ОБЛАСТЬ ТЕХНИКИ, К КОТОРОЙ ОТНОСИТСЯ ИЗОБРЕТЕНИЕ
Настоящее изобретение относится к устройству распознавания речи и к способу распознавания речи, которые могут осуществлять распознавание речи, состоящей из смешанного словаря зарегистрированных слов, являющихся уникальными для конкретного человека, и слов общего характера, являющихся общими для всех людей.
УРОВЕНЬ ТЕХНИКИ
Способ распознавания зарегистрированных слов, являющихся уникальными для конкретного человека, обычно называют распознаванием речи конкретного говорящего субъекта. В способе распознавания речи конкретного говорящего субъекта задачу решают посредством записи голоса конкретного человека (его или ее), произносящего слова, которые он или она желают распознать. В частности, эта задача включает в себя преобразование образцов речевой информации в виде слов, которые говорящий субъект создает заранее путем произнесения этих слов, в последовательность параметров отличительных признаков (именуемых эталонами) и накопления последовательности вместе с обозначениями слов в запоминающем устройстве, например в устройстве памяти или на жестком диске. Одними из известных способов преобразования образцов речевой информации в последовательность параметров отличительных признаков являются спектральный анализ и анализ с линейным предсказанием. Они подробно описаны в книге К. Кано, Т. Накамуры и С. Изе "Цифровая обработка сигналов речевой/звуковой информации" издательства Шокодо ("Digital Signal Processing of Speech/Sound Information" by K. Kano, T. Nakamura and S. Ise, published by Shokodo). Процесс распознавания речи конкретного говорящего субъекта заключается в сравнении последовательности параметров отличительных признаков, полученной путем преобразования вводимых речевых данных, с последовательностью параметров отличительных признаков, хранящейся в запоминающем устройстве, а на выходе в качестве результата получают обозначение того слова, последовательность параметров отличительных признаков которого является наиболее близкой к последовательности, полученной путем преобразования вводимых речевых данных.
Широко используемым способом сравнения последовательности параметров отличительных признаков, хранящейся в запоминающем устройстве, с последовательностью параметров отличительных признаков, полученной путем преобразования вводимых речевых данных, является способ динамической трансформации шкалы времени (ДТШВ) (DTW), основанный на динамическом программировании. Этот способ подробно изложен в книге "Цифровая обработка сигналов речевой/звуковой информации" ("Digital Signal Processing of Speech/Sound Information").
Способ распознавания слов общего характера, являющихся общими для всех людей, обычно называют распознаванием речи произвольного говорящего субъекта. При распознавании речи произвольного говорящего субъекта информацию о параметрах отличительных признаков слов общего характера, являющихся общими для произвольных говорящих субъектов, предварительно запоминают в запоминающем устройстве, и, следовательно, отсутствует необходимость осуществлять запись произносимых слов, которые пользователь желает распознать, что является необходимым условием при распознавании речи конкретного говорящего субъекта. Как и при распознавании речи конкретного говорящего субъекта, известные способы преобразования образцов речевой информации в последовательность параметров отличительных признаков включают в себя спектральный анализ и анализ с линейным предсказанием. Генерацию информации о параметрах отличительных признаков слов общего характера, являющихся общими для произвольных говорящих субъектов, и сравнение этой информации с последовательностью параметров отличительных признаков, полученной путем преобразования вводимых речевых данных, обычно осуществляют с использованием способа скрытой марковской модели (СММ).
Способ распознавания речи произвольного говорящего субъекта также подробно изложен в книге "Цифровая обработка сигналов речевой/звуковой информации" ("Digital Signal Processing of Speech/Sound Information"). Например, для японского языка предполагают, что каждый из единичных элементов речи состоит из набора фонем, которые описаны во второй главе книги "Цифровая обработка сигналов речевой/звуковой информации", и что отдельные фонемы моделируют посредством СММ. В Таблице 1 приведен список обозначений для набора фонем.
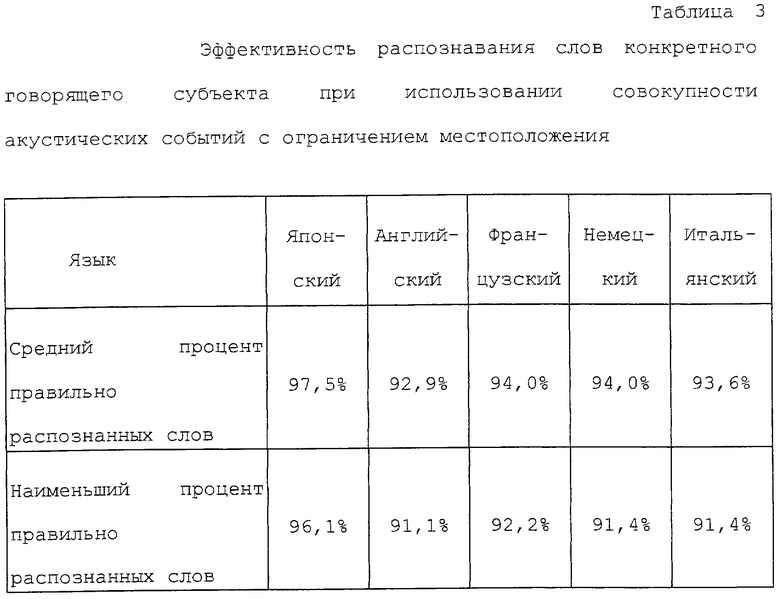
Например, фонетический звук "СиДи" ("компакт-диск") ("CD") может быть смоделирован посредством совокупности обозначений фонем, являющихся общими для говорящих субъектов (именуемой последовательностью обозначений для слов общего характера), которая показана на Фиг.2А.
Например, фонетический звук "ЭмДи" ("минидиск") ("MD") может быть смоделирован посредством последовательности обозначений для слов общего характера, показанной на Фиг.2Б. Путем обработки данных о модели фонемы, полученной посредством СММ, и последовательностей обозначений для слов общего характера, специалист в данной области техники может создать устройство распознавания речи произвольного говорящего субъекта с использованием алгоритма Витерби, который описан в четвертой главе книги "Цифровая обработка сигналов речевой/звуковой информации".
В устройстве распознавания речи необходимо обеспечить наличие функции распознавания смешанного словаря, состоящего из зарегистрированных слов, являющихся уникальными для конкретного говорящего субъекта, и из слов общего характера, являющихся общими для произвольных говорящих субъектов. Например, в звуковом оборудовании для автомобиля, исходя из соображений обеспечения безопасности, управление такими устройствами как "компакт-диск" ("СиДи") ("CD") и "минидиск" ("ЭмДи") ("MD") необходимо осуществлять посредством речевых команд. Поскольку названия этих устройств могут быть заданы, как правило, произвольными говорящими субъектами, то это условие может быть удовлетворено посредством способа распознавания речи произвольного говорящего субъекта, в котором отсутствует процесс записи, являющийся обязательным в способе распознавания речи конкретного говорящего субъекта. Этот вариант является преимущественным с точки зрения интерфейса пользователя.
Также существует необходимость обеспечения возможности выбора и воспроизведения одного желательного компакт-диска из множества компакт-дисков, вставленных в устройство автоматической смены компакт-дисков. В этом случае считают, что имена исполнителей и заголовки компакт-дисков, вставленных в устройство автоматической смены компакт дисков, являются различными в зависимости от пользователя. Следовательно, вместо обычного способа распознавания речи произвольного говорящего субъекта необходимо использовать способ распознавания речи конкретного говорящего субъекта. То есть пользователь должен заранее зарегистрировать посредством голоса названия заголовков и имена исполнителей тех компакт-дисков, которые будут вставлены в устройство автоматической смены компакт дисков. В том случае, если распознавание речи может быть осуществлено посредством смешанного словаря, состоящего из названий устройств, таких как "компакт-диск" ("СиДи") или "минидиск" ("ЭмДи"), и названий заголовков компакт-дисков и имен исполнителей, то нет никакой необходимости осуществлять переключение между режимом, при котором может быть выполнено распознавание слов общего характера, являющихся общими для произвольных говорящих субъектов, таких как "СиДи" ("компакт-диск") или "ЭмДи" ("минидиск"), и режимом, при котором может быть выполнено распознавание зарегистрированных слов, являющихся уникальными для конкретного говорящего субъекта, таких как названия заголовков компакт-дисков и имена исполнителей. Полагают, что посредством этого может быть обеспечена функция распознавания речи, которая является удобной для пользователя.
