[01] Настоящая технология относится к области индексирования поисковой системы и, конкретнее, к способам и серверам для индексирования веб-страницы в индексе.
УРОВЕНЬ ТЕХНИКИ
[02] Современные большие центры обработки данных обрабатывают наборы данных, содержащих миллиарды элементов данных. В таких больших наборах поиск конкретных элементов, которые отвечают условиям данного поискового запроса, является задачей, которая требует значительного (и ощутимого) количества времени и значительных вычислительных ресурсов. Время ответа на запрос может быть критичным во многих случаях, как из-за специфичных технических характеристик, так и из-за высоких ожиданий пользователей. Следовательно, существуют различные технологии для уменьшения времени выполнения поискового запроса.
[03] Обычно при формировании эффективной системы управления набором данных, элементы данных "индексируются" в соответствии с некоторыми или всеми возможными поисковыми терминами, содержащимися в документе, которые могут быть "потенциально" включены в один или несколько будущих поисковых запросов. Так называемый инвертированный индекс коллекции данных поддерживается и обновляется системой, и используется при выполнении данного поискового запроса. Инвертированный индекс включает в себя множество "списков словопозиций", причем каждый список словопозиций соответствует поисковому термину и содержит ссылки на элементы данных, которые содержат этот поисковый термин.
[04] В качестве примера поисковой системы общего назначения, элементы данных которой могут принимать форму цифровых документов, например, веб-страниц, и проиндексированные термины могут представлять собой индивидуальные слова или некоторые наиболее часто используемые комбинации. Инвертированный индекс таким образом может содержать один список словопозиций для каждого слова, представленного по меньшей мере в некоторых цифровых документах.
[05] Также известно применение вертикальных поисковых систем, которые являются поисковыми системами, предназначенными для поиска цифровых документов, обладающих конкретными темами или типами, например, изображения, новости, видеозаписи и так далее. Вертикальные поисковые системы могут быть выполнены с возможностью использовать соответствующие индексы, адаптированные или созданные для сохранения данных о конкретных цифровых документах. Например, вертикальный поиск по изображениям может быть выполнен с возможностью использовать индекс, хранящий данные о файлах изображений. В другом примере, вертикальный поиск по новостям может быть выполнен с возможностью использовать индекс, хранящий данные о "свежих" или недавно ставших доступными цифровых документах. Это может позволить ответить на большое количество запросов и предоставить релевантные результаты вовремя.
[06] В процедуре индексирования, процесс, во время которого создается данный индекс, является затратной с точки зрения ресурсов задачей, из-за большого числа цифровых документов, предназначенных для индексирования, которые, как было упомянуто ранее, требуют больших дата-центров. Тем не менее, реальные дата-центры дорого содержать, и они обладают ограниченным количеством вычислительной мощности, которая может выделяться в режиме реального времени для индексирования, поскольку они обычно используются операторами для большого ряда различных вычислительных процессов.
РАСКРЫТИЕ ТЕХНОЛОГИИ
[07] Разработчики настоящей технологии обратили внимание на некоторые технические недостатки, связанные с существующими системами индексирования. Обычные системы индексирования сфокусированы на эффективно использующих время алгоритмах для извлечения результатов из индексов или, другими словами, на снижении времени между получением запроса и предоставлением результатов. Улучшения операций индексирования обычно направлены на создание структур индекса, которые позволяют быстро "найти" процедуры для извлечения списка цифровых документов, которые предположительно удовлетворяют данному поисковому запросу.
[08] Тем не менее, в некоторых случаях, существует глубинная проблема релевантности или качества цифровых документов, извлекаемых из индекса для удовлетворения запроса. Даже если структура индекса была создана таким образом, чтобы очень быстро извлекать цифровые документы для данного поискового запроса, который, в свою очередь, позволяет быстро предоставить эти цифровые документы пользователю, в некоторых случаях, эти документы могут быть не лучшими цифровыми документами для удовлетворения поискового запроса.
[09] Например, если пользователь заинтересован в свежих новостях о самых недавних событиях, даже если (i) некоторые цифровые документы могут предоставляться быстро при запросе, и (ii) эти цифровые документы могут быть до некоторой степени релевантны для запроса, пользователь с наибольшей вероятностью не будет удовлетворен, поскольку они были индексированы до самых недавних событий, и по существу не являются лучшими цифровыми документами, которые доступны в сети, для удовлетворения пользовательского интереса в самых недавних событиях.
[10] Задачей предлагаемой технологии является устранение по меньшей мере некоторых недостатков, присущих известному уровню техники. Разработчики настоящей технологии предлагают системы, которая может снизить время между (i) моментом создания или получения доступа к содержимому данного цифрового документа в сети и (ii) моментом, когда индексируется данный цифровой документ. Подобная система нацелена на необходимость предоставления пользователям, которые ищут информацию о недавних событиях, удовлетворительных цифровых документов, содержимое которых тоже является недавним.
[11] Подразумевается, что система, предлагаемая разработчиками настоящей технологии, может также позволить управлять ограниченной вычислительной мощью, которая может выделяться в режиме реального времени для индексирования путем индексирования с выборочным приоритетом некоторых цифровых документов перед другими. В самом деле, срочность индексирования некоторых цифровых документов, например, веб-страниц, связанных с новой информацией (например, новостных статей), может быть выше, чем индексирование других цифровых документов, например, веб-страниц, связанных со старой информацией (например, историческая литература).
[12] Подразумевается, что система, предлагаемая разработчиками настоящей технологии, может также позволить управлять ограниченной вычислительной мощью, которая может выделяться в режиме реального времени для индексирования путем индексирования с выборочным откладыванием некоторых цифровых документов на более позднее время, когда большее число вычислительных мощностей может быть выделено для индексирования. Например, система может определять, что некоторые цифровые документы могут быть менее полезными для пользователей поисковой системы как свежие поисковые результаты, чем другие и, следовательно, могут выборочно откладывать их индексирование для индексирования с приоритетом более полезных цифровых документов.
[13] Подразумевается, что система, предлагаемая разработчиками настоящей технологии, также может предоставлять масштабируемое решение для индексирования в режиме реального времени цифровых документов путем мониторинга вычислительных мощностей, которые могут выделяться в режиме реального времени для процедуры индексирования и, в ответ, адаптации выборочного приоритета цифровых документов для индексирования. Например, различные элементы или операции могут обладать различными дата-центрами, которые обладают различными вычислительными мощностями и, следовательно, желательно предоставлять масштабируемые решения, которые могут быть адаптированы для различных дата-центров.
[14] Следует иметь в виду, что вычислительная мощность, которая может быть выделена в режиме реального времени для индексирования, может изменяться в зависимости от многих факторов. Масштабируемость настоящей технологии может позволить выполнять процедуру адаптации выборочного приоритета таким образом, что когда вычислительная мощность, которая может выделяться в режиме реального времени для процедуры индексирования, растет, растет и число цифровых документов, которые выборочно индексируются в режиме реального времени. Аналогичным образом, масштабируемость настоящей технологии может позволить выполнять процедуру адаптации выборочного приоритета таким образом, что когда вычислительная мощность, которая может выделяться в режиме реального времени для процедуры индексирования, снижается, снижается и число цифровых документов, которые выборочно индексируются в режиме реального времени.
[15] Первым объектом настоящей технологии является способ индексирования веб-страницы в индексе. Индекс расположен в системе дата-центра, функционально связанной с сортировочным сервером. Индекс для предоставления указаний на возможные поисковые результаты поисковой системе. Способ выполняется сортировочным сервером. Способ включает в себя идентификацию сортировочным сервером, который выполняет приложение поискового робота, недавних данных, связанных с веб-страницей, предназначенной для индексирования. Способ включает в себя создание сортировочным сервером, который выполняет алгоритм машинного обучения, оценки значимости для веб-страницы на основе недавних данных, связанных с веб-страницей, причем оценка значимости указывает на полезность веб-страницы в качестве поискового результата. Алгоритм машинного обучения был обучен на основе обучающего набора, который включает в себя: (i) обучающий вектор, указывающий на данные, связанные с обучающей веб-страницей в первый момент времени после создания содержимого на обучающей вебстранице, и (ii) отметка, указывающая на пользу обучающей веб-страницы в качестве поискового результата, и на основе данных, связанных с обучающей веб-страницей во второй момент времени, причем второй момент времени по времени расположен позже, чем первый момент времени. Способ включает в себя выборочное добавление сортировочным сервером веб-страницы к одной из (i) очереди индексирования в режиме реального времени и (ii) очереди отложенного индексирования на основе сравнения между оценкой значимости веб-страницы и порога сортировки таким образом, что: если оценка значимости находится ниже порога сортировки, веб-страница добавляется к очереди отложенного индексирования веб-страниц; и если оценка значимости находится выше порога сортировки, веб-страница добавляется к очереди индексирования в режиме реального времени для индексирования веб-страницы в режиме реального времени.
[16] В некоторых вариантах осуществления способа, недавние данные связаны с веб-страницей в данный момент времени после создания содержимого веб-страницы.
[17] В некоторых вариантах осуществления способа, недавние данные связаны с веб-страницей в данный момент времени после того как веб-страница была просмотрена приложением поискового робота.
[18] В некоторых вариантах осуществления способа, оценка значимости указывает на пользу веб-страницы как свежего поискового результата.
[19] В некоторых вариантах осуществления способа, обучающий вектор основан на небольшом количестве данных, связанных с обучающей веб-страницей, доступной в первый момент времени.
[20] В некоторых вариантах осуществления способа, веб-страницы добавлены к очереди индексирования в режиме реального времени для индексирования в реальном времени, индексируются независимо от веб-страниц, которые добавляются к очереди отложенного индексирования.
[21] В некоторых вариантах осуществления способа, веб-страницы добавлены к очереди индексирования в режиме реального времени для индексирования в реальном времени, индексируются до каких-либо веб-страниц, которые добавляются к очереди отложенного индексирования.
[22] В некоторых вариантах осуществления способа, которые добавляются либо к (i) очереди индексирования в режиме реального времени, либо к (ii) очереди отложенного индексирования, упорядочиваются по отношению друг к другу в соответствии с их оценками значимости.
[23] В некоторых вариантах осуществления способа, веб-страница представляет собой одно из: новую веб-страницу и обновленную веб-страницу.
[24] В некоторых вариантах осуществления способа, новая веб-страница представляет собой данную веб-страницу, которая ранее не была индексирована. Польза новой веб-страницы как поискового результата с большей вероятностью выше, чем польза старой веб-страницы как поискового результата. Старая веб-страница была ранее проиндексирована.
[25] В некоторых вариантах осуществления способа, обновленная веб-страница является обновленной версией старой веб-страницы. Обновленная веб-страница не была ранее проиндексирована. Старая веб-страница была ранее проиндексирована, Польза обновленной веб-страницы как поискового результата с большей вероятностью выше, чем польза старой веб-страницы как поискового результата.
[26] В некоторых вариантах осуществления способа, в ответ на то, что веб-страница является новой веб-страницей, оценка значимости взвешивается для проверки того, что она выше порога сортировки, таким образом, что веб-страница добавляется к очереди индексирования в режиме реального времени для индексирования новой веб-страницы в режиме реального времени.
[27] В некоторых вариантах осуществления способа, способ далее включает в себя: передачу сортировочным сервером данных, указывающих на веб-страницы в очереди на индексирование в режиме реального времени, в систему дата-центра для индексирования в режиме реального времени; и передачу сортировочным сервером данных, указывающих на веб-страницы в очереди на отложенное индексирование, в систему дата-центра для отложенного индексирования.
[28] В некоторых вариантах осуществления способа, сортировочный сервер выполняет алгоритм балансировки нагрузки для балансировки нагрузки на систему дата-центра, и где способ далее включает в себя определение сортировочным сервером, выполняющим алгоритм балансировки нагрузки, того, что система дата-центра обладает доступной вычислительной мощностью для выполнения индексирования в режиме реального времени.
[29] В некоторых вариантах осуществления способа, порог сортировки зависит от доступного количества вычислительной мощности для выполнения индексирования в режиме реального времени.
[30] В некоторых вариантах осуществления способа, в ответ на определение сортировочным сервером, который выполняет алгоритм балансировки нагрузки, того, что доступное количество вычислительной мощности для выполнения индексирования в режиме реального времени было изменено, способ включает в себя настройку сортировочным сервером порога сортировки.
[31] В некоторых вариантах осуществления способа, недавние данные включают в себя по меньшей мере одно из: время создания веб-страницы, число визитов на URL веб-страницы, число входящих гиперссылок на веб-страницу, число исходящих гиперссылок с веб-страницы и тип содержимого веб-страницы.
