Изобретение относится к области обработки цифровых данных с помощью вычислительных машин, а именно к способам построения программ, предназначенных для микропроцессорных вычислительных систем, и может найти применение в процессе построения оптимизированных программных продуктов для процессоров семейства ARM, которые используются во множестве потребительских электронных устройств. Также имеется возможность адаптировать способ для других типов процессоров с незначительными изменениями.
Оптимизация программ по времени выполнения является важной задачей как для программных приложений для компьютеров, так и для оборудования. Средства построения программного обеспечения, такие как компиляторы и компоновщики, позволяют создавать оптимизированные программы. Однако обычная однопроходная оптимизация имеет два недостатка. Первый: не используются измеряемые характеристики выполнения программ в системе, и информация о наиболее критических частях кода не может быть учтена на стадии разработки. Второй: современные микропроцессорные системы очень сложны, и средства построения программных приложений используют для оптимизации только часть имеющихся возможностей.
Большинство процессоров имеют кэш (сверхоперативную память) инструкций и кэш данных для быстрого доступа процессора к памяти. Оптимизация обращений к памяти является типичным методом повышения эффективности. В нем оптимизация заключается в минимизации числа операций загрузки строк кэша, при которой уменьшают число перезагрузок кэша, вызванных промахами кэша (попытками доступа к той части данных, которые отсутствуют в кэше). Существует множество патентов и статей, в которых описаны способы оптимизации программ по времени их выполнения за счет эффективного использования кэша.
В патенте США №6,907,509 [1] описан автоматический способ реструктурирования программы, имеющей массивы во внутренних циклах, для уменьшения накладных расходов доступа к кэшу при отсутствии нужных данных в кэш-памяти. В способе определяют дополнение, необходимое для каждого массива, в соответствии с размером строки кэша данных, так чтобы начальная позиция массива соответствовала адресу начала строки кэша для согласования начальных адресов массивов.
В выложенной патентной заявке США №2006/0248520 [2] описан способ оптимизации по времени путем трансформации структуры цикла и установки инструкций предварительной выборки данных для загрузки массивов в критические по времени циклы, при этом циклы определяют путем профилирования в вычислительной системе, для которой предназначено программное обеспечение (далее упоминается как «ПО»). В отличие от обычных однопроходных процедур построения в данном способе существует обратная связь: в нем сначала создают программу без предложенного подхода оптимизации; далее в нем измеряют рабочие характеристики на вычислительной системе; определяют критические циклы; в нем устанавливают подходящие параметры оптимизации для данной вычислительной системы, модифицируют исходный код и перестраивают программу.
Данные способы позволяют улучшить использование кэша данных, но в них не выполняют никаких действий для оптимизации обработки инструкций.
Наиболее близким к заявленному изобретению является способ реорганизации части кода на стадии компоновки, описанный в статье "Code Reorganization for Instruction Caches" (опубликовано в Proc. of the Twenty-Sixth Hawaii International Conference on System Sciences, vol.1, pp.214-223, 1993, авторы К.Gosmann, C.Hafer, H.Lindmeier, J.Plankl, K.Westerholz) [3], в котором предлагают реорганизовывать части кода на стадии компоновки для увеличения частоты успешных обращений к кэшу. Реорганизация основана на взаимном расположении частей кода, которые вызывают последовательно. Данный способ выбран в качестве прототипа предложенного изобретения. В целом подход, описанный в способе-прототипе, полезен, но его эффективность для реальных программ мала. В способе-прототипе не учитывают следующие факторы: характеристики кэша инструкций; иные возможности процессора по обработке инструкций в центральном процессоре, такие как блок предварительной выборки инструкций. К тому же данный подход не позволяет определять критические части кода.
Задача, на решение которой направлено заявляемое изобретение, состоит в том, чтобы разработать усовершенствованный способ автоматического построения программы, который позволил бы ускорить выполнение построенной программы, например, за счет выравнивания адресов инструкций для процедур и циклов с высоким покрытием. При этом под термином покрытие здесь понимается частота использования строки кода программы.
