должно быть понятно, что новейшие процессы и схемотехника, описанная ниже, могли бы быть реализованы при других конфигурациях шины интерфейса, в которых не используется ПВКП.
Кроме того, хотя реализация примера, описанного ниже, включает в себя нагруженную шину, на которую подано смещение со среднего отвода (СТТ), можно было бы использовать любую схемотехнику шины с параллельной нагрузкой. Кроме того, если не оговаривается иное, ссылки на формирователи могут включать в себя как формирователи данных, так и формирователи стробов.
Приемники зависят от целостности сигнала шины ПВКП, так, что переключения стробирующего сигнала не будет детектироваться, если какой-нибудь из них не происходит. Если на шине ПВКП допустить “плавание” стробирующего сигнала, то целостность сигнала может быть поставлена под угрозу. Тогда может произойти фатальная системная ошибка, которая может потребовать нежелательной перезагрузки процессора. Одно из обстоятельств, которые могут заставить “плавать” стробирующий сигнал, возникает тогда, когда имеется переопределение главного устройства шины, определяемое как случай, когда процессор останавливает выдачу сигналов, а кэш-память начинает их выдачу, или наоборот. Например, если стробирующий сигнал оставлен “плавать” до неопределенного значения, тогда логический элемент или схема, расположенная после приемника, может начать работать со сбоями. Даже если не ожидается прием данных приемником, если стробирующему сигналу или другому сигналу позволить “плавать” на ПВКП шине, то мощность будет потеряна из-за большой утечки тока “на землю” в приемнике.
Фиг.3 изображает вариант воплощения временной диаграммы 30 цикла считывания согласно протоколу СТТ ПВКП шины при соотношении тактовых импульсов ядра процессора к стробирующим сигналам ПВКП шины, равном 1:1, в режиме работы с нулевой задержкой линии передачи. Указанный рабочий режим позволяет описывать сигналы идеализированным образом, когда задержки распространения игнорируются. Соотношение тактовых импульсов 31 ядра процессора к стробирующим сигналам данных, равное 1:1, в данном случае было выбрано для простоты понимания и показывает, что скорость переключения по существу является синхронной. Должно быть понятно, что можно использовать другие соотношения и что в реальной общепринятой практике отношение может быть другим, а также и то, что задержка линии передачи может быть значительной.
Что касается транзакций примера фиг.3, сигналы 32 данных и стробирующие сигналы 34 являются двунаправленными сигналами между процессором и кэш-памятью. СТТ протокол передачи сигналов 32 данных, относящихся к кэш-памяти, задает окно 36 "перед выдачей" и окно 38 "после выдачи" двух тактовых циклов для стробирующих сигналов 34. Окна "перед выдачей" и "после выдачи" рассчитываются так, чтобы предотвратить уплывание сигнала на ПВКП шине во время переопределения главного устройства шины путем обеспечения гарантии перекрывания выдачи сигналов между главными устройствами на ПВКП шине на возможно более высокой рабочей частоте и по всему рабочему диапазону частот. По мере возрастания частоты увеличивается задержка линии передачи в терминах тактовых циклов, что вызывает уменьшение перекрывания времени выдачи сигналов и может вызвать исчезновение перекрывания времени выдачи. Если перекрывание выдачи исчезает, то стробирующий сигнал может плавать на ПВКП шине. Другая возможная ситуация, которая может заставить стробирующий сигнал плавать, состоит в том, что кэш-память отвечает переключением с одного конца шины на другой на запрос данных с интервалом, который приводит к условию не перекрывания сигнала "после выдачи" от первого ответа и сигнала "перед выдачей" второго ответа. Этот случай следует понимать так, что процессор будет выдавать сигнал на ПВКП шине, чтобы предотвратить условие уплывания стробирующего сигнала.
