Область техники, к которой относится изобретение
Настоящее изобретение относится к иммуноглобулинам, которые связывают аггрекан, а более конкретно к полипептидам, которые включают или по существу состоят из одного или нескольких таких иммуноглобулинов (также называемых в данном документе «иммуноглобулин(ы) по изобретению») и «полипептиды по изобретению», соответственно). Изобретение также относится к конструкциям, содержащим такие иммуноглобулины или полипептиды, а также к нуклеиновым кислотам, кодирующим такие иммуноглобулины или полипептиды (также называемые в данном документе «нуклеиновая(ые) кислота(ы) по изобретению»), к способам получения таких иммуноглобулинов, полипептидов и конструкций; клеткам-хозяевам, экспрессирующим или способным экспрессировать такие иммуноглобулины или полипептиды, к композициям и, в частности, к фармацевтическим композициям, которые включают такие иммуноглобулины, полипептиды, конструкции, нуклеиновые кислоты и/или клетки-хозяева, и к применению иммуноглобулинов, полипептидов, конструкций, нуклеиновых кислот, клеток-хозяев и/или композиций, в частности, для профилактических и/или терапевтических целей, таких как профилактические и/или терапевтические цели, упомянутые в данном документе. Другие аспекты, воплощения, преимущества и применения изобретения станут понятными из дальнейшего описания, приведенного в данном документе.
Предшествующий уровень техники
Остеоартрит является одной из наиболее распространенных причин инвалидности во всем мире. Он затрагивает 30 миллионов американцев и является наиболее распространенным заболеванием суставов. Предполагается, что в США он затронет более 20 процентов населения к 2025 году. Заболевание может возникнуть во всех суставах, чаще всего в коленях, бедрах, руках и позвоночнике. Остеоартрит (ОА) можно определить как разнообразную группу состояний, характеризующихся сочетанием симптомов суставов, признаков, обусловленных дефектами суставного хряща и изменениями в соседних тканях, включая кости, сухожилия и мышцы. ОА характеризуется прогрессирующей эрозией суставного хряща (хряща, который покрывает кости). В конце концов, болезнь приводит к полному разрушению суставного хряща, склерозу лежащей в основе кости, образованию остеофитов и т.д., что приводит к потере подвижности и к боли. Боль является наиболее заметным симптомом ОА, и именно по этой причине пациенты обращаются за медицинской помощью.
Аггрекан является основным протеогликаном в суставном хряще (Kiani et al., 2002 Cell Research 12:19-32). Эта молекула важна для правильного функционирования суставного хряща, потому что она обеспечивает гидратированную гелевую структуру, которая наделяет хрящ несущими свойствами. Аггрекан - это большая, многомодульная молекула (2317 аминокислот), экспрессируемая хондроцитами. Его основной белок состоит из трех глобулярных доменов (G1, G2 и G3) и большой протяженной области между G2 и G3 для прикрепления цепи гликозаминогликана. Эта протяженная область содержит два домена, один из которых замещен кератансульфатными цепями (домен KS), а другой - хондроитинсульфатными цепями (домен CS). Домен CS имеет 100-150 цепей гликозаминогликана (GAG), прикрепленных к нему. Аггрекан образует крупные комплексы с гиалуронаном, в которых 50-100 молекул аггрекана взаимодействуют через домен G1 и линкерный белок с одной молекулой гиалуронана. При поглощении воды (из-за содержания GAG) эти комплексы образуют обратимо деформируемый гель, который сопротивляется сжатию. Структура, удержание жидкости и функции суставного хряща связаны с содержанием в матрице аггрекана и количеством сульфата хондроитина, связанного с интактным белком сердцевины.
ОА характеризуется 1) деградацией аггрекана, постепенным высвобождением доменов G3 и G2 (что приводит к «дефляции» хряща) и, в конечном итоге, высвобождением домена G1 и 2) деградацией коллагена, необратимо разрушающей структуру хряща.
Хотя старение, ожирение и травмы суставов были определены как факторы риска, приводящие к остеоартриту, причина ОА неизвестна, и в настоящее время нет фармакологических методов лечения, которые бы останавливали прогрессирование заболевания или излечивали суставы. Для крупных суставов лекарственное средство может вводиться в сустав, чтобы помочь ограничить потенциальные побочные эффекты, такие как боль. Терапевтические стратегии в первую очередь направлены на уменьшение боли и улучшение функции суставов. Было показано, что Фасинумаб, неопиоидное обезболивающее лекарство против NGF, приводит к улучшению ключевого показателя боли во время испытаний фазы II/III. Дулоксетин был одобрен для лечения хронической боли в колене вследствие остеоартрита и был условно рекомендован Американским колледжем ревматологии. Было обнаружено, что ранелат стронция значительно снижает скорость уменьшения ширины суставного пространства, а также улучшает показатели боли по сравнению с плацебо в большом многоцентровом исследовании у пациентов с симптоматическим остеоартритом коленного сустава. Однако в тоже время биологические агенты, антагонисты рецептора интерлейкина-1 и антитела против фактора некроза опухоли, не продемонстрировали ни эффективности, ни изменения течения остеоартрита (Smelter Hochberg, 2013, Current Opin. Rheumatol. 25:310). Следовательно, многие такие методы лечения неэффективны и/или связаны с побочными эффектами. В конечном итоге пациенты будут проходить полную заместительную терапию коленного или тазобедренного сустава, если боль не поддастся контролю.
Фармакологическая терапия начинается с перорального введения парацетамола в сочетании с НПВП или ингибиторами COX-2 и слабым опиоидом. Основными недостатками перорального приема лекарств являются ограниченная биодоступность в интересующем месте и риск возникновения побочных эффектов, таких как повреждение печени, желудочно-кишечные (ЖК) язвы, желудочно-кишечные кровотечения и запоры.
Поскольку ОА имеет локализованный характер, внутрисуставное введение лекарств дает прекрасную возможность улучшить лечение. Тем не менее большинство вновь разработанных лекарств от остеоартрита, модифицирующих заболевание (DMOAD), имеют короткое время пребывания в суставе, даже при внутрисуставном введении (Edwards 2011 Vet. J. 190: 15-21; Larsen et al., 2008, J Pham Sci 97: 4622-4654). Внутрисуставная (IA) доставка терапевтических белков была ограничена их быстрым выведением из суставного пространства и отсутствием удержания в хряще. Синовиальное время удержания лекарственного средства в суставе часто составляет менее 24 часов. Из-за быстрого выведения большинства препаратов, вводимых IA, для поддержания эффективной концентрации потребуются частые инъекции (Owen et al., 1994, Br. J. Clin Pharmacol. 38:349-355). Тем не менее частые внутривенные инъекции нежелательны из-за боли и дискомфорта, которые могут привести к нарушению исполнительности пациента, а также из-за риска введения инфекции суставов.
Loffredo et al. проверили, будет ли целенаправленная доставка к хрящу путем слияния с гепарин-связывающим доменом достаточной для продления функции in vivo инсулиноподобного фактора роста 1 (IGF-1). Гепарин присутствует в тучных клетках. Тем не менее естественная роль гепарина неизвестна, но он широко используется в качестве разжижителя крови (Loffredo et al., 2014. Arthritis Rheumatol. 66:1247-1255).
Остается потребность в дополнительных белках, заякоривающихся на хряще (CAP, cartilage anchoring proteins).
Сущность изобретения
Авторы настоящего изобретения выдвинули гипотезу о том, что эффективность терапевтического лекарственного средства может быть значительно повышена путем соединения терапевтического лекарственного средства с компонентом, который «закрепляет» лекарственное средство в суставе и, следовательно, увеличивает удерживание лекарственного средства, но который не должен нарушать эффективность указанного терапевтического лекарственного средства (также обозначаемый в данном документе как «белок, заякоривающийся на хряще» или «CAP»). Эта концепция заякоривания будет не только повышать эффективность лекарственного средства, но также и функциональную специфичность для больного сустава за счет снижения токсичности и побочных эффектов, таким образом, увеличивая количество возможных полезных лекарств. Авторы настоящего изобретения также выдвинули гипотезу о том, что агенты, связывающие аггрекан, могут потенциально функционировать в качестве такого якоря, хотя аггрекан сильно гликозилирован и деградирует при различных нарушениях, влияющих на хрящ в суставах. Кроме того, ввиду затрат и обширных испытаний в различных моделях на животных, необходимых для того, чтобы лекарственное средство могло поступить в клинику, такие агенты, связывающие аггрекан, должны предпочтительно иметь широкую перекрестную реактивность, например, агенты, связывающие аггрекан, должны связываться с аггреканом различных видов.
Используя различные оригинальные способы иммунизации, скрининга и определения характеристик, авторы настоящего изобретения смогли идентифицировать ряд агентов, связывающих аггрекан, с превосходными свойствами селективности, стабильности и/или специфичности, которые обеспечили возможность длительного удержания и активности в суставе.
Соответственно, настоящее изобретение относится к иммуноглобулиновому одиночному вариабельному домену (ISV), который специфически связывается с аггреканом, предпочтительно указанный ISV специфически связывается с аггреканом человека (SEQ ID NO: 125), и/или где указанный ISV специфически связывается с аггреканом собаки (SEQ ID NO: 126), аггреканом коровы (SEQ ID NO: 127), аггреканом крысы (SEQ ID NO: 128), аггреканом свиньи (ядро) (SEQ ID NO: 129), аггреканом мыши (SEQ ID NO: 130), аггреканом кролика (SEQ ID NO: 131), аггреканом яванского макака (SEQ ID NO: 132) и/или аггреканом макака-резуса (SEQ ID NO: 133), еще более предпочтительно, где указанный ISV по существу не связывается с нейроканом (SEQ ID NO: 134) и/или бревиканом (SEQ ID NO: 135).
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, где ISV имеет более чем 10-кратную, более чем 100-кратную, предпочтительно более чем 1000-кратную селективность связывания с аггреканом по отношению к нейрокану и/или бревикану, и/или указанный ISV предпочтительно связывается с хрящевой тканью, такой как хрящ и/или мениск, и/или указанный ISV обладает стабильностью, по меньшей мере, 7 дней, например, 14 дней, 21 день, 1 месяц, 2 месяца или даже 3 месяца в синовиальной жидкости (SF) при 37°C, и/или указанный ISV имеет удержание в хряще, по меньшей мере, 2, например, по меньшей мере, 3, 4, 5 или 6 RU в анализе удержания в хряще, и/или указанный ISV проникает в хрящ, по меньшей мере, на 5 мкм, например, по меньшей мере, 10 мкм, 20 мкм, 30 мкм, 40 мкм, 50 мкм или даже более, и/или указанный ISV по существу состоит из доменного антитела, иммуноглобулина, который подходит для применения в качестве доменного антитела, однодоменного антитела, иммуноглобулина, который подходит для применения в качестве однодоменного антитела, dAb, иммуноглобулина, который подходит для применения в качестве dAb, нанотела, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена путем созревания аффинности.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, который по существу состоит из 4 каркасных областей (FR1-FR4 соответственно) и 3 областей, определяющих комплементарность (CDR1-CDR3 соответственно), в которых: CDR1 выбран из группы, состоящей из SEQ ID NO: 24, 20, 21, 22, 23, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37 и 109; CDR2 выбран из группы, состоящей из SEQ ID NO: 42, 38, 39, 40, 41, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55 и 110; и CDR3 выбран из группы, состоящей из SEQ ID NO: 60, 56, 57, 58, 59, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74 и 111.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, где указанный ISV связывается с доменом G1 аггрекана, предпочтительно указанный ISV имеет pI более 8 и/или указанный ISV имеет Koff менее 2⋅10-2с-1, и/или указанный ISV имеет EC50 менее 1⋅10-6M.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, который по существу состоит из 4 каркасных областей (FR1-FR4 соответственно) и 3 областей, определяющих комплементарность (CDR1-CDR3 соответственно), в которых:
i) CDR1 выбран из группы, состоящей из: a) SEQ ID NO: 24, 20 или 21; или b) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 24, где в положении 2 S изменен на R, F, I или Т; в положении 3 Т изменен на I; в положении 5 I изменен на S; в положении 6 I изменен на S, T или M; в положении 7 N изменен на Y или R; в положении 8 V изменен на A, Y, T или G; в положении 9 V изменен на М; и/или в положении 10 R изменен на G, K или A; и/или
ii) CDR2 выбран из группы, состоящей из: c) SEQ ID NO: 42, 38 или 39; или d) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 42, где в положении 1 Т изменен на А или G; S или N вставляется между положением 3 и положением 4 (положение 2a, таблица 1.3B); в положении 3 S изменен на R, W, N или T; в положении 4 S изменен на T или G; в положении 5 G изменен на S; в положении 6 G изменен на S или R; в положении 7 N изменен на S, T или R; в положении 8 A изменен на T; и/или в положении 9 N изменен на D или Y; и/или
iii) CDR3 выбран из группы, состоящей из: e) SEQ ID NO: 60, 56 или 57; или f) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 60, где в положении 1 P изменен на G, R, D, или E, или отсутствует; в положении 2 Т изменен на R, L, P или V или отсутствует; в положении 3 Т изменен на М, S или R или отсутствует; в положении 4 H изменен на D, Y, G или T; в положении 5 Y изменен на F, V, T или G; в положении 6 G изменен на L, D, S, Y или W; R, T, Y или V вставляются между положением 6 и положением 7 (положение 6a, Таблица 1.3C); в положении 7 G изменен на P или S; в положении 8 V изменен на G, T, H, R, L или Y; в положении 9 Y изменен на R, A, S, D или G; в положении 10 Y изменен на N, E, G, W или S; W вставлена между положением 10 и положением 11 (положение 10a, таблица 1.3C); в положении 11 G изменен на S, K или Y; в положении 12 P изменен на E, или D, или отсутствует; и/или в положении 13 Y изменен на L или отсутствует.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, в котором указанный ISV выбран из группы ISV, где: CDR1 выбран из группы, состоящей из SEQ ID NO: 24, 20, 21, 25, 27, 29, 31, 34, 35, 36, 37 и 109; CDR2 выбран из группы, состоящей из SEQ ID NO: 42, 38, 39, 43, 45, 47, 49, 50, 53, 54, 55 и 110; и CDR3 выбран из группы, состоящей из SEQ ID NO: 60, 56, 57, 61, 63, 65, 67, 71, 72, 73, 74 и 111.
В аспекте настоящее изобретение относится к ISV, описанному в данном документе, в котором указанный ISV выбран из группы ISV, в которой:
- CDR1 представляет собой SEQ ID NO: 24, CDR2 представляет собой SEQ ID NO: 42 и CDR3 представляет собой SEQ ID NO: 60;
- CDR1 представляет собой SEQ ID NO: 20, CDR2 представляет собой SEQ ID NO: 38 и CDR3 представляет собой SEQ ID NO: 56;
- CDR1 представляет собой SEQ ID NO: 21, CDR2 представляет собой SEQ ID NO: 39 и CDR3 представляет собой SEQ ID NO: 57;
- CDR1 представляет собой SEQ ID NO: 25, CDR2 представляет собой SEQ ID NO: 43 и CDR3 представляет собой SEQ ID NO: 61;
- CDR1 представляет собой SEQ ID NO: 27, CDR2 представляет собой SEQ ID NO: 45 и CDR3 представляет собой SEQ ID NO: 63;
- CDR1 представляет собой SEQ ID NO: 29, CDR2 представляет собой SEQ ID NO: 47 и CDR3 представляет собой SEQ ID NO: 65;
- CDR1 представляет собой SEQ ID NO: 31, CDR2 представляет собой SEQ ID NO: 49 и CDR3 представляет собой SEQ ID NO: 67;
- CDR1 представляет собой SEQ ID NO: 34, CDR2 представляет собой SEQ ID NO: 50 и CDR3 представляет собой SEQ ID NO: 71;
- CDR1 представляет собой SEQ ID NO: 35, CDR2 представляет собой SEQ ID NO: 53 и CDR3 представляет собой SEQ ID NO: 72;
- CDR1 представляет собой SEQ ID NO: 36, CDR2 представляет собой SEQ ID NO: 54 и CDR3 представляет собой SEQ ID NO: 73; и
- CDR1 представляет собой SEQ ID NO: 37, CDR2 представляет собой SEQ ID NO: 55 и CDR3 представляет собой SEQ ID NO: 74.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, который по существу состоит из 4 каркасных областей (FR1-FR4 соответственно) и 3 областей, определяющих комплементарность (CDR1-CDR3 соответственно), в которых:
i) CDR1 выбран из группы, состоящей из: a) SEQ ID NO: 24 и 109; или b) аминокислотных последовательностей, которые имеют различие в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 24, где в положении 7 N изменен на S; и/или в положении 9 V изменен на М; и/или
ii) CDR2 выбран из группы, состоящей из: c) SEQ ID NO: 42 и 110; или d) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 42, где в положении 1 Т изменен на А; в положении 3 S изменен на R; в положении 4 S изменен на T; в положении 8 A изменен на T; и/или в положении 9 N изменен на D; и/или
iii) CDR3 выбран из группы, состоящей из: e) SEQ ID NO: 60 и 111; или f) аминокислотных последовательностей, которые имеют различие в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 60, где в положении 4 H изменен на R; и/или в положении 8 V изменен на D.
В аспекте настоящее изобретение относится к ISV, описанному в данном документе, в котором указанный ISV выбран из группы ISV, где CDR1 выбран из группы, состоящей из SEQ ID NO: 24 и 109; CDR2 выбран из группы, состоящей из SEQ ID NO: 42 и 110; и CDR3 выбран из группы, состоящей из SEQ ID NO: 60 и 111.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, в котором указанный ISV принадлежит к эпитопной группе 1 или эпитопной группе 4, предпочтительно указанный ISV по существу состоит из 4 каркасных областей (от FR1 до FR4, соответственно) и 3 областей, определяющих комплементарность (CDR1-CDR3 соответственно), в котором:
i) CDR1 выбран из группы, состоящей из: a) SEQ ID NO: 36; и b) аминокислотных последовательностей, которые имеют различие в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 36, где в положении 3 Т изменен на S; в положении 6 Т изменен на S; в положении 8 Т изменен на А; и/или в положении 9 М изменен на V; и/или
ii) CDR2 выбран из группы, состоящей из: c) SEQ ID NO: 54; и d) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 54, где в положении 1 A изменен на I; в положении 4 W изменен на R; в положении 7 G изменен на R; и/или в положении 8 Т изменен на S; и/или
iii) CDR3 выбран из группы, состоящей из: e) SEQ ID NO: 73; и f) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 73, где в положении 1 R изменен на G; в положении 2 P изменен на R или L; в положении 3 R изменен на L или S; в положении 5 Y изменен на R; в положении 6 Y изменен на S или A; в положении 7 Y изменен на T или отсутствует; в положении 8 S изменен на P; в положении 9 L изменен на H или R; в положении 10 Y изменен на P или A; в положении 11 S изменен на A или Y; в положении 12 Y изменен на D; в положении 13 D изменен на F; в положении 14 Y изменен на G или отсутствует; и/или после положения 14 вставляется S.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, где указанный ISV выбран из группы ISV, где: CDR1 выбран из группы, состоящей из SEQ ID NO: 20, 29 и 36; CDR2 выбран из группы, состоящей из SEQ ID NO: 38, 47 и 54; и CDR3 выбран из группы, состоящей из SEQ ID NO: 56, 65 и 73.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, где указанный ISV перекрестно блокирует связывание доменного антитела, иммуноглобулина, который подходит для применения в качестве доменного антитела, однодоменного антитела, иммуноглобулина, который подходит для применения в качестве однодоменного антитела, dAb, иммуноглобулина, который подходит для применения в качестве dAb, нанотела, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена путем созревания аффинности к домену G1 аггрекана.
В одном аспекте настоящее изобретение относится к ISV, доменному антителу, иммуноглобулину, который подходит для применения в качестве доменного антитела, однодоменному антителу, иммуноглобулину, который подходит для применения в качестве однодоменного антитела, dAb, иммуноглобулину, который подходит для применения в качестве dAb, нанотелу, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена путем созревания аффинности и которая связывается с эпитопной группой 1 домена G1 аггрекана, и который конкурирует за связывание с доменом G1 аггрекана с ISV, описанным в данном документе.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, который, по существу, состоит из 4 каркасных областей (FR1-FR4 соответственно) и 3 областей, определяющих комплементарность (CDR1-CDR3 соответственно), в которых: i) выбран CDR1 из группы, состоящей из: а) SEQ ID NO: 24; и b) аминокислотных последовательностей, которые имеют различие в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 24, где в положении 2 S изменен на I или F; в положении 5 I было изменено на S; в положении 6 I было изменено на S или M; в положении 7 N изменен на R или Y; в положении 8 V изменен на A или Y; в положении 9 V изменен на М; и/или в положении 10 R изменен на K; и/или ii) CDR2 выбран из группы, состоящей из: c) SEQ ID NO: 42; и d) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 42, где в положении 1 Т изменен на А или G; N вставляется между положением 2 и положением 3 (положение 2a, таблица 2.3B); в положении 7 N изменен на R; в положении 8 A изменен на T; и/или в положении 9 N изменен на D; и/или iii) CDR3 выбран из группы, состоящей из: e) SEQ ID NO: 60; и f) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 60, где в положении 1 P отсутствует; в положении 2 Т изменен на R или отсутствует; в положении 3 Т изменен на М или отсутствует; в положении 4 H изменен на D или Y; в положении 5 Y изменен на F или V; в положении 6 G изменен на L или D; в положении 8 V изменен на G или T; в положении 9 Y изменен на R; в положении 10 Y изменен на N или E; в положении 11 G изменен на S или K; в положении 12 P изменен на E или отсутствует; и/или в положении 13 Y изменен на L или отсутствует; предпочтительно CDR1 выбран из группы, состоящей из SEQ ID NO: 24, 25 и 27; CDR2 выбран из группы, состоящей из SEQ ID NO: 42, 43 и 45; и CDR3 выбран из группы, состоящей из SEQ ID NO: 60, 61 и 63; еще более предпочтительно, где указанный ISV перекрестно блокирует связывание доменного антитела, иммуноглобулина, который подходит для применения в качестве доменного антитела, однодоменного антитела, иммуноглобулина, который подходит для применения в качестве однодоменного антитела, dAb, иммуноглобулина, который подходит для применения в качестве dAb, нанотела, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена путем созревания аффинности к домену G1 аггрекана.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, к доменному антителу, иммуноглобулину, который подходит для применения в качестве доменного антитела, к однодоменному антителу, иммуноглобулину, который подходит для применения в качестве однодоменного антитела, dAb, иммуноглобулину, который подходит для применения в качестве dAb, нанотела, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена путем созревания аффинности, которая связывается с эпитопной группой 4 домена G1 аггрекана и которая конкурирует за связывание с доменом G1 аггрекана с ISV, описанным в данном документе.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, в котором указанный ISV выбран из группы, состоящей из ISV с SEQ ID NO: 5, 1, 2, 6, 8, 10, 12, 16, 17, 18 и 19, и ISV, которые имеют более 80%, например, 90% или 95% идентичности последовательностей с любой из SEQ ID NO: 5, 1, 2, 6, 8, 10, 12, 16, 17, 18, и 19.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, в котором указанный ISV связывается с доменом G1-IGD-G2 аггрекана, предпочтительно, в котором указанный ISV имеет pI более 8 и/или имеет Koff менее чем 2⋅10-2с-1 и/или имеет EC50 менее 1⋅10-6M.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, в котором: i) CDR1 выбран из группы, состоящей из: a) SEQ ID NO: 32, 30 и 23; и b) аминокислотных последовательностей, которые имеют различие в 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 32, где в положении 2 R изменен на L; в положении 6 S изменен на T; и/или в положении 8 Т изменен на А; и/или ii) CDR2 выбран из группы, состоящей из: c) SEQ ID NO: 50, 41, 48 и 51; и d) аминокислотных последовательностей, которые имеют различие в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 50, где в положении 7 G изменен на S или R; и/или в положении 8 R изменен на T; и/или iii) CDR3 выбран из группы, состоящей из: e) SEQ ID NO: 68, 59, 66 и 69; и f) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 68, где в положении 4 R изменен на V или P; в положении 6 A изменен на Y; в положении 7 S изменен на T; в положении 8 S отсутствует; в положении 9 N изменен на P; в положении 10 R изменен на T или L; в положении 11 G изменен на E; и/или в положении 12 L изменен на T или V, предпочтительно, где указанный ISV выбран из группы ISV, где: CDR1 выбран из группы, состоящей из SEQ ID NO: 32, 30 и 23; CDR2 выбран из группы, состоящей из SEQ ID NO: 50, 41, 48 и 51; и CDR3 выбран из группы, состоящей из SEQ ID NO: 68, 59, 66 и 69, еще более предпочтительно, где указанный ISV выбран из группы ISV, где: CDR1 представляет собой SEQ ID NO: 32, CDR2 представляет собой SEQ ID NO: 50 и CDR3 представляет собой SEQ ID NO: 68; CDR1 представляет собой SEQ ID NO: 32, CDR2 представляет собой SEQ ID NO: 51 и CDR3 представляет собой SEQ ID NO: 69; CDR1 представляет собой SEQ ID NO: 30, CDR2 представляет собой SEQ ID NO: 48 и CDR3 представляет собой SEQ ID NO: 66; и CDR1 представляет собой SEQ ID NO: 23, CDR2 представляет собой SEQ ID NO: 41, и CDR3 представляет собой SEQ ID NO: 59.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, в котором указанный ISV выбран из группы, состоящей из ISV с SEQ ID NO: 13, 4, 11 и 14 и ISV, которые имеют более 80%, например, 90% или 95% идентичности последовательностей с любой из SEQ ID NO: 13, 4, 11 и 14.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, где указанный ISV перекрестно блокирует связывание доменного антитела, иммуноглобулина, который подходит для применения в качестве доменного антитела, однодоменного антитела, иммуноглобулина, который подходит для применения в качестве однодоменного антитела, dAb, иммуноглобулина, который подходит для применения в качестве dAb, нанотела, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена путем созревания аффинности к домену G1-IGD-G2 аггрекана. В одном аспекте настоящее изобретение относится к ISV, доменному антителу, иммуноглобулину, который подходит для применения в качестве доменного антитела, однодоменному антителу, иммуноглобулину, который подходит для применения в качестве однодоменного антитела, dAb, иммуноглобулин, который подходит для применения в качестве dAb, нанотела, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена путем созревания аффинности и которая связывается с доменом G1-IGD-G2 аггрекана и которая конкурирует за связывание с доменом G1-IGD-G2 аггрекана с ISV, описанным в данном документе.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, где указанный ISV связывается с доменом G2 аггрекана, предпочтительно, где указанный ISV имеет pI более 8 и/или имеет Koff менее 2⋅10-2с-1 и/или имеет EC50 менее 1⋅10-6M.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, в котором: i) CDR1 выбран из группы, состоящей из: a) SEQ ID NO: 28; и b) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 28, где в положении 1 G изменен на R; в положении 2 P изменен на S или R; в положении 3 Т изменен на I; в положении 5 S изменен на N; в положении 6 R изменен на N, M или S; в положении 7 Y изменен на R или отсутствует; в положении 8 A изменен на F или отсутствует; и/или в положении 10 G изменен на Y; и/или ii) CDR2 выбран из группы, состоящей из: c) SEQ ID NO: 46; и d) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 46, где в положении 1 А изменен на S или Y; в положении 4 W изменен на L; в положении 5 S изменен на N; в положении 6 S отсутствует; в положении 7 G отсутствует; в положении 8 G изменен на A; в положении 9 R изменен на S, D или T; и/или в положении 11 Y изменен на N или R; и/или iii) CDR3 выбран из группы, состоящей из: e) SEQ ID NO: 64; и f) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 64, где в положении 1 А изменен на R или F; в положении 2 R изменен на I или L; в положении 3 I было изменено на H или Q; в положении 4 P изменен на G или N; в положении 5 V изменен на S; в положении 6 R изменен на G, N или F; в положении 7 Т изменен на R, W или Y; в положении 8 Y изменен на R или S или отсутствует; в положении 9 Т изменен на S или отсутствует; в положении 10 S изменен на E, K или отсутствует; в положении 11 E изменен на N, A или отсутствует; в положении 12 W изменен на D или отсутствует; в положении 13 N изменен на D или отсутствует; в положении 14 Y отсутствует; и/или D и/или N добавляются после положения 14 SEQ ID NO: 64; предпочтительно, когда указанный ISV выбран из группы ISV, где: CDR1 выбран из группы, состоящей из SEQ ID NO: 28, 22, 26 и 33; CDR2 выбран из группы, состоящей из SEQ ID NO: 46, 40, 44 и 52; и CDR3 выбран из группы, состоящей из SEQ ID NO: 64, 58, 62 и 70; еще более предпочтительно, где указанный ISV выбран из группы ISV, где: CDR1 представляет собой SEQ ID NO: 28, CDR2 представляет собой SEQ ID NO: 46 и CDR3 представляет собой SEQ ID NO: 64; CDR1 представляет собой SEQ ID NO: 22, CDR2 представляет собой SEQ ID NO: 40 и CDR3 представляет собой SEQ ID NO: 58; CDR1 представляет собой SEQ ID NO: 26, CDR2 представляет собой SEQ ID NO: 44 и CDR3 представляет собой SEQ ID NO: 62; и CDR1 представляет собой SEQ ID NO: 33, CDR2 представляет собой SEQ ID NO: 52 и CDR3 представляет собой SEQ ID NO: 70.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, где указанный ISV выбран из группы, состоящей из ISV с SEQ ID NO: 9, 3, 7 и 15 и ISV, которые имеют более 80%, например, 90% или 95% идентичности последовательностей с любой из SEQ ID NO: 9, 3, 7 и 15.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, где указанный ISV перекрестно блокирует связывание доменного антитела, иммуноглобулина, который подходит для применения в качестве доменного антитела, однодоменного антитела, иммуноглобулина, который подходит для применения в качестве однодоменного антитела, dAb, иммуноглобулина, который подходит для применения в качестве dAb, нанотела, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена путем созревания аффинности к домену G2 аггрекана. В одном аспекте настоящее изобретение относится к ISV, доменному антителу, иммуноглобулину, который подходит для применения в качестве доменного антитела, однодоменному антителу, иммуноглобулину, который подходит для применения в качестве однодоменного антитела, dAb, иммуноглобулину, который подходит для применения в качестве dAb, нанотелу, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена путем созревания аффинности и которая связывается с доменом G2 аггрекана и которая конкурирует за связывание с доменом G2 аггрекана с ISV, описанным в данном документе.
В одном аспекте настоящее изобретение относится к ISV, описанному в данном документе, где указанный ISV выбран из группы, состоящей из SEQ ID NO: 1-19 и 114-118 и ISV, которые имеют более 80%, например, 90% или 95% идентичности последовательностей с любой из SEQ ID NO: 1-19 и 114-118.
В одном аспекте настоящее изобретение относится к полипептиду, содержащему, по меньшей мере, один ISV, описанный в данном документе, предпочтительно указанное включает по меньшей мере два ISV, описанных в данном документе, где указанные по меньшей мере два ISV могут быть одинаковыми или разными. Предпочтительно указанные по меньшей мере два ISV независимо выбраны из группы, состоящей из SEQ ID NO: 1-19 и 114-118, более предпочтительно, где указанные по меньшей мере два ISV выбраны из группы, состоящей из SEQ ID NO: 5, 6, 8 и 114-117, или в которых указанные по меньшей мере два ISV выбраны из группы, состоящей из SEQ ID NO: 13 и 118.
Предпочтительно в одном аспекте полипептид по изобретению содержит по меньшей мере один дополнительный ISV, например, терапевтический ISV. Предпочтительно, указанный по меньшей мере один дополнительный ISV связывается с представителем семейства сериновых протеаз, катепсинами, матриксными металлопротеиназами (MMP)/матриксинами или дезинтегрином и металлопротеиназой с мотивами тромбоспондина (ADAMTS), предпочтительно MMP8, MMP13, MMP19, MMP20, ADAMTS5 (аггреканазой-2), ADAMTS4 (аггреканазой-1) и/или ADAMTS11; причем указанный по меньшей мере один дополнительный ISV, например, терапевтический ISV, предпочтительно, сохраняет активность. Еще более предпочтительно, указанный по меньшей мере один дополнительный ISV, такой как терапевтический ISV, ингибирует активность представителя семейства сериновых протеаз, катепсинов, матриксных металлопротеиназ (ММР)/матриксинов или дезинтегрина и металлопротеиназы с мотивами тромбоспондина (ADAMTS), предпочтительно MMP8, MMP13, MMP19, MMP20, ADAMTS5 (аггреканазы-2), ADAMTS4 (аггреканазы-1) и/или ADAMTS11.
В одном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где указанный полипептид имеет стабильность по меньшей мере 7 дней, например по меньшей мере 14 дней, 21 день, 1 месяц, 2 месяца или даже 3 месяца в синовиальной жидкости (SF) при 37°C и/или имеет удержание в хряще по меньшей мере 2, например по меньшей мере 3, 4, 5 или 6 RU в анализе удержания в хряще, и/или проникает в хрящ по меньшей мере на 5 мкм, например по меньшей мере 10 мкм, 20 мкм, 30 мкм, 40 мкм, 50 мкм или даже больше.
В одном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, дополнительно включающему белок, связывающий сывороточный белок, или белок сыворотки, предпочтительно указанный фрагмент, связывающий сывороточный белок, связывает сывороточный альбумин; еще более предпочтительно указанный фрагмент, связывающий сывороточный белок, представляет собой ISV, связывающий сывороточный альбумин; еще более предпочтительно, указанный ISV, связывающий сывороточный альбумин, по существу, состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 областей, определяющих комплементарность (CDR1-CDR3 соответственно), в которых CDR1 представляет собой SFGMS, CDR2 представляет собой SISGSGSDTLYADSVKG и CDR3 представляет собой GGSLSR; еще более предпочтительно указанный ISV, связывающий сывороточный альбумин включает Alb8, Alb23, Alb129, Alb132, Alb135, Alb11, Alb11 (S112K) -A, Alb82, Alb82-A, Alb82-AA, Alb82-AAA, Alb82-G, Alb82-GG, Alb82-GGG (см. также Таблицу C). В одном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, дополнительно включающему связывающий белок сыворотки или сывороточный белок, где указанным связывающим белок сыворотки компонентом является полипептид, не основанный на антителах. В одном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, дополнительно включающему PEG.
В одном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где указанные ISV непосредственно связаны друг с другом или связаны через линкер. В одном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где первый ISV и/или второй ISV, и/или, возможно, третий ISV, и/или, возможно, четвертый ISV, и/или, возможно, указанный ISV, связывающий сывороточный альбумин, связаны через линкер(ы); предпочтительно указанный линкер выбирают из группы, состоящей из линкеров 5GS, 7GS, 9GS, 10GS, 15GS, 18GS, 20GS, 25GS, 30GS и 35GS (см. также Таблицу D).
В одном аспекте настоящее изобретение относится к полипептиду, описанному в данном документе, где указанный полипептид выбран из группы полипептидов и/или конструкций, включающих ISV, связывающий мишень, как указано, и один или два ISV, связывающих аггрекан, как указано в таблице E- 1 и Таблице E-2, соответственно.
В одном аспекте настоящее изобретение относится к конструкции, которая содержит или, по существу, состоит из ISV, описанного в данном документе, или полипептида, описанного в данном документе, и которая необязательно дополнительно включает одну или несколько других групп, остатков, фрагментов или связывающих единиц, необязательно связанных через один или несколько пептидных линкеров; предпочтительно указанные одну или несколько других групп, остатков, фрагментов или связывающих звеньев выбирают из группы, состоящей из молекулы полиэтиленгликоля, белков сыворотки или ее фрагментов, связывающих единиц, которые могут связываться с белками сыворотки, Fc-частью и небольшими белками или пептидами, которые могут связываться с сывороточными белками.
В одном аспекте настоящее изобретение относится к нуклеиновой кислоте, кодирующей ISV, описанный в данном документе, полипептиду, описанному в данном документе, или конструкции, описанной в данном документе.
В одном аспекте настоящее изобретение относится к экспрессирующему вектору, содержащему нуклеиновую кислоту, описанную в данном документе.
В одном аспекте настоящее изобретение относится к клетке-хозяину или хозяину, содержащему нуклеиновую кислоту, описанную в данном документе, или экспрессирующий вектор, описанный в данном документе.
В одном аспекте настоящее изобретение относится к способу получения ISV, описанного в данном документе, или полипептиду, описанному в данном документе, причем указанный способ по меньшей мере включает стадии: а) экспрессии в подходящей клетке-хозяине или организме-хозяине или в другой подходящей системе экспрессии, нуклеиновой кислоты, описанной в данном документе; необязательно с последующим: b) выделением и/или очисткой ISV, описанного в данном документе, или полипептида, описанного в данном документе.
В одном аспекте настоящее изобретение относится к композиции, содержащей по меньшей мере один ISV, описанный в данном документе, полипептид, описанный в данном документе, конструкцию, описанную в данном документе, или нуклеиновую кислоту, описанную в данном документе; предпочтительно указанная композиция представляет собой фармацевтическую композицию, которая предпочтительно дополнительно включает по меньшей мере один фармацевтически приемлемый носитель, разбавитель или наполнитель и/или адъювант и необязательно содержит один или несколько других фармацевтически активных полипептидов и/или соединений.
В одном аспекте настоящее изобретение относится к композиции, описанной в данном документе, ISV, описанному в данном документе, полипептиду, описанному в данном документе, или конструкции, описанной в данном документе, для применения в качестве лекарственного средства. Предпочтительно композиция, ISV, полипептид или конструкция, описанные в данном документе, предназначена для предотвращения или лечения артропатий и хондродистрофий, артритного заболевания, такого как остеоартрит, ревматоидный артрит, подагрический артрит, псориатический артрит, травматический разрыв или отслоение, ахондроплазия, костохондрит, спондилоэпиметафизальная дисплазия, грыжа позвоночного диска, дегенеративные заболевания поясничного диска, дегенеративные заболевания суставов и рецидивирующий полихондрит.
В одном аспекте настоящее изобретение относится к способу профилактики или лечения артропатий и хондродистрофий, артритного заболевания, такого как остеоартрит, ревматоидный артрит, подагрический артрит, псориатический артрит, травматический разрыв или отслоение, ахондроплазия, костохондрит, спондилоэпиметафизарная дисплазия, грыжа позвоночника, дегенерация поясничного диска, дегенеративные заболевания суставов и рецидивирующий полихондрит, где указанный способ включает введение объекту, нуждающемуся в этом, фармацевтически активного количества по меньшей мере композиции, ISV, полипептида или конструкции, описанной в данном документе, персоне, нуждающейся в этом.
В одном аспекте настоящее изобретение относится к способу уменьшения и/или ингибирования оттока соединения, полипептида или конструкции из хрящевой ткани, где указанный способ включает введение фармацевтически активного количества по меньшей мере одного полипептида, описанного в данном документе, соединения или конструкции, описанных в данном документе, или композиции, описанной в данном документе, нуждающемуся в этом человеку.
В одном аспекте настоящее изобретение относится к способу ингибирования и/или блокирования активности ADAMTS5 и/или активности MMP13, где указанный способ включает введение фармацевтически активного количества по меньшей мере одного полипептида, описанного в данном документе, конструкции, описанной в данном документе, или композиции, описанной в данном документе нуждающемуся в этом человеку.
В одном аспекте настоящее изобретение относится к применению ISV, как описано в данном документе, полипептида, как описано в данном документе, конструкции, как описано в данном документе, или композиции, как описано в данном документе, для приготовления фармацевтической композиции для лечения или профилактики артропатий и хондродистрофии, артритного заболевания, такого как остеоартрит, ревматоидный артрит, подагрический артрит, псориатический артрит, травматический разрыв или отслоение, ахондроплазия, костохондрит, спондилоэпиметафизарная дисплазия, грыжа позвоночника, дегенерация поясничного диска, дегенеративные заболевания суставов и рецидивирующий полихондрит.
Другие аспекты, преимущества, применения и применения полипептидов и композиций станут ясны из дальнейшего раскрытия в данном документе. Несколько документов цитируется по всему тексту данного описания. Каждый из документов, процитированных в данном документе (включая все патенты, патентные заявки, научные публикации, спецификации производителя, инструкции и т.д.), будь то выше или ниже, настоящим полностью включен ссылкой. Ничто в данном документе не должно быть истолковано как признание того, что изобретение не имеет права предшествовать такому раскрытию в силу предшествующего изобретения.
Подписи к чертежам
Фигура 1: Примеры авторадиографических изображений срезов суставов крыс через 2 или 4 недели после введения 125I-меченных конструкций ALB26-CAP. Для каждого из результатов через 2 недели после инъекции и через 4 недели после инъекции: левая панель: гистологический разрез; Правая панель: авторадиография.
Фигура 2: Репрезентативные изображения MARG. Специфическое окрашивание MARG отображается на изображениях в виде черных зерен и показано стрелками.
Фигура 3: Ингибирование деградации хряща нанотелами на крысиной модели ММТ с использованием нанотела против MMP13-CAP (C010100754) или нанотела против ADAMTS5-CAP (C010100954). Обработка началась через 3 дня после операции IA-введением. Гистопатология была выполнена на 42 день после операции. Была определена медиальная и общая фактическая ширина дегенерации хряща, а также процент снижения дегенерации хряща. На группу использовали по 20 животных.
Фигура 4: Концентрации в сыворотке (средняя концентрация в нг/мл) в зависимости от времени после первой дозы (h) полипептидов у крыс с остеоартритом и у здоровых крыс, получающих одну внутрисуставную инъекцию 400 мкг нанотела на сустав (правое колено). Точки представляют индивидуальные концентрации у здоровых животных; треугольники представляют индивидуальные концентрации у животных ОА; а линии представляют средние концентрации.
Подробное описание
Если не указано или не определено иначе, все используемые термины имеют свое обычное значение в данной области, что будет понятно специалисту. Источниками могут служить, например, стандартные справочники, такие как Sambrook et al. (Molecular Cloning: A Laboratory Manual (2nd Ed.) Vols. 1-3, Cold Spring Harbor Laboratory Press, 1989), F. Ausubel et al. (Current protocols in molecular biology, Green Publishing and Wiley Interscience, New York, 1987), Lewin (Genes II, John Wiley & Sons, New York, N.Y., 1985), Old et al. (Principles of Gene Manipulation: An Introduction to Genetic Engineering (2nd edition) University of California Press, Berkeley, CA, 1981); Roitt et al. (Immunology (6th Ed.) Mosby/Elsevier, Edinburgh, 2001), Roitt et al. (Roitt's Essential Immunology (10th Ed.) Blackwell Publishing, UK, 2001) и Janeway et al. (Immunobiology (6th Ed.) Garland Science Publishing/Churchill Livingstone, New York, 2005), а также общий уровень техники, цитируемый в данном документе.
Если не указано иное, все способы, стадии, методики и манипуляции, которые в частности не описаны подробно, могут быть выполнены и были выполнены способом, известным по существу, как будет понятно специалисту в данной области. Например, опять может быть сделана отсылка к стандартным справочникам и общему уровню техники, упомянутым в данном документе, и к дополнительным источникам, цитируемым в них; и, например, к следующим обзорам Presta (Adv. Drug Deliv. Rev. 58 (5-6): 640-56, 2006), Levin and Weiss (Mol. Biosyst. 2 (1): 49-57, 2006), Irving et al. (J. Immunol. Methods 248(1-2): 31-45, 2001), Schmitz et al. (Placenta 21 Suppl. A: S106-12, 2000), Gonzales et al. (Tumour Biol. 26 (1): 31-43, 2005), в которых описаны методы белковой инженерии, такие как созревание аффинности, и другие методы улучшения специфичности и других желательных свойств у белков, таких как иммуноглобулины.
Используемый в данном документе термин «последовательность» (например, в таких терминах, как «последовательность иммуноглобулина», «последовательность антитела», «последовательность вариабельного домена», «последовательность VHH» или «последовательность белка»), как правило, следует понимать как включающий как релевантную аминокислотную последовательность, так и нуклеиновые кислоты или нуклеотидные последовательности, кодирующие ее, если контекст не требует более ограниченной интерпретации.
Аминокислотные последовательности интерпретируются как означающие одну аминокислоту или неразветвленную последовательность из двух или более аминокислот, в зависимости от контекста. Нуклеотидные последовательности интерпретируются как означающие неразветвленную последовательность из 3 или более нуклеотидов.
Аминокислоты - это те L-аминокислоты, которые обычно встречаются в природных белках. Аминокислотные остатки будут указаны в соответствии со стандартным трехбуквенным или однобуквенным аминокислотным кодом. Источником может служить, например, таблица A-2 на стр. 48 WO 08/020079. Эти аминокислотные последовательности, содержащие D-аминокислоты, не предназначены для охвата этим определением. Любая аминокислотная последовательность, которая содержит посттрансляционно модифицированные аминокислоты, может быть описана как аминокислотная последовательность, которая первоначально транслируется с использованием символов, показанных в этой таблице A-2, с измененными положениями; например, гидроксилирования или гликозилирования, но эти модификации не должны быть явно показаны в аминокислотной последовательности. Любой пептид или белок, который может быть экспрессирован в виде последовательных модифицированных связей, поперечных связей и кэпов, непептидильных связей и т.д., охватывается этим определением.
Термины «белок», «пептид», «белок/пептид» и «полипептид» используются взаимозаменяемо по всему раскрытию, и каждый из них имеет одинаковое значение для целей настоящего раскрытия. Каждый термин относится к органическому соединению, состоящему из линейной цепи из двух или более аминокислот. Соединение может содержать десять или более аминокислот; двадцать пять или более аминокислот; пятьдесят или более аминокислот; сто или более аминокислот, двести или более аминокислот и даже триста или более аминокислот. Специалист в данной области поймет, что полипептиды обычно содержат меньше аминокислот, чем белков, хотя в данной области техники не существует общепризнанного предела числа аминокислот, которые отличают полипептид от белка; что полипептиды могут быть получены химическим синтезом или рекомбинантными способами; и что белки, как правило, получают in vitro или in vivo рекомбинантными способами, которые все известны в данной области.
Последовательность нуклеиновой кислоты или аминокислоты считается «(в) (по существу) выделенной (в форме)» - например, по сравнению с реакционной средой или средой для культивирования, из которой она была получена, когда она была отделена по меньшей мере от одного другого компонента, с которым она обычно связана в указанном источнике или среде, такого как другая нуклеиновая кислота, другой белок/полипептид, другой биологический компонент или макромолекула или по меньшей мере один загрязнитель, примесь или минорный компонент. В частности, последовательность нуклеиновой кислоты или аминокислоты считается «(по существу) выделенной», когда она очищена по меньшей мере в 2 раза, в частности по меньшей мере в 10 раз, более конкретно по меньшей мере в 100 раз и до 1000 раза или больше. Нуклеиновая кислота или аминокислота, которая находится «(по существу) в выделенной форме», предпочтительно является по существу гомогенной, что определяется с помощью подходящего метода, такого как подходящий хроматографический метод, такой как электрофорез в полиакриламидном геле.
Когда говорят, что нуклеотидная последовательность или аминокислотная последовательность «включает» другую нуклеотидную последовательность или аминокислотную последовательность соответственно или «по существу состоят из» другой нуклеотидной последовательности или аминокислотной последовательности, это может означать, что последняя нуклеотидная последовательность или аминокислота последовательность была включена в первую упомянутую нуклеотидную последовательность или аминокислотную последовательность, соответственно, но чаще это обычно означает, что первая упомянутая нуклеотидная последовательность или аминокислотная последовательность содержит в своей последовательности участок нуклеотидов или аминокислотных остатков, соответственно, который имеет ту же самую нуклеотидную последовательность или аминокислотную последовательность, соответственно, что и последняя последовательность, независимо от того, как фактически была создана или получена первая упомянутая последовательность (что может быть, например, любым подходящим способом, описанным в данном документе). Посредством неограничивающего примера, когда говорят, что полипептид по изобретению включает иммуноглобулиновый одиночный вариабельный домен («ISV»), это может означать, что указанная последовательность иммуноглобулинового одиночного вариабельного домена была включена в последовательность полипептида по изобретению, но чаще это обычно означает, что полипептид по изобретению содержит в своей последовательности последовательность ISV независимо от того, как указанный полипептид по изобретению был создан или получен. Кроме того, когда говорят, что нуклеиновая кислота или нуклеотидная последовательность включает другую нуклеотидную последовательность, первая упомянутая нуклеиновая кислота или нуклеотидная последовательность предпочтительно являются такими, что, когда они экспрессируются в продукт экспрессии (например, полипептид), аминокислотная последовательность, кодируемая последней нуклеотидной последовательности образует часть указанного продукта экспрессии (иными словами, последняя нуклеотидная последовательность находится в той же рамке считывания, что и первая упомянутая большая нуклеиновая кислота или нуклеотидная последовательность). Кроме того, когда говорят, что конструкция по изобретению содержит полипептид или ISV, это может означать, что указанная конструкция по меньшей мере охватывает указанный полипептид или ISV, соответственно, но чаще это означает, что указанная конструкция включает группы, остатки (например, аминокислотные остатки), фрагменты и/или связывающие единицы в дополнение к указанному полипептиду или ISV, независимо от того, как указанный полипептид или ISV связан с указанными группами, остатками (например, аминокислотными остатками), фрагментами и/или связывающими единицами и независимо от того, как указанная конструкция была создана или получена.
«По существу состоит из» означает, что ISV, используемый в способе по изобретению, либо является точно таким же, как ISV по изобретению, либо соответствует ISV по изобретению, который имеет ограниченное количество аминокислотных остатков, например, 1-20 аминокислотных остатков, например, 1-10 аминокислотных остатков и предпочтительно 1-6 аминокислотных остатков, таких как 1, 2, 3, 4, 5 или 6 аминокислотных остатков, добавленных на амино-конце, на карбокси-конце или как на амино-конце, так и на карбокси-конце ISV.
В целях сравнения двух или более нуклеотидных последовательностей процент «идентичности последовательности» между первой нуклеотидной последовательностью и второй нуклеотидной последовательностью можно рассчитать путем деления [числа нуклеотидов в первой нуклеотидной последовательности, которые идентичны нуклеотидам в соответствующие позиции во второй нуклеотидной последовательности] на [общее количество нуклеотидов в первой нуклеотидной последовательности] и умножения на [100%], при этом каждая делеция, вставка, замена или добавление нуклеотида во второй нуклеотидной последовательности (по сравнению с первой нуклеотидной последовательностью) рассматривается как различие в одном нуклеотиде (положении). Альтернативно, степень идентичности последовательностей между двумя или более нуклеотидными последовательностями может быть рассчитана с использованием известного компьютерного алгоритма для выравнивания последовательностей, такого как, например, NCBI Blast v2.0, используя стандартные настройки. Некоторые другие методы, компьютерные алгоритмы и настройки для определения степени идентичности последовательности, например, описаны в WO 04/037999, EP 0967284, EP 1085089, WO 00/55318, WO 00/78972, WO 98/49185 и GB 2357768. Обычно, с целью определения процента «идентичности последовательности» между двумя нуклеотидными последовательностями в соответствии со способом вычисления, описанным выше, нуклеотидная последовательность с наибольшим числом нуклеотидов будет принята за «первую» нуклеотидную последовательность, а другая нуклеотидная последовательность будет принята за «вторую» нуклеотидную последовательность.
В целях сравнения двух или более аминокислотных последовательностей процент «идентичности последовательности» между первой аминокислотной последовательностью и второй аминокислотной последовательностью (также называемой в данном документе «аминокислотной идентичностью») может быть рассчитан путем деления [числа аминокислотных остатков в первой аминокислотной последовательности, которые идентичны аминокислотным остаткам в соответствующих положениях во второй аминокислотной последовательности] на [общее количество аминокислотных остатков в первой аминокислотной последовательности] и умножения на [100%], при этом каждая делеция, вставка, замена или добавление аминокислотного остатка во второй аминокислотной последовательности - по сравнению с первой аминокислотной последовательностью - рассматривается как различие в одном аминокислотном остатке (положении), т.е. как «различие аминокислот», как определено в данном документе. Альтернативно, степень идентичности последовательности между двумя аминокислотными последовательностями может быть рассчитана с использованием известного компьютерного алгоритма, такого как упомянутые выше, для определения степени идентичности последовательности для нуклеотидных последовательностей, опять же с использованием стандартных настроек. Обычно, с целью определения процента «идентичности последовательности» между двумя аминокислотными последовательностями в соответствии с методом вычисления, описанным выше, аминокислотная последовательность с наибольшим количеством аминокислотных остатков будет принята за «первую» аминокислотную последовательность, а другая аминокислотная последовательность будет принята за «вторую» аминокислотную последовательность.
Кроме того, при определении степени идентичности последовательностей между двумя аминокислотными последовательностями специалист в данной области может принять во внимание так называемые «консервативные» аминокислотные замены, которые обычно могут быть описаны как аминокислотные замены, в которых аминокислотный остаток изменен на другой аминокислотный остаток с аналогичной химической структурой, который мало или практически не влияет на функцию, активность или другие биологические свойства полипептида. Такие консервативные аминокислотные замены хорошо известны в данной области, например, из WO 04/037999, GB 335768, WO 98/49185, WO 00/46383 и WO 01/09300; и (предпочтительные) типы и/или комбинации таких замен могут быть выбраны на основе соответствующих принципов, например, из WO 04/037999 или, например, WO 98/49185 и из приведенных там дополнительных источников.
Такие консервативные замены предпочтительно представляют собой замены, в которых одна аминокислота в следующих группах (а) - (е) замещена другим аминокислотным остатком в той же группе: (а) небольшие алифатические, неполярные или слегка полярные остатки: Ala, Ser, Thr, Pro и Gly; (b) полярные отрицательно заряженные остатки и их (незаряженные) амиды: Asp, Asn, Glu и Gln; (c) полярные положительно заряженные остатки: His, Arg и Lys; (d) большие алифатические неполярные остатки: Met, Leu, Ile, Val и Cys; и (е) ароматические остатки: Phe, Tyr и Trp. Особенно предпочтительными консервативными заменами являются следующие: Ala в Gly или в Ser; Arg в Lys; Asn в Gln или в His; Asp в Glu; Cys в Ser; Gln в Asn; Glu в Asp; Gly в Ala или в Pro; His в Asn или в Gln; Ile в Leu или в Val; Leu в Ile или в Val; Lys в Arg, в Gln или в Glu; Met в Leu, в Tyr или в Ile; Phe в Met, в Leu или в Tyr; Ser в Thr; Thr в Ser; Trp в Tyr; Tyr в Trp; и/ или Phe в Val, в Ile или в Leu.
Любые аминокислотные замены, применяемые к полипептидам, описанным в данном документе, также могут быть основаны на анализе частот вариаций аминокислот между гомологичными белками различных видов, такими как, например, разработанный Schulz et al. («Principles of Protein Structure», Springer-Verlag, 1978), относительно анализов структурообразующих потенциалов, разработанных, например, Chou and Fasman (Biochemistry 13: 211, 1974; Adv. Enzymol., 47: 45-149, 1978), и на анализе паттернов гидрофобности в белках, разработанном, например, Eisenberg et al. (Proc. Natl. Акад. USA 81: 140-144, 1984), Kyte and Doolittle (J. Molec. Biol. 157: 105-132, 1981) или Goldman et al. (Ann. Rev. Biophys. Chem. 15: 321-353, 1986), все они включены в данный документ в полном объеме ссылкой. Информация о первичной, вторичной и третичной структуре нанотел дана в описании в данном документе и в общем уровне техники, указанном выше. Кроме того, для этой цели кристаллическая структура домена VHH из ламы, например, приведена Desmyter et al. (Nature Structural Biology, 3: 803, 1996), Spinelli et al. (Natural Structural Biology, 3: 752-757, 1996) или Decanniere et al. (Structure, 7 (4): 361, 1999). Дополнительную информацию о некоторых аминокислотных остатках, которые в обычных доменах VH образуют интерфейс VH/VL, и потенциальных верблюжьих заменах в этих положениях, можно найти в известном уровне техники, указанном выше.
Считается, что аминокислотные последовательности и последовательности нуклеиновых кислот являются «абсолютно одинаковыми», если они имеют 100% идентичность последовательностей (как определено в данном документе) по всей их длине.
При сравнении двух аминокислотных последовательностей термин «различие по аминокислоте(ам)» относится к вставке, делеции или замене одного аминокислотного остатка в положении первой последовательности по сравнению со второй последовательностью; следует понимать, что две аминокислотные последовательности могут содержать одно, два или более таких аминокислотных различий. Более конкретно, в аминокислотных последовательностях и/или полипептидах по настоящему изобретению термин «различие между аминокислотами» относится к вставке, делеции или замене одного аминокислотного остатка в положении последовательности CDR, указанной в b), d) или f) по сравнению с последовательностью CDR соответственно а), с) или е); следует понимать, что последовательность CDR b), d) и f) может содержать одно, два, три, четыре или максимум пять таких различий по аминокислотам по сравнению с последовательностью CDR соответственно а), с) или е).
«Различие(я) по аминокислоте(ам)» может представлять собой любую одну, две, три, четыре или максимум пять замен, делеций или вставок или любую их комбинацию, которые улучшают свойства агента, связывающего аггрекан по изобретению, такого как полипептид по изобретению, или которые по меньшей мере не слишком сильно умаляют желательные свойства или баланс или комбинацию желательных свойств агента, связывающего аггрекан по изобретению, такого как полипептид по изобретению. В этом отношении результирующий агент по изобретению, связывающий аггрекан, такой как полипептид по изобретению, должен по меньшей мере связывать аггрекан с такой же, примерно одинаковой или более высокой аффинностью по сравнению с полипептидом, содержащим одну или несколько последовательностей CDR без одной, двух, трех, четырех или максимум пять замен, делеций или вставок, где указанная аффинность измеряется с помощью поверхностного плазмонного резонанса (SPR).
В этом отношении аминокислотная последовательность CDR в соответствии с b), d) и/или f) может представлять собой аминокислотную последовательность, полученную из аминокислотной последовательности в соответствии с a), c) и/или e), соответственно, посредством созревания аффинности с использованием одной или нескольких известных технологий созревания аффинности по существу.
Например, и в зависимости от организма-хозяина, используемого для экспрессии полипептида по изобретению, такие делеции и/или замены могут быть сконструированы таким образом, что один или несколько сайтов для посттрансляционной модификации (такие как один или несколько сайтов гликозилирования) удаляются, что будет в пределах компетенции специалиста в данной области.
«Семейство нанотел», «семейство VHH» или «семейство», используемое в настоящем описании, относится к группе последовательностей нанотел и/или VHH, которые имеют одинаковую длину (т.е. они имеют одинаковое количество аминокислот в своей последовательности), и из которых аминокислотная последовательность между положением 8 и положением 106 (согласно нумерации по Kabat) имеет идентичность аминокислотной последовательности 89% или более.
Термины «эпитоп» и «антигенная детерминанта», которые можно использовать взаимозаменяемо, относятся к части макромолекулы, такой как полипептид или белок, который распознается антигенсвязывающими молекулами, такими как иммуноглобулины, обычные антитела, ISV и/или или полипептиды по изобретению и, более конкретно, антигенсвязывающим сайтом указанных молекул. Эпитопы определяют минимальный сайт связывания иммуноглобулина и, таким образом, представляют собой мишень специфичности иммуноглобулина.
Часть антигенсвязывающей молекулы (такой как иммуноглобулин, обычное антитело, ISV и/или полипептид по изобретению), которая распознает эпитоп, называется «паратопом».
Аминокислотная последовательность (такая как ISV, антитело, полипептид по изобретению или, как правило, антигенсвязывающий белок или полипептид или их фрагмент), которая может «связываться» или «специфически связываться», которая «имеет аффинность к» и/или которая «обладает специфичностью» к определенному эпитопу, антигену или белку (или по меньшей мере к одной его части, фрагменту или эпитопу), называется «против» или «направлена против» указанного эпитопа, антигена или белка или является «связывающей» молекулой по отношению к такому эпитопу, антигену или белку, или, упоминается как «анти»-эпитоп, «анти»-антиген или «анти»-белок (например, «анти»-аггрекан).
Аффинность обозначает силу или стабильность молекулярного взаимодействия. Аффинность обычно задается как KD, или константа диссоциации, которая имеет единицы моль/литр (или М). Аффинность также может быть выражена как константа ассоциации KA, которая равна 1/KD и имеет единицы (моль/литр)-1 (или M-1). В настоящем описании стабильность взаимодействия между двумя молекулами будет в основном выражаться через значение KD их взаимодействия; специалисту в данной области техники ясно, что с учетом отношения KA = 1/KD, определение силы молекулярного взаимодействия по его значению KD также может быть использовано для вычисления соответствующего значения KA. Значение KD характеризует силу молекулярного взаимодействия также в термодинамическом смысле, поскольку оно связано с изменением свободной энергии (DG) связывания с помощью хорошо известного соотношения DG=RT.ln(KD) (эквивалентно DG=-RT.ln(KA)), где R - газовая постоянная, T - абсолютная температура, а ln - натуральный логарифм.
KD для биологических взаимодействий, которые считаются значимыми (например, специфическими), обычно находятся в диапазоне от 10-12 М (0,001 нМ) до 10-5 М (10000 нМ). Чем сильнее взаимодействие, тем ниже его KD.
KD также можно выразить как отношение константы скорости диссоциации комплекса, обозначенной как koff, к скорости его ассоциации, обозначенной как kon (так что KD = koff/kon и KA = kon/koff). Скорость диссоциации Koff имеет единицу измерения с-1 (где с - это единица измерения СИ для секунды). Скорость ассоциации kon есть единицы M-1с-1. Скорость ассоциации может варьировать от 102 M-1с-1 до примерно 107 M-1с-1, приближаясь к диффузионно-ограниченной константе скорости ассоциации для бимолекулярных взаимодействий. Скорость диссоциации связана с периодом полувыведения данного молекулярного взаимодействия соотношением t1/2 = ln (2)/koff. Скорость дисооциации может варьировать от 10-6с-1 (около необратимого комплекса с t1/2 нескольких дней) до 1 с-1 (t1/2 = 0,69 с).
Специфическое связывание антигенсвязывающего белка, такого как ISVD, с антигеном или антигенной детерминантой может быть определено любым подходящим способом, известным по существу, включая, например, анализы связывания с насыщением и/или анализы конкурентного связывания, такие как радиоиммуноанализы (RIA), иммуноферментные анализы (EIA) и сэндвич-конкурентные анализы и их различные варианты, известные по существу в данной области; и другие методы, упомянутые в данном документе.
Аффинность молекулярного взаимодействия между двумя молекулами может быть измерено различными способами, известными по существу, такими как хорошо известный биосенсорный метод поверхностного плазмонного резонанса (см. например, Ober et al. 2001, Intern. Immunology 13: 1551-1559), где одна молекула иммобилизована на чипе биосенсора, а другая молекула пропускается над иммобилизованной молекулой в условиях потока, что дает измерения kon, Koff и, следовательно, значения KD (или KA). Это может быть выполнено, например, с использованием хорошо известных инструментов BIACORE® (Pharmacia Biosensor AB, Упсала, Швеция). Анализ кинетического исключения (KINEXA®) (Drake et al. 2004, Analytical Biochemistry 328: 35-43) измеряет события связывания в растворе без мечения партнеров связывания и основывается на кинетическом исключении диссоциации комплекса. Анализ аффинности в растворе также можно проводить с использованием системы иммуноанализа GYROLAB®, которая обеспечивает платформу для автоматического биоанализа и быстрого анализа образцов (Fraley et al. 2013, Bioanalysis 5: 1765-74) или ELISA.
Специалисту также будет понятно, что измеренный KD может соответствовать кажущемуся KD, если процесс измерения каким-либо образом влияет на внутреннюю аффинность связывания подразумеваемых молекул, например, из-за артефактов, связанных с покрытием на биосенсоре одной молекулы. Кроме того, кажущийся KD может быть измерен, если одна молекула содержит более одного сайта узнавания для другой молекулы. В такой ситуации на измеренную аффинность может влиять авидность взаимодействия двух молекул. В частности, точное измерение KD может быть довольно трудоемким, и, как следствие, часто значения кажущегося KD определяются для оценки силы связывания двух молекул. Следует отметить, что до тех пор, пока все измерения выполняются согласованным образом (например, сохраняя неизменными условия анализа), измерения кажущегося KD можно использовать как приближение к истинному KD, и, следовательно, в данном документе следует рассматривать KD и кажущееся KD с равной важностью или актуальностью.
Термин «специфичность» относится к числу различных типов антигенов или антигенных детерминант, с которыми может связываться конкретная антигенсвязывающая молекула или антигенсвязывающий белок (такой как ISVD или полипептид по изобретению). Специфичность антигенсвязывающего белка может быть определена на основе аффинности и/или авидности, например, как описано на страницах 53-56 WO 08/020079 (включена в настоящее описание ссылкой), которая также описывает некоторые предпочтительные методики для измерения связывания между антигенсвязывающей молекулой (такой как полипептид или ISVD по изобретению) и соответствующим антигеном. Как правило, антигенсвязывающие белки (такие как ISVD и/или полипептиды по изобретению) будут связываться со своим антигеном с константой диссоциации (KD) от 10-5 до 10-12 моль/л или менее и предпочтительно 10-7 до 10-12 моль/литр или менее и более предпочтительно от 10-8 до 10-12 моль/литр (то есть с константой ассоциации (КА) от 105 до 1012 л/моль или более, и предпочтительно от 107 до 1012 л/моль или более, а более предпочтительно от 108 до 1012 л/моль). Обычно считается, что любое значение KD выше 10-4 моль/литр (или любое значение KA ниже 104 л/моль) указывает на неспецифическое связывание. Предпочтительно, одновалентный ISVD по изобретению будет связываться с желаемым антигеном с аффинностью менее 500 нМ, предпочтительно менее 200 нМ, более предпочтительно менее 10 нМ, например, менее 500 пМ, например, от 10 до 5 пМ или меньше. Также отсылаем к пункту n) на страницах 53-56 в WO 08/020079.
Считается, что ISV и/или полипептид являются «специфичными» для (первой) мишени или антигена по сравнению с другой (второй) мишенью или антигеном, когда связывается с первым антигеном с аффинностью (как описано выше, и соответственно выражается как значение KD, значение KA, скорость Koff и/или скорость Kon), которая по меньшей мере в 10 раз, например по меньшей мере в 100 раз и предпочтительно по меньшей мере в 1000 раз или более лучше, чем аффинность, с которой ISVD и/или полипептид связывается со второй мишенью или антигеном. Например, ISVD и/или полипептид может связываться с первой мишенью или антигеном со значением KD, которое по меньшей мере в 10 раз меньше, например, по меньшей мере в 100 раз меньше, и предпочтительно по меньшей мере в 1000 раз меньше или даже меньше, чем, чем KD, с которым указанный ISV и/или полипептид связывается со второй мишенью или антигеном. Предпочтительно, когда ISV и/или полипептид является «специфичным для» первой мишени или антигена по сравнению со второй мишенью или антигеном, он направлен против (как определено в данном документе) указанной первой мишени или антигена, но не направлен против указанной второй мишени или антигена.
