Изобретение относится к способам анализа текстов, написанных на естественном языке, а именно к способам извлечения информации и разметки текстовых данных. Изобретение позволяет находить искомую информацию в текстах и приписывать текстам метки заданных классов за минимальное количество времени.
Известен способ извлечения информации с помощью подготовленных словарей или онтологий, например, примененный в работе [1]. Недостатки этого способа заключаются в необходимости подготовки специализированных онтологий для конкретной предметной области, или перевода существующих онтологий на язык, на котором написаны тексты, если готовые онтологии отсутствуют. Этот этап требует значительных затрат ресурсов и времени (как правило, в масштабе не одной организации), и потому не всегда осуществим.
Известен также способ извлечения информации из неструктурированных текстов, написанных на естественном языке, заключающийся в том, что определяют все источники текстовых данных, в которых содержится искомая информация, составляют множество текстов из всех определенных источников текстовых данных, токенизируют множество текстов на слова, удаляют слова, встречающиеся в текстах реже заданного числа раз, все слова приводят к начальной форме и исправляют в них опечатки, по словам в начальной форме отбирают все слова в исходной форме, которые могут быть использованы в описании искомой информации, и тем самым формируют избранное множество слов, токенизируют множество текстов на последовательности слов длины N, во всех последовательностях слов длины N, содержащих все слова из избранного множества слов, устанавливают наличие или отсутствие искомой информации, для всех документов, содержащих последовательности слов длины N, для которых установлено наличие или отсутствие искомой информации и устанавливают наличие или отсутствие искомой информации [2].
Недостатки этого способа заключаются в невысокой эффективности, а именно: избыточном объеме обрабатываемых данных, отсутствии методов уменьшения этого объема без потери качества, больших затратах времени на реализацию способа, а также в недостаточном качестве извлечения информации из источников текстовых данных и разметки источников текстовых данных, например, текстовых документов связанном с потерей информации из предложений, состоящих менее, чем из N слов. Этот способ выбран в качестве прототипа предложенного решения. Технический результат применения изобретения, в целом, заключается в повышении эффективности и качества извлечения информации из источников текстовых данных и разметки источников текстовых данных, например, текстовых документов при сокращении времени на решение этих задач.
Сущностью изобретения является и указанный технический результат достигается тем, что в способе извлечения информации из неструктурированных текстов, написанных на естественном языке, заключающемся в том, что определяют все источники текстовых данных, в которых содержится искомая информация, составляют множество текстов из всех определенных источников текстовых данных, токенизируют множество текстов на слова, удаляют слова, встречающиеся в текстах реже заданного числа раз, все слова приводят к начальной форме и исправляют в них опечатки, по словам в начальной форме отбирают все слова в исходной форме, которые могут быть использованы в описании искомой информации, и тем самым формируют избранное множество слов, токенизируют множество текстов на последовательности слов длины N, во всех последовательностях слов длины N, содержащих все слова из избранного множества слов, устанавливают наличие или отсутствие искомой информации, для всех документов, содержащих последовательности слов длины N, для которых установлено наличие или отсутствие искомой информации и устанавливают наличие или отсутствие искомой информации, уменьшают число источников текстовых данных до минимального так, чтобы обеспечить заданное качество извлечения информации, перед отбором слов в избранное множество слов удаляют слова, встречающиеся в текстах реже заданного числа раз так, чтобы обеспечить заданное качество извлечения информации при минимальном объеме обрабатываемых данных, определяют набор частей речи и отбирают только им соответствующие слова так, чтобы обеспечить заданное качество извлечения информации при минимальном объеме обрабатываемых данных, для получения последовательностей слов длины N множество текстов сначала токенизируют на предложения, затем предложения токенизируют на последовательности слов длины N, отбирают последовательности слов длины N, в которых слова из избранного множества слов содержатся на центральных позициях, если с последовательности слов длины N предложение не начинается и этой последовательностью не заканчивается, на первых позициях, если с последовательности слов длины N предложение начинается, и на последних позициях, если последовательностью слов длины N предложение заканчивается, во всех предложениях, содержащих менее N слов и хотя бы одно слово из избранного множества слов, устанавливают наличие или отсутствие искомой информации, устанавливают наличие или отсутствие искомой информации в последовательности слов длины N и в предложении, содержащем менее N слов, с помощью значения из числового интервала от 0 включительно, если искомой информации нет, до 1, если искомая информация имеется, принимают решение о наличии или отсутствии искомой информации в исходном источнике текстов по совокупности в нем последовательностей слов длины N и предложений, содержащих менее N слов, для которых установлено наличие или отсутствие искомой информации, при этом число источников текстов, порог встречаемости слов, набор частей речи совместно подбирают так, чтобы обеспечить заданное качество извлечения информации при минимальном объеме обрабатываемых данных. При значении N, превышающем число слов в самом длинном предложении всего множества текстов, устанавливают наличие или отсутствие искомой информации во всех предложениях множества текстов, содержащих хотя бы одно слово из избранного множества слов, без использования последовательностей слов длины N. Существует вариант, в котором принимают решение о наличии или отсутствии искомой информации в исходном источнике текстов по совокупности в нем последовательностей слов длины N и предложений, содержащих менее N слов, для которых установлено наличие или отсутствие искомой информации, по факту наличия хотя бы одной последовательности слов длины N или предложения, содержащего менее N слов, которые оценили как 0 или 1.
