Уровень техники.
Кофе содержит очень сложную смесь ароматических молекул. До настоящего времени в ходе интенсивных исследований состава напитков из быстрорастворимого и свежемолотого кофе идентифицировано свыше 850 соединений, многие из которых представляют собой активные ароматические молекулы (Flament I. (2002) Coffee Flavor Chemistry, John Wiley and Sons, UK). Однако некоторые из ароматических молекул, обнаруженных в чашке готового кофе, присутствуют в сырье, т.е. в сырых зернах (зеленых бобах) растений видов Coffea arabica или Coffea canephora (robustd). Фактически большинство ароматических соединений кофе генерируется в процессе одной или более многочисленных стадий обработки, начиная со сбора зрелых красных плодов кофейного дерева и кончая готовым продуктом из обжаренных молотых зерен кофе или экстрактами из них, например, растворимым кофе.
Различные стадии производства кофе описаны Smith A.W., in Coffee; Volume 1: Chemistry, pp.1-41, dark R.J. and Macrea R. Eds. Elsevier Applied Science, London and New York, 1985; Clarke R.J., in Coffee: Botany, Biochemistry, and Production of Beans and Beverage, pp.230-250 and pp.375-393; and Clifford M.N. and Willson K.C., Eds. Croom Helm Ltd., London. Если говорить кратко, то процесс начинается со сбора зрелых, выдержанных красных плодов (костянок) кофейного дерева. Затем может удаляться наружный слой, или перикарпий, с применением либо сухого, либо влажного способа. Сухой способ является наиболее простым и включает: 1) классификацию и мойку плодов, 2) сушку плодов после классификации (либо естественной воздушной сушкой, либо механическим способом) и 3) шелушение высушенных плодов с целью удаления сухого перикарпия. Влажный способ является несколько более сложным и обычно приводит к производству высококачественных зеленых бобов. Влажный способ чаще ассоциируется с плодами С. arabica. Влажный способ включает (1) классификацию плодов кофейного дерева, (2) удаление плодовой мякоти (пульпы), эта стадия проводится сразу после сбора плодов и обычно включает механическое удаление "пульпы", или перикарпия, из зрелых плодов, (3) "ферментацию", т.е. удаление слизи, остающейся на зернах плодов после удаления мякоти, путем инкубации их вместе с оставшейся слизью водой в танках в периодическом режиме (процесс "ферментации" может продолжаться в течение до 80 часов, хотя зачастую 24 часов бывает вполне достаточно для достижения приемлемой ферментации и снижения рН примерно с 6,8-6,9 до 4,2-4,6 под действием различной ферментной активности и метаболическим действием микроорганизмов, рост которых происходит в процессе ферментации), (4) сушку (эта стадия включает либо воздушную, либо механическую сушку нагретым воздухом ферментированного кофейного зерна) и (5) "лущение", эта стадия включает механическое удаление "пергаментной оболочки" с высушенного кофейного зерна (с так называемого высушенного кофейного зерна с пергаментной оболочкой); на этой стадии часто удаляется также и серебристая семенная оболочка. Полученное после влажной или сухой обработки сырое кофейное зерно зачастую подвергают сортировке, при этом большинство процессов сортировки основано на сортировке по размерам и/или форме зерна.
Следующая стадия обработки кофе - обжарка сырого кофейного зерна после шелушения или лущения обработанного сухим или влажным способом кофе, соответственно. Этот процесс зависит от времени и индуцирует значительные химические изменения в зерне. В первой фазе обжарки происходит выпаривание оставшейся в зерне воды за счет подачи теплоты. После испарения основной массы воды начинается собственно обжарка, когда температура повышается до 190-200°С. Степень обжарки, которая обычно регулируется по изменению цвета кофейного зерна, играет важную роль в формировании ароматических характеристик готового кофейного напитка. Поэтому время и температура обжарки строго контролируются в целях достижения требуемого ароматического профиля кофе. После обжарки проводят помол кофе с тем, чтобы облегчить экстракцию в процессе производства кофейного напитка или кофейных экстрактов (последние используются для производства быстрорастворимых кофейных продуктов). Вид помола также может влиять на конечный аромат напитка.
В то время как по проблеме идентификации ароматических молекул в кофе проводилось значительное число научных исследований, вопросам изучения физических и химических реакций, происходящих внутри кофейных зерен на каждой из стадий их обработки, посвящено намного меньше исследовательских работ. В большей степени это относится к обжарке, в ходе которой большое количество компонентов зерен подвергается чрезвычайно сложной серии индуцируемых нагревом реакций (Homma S. 2001, in "Coffee: Recent Developments", R.J. dark and O.G. Vitzthum, Eds. Blackwell Science, London; Yeretzian C., et al. (2002) Eur. Food Res. Technol. 214, 92-104; Flament I. (2002) Coffee Flavor Chemistry, John Wiley and Sons, UK; Reineccius G.A., "The Maillard Reaction and Coffee Flavor", Conference Proceedings of ASIC, 16th Colloque, Kyoto, Japan 1995).
Хотя подробности большинства реакций, происходящих на различных стадиях обработки кофе, остаются относительно не изученными, предполагается, что наиболее важной, генерирующей аромат реакцией, ответственной за многие оттенки, связанные с ароматом кофе, является реакция Майяра (Maillard reaction) в ходе обжарки кофе. Интенсивная реакция Майяра происходит между содержащимися в кофейном зерне продуктами распада сахаров/полисахаридов и содержащими аминогруппу молекулами (в частности, белками, пептидами и аминокислотами) в процессе обжарки.
Очевидно, что реакция Майяра вносит важный вклад в формирование кофейного аромата и образование ароматических молекул в процессе обжарки кофе, постольку существует взаимосвязь между уровнем первичных реагентов-участников реакции Майяра в сыром кофейном зерне и качеством аромата, формирующегося после обжарки.
Как отмечалось выше, важной группой субстратов в реакции Майяра являются аминокислоты, пептиды и белки. С использованием двумерного (2-D) электрофореза было показано, что существуют различия в уровнях и количествах основных запасных белков в сыром (необжаренном) кофейном зерне между сортами арабика (arabica) и робуста (robusta), однако взаимосвязи между указанными различиями в содержании запасных белков и качеством аромата установить не удалось (Rogers et al., 1999, Plant Physiol. Biochem. Vol.37, 261-272). В последнее время было обнаружено, что небольшие различия существуют и между запасными белками незрелых и зрелых кофейных зерен, обладающих различным качеством аромата (Montavon Р. et al., 2003, J. Agric. and Food Chemistry Vol.51, 2328-2334). Поскольку в процессе созревания зерен происходит много изменений, в этой последней работе высказывается предположение о возможном существовании связи между улучшением качества, вызываемым созреванием зерен, и различиями в миграции основных запасных белков кофейных зерен в 2-D геле.
В последнее время было установлено, что существуют различия и в профилях пептидов, выделенных из сырых кофейных зерен сортов арабика и робуста (Ludwig et al., 2000, Eur. Food Res. Technol., Vol.211, 111-116). Хотя результаты указанных авторов показали, что пептидные экстракты из арабики и робусты различаются профилем предшественников аромата, данные, представленные в их работе, не идентифицируют, какой компонент (компоненты) в экстрактах является/являются ответственными за указанные различия в профилях предшественников аромата. Эти ученые обнаружили также, по меньшей мере, две различные протеазные активности в неочищенных экстрактах из сырого (необжаренного) кофейного зерна, которые, однако, не коррелировали ни с какой специфической активностью, связанной с качеством аромата (Ludwig et al., 2000, Eur. Food Res. Technol., Vol.211, 111-116). И, наконец, также выдвинуто предположение о том, что очень высокие температуры на поздних стадиях обжарки сырого кофейного зерна вызывают значительный распад белков, присутствующих в кофейном зерне (Homma S. 2001, в "Coffee: Recent Developments". R.J. dark and O.G. Vitzthum, Eds. Blackwell Science, London; Montavon, P., et al., 2003, "Changes in green coffee protein profiles during roasting = Изменения белковых профилей сырого кофейного зерна в процессе его обжарки", J. Agric. Food Chem. 51, 2335-2343). Однако общая схема этого распада белков очень плохо изучена, но предположительно она зависит, помимо прочего, от определенного состояния основных белков кофе в сырье до начала обжарки. Насколько известно авторам настоящей заявки, других значительных публикаций о возможном участии пептидного профиля кофе в формировании аромата кофе не имеется.
В процессе обжарки ферментированных семян Theobroma cacao (какао-бобов), как предполагается, содержащиеся в семенах аминокислоты и пептиды вовлекаются в формирование аромата с помощью реакции Майяра. В сравнении с семенами других растений, семена Т. cacao обладают, как было показано, необычайно высоким уровнем специфичной к аспарагиновой кислоте протеазной активности (Biehl В., Voigt J., Voigt G., Heinrichs H., Senyuk V. and Bytof G. (1994) "pH dependent enzymatic formation of oligopeptides and amino acids, the aroma precursors in raw cocoa beans = рН-зависимое ферментативное образование олигопептидов и аминокислот - предшественников аромата в сырых какао-бобах"; в The Proceedings of the 11th International Cocoa Research Conference, 18-24 July 1993, Yamoussoukro, Ivory Coast). Для получения какао-бобов с высоким уровнем предшественников аромата какао необходимо проводить стадию естественной ферментации (при обжарке неферментированных какао-бобов формируется очень слабый аромат). Во время этой стадии ферментации сахара плодовой мякоти ферментируются, генерируя высокий уровень кислот, в частности, уксусной кислоты (Carr J.G. (1982) Cocoa. В Fermented Foods. Economic Microbiology. Vol.7, pages 275-292, A.H. Rose ed., Academic Press). По мере продолжения ферментации рН в семенах снижается, и клеточные структуры разрушаются. Низкий рН инициирует мобилизацию и/или активацию специфичной к аспарагиновой кислоте протеазы, содержащейся в большом количестве в семенах какао, что приводит к массовому распаду клеточного белка (Biehl В., Passem D. and Sagemann W. (1982) "Effect of Acetic Acid on Subcellular Structures of Cocoa Bean Cotyledons = Влияние уксусной кислоты на субклеточные структуры семядолей какао-бобов". J. Sci. Food Agric. 33, 1101-1109; Biehl В., Brunner E., Passem D., Quesnel V.C. and Adomako D. (1985) "Acidification, proteolysis and flavour potential in fermenting cocoa beans = Подкисление, протеолиз и ароматический потенциал в ферментированных какао-бобах". J. Sci. Food Agric. 36, 583-598). Пептиды и аминокислоты, как было показано, являются предшественниками аромата какао (Rohan Т., 1964, "The precursors of chocolate aroma: a comparative study of fermented and unfermented cocoa beans = Предшественники шоколадного аромата: сравнительное исследование ферментированных и неферментированных какао-бобов". J. Food Sci., 29, 456-459; Voigt J. and Biehl В., 1995, "Precursors of the cocoa specific aroma components are derived from the vicilin-class (7S) globulin of the cocoa seeds by proteolytic processing = Предшественники компонентов специфического аромата какао образуются из глобулина класса викилина (7S) какао-бобов путем протеолиза". Bot. Acta, 108, 283-289). Таким образом, специфичная к аспарагиновой кислоте протеаза семян Т. cacao вместе с содержащейся в семенах серин-карбоксипептидазой являются, как предполагается, критическими для образования предшественников аромата какао в процессе ферментации (Voigt J. and Biehl В., 1995, "Precursors of the cocoa specific aroma components are derived from the vicilin-class (7S) globulin of the cocoa seeds by proteolytic processing". Bot. Acta 108, 283-289; Voigt J., Heinrichs H., Voigt G. and Biehl В., 1994, "Cocoa-specific aroma precursors are generated by proteolytic digestion of the vicilin-like globulin of cocoa seeds = Предшественники специфического аромата какао образуются в результате протеолиза глобулина класса викилина (7S) какао-бобов". Food Chemistry, 50, 177-184). Идентифицирован ген, кодирующий специфичную к аспарагиновой кислоте протеазу, содержащуюся в большом количестве в семенах какао, а совсем недавно в опубликованной заявке на Международный патент №02/04617, включенной в полном объеме в перечень ссылок к настоящей заявке, описан метод сверхэкспрессии указанного белка в семенах какао, который может генерировать повышенный уровень аминокислот и пептидов -предшественников аромата какао в ферментированных какао-бобах. Однако содержание опубликованной заявки на Международный патент №02/04617 направлено на семена какао, которые подвергаются специфической длительной стадии кислотной ферментации, в отличие от кофейных зерен, которые не подвергаются такой ферментации.
Важной цистеинпротеазой (СР, cysteine proteinase) вакуолей является KDEL-содержащая цистеинпротеаза. Этот тип протеазы был охарактеризован в нескольких растениях. В последнее время были обнаружены три гена, кодирующие цистеинпротеазы с С-концевыми KDEL последовательностями в arabidopsis (Gietl С. and Schmid M., 2001, Naturwissenschaften, 88, 49-58). Один экспрессируется в стареющих семяпочках, второй - в сосудах, а третий - в зрелых стручках. Однако более подробные исследования этого белка были проведены в других растениях. Например, СР, называемая сульфгидрильной эндопротеазой (SH-EP), была охарактеризована в семядолях семян Vigna mungo (Toyooka К., Okamoto Т. and Minamikawa Т., 2000, J. Cell Biol. 148, 453-463). SH-EP экспрессируется de novo в прорастающих семядолях V. mungo', предполагается, что она вовлекается в распад запасных белков, аккумулированных в запасающих белки вакуолях (Okamoto Т. and Minamikawa Т. J. Plant Physiol. 152, 675-682). Ключевым отличием SH-EP полипептида является то, что он обладает специфической СООН-концевой последовательностью KDEL, которая управляет транспортом этого белка из эндоплазматического ретикулума (ER) в запасающие белки вакуоли (Toyooka et al., 2000). В последнее время выдвинуто также предположение о том, что SH-EP белок действительно вовлекается, благодаря наличию в нем KDEL последовательности, в образование специфических везикул, называемых KV (KDEL Vesicles), в ранее не описанной в литературе везикулярной транспортной системе (Okamoto Т., Shimada Т., Hara-Nishimura I., Nishimura M. and Minamikawa Т., 2003, Plant Physiology, 132, 1892-1900).
Аналогичное предположение было сделано и в отношении KDEL-содержащего СР белка, обнаруженного в прорастающих семядолях касторового боба (Ricinus communis). В этом растении, как подразумевают авторы, указанная KDEL-содержащая протеаза в рамках запрограммированной гибели клеток (алоптоза) эндосперма продолжает поставлять питательные вещества для прорастающего зародыша касторового боба (Gietl С. and Schmid M., 2001, Naturwissenschaften, 88, 49-58). Указанные авторы предполагают, что в касторовом бобе KDEL протеаза образуется в ER прорастающих семян до наступления 3-их суток. Когда семенная оболочка сбрасывается, примерно на 3 сутки, KDEL-содержащий СР оказывается упакованным в специфическую везикулу, называемую рициносомой. Позднее, когда эндосперм становится мягким (между 4 и 5 сутками), от KDEL-CP отщепляется прикрепившаяся последовательность (KDEL), и эта протеаза мигрирует в цитоплазму, где она участвует в основном распаде клеточного белка.