Специфическое связывание антигенсвязывающего белка с антигеном или антигенной детерминантой может быть определено любым подходящим способом, известным по существу , включая, например, анализы связывания с насыщением и/или анализы конкурентного связывания, такие как радиоиммуноанализ (RIA), иммуноферментный анализ (EIA) и различные его варианты, известные в данной области; и другие методы, упомянутые в данном документе.
Предпочтительным подходом, который можно использовать для оценки аффинности, является процедура двухстадийного ELISA (иммуноферментного анализа) Friguet et al. 1985 (J. Immunol. Methods 77: 305-19). Этот способ устанавливает измерение равновесного связывания фазы раствора и позволяет избежать возможных артефактов, связанных с адсорбцией одной из молекул на подложке, такой как пластик. Как будет понятно специалисту в данной области, константа диссоциации может быть фактической или кажущейся константой диссоциации. Способы определения константы диссоциации будут понятны специалисту в данной области и, например, включают методики, упомянутые на страницах 53-56 в WO 08/020079.
Наконец, следует отметить, что во многих ситуациях опытный ученый может посчитать удобным определить аффинность связывания относительно некоторой стандартной молекулы. Например, чтобы оценить силу связывания между молекулами А и В, можно, например, использовать стандартную молекулу C, которая, как известно, связывается с B и которая соответствующим образом помечена флуорофорной или хромофорной группой или другим химическим фрагментом, таким как биотин, для легкого обнаружения в ELISA или FACS (флуоресцентно-активируемая сортировка клеток) или в другом формате (флуорофор для определения флуоресценции, хромофор для определения поглощения света, биотин для стрептавидин-опосредованного определения ELISA). Как правило, стандартную молекулу C поддерживают при фиксированной концентрации, и концентрация A варьируется для данной концентрации или количестве B. В результате получается значение IC50, соответствующее концентрации A, при которой измеряется сигнал для C в отсутствие А, уменьшается вдвое. При условии, что KD ref, KD стандартной молекулы, известен, а также общая концентрация Cref стандартной молекулы, кажущийся KD для взаимодействия A-B можно получить из следующей формулы: KD =IC50/(1+cref/ KDref). Обратите внимание, что если cref << KD ref, KD ≈ IC50. При условии, что измерение IC50 выполняется согласованным образом (например, сохранение cref фиксированным) для сравниваемых связующих, различие в силе или стабильности молекулярного взаимодействия может быть оценено путем сравнения IC50, и это измерение оценивается как эквивалентное KD или кажущемуся KD по всему тексту.
Полумаксимальная ингибирующая концентрация (IC50) также может быть мерой эффективности соединения в ингибировании биологической или биохимической функции, например, фармакологического эффекта. Эта количественная мера показывает, сколько полипептида или ISV (например, нанотела) необходимо для ингибирования данного биологического процесса (или компонента процесса, т.е. фермента, клетки, клеточного рецептора, хемотаксиса, анаплазии, метастазирования, инвазивности и т.д.) вдвое. Другими словами, это половина максимальной (50%) ингибирующей концентрации (IC) вещества (50% IC или IC50). Значения IC50 могут быть рассчитаны для данного антагониста, такого как полипептид или ISV (например, нанотела) по изобретению, путем определения концентрации, необходимой для ингибирования половины максимального биологического ответа агониста. KD лекарственного средства может быть определено путем построения кривой доза-эффект и изучения влияния различных концентраций антагониста, такого как полипептид или ISV (например, нанотел) по настоящему изобретению, на изменение активности агониста.
Термин половинная максимальная эффективная концентрация (ЕС50) относится к концентрации соединения, которая вызывает реакцию на полпути между исходным уровнем и максимумом после определенного времени воздействия. В настоящем контексте этот термин используется в качестве меры активности полипептида, ISV (например, нанотела). ЕС50 кривой постепенного изменения дозы представляет собой концентрацию соединения, при которой наблюдается 50% его максимального эффекта. Концентрация предпочтительно выражается в молярных единицах.
В биологических системах небольшие изменения в концентрации лиганда обычно приводят к быстрым изменениям ответа, исходя из сигмоидальной функции. Точка перегиба, в которой увеличение реакции с увеличением концентрации лиганда начинает замедляться, - это EC50. Она может быть определена математически путем выведения наиболее подходящей линии. Полагаться на график для оценки удобно в большинстве случаев. В случае если EC50 указан в разделе примеров, эксперименты были разработаны так, чтобы максимально точно отразить KD. Другими словами, значения EC50 могут затем рассматриваться как значения KD. Термин «средний KD» относится к среднему значению KD, полученному по меньшей мере в 1, но предпочтительно более чем в 1, например по меньшей мере в 2 экспериментах. Термин «средний» относится к математическому термину «средний» (суммы данных, деленные на количество элементов в данных).
Это также относится к IC50, который является мерой ингибирования соединения (ингибирование 50%). Для анализов конкурентного связывания и анализов функциональных антагонистов IC50 является наиболее распространенным суммарным показателем кривой доза-ответ. Для анализов агонистов/стимуляторов наиболее распространенной суммарной мерой является EC50.
Константа ингибирования (Ki) является показателем того, насколько сильным является ингибитор; это концентрация, необходимая для получения половины максимального ингибирования. В отличие от IC50, который может изменяться в зависимости от условий эксперимента, Ki является абсолютной величиной и часто упоминается как константа ингибирования лекарственного средства. Константу ингибирования Ki можно рассчитать с использованием уравнения Ченга-Прусоффа:
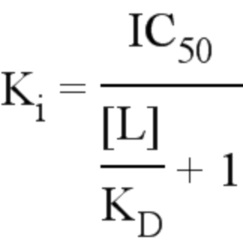
в котором [L] является фиксированной концентрацией лиганда.
Считается, что ISV и/или полипептид являются «специфичными» для (первой) мишени или антигена по сравнению с другой (второй) мишенью или антигеном, когда он связывается с первым антигеном с аффинностью (как описано выше, и соответственно выражается как значение KD, значение KA, скорость Koff и/или скорость Kon), которая по меньшей мере в 10 раз, например по меньшей мере в 100 раз и предпочтительно по меньшей мере в 1000 раз или более лучше, чем аффинность, с которой ISV и/или полипептид связывается со второй мишенью или антигеном. Например, ISV и/или полипептид может связываться с первой мишенью или антигеном со значением KD, которое по меньшей мере в 10 раз меньше, например, по меньшей мере в 100 раз меньше, и предпочтительно по меньшей мере в 1000 раз меньше или даже меньше, чем, чем KD, с которым указанный ISV и/или полипептид связывается со второй мишенью или антигеном. Предпочтительно, когда ISV и/или полипептид является «специфичным для» первой мишени или антигена по сравнению со второй мишенью или антигеном, он направлен против (как определено в данном документе) указанной первой мишени или антигена, но не направлен против указанной второй мишени или антигена.
Термины «(перекрестная) блокировка», «(перекрестно) блокированный», «(перекрестное) блокирование», «конкурентное связывание», «(перекрестно)-конкурировать», «(перекрестно)-конкурирующий» и «(перекрестная) конкуренция» используемые взаимозаменяемо в данном документе, означают способность иммуноглобулина, антитела, иммуноглобулинового одиночного вариабельного домена, полипептида или другого связывающего агента вмешиваться в связывание других иммуноглобулинов, антител, иммуноглобулиновых одиночных вариабельных доменов, полипептидов или связывающих агентов с заданной мишенью. Степень, в которой иммуноглобулин, антитело, ISV, полипептид или другой связывающий агент способны влиять на связывание другого с мишенью, и, следовательно, можно ли сказать, что он перекрестно блокируется в соответствии с изобретением, может определяться с помощью конкурентных анализов, которые общеизвестны в данной области. Особенно подходящие количественные анализы перекрестной блокировки включают ELISA и анализ связывания с активированной флуоресценцией (FACS) с аггреканом, экспрессированным на клетках. В настройках FACS степень (перекрестного) блокирования может быть измерена по (уменьшенной) флуоресценции канала.
Способы определения того, способен ли иммуноглобулин, антитело, ISV, полипептид или другой связывающий агент, направленный против мишеней (перекрестно)-блокировать, конкурентно связывается или является (перекрестно)-конкурирующим, как определено в данном документе, например, описаны в Xiao-Chi Jia et al. (Journal of Immunological Methods 288: 91-98, 2004), Miller et al. (Journal of Immunological Methods 365: 118-125, 2011) и/или способах, описанных в данном документе (см., например, Пример 2.3).
Говорят, что аминокислотная последовательность является «перекрестно-реактивной» для двух разных антигенов или антигенных детерминант (таких как, например, аггрекан от различных видов млекопитающих, таких как, например, аггрекан человека, аггрекан собаки, аггрекан коровы, аггрекан крысы, аггрекан свиньи, аггрекан мыши, аггрекан кролика, аггрекан яванского макака и/или аггрекан макака-резуса), если он специфичен (как определено в данном документе) к этим различным антигенам или антигенным детерминантам.
В контексте настоящего изобретения «модулирование» или «модуляция» обычно означает снижение или ингибирование активности представителя семейства сериновых протеаз, катепсинов, матриксных металлопротеиназ (ММР)/матриксинов или дезинтегрина и металлопротеиназы с мотивом тромбоспондина (ADAMTS), предпочтительно MMP8, MMP13, MMP19, MMP20, ADAMTS5 (аггреканазы-2), ADAMTS4 (аггреканазы-1), ADAMTS11 и/или провоспалительных цитокинов, такие как, например, интерлейкин-1α и -β, интерлейкина-6 и TNF-α с помощью ISV, полипептида или конструкции по изобретению, измеренное с использованием подходящего анализа in vitro, клеточного анализа, анализа ex vivo или in vivo (например, упомянутые в данном документе). В частности, «модулирование» или «модулировать» может означать либо уменьшение, либо ингибирование активности вышеупомянутых представителей, измеренную с использованием подходящего анализа in vitro, клеточного анализа, анализа ex vivo или in vivo (такого как упомянутые в данном документе) по меньшей мере на 1%, предпочтительно по меньшей мере 5%, например по меньшей мере 10% или по меньшей мере 25%, например по меньшей мере на 50% по меньшей мере на 60% по меньшей мере на 70% по меньшей мере на 80% или на 90% или более, по сравнению с активностью вышеупомянутых представителей в том же анализе в тех же условиях, но без присутствия иммуноглобулина или полипептида по изобретению.
В контексте настоящего изобретения «усиление» или «усилить» обычно означает увеличение, потенциирование или стимуляцию активности полипептидов или конструкций по изобретению, измеренное с использованием подходящего анализа in vitro, клеточного анализа, анализа ex vivo или in vivo (такого как упомянутые в данном документе). В частности, повышение или усиление активности полипептида или конструкции по изобретению, как измерено с использованием подходящего анализа in vitro, клеточного анализа, анализа ex vivo или in vivo (такого как упомянутые в данном документе) по меньшей мере на 5%, предпочтительно по меньшей мере 10%, минимум 15%, минимум 20%, минимум 25%, минимум 30%, минимум 35%, минимум 40%, минимум 45%, минимум 50%, минимум 55%, минимум 60% по меньшей мере 65% по меньшей мере 70% по меньшей мере 75% по меньшей мере 80% по меньшей мере 85% по меньшей мере 90% по меньшей мере 95% или более, например, 100%, по сравнению с активностью конструкции или полипептида в том же анализе в тех же условиях, но без присутствия агента, связывающего аггрекан, например, ISV, связывающего аггрекан, по изобретению.
«Синергетический эффект» двух соединений представляет собой эффект, при котором эффект комбинации двух агентов больше, чем сумма их индивидуальных эффектов, и предпочтительно статистически отличается от стандарта и отдельных лекарственных средств.
Используемый в данном документе термин «активность» ISV или полипептида по изобретению является функцией количества ISV или полипептида по изобретению, необходимого для его специфического эффекта, такого как, например, проникновение в хрящ, специфическое связывание с аггреканом и/или удержание в хряще. Ее можно измерить просто способами, известными специалисту в данной области, и, например, такими, которые используются в разделе Примеров.
Напротив, «эффективность» ISV или полипептида по изобретению измеряет максимальную силу самого эффекта при насыщении концентраций ISV или полипептида. Эффективность указывает на максимальный ответ, достижимый от ISV или полипептида по изобретению. Это относится к способности ISV или полипептида производить желаемый (терапевтический) эффект, такой как, например, связывание с аггреканом или удержание аггрекана и/или ингибирование активности представителя семейства ADAMTS или представителя семейства MMP.
«Период полувыведения» полипептида или конструкции по изобретению относится ко времени, которое требуется для снижения концентрации сыворотки конструкции или полипептида на 50% in vivo, например, из-за деградации конструкции или полипептида и/или клиренса или секвестрации конструкции или полипептида с помощью природных механизмов, см., например, абзац о) на стр. 57 в WO 08/020079. Период полувыведения in vivo конструкции или полипептида по изобретению может быть определен любым известным способом, таким как фармакокинетический анализ. Подходящие методики будут понятны специалисту в данной области техники и могут, например, в целом соответствовать описанному в абазце о) на странице 57 в WO 08/020079. Как также упомянуто в абзаце o) на странице 57 в WO 08/020079, период полувыведения может быть выражен с использованием таких параметров, как t1/2-альфа, t1/2-бета и площадь под кривой (AUC). Источниками могут служить, например, стандартные справочники, такие как Kenneth et al. (Chemical Stability of Pharmaceuticals: A Handbook for Pharmacists, John Wiley & Sons Inc, 1986) и M Gibaldi and D Perron ("Pharmacokinetics", Marcel Dekker, 2nd Rev. Edition, 1982). Термины «увеличение периода полувыведения» или «увеличенный период полувыведения» относятся к увеличению t1/2-бета, либо с увеличением или без увеличения t1/2-альфа и/или AUC, либо с обоими, например, как описано в абзаце о) на стр. 57 в WO 08/020079.
Если не указано иное, термины «иммуноглобулин» и «последовательность иммуноглобулина» - вне зависимости, используются ли они в данном документе для обозначения антитела, состоящего только из тяжелых цепей, или обычного антитела с 4 цепями - используются в качестве общего термина для включения как полноразмерного антитела, так и его отдельных цепей, а также всех частей, доменов или их фрагментов (включая, без ограничения указанным, антигенсвязывающие домены или фрагменты, такие как домены VHH или домены VH/VL, соответственно).
Используемый в данном документе термин «домен» (полипептида или белка) относится к структуре свернутого белка, которая обладает способностью сохранять свою третичную структуру независимо от остальной части белка. Как правило, домены ответственны за дискретные функциональные свойства белков, и во многих случаях могут быть добавлены, удалены или перенесены в другие белки без потери функции остальной части белка и/или домена.
Используемый в данном документе термин «иммуноглобулиновый домен» относится к глобулярной области цепи антитела (такой как, например, цепь обычного 4-цепочечного антитела или антитела тяжелой цепи) или к полипептиду, который по существу состоит из такой глобулярной области. Иммуноглобулиновые домены характеризуются тем, что они сохраняют иммуноглобулиновое сворачивание, характерное для молекул антител, которое представлено двухслойным сэндвича из около семи антипараллельных бета-нитей, расположенных в двух бета-листах, необязательно стабилизированных консервативной дисульфидной связью.
Используемый в данном документе термин «иммуноглобулиновый вариабельный домен» означает иммуноглобулиновый домен, по существу состоящий из четырех «каркасных областей», которые упоминаются в данной области и в данном документе ниже как «каркасная область 1» или «FR1»; как «каркасная область 2» или «FR2»; как «каркасная область 3» или «FR3»; и как «каркасная область 4» или «FR4», соответственно; при этом каркасные области прерываются тремя «определяющими комплементарность областями» или «CDR», которые упоминаются в данной области и ниже, как «область 1 определения комплементарности» или «CDR1»; как «область 2 определения комплементарности» или «CDR2»; и как «область 3 определения комплементарности» или «CDR3», соответственно. Таким образом, общая структура или последовательность вариабельного домена иммуноглобулина может быть указана следующим образом: FR1 - CDR1 - FR2 - CDR2 - FR3 - CDR3 - FR4. Он является вариабельным доменом (или доменами) иммуноглобулина, который придает специфичность антитела к антигену, поскольку заключает в себе антигенсвязывающий сайт.
Термин «иммуноглобулиновый одиночный вариабельный домен» («ISV» или «ISVD»), взаимозаменяемо используемый с «одиночным вариабельным доменом», определяет молекулы, в которых сайт связывания антигена присутствует и образован одиночным иммуноглобулиновым доменом. Это ставит ISV отдельно от «обычных» иммуноглобулинов или их фрагментов, в которых два иммуноглобулиновых домена, в частности два вариабельных домена, взаимодействуют с образованием антигенсвязывающего сайта. Как правило, в обычных иммуноглобулинах вариабельный домен тяжелой цепи (VH) и вариабельный домен легкой цепи (VL) взаимодействуют с образованием сайта связывания антигена. В этом случае определяющие комплементарность области (CDR) как VH, так и VL, будут способствовать созданию сайта связывания антигена, т.е. в создании антигенсвязывающего сайта будет задействовано в общей сложности 6 CDR.
Ввиду вышеприведенного определения антигенсвязывающий домен обычного антитела из 4 цепей (такого как молекула IgG, IgM, IgA, IgD или IgE; известного в данной области) или фрагмента Fab, фрагмента F(ab')2, фрагмента Fv, такого как связанный с дисульфидом Fv или scFv-фрагмент, или диатела (все известные в данной области), полученный из такого обычного антитела из 4 цепей, обычно не считаются иммуноглобулиновым одиночным вариабельным доменом, поскольку, в этих случаях, связывание с соответствующим эпитопом антигена обычно осуществляется не одним (одиночным) иммуноглобулиновым доменом, а парой (ассоциированных) доменов иммуноглобулина, таких как вариабельные домены легкой и тяжелой цепи, т.е. с помощью VH-VL-пары иммуноглобулиновых доменов, которые совместно связываются с эпитопом соответствующего антигена.
Напротив, ISV способны специфически связываться с эпитопом антигена без спаривания с дополнительным иммуноглобулиновым вариабельным доменом. Сайт связывания ISV образован одним доменом VH/VHH или VL. Следовательно, сайт связывания антигена ISV образуется не более чем тремя CDR.
Таким образом, одиночный вариабельный домен может представлять собой последовательность вариабельной области легкой цепи (например, VL- последовательность) или ее подходящий фрагмент; или последовательность вариабельной области тяжелой цепи (например, VH-последовательность или VHH-последовательность) или ее подходящий фрагмент; поскольку такой домен способен образовывать одиночную антигенсвязывающую единицу (т.е. функциональную антигенсвязывающую единицу, которая по существу состоит из одного вариабельного домена, так что одному антигенсвязывающему домену не требуется взаимодействовать с другим вариабельным доменом для образования функциональной антигенсвязывающей единицы).
В одном воплощении изобретения ISV представляют собой последовательности вариабельного домена тяжелой цепи (например, VH-последовательность); более конкретно, иммуноглобулиновые одиночные вариабельные домены могут представлять собой последовательности вариабельного домена тяжелой цепи, которые получены из обычного четырехцепочечного антитела, или последовательности вариабельного домена тяжелой цепи, которые получены из антитела на основе только тяжелой цепи.
Например, иммуноглобулиновый одиночный вариабельный домен может быть антителом из (одиночного) домена (или аминокислотой, подходящей для применения в качестве антитела из (одиночного) домена), «dAb» или dAb (или аминокислотой, которая подходит для применения в качестве dAb) или нанотелом (как определено в данном документе и включая, без ограничения указанным, VHH); другими одиночными вариабельными доменами или любым подходящим фрагментом любого из них.
В частности, иммуноглобулиновый одиночный вариабельный домен может быть Нанотелом® (как определено в данном документе) или его подходящим фрагментом. [Примечание: Нанотело® и Нанотела® являются зарегистрированными товарными знаками Ablynx N.V.]. Для общего описания нанотел настоящим можно сослаться на последующее описание, а также на предшествующий уровень техники, упомянутый в данном документе, например, описанный в WO 08/020079 (стр. 16).
«VHH-домены», также известные как VHH, VHH-домены, антительные фрагменты VHH и VHH-антитела, первоначально были описаны как антигенсвязывающий иммуноглобулиновый (вариабельный) домен «антител, состоящих только из тяжелой цепи» (т.е. «антител, лишенных легких цепей», Hamers-Casterman et al. Nature 363: 446-448, 1993). Термин «домен VHH» был выбран для того, чтобы отличать эти вариабельные домены от вариабельных доменов тяжелой цепи, которые присутствуют в обычных антителах из 4 цепей (которые упоминаются в данном документе как «VH-домены» или «VH-домены») и от вариабельных доменов легкой цепи, которые присутствуют в обычных антителах из 4 цепей (которые называются в данном документе «VL-доменами» или «VL-доменами»). Дальнейшее описание VHH и нанотел см. в обзорной статье Muyldermans (Reviews in Molecular Biotechnology 74: 277-302, 2001), а также в следующих патентных заявках, которые упоминаются в качестве предшествующего уровня техники: WO 94/04678, WO 95/04079 и WO 96/34103 от Vrije Universiteit Brussel; WO 94/25591, WO 99/37681, WO 00/40968, WO 00/43507, WO 00/65057, WO 01/40310, WO 01/44301, EP 1134231 и WO 02/48193 от Unilever; WO 97/49805, WO 01/21817, WO 03/035694, WO 03/054016 и WO 03/055527 от Vlaams Instituut voor Biotechnologie (VIB); WO 03/050531 от Algonomics N.V. и Ablynx N.V.; WO 01/90190 от Национального исследовательского совета Канады; WO 03/025020 (= EP 1433793) от Института антител; и WO 04/041867, WO 04/041862, WO 04/041865, WO 04/041863, WO 04/062551, WO 05/044858, WO 06/40153, WO 06/079372, WO 06/122786, WO 06/122787 и WO 06/122825 от Ablynx N.V. и дальнейших опубликованных патентных заявках от Ablynx N.V. Также можно сделать отсылку на дополнительный предшествующий уровень техники, упомянутый в этих заявках и, в частности, на список литературы, упомянутый на страницах 41-43 Международной заявки WO 06/040153, перечень и источники которой включены в данный документ ссылкой. Как описано в этих источниках, ISV, нанотела (в частности, последовательности VHH и частично гуманизированные нанотела), в частности, могут быть охарактеризованы наличием одного или нескольких «характерных остатков» в одной или нескольких каркасных последовательностях. Дальнейшее описание ISV, нанотел, включая гуманизацию и/или оверблюживание нанотел, а также другие модификации, части или фрагменты, производные или «молекулы на основе слияния с нанотелами», мультивалентные конструкции (включая некоторые неограничивающие примеры линкерных последовательностей) и различные модификации для увеличения периода полувыведения ISV, нанотел и их составов с ними, можно найти, например, в WO 08/101985 и WO 08/142164. Для дальнейшего общего описания нанотел настоящим ссылаемся на предшествующий уровень техники, процитированный в данном документе, такой как, например, описанный в WO 08/020079 (стр. 16).
«Доменные антитела», также известные как «Dab», «Доменные Антитела» и «dAb» (термины «Доменные Антитела» и «dAb», используются в качестве товарных знаков группой GlaxoSmithKline) были описаны, например, в EP 0368684, Ward et al. (Nature 341: 544-546, 1989), Holt et al. (Tends in Biotechnology 21: 484-490, 2003) и WO 03/002609, а также, например, в WO 04/068820, WO 06/030220, WO 06/003388 и других опубликованных патентных заявках Domantis Ltd. Доменные антитела, по существу, соответствуют VH или VL-доменам млекопитающих, отличных от верблюдовых, в частности, из человеческих антител с 4 цепями. Для связывания эпитопа в качестве одиночного антигенсвязывающего домена, т.е. без сопряжения с VL или VH-доменом, соответственно, требуется специфический отбор таких антигенсвязывающих свойств, например, с использованием библиотек последовательностей одиночных VH- или VL-доменов человека. Доменные антитела имеют, подобно VHH, молекулярную массу от около 13 до около 16 кДа и, если они получены из полностью человеческих последовательностей, не требуют гуманизации, например, для терапевтического применения у людей.
Следует также отметить, что отдельные вариабельные домены могут быть получены из некоторых видов акул (например, так называемые «домены IgNAR», см. например, WO 05/18629), хотя это менее предпочтительно в контексте настоящего изобретения, поскольку они происходят не из млекопитающих.
Таким образом, по смыслу настоящего изобретения термин «иммуноглобулиновый одиночный вариабельный домен» или «одиночный вариабельный домен» включает полипептиды, которые получены из источника, не являющегося человеком, предпочтительно верблюда, предпочтительно верблюжьего антитела на основе только тяжелой цепи. Они могут быть гуманизированы, как описано выше. Кроме того, этот термин включает полипептиды, полученные из источников, не являющихся верблюдовыми, например, мыши или человека, которые были «оверблюжены», как, например, описано в Davies and Riechmann (FEBS 339: 285-290, 1994; Biotechnol. 13: 475-479, 1995; Prot. Eng. 9: 531-537, 1996) и Riechmann and Muyldermans (J. Immunol. Methods 231: 25-38, 1999).
Аминокислотные остатки домена VHH пронумерованы в соответствии с общей нумерацией для доменов VH, приведенной в Kabat et al. ("Sequence of proteins of immunological interest", US Public Health Services, NIH Bethesda, MD, Publication No. 91), применительно к доменам VHH верблюдовых, как показано, например, на фигуре 2 в Riechmann and Muyldermans (J. Immunol. Methods 231: 25-38, 1999). Альтернативные способы нумерации аминокислотных остатков доменов VH, которые также могут быть применены аналогичным образом к доменам VHH, известны в данной области. Однако в настоящем описании, пунктах формулы и фигурах, будет соблюдаться нумерация согласно Kabat применимая к доменам VHH, как описано выше, если не указано иное.
Следует отметить, что - как хорошо известно в данной области для доменов VH и для доменов VHH - общее количество аминокислотных остатков в каждом из CDR может изменяться и может не соответствовать общему количеству аминокислотных остатков, указанному нумерацией Kabat (т.е. одно или несколько положений в соответствии с нумерацией Kabat могут быть не заняты в реальной последовательности, или фактическая последовательность может содержать больше аминокислотных остатков, чем число, допустимое нумерацией Kabat). Это означает, что, как правило, нумерация по Kabat может соответствовать или не соответствовать фактической нумерации аминокислотных остатков в фактической последовательности. Общее количество аминокислотных остатков в домене VH и домене VHH обычно будет находиться в диапазоне от 110 до 120, часто от 112 до 115. Следует, однако, отметить, что менее и более длинные последовательности также могут быть пригодны для целей, описанных в данном документе.
Определение областей CDR также может быть выполнено в соответствии с различными способами. В определении CDR согласно Kabat FR1 из VHH включает аминокислотные остатки в положениях 1-30, CDR1 из VHH включает аминокислотные остатки в положениях 31-35, FR2 из VHH включает аминокислоты в положениях 36- 49, CDR2 из VHH включает аминокислотные остатки в положениях 50-65, FR3 из VHH включает аминокислотные остатки в положениях 66-94, CDR3 из VHH включает аминокислотные остатки в положениях 95-102 и FR4 из VHH включает аминокислотные остатки в положениях 103-113.
Однако в настоящей заявке последовательности CDR были определены в соответствии с Kontermann и  (Eds., Antibody Engineering, vol 2, Springer Verlag Heidelberg Berlin, Martin, Chapter 3, pp. 33-51, 2010). Согласно этому способу FR1 включает аминокислотные остатки в положениях 1-25, CDR1 включает аминокислотные остатки в положениях 26-35, FR2 включает аминокислоты в положениях 36-49, CDR2 включает аминокислотные остатки в положениях 50-58, FR3 включает аминокислотные остатки в положениях 59-94, CDR3 включает аминокислотные остатки в положениях 95-102, а FR4 включает аминокислотные остатки в положениях 103-113 (по нумерации Kabat).
(Eds., Antibody Engineering, vol 2, Springer Verlag Heidelberg Berlin, Martin, Chapter 3, pp. 33-51, 2010). Согласно этому способу FR1 включает аминокислотные остатки в положениях 1-25, CDR1 включает аминокислотные остатки в положениях 26-35, FR2 включает аминокислоты в положениях 36-49, CDR2 включает аминокислотные остатки в положениях 50-58, FR3 включает аминокислотные остатки в положениях 59-94, CDR3 включает аминокислотные остатки в положениях 95-102, а FR4 включает аминокислотные остатки в положениях 103-113 (по нумерации Kabat).
ISV, такие как доменные антитела и нанотела (включая домены VHH), могут быть подвергнуты гуманизации. В частности, гуманизированные иммуноглобулиновые одиночные вариабельные домены, такие как нанотела (включая VHH-домены), могут быть иммуноглобулиновыми одиночными вариабельными доменами, которые, как правило, определены в предыдущих абзацах, но в которых присутствует по меньшей мере один аминокислотный остаток (и, в частности по меньшей мере один из остатков каркаса), который является и/или соответствует гуманизирующей замене (как определено в данном документе). Потенциально полезные гуманизирующие замены могут быть установлены путем сравнения последовательности каркасных областей встречающейся в природе последовательности VHH с соответствующей каркасной последовательностью одной или нескольких близко родственных человеческих последовательностей VH, после чего одна или несколько из потенциально полезных гуманизирующих замен (или их комбинации), определенные таким образом, могут быть введены в указанную последовательность VHH (любым способом, известным по существу, как дополнительно описано в данном документе), и полученные гуманизированные последовательности VHH можно проверить на аффинность к мишени, на стабильность, на легкость и уровень экспрессии и/или на другие искомые свойства. Таким образом, с помощью ограниченной степени проб и ошибок другие подходящие гуманизирующие замены (или их подходящие сочетания) могут быть определены специалистом в данной области на основании раскрытого в данном документе описания. Кроме того, на основании вышеизложенного (каркасные области) иммуноглобулинового одиночного вариабельного домена, такого как Нанотело (включая домены VHH), могут быть частично гуманизированы или полностью гуманизированы.
ISV, такие как доменные антитела и Нанотела (включая домены VHH и гуманизированные домены VHH), также могут быть подвергнуты созреванию аффинности путем введения одного или нескольких изменений в аминокислотной последовательности одного или нескольких CDR, причем эти изменения приводят к улучшению аффинности полученного в результате иммуноглобулинового одиночного вариабельного домена к его соответствующему антигену по сравнению с соответствующей исходной молекулой. Молекулы иммуноглобулинновых одиночных вариабельных доменов с созревшей аффинностью по изобретению могут быть получены способами, известными в данной области, например, как описано Marks et al. (Biotechnology 10: 779-783, 1992), Barbas et al. (Proc. Nat. Acad. Sci, USA 91: 3809-3813, 1994), Shier et al. (Gene 169: 147-155, 1995), Yelton et al. (Immunol. 155: 1994-2004, 1995), Jackson et al. (J. Immunol. 154: 3310-9, 1995), Hawkins et al. (J. MoI. Biol. 226: 889 896, 1992), Johnson and Hawkins (Affinity maturation of antibodies using phage display, Oxford University Press, 1996).
Процесс конструирования/выбора и/или получения полипептида, начиная с ISV, такого как доменное антитело или нанотело, также называют в данном документе «форматированием» указанного ISV; и считается, что ISV, который является частью полипептида, «отформатирован» или находится «в формате» указанного полипептида. Примеры способов, в которых может быть отформатирован ISV, и примеры таких форматов будут понятны специалисту в данной области на основе раскрытия в данном документе; и такой форматированный ISV образует дополнительный аспект изобретения.
Например, и без ограничения указанным, один или несколько иммуноглобулиновых одиночных вариабельных доменов можно использовать в качестве «связывающей единицы», «связывающего домена» или «структурного элемента» (эти термины используются взаимозаменяемо) для получения полипептида, который может необязательно содержит один или несколько дополнительных ISV, которые могут служить связывающей единицей (т.е. против того же или другого эпитопа на аггрекане и/или против одного или нескольких других антигенов, белков или мишеней, отличных от аггрекана).
Настоящее изобретение предлагает агенты, связывающие аггрекан, такие как ISV (также называемые в данном документе «ISV по изобретению») и/или полипептиды (также называемые в данном документе «полипептиды по изобретению»), которые обладают специфичностью и/или связывают аггрекан.
Аггрекан также известен как аггрекан 1, ACAN, AGC1, AGCAN, CSPGCP, MSK16, SEDK, хрящ-специфический протеогликановый основной белок (CSPCP) или хондроитинсульфат протеогликан 1 (CSPG1). Аггрекан у людей кодируется геном ACAN, который находится в хромосоме Chr 15: q26.1.
Аггрекан - большая мультимодульная молекула (2317 аминокислот). Его основной белок состоит из трех глобулярных доменов (G1, G2 и G3) и большой протяженной области (CS) между G2 и G3, к которой присоединено множество N-связанных олигосахаридов и хондроитинсульфатных цепей и кератансульфатных цепей. Аггрекан является основным протеогликаном в суставном хряще. Он играет важную роль в правильном функционировании суставного хряща, обеспечивая гидратированную структуру геля за счет его взаимодействия с гиалуронаном и связывающими белками, что наделяет хрящ несущими свойствами. Домен G1 взаимодействует с гиалуроновой кислотой и связывает белки, образуя стабильные тройные комплексы во внеклеточном матриксе (ЕСМ). Домен G2 гомологичен тандемным повторам G1 и связывающим белкам и участвует в обработке продукта. G3 составляет карбоксильный конец основного белка и усиливает модификацию гликозаминогликана и секрецию продукта. Кроме того, домен G3 связывает агрегаты протеогликана с белками ЕСМ (фибулинами и тенасцинами). Деградация аггрекана, по-видимому, начинается на С-конце. Популяция молекул аггрекана без домена G3 увеличивается с возрастом. Аггрекан взаимодействует с ламинином, фибронектином, тенасцином и коллагеном, но он также является ферментативным субстратом различных дезинтегринов и металлопротеаз с мотивами тромбо-спондина (ADAMTS), таких как ADAMTS4, ADAMTS5 и ADAMTS11, и матриксных металло-протеиназ (MMP), таких как MMP8, MMP13, MMP19 и MMP20.
В одном аспекте изобретение относится к агентам, связывающим аггрекан, таким как ISV и полипептиды, которые специфически связывают аггрекан.
Агенты, связывающие аггрекан, по изобретению в конечном итоге предназначены для применения в качестве лекарственных средств у людей. Соответственно, в одном аспекте изобретение относится к агентам, связывающим аггрекан, таким как ISV и полипептиды, которые специфически связывают аггрекан человека (SEQ ID NO: 125).
Авторы изобретения идентифицировали агенты, связывающие аггрекан, со значительноо улучшенной межвидовой перекрестной реактивностью и исключительными свойствами селективности.
Соответственно, в одном аспекте изобретение относится к агенту, связывающему аггрекан, такому как ISV или полипептид, где указанный агент, связывающий аггрекан, специфически связывается с аггреканом человека (P16112; SEQ ID NO: 125), аггреканом собаки (Q28343; SEQ ID NO: 126), аггреканом коровы (P13608; SEQ ID NO: 127), аггреканом крысы (P07897; SEQ ID NO: 128), аггреканом свиньи (ядро; Q29011, SEQ ID NO: 129); аггреканом мыши (Q61282; SEQ ID NO: 130), аггреканом кролика (G1U677-1; SEQ ID NO: 131), аггреканом яванскгого макака (XP_005560513.1; SEQ ID NO: 132) и/или аггреканом макака-резуса (XP_002804990.1; SEQ ID NO: 133) (см. также Таблицу B).
Авторы настоящего изобретения неожиданно обнаружили, что агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды по изобретению, имеют благоприятные характеристики по сравнению с молекулами предшествующего уровня техники; они стабильны в суставах, они сохраняются в хряще в течение продолжительного времени и специфичны для хрящевой ткани, например, по существу не связываются с нейроканом (O14594, SEQ ID NO: 134) и/или бревиканом (Q96GW7, SEQ ID NO: 135) (см. также Таблицу B).
Соответственно, в одном аспекте изобретение относится к агенту, связывающему аггрекан, такому как ISV или полипептид, который по существу не связывается с нейроканом (O14594, SEQ ID NO: 134) и/или бревиканом (Q96GW7, SEQ ID NO: 135), предпочтительно, где указанный аггрекан связывается с нейроканом и/или бревиканом со значением KD, превышающим 10-5 моль/литр, таким как 10-4 моль/литр.
В одном аспекте изобретение относится к агенту, связывающему аггрекан, такому как ISV, где имеет более чем 10-кратную, более чем 100-кратную, предпочтительно более 1000-кратную селективность по сравнению с нейроканом и/или бревиканом при связывании с аггреканом.
Предпочтительные агенты по изобретению, связывающие аггрекан, включают иммуноглобулины (такие как антитела, состоящие только из тяжелой цепи, обычные 4-цепочечные антитела (такие как молекулы IgG, IgM, IgA, IgD или IgE), фрагменты Fab, фрагменты F (ab')2, фрагменты Fv, такие как дисульфид-связанные Fv или фрагменты scFv или диатела, полученные из такого обычного 4-цепочечного антитела, его отдельных цепей, а также всех их частей, доменов или фрагментов (включая, без ограничения указанным, антигенсвязывающие домены или фрагменты, такие как иммуноглобулиновые одиночные вариабельные домены), одновалентные полипептиды по изобретению или другие связывающие агенты).
Замечено, что агенты по изобретению, связывающие аггрекан, имели pI более 8, только с одним исключением (см. также Таблицу 2.2). Не ограничиваясь какой-либо теорией, авторы настоящего изобретения выдвинули гипотезу о том, что высокий положительный заряд аггрекана может влиять на задержку и проникновение в хрящ всей группы, то есть даже в сочетании с другим структурным блоком, как в мультиспецифическом полипептиде. Соответственно, настоящее изобретение относится к агенту, связывающему аггрекан, такому как ISV, полипептид или конструкция по изобретению, предпочтительно ISV по изобретению, с pI более 8, таким как 8,1, 8,2, 8,3, 8,4, 8,5, 8,6, 8,7, 8,8, 8,9, 9,0 или даже больше, например, 9,1, 9,2, 9,3, 9,4, 9,5, 9,6, 9,7, 9,8 или даже 9,8.
Связывание агентов по изобретению, связывающих аггрекан, таких как ISV и/или полипептиды по изобретению, с аггреканом можно измерить в различных анализах связывания, обычно известных в данной области. Типичные анализы включают (без ограничения) анализы связывания флуоресцентного лиганда, флуоресцентно-активированную сортировку клеток (FACS), анализы связывания радиолиганда, поверхностный плазмонный резонанс (SPR), плазмонно-волноводный резонанс (PWR), SPR-визуализацию для биосенсоров на основе аффинности, микрорезонатор с модами шепчущей галереи (WGM), резонансную волноводную решетку (RWG), биослойную интерферометрию, биосенсор (BIB), ядерно-магнитный резонанс (NMR), рентгеновскую кристаллографию, термическую денатурацию (TDA), изотермическую титрационную калориметрию (ITC), ELISA и т.д. анализы связывания клеточного лиганда, такие как биосенсор поверхностной акустической волны (SAW) и биосенсорный анализ RWG. Предпочтительным анализом для измерения связывания агентов по изобретению, связывающих аггрекан, таких как ISV и/или полипептиды по изобретению, с аггреканом является SPR, такой как, например, SPR, описанный в примерах, в котором определяли связывание агентов по изобретению, связывающих аггрекан, таких как ISV и/или полипептиды по изобретению, с аггреканом. Некоторые предпочтительные значения KD для связывания агентов по изобретению, связывающих аггрекан, таких как ISV и/или полипептиды по изобретению, с аггреканом станут ясными из дальнейшего описания и примеров, приведенных в данном документе. Другим особенно предпочтительным анализом является ELISA, как подробно описано в примерах (см. также примеры 1.2 и 2.4).
Связывание агентов по изобретению, связывающих аггрекан, с аггреканом также можно измерить в анализах связывания, которые предпочтительно сохраняют конформацию аггрекановой мишени. Типичные анализы включают (без ограничения) анализы, в которых аггрекан экспонируется на клеточной поверхности (такой как, например, клетки СНО).
В воплощении изобретения агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды по изобретению, имеют константу скорости (Kon) для связывания с указанным аггреканом, выбранным из группы, состоящей по меньшей мере из примерно 102 M-1с-1 по меньшей мере около 103 M-1с-1 по меньшей мере около 104 M-1с-1 по меньшей мере около 105 M-1с-1 по меньшей мере около 106 M-1с-1, 107 M-1с-1 по меньшей мере около 108 M-1с-1 по меньшей мере около 109 M-1с-1 и по меньшей мере около 1010 M-1с-1, предпочтительно, в соответствии с измерением поверхностным плазмонным резонансом.
В воплощении изобретения агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды по изобретению, имеют константу скорости выключения (Koff) для связывания с указанным аггреканом, выбранным из группы, состоящей максимум из 10-3 с-1, максимум около 10-4 с-1, максимум около 10-5 с-1, максимум около 10-6 с-1, максимум около 10-7 с-1, максимум около 10-8 с-1, самое большее примерно 10-9 с-1 и самое большее примерно 10-10 с-1, предпочтительно, как измерено поверхностным плазмонным резонансом.
В воплощении изобретения агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды по изобретению, связываются с указанным аггреканом со средним значением KD от 100 нМ до 10 пМ, таким как при среднем значении KD 90 нМ или менее, еще более предпочтительно при среднем значении KD 80 нМ или менее, например, менее 70, 60, 50, 40, 30, 20, 10, 5 нМ или даже менее, например, менее 4, 3, 2 или 1 нМ, например, менее 500, 400, 300, 200, 100, 90, 80, 70, 60, 50, 40, 30, 20 пМ или даже менее, например, менее 10 пМ. Предпочтительно, KD определяется с помощью SPR, например, определяется с помощью Proteon.
Некоторые предпочтительные значения EC50 для связывания иммуноглобулинов и/или полипептидов по изобретению с аггрекан станут ясными из дальнейшего описания и примеров, приведенных в данном документе.
В анализе связывания ELISA агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды по настоящему изобретению, предпочтительно связывающие домен G1 и/или домен G1-IGD-G2, могут иметь значения EC50 при связывании человеческого аггрекана, равного 10-8 М или ниже, более предпочтительно, 10-9 М или ниже, или даже 10-10 М или ниже. Например, в таком анализе связывания ELISA иммуноглобулины и/или полипептиды по настоящему изобретению могут иметь значения EC50 при связывании аггрекана человека между 10-10 М и 10-8 М, например, между 10-9 М и 10-8 М или между 10-10 М и 10-9 М.
В таком анализе связывания ELISA агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды по настоящему изобретению, предпочтительно связывающие домен G1 и/или домен G1-IGD-G2, могут иметь значения EC50 при связывании аггрекана яванского макака (cyno) 10-7 М или ниже, предпочтительно 10-8 М или ниже, более предпочтительно 10-9 М или ниже, или даже 10-10 М или ниже. Например, в таком анализе связывания ELISA полипептиды по настоящему изобретению могут иметь значения EC50 при связывании аггрекана яванского макака от 10-10 M до 10-7 M, например, от 10-10 M до 10-8 M, от 10-10 M до 10-9 M.
В таком анализе связывания ELISA агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды по настоящему изобретению, предпочтительно связывающие домен G1 и/или домен G1-IGD-G2, могут иметь значения EC50 при связывании аггрекана крысы, равном 10-6 М или ниже, предпочтительно 10-7 М или ниже, предпочтительно 10-8 М или ниже, более предпочтительно 10-9 М или ниже, или даже 10-10 М или ниже. Например, в таком анализе связывания ELISA полипептиды по настоящему изобретению могут иметь значения EC 50 при связывании аггрекана крысы от 10-10 M до 10-6 M, например, от 10-10 M до 10-7 M, от 10-10 M до 10-8 M, от 10-10 M до 10-9 M.
В таком анализе связывания ELISA агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды по настоящему изобретению, предпочтительно связывающие домен G1 и/или домен G1-IGD-G2, могут иметь значение EC50 при связывании аггрекана собаки, равное 10-6 М или ниже, предпочтительно 10-7 М или ниже, предпочтительно 10-8 М или ниже, более предпочтительно 10-9 М или ниже, или даже 10-10 М или ниже. Например, в таком анализе связывания ELISA полипептиды по настоящему изобретению могут иметь значения EC50 при связывании аггрекана собаки от 10-10 M до 10-6 M, например, от 10-10 M до 10-7 M, от 10-10 M до 10-8 M, от 10-10 M до 10-9 M.
В таком анализе связывания ELISA агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды по настоящему изобретению, могут, предпочтительно, связывать домен G1 и/или домен G1-IGD-G2, иметь значения EC50 при связывании коровьего аггрекан, равного 10-6 М или ниже, предпочтительно 10-7 М или ниже, предпочтительно 10-8 М или ниже, более предпочтительно 10-9 М или ниже, или даже 10-10 М или ниже. Например, в таком анализе связывания ELISA полипептиды по настоящему изобретению могут иметь значения EC50 при связывании аггрекана коровы от 10-10 M до 10-6M, например, от 10-10M до 10-7M, от 10-10M до 10-8M, от 10-10M до 10-9M.
Используемый в данном документе термин «хрящевая ткань» относится к хрящу, включая эластичный хрящ, гиалиновый хрящ и волокнистый хрящ, которые определяются отношением клеток (хондроцитов) к межклеточному пространству и относительными количествами коллагена и протеогликана. «Суставной хрящ» - это хрящ, найденный на суставной поверхности костей, и в основном это гиалиновый хрящ. Мениски сделаны полностью из фиброзно-хрящевой ткани. Аггрекан является основным протеогликаном во внеклеточном матриксе (ECM) и составляет около 50% от общего содержания белка (остальные ок. 50% составляют коллаген II и некоторые минорные белки, такие как, например, коллаген IX).
Агенты по изобретению, связывающие аггрекан, продемонстрировали предпочтительное связывание с хрящевыми тканями в суставе, такими как хрящ и мениск, по сравнению с не хрящевой тканью, такой как синовиальная мембрана, сухожилие и/или эпимизий. Соответственно, настоящее изобретение относится к агенту, связывающему аггрекан, такому как ISV или полипептид, где указанный агент, связывающий аггрекан, предпочтительно связывается с хрящевой тканью, такой как хрящ и/или мениск, предпочтительно по меньшей мере в 1,5 раза, в 2 раза, в 3 раза, 4 раза, 5 раза или даже больше по сравнению с нехрящевой тканью.
Следует принять во внимание, что суставы - это области, где встречаются две или более кости. Большинство суставов подвижны, что позволяет костям двигаться. Суставы состоят из: хряща, синовиальной оболочки, связок, сухожилий, бурсы и синовиальной жидкости. У некоторых суставов также есть мениск.
Как показано в примерах, агенты по изобретению, связывающие аггрекан, имеют различные характеристики удержания в хряще, что позволяет настраивать удерживание в суставах в соответствии с конкретными потребностями (см. также пример 2.2). Предпочтительно, агенты, связывающие аггрекан, обладают способностью удерживаться в хряще в течение более длительных периодов времени после относительно короткого воздействия агентов, связывающих аггрекан, на хрящ, чем можно ожидать при внутрисуставной инъекции. Удержание в хряще может быть измерено с помощью анализа удержания в хряще ex vivo, как изложено в разделе примеров. Степень удержания может быть измерена визуальным осмотром вестерн-блоттинга или с помощью денситометрического количественного анализа. Шкала, используемая для определения степени удержания, может быть определена специалистом в данной области, например, шкала от 0 до 6 RU (Единицы удержания), где 0 - отсутствие удержания, а 6 - полное удержание в этом анализе. Если необходимо, шкалу можно определить количественно с использованием агентов по изобретению, связывающих аггрекан, в которых каждому агенту, связующему аггрекан, присваивается балл, например, полное удержание и отсутствие удержания фиксируются. В альтернативном варианте шкала может быть построена с различными промежуточными баллами, которые назначаются с помощью агентов по изобретению, связывающих аггрекан, например, агент, связывающий аггрекан, содержащий два 114F08 = 6 RU и ложный агент, связывающий аггрекан, например, ALB26-ALB26 = 0 RU; или агент, связывающий аггрекан, содержащий два 114F08 = 6; агент, связывающий аггрекан, содержащий 608A05 = 5; агент, связывающий аггрекан, 604G01 = 4; агент, связывающий аггрекан, содержащий два 601D02 = 3; агент, связывающий аггрекан, содержащий два 606A07 = 2; агент, связывающий аггрекан, 112A01 = 1; и ложный агент, связывающий аггрекан, например, ALB26-ALB26 = 0 (см. также Таблицу 2.2). Соответственно, настоящее изобретение относится к агенту, связывающему аггрекан, такому как ISV и/или полипептид по изобретению, где указанный агент, связывающий аггрекан, имеет удержание в хряще по меньшей мере 2, например, по меньшей мере 3, 4, 5 или 6 RU в анализе удержания в хряще.
Агенты, по изобретению связывающие аггрекан, предпочтительно должны быть стабильными. В качестве первой предпосылки биофизические свойства агентов, связывающих аггрекан, были испытаны, как подробно описано в примере 3, в котором было продемонстрировано, что эти агенты, связывающие аггрекан, продемонстрировали благоприятные характеристики стабильности, о чем свидетельствуют высокие температуры плавления и отсутствие признаков агрегации и мультимеризации. Затем агенты, связывающие аггрекан, были проверены на их активность в суставах в течение длительных периодов путем инкубации в синовиальной жидкости при 37°С (см. также Пример 6). Деградации какой-либо из конструкций не было обнаружено, что указывает на то, что конструкции были стабильны в условиях, имитирующих ситуацию in vivo.
В одном аспекте изобретение относится к агентам, связывающим аггрекан, таким как ISV, которые имеют стабильность по меньшей мере 3 дня, 4 дня, 5 дней, 6 дней, 7 дней, например, 14 дней, 21 день, 1 месяц, 2 месяца или даже 3 месяца в синовиальной жидкости (SF) при 37°C.
Настоящее изобретение обеспечивает участки аминокислотных остатков (SEQ ID NO: 20-37 и 109, SEQ ID NO: 38-55 и 110 и SEQ ID NO: 56-74 и 111; Таблица A-2), которые особенно подходят для связывания с аггреканом. В частности, изобретение обеспечивает участки аминокислотных остатков, которые связываются с аггреканом человека, и в которых связывание указанных участков с указанным аггреканом сохраняет присутствие в хрящевой ткани (как описано выше). Эти участки аминокислотных остатков могут присутствовать и/или могут быть включены в конструкцию или полипептид по изобретению, в частности, таким образом, что они образуют (часть) антигенсвязывающего сайта полипептида по изобретению. Эти участки аминокислотных остатков были получены в виде последовательностей CDR антител тяжелой цепи или последовательностей VHH, которые были получены против аггрекана. Эти участки аминокислотных остатков также обозначаются в данном документе как «последовательность(и) CDR по изобретению» («последовательность(и) CDR1 по изобретению», «последовательность(и) CDR2 по изобретению» и «последовательность(и) CDR3 изобретения», соответственно).
Однако следует отметить, что изобретение в его самом широком смысле не ограничивается специфической структурной ролью или функцией, которую эти участки аминокислотных остатков могут иметь в полипептиде по изобретению, при условии, что эти участки аминокислотных остатков позволяют полипептиду изобретения связываться с аггреканом с желаемой аффинностью и эффективностью. Таким образом, как правило, изобретение в самом широком смысле обеспечивает полипептиды (также называемые в данном документе «полипептидом(ами) по изобретению»), которые способны связываться с аггреканом с определенной заданной аффинностью, авидностью, эффективностью и/или эффективной концентрацией, и которые содержат одну или несколько последовательностей CDR, описанный в данном документе, и, в частности, подходящую комбинацию двух или более таких последовательностей CDR, которые подходящим образом связаны друг с другом через одну или несколько дополнительных аминокислотных последовательностей, так что весь полипептид образует связывающий домен и/или блок связывания, способный связываться с аггреканом. Однако следует также отметить, что присутствие только одной такой последовательности CDR в полипептиде по изобретению само по себе уже может быть достаточным для того, чтобы обеспечить полипептиду по изобретению способность связываться с аггреканом; например, снова можно сделать отсылку на так называемые «содействующие фрагменты», описанные в WO 03/050531.
В частности, но не в ограничивающем аспекте, агент по изобретению, связывающий, аггрекан, такой как ISV и/или полипептид по изобретению, может, по существу, состоять или содержать по меньшей мере один фрагмент аминокислотных остатков, который выбран из группы, состоящей из:
i) последовательности CDR1:
a) SEQ ID NO: 24, 32, 20, 21, 22, 23, 25, 26, 27, 28, 29, 30, 31, 33, 34, 35, 36, 37 и 109; и
b) аминокислотные последовательности, которые имеют различие в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 24;
и/или
ii) последовательности CDR2:
c) SEQ ID NO: 42, 50, 38, 39, 40, 41, 43, 44, 45, 46, 47, 48, 49, 51, 52, 53, 54, 55 и 110; и
d) аминокислотные последовательности, которые имеют различие в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 42;
и/или
iii) последовательности CDR3:
e) SEQ ID NO: 60, 68, 56, 57, 58, 59, 61, 62, 63, 64, 65, 66, 67, 69, 70, 71, 72, 73, 74 и 111; и
f) аминокислотные последовательности, которые имеют различие в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 60,
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, содержит структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В дополнительном аспекте предпочтительно агент по изобретению, связывающий аггрекан, такой как полипептид и/или ISV по изобретению, может содержать по меньшей мере один фрагмент аминокислотных остатков, который выбран из группы, состоящей из SEQ ID NO: 20-74 и 109-111.
В частности, предпочтительно агент по изобретению, связывающий аггрекан, такой как полипептид и/или ISV по изобретению, может представлять собой агент, связывающий аггрекан, который содержит один антигенсвязывающий сайт, где указанный антигенсвязывающий сайт содержит по меньшей мере один участок аминокислотных остатков, который выбран из группы, состоящей из последовательностей CDR1, последовательностей CDR2 и последовательностей CDR3, как описано выше (или любой подходящей их комбинации). Однако в предпочтительном аспекте предпочтительно агент по изобретению, связывающий аггрекан, такой как полипептид и/или ISV по изобретению, содержит более одного, например, два или более фрагментов аминокислотных остатков, выбранных из группы, состоящей из последовательностей CDR1 по изобретению, последовательности CDR2 по изобретению и/или последовательности CDR3 по изобретению. Предпочтительно агент по изобретению, связывающий аггрекан, такой как полипептид и/или ISV по изобретению, содержит три участка аминокислотных остатков, выбранных из группы, состоящей из последовательностей CDR1 по изобретению, последовательностей CDR2 по изобретению и CDR3 последовательности по изобретению, соответственно. Комбинации CDR, которые упомянуты в данном документе как предпочтительные для агента по изобретению, связывающего аггрекан, такого как полипептид и/или ISV по изобретению, перечислены в таблице A-2, т.е. предпочтительно комбинация CDR, показанная в одной строке в указанной таблице.
Репрезентативные полипептиды по настоящему изобретению, имеющие CDR, описанные выше, показаны в таблице A-1 (SEQ ID NO: 1-19 и 114-118).
В предпочтительном воплощении настоящее изобретение относится к агенту по изобретению, связывающему аггрекан, такому как ISV и/или полипептид по изобретению, который содержит 3 определяющие комплементарность области (CDR1-CDR3 соответственно), где:
- CDR1 выбран из группы, состоящей из SEQ ID NO: 24, 32, 20, 21, 22, 23, 25, 26, 27, 28, 29, 30, 31, 33, 34, 35, 36, 37 и 109;
- CDR2 выбран из группы, состоящей из SEQ ID NO: 42, 50, 38, 39, 40, 41, 43, 44, 45, 46, 47, 48, 49, 51, 52, 53, 54, 55 и 110; и
- CDR3 выбран из группы, состоящей из SEQ ID NO: 60, 68, 56, 57, 58, 59, 61, 62, 63, 64, 65, 66, 67, 69, 70, 71, 72, 73, 74 и 111
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В предпочтительном воплощении настоящее изобретение относится к агенту по изобретению, связывающему аггрекан, такому как ISV и/или полипептид по изобретению, которое содержит 3 определяющие комплементарность области (CDR1-CDR3 соответственно), где:
- CDR1 представляет собой SEQ ID NO: 24, CDR2 представляет собой SEQ ID NO: 42 и CDR3 представляет собой SEQ ID NO: 60;
- CDR1 представляет собой SEQ ID NO: 32, CDR2 представляет собой SEQ ID NO: 50 и CDR3 представляет собой SEQ ID NO: 68;
- CDR1 представляет собой SEQ ID NO: 20, CDR2 представляет собой SEQ ID NO: 38 и CDR3 представляет собой SEQ ID NO: 56;
- CDR1 представляет собой SEQ ID NO: 21, CDR2 представляет собой SEQ ID NO: 39 и CDR3 представляет собой SEQ ID NO: 57;
- CDR1 представляет собой SEQ ID NO: 22, CDR2 представляет собой SEQ ID NO: 40 и CDR3 представляет собой SEQ ID NO: 58;
- CDR1 представляет собой SEQ ID NO: 23, CDR2 представляет собой SEQ ID NO: 41 и CDR3 представляет собой SEQ ID NO: 59;
- CDR1 представляет собой SEQ ID NO: 25, CDR2 представляет собой SEQ ID NO: 43 и CDR3 представляет собой SEQ ID NO: 61;
- CDR1 представляет собой SEQ ID NO: 26, CDR2 представляет собой SEQ ID NO: 44 и CDR3 представляет собой SEQ ID NO: 62;
- CDR1 представляет собой SEQ ID NO: 27, CDR2 представляет собой SEQ ID NO: 45 и CDR3 представляет собой SEQ ID NO: 63;
- CDR1 представляет собой SEQ ID NO: 28, CDR2 представляет собой SEQ ID NO: 46 и CDR3 представляет собой SEQ ID NO: 64;
- CDR1 представляет собой SEQ ID NO: 29, CDR2 представляет собой SEQ ID NO: 47 и CDR3 представляет собой SEQ ID NO: 65;
- CDR1 представляет собой SEQ ID NO: 30, CDR2 представляет собой SEQ ID NO: 48 и CDR3 представляет собой SEQ ID NO: 66;
- CDR1 представляет собой SEQ ID NO: 31, CDR2 представляет собой SEQ ID NO: 49 и CDR3 представляет собой SEQ ID NO: 67;
- CDR1 представляет собой SEQ ID NO: 32, CDR2 представляет собой SEQ ID NO: 51 и CDR3 представляет собой SEQ ID NO: 69;
- CDR1 представляет собой SEQ ID NO: 33, CDR2 представляет собой SEQ ID NO: 52 и CDR3 представляет собой SEQ ID NO: 70;
- CDR1 представляет собой SEQ ID NO: 34, CDR2 представляет собой SEQ ID NO: 50 и CDR3 представляет собой SEQ ID NO: 71;
- CDR1 представляет собой SEQ ID NO: 35, CDR2 представляет собой SEQ ID NO: 53 и CDR3 представляет собой SEQ ID NO: 72;
- CDR1 представляет собой SEQ ID NO: 36, CDR2 представляет собой SEQ ID NO: 54 и CDR3 представляет собой SEQ ID NO: 73;
- CDR1 представляет собой SEQ ID NO: 37, CDR2 представляет собой SEQ ID NO: 55 и CDR3 представляет собой SEQ ID NO: 74; или
- CDR1 представляет собой SEQ ID NO: 109, CDR2 представляет собой SEQ ID NO: 110, и CDR3 представляет собой SEQ ID NO: 111;
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В предпочтительном воплощении настоящее изобретение относится к агенту, связывающему аггрекан, такому как ISV, где указанный ISV был выбран из группы, состоящей из SEQ ID NO: 117, 5, 118, 13, 114-116, 1-4, 6-12 и 14-19.
Кроме того, следует отметить, что изобретение не ограничено происхождением агента по изобретению, связывающего аггрекан, такого как ISV и/или полипептид по изобретению (или нуклеиновой кислоты по изобретению, используемой для его экспрессии), ни относительно того, каким образом создается или получается (или был создан или получен) предпочтительно агент по изобретению, связывающий аггрекан, такой как ISV и/или полипептид по изобретению, или нуклеиновая кислота по изобретению. Таким образом, предпочтительно агент по изобретению, связывающий аггрекан, такой как ISV и/или полипептид по изобретению, может быть встречающимся в природе ISV (из любых подходящих видов) или синтетическими или полусинтетическими ISV и/или полипептидами.
Кроме того, специалисту в данной области также будет понятно, что можно «привить» один или несколько CDR, упомянутых выше, на другие «каркасы», включая, без ограничения указанным, каркасы человека или неиммуноглобулиновые каркасы. Подходящие каркасы и методы для такой прививки CDR будут понятны специалисту и хорошо известны в данной области, см., например, US 7,180,370, WO 01/27160, EP 0605522, EP 0460167, US 7,054,297, Nicaise et al. (Protein Science 13: 1882-1891, 2004), Ewert et al. (Methods 34: 184-199, 2004), Kettleborough et al. (Protein Eng. 4: 773-783, 1991), O'Brien and Jones (Methods Mol. Biol. 207: 81-100, 2003), Skerra (J. Mol. Recognit. 13: 167-187, 2000) и Saerens et al. (J. Mol. Biol. 352: 597-607, 2005) и другие источники, цитируемые в них. Например, способы, известные по существу для прививки CDR мыши или крысы на человеческие каркасы и подложки, могут быть использованы аналогичным образом для получения химерных белков, включающих одну или несколько последовательностей CDR, определенных в данном документе, для моновалентных полипептидов по изобретению и одну или несколько человеческих каркасных областей или последовательностей. Подходящие каркасы для презентации аминокислотных последовательностей будут понятны специалисту в данной области и, например, включают связывающие каркасы, основанные или полученные из иммуноглобулинов (т.е. отличные от последовательностей иммуноглобулинов, уже описанных в данном документе), белковые каркасы, полученные из доменов протеина А (такие как Affibodies™), тендамистата, фибронектина, липокалина, CTLA-4, T-клеточных рецепторов, анкириновых повторов, авимеров и PDZ-доменов (Binz et al. Nat Biotech 23: 1257, 2005) и связывающие фрагменты на основе ДНК или РНК, включая, без ограничения указанным, аптамеры ДНК или РНК (Ulrich et al. Com Chem High Throughput Screen 9:619-32, 2006).
В агенте по изобретению, связывающем аггрекан, таком как ISV и/или полипептид по изобретению, CDR могут быть связаны с дополнительными аминокислотными последовательностями и/или могут быть связаны друг с другом через аминокислотные последовательности, в которых указанные аминокислотные последовательности предпочтительно представляют собой каркасные последовательности или представляют собой аминокислотные последовательности, которые действуют как каркасные последовательности, или вместе образуют каркас для презентации CDR.
Согласно предпочтительному воплощению, агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды по изобретению, содержат по меньшей мере три последовательности CDR, связанные по меньшей мере с двумя каркасными последовательностями, в которых предпочтительно по меньшей мере одна из трех последовательностей CDR представляет собой последовательность CDR3, причем две другие последовательности CDR представляют собой последовательности CDR1 или CDR2 и предпочтительно представляют собой одну последовательность CDR1 и одну последовательность CDR2. Согласно одному особенно предпочтительному, но не ограничивающему воплощению, агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды по изобретению, имеют структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой CDR1, CDR2 и CDR3 являются такими, как определено в данном документе для агентов, связывающих аггрекан, по изобретению, таких как ISV и/или полипептиды по изобретению, и FR1, FR2, FR3 и FR4 являются каркасными последовательностями. В таком агенте по изобретению, связывающем аггрекан, таком как ISV и/или полипептид по изобретению, каркасные последовательности могут представлять собой любую подходящую каркасную последовательность, и примеры подходящих каркасных последовательностей будут понятны специалисту, например, на основе стандартных справочников и дальнейшего раскрытия и предшествующего уровня техники, упомянутых в данном документе.
Соответственно, предпочтительно агент по изобретению, связывающий аггрекан, такой как ISV и/или полипептид по изобретению, содержит 3 определяющие комплементарность области (CDR1-CDR3 соответственно), в которых:
(i) CDR1 выбран из группы, состоящей из:
(a) SEQ ID NO: 24, 32, 20, 21, 22, 23, 25, 26, 27, 28, 29, 30, 31, 33, 34, 35, 36, 37 и 109; и
(b) аминокислотных последовательностей, которые имеют различие в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 24 или с любой из SEQ ID NO: 20-23, 25-37 и 109; и/или
(ii) CDR2 выбран из группы, состоящей из:
(c) SEQ ID NO: 42, 50, 38, 39, 40, 41, 43, 44, 45, 46, 47, 48, 49, 51, 52, 53, 54, 55 и 110; и
(d) аминокислотных последовательностей, которые имеют различие в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 42 или с любой из SEQ ID NO: 38-41, 43-55 и 110; и/или
(iii) CDR3 выбран из группы, состоящей из:
(e) SEQ ID NO: 60, 68, 56, 57, 58, 59, 61, 62, 63, 64, 65, 66, 67, 69, 70, 71, 72, 73, 74 и 111; и
(f) аминокислотных последовательностей, которые имеют различие в 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 60 или с любой из SEQ ID NO: 56-59, 61-74 и 111
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
Агенты по изобретению, связывающие аггрекан, могут быть картированы в области G1, области G1-IGD-G2 или области G2 аггрекана.
Соответственно, настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, которые связываются с доменом G2 аггрекана. Как указано в примерах, эти агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды, имеют различные предпочтительные характеристики. Предпочтительно агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды, имеют pI более 8 и/или имеют Koff менее 2⋅10-2с-1 и/или имеют EC50 менее чем 1⋅10-6M.
Сравнение CDR агентов по изобретению, связующих аггрекан, таких как ISV и/или полипептиды по изобретению, выявило ряд допустимых изменений аминокислот в CDR при сохранении связывания с доменом G2 аггрекана. Вариабельность последовательности в CDR всех клонов против CDR из 601D02, которые использовались в качестве стандарта, представлена в таблицах 1.5A, 1.5B и 1.5C.
