Область техники, к которой относится изобретение
[001] Настоящая технология относится в целом к обработке естественного языка и, в частности, к способу и системе для формирования текстового представления фрагмента устной речи пользователя.
Уровень техники
[002] Электронные устройства, такие как смартфоны и планшеты, имеют доступ к постоянно растущему количеству разнообразных приложений и сервисов для обработки информации различных видов и/или для доступа к ней. Тем не менее, начинающие пользователи и/или пользователи с ограниченными возможностями и/или пользователи, управляющие транспортным средством, могут быть неспособны эффективно взаимодействовать с такими устройствами, главным образом, вследствие разнообразия функций, выполняемых этими устройствами, или невозможности использовать интерфейсы пользователь-машина, предоставляемые такими устройствами (например, клавиатуру). В частности, пользователь, управляющий транспортным средством, или пользователь с нарушениями зрения может быть неспособен использовать клавиатуру на сенсорном экране, характерную для некоторых из этих устройств.
[003] Для выполнения действий по запросам пользователя разработаны приложения виртуального помощника. Например, такие приложения виртуального помощника могут использоваться для поиска информации, навигации и выполнения других разнообразных запросов. Традиционное приложение виртуального помощника, такое как Siri®, способно принимать от устройства фрагмент устной речи пользователя в виде цифрового аудиосигнала и выполнять разнообразные задачи для этого пользователя. В частности, пользователь может общаться с приложением Siri®, используя фрагменты устной речи, чтобы узнать, например, текущую погоду, местоположение ближайшего торгового центра и т.п. Пользователь также может запрашивать выполнение различных приложений, установленных на электронном устройстве.
[004] В общем случае традиционные приложения виртуального помощника обучены формировать на основе фрагмента речи множество гипотез и выбирать наиболее вероятную гипотезу в качестве верного текстового представления этого фрагмента речи, основываясь на фразах, которые ранее были использованы для обучения приложения.
[005] В патенте US5040215 «Speech Recognition Apparatus Using Neural Network and Fuzzy Logic» (Hitachi Ltd., опубликован 13 августа 1991 г.) описано устройство распознавания речи, содержащее блок речевого ввода для ввода речи; блок анализа речи для анализа введенной речи с целью вывода  ряда векторов признаков; блок выбора возможных результатов для ввода ряда векторов признаков из блока анализа речи с целью выбора из категорий речи множества возможных результатов распознавания; и обрабатывающий блок дискриминатора для выделения выбранных возможных результатов с целью получения окончательного результата распознавания. Обрабатывающий блок дискриминатора содержит три компонента: блок формирования пар для формирования всех парных сочетаний из n возможных результатов, выбранных блоком выбора возможных результатов; блок дискриминатора пар для выделения более достоверных возможных сочетаний для всех nC2-сочетаний (или пар) на основе извлеченного результата акустического признака, присущего каждому возможному речевому сигналу; блок принятия окончательного решения для сбора всех результатов выделения пар, полученных из блока дискриминатора пар для всех nC2-сочетаний (или пар), с целью определения окончательного результата. Блок дискриминатора пар обрабатывает извлеченный результат акустического признака, присущего каждому возможному речевому сигналу, как неопределенную информацию и выполняет выделение на основе алгоритмов нечеткой логики. Блок принятия окончательного решения выполняет сбор информации на основе алгоритмов нечеткой логики.
ряда векторов признаков; блок выбора возможных результатов для ввода ряда векторов признаков из блока анализа речи с целью выбора из категорий речи множества возможных результатов распознавания; и обрабатывающий блок дискриминатора для выделения выбранных возможных результатов с целью получения окончательного результата распознавания. Обрабатывающий блок дискриминатора содержит три компонента: блок формирования пар для формирования всех парных сочетаний из n возможных результатов, выбранных блоком выбора возможных результатов; блок дискриминатора пар для выделения более достоверных возможных сочетаний для всех nC2-сочетаний (или пар) на основе извлеченного результата акустического признака, присущего каждому возможному речевому сигналу; блок принятия окончательного решения для сбора всех результатов выделения пар, полученных из блока дискриминатора пар для всех nC2-сочетаний (или пар), с целью определения окончательного результата. Блок дискриминатора пар обрабатывает извлеченный результат акустического признака, присущего каждому возможному речевому сигналу, как неопределенную информацию и выполняет выделение на основе алгоритмов нечеткой логики. Блок принятия окончательного решения выполняет сбор информации на основе алгоритмов нечеткой логики.
[006] В патентной заявке US 2017193387 A1 «Probabilistic Ranking for Neural Language Understanding» (Nuance Communications Inc., опубликована 6 июля 2017 г.) описана обработка естественного языка или понимание естественного языка, включая выполнение вероятностного или основанного на вероятностном подходе ранжирования потенциальных результатов. Например, входные данные естественного языка могут приниматься в виде речевого сигнала или текста. Обработка естественного языка может выполняться с целью определения одного или нескольких потенциальных результатов для входных данных. Для определения парных оценок элементов из потенциальных результатов может использоваться попарный классификатор. На основе оценок могут быть определены вероятности для пар элементов. На основе вероятностей для пар элементов могут быть определены дополнительные вероятности, например, путем оценивания вероятности того, что текущий результат соответствует высшему рангу или наилучшему выбору. На основе оценок вероятности того, что текущий результат соответствует высшему рангу или наилучшему выбору, может быть выполнено ранжирование, которое может представлять собой основу для вывода результатов обработки естественного языка.
[007] В патентной заявке US 2018130460 A1 «Splitting Utterances for Quick Responses» (International Business Machines Corp., опубликована 15 мая 2018 г.) описан способ, включающий в себя подготовку процессором пар для задачи поиска информации. Каждая пара содержит (а) результат распознавания речи на этапе обучения для соответствующей последовательности обучающих слов и (б) метку ответа, соответствующую результату распознавания речи на этапе обучения. Способ дополнительно включает в себя получение процессором соответствующего ранга для метки ответа, включенной в состав каждой пары, с целью получения набора рангов. Способ также включает в себя определение процессором для каждой пары конечной части вопроса в результате распознавания речи на этапе обучения на основе набора рангов. Способ дополнительно включает в себя построение процессором классификатора так, чтобы этот классификатор принимал результат распознавания речи на этапе распознавания и определял соответствующую конечную часть вопроса для результата распознавания речи на этапе распознавания на основе конечной части вопроса, определенной для этих пар.
Раскрытие изобретения
[008] Целью настоящего изобретения является устранение по меньшей мере некоторых недостатков известных решений. Разработчиками настоящей технологии реализованы способ и система для формирования текстового представления фрагмента устной речи пользователя с учетом характеристик пользователя и акустических свойств фрагмента речи.
[009] Разработчики настоящей технологии обнаружили определенные технические недостатки, связанные с существующими приложениями виртуального помощника. В традиционных приложениях виртуального помощника основное внимание уделяется определению правильной гипотезы на основе признаков уровня гипотезы или, иными словами, признаков, связанных с каждой сформированной гипотезой. Тем не менее, даже в случае большого объема набора обучающих данных на определение верного текстового представления фрагмента речи пользователя влияют многие факторы. Например, люди естественным образом изменяют тон фрагмента устной речи при разговоре в шумной обстановке, что может повлиять на определение верного текстового представления этого фрагмента речи. Следовательно, приложение виртуального помощника должно отличать акустический шум окружающей среды от фрагмента речи. Кроме того, тембр может изменяться в зависимости от возраста и пола говорящего.
[0010] В соответствии с одним из аспектов настоящей технологии реализован компьютерный способ формирования текстового представления фрагмента устной речи пользователя, выполняемый электронным устройством. Способ включает в себя: прием электронным устройством от пользователя указания на фрагмент устной речи пользователя на естественном языке; формирование электронным устройством на основе этого фрагмента устной речи пользователя по меньшей мере двух гипотез, каждая из которых соответствует возможному текстовому представлению этого фрагмента устной речи пользователя; формирование электронным устройством из этих по меньшей мере двух гипотез набора спаренных гипотез, одна из которых содержит первую гипотезу, спаренную со второй гипотезой; определение с использованием попарного классификатора, выполняемого электронным устройством, для одной пары из набора спаренных гипотез парной оценки, указывающей на относительную вероятность соответствия первой гипотезы и второй гипотезы верному представлению этого фрагмента устной речи пользователя; формирование набора признаков фрагмента речи, указывающего на одну или несколько характеристик, связанных с этим фрагментом устной речи пользователя; ранжирование алгоритмом ранжирования, выполняемым электронным устройством, первой гипотезы и второй гипотезы на основе по меньшей мере парной оценки и набора признаков фрагмента речи; и выбор первой гипотезы в качестве текстового представления этого фрагмента устной речи пользователя, если первая гипотеза представляет собой гипотезу с наибольшим рангом.
[0011] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения по меньшей мере две гипотезы включают в себя первую гипотезу, вторую гипотезу и по меньшей мере одну дополнительную гипотезу, набор спаренных гипотез включает в себя множество спаренных гипотез, содержащее каждую из этих по меньшей мере двух гипотез, спаренную с каждой оставшейся гипотезой из этих по меньшей мере двух гипотез, а определение парной оценки включает в себя определение набора парных оценок, содержащего одну или несколько парных оценок, связанных с каждой парой гипотез из этого множества спаренных гипотез.
[0012] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения ранжирование алгоритмом ранжирования включает в себя ранжирование этих по меньшей мере двух гипотез на основе по меньшей мере всего набора парных оценок и набора признаков фрагмента речи.
[0013] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения определение парной оценки включает в себя: определение первой оценки, указывающей на относительную вероятность того, что верному представлению фрагмента устной речи пользователя соответствует первая гипотеза, а не вторая гипотеза; определение второй оценки, указывающей на относительную вероятность того, что верному представлению этого фрагмента устной речи пользователя соответствует вторая гипотеза, а не первая гипотеза; определение первой нормализованной оценки на основе первой оценки и второй нормализованной оценки на основе второй оценки так, чтобы сумма первой нормализованной оценки и второй нормализованной оценки была равна заранее заданной суммарной оценке.
[0014] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения способ дополнительно включает в себя: формирование первого профиля гипотезы, соответствующего первому набору векторов, представляющих одну или несколько контекстно-зависимых характеристик первой гипотезы; формирование второго профиля гипотезы, соответствующего второму набору векторов, представляющих одну или несколько контекстно-зависимых характеристик второй гипотезы; при этом формирование парной оценки включает в себя формирование парной оценки на основе по меньшей мере первого профиля гипотезы и второго профиля гипотезы.
[0015] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения попарный классификатор представляет собой алгоритм Прайса (Price), Кнера (Kner), Персоназа (Personnaz) и Дрейфуса (Dreyfus) (далее - алгоритм PKPD), а способ дополнительно включает в себя: обучение алгоритма PKPD перед приемом фрагмента устной речи пользователя с использованием обучающего набора данных, содержащего по меньшей мере обучающую пару гипотез, включающую в себя первую обучающую гипотезу, спаренную со второй обучающей гипотезой, при этом первая обучающая гипотеза и вторая обучающая гипотеза сформированы в ответ на обучающий фрагмент речи; первый профиль обучающей гипотезы, соответствующий первому обучающему набору векторов, представляющих один или несколько контекстно-зависимых признаков первой обучающей гипотезы; второй профиль обучающей гипотезы, соответствующий второму обучающему набору векторов, представляющих один или несколько контекстно-зависимых признаков второй обучающей гипотезы; оценку различия профилей, соответствующую разности между первым обучающим набором векторов и вторым обучающим набором векторов; совокупную оценку профилей, соответствующую частному от деления первого обучающего набора векторов на второй обучающий набор векторов; и метку, указывающую на соответствие первой обучающей гипотезы или второй обучающей гипотезы этому обучающему фрагменту речи.
[0016] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения формирование первого профиля гипотезы включает в себя: анализ первой гипотезы с использованием одной или нескольких контекстно-зависимых моделей, каждая из которых обучена на множестве контекстно-зависимых слов; назначение каждой из этой одной или нескольких контекстно-зависимых моделей относительной контекстно-зависимой оценки, соответствующей вектору, который представляет собой долю контекстно-зависимых слов, связанных с контекстно-зависимой моделью в рамках первой гипотезы; и объединение одного или нескольких векторов, назначенных этой одной или нескольким контекстно-зависимыми моделям.
[0017] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения набор признаков фрагмента речи содержит характерные для пользователя признаки, включая возраст пользователя и/или пол пользователя и/или профиль интересов пользователя.
[0018] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения электронное устройство дополнительно соединено с базой данных, содержащей журнал просмотра или журнал поиска, связанный с пользователем, а характерные для пользователя признаки формируются на основе истории просмотра, связанной с этим пользователем, и/или истории поиска, связанной с этим пользователем.
[0019] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения электронное устройство представляет собой пользовательское устройство, а характерные для пользователя признаки формируются на основе предыдущих взаимодействий этого пользователя с этим пользовательским устройством.
[0020] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения, где набор признаков фрагмента устной речи содержит акустические признаки, эти акустические признаки включают в себя тембр фрагмента устной речи пользователя и/или тон фрагмента устной речи пользователя и/или отношение сигнал-шум.
[0021] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения электронное устройство представляет собой сервер, соединенный с пользовательским устройством, связанным с пользователем, а прием фрагмента устной речи пользователя от пользователя включает в себя прием фрагмента устной речи пользователя от этого пользовательского устройства.
[0022] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения алгоритм ранжирования представляет собой нейронную сеть, а способ дополнительно включает в себя обучение нейронной сети с использованием обучающего набора данных перед приемом входных данных на естественном языке.
[0023] В соответствии с другим аспектом настоящей технологии реализован компьютерный способ формирования текстового представления фрагмента устной речи пользователя, выполняемый электронным устройством. Способ включает в себя: прием электронным устройством от пользователя указания на фрагмент устной речи пользователя на естественном языке; формирование электронным устройством на основе этого фрагмента устной речи пользователя по меньшей мере двух гипотез, каждая из которых соответствует возможному текстовому представлению этого фрагмента устной речи пользователя; формирование электронным устройством набора спаренных гипотез, содержащего каждую гипотезу из этих по меньшей мере двух гипотез, спаренную с каждой оставшейся гипотезой из этих по меньшей мере двух гипотез; определение с использованием попарного классификатора, выполняемого электронным устройством, набора парных оценок, содержащего парную оценку для каждой пары в наборе спаренных гипотез, при этом парная оценка для спаренной гипотезы указывает на относительную вероятность соответствия первой гипотезы и второй гипотезы из этой спаренной гипотезы верному представлению этого фрагмента устной речи пользователя; ранжирование этих по меньшей мере двух гипотез алгоритмом ранжирования, выполняемым электронным устройством и способным ранжировать эти по меньшей мере две гипотезы на основе всего набора парных оценок; выбор первой гипотезы в качестве текстового представления этого фрагмента устной речи пользователя, если первая гипотеза представляет собой гипотезу с наибольшим рангом.