Раскрытие изобретения
Целью настоящего изобретения является модификация пула белковых/пептидных/аминокислотных предшественников аромата в кофе.
Если говорить более конкретно, то целью настоящего изобретения является модификация уровня предшественников аромата в сырье (сыром кофейном зерне) таким образом, чтобы в процессе последующей послеуборочной обработки и обжарки мог достигаться измененный аромат. Не останавливаясь на теории, авторы заявки выдвинули предположение, что, если между сортами кофе с совершенно разным ароматом существуют различия в уровне пептидов и распада белка, то эти различия скорей всего обусловлены разной эндогенной протеазной активностью в указанных сортах кофейного зерна. Эти различия могут быть обнаружены по различию в уровне экспрессии мРНК при экспрессии определенных генов протеазы кофейного зерна.
Таким образом, настоящее изобретение включает идентификацию последовательностей генов, кодирующих специфичные протеазы кофейного зерна (семян), и доказательство того, что различия в экспрессии этих генов в арабике и робусте существуют на самом деле.
Если говорить более конкретно, то настоящее изобретение раскрывает две основные цистеинпротеазы кофе (СсСР-1 и СсСР-4), четыре ингибитора основных цистеинпротеаз кофе (CcCPI-1, CcCPI-2, CcCPI-3 и CcCPI-4) и две специфичные к аспарагиновой кислоте протеазы кофе (СсАР-1 и СсАР-2), все из которых экспрессируются в кофейном зерне. Авторы заявки показывают, как сверхэкспрессия этих белков, особенно на поздней стадии развития зерна, или пониженная экспрессия указанных белков, особенно на поздней стадии развития зерна, может изменить аминокислотный/пептидный/белковый профиль зрелого зерна. Используя одну или более раскрытых последовательностей и генных конструкций для изменения аминокислотного/пептидного/белкового профиля зрелых кофейных зерен, авторы заявки открыли новый способ изменения профиля предшественников аромата в зрелом кофейном зерне.
В первом аспекте настоящее изобретение обеспечивает изолированный полинуклеотид, содержащий нуклеотидную последовательность, кодирующую полипептид, обладающий цистеинпротеазной активностью, в котором аминокислотная последовательность полипептида и аминокислотная последовательность, выбираемая из SEQ ID No 2 или 16, идентичны, по меньшей мере, на 70%, предпочтительно, по меньшей мере, на 80%, при этом идентичность последовательностей основывается на методе выравнивания ClustalW; или комплемент нуклеотидной последовательности, в которой комплемент содержит такое же число нуклеотидов, что и нуклеотидная последовательность, и комплемент и нуклеотидная последовательности являются на 100% комплементарными. Предпочтительно аминокислотная последовательность полипептида и аминокислотная последовательность SEQ ID No 2 или 16 идентичны, по меньшей мере, на 85%, более предпочтительно, по меньшей мере, на 90% и необязательно, по меньшей мере, на 95%, при этом идентичность последовательностей основывается на методе выравнивания ClustalW. Предпочтительно нуклеотидная последовательность содержит нуклеотидную последовательность SEQ ID No 1 или 15. Предпочтительно полипептид содержит аминокислотную последовательность SEQ ID No 2 или 16.
Во втором аспекте обеспечивается изолированный полинуклеотид, содержащий нуклеотидную последовательность, кодирующую полипептид, обладающий активностью ингибитора цистеинпротеазы, в котором аминокислотная последовательность полипептида и аминокислотная последовательность, выбираемая из SEQ ID No 4, 10, 12 и 14, идентичны, по меньшей мере, на 70%, предпочтительно, по меньшей мере, на 80%, при этом идентичность последовательностей основывается с помощью метода выравнивания ClustalW; или комплемент нуклеотидной последовательности, в котором комплемент содержит такое же число нуклеотидов, что и нуклеотидная последовательность, и комплемент и нуклеотидная последовательность являются на 100% комплементарными. Предпочтительно аминокислотная последовательность полипептида и аминокислотная последовательность SEQ ID No 4, 10, 12 и 14 идентичны, по меньшей мере, на 85%, предпочтительно, по меньшей мере, на 90% и необязательно, по меньшей мере, на 95%, при этом идентичность последовательностей основывается на методе выравнивания ClustalW. Предпочтительно нуклеотидная последовательность содержит нуклеотидную последовательность, выбираемую из SEQ ID No 3, 9, 11 или 13, необязательно из SEQ ID No 9, 11 или 13, также необязательно из SEQ ID No 9 или 13, либо, что тоже необязательно, из SEQ ID No 9. Предпочтительно полипептид содержит аминокислотную последовательность, выбираемую из SEQ ID No 4, 10, 12 и 14, необязательно из SEQ ID No 10, 12 и 14, также необязательно из SEQ ID No 10 или 14, либо, что тоже необязательно, из SEQ ID No 10.
В третьем аспекте обеспечивается изолированный полинуклеотид, содержащий нуклеотидную последовательность, кодирующую полипептид, обладающий специфичной к аспарагиновой кислоте эндопротеазной активностью, в котором аминокислотная последовательность полипептида и аминокислотная последовательность, выбираемая из SEQ ID No 6 или 8, предпочтительно из SEQ ID No 8, идентичны, по меньшей мере, на 75%, предпочтительно, по меньшей мере, на 80%, при этом идентичность последовательностей основывается на методе выравнивания ClustalW; или комплемент нуклеотидной последовательности, в котором комплемент содержит такое же число нуклеотидов, что и нуклеотидная последовательность, и комплемент и нуклеотидная последовательность являются на 100% комплементарными. Предпочтительно аминокислотная последовательность полипептида и аминокислотная последовательность, выбираемая из SEQ ID No 6 или 8, предпочтительно из SEQ ID No 8, идентичны, по меньшей мере, на 85%, предпочтительно, по меньшей мере, на 90% и, необязательно, по меньшей мере, на 95%, при этом идентичность последовательностей основывается на методе выравнивания ClustalW. Предпочтительно нуклеотидная последовательность содержит нуклеотидную последовательность SEQ ID No 5 или 7, предпочтительно SEQ ID No 7. Предпочтительно полипептид содержит аминокислотную последовательность SEQ ID No 6 или 8, предпочтительно SEQ ID No 8.
В следующем аспекте обеспечивается вектор, содержащий полинуклеотид согласно любому из предшествующих (с первого по третий) аспектов изобретения.
В следующем аспекте обеспечивается конструкция чужеродной рекомбинантной ДНК, содержащая полинуклеотид согласно любому из предшествующих (с первого по третий) аспектов изобретения, оперативно связанный с регуляторной последовательностью. Важно, чтобы в чужеродной конструкции либо полинуклеотид был чужеродным, либо регуляторная последовательность была чужеродной, либо оба они были чужеродными.
В следующем аспекте обеспечивается метод трансформации клетки, предусматривающий трансформацию клетки полинуклеотидом согласно любому из предшествующих (с первого по третий) аспектов настоящего изобретения.
В следующем аспекте обеспечивается клетка, содержащая вышеупомянутую конструкцию чужеродной рекомбинантной ДНК, в которой клетка предпочтительно является прокариотической клеткой, эукариотической клеткой или растительной клеткой, предпочтительно клеткой кофейного дерева.
В следующем аспекте обеспечивается трансгенное растение, содержащее такую трансформированную клетку.
В контексте настоящего описания термин "плод кофейного дерева" (coffee cherry) обозначает костянку (плод) кофейного дерева; целый плод; экзокарпий (кожица); перикарпий (мясистый основной наружный слой плода); кофейное зерно. Более подробное разъяснение указанного термина см. Clarke R.J., Coffee: Botany,Biochemistry, and Production of Beans and Beverage, pp.230, Clifford M.N. and Willson K.C. eds, Croom Helm Ltd., London (указанный источник в полном объеме включен в перечень ссылок к настоящей заявке).
Изобретение можно лучше понять из нижеследующего подробного описания и сопровождающего его Перечня последовательностей, который является частью настоящей заявки.
В приведенной ниже таблице 1 перечислены описанные в настоящем изобретении полипептиды вместе с идентификатором соответствующих последовательностей (SEQ ID No).
В перечне последовательностей однобуквенные коды обозначают нуклеотидные последовательности, а трехбуквенные коды обозначают аминокислоты, как они определяются в стандартах IUPAC-IUBMB и как они описываются в Nucleic Acids Research 13: 3021-3030 (1985), которая включена в перечень ссылок к настоящей заявке.
Краткое описание чертежей.
Фигура 1 показывает нозерн-блот анализ гена цистеинпротеазы в различных тканях Coffea arabica, в котором дорожки в геле обозначены следующим образом: R -корневище; S - стебель; L - молодые листочки; SG, LG, Y и Red - зерно из мелких зеленых плодов, крупных зеленых плодов, желтых плодов и красных плодов, соответственно. Загрузка суммарной РНК в каждую дорожку геля составила пять микрограммов. MW обозначает маркерную "лесницу" размеров РНК. Панель В представляет собой авторадиограмму через 24 часа экспозиции, показывающую появление СсСР-1 мРНК в исследуемых тканях, а панель А показывает гель, окрашенный бромистым этидием перед блоттингом.
Фигура 2 показывает нозерн-блот анализ экспрессии гена СсСР-1 цистеинпротеазы в различных тканях Coffea arabica, в котором дорожки в геле обозначены следующим образом: R - корневище; S - стебель; L - молодые листочки; F - цветки; SG(g), LG(g), Y(g) и Red(g) соответствуют РНК, выделенной из зерна мелких зеленых, крупных зеленых, желтых и красных плодов, соответственно, а дорожки в геле, обозначенные SG(p), LG(p), Y(p) и Red(p), соответствуют РНК, выделенной из ткани перикарпия мелких зеленых, крупных зеленых, желтых и красных плодов, соответственно. Загрузка суммарной РНК в каждую дорожку геля составила пять микрограммов. Панель А показывает окрашенные бромистым этидием большие субъединицы рибосомальной РНК перед блоттингом, которые являются контролем загрузки, а панель В представляет собой авторадиограмму, показывающую появление СсСР-1 мРНК в специфических исследуемых тканях.
Фигура 2А: Выравнивание полноразмерной последовательности белка, кодируемого СсСР-1 кДНК, по отношению к другим полноразмерным цистеинпротеазам из базы данных NCBI. Оно выполнялось с использованием программы CLUSTAL из пакета программ MegAlign (DNASTAR). Зачерненные блоки показывают идентичные аминокислоты. Номера доступа в базу данных EMBL указываются в круглых скобках: Arabidopsis thaliana (AY070063); Vicia sativa (Z99172); Glycine max. GMCP3 (Z32795); Glycine max GmPM33 (AF 167986); Phaseolus vulgaris Moldavain (Z99955); Solanum melongena (AF082181); Nicotiana tabacum (AJ242994); Lycopersicon esculentum (Z14028); Vicia faba (АY161277).
Фигура 3 показывает нозерн-блот анализ гена ингибитора цистеинпротеазы (CcCPI-1) в различных тканях Coffea arabica, в котором дорожки в геле обозначены следующим образом: R - корневище; S - стебель; L - молодые листочки; SG, LG, Y и Red - зерно из мелких зеленых плодов, крупных зеленых плодов, желтых плодов и красных плодов, соответственно. Загрузка суммарной РНК в каждую дорожку геля составила пять микрограммов. MW обозначает маркерную "лесницу" размеров РНК. Панель В представляет собой авторадиограмму через 24 часа экспозиции, а панель А показывает гель, окрашенный бромистым этидием перед блоттингом.
Фигура 4 показывает нозерн-блот анализ гена ингибитора цистеинпротеазы (CcCPI-1) на различных стадиях развития плодов Coffea arabica (ARA) и Coffea robusta (ROB). Дорожки вгеле обозначены следующим образом: мелкий зеленый плод (SG), крупный зеленый плод (LG), желтый плод (Y) и красный плод (Red), соответственно. Загрузка суммарной РНК в каждую дорожку геля составила пять микрограммов. MW обозначает маркерную "лесницу" размеров РНК. Панель В представляет собой авторадиограмму через 24 часа экспозиции, показывающую появление CcCPI-1 мРНК в специфических исследуемых тканях. Панель А показывает гель, окрашенный бромистым этидием перед блоттингом.
Фигура 5 показывает анализ методом полимеразной цепной реакции с матрицы кДНК, полученной с мРНК с помощью реакции обратной транскрипции (так называемый метод RT-PCR) экспрессии гена СсСР-1 в процессе прорастания зерна Coffea arabica. Полимеразную цепную реакцию (ПЦР) проводили с использованием 10 мкл каждой реакционной смеси для получения кДНК, разбавленной в соотношении 1/100. Режимы циклов ПЦР: 2 мин при 94°С и затем 35 циклов: 94°С и 61°С в течение 1,5 мин, 72°С в течение 2,5 мин. Стадия конечной достройки цепей продолжалась 7 мин при 72°С. Используемые ПЦР праймеры:
A4-43-Верхний: 5'-ACCGAGGAGGAGTTTGAGGCTACG-3'
А4-43-нижний: 5'-АСССТТСССССАТСАСТТСТТСА-3'.
мРНК амплифицировали методом RT-PCR с использованием специфичных праймеров (СсСР-1 верхний/СсСР-1 нижний) на различных матрицах: кДНК из стерилизованного зерна (Т0) и зерен, отобранных спустя 2 суток (2d), 3 суток (3d), 5 суток (5d), 1 месяц (1m) и 2 месяца (2m) прорастания, соответственно. ПЦР продукты разделяли в 1% (масса/объем) агарозном геле и окрашивали бромистым этидием. RPL39: амплифицированный фрагмент кДНК, кодирующий белок L39 большой субъединицы рибосом 60S.
Фигура 6 показывает вестерн-блот анализ экспрессии белка СсСР-1 (А). Общий белок экстрагировали из зерен (g) и перикарпия (р), отобранных из развивающихся плодов кофейного дерева на стадиях мелких зеленых (SG), крупных зеленых (LG), желтых (Y) и красных (Red) плодов. Панель В: Разделение 50 мкг общего белка в 12% SDS-PAGE геле и окрашивание "кумасси голубым". Панель А: Обнаружение белка проводили с использованием анти-CКР4 поликлональных антител (кролика), как описывается в методах. Приблизительный размер окрашенных полос в панели В указан стрелками слева. Большая стрелка внутри каждой панели указывает на присутствие основного запасного белка, который участвует в перекрестной реакции связывания с одним из антител.
Фигура 6А показывает оптимальное выравнивание полноразмерного белка, кодируемого CcCPI-1 кДНК, по отношению к другим гомологичным полноразмерным цистеинпротеазам из базы данных NCBI. Зачерненные блоки показывают идентичные аминокислоты. Номера доступа в базу данных EMBL и процент идентичности приводятся в круглых скобках. Malus x domestica (AAО18638; идентичность 42,3%), Common sunflower (JE0308; идентичность 41,5%), Arabidopsis thaliana (AAM64985; идентичность 30%) и Rumex obtusifolius (CAD21441; идентичность 29,3%).