До сих пор при распознавании речи конкретного говорящего субъекта в большинстве случаев использовали способ, основанный на алгоритме динамической трансформации шкалы времени (ДТШВ) (DTW), а при распознавании речи произвольного говорящего субъекта использовали способ, основанный на СММ. Одним из возможных решений, обеспечивающим выполнение описанных выше требований, может являться объединение способа распознавания речи конкретного говорящего субъекта, основанного на алгоритме ДТШВ и способа распознавания речи произвольного говорящего субъекта, основанного на СММ. Используемые в этих двух способах критерии сравнения последовательности параметров введенной речевой информации с информацией о последовательности параметров из словаря, хранящегося в запоминающем устройстве, являются, в общем случае, различными. Следовательно, принятие решения о том, какое из слов: зарегистрированное слово, являющееся уникальным для конкретного говорящего субъекта, которое определено посредством способа распознавания речи конкретного говорящего субъекта на основе алгоритма ДТШВ в качестве наиболее близкого к введенной речевой информации, или слово общего характера, являющееся общим для произвольных говорящих субъектов, которое определено посредством способа распознавания речи произвольного говорящего субъекта, основанного на СММ, в качестве наиболее близкого к введенной речевой информации, является более близким к введенному речевому сигналу, представляет собой непростую задачу.
В способе распознавания речи конкретного говорящего субъекта на основе алгоритма ДТШВ распознавание речи произвольного говорящего субъекта можно реализовать посредством использования для слова общего характера речевых сигналов от множества говорящих субъектов и запоминания множества эталонов для этого слова. Следовательно, вышеуказанные требования могут быть выполнены посредством использования способа ДТШВ. Однако этот способ имеет недостатки, заключающиеся в том, что использование множества эталонов для каждого слова общего характера приводит к увеличению емкости запоминающего устройства, в том, что возрастает время, затрачиваемое в способе ДТШВ на обращение к множеству эталонов, и в том, что при необходимости замены слов общего характера должен быть выполнен сбор образцов речевой информации от большого количества говорящих субъектов.
В итоге, в том случае, когда устройство распознавания речи установлено, например, в автомобильном звуковом оборудовании, преимущественным вариантом для изготовителя является использование устройства распознавания речи произвольного говорящего субъекта, что обусловлено отсутствием необходимости осуществлять запись большого количества образцов речевой информации пользователя, но для пользователя этот вариант имеет недостаток, заключающийся в том, что точность распознавания оказывается несколько меньшей, чем точность распознавания в устройстве распознавания речи конкретного говорящего субъекта.
Несмотря на то что устройство распознавания речи конкретного говорящего субъекта имеет более высокую точность распознавания, для изготовителя чрезвычайно сложно осуществить извлечение параметров отличительных признаков из образцов речевой информации отдельных пользователей и предварительное запоминание их в устройстве распознавания речи. В том случае, когда запись своей речи осуществляет сам пользователь, запись многих слов является очень обременительной.
Кроме того, поскольку известный способ, используемый для распознавания речи конкретного говорящего субъекта, и способ, используемый для распознавания речи произвольного говорящего субъекта, отличаются между собой как по виду, так и по сущности, объединение этих двух способов распознавания речи в едином устройстве приводит к увеличению размеров устройства.
СУЩНОСТЬ ИЗОБРЕТЕНИЯ
Для решения этих проблем предложено настоящее изобретение, целью которого является создание устройства распознавания речи и способа распознавания речи, в которых распознавание зарегистрированных слов, произнесенных конкретным говорящим субъектом, может быть осуществлено с высокой точностью даже при использовании способа распознавания речи произвольного говорящего субъекта.
Согласно настоящему изобретению в нем предложено устройство распознавания речи, осуществляющее распознавание слов по введенной речевой информации посредством использования информации о моделях единичных элементов речи, каждый из которых является более коротким, чем слово. Такое устройство распознавания речи содержит в себе средство накопления совокупности словарных обозначений, осуществляющее накопление последовательностей обозначений указанных единичных элементов речи для слов общего характера, обычно используемых для выполнения распознавания слов по введенной речевой информации произвольных говорящих субъектов; средство извлечения последовательностей обозначений зарегистрированных слов, осуществляющее генерацию последовательностей обозначений указанных единичных элементов речи для зарегистрированных слов из введенной речевой информации конкретного говорящего субъекта; и средство регистрации, осуществляющее запоминание последовательностей обозначений единичных элементов речи для слов общего характера, обычно используемых для распознавания слов из введенной речевой информации указанных произвольных говорящих субъектов, и созданных последовательностей обозначений для зарегистрированных слов в виде параллельных совокупностей в указанном средстве накопления совокупности словарных обозначений; в котором указанные единичные элементы речи представляют собой акустические события, генерация которых выполнена посредством разделения скрытой марковской модели фонемы на отдельные состояния без изменения значений вероятности перехода, результирующей вероятности и количества состояний.
Изобретение относится к устройству распознавания речи, осуществляющему распознавание слов по введенной речевой информации посредством использования информации о моделях единичных элементов речи, каждый из которых является более коротким, чем слово. Устройство распознавания речи содержит в себе средство накопления совокупности словарных обозначений, осуществляющее накопление последовательностей обозначений указанных единичных элементов речи для слов общего характера, обычно используемых для выполнения распознавания слов по введенной речевой информации произвольных говорящих субъектов; средство извлечения последовательностей обозначений для зарегистрированных слов, осуществляющее генерацию последовательностей обозначений, которые соответствуют связи указанных единичных элементов речи между собой, причем последовательности обозначений указанных единичных элементов речи имеют наибольшую вероятность для зарегистрированных слов из введенной речевой информации конкретного говорящего субъекта, посредством использования совокупности, в которой описано указанное условие о связи единичных элементов речи; и средство регистрации, осуществляющее регистрацию таким образом, что добавляет созданные последовательности обозначений для зарегистрированных слов в указанное средство накопления совокупности словарных обозначений; в котором указанные единичные элементы речи представляют собой акустические события, генерация которых выполнена посредством разделения скрытой марковской модели фонемы на отдельные состояния без изменения значений вероятности перехода, результирующей вероятности и количества состояний.
Согласно изобретению в нем предложено устройство распознавания речи, осуществляющее распознавание слов по введенной речевой информации посредством использования информации о моделях единичных элементов речи, каждый из которых является более коротким, чем слово. Устройство распознавания речи содержит в себе средство накопления совокупности словарных обозначений, осуществляющее накопление последовательностей обозначений указанных единичных элементов речи для слов общего характера, обычно используемых для выполнения распознавания слов по введенной речевой информации произвольных говорящих субъектов; средство извлечения последовательностей обозначений для зарегистрированных слов, осуществляющее генерацию последовательностей обозначений, которые соответствуют связи указанных единичных элементов речи между собой, причем последовательности обозначений указанных единичных элементов речи имеют наибольшую вероятность для зарегистрированных слов из введенной речевой информации конкретного говорящего субъекта, посредством использования совокупности, в которой описано указанное условие о связи единичных элементов речи; и средство регистрации, осуществляющее запоминание указанных последовательностей обозначений единичных элементов речи для слов общего характера, обычно используемых для выполнения распознавания слов по введенной речевой информации произвольных говорящих субъектов, и созданных последовательностей обозначений для зарегистрированных слов в виде параллельных совокупностей в указанном средстве накопления совокупности словарных обозначений; в котором указанные единичные элементы речи представляют собой акустические события, генерация которых выполнена посредством разделения скрытой марковской модели фонемы на отдельные состояния без изменения значений вероятности перехода, результирующей вероятности и количества состояний.
Согласно изобретению устройство распознавания речи может дополнительно содержать в себе средство, осуществляющее регистрацию указанных слов общего характера при помощи указанного средства накопления совокупности словарных обозначений.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
Фиг. 1 представляет собой блок-схему, на которой изображена структура системы согласно одному из вариантов осуществления изобретения.
Фиг. 2А представляет собой пояснительную схему, на которой показана последовательность обозначений для слова общего характера "СиДи" ("компакт-диск").
Фиг. 2Б представляет собой пояснительную схему, на которой показана последовательность обозначений для слова общего характера "ЭмДи" ("минидиск").