Технический результат достигается путем создания нового способа построения программы, предназначенной для вычислительной системы, содержащей центральный процессор, память и кэш инструкций, в котором с помощью центрального процессора выполняют следующие операции:
- строят исходный код программы;
- формируют отчет о покрытии программы, причем сохраняют отчет о покрытии в памяти;
- определяют в исходном коде программы циклы с высоким покрытием из отчета о покрытии;
- модифицируют исходный код программы, при этом помечают в нем специальными метками циклы с высоким покрытием, выполненные с возможностью вставления в исходный код программы на ассемблере, и сохраняют модифицированный код программы в памяти;
- компилируют модифицированный исходный код программы в исходный код программы на ассемблере для устройства назначения, добавляя при этом циклы с высоким покрытием и инструкции по выравниванию адресов процедур равномерно по размеру строки кэша и сохраняя исходный код на ассемблере в памяти;
- определяют в исходном коде программы на ассемблере помеченные циклы и классифицируют их на несколько предопределенных типов;
- строят модифицированный код программы.
Таким образом, реализуется возможность ускорения выполнения построенной программы путем выравнивания адресов инструкций для процедур и циклов с высоким покрытием, при этом выравнивание адресов инструкций предназначено для более эффективной обработки инструкций за счет средств центрального процессора вычислительной системы, таких как кэш инструкции, блок предварительной выборки инструкций и других, причем отчет о покрытии, то есть информацию о том, как часто выполнялась каждая строка кода программы, используют для определения частей кода с высоким покрытием, то есть критических частей кода, а покрытие измеряют для репрезентативного тестового набора, который формируют заранее.