Существует также вариант, в котором принимают решение о наличии или отсутствии искомой информации в исходном источнике текстов по совокупности в нем последовательностей слов длины N или предложений, содержащих менее N слов, для которых установлено наличие или отсутствие искомой информации, по сумме оценок и ее пороговому значению, полученному при оптимизации показателей качества изложенного способа извлечения информации на тестовой выборке.
Существует также вариант, в котором измеряют точность извлечения информации с помощью заданных метрик качества и программного обеспечения на выборке текстов из ранее определенных источников текстовых данных.
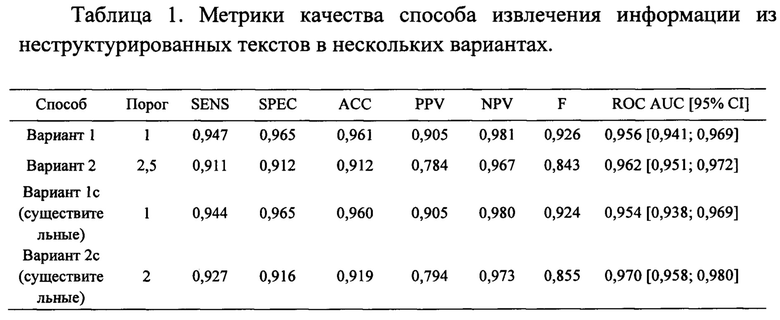
На прилагаемых графических материалах представлены результаты применения изобретения для идентификации мышечной слабости в конечностях до операции у 1167 пациентов нейрохирургической клиники. На фиг. 1 изображена ROC-кривая для способа извлечения информации в варианте 2. На фиг.2 представлена ROC-кривая для способа извлечения информации в варианте 2 с с использованием только существительных. На фиг. 3 показаны графики метрик качества способа извлечения информации в варианте 1 с с использованием только существительных в зависимости от порогового значения числа встречаемости слов в исходном множестве текстов. На фиг.4 показаны графики метрик качества способа извлечения информации в варианте 1 с с использованием только существительных в зависимости от порогового значения числа встречаемости слов в диапазоне 0-10.
Осуществление изобретения
Способ извлечения информации из неструктурированных текстов, написанных на естественном языке, включает следующие этапы. Сначала определяют все источники текстовых данных, в которых содержится искомая информация. Это может быть осуществлено следующим образом. Выбирают электронные и неэлектронные библиотеки, архивы, документы, интернет-ресурсы, информационные системы, телекоммуникационные системы, файлы и любые другие хранилища неструктурированной текстовой информации, а также их внутренние разделы и подразделы, поля баз данных и другие источники, содержащие искомую информацию на любых носителях текстовых данных (бумага, фотопленка, электронные запоминающие устройства, прочие носители). Далее составляют множество текстов из всех определенных источников текстовых данных, при этом, например, предварительно переводят текст в электронный текстовый формат с помощью набора текста на клавиатуре, сканирования источника и последующего распознавания программными средствами, диктования компьютеру и последующего распознавания речи и преобразования ее в текстовый формат программными средствами, а также прочими возможными способами. Множество текстов из всех источников формируют в таком виде, в котором для каждого текста указан источник и при необходимости другие идентифицирующие текст структурированные метаданные. Дальнейшую работу с текстами проводят в электронном виде. Токенизируют множество текстов на слова (например, так, как это описано в работе [3]), удаляют слова, встречающиеся в текстах реже заданного числа раз [4], все слова приводят к начальной форме и исправляют в них опечатки (например, по методам, описанным в работах [2, 5, 6]). При этом токенизацию производят с помощью написанных на языках программирования функций, в том числе, входящих в состав специальных библиотек (например, в языках программирования R, Python). Слова приводят к начальной (нормальной, словарной) форме с помощью программных средств лемматизации, заложенных в возможности языков программирования [3], функций специальных библиотек для языков программирования или специального программного обеспечения (например, MyStem, TreeTagger, UDPipe [7-9]), с помощью словарей и других инструментов для приведения слов к начальной форме [2]. Для исправления опечаток в словах используют методы, основанные на кластеризации по расстоянию Левенштейна в модификациях, фонетических и других правилах, специальные словари, функции, написанные на языках программирования, программное обеспечение (например, Hunspell checker) [2, 5, 10]. По словам в начальной форме отбирают все слова в исходной форме, которые могут быть использованы в описании искомой информации, и тем самым формируют избранное множество слов. Это может быть выполнено следующим образом. Из полного списка слов в начальной форме отбирают в отдельный список только те слова, которые в разных словарных формах с учетом возможных опечаток используются в описании искомой информации. Данный этап может быть реализован с помощью программного обеспечения, обеспечивающего просмотр и отбор слов в начальной форме (например, обозначенного в работе [2]). Далее токенизируют множество текстов на последовательности слов длины N, во всех последовательностях слов длины N, содержащих все слова из избранного множества слов, устанавливают наличие или отсутствие искомой информации, для всех документов, содержащих последовательности слов длины N, для которых установлено наличие или отсутствие искомой информации и устанавливают наличие или отсутствие искомой информации. Это может быть осуществлено следующим образом. Токенизацию множества текстов на последовательности слов длины N производят с помощью написанных на языках программирования функций, в том числе, входящих в состав специальных библиотек (например, в языках программирования R, Python). Отбор последовательности слов длины N, содержащих слова из