СТТ протокол требует, чтобы и двунаправленные сигналы 32 данных, и стробирующие сигналы 34 непрерывно выдавались на ПВКП шину процессором или кэш-памятью. При приеме "последнего стробирующего" сигнала для конкретной транзакции процессор должен асинхронно (в режиме источников, синхронных со стробом) включать свой формирователь. Последний стробирующий сигнал может быть определен как стробирующий сигнал для транзакции, за которой не сразу следуют стробирующие сигналы другой транзакции, идея чего будет поясняться более подробно со ссылкой на фиг.4. На фиг.3, последний стробирующий сигнал показан номером позиции 37. Затем, когда процессор ожидает приема данных и/или стробирующих сигналов из кэш-памяти, он должен синхронно выключать свои формирователи. Таким образом, точки осечки процессора должны быть синхронно установлены, чтобы появляться в более ранние моменты времени относительно моментов, когда процессор должен принимать данные на ПВКП шине. Хотя теоретически это кажется легко выполнимым, в реальных рабочих условиях системы трудно установить, является ли фронт конкретного стробирующего сигнала "последним стробом", который требует генерации сигнала фиксации и обратной выдачи. В последующем обсуждении, сигнал "фиксации и обратной выдачи" определяется как сигнал, являющийся результатом процесса фиксации и обратной выдачи, происходящего, когда принимающее устройство (принимающий абонент шины) захватывает значение на шине от передающего устройства (передающий абонент шины), для использования при выдаче его обратно на шину, если потребуется. Описанная методика также может использоваться, чтобы предотвратить уплывание сигналов на однонаправленной шине или на линии передачи сигнала.
Обратимся опять к фиг.3, когда система впервые включается, чип процессора будет выдавать на двунаправленную шину стробирующие сигналы 34 и сигналы данных 32. Кэш-память будет выдавать стробирующие сигналы 40 на однонаправленную шину. Процессор на основе стробирующих сигналов 40 знает, когда принимать данные 41-44 из кэш-памяти. Таким образом, при включении питания формирователи процессора и формирователи кэш-памяти посылают стробирующие сигналы так, что не возникает вопроса о плавающих сигналах. Но когда должна произойти передача управления, в большинстве случаев следует принять меры, чтобы гарантировать, что отсутствует плавание сигналов на шине. Однако имеются случаи, когда не требуется никакой специальной обработки, например, когда приходит последний из стробирующих сигналов 40, потому что кэш-память будет выдавать эти сигналы на низком уровне и предотвращать любые сбои системы. В других случаях, когда стробирующие сигналы плавают, один из абонентов, например, такой, как кэш-память, может быть способен переустанавливаться прежде, чем будут сделаны любые дальнейшие запросы, в результате чего можно устранить любые проблемы, вызванные плавающими сигналами.
Фиг.4А изображает временную диаграмму 50, иллюстрирующую сигналы операции отсечки по СТТ протоколу и фиксации и обратной выдачи для процессора и кэш-памяти, при работе в двух экстремальных случаях: процессор, осуществляющий считывание данных на высокой частоте (в данном примере 733 Мегагерц (МГц)) и на низкой частоте (в данном примере 1 Герц (Гц)). В случае работы на высокой частоте за сигналами 52 данных, обозначенных как А1-А4 и В1-В4, после задержки 54 следуют сигналы 56 данных, обозначенные как С1-С4. В сигналы данных включены взаимодополняющие стробирующие сигналы 53 и 55, которые могут быть различными сигналами (например, один является активным при высоком уровне, а другой является активным при низком уровне сигнала), предназначенные для того, чтобы повысить надежность и рабочие характеристики системы. Для работы на низких частотах за сигналами 62 данных, обозначенных как А1-А4 и В1-В4, после задержки 64 следуют сигналы 66 данных, обозначенные как С1-С4. Снова включаются (в состав данных) взаимодополняющие стробирующие сигналы 63 и 65. Интервал 57 является дополнительной задержкой линии передачи в терминах тактовых циклов при работе на высокой частоте (что в данном примере составляет приблизительно 4 тактовых цикла), как вычислено из уравнения: задержка линии передачи, деленная на период тактовых импульсов ядра процессора.