В некотором варианте осуществления настоящее изобретение относится к агентам по изобретению, связывающим аггреканам, таким как ISV и/или полипептиды, в которых:
i) CDR1 выбран из группы, состоящей из:
a) SEQ ID NO: 28, 22, 26 и 33; и
b) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 28, где различие по аминокислотам определено следующим образом:
- в положении 1 G изменен на R;
- в положении 2 P изменен на S или R;
- в положении 3 Т изменен на I;
- в положении 5 S изменен на N;
- в положении 6 R изменен на N, M или S;
- в положении 7 Y изменен на R или отсутствует;
- в положении 8 A изменен на F или отсутствует; и/или
- в позиции 10 G изменен на Y;
и/или
ii) CDR2 выбран из группы, состоящей из:
c) SEQ ID NO: 46, 40, 44 и 52; и
d) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 46, где различие по аминокислотам определено следующим образом:
- в положении 1 A изменен на S или Y;
- в положении 4 W изменен на L;
- в положении 5 S изменен на N;
- в положении 6 S отсутствует;
- в положении 7 G отсутствует;
- в положении 8 G изменен на A;
- в положении 9 R изменен на S, D или T; и/или
- в положении 11 Y изменен на N или R;
и/или
iii) CDR3 выбран из группы, состоящей из:
e) SEQ ID NO: 64, 58, 62 и 70; и
f) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 64, где различие по аминокислотам определено следующим образом:
- в положении 1 A изменен на R или F;
- в положении 2 R изменен на I или L;
- в положении 3 I было изменено на H или Q;
- в положении 4 P изменен на G или N;
- в положении 5 V изменен на S;
- в положении 6 R изменен на G, N или F;
- в положении 7 Т изменен на R, W или Y;
- в положении 8 Y изменен на R или S или отсутствует;
- в положении 9 Т изменен на S или отсутствует;
- в положении 10 S изменен на E, K или отсутствует;
- в положении 11 E изменен на N, A или отсутствует;
- в положении 12 W изменен на D или отсутствует;
- в положении 13 N изменен на D или отсутствует;
- в положении 14 Y отсутствует; и/или
- D и N добавляются после положения 14 в SEQ ID NO: 64;
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В одном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, выбранные из группы агентов, связывающих аггрекан, где:
- CDR1 выбран из группы, состоящей из SEQ ID NO: 28, 22, 26 и 33;
- CDR2 выбран из группы, состоящей из SEQ ID NO: 46, 40, 44 и 52; и
- CDR3 выбран из группы, состоящей из SEQ ID NO: 64, 58, 62 и 70;
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В одном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, выбранные из группы агентов, связывающих аггрекан, где:
- CDR1 представляет собой SEQ ID NO: 28, CDR2 представляет собой SEQ ID NO: 46 и CDR3 представляет собой SEQ ID NO: 64;
- CDR1 представляет собой SEQ ID NO: 22, CDR2 представляет собой SEQ ID NO: 40 и CDR3 представляет собой SEQ ID NO: 58;
- CDR1 представляет собой SEQ ID NO: 26, CDR2 представляет собой SEQ ID NO: 44 и CDR3 представляет собой SEQ ID NO: 62; и
- CDR1 представляет собой SEQ ID NO: 33, CDR2 представляет собой SEQ ID NO: 52 и CDR3 представляет собой SEQ ID NO: 70;
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В одном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, выбранные из группы агентов, связывающих аггрекан, выбранной из группы, состоящей из SEQ ID NO: 9, 3, 7 и 15, и агентам, связывающим аггрекан, которые имеют более 80%, например, 90% или 95% идентичности последовательностей с любой из SEQ ID NO: 9, 3, 7 и 15.
В одном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, которые перекрестно блокируют связывание доменного антитела, иммуноглобулина, который подходит для применения в качестве доменного антитела, однодоменного антитела, иммуноглобулина, который подходит для применения в качестве однодоменного антитела, dAb, иммуноглобулина, который подходит для применения в качестве dAb, нанотела, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена созреванием аффинности к домену G2 аггрекана.
В одном аспекте настоящее изобретение относится к доменному антителу, иммуноглобулину, который подходит для применения в качестве доменного антитела, однодоменному антителу, иммуноглобулину, который подходит для применения в качестве однодоменного антитела, к dAb, иммуноглобулину, который подходит для применения в качестве dAb, нанотелу, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена путем созревания аффинности, которая связывается с доменом G2 аггрекана и которая конкурирует за связывание с доменом G2 аггрекана с агентами по изобретению, связывающими аггрекан, такими как ISV и/или полипептиды по изобретению, предпочтительно представленные в любой из SEQ ID NO: 9, 3, 7 и 15.
Настоящее изобретение также относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, которые связываются с доменом G1-IGD-G2 аггрекана. Как указано в примерах, эти агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды, имеют различные предпочтительные характеристики. Предпочтительно агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды, имеют pI более 8 и/или имеют Koff менее 2⋅10-2с-1 и/или имеют EC50 менее чем 1⋅10-6М.
Сравнение CDR агентов по изобретению, связывающих аггрекан, таких как ISV и/или полипептиды по изобретению, выявило ряд допустимых изменений аминокислот в CDR при сохранении связывания с G1-IGD-G2 доменом аггрекана. Изменчивость последовательности в CDR всех клонов против CDR из 604F02, который использовался в качестве стандарта, представлена в таблицах 1.4A, 1.4B и 1.4C.
В аспекте настоящее изобретение также относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, в которых:
i) CDR1 выбран из группы, состоящей из:
a) SEQ ID NO: 32, 30 и 23; и
b) аминокислотных последовательностей, которые имеют различие в 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 32, где различие по аминокислотам определено следующим образом:
- в положении 2 R изменен на L;
- в положении 6 S изменен на T; и/или
- в положении 8 Т изменен на А;
и/или
ii) CDR2 выбран из группы, состоящей из:
c) SEQ ID NO: 50, 41, 48 и 51; и
d) аминокислотных последовательностей, которые имеют различие в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 36, где различие по аминокислотам определено следующим образом:
- в положении 7 G изменен на S или R; и/или
- в положении 8 R изменен на T;
и/или
iii) CDR3 выбран из группы, состоящей из:
e) SEQ ID NO: 68, 59, 66 и 69; и
f) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 68, где различие по аминокислотам определено следующим образом:
- в положении 4 R изменен на V или P;
- в положении 6 A изменен на Y;
- в положении 7 S изменен на T;
- в положении 8 S отсутствует;
- в положении 9 N изменен на P;
- в положении 10 R изменен на T или L;
- в положении 11 G изменен на E; и/или
- в положении 12 L изменен на T или V;
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В одном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, где:
- CDR1 выбран из группы, состоящей из SEQ ID NO: 32, 30 и 23;
- CDR2 выбран из группы, состоящей из SEQ ID NO: 50, 41, 48 и 51; и
- CDR3 выбран из группы, состоящей из SEQ ID NO: 68, 59, 66 и 69;
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В одном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, выбранные из группы агентов, связывающих аггрекан, где:
- CDR1 представляет собой SEQ ID NO: 32, CDR2 представляет собой SEQ ID NO: 50 и CDR3 представляет собой SEQ ID NO: 68;
- CDR1 представляет собой SEQ ID NO: 32, CDR2 представляет собой SEQ ID NO: 51 и CDR3 представляет собой SEQ ID NO: 69;
- CDR1 представляет собой SEQ ID NO: 30, CDR2 представляет собой SEQ ID NO: 48 и CDR3 представляет собой SEQ ID NO: 66; и
- CDR1 представляет собой SEQ ID NO: 23, CDR2 представляет собой SEQ ID NO: 41 и CDR3 представляет собой SEQ ID NO: 59;
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В одном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, выбранные из группы, состоящей из агентов, связывающих аггрекан, с SEQ ID NO: 118, 13, 4, 11 и 14, и агентов, связывающих аггрекан, которые имеют более 80%, например, 90% или 95% идентичности последовательностей с любой из SEQ ID NO: 118, 13, 4, 11 и 14.
В одном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, которые перекрестно блокируют связывание доменного антитела, иммуноглобулина, который подходит для применения в качестве доменного антитела, однодоменного антитела, иммуноглобулин, который подходит для применения в качестве однодоменного антитела, dAb, иммуноглобулина, который подходит для применения в качестве dAb, нанотела, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена созреванием аффинности к домену G1-IGD-G2 аггрекана.
В одном аспекте настоящее изобретение относится к доменному антителу, иммуноглобулину, который подходит для применения в качестве доменного антитела, однодоменному антителу, иммуноглобулину, который подходит для применения в качестве однодоменного антитела, к dAb, иммуноглобулину, который подходит для применения в качестве dAb, нанотелу, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена путем созревания аффинности, которая связывается с доменом G1-IGD-G2 аггрекана и которая конкурирует за связывание с доменом Gg-IGD-G2 аггрекана с агентом по изобретению, связывающим аггрекан, таким как ISV и/или полипептид по изобретению, предпочтительно представленный в любой из SEQ ID NO: 118, 13, 4, 11 и 14.
В особенно предпочтительном воплощении настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды по изобретению, которые связываются с доменом G1 аггрекана. Как указано в примерах, эти агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды по изобретению, имеют различные предпочтительные характеристики. Предпочтительно агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды, имеют pI более 8 и/или имеют Koff менее 2⋅10-2с-1 и/или имеют EC50 менее чем 1⋅10-6М.
Сравнение CDR агентов по изобретению, связывающих аггрекан, таких как ISV и/или полипептиды по изобретению, выявило ряд допустимых изменений аминокислот в CDR при сохранении связывания с доменом G1 аггрекана. Изменчивость последовательности в CDR всех клонов против CDR из 114F08, который использовался в качестве стандарта, представлена в таблицах 1.3A, 1.3B и 1.3C.
В предпочтительном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды по изобретению, которые содержат 3 определяющие комплементарность области (CDR1-CDR3 соответственно), в которых:
i) CDR1 выбран из группы, состоящей из:
a) SEQ ID NO: 24, 20, 21, 25, 27, 29, 31, 34, 35, 36 и 37; и
b) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 24, где различие по аминокислотам определено следующим образом:
- в положении 2 S изменен на R, F, I или T;
- в положении 3 Т изменен на I;
- в положении 5 I было изменено на S;
- в положении 6 I было изменено на S, T или M;
- в положении 7 N изменен на Y или R;
- в положении 8 V изменен на A, Y, T или G;
- в положении 9 V изменен на М; и/или
- в положении 10 R изменен на G, K или A;
и/или
ii) CDR2 выбран из группы, состоящей из:
c) SEQ ID NO: 42, 38, 39, 43, 45, 47, 49, 50, 53, 54 и 55; и
d) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 42, где различие по аминокислотам определено следующим образом:
- в положении 1 Т изменен на А или G;
- S или N вставляется между положением 3 и положением 4 (положение 2a, таблица 1.3B);
- в положении 3 S изменен на R, W, N или T;
- в положении 4 S изменен на T или G;
- в положении 5 G изменен на S;
- в положении 6 G изменен на S или R;
- в положении 7 N изменен на S, T или R;
- в положении 8 A изменен на T; и/или
- в положении 9 N изменен на D или Y;
и/или
iii) CDR3 выбран из группы, состоящей из:
e) SEQ ID NO: 60, 56, 57, 61, 63, 65, 67, 71, 72, 73 и 74; и
f) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 60, где различие по аминокислотам определено следующим образом:
- в положении 1 P изменен на G, R, D или E или отсутствует;
- в положении 2 Т изменен на R, L, P или V или отсутствует;
- в положении 3 Т изменен на М, S или R или отсутствует;
- в положении 4 H изменен на D, Y, G или T;
- в положении 5 Y изменен на F, V, T или G;
- в положении 6 G изменен на L, D, S, Y или W;
- R, T, Y или V вставляются между положением 6 и положением 7 (положение 6a, таблица 1.3C);
- в положении 7 G изменен на P или S;
- в положении 8 V изменен на G, T, H, R, L или Y;
- в положении 9 Y изменен на R, A, S, D или G;
- в положении 10 Y изменен на N, E, G, W или S;
- W вставлена между положением 10 и положением 11 (положение 10a, таблица 1.3C);
- в положении 11 G изменен на S, K или Y;
- в положении 12 P изменен на E, или D, или отсутствует; и/или
- в положении 13 Y изменен на L или отсутствует;
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В предпочтительном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, выбранные из группы агентов, связывающих аггрекан, где: CDR1 выбран из группы, состоящей из SEQ ID NO: 24, 20, 21, 25, 27, 29, 31, 34, 35, 36, 37 и 109; CDR2 выбран из группы, состоящей из SEQ ID NO: 42, 38, 39, 43, 45, 47, 49, 50, 53, 54, 55 и 110; и CDR3 выбран из группы, состоящей из SEQ ID NO: 60, 56, 57, 61, 63, 65, 67, 71, 72, 73, 74 и 111; предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В предпочтительном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, выбранные из группы агентов, связывающих аггрекан, где:
- CDR1 представляет собой SEQ ID NO: 24, CDR2 представляет собой SEQ ID NO: 42 и CDR3 представляет собой SEQ ID NO: 60;
- CDR1 представляет собой SEQ ID NO: 20, CDR2 представляет собой SEQ ID NO: 38 и CDR3 представляет собой SEQ ID NO: 56;
- CDR1 представляет собой SEQ ID NO: 21, CDR2 представляет собой SEQ ID NO: 39 и CDR3 представляет собой SEQ ID NO: 57;
- CDR1 представляет собой SEQ ID NO: 25, CDR2 представляет собой SEQ ID NO: 43 и CDR3 представляет собой SEQ ID NO: 61;
- CDR1 представляет собой SEQ ID NO: 27, CDR2 представляет собой SEQ ID NO: 45 и CDR3 представляет собой SEQ ID NO: 63;
- CDR1 представляет собой SEQ ID NO: 29, CDR2 представляет собой SEQ ID NO: 47 и CDR3 представляет собой SEQ ID NO: 65;
- CDR1 представляет собой SEQ ID NO: 31, CDR2 представляет собой SEQ ID NO: 49 и CDR3 представляет собой SEQ ID NO: 67;
- CDR1 представляет собой SEQ ID NO: 34, CDR2 представляет собой SEQ ID NO: 50 и CDR3 представляет собой SEQ ID NO: 71;
- CDR1 представляет собой SEQ ID NO: 35, CDR2 представляет собой SEQ ID NO: 53 и CDR3 представляет собой SEQ ID NO: 72;
- CDR1 представляет собой SEQ ID NO: 36, CDR2 представляет собой SEQ ID NO: 54 и CDR3 представляет собой SEQ ID NO: 73;
- CDR1 представляет собой SEQ ID NO: 37, CDR2 представляет собой SEQ ID NO: 55 и CDR3 представляет собой SEQ ID NO: 74; и
- CDR1 представляет собой SEQ ID NO: 109, CDR2 представляет собой SEQ ID NO: 110, и CDR3 представляет собой SEQ ID NO: 111;
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В разделе примеров было продемонстрировано, что примерный клон 114F08 имеет особенно предпочтительные характеристики. Клон 114F08 представляет семейство или набор клонов, дополнительно включающих клоны 114A09 (SEQ ID NO: 114) и 114B04 (SEQ ID NO: 115), которые были сгруппированы на основе сходства в CDR (см. также таблицу A-2 и таблицы 3.3A, 3.3B и 3.3C), что выражается в сходстве функциональных характеристик. Следовательно, в другом особенно предпочтительном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, которые содержат 3 определяющие комплементарность области (CDR1-CDR3 соответственно), в которых:
i) CDR1 выбран из группы, состоящей из:
a) SEQ ID NO: с 24 и 109; и
b) аминокислотных последовательностей, которые имеют различие в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 24, где различие по аминокислотам определено следующим образом:
- в положении 7 N изменен на S; и/или
- в положении 9 V изменен на М;
и/или
ii) CDR2 выбран из группы, состоящей из:
c) SEQ ID NO: 42 и 110; и
d) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 42, где различие по аминокислотам определено следующим образом:
- в положении 1 Т изменен на А;
- в положении 3 S изменен на R;
- в положении 4 S изменен на T;
- в положении 8 A изменен на T; и/или
- в положении 9 N изменен на D;
и/или
iii) CDR3 выбран из группы, состоящей из:
e) SEQ ID NO: 60 и 111; и
f) аминокислотных последовательностей, которые имеют различие в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 60, где аминокислотная разница определена следующим образом:
- в положении 4 H изменен на R; и/или
- в положении 8 V изменен на D;
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В одном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, выбранные из группы агентов, связывающих аггрекан, где:
- CDR1 выбран из группы, состоящей из SEQ ID NO: 24 и 109;
- CDR2 выбран из группы, состоящей из SEQ ID NO: 42 и 110; и
- CDR3 выбран из группы, состоящей из SEQ ID NO: 60 и 111
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
Кроме того, в разделе примеров было продемонстрировано, что агенты, связывающие аггрекан, связывающиеся с областью G1 аггрекана, и принадлежащие к эпитопной группе 1 или эпитопной группе 4, особенно эффективны в анализах удержания в хряще. В одном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, которые относятся к эпитопной группе 1 или эпитопной группе 4.
Сравнение CDR агентов по изобретению, связывающих аггрекан, таких как ISV и/или полипептиды по изобретению, принадлежащих эпитопной группе 1, выявило ряд допустимых изменений аминокислот в CDR при сохранении связывания с доменом G1 аггрекана. Изменчивость последовательности в CDR всех клонов против CDR 608A05, который использовался в качестве стандарта, представлена в таблицах 2.3D, 2.3E и 2.3F.
В предпочтительном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, которые содержат 3 определяющие комплементарность области (CDR1-CDR3, соответственно), в которых:
i) CDR1 выбран из группы, состоящей из:
a) SEQ ID NO: 36, 20 и 29; и
b) аминокислотных последовательностей, которые имеют различие в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 36, где различие по аминокислотам определено следующим образом:
- в положении 3 Т изменен на S;
- в положении 6 Т изменен на S;
- в положении 8 Т изменен на А; и/или
- в положении 9 М изменен на V;
и/или
ii) CDR2 выбран из группы, состоящей из:
c) SEQ ID NO: 54, 38 и 37; и
d) аминокислотных последовательностей, которые имеют различие в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 54, где различие по аминокислотам определено следующим образом:
- в положении 1 A изменен на I;
- в положении 4 W изменен на R;
- в положении 7 G изменен на R; и/или
- в положении 8 Т изменен на S;
и/или
iii) CDR3 выбран из группы, состоящей из:
e) SEQ ID NO: 73, 56 и 65; и
f) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 73, где различие по аминокислотам определено следующим образом:
- в положении 1 R изменен на G;
- в положении 2 P изменен на R или L;
- в положении 3 R изменен на L или S;
- в положении 5 Y изменен на R;
- в положении 6 Y изменен на S или A;
- в положении 7 Y изменен на T или отсутствует;
- в положении 8 S изменен на P;
- в положении 9 L изменен на H или R;
- в положении 10 Y изменен на P или A;
- в положении 11 S изменен на A или Y;
- в положении 12 Y изменен на D;
- в положении 13 D изменен на F;
- в положении 14 Y изменен на G или отсутствует; и/или
- после позиции 14 вставляется S;
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В одном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, выбранные из группы агентов, связывающих аггрекан, где:
- CDR1 выбран из группы, состоящей из SEQ ID NO: 20, 29 и 36;
- CDR2 выбран из группы, состоящей из SEQ ID NO: 38, 47 и 54; и
- CDR3 выбран из группы, состоящей из SEQ ID NO: 56, 65 и 73;
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В одном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, принадлежащие к эпитопной группе 1, которые перекрестно блокируют связывание доменного антитела, иммуноглобулина, который подходит для применения в качестве доменного антитела, однодоменного антитела, иммуноглобулина, который подходит для применения в качестве однодоменного антитела, dAb, иммуноглобулина, который подходит для применения в качестве dAb, нанотела, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена путем созревания аффинности к домену G1 аггрекана.
В одном аспекте настоящее изобретение относится к доменному антителу, иммуноглобулину, который подходит для применения в качестве доменного антитела, однодоменному антителу, иммуноглобулину, который подходит для применения в качестве однодоменного антитела, dAb, иммуноглобулину, который подходит для применения в качестве dAb, нанотелу, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена путем созревания аффинности, которая связывается с эпитопной группой 1 домена G1 аггрекана, и которая конкурирует за связывание с доменом G1 аггрекана с агентами по изобретению, связывающимися с аггреканом, такими как ISV и/или полипептиды, которые принадлежат эпитопной группе 1, предпочтительно такие как, например, например, представленные в любой из SEQ ID NO: 1, 10 и 18.
Сравнение CDR агентов по изобретению, связывающих аггрекан, таких как ISV и/или полипептиды по изобретению, принадлежащих эпитопной группе 4, выявило ряд допустимых изменений аминокислот в CDR при сохранении связывания с доменом G1 аггрекана. Изменчивость последовательности в CDR всех клонов против CDR из 114F08, который использовался в качестве стандарта, представлена в таблицах 2.3A, 2.3B и 2.3C.
В одном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, которые содержат 3 определяющие комплементарность области (CDR1-CDR3 соответственно), в которых:
i) CDR1 выбран из группы, состоящей из:
a) SEQ ID NO: 24, 25 и 27; и
b) аминокислотных последовательностей, которые имеют различие в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 24, где различие по аминокислотам определено следующим образом:
- в положении 2 S изменен на I или F;
- в положении 5 I было изменено на S;
- в положении 6 I было изменено на S или M;
- в положении 7 N изменен на R или Y;
- в положении 8 V изменен на A или Y;
- в положении 9 V изменен на М; и/или
- в положении 10 R изменен на K;
и/или
ii) CDR2 выбран из группы, состоящей из:
c) SEQ ID NO: 42, 43 и 45; и
d) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 42, где различие по аминокислотам определено следующим образом:
- в положении 1 Т изменен на А или G;
- N вставляется между положением 2 и положением 3 (положение 2a, таблица 2.3B);
- в положении 7 N изменен на R;
- в положении 8 A изменен на T; и/или
- в положении 9 N изменен на D;
и/или
iii) CDR3 выбран из группы, состоящей из:
e) SEQ ID NO: 60, 61 и 63; и
f) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 60, где различие по аминокислотам определено следующим образом:
- в положении 1 P отсутствует;
- в положении 2 Т изменен на R или отсутствует;
- в положении 3 Т изменен на М или отсутствует;
- в положении 4 H изменен на D или Y;
- в положении 5 Y изменен на F или V;
- в положении 6 G изменен на L или D;
- в положении 8 V изменен на G или T;
- в положении 9 Y изменен на R;
- в положении 10 Y изменен на N или E;
- в положении 11 G изменен на S или K;
- в положении 12 P изменен на E или отсутствует; и/или
- в положении 13 Y изменен на L или отсутствует;
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В одном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, выбранные из группы агентов, связывающих аггрекан, где:
- CDR1 выбран из группы, состоящей из SEQ ID NO: 24, 25 и 27;
- CDR2 выбран из группы, состоящей из SEQ ID NO: 42, 43 и 45; и
- CDR3 выбран из группы, состоящей из SEQ ID NO: 60, 61 и 63;
предпочтительно агент, связывающий аггрекан, такой как ISV и/или полипептид, включает структуру FR1-CDR1-FR2-CDR2-FR3-CDR3-FR4, в которой FR1, FR2, FR3 и FR4 являются каркасными последовательностями.
В одном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, принадлежащие к эпитопной группе 4, которые перекрестно блокируют связывание доменного антитела, иммуноглобулина, который подходит для применения в качестве доменного антитела, однодоменного антитела, иммуноглобулина, который подходит для применения в качестве однодоменного антитела, dAb, иммуноглобулина, который подходит для применения в качестве dAb, нанотела, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена путем созревания аффинности к домену G1 аггрекана.
В одном аспекте настоящее изобретение относится к доменному антителу, иммуноглобулину, который подходит для применения в качестве доменного антитела, к однодоменному антителу, иммуноглобулину, который подходит для применения в качестве однодоменного антитела, к dAb, иммуноглобулину, который подходит для применения в качестве dAb, нанотела, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена путем созревания аффинности, которая связывается с эпитопной группой 4 домена G1 аггрекана, и который конкурирует за связывание с доменом G1 аггрекана с агентами, связывающими аггрекан, и по изобретению, такими как ISV и/или полипептиды, которые принадлежат к эпитопной группе 4, такие как, например, представленные в любой из SEQ ID NO: 117, 114, 115, 116, 5, 6 и 8.
В одном аспекте настоящее изобретение относится к агентам по изобретению, связывающим аггрекан, таким как ISV и/или полипептиды, выбранные из группы, состоящей из агентов, связывающих аггрекан, представленных в SEQ ID NO: 117, 118, 116, 114, 115, 5, 13, 1, 2, 6, 8, 10, 12, 16, 17, 18 и 19 и ISV, которые имеют более 80%, например, 90% или 95%, или даже больше идентичности последовательностей с любой из SEQ ID NO: 117, 118, 116, 114, 115, 5, 13, 1, 2, 6, 8, 10, 12, 16, 17, 18 и 19.
В частном, но не ограничивающем аспекте, агент по изобретению, связывающий аггрекан, может представлять собой участок аминокислотных остатков, который имеет характерную для иммуноглобулинов укладку цепи, или агент, связывающий аггрекан, который в подходящих условиях (таких как физиологические условия) способен образовывать характерную для иммуноглобулинов укладку цепи (т.е. фолдинг). Помимо прочего можно сделать к обзору Halaby et al. (J. Protein Eng. 12: 563-71, 1999). Предпочтительно, при правильной укладке, формирующей характерную для иммуноглобулинов укладку цепи, участки аминокислотных остатков могут иметь способность правильно образовывать антигенсвязывающий сайт для связывания с аггреканом. Соответственно, в предпочтительном аспекте агент по изобретению, связывающий аггрекан, представляет собой иммуноглобулин, такой как, например, иммуноглобулиновый одиночный вариабельный домен.
Соответственно, каркасные последовательности предпочтительно представляют собой (подходящую комбинацию) каркасных последовательностей иммуноглобулина или каркасных последовательностей, которые были получены из каркасных последовательностей иммуноглобулина (например, путем оптимизации последовательности, такой как гуманизация или оверблюживание). Например, каркасные последовательности могут быть каркасными последовательностями, полученными из иммуноглобулинового одиночного вариабельного домена, такого как вариабельный домен легкой цепи (например, VL-последовательность), и/или из вариабельного домена тяжелой цепи (например, VH-последовательность). В одном особенно предпочтительном аспекте каркасные последовательности представляют собой либо каркасные последовательности, которые были получены из VHH-последовательности (в которых указанные каркасные последовательности могут быть необязательно частично или полностью гуманизированы), либо являются обычными VH-последовательностями, которые были оверблюжены (как определено в данном документе).
Каркасные последовательности предпочтительно могут быть такими, чтобы агент по изобретению, связывающий аггрекан, представлял собой ISV, такой как доменное антитело (или аминокислотную последовательность, которая подходит для применения в качестве доменного антитела); однодоменное антитело (или аминокислота, которая подходит для применения в качестве однодоменного антитела); «dAb» (или аминокислота, которая подходит для применения в качестве dAb); Нанотело®; последовательность VHH; гуманизированную последовательность VHH; оверблюженную последовательность VH; или последовательность VHH, которая была получена путем созревания аффинности. Опять же, подходящие каркасные последовательности будут понятны для специалиста, например, на основе стандартных справочников и дальнейшего раскрытия и предшествующего уровня техники, упомянутых в данном документе.
Другой особенно предпочтительный класс ISV по изобретению включает ISV с аминокислотной последовательностью, которая соответствует аминокислотной последовательности встречающегося в природе домена VH, но которая была «оверблюжена», то есть получена путем замены одного или нескольких аминокислотных остатков в аминокислотной последовательности встречающегося в природе домена VH из обычного 4-цепочечного антитела одним или несколькими аминокислотными остатками, которые находятся в соответствующем(их) положении(ях) в домене VHH антитела, состоящего только из тяжелой цепи. Это может быть выполнено известным способом, который будет понятен специалисту в данной области, например, на основании приведенного в данном документе описания. Такие «оверблюживающие» замены предпочтительно вводятся в положениях аминокислот, которые образуют и/или присутствуют на границе VH-VL, и/или в так называемых характерных остатках Camelidae, которые хорошо известны специалисту в данной области техники и которые были определены, например, в WO 94/04678 и Davies and Riechmann (1994 и 1996). Предпочтительно последовательность VH, которая используется в качестве исходного материала или отправной точки для создания или конструирования оверблюженных ISV, предпочтительно представляет собой последовательность VH млекопитающего, более предпочтительно последовательность VH человека, такую как последовательность VH3. Однако следует отметить, что такие оверблюженные ISV по изобретению могут быть получены любым подходящим способом, известным по существу, и, таким образом, не ограничиваются строго полипептидами, которые были получены с использованием полипептида, который содержит природный домен VH в качестве исходного материала.
Например, снова, как дополнительно описано в данном документе, и «гуманизация», и «оверблюживание» могут быть выполнены путем предоставления нуклеотидной последовательности, которая кодирует встречающийся в природе домен VHH или домен VH, соответственно, и последующего изменения, известным по существу способом, одного или нескольких кодонов в указанной нуклеотидной последовательности таким образом, чтобы новая нуклеотидная последовательность кодировала «гуманизированный» или «оверблюженный» ISV по изобретению, соответственно. Затем эту нуклеиновую кислоту можно экспрессировать известным способом, чтобы получить желаемые ISV по изобретению. Альтернативно, на основе аминокислотной последовательности встречающегося в природе домена VHH или домена VH, соответственно, аминокислотная последовательность желаемых гуманизированных или оверблюженных ISV по изобретению, соответственно, может быть сконструирована и затем синтезирована de novo с использованием известных по существу методов синтеза пептидов. Кроме того, на основе аминокислотной последовательности или нуклеотидной последовательности встречающегося в природе домена VHH или домена VH, соответственно, можно сконструировать нуклеотидную последовательность, кодирующую требуемые гуманизированные или оверблюженные ISV по изобретению, соответственно, и затем синтезировать de novo с использованием по сути известных методов для синтеза нуклеиновой кислоты, после чего полученная таким образом нуклеиновая кислота может быть экспрессирована известным по существу способом, чтобы обеспечить требуемые ISV по изобретению.
В частности, каркасные последовательности, присутствующие в агентах, связывающих аггрекан по изобретению, таких как ISV и/или полипептиды по изобретению, могут содержать один или несколько характерных остатков, например, как определено в WO 08/020079 (таблицы A-3 - A-8), так, что агент по изобретению, связывающий аггрекан, представляет собой нанотело. Некоторые предпочтительные, но не ограничивающие примеры (подходящих комбинаций) таких каркасных последовательностей станут понятными из дальнейшего раскрытия в данном документе (см., например, таблицу A-2). Как правило, нанотела (в частности последовательности VHH и частично гуманизированные нанотела) могут, в частности, характеризоваться присутствием одного или нескольких «характерных остатков» в одной или нескольких каркасных последовательностях (как, например, дополнительно описано в WO 08/020079, стр. 61, стр. 24 - стр. 98, строка 3). Используемый в данном документе термин «представлен» в контексте любой SEQ ID NO эквивалентен «содержит или состоит из» указанного SEQ ID NO и предпочтительно эквивалентен «состоит из» указанного SEQ ID NO.
Более конкретно, изобретение предлагает агенты, связывающие аггрекан, содержащие по меньшей мере один ISV, который представляет собой аминокислотную последовательность с (общей) структурой
FR1 - CDR1 - FR2 - CDR2 - FR3 - CDR3 - FR4
в которой FR1-FR4 относятся к каркасным областям 1-4 соответственно и в которых CDR1-CDR3 относятся к областям 1-3, определяющим комплементарность, соответственно, и которые:
- имеют по меньшей мере 80%, более предпочтительно 90%, еще более предпочтительно 95% идентичности по аминокислотам по меньшей мере с одной из аминокислотных последовательностей SEQ ID NO: 117, 116, 118, 116, 115, 114 и 1-19 (см. Таблица A-2), в которой для целей определения степени идентичности аминокислот аминокислотные остатки, которые образуют последовательности CDR, не учитываются. В этом отношении также источником может служить, например, таблица A-2, в которой перечислены последовательности каркаса 1 (SEQ ID NO: 119, 120 и 75-84), последовательности каркаса 2 (SEQ ID NO: 121 и 85-93), последовательности каркаса 3 (SEQ ID NO: 123, 124, 122, 94-104 и 112-113) и последовательности каркаса 4 (SEQ ID NO: 105-108) иммуноглобулиновых одиночных вариабельных доменов SEQ ID NO: 117, 118, 116, 115, 114 и 1-19; или
- комбинации последовательностей каркаса, показанных в таблице A-2;
и в котором:
- предпочтительно один или несколько аминокислотных остатков в положениях 11, 37, 44, 45, 47, 83, 84, 103, 104 и 108 в соответствии с нумерацией Kabat выбраны из характерных остатков, таких как, например, упоминаемые в таблицах А-3 и А-8 WO 08/020079.
Соответственно, настоящее изобретение относится к ISV и/или полипептиду, где указанный ISV по существу состоит из 4 каркасных областей (FR1-FR4 соответственно) и указанных 3 определяющих комплементарность областей CDR1-CDR3, например, ISV, который специфически связывает аггрекан, состоит из 4 каркасных областей (FR1-FR4 соответственно) и указанных трех определяющих комплементарность областей CDR1-CDR3, терапевтического ISV, например, ISV, который связывается с представителем семейства сериновых протеаз, катепсинами, матриксными металлопротеиназами (ММР)/матриксинами или дезинтегрином и металлопротеиназой с мотивами тромбоспондина (ADAMTS), предпочтительно MMP8, MMP13, MMP19, MMP20, ADAMTS5 (аггреканазой-2) ADAMTS4 (аггреканазой-1) и/или ADAMTS11, состоит из 4 каркасных областей (FR1-FR4, соответственно) и указанных трех определяющих комплементарность областей CDR1-CDR3; ISV, связывающий сывороточный альбумин по существу состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 областей, определяющих комплементарность (CDR1-CDR3, соответственно).
Агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды по изобретению, могут также содержать специфические мутации/аминокислотные остатки, описанные в следующих одновременно находящихся на рассмотрении предварительных заявках США, которые все озаглавлены «Улучшенные иммуноглобулиновые вариабельные домены»: US 61/994552, поданная в 16 мае 16 2014 года; US 61/014015, поданная 18 июня 2014 года; Патент США 62/040167, поданный 21 августа 2014 года; и US 62/047,560, поданной 8 сентября 2014 года (все закреплены за Ablynx NV).
В частности, агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды по изобретению, могут подходящим образом содержать (i) K или Q в положении 112; или (ii) K или Q в положении 110 в сочетании с V в положении 11; или (iii) Т в положении 89; или (iv) L в положении 89 с K или Q в положении 110; или (v) V в положении 11 и L в положении 89; или любую подходящую комбинацию (i)-(v).
Как также описано в указанных одновременно находящихся на рассмотрении предварительных заявках США, когда агент по изобретению, связывающий аггрекан, такой как ISV и/или полипептид по изобретению, содержит мутации в соответствии с одним из (i)-(v) выше (или подходящей их комбинации):
- аминокислотный остаток в положении 11 предпочтительно выбран из L, V или K (и наиболее предпочтительно V); и
- аминокислотный остаток в положении 14 предпочтительно выбирают из А или Р; и
- аминокислотный остаток в положении 41 предпочтительно выбирают из А или Р; и
- аминокислотный остаток в положении 89 предпочтительно выбирают из Т, V или L; и
- аминокислотный остаток в положении 108 предпочтительно выбирают из Q или L; и
- аминокислотный остаток в положении 110 предпочтительно выбирают из Т, К или Q; и
- аминокислотный остаток в положении 112 предпочтительно выбирают из S, K или Q.
Как упомянуто в указанных одновременно находящихся на рассмотрении предварительных заявках США, указанные мутации эффективны в предотвращении или уменьшении связывания так называемых «ранее существующих антител» с ISV, полипептидами и конструкциями по изобретению. Для этой цели агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды по изобретению, могут также содержать (необязательно в комбинации с указанными мутациями) C-концевое удлинение (X)n (в котором n равно от 1 до 10, предпочтительно от 1 до 5, например, 1, 2, 3, 4 или 5 (и предпочтительно 1 или 2, например, 1), и каждый X представляет собой (предпочтительно встречающийся в природе) аминокислотный остаток, который независимо выбран, и предпочтительно независимо выбран из группы, состоящей из аланина (A), глицина (G), валина (V), лейцина (L) или изолейцина (I)), для чего снова отсылаем к указанным предварительным заявкам США, а также к WO 12/175741. В частности, предпочтительно агент по изобретению, связывающий аггрекан, такой как ISV и/или полипептид по изобретению, может содержать такое C-концевое удлинение, когда оно образует C-концевой конец белка, полипептида или другого соединения или конструкции, содержащей то же самое (опять же, как дополнительно описано, например, в упомянутых предварительных заявках США, а также в WO 12/175741).
Агент по изобретению, связывающий аггрекан, может представлять собой иммуноглобулин, такой как ISV, полученный любым подходящим способом и из любого подходящего источника, и может, например, представлять собой встречающиеся в природе последовательности VHH (т.е. из подходящего вида верблюдовых) или синтетические или полусинтетические аминокислотные последовательности, включая, без ограничения указанным, «гуманизированные» (как определено в данном документе) последовательности нанотел или VHH, «оверблюженные» (как определено в данном документе) последовательности иммуноглобулина (и, в частности, последовательности вариабельного домена тяжелой цепи верблюда), а также нанотела которые были получены такими методами, как созревание аффинности (например, начиная с синтетических, случайных или встречающихся в природе последовательностей иммуноглобулина), прививка CDR, венирование, объединение фрагментов, полученных из разных последовательностей иммуноглобулина, сборка ПЦР с использованием перекрывающихся праймеров и аналогичные методы для конструирования последовательности иммуноглобулина, хорошо известные специалисту в данной области; или любой подходящей комбинацией любого из вышеперечисленного, как дополнительно описано в данном документе. Кроме того, когда иммуноглобулин содержит последовательность VHH, указанный иммуноглобулин может быть подходящим образом гуманизирован, как дополнительно описано в данном документе, с тем чтобы обеспечить один или несколько дополнительных (частично или полностью) гуманизированных иммуноглобулинов по изобретению. Подобным образом, когда иммуноглобулин содержит синтетическую или полусинтетическую последовательность (такую как частично гуманизированная последовательность), указанный иммуноглобулин может необязательно быть дополнительно подходящим образом гуманизирован, опять же, как описано в данном документе, снова, чтобы обеспечить один или несколько дополнительных (частично или полностью) гуманизированных иммуноглобулинов по изобретению.
В одном аспекте настоящее изобретение относится к агенту по изобретению, связывающему аггрекан, такому как ISV, где указанный агент, связывающий аггрекан, выбран из группы, состоящей из SEQ ID NO: 117, 118, 116, 115, 114 и 1-19.
ISV могут использоваться в качестве «структурного элемента» для получения полипептида, который может необязательно содержать один или несколько дополнительных «структурных элементов», таких как ISV, против того же или другого эпитопа на аггрекане и/или против одного или нескольких другие антигенов, белков или мишеней, отличных от аггрекана, например, структурные элементы, имеющие терапевтический режим действия, например, терапевтические ISV.
Как правило, белки или полипептиды или конструкции, которые содержат или, по существу, состоят из одного структурного элемента, одного ISV или одного нанотела, будут упоминаться в данном документе как «одновалентные» белки или полипептиды или как «одновалентные конструкции», соответственно. Полипептиды или конструкции, которые содержат два или более структурных элементов или связывающих единиц (таких как, например, ISV), также будут упоминаться в данном документе как «многовалентные» полипептиды или конструкции, и структурные элементы/ISV, присутствующие в таких полипептидах или конструкциях, также будут упоминаться в данном документе как в «многовалентном формате». Например, «двухвалентный» полипептид может содержать два ISV, необязательно связанные через линкерную последовательность, тогда как «трехвалентный» полипептид может содержать три ISV, необязательно связанные через две линкерные последовательности; тогда как «четырехвалентный» полипептид может содержать четыре ISV, необязательно связанные через три линкерные последовательности и т.д.
В поливалентном полипептиде или конструкции два или более ISV, такие как нанотела, могут быть одинаковыми или разными и могут быть направлены против одного и того же антигена или антигенной детерминанты (например, против одной и той же части(частей) или эпитопа(ов) или против различных частей или эпитопов) или могут альтернативно быть направлены против разных антигенов или антигенных детерминант; или в любой подходящей их комбинации. Полипептиды или конструкции, которые содержат по меньшей мере два структурных элемента (такие как, например, ISV), в которых по меньшей мере один структурный элемент направлен против первого антигена (т.е. аггрекана), и по меньшей мере один структурный элемент направлен против второго антигена (т.е. отличающегося от аггрекана, такого как, например, терапевтическая мишень), также будет называться «мультиспецифичными» полипептидами или мультиспецифическими конструкциями, соответственно, и структурные элементы (такие как, например, ISV), присутствующие в таких полипептидах или конструкциях, также будут упоминаться в данном документе как в «мультиспецифическом формате». Таким образом, например, «биспецифичный» полипептид по изобретению представляет собой полипептид, который содержит по меньшей мере один ISV, направленный против первого антигена (т.е. аггрекана), и по меньшей мере один дополнительный ISV, направленный против второго антигена (т.е. отличающегося от аггрекана, такой как, например, терапевтическая мишень), тогда как «триспецифичный» полипептид по изобретению представляет собой полипептид, который содержит по меньшей мере один ISV, направленный против первого антигена (то есть, аггрекана) по меньшей мере один дополнительный ISV, направленный против второго антигена (т.е. отличающегося от аггрекана, такого как, например, терапевтическая мишень) и по меньшей мере еще один ISV, направленный против третьего антигена (т.е. отличающегося как от аггрекана, так и от второго антигена); и т.п.
«Мультипаратопные» полипептиды и «мультипаратопные» конструкции, такие как, например, «бипаратопические» полипептиды или конструкции и «трипаратопные» полипептиды или конструкции, содержат или по существу состоят из двух или более структурных элементов, каждый из которых имеет свой отдельный паратоп.
Соответственно, ISV по изобретению, которые связывают аггрекан, могут быть по существу в выделенной форме (как определено в данном документе), или они могут образовывать часть конструкции или полипептида, которые могут включать или по существу состоять из одного или нескольких ISV, которые связывают аггрекан и которые могут необязательно дополнительно включать одну или несколько дополнительных аминокислотных последовательностей (все необязательно связаны через один или несколько подходящих линкеров). Настоящее изобретение относится к полипептиду или конструкции, которая содержит или, по существу, состоит по меньшей мере из одного ISV по изобретению, такого как один или несколько ISV по изобретению (или их подходящих фрагментов), связывающих аггрекан.
Один или несколько ISV по изобретению можно использовать в качестве связывающей единицы или в таком полипептиде или конструкции, чтобы обеспечить одновалентный, многовалентный или мультипаратопный полипептид или конструкцию изобретения, соответственно, все, как описано в данном документе. Таким образом, настоящее изобретение также относится к полипептиду, который представляет собой моновалентную конструкцию, включающую или, по существу, состоящую из одного одновалентного полипептида или ISV по изобретению. Таким образом, настоящее изобретение также относится к полипептиду или конструкции, которая представляет собой многовалентный полипептид или многовалентную конструкцию соответственно, такую как, например, двухвалентный или трехвалентный полипептид или конструкция, включающая или, по существу, состоящая из двух или более ISV по изобретению (для многовалентных и полиспецифичных полипептидов, содержащих один или несколько доменов VHH, и их получение, также отсылаем, например, к Conrath et al. (J. Biol. Chem. 276: 7346-7350, 2001), а также, например, к WO 96/34103, WO 99/23221 и WO 2010/115998.
Изобретение также относится к поливалентному полипептиду (также называемому в данном документе «многовалентным(ыми) полипептидом(ами) по изобретению»), который включает или (по существу) состоит по меньшей мере из одного ISV, такого как один или два ISV (или их подходящие фрагменты), направленных против аггрекана, предпочтительно аггрекана человека, и еще одного дополнительного ISV.
В одном аспекте в своей простейшей форме многовалентный полипептид или конструкция по изобретению представляет собой двухвалентный полипептид или конструкцию по изобретению, содержащую первый ISV, такой как нанотело, направленный против аггрекана, и идентичный второй ISV, такой как нанотело, направленное против аггрекана, где указанный первый и указанный второй ISV, такой как нанотело, необязательно могут быть связаны через последовательность линкера (как определено в данном документе). В другой форме поливалентный полипептид или конструкция по изобретению может представлять собой трехвалентный полипептид или конструкцию по изобретению, включающую первый ISV, такой как нанотело, направленное против аггрекана, идентичный второй ISV, такой как нанотело, направленное против аггрекана, и третий ISV, такой как нанотело, направлен против антигена, отличного от аггрекана, такого как, например, терапевтическая мишень, в котором указанные первый, второй и третий ISV, такие как нанотела, могут быть необязательно связаны через одну или несколько, в частности две, линкерных последовательностей.
В другом аспекте поливалентный полипептид или конструкция по изобретению может представлять собой биспецифичный полипептид или конструкцию по изобретению, включающую первый ISV, такой как нанотело, направленное против аггрекана, и второй ISV, такой как нанотело, направленное против второго антигена, такого как, например, терапевтическая мишень, в которой указанные первый и второй ISV, такие как нанотела, могут быть необязательно связаны через линкерную последовательность (как определено в данном документе); тогда как многовалентный полипептид или конструкция по изобретению также может быть триспецифическим полипептидом или конструкцией по изобретению, включающим первый ISV, такой как нанотело, направленное против аггрекана, второй ISV, такой как нанотело, направленное против второго антигена, такие как например, терапевтическая мишень и третий ISV, такой как нанотело, направленное против третьего антигена, такого как, например, также терапевтическая мишень, но отличающаяся от указанного второго антигена, в котором указанные первый, второй и третий ISV, такие как нанотела, могут быть необязательно связаны через одну или несколько, и в частности две, линкерных последовательностей.
В предпочтительном аспекте полипептид или конструкция по изобретению представляет собой трехвалентный, биспецифичный полипептид или конструкцию, соответственно. Трехвалентный, биспецифичный полипептид или конструкция по изобретению, в его простейшей форме, может представлять собой трехвалентный полипептид или конструкцию по изобретению (как определено в данном документе), включающую два идентичных ISV, таких как нанотела, против аггрекана, и третий ISV, такой как нанотела, направленные против другого антигена, такого как, например, терапевтическая мишень, в которой указанные первое, второе и третье ISV, такие как нанотела, могут быть необязательно связаны через одну или несколько, в частности две, линкерных последовательностей.
В предпочтительном аспекте полипептид или конструкция по изобретению представляет собой трехвалентные, биспецифичные полипептид или конструкцию, соответственно. Трехвалентные, биспецифичные полипептид или конструкция по изобретению могут представлять собой трехвалентный полипептид или конструкцию по изобретению (как определено в данном документе), включающие два ISV, таких как нанотела, против аггрекана, где указанные ISV против аггрекана могут быть одинаковыми или различными, и третий ISV, такой как нанотело, направленное против другого антигена, такого как, например, терапевтическая мишень, где указанные первый, второй и третий ISV, такие как нанотела, могут быть необязательно связаны через одну или несколько, в частности две, линкерных последовательностей.
Особенно предпочтительными трехвалентными, биспецифичными полипептидами или конструкциями в соответствии с изобретением являются те, которые показаны в описанных в данном документе примерах и в таблицах E-1 и E-2.
В другом аспекте полипептид по изобретению представляет собой биспецифический полипептид или конструкцию. Биспецифический полипептид или конструкция по изобретению в его простейшей форме может представлять собой двухвалентный полипептид или конструкцию по изобретению (как определено в данном документе), включающую ISV, такой как нанотело, против аггрекана, и второй ISV, такой как нанотело, направленное против другого антигена, такого как, например, терапевтическая мишень, в которой указанные первый и второй ISV, такие как нанотела, могут быть необязательно связаны через линкерную последовательность.
В предпочтительном аспекте многовалентные полипептид или конструкция по изобретению содержит или, по существу, состоит из двух или более ISV, направленных против аггрекана. В одном аспекте изобретение относится к полипептиду или конструкции, которая содержит или, по существу, состоит по меньшей мере из двух ISV по изобретению, таких как 2, 3 или 4 ISV (или их подходящих фрагментов), связывающих аггрекан. Два или более ISV могут быть необязательно связаны через один или несколько пептидных линкеров.
Два или более ISV, присутствующих в поливалентном полипептиде или конструкции по изобретению, могут состоять из последовательности вариабельного домена легкой цепи (например, последовательности VL) или последовательности вариабельного домена тяжелой цепи (например, последовательности VH); они могут состоять из последовательности вариабельного домена тяжелой цепи, которая получена из обычного четырехцепочечного антитела, или из последовательности вариабельного домена тяжелой цепи, которая получена из антитела, состоящего только из тяжелой цепи. В предпочтительном аспекте они состоят из доменного антитела (или аминокислоты, которая подходит для применения в качестве доменного антитела), однодоменного антитела (или аминокислоты, которая подходит для применения в качестве однодоменного антитела), «dAb» (или аминокислоты, которая подходит для применения в качестве dAb), Нанотела® (включая, без ограничения указанным, VHH), гуманизированной последовательности VHH, оверблюженной последовательности VH; или последовательности VHH, которая была получена путем созревания аффинности. Два или более ISV могут состоять из частично или полностью гуманизированного нанотела или частично или полностью гуманизированной VHH.
В одном аспекте изобретения первый ISV и второй ISV, присутствующие в мультипаратопическом (предпочтительно бипаратопическом или трипаратопическом) полипептиде или конструкции по изобретению, не (перекрестно) конкурируют друг с другом за связывание с аггреканом и, как таковые, принадлежат в разным семействам. Соответственно, настоящее изобретение относится к мультипаратопическому (предпочтительно бипаратопическому) полипептиду или конструкции, содержащей два или более ISV, где каждый ISV принадлежит к иному семейству. В одном аспекте первый ISV этого мультипаратопического (предпочтительно бипаратопического) полипептида или конструкции по изобретению не блокирует перекрестное связывание с аггреканом второго ISV этого мультипаратопического (предпочтительно, бипаратопического) полипептида или конструкции по изобретению и/или первый ISV перекрестно не блокирует связывание с аггреканом второго ISV. В другом аспекте первый ISV мультипаратопического (предпочтительно бипаратопического) полипептида или конструкции по изобретению перекрестно блокирует связывание с аггреканом второго ISV этого мультипаратопического (предпочтительно бипаратопического) полипептида или конструкции по изобретению и/или первый ISV перекрестно блокирует связывание с аггреканом второго ISV.
В предпочтительном аспекте полипептид или конструкция по изобретению содержит или, по существу, состоит из двух или более ISV, из которых по меньшей мере один ISV направлен против аггрекана. В особенно предпочтительном аспекте полипептид или конструкция по изобретению содержит или, по существу, состоит из трех или более ISV, из которых по меньшей мере два ISV направлены против аггрекана. Понятно, что указанные по меньшей мере два ISV, направленные против аггрекана, могут быть одинаковыми или разными, могут быть направлены против одного и того же эпитопа или разных эпитопов аггрекана, могут принадлежать одной и той же эпитопной группе или разным эпитопным группам и/или могут связываться с одним или разными доменами аггрекана.
В предпочтительном аспекте полипептид или конструкция по изобретению содержит или, по существу, состоит по меньшей мере из двух ISV, где указанные по меньшей мере два ISV могут быть одинаковыми или разными, которые независимо выбраны из группы, состоящей из SEQ ID NO: 117, 118, 116, 115 и 1-19, более предпочтительно указанные по меньшей мере два ISV выбраны из группы, состоящей из SEQ ID NO: 117, 5, 6, 8, 114-116 и/или указанные по меньшей мере два ISV выбраны из группы, состоящей из SEQ ID NO: 118 и 13.
В дополнительном аспекте изобретение относится к мультипаратопическому (предпочтительно бипаратопическому) полипептиду или конструкции, содержащей два или более иммуноглобулиновых одиночных вариабельных домена, направленных против аггрекана, которые связывают тот же эпитоп(ы), что и любой другой из SEQ ID NO: 117, 118, 114, 115, 116 и 1-19.
Предполагается, что окончательный формат молекулы для клинического применения включает один или два структурных элемента, таких как ISV, связывающие аггрекан, и один или несколько структурных элементов, таких как ISV, с терапевтическим способом действия и, возможно, дополнительные фрагменты. В разделе примеров показано, что такие форматы сохраняют свойства связывания аггрекана и удержания, а также терапевтический эффект, например, ферментативные и/или ингибирующие функции. Одним или несколькими структурными элементами, такими как ISV с терапевтическим способом действия, может быть любой структурный элемент, обладающий терапевтическим эффектом («терапевтический структурный элемент» или «терапевтический ISV») при заболеваниях, в которые вовлечен аггрекан, например, при артритном заболевании, остеоартрите, спондилоэпиметафизарной дисплазии, заболевании дегенерации поясничного диска, дегенеративном заболевании суставов, ревматоидном артрите, рассекающем остеохондрите, аггреканопатии и/или при которых аггрекан используется для направления, закрепления и/или сохранения других, например, терапевтических структурных элементов на желаемом участке, например, таком как сустав. Таким образом, настоящее изобретение относится к полипептиду или конструкции по изобретению, где один или несколько дополнительных структурных элементов, например, дополнительные ISV, сохраняли активность.
Настоящее изобретение относится к полипептиду или конструкции, которая содержит или по существу состоит по меньшей мере из одного ISV по изобретению, такого как один или несколько ISV по изобретению (или их подходящих фрагментов), связывающего аггрекан и по меньшей мере одного дополнительного ISV, в частности, терапевтический ISV, где указанный по меньшей мере один дополнительный ISV предпочтительно связывается с терапевтической мишенью, например, связывается с представителем семейства сериновых протеаз, катепсинами, матриксными металлопротеиназами (ММР)/матриксинами или дисинтегрином и металлопротеиназой с мотивами тромбоспондина (ADAMTS), предпочтительно MMP8, MMP13, MMP19, MMP20, ADAMTS5 (аггреканазой-2), ADAMTS4 (аггреканазой-1) и/или ADAMTS11.
В одном аспекте настоящее изобретение относится к полипептиду или конструкции по изобретению, по существу состоящим из или включающим по меньшей мере один ISV, связывающий аггрекан и по меньшей мере один дополнительный ISV, который оказывает терапевтическое действие, например, терапевтический структурный элемент. Терапевтическим эффектом может быть любой желаемый эффект, который улучшает, лечит или предотвращает заболевание, как будет дополнительно подробно описано ниже. Предпочтительно дополнительный ISV, например, терапевтический ISV ингибирует или уменьшает активность протеазы, например, ингибирует или снижает активность терапевтической мишени, то есть представителя семейства сериновых протеаз, катепсинов, матриксных металлопротеиназ (ММР)/матриксинов или дезинтегрина и металлопротеиназы с мотивами тромбоспондина (ADAMTS), предпочтительно ММР8, ММР13, ММР19, ММР20, ADAMTS5 (аггреканазы-2), ADAMTS4 (аггреканазы-1) и/или ADAMTS11. Ингибирование или снижение активности может быть достигнуто путем связывания с активным сайтом или путем изменения структуры протеазы или протеиназы, тем самым предотвращая и/или уменьшая гидролиз целевого белка протеазой или протеиназой.
В одном аспекте настоящее изобретение относится к полипептиду или конструкции по изобретению, выбранной из полипептидов и конструкций таблицы E-1 и таблицы E-2.
В одном аспекте настоящее изобретение относится к ISV, полипептиду или конструкции по изобретению, имеющим стабильность по меньшей мере 7 дней, например, по меньшей мере 14 дней, 21 день, 1 месяц, 2 месяца или даже 3 месяца в синовиальной жидкости (SF) при 37°С.
В одном аспекте настоящее изобретение относится к ISV, полипептиду или конструкции по изобретению, у которых удержание в хряще составляет по меньшей мере 2, например, по меньшей мере 3, 4, 5 или 6 RU в анализе удержания в хряще.
В одном аспекте настоящее изобретение относится к ISV, полипептиду или конструкции по изобретению, проникающим в хрящ по меньшей мере на 5 мкм, например по меньшей мере на 10 мкм, 20 мкм, 30 мкм, 40 мкм, 50 мкм или даже более.
Стабильность полипептида, конструкции или ISV по изобретению может быть измерена с помощью рутинных анализов, известных специалисту в данной области. Типичные анализы включают (без ограничения указанным) анализы, в которых определяют активность указанного полипептида, конструкции или ISV, с последующей инкубацией в синовиальной жидкости в течение желаемого периода времени, после чего активность определяют снова, например, как подробно описано в раздел примеров (см. также Пример 6).
Желаемая активность терапевтического структурного элемента в мультивалентном полипептиде или конструкции по изобретению может быть измерена с помощью рутинных анализов, известных специалисту в данной области. Типичные анализы включают анализы, в которых анализируют высвобождение GAG, как подробно описано в разделе примеров (см. Пример 8).
Относительная аффинность может зависеть от расположения ISVD в полипептиде. Понятно, что порядок ISVD в полипептиде по изобретению (ориентация) может быть выбран в соответствии с потребностями специалиста в данной области. Порядок отдельных ISVD, а также то, содержит ли полипептид линкер, является вопросом выбора конструкции. Некоторые ориентации с линкерами или без них могут обеспечивать предпочтительные характеристики связывания по сравнению с другими ориентациями. Например, порядок первого ISV (например, ISV 1) и второго ISV (например, ISV 2) в полипептиде по изобретению может быть (от N-конца до C-конца): (i) ISV 1 (например, Нанотело 1) - [линкер] - ISV 2 (например, Нанотело 2) - [С-концевое удлинение]; или (ii) ISV 2 (например, Нанотело 2) - [линкер] - ISV 1 (например, Нанотело 1) - [С-концевое удлинение]; (где фрагменты между квадратными скобками, то есть линкером и С-концевым удлинением, являются необязательными). Все ориентации охватываются изобретением. Полипептиды, которые содержат ориентацию ISV, которая обеспечивает желаемые характеристики связывания, могут быть легко идентифицированы путем обычного скрининга, например, как показано в разделе примеров. Предпочтительный порядок - от N-конца к C-концу: терапевтический ISV - [линкер] - ISV, связывающий аггрекан - [С-концевое удлинение], где фрагменты между квадратными скобками являются необязательными. Другим предпочтительным порядком является от N-конца к С-концу: терапевтический ISV - [линкер] - ISV, связывающий аггрекан - [линкер] - ISV, связывающий аггрекан - [С-концевое удлинение], где фрагменты между квадратными скобками являются необязательными.
Агенты по изобретению, связывающие аггрекан, такие как полипептиды и/или ISV по изобретению, могут дополнительно содержать или не содержать одну или несколько других групп, остатков (например, аминокислотных остатков), фрагментов или связывающих единиц (эти агенты, связывающие аггрекан, такие как полипептиды и/или ISV (с или без дополнительных групп, остатков, фрагментов или связывающих единиц) все упоминаются как «соединение(я) по изобретению», «конструкция(и) по изобретению» и/или «полипептид(ы) по изобретению»). Если они присутствуют, такие дополнительные группы, остатки, фрагменты или связывающие единицы могут предоставлять или не предоставлять дополнительную функциональность агенту, связывающему аггрекан, такому как полипептид и/или ISV, и могут изменять или не изменять свойства агента, связывающего аггрекан, такого как полипептид и/или или ISV.
Например, такие дополнительные группы, остатки, фрагменты или связывающие единицы могут представлять собой одну или несколько дополнительных аминокислотных последовательностей, так что полученный полипептид представляет собой (гибридный) полипептид. В предпочтительном, но не ограничивающем аспекте указанные одна или несколько других групп, остатков, фрагментов или связыващих единиц представляют собой иммуноглобулины. Еще более предпочтительно, указанные одна или несколько других групп, остатков, фрагментов или связывающих единиц представляют собой ISV, выбранные из группы, состоящей из доменных антител, аминокислот, которые подходят для применения в качестве доменного антитела, однодоменных антител, аминокислот, которые подходят для применения в качестве однодоменного антитела dAb, аминокислот, которые подходят для применения в качестве dAb, нанотел (таких как, например, VHH, гуманизированные VHH- или оверблюженные VH-последовательности).
Как описано выше, дополнительные связывающие единицы, такие как ISV, имеющие различную антигенную специфичность, могут быть связаны с образованием полиспецифических полипептидов. Комбинируя ISV двух или более специфичностей, можно получить биспецифичные, триспецифичные и т.д. полипептиды или конструкции. Например, полипептид по изобретению может содержать один, два или более ISV, направленных против аггрекана, и по меньшей мере один домен ISV против другой мишени. Такие конструкции и их модификации, которые специалист в данной области может легко предвидеть, охватываются термином «соединение по изобретению, конструкция по изобретению и/или полипептид по изобретению», при использовании в данном документе.
В описанных выше соединениях, конструкциях и/или полипептидах один, два, три или более ISV и одна или несколько групп, остатков, фрагментов или могут быть связаны непосредственно друг с другом и/или через один или несколько подходящих линкеров или спейсеров. Например, когда одна или несколько групп, остатков, фрагментов или являются аминокислотными последовательностями, линкеры также могут быть аминокислотными последовательностями, так что полученный полипептид представляет собой гибрид (белок) или гибрид (полипептид).
Одна или несколько дополнительных групп, остатков, фрагментов или связывающих единиц могут быть любыми подходящими и/или желаемыми аминокислотными последовательностями. Дополнительные аминокислотные последовательности могут изменять или не изменять, преобразовывать или иным образом влиять на (биологические) свойства полипептида по изобретению и могут как добавлять, так и не добавлять дополнительную функциональность к полипептиду по изобретению. Предпочтительно дополнительная аминокислотная последовательность такова, что она придает одно или несколько желаемых свойств или функциональных возможностей полипептиду по изобретению.
Примеры таких аминокислотных последовательностей будут понятны специалисту и могут, как правило, включать все аминокислотные последовательности, которые используются в пептидных гибридах на основе обычных антител и их фрагментов (включая, но без ограничения, антитела ScFv и однодоменные антитела). Источниками могут служить, например, обзор Holliger and Hudson (Nature Biotechnology 23: 1126-1136, 2005).
Например, такая аминокислотная последовательность может представлять собой аминокислотную последовательность, которая увеличивает период полувыведения, растворимость или абсорбцию, снижает иммуногенность или токсичность, устраняет или ослабляет нежелательные побочные эффекты и/или придает другие полезные свойства и/или снижает нежелательные свойства соединения, конструкции и/или полипептида по изобретению по сравнению с полипептидом по изобретению как таковым. Некоторыми неограничивающими примерами таких аминокислотных последовательностей являются сывороточные белки, такие как человеческий сывороточный альбумин (см., например, WO 00/27435) или гаптеновые молекулы (например, гаптены, которые распознаются циркулирующими антителами, см., например, WO 98/22141).
В частном аспекте изобретения конструкция или полипептид по изобретению может иметь фрагмент, обеспечивающий увеличенный период полувыведения, по сравнению с соответствующей конструкцией или полипептидом по изобретению без указанного фрагмента. Некоторые предпочтительные, но не ограничивающие примеры таких конструкций и полипептидов по изобретению станут понятными для специалиста на основании дальнейшего раскрытия в данном документе и, например, включают ISV или полипептиды по изобретению, которые были химически модифицированы для увеличения периода полувыведения (например, с помощью ПЭГ-илирования); агенты по изобретению, связывающие аггрекан, такие как ISV и/или полипептиды по изобретению, которые содержат по меньшей мере один дополнительный сайт связывания для связывания с сывороточным белком (таким как сывороточный альбумин); или полипептиды по изобретению, которые содержат по меньшей мере одну аминокислотную последовательность по изобретению, которая связана по меньшей мере с одним фрагментом (и, в частности по меньшей мере с одной аминокислотной последовательностью), который увеличивает период полувыведения аминокислотной последовательности по изобретению. Примеры конструкций по изобретению, таких как полипептиды по изобретению, которые содержат такие увеличивающие период полувыведения фрагменты или ISV, станут понятными для специалиста на основании дальнейшего раскрытия в данном документе; и, например, включают, без ограничения указанным, полипептиды, в которых один или несколько ISV по изобретению соответствующим образом связаны с одним или несколькими белками сыворотки или их фрагментами (такими как (человеческий) сывороточный альбумин или его подходящие фрагменты) или с одной или несколькими связывающими единицами, которые могут связываться с сывороточными белками (такими как, например, доменные антитела, ISV, которые подходят для применения в качестве доменного антитела, однодоменные антитела, ISV, которые подходят для применения в качестве однодоменного антитела, dAb, ISV, которые являются подходящими для применения в качестве dAb или нанотела, которые могут связываться с сывороточными белками, такими как сывороточный альбумин (например, человеческий сывороточный альбумин), сывороточными иммуноглобулинами, такими как IgG, или трансферрин; настоящим ссылаемся на дополнительное описание и источники, упомянутые в данном документе); полипептиды, в которых аминокислотная последовательность по изобретению связана с частью Fc (такой как Fc человека) или ее подходящей частью или фрагментом; или полипептиды, в которых один или несколько ISV по изобретению подходят для связывания с одним или несколькими небольшими белками или пептидами, которые могут связываться с белками сыворотки, такими как, например, белки и пептиды, описанные в WO 91/01743, WO 01/45746, WO 02/076489, WO2008/068280, WO2009/127691 и PCT/EP2011/051559.
В одном аспекте настоящее изобретение предоставляет конструкцию по изобретению, такую как полипептид, где указанный полипептид дополнительно включает фрагмент, связывающий белок сыворотки или белок сыворотки.
Предпочтительно указанный фрагмент, связывающий сывороточный белок, связывает сывороточный альбумин, такой как человеческий сывороточный альбумин.
Как правило, конструкции или полипептиды по изобретению с увеличенным периодом полувыведения предпочтительно имеют период полувыведения, который по меньшей мере в 1,5 раза, предпочтительно по меньшей мере 2 раза, например по меньшей мере 5 раз, например по меньшей мере 10 раз или более чем 20 раз, превышает период полувыведения соответствующих конструкций или полипептидов по изобретению как таковых, то есть без части, обеспечивающей увеличение периода полувыведения. Например, конструкции или полипептиды по изобретению с увеличенным периодом полувыведения могут иметь период полувыведения, например, у людей, который увеличивается более чем на 1 час, предпочтительно более чем на 2 часа, более предпочтительно более чем на 6 часов, например, более чем 12 часов или даже больше, чем 24, 48 или 72 часа, по сравнению с соответствующими конструкциями или полипептидами по изобретению как таковыми, то есть без фрагмента, придающего увеличенный период полувыведения.
В предпочтительном, но не ограничивающем аспекте изобретения конструкции по изобретению, такие как полипептиды по изобретению, имеют период полувыведения в сыворотке, например, у людей это увеличивается более чем на 1 час, предпочтительно более чем на 2 часа, более предпочтительно более чем на 6 часов, например, более чем на 12 часов или даже более чем на 24, 48 или 72 часа, по сравнению с соответствующими конструкциями или полипептидами по изобретению по существу, т.е. без остатка, дающего увеличение периода полувыведения.