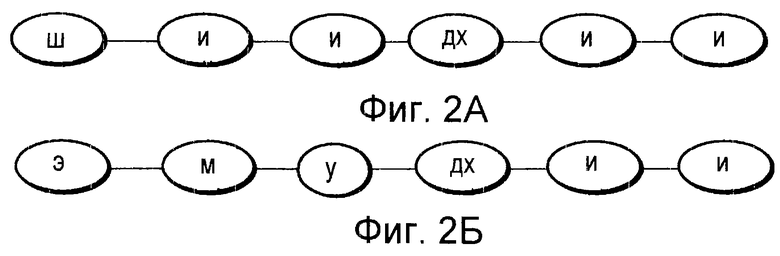
Фиг. 3 представляет собой пояснительную схему, на которой показано содержание фонематической совокупности.
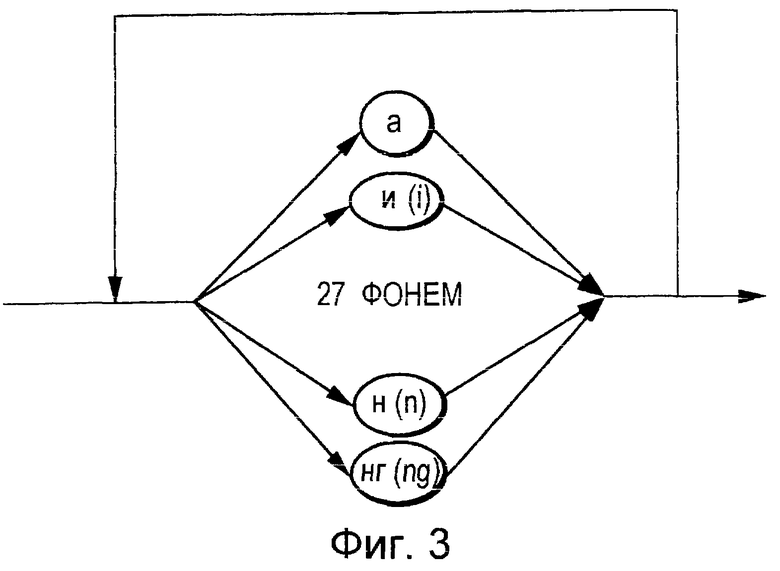
Фиг.4А представляет собой пояснительную схему, на которой показана последовательность обозначений для зарегистрированного слова "джаз".
Фиг.4Б представляет собой пояснительную схему, на которой показана последовательность обозначений для зарегистрированного слова "попс" ("популярная музыка").
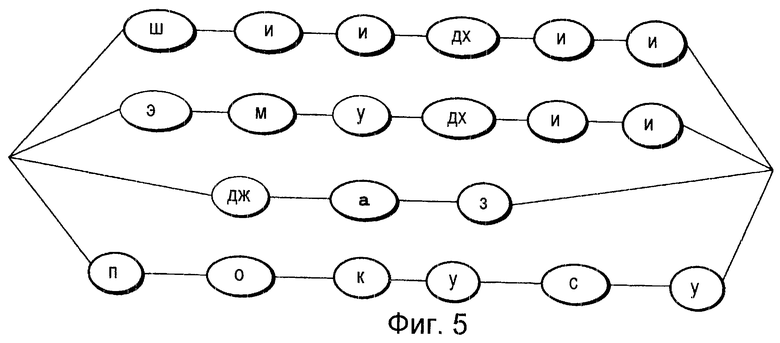
Фиг. 5 представляет собой пояснительную схему, на которой показана смешанная совокупность словарных обозначений, состоящая из слов общего характера и зарегистрированных слов.
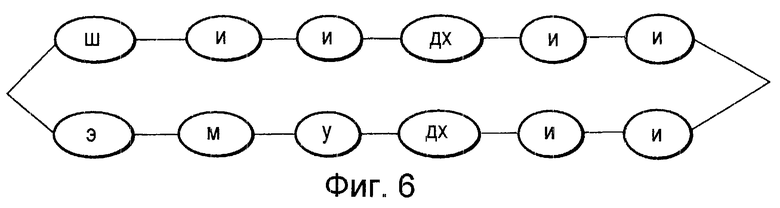
Фиг.6 представляет собой пояснительную схему, на которой показана совокупность словарных обозначений, состоящая только из слов общего характера.
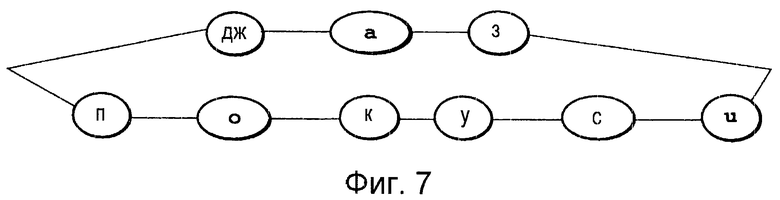
Фиг.7 представляет собой пояснительную схему, на которой показана совокупность словарных обозначений, состоящая только из зарегистрированных слов.
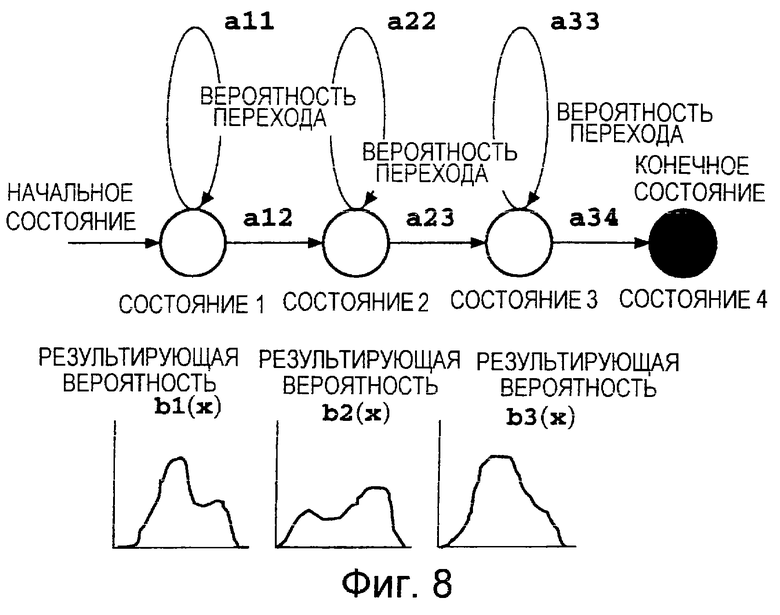
Фиг.8 представляет собой пояснительную схему, на которой показана фонематическая структура СММ.
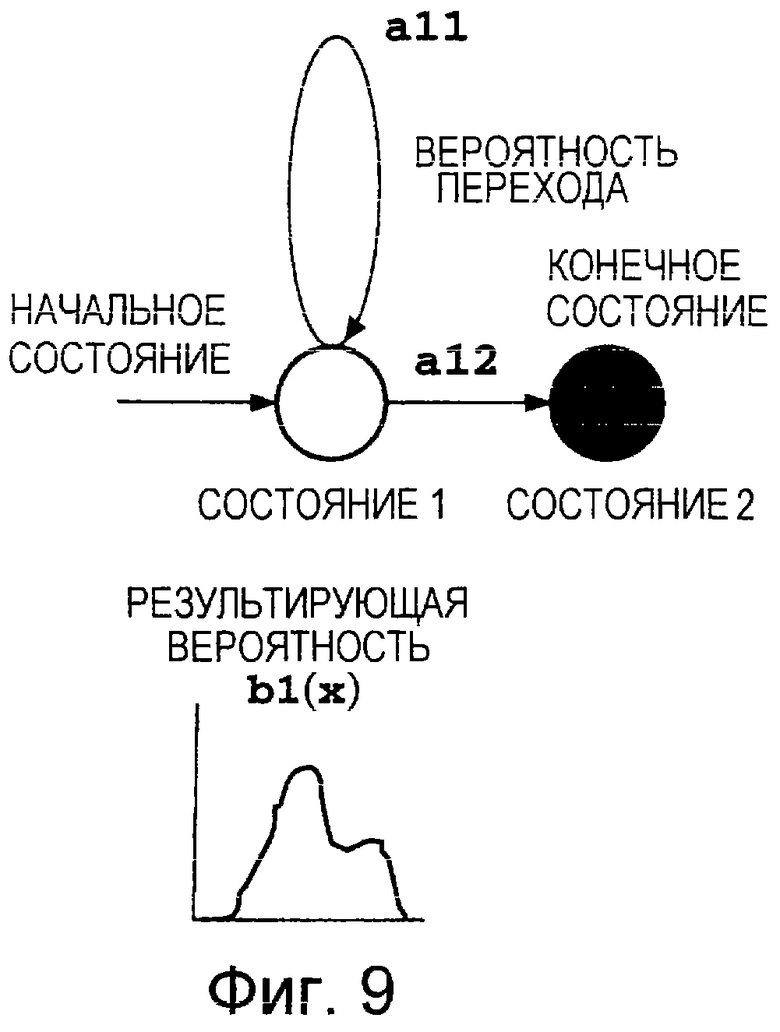
Фиг.9 представляет собой пояснительную схему, на которой показана структура акустического события СММ*.1.