[0024] В соответствии с другим аспектом настоящей технологии реализована система для формирования текстового представления фрагмента устной речи пользователя, содержащая электронное устройство, содержащее процессор, выполненный с возможностью: приема электронным устройством от пользователя указания на фрагмент устной речи пользователя на естественном языке; формирования электронным устройством на основе этого фрагмента устной речи пользователя по меньшей мере двух гипотез, каждая из которых соответствует возможному текстовому представлению этого фрагмента устной речи пользователя; формирования электронным устройством из по меньшей мере двух гипотез набора спаренных гипотез, одна из которых содержит первую гипотезу, спаренную со второй гипотезой; определения с использованием попарного классификатора, выполняемого электронным устройством, набора парных оценок, содержащего парную оценку, связанную с одной парой из набора спаренных гипотез и указывающую на относительную вероятность соответствия первой гипотезы и второй гипотезы верному представлению этого фрагмента устной речи пользователя; формирования набора признаков фрагмента речи, указывающего на одну или несколько характеристик, связанных с этим фрагментом устной речи пользователя; ранжирования алгоритмом ранжирования, выполняемым электронным устройством, первой гипотезы и второй гипотезы на основе по меньшей мере всего набора парных оценок и набора признаков фрагмента речи; и выбора первой гипотезы в качестве текстового представления этого фрагмента устной речи пользователя, если первая гипотеза представляет собой гипотезу с наибольшим рангом.
[0025] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения по меньшей мере две гипотезы включают в себя первую гипотезу, вторую гипотезу и по меньшей мере одну дополнительную гипотезу; при этом набор спаренных гипотез включает в себя множество спаренных гипотез, содержащее каждую из этих по меньшей мере двух гипотез, спаренную с каждой оставшейся гипотезой из этих по меньшей мере двух гипотез; а для определения парной оценки процессор выполнен с возможностью определения набора парных оценок, содержащего одну или несколько парных оценок, связанных с каждой парой из этого множества спаренных гипотез.
[0026] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения для определения парной оценки процессор выполнен с возможностью: определения первой оценки, указывающей на относительную вероятность того, что верному представлению фрагмента устной речи пользователя соответствует первая гипотеза, а не вторая гипотеза, определения второй оценки, указывающей на относительную вероятность того, что верному представлению фрагмента устной речи пользователя соответствует вторая гипотеза, а не первая гипотеза, и определения первой нормализованной оценки на основе первой оценки и второй нормализованной оценки на основе второй оценки так, чтобы сумма первой нормализованной оценки и второй нормализованной оценки была равна заранее заданной суммарной оценке.
[0027] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения набор признаков фрагмента речи содержит характерные для пользователя признаки, включая возраст пользователя и/или пол пользователя и/или профиль интересов пользователя.
[0028] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения набор признаков фрагмента речи содержит акустические признаки, включая тембр фрагмента устной речи пользователя и/или тон фрагмента устной речи пользователя и/или отношение сигнал-шум.
[0029] В некоторых не имеющих ограничительного характера вариантах осуществления изобретения алгоритм ранжирования представляет собой нейронную сеть, а процессор дополнительно выполнен с возможностью обучения нейронной сети с использованием обучающего набора данных перед приемом входных данных на естественном языке.
[0030] В контексте настоящего описания термин «сервер» означает компьютерную программу, выполняемую соответствующими аппаратными средствами и способную принимать запросы (например, от клиентских устройств) через сеть и выполнять эти запросы или инициировать их выполнение. Аппаратные средства могут представлять собой один физический компьютер или одну компьютерную систему, что не критично для настоящей технологии. В настоящем контексте выражение «сервер» не означает, что каждая задача (например, принятая команда или запрос) или некоторая конкретная задача принимается, выполняется или запускается одним и тем же сервером (т.е. одними и теми же программными и/или аппаратными средствами). Это выражение означает, что любое количество программных средств или аппаратных средств может принимать, отправлять, выполнять или инициировать выполнение любой задачи или запроса либо результатов любых задач или запросов. Все эти программные и аппаратные средства могут представлять собой один сервер или несколько серверов, при этом оба эти случая подразумеваются в выражении «по меньшей мере один сервер».
[0031] В контексте настоящего описания термин «клиентское устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры клиентских устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты, а также сетевое оборудование, такое как маршрутизаторы, коммутаторы и шлюзы. Следует отметить, что в данном контексте устройство, функционирующее как клиентское устройство, также может функционировать как сервер для других клиентских устройств. Использование выражения «клиентское устройство» не исключает использования нескольких клиентских устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов любых задач или запросов, либо шагов любого описанного здесь способа.
[0032] В контексте настоящего описания термин «база данных» означает любой структурированный набор данных, независимо от его конкретной структуры, программного обеспечения для управления базой данных или компьютерных аппаратных средств для хранения этих данных, их применения или обеспечения их использования иным способом. База данных может располагаться в тех же аппаратных средствах, что и процесс, обеспечивающий хранение или использование информации, хранящейся в этой базе данных, либо база данных может располагаться в отдельных аппаратных средствах, таких как специализированный сервер или множество серверов.
[0033] В контексте настоящего описания выражение «информация» включает в себя информацию любого рода или вида, допускающую хранение в базе данных. Таким образом, информация включает в себя аудиовизуальные произведения (изображения, фильмы, звукозаписи, презентации и т.д.), данные (данные о местоположении, числовые данные и т.д.), текст (мнения, комментарии, вопросы, сообщения и т.д.), документы, электронные таблицы, списки слов и т.д., но не ограничивается ими.
[0034] В контексте настоящего описания выражение «компонент» включает в себя обозначение программного обеспечения (подходящего для определенных аппаратных средств), необходимого и достаточного для выполнения определенной функции или нескольких функций.
[0035] В контексте настоящего описания выражение «пригодный для использования в компьютере носитель информации» означает носители любого рода и вида, включая ОЗУ, ПЗУ, диски (CD-ROM, DVD, гибкие диски, жесткие диски и т.д.), USB-накопители, твердотельные накопители, накопители на магнитных лентах и т.д.
[0036] В контексте настоящего описания числительные «первый» «второй», «третий» и т.д. используются лишь для указания различия между существительными, к которым они относятся, но не для описания каких-либо определенных взаимосвязей между этими существительными. Например, должно быть понятно, что использование терминов «первый сервер» и «третий сервер» не подразумевает какого-либо определенного порядка, типа, хронологии, иерархии или классификации, в данном случае, серверов, а также что их использование (само по себе) не подразумевает наличие «второго сервера» в любой ситуации. Кроме того, как встречается в настоящем описании в другом контексте, ссылка на «первый» элемент и «второй» элемент не исключает того, что эти два элемента в действительности могут быть одним и тем же элементом. Таким образом, например, в некоторых случаях «первый» сервер и «второй» сервер могут представлять собой одно и то же программное и/или аппаратное средство, а в других случаях - различные программные и/или аппаратные средства.
[0037] Каждый вариант осуществления настоящей технологии относится к по меньшей мере одной из вышеупомянутых целей и/или аспектов, но не обязательно ко всем ним. Должно быть понятно, что некоторые аспекты настоящей технологии, связанные с попыткой достижения вышеупомянутой цели, могут не соответствовать этой цели и/или могут соответствовать другим целям, явным образом здесь не упомянутым.
[0038] Дополнительные и/или альтернативные признаки, аспекты и преимущества вариантов реализации настоящей технологии должны быть ясны из дальнейшего описания, приложенных чертежей и формулы изобретения.
Краткое описание чертежей
[0039] Дальнейшее описание приведено для лучшего понимания настоящей технологии, а также других аспектов и их признаков, и должно использоваться совместно с приложенными чертежами.
[0040] На фиг. 1 представлена схема системы, реализованной согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии.
[0041] На фиг. 2 представлена схема процесса для формирования объединенного профиля пользователя.
[0042] На фиг. 3 приведен пример процесса для определения текстового представления фрагмента устной речи пользователя.
[0043] На фиг. 4 представлена схема процесса определения профиля гипотезы, выполняемого в качестве части процесса, представленного на фиг. 3.
[0044] На фиг. 5 представлена схема процесса обучения попарного классификатора, выполняемого перед процессом, представленным на фиг. 3.
[0045] На фиг. 6 представлена схема процесса определения набора парных оценок и набора нормализованных оценок вероятности, выполняемого в качестве части процесса, представленного на фиг. 3.
[0046] На фиг. 7 представлена блок-схема способа формирования текстового представления фрагмента устной речи пользователя.
Осуществление изобретения
[0047] На фиг. 1 представлена схема системы 100, пригодной для реализации вариантов осуществления настоящей технологии, не имеющих ограничительного характера. Очевидно, что система 100 приведена только для демонстрации варианта реализации настоящей технологии. Таким образом, дальнейшее описание системы представляет собой описание примеров, иллюстрирующих данную технологию. Это описание не предназначено для определения объема или границ данной технологии. В некоторых случаях приведены полезные примеры модификаций системы 100. Они способствуют пониманию, но также не определяют объем или границы данной технологии. Эти модификации не составляют исчерпывающего списка. Как должно быть понятно специалисту в данной области, возможны и другие модификации. Кроме того, если в некоторых случаях модификации не описаны (т.е. примеры модификаций отсутствуют), это не означает, что они невозможны и/или что описание содержит единственно возможный вариант реализации того или иного элемента настоящей технологии. Специалисту в данной области должно быть понятно, что это не так. Кроме того, следует понимать, что система 100 в некоторых случаях может представлять собой упрощенную реализацию настоящей технологии, и что такие варианты представлены для того, чтобы способствовать лучшему ее пониманию. Специалисту в данной области должно быть понятно, что различные варианты осуществления данной технологии могут быть значительно сложнее.
[0048] Представленные в данном описании примеры и условный язык предназначены для лучшего понимания принципов настоящей технологии, а не для ограничения ее объема до таких специально приведенных примеров и условий. Очевидно, что специалисты в данной области техники могут разработать различные способы и устройства, которые явно не описаны и не показаны, но осуществляют принципы настоящей технологии в пределах ее существа и объема. Кроме того, чтобы способствовать лучшему пониманию, последующее описание может содержать упрощенные варианты реализации настоящей технологии. Специалисту в данной области должно быть понятно, что различные варианты осуществления данной технологии могут быть значительно сложнее.
[0049] Более того, описание принципов, аспектов и вариантов реализации настоящей технологии, а также их конкретные примеры предназначены для охвата их структурных и функциональных эквивалентов, независимо от того, известны они в настоящее время или будут разработаны в будущем. Например, специалистам в данной области техники должно быть очевидно, что любые описанные структурные схемы соответствуют концептуальным представлениям иллюстративных принципиальных схем, реализующих основы настоящей технологии. Также должно быть очевидно, что любые блок-схемы, схемы процессов, диаграммы изменения состояния, псевдокоды и т.п. соответствуют различным процессам, которые могут быть представлены в пригодной для чтения компьютером среде и выполняться с использованием компьютера или процессора, независимо от того, показан явно такой компьютер или процессор либо нет.
[0050] Функции различных элементов, показанных на чертежах, включая любой функциональный блок, обозначенный как «процессор» или «графический процессор», могут осуществляться с использованием специализированных аппаратных средств, а также аппаратных средств, способных выполнять соответствующее программное обеспечение. Если используется процессор, его функции могут выполняться одним выделенным процессором, одним совместно используемым процессором или множеством отдельных процессоров, некоторые из которых могут использоваться совместно. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии процессор может представлять собой процессор общего назначения, такой как центральный процессор (CPU), или специализированный процессор, такой как графический процессор (GPU). Кроме того, явное использование термина «процессор» или «контроллер» не должно трактоваться как указание исключительно на аппаратные средства, способные выполнять программное обеспечение, и может, помимо прочего, подразумевать аппаратные средства цифрового сигнального процессора (DSP), сетевой процессор, специализированную интегральную схему (ASIC), программируемую вентильную матрицу (FPGA), ПЗУ для хранения программного обеспечения, ОЗУ и энергонезависимое ЗУ. Также могут подразумеваться другие аппаратные средства, общего применения и/или заказные.
[0051] Учитывая вышеизложенные принципы, далее рассмотрены некоторые не имеющие ограничительного характера примеры, иллюстрирующие различные варианты реализации аспектов настоящей технологии.
[0052] Система 100 содержит электронное устройство 102. Электронное устройство 102 взаимодействует с пользователем 101 и иногда может называться «клиентским устройством». Следует отметить, что связь электронного устройства 102 с пользователем 101 не означает необходимости указывать или предполагать какой-либо режим работы, например, вход в систему, регистрацию и т.п.
[0053] В контексте настоящего описания, если явно не указано другое, термин «электронное устройство» означает любое компьютерное аппаратное средство, способное выполнять программы, подходящие для решения поставленной задачи. Таким образом, некоторые (не имеющие ограничительного характера) примеры электронных устройств включают в себя персональные компьютеры (настольные, ноутбуки, нетбуки и т.п.), смартфоны и планшеты. Следует отметить, что в данном контексте устройство, функционирующее как электронное устройство, также может функционировать как сервер для других электронных устройств. Использование выражения «электронное устройство» не исключает использования нескольких электронных устройств для приема, отправки, выполнения или инициирования выполнения любой задачи или запроса либо результатов любых задач или запросов, либо шагов любого описанного здесь способа.
[0054] Электронное устройство 102 содержит энергонезависимое ЗУ 104. Энергонезависимое ЗУ 104 может содержать один или несколько носителей информации и в общем случае обеспечивает пространство для хранения компьютерных команд, выполняемых процессором 106. Например, энергонезависимое ЗУ 104 может реализовываться как пригодная для чтения компьютером среда, включая ПЗУ, жесткие диски (HDD), твердотельные накопители (SSD) и карты флэш-памяти.
[0055] Электронное устройство 102 содержит аппаратные средства и/или программное обеспечение и/или встроенное программное обеспечение (либо их сочетание) для выполнения приложения 108 виртуального помощника. В общем случае приложение 108 виртуального помощника может активироваться без использования рук в ответ на одно ли несколько активирующих слов и способно выполнять задачи или сервисы в ответ на команды, принятые от пользователя 101. Например, приложение 108 виртуального помощника может быть реализовано в виде виртуального голосового помощника ALICE (предоставляется компанией Yandex LLC, ул. Льва Толстого, 16, Москва, 119021, Россия) в смартфоне либо в виде других коммерческих или проприетарных приложений виртуального помощника. Электронное устройство 102 может принимать команду с использованием микрофона 110, реализованного в электронном устройстве 102. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии микрофон 110 представляет собой отдельное устройство, связанное с электронным устройством 102.