Тактовый сигнал 70 показывает, что при работе на низкой частоте с момента времени, когда была запрошена транзакция считывания кэш-памяти, до момента времени, когда первый блок А1 сигналов 62 данных поступает в процессор, проходит 6 циклов, в предположении, что транзакция начинается с первого тактового цикла. Таким образом, время ожидания кэш-памяти для сигналов 62 данных составляет 6 циклов. При работе на высокой частоте время ожидания кэш-памяти для сигналов 52 данных составляет 10 циклов. Следовательно, для различных рабочих частот время ожидания кэш-памяти будет различно, и прием данных будет происходить во время различных тактовых циклов. Например, сравнивая транзакции переключения с одного конца шины на другой на некоторых частотах, последний блок данных В4 сигналов 62 данных и блок данных А4 сигналов 52 данных могли бы быть приняты приблизительно в одно и то же время (во время тактового цикла 14). Если бы блоки данных С1-С4 не существовали, то в случае работы на низкой частоте, процессор должен выполнить операцию "фиксации и обратной выдачи" приблизительно на тактовом цикле четырнадцать, в то время как в случае работы на высокой частоте, процессор должен выполнить операцию фиксации и обратной выдачи приблизительно на тактовом цикле 18.
Интервал между транзакциями также зависит от того, должен ли процессор выполнить операцию фиксации и обратной выдачи. Например, фиг.4А показывает, что временной интервал 54 или 64 между блоками данных, который составляет менее четырех (4) тактовых циклов, обычно дает достаточное время для перекрывания стробирующих сигналов кэш-памяти "перед выдачей" и "после выдачи", в предположении, что имеется два тактовых цикла "перед выдачей" и два тактовых цикла "после выдачи", и, таким образом, фиксацию и обратную выдачу можно было бы не выполнять.
Поскольку сигнал "после выдачи" после блока В4 данных занимает два цикла, а сигнал "перед выдачей" перед блоком данных С1 также занимает два цикла, всегда будет существовать сигнал перекрывания или известное значение на шине ПВКП. Однако две группы могут обрабатываться различными банками кэш-памяти, и если первый банк кэш-памяти отвечает быстрее, чем обычно или чем ожидается (например, вследствие отклонений при производстве или воздействий при работе, обусловленных отклонениями напряжений, и т.д.), в то время как второй банк кэш-памяти отвечает медленнее, чем ожидается, то не будет существовать никакого перекрывания, и процессор должен выполнять операцию фиксации и обратной выдачи для того, чтобы предотвратить плавание стробирующего сигнала на ПВКП шине.
Схемотехника формирователя отсечки и фиксации и обратной выдачи также должна быть способна функционировать в диапазоне от очень низкой частоты (~0 Гц) до наивысшей рабочей частоты процессора. Указанное требование частотной независимости необходимо для того, чтобы позволить осуществлять плавное управление работой интегральной схемой в испытательном режиме и гарантировать, что данные компоненты будут функционировать в изделии. Указанное требование выполняется гарантированием того, что отсечка формирователя процессора начинается на том же самом фронте синхроимпульса (синхронно), что и ответ кэш-памяти. Поскольку данный ответ зависит от времени ожидания кэш-памяти, которое может не быть одинаковым при различных конфигурациях системы, можно было бы внести некоторую гибкость посредством включения "кнопки", называемой "кнопка отсечки".
Указанная "кнопка" может быть определена в качестве механизма корректировки для установки управляющих значений в полупроводниковом чипе. "Кнопка" может быть выполнена на базе аппаратного или программного обеспечения и используется для того, чтобы изменять рабочий режим чипа интегральной схемы процессора. "Кнопка" отсечки может быть связана с "кнопкой" времени ожидания кэш-памяти, функционирующей таким образом, чтобы осуществлять коррекцию как для быстрого, так и для медленного времени ответа кэш-памяти. Если для специфической системы известно время ожидания кэш-памяти, то для того, чтобы облегчить коррекцию процессора, "кнопка" отсечки предпочтительно реализуется на основе программного обеспечения. Для того чтобы гарантировать частотно-независимую, полностью переконфигурируемую работу операций отсечки и "фиксации и обратной выдачи", системы могут иметь различные установки кнопок. Для того чтобы управлять точками отсечки для различных сигналов, могут быть необходимы многочисленные "кнопки".