Для функционирования способа имеет смысл, чтобы отчет о покрытии создавали в устройстве назначения, предназначенном для выполнения построенной программы.
Для функционирования способа имеет смысл, чтобы выравнивание выполняли с помощью обработки циклов с высоким покрытием, вставляя требуемое число инструкций NOP ("нет операции").
Для функционирования способа имеет смысл, чтобы циклы с высоким покрытием помечали, по меньшей мере, одной NOP инструкцией, которая находится в блоке встроенного ассемблера внутри исходного кода программы.
Для функционирования способа имеет смысл, чтобы помеченные циклы классифицировали по следующим классам: циклы без внутренних циклов, циклы с одним внутренним циклом, циклы с несколькими внутренними циклами.
Для функционирования способа имеет смысл, чтобы для циклов без внутренних циклов NOP инструкции вставляли до первой инструкции цикла, если адрес обратной ветви цикла выровнен по границе двойного слова.
Для функционирования способа имеет смысл, чтобы для циклов с одним внутренним циклом NOP инструкции вставляли до цикла с большим покрытием, если адрес обратной ветви этого цикла выровнен по границе двойного слова.
Для лучшего понимания заявленного изобретения далее приводится его подробное описание с соответствующими чертежами.
Фиг.1 Блок-схема способа согласно изобретению.
Фиг.2 Схема основных компонентов системы, в которой выполняют способ согласно изобретению.
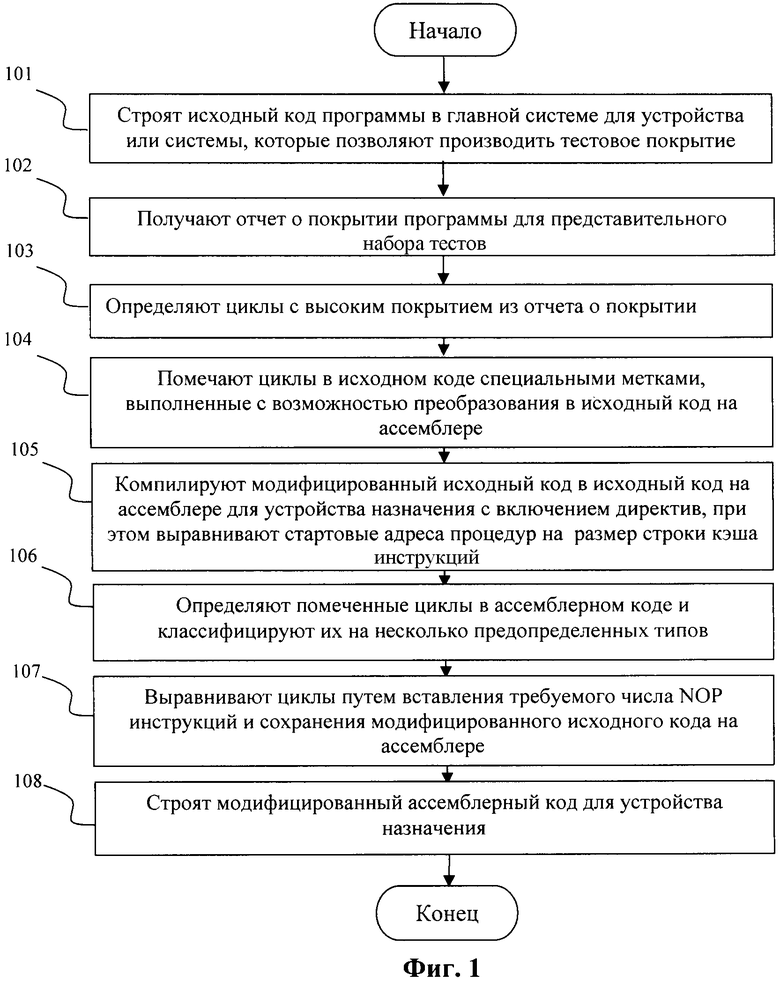
Фиг.3 Фрагмент исходного кода программы на языке С, который содержит цикл с большим покрытием согласно изобретению.
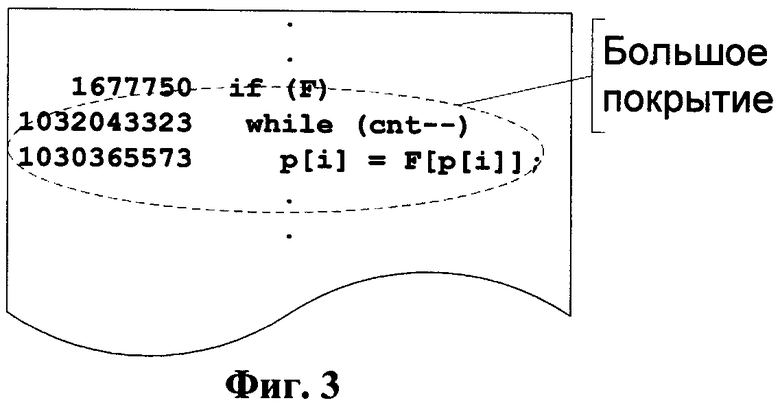
Фиг.4 тот же фрагмент исходного кода на языке С с добавленной меткой согласно изобретению.
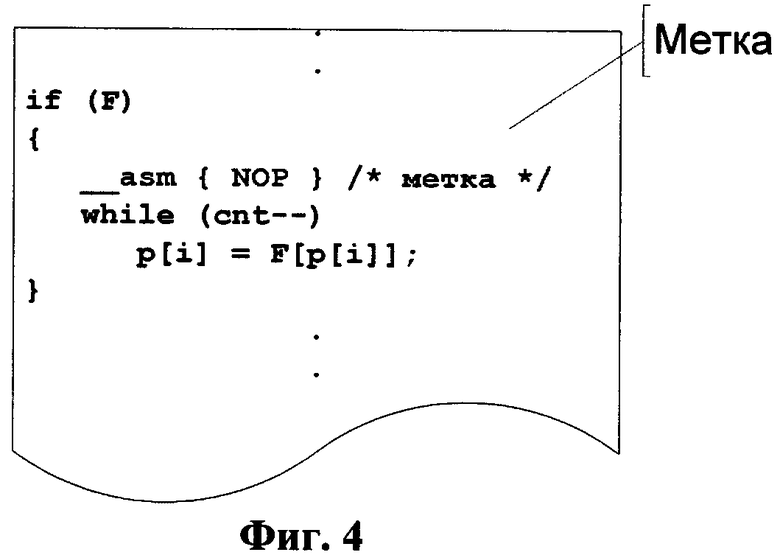
Фиг.5 тот же фрагмент на языке ассемблер с меткой согласно изобретению.
Фиг.6 тот же фрагмент на языке ассемблер с выровненным адресом цикла согласно изобретению.
