УРОВЕНЬ ТЕХНИКИ
[0001] Текстовое изображение (растровое изображение текста), полученное путем сканирования или фотографирования документа, обычно имеет большое количество искажений и шумов, видимых при чтении с экрана и при печати в большом разрешении. Шум может носить, например, поверхностный характер (отдельные шумовые пиксели вдоль очертания символа). Подобные искажения присущи не только изображениям с текстовой информацией, но также и изображениям с графическим содержанием (схемы, графики, диаграммы и/или другие синтетические изображения).
[0002] Существует несколько решений для улучшения визуального восприятия растрового изображения документа. Например, можно распознать текст в документе и выбрать шрифт, наиболее близкий к исходному. К сожалению, не всегда возможно точно подобрать шрифт, а ошибки распознавания могут привести к подстановке неправильных символов. Более того, распознавание символов требует значительного времени и вычислительных ресурсов. По этим причинам распознавание символов не является практичным решением, когда требуется только улучшение визуального восприятия текста.
[0003] Другим возможным решением является векторизация растрового изображения. Векторизация - это сложный и ресурсоемкий процесс. Кроме того, векторизация не гарантирует, что сохраненный в векторном представлении документ не будет иметь больший размер и/или не будет содержать значительные искажения.
[0004] Еще одним простым подходом является использование метода фильтрации изображения. Существующие методы обычно не дают достаточно хороших результатов, когда применяются на текстовых изображениях. Различные способы локальной обработки, в которых улучшение качества изображения основано на значениях соседних пикселей, не способны обеспечить необходимые результаты.
[0005] Следовательно, существует потребность в способе улучшения изображения документа, который использует особые, недостаточно проработанные подходы в областях обработки изображений и/или компьютерной графики.
РАСКРЫТИЕ ИЗОБРЕТЕНИЯ
[0006] Один из вариантов осуществления настоящего описания относится к способу снижения визуально обнаруживаемых дефектов в предварительно полученном изображении документа. Способ включает в себя идентификацию при помощи вычислительного устройства, содержащего один или более процессоров, множества изображений фрагментов в пределах изображения документа. Способ дополнительно включает в себя разделение при помощи вычислительного устройства множества изображений фрагментов на множество классов. Каждый класс из множества классов включает в себя подмножество множества изображений фрагментов, которые в значительной степени похожи друг на друга. Способ дополнительно включает в себя для каждого из множества классов: (1) обработку при помощи вычислительного устройства класса изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса; и (2) фильтрацию при помощи вычислительного устройства комбинированного и существенно увеличенного изображения класса для создания отфильтрованного изображения для класса. Способ дополнительно включает в себя создание при помощи вычислительного устройства улучшенного изображения документа путем замены или изменения изображений фрагментов в пределах изображения документа на основе отфильтрованных изображений для соответствующих классов изображений фрагментов.
[0007] Другой вариант осуществления относится к системе, включающей в себя по меньшей мере одно вычислительное устройство, функционально связанное с по меньшей мере одним устройством памяти. По меньшей мере одно вычислительное устройство выполнено с возможностью идентификации множества изображений фрагментов в пределах изображения документа. По меньшей мере одно вычислительное устройство дополнительно выполнено с возможностью разделения множества изображений фрагментов на множество классов. Каждый класс из множества классов включает в себя подмножество множества изображений фрагментов, которые в значительной степени похожи друг на друга. По меньшей мере одно вычислительное устройство для каждого из множества классов дополнительно выполнено с возможностью: (1) обработки класса изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса; и (2) фильтрации комбинированного и существенно увеличенного изображения класса для создания отфильтрованного изображения для класса. По меньшей мере одно вычислительное устройство дополнительно выполнено с возможностью создания улучшенного изображения документа путем замены или изменения изображений фрагментов в пределах изображения документа на основе отфильтрованных изображений для соответствующих классов изображений фрагментов.
[0008] Другой вариант осуществления относится к машиночитаемому носителю данных, на котором хранятся инструкции, исполнение которых процессором приводит к выполнению процессором операций. Операции включают в себя идентификацию множества изображений фрагментов в пределах изображения документа. Каждый из множества изображений фрагментов представляет собой один отдельный символ или часть отдельного символа. Операции дополнительно включают в себя разделение множества изображений фрагментов на множество классов. Каждый класс из множества классов включает в себя подмножество из множества изображений фрагментов, которые в значительной степени похожи друг на друга, и изображения фрагментов, представляющие одинаковый символ или одинаковую часть символа, сгруппированы в отдельный класс из множества классов. Операции дополнительно включают в себя для каждого из множества классов: (1) нормализацию изображений фрагментов класса для создания нормализованного набора изображений фрагментов класса; (2) обработку нормализованного набора изображений фрагментов класса для создания комбинированного и существенно увеличенного изображения класса; (3) фильтрацию комбинированного и существенно увеличенного изображения класса с использованием по меньшей мере одной из процедур ранговой фильтрации и процедур контурной фильтрации для создания отфильтрованного изображения для класса; (4) изменение каждого изображения фрагмента из нормализованного набора изображений фрагментов класса на основе отфильтрованного изображения для класса; и (5) выполнение обратной нормализации для каждого изображения фрагмента из нормализованного набора изображений фрагментов для создания итогового набора изображений фрагментов для класса. Операции дополнительно включают в себя создание улучшенного изображения документа путем замены или изменения изображений фрагментов в пределах изображения документа на основе изображений фрагментов в итоговом наборе изображений фрагментов для соответствующих классов изображений фрагментов.
[0009] Еще один вариант осуществления настоящего изобретения относится к способу снижения визуально обнаруживаемых дефектов в по меньшей мере части предварительно полученного изображения документа. Способ включает в себя получение выбранного пользователем участка изображения документа с пользовательского устройства ввода. Способ дополнительно включает в себя идентификацию при помощи вычислительного устройства множества изображений фрагментов в пределах по меньшей мере выбранной части изображения документа. Способ дополнительно включает в себя разделение при помощи вычислительного устройства множества изображений фрагментов на множество классов. Каждый класс из множества классов включает в себя подмножество множества изображений фрагментов, которые в значительной степени похожи друг на друга. Способ дополнительно включает в себя для каждого из множества классов: (1) обработку при помощи вычислительного устройства класса изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса; и (2) фильтрацию при помощи вычислительного устройства комбинированного и существенно увеличенного изображения класса для создания отфильтрованного изображения для класса. Способ дополнительно включает в себя создание при помощи вычислительного устройства улучшенной выбранной части путем замены или изменения изображений фрагментов в пределах выбранной части изображения документа на основе отфильтрованных изображений для соответствующих классов изображений фрагментов.
[0010] Другой вариант осуществления относится к системе, включающей в себя по меньшей мере одно вычислительное устройство, функционально связанное с по меньшей мере одним устройством памяти. По меньшей мере одно вычислительное устройство выполнено с возможностью принимать выбранную пользователем часть изображения документа. По меньшей мере одно вычислительное устройство выполнено с возможностью идентификации множества изображений фрагментов в пределах по меньшей мере выбранной части изображения документа. По меньшей мере одно вычислительное устройство дополнительно выполнено с возможностью разделения множества изображений фрагментов на множество классов. Каждый класс из множества классов включает в себя подмножество множества изображений фрагментов, которые в значительной степени похожи друг на друга. По меньшей мере одно вычислительное устройство для каждого из множества классов дополнительно выполнено с возможностью: (1) обработки класса изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса; и (2) фильтрации комбинированного и существенно увеличенного изображения класса для создания отфильтрованного изображения для класса. По меньшей мере одно вычислительное устройство дополнительно выполнено с возможностью создания улучшенной выбранной части путем замены или изменения изображений фрагментов в пределах выбранной части изображения документа на основе отфильтрованных изображений для соответствующих классов изображений фрагментов.
[0011] Еще один вариант осуществления относится к машиночитаемому носителю данных, на котором хранятся инструкции, исполнение которых процессором приводит к выполнению процессором операций. Операции включают в себя получение выбранной пользователем части изображения документа. Операции дополнительно включают в себя идентификацию множества изображений фрагментов в пределах по меньшей мере выбранной части изображения документа. Каждый из множества изображений фрагментов представляет собой один отдельный символ или часть отдельного символа. Операции дополнительно включают в себя разделение множества изображений фрагментов на множество классов. Каждый класс из множества классов включает в себя подмножество множества изображений фрагментов, которые в значительной степени похожи друг на друга. Изображения фрагментов, представляющие одинаковый символ или одинаковую часть символа, группируются в пределах отдельного класса из множества классов. Операции дополнительно включают в себя для каждого из множества классов: (1) нормализацию изображений фрагментов класса для создания нормализованного набора изображений фрагментов класса; (2) обработку нормализованного набора изображений фрагментов класса для создания комбинированного и существенно увеличенного изображения класса; (3) фильтрацию комбинированного и существенно увеличенного изображения класса с использованием по меньшей мере одной из процедур ранговой фильтрации и процедур контурной фильтрации для создания отфильтрованного изображения для класса; (4) изменение каждого изображения фрагмента из нормализованного набора изображений фрагментов класса на основе отфильтрованного изображения для класса; и (5) выполнение обратной нормализации для каждого изображения фрагмента из нормализованного набора изображений фрагментов для создания итогового набора изображений фрагментов для класса. Операции дополнительно включают в себя создание улучшенной выбранной части путем замены или изменения изображений фрагментов в пределах выбранной части изображения документа на основе изображений фрагментов в первых наборах изображений фрагментов для соответствующих классов изображений фрагментов.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[0012] Изложенное описание будет более понятным из последующего подробного описания в сочетании с прилагаемыми чертежами, на которых одинаковыми числами обозначены ссылки на одинаковые элементы.