Фигура 7 показывает RT-PCR анализ экспрессии гена CcCPI-1 в различных тканях Coffea arabica CCCA2 (А) и Coffea robusta FRT-32 (В). ПЦР проводили с использованием 10 мкл каждой смеси с полученной кДНК, разбавленной в соотношении 1/1000. Режимы циклов: 2 мин при 94°С и затем 40 циклов: 94°С, 1 мин - 60°С, 1,5 мин - 72°С, 1 мин. Стадия конечной достройки цепей продолжалась 7 мин при 72°С. Используемые ПЦР праймеры:
CcCPI-1 (верхний): 5'-AGGAAAGTGGGAGCAAGGGAGAAGA-3'
CcCPI-1 (нижний): 5'-TAGTATGAACCCAAGGCCGAACCAC-3'.
Дорожки в геле обозначены следующим образом: М - маркеры; +Р - разбавленная плазмида, содержащая ген CcCPI-1; R - корневище; S - стебель; L - молодые листочки; F - цветки. SGg, LGg, Yg и Rg - зерно, выбранное из мелких зеленых, крупных зеленых, желтых и красных плодов, соответственно. SGp, LGp, Yp и Rp - ткань перикарпия, изолированная из мелких зеленых, крупных зеленых, желтых и красных плодов, соответственно.
Фигура 8 показывает оптимальное выравнивание полноразмерного белка, кодируемого CcCPI-2 кДНК, по отношению к другим гомологичным полноразмерным цистеинпротеазам из базы данных NCBI. Зачерненные блоки показывают идентичные аминокислоты. Номера доступа в базу данных EMBL и процент идентичности приводятся в круглых скобках. Rumex obtusifolius (CAD21441; идентичность 66,7%), Dianthus caryophyllus (AAK30004; идентичность 71,7%), Manihot esculenta (AAF72202; идентичность 65,2%).
Фигура 9 показывает RT-PCR анализ экспрессии гена CcCPI-2 в различных тканях Coffea arabica CCCA2 (А) и Coffea robusta FRT-32 (В). ПЦР проводили с использованием 10 мкл каждой смеси для получения кДНК, разбавленной в соотношении 1/1000. Режимы циклов: 2 мин при 94°С и 40 циклов: 94°С, 1 мин - 57°С, 1,5 мин. - 72°С, 1 мин. Стадия конечной достройки цепей продолжалась 7 мин при 72°С. Используемые ПЦР праймеры:
CcCPI-2 (верхний): 5'-GTGAAGCCATGGTTGAACTT-3'
CcCPI-2 (нижний): 5'-GTAATGATACTCAAGCCAGA-3'.
Дорожки в геле обозначены следующим образом: М - маркеры; +Р - разбавленная плазмида, содержащая ген CcCPI-2; R - корневище; S - стебель; L - молодые листочки; F - цветки. SGg, LGg, Yg и Rg - зерно, выбранное из мелких зеленых, крупных зеленых, желтых и красных плодов, соответственно. SGp, LGp, Yp и Rp - ткань перикарпия, изолированная из мелких зеленых, крупных зеленых, желтых и красных плодов, соответственно.
Фигура 10 показывает оптимальное выравнивание полноразмерного белка, кодируемого CcCPI-3 кДНК, по отношению к другим гомологичным полноразмерным цистеинпротеазам из базы данных NCBI. Зачерненные блоки показывают идентичные аминокислоты. Номера доступа в базу данных EMBL и процент идентичности приводятся в круглых скобках. Citrus x paradisi (AAG38521; идентичность 42,4%), Actinidia deliciosa (AAR92223; идентичность 44,4%) и Arabidopsis thaliana (AAM64661; идентичность 44%).
Фигура 11 показывает оптимальное выравнивание полноразмерного белка, кодируемого CcCPI-4 кДНК, по отношению к другим гомологичным полноразмерным цистеинпротеазам из базы данных NCBI. Зачерненные блоки показывают идентичные аминокислоты. Номера доступа в базу данных EMBL и процент идентичности даются в круглых скобках. Citrus x paradisi (AAG38521; идентичность 23,6%) и Arabidopsis thaliana (AAM64661; идентичность 20%).
Фигура 12 показывает RT-PCR анализ экспрессии гена CcCPI-4 в различных тканях Coffea arabica CCCA2 (А) и Coffea robusta FRT-32 (В). ПЦР проводили с использованием 10 мкл каждой смеси для получения кДНК, разбавленной в соотношении 1/100. Режимы циклов были следующие: 2 мин при 94°С и 40 циклов: 94°С, 1 мин - 60°С, 1,5 мин - 72°С, 1 мин. Стадия конечной достройки цепей продолжалась 7 мин. при 72°С. Используемые ПЦР праймеры:
CcCPI-4 (верхний): 5'-CTACGGTCGCAGCCAAATC-3'
CcCPI-4 (нижний): 5'-ACAACTGCACCTTCAATGTAC-3'.
Дорожки в геле обозначены следующим образом: М - маркеры; +Р - разбавленная плазмида, содержащая ген CcCPI-4; R - корневище; S - стебель; L - молодые листочки; F - цветы. SGg, LGg, Yg и Rg - зерно, выбранное из мелких зеленых, крупных зеленых, желтых и красных плодов, соответственно. SGp, LGp, Yp и Rp - ткань перикарпия, изолированная из мелких зеленых, крупных зеленых, желтых и красных плодов, соответственно.
Фигура 13 показывает нозерн-блот анализ гена специфичной к аспарагиновой кислоте протеазы 2 (СсАР2) в различных тканях Coffea arabica, в котором дорожки в геле обозначены следующим образом: R - корневище; S - стебель; L - молодые листочки; F -цветки; SG (G) и (Р), LG (G) и (Р), Y (G) и (Р) и Red (G) и (Р) - соответственно зерно и перикарпий мелких зеленых, крупных зеленых, желтых и красных плодов; SG (G), LG (G), Y (G) и R (G) - перикарпий мелких зеленых, крупных зеленых, желтых и красных плодов кофейного дерева. В каждую дорожку геля загружали по пять микрограммов суммарной РНК. Панель А показывает в качестве контроля загрузки окрашенную бромистым этидием большую рибосомальную РНК перед блоттингом, а панель В представляет собой авторадиограмму, показывающую появление СсАР2 мРНК в специфических исследуемых тканях.
Фигура 14 показывает последовательность кДНК и предсказанную по ней аминокислотную последовательность СсСР-4. Строчные буквы: 5' и 3' нетранслируемые области гена. Прописные буквы: открытая рамка считывания. Жирный шрифт: аминокислотная последовательность; * - терминирующий трансляцию кодон (стоп-кодон).
Фигура 15 показывает выравнивание полноразмерной последовательности белка, кодируемого СсСР-4 кДНК, по отношению к другим полноразмерным цистеинпротеазам из базы данных NCBI. Оно выполнялось с использованием программы CLUSTAL W из пакета программ MegAlign (пакет Lasergene, DNASTAR). Зачерненные блоки показывают идентичные аминокислоты. Номера доступа даются в круглых скобках: Dacus carrota (JC7787); Ricinus communis (AF050756); Vicia sativa (Z34895); Phaseolus vulgaris (X56753); Helianthus annuus (AB109188); Glycine max Cysl (AB092555); Glycine max Cys2 (AB092557); Canavalia ensiformis (P49046); Oryza sativa (AB004648); Vigna mungo (PI 2412); Pisum sativum (AJ004985).
Фигура 16 показывает выравнивание полноразмерной кДНК последовательности СсСР-4 (KDDL) и неполной кДНК последовательности СсСР-4 (KDEL) с использованием программы ClustalW в пакете программ MegAlign.
Фигура 17 показывает выравнивание полноразмерной открытой рамки считывания СсСР-4 (KDDL) и неполной открытой рамки считывания СсСР-4 (KDEL) с использованием программы ClustalW в пакете программ MegAlign.
Фигура 18 показывает хроматограммы определения последовательностей ДНК в амплифицированной методом ПЦР геномной ДНК, кодирующей KDEL/KDDL область гена СсСР-4. "Rob" обозначает сорт робуста, "Arab" - сорт арабика.
Фигура 19 показывает нозерн-блот анализ экспрессии гена цистеинпротеазы СсСР-4 в различных тканях Coffea arabica. Дорожки в геле обозначены следующим образом: R - корневище; S - стебель; L - молодые листочки; F - цветки; SG(g), LG(g), Y(g) и Red(g) - зерно, выбранное из мелких зеленых, крупных зеленых, желтых и красных плодов, соответственно. SG(p), LG(p), Y(p) и Red(p) - ткань перикарпия, изолированная из мелких зеленых, крупных зеленых, желтых и красных плодов кофейного дерева, соответственно. В каждую дорожку геля загружали по пять микрограммов суммарной РНК. Панель А показывает в качестве контроля загрузки окрашенную бромистьм этидием большую субъединицу рибосомальной РНК перед блоттингом, а панель В представляет собой авторадиограмму, показывающую появление СсСР-3 мРНК в специфических исследуемых тканях.
Фигура 20 показывает RT-PCR анализ экспрессии СсСР-4 в цельном зерне в процессе прорастания. Образцы отбирали спустя 0 суток, т.е. сразу после обработки стерилизацией, 2D - 2 суток после обработки, 3D - 3 суток после обработки, 5D - 5 суток после обработки, 1М - один месяц после обработки, 2М - два месяца после обработки, "-" - контроль без ДНК; +Р - разведенная ДНК плазмиды СсСР-4; М - маркеры молекулярной массы.
Фигура 21 показывает оптимальное выравнивание полноразмерного белка, кодируемого СсАР-1 кДНК, по отношению к другим гомологичным полноразмерным последовательностями специфичных к аспарагиновой кислоте протеаз из базы данных NCBI. Зачерненные блоки показывают идентичные аминокислоты. Номера доступа в базу данных указываются в круглых скобках. Arabidopsis thaliana (AY099617) и Arabidopsis thaliana (BAB09366).
Фигура 22 показывает оптимальное выравнивание полноразмерного белка, кодируемого кДНК СсАР-2, по отношению к другим гомологичным полноразмерным последовательностями специфичных к аспарагиновой кислоте протеаз из базы данных NCBI. Зачерненные блоки показывают идентичные аминокислоты. Номера доступа в базу данных указываются в круглых скобках: Glycine max (BAB64296), Ipomoea batatas (ААК48494), Lycopersicon esculentum (S71591) и Nepenthes alata (BAB20972).
Осуществление изобретения.
Принятая терминология.
В контексте описания термин "полинуклеотид" обозначает нуклеотидную последовательность, например, фрагмент нуклеиновой кислоты. Полинуклеотид может быть полимером РНК или ДНК, т.е. одно- или двунитевым, который необязательно содержит синтетические, неприродные или измененные основания нуклеотидов. Полинуклеотид в форме полимера ДНК может содержать один или более сегментов кДНК, геномной ДНК, синтетической ДНК или их смеси.
Сходные фрагменты нуклеиновых кислот характеризуются в настоящем изобретении процентом идентичности кодируемых ими аминокислотных последовательностей с раскрываемыми здесь аминокислотными последовательностями, определяемым алгоритмами, традиционно используемыми квалифицированными специалистами в данной области. Пригодные для данной цели фрагменты нуклеиновых кислот (или выделенные полинуклеотиды согласно аспектам с первого по третий настоящего изобретения) кодируют полипептиды, которые идентичны, по меньшей мере, на 70%, предпочтительно, по меньшей мере, на 80%, аминокислотным последовательностям, раскрываемым в настоящем описании. Предпочтительные фрагменты нуклеиновых кислот кодируют аминокислотные последовательности, которые идентичны, по меньшей мере, на 85% аминокислотным последовательностям, раскрываемым в настоящем описании. Более предпочтительные фрагменты нуклеиновых кислот кодируют аминокислотные последовательности, которые идентичны, по меньшей мере, на 90% аминокислотным последовательностям, раскрываемым в настоящем описании. Еще более предпочтительными являются фрагменты нуклеиновых кислот, которые кодируют аминокислотные последовательности, которые, по меньшей мере, на 95% идентичны аминокислотным последовательностям, раскрываемым в настоящем описании. Множественное выравнивание последовательностей должно осуществляться с применением метода выравнивания ClustalW (Thompson et al., 1994, Nucleic Acids Research, Vol.22, p.4673-4680; Higgins & Sharp, 1989, Cabios. 5: 151-153).
В контексте описания термин "сходные фрагменты нуклеиновых кислот" обозначает полинуклеотидные последовательности, в которых изменения в одном или более оснований нуклеотидов приводят к замене одной или более аминокислот, но при этом указанные изменения либо не влияют на функцию полипептида, кодируемого нуклеотидной последовательностью, либо не влияют на способность фрагмента нуклеиновой кислоты служить посредником для сайленсинга ("замолкания") экспрессии гена с применением, например, антисмысловой технологии или технологии коэкспрессии. Термин "сходные фрагменты нуклеиновых кислот" относится также к модифицированным полинуклеотидным последовательностям, в которых одно или более оснований нуклеотидов делегируется (делегируются) или встраивается (встраиваются) при условии, что модификации либо не влияют на функцию полипептида, кодируемого нуклеотидной последовательностью, либо не влияют на способность фрагмента нуклеиновой кислоты служить посредником для сайленсинга экспрессии гена. Отсюда можно видеть, что масштаб настоящего изобретения выходит за рамки полинуклеотидных и полипептидных последовательностей, раскрываемых в описании.
Сходные фрагменты нуклеиновых кислот могут отбираться скринингом фрагментов нуклеиновых кислот в форме субфрагментов или модифицированных фрагментов нуклеиновых кислот по их способности влиять на уровень полипептида, кодируемого немодифицированными фрагментами нуклеиновых кислот в растении или растительной клетке.
Термин "оперативно связанный" определяет связывание двух или более фрагментов нуклеиновой кислоты в один фрагмент нуклеиновой кислоты таким образом, чтобы функция одного из них влияла на функцию другого.
Термин "регуляторные последовательности" относится к нуклеотидным последовательностям, локализованным перед, внутри или после кодирующей последовательности, которые влияют на транскрипцию, процессинг или стабильность РНК, либо на трансляцию кодирующей последовательности, связанной с ними. Регуляторные последовательности могут включать промоторы, лидерные последовательности трансляции, интроны, терминаторы транскрипции и последовательности распознавания полиаденилирования. Если регуляторная последовательность в форме промотора оперативно связана с кодирующей последовательностью, то такая регуляторная последовательность способна влиять на экспрессию кодирующей последовательности. Кодирующие последовательности могут быть оперативно связаны с регуляторными последовательностями в смысловой или антисмысловой ориентации.
Термин "экспрессия" относится к транскрипции (и стабильному накоплению) смысловой РНК (мРНК) или антисмысловой РНК, выделенной из фрагментов нуклеиновых кислот настоящего изобретения. Экспрессия может также относиться к трансляции мРНК в полипептид. "Сверхэкспрессия" относится к такому продуцированию генного продукта в трансгенной клетке, которое превышает уровень продуцирования в нормальных, или нетрансформированных, клетках. Термин "измененные уровни" относится к продуцированию генного продукта (продуктов) в трансгенной клетке в количествах или соотношениях, которые отличаются от его (их) количества или соотношения в нормальных, или нетрансформированных, клетках.