Фиг.4Б изображает упрощенную блок-схему системы 90 для выдачи, когда требуется, сигнала на ПВКП шину. Схема 100 контроллера фиксации и обратной выдачи включает в себя вход 110 сигнала отсечки ПВКП шины и вход 125 сигнала общего сброса и действует так, чтобы генерировать импульс фиксации и обратной выдачи на линии 146 для подачи в схему 150 разрешения выдачи. Схема 92 расширения сигнала действует так, чтобы обеспечить ввод расширенного сигнала отсечки ПВКП шины по линии 154 в схему 150 разрешения выдачи (что будет поясняться ниже со ссылкой на фиг.6), и на линии 166 генерируется сигнал разрешения выдачи для схемы 200 буфера ввода/вывода. Схема 200 ввода/вывода генерирует сигнал, имеющий специфическое значение при вводе/выводе PAD 202, для осуществления выдачи на ПВКП шину и включает в себя входную линию 218 CORE2PAD. CORE2PAD представляет собой линию, которая соединяет ядро процессора с линией шины. Варианты воплощения схемы контроллера фиксации и обратной выдачи, схемы разрешения выдачи, а также схемы буфера ввода/вывода описаны со ссылкой на фиг.5-7.
Фиг.5 изображает блок-схему варианта воплощения схемы 100 контроллера фиксации и обратной выдачи, которая может быть выполнена как часть процессора. Схема контроллера фиксации и обратной выдачи действует так, чтобы подсчитывать запросы, которые были выданы, и полученные ответы, и, когда указанные отсчеты равны, тогда она выдает команду фиксации и обратной выдачи. Контроллер фиксации и обратной выдачи включает в себя схему 102 синхронного счетчика отсечки ПВКП шины и две схемы 120 и 130 счетчиков стробов, синхронизированных по источнику. Схема 102 счетчика транзакций ПВКП шины осуществляет слежение за выданными транзакциями процессора, а схемы 120 и 130 счетчиков стробов, синхронизированных по источнику, осуществляют слежение за ответами кэш-памяти, которые были приняты для данных транзакций.
В настоящем варианте воплощения схема 102 счетчика транзакций ПВКП шины представляет собой двухразрядный счетчик, включающий в себя первый синхронизированный с тактовым сигналом ядра процессора триггер 104 и второй синхронизированный с тактовым сигналом ядра процессора триггер 106, каждый из которых имеет вход для данных, вход сброса и вход разрешения ввода. Сигнал отсечки ПВКП шины подается по линии 110 на оба триггера, и схема 102 действует так, чтобы считать число сигналов отсечки и выводить отсчет на линию 112 в схему 114 компаратора. Сигналы отсечки посылаются ядром процессора, через некоторое число тактов после каждого из них, и каждая транзакция инициируется на шине. Также посылается индикация фиксации и обратной выдачи каждый раз, когда ядро процессора распознает, что разделение между двумя группами транзакций достаточно велико для того, чтобы происходила фиксация и обратная выдача. Ядро процессора может быть определено как реальная логическая схема процессора на полупроводниковом чипе.