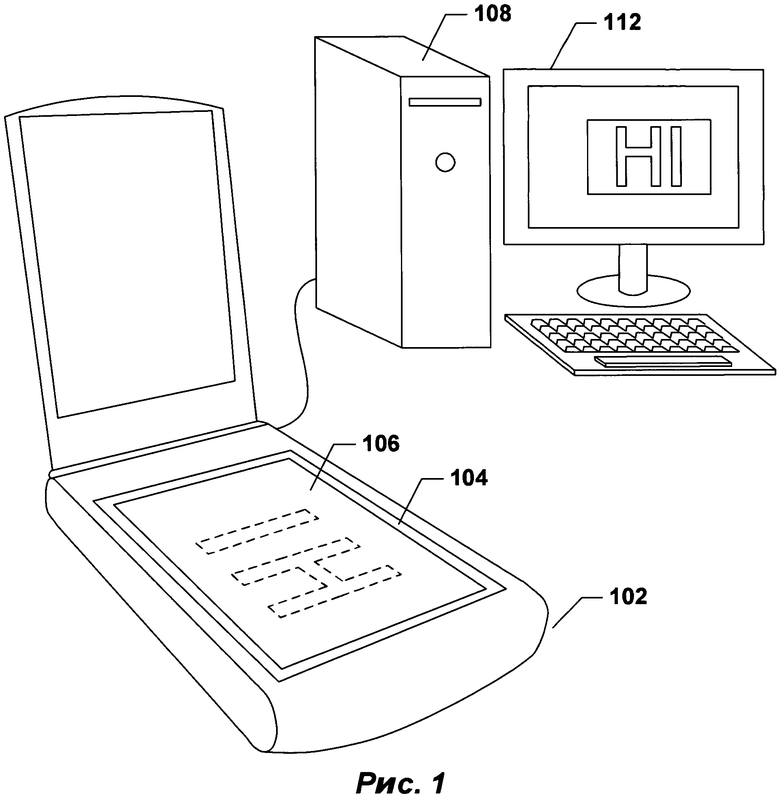
[0013] На РИС. 1 представлен типовой настольный сканер и персональный компьютер, которые используются вместе для преобразования печатных документов в оцифрованные электронные документы сохраненные на запоминающих устройствах и/или в электронной памяти в соответствии с примером осуществления изобретения.
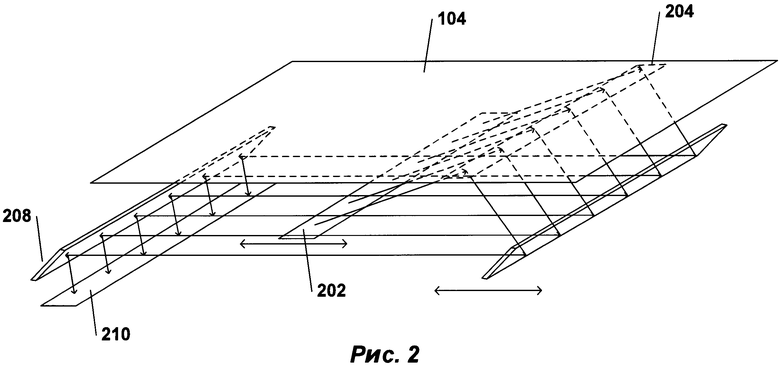
[0014] На РИС. 2 представлена схема работы оптических компонентов настольного сканера, показанного на РИС. 1, в соответствии с примером осуществления изобретения.
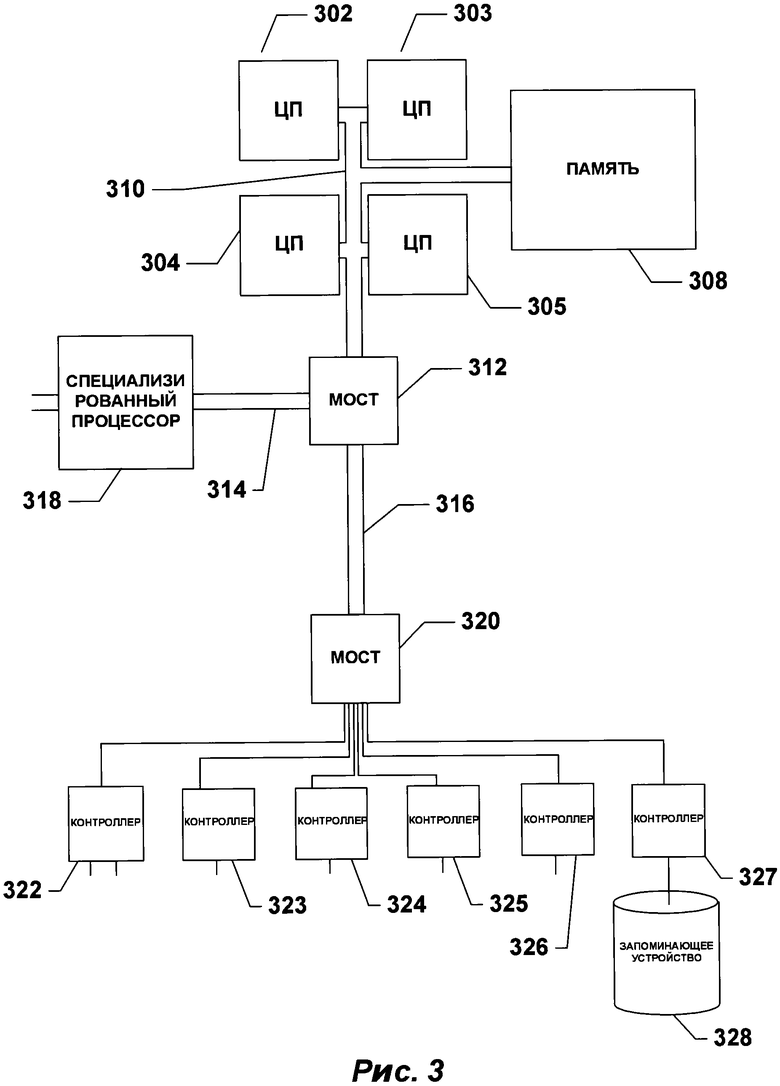
[0015] На РИС. 3 представлена общая схема архитектуры различных типов компьютеров и других устройств с процессорным управлением в соответствии с примером осуществления изобретения.
[0016] На РИС. 4 показано цифровое представление отсканированного документа в соответствии с примером осуществления изобретения.
[0017] На РИС. 5 представлена блок-схема способа повышения качества изображения документа в соответствии с примером осуществления изобретения.
[0018] На РИС. 6 представлены участки на изображении, измененные с использованием функции гистограммы в соответствии с примером осуществления изобретения.
[0019] На РИС. 7А представлено бинаризованное изображение в соответствии с примером осуществления изобретения.
[0020] На РИС. 7В представлено бинаризованное изображение, показанное на РИС. 7А, с улучшенным качеством за счет применения способа, представленного на РИС. 5, в соответствии с примером осуществления изобретения.
[0021] На РИС. 8А представлен класс изображений похожих фрагментов, обнаруженных на изображении, в соответствии с примером осуществления изобретения.
[0022] На РИС. 8В представлено усредненное изображение для класса изображений похожих фрагментов, показанных на РИС. 8А, в соответствии с примером осуществления изобретения.
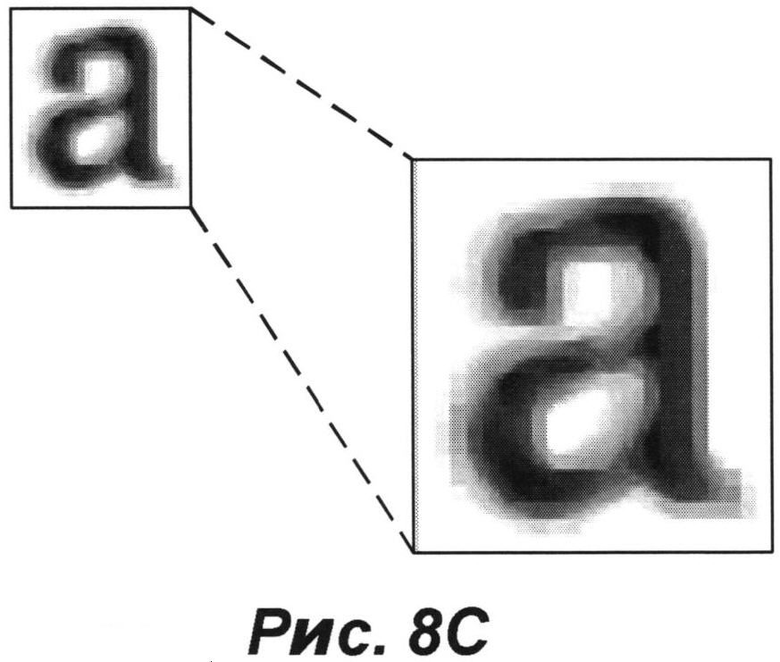
[0023] На РИС. 8С представлено увеличенное изображение класса, полученное из усредненного изображения для класса, показанного на РИС. 8В, в соответствии с примером осуществления изобретения.