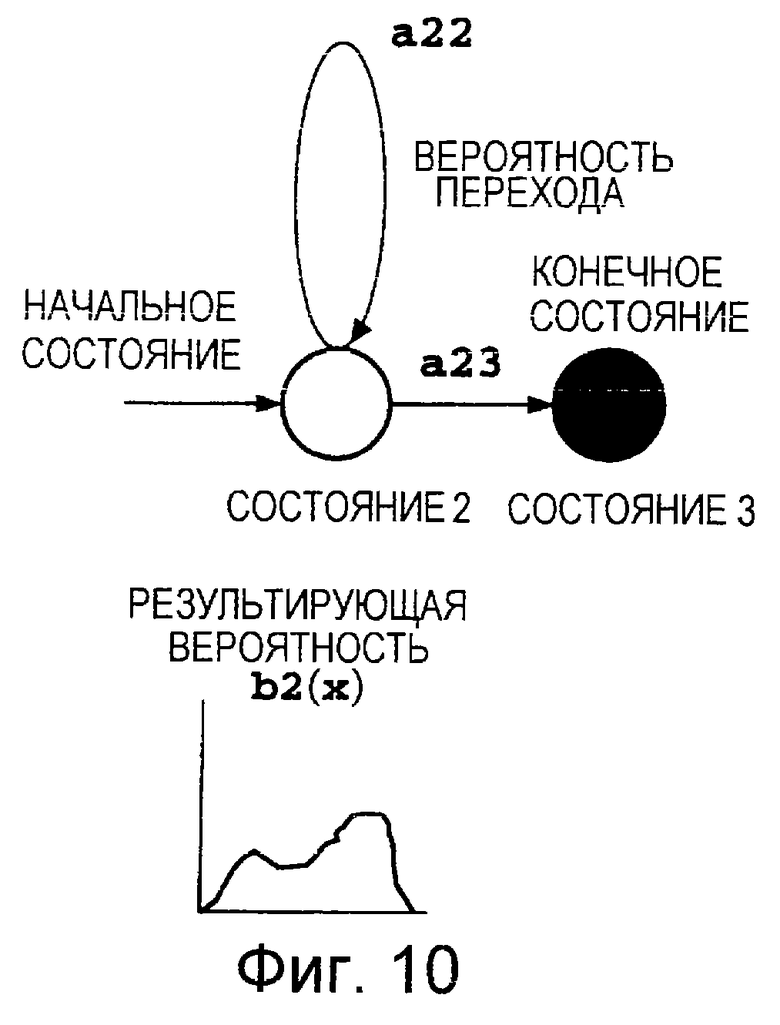
Фиг. 10 представляет собой пояснительную схему, на которой показана структура акустического события СММ*.2.
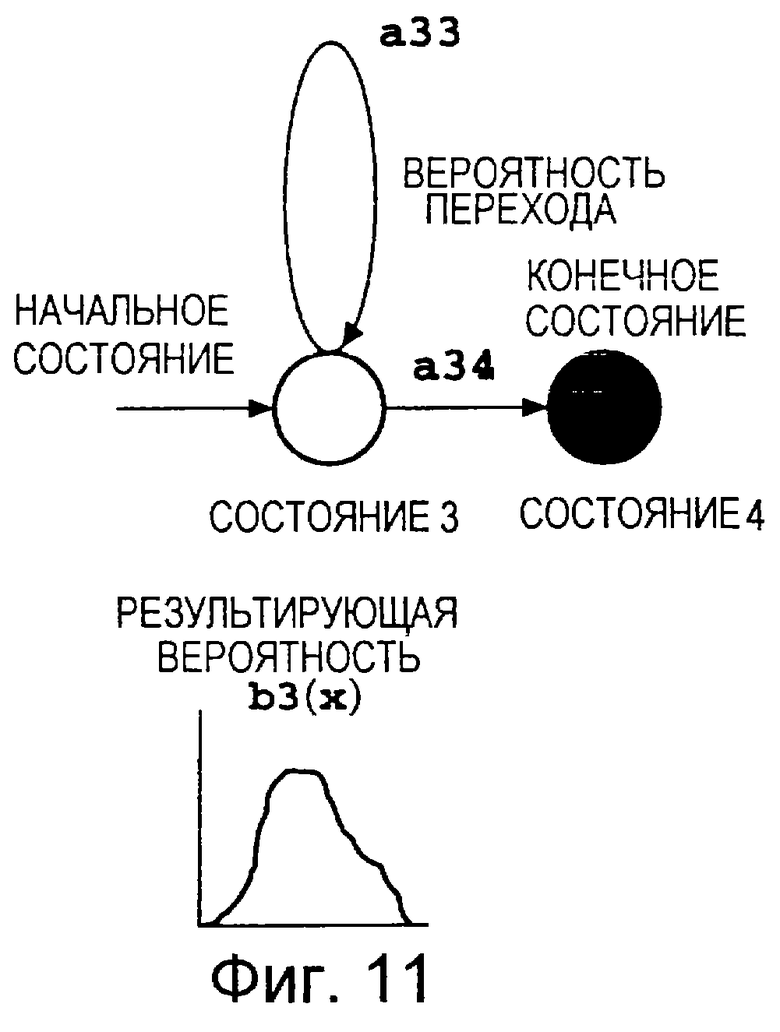
Фиг. 11 представляет собой пояснительную схему, на которой показана структура акустического события СММ*.3.
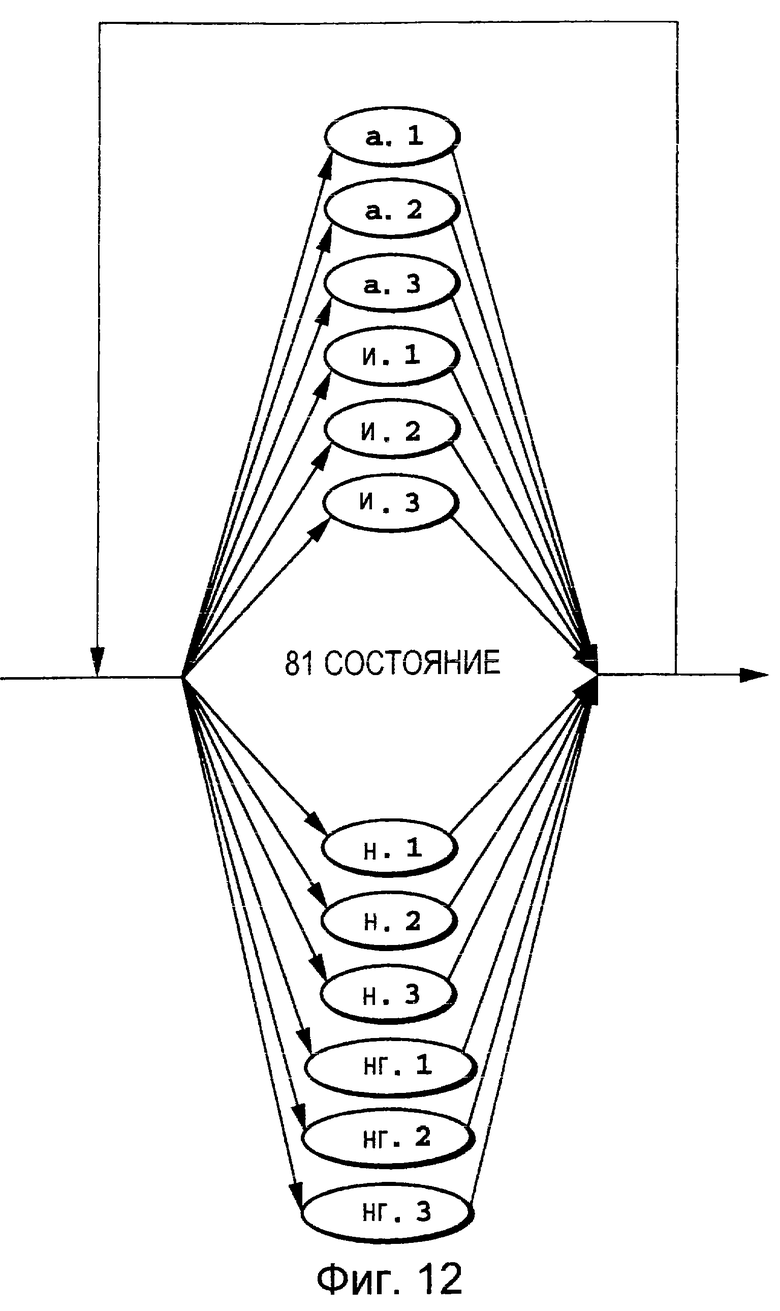
Фиг. 12 представляет собой пояснительную схему, на которой показана совокупность произвольных акустических событий.