Обратимся снова к фиг.5, схема 120 двухразрядного счетчика включает в себя два асинхронных триггера 122 и 124, работающих в режиме синхронных источников по стробу. Должно быть понятно, что могут использоваться варианты воплощения, включающие в себя счетчики, отличающиеся от двухразрядных, а также число триггеров может быть больше или меньше двух. После того как на линии 125 принят сигнал общего сброса, схема 120 подсчитывает каждое появление строба, и отсчет вводится в схему 130 двухразрядного счетчика. Схема 130 включает в себя два асинхронно сбрасываемых триггера 132, 134, которые генерируют отсчет последнего строба на линии 138, являющейся входной для компаратора 114. Выходной сигнал из компаратора 114 подается на линию 140 в логическую схему И 145, которая также соединена с линией 144. Обращаясь к обеим фигурам - фиг.4А и фиг.5, если отсчет сигналов отсечки (выданных транзакций) на линии 112 равняется последнему отсчету стробов (отсчету принятых ответов) на линии 138, то сигнал на линии 140 позволяет фронту сигнала 144 распространиться на линию 146. Последний стробирующий сигнал на линии 141 подсчитывается по фронту, прежде последнего фронта полного набора стробов, и данный подсчет выполняется для того, чтобы гарантировать скорость генерации импульсов фиксации и обратной выдачи.
Сигнал на линии 140 является стабильным, поскольку, когда из ядра процессора принимается индикация "фиксация и обратная выдача", схема 102 блокируется или “замораживается”. Следовательно, сигнал 144 фронта генерируется по фронту последнего строба ответа кэш-памяти посредством схемы 142 генератора импульсов, которая использует строб в качестве входного импульса 143. Выходной сигнал 146 большую часть времени равен нулю, за исключением того времени, когда должна выполняться фиксация и обратная выдача. Активный сигнал на линии 140 показывает, что число выданных транзакций и полученных ответов равно. Когда возникает такая ситуация, процессором на ПВКП шине выполняется фиксация и обратная выдача. Снова полученные отсчеты сбрасываются во время ответа, следующего за транзакцией, которая вызвала возникновение фиксации и обратной выдачи. Указанная процедура выполняется так, чтобы также можно было осуществлять фиксацию и обратную выдачу для последующей транзакции.
Если транзакции могут выдаваться прежде, чем возникает фиксация и обратная выдача, для ожидающих обработки транзакций могут понадобиться многочисленные схемы (102) счетчиков отсечки. Таким образом, ожидающие обработки транзакции кэш-памяти отслеживаются по мере того, как данные передаются с, по меньшей мере, одним из счетчиков. Например, если бы использовались две схемы счетчиков, счетчики бы чередовались каждый раз, когда ядро процессора посылает индикацию 170 синхронизованной фиксации и обратной выдачи (фиг.4А), прежняя индикация счетчика 112 “замораживает” свое значение, в то время как новая индикация счетчика 113 сбрасывается самостоятельно и выдает разрешение подсчитывать сигналы отсечки. Когда данные передаются из кэш-памяти в процессор по шине ПВКП, транзакция отслеживается схемой счетчика 120, синхронизированной с источником. Когда отсчеты синхронного счетчика и счетчика, синхронизированного с источником, согласованы, на ПВКП шину выдается сигнал, чтобы гарантировать то, что никаким сигналам не разрешается "плавать". Таким образом, когда транзакции возвращают данные, фиксация и обратная выдача выполняется только тогда, когда показания синхронного счетчика совпадают с показанием счетчика, синхронизированного с источником, и контроллер фиксации и обратной выдачи выдает импульс фиксации и обратной выдачи (L-B импульс) на последнем срезе поступающего стробирующего сигнала.
Фиг.6 изображает блок-схему схемы 150 разрешения выдачи. Асинхронный триггер 156 с раздельной установкой 0 и 1 действует таким образом, чтобы выдавать нулевой или низкий выходной сигнал, когда сигнал сброса является высоким, и единицу или высокий выходной сигнал, когда сигнал предварительной установки является высоким. Асинхронный триггер 156 с раздельной установкой 0 и 1 также функционирует в качестве приоритетного триггера для генерации нулевого или низкого выходного сигнала, если сигнал сброса и сигнал предварительной установки оба одновременно имеют высокий уровень. Выходной сигнал разрешения выдачи на линии 166 (см. фиг.4А) определяет, должен ли процессор выдавать сигнал на ПВКП шину.