избранного множества слов, проводят автоматически с помощью средств языков программирования или специального программного обеспечения при наличии такового [2]. Наличие или отсутствие искомой информации для всех документов, содержащих последовательности слов длины N, для которых установлено наличие или отсутствие искомой информации, устанавливается автоматически с помощью средств языков программирования или специального программного обеспечения при наличии такового [2]. Отличительным признаком предложенного решения является то, что уменьшают число источников текстовых данных до минимального так, чтобы обеспечить заданное качество извлечения информации. Это может быть осуществлено следующим образом. Способ извлечения информации из неструктурированных текстов, написанных на естественном языке, тестируют на наборе текстовых данных, для которых известно наличие или отсутствие искомой информации, варьируя число и состав источников информации. При тестировании с помощью средств языков программирования определяют метрики качества, например: точность, чувствительность, специфичность, положительное прогностическое значение, отрицательное прогностическое значение, площадь под ROC-кривой с доверительными интервалами, F1-меру. С помощью средств языков программирования (например, R, Python) отбирают минимальное число и состав источников, при использовании которых способ извлечения информации из неструктурированных текстов, написанных на естественном языке, обеспечивает заданные или более высокие значения метрик в тесте на наборе текстовых данных, для которых известно наличие или отсутствие искомой информации. Далее перед отбором слов в избранное множество слов удаляют слова, встречающиеся в текстах реже заданного числа раз так, чтобы обеспечить заданное качество извлечения информации при минимальном объеме обрабатываемых данных. Это может быть осуществлено следующим образом. С помощью средств языков программирования (например, R, Python) варьируют порог числа встречаемости слов в исходном множестве текстов, по которому удаляют слова, и отбирают максимальное пороговое значение так, что при удалении слов, встречающиеся в текстах реже порогового числа раз, способ извлечения информации из неструктурированных текстов, написанных на естественном языке, обеспечивает заданные или более высокие значения метрик качества в тесте на наборе текстовых данных, для которых известно наличие или отсутствие искомой информации. После этого определяют набор частей речи и отбирают только им соответствующие слова так, чтобы обеспечить заданное качество извлечения информации при минимальном объеме обрабатываемых данных. Это может быть осуществлено следующим образом. С помощью средств языков программирования (например, R, Python) перед отбором слов в начальной форме в избранное множество слов варьируют число и комбинацию частей речи и отбирают минимальное число и комбинацию частей речи так, что при удалении слов, соответствующих, прочим частям речи, способ извлечения информации из неструктурированных текстов, написанных на естественном языке, обеспечивает заданные или более высокие значения метрик качества в тесте на наборе текстовых данных, для которых известно наличие или отсутствие искомой информации. Для получения последовательностей слов длины N множество текстов сначала токенизируют на предложения, затем предложения токенизируют на последовательности слов длины N, отбирают последовательности слов длины N, в которых слова из избранного множества слов содержатся на центральных позициях, если с последовательности слов длины N предложение не начинается и этой последовательностью не заканчивается, на первых позициях, если с последовательности слов длины N предложение начинается, и на последних позициях, если последовательностью слов длины N предложение заканчивается. Это может быть осуществлено следующим образом. Токенизацию множества текстов на предложения, а также токенизацию предложений на последовательности слов длины N производят с помощью написанных на языках программирования функций, в том числе, входящих в состав специальных библиотек (например, в языках программирования R, Python). Определяют позицию каждого слова из избранного множества слов внутри последовательности слов длины N, отбирают последовательности слов длины N при наличии слова на определенной позиции с помощью написанных на языках программирования функций, в том числе, входящих в состав специальных библиотек (например, в языках программирования R, Python). Во всех предложениях, содержащих менее N слов и хотя бы одно слово из избранного множества слов, устанавливают наличие или отсутствие искомой информации. При значении N, превышающем число слов в самом длинном предложении всего множества текстов, устанавливают наличие или отсутствие искомой информации во всех предложениях множества текстов, содержащих хотя бы одно слово из избранного множества слов. Устанавливают наличие или отсутствие искомой информации в последовательности слов длины N и в предложении, содержащем менее N слов, с помощью значения из числового интервала от 0 включительно, если искомой информации нет, до 1. При этом устанавливают значение 1, если в последовательности слов длины N и в предложении содержится искомая информация; значение 0, если в последовательности слов длины N и в предложении искомая информация не содержится; значение 0,5, если в последовательности слов длины N и в предложении