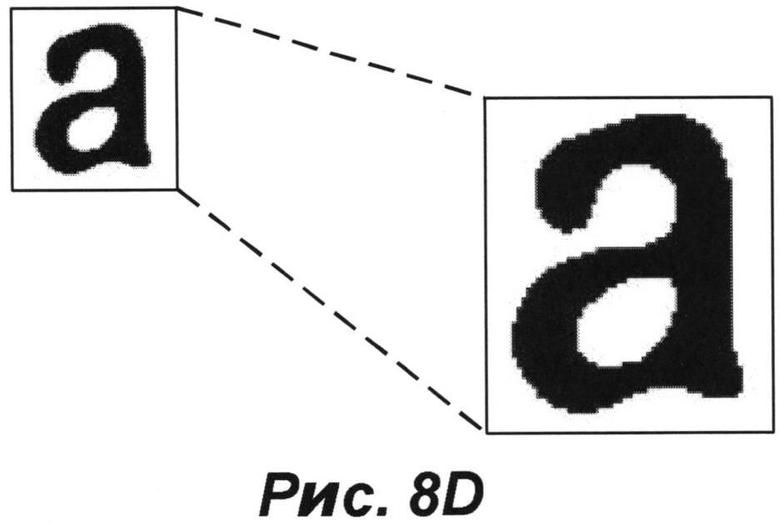
[0024] На РИС. 8D представлено улучшенное изображение класса после выполнения дополнительной обработки изображения фрагмента, показанного на РИС. 8С, в соответствии с примером осуществления изобретения.
[0025] На РИС. 9А представлено серое изображение в соответствии с примером осуществления изобретения.
[0026] На РИС. 9В представлено серое изображение, показанное на РИС. 9А, с улучшенным качеством за счет применения способа, представленного на РИС. 5, в соответствии с примером осуществления изобретения.
[0027] На РИС. 10 представлена функциональная схема системы повышения качества изображения в соответствии с примером осуществления.
ПОДРОБНОЕ ОПИСАНИЕ
[0028] Настоящее описание представляет системы и способы, которые можно использовать для улучшения качества изображения с точки зрения визуального восприятия. В некоторых вариантах осуществления изобретения способ может позволять пользователю обрабатывать и сохранять отсканированное или сфотографированное изображение документа так, что текст на изображении визуально улучшается, становясь похожим на цифровой текст. В некоторых вариантах осуществления изобретения обработка изображения документа может выполняться автоматическим способом, например, когда открыт файл с документом. В некоторых вариантах осуществления, улучшения могут быть достигнуты, по меньшей мере частично, за счет увеличения растровых изображений символов и применения серии сглаживающих и ранговых фильтраций к участкам увеличенного изображения.
[0029] В некоторых вариантах осуществления система, приведенная в качестве примера, может выполнять увеличение и фильтрацию для каждого отдельного символа. В некоторых вариантах осуществления может выполняться поиск любых похожих изображений символа (и/или изображений фрагментов) и последующее усреднение их растровых изображений. Система впоследствии может увеличивать и фильтровать усредненные изображения символа. В дальнейшем фрагмент следует понимать как часть изображения, на которой может быть представлен целый символ или его часть и/или часть синтезированного изображения, графика, диаграммы, формулы, графического изображения, фона и т.д.
[0030] Обнаружение и усреднение фрагментов (например, изображений похожих символов) с последующей обработкой усредненных растровых изображений может дать в результате изображения с более высоким качеством, чем обработка каждого фрагмента (например, изображения символа) по отдельности. Изображение, содержащее текст, всегда имеет ограниченный набор символов; следовательно, изображение обычно содержит повторяющиеся символы. В случаях участков синтезированных изображений, неповторяющихся символов и/или фоновых участков изображения могут быть найдены самоподобные области (фрагменты) на изображении.
[0031] Низкое визуальное качество изображения зачастую является результатом разного рода шумов, искажений и/или других дефектов. В некоторых вариантах осуществления изобретения способ обработки изображений может выявлять все экземпляры изображений фрагмента конкретного типа (например, символа или части символа) в пределах полученного изображения. Часто разные экземпляры идентичных или в значительной степени похожих фрагментов (например, конкретного символа) могут быть повреждены по-разному (например, искажения и шумы могут различаться или возникать в разных частях символа). В таких случаях поврежденные символы можно восстановить путем применения специально вычисленной фильтрации, как подробно описано ниже.
[0032] Печатные документы могут быть преобразованы в оцифрованные изображения отсканированных документов с помощью различных средств, включающих в себя электронные оптико-механические сканирующие устройства и цифровые камеры. На РИС. 1 представлен типовой настольный сканер и персональный компьютер, которые используются вместе для преобразования печатных документов в оцифрованные электронные документы для хранения на запоминающих устройствах и/или в электронной памяти. Настольное сканирующее устройство 102 включает в себя прозрачное стеклянное дно 104, на которое лицевой стороной вниз помещается документ 106. Запуск сканирования приводит к получению оцифрованного изображения отсканированного документа, которое может быть передано на персональный компьютер (ПК) 108 для хранения на запоминающем устройстве. Программа, предназначенная для отображения изображения отсканированного документа, может вывести оцифрованное изображение отсканированного документа на экран 110 отображающего устройства ПК 112.
[0033] На РИС. 2 представлена схема работы оптических компонентов настольного сканера, показанного на РИС. 1. Оптические компоненты этого сканера с полупроводниковой светочувствительной матрицей (CCD) расположены под прозрачным стеклянным дном 104. Перемещаемый фронтально источник яркого света 202 освещает часть сканируемого документа 204, которая, в свою очередь, переизлучает и отражает свет вниз. Этот переизлученный и отраженный свет отражается от перемещаемого фронтально зеркала 206 на неподвижное зеркало 208, которое отражает излучаемый свет на массив CCD-элементов 210, генерирующих электрические сигналы пропорционально интенсивности света, поступающего на каждый из них. Цветные сканеры могут включать в себя три отдельных строки или массива CCD-элементов с красным, зеленым и синим фильтрами. Перемещаемые фронтально источник яркого света и зеркало двигаются вместе вдоль документа для получения изображения сканируемого документа. Другой тип сканера, использующего контактный датчик изображения, называется CIS-сканером. В CIS-сканере подсветка документа осуществляется перемещаемыми цветными светодиодами (LED), при этом отраженный свет светодиодов улавливается массивом фотодиодов, который перемещается вместе с цветными светодиодами.
[0034] На РИС. 3 представлена общая схема архитектуры различных типов компьютеров и других устройств, управляемых процессором. Схема архитектуры высокого уровня позволяет описать современную компьютерную систему (например, такую как ПК, представленный на РИС. 1), в которой программы отображения отсканированного документа и программы оптического распознавания символов хранятся на запоминающих устройствах для передачи в электронную память и выполнения одним или более процессорами, что преобразует компьютерную систему в специализированную систему оптического распознавания символов. Компьютерная система содержит один или множество центральных процессоров (ЦП) 302-305, один или более модулей электронной памяти 308, соединенных с ЦП при помощи шины подсистемы ЦП/память 310 или множества шин, первый мост 312, который соединяет шину подсистемы ЦП/память 310 с дополнительными шинами 314 и 316 или другими средствами высокоскоростного взаимодействия, включающими в себя множество высокоскоростных последовательных линий. Эти шины или последовательные линии в свою очередь соединяют ЦП и память со специализированными процессорами, такими как графический процессор 318, а также с одним или более дополнительными мостами 320, взаимодействующими с высокоскоростными последовательными линиями или с множеством контроллеров 322-327, например с контроллером 327, которые предоставляют доступ к различным типам запоминающих устройств 328, электронным дисплеям, устройствам ввода и другим подобным компонентам, подкомпонентам и вычислительным ресурсам.