Термин "трансформация" относится к переносу фрагмента нуклеиновой кислоты в геном клетки-хозяина, приводящему к генетически стабильной наследственности. Клетки-хозяева, содержащие трансформированные фрагменты нуклеиновых кислот, обозначаются в контексте описания как "трансгенные клетки".
Стандартная рекомбинантная ДНК и методы молекулярного клонирования, применяемые в настоящем изобретении, хорошо известны из уровня техники и очень подробно описаны в книге Sambrook et al. "Molecular Cloning: A Laboratory Manual"; Cold Spring Harbor Laboratory Press: Cold Spring Harbor, 1989, которая включена в перечень ссылок к настоящей заявке.
Примеры
Нижеследующие примеры служат иллюстрацией изобретения и не ограничивают масштаба изобретения. В примерах количество в частях и процентах указывается в мас.частях и % мас., градусы - в градусах Цельсия, если нет ссылки на другую размерность.
В нижеприведенных примерах используются следующие аббревиатуры:
ПЦР: полимеразная цепная реакция (PCR, polymerase chain reaction);
RACE: скоростная амплификация концов кДНК (rapid amplification cDNA ends);
RT-PCR: ПЦР с предварительным получением кДНК с матрицы РНК за счет реакции обратной транскрипции (reverse transcriptase PCR).
Из вышеприведенного обсуждения и нижеприведенных примеров квалифицированные специалисты в данной области могут оценить существенные отличия настоящего изобретения и, не выходя за пределы изобретения, могут вносить различные изменения и модификации с целью адаптации его в случае необходимости к различным областям применения и условиям.
Получение библиотек кДНК и скрининг кДНК
Получение специфической РНК из кофейного зерна
Кофейные плоды сорта Robusta Q 121 собирали спустя 30 WAF (недель после цветения) в ICCRI, Индонезия. Затем из собранных плодов удаляли перикарпий, а оставшийся материал - перисперм/эндосперм - замораживали и измельчали в порошок в жидком азоте. РНК экстрагировали из замороженного порошкообразного материала с помощью метода, описанного ранее для экстракции РНК из какао-бобов (Guilloteau M. et al., 2003, "Oil bodies in Theobroma cacao seeds: cloning and characterisation of cDNA encoding the 15.8 and 16.9 kDa oleosins". Plant Science, Vol.164, 597-606). Поли А+ РНК готовили примерно из 250 мкг суммарной РНК с использованием готового набора реактивов "PolyA Purist™" kit AMBION (фирма-изготовитель Ambion, Inc.) в соответствии с инструкцией к указанному набору.
Получение первой серии клонов кДНК из кофейного зерна.
Примерно 50-100 нг указанной поли А+ РНК использовали для синтеза первой цепи кДНК с применением готового препарата обратной транскриптазы "Superscript™ II RNase Н- (GIBCOBRL™) и готового набора реактивов для синтеза кДНК "SMART™ PCR cDNA synthesis" (Clontech). Готовили реакционную смесь, содержащую 2 мкл 30 WAF поли А РНК, 1 мкл CDS oligo ("SMART™ PCR cDNA kit", Clontech), 1 мкл Smart II oligo ("SMART™ PCR cDNA kit", Clontech) и 8 мкл деионизованной Н20. Полученную смесь прогревали при 72°С в течение 5 минут, а затем помещали на лед. После этого добавляли следующее: 1 мкл 10 мМ смеси дезокситринуклеотидов (dNTP), 4 мкл SuperScriptII™ буфера для 1-й цепи и 2 мкл дитиотреитола (DTT). Эту смесь выдерживали при 42°С в течение 2 минут, после чего добавляли 1 мкл готового препарата обратной транскриптазы "SuperScriptII™ RNaseH" reverse transcriptase" (200 единиц/мкл, GIBCO BRL™) и инкубировали смесь в термостате с циркуляцией воздуха при 42°С в течение 50 минут.
После реакции обратной транскрипции проводили ПЦР. 98 мкл Master Mix, описанной в "SMART™ PCR cDNA kit" (Clontech), содержащей полимеразу Advantage™2 (готовый набор "Advantage™ 2 PCR kit", ClonTech), помещали на лед, а затем добавляли 3 мкл описанной выше реакционной смеси для синтеза 1-й цепи кДНК. Эти 100 мкл смеси для ПЦР помещали в аппарат "MJ Research РТС-150" (НВ), в котором поддерживались следующие условия ПЦР: 95°С в течение 1 мин, затем 16 циклов: 95°С, 15 секунд - 65°С, 30 секунд - 68°С, 6 минут. Амплифицированную ДНК очищали с использованием готового набора "Strataprep™ PCR Purification Kit" (Stratagene) в соответствии с инструкцией поставщика. ДНК элюировали 50 мкл деионизованной воды, а затем ДНК "заглаживали" (polished, в данном случае, это процесс "затупления" концов ДНК) с использованием Pfu-1 полимеразных реагентов, содержавшихся в готовом наборе "PCR-Script™ Amp cloning kit" (Stratagene) в следующей смеси: 50 мкл ДНК, 5 мкл 10 мМ смеси dNTP, 6,5 мкл 10 × Pfu-1 "polished" буфера, 5 мкл клонированной Pfu-1 ДНК полимеразы (0,5 ед./мкл). Эту реакционную смесь инкубировали при 72°С в течение 30 минут в ПНР-аппарате с обогреваемой крышкой (Perkin Elmer). Пользуясь методикой, описанной в инструкции к готовому набору реактивов "pPCR-Script™ Amp kit" (Stratagene), затупленные ПЦР продукты лигировали с гидролизованным Srf-1 вектором pPCR-Script™ Amp SK(+) в присутствии Srf-1 фермента, а продукты реакции лигирования трансформировали в "XL-10 Gold™ Kan" ультракомпетентные клетки Е.coli. Отбор клонов, трансформированных плазмидами, содержащими вставки, проводили с использованием LB-Amp чашек Петри, a IPTG и Xgal распределяли по поверхности, как указано в инструкции к готовому набору реактивов "pPCR-Script™ Amp kit". Отбирали колонии белого цвета и обозначали их как клоны Davl-1 и т.д.
Получение второй серии клонов кДНКиз кофейного зерна с отобранной по размеру кДНК.
Зерна сильно экспрессируют небольшое количество белков, таких как запасные белки зерен (White et al., 2000, Plant Physiology, Vol. 124, 1582-1594). Если кДНК получают из такой ткани, то очень высокий уровень запасных белков и других специфических белков зерен приводит к высокому уровню "избыточности" кодирующих их кДНК, т.е. популяция получаемой кДНК содержит высокие относительные количества одной и той же кДНК. Для снижения избыточности кДНК, полученной из мРНК кофейного зерна, и селективной характеризации протяженных и слабо экспрессируемых кДНК применяли также стратегию клонирования второй кДНК. Продукты описанной выше реакции с обратной транскриптазой использовали в качестве матрицы для последующий ПЦР с применением готового набора реактивов "Advantage™ 2 PCR" (ClonTech): 3 мкл реакционной смеси обратной транскриптазы, 5 мкл 10 х Advantage™ 2 ПЦР буфера, 1 мкл смеси dNTP (по 10 мМ каждого дезокситрифосфата), 2 мкл ПЦР праймера (готовый набор "SMART™ PCR cDNA kit", ClonTech), 39 мкл деионизованной воды и 1 мкл 50 × Advantage™ 2 полимеразной смеси. Полученную ПЦР смесь помещали в аппарат "MJ ResearchPTC-150" (НВ), где поддерживались следующие режимы ПЦР: 95°С в течение 1 минуты, а затем 16 циклов: 95°С, 15 секунд - 65°С, 30 секунд - б8°С, 6 минут. В конце ПЦР добавляли 1 мкл 10% SDS в гель-загрузочном буфере, образец нагревали до 37°С в течение 10 минут. Затем образец делили на части для загрузки в 0,7% агарозный гель без бромистого этидия: 10% загружали в небольшую лунку рядом с лункой маркерной ДНК, а остальные 90% загружали в соседнюю, большую препаративную лунку. После электрофореза участок геля с маркерами размера плюс 10% реакционного образца окрашивали бромистьм этидием. Этот окрашенный участок геля использовали затем в качестве маркера для вырезания тонких слоев геля, содержащих амплифицированную ПЦР кДНК различных размеров, из остальной неокрашенной (препаративной) части геля. Получили шесть тонких слоев геля, имеющие указанный диапазон размеров ПЦР фрагментов: А1А (0,8-1 kb), A1B (1-1,5 kb), A2 (1,5-2,25 kb), A3 (2,25-3,25 kb), A4 (3,25-4 kb) и А5 (4-6,5 kb).
ДНК из каждого слоя элюировали из агарозы с использованием готового набора "QIAEX II kit" от фирмы Qiagen согласно инструкциям поставщика (образцы 3А, 4А и 5А нагревали в течение 10 минут при 50°С, а образцы 1А, 1В и 2 А нагревали в течение 10 минут при комнатной температуре). Очищенную двунитевую кДНК амплифицировали повторно, используя ПЦР с TAQ ферментной смесью, которая позволяет получить фрагменты с 3' Т выступом, следующим образом: 30 мкл выделенной из геля двунитевой кДНК, 5 мкл 10 × TAQ буфера (поставляемого вместе с полимеразной смесью "TAQ PLUS precision polymerase mix", Stratagene), 1 мкл 40 мМ смеси dNTP (no 10 мМ каждого), 2 мкл ПЦР праймера (готовый набор "SMART™ PCR cDNA", Clontech), 0,5 мкл полимеразной смеси "TAQ PLUS precision polymerase mix" (Stratagene) и 11,5 мкл деионизованной воды. Режимы ПЦР: 95°С в течение 1 минуты, затем 7 циклов: 95°С, 15 секунд - 65°С, 1 минута - 72°С, 8 минут, а затем 1 цикл: 95°С, 15 секунд - 65°С, 1 минута- 72°С, 10 минут.
Полученную амплифицированную ДНК затем лигировали в вектор pCR™-TOPO™ и клонировали в ТОР10 клетки Е.coli с использованием готового набора "ТОРО™ ТА kit" (Invitrogen) согласно инструкции поставщика. Клоны называли в порядке их выделения и позиционирования в размерном геле (например, А2-1, А2-2 и т.д.).
Скрининг и предварительная идентификация кДНК из кофейное зерна.
Первую серию белых колоний, полученной в библиотеке Dav-1, подвергали скринингу с целью определения сначала размера каждой вставки путем амплификации ПЦР вставки, используя праймеры Т3 и Т7, примыкающие к участку клонирования, и проверки амплифицированных ПЦР фрагментов гель-электрофорезом.
Каждую колонию белого цвета ресуспендировали в 200 мкл стерильной воды, к 10-30 мкл полученной суспензии добавляли 5 мкл 10Х Taq polymerase буфера (Stratagene), I мкл 10 мМ смеси dNTP, 2,5 мкл 20 мкМ праймера Т3, 2,5 мкл 20 мкМ праймера Т7, 1 мкл диметилсульфоксида (DMSO), 0,5 мкл Taq полимеразы (Stratagene) и НзО до конечного объема 50 мкл. Использовали следующую программу ПЦР: 94°С в течение 1 мин, затем 30 циклов: 94°С, 1 мин - 55°С, 1,5 мин - 72°С, 3,5 мин, и заключительный цикл - 7 мин при 72°С. Для снижения уровня "избыточности", ПЦР вставки одинакового размера подвергали гидролизу рестриктазой Пае III. ПЦР фрагменты с одним и тем же образцом фрагментов Нае III рестрикции далее не изучались. Плазмиды клонов с ПЦР фрагментами >500 п.н. и имеющие уникальные образцы фрагментов Нае III рестрикции очищали с использованием готового набора "Qiawall 8 ultra plasmid kit" (Qiagen) для дидезокси-секвенирования с 5'-конца с помощью соответствующих праймеров секвенирования Т7 или Т3, кодируемых во фланкирующих вставку последовательностях вектора. Так как вставки напрямую не клонировались, то сначала необходимо было определить 5'-конец каждого клона путем гидролиза очищенной плазмидной ДНК рестриктазой Seal (праймер CDS SMART содержит Sea 1 сайт, что позволяет определить ориентацию вставки в векторе). Полученные данные о последовательности ДНК впоследствии использовали для поиска гомологичных белков в лишенной повторов базе данных GENEBANK с целью получения предварительной аннотации кДНК каждого клона с применением программы BLASTX™.
Банки кДНК из зерен характеризуются высоким уровнем повторов. То есть небольшое число мРНК из зерен обладает необычайно высоким уровнем экспрессии, например, те из них, которые кодируют запасные белки зерна, и поэтому их кДНК в большом изобилии содержатся в банках кДНК из зерен (White et al., 2000, Plant Physiology, Vol.124, 1582-1594). Поэтому, как только в первой серии секвенирования кДНК из кофейных зерен были идентифицированы основные изобилующие (повторяющиеся) кДНК, так сразу понадобилось введение стадии предварительного скрининга вставок, содержащих колонии белого цвета, еще до определения размера вставок. Четыре последовательности ДНК экспрессировались очень сильно и для каждой из этих изобилующих последовательностей были сконструированы следующие специфичные праймеры:
1) белок 2S, контиг 8А 5'-AGCAACTGCAGCAAGGTGGAG-3' и контиг 8В 5'-CGATTTGGCACTGCTGTGGTTC-3' (55°C для ПЦР, фрагмент 114 п.н.),
2) белок 2S, контиг 15А 5'-GCCCGTGCTCCTGAACCA-3' и контиг 15В 5'-GTATGGTTGCGGTGGCTGAA-3' (55°C для ПЦР, фрагмент 256 п.н.),
3) олеозин 15,5, контиг ЗОА 5'-ACCCCGCTTTTCGTTAT-3' и контиг 30В 5'-TCTGGCTACATCTTGAGTTCT-3' (55°C для ПЦР, фрагмент 261 п.н.),
4) белок 11S, контиг 37А 5'-GTTTCCAGACCGCCATCAG-3' и контиг 37В 5'-АТАТССАТССТСТТССААСАСС-3' (59°С для ПЦР, фрагмент 261 п.н.).
ПЦР для этой стадии предварительного скрининга проводили в следующих условиях: 10-30 мкл колоний белого цвета в стерильной Н3О, 5 мкл 10 х Taq буфера (Stratagene), 1 мкл 10 мМ dNTP, 2,5 мкл каждого праймера (20 мкМ), 1 мкл DMSO, 0,5 мкл Taq полимеразы (Stratagene 10 ед./мкл), стерильную НзО добавляли до конечного общего объема реакционной смеси 50 мкл. Программа ПЦР предусматривала 1 мин при 94°С, затем 30 циклов: 94°С, 1 мин - 1,5 мин при специфической температуре для каждой пары праймеров - 72°С, 2,5 мин, в последним цикле - 7 мин при 72°С.