нельзя исключить содержание искомой информации; прочие значения в интервале от 0 до 1, если это оправдано в задаче извлечения конкретной искомой информации. Если искомая информация имеется, принимают решение о наличии или отсутствии искомой информации в исходном источнике текстов по совокупности в нем последовательностей слов длины N и предложений, содержащих менее N слов, для которых установлено наличие или отсутствие искомой информации. Это может быть осуществлено следующим образом. С помощью средств языков программирования (например, R, Python) определяют вхождение последовательности слов длины N и предложений, для которых установлено наличие или отсутствие искомой информации, в каждый исходный источник текстов и анализируют совокупность оценок последовательностей слов длины N и предложений в каждом источнике текстов. С помощью средств языков программирования (например, R, Python) на основании совокупности оценок последовательностей слов длины N и предложений в каждом источнике текстов определяют наличие или отсутствие искомой информации. При этом число источников текстов, порог встречаемости слов, набор частей речи подбирают в совокупности так, чтобы обеспечить заданное качество извлечения информации при минимальном объеме обрабатываемых данных. Это может быть осуществлено следующим образом. С помощью средств языка программирования (например, R, Python) минимизируются число источников текстов и набор частей речи, при этом максимизируется порог встречаемости слов, при котором слова могут быть отобраны в избранное множество слов - так, что способ извлечения информации из неструктурированных текстов, написанных на естественном языке, обеспечивает заданные или более высокие значения метрик качества в тесте на наборе текстовых данных, для которых известно наличие или отсутствие искомой информации.
Существует вариант, в котором принимают решение о наличии или отсутствии искомой информации в исходном источнике текстов по совокупности в нем последовательностей слов длины N и предложений, содержащих менее N слов, для которых установлено наличие или отсутствие искомой информации, по факту наличия хотя бы одной последовательности слов длины N или предложения, содержащего менее N слов, которые оценили как 0 или 1. Это может быть осуществлено следующим образом. При наличии хотя бы одной последовательности длины N или предложения, оцененных как 1 в исходном источнике документов, устанавливается наличие искомой информации в данном исходном источнике текстовых данных. В противном случае устанавливается отсутствие информации в данном исходном источнике текстов.
Существует также вариант, в котором принимают решение о наличии или отсутствии искомой информации в исходном источнике текстов по совокупности в нем последовательностей слов длины N или предложений, содержащих менее N слов, для которых установлено наличие или отсутствие искомой информации, по сумме оценок и ее пороговому значению, полученному при оптимизации показателей качества изложенного способа извлечения информации на тестовой выборке. Это может быть осуществлено следующим образом. С помощью средств языков программирования (например, R, Python) определяют вхождение последовательности слов длины N и предложений, для которых установлено наличие или отсутствие искомой информации, в каждый исходный источник текстов и суммируют оценки последовательностей слов длины N и предложений в каждом источнике текстов. С помощью средств языков программирования (например, R, Python) определяют значение суммы оценок последовательностей слов длины N и предложений в каждом источнике текстов, пороговое для принятия решений о наличии или отсутствии искомой информации в каждом источнике текстов, так, чтобы на тестовом наборе текстовых данных максимизировалась сумма чувствительности и специфичности способа извлечения информации из неструктурированных текстов, написанных на естественном языке, или оптимизировалась другая метрика интереса.
Существует также вариант, в котором дополнительно измеряют точность извлечения информации с помощью заданных метрик качества и программного обеспечения на выборке текстов из ранее определенных источников текстовых данных, которая не использовалась для минимизации числа источников текстов и набора частей речи, а также максимизации порога встречаемости слов, по которому слова могут быть отобраны в избранное множество слов. Это может быть осуществлено следующим образом. Используют набор источников текстовых данных, для которых установлено наличие или отсутствие искомой информации и который не используется для минимизации числа источников текстов и набора частей речи, а также максимизации порога встречаемости слов, по которому слова могут быть отобраны в избранное множество слов. С помощью средств языков программирования (например, R, Python), используя данный набор источников текстовых данных, определяют заданные метрики качества: точность, чувствительность, специфичность, положительное прогностическое значение, отрицательное прогностическое значение, площадь под ROC-кривой с доверительными интервалами, F1-меру и другие метрики качества при необходимости.
Технические результаты Технический результат применения изобретения заключается в повышении эффективности и качества извлечения информации из источников текстовых данных и разметки источников текстовых данных (например, текстовых документов) при сокращении времени на решение этих задач.