В другом предпочтительном, но не ограничивающем аспекте изобретения такие конструкции по изобретению, такие как полипептиды по изобретению, проявляют период полувыведения в сыворотке у человека по меньшей мере около 12 часов, предпочтительно по меньшей мере 24 часа, более предпочтительно по меньшей мере 48 часов, еще более предпочтительно по меньшей мере 72 часа или более. Например, соединения или полипептиды по изобретению могут иметь период полувыведения по меньшей мере 5 дней (например, примерно от 5 до 10 дней), предпочтительно по меньшей мере 9 дней (например, примерно от 9 до 14 дней), более предпочтительно по меньшей мере около 10 дней (например, примерно от 10 до 15 дней) или по меньшей мере около 11 дней (например, примерно от 11 до 16 дней), более предпочтительно по меньшей мере около 12 дней (например, примерно от 12 до 18 дней или более) или более 14 дней (например, около 14-19 дней).
В особенно предпочтительном, но не ограничивающем аспекте изобретения, изобретение предоставляет конструкцию по изобретению, такую как полипептид по изобретению, включающую помимо одного или нескольких структурных элементов, связывающих аггрекан, и, возможно, один или несколько терапевтических структурных элементов по меньшей мере один структурный элемент, связывающий сывороточный альбумин, такой как ISV, связывающий сывороточный альбумин, такой как человеческий сывороточный альбумин, описанный в данном документе, где указанный ISV, связывающий сывороточный альбумин содержит или, по существу, состоит из 4 каркасных областей (FR1-FR4, соответственно) и 3 областей, определяющих комплементарность (CDR1-CDR3, соответственно), в которых CDR1 представляет собой SFGMS, CDR2 представляет собой SISGSGSDTLYADSVKG, а CDR3 представляет собой GGSLSR. Предпочтительно, указанный ISV, связывающий сывороточный альбумин человека выбран из группы, состоящей из Alb8, Alb23, Alb129, Alb132, Alb135, Alb11, Alb11 (S112K) -A, Alb82, Alb82-A, Alb82-AA, Alb82-AAA, Alb82- G, Alb82-GG, Alb82-GGG, Alb92 или Alb223 (см. также таблицу C).
В воплощении настоящее изобретение относится к конструкции по изобретению, такой как полипептид, содержащий связывающий белок сывороточный фрагмент, где указанный связывающий белок сывороточный фрагмент представляет собой полипептид не на основе антител.
В одном аспекте настоящее изобретение относится к соединению или конструкции, описанной в данном документе, содержащей одну или несколько других групп, остатков, фрагментов или связывающих единиц, предпочтительно выбранных из группы, состоящей из молекулы полиэтиленгликоля, сывороточных белков или их фрагментов, связывающих единиц, которые могут связываться с сывороточными белками, частью Fc и небольшими белками или пептидами, которые могут связываться с сывороточными белками.
В одном воплощении настоящее изобретение относится к конструкции изобретения, такой как полипептид, содержащий фрагмент, обеспечивающий увеличение периода полувыведения, где указанный фрагмент представляет собой PEG. Следовательно, настоящее изобретение относится к конструкции или полипептиду по изобретению, содержащему ПЭГ.
Дополнительные аминокислотные остатки могут изменять или не изменять, преобразовывать или иным образом влиять на другие (биологические) свойства полипептида по изобретению и могут как добавлять, так и не добавлять дополнительную функциональность полипептиду по изобретению. Например, такие аминокислотные остатки:
- могут содержать N-концевой остаток Met, например, в результате экспрессии в гетерологичной клетке-хозяине или организме-хозяине.
- могут образовывать сигнальную последовательность или лидерную последовательность, которая направляет секрецию полипептида из клетки-хозяина при синтезе (например, для обеспечения пре-, про- или препроформы полипептида по изобретению в зависимости от клетки-хозяина, используемой для экспрессии полипептида по изобретению). Подходящие секреторные лидерные пептиды будут понятны специалисту в данной области и могут быть такими, как описано ниже. Обычно такая лидерная последовательность будет связана с N-концом полипептида, хотя изобретение в его самом широком смысле этим не ограничивается;
- могут образовывать «метку», например, аминокислотную последовательность или остаток, которая позволяет или облегчает очистку полипептида, например, с использованием аффинных методов, направленных против указанной последовательности или остатка. После этого указанную последовательность или остаток можно удалить (например, путем химического или ферментативного расщепления), чтобы получить полипептид (для этой цели метка может быть необязательно связана с аминокислотной последовательностью или полипептидной последовательностью через расщепляемую линкерную последовательность или содержать расщепляемый мотив). Некоторыми предпочтительными, но не ограничивающими примерами таких остатков являются множественные остатки гистидина, остатки глутатиона и myc-метка, такая как AAAEQKLISEEDLNGAA;
- может быть одним или несколькими аминокислотными остатками, которые были функционализированы и/или которые могут служить в качестве сайта для присоединения функциональных групп. Подходящие аминокислотные остатки и функциональные группы будут понятны специалисту в данной области и включают, без ограничения указанным, аминокислотные остатки и функциональные группы, упомянутые в данном документе для производных полипептидов по изобретению.
В конструкциях по изобретению, таких как полипептиды по изобретению, два или более структурных элементов, таких как, например, ISV и, необязательно, одна или несколько других групп, лекарств, агентов, остатков, фрагментов или связывающих звеньев могут быть непосредственно связаны друг с другом (как, например, описано в WO 99/23221) и/или могут быть связаны друг с другом через один или более подходящих спейсеров или линкеров, или любой их комбинации. Специалисту будет ясно, какие спейсеры или линкеры для применения в мультивалентных и полиспецифических полипептидах являются подходящими, и они, как правило, могут быть любым линкером или спейсером, используемыми в данной области для связывания аминокислотных последовательностей. Предпочтительно указанный линкер или спейсер подходит для применения при конструировании конструкций, белков или полипептидов, которые предназначены для фармацевтического применения.
Например, полипептид по изобретению может представлять собой, например, трехвалентный триспецифичный полипептид, содержащий один структурный элемент, такой как ISV, связывающий аггрекан, один терапевтический структурный элемент, такой как ISV, и один структурный элемент, такой как ISV, связывающий (человеческий) сывороточный альбумин, в котором указанные первый, второй и третий структурные элементы, такие как ISV, могут быть необязательно связаны через одну или несколько, и в частности две, линкерные последовательности. Кроме того, настоящее изобретение относится к конструкции или полипептиду по изобретению, содержащему первый ISV, связывающий аггрекан, и/или второй ISV и/или, возможно, третий ISV и/или, возможно, ISV, связывающий сывороточный альбумин, где указанный первый ISV и/или указанный второй ISV и/или, возможно, указанный третий ISV и/или, возможно, указанный ISV, связывающий сывороточный альбумин связаны через линкер.
Некоторые особенно предпочтительные спейсеры включают спейсеры и линкеры, которые используются в данной области для связывания фрагментов антител или доменов антител. К ним относятся линкеры, упомянутые в общем уровне техники, процитированном выше, а также, например, линкеры, которые используются в данной области для конструирования диател или фрагментов ScFv (однако в этом отношении следует отметить, что, хотя используемая в диателах и фрагментах ScFv линкерная последовательность должна иметь длину, степень гибкости и другие свойства, которые позволяют подходящим доменам VH и VL объединяться для образования полного антигенсвязывающего сайта, нет особых ограничений по длине или гибкости линкера, используемого в полипептиде по изобретению, поскольку каждый ISV, такой как нанотело, сам по себе образует полный антигенсвязывающий сайт).
Например, линкер может представлять собой подходящую аминокислотную последовательность и, в частности, аминокислотные последовательности от 1 до 50, предпочтительно от 1 до 30, например, от 1 до 10 аминокислотных остатков. Некоторые предпочтительные примеры таких аминокислотных последовательностей включают gly-ser-линкеры, например, типа (glyxsery)z, такие как (например, (gly4ser)3 или (gly3ser2)3, как описано в WO 99/42077 и GS30, Линкеры GS15, GS9 и GS7, описанные в заявках Ablynx, упомянутых в данном документе (см., например, WO 06/040153 и WO 06/122825), а также шарнироподобные области, такие как шарнирные участки тяжелой цепи природных антител или аналогичные последовательности (такие как, например, описанные в WO 94/04678). Предпочтительные линкеры изображены в таблице D (SEQ ID NO: 154-170).
Другие подходящие линкеры обычно включают органические соединения или полимеры, в частности те, которые подходят для применения в белках для фармацевтического применения. Например, поли(этиленгликоль)-фрагменты были применены для связывания доменов антител, см., например, WO 04/081026.
Объемом изобретения охватывается то, что длина, степень гибкости и/или другие свойства используемого(ых) линкера(ов) (хотя это и не критично, как это обычно бывает для линкеров, используемых во фрагментах ScFv), могут оказывать некоторое влияние на свойства конечной конструкции по изобретению, такой как полипептид по изобретению, включая, без ограничения указанным, аффинность, специфичность или авидность к хемокину или к одному или нескольким другим антигенам. Основываясь на раскрытии в данном документе, специалист в данной области сможет определить оптимальный(ые) линкер(ы) для применения в специфичной конструкции по изобретению, такой как полипептид по изобретению, необязательно после некоторых ограниченных рутинных экспериментов.
Например, в поливалентных полипептидах по изобретению, которые содержат структурные элементы, ISV или нанотела, направленные против аггрекана и другой мишени, длина и гибкость линкера предпочтительно таковы, что он позволяет каждому структурному элементу, такому как ISV, настоящего изобретения присутствовать в полипептиде для связывания с его родственной мишенью, например, антигенной детерминантой на каждой из мишеней. Опять же, основываясь на раскрытии в данном документе, специалист в данной области сможет определить оптимальный(ые) линкер(ы) для применения в специфичной конструкции по изобретению, такой как полипептид по изобретению, необязательно после некоторых ограниченных рутинных экспериментов.
Также в пределах объема изобретения находится то, что используемый(ые) линкер(ы) придает одно или несколько других благоприятных свойств или функциональных возможностей конструкциям по изобретению, таким как полипептиды по изобретению, и/или обеспечивает один или несколько сайтов для образования производных и/или для присоединения функциональных групп (например, как описано в данном документе для производных ISV по изобретению). Например, линкеры, содержащие один или несколько заряженных аминокислотных остатков, могут обеспечивать улучшенные гидрофильные свойства, тогда как линкеры, которые образуют или содержат небольшие эпитопы или метки, могут использоваться для целей обнаружения, идентификации и/или очистки. Опять же, основываясь на раскрытии в данном документе, специалист в данной области сможет определить оптимальные линкеры для применения в специфическом полипептиде по изобретению, возможно, после некоторых ограниченных рутинных экспериментов.
Наконец, когда два или более линкера используются в конструкциях, таких как полипептиды по изобретению, эти линкеры могут быть одинаковыми или разными. Опять же, основываясь на раскрытии в данном документе, специалист в данной области сможет определить оптимальные линкеры для применения в конкретной конструкции или полипептиде по изобретению, возможно, после некоторых ограниченных рутинных экспериментов.
Обычно для простоты экспрессии и продуцирования конструкция по изобретению, такая как полипептид по изобретению, будет представлять собой линейный полипептид. Однако изобретение в его самом широком смысле не ограничивается этим. Например, когда конструкция по изобретению, такая как полипептид по изобретению, содержит три или более структурных элементов, ISV или нанотела, их можно связать с помощью линкера с тремя или более «плечами», где каждое из «плеч» связано со структурным элементом, ISV или нанотелом, чтобы обеспечить «звездообразную» конструкцию. Также возможно, хотя обычно менее предпочтительно, использовать кольцевые конструкции.
Соответственно, настоящее изобретение относится к конструкции изобретения, такой как полипептид по изобретению, где указанные ISV непосредственно связаны друг с другом или связаны через линкер.
Соответственно, настоящее изобретение относится к конструкции изобретения, такой как полипептид по изобретению, где первый ISV и/или второй ISV и/или, возможно, ISV, связывающий сывороточный альбумин связаны через линкер.
Соответственно, настоящее изобретение относится к конструкции по изобретению, такой как полипептид по изобретению, где указанный линкер выбран из группы, состоящей из линкеров 5GS, 7GS, 9GS, 10GS, 15GS, 18GS, 20GS, 25GS, 30GS, 35GS, поли-A, 8GS, 40GS, шарнира G1, шарнира 9GS-G1, верхней длинной шарнирной области ламы и шарнира G3.
Соответственно, настоящее изобретение относится к конструкции изобретения, такой как полипептид по изобретению, где указанный полипептид выбран из группы, состоящей из полипептидов таблицы E-1 и таблицы E-2.
В настоящее изобретение также включены соединения, конструкции и/или полипептиды, которые содержат ISV или полипептид по изобретению и дополнительно содержат метки или другие функциональные фрагменты, например, токсины, метки, радиохимические вещества и т.д.
Другие группы, остатки, фрагменты или связывающие единицы могут, например, представлять собой химические группы, остатки, фрагменты, которые сами по себе могут быть биологически и/или фармакологически активными или не быть биологически и/или фармакологически активными. Например, и без ограничения указанным, такие группы могут быть связаны с одним или несколькими ISV или полипептидами по изобретению, чтобы обеспечить «производное» полипептида по изобретению.
Соответственно, изобретение в его самом широком смысле также включает соединения, конструкции и/или полипептиды, которые являются производными полипептидов по изобретению. Такие производные обычно могут быть получены путем модификации и, в частности, путем химической и/или биологической (например, ферментативной) модификации полипептидов по изобретению и/или одного или нескольких аминокислотных остатков, которые образуют полипептид по изобретению.
Примеры таких модификаций, а также примеры аминокислотных остатков в полипептидных последовательностях, которые можно модифицировать таким образом (т.е. либо на основной цепи белка, но предпочтительно на боковой цепи), способы и методики, которые можно использовать для введения таких модификации и потенциальное использование и преимущества таких модификаций будут понятны специалисту (см. также Zangi et al., Nat Biotechnol 31 (10): 898-907, 2013).
Например, такая модификация может включать введение (например, путем ковалентного связывания или любым другим подходящим способом) одной или нескольких (функциональных) групп, остатков или фрагментов в или на полипептид по изобретению и, в частности, одной или нескольких функциональных групп, остатков или фрагментов, которые придают одно или несколько желаемых свойств или функциональных возможностей полипептиду по изобретению. Примеры таких функциональных групп будут понятны специалисту в данной области.
Например, такая модификация может включать введение (например, путем ковалентного связывания или любым другим подходящим способом) одной или нескольких функциональных групп, которые увеличивают период полувыведения, растворимость и/или абсорбцию полипептида по изобретению, уменьшают иммуногенность и/или токсичность полипептида по изобретению, устраняют или ослабляют любые нежелательные побочные эффекты полипептида по изобретению и/или придают другие полезные свойства и/или уменьшают нежелательные свойства полипептида по изобретению, или любую комбинацию двух или более из вышеперечисленного. Примеры таких функциональных групп и методик их введения будут понятны специалисту в данной области и, как правило, могут включать все функциональные группы и методики, упомянутые в общем уровне техники, процитированном выше, а также функциональные группы и методики, известные по существу для модификации фармацевтических белков и, в частности, для модификации антител или фрагментов антител (включая ScFv и однодоменные антитела), в этой связи, например, делается ссылка на Remington (Pharmaceutical Sciences, 16th ed., Mack Publishing Co., Easton, PA, 1980). Такие функциональные группы могут, например, быть связаны непосредственно (например, ковалентно) с полипептидом по изобретению или, необязательно, через подходящий линкер или спейсер, что опять же будет понятно специалисту в данной области.
Одним конкретным примером является производный полипептид по изобретению, где полипептид по изобретению был химически модифицирован для увеличения его периода полувыведения (например, посредством ПЭГ-илирования). Это один из наиболее широко используемых методов увеличения периода полувыведения и/или снижения иммуногенности фармацевтических белков и включает присоединение подходящего фармакологически приемлемого полимера, такого как поли (этиленгликоль) (ПЭГ) или его производных (таких как метоксиполи(этиленгликоль) или мПЭГ). Обычно можно использовать любую подходящую форму ПЭГ-илирования, такую как ПЭГ-илирование, используемое в данной области для антител и фрагментов антител, таких как, например, (одно)доменные антитела и ScFv; источником может служить, например, Chapman (Nat. Biotechnol. 54: 531-545, 2002), Veronese and Harris (Adv. Drug Deliv. Rev. 54: 453-456, 2003), Harris and Chess (Nat. Rev. Drug. Discov. 2: 214-221, 2003) и WO 04/060965. Различные реагенты для ПЭГ-илирования белков также коммерчески доступны, например, от Nektar Therapeutics, США.
Предпочтительно используют сайт-направленное ПЭГ-илирование, в частности, через остаток цистеина (см., например, Yang et al. (Protein Engineering 16: 761-770, 2003). Например, для этой цели ПЭГ может быть присоединен к остатку цистеина, который естественным образом встречается в полипептиде по изобретению, полипептид по изобретению может быть модифицирован таким образом, чтобы подходящим образом ввести один или несколько остатков цистеина для присоединения ПЭГ, или аминокислотная последовательность, содержащая один или несколько остатков цистеина для присоединения ПЭГ, может быть объединена с N- и/или С-концом полипептида по изобретению, причем все с использованием методов белковой инженерии, известных по существу специалисту в данной области.
Предпочтительно для полипептидов по изобретению используют PEG с молекулярной массой более 5000, например, более 10000 и менее 200000, например, менее 100000; например, в диапазоне от 20000 до 80000.
Другая, обычно менее предпочтительная модификация включает N-связанное или O-связанное гликозилирование, обычно как часть котрансляционной и/или посттрансляционной модификации, в зависимости от клетки-хозяина, используемой для экспрессии полипептида по изобретению.
Еще одна модификация может включать введение одной или нескольких обнаруживаемых меток или других генерирующих сигнал групп или фрагментов в зависимости от предполагаемого применения меченого полипептида по изобретению. Подходящие метки и методы их прикрепления, применения и обнаружения будут понятны специалисту в данной области и, например, включают, без ограничения указанным, флуоресцентные метки (такие как флуоресцеин, изотиоцианат, родамин, фикоэритрин, фикоцианин, аллофикоцианин, о-фтальдегид). и флуоресцины и флуоресцентные металлы, такие как 152Eu или другие металлы из серии лантаноидов), фосфоресцентные метки, хемилюминесцентные метки или биолюминесцентные метки (такие как люминал, изолюминол, ароматический эфир акридиния, имидазол, соли акридиния, оксалатный эфир, диоксетан или GFP и его аналоги), радиоизотопы (такие как 3H, 125I, 32P, 35S, 14C, 51Cr, 36Cl, 57Co, 58Co, 59Fe и 75Se), металлы, хелаты металлов или катионы металлов (например, катионы металлов, такие как 99mTc, 123I, 111In, 131I, 97Ru, 67Cu, 67Ga и 68Ga или других металлов или катионов металлов, которые особенно подходят для диагностики и визуализации in vivo, in vitro или in situ, таких как (157Gd, 55Mn, 162Dy, 52Cr и 56Fe)), а также хромофоры и ферменты (такие как малатдегидрогеназа, стафилококковая нуклеаза, дельта-V-стероидная изомераза, дрожжевая алкогольдегидрогеназа, альфа-глицерофосфатдегидрогеназа, триозофосфатизомераза, биотинавидинпероксидаза, пероксидаза хрена, щелочная фосфатаза, аспарагиназа, глюкозооксидаза, β-галактоза, β-галактоза глюкозо-VI-фосфатдегидрогеназа, глюкоамилаза и ацетилхолинэстераза). Другие подходящие метки будут понятны специалисту в данной области и, например, включают фрагменты, которые могут быть обнаружены с помощью ЯМР или ESR-спектроскопии.
Такие меченые полипептиды по изобретению могут, например, использоваться для анализов in vitro, in vivo или in situ (включая известные сами по себе иммуноанализы, такие как ELISA, RIA, EIA и другие «сэндвич-анализы» и т.д.), а также для диагностики in vivo и в целях визуализации, в зависимости от выбора специфической метки.
Как будет понятно специалисту в данной области, другая модификация может включать введение хелатной группы, например, для хелатирования одного из металлов или катионов металлов, упомянутых выше. Подходящие хелатирующие группы, например, включают, без ограничения, диэтил-энетриаминпентауксусную кислоту (DTPA) или этилендиаминтетрауксусную кислоту (EDTA).
Еще одна модификация может включать введение функциональной группы, которая является одной частью пары специфического связывания, такой как пара связывания биотин-(стрепт)авидин. Такая функциональная группа может быть использована для связывания полипептида по изобретению с другим белком, полипептидом или химическим соединением, которое связано с другой половиной пары связывания, то есть путем образования пары связывания. Например, полипептид по изобретению может быть конъюгирован с биотином и связан с другим белком, полипептидом, соединением или носителем, конъюгированным с авидином или стрептавидином. Например, такой конъюгированный полипептид по изобретению можно использовать в качестве репортера, например, в диагностической системе, где детектируемый агент, продуцирующий сигнал, конъюгирован с авидином или стрептавидином. Такие пары связывания могут, например, также использоваться для связывания полипептида по изобретению с носителем, включая носители, подходящие для фармацевтических целей. См., например, липосомные составы, описанные Cao и Suresh (Journal of Drug Targeting 8: 257, 2000). Такие пары связывания могут также использоваться для связывания терапевтически активного агента с полипептидом по изобретению.
Другие потенциальные химические и ферментативные модификации будут понятны специалисту. Такие модификации также могут быть введены для исследовательских целей (например, для изучения отношений функция-активность). Например, опять отсылаем к Lundblad и Bradshaw (Biotechnol. Appl. Biochem. 26: 143-151, 1997).
Предпочтительно, соединения, конструкции, полипептиды и/или производные являются такими, что они связываются с аггреканом с аффинностью (подходящим образом измеренной и/или выраженной в виде значения KD (фактического или кажущегося), значения KA (фактического или кажущегося) скорости kon и/или скорости Koff или, альтернативно, значения IC50, как дополнительно описано в данном документе), определенных в данном документе (т.е. определенных для полипептидов по изобретению).
Такие соединения, конструкции и/или полипептиды по изобретению и их производные также могут быть по существу в выделенной форме.
В одном аспекте настоящее изобретение относится к конструкции изобретения, которая включает или, по существу, состоит из ISV по изобретению или полипептида по изобретению и которая дополнительно включает одну или несколько других групп, остатков, фрагментов или связывание единицы, необязательно связанные через один или несколько пептидных линкеров.
В одном аспекте настоящее изобретение относится к конструкции изобретения, в которой одну или несколько других групп, остатков, фрагментов или связывающих единиц выбирают из группы, состоящей из молекулы полиэтиленгликоля, сывороточных белков или их фрагментов, связывающих единиц, которые могут связываться с сывороточными белками, частью Fc и небольшими белками или пептидами, которые могут связываться с сывороточными белками.
Изобретение, кроме того, относится к способам получения соединений, конструкций, полипептидов, нуклеиновых кислот, клеток-хозяев и композиций, описанных в данном документе.
Поливалентные полипептиды по изобретению, как правило, могут быть получены способом, который включает по меньшей мере стадию подходящего связывания ISV и/или моновалентного полипептида по изобретению с одним или несколькими дополнительными ISV, необязательно через один или несколько подходящих линкеров, так чтобы обеспечить поливалентный полипептид по изобретению. Полипептиды по изобретению также могут быть получены способом, который обычно включает по меньшей мере стадии получения нуклеиновой кислоты, кодирующей полипептид по изобретению, экспрессии указанной нуклеиновой кислоты подходящим способом и выделения экспрессированного полипептида по изобретению. Такие способы могут быть выполнены известным способом, который будет понятен специалисту в данной области, например, на основе способов и методик, дополнительно описанных в данном документе.
Способ получения поливалентных полипептидов по изобретению может включать по меньшей мере стадии связывания двух или более ISV по изобретению и, например, одного или нескольких линкеров вместе подходящим образом. ISV по изобретению (и линкеры) могут быть связаны любым способом, известным в данной области техники и описанным в данном документе далее. Предпочтительные способы включают связывание последовательностей нуклеиновых кислот, которые кодируют ISV по изобретению (и линкеры), для получения генетической конструкции, которая экспрессирует многовалентный полипептид. Методы связывания аминокислот или нуклеиновых кислот будут понятны специалисту в данной области, и опять модет быть сделана отсылка к стандартным руководствам, таким как Sambrook et al. и Ausubel et al., упомянутым выше, а также к примерам ниже.
Соответственно, настоящее изобретение также относится к применению ISV по изобретению для получения поливалентного полипептида по изобретению. Способ получения поливалентного полипептида будет включать связывание ISV по изобретению по меньшей мере с одним дополнительным ISV по изобретению, необязательно, через один или несколько линкеров. ISV по изобретению затем используют в качестве связывающего домена или для обеспечения и/или получения поливалентного полипептида, включающего 2 (например, в двухвалентном полипептиде), 3 (например, в трехвалентном полипептиде), 4 (например, в тетравалентный) или более (например, в поливалентном полипептиде) структурных элементов. В этом отношении ISV по изобретению можно использовать в качестве связывающего домена или связывающей единицы при обеспечении и/или при получении многовалентного, например, двухвалентного, трехвалентного или четырехвалентного полипептида по изобретению, содержащего 2, 3, 4 или более структурных элементов.
Соответственно, настоящее изобретение также относится к применению полипептида ISV по изобретению (как описано в данном документе) при получении поливалентного полипептида. Способ получения поливалентного полипептида будет включать связывание ISV по изобретению по меньшей мере с одним дополнительным ISV по изобретению, необязательно, через один или несколько линкеров.
Полипептиды и нуклеиновые кислоты по изобретению могут быть получены известным по существу способом, как будет понятно специалисту из дальнейшего описания. Например, полипептиды по изобретению могут быть получены любым известным способом для получения антител и, в частности, для получения фрагментов антител (включая, без ограничения указанным, (одно)доменные антитела и фрагменты ScFv). Некоторые предпочтительные, но не ограничивающие способы получения полипептидов и нуклеиновых кислот включают способы и методики, описанные в данном документе.
Способ получения полипептида по изобретению может включать следующие стадии:
- экспрессию в подходящей клетке-хозяине или организме-хозяине (также называемом в данном документе «хозяином по изобретению») или в другой подходящей системе экспрессии нуклеиновой кислоты, которая кодирует указанный полипептид по изобретению (также упоминаемой в данном документе как «нуклеиновая кислота по изобретению»),
за которой необязательно следует:
- выделения и/или очистки полипептида по изобретению, полученного таким образом.
В частности, такой способ может включать стадии культивирования и/или поддержания хозяина по изобретению в условиях, которые таковы, что указанный хозяин по изобретению экспрессирует и/или продуцирует по меньшей мере один полипептид по изобретению, за которыми необязательно следуют выделение и/или очистка полипептида по изобретению, полученного таким образом.
Соответственно, настоящее изобретение также относится к нуклеиновой кислоте или нуклеотидной последовательности, которая кодирует полипептид, ISV или конструкцию по изобретению (также называемую «нуклеиновая кислота по изобретению»).
Нуклеиновая кислота по изобретению может быть в форме одноцепочечной или двухцепочечной ДНК или РНК. Согласно одному воплощению изобретения нуклеиновая кислота по изобретению по существу выделена, как определено в данном документе. Нуклеиновая кислота по изобретению также может быть в форме, присутствовать и/или быть частью вектора, например, экспрессирующего вектора, такого как, например, плазмида, космида или YAC, который опять же может быть по существу в выделенной форме. Соответственно, настоящее изобретение также относится к экспрессирующему вектору, содержащему нуклеиновую кислоту или нуклеотидную последовательность по изобретению.
Нуклеиновые кислоты по изобретению могут быть приготовлены или получены способом, который сам по себе известен на основе информации о полипептидах по изобретению, приведенной в данном документе, и/или могут быть выделены из подходящего природного источника. Также, как будет понятно специалисту в данной области, для получения нуклеиновой кислоты по изобретению могут быть связаны также несколько нуклеотидных последовательностей, таких как по меньшей мере две нуклеиновые кислоты, кодирующие ISV по изобретению, и, например, нуклеиновые кислоты, кодирующие один или несколько линкеров могут быть связаны вместе подходящим образом. Методы получения нуклеиновых кислот по изобретению будут понятны специалисту в данной области и могут, например, включать, без ограничения указанным, автоматический синтез ДНК; сайт-направленный мутагенез; объединение двух или более встречающихся в природе и/или синтетических последовательностей (или двух или более их частей), введение мутаций, которые приводят к экспрессии усеченного продукта экспрессии; введение одного или нескольких сайтов рестрикции (например, для создания кассет и/или областей, которые можно легко разрезать и/или лигировать с использованием подходящих ферментов рестрикции), и/или введение мутаций посредством реакции ПЦР с использованием одного или нескольких праймеров, «ошибочно спаривающихся». Эти и другие методики будут понятны специалисту, и опять же источниками могут служить стандартные руководства, такие как Sambrook et al. и Ausubel et al., упомянутые выше, а также примеры ниже.
В предпочтительном, но не ограничивающем воплощении генетическая конструкция по изобретению включает
a) по меньшей мере, одну нуклеиновую кислоту по изобретению;
b) функционально связанную с одним или несколькими регуляторными элементами, такими как промотор и, необязательно, подходящим терминатором, и, возможно, также с
c) одним или несколькими дополнительными элементами генетических конструкций, известных по существу;
где термины «регуляторный элемент», «промотор», «терминатор» и «функционально связанный» имеют свое обычное значение в данной области техники.
Генетические конструкции по изобретению, как правило, могут быть получены путем соответствующего связывания нуклеотидной(ых) последовательности(ей) по изобретению с одним или несколькими дополнительными элементами, описанными выше, например, с использованием методик, описанных в общих руководствах, таких как Sambrook et al. и Ausubel et al., упомянутые выше.
Нуклеиновые кислоты по изобретению и/или генетические конструкции по изобретению можно использовать для трансформации клетки-хозяина или организма-хозяина, то есть для экспрессии и/или продуцирования полипептида по изобретению. Подходящие хозяева или клетки-хозяева будут понятны специалисту и могут, например, представлять собой любые подходящие грибные, прокариотические или эукариотические клетки или клеточные линии или любой подходящий грибной, прокариотический или (не человеческий) эукариотический организм, а также все другие клетки-хозяева или хозяева (не являющиеся человеком), известные по существу для экспрессии и продуцирования антител и фрагментов антител (включая, без ограничения указанным (одно)доменные антитела и фрагменты ScFv), что будет ясно специалисту. Источником может служить также общий уровень техники, процитированный выше, а также, например, на WO 94/29457; WO 96/34103; WO 99/42077; Frenken et al. (Res Immunol. 149: 589-99, 1998); Riechmann and Muyldermans (1999), выше; van der Linden (J. Biotechnol. 80: 261-70, 2000); Joosten et al. (Microb. Cell Fact. 2: 1, 2003); Joosten et al. (Appl. Microbiol. Biotechnol. 66: 384-92, 2005); дополнительные источники, процитированные в данном документе. Кроме того, полипептиды по изобретению также могут экспрессироваться и/или продуцироваться в бесклеточных системах экспрессии, и подходящие примеры таких систем будут понятны специалисту в данной области. Подходящие способы трансформации клетки-хозяина или клетки-хозяина по изобретению будут понятны специалисту в данной области и могут зависеть от предполагаемой клетки-хозяина/организма-хозяина и используемой генетической конструкции. Источником опять могут служить упомянутые выше руководства и патентные заявки. Трансформированная клетка-хозяин (которая может быть в форме стабильной клеточной линии или штамма) или организмы-хозяева (которые могут быть в форме стабильной мутантной линии или штамма) образуют дополнительные аспекты настоящего изобретения. Соответственно, настоящее изобретение относится к клеткам-хозяевам или организмам-хозяевам, содержащим нуклеиновую кислоту по изобретению или экспрессирующий вектор по изобретению. Предпочтительно эти клетки-хозяева или организмы-хозяева таковы, что они экспрессируют или (по меньшей мере) способны экспрессировать (например, в подходящих условиях) полипептид по изобретению (а в случае организма-хозяина по меньшей мере в одной клетке, части, ткани или органе). Изобретение также включает следующие поколения, потомство и/или потомки клетки-хозяина или организма-хозяина по изобретению, которые могут быть получены, например, путем деления клеток или путем полового или бесполого размножения.
Для продуцирования/получения экспрессии полипептидов по изобретению трансформированная клетка-хозяин или трансформированный организм-хозяин, как правило, могут храниться, поддерживаться и/или культивироваться в условиях, при которых (желательный) полипептид по изобретению экспрессируется/продуцируется. Подходящие условия будут понятны специалисту в данной области и будут обычно зависеть от используемой клетки-хозяина/организма-хозяина, а также от регуляторных элементов, которые контролируют экспрессию (соответствующей) нуклеотидной последовательности по изобретению. Опять же можно сделать отсылку к руководствам и заявкам на патенты, упомянутые выше в абзацах о генетических конструкциях изобретения.
Затем полипептид по изобретению может быть выделен из клетки-хозяина/организма-хозяина и/или из среды, в которой указанная клетка-хозяин или организм-хозяин культивировался, с использованием известных по существу методов выделения и/или очистки белка, таких как (препаративные) методы хроматографии и/или электрофореза, методы дифференциального осаждения, методы аффинности (например, с использованием специфической, расщепляемой аминокислотной последовательности, слитой с полипептидом по изобретению) и/или препаративные иммунологические методы (т.е. использование антител против подлежащего выделению полипептида).
В одном аспекте изобретение относится к способу получения конструкции, полипептида или ISV по изобретению, включающему по меньшей мере стадии: (а) экспрессии в подходящей клетке-хозяине или организме-хозяине или в другой подходящей системе экспрессии нуклеиновой кислоты последовательность по изобретению; необязательно с последующим (b) выделением и/или очисткой конструкции, полипептида или ISV по изобретению.
В аспекте изобретение относится к композиции, содержащей конструкцию, полипептид, ISV или нуклеиновую кислоту по изобретению.
Как правило, для фармацевтического применения конструкции, полипептиды и/или ISVD по изобретению могут быть составлены в виде фармацевтического препарата или композиции, содержащей по меньшей мере одну конструкцию, полипептид и/или ISVD по изобретению и по меньшей мере один фармацевтически приемлемый носитель, разбавитель или эксципиент и/или адъювант, и необязательно один или несколько фармацевтически активных полипептидов и/или соединений. Посредством неограничивающих примеров такая композиция может быть в форме, подходящей для перорального введения, для парентерального введения (например, путем внутривенной, внутримышечной или подкожной инъекции или внутривенной инфузии), для местного введения (такого как внутрисуставное введение), для введения ингаляцией, с помощью накожного пластыря, имплантата, суппозитория и т.д., где внутрисуставное введение является предпочтительным. Такие подходящие формы введения, которые могут быть твердыми, полутвердыми или жидкими, в зависимости от способа введения, а также способы и носители для использования при их приготовлении, будут понятны специалисту в данной области и будут дополнительно описаны в данном документе. Такой фармацевтический препарат или композиция, как правило, будут упоминаться в данном документе как «фармацевтическая композиция».
Таким образом, в дополнительном аспекте изобретение относится к фармацевтической композиции, которая содержит по меньшей мере по меньшей мере одну конструкцию по изобретению по меньшей мере один полипептид по изобретению по меньшей мере один ISV по изобретению, или по меньшей мере одну нуклеиновую кислоту изобретение и по меньшей мере один подходящий носитель, разбавитель или наполнитель (то есть подходящий для фармацевтического применения) и, необязательно, одно или несколько других активных веществ. В частном аспекте изобретение относится к фармацевтической композиции, которая содержит конструкцию, полипептид, ISV или нуклеиновую кислоту по изобретению, предпочтительно по меньшей мере одну из таблицы E-1 или таблицы E-2 и по меньшей мере один подходящий носитель, разбавитель или эксципиент (т.е. подходящий для фармацевтического применения), и, необязательно, одно или несколько других активных веществ.
Как правило, конструкции, полипептиды и/или ISV по изобретению могут быть составлены и введены любым подходящим способом, известным по существу. Источником могут служить, например, общий уровень техники, упомянутый выше (и, в частности, WO 04/041862, WO 04/041863, WO 04/041865, WO 04/041867 и WO 08/020079), а также стандартные руководства, такие как Remington’s Pharmaceutical Sciences, 18th Ed., Mack Publishing Company, USA (1990), Remington, the Science and Practice of Pharmacy, 21st Edition, Lippincott Williams and Wilkins (2005); или the Handbook of Therapeutic Antibodies (S. Dubel, Ed.), Wiley, Weinheim, 2007 (см., например, страницы 252-255).
В частном аспекте изобретение относится к фармацевтической композиции, которая содержит конструкцию, полипептид, ISV или нуклеиновую кислоту по изобретению, и которая дополнительно включает по меньшей мере один фармацевтически приемлемый носитель, разбавитель или наполнитель и/или адъювант и необязательно содержит один или несколько других фармацевтически активных полипептидов и/или соединений.
Конструкции, полипептиды и/или ISV по изобретению могут быть составлены и введены любым способом, известным по существу для обычных антител и фрагментов антител (включая ScFv и диантитела) и других фармацевтически активных белков. Такие составы и способы их приготовления будут понятны для специалиста и, например, включают составы, подходящие для парентерального введения (например, внутривенного, внутрибрюшного, подкожного, внутримышечного, внутрипросветного, внутриартериального или интратекального введения) или для местного (например, внутрисуставного, трансдермального или внутрикожного) введения.
Составы для парентерального введения могут, например, представлять собой стерильные растворы, суспензии, дисперсии или эмульсии, которые подходят для инфузии или инъекции. Подходящие носители или разбавители для таких препаратов, например, включают те, которые упомянуты на странице 143 в WO 08/020079. Обычно водные растворы или суспензии будут предпочтительными.
Конструкции, полипептиды и/или ISV по изобретению также можно вводить с использованием способов доставки, известных из генной терапии, см., например, патент США №5399346, который включен посредством отсылки в связи с его способами доставки для генной терапии. Используя способ доставки генной терапии, первичные клетки, трансфицированные геном, кодирующим конструкцию, полипептид и/или ISV по изобретению, могут дополнительно трансфицироваться тканеспецифичными промоторами для нацеливания на конкретные органы, ткани, трансплантаты, опухоли, суставы или клетки и могут быть дополнительно трансфицированы сигнальными и стабилизирующими последовательностями для экспрессии, локализованной внутри клетки.
Конструкции, полипептиды и/или ISV по изобретению также можно вводить внутривенно, внутрисуставно или внутрибрюшинно путем инфузии или инъекции. Конкретные примеры описаны далее на страницах 144 и 145 в WO 08/020079 или в PCT/EP2010/062975 (весь документ).
Полезные дозировки конструкций, полипептидов и/или ISV по изобретению могут быть определены путем сравнения их активности in vitro и активности in vivo на животных моделях. Способы экстраполяции эффективных доз у мышей и других животных на людей известны в данной области, см., например, US 4,938,949.
Количество конструкций, полипептидов и/или ISV по изобретению, необходимое для применения при лечении, будет варьироваться не только в зависимости от специфичного выбранного ISV, полипептида, соединения и/или конструкции, но также от пути введения, природы состояния, подвергаемого лечению и возраста и состояния пациента, и, в конечном счете, будут определяться лечащим или клиническим врачом. Также дозировка конструкций, полипептидов и/или ISV по изобретению варьируется в зависимости от клетки-мишени, опухоли, сустава, ткани, трансплантата или органа.
Желаемая доза может быть удобно представлена в виде одной дозы или в виде разделенных доз, вводимых через соответствующие интервалы, например, в виде двух, трех, четырех или более субдоз в день. Сама субдоза может быть дополнительно разделена, например, на несколько отдельных свободно распределенных введений. Предпочтительно доза вводится один раз в неделю или даже реже, например, один раз в две недели, один раз в три недели, один раз в месяц или даже один раз в два месяца.
Режим введения может включать длительное лечение. Под «долгосрочным» подразумевается по меньшей мере две недели, а предпочтительно несколько недель, месяцев или лет. Необходимые модификации в этом диапазоне доз могут быть определены специалистом в данной области с использованием только рутинных экспериментов, приведенных в данном документе. См., например, Remington's Pharmaceutical Sciences (Martin, E.W., ed. 4th), Mack Publishing Co., Easton, PA. Дозировка также может быть скорректирована индивидуальным лечащим врачом в случае каких-либо осложнений.
В данной области необходимы более эффективные способы лечения нарушений, влияющих на хрящ в суставах, таких как остеоартрит. Даже при внутрисуставном введении время пребывания большинства лекарственных средств при лечении пораженного хряща недостаточно. Авторы настоящего изобретения выдвинули гипотезу о том, что эффективность терапевтического лекарственного средства может быть значительно повышена путем соединения терапевтического лекарственного средства с компонентом, который «закрепляет» лекарственное средство в суставе и, следовательно, увеличивает удерживание лекарственного средства, но это не должно нарушать эффективность указанного терапевтического лекарственного средства (также обозначаемого как «белок, заякоривающийся на хряще» или «CAP»). Эта концепция заякоривания не только повышает эффективность лекарственного средства, но также и функциональную специфичность для больного сустава за счет снижения токсичности и побочных эффектов, таким образом, увеличивая количество возможных полезных лекарственных средств. Авторы настоящего изобретения также выдвинули гипотезу о том, что агенты, связывающие аггрекан, могут потенциально функционировать в качестве такого якоря, хотя аггрекан сильно гликозилирован и деградирует при различных нарушениях, влияющих на хрящ в суставах. Кроме того, ввиду затрат и обширных испытаний на различных моделях на животных, необходимых для того, чтобы лекарственное средство могло поступить в клинику, такие агенты, связывающие аггрекан, должны предпочтительно иметь широкую перекрестную реактивность, например, агенты, связывающие аггрекан, должны связываться с аггреканом различных видов. Используя различные оригинальные способы иммунизации, скрининга и определения характеристик, авторы настоящего изобретения смогли идентифицировать различные агенты, связывающие аггрекан, с превосходными свойствами селективности, стабильности и специфичности, которые обеспечили возможность длительного удержания и активности в суставе.
В одном аспекте настоящее изобретение относится к композиции по изобретению, ISV по изобретению, полипептиду по изобретению и/или конструкции по изобретению для применения в качестве лекарственного средства.
В одном аспекте настоящее изобретение относится к способу уменьшения и/или ингибирования оттока композиции, полипептида или конструкции из сустава, где указанный способ включает введение фармацевтически активного количества по меньшей мере одного полипептида по изобретению, конструкции по изобретению или композиции по изобретению нуждающейся в этом персоне.
В настоящем изобретении термин «уменьшение и/или ингибирование оттока» означает уменьшение и/или ингибирование потока наружу композиции, полипептида или конструкции изнутри сустава наружу. Предпочтительно отток уменьшается и/или ингибируется по меньшей мере на 10%, например, по меньшей мере на 20, 30, 40 или 50% или даже более, например, по меньшей мере на 60, 70, 80, 90 или даже более 100% по сравнению с оттоком вышеуказанной композиции, полипептида или конструкции в суставе в тех же условиях, но без присутствия агента по изобретению, связывающего аггрекан, например, ISV, связывающих аггрекан.
Предполагается, что агенты по изобретению, связывающие аггрекан, могут быть использованы при различных заболеваниях, поражающих хрящ, такие как артропатии и хондродистрофии, подагрические заболевания, такие как остеоартрит, ревматоидный артрит, подагрический артрит, псориатический артрит, травматический разрыв или отслоение, ахондроплазия, костохондрит, спондилоэпиметафизальная дисплазия, грыжа позвоночника, дегенерация поясничного диска, дегенеративное заболевание суставов и рецидивирующий полихондрит (обычно обозначаемый в данном документе как «заболевания, связанные с аггреканом»).
В одном аспекте настоящее изобретение относится к композиции, ISV, полипептиду и/или конструкции по изобретению для применения при профилактике или лечении заболевания, связанного с аггреканом, такого как, например, артропатии и хондродистрофии, артритное заболевание, такое как остеоартрит, ревматоидный артрит, подагрический артрит, псориатический артрит, травматический разрыв или отрыв, ахондроплазия, костохондрит, спондилоэпиметафизальная дисплазия, спинная грыжа диска, дегенеративные заболевания поясничного диска, дегенеративные заболевания суставов и рецидивирующий полихондрит.
В одном аспекте настоящее изобретение относится к способу профилактики или лечения артропатий и хондродистрофий, артритного заболевания, такого как остеоартрит, ревматоидный артрит, подагрический артрит, псориатический артрит, травматический разрыв или отслоение, ахондроплазия, костохондрит, спондилоэпиметафизарная дисплазия, грыжа позвоночника, дегенерация поясничного диска, дегенеративные заболевания суставов и рецидивирующий полихондрит, где указанный способ включает введение объекту, нуждающемуся в этом, фармацевтически активного количества по меньшей мере композиции, ISV, полипептида или конструкции по изобретению, человеку нуждающихся в этом.
В одном аспекте настоящее изобретение относится к применению ISV, полипептида, композиции или конструкции по изобретению, при приготовлении фармацевтической композиции для лечения или профилактики артропатий и хондродистрофий, артритного заболевания, такого как остеоартрит, ревматоидный артрит, подагра артрит, псориатический артрит, травматический разрыв или отслоение, ахондроплазия, костохондрит, спондилоэпиметафизальная дисплазия, грыжа позвоночного диска, дегенеративные заболевания поясничного диска, дегенеративные заболевания суставов и рецидивирующий полихондрит.
Ожидается, что связываясь с аггреканом, агенты по изобретению, связывающие аггрекан, могут снижать или ингибировать активность представителя семейства сериновых протеаз, катепсинов, матриксных металлопротеиназ (MMP)/матриксинов или дезинтегрина и металлопротеиназы с мотивами тромбоспондина (ADAMTS), предпочтительно MMP8, MMP13, MMP19, MMP20, ADAMTS5 (аггреканазы-2), ADAMTS4 (аггреканазы-1) и/или ADAMTS11, при деградации аггрекана.
Соответственно, в одном аспекте изобретение относится к способу снижения или ингибирования активности представителя семейства сериновых протеаз, катепсинов, матриксных металлопротеиназ (ММР)/матриксинов или дезинтегрина и металлопротеиназы с мотивами тромбоспондина (ADAMTS), предпочтительно MMP8, MMP13, MMP19, MMP20, ADAMTS5 (аггреканазы-2), ADAMTS4 (аггреканазы-1) и/или ADAMTS11, при деградации аггрекана, где указанный способ включает введение фармацевтически активного количества, по меньшей мере, ISV, полипептида, конструкции или композиции в соответствии с изобретением нуждающемуся в этом лицу.
В контексте настоящего изобретения термин «профилактика и/или лечение» включает не только предотвращение и/или лечение заболевания, но также обычно включает предотвращение возникновения заболевания, замедление или изменение хода заболевания, предотвращение или замедление наступления одного или нескольких симптомов, связанных с заболеванием, уменьшение и/или ослабление одного или нескольких симптомов, связанных с заболеванием, уменьшение тяжести и/или продолжительности заболевания и/или любых симптомов, связанных с ним, и/или предотвращение дальнейшего увеличения тяжести заболевания и/или любых связанных с ним симптомов, предотвращение, уменьшение или устранение любого физиологического повреждения, вызванного заболеванием, и, как правило, любое фармакологическое действие, которое полезно для подвергаемого лечению пациента.
Объектом, подлежащим лечению, может быть любое теплокровное животное, но, в частности, это млекопитающее и, в частности, человек. Как будет понятно специалисту в данной области, объектом, подлежащим лечению, будет, в частности, человек, страдающий или подверженный риску заболеваний, расстройств и состояний, упомянутых в данном документе.
Обычно схема лечения включает введение одного или нескольких ISV, полипептидов, соединений и/или конструкций по изобретению или одной или нескольких композиций, содержащих их, в одном или нескольких фармацевтически эффективных количествах или дозах. Конкретное количество или дозы, которые следует вводить, может быть определено врачом, опять же, на основе факторов, указанных выше.
Как правило, в зависимости от специфичного заболевания, расстройства или состояния, подлежащего лечению, активности специфичного ISV, полипептида, соединения и/или конструкции по изобретению, которые следует использовать, специфичного пути введения и специфичного используемого фармацевтического состава или композиции, клинический врач сможет определить подходящую суточную дозу.
Обычно в вышеуказанном способе будут использоваться ISV, полипептид, соединение и/или конструкция по изобретению. Однако в объем изобретения входит применение двух или более ISV, полипептидов и/или конструкций по изобретению в комбинации.
ISV, полипептиды и/или конструкции по изобретению могут быть использованы в комбинации с одним или несколькими другими фармацевтически активными соединениями или действующими началами, то есть в качестве комбинированной схемы лечения, которая может приводить или не приводить к синергетическому эффекту.
Опять же, клинический врач сможет выбрать такие дополнительные соединения или действующие начала, а также подходящую комбинированную схему лечения, основываясь на вышеупомянутых факторах и своем экспертном заключении.
В частности, ISV, полипептиды и/или конструкции по изобретению могут быть использованы в комбинации с другими фармацевтически активными соединениями или действующими началами, которые используются или могут быть использованы для профилактики и/или лечения заболеваний, расстройств и состояний, указанных в настоящем описании, в результате чего может быть получен или не получен синергетический эффект. Примеры таких соединений и действующих начал, а также путей, способов и фармацевтических составов или композиций для их введения будут понятны врачу.
Когда два или более вещества или действующих начала должны использоваться как часть комбинированной схемы лечения, их можно вводить одним и тем же путем введения или разными способами введения по существу в одно и то же время или в разные моменты времени (например, по существу одновременно, последовательно или в соответствии с режимом чередования). Когда вещества или действующие начала должны вводиться одновременно посредством одного и того же пути введения, их можно вводить в виде различных фармацевтических составов или композиций или части комбинированных фармацевтических составов или композиций, как будет понятно специалисту в данной области.
Кроме того, когда два или более активных вещества или действующих начала должны использоваться как часть комбинированного режима лечения, каждое из веществ или действующих начал может вводиться в том же количестве и в соответствии с тем же режимом, который используется, когда используется само по себе соединение или действующее начало, и такое комбинированное применение может привести или не привести к синергетическому эффекту. Однако когда комбинированное применение двух или более активных веществ или действующих начал приводит к синергетическому эффекту, также может быть возможно уменьшить количество одного, нескольких или всех веществ или действующих начал, которые следует вводить, при этом все еще достигая желаемого терапевтического действия. Это может, например, быть полезным для предотвращения, ограничения или уменьшения любых нежелательных побочных эффектов, которые связаны с использованием одного или нескольких веществ или действующих начал, когда они используются в их обычных количествах, при одновременном получении желаемого фармацевтического или терапевтического эффекта.
Эффективность схемы лечения, используемой в соответствии с изобретением, может быть определена и/или отслежена любым способом, известным по существу для заболевания, расстройства или состояния, как будет понятно клинический врачу. Клинический врач также сможет, при необходимости и в каждом в специфическом случае, изменять или модифицировать конкретную схему лечения, чтобы достичь желаемого терапевтического эффекта, чтобы избежать, ограничить или уменьшить нежелательные побочные эффекты, и/или для достижения надлежащего баланса между достижением желаемого терапевтического эффекта, с одной стороны, и предотвращением, ограничением или уменьшением нежелательных побочных эффектов, с другой стороны.
Как правило, режим лечения будет соблюдаться до тех пор, пока не будет достигнут желаемый терапевтический эффект и/или до тех пор, пока должен поддерживаться желаемый терапевтический эффект. Опять же, это может определить клинический врач.
В другом аспекте изобретение относится к применению ISV, полипептида, соединения и/или конструкции по изобретению при приготовлении фармацевтической композиции для профилактики и/или лечения по меньшей мере заболевания, связанного с аггреканом, и/или для применения в одном или нескольких из способов лечения, упомянутых в данном документе.
Изобретение также относится к применению ISV, полипептида, соединения и/или конструкции по изобретению в приготовлении фармацевтической композиции для профилактики и/или лечения по меньшей мере одного заболевания или расстройства, которое можно предотвратить и/или лечить, модулируя аггрекан, например, ингибированием деградации аггрекана.
Изобретение также относится к применению ISV, полипептида, соединения и/или конструкции по изобретению в приготовлении фармацевтической композиции для профилактики и/или лечения по меньшей мере одного заболевания, расстройства или состояния, которое можно предотвратить, и/или лечить путем введения ISV, полипептида, соединения и/или конструкции по изобретению пациенту.
Изобретение, кроме того, относится к ISV, полипептиду, соединению и/или конструкции по изобретению или фармацевтической композиции, содержащей ее, для применения при профилактике и/или лечении по меньшей мере одного заболевания, связанного с аггреканом.
Объектом, подлежащим лечению, может быть любое теплокровное животное, но, в частности, это млекопитающее и, в частности, человек. В ветеринарных применениях объект, подлежащий лечению, включает любое животное, выращенное в коммерческих целях или содержащееся в качестве домашнего животного. Как будет понятно специалисту в данной области, объектом, подлежащим лечению, будет, в частности, человек, страдающий или подверженный риску заболеваний, расстройств и состояний, упомянутых в данном документе.
Опять же, в такой фармацевтической композиции один или несколько ISV, полипептидов, соединений и/или конструкций по изобретению или нуклеотида, кодирующего их, и/или фармацевтическую композицию, содержащую их, также можно соответствующим образом комбинировать с одним или несколькими другими действующими началами, такими как упомянуты в данном документе.
Изобретение также относится к композиции (такой как, без ограничения указанным, фармацевтические композиция или состав, как дополнительно описано в данном документе) для применения либо in vitro (например, в анализе in vitro или клеточном анализе), либо in vivo (например, в отдельной клетке или многоклеточном организме, и, в частности, у млекопитающего, и более конкретно, у человека, такого как человек, который находится в опасности или страдает от заболевания, расстройства или состояния по настоящему изобретению).
Следует понимать, что, когда говорится о лечении, это включает как лечение установленных симптомов, так и профилактическое лечение, если прямо не указано иное.
Последовательности раскрыты в основной части описания и в отдельном перечне последовательностей в соответствии со стандартом WIPO ST.25. SEQ ID, указанный с определенным номером, должен быть одинаковым в основной части описания и в отдельном перечне последовательностей. В качестве примера SEQ ID NO.: 1 должна определять одну и ту же последовательность в основной части описания и в отдельном перечне последовательностей. В случае несоответствия между определением последовательности в основном тексте описания и отдельным списком последовательностей (например, если SEQ ID NO.: 1 в основном тексте описания ошибочно соответствует SEQ ID NO.: 2 в отдельном перечне последовательностей), тогда ссылка на конкретную последовательность в приложении, в частности на конкретные воплощения, должна пониматься как ссылка на последовательность в основном тексте приложения, а не в отдельном перечне последовательностей. Другими словами, несоответствие между определением/обозначением последовательности в основной части описания и отдельным перечнем последовательностей должно быть устранено путем исправления отдельного перечня последовательностей в части последовательностей и их обозначений, раскрытых в основной части заявки, которая включает описание, примеры, фигуры и формулу изобретения.
Теперь изобретение будет дополнительно описано с помощью следующих неограничивающих предпочтительных аспектов, примеров и фигур.
Полное содержание всех источников (включая ссылки на литературу, выданные патенты, опубликованные патентные заявки и патентные заявки, рассматриваемые в данной заявке), цитированные повсеместно в данной заявке, явно включено в данный документ посредством отсылки, в частности, в связи с руководствами, на которые есть отссылки выше.
ПРИМЕРЫ
Пример 1. Иммунизация лам с помощью аггрекана, клонирование репертуаров фрагментов антител, содержащих только тяжелые цепи, и получение фага
Авторы настоящего изобретения отдают себе отчет в том, что цель моделей ОА на животных заключается в контролируемом воспроизведении масштаба и прогрессирования повреждения суставов, так что можно идентифицировать возможности детекции и модуляции симптомов и прогрессирования заболевания и разработать новые методы лечения. Идеальная животная модель имеет относительно низкую стоимость и демонстрирует воспроизводимую прогрессию заболевания с масштабом эффекта, достаточно большим, чтобы обнаружить различия в течение короткого периода времени. Если модель прогрессирует слишком быстро до конечной стадии дегенерации, промежуточные моменты времени, которые являются репрезентативными для патофизиологии ОА, могут быть недоступны, и в отсутствие этой информации, тонкие эффекты потенциальных вмешательств могут быть упущены. Отдавая себе отчет в том, что ОА является фенотипом конечной стадии, результатом взаимодействия механических и биохимических процессов, модели на животных позволяют изучать эти факторы в контролируемой среде (см. также Teeple et al. 2013 AAPS J. 15: 438-446).
Конечная цель моделей на животных - воспроизвести болезни человека (см. также Cohen-Solal et al. 2013 Bonekey Rep. 2: 422). Учитывая неоднородность профилей в ОА человека, необходимо множество моделей. Они являются либо спонтанными, либо индуцированными. Большинство из них сосредоточены на одном факторе, который способствует развитию ОА, таком как старение, механический стресс (хирургия), химический дефект (фермент) или генетические факторы. Все они различаются по степени тяжести, локализации поражений и патогенезу. Однако ни одна животная модель не затрагивает все аспекты развития ОА.
Таким образом, чтобы быть полезным в различных моделях на животных, а также, в конечном счете, в пациенте, агент, связывающий CAP, предпочтительно обладает широкой перекрестной реактивностью, например, связывает с аггреканом более чем одного вида. Предпочтительно, если агент, связывающий аггрекан, связывается с аггреканом человека, а также с одним или несколькими из аггрекана собаки, аггрекана коровы, аггрекана крысы, аггрекана свиньи, аггрекана мыши, аггрекана кролика, аггрекана яванского макака и/или аггрекана макака-резуса.
Кроме того, авторы настоящего изобретения поняли, что деградация аггрекана, по-видимому, инициируется в С-концевой области. Популяция молекул аггрекана без домена G3 увеличивается также с возрастом. Основной особенностью дегенерации хряща, связанной с артритом, является потеря аггрекана из-за протеолитического расщепления в межглобулярной области между доменами G1 и G2. Следовательно, предпочтительно, если агент, связывающий аггрекан, связывается с N-концевой областью аггрекана, то есть с областью, отличной от домена CS или G3, такой как область G1-IGD-G2, или с доменом G1, IGD или домен G2. Наиболее предпочтительно, если агент, связывающий аггрекан, будет связываться с доменом G1, который остается в хондроцитах и в ЕСМ.
1.1 Иммунизации
Пять лам иммунизировали рекомбинантным (rec) человеческим аггреканом (домены G1-IGD-G2, R & D Systems # 1220-PG) (см. Пример 1.2). Образцы сыворотки отбирали после введения антигена и определяли титры с помощью ELISA против человеческого рекомбинантного аггрекана G1-IGD-G2. Все ламы давали определенные титры в сыворотке.
1.2 Первичный скрининг
РНК выделяли из PBL (первичных лимфоцитов крови) и использовали в качестве матрицы для ОТ-ПЦР для амплификации фрагментов гена, кодирующего ISV. Эти фрагменты были клонированы в фагемидный вектор pAX212, позволяющий получить частицы фага, демонстрирующие ISV, слитые с His6- и FLAG3-метками. Фаги готовили и хранили в соответствии со стандартными протоколами (см. также Phage Display of Peptides and Proteins: A Laboratory Manual 1st Edition, Brian K. Kay, Jill Winter, John McCafferty, Academic Press, 1996).
Селекции фагового дисплея проводили на пяти иммунных библиотека и двух синтетических библиотеках ISV. Библиотеки были подвергнуты двум-трем циклам обогащения против различных комбинаций рекомбинантного домена G1-IGD-G2 аггрекана человека и биотинилированного агрекана крысы, экстрагированного полноразмерного аггрекана коровы или интактного коровьего хряща. Отдельные клоны из продуктов селекции подвергали скринингу на связывание в ELISA (с использованием периплазматических экстрактов из клеток E.coli, экспрессирующих ISV) против человеческого домена G1-IGD-G2. Секвенирование 542 клонов, положительных по ELISA, идентифицировало 144 уникальных последовательности ISV. ISV были оценены на перекрестную реактивность видов и картированы с помощью ELISA на связывание с отдельными человеческими доменами G1, IGD и G2. Только несколько ISV показали сходные уровни связывания с рекомбинантным G1-IGD-G2 аггрекана человека, крысы, собаки и коровы. Ограниченная перекрестная реактивность видов была особенно очевидна для агентов, связывающих домен G1, для которых связывание с аггреканами коровы и собаки было особенно плохим. Чтобы идентифицировать больше видов перекрестно-реактивных ISV, связывающихся с доменом G1, проводили фаговый дисплей в отношении доменов G1-IGD-G2 крупного рогатого скота, G1-IGD-G2 собаки и G1 человека. Из 1245 клонов, подвергнутых скринингу в ELISA на связывание с G1-IGD-G2 человека, яванского макака, крысы, собаки и коровы, были идентифицированы только 15 новых видов перекрестно-реактивных ISV, девять из которых могли быть картированы в домене G1.
Всего 19 уникальных клонов были выбраны в качестве «ведущей панели» для дальнейшей характеризации. Обзор данных по картированию доменов и перекрестной реактивности видов для этой ведущей панели приведен в таблице 1.2.
Таблица 1.2. Обзор данных скрининга периплазматического экстракта для ведущей панели. Nd: не определено.
1.3 Агенты, связывающие G1
Вариабельность последовательности CDR агентов, связывающих G1, была определена относительно клона 114F08. Аминокислотные последовательности CDR клона 114F08 были использованы в качестве стандарта, с которым сравнивали CDR всех других клонов (агентов, связвающих G1), и они представлены в приведенных ниже таблицах 1.3A, 1.3B и 1.3C (CDR1 начинается с Положения 26 по Kabat, CDR2 начинается с положения 50 по Kabat, а CDR3 начинается с положения 95 по Kabat).
Таблица 1.3А
*вплоть до 2 мутаций CDR1 в одном клоне.
Таблица 1.3В
*вплоть до 5 мутаций CDR2 в одном клоне.
Таблица 1.3C
*вплоть до 5 мутаций CDR3 в одном клоне.
1.4 Агенты, связывающие G1-IGD-G2
Вариабельность последовательности CDR агентов, связывающих G1-IGD-G2 (GIG), была определена относительно клона 604F02. Аминокислотные последовательности CDR клона 604F02 были использованы в качестве стандарта, с которым сравнивали CDR всех других клонов (связывающих GIG), и они представлены в приведенных ниже таблицах 1.4A, 1.4B и 1.4C (CDR1 начинается с положения 26 по Kabat, CDR2 начинается с положения 50 по Kabat, а CDR3 начинается с положения 95 по Kabat).
Таблица 1.4А
*вплоть до 2 мутаций CDR1 в одном клоне.
Таблица 1.4В
*вплоть до 2 мутаций CDR2 в одном клоне.
Таблица 1.4C
*вплоть до 5 мутаций CDR3 в одном клоне.
1.5 Агенты, связывающие G2
Вариабельность последовательности CDR агентов, связывающих G2, была определена относительно клона 601D02. Аминокислотные последовательности CDR клона 601D02 были использованы в качестве стандарта, с которым сравнивали CDR всех других клонов (агентов, связывающих G2), и они представлены в приведенных ниже таблицах 1.5A, 1.5B и 1.5C (CDR1 начинается с положения 26 по Kabat, CDR2 начинается с положения 50 по Kabat, а CDR3 начинается с положения 95 по Kabat).
Таблица 1.5А
*вплоть до 5 мутаций CDR3 в одном клоне.
Таблица 1.5В
*вплоть до 5 мутаций CDR2 в одном клоне.
Таблица 1.5С
*вплоть до 5 мутаций CDR3 в одном клоне.
1.6 Оптимизация последовательности ISV
Различные ISV были подвергнуты процессу оптимизации последовательности. Оптимизация последовательности - это процесс, в котором родительская последовательность ISV подвергается мутированию. Этот процесс охватывает гуманизацию (i) ISV и нокаутные посттрансляционные модификации (ii), а также эпитопы для потенциальных предсуществующих антител (iii).
(i) В целях гуманизации родительскую последовательность ISV мутируют, чтобы получить последовательность ISV, которая более идентична консенсусной последовательности зародышевой линии человеческого IGHV3-IGHJ. Специфические аминокислоты в каркасных областях (за исключением так называемых характерных остатков), которые различаются между ISV и консенсусом зародышевой линии человеческого IGHV3-IGHJ, изменяются для человеческого аналога таким образом, что структура белка, активность и стабильность сохранялись интактными. Известно, что несколько характерных остатков имеют решающее значение для стабильности, активности и аффинности ISV и поэтому не подвергались мутации.
(ii) Те аминокислоты, которые присутствуют в CDR и для которых есть экспериментальные доказательства того, что они чувствительны к посттрансляционным модификациям (PTM), изменяются таким образом, что сайт PTM инактивируется, в то время как структура, активность и стабильность белка сохраняются неизменными.
(iii) Последовательность ISV оптимизирована, не влияя на структуру, активность и стабильность белка, чтобы минимизировать связывание любых встречающихся в природе предсуществующих антител и уменьшить возможность вызывать иммуногенную реакцию, возникающую при лечении - внезапный иммуногенный ответ.
Для создания оптимизированных по последовательности форматированных ISV, сконструированные ISV продуцировали в Pichia pastoris в виде белков без меток и очищали с помощью аффинной хроматографии с протеином A с последующим обессоливанием, все согласно стандартным протоколам.
Различные форматированные ISV с оптимизированной последовательностью показаны в таблицах A-1 и A-2.
Пример 2. Характеризация ведущей панели (очищенные ISV) - аггрекан
После первичного скрининга, первоначальной оценки связывания с помощью ELISA, определения скорости диссоциации и видовой перекрестной реактивности, ISV ведущей панели подвергали дальнейшей характеризации.
2.1 Форматирование ведущей панели против аггрекана с помощью ALB26 (n = 19)
Предполагается, что окончательный формат молекулы для клинического применения включает один или два связывающих аггрекан ISV («якоря»), а также один, два или более ISV или другие фрагменты с терапевтическим способом действия. Следовательно, 19 отобранных клонов были слиты в моновалентном или двухвалентном формате с ALB26 (CAP-ALB26 или ALB26-CAP-CAP) и экспрессированы в P. pastoris. ALB26 представляет собой вариант ALB11 (альбумин-связывающий ISV) с двумя мутациями в CDR1, которые полностью устраняют связывание с альбумином из разных видов. Слияние с ALB26 проводили для имитации размера конечного полипептидного формата, содержащего агент, связывающий аггрекан. Не ограничиваясь какой-либо теорией, авторы выдвинули гипотезу, что pI может влиять на проникновение и удержание в хряще. В качестве отрицательного контроля или «пустышки» использовали двухвалентный ALB26 (C01010030).
2.2 Удержание в коровьем хряще ex vivo
Поскольку не существует анализа установленного образца для оценки удержания в хряще, авторы изобретения разработали надежный и воспроизводимый анализ удержания в хряще ex vivo с использованием коровьего хряща.