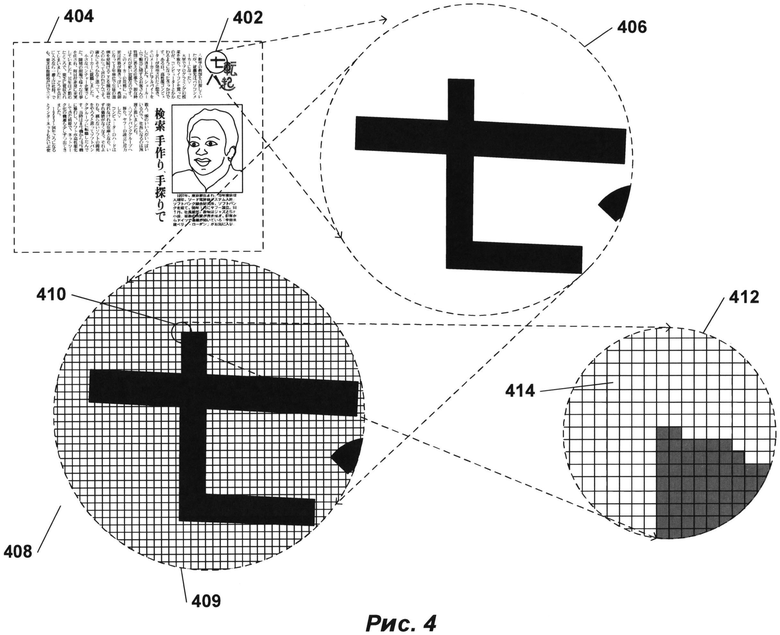
[0035] На РИС. 4 показано цифровое представление отсканированного документа. На РИС. 4 небольшой участок изображения круглой формы 402, выделенный на примере печатного документа 404, показан в увеличенном виде 406. Соответствующий участок оцифрованного изображения отсканированного документа 408 также представлен на РИС. 4. Оцифрованный отсканированный документ включает в себя данные, которые представляют собой двухмерный массив значений пикселей. В представлении 408 каждая ячейка сетки под символами (такая как, например, ячейка 409) представляет собой квадратную матрицу пикселей. Небольшой участок 410 сетки показан с еще большим увеличением (412 на РИС. 4), при котором отдельные пиксели представлены в виде элементов матрицы (таких как элемент матрицы 414). При таком уровне увеличения края символов выглядят зазубренными, поскольку пиксель является наименьшим элементом детализации, который можно использовать для излучения света заданной яркости. В файле оцифрованного отсканированного документа каждый пиксель представлен фиксированным числом битов, при этом кодирование пикселей осуществляется последовательно. Заголовочная информация, содержащаяся в файле, указывает на тип кодировки пикселей, размерах отсканированного изображения и другую информацию, позволяющую программе отображения оцифрованного отсканированного документа получать данные кодирования пикселей и передавать команды устройству отображения или принтеру с целью воспроизведения двухмерного изображения исходного документа по этим кодировкам. Изображения отсканированных документов, представленных в виде монохромных изображений в оттенках серого, обычно используют 8-разрядное или 16-разрядное кодирование пикселей, в то время как при представлении цветного отсканированного изображения может выделяться 24 или более бит для кодирования каждого пикселя, в соответствии с множеством различных стандартов кодирования цвета. Например, в широко применяемом стандарте RGB для представления интенсивности красного, зеленого и синего цветов используются три 8-разрядных значения, закодированных в рамках 24-разрядного значения. Таким образом, оцифрованное отсканированное изображение по существу представляет собой документ в той же степени, в какой цифровые фотографии представляют визуальные образы. Каждый закодированный пиксель содержит информацию о яркости света в определенных крошечных областях изображения, а для цветных изображений в нем также содержится информация о цвете. В оцифрованном изображении отсканированного документа отсутствует какая-либо информация о значении кодирования пикселей, например указание на то, что небольшая двухмерная зона соседних пикселей представляет собой текстовый символ. Изображение области, содержащей текст, можно преобразовать из пиксельного изображения в растровое при помощи процесса, называемого «бинаризацией», где каждый пиксель представлен либо значением бита «0» (указывающим, что пиксель не содержится в участке текстового символа), либо значением бита «1» (указывающим, что пиксель содержится в участке текстового символа). Обозначение битов является, конечно, произвольным, и можно применять обратные обозначения, когда значение «1» указывает на фон, а значение «0» - на символ.
[0036] В отличие от этого обычный электронный документ, созданный с помощью текстового редактора, содержит различные типы команд рисования линий, ссылки на представления изображений, таких как оцифрованные фотографии, а также текстовые символы, закодированные в цифровом виде. Одним из наиболее часто используемых стандартов для кодирования текстовых символов является стандарт Юникод. В стандарте Юникод обычно применяется 8-разрядный байт для кодирования символов ASCII (американский стандартный код для обмена информацией) и 16-разрядные слова для кодирования символов и знаков множества языков, включая японский, китайский и другие языки с неалфавитными символами. Большая часть вычислительной работы, которую выполняет программа OCR (оптического распознавания символов), связана с распознаванием изображений текстовых символов на оцифрованном изображении отсканированного документа, и с преобразованием изображений символов в соответствующие кодовые комбинации стандарта Юникод. Очевидно, что для хранения текстовых символов стандарта Юникод будет требоваться гораздо меньше места, чем для хранения пиксельных изображений текстовых символов. Кроме того, текстовые символы стандарта Юникод можно редактировать, форматировать с использованием различных шрифтов, а также обрабатывать всеми доступными в текстовых редакторах способами, в то время как оцифрованные изображения отсканированного документа можно изменить только с помощью специальных программ редактирования изображений.
[0037] На начальном этапе преобразования изображения отсканированного документа в электронный документ печатный документ анализируется для определения в нем различных областей. Во многих случаях области могут быть логически упорядочены в виде иерархического ациклического дерева, состоящего из корня, представляющего документ как единое целое, промежуточных узлов, представляющих области, содержащие меньшие области, и конечных узлов, представляющих наименьшие области. Дерево, представляющее документ, включает в себя корневой узел, соответствующий всему документу, и шесть конечных узлов, каждый из которых соответствует одной установленной области. Области можно определить, применяя к изображению разные методы, включая различные типы статистического анализа распределения кодов пикселей или значений пикселей по изображению. Например, в цветном документе фотография может показать большее изменение цвета в области фотографии, также как и более частое изменение значений яркости пикселей по сравнению с областями, содержащими текст.
[0038] Как только начальная стадия анализа определит различные области на изображении отсканированного документа, области, которые с большой вероятностью содержат текст, дополнительно обрабатываются подпрограммами OCR с целью выявления текстовых символов и преобразования их в символы стандарта Юникод или любого другого стандарта кодировки символов. Для того чтобы подпрограммы OCR могли обработать области, содержащие текст, определяется начальная ориентация области, содержащей текст, благодаря чему различные способы сопоставления эталонов могут быть успешно применены подпрограммами OCR для определения текстовых символов. Следует отметить, что изображения документов могут быть не выровнены должным образом в рамках изображений отсканированного документа из-за погрешности в расположении документа на сканере или другом устройстве, создающем изображение, из-за нестандартной ориентации областей, содержащих текст, или по другим причинам. Области, содержащие текст, затем делят на изображения подобластей, содержащие отдельные знаки или символы, после чего эти изображения подобластей, как правило, масштабируются и ориентируются, а изображения символов центрируются внутри этих изображений подобластей для облегчения последующего автоматического распознавания символов, соответствующих изображениям символов.
[0039] Следует понимать, что представленные варианты осуществления, показанные и описанные применительно к РИС. 1-4, приводятся только в качестве примера, и способы, описанные в настоящем документе, не ограничиваются конкретными реализациями, описанными на этих рисунках. В различных вариантах осуществления изображение оригинального документа может быть получено со сканирующего устройства, фотографирующего устройства (например фотокамеры), другого устройства, оснащенного камерой (например мобильных устройств, таких как смартфоны, телефоны, планшетные ПК, ноутбуки и т.п.), из файла, хранимого в памяти компьютерного устройства, из учетной записи электронной почты, из онлайн хранилища или из любого другого источника, из которого может быть получено изображение документа.
[0040] На РИС. 5, показан способ улучшения качества по меньшей мере части изображения (например, изображения, содержащего текст) в соответствии с примером осуществления изобретения. Система обработки изображения может получать или иметь заранее полученное исходное изображение документа (501). В некоторых вариантах осуществления исходное изображение документа может быть заключено в файл данных, полученный системой (например: PDF, TIFF, JPEG, RAW, GIF, BMP, PNG, документ текстового редактора, электронная таблица, набор слайдов презентации и/или любой другой формат файла, способный отображать и/или включать в себя данные в виде изображений). В некоторых вариантах осуществления исходное изображение документа может быть получено от сканирующего устройства, такого как отдельный сканер, многофункциональное устройство или другое устройство, выполненное с возможностью сканирования изображений с печатных поверхностей (например, с бумаги). В различных вариантах осуществления система может получать исходный документ от пользователя системы или от третьего лица (например, лица, не являющегося пользователем системы). В некоторых вариантах осуществления система может получать исходный документ после того, как качество документа снизилось по сравнению с исходным качеством (например, с целью снижения размера файла перед передачей по сети данных, в результате процедуры сканирования сканирующим устройством и т.п.), и процесс, представленный на РИС. 5, может использоваться для по меньшей мере частичного восстановления качества документа. В некоторых вариантах осуществления система может улучшить качество изображения отсканированного документа с дефектами качества или со сниженным качеством исходного (например, бумажного) документа (например, неправильно отсканированного документа) без необходимости в получении исходного документа (например, в случае отсутствия или недоступности исходного документа) и/или без необходимости повторного сканирования с изменением ручных настроек сканирующего устройства (например, изменений настроек для оттенков серого), необходимых для улучшения качества изображения документа.
[0041] Система может быть выполнена с возможностью анализировать изображение и сегментировать изображение на подобные участки фрагментов изображения (502). Система может выполнять поиск самоподобных областей изображения, определяя степень сходства различных областей изображения. В некоторых вариантах осуществления, где часть изображения содержит текст, система может быть выполнена с возможностью сегментирования областей изображения таким образом, чтобы каждая выделенная область содержала отдельный символ. В некоторых вариантах осуществления объединенные сегменты могут покрывать площадь, которая меньше полного исходного изображения. В некоторых вариантах осуществления самоподобные области могут перекрывать друг друга. В некоторых вариантах осуществления система может быстро искать подобные фрагменты на изображении, содержащем текст, путем применения метода или алгоритма грубого оптического распознавания символов (OCR). Система может классифицировать распознанные одинаковые символы как часть отдельного класса символов или изображений фрагментов.
[0042] Для обнаружения подобных фрагментов на изображении может быть выбрана мера, определяющая степень сходства обнаруженных фрагментов. Система может определять в значительной степени похожие фрагменты как часть класса фрагментов, где каждый фрагмент из класса является представителем класса. Система может определять, принадлежат ли фрагменты конкретному классу, по меньшей мере частично на основе того, не превышает ли мера, связанная с фрагментами, пороговое значение для выбранной меры. Размерность класса определяется количеством фрагментов в классе (например, класс размерностью 1 включает в себя один единственный фрагмент, класс размерностью 5 включает в себя пять фрагментов, и т.д.). Неповторяющийся фрагмент (то есть фрагмент, не имеющий самоподобного) может образовать отдельный класс с размерностью 1, таким образом улучшение может быть применено ко всем областям изображения. Каждый класс включает в себя подмножество выявленных в пределах документа фрагментов. Например, первый класс может включать в себя подмножество фрагментов, включающее символ «а», второй класс может включать в себя подмножество фрагментов, включающее символ «b», и т.д.