Уменьшение числа источников текстов, удаление слов, встречающиеся в текстах реже заданного числа раз, минимизация набора частей речи позволяют сократить объем обрабатываемых данных при извлечении информации и разметке источников текстовых данных, что обеспечивает сокращение времени на извлечение информации и разметку источников текстовых данных без потери качества - то есть приводит к техническому результату - повышению эффективности извлечения информации и разметки источников текстовых данных.
Предварительная токенизация множества текстов на предложения перед токенизацией предложений на последовательности слов длины N позволяет сократить объем последовательностей слов длины N и предотвратить создание последовательностей слов длины N, ранее не встречавшихся внутри предложений, что обеспечивает сокращение времени на извлечение информации и разметки текстовых данных и уменьшает число возможных ошибок извлечения информации и разметки текстовых данных - то есть приводит к техническим результатам - повышению эффективности и качества извлечения информации и разметки источников текстовых данных.
Отбор последовательностей слов длины N, в которых слова из избранного множества слов содержатся на центральных позициях, если с последовательности слов длины N предложение не начинается и этой последовательностью не заканчивается, на первых позициях, если с последовательности слов длины N предложение начинается, и на последних позициях, если последовательностью слов длины N предложение заканчивается, позволяет сократить объем последовательностей слов длины N, что обеспечивает сокращение времени на извлечение информации и разметки текстовых данных - то есть приводит к техническому результату -повышению эффективности извлечения информации и разметки источников текстовых данных.
Установление наличия или отсутствия искомой информации во всех предложениях, содержащих менее N слов и хотя бы одно слово из избранного множества слов, позволяет не потерять часть информации, то есть приводит к техническому результату - повышению качества извлечения информации и разметки источников текстовых данных.
Установление наличия или отсутствия искомой информации в последовательностях слов длины N и в предложениях, содержащих менее N слов, с помощью значения из числового интервала от 0 до 1 обеспечивает увеличение надежности и гибкости извлечения информации и разметки текстовых данных, то есть приводит к техническому результату - повышению качества извлечения информации и разметки источников текстовых данных.
Принятие решения о наличии или отсутствии искомой информации в исходном источнике текстов по совокупности в нем последовательностей слов длины N и предложений, содержащих менее N слов, для которых установлено наличие или отсутствие искомой информации, обеспечивает увеличение надежности и гибкости извлечения информации и разметки текстовых данных, то есть приводит к техническому результату - повышению качества извлечения информации и разметки источников текстовых данных.
Совместный подбор источников текстов, порога встречаемости слов, набора частей речи обеспечивает заданное качество извлечения информации и разметки источников текстовых данных при минимальном объеме обрабатываемых данных, то есть приводит к техническому результату -повышению эффективности и качества извлечения информации и разметки источников текстовых данных.
Контроль заданных метрик качества: точности, чувствительности, специфичности, положительного прогностического значения, отрицательного прогностического значения, площади под ROC-кривой с доверительными интервалами, F1-меры и при необходимости других метрик качества на наборе источников текстовых данных, для которых установлено наличие или отсутствие искомой информации и который не используется для минимизации числа источников текстов и набора частей речи, а также максимизации порога встречаемости слов, по которому слова могут быть отобраны в избранное множество слов, приводит к техническому результату - повышению качества извлечения информации и разметки источников текстовых данных.
Пример использования изобретения Изложенный способ извлечения информации из неструктурированных текстов, написанных на естественном языке, был применен для извлечения информации о наличии или отсутствии мышечной слабости у 1167 пациентов с опухолью головного мозга при поступлении в нейрохирургическую клинику. Для реализации способа были определены все источники текстовых данных в электронной истории болезни, в которых содержалась искомая информация о наличии или отсутствии мышечной слабости у данных пациентов при поступлении в нейрохирургическую клинику: документ, отражающий данные первичного осмотра пациента, и раздел выписного эпикриза, повторяющий в свободной форме данные первичного осмотра. Для 1167 пациентов из указанных источников текстовых данных составлено множество текстов. Это множество текстов далее было токенизировано на 9932 уникальных слова, и для каждого слова было подсчитано число употреблений во всем множестве текстов. Далее все слова были приведены к начальной форме с помощью лемматизатора MyStem (Yandex). С помощью слов в начальной форме в избранное множество слов были отобраны все слова (738), используемые для описания мышечной слабости.
Множество текстов далее токенизировали на последовательности слов длины N и отобрали 7413 последовательностей слов длины N и предложений, из менее N слов, содержащих слова из избранного множества слов, как описано в способе. Для каждой последовательности слов длины N и предложения, содержащего менее N слов, устанавливали наличие или отсутствие искомой информации о мышечной слабости, присваивая оценки 1 или 0 соответственно, а также оценку 0,5, если наличие искомой информации о мышечной слабости нельзя было подтвердить или исключить. Вышеописанные этапы работы были выполнены в течение 13 часов. Далее устанавливали наличие или отсутствие искомой информации о мышечной слабости для всех документов, содержащих последовательности слов длины N и предложения, содержащие менее N слов, для которых было установлено наличие или отсутствие искомой информации, с помощью нескольких вариантов.