Схема 150 разрешения выдачи принимает импульс фиксации и обратной выдачи на линии 146 и синхронизированный сигнал индикации отсечки на линии 154 для выключения строба и/или сигнала разрешения выдачи данных. Тот же самый сигнал отсечки ПВКП шины, который является входным для схемы 102 счетчика стробов ПВКП шины из фиг.5 на линии 110, подается на вход по линии 154, и каждый цикл расширяется до 3 циклов для того, чтобы гарантировать, что отсечка ПВКП шины происходит даже после того, как возникает по существу одновременная индикация предварительной установки в тот же момент, что и индикация сброса. Асинхронный фиксатор 156 с раздельной установкой 0 и 1 соединяется со схемой ИЛИ 158, которая также соединяется с входом импульса фиксации и обратной выдачи через схему ИЛИ 160. Инвертированный растянутый и зафиксированный сигнал отсечки ПВКП шины подается по линии 162 к схеме И 164, наряду с выходным сигналом 165 из схемы ИЛИ 158.
Сложность схемы 150 разрешения выдачи из фиг.6 обусловлена тем, что бывают случаи, когда оказывается, что должна быть выполнена фиксация и обратная выдача, но в этот момент поступает сигнал индикации отсечки, чтобы ее предотвратить. Кроме того, схема разрешения выдачи гарантирует, что ПВКП шина не будет плавать, поскольку ответ кэш-памяти включает в себя уже недостаточное перекрывание выдачи. Последний случай мог бы возникнуть, например, если первый и второй чипы кэш-памяти отвечают на два последовательных запроса (переключение банка) данных, а стробирующие сигналы не перекрываются, тогда генерируется импульс фиксации и обратной выдачи, что приводило бы к включению разрешения выдачи, по меньшей мере, временно, для того, чтобы предотвратить уплывание сигнала на ПВКП шине. Импульс отсечки должен иметь приоритет над импульсом фиксации и обратной выдачи, так, чтобы не выдавалось никакого сигнала на ПВКП шину в течение определенного числа тактовых импульсов после выполненной транзакции.
В случае переключения банка отсечка для второй транзакции гарантирует, что процессор выключается прежде, чем принимается второй ответ. Точно так же, если индикация фиксации и обратной выдачи и индикация отсечки возникают одновременно, то импульс отсечки должен иметь приоритет. Схема 150 разрешения выдачи гарантирует, что сигналы индикации отсечки имеют приоритет над сигналами индикации фиксации и обратной выдачи, позволяя процессору выдавать сигнал даже за очень короткие интервалы, когда сигналы кэш-памяти "перед выдачей" и сигналы "после выдачи" не перекрываются. Следовательно, схема разрешения выдачи справляется с такими случаями, которые могут возникать в процессе функционирования системы, в которой генерируются явно противоречивые сигналы.
Фиг.7 изображает блок-схему схемы 200 буфера ввода/вывода, иллюстрирующую, как импульс фиксации и обратной выдачи и сигнал разрешения выдачи используются для того, чтобы гарантировать правильное функционирование ПВКП шины. Когда кэш-память останавливает выдачу, и процессор должен начинать выдачу в отсутствие дальнейших транзакций, должно использоваться значение на шине в этот момент (которое выдала кэш-память). Схема 200 действует таким образом, чтобы зафиксировать указанное значение для указанного использования.
