Введение
[001] В настоящее время, более одной трети населения мира инфицированы вирусом гепатита В (HBV), и 240 миллионов человек имеют хронические инфекции. HBV-инфекция и связанные с ней заболевания являются причиной гибели около одного миллиона человек ежегодно.
[002] Поверхностный антиген HBV состоит из большого (L), среднего (М) и малого (S) белков. Белки L и М имеют дополнительные домены на своем N-конце, в отличие от белка S, который имеет только домен S. L содержит домены Pre-S1, Pre-S2, и S; М содержит домены Pre-S2 и S, а белок S содержит только домен S. Домен Pre-S в белке L является молекулой-мишенью для рецептора(ов) HBV, которая экспрессируется на поверхности клеток печени человека; и антитела к домену pre-S1 HBV описаны, например, Watashi и др., Int. J. Mol. Sci. 2014, 15, 2892-2905, refs 22-27. Соответствующее описание рецептора HBV приводится в WO2013159243A1, описние гуманизованного антитела, полученного из мышиной гибридомы, KR127, приводится в патенте США 7115723, а описание пептидов pre-S1 приводится в патенте США 7892754.
Сущность изобретения
[003] Настоящее изобретение относится к способам и к композициям для иммунной активации посредством ингибирования HBV и/или HDV. В одном из своих аспектов, настоящее изобретение относится к антигенсвязывающему домену антитела, который специфически связывается с Pre-S1 HBV и включает комплементарность-определяющую область CDR1, CDR2 и CDR3 в комбинации, выбранной из нижеследущих комбинаций (a)-(r), где антитело (Ab), тяжелая цепь (НС) или легкая цепь (LC) и CDR (пронумерованные в соответствии с номенклатурной системой по Кэбату, IMGT или по той и другой системе), от которых происходят комбинации CDR, приведены в первом столбце, и где остатки, выделенные жирным шрифтом, пронумерованы по системе Кэбата, а подчеркнутые остатки пронумерованы по системе IMGT:
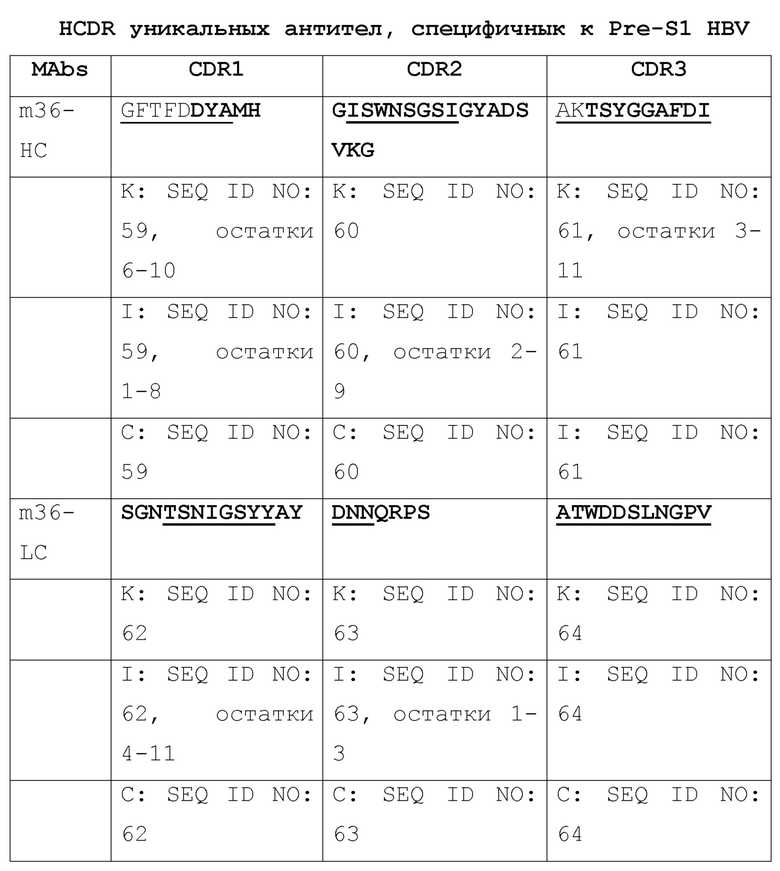
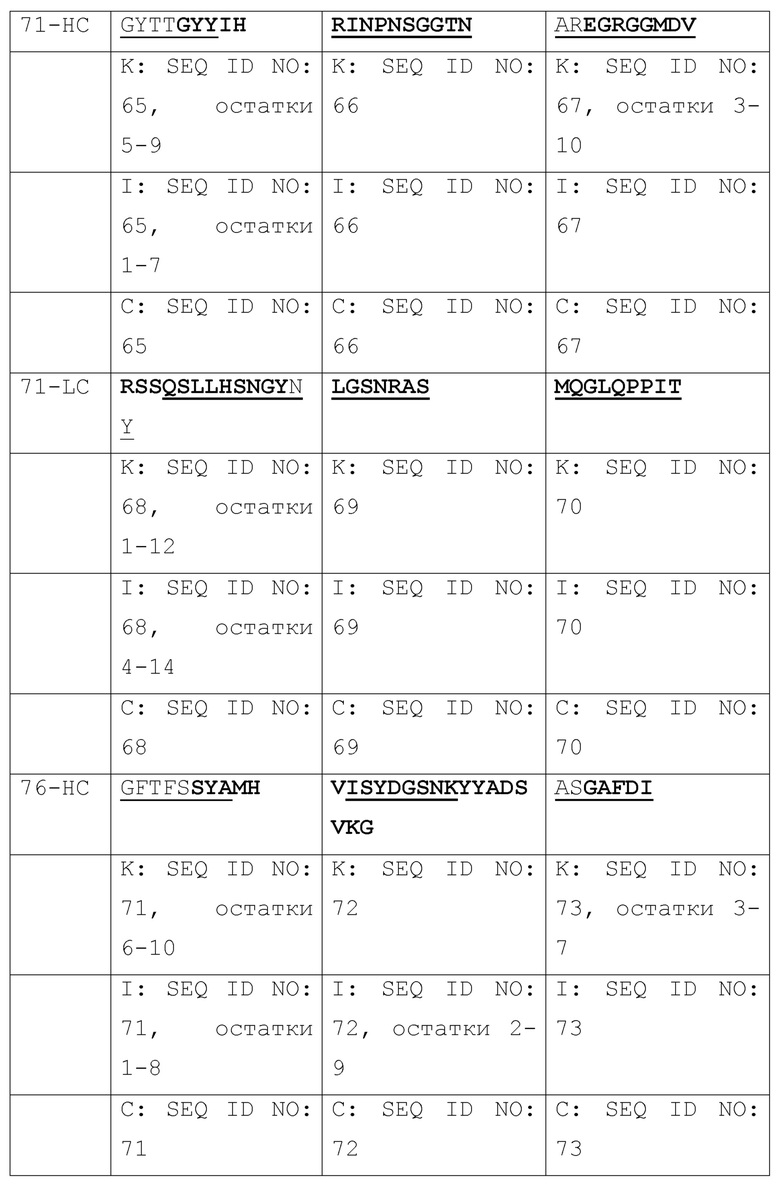
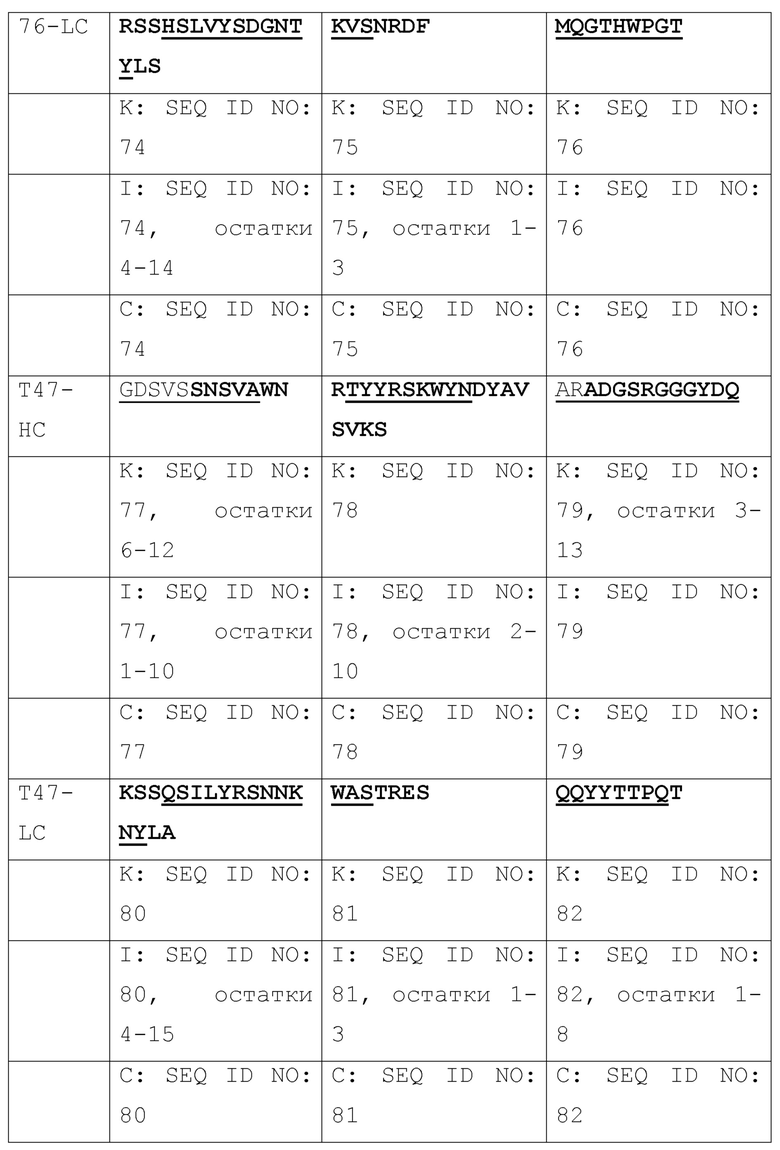
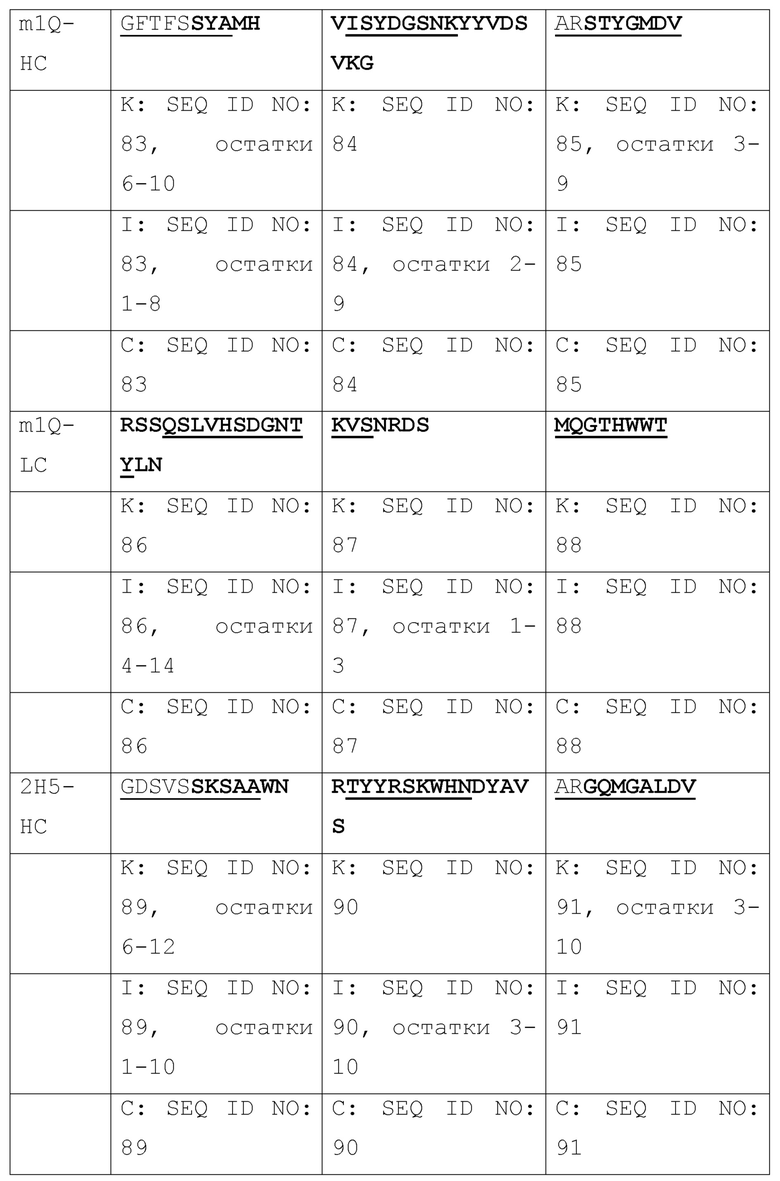
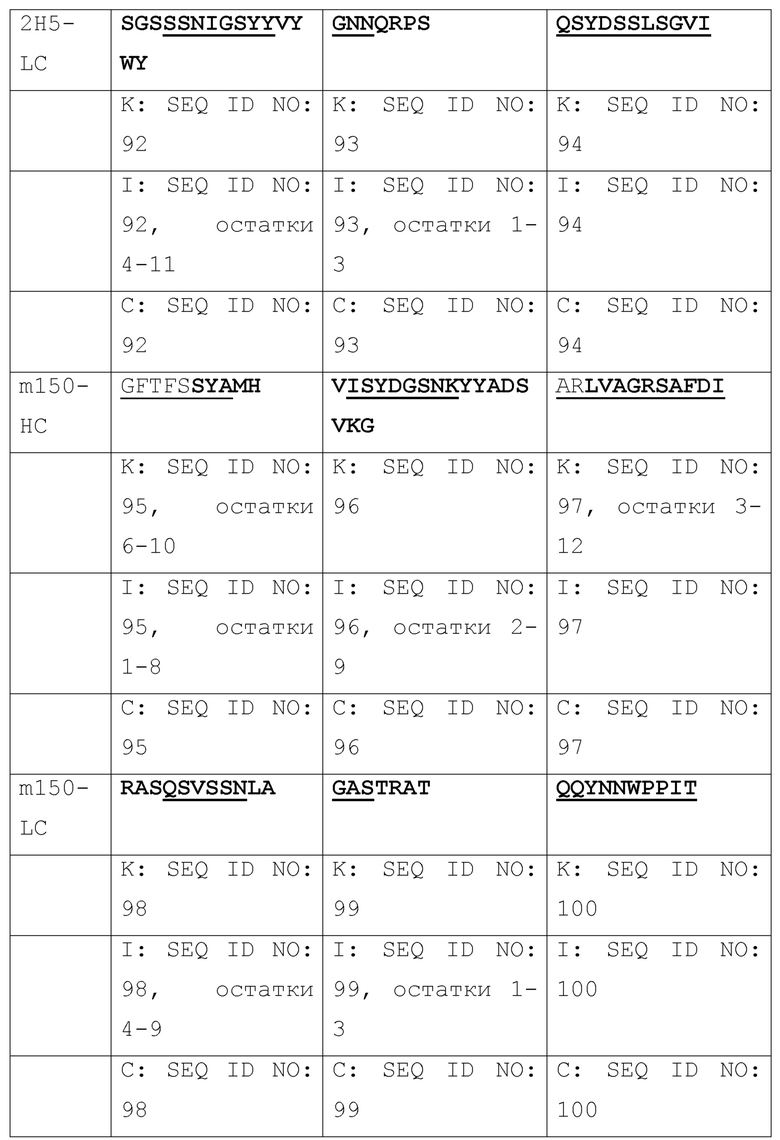