Секвенирование вставки полноразмерной кДНК и анализ последовательности
Клоны кДНК, чьи неполные последовательности показали начальную гомологию с протеазами и ингибиторами протеаз, были полностью секвенированы по обеим цепям с применением стратегии "прогулки" стандартными дидезокси праймерами. Последовательности представлены как SEQ ID Nos. 1, 3, 5, 7, 9, 11, 13 и 15. Для подтверждения предварительной аннотации проводили поиск последовательностей, гомологичных полученым полноразмерным последовательностями, с использованием BLASTX и базы данных GenBank, исключающей повторы белков.
Идентичность последовательностей в парах последовательностей рассчитывали с помощью программы ClustalW™ в модуле MegAlign™ пакета программ Lasergene™ (DNASTAR Inc.). Были выбраны следующие параметры по умолчанию: (1. ПАРАМЕТРЫ МНОЖЕСТВЕННОГО ВЫРАВНИВАНИЯ - Gap penalty (ограничение промежутка) 15,00; Gap length penalty (ограничение длины промежутка) 6,66; Delay divergent Seqs (расходящиеся с задержкой последовательностисти) (%) 30; DNA transition weight (варьирование массы ДНК) 0,5; Protein Weight Matrix (взвешанная матрица белка) - Gonnet Series; DNA Weight Matrix (взвешенная матрица ДНК) - ШВ. 2- ПАРАМЕТРЫ ПАРНОГО ВЫРАВНИВАНИЯ - Slow/Accurate (Медленно/Точно) (Gap penalty - 15,00;
Gap length penalty - 6,66; Protein Weight Matrix - Gonnet Series; DNA Weight Matrix - IUB). Используемые последовательности представляли собой либо полноразмерную нуклеотидную последовательность каждой кДНК, либо полную ORF (open reading frame, открытую рамку считывания) каждой кДНК.
Процент идентичности между последовательностями нуклеиновых кислот и аминокислот генов СсСР-1, CcCPI-1, CcAP-1 и СсАР-2 и родственных генов, обнаруженных в банке данных GenBank, исключающем повтор белков, а также белков из WO 02/04617.
5'RACE ПЦР.
Установлено, что вставка кДНК клона А5-812 содержит интроны. Поэтому для подтверждения кодирующей этот белок последовательности необходимо было выделить новую кДНК, содержащую полноразмерную кодирующую последовательность. Это было сделано с использованием готового набора реактивов для амплификации кДНК "SMART™ RACE cDNA amplification Kit" (Clontech). Первую цепь кДНК, используемую для 5' RACE, получали, как описано выше для создания кДНК библиотек. Был сконструирован специфичный праймер к гену rАР2 (5'-CATATAATATTAAAAGCACCACCCATAA-3') - эта последовательность локализуется на расстоянии 92 п.н. от поли (А) "хвоста" клона А5-812. Впоследствии этот специфичный праймер использовали со смесью универсальных праймеров (UPM) из набора CLONTECH в ПЦР при следующих условиях: 2,5 мкл продукта первой цепи кДНК, 5 мкл 10Х Advantage 2 ПЦР буфера (CLONTECH), 1 мкл смеси dNTP (10 мМ), 1 мкл 50Х Advantage 2 полимеразной смеси (CLONTECH), 5 мкл "смеси универсальных праймеров А" (10Х) (CLONTECH), 1 мкл rАР2 (10 мкМ) с добавлением стерильной воды до конечного объема 50 мкл. ПЦР проводили в следующем режиме: 20 циклов - 94°С, 30 сек - 68°С, 30 сек - 72°С, 3 мин, с последующей заключительной реакцией достройки цепи в течение 5 мин при 72°С. Был получен фрагмент длиной примерно 1700 п.н., для извлечения которого из геля использовали готовый набор "CONCERT™ Rapid Gel Extraction kit" (GibcoBRL). Выделенный фрагмент клонировали в вектор pCR 4-TOPO и трансформировали в Escherichia coli с использованием готового набора для клонирования "Торо-ТА cloning kit" (Invitrogen). Полученную плазмиду очищали с использованием готового набора реактивов для экстракции плазмиды ("QIAfilter Plasmid Midi Kit", Qiagen, Франция) и вставку этой плазмиды секвенировали по двум цепям.
Установлено, что в ДНК клона А5-442 (AP1) полностью отсутствует 5' область кДНК. Для выделения этой области проводили 5'RACE с использованием готового набора для амплификации кДНК "SMART™ RACE cDNA amplification Kit" (Clontech). Был сконструирован специфичный к последовательности праймер rAPl (5'-TGGAGTCACAAGATGTCTCGACGAACTG-3'), размещенный на расстоянии 396 п.н. от поли (А) хвоста. Этот специфичный праймер использовали затем со смесью универсальных праймеров (UPM) из готового набора CLONTECH kit в ПЦР в следующих условиях: 2,5 мкл первой цепи кДНК, 5 мкл 10Х Advantage 2 ПЦР буфера (CLONTECH), 1 мкл смеси dNTP (10 мМ), 1 мкл 50Х Advantage 2 полимеразной смеси (CLONTECH), 5 мкл "смеси универсальных праймеров А" (10Х) (CLONTECH), 1 мкл rAPl с последующим добавлением стерильной воды до конечного объема 50 мкл. Режим циклов ПЦР: 20 циклов по 30 сек при 94°С, 30 сек при 68°С и 3 мин при 72°С с последующей реакцией конечной достройки цепи в течение 5 мин при 72°С. Получен фрагмент длиной около 2000 п.н., извлеченный из геля с использованием готового набора реактивов для быстрой экстракции из геля "CONCERT™ Rapid Gel Extraction kit" (GibcoBRL). Выделенный фрагмент клонировали в вектор pCR 4-TOPO и трансформировали в Escherichia coli с использованием готового набора для клонирования "Торо-ТА cloning kit" (Invitrogen). Полученную плазмиду затем очищали с использованием готового набора для экстракции плазмиды (QIAfilter Plasmid Midi Kit, Qiagen, Франция) и вставку этой плазмиды секвенировали по двум цепям.
Получение РНК для крупных EST библиотек.
РНК выделяли из рассеченного зерна и тканей перикарпия на разных стадиях развития и из молодых листочков с применением описанного ранее метода. Для получения РНК с целью создания различных EST библиотек (библиотек, содержащих экспрессирующиеся последовательности) использовали следующие сорта и ткани кофе: (1) молодые листочки, один сорт (FRT-32); (2) перикарпий (с 8 различных стадий развития) от 5 сортов (FRT-32, FRT-31, FRT-400, FRT-4001 и Q121); (3) целые плоды кофейного дерева спустя 22 недели после оплодотворения (WAF, weeks after fertilisation) от одного сорта (FRT-31); (4) кофейное зерно спустя 18+22 WAF от пяти сортов (FRT-32, FRT-31, FRT-400, FRT-4001 и Q121); (5) кофейное зерно спустя 30 WAF от 5 сортов (FRT-32, FRT-31, FRT-400, FRT-4001 и Q121); (6) кофейное зерно спустя 42 WAF от пяти сортов (FRT-32, FRT-31, FRT-400, FRT-4001 и Q121) и (7) кофейное зерно спустя 46 WAF от 2 сортов (FRT-32 и Q121).
Получение клонов кДНК и анализ последовательности ДНК.
Клоны кДНК для различных EST библиотек получали следующим образом: поли А+ мРНК выделяли с использованием готового набора для выделения мРНК "PolyTrack™ mRNA Isolation System" (System TV, Promega) согласно инструкции изготовителя для мелкомасштабного выделения. Очищенную поли A+ мРНК использовали для получения кДНК, которую затем однонаправленно клонировали в векторе на основе фага лямбда, как описано в инструкции к готовому набору для создания библиотеки "ZAP-cDNA™ library construction kit" (кат.# 200450 Stratagene). Протокол массовой эксцизии (вырезание клонируемой ДНК из вектора) предусматривал эксцизию PBlueScript phagemid (плазмидный вектор, встроенный внутрь фага) из вектора Uni-Zap XR (фаговый вектор) и получение колоний белого цвета после посева на 150 мм чашки с LB-ампицилиновым агаром, к которому были добавлены 80 мкл X-gal (20 мг/мл) и 16 мкл IPTG (0,5 М). Единичные колонии отбирали произвольно для получения плазмидной ДНК, которую затем использовали для секвенирования 5'-концов вставок кДНК.
Полученные последовательности ДНК являются EST последовательностями (Expressed Seguence Tags=маркеры экспрессирующихся последовательностей) для каждого клона. Затем все данные по EST последовательностям из 7 библиотек сгруппировали "in-silico", создав тем самым уникальную группу последовательностей, названную набор последовательностей "унигенов" (unigene, уникальные гены). Таким образом, каждая последовательность унигена теоретически соответствует отдельному генетическому продукту. Однако следует заметить, что вследствие того, что многие унигены представляют собой лишь неполные последовательности кДНК, то вполне вероятно, что некоторые гены могут быть представлены двумя или более унигенами. Предварительную аннотацию набора унигенов проводили с помощью программы автоматического поиска BLAST, в которой поиск последовательности каждого унигена осуществляется в базе данных GenBank, исключающей повтор белков. Указанный BLAST подход к поиску позволил получить пять успешных BLAST "хитов" (hits, "выдачи" с наиболее низкими е-значениями), которые относились к "унигенной аннотации".
Нозерн-блот анализ.
Свежесобранные корневища, молодые листочки, стебель, цветки и плоды на различных стадиях развития [мелкие зеленые плоды (SG), крупные зеленые плоды (LG), желтые плоды (Y) и красные плоды (R)] отбирали от сортов Coffea arabica CCCA2, выращенных в условиях теплиц (25°С, относительная влажность, 0В, 70%) в Tours, Франция, и Coffea canephora FRT32, выращенных либо в Эквадоре, либо в ICCRI, Индонезия. Свежие ткани сразу же замораживали в жидком азоте и выделяли суммарную РНК из каждой ткани, используя методику экстракции, описанную выше. 5 мкг суммарной РНК наносили на 1,2% (масса/объем) денатурирующий РНК гель, содержащий формальдегид. Образцы суммарной РНК из каждой растительной ткани нагревали при 65°С в течение 15 мин в присутствии 7 мкл загружающего буфера для образцов РНК "RNA Sample Loading Buffer" (без бромистого этидия, Sigma), а затем сразу же помещали на лед на 2 минуты перед последующим нанесением РНК на 1,2% гель. К гелю подводили напряжение 60 вольт в течение 5 часов. Затем гель дважды вымачивали в 10xSSC в течение 20 мин. РНК из геля переносили в течение ночи за счет капиллярной диффузии на "Positive TM Membrane" (Qbiogene) в 10xSSC; РНК фиксировали на мембране нагреванием в течение 30 мин при 80°С. Зонды готовили с использованием набора "Rediprime™ II random prime labelling system kit" (Amersham) в присутствии (Р32) dCTP. Гибридизацию проводили при 65°С в течение 24 ч в растворе для гибридизации (5Х SSC, 40 мкг/мл денатурированной ДНК спермы лосося, 5% [масса/объем] SDS и 5х раствор Денхардта). Мембрану промывали дважды в течении 30 мин при 65°С с использованием 2Х SSC, 0,1% SDS (масса/объем) и IX SSC, 0,1% SDS (масса/объем).
Нозерн-блот анализ, представленный на фиг.1, показывает, что ген СсСР-1 цистеинпротеазы кофе экспрессируется в плодах кофе С. arabica на всех изучаемых стадиях, при этом в желтых плодах уровень экспрессии был несколько выше, чем на других стадиях. Не обнаружено экспрессии указанного гена в корневище, стебле или листьях С. arabica. На фиг.2 показан другой нозерн-блот эксперимент по контролю экспрессии СсСР-1 в С. arabica с использованием нового препарата РНК. В этом эксперименте плоды с четырех стадий рассекали для выделения тканей перикарпия и тканей зерен, соответствующих каждой стадии развития плодов. Затем из полученных тканей экстрагировали суммарную РНК. Полученные результаты показали такой же временной образец экспрессии СсСР-1 в ходе развития плодов, но этот новый эксперимент дополнительно показал высокий уровень первичной экспрессии СсСР-1 только в тканях зерен плодов. В перикарпии плодов кофейного дерева значительной экспрессии гена СсСР-1 не наблюдалось. Этот последний результат подчеркивает роль указанного генетического продукта в эксклюзивном изменении белкового, пептидного и аминокислотного профиля кофейного зерна при нормальных условиях выращивания.
Авторами заявки созданы EST библиотеки из листьев кофейного дерева, а также из тканей зерен и перикарпия, полученных на различных стадиях развития плодов кофейного дерева. Обнаружение EST СсСР-1 в различных библиотеках (показано ниже - см. табл. 3) также показывает, что указанный ген сильно экспрессируется в зерне, но не экспрессируется в значительной степени в перикарпии или в листьях. Образец экспрессии СсСР-1 в процессе формирования зерна сходен с характером экспрессии, наблюдаемом для возможно гомологичной с ней последовательностью из Vicia sativa (ген CPR4: Fischer, J. et al., 2000. Plant Molecular Biology, 43, 83-101). Эти авторы показали, что CPR4 не обнаруживается нозерн-блоттингом ни в листьях, ни в корневище или стебле, что еще раз подтверждает тот факт, что СсСР-1 является специфичным для кофейного зерна. Вряд ли можно ожидать, что изменения экспрессии СсСР-1, особенно в зерне, как предлагается здесь, за счет использования, например, специфичного для зерна промотора в антисмысловой конструкции СсСР-1 или сверхэкспрессирующейся конструкции СсСР-1 могут помешать метаболизму в других тканях.
Оптимальное выравнивание последовательностей в случае СсСР-1 (фиг.2А) показывает, что эта кДНК кодирует цистеинпротеазу.
Нозерн-блот анализ, представленный на фиг.3, показывает, что ген ингибитора цистеинпротеазы CcCPI-1 из кофе экспрессируется в плодах С. arabica на всех исследуемых стадиях. Однако в противоположность экспрессии, наблюдавшейся у цистеинпротеазы СсСР-1, ген CcCPI-1 показывает более высокий уровень экспрессии на двух ранних стадиях развития плодов кофе (на стадиях мелких зеленых и крупных зеленых плодов), а на двух более поздних стадиях формирования плодов указанный ген экспрессируется на более низком уровне. Такой характер экспрессии согласуется с существующей гипотезой о том, что белок ингибитора цистеинпротеазы (CcCPI-1) контролирует уровень активности цистеинпротеазы, которая специфически экспрессируется в зерне, тогда как СсСР-1 - в плодах кофейного дерева. Можно ожидать, что контролирующий белок, такой как белок ингибитора цистеинпротеазы, будет экспрессироваться раньше, чем его белок-мишень, когда необходимо контролировать уровень активности этого белка-мишени непрерывно, начиная со времени экспрессии белка-мишени. Не обнаружено экспрессии этого гена в корневище, стебле или листьях С. arabica. Примечательно, что сходство образцов экспрессии СсСР-1 и CcCPI-1 согласуется с существующей гипотезой о том, что эти белки могут, вероятно, функционально взаимодействовать.