[0043] В некоторых вариантах осуществления степень сходства обнаруженных фрагментов может определяться при помощи таких мер, как среднеквадратичная мера (MSE от Mean Squared Error) или средне-абсолютная мера (МАЕ от Mean Absolute Error). Такие меры являются простыми, но могут не обеспечивать столь же точную меру степени сходства двух изображений, как может быть получена посредством субъективной оценки.
[0044] В некоторых вариантах осуществления могут использоваться другие меры сходства, например: корреляция двух изображений, расстояние Хаусдорфа (или метрика Хаусдорфа) или различные модификации разных мер. Такие меры, как расстояние Хаусдорфа, являются более точными способами измерения сходства, чем МАЕ, но требуют больших вычислительных ресурсов.
[0045] В некоторых вариантах осуществления на разных стадиях могут использоваться обе меры. Например, в некоторых вариантах осуществления система может использовать такие меры, как МАЕ или MSE, для грубой оценки сходства на первом быстром этапе выявления классов и использовать другие меры (например, более точные меры, такие как расстояние Хаусдорфа) для определения представителей классов.
[0046] В некоторых вариантах осуществления система может выполнять дополнительную обработку обнаруженных подобных фрагментов для нормализации размера, формы и/или других характеристик фрагментов в пределах каждого класса (503). Например, размер и/или форма фрагментов могут быть нормализованы таким образом, что нормализованные фрагменты будут иметь в основном одинаковые размер и/или форму после обработки. Если исходное изображение является цветным или серым, фрагменты можно нормализовать к однородной степени яркости и контраста. В некоторых вариантах осуществления для цветных фрагментов может применяться нормализация оттенков. В некоторых вариантах осуществления система может быть выполнена с возможностью нормализации фрагментов в пределах класса путем использования настроек нормализации и приведения к однородности (выравниванию) одного или множества параметров изображения, таких как яркость, контраст, насыщенность, интенсивность, тон, оттенок, гамма-коррекция и т.д. Для черно-белых (бинаризованных) изображений нормализация (например, цвета и/или яркости) может не потребоваться; выбора фрагментов с идентичным или практически похожим размером может быть достаточно.
[0047] Нормализация может быть выполнена с использованием множества различных способов. В некоторых вариантах осуществления преобразование яркости и контраста может вычисляться для каждого изображения фрагмента на основе характеристик его гистограммы с применением выравнивания гистограммы.
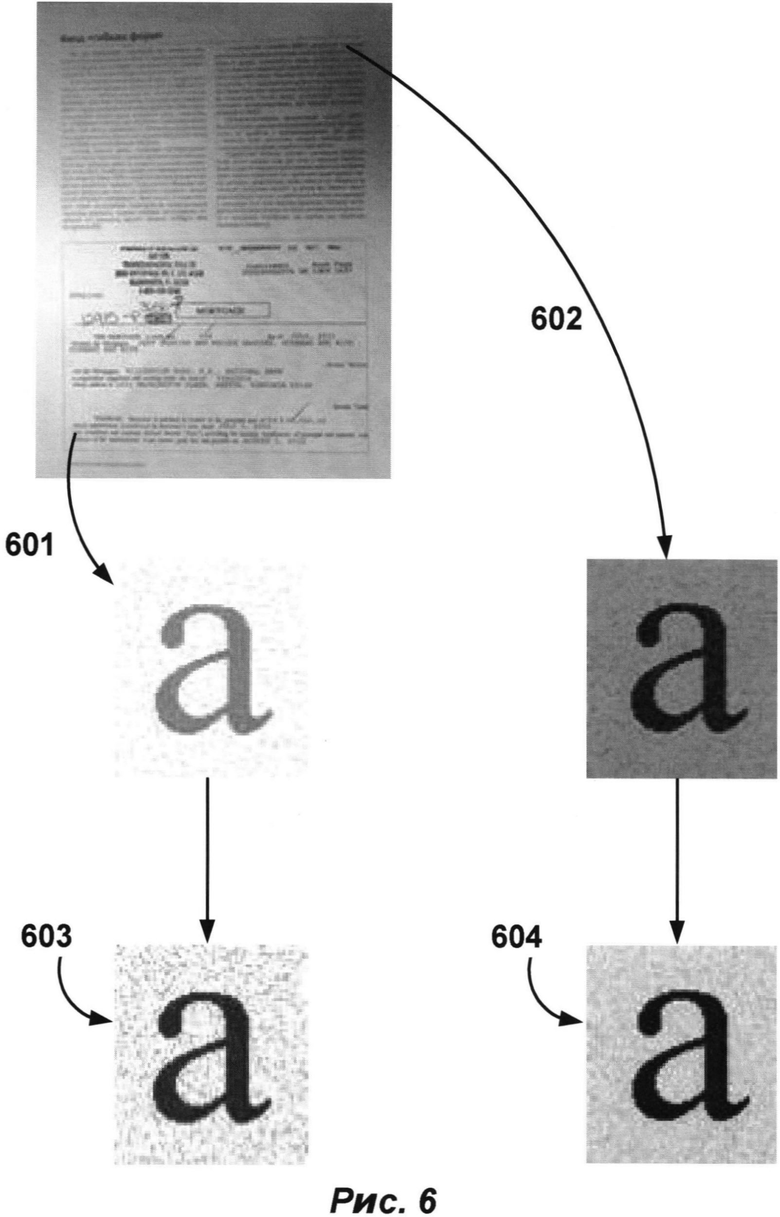
[0048] В некоторых вариантах осуществления может использоваться гистограмма, и может использоваться функция, которая для каждого значения яркости определяет количество пикселей с таким значением яркости. Обычно эту функцию представляют на графике, где ось х соответствует значениям яркости (например, от 0 до 255), а ось у обозначает количество пикселей на изображении или фрагменте изображения, имеющем данное значение яркости. Поэтому гистограмма темного участка изображения, например, такого как темный участок изображения 602, представленный на РИС. 6, будет значительно «сдвинута» влево. И наоборот, гистограмма светлого участка изображения, например такого как светлый участок изображения 601, представленный на РИС. 6, будет значительно «сдвинута» вправо. После приведения подобных фрагментов к одному диапазону контраста система может выполнить выравнивание гистограммы, чтобы распределение яркости на гистограмме фрагмента стало более ровным (см., например, обработанное светлое изображение фрагмента 603 и обработанное темное изображение фрагмента 604 на ФПГ. 6). В результате нормализации изображений фрагментов в пределах класса гистограммы всех фрагментов в пределах класса могут быть похожими.
[0049] В некоторых вариантах осуществления параметры нормализации, применяемые к конкретному фрагменту, и/или функции, связанные с каждым преобразованием гистограммы, могут быть сохранены для каждого фрагмента, чтобы система впоследствии могла применить обратные преобразования нормализации (см. 507).
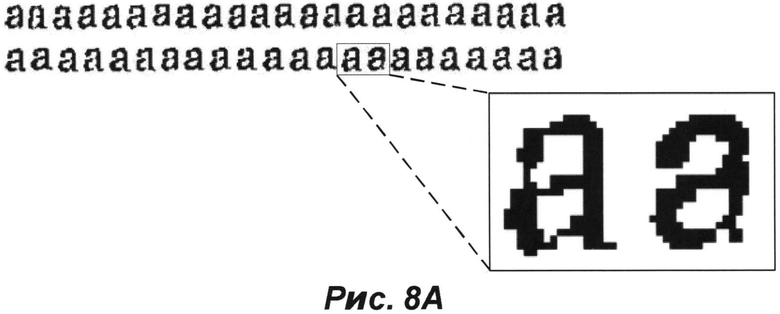
[0050] На РИС. 7А представлено бинаризованное изображение в соответствии с примером осуществления изобретения. На РИС. 8А представлено изображение конкретного класса подобных фрагментов, соответствующих символу «а», которые обнаружены на изображении показанном на РИС. 7А. Как можно увидеть на РИС. 8А, существуют визуальные различия между разными изображениями фрагментов класса, показанных на РИС. 8А до выполнения операций обработки изображения 504-508, представленных на РИС. 5.
[0051] Возвращаясь к РИС. 5 также видно, что, используя класс фрагментов (например, нормализованные фрагменты из одного класса), система может создавать комбинированное изображение фрагментов для этого класса (например, усредненное или средневзвешенное изображение класса) (504). В некоторых вариантах осуществления усредненное изображение класса может быть серым в случае черно-белых или серых фрагментов (если исходное изображение является черно-белым или серым), и значение каждого пикселя может вычисляться как среднее значение яркости соответствующих пикселей в фрагментах класса.
[0052] Формула для вычисления яркости пикселей усредненного изображения в соответствии с одним примером осуществления имеет вид: 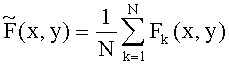
[0053] Усредненное изображение класса может быть цветным в случае цветных фрагментов и вычисляется подобным образом в зависимости от цветовой модели. Например, в модели RGB может вычисляться среднее значение каждого цветового параметра (красного, зеленого и синего) для пикселя.
[0054] В некоторых вариантах осуществления могут применяться более сложные методы усреднения. Например, вместо применения усредненного изображения может вычисляться средневзвешенное изображение класса с использованием определенных оценок (весов) для каждого фрагмента в классе.