В варианте 1 принимали решение о наличии искомой информации о мышечной слабости, если в исходном источнике текстов содержалась хотя бы одна последовательность слов длины N и или хотя бы одно предложение, содержащее менее N слов, которые оценили как 1.
В варианте 2 принимали решение о наличии искомой информации о мышечной слабости, суммируя оценки последовательностей слов длины N и предложений в каждом источнике текстов и определяя пороговое значение суммы так, чтобы максимизировать сумму чувствительности и специфичности способа извлечения информации из неструктурированных текстов. В результате принимали решение о наличии искомой информации о мышечной слабости, если сумма была равна или превышала 2,5 (значение порога). ROC-кривая для способа извлечения информации в варианте 2 показана на фиг. 1.
Вариант 1 с (существительные) отличался от варианта 1 тем, что из 9932 уникальных слов были использованы только существительные (4061), из которых в избранное множество слов попадали только 320, а число анализируемых последовательностей длины N и предложений, содержавших менее N слов, составило 4885. При существенном сокращении объема анализируемых слов и последовательностей слов длины N и предложений, содержавших менее N слов, высокое качество работы извлечения информации из неструктурированных текстов практически не изменилось (Таблица 1).
Вариант 2 с (существительные) отличался от варианта 2 тем, что из 9932 уникальных слов были использованы только существительные (4061), из которых в избранное множество слов попадали только 320, а число анализируемых последовательностей длины N и предложений, содержавших менее N слов, составило 4885. В результате принимали решение о наличии искомой информации о мышечной слабости, если сумма была равна или превышала 2. На фиг. 2 представлена ROC-кривая для способа извлечения информации в варианте 2 с (существительные). Такой подход приводил к сокращению времени работы и улучшению качества извлечения информации по сравнению с исходным способом 2 (Таблица 1).
Метрики качества (SENS - чувствительность, SPEC - специфичность, АСС - точность, PPV - положительное прогностическое значение, NPV -отрицательное прогностическое значение, F - F-мера, Порог - порог встречаемости слова, ROC AUC - площадь под ROC-кривой) способа извлечения информации из неструктурированных текстов в нескольких вариантах представлены в Таблице 1.
При реализации способа извлечения информации в варианте 1 с (существительные) и удалении слов, встречавшихся менее 4 раз во всем множестве текстов, общее число слов уменьшилось до 2376, при этом число слов в избранном множестве слов уменьшилось до 152, а число последовательностей слов длины N и предложений, содержащих менее N слов, сократилось до 4663 без потери качества извлечения информации. Фиг. 3 показывает, как менялись значения метрик качества извлечения информации по способу в варианте 1 с (существительные) при изменении порогового значения числа встречаемости слов, по которому «редко» встречающиеся в тексте слова удаляются перед отбором слов в избранное множество слов. Фиг. 4 иллюстрируют эту закономерность на интервале порогового значения числа встречаемости слов от 0 до 10.
Указанные варианты оптимизации способа извлечения информации позволили сократить время работы по способу извлечения информации о мышечной слабости при поступлении в нейрохирургическую клинику до 6 часов без потери качества извлечения информации.
Литература
1. Yang Y. Ontology-based venous thromboembolism risk assessment model developing from medical records From The Third International Workshop on Semantics-Powered Data Analytics / Yang Y., Wang X., Huang Y., Chen N., Shi J., Chen Т., Madrid S. - 2018.
2. Danilov G. An Information Extraction Algorithm for Detecting Adverse Events in Neurosurgery Using Documents Written in a Natural Rich-in-Morphology Language. / Danilov G., Shifrin M., Strunina U., Pronkina Т., Potapov A. // Studies in health technology and informatics - 2019. - T. 262 - C. 194-197.
3. Jurafsky D. Regular Expressions, Text Normalization, Edit Distance, 2019. Вып. 3-1-98 c.
4. Silge J.Text Mining with R: A tidy approach / J. Silge, D. Robinson - O’Reilly Media, Inc., 2017.
5. Jurafsky D. Spelling Correction and the Noisy Channel, 2019. - 1-14 c.
6. Sarker A. An unsupervised and customizable misspelling generator for mining noisy health-related text sources / Sarker Α., Gonzalez-Hernandez G. // Journal of Biomedical Informatics - 2018. - T. 88 - C. 98-107.
7. MyStem - Технологии Яндекса [Электронный ресурс]. URL: https://yandex.ru/dev/mystem/ (accessed: 14.06.2020).
8. TreeTagger [Электронный ресурс]. URL: https://www.cis.uni-muenchen.de/~schmid/tools/TreeTagger/ (accessed: 14.06.2020).