[004] В некоторых своих вариантах, настоящее изобретение относится к антигенсвязывающему домену антитела, содержащему вариабельную область тяжелой цепи (Vh), включающую комбинации CDR1, CDR2 и CDR3, и вариабельную область легкой цепи (Vl), включающую комбинацию CDR1, CDR2 и CDR3, или содержащему вариабельную область тяжелой цепи (Vh) и/или вариабельную область легкой цепи (Vl), выбранные из: m36, 71, 76, T47, m1Q, 2H5, m150; и 4, 31, 32, 69, A14, A21, B103, B129, B139, B172; и 8, 20, 20-m1, 20-m2, 20-m3.
[005] В вариантах осуществления изобретения, антигенсвязывающий домен антитела специфически связывается с аминокислотами 11-28 или аминокислотами 19-25 pre-S1.
[006] Настоящее изобретение также относится к антителам, а в частности, к моноклональным антителам и к F(ab) или F(ab)2, содержащим рассматриваемый связывающий домен.
[007] Настоящее изобретение также относится к новым полинуклеотидам, таким как кДНК, и к экспрессионным векторам, кодирующим рассматриваемый антигенсвязывающий домен, а также к клеткам, содержащим такие полинуклеотиды, и к животным, содержащим такие клетки. Полинуклеотиды могут быть функционально присоединены к гетерологичной последовательности регулации транскрипции для экспрессии и могут быть включены в такие векторы, клетки и т.п.
[008] Настоящее изобретение относится к способам применения рассматриваемых доменов для лечения HBV- или HDV-инфекции или для индуцирования антитело-зависимо клеточно-опосредуемой цитотоксичности (ADCC), где указанные способы включают введение домена индивидууму, у которого, как было определено, имеется HBV- или HDV-инфекция, и который подвергался воздействию HBV или HDV или имеет высокий риск воздействия или инфицирования HBV или HDV, или нуждается в ингибировании домена Pre-S1 или т.п. Настоящее изобретение также относится к применению рассматриваемых композиций в целях приготовления лекарственного препарата для лечения HBV- или HDV-инфекции, необязательно в комбинации с ингибитором репликации вируса.
[009] Настоящее изобретение включает все комбинации конкретно описанных вариантов его осуществления. Другие варианты осуществления изобретения и полный объем применения настоящего изобретения будут очевидны из нижеследующего подробного описания. Однако, следует отметить, что подробное описание и конкретные примеры, а также предпочтительные варианты осуществления изобретения приводятся лишь в целях иллюстрации, и в них могут быть введены различные изменения и модификации, не выходящие за рамки существа и объема изобретения, которые будут очевидны для специалиста из подробного описания изобретения. Все цитируемые здесь публикации, патенты и патентные заявки, включая цитируемые в них работы, во всей своей полноте и во всех целях вводятся в настоящее описание посредством ссылки.
Краткое описание чертежей
[010] Фиг. 1. Нейтрализация HBV под действием 10 антител, происходящих от выбранных библиотек, полученных путем перестановки VH-цепи 2H5.
Описание конкретных вариантов осуществления изобретения
[011] Если это не следует из контекста описания, то термин «антитело» употребляется здесь в самом широком смысле и, в частности, охватывает антитела (включая полноразмерные моноклональные антитела) и фрагменты антител, при условии, что они будут распознавать Pre-S1 HBV/HDV или как-либо иначе ингибировать HBV/HDV. Молекула антитела обычно является моноспецифической, но она может быть также идиоспецифической, гетероспецифической или полиспецифической. Молекулы антитела связываются посредством сайтов специфического связывания со специфическими антигенными детерминантами или эпитопами на антигенах. «Фрагменты антитела» содержат часть полноразмерного антитела, а обычно, его антигенсвязывающую или вариабельную область. Примерами фрагментов антител являются Fab-, Fab'-, F(аb')2- и Fv-фрагменты; диантитела; линейные антитела; молекулы одноцепочечных антител и мультиспецифические антитела, происходящие от фрагментов антител.
[012] Структуры природных и сконструированных антител хорошо известны специалистам, см., например, Strohl et al., Therapeutic antibody engineering: Current and future advances driving the strongest growth area in the pharmaceutical industry, Woodhead Publishing Series in Biomedicine No. 11, Oct 2012: Holliger et al. Nature Biotechnol 23, 1126-1136 (2005): Chames et al. Br. J. Pharmacol. 2009 May; 157 (2): 220-233.
[013] Моноклональные антитела (MAb) могут быть получены методами, известными специалистам. См., например, Kohler et al (1975); патент США 4376110; Ausubel et al. (1987-1999); Harlow et al. (1988); и Colligan et al. (1993). mAb согласно изобретению могут принадлежать к любому классу иммуноглобулинов, включая IgG, IgM, IgE, IgA и к любому их подклассу. Гибридома, продуцирующая mAb, может быть культивирована in vitro или in vivo. Высокие титры mAb могут быть получены путем продуцирования in vivo, где клетки, происходящие от человеческих гибридом, внутрибрюшинно инъецируют мышам, таким как примированные пристином мыши Balb/c, для продуцирования асцитной жидкости, содержащей высокие концентрации нужных mAb. MAb изотипа IgM или IgG могут быть выделены из асцитной жидкости или из супернатантов культуры методами колоночной хроматографии, хорошо известными специалистам.
[014] «Выделенный полинуклеотид» означает полинуклеотидный сегмент или фрагмент, который был отделен от последовательностей, фланкирующих сегмент или фрагмент, встречающийся в природе, например, фрагмент ДНК, удаленный из последовательностей, которые обычно являются смежными с этим фрагментом, например, последовательностей, смежных с данным фрагментом в геноме, в котором он присутствует в природе. Следовательно, этот термин включает, например, рекомбинантную ДНК, которая была введена в вектор, в автономно реплицирующуюся плазмиду или вирус или в геномную ДНК прокариота или эукариота, или которая существует как отдельная молекула (например, как кДНК или фрагмент геномной ДНК или фрагмент кДНК, полученный с помощью ПЦР или посредством гидролиза рестриктирующими ферментами) независимо от других последовательностей. Этот термин также включает рекомбинантную ДНК, которая представляет собой часть гибридного гена, кодирующего дополнительную полипептидную последовательность.
[015] «Конструкция» означает любую рекомбинантную полинуклеотидную молекулу, такую как плазмида, космида, вирус, автономно реплицирующаяся полинуклеотидная молекула, фаг или линейная или кольцевая одноцепочечная или двухцепочечная полинуклеотидная молекула ДНК или РНК, происходящая от любого источника, способная к интеграции в геном или к автономной репликации и содержащая полинуклеотидную молекулу, где одна или более полинуклеотидных молекул связаны посредством функционального присоединения друг к другу, то есть, являются функционально связанными. Рекомбинантная конструкция обычно содержит полинуклеотиды согласно изобретению, функционально присоединенные к регуляторным последовательностям инициации транскрипции, которые обеспецивают регуляцию транскрипции полинуклеотида в выбранной клетке-хозяине. Для регуляции экспрессии нуклеиновых кислот согласно изобретению могут быть использованы гетерологичные и не-гетерологичные (то есть, эндогенные) промоторы.
[016] «Вектор» означает любую рекомбинантную полинуклеотидную конструкцию, которая может быть использована для трансформации, то есть, для введения гетерологичной ДНК в клетку-хозяина. Одним из типов вектора является «плазмида», которая представляет собой кольцевую двухцепочечную ДНК-петлю, где дополнительные ДНК-сегменты могут бить лигированы. Вектором другого типа является вирусный вектор, где дополнительные ДНК-сегменты могут бить лигированы в вирусный геном. Некоторые векторы способны автономно реплицироваться в клетке-хозяине, в которую они были введены (например, бактериальные векторы, имеющие бактериальный ориджин репликации, и эписомные векторы млекопитающих). Другие векторы (например, не-эписомные векторы млекопитающих) интегрируются в геном клетки-хозяина после их введения в эту клетку и тем самым могут реплицироваться в геноме хозяина. Кроме того, некотоые векторы способны регулировать экспрессию генов, к которым они функционально присоединены. Такие векторы называются здесь «экспрессионными векторами».
[017] Используемый здесь термин «экспрессионный вектор» означает молекулу нуклеиновой кислоты, способную реплицироваться и экспрессировать представляющий интерес ген в клетке-хозяине после его трансформации, трансфекции или трансдукции. Экспрессионные векторы содержат один или более фенотипических селективных маркеров и ориджин репликации, обеспечивающих сохранение вектора и, если это необходимо, его амплификацию в хозяине. Экспрессионный вектор также содержит промотор, инициирующий экспрессию полипептида в клетках. Подходящими экспрессионными векторами могут быть плазмиды, происходящие, например, от pBR322, или различные плазмиды pUC, которые являются коммерчески доступными. Другие экспрессионные векторы могут происходить от векторов, экспрессирующихся в бактериофаге, фагмиде или космиде.
Примеры
[018] Человеческие моноклональные антитела блокируют вирусную инфекцию, вызываемую вирусом гепатита B и D. Авторами настоящего изобретения были раскрыты человеческие моноклональные антитела, которые могут блокировать HDV- и HBV-вирусные инфекции. Эти антитела были идентифицированы из крупной библиотеки фагового представления антител, которая была получена с использованием мононуклеарных клеток периферической крови, выделенных у 93 здоровых доноров. Путем отбора и скрининга библиотеки антител с использованием домена pre-S1 оболочесного белка HBV в качестве мишени была идентифицирована панель человеческих моноклональных антител, обладающих активностью, направленной на нейтрализацию HDV- и HBV-инфекций. Было обнаружено, что из этих антител, 2H5 обладало наилучшей нейтрализующей активностью, направленной против HDV- и HBV-инфекций. Была идентифицирована общая кристаллическая структура 2H5 в комплексе с его мишенью (8 аминокислот домена Pre-S1). Путем оптимизации 2H5 методом перестановки цепей, авторами были получены даже еще более эффективные нейтрализующие антитела. Эти антитела распознают эпитоп, аналогичный эпитопу для 2H5, и такой эпитоп является в высокой степени консервативным среди различных генотипов HBV. Репрезентативное антитело A14 было протестировано у мышей, несущих гуманизованный NTCP, на способность к полной защите мышей от HDV-инфекции, и исследования на животных подтвердили такую защиту от HBV-инфекции.
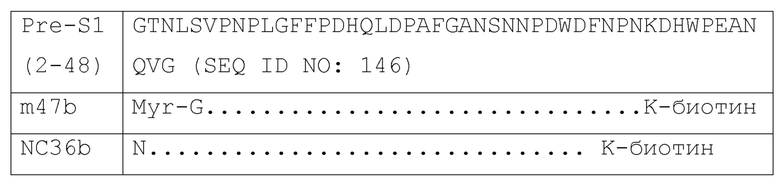
[019] Антиген-мишень: пептиды pre-S1. В качестве антигена для отбора авторами были использованы два пептида, происходящие от домена pre-S1 HBV. Они были синтезированы с использованием пептида Scilight (Пекин, Китай) с чистотой более, чем 95%. NC36b: пептид, содержащий остатки 4-38 домена pre-S1 белка L HBV с модификацией биотином у его С-конца. m47b: миристоилированный липопептид, содержащий аминокислоты 2-48 домена pre-S1 с модификацией биотином у С-конца и модификацией посредством миристоилирования у N-конца.
[020] Человеческие моноклональные антитела против пептидов pre-S1 были получены методом фагового представления антител с модификациями [1, 2].
[021] Библиотека фагового представления антител. Библиотеку человеческих неиммунных scFv-фрагментов (одноцепочечных вариабельных фрагментов) антитела конструировали из мононуклеарных клеток периферической крови (МКПК), выделенных у 93 здоровых доноров. Размер этой библиотеки составлял всего 1,1×1010 членов.
[022] Отбор и скрининг библиотеки фаговых антител. Фаговые частицы, экспрессирующие scFv на своей поверхности (фаг-scFv), получали из библиотеки и использовали для отбора scFv против синтезированных NC36b и m47b. Пептиды захватывали на конъюгированных со стрептавидином магнитных сферах M-280 Dynabeads® (Life Technologies), а затем инкубировали с 5×1012 фаговых частиц, полученных из библиотеки, соответственно. Для каждого пептида проводили два раунда отбора. Для каждого раунда отбора, в целях получения высокоаффинных антител, количество пептидов, захваченных на магнитных сферах, оптимизировали и проводили стадии интенсивной промывки. Кроме того, для отделения высокоаффинных связывающих агентов от магнитных сфер и увеличения разнообразия выделенных фаг-scFv было применено два метода элюирования, включая конкурентное элюирование пептидом и элюирование стандартным основным раствором триэтаноламина. В результате было собрано всего приблизительно 2000 отдельных клонов, а затем проводили стадию их «спасения» для продуцирования фаг-scFv в супернатанте бактериальной культуры и скринировали на специфическое связывание с m47b и/или NC36b с помощью твердофазного иммуноферментного анализа (ELISA). Клоны, которые связывались с m47b и/или NC36b, с величинами оптической плотности 450 нМ>1,0, были оценены как позитивные, а негативные клоны давали величины <0,1. Для клонов, специфически связывающихся с m47b и/или NC36b, были секвенированы гены вариабельных областей тяжелой цепи (VH) и легкой цепи (VL), и их соответствующие аминокислотные последовательности выравнивали для исключения повторяющихся клонов и идентификации антител с другими последовательностями, используемыми для дополнительной характеризации. Всего было идентифицировано 109 клонов с уникальной последовательностью.
[023] Дополнительная характеризация антител с уникальными последовательностями антител для идентификация наилучшего антитела-кандидата. Клоны антител с уникальными последовательностями либо были продуцированы в виде очищенных частиц фаг-scFv, либо были превращены в миниантитела scFv-Fc или полноразмерные человеческие IgG1, а затем они были протестированы на их активность связывания с помощью ELISA и на их способность нейтрализовать HBV и HDV в клеточных культурах. В этих анализах, антитела ранжировали по их активности связывания и нейтрализующей активности. Наилучшее антитело с самой высокой нейтрализующей активностью было выбрано для последующего исследования.