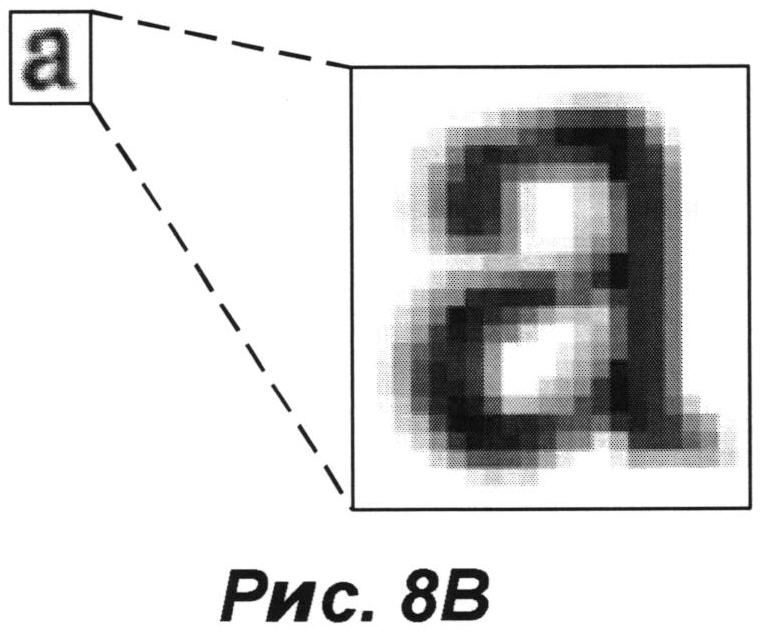
[0055] На РИС. 8В представлено усредненное изображение для класса фрагментов, состоящего из изображений символа «а», показанного на РИС. 8А, которое можно получить в результате операций усреднения, таких как операция (504), в соответствии с примером осуществления изобретения.
[0056] В некоторых вариантах осуществления могут использоваться способы комбинации отличные от усреднения.
[0057] Возвращаясь снова к РИС. 5, различные способы фильтрации для обработки серых и/или цветных изображений могут применяться к усредненному изображению. В некоторых вариантах осуществления система может быть выполнена с возможностью существенного увеличения полученного усредненного изображений классов (505) и/или выполнения специальной фильтрации на изображениях фрагментов (506). Для получения улучшенного визуального качества может применяться способ масштабирования изображения (например, билинейная интерполяция, бикубическая интерполяция сплайнами, алгоритмы масштабирования пиксельной графики и т.д.), в котором учитываются значения пикселей, расположенных в окрестности увеличиваемого пикселя. На РИС. 8С представлено увеличенное изображение класса, полученное из усредненного изображения класса, показанного на РИС. 8 В, в соответствии с примером осуществления. В некоторых вариантах осуществления система может увеличивать изображения классов в несколько раз (например, в 2, в 3, в 5 и т.д.) по отношению к исходному размеру фрагмента(-ов) изображения. В некоторых вариантах осуществления система может значительно увеличивать изображение классов, вследствие чего фрагмент(-ы) изображения выглядит(-ят) заметно больше при представлении пользователю, а дефекты документа более заметны читателю. В некоторых вариантах осуществления система может существенно увеличивать изображения классов таким образом, что при использовании мобильного вычислительного устройства и просмотре изображения документа на маленьком экране изображение классов можно увеличивать до размера, приемлемого для чтения пользователем.
[0058] В некоторых вариантах осуществления система может быть выполнена с возможностью увеличения изображений фрагментов перед созданием усредненного изображения фрагментов для класса. В таких вариантах осуществления усредненное изображение может вычисляться используя увеличенные фрагменты.
[0059] Возвращаясь к РИС. 5, появление различных шумов и искажений на контурах (очертаниях) объектов или частей объектов неизбежно, даже после масштабирования усредненного изображения. Для снижения шумов и сглаживания контуров может применяться специальный фильтр (506). Такой фильтр может учитывать природу искажений, присущих выбранному способу масштабирования, и/или информацию, содержащуюся в изображении (текстовая информация, графическая и т.д.).
[0060] В некоторых вариантах осуществления, в случаях масштабирования методом билинейной или бикубической интерполяции, фильтр является нелинейным, двумерным ранговым оператором с квадратным окном (2r+1)*(2r+1). Окно покрывает текущий пиксель (в центре) и учитывает его соседние пиксели. Для каждого элемента окна можно вычислить свертку с предварительно заданным ядром.
[0061] Затем система может упорядочить полученные значения по возрастанию, и элемент упорядоченного массива с номером ((2r+1)*(2r+1)+1)/2 может быть результатом рангового оператора. Такой фильтр может значительно снизить смешанные равномерные и импульсные шумы вокруг контуров объектов.
[0062] Например, в некоторых вариантах осуществления могут использоваться следующие параметры. В случае трехкратного масштабирования посредством бикубической интерполяцией сглаживание может выполняться описанным фильтром, где свертка выполняется с ядром 3×3 следующего типа:

[0063] Изображение, сглаженное таким фильтром, может подвергаться дополнительной обработке. Например, в некоторых вариантах осуществления может выполняться дополнительная фильтрация контура, такая как способы фильтрации, описанные ниже.
[0064] В некоторых вариантах осуществления, например, для нетекстовых изображений (или областей изображений) может применяться коллаборативная (совместная) фильтрация и/или винеровская фильтрация. Процедура коллаборативной фильтрации может выполнять поиск подобных фрагментов, которые могут частично перекрывать друг друга, и сбор фрагментов в серию по одному (наподобие стопки) для последующего выполнения совместной фильтрации этой серии. В некоторых вариантах осуществления система может использовать для фильтрации алгоритм сопоставления блоков с ЗD-преобразованием (BM3D от "Block-Matching and 3D") или подобный коллаборативный алгоритм.
[0065] Если исходное изображение является черно-белым, итоговое изображение также может быть черно-белым. В таких вариантах осуществления предварительно сглаженное изображение может быть бинаризовано, а затем координатный фильтр может обработать точки контура. Координаты точек можно рассматривать как одномерные сигналы xi и yi. Одномерный сигнал может обрабатываться фильтром, использующим усреднение, сглаживание Гаусса, фильтрацию Баттерворта или другие способы фильтрационной обработки. В некоторых вариантах осуществления могут использоваться рекурсивные способы фильтрации. Затем полученные координаты точек контура могут быть перерисованы в итоговом изображении.
[0066] В некоторых вариантах осуществления, когда исходное изображение является серым или черно-белым, может выполняться растровая контурная фильтрация. Сначала находятся области контуров, на которых следует применить пространственное сглаживание вдоль линии контура. Для этой цели может вычисляться градиент в каждой точке изображения. Модуль градиента и направление его вектора могут указывать на необходимость сглаживания. Можно избегать сглаживания в местах резких ступенчатых изменений направления градиента. Наилучшие результаты могут достигаться, если сглаживание выполняется итеративно, пока не будет достигнута требуемая степень сглаженности.
[0067] После применения всех требуемых улучшающих фильтров к увеличенному усредненному изображению класса, улучшенное большое изображение класса будет иметь более высокое визуальное качество. Например, на ФПГ. 8D представлено улучшенное изображение класса после выполнения фильтрации изображения, показанного на РИС. 8С, в соответствии с примером осуществления.
[0068] Упрощенная процедура улучшения визуального качества может применяться для классов с размерностью 1 (если только один единственный фрагмент создает класс). Например, в некоторых таких вариантах осуществления может применяться только контурная фильтрация или контурная фильтрация в комбинации только с набором дополнительных упрощенных фильтров. В некоторых вариантах осуществления все неповторяющиеся фрагменты обрабатываются совместно в пределах исходного изображения.
[0069] В некоторых вариантах осуществления улучшенное усредненное изображение класса может использоваться в качестве замены для каждого представителя класса на увеличенном изображении. В некоторых вариантах осуществления из улучшенного усредненного изображения класса можно получить улучшенный фрагмент для каждого представителя класса путем преобразования обратного нормализации (507). Параметры обратной нормализации можно получить для каждого фрагмента на основе параметров, которые были использованы для нормализации этого фрагмента.
[0070] Качество исходного изображения можно улучшить путем изменения изображений фрагментов, соотнесенных с каждым классом, на основе обработанного показательного (например, усредненного) изображения для класса и/или обратно нормализованных представителей класса (508). В некоторых вариантах осуществления фрагменты в исходном изображении можно заменять улучшенными изображениями фрагментов или улучшенным изображением соответствующего класса. В некоторых вариантах осуществления фрагменты в исходном изображении могут быть изменены на основе улучшенных изображений фрагментов для повышения качества исходных фрагментов. Полученное в результате изображение документа может являться улучшенным изображением документа с более высоким качеством, чем у исходного изображения документа (509). Например, на РИС. 7В представлена улучшенная версия бинаризованного изображения, показанного на РИС. 7А, после применения такой обработки, как процесс, представленный на РИС. 5, в соответствии с примером осуществления. Что касается серых изображений, на РИС. 9В представлена улучшенная версия серого изображения, показанного на РИС. 9А, после применения такой обработки, как процесс, представленный на РИС. 5, в соответствии с примером осуществления.
[0071] В некоторых вариантах осуществления такой способ, как способ, представленный на РИС. 5, может применяться в таких технологиях, как MRC-сжатие (от "Mixed Raster Content" - смешанное растровое содержимое), для получения улучшенного качества монохромной маски. Применение такой улучшенной маски может привести к повышению визуального качества текста в сжатых файлах.