Результаты нозерн-блоттинга (фиг.3) показали, что CcCPI-1 экспрессируется на всех стадиях в плодах кофейного дерева. Однако указанный эксперимент не позволил определить, происходит ли эта экспрессия в целых плодах или только в перикарпии либо зерне. Экспрессию в листьях также не удалось проконтролировать. Однако экспрессия CcCPI-1 в различных EST библиотеках (показано ниже в табл. 4) показывает, что этот ген экспрессируется главным образом только в зерне, в перикарпии или листьях экспрессии указанного гена не обнаружено. Этот результат также предполагает, что CcCPI-1 контролирует уровень активности цистеинпротеазы, которая специфически экспрессируется в зерне, например, СсСР-1.
Нозерн-блот анализ, представленный на фиг.4, показывает, что ген ингибитора цистеинпротеазы CcCPI-1 из кофе экспрессируется по-разному в плодах С. canephora (robusta) по сравнению с плодами С. arabica. Во-первых, данные фиг.4 показывают, что ген CcCPI-1 экспрессируется в С. arabica несколько раньше. Во-вторых, что более важно, ген CcCPI-1 экспрессируется в плодах С. canephora на значительно более высоком уровне. Это различие в экспрессии, вероятно, влияет на уровень активности цистеинпротеазы, обнаруженной в плодах С. arabica, по сравнению с плодами С. canephora. Поскольку этот класс белков тесно связан с устойчивостью растений к вредителям, вполне вероятно также, что высокий уровень экспрессии гена CcCPI-1 в С. canephora вносит свой вклад в повышенную устойчивость к заболеваниям, зачастую наблюдаемую у сортов "робуста" по сравнению с сортами "арабика".
RT-PCR анализ экспрессии СсСР-1 в процессе прорастания зерна.
Для определения экспрессии СсСР-1 в процессе прорастания кофейного зерна плоды кофейного дерева собирали на стадии полного вызревания, ополаскивали водой и удаляли из них перикарпий (каждый плод обычно содержит два зерна). Полученные зерна подсушивали в течение одной недели на открытом воздухе при комнатной температуре. Перед проращиванием с каждого зерна вручную удаляли пергаментную оболочку и серебристую семенную оболочку (эписпермий), затем зерна стерилизовали, опустив их в 1% (масса/объем) раствор гипохлорита натрия на 1 час, после чего дважды промывали стерильной дистиллированной водой. Для проращивания 150 стерильных зерен помещали по отдельности в пробирки, содержащие соли Хеллера (Heller, 1953) и 7 г/л агара, и инкубировали при 25°С ежедневно в условиях 8-часового светового дня.
Спустя 2 суток, 3 суток, 5 суток, 1 месяц и 2 месяца проращивания отбирали три партии по десять зерен в каждой, сразу же замораживали в жидком азоте и хранили при - 80°С до экстракции РНК. Из зерен, проращиваемых в течение 1 и 2 месяцев, в момент отбора образцов вырезали первичные (зародышевые) корешки и замораживали отдельно от зерен. Было отобрано тридцать стерильных зерен при Т=0 и заморожено для последующего использования в качестве Т(0) контроля.
4 мкг обработанной ДНК-азой суммарной РНК, экстрагированной из каждого образца, использовали для синтеза кДНК с применением гексамерных олигонуклеотидов согласно инструкции к готовому набору с обратной транскриптазой "Superscript II Reverse Transcriptase" (Invitrogen, Carlsbad, Ca). Фрагмент гена рибосомального белка кофе L39 амплифицировали в каждом образце кДНК в качестве контроля стадии синтеза кДНК. ПЦР проводили с использованием 50 мкл реакционных смесей, содержащих 10 мкл разбавленных в соотношении 1/100 растворов кДНК, 1 мкМ каждого праймера, 5 мкл 10Х ПЦР буфера ThermoPol [10 мМ (NH4)2SO4, 2мМ MgSO4, 20 мМ Трис-HCl с рН 8,8 при 25°С, 10 мМ КС1 и 0,1% Тритон Х-100] и 2,5 единицы Taq полимеразы (New England Biolabs, Beverly, MA). Режимы ПЦР: 2 мин при 94°С, с последующими 35 циклами: 94°С, 1 мин - 60°С, 1,5 мин - 72°С, 2,5 мин Конечная стадия достройки цепи - в течение 7 мин при 72°С. Следующие праймеры использовали для амплификации методом ПЦР:
СсСР-1 верхний 5'-ACCGAGGAGGAGTTTGAGGCTACG-3' и
СсСР-1 нижний 5'-ACGCTTCCCCCATGAGTTCTTGA-3',
обеспечивших выход продуктов кДНК 726 п.н.
Праймерами к белку Rpl39 были:
А5-1750-верхний 5'-TGGCGAAGAAGCAGAGGCAGA-3'
А5-1750-нижний 5'-TTGAGGGGGAGGGTAAAAAG-3'.
RT-PCR использовали для определения экспрессии СсСР-1 на различных стадиях проращивания. Полученные результаты показывают, что транскрипты СсСР-1 обнаруживаются в цельном зерне практически на всех исследуемых стадиях (фиг.5). Ранее было показано (Fischer, J. et aL, 2000, Plant Molecular Biology, 43, 83-101), что РНК предполагаемого гомолога СсСР-1 - CPR4 из V, sativa - также экспрессируется как в зародышевом главном стебле, так и в семядолях семян V. sativa в процессе прорастания.
Вестерн-блот анализ
Ткани листьев и плодов для анализа получали из Coffea arabica CCCA2, до анализа ткани хранили в замороженном виде при -80°С. Ткани зерна и перикарпия плодов кофейного дерева на различных стадиях их развития рассекали по отдельности с незначительным, насколько это было возможно, размораживанием перикарпия. Затем эти разные ткани быстро измельчали в тонкий порошок, какой только можно получить с использованием жидкого азота в предварительно замороженной лабораторной ступке с пестиком. Белковый экстракт из указанной ткани готовили по модифицированной версии методики экстракции, описанной Tanaka et al., 1986 (Plant Physiology, 81, 802-806). Использовали следующие буферы:
буфер Танака:
сахароза - 0,7 М
трис-HCl, рН 8 - 0,5 М
Р-меркаптоэтанол - 2% (об./об.)
NaCl - 0,1 M
Перед использованием вышеуказанного буфера добавляли:
ЭДТУ - до 5 мМ
PMSF - до 2 мМ
Буфер для загрузки в гель:
Глицерин - 15% (об./об.)
β-меркаптоэтанол - 2% (об./об.)
SDS - 3% (об./об.)
трис-HCl, рН 6,8 - 62,5 мМ.
Несколько сотен миллиграммов замороженных измельченных в порошок тканей добавляли к 650 мкл буфера Танака. Белки экстрагировали добавлением одного объема трис-насыщенного фенола, рН 8 (т.е. фенола, насыщенного раствором 10 мМ трис-HCl, рН 8). Каждый образец интенсивно перемешивали в течение 20 мин, а затем центрифугировали 20 мин при комнатной температуре при 13000g. После центрифугирования белки присутствуют в фенольной фазе. Образцы 20 мкл сохраняли для анализа (см. ниже), а остальное количество белков в фенольной фазе осаждали преципитацией в течение ночи при -20С с последующим добавлением пяти объемов метанола, содержащего 0,1 М ацетата аммония. После этого образцы центрифугировали 20 мин при комнатной температуре при 13000g, и полученные осадки промывали дважды в 500 мкл метанола, содержащего 0,1 М ацетата аммония. Затем осадки ресуспендировали в 30 мкл буфера для загрузки в гель до проведения количественной оценки белков.
Белок в 20 мкл образцах фенольной фазы также осаждали преципитацией, как описано выше, и полученный осадок ресуспендировали в буфере для образцов из готового набора для анализа белков "BioRad dc Protein assay Kit". Количественную оценку суммарного белка в этом образце проводили с использованием готового набора "BioRad dc Protein assay Kit" согласно инструкции поставщика. После этого все основные образцы доводили до 5 мкг/мкл добавлением буфера для загрузки в гель.
Образцы, содержащие примерно 50 мкг белка каждый, разделяли электрофорезом в SDS-полиакриламидном геле (12% трис-глицин, Novex® Invitrogen™). Затем белки переносили электро-блоттингом на PVDF мембрану по стандартной методике. Неспецифические участки связывания на мембране блокировали инкубацией мембраны в 10% растворе сухого обезжиренного молока в TBS буфере (BioRad™) в течение одного часа при комнатной температуре или в течение ночи при 4°С. Блоттированные белки были тестировали в течение двух часов при комнатной температуре или в течение ночи при 4°С с поликлональным антителом (разбавление 1/5000 е в 10% растворе сухого обезжиренного молока в TBS), наработанным для предполагаемого гомолога - CPR4 из Vicia sativa, которые были любезно предоставлены A.Schlereth и K.Muntz из Institut fur Pflanzengenetik und Kulturpflanzenforschung (IPK, Институт генетики и изучения культурных растений, Германия; A.Schlereth, C.Becker, C.Horstmann, J.Tiedmarm and K.Muntz 2000, Journal of Experimental Botany, 51: 1423-1433). Затем мембрану трижды промывали в течение 20 минут в TBS +0,1% Tween 20 буфере, после чего инкубировали в течение одного часа с вторым антителом, меченым пероксидазой хрена (Ig кролика против антигенов козы, Immunopure®, Pierce). Затем мембрану дважды промывали в течение 20 минут в TBS +0,1% Tween 20 буфере и один раз в течение 20 минут в TBS. Присутствие фермента, связанного со вторым антителом, визуализировали хемилюминесцентным обнаружением с использованием усиливающей системы ECL+® system (Amersham Life Science) согласно инструкций поставщика.
Полученные результаты показывают, что полипептид примерно 41 кДа, который точно соответствует предполагаемой молекулярной массе полипептида-предшественника СсСР-1 (43735 Да), обнаруживается на всех изучаемых стадиях созревания кофейного зерна, но только не в тканях перикарпия (фиг.6). Характер экспрессии этого белка схож с характером экспрессии мРНК СсСР-1 (фиг.2). Другой полипептид примерно 22 кДа также обнаруживается на стадиях желтых и красных плодов кофейного дерева, но в меньших количествах, чем полипептид 41 кДа. Размер этого второго полипептида совпадает с предполагаемым размером зрелой формы СсСР-1 (25239 Да). Предполагаемый размер зрелого СсСР-1 после процессинга определяли путем белкового выравнивания между полноразмерной последовательностью ORF СсСР-1 и последовательностью предсказанной зрелой формы CPR4 (Vicia sativa - №доступ # Z99172, идентичность с СсСР-1 = 60,9%). N-концевой сайт процессинга полипептида CRP4 при генерации зрелой формы был спрогнозирован на основе сравнения последовательности с другими полипептидами, типа CPR папаина (J. Fischer, С. Becker, S. Hillmer, С. Horstmann, В. Neubohn, A. Schlereth, V. Senyuk, A. Shutov and К. Muntz, 2000, Plant Molecular Biology, 43, 83-101). Интересно, что, в противоположность представленным здесь результатам, согласно которым в процессе формирования зерна обнаруживаются и предшественник, и зрелые формы СсСР-1, в развивающихся семенах, а также в процессе прорастания семян V. sativa была обнаружена только зрелая форма полипептида CPR4 (Fischer et al., 2000).
RT-PCR анализ экспрессии гена в сорте робуста FRT-32.
Изолировали различные ткани FRT-32 и суммарную РНК экстрагировали из этих тканей описанным ранее методом. кДНК получали из обработанной ДНК-азой суммарной РНК, как описывалось выше для RT-PCR экспериментов с кДНК арабики. Затем проводили специфичные ПЦР в условиях, описанных выше для RT-PCR экспериментов с кДНК арабики. Специфические условия амплификации и использованные праймеры к олигонуклеотидам приводятся в подписи к фигуре для каждого эксперимента.
CcCPI-1.
а) оптимальное выравнивание CcCPI-1 (фиг.6А), показывающее, что эта кДНК кодирует ингибитор цистеинпротеазы.
б) Данные RT-PCR по экпрессии CcCPI-1 (фиг.7) в арабике и робусте. ПЦР проводили, как описано ранее; режимы реакций и используемые ПЦР праймеры указаны в подписи к фигуре. Эти данные подтверждают и расширяют представленные ранее данные об экспрессии в арабике, которые показывают, что CcCPI-1 экспрессируется только в зерне, а не в перикарпии. Слабая экспрессия этого гена обнаружена также в цветках (результат, который не удалось определить нозерн-блот анализом). Методом RT-PCR определена также экспрессия в робусте (фиг.7). Образец этой экспрессии такой же, что и в арабике, за исключением того, что в цветках или на стадии мелких зеленых зерен никакой экспрессии не было обнаружено. Отсутствие экспрессии в робусте на стадии мелких зеленых зерен отмечалось также и в случае других генов, т.е. в этом плане ген CcCPI-1 не является уникальным.
Частота встречаемости генов ингибитора цистеинпротеаз CPI-2, CPI-3 и С в различных EST библиотеках.
CcCPI-2
а) оптимальное выравнивание CcCPI-2 (фиг.8), показывающее, что эта кДНК кодирует ингибитор цистеинпротеазы.
б) Данные RT-PCR по экпрессии CcCPI-2 (фиг.9) в арабике и робусте. ПЦР проводили, как описано выше; используемые ПЦР праймеры указаны в подписи к фигуре. Эти данные показывают, что CcCPI-2 экспрессируется во всех тканях, поэтому белковый продукт этого гена, вероятно, играет важную роль в контроле одной или более цистеинпротеаз, присутствующих в этих тканях. Количество ESTs каждой библиотеке, приведенное в табл. 5 (см. выше), позволяет предположить, что CPI-2 может экспрессироваться в зерне (семени) спустя 30 недель после оплодотворения в большей степени, чем в листьях, перикарпии или зерне спустя 46 недель после оплодотворения.
CcCPI-3
а) оптимальное выравнивание CcCPI-3 (фиг.10), показывающее, что эта кДНК кодирует ингибитор цистеинпротеазы.
б) Данных RT-PCR по экспрессии этого ингибитора цистеинпротеазы на сегодняшний день не имеется. Однако экспрессия этого гена "in silico", если судить по количеству ESTs в каждой библиотеке (табл. 5, см. выше), указывает на то, что CcCPI-3 экспрессируется в кофейном зерне (присутствует в библиотеках зерен "Зерна 30w" и "Зерна 46w", т.е. спустя 30 и 46 недель). Отсутствие ESTs указанного гена в перикарпии, листьях или целых плодах кофейного дерева позволяет предположить, что этот ген, вероятно, является специфичным для кофейного зерна геном.
CcCPI-4
а) Оптимальное выравнивание CcCPI-4 (фиг.11), показывающее, что эта кДНК кодирует ингибитор цистеинпротеазы.