9. UDPipe | UFAL [Электронный ресурс]. URL: http://ufal.mff.cuni.cz/udpipe (accessed: 14.06.2020).
10. Hunspell [Электронный ресурс]. URL: http://hunspell.github.io/ (accessed: 14.06.2020).
| название | год | авторы | номер документа |
|---|---|---|---|
| Способ определения и классификации понятия исходя из контекста его употребления | 2022 |
|
RU2795870C1 |
| СПОСОБ И СИСТЕМА РАСПОЗНАВАНИЯ ИНФОРМАЦИИ, СОСТАВЛЯЮЩЕЙ КОММЕРЧЕСКУЮ ТАЙНУ | 2024 |
|
RU2841161C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2804747C1 |
| СПОСОБ И СИСТЕМА ОБЕЗЛИЧИВАНИЯ КОНФИДЕНЦИАЛЬНЫХ ДАННЫХ | 2022 |
|
RU2802549C1 |
| СПОСОБ И СИСТЕМА ИЗВЛЕЧЕНИЯ ИМЕНОВАННЫХ СУЩНОСТЕЙ | 2021 |
|
RU2823914C2 |
| СПОСОБ СОЗДАНИЯ И ИСПОЛЬЗОВАНИЯ РЕКУРСИВНОГО ИНДЕКСА ПОИСКОВЫХ МАШИН | 2011 |
|
RU2459242C1 |
| СПОСОБ И СИСТЕМА ОПРЕДЕЛЕНИЯ АКТИВНОСТИ УЧЕТНЫХ ЗАПИСЕЙ В ВЫЧИСЛИТЕЛЬНОЙ СРЕДЕ | 2023 |
|
RU2824919C1 |
| РАСШИРЕНИЕ ВОЗМОЖНОСТЕЙ ИНФОРМАЦИОННОГО ПОИСКА | 2015 |
|
RU2618375C2 |
| СИСТЕМА ДЛЯ СОЗДАНИЯ ДОКУМЕНТОВ НА ОСНОВЕ АНАЛИЗА ТЕКСТА НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2016 |
|
RU2639655C1 |
| СПОСОБ ПРОГНОЗИРОВАНИЯ РЕЧЕВЫХ НАРУШЕНИЙ ПРИ ПРОВЕДЕНИИ НЕЙРОХИРУРГИЧЕСКИХ ВМЕШАТЕЛЬСТВ ПО ДАННЫМ ИНТРАОПЕРАЦИОННОЙ РЕГИСТРАЦИИ КОРТИКО-КОРТИКАЛЬНЫХ ВЫЗВАННЫХ ПОТЕНЦИАЛОВ | 2022 |
|
RU2806013C1 |
Изобретение относится к способу извлечения информации из неструктурированных текстов, написанных на естественном языке. Технический результат заключается в повышении качества извлечения информации из источников текстовых данных. В способе множество текстов токенизируют на предложения, слова и последовательности слов, удаляют редкие слова, приводят слова к начальной форме без опечаток, по словам в начальной форме отбирают избранное множество слов определенных частей речи, используемое в описании искомой информации, в последовательностях слов, содержащих все слова из избранного множества, устанавливают наличие искомой информации, для всех текстовых документов, содержащих размеченные последовательности слов, устанавливают наличие искомой информации, оптимизируют число источников текстов, порог встречаемости слов, набор частей речи для достижения заданного качества извлечения информации. 2 з.п. ф-лы, 4 ил., 1 табл.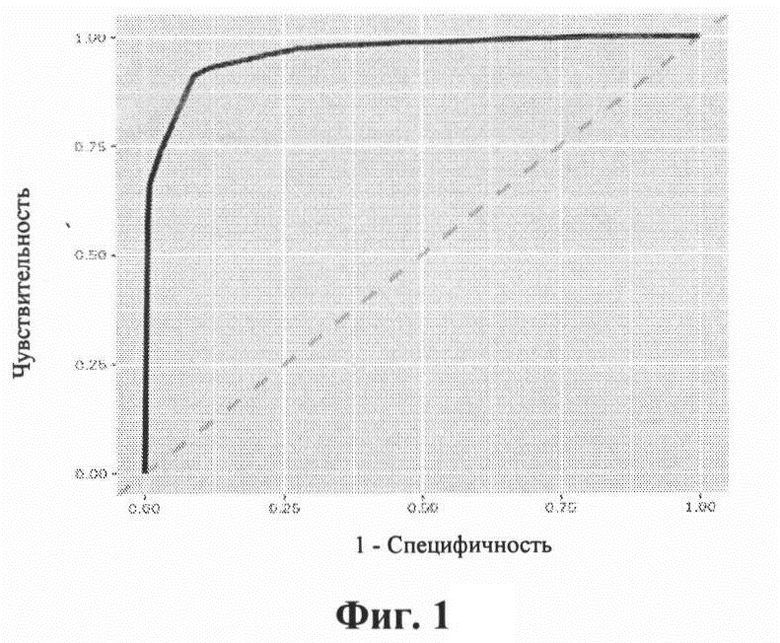
1. Компьютерно-реализуемый способ извлечения информации из неструктурированных текстов, написанных на естественном языке, заключающийся в том, что определяют все источники текстовых данных, в которых содержится искомая информация, составляют множество текстов из всех определенных источников текстовых данных, токенизируют множество текстов на слова, удаляют слова, встречающиеся в текстах реже заданного числа раз, все слова приводят к начальной форме и исправляют в них опечатки, по словам в начальной форме отбирают все слова в исходной форме, которые могут быть использованы в описании искомой информации, и тем самым формируют избранное множество слов, токенизируют множество текстов на последовательности слов длины N, во всех последовательностях слов длины N, содержащих все слова из избранного множества слов, устанавливают наличие или отсутствие искомой информации, для всех документов, содержащих последовательности слов длины N, для которых установлено наличие или отсутствие искомой информации, устанавливают наличие или отсутствие искомой информации, отличающийся тем, что уменьшают число источников текстовых данных в соответствии с заданным значением минимального числа и состава источников данных, перед отбором слов в избранное множество слов удаляют слова, встречающиеся в текстах реже, чем заданное пороговое значение встречаемости слов, определяют части речи и