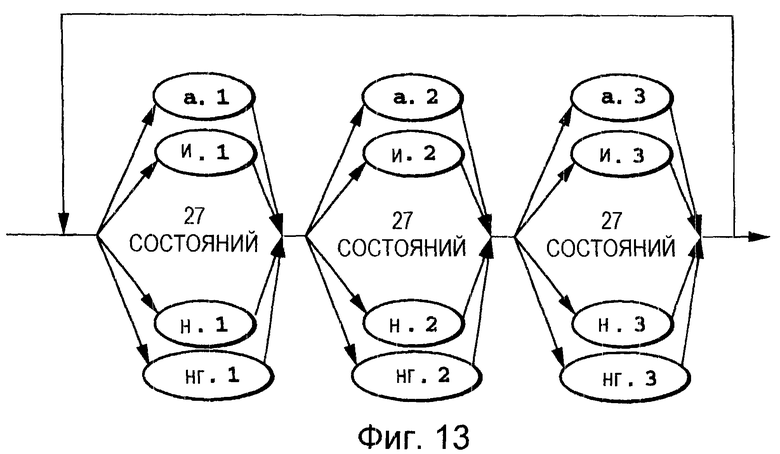
Фиг. 13 представляет собой пояснительную схему, на которой показана совокупность акустических событий с ограничением местоположения.
НАИЛУЧШИЙ СПОСОБ ОСУЩЕСТВЛЕНИЯ ИЗОБРЕТЕНИЯ
В настоящем изобретении создано устройство распознавания речи, которое может осуществлять распознавание речи, состоящей из смешанного словаря зарегистрированных слов, являющихся уникальными для конкретного человека, и слов общего характера, являющихся общими для произвольных субъектов, посредством использования СММ, которую обычно используют при распознавании речи произвольного говорящего субъекта. При распознавании речи произвольного говорящего субъекта с использованием СММ распознавание слов общего характера, содержащихся во введенной речевой информации, осуществляют согласно вышеописанному алгоритму Витерби посредством использования данных о моделях единичных элементов речи (слогов, полуслогов, фонем, акустических событий и т.д.), последовательностей обозначений единичных элементов речи для слов общего характера, являющихся общими для произвольных говорящих субъектов, и информации о связях между последовательностями обозначений для каждого слова общего характера.
В том случае, если каким-либо средством могут быть получены последовательности обозначений единичных элементов речи для зарегистрированных слов, являющихся уникальными для конкретного говорящего субъекта, то считают, что распознавание согласно алгоритму Витерби возможно осуществить по смешанному словарю, состоящему из зарегистрированных слов, являющихся уникальными для конкретного говорящего субъекта, и из слов общего характера, являющихся общими для произвольных говорящих субъектов, путем добавления последовательностей обозначений к информации о связях между последовательностями обозначений.
В способе получения последовательностей обозначений единичных элементов речи для зарегистрированных слов, являющихся уникальными для конкретного говорящего субъекта, вместо использования информации о связях между последовательностями обозначений для каждого слова общего характера используют информацию о связях, посредством которой единичные элементы речи могут быть связаны между собой в произвольном порядке и иметь при этом произвольную длину, и получают все последовательности единичных элементов речи, содержащихся во введенной речевой информации.
Теперь будет приведено подробное объяснение варианта осуществления этого изобретения со ссылкой на сопроводительные чертежи. На Фиг.1 показана базовая конфигурация одного из вариантов осуществления изобретения.
На Фиг. 1 аналоговый речевой сигнал 11, поступивший с микрофона (не показан), преобразуют в цифровой сигнал 22 посредством аналого-цифрового преобразователя, служащего в качестве средства А ввода. Средство Б преобразования осуществляет преобразование цифрового сигнала 22 в акустический параметр 33 с заранее заданным периодом кадра. В качестве акустического параметра (отличительный признак) может быть использован спектр, описанный в указанной выше книге "Цифровая обработка сигналов речевой/звуковой информации".
(Регистрация слов, произнесенных конкретным говорящим субъектом)
Регистрацию слов, являющихся уникальными для конкретного говорящего субъекта, осуществляют путем задания операции регистрации слов посредством переключателя, который в устройстве распознавания речи не показан, и подключения средства Б преобразования к средству Г извлечения последовательностей обозначений для зарегистрированных слов. Ввод требуемого его или ее речевого сигнала конкретный говорящий субъект, то есть пользователь автомобильного звукового оборудования, соединенного с устройством распознавания речи, осуществляет через микрофон.
Средство Б преобразования преобразует полученный посредством микрофона аналоговый речевой сигнал 11 в акустический параметр 33, который затем передают в средство Г извлечения последовательностей обозначений для зарегистрированных слов. Средство Г извлечения последовательностей обозначений для зарегистрированных слов осуществляет проверку данных 44 распознавания, накопленных в средстве В накопления данных распознавания, представляющем собой, например, жесткий диск или устройство памяти, распознавание последовательности обозначений единичных элементов речи и преобразование акустического параметра 33 в последовательность 55 обозначений для зарегистрированного слова. Данные 44 распознавания, запомненные в средстве В накопления данных распознавания содержат в себе два типа данных: данные о моделях единичных элементов речи, моделирование которых осуществлено посредством скрытой марковской модели, и совокупности данных о моделях единичного элемента речи, использованных для преобразования акустического параметра 33 в последовательность 55 обозначений для зарегистрированного слова.
Как было описано в патенте США 5732187, полагают, что единичный элемент речи содержит в себе слог, полуслог и фонему.
Ниже в качестве примера будут взяты фонемы и будет приведено объяснение устройства распознавания речи и способа распознавания речи для распознавания смешанного словаря, состоящего из слов общего характера, являющихся общими для произвольных говорящих субъектов, и из зарегистрированных слов, являющихся уникальными для конкретного говорящего субъекта. Совокупность данных о моделях единичных элементов речи (которую в этом случае не применяют), которую используют для преобразования акустического параметра 33 в последовательность 55 обозначений для зарегистрированного слова, представляет собой совокупность, которая отображает связи допустимых фонем.
Например, фонематическая совокупность, приведенная на Фиг.3, показывает, что 27 фонем из Таблицы 1 могут быть соединены в произвольном порядке и иметь произвольную длину. Преобразование речи, состоящей из зарегистрированных слов, являющихся уникальными для конкретного говорящего субъекта, в последовательность обозначений фонем можно осуществить по алгоритму Витерби посредством использования данных о модели фонемы, соответствующей совокупности данных и СММ. На Фиг.4А показан пример совокупности обозначений фонем, полученных из введенного слова "джаз", произнесенного конкретным говорящим субъектом для осуществления регистрации. В том случае, когда процент правильно распознанных фонем равен 100%, речевой сигнал "джаз" приводит к получению следующей последовательности обозначений фонем: дж+а+з+ю (j+a+z+u). В этом случае последняя фонема "ю" оказывается глухой и пропадает.
На Фиг. 4Б показан пример совокупности обозначений фонем, полученных из введенного слова "попс" (популярная музыка), произнесенного конкретным говорящим субъектом для осуществления регистрации. В том случае, когда процент правильно распознанных фонем равен 100%, речевой сигнал "попс" (популярная музыка) приводит к получению следующей последовательности обозначений фонем: п+о+п+ю+с+ю (p+o+p+u+s+u). В этом случае второе "п" ("р") заменяют на "к" ("k"), поскольку фонемы "п, т, к" ("р, t, k") являются, в общем случае, труднораспознаваемыми. Полученную таким способом при помощи средства Г извлечения последовательностей обозначений для зарегистрированных слов совокупность обозначений фонем называют последовательностью 55 обозначений для зарегистрированного слова. Последовательность 55 обозначений для зарегистрированного слова добавляют, регистрируют и запоминают в средстве Е накопления совокупности словарных обозначений, например на жестком диске или в устройстве памяти, при помощи средства "И" регистрации.