[32] Другим объектом настоящей технологии является сервер для индексирования вебстраницы в индексе. Индекс расположен в системе дата-центра, функционально связанной с сервером. Индекс для предоставления указаний на возможные поисковые результаты поисковой системе. Сервер выполнен с возможностью выполнять приложение поискового робота и алгоритм машинного обучения. Сервер выполнен с возможностью выполнять идентификацию, путем выполнения приложения поискового робота, недавних данных, связанных с веб-страницей, предназначенной для индексирования. Сервер выполнен с возможностью выполнять создание, путем выполнения алгоритма машинного обучения, оценки значимости для веб-страницы на основе недавних данных, связанных с веб-страницей, причем оценка значимости указывает на полезность веб-страницы в качестве поискового результата. Алгоритм машинного обучения был обучен на основе обучающего набора, который включает в себя: (i) обучающий вектор, указывающий на данные, связанные с обучающей веб-страницей в первый момент времени после создания содержимого на обучающей веб-странице, и (ii) отметка, указывающая на пользу обучающей веб-страницы в качестве поискового результата, и на основе данных, связанных с обучающей веб-страницей во второй момент времени, причем второй момент времени по времени расположен позже, чем первый момент времени. Сервер выполнен с возможностью выполнять выборочное добавление сортировочным сервером веб-страницы к одной из (i) очереди индексирования в режиме реального времени и (ii) очереди отложенного индексирования на основе сравнения между оценкой значимости веб-страницы и порога сортировки таким образом, что: если оценка значимости находится ниже порога сортировки, веб-страница добавляется к очереди отложенного индексирования веб-страниц; и если оценка значимости находится выше порога сортировки, веб-страница добавляется к очереди индексирования в режиме реального времени для индексирования веб-страницы в режиме реального времени.
[33] В некоторых вариантах осуществления сервера, порог сортировки зависит от доступного количества вычислительной мощности системы дата-центра для выполнения индексирования в режиме реального времени.
[34] В некоторых вариантах осуществления сервера, веб-страница представляет собой одно из: новую веб-страницу и обновленную веб-страницу.
[35] В контексте настоящего описания "сервер" подразумевает под собой компьютерную программу, работающую на соответствующем оборудовании, которая способна получать запросы (например, от устройств) по сети и выполнять эти запросы или инициировать выполнение этих запросов. Оборудование может представлять собой один физический компьютер или одну физическую компьютерную систему, но ни то, ни другое не является обязательным для данной технологии. В контексте настоящей технологии использование выражения "сервер" не означает, что каждая задача (например, полученные команды или запросы) или какая-либо конкретная задача будет получена, выполнена или инициирована к выполнению одним и тем же сервером (то есть одним и тем же программным обеспечением и/или аппаратным обеспечением); это означает, что любое количество элементов программного обеспечения или аппаратных устройств может быть вовлечено в прием/передачу, выполнение или инициирование выполнения любого запроса или последствия любого запроса, связанного с клиентским устройством, и все это программное и аппаратное обеспечение может быть одним сервером или несколькими серверами, оба варианта включены в выражение "по меньшей мере один сервер".
[36] В контексте настоящего описания "устройство" подразумевает под собой аппаратное устройство, способное работать с программным обеспечением, подходящим к решению соответствующей задачи. Таким образом, примерами устройств (среди прочего) могут служить персональные компьютеры (настольные компьютеры, ноутбуки, нетбуки и т.п.) смартфоны, планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует иметь в виду, что устройство, ведущее себя как устройство в настоящем контексте, может вести себя как сервер по отношению к другим устройствам. Использование выражения "клиентское устройство" не исключает возможности использования множества клиентских устройств для получения/отправки, выполнения или инициирования выполнения любой задачи или запроса, или же последствий любой задачи или запроса, или же этапов любого вышеописанного способа.
[37] В контексте настоящего описания, "база данных" подразумевает под собой любой структурированный набор данных, не зависящий от конкретной структуры, программного обеспечения по управлению базой данных, аппаратного обеспечения компьютера, на котором данные хранятся, используются или иным образом оказываются доступны для использования. В контексте настоящего описания слова "первый", "второй", "третий" и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными.
[38] В контексте настоящего описания "информация" включает в себя информацию любую информацию, которая может храниться в базе данных. Таким образом, информация включает в себя, среди прочего, аудиовизуальные произведения (изображения, видео, звукозаписи, презентации и т.д.), данные (данные о местоположении, цифровые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, таблицы, списки слов и т.д.
[39] В контексте настоящего описания "компонент" подразумевает под собой программное обеспечение (соответствующее конкретному аппаратному контексту), которое является необходимым и достаточным для выполнения конкретной(ых) указанной(ых) функции(й).
[40] В контексте настоящего описания "используемый компьютером носитель компьютерной информации" подразумевает под собой носитель абсолютно любого типа и характера, включая ОЗУ, ПЗУ, диски (компакт диски, DVD-диски, дискеты, жесткие диски и т.д.), USB флеш-накопители, твердотельные накопители, накопители на магнитной ленте и т.д.
[41] В контексте настоящего описания слова "первый", "второй", "третий" и т.д. используются в виде прилагательных исключительно для того, чтобы отличать существительные, к которым они относятся, друг от друга, а не для целей описания какой-либо конкретной взаимосвязи между этими существительными. Так, например, следует иметь в виду, что использование терминов "первый сервер" и "третий сервер" не подразумевает какого-либо порядка, отнесения к определенному типу, хронологии, иерархии или ранжирования (например) серверов/между серверами, равно как и их использование (само по себе) не предполагает, что некий "второй сервер" обязательно должен существовать в той или иной ситуации. В дальнейшем, как указано здесь в других контекстах, упоминание "первого" элемента и "второго" элемента не исключает возможности того, что это один и тот же фактический реальный элемент. Так, например, в некоторых случаях, "первый" сервер и "второй" сервер могут являться одним и тем же программным и/или аппаратным обеспечением, а в других случаях они могут являться разным программным и/или аппаратным обеспечением.
[42] Каждый вариант осуществления настоящей технологии преследует по меньшей мере одну из вышеупомянутых целей и/или объектов, но наличие всех не является обязательным. Следует иметь в виду, что некоторые объекты данной технологии, полученные в результате попыток достичь вышеупомянутой цели, могут не удовлетворять этой цели и/или могут удовлетворять другим целям, отдельно не указанным здесь.
[43] Дополнительные и/или альтернативные факторы, аспекты и преимущества вариантов осуществления настоящей технологии станут очевидными из последующего описания, прилагаемых чертежей и прилагаемой формулы изобретения.
КРАТКОЕ ОПИСАНИЕ ЧЕРТЕЖЕЙ
[44] Для лучшего понимания настоящей технологии, а также других ее аспектов и факторов сделана ссылка на следующее описание, которое должно использоваться в сочетании с прилагаемыми чертежами, где:
[45] На Фиг. 1 представлена система, подходящая для реализации неограничивающих вариантов осуществления настоящей технологии;
[46] На Фиг. 2 показано схематическое представление данных, связанных с данной вебстраницей, которая может храниться в обрабатывающей базе данных системы, показанной на Фиг. 1, как представлено в некоторых неограничивающих вариантах осуществления настоящей технологии;
[47] На Фиг. 3 представлена одиночная итерация обучающей фазы и одиночная итерация фазы использования алгоритма машинного обучения сортировочного сервера системы, показанной на Фиг. 1, как представлено в некоторых неограничивающих вариантах осуществления настоящей технологии;
[48] На Фиг. 4 показано схематическое представление сортировочного порога, очереди на индексирование в режиме реального времени и отложенной очереди на индексирование, которые подходят для выполнения неограничивающих вариантов осуществления настоящей технологии; и
[49] На Фиг. 5 представлена блок-схема способа индексирования веб-страницы, как показано в некоторых неограничивающих вариантах осуществления настоящей технологии.
ОСУЩЕСТВЛЕНИЕ
[50] На Фиг. 1 представлена принципиальная схема системы 100, с возможностью реализации вариантом осуществления настоящей технологии, не ограничивающих ее объем. Важно иметь в виду, что нижеследующее описание системы 100 представляет собой описание иллюстративных вариантов осуществления настоящего технического решения. Таким образом, все последующее описание представлено только как описание иллюстративного примера настоящей технологии. Это описание не предназначено для определения объема или установления границ настоящей технологии. Некоторые полезные примеры модификаций системы 100 также могут быть охвачены нижеследующим описанием. Целью этого является также исключительно помощь в понимании, а не определение объема и границ настоящей технологии.
[51] Эти модификации не представляют собой исчерпывающий список, и специалистам в данной области техники будет понятно, что возможны и другие модификации. Кроме того, это не должно интерпретироваться так, что там, где это еще не было сделано, т.е. там, где не были изложены примеры модификаций, никакие модификации невозможны, и/или что то, что описано, является единственным вариантом осуществления этого элемента настоящего технического решения. Как будет понятно специалисту в данной области техники, это, скорее всего, не так. Кроме того, следует иметь в виду, что система 100 представляет собой в некоторых конкретных проявлениях достаточно простой вариант осуществления настоящей технологии, и в подобных случаях этот вариант представлен здесь с целью облегчения понимания. Как будет понятно специалисту в данной области техники, многие варианты осуществления настоящей технологии будут обладать гораздо большей сложностью.
[52] В общем случае, система 100 выполнена с возможностью управлять операцией индексирования цифровых документов, например, веб-страниц в индексе. То, как именно структурирован индекс, как выполняется индексирование данных данного цифрового документа, и как цифровые документы могут располагаться в индексе в общем случае описано в находящейся на рассмотрении патентной заявке US 2016/0070734, опубликованной 10 марта 2016 года, и озаглавленной "METHODS AND SYSTEMS FOR INDEXING REFERENCES TO DOCUMENTS OF A DATABASE AND FOR LOCATING DOCUMENTS IN THE DATABASE" ("СПОСОБЫ И СИСТЕМЫ ДЛЯ ИНДЕКСИРОВАНИЯ ССЫЛОК НА ДОКУМЕНТЫ В БАЗЕ ДАННЫХ И ДЛЯ НАХОЖДЕНИЯ ДОКУМЕНТОВ В БАЗЕ ДАННЫХ"), содержимое которой представлено здесь в полном объеме посредством ссылки. Следовательно, для краткости, структура индекса, расположенного в системе 100, не будет здесь описана.
[53] В широком смысле, система 100 может быть выполнена с возможностью определять, какие цифровые документы индексируются и когда. Другими словами, система 100 выполнена с возможностью управлять (i) индексированием в режиме реального времени некоторых цифровых документов и (ii) отложенным индексированием других цифровых документов. С этой целью, система 100 имеет доступ ко множеству цифровых документов 104. Цифровые документы 104 могут, например, быть найдены (т.е. "просмотрены поисковым роботом") в Интернете, как известно специалистам в данной области техники. Система 100 включает в себя систему 110 передачи данных, сортировочный сервер 106, обрабатывающую базу 124 данных и систему 120 дата-центра. То, как именно компоненты системы 100 выполнены с возможностью управлять (i) индексированием в режиме реального времени некоторых цифровых документов и (ii) отложенным индексированием других цифровых документов, будет описано далее.
Множество Цифровых документов
[54] Множество цифровых документов 104 может быть расположено на различных компьютерных системах, доступных, например, через Интернет. Природа множества цифровых документов 104 никак конкретно не ограничена. В контексте настоящей технологии, множество цифровых документов 104 может также упоминаться как "множество веб-страниц", "веб-страницы", "веб-документы" или просто "документы". Тем не менее, подразумевается, что данный один из множества цифровых документов 104 может представлять собой любую форму структурированной цифровой информации, которая может извлекаться или быть доступной с помощью соответствующего URL, не выходя за пределы настоящей технологии.
[55] В широком смысле, данный один из множества цифровых документов 104 может содержать одно или несколько предложений. Данный один из множества цифровых документов 104 может представлять собой, например, веб-страниц, содержащую текст и/или изображения (например, опубликованная новостная статья, связанная с какими-то экстренными новостями). Другой данный из множества цифровых документов 104 может представлять собой, в качестве другого примера, цифровую версию книги (например, цифровую версию книги «Гордость и Предубеждение» Джейн Остин). Другой данный из множества цифровых документов 104, может, например, представлять собой статью в Википедии™, которая время от времени может обновляться.
[56] Подразумевается, что по меньшей мере некоторые из множества цифровых документов 104 могли быть созданы (или обновлены) недавно или иным образом могли стать доступными в Сети. В самом деле, большое число веб-страниц создается или иным образом становится доступным в Сети каждый день и, таким образом, может быть необходимо индексировать по меньшей мере некоторые из этих веб-страниц, чтобы предоставлять их содержимое пользователям данной поисковой системы.
[57] Следует отметить, что по меньшей мере некоторые из множества цифровых документов 104 могут быть "свежими" веб-страницами, например, веб-страницами, у которых самое свежее содержимое, которое достаточно часто обновляется (например, погода), при этом по меньшей мере некоторые другие из множества цифровых документов 104 могут быть "неподвижными" веб-страницами, например, веб-страницы, которые обладают "неподвижным" содержимым, которое с меньшей вероятностью будет обновляться или будет обновляться с менее частыми интервалами (например, статья в Википедии™ о конституции Канады). С одной стороны, для пользователей данной поисковой системы польза свежего содержимого обычно (i) максимальна в момент времени, близкий к моменту его создания, и (ii) снижается после некоторого времени. С другой стороны, польза неподвижного содержимого для пользователей данной поисковой системы обычно (i) меньше в момент времени, близкий к моменту его создания, чем польза свежего содержимого в момент времени, близкий к моменту его создания, но (ii) достаточно постоянна во времени.