На Фиг.2 показана схема основных компонентов вычислительной системы, которая реализует предложенный способ. Вычислительная система содержит главную систему 200, выполненную с возможностью построения и оптимизации программы, а также получения отчета о покрытии, которая соединена с устройством 201 назначения (устройством, предназначенным для выполнения построенной программы) посредством интерфейса 214. Процесс выполнения операций в главной системе контролируют с помощью процессора 202, который управляет работой средств построения программы (компиляторов, компоновщики и др.), которые также хранятся в памяти. Информацию о процессе построения программы демонстрируют на дисплее 204. Параметры для создания программы заносят в систему с помощью устройства 205 ввода. Обмен информацией в главной системе осуществляют через шину 206 данных. На выходе предложенного способа получают рабочую программу для устройства 201 назначения; ее передают в память 212 устройства 201 назначения через интерфейс 214. В процессе функционирования устройство назначения управляется процессором 207, который выполняет программу для получения отчета о покрытии или выполняет оптимизированную программу. Процессор 207 устройства 201 назначения содержит кэш 208 данных, кэш 209 инструкций, АЛУ 211, модуль 210 предварительной выборки инструкций. Оптимизация согласно предложенному способу направлена на более эффективное использование кэша инструкций и модуля предварительной выборки инструкций устройства назначения. Обмен информацией в устройстве 201 назначения осуществляют через шину 213 данных.
Рассмотрим пошаговое выполнение предложенного способа построения программы в описанной выше системе (Фиг.1, 2). Исходный код программы строят (компилируют и компонуют) в главной системе 200 для устройства 201 назначения, которое позволяет получить отчет о покрытии для тестового набора (шаг 101). Получают отчет о покрытии программы для тестового набора и сохраняют в памяти 203 (шаг 102). Циклы с высоким покрытием определяют из отчета о покрытии (шаг 103). Циклы помечают в исходном коде специальными метками, которые должны быть перенесены в ассемблер компилятором (шаг 104). Исходный код компилируют посредством компилятора в ассемблер для устройства назначения; добавляют директивы для выравнивания адресов процедур на размер строки кэша 209 инструкций (шаг 105). Анализируют ассемблерный код: начало циклов определяют как первый цикл ниже метки; определяют метки и определяют адреса первой и последней инструкций выбранных циклов; циклы классифицируют на несколько предопределенных типов (шаг 106). Для выравнивания цикла требуемое число NOP ("нет операции") инструкций вставляют перед первой инструкцией цикла в ассемблере, если это требуется для цикла текущего типа (шаг 107). Собирают модифицированный ассемблерный код для устройства назначения (шаг 108).
Далее приведено описание примера применения предложенного способа для построения программы с исходным кодом на языке программирования С для процессора ARM1020E (Фиг.3-6).
На первой стадии исходный код программы на языке С компилируют для операционной системы Linux, поскольку в нашем случае устройство назначения не имеет средств для создания отчета о покрытии. На следующей стадии утилиту Linux используют для создания отчета о покрытии. Отчет о покрытии создают для репрезентативного тестового набора данных, который формируют заранее. Фрагмент отчета о покрытии, который содержит цикл с большим покрытием, показан на Фиг.3. Циклы в отчете о покрытии определяют путем применения поиска ключевых слов циклов для используемого языка программирования; для языка С это "for", "do", "while". Для каждого цикла покрытие считывают из отчета. Если покрытие больше предопределенной пороговой величины, тогда цикл помечают специальной меткой. Метку выбирают в соответствии со следующими требованиями: сам компилятор не должен генерировать такую метку из исходного кода на С при компиляции в ассемблер, но компилятор должен переносить метку из исходного кода на С в исходный код на ассемблере. В нашем случае компилятор (ADS v1.2.1) переносит из исходного кода на С в исходный код на ассемблере только корректные инструкции встроенного ассемблера, заключенные в блоке _asm {}. Таким образом метка должна представлять собой инструкцию на ассемблере, которая не влияет на логику программы и состояние процессора. Данной цели соответствует одна или несколько NOP ("нет операции") инструкций. Используемый компилятор сам не генерирует NOP инструкции; поэтому в исходном коде на С делают пометку _asm {NOP } (см. Фиг.4).