[024] Получение очищенного фаг-scFv для ELISA или анализа на нейтрализацию. Фаг-scFv в супернатанте 10-30 мл бактериальной культуры осаждали ПЭГ/NaCl, а затем количественно оценивали на спектрометре. Активности различных фаг-scFv с точки зрения их связывания с антигеном или способности нейтрализовать вирусную инфекцию оценивали по кривой доза-ответ для серийно разведенных фаг-Ab, которые были нормализованы по той же самой концентрации.
[025] Получение миниантител scFv-Fc. scFv-кодирующий ген, происходящий от вектора, экспрессирующего фаг-scFv, субклонировали в экспрессионный вектор, содержащий Fc-фрагмент человеческого IgG1 у C-конца scFv. Для получения scFv-Fc, клетки 293F (Life Technologies) или 293T (ATCC) были транзиентно трансфецированы scFv-Fc-экспрессирующей плазмидой, и через 72 часа после трансфекции, супернатант клеточной культуры собирали и scFv-Fc очищали с помощью аффинной хроматографии на белке A (на белок A-сефарозе CL-4B, GE Healthcare).
[026] Получение полноразмерного антитела IgG1. VH- и VL-кодирующую последовательность scFv отдельно субклонировали в вектор, экспрессирующий тяжелую цепь (HC) антитела, и вектор, экспрессирующий легкую цепь (LC) антитела. Для получения антитела IgG1, клетки 293F или 293T транзиентно котрансфецировали двумя экспрессионными плазмидами (HC+LC-плазмидами) в отношении 1:1. Через 72 часа после трансфекции, супернатант клеточной культуры собирали для очистки IgG1 с помощью аффинной хроматографии на белке А.
[027] ELISA-анализ. 5 мкг/мл стрептавидина (Sigma) в забуференном фосфатом физиологическом растворе (PBS) наносили на 96-луночный планшет с U-дном (Nunc, MaxiSorp™) в количестве 100 мкл/лунку, и оставляли на ночь при 4°C или на 1 час при 37°C. Затем 2 мкг/мл (370 нМ) пептида m47b или NC36b в количестве 100 мкл на лунку захватывали на планшетах путем инкубирования при 30°C в течение 0,5-1 часа. Для ELISA на основе фаг-scFv, в каждую лунку добавляли серийные разведения фаг-scFv в PBS, содержащем 2% обезжиренное молоко в количестве 100 мкл на лунку. Специфически связанные фаг-scFv детектировали путем добавления ПХ-конъюгированного мышиного анти-M13 антитела (GE Healthcare) и инкубировали в течение 30 минут при 30°C. Между каждой стадией инкубирования, ELISA-планшет 6 раз промывали раствором PBSТ (0,05% твином 20, содержащим PBS) в количестве 200 мкл на лунку. После инкубирования с ПХ-конъюгированным антителом, ELISA-сигнал проявляли путем инкубирования с субстратом TMB (Sigma) в течение 5-10 минут при 30°C, а затем реакцию прекращали путем добавления 2M H2SO4 в количестве 25 мкл на лунку. Оптическую плотность на 450 нм считывали на микропланшет-ридере (Bio-Rad). Анализ ELISA на основе scFv-Fc или IgG1 проводили методом, в основном, аналогичным методу, описанному выше для фаг-scFv, за исключением того, что связанные антитела детектировали с использованием ПХ-конъюгированного мышиного Fc-антитела против человеческого IgG (Sigma).
[028] Получение вирусов HBV и HDV. HBV и HDV были продуцированы как описано в литературе [3]. HDV. Вкратце, плазмиду, содержащую тример 1,0 × кДНК вируса HDV генотипа I, расположенный от головы к хвосту (Genebank рег. №: AF425644.1) и находящийся под контролем промотора CMV, конструировали с использованием de novo синтезированной кдНК HDV для продуцирования RNP HDV. Плазмиду pUC18, содержащую нуклеотиды 2431~1990 HBV (генотипа D, Genebank рег. №: U95551.1), использовали для экспрессии оболочечных белков HBV под контролем эндогенного промотора HBV. Вирионы HDV продуцировали путем трансфекции плазмид в Huh-7 как описано в публикации Sureau et al. [4]. Супернатант трансфецированной клеточной культуры собирали и использовали непосредственно для анализа на нейтрализацию HDV. HBV. Вирусы HBV генотипов B, C и D продуцированли путем трансфекции клеток Huh-7 плазмидой, содержащей 1,05 копий генома HBV под контролем промотора CMV. Вирусы HBV генотипа B или C были также выделены из плазмы пациентов с HBV.
[029] Анализы на нейтрализацию HBV и HDV. Анализы на нейтрализацию осуществляли как описано в литературе [3, 5] с небольшими модификациями. В этих анализах использовали клетки HepG2-hNTCP (клеточную линию HepG2, стабильно экспрессирующую hNTCP-рецептор HBV и HDV (человеческий полипептид, осуществляющий совместный транспорт таурохолата натрия)). Клетки HepG2-hNTCP культивировали в среде PMM [3] в 48-луночном планшете за 12-24 часа до инфицирования вирусом. Геномные эквиваленты HDV со множественностью приблизительно 500 (м.г.э.) или HBV со множественностью приблизительно 200 м.г.э., смешанные с различными формами антител: фаг-scFv, scFv-Fc или IgG1, инокулировали клетками HepG2-hNTCP в присутствии 5% ПЭГ8000 и инкубировали в течение 16 часов. Затем клетки три раза промывали средой и выдерживали в PMM. Среду для культивирования клеток каждые 2-3 дня заменяли свежей средой PMM. Для HDV-инфицирования, через 7 дней после инфицирования (dpi), HDV-инфицированные клетки фиксировали 100% метанолом при комнатной температуре в течение 10 минут; а затем, внутриклеточный антиген дельта окрашивали 5 мкг/мл ФИТЦ-конъюгированного 4G5 (мышиного моноклонального антитела против антигена дельта HDV) и ядро окрашивали DAPI. Изображения получали на флуоресцентном микроскопе (Nikon). HDV-нейтрализующая активность была определена исходя из количества и интенсивности окрашивания антигена дельта. Для HBV-инфицирования, через 3, 5 и 7 дней после инфицирования (dpi), супернатант культуры собирали и тестировали на HBV-секретируемый вирусный антиген HBsAg и/или HBeAg с использованием коммерчески доступных наборов для ELISA (Wantai, Beijing, China). Оценку HBV-нейтрализующей активности антител осуществляли исходя из уровней HBeAg и/или HBsAg.
[030] С помощью вышеописанных ELISA-анализов и анализов на нейтрализацию HBV авторами было идентифицировано несколько наилучших антител, которые обнаруживали специфическое связывание с NC36b, а также с m47b и 47b (пептидом, аналогичным m47b, но без миристоильной группы), и HBV-нейтрализующую активность.
[031] Среди этих наилучших антител, m36, 2H5 и m1Q являются тремя самыми лучшими антителами, обладающими наивысшей активностью нейтрализации HBV (генотипа D). m36 было исключено из последующего анализа, поскольку оно обнаруживало пониженную экспрессию при превращении в полноразмерный IgG1. 2H5 и m1Q также сравнивали по их HDV-нейтрализующей активности, и было обнаружено, что 2H5 обладало более высокой активностью нейтрализации HDV-инфекции. 2H5, исходя из его высокой активности связывания с пептидом и сильной HBV- и HDV-нейтрализующей активности, было отобрано для дальнейшего исследования. Кроме того, 2H5 обнаруживало более сильную HBV- и HDV-нейтрализующую активность, чем ранее описанное антитело KR127 против пептида pre-S1 [6-8]. В анализе на HBV-инфицирование, 2H5-IgG1 был в 11 раз более эффективным, чем KR127, на что указывала IC50 (концентрация антитела, которая на 50% ингибировала HBV-инфекцию); 2H5 также оказывало более сильное ингибирующе действие в анализе на HDV-инфекцию.
[032] Картирование эпитопа, связывающегося с антителом 2H5. Для картирования эпитопа для 2H5 на области pre-S1, авторами были синтезированы короткие пептиды, охватывающие различные области домена pre-S1, и эти пептиды были протестированы на их способность конкурировать за связывание 2H5 с m47b в ELISA-анализе на конкурентное связывание. Самым коротким пептидом, который может конкурировать за связывание, является пептид LN16 (соответствующий аминокислотам NT (а.к.) 11-28 домена pre-S1 белка L HBV (генотипа D)), что указывало на то, что эпитоп, связывающийся с 2H5, локализован в этой области. Пептиды LD15 и LA15 также обнаруживали некоторую степень активности конкурентного связывания, но на более низком уровне, чем LN16. Общими аминокислотами для этих трех пептидов LN16, LD15 и LA15 являются аминокислоты 19-25 pre-S1. Поэтому, авторами были протестированы пептиды LN16, каждый из которых имел одну аланиновую замену в положениях 19, 20, 22 и 23, LN16-L19A, -D20A, -P21A, -F23A, на их активность конкурентного связывания, и полученый результат показал, что все эти пептиды обладали пониженной активностью конкурентного связывания (LN16-L19A) или полностью теряли свою активность (LN16-D20A, -P21A, -F23A), что указывало на то, что эти аминокислоты играют очень важную роль в связывании pre-S1 с 2H5.
[033] Эпитоп для 2H5 является в высокой степени консервативным среди множества генотипов HBV. Выравнивание последовательностей пептидов pre-S1 от восьми генотипов HBV показало, что этот эпитоп для 2Н5 является самым консервативным. Главная вариабельная аминокислота находится в положении 24: глицин в генотипе A и C, и лизин или аргинин в генотипе D и в других генотипах. Для того, чтобы определить, влияет ли эта аминокислотная замена на связывание 2H5 с пептидом pre-S1, был синтезирован пептил NC36b, содержащий аргинин в положении 24, и этот пептид был протестирован на связывание с 2H5 с помощью ELISA. Результат показал, что эта аминокислотная замена оказывает лишь минимальное влияние на связывание. Этот результат соответствует результату анализа на нейтрализацию вирусов HBV и HDV и указывает на то, что 2H5 нейтрализует HBV генотипа D и HDV, несущий оболочечные белки HBV генотипа D.
[034] Структурная характеризация комплекса scFv 2H5 и пептида pre-S1. Авторами была также определена кристаллическая структура 2H5 (как scFv-фрагмента, присоединенного к His6-метке у N-конца) в комплексе с пептидом pre-S1, 59C. Аминокислотная последовательность 59C соответствует аминокислотам 10~48 pre-S1 генотипа C: GGWSSKPRQGMGTNLSVPNPLGFFPDHQLDPAFGANSNNPDWDFNPNKDHWPEANQV (SEQ ID NO: 147). 2H5-scFv и 59C ко-экспрессировали в E. coli. Комплекс очищали с помощью аффинной хроматографии на иммобилизованных ионах металла (IMAC) с использованием агарозных сфер Ni-NTA (QIAGEN), а затем с помощью эксклюзионной хроматографии-ВЭЖХ (ЭХ-ВЭЖХ) на колонке с Superdex S200 10/300 (GE Healthcare). Затем очищенный комплекс 2H5-scFv/59C концентрировали и кристаллизовали при 20°C методом диффузного выпаривания с висячей каплей путем смешивания 1 мкл белка (29 мг/мл в 10 мМ трис-HCl, pH 8,0, и 100 мМ NaCl) и 1 мкл раствора в резервуаре, содержащего 2,8 M ацетата натрия, pH 7,0. Через 10 дней появлялись игольчатые кристаллы. Данные рентгеновской дифракции собирали на синхротроннои устройстве для подачи излучения (Shanghai Synchrotron Radiation Facility beamline BL17U) и обрабатывали с помощью HKL2000 [9]. Структуру определяли при разрешении 2,7 Å путем молекулярной замены в фазирующем устройстве Phaser [10, 11] с использованием VH и VL, происходящих от структуры комплекса «герцептин-Fab» (PDB 3H0T) [12] в качестве исходной модели. Исходную модель, полученную путем молекулярной замены, дополнительно уточняли в устройстве Phenix [13] и вручную перемоделировали с использованием Coot [14]. Конечная модель включала 220 остатков scFv 2H5, остатки 20-27 пептида 59C. Анализ RAMPAGE показал, что 96,71% остатков находятся в предпочтительной области, а 3,29% остатков находятся в допустимой области [15]. Анализ структуры показал, что VH и VL scFv 2H5 участвуют во взаимодействии с пептидом. Восемь аминокислот пептида, включенных в эту структуру, представляют собой D20P21A22F23G24N25A26S27. Среди них, D20, P21, A22, F23, A26 и S27 взаимодействуют с 2H5. Три аминокислоты D20, P21 и F23 играют важную роль в связывании с 2H5.
[035] Повышение аффинности связывания 2H5 и нейтрализующей активности посредством перестановки цепи VH.
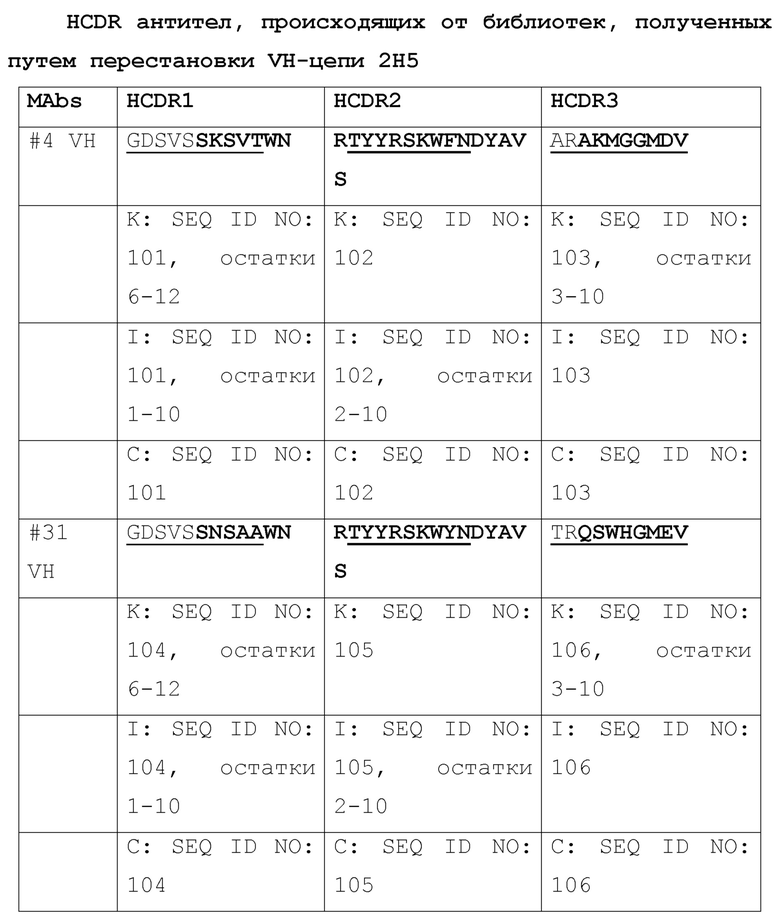
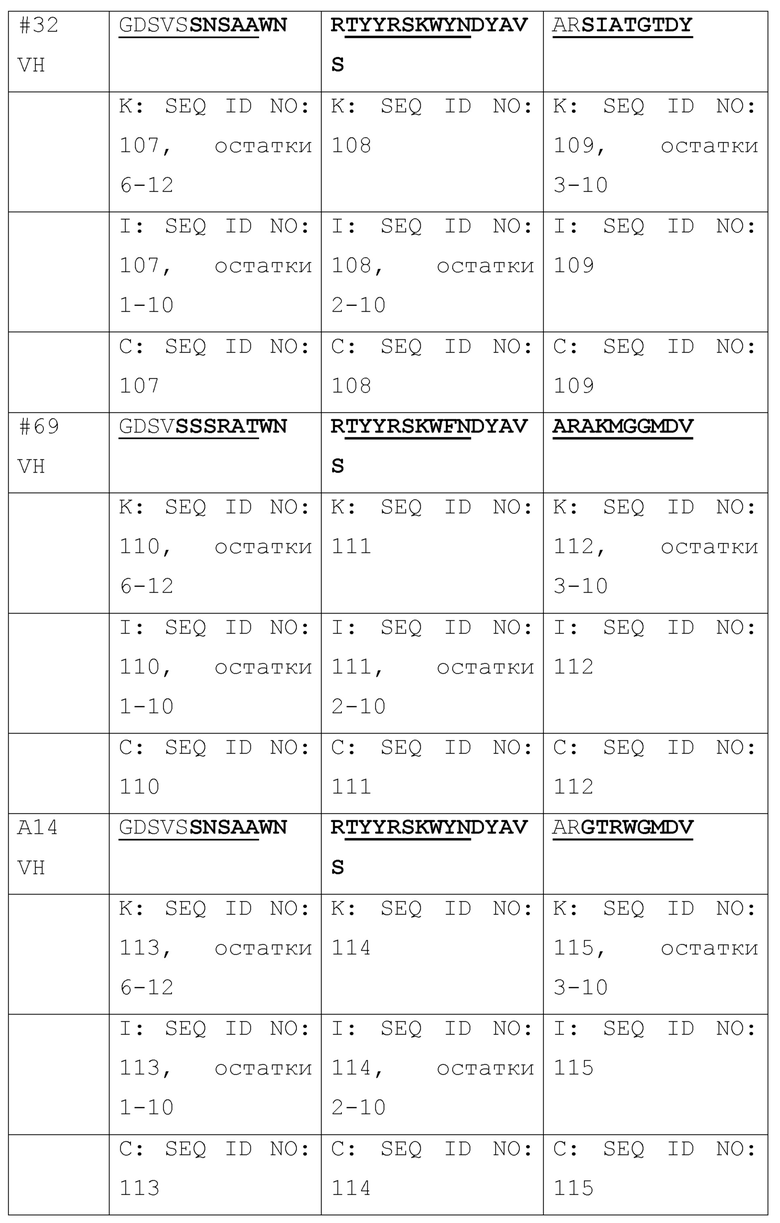
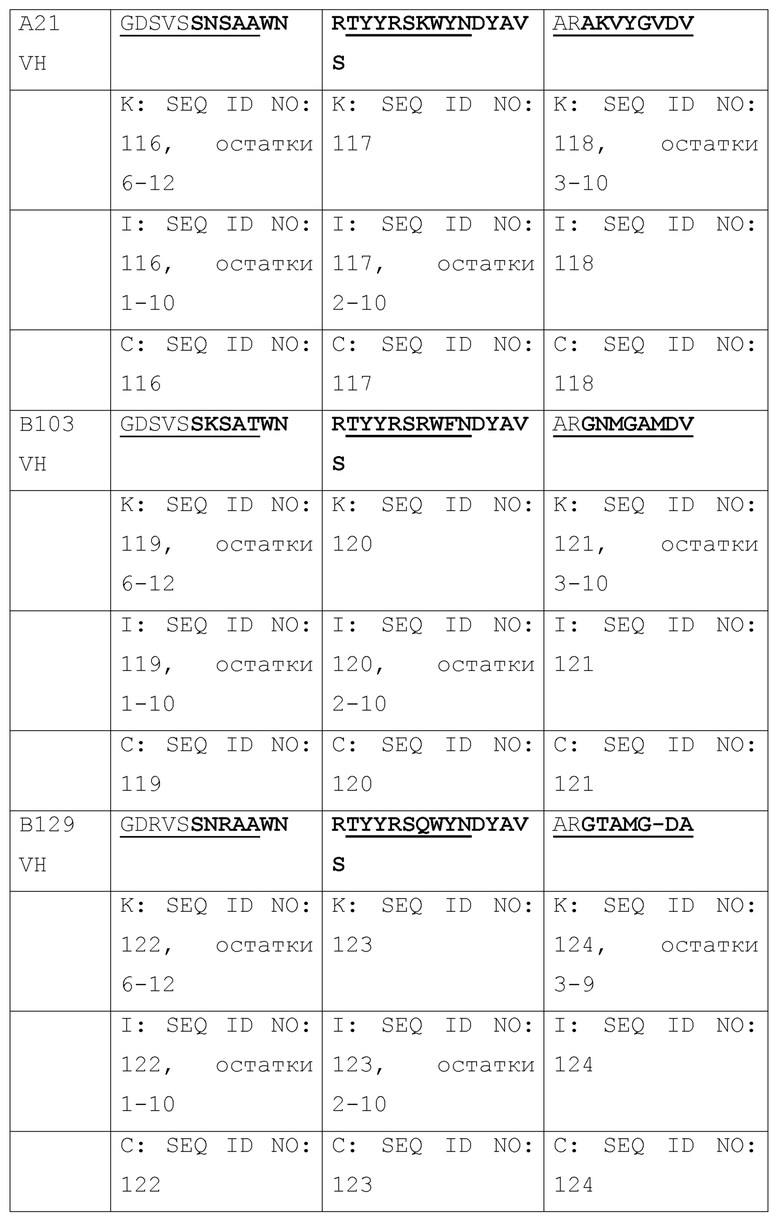
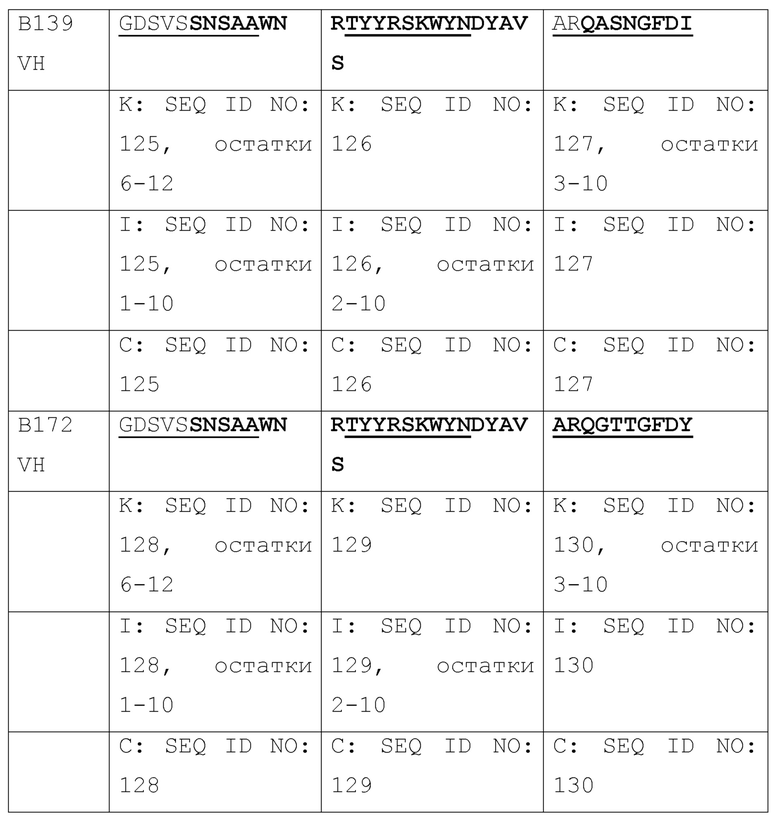
[036] Идентификация четырех наилучших антител, выделенных из библиотеки путем перестановки цепи VH 2H5. Авторами была проведена перестановка цепи для повышения аффинности связывания 2H5 и нейтрализующей активности, где одну из двух цепей (VH и VL) фиксировали и объединяли с набором другой цепи с получением второй библиотеки, которая может быть отобрана на наилучшую активность. Сначала, авторами была проведена перестановка цепи VH, где VL 2H5 фиксировали и спаривали с библиотекой цепей VH. Было сконструировано две библиотеки фагового представления VH-Lib/2H5VL. Размер одной библиотеки составлял ~2×108, а размер другой библиотеки составлял приблизительно 9×108. С использованием пептидов, захваченных на конъюгированных со стрептавидином магнитных сферах M-280 Dynadeads® (Life Technologies) в качестве мишени, две библиотеки VH-Lib/2H5VL отдельно отбирали для каждого раунда отбора. По окончании одного раунда отбора из обеих библиотек, всего 576 отдельных клонов произвольно собирали и скринировали на связывание с m47b с помощью ELISA. Позитивные ELISA-клоны отбирали и секвенировали. Было идентифицировано 10 клонов с уникальными последовательностями VH (Таблица 1), и было обнаружено, что их активность связывания с m47b в фаговом антителе была такой же, как активность связывания 2H5 или выше. Затем эти 10 клонов превращали в полноразмерный человеческий IgG1 и оценивали на связывание с m47b с помощью ELISA, и на нейтрализацию HBV (генотипа D) (Фиг. 1) и HDV в анализах на нейтрализацию in vitro. Четыре наилучших антитела #31, #32, A14 и A21 были отобраны по их общей активности связывания с m47b и нейтрализации HBV и HDV.
[037] Таблица 1. Выравнивание последовательностей VH от 10 антител, полученных путем отбора библиотек после перестановки цепи VH 2H5.