[0056] В общем случае приложение 108 виртуального помощника содержит (или осуществляет доступ к нему иным образом) аналого-цифровой преобразователь (не показан), способный преобразовывать в цифровой сигнал команду, представленную в виде аналогового сигнала, принятого микрофоном 110 от пользователя 101.
[0057] Электронное устройство 102 также содержит аппаратные средства и/или программное обеспечение и/или встроенное программное обеспечение (либо их сочетание) для выполнения одного или нескольких приложений 112 услуг. В общем случае одно или несколько приложений 112 услуг соответствуют электронным приложениям, доступным с использованием электронного устройства 102. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии одно или несколько приложений 112 услуг включают в себя по меньшей мере одно приложение услуги (не обозначено), управляемое организацией, предоставляющей описанное выше приложение 108 виртуального помощника. Например, если приложение 108 виртуального помощника представляет собой виртуальный голосовой помощник ALICE, то одно или несколько приложений услуг могут включать в себя приложение веб-браузера Yandex.Browser™, новостное приложение Yandex.News™, приложение для поиска и подбора товаров Yandex.Market™ и т.п. Очевидно, что одно или несколько приложений 112 услуг также могут включать в себя приложения услуги, не управляемые организацией, предоставляющей описанное выше приложение 108 виртуального помощника, например, приложение социальных медиа, такое как приложение социальной сети Vkontakte™, и приложение потоковой передачи музыки, такое как Spotify™.
[0058] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии приложение 108 виртуального помощника способно назначать идентификатор 114 пользовательского устройства для электронного устройства 102. Например, идентификатор 114 пользовательского устройства может соответствовать проприетарному идентификационному номеру, назначенному приложением 108 виртуального помощника, а также другим соответствующим одним или несколькими приложениями 112 услуг (описано ниже).
[0059] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии действия пользователя, выполненные в одном или нескольких приложениях 112 услуг, собираются одним или несколькими соответствующими веб-серверами (не показаны) и используются для построения профиля пользователя, связанного с электронным устройством 102. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии одно или несколько приложений 112 услуг, управляемых той же организацией, что и приложение 108 виртуального помощника, способны сохранять и собирать действия с указанием идентификатора 114 пользовательского устройства (более подробно описано ниже).
[0060] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии электронное устройство 102 реализовано в виде интеллектуального устройства, такого как Yandex.Station™. В случае его реализации в виде интеллектуального устройства предполагается, что клиентское устройство, такое как смартфон (не показан), связанное с пользователем 101, синхронизировано с электронным устройством 102, которое таким образом получает идентификатор 114 пользовательского устройства от клиентского устройства. В качестве альтернативы, интеллектуальное устройство может быть реализовано с подходящим интерфейсом связи (как описано ниже) для получения идентификатора 114 пользовательского устройства от сервера, ответственного за предоставляемые этим интеллектуальным устройством услуги.
[0061] Электронное устройство 102 содержит интерфейс связи (не показан) для обеспечения двухсторонней связи с сетью 116 связи по линии 118 связи. В некоторых не имеющих ограничительного характера вариантах осуществления данной технологии в качестве сети 116 связи может использоваться сеть Интернет. В других вариантах реализации настоящей технологии сеть 116 связи может быть реализована иначе, например, в виде любой глобальной сети связи, локальной сети связи, частной сети связи и т.п.
[0062] На реализацию линии 118 связи не накладывается каких-либо особых ограничений, она зависит от реализации электронного устройства 102. Лишь в качестве примера, не имеющего ограничительного характера, в тех вариантах осуществления настоящей технологии, в которых электронное устройство 102 реализовано в виде беспроводного устройства связи (такого как смартфон), линия 118 связи может быть реализована в виде беспроводной линии связи (такой как канал сети связи 3G, канал сети связи 4G, Wireless Fidelity или сокращенно WiFi®, Bluetooth® и т.п.) или проводной линии связи (такой как соединение на основе Ethernet).
[0063] Должно быть очевидно, что варианты реализации электронного устройства 102, линии 118 связи и сети 116 связи приведены только для иллюстрации. Специалисту в данной области должны быть понятны и другие конкретные детали реализации электронного устройства 102, лини 118 связи и сети 116 связи. Представленные выше примеры никак не ограничивают объем настоящей технологии.
[0064] Система также содержит сервер 120, соединенный с сетью 116 связи. Сервер 120 может быть реализован как компьютерный сервер. В примере осуществления настоящей технологии сервер 120 может быть реализован в виде сервера Dell™ PowerEdge™, работающего под управлением операционной системы Microsoft™ Windows Server™. Очевидно, что сервер 120 может быть реализован с использованием любых других подходящих аппаратных средств и/или прикладного программного обеспечения и/или встроенного программного обеспечения либо их сочетания. В представленном не имеющем ограничительного характера варианте осуществления настоящей технологии сервер 120 представляет собой один сервер. В других не имеющих ограничительного характера вариантах осуществления настоящей технологии функции сервера 120 могут быть распределены между несколькими серверами.
[0065] Сервер 120 содержит интерфейс связи (не показан), структура и конфигурация которого позволяет осуществлять связь с различными элементами (такими как электронное устройство 102 и другие устройства, которые могут быть соединены с сетью 116 связи) через сеть 116 связи. Сервер 120 содержит память 122 сервера, включая один или несколько носителей информации, и в общем случае обеспечивает пространство для хранения компьютерных программных команд, выполняемых процессором 124 сервера. Например, память 122 сервера может быть реализована как машиночитаемый физический носитель информации, включая ПЗУ и/или ОЗУ. Память 122 сервера также может включать в себя одно или несколько устройств постоянного хранения, таких как жесткие диски (HDD), твердотельные накопители (SSD) и карты флэш-памяти.
[0066] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 120 может управляться организацией, предоставляющей описанное выше приложение 108 виртуального помощника. Например, если приложение 108 виртуального помощника представляет собой виртуальный голосовой помощник ALICE, то сервер 120 также может управляться компанией Yandex LLC (ул. Льва Толстого, 16, Москва, 119021, Россия). В других вариантах осуществления сервер 120 может управляться организацией, отличной от предоставляющей описанное выше приложение 108 виртуального помощника.
[0067] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии сервер 120 способен выполнять приложение 126 автоматического распознавания речи (сокращенно приложение 126 ASR (Automated Speech Recognition)). Способ реализации приложения 126 ASR подробно описан ниже.
[0068] С этой целью сервер 120 связан с базой 128 данных. В других не имеющих ограничительного характера вариантах осуществления изобретения база 128 данных может быть связана с сервером 120 через сеть 116 связи. Несмотря на то, что база 128 данных схематично показана здесь как один элемент, предполагается, что база 128 данных может быть распределенной.
[0069] База 128 данных наполнена множеством пользовательских профилей (отдельно не обозначены). На реализацию одного или нескольких пользовательских профилей не накладывается каких-либо ограничений. Например, они могут представлять собой набор векторов, представляющих интересы пользователя.
[0070] На фиг. 2 представлена схема процесса для объединения различных пользовательских профилей, связанных с пользователем 101.
[0071] Первый профиль 202 принимается от первого сервера 204 услуги. Например, первый сервер 204 услуги может быть связан с первым приложением 201 услуги, представляющим собой приложение Yandex.Browser™, которое управляется организацией, предоставляющей описанное выше приложение 108 виртуального помощника. Первый профиль 202 может быть сформирован первым сервером 204 услуги на основе журналов 203 просмотра, связанных с электронным устройством 102. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии журналы 203 просмотра могут быть ограничены по времени или по действиям. Например, журналы 203 просмотра могут содержать веб-ресурсы, посещенные в течение предыдущих 24 часов, или 100 последних посещенных веб-ресурсов. Очевидно, что могут использоваться другой период времени или другие действия.
[0072] Первый профиль 202 связан с первым набором 206 уникальных идентификаторов. Например, первый набор 206 уникальных идентификаторов может содержать проприетарный идентификатор пользователя, назначенный электронному устройству 102 первым приложением 201 услуги. С учетом того, что первое приложение 201 услуги управляется организацией, предоставляющей вышеупомянутое приложение 108 виртуального помощника, первый набор 206 уникальных идентификаторов содержит идентификатор 114 пользовательского устройства (ABCDE).
[0073] Второй профиль 208 принимается от второго сервера 210 услуги. Например, второй сервер 210 услуги может быть связан со вторым приложением 209 услуги, представляющим собой приложение Yandex.Market™, которое управляется организацией, предоставляющей описанное выше приложение 108 виртуального помощника. Второй профиль 208 может быть сформирован вторым сервером 210 услуги на основе журналов 211 поиска, связанных с электронным устройством 102, а также на основе относящейся к пользователю информации, необходимой для авторизации, такой как возраст, пол, местоположение пользователя, его интересы и т.п. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии журналы 211 поиска могут быть ограничены по времени или по действиям. Например, журналы 203 поиска могут содержать строки поиска, введенные в течение предыдущих 24 часов, или 100 последних строк поиска. Очевидно, что могут использоваться другой период времени или другие действия.
[0074] Второй профиль 208 также связан со вторым набором 212 уникальных идентификаторов. С учетом того, что второе приложение 209 услуги управляется организацией, предоставляющей вышеупомянутое приложение 108 виртуального помощника, второй набор 212 уникальных идентификаторов содержит идентификатор 114 пользовательского устройства (ABCDE). Кроме того, второй набор 212 уникальных идентификаторов также может содержать адрес электронной почты пользователя 101, используемый для авторизации (ABC@XYZ.CA).
[0075] База 128 данных способна выполнять процедуру объединения профилей (не показана). Процедура объединения профилей способна определять, соответствуют ли первый профиль 202 и второй профиль 208 одному пользователю. Например, процедура объединения профилей может быть способной определить, соответствует ли, по меньшей мере частично, первый набор 206 уникальных идентификаторов второму набору 212 уникальных идентификаторов.
[0076] Если определено, что первый набор 206 уникальных идентификаторов по меньшей мере частично соответствует второму набору 212 уникальных идентификаторов, процедура объединения профилей способна объединить первый профиль 202 и второй профиль 208, чтобы сформировать первый объединенный профиль 214 пользователя.
[0077] В результате выполнения процедуры объединения профилей в базе 128 данных сохраняется первый объединенный профиль 214 пользователя со списком 216 соответствующих уникальных идентификаторов (который содержит идентификатор 114 пользовательского устройства и адрес электронной почты).
[0078] С другой стороны, если процедура объединения профилей определяет, что первый набор 206 уникальных идентификаторов не соответствует второму набору 212 уникальных идентификаторов даже частично, первый профиль 202 и второй профиль 208 рассматриваются как связанные с различными пользователями. Следовательно, первый профиль 202 (и первый набор 206 уникальных идентификаторов) и второй профиль 208 (и второй набор уникальных идентификаторов) хранятся в базе 128 данных раздельно.
[0079] Должно быть понятно, что предполагается, что сервер 120 может быть связан с первым сервером 204 услуги и со вторым сервером 210 услуги, а процессор 124 сервера способен выполнять процедуру объединения профилей вместо базы 128 данных, чтобы сформировать и сохранить первый объединенный профиль 214 пользователя в базе 128 данных.
[0080] Кроме того, несмотря на то, что для формирования первого объединенного профиля 214 пользователя показаны два профиля пользователя (первый профиль 202 и второй профиль 208), должно быть понятно, что первый объединенный профиль 214 пользователя может быть сформирован на основе более чем двух профилей пользователя. Например, предполагается, что в дополнение к первому профилю 202 и второму профилю 208 от третьего приложения услуги (не показано) может приниматься третий профиль (не показан), связанный с третьим приложением услуги, соответствующим приложению поиска, такому как поисковая система Yandex™, управляемая организацией, предоставляющей описанное выше приложение 108 виртуального помощника. Третий профиль может быть сформирован третьим сервером услуги на основе журналов поиска (не показаны), связанных с электронным устройством 102.
[0081] Кроме того, несмотря на то, что первый объединенный профиль 214 пользователя сформирован исключительно на основе приложений услуг, управляемых той же организацией, очевидно, что объем изобретения этим не ограничивается. Поскольку второй профиль 208 содержит адрес электронной почты, связанный с пользователем 101, можно дополнительно объединить профиль пользователя с четвертым профилем (не показан), принятым от другой организации (такой как Spotify™), если этот четвертый профиль также связан с уникальным идентификатором, соответствующим адресу электронной почты, содержащемуся в списке 216 связанных уникальных идентификаторов.
Приложение 126 ASR
[0082] На фиг. 3 представлена схема приложения 126 ASR, реализованного согласно не имеющему ограничительного характера варианту осуществления настоящей технологии. Приложение 126 ASR выполняет (или осуществляет доступ к ним иным образом) процедуру 302 приема, процедуру 304 формирования гипотез, процедуру 306 попарного объединения, процедуру 308 анализа фрагмента речи и процедуру 310 ранжирования.
[0083] В контексте настоящего описания термин «процедура» подразумевает подмножество компьютерных программных команд приложения 126 ASR, выполняемых процессором 124 сервера для выполнения описанных ниже функций, связанных с различными процедурами (с процедурой 302 приема, процедурой 304 формирования гипотез, процедурой 306 попарного объединения, процедурой 308 анализа фрагмента речи и процедурой 310 ранжирования). Должно быть понятно, что процедура 302 приема, процедура 304 формирования гипотез, процедура 306 попарного объединения, процедура 308 анализа фрагмента речи и процедура 310 ранжирования показаны по отдельности лишь для удобства объяснения процессов, выполняемых приложением 126 ASR. Предполагается, что некоторые или все процедуры из числа процедуры 302 приема, процедуры 304 формирования гипотез, процедуры 306 попарного объединения, процедуры 308 анализа фрагмента речи и процедуры 310 ранжирования могут быть реализованы в виде одной или нескольких комбинированных процедур.
[0084] Для лучшего понимания настоящей технологии ниже описаны функции и обрабатываемые или сохраняемые данные и/или информация процедуры 302 приема, процедуры 304 формирования гипотез, процедуры 306 попарного объединения, процедуры 308 анализа фрагмента речи и процедуры 310 ранжирования.
Процедура 302 приема
[0085] Процедура 302 приема способна принимать пакет 312 данных от приложения 108 виртуального помощника. Например, пакет 312 данных содержит фрагмент речи 314 пользователя 101 на естественном языке и идентификатор 114 пользовательского устройства.