На следующей стадии исходный код на С компилируют в исходный код на ассемблере для устройства назначения. Во время или после компиляции каждую процедуру располагают в отдельной секции памяти и для каждой процедуры добавляют директиву ALIGN=X для выравнивания стартового адреса процедуры на размер строки кэша инструкций, где Х степень двойки. Это обеспечивает оптимизацию по времени, поскольку выровненная процедура занимает меньше строк в кэше, и кэш инструкций используется более эффективно. Кроме того, трудно выполнять оптимизацию внутри процедур путем выравнивания адресов циклов без выравнивания стартового адреса каждой процедуры. Затем автоматический скрипт ищет метки в сгенерированных исходных кодах на ассемблере. На Фиг.5 показан фрагмент исходного ассемблерного кода с меткой. Ассемблерный код около метки анализируют: начало цикла определяют как первый цикл ниже метки; метку удаляют и определяют адреса первой и последней инструкций цикла. Циклы классифицируют на несколько предопределенных типов: без внутренних циклов, с одним внутренним циклом, с несколькими внутренними циклами. Признаком цикла в ассемблере является переход назад (обратная ветвь цикла). На данной стадии наш подход основан на принципах скалярной обработки инструкций в процессоре ARM, точнее в блоке предварительной выборки инструкций. Блок предварительной выборки инструкций отвечает за загрузку инструкций из кэша инструкций и может загружать по две инструкции за такт. Работа процессора ARM подробно описана в соответствующем руководстве ("ARM1020E; Technical Reference Manual"). Теоретический анализ и экспериментальные результаты показывают, что переход назад (обратная ветвь) в цикле обрабатывается более эффективно в случае, если адрес команды перехода не выровнен по двойному слову. Чтобы выровнять цикл, а именно выровнять адрес перехода назад в цикле на границу слова, но не на границу двойного слова, необходимое число NOP инструкций вставляют в исходный код на ассемблере, если это требуется для данного цикла. В нашем случае 0 или 1 NOP инструкций должны быть вставлены для выравнивания. Для циклов без внутренних циклов NOP инструкции должны быть вставлены перед первой инструкцией цикла, если адрес перехода назад в цикле выровнен на границу двойного слова. Для циклов с одним внутренним циклом отчет о покрытии анализируют для получения решения о месте, предпочтительном для выравнивания. Пусть внутренний цикл выполняют М раз; внешний цикл выполняют N раз, и концы цикла (переходы назад) выровнены по-разному (один на двойное слово, а другой нет). Для выбора цикла, который должен быть выровнен, необходимо сравнить количество итераций в циклах. Если М>N, тогда должен быть выровнен внутренний цикл, иначе, наоборот, должен быть выровнен внешний цикл. Для циклов с несколькими внутренними циклами результат выравнивания часто может быть непредсказуемым, в этом случае требуется дополнительный анализ. Добавление NOP инструкций увеличивает размер кода и требует дополнительного времени процессора на их выполнение, по этой причине только циклы с большим покрытием модифицируют путем добавления NOP. На Фиг.6 показан модифицированный исходный код на ассемблере с выровненными циклами. Конечным этапом способа является создание модифицированного исходного кода на ассемблере для устройств назначения.
Описанный подход позволяет ускорить выполнение некоторых циклов до 15%, время выполнения большого встроенного приложения, которое содержит около миллиона строк кода, было уменьшено примерно на 1% в автоматическом режиме.
Другие аспекты изобретения станут очевидными из рассмотрения рисунков и соответствующего описания предпочтительных вариантов выполнения изобретения. Специалисту ясно, что возможны другие варианты выполнения изобретения и что детали изобретения могут быть выполнены во множестве вариантов, не выходящих из объема настоящего изобретения. Таким образом, чертежи и описание должны рассматриваться как иллюстрации, а не ограничения. Например, отчет о покрытии может быть создан на устройстве назначения для программы; специальная метка может состоять из нескольких последовательно расположенных NOP инструкций и так далее.