Коровьи кости, как правило, собирали на местной бойне. Хрящ отрезали от костей полосками толщиной ~1 мм и затем разрезали на круглые диски диаметром 3 мм с помощью биопсийных резаков. Хрящевые диски были преимущественно взяты из свежего хряща.
Определяли способность ISV удерживаться в хряще в течение длительного периода времени после относительно короткого воздействия нанотела на хрящ (что можно ожидать при внутрисуставной инъекции). Анализ состоял из инкубации хряща ex vivo, как правило, 3-миллиметровых бычьих дисков (~10 мг сырой массы) с 10 мкг/мл нанотела (100 мкл) с последующим промыванием в течение до 5 дней (PBS/0,1% BSA/0,1%). NaN3/100 мМ NaCl). Далее связанное (удержанное) нанотело высвобождалось из хряща в SDS-содержащий буфер для образцов SDS-PAGE (буфер для образцов LDS Invitrogen) и анализировалось с помощью вестерн-блоттинга (WB). Анализ обычно выполняли с 4 хрящевыми дисками на образец нанотела; 2 диска были проанализированы сразу после инкубации нанотела (t0) для определения начального количества связанного нанотела; 2 диска были проанализированы после промывки (t1-5 дней). Степень удержания определяли как отношение количества нанотела, обнаруженного в дни t1-5 и t0. Чтобы увеличить пропускную способность анализа, определение этого отношения было выполнено путем визуального осмотра вестерн-блоттинга с оценкой 0-6, где 0 - отсутствие удержания, а 6 - полное удержание.
Сводка результатов показана в таблице 2.2.
Таблица 2.2. Эпитопное связывание и удержание в хряще ведущей панели против аггрекана в формате с применением ALB26. *В таблице приведены средние оценки из числа (n) независимых анализов удержания в хряще быка ex vivo по шкале от 0 до 6, в которых 0 - отсутствие удержания, а 6 - полное удержание.
Было обнаружено, что 9 конструкций удерживались очень хорошо (5-6 баллов) в хряще. Эти «топ-9» включали как одновалентные, так и двухвалентные конструкции для фрагмента, связывающего аггрекан, которые связывались со всеми рекомбинантными доменами G1, G2 или G1-IGD-G2. В этом анализе 14 конструкций показали умеренное удерживание (оценки между <5 и 2), а 5 конструкций показали низкое, хотя и обнаруживаемое удерживание (оценки между <2 и 1). Примечательно, что все конструкции против аггрекана, кроме одной, имели значения pI в диапазоне от 8 до 9.
2.3 Сортировка антител в зависимости от связываемого эпитопа
Для сортировки антител в зависимости от связываемого эпитопа очищенные конструкции слитых с ALB26 нанотел подвергали скринингу против того же набора нанотел, слитых с FLAG-меткой, в конкурентном ELISA.
Вкратце анализ был следующим. ELISA на основе моноклональных фагов инкубировали при полунасыщенном разведении фага с или без 1 мкМ очищенного нанотела (или 5 мкг/мл mAb). Соотношение между оптической плотностью при 450 нм в присутствии и отсутствии очищенного нанотела (или mAb) использовали для определения, распознают ли нанотела перекрывающиеся или неперекрывающиеся эпитопы.
Полученные эпитопные группы показаны в таблице 2.2 (выше). Конструкции в эпитопных группах 2 и 3 (на G1-домене) имели низкие показатели удержания в хряще (0-1) в анализе удержания в коровьем хряще ex vivo. Однако, по-видимому, нет прямой корреляции между связыванием с коровьим аггреканом G1-IGD-G2, измеренным с помощью ELISA, и удерживанием в коровьем хряще. Не ограничиваясь какой-либо теорией, авторы предположили, что эти эпитопы могут быть труднодоступны в нативной хрящевой ткани.
Вариабельность последовательности CDR клонов, принадлежащих к группе, изображена ниже и выше (т.е. группа 8 с 604F02 в качестве эталонного соединения; таблицы 1.4A-C).
Изменчивость последовательности агентов, связывающих G1 из эпитопной группы 4 против 114F08, показана в таблицах 2.3A, 2.3B и 2.3C ниже. Аминокислотные последовательности CDR клона 114F08 были использованы в качестве эталона, с которым сравнивали CDR всех других клонов (агенты, связывающей группы 4) (CDR1 начинается в положении 26 по Kabat, CDR2 начинается в положении 50 по Kabat, а CDR3 начинается в положении 95 по Kabat).
Таблица 2.3A (114F08)
*вплоть до 2 мутаций CDR1 в одном клоне.
Таблица 2.3B (114F08)
*вплоть до 2 мутаций CDR2 в одном клоне.
Таблица 2.3C (114F08)
*вплоть до 5 мутаций CDR3 в одном клоне.
Изменчивость последовательностей агентов, связывающих G1 из эпитопной группы 1, против 608A05 показана в таблицах 2.3D, 2.3E и 2.3F ниже. Аминокислотные последовательности CDR клона 608A05 были использованы в качестве эталона, с которым сравнивали CDR всех других клонов (свызывающих агентов эпитопной группы 1) (CDR1 начинается в положении 26 по Kabat, CDR2 начинается в положении 50 по Kabat, а CDR3 начинается в положении 95 по Kabat).
Таблица 2.3D (608A05)
*вплоть до 2 мутаций CDR1 в одном клоне.
Таблица 2.3E (608A05)
*вплоть до 2 мутаций CDR2 в одном клоне.
Таблица 2.3F (608A05)
*вплоть до 5 мутаций CDR3 в одном клоне.
2.4 Характеристики связывания - ELISA и SPR
На основании данных об удержании в коровьем хряще ex vivo и данных о сортировке антител в зависимости от связываемого эпитопа, некоторые типичные конструкции из разных эпитопных групп были отобраны для дальнейшей характеризации. Агенты, связывающие домен G2, были исключены из дальнейшей характеризации на этой стадии по причинам, изложенным ранее.
Отобранные конструкции были охарактеризованы в ELISA на рекомбинантной области G1-IGD-G2 аггрекана человека, яванского макака, крысы, собаки и коровы, чтобы определить перекрестную реактивность их видов, и на рекомбинантном нейрокане и бревикане человека для определения селективности. Определенные значения EC50 приведены в таблице 2.4A.
Эксперименты SPR (ProteOn) были проведены для «одновалентных» форматов аггрекан-ALB26 с целью определения скоростей диссоциации. Взаимодействие нанотел с поверхностью аггрекана оказалось неоднородным. Неоднородность может быть обусловлена событиями повторного связывания, гетерогенной популяцией иммобилизованного аггрекана и/или гетерогенных паттернов гликозилирования. Как следствие, рассчитанные отклонения являются ориентировочными. В целом, похоже, что кинетика диссоциации была быстрой для нанотел, включающих аггрекан (Таблица 2.4B).
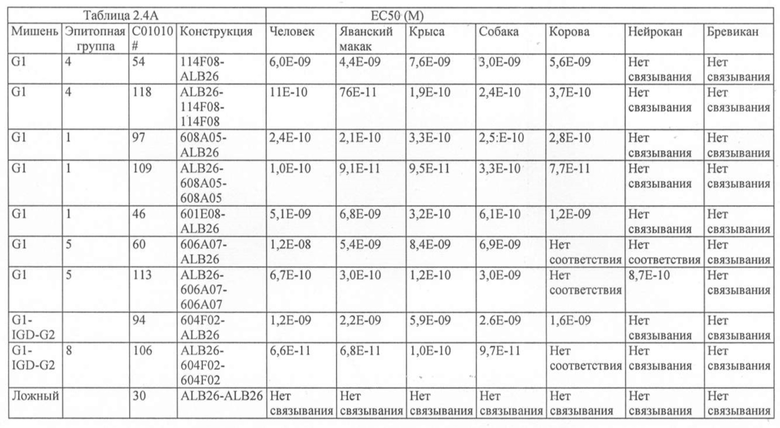
Таблица 2.4A. Характеризация ведущей панели против аггрекана в формате ALB26 методом ELISA
#
Таблица 2.4B: Характеризация «одновалентной» ведущей панели против аггрекана в формате ALB26 (n = 5) по SPR (скорость диссоциации). Скорости диссоциации являются ориентировочными только из-за гетерогенных паттернов связывания.
Пример 3. Биофизическая характеризация моновалентных ведущих конструкций - аггрекан
Поскольку все выбранные конструкции демонстрировали различные благоприятные характеристики, независимо от того, были ли они в комбинации или нет, ISV 114F08 и 604F02 и их соответствующие ALB26-форматы (C010100054, -118 и 094) использовались в качестве примерных конструкций, представляющих ведущую панель для дальнейшей характеризации.
3.1 Экспрессия одновалентных 114F08 и 604F02 в E.coli и P. pastoris
Для биофизической характеризации моновалентные нанотела 114F08 и 604F02 экспрессировали с помощью меток FLAG3-His6 в E.coli и/или P. pastoris и очищали в соответствии со стандартными протоколами (например, Maussang et al. 2013 J Biol Chem 288 (41): 29562-72).
3.2 pI, Tm и аналитическая SEC для 114F08 и 604F02
Для анализа теплового сдвига (TSA) 5 мкл очищенного одновалентного нанотела (800 мкг/мл) инкубировали с 5 мкл флуоресцентного зонда Sypro Orange (Invitrogen, S6551) (конечная концентрация 10×) в 10 мкл буфера (100 мМ фосфата, 100 мМ боратв, 100 мМ цитратв, 115 мМ NaCl, забуференный при различных значениях рН в диапазоне от 3,5 до 9). Образцы нагревали в установке LightCycler 480II (Roche) со скоростью 37-99°С со скоростью 4,4°С/с, после чего охлаждали до 37°С со скоростью 0,03°С/с. При тепловом разворачивании экспонируются гидрофобные участки белков, с которыми связывается Sypro Orange, что приводит к увеличению интенсивности флуоресценции (Ex/Em = 465/580 нм). Точка перегиба первой производной кривой интенсивности флуоресценции служит мерой температуры плавления (Tm), по существу, согласно Ericsson et al. 2006 (Anals of Biochemistry, 357: 289-298).
Эксперименты с аналитической эксклюзионной хроматографией (Analytical SEC) проводили на устройстве Ultimate 3000 (Dionex) в комбинации с колонкой Biosep-SEC-3 (Agilent), используя 10 мМ фосфат, 300 мМ Arg-HCl, pH 6,0 в качестве подвижной фазы. Инъецировали 8 мкг образца нанотела (0,5 мг/мл в d-PBS).
Изоэлектрические точки двух ISV против аггрекана являются относительно основными. Последовательности показаны в таблице A-1). Температура плавления была определена равной 61,0°С для 114F08 и 70,0°С для 604F02. Ни один из клонов не показал признаков агрегации или мультимеризации, как определено аналитическим SEC.
Соответственно, наряду с положительными функциональными свойствами, ISV демонстрируют благоприятные биофизические свойства.
3.3 Представители семейства 114F08
Изменчивость последовательностей в CDR представителей семейства 114F08 показана в таблицах 3.3A, 3.3B и 3.3C ниже. Аминокислотные последовательности CDR клона 114F08 были использованы в качестве стандарта, с которым сравнивали CDR всех других клонов (представителей семейства 114F08) (CDR1 начинается в положении 26 по Kabat, CDR2 начинается в положении 50 по Kabat, а CDR3 начинается в положении 95 по Kabat).
Таблица 3.3А
*вплоть до 2 мутаций CDR1 в одном клоне.
Таблица 3.3В
*вплоть до 5 мутаций CDR2 в одном клоне.
Таблица 3.3С
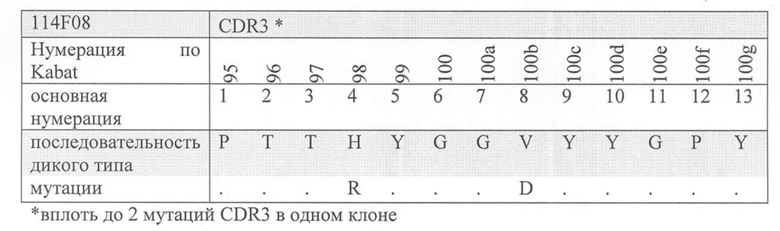
Пример 4. Ex vivo связывание с хрящами различных видов
Показано, что типичные CAP-содержащие полипептиды (также обозначаемые в данном документе как «CAP-содержащие конструкции» или «конструкции») связывают рекомбинантные/экстрагированные человеческие белки и коровий хрящ в анализе удержания в хряще коровы ex vivo. Чтобы продемонстрировать, что эти примерные конструкции, содержащие CAP, также связываются с хрящами других видов, эксперименты, как изложено выше, с хрящом коровы, по существу, повторяли с хрящом человека и хрящом крысы.
4.1 Связывание ex vivo с хрящом человека
Чтобы подтвердить, что примерные конструкции, содержащие CAP, также связываются с хрящом человека, выбранные конструкции тестировали в анализе связывания хряща ex vivo с использованием замороженных чипов хряща человека. Связывание определяли после 30-минутной промывки с помощью Вестерн-блоттинга.
Результаты суммированы в таблице 4.1.
#



Таблица 4.1. Связывание с хрящем человека ex vivo. Количество конструкции, связанной с хрящом после 30-минутной промывки (T0), анализировали Вестерн-блоттингом.
Было обнаружено, что все конструкции лучше связываются с хрящом человека, чем ложная конструкция.
4.2 Связывание с хрящом крысы ex vivo
Чтобы облегчить тестирование конструкций на крысиной модели in vivo, оценивали связывание с хрящом крысы. Поэтому был проведен анализ с использованием бедренной кости от крысы с неповрежденным хрящом. Типичные конструкции C010100054, -118 и -094 инкубировали с хрящом крысы в течение ночи с последующей 30-минутной промывкой, высвобождением связанных конструкций с последующим Вестерн-блот-анализом.
Результаты приведены в таблице 4.2.
Было обнаружено, что все испытанные конструкции хорошо связываются с хрящом крысы.
#


Таблица 4.2: Связывание крысиного хряща. Конструкции инкубировали с головками бедренной кости. После инкубации конструкции нанотел несвязанную конструкцию вымывали, а связанную конструкцию анализировали с помощью Вестерн-блоттинга.
Пример 5. Тканевая специфичность
Выше было продемонстрировано, что конструкции по изобретению специфически связываются с аггреканом как in vitro, так и ex vivo. Кроме того, эти конструкции должны также предпочтительно связываться с хрящом сустава, в то время как не должны связываться или связываться меньше с другими тканями сустава.
Связывание типичных CAP-содержащих конструкций, с синовиальной мембраной, сухожилием, эпимизием и мениском оценивали с использованием той же схемы, что и для анализа связывания хряща ex vivo. Высвобождение конструкции и анализ Вестерн-блоттинга проводили после кратковременной промывки тканей (30 мин) после инкубации с конструкциями.
Результаты суммированы в таблице 5.
Результаты показывают, что связующие CAP демонстрируют преимущественное связывание с хрящевыми тканями, включая мениск, по сравнению с другими тканями, обнаруженными в суставе.
#
Таблица 5. Специфичность ткани. Связывание ведущей панели в формате с применением ALB26 (n = 10) с суставным хрящом, синовиальной мембраной, сухожилием, эпимизием и мениском.
Пример 6. Устойчивость нанотел в коровьей синовиальной жидкости
По различным причинам, включая удобство и безопасность пациента, предпочтительно, чтобы конструкции оставались стабильными в течение более длительных периодов в синовиальной оболочке.
Соответственно, стабильность типичных CAP-конструкций, слитых с ALB26, в синовиальной жидкости (SF) оценивали инкубацией конструкций в неартритной коровьей SF в течение до 7 дней при 37°C.
Результаты суммированы в таблице 6.
Таблица 6. Стабильность ведущей панели в формате с применением ALB26 в коровьей синовиальной жидкости (SF).
Никакой деградации какой-либо из конструкций обнаружено не было.
Пример 7. Удержание в ИЛ-1α-стимулированном эксплантате хряща
До этого момента все эксперименты, касающиеся связывания хряща и удержания CAP, содержащего нанотела, проводили в здоровом (не артритном) хряще ex vivo. Артритный хрящ характеризуется деградированным коллагеном и аггреканом. Поэтому важно также оценить связывание и удержание агентов, свызывающих аггрекан, в хряще, где произошла деградация этих белков. С этой целью типичные CAP-конструкции, слитые с ALB26, тестировали в анализе эксплантации хряща, в котором в хряще стимулировали индукцию деградации.
Вкратце, типичные, CAP-содержащие конструкции инкубировали в течение ночи (ON) с эксплантатами коровьего хряща, которые культивировали с IL-1α или онкостатином М или без него, с последующим 5-дневным культивированием с ежедневной сменой среды (промывка). IL-1α и онкостатин М главным образом вызывают деградацию аггрекана в течение 6 дней эксперимента. Экспланты хряща проанализировали на предмет связывания и удержания конструкции с помощью WB. Были проведены два независимых эксперимента (Exp A и Exp B).
Результаты вестерн-блоттинга представлены в таблице 7.1.









Таблица 7.1. Сохранение ведущей панели в формате ALB26 в эксплантах стимулированного коровьего хряща. Были проведены два независимых эксперимента: A и B.
Результаты удержания CAP-содержащей конструкции в эксплантах стимулированного хряща, суммированы в таблице 7.2.
#
Таблица 7.2. Сводная информация о связывании и удержании CAP в анализе экспланта стимулированного коровьего хряща
Результаты показывают, что конструкции C01010054 («054» или «54») и C01010045 («045» или «45») имеют пониженное удержание в стимулированном хряще после 5 дней промывки по сравнению с нестимулированным хрящом, в то время как конструкции C01010118 («118») и C01010094 («094» или «94») показали небольшую чувствительность к стимуляции.
Кроме того, представляется, что связывание с доменом G2 аггрекана (на примере C01010045) снижается в большей степени, чем привязка к другим доменам, что согласуется с гипотезой о том, что деградация аггрекана идет с C-конца.
Пример 8. Анализ высвобождения ADAMTS5-CAP GAG
Чтобы учесть возможное влияние CAP, фрагмента, заякоривающего в хряще, на активность нанотела, ингибирующего протеазу в хрящевой ткани, примерные конструкции CAP были объединены с ADAMTS5 (ATS5)-блокирующим ISV и протестированы в анализе высвобождения GAG (гликозаминогликана) в экспланте хряща.
Перед тестированием конструкций в анализе высвобождения GAG в экспланте хряща, были подтверждены in vitro свойства связывания хряща и ингибирования ADAMTS5. Для последнего был проведен анализ ферментативного пептида, который показал, что функция блокирования фермента ISAM ADAMTS5 не нарушалась ни в одной из гибридных конструкций CAP in vitro.
В анализе высвобождения GAG эксплантаты коровьего хряща культивировали в течение 5 дней в присутствии IL-1α и онкостатина М (для индукции ADAMTS5) и диапазона доз конструкций с последующим количественным определением содержания высвобожденного GAG в надосадочной жидкости культуры.
Протестированные конструкции и результаты анализа высвобождения GAG приведены в таблице 8.
Таблица 8. Краткая сводка анализа высвобождения ADAMTS5-CAP GAG
Результаты показывают, что добавление якорного плеча (конструкции CAP-ISV) к ингибитору ADAMTS5 все же позволило эффективно ингибировать высвобождение GAG.
Пример 9 Биологическая визуализация CAP-конструкций in vivo
Параллельно с характеристикой in vitro и ex vivo типичных CAP-конструкций против аггрекана было определено биораспределение in vivo для нескольких гибридных конструкций ALB26, чтобы подтвердить свойства удержания.
9.1 Исследования биораспределения конструкций ALB26-CAP
Нанотела были помечены 125I (посредством присоединения лизина 125I-SIB). Конструкции инъецировали в коленные суставы здоровых крыс. Авторадиографические изображения суставов были получены в разные моменты времени вплоть до 4 недель после инъекции. Эти изображения позволили оценить удержание и тканевую (хрящевую) специфичность конструкций в условиях in vivo.
Репрезентативные изображения показаны на Фигуре 1.
Из результатов можно сделать вывод, что все конструкции показали специфическое связывание с хрящом. Четкое окрашивание - даже через 4 недели после инъекции - наблюдалось как для «одновалентных», так и для «двухвалентных» агентов, связывающих аггрекан.
9.2 MARG конструкций ALB26-CAP
Описанное выше исследование биораспределения (пример 9.1) продемонстрировало специфическое удержание в хряще конструкций ALB26-CAP. Однако разрешение изображений не позволило исследовать глубину проникновения в хрящ. Для увеличения разрешения изображения и, таким образом, для оценки проникновения в хрящ использовали MARG (микроавторадиографию).
Примерные конструкции, которые вошли в исследование, перечислены в таблице 9.2А. Для этого исследования нанотела были помечены 3H (посредством присоединения лизина к 3H-NSP (N-сукцинимидилпропионат)) и введены в здоровые и остеоартритные (хирургически индуцированный путем разреза суставов передней крестообразной связки) суставы крысы; 8 крыс на группу. Через 7-14 дней после инъекции крыс умерщвляли и инъецированные здоровые и ОА-индуцированные суставы подвергали MARG.
Типичные изображения MARG показаны на фигуре 2.
Таблица 9.2А. Протестированные примерные конструкций нанотел
Все агенты, связывающие аггрекан, обычно демонстрировали проникновение в здоровый хрящ. Конструкция 626 иногда также демонстрировала более интенсивное окрашивание на поверхности. В оперированном колене были обнаружены различные степени окрашивания и проникновения в хрящ: окрашивания моновалентной конструкцией 054 не наблюдалось; окрашивание отсутствовало или было слабым при использовании одновалентной конструкции 094, в то время как двухвалентная конструкция 626 приводила к несколько более стойкому окрашиванию, хотя и с различной глубиной проникновения (см. Таблицу 9.2B).
Таблица 9.2B. Сводные результаты окрашивания MARG. *Представлены общие результаты для 8 животных, основанные на оценке зерна серебра. Оценка распределения: A = поверхность хряща без по сути более глубокого окрашивания, B = поверхность хряща с более глубоким окрашиванием, C = окрашивание в более глубоких слоях хряща без накопления на поверхности.
Пример 10. In Vivo MMT DMOAD у крыс продемонстрировал статистически значимый эффект
Чтобы дополнительно продемонстрировать эффективность in vivo агентов по изобретению, связующих CAP, использовали хирургически индуцированную модель разрыва медиального мениска (MMT) на крысах. Вкратце, агенты по изобретению, связывающие CAP, были соединены с анти-MMP13 ISV (обозначенным как «0754» или «C010100754») или анти-ADAMTS5 ISV (обозначенным как «0954» или «C010100954»). Крыс оперировали в одном колене, чтобы вызвать ОА-подобные симптомы. Обработка началась через 3 дня после операции с помощью внутрисоставного введения. Гистопатология была выполнена на 42 день после операции. Промежуточные и конечные образцы сыворотки отбирали для исследовательского анализа биомаркеров. Была определена медиальная и общая значительная ширина дегенерации хряща, а также процент снижения дегенерации хряща. В группе использовали по 20 животных.
Ингибирование деградации хряща нанотелами в средней голени показано на фигуре 3.
Результаты показывают, что ширина хряща была существенно уменьшена конструкцией ADAMTS5-CAP и конструкцией MMP13-CAP через 42 дня по сравнению с носителем. Эти результаты позволяют предположить, что CAP-фрагмент (а) не оказывает отрицательного влияния на активность ISV против MMP13 (0754) или ISV против ADAMTS5 (0954); и (b) позволяет удерживать эти конструкции в суставах в течение длительного периода времени.
Пример 11. Удержание агентов, связывающих CAP, сходно in vivo у здоровых и остеоартритных крыс
В исследовании удержания в хряще у здоровых крыс было продемонстрировано, что полипептиды по изобретению можно обнаружить в измеримых количествах в хряще в течение 112 дней после внутрисуставной (I.A.) инъекции (данные не показаны). Поскольку хрящевая композиция может оказывать влияние на связывание в хряще и абсорбцию в системном кровотоке, фармакокинетику полипептидов по изобретению сравнивали у больных остеоартритом и здоровых крыс in vivo, следя за уровнем сывороточных полипептидов в зависимости от времени.
В частности, хирургически индуцированная модель разрыва медиального мениска (MMT) у крыс использовалась, как описано в примере 10, но с некоторыми модификациями. Вкратце, полипептиды по изобретению были связаны с ISV против MMP13 и ISV против ADAMTS5, что привело к получению конструкции MMP13-ADAMTS5-CAP-CAP (обозначенной как «0949» или «C010100949» нанотел). Крыс оперировали в одном колене, чтобы вызвать ОА-подобные симптомы (ОА-группа). Каждая группа обработки (здоровая и ОА) состояла из 15 животных и получала одну инъекцию I.A. 400 мкг/30 мкл нанотела в день 7 (здоровый) или через 7 дней после операции (MMT). Образцы сыворотки отбирали у анестезированных крыс в день 0, в день 7 (в 0 часов = образец до введения дозы), в день 8 (в разное время после обработки до 24 часов), в день 9 (48 часов после обработки), d10 (3 дня) после лечения), d14 (7 дней после лечения), d21 (14 дней после лечения) и d42 (35 дней после лечения). Собранные образцы сыворотки использовали для определения концентраций полипептида в формате общего PK-анализа, основанного на электрохемолюминесценции (ECL), с последующим некомпартментным анализом.
Задержка полипептидов в сыворотке крови здоровых и ОА крыс показана на фигуре 4.
Результаты демонстрируют, что очевидных различий в сывороточных концентрациях полипептидов у здоровых крыс и крыс с ОА не наблюдается. Эти результаты предполагают, что деградация хряща не влияет на фармакокинетику полипептидов по изобретению.
Таблица A-1: Аминокислотные последовательности одновалентных агентов, свызывающих аггрекан («ID» относится к SEQ ID NO, при использовании в данном документе)
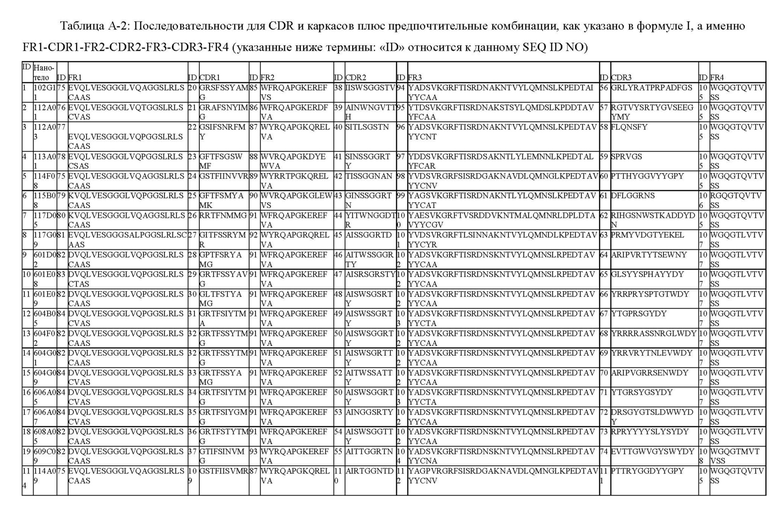
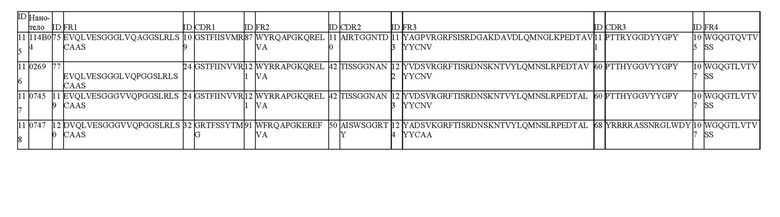
Таблица B: Последовательности аггрекан и другие от различных видов («ID» относится к SEQ ID NO, используемому в данном документе)
Таблица C: Последовательности ISV, связывающие сывороточный альбумин («ID» относится к SEQ ID NO, используемым в данном документе)
Таблица D: Линкерные последовательности («ID» относится к SEQ ID NO, используемым в данном документе)
Таблица E-1: Полипептиды/конструкции, содержащие указанный терапевтический ISV, и указанный ISV, связывающий аггрекан
(связываемая ISV)
(связываемая ISV)
(связываемая ISV)
Таблица E-2. Полипептиды/конструкции, содержащие указанный терапевтический ISV и два указанных ISV, связывающих аггрекан
(связываемая
ISV)
(связываемая
ISV)
(связываемая
ISV)
(или V)
(или X)
--->
Список последовательностей
<110> Ablynx NV
<120> Aggrecan binding Immunoglobulins
<130> 206 379
<150> US 62/514,180
<151> 2017-06-02
<160> 172
<170> PatentIn version 3.5
<210> 1
<211> 124
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 1
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Ser Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ser Ile Ile Ser Trp Ser Gly Gly Ser Thr Val Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Ile Tyr Tyr Cys
85 90 95
Ala Ala Gly Arg Leu Tyr Arg Ala Thr Pro Arg Pro Ala Asp Phe Gly
100 105 110
Ser Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 2
<211> 127
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 2
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Thr Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Arg Ala Phe Ser Asn Tyr
20 25 30
Ile Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Asp Phe Val
35 40 45
Ala Ala Ile Asn Trp Asn Gly Val Thr Thr His Tyr Thr Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Ser Thr Ser Tyr
65 70 75 80
Leu Gln Met Asp Ser Leu Lys Pro Asp Asp Thr Ala Val Tyr Phe Cys
85 90 95
Ala Ala Arg Gly Thr Val Tyr Ser Arg Thr Tyr Gly Val Ser Glu Glu
100 105 110
Gly Tyr Met Tyr Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120 125
<210> 3
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 3
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Ile Phe Ser Asn Arg
20 25 30
Phe Met Tyr Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Ser Ile Thr Leu Ser Gly Ser Thr Asn Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Thr Phe Leu Gln Asn Ser Phe Tyr Trp Gly Gln Gly Thr Gln Val Thr
100 105 110
Val Ser Ser
115
<210> 4
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 4
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ser Ala Ser Gly Phe Thr Phe Ser Gly Ser
20 25 30
Trp Met Phe Trp Val Arg Gln Ala Pro Gly Lys Asp Tyr Glu Trp Val
35 40 45
Ala Ser Ile Asn Ser Ser Gly Gly Arg Thr Tyr Tyr Asp Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Ser Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Glu Met Asn Asn Leu Lys Pro Glu Asp Thr Ala Leu Tyr Phe Cys
85 90 95
Ala Arg Ser Pro Arg Val Gly Ser Trp Gly Gln Gly Thr Gln Val Thr
100 105 110
Val Ser Ser
115
<210> 5
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 5
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ile Ile Asn
20 25 30
Val Val Arg Trp Tyr Arg Arg Thr Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Thr Ile Ser Ser Gly Gly Asn Ala Asn Tyr Val Asp Ser Val Arg
50 55 60
Gly Arg Phe Ser Ile Ser Arg Asp Gly Ala Lys Asn Ala Val Asp Leu
65 70 75 80
Gln Met Asn Gly Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Val Pro Thr Thr His Tyr Gly Gly Val Tyr Tyr Gly Pro Tyr Trp Gly
100 105 110
Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 6
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 6
Lys Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Met Tyr
20 25 30
Ala Met Lys Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gly Ile Asn Ser Ser Gly Gly Arg Thr Asn Tyr Ala Gly Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Thr Asp Phe Leu Gly Gly Arg Asn Ser Arg Gly Gln Gly Thr Gln
100 105 110
Val Thr Val Ser Ser
115
<210> 7
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 7
Lys Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Arg Arg Thr Phe Asn Met Met
20 25 30
Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala Tyr
35 40 45
Ile Thr Trp Asn Gly Gly Asp Thr Arg Tyr Ala Glu Ser Val Lys Gly
50 55 60
Arg Phe Thr Val Ser Arg Asp Asp Val Lys Asn Thr Met Ala Leu Gln
65 70 75 80
Met Asn Arg Leu Asp Pro Leu Asp Thr Ala Val Tyr Tyr Cys Gly Val
85 90 95
Arg Ile His Gly Ser Asn Trp Ser Thr Lys Ala Asp Asp Tyr Asp Asn
100 105 110
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 8
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 8
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Ala Leu Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ile Thr Phe Ser Ser Arg
20 25 30
Tyr Met Arg Trp Tyr Arg Gln Ala Pro Gly Arg Gln Arg Glu Leu Val
35 40 45
Ala Ala Ile Ser Ser Gly Gly Arg Thr Asp Tyr Val Asp Ser Val Arg
50 55 60
Gly Arg Phe Thr Leu Ser Ile Asn Asn Ala Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Asp Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Tyr
85 90 95
Arg Pro Arg Met Tyr Val Asp Gly Thr Tyr Glu Lys Glu Leu Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 9
<211> 124
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 9
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Pro Thr Phe Ser Arg Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Thr Trp Ser Ser Gly Gly Arg Thr Tyr Tyr Ala Asp Ser
50 55 60
Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val
65 70 75 80
Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr
85 90 95
Cys Ala Ala Ala Arg Ile Pro Val Arg Thr Tyr Thr Ser Glu Trp Asn
100 105 110
Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 10
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 10
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Ala Val Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Arg Ser Gly Arg Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Gly Leu Ser Tyr Tyr Ser Pro His Ala Tyr Tyr Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 11
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 11
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Leu Thr Phe Ser Thr Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Ser Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Tyr Arg Arg Pro Arg Tyr Ser Pro Thr Gly Thr Trp Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 12
<211> 119
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 12
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Arg Thr Phe Ser Ile Tyr
20 25 30
Thr Met Ala Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Ser Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ala Tyr Thr Gly Pro Arg Ser Gly Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 13
<211> 124
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 13
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Thr Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Tyr Arg Arg Arg Arg Ala Ser Ser Asn Arg Gly Leu Trp Asp
100 105 110
Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 14
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 14
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Thr Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Arg Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Tyr Arg Arg Val Arg Tyr Thr Asn Leu Glu Val Trp Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 15
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 15
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Ala Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Thr Trp Ser Ser Ala Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Ala Arg Ile Pro Val Gly Arg Arg Ser Glu Asn Trp Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 16
<211> 120
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 16
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Arg Thr Phe Ser Ile Tyr
20 25 30
Thr Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ala Tyr Thr Gly Arg Ser Tyr Gly Ser Tyr Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 17
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 17
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser Gly Arg Thr Phe Ser Ile Tyr
20 25 30
Gly Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Asn Gly Gly Ser Arg Thr Tyr Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Ala
85 90 95
Ala Asp Arg Ser Gly Tyr Gly Thr Ser Leu Asp Trp Trp Tyr Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 18
<211> 123
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 18
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Thr Tyr
20 25 30
Thr Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ala Arg Pro Arg Tyr Tyr Tyr Tyr Ser Leu Tyr Ser Tyr Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 19
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 19
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Thr Ile Phe Ser Ile Asn
20 25 30
Val Met Gly Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Thr Thr Gly Gly Arg Thr Asn Tyr Ala Asp Ser Val Lys
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Ala Glu Val Thr Thr Gly Trp Val Gly Tyr Ser Trp Tyr Asp Tyr Trp
100 105 110
Gly Gln Gly Thr Met Val Thr Val Ser Ser
115 120
<210> 20
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 20
Gly Arg Ser Phe Ser Ser Tyr Ala Met Gly
1 5 10
<210> 21
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 21
Gly Arg Ala Phe Ser Asn Tyr Ile Met Gly
1 5 10
<210> 22
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 22
Gly Ser Ile Phe Ser Asn Arg Phe Met Tyr
1 5 10
<210> 23
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 23
Gly Phe Thr Phe Ser Gly Ser Trp Met Phe
1 5 10
<210> 24
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 24
Gly Ser Thr Phe Ile Ile Asn Val Val Arg
1 5 10
<210> 25
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 25
Gly Phe Thr Phe Ser Met Tyr Ala Met Lys
1 5 10
<210> 26
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 26
Arg Arg Thr Phe Asn Met Met Gly
1 5
<210> 27
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 27
Gly Ile Thr Phe Ser Ser Arg Tyr Met Arg
1 5 10
<210> 28
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 28
Gly Pro Thr Phe Ser Arg Tyr Ala Met Gly
1 5 10
<210> 29
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 29
Gly Arg Thr Phe Ser Ser Tyr Ala Val Gly
1 5 10
<210> 30
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 30
Gly Leu Thr Phe Ser Thr Tyr Ala Met Gly
1 5 10
<210> 31
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 31
Gly Arg Thr Phe Ser Ile Tyr Thr Met Ala
1 5 10
<210> 32
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 32
Gly Arg Thr Phe Ser Ser Tyr Thr Met Gly
1 5 10
<210> 33
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 33
Gly Arg Thr Phe Ser Ser Tyr Ala Met Gly
1 5 10
<210> 34
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 34
Gly Arg Thr Phe Ser Ile Tyr Thr Met Gly
1 5 10
<210> 35
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 35
Gly Arg Thr Phe Ser Ile Tyr Gly Met Gly
1 5 10
<210> 36
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 36
Gly Arg Thr Phe Ser Thr Tyr Thr Met Gly
1 5 10
<210> 37
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 37
Gly Thr Ile Phe Ser Ile Asn Val Met Gly
1 5 10
<210> 38
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 38
Ile Ile Ser Trp Ser Gly Gly Ser Thr Val
1 5 10
<210> 39
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 39
Ala Ile Asn Trp Asn Gly Val Thr Thr His
1 5 10
<210> 40
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 40
Ser Ile Thr Leu Ser Gly Ser Thr Asn
1 5
<210> 41
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 41
Ser Ile Asn Ser Ser Gly Gly Arg Thr Tyr
1 5 10
<210> 42
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 42
Thr Ile Ser Ser Gly Gly Asn Ala Asn
1 5
<210> 43
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 43
Gly Ile Asn Ser Ser Gly Gly Arg Thr Asn
1 5 10
<210> 44
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 44
Tyr Ile Thr Trp Asn Gly Gly Asp Thr Arg
1 5 10
<210> 45
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 45
Ala Ile Ser Ser Gly Gly Arg Thr Asp
1 5
<210> 46
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 46
Ala Ile Thr Trp Ser Ser Gly Gly Arg Thr Tyr
1 5 10
<210> 47
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 47
Ala Ile Ser Arg Ser Gly Arg Ser Thr Tyr
1 5 10
<210> 48
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 48
Ala Ile Ser Trp Ser Gly Ser Arg Thr Tyr
1 5 10
<210> 49
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 49
Ala Ile Ser Trp Ser Ser Gly Arg Thr Tyr
1 5 10
<210> 50
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 50
Ala Ile Ser Trp Ser Gly Gly Arg Thr Tyr
1 5 10
<210> 51
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 51
Ala Ile Ser Trp Ser Gly Arg Thr Thr Tyr
1 5 10
<210> 52
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 52
Ala Ile Thr Trp Ser Ser Ala Thr Thr Tyr
1 5 10
<210> 53
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 53
Ala Ile Asn Gly Gly Ser Arg Thr Tyr
1 5
<210> 54
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 54
Ala Ile Ser Trp Ser Gly Gly Thr Thr Tyr
1 5 10
<210> 55
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 55
Ala Ile Thr Thr Gly Gly Arg Thr Asn
1 5
<210> 56
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 56
Gly Arg Leu Tyr Arg Ala Thr Pro Arg Pro Ala Asp Phe Gly Ser
1 5 10 15
<210> 57
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 57
Arg Gly Thr Val Tyr Ser Arg Thr Tyr Gly Val Ser Glu Glu Gly Tyr
1 5 10 15
Met Tyr
<210> 58
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 58
Phe Leu Gln Asn Ser Phe Tyr
1 5
<210> 59
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 59
Ser Pro Arg Val Gly Ser
1 5
<210> 60
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 60
Pro Thr Thr His Tyr Gly Gly Val Tyr Tyr Gly Pro Tyr
1 5 10
<210> 61
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 61
Asp Phe Leu Gly Gly Arg Asn Ser
1 5
<210> 62
<211> 16
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 62
Arg Ile His Gly Ser Asn Trp Ser Thr Lys Ala Asp Asp Tyr Asp Asn
1 5 10 15
<210> 63
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 63
Pro Arg Met Tyr Val Asp Gly Thr Tyr Glu Lys Glu Leu
1 5 10
<210> 64
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 64
Ala Arg Ile Pro Val Arg Thr Tyr Thr Ser Glu Trp Asn Tyr
1 5 10
<210> 65
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 65
Gly Leu Ser Tyr Tyr Ser Pro His Ala Tyr Tyr Asp Tyr
1 5 10
<210> 66
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 66
Tyr Arg Arg Pro Arg Tyr Ser Pro Thr Gly Thr Trp Asp Tyr
1 5 10
<210> 67
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 67
Tyr Thr Gly Pro Arg Ser Gly Tyr Asp Tyr
1 5 10
<210> 68
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 68
Tyr Arg Arg Arg Arg Ala Ser Ser Asn Arg Gly Leu Trp Asp Tyr
1 5 10 15
<210> 69
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 69
Tyr Arg Arg Val Arg Tyr Thr Asn Leu Glu Val Trp Asp Tyr
1 5 10
<210> 70
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 70
Ala Arg Ile Pro Val Gly Arg Arg Ser Glu Asn Trp Asp Tyr
1 5 10
<210> 71
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 71
Tyr Thr Gly Arg Ser Tyr Gly Ser Tyr Asp Tyr
1 5 10
<210> 72
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 72
Asp Arg Ser Gly Tyr Gly Thr Ser Leu Asp Trp Trp Tyr Asp Tyr
1 5 10 15
<210> 73
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 73
Arg Pro Arg Tyr Tyr Tyr Tyr Ser Leu Tyr Ser Tyr Asp Tyr
1 5 10
<210> 74
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 74
Glu Val Thr Thr Gly Trp Val Gly Tyr Ser Trp Tyr Asp Tyr
1 5 10
<210> 75
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 75
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 76
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 76
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Thr Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser
20 25
<210> 77
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 77
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 78
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 78
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ser Ala Ser
20 25
<210> 79
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 79
Lys Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 80
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 80
Lys Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 81
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 81
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Ser Ala Leu Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 82
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 82
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 83
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 83
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Thr Ala Ser
20 25
<210> 84
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 84
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Val Ala Ser
20 25
<210> 85
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 85
Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ser
1 5 10
<210> 86
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 86
Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Asp Phe Val Ala
1 5 10
<210> 87
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 87
Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val Ala
1 5 10
<210> 88
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 88
Trp Val Arg Gln Ala Pro Gly Lys Asp Tyr Glu Trp Val Ala
1 5 10
<210> 89
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 89
Trp Tyr Arg Arg Thr Pro Gly Lys Gln Arg Glu Leu Val Ala
1 5 10
<210> 90
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 90
Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val Ser
1 5 10
<210> 91
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 91
Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala
1 5 10
<210> 92
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 92
Trp Tyr Arg Gln Ala Pro Gly Arg Gln Arg Glu Leu Val Ala
1 5 10
<210> 93
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 93
Trp Tyr Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val Ala
1 5 10
<210> 94
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 94
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Ile Tyr Tyr Cys Ala Ala
35
<210> 95
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 95
Tyr Thr Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala
1 5 10 15
Lys Ser Thr Ser Tyr Leu Gln Met Asp Ser Leu Lys Pro Asp Asp Thr
20 25 30
Ala Val Tyr Phe Cys Ala Ala
35
<210> 96
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 96
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Asn Thr
35
<210> 97
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 97
Tyr Asp Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Ser Ala
1 5 10 15
Lys Asn Thr Leu Tyr Leu Glu Met Asn Asn Leu Lys Pro Glu Asp Thr
20 25 30
Ala Leu Tyr Phe Cys Ala Arg
35
<210> 98
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 98
Tyr Val Asp Ser Val Arg Gly Arg Phe Ser Ile Ser Arg Asp Gly Ala
1 5 10 15
Lys Asn Ala Val Asp Leu Gln Met Asn Gly Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Asn Val
35
<210> 99
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 99
Tyr Ala Gly Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala
1 5 10 15
Lys Asn Thr Leu Tyr Leu Gln Met Asn Ser Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Ala Thr
35
<210> 100
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 100
Tyr Ala Glu Ser Val Lys Gly Arg Phe Thr Val Ser Arg Asp Asp Val
1 5 10 15
Lys Asn Thr Met Ala Leu Gln Met Asn Arg Leu Asp Pro Leu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Gly Val
35
<210> 101
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 101
Tyr Val Asp Ser Val Arg Gly Arg Phe Thr Leu Ser Ile Asn Asn Ala
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Asp Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Tyr Arg
35
<210> 102
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 102
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Ala Ala
35
<210> 103
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 103
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Thr Ala
35
<210> 104
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 104
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Asn Ala
35
<210> 105
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> FR4
<400> 105
Trp Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 106
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> FR4
<400> 106
Arg Gly Gln Gly Thr Gln Val Thr Val Ser Ser
1 5 10
<210> 107
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> FR4
<400> 107
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
1 5 10
<210> 108
<211> 11
<212> PRT
<213> Artificial Sequence
<220>
<223> FR4
<400> 108
Trp Gly Gln Gly Thr Met Val Thr Val Ser Ser
1 5 10
<210> 109
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR1
<400> 109
Gly Ser Thr Phe Ile Ile Ser Val Met Arg
1 5 10
<210> 110
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR2
<400> 110
Ala Ile Arg Thr Gly Gly Asn Thr Asp
1 5
<210> 111
<211> 13
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR3
<400> 111
Pro Thr Thr Arg Tyr Gly Gly Asp Tyr Tyr Gly Pro Tyr
1 5 10
<210> 112
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 112
Tyr Ala Gly Pro Val Arg Gly Arg Phe Ser Ile Ser Arg Asp Gly Ala
1 5 10 15
Lys Asn Ala Val Asp Leu Gln Met Asn Gly Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Asn Val
35
<210> 113
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 113
Tyr Ala Gly Pro Val Arg Gly Arg Phe Ser Ile Ser Arg Asp Gly Ala
1 5 10 15
Lys Asp Ala Val Asp Leu Gln Met Asn Gly Leu Lys Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Asn Val
35
<210> 114
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 114
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ile Ile Ser
20 25 30
Val Met Arg Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Ala Ile Arg Thr Gly Gly Asn Thr Asp Tyr Ala Gly Pro Val Arg
50 55 60
Gly Arg Phe Ser Ile Ser Arg Asp Gly Ala Lys Asn Ala Val Asp Leu
65 70 75 80
Gln Met Asn Gly Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Val Pro Thr Thr Arg Tyr Gly Gly Asp Tyr Tyr Gly Pro Tyr Trp Gly
100 105 110
Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 115
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 115
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Ala Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ile Ile Ser
20 25 30
Val Met Arg Trp Tyr Arg Gln Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Ala Ile Arg Thr Gly Gly Asn Thr Asp Tyr Ala Gly Pro Val Arg
50 55 60
Gly Arg Phe Ser Ile Ser Arg Asp Gly Ala Lys Asp Ala Val Asp Leu
65 70 75 80
Gln Met Asn Gly Leu Lys Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Val Pro Thr Thr Arg Tyr Gly Gly Asp Tyr Tyr Gly Pro Tyr Trp Gly
100 105 110
Gln Gly Thr Gln Val Thr Val Ser Ser
115 120
<210> 116
<211> 121
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 116
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ile Ile Asn
20 25 30
Val Val Arg Trp Tyr Arg Arg Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Thr Ile Ser Ser Gly Gly Asn Ala Asn Tyr Val Asp Ser Val Arg
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys Asn
85 90 95
Val Pro Thr Thr His Tyr Gly Gly Val Tyr Tyr Gly Pro Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 117
<211> 122
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 117
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Ser Thr Phe Ile Ile Asn
20 25 30
Val Val Arg Trp Tyr Arg Arg Ala Pro Gly Lys Gln Arg Glu Leu Val
35 40 45
Ala Thr Ile Ser Ser Gly Gly Asn Ala Asn Tyr Val Asp Ser Val Arg
50 55 60
Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr Leu
65 70 75 80
Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys Asn
85 90 95
Val Pro Thr Thr His Tyr Gly Gly Val Tyr Tyr Gly Pro Tyr Trp Gly
100 105 110
Gln Gly Thr Leu Val Thr Val Ser Ser Ala
115 120
<210> 118
<211> 125
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 118
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Arg Thr Phe Ser Ser Tyr
20 25 30
Thr Met Gly Trp Phe Arg Gln Ala Pro Gly Lys Glu Arg Glu Phe Val
35 40 45
Ala Ala Ile Ser Trp Ser Gly Gly Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Val Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Ala Ala Tyr Arg Arg Arg Arg Ala Ser Ser Asn Arg Gly Leu Trp Asp
100 105 110
Tyr Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser Ala
115 120 125
<210> 119
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 119
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 120
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> FR1
<400> 120
Asp Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser
20 25
<210> 121
<211> 14
<212> PRT
<213> Artificial Sequence
<220>
<223> FR2
<400> 121
Trp Tyr Arg Arg Ala Pro Gly Lys Gln Arg Glu Leu Val Ala
1 5 10
<210> 122
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 122
Tyr Val Asp Ser Val Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Val Tyr Tyr Cys Asn Val
35
<210> 123
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 123
Tyr Val Asp Ser Val Arg Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Leu Tyr Tyr Cys Asn Val
35
<210> 124
<211> 39
<212> PRT
<213> Artificial Sequence
<220>
<223> FR3
<400> 124
Tyr Ala Asp Ser Val Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser
1 5 10 15
Lys Asn Thr Val Tyr Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr
20 25 30
Ala Leu Tyr Tyr Cys Ala Ala
35
<210> 125
<211> 2415
<212> PRT
<213> Homo sapiens
<400> 125
Met Thr Thr Leu Leu Trp Val Phe Val Thr Leu Arg Val Ile Thr Ala
1 5 10 15
Ala Val Thr Val Glu Thr Ser Asp His Asp Asn Ser Leu Ser Val Ser
20 25 30
Ile Pro Gln Pro Ser Pro Leu Arg Val Leu Leu Gly Thr Ser Leu Thr
35 40 45
Ile Pro Cys Tyr Phe Ile Asp Pro Met His Pro Val Thr Thr Ala Pro
50 55 60
Ser Thr Ala Pro Leu Ala Pro Arg Ile Lys Trp Ser Arg Val Ser Lys
65 70 75 80
Glu Lys Glu Val Val Leu Leu Val Ala Thr Glu Gly Arg Val Arg Val
85 90 95
Asn Ser Ala Tyr Gln Asp Lys Val Ser Leu Pro Asn Tyr Pro Ala Ile
100 105 110
Pro Ser Asp Ala Thr Leu Glu Val Gln Ser Leu Arg Ser Asn Asp Ser
115 120 125
Gly Val Tyr Arg Cys Glu Val Met His Gly Ile Glu Asp Ser Glu Ala
130 135 140
Thr Leu Glu Val Val Val Lys Gly Ile Val Phe His Tyr Arg Ala Ile
145 150 155 160
Ser Thr Arg Tyr Thr Leu Asp Phe Asp Arg Ala Gln Arg Ala Cys Leu
165 170 175
Gln Asn Ser Ala Ile Ile Ala Thr Pro Glu Gln Leu Gln Ala Ala Tyr
180 185 190
Glu Asp Gly Phe His Gln Cys Asp Ala Gly Trp Leu Ala Asp Gln Thr
195 200 205
Val Arg Tyr Pro Ile His Thr Pro Arg Glu Gly Cys Tyr Gly Asp Lys
210 215 220
Asp Glu Phe Pro Gly Val Arg Thr Tyr Gly Ile Arg Asp Thr Asn Glu
225 230 235 240
Thr Tyr Asp Val Tyr Cys Phe Ala Glu Glu Met Glu Gly Glu Val Phe
245 250 255
Tyr Ala Thr Ser Pro Glu Lys Phe Thr Phe Gln Glu Ala Ala Asn Glu
260 265 270
Cys Arg Arg Leu Gly Ala Arg Leu Ala Thr Thr Gly His Val Tyr Leu
275 280 285
Ala Trp Gln Ala Gly Met Asp Met Cys Ser Ala Gly Trp Leu Ala Asp
290 295 300
Arg Ser Val Arg Tyr Pro Ile Ser Lys Ala Arg Pro Asn Cys Gly Gly
305 310 315 320
Asn Leu Leu Gly Val Arg Thr Val Tyr Val His Ala Asn Gln Thr Gly
325 330 335
Tyr Pro Asp Pro Ser Ser Arg Tyr Asp Ala Ile Cys Tyr Thr Gly Glu
340 345 350
Asp Phe Val Asp Ile Pro Glu Asn Phe Phe Gly Val Gly Gly Glu Glu
355 360 365
Asp Ile Thr Val Gln Thr Val Thr Trp Pro Asp Met Glu Leu Pro Leu
370 375 380
Pro Arg Asn Ile Thr Glu Gly Glu Ala Arg Gly Ser Val Ile Leu Thr
385 390 395 400
Val Lys Pro Ile Phe Glu Val Ser Pro Ser Pro Leu Glu Pro Glu Glu
405 410 415
Pro Phe Thr Phe Ala Pro Glu Ile Gly Ala Thr Ala Phe Ala Glu Val
420 425 430
Glu Asn Glu Thr Gly Glu Ala Thr Arg Pro Trp Gly Phe Pro Thr Pro
435 440 445
Gly Leu Gly Pro Ala Thr Ala Phe Thr Ser Glu Asp Leu Val Val Gln
450 455 460
Val Thr Ala Val Pro Gly Gln Pro His Leu Pro Gly Gly Val Val Phe
465 470 475 480
His Tyr Arg Pro Gly Pro Thr Arg Tyr Ser Leu Thr Phe Glu Glu Ala
485 490 495
Gln Gln Ala Cys Pro Gly Thr Gly Ala Val Ile Ala Ser Pro Glu Gln
500 505 510
Leu Gln Ala Ala Tyr Glu Ala Gly Tyr Glu Gln Cys Asp Ala Gly Trp
515 520 525
Leu Arg Asp Gln Thr Val Arg Tyr Pro Ile Val Ser Pro Arg Thr Pro
530 535 540
Cys Val Gly Asp Lys Asp Ser Ser Pro Gly Val Arg Thr Tyr Gly Val
545 550 555 560
Arg Pro Ser Thr Glu Thr Tyr Asp Val Tyr Cys Phe Val Asp Arg Leu
565 570 575
Glu Gly Glu Val Phe Phe Ala Thr Arg Leu Glu Gln Phe Thr Phe Gln
580 585 590
Glu Ala Leu Glu Phe Cys Glu Ser His Asn Ala Thr Ala Thr Thr Gly
595 600 605
Gln Leu Tyr Ala Ala Trp Ser Arg Gly Leu Asp Lys Cys Tyr Ala Gly
610 615 620
Trp Leu Ala Asp Gly Ser Leu Arg Tyr Pro Ile Val Thr Pro Arg Pro
625 630 635 640
Ala Cys Gly Gly Asp Lys Pro Gly Val Arg Thr Val Tyr Leu Tyr Pro
645 650 655
Asn Gln Thr Gly Leu Pro Asp Pro Leu Ser Arg His His Ala Phe Cys
660 665 670
Phe Arg Gly Ile Ser Ala Val Pro Ser Pro Gly Glu Glu Glu Gly Gly
675 680 685
Thr Pro Thr Ser Pro Ser Gly Val Glu Glu Trp Ile Val Thr Gln Val
690 695 700
Val Pro Gly Val Ala Ala Val Pro Val Glu Glu Glu Thr Thr Ala Val
705 710 715 720
Pro Ser Gly Glu Thr Thr Ala Ile Leu Glu Phe Thr Thr Glu Pro Glu
725 730 735
Asn Gln Thr Glu Trp Glu Pro Ala Tyr Thr Pro Val Gly Thr Ser Pro
740 745 750
Leu Pro Gly Ile Leu Pro Thr Trp Pro Pro Thr Gly Ala Glu Thr Glu
755 760 765
Glu Ser Thr Glu Gly Pro Ser Ala Thr Glu Val Pro Ser Ala Ser Glu
770 775 780
Glu Pro Ser Pro Ser Glu Val Pro Phe Pro Ser Glu Glu Pro Ser Pro
785 790 795 800
Ser Glu Glu Pro Phe Pro Ser Val Arg Pro Phe Pro Ser Val Glu Leu
805 810 815
Phe Pro Ser Glu Glu Pro Phe Pro Ser Lys Glu Pro Ser Pro Ser Glu
820 825 830
Glu Pro Ser Ala Ser Glu Glu Pro Tyr Thr Pro Ser Pro Pro Glu Pro
835 840 845
Ser Trp Thr Glu Leu Pro Ser Ser Gly Glu Glu Ser Gly Ala Pro Asp
850 855 860
Val Ser Gly Asp Phe Thr Gly Ser Gly Asp Val Ser Gly His Leu Asp
865 870 875 880
Phe Ser Gly Gln Leu Ser Gly Asp Arg Ala Ser Gly Leu Pro Ser Gly
885 890 895
Asp Leu Asp Ser Ser Gly Leu Thr Ser Thr Val Gly Ser Gly Leu Thr
900 905 910
Val Glu Ser Gly Leu Pro Ser Gly Asp Glu Glu Arg Ile Glu Trp Pro
915 920 925
Ser Thr Pro Thr Val Gly Glu Leu Pro Ser Gly Ala Glu Ile Leu Glu
930 935 940
Gly Ser Ala Ser Gly Val Gly Asp Leu Ser Gly Leu Pro Ser Gly Glu
945 950 955 960
Val Leu Glu Thr Ser Ala Ser Gly Val Gly Asp Leu Ser Gly Leu Pro
965 970 975
Ser Gly Glu Val Leu Glu Thr Thr Ala Pro Gly Val Glu Asp Ile Ser
980 985 990
Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Thr Ala Pro Gly Val Glu
995 1000 1005
Asp Ile Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Thr Ala
1010 1015 1020
Pro Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu Val Leu
1025 1030 1035
Glu Thr Thr Ala Pro Gly Val Glu Asp Ile Ser Gly Leu Pro Ser
1040 1045 1050
Gly Glu Val Leu Glu Thr Thr Ala Pro Gly Val Glu Asp Ile Ser
1055 1060 1065
Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Ala Ala Pro Gly Val
1070 1075 1080
Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Ala
1085 1090 1095
Ala Pro Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu Val
1100 1105 1110
Leu Glu Thr Ala Ala Pro Gly Val Glu Asp Ile Ser Gly Leu Pro
1115 1120 1125
Ser Gly Glu Val Leu Glu Thr Ala Ala Pro Gly Val Glu Asp Ile
1130 1135 1140
Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Ala Ala Pro Gly
1145 1150 1155
Val Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr
1160 1165 1170
Ala Ala Pro Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu
1175 1180 1185
Val Leu Glu Thr Ala Ala Pro Gly Val Glu Asp Ile Ser Gly Leu
1190 1195 1200
Pro Ser Gly Glu Val Leu Glu Thr Ala Ala Pro Gly Val Glu Asp
1205 1210 1215
Ile Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Ala Ala Pro
1220 1225 1230
Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu Val Leu Glu
1235 1240 1245
Thr Ala Ala Pro Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly
1250 1255 1260
Glu Val Leu Glu Thr Ala Ala Pro Gly Val Glu Asp Ile Ser Gly
1265 1270 1275
Leu Pro Ser Gly Glu Val Leu Glu Thr Thr Ala Pro Gly Val Glu
1280 1285 1290
Glu Ile Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Thr Ala
1295 1300 1305
Pro Gly Val Asp Glu Ile Ser Gly Leu Pro Ser Gly Glu Val Leu
1310 1315 1320
Glu Thr Thr Ala Pro Gly Val Glu Glu Ile Ser Gly Leu Pro Ser
1325 1330 1335
Gly Glu Val Leu Glu Thr Ser Thr Ser Ala Val Gly Asp Leu Ser
1340 1345 1350
Gly Leu Pro Ser Gly Gly Glu Val Leu Glu Ile Ser Val Ser Gly
1355 1360 1365
Val Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu Val Val Glu Thr
1370 1375 1380
Ser Ala Ser Gly Ile Glu Asp Val Ser Glu Leu Pro Ser Gly Glu
1385 1390 1395
Gly Leu Glu Thr Ser Ala Ser Gly Val Glu Asp Leu Ser Arg Leu
1400 1405 1410
Pro Ser Gly Glu Glu Val Leu Glu Ile Ser Ala Ser Gly Phe Gly
1415 1420 1425
Asp Leu Ser Gly Val Pro Ser Gly Gly Glu Gly Leu Glu Thr Ser
1430 1435 1440
Ala Ser Glu Val Gly Thr Asp Leu Ser Gly Leu Pro Ser Gly Arg
1445 1450 1455
Glu Gly Leu Glu Thr Ser Ala Ser Gly Ala Glu Asp Leu Ser Gly
1460 1465 1470
Leu Pro Ser Gly Lys Glu Asp Leu Val Gly Ser Ala Ser Gly Asp
1475 1480 1485
Leu Asp Leu Gly Lys Leu Pro Ser Gly Thr Leu Gly Ser Gly Gln
1490 1495 1500
Ala Pro Glu Thr Ser Gly Leu Pro Ser Gly Phe Ser Gly Glu Tyr
1505 1510 1515
Ser Gly Val Asp Leu Gly Ser Gly Pro Pro Ser Gly Leu Pro Asp
1520 1525 1530
Phe Ser Gly Leu Pro Ser Gly Phe Pro Thr Val Ser Leu Val Asp
1535 1540 1545
Ser Thr Leu Val Glu Val Val Thr Ala Ser Thr Ala Ser Glu Leu
1550 1555 1560
Glu Gly Arg Gly Thr Ile Gly Ile Ser Gly Ala Gly Glu Ile Ser
1565 1570 1575
Gly Leu Pro Ser Ser Glu Leu Asp Ile Ser Gly Arg Ala Ser Gly
1580 1585 1590
Leu Pro Ser Gly Thr Glu Leu Ser Gly Gln Ala Ser Gly Ser Pro
1595 1600 1605
Asp Val Ser Gly Glu Ile Pro Gly Leu Phe Gly Val Ser Gly Gln
1610 1615 1620
Pro Ser Gly Phe Pro Asp Thr Ser Gly Glu Thr Ser Gly Val Thr
1625 1630 1635
Glu Leu Ser Gly Leu Ser Ser Gly Gln Pro Gly Val Ser Gly Glu
1640 1645 1650
Ala Ser Gly Val Leu Tyr Gly Thr Ser Gln Pro Phe Gly Ile Thr
1655 1660 1665
Asp Leu Ser Gly Glu Thr Ser Gly Val Pro Asp Leu Ser Gly Gln
1670 1675 1680
Pro Ser Gly Leu Pro Gly Phe Ser Gly Ala Thr Ser Gly Val Pro
1685 1690 1695
Asp Leu Val Ser Gly Thr Thr Ser Gly Ser Gly Glu Ser Ser Gly
1700 1705 1710
Ile Thr Phe Val Asp Thr Ser Leu Val Glu Val Ala Pro Thr Thr
1715 1720 1725
Phe Lys Glu Glu Glu Gly Leu Gly Ser Val Glu Leu Ser Gly Leu
1730 1735 1740
Pro Ser Gly Glu Ala Asp Leu Ser Gly Lys Ser Gly Met Val Asp
1745 1750 1755
Val Ser Gly Gln Phe Ser Gly Thr Val Asp Ser Ser Gly Phe Thr
1760 1765 1770
Ser Gln Thr Pro Glu Phe Ser Gly Leu Pro Ser Gly Ile Ala Glu
1775 1780 1785
Val Ser Gly Glu Ser Ser Arg Ala Glu Ile Gly Ser Ser Leu Pro
1790 1795 1800
Ser Gly Ala Tyr Tyr Gly Ser Gly Thr Pro Ser Ser Phe Pro Thr
1805 1810 1815
Val Ser Leu Val Asp Arg Thr Leu Val Glu Ser Val Thr Gln Ala
1820 1825 1830
Pro Thr Ala Gln Glu Ala Gly Glu Gly Pro Ser Gly Ile Leu Glu
1835 1840 1845
Leu Ser Gly Ala His Ser Gly Ala Pro Asp Met Ser Gly Glu His
1850 1855 1860
Ser Gly Phe Leu Asp Leu Ser Gly Leu Gln Ser Gly Leu Ile Glu
1865 1870 1875
Pro Ser Gly Glu Pro Pro Gly Thr Pro Tyr Phe Ser Gly Asp Phe
1880 1885 1890
Ala Ser Thr Thr Asn Val Ser Gly Glu Ser Ser Val Ala Met Gly
1895 1900 1905
Thr Ser Gly Glu Ala Ser Gly Leu Pro Glu Val Thr Leu Ile Thr
1910 1915 1920
Ser Glu Phe Val Glu Gly Val Thr Glu Pro Thr Ile Ser Gln Glu
1925 1930 1935
Leu Gly Gln Arg Pro Pro Val Thr His Thr Pro Gln Leu Phe Glu
1940 1945 1950
Ser Ser Gly Lys Val Ser Thr Ala Gly Asp Ile Ser Gly Ala Thr
1955 1960 1965
Pro Val Leu Pro Gly Ser Gly Val Glu Val Ser Ser Val Pro Glu
1970 1975 1980
Ser Ser Ser Glu Thr Ser Ala Tyr Pro Glu Ala Gly Phe Gly Ala
1985 1990 1995
Ser Ala Ala Pro Glu Ala Ser Arg Glu Asp Ser Gly Ser Pro Asp
2000 2005 2010
Leu Ser Glu Thr Thr Ser Ala Phe His Glu Ala Asn Leu Glu Arg
2015 2020 2025
Ser Ser Gly Leu Gly Val Ser Gly Ser Thr Leu Thr Phe Gln Glu
2030 2035 2040
Gly Glu Ala Ser Ala Ala Pro Glu Val Ser Gly Glu Ser Thr Thr
2045 2050 2055
Thr Ser Asp Val Gly Thr Glu Ala Pro Gly Leu Pro Ser Ala Thr
2060 2065 2070
Pro Thr Ala Ser Gly Asp Arg Thr Glu Ile Ser Gly Asp Leu Ser
2075 2080 2085
Gly His Thr Ser Gln Leu Gly Val Val Ile Ser Thr Ser Ile Pro
2090 2095 2100
Glu Ser Glu Trp Thr Gln Gln Thr Gln Arg Pro Ala Glu Thr His
2105 2110 2115
Leu Glu Ile Glu Ser Ser Ser Leu Leu Tyr Ser Gly Glu Glu Thr
2120 2125 2130
His Thr Val Glu Thr Ala Thr Ser Pro Thr Asp Ala Ser Ile Pro
2135 2140 2145
Ala Ser Pro Glu Trp Lys Arg Glu Ser Glu Ser Thr Ala Ala Ala
2150 2155 2160
Pro Ala Arg Ser Cys Ala Glu Glu Pro Cys Gly Ala Gly Thr Cys
2165 2170 2175
Lys Glu Thr Glu Gly His Val Ile Cys Leu Cys Pro Pro Gly Tyr
2180 2185 2190
Thr Gly Glu His Cys Asn Ile Asp Gln Glu Val Cys Glu Glu Gly
2195 2200 2205
Trp Asn Lys Tyr Gln Gly His Cys Tyr Arg His Phe Pro Asp Arg
2210 2215 2220
Glu Thr Trp Val Asp Ala Glu Arg Arg Cys Arg Glu Gln Gln Ser
2225 2230 2235
His Leu Ser Ser Ile Val Thr Pro Glu Glu Gln Glu Phe Val Asn
2240 2245 2250
Asn Asn Ala Gln Asp Tyr Gln Trp Ile Gly Leu Asn Asp Arg Thr
2255 2260 2265
Ile Glu Gly Asp Phe Arg Trp Ser Asp Gly His Pro Met Gln Phe
2270 2275 2280
Glu Asn Trp Arg Pro Asn Gln Pro Asp Asn Phe Phe Ala Ala Gly
2285 2290 2295
Glu Asp Cys Val Val Met Ile Trp His Glu Lys Gly Glu Trp Asn
2300 2305 2310
Asp Val Pro Cys Asn Tyr His Leu Pro Phe Thr Cys Lys Lys Gly
2315 2320 2325
Thr Val Ala Cys Gly Glu Pro Pro Val Val Glu His Ala Arg Thr
2330 2335 2340
Phe Gly Gln Lys Lys Asp Arg Tyr Glu Ile Asn Ser Leu Val Arg
2345 2350 2355
Tyr Gln Cys Thr Glu Gly Phe Val Gln Arg His Met Pro Thr Ile
2360 2365 2370
Arg Cys Gln Pro Ser Gly His Trp Glu Glu Pro Arg Ile Thr Cys
2375 2380 2385
Thr Asp Ala Thr Thr Tyr Lys Arg Arg Leu Gln Lys Arg Ser Ser
2390 2395 2400
Arg His Pro Arg Arg Ser Arg Pro Ser Thr Ala His
2405 2410 2415
<210> 126
<211> 2333
<212> PRT
<213> Canis lupus
<400> 126
Met Thr Thr Leu Leu Trp Val Phe Val Thr Leu Arg Val Ile Thr Ala
1 5 10 15
Ala Ser Ser Glu Glu Thr Ser Asp His Asp Asn Ser Leu Ser Val Ser
20 25 30
Ile Pro Glu Pro Ser Pro Met Arg Val Leu Leu Gly Ser Ser Leu Thr
35 40 45
Ile Pro Cys Tyr Phe Ile Asp Pro Met His Pro Val Thr Thr Ala Pro
50 55 60
Ser Thr Ala Pro Leu Ala Pro Arg Ile Lys Trp Ser Arg Ile Thr Lys
65 70 75 80
Glu Lys Glu Val Val Leu Leu Val Ala Thr Glu Gly Gln Val Arg Ile
85 90 95
Asn Ser Ala Tyr Gln Asp Lys Val Ser Leu Pro Asn Tyr Pro Ala Ile
100 105 110
Pro Ser Asp Ala Thr Leu Glu Ile Gln Asn Leu Arg Ser Asn Asp Ser
115 120 125
Gly Ile Tyr Arg Cys Glu Val Met His Gly Ile Glu Asp Ser Glu Ala
130 135 140
Thr Leu Glu Val Val Val Lys Gly Ile Val Phe His Tyr Arg Ala Ile
145 150 155 160
Ser Thr Arg Tyr Thr Leu Asp Phe Asp Arg Ala Gln Arg Ala Cys Leu
165 170 175
Gln Asn Ser Ala Ile Ile Ala Thr Pro Glu Gln Leu Gln Ala Ala Tyr
180 185 190
Glu Asp Gly Phe His Gln Cys Asp Ala Gly Trp Leu Ala Asp Gln Thr
195 200 205
Val Arg Tyr Pro Ile His Thr Pro Arg Glu Gly Cys Tyr Gly Asp Lys
210 215 220
Asp Glu Phe Pro Gly Val Arg Thr Tyr Gly Ile Arg Asp Thr Asn Glu
225 230 235 240
Thr Tyr Asp Val Tyr Cys Phe Ala Glu Glu Met Glu Gly Glu Val Leu
245 250 255
Tyr Ala Thr Ser Pro Glu Lys Phe Thr Phe Gln Glu Ala Ala Asn Glu
260 265 270
Cys Arg Arg Leu Gly Ala Arg Leu Ala Thr Thr Gly Gln Leu Tyr Leu
275 280 285
Ala Trp Gln Gly Gly Met Asp Met Cys Ser Ala Gly Trp Leu Ala Asp
290 295 300
Arg Ser Val Arg Tyr Pro Ile Ser Lys Ala Arg Pro Asn Cys Gly Gly
305 310 315 320
Asn Leu Leu Gly Val Arg Thr Val Tyr Leu His Ala Asn Gln Thr Gly
325 330 335
Tyr Pro Asp Pro Ser Ser Arg Tyr Asp Ala Ile Cys Tyr Thr Gly Glu
340 345 350
Asp Phe Val Asp Ile Pro Glu Asn Phe Phe Gly Val Gly Gly Glu Glu
355 360 365
Asp Ile Thr Ile Gln Thr Val Thr Trp Pro Asp Val Glu Leu Pro Leu
370 375 380
Pro Arg Asn Ile Thr Glu Gly Glu Ala Arg Gly Asn Val Ile Leu Thr
385 390 395 400
Val Lys Pro Ile Phe Asp Leu Ser Pro Thr Ala Pro Glu Pro Glu Glu
405 410 415
Pro Phe Thr Phe Val Pro Glu Pro Glu Lys Pro Phe Thr Phe Ala Thr
420 425 430
Asp Val Gly Val Thr Ala Phe Pro Glu Ala Glu Asn Arg Thr Gly Glu
435 440 445
Ala Thr Arg Pro Trp Gly Val Pro Glu Glu Ser Thr Pro Gly Pro Ala
450 455 460
Phe Thr Ala Phe Thr Ser Glu Asp His Val Val Gln Val Thr Ala Val
465 470 475 480
Pro Gly Ala Ala Glu Val Pro Gly Gln Pro Arg Leu Pro Gly Gly Val
485 490 495
Val Phe His Tyr Arg Pro Gly Ser Ala Arg Tyr Ser Leu Thr Phe Glu
500 505 510
Glu Ala Gln Gln Ala Cys Leu Arg Thr Gly Ala Val Ile Ala Ser Pro
515 520 525
Glu Gln Leu Gln Ala Ala Tyr Glu Ala Gly Tyr Glu Gln Cys Asp Ala
530 535 540
Gly Trp Leu Gln Asp Gln Thr Val Arg Tyr Pro Ile Val Ser Pro Arg
545 550 555 560
Thr Pro Cys Val Gly Asp Lys Asp Ser Ser Pro Gly Val Arg Thr Tyr
565 570 575
Gly Val Arg Pro Pro Ser Glu Thr Tyr Asp Val Tyr Cys Tyr Val Asp
580 585 590
Lys Leu Glu Gly Glu Val Phe Phe Ile Thr Arg Leu Glu Gln Phe Thr
595 600 605
Phe Gln Glu Ala Leu Ala Phe Cys Glu Ser His Asn Ala Thr Leu Ala
610 615 620
Ser Thr Gly Gln Leu Tyr Ala Ala Trp Arg Gln Gly Leu Asp Lys Cys
625 630 635 640
Tyr Ala Gly Trp Leu Ser Asp Gly Ser Leu Arg Tyr Pro Ile Val Thr
645 650 655
Pro Arg Pro Ser Cys Gly Gly Asp Lys Pro Gly Val Arg Thr Val Tyr
660 665 670
Leu Tyr Pro Asn Gln Thr Gly Leu Pro Asp Pro Leu Ser Arg His His
675 680 685
Val Phe Cys Phe Arg Gly Val Ser Gly Val Pro Ser Pro Gly Glu Glu
690 695 700
Glu Gly Gly Thr Pro Thr Pro Ser Val Val Glu Asp Trp Ile Pro Thr
705 710 715 720
Gln Val Gly Pro Val Val Pro Ser Val Pro Met Gly Glu Glu Thr Thr
725 730 735
Ala Ile Leu Asp Phe Thr Ile Glu Pro Glu Asn Gln Thr Glu Trp Glu
740 745 750
Pro Ala Tyr Ser Pro Ala Gly Thr Ser Pro Leu Pro Gly Ile Pro Pro
755 760 765
Thr Trp Pro Pro Thr Ser Thr Ala Thr Glu Glu Ser Thr Glu Gly Pro
770 775 780
Ser Gly Thr Glu Val Pro Ser Val Ser Glu Glu Pro Ser Pro Ser Glu
785 790 795 800
Glu Pro Phe Pro Trp Glu Glu Leu Ser Thr Leu Ser Pro Pro Gly Pro
805 810 815
Ser Gly Thr Glu Leu Pro Gly Ser Gly Glu Ala Ser Gly Val Pro Glu
820 825 830
Val Ser Gly Asp Phe Thr Gly Ser Gly Glu Val Ser Gly His Pro Asp
835 840 845
Ser Ser Gly Gln Leu Ser Gly Glu Ser Ala Ser Gly Leu Pro Ser Glu
850 855 860
Asp Leu Asp Ser Ser Gly Leu Thr Ser Ala Val Gly Ser Gly Leu Ala
865 870 875 880
Ser Gly Asp Glu Asp Arg Ile Thr Leu Ser Ser Ile Pro Lys Val Glu
885 890 895
Gly Glu Gly Leu Glu Thr Ser Ala Ser Gly Val Glu Asp Leu Ser Gly
900 905 910
Leu Pro Ser Gly Arg Glu Gly Leu Glu Thr Ser Thr Ser Gly Val Gly
915 920 925
Asp Leu Ser Gly Leu Pro Ser Gly Glu Gly Leu Glu Val Ser Ala Ser
930 935 940
Gly Val Glu Asp Leu Ser Gly Leu Pro Ser Gly Glu Gly Pro Glu Thr
945 950 955 960
Ser Thr Ser Gly Val Gly Asp Leu Ser Arg Leu Pro Ser Gly Glu Gly
965 970 975
Pro Glu Val Ser Ala Ser Gly Val Gly Asp Leu Ser Gly Leu Pro Ser
980 985 990
Gly Arg Glu Gly Leu Glu Thr Ser Thr Ser Gly Val Glu Asp Leu Ser
995 1000 1005
Gly Leu Pro Ser Gly Glu Gly Pro Glu Ala Ser Thr Ser Gly Val
1010 1015 1020
Gly Asp Leu Ser Arg Leu Pro Ser Gly Glu Gly Pro Glu Val Ser
1025 1030 1035
Ala Ser Gly Val Glu Asp Leu Ser Gly Leu Pro Ser Gly Glu Gly
1040 1045 1050
Leu Glu Ala Ser Ala Ser Gly Val Gly Asp Leu Ser Gly Leu Pro
1055 1060 1065
Ser Gly Glu Gly Pro Glu Ala Ser Ala Ser Gly Val Gly Asp Leu
1070 1075 1080
Ser Arg Leu Pro Ser Gly Glu Gly Pro Glu Val Ser Ala Ser Gly
1085 1090 1095
Val Glu Asp Leu Ser Gly Leu Ser Ser Gly Glu Ser Pro Glu Ala
1100 1105 1110
Ser Ala Ser Gly Val Gly Asp Leu Ser Gly Leu Pro Ser Gly Arg
1115 1120 1125
Glu Gly Leu Glu Thr Ser Ala Ser Gly Val Gly Asp Leu Ser Gly
1130 1135 1140
Leu Pro Ser Gly Glu Gly Gln Glu Ala Ser Ala Ser Gly Val Glu
1145 1150 1155
Asp Leu Ser Arg Leu Pro Ser Gly Glu Gly Pro Glu Ala Ser Ala
1160 1165 1170
Ser Gly Val Gly Glu Leu Ser Gly Leu Pro Ser Gly Arg Glu Gly
1175 1180 1185
Leu Glu Thr Ser Ala Ser Gly Val Gly Asp Leu Ser Gly Leu Pro
1190 1195 1200
Ser Gly Glu Gly Pro Glu Ala Phe Ala Ser Gly Val Glu Asp Leu
1205 1210 1215
Ser Ile Leu Pro Ser Gly Glu Gly Pro Glu Ala Ser Ala Ser Gly
1220 1225 1230
Val Gly Asp Leu Ser Gly Leu Pro Ser Gly Arg Glu Gly Leu Glu
1235 1240 1245
Thr Ser Thr Ser Gly Val Gly Asp Leu Ser Gly Leu Pro Ser Gly
1250 1255 1260
Arg Glu Gly Leu Glu Thr Ser Thr Ser Gly Val Gly Asp Leu Ser
1265 1270 1275
Gly Leu Pro Ser Gly Glu Gly Pro Glu Ala Ser Ala Ser Gly Ile
1280 1285 1290
Gly Asp Ile Ser Gly Leu Pro Ser Gly Arg Glu Gly Leu Glu Thr
1295 1300 1305
Ser Ser Ser Gly Val Glu Asp His Pro Glu Thr Ser Ala Ser Gly
1310 1315 1320
Val Glu Asp Leu Ser Gly Leu Pro Ser Gly Val Glu Gly His Pro
1325 1330 1335
Glu Thr Ser Ala Ser Gly Val Glu Asp Leu Ser Asp Leu Ser Ser
1340 1345 1350
Gly Gly Glu Gly Leu Glu Thr Ser Ala Ser Gly Ala Glu Asp Leu
1355 1360 1365
Ser Gly Phe Pro Ser Gly Lys Glu Asp Leu Ile Gly Ser Ala Ser
1370 1375 1380
Gly Ala Leu Asp Phe Gly Arg Ile Pro Ser Gly Thr Leu Gly Ser
1385 1390 1395
Gly Gln Ala Pro Glu Ala Ser Ser Leu Pro Ser Gly Phe Ser Gly
1400 1405 1410
Glu Tyr Ser Gly Val Asp Phe Gly Ser Gly Pro Ile Ser Gly Leu
1415 1420 1425
Pro Asp Phe Ser Gly Leu Pro Ser Gly Phe Pro Thr Ile Ser Leu
1430 1435 1440
Val Asp Thr Thr Leu Val Glu Val Ile Thr Thr Thr Ser Ala Ser
1445 1450 1455
Glu Leu Glu Gly Arg Gly Thr Ile Gly Ile Ser Gly Ala Gly Glu
1460 1465 1470
Thr Ser Gly Leu Pro Val Ser Glu Leu Asp Ile Ser Gly Ala Val
1475 1480 1485
Ser Gly Leu Pro Ser Gly Ala Glu Leu Ser Gly Gln Ala Ser Gly
1490 1495 1500
Ser Pro Asp Met Ser Gly Glu Thr Ser Gly Phe Phe Gly Val Ser
1505 1510 1515
Gly Gln Pro Ser Gly Phe Pro Asp Ile Ser Gly Gly Thr Ser Gly
1520 1525 1530
Leu Phe Glu Val Ser Gly Gln Pro Ser Gly Phe Ser Gly Glu Thr
1535 1540 1545
Ser Gly Val Thr Glu Leu Ser Gly Leu Tyr Ser Gly Gln Pro Asp
1550 1555 1560
Val Ser Gly Glu Ala Ser Gly Val Pro Ser Gly Ser Gly Gln Pro
1565 1570 1575
Phe Gly Met Thr Asp Leu Ser Gly Glu Thr Ser Gly Val Pro Asp
1580 1585 1590
Ile Ser Gly Gln Pro Ser Gly Leu Pro Glu Phe Ser Gly Thr Thr
1595 1600 1605
Ser Gly Ile Pro Asp Leu Val Ser Ser Thr Met Ser Gly Ser Gly
1610 1615 1620
Glu Ser Ser Gly Ile Thr Phe Val Asp Thr Ser Leu Val Glu Val
1625 1630 1635
Thr Pro Thr Thr Phe Lys Glu Lys Lys Arg Leu Gly Ser Val Glu
1640 1645 1650
Leu Ser Gly Leu Pro Ser Gly Glu Val Asp Leu Ser Gly Ala Ser
1655 1660 1665
Gly Thr Met Asp Ile Ser Gly Gln Ser Ser Gly Ala Thr Asp Ser
1670 1675 1680
Ser Gly Leu Thr Ser His Leu Pro Lys Phe Ser Gly Leu Pro Ser
1685 1690 1695
Gly Ala Ala Glu Val Ser Gly Glu Ser Ser Gly Ala Glu Val Gly
1700 1705 1710
Ser Ser Leu Pro Ser Gly Thr Tyr Glu Gly Ser Gly Asn Phe His
1715 1720 1725
Pro Ala Phe Pro Thr Val Phe Leu Val Asp Arg Thr Leu Val Glu
1730 1735 1740
Ser Val Thr Gln Ala Pro Thr Ala Gln Glu Ala Gly Glu Gly Pro
1745 1750 1755
Ser Gly Ile Leu Glu Leu Ser Gly Ala His Ser Gly Ala Pro Asp
1760 1765 1770
Val Ser Gly Asp His Ser Gly Ser Leu Asp Leu Ser Gly Met Gln
1775 1780 1785
Ser Gly Leu Val Glu Pro Ser Gly Glu Pro Ser Ser Thr Pro Tyr
1790 1795 1800
Phe Ser Gly Asp Phe Ser Gly Thr Met Asp Val Thr Gly Glu Pro
1805 1810 1815
Ser Thr Ala Met Ser Ala Ser Gly Glu Ala Ser Gly Leu Leu Glu
1820 1825 1830
Val Thr Leu Ile Thr Ser Glu Phe Val Glu Gly Val Thr Glu Pro
1835 1840 1845
Thr Val Ser Gln Glu Leu Ala Gln Arg Pro Pro Val Thr His Thr
1850 1855 1860
Pro Gln Leu Phe Glu Ser Ser Gly Glu Ala Ser Ala Ser Gly Glu
1865 1870 1875
Ile Ser Gly Ala Thr Pro Ala Phe Pro Gly Ser Gly Leu Glu Ala
1880 1885 1890
Ser Ser Val Pro Glu Ser Ser Ser Glu Thr Ser Asp Phe Pro Glu
1895 1900 1905
Arg Ala Val Gly Val Ser Ala Ala Pro Glu Ala Ser Gly Gly Ala
1910 1915 1920
Ser Gly Ala Pro Asp Val Ser Glu Ala Thr Ser Thr Phe Pro Glu
1925 1930 1935
Ala Asp Val Glu Gly Ala Ser Gly Leu Gly Val Ser Gly Gly Thr
1940 1945 1950
Ser Ala Phe Pro Glu Ala Pro Arg Glu Gly Ser Ala Thr Pro Glu
1955 1960 1965
Val Gln Glu Glu Pro Thr Thr Ser Tyr Asp Val Gly Arg Glu Ala
1970 1975 1980
Leu Gly Trp Pro Ser Ala Thr Pro Thr Ala Ser Gly Asp Arg Ile
1985 1990 1995
Glu Val Ser Gly Asp Leu Ser Gly His Thr Ser Gly Leu Asp Val
2000 2005 2010
Val Ile Ser Thr Ser Val Pro Glu Ser Glu Trp Ile Gln Gln Thr
2015 2020 2025
Gln Arg Pro Ala Glu Ala His Leu Glu Ile Glu Ala Ser Ser Pro
2030 2035 2040
Leu His Ser Gly Glu Glu Thr Gln Thr Ala Glu Thr Ala Thr Ser
2045 2050 2055
Pro Thr Asp Asp Ala Ser Ile Pro Thr Ser Pro Ser Gly Thr Asp
2060 2065 2070
Glu Ser Ala Pro Ala Ile Pro Asp Ile Asp Glu Cys Leu Ser Ser
2075 2080 2085
Pro Cys Leu Asn Gly Ala Thr Cys Val Asp Ala Ile Asp Ser Phe
2090 2095 2100
Thr Cys Leu Cys Leu Pro Ser Tyr Arg Gly Asp Leu Cys Glu Ile
2105 2110 2115
Asp Gln Glu Leu Cys Glu Glu Gly Trp Thr Lys Phe Gln Gly His
2120 2125 2130
Cys Tyr Arg Tyr Phe Pro Asp Arg Glu Ser Trp Val Asp Ala Glu
2135 2140 2145
Ser Arg Cys Arg Ala Gln Gln Ser His Leu Ser Ser Ile Val Thr
2150 2155 2160
Pro Glu Glu Gln Glu Phe Val Asn Asn Asn Ala Gln Asp Tyr Gln
2165 2170 2175
Trp Ile Gly Leu Asn Asp Arg Thr Ile Glu Gly Asp Phe Arg Trp
2180 2185 2190
Ser Asp Gly His Ser Leu Gln Phe Glu Asn Trp Arg Pro Asn Gln
2195 2200 2205
Pro Asp Asn Phe Phe Val Ser Gly Glu Asp Cys Val Val Met Ile
2210 2215 2220
Trp His Glu Lys Gly Glu Trp Asn Asp Val Pro Cys Asn Tyr Tyr
2225 2230 2235
Leu Pro Phe Thr Cys Lys Lys Gly Thr Val Ala Cys Gly Asp Pro
2240 2245 2250
Pro Val Val Glu His Ala Arg Thr Phe Gly Gln Lys Lys Asp Arg
2255 2260 2265
Tyr Glu Ile Asn Ser Leu Val Arg Tyr Gln Cys Thr Glu Gly Phe
2270 2275 2280
Val Gln Arg His Val Pro Thr Ile Arg Cys Gln Pro Ser Gly His
2285 2290 2295
Trp Glu Lys Pro Arg Ile Thr Cys Thr Asp Pro Ser Thr Tyr Lys
2300 2305 2310
Arg Arg Leu Gln Lys Arg Ser Ser Arg Ala Pro Arg Arg Ser Arg
2315 2320 2325
Pro Ser Thr Ala His
2330
<210> 127
<211> 2364
<212> PRT
<213> Bos taurus
<400> 127
Met Thr Thr Leu Leu Leu Val Phe Val Thr Leu Arg Val Ile Thr Ala
1 5 10 15
Ala Ile Ser Val Glu Val Ser Glu Pro Asp Asn Ser Leu Ser Val Ser
20 25 30
Ile Pro Glu Pro Ser Pro Leu Arg Val Leu Leu Gly Ser Ser Leu Thr
35 40 45
Ile Pro Cys Tyr Phe Ile Asp Pro Met His Pro Val Thr Thr Ala Pro
50 55 60
Ser Thr Ala Pro Leu Ala Pro Arg Ile Lys Trp Ser Arg Ile Ser Lys
65 70 75 80
Glu Lys Glu Val Val Leu Leu Val Ala Thr Glu Gly Arg Val Arg Val
85 90 95
Asn Ser Ala Tyr Gln Asp Lys Val Thr Leu Pro Asn Tyr Pro Ala Ile
100 105 110
Pro Ser Asp Ala Thr Leu Glu Ile Gln Asn Met Arg Ser Asn Asp Ser
115 120 125
Gly Ile Leu Arg Cys Glu Val Met His Gly Ile Glu Asp Ser Gln Ala
130 135 140
Thr Leu Glu Val Val Val Lys Gly Ile Val Phe His Tyr Arg Ala Ile
145 150 155 160
Ser Thr Arg Tyr Thr Leu Asp Phe Asp Arg Ala Gln Arg Ala Cys Leu
165 170 175
Gln Asn Ser Ala Ile Ile Ala Thr Pro Glu Gln Leu Gln Ala Ala Tyr
180 185 190
Glu Asp Gly Phe His Gln Cys Asp Ala Gly Trp Leu Ala Asp Gln Thr
195 200 205
Val Arg Tyr Pro Ile His Thr Pro Arg Glu Gly Cys Tyr Gly Asp Lys
210 215 220
Asp Glu Phe Pro Gly Val Arg Thr Tyr Gly Ile Arg Asp Thr Asn Glu
225 230 235 240
Thr Tyr Asp Val Tyr Cys Phe Ala Glu Glu Met Glu Gly Glu Val Phe
245 250 255
Tyr Ala Thr Ser Pro Glu Lys Phe Thr Phe Gln Glu Ala Ala Asn Glu
260 265 270
Cys Arg Arg Leu Gly Ala Arg Leu Ala Thr Thr Gly Gln Leu Tyr Leu
275 280 285
Ala Trp Gln Gly Gly Met Asp Met Cys Ser Ala Gly Trp Leu Ala Asp
290 295 300
Arg Ser Val Arg Tyr Pro Ile Ser Lys Ala Arg Pro Asn Cys Gly Gly
305 310 315 320
Asn Leu Leu Gly Val Arg Thr Val Tyr Leu His Ala Asn Gln Thr Gly
325 330 335
Tyr Pro Asp Pro Ser Ser Arg Tyr Asp Ala Ile Cys Tyr Thr Gly Glu
340 345 350
Asp Phe Val Asp Ile Pro Glu Ser Phe Phe Gly Val Gly Gly Glu Glu
355 360 365
Asp Ile Thr Ile Gln Thr Val Thr Trp Pro Asp Val Glu Leu Pro Leu
370 375 380
Pro Arg Asn Ile Thr Glu Gly Glu Ala Arg Gly Ser Val Ile Leu Thr
385 390 395 400
Ala Lys Pro Asp Phe Glu Val Ser Pro Thr Ala Pro Glu Pro Glu Glu
405 410 415
Pro Phe Thr Phe Val Pro Glu Val Arg Ala Thr Ala Phe Pro Glu Val
420 425 430
Glu Asn Arg Thr Glu Glu Ala Thr Arg Pro Trp Ala Phe Pro Arg Glu
435 440 445
Ser Thr Pro Gly Leu Gly Ala Pro Thr Ala Phe Thr Ser Glu Asp Leu
450 455 460
Val Val Gln Val Thr Leu Ala Pro Gly Ala Ala Glu Val Pro Gly Gln
465 470 475 480
Pro Arg Leu Pro Gly Gly Val Val Phe His Tyr Arg Pro Gly Ser Ser
485 490 495
Arg Tyr Ser Leu Thr Phe Glu Glu Ala Lys Gln Ala Cys Leu Arg Thr
500 505 510
Gly Ala Ile Ile Ala Ser Pro Glu Gln Leu Gln Ala Ala Tyr Glu Ala
515 520 525
Gly Tyr Glu Gln Cys Asp Ala Gly Trp Leu Gln Asp Gln Thr Val Arg
530 535 540
Tyr Pro Ile Val Ser Pro Arg Thr Pro Cys Val Gly Asp Lys Asp Ser
545 550 555 560
Ser Pro Gly Val Arg Thr Tyr Gly Val Arg Pro Pro Ser Glu Thr Tyr
565 570 575
Asp Val Tyr Cys Tyr Val Asp Arg Leu Glu Gly Glu Val Phe Phe Ala
580 585 590
Thr Arg Leu Glu Gln Phe Thr Phe Trp Glu Ala Gln Glu Phe Cys Glu
595 600 605
Ser Gln Asn Ala Thr Leu Ala Thr Thr Gly Gln Leu Tyr Ala Ala Trp
610 615 620
Ser Arg Gly Leu Asp Lys Cys Tyr Ala Gly Trp Leu Ala Asp Gly Ser
625 630 635 640
Leu Arg Tyr Pro Ile Val Thr Pro Arg Pro Ala Cys Gly Gly Asp Lys
645 650 655
Pro Gly Val Arg Thr Val Tyr Leu Tyr Pro Asn Gln Thr Gly Leu Leu
660 665 670
Asp Pro Leu Ser Arg His His Ala Phe Cys Phe Arg Gly Val Ser Ala
675 680 685
Ala Pro Ser Pro Glu Glu Glu Glu Gly Ser Ala Pro Thr Ala Gly Pro
690 695 700
Asp Val Glu Glu Trp Met Val Thr Gln Val Gly Pro Gly Val Ala Ala
705 710 715 720
Val Pro Ile Gly Glu Glu Thr Thr Ala Ile Pro Gly Phe Thr Val Glu
725 730 735
Pro Glu Asn Lys Thr Glu Trp Glu Leu Ala Tyr Thr Pro Ala Gly Thr
740 745 750
Leu Pro Leu Pro Gly Ile Pro Pro Thr Trp Pro Pro Thr Gly Glu Ala
755 760 765
Thr Glu Glu His Thr Glu Gly Pro Ser Ala Thr Glu Val Pro Ser Ala
770 775 780
Ser Glu Lys Pro Phe Pro Ser Glu Glu Pro Phe Pro Pro Glu Glu Pro
785 790 795 800
Phe Pro Ser Glu Lys Pro Phe Pro Pro Glu Glu Leu Phe Pro Ser Glu
805 810 815
Lys Pro Phe Pro Ser Glu Lys Pro Phe Pro Ser Glu Glu Pro Phe Pro
820 825 830
Ser Glu Lys Pro Phe Pro Pro Glu Glu Leu Phe Pro Ser Glu Lys Pro
835 840 845
Ile Pro Ser Glu Glu Pro Phe Pro Ser Glu Glu Pro Phe Pro Ser Glu
850 855 860
Lys Pro Phe Pro Pro Glu Glu Pro Phe Pro Ser Glu Lys Pro Ile Pro
865 870 875 880
Ser Glu Glu Pro Phe Pro Ser Glu Lys Pro Phe Pro Ser Glu Glu Pro
885 890 895
Phe Pro Ser Glu Glu Pro Ser Thr Leu Ser Ala Pro Val Pro Ser Arg
900 905 910
Thr Glu Leu Pro Ser Ser Gly Glu Val Ser Gly Val Pro Glu Ile Ser
915 920 925
Gly Asp Phe Thr Gly Ser Gly Glu Ile Ser Gly His Leu Asp Phe Ser
930 935 940
Gly Gln Pro Ser Gly Glu Ser Ala Ser Gly Leu Pro Ser Glu Asp Leu
945 950 955 960
Asp Ser Ser Gly Leu Thr Ser Thr Val Gly Ser Gly Leu Pro Val Glu
965 970 975
Ser Gly Leu Pro Ser Gly Glu Glu Glu Arg Ile Thr Trp Thr Ser Ala
980 985 990
Pro Lys Val Asp Arg Leu Pro Ser Gly Gly Glu Gly Pro Glu Val Ser
995 1000 1005
Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly Gly Glu Val His
1010 1015 1020
Leu Glu Ile Ser Ala Ser Gly Val Glu Asp Ile Ser Gly Leu Pro
1025 1030 1035
Ser Gly Gly Glu Val His Leu Glu Ile Ser Ala Ser Gly Val Glu
1040 1045 1050
Asp Leu Ser Arg Ile Pro Ser Gly Glu Gly Pro Glu Ile Ser Ala
1055 1060 1065
Ser Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu Glu Gly
1070 1075 1080
His Leu Glu Ile Ser Ala Ser Gly Val Glu Asp Leu Ser Gly Ile
1085 1090 1095
Pro Ser Gly Glu Gly Pro Glu Val Ser Ala Ser Gly Val Glu Asp
1100 1105 1110
Leu Ile Gly Leu Pro Ser Gly Glu Gly Pro Glu Val Ser Ala Ser
1115 1120 1125
Gly Val Glu Asp Leu Ser Arg Leu Pro Ser Gly Glu Gly Pro Glu
1130 1135 1140
Val Ser Ala Ser Gly Val Glu Asp Leu Ser Gly Leu Pro Ser Gly
1145 1150 1155
Glu Gly Pro Glu Val Ser Val Ser Gly Val Glu Asp Leu Ser Arg
1160 1165 1170
Leu Pro Ser Gly Glu Gly Pro Glu Val Ser Ala Ser Gly Val Glu
1175 1180 1185
Asp Leu Ser Arg Leu Pro Ser Gly Glu Gly Pro Glu Ile Ser Val
1190 1195 1200
Ser Gly Val Glu Asp Ile Ser Ile Leu Pro Ser Gly Glu Gly Pro
1205 1210 1215
Glu Val Ser Ala Ser Gly Val Glu Asp Leu Ser Val Leu Pro Ser
1220 1225 1230
Gly Glu Gly His Leu Glu Ile Ser Thr Ser Gly Val Glu Asp Leu
1235 1240 1245
Ser Val Leu Pro Ser Gly Glu Gly His Leu Glu Thr Ser Ser Gly
1250 1255 1260
Val Glu Asp Ile Ser Arg Leu Pro Ser Gly Glu Gly Pro Glu Val
1265 1270 1275
Ser Ala Ser Gly Val Glu Asp Leu Ser Val Leu Pro Ser Gly Glu
1280 1285 1290
Asp His Leu Glu Ile Ser Ala Ser Gly Val Glu Asp Leu Gly Val
1295 1300 1305
Leu Pro Ser Gly Glu Asp His Leu Glu Ile Ser Ala Ser Gly Val
1310 1315 1320
Glu Asp Ile Ser Arg Leu Pro Ser Gly Glu Gly Pro Glu Val Ser
1325 1330 1335
Ala Ser Gly Val Glu Asp Leu Ser Val Leu Pro Ser Gly Glu Gly
1340 1345 1350
His Leu Glu Ile Ser Ala Ser Gly Val Glu Asp Leu Ser Arg Leu
1355 1360 1365
Pro Ser Gly Gly Glu Asp His Leu Glu Thr Ser Ala Ser Gly Val
1370 1375 1380
Gly Asp Leu Ser Gly Leu Pro Ser Gly Arg Glu Gly Leu Glu Ile
1385 1390 1395
Ser Ala Ser Gly Ala Gly Asp Leu Ser Gly Leu Thr Ser Gly Lys
1400 1405 1410
Glu Asp Leu Thr Gly Ser Ala Ser Gly Ala Leu Asp Leu Gly Arg
1415 1420 1425
Ile Pro Ser Val Thr Leu Gly Ser Gly Gln Ala Pro Glu Ala Ser
1430 1435 1440
Gly Leu Pro Ser Gly Phe Ser Gly Glu Tyr Ser Gly Val Asp Leu
1445 1450 1455
Glu Ser Gly Pro Ser Ser Gly Leu Pro Asp Phe Ser Gly Leu Pro
1460 1465 1470
Ser Gly Phe Pro Thr Val Ser Leu Val Asp Thr Thr Leu Val Glu
1475 1480 1485
Val Val Thr Ala Thr Thr Ala Gly Glu Leu Glu Gly Arg Gly Thr
1490 1495 1500
Ile Asp Ile Ser Gly Ala Gly Glu Thr Ser Gly Leu Pro Phe Ser
1505 1510 1515
Glu Leu Asp Ile Ser Gly Gly Ala Ser Gly Leu Ser Ser Gly Ala
1520 1525 1530
Glu Leu Ser Gly Gln Ala Ser Gly Ser Pro Asp Ile Ser Gly Glu
1535 1540 1545
Thr Ser Gly Leu Phe Gly Val Ser Gly Gln Pro Ser Gly Phe Pro
1550 1555 1560
Asp Ile Ser Gly Glu Thr Ser Gly Leu Leu Glu Val Ser Gly Gln
1565 1570 1575
Pro Ser Gly Phe Tyr Gly Glu Ile Ser Gly Val Thr Glu Leu Ser
1580 1585 1590
Gly Leu Ala Ser Gly Gln Pro Glu Ile Ser Gly Glu Ala Ser Gly
1595 1600 1605
Ile Leu Ser Gly Leu Gly Pro Pro Phe Gly Ile Thr Asp Leu Ser
1610 1615 1620
Gly Glu Ala Pro Gly Ile Pro Asp Leu Ser Gly Gln Pro Ser Gly
1625 1630 1635
Leu Pro Glu Phe Ser Gly Thr Ala Ser Gly Ile Pro Asp Leu Val
1640 1645 1650
Ser Ser Ala Val Ser Gly Ser Gly Glu Ser Ser Gly Ile Thr Phe
1655 1660 1665
Val Asp Thr Ser Leu Val Glu Val Thr Pro Thr Thr Phe Lys Glu
1670 1675 1680
Glu Glu Gly Leu Gly Ser Val Glu Leu Ser Gly Leu Pro Ser Gly
1685 1690 1695
Glu Leu Gly Val Ser Gly Thr Ser Gly Leu Ala Asp Val Ser Gly
1700 1705 1710
Leu Ser Ser Gly Ala Ile Asp Ser Ser Gly Phe Thr Ser Gln Pro
1715 1720 1725
Pro Glu Phe Ser Gly Leu Pro Ser Gly Val Thr Glu Val Ser Gly
1730 1735 1740
Glu Ala Ser Gly Ala Glu Ser Gly Ser Ser Leu Pro Ser Gly Ala
1745 1750 1755
Tyr Asp Ser Ser Gly Leu Pro Ser Gly Phe Pro Thr Val Ser Phe
1760 1765 1770
Val Asp Arg Thr Leu Val Glu Ser Val Thr Gln Ala Pro Thr Ala
1775 1780 1785
Gln Glu Ala Gly Glu Gly Pro Ser Gly Ile Leu Glu Leu Ser Gly
1790 1795 1800
Ala Pro Ser Gly Ala Pro Asp Met Ser Gly Asp His Leu Gly Ser
1805 1810 1815
Leu Asp Gln Ser Gly Leu Gln Ser Gly Leu Val Glu Pro Ser Gly
1820 1825 1830
Glu Pro Ala Ser Thr Pro Tyr Phe Ser Gly Asp Phe Ser Gly Thr
1835 1840 1845
Thr Asp Val Ser Gly Glu Ser Ser Ala Ala Thr Ser Thr Ser Gly
1850 1855 1860
Glu Ala Ser Gly Leu Pro Glu Val Thr Leu Ile Thr Ser Glu Leu
1865 1870 1875
Val Glu Gly Val Thr Glu Pro Thr Val Ser Gln Glu Leu Gly Gln
1880 1885 1890
Arg Pro Pro Val Thr Tyr Thr Pro Gln Leu Phe Glu Ser Ser Gly
1895 1900 1905
Glu Ala Ser Ala Ser Gly Asp Val Pro Arg Phe Pro Gly Ser Gly
1910 1915 1920
Val Glu Val Ser Ser Val Pro Glu Ser Ser Gly Glu Thr Ser Ala
1925 1930 1935
Tyr Pro Glu Ala Glu Val Gly Ala Ser Ala Ala Pro Glu Ala Ser
1940 1945 1950
Gly Gly Ala Ser Gly Ser Pro Asn Leu Ser Glu Thr Thr Ser Thr
1955 1960 1965
Phe His Glu Ala Asp Leu Glu Gly Thr Ser Gly Leu Gly Val Ser
1970 1975 1980
Gly Ser Pro Ser Ala Phe Pro Glu Gly Pro Thr Glu Gly Leu Ala
1985 1990 1995
Thr Pro Glu Val Ser Gly Glu Ser Thr Thr Ala Phe Asp Val Ser
2000 2005 2010
Val Glu Ala Ser Gly Ser Pro Ser Ala Thr Pro Leu Ala Ser Gly
2015 2020 2025
Asp Arg Thr Asp Thr Ser Gly Asp Leu Ser Gly His Thr Ser Gly
2030 2035 2040
Leu Asp Ile Val Ile Ser Thr Thr Ile Pro Glu Ser Glu Trp Thr
2045 2050 2055
Gln Gln Thr Gln Arg Pro Ala Glu Ala Arg Leu Glu Ile Glu Ser
2060 2065 2070
Ser Ser Pro Val His Ser Gly Glu Glu Ser Gln Thr Ala Asp Thr
2075 2080 2085
Ala Thr Ser Pro Thr Asp Ala Ser Ile Pro Ala Ser Ala Gly Gly
2090 2095 2100
Thr Asp Asp Ser Glu Ala Thr Thr Thr Asp Ile Asp Glu Cys Leu
2105 2110 2115
Ser Ser Pro Cys Leu Asn Gly Ala Thr Cys Val Asp Ala Ile Asp
2120 2125 2130
Ser Phe Thr Cys Leu Cys Leu Pro Ser Tyr Gln Gly Asp Val Cys
2135 2140 2145
Glu Ile Gln Lys Leu Cys Glu Glu Gly Trp Thr Lys Phe Gln Gly
2150 2155 2160
His Cys Tyr Arg His Phe Pro Asp Arg Ala Thr Trp Val Asp Ala
2165 2170 2175
Glu Ser Gln Cys Arg Lys Gln Gln Ser His Leu Ser Ser Ile Val
2180 2185 2190
Thr Pro Glu Glu Gln Glu Phe Val Asn Asn Asn Ala Gln Asp Tyr
2195 2200 2205
Gln Trp Ile Gly Leu Asn Asp Lys Thr Ile Glu Gly Asp Phe Arg
2210 2215 2220
Trp Ser Asp Gly His Ser Leu Gln Phe Glu Asn Trp Arg Pro Asn
2225 2230 2235
Gln Pro Asp Asn Phe Phe Ala Thr Gly Glu Asp Cys Val Val Met
2240 2245 2250
Ile Trp His Glu Lys Gly Glu Trp Asn Asp Val Pro Cys Asn Tyr
2255 2260 2265
Gln Leu Pro Phe Thr Cys Lys Lys Gly Thr Val Ala Cys Gly Glu
2270 2275 2280
Pro Pro Val Val Glu His Ala Arg Ile Phe Gly Gln Lys Lys Asp
2285 2290 2295
Arg Tyr Glu Ile Asn Ala Leu Val Arg Tyr Gln Cys Thr Glu Gly
2300 2305 2310
Phe Ile Gln Gly His Val Pro Thr Ile Arg Cys Gln Pro Ser Gly
2315 2320 2325
His Trp Glu Glu Pro Arg Ile Thr Cys Thr Asp Pro Ala Thr Tyr
2330 2335 2340
Lys Arg Arg Leu Gln Lys Arg Ser Ser Arg Pro Leu Arg Arg Ser
2345 2350 2355
His Pro Ser Thr Ala His
2360
<210> 128
<211> 2124
<212> PRT
<213> Rattus norvegicus
<400> 128
Met Thr Thr Leu Leu Leu Val Phe Val Thr Leu Arg Val Ile Ala Ala
1 5 10 15
Val Ile Ser Glu Glu Val Pro Asp His Asp Asn Ser Leu Ser Val Ser
20 25 30
Ile Pro Gln Pro Ser Pro Leu Lys Ala Leu Leu Gly Thr Ser Leu Thr
35 40 45
Ile Pro Cys Tyr Phe Ile Asp Pro Met His Pro Val Thr Thr Ala Pro
50 55 60
Ser Thr Ala Pro Leu Thr Pro Arg Ile Lys Trp Ser Arg Val Ser Lys
65 70 75 80
Glu Lys Glu Val Val Leu Leu Val Ala Thr Glu Gly Gln Val Arg Val
85 90 95
Asn Ser Ile Tyr Gln Asp Lys Val Ser Leu Pro Asn Tyr Pro Ala Ile
100 105 110
Pro Ser Asp Ala Thr Leu Glu Ile Gln Asn Leu Arg Ser Asn Asp Ser
115 120 125
Gly Ile Tyr Arg Cys Glu Val Met His Gly Ile Glu Asp Ser Glu Ala
130 135 140
Thr Leu Glu Val Ile Val Lys Gly Ile Val Phe His Tyr Arg Ala Ile
145 150 155 160
Ser Thr Arg Tyr Thr Leu Asp Phe Asp Arg Ala Gln Arg Ala Cys Leu
165 170 175
Gln Asn Ser Ala Ile Ile Ala Thr Pro Glu Gln Leu Gln Ala Ala Tyr
180 185 190
Glu Asp Gly Phe His Gln Cys Asp Ala Gly Trp Leu Ala Asp Gln Thr
195 200 205
Val Arg Tyr Pro Ile His Thr Pro Arg Glu Gly Cys Tyr Gly Asp Lys
210 215 220
Asp Glu Phe Pro Gly Val Arg Thr Tyr Gly Ile Arg Asp Thr Asn Glu
225 230 235 240
Thr Tyr Asp Val Tyr Cys Phe Ala Glu Glu Met Glu Gly Glu Val Phe
245 250 255
Tyr Ala Thr Ser Pro Glu Lys Phe Thr Phe Gln Glu Ala Ala Asn Glu
260 265 270
Cys Arg Thr Val Gly Ala Arg Leu Ala Thr Thr Gly Gln Leu Tyr Leu
275 280 285
Ala Trp Gln Gly Gly Met Asp Met Cys Ser Ala Gly Trp Leu Ala Asp
290 295 300
Arg Ser Val Arg Tyr Pro Ile Ser Lys Ala Arg Pro Asn Cys Gly Gly
305 310 315 320
Asn Leu Leu Gly Val Arg Thr Val Tyr Leu His Ala Asn Gln Thr Gly
325 330 335
Tyr Pro Asp Pro Ser Ser Arg Tyr Asp Ala Ile Cys Tyr Thr Gly Glu
340 345 350
Asp Phe Val Asp Ile Pro Glu Asn Phe Phe Gly Val Gly Gly Glu Glu
355 360 365
Asp Ile Thr Ile Gln Thr Val Thr Trp Pro Asp Leu Glu Leu Pro Leu
370 375 380
Pro Arg Asn Ile Thr Glu Gly Glu Ala Arg Gly Asn Val Ile Leu Thr
385 390 395 400
Ala Lys Pro Ile Phe Asp Met Ser Pro Thr Val Ser Glu Pro Gly Glu
405 410 415
Ala Leu Thr Leu Ala Pro Glu Val Gly Thr Thr Val Phe Pro Glu Ala
420 425 430
Gly Glu Arg Thr Glu Lys Thr Thr Arg Pro Trp Gly Phe Pro Glu Glu
435 440 445
Ala Thr Arg Gly Pro Asp Ser Ala Thr Ala Phe Ala Ser Glu Asp Leu
450 455 460
Val Val Arg Val Thr Ile Ser Pro Gly Ala Val Glu Val Pro Gly Gln
465 470 475 480
Pro Arg Leu Pro Gly Gly Val Val Phe His Tyr Arg Pro Gly Ser Thr
485 490 495
Arg Tyr Ser Leu Thr Phe Glu Glu Ala Gln Gln Ala Cys Ile Arg Thr
500 505 510
Gly Ala Ala Ile Ala Ser Pro Glu Gln Leu Gln Ala Ala Tyr Glu Ala
515 520 525
Gly Tyr Glu Gln Cys Asp Ala Gly Trp Leu Gln Asp Gln Thr Val Arg
530 535 540
Tyr Pro Ile Val Ser Pro Arg Thr Pro Cys Val Gly Asp Lys Asp Ser
545 550 555 560
Ser Pro Gly Val Arg Thr Tyr Gly Val Arg Pro Ser Ser Glu Thr Tyr
565 570 575
Asp Val Tyr Cys Tyr Val Asp Lys Leu Glu Gly Glu Val Phe Phe Ala
580 585 590
Thr Gln Met Glu Gln Phe Thr Phe Gln Glu Ala Gln Ala Phe Cys Ala
595 600 605
Ala Gln Asn Ala Thr Leu Ala Ser Thr Gly Gln Leu Tyr Ala Ala Trp
610 615 620
Ser Gln Gly Leu Asp Lys Cys Tyr Ala Gly Trp Leu Ala Asp Gly Thr
625 630 635 640
Leu Arg Tyr Pro Ile Val Asn Pro Arg Pro Ala Cys Gly Gly Asp Lys
645 650 655
Pro Gly Val Arg Thr Val Tyr Leu Tyr Pro Asn Gln Thr Gly Leu Pro
660 665 670
Asp Pro Leu Ser Lys His His Ala Phe Cys Phe Arg Gly Val Ser Val
675 680 685
Val Pro Ser Pro Gly Gly Thr Pro Thr Ser Pro Ser Asp Ile Glu Asp
690 695 700
Trp Ile Val Thr Arg Val Glu Pro Gly Val Asp Ala Val Pro Leu Glu
705 710 715 720
Pro Glu Thr Thr Glu Val Pro Tyr Phe Thr Thr Glu Pro Glu Lys Gln
725 730 735
Thr Glu Trp Glu Pro Ala Tyr Thr Pro Val Gly Thr Ser Pro Leu Pro
740 745 750
Gly Ile Pro Pro Thr Trp Leu Pro Thr Val Pro Ala Ala Glu Glu His
755 760 765
Thr Glu Ser Pro Ser Ala Ser Gln Glu Pro Ser Ala Ser Gln Val Pro
770 775 780
Ser Thr Ser Glu Glu Pro Tyr Thr Pro Ser Leu Ala Val Pro Ser Gly
785 790 795 800
Thr Glu Leu Pro Ser Ser Gly Asp Thr Ser Gly Ala Pro Asp Leu Ser
805 810 815
Gly Asp Phe Thr Gly Ser Thr Asp Thr Ser Gly Arg Leu Asp Ser Ser
820 825 830
Gly Glu Pro Ser Gly Gly Ser Glu Ser Gly Leu Pro Ser Gly Asp Leu
835 840 845
Asp Ser Ser Gly Leu Gly Pro Thr Val Ser Ser Gly Leu Pro Val Glu
850 855 860
Ser Gly Ser Ala Ser Gly Asp Gly Glu Ile Pro Trp Ser Ser Thr Pro
865 870 875 880
Thr Val Asp Arg Leu Pro Ser Gly Gly Glu Ser Leu Glu Gly Ser Ala
885 890 895
Ser Ala Ser Gly Thr Gly Asp Leu Ser Gly Leu Pro Ser Gly Gly Glu
900 905 910
Ile Thr Glu Thr Ser Ala Ser Gly Thr Glu Glu Ile Ser Gly Leu Pro
915 920 925
Ser Gly Gly Asp Asp Leu Glu Thr Ser Thr Ser Gly Ile Asp Gly Ala
930 935 940
Ser Val Leu Pro Thr Gly Arg Gly Gly Leu Glu Thr Ser Ala Ser Gly
945 950 955 960
Val Glu Asp Leu Ser Gly Leu Pro Ser Gly Glu Glu Gly Ser Glu Thr
965 970 975
Ser Thr Ser Gly Ile Glu Asp Ile Ser Val Leu Pro Thr Gly Glu Ser
980 985 990
Pro Glu Thr Ser Ala Ser Gly Val Gly Asp Leu Ser Gly Leu Pro Ser
995 1000 1005
Gly Gly Glu Ser Leu Glu Thr Ser Ala Ser Gly Val Glu Asp Val
1010 1015 1020
Thr Gln Leu Pro Thr Glu Arg Gly Gly Leu Glu Thr Ser Ala Ser
1025 1030 1035
Gly Ile Glu Asp Ile Thr Val Leu Pro Thr Gly Arg Glu Asn Leu
1040 1045 1050
Glu Thr Ser Ala Ser Gly Val Glu Asp Val Ser Gly Leu Pro Ser
1055 1060 1065
Gly Lys Glu Gly Leu Glu Thr Ser Ala Ser Gly Ile Glu Asp Ile
1070 1075 1080
Ser Val Phe Pro Thr Glu Ala Glu Gly Leu Glu Thr Ser Ala Ser
1085 1090 1095
Gly Gly Tyr Val Ser Gly Ile Pro Ser Gly Glu Asp Gly Thr Glu
1100 1105 1110
Thr Ser Thr Ser Gly Val Glu Gly Val Ser Gly Leu Pro Ser Gly
1115 1120 1125
Gly Glu Gly Leu Glu Thr Ser Ala Ser Gly Val Glu Asp Leu Gly
1130 1135 1140
Leu Pro Thr Arg Asp Ser Leu Glu Thr Ser Ala Ser Gly Val Asp
1145 1150 1155
Val Thr Gly Tyr Pro Ser Gly Arg Glu Asp Thr Glu Thr Ser Val
1160 1165 1170
Pro Gly Val Gly Asp Asp Leu Ser Gly Leu Pro Ser Gly Gln Glu
1175 1180 1185
Gly Leu Glu Thr Ser Ala Ser Gly Ala Glu Asp Leu Gly Gly Leu
1190 1195 1200
Pro Ser Gly Lys Glu Asp Leu Val Gly Ser Ala Ser Gly Ala Leu
1205 1210 1215
Asp Phe Gly Lys Leu Pro Ser Gly Thr Leu Gly Ser Gly Gln Thr
1220 1225 1230
Pro Glu Ala Ser Gly Leu Pro Ser Gly Phe Ser Gly Glu Tyr Ser
1235 1240 1245
Gly Val Asp Ile Gly Ser Gly Pro Ser Ser Gly Leu Pro Asp Phe
1250 1255 1260
Ser Gly Leu Pro Ser Gly Phe Pro Thr Val Ser Leu Val Asp Ser
1265 1270 1275
Thr Leu Val Glu Val Ile Thr Ala Thr Thr Ala Ser Glu Leu Glu
1280 1285 1290
Gly Arg Gly Thr Ile Ser Val Ser Gly Ser Gly Glu Glu Ser Gly
1295 1300 1305
Pro Pro Leu Ser Glu Leu Asp Ser Ser Ala Asp Ile Ser Gly Leu
1310 1315 1320
Pro Ser Gly Thr Glu Leu Ser Gly Gln Thr Ser Gly Ser Leu Asp
1325 1330 1335
Val Ser Gly Glu Thr Ser Gly Phe Phe Asp Val Ser Gly Gln Pro
1340 1345 1350
Phe Gly Ser Ser Gly Thr Gly Glu Gly Thr Ser Gly Ile Pro Glu
1355 1360 1365
Val Ser Gly Gln Ala Val Arg Ser Pro Asp Thr Thr Glu Ile Ser
1370 1375 1380
Glu Leu Ser Gly Leu Ser Ser Gly Gln Pro Asp Val Ser Gly Glu
1385 1390 1395
Gly Ser Gly Ile Leu Phe Gly Ser Gly Gln Ser Ser Gly Ile Thr
1400 1405 1410
Ser Val Ser Gly Glu Thr Ser Gly Ile Ser Asp Leu Ser Gly Gln
1415 1420 1425
Pro Ser Gly Phe Pro Val Leu Ser Gly Thr Thr Pro Gly Thr Pro
1430 1435 1440
Asp Leu Ala Ser Gly Ala Met Ser Gly Ser Gly Asp Ser Ser Gly
1445 1450 1455
Ile Thr Phe Val Asp Thr Ser Leu Ile Glu Val Thr Pro Thr Thr
1460 1465 1470
Phe Arg Glu Glu Glu Gly Leu Gly Ser Val Glu Leu Ser Gly Leu
1475 1480 1485
Pro Ser Gly Glu Thr Asp Leu Ser Gly Thr Ser Gly Met Val Asp
1490 1495 1500
Val Ser Gly Gln Ser Ser Gly Ala Ile Asp Ser Ser Gly Leu Ile
1505 1510 1515
Ser Pro Thr Pro Glu Phe Ser Gly Leu Pro Ser Gly Val Ala Glu
1520 1525 1530
Val Ser Gly Glu Val Ser Gly Val Glu Thr Gly Ser Ser Leu Ser
1535 1540 1545
Ser Gly Ala Phe Asp Gly Ser Gly Leu Val Ser Gly Phe Pro Thr
1550 1555 1560
Val Ser Leu Val Asp Arg Thr Leu Val Glu Ser Ile Thr Leu Ala
1565 1570 1575
Pro Thr Ala Gln Glu Ala Gly Glu Gly Pro Ser Ser Ile Leu Glu
1580 1585 1590
Phe Ser Gly Ala His Ser Gly Thr Pro Asp Ile Ser Gly Asp Leu
1595 1600 1605
Ser Gly Ser Leu Asp Gln Ser Thr Trp Gln Pro Gly Trp Thr Glu
1610 1615 1620
Ala Ser Thr Glu Pro Pro Ser Ser Pro Tyr Phe Ser Gly Asp Phe
1625 1630 1635
Ser Ser Thr Thr Asp Ala Ser Gly Glu Ser Ile Thr Ala Pro Thr
1640 1645 1650
Gly Ser Gly Glu Thr Ser Gly Leu Pro Glu Val Thr Leu Ile Thr
1655 1660 1665
Ser Glu Leu Val Glu Gly Val Thr Glu Pro Thr Val Ser Gln Glu
1670 1675 1680
Leu Gly His Gly Pro Ser Met Thr Tyr Thr Pro Arg Leu Phe Glu
1685 1690 1695
Ala Ser Gly Glu Ala Ser Ala Ser Gly Asp Leu Gly Gly Pro Val
1700 1705 1710
Thr Ile Phe Pro Gly Ser Gly Val Glu Ala Ser Val Pro Glu Gly
1715 1720 1725
Ser Ser Asp Pro Ser Ala Tyr Pro Glu Ala Gly Val Gly Val Ser
1730 1735 1740
Ala Ala Pro Glu Ala Ser Ser Gln Leu Ser Glu Phe Pro Asp Leu
1745 1750 1755
His Gly Ile Thr Ser Ala Ser Arg Glu Thr Asp Leu Glu Met Thr
1760 1765 1770
Thr Pro Gly Thr Glu Val Ser Ser Asn Pro Trp Thr Phe Gln Glu
1775 1780 1785
Gly Thr Arg Glu Gly Ser Ala Ala Pro Glu Val Ser Gly Glu Ser
1790 1795 1800
Ser Thr Thr Ser Asp Ile Asp Ala Gly Thr Ser Gly Val Pro Phe
1805 1810 1815
Ala Thr Pro Met Thr Ser Gly Asp Arg Thr Glu Ile Ser Gly Glu
1820 1825 1830
Trp Ser Asp His Thr Ser Glu Val Asn Val Thr Val Ser Thr Thr
1835 1840 1845
Val Pro Glu Ser Arg Trp Ala Gln Ser Thr Gln His Pro Thr Glu
1850 1855 1860
Thr Leu Gln Glu Ile Gly Ser Pro Asn Pro Ser Tyr Ser Gly Glu
1865 1870 1875
Glu Thr Gln Thr Ala Glu Thr Ala Lys Ser Leu Thr Asp Thr Pro
1880 1885 1890
Thr Leu Ala Ser Pro Glu Gly Ser Gly Glu Thr Glu Ser Thr Ala
1895 1900 1905
Ala Asp Gln Glu Gln Cys Glu Glu Gly Trp Thr Lys Phe Gln Gly
1910 1915 1920
His Cys Tyr Arg His Phe Pro Asp Arg Glu Thr Trp Val Asp Ala
1925 1930 1935
Glu Arg Arg Cys Arg Glu Gln Gln Ser His Leu Ser Ser Ile Val
1940 1945 1950
Thr Pro Glu Glu Gln Glu Phe Val Asn Lys Asn Ala Gln Asp Tyr
1955 1960 1965
Gln Trp Ile Gly Leu Asn Asp Arg Thr Ile Glu Gly Asp Phe Arg
1970 1975 1980
Trp Ser Asp Gly His Ser Leu Gln Phe Glu Lys Trp Arg Pro Asn