б) Данные RT-PCR по экспрессии CcCPI-4 (фиг.12) в арабике и робусте. ПЦР проводили, как описано выше, используемые ПЦР праймеры указаны в подписи к фигуре. Полученные данные показывают, что указанный ген значительно экспрессируется в арабике в листьях, цветках и зерне на стадии красных плодов. Так как тщательный анализ исходного геля (панель А: арабика) показывает, что в случае мелких зеленых плодов и перикарпия крупных зеленых зерен в белковых полосах обнаруживаются также нечеткие пятна, то можно предположить, что указанный ген также может слабо экспрессироваться в арабике в зернах и перикарпии на всех изучаемых стадиях формирования плодов. Данные, полученные для робусты, показывают, что указанный ген значительно экспрессируется в листьях, цветках, мелких зеленых и крупных зеленых зернах. Только один EST для CcCPI-4 был обнаружен в библиотеках зерен или перикарпия (табл. 5, см. выше), что указывает на то, что экспрессия этого гена в зерне и/или перикарпии является относительно низкой или ограничивается небольшими определенными участками в указанных двух тканях.
В каждом случае генов ингибитора цистеинпротеазы (CPI) предполагается, что сверхэкспрессия или подавление экспрессии этих генов в процессе формирования зерен (т.е. под контролем очень сильного, специфичного для зерна, промотора, такого как промотор 11 S в кофе), будет изменять белковый, пептидный и аминокислотный профили в зрелых зернах (а также уровень предшественников аромата).
Прорастание зерен и RT-PCR анализ
Стерилизованное, высушенное кофейное зерно С. arabica CCCA2 (с удаленными пергаментной и серебристой семенной оболочками) помещали по одному в пробирки, содержащие 10 мл твердой питательной среды Хеллера HI 5 и 7 г/л агара, и инкубировали ежесуточно при 25°С в течение 8-часового светового дня. Спустя 2 суток, 3 суток, 5 суток, 1 месяц и 2 месяца проращивания отбирали по три зерна и удаляли из них первичный (зародышевый) корешок, если таковой имелся, а затем зерна и корешки сразу же замораживали в жидком азоте и хранили при -80°С до проведения экстракции РНК. Контролем служили таким же способом высушенные и стерилизованные, но не проросщие зерна (ТО). Экстракцию РНК из образцов зерен проводили, как описывалось ранее. Обработанную ДНК-азой суммарную РНК, экстрагированную из каждого образца, использовали для синтеза кДНК с использованием олиго-(с1Т)2о в качестве праймера в соответствии с инструкцией изготовителя к готовому набору обратной транскриптазы "Superscript II Reverse Transcriptase kit" (Invitrogen, Carlsbad, CA). Затем проводили ПНР с использованием аликвот каждой из реакционных смесей с кДНК. (50 мкл реакционных смесей содержали 10 мкл разбавленных в соотношении 1/10 растворов кДНК, 1 мкМ каждого праймера, 5 мкл 10Х ПЦР буфера ThermoPol, 200 мкМ dNTP и 2 единицы Taq полимеразы (New England Biolabs, Beverly, MA). Режимы циклов были следующими: 2 мин при 94°С, затем 40 циклов: 94°С, 1 мин - 54°С, 1,5 мин - 72°С, 2,5 мин. Конечная стадия достройки цепи продолжалась 7 мин при 72°С. ПЦР праймерами служили:
CP-4KDDL61: 5'-GAAGAACTCATGGGGAACAGGAT-3',
CP-4KDDL345: 5'-TTATTCAAACCATCACAGGAGGAG-3'
Геномная ПЦР и секвенирование ДНК очищенных ПЦР фрагментов.
Геномную ДНК пяти различных сортов кофе (FRT-07, FRT-19, FRT-32, CCCA2 и GPFA57) использовали в ПЦР, описанной выше в экспериментах по изучению экпрессии методом RT-PCR в проращиваемом зерне. Были получены ПЦР продукты предполагаемого размера, и эти фрагменты очищали из геля. Затем амплифицированную методом ПЦР ДНК подвергали второму раунду амплифицикации методом ПЦР и полученные в этой реакции последовательности ДНК секвенировали с использованием тех же праймеров, которые использовались для амплификации.
Выделение и характеристика гена цистеинпротеазы СсСР-4
С использованием коллекции ESTs, полученных с РНК, выделенных из кофейного зерна на различных стадиях его развития, ткани перикарпия на различных стадиях развития кофейного зерна и из листьев, авторам настоящей заявки удалось выделить полноразмерную кДНК, кодирующую цистеинпротеазу кофе, которая имеет С-концевую KDDL последовательность. Эту кДНК авторы назвали СсСР-4 (KDDL) (фиг.14). Выравнивание белка, кодируемого этой кДНК, с другими высокогомологичными цистеинпротеазами растений показано на фиг.15. Данные этого выравнивания и соответствующие поиски с помощью программы BLAST четко показывают, что белок, кодируемый последовательностью СсСР-4 (KDDL) кофе, является членом семейства растений KDEL, содержащего цистеинпротеазы (фиг.15). Прецизионная идентичность СсСР-4 (KDDL) и большинства гомологичных последовательностей из базы данных приводится в таблицах 6А и 6В.
Идентичность аминокислотной последовательности СсСР-4 (KDDL) цистеинпротеазы Coffea canephora аминокислотным последовательностям большинства гомологичных последовательностей из GenBank
Идентичность последовательности нуклеиновых кислот (кДНК) СсСР-4 (KDDL) цистеинпротеазы Coffea canephora последовательностям нуклеиновых кислот большинства гомологичных последовательностей из GenBank
Отсюда очевидно, что полученная последовательность СсСР-4 KDDL кофе имеет одно важное отличие от почти всех других последовательностей, показанных на фиг.15, а именно она не содержит предполагаемой последовательности, определяющей задержку (retention) белка в эндоплазматическом ретикулуме (ER) - С-концевую KDEL последовательность, а содержит только вариант этой последовательности - KDDL. На основе изучения способности вариантов С-концевой KDEL последовательности определять задержку белка в ER растительных клеток Denecke et al. (Denecke J., De Rycke R., Botterman J., 1992, EMBO J. 11, 2345-2355) ранее показали, что С-концевые варианты, такие как SDEL, KDDL, KDEI и KDEV, могут вызывать полную потерю функции задержки белка эндоплазматическим ретикулумом. Таким образом, присутствие последовательности KDDL в кофейном гомологе растительной KDEL цистеинпротеазы было полной неожиданностью. На табл. 7 показано, что униген, содержащий кДНК СсСР-4 (KDDL), имеет 21 ESTs. Поэтому авторы настоящей заявки изучили впоследствии последовательность других ESTs в этом унигене и установили, что семь из этих ESTs содержат положительные данные о последовательности KDDL участка. Из этих семи последовательностей кДНК шесть содержали KDDL последовательность, а одна - KDEL последовательность. Авторами заявки был выделен клон кДНК с С-концевой последовательностью KDEL и получена полноразмерная последовательность этого неполного клона кДНК. Полученные последовательности ДНК и белка показаны на фиг.16 и 17, соответственно.
Количество EST в унигене. содержащем полноразмерную кДНК СсСР-4 (KDDL)
кДНК, кодирующая последовательность СсСР-4 (KDEL), показанную на фиг.16, представляет собой только часть кДНК, т.е. только фрагмент длиной 817 п.н. против 1336 п.н. полноразмерной кДНК СсСР-4 (KDDL) клона. Неполная кДНК СсСР-4 (KDEL) содержит 8 однонуклеотидных замен по сравнению с эквивалентной последовательности, обнаруженной в кДНК клоне СсСР-4 (KDDL), хотя только две из этих нуклеотидных замен приводят к изменению аминокислотной последовательности открытой рамки считывания (фиг.17). В 3' нетранслируемой области имеются 3 четкие нуклеотидные замены. В дополнение к этому имеется также вставка из 12 нуклеотидов в 3' нетранслируемой области СсСР-4 (KDEL) кДНК последовательности, которая, вероятно, находится внутри микросателлитной области. Приведенные данные говорят о наличии двух различных и крайне важных молекулярных маркеров для двух аллелей гена СсСР-4 кофе, один из которых представляет собой SNP, ассоциированный с функционально важным KDEL участком, а второй является микросателлитным маркером, ассоциированным с 3' нетранслируемой областью указанного гена. Последний момент очень важен, поскольку микросателлитные последовательности обычно рассматриваются как генетические маркеры с высокой вариабельностью, и поэтому вполне вероятно, что, используя эту содержащую микросателлит область, можно обнаружить и другие аллели указанного гена.
С целью изучения распределения двух аллелей гена СсСР-4, идентифицированного выше в различных сортах арабики и робусты, небольшой участок геномной последовательности, укрывающей СсСР-4 ген, амплифицировали методом ПЦР из пяти различных генотипов. Из каждого образца геномной ДНК были получены ПЦР фрагменты предполагаемого размера (207 пар оснований); полученные ПЦР продукты очищали из геля, а затем повторно амплифицировали в целях получения достаточного количества ДНК для прямого секвенирования ДНК ПЦР продукта. Результаты, полученные в ходе реакций секвенирования, представлены на фиг.18. Хроматограммы секвенирования пяти последовательностей показывают, что два исследуемых сорта арабики четко содержат KDEL последовательности, а три исследуемых сорта робусты - KDDL последовательности. Это результат предполагает, что KDDL аллель, вероятно, ограничивается сортами робусты и не может быть обнаружен в сортах арабики. Хотя в изучаемых трех сортах робусты не было обнаружено KDEL последовательности, открытие одной KDEL последовательности в Comell EST библиотеке показывает, что этот аллель может существовать, по меньшей мере, в некоторых клонах некоторых сортов робусты.
Экспрессию гена СсСР-4 изучали с применением нозерн-блот и RT-PCR анализов. На фиг.19 показан результат, полученный в эксперименте с нозерн-блот анализом с использованием РНК, экстрагированной из кофейного зерна и перикарпия на различных стадиях развития, а также РНК, выделенной из корневища, молодых листочков, стеблей и цветков разных сортов арабики. Данные, полученные с использованием зонда СсСР-4 (KDDL), имеющего примерно 98% гомологии с известной ДНК последовательностью СсСР-4 (KDEL) аллеля, показали, что СсСР-4 экспрессируется только в зерне. В перикарпии или в корневище, стебле, цветках и листьях его экспрессии не наблюдалось. Вследствие очень высокого уровня идентичности между двумя аллелями высказано предположение о том, что зонд СсСР-4 (KDDL) будет гибридизироваться с транскриптами этих двух аллелей. Аналогичный эксперимент с использованием RT-PCR анализа также выявил такой же профиль экспрессии гена СсСР-4.
Экспрессию СсСР-4 изучали также в цельных зернах в процессе их проращивания с применением RT-PCR анализа. В этом эксперименте использовали праймеры, которые являются общими и для СеСР-4 KDEL, и для СсСР-4 KDDL аллелей. Результаты указанного эксперимента показаны на фиг.20. Транскрипты СсСР-4 были обнаружены на всех изучаемых стадиях прорастания, хотя уровень транскриптов, вероятно, несколько снижался в 3-суточных образцах, а затем вновь начинал повышаться по мере прогрессирования прорастания (самый высокий уровень отмечен в 1- и 2-месячных образцах).
Ling et al. (Ling J.-Q., Kojima Т., Shiraiwa M. and Takahara H., 2003, Biochim. Biophys. Acta, 1627,129-139) удалось выделить из семядолей соевых бобов две кДНК, кодирующие KDEL-содержащие цистеинпротеазы. Эти две кДНК имели 93,5% сходство на уровне ДНК и экспрессировались в корнях, цветках и в семенах в процессе их развития. В формирующихся или зрелых семенах их экспрессии не наблюдалось по результатам нозерн-блоттинга, хотя экспрессия была обнаружена в зрелых бобах. кДНК, кодирующая KDEL-содержащую цистеинпротеазу, была также выделена из моркови (SakutaC., Oda A., Konishi M., Yamakawa S., Kamada H. and Satoh S., 2001, Biosci. Biotechnol. Biochem., 65, 2243-2248). Транскрипты этого гена были обнаружены в зрелых высушенных семенах и в целых прорастающих семенах на 2 и 3 сутки после пропитки водой. Экспрессии этого гена в других тканях моркови или в процессе развития семян не наблюдалось. Другой KDEL-содержащий белок и соответствующая ему кДНК были выделены из V. sativa (Fischer J., Becker С., Hillmer S., Horstmann C., Neubohn В., Schlereth A., Senyuk V., Shutov A. and Muntz K., 2000, Plant Molecular Biol., 43, 83-101). С помощью нозерн-блоттинга транскрипты этого гена были обнаружены в семядолях в процессе прорастания, но не в главной оси зародыша прорастающих семян. В созревающих семенах, зрелых семенах или в листьях и корнях транскрипты не были обнаружены.
Представленные здесь результаты показывают, что цистеинпротеаза (СР) KDEL-типа из кофе проявляет некоторые новые и неожиданные особенности. Во-первых, авторы заявки открыли, что кофейное зерно робуста экспрессирует СР ген KDEL-типа, который имеет одну единственную мутацию в последовательности, кодирующей область KDEL, что приводит к изменению от KDEL к KDDL. Основываясь на данных Denecke et al. (1992), можно было ожидать, что это частное изменение в последовательности, связанной с задержкой бека в ER, изменит клеточную локализацию и/или контроль белка СсСР-4 (KDDL) робусты. Авторы заявки выдвинули предположение о том, что присутствие транскрибируемой копии гена СсСР-4 (KDDL) может продуцировать значительное изменение пептидного/аминокислотного профиля в кофейном зерне сортов с СсСР-4 (KDEL) последовательностью. Авторы заявки также показали, что цистеинпротеаза KDEL типа из кофе, показывающая ожидаемую экспрессию в процессе прорастания зерна, неожиданно экспрессируется также и на всех изученных стадиях развития зерна. Как отмечалось выше, до настоящего времени в опубликованной литературе нет четких данных, доказывающих значительную экспрессию цистеинпротеазы KDEL типа в других растениях в процессе развития семян, хотя ее транскрипты были обнаружены в зрелых семенах моркови (Sakuta et al., 2001).
Вновь обнаруженные свойства цистеинпротеазы KDEL типа из кофе, представленные выше, вероятно, оказывают важное влияние на пептидный и аминокислотный профили в зрелых зернах арабики и робусты и, тем самым, изменяют этот пул критических предшественников кофейного аромата. Принимая во внимание, что транскрипты цистеинпротеазы KDEL типа присутствуют в зрелом кофейном зерне, представляется также возможным, что белок KDEL типа может активироваться в процессе влажной обработки кофе и, тем самым, изменять в дальнейшем пептидный/аминокислотный профиль кофейного зерна после влажной обработки. Описанные эксперименты привели к созданию молекулярных маркеров (SNP и микросателлитный маркер), которые могут использоваться в классической селекционной работе по выведению сортов кофе со специфическими аллелями гена цистеинпротеазы KDEL типа (которые будут вызывать сопутствующие изменения белкового/пептидного/аминокислотного профилей). Например, можно селекционировать сорта робусты, которые будут иметь только KDEL аллель СсСР-4. Далее, с применением методов генетической модификации можно направленно изменять активность цистеинпротеазы KDEL типа в кофе или других растениях путем специфичной сверхэкспрессии цистеинпротеаз KDEL или KDDL типа в семенах. Альтернативно: можно снижать уровень цистеинпротеазы KDEL типа с применением антисмысловой, смысловой или PHKi технологий. В обоих случаях белковый/пептидный/аминокислотный пул во вновь выведенных трансформированных растениях будет изменяться, приводя к новым профилям белковых/пептидных/аминокислотных пулов предшественников аромата.