[0086] Передача пакета 312 данных приложением 108 виртуального помощника, на которую не накладывается каких-либо ограничений, может, например, выполняться в ответ на голосовую команду пользователя 101, поступившую в приложение 108 виртуального помощника. Иными словами, приложение 108 виртуального помощника может работать в режиме постоянного прослушивания или может выходить из режима ожидания в ответ на заранее заданный фрагмент устной речи пользователя. Фрагмент речи 314 передается в виде цифрового сигнала после преобразования аналогового сигнала аналого-цифровым преобразователем.
[0087] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии пакет 312 данных дополнительно содержит историю 318 взаимодействий устройства, которая может включать в себя историю взаимодействий пользователя 101 с одним или несколькими приложениями 112 услуг. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии история 318 взаимодействий устройства может быть ограничена по времени или по действиям. Например, история 318 взаимодействий устройства может содержать действия, выполненные с электронным устройством 102 в течение предыдущих 24 часов или 100 последних действий. Очевидно, что могут использоваться другой период времени или другие действия. В качестве альтернативы, история 318 взаимодействий устройства может передаваться через заранее заданные интервалы времени до передачи пакета 312 данных.
[0088] В ответ на прием пакета 312 данных процедура 302 приема способна передать пакет 320 данных в процедуру 304 формирования гипотез. Пакет 320 данных содержит фрагмент речи 314.
[0089] Кроме того, процедура 302 приема также способна передать пакет 322 данных в процедуру 308 анализа фрагмента речи. Пакет 322 данных содержит идентификатор 114 пользовательского устройства и историю 318 взаимодействий устройства.
Процедура 304 формирования гипотез
[0090] В ответ на прием пакета 320 данных процедура 304 формирования гипотез способна выполнять следующие функции.
[0091] Сначала процедура 304 формирования гипотез способна выполнить приложение 305 преобразования устной речи в текст для формирования множества 426 гипотез (см. фиг. 4), каждая из которых соответствует потенциальному текстовому представлению фрагмента речи 314.
[0092] Способ реализации приложения 305 преобразования устной речи в текст хорошо известен в данной области техники и подробно не описан. Достаточно сказать, что приложение 305 преобразования устной речи в текст способно формировать множество 426 гипотез путем анализа фрагмента речи 314 с использованием акустической модели (такой как скрытая модель Маркова и т.п.) и языковой модели (такой как модель n-грамм и т.п.).
[0093] После формирования множества 426 гипотез процедура 304 формирования гипотез дополнительно способна определить профиль гипотезы для каждой гипотезы из множества 426 гипотез. Например, профиль гипотезы может содержать набор векторов, представляющих одну или несколько контекстно-зависимых характеристик гипотезы (подробно описано ниже).
[0094] На фиг. 4 представлена схема процесса определения профиля гипотезы для каждой гипотезы из множества 426 гипотез.
[0095] Процедура 304 формирования гипотез сформировала три гипотезы: первую гипотезу 402, вторую гипотезу 404 и третью гипотезу 406. Первая гипотеза 402, вторая гипотеза 404 и третья гипотеза 406 для лучшего понимания схематически обозначены буквами («A», «B», «C»), при этом должно быть понятно, что первая гипотеза 402, вторая гипотеза 404 и третья гипотеза 406 соответствуют словам или последовательностям слов. Например, первая гипотеза может соответствовать словосочетанию «Play Korn» (музыкальная группа), вторая гипотеза 404 может соответствовать словосочетанию «pay corn» и т.д.
[0096] Несмотря на то, что здесь показаны только три гипотезы, очевидно, что объем изобретения этим не ограничивается. Предполагается, что приложением 305 преобразования устной речи в текст может быть сформировано меньше или больше трех гипотез.
[0097] Ниже описано формирование первого профиля 418 гипотезы для взятой в качестве примера первой гипотезы 402.
[0098] Сначала первая гипотеза 402 анализируется одной или несколькими контекстно-зависимыми моделями 410 (первой моделью 412, второй моделью 414 и третьей моделью 416). Каждая модель из числа первой модели 412, второй модели 414 и третьей модели 416 связана с конкретным контекстом или темой и способна сформировать зависящую от контекста оценку в виде вектора.
[0099] Например, первая модель 412 связана с темой музыки и поэтому способна сформировать оценку в контексте музыки. Вторая модель 414 связана с темой местоположений и поэтому способна сформировать оценку в контексте карты. Третья модель 416 связана с темой кулинарии и поэтому способна сформировать оценку в контексте кулинарии. Несмотря на то, что здесь показаны только три модели (первая модель 412, вторая модель 414 и третья модель 416), объем изобретения этим не ограничивается и предполагается, что может быть использовано больше или меньше трех моделей.
[00100] На способ формирования относительной контекстно-зависимой оценки первой моделью 412, второй моделью 414 и третьей моделью 416 не накладывается каких-либо ограничений. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии каждая модель из числа первой модели 412, второй модели 414 и третьей модели 416 может быть обучена на контекстно-зависимых словах, связанных с соответствующим контекстом или темой.
[00101] Например, первая модель 412, связанная с темой музыки, может быть обучена на множестве относящихся к музыке слов, таких как названия музыкальных групп, имена исполнителей, жанры и некоторые связанные музыкой глаголы (например, «play» («играть»)).
[00102] Затем первая модель 412 способна проанализировать гипотезу и сформировать оценку в контексте музыки. На реализацию оценки в контексте музыки (или любой другой контекстно-зависимой оценки) не накладывается каких-либо ограничений, например, она может представлять собой вектор, соответствующий отношению количества относящихся к музыке слов, присутствующих в гипотезе, к общему количеству слов в гипотезе. Первая модель 412 формирует оценку в контексте музыки, указывающую на то, что взятая в качестве примера первая гипотеза 402 (первая гипотеза 402 соответствует словам «play Korn») соответствует отношению 2:2, поскольку она содержит только относящиеся к музыке слова («play» и «Korn»).
[00103] Кроме того, первая гипотеза 402 анализируется второй моделью 414 и третьей моделью 416 и оценка формируется в контексте карты и в контексте кулинарии. Например, оценка в контексте карты и оценка в контексте кулинарии могут указывать на то, что первая гипотеза 402 соответствует отношению 0:2 для обеих оценок, поскольку она не содержит слов, относящихся к карте или к кулинарии.
[00104] После формирования каждой из одной или нескольких контекстно-зависимых моделей 410 контекстно-зависимой оценки процедура 304 формирования гипотез способна сформировать первый профиль 418 гипотезы, связанный с первой гипотезой 402 и соответствующий совокупности сформированных контекстно-зависимых оценок. С учетом того, что каждая контекстно-зависимая оценка представляет собой вектор, первый профиль 418 гипотезы может быть реализован в виде набора векторов.
[00105] Процедура 304 формирования гипотез дополнительно способна сформировать (а) оценку в контексте музыки для второй гипотезы 404 («pay corn»), которая соответствует отношению 0:2; (б) оценку в контексте карты для второй гипотезы 404, которая соответствует отношению 0:2; и (в) оценку в контексте кулинарии для второй гипотезы 404, которая соответствует отношению 1:2 (вследствие присутствия слова «corn»). После формирования контекстно-зависимой оценки каждой из одной или нескольких контекстно-зависимых моделей процедура 304 формирования гипотез способна сформировать второй профиль 420 гипотезы, связанный со второй гипотезой 404.
[00106] Процедура 304 формирования гипотез дополнительно способна определить третий профиль 422 гипотезы, связанный с третьей гипотезой 406, как описано выше.
[00107] После определения профиля гипотезы (т.е. первого профиля 418 гипотезы, второго профиля 420 гипотезы и третьего профиля 422 гипотезы) для каждой гипотезы (для первой гипотезы 402, второй гипотезы 404 и третьей гипотезы 406) процедура 304 формирования гипотез способна передать пакет 323 данных процедуре 306 попарного объединения (см. фиг. 3).
Процедура 306 попарного объединения
[00108] Процедура 306 попарного объединения способна принять пакет 323 данных от процедуры 304 формирования гипотез. Пакет 323 данных содержит все гипотезы из множества 426 гипотез (первую гипотезу 402, вторую гипотезу 404 и третью гипотезу 406) и их соответствующие профили (первый профиль 418 гипотезы, второй профиль 420 гипотезы и третий профиль 422 гипотезы).
[00109] Процедура 306 попарного объединения способна сформировать набор спаренных гипотез путем попарного объединения каждой гипотезы из содержащегося в пакете 323 данных множества 426 гипотез (т.е. первой гипотезы 402, второй гипотезы 404 и третьей гипотезы 406) с оставшейся гипотезой из этого множества гипотез.
[00110] Например, поскольку имеется три гипотезы, процедура 306 попарного объединения способна сформировать следующие три пары гипотез:
(1) первая гипотеза 402 - вторая гипотеза 404;
(2) первая гипотеза 402 - третья гипотеза 406;
(3) вторая гипотеза 404 - третья гипотеза 406.
[00111] Процедура 306 попарного объединения дополнительно способна выполнить попарный классификатор 324, способный назначить парную оценку для каждой пары гипотез, чтобы сформировать набор 606 парных оценок (подробно описано ниже).
[00112] Парная оценка для взятой в качестве примера первой пары гипотез (первая гипотеза 402, спаренная со второй гипотезой 404) указывает на относительную вероятность того, что (а) первая гипотеза 402 соответствует лучшему текстовому представлению фрагмента речи 314, чем вторая гипотеза 404, и что (б) вторая гипотеза 404 соответствует лучшему текстовому представлению фрагмента речи 314, чем первая гипотеза 402 (более подробно описано ниже).
Попарный классификатор 324 - этап обучения
[00113] На фиг. 5 схематически представлен процесс обучения попарного классификатора 324.
[00114] Для лучшего понимания основ настоящей технологии следует понимать, что обучение попарного классификатора 324 можно разделить на первый и второй этапы. На первом этапе формируются обучающие входные данные (описаны ниже). На втором этапе попарный классификатор 324 обучается с использованием этих обучающих входных данных. Несмотря на то, что шаги обучения попарного классификатора 324 описаны как выполняемые процедурой 306 попарного объединения, объем изобретения этим не ограничивается.
[00115] На первом этапе одна или несколько обучающих гипотез (первая обучающая гипотеза 502, вторая обучающая гипотеза 504, третья обучающая гипотеза 506 и четвертая обучающая гипотеза 508) формируются на основе обучающего фрагмента 510 речи. На формирование первой обучающей гипотезы 502, второй обучающей гипотезы 504, третьей обучающей гипотезы 506 и четвертой обучающей гипотезы 508 не накладывается каких-либо ограничений, они могут быть сформированы процедурой 304 формирования гипотез, как описано выше.
[00116] Несмотря на то, что первая обучающая гипотеза 502, вторая обучающая гипотеза 504, третья обучающая гипотеза 506 и четвертая обучающая гипотеза 508 для лучшего понимания схематически обозначены парами букв («AA», «BB», «CC», «DD»), должно быть понятно, что первая обучающая гипотеза 502, вторая обучающая гипотеза 504, третья обучающая гипотеза 506 и четвертая обучающая гипотеза 508 соответствуют словам или последовательностям слов.
[00117] Несмотря на то, что здесь показаны только четыре обучающих гипотезы, очевидно, что объем изобретения этим не ограничивается. Предполагается, что на основе обучающего фрагмента 510 речи может быть сформировано большее или меньшее количество обучающих гипотез.
[00118] С использованием одной или нескольких контекстно-зависимых моделей 410 для каждой гипотезы из числа одной или нескольких обучающих гипотез формируется соответствующий профиль обучающей гипотезы. Например, первый профиль 512 обучающей гипотезы формируется для первой обучающей гипотезы 502, второй профиль 514 обучающей гипотезы формируется для второй обучающей гипотезы 504, третий профиль 516 обучающей гипотезы формируется для третьей обучающей гипотезы 506 и четвертый профиль 518 обучающей гипотезы формируется для четвертой обучающей гипотезы 508.
[00119] Попарный классификатор 324 дополнительно способен сформировать набор 526 обучающих пар гипотез. Набор 526 обучающих пар гипотез содержит одну или несколько обучающих гипотез (первую обучающую гипотезу 502, вторую обучающую гипотезу 504, третью обучающую гипотезу 506 и четвертую обучающую гипотезу 508), спаренных с оставшейся гипотезой из числа одной или нескольких обучающих гипотез.
[00120] Например, набор 526 обучающих пар гипотез содержит 6 обучающих пар гипотез, включая первую обучающую пару 522 (содержит первую обучающую гипотезу 502, спаренную со второй обучающей гипотезой 504), вторую обучающую пару 524 (содержит первую обучающую гипотезу 502, спаренную с третьей обучающей гипотезой 506) и т.д.
[00121] Для каждой обучающей пары, включенной в набор 526 обучающих пар гипотез, процедура 306 попарного объединения способна рассчитать оценку 528 различия профилей, совокупную оценку 530 профилей и назначить метку 532 для каждой обучающей гипотезы, включенной в обучающую пару гипотез.
[00122] Оценка 528 различия профилей представляет собой разность между обучающими наборами векторов для обучающих гипотез в обучающей паре гипотез. Например, оценка 528 различия профилей первой обучающей пары 522 указывает на разность между первым профилем 512 обучающей гипотезы и вторым профилем 514 обучающей гипотезы (оба реализованы в виде обучающего набора векторов).
[00123] Совокупная оценка 530 профилей может быть рассчитана в виде произведения обучающих наборов векторов обучающих гипотез обучающей пары гипотез. Например, совокупная оценка 530 профилей первой обучающей пары 522 определяется путем умножения первого профиля 512 обучающей гипотезы на второй профиль 514 обучающей гипотезы (оба реализованы в виде обучающего набора векторов).
[00124] Кроме того, каждой обучающей гипотезе, включенной в состав обучающей пары гипотез, назначается метка 532. Метка 532 указывает на верное текстовое представление обучающего фрагмента 510 речи и может быть введена вручную администратором, контролирующим обучение попарного классификатора 324. Например, если предположить, что верное текстовое представление обучающего фрагмента 510 речи соответствует первой обучающей гипотезе 502, то первой обучающей гипотезе 502 назначается метка 532, имеющая значение 1, а всем оставшимся обучающим гипотезам назначается метка 532, имеющая значение 0.
[00125] Обучающие входные данные 520 передаются попарному классификатору 324 для обучения. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии попарный классификатор 324 представляет собой алгоритм PKPD. Попарный классификатор 324 содержит логику обучения для определения набора признаков, связанного с обучающими входными данными 520. На основе набора признаков, связанного с обучающими входными данными 520, попарный классификатор 324 способен обучаться прогнозированию оценки обучающей пары для каждой пары из спаренных обучающих гипотез, указывающей на относительную вероятность того, что каждая обучающая гипотеза соответствует лучшему верному представлению обучающего фрагмента 510 речи, чем спаренная с ней обучающая гипотеза.