1985 1990 1995
Gln Pro Asp Asn Phe Phe Ala Thr Gly Glu Asp Cys Val Val Met
2000 2005 2010
Ile Trp His Glu Arg Gly Glu Trp Asn Asp Val Pro Cys Asn Tyr
2015 2020 2025
Gln Leu Pro Phe Thr Cys Lys Lys Gly Thr Val Ala Cys Gly Glu
2030 2035 2040
Pro Pro Ala Val Glu His Ala Arg Thr Leu Gly Gln Lys Lys Asp
2045 2050 2055
Arg Tyr Glu Ile Ser Ser Leu Val Arg Tyr Gln Cys Thr Glu Gly
2060 2065 2070
Phe Val Gln Arg His Val Pro Thr Ile Arg Cys Gln Pro Ser Ala
2075 2080 2085
Asp Trp Glu Glu Pro Arg Ile Thr Cys Thr Asp Pro Asn Thr Tyr
2090 2095 2100
Lys His Arg Leu Gln Lys Arg Thr Met Arg Pro Thr Arg Arg Ser
2105 2110 2115
Arg Pro Ser Met Ala His
2120
<210> 129
<211> 537
<212> PRT
<213> Sus scrofa
<220>
<221> VARIANT
<222> (45)..(45)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> VARIANT
<222> (49)..(49)
<223> Xaa can be any naturally occurring amino acid
<220>
<221> VARIANT
<222> (146)..(146)
<223> Xaa can be any naturally occurring amino acid
<400> 129
Ala Ile Ser Val Glu Val Ser Glu Pro Asp Asn Ser Leu Ser Val Ser
1 5 10 15
Ile Pro Gln Pro Ser Pro Leu Arg Val Leu Leu Gly Gly Ser Leu Thr
20 25 30
Ile Pro Cys Tyr Phe Ile Asp Pro Met His Pro Val Xaa Thr Ala Pro
35 40 45
Xaa Thr Ala Pro Leu Ala Pro Arg Ile Lys Trp Ser Arg Val Ser Lys
50 55 60
Glu Lys Glu Val Val Leu Leu Val Ala Thr Glu Gly Gln Val Arg Val
65 70 75 80
Asn Ser Ala Tyr Gln Asp Arg Val Thr Leu Pro Asn Tyr Pro Ala Ile
85 90 95
Pro Ser Asp Ala Thr Leu Glu Ile Gln Asn Leu Arg Ser Asn Asp Ser
100 105 110
Gly Ile Tyr Arg Cys Glu Val Met His Gly Ile Glu Asp Ser Glu Ala
115 120 125
Thr Leu Glu Val Val Val Lys Gly Ile Val Phe His Tyr Arg Ala Ile
130 135 140
Ser Xaa Arg Tyr Thr Leu Asp Phe Asp Arg Ala Gln Arg Ala Cys Leu
145 150 155 160
Gln Asn Ser Ala Ile Ile Ala Thr Pro Glu Gln Leu Gln Ala Ala Tyr
165 170 175
Glu Asp Gly Phe His Gln Cys Asp Ala Gly Trp Leu Ala Asp Gln Thr
180 185 190
Val Arg Tyr Pro Ile His Thr Pro Arg Glu Gly Cys Tyr Gly Asp Lys
195 200 205
Asp Glu Phe Pro Gly Val Ile Thr Tyr Gly Ile Arg Asp Thr Asn Glu
210 215 220
Thr Tyr Asp Val Tyr Cys Phe Ala Glu Glu Met Glu Gly Glu Val Phe
225 230 235 240
Tyr Ala Thr Ser Pro Glu Lys Phe Thr Phe Gln Glu Ala Ala Asn Glu
245 250 255
Cys Arg Arg Leu Gly Ala Arg Leu Ala Thr Thr Gly Gln Leu Tyr Leu
260 265 270
Ala Trp Arg Gly Gly Met Asp Met Cys Ser Ala Gly Trp Leu Ala Asp
275 280 285
Arg Ser Val Arg Tyr Pro Ile Ser Lys Ala Arg Pro Asn Cys Gly Gly
290 295 300
Asn Leu Leu Gly Val Arg Thr Val Tyr Leu His Ala Asn Gln Thr Gly
305 310 315 320
Tyr Pro Asp Pro Ser Ser Arg Tyr Asp Ala Ile Cys Tyr Thr Gly Glu
325 330 335
Asp Phe Val Asp Ile Pro Glu Asn Phe Phe Gly Val Gly Gly Glu Glu
340 345 350
Asp Ile Thr Ile Gln Thr Val Thr Trp Pro Asp Val Glu Leu Pro Leu
355 360 365
Pro Arg Asn Ile Thr Glu Gly Glu Ala Arg Gly Thr Val Ile Leu Thr
370 375 380
Val Lys Pro Val Phe Glu Phe Ser Pro Thr Ala Pro Glu Pro Glu Glu
385 390 395 400
Pro Phe Thr Phe Ala Pro Gly Thr Gly Ala Thr Ala Phe Pro Glu Ala
405 410 415
Glu Asn Arg Thr Gly Glu Ala Thr Arg Pro Trp Ala Phe Pro Glu Glu
420 425 430
Ser Thr Pro Gly Leu Gly Ala Pro Thr Ala Phe Thr Ser Glu Asp Leu
435 440 445
Val Val Gln Val Thr Ser Ala Ala Thr Glu Glu Gly Thr Glu Gly Pro
450 455 460
Ser Ala Thr Glu Ala Pro Ser Thr Ser Glu Glu Pro Phe Pro Ser Glu
465 470 475 480
Lys Pro Phe Pro Ser Glu Glu Pro Phe Pro Ser Glu Glu Pro Phe Pro
485 490 495
Ser Glu Lys Pro Ser Ala Ser Glu Glu Pro Phe Pro Ser Glu Gln Pro
500 505 510
Ser Thr Leu Ser Ala Pro Val Pro Ser Arg Thr Glu Leu Pro Gly Ser
515 520 525
Gly Glu Val Ser Gly Ala Pro Glu Val
530 535
<210> 130
<211> 2132
<212> PRT
<213> Mus musculus
<400> 130
Met Thr Thr Leu Leu Leu Val Phe Val Thr Leu Arg Val Ile Ala Ala
1 5 10 15
Val Ile Ser Glu Glu Val Pro Asp His Asp Asn Ser Leu Ser Val Ser
20 25 30
Ile Pro Gln Pro Ser Pro Leu Lys Val Leu Leu Gly Ser Ser Leu Thr
35 40 45
Ile Pro Cys Tyr Phe Ile Asp Pro Met His Pro Val Thr Thr Ala Pro
50 55 60
Ser Thr Ala Pro Leu Thr Pro Arg Ile Lys Trp Ser Arg Val Ser Lys
65 70 75 80
Glu Lys Glu Val Val Leu Leu Val Ala Thr Glu Gly Gln Val Arg Val
85 90 95
Asn Ser Ile Tyr Gln Asp Lys Val Ser Leu Pro Asn Tyr Pro Ala Ile
100 105 110
Pro Ser Asp Ala Thr Leu Glu Ile Gln Asn Leu Arg Ser Asn Asp Ser
115 120 125
Gly Ile Tyr Arg Cys Glu Val Met His Gly Ile Glu Asp Ser Glu Ala
130 135 140
Thr Leu Glu Val Ile Val Lys Gly Ile Val Phe His Tyr Arg Ala Ile
145 150 155 160
Ser Thr Arg Tyr Thr Leu Asp Phe Asp Arg Ala Gln Arg Ala Cys Leu
165 170 175
Gln Asn Ser Ala Ile Ile Ala Thr Pro Glu Gln Leu Gln Ala Ala Tyr
180 185 190
Glu Asp Gly Phe His Gln Cys Asp Ala Gly Trp Leu Ala Asp Gln Thr
195 200 205
Val Arg Tyr Pro Ile His Thr Pro Arg Glu Gly Cys Tyr Gly Asp Lys
210 215 220
Asp Glu Phe Pro Gly Val Arg Thr Tyr Gly Ile Arg Asp Thr Asn Glu
225 230 235 240
Thr Tyr Asp Val Tyr Cys Phe Ala Glu Glu Met Glu Gly Glu Val Phe
245 250 255
Tyr Ala Thr Ser Pro Glu Lys Phe Thr Phe Gln Glu Ala Ala Asn Glu
260 265 270
Cys Arg Arg Leu Gly Ala Arg Leu Ala Thr Thr Gly Gln Leu Tyr Leu
275 280 285
Ala Trp Gln Gly Gly Met Asp Met Cys Ser Ala Gly Trp Leu Ala Asp
290 295 300
Arg Ser Val Arg Tyr Pro Ile Ser Lys Ala Arg Pro Asn Cys Gly Gly
305 310 315 320
Asn Leu Leu Gly Val Arg Thr Val Tyr Leu His Ala Asn Gln Thr Gly
325 330 335
Tyr Pro Asp Pro Ser Ser Arg Tyr Asp Ala Ile Cys Tyr Thr Gly Glu
340 345 350
Asp Phe Val Asp Ile Pro Glu Asn Phe Phe Gly Val Gly Gly Glu Asp
355 360 365
Asp Ile Thr Ile Gln Thr Val Thr Trp Pro Asp Leu Glu Leu Pro Leu
370 375 380
Pro Arg Asn Val Thr Glu Gly Glu Ala Leu Gly Ser Val Ile Leu Thr
385 390 395 400
Ala Lys Pro Ile Phe Asp Leu Ser Pro Thr Ile Ser Glu Pro Gly Glu
405 410 415
Ala Leu Thr Leu Ala Pro Glu Val Gly Ser Thr Ala Phe Pro Glu Ala
420 425 430
Glu Glu Arg Thr Gly Glu Ala Thr Arg Pro Trp Gly Phe Pro Ala Glu
435 440 445
Val Thr Arg Gly Pro Asp Ser Ala Thr Ala Phe Ala Ser Glu Asp Leu
450 455 460
Val Val Arg Val Thr Ile Ser Pro Gly Ala Ala Glu Val Pro Gly Gln
465 470 475 480
Pro Arg Leu Pro Gly Gly Val Val Phe His Tyr Arg Pro Gly Ser Thr
485 490 495
Arg Tyr Ser Leu Thr Phe Glu Glu Ala Gln Gln Ala Cys Met His Thr
500 505 510
Gly Ala Val Ile Ala Ser Pro Glu Gln Leu Gln Ala Ala Tyr Glu Ala
515 520 525
Gly Tyr Glu Gln Cys Asp Ala Gly Trp Leu Gln Asp Gln Thr Val Arg
530 535 540
Tyr Pro Ile Val Ser Pro Arg Thr Pro Cys Val Gly Asp Lys Asp Ser
545 550 555 560
Ser Pro Gly Val Arg Thr Tyr Gly Val Arg Pro Ser Ser Glu Thr Tyr
565 570 575
Asp Val Tyr Cys Tyr Val Asp Lys Leu Glu Gly Glu Val Phe Phe Ala
580 585 590
Thr Arg Leu Glu Gln Phe Thr Phe Gln Glu Ala Arg Ala Phe Cys Ala
595 600 605
Ala Gln Asn Ala Thr Leu Ala Ser Thr Gly Gln Leu Tyr Ala Ala Trp
610 615 620
Ser Gln Gly Leu Asp Lys Cys Tyr Ala Gly Trp Leu Ala Asp Gly Thr
625 630 635 640
Leu Arg Tyr Pro Ile Ile Thr Pro Arg Pro Ala Cys Gly Gly Asp Lys
645 650 655
Pro Gly Val Arg Thr Val Tyr Leu Tyr Pro Asn Gln Thr Gly Leu Pro
660 665 670
Asp Pro Leu Ser Lys His His Ala Phe Cys Phe Arg Gly Val Ser Val
675 680 685
Ala Pro Ser Pro Gly Glu Glu Gly Gly Ser Thr Pro Thr Ser Pro Ser
690 695 700
Asp Ile Glu Asp Trp Ile Val Thr Gln Val Gly Pro Gly Val Asp Ala
705 710 715 720
Val Pro Leu Glu Pro Lys Thr Thr Glu Val Pro Tyr Phe Thr Thr Glu
725 730 735
Pro Arg Lys Gln Thr Glu Trp Glu Pro Ala Tyr Thr Pro Val Gly Thr
740 745 750
Ser Pro Gln Pro Gly Ile Pro Pro Thr Trp Leu Pro Thr Leu Pro Ala
755 760 765
Ala Glu Glu His Thr Glu Ser Pro Ser Ala Ser Glu Glu Pro Ser Ala
770 775 780
Ser Ala Val Pro Ser Thr Ser Glu Glu Pro Tyr Thr Ser Ser Phe Ala
785 790 795 800
Val Pro Ser Met Thr Glu Leu Pro Gly Ser Gly Glu Ala Ser Gly Ala
805 810 815
Pro Asp Leu Ser Gly Asp Phe Thr Gly Ser Gly Asp Ala Ser Gly Arg
820 825 830
Leu Asp Ser Ser Gly Gln Pro Ser Gly Gly Ile Glu Ser Gly Leu Pro
835 840 845
Ser Gly Asp Leu Asp Ser Ser Gly Leu Ser Pro Thr Val Ser Ser Gly
850 855 860
Leu Pro Val Glu Ser Gly Ser Ala Ser Gly Asp Gly Glu Val Pro Trp
865 870 875 880
Ser His Thr Pro Thr Val Gly Arg Leu Pro Ser Gly Gly Glu Ser Pro
885 890 895
Glu Gly Ser Ala Ser Ala Ser Gly Thr Gly Asp Leu Ser Gly Leu Pro
900 905 910
Ser Gly Gly Glu Ile Thr Glu Thr Ser Thr Ser Gly Ala Glu Glu Thr
915 920 925
Ser Gly Leu Pro Ser Gly Gly Asp Gly Leu Glu Thr Ser Thr Ser Gly
930 935 940
Val Asp Asp Val Ser Gly Ile Pro Thr Gly Arg Glu Gly Leu Glu Thr
945 950 955 960
Ser Ala Ser Gly Val Glu Asp Leu Ser Gly Leu Pro Ser Gly Glu Glu
965 970 975
Gly Ser Glu Thr Ser Thr Ser Gly Ile Glu Asp Ile Ser Val Leu Pro
980 985 990
Thr Gly Gly Glu Ser Leu Glu Thr Ser Ala Ser Gly Val Gly Asp Leu
995 1000 1005
Ser Gly Leu Pro Ser Gly Gly Glu Ser Leu Glu Thr Ser Ala Ser
1010 1015 1020
Gly Ala Glu Asp Val Thr Gln Leu Pro Thr Glu Arg Gly Gly Leu
1025 1030 1035
Glu Thr Ser Ala Ser Gly Val Glu Asp Ile Thr Val Leu Pro Thr
1040 1045 1050
Gly Arg Glu Ser Leu Glu Thr Ser Ala Ser Gly Val Glu Asp Val
1055 1060 1065
Ser Gly Leu Pro Ser Gly Arg Glu Gly Leu Glu Thr Ser Ala Ser
1070 1075 1080
Gly Ile Glu Asp Ile Ser Val Phe Pro Thr Glu Ala Glu Gly Leu
1085 1090 1095
Asp Thr Ser Ala Ser Gly Gly Tyr Val Ser Gly Ile Pro Ser Gly
1100 1105 1110
Gly Asp Gly Thr Glu Thr Ser Ala Ser Gly Val Glu Asp Val Ser
1115 1120 1125
Gly Leu Pro Ser Gly Gly Glu Gly Leu Glu Thr Ser Ala Ser Gly
1130 1135 1140
Val Glu Asp Leu Gly Pro Ser Thr Arg Asp Ser Leu Glu Thr Ser
1145 1150 1155
Ala Ser Gly Val Asp Val Thr Gly Phe Pro Ser Gly Arg Gly Asp
1160 1165 1170
Pro Glu Thr Ser Val Ser Gly Val Gly Asp Asp Phe Ser Gly Leu
1175 1180 1185
Pro Ser Gly Lys Glu Gly Leu Glu Thr Ser Ala Ser Gly Ala Glu
1190 1195 1200
Asp Leu Ser Gly Leu Pro Ser Gly Lys Glu Asp Leu Val Gly Ser
1205 1210 1215
Ala Ser Gly Ala Leu Asp Phe Gly Lys Leu Pro Pro Gly Thr Leu
1220 1225 1230
Gly Ser Gly Gln Thr Pro Glu Val Asn Gly Phe Pro Ser Gly Phe
1235 1240 1245
Ser Gly Glu Tyr Ser Gly Ala Asp Ile Gly Ser Gly Pro Ser Ser
1250 1255 1260
Gly Leu Pro Asp Phe Ser Gly Leu Pro Ser Gly Phe Pro Thr Val
1265 1270 1275
Ser Leu Val Asp Ser Thr Leu Val Glu Val Ile Thr Ala Thr Thr
1280 1285 1290
Ser Ser Glu Leu Glu Gly Arg Gly Thr Ile Gly Ile Ser Gly Ser
1295 1300 1305
Gly Glu Val Ser Gly Leu Pro Leu Gly Glu Leu Asp Ser Ser Ala
1310 1315 1320
Asp Ile Ser Gly Leu Pro Ser Gly Thr Glu Leu Ser Gly Gln Ala
1325 1330 1335
Ser Gly Ser Pro Asp Ser Ser Gly Glu Thr Ser Gly Phe Phe Asp
1340 1345 1350
Val Ser Gly Gln Pro Phe Gly Ser Ser Gly Val Ser Glu Glu Thr
1355 1360 1365
Ser Gly Ile Pro Glu Ile Ser Gly Gln Pro Ser Gly Thr Pro Asp
1370 1375 1380
Thr Thr Ala Thr Ser Gly Val Thr Glu Leu Asn Glu Leu Ser Ser
1385 1390 1395
Gly Gln Pro Asp Val Ser Gly Asp Gly Ser Gly Ile Leu Phe Gly
1400 1405 1410
Ser Gly Gln Ser Ser Gly Ile Thr Ser Val Ser Gly Glu Thr Ser
1415 1420 1425
Gly Ile Ser Asp Leu Ser Gly Gln Pro Ser Gly Phe Pro Val Phe
1430 1435 1440
Ser Gly Thr Ala Thr Arg Thr Pro Asp Leu Ala Ser Gly Thr Ile
1445 1450 1455
Ser Gly Ser Gly Glu Ser Ser Gly Ile Thr Phe Val Asp Thr Ser
1460 1465 1470
Phe Val Glu Val Thr Pro Thr Thr Phe Arg Glu Glu Glu Gly Leu
1475 1480 1485
Gly Ser Val Glu Leu Ser Gly Phe Pro Ser Gly Glu Thr Glu Leu
1490 1495 1500
Ser Gly Thr Ser Gly Thr Val Asp Val Ser Glu Gln Ser Ser Gly
1505 1510 1515
Ala Ile Asp Ser Ser Gly Leu Thr Ser Pro Thr Pro Glu Phe Ser
1520 1525 1530
Gly Leu Pro Ser Gly Val Ala Glu Val Ser Gly Glu Phe Ser Gly
1535 1540 1545
Val Glu Thr Gly Ser Ser Leu Pro Ser Gly Ala Phe Asp Gly Ser
1550 1555 1560
Gly Leu Val Ser Gly Phe Pro Thr Val Ser Leu Val Asp Arg Thr
1565 1570 1575
Leu Val Glu Ser Ile Thr Gln Ala Pro Thr Ala Gln Glu Ala Gly
1580 1585 1590
Glu Gly Pro Ser Gly Ile Leu Glu Phe Ser Gly Ala His Ser Gly
1595 1600 1605
Thr Pro Asp Ile Ser Gly Glu Leu Ser Gly Ser Leu Asp Leu Ser
1610 1615 1620
Thr Leu Gln Ser Gly Gln Met Glu Thr Ser Thr Glu Thr Pro Ser
1625 1630 1635
Ser Pro Tyr Phe Ser Gly Asp Phe Ser Ser Thr Thr Asp Val Ser
1640 1645 1650
Gly Glu Ser Ile Ala Ala Thr Thr Gly Ser Gly Glu Ser Ser Gly
1655 1660 1665
Leu Pro Glu Val Thr Leu Asn Thr Ser Glu Leu Val Glu Gly Val
1670 1675 1680
Thr Glu Pro Thr Val Ser Gln Glu Leu Gly His Gly Pro Ser Met
1685 1690 1695
Thr Tyr Thr Pro Arg Leu Phe Glu Ala Ser Gly Asp Ala Ser Ala
1700 1705 1710
Ser Gly Asp Leu Gly Gly Ala Val Thr Asn Phe Pro Gly Ser Gly
1715 1720 1725
Ile Glu Ala Ser Val Pro Glu Ala Ser Ser Asp Leu Ser Ala Tyr
1730 1735 1740
Pro Glu Ala Gly Val Gly Val Ser Ala Ala Pro Glu Ala Ser Ser
1745 1750 1755
Lys Leu Ser Glu Phe Pro Asp Leu His Gly Ile Thr Ser Ala Phe
1760 1765 1770
His Glu Thr Asp Leu Glu Met Thr Thr Pro Ser Thr Glu Val Asn
1775 1780 1785
Ser Asn Pro Trp Thr Phe Gln Glu Gly Thr Arg Glu Gly Ser Ala
1790 1795 1800
Ala Pro Glu Val Ser Gly Glu Ser Ser Thr Thr Ser Asp Ile Asp
1805 1810 1815
Thr Gly Thr Ser Gly Val Pro Ser Ala Thr Pro Met Ala Ser Gly
1820 1825 1830
Asp Arg Thr Glu Ile Ser Gly Glu Trp Ser Asp His Thr Ser Glu
1835 1840 1845
Val Asn Val Ala Ile Ser Ser Thr Ile Thr Glu Ser Glu Trp Ala
1850 1855 1860
Gln Pro Thr Arg Tyr Pro Thr Glu Thr Leu Gln Glu Ile Glu Ser
1865 1870 1875
Pro Asn Pro Ser Tyr Ser Gly Glu Glu Thr Gln Thr Ala Glu Thr
1880 1885 1890
Thr Met Ser Leu Thr Asp Ala Pro Thr Leu Ser Ser Ser Glu Gly
1895 1900 1905
Ser Gly Glu Thr Glu Ser Thr Val Ala Asp Gln Glu Gln Cys Glu
1910 1915 1920
Glu Gly Trp Thr Lys Phe Gln Gly His Cys Tyr Arg His Phe His
1925 1930 1935
Asp Arg Glu Thr Trp Val Asp Ala Glu Arg Arg Cys Arg Glu Gln
1940 1945 1950
Gln Ser His Leu Ser Ser Ile Val Thr Pro Glu Glu Gln Glu Phe
1955 1960 1965
Val Asn Lys Asn Ala Gln Asp Tyr Gln Trp Ile Gly Leu Asn Asp
1970 1975 1980
Arg Thr Ile Glu Gly Asp Phe Arg Trp Ser Asp Gly His Ser Leu
1985 1990 1995
Gln Phe Glu Lys Trp Arg Pro Asn Gln Pro Asp Asn Phe Phe Ala
2000 2005 2010
Thr Gly Glu Asp Cys Val Val Met Ile Trp His Glu Arg Gly Glu
2015 2020 2025
Trp Asn Asp Val Pro Cys Asn Tyr Gln Leu Pro Phe Thr Cys Lys
2030 2035 2040
Lys Gly Thr Val Ala Cys Gly Asp Pro Pro Val Val Glu His Ala
2045 2050 2055
Arg Thr Leu Gly Gln Lys Lys Asp Arg Tyr Glu Ile Ser Ser Leu
2060 2065 2070
Val Arg Tyr Gln Cys Thr Glu Gly Phe Val Gln Arg His Val Pro
2075 2080 2085
Thr Ile Arg Cys Gln Pro Ser Gly His Trp Glu Glu Pro Arg Ile
2090 2095 2100
Thr Cys Thr Asp Pro Asn Thr Tyr Lys His Arg Leu Gln Lys Arg
2105 2110 2115
Ser Met Arg Pro Thr Arg Arg Ser Arg Pro Ser Met Ala His
2120 2125 2130
<210> 131
<211> 2167
<212> PRT
<213> Oryctolagus cuniculus
<400> 131
Met Thr Thr Leu Leu Leu Val Leu Val Ala Leu Arg Val Ile Ala Ala
1 5 10 15
Ala Ile Ser Gly Asp Val Ser Asp Leu Asp Asn Ala Leu Ser Val Ser
20 25 30
Ile Pro Gln Pro Ser Pro Val Arg Ala Leu Leu Gly Thr Ser Leu Thr
35 40 45
Ile Pro Cys Tyr Phe Ile Asp Pro Val His Pro Val Thr Thr Ala Pro
50 55 60
Ser Thr Ala Pro Leu Thr Pro Arg Ile Lys Trp Ser Arg Ile Ser Lys
65 70 75 80
Asp Lys Glu Val Val Leu Leu Val Ala Asn Glu Gly Arg Val Arg Ile
85 90 95
Asn Ser Ala Tyr Gln Asp Lys Val Ser Leu Pro Asn Tyr Pro Ala Ile
100 105 110
Pro Ser Asp Ala Thr Leu Glu Ile Gln Ser Leu Arg Ser Asn Asp Ser
115 120 125
Gly Ile Tyr Arg Cys Glu Val Met His Gly Leu Glu Asp Ser Glu Ala
130 135 140
Thr Leu Glu Val Val Val Lys Gly Val Val Phe His Tyr Arg Ala Ile
145 150 155 160
Ser Thr Arg Tyr Thr Leu Asp Phe Asp Arg Ala Gln Arg Ala Cys Leu
165 170 175
Gln Asn Ser Ala Ile Ile Ala Thr Pro Glu Gln Leu Gln Ala Ala Tyr
180 185 190
Glu Asp Gly Phe His Gln Cys Asp Ala Gly Trp Leu Ala Asp Gln Thr
195 200 205
Val Arg Tyr Pro Ile His Thr Pro Arg Glu Gly Cys Tyr Gly Asp Lys
210 215 220
Asp Glu Phe Pro Gly Val Arg Thr Tyr Gly Ile Arg Asp Thr Asn Glu
225 230 235 240
Thr Tyr Asp Val Tyr Cys Phe Ala Glu Glu Met Glu Gly Glu Val Phe
245 250 255
Tyr Ala Thr Ser Pro Glu Lys Phe Thr Phe Gln Glu Ala Ala Ser Glu
260 265 270
Cys Arg Arg Leu Gly Ala Arg Leu Ala Thr Thr Gly Gln Leu Tyr Leu
275 280 285
Ala Trp Gln Ala Gly Met Asp Met Cys Ser Ala Gly Trp Leu Ala Asp
290 295 300
Arg Ser Val Arg Tyr Pro Ile Ser Lys Ala Arg Pro Asn Cys Gly Gly
305 310 315 320
Asn Leu Leu Gly Val Arg Thr Val Tyr Val His Ala Asn Gln Thr Gly
325 330 335
Tyr Pro Asp Pro Ser Ser Arg Tyr Asp Ala Ile Cys Tyr Thr Gly Glu
340 345 350
Asp Phe Met Asp Ile Pro Glu Asn Phe Phe Gly Val Gly Gly Glu Glu
355 360 365
Asp Ile Thr Val Gln Thr Val Thr Trp Pro Asp Val Glu Leu Pro Val
370 375 380
Pro Arg Asn Ile Thr Glu Gly Glu Ala Arg Gly Ser Val Val Leu Thr
385 390 395 400
Ala Lys Pro Val Leu Asp Val Ser Pro Thr Ala Pro Gln Pro Glu Glu
405 410 415
Thr Phe Ala Pro Gly Val Gly Ala Thr Ala Phe Pro Gly Val Glu Asn
420 425 430
Gly Thr Glu Glu Ala Thr Arg Pro Arg Gly Phe Ala Asp Glu Ala Thr
435 440 445
Leu Gly Pro Ser Ser Ala Thr Ala Phe Thr Ser Ala Asp Leu Val Val
450 455 460
Gln Val Thr Ala Ala Pro Gly Val Ala Glu Val Pro Gly Gln Pro Arg
465 470 475 480
Leu Pro Gly Gly Val Val Phe His Tyr Arg Pro Gly Pro Thr Arg Tyr
485 490 495
Ser Leu Thr Phe Glu Glu Ala Gln Gln Ala Cys Leu Arg Thr Gly Ala
500 505 510
Ala Met Ala Ser Ala Glu Gln Leu Gln Ala Ala Tyr Glu Ala Gly Tyr
515 520 525
Glu Gln Cys Asp Ala Gly Trp Leu Gln Asp Gln Thr Val Arg Tyr Pro
530 535 540
Ile Val Ser Pro Arg Thr Pro Cys Val Gly Asp Lys Asp Ser Ser Pro
545 550 555 560
Gly Val Arg Thr Tyr Gly Val Arg Pro Pro Ser Glu Thr Tyr Asp Val
565 570 575
Tyr Cys Tyr Val Asp Arg Leu Glu Gly Glu Val Phe Phe Ala Thr Arg
580 585 590
Leu Glu Gln Phe Thr Phe Gln Glu Ala Leu Glu Phe Cys Glu Ser His
595 600 605
Asn Ala Thr Leu Ala Ser Thr Gly Gln Leu Tyr Ala Ala Trp Ser Arg
610 615 620
Gly Leu Asp Arg Cys Tyr Ala Gly Trp Leu Ala Asp Gly Ser Leu Arg
625 630 635 640
Tyr Pro Ile Val Thr Pro Arg Pro Ala Cys Gly Gly Asp Lys Pro Gly
645 650 655
Val Arg Thr Val Tyr Leu Tyr Pro Asn Gln Thr Gly Leu Pro Asp Pro
660 665 670
Leu Ser Arg His His Ala Phe Cys Phe Arg Gly Thr Ser Glu Ala Pro
675 680 685
Ser Pro Gly Pro Glu Glu Gly Gly Thr Ala Thr Pro Ala Ser Gly Leu
690 695 700
Glu Asp Trp Ile Val Thr Gln Val Gly Pro Gly Val Ala Ala Thr Pro
705 710 715 720
Arg Ala Glu Glu Arg Thr Ala Val Pro Ser Phe Ala Thr Glu Pro Gly
725 730 735
Asn Gln Thr Gly Trp Glu Ala Ala Ser Ser Pro Val Gly Thr Ser Leu
740 745 750
Leu Pro Gly Ile Pro Pro Thr Trp Pro Pro Thr Gly Thr Ala Ala Glu
755 760 765
Gly Thr Thr Glu Gly Leu Ser Thr Ala Ala Met Pro Ser Ala Ser Glu
770 775 780
Gly Pro Tyr Thr Pro Ser Ser Leu Val Ala Arg Glu Thr Glu Leu Pro
785 790 795 800
Gly Leu Gly Val Thr Ser Val Pro Pro Asp Ile Ser Gly Asp Leu Thr
805 810 815
Ser Ser Gly Glu Ala Ser Gly Leu Phe Gly Pro Thr Gly Gln Pro Leu
820 825 830
Gly Gly Ser Ala Ser Gly Leu Pro Ser Gly Glu Leu Asp Ser Gly Ser
835 840 845
Leu Thr Pro Thr Val Gly Ser Gly Leu Pro Ile Gly Ser Gly Leu Ala
850 855 860
Ser Gly Asp Glu Asp Arg Ile Gln Trp Ser Ser Ser Thr Glu Val Gly
865 870 875 880
Gly Val Thr Ser Gly Ala Glu Ile Pro Glu Thr Ser Ala Ser Gly Val
885 890 895
Gly Thr Asp Leu Ser Gly Leu Pro Ser Gly Ala Glu Ile Pro Glu Thr
900 905 910
Phe Ala Ser Gly Val Gly Thr Asp Leu Ser Gly Leu Pro Ser Gly Ala
915 920 925
Glu Ile Pro Glu Thr Phe Ala Ser Gly Val Gly Thr Asp Leu Ser Gly
930 935 940
Leu Pro Ser Gly Ala Glu Ile Leu Glu Thr Ser Ala Ser Gly Val Gly
945 950 955 960
Thr Asp Leu Ser Gly Leu Pro Ser Gly Ala Glu Ile Leu Glu Thr Ser
965 970 975
Ala Ser Gly Val Gly Thr Asp Leu Ser Gly Leu Pro Ser Gly Ala Glu
980 985 990
Ile Leu Glu Thr Ser Ala Ser Gly Val Gly Thr Asp Leu Ser Gly Leu
995 1000 1005
Pro Ser Gly Ala Glu Ile Pro Glu Thr Phe Ala Ser Gly Val Gly
1010 1015 1020
Thr Asp Leu Ser Gly Leu Pro Ser Gly Ala Glu Ile Leu Glu Thr
1025 1030 1035
Ser Ala Ser Gly Val Gly Thr Asp Leu Ser Gly Leu Pro Ser Gly
1040 1045 1050
Ala Glu Ile Pro Glu Thr Ser Ala Ser Gly Val Gly Thr Asp Leu
1055 1060 1065
Ser Gly Leu Pro Ser Gly Ala Glu Ile Leu Glu Thr Ser Ala Ser
1070 1075 1080
Gly Val Gly Thr Asp Leu Ser Gly Leu Pro Ser Gly Ala Glu Ile
1085 1090 1095
Leu Glu Thr Ser Ala Ser Gly Val Gly Thr Asp Leu Ser Gly Leu
1100 1105 1110
Pro Ser Gly Ala Glu Ile Leu Glu Thr Ser Ala Ser Gly Val Gly
1115 1120 1125
Thr Asp Leu Ser Gly Leu Pro Ser Gly Ala Glu Ile Leu Glu Thr
1130 1135 1140
Ser Ala Ser Gly Val Gly Thr Asp Leu Ser Gly Leu Pro Ser Gly
1145 1150 1155
Ala Glu Ile Leu Glu Thr Ser Ala Ser Gly Val Gly Thr Asp Leu
1160 1165 1170
Ser Gly Leu Pro Ser Gly Gly Glu Ile Pro Glu Thr Phe Ala Ser
1175 1180 1185
Gly Val Gly Asp Leu Ser Gly Leu Pro Pro Gly Arg Glu Asp Leu
1190 1195 1200
Glu Thr Leu Thr Ser Gly Val Gly Asp Leu Ser Gly Leu Ser Ser
1205 1210 1215
Gly Lys Asp Gly Leu Val Gly Ser Ala Ser Gly Ala Leu Asp Phe
1220 1225 1230
Gly Gly Thr Leu Gly Ser Gly Gln Ile Pro Glu Thr Ser Gly Leu
1235 1240 1245
Pro Ser Gly Tyr Ser Gly Glu Tyr Ser Glu Val Asp Leu Gly Ser
1250 1255 1260
Gly Pro Ser Ser Gly Leu Pro Asp Phe Ser Gly Leu Pro Ser Gly
1265 1270 1275
Phe Pro Thr Val Ser Leu Val Asp Thr Pro Leu Val Glu Val Val
1280 1285 1290
Thr Ala Thr Thr Ala Arg Glu Leu Glu Gly Arg Gly Thr Ile Gly
1295 1300 1305
Ile Ser Gly Ala Gly Glu Ile Ser Gly Leu Pro Ser Ser Glu Leu
1310 1315 1320
Asp Val Ser Gly Gly Thr Ser Gly Ala Asp Ile Ser Gly Glu Ala
1325 1330 1335
Asp Val Gly Gly Glu Ala Ser Gly Leu Ile Val Arg Gly Gln Pro
1340 1345 1350
Ser Gly Phe Pro Asp Thr Ser Gly Glu Ala Phe Gly Val Thr Glu
1355 1360 1365
Val Ser Gly Leu Ser Ser Gly Gln Pro Asp Leu Ser Gly Glu Ala
1370 1375 1380
Ser Gly Val Leu Phe Gly Ser Gly Pro Pro Phe Gly Ile Thr Asp
1385 1390 1395
Leu Ser Gly Glu Pro Ser Gly Gln Pro Ser Gly Leu Pro Glu Phe
1400 1405 1410
Ser Gly Thr Thr His Arg Ile Pro Asp Leu Val Ser Gly Ala Thr
1415 1420 1425
Ser Gly Ser Gly Glu Ser Ser Gly Ile Ala Phe Val Asp Thr Ser
1430 1435 1440
Val Val Glu Val Thr Pro Thr Thr Leu Arg Glu Glu Glu Gly Leu
1445 1450 1455
Gly Ser Val Glu Phe Ser Gly Phe Pro Ser Gly Glu Thr Gly Leu
1460 1465 1470
Ser Gly Thr Pro Glu Thr Ile Asp Val Ser Gly Gln Ser Ser Gly
1475 1480 1485
Thr Ile Asp Ser Ser Gly Phe Thr Ser Leu Ala Pro Glu Val Ser
1490 1495 1500
Gly Ser Pro Ser Gly Val Ala Glu Val Ser Gly Glu Ala Ser Gly
1505 1510 1515
Thr Glu Ile Thr Ser Gly Leu Pro Ser Gly Val Phe Asp Ser Ser
1520 1525 1530
Gly Leu Pro Ser Gly Phe Pro Thr Val Ser Leu Val Asp Arg Thr
1535 1540 1545
Leu Val Glu Ser Val Thr Gln Ala Pro Thr Ala Gln Glu Ala Glu
1550 1555 1560
Gly Pro Ser Asp Ile Leu Glu Leu Ser Gly Val His Ser Gly Leu
1565 1570 1575
Pro Asp Val Ser Gly Ala His Ser Gly Phe Leu Asp Pro Ser Gly
1580 1585 1590
Leu Gln Ser Gly Leu Val Glu Pro Ser Gly Glu Pro Pro Arg Thr
1595 1600 1605
Pro Tyr Phe Ser Gly Asp Phe Pro Ser Thr Pro Asp Val Ser Gly
1610 1615 1620
Glu Ala Ser Ala Ala Thr Ser Ser Ser Gly Asp Ile Ser Gly Leu
1625 1630 1635
Pro Glu Val Thr Leu Val Thr Ser Glu Phe Met Glu Gly Val Thr
1640 1645 1650
Arg Pro Thr Val Ser Gln Glu Leu Gly Gln Gly Pro Pro Met Thr
1655 1660 1665
His Val Pro Lys Leu Phe Glu Ser Ser Gly Glu Ala Leu Ala Ser
1670 1675 1680
Gly Asp Thr Ser Gly Ala Ala Pro Ala Phe Pro Gly Ser Gly Leu
1685 1690 1695
Glu Ala Ser Ser Val Pro Glu Ser His Gly Glu Thr Ser Ala Tyr
1700 1705 1710
Ala Glu Pro Gly Thr Lys Ala Ala Ala Ala Pro Asp Ala Ser Gly
1715 1720 1725
Glu Ala Ser Gly Ser Pro Asp Ser Gly Glu Ile Thr Ser Val Phe
1730 1735 1740
Arg Glu Ala Ala Gly Glu Gly Ala Ser Gly Leu Glu Val Ser Ser
1745 1750 1755
Ser Ser Leu Ala Ser Gln Gln Gly Pro Arg Glu Gly Ser Ala Ser
1760 1765 1770
Pro Glu Val Ser Gly Glu Ser Thr Thr Ser Tyr Glu Ile Gly Thr
1775 1780 1785
Glu Thr Ser Gly Leu Pro Leu Ala Thr Pro Ala Ala Ser Glu Asp
1790 1795 1800
Arg Ala Glu Val Ser Gly Asp Leu Ser Gly Arg Thr Pro Val Pro
1805 1810 1815
Val Asp Val Val Thr Asn Val Pro Glu Ala Glu Trp Ile Gln His
1820 1825 1830
Ser Gln Arg Pro Ala Glu Met Trp Pro Glu Thr Lys Ser Ser Ser
1835 1840 1845
Pro Ser Tyr Ser Gly Glu Asp Thr Ala Gly Thr Ala Ala Ser Pro
1850 1855 1860
Ala Ser Ala Asp Thr Pro Gly Glu Pro Gly Pro Thr Thr Ala Ala
1865 1870 1875
Pro Arg Ser Cys Ala Glu Glu Pro Cys Gly Pro Gly Thr Cys Gln
1880 1885 1890
Glu Thr Glu Gly Arg Val Thr Cys Leu Cys Pro Pro Gly His Thr
1895 1900 1905
Gly Glu Tyr Cys Asp Ile Asp Ile Asp Glu Cys Leu Ser Ser Pro
1910 1915 1920
Cys Val Asn Gly Ala Thr Cys Val Asp Ala Ser Asp Ser Phe Thr
1925 1930 1935
Cys Leu Cys Leu Pro Ser Tyr Gly Gly Asp Leu Cys Glu Thr Asp
1940 1945 1950
Gln Glu Val Cys Glu Glu Gly Trp Thr Lys Phe Gln Gly His Cys
1955 1960 1965
Tyr Arg His Phe Pro Asp Arg Glu Thr Trp Val Asp Ala Glu Gly
1970 1975 1980
Arg Cys Arg Glu Gln Gln Ser His Leu Ser Ser Ile Val Thr Pro
1985 1990 1995
Glu Glu Gln Glu Phe Val Asn Asn Asn Ala Gln Asp Tyr Gln Trp
2000 2005 2010
Ile Gly Leu Asn Asp Arg Thr Ile Glu Gly Asp Phe Arg Trp Ser
2015 2020 2025
Asp Gly His Pro Leu Gln Phe Glu Asn Trp Arg Pro Asn Gln Pro
2030 2035 2040
Asp Asn Phe Phe Ala Thr Gly Glu Asp Cys Val Val Met Ile Trp
2045 2050 2055
His Glu Lys Gly Glu Trp Asn Asp Val Pro Cys Asn Tyr His Leu
2060 2065 2070
Pro Phe Thr Cys Lys Lys Gly Thr Val Ala Cys Gly Asp Pro Pro
2075 2080 2085
Val Val Glu His Ala Arg Thr Phe Gly Gln Lys Lys Asp Arg Tyr
2090 2095 2100
Glu Ile Asn Ser Leu Val Arg Tyr Gln Cys Ala Glu Gly Phe Thr
2105 2110 2115
Gln Arg His Val Pro Thr Ile Arg Cys Gln Pro Ser Gly His Trp
2120 2125 2130
Glu Glu Pro Arg Ile Thr Cys Thr His Pro Thr Thr Tyr Lys Arg
2135 2140 2145
Arg Val Gln Lys Arg Ser Ser Arg Thr Leu Gln Arg Ser Gln Ala
2150 2155 2160
Ser Ser Ala Pro
2165
<210> 132
<211> 2266
<212> PRT
<213> Macaca fascicularis
<400> 132
Met Thr Thr Leu Leu Trp Val Phe Val Thr Leu Arg Val Ile Ala Ala
1 5 10 15
Ala Val Thr Val Glu Thr Ser Asp His Asp Asn Ser Leu Ser Val Ser
20 25 30
Ile Pro Gln Pro Ser Pro Leu Arg Val Leu Leu Gly Thr Ser Leu Thr
35 40 45
Ile Pro Cys Tyr Phe Ile Asp Pro Met His Pro Val Thr Thr Ala Pro
50 55 60
Ser Thr Ala Pro Leu Ala Pro Arg Ile Lys Trp Ser Arg Val Ser Lys
65 70 75 80
Glu Lys Glu Val Val Leu Leu Val Ala Thr Glu Gly Arg Val Arg Val
85 90 95
Asn Ser Ala Tyr Gln Asp Lys Val Ser Leu Pro Asn Tyr Pro Ala Ile
100 105 110
Pro Ser Asp Ala Thr Leu Glu Ile Gln Ser Leu Arg Ser Asn Asp Ser
115 120 125
Gly Val Tyr Arg Cys Glu Val Met His Gly Ile Glu Asp Ser Glu Ala
130 135 140
Thr Leu Glu Val Val Val Lys Gly Ile Val Phe His Tyr Arg Ala Ile
145 150 155 160
Ser Thr Arg Tyr Thr Leu Asp Phe Asp Arg Ala Gln Arg Ala Cys Leu
165 170 175
Gln Asn Ser Ala Ile Ile Ala Thr Pro Glu Gln Leu Gln Ala Ala Tyr
180 185 190
Glu Asp Gly Phe His Gln Cys Asp Ala Gly Trp Leu Ala Asp Gln Thr
195 200 205
Val Arg Tyr Pro Ile His Thr Pro Arg Glu Gly Cys Tyr Gly Asp Lys
210 215 220
Asp Glu Phe Pro Gly Val Arg Thr Tyr Gly Ile Arg Asp Thr Asn Glu
225 230 235 240
Thr Tyr Asp Val Tyr Cys Phe Ala Glu Glu Met Glu Gly Glu Val Phe
245 250 255
Tyr Ala Thr Ser Pro Glu Lys Phe Thr Phe Gln Glu Ala Ala Asn Glu
260 265 270
Cys Arg Arg Leu Gly Ala Arg Leu Ala Thr Thr Gly Gln Leu Tyr Leu
275 280 285
Ala Trp Gln Ala Gly Met Asp Met Cys Ser Ala Gly Trp Leu Ala Asp
290 295 300
Arg Ser Val Arg Tyr Pro Ile Ser Lys Ala Arg Pro Asn Cys Gly Gly
305 310 315 320
Asn Leu Leu Gly Val Arg Thr Val Tyr Leu His Ala Asn Gln Thr Gly
325 330 335
Tyr Pro Asp Pro Ser Ser Arg Tyr Asp Ala Ile Cys Tyr Thr Gly Glu
340 345 350
Asp Phe Val Asp Ile Pro Glu Asn Phe Phe Gly Val Gly Gly Glu Glu
355 360 365
Asp Ile Thr Val Gln Thr Val Thr Trp Pro Asp Met Glu Leu Pro Leu
370 375 380
Pro Arg Asn Ile Thr Glu Gly Glu Ala Arg Gly Ser Val Ile Leu Thr
385 390 395 400
Val Lys Pro Ile Phe Asp Val Ser Pro Ser Pro Leu Glu Pro Glu Glu
405 410 415
Pro Phe Thr Phe Ala Pro Glu Ile Gly Ala Thr Ala Phe Pro Glu Val
420 425 430
Glu Asn Glu Thr Gly Glu Ala Thr Arg Pro Trp Gly Phe Pro Thr Pro
435 440 445
Gly Leu Gly Pro Ala Thr Ala Phe Thr Ser Glu Asp Leu Val Val Gln
450 455 460
Val Thr Ala Val Pro Gly Gln Pro His Leu Pro Gly Gly Val Val Phe
465 470 475 480
His Tyr Arg Pro Gly Ser Thr Arg Tyr Ser Leu Thr Phe Glu Glu Ala
485 490 495
Gln Gln Ala Cys Leu Arg Thr Gly Ala Val Ile Ala Ser Pro Glu Gln
500 505 510
Leu Gln Ala Ala Tyr Glu Ala Gly Tyr Glu Gln Cys Asp Ala Gly Trp
515 520 525
Leu Arg Asp Gln Thr Val Arg Tyr Pro Ile Val Ser Pro Arg Thr Pro
530 535 540
Cys Val Gly Asp Lys Asp Ser Ser Pro Gly Val Arg Thr Tyr Gly Val
545 550 555 560
Arg Pro Ser Thr Glu Thr Tyr Asp Val Tyr Cys Tyr Val Asp Arg Leu
565 570 575
Glu Gly Glu Val Phe Phe Ala Thr Arg Leu Glu Gln Phe Thr Phe Gln
580 585 590
Glu Ala Leu Glu Phe Cys Glu Ser His Asn Ala Thr Leu Ala Thr Thr
595 600 605
Gly Gln Leu Tyr Ala Ala Trp Ser Arg Gly Leu Asp Lys Cys Tyr Ala
610 615 620
Gly Trp Leu Ala Asp Gly Ser Leu Arg Tyr Pro Ile Val Thr Pro Arg
625 630 635 640
Pro Ala Cys Gly Gly Asp Lys Pro Gly Val Arg Thr Val Tyr Leu Tyr
645 650 655
Pro Asn Gln Thr Gly Leu Pro Asp Pro Leu Ser Arg His His Ala Phe
660 665 670
Cys Phe Arg Gly Val Ser Ala Val Pro Ser Pro Gly Glu Glu Glu Gly
675 680 685
Gly Thr Pro Thr Ser Pro Ser Gly Val Glu Asp Trp Ile Ala Thr Gln
690 695 700
Val Val Pro Gly Val Ala Ala Val Pro Val Glu Glu Glu Thr Thr Ala
705 710 715 720
Val Pro Leu Gly Glu Thr Thr Ala Ile Leu Glu Phe Thr Thr Glu Pro
725 730 735
Glu Asn Gln Thr Glu Trp Glu Pro Ala Tyr Thr Pro Met Gly Thr Ser
740 745 750
Pro Leu Pro Gly Ile Leu Pro Thr Trp Pro Pro Thr Gly Thr Ala Thr
755 760 765
Glu Glu Ser Thr Glu Gly Pro Ser Ala Thr Glu Val Leu Thr Ala Ser
770 775 780
Lys Glu Pro Ser Pro Pro Glu Val Pro Phe Pro Ser Glu Glu Pro Ser
785 790 795 800
Pro Ser Glu Glu Pro Phe Pro Ser Val Arg Pro Phe Pro Ser Val Glu
805 810 815
Pro Ser Pro Ser Glu Glu Pro Phe Pro Ser Val Glu Pro Ser Pro Ser
820 825 830
Glu Glu Pro Ser Ala Ser Glu Glu Pro Tyr Thr Pro Ser Pro Pro Val
835 840 845
Pro Ser Trp Thr Glu Leu Pro Gly Ser Gly Glu Glu Ser Gly Ala Pro
850 855 860
Asp Val Ser Gly Asp Phe Ile Gly Ser Gly Asp Val Ser Gly His Leu
865 870 875 880
Asp Phe Ser Gly Gln Leu Ser Gly Asp Arg Ile Ser Gly Leu Pro Ser
885 890 895
Gly Asp Leu Asp Ser Ser Gly Leu Thr Ser Thr Val Gly Ser Gly Leu
900 905 910
Pro Val Asp Ser Gly Leu Ala Ser Gly Asp Glu Glu Arg Ile Glu Trp
915 920 925
Ser Ser Thr Pro Thr Val Gly Glu Leu Pro Ser Gly Ala Glu Ile Leu
930 935 940
Glu Gly Ser Ala Ser Glu Val Gly Asp Leu Ser Gly Leu Pro Ser Gly
945 950 955 960
Asp Val Leu Glu Thr Ser Ala Ser Gly Val Gly Asp Leu Ser Gly Leu
965 970 975
Pro Ser Gly Glu Val Leu Glu Thr Ser Ala Ser Gly Val Gly Asp Leu
980 985 990
Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Ser Thr Ser Gly Val
995 1000 1005
Gly Asp Leu Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Ser
1010 1015 1020
Thr Ser Gly Val Gly Asp Leu Ser Gly Leu Pro Ser Ala Gly Glu
1025 1030 1035
Val Leu Glu Thr Thr Ala Ser Gly Val Glu Asp Ile Ser Gly Leu
1040 1045 1050
Pro Ser Gly Glu Val Leu Glu Thr Thr Ala Ser Gly Val Glu Asp
1055 1060 1065
Ile Ser Gly Phe Pro Ser Gly Glu Val Leu Glu Thr Thr Ala Ser
1070 1075 1080
Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu Val Leu Glu
1085 1090 1095
Thr Thr Ala Ser Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly
1100 1105 1110
Glu Val Leu Glu Thr Thr Ala Ser Gly Val Gly Asp Leu Gly Gly
1115 1120 1125
Leu Pro Ser Gly Glu Val Leu Glu Thr Ser Thr Ser Gly Val Gly
1130 1135 1140
Asp Leu Ser Gly Leu Pro Ser Gly Glu Val Val Glu Thr Ser Thr
1145 1150 1155
Ser Gly Val Glu Asp Leu Ser Gly Leu Pro Ser Gly Gly Glu Val
1160 1165 1170
Leu Glu Thr Ser Thr Ser Gly Val Glu Asp Ile Ser Gly Leu Pro
1175 1180 1185
Ser Gly Glu Val Leu Glu Thr Thr Ala Ser Gly Ile Glu Asp Val
1190 1195 1200
Ser Glu Leu Pro Ser Gly Glu Gly Leu Glu Thr Ser Ala Ser Gly
1205 1210 1215
Val Glu Asp Leu Ser Arg Leu Pro Ser Gly Glu Val Leu Glu Thr
1220 1225 1230
Ser Ala Ser Gly Val Gly Asp Ile Ser Gly Leu Pro Ser Gly Gly
1235 1240 1245
Glu Val Leu Glu Ile Ser Ala Ser Gly Val Gly Asp Leu Ser Gly
1250 1255 1260
Leu Pro Ser Gly Gly Glu Gly Leu Glu Thr Ser Ala Ser Gly Val
1265 1270 1275
Gly Thr Asp Leu Ser Gly Leu Pro Ser Gly Arg Glu Gly Leu Glu
1280 1285 1290
Thr Ser Ala Ser Gly Ala Glu Asp Leu Ser Gly Leu Pro Ser Gly
1295 1300 1305
Lys Glu Asp Leu Val Gly Pro Ala Ser Gly Asp Leu Asp Leu Gly
1310 1315 1320
Lys Leu Pro Ser Gly Thr Leu Arg Ser Gly Gln Ala Pro Glu Thr
1325 1330 1335
Ser Gly Leu Pro Ser Gly Phe Ser Gly Glu Tyr Ser Gly Val Asp
1340 1345 1350
Leu Gly Ser Gly Pro Pro Ser Gly Leu Pro Asp Phe Ser Gly Leu
1355 1360 1365
Pro Ser Gly Phe Pro Thr Val Ser Leu Val Asp Ser Thr Leu Val
1370 1375 1380
Glu Val Val Thr Ala Ser Thr Ala Ser Glu Leu Glu Gly Arg Gly
1385 1390 1395
Thr Ile Gly Ile Ser Gly Ala Gly Glu Ile Ser Gly Leu Pro Ser
1400 1405 1410
Ser Glu Leu Asp Ile Ser Gly Glu Ala Ser Gly Leu Pro Ser Gly
1415 1420 1425
Thr Glu Leu Ser Gly Gln Ala Ser Gly Ser Pro Asp Val Ser Arg
1430 1435 1440
Glu Thr Pro Gly Leu Phe Asp Val Ser Gly Gln Pro Ser Gly Phe
1445 1450 1455
Pro Asp Ile Ser Gly Gly Thr Ser Gly Ile Ser Glu Val Ser Gly
1460 1465 1470
Gln Pro Ser Gly Phe Pro Asp Thr Ser Gly Glu Thr Ser Gly Val
1475 1480 1485
Thr Glu Leu Ser Gly Leu Pro Ser Gly Gln Pro Gly Val Ser Gly
1490 1495 1500
Glu Ala Ser Gly Val Pro Tyr Gly Ser Ser Gln Pro Phe Gly Ile
1505 1510 1515
Thr Asp Leu Ser Gly Glu Thr Ser Gly Val Pro Asp Leu Ser Gly
1520 1525 1530
Gln Pro Ser Gly Leu Pro Gly Phe Ser Gly Ala Thr Ser Gly Val
1535 1540 1545
Pro Asp Leu Val Ser Gly Ala Thr Ser Gly Ser Gly Glu Ser Ser
1550 1555 1560
Gly Ile Thr Phe Val Asp Thr Ser Leu Val Glu Val Thr Pro Thr
1565 1570 1575
Thr Phe Lys Glu Glu Glu Gly Leu Gly Ser Val Glu Leu Ser Gly
1580 1585 1590
Leu Pro Ser Gly Glu Ala Asp Leu Ser Gly Arg Ser Gly Met Val
1595 1600 1605
Asp Val Ser Gly Gln Phe Ser Gly Thr Val Asp Ser Ser Gly Phe
1610 1615 1620
Thr Ser Gln Thr Pro Glu Phe Ser Gly Leu Pro Ile Gly Ile Ala
1625 1630 1635
Glu Val Ser Gly Glu Ser Ser Gly Ala Glu Thr Gly Ser Ser Leu
1640 1645 1650
Pro Ser Gly Ala Tyr Tyr Gly Ser Gly Leu Pro Ser Gly Phe Pro
1655 1660 1665
Thr Val Ser Leu Val Asp Arg Thr Leu Val Glu Ser Val Thr Gln
1670 1675 1680
Ala Pro Thr Ala Gln Glu Ala Gly Glu Gly Pro Pro Gly Ile Leu
1685 1690 1695
Glu Leu Ser Gly Thr His Ser Gly Ala Pro Asp Met Ser Gly Asp
1700 1705 1710
His Ser Gly Phe Leu Asp Val Ser Gly Leu Gln Phe Gly Leu Val
1715 1720 1725
Glu Pro Ser Gly Glu Pro Pro Ser Thr Pro Tyr Phe Ser Gly Asp
1730 1735 1740
Phe Ala Ser Thr Thr Asp Val Ser Gly Glu Ser Ser Ala Ala Met
1745 1750 1755
Gly Thr Ser Gly Glu Ala Ser Gly Leu Pro Gly Val Thr Leu Ile
1760 1765 1770
Thr Ser Glu Phe Met Glu Gly Val Thr Glu Pro Thr Val Ser Gln
1775 1780 1785
Glu Leu Gly Gln Arg Pro Pro Val Thr His Thr Pro Gln Leu Phe
1790 1795 1800
Glu Ser Ser Gly Glu Ala Ser Ala Ala Gly Asp Ile Ser Gly Ala
1805 1810 1815
Thr Pro Val Leu Pro Gly Ser Gly Val Glu Val Ser Ser Val Pro
1820 1825 1830
Glu Ser Ser Ser Glu Thr Ser Ala Tyr Pro Glu Ala Gly Val Gly
1835 1840 1845
Ala Ser Ala Ala Pro Glu Thr Ser Gly Glu Asp Ser Gly Ser Pro
1850 1855 1860
Asp Leu Ser Glu Thr Thr Ser Ala Phe His Glu Ala Asp Leu Glu
1865 1870 1875
Arg Ser Ser Gly Leu Gly Val Ser Gly Ser Thr Leu Thr Phe Gln
1880 1885 1890
Glu Gly Glu Pro Ser Ala Ser Pro Glu Val Ser Gly Glu Ser Thr
1895 1900 1905
Thr Thr Gly Asp Val Gly Thr Glu Ala Pro Gly Leu Pro Ser Ala
1910 1915 1920
Thr Pro Thr Ala Ser Gly Asp Arg Thr Glu Ile Ser Gly Asp Leu
1925 1930 1935
Ser Gly His Thr Ser Gly Leu Gly Val Val Ile Ser Thr Ser Ile
1940 1945 1950
Pro Glu Ser Glu Trp Thr Gln Gln Thr Gln Arg Pro Ala Glu Ala
1955 1960 1965
His Leu Glu Thr Glu Ser Ser Ser Leu Leu Tyr Ser Gly Glu Glu
1970 1975 1980
Thr His Thr Ala Glu Thr Ala Thr Ser Pro Thr Asp Ala Ser Ile
1985 1990 1995
Pro Ala Ser Pro Glu Trp Thr Gly Glu Ser Glu Ser Thr Val Ala
2000 2005 2010
Asp Ile Asp Glu Cys Leu Ser Ser Pro Cys Leu Asn Gly Ala Thr
2015 2020 2025
Cys Val Asp Ala Ile Asp Ser Phe Thr Cys Leu Cys Leu Pro Ser
2030 2035 2040
Tyr Gly Gly Asp Leu Cys Glu Ile Asp Gln Glu Val Cys Glu Glu
2045 2050 2055
Gly Trp Thr Lys Tyr Gln Gly His Cys Tyr Arg His Phe Pro Asp
2060 2065 2070
Arg Glu Thr Trp Val Asp Ala Glu Arg Arg Cys Arg Glu Gln Gln
2075 2080 2085
Ser His Leu Ser Ser Ile Val Thr Pro Glu Glu Gln Glu Phe Val
2090 2095 2100
Asn Asn Asn Ala Gln Asp Tyr Gln Trp Ile Gly Leu Asn Asp Arg
2105 2110 2115
Thr Ile Glu Gly Asp Phe Arg Trp Ser Asp Gly His Pro Met Gln
2120 2125 2130
Phe Glu Asn Trp Arg Pro Asn Gln Pro Asp Asn Phe Phe Ala Ala
2135 2140 2145
Gly Glu Asp Cys Val Val Met Ile Trp His Glu Lys Gly Glu Trp
2150 2155 2160
Asn Asp Val Pro Cys Asn Tyr His Leu Pro Phe Thr Cys Lys Lys
2165 2170 2175
Gly Thr Val Ala Cys Gly Glu Pro Pro Met Val Gln His Ala Arg
2180 2185 2190
Thr Phe Gly Gln Lys Lys Asp Arg Tyr Glu Ile Asn Ser Leu Val
2195 2200 2205
Arg Tyr Gln Cys Thr Glu Gly Phe Val Gln Arg His Val Pro Thr
2210 2215 2220
Ile Arg Cys Gln Pro Ser Gly His Trp Glu Glu Pro Arg Ile Thr
2225 2230 2235
Cys Thr Asp Ala Thr Ala Tyr Lys Arg Arg Leu Gln Lys Arg Ser
2240 2245 2250
Ser Arg His Pro Arg Arg Ser Arg Pro Ser Thr Ala His
2255 2260 2265
<210> 133
<211> 2167
<212> PRT
<213> Macaca mulatta
<220>
<221> VARIANT
<222> (1910)..(1915)
<223> Xaa can be any naturally occurring amino acid
<400> 133
Met Thr Thr Leu Leu Trp Val Phe Val Thr Leu Arg Val Ile Ala Ala
1 5 10 15
Ala Val Thr Val Glu Thr Ser Asp His Asp Asn Ser Leu Ser Val Ser
20 25 30
Ile Pro Gln Pro Ser Pro Leu Arg Val Leu Leu Gly Thr Ser Leu Thr
35 40 45
Ile Pro Cys Tyr Phe Ile Asp Pro Met His Pro Val Thr Thr Ala Pro
50 55 60
Ser Thr Ala Pro Leu Ala Pro Arg Ile Lys Trp Ser Arg Val Ser Lys
65 70 75 80
Glu Lys Glu Val Val Leu Leu Val Ala Thr Glu Gly Arg Val Arg Val
85 90 95
Asn Ser Ala Tyr Gln Asp Lys Val Ser Leu Pro Asn Tyr Pro Ala Ile
100 105 110
Pro Ser Asp Ala Thr Leu Glu Ile Gln Ser Leu Arg Ser Asn Asp Ser
115 120 125
Gly Val Tyr Arg Cys Glu Val Met His Gly Ile Glu Asp Ser Glu Ala
130 135 140
Thr Leu Glu Val Val Val Lys Gly Ile Val Phe His Tyr Arg Ala Ile
145 150 155 160
Ser Thr Arg Tyr Thr Leu Asp Phe Asp Arg Ala Gln Arg Ala Cys Leu
165 170 175
Gln Asn Ser Ala Ile Ile Ala Thr Pro Glu Gln Leu Gln Ala Ala Tyr
180 185 190
Glu Asp Gly Phe His Gln Cys Asp Ala Gly Trp Leu Ala Asp Gln Thr
195 200 205
Val Arg Tyr Pro Ile His Thr Pro Arg Glu Gly Cys Tyr Gly Asp Lys
210 215 220
Asp Glu Phe Pro Gly Val Arg Thr Tyr Gly Ile Arg Asp Thr Asn Glu
225 230 235 240
Thr Tyr Asp Val Tyr Cys Phe Ala Glu Glu Met Glu Gly Glu Val Phe
245 250 255
Tyr Ala Thr Ser Pro Glu Lys Phe Thr Phe Gln Glu Ala Ala Asn Glu
260 265 270
Cys Arg Arg Leu Gly Ala Arg Leu Ala Thr Thr Gly Gln Leu Tyr Leu
275 280 285
Ala Trp Gln Ala Gly Met Asp Met Cys Ser Ala Gly Trp Leu Ala Asp
290 295 300
Arg Ser Val Arg Tyr Pro Ile Ser Lys Ala Arg Pro Asn Cys Gly Gly
305 310 315 320
Asn Leu Leu Gly Val Arg Thr Val Tyr Leu His Ala Asn Gln Thr Gly
325 330 335
Tyr Pro Asp Pro Ser Ser Arg Tyr Asp Ala Ile Cys Tyr Thr Gly Glu
340 345 350
Asp Phe Val Asp Ile Pro Glu Asn Phe Phe Gly Val Gly Gly Glu Glu
355 360 365
Asp Ile Thr Val Gln Thr Val Thr Trp Pro Asp Met Glu Leu Pro Leu
370 375 380
Pro Arg Asn Ile Thr Glu Gly Glu Ala Arg Gly Ser Val Ile Leu Thr
385 390 395 400
Val Lys Pro Ile Phe Asp Val Ser Pro Ser Pro Leu Glu Pro Glu Glu
405 410 415
Pro Phe Thr Phe Ala Pro Glu Ile Gly Ala Thr Ala Phe Pro Glu Val
420 425 430
Glu Asn Glu Thr Gly Glu Ala Thr Arg Pro Trp Gly Phe Pro Thr Pro
435 440 445
Gly Leu Gly Pro Ala Thr Ala Phe Thr Ser Glu Asp Leu Val Val Gln
450 455 460
Val Thr Ala Val Pro Gly Gln Pro His Leu Pro Gly Gly Val Val Phe
465 470 475 480
His Tyr Arg Pro Gly Ser Thr Arg Tyr Ser Leu Thr Phe Glu Glu Ala
485 490 495
Gln Gln Ala Cys Leu Arg Thr Gly Ala Val Ile Ala Ser Pro Glu Gln
500 505 510
Leu Gln Ala Ala Tyr Glu Ala Gly Tyr Glu Gln Cys Asp Ala Gly Trp
515 520 525
Leu Arg Asp Gln Thr Val Arg Tyr Pro Ile Val Ser Pro Arg Thr Pro
530 535 540
Cys Val Gly Asp Lys Asp Ser Ser Pro Gly Val Arg Thr Tyr Gly Val
545 550 555 560
Arg Pro Ser Thr Glu Thr Tyr Asp Val Tyr Cys Tyr Val Asp Arg Leu
565 570 575
Glu Gly Glu Val Phe Phe Ala Thr Arg Leu Glu Gln Phe Thr Phe Gln
580 585 590
Glu Ala Leu Glu Phe Cys Glu Ser His Asn Ala Thr Leu Ala Thr Thr
595 600 605
Gly Gln Leu Tyr Ala Ala Trp Ser Arg Gly Leu Asp Lys Cys Tyr Ala
610 615 620
Gly Trp Leu Ala Asp Gly Ser Leu Arg Tyr Pro Ile Val Thr Pro Arg
625 630 635 640
Pro Ala Cys Gly Gly Asp Lys Pro Gly Val Arg Thr Val Tyr Leu Tyr
645 650 655
Pro Asn Gln Thr Gly Leu Pro Asp Pro Leu Ser Arg His His Ala Phe
660 665 670
Cys Phe Arg Gly Val Ser Ala Val Pro Ser Pro Gly Glu Glu Glu Gly
675 680 685
Gly Thr Pro Thr Ser Pro Ser Gly Val Glu Asp Trp Ile Ala Thr Gln
690 695 700
Val Val Pro Gly Val Ala Ala Val Pro Val Glu Glu Glu Thr Thr Ala
705 710 715 720
Val Pro Leu Gly Glu Thr Thr Ala Ile Leu Glu Phe Thr Thr Glu Pro
725 730 735
Glu Asn Gln Thr Glu Trp Glu Pro Ala Tyr Thr Pro Met Gly Thr Ser
740 745 750
Pro Leu Pro Gly Ile Leu Pro Thr Trp Pro Pro Thr Gly Thr Ala Thr
755 760 765
Glu Glu Ser Thr Glu Gly Pro Ser Ala Thr Glu Val Leu Thr Ala Ser
770 775 780
Lys Glu Pro Ser Pro Pro Glu Val Pro Phe Pro Ser Glu Glu Pro Ser
785 790 795 800
Pro Ser Glu Glu Pro Phe Pro Ser Val Arg Pro Phe Pro Ser Val Glu
805 810 815
Pro Ser Pro Ser Glu Glu Pro Phe Pro Ser Val Glu Pro Ser Pro Ser
820 825 830
Glu Glu Pro Ser Ala Ser Glu Glu Pro Tyr Thr Pro Ser Pro Pro Val
835 840 845
Pro Ser Trp Thr Glu Leu Pro Gly Ser Gly Glu Glu Ser Gly Ala Pro
850 855 860
Asp Val Ser Gly Asp Phe Ile Gly Ser Gly Asp Val Ser Gly His Leu
865 870 875 880
Asp Phe Ser Gly Gln Leu Ser Gly Asp Arg Ile Ser Gly Leu Pro Ser
885 890 895
Gly Asp Leu Asp Ser Ser Gly Leu Thr Ser Thr Val Gly Ser Gly Leu
900 905 910
Pro Val Asp Ser Gly Leu Ala Ser Gly Asp Glu Glu Arg Ile Glu Trp
915 920 925
Ser Ser Thr Pro Thr Val Gly Glu Leu Pro Ser Gly Ala Glu Ile Leu
930 935 940
Glu Gly Ser Ala Ser Glu Val Gly Asp Leu Ser Gly Leu Pro Ser Gly
945 950 955 960
Asp Val Leu Glu Thr Ser Ala Ser Gly Val Gly Asp Leu Ser Gly Leu
965 970 975
Pro Ser Gly Glu Val Leu Glu Thr Ser Val Ser Gly Val Gly Asp Leu
980 985 990
Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Ser Thr Ser Gly Val
995 1000 1005
Gly Asp Leu Ser Gly Leu Pro Ser Gly Glu Val Leu Glu Thr Ser
1010 1015 1020
Thr Ser Gly Val Gly Asp Leu Ser Gly Leu Pro Ser Ala Gly Glu
1025 1030 1035
Val Leu Glu Thr Thr Ala Ser Gly Val Glu Asp Ile Ser Gly Leu
1040 1045 1050
Pro Ser Gly Glu Val Leu Glu Thr Thr Ala Ser Gly Val Glu Asp
1055 1060 1065
Ile Ser Gly Phe Pro Ser Gly Glu Val Leu Glu Thr Thr Ala Ser
1070 1075 1080
Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly Glu Val Leu Glu
1085 1090 1095
Thr Thr Ala Ser Gly Val Glu Asp Ile Ser Gly Leu Pro Ser Gly
1100 1105 1110
Glu Val Leu Glu Thr Thr Ala Ser Gly Val Gly Asp Leu Gly Gly
1115 1120 1125
Leu Pro Ser Gly Glu Val Leu Glu Thr Ser Thr Ser Gly Val Gly
1130 1135 1140
Asp Leu Ser Gly Leu Pro Ser Gly Glu Val Val Glu Thr Ser Thr
1145 1150 1155
Ser Gly Val Glu Asp Leu Ser Gly Leu Pro Ser Gly Gly Glu Val
1160 1165 1170
Leu Glu Thr Ser Thr Ser Gly Val Glu Asp Ile Ser Gly Leu Pro
1175 1180 1185
Ser Gly Glu Val Leu Glu Thr Thr Ala Ser Gly Ile Glu Asp Val
1190 1195 1200
Ser Glu Leu Pro Ser Gly Glu Gly Leu Glu Thr Ser Ala Ser Gly
1205 1210 1215
Val Glu Asp Leu Ser Arg Leu Pro Ser Gly Glu Val Leu Glu Thr
1220 1225 1230
Ser Ala Ser Gly Val Gly Asp Ile Ser Gly Leu Pro Ser Gly Gly
1235 1240 1245
Glu Val Leu Glu Ile Ser Ala Ser Gly Val Gly Asp Leu Ser Gly
1250 1255 1260
Leu Pro Ser Gly Gly Glu Gly Leu Glu Thr Ser Ala Ser Gly Val
1265 1270 1275
Gly Thr Asp Leu Ser Gly Leu Pro Ser Gly Arg Glu Gly Leu Glu
1280 1285 1290
Thr Ser Ala Ser Gly Ala Glu Asp Leu Ser Gly Leu Pro Ser Gly
1295 1300 1305
Lys Glu Asp Leu Val Gly Pro Ala Ser Gly Asp Leu Asp Leu Gly
1310 1315 1320
Lys Leu Pro Ser Gly Thr Leu Gly Ser Gly Gln Ala Pro Glu Thr
1325 1330 1335
Ser Gly Leu Pro Ser Gly Phe Ser Gly Glu Tyr Ser Gly Val Asp
1340 1345 1350
Leu Gly Ser Gly Pro Pro Ser Gly Leu Pro Asp Phe Ser Gly Leu
1355 1360 1365
Pro Ser Gly Phe Pro Thr Val Ser Leu Val Asp Ser Thr Leu Val
1370 1375 1380
Glu Val Val Thr Ala Ser Thr Ala Ser Glu Leu Glu Gly Arg Gly
1385 1390 1395
Thr Ile Gly Ile Ser Gly Ala Gly Glu Ile Ser Gly Leu Pro Ser
1400 1405 1410
Ser Glu Leu Asp Ile Ser Gly Glu Ala Ser Gly Leu Pro Ser Gly
1415 1420 1425
Thr Glu Leu Ser Gly Gln Ala Ser Gly Ser Pro Asp Val Ser Arg
1430 1435 1440
Glu Thr Ser Gly Leu Phe Asp Val Ser Gly Gln Pro Ser Gly Phe
1445 1450 1455
Pro Asp Thr Ser Gly Glu Thr Ser Gly Val Thr Glu Leu Ser Gly
1460 1465 1470
Leu Pro Ser Gly Gln Pro Gly Val Ser Gly Glu Ala Ser Gly Val
1475 1480 1485
Pro Tyr Gly Ser Ser Gln Pro Phe Gly Ile Thr Asp Leu Ser Gly
1490 1495 1500
Glu Thr Ser Gly Val Pro Asp Leu Ser Gly Gln Pro Ser Gly Leu
1505 1510 1515
Pro Gly Phe Ser Gly Ala Thr Ser Gly Val Pro Asp Leu Val Ser
1520 1525 1530
Gly Ala Thr Ser Gly Ser Gly Glu Ser Ser Asp Ile Thr Phe Val
1535 1540 1545
Asp Thr Ser Leu Val Glu Val Thr Pro Thr Thr Phe Lys Glu Glu
1550 1555 1560
Glu Gly Leu Gly Ser Val Glu Leu Ser Gly Leu Pro Ser Gly Glu
1565 1570 1575
Ala Asp Leu Ser Gly Arg Ser Gly Met Val Asp Val Ser Gly Gln
1580 1585 1590
Phe Ser Gly Thr Val Asp Ser Ser Gly Phe Thr Ser Gln Thr Pro
1595 1600 1605
Glu Phe Ser Gly Leu Pro Ile Gly Ile Ala Glu Val Ser Gly Glu
1610 1615 1620
Ser Ser Gly Ala Glu Thr Gly Ser Ser Leu Pro Ser Gly Ala Tyr
1625 1630 1635
Tyr Gly Ser Glu Leu Pro Ser Gly Phe Pro Thr Val Ser Leu Val
1640 1645 1650
Asp Arg Thr Leu Val Glu Ser Val Thr Gln Ala Pro Thr Ala Gln
1655 1660 1665
Glu Ala Gly Glu Gly Pro Pro Gly Ile Leu Glu Leu Ser Gly Thr
1670 1675 1680
His Ser Gly Ala Pro Asp Met Ser Gly Asp His Ser Gly Phe Leu
1685 1690 1695
Asp Val Ser Gly Leu Gln Phe Gly Leu Val Glu Pro Ser Gly Glu
1700 1705 1710
Pro Pro Ser Thr Pro Tyr Phe Ser Gly Asp Phe Ala Ser Thr Thr
1715 1720 1725
Asp Val Ser Gly Glu Ser Ser Ala Ala Met Gly Thr Asn Gly Glu
1730 1735 1740
Ala Ser Gly Leu Pro Glu Val Thr Leu Ile Thr Ser Glu Phe Met
1745 1750 1755
Glu Gly Val Thr Glu Pro Thr Val Ser Gln Glu Leu Gly Gln Arg
1760 1765 1770
Pro Pro Val Thr His Thr Pro Gln Leu Phe Glu Ser Ser Gly Glu
1775 1780 1785
Ala Ser Ala Ala Gly Asp Ile Ser Gly Ala Thr Pro Val Leu Pro
1790 1795 1800
Gly Ser Gly Val Glu Val Ser Ser Val Pro Glu Ser Ser Ser Glu
1805 1810 1815
Thr Ser Ala Tyr Pro Glu Ala Gly Val Gly Ala Ser Ala Ala Pro
1820 1825 1830
Glu Thr Ser Gly Glu Asp Ser Gly Ser Pro Asp Leu Ser Glu Thr
1835 1840 1845
Thr Ser Ala Phe His Glu Ala Asp Leu Glu Arg Ser Ser Gly Leu
1850 1855 1860
Gly Val Ser Gly Ser Thr Leu Thr Phe Gln Glu Gly Glu Pro Ser
1865 1870 1875
Ala Ser Pro Glu Val Ser Gly Glu Ser Thr Thr Thr Gly Asp Val
1880 1885 1890
Gly Thr Glu Ala Pro Gly Leu Pro Ser Ala Thr Pro Thr Ala Ser
1895 1900 1905
Gly Xaa Xaa Xaa Xaa Xaa Xaa Pro Thr Arg Ser Cys Ala Glu Glu
1910 1915 1920
Pro Cys Gly Ala Gly Thr Cys Lys Glu Thr Glu Gly His Val Ile
1925 1930 1935
Cys Leu Cys Pro Pro Gly Tyr Thr Gly Glu His Cys Asn Ile Asp
1940 1945 1950
Gln Glu Val Cys Glu Glu Gly Trp Thr Lys Tyr Gln Gly His Cys
1955 1960 1965
Tyr Arg His Phe Pro Asp Arg Glu Thr Trp Val Asp Ala Glu Arg
1970 1975 1980
Arg Cys Arg Glu Gln Gln Ser His Leu Ser Ser Ile Val Thr Pro
1985 1990 1995
Glu Glu Gln Glu Phe Val Asn Asn Asn Ala Gln Asp Tyr Gln Trp
2000 2005 2010
Ile Gly Leu Asn Asp Arg Thr Ile Glu Gly Asp Phe Arg Trp Ser
2015 2020 2025
Asp Gly His Pro Met Gln Phe Glu Asn Trp Arg Pro Asn Gln Pro
2030 2035 2040
Asp Asn Phe Phe Ala Ala Gly Glu Asp Cys Val Val Met Ile Trp
2045 2050 2055
His Glu Lys Gly Glu Trp Asn Asp Val Pro Cys Asn Tyr His Leu
2060 2065 2070
Pro Phe Thr Cys Lys Lys Gly Thr Val Ala Cys Gly Glu Pro Pro
2075 2080 2085
Met Val Gln His Ala Arg Thr Phe Gly Gln Lys Lys Asp Arg Tyr
2090 2095 2100
Glu Ile Asn Ser Leu Val Arg Tyr Gln Cys Thr Glu Gly Phe Val
2105 2110 2115
Gln Arg His Val Pro Thr Ile Arg Cys Gln Pro Ser Gly His Trp
2120 2125 2130
Glu Glu Pro Arg Ile Thr Cys Thr Asp Ala Thr Ala Tyr Lys Arg
2135 2140 2145
Arg Leu Gln Lys Arg Ser Ser Arg His Pro Arg Arg Ser Arg Pro
2150 2155 2160
Ser Thr Ala His
2165
<210> 134
<211> 1321
<212> PRT
<213> Homo sapiens