Нозерн-блот анализ, представленный на фиг.13, показывает, что ген СсАР-2 специфичной к аспарагиновой кислоте протеазы кофе экспрессируется как в зерне, так и перикарпии плодов кофейного дерева сорта С. arabica на всех изучаемых стадиях развития плодов. Ген СсАР-2 проявляет также относительно высокую экспрессию в корневище. При более длительной экспозиции пленок при авторадиографии экспрессия СсАР-2 может быть обнаружена также в тканях стеблей, листьев и цветков С. arabica.
СсАР-1 и СсАР-2
На фиг.21 и 22 показано, что каждый из СсАР-1 и СсАР-2 кодирует специфичную к аспарагиновой кислоте протеазу.
Сверхэкспрессия и неполная экспрессия последовательностей генов протеаз CcCP-1, СсСР-4, СсАР-1 и СсАР-2 и ингибиторов протеаз CcCPI-1,2,3 и - 4 в кофейных зернах.
Предполагается, что основной профиль запасных белков и аминокислотный/пептидный профиль могут изменяться в зрелом кофейном зерне в результате изменения (либо повышения, либо снижения) экспрессии одного или более указанных генов.
Представляющие интерес методы сверхэкспрессии гена хорошо известны из уровня техники. Эти методы заключаются в создании химерного гена по трем основным компонентам:
1) по последовательности промотора на 5' конце гена, предпочтительно специфичного промотора семян, которые начали применять в последнее время, такие как, например, специфичный промотор кофейных зерен, описанный Marraccini et al.(Marraccini et al., 1999, Molecular cloning of the complete US storage protein gene of Coffea arabica and promoter analysis in transgenic tobacco plants=Молекулярное клонирование гена суммарного запасного белка US Coffea arabica и анализ промотора в трансгенных растениях табака. Plant Physiol. Biochem., Vol.37, 273-282, и WO 99/026688);
2) по полноразмерной кодирующей последовательности экспрессируемого гена;
3) по 3' контролирующей области, например, 3' области гена нопалинсинтазы из Т-ДНК Ti-плазмиды Agrobacterium tumefaciens.
Затем химерный ген может быть клонирован в трансформационный вектор Agrobacterium tumefaciens, а этим вектором может быть трансформирован штамм Agrobacterium tumefaciens для его использования при трансформации кофе, которая подробна трансформации, описанной Leroy et al., 2000 (Leroy et al., 2000, Genetically modified coffee plants expressing the Bacillus thuringiensis cry1Ac gene for resistance to leaf minor. = Генетически модифицированные кофейные деревья, экспрессирующие ген Bacillus thuringiensis cry1Ac с устойчивостью к образованию слабого листа. Plant Cell Reposts, 19, 382-389). Затем растения со стабильными вставками трансформации можно скринировать с целью отбора семян таких растений, которые сверхэкспрессируют специфические гены, используемые в эксперименте по трансформации, особенно в зрелых семенах, с применением таких методов, как методы обнаружения сверхэкспрессии гена или сверхэкспрессии активности белков по сравнению с семенами псевдотрансформированных растений.
Например, высоковалифицированный специалист в данной области может создать рекомбинантную конструкцию, состоящую из (1) самой длинной промоторной последовательности гена 11S кофе, описанной Marraccini et al. (1999), (2) полноразмерной последовательности кДНК гена СсСР-1 или СсСР-4 (KDDL) без поли (А) "хвоста" и (3) известной последовательности терминации транскрипции, такой как хорошо изученный терминатор нопалина. Представляется также возможным, что повышенный уровень сверхэкспрессии рекомбинантных конструкций может быть результатом замены 5' некодирующей области СсСР-4 или других последовательностей кДНК на 5' кодирующую область гена 11S кофе или 5' некодирующие области других сильных специфических промоторов семян либо кофе, либо других соответствующих разновидностей растений. Затем последовательности рекомбинантного гена могут быть встроены в соответствующий участок вектора Agrobacterium Т-ДНК, описанный Leroy et al. Сконструированный таким образом Т-ДНК вектор можно вводить в соответствующий штамм Agrobacterium, например, в штамм, описанный Leroy et al., а содержащий Т-ДНК штамм Agrobacterium можно использовать для трансформации кофе согласно методу, подробному описанному Leroy et al.
Из уровня техники хорошо известно, что экспрессия известных последовательностей гена может понижаться или полностью блокироваться антисмысловой супрессией и экспрессией гена с использованием фрагментов нуклеиновых кислот, составляющих лишь часть полной кодирующей области гена, и нуклеиновыми кислотами, которые не имеют 100% идентичности последовательностей с супрессируемым геном. В этом случае последовательности, выбранные для конкретного эксперимента антисмысловой супрессии или косупрессии, будут заменять полноразмерный ген в представленной выше схеме конструирования химерного гена. Полученные химерные конструкции антисмысловой супрессией или косупрессией можно клонировать в трансформационный вектор Agrobacterium tumefaciens и им трансформировать штамм Agrobacterium tumefaciens в целях его испльзования для трансформации кофе, как описано выше. Затем растения со стабильными трансформационными вставками можно скринировать для отбора растений с пониженной экспрессией специфических генных последовательностей, используемых в семенах трансформированных растений. Пониженную экспрессию можно обнаружить такими методами, как нозерн-блоттинг, RT-PCR с неполной и/или полной количественной оценкой.
Другой метод снижения или подавления экспрессии гена в растениях предусматривает использование небольших фрагментов раскрытых здесь последовательностей гена для продуцирования РНК сайленсинга сиспользованием интерферирующей РНК (PHKi, см., например, Hannon G.J., 2002, Nature, Vol.418, 244-251;
Tang et al., 2003, Genes Dev, Vol.17, 49-63). Согласно этому подходу, небольшие участки одной или более раскрытых здесь последовательностей можно клонировать в трансформационный вектор Agrobacterium tumefaciens, как описано выше, который содержит специфичный для семян промотор и соответствующую 3' регуляторную область. Эта новая встраиваемая последовательность для PHKi должна конструироваться таким образом, чтобы продуцируемая РНК формировала РНК структуру in vivo, что приведет к образованию небольших двунитевых РНК в трансформированных клетках, при этом последовательности этих небоьших двунитевых РНК будут инициировать распад гомологичных им мРНК в указанных трансформированных клетках.
Скрипит естественно происходящих мутаций в генах СсСР-1. СсСР-4, CcAP-1,СсАР-2, CcCPI-1, CcCPI-2, CcCPI-3, CcCPI-4 и создание новых мутаций в указанных генах.
Раскрытые здесь последовательности могут использоваться дял скрининга природных популяций аллельных вариантов указанных генах. Это может осуществляться путем использования последовательностей СсСР-1, СсСР-4, СсАР-1, СсАР-2, CcCPI-1, CcCPI-2, CcCPI-3, CcCPI-4 в качестве зондов при поиске естественно возникших ПДРФ (полиморфизм длины рестрикционных фрагментов) в геномной ДНК из различных сортов кофе. Более высокопроизводительным методом обнаружения аллельных вариантов является применение технологии скрининга мутаций, связанной с TILLING-методом (Till B.J., et al., 2003, Large scale discovery of induced point mutations with highthroughput TILLING. = Крупномасштабное обнаружение индуцируемых точечных мутаций с помощью высокопроизводительного TILLING-метода. Genome Research, Vol.13, 524-530). В этом случае выделенная и клонированнная одна какая-нибудь специфическая последовательность гена, например, из раскрытых здесь СсСР-1, СсСР-4, СсАР-1, СсАР-2, CcCPI-1, CcCPI-2, CcCPI-3, CcCPI-4 последовательностей, при скрининге мутаций, связанном с TILLING-методом, может использоваться для идентификации вариантов последовательностей между клонированной последовательностью и соответствующей последовательностью кДНК или геномной последовательностью в различных сортах. Используя пары ПЦР праймеров, кодирующих сегментов ДНК из 700-1100 пар оснований известного клонированного гена, можно сканировать для выявления естественно возникших изменений в его последовательностях в различных сортах. В идеальном случае один или более вариантов последовательностей может коррелировать также с конкретным фенотипическим изменением, идентифицирующим, тем самым, генетический маркер этого фенотипического варианта.
Кроме того, используя раскрытые здесь последовательности СсСР-1, СсСР-4, СсАР-1, СсАР-2, CcCPI-1, CcCPI-2, CcCPI-3 и.CcCPI-4, можно применить полный TILLING-метод для создания и обнаружения новых мутантов по указанным генам и получить, таким образом, растения, содержащие эти специфические мутации. Например, используя полный TILLING-метод, можно вывести кофейные деревья, которые будут иметь специфические мутации, такие как, например, миссенс-мутации (приводящие к подстановке несоответствующей аминокислоты в белковую цепь) в кодирующей последовательности, которая инактивирует представляющий интерес ген-мишень.



























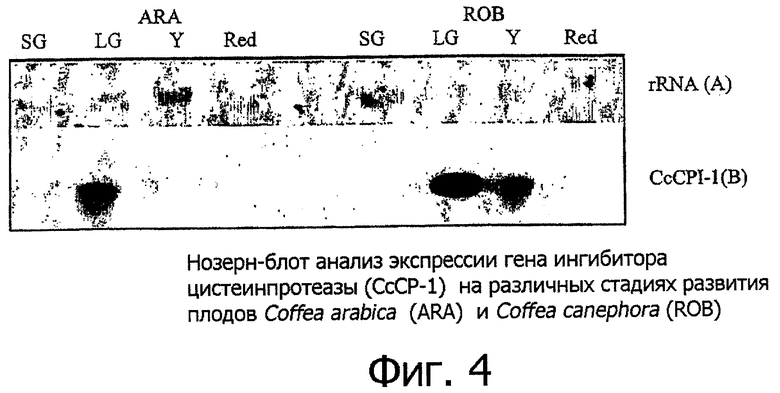




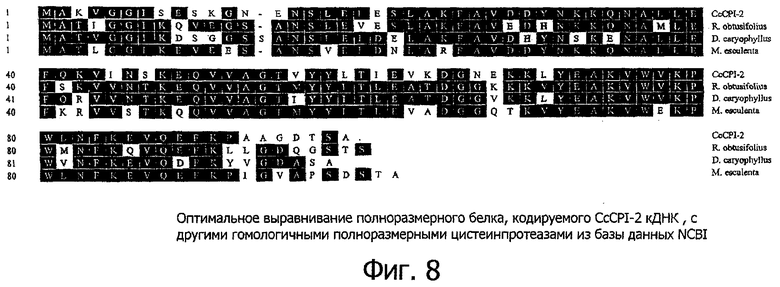









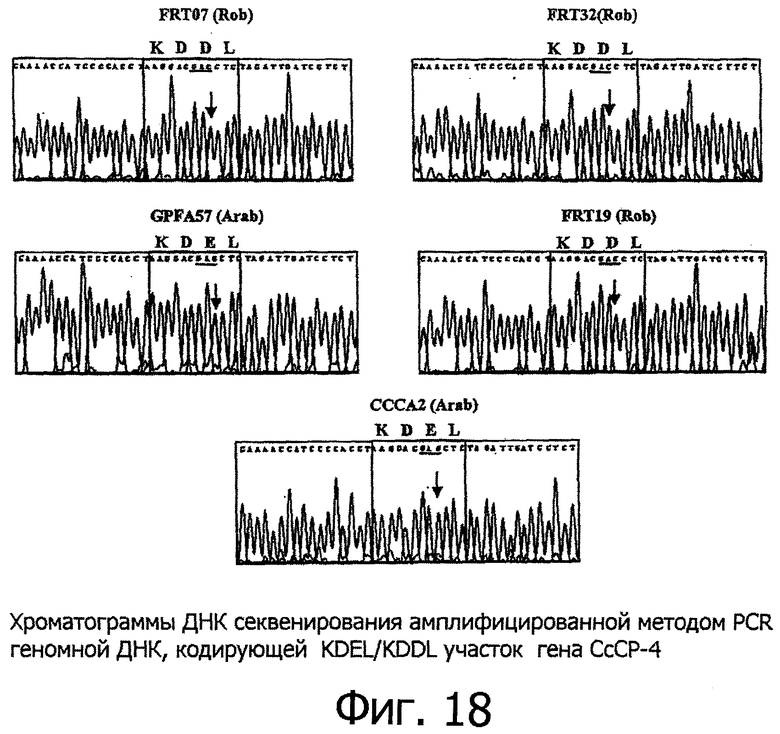
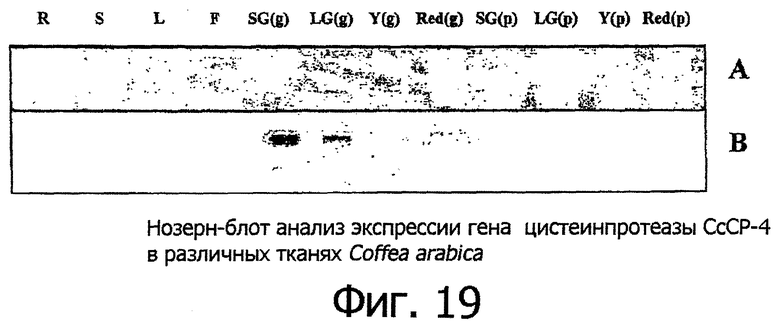



Настоящее изобретение относится к биотехнологии и касается полинуклеотида, кодирующего полипептид с цистеинпротеазной активностью. Изобретение относится также к трансформированной указанным полинуклеотидом клетке кофейного дерева. Изобретение позволяет модулировать уровень предшественников аромата кофе в сырых (необжаренных) кофейных зернах. 8 н. и 6 з.п. ф-лы, 24 ил., 7 табл.
| LING JQ et.al | |||
| Cloning of two cysteine proteinase genes, CysPl and CysP2, from soybean cotyledons by cDNA representational difference analysis | |||
| Biochim Biophys Acta | |||
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| Аппарат для очищения воды при помощи химических реактивов | 1917 |
|
SU2A1 |
| ДЕЗОКСИРИБОНУКЛЕИНОВАЯ КИСЛОТА, КОДИРУЮЩАЯ БЕЛОК ГЛУТАТИОН-S-ТРАНСФЕРАЗУ IIIC И БЕЛОК С СООТВЕТСТВУЮЩЕЙ АМИНОКИСЛОТНОЙ ПОСЛЕДОВАТЕЛЬНОСТЬЮ | 1996 |
|
RU2169196C2 |