[00126] Например, для первой обучающей пары 522 попарный классификатор 324 обучен формировать первую обучающую оценку, указывающую (а) на вероятность того, что первая обучающая гипотеза 502 соответствует лучшему текстовому представлению обучающего фрагмента 510 речи, чем вторая обучающая гипотеза 504; и (б) на вероятность того, что вторая обучающая гипотеза 504 соответствует лучшему текстовому представлению обучающего фрагмента 510 речи, чем первая обучающая гипотеза 502.
[00127] Несмотря на то, что здесь представлен только один экземпляр процесса обучения попарного классификатора 324, это сделано исключительно для лучшего понимания. Очевидно, что обучение попарного классификатора 324 выполняется итеративно с использованием множества различных обучающих фрагментов речи.
Попарный классификатор 324 - этап использования
[00128] Ниже со ссылками на фиг. 3 описано определение набора 606 парных оценок (см. фиг. 6).
[00129] Попарный классификатор 324 способен прогнозировать относительную парную оценку для каждой пары из спаренных гипотез на основе (а) двух спаренных гипотез, (б) оценки различия профилей и (в) совокупной оценки профилей каждой спаренной гипотезы.
[00130] На фиг. 6 представлен не имеющий ограничительного характера пример таблицы 601, в которой хранится набор 606 парных оценок, сформированный попарным классификатором 324. Набор 606 парных оценок содержит множество парных оценок, каждая из которых связана со спаренными гипотезами.
[00131] Для первой пары 602 гипотез (представляющей собой первую гипотезу 402, спаренную со второй гипотезой 404) попарный классификатор сформировал первую оценку 604 пары, указывающую на то, что (а) вероятность того, что первая гипотеза 402 соответствует лучшему текстовому представлению фрагмента речи 314, чем вторая гипотеза 404, равна 0,4 (или 40%) и (б) вероятность того, что вторая гипотеза 404 соответствует лучшему текстовому представлению фрагмента речи 314, чем первая гипотеза 402, равна 0,1 (или 10%).
[00132] Должно быть понятно, что представленные в этом примере значения приведены лишь для иллюстрации, они не предназначены для представления конкретной ситуации и/или не должны быть неизменными в рамках настоящего документа.
[00133] Определив набор 606 парных оценок, процедура 306 попарного объединения может ввести набор 606 парных оценок в алгоритм 608 нормализации, способный нормализовать каждую парную оценку из набора 606 парных оценок.
[00134] Например, алгоритм 608 нормализации может определить набор 610 нормализованных оценок вероятности, каждая из которых связана с одной парой гипотез из набора спаренных гипотез. В представленном примере первая оценка 604 пары нормализована в первую нормализованную оценку 612 вероятности так, чтобы сумма (а) вероятности того, что первая гипотеза 402 соответствует лучшему текстовому представлению фрагмента речи 314, чем вторая гипотеза 404, и (б) вероятности, того что вторая гипотеза 404 соответствует лучшему текстовому представлению фрагмента речи 314, чем первая гипотеза 402, была равна заранее заданной суммарной оценке, которая в этом конкретном примере равна 100%.
[00135] Определив набор 610 нормализованных оценок вероятности, попарный классификатор 324 способен передать пакет 326 данных процедуре 310 ранжирования (более подробно описано ниже) (см. фиг. 3). Пакет 326 данных содержит набор 610 нормализованных оценок вероятности.
Процедура 308 анализа фрагмента речи
[00136] Процедура 308 анализа фрагмента речи ранее приняла пакет 322 данных от процедуры 302 приема. Пакет 322 данных содержит историю 318 взаимодействий устройства и идентификатор 114 пользовательского устройства.
[00137] Процедура 308 анализа фрагмента речи способна выполнять следующие функции.
[00138] Сначала процедура 308 анализа фрагмента речи способна сформировать набор признаков фрагмента речи. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии набор признаков фрагмента речи содержит (а) характерные для пользователя признаки и (б) акустические признаки. Как более подробно описано ниже, характерные для пользователя признаки включают в себя характеристики пользователя 101, а акустические признаки включают в себя акустические характеристики фрагмента речи 314.
[00139] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии характерные для пользователя признаки сформированы на основе объединенного профиля пользователя, хранящегося в базе 128 данных. Процедура 308 анализа фрагмента речи способна осуществить доступ к базе 128 данных и извлечь первый объединенный профиль 214 пользователя, связанный с идентификатором 114 пользовательского устройства. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии характерные для пользователя признаки включают в себя (а) возраст пользователя 101 и/или (б) пол пользователя 101 и/или (в) профиль интересов пользователя 101, определенный на основе действий пользователя 101 с первым приложением 201 услуги и вторым приложением 209 услуги.
[00140] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии после извлечения первого объединенного профиля 214 пользователя процедура 308 анализа фрагмента речи способна обновить профиль интересов пользователя 101 с использованием истории 318 взаимодействий устройства. В частности, в зависимости от последнего взаимодействия пользователя 101 с электронным устройством 102, процедура 308 анализа фрагмента речи способна дополнить профиль интересов пользователя 101. Например, если пользователь 101 недавно прослушивал музыку некоторого жанра, профиль интересов пользователя 101 изменяется так, чтобы отразить интерес пользователя 101 к музыке этого жанра.
[00141] Процедура 308 анализа фрагмента речи дополнительно способна проанализировать фрагмент речи 314 с целью формирования акустических признаков, связанных с фрагментом речи 314. Например, акустические признаки могут включать в себя тембр фрагмента устной речи 314 и/или тон фрагмента устной речи 314 и/или отношение сигнал-шум фрагмента речи 314.
Процедура 310 ранжирования
[00142] Сформировав набор признаков фрагмента речи, процедура 308 анализа фрагмента речи способна передать пакет 328 данных процедуре 310 ранжирования. Пакет 328 данных содержит набор признаков фрагмента речи.
[00143] Кроме того, процедура 310 ранжирования ранее приняла от процедуры 306 попарного объединения пакет 326 данных, содержащий набор 610 нормализованных оценок вероятности.
[00144] Процедура 310 ранжирования способна выполнять следующие функции.
[00145] Процедура 310 ранжирования способна выполнить алгоритм 330 машинного обучения (MLA, Machine Learning Algorithm), обученный формировать рейтинговую оценку для каждой гипотезы из множества 426 гипотез (для первой гипотезы 402, второй гипотезы 404 и третьей гипотезы 406) на основе (а) набора признаков фрагмента речи, содержащегося в пакете 328 данных, и (б) набора 610 нормализованных оценок вероятности, содержащегося в пакете 326 данных.
[00146] На реализацию рейтинговой оценки не накладывается каких-либо ограничений, например, она может представлять собой вероятность того, что некоторая гипотеза из множества 426 гипотез (первая гипотеза 402, вторая гипотеза 404 или третья гипотеза 406) соответствует текстовому представлению фрагмента речи 314. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии алгоритм 330 MLA способен определить абсолютную оценку вероятности того, что каждая гипотеза из множества 426 гипотез соответствует текстовому представлению фрагмента речи 314. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии рейтинговая оценка может быть выражена в процентах (от 0% до 100%) или по шкале (от 1 до 10). Очевидно, что рейтинговая оценка может быть выражена в нескольких различных форматах.
[00147] На обучение алгоритма 330 MLA не накладывается каких-либо ограничений, например, он может быть обучен с использованием набора обучающих нормализованных оценок вероятности, полученных из оценок обучающих пар из набора 526 обучающих пар гипотез (см. фиг. 5), и набора признаков обучающего фрагмента речи, связанного с обучающим фрагментом 510 речи. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии алгоритм 330 MLA представляет собой нейронную сеть.
[00148] Очевидно, что использование набора признаков фрагмента речи в качестве входных данных для алгоритма 330 MLA основано на понимании разработчиками того, что благодаря предоставлению признаков, указывающих на характеристики пользователя (такие как возраст, пол, местоположение, интересы и т.п.) алгоритм 330 MLA обучен учитывать больше признаков для точного ранжирования множества гипотез по сравнению с известными решениями. Кроме того, разработчики также предполагают, что благодаря использованию акустических признаков, связанных с фрагментом речи 314, алгоритм MLA обучен надлежащим образом различать посторонний шум и фрагмент речи 314 и надлежащим образом ранжировать множество гипотез с учетом тембра и тона фрагмента речи 314.
[00149] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии алгоритм 330 MLA способен сформировать рейтинговую оценку на основе набора 610 нормализованных оценок вероятности без набора признаков фрагмента речи. При разработке настоящей технологии разработчики установили, что даже в случае ввода в алгоритм 330 MLA только набора 610 нормализованных оценок вероятности алгоритм 330 MLA способен сформировать ранжированные оценки с учетом всего множества нормализованных оценок вероятности, включенных в состав набора 610 нормализованных оценок вероятности. В связи с этим в некоторых альтернативных не имеющих ограничительного характера вариантах осуществления настоящей технологии пакет 312 данных не содержит идентификатор 114 пользовательского устройства или историю 318 взаимодействий устройства, а алгоритм 330 MLA способен сформировать ранжированную оценку для каждой гипотезы из множества 426 гипотез на основе набора 610 нормализованных оценок вероятности, определенного процедурой 306 попарного объединения.
[00150] Определив ранжированные оценки для каждой гипотезы из множества 426 гипотез (для первой гипотезы 402, второй гипотезы 404 и третьей гипотезы 406), процедура 310 ранжирования способна передать пакет 332 данных приложению 108 виртуального помощника (см. фиг. 1). Пакет 332 данных содержит гипотезу, которой назначена самая высокая рейтинговая оценка.
[00151] Можно предположить, что первая гипотеза 402 связана с высшей рейтинговой оценкой, что означает, что первая гипотеза 402 представляет собой наиболее вероятную гипотезу, соответствующую текстовому представлению фрагмента речи 314.
[00152] В ответ на прием пакета 332 данных приложение 108 виртуального помощника способно выполнить команду, связанную с первой гипотезой 402. Например, если первая гипотеза 402 соответствует словам «Play Korn», приложение 108 виртуального помощника способно осуществить доступ к музыкальному приложению (такому как Spotify™), установленному на электронном устройстве 102, и воспроизвести соответствующую музыку.
[00153] Несмотря на то, что приложение 126 ASR описано выше как выполняемое сервером 120, объем изобретения этим не ограничивается. В некоторых не имеющих ограничительного характера вариантах осуществления данной технологии предполагается, что приложение 126 ASR выполняется в электронном устройстве 102. В таких вариантах осуществления изобретения электронное устройство 102 может быть связано с базой 128 данных.
[00154] Описанные выше архитектура и примеры позволяют выполнять компьютерный способ формирования текстового представления фрагмента устной речи пользователя. На фиг. 7 представлена блок-схема способа 700, выполняемого согласно не имеющим ограничительного характера вариантам осуществления настоящей технологии. Способ 700 может быть выполнен сервером 120 или электронным устройством 102.
[00155] Шаг 702: прием электронным устройством от пользователя указания на фрагмент устной речи пользователя на естественном языке.
[00156] Способ 700 начинается с шага 702, на котором процедура 302 приема получает пакет 312 данных от приложения 108 виртуального помощника (см. фиг. 1). Например, пакет 312 данных содержит фрагмент речи 314 пользователя 101 и идентификатор 114 пользовательского устройства.
[00157] На способ передачи пакета 312 данных приложением 108 виртуального помощника не накладывается каких-либо ограничений, например, она может выполняться в ответ на голосовую команду пользователя 101, поступившую в приложение 108 виртуального помощника. Иными словами, приложение 108 виртуального помощника может работать в режиме постоянного прослушивания или может выходить из режима ожидания в ответ на заранее заданный фрагмент устной речи пользователя.
[00158] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии пакет 312 данных дополнительно содержит историю 318 взаимодействий устройства.
[00159] В ответ на прием пакета 312 данных процедура 302 приема способна передать пакет 320 данных процедуре 304 формирования гипотез. Пакет 320 данных содержит фрагмент речи 314.
[00160] Кроме того, процедура 302 приема также способна передать пакет 322 данных процедуре 308 анализа фрагмента речи. Пакет 322 данных содержит идентификатор 114 пользовательского устройства и историю 318 взаимодействий устройства.
[00161] Шаг 704: формирование электронным устройством на основе фрагмента устной речи пользователя по меньшей мере двух гипотез, каждая из которых соответствует возможному текстовому представлению фрагмента устной речи пользователя.
[00162] На шаге 704 в ответ на прием пакета 320 данных процедура 304 формирования гипотез способна сформировать множество 426 гипотез (см. фиг. 4), соответствующих текстовому представлению фрагмента речи 314.
[00163] На формирование множества 426 гипотез не накладывается каких-либо ограничений, например, оно может быть сформировано с использованием приложения 305 преобразования речи в текст.
[00164] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии после формирования множества 426 гипотез процедура 304 формирования гипотез дополнительно способна определить профиль гипотезы для каждой гипотезы из множества 426 гипотез с использованием одной или нескольких контекстно-зависимых моделей 410 (см. фиг. 4).
[00165] После определения профиля гипотезы (т.е. первого профиля 418 гипотезы, второго профиля 420 гипотезы и третьего профиля 422 гипотезы) для каждой гипотезы (для первой гипотезы 402, второй гипотезы 404 и третьей гипотезы 406) процедура 304 формирования гипотез способна передать пакет 323 данных процедуре 306 попарного объединения.
[00166] Шаг 706: формирование электронным устройством из по меньшей мере двух гипотез набора спаренных гипотез, одна из которых содержит первую гипотезу, спаренную со второй гипотезой.
[00167] На шаге 706 процедура 306 попарного объединения способна принимать пакет 323 данных от процедуры 304 формирования гипотез. Пакет 323 данных содержит все гипотезы из множества 426 гипотез (первую гипотезу 402, вторую гипотезу 404 и третью гипотезу 406) и их соответствующие профили (первый профиль 418 гипотезы, второй профиль 420 гипотезы и третий профиль 422 гипотезы).
[00168] Процедура 306 попарного объединения способна сформировать набор спаренных гипотез путем попарного объединения каждой гипотезы из содержащегося в пакете 323 данных множества 426 гипотез (т.е. первой гипотезы 402, второй гипотезы 404 и третьей гипотезы 406) с оставшейся гипотезой из множества гипотез.
[00169] Например, поскольку имеется три гипотезы, процедура 306 попарного объединения способна сформировать следующие три пары гипотез:
(1) первая гипотеза 402 - вторая гипотеза 404;
(2) первая гипотеза 402 - третья гипотеза 406;
(3) вторая гипотеза 404 - третья гипотеза 406.
[00170] Шаг 708: определение с использованием попарного классификатора, выполняемого электронным устройством, для одной пары из набора спаренных гипотез парной оценки, указывающей на относительную вероятность соответствия первой гипотезы и второй гипотезы верному представлению фрагмента устной речи пользователя.