<400> 134
Met Gly Ala Pro Phe Val Trp Ala Leu Gly Leu Leu Met Leu Gln Met
1 5 10 15
Leu Leu Phe Val Ala Gly Glu Gln Gly Thr Gln Asp Ile Thr Asp Ala
20 25 30
Ser Glu Arg Gly Leu His Met Gln Lys Leu Gly Ser Gly Ser Val Gln
35 40 45
Ala Ala Leu Ala Glu Leu Val Ala Leu Pro Cys Leu Phe Thr Leu Gln
50 55 60
Pro Arg Pro Ser Ala Ala Arg Asp Ala Pro Arg Ile Lys Trp Thr Lys
65 70 75 80
Val Arg Thr Ala Ser Gly Gln Arg Gln Asp Leu Pro Ile Leu Val Ala
85 90 95
Lys Asp Asn Val Val Arg Val Ala Lys Ser Trp Gln Gly Arg Val Ser
100 105 110
Leu Pro Ser Tyr Pro Arg Arg Arg Ala Asn Ala Thr Leu Leu Leu Gly
115 120 125
Pro Leu Arg Ala Ser Asp Ser Gly Leu Tyr Arg Cys Gln Val Val Arg
130 135 140
Gly Ile Glu Asp Glu Gln Asp Leu Val Pro Leu Glu Val Thr Gly Val
145 150 155 160
Val Phe His Tyr Arg Ser Ala Arg Asp Arg Tyr Ala Leu Thr Phe Ala
165 170 175
Glu Ala Gln Glu Ala Cys Arg Leu Ser Ser Ala Ile Ile Ala Ala Pro
180 185 190
Arg His Leu Gln Ala Ala Phe Glu Asp Gly Phe Asp Asn Cys Asp Ala
195 200 205
Gly Trp Leu Ser Asp Arg Thr Val Arg Tyr Pro Ile Thr Gln Ser Arg
210 215 220
Pro Gly Cys Tyr Gly Asp Arg Ser Ser Leu Pro Gly Val Arg Ser Tyr
225 230 235 240
Gly Arg Arg Asn Pro Gln Glu Leu Tyr Asp Val Tyr Cys Phe Ala Arg
245 250 255
Glu Leu Gly Gly Glu Val Phe Tyr Val Gly Pro Ala Arg Arg Leu Thr
260 265 270
Leu Ala Gly Ala Arg Ala Gln Cys Arg Arg Gln Gly Ala Ala Leu Ala
275 280 285
Ser Val Gly Gln Leu His Leu Ala Trp His Glu Gly Leu Asp Gln Cys
290 295 300
Asp Pro Gly Trp Leu Ala Asp Gly Ser Val Arg Tyr Pro Ile Gln Thr
305 310 315 320
Pro Arg Arg Arg Cys Gly Gly Pro Ala Pro Gly Val Arg Thr Val Tyr
325 330 335
Arg Phe Ala Asn Arg Thr Gly Phe Pro Ser Pro Ala Glu Arg Phe Asp
340 345 350
Ala Tyr Cys Phe Arg Ala His His Pro Thr Ser Gln His Gly Asp Leu
355 360 365
Glu Thr Pro Ser Ser Gly Asp Glu Gly Glu Ile Leu Ser Ala Glu Gly
370 375 380
Pro Pro Val Arg Glu Leu Glu Pro Thr Leu Glu Glu Glu Glu Val Val
385 390 395 400
Thr Pro Asp Phe Gln Glu Pro Leu Val Ser Ser Gly Glu Glu Glu Thr
405 410 415
Leu Ile Leu Glu Glu Lys Gln Glu Ser Gln Gln Thr Leu Ser Pro Thr
420 425 430
Pro Gly Asp Pro Met Leu Ala Ser Trp Pro Thr Gly Glu Val Trp Leu
435 440 445
Ser Thr Val Ala Pro Ser Pro Ser Asp Met Gly Ala Gly Thr Ala Ala
450 455 460
Ser Ser His Thr Glu Val Ala Pro Thr Asp Pro Met Pro Arg Arg Arg
465 470 475 480
Gly Arg Phe Lys Gly Leu Asn Gly Arg Tyr Phe Gln Gln Gln Glu Pro
485 490 495
Glu Pro Gly Leu Gln Gly Gly Met Glu Ala Ser Ala Gln Pro Pro Thr
500 505 510
Ser Glu Ala Ala Val Asn Gln Met Glu Pro Pro Leu Ala Met Ala Val
515 520 525
Thr Glu Met Leu Gly Ser Gly Gln Ser Arg Ser Pro Trp Ala Asp Leu
530 535 540
Thr Asn Glu Val Asp Met Pro Gly Ala Gly Ser Ala Gly Gly Lys Ser
545 550 555 560
Ser Pro Glu Pro Trp Leu Trp Pro Pro Thr Met Val Pro Pro Ser Ile
565 570 575
Ser Gly His Ser Arg Ala Pro Val Leu Glu Leu Glu Lys Ala Glu Gly
580 585 590
Pro Ser Ala Arg Pro Ala Thr Pro Asp Leu Phe Trp Ser Pro Leu Glu
595 600 605
Ala Thr Val Ser Ala Pro Ser Pro Ala Pro Trp Glu Ala Phe Pro Val
610 615 620
Ala Thr Ser Pro Asp Leu Pro Met Met Ala Met Leu Arg Gly Pro Lys
625 630 635 640
Glu Trp Met Leu Pro His Pro Thr Pro Ile Ser Thr Glu Ala Asn Arg
645 650 655
Val Glu Ala His Gly Glu Ala Thr Ala Thr Ala Pro Pro Ser Pro Ala
660 665 670
Ala Glu Thr Lys Val Tyr Ser Leu Pro Leu Ser Leu Thr Pro Thr Gly
675 680 685
Gln Gly Gly Glu Ala Met Pro Thr Thr Pro Glu Ser Pro Arg Ala Asp
690 695 700
Phe Arg Glu Thr Gly Glu Thr Ser Pro Ala Gln Val Asn Lys Ala Glu
705 710 715 720
His Ser Ser Ser Ser Pro Trp Pro Ser Val Asn Arg Asn Val Ala Val
725 730 735
Gly Phe Val Pro Thr Glu Thr Ala Thr Glu Pro Thr Gly Leu Arg Gly
740 745 750
Ile Pro Gly Ser Glu Ser Gly Val Phe Asp Thr Ala Glu Ser Pro Thr
755 760 765
Ser Gly Leu Gln Ala Thr Val Asp Glu Val Gln Asp Pro Trp Pro Ser
770 775 780
Val Tyr Ser Lys Gly Leu Asp Ala Ser Ser Pro Ser Ala Pro Leu Gly
785 790 795 800
Ser Pro Gly Val Phe Leu Val Pro Lys Val Thr Pro Asn Leu Glu Pro
805 810 815
Trp Val Ala Thr Asp Glu Gly Pro Thr Val Asn Pro Met Asp Ser Thr
820 825 830
Val Thr Pro Ala Pro Ser Asp Ala Ser Gly Ile Trp Glu Pro Gly Ser
835 840 845
Gln Val Phe Glu Glu Ala Glu Ser Thr Thr Leu Ser Pro Gln Val Ala
850 855 860
Leu Asp Thr Ser Ile Val Thr Pro Leu Thr Thr Leu Glu Gln Gly Asp
865 870 875 880
Lys Val Gly Val Pro Ala Met Ser Thr Leu Gly Ser Ser Ser Ser Gln
885 890 895
Pro His Pro Glu Pro Glu Asp Gln Val Glu Thr Gln Gly Thr Ser Gly
900 905 910
Ala Ser Val Pro Pro His Gln Ser Ser Pro Leu Gly Lys Pro Ala Val
915 920 925
Pro Pro Gly Thr Pro Thr Ala Ala Ser Val Gly Glu Ser Ala Ser Val
930 935 940
Ser Ser Gly Glu Pro Thr Val Pro Trp Asp Pro Ser Ser Thr Leu Leu
945 950 955 960
Pro Val Thr Leu Gly Ile Glu Asp Phe Glu Leu Glu Val Leu Ala Gly
965 970 975
Ser Pro Gly Val Glu Ser Phe Trp Glu Glu Val Ala Ser Gly Glu Glu
980 985 990
Pro Ala Leu Pro Gly Thr Pro Met Asn Ala Gly Ala Glu Glu Val His
995 1000 1005
Ser Asp Pro Cys Glu Asn Asn Pro Cys Leu His Gly Gly Thr Cys
1010 1015 1020
Asn Ala Asn Gly Thr Met Tyr Gly Cys Ser Cys Asp Gln Gly Phe
1025 1030 1035
Ala Gly Glu Asn Cys Glu Ile Asp Ile Asp Asp Cys Leu Cys Ser
1040 1045 1050
Pro Cys Glu Asn Gly Gly Thr Cys Ile Asp Glu Val Asn Gly Phe
1055 1060 1065
Val Cys Leu Cys Leu Pro Ser Tyr Gly Gly Ser Phe Cys Glu Lys
1070 1075 1080
Asp Thr Glu Gly Cys Asp Arg Gly Trp His Lys Phe Gln Gly His
1085 1090 1095
Cys Tyr Arg Tyr Phe Ala His Arg Arg Ala Trp Glu Asp Ala Glu
1100 1105 1110
Lys Asp Cys Arg Arg Arg Ser Gly His Leu Thr Ser Val His Ser
1115 1120 1125
Pro Glu Glu His Ser Phe Ile Asn Ser Phe Gly His Glu Asn Thr
1130 1135 1140
Trp Ile Gly Leu Asn Asp Arg Ile Val Glu Arg Asp Phe Gln Trp
1145 1150 1155
Thr Asp Asn Thr Gly Leu Gln Phe Glu Asn Trp Arg Glu Asn Gln
1160 1165 1170
Pro Asp Asn Phe Phe Ala Gly Gly Glu Asp Cys Val Val Met Val
1175 1180 1185
Ala His Glu Ser Gly Arg Trp Asn Asp Val Pro Cys Asn Tyr Asn
1190 1195 1200
Leu Pro Tyr Val Cys Lys Lys Gly Thr Val Leu Cys Gly Pro Pro
1205 1210 1215
Pro Ala Val Glu Asn Ala Ser Leu Ile Gly Ala Arg Lys Ala Lys
1220 1225 1230
Tyr Asn Val His Ala Thr Val Arg Tyr Gln Cys Asn Glu Gly Phe
1235 1240 1245
Ala Gln His His Val Ala Thr Ile Arg Cys Arg Ser Asn Gly Lys
1250 1255 1260
Trp Asp Arg Pro Gln Ile Val Cys Thr Lys Pro Arg Arg Ser His
1265 1270 1275
Arg Met Arg Arg His His His His His Gln His His His Gln His
1280 1285 1290
His His His Lys Ser Arg Lys Glu Arg Arg Lys His Lys Lys His
1295 1300 1305
Pro Thr Glu Asp Trp Glu Lys Asp Glu Gly Asn Phe Cys
1310 1315 1320
<210> 135
<211> 911
<212> PRT
<213> Homo sapiens
<400> 135
Met Ala Gln Leu Phe Leu Pro Leu Leu Ala Ala Leu Val Leu Ala Gln
1 5 10 15
Ala Pro Ala Ala Leu Ala Asp Val Leu Glu Gly Asp Ser Ser Glu Asp
20 25 30
Arg Ala Phe Arg Val Arg Ile Ala Gly Asp Ala Pro Leu Gln Gly Val
35 40 45
Leu Gly Gly Ala Leu Thr Ile Pro Cys His Val His Tyr Leu Arg Pro
50 55 60
Pro Pro Ser Arg Arg Ala Val Leu Gly Ser Pro Arg Val Lys Trp Thr
65 70 75 80
Phe Leu Ser Arg Gly Arg Glu Ala Glu Val Leu Val Ala Arg Gly Val
85 90 95
Arg Val Lys Val Asn Glu Ala Tyr Arg Phe Arg Val Ala Leu Pro Ala
100 105 110
Tyr Pro Ala Ser Leu Thr Asp Val Ser Leu Ala Leu Ser Glu Leu Arg
115 120 125
Pro Asn Asp Ser Gly Ile Tyr Arg Cys Glu Val Gln His Gly Ile Asp
130 135 140
Asp Ser Ser Asp Ala Val Glu Val Lys Val Lys Gly Val Val Phe Leu
145 150 155 160
Tyr Arg Glu Gly Ser Ala Arg Tyr Ala Phe Ser Phe Ser Gly Ala Gln
165 170 175
Glu Ala Cys Ala Arg Ile Gly Ala His Ile Ala Thr Pro Glu Gln Leu
180 185 190
Tyr Ala Ala Tyr Leu Gly Gly Tyr Glu Gln Cys Asp Ala Gly Trp Leu
195 200 205
Ser Asp Gln Thr Val Arg Tyr Pro Ile Gln Thr Pro Arg Glu Ala Cys
210 215 220
Tyr Gly Asp Met Asp Gly Phe Pro Gly Val Arg Asn Tyr Gly Val Val
225 230 235 240
Asp Pro Asp Asp Leu Tyr Asp Val Tyr Cys Tyr Ala Glu Asp Leu Asn
245 250 255
Gly Glu Leu Phe Leu Gly Asp Pro Pro Glu Lys Leu Thr Leu Glu Glu
260 265 270
Ala Arg Ala Tyr Cys Gln Glu Arg Gly Ala Glu Ile Ala Thr Thr Gly
275 280 285
Gln Leu Tyr Ala Ala Trp Asp Gly Gly Leu Asp His Cys Ser Pro Gly
290 295 300
Trp Leu Ala Asp Gly Ser Val Arg Tyr Pro Ile Val Thr Pro Ser Gln
305 310 315 320
Arg Cys Gly Gly Gly Leu Pro Gly Val Lys Thr Leu Phe Leu Phe Pro
325 330 335
Asn Gln Thr Gly Phe Pro Asn Lys His Ser Arg Phe Asn Val Tyr Cys
340 345 350
Phe Arg Asp Ser Ala Gln Pro Ser Ala Ile Pro Glu Ala Ser Asn Pro
355 360 365
Ala Ser Asn Pro Ala Ser Asp Gly Leu Glu Ala Ile Val Thr Val Thr
370 375 380
Glu Thr Leu Glu Glu Leu Gln Leu Pro Gln Glu Ala Thr Glu Ser Glu
385 390 395 400
Ser Arg Gly Ala Ile Tyr Ser Ile Pro Ile Met Glu Asp Gly Gly Gly
405 410 415
Gly Ser Ser Thr Pro Glu Asp Pro Ala Glu Ala Pro Arg Thr Leu Leu
420 425 430
Glu Phe Glu Thr Gln Ser Met Val Pro Pro Thr Gly Phe Ser Glu Glu
435 440 445
Glu Gly Lys Ala Leu Glu Glu Glu Glu Lys Tyr Glu Asp Glu Glu Glu
450 455 460
Lys Glu Glu Glu Glu Glu Glu Glu Glu Val Glu Asp Glu Ala Leu Trp
465 470 475 480
Ala Trp Pro Ser Glu Leu Ser Ser Pro Gly Pro Glu Ala Ser Leu Pro
485 490 495
Thr Glu Pro Ala Ala Gln Glu Glu Ser Leu Ser Gln Ala Pro Ala Arg
500 505 510
Ala Val Leu Gln Pro Gly Ala Ser Pro Leu Pro Asp Gly Glu Ser Glu
515 520 525
Ala Ser Arg Pro Pro Arg Val His Gly Pro Pro Thr Glu Thr Leu Pro
530 535 540
Thr Pro Arg Glu Arg Asn Leu Ala Ser Pro Ser Pro Ser Thr Leu Val
545 550 555 560
Glu Ala Arg Glu Val Gly Glu Ala Thr Gly Gly Pro Glu Leu Ser Gly
565 570 575
Val Pro Arg Gly Glu Ser Glu Glu Thr Gly Ser Ser Glu Gly Ala Pro
580 585 590
Ser Leu Leu Pro Ala Thr Arg Ala Pro Glu Gly Thr Arg Glu Leu Glu
595 600 605
Ala Pro Ser Glu Asp Asn Ser Gly Arg Thr Ala Pro Ala Gly Thr Ser
610 615 620
Val Gln Ala Gln Pro Val Leu Pro Thr Asp Ser Ala Ser Arg Gly Gly
625 630 635 640
Val Ala Val Val Pro Ala Ser Gly Asp Cys Val Pro Ser Pro Cys His
645 650 655
Asn Gly Gly Thr Cys Leu Glu Glu Glu Glu Gly Val Arg Cys Leu Cys
660 665 670
Leu Pro Gly Tyr Gly Gly Asp Leu Cys Asp Val Gly Leu Arg Phe Cys
675 680 685
Asn Pro Gly Trp Asp Ala Phe Gln Gly Ala Cys Tyr Lys His Phe Ser
690 695 700
Thr Arg Arg Ser Trp Glu Glu Ala Glu Thr Gln Cys Arg Met Tyr Gly
705 710 715 720
Ala His Leu Ala Ser Ile Ser Thr Pro Glu Glu Gln Asp Phe Ile Asn
725 730 735
Asn Arg Tyr Arg Glu Tyr Gln Trp Ile Gly Leu Asn Asp Arg Thr Ile
740 745 750
Glu Gly Asp Phe Leu Trp Ser Asp Gly Val Pro Leu Leu Tyr Glu Asn
755 760 765
Trp Asn Pro Gly Gln Pro Asp Ser Tyr Phe Leu Ser Gly Glu Asn Cys
770 775 780
Val Val Met Val Trp His Asp Gln Gly Gln Trp Ser Asp Val Pro Cys
785 790 795 800
Asn Tyr His Leu Ser Tyr Thr Cys Lys Met Gly Leu Val Ser Cys Gly
805 810 815
Pro Pro Pro Glu Leu Pro Leu Ala Gln Val Phe Gly Arg Pro Arg Leu
820 825 830
Arg Tyr Glu Val Asp Thr Val Leu Arg Tyr Arg Cys Arg Glu Gly Leu
835 840 845
Ala Gln Arg Asn Leu Pro Leu Ile Arg Cys Gln Glu Asn Gly Arg Trp
850 855 860
Glu Ala Pro Gln Ile Ser Cys Val Pro Arg Arg Pro Ala Arg Ala Leu
865 870 875 880
His Pro Glu Glu Asp Pro Glu Gly Arg Gln Gly Arg Leu Leu Gly Arg
885 890 895
Trp Lys Ala Leu Leu Ile Pro Pro Ser Ser Pro Met Pro Gly Pro
900 905 910
<210> 136
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 136
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 137
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 137
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 138
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 138
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala
115
<210> 139
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 139
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Thr Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala
115
<210> 140
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 140
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 141
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 141
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Lys
100 105 110
Val Ser Ser Ala
115
<210> 142
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 142
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 143
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 143
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala
115
<210> 144
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 144
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala Ala
115
<210> 145
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 145
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala Ala Ala
115
<210> 146
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 146
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Gly
115
<210> 147
<211> 117
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 147
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Gly Gly
115
<210> 148
<211> 118
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 148
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Gly Gly Gly
115
<210> 149
<211> 115
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 149
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser
115
<210> 150
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 150
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Val Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Arg Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Leu Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Ser Ser Ala
115
<210> 151
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 151
Ser Phe Gly Met Ser
1 5
<210> 152
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 152
Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val Lys
1 5 10 15
Gly
<210> 153
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 153
Gly Gly Ser Leu Ser Arg
1 5
<210> 154
<211> 3
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 154
Ala Ala Ala
1
<210> 155
<211> 5
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 155
Gly Gly Gly Gly Ser
1 5
<210> 156
<211> 7
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 156
Ser Gly Gly Ser Gly Gly Ser
1 5
<210> 157
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 157
Gly Gly Gly Gly Gly Gly Gly Ser
1 5
<210> 158
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 158
Gly Gly Gly Gly Ser Gly Gly Gly Ser
1 5
<210> 159
<211> 10
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 159
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10
<210> 160
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 160
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
1 5 10 15
<210> 161
<211> 18
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 161
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Gly Gly
1 5 10 15
Gly Ser
<210> 162
<211> 20
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 162
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser
20
<210> 163
<211> 25
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 163
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser
20 25
<210> 164
<211> 30
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 164
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser
20 25 30
<210> 165
<211> 35
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 165
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser
35
<210> 166
<211> 40
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 166
Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly
1 5 10 15
Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly Gly Gly Ser Gly Gly
20 25 30
Gly Gly Ser Gly Gly Gly Gly Ser
35 40
<210> 167
<211> 15
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 167
Glu Pro Lys Ser Cys Asp Lys Thr His Thr Cys Pro Pro Cys Pro
1 5 10 15
<210> 168
<211> 24
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 168
Gly Gly Gly Gly Ser Gly Gly Gly Ser Glu Pro Lys Ser Cys Asp Lys
1 5 10 15
Thr His Thr Cys Pro Pro Cys Pro
20
<210> 169
<211> 12
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 169
Glu Pro Lys Thr Pro Lys Pro Gln Pro Ala Ala Ala
1 5 10
<210> 170
<211> 62
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker Sequence
<400> 170
Glu Leu Lys Thr Pro Leu Gly Asp Thr Thr His Thr Cys Pro Arg Cys
1 5 10 15
Pro Glu Pro Lys Ser Cys Asp Thr Pro Pro Pro Cys Pro Arg Cys Pro
20 25 30
Glu Pro Lys Ser Cys Asp Thr Pro Pro Pro Cys Pro Arg Cys Pro Glu
35 40 45
Pro Lys Ser Cys Asp Thr Pro Pro Pro Cys Pro Arg Cys Pro
50 55 60
<210> 171
<211> 116
<212> PRT
<213> Artificial Sequence
<220>
<223> Nanobody Sequence
<400> 171
Glu Val Gln Leu Val Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Asn
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Ser Phe
20 25 30
Gly Met Ser Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Gly Ser Gly Ser Asp Thr Leu Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ala Lys Thr Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Pro Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Thr Ile Gly Gly Ser Leu Ser Arg Ser Ser Gln Gly Thr Leu Val Thr
100 105 110
Val Lys Ser Ala
115
<210> 172
<211> 17
<212> PRT
<213> Artificial Sequence
<220>
<223> myc tag
<400> 172
Ala Ala Ala Glu Gln Lys Leu Ile Ser Glu Glu Asp Leu Asn Gly Ala
1 5 10 15
Ala
<---
| название | год | авторы | номер документа |
|---|---|---|---|
| РЕКРУТИРУЮЩИЕ Т-КЛЕТКИ ПОЛИПЕПТИДЫ, СПОСОБНЫЕ СВЯЗЫВАТЬ CD123 И TCR АЛЬФА/БЕТА | 2017 |
|
RU2775063C2 |
| МЕТОДЫ ПРЕДСКАЗАНИЯ, ОБНАРУЖЕНИЯ И УМЕНЬШЕНИЯ НЕСПЕЦИФИЧЕСКОЙ ИНТЕРФЕРЕНЦИИ БЕЛКОВ В СПОСОБАХ АНАЛИЗА С ИСПОЛЬЗОВАНИЕМ ОДИНОЧНЫХ ВАРИАБЕЛЬНЫХ ДОМЕНОВ ИММУНОГЛОБУЛИНОВ | 2012 |
|
RU2822520C2 |
| МЕТОДЫ ПРЕДСКАЗАНИЯ, ОБНАРУЖЕНИЯ И УМЕНЬШЕНИЯ НЕСПЕЦИФИЧЕСКОЙ ИНТЕРФЕРЕНЦИИ БЕЛКОВ В СПОСОБАХ АНАЛИЗА С ИСПОЛЬЗОВАНИЕМ ОДИНОЧНЫХ ВАРИАБЕЛЬНЫХ ДОМЕНОВ ИММУНОГЛОБУЛИНОВ | 2012 |
|
RU2798971C2 |
| ПОЛИПЕПТИДЫ, СВЯЗЫВАЮЩИЕСЯ С ADAMTS5, MMP13 И АГГРЕКАНОМ | 2018 |
|
RU2786659C2 |
| СВЯЗЫВАЮЩИЕ ADAMTS ИММУНОГЛОБУЛИНЫ | 2018 |
|
RU2781182C2 |
| ММР13-СВЯЗЫВАЮЩИЕ ИММУНОГЛОБУЛИНЫ | 2018 |
|
RU2784069C2 |
| УЛУЧШЕННЫЕ ВАРИАБЕЛЬНЫЕ ДОМЕНЫ ИММУНОГЛОБУЛИНА | 2015 |
|
RU2746738C2 |
| УЛУЧШЕННЫЕ ВАРИАБЕЛЬНЫЕ ДОМЕНЫ ИММУНОГЛОБУЛИНА | 2015 |
|
RU2809788C2 |
| АНТАГОНИСТЫ NGF ДЛЯ МЕДИЦИНСКОГО ИСПОЛЬЗОВАНИЯ | 2020 |
|
RU2829812C2 |
| ВАРИАНТЫ FC-ОБЛАСТИ С ИЗМЕНЕННЫМ СВЯЗЫВАНИЕМ С НЕОНАТАЛЬНЫМ FC-РЕЦЕПТОРОМ (FCRN) ДЛЯ ПРИМЕНЕНИЯ В ВЕТЕРИНАРИИ | 2019 |
|
RU2830231C2 |


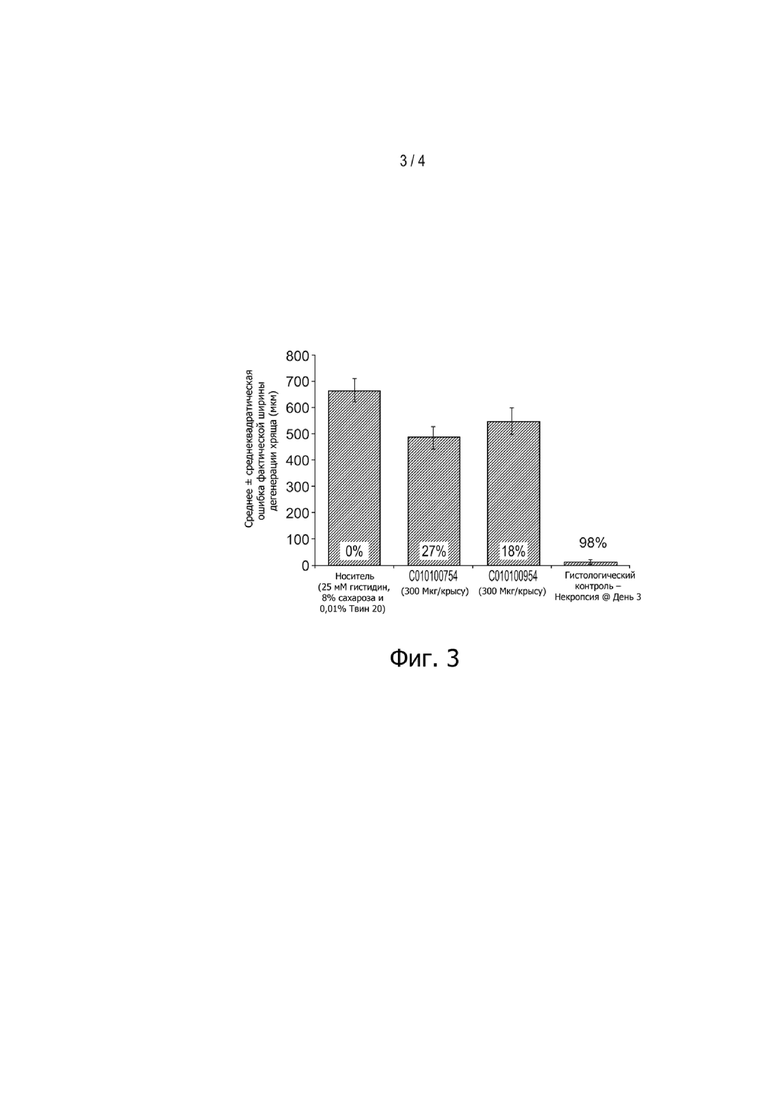
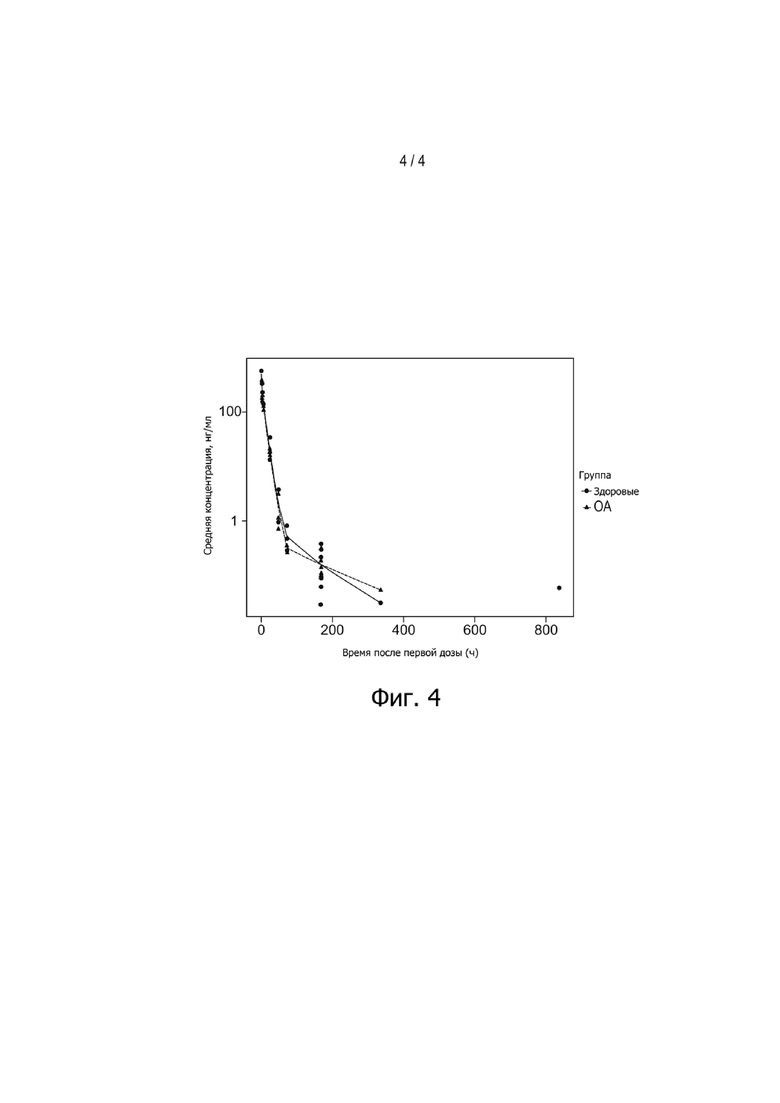
Изобретение относится к области биотехнологии, конкретно к новым иммуноглобулинам и конструкциям на их основе, которые способны специфически связывать белок аггрекан. Фармацевтические композиции, содержащие в качестве активного ингредиента иммуноглобулины согласно настоящему изобретению, могут быть использованы в медицинской практике для профилактических, терапевтических или диагностических целей, в частности при лечении различных заболеваний суставов, например остеоартрита. 8 н. и 11 з.п. ф-лы, 15 табл., 11 пр., 4 ил.
1. Иммуноглобулиновый одиночный вариабельный домен (ISV), который специфически связывается с аггреканом человека, предпочтительно с аггреканом человека, имеющим последовательность, представленную в SEQ ID NO: 125, и необязательно с аггреканом собаки, имеющим последовательность, представленную в SEQ ID NO: 126, аггреканом коровы, имеющим последовательность, представленную в SEQ ID NO: 127, аггреканом крысы, имеющим последовательность, представленную в SEQ ID NO: 128; аггреканом свиньи, имеющим последовательность, представленную в SEQ ID NO: 129; аггреканом мыши, имеющим последовательность, представленную в SEQ ID NO: 130, аггреканом кролика, имеющим последовательность, представленную в SEQ ID NO: 131; аггреканом яванского макака, имеющим последовательность, представленную в SEQ ID NO: 132 и/или аггреканом макака-резуса, имеющим последовательность, представленную в SEQ ID NO: 133, в котором
(A)
i) CDR1 выбран из группы, состоящей из:
a) SEQ ID NO: 24, 20, 21, 109; и
b) аминокислотных последовательностей, в которых имеются отличия в 5, 4, 3, 2 аминокислотах или 1 аминокислоте по сравнению с аминокислотной последовательностью SEQ ID NO: 24, где
- в положении 2 S заменен на R, F, I или T;
- в положении 3 T заменен на I;
- в положении 5 I заменен на S;
- в положении 6 I заменен на S, T или M;
- в положении 7 N заменен на Y или R;
- в положении 8 V заменен на A, Y, T или G;
- в положении 9 V заменен на M; и/или
- в положении 10 R заменен на G, K или A;
и
ii) CDR2 выбран из группы, состоящей из:
c) SEQ ID NO: 42, 38, 39 и 110; и
d) аминокислотных последовательностей, в которых имеются отличия в 5, 4, 3, 2 или 1 аминокислотах по сравнению с аминокислотной последовательностью SEQ ID NO: 42, где
- в положении 1 T заменен на A или G;
- S или N вставлены между положением 3 и положением 4;
- в положении 3 S заменен на R, W, N или T;
- в положении 4 S заменен на T или G;
- в положении 5 G заменен на S;
- в положении 6 G заменен на S или R;
- в положении 7 N заменен на S, T или R;
- в положении 8 A заменен на T; и/или
- в положении 9 N заменен на D или Y;
и
iii) CDR3 выбран из группы, состоящей из:
e) SEQ ID NO: 60, 56, 57 и 111; и
f) аминокислотных последовательностей, в которых имеются отличия в 5, 4, 3, 2 аминокислотах или 1 аминокислоте по сравнению с аминокислотной последовательностью SEQ ID NO: 60, где
- в положении 1 P заменен на G, R, D или E или отсутствует;
- в положении 2 T заменен на R, L, P или V или отсутствует;
- в положении 3 T заменен на M, S или R или отсутствует;
- в положении 4 H заменен на D, Y, G или T;
- в положении 5 Y заменен на F, V, T или G;
- в положении 6 G заменен на L, D, S, Y или W;
- R, T, Y или V вставлен между положениями 6 и 7;
- в положении 7 G заменен на P или S;
- в положении 8 V заменен на G, T, H, R, L или Y;
- в положении 9 Y заменен на R, A, S, D или G;
- в положении 10 Y заменен на N, E, G, W или S;
- W вставлен между положениями 10 и 11;
- в положении 11 G заменен на S, K или Y;
- в положении 12 P заменен на E или D или отсутствует; и/или
- в положении 13 Y заменен на L или отсутствует;
(B)
(i) CDR1 выбран из группы, состоящей из:
a) SEQ ID NO: 32, 30 и 23; и
b) аминокислотных последовательностей, в которых имеются отличия в 3, 2 или 1 аминокислотах по сравнению с аминокислотной последовательностью SEQ ID NO: 32, где
- в положении 2 R заменен на L;
- в положении 6 S заменен на T; и/или
- в положении 8 T заменен на A;
и
ii) CDR2 выбран из группы, состоящей из:
c) SEQ ID NO: 50, 41, 48 и 51; и
d) аминокислотных последовательностей, в которых имеются отличия в 2 или 1 аминокислотах по сравнению с аминокислотной последовательностью SEQ ID NO: 50, где
- в положении 7 G заменен на S или R; и/или
- в положении 8 R заменен на T;
и
iii) CDR3 выбран из группы, состоящей из:
e) SEQ ID NO: 68, 59, 66 и 69; и
f) аминокислотных последовательностей, в которых имеются отличия в 5, 4, 3, 2 или 1 аминокислотах по сравнению с аминокислотной последовательностью SEQ ID NO: 68, где
- в положении 4 R заменен на V или P;
- в положении 6 A заменен на Y;
- в положении 7 S заменен на T;
- в положении 8 S отсутствует;
- в положении 9 N заменен на P;
- в положении 10 R заменен на T или L;
- в положении 11 G заменен на E; и/или
- в положении 12 L заменен на T или V;
или
(C)
(i) CDR1 выбран из группы, состоящей из:
a) SEQ ID NO: 28; и
b) аминокислотных последовательностей, в которых имеются отличия в 5, 4, 3, 2 или 1 аминокислотах по сравнению с аминокислотной последовательностью SEQ ID NO: 28, где
- в положении 1 G заменен на R;
- в положении 2 P заменен на S или R;
- в положении 3 T заменен на I;
- в положении 5 S заменен на N;
- в положении 6 R заменен на N, M или S;
- в положении 7 Y заменен на R или отсутствует;
- в положении 8 A заменен на F или отсутствует; и/или
- в положении 10 G заменен на Y;
и
ii) CDR2 выбран из группы, состоящей из:
c) SEQ ID NO: 46; и
d) аминокислотных последовательностей, в которых имеются отличия в 5, 4, 3, 2 или 1 аминокислотах по сравнению с аминокислотной последовательностью SEQ ID NO: 46, где
- в положении 1 A заменен на S или Y;
- в положении 4 W заменен на L;
- в положении 5 S заменен на N;
- в положении 6 S отсутствует;
- в положении 7 G отсутствует;
- в положении 8 G заменен на A;
- в положении 9 R заменен на S, D или T; и/или
- в положении 11 Y заменен на N или R;
и
iii) CDR3 выбран из группы, состоящей из:
e) SEQ ID NO: 64; и
f) аминокислотных последовательностей, в которых имеются отличия в 5, 4, 3, 2 или 1 аминокислотах по сравнению с аминокислотной последовательностью SEQ ID NO: 64, где
- в положении 1 A заменен на R или F;
- в положении 2 R заменен на I или L;
- в положении 3 I заменен на H или Q;
- в положении 4 P заменен на G или N;
- в положении 5 V заменен на S;
- в положении 6 R заменен на G, N или F;
- в положении 7 T заменен на R, W или Y;
- в положении 8 Y заменен на R или S или отсутствует;
- в положении 9 T заменен на S или отсутствует;
- в положении 10 S заменен на E, K или отсутствует;
- в положении 11 E заменен на N, A или отсутствует;
- в положении 12 W заменен на D или отсутствует;
- в положении 13 N заменен на D или отсутствует;
- в положении 14 Y отсутствует; и/или
- D и N добавлены за положением 14 в SEQ ID NO: 64.
2. ISV по п. 1, отличающийся тем, что по существу состоит из 4 каркасных областей FR1-FR4 соответственно и 3 областей, определяющих комплементарность CDR1-CDR3 соответственно, в которых:
- CDR1 выбран из группы, состоящей из SEQ ID NO: 24, 20, 21, 22, 23, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37 и 109, предпочтительно выбран из группы, состоящей из SEQ ID NO: 24, 20, 21, 25, 27, 29, 31, 34, 35, 36, 37 и 109;
- CDR2 выбран из группы, состоящей из SEQ ID NO: 42, 38, 39, 40, 41, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55 и 110, предпочтительно выбран из группы, состоящей из SEQ ID NO: 42, 38, 39, 43, 45, 47, 49, 50, 53, 54, 55 и 110; и
- CDR3 выбран из группы, состоящей из SEQ ID NO: 60, 56, 57, 58, 59, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74 и 111, предпочтительно выбран из группы, состоящей из SEQ ID NO: 60, 56, 57, 61, 63, 65, 67, 71, 72, 73, 74 и 111.
3. ISV по п. 1 или 2, который по существу состоит из 4 каркасных областей FR1-FR4 соответственно и 3 областей, определяющих комплементарность CDR1-CDR3 соответственно, в которых:
i) CDR1 выбран из группы, состоящей из:
a) SEQ ID NO: 24, 20, 21, 109;
b) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 24, где
- в положении 2 S изменен на R, F, I или T;
- в положении 3 Т изменен на I;
- в положении 5 I было изменено на S;
- в положении 6 I было изменено на S, T или M;
- в положении 7 N изменен на Y или R;
- в положении 8 V изменен на A, Y, T или G;
- в положении 9 V изменен на М; и/или
- в положении 10 R изменен на G, K или A;
и/или
ii) CDR2 выбран из группы, состоящей из:
c) SEQ ID NO: 42, 38, 39 и 110; и
d) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 42, где
- в положении 1 Т изменен на А или G;
- S или N вставлен между положением 3 и положением 4;
- в положении 3 S изменен на R, W, N или T;
- в положении 4 S изменен на T или G;
- в положении 5 G изменен на S;
- в положении 6 G изменен на S или R;
- в положении 7 N изменен на S, T или R;
- в положении 8 A изменен на T; и/или
- в положении 9 N изменен на D или Y;
и/или
iii) CDR3 выбран из группы, состоящей из:
e) SEQ ID NO: 60, 56, 57 и 111; и
f) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 60, где
- в положении 1 P изменен на G, R, D или E или отсутствует;
- в положении 2 Т изменен на R, L, P или V или отсутствует;
- в положении 3 Т изменен на М, S или R или отсутствует;
- в положении 4 H изменен на D, Y, G или T;
- в положении 5 Y изменен на F, V, T или G;
- в положении 6 G изменен на L, D, S, Y или W;
- R, T, Y или V вставлен между положением 6 и положением 7;
- в положении 7 G изменен на P или S;
- в положении 8 V изменен на G, T, H, R, L или Y;
- в положении 9 Y изменен на R, A, S, D или G;
- в положении 10 Y изменен на N, E, G, W или S;
- W вставлена между положением 10 и положением 11;
- в положении 11 G изменен на S, K или Y;
- в положении 12 P изменен на E, или D, или отсутствует; и/или
- в позиции 13 Y изменен на L или отсутствует.
4. ISV по п. 1 или 2, отличающийся тем, что по существу состоит из 4 каркасных областей FR1-FR4 соответственно и 3 областей, определяющих комплементарность CDR1-CDR3 соответственно, в которых:
i) CDR1 выбран из группы, состоящей из:
a) SEQ ID NO: 32, 30 и 23; и
b) аминокислотных последовательностей, которые имеют различие в 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 32, где
- в положении 2 R изменен на L;
- в положении 6 S изменен на T; и/или
- в положении 8 Т изменен на А;
и/или
ii) CDR2 выбран из группы, состоящей из:
c) SEQ ID NO: 50, 41, 48 и 51; и
d) аминокислотных последовательностей, которые имеют различие в 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 50, где
- в положении 7 G изменен на S или R; и/или
- в положении 8 R изменен на T;
и/или
iii) CDR3 выбран из группы, состоящей из:
e) SEQ ID NO: 68, 59, 66 и 69; и
f) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 68, где
- в положении 4 R изменен на V или P;
- в положении 6 A изменен на Y;
- в положении 7 S изменен на T;
- в положении 8 S отсутствует;
- в положении 9 N изменен на P;
- в положении 10 R изменен на T или L;
- в положении 11 G изменен на E; и/или
- в положении 12 L изменен на T или V.
5. ISV по п. 1 или 2, что по существу состоит из 4 каркасных областей FR1-FR4 соответственно и 3 областей, определяющих комплементарность CDR1-CDR3 соответственно, в котором:
i) CDR1 выбран из группы, состоящей из:
a) SEQ ID NO: 28; и
b) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 28, где
- в положении 1 G изменен на R;
- в положении 2 P изменен на S или R;
- в положении 3 Т изменен на I;
- в положении 5 S изменен на N;
- в положении 6 R изменен на N, M или S;
- в положении 7 Y изменен на R или отсутствует;
- в положении 8 A изменен на F или отсутствует; и/или
- в позиции 10 G изменен на Y;
и/или
ii) CDR2 выбран из группы, состоящей из:
c) SEQ ID NO: 46; и
d) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 46, где
- в положении 1 A изменен на S или Y;
- в положении 4 W изменен на L;
- в положении 5 S изменен на N;
- в положении 6 S отсутствует;
- в положении 7 G отсутствует;
- в положении 8 G изменен на A;
- в положении 9 R изменен на S, D или T; и/или
- в положении 11 Y изменен на N или R;
и/или
iii) CDR3 выбран из группы, состоящей из:
e) SEQ ID NO: 64; и
f) аминокислотных последовательностей, которые имеют различие в 5, 4, 3, 2 или 1 аминокислоту с аминокислотной последовательностью SEQ ID NO: 64, где
- в положении 1 A изменен на R или F;
- в положении 2 R изменен на I или L;
- в положении 3 I было изменено на H или Q;
- в положении 4 P изменен на G или N;
- в положении 5 V изменен на S;
- в положении 6 R изменен на G, N или F;
- в положении 7 Т изменен на R, W или Y;
- в положении 8 Y изменен на R или S или отсутствует;
- в положении 9 Т изменен на S или отсутствует;
- в положении 10 S изменен на E, K или отсутствует;
- в положении 11 E изменен на N, A или отсутствует;
- в положении 12 W изменен на D или отсутствует;
- в положении 13 N изменен на D или отсутствует;
- в положении 14 Y отсутствует; и/или
- D и N добавляются после позиции 14 SEQ ID NO: 64.
6. ISV по любому из пп. 2-5, отличающийся тем, что указанный ISV выбран из группы ISV, в которой:
- CDR1 представляет собой SEQ ID NO: 24, CDR2 представляет собой SEQ ID NO: 42 и CDR3 представляет собой SEQ ID NO: 60;
- CDR1 представляет собой SEQ ID NO: 20, CDR2 представляет собой SEQ ID NO: 38 и CDR3 представляет собой SEQ ID NO: 56;
- CDR1 представляет собой SEQ ID NO: 21, CDR2 представляет собой SEQ ID NO: 39 и CDR3 представляет собой SEQ ID NO: 57;
- CDR1 представляет собой SEQ ID NO: 25, CDR2 представляет собой SEQ ID NO: 43 и CDR3 представляет собой SEQ ID NO: 61;
- CDR1 представляет собой SEQ ID NO: 27, CDR2 представляет собой SEQ ID NO: 45 и CDR3 представляет собой SEQ ID NO: 63;
- CDR1 представляет собой SEQ ID NO: 29, CDR2 представляет собой SEQ ID NO: 47 и CDR3 представляет собой SEQ ID NO: 65;
- CDR1 представляет собой SEQ ID NO: 31, CDR2 представляет собой SEQ ID NO: 49 и CDR3 представляет собой SEQ ID NO: 67;
- CDR1 представляет собой SEQ ID NO: 34, CDR2 представляет собой SEQ ID NO: 50 и CDR3 представляет собой SEQ ID NO: 71;
- CDR1 представляет собой SEQ ID NO: 35, CDR2 представляет собой SEQ ID NO: 53 и CDR3 представляет собой SEQ ID NO: 72;
- CDR1 представляет собой SEQ ID NO: 36, CDR2 представляет собой SEQ ID NO: 54 и CDR3 представляет собой SEQ ID NO: 73;
- CDR1 представляет собой SEQ ID NO: 37, CDR2 представляет собой SEQ ID NO: 55 и CDR3 представляет собой SEQ ID NO: 74;
- CDR1 представляет собой SEQ ID NO: 32, CDR2 представляет собой SEQ ID NO: 50 и CDR3 представляет собой SEQ ID NO: 68;
- CDR1 представляет собой SEQ ID NO: 32, CDR2 представляет собой SEQ ID NO: 51 и CDR3 представляет собой SEQ ID NO: 69;
- CDR1 представляет собой SEQ ID NO: 30, CDR2 представляет собой SEQ ID NO: 48 и CDR3 представляет собой SEQ ID NO: 66;
- CDR1 представляет собой SEQ ID NO: 23, CDR2 представляет собой SEQ ID NO: 41 и CDR3 представляет собой SEQ ID NO: 59;
- CDR1 представляет собой SEQ ID NO: 28, CDR2 представляет собой SEQ ID NO: 46 и CDR3 представляет собой SEQ ID NO: 64;
CDR1 представляет собой SEQ ID NO: 22, CDR2 представляет собой SEQ ID NO:40, и CDR3 представляет собой SEQ ID NO: 58;
- CDR1 представляет собой SEQ ID NO: 26, CDR2 представляет собой SEQ ID NO: 44 и CDR3 представляет собой SEQ ID NO: 62; и
- CDR1 представляет собой SEQ ID NO: 33, CDR2 представляет собой SEQ ID NO:52; и CDR3 представляет собой SEQ ID NO: 70.
7. ISV по любому из пп. 1-6, отличающийся тем, что указанный ISV выбран из группы, состоящей из ISV, состоящих из SEQ ID NO: 1-19 и 114-118, предпочтительно SEQ ID NO: 5, 1, 2, 6, 8, 10, 12, 16, 17, 18 и 19, и ISV, которые имеют более 80%, например, 90% или 95% идентичности последовательностей с любой из SEQ ID NO: 1-19 и 114-118, предпочтительно SEQ ID NO: 5, 1, 2, 6, 8, 10, 12, 16, 17, 18 и 19.
8. Направленный против аггрекана полипептид, который связывается с доменом G2 аггрекана, в котором
(A)
i) CDR1 выбран из группы, состоящей из:
a) SEQ ID NO: 24, 20, 21, 109; и
b) аминокислотных последовательностей, в которых имеются отличия в 5, 4, 3, 2 аминокислотах или 1 аминокислоте по сравнению с аминокислотной последовательностью SEQ ID NO: 24, где
- в положении 2 S заменен на R, F, I или T;
- в положении 3 T заменен на I;
- в положении 5 I заменен на S;
- в положении 6 I заменен на S, T или M;
- в положении 7 N заменен на Y или R;
- в положении 8 V заменен на A, Y, T или G;
- в положении 9 V заменен на M; и/или
- в положении 10 R заменен на G, K или A;
и
ii) CDR2 выбран из группы, состоящей из:
c) SEQ ID NO: 42, 38, 39 и 110; и
d) аминокислотных последовательностей, в которых имеются отличия в 5, 4, 3, 2 аминокислотах или 1 аминокислоте по сравнению с аминокислотной последовательностью SEQ ID NO: 42, где
- в положении 1 T заменен на A или G;
- S или N вставлен между положениями 3 и 4;
- в положении 3 S заменен на R, W, N или T;
- в положении 4 S заменен на T или G;
- в положении 5 G заменен на S;
- в положении 6 G заменен на S или R;
- в положении 7 N заменен на S, T или R;
- в положении 8 A заменен на T; и/или
- в положении 9 N заменен на D или Y;
и
iii) CDR3 выбран из группы, состоящей из:
e) SEQ ID NO: 60, 56, 57 и 111; и
f) аминокислотных последовательностей, в которых имеются отличия в 5, 4, 3, 2 аминокислотах или 1 аминокислоте по сравнению с аминокислотной последовательностью SEQ ID NO: 60, где
- в положении 1 P заменен на G, R, D или E или отсутствует;
- в положении 2 T заменен на R, L, P или V или отсутствует;
- в положении 3 T заменен на M, S или R или отсутствует;
- в положении 4 H заменен на D, Y, G или T;
- в положении 5 Y заменен на F, V, T или G;
- в положении 6 G заменен на L, D, S, Y или W;
- R, T, Y или V вставлен между положениями 6 и 7;
- в положении 7 G заменен на P или S;
- в положении 8 V заменен на G, T, H, R, L или Y;
- в положении 9 Y заменен на R, A, S, D или G;
- в положении 10 Y заменен на N, E, G, W или S;
- a W вставлен между положениями 10 и 11;
- в положении 11 G заменен на S, K или Y;
- в положении 12 P заменен на E или D или отсутствует; и/или
- в положении 13 Y заменен на L или отсутствует;
(B)
(i) CDR1 выбран из группы, состоящей из:
a) SEQ ID NO: 32, 30 и 23; и
b) аминокислотных последовательностей, в которых имеются отличия в 3, 2 аминокислотах или 1 аминокислоте по сравнению с аминокислотной последовательностью SEQ ID NO: 32, где
- в положении 2 R заменен на L;
- в положении 6 S заменен на T; и/или
- в положении 8 T заменен на A;
и
ii) CDR2 выбран из группы, состоящей из:
c) SEQ ID NO: 50, 41, 48 и 51; и
d) аминокислотных последовательностей, в которых имеются отличия в 2 аминокислотах или 1 аминокислоте по сравнению с аминокислотной последовательностью SEQ ID NO: 50, где
- в положении 7 G заменен на S или R; и/или
- в положении 8 R заменен на T;
и
iii) CDR3 выбран из группы, состоящей из:
e) SEQ ID NO: 68, 59, 66 и 69; и
f) аминокислотных последовательностей, в которых имеются отличия в 5, 4, 3, 2 аминокислотах или 1 аминокислоте по сравнению с аминокислотной последовательностью SEQ ID NO: 68, где
- в положении 4 R заменен на V или P;
- в положении 6 A заменен на Y;
- в положении 7 S заменен на T;
- в положении 8 S отсутствует;
- в положении 9 N заменен на P;
- в положении 10 R заменен на T или L;
- в положении 11 G заменен на E; и/или
- в положении 12 L заменен на T или V;
или
(C)
(i) CDR1 выбран из группы, состоящей из:
a) SEQ ID NO: 28; и
b) аминокислотных последовательностей, в которых имеются отличия в 5, 4, 3, 2 аминокислотах или 1 аминокислоте по сравнению с аминокислотной последовательностью SEQ ID NO: 28, где
- в положении 1 G заменен на R;
- в положении 2 P заменен на S или R;
- в положении 3 T заменен на I;
- в положении 5 S заменен на N;
- в положении 6 R заменен на N, M или S;
- в положении 7 Y заменен на R или отсутствует;
- в положении 8 A заменен на F или отсутствует; и/или
- в положении 10 G заменен на Y;
и
ii) CDR2 выбран из группы, состоящей из:
c) SEQ ID NO: 46; и
d) аминокислотных последовательностей, в которых имеются отличия в 5, 4, 3, 2 аминокислотах или 1 аминокислоте по сравнению с аминокислотной последовательностью SEQ ID NO: 46, где
- в положении 1 A заменен на S или Y;
- в положении 4 W заменен на L;
- в положении 5 S заменен на N;
- в положении 6 S отсутствует;
- в положении 7 G отсутствует;
- в положении 8 G заменен на A;
- в положении 9 R заменен на S, D или T; и/или
- в положении 11 Y заменен на N или R;
и
iii) CDR3 выбран из группы, состоящей из:
e) SEQ ID NO: 64; и
f) аминокислотных последовательностей, в которых имеются отличия в 5, 4, 3, 2 аминокислотах или 1 аминокислоте по сравнению с аминокислотной последовательностью SEQ ID NO: 64, где
- в положении 1 A заменен на R или F;
- в положении 2 R заменен на I или L;
- в положении 3 I заменен на H или Q;
- в положении 4 P заменен на G или N;
- в положении 5 V заменен на S;
- в положении 6 R заменен на G, N или F;
- в положении 7 T заменен на R, W или Y;
- в положении 8 Y заменен на R или S или отсутствует;
- в положении 9 T заменен на S или отсутствует;
- в положении 10 S заменен на E, K или отсутствует;
- в положении 11 E заменен на N, A или отсутствует;
- в положении 12 W заменен на D или отсутствует;
- в положении 13 N заменен на D или отсутствует;
- в положении 14 Y отсутствует; и/или
- D и N добавлены за положением 14 в SEQ ID NO: 64,
и который конкурирует за связывание с аггреканом с ISV по пункту 6, где указанный на правленный против аггрекана полипептид выбран из доменного антитела, иммуноглобулина, который подходит для применения в качестве доменного антитела, однодоменного антитела, иммуноглобулина, который подходит для применения в качестве однодоменного антитела, dAb, иммуноглобулина, который подходит для применения в качестве dAb, нанотела, последовательности VHH, гуманизированной последовательности VHH, оверблюженной последовательности VH или последовательности VHH, которая была получена путем созревания аффинности, которая связывается с эпитопной группой 1 домена G1 аггрекана, последовательности VHH, которая была получена путем созревания аффинности и которая связывается с доменом G1-IGD-G2 аггрекана, или последовательности VHH, которая была получена путем созревания аффинности.
9. Полипептид, который специфически связывается с аггреканом человека, предпочтительно с аггреканом человека, имеющим последовательность, представленную в SEQ ID NO: 125, и необязательно с аггреканом собаки, имеющим последовательность, представленную в SEQ ID NO: 126, аггреканом коровы, имеющим последовательность, представленную в SEQ ID NO: 127, аггреканом крысы, имеющим последовательность, представленную в SEQ ID NO: 128; аггреканом свиньи, имеющим последовательность, представленную в SEQ ID NO: 129; аггреканом мыши, имеющим последовательность, представленную в SEQ ID NO: 130, аггреканом кролика, имеющим последовательность, представленную в SEQ ID NO: 131; аггреканом яванского макака, имеющим последовательность, представленную в SEQ ID NO: 132, и/или аггреканом макака-резуса, имеющим последовательность, представленную в SEQ ID NO: 133, содержащий по меньшей мере один ISV по любому из пп. 1-7 и, возможно, второй ISV, возможно, третий ISV и, возможно, четвертый ISV, или содержащий полипептид по п. 8.
10. Полипептид, который специфически связывается с аггреканом человека, предпочтительно с аггреканом человека, имеющим последовательность, представленную в SEQ ID NO: 125, и необязательно с аггреканом собаки, имеющим последовательность, представленную в SEQ ID NO: 126, аггреканом коровы, имеющим последовательность, представленную в SEQ ID NO: 127, аггреканом крысы, имеющим последовательность, представленную в SEQ ID NO: 128; аггреканом свиньи, имеющим последовательность, представленную в SEQ ID NO: 129; аггреканом мыши, имеющим последовательность, представленную в SEQ ID NO: 130, аггреканом кролика, имеющим последовательность, представленную в SEQ ID NO: 131; аггреканом яванского макака, имеющим последовательность, представленную в SEQ ID NO: 132 и/или аггреканом макака-резуса, имеющим последовательность, представленную в SEQ ID NO: 133, который содержит по меньшей мере два ISV по любому из пп. 1-7 и, возможно, третий ISV и, возможно, четвертый ISV.
11. Полипептид по п. 10, отличающийся тем, что указанные по меньшей мере два ISV могут быть одинаковыми или разными, предпочтительно указанные по меньшей мере два ISV независимо выбраны из группы, состоящей из SEQ ID NO: 1-19 и 114-118.
12. Полипептид по любому из пп. 9-11, отличающийся тем, что указанный по меньшей мере один ISV по любому из пп. 1-8 или указанные по меньшей мере два ISV по любому из пп. 1-8, связываются с представителем семейства сериновых протеаз, катепсинами, (ММР)/матриксинами матриксных металлопротеиназ или дезинтегрином А и металлопротеиназой с мотивами тромбоспондина (ADAMTS), предпочтительно MMP8, MMP13, MMP19, MMP20, ADAMTS5 (аггреканазой-2), ADAMTS4 (аггреканазой-1) и/или ADAMTS11.
13. Полипептид по любому из пп. 9-12, отличающийся тем, что указанный полипептид дополнительно включает фрагмент, связывающий сывороточный белок, или сывороточный белок.
14. Конструкция, которая специфически связывается с аггреканом человека, предпочтительно с аггреканом человека, имеющим последовательность, представленную в SEQ ID NO: 125, и необязательно с аггреканом собаки, имеющим последовательность, представленную в SEQ ID NO: 126, аггреканом коровы, имеющим последовательность, представленную в SEQ ID NO: 127, аггреканом крысы, имеющим последовательность, представленную в SEQ ID NO: 128; аггреканом свиньи, имеющим последовательность, представленную в SEQ ID NO: 129; аггреканом мыши, имеющим последовательность, представленную в SEQ ID NO: 130, аггреканом кролика, имеющим последовательность, представленную в SEQ ID NO: 131; аггреканом яванского макака, имеющим последовательность, представленную в SEQ ID NO: 132, и/или аггреканом макака-резуса, имеющим последовательность, представленную в SEQ ID NO: 133, и которая содержит или, по существу, состоит из ISV по любому из пп. 1-7 или полипептида по любому из пп. 8-13 и которая дополнительно включает одну или несколько других групп, остатков, фрагментов или связывающих единиц, необязательно связанных через один или несколько пептидных линкеров.
15. Композиция, которая специфически связывается с аггреканом человеком, предпочтительно с аггреканом человека, имеющим последовательность, представленную в SEQ ID NO: 125, и необязательно с аггреканом собаки, имеющим последовательность, представленную в SEQ ID NO: 126, аггреканом коровы, имеющим последовательность, представленную в SEQ ID NO: 127, аггреканом крысы, имеющим последовательность, представленную в SEQ ID NO: 128; аггреканом свиньи, имеющим последовательность, представленную в SEQ ID NO: 129; аггреканом мыши, имеющим последовательность, представленную в SEQ ID NO: 130, аггреканом кролика, имеющим последовательность, представленную в SEQ ID NO: 131; аггреканом яванского макака, имеющим последовательность, представленную в SEQ ID NO: 132 и/или аггреканом макака-резуса, имеющим последовательность, представленную в SEQ ID NO: 133, содержащая в фармацевтически эффективном количестве по меньшей мере один ISV по любому из пп. 1-7, полипептид по любому из пп. 8-13, или конструкция по п. 14, где указанная композиция, предпочтительно представляет собой фармацевтическую композицию, необязательно дополнительно включающую по меньшей мере один фармацевтически приемлемый носитель, разбавитель или наполнитель и/или адъювант и необязательно содержит один или несколько других фармацевтически активных полипептидов и/или соединений.
16. Применение ISV по любому из пп. 1-7 или продукта, содержащего ISV по любому из пп. 1-7, для закрепления лекарства в суставе при терапии различных заболеваний сустава, где указанный продукт, содержащий ISV по любому из пп. 1-7, выбран из композиции по п. 15, полипептида по любому из пп. 8-13, или конструкции по п. 14.
17. Применение ISV по любому из пп. 1-7 или продукта, содержащего ISV по любому из пп. 1-7 в профилактике или лечении артропатий и хондродистрофий, артритного заболевания, такого как остеоартрит, ревматоидный артрит, подагрический артрит, псориатический артрит, травматический разрыв или отслоение, ахондроплазия, костохондрит, спондилоэпиметафизальная дисплазия, грыжа позвоночного диска, дегенеративные заболевания поясничного диска, дегенеративные заболевания суставов и рецидивирующий полихондрит, где указанный продукт, содержащий ISV по любому из пп. 1-7, выбран из композиции по п. 15, полипептида по любому из пп. 8-13, или конструкции по п. 14.
| SZTROLOVICS R | |||
| et al.: "The mechanism of aggrecan release from cartilage differs with tissue origin and the agent used to stimulate catabolism", Biochem J., 2002, v | |||
| Способ получения и применения продуктов конденсации фенола или его гомологов с альдегидами | 1920 |
|
SU362A1 |
| JANUNE D | |||
| Переносная печь для варки пищи и отопления в окопах, походных помещениях и т.п. | 1921 |
|
SU3A1 |
| Аппарат для предохранения паровых котлов, экономайзеров, кипятильников и т.п. приборов от разъедания воздухом, растворенным в питательной воде | 1918 |
|
SU585A1 |
| WO 2007045661 A1, | |||