[0072] В некоторых вариантах осуществления такой способ, как способ, представленный на РИС. 5, может применяться к широкому спектру типов изображений. Если характеристики обрабатываемого изображения изначально неизвестны, можно использовать более специфичные параметры и фильтры. Более того, предварительные профили с подобранными параметрами могут быть созданы для разных типов изображений, позволяющие пользователю выбрать профиль, соответствующий обрабатываемому изображению. В некоторых вариантах осуществления профили могут автоматически выбираться системой за счет использования способов обработки и/или распознавания изображений.
[0073] В некоторых вариантах осуществления такой способ, как способ, представленный на РИС. 5, может использоваться для повышения качества участка изображения, а не целого изображения. Например, выбор участка изображения может быть получен от пользовательского устройства ввода. В некоторых вариантах осуществления выбор может выполняться через сенсорный экран мобильного вычислительного устройства, например, смартфона, планшета, ноутбука и т.п. Например, пользователь может указать на необходимое изменение масштаба участка отображаемого изображения документа путем растяжения пальцами, двойного касания или иным способом. В ответ устройство пользователя может отобразить увеличенное представление выбранного участка изображения документа. Устройство пользователя и/или серверное устройство, предоставляющее изображение документа, может быть выполнено с возможностью обработки для предоставления более детального отображения увеличенного участка по сравнению с нормальным, полноэкранным отображением изображения документа.
[0074] В некоторых вариантах осуществления система (например, устройство пользователя и/или серверное устройство, предоставляющее изображение документа устройству пользователя) может быть выполнена с возможностью выполнения обработки, подобной операциям, показанным на РИС. 5, для создания увеличенного участка изображения с более высоким качеством. Система может анализировать выбранный участок изображения и разделять этот участок изображения на фрагменты изображения. В некоторых вариантах осуществления система может обрабатывать изображение документа целиком для выявления изображений подобных фрагментов и включения их в классы изображений фрагментов. Исползование целого документа для классификации изображений фрагментов может повысить качество итогового увеличенного участка изображения, поскольку стадии усреднения и/или фильтрации могут опираться на большее количество образцов изображений фрагментов из изображения документа. В некоторых вариантах осуществления классификация изображений фрагментов может выполняться на основе только тех фрагментов (например, символов), которые включены в выбранный участок изображения. Использование только выбранного участка изображения может снизить требования к вычислительным ресурсам, необходимым для выполнения операций обработки изображения.
[0075] После того как изображения фрагментов были разделены по классам, фрагменты могут быть усреднены, увеличены и/или отфильтрованы в соответствии с операциями, представленными на РИС. 5 и подробно описанными выше. В некоторых вариантах осуществления система может существенно увеличивать изображения классов, вследствие чего при просмотре изображения документа на небольшом экране мобильного вычислительного устройства, такого как смартфон, изображения фрагмента (фрагментов) могут быть увеличены до размера, котрый обычно удобен пользователю для чтения. Полученные в результате обработанные изображения фрагментов можно использовать для замены или других изменений фрагментов изображения на выбранной области, для создания увеличенной области с улучшенным качеством изображения. Улучшенная увеличенная область может затем отображаться на устройстве пользователя. В некоторых вариантах осуществления этот способ может выполняться в фоне (то есть незаметно от пользователя). В некоторых вариантах осуществления параметры, результаты и/или другие данные, связанные с выполненной обработкой, могут сохраняться в памяти для ускоренной обработки других областей в пределах изображения документа. В некоторых вариантах осуществления может быть выполнено повышение качества всего изображения документа во время улучшения качества выбранного участка, но отображать можно только выбранный участок, пока пользователь не уменьшит масштаб выбранного участка.
[0076] На РИС. 10 представлена система 1000, которая может улучшить текстовое изображение за счет применения методик, описанных выше, согласно некоторым вариантам осуществления, приведенным в описании. Система 1000, как правило, включает в себя по меньшей мере один процессор 1002, связанный с памятью 1004. Процессор 1002 может представлять собой один или более процессоров (например, микропроцессоров), а память 1004 может представлять собой оперативные запоминающие устройства (ОЗУ), содержащие главное устройство хранения системы 1000 и/или любые дополнительные уровни памяти, например кэш-память, энергонезависимую память или резервные запоминающие устройства (например, программируемая или флэш-память), ПЗУ и т.п. Кроме того, память 1004 может включать в себя запоминающие устройства, физически расположенные в каком-либо другом месте в системе 1000 (например, любая кэш-память в процессоре) 1002, а также любые запоминающие устройства, используемые в качестве виртуальной памяти (например, съемные запоминающие устройства 1010).
[0077] Как правило, система 1000 также имеет ряд входов и выходов для обмена информацией с внешними устройствами. Система 1000 может включать в себя одно или более устройств пользовательского ввода 1006 (например, клавиатуру, мышь, сканер и т.п.) и дисплей 1008 (например, жидкокристаллический дисплей (ЖКД)) для взаимодействия с пользователем и/или оператором. В качестве дополнительного устройства хранения аппаратное обеспечение 1000 также может включать в себя одно или более съемных запоминающих устройств 1010, например, помимо прочего, накопитель на гибких магнитных или иных съемных дисках, накопитель на жестком магнитном диске, запоминающее устройство с прямым доступом (DASD), оптический привод (например, привод компакт-дисков (CD), компакт-дисков в формате DVD и т.д.) и/или ленточный накопитель. Более того, система 1000 может включать в себя интерфейс для взаимодействия с одной или более сетями 1012 (например, помимо прочего, локальной сетью (LAN), глобальной сетью (WAN), беспроводной сетью и/или Интернетом) для обеспечения обмена информацией с другими компьютерами, подключенными к сетям. Следует принимать во внимание, что система 1000, как правило, включает в себя подходящие аналоговые и/или цифровые интерфейсы между процессором 1002 и каждым из компонентов 1004, 1006, 1008 и 1012, что хорошо известно специалистам в данной области.
[0078] Система 1000 работает под управлением операционной системы 1014, и на ней выполняются различные компьютерные программные приложения, компоненты, программы, объекты, модули и т.п., в совокупности обозначенные ссылкой под номером 1016, для реализации вышеописанных методик коррекции.
[0079] В общем случае процедуры, выполняемые для реализации вариантов осуществления настоящего описания, могут быть реализованы в виде компонента операционной системы или специального приложения, компонента, программы, объекта, модуля или последовательности команд, которые именуют «компьютерными программами». Компьютерные программы, как правило, содержат один или более наборов команд, размещенных в разное время на разных устройствах памяти и хранения в компьютере, которые при их считывании и исполнении одним или более процессорами компьютера приводят к выполнению компьютером операций, необходимых для исполнения элементов описанных вариантов осуществления. Более того, настоящее изобретение описано в контексте полностью функциональных компьютеров и компьютерных систем, и специалистам в данной области будет понятно, что различные варианты осуществления описания можно распространять в качестве программного продукта в различных формах, и что описание в равной степени применяется независимо от конкретного типа устройства или машиночитаемого носителя, используемого для осуществления распространения. Примеры машиночитаемых носителей включают в себя, без ограничений, носители с возможностью записи, такие как устройства оперативной и энергонезависимой памяти, гибкие магнитные и другие съемные диски, жесткие диски, оптические диски (например, ПЗУ на компакт-дисках (CD-ROM), компакт-диски в формате DVD, и т.д.) и носители с возможностью передачи данных, такие как цифровые и аналоговые каналы связи. Машиночитаемые носители, входящие в настоящее описание, включают в себя только некратковременные носители (то есть не включают в себя кратковременные сигналы в пространстве).
[0080] Хотя настоящее описание приводится со ссылкой на конкретные примеры осуществления, следует понимать, что к этим вариантам осуществления могут применяться различные модификации без изменения изначальной сущности изобретения. В связи с этим спецификации и рисунки следует рассматривать как иллюстрации, а не как ограничения.




Изобретение относится к области обработки изображений. Техническим результатом является повышение качества исходных фрагментов изображений за счет осуществления фильтрации. Предложен способ обработки изображения документа. Способ включает в себя этап, на котором осуществляют идентификацию при помощи вычислительного устройства, содержащего один или более процессоров, множества изображений фрагментов в пределах изображения документа. Далее согласно способу осуществляют разделение при помощи вычислительного устройства множества изображений фрагментов на множество классов, причем каждый класс из множества классов включает в себя подмножество из множества изображений фрагментов, которые в значительной степени похожи друг на друга, где определение степени похожести одного фрагмента изображения на другой осуществляется на основании заданной меры, определяющей степень сходства между этими фрагментами. 3 н. и 18 з.п. ф-лы, 15 ил.
1. Способ обработки изображения документа, содержащий: идентификацию при помощи вычислительного устройства, содержащего один или более процессоров, множества изображений фрагментов в пределах изображения документа;
разделение при помощи вычислительного устройства множества изображений фрагментов на множество классов, причем каждый класс из множества классов включает в себя подмножество из множества изображений фрагментов, которые в значительной степени похожи друг на друга, где определение степени похожести одного фрагмента изображения на другой осуществляется на основании заданной меры, определяющей степень сходства между этими фрагментами;
для каждого из множества классов:
обработку при помощи вычислительного устройства класса изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса, где комбинированное изображение представляет по меньшей мере усредненное или средневзвешенное изображение; где существенно увеличенное изображение класса представляет по меньшей мере увеличение изображения класса до размера, приемлемого для чтения пользователем;
фильтрацию при помощи вычислительного устройства комбинированного и существенно увеличенного изображения класса с использованием по меньшей мере одной из процедур ранговой фильтрации и процедур контурной фильтрации для создания отфильтрованного изображения для класса; и
создание при помощи вычислительного устройства улучшенного изображения документа путем замены или изменения изображений фрагментов в пределах изображения документа на основе отфильтрованных изображений для соответствующих классов изображений фрагментов.