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ автоматического создания параллельной программы с временной параметризацией многопроцессорных вычислительных систем с одинаковым доступом к памяти | 2022 |
|
RU2786347C1 |
| Способ распределения данных по уровням памяти вычислительной системы с разноуровневой общей памятью | 2022 |
|
RU2802777C1 |
| Способ временной синхронизации работы массивно-параллельной вычислительной системы с распределенной памятью | 2022 |
|
RU2815189C1 |
| Способ параллельного программирования | 2021 |
|
RU2771739C1 |
| Способ распределения данных по многофункциональным блокам процессора со сверхдлинной командной строкой | 2024 |
|
RU2818498C1 |
| СХЕМА ДЛЯ УПАКОВКИ И СВЯЗЫВАНИЯ ПЕРЕМЕННОЙ В ГРАФИЧЕСКИХ СИСТЕМАХ | 2008 |
|
RU2448369C2 |
| СПОСОБЫ И УСТРОЙСТВО ДЛЯ ОБЕСПЕЧЕНИЯ КОРРЕКТНОГО ПРЕДВАРИТЕЛЬНОГО ДЕКОДИРОВАНИЯ | 2006 |
|
RU2405188C2 |
| ОТЛАДКА МАШИННОГО КОДА ПУТЕМ ПЕРЕХОДА ОТ ИСПОЛНЕНИЯ В СОБСТВЕННОМ РЕЖИМЕ К ИСПОЛНЕНИЮ В ИНТЕРПРЕТИРУЕМОМ РЕЖИМЕ | 2014 |
|
RU2668973C2 |
| МУЛЬТИПРОЦЕССОРНАЯ АРХИТЕКТУРА, ОПТИМИЗИРОВАННАЯ ДЛЯ ПОТОКОВ | 2008 |
|
RU2450339C2 |
| СПОСОБ И УСТРОЙСТВО ДЛЯ КОМПИЛЯЦИИ НЕЙРОННЫХ СЕТЕЙ | 2024 |
|
RU2835757C1 |

Изобретение относится к области обработки цифровых данных с помощью вычислительных машин, а именно к способам построения программ, предназначенных для микропроцессорных вычислительных систем. Техническим результатом является ускорение выполнения построенной программы. Для достижения технического результата реализован способ построения программы для выполнения в вычислительной системе, содержащей центральный процессор, память и кэш инструкций, содержащий этапы, на которых с помощью центрального процессора строят исходный код программы, формируют отчет о частоте использования каждой строки программы, сохраняют этот отчет в памяти, определяют в исходном коде программы часто выполняемые циклы из упомянутого отчета, модифицируют исходный код программы, при этом помечают в нем метками, негенерирующимися компилятором, а переносящимися из исходного кода на языке программирования в исходный код на ассемблере, часто выполняемые циклы, сохраняют модифицированный код программы в памяти, компилируют модифицированный исходный код программы в исходный код программы на ассемблере для устройства назначения, при этом выравнивают адреса процедур по размеру строки кэша, определяют в исходном коде программы на ассемблере помеченные циклы и классифицируют их на несколько предопределенных типов, выравнивают адреса начала помеченных циклов, если это требуется для цикла данного типа, путем добавления ассемблерных инструкций и сохраняя исходный код на ассемблере в памяти, строят путем компиляции и компоновки модифицированный ассемблерный код для устройства назначения. 6 з.п. ф-лы, 6 ил.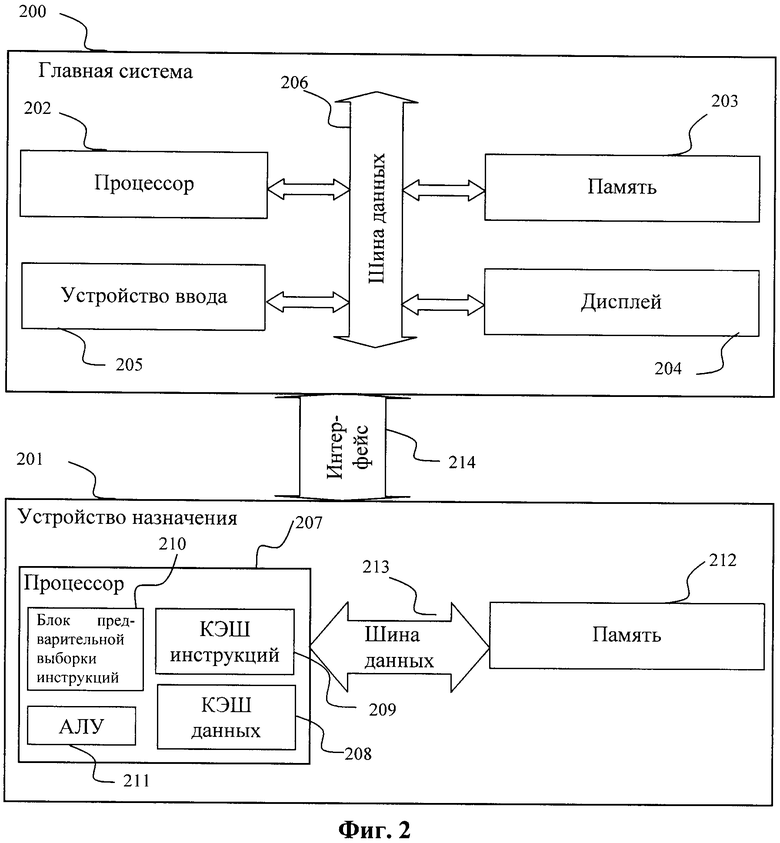