Обратимся к фиг.7, PAD202 показывает реальный провод, соединяющий процессор с кэш-памятью. Таким образом, в этой точке появится значение последнего сигнала из кэш-памяти, и оно будет помещено в буфер 204, соединенный со схемами-фиксаторами 206, 208. Фиксаторы 206 и 208 синхронизируются сигналом фиксации и обратной выдачи на линии 146 из схемы 100 контроллера фиксации и обратной выдачи из фиг.5. Таким образом, когда выдается импульсный сигнал фиксации и обратной выдачи, значение сигнала в точке 202 фиксируется в I02 PAD212. Затем буфер 214 будет выдавать значение сигнала на 202, когда сигнал разрешения выдачи на линии 230 находится в состоянии “Включен” (который генерируется из сигнала разрешения выдачи на линии 166, выходной сигнал схемы 150 разрешения выдачи из фиг.6). Схема 216 мультиплексора действует так, чтобы быстро выдавать сигнал на линию 230, показывая, когда требуется, включение буфера 214 разрешения выдачи. Входные сигналы на линиях 217 и 219, поступающие в схему мультиплексора, генерируются предварительно с учетом множественности возможных условий системы, которые могли бы возникнуть для того, чтобы гарантировать, что сигнал выдачи будет присутствовать, чтобы включать буфер 214 только тогда, когда требуется. Заранее генерируемые входные сигналы на линиях 217 и 219 формируются логическими схемами преобразования, соответствуя всем возможным переменным входным сигналам и выходным перестановкам, так, что сигнал разрешения выдачи на линии 166 является контрольным сигналом (управление мультиплексора), и сигнал разрешения выдачи не должен распространяться через большой набор логических схем. Указанные функциональные возможности могут требовать увеличения аппаратных средств для моделирования каждого из возможных условий сигнала, но такие затраты оправдывают возросшую стоимость, чтобы обеспечить быстродействие, необходимое для того, чтобы гарантировать наиболее скоростное функционирование ПВКП шины, при этом гарантируя корректное функционирование при множестве условий. Следовательно, процессор будет запускать сигнал на шину ПВКП через PAD202 с тем же самым значением, что и сигнал, который должен был бы запускать кэш, когда требуется.
В дополнение к функционированию в соответствии с вышеописанным способом схема фиг.7 может функционировать, чтобы выдавать сигнал Core2Pad, присутствующий на линии 218, на PAD202. Линия 218 соединяет ядро чипа для записи данных и соединяется со схемами-фиксаторами 220 и 222. Фиксатор 220 синхронизируется тактовым генератором ядра процессора, а фиксатор 222 синхронизируется выходным сигналом логической схемы И 224. Схема И имеет вход 226 разрешения ввода данных и вход 228 тактовых импульсов. Вход 226 разрешения ввода данных управляется процессором и действует так, чтобы посылать значение сигнала Core2Pad на линию 218 к I02PAD 212 только тогда, когда на линии 226 присутствует сигнал разрешения выдачи, который возникает тогда, когда процессор предполагает производить запись данных, таким образом предотвращая любое разногласие в записи значения на I02PAD. Таким образом, последнее принятое значение выдается на ПВКП шину только при необходимости. В итоге, когда происходит фиксация и обратная выдача, текущее значение на ПВКП шине дискретизируется в I02PAD узле 212 и выдается. Когда ПВКП шина хочет выдать стробирующие сигналы и/или данные, она проводит эту операцию от Core2Pad 218 к I02Pad 212. Тщательно управляемый сигнал “Разрешения ввода данных” гарантирует, что в I02PAD узле шины не возникает никакого разногласия.
Фиг.8 изображает принципиальную схему СТТ контроллера варианта воплощения схемотехники контроллера фиксации и обратной выдачи и схемотехники генерации разрешения выдачи, описанной со ссылкой на фиг.5 и 6.
Фиг.9 изображает вариант воплощения схемы генерации стробирующих импульсов.
Фиг.10 и 11 иллюстрируют варианты воплощения триггера с раздельной установкой 0 и 1.
Фиг.12 и 13 изображают принципиальные схемы варианта воплощения схемы управления буфером ввода/вывода и схемы управления логикой.
Фиг.13 иллюстрирует, как оптимальная логика управляет потоком данных из "Core2Pad" и "SensedPad" к "I02Pad".