[00171] На шаге 708 процедура 306 попарного объединения способна выполнить попарный классификатор 324, способный назначить парную оценку для каждой пары гипотез, чтобы сформировать набор парных оценок. Парная оценка для взятой в качестве примера первой пары гипотез (первая гипотеза 402, спаренная со второй гипотезой 404) указывает на относительную вероятность того, что (а) первая гипотеза 402 соответствует лучшему текстовому представлению фрагмента речи 314, чем вторая гипотеза 404, и что (б) вторая гипотеза 404 соответствует лучшему текстовому представлению фрагмента речи 314, чем первая гипотеза 402.
[00172] Попарный классификатор 324 способен назначить относительную парную оценку для каждой пары спаренных гипотез на основе (а) двух спаренных гипотез в каждой паре гипотез, (б) оценки различия профилей и (в) совокупной оценки профилей каждой спаренной гипотезы.
[00173] Определив набор 606 парных оценок, попарный классификатор 324 дополнительно способен ввести набор 606 парных оценок в алгоритм 608 нормализации, который способен рассчитать набор 610 нормализованных оценок вероятности, каждая из которых связана с одной парой гипотез из набора спаренных гипотез.
[00174] Определив набор 610 нормализованных оценок вероятности, попарный классификатор 324 способен передать пакет 326 данных процедуре 310 ранжирования (более подробно описано ниже). Пакет 326 данных содержит набор 610 нормализованных оценок вероятности.
[00175] Шаг 710: формирование набора признаков фрагмента речи, указывающего на одну или несколько характеристик, связанных с фрагментом устной речи пользователя.
[00176] На шаге 710 процедура 308 анализа фрагмента речи способна принять пакет 322 данных от процедуры 302 приема. Пакет 322 данных содержит историю 318 взаимодействий устройства и идентификатор 114 пользовательского устройства.
[00177] Процедура 308 анализа фрагмента речи способна выполнять следующие функции. Сначала процедура 308 анализа фрагмента речи способна сформировать набор признаков фрагмента речи. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии набор признаков фрагмента речи содержит (а) характерные для пользователя признаки и (б) акустические признаки.
[00178] Характерные для пользователя признаки формируются путем доступа к базе 128 данных и извлечения первого объединенного профиля 214 пользователя, связанного с идентификатором 114 пользовательского устройства.
[00179] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии характерные для пользователя признаки сформированы на основе объединенного профиля пользователя, хранящегося в базе 128 данных. Процедура 308 анализа фрагмента речи способна осуществить доступ к базе 128 данных и извлечь объединенный профиль пользователя, основываясь на идентификаторе 114 пользовательского устройства, содержащемся в пакете 322 данных. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии характерные для пользователя признаки включают в себя (а) возраст пользователя 101 и/или (б) пол пользователя 101 и/или (в) профиль интересов пользователя 101.
[00180] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии после извлечения первого объединенного профиля 214 пользователя процедура 308 анализа фрагмента речи способна обновить профиль интересов пользователя 101 с использованием истории 318 взаимодействий устройства. В частности, в зависимости от последнего взаимодействия пользователя 101 с электронным устройством 102, процедура 308 анализа фрагмента речи способна дополнить профиль интересов пользователя 101.
[00181] Процедура 308 анализа фрагмента речи дополнительно способна проанализировать фрагмент речи 314 с целью формирования акустических признаков, связанных с фрагментом речи 314. Например, акустические признаки могут включать в себя тембр фрагмента устной речи 314 и/или тон фрагмента устной речи 314 и/или отношение сигнал-шум фрагмента речи 314.
[00182] Шаг 712: ранжирование алгоритмом ранжирования, выполняемым электронным устройством, первой гипотезы и второй гипотезы на основе по меньшей мере парной оценки и набора признаков фрагмента речи.
[00183] Сформировав набор признаков фрагмента речи, на шаге 712 процедура 308 анализа фрагмента речи способна передать пакет 328 данных процедуре 310 ранжирования. Пакет 328 данных содержит набор признаков фрагмента речи.
[00184] Процедура 310 ранжирования способна выполнять следующие функции.
[00185] Процедура 310 ранжирования способна выполнить алгоритм 330 MLA, обученный формировать рейтинговую оценку для каждой гипотезы из множества 426 гипотез (для первой гипотезы 402, второй гипотезы 404 и третьей гипотезы 406) на основе (а) набора признаков фрагмента речи, содержащегося в пакете 328 данных, и (б) набора 610 нормализованных оценок вероятности.
[00186] На реализацию рейтинговой оценки не накладывается каких-либо ограничений, например, она может представлять собой вероятность того, что гипотеза из множества 426 гипотез (первая гипотеза 402, вторая гипотеза 404 или третья гипотеза 406) соответствует текстовому представлению фрагмента речи 314. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии алгоритм 330 MLA способен определить абсолютную оценку вероятности соответствия текстовому представлению фрагмента речи 314 для каждой гипотезы из множества 426 гипотез. В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии рейтинговая оценка может быть выражена в процентах (от 0% до 100%) или по шкале (от 1 до 10). Очевидно, что рейтинговая оценка может быть выражена в нескольких различных форматах.
[00187] Шаг 714: выбор первой гипотезы в качестве текстового представления фрагмента устной речи пользователя, если первая гипотеза представляет собой гипотезу с наибольшим рангом.
[00188] На шаге 714 процедура 310 ранжирования способна выбрать гипотезу с наибольшей рейтинговой оценкой в качестве верного текстового представления фрагмента речи 314.