[038] На фиг. 1 проиллюстрирована нейтрализация HBV 10 антителами, происходящими из библиотеки, полученной путем перестановки VH-цепи 2Н5. Клетки HepG2-hNTCP инфицировали путем инкубирования HBV (генотипа D) в присутствии антител в различных концентрациях в течение 16 часов. Затем антитела и вирусы промывали и продолжали культивировать в течение 7 дней, после чего среду для культивирования клеток заменяли через каждые 2 дня. Секретированный HBeAg детектировали с помощью ELISA через 7 дней после инфицирования. Исходя из снижения уровня HBeAg вычислали HBV-нейтрализующую активность, которую выражали как процент изменения количества инфицированных клеток в присутствии антител по отношению к контролю (к клеткам, инфицированным в присутствии контрольного антитела).
[039] Картирование эпитопов для четырех наилучших антител, происходящих из библиотеки, полученной путем перестановки VH-цепи 2Н5. Как описано выше, авторами был использован метод ELISA на конкурентное связывание пептидов для картирования эпитопа, связывающегося с четырьмя наилучшими антителами, идентифицированными из библиотеки, полученной путем перестановки VH-цепи 2Н5. Пептид LN16 (соответствующий аминокислотам NT (а.к.) 11-28 домена пре-S1), и пептидные мутанты LN16, LN16-L19A, -D20A, -P21A, -F23A были использованы в анализе на конкурентное связывание этих антител с пептидом m47b. Полученные авторами данные показали, что все они имели паттерн конкурентного связывания с пептидом, как и 2Н5, а аминокислоты L19, D20, P21 и F23 имеют важное значение для связывания этих антител. D20 и F23 являются наиболее важными для всех антител, тогда как L19 и Р21 играют несколько различную роль для различных антител.
[040] Дополнительная характеризация четырех наилучших антител, происходящих из библиотеки, полученной путем перестановки VH-цепи 2Н5. Эти антитела обладают в 15-20 раз более высокой активностью нейтрализации HBV (генотипа D) по сравнению с родительским антителом 2Н5. IC50 для этих антител составляет приблизительно 10-40 пM. Из этих 4 антител, репрезентативное антитело A14 также сравнивали с иммуноглобулином вируса гепатита B с точки зрения нейтрализации HBV-инфекции (генотипа D). HBIG получали из плазмы доноров, которые имели высокие уровни антител против поверхностного антигена гепатита В (HBsAg) и были использованы в профилактических целях у людей с повышенным риском развития гепатита В, которые могли подвергаться контакту с этим вирусом в клинике. А14 обнаруживало в 1000 раз большую нейтрализующую активность, чем HBIG. Кроме того, в целом, А14 обнаруживало нейтрализующую активность против HBV двух других генотипов В и С. IC50 для генотипов B, C и D составляла 80 пМ, 30 пМ и 10 пМ, соответственно. A14 также оценивали на нейтрализацию шести вирусов HBV генотипа C, выделенных из плазмы HBV-инфицированных пациентов. И в этом случае, А14 обладало по меньшей мере от несколько сот до 1000 раз большей активностью нейтрализации этих вирусов, чем HBIG.
[041] А14 представляет собой один из Fab-фрагментов с самой высокой температурой плавления (Tm), равной 80,2°C, что указывает на наилучшую термостабильность его вариабельных доменов. А14, по сравнению с исходным 2Н5, стабилизируется приблизительно при 2°C, в то время как другие три nAb обладают несколько более низкой термостабильностью. Термостабильность была измерена с помощью дифференциальной сканирующей калориметрии (ДСК).
[042] С использованием первичных человеческих гепатоцитов (PHH), авторами также была продемонстрирована сильная нейтрализующая активность A14 против двух клинических штаммов HBV, выделенных из проб плазмы пациента с HBV. Один из вирусов принадлежит к генотипу B, а другой вирус принадлежит к генотипу C. HBsAg или HBeAg, секретируеые в супернатанты клеточных культур, анализировали через каждые два дня в течение всей процедуры инфицирования с использованием коммерчески доступных наборов (Autobio Diagnostics Co., Ltd.).
[043] А14 конкурировало с pre-S за связывание с NTCP, экспрессируемыми на клетках. А14 эффективно конкурировало с pre-S1 (ФИТЦ-меченным пептидом pre-S1: M59) за связывание с NTCP, экспрессируемыми на клетках HepG2 в зависимости от дозы.
[044] А14 не обладало способностью перекрестно реагировать с 12 различными клеточными линиями, представляющими 6 различных тканей. Это было подтвержднео с помощью вестерн-блот-анализа и анализа методом иммуноокрашивания.
[045] А14 обладает антитело-опосредуемой цитотоксической (ADCC) активностью, направленной против клеток, несущих на своей поверхности эпитоп, и HBV-продуцирующих клеток, а также инфицированных клеток. В анализе на ADCC, эпитоп для А14 стабильно экспрессировался на поверхности клеток СНО, HBV-продуцирующих клеток DE19, а в качестве клеток-мишеней были использованы инфицированные клетки HepG2-hNTCP. Человеческая клеточная линия NK (NK92-MI, экспрессирующая CD16 (аллель V158) и цепь FcR-гамма) была использована в качестве эффекторных клеток. Эффекторные клетки и клетки-мишени (Е/Т) совместно культивировали в отношении 6:1 в течение 6 часов в присутствии А14 или его Fc-мутанта. Гибель клеток была определена с помощью набора Promega для анализа на высвобождение LDH. Этот анализ на ADCC показал, что А14 обладало сильной специфической активностью, направленной на уничтожение эпитоп-экспрессирующих клеток СНО, HBV-продуцирующих клеток и HBV-инфицированных клеток HepG2-hNTCP, но не контрольных клетки, которые не экспрессировали эпитоп, клеток, которые не продуцировали HBV и не были HBV- инфицированными. Кроме того, Fc-мутант А14 (D265A/N297A) не обладал ADCC-активностью, но сохранял свою активность связывания.
[046] ADCC-активность является общей для антител, имеющих такой же эпитоп, как антитело А14, или аналогичный эпитоп, где указанные антитела включают 2Н5 и происходящие от него антитела, полученные путем перестановки VH-цепи: 4, 31, 32, 69, A14, A21, B103, B129, B139, B172, и антитела, полученные путем перестановки VL-цепи: #8, 20, 20-m1, 20-m2, 20-m3; причем антитела, имеющие различные эпитопы, такие как M36, 71, 76, T47, M150, m1Q, могут также обладать ADCC-активностью, например, такой ADCC-активностью также обладает m1Q, эпитоп которого расположен близко к С-концу эпитопа A14 на preS1.
[047] A14 защищает мышей от HDV-инфекции. Ранее авторами было показано, что мышиный NTCP, рестриктированный молекулярной детерминантой (mNTCP) и способствующий проникновению HBV и HDV, находится в остатках 84-87 mNTCP. Когда остатки 84-87 были заменены человеческими аналогами NTCP, то NTCP может эффективно поддерживать вирусные инфекции в клеточных культурах [16]. Исходя из этого, авторами была создана мышиная модель («фон» штамма FVB), который может поддерживать HDV-инфекцию после замены остатков mNTCP в положениях 84-87 соответствующими остатками hNTCP с применением метода «редактирования» генома, TALEN [17, 18]. С использованием этой мышиной модели авторы провели анализ для того, чтобы определить, может ли A14 защитить мышей от HDV-инфекции. FVB-мышам (в возрасте 9 дней), имеющим аминокислоты 84-87 в mNTCP-модифицированных гомозиготах, вводили mAb A14 в дозе 10 мг/кг массы тела. Через 1 час после введения mAb, мышей заражали вирусами HDV. На 6-й день после HDV-заражения, мышей умерщвляли, и ткани печени помещали в жидкий азот сразу после сбора. Затем образцы печени мышей гомогенизировали и лизировали реагентом Trizol® для экстракции общей РНК. Образцы РНК подвергали обратной транскрипции в кДНК с использованием набора для OT-ПЦР Prime Script (Takara). Для количественной оценки общей РНК HDV (геномного эквивалента) и «отредактированных» копий РНК NTCP, кДНК, полученную из 20 нг РНК, использовали в качестве матрицы для ПЦР-анализа в реальном времени. ПЦР в реальном времени проводили на системе ABI Fast 7500 в режиме реального времени (Applied Biosystems, USA). Отредактированные копии NTCP и геномного эквивалента вируса HDV оценивали по стандартной кривой, а клеточную РНК GAPDH использовали в качестве внутреннего контроля. mAb A14 полностью блокировало HDV-инфекцию, тогда как в контрольной группе, HDV-инфекция достигала 1-10×106 копий/20 нг РНК печени. Мыши в обеих группах имели сравнимое число копий мРНК NTCP в ткани печени.
[048] A14 защищает мышей от HDV-инфекции в профилактической мышиной модели и ингибирует HBV-инфекцию в лечебной мышиной модели. Мышиная модель HBV-инфекции была создана с использованием мышей, которые имели три нокаут-гена FRG (Fah-/-Rag2-/-/IL2rg-/-), и которым трансплантировали человеческие гепатоциты [19, 20]. FRG-мышам трансплантировали человеческие гепатоциты, реплицирующиеся в печени мышей с образованием химерной печени, содержащей до 98% гепатоцитов человека, и такие FRG-мыши с гуманизованной печенью (FRGC) являются в высокой степени восприимчивыми к HBV-инфекции. Для оценки профилактического эффекта A14, 10 FRGC-мышей были разделены на две группы, по пять мышей в каждой. Мышам профилактической A14-группы вводили А14 в дозе 15 мг/кг путем одного IP-введения за один день до инфицирования вирусом HBV, а мышам контрольной группы вводили PBS в том же объеме. На день 0, всем мышам в хвостовую вену вводили 109 GE (геномных эквивалентов) HBV. Для оценки терапевтического эффекта A14, FRGC-мышей заражали 109 GE HBV на мышь через хвостовую вену на день 0, а на 5-й день после инфицирования, мышей обрабатывали энтекавиром (ETV), используемым в качестве контроля, или А14 или HBIG. ETV перорально вводили в дозе 0,1 мг/кг в день; А14 или HBIG через каждые три дня вводили путем IP-инъекции в дозе 20 мг/кг и 72 мг/кг (40 МЕ/кг), соответственно. У всех мышей профилактических и лечебных моделей брали пробы крови через каждые 3 дня для определения титра ДНК HBsAg и HBV в сыворотке. По окончании эксперимента мышей умерщвляли, и через 35 дней после инфицирования (dpi35) брали ткани печени для иммуногистохимического окрашивания (IHC) на HBsAg и HBcAg. A14 на 100% защищало FRGC-мышей профилактической модели, а также значительно ингибировало HBV-инфекцию в лечебной модели.
[049] В целом, полученные результаты явно продемонстрировали, что mAb A14 является сильным ингибитором HBV- и HDV-инфекции у животного-модели. mAb A14 может быть использовано в целях замены HBIG для профилактики HDV- и HBV-инфекции. С другой стороны, обработка HBV-инфецированных мышей антителом А14 приводила к значительному ингибированию HBV-инфекции, и кроме того, А14 обладало специфической ADCC-активностью, направленной против HBV-инфицированных клеток, но не клеток, не инфицированных HBV. Эти результаты показали, что mAb A14 может быть объединено с ETV для лечения пациента с хронической HBV-инфекцией. Поскольку A14 блокирует проникновение новых вирусов в клетки-хозяева и обладает ADCC-активностью против инфицированных клеток, а ETV ингибирует репликацию вируса, то комбинация A14 с ингибитором репликации вируса, таким как ETV, ламивудин, адефовир, тенофовир, телбивудин или другие нуклеозидные и нуклеотидные аналоги (NUC), может рассматриваться как новое терапевтическое и профилактическое средство для лечения пациентов и позволит более эффективно бороться с виремией и снижать уровень HBsAg.
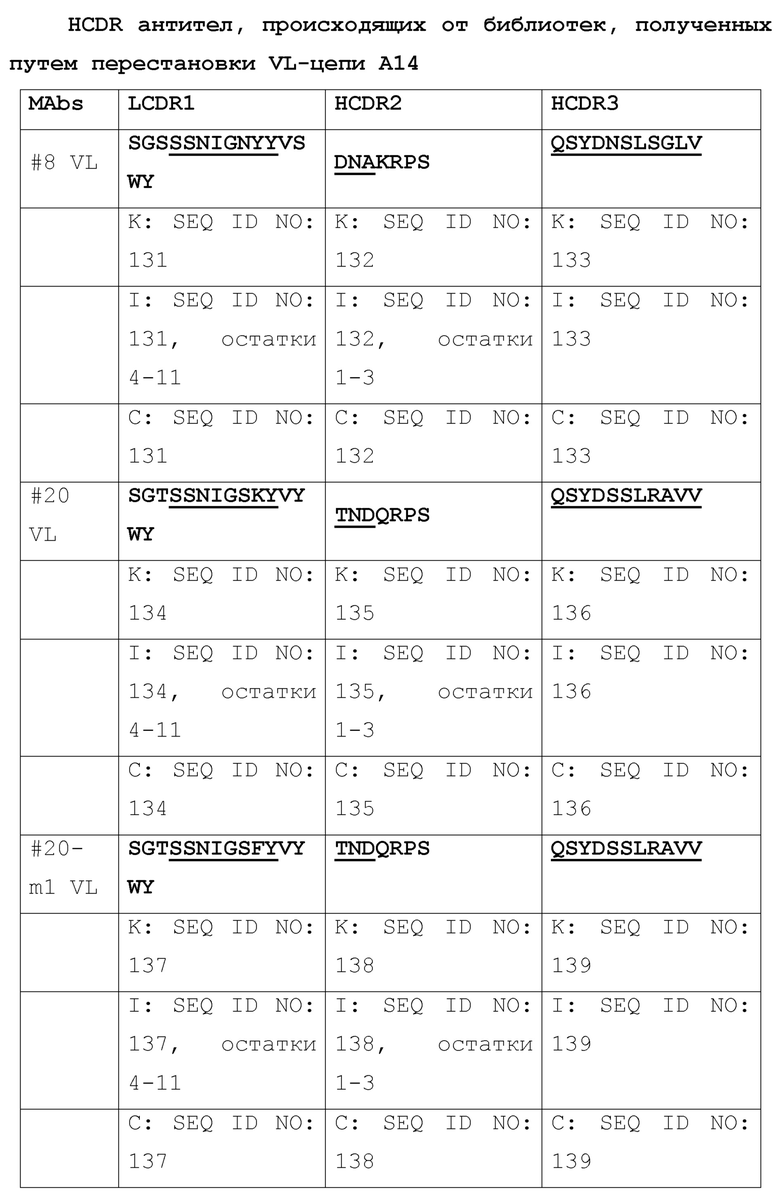
[050] Повышение аффинности связывания А14 и нейтрализующей активности посредством перестановки VL-цепи. Для дополнительного повышения активности А14, авторами была создана библиотека фагового представления путем перестановки VL-цепи А14, где VH А14 фиксировали и объединяли с библиотекой VL-цепей. Конечная сконструированная библиотека (A14VH/VLlib) имела размер ~3×108. С использованием пептида m47b, захваченного на конъюгированных со стрептавидином магнитных сферах M-280 Dynadeads® (Life Technologies) в качестве мишени, библиотека A14VH/VLLib была отобрана за два раунда. 196 клонов скринировали на связывание с m47b с помощью ELISA. Все клоны были позитивными, но 24 клона с наибольшими величинами OD450 были выбраны для секвенирования. Было идентифицировано два клона #8 и #20 с последовательностями VL-цепи, отличающимися от последовательности VL A14. Эти два антитела были превращены в полноразмерный человеческий IgG1 и протестированы на связывание с m47b с помощью ELISA. Эти антитела обладали более высокой активностью связывания с m47b, чем A14. В анализе на нейтрализацию вируса HBV (генотипа D), антитело #8 обладало в 5 раз большей эффективностью нейтрализации HBV-инфекции, а антитело #20 обладало такой же активностью, как и A14. Последующий мутагенез VL антитела #20 (#20-m1, -m2, -m3) приводил к повышению нейтрализующей активности в ~3-5 раз, по сравнению с A14, и достигал уровня, аналогичного уровню #8. Была продемонстрирована повышенная HDV-нейтрализующая активность этих мутантов #20 по сравнению с А14. Таким образом, эти антитела, происходящие от A14 и обладающие повышенной активностью, могут быть использованы также как A14, описанное выше, если указанные антитела были взяты отдельно или в комбинации с ингибитором репликации вируса.
[051] Библиография
1. Harrison, J.L., et al., Screening of phage antibody libraries. Methods Enzymol, 1996. 267: p. 83-109.
2. McCafferty, J., et al., Phage antibodies: filamentous phage displaying antibody variable domains. Nature, 1990. 348 (6301): p. 552-4.
3. Yan, H., et al., Sodium taurocholate cotransporting polypeptide is a functional receptor for human hepatitis B and D virus. Elife, 2012. 1: p. e00049.
4. Sureau, C., et al., Production of infectious hepatitis delta virus in vitro and neutralization with antibodies directed against hepatitis B virus pre-S antigens. J Virol, 1992. 66 (2): p. 1241-5.
5. Yan, H., et al., Viral entry of hepatitis B and D viruses and bile salts transportation share common molecular determinants on sodium taurocholate cotransporting polypeptide. J Virol, 2014. 88 (6): p. 3273-84.
6. Hong, H.J., et al., In vivo neutralization of hepatitis B virus infection by an anti-preS1 humanized antibody in chimpanzees. Virology, 2004. 318 (1): p. 134-41.
7. Ryu, C.J., et al., Mouse monoclonal antibodies to hepatitis B virus preS1 produced after immunization with recombinant preS1 peptide. Hybridoma, 2000. 19 (2): p. 185-9.
8. Chi, S.W., et al., Broadly neutralizing anti-hepatitis B virus antibody reveals a complementarity determining region H3 lid-opening mechanism. Proc Natl Acad Sci USA, 2007. 104 (22): p. 9230-5.
9. Otwinowski, Z. and W. Minor, Processing of X-ray diffraction data collected in oscillation mode. Methods Enzymol, 1997. 276: p. 307-326.
10. McCoy, A.J., et al., Phaser crystallographic software. J Appl Crystallogr, 2007. 40 (Pt 4): p. 658-674.
11. McCoy, A.J., Solving structures of protein complexes by molecular replacement with Phaser. Acta Crystallogr D Biol Crystallogr, 2007. 63 (Pt 1): p. 32-41.
12. Jordan, J.B., et al., Hepcidin revisited, disulfide connectivity, dynamics, and structure. J Biol Chem, 2009. 284 (36): p. 24155-67.
13. Adams, P.D., et al., PHENIX: a comprehensive Python-based system for macromolecular structure solution. Acta Crystallogr D Biol Crystallogr, 2010. 66 (Pt 2): p. 213-21.
14. Emsley, P. and K. Cowtan, Coot: model-building tools for molecular graphics. Acta Crystallogr D Biol Crystallogr, 2004. 60 (Pt 12 Pt 1): p. 2126-32.
15. Lovell, S.C., et al., Structure validation by Calpha geometry: phi, psi and Cbeta deviation. Proteins, 2003. 50 (3): p. 437-50.
16. Yan, H., et al., Molecular determinants of hepatitis B and D virus entry restriction in mouse sodium taurocholate cotransporting polypeptide. J Virol, 2013. 87 (14): p. 7977-91.
17. Moscou, M.J. and A.J. Bogdanove, A simple cipher governs DNA recognition by TAL effectors. Science, 2009. 326 (5959): p. 1501.
18. Boch, J., et al., Breaking the code of DNA binding specificity of TAL-type III effectors. Science, 2009. 326 (5959): p. 1509-12.
19. Strom, S.C., J. Davila, and M. Grompe, Chimeric mice with humanized liver: tools for the study of drug metabolism, excretion, and toxicity. Methods Mol Biol, 2010. 640: p. 491-509.
20. Bissig, K.D., et al., Human liver chimeric mice provide a model for hepatitis B and C virus infection and treatment. J Clin Invest, 2010. 120 (3): p. 924-30.
Последовательности 7 антител, происходящих из исходной библиотеки
m36
ДНК VH m36:

ДНК VL m36:

Аминокислоты VH m36:

Аминокислоты VL m36:

71:
ДНК VH 71:

ДНК VL 71:

Аминокислоты VH 71:

Аминокислоты VL 71:

76:
ДНК VH 76:

ДНК VL 76:

Аминокислоты VH 76:

Аминокислоты VL 76:
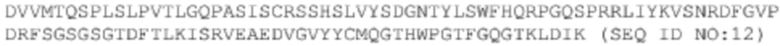
T47:
ДНК VH T47:

ДНК VL T47:

Аминокислоты VH T47:

Аминокислоты VL T47:
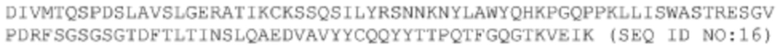
m1Q
ДНК VH m1Q

ДНК VL m1Q

Аминокислоты VH m1Q:

Аминокислоты Vk m1Q:

2H5:
ДНК VH 2H5:

ДНК VL 2H5:

Аминокислоты VH 2H5:
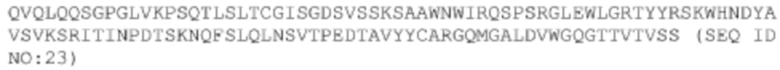
Аминокислоты VL 2H5:
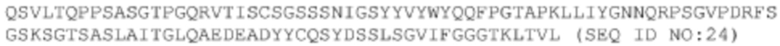
m150
ДНК VH m150:

ДНК VK m150:


Аминокислоты VH m150:

Аминокислоты VK m150:
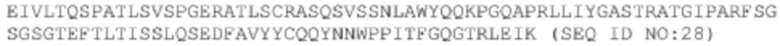
Последовательности 10 антител, происходящих от библиотеки, полученной путем перестановки VH-цепи 2H5. Следует отметить, что эти антитела имеют такую же последовательность VL, как и 2H5, а поэтому, ниже перечислены только последовательности VH этих антител.
#4
ДНК VH #4:

Аминокислоты VH #4:
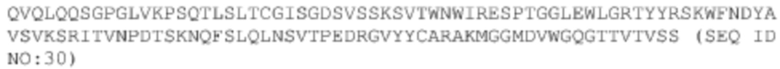
ДНК VH #31:

Аминокислоты VH #31:

ДНК VH #32:

Аминокислоты VH #32:

ДНК VH #69:

Аминокислоты VH #69:

ДНК VH A14:

Аминокислоты VH A14:

ДНК VH A21:

Аминокислоты VH A21:

ДНК VH B103:

Аминокислоты VH B103:

ДНК VH B129:

Аминокислоты VH B129:

ДНК VH B139:

Аминокислоты VH B139:

ДНК VH B172:

Аминокислоты VH B172:

Последовательности двух антител, происходящих от библиотеки, полученной путем перестановки VL-цепи A14. Следует отметить, что эти антитела имеют такую же последовательность VH, как и последовательность А14, а поэтому, ниже перечислены только последовательности VL этих двух антител.
ДНК VL #8:

Аминокислоты VL #8:

ДНК VL #20:

Аминокислоты VL #20:
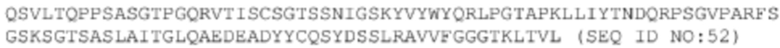
ДНК VL #20-m1:

Аминокислоты VL #20-m1:
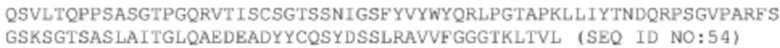
ДНК VL #20-m2:

Аминокислоты VL #20-m2:
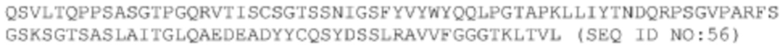
ДНК VL #20-m3:

Аминокислоты VL #20-m3:
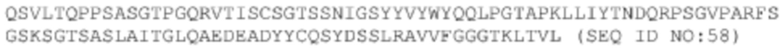
--->
СПИСОК ПОСЛЕДОВАТЕЛЬНОСТЕЙ
<110> Huahui Health Ltd.
Sui, Jianhua
Li, Dan
Li, Wenhui
<120> АНТИ-PRE-S1 HBV АНТИТЕЛА
<130> HUAH-001/01US 330471-2005
<150> PCT/CN2016/082985
<151> 2016-05-23
<150> PCT/CN2015/079534
<151> 2015-05-22
<160> 148
<170> PatentIn version 3.5
<210> 1
<211> 459
<212> ДНК
<213> Homo sapiens
<400> 1
caagttcctt tatgtgctgt ctcatcattt tggcaagaat tcgccaccat gaaacatctg 60
tggttcttcc ttctcctggt ggcagcggcc cagccggcca tggcccagat gcagctggtg 120
cagtctgggg gaggcttggt acagcctggc aggtccctga gactctcctg tgcagcctct 180
ggattcacct ttgatgatta tgccatgcac tgggtccggc aagctccagg gaagggcctg 240
gagtgggtct caggtattag ttggaatagt ggtagcatag gctatgcgga ctctgtgaag 300
ggccgattca ccatctccag agacaacgcc aagaactccc tgtatctgca aatgaacagt 360
ctgagagctg aggacacggc cttgtattac tgtgcaaaaa cgtcctacgg gggggctttt 420
gatatctggg gccaagggac aatggtcacc gtctcctca 459
<210> 2
<211> 330
<212> ДНК
<213> Homo sapiens
<400> 2
cagcctgtgc tgactcaatc gccctcagcg tctgggaccc ccgggcagag ggtcaccatc 60
tcttgttctg gaaacacttc caacatcgga agttattatg catactggta tcagcaactc 120
ccaggaacgg cccccaaact cctcatctat gataataatc agcggccctc ggggatccct 180
gcccgattct ctggctccaa gtctggcacc tcagcctccc tggccatcag tgggctccag 240
tctgaggatg aggcagatta ttactgtgca acatgggatg acagcctgaa tggtccggtg 300
ttcggcggag ggaccaaggt caccgtccta 330
<210> 3
<211> 118
<212> PRT
<213> Homo sapiens
<400> 3
Gln Met Gln Leu Val Gln Ser Gly Gly Gly Leu Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asp Asp Tyr
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Ser Trp Asn Ser Gly Ser Ile Gly Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Lys Thr Ser Tyr Gly Gly Ala Phe Asp Ile Trp Gly Gln Gly Thr
100 105 110
Met Val Thr Val Ser Ser
115
<210> 4
<211> 110
<212> PRT
<213> Homo sapiens
<400> 4
Gln Pro Val Leu Thr Gln Ser Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Asn Thr Ser Asn Ile Gly Ser Tyr
20 25 30
Tyr Ala Tyr Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Asp Asn Asn Gln Arg Pro Ser Gly Ile Pro Ala Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Ser Gly Leu Gln
65 70 75 80
Ser Glu Asp Glu Ala Asp Tyr Tyr Cys Ala Thr Trp Asp Asp Ser Leu
85 90 95
Asn Gly Pro Val Phe Gly Gly Gly Thr Lys Val Thr Val Leu
100 105 110
<210> 5
<211> 351
<212> ДНК
<213> Homo sapiens
<400> 5
caggtgcagc tggtggagtc tggggctgag gtgaagaagc ctggggcctc agtgaaggtc 60
tcctgcaagg cttctggata caccttcacc ggctactata tacattgggt gcgacaggcc 120
cctggacaag ggcttgagtg gatgggacgg atcaacccta acagtggtgg cacaaactat 180
gcacagaagt ttcagggcag ggtcaccatg accagggaca cgtccatcag gacggcctac 240
atggaactga gtacactgac atctgacgac acggccgttt attactgtgc gagagaagga 300
aggggcggca tggacgtctg gggccaaggg accacggtca ccgtctcctc a 351
<210> 6
<211> 336
<212> ДНК
<213> Homo sapiens
<400> 6
gatgttgtga tgactcagtc tccactctcc ctgcccgtca cccctggaga gccggcctcc 60
atctcctgca ggtctagtca gagcctcctg catagtaatg gatacaacta tttggattgg 120
tacctgcaga agccagggca gtctccacag ctcctgatct atttgggttc taatcgggcc 180
tccggggtcc ctgacaggtt cagtggcagt ggatcaggca cagattttac actgaaaatc 240
agcagagtgg aggctgagga tgttgggatt tattactgca tgcaaggtct acaacctccc 300
atcaccttcg gccaggggac acgactggag attaaa 336
<210> 7
<211> 117
<212> PRT
<213> Homo sapiens
<400> 7
Gln Val Gln Leu Val Glu Ser Gly Ala Glu Val Lys Lys Pro Gly Ala
1 5 10 15
Ser Val Lys Val Ser Cys Lys Ala Ser Gly Tyr Thr Phe Thr Gly Tyr
20 25 30
Tyr Ile His Trp Val Arg Gln Ala Pro Gly Gln Gly Leu Glu Trp Met
35 40 45
Gly Arg Ile Asn Pro Asn Ser Gly Gly Thr Asn Tyr Ala Gln Lys Phe
50 55 60
Gln Gly Arg Val Thr Met Thr Arg Asp Thr Ser Ile Arg Thr Ala Tyr
65 70 75 80
Met Glu Leu Ser Thr Leu Thr Ser Asp Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Glu Gly Arg Gly Gly Met Asp Val Trp Gly Gln Gly Thr Thr
100 105 110
Val Thr Val Ser Ser
115
<210> 8
<211> 112
<212> PRT
<213> Homo sapiens
<400> 8
Asp Val Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Pro Gly
1 5 10 15
Glu Pro Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Leu His Ser
20 25 30
Asn Gly Tyr Asn Tyr Leu Asp Trp Tyr Leu Gln Lys Pro Gly Gln Ser
35 40 45
Pro Gln Leu Leu Ile Tyr Leu Gly Ser Asn Arg Ala Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Ile Tyr Tyr Cys Met Gln Gly
85 90 95
Leu Gln Pro Pro Ile Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys
100 105 110
<210> 9
<211> 342
<212> ДНК
<213> Homo sapiens
<400> 9
gaggtgcagc tgttggagac cgggggaggc gtggtccagc ctgggaggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt agctatgcta tgcactgggt ccgccaggct 120
ccaggcaagg ggctggagtg ggtggcagtt atatcatatg atggaagcaa taaatactac 180
gcagactccg tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agctgaggac acggctgtgt attactgtgc gagtggtgct 300
tttgatatct ggggccaagg gacaatggtc accgtctctt ca 342
<210> 10
<211> 336
<212> ДНК
<213> Homo sapiens
<400> 10
gatgttgtga tgactcagtc tccactctcc ctgcccgtca cccttggaca gccggcctcc 60
atctcctgca ggtctagtca cagcctcgta tacagtgatg gaaacaccta cttgagttgg 120
tttcaccaga ggccaggcca atctccaagg cgcctaattt ataaggtttc taatcgggac 180
tttggggtcc cagacagatt cagcggcagt gggtcaggca ctgacttcac actgaagatc 240
agcagggtgg aggctgagga tgttggagtt tattactgca tgcaaggtac acactggcct 300
gggacgttcg gccaggggac caaactggat atcaaa 336
<210> 11
<211> 114
<212> PRT
<213> Homo sapiens
<400> 11
Glu Val Gln Leu Leu Glu Thr Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ser Gly Ala Phe Asp Ile Trp Gly Gln Gly Thr Met Val Thr Val
100 105 110
Ser Ser
<210> 12
<211> 112
<212> PRT
<213> Homo sapiens
<400> 12
Asp Val Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Leu Gly
1 5 10 15
Gln Pro Ala Ser Ile Ser Cys Arg Ser Ser His Ser Leu Val Tyr Ser
20 25 30
Asp Gly Asn Thr Tyr Leu Ser Trp Phe His Gln Arg Pro Gly Gln Ser
35 40 45
Pro Arg Arg Leu Ile Tyr Lys Val Ser Asn Arg Asp Phe Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Lys Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Val Tyr Tyr Cys Met Gln Gly
85 90 95
Thr His Trp Pro Gly Thr Phe Gly Gln Gly Thr Lys Leu Asp Ile Lys
100 105 110
<210> 13
<211> 369
<212> ДНК
<213> Homo sapiens
<400> 13
caggtacagc tgcagcagtc aggtccagga ctggtgaagc cctcgcagac cctctcactc 60
tcctgtgcca tctccgggga cagtgtctcc agcaacagtg ttgcttggaa ctggatcagg 120
cagtccccat cgagaggcct tgagtggctg ggaaggacat actacaggtc caagtggtat 180
aatgattatg cagtctctgt gaaaagtcga ataaccatca acccagacac atccaagaac 240
cagttctccc tgcagctgag ctctgtgact cccgaggaca cggctgtata ttactgtgca 300
agagccgatg gttcgcgagg gggagggtat gaccagtggg gccagggaac cctggtcacc 360
gtctcttca 369
<210> 14
<211> 339
<212> ДНК
<213> Homo sapiens
<400> 14
gacatcgtga tgacccagtc tccagactcc ctggctgtgt ctctgggcga gagggccacc 60
atcaaatgca agtccagtca gtctatttta tacaggtcca acaataagaa ctacttagct 120
tggtaccaac acaaaccagg acagcctcct aagctgctca tttcctgggc atctacccgg 180
gaatccgggg tccctgaccg attcagtggc agcgggtctg ggacagattt cactctcacc 240
atcaacagcc tgcaggctga agatgtggcg gtttattact gtcagcaata ttatactact 300
cctcagactt ttggccaggg gaccaaggtg gagatcaaa 339
<210> 15
<211> 123
<212> PRT
<213> Homo sapiens
<400> 15
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Ser Cys Ala Ile Ser Gly Asp Ser Val Ser Ser Asn
20 25 30
Ser Val Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala
50 55 60
Val Ser Val Lys Ser Arg Ile Thr Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Ser Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Ala Asp Gly Ser Arg Gly Gly Gly Tyr Asp Gln
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 16
<211> 113
<212> PRT
<213> Homo sapiens
<400> 16
Asp Ile Val Met Thr Gln Ser Pro Asp Ser Leu Ala Val Ser Leu Gly
1 5 10 15
Glu Arg Ala Thr Ile Lys Cys Lys Ser Ser Gln Ser Ile Leu Tyr Arg
20 25 30
Ser Asn Asn Lys Asn Tyr Leu Ala Trp Tyr Gln His Lys Pro Gly Gln
35 40 45
Pro Pro Lys Leu Leu Ile Ser Trp Ala Ser Thr Arg Glu Ser Gly Val
50 55 60
Pro Asp Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr
65 70 75 80
Ile Asn Ser Leu Gln Ala Glu Asp Val Ala Val Tyr Tyr Cys Gln Gln
85 90 95
Tyr Tyr Thr Thr Pro Gln Thr Phe Gly Gln Gly Thr Lys Val Glu Ile
100 105 110
Lys
<210> 17
<211> 348
<212> ДНК
<213> Homo sapiens
<400> 17
caggtccagt tggtggagtc tgggggaggc gtggtccagc ctgggaggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt agctatgcta tgcactgggt ccgccaggct 120
ccaggcaagg ggctggagca ggtggcagtt atatcatatg atggaagtaa taaatactac 180
gtagactccg tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agctgaggac acggctgtgt attactgtgc gagatctaca 300
tacggtatgg acgtctgggg ccaagggacc acggtcaccg tctcctca 348
<210> 18
<211> 333
<212> ДНК
<213> Homo sapiens
<400> 18
gatgttgtga tgactcagtc tccactctcc ctgcccgtca cccttggaca gtcggcctcc 60
atctcctgca ggtctagtca aagcctcgta cacagtgatg gaaacaccta cttgaattgg 120
tttcagcaga ggccaggcca atctccaagg cgcctaattt ataaggtttc taatcgggac 180
tccggggtcc cagacagatt cagcggcagt gggtcagaca ctgatttcac actggaaatc 240
agcagggtgg aggccgagga tgttgggatt tattactgca tgcaaggtac acactggtgg 300
acgttcggcc aagggaccaa gctggatatc aaa 333
<210> 19
<211> 116
<212> PRT
<213> Homo sapiens
<400> 19
Gln Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Gln Val
35 40 45
Ala Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Val Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Ser Thr Tyr Gly Met Asp Val Trp Gly Gln Gly Thr Thr Val
100 105 110
Thr Val Ser Ser
115
<210> 20
<211> 111
<212> PRT
<213> Homo sapiens
<400> 20
Asp Val Val Met Thr Gln Ser Pro Leu Ser Leu Pro Val Thr Leu Gly
1 5 10 15
Gln Ser Ala Ser Ile Ser Cys Arg Ser Ser Gln Ser Leu Val His Ser
20 25 30
Asp Gly Asn Thr Tyr Leu Asn Trp Phe Gln Gln Arg Pro Gly Gln Ser
35 40 45
Pro Arg Arg Leu Ile Tyr Lys Val Ser Asn Arg Asp Ser Gly Val Pro
50 55 60
Asp Arg Phe Ser Gly Ser Gly Ser Asp Thr Asp Phe Thr Leu Glu Ile
65 70 75 80
Ser Arg Val Glu Ala Glu Asp Val Gly Ile Tyr Tyr Cys Met Gln Gly
85 90 95
Thr His Trp Trp Thr Phe Gly Gln Gly Thr Lys Leu Asp Ile Lys
100 105 110
<210> 21
<211> 360
<212> ДНК
<213> Homo sapiens
<400> 21
caggtacagc tgcagcagtc aggtccagga ctggtgaagc cctcgcagac cctctcactc 60
acctgtggca tctccgggga cagtgtctct agcaagagtg ctgcttggaa ctggatcagg 120
cagtcccctt cgagaggcct tgagtggctg ggaaggacat actacaggtc caagtggcat 180
aatgattatg cagtatctgt gaaaagtcga ataaccatca acccagacac atccaagaac 240
cagttttccc tgcagctgaa ctctgtgacc cccgaagaca cggctgtgta ttattgtgcg 300
cgcggccaga tgggagcttt ggacgtctgg ggccaaggga ccacggtcac cgtctcctca 360
<210> 22
<211> 330
<212> ДНК
<213> Homo sapiens
<400> 22
cagtctgtgt tgacgcagcc gccctcagcg tctgggaccc ccgggcagag ggtcaccatc 60
tcttgttctg gaagcagctc caacatcgga agttattatg tatactggta ccagcaattc 120
ccaggaacgg cccccaaact cctcatctat ggtaataatc agcggccctc aggggtccct 180
gaccgattct ctggctccaa gtctggcacc tcagcctccc tggccatcac tgggctccag 240
gctgaggatg aggctgatta ttactgtcag tcctatgaca gcagcctgag tggtgtgata 300
ttcggcggag ggaccaagct gaccgtccta 330
<210> 23
<211> 120
<212> PRT
<213> Homo sapiens
<400> 23
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Gly Ile Ser Gly Asp Ser Val Ser Ser Lys
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp His Asn Asp Tyr Ala
50 55 60
Val Ser Val Lys Ser Arg Ile Thr Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Gly Gln Met Gly Ala Leu Asp Val Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 24
<211> 110
<212> PRT
<213> Homo sapiens
<400> 24
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Ser Tyr
20 25 30
Tyr Val Tyr Trp Tyr Gln Gln Phe Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Gly Asn Asn Gln Arg Pro Ser Gly Val Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu Gln
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser Leu
85 90 95
Ser Gly Val Ile Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 25
<211> 357
<212> ДНК
<213> Homo sapiens
<400> 25
gaggtgcagc tggtgcagtc tgggggaggc gtggtccagc ctgggaggtc cctgagactc 60
tcctgtgcag cctctggatt caccttcagt agctatgcta tgcactgggt ccgccaggct 120
ccaggcaagg ggctggagtg ggtggcagtt atatcatatg atggaagtaa taaatactat 180
gcagactccg tgaagggccg attcaccatc tccagagaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgag agccgaggac acggctgtgt attactgtgc gaggttggtg 300
gctggtcgaa gtgcttttga tatctggggc caagggacca cggtcaccgt ctcctca 357
<210> 26
<211> 324
<212> ДНК
<213> Homo sapiens
<400> 26
gaaattgtgc tgactcagtc tccagccacc ctgtctgtgt ctccagggga aagagccacc 60
ctctcctgca gggccagtca gagtgttagc agcaacttag cctggtacca gcagaaacct 120
ggccaggctc ccaggctcct catctatggt gcatccacca gggccactgg tatcccagcc 180
aggttcagtg gcagtgggtc tgggacagag ttcactctca ccatcagcag cctgcagtct 240
gaagattttg cagtttatta ctgtcagcag tataataact ggcctccgat caccttcggc 300
caagggacac gactggagat taaa 324
<210> 27
<211> 119
<212> PRT
<213> Homo sapiens
<400> 27
Glu Val Gln Leu Val Gln Ser Gly Gly Gly Val Val Gln Pro Gly Arg
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Tyr
20 25 30
Ala Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ala Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Arg Leu Val Ala Gly Arg Ser Ala Phe Asp Ile Trp Gly Gln Gly
100 105 110
Thr Thr Val Thr Val Ser Ser
115
<210> 28
<211> 108
<212> PRT
<213> Homo sapiens
<400> 28
Glu Ile Val Leu Thr Gln Ser Pro Ala Thr Leu Ser Val Ser Pro Gly
1 5 10 15
Glu Arg Ala Thr Leu Ser Cys Arg Ala Ser Gln Ser Val Ser Ser Asn
20 25 30
Leu Ala Trp Tyr Gln Gln Lys Pro Gly Gln Ala Pro Arg Leu Leu Ile
35 40 45
Tyr Gly Ala Ser Thr Arg Ala Thr Gly Ile Pro Ala Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Glu Phe Thr Leu Thr Ile Ser Ser Leu Gln Ser
65 70 75 80
Glu Asp Phe Ala Val Tyr Tyr Cys Gln Gln Tyr Asn Asn Trp Pro Pro
85 90 95
Ile Thr Phe Gly Gln Gly Thr Arg Leu Glu Ile Lys
100 105
<210> 29
<211> 360
<212> ДНК
<213> Homo sapiens
<400> 29
caggtacagc tgcagcagtc aggtccagga ctggtgaagc cctcgcagac cctctcactc 60
acctgtggca tctccgggga cagtgtctct agcaagagtg ttacttggaa ctggatcagg 120
gagtctccaa cgggaggcct tgagtggctg ggcaggacat actataggtc caagtggttt 180
aatgattatg cagtatctgt gaaaagtcga ataactgtca acccagacac atccaagaac 240
cagttttccc tgcagctaaa ctctgtgact cccgaggaca ggggtgtcta ttactgcgca 300
cgcgccaaga tgggaggtat ggacgtctgg ggccagggga ccacggtcac cgtctcttca 360
<210> 30
<211> 120
<212> PRT
<213> Homo sapiens
<400> 30
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Gly Ile Ser Gly Asp Ser Val Ser Ser Lys
20 25 30
Ser Val Thr Trp Asn Trp Ile Arg Glu Ser Pro Thr Gly Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp Phe Asn Asp Tyr Ala
50 55 60
Val Ser Val Lys Ser Arg Ile Thr Val Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Arg Gly Val
85 90 95
Tyr Tyr Cys Ala Arg Ala Lys Met Gly Gly Met Asp Val Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 31
<211> 360
<212> ДНК
<213> Homo sapiens
<400> 31
caggtacagc tgcagcagtc aggtccagga ctggtgaagc cctcgcagac cctctcactc 60
acctgtgcca tctccgggga cagtgtctct agcaacagtg ctgcttggaa ctggatcagg 120
cagtccccat cgagaggcct tgagtggctg ggaaggacat actacaggtc caagtggtat 180
aatgattatg cagtatctgt gaaaagtcga ataaccatca acccagacac atccaagaac 240
cagttctccc tgcagctgaa ctctgtgact cccgaggaca cggctgttta ttactgtaca 300
agacagagtt ggcacggtat ggaagtctgg ggccaaggga ccacggtcac cgtctcctca 360
<210> 32
<211> 120
<212> PRT
<213> Homo sapiens
<400> 32
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp Ser Val Ser Ser Asn
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala
50 55 60
Val Ser Val Lys Ser Arg Ile Thr Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Thr Arg Gln Ser Trp His Gly Met Glu Val Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 33
<211> 360
<212> ДНК
<213> Homo sapiens
<400> 33
caggtacagc tgcagcagtc aggtccagga ctggtgaagc cctcgcagac cctctcactc 60
acctgtgcca tctccgggga cagtgtctct agcaacagtg ctgcttggaa ctggatcagg 120
cagtccccat cgagaggcct tgagtggctg ggaaggacat actacaggtc caagtggtat 180
aatgattatg cagtatctgt gaaaagtcga ataaccatca actcagacac atcgaagaac 240
cagttctccc tgcagctgaa gtctgtgact cccgaggaca cggctgtgta ttactgtgca 300
aggagtatag caacaggtac tgactactgg ggccagggaa ccctggtcac cgtctcctca 360
<210> 34
<211> 120
<212> PRT
<213> Homo sapiens
<400> 34
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp Ser Val Ser Ser Asn
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala
50 55 60
Val Ser Val Lys Ser Arg Ile Thr Ile Asn Ser Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Lys Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Ser Ile Ala Thr Gly Thr Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 35
<211> 360
<212> ДНК
<213> Homo sapiens
<400> 35
caggtacagc tgcagcagtc aggtccagga ctgatgaagc cctcgcagac cctctcactc 60
acctgtgcca tctccgggga cagtgtctct agtagccgtg ctacttggaa ctggatcagg 120
gagtctccaa cgggaggcct tgagtggctg ggcaggacat actataggtc caagtggttt 180
aatgattatg cagtatctgt gaaaagtcga ataactgtca acccagacac atccaagaac 240
cagttttccc tgcagctaaa ctctgtgact cccgaggaca ggggtgtcta ttactgcgca 300
cgcgccaaga tgggaggtat ggacgtctgg ggccagggga ccacggtcac cgtctcctca 360
<210> 36
<211> 120
<212> PRT
<213> Homo sapiens
<400> 36
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Met Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp Ser Val Ser Ser Ser
20 25 30
Arg Ala Thr Trp Asn Trp Ile Arg Glu Ser Pro Thr Gly Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp Phe Asn Asp Tyr Ala
50 55 60
Val Ser Val Lys Ser Arg Ile Thr Val Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Arg Gly Val