[58] Подразумевается, что по меньшей мере некоторые из множества веб-страниц 104 могут быть ранее индексированы, поскольку по меньшей мере некоторые другие из множества цифровых документов 104 могли не быть ранее индексированы. Например, множество цифровых документов 104 может включать в себя "новые" веб-страницы, которые не были ранее индексированы. В другом примере, множество цифровых документов 104 может включать в себя "старые" веб-страницы, которые были ранее индексированы. В еще одном другом примере, множество цифровых документов 104 может включать в себя "обновленные" веб-страницы, которые, в некотором смысле, являются "обновленными" версиями старых веб-страниц, где содержимое обновленной версии веб-страницы отличается от содержимого старой версии веб-страницы, которая была ранее индексирована.
[59] В самом деле, как будет описано далее со ссылкой на сортировочный сервер 106, по меньшей мере некоторые из множества цифровых документов 104 могли быть ранее "просмотрены поисковым роботом" и данные о них могли ранее быть "получены" для индексирования. Также подразумевается, что по меньшей мере некоторые из множества цифровых документов 104 могут быть "убраны" или иным образом стать недоступными с момента их индексирования.
Сеть передачи данных;
[60] В представленном примере системы 100, множество цифровых документов 104 доступно сортировочному серверу 106 через сеть 110 передачи данных. В некоторых вариантах осуществления настоящего технического решения, не ограничивающих ее объем, сеть 110 передачи данных может представлять собой Интернет. В других неограничивающих вариантах осуществления настоящей технологии, сеть 110 передачи данных может быть реализована иначе - в виде глобальной сети связи, локальной сети связи, частной сети связи и т.п.
[61] В качестве примера, но не ограничения, линия передачи данных между множеством цифровых документов 104 и сортировочным сервером 105 может представлять собой беспроводную линию передачи данных (например, среди прочего, линию передачи данных 3G, линию передачи данных 4G, беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.). В других примерах, линия передачи данных может быть как беспроводной (беспроводной интернет Wireless Fidelity или коротко WiFi®, Bluetooth® и т.п.) так и проводной (соединение на основе сети Ethernet).
Система дата-центра
[62] В общем случае, система 120 дата-центра является кластером компьютерных систем, как, например, серверные компьютеры, который предоставляет компьютерные вычислительные мощности для различных вычислительных процессов, для выполнения которых они настраиваются оператором. В качестве примера вычислительных процессов, данная система дата-центра может предоставлять вычислительную мощность для создания и поддержки индекса (например, процедуры индексирования). В другом варианте, данная система дата-центра может предоставлять вычислительную мощность для другой обработки "со стороны сервера" (бэкэнд), для выполнения которой она настраивается оператором.
[63] Несмотря на то, что система 120 дата-центра представлена на Фиг. 1 в виде единого элемента, но это не является обязательным для каждого варианта осуществления настоящей технологии. Другими словами, подразумевается, что система 120 дата-центра может быть распределена среди удаленных друг от друга систем дата-центров (возможно, расположенных в различных зданиях дата-центров и/или различных географических областях), представляющих собой саб-кластеры компьютерных систем, не выходя за пределы настоящей технологии.
[64] Система 120 дата-центра функционально соединена с сортировочным сервером 106. Подразумевается, что связь между сортировочным сервером 106 и системой 102 дата-центра может быть установлена как с сетью 110 передачи данных, так и без нее, и будет зависеть, среди прочего, от различных вариантов осуществления настоящей технологии. В некоторых вариантах осуществления настоящей технологии, сортировочный сервер 106 и система 120 дата-центра может быть частью общего здания дата-центра.
Сортировочный сервер
[65] Система 100 также включает в себя сортировочный сервер 106, который может быть реализован как обычный сервер. В примере варианта осуществления настоящей технологии сортировочный сервер 106 может представлять собой сервер Dell™ PowerEdge™, на котором используется операционная система Microsoft™ Windows Server™. Излишне говорить, что сортировочный сервер 106 может представлять собой любое другое подходящее аппаратное, прикладное программное, и/или системное программное обеспечение или их комбинацию. В представленных неограничивающих вариантах осуществления настоящей технологии сортировочный сервер 106 является одиночным сервером. В других неограничивающих вариантах осуществления настоящей технологии, функциональность сортировочный сервера 106 может быть разделена, и может выполняться с помощью нескольких серверов.
[66] В общем случае, сортировочный сервер 106 выполнен с возможностью осуществлять, среди прочего:
• идентификацию недавних данных, связанных с данной веб-страницей, предназначенной для индексирования;
• создания оценки значимости для данной веб-страницы на основе недавних данных, связанных с данной веб-страницей; и
• выборочного добавления данной веб-страницы, на основе сравнения между оценкой важности веб-страницы и данного порога сортировки, к одной из:
(i) очереди индексирования в режиме реального времени; и
(ii) очереди отложенного индексирования.
[67] Подразумевается, что для выполнения по меньшей мере некоторых их функций, сортировочный сервер 106 может выполнять приложение 107 поискового робота, алгоритм 108 машинного обучения и алгоритм 109 балансировки нагрузки. Варианты осуществления приложения 107 поискового робота, алгоритма 108 машинного обучения и алгоритма 109 балансировки нагрузки будут описаны далее.
Приложение поискового робота
[68] В общем случае, данное приложение поискового робота, приложение поискового робота или просто "поисковый робот" обычно используется поисковыми системами для просмотра всемирной паутины с целью индексирования. Таким образом, приложение 107 поискового робота выполнено с возможностью посещать или просматривать различные веб-страницы, доступные через сеть 110 передачи данных (например, множество цифровых документов 104) с помощью их соответствующих URL, и собирать данные, представляющие различные веб-страницы для индексирования. Сбор данных, указывающих на различные веб-страницы, иногда упоминается как "получение", а субкомпонент приложения 107 поискового робота, называемый "получатель", выполнен с возможностью загружать данные, например, выполняемые компьютером файлы, представляющие различные веб-страницы.
[69] Например, сортировочный сервер 106 может быть выполнен с возможностью выполнять приложение 107 поискового робота для просмотра или посещения веб-страниц по их соответствующим URL и загрузки данных, представляющих соответствующие вебстраницы для, среди прочего, целей индексирования.
Алгоритм машинного обучения
[70] В общем случае, алгоритмы машинного обучения могут обучаться и делать прогнозы на основе данных. Алгоритмы машинного обучения обычно используются сначала для создания модели на основе обучающих данных для дальнейших прогнозов данных или решений, выраженных в качестве выходных данных, вместо следования статичным машиночитаемым инструкциям. Алгоритмы машинного обучения используются для различных задач, связанных с прогнозированием, на основе некоторых наборов свойств, доступных как часть вводных данных.
[71] Во время обучения данный алгоритм машинного обучения может получать множество обучающих наборов, содержащих соответствующих обучающих векторов и соответствующих отметок. Обучающие векторы обычно указывают на некоторые свойства обучающего элемента, а отметки обычно указывают на вывод, который, в некотором смысле, является "желаемым" для соответствующих обучающих векторов. Следовательно, отметки в некотором смысле представляют собой целевые результаты для данного алгоритма машинного обучения, для вывода для соответствующих обучающих векторов. В результате, во время процедуры использования, если данный алгоритм машинного обучения получает вектор, аналогичный данному обучающему вектору, на основе которого он был обучен, данный алгоритм машинного обучения может предоставлять вывод, аналогичный отметке данного обучающего вектора.
[72] Суммируя, использование данного алгоритма 108 машинного обучения сортировочным сервером 106 может быть в широком смысле разделено на две фазы - фазу обучения и фазу использования. Сначала данный алгоритм 108 машинного обучения обучается в фазе обучения. Далее, после того как данный алгоритм 108 машинного обучения знает, какие данные ожидаются в виде входных данных и какие данные предоставлять в виде выходных данных, данный алгоритм 108 машинного обучения фактически работает, используя рабочие данные в фазе использования.
[73] Подразумевается, что сортировочный сервер 106 может выполнять алгоритм 108 машинного обучения во время фазы использования для создания оценок значимости для веб-страниц. То как создаются обучающие наборы для обучения алгоритма 108 машинного обучения (например, обучающие векторы и отметки), как обучается алгоритм 108 машинного обучения и как алгоритм 108 машинного обучения далее используется во время фазы используется для создания оценок значимости, будет описано далее более подробно.
Алгоритм балансировки нагрузки
[74] Следует отметить, что обработка нагрузки системы 120 дата-центра может управляться алгоритмом 109 балансировки нагрузки, выполняемом сортировочным сервером 106. В общем случае, данный алгоритм балансировки нагрузки выполнен с возможностью распределять или балансировать выполнение вычислительных процессов среди ряда компьютерных систем. Таким образом, в некоторых вариантах осуществления настоящей технологии, сортировочный сервер 106 может быть выполнен с возможностью выполнять процедуры "балансировки нагрузки", которые нацелены на оптимизацию использования ресурсов (в данном случае, вычислительные ресурсы, предоставляемые системой 120 дата-центра), минимизирует время ответа и позволяют избежать перегрузки какого-либо вычислительного ресурса. Использование нескольких вычислительных ресурсов (например, кластеров компьютерных систем системы 120 дата-центра) в процедурах балансировки нагрузки сортировочным сервером 106 вместо одной компьютерной системы может увеличить, например, надежность и доступность данных за счет избыточности.
[75] Подразумевается, что сортировочный сервер 106, который применяет алгоритм балансировки нагрузки, может отслеживать объем вычислительной мощности системы 120 дата-центра, который используется в режиме реального время для различных обработок со стороны сервера, и объем вычислительной мощности системы 120 дата-центра, который доступен в режиме реального времени для процедуры индексирования.
[76] Также подразумевается, что сортировочный сервер 106, который применяет алгоритм балансировки нагрузки, может отслеживать объем вычислительной мощности системы 120 дата-центра, который может потребоваться в более поздний момент для различных обработок со стороны сервера и объект вычислительной мощности системы 120 дата-центра, который может потребоваться в более поздний момент для отложенной процедуры индексирования.
[77] Подразумевается, что в некоторых вариантах осуществления настоящей технологии, алгоритм 109 балансировки нагрузки может предоставлять информацию сортировочному серверу 106 для помощи в определении того, какие из множества цифровых документов 104 могут индексироваться в режиме реального времени, а какие следует отложить для индексирования на более поздний момент времени. Какую информацию алгоритм 109 балансировки нагрузки может предоставлять сортировочному серверу 106, и что сортировочный сервер 106 выполнен с возможностью выполнять в ответ на эту информацию, будет описано более подробно далее.
База данных обработки
[78] Сортировочный сервер 106 также коммуникативно соединен с базой 124 данных обработки. В представленной иллюстрации, база 124 данных обработки представлена как единый физический элемент. Но это не является обязательным для каждого варианта осуществления настоящей технологии. Таким образом, база 124 данных обработки может быть реализована как множество отдельных баз данных. Опционально, база 124 данных обработки может быть разделена на несколько распределенных баз данных.
[79] База 124 данных обработки в общем случае выполнена с возможностью сохранять информацию, извлеченную или иным образом определенную или созданную сортировочным сервером 106 во время обработки. В общем случае, база 124 данных обработки может получать данные с сортировочного сервера 106, которые были извлечены или иным образом определены или созданы сортировочным сервером 106 во время обработки для временного и/или постоянного хранения, и могут предоставлять сохраненные данные сортировочному серверу 106 для их использования.
[80] Также подразумевается, что база 124 данных обработки может быть выполнена с возможностью сохранять данные, связанные с различными веб-страницами. В одном примере, база 124 данных обработки может хранить данные, связанные с веб-страницами, и которые представляют выполняемые на компьютере файлы, представляющие соответствующие веб-страницы. В другом примере, база 124 данных обработки может быть выполнена с возможностью, альтернативно или дополнительно, сохранять данные, связанные с веб-страницами, и которые указывают на взаимодействия пользователей данной поисковой системы с соответствующими веб-страницами. Подразумевается, что данные, указывающие на взаимодействия пользователей, могут быть разделены на различные типы пользовательских взаимодействий (и потенциально сохраняться с учетом этого разделения в базе 124 данных обработки), например, не устанавливая ограничений: выбор данной веб-страницы в качестве поискового результата, число кликов на данной веб-странице, время, проведенное на данной веб-странице, число раз, когда данной вебстраницей "поделились", число "лайков" на данной веб-страницы и так далее.