(Регистрация слов общего характера, являющихся общими для произвольных говорящих субъектов)
Совокупность обозначений фонем может быть извлечена заранее, исходя из правил проверки правописания слова общего характера, являющегося общим для произвольных говорящих субъектов. В альтернативном варианте генерация одной или большего количества совокупностей обозначений фонем из одного или более образцов речевой информации для слова общего характера, полученных от произвольных говорящих субъектов, может быть осуществлена способом, аналогичным описанному выше (подобным способу регистрации слов конкретным говорящим субъектом). Эти совокупности называют последовательностями 66 обозначений для слов общего характера, а средство временного хранения данных, например центральный процессор или оперативное запоминающее устройство, служащее для их передачи в средство Е накопления совокупности словарных обозначений, называют средством Д запоминания последовательностей обозначений для слов общего характера. Например, для слов общего характера "СиДи" (компакт-диск) и "ЭмДи" (минидиск) получают последовательности обозначений для слов общего характера, изображенные на Фиг.2А и 2Б. Данные о последовательностях обозначений для слов общего характера могут быть записаны изготовителем на носитель записи, например на гибкий диск или на компакт-диск, с которого их затем передают в средство Д запоминания последовательностей обозначений для слов общего характера, находящееся в устройстве распознавания речи. Регистрацию последовательностей обозначений для слов общего характера для произвольных говорящих субъектов в устройстве распознавания речи осуществляют путем их запоминания в средстве Е накопления совокупности словарных обозначений при помощи средства Д запоминания последовательностей обозначений для слов общего характера.
Совокупность 77 словарных обозначений, накопленная в средстве Е накопления совокупности словарных обозначений, которая содержит в себе последовательности 55 обозначений для зарегистрированных слов, извлеченные из средства Г извлечения последовательностей обозначений для зарегистрированных слов, добавлена и зарегистрирована в средстве Е накопления совокупности словарных обозначений средством И регистрации, и последовательности 66 обозначений для слов общего характера, хранящиеся в средстве Д запоминания последовательностей обозначений для слов общего характера, - может быть создана следующими тремя возможными способами.
Первый способ включает в себя операцию генерации совокупности, содержащей в себе как последовательности 55 обозначений для зарегистрированных слов, так и последовательности 66 обозначений для слов общего характера, и использование ее в качестве совокупности 77 словарных обозначений. На Фиг.5 показана совокупность словарных обозначений, в которой объединены последовательности обозначений для слов общего характера "СиДи" (компакт-диск) и "ЭмДи" (минидиск) и последовательности обозначений для зарегистрированных слов "джаз" и "попс" (популярная музыка).
Посредством такой совокупности можно реализовать устройство распознавания речи, которое может осуществлять распознавание любого из четырех слов: "СиДи" (компакт-диск) и "ЭмДи" (минидиск) в качестве слов общего характера и "джаз" и "попс" (популярная музыка) в качестве зарегистрированных слов.
Второй способ включает в себя операцию генерации совокупности, содержащей в себе только последовательности 66 обозначений для слов общего характера, и использование ее в качестве совокупности 77 словарных обозначений.
На Фиг. 6 показана совокупность словарных обозначений, в которой объединены последовательности обозначений для слов общего характера "СиДи" (компакт-диск) и "ЭмДи" (минидиск). Посредством такой совокупности может быть реализовано устройство распознавания речи произвольного говорящего субъекта, которое может осуществлять распознавание любого из двух слов общего характера: "СиДи" (компакт-диск) и "ЭмДи" (минидиск).
Третий способ включает в себя операцию генерации совокупности, содержащей в себе только последовательности 55 обозначений для зарегистрированных слов, и использование ее в качестве совокупности 77 словарных обозначений. На Фиг. 7 показана совокупность словарных обозначений, в которой объединены последовательности обозначений для зарегистрированных слов "джаз" и "попс" (популярная музыка). Посредством такой совокупности может быть реализовано устройство распознавания речи конкретного говорящего субъекта, которое может осуществлять распознавание любого из двух зарегистрированных слов "джаз" и "попс" (популярная музыка).
Управление устройством автоматической смены компакт-дисков посредством голосовых команд может быть реализовано посредством предварительного установления зависимости между последовательностями обозначений для слов общего характера, произносимых произвольными говорящими субъектами, и управляющими командами. Если точность распознавания является недостаточной, то управляющая команда может быть связана с последовательностью обозначений для зарегистрированного слова, полученной из введенной речевой информации конкретного говорящего субъекта (пользователя) в соответствии с описанным выше способом.
Этот процесс может, например, включать в себя операции отображения выбранных управляющих команд на дисплее, выбора одной из управляющих команд посредством клавиши курсора и ввода через микрофон произнесенного слова, которое должно быть связано с этой управляющей командой, результатом чего является регистрация последовательности 55 обозначений для зарегистрированного слова, извлеченной средством Г извлечения последовательностей обозначений для зарегистрированных слов, средством Е накопления совокупности словарных обозначений при помощи средства И регистрации. Кроме того, если запоминание совокупности кодов, посредством которых заданы управляющие команды, и соответствующих последовательностей обозначений для зарегистрированных слов осуществлено на жестком диске в виде таблицы (таблицы соответствия), то последующие операции могут быть заданы посредством речевых команд. В таблице соответствия, конечно же, может быть осуществлено запоминание составленных изготовителем последовательностей обозначений для слов общего характера и соответствующих кодов управляющих команд.
(Обработка распознавания речи)
В том случае, когда пользователь задает режим распознавания речи с использованием не изображенного на чертеже переключателя задания режима, средство Б преобразования подключают к средству Ж распознавания. В средстве Ж распознавания используют акустический параметр 33, ввод которого осуществлен средством А ввода и который преобразован средством Б преобразования, данные 45 распознавания, состоящие из данных о моделях фонем, которые хранят в средстве В накопления данных распознавания, и из совокупности 77 словарных обозначений, накопленной в средстве Е накопления совокупности словарных обозначений, а результат 88 распознавания слова получают согласно описанному выше алгоритму Витерби. Результат 88 распознавания передают в средство З вывода, представляющее собой, например, громкоговоритель и дисплей, где осуществляют его вывод в качестве выходного результата 99 в виде речевого сигнала и изображения. После подачи речевой команды для устройства автоматической смены компакт-дисков для определения содержания команды осуществляют сверку результата распознавания речи с таблицей соответствия и выполняют соответствующую управляющую программу.
При вышеуказанной конфигурации системы может быть осуществлено более точное управление функционированием устройства посредством регистрации часто используемых команд в виде слов, произнесенных голосом пользователя. Преимущество этой системы состоит в том, что если в процессе распознавания обозначений (при преобразовании акустического параметра в обозначение посредством использования данных распознавания) будет неправильно распознана последовательность обозначений для зарегистрированного слова, произнесенного пользователем (конкретным говорящим субъектом), то это не окажет никакого вредного влияния.
В том случае, если регистрация речевой команды осуществлена с ошибочно распознанными последовательностями обозначений, то при произнесении той же самой команды конкретным говорящим субъектом в режиме распознавания речи устройство распознавания речи вырабатывает тот же самый ошибочный результат распознавания, то есть ошибочно распознанную последовательность обозначений для зарегистрированной команды, причем выбор осуществляют без пропуска заданной команды, взаимосвязь с которой была установлена заранее.
С другой стороны, при использовании для распознавания речи последовательностей обозначений для слов общего характера, произносимых произвольными говорящими субъектами, любое ошибочное распознавание обозначений вызывает несовпадение между последовательностью обозначений, соответствующей зарегистрированной команде, и ошибочным результатом распознавания или ошибочно распознанной последовательностью обозначений, что приводит к возможности неправильного распознавания произнесенной команды. В этой ситуации для обеспечения правильного распознавания речи конкретному говорящему субъекту предоставлена возможность зарегистрировать посредством его собственного голоса любую из команд, уже имеющих составленные изготовителем последовательности обозначений для слов общего характера, и использовать последовательности обозначений для зарегистрированных слов конкретного говорящего субъекта в режиме распознавания речи.
В этом варианте осуществления для обеспечения высокой точности распознавания зарегистрированных слов, произнесенных конкретным говорящим субъектом, вне зависимости от используемого языка, для произвольных говорящих субъектов используют модели акустических событий, генерацию которых в качестве единичных элементов речи осуществляют путем разделения фонем на составные части.