отбирают слова, соответствующие заданному набору частей речи, для получения последовательностей слов длины N множество текстов сначала токенизируют на предложения, затем предложения токенизируют на последовательности слов длины N, отбирают последовательности слов длины N, в которых слова из избранного множества слов содержатся на центральных позициях, если с последовательности слов длины N предложение не начинается и этой последовательностью не заканчивается, на первых позициях, если с последовательности слов длины N предложение начинается, и на последних позициях, если последовательностью слов длины N предложение заканчивается, во всех предложениях, содержащих менее N слов и хотя бы одно слово из избранного множества слов, устанавливают наличие или отсутствие искомой информации, устанавливают наличие или отсутствие искомой информации в последовательности слов длины N и в предложении, содержащем менее N слов, с помощью значения из числового интервала от 0 включительно, если искомой информации нет, до 1, если искомая информация имеется, принимают решение о наличии или отсутствии искомой информации в исходном источнике текстов по совокупности в нем последовательностей слов длины N и предложений, содержащих менее N слов, для которых установлено наличие или отсутствие искомой информации, при этом в заявленном способе также измеряют качество извлечения информации с помощью заданных метрик качества и программного обеспечения на выборке текстов из ранее определенных источников текстовых данных, а вышеуказанные значение минимального числа и состав источников текстовых данных, пороговое значение встречаемости слов и набор частей речи задают посредством осуществления совместного подбора этих данных в процессе тестового извлечения информации из неструктурированных текстов, написанных на естественном языке, из тестового набора текстовых данных, для которых известно наличие или отсутствие искомой информации, при котором обеспечиваются заданные или более высокие значения вышеупомянутых метрик качества.
2. Способ по п. 1, отличающийся тем, что принимают решение о наличии или отсутствии искомой информации в исходном источнике текстов по совокупности в нем последовательностей слов длины N и предложений, содержащих менее N слов, для которых установлено наличие или отсутствие искомой информации, по факту наличия хотя бы одной последовательности слов длины N или предложения, содержащего менее N слов, которые оценили как 0 или 1.
3. Способ по п. 1, отличающийся тем, что принимают решение о наличии или отсутствии искомой информации в исходном источнике текстов по совокупности в нем последовательностей слов длины N или предложений, содержащих менее N слов, для которых установлено наличие или отсутствие искомой информации, по сумме оценок и ее пороговому значению, полученному при оптимизации показателей качества изложенного способа извлечения информации на тестовой выборке.
| СПОСОБ И СИСТЕМА ДЛЯ СОПОСТАВЛЕНИЯ ИСХОДНОГО ЛЕКСИЧЕСКОГО ЭЛЕМЕНТА ПЕРВОГО ЯЗЫКА С ЦЕЛЕВЫМ ЛЕКСИЧЕСКИМ ЭЛЕМЕНТОМ ВТОРОГО ЯЗЫКА | 2016 |
|
RU2682002C2 |
| СПОСОБ ИЗВЛЕЧЕНИЯ ФАКТОВ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2016 |
|
RU2637992C1 |
| ИЗВЛЕЧЕНИЕ СУЩНОСТЕЙ ИЗ ТЕКСТОВ НА ЕСТЕСТВЕННОМ ЯЗЫКЕ | 2015 |
|
RU2626555C2 |
| Автоматическое извлечение именованных сущностей из текста | 2014 |
|
RU2665239C2 |
| Способ и приспособление для нагревания хлебопекарных камер | 1923 |
|
SU2003A1 |
| Способ получения цианистых соединений | 1924 |
|
SU2018A1 |
| US 10387469 B1, 20.08.2019 | |||
| Станок для придания концам круглых радиаторных трубок шестигранного сечения | 1924 |
|
SU2019A1 |
| US 7912705 B2, 22.03.2011. | |||