2. Способ по п. 1, в котором обработка класса изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса содержит:
создание комбинированного изображения класса на основе изображений фрагментов из класса; и
создание комбинированного и существенно увеличенного изображения класса путем существенного увеличения комбинированного изображения класса.
3. Способ по п. 1, в котором обработка класса изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса содержит:
существенное увеличение изображений фрагментов из класса для создания существенно увеличенных изображений фрагментов; и
комбинирование существенно увеличенных изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса.
4. Способ по п. 1, дополнительно содержащий для каждого из множества классов нормализацию изображений фрагментов из класса перед обработкой класса изображений фрагментов с целью создания комбинированного и существенно увеличенного изображения класса.
5. Способ по п. 4, дополнительно содержащий для каждого из множества классов выполнение обратной нормализации для каждого изображения фрагмента в классе изображений фрагментов перед созданием улучшенного изображения документа, причем создание улучшенного изображения документа содержит замену изображений фрагментов в пределах изображения документа соответствующими улучшенными изображениями фрагментов из множества классов после выполнения обратной нормализации.
6. Способ по п. 1, в котором обработка класса изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса содержит усреднение изображений фрагментов класса.
7. Способ по п. 1, в котором каждый из множества изображений фрагментов представляет собой один отдельный символ или часть отдельного символа, и разделение множества изображений фрагментов на множество классов содержит группирование вместе всех изображений фрагментов, представляющих одинаковый символ или одинаковую часть символа, в пределах отдельного класса из множества классов.
8. Способ по п. 1, в котором множество классов содержит первое множество классов, и в котором разделение множества изображений фрагментов содержит выделение множества изображений фрагментов в первое множество классов и во второе множество классов, причем каждый из второго множества классов содержит единственное изображение фрагмента, не имеющее других в значительной степени подобных изображений фрагментов в пределах множества изображений фрагментов, причем способ дополнительно содержит для каждого из второго множества классов фильтрацию единственного изображения фрагмента из класса для создания отфильтрованного изображения фрагмента для класса.
9. Способ по п. 1, в котором изображение документа содержит отсканированное изображение документа, полученное от третьего лица, и причем создание улучшенного изображения документа содержит восстановление по меньшей мере части качества изображения, потерянного в результате по меньшей мере одной из процедур сканирования или уменьшения размера файла перед получением изображения документа вычислительным устройством.
10. Способ по п. 9, в котором изображение документа было предварительно получено от сканирующего устройства, причем изображение документа было отсканировано сканирующим устройством из по меньшей мере одного физического документа, и причем качество предварительно полученного изображения документа хуже, чем качество по меньшей мере одного физического документа.
11. Способ по п. 10, в котором качество предварительно полученного изображения документа хуже, чем качество по меньшей мере одного физического документа из-за применения неправильных настроек сканирующего устройства во время процедуры сканирования, и в котором создание улучшенного изображения документа содержит восстановление по меньшей мере части качества изображения, потерянного в результате использования неправильных настроек сканирующего устройства, без необходимости повторного сканирования документа.
12. Способ по п. 1, в котором обработка класса изображений фрагментов для создания комбинированного и существенно увеличенного изображения фрагмента для класса содержит существенное увеличение одного или более изображений фрагментов, вследствие чего они становятся заметно больше при представлении пользователю, а дефекты в одном или более изображениях фрагментов становятся более заметны пользователю.
13. Система обработки изображения документа, содержащая:
по меньшей мере одно вычислительное устройство, функционально связанное с по меньшей мере одним устройством памяти и выполненное с возможностью:
идентификации множества изображений фрагментов в пределах изображения документа;
разделения множества изображений фрагментов на множество классов, причем каждый класс из множества классов включает в себя подмножество из множества изображений фрагментов, которые в значительной степени похожи друг на друга, где определение степени похожести одного фрагмента изображения на другой осуществляется на основании заданной меры, определяющей степень сходства между этими фрагментами;
для каждого из множества классов:
обработки класса изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса, где комбинированное изображение представляет по меньшей мере усредненное или средневзвешенное изображение, где существенно увеличенное изображение класса представляет по меньшей мере увеличение изображения класса до размера, приемлемого для чтения пользователем;
фильтрации комбинированного и существенно увеличенного изображения класса с использованием по меньшей мере одной из процедур ранговой фильтрации и процедур контурной фильтрации для создания отфильтрованного изображения для класса; и
создания улучшенного изображения документа путем замены или изменения изображений фрагментов в пределах изображения документа на основе отфильтрованных изображений для соответствующих классов изображений фрагментов.
14. Система по п. 13, в которой по меньшей мере одно вычислительное устройство выполнено с возможностью обработки класса изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса путем:
усреднения изображений фрагментов из класса для создания усредненного изображения класса; и
создания комбинированного и существенно увеличенного изображения класса путем существенного увеличения усредненного изображения класса.
15. Система по п. 13, в которой по меньшей мере одно вычислительное устройство выполнено с возможностью обработки класса изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса путем:
существенного увеличения изображений фрагментов из класса для создания существенно увеличенных изображений фрагментов; и
усреднения существенно увеличенных изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса.
16. Система по п. 13, в которой по меньшей мере одно вычислительное устройство дополнительно выполнено с возможностью для каждого из множества классов нормализации изображений фрагментов из класса перед обработкой класса изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса.
17. Система по п. 16, в которой по меньшей мере одно вычислительное устройство дополнительно выполнено с возможностью осуществления для каждого из множества классов обратной нормализации для каждого изображения фрагмента в классе изображений фрагментов перед созданием улучшенного изображения документа, причем по меньшей мере одно вычислительное устройство выполнено с возможностью замены изображений фрагментов в пределах изображения документа соответствующими улучшенными изображениями фрагментов из множества классов после выполнения обратной нормализации.
18. Система по п. 13, в которой каждый из множества изображений фрагментов представляет собой один отдельный символ или часть отдельного символа, и причем по меньшей мере одно вычислительное устройство выполнено с возможностью разделения множества изображений фрагментов на множество классов путем группирования вместе всех изображений фрагментов, представляющих одинаковый символ или одинаковую часть символа, в пределах отдельного класса из множества классов.
19. Машиночитаемый носитель данных, имеющий хранящиеся на нем инструкции, исполнение которых процессором приводит к выполнению процессором операций, содержащих:
идентификацию множества изображений фрагментов в пределах изображения документа, причем каждый из множества изображений фрагментов представляет собой один отдельный символ или часть отдельного символа;
разделение множества изображений фрагментов на множество классов, причем каждый класс из множества классов включает в себя подмножество из множества изображений фрагментов, которые в значительной степени похожи друг на друга, и причем изображения фрагментов, представляющие одинаковый символ или одинаковую часть символа, сгруппированы в отдельный класс из множества классов;
для каждого из множества классов:
нормализацию изображений фрагментов из класса для создания нормализованного набора изображений фрагментов класса;
обработку нормализованного набора изображений фрагментов из класса для создания комбинированного и существенно увеличенного изображения класса;
фильтрацию комбинированного и существенно увеличенного изображения класса с использованием по меньшей мере одной из процедур ранговой фильтрации и процедур контурной фильтрации для создания отфильтрованного изображения для класса;
изменение каждого изображения фрагмента из нормализованного набора изображений фрагментов класса на основе отфильтрованного изображения для класса; и
выполнение обратной нормализации для каждого изображения фрагмента из нормализованного набора изображений фрагментов для создания итогового набора изображений фрагментов для класса; и
создание улучшенного изображения документа путем замены или изменения изображений фрагментов в пределах изображения документа на основе изображений фрагментов в итоговом наборе изображений фрагментов для соответствующих классов изображений фрагментов.
20. Машиночитаемый носитель данных по п. 19, в котором обработка нормализованного набора изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса содержит:
усреднение нормализованного набора изображений фрагментов для создания усредненного изображения класса; и
создание комбинированного и существенно увеличенного изображения класса путем существенного увеличения усредненного изображения класса.
21. Машиночитаемый носитель данных по п. 19, в котором обработка нормализованного набора изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса содержит:
существенное увеличение нормализованного набора изображений фрагментов для создания двух или более существенно увеличенных изображений фрагментов; и
усреднение двух или более существенно увеличенных изображений фрагментов для создания комбинированного и существенно увеличенного изображения класса.
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Изложница с суживающимся книзу сечением и с вертикально перемещающимся днищем | 1924 |
|
SU2012A1 |
| Приспособление для суммирования отрезков прямых линий | 1923 |
|
SU2010A1 |
| Топчак-трактор для канатной вспашки | 1923 |
|
SU2002A1 |
| СПОСОБ РАСПОЗНАВАНИЯ ТЕКСТА С ПРИМЕНЕНИЕМ НАСТРАИВАЕМОГО КЛАССИФИКАТОРА | 2002 |
|
RU2234126C2 |
| СПОСОБ АВТОМАТИЧЕСКОЙ КЛАССИФИКАЦИИ ДОКУМЕНТОВ | 2003 |
|
RU2254610C2 |