Ниже приведено пояснение того случая, в котором в качестве единичных элементов речи используют состояния, меньшие чем фонемы, которые образуют фонематическую СММ. В общем случае фонемы зачастую моделируют в виде СММ, образованной четырьмя состояниями, которые показаны на Фиг.8.
Состояние 1 представляет собой начальное состояние, а переход из одного состояния в другое должен начинаться с состояния 1. Состояние 4 представляет собой конечное состояние. После осуществления перехода в состояние 4 дальнейшие переходы из одного состояния в другое не происходят. Значение aij обозначает вероятность перехода из состояния i в состояние j и его называют вероятностью перехода. Если j=i+1, то aii+aij=1,0.
Значение bi(x), называемое результирующей вероятностью, обозначает вероятность того, что при переходе из состояния i в другое состояние на выходе будет получен вектор х результата наблюдения. Для вектора результата наблюдения в качестве акустического параметра 33 из Фиг.1 часто используют спектр. Результирующая вероятность bi(x) представляет собой суперпозицию одного или более нормальных распределений, наложенных одно на другое. Результирующая вероятность может быть задана как вероятность bi(x) получения на выходе вектора х результата наблюдения при возникновении перехода в состояние i из другого состояния, или же как вероятность bij(x) получения на выходе вектора х результата наблюдения при переходе состояния от состояния i в состояние j.
В том случае, когда результирующая вероятность bi(x) задана как суперпозиция одного или более нормальных распределений, СММ называют непрерывной СММ. Другие способы моделирования включают в себя операции моделирования фонем с полунепрерывной СММ и с дискретной СММ. Это изобретение может быть аналогичным образом применено и для этих случаев.
Согласно уже известному способу, который описан, например, в публикации Рабинера и др. "Основные принципы распознавания речи", издательство Прентис-Холл, Нью-Джерси (США) 1993, ISBNO-13-015157-2, с. 441-447 (Rablner et al. "Fundamentals of Speech Recognition", New Jersey, Prentice-Hall, 1993, ISBNO-13-015157-2, p.441-447), изображенную на Фиг.8 фонематическую СММ, имеющую четыре состояния, разделяют на три СММ, имеющих два состояния, которые показаны на Фиг.9, 10 и 11.
Здесь значок "*" представляет собой обозначение фонемы в Таблице 1.
Можно полагать, что эти вновь созданные СММ отображают акустические события в фонемах и, следовательно, их называют СММ акустических событий. В качестве способа разделения СММ фонемы на СММ акустических событий известен способ разделения последовательных состояний (РПС) (SSS) ("Алгоритм разделения последовательных состояний для эффективного алофонного моделирования". Труды ИИЭРА, Международная конференция по акустике, 1992, Обработка речи и сигналов, том 1, ИИЭР, 1992, с. 11573-1576) ("A Successive State Splitting Algorithm for Efficient Alophone Modeling", Proceedings of 1992 IEEE International Conference on Acoustics, Speech and Signal Processing, Vo. 1, 1992 IEEE, p. 11573-1576), который основан на оценке максимального правдоподобия. В этом способе используют речевые данные многих говорящих субъектов, а для разложения модели фонемы на СММ акустических событий необходимо большое количество времени вычислений и большой объем памяти. При этом осуществляют перезапись вероятности перехода и результирующей вероятности, а количество состояний увеличивают по сравнению с первоначальным значением. С другой стороны, как показано на Фиг.9-11, в настоящем изобретении СММ фонема, созданная заранее для произвольных говорящих субъектов, может быть разделена на СММ акустических событий посредством простой операции без изменения параметров вероятности перехода, результирующей вероятности и общего количества состояний. На Фиг.12 показана совокупность, в которой СММ акустических событий, генерация которых осуществлена так, как описано выше, могут быть соединены в произвольном порядке и иметь произвольную длину.
Эту совокупность называют совокупностью акустических событий, не имеющей ограничений. Совокупность акустических событий, не имеющая ограничений, обладает более высокой степенью свободы при соединении последовательностей акустических событий, чем фонематическая совокупность из Фиг.3, и, следовательно, считают, что она намного увеличивает количество возможных способов представления последовательностей акустических событий.
Поэтому можно ожидать, что по сравнению с последовательностями фонем, которые созданы из совокупности фонем Фиг.3 по алгоритму Витерби, последовательности акустических событий, созданные из совокупности акустических событий, не имеющей ограничений, из Фиг.12 согласно алгоритму Витерби, более точно аппроксимируют произнесенные посредством голоса зарегистрированные слова, являющиеся уникальными для конкретного говорящего субъекта.
Следовательно, полагают, что посредством использования в качестве изображенной на Фиг.1 последовательности 55 обозначений для зарегистрированного слова последовательности акустических событий, созданной согласно алгоритму Витерби из совокупности акустических событий, не имеющей ограничений, можно обеспечить более высокую эффективность распознавания зарегистрированных слов.
Однако совокупность акустических событий, не имеющая ограничений, из Фиг. 12 имеет большое количество возможных последовательностей акустических событий, которые представляют собой приближенные значения произнесенных посредством речи зарегистрированных слов, являющихся уникальными для конкретного говорящего субъекта, поэтому обработка, необходимая для обеспечения выбора правильных последовательностей акустических событий, может потребовать длительного времени.
Полагают, что эффективным способом сокращения времени обработки является использование совокупности, которая ограничена местоположением состояния, что показано на Фиг.13. Совокупность по Фиг.13 называют совокупностью акустических событий с ограничением местоположения. В этой совокупности количество акустических событий, которые могут быть связаны между собой, равно одной трети от количества акустических событий в совокупности акустических событий, не имеющей ограничений, из Фиг.12, а это означает, что уменьшено количество возможных последовательностей акустических событий, которые представляют собой приближенные значения зарегистрированных слов, являющихся уникальными для конкретного говорящего субъекта. Полагают, что, несмотря на незначительное снижение эффективности распознавания, это может сократить время, требуемое для обработки и определения правильных последовательностей акустических событий для получения приближенных значений зарегистрированных слов, являющихся уникальными для конкретного говорящего субъекта.
Были проведены исследования по сравнению эффективности распознавания зарегистрированных слов конкретного говорящего субъекта, выполненному с использованием последовательности фонем и с использованием последовательности акустических событий.
Из СММ японских фонем посредством алгоритма Витерби были определены последовательности фонем для 128 слов, а в качестве словаря распознавания была использована совокупность фонем по Фиг.3. Для распознавания слов конкретного говорящего субъекта были выбраны двое мужчин и две женщины, которые произносили слова на японском, английском, французском, немецком и итальянском языках. В Таблице 2 приведены средний процент правильно распознанных слов и наименьший процент правильно распознанных слов, полученные при распознавании речи. Отношение речевого сигнала к шуму в каждом случае было равно 10 дБ.
Затем из СММ акустических событий, созданной путем разделения СММ японских фонем на части согласно описанному выше способу, и из приведенной на Фиг. 13 совокупности акустических событий с ограничением местоположения посредством алгоритма Витерби были определены последовательности акустических событий для 128 слов. Полученные таким способом последовательности акустических событий были использованы в качестве словаря распознавания. В Таблице 2 приведены средний процент правильно распознанных слов и наименьший процент правильно распознанных слов, полученные при распознавании слов конкретного говорящего субъекта на японском, английском, французском, немецком и итальянском языках.
Сравнение Таблицы 2 с Таблицей 3 показывает, что использование последовательностей акустических событий приводит к увеличению среднего процента правильно распознанных слов по сравнению с полученным при использовании последовательности фонем примерно на 2-6%. Также установлено, что наименьший процент правильно распознанных слов увеличен на 4-8%. Эти результаты свидетельствуют о том, что по сравнению с последовательностями фонем, полученными согласно алгоритму Витерби из совокупности фонем, приведенной на Фиг.3, использование последовательностей акустических событий, полученных согласно алгоритму Витерби из совокупности акустических событий с ограничением местоположения, приведенной на Фиг.13, обеспечивает более высокую эффективность распознавания зарегистрированных слов, являющихся уникальными для конкретного говорящего субъекта.