[81] Следует иметь в виду, что данные, связанные с данной веб-страницей, могут изменяться с течением времени. Подразумевается, что база 124 данных обработки может сохранять временные отметки, связанные с различными данными, связанными с веб-страницей. Это означать, что для данной веб-страницы база 124 данных обработки может быть выполнена для сохранения данных, связанных с данной веб-страницей, связанной с данной линией времени, причем различные данные, которые связаны с данной веб-страницей, могут "сопоставляться" или проецироваться на данную линию времени на основе соответствующих временных отметок.
[82] Например, со ссылкой на Фиг. 2, показано представление 200 данных, связанных с данной веб-страницей, которая может храниться в базе 124 данных обработки. Представлены данные 202, демонстрирующие выполняемые на компьютере файлы, представленные на данной веб-странице. Также представлена линия времени по меньшей мере некоторых других данных, связанных с данной веб-страницей.
[83] Первый набор данных 204 связан с данной веб-страницей и указывает на все данные, которые были связаны с данной веб-страницей до момента времени to. Второй набор данных 206 связан с данной веб-страницей и указывает на все данные, которые были связаны с данной веб-страницей до момента времени ti.
[84] Подразумевается, что первый набор данных 204 может по меньшей мере частично быть включенным во второй набор данных 206. Тем не менее, первый набор данных 204 не включает в себя данные, которые были связаны с данной веб-страницей во временном интервале 208, и данные включены во второй набор данных 206. Подразумевается, что данные 202 могут быть выключены по меньшей мере в один или в оба - первый набор данных 204 и второй набор данных 206.
[85] В результате, можно сказать, что база 124 данных обработки может сохранять данные, связанные с данной веб-страницей, таким образом, чтобы была доступна "информация" о том, как данные, связанные с данной веб-страницей, изменяются во времени. Другими словами, можно сказать, что база 124 данных обработки не только может быть выполнена с возможностью сохранять данные, связанные с данной вебстраницей, но также может быть выполнена с возможностью сохранять данные таким образом, чтобы информацию о "влиянии времени", указывающую на изменение (во времени) данных, связанных с данной веб-страницей, можно было добыть или определить на их основе.
[86] Также подразумевается, что база 124 данных обработки может также сохранять обучающие данные для обучения алгоритма 108 машинного обучения. Обучающие данные могут содержать множество обучающих наборов, причем каждый обучающий набор включает в себя (i) соответствующий обучающий вектор и (ii) соответствующую метку, связанную с соответствующим обучающим вектором. Каждый обучающий набор связан с соответствующей обучающей веб-страницей, которая была (i) ранее просмотрена поисковым роботом (например, приложением 107 поискового робота, например, сортировочного сервера 106), (ii) ранее индексирована в индексе данной поисковой системы, и (iii) ранее предоставлялась в качестве поискового результата пользователям данной поисковой системы.
[87] То, как именно создаются (i) обучающий вектор и (ii) отметка для данного обучающего набора (и для данной обучающей веб-страницы) будет описано далее.
[88] Для данной обучающей веб-страницы, соответствующий обучающий вектор мог быть создан сортировочным сервером 106 (или каким-то другим сервером, связанным с данной поисковой системой) на основе данных, которые были уже связаны с данной обучающей веб-страницей в первый момент времени после создания содержимого обучающей веб-страницы. Например, первый момент времени после создания содержимого обучающей веб-страницы может соответствовать моменту времени, когда данная обучающая веб-страница была просмотрена приложением 107 поискового робота сортировочного сервера 106 (или какого-то другого приложения 107 поискового робота какого-то другого сервера, связанного с данной поисковой системой).
[89] Можно сказать, что соответствующий обучающий вектор представляет свойства данной обучающей веб-страницы в первый момент времени. Например, соответствующий обучающий вектор может представлять свойства, такие как, без установления ограничений: время создания веб-страницы, различные счетчики данных, связанные с соответствующим URL (например, число визитов, число входящих гиперссылок, число исходящих гиперссылок, число логинов и так далее), тип содержимого данной обучающей веб-страницы (например, новостного типа), определенный дополнительными системами данной поисковой системы на основе содержимого обучающей веб-страницы, и так далее. Следует иметь в виду, что эти свойства могут определяться, напрямую или косвенно, из данных, связанных с данной обучающей веб-страницей в первый момент времени.
[90] Следует отметить, что данные, связанные с данной обучающей веб-страницей в первый момент времени некоторым образом "ограничены" или "немногочисленны" в том смысле, что в первый момент времени данный поисковая система еще не использовала обучающую веб-страницу как поисковый результат для своих пользователей и, следовательно, данные, указывающие на пользовательские взаимодействия пользователей данной поисковой системы с обучающей веб-страницей, еще не доступны.
[91] Для данной обучающей веб-страницы, соответствующая отметка могла быть создана сортировочным сервером 106 (или каким-то другим сервером, связанным с данной поисковой системой) или размечены человеком-асессором на основе данных, которые были уже связаны с данной обучающей веб-страницей во второй момент времени, который находится позже во времени, чем первый момент времени. Например, второй момент времени может соответствовать моменту во времени, который отдален во времени от первого момента времени на заранее определенный временной интервал. Длина заранее определенного временного интервала будет зависеть от, среди прочего, различных вариантов осуществления технологии.
[92] Тем не менее, подразумевается, что во второй момент времени поисковая система могла уже использовать данную обучающую веб-страницу как результат поиска для своих пользователей и, следовательно, во второй момент времени, данные, связанные с обучающей веб-страницей, могут теперь включать в себя данные, указывающие на по меньшей мере некоторые пользовательские взаимодействия пользователей данной поисковой системы с обучающей веб-страницей.
[93] Следует иметь в виду, что соответствующая отметка указывает на пользу данной обучающей веб-страницы в качестве поискового результата и/или в качестве "свежего" поискового результата. В самом деле, данные, связанные с обучающей веб-страницей, могут анализироваться сортировочным сервером 106 (или некоторым другим сервером, связанным с данной поисковой системой) или размечаться человеком-асессором для определения того, была ли данная обучающая веб-страница полезной в качестве поискового результата пользователям поисковой системы. Например, во время анализа или оценки (данных, связанных с данной обучающей веб-страницей во второй момент времени), по меньшей мере некоторые из различных типов пользовательских взаимодействий, связанных с обучающей веб-страницей во второй момент времени, могут учитываться для определения того, была ли данная обучающая веб-страница полезна как поисковый результат для пользователей поисковой системы. По меньшей мере некоторые из различных типов пользовательских взаимодействий могут включать в себя, без установления ограничений: число выборов обучающих веб-страниц в качестве поискового результата, ранги данных обучающих веб-страниц при отображении поисковых результатов, число кликов на данные обучающие веб-страницы, время, проведенное на данных обучающих веб-страницах и так далее.
[94] В результате, на основе анализа или оценки, если определено, что данная обучающая веб-страница была была полезна как поисковый результат для пользователей данной поисковой системы, сортировочный сервер 106 (или как-то другой сервер, связанный с данной поисковой системой) может создавать, или человек-асессор может назначать соответствующую оценку "1" или любое другое значение, указывающее на то, что данная обучающая веб-страница была полезной в качестве поискового результата. Альтернативно, на основе анализа или оценки, если определено, что данная обучающая веб-страница была не была полезна как поисковый результат для пользователей данной поисковой системы, сортировочный сервер 106 (или как-то другой сервер, связанный с поисковой системой) может создавать, или человек-асессор может назначать соответствующую оценку "0" или любое другое значение, указывающее на то, что данная обучающая веб-страница не была полезной в качестве поискового результата.
[95] Не ограничиваясь какой-либо конкретной теорией, разработчики настоящей технологии учитывают, что из-за "ограниченных" или "немногочисленных" данных, связанных с данной веб-страницей в первый момент времени, сложно коррелировать данные, доступные в первый момент времени, с возможной будущей пользой данной веб-страницы. Другими словами, подразумевается, что "ограниченные" или "немногочисленные" данные, связанные с данной веб-страницей в первый момент времени, в общем случае состоят из данных, которые являются "независимыми от времени", в то время как польза в общем случае логически выводится из данных, которые "зависимы от времени".
[96] Суммируя, база 124 данных обработки (Фиг. 1) может сохранять обучающие данные для обучения алгоритма 108 машинного обучения. Обучающие данные могут включать в себя множество обучающих наборов, причем каждый обучающий набор связан с соответствующей обучающей веб-страницей. Каждый обучающий набор включает в себя (i) соответствующий обучающий вектор, который был создан на основе данных, которые были связаны с обучающей веб-страницей в первый момент времени, и (ii) соответствующую отметку, которая была создана на основе данных, которые связаны с обучающей веб-страницей во второй момент времени, находящийся позже во времени, чем первый момент времени, и причем соответствующая отметка указывает на пользу соответствующей обучающей веб-страницы как поискового результата для пользователей данной поисковой системы.
[97] Следует также отметить, что в некоторых вариантах осуществления настоящей технологии подразумевается, что множество обучающих наборов может быть разделено на две категории - (i) "положительные" обучающие наборы, которые связаны с обучающими веб-страницами, которые были определены как полезные в качестве поисковых результатов для пользователей поисковой системы и (ii) "отрицательные" обучающие наборы, которые связаны с обучающими веб-страницами, которые были определены как бесполезные в качестве поисковых результатов или не особенно полезные в качестве поисковых результатов для пользователей данной поисковой системы.
[98] Как было ранее упомянуто, сортировочный сервер 106 выполняет алгоритм 108 машинного обучения для создания оценок значимости для соответствующих веб-страниц. То, как алгоритм 108 машинного обучения обучается и используется сортировочным сервером 106 для создания оценок значимости для соответствующих веб-страниц, будет описано далее.
[99] На Фиг. 3 представлена одиночная итерация 300 обучающей фазы алгоритма 108 машинного обучения. Несмотря на то, что представлена только одна обучающая итерация на Фиг. 4, следует иметь в виду, что большое число обучающих итераций может выполняться сортировочным сервером 106 как часть обучающей фазы алгоритма 108 машинного обучения, аналогично тому, как одиночная итерация 300 выполняется сортировочным сервером 106, не выходя за пределы настоящей технологии.
[100] Как часть одиночной итерации 300, сортировочный сервер 106 может извлекать обучающий набор 302 из базы 124 данных обработки. Обучающий набор 302 связан с обучающей веб-страницей 301 и включает в себя обучающий вектор 304 и отметку 306, оба из которых связаны с обучающей веб-страницей 301.
[101] Сортировочный сервер 106 далее выполнен с возможностью вводить обучающий набор 302 в алгоритм 108 машинного обучения. Можно сказать, что алгоритм 108 машинного обучения, в некотором смысле, "обучается" корреляции обучающего вектора 304 и отметки 306. Другими словами, можно сказать, что алгоритм 108 машинного обучения "обучается" тому, что для обучающего вектора 304 "желаемое" значение, которое будет выводиться, представляет собой отметку 306. В результате, алгоритм 108 машинного обучения обучается тому, что при вводе в него данного вектора, аналогичного обучающему вектору 304, он может создавать данное значение вывода, аналогичное отметке 306.
[102] Например, если обучающий набор 302 является данным положительным обучающим набором (например, обучающая веб-страница 301, которая была определена как полезная в качестве результата для пользователей поисковой системы, и что отметка 306 "1"), алгоритм 108 машинного обучения обучается таким образом, что, при вводе данного вектора фазы использования, который аналогичен обучающему вектору 304, он может создавать данное значение вывода, близкое к "1".
[103] В другом примере, если обучающий набор 302 является данным отрицательным обучающим набором (например, обучающая веб-страница 301 была определена как бесполезная в качестве результата для пользователей поисковой системы, и отметка 306 -"0"), алгоритм 108 машинного обучения обучается таким образом, что, при вводе данного вектора фазы использования, который аналогичен обучающему вектору 304, он может создавать данное значение вывода, близкое к "0".
[104] Следовательно, подразумевается, что в некоторых вариантах осуществления настоящей технологии, алгоритм 108 машинного обучения обучения обучается для оценки или прогноза пользы данной веб-страницы в фазе использования для пользователей данной поисковой системы на основе данного вектора в фазе использования, связанного с данной веб-страницей в фазе использования, которая создается на основе "ограниченных" или "немногочисленных" данных, которые доступны в момент времени, когда данная веб-страница в фазе использования просматривается поисковым роботом.
[105] Подразумевается, что алгоритм 108 машинного обучения может обучаться оценке или прогнозу влияния "независимых от времени" данных с данной веб-страницы в фазе использования на "зависимые от времени" данные с данной веб-страницы в фазе использования. Подразумевается, что алгоритм 108 машинного обучения может обучаться оценке или прогнозу влияния "независимых от времени" данных с данной веб-страницы в фазе использования на "зависимые от времени" данных с данной веб-страницы в фазе использования на пользу данной веб-страницы в фазе использования.