[00189] В некоторых не имеющих ограничительного характера вариантах осуществления настоящей технологии процедура 310 ранжирования способна передать пакет 332 данных, содержащий гипотезу с наибольшей рейтинговой оценкой, приложению 108 виртуального помощника.
[00190] Способ 700 может завершиться или вернуться к шагу 702 и ожидать другой новый фрагмент речи от электронного устройства 102.
[00191] Специалистам в данной области техники должно быть очевидно, что по меньшей некоторые варианты осуществления настоящей технологии преследуют цель расширения арсенала технических решений определенной технической проблемы, присущей традиционной технологии ASR - определения текстового представления фрагмента устной речи пользователя.
[00192] Очевидно, что не все упомянутые в данном описании технические эффекты должны присутствовать в каждом варианте осуществления настоящей технологии. Например, возможны варианты осуществления настоящей технологии, когда пользователь не получает некоторые из этих технических эффектов, или другие варианты реализации, когда пользователь получает другие технические эффекты либо технический эффект отсутствует.
[00193] Для специалиста в данной области могут быть очевидными изменения и усовершенствования описанных выше вариантов осуществления настоящей технологии. Предшествующее описание приведено лишь в качестве примера, но не для ограничения объема изобретения. Объем охраны настоящей технологии определяется исключительно объемом приложенной формулы изобретения.
[00194] Несмотря на то что описанные выше варианты реализации приведены со ссылкой на конкретные шаги, выполняемые в определенном порядке, должно быть понятно, что эти шаги могут быть объединены, разделены или их порядок может быть изменен без отклонения от настоящей технологии. Соответственно, порядок и группировка шагов не носят ограничительного характера для настоящей технологии.
| название | год | авторы | номер документа |
|---|---|---|---|
| СПОСОБ И СИСТЕМА ДЛЯ ОБРАБОТКИ ПОЛЬЗОВАТЕЛЬСКОГО РАЗГОВОРНОГО РЕЧЕВОГО ФРАГМЕНТА | 2019 |
|
RU2757264C2 |
| СПОСОБ И СИСТЕМА ДЛЯ РАСПОЗНАВАНИЯ РЕЧЕВОГО ФРАГМЕНТА ПОЛЬЗОВАТЕЛЯ | 2021 |
|
RU2808582C2 |
| ИСПОЛЬЗОВАНИЕ КОНТЕКСТНОЙ ИНФОРМАЦИИ ДЛЯ ОБЛЕГЧЕНИЯ ОБРАБОТКИ КОМАНД В ВИРТУАЛЬНОМ ПОМОЩНИКЕ | 2012 |
|
RU2542937C2 |
| Способ и система для формирования карточки объекта | 2018 |
|
RU2739554C1 |
| СПОСОБ И СИСТЕМА ГЕНЕРАЦИИ ТЕКСТА | 2023 |
|
RU2817524C1 |
| Способ и система для синтеза речи из текста | 2017 |
|
RU2692051C1 |
| СИСТЕМА И СПОСОБ РАНЖИРОВАНИЯ РЕЗУЛЬТАТОВ ПОИСКА В ПОИСКОВОЙ СИСТЕМЕ | 2024 |
|
RU2839310C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ФОРМИРОВАНИЯ МОДЕЛИ МАШИННОГО ОБУЧЕНИЯ | 2022 |
|
RU2828354C2 |
| СПОСОБ И СИСТЕМА ДЛЯ ОБУЧЕНИЯ МОДЕЛИ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПЕРЕВОДА | 2023 |
|
RU2835121C1 |
| СПОСОБ И СЕРВЕР ДЛЯ ОБУЧЕНИЯ НЕЙРОННОЙ СЕТИ ФОРМИРОВАНИЮ ТЕКСТОВОЙ ВЫХОДНОЙ ПОСЛЕДОВАТЕЛЬНОСТИ | 2020 |
|
RU2798362C2 |
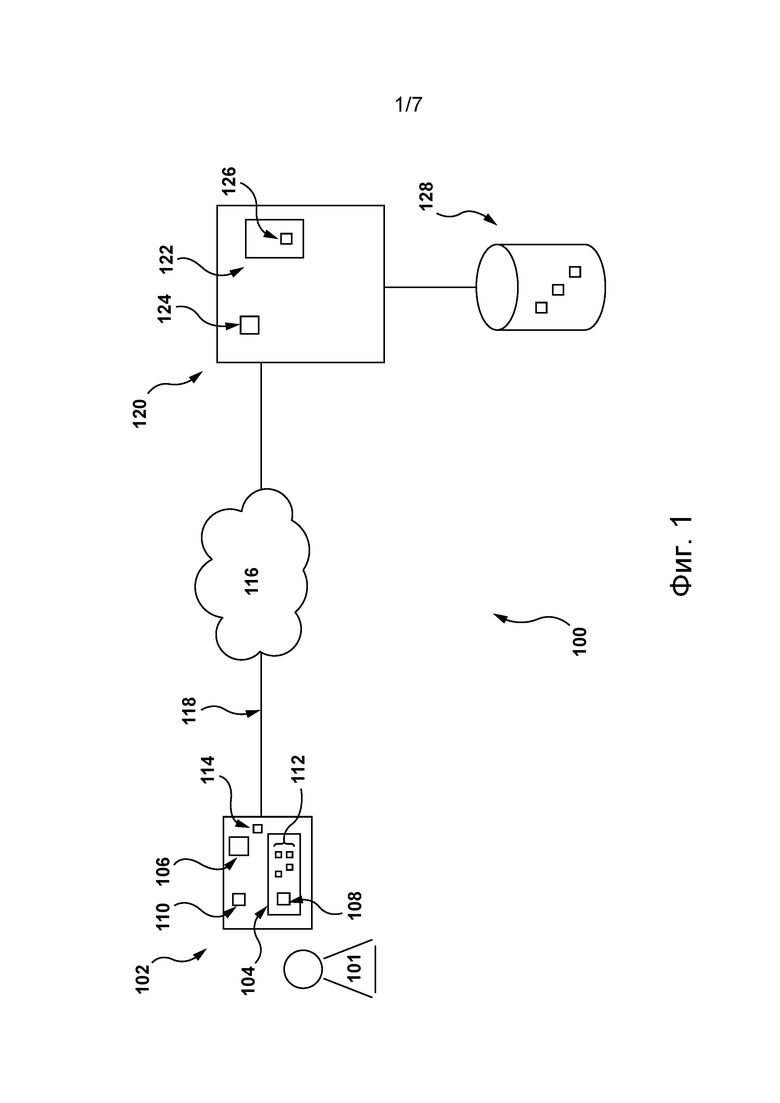
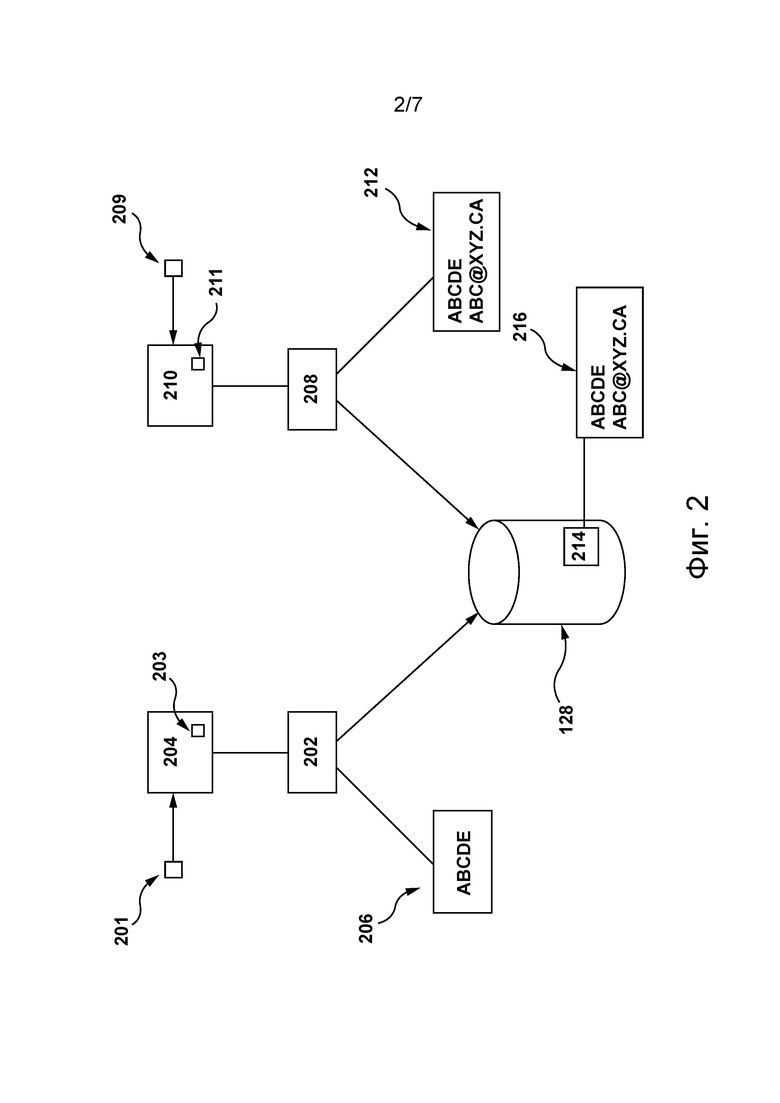
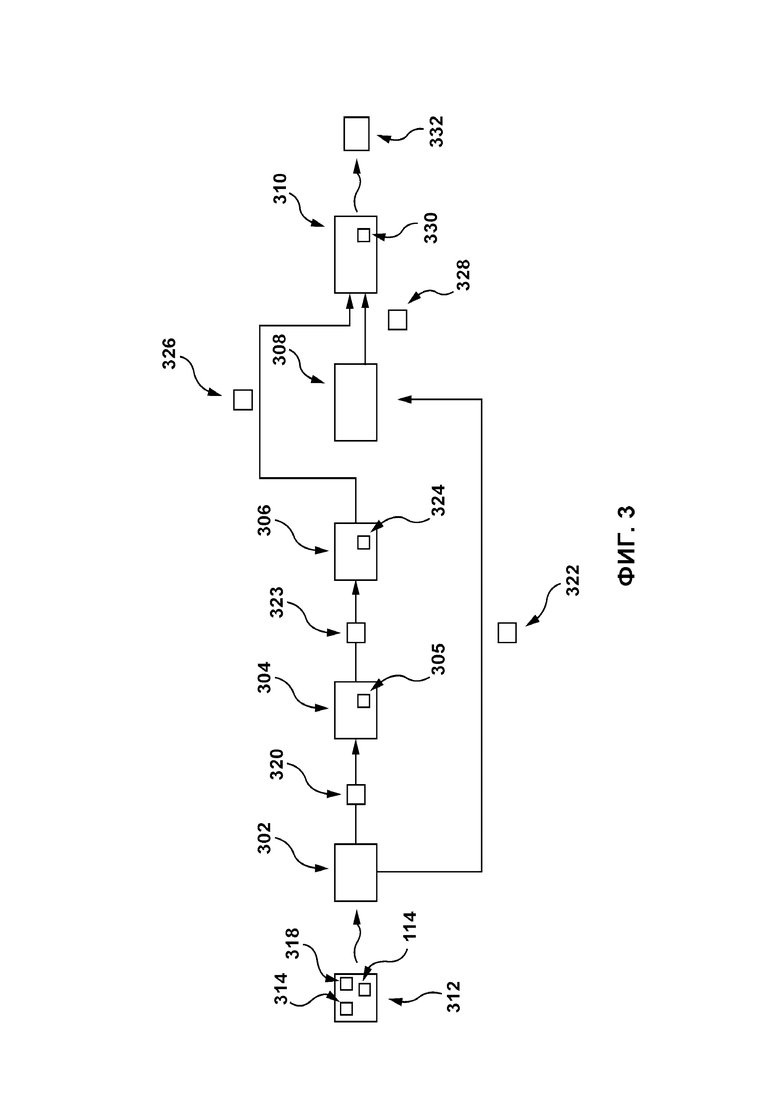
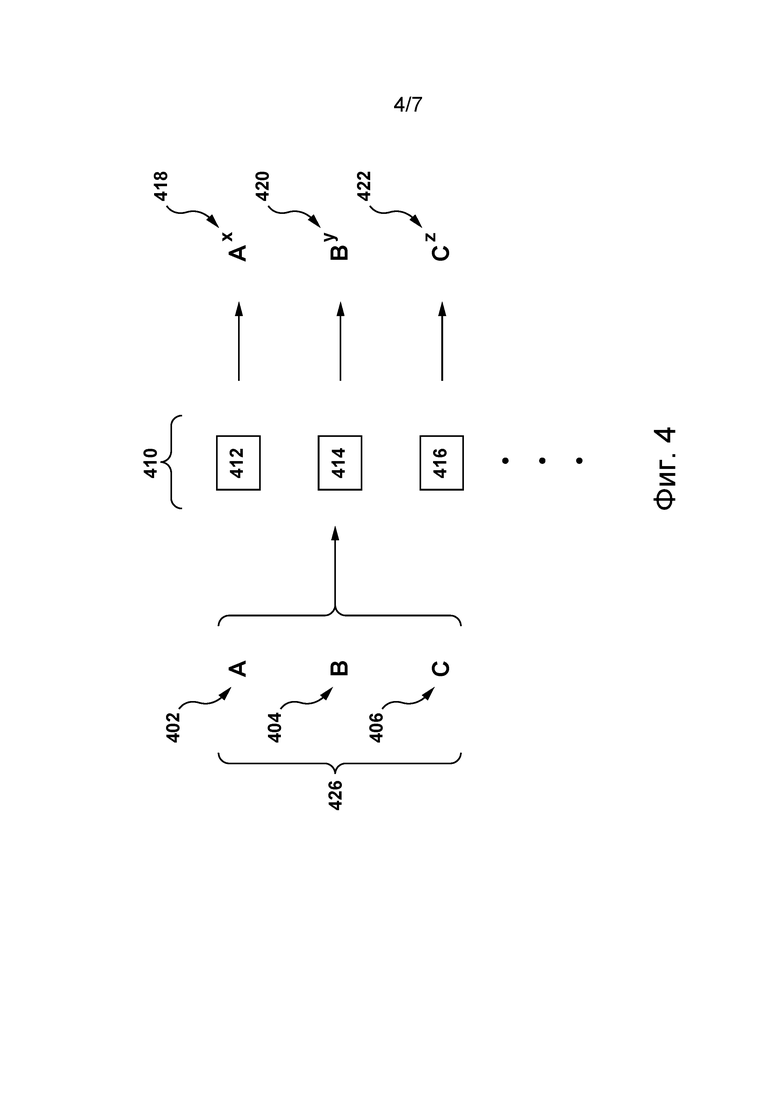
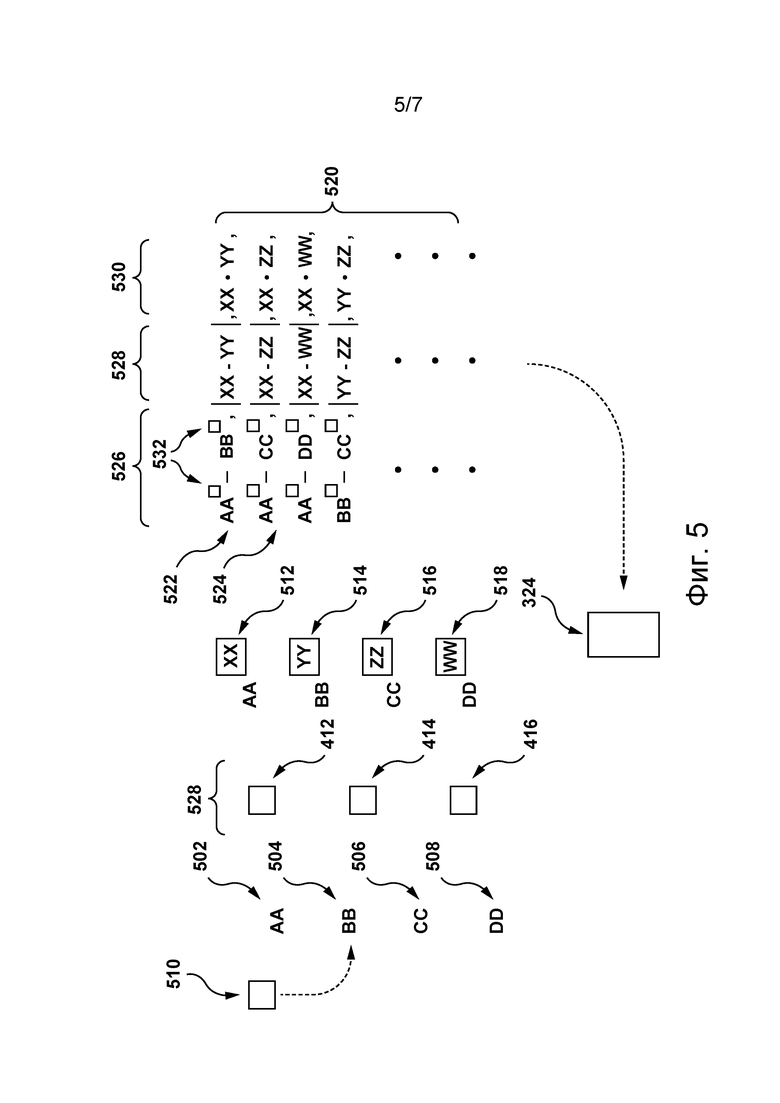
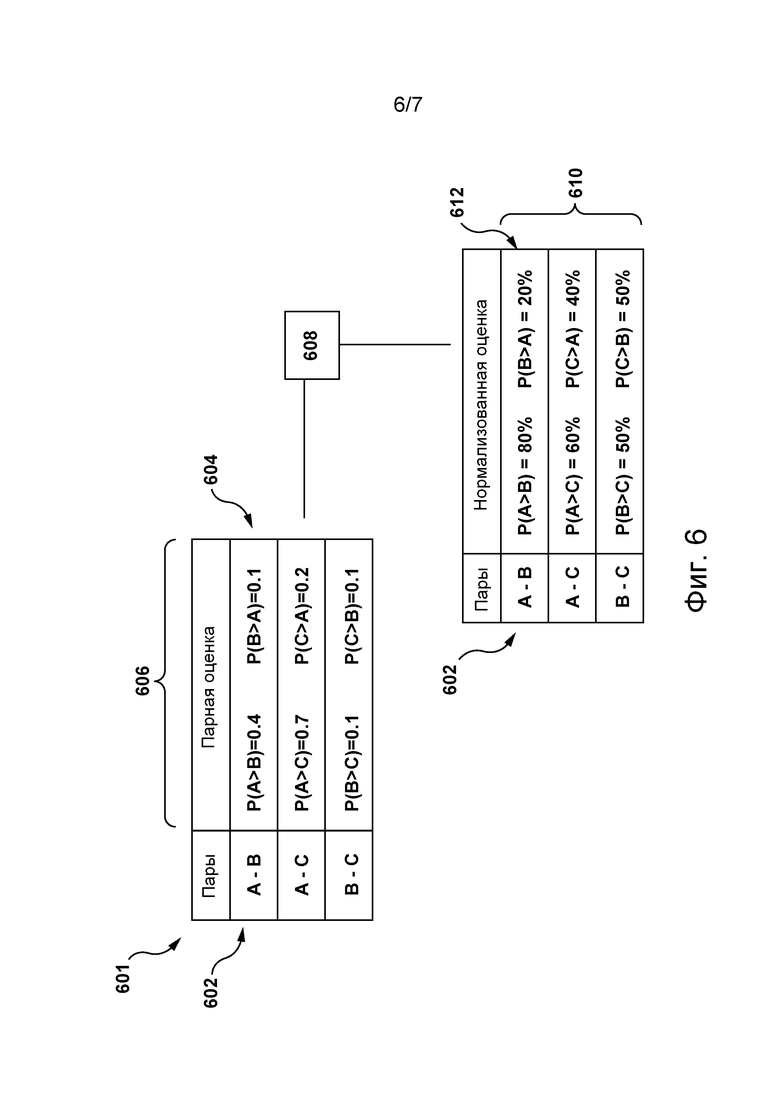
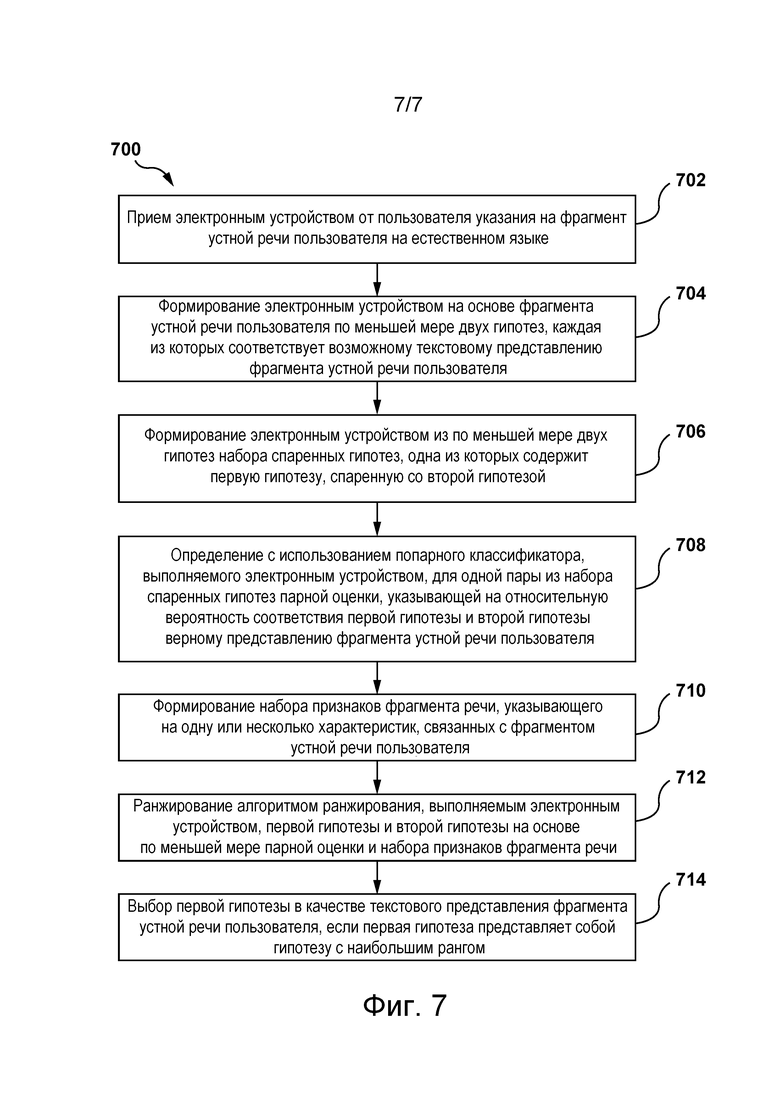
Группа изобретений относится к области обработки естественного языка. Техническим результатом является формирование текстового представления фрагмента устной речи пользователя с учетом характеристик пользователя и акустических свойств фрагмента речи. Способ включает в себя: прием указания на фрагмент устной речи пользователя; формирование по меньшей мере двух гипотез; формирование электронным устройством из этих по меньшей мере двух гипотез набора спаренных гипотез, одна из которых содержит первую гипотезу, спаренную со второй гипотезой; определение для одной пары спаренных гипотез из набора спаренных гипотез парной оценки; формирование набора признаков фрагмента речи, указывающего на одну или несколько характеристик, связанных с этим фрагментом устной речи пользователя; ранжирование первой гипотезы и второй гипотезы на основе по меньшей мере парной оценки и набора признаков этого фрагмента речи и выбор первой гипотезы в качестве текстового представления этого фрагмента устной речи пользователя, если первая гипотеза представляет собой гипотезу с наибольшим рангом. 3 н. и 17 з.п. ф-лы, 7 ил.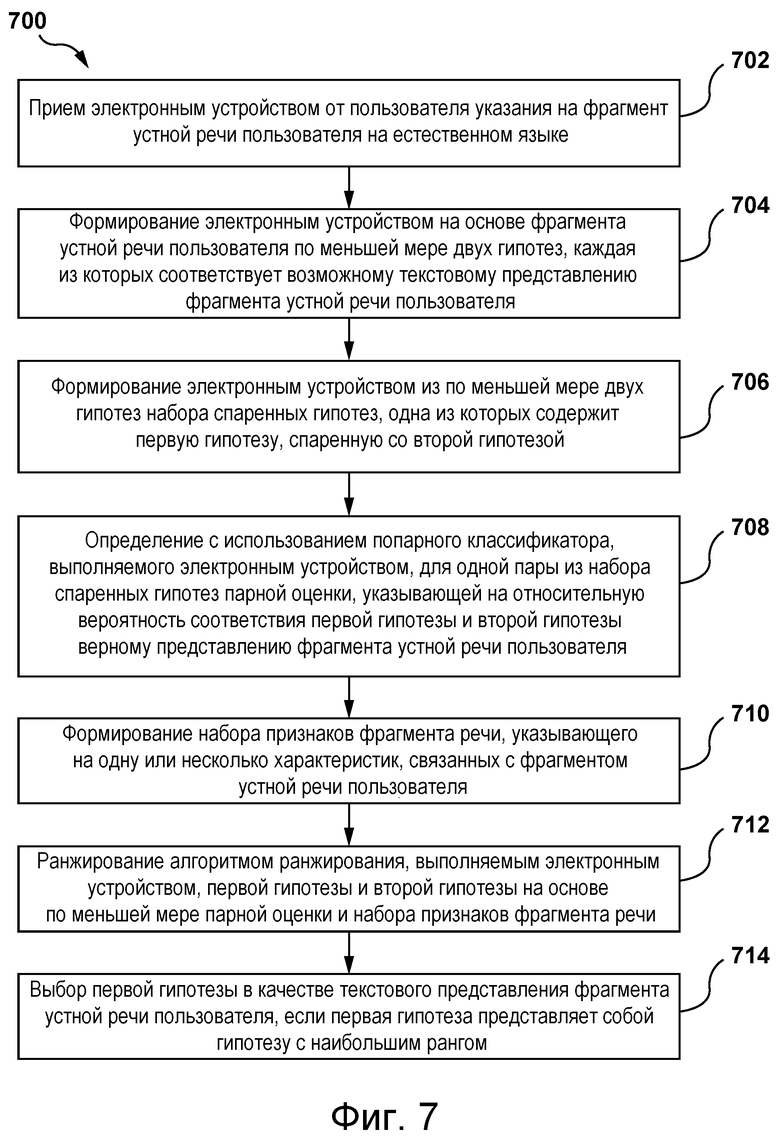
1. Компьютерный способ формирования текстового представления фрагмента устной речи пользователя, выполняемый электронным устройством и включающий в себя:
- прием электронным устройством от пользователя указания на фрагмент речи устной пользователя на естественном языке;
- формирование электронным устройством на основе этого фрагмента устной речи пользователя по меньшей мере двух гипотез, каждая из которых соответствует возможному текстовому представлению этого фрагмента устной речи пользователя;
- формирование электронным устройством из этих по меньшей мере двух гипотез набора спаренных гипотез, одна из которых содержит первую гипотезу, спаренную со второй гипотезой;
- определение с использованием попарного классификатора, выполняемого электронным устройством, для одной пары из набора спаренных гипотез парной оценки, указывающей на относительную вероятность соответствия первой гипотезы и второй гипотезы верному представлению этого фрагмента устной речи пользователя;
- формирование набора признаков фрагмента речи, указывающего на одну или несколько характеристик, связанных с этим фрагментом устной речи пользователя;
- ранжирование алгоритмом ранжирования, выполняемым электронным устройством, первой гипотезы и второй гипотезы на основе по меньшей мере парной оценки и набора признаков фрагмента речи; и
- выбор первой гипотезы в качестве текстового представления этого фрагмента устной речи пользователя, если первая гипотеза представляет собой гипотезу с наибольшим рангом.