1. Способ построения программы для выполнения в вычислительной системе, содержащей центральный процессор, память и кэш инструкций, в котором с помощью центрального процессора выполняют следующие операции:
строят исходный код программы;
формируют отчет о частоте использования каждой строки программы на репрезентативном тестовом наборе, причем сохраняют этот отчет в памяти;
определяют в исходном коде программы часто выполняемые циклы из отчета о частоте использования каждой строки программы;
модифицируют исходный код программы, при этом помечают в нем метками, не генерирующимися компилятором при компиляции из исходного кода на языке программирования в ассемблер, а переносящимися из исходного кода на языке программирования в исходный код на ассемблер, часто выполняемые циклы, и выполненными с возможностью вставления в исходный код программы на ассемблере, и сохраняют модифицированный код программы в памяти;
компилируют модифицированный исходный код программы в исходный код программы на ассемблере для устройства назначения, при этом выравнивают адреса процедур по размеру строки кэша;
определяют в исходном коде программы на ассемблере помеченные циклы и классифицируют их на несколько предопределенных типов;
выравнивают адреса начала помеченных циклов, если это требуется для цикла данного типа, путем добавления ассемблерных инструкций и сохраняя исходный код на ассемблере в памяти;
строят путем компиляции и компоновки модифицированный ассемблерный код для устройства назначения.
2. Способ по п.1, отличающийся тем, что отчет о частоте использования каждой строки программы создают в устройстве назначения, предназначенном для выполнения программы.
3. Способ по п.1, отличающийся тем, что помеченные циклы классифицируют по следующим классам: циклы без внутренних циклов, циклы с одним внутренним циклом, циклы с несколькими внутренними циклами.
4. Способ по п.1, отличающийся тем, что при выравнивании циклов вставляют требуемое число инструкций NOP ("нет операции").
5. Способ по п.3, отличающийся тем, что для циклов без внутренних циклов NOP инструкции вставляют до первой инструкции цикла, если адрес перехода назад в цикле выровнен по границе двойного слова.
6. Способ по п.3, отличающийся тем, что для циклов с одним внутренним циклом NOP инструкции вставляют до цикла, выполняемого чаще, если адрес перехода назад этого цикла выровнен по границе двойного слова.
7. Способ по п.1, отличающийся тем, что часто выполняемые циклы помечают, по меньшей мере, одной NOP инструкцией, которая находится в блоке встроенного ассемблера внутри исходного кода программы.
| СПОСОБ ПОЛУЧЕНИЯ ОБЪЕКТНОГО КОДА | 2000 |
|
RU2206119C2 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |
| КРИС КАСПЕРСКИ | |||
| Техника оптимизации программ | |||
| Эффективное использование памяти | |||
| - СПб.: БХВ-Петербург, 30.04.2003, Введение, Главы 1-3. | |||