85 90 95
Tyr Tyr Cys Ala Arg Ala Lys Met Gly Gly Met Asp Val Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 37
<211> 360
<212> ДНК
<213> Homo sapiens
<400> 37
caggtacagc tgcagcagtc aggtccagga ctggtgaagc cctcgcagac cctctcactc 60
acctgtgcca tctccgggga cagtgtctct agcaacagtg ctgcttggaa ctggatcagg 120
cagtccccat cgagaggcct tgagtggctg ggaaggacat actacaggtc caagtggtat 180
aatgattatg cagtatctgt gaaaagtcga ataaccatca acccagacac atccaagaac 240
cagttctccc tgcagctgaa ctctgtgact cccgaggaca cggctgtgta ttactgtgca 300
agaggaacac gttggggtat ggacgtctgg ggccaaggga ccctggtcac tgtctcctca 360
<210> 38
<211> 120
<212> PRT
<213> Homo sapiens
<400> 38
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp Ser Val Ser Ser Asn
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala
50 55 60
Val Ser Val Lys Ser Arg Ile Thr Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Gly Thr Arg Trp Gly Met Asp Val Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 39
<211> 360
<212> ДНК
<213> Homo sapiens
<400> 39
caggtacagc tgcagcagtc aggtccagga ctggtgaagc cctcgcagac cctctcactc 60
acctgtgcca tctccgggga cagtgtctct agcaacagtg ctgcttggaa ctggatcagg 120
cagtccccat cgagaggcct tgagtggctg ggaaggacat actacaggtc caagtggtat 180
aatgattatg cagtatctgt gaaaagtcga ataaccatca acccagacac atccaagaac 240
cagttctccc tgcagctgaa ctctgtgact cccgaggaca cggctgtgta ttactgtgca 300
agagcgaaag tgtacggtgt ggacgtctgg ggccaaggga ccacggtcac cgtctcctca 360
<210> 40
<211> 120
<212> PRT
<213> Homo sapiens
<400> 40
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp Ser Val Ser Ser Asn
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala
50 55 60
Val Ser Val Lys Ser Arg Ile Thr Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Ala Lys Val Tyr Gly Val Asp Val Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 41
<211> 360
<212> ДНК
<213> Homo sapiens
<400> 41
caggtacagc tgcagcagtc aggtccagga ctggtgaagc cctcgcagac cctctcactc 60
acctgtggca tctccgggga cagtgtctct agcaagagtg ccacttggaa ctgggtcagg 120
cagtccgcat cgagaggcct tgagtggctg ggaaggacat actacaggtc caggtggttt 180
aatgattatg cagtgtctgt gaaaagtcga ataaccgtca agccagacac atccaagaac 240
cagttttccc tgcaattaaa ttctgtgagt cccgaggaca cggctatcta ttactgtgca 300
cgcggcaaca tgggagctat ggacgtctgg ggccaaggga ccacggtcac cgtctcttca 360
<210> 42
<211> 120
<212> PRT
<213> Homo sapiens
<400> 42
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Gly Ile Ser Gly Asp Ser Val Ser Ser Lys
20 25 30
Ser Ala Thr Trp Asn Trp Val Arg Gln Ser Ala Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Arg Trp Phe Asn Asp Tyr Ala
50 55 60
Val Ser Val Lys Ser Arg Ile Thr Val Lys Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Ser Pro Glu Asp Thr Ala Ile
85 90 95
Tyr Tyr Cys Ala Arg Gly Asn Met Gly Ala Met Asp Val Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 43
<211> 357
<212> ДНК
<213> Homo sapiens
<400> 43
caggtacagc tgcagcagtc aggtccagga ctgctgaagc cctcgcagac cctctcactc 60
acctgtgcca tctccgggga cagggtctct agcaatagag ctgcttggaa ctgggtcagg 120
cagtccccat cgagaggcct tgagtggctg ggaaggacat actacaggtc ccagtggtat 180
aatgattatg cagtctctgt aaaaagtcga gtgaccatca gcccagacgc atccaagaac 240
caagtctccc tgcagctgaa ctctgtgact cccgaggaca cggctgtgta ttactgtgca 300
agaggtacag ctatgggtga cgcctggggc cagggaaccc tggtcaccgt ctcttca 357
<210> 44
<211> 119
<212> PRT
<213> Homo sapiens
<400> 44
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Leu Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp Arg Val Ser Ser Asn
20 25 30
Arg Ala Ala Trp Asn Trp Val Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Gln Trp Tyr Asn Asp Tyr Ala
50 55 60
Val Ser Val Lys Ser Arg Val Thr Ile Ser Pro Asp Ala Ser Lys Asn
65 70 75 80
Gln Val Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Gly Thr Ala Met Gly Asp Ala Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 45
<211> 360
<212> ДНК
<213> Homo sapiens
<400> 45
caggtacagc tgcagcagtc aggtccagga ctggtgaagc cctcgcagac cctcacactc 60
acctgtgtca tctccgggga cagtgtctct agcaacagtg ctgcttggaa ctggatcagg 120
cagtccccat cgagaggcct tgagtggctg ggaaggacat actacaggtc caagtggtat 180
aatgattatg cagtttctct gaaaagtcga ataaccatca acccagacac atccaagaac 240
cagttctccc tgcagctgaa ctctgtgact cccgaggaca cggctgtgta ttactgtgca 300
agacaagcct ccaacggttt tgatatctgg ggccaaggga caatggtcac cgtctcttca 360
<210> 46
<211> 120
<212> PRT
<213> Homo sapiens
<400> 46
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Thr Leu Thr Cys Val Ile Ser Gly Asp Ser Val Ser Ser Asn
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala
50 55 60
Val Ser Leu Lys Ser Arg Ile Thr Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Gln Ala Ser Asn Gly Phe Asp Ile Trp Gly Gln
100 105 110
Gly Thr Met Val Thr Val Ser Ser
115 120
<210> 47
<211> 360
<212> ДНК
<213> Homo sapiens
<400> 47
caggtacagc tgcagcagtc aggtccagga ctggtgaagc cctcgcagac cctctcactc 60
acctgtgcca tctccgggga cagtgtctct agcaacagtg ctgcttggaa ctggatcagg 120
cagtccccat cgagaggcct tgagtggctg ggaaggacat actacaggtc caagtggtat 180
aatgattatg cagtatctgt gaaaagtcga ataaccatca acccagacac atccaagaac 240
cagttctccc tgcagctgaa ctctgtgact cccgaggaca cggctgtgta ttactgtgca 300
agacagggga cgacaggctt tgactactgg ggccagggaa ccacggtcac cgtctcctca 360
<210> 48
<211> 120
<212> PRT
<213> Homo sapiens
<400> 48
Gln Val Gln Leu Gln Gln Ser Gly Pro Gly Leu Val Lys Pro Ser Gln
1 5 10 15
Thr Leu Ser Leu Thr Cys Ala Ile Ser Gly Asp Ser Val Ser Ser Asn
20 25 30
Ser Ala Ala Trp Asn Trp Ile Arg Gln Ser Pro Ser Arg Gly Leu Glu
35 40 45
Trp Leu Gly Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala
50 55 60
Val Ser Val Lys Ser Arg Ile Thr Ile Asn Pro Asp Thr Ser Lys Asn
65 70 75 80
Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu Asp Thr Ala Val
85 90 95
Tyr Tyr Cys Ala Arg Gln Gly Thr Thr Gly Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Thr Val Thr Val Ser Ser
115 120
<210> 49
<211> 330
<212> ДНК
<213> Homo sapiens
<400> 49
cagtctgtcg tgacgcagcc gccctcagtg tctgcggccc caggacagaa ggtcaccatc 60
tcctgctctg gaagcagctc caacattggg aattattatg tgtcctggta ccagcacctc 120
ccaggaacag cccccaaact cctcatttat gacaatgcta agcgaccctc agggattcct 180
gaccgattct ctggctccaa gtctggcacg tcagccaccc tgggcatcac tgggctccgg 240
gctgaggatg aggctgatta ttactgccag tcctatgaca atagccttag tggtttggtg 300
ttcggcggag ggaccaagct gaccgtccta 330
<210> 50
<211> 110
<212> PRT
<213> Homo sapiens
<400> 50
Gln Ser Val Val Thr Gln Pro Pro Ser Val Ser Ala Ala Pro Gly Gln
1 5 10 15
Lys Val Thr Ile Ser Cys Ser Gly Ser Ser Ser Asn Ile Gly Asn Tyr
20 25 30
Tyr Val Ser Trp Tyr Gln His Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Asp Asn Ala Lys Arg Pro Ser Gly Ile Pro Asp Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Thr Leu Gly Ile Thr Gly Leu Arg
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Asn Ser Leu
85 90 95
Ser Gly Leu Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 51
<211> 330
<212> ДНК
<213> Homo sapiens
<400> 51
cagtctgtgt tgacgcagcc accctcagcg tctgggaccc ccgggcagag ggtcaccatc 60
tcttgttctg gaaccagctc caacatcgga agtaagtatg tatactggta ccagcggctc 120
ccaggaacgg cccccaaact cctcatctat actaatgatc agcggccctc aggggtccct 180
gcccgattct ctggctccaa gtctggcacc tcagcctccc tggccatcac tgggctccag 240
gctgaggatg aggctgatta ttactgccag tcctatgaca gcagcctgcg tgctgtggtt 300
ttcggcggag ggaccaagct gaccgtccta 330
<210> 52
<211> 110
<212> PRT
<213> Homo sapiens
<400> 52
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Thr Ser Ser Asn Ile Gly Ser Lys
20 25 30
Tyr Val Tyr Trp Tyr Gln Arg Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Thr Asn Asp Gln Arg Pro Ser Gly Val Pro Ala Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu Gln
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser Leu
85 90 95
Arg Ala Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 53
<211> 330
<212> ДНК
<213> Homo sapiens
<400> 53
cagtctgtgt tgacgcagcc accctcagcg tctgggaccc ccgggcagag ggtcaccatc 60
tcttgttctg gaaccagctc caacatcgga agtttctatg tatactggta ccagcggctc 120
ccaggaacgg cccccaaact cctcatctat actaatgatc agcggccctc aggggtccct 180
gcccgattct ctggctccaa gtctggcacc tcagcctccc tggccatcac tgggctccag 240
gctgaggatg aggctgatta ttactgccag tcctatgaca gcagcctgcg tgctgtggtt 300
ttcggcggag ggaccaagct gaccgtccta 330
<210> 54
<211> 110
<212> PRT
<213> Homo sapiens
<400> 54
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Thr Ser Ser Asn Ile Gly Ser Phe
20 25 30
Tyr Val Tyr Trp Tyr Gln Arg Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Thr Asn Asp Gln Arg Pro Ser Gly Val Pro Ala Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu Gln
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser Leu
85 90 95
Arg Ala Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 55
<211> 330
<212> ДНК
<213> Homo sapiens
<400> 55
cagtctgtgt tgacgcagcc accctcagcg tctgggaccc ccgggcagag ggtcaccatc 60
tcttgttctg gaaccagctc caacatcgga agtttctatg tatactggta ccagcagctc 120
ccaggaacgg cccccaaact cctcatctat actaatgatc agcggccctc aggggtccct 180
gcccgattct ctggctccaa gtctggcacc tcagcctccc tggccatcac tgggctccag 240
gctgaggatg aggctgatta ttactgccag tcctatgaca gcagcctgcg tgctgtggtt 300
ttcggcggag ggaccaagct gaccgtccta 330
<210> 56
<211> 110
<212> PRT
<213> Homo sapiens
<400> 56
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Thr Ser Ser Asn Ile Gly Ser Phe
20 25 30
Tyr Val Tyr Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Thr Asn Asp Gln Arg Pro Ser Gly Val Pro Ala Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu Gln
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser Leu
85 90 95
Arg Ala Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 57
<211> 330
<212> ДНК
<213> Homo sapiens
<400> 57
cagtctgtgt tgacgcagcc accctcagcg tctgggaccc ccgggcagag ggtcaccatc 60
tcttgttctg gaaccagctc caacatcgga agttactatg tatactggta ccagcagctc 120
ccaggaacgg cccccaaact cctcatctat actaatgatc agcggccctc aggggtccct 180
gcccgattct ctggctccaa gtctggcacc tcagcctccc tggccatcac tgggctccag 240
gctgaggatg aggctgatta ttactgccag tcctatgaca gcagcctgcg tgctgtggtt 300
ttcggcggag ggaccaagct gaccgtccta 330
<210> 58
<211> 110
<212> PRT
<213> Homo sapiens
<400> 58
Gln Ser Val Leu Thr Gln Pro Pro Ser Ala Ser Gly Thr Pro Gly Gln
1 5 10 15
Arg Val Thr Ile Ser Cys Ser Gly Thr Ser Ser Asn Ile Gly Ser Tyr
20 25 30
Tyr Val Tyr Trp Tyr Gln Gln Leu Pro Gly Thr Ala Pro Lys Leu Leu
35 40 45
Ile Tyr Thr Asn Asp Gln Arg Pro Ser Gly Val Pro Ala Arg Phe Ser
50 55 60
Gly Ser Lys Ser Gly Thr Ser Ala Ser Leu Ala Ile Thr Gly Leu Gln
65 70 75 80
Ala Glu Asp Glu Ala Asp Tyr Tyr Cys Gln Ser Tyr Asp Ser Ser Leu
85 90 95
Arg Ala Val Val Phe Gly Gly Gly Thr Lys Leu Thr Val Leu
100 105 110
<210> 59
<211> 10
<212> PRT
<213> Homo sapiens
<400> 59
Gly Phe Thr Phe Asp Asp Tyr Ala Met His
1 5 10
<210> 60
<211> 17
<212> PRT
<213> Homo sapiens
<400> 60
Gly Ile Ser Trp Asn Ser Gly Ser Ile Gly Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 61
<211> 11
<212> PRT
<213> Homo sapiens
<400> 61
Ala Lys Thr Ser Tyr Gly Gly Ala Phe Asp Ile
1 5 10
<210> 62
<211> 13
<212> PRT
<213> Homo sapiens
<400> 62
Ser Gly Asn Thr Ser Asn Ile Gly Ser Tyr Tyr Ala Tyr
1 5 10
<210> 63
<211> 7
<212> PRT
<213> Homo sapiens
<400> 63
Asp Asn Asn Gln Arg Pro Ser
1 5
<210> 64
<211> 11
<212> PRT
<213> Homo sapiens
<400> 64
Ala Thr Trp Asp Asp Ser Leu Asn Gly Pro Val
1 5 10
<210> 65
<211> 9
<212> PRT
<213> Homo sapiens
<400> 65
Gly Tyr Thr Thr Gly Tyr Tyr Ile His
1 5
<210> 66
<211> 10
<212> PRT
<213> Homo sapiens
<400> 66
Arg Ile Asn Pro Asn Ser Gly Gly Thr Asn
1 5 10
<210> 67
<211> 10
<212> PRT
<213> Homo sapiens
<400> 67
Ala Arg Glu Gly Arg Gly Gly Met Asp Val
1 5 10
<210> 68
<211> 14
<212> PRT
<213> Homo sapiens
<400> 68
Arg Ser Ser Gln Ser Leu Leu His Ser Asn Gly Tyr Asn Tyr
1 5 10
<210> 69
<211> 7
<212> PRT
<213> Homo sapiens
<400> 69
Leu Gly Ser Asn Arg Ala Ser
1 5
<210> 70
<211> 9
<212> PRT
<213> Homo sapiens
<400> 70
Met Gln Gly Leu Gln Pro Pro Ile Thr
1 5
<210> 71
<211> 10
<212> PRT
<213> Homo sapiens
<400> 71
Gly Phe Thr Phe Ser Ser Tyr Ala Met His
1 5 10
<210> 72
<211> 17
<212> PRT
<213> Homo sapiens
<400> 72
Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 73
<211> 7
<212> PRT
<213> Homo sapiens
<400> 73
Ala Ser Gly Ala Phe Asp Ile
1 5
<210> 74
<211> 16
<212> PRT
<213> Homo sapiens
<400> 74
Arg Ser Ser His Ser Leu Val Tyr Ser Asp Gly Asn Thr Tyr Leu Ser
1 5 10 15
<210> 75
<211> 7
<212> PRT
<213> Homo sapiens
<400> 75
Lys Val Ser Asn Arg Asp Phe
1 5
<210> 76
<211> 9
<212> PRT
<213> Homo sapiens
<400> 76
Met Gln Gly Thr His Trp Pro Gly Thr
1 5
<210> 77
<211> 12
<212> PRT
<213> Homo sapiens
<400> 77
Gly Asp Ser Val Ser Ser Asn Ser Val Ala Trp Asn
1 5 10
<210> 78
<211> 18
<212> PRT
<213> Homo sapiens
<400> 78
Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala Val Ser Val
1 5 10 15
Lys Ser
<210> 79
<211> 13
<212> PRT
<213> Homo sapiens
<400> 79
Ala Arg Ala Asp Gly Ser Arg Gly Gly Gly Tyr Asp Gln
1 5 10
<210> 80
<211> 17
<212> PRT
<213> Homo sapiens
<400> 80
Lys Ser Ser Gln Ser Ile Leu Tyr Arg Ser Asn Asn Lys Asn Tyr Leu
1 5 10 15
Ala
<210> 81
<211> 7
<212> PRT
<213> Homo sapiens
<400> 81
Trp Ala Ser Thr Arg Glu Ser
1 5
<210> 82
<211> 9
<212> PRT
<213> Homo sapiens
<400> 82
Gln Gln Tyr Tyr Thr Thr Pro Gln Thr
1 5
<210> 83
<211> 10
<212> PRT
<213> Homo sapiens
<400> 83
Gly Phe Thr Phe Ser Ser Tyr Ala Met His
1 5 10
<210> 84
<211> 17
<212> PRT
<213> Homo sapiens
<400> 84
Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Val Asp Ser Val Lys
1 5 10 15
Gly
<210> 85
<211> 9
<212> PRT
<213> Homo sapiens
<400> 85
Ala Arg Ser Thr Tyr Gly Met Asp Val
1 5
<210> 86
<211> 16
<212> PRT
<213> Homo sapiens
<400> 86
Arg Ser Ser Gln Ser Leu Val His Ser Asp Gly Asn Thr Tyr Leu Asn
1 5 10 15
<210> 87
<211> 7
<212> PRT
<213> Homo sapiens
<400> 87
Lys Val Ser Asn Arg Asp Ser
1 5
<210> 88
<211> 8
<212> PRT
<213> Homo sapiens
<400> 88
Met Gln Gly Thr His Trp Trp Thr
1 5
<210> 89
<211> 12
<212> PRT
<213> Homo sapiens
<400> 89
Gly Asp Ser Val Ser Ser Lys Ser Ala Ala Trp Asn
1 5 10
<210> 90
<211> 15
<212> PRT
<213> Homo sapiens
<400> 90
Arg Thr Tyr Tyr Arg Ser Lys Trp His Asn Asp Tyr Ala Val Ser
1 5 10 15
<210> 91
<211> 10
<212> PRT
<213> Homo sapiens
<400> 91
Ala Arg Gly Gln Met Gly Ala Leu Asp Val
1 5 10
<210> 92
<211> 15
<212> PRT
<213> Homo sapiens
<400> 92
Ser Gly Ser Ser Ser Asn Ile Gly Ser Tyr Tyr Val Tyr Trp Tyr
1 5 10 15
<210> 93
<211> 7
<212> PRT
<213> Homo sapiens
<400> 93
Gly Asn Asn Gln Arg Pro Ser
1 5
<210> 94
<211> 11
<212> PRT
<213> Homo sapiens
<400> 94
Gln Ser Tyr Asp Ser Ser Leu Ser Gly Val Ile
1 5 10
<210> 95
<211> 10
<212> PRT
<213> Homo sapiens
<400> 95
Gly Phe Thr Phe Ser Ser Tyr Ala Met His
1 5 10
<210> 96
<211> 17
<212> PRT
<213> Homo sapiens
<400> 96
Val Ile Ser Tyr Asp Gly Ser Asn Lys Tyr Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 97
<211> 12
<212> PRT
<213> Homo sapiens
<400> 97
Ala Arg Leu Val Ala Gly Arg Ser Ala Phe Asp Ile
1 5 10
<210> 98
<211> 11
<212> PRT
<213> Homo sapiens
<400> 98
Arg Ala Ser Gln Ser Val Ser Ser Asn Leu Ala
1 5 10
<210> 99
<211> 7
<212> PRT
<213> Homo sapiens
<400> 99
Gly Ala Ser Thr Arg Ala Thr
1 5
<210> 100
<211> 10
<212> PRT
<213> Homo sapiens
<400> 100
Gln Gln Tyr Asn Asn Trp Pro Pro Ile Thr
1 5 10
<210> 101
<211> 12
<212> PRT
<213> Homo sapiens
<400> 101
Gly Asp Ser Val Ser Ser Lys Ser Val Thr Trp Asn
1 5 10
<210> 102
<211> 15
<212> PRT
<213> Homo sapiens
<400> 102
Arg Thr Tyr Tyr Arg Ser Lys Trp Phe Asn Asp Tyr Ala Val Ser
1 5 10 15
<210> 103
<211> 10
<212> PRT
<213> Homo sapiens
<400> 103
Ala Arg Ala Lys Met Gly Gly Met Asp Val
1 5 10
<210> 104
<211> 12
<212> PRT
<213> Homo sapiens
<400> 104
Gly Asp Ser Val Ser Ser Asn Ser Ala Ala Trp Asn
1 5 10
<210> 105
<211> 15
<212> PRT
<213> Homo sapiens
<400> 105
Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala Val Ser
1 5 10 15
<210> 106
<211> 10
<212> PRT
<213> Homo sapiens
<400> 106
Thr Arg Gln Ser Trp His Gly Met Glu Val
1 5 10
<210> 107
<211> 12
<212> PRT
<213> Homo sapiens
<400> 107
Gly Asp Ser Val Ser Ser Asn Ser Ala Ala Trp Asn
1 5 10
<210> 108
<211> 15
<212> PRT
<213> Homo sapiens
<400> 108
Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala Val Ser
1 5 10 15
<210> 109
<211> 10
<212> PRT
<213> Homo sapiens
<400> 109
Ala Arg Ser Ile Ala Thr Gly Thr Asp Tyr
1 5 10
<210> 110
<211> 12
<212> PRT
<213> Homo sapiens
<400> 110
Gly Asp Ser Val Ser Ser Ser Arg Ala Thr Trp Asn
1 5 10
<210> 111
<211> 15
<212> PRT
<213> Homo sapiens
<400> 111
Arg Thr Tyr Tyr Arg Ser Lys Trp Phe Asn Asp Tyr Ala Val Ser
1 5 10 15
<210> 112
<211> 10
<212> PRT
<213> Homo sapiens
<400> 112
Ala Arg Ala Lys Met Gly Gly Met Asp Val
1 5 10
<210> 113
<211> 12
<212> PRT
<213> Homo sapiens
<400> 113
Gly Asp Ser Val Ser Ser Asn Ser Ala Ala Trp Asn
1 5 10
<210> 114
<211> 15
<212> PRT
<213> Homo sapiens
<400> 114
Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala Val Ser
1 5 10 15
<210> 115
<211> 10
<212> PRT
<213> Homo sapiens
<400> 115
Ala Arg Gly Thr Arg Trp Gly Met Asp Val
1 5 10
<210> 116
<211> 12
<212> PRT
<213> Homo sapiens
<400> 116
Gly Asp Ser Val Ser Ser Asn Ser Ala Ala Trp Asn
1 5 10
<210> 117
<211> 15
<212> PRT
<213> Homo sapiens
<400> 117
Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala Val Ser