[106] Как было упомянуто ранее, после того как алгоритм 108 был обучен, сортировочный сервер 106 выполнен с возможностью выполнять алгоритм 108 машинного обучения во время фазы использования для создания оценок значимости для соответствующих веб-страниц в фазе использования.
[107] На Фиг. 3 также представлена одиночная итерация 300 фазы использования алгоритма 108 машинного обучения. Несмотря на то, что представлена только одна итерация фазы использования на Фиг. 3, следует иметь в виду, что сортировочный сервер 106 может выполнять итерацию фазы использования для каждой данной веб-страницы в фазе использования, аналогично тому, как одиночная итерация 350 выполняется сортировочным сервером 106, не выходя за пределы настоящей технологии.
[108] Как часть одиночной итерации 350, сортировочный сервер 106 может создавать вектор 354 фазы использования для веб-страницы 351 фазы использования, аналогично тому как обучающие векторы были созданы для обучения веб-страниц.
[109] Следует предположить, что веб-страница 351 является данной из множества цифровых документов 104 (см. Фиг. 1). Таким образом, сортировочный сервер 106 может выполнять приложение 107 поискового робота для просмотра веб-страницы 351, следовательно получая последние данные, связанные с веб-страницей 351 в данный момент времени после создания содержимого веб-страницы 351. Подразумевается, что данный момент времени может соответствовать данному моменту времени после (возможно, сразу после) того, как веб-страница 351 была просмотрена приложением 107 поискового робота. Следовательно, сортировочный сервер 106 может быть выполнено с возможностью создавать вектор 354 фазы использования для веб-страницы 351 на основе последних данных, связанных с веб-страницей 351.
[110] Сортировочный сервер 106 далее выполнен с возможностью выводить вектор 354 фазы использования в "уже обученный" алгоритм 108 машинного обучения, который выполнен с возможностью создавать, в ответ, значение 356 вывода в фазе использования, которое представляет оценку значимости веб-страницы 351 в фазе использования. Следовательно, оценка 356 (например, значение вывода в фазе использования для вектора 354 в фазе использования) указывает на пользу веб-страницы 351 в качестве поискового результата для пользователя данной поисковой системы. Подразумевается, что оценка 356 значимости может быть данным значением между "1" и "0", например, которое указывает на вероятность веб-страницы 351 в фазе использования быть полезной в качестве поискового результата для пользователей данной поисковой системы.
[111] В некоторых вариантах осуществления настоящей технологии, сортировочный сервер 106 может быть создан с возможностью применять алгоритм 108 машинного обучения для создания оценок значимости для по меньшей мере некоторых из множества цифровых документов 104, аналогично тому как сортировочный сервер 106 выполнен с возможностью создавать оценку 356 значимости для веб-страницы 351 в фазе использования.
[112] На Фиг. 4 представлено множество оценок 401 значимости, созданных сортировочным сервером 106 для множества веб-страниц 421 (например, по меньшей мере некоторых из множества цифровых документов 104). Следует иметь в виду, что сортировочный сервер 106 выполнен с возможностью создавать каждую из множества оценок 401 значимости после (возможно, сразу после) того, как соответствующая одна из множества веб-страниц 421 была просмотрена поисковым роботом. Другими словами, подразумевается, что после того как приложение 107 поискового робота просмотрело данную веб-страницу, создание соответствующей оценки значимости выполняется в режиме реального времени.
[113] Например, предположим, что приложение 107 поискового робота просмотрело веб-страницу 426. Сортировочный сервер 106 далее выполнен с возможностью создавать оценку 406 значимости аналогично тому, что было описано выше. Подразумевается, что после того как оценка 406 значимости была создана, сортировочный сервер 106 выполнен с возможностью сравнивать оценку 406 значимости с сортировочным порогом 400 для выборочного добавления веб-страницы 426 к одному из (i) очередь 450 индексирования в режиме реального времени для индексирования веб-страницы 426 в режиме реального времени и (ii) очередь 460 отложенного индексирования для отложенного индексирования веб-страницы 426.
[114] В некоторых вариантах осуществления настоящей технологии, сортировочный сервер 400 может быть заранее определен оператором данной поисковой системы, оператором сортировочного сервера 106 или оператором системы 120 дата-центра. В этом случае, сортировочный порог 400 указывает на значение "базовой пользы" веб-страниц, которые должны индексироваться в режиме реального времени.
[115] В других вариантах осуществления настоящей технологии сервер 106 может выполнить этап 109 параллельно с этапом 400. В некоторых вариантах осуществления настоящей технологии, алгоритм 109 балансировки нагрузки выполнен с возможностью определять сортировочный порог 400 в режиме реального времени. Далее будет описано то, как сортировочный сервер 106 выполнен с возможностью применять алгоритм 109 балансировки нагрузки для определения сортировочного порога 400.
[116] Как уже ранее упоминалось, сортировочный сервер 106 может выполнять алгоритм 109 балансировки нагрузки для определения того, обладает ли система 120 дата-центра доступным объемом вычислительной мощностей для выполнения индексирования в режиме реального времени (например, в некоторых случаях, вся вычислительная мощность может "использоваться" в режиме реального времени для других операций обработки со стороны сервера, и нагрузка обработки на систему 120 дата-центра в режиме реального времени очень велика). В некоторых вариантах осуществления технологии, если определено, что система 120 дата-центра в самом деле обладает доступным объемом обрабатывающей мощности для выполнения индексирования в режиме реального времени, сортировочный сервер 106 может выполнять алгоритм 109 балансировки нагрузки для определения того, какое количество обрабатывающей мощности фактически доступно для выполнения индексирования в режиме реального времени.
[117] После того как объем вычислительной мощности, которая доступна для выполнения индексирования в режиме реального времени, был определен, алгоритм 109 балансировки нагрузки может быть выполнен с возможностью "конвертировать" элементы вычислительной нагрузки (их объем), которые доступны для индексирования в режиме реального времени, в оценку, которая указывает на сортировочный порог 400. В некоторых вариантах осуществления настоящей технологии, эта конверсия может быть линейной или пропорциональной, логарифмической, экспоненциальной и так далее, и будет зависеть от среди прочего различных вариантов осуществления настоящей технологии.
[118] Тем не менее, следует иметь в виду, что если сортировочный сервер 106, выполняющий алгоритм 109 балансировки нагрузки определяет, что объем вычислительной мощности, доступной для выполнения индексирования в режиме реального времени, возрастает во второй момент времени по сравнению с первым данным моментом времени, причем сортировочный сервер 106, который выполняет алгоритм 109 балансировки нагрузки, может определять, что сортировочный порог 400 во второй данный момент времени должен быть ниже, чем в первый данный момент времени. В самом деле, более низкий сортировочный порог может приводить к большему числу веб-страниц, которые выборочно добавлены к очереди 450 индексирования в режиме реального времени.
[119] И наоборот, следует иметь в виду, что если сортировочный сервер 106, выполняющий алгоритм 109 балансировки нагрузки определяет, что объем вычислительной мощности, доступной для выполнения индексирования в режиме реального времени, уменьшается во второй момент времени по сравнению с первым данным моментом времени, причем сортировочный сервер 106, который выполняет алгоритм 109 балансировки нагрузки, может определять, что сортировочный порог 400 во второй данный момент времени должен быть выше, чем в первый данный момент времени. В самом деле, более высокий сортировочный порог может приводить к меньшему числу веб-страниц, которые выборочно добавлены к очереди 450 индексирования в режиме реального времени.
[120] Возвращаясь к описанию Фиг. 4, также предположим, что сортировочный сервер 106 определяет, что оценка 406 значимости выше сортировочного сервера 400. В результате, сортировочный сервер 106 выполнен с возможностью выборочно добавлять веб-страницу 426 к очереди 450 индексирования в режиме реального времени для индексирования веб-страницы 426 в режиме реального времени.
[121] Продолжая с тем же примером, предположим, что приложение 107 поискового робота просмотрело веб-страницу 428 (возможно, после веб-страницы 426). Сортировочный сервер 106 далее выполнен с возможностью создавать оценку 408 значимости аналогично тому, что было описано выше. Подразумевается, что после того как оценка 408 значимости была создана, сортировочный сервер 106 выполнен с возможностью сравнивать оценку 408 значимости с сортировочным порогом 400 для выборочного добавления веб-страницы 428 к одному из (i) очередь 450 индексирования в режиме реального времени для индексирования веб-страницы 426 в режиме реального времени и (ii) очередь 460 отложенного индексирования для отложенного индексирования веб-страницы 426.
[122] Теперь предположим, что сортировочный сервер 106 определяет, что оценка 408 значимости ниже сортировочного сервера 400. В результате, сортировочный сервер 106 выполнен с возможностью выборочно добавлять веб-страницу 428 к очереди 460 отложенного индексирования для отложенного индексирования веб-страницы 428.
[123] Та же логика может применяться последовательно к каждой из веб-страниц 422, 424, 430 и 432, когда приложение 107 поискового робота просматривает соответствующие веб-страницы 422, 424, 430 и 432. Предположим, что, как показано на Фиг. 4, сортировочный сервер 106 определяет, что оценки 402 и 404 значимости находятся выше сортировочного порога 400 и оценки 410 и 412 находятся ниже сортировочного порога 400. В результате, сортировочный сервер 106 может выборочно добавлять веб-страницы 422 и 424 к очереди 450 индексирования в режиме реального времени для индексирования веб-страниц 422 и 424 в режиме реального времени. Также, сортировочный сервер 106 может выборочно добавлять веб-страницы 430 и 432 к очереди 460 отложенного индексирования для отложенного индексирования веб-страниц 430 и 432.
[124] Следует иметь в виду, что поскольку выборочное добавление данных веб-страницы к одной из (i) очереди 450 индексирования в режиме реального времени, и (ii) очереди 460 отложенного индексирования выполняется последовательно сортировочным сервером 105, в некоторых вариантах осуществления настоящей технологии, подразумевается, что веб-страницы, которые добавляются к очереди 450 индексирования в режиме реального времени для индексирования веб-страниц в режиме реального времени, могут индексироваться независимо от веб-страниц, добавленных в очередь 460 отложенного индексирования. Это означает, что в некоторых вариантах осуществления настоящей технологии, веб-страницы, добавленные к очереди 460 отложенного индексирования не влияют или не действуют на индексирование веб-страниц в режиме реального времени в очереди 450 индексирования в режиме реального времени.
[125] Подразумевается, что в некоторых вариантах осуществления настоящей технологии, веб-страницы в очереди 450 индексирования в режиме реального времени могут быть упорядочены сортировочным сервером 106 в соответствии с их оценками значимости. Также подразумевается, что веб-страницы в очереди 460 отложенного индексирования в режиме реального времени могут быть упорядочены сортировочным сервером 106 в соответствии с их оценками значимости. Это означает, что в некоторых вариантах осуществления настоящей технологии, две данных веб-страницы в любой из (i) очереди 450 индексирования в режиме реального времени и (ii) очереди 460 отложенного индексирования не упорядочены в том же порядке, в котором они были просмотрены приложением 107 поискового робота сортировочного сервера 106.
[126] В некоторых вариантах осуществления настоящей технологии, сортировочный сервер 106 может также быть выполнен с возможностью передавать данные, указывающие на веб-страницы (просмотренные поисковым роботом данные) в очереди 350 на индексирование в режиме реального времени системе 120 дата-центра для индексирования в режиме реального времени. Также сортировочный сервер 106 может также быть выполнен с возможностью передавать данные, указывающие на веб-страницы (просмотренные поисковым роботом данные) в очереди 350 отложенного индексирования системе 120 дата-центра для отложенного индексирования.
[127] Следует иметь в виду, что поскольку сортировочный сервер 106 может передавать данные, указывающие на веб-страницы в очереди 450 на индексирование в режиме реального времени, системе 120 дата-центру в режиме реального времени, это может не быть обязательным для передачи данных, указывающих на веб-страницы в очереди 460 отложенного индексирования. Это означает, что передача данных, указывающих на веб-страницы в очереди 460 отложенного индекса системе 120 дата-центра для отложенного индексирования, может выполняться (i) в режиме реального времени, но для индексирования позднее во времени и (ii) в более поздний момент времени для индексирования в какой-то еще момент времени.
[128] Как было ранее упомянуто, в некоторых вариантах осуществления настоящей технологии, сортировочный порог 400 будет зависеть от доступного количества вычислительной мощности системы 120 дата-центра для выполнения индексирования в режиме реального времени. Подразумевается, что в дополнительных вариантах осуществления настоящей технологии, когда алгоритм 109 балансировки нагрузки, выполняемый сортировочным сервером 106, определяет, что доступный объем вычислительной мощности системы 120 дата-центра изменился во второй момент времени по сравнению с данным первым моментом времени, сортировочный сервер 106 может быть выполнен с возможностью соответственно настраивать сортировочный порог 400.