Описанная техника включает и выключает сигнал разрешения выдачи сигналов процессора таким образом, чтобы гарантировать, что стробирующие сигналы и/или сигналы данных на ПВКП шине никогда не станут плавать. Варианты воплощения способов и схемы согласно настоящему изобретению также значительно снижают возникновение межсимвольных полей (ISI) в шине, которая соединяет между собой различные объекты, выдающие и принимающие сигналы.
Должно быть понятно, что хотя были описаны определенные варианты воплощения изобретения, другие аспекты, достоинства и модификации находятся в рамках следующей формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| АРХИТЕКТУРА И ПРОТОКОЛ ШИНЫ С УЧЕТВЕРЕННОЙ ПОДКАЧКОЙ | 2000 |
|
RU2271566C2 |
| СПОСОБ И УСТРОЙСТВО ДИФФЕРЕНЦИАЛЬНОГО СТРОБИРОВАНИЯ НА КОММУНИКАЦИОННОЙ ШИНЕ | 2000 |
|
RU2256949C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ ПОДДЕРЖАНИЯ УПОРЯДОЧЕНИЯ ТРАНЗАКЦИЙ И РАЗРЕШЕНИЯ КОНФЛИКТНЫХ СИТУАЦИЙ В МОСТОВОЙ СХЕМЕ ШИН | 1995 |
|
RU2182356C2 |
| Устройство для сопряжения ЭВМ с внешними устройствами | 1984 |
|
SU1332326A1 |
| ЗВЕНО СВЯЗИ МНОГОКРИСТАЛЬНОЙ ИНТЕГРАЛЬНОЙ СХЕМЫ | 2013 |
|
RU2656732C2 |
| ПОЛУПРОВОДНИКОВАЯ ПАМЯТЬ | 1993 |
|
RU2156506C2 |
| Устройство для сопряжения процессора с периферийным устройством | 1984 |
|
SU1246102A1 |
| СХЕМА УМЕНЬШЕНИЯ ЗАДЕРЖКИ ПРИ ПЕРЕДАЧЕ БУФЕРИЗОВАННЫХ ДАННЫХ МЕЖДУ ДВУМЯ ВЗАИМНО АСИНХРОННЫМИ ШИНАМИ | 1996 |
|
RU2176814C2 |
| Устройство для сопряжения вычислительного модуля с магистралью | 1985 |
|
SU1325495A1 |
| ПОСТОЯННЫЕ ЗАПИСИ ДЛЯ ЭНЕРГОНЕЗАВИСИМОЙ ПАМЯТИ | 2018 |
|
RU2780441C2 |
Изобретение относится к устройству и способу функционирования компьютерной системы. Технический результат заключается в создании способа и устройства, позволяющих реализовать протокол параллельного согласования в более широком диапазоне рабочих частот с более четкими переходами сигналов. Один из вариантов способа включает следующие действия: передачу данных между первым устройством (абонентом шины) и вторым устройством (абонентом шины) по параллельно согласованной шине; отслеживание запросов ожидающих обработки данных от первого устройства ко второму устройству, по меньшей мере, с одним синхронным счетчиком; отслеживание ответов ожидающих обработки данных от второго устройства с использованием счетчика, синхронизированного с источником; и выдачу сигнала на параллельно согласованную шину, когда отсчеты синхронного счетчика и синхронизированного с источником счетчика совпадают. 4 с. и 29 з.п. ф-лы, 13 ил.
| US 5964856 А, 12.10.1999 | |||
| Устройство для закручивания гаек | 1979 |
|
SU848333A1 |
| US 5828850 A, 27.10.1998 | |||
| US 5978861 A, 02.11.1999 | |||
| US 6026456 А, 15.02.2000 | |||
| Устройство для обмена информацией между персональной ЭВМ и управляющим вычислительным комплексом | 1991 |
|
SU1838819A3 |
| Устройство для управления обменом информацией между ЭВМ и группой периферийных устройств | 1989 |
|
SU1711170A2 |