Полагают, что преимущество последовательностей акустических событий обусловлено тем, что последовательности акустических событий имеют более высокую точность аппроксимации зарегистрированных слов, являющихся уникальными для конкретного говорящего субъекта, чем последовательности фонем, даже в том случае, когда используют совокупность акустических событий, имеющую ограничения, например совокупность акустических событий с ограничением местоположения по Фиг. 13. Кроме того, в патенте Японии JP7-104678, В2 (фирмы "Саньо Денки" К.К.) от 13 ноября 1995 г. (12.11.95) (не имеющем родственных патентов) описано устройство распознавания речи, в котором осуществляют генерацию последовательности обозначений единичного элемента речи из введенной речевой информации конкретного говорящего субъекта и дополнительно осуществляют регистрацию созданной последовательности обозначений. Однако в этой публикации раскрыт способ, в котором в качестве единичного элемента речи используют слог и, как описано в параграфе "Вариант осуществления", сначала осуществляют регистрацию стандартных образцов слогов в качестве единичных элементов речи (например, "а" и "и"), а затем осуществляют регистрацию желательного слова в виде речевого сигнала посредством использования зарегистрированных стандартных образцов слогов. Другими словами, в упомянутом способе необходимо осуществлять регистрацию стандартных образцов слогов конкретного говорящего субъекта, и без выполнения этого в нем невозможно с достаточно высокой точностью зарегистрировать произвольное слово в виде последовательностей обозначений слогов для обеспечения высокой эффективности распознавания.
С другой стороны, посредством данного изобретения можно сделать вывод о том, что, как показано в Таблице 3, в устройстве распознавания речи произвольного говорящего субъекта может быть осуществлена не только регистрация произнесенных устно конкретным говорящим субъектом требуемых регистрируемых слов на японском или ином языке посредством простого использования акустических событий, подобных тем, которые показаны на Фиг.9-11, генерация которых осуществлена простым способом, который не изменяет ни значений вероятности перехода или результирующей вероятности, ни количества состояний, но также может быть получена и высокая эффективность распознавания. Это составляет основу для оценки степени новизны этого изобретения, отличающегося от описанного ранее обычного уровня техники.
Вышеуказанный вариант осуществления может быть реализован в виде следующих устройств.
1) Показанная на Фиг.1 структура системы может быть осуществлена посредством цифровых схем или посредством программной обработки в микрокомпьютере и персональном компьютере. В этом случае функции средства Б преобразования, средства Г извлечения последовательностей обозначений зарегистрированных слов и средства Ж распознавания могут быть реализованы посредством выполнения компьютерных программ центральным процессором. Компоновка схемы может зависеть от конкретного использования устройства распознавания речи. Например, в том случае, когда ввод символов и клавиш управления в персональный компьютер осуществляют посредством диктовки, система из Фиг.1 может быть создана в персональном компьютере с использованием центрального процессора, жесткого диска и т.д.
2) В вышеуказанном варианте осуществления запись последовательностей обозначений для слов общего характера, являющихся общими для произвольных говорящих субъектов, в устройство распознавания речи может быть осуществлена не только из постоянного запоминающего устройства на компакт-диске, но также может быть выполнено их запоминание во встроенном в устройство распознавания речи энергонезависимом программируемом устройстве памяти, например в ЭСППЗУ (электрически стираемом программируемом постоянном запоминающем устройстве (EEPROM)). В этом случае слова, не включенные в словарь, и те слова, точность распознавания которых пользователь желает увеличить, могут быть зарегистрированы путем произнесения этих слов пользователем.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И УСТРОЙСТВО ДЛЯ ДИНАМИЧЕСКОЙ РЕГУЛИРОВКИ ЛУЧА В ПОИСКЕ ПО ВИТЕРБИ | 2001 |
|
RU2276810C2 |
| СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ НА ОСНОВЕ ДВУХУРОВНЕВОГО МОРФОФОНЕМНОГО ПРЕФИКСНОГО ГРАФА | 2015 |
|
RU2597498C1 |
| СПОСОБ ИДЕНТИФИКАЦИИ ГОВОРЯЩЕГО ПО ФОНОГРАММАМ ПРОИЗВОЛЬНОЙ УСТНОЙ РЕЧИ НА ОСНОВЕ ФОРМАНТНОГО ВЫРАВНИВАНИЯ | 2009 |
|
RU2419890C1 |
| УНИВЕРСАЛЬНЫЕ ОРФОГРАФИЧЕСКИЕ МНЕМОСХЕМЫ | 2005 |
|
RU2441287C2 |
| СПОСОБ ГИБРИДНОЙ ГЕНЕРАТИВНО-ДИСКРИМИНАТИВНОЙ СЕГМЕНТАЦИИ ДИКТОРОВ В АУДИО-ПОТОКЕ | 2013 |
|
RU2530314C1 |
| СИСТЕМА ДЛЯ ВЕРИФИКАЦИИ ГОВОРЯЩЕГО | 1996 |
|
RU2161336C2 |
| АДАПТИВНОЕ УЛУЧШЕНИЕ АУДИО ДЛЯ РАСПОЗНАВАНИЯ МНОГОКАНАЛЬНОЙ РЕЧИ | 2016 |
|
RU2698153C1 |
| ДИНАМИЧЕСКАЯ АКУСТИЧЕСКАЯ МОДЕЛЬ ДЛЯ ТРАНСПОРТНОГО СРЕДСТВА | 2015 |
|
RU2704746C2 |
| СИСТЕМА И СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ | 2011 |
|
RU2466468C1 |
| СПОСОБ ЛЕКСИЧЕСКОЙ ИНТЕРПРЕТАЦИИ СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1997 |
|
RU2119196C1 |


Изобретение относится к распознаванию речи. Его использование при распознавании речи, состоящей из смешанного словаря уникальных для каждого человека слов и слов общего характера, позволяет обеспечить технический результат в виде распознавания речи произвольного говорящего субъекта. Этот технический результат достигается в устройстве, содержащем средство накопления совокупности словарных обозначений, осуществляющее накопление последовательностей обозначений указанных единичных элементов речи для слов общего характера, средство извлечения последовательностей обозначений для зарегистрированных слов, осуществляющее генерацию последовательностей обозначений единичных элементов речи для зарегистрированных слов из введенной речевой информации конкретного говорящего субъекта, и средство регистрации, осуществляющее запоминание последовательностей обозначений единичных элементов речи для слов общего характера из введенной речевой информации произвольных говорящих субъектов, и созданных последовательностей обозначений для зарегистрированных слов в виде параллельных совокупностей в средстве накопления совокупности словарных обозначений, причем единичные элементы речи представляют собой акустические события, генерация которых выполнена посредством разделения скрытой марковской модели фонемы на отдельные состояния без изменения значений вероятности перехода, результирующей вероятности и количества состояний. 6 с. и 6 з.п. ф-лы, 15 ил., 3 табл.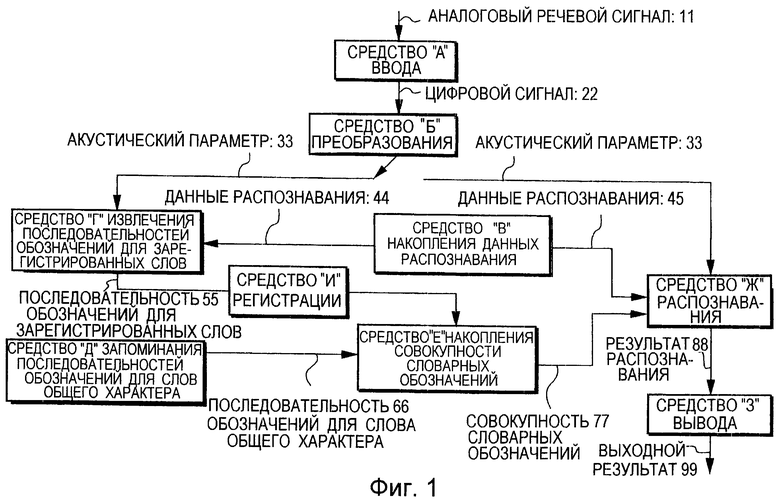
| Разборный с внутренней печью кипятильник | 1922 |
|
SU9A1 |
| СПОСОБ РАСПОЗНАВАНИЯ СЛОВ В СЛИТНОЙ РЕЧИ И СИСТЕМА ДЛЯ ЕГО РЕАЛИЗАЦИИ | 1996 |
|
RU2101782C1 |
| СПОСОБ ДИКТОРОНЕЗАВИСИМОГО РАСПОЗНАВАНИЯ ИЗОЛИРОВАННЫХ РЕЧЕВЫХ КОМАНД | 1997 |
|
RU2103753C1 |
| US 5799277 А, 25.08.1998 | |||
| US 5677988 А, 14.10.1997. | |||