[129] В результате, может предоставляться масштабируемое решение для обращения с ограниченными объемами мощностями обработки, доступным в различных системах дата-центра. В самом деле, различные операции или элементы могут обладать различными зданиями дата-центров, предоставляющими различные объемы обрабатывающей мощности для выполнения различных задач обработки со стороны сервера и процедуры индексирования. Таким образом, настройка данного сортировочного порога в ответ на изменение объема мощности обработки, доступной в режиме реального времени для выполнения индексирования, позволяет учитывать присущие ограничения для различных систем дата-центров и может, следовательно, быть масштабируемой для вариантов осуществления для различных систем дата-центров.
[130] В некоторых вариантах осуществления настоящей технологии, при настройке сортировочного порога 400, сортировочный сервер 106 может "пересматривать", какие веб-страницы следует выборочно добавлять в очередь 450 индексирования в режиме реального времени, а какие будут выборочно добавлены к очереди 460 отложенного индексирования.
[131] Например, предположим, что когда веб-страница 428 была просмотрена поисковым роботом и оценка 408 была создана, оценка 408 значимости находится ниже сортировочного порога 400 и, в результате, веб-страница 428 добавляется к очереди 460 отложенного индексирования. Теперь предположим, что в более поздний момент времени алгоритм 109 балансировки нагрузки, выполняемый сортировочным сервером 106, определяет, что доступный объем мощности обработки системы 120 дата-центра увеличился, и, в результате, в более поздний момент времени, сортировочный сервер 106 понижает значение сортировочного порога 400. Далее, в более поздний момент времени, сортировочный сервер 106 может сравнивать оценку 408 значимости веб-страницы 428 (которая был уже выборочно добавлена к очереди 460 отложенного индексирования) с "измененным" более низким значением сортировочного порога 400. Если оценка 408 значимости веб-страницы 428 определена как превышающая измененное более низкое значение сортировочного порога 400, сортировочный сервер 106 может (i) выборочно удалять веб-страницу 428 из очереди 426 отложенного индексирования, и (ii) выборочно добавлять веб-страницу 428 в очередь 450 индексирования в режиме реального времени,
[132] Подобный "пересмотр" сортировочным сервером 106 может позволить избежать выборочного добавления данной веб-страницы к связке со временем, когда происходит сравнение между соответствующей оценкой значимости и сортировочным порогом 400.
[133] На Фиг. 5 представлен способ 500 индексирования данной веб-страницы. Различные этапы способа 500 теперь будут описаны далее более подробно.
ЭТАП 502: идентификация недавних данных, связанных с веб-страницей, предназначенной
[134] Способ 500 начинается на этапе 502, когда сортировочный сервер 106 идентифицирует недавние данные, связанные с данной веб-страницей. Сортировочный сервер 106 может выполнять приложение 107 поискового робота для просмотра данной веб-страницы из множества цифровых документов 104.
[135] В некоторых вариантах осуществления настоящей технологии, данная веб-страница может быть либо данной новой веб-страницей или данной обновленной веб-страницей. Сортировочный сервер 106 может в некоторых случаях определять, является ли данная веб-страница данной новой веб-страницей или данной обновленной веб-страницей на основе сравнения URL данной веб-страницы и URL, связанным с вебстраницами (старыми веб-страницами), которые были индексированы ранее.
[136] Например, данная новая веб-страница может быть данной веб-страницей, которая не была ранее индексирована. Подразумевается, что польза данной новой веб-страницы как поискового результата более вероятно будет выше, чем польза данной старой вебстраницы в качестве поискового результата, причем данная старая веб-страница была ранее индексирована.
[137] В другом примере, данная обновленная веб-страница может быть обновленной версией данной старой веб-страницы, и при этом данная обновленная веб-страница не была ранее индексирована, и данная старая веб-страница была ранее индексирована. Подразумевается, что польза данной обновленной веб-страницы как поискового результата более вероятно будет выше, чем польза данной старой веб-страницы (старая версия) в качестве поискового результата.
[138] Недавние данные, связанные с данной веб-страницей, могут быть связаны с данной веб-страницей в данный момент времени после создания содержимого данной веб-страницы. Например, недавние данные связаны с веб-страницей в данный момент времени после того как веб-страница была просмотрена приложением поискового робота.
[139] В некоторых вариантах осуществления способа, недавние данные могут включать в себя, без установки ограничений: время создания данной веб-страницы, число визитов на URL данной веб-страницы, число входящих гиперссылок на данную веб-страницу, число исходящих гиперссылок с данной веб-страницы и тип содержимого данной веб-страницы. Подразумевается, что по меньшей мере некоторые из недавних данных данной веб-страницы могут быть основаны, определены с помощью или являются частью данных, полученных поисковым роботом с данной веб-страницы.
ЭТАП 504: Создание оценки значимости для веб-страницы на странице недавних данных
[140] Способ 500 продолжается на этапе 504, где сортировочный сервер 106, путем выполнения алгоритма 108 машинного обучения, осуществляет создание соответствующей оценки значимости для данной веб-страницы на основе недавних данных, связанных с данной веб-страницей.
[141] Например, предположим, что данная веб-страница является веб-страницей 426 (см. Фиг. 4), и, таким образом, ML А 108 создает оценку 406 значимости. Оценка 406 значимости указывает на пользу веб-страницы 426 как поискового результата и/или нового поискового результата в качестве нового поискового результата для пользователей данной поисковой системы. Подразумевается, что в некоторых вариантах осуществления настоящей технологии, оценка 406 значимости указывает на пользу веб-страницы 426 как свежего поискового результата для пользователей данной поисковой системы.
[142] Следует иметь в виду, что польза свежего содержимого для пользователей данной поисковой системы обычно (i) максимальна в момент времени, близкий к моменту его создания, и (ii) снижается после некоторого времени. Напротив, следует иметь в виду, что польза неподвижного содержимого для пользователей данной поисковой системы обычно (i) меньше в момент времени, близкий к моменту его создания, чем польза свежего содержимого в момент времени, близкий к моменту его создания, но (ii) достаточно постоянна во времени.
[143] Следовательно, в некоторых вариантах осуществления настоящей технологии, определение пользы данных веб-страниц в качестве свежих поисковых результатов может позволить выборочно присваивать приоритет веб-страницам со свежим содержимым для индексирования в режиме реального времени, поскольку польза будет максимальной раньше или, другими словами, веб-страницы со свежим содержимым могут быть полезными для пользователей только в момент времени, близкий к их созданию. Например, новостная статья об экстренных новостях в отношении каких-то недавних событий, например, "All patent agent trainees of a firm passed their patent agent qualification exams" (англ. "Все стажеры патентного поверенного фирмы сдали квалификационные экзамены на патентного поверенного"), может быть полезна пользователям данной поисковой системы только в момент времени, близкий к созданию новостной статьи.
[144] На Фиг. 3 представлена одиночная итерация 300 обучающей фазы алгоритма 108 машинного обучения. Алгоритм 108 машинного обучения может быть обучен на обучающем наборе 302, связанном с обучающей веб-страницей 301. Обучающий набор 302 включает в себя обучающий вектор 304 и отметку 306.
[145] Обучающий вектор 304 указывает на данные, связанные с обучающей веб-страницей 301 в первый момент времени после создания содержимого обучающей веб-страницы 301. Например, данный первый момент времени может соответствовать моменту времени, когда обучающая веб-страница может быть просмотрена поисковым роботом. Как уже ранее упоминалось, "ограниченные" или "немногочисленные" данные могут быть доступны в первый момент времени, когда данная обучающая веб-страница 301 просматривается поисковым роботом.
[146] Следует иметь в виду, что соответствующая отметка 306 указывает на пользу обучающей веб-страницы 301 в качестве поискового результата (или, в других случаях, в качестве свежего поискового результата). В самом деле, данные, связанные с обучающей веб-страницей 310 могут анализироваться сортировочным сервером 106 или оцениваться человеком-асессором для определения того, была ли обучающая веб-страница 301 полезна в качестве поискового результата (или, альтернативно, в качестве свежего поискового результата) пользователям поисковой системы. Например, во время анализа или оценки, по меньшей мере некоторые из различных типов пользовательских взаимодействий, связанные с обучающей веб-страницей 301 в данный момент времени, могут учитываться для определения того, является ли обучающая веб-страница 301 полезной в качестве поискового результата (или, альтернативно, в качестве свежего поискового результат), для пользователей данной поисковой системы. По меньшей мере некоторые из различных типов пользовательских взаимодействий могут включать в себя, без установления ограничений: число выборов обучающей веб-страницы 310 в качестве поискового результата (и/или в качестве свежего поискового результата), ранги данной обучающей веб-страницы 301 при отображении в качестве поискового результата (и/или в качестве свежего поискового результата), число кликов на данную обучающую веб-страницу 301, время, проведенное на обучающей веб-странице 301 и так далее.
ЭТАП 506: Выборочное добавление веб-страницы к одной из: очереди индексирования в режиме реального времени и очереди отложенного индексирования на основе сравнения между оценкой значимости веб-страницы и порога сортировки
[147] Способ 500 завершается на этапе 506, когда сортировочный сервер 106 выборочно добавляет данную веб-страницу к одной из (i) очереди 450 индексирования в реальном времени и (ii) очереди 460 отложенного индексирования - на основе сравнения между соответствующей оценкой и сортировочным порогом 400.
[148] Например, предположим, что данная веб-страница является веб-страницей 426, и соответствующая оценка 406 значимости сравнивается с сортировочным порогом 400. Если оценка 406 значимости находится ниже сортировочного порога 400, веб-страница 426 добавляется к очереди 460 отложенного индексирования для отложенного индексирования веб-страницы 426. Если оценка 406 значимости находится выше сортировочного порога 400, веб-страница 426 добавляется к очереди 450 индексирования в режиме реального времени для индексирования веб-страницы в режиме реального времени.
[149] В некоторых вариантах осуществления настоящей технологии, веб-страницы добавлены к очереди индексирования в режиме реального времени для индексирования в реальном времени, индексируются независимо от веб-страниц, которые добавляются к очереди отложенного индексирования. Это означает, что в некоторых вариантах осуществления настоящей технологии, оценки значимости веб-страниц, добавленных к очереди 460 отложенного индексирования не влияют или не действуют на индексирование веб-страниц в режиме реального времени в очереди 450 индексирования в режиме реального времени.
[150] В некоторых других вариантах осуществления настоящей технологии, подразумевается, что веб-страницы, которые добавлены к очереди 450 индексирования в режиме реального времени для индексирования в реальном времени, индексируются до каких-либо веб-страниц, которые добавляются к очереди 460 отложенного индексирования. В результате, веб-страницы, добавленные к очереди 450 для индексирования в режиме реального времени выборочно приоритезированы для индексирования раньше веб-страниц, добавленных в очередь 460 отложенного индексирования.
[151] В дополнительных вариантах осуществления настоящей технологии, сортировочный сервер 106 определяет, что данная веб-страница является данной новой веб-страницей, и сортировочный сервер 106 может либо (i) напрямую ей назначать оценку "1" значимости, либо (ii) назначать ей соответствующую оценку значимости, созданную алгоритмом 108 машинного обучения, чтобы убедиться в том, что она находится выше сортировочного порога 400. Это означает, что новая веб-страница может быть добавлена в очередь 450 на индексирование в режиме реального времени и, следовательно, выборочно приоритезирована для индексирования раньше других веб-страниц.
[152] В некоторых вариантах осуществления настоящей технологии, сортировочный сервер 106 может передавать данные (просмотренные поисковым роботом данные), указывающие на веб-страницы в очереди 350 на индексирование в режиме реального времени системе 120 дата-центра для индексирования в режиме реального времени. Также подразумевается, что сортировочный сервер 106 может передавать данные (просмотренные поисковым роботом данные), указывающие на веб-страницы в очереди 460 на отложенное индексирование, в систему 120 дата-центра для отложенного индексирования.
[153] В других вариантах осуществления настоящей технологии сервер 106 может выполнить алгоритм 109 балансировки нагрузки системы 120 дата-центра. Подразумевается, что сортировочный сервер может выполнять алгоритм 109 балансировки нагрузки для определения того, что система 120 дата-центра обладает доступным количеством вычислительных мощностей для выполнения индексирования в режиме реального времени.
[154] Также, как было описано выше, сортировочный порог 400 (его значение) может зависеть от доступного объема вычислительной мощности для выполнения индексирования в режиме реального времени, как было определено алгоритмом 109 балансировки нагрузки. Подразумевается, что в ответ на определение, сортировочным сервером 106, выполняющим алгоритм 109 балансировки нагрузки, что доступный объем вычислительной мощности для выполнения индексирования в режиме реального времени поменялся, сортировочный сервер 106 может корректировать значение сортировочного порога 400, как описано выше.