1 5 10 15
<210> 118
<211> 10
<212> PRT
<213> Homo sapiens
<400> 118
Ala Arg Ala Lys Val Tyr Gly Val Asp Val
1 5 10
<210> 119
<211> 12
<212> PRT
<213> Homo sapiens
<400> 119
Gly Asp Ser Val Ser Ser Lys Ser Ala Thr Trp Asn
1 5 10
<210> 120
<211> 15
<212> PRT
<213> Homo sapiens
<400> 120
Arg Thr Tyr Tyr Arg Ser Arg Trp Phe Asn Asp Tyr Ala Val Ser
1 5 10 15
<210> 121
<211> 10
<212> PRT
<213> Homo sapiens
<400> 121
Ala Arg Gly Asn Met Gly Ala Met Asp Val
1 5 10
<210> 122
<211> 12
<212> PRT
<213> Homo sapiens
<400> 122
Gly Asp Arg Val Ser Ser Asn Arg Ala Ala Trp Asn
1 5 10
<210> 123
<211> 15
<212> PRT
<213> Homo sapiens
<400> 123
Arg Thr Tyr Tyr Arg Ser Gln Trp Tyr Asn Asp Tyr Ala Val Ser
1 5 10 15
<210> 124
<211> 9
<212> PRT
<213> Homo sapiens
<400> 124
Ala Arg Gly Thr Ala Met Gly Asp Ala
1 5
<210> 125
<211> 12
<212> PRT
<213> Homo sapiens
<400> 125
Gly Asp Ser Val Ser Ser Asn Ser Ala Ala Trp Asn
1 5 10
<210> 126
<211> 15
<212> PRT
<213> Homo sapiens
<400> 126
Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala Val Ser
1 5 10 15
<210> 127
<211> 10
<212> PRT
<213> Homo sapiens
<400> 127
Ala Arg Gln Ala Ser Asn Gly Phe Asp Ile
1 5 10
<210> 128
<211> 12
<212> PRT
<213> Homo sapiens
<400> 128
Gly Asp Ser Val Ser Ser Asn Ser Ala Ala Trp Asn
1 5 10
<210> 129
<211> 15
<212> PRT
<213> Homo sapiens
<400> 129
Arg Thr Tyr Tyr Arg Ser Lys Trp Tyr Asn Asp Tyr Ala Val Ser
1 5 10 15
<210> 130
<211> 10
<212> PRT
<213> Homo sapiens
<400> 130
Ala Arg Gln Gly Thr Thr Gly Phe Asp Tyr
1 5 10
<210> 131
<211> 15
<212> PRT
<213> Homo sapiens
<400> 131
Ser Gly Ser Ser Ser Asn Ile Gly Asn Tyr Tyr Val Ser Trp Tyr
1 5 10 15
<210> 132
<211> 7
<212> PRT
<213> Homo sapiens
<400> 132
Asp Asn Ala Lys Arg Pro Ser
1 5
<210> 133
<211> 11
<212> PRT
<213> Homo sapiens
<400> 133
Gln Ser Tyr Asp Asn Ser Leu Ser Gly Leu Val
1 5 10
<210> 134
<211> 15
<212> PRT
<213> Homo sapiens
<400> 134
Ser Gly Thr Ser Ser Asn Ile Gly Ser Lys Tyr Val Tyr Trp Tyr
1 5 10 15
<210> 135
<211> 7
<212> PRT
<213> Homo sapiens
<400> 135
Thr Asn Asp Gln Arg Pro Ser
1 5
<210> 136
<211> 11
<212> PRT
<213> Homo sapiens
<400> 136
Gln Ser Tyr Asp Ser Ser Leu Arg Ala Val Val
1 5 10
<210> 137
<211> 15
<212> PRT
<213> Homo sapiens
<400> 137
Ser Gly Thr Ser Ser Asn Ile Gly Ser Phe Tyr Val Tyr Trp Tyr
1 5 10 15
<210> 138
<211> 7
<212> PRT
<213> Homo sapiens
<400> 138
Thr Asn Asp Gln Arg Pro Ser
1 5
<210> 139
<211> 11
<212> PRT
<213> Homo sapiens
<400> 139
Gln Ser Tyr Asp Ser Ser Leu Arg Ala Val Val
1 5 10
<210> 140
<211> 15
<212> PRT
<213> Homo sapiens
<400> 140
Ser Gly Thr Ser Ser Asn Ile Gly Ser Phe Tyr Val Tyr Trp Tyr
1 5 10 15
<210> 141
<211> 7
<212> PRT
<213> Homo sapiens
<400> 141
Thr Asn Asp Gln Arg Pro Ser
1 5
<210> 142
<211> 11
<212> PRT
<213> Homo sapiens
<400> 142
Gln Ser Tyr Asp Ser Ser Leu Arg Ala Val Val
1 5 10
<210> 143
<211> 15
<212> PRT
<213> Homo sapiens
<400> 143
Ser Gly Thr Ser Ser Asn Ile Gly Ser Tyr Tyr Val Tyr Trp Tyr
1 5 10 15
<210> 144
<211> 7
<212> PRT
<213> Homo sapiens
<400> 144
Thr Asn Asp Gln Arg Pro Ser
1 5
<210> 145
<211> 11
<212> PRT
<213> Homo sapiens
<400> 145
Gln Ser Tyr Asp Ser Ser Leu Arg Ala Val Val
1 5 10
<210> 146
<211> 47
<212> PRT
<213> Вирус гепатита B
<400> 146
Gly Thr Asn Leu Ser Val Pro Asn Pro Leu Gly Phe Phe Pro Asp His
1 5 10 15
Gln Leu Asp Pro Ala Phe Gly Ala Asn Ser Asn Asn Pro Asp Trp Asp
20 25 30
Phe Asn Pro Asn Lys Asp His Trp Pro Glu Ala Asn Gln Val Gly
35 40 45
<210> 147
<211> 57
<212> PRT
<213> Вирус гепатита B
<400> 147
Gly Gly Trp Ser Ser Lys Pro Arg Gln Gly Met Gly Thr Asn Leu Ser
1 5 10 15
Val Pro Asn Pro Leu Gly Phe Phe Pro Asp His Gln Leu Asp Pro Ala
20 25 30
Phe Gly Ala Asn Ser Asn Asn Pro Asp Trp Asp Phe Asn Pro Asn Lys
35 40 45
Asp His Trp Pro Glu Ala Asn Gln Val
50 55
<210> 148
<211> 60
<212> PRT
<213> Homo sapiens
<400> 148
Asn Asp Tyr Ala Val Ser Val Lys Ser Arg Ile Thr Ile Asn Pro Asp
1 5 10 15
Thr Ser Lys Asn Gln Phe Ser Leu Gln Leu Asn Ser Val Thr Pro Glu
20 25 30
Asp Thr Ala Val Tyr Tyr Cys Ala Arg Gly Lys Met Gly Gly Met Asp
35 40 45
Val Trp Gly Gln Gly Thr Thr Val Thr Val Ser Ser
50 55 60
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| НОВЫЕ МОЛЕКУЛЫ АГОНИСТИЧЕСКИХ АНТИ-TNFR2 АНТИТЕЛ | 2019 |
|
RU2840049C2 |
| АНТИТЕЛА, СВЯЗЫВАЮЩИЕ CD3 | 2017 |
|
RU2779489C2 |
| СПЕЦИФИЧЕСКИЕ АНТИТЕЛА К PD-L1 И СПОСОБЫ ИХ ПРИМЕНЕНИЯ | 2017 |
|
RU2749109C2 |
| АНТИТЕЛА, СВЯЗЫВАЮЩИЕ CTLA-4, И ИХ ПРИМЕНЕНИЕ | 2018 |
|
RU2756100C1 |
| КОМПОЗИЦИИ И СПОСОБЫ ПОЛУЧЕНИЯ КОМПОЗИЦИЙ T-КЛЕТОК И ИХ ПРИМЕНЕНИЕ | 2020 |
|
RU2835034C2 |
| СПОСОБЫ ПРОФИЛАКТИКИ И ЛЕЧЕНИЯ РАКОВОГО МЕТАСТАЗА И РАЗРЕЖЕНИЯ КОСТИ, СВЯЗАННОГО С РАКОВЫМ МЕТАСТАЗОМ | 2007 |
|
RU2470665C2 |
| АНТИТЕЛО ПРОТИВ VSIG4 ИЛИ ЕГО АНТИГЕНСВЯЗЫВАЮЩИЙ ФРАГМЕНТ И ИХ ПРИМЕНЕНИЕ | 2020 |
|
RU2826236C1 |
| CD3-СПЕЦИФИЧЕСКИЕ СВЯЗЫВАЮЩИЕ МОЛЕКУЛЫ | 2020 |
|
RU2826453C2 |
| Антитела к TSLP человека и их применение | 2021 |
|
RU2825460C1 |
| ПОЛИПЕПТИДНЫЙ ЛИНКЕР ДЛЯ ПОЛУЧЕНИЯ МУЛЬТИСПЕЦИФИЧЕСКИХ АНТИТЕЛ | 2018 |
|
RU2776302C2 |
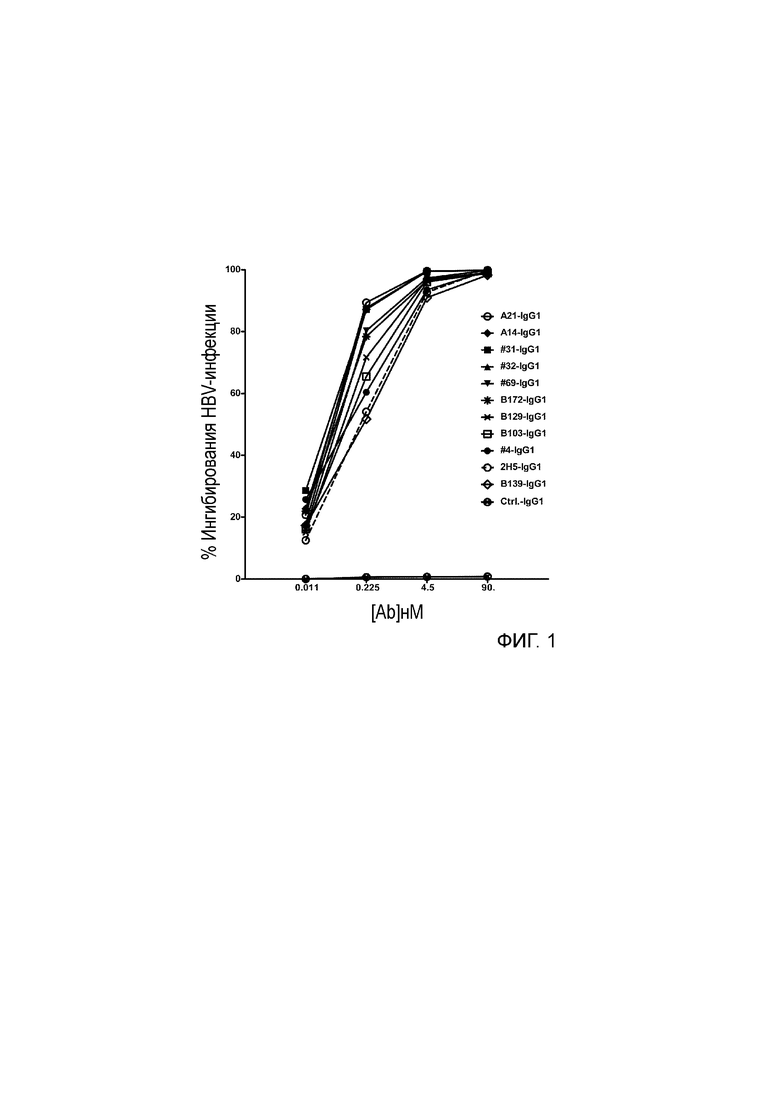
Настоящая группа изобретений относится к иммунологии. Предложено антитело и его антиген-связывающий фрагмент, которые специфично связываются с доменом Pre-S1 поверхностного антигена вируса гепатита B (HBV). Кроме того, описана нуклеиновая кислота, экспрессионный вектор и клетка для экспрессии антитела или его антиген-связывающего фрагмента. Данная группа изобретений может найти применение в профилактике, лечении или диагностике HBV-инфекции. 4 н. и 5 з.п. ф-лы, 1 ил., 1 табл.
1. Антитело или его антиген-связывающий фрагмент, которые специфично связываются с доменом Pre-S1 поверхностного антигена вируса гепатита B (HBV) и содержат:
a) CDR1 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 6-12 SEQ ID NO: 113, CDR2 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 114, и CDR3 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 3-10 SEQ ID NO: 115; и CDR1 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 92, CDR2 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 93, и CDR3 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 94;
b) CDR1 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 6-12 SEQ ID NO: 89, CDR2 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 90, и CDR3 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 3-10 SEQ ID NO: 91; и CDR1 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 92, CDR2 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 93, и CDR3 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 94;
c) CDR1 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 6-12 SEQ ID NO: 101, CDR2 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 102, и CDR3 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 3-10 SEQ ID NO: 103; и CDR1 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 92, CDR2 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 93, и CDR3 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 94;
d) CDR1 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 6-12 SEQ ID NO: 104, CDR2 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 105, и CDR3 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 3-10 SEQ ID NO: 106; и CDR1 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 92, CDR2 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 93, и CDR3 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 94;
e) CDR1 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 6-12 SEQ ID NO: 107, CDR2 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 108, и CDR3 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 3-10 SEQ ID NO: 109; и CDR1 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 92, CDR2 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 93, и CDR3 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 94;
f) CDR1 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 6-12 SEQ ID NO: 110, CDR2 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 111, и CDR3 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 3-10 SEQ ID NO: 112; и CDR1 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 92, CDR2 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 93, и CDR3 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 94;
g) CDR1 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 6-12 SEQ ID NO: 116, CDR2 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 117, и CDR3 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 3-10 SEQ ID NO: 118; и CDR1 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 92, CDR2 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 93, и CDR3 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 94;
h) CDR1 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 6-12 SEQ ID NO: 119, CDR2 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 120, и CDR3 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 3-10 SEQ ID NO: 121; и CDR1 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 92, CDR2 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 93, и CDR3 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 94;
i) CDR1 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 6-12 SEQ ID NO: 122, CDR2 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 123, и CDR3 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 3-9 SEQ ID NO: 124; и CDR1 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 92, CDR2 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 93, и CDR3 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 94;
j) CDR1 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 6-12 SEQ ID NO: 125, CDR2 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 126, и CDR3 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 3-10 SEQ ID NO: 127; и CDR1 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 92, CDR2 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 93, и CDR3 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 94;
k) CDR1 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 6-12 SEQ ID NO: 128, CDR2 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 129, и CDR3 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 3-10 SEQ ID NO: 130; и CDR1 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 92, CDR2 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 93, и CDR3 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 94;
l) CDR1 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 6-12 SEQ ID NO: 113, CDR2 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 114, и CDR3 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 3-10 SEQ ID NO: 115; и CDR1 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 131, CDR2 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 132, и CDR3 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 133;
m) CDR1 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 6-12 SEQ ID NO: 113, CDR2 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 114, и CDR3 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 3-10 SEQ ID NO: 115; и CDR1 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 134, CDR2 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 135, и CDR3 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 136;
n) CDR1 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 6-12 SEQ ID NO: 113, CDR2 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 114, и CDR3 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 3-10 SEQ ID NO: 115; и CDR1 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 137, CDR2 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 138, и CDR3 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 139;
o) CDR1 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 6-12 SEQ ID NO: 113, CDR2 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 114, и CDR3 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 3-10 SEQ ID NO: 115; и CDR1 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 140, CDR2 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 141, и CDR3 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 142; или
p) CDR1 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 6-12 SEQ ID NO: 113, CDR2 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 114, и CDR3 вариабельной области тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в остатках 3-10 SEQ ID NO: 115; и CDR1 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 143, CDR2 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 144, и CDR3 вариабельной области легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 145.
2. Антитело или его антиген-связывающий фрагмент по п.1, содержащие:
a) вариабельную область тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 38, и вариабельную область легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 24;
b) вариабельную область тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 23, и вариабельную область легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 24;
c) вариабельную область тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 30, и вариабельную область легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 24;
d) вариабельную область тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 32, и вариабельную область легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 24;
e) вариабельную область тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 34, и вариабельную область легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 24;
f) вариабельную область тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 36, и вариабельную область легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 24;
g) вариабельную область тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 40, и вариабельную область легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 24;
h) вариабельную область тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 42, и вариабельную область легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 24;
i) вариабельную область тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 44, и вариабельную область легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 24;
j) вариабельную область тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 46, и вариабельную область легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 24;
k) вариабельную область тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 48, и вариабельную область легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 24;
l) вариабельную область тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 38, и вариабельную область легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 50;
m) вариабельную область тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 38, и вариабельную область легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 52;
n) вариабельную область тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 38, и вариабельную область легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 54;
o) вариабельную область тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 38, и вариабельную область легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 56; или
p) вариабельную область тяжелой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 38, и вариабельную область легкой цепи, содержащую аминокислоты, имеющие последовательность, приведенную в SEQ ID NO: 58.
3. Антитело или его антиген-связывающий фрагмент по любому из пп.1, 2, где указанные антитело или его антиген-связывающий фрагмент проявляют активность, состоящую в антитело-зависимой клеточно-опосредуемой цитотоксичности (ADCC), в анализе ADCC.
4. Антитело или его антиген-связывающий фрагмент по любому из предыдущих пунктов, где указанное антитело представляет собой моноклональное антитело.
5. Антитело или его антиген-связывающий фрагмент по любому из предыдущих пунктов, где указанное антитело представляет собой человеческое моноклональное антитело.
6. Нуклеиновая кислота, кодирующая антитело или его антиген-связывающий фрагмент по любому из предыдущих пунктов.
7. Экспрессионный вектор, включающий нуклеиновую кислоту по п.6.
8. Клетка для экспрессии антитела или его антиген-связывающего фрагмента по любому из пп.1-5, содержащая нуклеиновую кислоту по п.6 или экспрессионный вектор по п.7.
9. Антитело или его антиген-связывающий фрагмент по любому из пп.1-5 для применения в способе лечения HBV- или HDV-инфекции, включающем введение указанных антитела или его антиген-связывающего фрагмента индивидууму, у которого, как было определено, имеется HBV- или HDV-инфекция, или который подвергался воздействию HBV или HDV, или имеет высокий риск воздействия или инфицирования HBV или HDV, или нуждается в антагонизме домена Pre-S1, или который нуждается в этом по иной причине.
| GRIPON P | |||
| et al | |||
| "Efficient inhibition of hepatitis B virus infection by acylated peptides derived from the large viral surface protein." Journal of virology, 2005, 79(3): 1613-1622 | |||
| MAENG, CHEOL-YOUNG, et al | |||
| Печь для непрерывного получения сернистого натрия | 1921 |
|
SU1A1 |
| WO 00/31141 A1, 02.06.2000 | |||
| WO | |||