2. Способ по п. 1, отличающийся тем, что:
- по меньшей мере две гипотезы включают в себя первую гипотезу, вторую гипотезу и по меньшей мере одну дополнительную гипотезу; и
- набор спаренных гипотез включает в себя множество спаренных гипотез, содержащее каждую из этих по меньшей мере двух гипотез, спаренную с каждой оставшейся гипотезой из этих по меньшей мере двух гипотез;
при этом определение парной оценки включает в себя определение набора парных оценок, содержащего одну или несколько парных оценок, связанных с каждой из этого множества спаренных гипотез.
3. Способ по п. 2, отличающийся тем, что ранжирование алгоритмом ранжирования включает в себя ранжирование по меньшей мере двух гипотез на основе по меньшей мере всего набора парных оценок и набора признаков фрагмента речи.
4. Способ по п. 1, отличающийся тем, что определение парной оценки включает в себя:
- определение первой оценки, указывающей на относительную вероятность того, что верному представлению фрагмента устной речи пользователя соответствует первая гипотеза, а не вторая гипотеза;
- определение второй оценки, указывающей на относительную вероятность того, что верному представлению этого фрагмента устной речи пользователя соответствует вторая гипотеза, а не первая гипотеза;
- определение первой нормализованной оценки на основе первой оценки и второй нормализованной оценки на основе второй оценки так, чтобы сумма первой нормализованной оценки и второй нормализованной оценки была равна заранее заданной суммарной оценке.
5. Способ по п. 1, отличающийся тем, что дополнительно включает в себя:
- формирование первого профиля гипотезы, соответствующего первому набору векторов, представляющих одну или несколько контекстно-зависимых характеристик первой гипотезы; и
- формирование второго профиля гипотезы, соответствующего второму набору векторов, представляющих одну или несколько контекстно-зависимых характеристик второй гипотезы;
при этом формирование парной оценки включает в себя формирование парной оценки на основе по меньшей мере первого профиля гипотезы и второго профиля гипотезы.
6. Способ по п. 5, отличающийся тем, что попарный классификатор представляет собой алгоритм Прайса, Кнера, Персоназа и Дрейфуса (PKPD), а способ дополнительно включает в себя обучение алгоритма PKPD перед приемом фрагмента устной речи пользователя с использованием обучающего набора данных, содержащего по меньшей мере:
- обучающую пару гипотез, включающую в себя первую обучающую гипотезу, спаренную со второй обучающей гипотезой, при этом первая обучающая гипотеза и вторая обучающая гипотеза сформированы в ответ на обучающий фрагмент речи;
- первый профиль обучающей гипотезы, соответствующий первому обучающему набору векторов, представляющих один или несколько контекстно-зависимых признаков первой обучающей гипотезы;
- второй профиль обучающей гипотезы, соответствующий второму обучающему набору векторов, представляющих один или несколько контекстно-зависимых признаков второй обучающей гипотезы;
- оценку различия профилей, соответствующую разности между первым обучающим набором векторов и вторым обучающим набором векторов;
- совокупную оценку профилей, соответствующую частному от деления первого обучающего набора векторов на второй обучающий набор векторов; и
- метку, указывающую на соответствие первой обучающей гипотезы или второй обучающей гипотезы этому обучающему фрагменту речи.
7. Способ по п. 5, отличающийся тем, что формирование первого профиля гипотезы включает в себя:
- анализ первой гипотезы с использованием одной или нескольких контекстно-зависимых моделей, каждая из которых обучена на множестве контекстно-зависимых слов;
- назначение каждой из одной или нескольких контекстно-зависимых моделей относительной контекстно-зависимой оценки, соответствующей вектору, который представляет долю контекстно-зависимых слов, связанных с конкретной контекстно-зависимой моделью в рамках первой гипотезы; и
- объединение одного или нескольких векторов, назначенных каждой из одной или нескольких контекстно-зависимых моделей.
8. Способ по п. 1, отличающийся тем, что набор признаков фрагмента речи содержит характерные для пользователя признаки, включающие в себя возраст пользователя, и/или пол пользователя, и/или профиль интересов пользователя.
9. Способ по п. 8, отличающийся тем, что электронное устройство дополнительно соединено с базой данных, содержащей журнал просмотра или журнал поиска, связанный с пользователем, а характерные для пользователя признаки формируются на основе
истории просмотра, связанной с этим пользователем, и/или истории поиска, связанной с этим пользователем.
10. Способ по п. 8, отличающийся тем, что электронное устройство представляет собой пользовательское устройство, а характерные для пользователя признаки формируются на основе предыдущих взаимодействий этого пользователя с этим пользовательским устройством.
11. Способ по п. 1, отличающийся тем, что набор признаков фрагмента речи содержит акустические признаки, включающие в себя
тембр фрагмента устной речи пользователя, и/или тон фрагмента устной речи пользователя, и/или отношение сигнал-шум.
12. Способ по п. 1, отличающийся тем, что электронное устройство представляет собой сервер, соединенный с пользовательским устройством, связанным с пользователем, а прием фрагмента устной речи пользователя от пользователя включает в себя прием этого фрагмента устной речи пользователя от этого пользовательского устройства.
13. Способ по п. 1, отличающийся тем, что алгоритм ранжирования представляет собой нейронную сеть и способ дополнительно включает в себя обучение нейронной сети с использованием обучающего набора данных перед приемом входных данных на естественном языке.
14. Компьютерный способ формирования текстового представления фрагмента устной речи пользователя, выполняемый электронным устройством и включающий в себя:
- прием электронным устройством от пользователя указания на фрагмент устной речи пользователя на естественном языке;
- формирование электронным устройством на основе этого фрагмента устной речи пользователя по меньшей мере двух гипотез, каждая из которых соответствует возможному текстовому представлению этого фрагмента устной речи пользователя;
- формирование электронным устройством набора спаренных гипотез, содержащего каждую гипотезу из этих по меньшей мере двух гипотез, спаренную с каждой оставшейся гипотезой из этих по меньшей мере двух гипотез;
- определение с использованием попарного классификатора, выполняемого электронным устройством, набора парных оценок, содержащего парную оценку для каждой пары в наборе спаренных гипотез, при этом парная оценка для спаренной гипотезы указывает на относительную вероятность соответствия первой гипотезы и второй гипотезы из этой спаренной гипотезы верному представлению этого фрагмента устной речи пользователя;
- ранжирование этих по меньшей мере двух гипотез алгоритмом ранжирования, выполняемым электронным устройством и способным ранжировать эти по меньшей мере две гипотезы на основе всего набора парных оценок;
- выбор первой гипотезы в качестве текстового представления этого фрагмента устной речи пользователя, если первая гипотеза представляет собой гипотезу с наибольшим рангом.
15. Система для формирования текстового представления фрагмента устной речи пользователя, содержащая электронное устройство, содержащее процессор, выполненный с возможностью:
- приема электронным устройством от пользователя указания на фрагмент устной речи пользователя на естественном языке;
- формирования электронным устройством на основе этого фрагмента устной речи пользователя по меньшей мере двух гипотез, каждая из которых соответствует возможному текстовому представлению этого фрагмента устной речи пользователя;
- формирования электронным устройством из этих по меньшей мере двух гипотез набора спаренных гипотез, одна из которых содержит первую гипотезу, спаренную со второй гипотезой;
- определения с использованием попарного классификатора, выполняемого электронным устройством, набора парных оценок, содержащего парную оценку, связанную с одной парой из набора спаренных гипотез и указывающую на относительную вероятность соответствия первой гипотезы и второй гипотезы верному представлению этого фрагмента устной речи пользователя;
- формирования набора признаков фрагмента речи, указывающего на одну или несколько характеристик, связанных с этим фрагментом устной речи пользователя;
- ранжирования алгоритмом ранжирования, выполняемым электронным устройством, первой гипотезы и второй гипотезы на основе по меньшей мере всего набора парных оценок и набора признаков фрагмента речи; и
- выбора первой гипотезы в качестве текстового представления фрагмента устной речи пользователя, если первая гипотеза представляет собой гипотезу с наибольшим рангом.
16. Система по п. 15, отличающаяся тем, что:
- по меньшей мере две гипотезы включают в себя первую гипотезу, вторую гипотезу и по меньшей мере одну дополнительную гипотезу; и
- набор спаренных гипотез включает в себя множество спаренных гипотез, содержащее каждую из этих по меньшей мере двух гипотез, спаренную с каждой оставшейся гипотезой из этих по меньшей мере двух гипотез;
при этом для определения парной оценки процессор выполнен с возможностью определения набора парных оценок, содержащего одну или несколько парных оценок, связанных с каждой парой из этого множества спаренных гипотез.
17. Система по п. 15, отличающаяся тем, для определения парной оценки процессор выполнен с возможностью:
- определения первой оценки, указывающей на относительную вероятность того, что верному представлению фрагмента устной речи пользователя соответствует первая гипотеза, а не вторая гипотеза;
- определения второй оценки, указывающей на относительную вероятность того, что верному представлению фрагмента устной речи пользователя соответствует вторая гипотеза, а не первая гипотеза;
- определения первой нормализованной оценки на основе первой оценки и второй нормализованной оценки на основе второй оценки так, чтобы сумма первой нормализованной оценки и второй нормализованной оценки была равна заранее заданной суммарной оценке.
18. Система по п. 15, отличающаяся тем, что набор признаков фрагмента речи содержит характерные для пользователя признаки, включающие в себя возраст пользователя, и/или пол пользователя, и/или профиль интересов пользователя.
19. Система по п. 15, отличающаяся тем, что набор признаков фрагмента речи содержит акустические признаки, включающие в себя тембр фрагмента устной речи пользователя, и/или тон фрагмента устной речи пользователя, и/или отношение сигнал-шум.
20. Система по п. 15, отличающаяся тем, что алгоритм ранжирования представляет собой нейронную сеть, а процессор дополнительно выполнен с возможностью обучения этой нейронной сети с использованием обучающего набора данных перед приемом входных данных на естественном языке.
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| Автомобиль-сани, движущиеся на полозьях посредством устанавливающихся по высоте колес с шинами | 1924 |
|
SU2017A1 |
| Перекатываемый затвор для водоемов | 1922 |
|
SU2001A1 |
| ГОЛОСОВАЯ СВЯЗЬ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ МЕЖДУ ЧЕЛОВЕКОМ И УСТРОЙСТВОМ | 2014 |
|
RU2583150C1 |
| СИСТЕМА И СПОСОБ РАСПОЗНАВАНИЯ РЕЧИ | 2011 |
|
RU2466468C1 |