[155] Модификации и улучшения вышеописанных вариантов осуществления настоящей технологии будут ясны специалистам в данной области техники. Предшествующее описание представлено только в качестве примера и не устанавливает никаких ограничений. Таким образом, объем настоящей технологии ограничен только объемом прилагаемой формулы изобретения.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ПОСТРОЕНИЯ ПОИСКОВОГО ИНДЕКСА С ИСПОЛЬЗОВАНИЕМ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2018 |
|
RU2720954C1 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБНОВЛЕНИЯ БАЗЫ ДАННЫХ ПОИСКОВОГО ИНДЕКСА | 2018 |
|
RU2733482C2 |
| Способ и сервер для ранжирования цифровых документов в ответ на запрос | 2020 |
|
RU2818279C2 |
| СИСТЕМА И СПОСОБ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА В ПОИСКОВОЙ СИСТЕМЕ | 2024 |
|
RU2839310C1 |
| СПОСОБ СОЗДАНИЯ ОБУЧАЮЩЕГО ОБЪЕКТА ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2016 |
|
RU2637883C1 |
| Способ и система для формирования карточки объекта | 2018 |
|
RU2739554C1 |
| Способы и серверы для ранжирования цифровых документов в ответ на запрос | 2020 |
|
RU2775815C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ПОВТОРНОГО ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ | 2019 |
|
RU2743932C2 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ АЛГОРИТМА МАШИННОГО ОБУЧЕНИЯ РАНЖИРОВАНИЮ ОБЪЕКТОВ | 2020 |
|
RU2782502C1 |
| СПОСОБ И СИСТЕМА ДЛЯ РАНЖИРОВАНИЯ ЦИФРОВЫХ ОБЪЕКТОВ НА ОСНОВЕ СВЯЗАННОЙ С НИМИ ЦЕЛЕВОЙ ХАРАКТЕРИСТИКИ | 2019 |
|
RU2757174C2 |
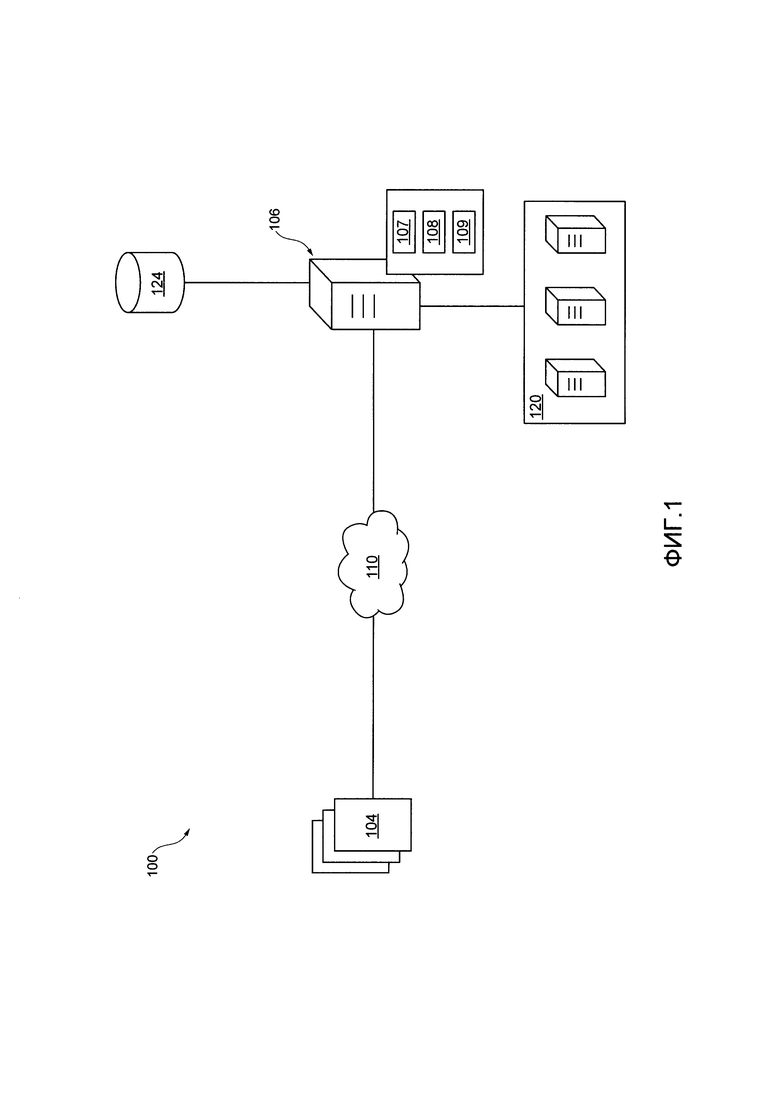
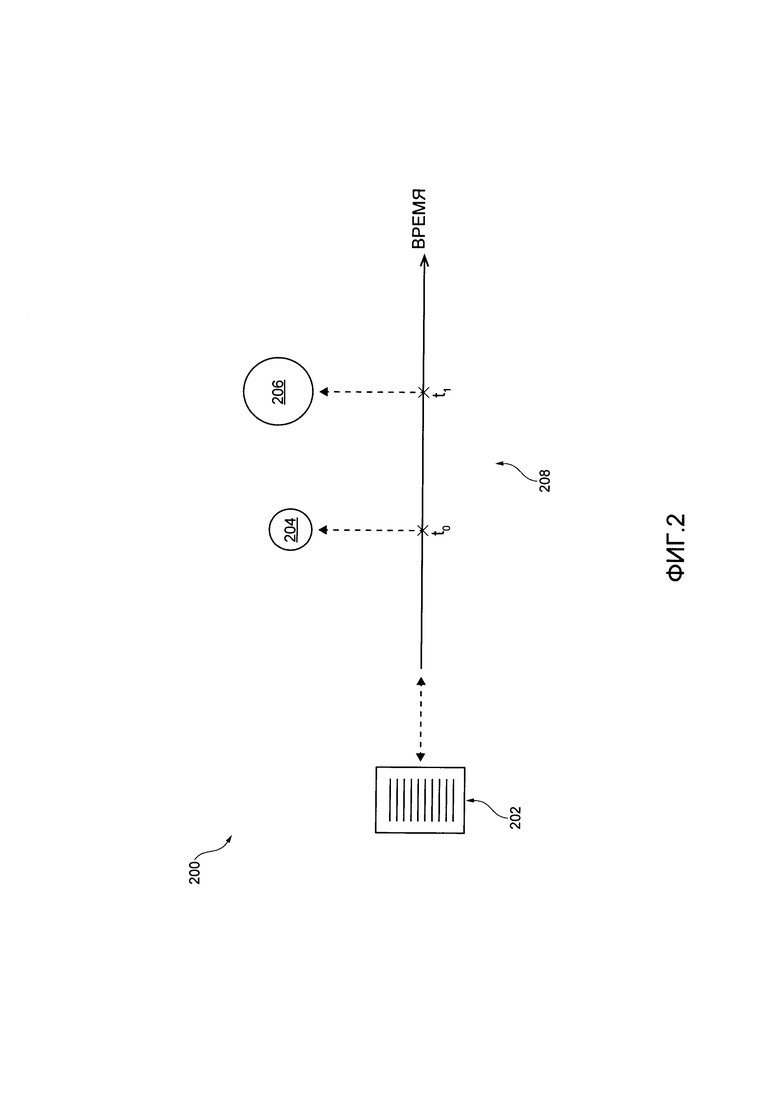
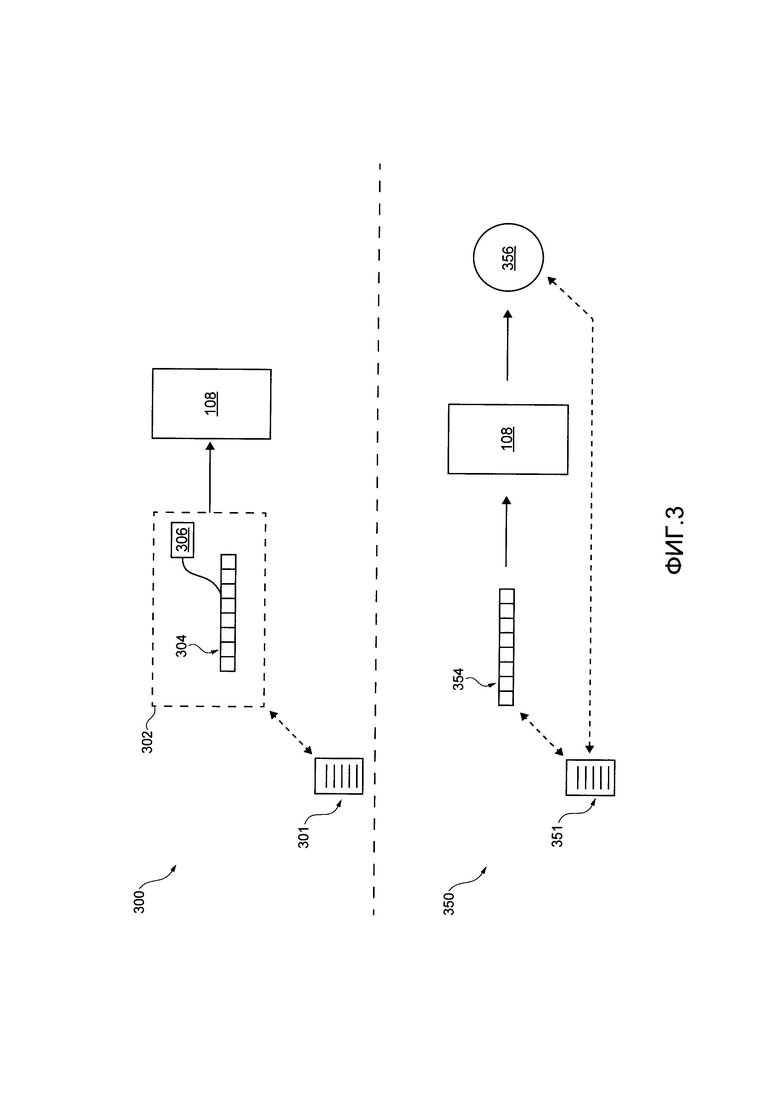
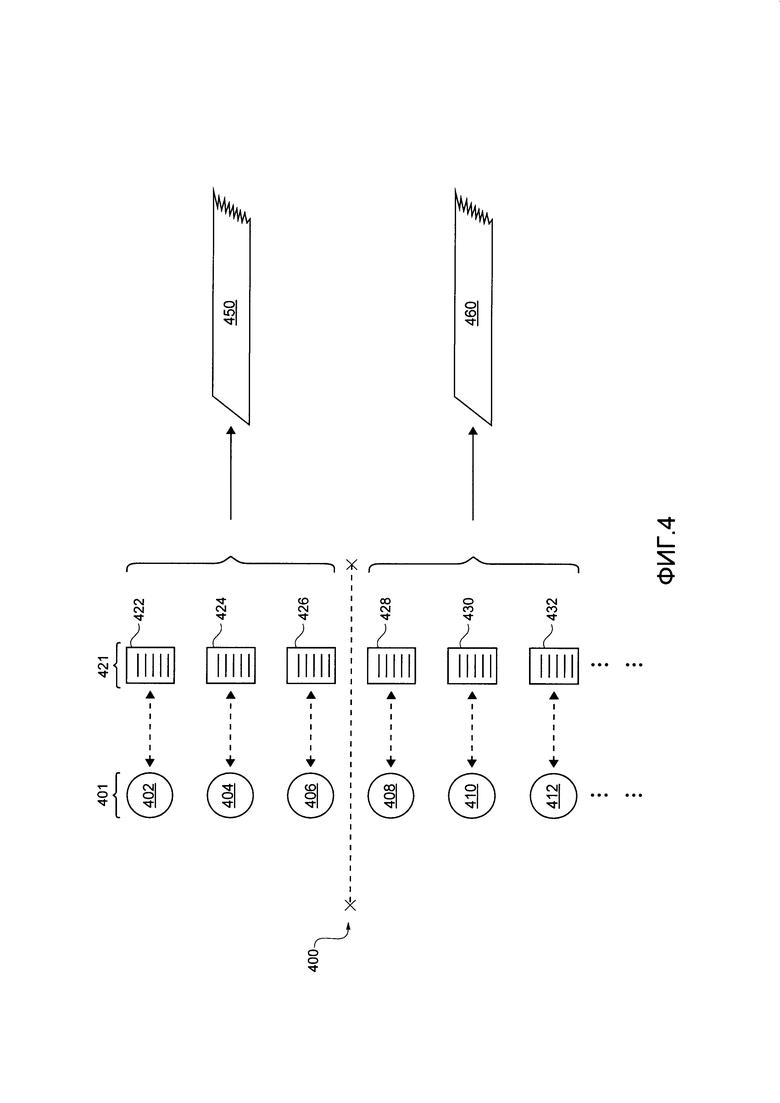
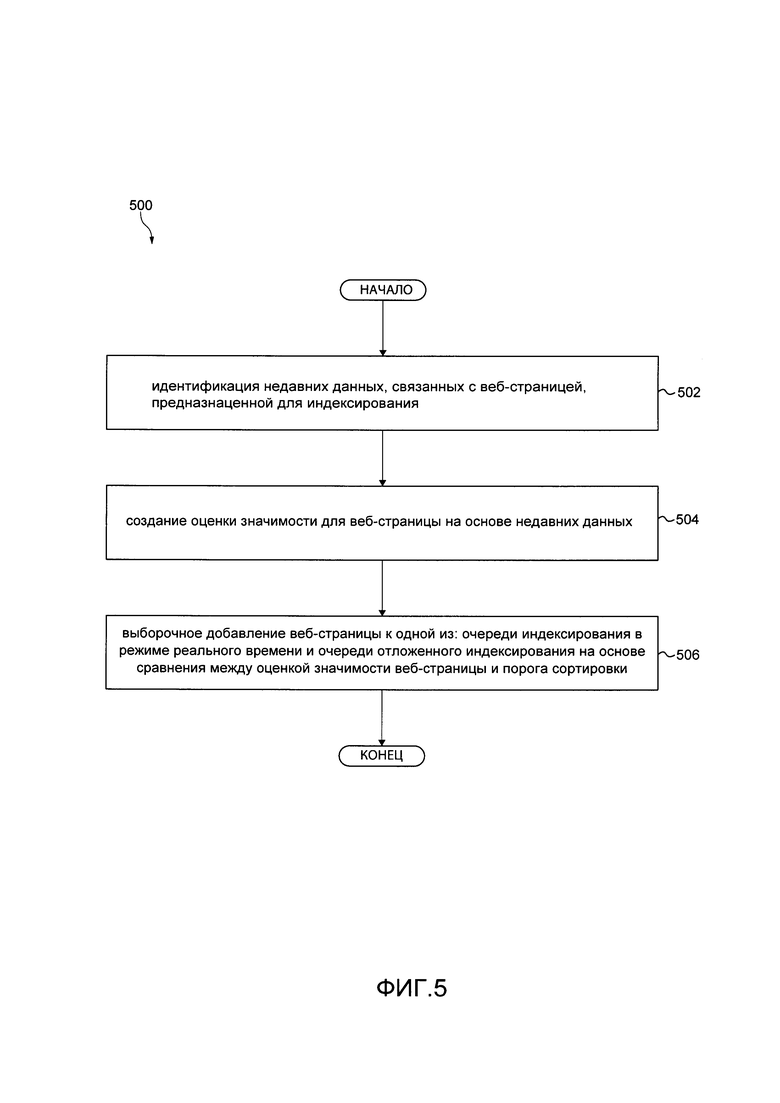
Изобретение относится к области вычислительной техники. Технический результат заключается в повышении точности индексирования веб-страницы в индексе, который расположен в системе дата-центра. Технический результат достигается за счет идентификации недавних данных, связанных со страницей, и создания с помощью алгоритма машинного обучения, оценки для страницы на основе недавних данных, которые указывают на пользу страницы в качестве поискового результата поисковой системы. Алгоритм машинного обучения был обучен на обучающей странице, которая обладает данными в первый момент времени и данными во второй момент времени. Также происходит выборочное добавление страницы к одной из: очереди индексирования в режиме реального времени или очереди отложенного индексирования на основе сравнения между оценкой и порогом. Если оценка находится ниже порога, страница добавляется к очереди отложенного индексирования. Если оценка находится выше порога, страница добавляется к очереди индексирования в режиме реального времени. 2 н. и 18 з.п. ф-лы, 5 ил.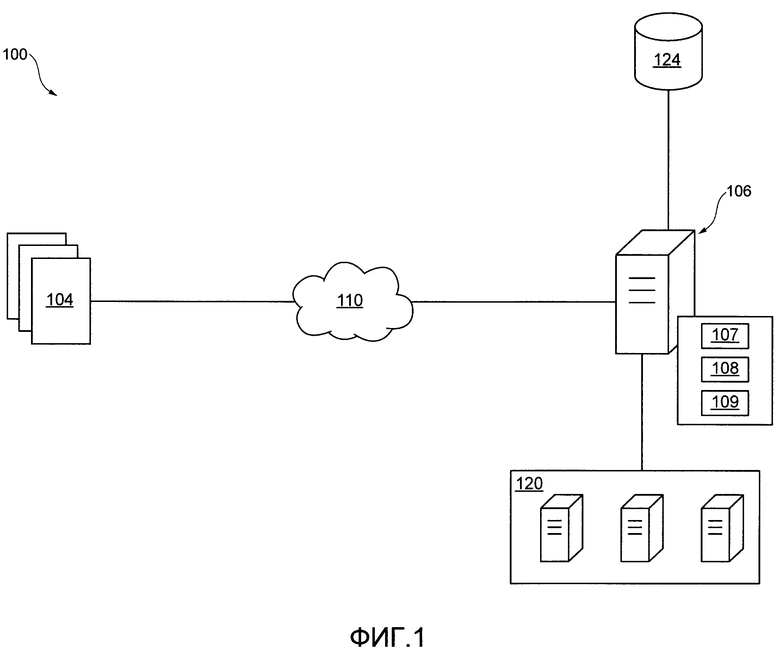
1. Способ индексирования веб-страницы в индексе, который расположен в системе дата-центра, который функционально связан с сортировочным сервером, причем индекс предназначен для предоставления указаний на возможные поисковые результаты поисковой системе, причем способ выполняется сортировочным сервером и включает в себя:
• идентификацию сортировочным сервером, который выполняет приложение поискового робота, недавних данных, связанных с веб-страницей, предназначенной для индексирования;
• создание сортировочным сервером, который выполняет алгоритм машинного обучения, оценки значимости для веб-страницы на основе недавних данных, связанных с веб-страницей, причем оценка значимости указывает на полезность веб-страницы в качестве поискового результата, и алгоритм машинного обучения был обучен на основе обучающего набора, включающего в себя:
(i) обучающий вектор, указывающий на данные, связанные с обучающей веб-страницей в первый момент времени после создания содержимого обучающей веб-страницы; и
(ii) отметку, указывающую на пользу обучающей веб-страницы как поискового результата и на основе данных, связанных с обучающей веб-страницей во второй момент времени, причем второй момент времени находится позже во времени, чем первый момент времени;
• выборочное добавление с помощью сортировочного сервера веб-страницы к одной из (i) очереди индексирования в режиме реального времени и (ii) очереди отложенного индексирования на основе сравнения между оценкой значимости веб-страницы и порога сортировки таким образом, что:
 если оценка значимости находится ниже порога сортировки, веб-страница добавляется к очереди отложенного индексирования веб-страниц; и
если оценка значимости находится ниже порога сортировки, веб-страница добавляется к очереди отложенного индексирования веб-страниц; и
если оценка значимости находится выше порога сортировки, веб-страница добавляется к очереди индексирования в режиме реального времени для индексирования веб-страницы в режиме реального времени.
2. Способ по п. 1, в котором недавние данные связаны с веб-страницей в данный момент времени после создания содержимого веб-страницы.
3. Способ по п. 1, в котором недавние данные связаны с веб-страницей в данный момент времени, после того как веб-страница была просмотрена приложением поискового робота.
4. Способ по п. 1, в котором оценка значимости указывает на пользу веб-страницы как свежего поискового результата.
5. Способ по п. 1, в котором обучающий вектор основан на небольшом количестве данных, связанных с обучающей веб-страницей, доступной в первый момент времени.
6. Способ по п. 1, в котором веб-страницы, которые добавлены к очереди индексирования в режиме реального времени для индексирования в реальном времени, индексируются независимо от веб-страниц, которые добавляются к очереди отложенного индексирования.
7. Способ по п. 1, в котором веб-страницы, которые добавлены к очереди индексирования в режиме реального времени для индексирования в реальном времени, индексируются раньше любой другой веб-страницы, которые добавляются к очереди отложенного индексирования.
8. Способ по п. 1, в котором веб-страницы, которые добавляются либо к (i) очереди индексирования в режиме реального времени, либо к (ii) очереди отложенного индексирования, упорядочиваются по отношению друг к другу в соответствии с их оценками значимости.
9. Способ по п. 1, в котором веб-страница представляет собой одно из следующего:
• новую веб-страницу; и
• обновленную веб-страницу.
10. Способ по п. 9, в котором новая веб-страница представляет собой данную веб-страницу, которая не была ранее индексирована, причем польза новой веб-страницы в качестве поискового результата с большей вероятностью выше, чем польза старой веб-страницы в качестве поискового результата, причем старая веб-страница была ранее индексирована.
11. Способ по п. 9, в котором обновленная веб-страница является обновленной версией старой веб-страницы, причем обновленная веб-страница не была ранее индексирована, а старая веб-страница была ранее индексирована, и польза обновленной веб-страницы в качестве поискового результата с большей вероятностью выше, чем польза старой веб-страницы в качестве поискового результата.
12. Способ по п. 7, в котором в ответ на то, что веб-страница является новой веб-страницей, оценка значимости взвешивается для проверки того, что она выше порога сортировки, таким образом, что веб-страница добавляется к очереди индексирования в режиме реального времени для индексирования новой веб-страницы в режиме реального времени.
13. Способ по п. 1, дополнительно включающий в себя:
• передачу сортировочным сервером данных, указывающих на веб-страницы в очереди на индексирование в режиме реального времени, в систему дата-центра для индексирования в режиме реального времени; и
• передачу сортировочным сервером данных, указывающих на веб-страницы в очереди на отложенное индексирование, в систему дата-центра для отложенного индексирования.
14. Способ по п. 1, в котором сортировочный сервер выполняет алгоритм балансирования нагрузки для балансировки нагрузки на систему дата-центра, и причем способ включает в себя:
• определение сортировочным сервером, выполняющим алгоритм балансировки нагрузки, того что система дата-центра обладает доступным количеством вычислительных мощностей для выполнения индексирования в режиме реального времени.
15. Способ по п. 14, в котором порог сортировки зависит от доступного количества вычислительной мощности для выполнения индексирования в режиме реального времени.
16. Способ по п. 14, в котором в ответ на определение сортировочным сервером, который выполняет алгоритм балансировки нагрузки, того, что доступное количество вычислительной мощности для выполнения индексирования в режиме реального времени было изменено, настройка сортировочным сервером порога сортировки.
17. Способ по п. 1, в котором недавние данные включают в себя по меньшей мере одно из:
• время создания веб-страницы;
• число визитов на URL веб-страницы;
• число входящих гиперссылок на веб-страницу;
• число исходящих гиперссылок с веб-страницы; и
• тип содержимого веб-страницы.
18. Сервер для индексирования веб-страницы в индексе, который расположен в системе дата-центра, который функционально связан с сервером, причем индекс предназначен для предоставления указаний на возможные поисковые результаты поисковой системе, причем сервер выполнен с возможностью выполнять приложение поискового робота и алгоритм машинного обучения, и сервер выполнен с возможностью осуществлять:
• идентификацию, путем выполнения приложения поискового робота, недавних данных, связанных с веб-страницей, предназначенной для индексирования;
• создание, путем выполнения алгоритма машинного обучения, оценки значимости для веб-страницы на основе недавних данных, связанных с веб-страницей, причем оценка значимости указывает на полезность веб-страницы в качестве поискового результата, и алгоритм машинного обучения был обучен на основе обучающего набора, включающего в себя:
(i) обучающий вектор, указывающий на данные, связанные с обучающей веб-страницей в первый момент времени после создания содержимого обучающей веб-страницы; и
(ii) отметку, указывающую на пользу обучающей веб-страницы как поискового результата и на основе данных, связанных с обучающей веб-страницей во второй момент времени, причем второй момент времени находится позже во времени, чем первый момент времени;
• выборочное добавление веб-страницы к одной из (i) очереди индексирования в режиме реального времени и (ii) очереди отложенного индексирования на основе сравнения между оценкой значимости веб-страницы и порога сортировки таким образом, что:
если оценка значимости находится ниже порога сортировки, веб-страница добавляется к очереди отложенного индексирования веб-страниц; и
если оценка значимости находится выше порога сортировки, веб-страница добавляется к очереди индексирования в режиме реального времени для индексирования веб-страницы в режиме реального времени.
19. Сервер по п. 18, в котором порог сортировки зависит от доступного количества вычислительной мощности системы дата-центра для выполнения индексирования в режиме реального времени.
20. Сервер по п. 18, в котором веб-страница представляет собой одно из следующего:
• новую веб-страницу; и
• обновленную веб-страницу.
| СПОСОБ ПРОВЕРКИ ВЕБ-СТРАНИЦ НА СОДЕРЖАНИЕ В НИХ ЦЕЛЕВОГО АУДИО И/ИЛИ ВИДЕО (AV) КОНТЕНТА РЕАЛЬНОГО ВРЕМЕНИ | 2013 |
|
RU2530671C1 |
| US 7801896 B2, 21.09.2010 | |||
| Способ приготовления лака | 1924 |
|
SU2011A1 |
| Устройство для закрепления лыж на раме мотоциклов и велосипедов взамен переднего колеса | 1924 |
|
SU2015A1 |
| Пломбировальные щипцы | 1923 |
|
SU2006A1 |

